跟煎魚學 Go
寫寫程式碼,喝喝茶,搞搞 Go,一起吧,這是我的專案地址:https://github.com/EDDYCJY/blog
線上閱讀
我的微信公眾號
推薦大家關注我的微信公眾號,長期堅持更新原創知識。也可以加我 WeChat,拉你進 Go 技術交流群:

煎魚的微信公眾號
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見
如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進 😀
License
所有文章採用知識共享署名-非商業性使用-相同方式共享 3.0 中國大陸許可協議進行許可
第1課 雜談
- 1.1 聊一聊,Go 的相對路徑問題
- 1.2 Go 的 fake-useragent 瞭解一下
- 1.3 用 Go 來了解一下 Redis 通訊協議
- 1.4 使用 Gomock 進行單元測試
- 1.5 在 Go 中恰到好處的記憶體對齊
- 1.6 來,控制一下 goroutine 的併發數量
- 1.7 for-loop 與 json.Unmarshal 效能分析概要
- 1.8 簡單圍觀一下有趣的 //go: 指令
- 1.9 我要在棧上。不,你應該在堆上
- 1.10 defer 會有效能損耗,儘量不要用
- 1.11 從實踐到原理,帶你參透 gRPC
- 1.12 Go1.13 defer 的效能是如何提高的?
- 1.13 Go 應用記憶體佔用太多,讓排查?(VSZ篇)
- 1.14 乾貨滿滿的 Go Modules 和 goproxy.cn
1.1 聊一聊,Go 的相對路徑問題
前言
Golang 中存在各種執行方式,如何正確的引用檔案路徑成為一個值得商議的問題
以 gin-blog 為例,當我們在專案根目錄下,執行 go run main.go 時能夠正常執行(go build也是正常的)
[$ gin-blog]# go run main.go
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /api/v1/tags --> gin-blog/routers/api/v1.GetTags (3 handlers)
...
那麼在不同的目錄層級下,不同的方式執行,又是怎麼樣的呢,帶著我們的疑問去學習
問題
1、 go run 我們上移目錄層級,到 $GOPATH/src 下,執行 go run gin-blog/main.go
[$ src]# go run gin-blog/main.go
2018/03/12 16:06:13 Fail to parse 'conf/app.ini': open conf/app.ini: no such file or directory
exit status 1
2、 go build,執行 ./gin-blog/main
[$ src]# ./gin-blog/main
2018/03/12 16:49:35 Fail to parse 'conf/app.ini': open conf/app.ini: no such file or directory
這時候你要打一個大大的問號,就是我的程式讀取到什麼地方去了
我們透過分析得知,Golang的相對路徑是相對於執行命令時的目錄;自然也就讀取不到了
思考
既然已經知道問題的所在點,我們就可以尋思做點什麼 : )
我們想到相對路徑是相對執行命令的目錄,那麼我們取得可執行檔案的地址,拼接起來不就好了嗎?
實踐
我們編寫取得當前可執行檔案路徑的方法
import (
"path/filepath"
"os"
"os/exec"
"string"
)
func GetAppPath() string {
file, _ := exec.LookPath(os.Args[0])
path, _ := filepath.Abs(file)
index := strings.LastIndex(path, string(os.PathSeparator))
return path[:index]
}
將其放到啟動程式碼處檢視路徑
log.Println(GetAppPath())
我們分別執行以下兩個命令,檢視輸出結果 1、 go run
$ go run main.go
2018/03/12 18:45:40 /tmp/go-build962610262/b001/exe
2、 go build
$ ./main
2018/03/12 18:49:44 $GOPATH/src/gin-blog
剖析
我們聚焦在 go run 的輸出結果上,發現它是一個臨時檔案的地址,這是為什麼呢?
在go help run中,我們可以看到
Run compiles and runs the main package comprising the named Go source files.
A Go source file is defined to be a file ending in a literal ".go" suffix.
也就是 go run 執行時會將檔案放到 /tmp/go-build... 目錄下,編譯並執行
因此go run main.go出現/tmp/go-build962610262/b001/exe結果也不奇怪了,因為它已經跑到臨時目錄下去執行可執行檔案了
這就已經很清楚了,那麼我們想想,會出現哪些問題呢
- 依賴相對路徑的檔案,出現路徑出錯的問題
go run和go build不一樣,一個到臨時目錄下執行,一個可手動在編譯後的目錄下執行,路徑的處理方式會不同- 不斷
go run,不斷產生新的臨時檔案
這其實就是根本原因了,因為 go run 和 go build 的編譯檔案執行路徑並不同,執行的層級也有可能不一樣,自然而然就出現各種讀取不到的奇怪問題了
解決方案
一、取得編譯後的可執行檔案路徑
1、 將設定檔案的相對路徑與GetAppPath()的結果相拼接,可解決go build main.go的可執行檔案跨目錄執行的問題(如:./src/gin-blog/main)
import (
"path/filepath"
"os"
"os/exec"
"string"
)
func GetAppPath() string {
file, _ := exec.LookPath(os.Args[0])
path, _ := filepath.Abs(file)
index := strings.LastIndex(path, string(os.PathSeparator))
return path[:index]
}
但是這種方式,對於go run依舊無效,這時候就需要2來補救
2、 透過傳遞引數指定路徑,可解決go run的問題
package main
import (
"flag"
"fmt"
)
func main() {
var appPath string
flag.StringVar(&appPath, "app-path", "app-path")
flag.Parse()
fmt.Printf("App path: %s", appPath)
}
執行
go run main.go --app-path "Your project address"
二、增加os.Getwd()進行多層判斷
參見 beego 讀取 app.conf 的程式碼
該寫法可相容 go build 和在專案根目錄執行 go run ,但是若跨目錄執行 go run 就不行
三、設定全域性系統變數
我們可以透過os.Getenv來取得系統全域性變數,然後與相對路徑進行拼接
1、 設定專案工作區
簡單來說,就是設定專案(應用)的工作路徑,然後與設定檔案、日誌檔案等相對路徑進行拼接,達到相對的絕對路徑來保證路徑一致
參見 gogs 讀取GOGS_WORK_DIR進行拼接的程式碼
2、 利用系統自帶變數
簡單來說就是透過系統自帶的全域性變數,例如$HOME等,將設定檔案存放在$HOME/conf或/etc/conf下
這樣子就能更加固定的存放設定檔案,不需要額外去設定一個環境變數
(這點今早與一位SFer討論了一波,感謝)
拓展
go test 在一些場景下也會遇到路徑問題,因為go test只能夠在當前目錄執行,所以在執行測試用例的時候,你的執行目錄已經是測試目錄了
需要注意的是,如果採用取得外部引數的辦法,用 os.args 時,go test -args 和 go run、go build 會有命令列引數位置的不一致問題
小結
這三種解決方案,在目前可見的開源專案或介紹中都能找到這些的身影
優缺點也是顯而易見的,我認為應在不同專案選定合適的解決方案即可
建議大家不要強依賴讀取設定檔案的模組,應當將其“堆積木”化,需要什麼設定才去註冊什麼設定變數,可以解決一部分的問題
大家又有什麼想法呢,一起討論一波?
1.2 Go 的 fake-useragent 瞭解一下
有的網站會根據 User-Agent 的不同,跳轉到不同(PC、M)的站點,也有根據版本的不同給出不一樣的提示等等,而 User-Agent 的變化更是爬蟲裡的基礎姿勢
使用 Go 編寫網路爬蟲或需要模擬瀏覽器頭(User-Agent)的時候,你是否會覺得很麻煩,取得請求頭(Request Headers)的 User-Agent 還得找來找去,挺繁瑣。先前我也遇到了這個問題,因此有了這個專案 fake-useragent,用來解決你我的痛點
專案地址:https://github.com/EDDYCJY/fake-useragent
支援
- All User-Agent Random
- Chrome
- InternetExplorer (IE)
- Firefox
- Safari
- Android
- MacOSX
- IOS
- Linux
- IPhone
- IPad
- Computer
- Mobile
安裝
$ go get github.com/EDDYCJY/fake-useragent
用法
package main
import (
"log"
"github.com/EDDYCJY/fake-useragent"
)
func main() {
// 推荐使用
random := browser.Random()
log.Printf("Random: %s", random)
chrome := browser.Chrome()
log.Printf("Chrome: %s", chrome)
internetExplorer := browser.InternetExplorer()
log.Printf("IE: %s", internetExplorer)
firefox := browser.Firefox()
log.Printf("Firefox: %s", firefox)
safari := browser.Safari()
log.Printf("Safari: %s", safari)
android := browser.Android()
log.Printf("Android: %s", android)
macOSX := browser.MacOSX()
log.Printf("MacOSX: %s", macOSX)
ios := browser.IOS()
log.Printf("IOS: %s", ios)
linux := browser.Linux()
log.Printf("Linux: %s", linux)
iphone := browser.IPhone()
log.Printf("IPhone: %s", iphone)
ipad := browser.IPad()
log.Printf("IPad: %s", ipad)
computer := browser.Computer()
log.Printf("Computer: %s", computer)
mobile := browser.Mobile()
log.Printf("Mobile: %s", mobile)
}
定製
你可以調整抓取資料來源的最大頁數、時間間隔以及最大超時時間。 如果不填寫,則為預設值。
client := browser.Client{
MaxPage: 3,
Delay: 200 * time.Millisecond,
Timeout: 10 * time.Second,
}
cache := browser.Cache{}
b := browser.NewBrowser(client, cache)
random := b.Random()
更新瀏覽器頭的臨時檔案快取
client := browser.Client{}
cache := browser.Cache{
UpdateFile: true,
}
b := browser.NewBrowser(client, cache)
最後,建議常規用法就好,預設引數能夠滿足日常需求
輸出
Random: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Chrome: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36
IE: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)
Firefox: Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0
Safari: Mozilla/5.0 (iPhone; CPU iPhone OS 11_2_5 like Mac OS X) AppleWebKit/604.5.6 (KHTML, like Gecko) Version/11.0 Mobile/15D60 Safari/604.1
Android: Mozilla/5.0 (Linux; Android 6.0; MYA-L22 Build/HUAWEIMYA-L22) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.84 Mobile Safari/537.36
MacOSX: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0.1 Safari/602.2.14
IOS: Mozilla/5.0 (iPhone; CPU iPhone OS 10_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0 Mobile/14B72 Safari/602.1
Linux: Mozilla/5.0 (X11; Linux x86_64; rv:42.0) Gecko/20100101 Firefox/42.0
IPhone: Mozilla/5.0 (iPhone; CPU iPhone OS 10_2 like Mac OS X) AppleWebKit/602.3.12 (KHTML, like Gecko) Version/10.0 Mobile/14C92 Safari/602.1
IPad: Mozilla/5.0 (iPad; CPU OS 5_0_1 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A405 Safari/7534.48.3
Computer: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0
Mobile: Mozilla/5.0 (Linux; Android 7.0; Redmi Note 4 Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.111 Mobile Safari/537.36
注意
如果第一次使用,fake-useragent 將收集資料並在臨時目錄中建立一個檔案作為檔案快取,請耐心等待幾秒鐘
最後
如果在專案中發現了什麼問題,歡迎提交 PR 或者 issue。希望你能夠喜歡這個專案,根本目的還是為了解決痛點,歡迎 Star!😁
專案地址:https://github.com/EDDYCJY/fake-useragent
1.3 用 Go 來了解一下 Redis 通訊協議
Go、PHP、Java... 都有那麼多包來支撐你使用 Redis,那你是否有想過
有了服務端,有了客戶端,他們倆是怎樣通訊,又是基於什麼通訊協議做出互動的呢?
介紹
基於我們的目的,本文主要講解和實踐 Redis 的通訊協議
Redis 的客戶端和服務端是透過 TCP 連線來進行資料互動, 伺服器預設的埠號為 6379
客戶端和伺服器傳送的命令或資料一律以 \r\n (CRLF)結尾(這是一條約定)
協議
在 Redis 中分為請求和回覆,而請求協議又分為新版和舊版,新版統一請求協議在 Redis 1.2 版本中引入,最終在 Redis 2.0 版本成為 Redis 伺服器通訊的標準方式
本文是基於新版協議來實作功能,不建議使用舊版(1.2 挺老舊了)。如下是新協議的各種範例:
請求協議
1、 格式示例
*<参数数量> CR LF
$<参数 1 的字节数量> CR LF
<参数 1 的数据> CR LF
...
$<参数 N 的字节数量> CR LF
<参数 N 的数据> CR LF
在該協議下所有傳送至 Redis 伺服器的引數都是二進位制安全(binary safe)的
2、列印示例
*3
$3
SET
$5
mykey
$7
myvalue
3、實際協議值
"*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n"
這就是 Redis 的請求協議規範,按照範例1編寫客戶端邏輯,最終傳送的是範例3,相信你已經有大致的概念了,Redis 的協議非常的簡潔易懂,這也是好上手的原因之一,你可以想想協議這麼定義的好處在哪?
回覆
Redis 會根據你請求協議的不同(執行的命令結果也不同),返回多種不同型別的回覆。在這個回覆“協議”中,可以透過檢查第一個位元組,確定這個回覆是什麼型別,如下:
- 狀態回覆(status reply)的第一個位元組是 "+"
- 錯誤回覆(error reply)的第一個位元組是 "-"
- 整數回覆(integer reply)的第一個位元組是 ":"
- 批量回復(bulk reply)的第一個位元組是 "$"
- 多條批量回復(multi bulk reply)的第一個位元組是 "*"
有了回覆的頭部標識,結尾的 CRLF,你可以大致猜想出回覆“協議”是怎麼樣的,但是實踐才能得出真理,斎知道怕是你很快就忘記了 😀
實踐
與 Redis 伺服器互動
package main
import (
"log"
"net"
"os"
"github.com/EDDYCJY/redis-protocol-example/protocol"
)
const (
Address = "127.0.0.1:6379"
Network = "tcp"
)
func Conn(network, address string) (net.Conn, error) {
conn, err := net.Dial(network, address)
if err != nil {
return nil, err
}
return conn, nil
}
func main() {
// 读取入参
args := os.Args[1:]
if len(args) <= 0 {
log.Fatalf("Os.Args <= 0")
}
// 获取请求协议
reqCommand := protocol.GetRequest(args)
// 连接 Redis 服务器
redisConn, err := Conn(Network, Address)
if err != nil {
log.Fatalf("Conn err: %v", err)
}
defer redisConn.Close()
// 写入请求内容
_, err = redisConn.Write(reqCommand)
if err != nil {
log.Fatalf("Conn Write err: %v", err)
}
// 读取回复
command := make([]byte, 1024)
n, err := redisConn.Read(command)
if err != nil {
log.Fatalf("Conn Read err: %v", err)
}
// 处理回复
reply, err := protocol.GetReply(command[:n])
if err != nil {
log.Fatalf("protocol.GetReply err: %v", err)
}
// 处理后的回复内容
log.Printf("Reply: %v", reply)
// 原始的回复内容
log.Printf("Command: %v", string(command[:n]))
}
在這裡我們完成了整個 Redis 客戶端和服務端互動的流程,分別如下:
1、讀取命令列引數:取得執行的 Redis 命令
2、取得請求協議引數
3、連線 Redis 伺服器,取得連線控制代碼
4、將請求協議引數寫入連線:傳送請求的命令列引數
5、從連線中讀取返回的資料:讀取先前請求的回覆資料
6、根據回覆“協議”內容,處理回覆的資料集
7、輸出處理後的回覆內容及原始回覆內容
請求
func GetRequest(args []string) []byte {
req := []string{
"*" + strconv.Itoa(len(args)),
}
for _, arg := range args {
req = append(req, "$"+strconv.Itoa(len(arg)))
req = append(req, arg)
}
str := strings.Join(req, "\r\n")
return []byte(str + "\r\n")
}
透過對 Redis 的請求協議的分析,可得出它的規律,先加上標誌位,計算引數總數量,再迴圈合併各個引數的位元組數量、值就可以了
回覆
func GetReply(reply []byte) (interface{}, error) {
replyType := reply[0]
switch replyType {
case StatusReply:
return doStatusReply(reply[1:])
case ErrorReply:
return doErrorReply(reply[1:])
case IntegerReply:
return doIntegerReply(reply[1:])
case BulkReply:
return doBulkReply(reply[1:])
case MultiBulkReply:
return doMultiBulkReply(reply[1:])
default:
return nil, nil
}
}
func doStatusReply(reply []byte) (string, error) {
if len(reply) == 3 && reply[1] == 'O' && reply[2] == 'K' {
return OkReply, nil
}
if len(reply) == 5 && reply[1] == 'P' && reply[2] == 'O' && reply[3] == 'N' && reply[4] == 'G' {
return PongReply, nil
}
return string(reply), nil
}
func doErrorReply(reply []byte) (string, error) {
return string(reply), nil
}
func doIntegerReply(reply []byte) (int, error) {
pos := getFlagPos('\r', reply)
result, err := strconv.Atoi(string(reply[:pos]))
if err != nil {
return 0, err
}
return result, nil
}
...
在這裡我們對所有回覆型別進行了分發,不同的回覆標誌位對應不同的處理方式,在這裡需求注意幾項問題,如下:
1、當請求的值不存在,會將特殊值 -1 用作回覆
2、伺服器傳送的所有字串都由 CRLF 結尾
3、多條批量回復是可基於批量回復的,要注意理解
4、無內容的多條批量回復是存在的
最重要的是,對不同回覆的規則的把控,能夠讓你更好的理解 Redis 的請求、回覆的互動過程 👌
小結
寫這篇文章的起因,是因為常常在使用 Redis 時,只是用,你不知道它是基於什麼樣的通訊協議來通訊,這樣的感覺是十分難受的
透過本文的講解,我相信你已經大致瞭解 Redis 客戶端是怎麼樣和服務端互動,也清楚了其所用的通訊原理,希望能夠對你有所幫助!
最後,如果想詳細檢視程式碼,右拐專案地址:https://github.com/EDDYCJY/redis-protocol-example
如果對你有所幫助,歡迎點個 Star 👍
參考
1.4 使用 Gomock 進行單元測試
在實際專案中,需要進行單元測試的時候。卻往往發現有一大堆依賴項。這時候就是 Gomock 大顯身手的時候了
Gomock 是 Go 語言的一個 mock 框架,官方的那種 🤪
安裝
$ go get -u github.com/golang/mock/gomock
$ go install github.com/golang/mock/mockgen
- 第一步:我們將安裝 gomock 第三方庫和 mock 程式碼的生成工具 mockgen。而後者可以大大的節省我們的工作量。只需要瞭解其使用方式就可以
- 第二步:輸入
mockgen驗證程式碼生成工具是否安裝正確。若無法正常響應,請檢查bin目錄下是否包含該二進位制檔案
用法
在 mockgen 命令中,支援兩種生成模式:
- source:從原始檔生成 mock 介面(透過 -source 啟用)
mockgen -source=foo.go [other options]
- reflect:透過使用反射程式來生成 mock 介面。它透過傳遞兩個非標誌引數來啟用:匯入路徑和逗號分隔的介面列表
mockgen database/sql/driver Conn,Driver
從本質上來講,兩種方式生成的 mock 程式碼並沒有什麼區別。因此選擇合適的就可以了
寫測試用例
在本文將模擬一個簡單 Demo 來編寫測試用例,熟悉整體的測試流程
步驟
- 想清楚整體邏輯
- 定義想要(模擬)依賴項的 interface(介面)
- 使用
mockgen命令對所需 mock 的 interface 生成 mock 檔案 - 編寫單元測試的邏輯,在測試中使用 mock
- 進行單元測試的驗證
目錄
├── mock
├── person
│ └── male.go
└── user
├── user.go
└── user_test.go
編寫
interface 方法
開啟 person/male.go 檔案,寫入以下內容:
package person
type Male interface {
Get(id int64) error
}
呼叫方法
開啟 user/user.go 檔案,寫入以下內容:
package user
import "github.com/EDDYCJY/mockd/person"
type User struct {
Person person.Male
}
func NewUser(p person.Male) *User {
return &User{Person: p}
}
func (u *User) GetUserInfo(id int64) error {
return u.Person.Get(id)
}
生成 mock 檔案
回到 mockd/ 的根目錄下,執行以下命令
$ mockgen -source=./person/male.go -destination=./mock/male_mock.go -package=mock
在執行完畢後,可以發現 mock/ 目錄下多出了 male_mock.go 檔案,這就是 mock 檔案。那麼命令中的指令又分別有什麼用呢?如下:
- -source:設定需要模擬(mock)的介面檔案
- -destination:設定 mock 檔案輸出的地方,若不設定則列印到標準輸出中
- -package:設定 mock 檔案的包名,若不設定則為
mock_字首加上檔名(如本文的包名會為 mock_person)
想了解更多的指令符,可參見 官方文件
輸出的 mock 檔案
// Code generated by MockGen. DO NOT EDIT.
// Source: ./person/male.go
// Package mock is a generated GoMock package.
package mock
import (
gomock "github.com/golang/mock/gomock"
reflect "reflect"
)
// MockMale is a mock of Male interface
type MockMale struct {
ctrl *gomock.Controller
recorder *MockMaleMockRecorder
}
// MockMaleMockRecorder is the mock recorder for MockMale
type MockMaleMockRecorder struct {
mock *MockMale
}
// NewMockMale creates a new mock instance
func NewMockMale(ctrl *gomock.Controller) *MockMale {
mock := &MockMale{ctrl: ctrl}
mock.recorder = &MockMaleMockRecorder{mock}
return mock
}
// EXPECT returns an object that allows the caller to indicate expected use
func (m *MockMale) EXPECT() *MockMaleMockRecorder {
return m.recorder
}
// Get mocks base method
func (m *MockMale) Get(id int64) error {
ret := m.ctrl.Call(m, "Get", id)
ret0, _ := ret[0].(error)
return ret0
}
// Get indicates an expected call of Get
func (mr *MockMaleMockRecorder) Get(id interface{}) *gomock.Call {
return mr.mock.ctrl.RecordCallWithMethodType(mr.mock, "Get", reflect.TypeOf((*MockMale)(nil).Get), id)
}
測試用例
開啟 user/user_test.go 檔案,寫入以下內容:
package user
import (
"testing"
"github.com/EDDYCJY/mockd/mock"
"github.com/golang/mock/gomock"
)
func TestUser_GetUserInfo(t *testing.T) {
ctl := gomock.NewController(t)
defer ctl.Finish()
var id int64 = 1
mockMale := mock.NewMockMale(ctl)
gomock.InOrder(
mockMale.EXPECT().Get(id).Return(nil),
)
user := NewUser(mockMale)
err := user.GetUserInfo(id)
if err != nil {
t.Errorf("user.GetUserInfo err: %v", err)
}
}
- gomock.NewController:返回
gomock.Controller,它代表 mock 生態系統中的頂級控制元件。定義了 mock 物件的範圍、生命週期和期待值。另外它在多個 goroutine 中是安全的 - mock.NewMockMale:建立一個新的 mock 例項
- gomock.InOrder:宣告給定的呼叫應按順序進行(是對 gomock.After 的二次封裝)
- mockMale.EXPECT().Get(id).Return(nil):這裡有三個步驟,
EXPECT()返回一個允許呼叫者設定期望和返回值的物件。Get(id)是設定入參並呼叫 mock 例項中的方法。Return(nil)是設定先前呼叫的方法出參。簡單來說,就是設定入參並呼叫,最後設定返回值 - NewUser(mockMale):建立 User 例項,值得注意的是,在這裡注入了 mock 物件,因此實際在隨後的
user.GetUserInfo(id)呼叫(入參:id 為 1)中。它呼叫的是我們事先模擬好的 mock 方法 - ctl.Finish():進行 mock 用例的期望值斷言,一般會使用
defer延遲執行,以防止我們忘記這一操作
測試
回到 mockd/ 的根目錄下,執行以下命令
$ go test ./user
ok github.com/EDDYCJY/mockd/user
看到這樣的結果,就大功告成啦!你可以自己調整一下 Return() 的返回值,以此得到不一樣的測試結果哦 😄
檢視測試情況
測試覆蓋率
$ go test -cover ./user
ok github.com/EDDYCJY/mockd/user (cached) coverage: 100.0% of statements
可透過設定 -cover 標誌符來開啟覆蓋率的統計,展示內容為 coverage: 100.0%。
視覺化介面
- 生成測試覆蓋率的 profile 檔案
$ go test ./... -coverprofile=cover.out
- 利用 profile 檔案生成視覺化介面
$ go tool cover -html=cover.out
- 檢視視覺化介面,分析覆蓋情況
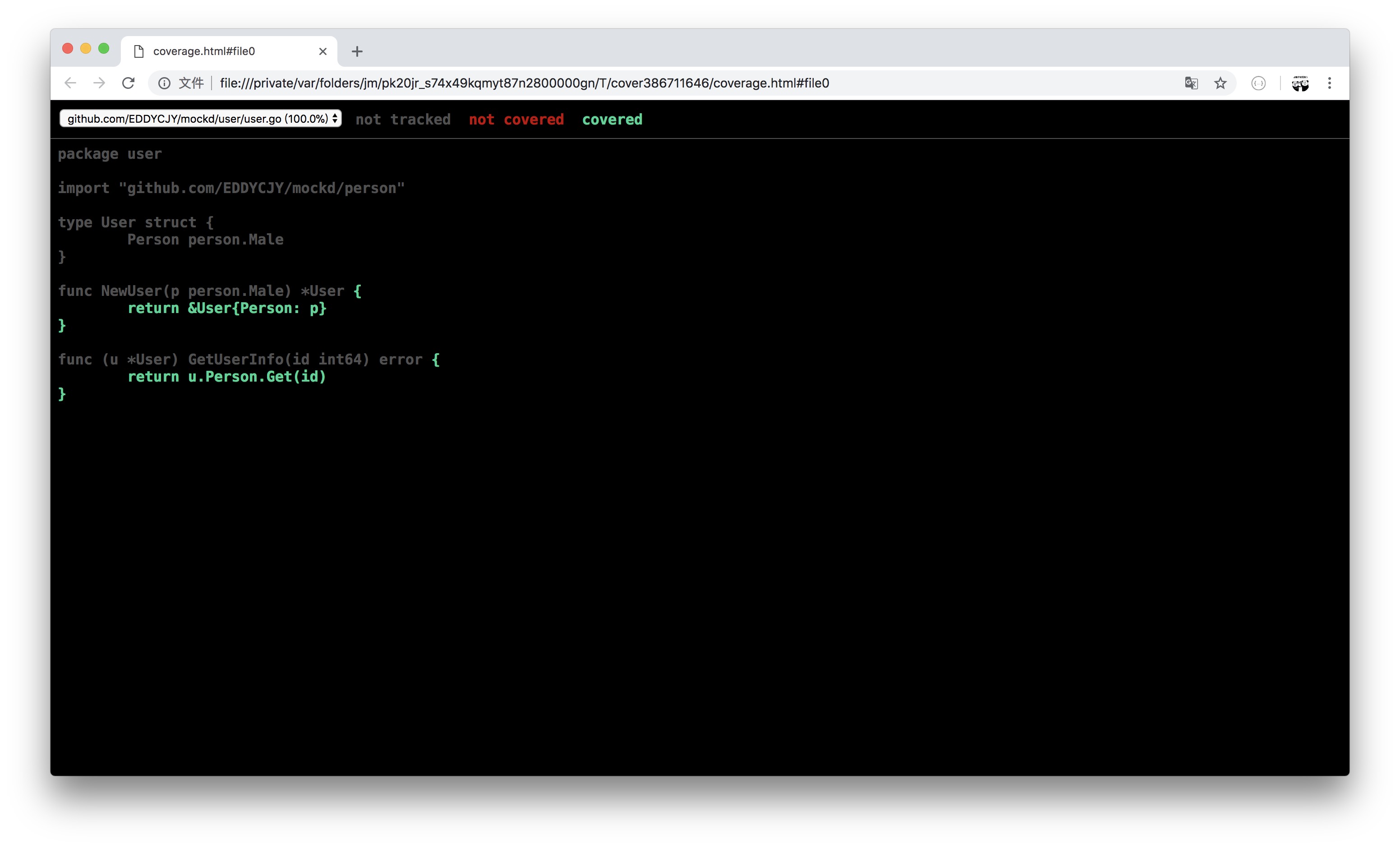
更多
一、常用 mock 方法
呼叫方法
- Call.Do():宣告在匹配時要執行的操作
- Call.DoAndReturn():宣告在匹配呼叫時要執行的操作,並且模擬返回該函式的返回值
- Call.MaxTimes():設定最大的呼叫次數為 n 次
- Call.MinTimes():設定最小的呼叫次數為 n 次
- Call.AnyTimes():允許呼叫次數為 0 次或更多次
- Call.Times():設定呼叫次數為 n 次
引數匹配
- gomock.Any():匹配任意值
- gomock.Eq():透過反射匹配到指定的型別值,而不需要手動設定
- gomock.Nil():返回 nil
建議更多的方法可參見 官方文件
二、生成多個 mock 檔案
你可能會想一條條命令生成 mock 檔案,豈不得崩潰?
當然,官方提供了更方便的方式,我們可以利用 go:generate 來完成批次處理的功能
go generate [-run regexp] [-n] [-v] [-x] [build flags] [file.go... | packages]
修改 interface 方法
開啟 person/male.go 檔案,修改為以下內容:
package person
//go:generate mockgen -destination=../mock/male_mock.go -package=mock github.com/EDDYCJY/mockd/person Male
type Male interface {
Get(id int64) error
}
我們關注到 go:generate 這條語句,可分為以下部分:
- 宣告
//go:generate(注意不要留空格) - 使用
mockgen命令 - 定義
-destination - 定義
-package - 定義
source,此處為 person 的包路徑 - 定義
interfaces,此處為Male
重新生成 mock 檔案
回到 mockd/ 的根目錄下,執行以下命令
$ go generate ./...
再檢查 mock/ 發現也已經正確生成了,在多個檔案時是不是很方便呢 🤩
總結
在單元測試這一環,gomock 給我們提供了極大的便利。能夠 mock 掉許許多多的依賴項
其中還有很多的使用方式和功能。你可以 mark 住後詳細閱讀下官方文件,記憶會更深刻
1.5 在 Go 中恰到好處的記憶體對齊

問題
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
在開始之前,希望你計算一下 Part1 共佔用的大小是多少呢?
func main() {
fmt.Printf("bool size: %d\n", unsafe.Sizeof(bool(true)))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(int32(0)))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(int8(0)))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(int64(0)))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(byte(0)))
fmt.Printf("string size: %d\n", unsafe.Sizeof("EDDYCJY"))
}
輸出結果:
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1
string size: 16
這麼一算,Part1 這一個結構體的佔用記憶體大小為 1+4+1+8+1 = 15 個位元組。相信有的小夥伴是這麼算的,看上去也沒什麼毛病
真實情況是怎麼樣的呢?我們實際呼叫看看,如下:
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
func main() {
part1 := Part1{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
}
輸出結果:
part1 size: 32, align: 8
最終輸出為佔用 32 個位元組。這與前面所預期的結果完全不一樣。這充分地說明了先前的計算方式是錯誤的。為什麼呢?
在這裡要提到 “記憶體對齊” 這一概念,才能夠用正確的姿勢去計算,接下來我們詳細的講講它是什麼
記憶體對齊
有的小夥伴可能會認為記憶體讀取,就是一個簡單的位元組陣列擺放

上圖表示一個坑一個蘿蔔的記憶體讀取方式。但實際上 CPU 並不會以一個一個位元組去讀取和寫入記憶體。相反 CPU 讀取記憶體是一塊一塊讀取的,塊的大小可以為 2、4、6、8、16 位元組等大小。塊大小我們稱其為記憶體訪問粒度。如下圖:
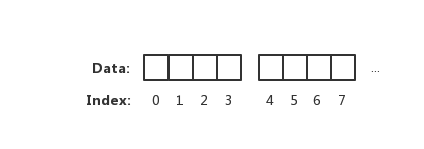
在樣例中,假設訪問粒度為 4。 CPU 是以每 4 個位元組大小的訪問粒度去讀取和寫入記憶體的。這才是正確的姿勢
為什麼要關心對齊
- 你正在編寫的程式碼在效能(CPU、Memory)方面有一定的要求
- 你正在處理向量方面的指令
- 某些硬體平臺(ARM)體系不支援未對齊的記憶體訪問
另外作為一個工程師,你也很有必要學習這塊知識點哦 :)
為什麼要做對齊
- 平臺(移植性)原因:不是所有的硬體平臺都能夠訪問任意地址上的任意資料。例如:特定的硬體平臺只允許在特定地址取得特定型別的資料,否則會導致異常情況
- 效能原因:若訪問未對齊的記憶體,將會導致 CPU 進行兩次記憶體訪問,並且要花費額外的時鐘週期來處理對齊及運算。而本身就對齊的記憶體僅需要一次訪問就可以完成讀取動作
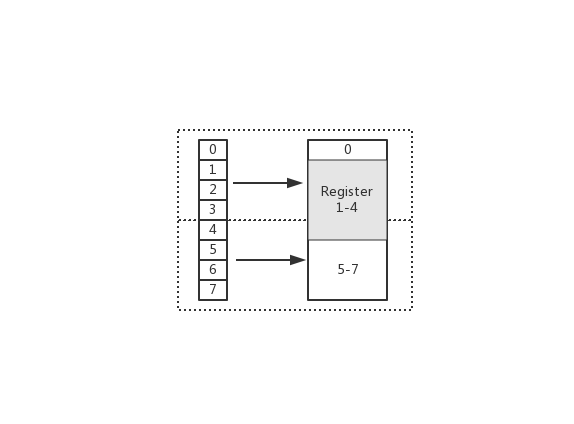
在上圖中,假設從 Index 1 開始讀取,將會出現很崩潰的問題。因為它的記憶體訪問邊界是不對齊的。因此 CPU 會做一些額外的處理工作。如下:
- CPU 首次讀取未對齊地址的第一個記憶體塊,讀取 0-3 位元組。並移除不需要的位元組 0
- CPU 再次讀取未對齊地址的第二個記憶體塊,讀取 4-7 位元組。並移除不需要的位元組 5、6、7 位元組
- 合併 1-4 位元組的資料
- 合併後放入暫存器
從上述流程可得出,不做 “記憶體對齊” 是一件有點 "麻煩" 的事。因為它會增加許多耗費時間的動作
而假設做了記憶體對齊,從 Index 0 開始讀取 4 個位元組,只需要讀取一次,也不需要額外的運算。這顯然高效很多,是標準的空間換時間做法
預設係數
在不同平臺上的編譯器都有自己預設的 “對齊係數”,可透過預編譯命令 #pragma pack(n) 進行變更,n 就是代指 “對齊係數”。一般來講,我們常用的平臺的係數如下:
- 32 位:4
- 64 位:8
另外要注意,不同硬體平臺佔用的大小和對齊值都可能是不一樣的。因此本文的值不是唯一的,除錯的時候需按本機的實際情況考慮
成員對齊
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
輸出結果:
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
在 Go 中可以呼叫 unsafe.Alignof 來返回相應型別的對齊係數。透過觀察輸出結果,可得知基本都是 2^n,最大也不會超過 8。這是因為我手提(64 位)編譯器預設對齊係數是 8,因此最大值不會超過這個數
整體對齊
在上小節中,提到了結構體中的成員變數要做位元組對齊。那麼想當然身為最終結果的結構體,也是需要做位元組對齊的
對齊規則
- 結構體的成員變數,第一個成員變數的偏移量為 0。往後的每個成員變數的對齊值必須為編譯器預設對齊長度(
#pragma pack(n))或當前成員變數型別的長度(unsafe.Sizeof),取最小值作為當前型別的對齊值。其偏移量必須為對齊值的整數倍 - 結構體本身,對齊值必須為編譯器預設對齊長度(
#pragma pack(n))或結構體的所有成員變數型別中的最大長度,取最大數的最小整數倍作為對齊值 - 結合以上兩點,可得知若編譯器預設對齊長度(
#pragma pack(n))超過結構體內成員變數的型別最大長度時,預設對齊長度是沒有任何意義的
分析流程
接下來我們一起分析一下,“它” 到底經歷了些什麼,影響了 “預期” 結果
| 成員變數 | 型別 | 偏移量 | 自身佔用 |
|---|---|---|---|
| a | bool | 0 | 1 |
| 位元組對齊 | 無 | 1 | 3 |
| b | int32 | 4 | 4 |
| c | int8 | 8 | 1 |
| 位元組對齊 | 無 | 9 | 7 |
| d | int64 | 16 | 8 |
| e | byte | 24 | 1 |
| 位元組對齊 | 無 | 25 | 7 |
| 總佔用大小 | - | - | 32 |
成員對齊
- 第一個成員 a
- 型別為 bool
- 大小/對齊值為 1 位元組
- 初始地址,偏移量為 0。佔用了第 1 位
- 第二個成員 b
- 型別為 int32
- 大小/對齊值為 4 位元組
- 根據規則 1,其偏移量必須為 4 的整數倍。確定偏移量為 4,因此 2-4 位為 Padding。而當前數值從第 5 位開始填充,到第 8 位。如下:axxx|bbbb
- 第三個成員 c
- 型別為 int8
- 大小/對齊值為 1 位元組
- 根據規則1,其偏移量必須為 1 的整數倍。當前偏移量為 8。不需要額外對齊,填充 1 個位元組到第 9 位。如下:axxx|bbbb|c...
- 第四個成員 d
-
型別為 int64
-
大小/對齊值為 8 位元組
-
根據規則 1,其偏移量必須為 8 的整數倍。確定偏移量為 16,因此
9-16 位為 Padding。而當前數值從第 17 位開始寫入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd
-
- 第五個成員 e
- 型別為 byte
- 大小/對齊值為 1 位元組
- 根據規則 1,其偏移量必須為 1 的整數倍。當前偏移量為 24。不需要額外對齊,填充 1 個位元組到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e...
整體對齊
在每個成員變數進行對齊後,根據規則 2,整個結構體本身也要進行位元組對齊,因為可發現它可能並不是 2^n,不是偶數倍。顯然不符合對齊的規則
根據規則 2,可得出對齊值為 8。現在的偏移量為 25,不是 8 的整倍數。因此確定偏移量為 32。對結構體進行對齊
結果
Part1 記憶體佈局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
小結
透過本節的分析,可得知先前的 “推算” 為什麼錯誤?
是因為實際記憶體管理並非 “一個蘿蔔一個坑” 的思想。而是一塊一塊。透過空間換時間(效率)的思想來完成這塊讀取、寫入。另外也需要兼顧不同平臺的記憶體操作情況
巧妙的結構體
在上一小節,可得知根據成員變數的型別不同,其結構體的記憶體會產生對齊等動作。那假設欄位順序不同,會不會有什麼變化呢?我們一起來試試吧 :-)
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
e byte
c int8
a bool
b int32
d int64
}
func main() {
part1 := Part1{}
part2 := Part2{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
}
輸出結果:
part1 size: 32, align: 8
part2 size: 16, align: 8
透過結果可以驚喜的發現,只是 “簡單” 對成員變數的欄位順序進行改變,就改變了結構體佔用大小
接下來我們一起剖析一下 Part2,看看它的內部到底和上一位之間有什麼區別,才導致了這樣的結果?
分析流程
| 成員變數 | 型別 | 偏移量 | 自身佔用 |
|---|---|---|---|
| e | byte | 0 | 1 |
| c | int8 | 1 | 1 |
| a | bool | 2 | 1 |
| 位元組對齊 | 無 | 3 | 1 |
| b | int32 | 4 | 4 |
| d | int64 | 8 | 8 |
| 總佔用大小 | - | - | 16 |
成員對齊
- 第一個成員 e
- 型別為 byte
- 大小/對齊值為 1 位元組
- 初始地址,偏移量為 0。佔用了第 1 位
- 第二個成員 c
- 型別為 int8
- 大小/對齊值為 1 位元組
- 根據規則1,其偏移量必須為 1 的整數倍。當前偏移量為 2。不需要額外對齊
- 第三個成員 a
- 型別為 bool
- 大小/對齊值為 1 位元組
- 根據規則1,其偏移量必須為 1 的整數倍。當前偏移量為 3。不需要額外對齊
- 第四個成員 b
- 型別為 int32
- 大小/對齊值為 4 位元組
- 根據規則1,其偏移量必須為 4 的整數倍。確定偏移量為 4,因此第 3 位為 Padding。而當前數值從第 4 位開始填充,到第 8 位。如下:ecax|bbbb
- 第五個成員 d
- 型別為 int64
- 大小/對齊值為 8 位元組
- 根據規則1,其偏移量必須為 8 的整數倍。當前偏移量為 8。不需要額外對齊,從 9-16 位填充 8 個位元組。如下:ecax|bbbb|dddd|dddd
整體對齊
符合規則 2,不需要額外對齊
結果
Part2 記憶體佈局:ecax|bbbb|dddd|dddd
總結
透過對比 Part1 和 Part2 的記憶體佈局,你會發現兩者有很大的不同。如下:
- Part1:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
- Part2:ecax|bbbb|dddd|dddd
仔細一看,Part1 存在許多 Padding。顯然它佔據了不少空間,那麼 Padding 是怎麼出現的呢?
透過本文的介紹,可得知是由於不同型別導致需要進行位元組對齊,以此保證記憶體的訪問邊界
那麼也不難理解,為什麼調整結構體內成員變數的欄位順序就能達到縮小結構體佔用大小的疑問了,是因為巧妙地減少了 Padding 的存在。讓它們更 “緊湊” 了。這一點對於加深 Go 的記憶體佈局印象和大物件的最佳化非常有幫
當然了,沒什麼特殊問題,你可以不關注這一塊。但你要知道這塊知識點 😄
參考
1.6 來,控制一下 goroutine 的併發數量

問題
func main() {
userCount := math.MaxInt64
for i := 0; i < userCount; i++ {
go func(i int) {
// 做一些各种各样的业务逻辑处理
fmt.Printf("go func: %d\n", i)
time.Sleep(time.Second)
}(i)
}
}
在這裡,假設 userCount 是一個外部傳入的引數(不可預測,有可能值非常大),有人會全部丟進去迴圈。想著全部都併發 goroutine 去同時做某一件事。覺得這樣子會效率會更高,對不對!
那麼,你覺得這裡有沒有什麼問題?
噩夢般的開始
當然,在特定場景下,問題可大了。因為在本文被丟進去同時併發的可是一個極端值。我們可以一起觀察下圖的指標分析,看看情況有多 “崩潰”。下圖是上述程式碼的表現:
輸出結果
...
go func: 5839
go func: 5840
go func: 5841
go func: 5842
go func: 5915
go func: 5524
go func: 5916
go func: 8209
go func: 8264
signal: killed
如果你自己執行過程式碼,在 “輸出結果” 上你會遇到如下問題:
- 系統資源佔用率不斷上漲
- 輸出一定數量後:控制檯就不再重新整理輸出最新的值了
- 訊號量:signal: killed
系統負載
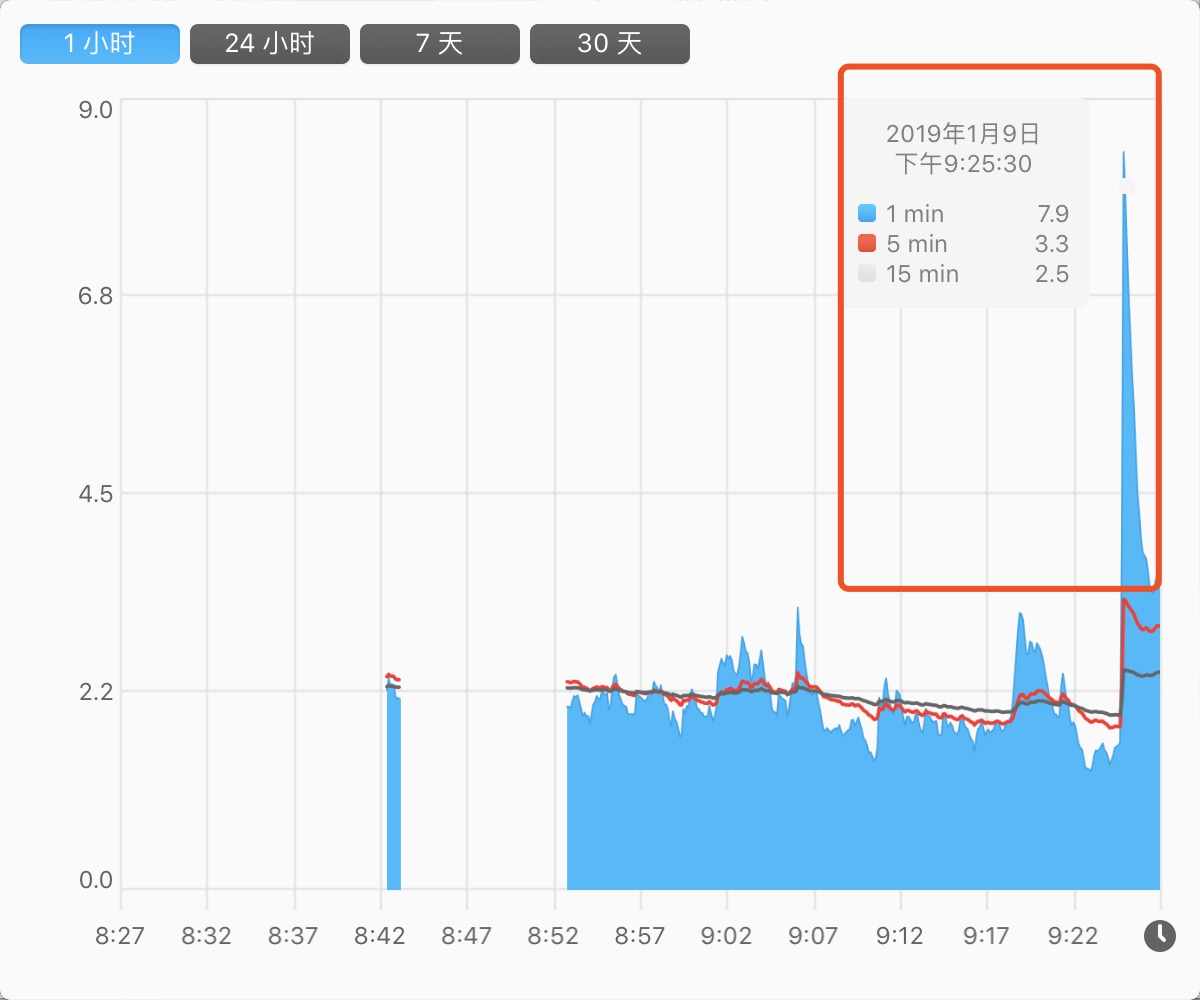
CPU
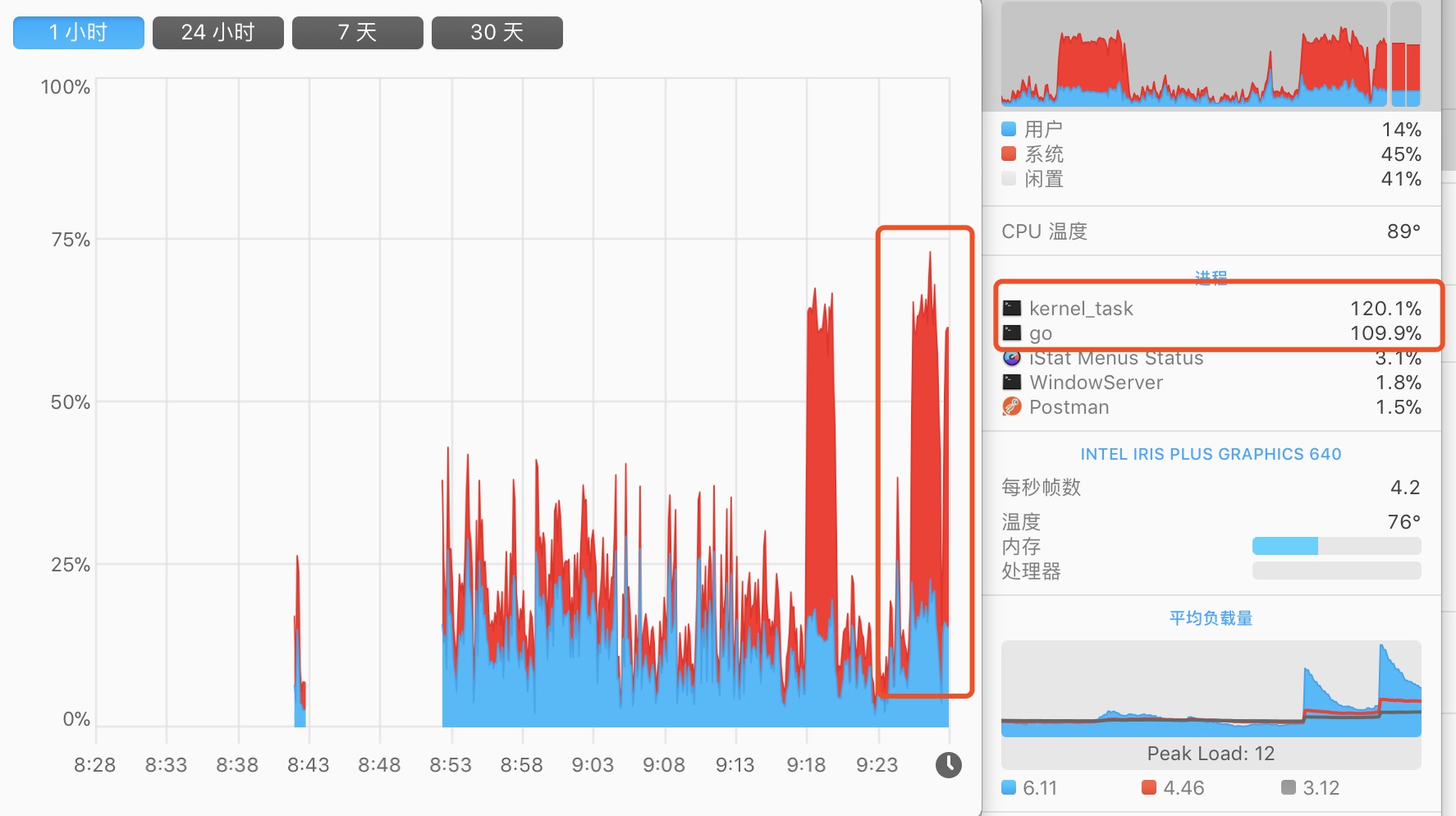
短時間內系統負載暴增
虛擬記憶體
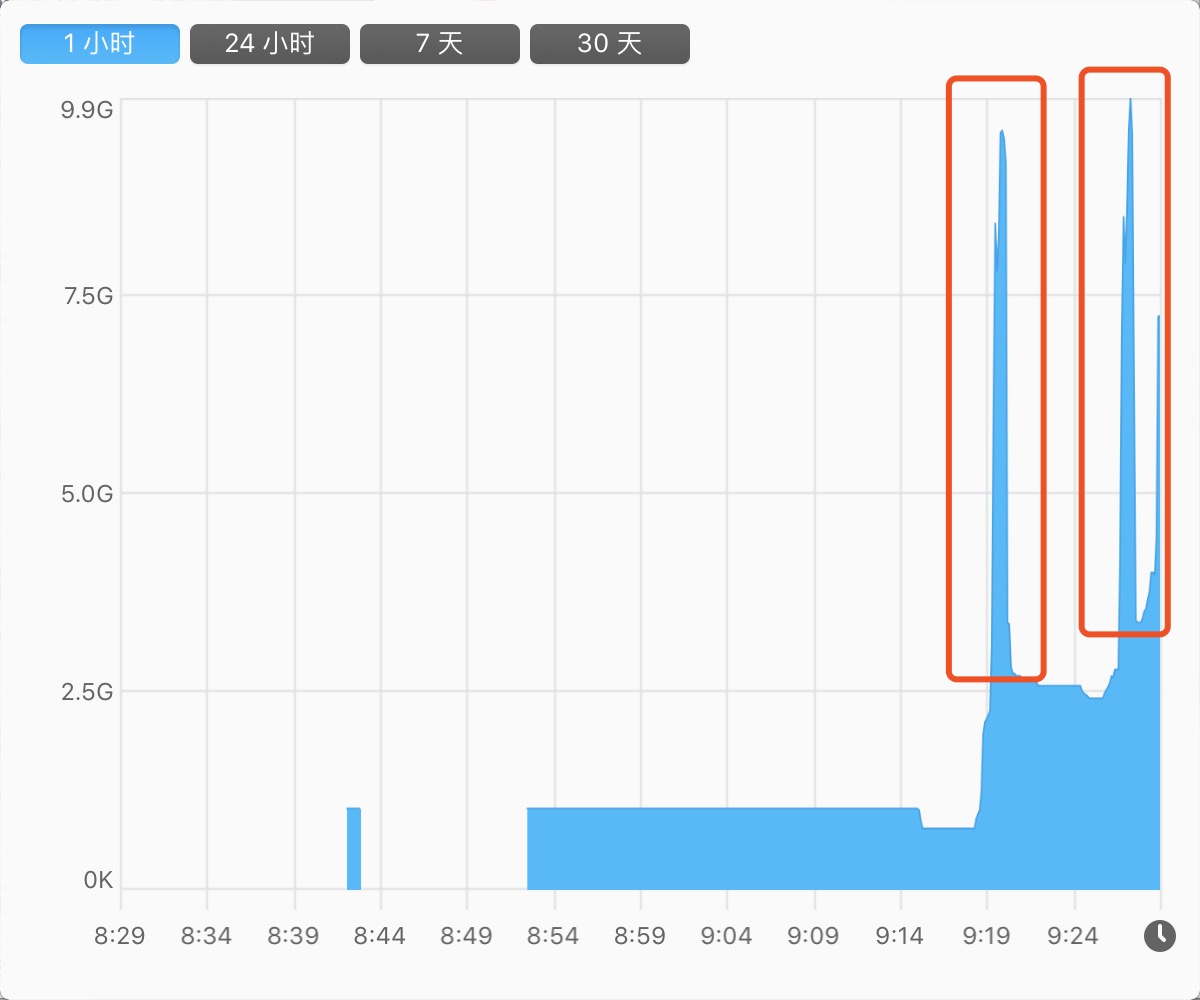
短時間內佔用的虛擬記憶體暴增
top
PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS
...
73414 test 100.2 01:59.50 9/1 0 18 6801M+ 0B 114G+ 73403 73403 running *0[1]
小結
如果仔細看過監控工具的示意圖,就可以知道其實我間隔的執行了兩次,能看到系統間的使用率幅度非常大。當程序被殺掉後,整體又恢復為正常值
在這裡,我們回到主題,就是在不控制併發的 goroutine 數量 會發生什麼問題?大致如下:
- CPU 使用率浮動上漲
- Memory 佔用不斷上漲。也可以看看 CMPRS,它表示程序的壓縮資料的位元組數。已經到達 114G+ 了
- 主程序崩潰(被殺掉了)
簡單來說,“崩潰” 的原因就是對系統資源的佔用過大。常見的比如:開啟檔案數(too many files open)、記憶體佔用等等
危害
對該臺伺服器產生非常大的影響,影響自身及相關聯的應用。很有可能導致不可用或響應緩慢,另外啟動了複數 “失控” 的 goroutine,導致程式流轉混亂
解決方案
在前面花了大量篇幅,渲染了在存在大量併發 goroutine 數量時,不控制的話會出現 “嚴重” 的問題,接下來一起思考下解決方案。如下:
- 控制/限制 goroutine 同時併發執行的數量
- 改變應用程式的邏輯寫法(避免大規模的使用系統資源和等待)
調整服務的硬體設定、最大開啟數、記憶體等閾值
控制 goroutine 併發數量
接下來正式的開始解決這個問題,希望你認真閱讀的同時加以思考,因為這個問題在實際專案中真的是太常見了!
問題已經丟擲來了,你需要做的是想想有什麼辦法解決這個問題。建議你自行思考一下技術方案。再接著往下看 :-)
嘗試 chan
func main() {
userCount := 10
ch := make(chan bool, 2)
for i := 0; i < userCount; i++ {
ch <- true
go Read(ch, i)
}
//time.Sleep(time.Second)
}
func Read(ch chan bool, i int) {
fmt.Printf("go func: %d\n", i)
<- ch
}
輸出結果:
go func: 1
go func: 2
go func: 3
go func: 4
go func: 5
go func: 6
go func: 7
go func: 8
go func: 0
嗯,我們似乎很好的控制了 2 個 2 個的 “順序” 執行多個 goroutine。但是,問題出現了。你仔細數一下輸出結果,才 9 個值?
這明顯就不對。原因出在當主協程結束時,子協程也是會被終止掉的。因此剩餘的 goroutine 沒來及把值輸出,就被送上路了(不信你把 time.Sleep 開啟看看,看看輸出數量)
嘗試 sync
...
var wg = sync.WaitGroup{}
func main() {
userCount := 10
for i := 0; i < userCount; i++ {
wg.Add(1)
go Read(i)
}
wg.Wait()
}
func Read(i int) {
defer wg.Done()
fmt.Printf("go func: %d\n", i)
}
嗯,單純的使用 sync.WaitGroup 也不行。沒有控制到同時併發的 goroutine 數量(代指達不到本文所要求的目標)
小結
單純簡單使用 channel 或 sync 都有明顯缺陷,不行。我們再看看元件配合能不能實作
嘗試 chan + sync
...
var wg = sync.WaitGroup{}
func main() {
userCount := 10
ch := make(chan bool, 2)
for i := 0; i < userCount; i++ {
wg.Add(1)
go Read(ch, i)
}
wg.Wait()
}
func Read(ch chan bool, i int) {
defer wg.Done()
ch <- true
fmt.Printf("go func: %d, time: %d\n", i, time.Now().Unix())
time.Sleep(time.Second)
<-ch
}
輸出結果:
go func: 9, time: 1547911938
go func: 1, time: 1547911938
go func: 6, time: 1547911939
go func: 7, time: 1547911939
go func: 8, time: 1547911940
go func: 0, time: 1547911940
go func: 3, time: 1547911941
go func: 2, time: 1547911941
go func: 4, time: 1547911942
go func: 5, time: 1547911942
從輸出結果來看,確實實作了控制 goroutine 以 2 個 2 個的數量去執行我們的 “業務邏輯”,當然結果集也理所應當的是亂序輸出
方案一:簡單 Semaphore
在確立了簡單使用 chan + sync 的方案是可行後,我們重新將流轉邏輯封裝為 gsema,主程式變成如下:
import (
"fmt"
"time"
"github.com/EDDYCJY/gsema"
)
var sema = gsema.NewSemaphore(3)
func main() {
userCount := 10
for i := 0; i < userCount; i++ {
go Read(i)
}
sema.Wait()
}
func Read(i int) {
defer sema.Done()
sema.Add(1)
fmt.Printf("go func: %d, time: %d\n", i, time.Now().Unix())
time.Sleep(time.Second)
}
分析方案
在上述程式碼中,程式執行流程如下:
- 設定允許的併發數目為 3 個
- 迴圈 10 次,每次啟動一個 goroutine 來執行任務
- 每一個 goroutine 在內部利用
sema進行調控是否阻塞 - 按允許併發數逐漸釋出 goroutine,最後結束任務
看上去人模人樣,沒什麼嚴重問題。但卻有一個 “大” 坑,認真看到第二點 “每次啟動一個 goroutine” 這句話。這裡有點問題,提前產生那麼多的 goroutine 會不會有什麼問題,接下來一起分析下利弊,如下:
利
- 適合量不大、複雜度低的使用場景
- 幾百幾千個、幾十萬個也是可以接受的(看具體業務場景)
- 實際業務邏輯在執行前就已經被阻塞等待了(因為併發數受限),基本實際業務邏輯損耗的效能比 goroutine 本身大
- goroutine 本身很輕便,僅損耗極少許的記憶體空間和排程。這種等待響應的情況都是躺好了,等待任務喚醒
- Semaphore 操作複雜度低且流轉簡單,容易控制
弊
- 不適合量很大、複雜度高的使用場景
- 有幾百萬、幾千萬個 goroutine 的話,就浪費了大量排程 goroutine 和記憶體空間。恰好你的伺服器也接受不了的話
- Semaphore 操作複雜度提高,要管理更多的狀態
小結
- 基於什麼業務場景,就用什麼方案去做事
- 有足夠的時間,允許你去追求更優秀、極致的方案(用第三方庫也行)
用哪種方案,我認為主要基於以上兩點去思考,都是 OK 的。沒有對錯,只有當前業務場景能不能接受,這個預先啟動的 goroutine 數量你的系統是否能夠接受
當然了,常見/簡單的 Go 應用採用這類技術方案,基本就能解決問題了。因為像本文第一節 “問題” 如此超巨大數量的情況,情況很少。其並不存在那些 “特殊性”。因此用這個方案基本 OK
靈活控制 goroutine 併發數量
小手一緊。隔壁老王發現了新的問題。“方案一” 中,在輸入輸出一體的情況下,在常見的業務場景中確實可以
但,這次新的業務場景比較特殊,要控制輸入的數量,以此達到改變允許併發執行 goroutine 的數量。我們仔細想想,要做出如下改變:
- 輸入/輸出要抽離,才可以分別控制
- 輸入/輸出要可變,理所應當在 for-loop 中(可設定數值的地方)
- 允許改變 goroutine 併發數量,但它也必須有一個最大值(因為允許改變是相對)
方案二:靈活 chan + sync
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
userCount := 10
ch := make(chan int, 5)
for i := 0; i < userCount; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for d := range ch {
fmt.Printf("go func: %d, time: %d\n", d, time.Now().Unix())
time.Sleep(time.Second * time.Duration(d))
}
}()
}
for i := 0; i < 10; i++ {
ch <- 1
ch <- 2
//time.Sleep(time.Second)
}
close(ch)
wg.Wait()
}
輸出結果:
...
go func: 1, time: 1547950567
go func: 3, time: 1547950567
go func: 1, time: 1547950567
go func: 2, time: 1547950567
go func: 2, time: 1547950567
go func: 3, time: 1547950567
go func: 1, time: 1547950568
go func: 2, time: 1547950568
go func: 3, time: 1547950568
go func: 1, time: 1547950568
go func: 3, time: 1547950569
go func: 2, time: 1547950569
在 “方案二” 中,我們可以隨時隨地的根據新的業務需求,做如下事情:
- 變更 channel 的輸入數量
- 能夠根據特殊情況,變更 channel 的迴圈值
- 變更最大允許併發的 goroutine 數量
總的來說,就是可控空間都儘量放開了,是不是更加靈活了呢 :-)
方案三:第三方庫
比較成熟的第三方庫也不少,基本都是以生成和管理 goroutine 為目標的池工具。我簡單列了幾個,具體建議大家閱讀下原始碼或者多找找,原理相似
總結
在本文的開頭,我花了大力氣(極端數量),告訴你同時併發過多的 goroutine 數量會導致系統佔用資源不斷上漲。最終該服務崩盤的極端情況。為的是希望你今後避免這種問題,給你留下深刻的印象
接下來我們以 “控制 goroutine 併發數量” 為主題,展開了一番分析。分別給出了三種方案。在我看來,各具優缺點,我建議你挑選合適自身場景的技術方案就可以了
因為,有不同型別的技術方案也能解決這個問題,千人千面。本文推薦的是較常見的解決方案,也歡迎大家在評論區繼續補充 :-)
1.7 for-loop 與 json.Unmarshal 效能分析概要
在專案中,常常會遇到迴圈交換賦值的資料處理場景,尤其是 RPC,資料互動格式要轉為 Protobuf,賦值是無法避免的。一般會有如下幾種做法:
- for
- for range
- json.Marshal/Unmarshal
這時候又面臨 “選擇困難症”,用哪個好?又想程式碼量少,又擔心效能有沒有影響啊...
為了弄清楚這個疑惑,接下來將分別編寫三種使用場景。來簡單看看它們的效能情況,看看誰更 “好”
功能程式碼
...
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Avatar string `json:"avatar"`
Type string `json:"type"`
}
type AgainPerson struct {
Name string `json:"name"`
Age int `json:"age"`
Avatar string `json:"avatar"`
Type string `json:"type"`
}
const MAX = 10000
func InitPerson() []Person {
var persons []Person
for i := 0; i < MAX; i++ {
persons = append(persons, Person{
Name: "EDDYCJY",
Age: i,
Avatar: "https://github.com/EDDYCJY",
Type: "Person",
})
}
return persons
}
func ForStruct(p []Person, count int) {
for i := 0; i < count; i++ {
_, _ = i, p[i]
}
}
func ForRangeStruct(p []Person) {
for i, v := range p {
_, _ = i, v
}
}
func JsonToStruct(data []byte, againPerson []AgainPerson) ([]AgainPerson, error) {
err := json.Unmarshal(data, &againPerson)
return againPerson, err
}
func JsonIteratorToStruct(data []byte, againPerson []AgainPerson) ([]AgainPerson, error) {
var jsonIter = jsoniter.ConfigCompatibleWithStandardLibrary
err := jsonIter.Unmarshal(data, &againPerson)
return againPerson, err
}
測試程式碼
...
func BenchmarkForStruct(b *testing.B) {
person := InitPerson()
count := len(person)
b.ResetTimer()
for i := 0; i < b.N; i++ {
ForStruct(person, count)
}
}
func BenchmarkForRangeStruct(b *testing.B) {
person := InitPerson()
b.ResetTimer()
for i := 0; i < b.N; i++ {
ForRangeStruct(person)
}
}
func BenchmarkJsonToStruct(b *testing.B) {
var (
person = InitPerson()
againPersons []AgainPerson
)
data, err := json.Marshal(person)
if err != nil {
b.Fatalf("json.Marshal err: %v", err)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
JsonToStruct(data, againPersons)
}
}
func BenchmarkJsonIteratorToStruct(b *testing.B) {
var (
person = InitPerson()
againPersons []AgainPerson
)
data, err := json.Marshal(person)
if err != nil {
b.Fatalf("json.Marshal err: %v", err)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
JsonIteratorToStruct(data, againPersons)
}
}
測試結果
BenchmarkForStruct-4 500000 3289 ns/op 0 B/op 0 allocs/op
BenchmarkForRangeStruct-4 200000 9178 ns/op 0 B/op 0 allocs/op
BenchmarkJsonToStruct-4 100 19173117 ns/op 2618509 B/op 40036 allocs/op
BenchmarkJsonIteratorToStruct-4 300 4116491 ns/op 3694017 B/op 30047 allocs/op
從測試結果來看,效能排名為:for < for range < json-iterator < encoding/json。接下來我們看看是什麼原因導致了這樣子的排名?
效能對比
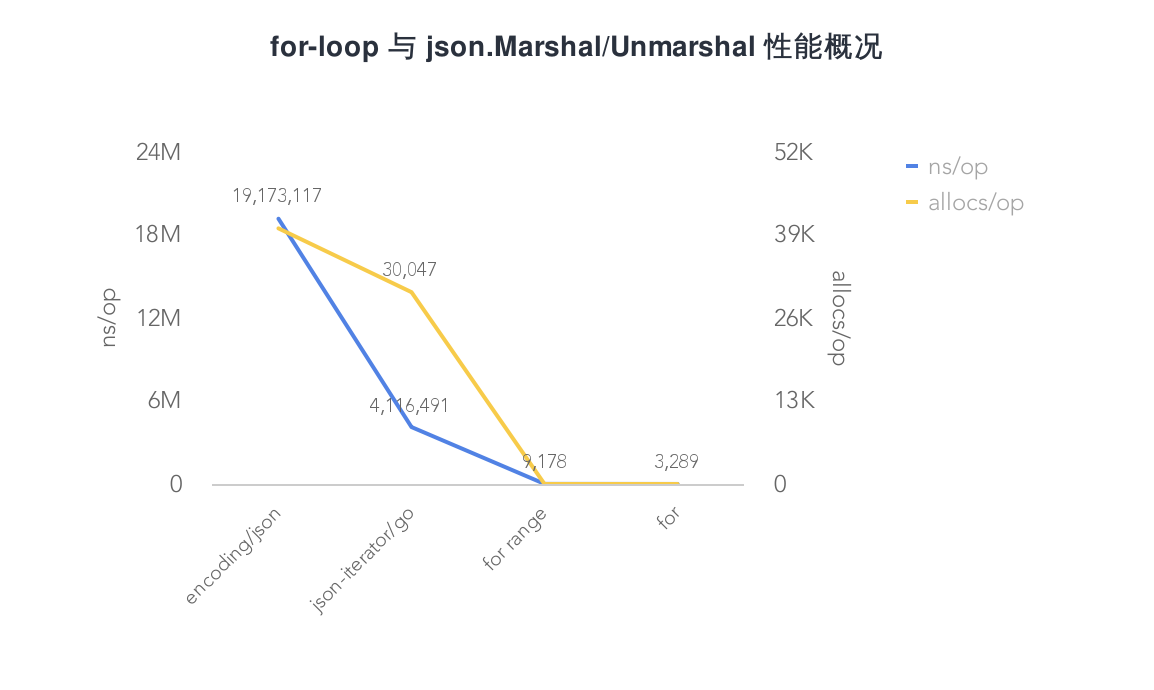
for-loop
在測試結果中,for range 在效能上相較 for 差。這是為什麼呢?在這裡我們可以參見 for range 的 實作,偽實作如下:
for_temp := range
len_temp := len(for_temp)
for index_temp = 0; index_temp < len_temp; index_temp++ {
value_temp = for_temp[index_temp]
index = index_temp
value = value_temp
original body
}
透過分析偽實作,可得知 for range 相較 for 多做了如下事項
Expression
RangeClause = [ ExpressionList "=" | IdentifierList ":=" ] "range" Expression .
在迴圈開始之前會對範圍表示式進行求值,多做了 “解” 表示式的動作,得到了最終的範圍值
Copy
...
value_temp = for_temp[index_temp]
index = index_temp
value = value_temp
...
從偽實作上可以得出,for range 始終使用值複製的方式來生成迴圈變數。通俗來講,就是在每次迴圈時,都會對迴圈變數重新分配
小結
透過上述的分析,可得知其比 for 慢的原因是 for range 有額外的效能開銷,主要為值複製的動作導致的效能下降。這是它慢的原因
那麼其實在 for range 中,我們可以使用 _ 和 T[i] 也能達到和 for 差不多的效能。但這可能不是 for range 的設計本意了
json.Marshal/Unmarshal
encoding/json
json 互轉是在三種方案中最慢的,這是為什麼呢?
眾所皆知,官方的 encoding/json 標準庫,是透過大量反射來實作的。那麼 “慢”,也是必然的。可參見下述程式碼:
...
func newTypeEncoder(t reflect.Type, allowAddr bool) encoderFunc {
...
switch t.Kind() {
case reflect.Bool:
return boolEncoder
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
return intEncoder
case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
return uintEncoder
case reflect.Float32:
return float32Encoder
case reflect.Float64:
return float64Encoder
case reflect.String:
return stringEncoder
case reflect.Interface:
return interfaceEncoder
case reflect.Struct:
return newStructEncoder(t)
case reflect.Map:
return newMapEncoder(t)
case reflect.Slice:
return newSliceEncoder(t)
case reflect.Array:
return newArrayEncoder(t)
case reflect.Ptr:
return newPtrEncoder(t)
default:
return unsupportedTypeEncoder
}
}
既然官方的標準庫存在一定的 “問題”,那麼有沒有其他解決方法呢?目前在社群裡,大多為兩類方案。如下:
- 預編譯生成程式碼(提前確定型別),可以解決執行時的反射帶來的效能開銷。缺點是增加了預生成的步驟
- 最佳化序列化的邏輯,效能達到最大化
接下來的實驗,我們用第二種方案的庫來測試,看看有沒有改變。另外也推薦大家瞭解如下專案:
json-iterator/go
目前社群較常用的是 json-iterator/go,我們在測試程式碼中用到了它
它的用法與標準庫 100% 相容,並且效能有較大提升。我們一起粗略的看下是怎麼做到的,如下:
reflect2
利用 modern-go/reflect2 減少執行時排程開銷
...
type StructDescriptor struct {
Type reflect2.Type
Fields []*Binding
}
...
type Binding struct {
levels []int
Field reflect2.StructField
FromNames []string
ToNames []string
Encoder ValEncoder
Decoder ValDecoder
}
type Extension interface {
UpdateStructDescriptor(structDescriptor *StructDescriptor)
CreateMapKeyDecoder(typ reflect2.Type) ValDecoder
CreateMapKeyEncoder(typ reflect2.Type) ValEncoder
CreateDecoder(typ reflect2.Type) ValDecoder
CreateEncoder(typ reflect2.Type) ValEncoder
DecorateDecoder(typ reflect2.Type, decoder ValDecoder) ValDecoder
DecorateEncoder(typ reflect2.Type, encoder ValEncoder) ValEncoder
}
struct Encoder/Decoder Cache
型別為 struct 時,只需要反射一次 Name 和 Type,會快取 struct Encoder 和 Decoder
var typeDecoders = map[string]ValDecoder{}
var fieldDecoders = map[string]ValDecoder{}
var typeEncoders = map[string]ValEncoder{}
var fieldEncoders = map[string]ValEncoder{}
var extensions = []Extension{}
....
fieldNames := calcFieldNames(field.Name(), tagParts[0], tag)
fieldCacheKey := fmt.Sprintf("%s/%s", typ.String(), field.Name())
decoder := fieldDecoders[fieldCacheKey]
if decoder == nil {
decoder = decoderOfType(ctx.append(field.Name()), field.Type())
}
encoder := fieldEncoders[fieldCacheKey]
if encoder == nil {
encoder = encoderOfType(ctx.append(field.Name()), field.Type())
}
文字解析最佳化
小結
相較於官方標準庫,第三方庫 json-iterator/go 在執行時上做的更好。這是它快的原因
有個需要注意的點,在 Go1.10 後 map 型別與標準庫的已經沒有太大的效能差異。但是,例如 struct 型別等仍然有較大的效能提高
總結
在本文中,我們首先進行了效能測試,再分析了不同方案,得知為什麼了快慢的原因。那麼最終在選擇方案時,可以根據不同的應用場景去抉擇:
- 對效能開銷有較高要求:選用
for,開銷最小 - 中規中矩:選用
for range,大物件慎用 - 量小、佔用小、數量可控:選用
json.Marshal/Unmarshal的方案也可以。其重複程式碼少,但開銷最大
在絕大多數場景中,使用哪種並沒有太大的影響。但作為工程師你應當清楚其利弊。以上就是不同的方案分析概要,希望對你有所幫助 :)
1.8 簡單圍觀一下有趣的 //go: 指令

前言
如果你平時有翻看原始碼的習慣,你肯定會發現。咦,怎麼有的方法上面總是寫著 //go: 這類指令呢。他們到底是幹嘛用的?
今天我們一同揭開他們的面紗,我將簡單給你介紹一下,它們都負責些什麼
go:linkname
//go:linkname localname importpath.name
該指令指示編譯器使用 importpath.name 作為原始碼中宣告為 localname 的變數或函式的目標檔案符號名稱。但是由於這個偽指令,可以破壞型別系統和包模組化。因此只有引用了 unsafe 包才可以使用
簡單來講,就是 importpath.name 是 localname 的符號別名,編譯器實際上會呼叫 localname 。但前提是使用了 unsafe 包才能使用
案例
time/time.go
...
func now() (sec int64, nsec int32, mono int64)
runtime/timestub.go
import _ "unsafe" // for go:linkname
//go:linkname time_now time.now
func time_now() (sec int64, nsec int32, mono int64) {
sec, nsec = walltime()
return sec, nsec, nanotime() - startNano
}
在這個案例中可以看到 time.now,它並沒有具體的實作。如果你初看可能會懵逼。這時候建議你全域性搜尋一下原始碼,你就會發現其實作在 runtime.time_now 中
配合先前的用法解釋,可得知在 runtime 包中,我們聲明瞭 time_now 方法是 time.now 的符號別名。並且在檔案頭引入了 unsafe 達成前提條件
go:noescape
//go:noescape
該指令指定下一個有宣告但沒有主體(意味著實作有可能不是 Go)的函式,不允許編譯器對其做逃逸分析
一般情況下,該指令用於記憶體分配最佳化。因為編譯器預設會進行逃逸分析,會透過規則判定一個變數是分配到堆上還是棧上。但凡事有意外,一些函式雖然逃逸分析其是存放到堆上。但是對於我們來說,它是特別的。我們就可以使用 go:noescape 指令強制要求編譯器將其分配到函式棧上
案例
// memmove copies n bytes from "from" to "to".
// in memmove_*.s
//go:noescape
func memmove(to, from unsafe.Pointer, n uintptr)
我們觀察一下這個案例,它滿足了該指令的常見特性。如下:
- memmove_*.s:只有宣告,沒有主體。其主體是由底層彙編實作的
- memmove:函式功能,在棧上處理效能會更好
go:nosplit
//go:nosplit
該指令指定檔案中宣告的下一個函式不得包含堆疊溢位檢查。簡單來講,就是這個函式跳過堆疊溢位的檢查
案例
//go:nosplit
func key32(p *uintptr) *uint32 {
return (*uint32)(unsafe.Pointer(p))
}
go:nowritebarrierrec
//go:nowritebarrierrec
該指令表示編譯器遇到寫屏障時就會產生一個錯誤,並且允許遞迴。也就是這個函式呼叫的其他函式如果有寫屏障也會報錯。簡單來講,就是針對寫屏障的處理,防止其死迴圈
案例
//go:nowritebarrierrec
func gcFlushBgCredit(scanWork int64) {
...
}
go:yeswritebarrierrec
//go:yeswritebarrierrec
該指令與 go:nowritebarrierrec 相對,在標註 go:nowritebarrierrec 指令的函式上,遇到寫屏障會產生錯誤。而當編譯器遇到 go:yeswritebarrierrec 指令時將會停止
案例
//go:yeswritebarrierrec
func gchelper() {
...
}
go:noinline
該指令表示該函式禁止進行內聯
案例
//go:noinline
func unexportedPanicForTesting(b []byte, i int) byte {
return b[i]
}
我們觀察一下這個案例,是直接透過索引取值,邏輯比較簡單。如果不加上 go:noinline 的話,就會出現編譯器對其進行內聯最佳化
顯然,內聯有好有壞。該指令就是提供這一特殊處理
go:norace
//go:norace
該指令表示禁止進行競態檢測。而另外一種常見的形式就是在啟動時執行 go run -race,能夠檢測應用程式中是否存在雙向的資料競爭。非常有用
案例
//go:norace
func forkAndExecInChild(argv0 *byte, argv, envv []*byte, chroot, dir *byte, attr *ProcAttr, sys *SysProcAttr, pipe int) (pid int, err Errno) {
...
}
go:notinheap
//go:notinheap
該指令常用於型別宣告,它表示這個型別不允許從 GC 堆上進行申請記憶體。在執行時中常用其來做較低層次的內部結構,避免排程器和記憶體分配中的寫屏障。能夠提高效能
案例
// notInHeap is off-heap memory allocated by a lower-level allocator
// like sysAlloc or persistentAlloc.
//
// In general, it's better to use real types marked as go:notinheap,
// but this serves as a generic type for situations where that isn't
// possible (like in the allocators).
//
//go:notinheap
type notInHeap struct{}
總結
在本文我們簡單介紹了一些常見的指令集,我建議僅供瞭解。一般我們是用不到的,因為你的瓶頸可能更多的在自身應用上
但是瞭解這一些,對你瞭解底層原始碼和執行機制會更有幫助。如果想再深入些,可閱讀我給出的參考連結 :)
參考
1.9 我要在棧上。不,你應該在堆上

我們在寫程式碼的時候,有時候會想這個變數到底分配到哪裡了?這時候可能會有人說,在棧上,在堆上。信我準沒錯...
但從結果上來講你還是一知半解,這可不行,萬一被人懵了呢。今天我們一起來深挖下 Go 在這塊的奧妙,自己動手豐衣足食
問題
type User struct {
ID int64
Name string
Avatar string
}
func GetUserInfo() *User {
return &User{ID: 13746731, Name: "EDDYCJY", Avatar: "https://avatars0.githubusercontent.com/u/13746731"}
}
func main() {
_ = GetUserInfo()
}
開局就是一把問號,帶著問題進行學習。請問 main 呼叫 GetUserInfo 後返回的 &User{...}。這個變數是分配到棧上了呢,還是分配到堆上了?
什麼是堆/棧
在這裡並不打算詳細介紹堆疊,僅簡單介紹本文所需的基礎知識。如下:
- 堆(Heap):一般來講是人為手動進行管理,手動申請、分配、釋放。一般所涉及的記憶體大小並不定,一般會存放較大的物件。另外其分配相對慢,涉及到的指令動作也相對多
- 棧(Stack):由編譯器進行管理,自動申請、分配、釋放。一般不會太大,我們常見的函式引數(不同平臺允許存放的數量不同),區域性變數等等都會存放在棧上
今天我們介紹的 Go 語言,它的堆疊分配是透過 Compiler 進行分析,GC 去管理的,而對其的分析選擇動作就是今天探討的重點
什麼是逃逸分析
在編譯程式最佳化理論中,逃逸分析是一種確定指標動態範圍的方法,簡單來說就是分析在程式的哪些地方可以訪問到該指標
通俗地講,逃逸分析就是確定一個變數要放堆上還是棧上,規則如下:
- 是否有在其他地方(非區域性)被引用。只要有可能被引用了,那麼它一定分配到堆上。否則分配到棧上
- 即使沒有被外部引用,但物件過大,無法存放在棧區上。依然有可能分配到堆上
對此你可以理解為,逃逸分析是編譯器用於決定變數分配到堆上還是棧上的一種行為
在什麼階段確立逃逸
在編譯階段確立逃逸,注意並不是在執行時
為什麼需要逃逸
這個問題我們可以反過來想,如果變數都分配到堆上了會出現什麼事情?例如:
- 垃圾回收(GC)的壓力不斷增大
- 申請、分配、回收記憶體的系統開銷增大(相對於棧)
- 動態分配產生一定量的記憶體碎片
其實總的來說,就是頻繁申請、分配堆記憶體是有一定 “代價” 的。會影響應用程式執行的效率,間接影響到整體系統。因此 “按需分配” 最大限度的靈活利用資源,才是正確的治理之道。這就是為什麼需要逃逸分析的原因,你覺得呢?
怎麼確定是否逃逸
第一,透過編譯器命令,就可以看到詳細的逃逸分析過程。而指令集 -gcflags 用於將標識引數傳遞給 Go 編譯器,涉及如下:
-m會打印出逃逸分析的最佳化策略,實際上最多總共可以用 4 個-m,但是資訊量較大,一般用 1 個就可以了-l會停用函式內聯,在這裡停用掉 inline 能更好的觀察逃逸情況,減少干擾
$ go build -gcflags '-m -l' main.go
第二,透過反編譯命令檢視
$ go tool compile -S main.go
注:可以透過 go tool compile -help 檢視所有允許傳遞給編譯器的標識引數
逃逸案例
案例一:指標
第一個案例是一開始丟擲的問題,現在你再看看,想想,如下:
type User struct {
ID int64
Name string
Avatar string
}
func GetUserInfo() *User {
return &User{ID: 13746731, Name: "EDDYCJY", Avatar: "https://avatars0.githubusercontent.com/u/13746731"}
}
func main() {
_ = GetUserInfo()
}
執行命令觀察一下,如下:
$ go build -gcflags '-m -l' main.go
# command-line-arguments
./main.go:10:54: &User literal escapes to heap
透過檢視分析結果,可得知 &User 逃到了堆裡,也就是分配到堆上了。這是不是有問題啊...再看看彙編程式碼確定一下,如下:
$ go tool compile -S main.go
"".GetUserInfo STEXT size=190 args=0x8 locals=0x18
0x0000 00000 (main.go:9) TEXT "".GetUserInfo(SB), $24-8
...
0x0028 00040 (main.go:10) MOVQ AX, (SP)
0x002c 00044 (main.go:10) CALL runtime.newobject(SB)
0x0031 00049 (main.go:10) PCDATA $2, $1
0x0031 00049 (main.go:10) MOVQ 8(SP), AX
0x0036 00054 (main.go:10) MOVQ $13746731, (AX)
0x003d 00061 (main.go:10) MOVQ $7, 16(AX)
0x0045 00069 (main.go:10) PCDATA $2, $-2
0x0045 00069 (main.go:10) PCDATA $0, $-2
0x0045 00069 (main.go:10) CMPL runtime.writeBarrier(SB), $0
0x004c 00076 (main.go:10) JNE 156
0x004e 00078 (main.go:10) LEAQ go.string."EDDYCJY"(SB), CX
...
我們將目光集中到 CALL 指令,發現其執行了 runtime.newobject 方法,也就是確實是分配到了堆上。這是為什麼呢?
分析結果
這是因為 GetUserInfo() 返回的是指標物件,引用被返回到了方法之外了。因此編譯器會把該物件分配到堆上,而不是棧上。否則方法結束之後,區域性變數就被回收了,豈不是翻車。所以最終分配到堆上是理所當然的
再想想
那你可能會想,那就是所有指標物件,都應該在堆上?並不。如下:
func main() {
str := new(string)
*str = "EDDYCJY"
}
你想想這個物件會分配到哪裡?如下:
$ go build -gcflags '-m -l' main.go
# command-line-arguments
./main.go:4:12: main new(string) does not escape
顯然,該物件分配到棧上了。很核心的一點就是它有沒有被作用域之外所引用,而這裡作用域仍然保留在 main 中,因此它沒有發生逃逸
案例二:未確定型別
func main() {
str := new(string)
*str = "EDDYCJY"
fmt.Println(str)
}
執行命令觀察一下,如下:
$ go build -gcflags '-m -l' main.go
# command-line-arguments
./main.go:9:13: str escapes to heap
./main.go:6:12: new(string) escapes to heap
./main.go:9:13: main ... argument does not escape
透過檢視分析結果,可得知 str 變數逃到了堆上,也就是該物件在堆上分配。但上個案例時它還在棧上,我們也就 fmt 輸出了它而已。這...到底發生了什麼事?
分析結果
相對案例一,案例二隻加了一行程式碼 fmt.Println(str),問題肯定出在它身上。其原型:
func Println(a ...interface{}) (n int, err error)
透過對其分析,可得知當形參為 interface 型別時,在編譯階段編譯器無法確定其具體的型別。因此會產生逃逸,最終分配到堆上
如果你有興趣追原始碼的話,可以看下內部的 reflect.TypeOf(arg).Kind() 語句,其會造成堆逃逸,而表象就是 interface 型別會導致該物件分配到堆上
案例三、洩露引數
type User struct {
ID int64
Name string
Avatar string
}
func GetUserInfo(u *User) *User {
return u
}
func main() {
_ = GetUserInfo(&User{ID: 13746731, Name: "EDDYCJY", Avatar: "https://avatars0.githubusercontent.com/u/13746731"})
}
執行命令觀察一下,如下:
$ go build -gcflags '-m -l' main.go
# command-line-arguments
./main.go:9:18: leaking param: u to result ~r1 level=0
./main.go:14:63: main &User literal does not escape
我們注意到 leaking param 的表述,它說明了變數 u 是一個洩露引數。結合程式碼可得知其傳給 GetUserInfo 方法後,沒有做任何引用之類的涉及變數的動作,直接就把這個變數返回出去了。因此這個變數實際上並沒有逃逸,它的作用域還在 main() 之中,所以分配在棧上
再想想
那你再想想怎麼樣才能讓它分配到堆上?結合案例一,舉一反三。修改如下:
type User struct {
ID int64
Name string
Avatar string
}
func GetUserInfo(u User) *User {
return &u
}
func main() {
_ = GetUserInfo(User{ID: 13746731, Name: "EDDYCJY", Avatar: "https://avatars0.githubusercontent.com/u/13746731"})
}
執行命令觀察一下,如下:
$ go build -gcflags '-m -l' main.go
# command-line-arguments
./main.go:10:9: &u escapes to heap
./main.go:9:18: moved to heap: u
只要一小改,它就考慮會被外部所引用,因此妥妥的分配到堆上了
總結
在本文我給你介紹了逃逸分析的概念和規則,並列舉了一些例子加深理解。但實際肯定遠遠不止這些案例,你需要做到的是掌握方法,遇到再看就好了。除此之外你還需要注意:
- 靜態分配到棧上,效能一定比動態分配到堆上好
- 底層分配到堆,還是棧。實際上對你來說是透明的,不需要過度關心
- 每個 Go 版本的逃逸分析都會有所不同(會改變,會最佳化)
- 直接透過
go build -gcflags '-m -l'就可以看到逃逸分析的過程和結果 - 到處都用指標傳遞並不一定是最好的,要用對
之前就有想過要不要寫 “逃逸分析” 相關的文章,直到最近看到在夜讀裡有人問,還是有寫的必要。對於這塊的知識點。我的建議是適當瞭解,但沒必要硬記。靠基礎知識點加命令除錯觀察就好了。像是曹大之前講的 “你琢磨半天逃逸分析,一壓測,瓶頸在鎖上”,完全沒必要過度在意...
參考
1.10 defer 會有效能損耗,儘量不要用
上個月在 @polaris @軒脈刃 的全棧技術群裡看到一個小夥伴問 “說 defer 在棧退出時執行,會有效能損耗,儘量不要用,這個怎麼解?”。
恰好前段時間寫了一篇 《深入理解 Go defer》 去詳細剖析 defer 關鍵字。那麼這一次簡單結合前文對這個問題進行探討一波,希望對你有所幫助,但在此之前希望你花幾分鐘,自己思考一下答案,再繼續往下看。
測試
func DoDefer(key, value string) {
defer func(key, value string) {
_ = key + value
}(key, value)
}
func DoNotDefer(key, value string) {
_ = key + value
}
基準測試:
func BenchmarkDoDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
DoDefer("煎鱼", "https://github.com/EDDYCJY/blog")
}
}
func BenchmarkDoNotDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
DoNotDefer("煎鱼", "https://github.com/EDDYCJY/blog")
}
}
輸出結果:
$ go test -bench=. -benchmem -run=none
goos: darwin
goarch: amd64
pkg: github.com/EDDYCJY/awesomeDefer
BenchmarkDoDefer-4 20000000 91.4 ns/op 48 B/op 1 allocs/op
BenchmarkDoNotDefer-4 30000000 41.6 ns/op 48 B/op 1 allocs/op
PASS
ok github.com/EDDYCJY/awesomeDefer 3.234s
從結果上來,使用 defer 後的函式開銷確實比沒使用高了不少,這損耗用到哪裡去了呢?
想一下
$ go tool compile -S main.go
"".main STEXT size=163 args=0x0 locals=0x40
...
0x0059 00089 (main.go:6) MOVQ AX, 16(SP)
0x005e 00094 (main.go:6) MOVQ $1, 24(SP)
0x0067 00103 (main.go:6) MOVQ $1, 32(SP)
0x0070 00112 (main.go:6) CALL runtime.deferproc(SB)
0x0075 00117 (main.go:6) TESTL AX, AX
0x0077 00119 (main.go:6) JNE 137
0x0079 00121 (main.go:7) XCHGL AX, AX
0x007a 00122 (main.go:7) CALL runtime.deferreturn(SB)
0x007f 00127 (main.go:7) MOVQ 56(SP), BP
0x0084 00132 (main.go:7) ADDQ $64, SP
0x0088 00136 (main.go:7) RET
0x0089 00137 (main.go:6) XCHGL AX, AX
0x008a 00138 (main.go:6) CALL runtime.deferreturn(SB)
0x008f 00143 (main.go:6) MOVQ 56(SP), BP
0x0094 00148 (main.go:6) ADDQ $64, SP
0x0098 00152 (main.go:6) RET
...
我們在前文提到 defer 關鍵字其實涉及了一系列的連鎖呼叫,內部 runtime 函式的呼叫就至少多了三步,分別是 runtime.deferproc 一次和 runtime.deferreturn 兩次。
而這還只是在執行時的顯式動作,另外編譯器做的事也不少,例如:
- 在
deferproc階段(註冊延遲呼叫),還得取得/傳入目標函式地址、函式引數等等。 - 在
deferreturn階段,需要在函式呼叫結尾處插入該方法的呼叫,同時若有被defer的函式,還需要使用runtime·jmpdefer進行跳轉以便於後續呼叫。
這一些動作途中還要涉及最小單元 _defer 的取得/生成, defer 和 recover 連結串列的邏輯處理和消耗等動作。
Q&A
最後討論的時候有提到 “問題指的是本來就是用來執行 close() 一些操作的,然後說盡量不能用,例子就把 defer db.close() 前面的 defer 刪去了” 這個疑問。
這是一個比較類似 “教科書” 式的說法,在一些入門教程中會潛移默化的告訴你在資源控制後加個 defer 延遲關閉一下。例如:
resp, err := http.Get(...)
if err != nil {
return err
}
defer resp.Body.Close()
但是一定得這麼寫嗎?其實並不,很多人給出的理由都是 “怕你忘記” 這種說辭,這沒有毛病。但需要認清場景,假設我的應用場景如下:
resp, err := http.Get(...)
if err != nil {
return err
}
defer resp.Body.Close()
// do something
time.Sleep(time.Second * 60)
嗯,一個請求當然沒問題,流量、併發一下子大了呢,那可能就是個災難了。你想想為什麼?從常見的 defer + close 的使用組合來講,用之前建議先看清楚應用場景,在保證無異常的情況下確保儘早關閉才是首選。如果只是小範圍呼叫很快就返回的話,偷個懶直接一套組合拳出去也未嘗不可。
結論
一個 defer 關鍵字實際上包含了不少的動作和處理,和你單純呼叫一個函式一條指令是沒法比的。而與對照物相比,它確確實實是有效能損耗,目前延遲呼叫的全部開銷大約在 50ns,但 defer 所提供的作用遠遠大於此,你從全域性來看,它的損耗非常小,並且官方還不斷地在最佳化中。
因此,對於 “Go defer 會有效能損耗,儘量不能用?” 這個問題,我認為該用就用,應該及時關閉就不要延遲,在 hot paths 用時一定要想清楚場景。
補充
最後補充上柴大的回覆:“不是效能問題,defer 最大的功能是 Panic 後依然有效。如果沒有 defer,Panic 後就會導致 unlock 丟失,從而導致死鎖了”,非常經典。
1.11 從實踐到原理,帶你參透 gRPC

gRPC 在 Go 語言中大放異彩,越來越多的小夥伴在使用,最近也在公司安利了一波,希望這一篇文章能帶你一覽 gRPC 的巧妙之處,本文篇幅比較長,請做好閱讀準備。本文目錄如下:

簡述
gRPC 是一個高效能、開源和通用的 RPC 框架,面向移動和 HTTP/2 設計。目前提供 C、Java 和 Go 語言版本,分別是:grpc, grpc-java, grpc-go. 其中 C 版本支援 C, C++, Node.js, Python, Ruby, Objective-C, PHP 和 C# 支援。
gRPC 基於 HTTP/2 標準設計,帶來諸如雙向流、流控、頭部壓縮、單 TCP 連線上的多複用請求等特性。這些特性使得其在移動裝置上表現更好,更省電和節省空間佔用。
呼叫模型
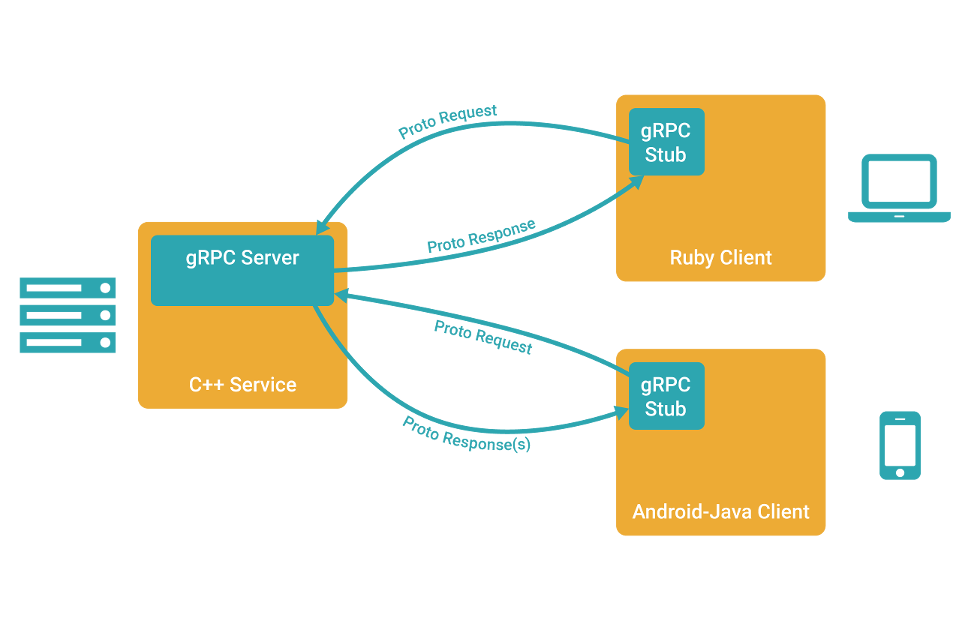
1、客戶端(gRPC Stub)呼叫 A 方法,發起 RPC 呼叫。
2、對請求資訊使用 Protobuf 進行物件序列化壓縮(IDL)。
3、服務端(gRPC Server)接收到請求後,解碼請求體,進行業務邏輯處理並返回。
4、對響應結果使用 Protobuf 進行物件序列化壓縮(IDL)。
5、客戶端接受到服務端響應,解碼請求體。回撥被呼叫的 A 方法,喚醒正在等待響應(阻塞)的客戶端呼叫並返回響應結果。
呼叫方式
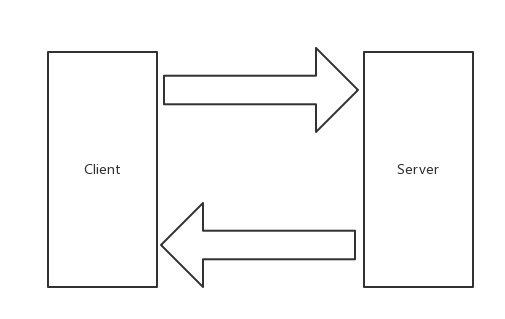
一、Unary RPC:一元 RPC
Server
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
return &pb.SearchResponse{Response: r.GetRequest() + " Server"}, nil
}
const PORT = "9001"
func main() {
server := grpc.NewServer()
pb.RegisterSearchServiceServer(server, &SearchService{})
lis, err := net.Listen("tcp", ":"+PORT)
...
server.Serve(lis)
}
- 建立 gRPC Server 物件,你可以理解為它是 Server 端的抽象物件。
- 將 SearchService(其包含需要被呼叫的服務端介面)註冊到 gRPC Server。 的內部註冊中心。這樣可以在接受到請求時,透過內部的 “服務發現”,發現該服務端介面並轉接進行邏輯處理。
- 建立 Listen,監聽 TCP 埠。
- gRPC Server 開始 lis.Accept,直到 Stop 或 GracefulStop。
Client
func main() {
conn, err := grpc.Dial(":"+PORT, grpc.WithInsecure())
...
defer conn.Close()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(context.Background(), &pb.SearchRequest{
Request: "gRPC",
})
...
}
- 建立與給定目標(服務端)的連線控制代碼。
- 建立 SearchService 的客戶端物件。
- 傳送 RPC 請求,等待同步響應,得到回撥後返回響應結果。
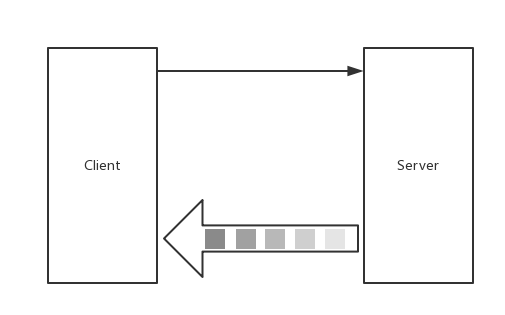
二、Server-side streaming RPC:服務端流式 RPC
Server
func (s *StreamService) List(r *pb.StreamRequest, stream pb.StreamService_ListServer) error {
for n := 0; n <= 6; n++ {
stream.Send(&pb.StreamResponse{
Pt: &pb.StreamPoint{
...
},
})
}
return nil
}
Client
func printLists(client pb.StreamServiceClient, r *pb.StreamRequest) error {
stream, err := client.List(context.Background(), r)
...
for {
resp, err := stream.Recv()
if err == io.EOF {
break
}
...
}
return nil
}
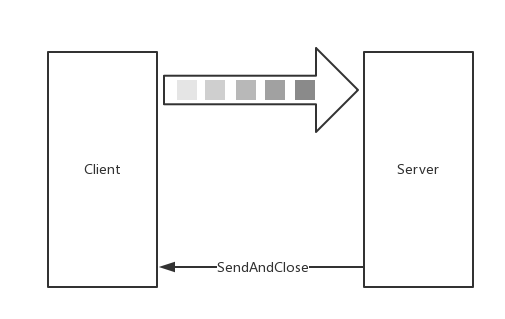
三、Client-side streaming RPC:客戶端流式 RPC
Server
func (s *StreamService) Record(stream pb.StreamService_RecordServer) error {
for {
r, err := stream.Recv()
if err == io.EOF {
return stream.SendAndClose(&pb.StreamResponse{Pt: &pb.StreamPoint{...}})
}
...
}
return nil
}
Client
func printRecord(client pb.StreamServiceClient, r *pb.StreamRequest) error {
stream, err := client.Record(context.Background())
...
for n := 0; n < 6; n++ {
stream.Send(r)
}
resp, err := stream.CloseAndRecv()
...
return nil
}
四、Bidirectional streaming RPC:雙向流式 RPC
Server
func (s *StreamService) Route(stream pb.StreamService_RouteServer) error {
for {
stream.Send(&pb.StreamResponse{...})
r, err := stream.Recv()
if err == io.EOF {
return nil
}
...
}
return nil
}
Client
func printRoute(client pb.StreamServiceClient, r *pb.StreamRequest) error {
stream, err := client.Route(context.Background())
...
for n := 0; n <= 6; n++ {
stream.Send(r)
resp, err := stream.Recv()
if err == io.EOF {
break
}
...
}
stream.CloseSend()
return nil
}
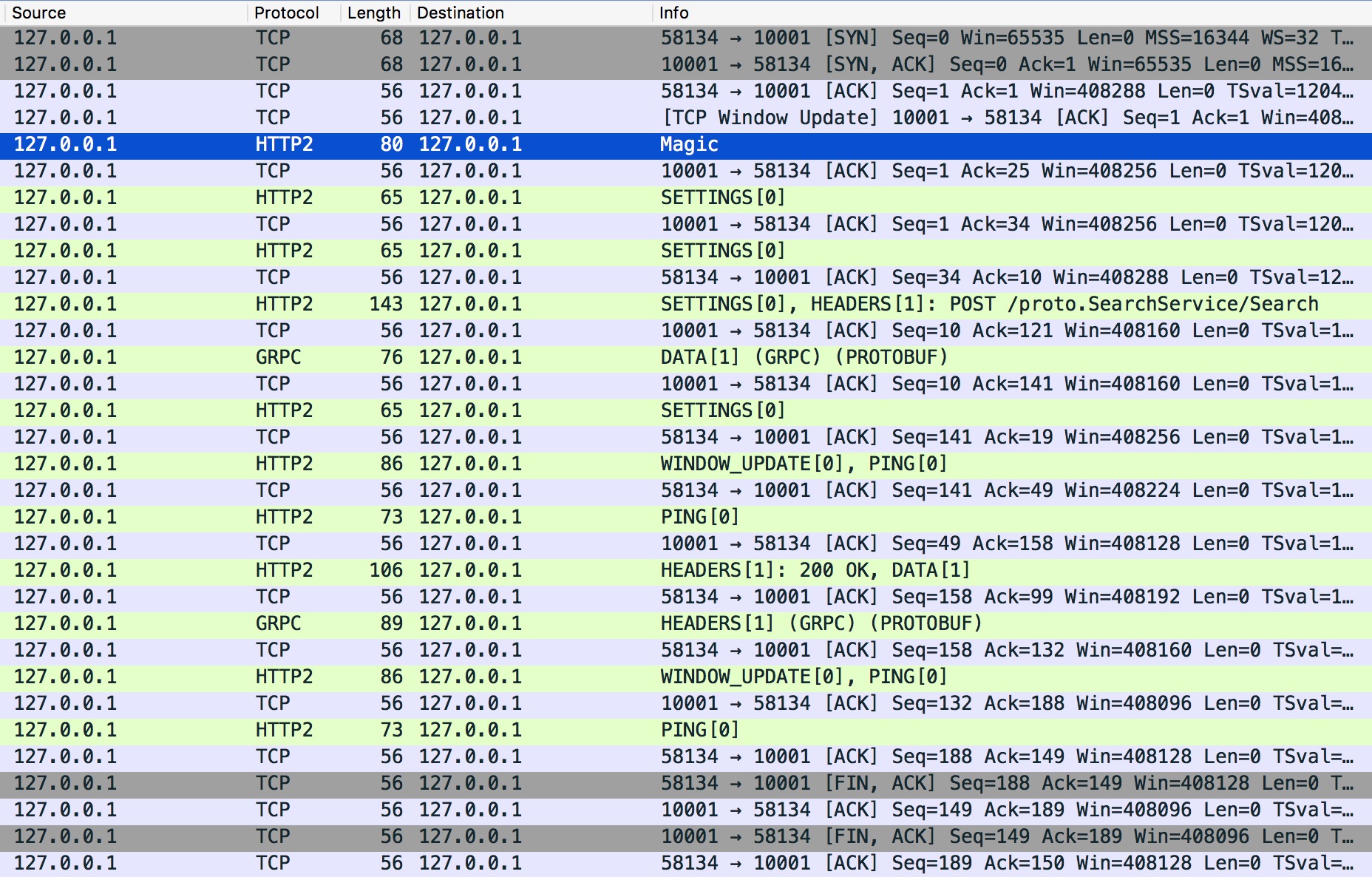
客戶端與服務端是如何互動的
在開始分析之前,我們要先 gRPC 的呼叫有一個初始印象。那麼最簡單的就是對 Client 端呼叫 Server 端進行抓包去剖析,看看整個過程中它都做了些什麼事。如下圖:
- Magic
- SETTINGS
- HEADERS
- DATA
- SETTINGS
- WINDOW_UPDATE
- PING
- HEADERS
- DATA
- HEADERS
- WINDOW_UPDATE
- PING
我們略加整理發現共有十二個行為,是比較重要的。在開始分析之前,建議你自己先想一下,它們的作用都是什麼?大膽猜測一下,帶著疑問去學習效果更佳。
行為分析
Magic
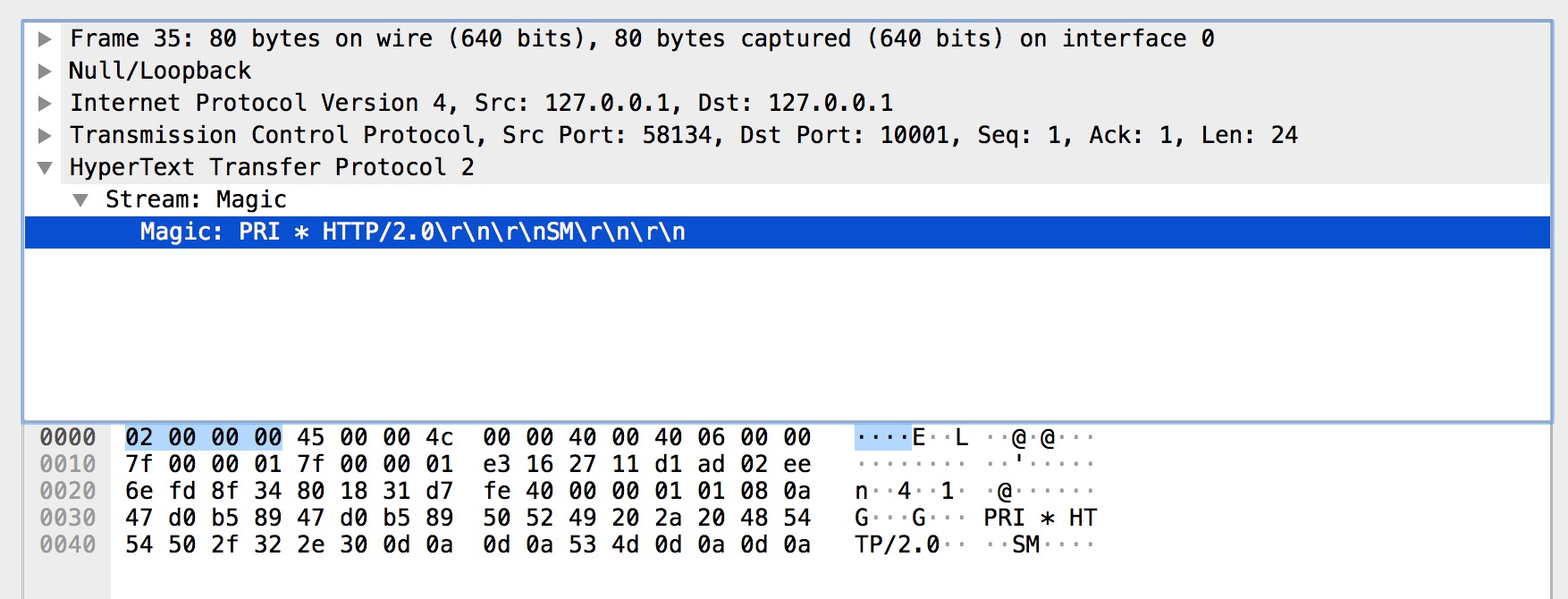
Magic 幀的主要作用是建立 HTTP/2 請求的前言。在 HTTP/2 中,要求兩端都要傳送一個連線前言,作為對所使用協議的最終確認,並確定 HTTP/2 連線的初始設定,客戶端和服務端各自發送不同的連線前言。
而上圖中的 Magic 幀是客戶端的前言之一,內容為 PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n,以確定啟用 HTTP/2 連線。
SETTINGS
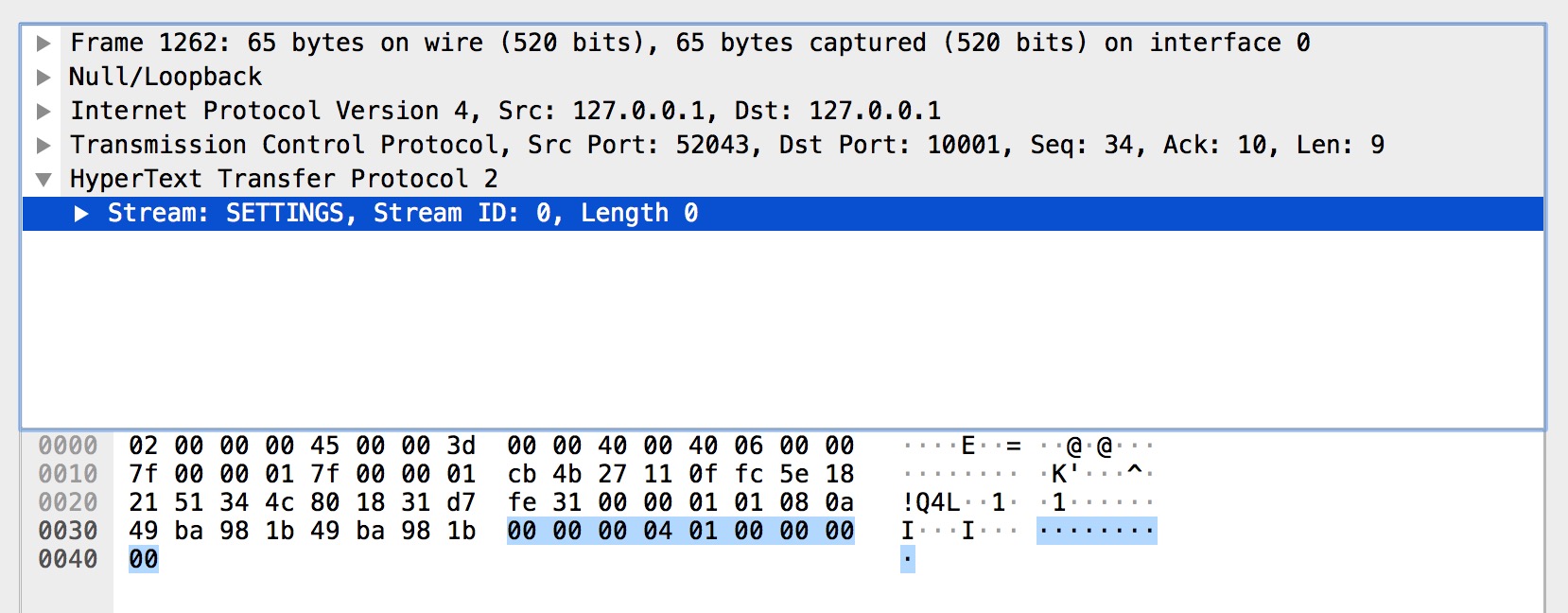
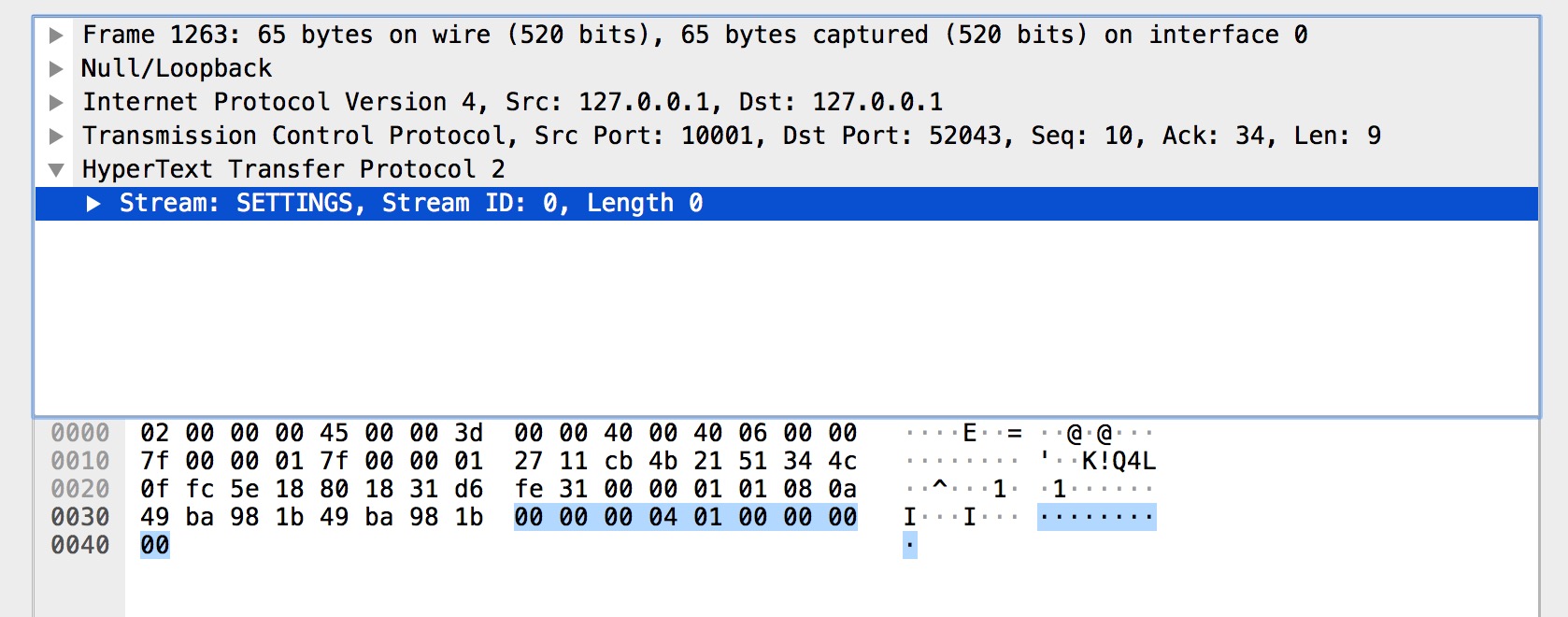
SETTINGS 幀的主要作用是設定這一個連線的引數,作用域是整個連線而並非單一的流。
而上圖的 SETTINGS 幀都是空 SETTINGS 幀,圖一是客戶端連線的前言(Magic 和 SETTINGS 幀分別組成連線前言)。圖二是服務端的。另外我們從圖中可以看到多個 SETTINGS 幀,這是為什麼呢?是因為傳送完連線前言後,客戶端和服務端還需要有一步互動確認的動作。對應的就是帶有 ACK 標識 SETTINGS 幀。
HEADERS
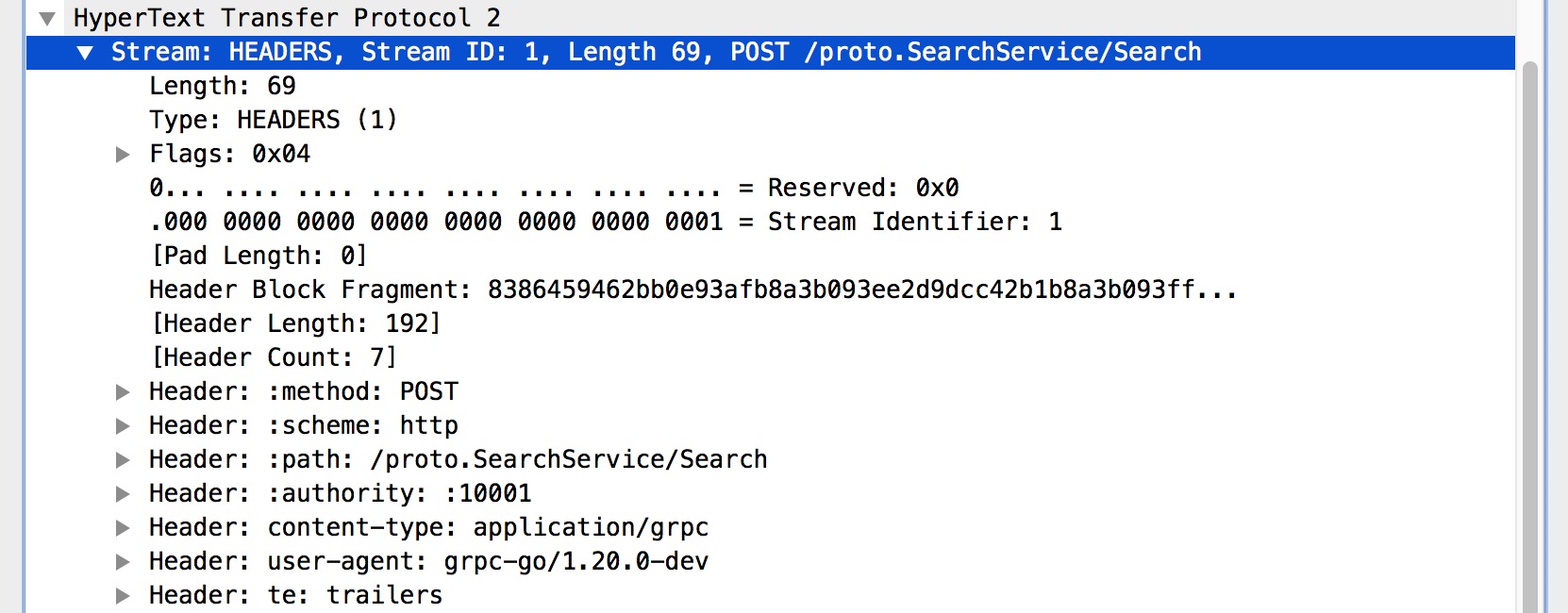
HEADERS 幀的主要作用是儲存和傳播 HTTP 的標頭資訊。我們關注到 HEADERS 裡有一些眼熟的資訊,分別如下:
- method:POST
- scheme:http
- path:/proto.SearchService/Search
- authority::10001
- content-type:application/grpc
- user-agent:grpc-go/1.20.0-dev
你會發現這些東西非常眼熟,其實都是 gRPC 的基礎屬性,實際上遠遠不止這些,只是設定了多少展示多少。例如像平時常見的 grpc-timeout、grpc-encoding 也是在這裡設定的。
DATA
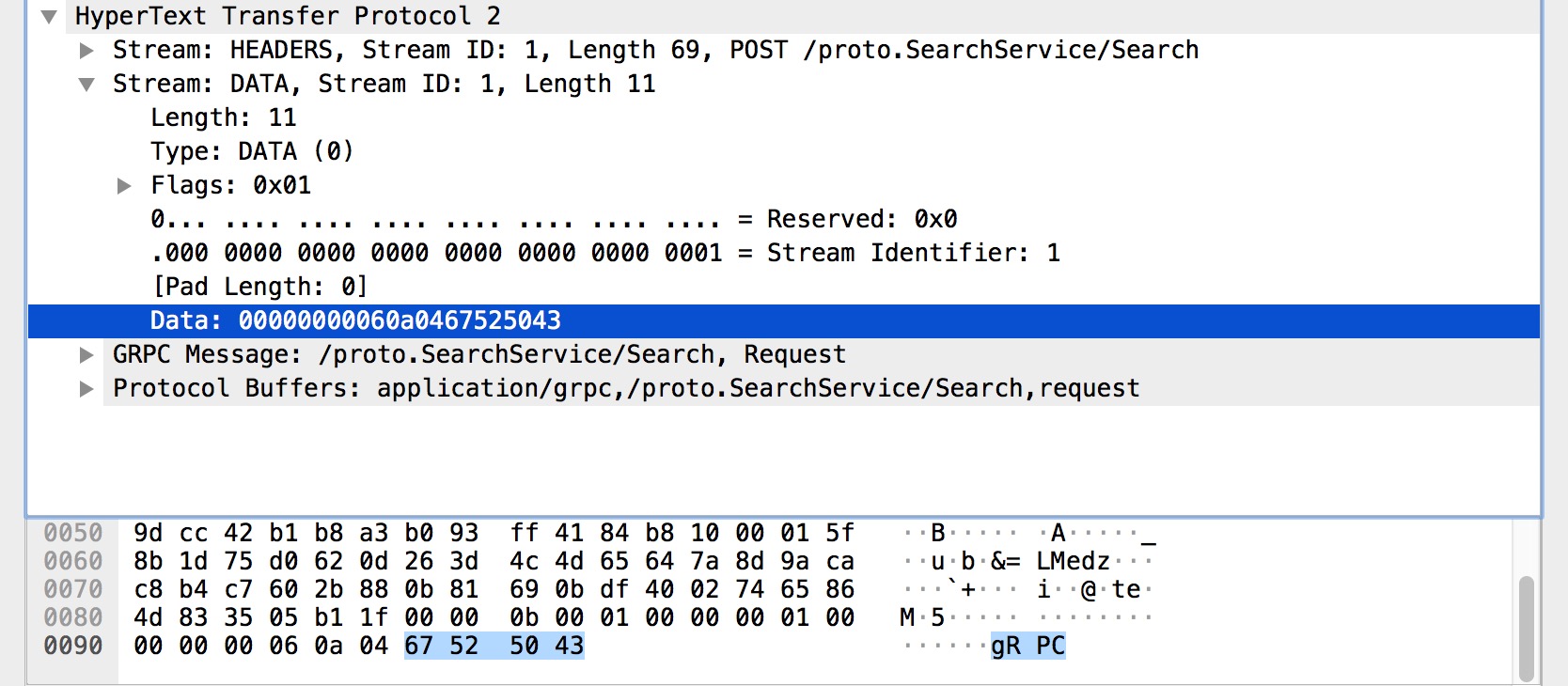
DATA 幀的主要作用是裝填主體資訊,是資料幀。而在上圖中,可以很明顯看到我們的請求引數 gRPC 儲存在裡面。只需要瞭解到這一點就可以了。
HEADERS, DATA, HEADERS
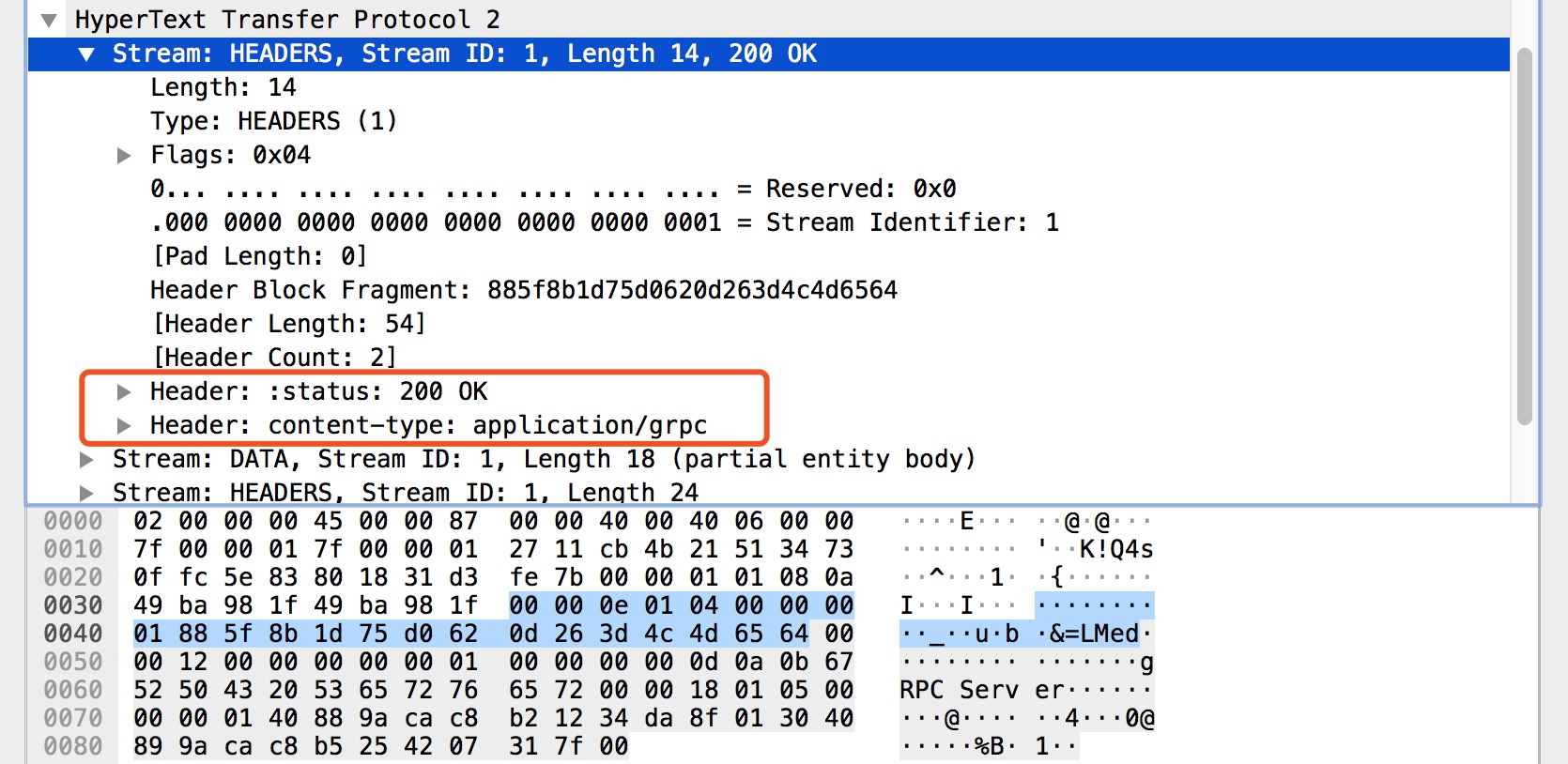
在上圖中 HEADERS 幀比較簡單,就是告訴我們 HTTP 響應狀態和響應的內容格式。
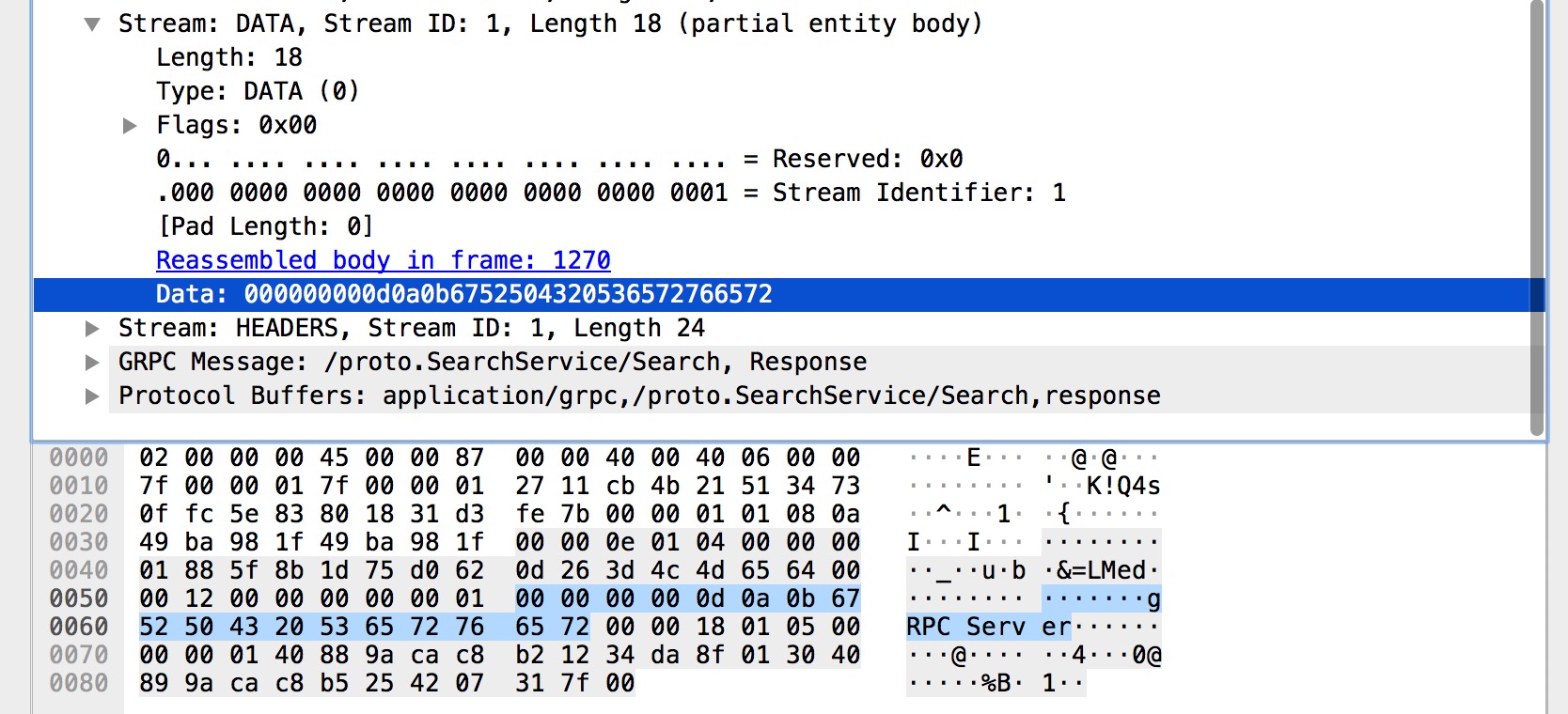
在上圖中 DATA 幀主要承載了響應結果的資料集,圖中的 gRPC Server 就是我們 RPC 方法的響應結果。
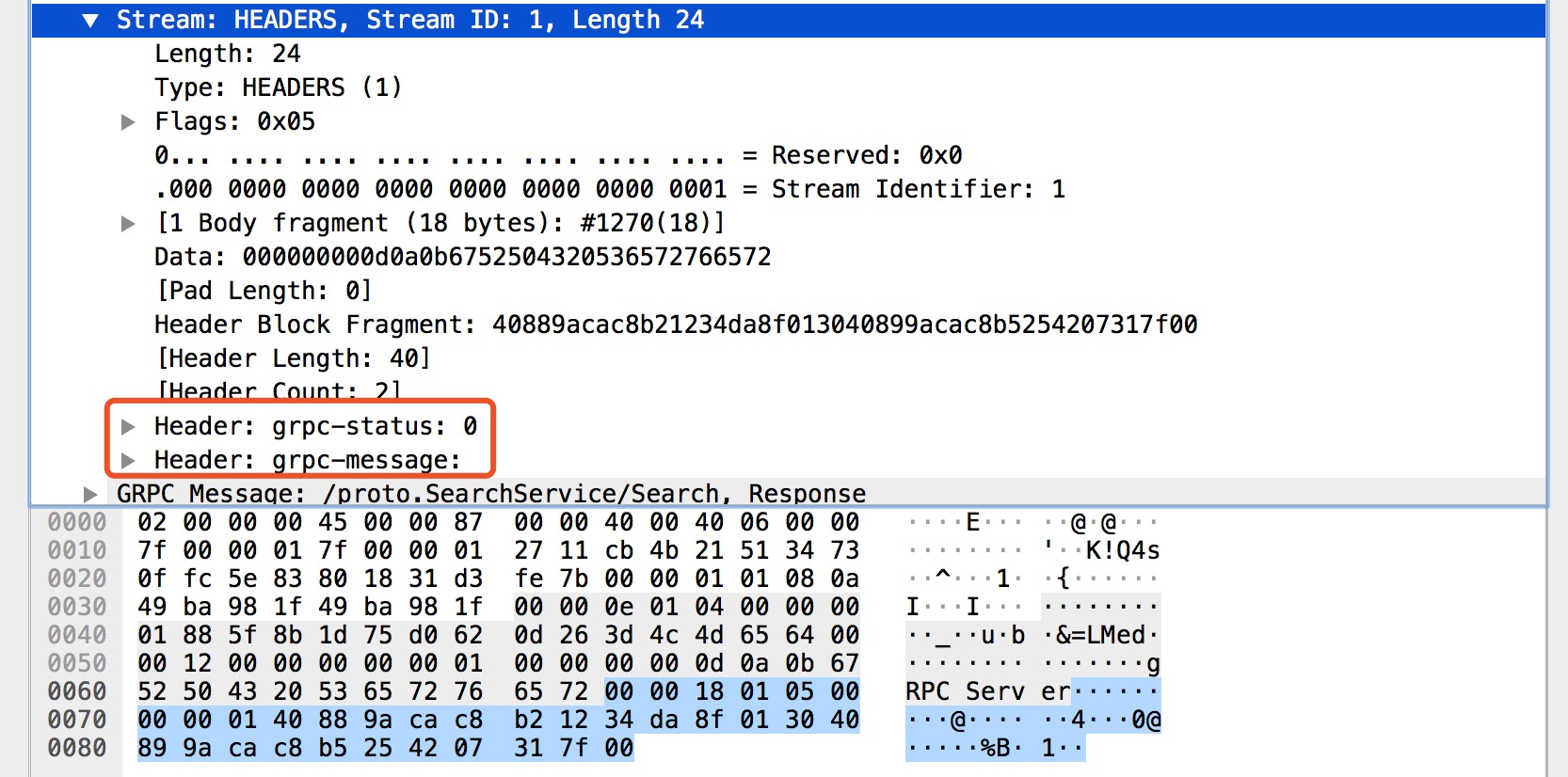
在上圖中 HEADERS 幀主要承載了 gRPC 狀態 和 gRPC 狀態訊息,圖中的 grpc-status 和 grpc-message 就是我們的 gRPC 呼叫狀態的結果。
其它步驟
WINDOW_UPDATE
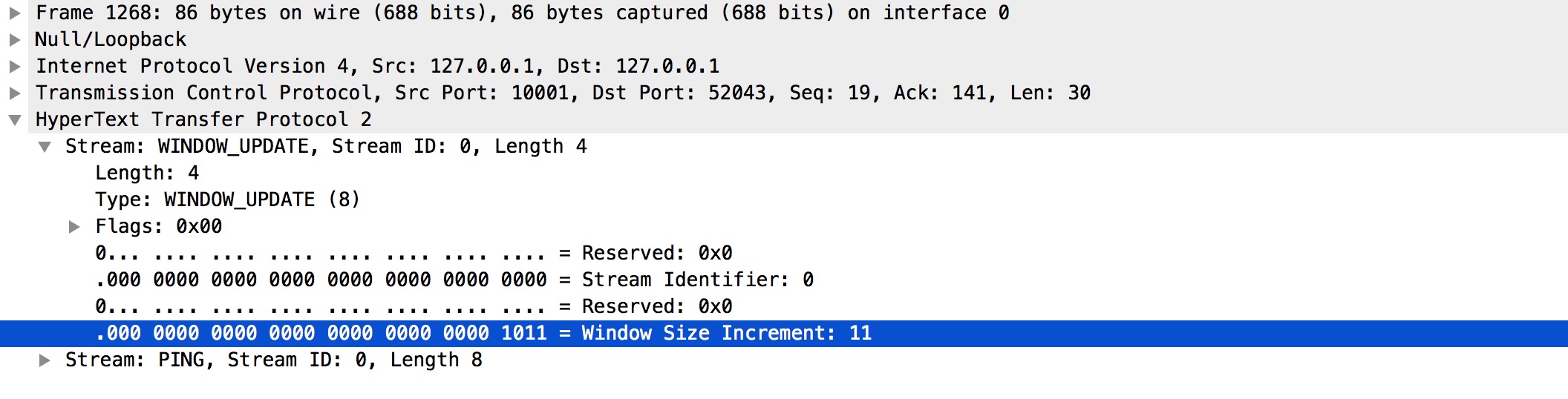
主要作用是管理和流的視窗控制。通常情況下開啟一個連線後,伺服器和客戶端會立即交換 SETTINGS 幀來確定流控制視窗的大小。預設情況下,該大小設定為約 65 KB,但可透過發出一個 WINDOW_UPDATE 幀為流控制設定不同的大小。
PING/PONG
主要作用是判斷當前連線是否仍然可用,也常用於計算往返時間。其實也就是 PING/PONG,大家對此應該很熟。
小結
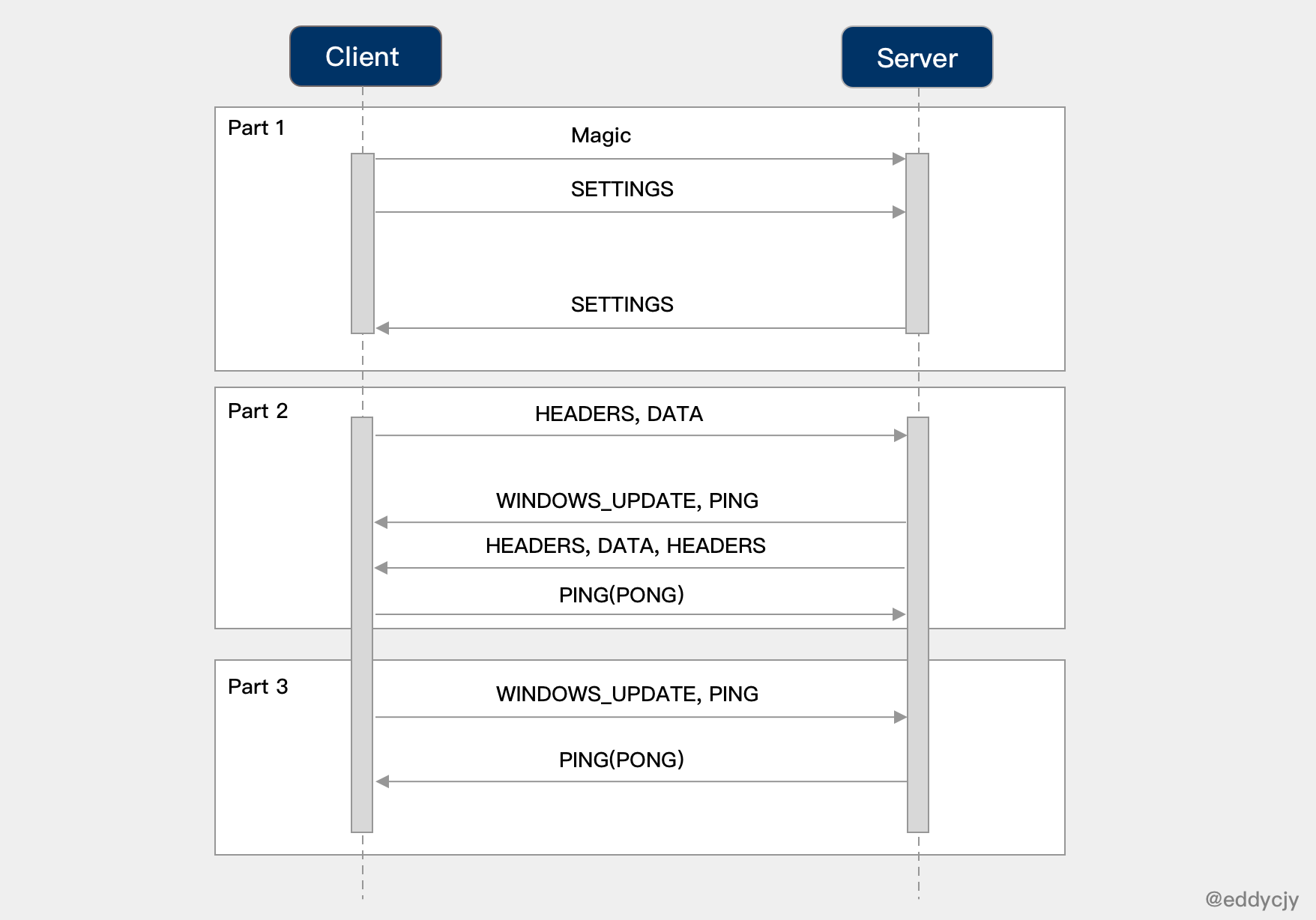
- 在建立連線之前,客戶端/服務端都會發送連線前言(Magic+SETTINGS),確立協議和設定項。
- 在傳輸資料時,是會涉及滑動視窗(WINDOW_UPDATE)等流控策略的。
- 傳播 gRPC 附加資訊時,是基於 HEADERS 幀進行傳播和設定;而具體的請求/響應資料是儲存的 DATA 幀中的。
- 請求/響應結果會分為 HTTP 和 gRPC 狀態響應兩種型別。
- 客戶端發起 PING,服務端就會回應 PONG,反之亦可。
這塊 gRPC 的基礎使用,你可以看看我另外的 《gRPC 入門系列》,相信對你一定有幫助。
淺談理解
服務端
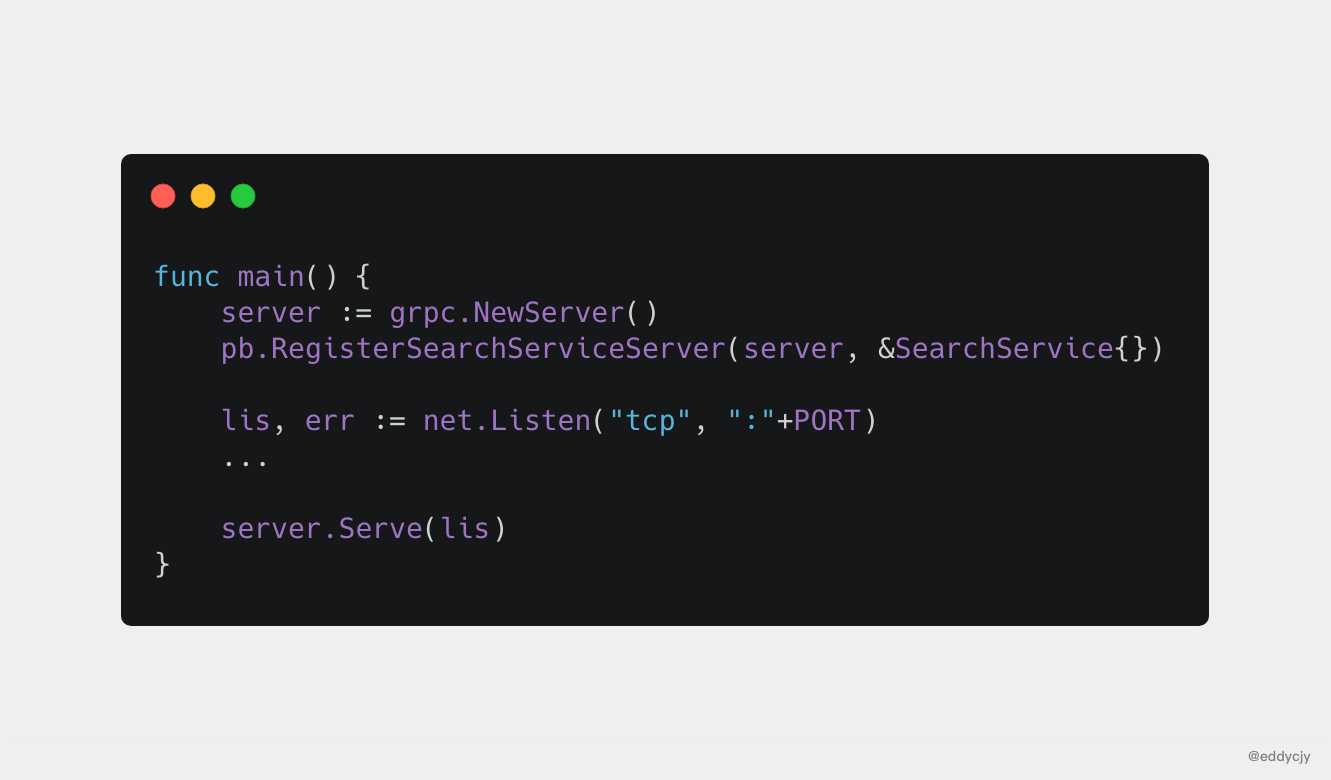
為什麼四行程式碼,就能夠起一個 gRPC Server,內部做了什麼邏輯。你有想過嗎?接下來我們一步步剖析,看看裡面到底是何方神聖。
一、初始化
// grpc.NewServer()
func NewServer(opt ...ServerOption) *Server {
opts := defaultServerOptions
for _, o := range opt {
o(&opts)
}
s := &Server{
lis: make(map[net.Listener]bool),
opts: opts,
conns: make(map[io.Closer]bool),
m: make(map[string]*service),
quit: make(chan struct{}),
done: make(chan struct{}),
czData: new(channelzData),
}
s.cv = sync.NewCond(&s.mu)
...
return s
}
這塊比較簡單,主要是例項 grpc.Server 並進行初始化動作。涉及如下:
- lis:監聽地址列表。
- opts:服務選項,這塊包含 Credentials、Interceptor 以及一些基礎設定。
- conns:客戶端連線控制代碼列表。
- m:服務資訊對映。
- quit:退出訊號。
- done:完成訊號。
- czData:用於儲存 ClientConn,addrConn 和 Server 的channelz 相關資料。
- cv:當優雅退出時,會等待這個訊號量,直到所有 RPC 請求都處理並斷開才會繼續處理。
二、註冊
pb.RegisterSearchServiceServer(server, &SearchService{})
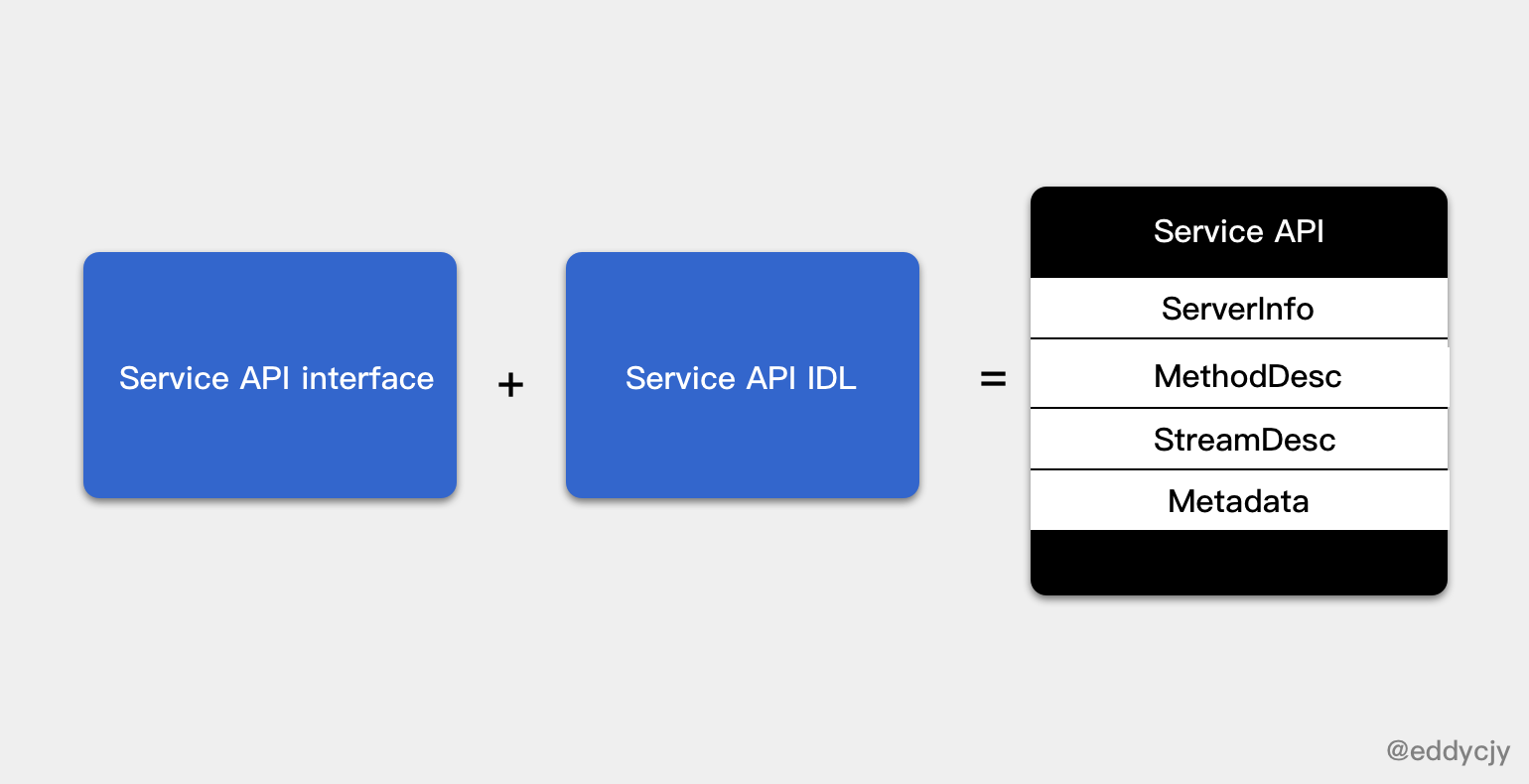
步驟一:Service API interface
// search.pb.go
type SearchServiceServer interface {
Search(context.Context, *SearchRequest) (*SearchResponse, error)
}
func RegisterSearchServiceServer(s *grpc.Server, srv SearchServiceServer) {
s.RegisterService(&_SearchService_serviceDesc, srv)
}
還記得我們平時編寫的 Protobuf 嗎?在生成出來的 .pb.go 檔案中,會定義出 Service APIs interface 的具體實作約束。而我們在 gRPC Server 進行註冊時,會傳入應用 Service 的功能介面實作,此時生成的 RegisterServer 方法就會保證兩者之間的一致性。
步驟二:Service API IDL
你想亂傳糊弄一下?不可能的,請乖乖定義與 Protobuf 一致的介面方法。但是那個 &_SearchService_serviceDesc 又有什麼作用呢?程式碼如下:
// search.pb.go
var _SearchService_serviceDesc = grpc.ServiceDesc{
ServiceName: "proto.SearchService",
HandlerType: (*SearchServiceServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "Search",
Handler: _SearchService_Search_Handler,
},
},
Streams: []grpc.StreamDesc{},
Metadata: "search.proto",
}
這看上去像服務的描述程式碼,用來向內部表述 “我” 都有什麼。涉及如下:
- ServiceName:服務名稱
- HandlerType:服務介面,用於檢查使用者提供的實作是否滿足介面要求
- Methods:一元方法集,注意結構內的
Handler方法,其對應最終的 RPC 處理方法,在執行 RPC 方法的階段會使用。 - Streams:流式方法集
- Metadata:元資料,是一個描述資料屬性的東西。在這裡主要是描述
SearchServiceServer服務
步驟三:Register Service
func (s *Server) register(sd *ServiceDesc, ss interface{}) {
...
srv := &service{
server: ss,
md: make(map[string]*MethodDesc),
sd: make(map[string]*StreamDesc),
mdata: sd.Metadata,
}
for i := range sd.Methods {
d := &sd.Methods[i]
srv.md[d.MethodName] = d
}
for i := range sd.Streams {
...
}
s.m[sd.ServiceName] = srv
}
在最後一步中,我們會將先前的服務介面資訊、服務描述資訊給註冊到內部 service 去,以便於後續實際呼叫的使用。涉及如下:
- server:服務的介面資訊
- md:一元服務的 RPC 方法集
- sd:流式服務的 RPC 方法集
- mdata:metadata,元資料
小結
在這一章節中,主要介紹的是 gRPC Server 在啟動前的整理和註冊行為,看上去很簡單,但其實一切都是為了後續的實際執行的預先準備。因此我們整理一下思路,將其串聯起來看看,如下:
三、監聽
接下來到了整個流程中,最重要也是大家最關注的監聽/處理階段,核心程式碼如下:
func (s *Server) Serve(lis net.Listener) error {
...
var tempDelay time.Duration
for {
rawConn, err := lis.Accept()
if err != nil {
if ne, ok := err.(interface {
Temporary() bool
}); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
...
timer := time.NewTimer(tempDelay)
select {
case <-timer.C:
case <-s.quit:
timer.Stop()
return nil
}
continue
}
...
return err
}
tempDelay = 0
s.serveWG.Add(1)
go func() {
s.handleRawConn(rawConn)
s.serveWG.Done()
}()
}
}
Serve 會根據外部傳入的 Listener 不同而呼叫不同的監聽模式,這也是 net.Listener 的魅力,靈活性和擴充套件性會比較高。而在 gRPC Server 中最常用的就是 TCPConn,基於 TCP Listener 去做。接下來我們一起看看具體的處理邏輯,如下:
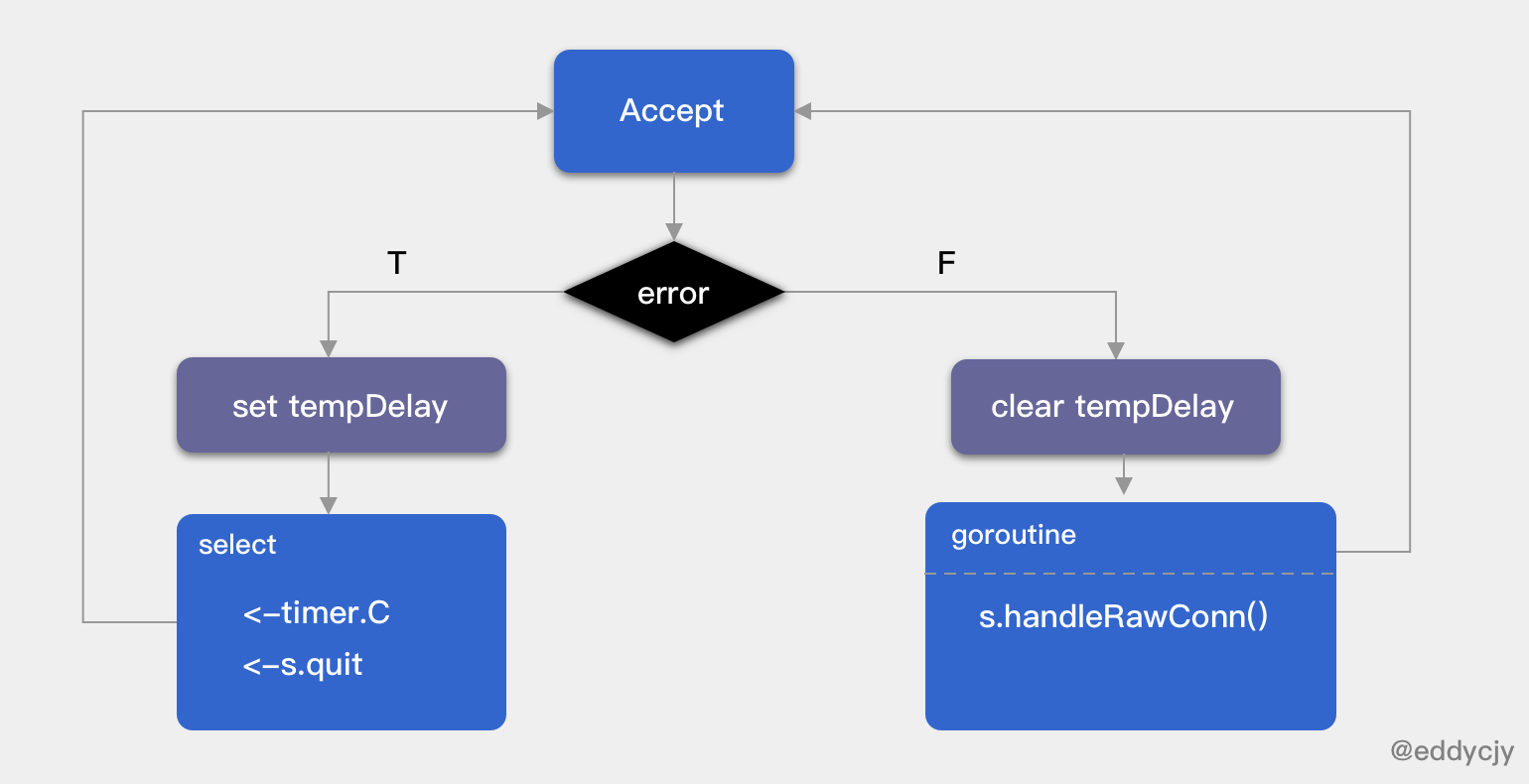
- 迴圈處理連線,透過
lis.Accept取出連線,如果佇列中沒有需處理的連線時,會形成阻塞等待。 - 若
lis.Accept失敗,則觸發休眠機制,若為第一次失敗那麼休眠 5ms,否則翻倍,再次失敗則不斷翻倍直至上限休眠時間 1s,而休眠完畢後就會嘗試去取下一個 “它”。 - 若
lis.Accept成功,則重置休眠的時間計數和啟動一個新的 goroutine 呼叫handleRawConn方法去執行/處理新的請求,也就是大家很喜歡說的 “每一個請求都是不同的 goroutine 在處理”。 - 在迴圈過程中,包含了 “退出” 服務的場景,主要是硬關閉和優雅重啟服務兩種情況。
客戶端
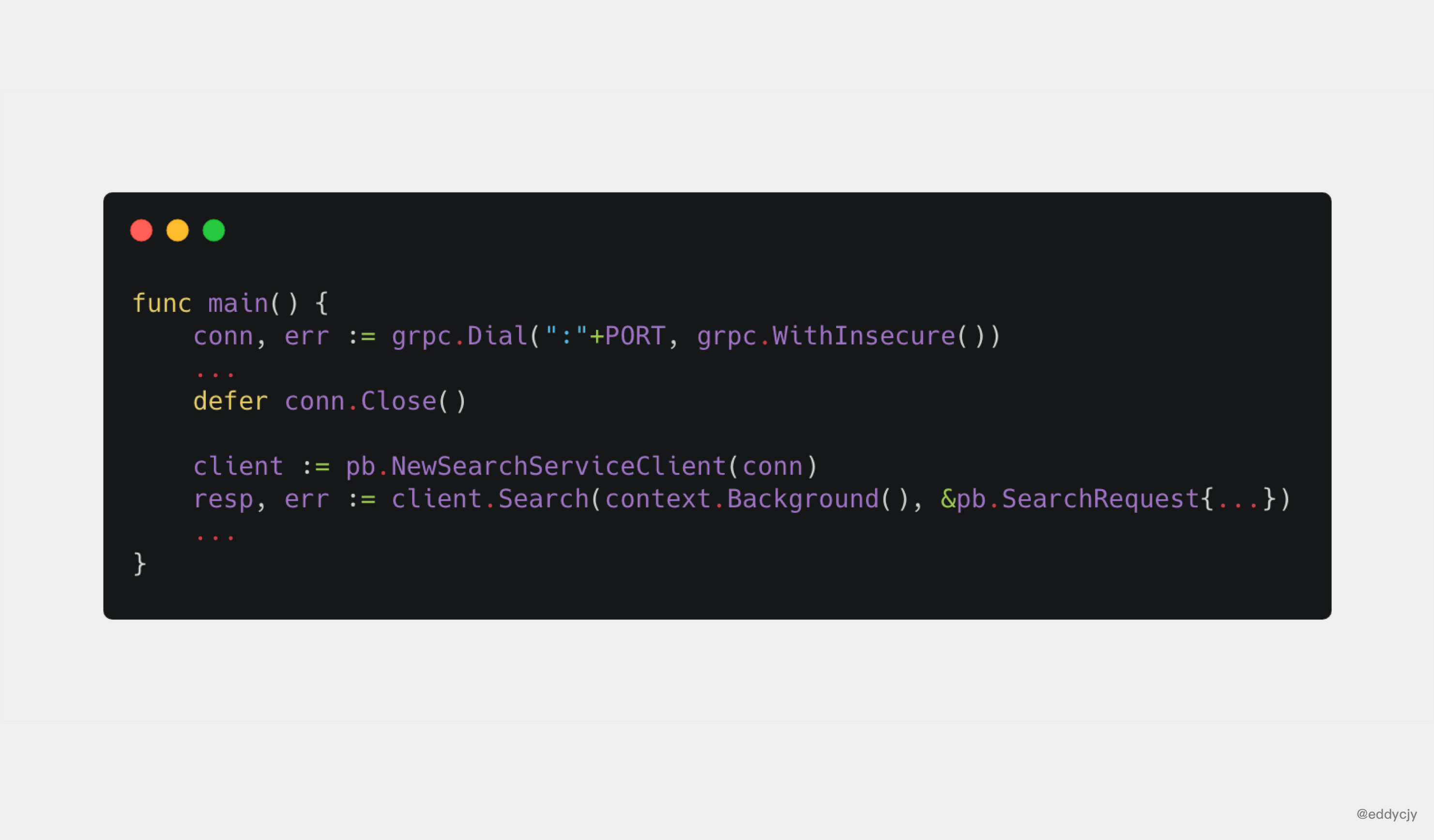
一、建立撥號連線
// grpc.Dial(":"+PORT, grpc.WithInsecure())
func DialContext(ctx context.Context, target string, opts ...DialOption) (conn *ClientConn, err error) {
cc := &ClientConn{
target: target,
csMgr: &connectivityStateManager{},
conns: make(map[*addrConn]struct{}),
dopts: defaultDialOptions(),
blockingpicker: newPickerWrapper(),
czData: new(channelzData),
firstResolveEvent: grpcsync.NewEvent(),
}
...
chainUnaryClientInterceptors(cc)
chainStreamClientInterceptors(cc)
...
}
grpc.Dial 方法實際上是對於 grpc.DialContext 的封裝,區別在於 ctx 是直接傳入 context.Background。其主要功能是建立與給定目標的客戶端連線,其承擔了以下職責:
- 初始化 ClientConn
- 初始化(基於程序 LB)負載均衡設定
- 初始化 channelz
- 初始化重試規則和客戶端一元/流式攔截器
- 初始化協議棧上的基礎資訊
- 相關 context 的超時控制
- 初始化並解析地址資訊
- 建立與服務端之間的連線
連沒連
之前聽到有的人說呼叫 grpc.Dial 後客戶端就已經與服務端建立起了連線,但這對不對呢?我們先鳥瞰全貌,看看正在跑的 goroutine。如下:

我們可以有幾個核心方法一直在等待/處理訊號,透過分析底層原始碼可得知。涉及如下:
func (ac *addrConn) connect()
func (ac *addrConn) resetTransport()
func (ac *addrConn) createTransport(addr resolver.Address, copts transport.ConnectOptions, connectDeadline time.Time)
func (ac *addrConn) getReadyTransport()
在這裡主要分析 goroutine 提示的 resetTransport 方法,看看都做了啥。核心程式碼如下:
func (ac *addrConn) resetTransport() {
for i := 0; ; i++ {
if ac.state == connectivity.Shutdown {
return
}
...
connectDeadline := time.Now().Add(dialDuration)
ac.updateConnectivityState(connectivity.Connecting)
newTr, addr, reconnect, err := ac.tryAllAddrs(addrs, connectDeadline)
if err != nil {
if ac.state == connectivity.Shutdown {
return
}
ac.updateConnectivityState(connectivity.TransientFailure)
timer := time.NewTimer(backoffFor)
select {
case <-timer.C:
...
}
continue
}
if ac.state == connectivity.Shutdown {
newTr.Close()
return
}
...
if !healthcheckManagingState {
ac.updateConnectivityState(connectivity.Ready)
}
...
if ac.state == connectivity.Shutdown {
return
}
ac.updateConnectivityState(connectivity.TransientFailure)
}
}
在該方法中會不斷地去嘗試建立連線,若成功則結束。否則不斷地根據 Backoff 演算法的重試機制去嘗試建立連線,直到成功為止。從結論上來講,單純呼叫 DialContext 是非同步建立連線的,也就是並不是馬上生效,處於 Connecting 狀態,而正式下要到達 Ready 狀態才可用。
真的連了嗎
在抓包工具上提示一個包都沒有,那麼這算真正連線了嗎?我認為這是一個表述問題,我們應該儘可能的嚴謹。如果你真的想透過 DialContext 方法就打通與服務端的連線,則需要呼叫 WithBlock 方法,雖然會導致阻塞等待,但最終連線會到達 Ready 狀態(握手成功)。如下圖:
二、例項化 Service API
type SearchServiceClient interface {
Search(ctx context.Context, in *SearchRequest, opts ...grpc.CallOption) (*SearchResponse, error)
}
type searchServiceClient struct {
cc *grpc.ClientConn
}
func NewSearchServiceClient(cc *grpc.ClientConn) SearchServiceClient {
return &searchServiceClient{cc}
}
這塊就是例項 Service API interface,比較簡單。
三、呼叫
// search.pb.go
func (c *searchServiceClient) Search(ctx context.Context, in *SearchRequest, opts ...grpc.CallOption) (*SearchResponse, error) {
out := new(SearchResponse)
err := c.cc.Invoke(ctx, "/proto.SearchService/Search", in, out, opts...)
if err != nil {
return nil, err
}
return out, nil
}
proto 生成的 RPC 方法更像是一個包裝盒,把需要的東西放進去,而實際上呼叫的還是 grpc.invoke 方法。如下:
func invoke(ctx context.Context, method string, req, reply interface{}, cc *ClientConn, opts ...CallOption) error {
cs, err := newClientStream(ctx, unaryStreamDesc, cc, method, opts...)
if err != nil {
return err
}
if err := cs.SendMsg(req); err != nil {
return err
}
return cs.RecvMsg(reply)
}
透過概覽,可以關注到三塊呼叫。如下:
- newClientStream:取得傳輸層 Trasport 並組合封裝到 ClientStream 中返回,在這塊會涉及負載均衡、超時控制、 Encoding、 Stream 的動作,與服務端基本一致的行為。
- cs.SendMsg:傳送 RPC 請求出去,但其並不承擔等待響應的功能。
- cs.RecvMsg:阻塞等待接受到的 RPC 方法響應結果。
連線
// clientconn.go
func (cc *ClientConn) getTransport(ctx context.Context, failfast bool, method string) (transport.ClientTransport, func(balancer.DoneInfo), error) {
t, done, err := cc.blockingpicker.pick(ctx, failfast, balancer.PickOptions{
FullMethodName: method,
})
if err != nil {
return nil, nil, toRPCErr(err)
}
return t, done, nil
}
在 newClientStream 方法中,我們透過 getTransport 方法取得了 Transport 層中抽象出來的 ClientTransport 和 ServerTransport,實際上就是取得一個連線給後續 RPC 呼叫傳輸使用。
四、關閉連線
// conn.Close()
func (cc *ClientConn) Close() error {
defer cc.cancel()
...
cc.csMgr.updateState(connectivity.Shutdown)
...
cc.blockingpicker.close()
if rWrapper != nil {
rWrapper.close()
}
if bWrapper != nil {
bWrapper.close()
}
for ac := range conns {
ac.tearDown(ErrClientConnClosing)
}
if channelz.IsOn() {
...
channelz.AddTraceEvent(cc.channelzID, ted)
channelz.RemoveEntry(cc.channelzID)
}
return nil
}
該方法會取消 ClientConn 上下文,同時關閉所有底層傳輸。涉及如下:
- Context Cancel
- 清空並關閉客戶端連線
- 清空並關閉解析器連線
- 清空並關閉負載均衡連線
- 新增跟蹤引用
- 移除當前通道資訊
Q&A
1. gRPC Metadata 是透過什麼傳輸?
2. 呼叫 grpc.Dial 會真正的去連線服務端嗎?
會,但是是非同步連線的,連線狀態為正在連線。但如果你設定了 grpc.WithBlock 選項,就會阻塞等待(等待握手成功)。另外你需要注意,當未設定 grpc.WithBlock 時,ctx 超時控制對其無任何效果。
3. 呼叫 ClientConn 不 Close 會導致洩露嗎?
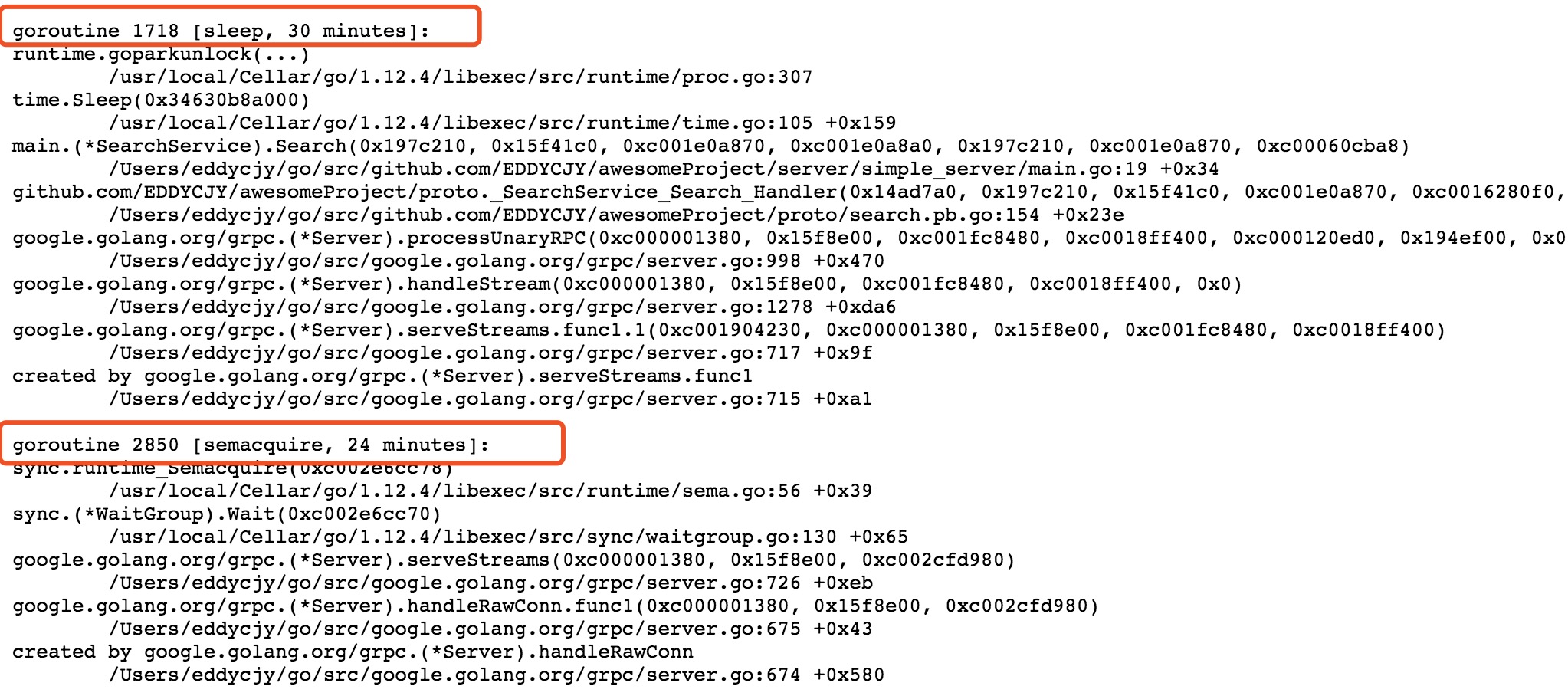
會,除非你的客戶端不是常駐程序,那麼在應用結束時會被動地回收資源。但如果是常駐程序,你又真的忘記執行 Close 語句,會造成的洩露。如下圖:
3.1. 客戶端
3.2. 服務端
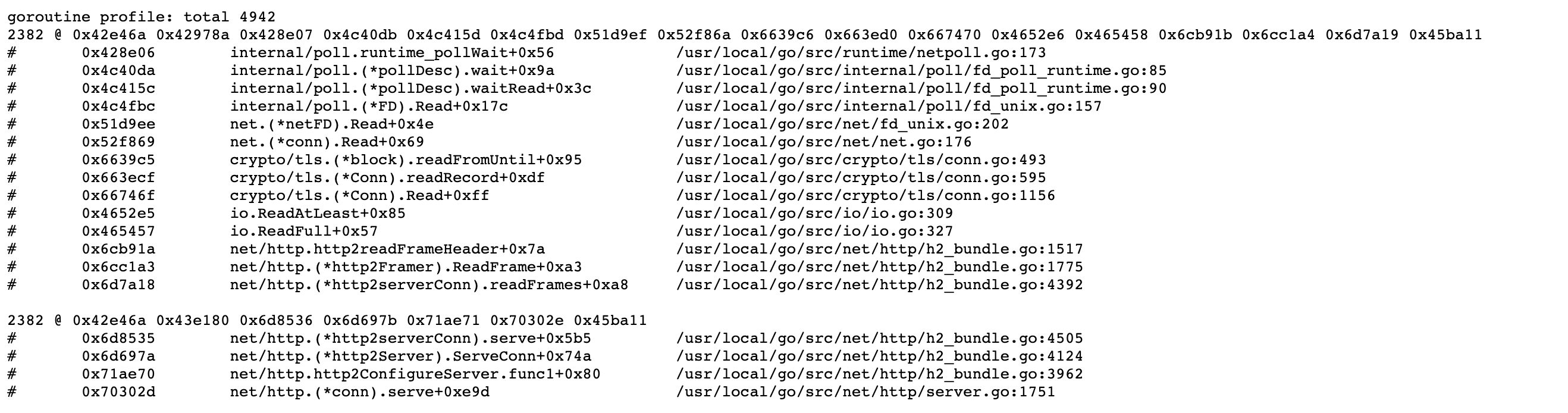
3.3. TCP

4. 不控制超時呼叫的話,會出現什麼問題?
短時間內不會出現問題,但是會不斷積蓄洩露,積蓄到最後當然就是服務無法提供響應了。如下圖:
5. 為什麼預設的攔截器不可以傳多個?
func chainUnaryClientInterceptors(cc *ClientConn) {
interceptors := cc.dopts.chainUnaryInts
if cc.dopts.unaryInt != nil {
interceptors = append([]UnaryClientInterceptor{cc.dopts.unaryInt}, interceptors...)
}
var chainedInt UnaryClientInterceptor
if len(interceptors) == 0 {
chainedInt = nil
} else if len(interceptors) == 1 {
chainedInt = interceptors[0]
} else {
chainedInt = func(ctx context.Context, method string, req, reply interface{}, cc *ClientConn, invoker UnaryInvoker, opts ...CallOption) error {
return interceptors[0](ctx, method, req, reply, cc, getChainUnaryInvoker(interceptors, 0, invoker), opts...)
}
}
cc.dopts.unaryInt = chainedInt
}
當存在多個攔截器時,取的就是第一個攔截器。因此結論是允許傳多個,但並沒有用。
6. 真的需要用到多個攔截器的話,怎麼辦?
可以使用 go-grpc-middleware 提供的 grpc.UnaryInterceptor 和 grpc.StreamInterceptor 鏈式方法,方便快捷省心。
單單會用還不行,我們再深剖一下,看看它是怎麼實作的。核心程式碼如下:
func ChainUnaryClient(interceptors ...grpc.UnaryClientInterceptor) grpc.UnaryClientInterceptor {
n := len(interceptors)
if n > 1 {
lastI := n - 1
return func(ctx context.Context, method string, req, reply interface{}, cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {
var (
chainHandler grpc.UnaryInvoker
curI int
)
chainHandler = func(currentCtx context.Context, currentMethod string, currentReq, currentRepl interface{}, currentConn *grpc.ClientConn, currentOpts ...grpc.CallOption) error {
if curI == lastI {
return invoker(currentCtx, currentMethod, currentReq, currentRepl, currentConn, currentOpts...)
}
curI++
err := interceptors[curI](currentCtx, currentMethod, currentReq, currentRepl, currentConn, chainHandler, currentOpts...)
curI--
return err
}
return interceptors[0](ctx, method, req, reply, cc, chainHandler, opts...)
}
}
...
}
當攔截器數量大於 1 時,從 interceptors[1] 開始遞迴,每一個遞迴的攔截器 interceptors[i] 會不斷地執行,最後才真正的去執行 handler 方法。同時也經常有人會問攔截器的執行順序是什麼,透過這段程式碼你得出結論了嗎?
7. 頻繁建立 ClientConn 有什麼問題?
這個問題我們可以反向驗證一下,假設不公用 ClientConn 看看會怎麼樣?如下:
func BenchmarkSearch(b *testing.B) {
for i := 0; i < b.N; i++ {
conn, err := GetClientConn()
if err != nil {
b.Errorf("GetClientConn err: %v", err)
}
_, err = Search(context.Background(), conn)
if err != nil {
b.Errorf("Search err: %v", err)
}
}
}
輸出結果:
... connection error: desc = "transport: Error while dialing dial tcp :10001: socket: too many open files"
... connection error: desc = "transport: Error while dialing dial tcp :10001: socket: too many open files"
... connection error: desc = "transport: Error while dialing dial tcp :10001: socket: too many open files"
... connection error: desc = "transport: Error while dialing dial tcp :10001: socket: too many open files"
FAIL
exit status 1
當你的應用場景是存在高頻次同時生成/呼叫 ClientConn 時,可能會導致系統的檔案控制代碼佔用過多。這種情況下你可以變更應用程式生成/呼叫 ClientConn 的模式,又或是池化它,這塊可以參考 grpc-go-pool 專案。
8. 客戶端請求失敗後會預設重試嗎?
會不斷地進行重試,直到上下文取消。而重試時間方面採用 backoff 演算法作為的重連機制,預設的最大重試時間間隔是 120s。
9. 為什麼要用 HTTP/2 作為傳輸協議?
許多客戶端要透過 HTTP 代理來訪問網路,gRPC 全部用 HTTP/2 實作,等到代理開始支援 HTTP/2 就能透明轉發 gRPC 的資料。不光如此,負責負載均衡、訪問控制等等的反向代理都能無縫相容 gRPC,比起自己設計 wire protocol 的 Thrift,這樣做科學不少。@ctiller @滕亦飛
10. 在 Kubernetes 中 gRPC 負載均衡有問題?
gRPC 的 RPC 協議是基於 HTTP/2 標準實作的,HTTP/2 的一大特性就是不需要像 HTTP/1.1 一樣,每次發出請求都要重新建立一個新連線,而是會複用原有的連線。
所以這將導致 kube-proxy 只有在連線建立時才會做負載均衡,而在這之後的每一次 RPC 請求都會利用原本的連線,那麼實際上後續的每一次的 RPC 請求都跑到了同一個地方。
注:使用 k8s service 做負載均衡的情況下
總結
- gRPC 基於 HTTP/2 + Protobuf。
- gRPC 有四種呼叫方式,分別是一元、服務端/客戶端流式、雙向流式。
- gRPC 的附加資訊都會體現在 HEADERS 幀,資料在 DATA 幀上。
- Client 請求若使用 grpc.Dial 預設是非同步建立連線,當時狀態為 Connecting。
- Client 請求若需要同步則呼叫 WithBlock(),完成狀態為 Ready。
- Server 監聽是迴圈等待連線,若沒有則休眠,最大休眠時間 1s;若接收到新請求則起一個新的 goroutine 去處理。
- grpc.ClientConn 不關閉連線,會導致 goroutine 和 Memory 等洩露。
- 任何內/外呼叫如果不加超時控制,會出現洩漏和客戶端不斷重試。
- 特定場景下,如果不對 grpc.ClientConn 加以調控,會影響呼叫。
- 攔截器如果不用 go-grpc-middleware 鏈式處理,會覆蓋。
- 在選擇 gRPC 的負載均衡模式時,需要謹慎。
參考
- http://doc.oschina.net/grpc
- https://github.com/grpc/grpc/blob/master/doc/PROTOCOL-HTTP2.md
- https://juejin.im/post/5b88a4f56fb9a01a0b31a67e
- https://www.ibm.com/developerworks/cn/web/wa-http2-under-the-hood/index.html
- https://github.com/grpc/grpc-go/issues/1953
- https://www.zhihu.com/question/52670041
1.12 Go1.13 defer 的效能是如何提高的?
最近 Go1.13 終於釋出了,其中一個值得關注的特性就是 defer 在大部分的場景下效能提升了30%,但是官方並沒有具體寫是怎麼提升的,這讓大家非常的疑惑。而我因為之前寫過《深入理解 Go defer》 和 《Go defer 會有效能損耗,儘量不要用?》 這類文章,因此我挺感興趣它是做了什麼改變才能得到這樣子的結果,所以今天和大家一起探索其中奧妙。
一、測試
Go1.12
$ go test -bench=. -benchmem -run=none
goos: darwin
goarch: amd64
pkg: github.com/EDDYCJY/awesomeDefer
BenchmarkDoDefer-4 20000000 91.4 ns/op 48 B/op 1 allocs/op
BenchmarkDoNotDefer-4 30000000 41.6 ns/op 48 B/op 1 allocs/op
PASS
ok github.com/EDDYCJY/awesomeDefer 3.234s
Go1.13
$ go test -bench=. -benchmem -run=none
goos: darwin
goarch: amd64
pkg: github.com/EDDYCJY/awesomeDefer
BenchmarkDoDefer-4 15986062 74.7 ns/op 48 B/op 1 allocs/op
BenchmarkDoNotDefer-4 29231842 40.3 ns/op 48 B/op 1 allocs/op
PASS
ok github.com/EDDYCJY/awesomeDefer 3.444s
在開場,我先以不標準的測試基準驗證了先前的測試用例,確確實實在這兩個版本中,defer 的效能得到了提高,但是看上去似乎不是百分百提高 30 %。
二、看一下
之前(Go1.12)
0x0070 00112 (main.go:6) CALL runtime.deferproc(SB)
0x0075 00117 (main.go:6) TESTL AX, AX
0x0077 00119 (main.go:6) JNE 137
0x0079 00121 (main.go:7) XCHGL AX, AX
0x007a 00122 (main.go:7) CALL runtime.deferreturn(SB)
0x007f 00127 (main.go:7) MOVQ 56(SP), BP
現在(Go1.13)
0x006e 00110 (main.go:4) MOVQ AX, (SP)
0x0072 00114 (main.go:4) CALL runtime.deferprocStack(SB)
0x0077 00119 (main.go:4) TESTL AX, AX
0x0079 00121 (main.go:4) JNE 139
0x007b 00123 (main.go:7) XCHGL AX, AX
0x007c 00124 (main.go:7) CALL runtime.deferreturn(SB)
0x0081 00129 (main.go:7) MOVQ 112(SP), BP
從彙編的角度來看,像是 runtime.deferproc 改成了 runtime.deferprocStack 呼叫,難道是做了什麼最佳化,我們抱著疑問繼續看下去。
三、觀察原始碼
_defer
type _defer struct {
siz int32
siz int32 // includes both arguments and results
started bool
heap bool
sp uintptr // sp at time of defer
pc uintptr
fn *funcval
...
相較於以前的版本,最小單元的 _defer 結構體主要是新增了 heap 欄位,用於標識這個 _defer 是在堆上,還是在棧上進行分配,其餘欄位並沒有明確變更,那我們可以把聚焦點放在 defer 的堆疊分配上了,看看是做了什麼事。
deferprocStack
func deferprocStack(d *_defer) {
gp := getg()
if gp.m.curg != gp {
throw("defer on system stack")
}
d.started = false
d.heap = false
d.sp = getcallersp()
d.pc = getcallerpc()
*(*uintptr)(unsafe.Pointer(&d._panic)) = 0
*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))
*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))
return0()
}
這一塊程式碼挺常規的,主要是取得呼叫 defer 函式的函式棧指標、傳入函式的引數具體地址以及PC(程式計數器),這塊在前文 《深入理解 Go defer》 有詳細介紹過,這裡就不再贅述了。
那這個 deferprocStack 特殊在哪呢,我們可以看到它把 d.heap 設定為了 false,也就是代表 deferprocStack 方法是針對將 _defer 分配在棧上的應用場景的。
deferproc
那麼問題來了,它又在哪裡處理分配到堆上的應用場景呢?
func newdefer(siz int32) *_defer {
...
d.heap = true
d.link = gp._defer
gp._defer = d
return d
}
那麼 newdefer 是在哪裡呼叫的呢,如下:
func deferproc(siz int32, fn *funcval) { // arguments of fn follow fn
...
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz)
...
}
非常明確,先前的版本中呼叫的 deferproc 方法,現在被用於對應分配到堆上的場景了。
小結
- 第一點:可以確定的是
deferproc並沒有被去掉,而是流程被優化了。 - 第二點:編譯器會根據應用場景去選擇使用
deferproc還是deferprocStack方法,他們分別是針對分配在堆上和棧上的使用場景。
四、編譯器如何選擇
esc
// src/cmd/compile/internal/gc/esc.go
case ODEFER:
if e.loopdepth == 1 { // top level
n.Esc = EscNever // force stack allocation of defer record (see ssa.go)
break
}
ssa
// src/cmd/compile/internal/gc/ssa.go
case ODEFER:
d := callDefer
if n.Esc == EscNever {
d = callDeferStack
}
s.call(n.Left, d)
小結
這塊結合來看,核心就是當 e.loopdepth == 1 時,會將逃逸分析結果 n.Esc 設定為 EscNever,也就是將 _defer 分配到棧上,那這個 e.loopdepth 到底又是何方神聖呢,我們再詳細看看程式碼,如下:
// src/cmd/compile/internal/gc/esc.go
type NodeEscState struct {
Curfn *Node
Flowsrc []EscStep
Retval Nodes
Loopdepth int32
Level Level
Walkgen uint32
Maxextraloopdepth int32
}
這裡重點檢視 Loopdepth 欄位,目前它共有三個值標識,分別是:
- -1:全域性。
- 0:返回變數。
- 1:頂級函式,又或是內部函式的不斷增長值。
這個讀起來有點繞,結合我們上述 e.loopdepth == 1 的表述來看,也就是當 defer func 是頂級函式時,將會分配到棧上。但是若在 defer func 外層出現顯式的迭代迴圈,又或是出現隱式迭代,將會分配到堆上。其實深層表示的還是迭代深度的意思,我們可以來證實一下剛剛說的方向,顯式迭代的程式碼如下:
func main() {
for p := 0; p < 10; p++ {
defer func() {
for i := 0; i < 20; i++ {
log.Println("EDDYCJY")
}
}()
}
}
檢視彙編情況:
$ go tool compile -S main.go
"".main STEXT size=122 args=0x0 locals=0x20
0x0000 00000 (main.go:15) TEXT "".main(SB), ABIInternal, $32-0
...
0x0048 00072 (main.go:17) CALL runtime.deferproc(SB)
0x004d 00077 (main.go:17) TESTL AX, AX
0x004f 00079 (main.go:17) JNE 83
0x0051 00081 (main.go:17) JMP 33
0x0053 00083 (main.go:17) XCHGL AX, AX
0x0054 00084 (main.go:17) CALL runtime.deferreturn(SB)
...
顯然,最終 defer 呼叫的是 runtime.deferproc 方法,也就是分配到堆上了,沒毛病。而隱式迭代的話,你可以藉助 goto 語句去實作這個功能,再自己驗證一遍,這裡就不再贅述了。
總結
從分析的結果上來看,官方說明的 Go1.13 defer 效能提高 30%,主要來源於其延遲物件的堆疊分配規則的改變,措施是由編譯器透過對 defer 的 for-loop 迭代深度進行分析,如果 loopdepth 為 1,則設定逃逸分析的結果,將分配到棧上,否則分配到堆上。
的確,我個人覺得對大部分的使用場景來講,是優化了不少,也解決了一些人吐槽 defer 效能 “差” 的問題。另外,我想從 Go1.13 起,你也需要稍微瞭解一下它這塊的機制,別隨隨便便就來個狂野版巢狀迭代 defer,可能沒法效能最大化。
如果你還想了解更多細節,可以看看 defer 這塊的的提交內容,官方的測試用例也包含在裡面。
1.13 Go 應用記憶體佔用太多,讓排查?(VSZ篇)
前段時間,某同學說某服務的容器因為超出記憶體限制,不斷地重啟,問我們是不是有記憶體洩露,趕緊排查,然後解決掉,省的出問題。我們大為震驚,趕緊檢視監控+報警系統和效能分析,發現應用指標壓根就不高,不像有洩露的樣子。
那麼問題是出在哪裡了呢,我們進入某個容器裡查看了 top 的系統指標,結果如下:
PID VSZ RSS ... COMMAND
67459 2007m 136m ... ./eddycjy-server
從結果上來看,也沒什麼大開銷的東西,主要就一個 Go 程序,一看,某同學就說 VSZ 那麼高,而某雲上的容器記憶體指標居然恰好和 VSZ 的值相接近,因此某同學就懷疑是不是 VSZ 所導致的,覺得存在一定的關聯關係。
而從最終的結論上來講,上述的表述是不全對的,那麼在今天,本篇文章將主要圍繞 Go 程序的 VSZ 來進行剖析,看看到底它為什麼那麼 "高",而在正式開始分析前,第一節為前置的補充知識,大家可按順序閱讀。
基礎知識
什麼是 VSZ
VSZ 是該程序所能使用的虛擬記憶體總大小,它包括程序可以訪問的所有記憶體,其中包括了被換出的記憶體(Swap)、已分配但未使用的記憶體以及來自共享庫的記憶體。
為什麼要虛擬記憶體
在前面我們有了解到 VSZ 其實就是該程序的虛擬記憶體總大小,那如果我們想了解 VSZ 的話,那我們得先了解 “為什麼要虛擬記憶體?”。
本質上來講,在一個系統中的程序是與其他程序共享 CPU 和主存資源的,而在現代的作業系統中,多程序的使用非常的常見,那麼如果太多的程序需要太多的記憶體,那麼在沒有虛擬記憶體的情況下,物理記憶體很可能會不夠用,就會導致其中有些任務無法執行,更甚至會出現一些很奇怪的現象,例如 “某一個程序不小心寫了另一個程序使用的記憶體”,就會造成記憶體破壞,因此虛擬記憶體是非常重要的一個媒介。
虛擬記憶體包含了什麼
而虛擬記憶體,又分為核心虛擬記憶體和程序虛擬記憶體,每一個程序的虛擬記憶體都是獨立的, 呈現如上圖所示。
這裡也補充說明一下,在核心虛擬記憶體中,是包含了核心中的程式碼和資料結構,而核心虛擬記憶體中的某些區域會被對映到所有程序共享的物理頁面中去,因此你會看到 ”核心虛擬記憶體“ 中實際上是包含了 ”物理記憶體“ 的,它們兩者存在對映關係。而在應用場景上來講,每個程序也會去共享核心的程式碼和全域性資料結構,因此就會被對映到所有程序的物理頁面中去。
虛擬記憶體的重要能力
為了更有效地管理記憶體並且減少出錯,現代系統提供了一種對主存的抽象概念,也就是今天的主角,叫做虛擬記憶體(VM),虛擬記憶體是硬體異常、硬體地址翻譯、主存、磁碟檔案和核心軟體互動的地方,它為每個程序提供了一個大的、一致的和私有的地址空間,虛擬記憶體提供了三個重要的能力:
- 它將主存看成是一個儲存在磁碟上的地址空間的快取記憶體,在主存中只儲存活動區域,並根據需要在磁碟和主存之間來回傳送資料,透過這種方式,它高效地使用了主存。
- 它為每個程序提供了一致的地址空間,從而簡化了記憶體管理。
- 它保護了每個程序的地址空間不被其他程序破壞。
小結
上面發散的可能比較多,簡單來講,對於本文我們重點關注這些知識點,如下:
- 虛擬記憶體它是有各式各樣記憶體互動的地方,它包含的不僅僅是 "自己",而在本文中,我們只需要關注 VSZ,也就是程序虛擬記憶體,它包含了你的程式碼、資料、堆、棧段和共享庫。
- 虛擬記憶體作為記憶體保護的工具,能夠保證程序之間的記憶體空間獨立,不受其他程序的影響,因此每一個程序的 VSZ 大小都不一樣,互不影響。
- 虛擬記憶體的存在,系統給各程序分配的記憶體之和是可以大於實際可用的物理記憶體的,因此你也會發現你程序的物理記憶體總是比虛擬記憶體低的多的多。
排查問題
在瞭解了基礎知識後,我們正式開始排查問題,第一步我們先編寫一個測試程式,看看沒有什麼業務邏輯的 Go 程式,它初始的 VSZ 是怎麼樣的。
測試
應用程式碼:
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
r.Run(":8001")
}
檢視程序情況:
$ ps aux 67459
USER PID %CPU %MEM VSZ RSS ...
eddycjy 67459 0.0 0.0 4297048 960 ...
從結果上來看,VSZ 為 4297048K,也就是 4G 左右,咋一眼看過去還是挺嚇人的,明明沒有什麼業務邏輯,但是為什麼那麼高呢,真是令人感到好奇。
確認有沒有洩露
在未知的情況下,我們可以首先看下 runtime.MemStats 和 pprof,確定應用到底有沒有洩露。不過我們這塊是演示程式,什麼業務邏輯都沒有,因此可以確定和應用沒有直接關係。
# runtime.MemStats
# Alloc = 1298568
# TotalAlloc = 1298568
# Sys = 71893240
# Lookups = 0
# Mallocs = 10013
# Frees = 834
# HeapAlloc = 1298568
# HeapSys = 66551808
# HeapIdle = 64012288
# HeapInuse = 2539520
# HeapReleased = 64012288
# HeapObjects = 9179
...
Go FAQ
接著我第一反應是去翻了 Go FAQ(因為看到過,有印象),其問題為 "Why does my Go process use so much virtual memory?",回答如下:
The Go memory allocator reserves a large region of virtual memory as an arena for allocations. This virtual memory is local to the specific Go process; the reservation does not deprive other processes of memory.
To find the amount of actual memory allocated to a Go process, use the Unix top command and consult the RES (Linux) or RSIZE (macOS) columns.
這個 FAQ 是在 2012 年 10 月 提交 的,這麼多年了也沒有更進一步的說明,再翻了 issues 和 forum,一些關閉掉的 issue 都指向了 FAQ,這顯然無法滿足我的求知慾,因此我繼續往下探索,看看裡面到底都擺了些什麼。
檢視記憶體對映
在上圖中,我們有提到程序虛擬記憶體,主要包含了你的程式碼、資料、堆、棧段和共享庫,那初步懷疑是不是程序做了什麼記憶體對映,導致了大量的記憶體空間被保留呢,為了確定這一點,我們透過如下命令去排查:
$ vmmap --wide 67459
...
==== Non-writable regions for process 67459
REGION TYPE START - END [ VSIZE RSDNT DIRTY SWAP] PRT/MAX SHRMOD PURGE REGION DETAIL
__TEXT 00000001065ff000-000000010667b000 [ 496K 492K 0K 0K] r-x/rwx SM=COW /bin/zsh
__LINKEDIT 0000000106687000-0000000106699000 [ 72K 44K 0K 0K] r--/rwx SM=COW /bin/zsh
MALLOC metadata 000000010669b000-000000010669c000 [ 4K 4K 4K 0K] r--/rwx SM=COW DefaultMallocZone_0x10669b000 zone structure
...
__TEXT 00007fff76c31000-00007fff76c5f000 [ 184K 168K 0K 0K] r-x/r-x SM=COW /usr/lib/system/libxpc.dylib
__LINKEDIT 00007fffe7232000-00007ffff32cb000 [192.6M 17.4M 0K 0K] r--/r-- SM=COW dyld shared cache combined __LINKEDIT
...
==== Writable regions for process 67459
REGION TYPE START - END [ VSIZE RSDNT DIRTY SWAP] PRT/MAX SHRMOD PURGE REGION DETAIL
__DATA 000000010667b000-0000000106682000 [ 28K 28K 28K 0K] rw-/rwx SM=COW /bin/zsh
...
__DATA 0000000106716000-000000010671e000 [ 32K 28K 28K 4K] rw-/rwx SM=COW /usr/lib/zsh/5.3/zsh/zle.so
__DATA 000000010671e000-000000010671f000 [ 4K 4K 4K 0K] rw-/rwx SM=COW /usr/lib/zsh/5.3/zsh/zle.so
__DATA 0000000106745000-0000000106747000 [ 8K 8K 8K 0K] rw-/rwx SM=COW /usr/lib/zsh/5.3/zsh/complete.so
__DATA 000000010675a000-000000010675b000 [ 4K 4K 4K 0K] rw-
...
這塊主要是利用 macOS 的 vmmap 命令去檢視記憶體對映情況,這樣就可以知道這個程序的記憶體對映情況,從輸出分析來看,這些關聯共享庫佔用的空間並不大,導致 VSZ 過高的根本原因不在共享庫和二進位制檔案上,但是並沒有發現大量保留記憶體空間的行為,這是一個問題點。
注:若是 Linux 系統,可使用 cat /proc/PID/maps 或 cat /proc/PID/smaps 檢視。
檢視系統呼叫
既然在記憶體對映中,我們沒有明確的看到保留記憶體空間的行為,那我們接下來看看該程序的系統呼叫,確定一下它是否存在記憶體操作的行為,如下:
$ sudo dtruss -a ./awesomeProject
...
4374/0x206a2: 15620 6 3 mprotect(0x1BC4000, 0x1000, 0x0) = 0 0
...
4374/0x206a2: 15781 9 4 sysctl([CTL_HW, 3, 0, 0, 0, 0] (2), 0x7FFEEFBFFA64, 0x7FFEEFBFFA68, 0x0, 0x0) = 0 0
4374/0x206a2: 15783 3 1 sysctl([CTL_HW, 7, 0, 0, 0, 0] (2), 0x7FFEEFBFFA64, 0x7FFEEFBFFA68, 0x0, 0x0) = 0 0
4374/0x206a2: 15899 7 2 mmap(0x0, 0x40000, 0x3, 0x1002, 0xFFFFFFFFFFFFFFFF, 0x0) = 0x4000000 0
4374/0x206a2: 15930 3 1 mmap(0xC000000000, 0x4000000, 0x0, 0x1002, 0xFFFFFFFFFFFFFFFF, 0x0) = 0xC000000000 0
4374/0x206a2: 15934 4 2 mmap(0xC000000000, 0x4000000, 0x3, 0x1012, 0xFFFFFFFFFFFFFFFF, 0x0) = 0xC000000000 0
4374/0x206a2: 15936 2 0 mmap(0x0, 0x2000000, 0x3, 0x1002, 0xFFFFFFFFFFFFFFFF, 0x0) = 0x59B7000 0
4374/0x206a2: 15942 2 0 mmap(0x0, 0x210800, 0x3, 0x1002, 0xFFFFFFFFFFFFFFFF, 0x0) = 0x4040000 0
4374/0x206a2: 15947 2 0 mmap(0x0, 0x10000, 0x3, 0x1002, 0xFFFFFFFFFFFFFFFF, 0x0) = 0x1BD0000 0
4374/0x206a2: 15993 3 0 madvise(0xC000000000, 0x2000, 0x8) = 0 0
4374/0x206a2: 16004 2 0 mmap(0x0, 0x10000, 0x3, 0x1002, 0xFFFFFFFFFFFFFFFF, 0x0) = 0x1BE0000 0
...
在這小節中,我們透過 macOS 的 dtruss 命令監聽並查看了執行這個程式所進行的所有系統呼叫,發現了與記憶體管理有一定關係的方法如下:
- mmap:建立一個新的虛擬記憶體區域,但這裡需要注意,就是當系統呼叫 mmap 時,它只是從虛擬記憶體中申請了一段空間出來,並不會去分配和對映真實的物理記憶體,而當你訪問這段空間的時候,才會在當前時間真正的去分配物理記憶體。那麼對應到我們實際應用的程序中,那就是 VSZ 的增長後,而該記憶體空間又未正式使用的話,物理記憶體是不會有增長的。
- madvise:提供有關使用記憶體的建議,例如:MADV_NORMAL、MADV_RANDOM、MADV_SEQUENTIAL、MADV_WILLNEED、MADV_DONTNEED 等等。
- mprotect:設定記憶體區域的保護情況,例如:PROT_NONE、PROT_READ、PROT_WRITE、PROT_EXEC、PROT_SEM、PROT_SAO、PROT_GROWSUP、PROT_GROWSDOWN 等等。
- sysctl:在核心執行時動態地修改核心的執行引數。
在此比較可疑的是 mmap 方法,它在 dtruss 的最終統計中一共呼叫了 10 餘次,我們可以相信它在 Go Runtime 的時候進行了大量的虛擬記憶體申請,我們再接著往下看,看看到底是在什麼階段進行了虛擬記憶體空間的申請。
注:若是 Linux 系統,可使用 strace 命令。
檢視 Go Runtime
啟動流程
透過上述的分析,我們可以知道在 Go 程式啟動的時候 VSZ 就已經不低了,並且確定不是共享庫等的原因,且程式在啟動時系統呼叫確實存在 mmap 等方法的呼叫,那麼我們可以充分懷疑 Go 在初始化階段就保留了該記憶體空間。那我們第一步要做的就是檢視一下 Go 的引導啟動流程,看看是在哪裡申請的,引導過程如下:
graph TD
A(rt0_darwin_amd64.s:8<br/>_rt0_amd64_darwin) -->|JMP| B(asm_amd64.s:15<br/>_rt0_amd64)
B --> |JMP|C(asm_amd64.s:87<br/>runtime-rt0_go)
C --> D(runtime1.go:60<br/>runtime-args)
D --> E(os_darwin.go:50<br/>runtime-osinit)
E --> F(proc.go:472<br/>runtime-schedinit)
F --> G(proc.go:3236<br/>runtime-newproc)
G --> H(proc.go:1170<br/>runtime-mstart)
H --> I(在新创建的 p 和 m 上运行 runtime-main)
- runtime-osinit:取得 CPU 核心數。
- runtime-schedinit:初始化程式執行環境(包括棧、記憶體分配器、垃圾回收、P等)。
- runtime-newproc:建立一個新的 G 和 繫結 runtime.main。
- runtime-mstart:啟動執行緒 M。
注:來自@曹大的 《Go 程式的啟動流程》和@全成的 《Go 程式是怎樣跑起來的》,推薦大家閱讀。
初始化執行環境
顯然,我們要研究的是 runtime 裡的 schedinit 方法,如下:
func schedinit() {
...
stackinit()
mallocinit()
mcommoninit(_g_.m)
cpuinit() // must run before alginit
alginit() // maps must not be used before this call
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
msigsave(_g_.m)
initSigmask = _g_.m.sigmask
goargs()
goenvs()
parsedebugvars()
gcinit()
...
}
從用途來看,非常明顯, mallocinit 方法會進行記憶體分配器的初始化,我們繼續往下看。
初始化記憶體分配器
mallocinit
接下來我們正式的分析一下 mallocinit 方法,在引導流程中, mallocinit 主要承擔 Go 程式的記憶體分配器的初始化動作,而今天主要是針對虛擬記憶體地址這塊進行拆解,如下:
func mallocinit() {
...
if sys.PtrSize == 8 {
for i := 0x7f; i >= 0; i-- {
var p uintptr
switch {
case GOARCH == "arm64" && GOOS == "darwin":
p = uintptr(i)<<40 | uintptrMask&(0x0013<<28)
case GOARCH == "arm64":
p = uintptr(i)<<40 | uintptrMask&(0x0040<<32)
case GOOS == "aix":
if i == 0 {
continue
}
p = uintptr(i)<<40 | uintptrMask&(0xa0<<52)
case raceenabled:
...
default:
p = uintptr(i)<<40 | uintptrMask&(0x00c0<<32)
}
hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())
hint.addr = p
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
} else {
...
}
}
- 判斷當前是 64 位還是 32 位的系統。
- 從 0x7fc000000000~0x1c000000000 開始設定保留地址。
- 判斷當前
GOARCH、GOOS或是否開啟了競態檢查,根據不同的情況申請不同大小的連續記憶體地址,而這裡的p是即將要要申請的連續記憶體地址的開始地址。 - 儲存剛剛計算的 arena 的資訊到
arenaHint中。
可能會有小夥伴問,為什麼要判斷是 32 位還是 64 位的系統,這是因為不同位數的虛擬記憶體的定址範圍是不同的,因此要進行區分,否則會出現高位的虛擬記憶體對映問題。而在申請保留空間時,我們會經常提到 arenaHint 結構體,它是 arenaHints連結串列裡的一個節點,結構如下:
type arenaHint struct {
addr uintptr
down bool
next *arenaHint
}
- addr:
arena的起始地址 - down:是否最後一個
arena - next:下一個
arenaHint的指標地址
那麼這裡瘋狂提到的 arena 又是什麼東西呢,這其實是 Go 的記憶體管理中的概念,Go Runtime 會把申請的虛擬記憶體分為三個大塊,如下:

- spans:記錄 arena 區域頁號和 mspan 的對映關係。
- bitmap:標識 arena 的使用情況,在功能上來講,會用於標識 arena 的哪些空間地址已經儲存了物件。
- arean:arean 其實就是 Go 的堆區,是由 mheap 進行管理的,它的 MaxMem 是 512GB-1。而在功能上來講,Go 會在初始化的時候申請一段連續的虛擬記憶體空間地址到 arean 保留下來,在真正需要申請堆上的空間時再從 arean 中取出來處理,這時候就會轉變為物理記憶體了。
在這裡的話,你需要理解 arean 區域在 Go 記憶體裡的作用就可以了。
mmap
我們剛剛透過上述的分析,已經知道 mallocinit 的用途了,但是你可能還是會有疑惑,就是我們之前所看到的 mmap 系統呼叫,和它又有什麼關係呢,怎麼就關聯到一起了,接下來我們先一起來看看更下層的程式碼,如下:
func sysAlloc(n uintptr, sysStat *uint64) unsafe.Pointer {
p, err := mmap(nil, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
...
mSysStatInc(sysStat, n)
return p
}
func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
...
}
func sysMap(v unsafe.Pointer, n uintptr, sysStat *uint64) {
...
munmap(v, n)
p, err := mmap(v, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE, -1, 0)
...
}
在 Go Runtime 中存在著一系列的系統級記憶體呼叫方法,本文涉及的主要如下:
- sysAlloc:從 OS 系統上申請清零後的記憶體空間,呼叫引數是
_PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE,得到的結果需進行記憶體對齊。 - sysReserve:從 OS 系統中保留記憶體的地址空間,這時候還沒有分配物理記憶體,呼叫引數是
_PROT_NONE, _MAP_ANON|_MAP_PRIVATE,得到的結果需進行記憶體對齊。 - sysMap:通知 OS 系統我們要使用已經保留了的記憶體空間,呼叫引數是
_PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE。
看上去好像很有道理的樣子,但是 mallocinit 方法在初始化時,到底是在哪裡涉及了 mmap 方法呢,表面看不出來,如下:
for i := 0x7f; i >= 0; i-- {
...
hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())
hint.addr = p
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
實際上在呼叫 mheap_.arenaHintAlloc.alloc() 時,呼叫的是 mheap 下的 sysAlloc 方法,而 sysAlloc 又會與 mmap 方法產生呼叫關係,並且這個方法與常規的 sysAlloc 還不大一樣,如下:
var mheap_ mheap
...
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
...
for h.arenaHints != nil {
hint := h.arenaHints
p := hint.addr
if hint.down {
p -= n
}
if p+n < p {
v = nil
} else if arenaIndex(p+n-1) >= 1<<arenaBits {
v = nil
} else {
v = sysReserve(unsafe.Pointer(p), n)
}
...
}
你可以驚喜的發現 mheap.sysAlloc 裡其實有呼叫 sysReserve 方法,而 sysReserve 方法又正正是從 OS 系統中保留記憶體的地址空間的特定方法,是不是很驚喜,一切似乎都串起來了。
小結
在本節中,我們先寫了一個測試程式,然後根據非常規的排查思路進行了一步步的跟蹤懷疑,整體流程如下:
- 透過
top或ps等命令,檢視程序執行情況,分析基礎指標。 - 透過
pprof或runtime.MemStats等工具鏈檢視應用執行情況,分析應用層面是否有洩露或者哪兒高。 - 透過
vmmap命令,檢視程序的記憶體對映情況,分析是不是程序虛擬空間內的某個區域比較高,例如:共享庫等。 - 透過
dtruss命令,檢視程式的系統呼叫情況,分析可能出現的一些特殊行為,例如:在分析中我們發現mmap方法呼叫的比例是比較高的,那我們有充分的理由懷疑 Go 在啟動時就進行了大量的記憶體空間保留。 - 透過上述的分析,確定可能是在哪個環節申請了那麼多的記憶體空間後,再到 Go Runtime 中去做進一步的原始碼分析,因為原始碼面前,了無秘密,沒必要靠猜。
從結論上而言,VSZ(程序虛擬記憶體大小)與共享庫等沒有太大的關係,主要與 Go Runtime 存在直接關聯,也就是在前圖中表示的執行時堆(malloc)。轉換到 Go Runtime 裡,就是在 mallocinit 這個記憶體分配器的初始化階段裡進行了一定量的虛擬空間的保留。
而保留虛擬記憶體空間時,受什麼影響,又是一個哲學問題。從原始碼上來看,主要如下:
- 受不同的 OS 系統架構(GOARCH/GOOS)和位數(32/64 位)的影響。
- 受記憶體對齊的影響,計算回來的記憶體空間大小是需要經過對齊才會進行保留。
總結
我們透過一步步地分析,講解了 Go 會在哪裡,又會受什麼因素,去呼叫了什麼方法保留了那麼多的虛擬記憶體空間,但是我們肯定會憂心程序虛擬記憶體(VSZ)高,會不會存在問題呢,我分析如下:
- VSZ 並不意味著你真正使用了那些物理記憶體,因此是不需要擔心的。
- VSZ 並不會給 GC 帶來壓力,GC 管理的是程序實際使用的物理記憶體,而 VSZ 在你實際使用它之前,它並沒有過多的代價。
- VSZ 基本都是不可訪問的記憶體對映,也就是它並沒有記憶體的訪問許可權(不允許讀、寫和執行)。
看到這裡舒一口氣,因為 Go VSZ 的高,並不會對我們產生什麼非常實質性的問題,但是又仔細一想,為什麼 Go 要申請那麼多的虛擬記憶體呢,到底有啥用呢,考慮如下:Go 的設計是考慮到 arena 和 bitmap 的後續使用,先提早保留了整個記憶體地址空間。 然後隨著 Go Runtime 和應用的逐步使用,肯定也會開始實際的申請和使用記憶體,這時候 arena 和 bitmap 的記憶體分配器就只需要將事先申請好的記憶體地址空間保留更改為實際可用的物理記憶體就好了,這樣子可以極大的提高效能。
參考
- 曹大的 Go 程式的啟動流程
- 全成的 Go 程式是怎樣跑起來的
- 推薦閱讀 歐神的 go-under-the-hood
- High virtual memory allocation by golang
- GO MEMORY MANAGEMENT
- GoBigVirtualSize
- GoProgramMemoryUse
1.14 乾貨滿滿的 Go Modules 和 goproxy.cn
大家好,我是一隻普通的煎魚,週四晚上很有幸邀請到 goproxy.cn 的作者 @盛傲飛(@aofei) 到 Go 夜讀給我們進行第 61 期 《Go Modules、Go Module Proxy 和 goproxy.cn》的技術分享。
本次 @盛傲飛 的夜讀分享,是對 Go Modules 的一次很好的解讀,比較貼近工程實踐,我必然希望把這塊的知識更多的分享給大家,因此有了今天本篇文章,同時大家也可以多關注 Go 夜讀,每週會透過 zoom 線上直播的方式分享 Go 相關的技術話題,希望對大家有所幫助。
前言
Go 1.11 推出的模組(Modules)為 Go 語言開發者打開了一扇新的大門,理想化的依賴管理解決方案使得 Go 語言朝著計算機程式設計史上的第一個依賴烏托邦(Deptopia)邁進。隨著模組一起推出的還有模組代理協議(Module proxy protocol),透過這個協議我們可以實作 Go 模組代理(Go module proxy),也就是依賴映象。
Go 1.13 的釋出為模組帶來了大量的改進,所以模組的扶正就是這次 Go 1.13 釋出中開發者能直接感覺到的最大變化。而問題在於,Go 1.13 中的 GOPROXY 環境變數擁有了一個在中國大陸無法訪問到的預設值 proxy.golang.org,經過大家在 golang/go#31755 中激烈的討論(有些人甚至將話提上升到了“自由世界”的層次),最終 Go 核心團隊仍然無法為中國開發者提供一個可在中國大陸訪問的官方模組代理。
為了今後中國的 Go 語言開發者能更好地進行開發,七牛雲推出了非營利性專案 goproxy.cn,其目標是為中國和世界上其他地方的 Gopher 們提供一個免費的、可靠的、持續線上的且經過 CDN 加速的模組代理。可以預見未來是屬於模組化的,所以 Go 語言開發者能越早切入模組就能越早進入未來。
如果說 Go 1.11 和 Go 1.12 時由於模組的不完善你不願意切入,那麼 Go 1.13 你則可以大膽地開始放心使用。本次分享將討論如何使用模組和模組代理,以及在它們的使用中會常遇見的坑,還會講解如何快速搭建自己的私有模組代理,並簡單地介紹一下七牛雲推出的 goproxy.cn 以及它的出現對於中國 Go 語言開發者來說重要在何處。
目錄
- Go Modules 簡介
- 快速遷移專案至 Go Modules
- 使用 Go Modules 時常遇見的坑
- 坑 1:判斷專案是否啟用了 Go Modules
- 坑 2:管理 Go 的環境變數
- 坑 3:從 dep、glide 等遷移至 Go Modules
- 坑 4:拉取私有模組
- 坑 5:更新現有的模組
- 坑 6:主版本號
- Go Module Proxy 簡介
- Goproxy 中國(goproxy.cn)
Go Modules 簡介
Go modules (前身 vgo) 是 Go team (Russ Cox) 強推的一個理想化的類語言級依賴管理解決方案,它是和 Go1.11 一同釋出的,在 Go1.13 做了大量的最佳化和調整,目前已經變得比較不錯,如果你想用 Go modules,但還停留在 1.11/1.12 版本的話,強烈建議升級。
三個關鍵字
強推
首先這並不是亂說的,因為 Go modules 確實是被強推出來的,如下:
- 之前:大家都知道在 Go modules 之前還有一個叫 dep 的專案,它也是 Go 的一個官方的實驗性專案,目的同樣也是為了解決 Go 在依賴管理方面的短板。在 Russ Cox 還沒有提出 Go modules 的時候,社群裡面幾乎所有的人都認為 dep 肯定就是未來 Go 官方的依賴管理解決方案了。
- 後來:誰都沒想到半路殺出個程咬金,Russ Cox 義無反顧地推出了 Go modules,這瞬間導致一石激起千層浪,讓社群炸了鍋。大家一致認為 Go team 實在是太霸道、太獨裁了,連個招呼都不打一聲。我記得當時有很多人在網上跟 Russ Cox 口水戰,各種依賴管理解決方案的專家都冒出來發表意見,討論範圍甚至一度超出了 Go 語言的圈子觸及到了其他語言的領域。
理想化
從他強制要求使用語義化版本控制這一點來說就很理想化了,如下:
- Go modules 狠到如果你的 Tag 沒有遵循語義化版本控制那麼它就會忽略你的 Tag,然後根據你的 Commit 時間和雜湊值再為你生成一個假定的符合語義化版本控制的版本號。
- Go modules 還預設認為,只要你的主版本號不變,那這個模組版本肯定就不包含 Breaking changes,因為語義化版本控制就是這麼規定的啊。是不是很理想化。
類語言級:
這個關鍵詞其實是我自己瞎編的,我只是單純地個人認為 Go modules 在設計上就像個語言級特性一樣,比如如果你的主版本號發生變更,那麼你的程式碼裡的 import path 也得跟著變,它認為主版本號不同的兩個模組版本是完全不同的兩個模組。此外,Go moduels 在設計上跟 go 整個命令都結合得相當緊密,無處不在,所以我才說它是一個有點兒像語言級的特性,雖然不是太嚴謹。
推 Go Modules 的人是誰
那麼在上文中提到的 Russ Cox 何許人也呢,很多人應該都知道他,他是 Go 這個專案目前程式碼提交量最多的人,甚至是第二名的兩倍還要多。
Russ Cox 還是 Go 現在的掌舵人(大家應該知道之前 Go 的掌舵人是 Rob Pike,但是聽說由於他本人不喜歡特朗普執政所以離開了美國,然後他歲數也挺大的了,所以也正在逐漸交權,不過現在還是在參與 Go 的發展)。
Russ Cox 的個人能力相當強,看問題的角度也很獨特,這也就是為什麼他剛一提出 Go modules 的概念就能引起那麼大範圍的響應。雖然是被強推的,但事實也證明當下的 Go modules 表現得確實很優秀,所以這表明一定程度上的 “獨裁” 還是可以接受的,至少可以保證一個專案能更加專一地朝著一個方向發展。
總之,無論如何 Go modules 現在都成了 Go 語言的一個密不可分的元件。
GOPATH
Go modules 出現的目的之一就是為了解決 GOPATH 的問題,也就相當於是拋棄 GOPATH 了。
Opt-in
Go modules 還處於 Opt-in 階段,就是你想用就用,不用就不用,不強制你。但是未來很有可能 Go2 就強制使用了。
"module" != "package"
有一點需要糾正,就是“模組”和“包”,也就是 “module” 和 “package” 這兩個術語並不是等價的,是 “集合” 跟 “元素” 的關係,“模組” 包含 “包”,“包” 屬於 “模組”,一個 “模組” 是零個、一個或多個 “包” 的集合。
Go Modules 相關屬性
go.mod
module example.com/foobar
go 1.13
require (
example.com/apple v0.1.2
example.com/banana v1.2.3
example.com/banana/v2 v2.3.4
example.com/pineapple v0.0.0-20190924185754-1b0db40df49a
)
exclude example.com/banana v1.2.4
replace example.com/apple v0.1.2 => example.com/rda v0.1.0
replace example.com/banana => example.com/hugebanana
go.mod 是啟用了 Go moduels 的專案所必須的最重要的檔案,它描述了當前專案(也就是當前模組)的元資訊,每一行都以一個動詞開頭,目前有以下 5 個動詞:
- module:用於定義當前專案的模組路徑。
- go:用於設定預期的 Go 版本。
- require:用於設定一個特定的模組版本。
- exclude:用於從使用中排除一個特定的模組版本。
- replace:用於將一個模組版本替換為另外一個模組版本。
這裡的填寫格式基本為包引用路徑+版本號,另外比較特殊的是 go $version,目前從 Go1.13 的程式碼裡來看,還只是個標識作用,暫時未知未來是否有更大的作用。
go.sum
go.sum 是類似於比如 dep 的 Gopkg.lock 的一類檔案,它詳細羅列了當前專案直接或間接依賴的所有模組版本,並寫明瞭那些模組版本的 SHA-256 雜湊值以備 Go 在今後的操作中保證專案所依賴的那些模組版本不會被篡改。
example.com/apple v0.1.2 h1:WXkYYl6Yr3qBf1K79EBnL4mak0OimBfB0XUf9Vl28OQ=
example.com/apple v0.1.2/go.mod h1:xHWCNGjB5oqiDr8zfno3MHue2Ht5sIBksp03qcyfWMU= example.com/banana v1.2.3 h1:qHgHjyoNFV7jgucU8QZUuU4gcdhfs8QW1kw68OD2Lag=
example.com/banana v1.2.3/go.mod h1:HSdplMjZKSmBqAxg5vPj2TmRDmfkzw+cTzAElWljhcU= example.com/banana/v2 v2.3.4 h1:zl/OfRA6nftbBK9qTohYBJ5xvw6C/oNKizR7cZGl3cI= example.com/banana/v2 v2.3.4/go.mod h1:eZbhyaAYD41SGSSsnmcpxVoRiQ/MPUTjUdIIOT9Um7Q=
...
我們可以看到一個模組路徑可能有如下兩種:
example.com/apple v0.1.2 h1:WXkYYl6Yr3qBf1K79EBnL4mak0OimBfB0XUf9Vl28OQ=
example.com/apple v0.1.2/go.mod h1:xHWCNGjB5oqiDr8zfno3MHue2Ht5sIBksp03qcyfWMU=
前者為 Go modules 打包整個模組包檔案 zip 後再進行 hash 值,而後者為針對 go.mod 的 hash 值。他們兩者,要不就是同時存在,要不就是隻存在 go.mod hash。
那什麼情況下會不存在 zip hash 呢,就是當 Go 認為肯定用不到某個模組版本的時候就會省略它的 zip hash,就會出現不存在 zip hash,只存在 go.mod hash 的情況。
GO111MODULE
這個環境變數主要是 Go modules 的開關,主要有以下引數:
- auto:只在專案包含了 go.mod 檔案時啟用 Go modules,在 Go 1.13 中仍然是預設值,詳見 :golang.org/issue/31857。
- on:無腦啟用 Go modules,推薦設定,未來版本中的預設值,讓 GOPATH 從此成為歷史。
- off:停用 Go modules。
GOPROXY
這個環境變數主要是用於設定 Go 模組代理,主要如下:
- 它的值是一個以英文逗號 “,” 分割的 Go module proxy 列表(稍後講解)
- 作用:用於使 Go 在後續拉取模組版本時能夠脫離傳統的 VCS 方式從映象站點快速拉取。它擁有一個預設:
https://proxy.golang.org,direct,但很可惜proxy.golang.org在中國無法訪問,故而建議使用goproxy.cn作為替代,可以執行語句:go env -w GOPROXY=https://goproxy.cn,direct。 - 設定為 “off” :禁止 Go 在後續操作中使用任 何 Go module proxy。
- 作用:用於使 Go 在後續拉取模組版本時能夠脫離傳統的 VCS 方式從映象站點快速拉取。它擁有一個預設:
剛剛在上面,我們可以發現值列表中有 “direct” ,它又有什麼作用呢。其實值列表中的 “direct” 為特殊指示符,用於指示 Go 回源到模組版本的源地址去抓取(比如 GitHub 等),當值列表中上一個 Go module proxy 返回 404 或 410 錯誤時,Go 自動嘗試列表中的下一個,遇見 “direct” 時回源,遇見 EOF 時終止並丟擲類似 “invalid version: unknown revision...” 的錯誤。
GOSUMDB
它的值是一個 Go checksum database,用於使 Go 在拉取模組版本時(無論是從源站拉取還是透過 Go module proxy 拉取)保證拉取到的模組版本資料未經篡改,也可以是“off”即禁止 Go 在後續操作中校驗模組版本
- 格式 1:
<SUMDB_NAME>+<PUBLIC_KEY>。 - 格式 2:
<SUMDB_NAME>+<PUBLIC_KEY> <SUMDB_URL>。 - 擁有預設值:
sum.golang.org(之所以沒有按照上面的格式是因為 Go 對預設值做了特殊處理)。 - 可被 Go module proxy 代理 (詳見:Proxying a Checksum Database)。
sum.golang.org在中國無法訪問,故而更加建議將 GOPROXY 設定為goproxy.cn,因為goproxy.cn支援代理sum.golang.org。
Go Checksum Database
Go checksum database 主要用於保護 Go 不會從任何源頭拉到被篡改過的非法 Go 模組版本,其作用(左)和工作機制(右)如下圖:

如果有興趣的小夥伴可以看看 Proposal: Secure the Public Go Module Ecosystem,有詳細介紹其演算法機制,如果想簡單一點,檢視 go help module-auth 也是一個不錯的選擇。
GONOPROXY/GONOSUMDB/GOPRIVATE
這三個環境變數都是用在當前專案依賴了私有模組,也就是依賴了由 GOPROXY 指定的 Go module proxy 或由 GOSUMDB 指定 Go checksum database 無法訪問到的模組時的場景
- 它們三個的值都是一個以英文逗號 “,” 分割的模組路徑字首,匹配規則同 path.Match。
- 其中 GOPRIVATE 較為特殊,它的值將作為 GONOPROXY 和 GONOSUMDB 的預設值,所以建議的最佳姿勢是隻是用 GOPRIVATE。
在使用上來講,比如 GOPRIVATE=*.corp.example.com 表示所有模組路徑以 corp.example.com 的下一級域名 (如 team1.corp.example.com) 為字首的模組版本都將不經過 Go module proxy 和 Go checksum database,需要注意的是不包括 corp.example.com 本身。
Global Caching
這個主要是針對 Go modules 的全域性快取資料說明,如下:
- 同一個模組版本的資料只快取一份,所有其他模組共享使用。
- 目前所有模組版本資料均快取在
$GOPATH/pkg/mod和 $GOPATH/pkg/sum下,未來或將移至$GOCACHE/mod和$GOCACHE/sum下( 可能會在當$GOPATH被淘汰後)。 - 可以使用
go clean -modcache清理所有已快取的模組版本資料。
另外在 Go1.11 之後 GOCACHE 已經不允許設定為 off 了,我想著這也是為了模組資料快取移動位置做準備,因此大家應該儘快做好適配。
快速遷移專案至 Go Modules
- 第一步: 升級到 Go 1.13。
- 第二步: 讓 GOPATH 從你的腦海中完全消失,早一步踏入未來。
- 修改 GOBIN 路徑(可選):
go env -w GOBIN=$HOME/bin。 - 開啟 Go modules:
go env -w GO111MODULE=on。 - 設定 GOPROXY:
go env -w GOPROXY=https://goproxy.cn,direct# 在中國是必須的,因為它的預設值被牆了。
- 修改 GOBIN 路徑(可選):
- 第三步(可選): 按照你喜歡的目錄結構重新組織你的所有專案。
- 第四步: 在你專案的根目錄下執行
go mod init <OPTIONAL_MODULE_PATH>以生成 go.mod 檔案。 - 第五步: 想辦法說服你身邊所有的人都去走一下前四步。
遷移後 go get 行為的改變
- 用
go help module-get和go help gopath-get分別去了解 Go modules 啟用和未啟用兩種狀態下的 go get 的行為 - 用
go get拉取新的依賴- 拉取最新的版本(優先擇取 tag):
go get golang.org/x/text@latest - 拉取
master分支的最新 commit:go get golang.org/x/text@master - 拉取 tag 為 v0.3.2 的 commit:
go get golang.org/x/text@v0.3.2 - 拉取 hash 為 342b231 的 commit,最終會被轉換為 v0.3.2:
go get golang.org/x/text@342b2e - 用
go get -u更新現有的依賴 - 用
go mod download下載 go.mod 檔案中指明的所有依賴 - 用
go mod tidy整理現有的依賴 - 用
go mod graph檢視現有的依賴結構 - 用
go mod init生成 go.mod 檔案 (Go 1.13 中唯一一個可以生成 go.mod 檔案的子命令)
- 拉取最新的版本(優先擇取 tag):
- 用
go mod edit編輯 go.mod 檔案 - 用
go mod vendor匯出現有的所有依賴 (事實上 Go modules 正在淡化 Vendor 的概念) - 用
go mod verify校驗一個模組是否被篡改過
這裡我們注意到有兩點比較特別,分別是:
- 第一點:為什麼 “拉取 hash 為 342b231 的 commit,最終會被轉換為 v0.3.2” 呢。這是因為雖然我們設定了拉取 @342b2e commit,但是因為 Go modules 會與 tag 進行對比,若發現對應的 commit 與 tag 有關聯,則進行轉換。
- 第二點:為什麼不建議使用
go mod vendor,因為 Go modules 正在淡化 Vendor 的概念,很有可能 Go2 就去掉了。
使用 Go Modules 時常遇見的坑
坑 1: 判斷專案是否啟用了 Go Modules

坑 2: 管理 Go 的環境變數
這裡主要是提到 Go1.13 新增了 go env -w 用於寫入環境變數,而寫入的地方是 os.UserConfigDir 所返回的路徑,需要注意的是 go env -w 不會覆寫。
坑 3: 從 dep、glide 等遷移至 Go Modules

這裡主要是指從舊有的依賴包管理工具(dep/glide 等)進行遷移時,因為 BUG 的原因會導致不經過 GOPROXY 的代理,解決方法有如下兩個:
- 手動建立一個 go.mod 檔案,再執行 go mod tidy 進行補充。
- 上代理,相當於不使用 GOPROXY 了。
坑 4:拉取私有模組

這裡主要想涉及兩塊知識點,如下:
- GOPROXY 是無權訪問到任何人的私有模組的,所以你放心,安全性沒問題。
- GOPROXY 除了設定模組代理的地址以外,還需要增加 “direct” 特殊標識才可以成功拉取私有庫。
坑 5:更新現有的模組

坑 6:主版本號

Go Module Proxy 簡介

在這裡再次強調了 Go Module Proxy 的作用(圖左),以及其對應的協議互動流程(圖右),有興趣的小夥伴可以認真看一下。
Goproxy 中國(goproxy.cn)
在這塊主要介紹了 Goproxy 的實踐操作以及 goproxy.cn 的一些 Q&A 和 近況,如下:
Q&A
Q:如果中國 Go 語言社群沒有咱們自己家的 Go Module Proxy 會怎麼樣?
A:在 Go 1.13 中 GOPROXY 和 GOSUMDB 這兩個環境變數都有了在中國無法 訪問的預設值,儘管我在 golang.org/issue/31755 裡努力嘗 試過,但最終仍然無法為咱們中國的 Go 語言開發者謀得一個完美的解決方案。所以從今以後咱 們中國的所有 Go 語言開發者,只要是 使用了 Go modules 的,那麼都必須先修改 GOPROXY 和 GOSUMDB 才能正常使用 Go 做開發,否則可能連一個最簡單的程式都跑不起 來(只要它有依 賴第三方模 塊)。
Q: 我建立 Goproxy 中國(goproxy.cn)的主要原因?
A:其實更早的時候,也就是今年年初我也曾 試圖在 golang.org/issue/31020 中請求 Go team 能想辦法避免那時的 GOPROXY 即將擁有的預設值可以在中國正常訪問,但 Go team 似乎也無能為力,為此我才堅定了建立 goproxy.cn 的信念。既然別人沒法兒幫忙,那咱們就 得自己動手,不為別的,就為了讓大家以後能夠更愉快地使用 Go 語言配合 Go modules 做開發。
最初我先是和七牛雲的 許叔(七牛雲的 創始人兼 CEO 許式偉)提出了我打算 建立 goproxy.cn 的想法,本是抱著 試試看的目的,但沒想 到 許叔幾乎是沒有超過一分鐘的考慮便認可了我的想法並表示願意一起推 動。那一陣子剛好趕上我在寫畢業論文,所以專案開發完後就 一直沒和七牛雲做交接,一直跑在我的個人服 務器上。直到有一次 goproxy.cn 被攻擊了,一下午的功夫 燒了我一百多美元,然後我才 意識到這種專案真不能個人來做。個人來做不靠 譜,萬一依賴這個專案的人多了,專案再出什麼事兒,那就會給大家成不必要的損 失。所以我趕緊和七牛雲做了交接,把 goproxy.cn 完全交給了七牛雲,甚至連域名都過戶了去。
近況
- Goproxy 中國 (goproxy.cn) 是目前中國最可靠的 Go module proxy (真不是在自賣自誇)。
- 為中國 Go 語言開發者量身打,支援代理 GOSUMDB 的預設值,經過全球 CDN 加速,高可用,可 應用進公司複雜的開發環境中,亦可用作上游代理。
- 由中國倍受信賴的雲服務提供商七牛雲無償提供基礎設施支援的開源的非營利性專案。
- 目標是為中國乃至全世界的 Go 語言開發者提供一個免 費的、可靠的、持 續線上的且經過 CDN 加的 Go module proxy。
- 域名已由七牛雲進行了備案 (滬ICP備11037377號-56)。
情況

此處呈現的是儲存大小,主要是針對模組包程式碼,而一般來講程式碼並不會有多大,0-10MB,10-50MB 佔最大頭,也是能夠理解,但是大於 100MB 的模組包程式碼就比較誇張了。

此時主要是展示了一下近期 goproxy.cn 的網路資料情況,我相信未來是會越來越高的,值得期待。
Q&A
Q:如何解決 Go 1.13 在從 GitLab 拉取模組版本時遇到的,Go 錯誤地按照非期望值的路徑尋找目標模組版本結果致使最終目標模組拉取失敗的問題?
A:GitLab 中配合 goget 而設定的 <meta> 存在些許問題,導致 Go 1.13 錯誤地識別了模組的具體路徑,這是個 Bug,據說在 GitLab 的新版本中已經被修復了,詳細內容可以看 https://github.com/golang/go/issues/34094 這個 Issue。然後目前的解決辦法的話除了升級 GitLab 的版本外,還可以參考 https://github.com/developer-learning/night-reading-go/issues/468#issuecomment-535850154 這條回覆。
Q:使用 Go modules 時可以同時依賴同一個模組的不同的兩個或者多個小版本(修訂版本號不同)嗎?
A:不可以的,Go modules 只可以同時依賴一個模組的不同的兩個或者多個大版本(主版本號不同)。比如可以同時依賴 example.com/foobar@v1.2.3 和 example.com/foobar/v2@v2.3.4,因為他們的模組路徑(module path)不同,Go modules 規定主版本號不是 v0 或者 v1 時,那麼主版本號必須顯式地出現在模組路徑的尾部。但是,同時依賴兩個或者多個小版本是不支援的。比如如果模組 A 同時直接依賴了模組 B 和模組 C,且模組 A 直接依賴的是模組 C 的 v1.0.0 版本,然後模組 B 直接依賴的是模組 C 的 v1.0.1 版本,那麼最終 Go modules 會為模組 A 選用模組 C 的 v1.0.1 版本而不是模組 A 的 go.mod 檔案中指明的 v1.0.0 版本。
這是因為 Go modules 認為只要主版本號不變,那麼剩下的都可以直接升級採用最新的。但是如果採用了最新的結果導致專案 Break 掉了,那麼 Go modules 就會 Fallback 到上一個老的版本,比如在前面的例子中就會 Fallback 到 v1.0.0 版本。
Q:在 go.sum 檔案中的一個模組版本的 Hash 校驗資料什麼情況下會成對出現,什麼情況下只會存在一行?
A:通常情況下,在 go.sum 檔案中的一個模組版本的 Hash 校驗資料會有兩行,前一行是該模組的 ZIP 檔案的 Hash 校驗資料,後一行是該模組的 go.mod 檔案的 Hash 校驗資料。但是也有些情況下只會出現一行該模組的 go.mod 檔案的 Hash 校驗資料,而不包含該模組的 ZIP 檔案本身的 Hash 校驗資料,這個情況發生在 Go modules 判定為你當前這個專案完全用不到該模組,根本也不會下載該模組的 ZIP 檔案,所以就沒必要對其作出 Hash 校驗保證,只需要對該模組的 go.mod 檔案作出 Hash 校驗保證即可,因為 go.mod 檔案是用得著的,在深入挖取專案依賴的時候要用。
Q:能不能更詳細地講解一下 go.mod 檔案中的 replace 動詞的行為以及用法?
A:这個 replace 動詞的作用是把一個“模組版本”替換為另外一個“模組版本”,這是“模組版本”和“模組版本(module path)”之間的替換,“=>”識別符號前面的內容是待替換的“模組版本”的“模組路徑”,後面的內容是要替換的目標“模組版本”的所在地,即路徑,這個路徑可以是一個本地磁碟的相對路徑,也可以是一個本地磁碟的絕對路徑,還可以是一個網路路徑,但是這個目標路徑並不會在今後你的專案程式碼中作為你“匯入路徑(import path)”出現,程式碼裡的“匯入路徑”還是得以你替換成的這個目標“模組版本”的“模組路徑”作為字首。
另外需要注意,Go modules 是不支援在 “匯入路徑” 裡寫相對路徑的。舉個例子,如果專案 A 依賴了模組 B,比如模組 B 的“模組路徑”是 example.com/b,然後它在的磁碟路徑是 ~/b,在專案 A 裡的 go.mod 檔案中你有一行 replace example.com/b=>~/b,然後在專案 A 裡的程式碼中的“匯入路基”就是 import"example.com/b",而不是 import"~/b",剩下的工作是 Go modules 幫你自動完成了的。
然後就是我在分享中也提到了, exclude 和 replace 這兩個動詞只作用於當前主模組,也就是當前專案,它所依賴的那些其他模組版本中如果出現了你待替換的那個模組版本的話,Go modules 還是會為你依賴的那個模組版本去拉取你的這個待替換的模組版本。
舉個例子,比如專案 A 直接依賴了模組 B 和模組 C,然後模組 B 也直接依賴了模組 C,那麼你在專案 A 中的 go.mod 檔案裡的 replace c=>~/some/path/c 是隻會影響專案 A 裡寫的程式碼中,而模組 B 所用到的還是你 replace 之前的那個 c,並不是你替換成的 ~/some/path/c 這個。
總結
在 Go1.13 釋出後,接觸 Go modules 和 Go module proxy 的人越來越多,經常在各種群看到各種小夥伴在諮詢,包括我自己也貢獻了好幾枚 “坑”,因此我覺得傲飛的這一次 《Go Modules、Go Module Proxy 和 goproxy.cn》的技術分享,非常的有實踐意義。如果後續大家還有什麼建議或問題,歡迎隨時來討論。
最後,感謝 goproxy.cn 背後的人們(@七牛雲 和 @盛傲飛)對中國 Go 語言社群的無私貢獻和奉獻。
進一步閱讀
- night-reading-go/issues/468
- B站:【Go 夜讀】第 61 期 Go Modules、Go Module Proxy 和 goproxy.cn
- youtube:【Go 夜讀】第 61 期 Go Modules、Go Module Proxy 和 goproxy.cn
第2課 包管理
2.1 Go依賴管理工具dep
Go dependency management tool
環境要求
- Golang >= 1.9
- Dep
目前版本:
dep:
version : devel
build date :
git hash :
go version : go1.10
go compiler : gc
platform : linux/amd64
Latest release為v0.4.1
安裝
go get -u github.com/golang/dep/cmd/dep
若$GOPATH/bin不在PATH下,則需要將生成的dep檔案從$GOPATH/bin移動至$GOBIAN下
驗證
$ dep
Dep is a tool for managing dependencies for Go projects
Usage: "dep [command]"
Commands:
init Set up a new Go project, or migrate an existing one
status Report the status of the project's dependencies
ensure Ensure a dependency is safely vendored in the project
prune Pruning is now performed automatically by dep ensure.
version Show the dep version information
Examples:
dep init set up a new project
dep ensure install the project's dependencies
dep ensure -update update the locked versions of all dependencies
dep ensure -add github.com/pkg/errors add a dependency to the project
Use "dep help [command]" for more information about a command.
初始化
在專案根目錄執行初始化命令,dep在初始化時會分析應用程式所需要的所有依賴包,得出依賴包清單
並生成vendor目錄,Gopkg.toml、Gopkg.lock檔案
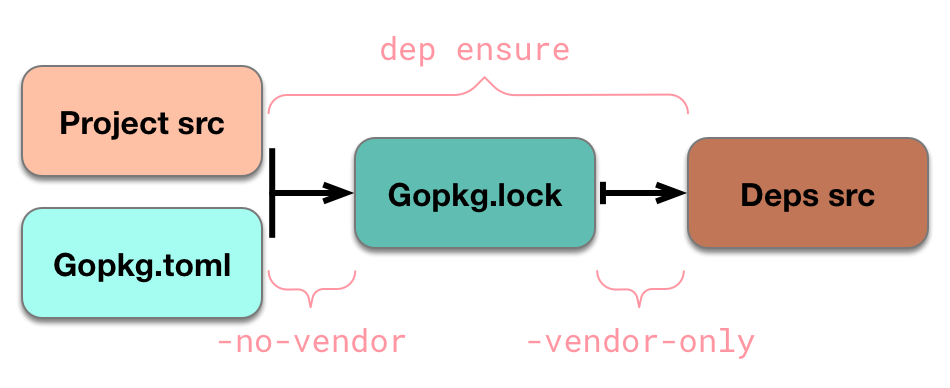
預設初始化
$ dep init -v
直接從對應網路資源處下載
優先從$GOPATH初始化
$ dep init -gopath -v
該命令會先從$GOPATH查詢既有的依賴包,若不存在則從對應網路資源處下載
Gopkg.toml
該檔案由dep init生成,包含管理dep行為的規則宣告
required = ["github.com/user/thing/cmd/thing"]
ignored = [
"github.com/user/project/pkgX",
"bitbucket.org/user/project/pkgA/pkgY"
]
[metadata]
key1 = "value that convey data to other systems"
system1-data = "value that is used by a system"
system2-data = "value that is used by another system"
[[constraint]]
# Required: the root import path of the project being constrained.
name = "github.com/user/project"
# Recommended: the version constraint to enforce for the project.
# Note that only one of "branch", "version" or "revision" can be specified.
version = "1.0.0"
branch = "master"
revision = "abc123"
# Optional: an alternate location (URL or import path) for the project's source.
source = "https://github.com/myfork/package.git"
# Optional: metadata about the constraint or override that could be used by other independent systems
[metadata]
key1 = "value that convey data to other systems"
system1-data = "value that is used by a system"
system2-data = "value that is used by another system"
Gopkg.lock
該檔案由dep ensure和dep init生成,包含一個專案依賴關係圖的傳遞完整快照,表示為一系列[[project]]節
# This file is autogenerated, do not edit; changes may be undone by the next 'dep ensure'.
[[projects]]
branch = "master"
name = "github.com/golang/protobuf"
packages = [
"jsonpb",
"proto",
"protoc-gen-go/descriptor",
"ptypes",
"ptypes/any",
"ptypes/duration",
"ptypes/struct",
"ptypes/timestamp"
]
revision = "bbd03ef6da3a115852eaf24c8a1c46aeb39aa175"
常用命令
dep ensure
從專案中的Gopkg.toml和Gopkg.lock中分析關係圖,並取得所需的依賴包
用於確保本地的關係圖、鎖、依賴包清單完全一致
dep ensure -add
# 引入该依赖包的最新版本
dep ensure -add github.com/pkg/foo
# 引入具有特定约束(指定版本)的依赖包
dep ensure -add github.com/pkg/foo@^1.0.1
dep ensure -update
將Gopkg.lock中的約定依賴項更新為Gopkg.toml允許的最新版本
最後
目前dep還在官方試驗階段,但已表示生產可安全使用
如果出現什麼問題,大家可以一起留個言討論討論
2.2 如此,用dep取得私有庫
介紹
dep是一個依賴管理工具。它需要1.9或更新的Golang版本才能編譯
dep已經能夠在生產環節安全使用,但還在官方的試驗階段,也就是還不在go tool中。但我想是遲早的事 :=)
指南和參考資料,請參閱文件
取得私有庫
我們常用的git方式有兩種,第一種是透過ssh,第二種是https
本文中我們以gitlab.com為案例,建立一個private的私有倉庫
透過ssh方式
首先我們需要在本機上生成ssh-key,若沒有生成過可右拐傳送門
得到需要使用的ssh-key後,我們開啟我們的gitlab.com,複製貼上入我們的Settings -> SSH Keys中
新增成功後,我們直接在Gopkg.toml裡設定好我們的引數
[[constraint]]
branch = "master"
name = "gitlab.com/eddycjy/test"
source = "git@gitlab.com:EDDYCJY/test.git"
在拉取資源前,要注意假設你是第一次用該ssh-key拉取,需要先手動用git clone拉取一遍,同意ECDSA key fingerprint:
$ git clone git@gitlab.com:EDDYCJY/test.git
Cloning into 'test'...
The authenticity of host 'gitlab.com (52.167.219.168)' can't be established.
ECDSA key fingerprint is xxxxxxxxxxxxx.
Are you sure you want to continue connecting (yes/no)? yes
...
接下來,我們在專案下直接執行dep ensure就可以拉取下來了!
問題
-
假設你是第一次,又沒有執行上面那一步(
ECDSA key fingerprint),會一直卡住 -
正確的反饋應當是執行完命令後沒有錯誤,但如果出現該錯誤提示,那說明該儲存倉庫沒有被納入
dep中(例:gitee)``` $ dep ensure
The following issues were found in Gopkg.toml:
unable to deduce repository and source type for "xxxx": unable to read metadata: go-import metadata not found
ProjectRoot name validation failed
### 通过`https`方式
我们直接在`Gopkg.toml`里配置好我们的参数
[[constraint]] branch = "master" name = "gitlab.com/eddycjy/test" source = "https://{username}:{password}@gitlab.com"
```
主要是修改source的設定項,username填寫在gitlab的使用者名稱,password為密碼
最後回到專案下執行dep ensure拉取資源就可以了
最後
dep目前還是官方試驗階段,還可能存在變數,多加註意
第3課 gin
- 3.1 Golang 介紹與環境安裝
- 3.2 Gin搭建Blog API's (一)
- 3.3 Gin搭建Blog API's (二)
- 3.4 Gin搭建Blog API's (三)
- 3.5 使用JWT進行身份校驗
- 3.6 編寫一個簡單的檔案日誌
- 3.7 優雅的重啟服務
- 3.8 為它加上Swagger
- 3.9 將Golang應用部署到Docker
- 3.10 定製 GORM Callbacks
- 3.11 Cron定時任務
- 3.12 最佳化設定結構及實作圖片上傳
- 3.13 最佳化你的應用結構和實作Redis快取
- 3.14 實作匯出、匯入 Excel
- 3.15 生成二維碼、合併海報
- 3.16 在圖片上繪製文字
- 3.17 用Nginx部署Go應用
- 3.18 Golang交叉編譯
- 3.19 請入門 Makefile
3.1 Golang 介紹與環境安裝
專案地址:https://github.com/EDDYCJY/go-gin-example
本文目標
- 學會安裝 Go。
- 知道什麼是 Go。
- 知道什麼是 Go modules。
- 瞭解 Go modules 的小歷史。
- 學會簡單的使用 Go modules。
- 瞭解 Gin,並簡單跑起一個 Demo。
準備環節
安裝 Go
Centos
首先,根據對應的作業系統選擇安裝包 下載,在這裡我使用的是Centos 64位系統,如下:
$ wget https://studygolang.com/dl/golang/go1.13.1.linux-amd64.tar.gz
$ tar -zxvf go1.13.1.linux-amd64.tar.gz
$ mv go/ /usr/local/
設定 /etc/profile
vi /etc/profile
新增環境變數GOROOT和將GOBIN新增到PATH中
export GOROOT=/usr/local/go
export PATH=$PATH:$GOROOT/bin
設定完畢後,執行命令令其生效
source /etc/profile
在控制檯輸入go version,若輸出版本號則安裝成功,如下:
$ go version
go version go1.13.1 linux/amd64
MacOS
在 MacOS 上安裝 Go 最方便的辦法就是使用 brew,安裝如下:
$ brew install go
升級命令如下:
$ brew upgrade go
注:升級命令你不需要執行,但我想未來你有一天會用到的。
同樣在控制檯輸入go version,若輸出版本號則安裝成功。
瞭解 Go
是什麼
Go is an open source programming language that makes it easy to build simple, reliable, and efficient software.
上述為官方說明,如果簡單來講,大致為如下幾點:
- Go 是程式語言。
- 谷歌爸爸撐腰。
- 語言級高併發。
- 上手快,入門簡單。
- 簡潔,很有特色。
- 國內使用人群逐年增多。
誰在用
有什麼
那麼大家會有些疑問,糾結 Go 本身有什麼東西,我們剛剛設定的環境變數又有什麼用呢,甚至作為一名老粉,你會糾結 GOPATH 去哪裡了,我們一起接著往下看。
目錄結構
首先,我們在解壓的時候會得到一個名為 go 的資料夾,其中包括了所有 Go 語言相關的一些檔案,如下:
$ tree -L 1 go
go
├── api
├── bin
├── doc
├── lib
├── misc
├── pkg
├── src
├── test
└── ...
在這之中包含了很多資料夾和檔案,我們來簡單說明其中主要資料夾的作用:
- api:用於存放依照
Go版本順序的API增量列表檔案。這裡所說的API包含公開的變數、常量、函式等。這些API增量列表檔案用於Go語言API檢查 - bin:用於存放主要的標準命令檔案(可執行檔案),包含
go、godoc、gofmt - blog:用於存放官方部落格中的所有文章
- doc:用於存放標準庫的HTML格式的程式文件。我們可以透過
godoc命令啟動一個Web程式展示這些文件 - lib:用於存放一些特殊的庫檔案
- misc:用於存放一些輔助類的說明和工具
- pkg:用於存放安裝
Go標準庫後的所有歸檔檔案(以.a結尾的檔案)。注意,你會發現其中有名稱為linux_amd64的資料夾,我們稱為平臺相關目錄。這類資料夾的名稱由對應的作業系統和計算架構的名稱組合而成。透過go install命令,Go程式會被編譯成平臺相關的歸檔檔案存放到其中 - src:用於存放
Go自身、Go標準工具以及標準庫的所有原始碼檔案 - test:存放用來測試和驗證
Go本身的所有相關檔案
環境變數
你可能會疑惑剛剛設定的環境變數是什麼,如下:
- GOROOT:
Go的根目錄。 - PATH 下增加
$GOROOT/bin:Go的bin下會存放可執行檔案,我們把他加入$PATH後,未來拉下來並編譯後的二進位制檔案就可以直接在命令列使用。
那在什麼東西都不下載的情況下,$GOBIN 下面有什麼呢,如下:
bin/ $ls
go gofmt
- go:
Go二進位制本身。 - gofmt:程式碼格式化工具。
因此我們剛剛把 $GOBIN 加入到 $PATH 後,你執行 go version 命令後就可以檢視到對應的輸出結果。
注:MacOS 用 brew 安裝的話就不需要。
放在哪
你現在知道 Go 是什麼了,也知道 Go 的原始碼擺在哪了,你肯定會想,那我應用程式碼放哪呢,答案是在 Go1.11+ 和開啟 Go Modules 的情況下襬哪都行。
瞭解 Go Modules
瞭解歷史
在過去,Go 的依賴包管理在工具上混亂且不統一,有 dep,有 glide,有 govendor...甚至還有因為外網的問題,頻頻導致拉不下來包,很多人苦不堪言,盼著官方給出一個大一統做出表率。
而在 Go modules 正式出來之前還有一個叫 dep 的專案,我們在上面有提到,它是 Go 的一個官方實驗性專案,目的也是為了解決 Go 在依賴管理方面的問題,當時社群裡面幾乎所有的人都認為 dep 肯定就是未來 Go 官方的依賴管理解決方案了。
但是萬萬沒想到,半路殺出個程咬金,Russ Cox 義無反顧地推出了 Go modules,這瞬間導致一石激起千層浪,讓社群炸了鍋。大家一致認為 Go team 實在是太霸道、太獨裁了,連個招呼都不打一聲。我記得當時有很多人在網上跟 Russ Cox 口水戰,各種依賴管理解決方案的專家都冒出來發表意見,討論範圍甚至一度超出了 Go 語言的圈子觸及到了其他語言的領域。
當然,最後,推成功了,Go modules 已經進入官方工具鏈中,與 Go 深深結合,以前常說的 GOPATH 終將會失去它原有的作用,而且它還提供了 GOPROXY 間接解決了國內訪問外網的問題。
瞭解 Russ Cox
在上文中提到的 Russ Cox 是誰呢,他是 Go 這個專案目前程式碼提交量最多的人,甚至是第二名的兩倍還要多(從 2019年 09 月 30 日前來看)。
Russ Cox 還是 Go 現在的掌舵人(大家應該知道之前 Go 的掌舵人是 Rob Pike,但是聽說由於他本人不喜歡特朗普執政所以離開了美國,然後他歲數也挺大的了,所以也正在逐漸交權,不過現在還是在參與 Go 的發展)。
Russ Cox 的個人能力相當強,看問題的角度也很獨特,這也就是為什麼他剛一提出 Go modules 的概念就能引起那麼大範圍的響應。雖然是被強推的,但事實也證明當下的 Go modules 表現得確實很優秀,所以這表明一定程度上的 “獨裁” 還是可以接受的,至少可以保證一個專案能更加專一地朝著一個方向發展。
初始化行為
在前面我們已經瞭解到 Go 依賴包管理的歷史情況,接下來我們將正式的進入使用,首先你需要有一個你喜歡的目錄,例如:$ mkdir ~/go-application && cd ~/go-application,然後執行如下命令:
$ mkdir go-gin-example && cd go-gin-example
$ go env -w GO111MODULE=on
$ go env -w GOPROXY=https://goproxy.cn,direct
$ go mod init github.com/EDDYCJY/go-gin-example
go: creating new go.mod: module github.com/EDDYCJY/go-gin-example
$ ls
go.mod
mkdir xxx && cd xxx:建立並切換到專案目錄裡去。go env -w GO111MODULE=on:開啟 Go modules 開關(目前在 Go1.13 中預設值為auto)。go env -w GOPROXY=...:設定 GOPROXY 代理,這裡主要涉及到兩個值,第一個是https://goproxy.cn,它是由七牛雲背書的一個強大穩定的 Go 模組代理,可以有效地解決你的外網問題;第二個是direct,它是一個特殊的 fallback 選項,它的作用是用於指示 Go 在拉取模組時遇到錯誤會回源到模組版本的源地址去抓取(比如 GitHub 等)。go mod init [MODULE_PATH]:初始化 Go modules,它將會生成 go.mod 檔案,需要注意的是MODULE_PATH填寫的是模組引入路徑,你可以根據自己的情況修改路徑。
在執行了上述步驟後,初始化工作已完成,我們開啟 go.mod 檔案看看,如下:
module github.com/EDDYCJY/go-gin-example
go 1.13
預設的 go.mod 檔案裡主要是兩塊內容,一個是當前的模組路徑和預期的 Go 語言版本。
基礎使用
- 用
go get拉取新的依賴- 拉取最新的版本(優先擇取 tag):
go get golang.org/x/text@latest - 拉取
master分支的最新 commit:go get golang.org/x/text@master - 拉取 tag 為 v0.3.2 的 commit:
go get golang.org/x/text@v0.3.2 - 拉取 hash 為 342b231 的 commit,最終會被轉換為 v0.3.2:
go get golang.org/x/text@342b2e - 用
go get -u更新現有的依賴 - 用
go mod download下載 go.mod 檔案中指明的所有依賴 - 用
go mod tidy整理現有的依賴 - 用
go mod graph檢視現有的依賴結構 - 用
go mod init生成 go.mod 檔案 (Go 1.13 中唯一一個可以生成 go.mod 檔案的子命令)
- 拉取最新的版本(優先擇取 tag):
- 用
go mod edit編輯 go.mod 檔案 - 用
go mod vendor匯出現有的所有依賴 (事實上 Go modules 正在淡化 Vendor 的概念) - 用
go mod verify校驗一個模組是否被篡改過
這一小節主要是針對 Go modules 的基礎使用講解,還沒具體的使用,是希望你能夠留個印象,因為在後面章節會不斷夾雜 Go modules 的知識點。
注:建議閱讀官方文件 wiki/Modules。
開始 Gin 之旅
是什麼
Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance -- up to 40 times faster. If you need smashing performance, get yourself some Gin.
Gin是用 Go 開發的一個微框架,類似 Martinier 的API,重點是小巧、易用、效能好很多,也因為 httprouter 的效能提高了40倍。
安裝
我們回到剛剛建立的 go-gin-example 目錄下,在命令列下執行如下命令:
$ go get -u github.com/gin-gonic/gin
go: downloading golang.org/x/sys v0.0.0-20190222072716-a9d3bda3a223
go: extracting golang.org/x/sys v0.0.0-20190222072716-a9d3bda3a223
go: finding github.com/gin-contrib/sse v0.1.0
go: finding github.com/ugorji/go v1.1.7
go: finding gopkg.in/yaml.v2 v2.2.3
go: finding golang.org/x/sys latest
go: finding github.com/mattn/go-isatty v0.0.9
go: finding github.com/modern-go/concurrent latest
...
go.sum
這時候你再檢查一下該目錄下,會發現多個了個 go.sum 檔案,如下:
github.com/davecgh/go-spew v1.1.0/go.mod h1:J7Y8YcW...
github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW...
github.com/gin-contrib/sse v0.0.0-20190301062529-5545eab6dad3 h1:t8FVkw33L+wilf2QiWkw0UV77qRpcH/JHPKGpKa2E8g=
github.com/gin-contrib/sse v0.0.0-20190301062529-5545eab6dad3/go.mod h1:VJ0WA2...
github.com/gin-contrib/sse v0.1.0 h1:Y/yl/+YNO...
...
go.sum 檔案詳細羅列了當前專案直接或間接依賴的所有模組版本,並寫明瞭那些模組版本的 SHA-256 雜湊值以備 Go 在今後的操作中保證專案所依賴的那些模組版本不會被篡改。
go.mod
既然我們下載了依賴包,go.mod 檔案會不會有所改變呢,我們再去看看,如下:
module github.com/EDDYCJY/go-gin-example
go 1.13
require (
github.com/gin-contrib/sse v0.1.0 // indirect
github.com/gin-gonic/gin v1.4.0 // indirect
github.com/golang/protobuf v1.3.2 // indirect
github.com/json-iterator/go v1.1.7 // indirect
github.com/mattn/go-isatty v0.0.9 // indirect
github.com/ugorji/go v1.1.7 // indirect
golang.org/x/sys v0.0.0-20190927073244-c990c680b611 // indirect
gopkg.in/yaml.v2 v2.2.3 // indirect
)
確確實實發生了改變,那多出來的東西又是什麼呢,go.mod 檔案又儲存了什麼資訊呢,實際上 go.mod 檔案是啟用了 Go modules 的專案所必須的最重要的檔案,因為它描述了當前專案(也就是當前模組)的元資訊,每一行都以一個動詞開頭,目前有以下 5 個動詞:
- module:用於定義當前專案的模組路徑。
- go:用於設定預期的 Go 版本。
- require:用於設定一個特定的模組版本。
- exclude:用於從使用中排除一個特定的模組版本。
- replace:用於將一個模組版本替換為另外一個模組版本。
你可能還會疑惑 indirect 是什麼東西,indirect 的意思是傳遞依賴,也就是非直接依賴。
測試
編寫一個test.go檔案
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
r.Run() // listen and serve on 0.0.0.0:8080
}
執行test.go
$ go run test.go
...
[GIN-debug] GET /ping --> main.main.func1 (3 handlers)
[GIN-debug] Environment variable PORT is undefined. Using port :8080 by default
[GIN-debug] Listening and serving HTTP on :8080
訪問 $HOST:8080/ping,若返回{"message":"pong"}則正確
curl 127.0.0.1:8080/ping
至此,我們的環境安裝和初步執行都基本完成了。
再想一想
剛剛在執行了命令 $ go get -u github.com/gin-gonic/gin 後,我們查看了 go.mod 檔案,如下:
...
require (
github.com/gin-contrib/sse v0.1.0 // indirect
github.com/gin-gonic/gin v1.4.0 // indirect
...
)
你會發現 go.mod 裡的 github.com/gin-gonic/gin 是 indirect 模式,這顯然不對啊,因為我們的應用程式已經實際的編寫了 gin server 程式碼了,我就想把它調對,怎麼辦呢,在應用根目錄下執行如下命令:
$ go mod tidy
該命令主要的作用是整理現有的依賴,非常的常用,執行後 go.mod 檔案內容為:
...
require (
github.com/gin-contrib/sse v0.1.0 // indirect
github.com/gin-gonic/gin v1.4.0
...
)
可以看到 github.com/gin-gonic/gin 已經變成了直接依賴,調整完畢。
參考
本系列示例程式碼
相關文件
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號

3.2 Gin搭建Blog API's (一)
專案地址:https://github.com/EDDYCJY/go-gin-example
思考
首先,在一個初始專案開始前,大家都要思考一下
- 程式的文字設定寫在程式碼中,好嗎?
- API 的錯誤碼硬編碼在程式中,合適嗎?
- db控制代碼誰都去
Open,沒有統一管理,好嗎? - 取得分頁等公共引數,誰都自己寫一套邏輯,好嗎?
顯然在較正規的專案中,這些問題的答案都是不可以,為了解決這些問題,我們挑選一款讀寫設定檔案的庫,目前比較火的有 viper,有興趣你未來可以簡單瞭解一下,沒興趣的話等以後接觸到再說。
但是本系列選用 go-ini/ini ,它的 中文文件。大家是必須需要要簡單閱讀它的文件,再接著完成後面的內容。
本文目標
- 編寫一個簡單的API錯誤碼包。
- 完成一個 Demo 示例。
- 講解 Demo 所涉及的知識點。
介紹和初始化專案
初始化專案目錄
在前一章節中,我們初始化了一個 go-gin-example 專案,接下來我們需要繼續新增如下目錄結構:
go-gin-example/
├── conf
├── middleware
├── models
├── pkg
├── routers
└── runtime
- conf:用於儲存設定檔案
- middleware:應用中介軟體
- models:應用資料庫模型
- pkg:第三方包
- routers 路由邏輯處理
- runtime:應用執行時資料
新增 Go Modules Replace
開啟 go.mod 檔案,新增 replace 設定項,如下:
module github.com/EDDYCJY/go-gin-example
go 1.13
require (...)
replace (
github.com/EDDYCJY/go-gin-example/pkg/setting => ~/go-application/go-gin-example/pkg/setting
github.com/EDDYCJY/go-gin-example/conf => ~/go-application/go-gin-example/pkg/conf
github.com/EDDYCJY/go-gin-example/middleware => ~/go-application/go-gin-example/middleware
github.com/EDDYCJY/go-gin-example/models => ~/go-application/go-gin-example/models
github.com/EDDYCJY/go-gin-example/routers => ~/go-application/go-gin-example/routers
)
可能你會不理解為什麼要特意跑來加 replace 設定項,首先你要看到我們使用的是完整的外部模組引用路徑(github.com/EDDYCJY/go-gin-example/xxx),而這個模組還沒推送到遠端,是沒有辦法下載下來的,因此需要用 replace 將其指定讀取本地的模組路徑,這樣子就可以解決本地模組讀取的問題。
注:後續每新增一個本地應用目錄,你都需要主動去 go.mod 檔案裡新增一條 replace(我不會提醒你),如果你漏了,那麼編譯時會出現報錯,找不到那個模組。
初始專案資料庫
新建 blog 資料庫,編碼為utf8_general_ci,在 blog 資料庫下,新建以下表
1、 標籤表
CREATE TABLE `blog_tag` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT '' COMMENT '标签名称',
`created_on` int(10) unsigned DEFAULT '0' COMMENT '创建时间',
`created_by` varchar(100) DEFAULT '' COMMENT '创建人',
`modified_on` int(10) unsigned DEFAULT '0' COMMENT '修改时间',
`modified_by` varchar(100) DEFAULT '' COMMENT '修改人',
`deleted_on` int(10) unsigned DEFAULT '0',
`state` tinyint(3) unsigned DEFAULT '1' COMMENT '状态 0为禁用、1为启用',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='文章标签管理';
2、 文章表
CREATE TABLE `blog_article` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`tag_id` int(10) unsigned DEFAULT '0' COMMENT '标签ID',
`title` varchar(100) DEFAULT '' COMMENT '文章标题',
`desc` varchar(255) DEFAULT '' COMMENT '简述',
`content` text,
`created_on` int(11) DEFAULT NULL,
`created_by` varchar(100) DEFAULT '' COMMENT '创建人',
`modified_on` int(10) unsigned DEFAULT '0' COMMENT '修改时间',
`modified_by` varchar(255) DEFAULT '' COMMENT '修改人',
`deleted_on` int(10) unsigned DEFAULT '0',
`state` tinyint(3) unsigned DEFAULT '1' COMMENT '状态 0为禁用1为启用',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='文章管理';
3、 認證表
CREATE TABLE `blog_auth` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(50) DEFAULT '' COMMENT '账号',
`password` varchar(50) DEFAULT '' COMMENT '密码',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `blog`.`blog_auth` (`id`, `username`, `password`) VALUES (null, 'test', 'test123456');
編寫專案設定包
在 go-gin-example 應用目錄下,拉取 go-ini/ini 的依賴包,如下:
$ go get -u github.com/go-ini/ini
go: finding github.com/go-ini/ini v1.48.0
go: downloading github.com/go-ini/ini v1.48.0
go: extracting github.com/go-ini/ini v1.48.0
接下來我們需要編寫基礎的應用設定檔案,在 go-gin-example 的conf目錄下新建app.ini檔案,寫入內容:
#debug or release
RUN_MODE = debug
[app]
PAGE_SIZE = 10
JWT_SECRET = 23347$040412
[server]
HTTP_PORT = 8000
READ_TIMEOUT = 60
WRITE_TIMEOUT = 60
[database]
TYPE = mysql
USER = 数据库账号
PASSWORD = 数据库密码
#127.0.0.1:3306
HOST = 数据库IP:数据库端口号
NAME = blog
TABLE_PREFIX = blog_
建立呼叫設定的setting模組,在go-gin-example的pkg目錄下新建setting目錄(注意新增 replace 設定),新建 setting.go 檔案,寫入內容:
package setting
import (
"log"
"time"
"github.com/go-ini/ini"
)
var (
Cfg *ini.File
RunMode string
HTTPPort int
ReadTimeout time.Duration
WriteTimeout time.Duration
PageSize int
JwtSecret string
)
func init() {
var err error
Cfg, err = ini.Load("conf/app.ini")
if err != nil {
log.Fatalf("Fail to parse 'conf/app.ini': %v", err)
}
LoadBase()
LoadServer()
LoadApp()
}
func LoadBase() {
RunMode = Cfg.Section("").Key("RUN_MODE").MustString("debug")
}
func LoadServer() {
sec, err := Cfg.GetSection("server")
if err != nil {
log.Fatalf("Fail to get section 'server': %v", err)
}
HTTPPort = sec.Key("HTTP_PORT").MustInt(8000)
ReadTimeout = time.Duration(sec.Key("READ_TIMEOUT").MustInt(60)) * time.Second
WriteTimeout = time.Duration(sec.Key("WRITE_TIMEOUT").MustInt(60)) * time.Second
}
func LoadApp() {
sec, err := Cfg.GetSection("app")
if err != nil {
log.Fatalf("Fail to get section 'app': %v", err)
}
JwtSecret = sec.Key("JWT_SECRET").MustString("!@)*#)!@U#@*!@!)")
PageSize = sec.Key("PAGE_SIZE").MustInt(10)
}
當前的目錄結構:
go-gin-example
├── conf
│ └── app.ini
├── go.mod
├── go.sum
├── middleware
├── models
├── pkg
│ └── setting.go
├── routers
└── runtime
編寫API錯誤碼包
建立錯誤碼的e模組,在go-gin-example的pkg目錄下新建e目錄(注意新增 replace 設定),新建code.go和msg.go檔案,寫入內容:
1、 code.go:
package e
const (
SUCCESS = 200
ERROR = 500
INVALID_PARAMS = 400
ERROR_EXIST_TAG = 10001
ERROR_NOT_EXIST_TAG = 10002
ERROR_NOT_EXIST_ARTICLE = 10003
ERROR_AUTH_CHECK_TOKEN_FAIL = 20001
ERROR_AUTH_CHECK_TOKEN_TIMEOUT = 20002
ERROR_AUTH_TOKEN = 20003
ERROR_AUTH = 20004
)
2、 msg.go:
package e
var MsgFlags = map[int]string {
SUCCESS : "ok",
ERROR : "fail",
INVALID_PARAMS : "请求参数错误",
ERROR_EXIST_TAG : "已存在该标签名称",
ERROR_NOT_EXIST_TAG : "该标签不存在",
ERROR_NOT_EXIST_ARTICLE : "该文章不存在",
ERROR_AUTH_CHECK_TOKEN_FAIL : "Token鉴权失败",
ERROR_AUTH_CHECK_TOKEN_TIMEOUT : "Token已超时",
ERROR_AUTH_TOKEN : "Token生成失败",
ERROR_AUTH : "Token错误",
}
func GetMsg(code int) string {
msg, ok := MsgFlags[code]
if ok {
return msg
}
return MsgFlags[ERROR]
}
編寫工具包
在go-gin-example的pkg目錄下新建util目錄(注意新增 replace 設定),並拉取com的依賴包,如下:
go get -u github.com/unknwon/com
編寫分頁頁碼的取得方法
在util目錄下新建pagination.go,寫入內容:
package util
import (
"github.com/gin-gonic/gin"
"github.com/unknwon/com"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
func GetPage(c *gin.Context) int {
result := 0
page, _ := com.StrTo(c.Query("page")).Int()
if page > 0 {
result = (page - 1) * setting.PageSize
}
return result
}
編寫models init
拉取gorm的依賴包,如下:
go get -u github.com/jinzhu/gorm
拉取mysql驅動的依賴包,如下:
go get -u github.com/go-sql-driver/mysql
完成後,在go-gin-example的models目錄下新建models.go,用於models的初始化使用
package models
import (
"log"
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
var db *gorm.DB
type Model struct {
ID int `gorm:"primary_key" json:"id"`
CreatedOn int `json:"created_on"`
ModifiedOn int `json:"modified_on"`
}
func init() {
var (
err error
dbType, dbName, user, password, host, tablePrefix string
)
sec, err := setting.Cfg.GetSection("database")
if err != nil {
log.Fatal(2, "Fail to get section 'database': %v", err)
}
dbType = sec.Key("TYPE").String()
dbName = sec.Key("NAME").String()
user = sec.Key("USER").String()
password = sec.Key("PASSWORD").String()
host = sec.Key("HOST").String()
tablePrefix = sec.Key("TABLE_PREFIX").String()
db, err = gorm.Open(dbType, fmt.Sprintf("%s:%s@tcp(%s)/%s?charset=utf8&parseTime=True&loc=Local",
user,
password,
host,
dbName))
if err != nil {
log.Println(err)
}
gorm.DefaultTableNameHandler = func (db *gorm.DB, defaultTableName string) string {
return tablePrefix + defaultTableName;
}
db.SingularTable(true)
db.LogMode(true)
db.DB().SetMaxIdleConns(10)
db.DB().SetMaxOpenConns(100)
}
func CloseDB() {
defer db.Close()
}
編寫專案啟動、路由檔案
最基礎的準備工作完成啦,讓我們開始編寫Demo吧!
編寫Demo
在go-gin-example下建立main.go作為啟動檔案(也就是main包),我們先寫個Demo,幫助大家理解,寫入檔案內容:
package main
import (
"fmt"
"net/http"
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
func main() {
router := gin.Default()
router.GET("/test", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "test",
})
})
s := &http.Server{
Addr: fmt.Sprintf(":%d", setting.HTTPPort),
Handler: router,
ReadTimeout: setting.ReadTimeout,
WriteTimeout: setting.WriteTimeout,
MaxHeaderBytes: 1 << 20,
}
s.ListenAndServe()
}
執行go run main.go,檢視命令列是否顯示
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /test --> main.main.func1 (3 handlers)
在本機執行curl 127.0.0.1:8000/test,檢查是否返回{"message":"test"}。
知識點
那麼,我們來延伸一下Demo所涉及的知識點!
標準庫
Gin
- gin.Default():返回Gin的
type Engine struct{...},裡面包含RouterGroup,相當於建立一個路由Handlers,可以後期繫結各類的路由規則和函式、中介軟體等 - router.GET(...){...}:建立不同的HTTP方法繫結到
Handlers中,也支援POST、PUT、DELETE、PATCH、OPTIONS、HEAD 等常用的Restful方法 - gin.H{...}:就是一個
map[string]interface{} - gin.Context:
Context是gin中的上下文,它允許我們在中介軟體之間傳遞變數、管理流、驗證JSON請求、響應JSON請求等,在gin中包含大量Context的方法,例如我們常用的DefaultQuery、Query、DefaultPostForm、PostForm等等
&http.Server 和 ListenAndServe?
1、http.Server:
type Server struct {
Addr string
Handler Handler
TLSConfig *tls.Config
ReadTimeout time.Duration
ReadHeaderTimeout time.Duration
WriteTimeout time.Duration
IdleTimeout time.Duration
MaxHeaderBytes int
ConnState func(net.Conn, ConnState)
ErrorLog *log.Logger
}
- Addr:監聽的TCP地址,格式為
:8000 - Handler:http控制代碼,實質為
ServeHTTP,用於處理程式響應HTTP請求 - TLSConfig:安全傳輸層協議(TLS)的設定
- ReadTimeout:允許讀取的最大時間
- ReadHeaderTimeout:允許讀取請求頭的最大時間
- WriteTimeout:允許寫入的最大時間
- IdleTimeout:等待的最大時間
- MaxHeaderBytes:請求頭的最大位元組數
- ConnState:指定一個可選的回撥函式,當客戶端連線發生變化時呼叫
- ErrorLog:指定一個可選的日誌記錄器,用於接收程式的意外行為和底層系統錯誤;如果未設定或為
nil則預設以日誌包的標準日誌記錄器完成(也就是在控制檯輸出)
2、 ListenAndServe:
func (srv *Server) ListenAndServe() error {
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(tcpKeepAliveListener{ln.(*net.TCPListener)})
}
開始監聽服務,監聽TCP網路地址,Addr和呼叫應用程式處理連線上的請求。
我們在原始碼中看到Addr是呼叫我們在&http.Server中設定的引數,因此我們在設定時要用&,我們要改變引數的值,因為我們ListenAndServe和其他一些方法需要用到&http.Server中的引數,他們是相互影響的。
3、 http.ListenAndServe和 連載一 的r.Run()有區別嗎?
我們看看r.Run的實作:
func (engine *Engine) Run(addr ...string) (err error) {
defer func() { debugPrintError(err) }()
address := resolveAddress(addr)
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine)
return
}
透過分析原始碼,得知本質上沒有區別,同時也得知了啟動gin時的監聽debug資訊在這裡輸出。
4、 為什麼Demo裡會有WARNING?
首先我們可以看下Default()的實作
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default() *Engine {
debugPrintWARNINGDefault()
engine := New()
engine.Use(Logger(), Recovery())
return engine
}
大家可以看到預設情況下,已經附加了日誌、恢復中介軟體的引擎例項。並且在開頭呼叫了debugPrintWARNINGDefault(),而它的實作就是輸出該行日誌
func debugPrintWARNINGDefault() {
debugPrint(`[WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
`)
}
而另外一個Running in "debug" mode. Switch to "release" mode in production.,是執行模式原因,並不難理解,已在設定檔案的管控下 :-),運維人員隨時就可以修改它的設定。
5、 Demo的router.GET等路由規則可以不寫在main包中嗎?
我們發現router.GET等路由規則,在Demo中被編寫在了main包中,感覺很奇怪,我們去抽離這部分邏輯!
在go-gin-example下routers目錄新建router.go檔案,寫入內容:
package routers
import (
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
func InitRouter() *gin.Engine {
r := gin.New()
r.Use(gin.Logger())
r.Use(gin.Recovery())
gin.SetMode(setting.RunMode)
r.GET("/test", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "test",
})
})
return r
}
修改main.go的檔案內容:
package main
import (
"fmt"
"net/http"
"github.com/EDDYCJY/go-gin-example/routers"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
func main() {
router := routers.InitRouter()
s := &http.Server{
Addr: fmt.Sprintf(":%d", setting.HTTPPort),
Handler: router,
ReadTimeout: setting.ReadTimeout,
WriteTimeout: setting.WriteTimeout,
MaxHeaderBytes: 1 << 20,
}
s.ListenAndServe()
}
當前目錄結構:
go-gin-example/
├── conf
│ └── app.ini
├── main.go
├── middleware
├── models
│ └── models.go
├── pkg
│ ├── e
│ │ ├── code.go
│ │ └── msg.go
│ ├── setting
│ │ └── setting.go
│ └── util
│ └── pagination.go
├── routers
│ └── router.go
├── runtime
重啟服務,執行 curl 127.0.0.1:8000/test檢視是否正確返回。
下一節,我們將以我們的 Demo 為起點進行修改,開始編碼!
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.3 Gin搭建Blog API's (二)
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- Gin:Golang的一個微框架,效能極佳。
- beego-validation:本節採用的beego的表單驗證庫,中文文件。
- gorm,對開發人員友好的ORM框架,英文文件
- com,一個小而美的工具包。
本文目標
- 完成部落格的標籤類介面定義和編寫
定義介面
本節正是編寫標籤的邏輯,我們想一想,一般介面為增刪改查是基礎的,那麼我們定義一下介面吧!
- 取得標籤列表:GET("/tags")
- 新建標籤:POST("/tags")
- 更新指定標籤:PUT("/tags/:id")
- 刪除指定標籤:DELETE("/tags/:id")
編寫路由空殼
開始編寫路由檔案邏輯,在routers下新建api目錄,我們當前是第一個API大版本,因此在api下新建v1目錄,再新建tag.go檔案,寫入內容:
package v1
import (
"github.com/gin-gonic/gin"
)
//获取多个文章标签
func GetTags(c *gin.Context) {
}
//新增文章标签
func AddTag(c *gin.Context) {
}
//修改文章标签
func EditTag(c *gin.Context) {
}
//删除文章标签
func DeleteTag(c *gin.Context) {
}
註冊路由
我們開啟routers下的router.go檔案,修改檔案內容為:
package routers
import (
"github.com/gin-gonic/gin"
"gin-blog/routers/api/v1"
"gin-blog/pkg/setting"
)
func InitRouter() *gin.Engine {
r := gin.New()
r.Use(gin.Logger())
r.Use(gin.Recovery())
gin.SetMode(setting.RunMode)
apiv1 := r.Group("/api/v1")
{
//获取标签列表
apiv1.GET("/tags", v1.GetTags)
//新建标签
apiv1.POST("/tags", v1.AddTag)
//更新指定标签
apiv1.PUT("/tags/:id", v1.EditTag)
//删除指定标签
apiv1.DELETE("/tags/:id", v1.DeleteTag)
}
return r
}
當前目錄結構:
gin-blog/
├── conf
│ └── app.ini
├── main.go
├── middleware
├── models
│ └── models.go
├── pkg
│ ├── e
│ │ ├── code.go
│ │ └── msg.go
│ ├── setting
│ │ └── setting.go
│ └── util
│ └── pagination.go
├── routers
│ ├── api
│ │ └── v1
│ │ └── tag.go
│ └── router.go
├── runtime
檢驗路由是否註冊成功
回到命令列,執行go run main.go,檢查路由規則是否註冊成功。
$ go run main.go
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /api/v1/tags --> gin-blog/routers/api/v1.GetTags (3 handlers)
[GIN-debug] POST /api/v1/tags --> gin-blog/routers/api/v1.AddTag (3 handlers)
[GIN-debug] PUT /api/v1/tags/:id --> gin-blog/routers/api/v1.EditTag (3 handlers)
[GIN-debug] DELETE /api/v1/tags/:id --> gin-blog/routers/api/v1.DeleteTag (3 handlers)
執行成功,那麼我們愉快的開始編寫我們的介面吧!
下載依賴包
首先我們要拉取validation的依賴包,在後面的接口裡會使用到表單驗證
go get -u github.com/astaxie/beego/validation
編寫標籤列表的models邏輯
建立models目錄下的tag.go,寫入檔案內容:
package models
type Tag struct {
Model
Name string `json:"name"`
CreatedBy string `json:"created_by"`
ModifiedBy string `json:"modified_by"`
State int `json:"state"`
}
func GetTags(pageNum int, pageSize int, maps interface {}) (tags []Tag) {
db.Where(maps).Offset(pageNum).Limit(pageSize).Find(&tags)
return
}
func GetTagTotal(maps interface {}) (count int){
db.Model(&Tag{}).Where(maps).Count(&count)
return
}
- 我們建立了一個
Tag struct{},用於Gorm的使用。並給予了附屬屬性json,這樣子在c.JSON的時候就會自動轉換格式,非常的便利 - 可能會有的初學者看到
return,而後面沒有跟著變數,會不理解;其實你可以看到在函式末端,我們已經顯示聲明瞭返回值,這個變數在函式體內也可以直接使用,因為他在一開始就被聲明瞭 - 有人會疑惑
db是哪裡來的;因為在同個models包下,因此db *gorm.DB是可以直接使用的
編寫標籤列表的路由邏輯
開啟routers目錄下v1版本的tag.go,第一我們先編寫取得標籤列表的介面
修改檔案內容:
package v1
import (
"net/http"
"github.com/gin-gonic/gin"
//"github.com/astaxie/beego/validation"
"github.com/Unknwon/com"
"gin-blog/pkg/e"
"gin-blog/models"
"gin-blog/pkg/util"
"gin-blog/pkg/setting"
)
//获取多个文章标签
func GetTags(c *gin.Context) {
name := c.Query("name")
maps := make(map[string]interface{})
data := make(map[string]interface{})
if name != "" {
maps["name"] = name
}
var state int = -1
if arg := c.Query("state"); arg != "" {
state = com.StrTo(arg).MustInt()
maps["state"] = state
}
code := e.SUCCESS
data["lists"] = models.GetTags(util.GetPage(c), setting.PageSize, maps)
data["total"] = models.GetTagTotal(maps)
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : data,
})
}
//新增文章标签
func AddTag(c *gin.Context) {
}
//修改文章标签
func EditTag(c *gin.Context) {
}
//删除文章标签
func DeleteTag(c *gin.Context) {
}
c.Query可用於取得?name=test&state=1這類URL引數,而c.DefaultQuery則支援設定一個預設值code變數使用了e模組的錯誤編碼,這正是先前規劃好的錯誤碼,方便排錯和識別記錄util.GetPage保證了各介面的page處理是一致的c *gin.Context是Gin很重要的組成部分,可以理解為上下文,它允許我們在中介軟體之間傳遞變數、管理流、驗證請求的JSON和呈現JSON響應
在本機執行curl 127.0.0.1:8000/api/v1/tags,正確的返回值為{"code":200,"data":{"lists":[],"total":0},"msg":"ok"},若存在問題請結合gin結果進行拍錯。
在取得標籤列表介面中,我們可以根據name、state、page來篩選查詢條件,分頁的步長可透過app.ini進行設定,以lists、total的組合返回達到分頁效果。
編寫新增標籤的models邏輯
接下來我們編寫新增標籤的介面
開啟models目錄下的tag.go,修改檔案(增加2個方法):
...
func ExistTagByName(name string) bool {
var tag Tag
db.Select("id").Where("name = ?", name).First(&tag)
if tag.ID > 0 {
return true
}
return false
}
func AddTag(name string, state int, createdBy string) bool{
db.Create(&Tag {
Name : name,
State : state,
CreatedBy : createdBy,
})
return true
}
...
編寫新增標籤的路由邏輯
開啟routers目錄下的tag.go,修改檔案(變動AddTag方法):
package v1
import (
"log"
"net/http"
"github.com/gin-gonic/gin"
"github.com/astaxie/beego/validation"
"github.com/Unknwon/com"
"gin-blog/pkg/e"
"gin-blog/models"
"gin-blog/pkg/util"
"gin-blog/pkg/setting"
)
...
//新增文章标签
func AddTag(c *gin.Context) {
name := c.Query("name")
state := com.StrTo(c.DefaultQuery("state", "0")).MustInt()
createdBy := c.Query("created_by")
valid := validation.Validation{}
valid.Required(name, "name").Message("名称不能为空")
valid.MaxSize(name, 100, "name").Message("名称最长为100字符")
valid.Required(createdBy, "created_by").Message("创建人不能为空")
valid.MaxSize(createdBy, 100, "created_by").Message("创建人最长为100字符")
valid.Range(state, 0, 1, "state").Message("状态只允许0或1")
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
if ! models.ExistTagByName(name) {
code = e.SUCCESS
models.AddTag(name, state, createdBy)
} else {
code = e.ERROR_EXIST_TAG
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : make(map[string]string),
})
}
...
用Postman用POST訪問http://127.0.0.1:8000/api/v1/tags?name=1&state=1&created_by=test,檢視code是否返回200及blog_tag表中是否有值,有值則正確。
編寫models callbacks
但是這個時候大家會發現,我明明新增了標籤,但created_on居然沒有值,那做修改標籤的時候modified_on會不會也存在這個問題?
為了解決這個問題,我們需要開啟models目錄下的tag.go檔案,修改檔案內容(修改包引用和增加2個方法):
package models
import (
"time"
"github.com/jinzhu/gorm"
)
...
func (tag *Tag) BeforeCreate(scope *gorm.Scope) error {
scope.SetColumn("CreatedOn", time.Now().Unix())
return nil
}
func (tag *Tag) BeforeUpdate(scope *gorm.Scope) error {
scope.SetColumn("ModifiedOn", time.Now().Unix())
return nil
}
重啟服務,再在用Postman用POST訪問http://127.0.0.1:8000/api/v1/tags?name=2&state=1&created_by=test,發現created_on已經有值了!
在這幾段程式碼中,涉及到知識點:
這屬於gorm的Callbacks,可以將回調方法定義為模型結構的指標,在建立、更新、查詢、刪除時將被呼叫,如果任何回撥返回錯誤,gorm將停止未來操作並回滾所有更改。
gorm所支援的回撥方法:
- 建立:BeforeSave、BeforeCreate、AfterCreate、AfterSave
- 更新:BeforeSave、BeforeUpdate、AfterUpdate、AfterSave
- 刪除:BeforeDelete、AfterDelete
- 查詢:AfterFind
編寫其餘介面的路由邏輯
接下來,我們一口氣把剩餘的兩個介面(EditTag、DeleteTag)完成吧
開啟routers目錄下v1版本的tag.go檔案,修改內容:
...
//修改文章标签
func EditTag(c *gin.Context) {
id := com.StrTo(c.Param("id")).MustInt()
name := c.Query("name")
modifiedBy := c.Query("modified_by")
valid := validation.Validation{}
var state int = -1
if arg := c.Query("state"); arg != "" {
state = com.StrTo(arg).MustInt()
valid.Range(state, 0, 1, "state").Message("状态只允许0或1")
}
valid.Required(id, "id").Message("ID不能为空")
valid.Required(modifiedBy, "modified_by").Message("修改人不能为空")
valid.MaxSize(modifiedBy, 100, "modified_by").Message("修改人最长为100字符")
valid.MaxSize(name, 100, "name").Message("名称最长为100字符")
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
code = e.SUCCESS
if models.ExistTagByID(id) {
data := make(map[string]interface{})
data["modified_by"] = modifiedBy
if name != "" {
data["name"] = name
}
if state != -1 {
data["state"] = state
}
models.EditTag(id, data)
} else {
code = e.ERROR_NOT_EXIST_TAG
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : make(map[string]string),
})
}
//删除文章标签
func DeleteTag(c *gin.Context) {
id := com.StrTo(c.Param("id")).MustInt()
valid := validation.Validation{}
valid.Min(id, 1, "id").Message("ID必须大于0")
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
code = e.SUCCESS
if models.ExistTagByID(id) {
models.DeleteTag(id)
} else {
code = e.ERROR_NOT_EXIST_TAG
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : make(map[string]string),
})
}
編寫其餘介面的models邏輯
開啟models下的tag.go,修改檔案內容:
...
func ExistTagByID(id int) bool {
var tag Tag
db.Select("id").Where("id = ?", id).First(&tag)
if tag.ID > 0 {
return true
}
return false
}
func DeleteTag(id int) bool {
db.Where("id = ?", id).Delete(&Tag{})
return true
}
func EditTag(id int, data interface {}) bool {
db.Model(&Tag{}).Where("id = ?", id).Updates(data)
return true
}
...
驗證功能
重啟服務,用Postman
- PUT訪問http://127.0.0.1:8000/api/v1/tags/1?name=edit1&state=0&modified_by=edit1,檢視code是否返回200
- DELETE訪問http://127.0.0.1:8000/api/v1/tags/1,檢視code是否返回200
至此,Tag的API's完成,下一節我們將開始Article的API's編寫!
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.4 Gin搭建Blog API's (三)
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- Gin:Golang的一個微框架,效能極佳。
- beego-validation:本節採用的beego的表單驗證庫,中文文件。
- gorm,對開發人員友好的ORM框架,英文文件
- com,一個小而美的工具包。
本文目標
- 完成部落格的文章類介面定義和編寫
定義介面
本節編寫文章的邏輯,我們定義一下介面吧!
- 取得文章列表:GET("/articles")
- 取得指定文章:POST("/articles/:id")
- 新建文章:POST("/articles")
- 更新指定文章:PUT("/articles/:id")
- 刪除指定文章:DELETE("/articles/:id")
編寫路由邏輯
在routers的v1版本下,新建article.go檔案,寫入內容:
package v1
import (
"github.com/gin-gonic/gin"
)
//获取单个文章
func GetArticle(c *gin.Context) {
}
//获取多个文章
func GetArticles(c *gin.Context) {
}
//新增文章
func AddArticle(c *gin.Context) {
}
//修改文章
func EditArticle(c *gin.Context) {
}
//删除文章
func DeleteArticle(c *gin.Context) {
}
我們開啟routers下的router.go檔案,修改檔案內容為:
package routers
import (
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/routers/api/v1"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
func InitRouter() *gin.Engine {
...
apiv1 := r.Group("/api/v1")
{
...
//获取文章列表
apiv1.GET("/articles", v1.GetArticles)
//获取指定文章
apiv1.GET("/articles/:id", v1.GetArticle)
//新建文章
apiv1.POST("/articles", v1.AddArticle)
//更新指定文章
apiv1.PUT("/articles/:id", v1.EditArticle)
//删除指定文章
apiv1.DELETE("/articles/:id", v1.DeleteArticle)
}
return r
}
當前目錄結構:
go-gin-example/
├── conf
│ └── app.ini
├── main.go
├── middleware
├── models
│ ├── models.go
│ └── tag.go
├── pkg
│ ├── e
│ │ ├── code.go
│ │ └── msg.go
│ ├── setting
│ │ └── setting.go
│ └── util
│ └── pagination.go
├── routers
│ ├── api
│ │ └── v1
│ │ ├── article.go
│ │ └── tag.go
│ └── router.go
├── runtime
在基礎的路由規則設定結束後,我們開始編寫我們的介面吧!
編寫models邏輯
建立models目錄下的article.go,寫入檔案內容:
package models
import (
"github.com/jinzhu/gorm"
"time"
)
type Article struct {
Model
TagID int `json:"tag_id" gorm:"index"`
Tag Tag `json:"tag"`
Title string `json:"title"`
Desc string `json:"desc"`
Content string `json:"content"`
CreatedBy string `json:"created_by"`
ModifiedBy string `json:"modified_by"`
State int `json:"state"`
}
func (article *Article) BeforeCreate(scope *gorm.Scope) error {
scope.SetColumn("CreatedOn", time.Now().Unix())
return nil
}
func (article *Article) BeforeUpdate(scope *gorm.Scope) error {
scope.SetColumn("ModifiedOn", time.Now().Unix())
return nil
}
我們建立了一個Article struct {},與Tag不同的是,Article多了幾項,如下:
gorm:index,用於宣告這個欄位為索引,如果你使用了自動遷移功能則會有所影響,在不使用則無影響Tag欄位,實際是一個巢狀的struct,它利用TagID與Tag模型相互關聯,在執行查詢的時候,能夠達到Article、Tag關聯查詢的功能time.Now().Unix()返回當前的時間戳
接下來,請確保已對上一章節的內容通讀且瞭解,由於邏輯偏差不會太遠,我們本節直接編寫這五個介面
開啟models目錄下的article.go,修改檔案內容:
package models
import (
"time"
"github.com/jinzhu/gorm"
)
type Article struct {
Model
TagID int `json:"tag_id" gorm:"index"`
Tag Tag `json:"tag"`
Title string `json:"title"`
Desc string `json:"desc"`
Content string `json:"content"`
CreatedBy string `json:"created_by"`
ModifiedBy string `json:"modified_by"`
State int `json:"state"`
}
func ExistArticleByID(id int) bool {
var article Article
db.Select("id").Where("id = ?", id).First(&article)
if article.ID > 0 {
return true
}
return false
}
func GetArticleTotal(maps interface {}) (count int){
db.Model(&Article{}).Where(maps).Count(&count)
return
}
func GetArticles(pageNum int, pageSize int, maps interface {}) (articles []Article) {
db.Preload("Tag").Where(maps).Offset(pageNum).Limit(pageSize).Find(&articles)
return
}
func GetArticle(id int) (article Article) {
db.Where("id = ?", id).First(&article)
db.Model(&article).Related(&article.Tag)
return
}
func EditArticle(id int, data interface {}) bool {
db.Model(&Article{}).Where("id = ?", id).Updates(data)
return true
}
func AddArticle(data map[string]interface {}) bool {
db.Create(&Article {
TagID : data["tag_id"].(int),
Title : data["title"].(string),
Desc : data["desc"].(string),
Content : data["content"].(string),
CreatedBy : data["created_by"].(string),
State : data["state"].(int),
})
return true
}
func DeleteArticle(id int) bool {
db.Where("id = ?", id).Delete(Article{})
return true
}
func (article *Article) BeforeCreate(scope *gorm.Scope) error {
scope.SetColumn("CreatedOn", time.Now().Unix())
return nil
}
func (article *Article) BeforeUpdate(scope *gorm.Scope) error {
scope.SetColumn("ModifiedOn", time.Now().Unix())
return nil
}
在這裡,我們拿出三點不同來講,如下:
1、 我們的Article是如何關聯到Tag?
func GetArticle(id int) (article Article) {
db.Where("id = ?", id).First(&article)
db.Model(&article).Related(&article.Tag)
return
}
能夠達到關聯,首先是gorm本身做了大量的約定俗成
Article有一個結構體成員是TagID,就是外來鍵。gorm會透過類名+ID的方式去找到這兩個類之間的關聯關係Article有一個結構體成員是Tag,就是我們巢狀在Article裡的Tag結構體,我們可以透過Related進行關聯查詢
2、 Preload是什麼東西,為什麼查詢可以得出每一項的關聯Tag?
func GetArticles(pageNum int, pageSize int, maps interface {}) (articles []Article) {
db.Preload("Tag").Where(maps).Offset(pageNum).Limit(pageSize).Find(&articles)
return
}
Preload就是一個預載入器,它會執行兩條SQL,分別是SELECT * FROM blog_articles;和SELECT * FROM blog_tag WHERE id IN (1,2,3,4);,那麼在查詢出結構後,gorm內部處理對應的對映邏輯,將其填充到Article的Tag中,會特別方便,並且避免了迴圈查詢
那麼有沒有別的辦法呢,大致是兩種
gorm的Join- 迴圈
Related
綜合之下,還是Preload更好,如果你有更優的方案,歡迎說一下 :)
3、 v.(I) 是什麼?
v表示一個介面值,I表示介面型別。這個實際就是Golang中的型別斷言,用於判斷一個介面值的實際型別是否為某個型別,或一個非介面值的型別是否實作了某個介面型別
開啟routers目錄下v1版本的article.go檔案,修改檔案內容:
package v1
import (
"net/http"
"log"
"github.com/gin-gonic/gin"
"github.com/astaxie/beego/validation"
"github.com/unknwon/com"
"github.com/EDDYCJY/go-gin-example/models"
"github.com/EDDYCJY/go-gin-example/pkg/e"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
"github.com/EDDYCJY/go-gin-example/pkg/util"
)
//获取单个文章
func GetArticle(c *gin.Context) {
id := com.StrTo(c.Param("id")).MustInt()
valid := validation.Validation{}
valid.Min(id, 1, "id").Message("ID必须大于0")
code := e.INVALID_PARAMS
var data interface {}
if ! valid.HasErrors() {
if models.ExistArticleByID(id) {
data = models.GetArticle(id)
code = e.SUCCESS
} else {
code = e.ERROR_NOT_EXIST_ARTICLE
}
} else {
for _, err := range valid.Errors {
log.Printf("err.key: %s, err.message: %s", err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : data,
})
}
//获取多个文章
func GetArticles(c *gin.Context) {
data := make(map[string]interface{})
maps := make(map[string]interface{})
valid := validation.Validation{}
var state int = -1
if arg := c.Query("state"); arg != "" {
state = com.StrTo(arg).MustInt()
maps["state"] = state
valid.Range(state, 0, 1, "state").Message("状态只允许0或1")
}
var tagId int = -1
if arg := c.Query("tag_id"); arg != "" {
tagId = com.StrTo(arg).MustInt()
maps["tag_id"] = tagId
valid.Min(tagId, 1, "tag_id").Message("标签ID必须大于0")
}
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
code = e.SUCCESS
data["lists"] = models.GetArticles(util.GetPage(c), setting.PageSize, maps)
data["total"] = models.GetArticleTotal(maps)
} else {
for _, err := range valid.Errors {
log.Printf("err.key: %s, err.message: %s", err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : data,
})
}
//新增文章
func AddArticle(c *gin.Context) {
tagId := com.StrTo(c.Query("tag_id")).MustInt()
title := c.Query("title")
desc := c.Query("desc")
content := c.Query("content")
createdBy := c.Query("created_by")
state := com.StrTo(c.DefaultQuery("state", "0")).MustInt()
valid := validation.Validation{}
valid.Min(tagId, 1, "tag_id").Message("标签ID必须大于0")
valid.Required(title, "title").Message("标题不能为空")
valid.Required(desc, "desc").Message("简述不能为空")
valid.Required(content, "content").Message("内容不能为空")
valid.Required(createdBy, "created_by").Message("创建人不能为空")
valid.Range(state, 0, 1, "state").Message("状态只允许0或1")
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
if models.ExistTagByID(tagId) {
data := make(map[string]interface {})
data["tag_id"] = tagId
data["title"] = title
data["desc"] = desc
data["content"] = content
data["created_by"] = createdBy
data["state"] = state
models.AddArticle(data)
code = e.SUCCESS
} else {
code = e.ERROR_NOT_EXIST_TAG
}
} else {
for _, err := range valid.Errors {
log.Printf("err.key: %s, err.message: %s", err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : make(map[string]interface{}),
})
}
//修改文章
func EditArticle(c *gin.Context) {
valid := validation.Validation{}
id := com.StrTo(c.Param("id")).MustInt()
tagId := com.StrTo(c.Query("tag_id")).MustInt()
title := c.Query("title")
desc := c.Query("desc")
content := c.Query("content")
modifiedBy := c.Query("modified_by")
var state int = -1
if arg := c.Query("state"); arg != "" {
state = com.StrTo(arg).MustInt()
valid.Range(state, 0, 1, "state").Message("状态只允许0或1")
}
valid.Min(id, 1, "id").Message("ID必须大于0")
valid.MaxSize(title, 100, "title").Message("标题最长为100字符")
valid.MaxSize(desc, 255, "desc").Message("简述最长为255字符")
valid.MaxSize(content, 65535, "content").Message("内容最长为65535字符")
valid.Required(modifiedBy, "modified_by").Message("修改人不能为空")
valid.MaxSize(modifiedBy, 100, "modified_by").Message("修改人最长为100字符")
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
if models.ExistArticleByID(id) {
if models.ExistTagByID(tagId) {
data := make(map[string]interface {})
if tagId > 0 {
data["tag_id"] = tagId
}
if title != "" {
data["title"] = title
}
if desc != "" {
data["desc"] = desc
}
if content != "" {
data["content"] = content
}
data["modified_by"] = modifiedBy
models.EditArticle(id, data)
code = e.SUCCESS
} else {
code = e.ERROR_NOT_EXIST_TAG
}
} else {
code = e.ERROR_NOT_EXIST_ARTICLE
}
} else {
for _, err := range valid.Errors {
log.Printf("err.key: %s, err.message: %s", err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : make(map[string]string),
})
}
//删除文章
func DeleteArticle(c *gin.Context) {
id := com.StrTo(c.Param("id")).MustInt()
valid := validation.Validation{}
valid.Min(id, 1, "id").Message("ID必须大于0")
code := e.INVALID_PARAMS
if ! valid.HasErrors() {
if models.ExistArticleByID(id) {
models.DeleteArticle(id)
code = e.SUCCESS
} else {
code = e.ERROR_NOT_EXIST_ARTICLE
}
} else {
for _, err := range valid.Errors {
log.Printf("err.key: %s, err.message: %s", err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : make(map[string]string),
})
}
當前目錄結構:
go-gin-example/
├── conf
│ └── app.ini
├── main.go
├── middleware
├── models
│ ├── article.go
│ ├── models.go
│ └── tag.go
├── pkg
│ ├── e
│ │ ├── code.go
│ │ └── msg.go
│ ├── setting
│ │ └── setting.go
│ └── util
│ └── pagination.go
├── routers
│ ├── api
│ │ └── v1
│ │ ├── article.go
│ │ └── tag.go
│ └── router.go
├── runtime
驗證功能
我們重啟服務,執行go run main.go,檢查控制檯輸出結果
$ go run main.go
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /api/v1/tags --> gin-blog/routers/api/v1.GetTags (3 handlers)
[GIN-debug] POST /api/v1/tags --> gin-blog/routers/api/v1.AddTag (3 handlers)
[GIN-debug] PUT /api/v1/tags/:id --> gin-blog/routers/api/v1.EditTag (3 handlers)
[GIN-debug] DELETE /api/v1/tags/:id --> gin-blog/routers/api/v1.DeleteTag (3 handlers)
[GIN-debug] GET /api/v1/articles --> gin-blog/routers/api/v1.GetArticles (3 handlers)
[GIN-debug] GET /api/v1/articles/:id --> gin-blog/routers/api/v1.GetArticle (3 handlers)
[GIN-debug] POST /api/v1/articles --> gin-blog/routers/api/v1.AddArticle (3 handlers)
[GIN-debug] PUT /api/v1/articles/:id --> gin-blog/routers/api/v1.EditArticle (3 handlers)
[GIN-debug] DELETE /api/v1/articles/:id --> gin-blog/routers/api/v1.DeleteArticle (3 handlers)
使用Postman檢驗介面是否正常,在這裡大家可以選用合適的引數傳遞方式,此處為了方便展示我選用了 GET/Param 傳參的方式,而後期會改為 POST。
- POST:http://127.0.0.1:8000/api/v1/articles?tag_id=1&title=test1&desc=test-desc&content=test-content&created_by=test-created&state=1
- GET:http://127.0.0.1:8000/api/v1/articles
- GET:http://127.0.0.1:8000/api/v1/articles/1
- PUT:http://127.0.0.1:8000/api/v1/articles/1?tag_id=1&title=test-edit1&desc=test-desc-edit&content=test-content-edit&modified_by=test-created-edit&state=0
- DELETE:http://127.0.0.1:8000/api/v1/articles/1
至此,我們的API's編寫就到這裡,下一節我們將介紹另外的一些技巧!
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.5 使用JWT進行身份校驗
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- JWT
本文目標
在前面幾節中,我們已經基本的完成了API's的編寫,但是,還存在一些非常嚴重的問題,例如,我們現在的API是可以隨意呼叫的,這顯然還不安全全,在本文中我們透過 jwt-go (GoDoc)的方式來簡單解決這個問題。
下載依賴包
首先,我們下載 jwt-go的依賴包,如下:
go get -u github.com/dgrijalva/jwt-go
編寫 jwt 工具包
我們需要編寫一個jwt的工具包,我們在pkg下的util目錄新建jwt.go,寫入檔案內容:
package util
import (
"time"
jwt "github.com/dgrijalva/jwt-go"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
var jwtSecret = []byte(setting.JwtSecret)
type Claims struct {
Username string `json:"username"`
Password string `json:"password"`
jwt.StandardClaims
}
func GenerateToken(username, password string) (string, error) {
nowTime := time.Now()
expireTime := nowTime.Add(3 * time.Hour)
claims := Claims{
username,
password,
jwt.StandardClaims {
ExpiresAt : expireTime.Unix(),
Issuer : "gin-blog",
},
}
tokenClaims := jwt.NewWithClaims(jwt.SigningMethodHS256, claims)
token, err := tokenClaims.SignedString(jwtSecret)
return token, err
}
func ParseToken(token string) (*Claims, error) {
tokenClaims, err := jwt.ParseWithClaims(token, &Claims{}, func(token *jwt.Token) (interface{}, error) {
return jwtSecret, nil
})
if tokenClaims != nil {
if claims, ok := tokenClaims.Claims.(*Claims); ok && tokenClaims.Valid {
return claims, nil
}
}
return nil, err
}
在這個工具包,我們涉及到
NewWithClaims(method SigningMethod, claims Claims),method對應著SigningMethodHMAC struct{},其包含SigningMethodHS256、SigningMethodHS384、SigningMethodHS512三種crypto.Hash方案func (t *Token) SignedString(key interface{})該方法內部生成簽名字串,再用於取得完整、已簽名的tokenfunc (p *Parser) ParseWithClaims用於解析鑑權的宣告,方法內部主要是具體的解碼和校驗的過程,最終返回*Tokenfunc (m MapClaims) Valid()驗證基於時間的宣告exp, iat, nbf,注意如果沒有任何宣告在令牌中,仍然會被認為是有效的。並且對於時區偏差沒有計算方法
有了jwt工具包,接下來我們要編寫要用於Gin的中介軟體,我們在middleware下新建jwt目錄,新建jwt.go檔案,寫入內容:
package jwt
import (
"time"
"net/http"
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/pkg/util"
"github.com/EDDYCJY/go-gin-example/pkg/e"
)
func JWT() gin.HandlerFunc {
return func(c *gin.Context) {
var code int
var data interface{}
code = e.SUCCESS
token := c.Query("token")
if token == "" {
code = e.INVALID_PARAMS
} else {
claims, err := util.ParseToken(token)
if err != nil {
code = e.ERROR_AUTH_CHECK_TOKEN_FAIL
} else if time.Now().Unix() > claims.ExpiresAt {
code = e.ERROR_AUTH_CHECK_TOKEN_TIMEOUT
}
}
if code != e.SUCCESS {
c.JSON(http.StatusUnauthorized, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : data,
})
c.Abort()
return
}
c.Next()
}
}
如何取得Token
那麼我們如何呼叫它呢,我們還要取得Token呢?
1、 我們要新增一個取得Token的API
在models下新建auth.go檔案,寫入內容:
package models
type Auth struct {
ID int `gorm:"primary_key" json:"id"`
Username string `json:"username"`
Password string `json:"password"`
}
func CheckAuth(username, password string) bool {
var auth Auth
db.Select("id").Where(Auth{Username : username, Password : password}).First(&auth)
if auth.ID > 0 {
return true
}
return false
}
在routers下的api目錄新建auth.go檔案,寫入內容:
package api
import (
"log"
"net/http"
"github.com/gin-gonic/gin"
"github.com/astaxie/beego/validation"
"github.com/EDDYCJY/go-gin-example/pkg/e"
"github.com/EDDYCJY/go-gin-example/pkg/util"
"github.com/EDDYCJY/go-gin-example/models"
)
type auth struct {
Username string `valid:"Required; MaxSize(50)"`
Password string `valid:"Required; MaxSize(50)"`
}
func GetAuth(c *gin.Context) {
username := c.Query("username")
password := c.Query("password")
valid := validation.Validation{}
a := auth{Username: username, Password: password}
ok, _ := valid.Valid(&a)
data := make(map[string]interface{})
code := e.INVALID_PARAMS
if ok {
isExist := models.CheckAuth(username, password)
if isExist {
token, err := util.GenerateToken(username, password)
if err != nil {
code = e.ERROR_AUTH_TOKEN
} else {
data["token"] = token
code = e.SUCCESS
}
} else {
code = e.ERROR_AUTH
}
} else {
for _, err := range valid.Errors {
log.Println(err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : data,
})
}
我們開啟routers目錄下的router.go檔案,修改檔案內容(新增取得token的方法):
package routers
import (
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/routers/api"
"github.com/EDDYCJY/go-gin-example/routers/api/v1"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
func InitRouter() *gin.Engine {
r := gin.New()
r.Use(gin.Logger())
r.Use(gin.Recovery())
gin.SetMode(setting.RunMode)
r.GET("/auth", api.GetAuth)
apiv1 := r.Group("/api/v1")
{
...
}
return r
}
驗證Token
取得token的API方法就到這裡啦,讓我們來測試下是否可以正常使用吧!
重啟服務後,用GET方式訪問http://127.0.0.1:8000/auth?username=test&password=test123456,檢視返回值是否正確
{
"code": 200,
"data": {
"token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6InRlc3QiLCJwYXNzd29yZCI6InRlc3QxMjM0NTYiLCJleHAiOjE1MTg3MjAwMzcsImlzcyI6Imdpbi1ibG9nIn0.-kK0V9E06qTHOzupQM_gHXAGDB3EJtJS4H5TTCyWwW8"
},
"msg": "ok"
}
我們有了token的API,也呼叫成功了
將中介軟體接入Gin
2、 接下來我們將中介軟體接入到Gin的訪問流程中
我們開啟routers目錄下的router.go檔案,修改檔案內容(新增引用包和中介軟體引用)
package routers
import (
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/routers/api"
"github.com/EDDYCJY/go-gin-example/routers/api/v1"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
"github.com/EDDYCJY/go-gin-example/middleware/jwt"
)
func InitRouter() *gin.Engine {
r := gin.New()
r.Use(gin.Logger())
r.Use(gin.Recovery())
gin.SetMode(setting.RunMode)
r.GET("/auth", api.GetAuth)
apiv1 := r.Group("/api/v1")
apiv1.Use(jwt.JWT())
{
...
}
return r
}
當前目錄結構:
go-gin-example/
├── conf
│ └── app.ini
├── main.go
├── middleware
│ └── jwt
│ └── jwt.go
├── models
│ ├── article.go
│ ├── auth.go
│ ├── models.go
│ └── tag.go
├── pkg
│ ├── e
│ │ ├── code.go
│ │ └── msg.go
│ ├── setting
│ │ └── setting.go
│ └── util
│ ├── jwt.go
│ └── pagination.go
├── routers
│ ├── api
│ │ ├── auth.go
│ │ └── v1
│ │ ├── article.go
│ │ └── tag.go
│ └── router.go
├── runtime
到這裡,我們的JWT編寫就完成啦!
驗證功能
我們來測試一下,再次訪問
正確的反饋應該是
{
"code": 400,
"data": null,
"msg": "请求参数错误"
}
{
"code": 20001,
"data": null,
"msg": "Token鉴权失败"
}
我們需要訪問http://127.0.0.1:8000/auth?username=test&password=test123456,得到token
{
"code": 200,
"data": {
"token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6InRlc3QiLCJwYXNzd29yZCI6InRlc3QxMjM0NTYiLCJleHAiOjE1MTg3MjQ2OTMsImlzcyI6Imdpbi1ibG9nIn0.KSBY6TeavV_30kfmP7HWLRYKP5TPEDgHtABe9HCsic4"
},
"msg": "ok"
}
再用包含token的URL引數去訪問我們的應用API,
訪問http://127.0.0.1:8000/api/v1/articles?token=eyJhbGci...,檢查介面返回值
{
"code": 200,
"data": {
"lists": [
{
"id": 2,
"created_on": 1518700920,
"modified_on": 0,
"tag_id": 1,
"tag": {
"id": 1,
"created_on": 1518684200,
"modified_on": 0,
"name": "tag1",
"created_by": "",
"modified_by": "",
"state": 0
},
"content": "test-content",
"created_by": "test-created",
"modified_by": "",
"state": 0
}
],
"total": 1
},
"msg": "ok"
}
返回正確,至此我們的jwt-go在Gin中的驗證就完成了!
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.6 編寫一個簡單的檔案日誌
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- 自定義 log。
本文目標
在上一節中,我們解決了API's可以任意訪問的問題,那麼我們現在還有一個問題,就是我們的日誌,都是輸出到控制檯上的,這顯然對於一個專案來說是不合理的,因此我們這一節簡單封裝log庫,使其支援簡單的檔案日誌!
新建logging包
我們在pkg下新建logging目錄,新建file.go和log.go檔案,寫入內容:
編寫file檔案
1、 file.go:
package logging
import (
"os"
"time"
"fmt"
"log"
)
var (
LogSavePath = "runtime/logs/"
LogSaveName = "log"
LogFileExt = "log"
TimeFormat = "20060102"
)
func getLogFilePath() string {
return fmt.Sprintf("%s", LogSavePath)
}
func getLogFileFullPath() string {
prefixPath := getLogFilePath()
suffixPath := fmt.Sprintf("%s%s.%s", LogSaveName, time.Now().Format(TimeFormat), LogFileExt)
return fmt.Sprintf("%s%s", prefixPath, suffixPath)
}
func openLogFile(filePath string) *os.File {
_, err := os.Stat(filePath)
switch {
case os.IsNotExist(err):
mkDir()
case os.IsPermission(err):
log.Fatalf("Permission :%v", err)
}
handle, err := os.OpenFile(filePath, os.O_APPEND | os.O_CREATE | os.O_WRONLY, 0644)
if err != nil {
log.Fatalf("Fail to OpenFile :%v", err)
}
return handle
}
func mkDir() {
dir, _ := os.Getwd()
err := os.MkdirAll(dir + "/" + getLogFilePath(), os.ModePerm)
if err != nil {
panic(err)
}
}
-
os.Stat:返回檔案資訊結構描述檔案。如果出現錯誤,會返回*PathErrortype PathError struct { Op string Path string Err error } -
os.IsNotExist:能夠接受ErrNotExist、syscall的一些錯誤,它會返回一個布林值,能夠得知檔案不存在或目錄不存在 -
os.IsPermission:能夠接受ErrPermission、syscall的一些錯誤,它會返回一個布林值,能夠得知許可權是否滿足 -
os.OpenFile:呼叫檔案,支援傳入檔名稱、指定的模式呼叫檔案、檔案許可權,返回的檔案的方法可以用於I/O。如果出現錯誤,則為*PathError。
const (
// Exactly one of O_RDONLY, O_WRONLY, or O_RDWR must be specified.
O_RDONLY int = syscall.O_RDONLY // 以只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 以只写模式打开文件
O_RDWR int = syscall.O_RDWR // 以读写模式打开文件
// The remaining values may be or'ed in to control behavior.
O_APPEND int = syscall.O_APPEND // 在写入时将数据追加到文件中
O_CREATE int = syscall.O_CREAT // 如果不存在,则创建一个新文件
O_EXCL int = syscall.O_EXCL // 使用O_CREATE时,文件必须不存在
O_SYNC int = syscall.O_SYNC // 同步IO
O_TRUNC int = syscall.O_TRUNC // 如果可以,打开时
)
os.Getwd:返回與當前目錄對應的根路徑名os.MkdirAll:建立對應的目錄以及所需的子目錄,若成功則返回nil,否則返回erroros.ModePerm:const定義ModePerm FileMode = 0777
編寫log檔案
2、log.go
package logging
import (
"log"
"os"
"runtime"
"path/filepath"
"fmt"
)
type Level int
var (
F *os.File
DefaultPrefix = ""
DefaultCallerDepth = 2
logger *log.Logger
logPrefix = ""
levelFlags = []string{"DEBUG", "INFO", "WARN", "ERROR", "FATAL"}
)
const (
DEBUG Level = iota
INFO
WARNING
ERROR
FATAL
)
func init() {
filePath := getLogFileFullPath()
F = openLogFile(filePath)
logger = log.New(F, DefaultPrefix, log.LstdFlags)
}
func Debug(v ...interface{}) {
setPrefix(DEBUG)
logger.Println(v)
}
func Info(v ...interface{}) {
setPrefix(INFO)
logger.Println(v)
}
func Warn(v ...interface{}) {
setPrefix(WARNING)
logger.Println(v)
}
func Error(v ...interface{}) {
setPrefix(ERROR)
logger.Println(v)
}
func Fatal(v ...interface{}) {
setPrefix(FATAL)
logger.Fatalln(v)
}
func setPrefix(level Level) {
_, file, line, ok := runtime.Caller(DefaultCallerDepth)
if ok {
logPrefix = fmt.Sprintf("[%s][%s:%d]", levelFlags[level], filepath.Base(file), line)
} else {
logPrefix = fmt.Sprintf("[%s]", levelFlags[level])
}
logger.SetPrefix(logPrefix)
}
-
log.New:建立一個新的日誌記錄器。out定義要寫入日誌資料的IO控制代碼。prefix定義每個生成的日誌行的開頭。flag定義了日誌記錄屬性func New(out io.Writer, prefix string, flag int) *Logger { return &Logger{out: out, prefix: prefix, flag: flag} } -
log.LstdFlags:日誌記錄的格式屬性之一,其餘的選項如下const ( Ldate = 1 << iota // the date in the local time zone: 2009/01/23 Ltime // the time in the local time zone: 01:23:23 Lmicroseconds // microsecond resolution: 01:23:23.123123. assumes Ltime. Llongfile // full file name and line number: /a/b/c/d.go:23 Lshortfile // final file name element and line number: d.go:23. overrides Llongfile LUTC // if Ldate or Ltime is set, use UTC rather than the local time zone LstdFlags = Ldate | Ltime // initial values for the standard logger )
當前目錄結構:
gin-blog/
├── conf
│ └── app.ini
├── main.go
├── middleware
│ └── jwt
│ └── jwt.go
├── models
│ ├── article.go
│ ├── auth.go
│ ├── models.go
│ └── tag.go
├── pkg
│ ├── e
│ │ ├── code.go
│ │ └── msg.go
│ ├── logging
│ │ ├── file.go
│ │ └── log.go
│ ├── setting
│ │ └── setting.go
│ └── util
│ ├── jwt.go
│ └── pagination.go
├── routers
│ ├── api
│ │ ├── auth.go
│ │ └── v1
│ │ ├── article.go
│ │ └── tag.go
│ └── router.go
├── runtime
我們自定義的logging包,已經基本完成了,接下來讓它接入到我們的專案之中吧。我們開啟先前包含log包的程式碼,如下:
- 開啟
routers目錄下的article.go、tag.go、auth.go。 - 將
log包的引用刪除,修改引用我們自己的日誌包為github.com/EDDYCJY/go-gin-example/pkg/logging。 - 將原本的
log.Println(...)改為logging.Info(...)。
例如auth.go檔案的修改內容:
package api
import (
"net/http"
"github.com/gin-gonic/gin"
"github.com/astaxie/beego/validation"
"github.com/EDDYCJY/go-gin-example/pkg/e"
"github.com/EDDYCJY/go-gin-example/pkg/util"
"github.com/EDDYCJY/go-gin-example/models"
"github.com/EDDYCJY/go-gin-example/pkg/logging"
)
...
func GetAuth(c *gin.Context) {
...
code := e.INVALID_PARAMS
if ok {
...
} else {
for _, err := range valid.Errors {
logging.Info(err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code" : code,
"msg" : e.GetMsg(code),
"data" : data,
})
}
驗證功能
修改檔案後,重啟服務,我們來試試吧!
取得到API的Token後,我們故意傳錯誤URL引數給介面,如:http://127.0.0.1:8000/api/v1/articles?tag_id=0&state=9999999&token=eyJhbG..
然後我們到$GOPATH/gin-blog/runtime/logs檢視日誌:
$ tail -f log20180216.log
[INFO][article.go:79]2018/02/16 18:33:12 [state 状态只允许0或1]
[INFO][article.go:79]2018/02/16 18:33:42 [state 状态只允许0或1]
[INFO][article.go:79]2018/02/16 18:33:42 [tag_id 标签ID必须大于0]
[INFO][article.go:79]2018/02/16 18:38:39 [state 状态只允许0或1]
[INFO][article.go:79]2018/02/16 18:38:39 [tag_id 标签ID必须大于0]
日誌結構一切正常,我們的記錄模式都為Info,因此字首是對的,並且我們是入參有問題,也把錯誤記錄下來了,這樣排錯就很方便了!
至此,本節就完成了,這只是一個簡單的擴充套件,實際上我們線上專案要使用的檔案日誌,是更復雜一些,開動你的大腦 舉一反三吧!
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.7 優雅的重啟服務
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 訊號量的瞭解。
- 應用熱更新。
本文目標
在前面編寫案例程式碼時,我相信你會想到,每次更新完程式碼,更新完設定檔案後,就直接這麼 ctrl+c 真的沒問題嗎,ctrl+c到底做了些什麼事情呢?
在這一節中我們簡單講述 ctrl+c 背後的訊號以及如何在Gin中優雅的重啟服務,也就是對 HTTP 服務進行熱更新。
ctrl + c
核心在某些情況下發送訊號,比如在程序往一個已經關閉的管道寫資料時會產生
SIGPIPE訊號
在終端執行特定的組合鍵可以使系統傳送特定的訊號給此程序,完成一系列的動作
| 命令 | 訊號 | 含義 |
|---|---|---|
| ctrl + c | SIGINT | 強制程序結束 |
| ctrl + z | SIGTSTP | 任務中斷,程序掛起 |
| ctrl + \ | SIGQUIT | 程序結束 和 dump core |
| ctrl + d | EOF | |
| SIGHUP | 終止收到該訊號的程序。若程式中沒有捕捉該訊號,當收到該訊號時,程序就會退出(常用於 重啟、重新載入程序) |
因此在我們執行ctrl + c關閉gin服務端時,會強制程序結束,導致正在訪問的使用者等出現問題
常見的 kill -9 pid 會發送 SIGKILL 訊號給程序,也是類似的結果
訊號
本段中反覆出現訊號是什麼呢?
訊號是 Unix 、類 Unix 以及其他 POSIX 相容的作業系統中程序間通訊的一種有限制的方式
它是一種非同步的通知機制,用來提醒程序一個事件(硬體異常、程式執行異常、外部發出訊號)已經發生。當一個訊號傳送給一個程序,作業系統中斷了程序正常的控制流程。此時,任何非原子操作都將被中斷。如果程序定義了訊號的處理函式,那麼它將被執行,否則就執行預設的處理函式
所有訊號
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
怎樣算優雅
目的
- 不關閉現有連線(正在執行中的程式)
- 新的程序啟動並替代舊程序
- 新的程序接管新的連線
- 連線要隨時響應使用者的請求,當用戶仍在請求舊程序時要保持連線,新使用者應請求新程序,不可以出現拒絕請求的情況
流程
1、替換可執行檔案或修改設定檔案
2、傳送訊號量 SIGHUP
3、拒絕新連線請求舊程序,但要保證已有連線正常
4、啟動新的子程序
5、新的子程序開始 Accet
6、系統將新的請求轉交新的子程序
7、舊程序處理完所有舊連線後正常結束
實作優雅重啟
endless
Zero downtime restarts for golang HTTP and HTTPS servers. (for golang 1.3+)
我們藉助 fvbock/endless 來實作 Golang HTTP/HTTPS 服務重新啟動的零停機
endless server 監聽以下幾種訊號量:
- syscall.SIGHUP:觸發
fork子程序和重新啟動 - syscall.SIGUSR1/syscall.SIGTSTP:被監聽,但不會觸發任何動作
- syscall.SIGUSR2:觸發
hammerTime - syscall.SIGINT/syscall.SIGTERM:觸發伺服器關閉(會完成正在執行的請求)
endless 正正是依靠監聽這些訊號量,完成管控的一系列動作
安裝
go get -u github.com/fvbock/endless
編寫
開啟 gin-blog 的 main.go檔案,修改檔案:
package main
import (
"fmt"
"log"
"syscall"
"github.com/fvbock/endless"
"gin-blog/routers"
"gin-blog/pkg/setting"
)
func main() {
endless.DefaultReadTimeOut = setting.ReadTimeout
endless.DefaultWriteTimeOut = setting.WriteTimeout
endless.DefaultMaxHeaderBytes = 1 << 20
endPoint := fmt.Sprintf(":%d", setting.HTTPPort)
server := endless.NewServer(endPoint, routers.InitRouter())
server.BeforeBegin = func(add string) {
log.Printf("Actual pid is %d", syscall.Getpid())
}
err := server.ListenAndServe()
if err != nil {
log.Printf("Server err: %v", err)
}
}
endless.NewServer 返回一個初始化的 endlessServer 物件,在 BeforeBegin 時輸出當前程序的 pid,呼叫 ListenAndServe 將實際“啟動”服務
驗證
編譯
$ go build main.go
執行
$ ./main
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
...
Actual pid is 48601
啟動成功後,輸出了pid為 48601;在另外一個終端執行 kill -1 48601 ,檢驗先前服務的終端效果
[root@localhost go-gin-example]# ./main
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /auth --> ...
[GIN-debug] GET /api/v1/tags --> ...
...
Actual pid is 48601
...
Actual pid is 48755
48601 Received SIGTERM.
48601 [::]:8000 Listener closed.
48601 Waiting for connections to finish...
48601 Serve() returning...
Server err: accept tcp [::]:8000: use of closed network connection
可以看到該命令已經掛起,並且 fork 了新的子程序 pid 為 48755
48601 Received SIGTERM.
48601 [::]:8000 Listener closed.
48601 Waiting for connections to finish...
48601 Serve() returning...
Server err: accept tcp [::]:8000: use of closed network connection
大致意思為主程序(pid為48601)接受到 SIGTERM 訊號量,關閉主程序的監聽並且等待正在執行的請求完成;這與我們先前的描述一致
喚醒
這時候在 postman 上再次訪問我們的介面,你可以驚喜的發現,他“復活”了!
Actual pid is 48755
48601 Received SIGTERM.
48601 [::]:8000 Listener closed.
48601 Waiting for connections to finish...
48601 Serve() returning...
Server err: accept tcp [::]:8000: use of closed network connection
$ [GIN] 2018/03/15 - 13:00:16 | 200 | 188.096µs | 192.168.111.1 | GET /api/v1/tags...
這就完成了一次正向的流轉了
你想想,每次更新發布、或者修改設定檔案等,只需要給該程序傳送SIGTERM訊號,而不需要強制結束應用,是多麼便捷又安全的事!
問題
endless 熱更新是採取建立子程序後,將原程序退出的方式,這點不符合守護程序的要求
http.Server - Shutdown()
如果你的Golang >= 1.8,也可以考慮使用 http.Server 的 Shutdown 方法
package main
import (
"fmt"
"net/http"
"context"
"log"
"os"
"os/signal"
"time"
"gin-blog/routers"
"gin-blog/pkg/setting"
)
func main() {
router := routers.InitRouter()
s := &http.Server{
Addr: fmt.Sprintf(":%d", setting.HTTPPort),
Handler: router,
ReadTimeout: setting.ReadTimeout,
WriteTimeout: setting.WriteTimeout,
MaxHeaderBytes: 1 << 20,
}
go func() {
if err := s.ListenAndServe(); err != nil {
log.Printf("Listen: %s\n", err)
}
}()
quit := make(chan os.Signal)
signal.Notify(quit, os.Interrupt)
<- quit
log.Println("Shutdown Server ...")
ctx, cancel := context.WithTimeout(context.Background(), 5 * time.Second)
defer cancel()
if err := s.Shutdown(ctx); err != nil {
log.Fatal("Server Shutdown:", err)
}
log.Println("Server exiting")
}
小結
在日常的服務中,優雅的重啟(熱更新)是非常重要的一環。而 Golang 在 HTTP 服務方面的熱更新也有不少方案了,我們應該根據實際應用場景挑選最合適的
參考
本系列示例程式碼
拓展閱讀
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.8 為它加上Swagger
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- Swagger
本文目標
一個好的 API's,必然離不開一個好的API文件,如果要開發純手寫 API 文件,不存在的(很難持續維護),因此我們要自動生成介面文件。
安裝 swag
$ go get -u github.com/swaggo/swag/cmd/swag
若 $GOROOT/bin 沒有加入$PATH中,你需要執行將其可執行檔案移動到$GOBIN下
mv $GOPATH/bin/swag /usr/local/go/bin
驗證是否安裝成功
檢查 $GOBIN 下是否有 swag 檔案,如下:
$ swag -v
swag version v1.1.1
安裝 gin-swagger
$ go get -u github.com/swaggo/gin-swagger
$ go get -u github.com/swaggo/gin-swagger/swaggerFiles
注:三個包都有一定大小,安裝需要等一會或要科學上網。
初始化
編寫API註釋
Swagger 中需要將相應的註釋或註解編寫到方法上,再利用生成器自動生成說明檔案
gin-swagger 給出的範例:
// @Summary Add a new pet to the store
// @Description get string by ID
// @Accept json
// @Produce json
// @Param some_id path int true "Some ID"
// @Success 200 {string} string "ok"
// @Failure 400 {object} web.APIError "We need ID!!"
// @Failure 404 {object} web.APIError "Can not find ID"
// @Router /testapi/get-string-by-int/{some_id} [get]
我們可以參照 Swagger 的註解規範和範例去編寫
// @Summary 新增文章标签
// @Produce json
// @Param name query string true "Name"
// @Param state query int false "State"
// @Param created_by query int false "CreatedBy"
// @Success 200 {string} json "{"code":200,"data":{},"msg":"ok"}"
// @Router /api/v1/tags [post]
func AddTag(c *gin.Context) {
// @Summary 修改文章标签
// @Produce json
// @Param id path int true "ID"
// @Param name query string true "ID"
// @Param state query int false "State"
// @Param modified_by query string true "ModifiedBy"
// @Success 200 {string} json "{"code":200,"data":{},"msg":"ok"}"
// @Router /api/v1/tags/{id} [put]
func EditTag(c *gin.Context) {
參考的註解請參見 go-gin-example。以確保取得最新的 swag 語法
路由
在完成了註解的編寫後,我們需要針對 swagger 新增初始化動作和對應的路由規則,才可以使用。開啟 routers/router.go 檔案,新增內容如下:
package routers
import (
...
_ "github.com/EDDYCJY/go-gin-example/docs"
...
)
// InitRouter initialize routing information
func InitRouter() *gin.Engine {
...
r.GET("/swagger/*any", ginSwagger.WrapHandler(swaggerFiles.Handler))
...
apiv1 := r.Group("/api/v1")
apiv1.Use(jwt.JWT())
{
...
}
return r
}
生成
我們進入到gin-blog的專案根目錄中,執行初始化命令
[$ gin-blog]# swag init
2018/03/13 23:32:10 Generate swagger docs....
2018/03/13 23:32:10 Generate general API Info
2018/03/13 23:32:10 create docs.go at docs/docs.go
完畢後會在專案根目錄下生成docs
docs/
├── docs.go
└── swagger
├── swagger.json
└── swagger.yaml
我們可以檢查 docs.go 檔案中的 doc 變數,詳細記載中我們檔案中所編寫的註解和說明 
驗證
大功告成,訪問一下 http://127.0.0.1:8000/swagger/index.html, 檢視 API 文件生成是否正確
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.9 將Golang應用部署到Docker
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- Go + Docker
本文目標
將我們的 go-gin-example 應用部署到一個 Docker 裡,你需要先準備好如下東西:
- 你需要安裝好
docker。 - 如果上外網比較吃力,需要配好映象源。
Docker
在這裡簡單介紹下Docker,建議深入學習

Docker 是一個開源的輕量級容器技術,讓開發者可以打包他們的應用以及應用執行的上下文環境到一個可移植的映象中,然後釋出到任何支援Docker的系統上執行。 透過容器技術,在幾乎沒有效能開銷的情況下,Docker 為應用提供了一個隔離執行環境
- 簡化設定
- 程式碼流水線管理
- 提高開發效率
- 隔離應用
- 快速、持續部署
接下來我們正式開始對專案進行 docker 的所需處理和編寫,每一個大標題為步驟大綱
Golang
一、編寫Dockerfile
在 go-gin-example 專案根目錄建立 Dockerfile 檔案,寫入內容
FROM golang:latest
ENV GOPROXY https://goproxy.cn,direct
WORKDIR $GOPATH/src/github.com/EDDYCJY/go-gin-example
COPY . $GOPATH/src/github.com/EDDYCJY/go-gin-example
RUN go build .
EXPOSE 8000
ENTRYPOINT ["./go-gin-example"]
作用
golang:latest 映象為基礎映象,將工作目錄設定為 $GOPATH/src/go-gin-example,並將當前上下文目錄的內容複製到 $GOPATH/src/go-gin-example 中
在進行 go build 編譯完畢後,將容器啟動程式設定為 ./go-gin-example,也就是我們所編譯的可執行檔案
注意 go-gin-example 在 docker 容器裡編譯,並沒有在宿主機現場編譯
說明
Dockerfile 檔案是用於定義 Docker 映象生成流程的設定檔案,檔案內容是一條條指令,每一條指令構建一層,因此每一條指令的內容,就是描述該層應當如何構建;這些指令應用於基礎映象並最終建立一個新的映象
你可以認為用於快速建立自定義的 Docker 映象
1、 FROM
指定基礎映象(必須有的指令,並且必須是第一條指令)
2、 WORKDIR
格式為 WORKDIR <工作目錄路徑>
使用 WORKDIR 指令可以來指定工作目錄(或者稱為當前目錄),以後各層的當前目錄就被改為指定的目錄,如果目錄不存在,WORKDIR 會幫你建立目錄
3、COPY
格式:
COPY <源路径>... <目标路径>
COPY ["<源路径1>",... "<目标路径>"]
COPY 指令將從構建上下文目錄中 <源路徑> 的檔案/目錄複製到新的一層的映象內的 <目標路徑> 位置
4、RUN
用於執行命令列命令
格式:RUN <命令>
5、EXPOSE
格式為 EXPOSE <埠1> [<埠2>...]
EXPOSE 指令是宣告執行時容器提供服務埠,這只是一個宣告,在執行時並不會因為這個宣告應用就會開啟這個埠的服務
在 Dockerfile 中寫入這樣的宣告有兩個好處
- 幫助映象使用者理解這個映象服務的守護埠,以方便設定對映
- 執行時使用隨機埠對映時,也就是
docker run -P時,會自動隨機對映EXPOSE的埠
6、ENTRYPOINT
ENTRYPOINT 的格式和 RUN 指令格式一樣,分為兩種格式
-
exec格式:<ENTRYPOINT> "<CMD>" -
shell格式:ENTRYPOINT [ "curl", "-s", "http://ip.cn" ]
ENTRYPOINT 指令是指定容器啟動程式及引數
二、構建映象
go-gin-example 的專案根目錄下執行 docker build -t gin-blog-docker .
該命令作用是建立/構建映象,-t 指定名稱為 gin-blog-docker,. 構建內容為當前上下文目錄
$ docker build -t gin-blog-docker .
Sending build context to Docker daemon 96.39 MB
Step 1/6 : FROM golang:latest
---> d632bbfe5767
Step 2/6 : WORKDIR $GOPATH/src/github.com/EDDYCJY/go-gin-example
---> 56294f978c5d
Removing intermediate container e112997b995d
Step 3/6 : COPY . $GOPATH/src/github.com/EDDYCJY/go-gin-example
---> 3b60960120cf
Removing intermediate container 63e310b3f60c
Step 4/6 : RUN go build .
---> Running in 52648a431450
go: downloading github.com/gin-gonic/gin v1.3.0
go: downloading github.com/go-ini/ini v1.32.1-0.20180214101753-32e4be5f41bb
go: downloading github.com/swaggo/gin-swagger v1.0.1-0.20190110070702-0c6fcfd3c7f3
...
---> 7bfbeb301fea
Removing intermediate container 52648a431450
Step 5/6 : EXPOSE 8000
---> Running in 98f5b387d1bb
---> b65bd4076c65
Removing intermediate container 98f5b387d1bb
Step 6/6 : ENTRYPOINT ./go-gin-example
---> Running in c4f6cdeb667b
---> d8a109c7697c
Removing intermediate container c4f6cdeb667b
Successfully built d8a109c7697c
三、驗證映象
檢視所有的映象,確定剛剛構建的 gin-blog-docker 映象是否存在
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
gin-blog-docker latest d8a109c7697c About a minute ago 946 MB
docker.io/golang latest d632bbfe5767 8 days ago 779 MB
...
四、建立並執行一個新容器
執行命令 docker run -p 8000:8000 gin-blog-docker
$ docker run -p 8000:8000 gin-blog-docker
dial tcp 127.0.0.1:3306: connect: connection refused
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
...
Actual pid is 1
執行成功,你以為大功告成了嗎?
你想太多了,仔細看看控制檯的輸出了一條錯誤 dial tcp 127.0.0.1:3306: connect: connection refused
我們研判一下,發現是 Mysql 的問題,接下來第二項我們將解決這個問題
Mysql
一、拉取映象
從 Docker 的公共倉庫 Dockerhub 下載 MySQL 映象(國內建議配個映象)
$ docker pull mysql
二、建立並執行一個新容器
執行 Mysql 容器,並設定執行成功後返回容器ID
$ docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=rootroot -d mysql
8c86ac986da4922492934b6fe074254c9165b8ee3e184d29865921b0fef29e64
連線 Mysql
初始化的 Mysql 應該如圖
Golang + Mysql
一、刪除映象
由於原本的映象存在問題,我們需要刪除它,此處有幾種做法
- 刪除原本有問題的映象,重新構建一個新映象
- 重新構建一個不同
name、tag的新映象
刪除原本的有問題的映象,-f 是強制刪除及其關聯狀態
若不執行 -f,你需要執行 docker ps -a 查到所關聯的容器,將其 rm 解除兩者依賴關係
$ docker rmi -f gin-blog-docker
Untagged: gin-blog-docker:latest
Deleted: sha256:d8a109c7697c3c2d9b4de7dbb49669d10106902122817b6467a031706bc52ab4
Deleted: sha256:b65bd4076c65a3c24029ca4def3b3f37001ff7c9eca09e2590c4d29e1e23dce5
Deleted: sha256:7bfbeb301fea9d8912a4b7c43e4bb8b69bdc57f0b416b372bfb6510e476a7dee
Deleted: sha256:3b60960120cf619181c1762cdc1b8ce318b8c815e056659809252dd321bcb642
Deleted: sha256:56294f978c5dfcfa4afa8ad033fd76b755b7ecb5237c6829550741a4d2ce10bc
二、修改設定檔案
將專案的設定檔案 conf/app.ini,內容修改為
#debug or release
RUN_MODE = debug
[app]
PAGE_SIZE = 10
JWT_SECRET = 233
[server]
HTTP_PORT = 8000
READ_TIMEOUT = 60
WRITE_TIMEOUT = 60
[database]
TYPE = mysql
USER = root
PASSWORD = rootroot
HOST = mysql:3306
NAME = blog
TABLE_PREFIX = blog_
三、重新構建映象
重複先前的步驟,回到 gin-blog 的專案根目錄下執行 docker build -t gin-blog-docker .
四、建立並執行一個新容器
關聯
Q:我們需要將 Golang 容器和 Mysql 容器關聯起來,那麼我們需要怎麼做呢?
A:增加命令 --link mysql:mysql 讓 Golang 容器與 Mysql 容器互聯;透過 --link,可以在容器內直接使用其關聯的容器別名進行訪問,而不透過IP,但是--link只能解決單機容器間的關聯,在分散式多機的情況下,需要透過別的方式進行連線
執行
執行命令 docker run --link mysql:mysql -p 8000:8000 gin-blog-docker
$ docker run --link mysql:mysql -p 8000:8000 gin-blog-docker
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
...
Actual pid is 1
結果
檢查啟動輸出、介面測試、資料庫內資料,均正常;我們的 Golang 容器和 Mysql 容器成功關聯執行,大功告成 :)
Review
思考
雖然應用已經能夠跑起來了
但如果對 Golang 和 Docker 有一定的瞭解,我希望你能夠想到至少2個問題
- 為什麼
gin-blog-docker佔用空間這麼大?(可用docker ps -as | grep gin-blog-docker檢視) Mysql容器直接這麼使用,資料儲存到哪裡去了?
建立超小的Golang映象
Q:第一個問題,為什麼這麼映象體積這麼大?
A:FROM golang:latest 拉取的是官方 golang 映象,包含Golang的編譯和執行環境,外加一堆GCC、build工具,相當齊全
這是有問題的,我們可以不在Golang容器中現場編譯的,壓根用不到那些東西,我們只需要一個能夠執行可執行檔案的環境即可
構建Scratch映象
Scratch映象,簡潔、小巧,基本是個空映象
一、修改Dockerfile
FROM scratch
WORKDIR $GOPATH/src/github.com/EDDYCJY/go-gin-example
COPY . $GOPATH/src/github.com/EDDYCJY/go-gin-example
EXPOSE 8000
CMD ["./go-gin-example"]
二、編譯可執行檔案
CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o go-gin-example .
編譯所生成的可執行檔案會依賴一些庫,並且是動態連結。在這裡因為使用的是 scratch 映象,它是空映象,因此我們需要將生成的可執行檔案靜態連結所依賴的庫
三、構建映象
$ docker build -t gin-blog-docker-scratch .
Sending build context to Docker daemon 133.1 MB
Step 1/5 : FROM scratch
--->
Step 2/5 : WORKDIR $GOPATH/src/github.com/EDDYCJY/go-gin-example
---> Using cache
---> ee07e166a638
Step 3/5 : COPY . $GOPATH/src/github.com/EDDYCJY/go-gin-example
---> 1489a0693d51
Removing intermediate container e3e9efc0fe4d
Step 4/5 : EXPOSE 8000
---> Running in b5630de5544a
---> 6993e9f8c944
Removing intermediate container b5630de5544a
Step 5/5 : CMD ./go-gin-example
---> Running in eebc0d8628ae
---> 5310bebeb86a
Removing intermediate container eebc0d8628ae
Successfully built 5310bebeb86a
注意,假設你的Golang應用沒有依賴任何的設定等檔案,是可以直接把可執行檔案給複製進去即可,其他都不必關心
這裡可以有好幾種解決方案
- 依賴檔案統一管理掛載
- go-bindata 一下
...
因此這裡如果解決了檔案依賴的問題後,就不需要把目錄給 COPY 進去了
四、執行
$ docker run --link mysql:mysql -p 8000:8000 gin-blog-docker-scratch
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /auth --> github.com/EDDYCJY/go-gin-example/routers/api.GetAuth (3 handlers)
...
成功執行,程式也正常接收請求
接下來我們再看看佔用大小,執行 docker ps -as 命令
$ docker ps -as
CONTAINER ID IMAGE COMMAND ... SIZE
9ebdba5a8445 gin-blog-docker-scratch "./go-gin-example" ... 0 B (virtual 132 MB)
427ee79e6857 gin-blog-docker "./go-gin-example" ... 0 B (virtual 946 MB)
從結果而言,佔用大小以Scratch映象為基礎的容器完勝,完成目標
Mysql掛載資料卷
倘若不做任何干涉,在每次啟動一個 Mysql 容器時,資料庫都是空的。另外容器刪除之後,資料就丟失了(還有各類意外情況),非常糟糕!
資料卷
資料卷 是被設計用來持久化資料的,它的生命週期獨立於容器,Docker 不會在容器被刪除後自動刪除 資料卷,並且也不存在垃圾回收這樣的機制來處理沒有任何容器引用的 資料卷。如果需要在刪除容器的同時移除資料卷。可以在刪除容器的時候使用 docker rm -v 這個命令
資料卷 是一個可供一個或多個容器使用的特殊目錄,它繞過 UFS,可以提供很多有用的特性:
- 資料卷 可以在容器之間共享和重用
- 對 資料卷 的修改會立馬生效
- 對 資料卷 的更新,不會影響映象
- 資料卷 預設會一直存在,即使容器被刪除
注意:資料卷 的使用,類似於 Linux 下對目錄或檔案進行 mount,映象中的被指定為掛載點的目錄中的檔案會隱藏掉,能顯示看的是掛載的 資料卷。
如何掛載
首先建立一個目錄用於存放資料卷;示例目錄 /data/docker-mysql,注意 --name 原本名稱為 mysql 的容器,需要將其刪除 docker rm
$ docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=rootroot -v /data/docker-mysql:/var/lib/mysql -d mysql
54611dbcd62eca33fb320f3f624c7941f15697d998f40b24ee535a1acf93ae72
建立成功,檢查目錄 /data/docker-mysql,下面多了不少資料庫檔案
驗證
接下來交由你進行驗證,目標是建立一些測試表和資料,然後刪除當前容器,重新建立的容器,資料庫資料也依然存在(當然了資料卷指向要一致)
我已驗證完畢,你呢?
參考
本系列示例程式碼
書籍
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.10 定製 GORM Callbacks
專案地址:https://github.com/EDDYCJY/go-gin-example
涉及知識點
- GORM
本文目標
GORM itself is powered by Callbacks, so you could fully customize GORM as you want
GORM 本身是由回撥驅動的,所以我們可以根據需要完全定製 GORM,以此達到我們的目的,如下:
- 註冊一個新的回撥
- 刪除現有的回撥
- 替換現有的回撥
- 註冊回撥的順序
在 GORM 中包含以上四類 Callbacks,我們結合專案選用 “替換現有的回撥” 來解決一個小痛點。
問題
在 models 目錄下,我們包含 tag.go 和 article.go 兩個檔案,他們有一個問題,就是 BeforeCreate、BeforeUpdate 重複出現了,那難道 100 個檔案,就要寫一百次嗎?
1、tag.go
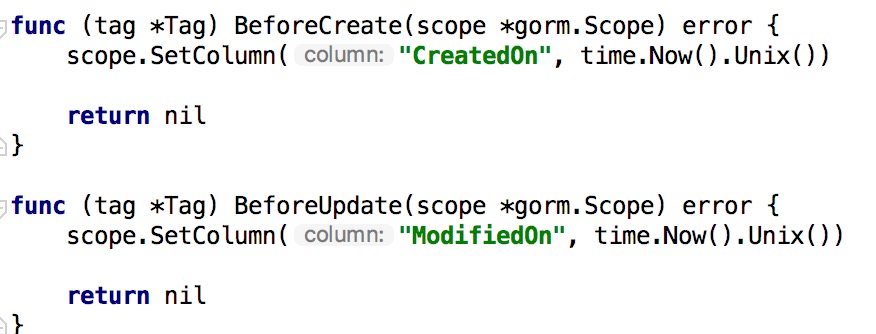
2、article.go
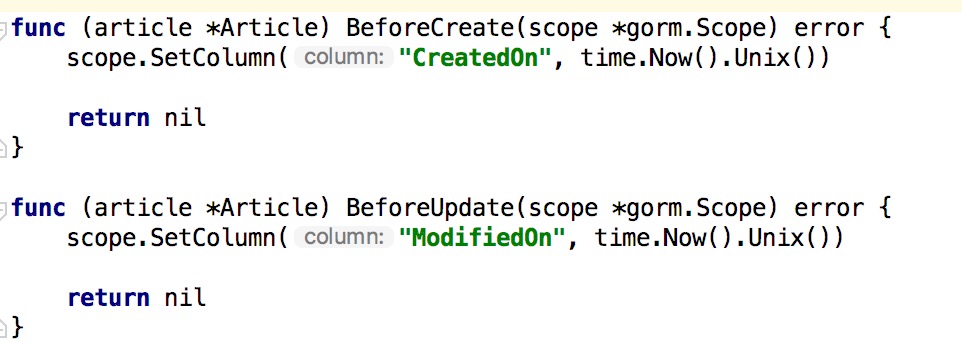
顯然這是不可能的,如果先前你已經意識到這個問題,那挺OK,但沒有的話,現在開始就要改
解決
在這裡我們透過 Callbacks 來實作功能,不需要一個個檔案去編寫
實作Callbacks
開啟 models 目錄下的 models.go 檔案,實作以下兩個方法:
1、updateTimeStampForCreateCallback
// updateTimeStampForCreateCallback will set `CreatedOn`, `ModifiedOn` when creating
func updateTimeStampForCreateCallback(scope *gorm.Scope) {
if !scope.HasError() {
nowTime := time.Now().Unix()
if createTimeField, ok := scope.FieldByName("CreatedOn"); ok {
if createTimeField.IsBlank {
createTimeField.Set(nowTime)
}
}
if modifyTimeField, ok := scope.FieldByName("ModifiedOn"); ok {
if modifyTimeField.IsBlank {
modifyTimeField.Set(nowTime)
}
}
}
}
在這段方法中,會完成以下功能
-
檢查是否有含有錯誤(db.Error)
-
scope.FieldByName透過scope.Fields()取得所有欄位,判斷當前是否包含所需欄位for _, field := range scope.Fields() { if field.Name == name || field.DBName == name { return field, true } if field.DBName == dbName { mostMatchedField = field } } -
field.IsBlank可判斷該欄位的值是否為空func isBlank(value reflect.Value) bool { switch value.Kind() { case reflect.String: return value.Len() == 0 case reflect.Bool: return !value.Bool() case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64: return value.Int() == 0 case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr: return value.Uint() == 0 case reflect.Float32, reflect.Float64: return value.Float() == 0 case reflect.Interface, reflect.Ptr: return value.IsNil() } return reflect.DeepEqual(value.Interface(), reflect.Zero(value.Type()).Interface()) } -
若為空則
field.Set用於給該欄位設定值,引數為interface{}
2、updateTimeStampForUpdateCallback
// updateTimeStampForUpdateCallback will set `ModifyTime` when updating
func updateTimeStampForUpdateCallback(scope *gorm.Scope) {
if _, ok := scope.Get("gorm:update_column"); !ok {
scope.SetColumn("ModifiedOn", time.Now().Unix())
}
}
scope.Get(...)根據入參取得設定了字面值的引數,例如本文中是gorm:update_column,它會去查詢含這個字面值的欄位屬性scope.SetColumn(...)假設沒有指定update_column的欄位,我們預設在更新回撥設定ModifiedOn的值
註冊Callbacks
在上面小節我已經把回撥方法編寫好了,接下來需要將其註冊進 GORM 的鉤子裡,但其本身自帶 Create 和 Update 回撥,因此呼叫替換即可
在 models.go 的 init 函式中,增加以下語句
db.Callback().Create().Replace("gorm:update_time_stamp", updateTimeStampForCreateCallback)
db.Callback().Update().Replace("gorm:update_time_stamp", updateTimeStampForUpdateCallback)
驗證
訪問 AddTag 介面,成功後檢查資料庫,可發現 created_on 和 modified_on 欄位都為當前執行時間
訪問 EditTag 介面,可發現 modified_on 為最後一次執行更新的時間
拓展
我們想到,在實際專案中硬刪除是較少存在的,那麼是否可以透過 Callbacks 來完成這個功能呢?
答案是可以的,我們在先前 Model struct 增加 DeletedOn 變數
type Model struct {
ID int `gorm:"primary_key" json:"id"`
CreatedOn int `json:"created_on"`
ModifiedOn int `json:"modified_on"`
DeletedOn int `json:"deleted_on"`
}
實作Callbacks
開啟 models 目錄下的 models.go 檔案,實作以下方法:
func deleteCallback(scope *gorm.Scope) {
if !scope.HasError() {
var extraOption string
if str, ok := scope.Get("gorm:delete_option"); ok {
extraOption = fmt.Sprint(str)
}
deletedOnField, hasDeletedOnField := scope.FieldByName("DeletedOn")
if !scope.Search.Unscoped && hasDeletedOnField {
scope.Raw(fmt.Sprintf(
"UPDATE %v SET %v=%v%v%v",
scope.QuotedTableName(),
scope.Quote(deletedOnField.DBName),
scope.AddToVars(time.Now().Unix()),
addExtraSpaceIfExist(scope.CombinedConditionSql()),
addExtraSpaceIfExist(extraOption),
)).Exec()
} else {
scope.Raw(fmt.Sprintf(
"DELETE FROM %v%v%v",
scope.QuotedTableName(),
addExtraSpaceIfExist(scope.CombinedConditionSql()),
addExtraSpaceIfExist(extraOption),
)).Exec()
}
}
}
func addExtraSpaceIfExist(str string) string {
if str != "" {
return " " + str
}
return ""
}
-
scope.Get("gorm:delete_option")檢查是否手動指定了delete_option -
scope.FieldByName("DeletedOn")取得我們約定的刪除欄位,若存在則UPDATE軟刪除,若不存在則DELETE硬刪除 -
scope.QuotedTableName()返回引用的表名,這個方法 GORM 會根據自身邏輯對錶名進行一些處理 -
scope.CombinedConditionSql()返回組合好的條件SQL,看一下方法原型很明瞭func (scope *Scope) CombinedConditionSql() string { joinSQL := scope.joinsSQL() whereSQL := scope.whereSQL() if scope.Search.raw { whereSQL = strings.TrimSuffix(strings.TrimPrefix(whereSQL, "WHERE ("), ")") } return joinSQL + whereSQL + scope.groupSQL() + scope.havingSQL() + scope.orderSQL() + scope.limitAndOffsetSQL() } -
scope.AddToVars該方法可以新增值作為SQL的引數,也可用於防範SQL注入func (scope *Scope) AddToVars(value interface{}) string { _, skipBindVar := scope.InstanceGet("skip_bindvar") if expr, ok := value.(*expr); ok { exp := expr.expr for _, arg := range expr.args { if skipBindVar { scope.AddToVars(arg) } else { exp = strings.Replace(exp, "?", scope.AddToVars(arg), 1) } } return exp } scope.SQLVars = append(scope.SQLVars, value) if skipBindVar { return "?" } return scope.Dialect().BindVar(len(scope.SQLVars)) }
註冊Callbacks
在 models.go 的 init 函式中,增加以下刪除的回撥
db.Callback().Delete().Replace("gorm:delete", deleteCallback)
驗證
重啟服務,訪問 DeleteTag 介面,成功後即可發現 deleted_on 欄位有值
小結
在這一章節中,我們結合 GORM 完成了新增、更新、查詢的 Callbacks,在實際專案中常常也是這麼使用
畢竟,一個鉤子的事,就沒有必要自己手寫過多不必要的程式碼了
(注意,增加了軟刪除後,先前的程式碼需要增加 deleted_on 的判斷)
參考
本系列示例程式碼
文件
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.11 Cron定時任務
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 完成定時任務的功能
本文目標
在實際的應用專案中,定時任務的使用是很常見的。你是否有過 Golang 如何做定時任務的疑問,莫非是輪詢,在本文中我們將結合我們的專案講述 Cron。
介紹
我們將使用 cron 這個包,它實作了 cron 規範解析器和任務執行器,簡單來講就是包含了定時任務所需的功能
Cron 表示式格式
| 欄位名 | 是否必填 | 允許的值 | 允許的特殊字元 |
|---|---|---|---|
| 秒(Seconds) | Yes | 0-59 | * / , - |
| 分(Minutes) | Yes | 0-59 | * / , - |
| 時(Hours) | Yes | 0-23 | * / , - |
| 一個月中的某天(Day of month) | Yes | 1-31 | * / , - ? |
| 月(Month) | Yes | 1-12 or JAN-DEC | * / , - |
| 星期幾(Day of week) | Yes | 0-6 or SUN-SAT | * / , - ? |
Cron表示式表示一組時間,使用 6 個空格分隔的欄位
可以留意到 Golang 的 Cron 比 Crontab 多了一個秒級,以後遇到秒級要求的時候就省事了
Cron 特殊字元
1、星號 ( * )
星號表示將匹配欄位的所有值
2、斜線 ( / )
斜線使用者 描述範圍的增量,表現為 “N-MAX/x”,first-last/x 的形式,例如 3-59/15 表示此時的第三分鐘和此後的每 15 分鐘,到59分鐘為止。即從 N 開始,使用增量直到該特定範圍結束。它不會重複
3、逗號 ( , )
逗號用於分隔列表中的專案。例如,在 Day of week 使用“MON,WED,FRI”將意味著星期一,星期三和星期五
4、連字元 ( - )
連字元用於定義範圍。例如,9 - 17 表示從上午 9 點到下午 5 點的每個小時
5、問號 ( ? )
不指定值,用於代替 “ * ”,類似 “ _ ” 的存在,不難理解
預定義的 Cron 時間表
| 輸入 | 簡述 | 相當於 |
|---|---|---|
| @yearly (or @annually) | 1月1日午夜執行一次 | 0 0 0 1 1 * |
| @monthly | 每個月的午夜,每個月的第一個月執行一次 | 0 0 0 1 |
| @weekly | 每週一次,週日午夜執行一次 | 0 0 0 0 |
| @daily (or @midnight) | 每天午夜執行一次 | 0 0 0 * |
| @hourly | 每小時執行一次 | 0 0 |
安裝
$ go get -u github.com/robfig/cron
實踐
在上一章節 Gin實踐 連載十 定製 GORM Callbacks 中,我們使用了 GORM 的回撥實作了軟刪除,同時也引入了另外一個問題
就是我怎麼硬刪除,我什麼時候硬刪除?這個往往與業務場景有關係,大致為
- 另外有一套硬刪除介面
- 定時任務清理(或轉移、backup)無效資料
在這裡我們選用第二種解決方案來進行實踐
編寫硬刪除程式碼
開啟 models 目錄下的 tag.go、article.go檔案,分別新增以下程式碼
1、tag.go
func CleanAllTag() bool {
db.Unscoped().Where("deleted_on != ? ", 0).Delete(&Tag{})
return true
}
2、article.go
func CleanAllArticle() bool {
db.Unscoped().Where("deleted_on != ? ", 0).Delete(&Article{})
return true
}
注意硬刪除要使用 Unscoped(),這是 GORM 的約定
編寫Cron
在 專案根目錄下新建 cron.go 檔案,用於編寫定時任務的程式碼,寫入檔案內容
package main
import (
"time"
"log"
"github.com/robfig/cron"
"github.com/EDDYCJY/go-gin-example/models"
)
func main() {
log.Println("Starting...")
c := cron.New()
c.AddFunc("* * * * * *", func() {
log.Println("Run models.CleanAllTag...")
models.CleanAllTag()
})
c.AddFunc("* * * * * *", func() {
log.Println("Run models.CleanAllArticle...")
models.CleanAllArticle()
})
c.Start()
t1 := time.NewTimer(time.Second * 10)
for {
select {
case <-t1.C:
t1.Reset(time.Second * 10)
}
}
}
在這段程式中,我們做了如下的事情
cron.New()
會根據本地時間建立一個新(空白)的 Cron job runner
func New() *Cron {
return NewWithLocation(time.Now().Location())
}
// NewWithLocation returns a new Cron job runner.
func NewWithLocation(location *time.Location) *Cron {
return &Cron{
entries: nil,
add: make(chan *Entry),
stop: make(chan struct{}),
snapshot: make(chan []*Entry),
running: false,
ErrorLog: nil,
location: location,
}
}
c.AddFunc()
AddFunc 會向 Cron job runner 新增一個 func ,以按給定的時間表執行
func (c *Cron) AddJob(spec string, cmd Job) error {
schedule, err := Parse(spec)
if err != nil {
return err
}
c.Schedule(schedule, cmd)
return nil
}
會首先解析時間表,如果填寫有問題會直接 err,無誤則將 func 新增到 Schedule 佇列中等待執行
func (c *Cron) Schedule(schedule Schedule, cmd Job) {
entry := &Entry{
Schedule: schedule,
Job: cmd,
}
if !c.running {
c.entries = append(c.entries, entry)
return
}
c.add <- entry
}
3、c.Start()
在當前執行的程式中啟動 Cron 排程程式。其實這裡的主體是 goroutine + for + select + timer 的排程控制哦
func (c *Cron) Run() {
if c.running {
return
}
c.running = true
c.run()
}
time.NewTimer + for + select + t1.Reset
如果你是初學者,大概會有疑問,這是幹嘛用的?
(1)time.NewTimer
會建立一個新的定時器,持續你設定的時間 d 後傳送一個 channel 訊息
(2)for + select
阻塞 select 等待 channel
(3)t1.Reset
會重置定時器,讓它重新開始計時
注:本文適用於 “t.C已經取走,可直接使用 Reset”。
總的來說,這段程式是為了阻塞主程式而編寫的,希望你帶著疑問來想,有沒有別的辦法呢?
有的,你直接 select{} 也可以完成這個需求 :)
驗證
$ go run cron.go
2018/04/29 17:03:34 [info] replacing callback `gorm:update_time_stamp` from /Users/eddycjy/go/src/github.com/EDDYCJY/go-gin-example/models/models.go:56
2018/04/29 17:03:34 [info] replacing callback `gorm:update_time_stamp` from /Users/eddycjy/go/src/github.com/EDDYCJY/go-gin-example/models/models.go:57
2018/04/29 17:03:34 [info] replacing callback `gorm:delete` from /Users/eddycjy/go/src/github.com/EDDYCJY/go-gin-example/models/models.go:58
2018/04/29 17:03:34 Starting...
2018/04/29 17:03:35 Run models.CleanAllArticle...
2018/04/29 17:03:35 Run models.CleanAllTag...
2018/04/29 17:03:36 Run models.CleanAllArticle...
2018/04/29 17:03:36 Run models.CleanAllTag...
2018/04/29 17:03:37 Run models.CleanAllTag...
2018/04/29 17:03:37 Run models.CleanAllArticle...
檢查輸出日誌正常,模擬已軟刪除的資料,定時任務工作OK
小結
定時任務很常見,希望你透過本文能夠熟知 Golang 怎麼實作一個簡單的定時任務排程管理
可以不依賴系統的 Crontab 設定,指不定哪一天就用上了呢
問題
如果你手動修改計算機的系統時間,是會導致定時任務錯亂的,所以一般不要亂來。
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月02日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.12 最佳化設定結構及實作圖片上傳
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 重構、調整結構
本文目標
這個應用程式跑了那麼久了,越來越大,越來越壯,彷彿我們的產品一樣,現在它需要進行小範圍重構了,以便於後續的使用,這非常重要。
前言
一天,產品經理突然跟你說文章列表,沒有封面圖,不夠美觀,!)&¥!&)#&¥!加一個吧,幾分鐘的事
你開啟你的程式,分析了一波寫了個清單:
- 最佳化設定結構(因為設定項越來越多)
- 抽離 原 logging 的 File 便於公用(logging、upload 各保有一份並不合適)
- 實作上傳圖片介面(需限制檔案格式、大小)
- 修改文章介面(需支援封面地址引數)
- 增加 blog_article (文章)的資料庫欄位
- 實作 http.FileServer
嗯,你發現要較優的話,需要調整部分的應用程式結構,因為功能越來越多,原本的設計也要跟上節奏
也就是在適當的時候,及時最佳化
最佳化設定結構
一、講解
在先前章節中,採用了直接讀取 KEY 的方式去儲存設定項,而本次需求中,需要增加圖片的設定項,總體就有些冗餘了
我們採用以下解決方法:
- 對映結構體:使用 MapTo 來設定設定引數
- 設定統管:所有的設定項統管到 setting 中
對映結構體(示例)
在 go-ini 中可以採用 MapTo 的方式來對映結構體,例如:
type Server struct {
RunMode string
HttpPort int
ReadTimeout time.Duration
WriteTimeout time.Duration
}
var ServerSetting = &Server{}
func main() {
Cfg, err := ini.Load("conf/app.ini")
if err != nil {
log.Fatalf("Fail to parse 'conf/app.ini': %v", err)
}
err = Cfg.Section("server").MapTo(ServerSetting)
if err != nil {
log.Fatalf("Cfg.MapTo ServerSetting err: %v", err)
}
}
在這段程式碼中,可以注意 ServerSetting 取了地址,為什麼 MapTo 必須地址入參呢?
// MapTo maps section to given struct.
func (s *Section) MapTo(v interface{}) error {
typ := reflect.TypeOf(v)
val := reflect.ValueOf(v)
if typ.Kind() == reflect.Ptr {
typ = typ.Elem()
val = val.Elem()
} else {
return errors.New("cannot map to non-pointer struct")
}
return s.mapTo(val, false)
}
在 MapTo 中 typ.Kind() == reflect.Ptr 約束了必須使用指標,否則會返回 cannot map to non-pointer struct 的錯誤。這個是表面原因
更往內探究,可以認為是 field.Set 的原因,當執行 val := reflect.ValueOf(v) ,函式透過傳遞 v 複製建立了 val,但是 val 的改變並不能更改原始的 v,要想 val 的更改能作用到 v,則必須傳遞 v 的地址
顯然 go-ini 裡也是包含修改原始值這一項功能的,你覺得是什麼原因呢?
設定統管
在先前的版本中,models 和 file 的設定是在自己的檔案中解析的,而其他在 setting.go 中,因此我們需要將其在 setting 中統一接管
你可能會想,直接把兩者的設定項複製貼上到 setting.go 的 init 中,一下子就完事了,搞那麼麻煩?
但你在想想,先前的程式碼中存在多個 init 函式,執行順序存在問題,無法達到我們的要求,你可以試試
(此處是一個基礎知識點)
在 Go 中,當存在多個 init 函式時,執行順序為:
- 相同包下的 init 函式:按照原始檔編譯順序決定執行順序(預設按檔名排序)
- 不同包下的 init 函式:按照包匯入的依賴關係決定先後順序
所以要避免多 init 的情況,儘量由程式把控初始化的先後順序
二、落實
修改設定檔案
開啟 conf/app.ini 將設定檔案修改為大駝峰命名,另外我們增加了 5 個設定項用於上傳圖片的功能,4 個檔案日誌方面的設定項
[app]
PageSize = 10
JwtSecret = 233
RuntimeRootPath = runtime/
ImagePrefixUrl = http://127.0.0.1:8000
ImageSavePath = upload/images/
# MB
ImageMaxSize = 5
ImageAllowExts = .jpg,.jpeg,.png
LogSavePath = logs/
LogSaveName = log
LogFileExt = log
TimeFormat = 20060102
[server]
#debug or release
RunMode = debug
HttpPort = 8000
ReadTimeout = 60
WriteTimeout = 60
[database]
Type = mysql
User = root
Password = rootroot
Host = 127.0.0.1:3306
Name = blog
TablePrefix = blog_
最佳化設定讀取及設定初始化順序
第一步
將散落在其他檔案裡的設定都刪掉,統一在 setting 中處理以及修改 init 函式為 Setup 方法
開啟 pkg/setting/setting.go 檔案,修改如下:
package setting
import (
"log"
"time"
"github.com/go-ini/ini"
)
type App struct {
JwtSecret string
PageSize int
RuntimeRootPath string
ImagePrefixUrl string
ImageSavePath string
ImageMaxSize int
ImageAllowExts []string
LogSavePath string
LogSaveName string
LogFileExt string
TimeFormat string
}
var AppSetting = &App{}
type Server struct {
RunMode string
HttpPort int
ReadTimeout time.Duration
WriteTimeout time.Duration
}
var ServerSetting = &Server{}
type Database struct {
Type string
User string
Password string
Host string
Name string
TablePrefix string
}
var DatabaseSetting = &Database{}
func Setup() {
Cfg, err := ini.Load("conf/app.ini")
if err != nil {
log.Fatalf("Fail to parse 'conf/app.ini': %v", err)
}
err = Cfg.Section("app").MapTo(AppSetting)
if err != nil {
log.Fatalf("Cfg.MapTo AppSetting err: %v", err)
}
AppSetting.ImageMaxSize = AppSetting.ImageMaxSize * 1024 * 1024
err = Cfg.Section("server").MapTo(ServerSetting)
if err != nil {
log.Fatalf("Cfg.MapTo ServerSetting err: %v", err)
}
ServerSetting.ReadTimeout = ServerSetting.ReadTimeout * time.Second
ServerSetting.WriteTimeout = ServerSetting.ReadTimeout * time.Second
err = Cfg.Section("database").MapTo(DatabaseSetting)
if err != nil {
log.Fatalf("Cfg.MapTo DatabaseSetting err: %v", err)
}
}
在這裡,我們做了如下幾件事:
- 編寫與設定項保持一致的結構體(App、Server、Database)
- 使用 MapTo 將設定項對映到結構體上
- 對一些需特殊設定的設定項進行再賦值
需要你去做的事:
- 將 models.go、setting.go、pkg/logging/log.go 的 init 函式修改為 Setup 方法
- 將 models/models.go 獨立讀取的 DB 設定項刪除,改為統一讀取 setting
- 將 pkg/logging/file 獨立的 LOG 設定項刪除,改為統一讀取 setting
這幾項比較基礎,並沒有貼出來,我希望你可以自己動手,有問題的話可右拐 專案地址
第二步
在這一步我們要設定初始化的流程,開啟 main.go 檔案,修改內容:
func main() {
setting.Setup()
models.Setup()
logging.Setup()
endless.DefaultReadTimeOut = setting.ServerSetting.ReadTimeout
endless.DefaultWriteTimeOut = setting.ServerSetting.WriteTimeout
endless.DefaultMaxHeaderBytes = 1 << 20
endPoint := fmt.Sprintf(":%d", setting.ServerSetting.HttpPort)
server := endless.NewServer(endPoint, routers.InitRouter())
server.BeforeBegin = func(add string) {
log.Printf("Actual pid is %d", syscall.Getpid())
}
err := server.ListenAndServe()
if err != nil {
log.Printf("Server err: %v", err)
}
}
修改完畢後,就成功將多模組的初始化函式放到啟動流程中了(先後順序也可以控制)
驗證
在這裡為止,針對本需求的設定最佳化就完畢了,你需要執行 go run main.go 驗證一下你的功能是否正常哦
順帶留個基礎問題,大家可以思考下
ServerSetting.ReadTimeout = ServerSetting.ReadTimeout * time.Second
ServerSetting.WriteTimeout = ServerSetting.ReadTimeout * time.Second
若將 setting.go 檔案中的這兩行刪除,會出現什麼問題,為什麼呢?
抽離 File
在先前版本中,在 logging/file.go 中使用到了 os 的一些方法,我們透過前期規劃發現,這部分在上傳圖片功能中可以複用
第一步
在 pkg 目錄下新建 file/file.go ,寫入檔案內容如下:
package file
import (
"os"
"path"
"mime/multipart"
"io/ioutil"
)
func GetSize(f multipart.File) (int, error) {
content, err := ioutil.ReadAll(f)
return len(content), err
}
func GetExt(fileName string) string {
return path.Ext(fileName)
}
func CheckExist(src string) bool {
_, err := os.Stat(src)
return os.IsNotExist(err)
}
func CheckPermission(src string) bool {
_, err := os.Stat(src)
return os.IsPermission(err)
}
func IsNotExistMkDir(src string) error {
if notExist := CheckNotExist(src); notExist == true {
if err := MkDir(src); err != nil {
return err
}
}
return nil
}
func MkDir(src string) error {
err := os.MkdirAll(src, os.ModePerm)
if err != nil {
return err
}
return nil
}
func Open(name string, flag int, perm os.FileMode) (*os.File, error) {
f, err := os.OpenFile(name, flag, perm)
if err != nil {
return nil, err
}
return f, nil
}
在這裡我們一共封裝了 7個 方法
- GetSize:取得檔案大小
- GetExt:取得檔案字尾
- CheckExist:檢查檔案是否存在
- CheckPermission:檢查檔案許可權
- IsNotExistMkDir:如果不存在則新建資料夾
- MkDir:新建資料夾
- Open:開啟檔案
在這裡我們用到了 mime/multipart 包,它主要實作了 MIME 的 multipart 解析,主要適用於 HTTP 和常見瀏覽器生成的 multipart 主體
multipart 又是什麼,rfc2388 的 multipart/form-data 瞭解一下
第二步
我們在第一步已經將 file 重新封裝了一層,在這一步我們將原先 logging 包的方法都修改掉
1、開啟 pkg/logging/file.go 檔案,修改檔案內容:
package logging
import (
"fmt"
"os"
"time"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
"github.com/EDDYCJY/go-gin-example/pkg/file"
)
func getLogFilePath() string {
return fmt.Sprintf("%s%s", setting.AppSetting.RuntimeRootPath, setting.AppSetting.LogSavePath)
}
func getLogFileName() string {
return fmt.Sprintf("%s%s.%s",
setting.AppSetting.LogSaveName,
time.Now().Format(setting.AppSetting.TimeFormat),
setting.AppSetting.LogFileExt,
)
}
func openLogFile(fileName, filePath string) (*os.File, error) {
dir, err := os.Getwd()
if err != nil {
return nil, fmt.Errorf("os.Getwd err: %v", err)
}
src := dir + "/" + filePath
perm := file.CheckPermission(src)
if perm == true {
return nil, fmt.Errorf("file.CheckPermission Permission denied src: %s", src)
}
err = file.IsNotExistMkDir(src)
if err != nil {
return nil, fmt.Errorf("file.IsNotExistMkDir src: %s, err: %v", src, err)
}
f, err := file.Open(src + fileName, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
return nil, fmt.Errorf("Fail to OpenFile :%v", err)
}
return f, nil
}
我們將引用都改為了 file/file.go 包裡的方法
2、開啟 pkg/logging/log.go 檔案,修改檔案內容:
package logging
...
func Setup() {
var err error
filePath := getLogFilePath()
fileName := getLogFileName()
F, err = openLogFile(fileName, filePath)
if err != nil {
log.Fatalln(err)
}
logger = log.New(F, DefaultPrefix, log.LstdFlags)
}
...
由於原方法形參改變了,因此 openLogFile 也需要調整
實作上傳圖片介面
這一小節,我們開始實作上次圖片相關的一些方法和功能
首先需要在 blog_article 中增加欄位 cover_image_url,格式為 varchar(255) DEFAULT '' COMMENT '封面图片地址'
第零步
一般不會直接將上傳的圖片名暴露出來,因此我們對圖片名進行 MD5 來達到這個效果
在 util 目錄下新建 md5.go,寫入檔案內容:
package util
import (
"crypto/md5"
"encoding/hex"
)
func EncodeMD5(value string) string {
m := md5.New()
m.Write([]byte(value))
return hex.EncodeToString(m.Sum(nil))
}
第一步
在先前我們已經把底層方法給封裝好了,實質這一步為封裝 image 的處理邏輯
在 pkg 目錄下新建 upload/image.go 檔案,寫入檔案內容:
package upload
import (
"os"
"path"
"log"
"fmt"
"strings"
"mime/multipart"
"github.com/EDDYCJY/go-gin-example/pkg/file"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
"github.com/EDDYCJY/go-gin-example/pkg/logging"
"github.com/EDDYCJY/go-gin-example/pkg/util"
)
func GetImageFullUrl(name string) string {
return setting.AppSetting.ImagePrefixUrl + "/" + GetImagePath() + name
}
func GetImageName(name string) string {
ext := path.Ext(name)
fileName := strings.TrimSuffix(name, ext)
fileName = util.EncodeMD5(fileName)
return fileName + ext
}
func GetImagePath() string {
return setting.AppSetting.ImageSavePath
}
func GetImageFullPath() string {
return setting.AppSetting.RuntimeRootPath + GetImagePath()
}
func CheckImageExt(fileName string) bool {
ext := file.GetExt(fileName)
for _, allowExt := range setting.AppSetting.ImageAllowExts {
if strings.ToUpper(allowExt) == strings.ToUpper(ext) {
return true
}
}
return false
}
func CheckImageSize(f multipart.File) bool {
size, err := file.GetSize(f)
if err != nil {
log.Println(err)
logging.Warn(err)
return false
}
return size <= setting.AppSetting.ImageMaxSize
}
func CheckImage(src string) error {
dir, err := os.Getwd()
if err != nil {
return fmt.Errorf("os.Getwd err: %v", err)
}
err = file.IsNotExistMkDir(dir + "/" + src)
if err != nil {
return fmt.Errorf("file.IsNotExistMkDir err: %v", err)
}
perm := file.CheckPermission(src)
if perm == true {
return fmt.Errorf("file.CheckPermission Permission denied src: %s", src)
}
return nil
}
在這裡我們實作了 7 個方法,如下:
- GetImageFullUrl:取得圖片完整訪問URL
- GetImageName:取得圖片名稱
- GetImagePath:取得圖片路徑
- GetImageFullPath:取得圖片完整路徑
- CheckImageExt:檢查圖片字尾
- CheckImageSize:檢查圖片大小
- CheckImage:檢查圖片
這裡基本是對底層程式碼的二次封裝,為了更靈活的處理一些圖片特有的邏輯,並且方便修改,不直接對外暴露下層
第二步
這一步將編寫上傳圖片的業務邏輯,在 routers/api 目錄下 新建 upload.go 檔案,寫入檔案內容:
package api
import (
"net/http"
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/pkg/e"
"github.com/EDDYCJY/go-gin-example/pkg/logging"
"github.com/EDDYCJY/go-gin-example/pkg/upload"
)
func UploadImage(c *gin.Context) {
code := e.SUCCESS
data := make(map[string]string)
file, image, err := c.Request.FormFile("image")
if err != nil {
logging.Warn(err)
code = e.ERROR
c.JSON(http.StatusOK, gin.H{
"code": code,
"msg": e.GetMsg(code),
"data": data,
})
}
if image == nil {
code = e.INVALID_PARAMS
} else {
imageName := upload.GetImageName(image.Filename)
fullPath := upload.GetImageFullPath()
savePath := upload.GetImagePath()
src := fullPath + imageName
if ! upload.CheckImageExt(imageName) || ! upload.CheckImageSize(file) {
code = e.ERROR_UPLOAD_CHECK_IMAGE_FORMAT
} else {
err := upload.CheckImage(fullPath)
if err != nil {
logging.Warn(err)
code = e.ERROR_UPLOAD_CHECK_IMAGE_FAIL
} else if err := c.SaveUploadedFile(image, src); err != nil {
logging.Warn(err)
code = e.ERROR_UPLOAD_SAVE_IMAGE_FAIL
} else {
data["image_url"] = upload.GetImageFullUrl(imageName)
data["image_save_url"] = savePath + imageName
}
}
}
c.JSON(http.StatusOK, gin.H{
"code": code,
"msg": e.GetMsg(code),
"data": data,
})
}
所涉及的錯誤碼(需在 pkg/e/code.go、msg.go 新增):
// 保存图片失败
ERROR_UPLOAD_SAVE_IMAGE_FAIL = 30001
// 检查图片失败
ERROR_UPLOAD_CHECK_IMAGE_FAIL = 30002
// 校验图片错误,图片格式或大小有问题
ERROR_UPLOAD_CHECK_IMAGE_FORMAT = 30003
在這一大段的業務邏輯中,我們做了如下事情:
- c.Request.FormFile:取得上傳的圖片(返回提供的表單鍵的第一個檔案)
- CheckImageExt、CheckImageSize檢查圖片大小,檢查圖片字尾
- CheckImage:檢查上傳圖片所需(許可權、資料夾)
- SaveUploadedFile:儲存圖片
總的來說,就是 入參 -> 檢查 -》 儲存 的應用流程
第三步
開啟 routers/router.go 檔案,增加路由 r.POST("/upload", api.UploadImage) ,如:
func InitRouter() *gin.Engine {
r := gin.New()
...
r.GET("/auth", api.GetAuth)
r.GET("/swagger/*any", ginSwagger.WrapHandler(swaggerFiles.Handler))
r.POST("/upload", api.UploadImage)
apiv1 := r.Group("/api/v1")
apiv1.Use(jwt.JWT())
{
...
}
return r
}
驗證
最後我們請求一下上傳圖片的介面,測試所編寫的功能
檢查目錄下是否含檔案(注意許可權問題)
$ pwd
$GOPATH/src/github.com/EDDYCJY/go-gin-example/runtime/upload/images
$ ll
... 96a3be3cf272e017046d1b2674a52bd3.jpg
... c39fa784216313cf2faa7c98739fc367.jpeg
在這裡我們一共返回了 2 個引數,一個是完整的訪問 URL,另一個為儲存路徑
實作 http.FileServer
在完成了上一小節後,我們還需要讓前端能夠訪問到圖片,一般是如下:
- CDN
- http.FileSystem
在公司的話,CDN 或自建分散式檔案系統居多,也不需要過多關注。而在實踐裡的話肯定是本地搭建了,Go 本身對此就有很好的支援,而 Gin 更是再封裝了一層,只需要在路由增加一行程式碼即可
r.StaticFS
開啟 routers/router.go 檔案,增加路由 r.StaticFS("/upload/images", http.Dir(upload.GetImageFullPath())),如:
func InitRouter() *gin.Engine {
...
r.StaticFS("/upload/images", http.Dir(upload.GetImageFullPath()))
r.GET("/auth", api.GetAuth)
r.GET("/swagger/*any", ginSwagger.WrapHandler(swaggerFiles.Handler))
r.POST("/upload", api.UploadImage)
...
}
它做了什麼
當訪問 $HOST/upload/images 時,將會讀取到 $GOPATH/src/github.com/EDDYCJY/go-gin-example/runtime/upload/images 下的檔案
而這行程式碼又做了什麼事呢,我們來看看方法原型
// StaticFS works just like `Static()` but a custom `http.FileSystem` can be used instead.
// Gin by default user: gin.Dir()
func (group *RouterGroup) StaticFS(relativePath string, fs http.FileSystem) IRoutes {
if strings.Contains(relativePath, ":") || strings.Contains(relativePath, "*") {
panic("URL parameters can not be used when serving a static folder")
}
handler := group.createStaticHandler(relativePath, fs)
urlPattern := path.Join(relativePath, "/*filepath")
// Register GET and HEAD handlers
group.GET(urlPattern, handler)
group.HEAD(urlPattern, handler)
return group.returnObj()
}
首先在暴露的 URL 中禁止了 * 和 : 符號的使用,透過 createStaticHandler 建立了靜態檔案服務,實質最終呼叫的還是 fileServer.ServeHTTP 和一些處理邏輯了
func (group *RouterGroup) createStaticHandler(relativePath string, fs http.FileSystem) HandlerFunc {
absolutePath := group.calculateAbsolutePath(relativePath)
fileServer := http.StripPrefix(absolutePath, http.FileServer(fs))
_, nolisting := fs.(*onlyfilesFS)
return func(c *Context) {
if nolisting {
c.Writer.WriteHeader(404)
}
fileServer.ServeHTTP(c.Writer, c.Request)
}
}
http.StripPrefix
我們可以留意下 fileServer := http.StripPrefix(absolutePath, http.FileServer(fs)) 這段語句,在靜態檔案服務中很常見,它有什麼作用呢?
http.StripPrefix 主要作用是從請求 URL 的路徑中刪除給定的字首,最終返回一個 Handler
通常 http.FileServer 要與 http.StripPrefix 相結合使用,否則當你執行:
http.Handle("/upload/images", http.FileServer(http.Dir("upload/images")))
會無法正確的訪問到檔案目錄,因為 /upload/images 也包含在了 URL 路徑中,必須使用:
http.Handle("/upload/images", http.StripPrefix("upload/images", http.FileServer(http.Dir("upload/images"))))
/*filepath
到下面可以看到 urlPattern := path.Join(relativePath, "/*filepath"),/*filepath 你是誰,你在這裡有什麼用,你是 Gin 的產物嗎?
透過語義可得知是路由的處理邏輯,而 Gin 的路由是基於 httprouter 的,透過查閱文件可得到以下資訊
Pattern: /src/*filepath
/src/ match
/src/somefile.go match
/src/subdir/somefile.go match
*filepath 將匹配所有檔案路徑,並且 *filepath 必須在 Pattern 的最後
驗證
重新執行 go run main.go ,去訪問剛剛在 upload 介面得到的圖片地址,檢查 http.FileSystem 是否正常
修改文章介面
接下來,需要你修改 routers/api/v1/article.go 的 AddArticle、EditArticle 兩個介面
- 新增、更新文章介面:支援入參 cover_image_url
- 新增、更新文章介面:增加對 cover_image_url 的非空、最長長度校驗
這塊前面文章講過,如果有問題可以參考專案的程式碼👌
總結
在這章節中,我們簡單的分析了下需求,對應用做出了一個小規劃並實施
完成了清單中的功能點和最佳化,在實際專案中也是常見的場景,希望你能夠細細品嚐並針對一些點進行深入學習
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月02日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.13 最佳化你的應用結構和實作Redis快取
專案地址:https://github.com/EDDYCJY/go-gin-example
前言
之前就在想,不少教程或示例的程式碼設計都是一步到位的(也沒問題)
但實際操作的讀者真的能夠理解透徹為什麼嗎?左思右想,有了今天這一章的內容,我認為實際經歷過一遍印象會更加深刻
本文目標
在本章節,將介紹以下功能的整理:
- 抽離、分層業務邏輯:減輕 routers/*.go 內的 api方法的邏輯(但本文暫不分層 repository,這塊邏輯還不重)。
- 增加容錯性:對 gorm 的錯誤進行判斷。
- Redis快取:對取得資料類的介面增加快取設定。
- 減少重複冗餘程式碼。
問題在哪?
在規劃階段我們發現了一個問題,這是目前的虛擬碼:
if ! HasErrors() {
if ExistArticleByID(id) {
DeleteArticle(id)
code = e.SUCCESS
} else {
code = e.ERROR_NOT_EXIST_ARTICLE
}
} else {
for _, err := range valid.Errors {
logging.Info(err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code": code,
"msg": e.GetMsg(code),
"data": make(map[string]string),
})
如果加上規劃內的功能邏輯呢,虛擬碼會變成:
if ! HasErrors() {
exists, err := ExistArticleByID(id)
if err == nil {
if exists {
err = DeleteArticle(id)
if err == nil {
code = e.SUCCESS
} else {
code = e.ERROR_XXX
}
} else {
code = e.ERROR_NOT_EXIST_ARTICLE
}
} else {
code = e.ERROR_XXX
}
} else {
for _, err := range valid.Errors {
logging.Info(err.Key, err.Message)
}
}
c.JSON(http.StatusOK, gin.H{
"code": code,
"msg": e.GetMsg(code),
"data": make(map[string]string),
})
如果快取的邏輯也加進來,後面慢慢不斷的迭代,豈不是會變成如下圖一樣?

現在我們發現了問題,應及時解決這個程式碼結構問題,同時把程式碼寫的清晰、漂亮、易讀易改也是一個重要指標
如何改?
在左耳朵耗子的文章中,這類程式碼被稱為 “箭頭型” 程式碼,有如下幾個問題:
1、我的顯示器不夠寬,箭頭型程式碼縮排太狠了,需要我來回拉水平捲軸,這讓我在讀程式碼的時候,相當的不舒服
2、除了寬度外還有長度,有的程式碼的 if-else 裡的 if-else 裡的 if-else 的程式碼太多,讀到中間你都不知道中間的程式碼是經過了什麼樣的層層檢查才來到這裡的
總而言之,“箭頭型程式碼”如果巢狀太多,程式碼太長的話,會相當容易讓維護程式碼的人(包括自己)迷失在程式碼中,因為看到最內層的程式碼時,你已經不知道前面的那一層一層的條件判斷是什麼樣的,程式碼是怎麼執行到這裡的,所以,箭頭型程式碼是非常難以維護和Debug的。
簡單的來說,就是讓出錯的程式碼先返回,前面把所有的錯誤判斷全判斷掉,然後就剩下的就是正常的程式碼了
(注意:本段引用自耗子哥的 如何重構“箭頭型”程式碼,建議細細品嚐)
落實
本專案將對既有程式碼進行最佳化和實作快取,希望你習得方法並對其他地方也進行最佳化
第一步:完成 Redis 的基礎設施建設(需要你先裝好 Redis)
第二步:對現有程式碼進行拆解、分層(不會貼上具體步驟的程式碼,希望你能夠實操一波,加深理解🤔)
Redis
一、設定
開啟 conf/app.ini 檔案,新增設定:
...
[redis]
Host = 127.0.0.1:6379
Password =
MaxIdle = 30
MaxActive = 30
IdleTimeout = 200
二、快取 Prefix
開啟 pkg/e 目錄,新建 cache.go,寫入內容:
package e
const (
CACHE_ARTICLE = "ARTICLE"
CACHE_TAG = "TAG"
)
三、快取 Key
(1)、開啟 service 目錄,新建 cache_service/article.go
寫入內容:傳送門
(2)、開啟 service 目錄,新建 cache_service/tag.go
寫入內容:傳送門
這一部分主要是編寫取得快取 KEY 的方法,直接參考傳送門即可
四、Redis 工具包
開啟 pkg 目錄,新建 gredis/redis.go,寫入內容:
package gredis
import (
"encoding/json"
"time"
"github.com/gomodule/redigo/redis"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
)
var RedisConn *redis.Pool
func Setup() error {
RedisConn = &redis.Pool{
MaxIdle: setting.RedisSetting.MaxIdle,
MaxActive: setting.RedisSetting.MaxActive,
IdleTimeout: setting.RedisSetting.IdleTimeout,
Dial: func() (redis.Conn, error) {
c, err := redis.Dial("tcp", setting.RedisSetting.Host)
if err != nil {
return nil, err
}
if setting.RedisSetting.Password != "" {
if _, err := c.Do("AUTH", setting.RedisSetting.Password); err != nil {
c.Close()
return nil, err
}
}
return c, err
},
TestOnBorrow: func(c redis.Conn, t time.Time) error {
_, err := c.Do("PING")
return err
},
}
return nil
}
func Set(key string, data interface{}, time int) error {
conn := RedisConn.Get()
defer conn.Close()
value, err := json.Marshal(data)
if err != nil {
return err
}
_, err = conn.Do("SET", key, value)
if err != nil {
return err
}
_, err = conn.Do("EXPIRE", key, time)
if err != nil {
return err
}
return nil
}
func Exists(key string) bool {
conn := RedisConn.Get()
defer conn.Close()
exists, err := redis.Bool(conn.Do("EXISTS", key))
if err != nil {
return false
}
return exists
}
func Get(key string) ([]byte, error) {
conn := RedisConn.Get()
defer conn.Close()
reply, err := redis.Bytes(conn.Do("GET", key))
if err != nil {
return nil, err
}
return reply, nil
}
func Delete(key string) (bool, error) {
conn := RedisConn.Get()
defer conn.Close()
return redis.Bool(conn.Do("DEL", key))
}
func LikeDeletes(key string) error {
conn := RedisConn.Get()
defer conn.Close()
keys, err := redis.Strings(conn.Do("KEYS", "*"+key+"*"))
if err != nil {
return err
}
for _, key := range keys {
_, err = Delete(key)
if err != nil {
return err
}
}
return nil
}
在這裡我們做了一些基礎功能封裝
1、設定 RedisConn 為 redis.Pool(連線池)並設定了它的一些引數:
- Dial:提供建立和設定應用程式連線的一個函式
- TestOnBorrow:可選的應用程式檢查健康功能
- MaxIdle:最大空閒連線數
- MaxActive:在給定時間內,允許分配的最大連線數(當為零時,沒有限制)
- IdleTimeout:在給定時間內將會保持空閒狀態,若到達時間限制則關閉連線(當為零時,沒有限制)
2、封裝基礎方法
檔案內包含 Set、Exists、Get、Delete、LikeDeletes 用於支撐目前的業務邏輯,而在裡面涉及到了如方法:
(1)RedisConn.Get():在連線池中取得一個活躍連線
(2)conn.Do(commandName string, args ...interface{}):向 Redis 伺服器傳送命令並返回收到的答覆
(3)redis.Bool(reply interface{}, err error):將命令返回轉為布林值
(4)redis.Bytes(reply interface{}, err error):將命令返回轉為 Bytes
(5)redis.Strings(reply interface{}, err error):將命令返回轉為 []string
在 redigo 中包含大量類似的方法,萬變不離其宗,建議熟悉其使用規則和 Redis命令 即可
到這裡為止,Redis 就可以愉快的呼叫啦。另外受篇幅限制,這塊的深入講解會另外開設!
拆解、分層
在先前規劃中,引出幾個方法去最佳化我們的應用結構
- 錯誤提前返回
- 統一返回方法
- 抽離 Service,減輕 routers/api 的邏輯,進行分層
- 增加 gorm 錯誤判斷,讓錯誤提示更明確(增加內部錯誤碼)
編寫返回方法
要讓錯誤提前返回,c.JSON 的侵入是不可避免的,但是可以讓其更具可變性,指不定哪天就變 XML 了呢?
1、開啟 pkg 目錄,新建 app/request.go,寫入檔案內容:
package app
import (
"github.com/astaxie/beego/validation"
"github.com/EDDYCJY/go-gin-example/pkg/logging"
)
func MarkErrors(errors []*validation.Error) {
for _, err := range errors {
logging.Info(err.Key, err.Message)
}
return
}
2、開啟 pkg 目錄,新建 app/response.go,寫入檔案內容:
package app
import (
"github.com/gin-gonic/gin"
"github.com/EDDYCJY/go-gin-example/pkg/e"
)
type Gin struct {
C *gin.Context
}
func (g *Gin) Response(httpCode, errCode int, data interface{}) {
g.C.JSON(httpCode, gin.H{
"code": errCode,
"msg": e.GetMsg(errCode),
"data": data,
})
return
}
這樣子以後如果要變動,直接改動 app 包內的方法即可
修改既有邏輯
開啟 routers/api/v1/article.go,檢視修改 GetArticle 方法後的程式碼為:
func GetArticle(c *gin.Context) {
appG := app.Gin{c}
id := com.StrTo(c.Param("id")).MustInt()
valid := validation.Validation{}
valid.Min(id, 1, "id").Message("ID必须大于0")
if valid.HasErrors() {
app.MarkErrors(valid.Errors)
appG.Response(http.StatusOK, e.INVALID_PARAMS, nil)
return
}
articleService := article_service.Article{ID: id}
exists, err := articleService.ExistByID()
if err != nil {
appG.Response(http.StatusOK, e.ERROR_CHECK_EXIST_ARTICLE_FAIL, nil)
return
}
if !exists {
appG.Response(http.StatusOK, e.ERROR_NOT_EXIST_ARTICLE, nil)
return
}
article, err := articleService.Get()
if err != nil {
appG.Response(http.StatusOK, e.ERROR_GET_ARTICLE_FAIL, nil)
return
}
appG.Response(http.StatusOK, e.SUCCESS, article)
}
這裡有幾個值得變動點,主要是在內部增加了錯誤返回,如果存在錯誤則直接返回。另外進行了分層,業務邏輯內聚到了 service 層中去,而 routers/api(controller)顯著減輕,程式碼會更加的直觀
例如 service/article_service 下的 articleService.Get() 方法:
func (a *Article) Get() (*models.Article, error) {
var cacheArticle *models.Article
cache := cache_service.Article{ID: a.ID}
key := cache.GetArticleKey()
if gredis.Exists(key) {
data, err := gredis.Get(key)
if err != nil {
logging.Info(err)
} else {
json.Unmarshal(data, &cacheArticle)
return cacheArticle, nil
}
}
article, err := models.GetArticle(a.ID)
if err != nil {
return nil, err
}
gredis.Set(key, article, 3600)
return article, nil
}
而對於 gorm 的 錯誤返回設定,只需要修改 models/article.go 如下:
func GetArticle(id int) (*Article, error) {
var article Article
err := db.Where("id = ? AND deleted_on = ? ", id, 0).First(&article).Related(&article.Tag).Error
if err != nil && err != gorm.ErrRecordNotFound {
return nil, err
}
return &article, nil
}
習慣性增加 .Error,把控絕大部分的錯誤。另外需要注意一點,在 gorm 中,查詢不到記錄也算一種 “錯誤” 哦
最後
顯然,本章節並不是你跟著我敲系列。我給你的課題是 “實作 Redis 快取並最佳化既有的業務邏輯程式碼”
讓其能夠不斷地適應業務的發展,讓程式碼更清晰易讀,且呈層級和結構性
如果有疑惑,可以到 go-gin-example 看看我是怎麼寫的,你是怎麼寫的,又分別有什麼優勢、劣勢,取長補短一波?
參考
本系列示例程式碼
推薦閱讀
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.14 實作匯出、匯入 Excel
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 匯出功能的實作
本文目標
在本節,我們將實作對標籤資訊的匯出、匯入功能,這是很標配功能了,希望你掌握基礎的使用方式。
另外在本文我們使用了 2 個 Excel 的包,excelize 最初的 XML 格式檔案的一些結構,是透過 tealeg/xlsx 格式檔案結構演化而來的,因此特意在此都展示了,你可以根據自己的場景和喜愛去使用。
設定
首先要指定匯出的 Excel 檔案的儲存路徑,在 app.ini 中增加設定:
[app]
...
ExportSavePath = export/
修改 setting.go 的 App struct:
type App struct {
JwtSecret string
PageSize int
PrefixUrl string
RuntimeRootPath string
ImageSavePath string
ImageMaxSize int
ImageAllowExts []string
ExportSavePath string
LogSavePath string
LogSaveName string
LogFileExt string
TimeFormat string
}
在這裡需增加 ExportSavePath 設定項,另外將先前 ImagePrefixUrl 改為 PrefixUrl 用於支撐兩者的 HOST 取得
(注意修改 image.go 的 GetImageFullUrl 方法)
pkg
新建 pkg/export/excel.go 檔案,如下:
package export
import "github.com/EDDYCJY/go-gin-example/pkg/setting"
func GetExcelFullUrl(name string) string {
return setting.AppSetting.PrefixUrl + "/" + GetExcelPath() + name
}
func GetExcelPath() string {
return setting.AppSetting.ExportSavePath
}
func GetExcelFullPath() string {
return setting.AppSetting.RuntimeRootPath + GetExcelPath()
}
這裡編寫了一些常用的方法,以後取值方式如果有變動,直接改內部程式碼即可,對外不可見
嘗試一下標準庫
f, err := os.Create(export.GetExcelFullPath() + "test.csv")
if err != nil {
panic(err)
}
defer f.Close()
f.WriteString("\xEF\xBB\xBF")
w := csv.NewWriter(f)
data := [][]string{
{"1", "test1", "test1-1"},
{"2", "test2", "test2-1"},
{"3", "test3", "test3-1"},
}
w.WriteAll(data)
在 Go 提供的標準庫 encoding/csv 中,天然的支援 csv 檔案的讀取和處理,在本段程式碼中,做了如下工作:
1、os.Create:
建立了一個 test.csv 檔案
2、f.WriteString("\xEF\xBB\xBF"):
\xEF\xBB\xBF 是 UTF-8 BOM 的 16 進位制格式,在這裡的用處是標識檔案的編碼格式,通常會出現在檔案的開頭,因此第一步就要將其寫入。如果不標識 UTF-8 的編碼格式的話,寫入的漢字會顯示為亂碼
3、csv.NewWriter:
func NewWriter(w io.Writer) *Writer {
return &Writer{
Comma: ',',
w: bufio.NewWriter(w),
}
}
4、w.WriteAll:
func (w *Writer) WriteAll(records [][]string) error {
for _, record := range records {
err := w.Write(record)
if err != nil {
return err
}
}
return w.w.Flush()
}
WriteAll 實際是對 Write 的封裝,需要注意在最後呼叫了 w.w.Flush(),這充分了說明了 WriteAll 的使用場景,你可以想想作者的設計用意
匯出
Service 方法
開啟 service/tag.go,增加 Export 方法,如下:
func (t *Tag) Export() (string, error) {
tags, err := t.GetAll()
if err != nil {
return "", err
}
file := xlsx.NewFile()
sheet, err := file.AddSheet("标签信息")
if err != nil {
return "", err
}
titles := []string{"ID", "名称", "创建人", "创建时间", "修改人", "修改时间"}
row := sheet.AddRow()
var cell *xlsx.Cell
for _, title := range titles {
cell = row.AddCell()
cell.Value = title
}
for _, v := range tags {
values := []string{
strconv.Itoa(v.ID),
v.Name,
v.CreatedBy,
strconv.Itoa(v.CreatedOn),
v.ModifiedBy,
strconv.Itoa(v.ModifiedOn),
}
row = sheet.AddRow()
for _, value := range values {
cell = row.AddCell()
cell.Value = value
}
}
time := strconv.Itoa(int(time.Now().Unix()))
filename := "tags-" + time + ".xlsx"
fullPath := export.GetExcelFullPath() + filename
err = file.Save(fullPath)
if err != nil {
return "", err
}
return filename, nil
}
routers 入口
開啟 routers/api/v1/tag.go,增加如下方法:
func ExportTag(c *gin.Context) {
appG := app.Gin{C: c}
name := c.PostForm("name")
state := -1
if arg := c.PostForm("state"); arg != "" {
state = com.StrTo(arg).MustInt()
}
tagService := tag_service.Tag{
Name: name,
State: state,
}
filename, err := tagService.Export()
if err != nil {
appG.Response(http.StatusOK, e.ERROR_EXPORT_TAG_FAIL, nil)
return
}
appG.Response(http.StatusOK, e.SUCCESS, map[string]string{
"export_url": export.GetExcelFullUrl(filename),
"export_save_url": export.GetExcelPath() + filename,
})
}
路由
在 routers/router.go 檔案中增加路由方法,如下
apiv1 := r.Group("/api/v1")
apiv1.Use(jwt.JWT())
{
...
//导出标签
r.POST("/tags/export", v1.ExportTag)
}
驗證介面
訪問 http://127.0.0.1:8000/tags/export,結果如下:
{
"code": 200,
"data": {
"export_save_url": "export/tags-1528903393.xlsx",
"export_url": "http://127.0.0.1:8000/export/tags-1528903393.xlsx"
},
"msg": "ok"
}
最終透過介面返回了匯出檔案的地址和儲存地址
StaticFS
那你想想,現在直接訪問地址肯定是無法下載檔案的,那麼該如何做呢?
開啟 router.go 檔案,增加程式碼如下:
r.StaticFS("/export", http.Dir(export.GetExcelFullPath()))
若你不理解,強烈建議溫習下前面的章節,舉一反三
驗證下載
再次訪問上面的 export_url ,如:http://127.0.0.1:8000/export/tags-1528903393.xlsx,是不是成功了呢?
匯入
Service 方法
開啟 service/tag.go,增加 Import 方法,如下:
func (t *Tag) Import(r io.Reader) error {
xlsx, err := excelize.OpenReader(r)
if err != nil {
return err
}
rows := xlsx.GetRows("标签信息")
for irow, row := range rows {
if irow > 0 {
var data []string
for _, cell := range row {
data = append(data, cell)
}
models.AddTag(data[1], 1, data[2])
}
}
return nil
}
routers 入口
開啟 routers/api/v1/tag.go,增加如下方法:
func ImportTag(c *gin.Context) {
appG := app.Gin{C: c}
file, _, err := c.Request.FormFile("file")
if err != nil {
logging.Warn(err)
appG.Response(http.StatusOK, e.ERROR, nil)
return
}
tagService := tag_service.Tag{}
err = tagService.Import(file)
if err != nil {
logging.Warn(err)
appG.Response(http.StatusOK, e.ERROR_IMPORT_TAG_FAIL, nil)
return
}
appG.Response(http.StatusOK, e.SUCCESS, nil)
}
路由
在 routers/router.go 檔案中增加路由方法,如下
apiv1 := r.Group("/api/v1")
apiv1.Use(jwt.JWT())
{
...
//导入标签
r.POST("/tags/import", v1.ImportTag)
}
驗證
在這裡我們將先前匯出的 Excel 檔案作為入參,訪問 http://127.0.0.01:8000/tags/import,檢查返回和資料是否正確入庫
總結
在本文中,簡單介紹了 Excel 的匯入、匯出的使用方式,使用了以下 2 個包:
你可以細細閱讀一下它的實作和使用方式,對你的把控更有幫助 🤔
課外
- tag:匯出使用 excelize 的方式去實作(可能你會發現更簡單哦)
- tag:匯入去重功能實作
- artice :匯入、匯出功能實作
也不失為你很好的練手機會,如果有興趣,可以試試
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月02日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.15 生成二維碼、合併海報
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 圖片生成
- 二維碼生成
本文目標
在文章的詳情頁中,我們常常會需要去宣傳它,而目前最常見的就是發海報了,今天我們將實作如下功能:
- 生成二維碼
- 合併海報(背景圖 + 二維碼)
實作
首先,你需要在 App 設定項中增加二維碼及其海報的儲存路徑,我們約定設定項名稱為 QrCodeSavePath,值為 qrcode/,經過多節連載的你應該能夠完成,若有不懂可參照 go-gin-example。
生成二維碼
安裝
$ go get -u github.com/boombuler/barcode
工具包
考慮生成二維碼這一動作貼合工具包的定義,且有公用的可能性,新建 pkg/qrcode/qrcode.go 檔案,寫入內容:
package qrcode
import (
"image/jpeg"
"github.com/boombuler/barcode"
"github.com/boombuler/barcode/qr"
"github.com/EDDYCJY/go-gin-example/pkg/file"
"github.com/EDDYCJY/go-gin-example/pkg/setting"
"github.com/EDDYCJY/go-gin-example/pkg/util"
)
type QrCode struct {
URL string
Width int
Height int
Ext string
Level qr.ErrorCorrectionLevel
Mode qr.Encoding
}
const (
EXT_JPG = ".jpg"
)
func NewQrCode(url string, width, height int, level qr.ErrorCorrectionLevel, mode qr.Encoding) *QrCode {
return &QrCode{
URL: url,
Width: width,
Height: height,
Level: level,
Mode: mode,
Ext: EXT_JPG,
}
}
func GetQrCodePath() string {
return setting.AppSetting.QrCodeSavePath
}
func GetQrCodeFullPath() string {
return setting.AppSetting.RuntimeRootPath + setting.AppSetting.QrCodeSavePath
}
func GetQrCodeFullUrl(name string) string {
return setting.AppSetting.PrefixUrl + "/" + GetQrCodePath() + name
}
func GetQrCodeFileName(value string) string {
return util.EncodeMD5(value)
}
func (q *QrCode) GetQrCodeExt() string {
return q.Ext
}
func (q *QrCode) CheckEncode(path string) bool {
src := path + GetQrCodeFileName(q.URL) + q.GetQrCodeExt()
if file.CheckNotExist(src) == true {
return false
}
return true
}
func (q *QrCode) Encode(path string) (string, string, error) {
name := GetQrCodeFileName(q.URL) + q.GetQrCodeExt()
src := path + name
if file.CheckNotExist(src) == true {
code, err := qr.Encode(q.URL, q.Level, q.Mode)
if err != nil {
return "", "", err
}
code, err = barcode.Scale(code, q.Width, q.Height)
if err != nil {
return "", "", err
}
f, err := file.MustOpen(name, path)
if err != nil {
return "", "", err
}
defer f.Close()
err = jpeg.Encode(f, code, nil)
if err != nil {
return "", "", err
}
}
return name, path, nil
}
這裡主要聚焦 func (q *QrCode) Encode 方法,做了如下事情:
- 取得二維碼生成路徑
- 建立二維碼
- 縮放二維碼到指定大小
- 新建存放二維碼圖片的檔案
- 將影象(二維碼)以 JPEG 4:2:0 基線格式寫入檔案
另外在 jpeg.Encode(f, code, nil) 中,第三個引數可設定其影象質量,預設值為 75
// DefaultQuality is the default quality encoding parameter.
const DefaultQuality = 75
// Options are the encoding parameters.
// Quality ranges from 1 to 100 inclusive, higher is better.
type Options struct {
Quality int
}
路由方法
1、第一步
在 routers/api/v1/article.go 新增 GenerateArticlePoster 方法用於介面開發
2、第二步
在 routers/router.go 的 apiv1 中新增 apiv1.POST("/articles/poster/generate", v1.GenerateArticlePoster) 路由
3、第三步
修改 GenerateArticlePoster 方法,編寫對應的生成邏輯,如下:
const (
QRCODE_URL = "https://github.com/EDDYCJY/blog#gin%E7%B3%BB%E5%88%97%E7%9B%AE%E5%BD%95"
)
func GenerateArticlePoster(c *gin.Context) {
appG := app.Gin{c}
qrc := qrcode.NewQrCode(QRCODE_URL, 300, 300, qr.M, qr.Auto)
path := qrcode.GetQrCodeFullPath()
_, _, err := qrc.Encode(path)
if err != nil {
appG.Response(http.StatusOK, e.ERROR, nil)
return
}
appG.Response(http.StatusOK, e.SUCCESS, nil)
}
驗證
透過 POST 方法訪問 http://127.0.0.1:8000/api/v1/articles/poster/generate?token=$token(注意 $token)
透過檢查兩個點確定功能是否正常,如下:
1、訪問結果是否 200
2、本地目錄是否成功生成二維碼圖片
合併海報
在這一節,將實作二維碼圖片與背景圖合併成新的一張圖,可用於常見的宣傳海報等業務場景
背景圖

將背景圖另存為 runtime/qrcode/bg.jpg(實際應用,可存在 OSS 或其他地方)
service 方法
開啟 service/article_service 目錄,新建 article_poster.go 檔案,寫入內容:
package article_service
import (
"image"
"image/draw"
"image/jpeg"
"os"
"github.com/EDDYCJY/go-gin-example/pkg/file"
"github.com/EDDYCJY/go-gin-example/pkg/qrcode"
)
type ArticlePoster struct {
PosterName string
*Article
Qr *qrcode.QrCode
}
func NewArticlePoster(posterName string, article *Article, qr *qrcode.QrCode) *ArticlePoster {
return &ArticlePoster{
PosterName: posterName,
Article: article,
Qr: qr,
}
}
func GetPosterFlag() string {
return "poster"
}
func (a *ArticlePoster) CheckMergedImage(path string) bool {
if file.CheckNotExist(path+a.PosterName) == true {
return false
}
return true
}
func (a *ArticlePoster) OpenMergedImage(path string) (*os.File, error) {
f, err := file.MustOpen(a.PosterName, path)
if err != nil {
return nil, err
}
return f, nil
}
type ArticlePosterBg struct {
Name string
*ArticlePoster
*Rect
*Pt
}
type Rect struct {
Name string
X0 int
Y0 int
X1 int
Y1 int
}
type Pt struct {
X int
Y int
}
func NewArticlePosterBg(name string, ap *ArticlePoster, rect *Rect, pt *Pt) *ArticlePosterBg {
return &ArticlePosterBg{
Name: name,
ArticlePoster: ap,
Rect: rect,
Pt: pt,
}
}
func (a *ArticlePosterBg) Generate() (string, string, error) {
fullPath := qrcode.GetQrCodeFullPath()
fileName, path, err := a.Qr.Encode(fullPath)
if err != nil {
return "", "", err
}
if !a.CheckMergedImage(path) {
mergedF, err := a.OpenMergedImage(path)
if err != nil {
return "", "", err
}
defer mergedF.Close()
bgF, err := file.MustOpen(a.Name, path)
if err != nil {
return "", "", err
}
defer bgF.Close()
qrF, err := file.MustOpen(fileName, path)
if err != nil {
return "", "", err
}
defer qrF.Close()
bgImage, err := jpeg.Decode(bgF)
if err != nil {
return "", "", err
}
qrImage, err := jpeg.Decode(qrF)
if err != nil {
return "", "", err
}
jpg := image.NewRGBA(image.Rect(a.Rect.X0, a.Rect.Y0, a.Rect.X1, a.Rect.Y1))
draw.Draw(jpg, jpg.Bounds(), bgImage, bgImage.Bounds().Min, draw.Over)
draw.Draw(jpg, jpg.Bounds(), qrImage, qrImage.Bounds().Min.Sub(image.Pt(a.Pt.X, a.Pt.Y)), draw.Over)
jpeg.Encode(mergedF, jpg, nil)
}
return fileName, path, nil
}
這裡重點留意 func (a *ArticlePosterBg) Generate() 方法,做了如下事情:
- 取得二維碼儲存路徑
- 生成二維碼影象
- 檢查合併後圖像(指的是存放合併後的海報)是否存在
- 若不存在,則生成待合併的影象 mergedF
- 開啟事先存放的背景圖 bgF
- 開啟生成的二維碼影象 qrF
- 解碼 bgF 和 qrF 返回 image.Image
- 建立一個新的 RGBA 影象
- 在 RGBA 影象上繪製 背景圖(bgF)
- 在已繪製背景圖的 RGBA 影象上,在指定 Point 上繪製二維碼影象(qrF)
- 將繪製好的 RGBA 影象以 JPEG 4:2:0 基線格式寫入合併後的影象檔案(mergedF)
錯誤碼
路由方法
開啟 routers/api/v1/article.go 檔案,修改 GenerateArticlePoster 方法,編寫最終的業務邏輯(含生成二維碼及合併海報),如下:
const (
QRCODE_URL = "https://github.com/EDDYCJY/blog#gin%E7%B3%BB%E5%88%97%E7%9B%AE%E5%BD%95"
)
func GenerateArticlePoster(c *gin.Context) {
appG := app.Gin{c}
article := &article_service.Article{}
qr := qrcode.NewQrCode(QRCODE_URL, 300, 300, qr.M, qr.Auto) // 目前写死 gin 系列路径,可自行增加业务逻辑
posterName := article_service.GetPosterFlag() + "-" + qrcode.GetQrCodeFileName(qr.URL) + qr.GetQrCodeExt()
articlePoster := article_service.NewArticlePoster(posterName, article, qr)
articlePosterBgService := article_service.NewArticlePosterBg(
"bg.jpg",
articlePoster,
&article_service.Rect{
X0: 0,
Y0: 0,
X1: 550,
Y1: 700,
},
&article_service.Pt{
X: 125,
Y: 298,
},
)
_, filePath, err := articlePosterBgService.Generate()
if err != nil {
appG.Response(http.StatusOK, e.ERROR_GEN_ARTICLE_POSTER_FAIL, nil)
return
}
appG.Response(http.StatusOK, e.SUCCESS, map[string]string{
"poster_url": qrcode.GetQrCodeFullUrl(posterName),
"poster_save_url": filePath + posterName,
})
}
這塊涉及到大量知識,強烈建議閱讀下,如下:
其所涉及、關聯的庫都建議研究一下
StaticFS
在 routers/router.go 檔案,增加如下程式碼:
r.StaticFS("/qrcode", http.Dir(qrcode.GetQrCodeFullPath()))
驗證
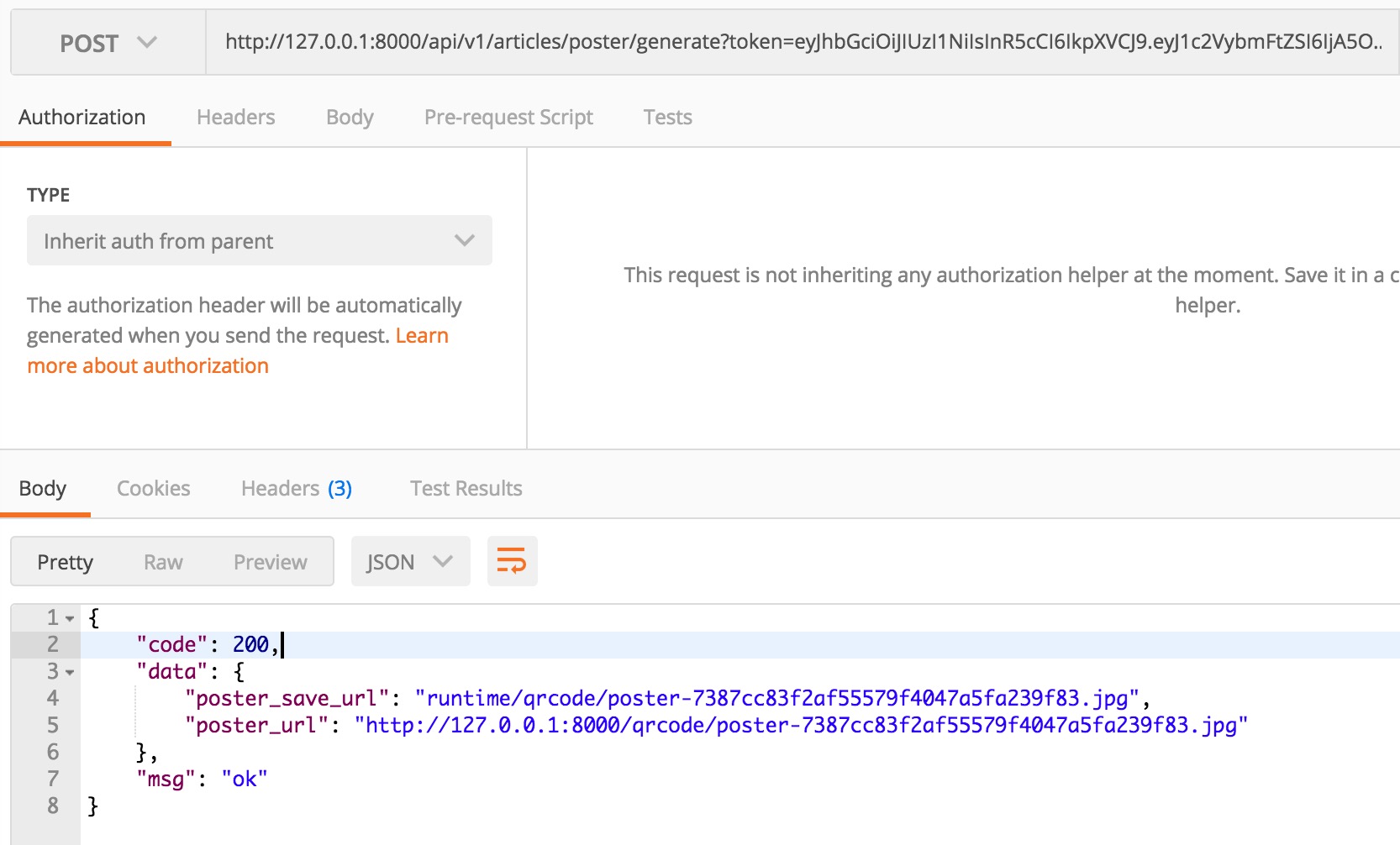
訪問完整的 URL 路徑,返回合成後的海報並掃除二維碼成功則正確 🤓
總結
在本章節實作了兩個很常見的業務功能,分別是生成二維碼和合並海報。希望你能夠仔細閱讀我給出的連結,這塊的知識量不少,想要用好影象處理的功能,必須理解對應的思路,舉一反三
最後希望對你有所幫助 👌
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月02日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.16 在圖片上繪製文字
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 字型庫使用
- 圖片合成
本文目標
主要實作合併後的海報上繪製文字的功能(這個需求也是常見的很了),內容比較簡單。
實作
這裡使用的是 微軟雅黑 的字型,請點選進行下載並存放到 runtime/fonts 目錄下(字型檔案佔 16 MB 大小)
安裝
$ go get -u github.com/golang/freetype
繪製文字
開啟 service/article_service/article_poster.go 檔案,增加繪製文字的業務邏輯,如下:
type DrawText struct {
JPG draw.Image
Merged *os.File
Title string
X0 int
Y0 int
Size0 float64
SubTitle string
X1 int
Y1 int
Size1 float64
}
func (a *ArticlePosterBg) DrawPoster(d *DrawText, fontName string) error {
fontSource := setting.AppSetting.RuntimeRootPath + setting.AppSetting.FontSavePath + fontName
fontSourceBytes, err := ioutil.ReadFile(fontSource)
if err != nil {
return err
}
trueTypeFont, err := freetype.ParseFont(fontSourceBytes)
if err != nil {
return err
}
fc := freetype.NewContext()
fc.SetDPI(72)
fc.SetFont(trueTypeFont)
fc.SetFontSize(d.Size0)
fc.SetClip(d.JPG.Bounds())
fc.SetDst(d.JPG)
fc.SetSrc(image.Black)
pt := freetype.Pt(d.X0, d.Y0)
_, err = fc.DrawString(d.Title, pt)
if err != nil {
return err
}
fc.SetFontSize(d.Size1)
_, err = fc.DrawString(d.SubTitle, freetype.Pt(d.X1, d.Y1))
if err != nil {
return err
}
err = jpeg.Encode(d.Merged, d.JPG, nil)
if err != nil {
return err
}
return nil
}
這裡主要使用了 freetype 包,分別涉及如下細項:
1、freetype.NewContext:建立一個新的 Context,會對其設定一些預設值
func NewContext() *Context {
return &Context{
r: raster.NewRasterizer(0, 0),
fontSize: 12,
dpi: 72,
scale: 12 << 6,
}
}
2、fc.SetDPI:設定螢幕每英寸的解析度
3、fc.SetFont:設定用於繪製文字的字型
4、fc.SetFontSize:以磅為單位設定字型大小
5、fc.SetClip:設定剪裁矩形以進行繪製
6、fc.SetDst:設定目標影象
7、fc.SetSrc:設定繪製操作的源影象,通常為 image.Uniform
var (
// Black is an opaque black uniform image.
Black = NewUniform(color.Black)
// White is an opaque white uniform image.
White = NewUniform(color.White)
// Transparent is a fully transparent uniform image.
Transparent = NewUniform(color.Transparent)
// Opaque is a fully opaque uniform image.
Opaque = NewUniform(color.Opaque)
)
8、fc.DrawString:根據 Pt 的座標值繪製給定的文字內容
業務邏輯
開啟 service/article_service/article_poster.go 方法,在 Generate 方法增加繪製文字的程式碼邏輯,如下:
func (a *ArticlePosterBg) Generate() (string, string, error) {
fullPath := qrcode.GetQrCodeFullPath()
fileName, path, err := a.Qr.Encode(fullPath)
if err != nil {
return "", "", err
}
if !a.CheckMergedImage(path) {
...
draw.Draw(jpg, jpg.Bounds(), bgImage, bgImage.Bounds().Min, draw.Over)
draw.Draw(jpg, jpg.Bounds(), qrImage, qrImage.Bounds().Min.Sub(image.Pt(a.Pt.X, a.Pt.Y)), draw.Over)
err = a.DrawPoster(&DrawText{
JPG: jpg,
Merged: mergedF,
Title: "Golang Gin 系列文章",
X0: 80,
Y0: 160,
Size0: 42,
SubTitle: "---煎鱼",
X1: 320,
Y1: 220,
Size1: 36,
}, "msyhbd.ttc")
if err != nil {
return "", "", err
}
}
return fileName, path, nil
}
驗證
訪問生成文章海報的介面 $HOST/api/v1/articles/poster/generate?token=$token,檢查其生成結果,如下圖

總結
在本章節在 連載十五 的基礎上增加了繪製文字,在實作上並不困難,而這兩塊需求一般會同時出現,大家可以多加練習,瞭解裡面的邏輯和其他 API 😁
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月02日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.17 用Nginx部署Go應用
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- Nginx。
- 反向代理。
本文目標
簡單部署後端服務。
做什麼
在本章節,我們將簡單介紹 Nginx 以及使用 Nginx 來完成對 go-gin-example 的部署,會實作反向代理和簡單負載均衡的功能。
Nginx
是什麼
Nginx 是一個 Web Server,可以用作反向代理、負載均衡、郵件代理、TCP / UDP、HTTP 伺服器等等,它擁有很多吸引人的特性,例如:
- 以較低的記憶體佔用率處理 10,000 多個併發連線(每10k非活動HTTP保持活動連線約2.5 MB )
- 靜態伺服器(處理靜態檔案)
- 正向、反向代理
- 負載均衡
- 透過OpenSSL 對 TLS / SSL 與 SNI 和 OCSP 支援
- FastCGI、SCGI、uWSGI 的支援
- WebSockets、HTTP/1.1 的支援
- Nginx + Lua
安裝
請右拐谷歌或百度,安裝好 Nginx 以備接下來的使用
簡單講解
常用命令
- nginx:啟動 Nginx
- nginx -s stop:立刻停止 Nginx 服務
- nginx -s reload:重新載入設定檔案
- nginx -s quit:平滑停止 Nginx 服務
- nginx -t:測試設定檔案是否正確
- nginx -v:顯示 Nginx 版本資訊
- nginx -V:顯示 Nginx 版本資訊、編譯器和設定引數的資訊
涉及設定
1、 proxy_pass:設定反向代理的路徑。需要注意的是如果 proxy_pass 的 url 最後為 /,則表示絕對路徑。否則(不含變數下)表示相對路徑,所有的路徑都會被代理過去
2、 upstream:設定負載均衡,upstream 預設是以輪詢的方式進行負載,另外還支援四種模式,分別是:
(1)weight:權重,指定輪詢的機率,weight 與訪問機率成正比
(2)ip_hash:按照訪問 IP 的 hash 結果值分配
(3)fair:按後端伺服器響應時間進行分配,響應時間越短優先級別越高
(4)url_hash:按照訪問 URL 的 hash 結果值分配
部署
在這裡需要對 nginx.conf 進行設定,如果你不知道對應的設定檔案是哪個,可執行 nginx -t 看一下
$ nginx -t
nginx: the configuration file /usr/local/etc/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/etc/nginx/nginx.conf test is successful
顯然,我的設定檔案在 /usr/local/etc/nginx/ 目錄下,並且測試透過
反向代理
反向代理是指以代理伺服器來接受網路上的連線請求,然後將請求轉發給內部網路上的伺服器,並將從伺服器上得到的結果返回給請求連線的客戶端,此時代理伺服器對外就表現為一個反向代理伺服器。(來自百科)
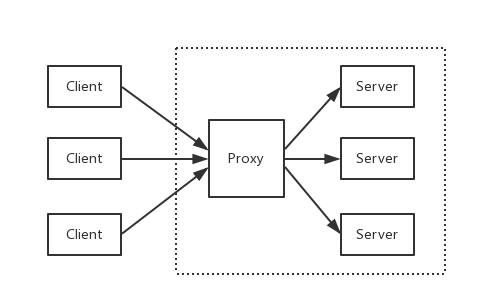
設定 hosts
由於需要用本機作為演示,因此先把對映配上去,開啟 /etc/hosts,增加內容:
127.0.0.1 api.blog.com
設定 nginx.conf
開啟 nginx 的設定檔案 nginx.conf(我的是 /usr/local/etc/nginx/nginx.conf),我們做了如下事情:
增加 server 片段的內容,設定 server_name 為 api.blog.com 並且監聽 8081 埠,將所有路徑轉發到 http://127.0.0.1:8000/ 下
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name api.blog.com;
location / {
proxy_pass http://127.0.0.1:8000/;
}
}
}
驗證
啟動 go-gin-example
回到 go-gin-example 的專案下,執行 make,再執行 ./go-gin-exmaple
$ make
github.com/EDDYCJY/go-gin-example
$ ls
LICENSE README.md conf go-gin-example middleware pkg runtime vendor
Makefile README_ZH.md docs main.go models routers service
$ ./go-gin-example
...
[GIN-debug] DELETE /api/v1/articles/:id --> github.com/EDDYCJY/go-gin-example/routers/api/v1.DeleteArticle (4 handlers)
[GIN-debug] POST /api/v1/articles/poster/generate --> github.com/EDDYCJY/go-gin-example/routers/api/v1.GenerateArticlePoster (4 handlers)
Actual pid is 14672
重啟 nginx
$ nginx -t
nginx: the configuration file /usr/local/etc/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/etc/nginx/nginx.conf test is successful
$ nginx -s reload
訪問介面
如此,就實作了一個簡單的反向代理了,是不是很簡單呢
負載均衡
負載均衡,英文名稱為Load Balance(常稱 LB),其意思就是分攤到多個操作單元上進行執行(來自百科)
你能從運維口中經常聽見,XXX 負載怎麼突然那麼高。 那麼它到底是什麼呢?
其背後一般有多臺 server,系統會根據設定的策略(例如 Nginx 有提供四種選擇)來進行動態調整,儘可能的達到各節點均衡,從而提高系統整體的吞吐量和快速響應
如何演示
前提條件為多個後端服務,那麼勢必需要多個 go-gin-example,為了演示我們可以啟動多個埠,達到模擬的效果
為了便於演示,分別在啟動前將 conf/app.ini 的應用埠修改為 8001 和 8002(也可以做成傳入引數的模式),達到啟動 2 個監聽 8001 和 8002 的後端服務
設定 nginx.conf
回到 nginx.conf 的老地方,增加負載均衡所需的設定。新增 upstream 節點,設定其對應的 2 個後端服務,最後修改了 proxy_pass 指向(格式為 http:// + upstream 的節點名稱)
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream api.blog.com {
server 127.0.0.1:8001;
server 127.0.0.1:8002;
}
server {
listen 8081;
server_name api.blog.com;
location / {
proxy_pass http://api.blog.com/;
}
}
}
重啟 nginx
$ nginx -t
nginx: the configuration file /usr/local/etc/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/etc/nginx/nginx.conf test is successful
$ nginx -s reload
驗證
再重複訪問 http://api.blog.com:8081/auth?username={USER_NAME}}&password={PASSWORD},多訪問幾次便於檢視效果
目前 Nginx 沒有進行特殊設定,那麼它是輪詢策略,而 go-gin-example 預設開著 debug 模式,看看請求 log 就明白了


總結
在本章節,希望您能夠簡單習得日常使用的 Web Server 背後都是一些什麼邏輯,Nginx 是什麼?反向代理?負載均衡?
怎麼簡單部署,知道了吧。
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.18 Golang交叉編譯
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 跨平臺編譯
本文目標
在 連載九 講解構建Scratch映象時,我們編譯可執行檔案用了另外一個形式的命令,如下:
$ CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o go-gin-example .
我想你可能會有疑問,今天本文會針對這塊進行講解。
說明
我們將講解命令各個引數的作用,希望你在閱讀時,將每一項串聯起來,你會發現這就是交叉編譯相關的小知識
也就是 Golang 令人心動的特性之一跨平臺編譯
一、CGO_ENABLED
作用:
用於標識(宣告) cgo 工具是否可用
意義:
存在交叉編譯的情況時,cgo 工具是不可用的。在標準go命令的上下文環境中,交叉編譯意味著程式構建環境的目標計算架構的標識與程式執行環境的目標計算架構的標識不同,或者程式構建環境的目標作業系統的標識與程式執行環境的目標作業系統的標識不同
小結:
結合案例來說,我們是在宿主機編譯的可執行檔案,而在 Scratch 映象執行的可執行檔案;顯然兩者的計算機架構、執行環境標識你無法確定它是否一致(畢竟構建的 docker 映象還可以給他人使用),那麼我們就要進行交叉編譯,而交叉編譯不支援 cgo,因此這裡要停用掉它
關閉 cgo 後,在構建過程中會忽略 cgo 並靜態連結所有的依賴庫,而開啟 cgo 後,方式將轉為動態連結
補充:
golang 是預設開啟 cgo 工具的,可執行 go env 命令檢視
$ go env
GOARCH="amd64"
GOBIN=""
GOCACHE="/root/.cache/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
...
GCCGO="gccgo"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
...
二、GOOS
用於標識(宣告)程式構建環境的目標作業系統
如:
- linux
- windows
三、GOARCH
用於標識(宣告)程式構建環境的目標計算架構
若不設定,預設值與程式執行環境的目標計算架構一致(案例就是採用的預設值)
如:
- amd64
- 386
| 系統 | GOOS | GOARCH |
|---|---|---|
| Windows 32位 | windows | 386 |
| Windows 64位 | windows | amd64 |
| OS X 32位 | darwin | 386 |
| OS X 64位 | darwin | amd64 |
| Linux 32位 | linux | 386 |
| Linux 64位 | linux | amd64 |
四、GOHOSTOS
用於標識(宣告)程式執行環境的目標作業系統
五、GOHOSTARCH
用於標識(宣告)程式執行環境的目標計算架構
六、go build
-a
強制重新編譯,簡單來說,就是不利用快取或已編譯好的部分檔案,直接所有包都是最新的程式碼重新編譯和關聯
-installsuffix
作用:
在軟體包安裝的目錄中增加字尾標識,以保持輸出與預設版本分開
補充:
如果使用 -race 標識,則字尾就會預設設定為 -race 標識,用於區別 race 和普通的版本
-o
指定編譯後的可執行檔名稱
小結
大部分引數指令,都有一定關聯性,且與交叉編譯的知識點相關,可以好好品味一下
最後可以看看 go build help 加深瞭解
$ go help build
usage: go build [-o output] [-i] [build flags] [packages]
...
-a
force rebuilding of packages that are already up-to-date.
-n
print the commands but do not run them.
-p n
the number of programs, such as build commands or
test binaries, that can be run in parallel.
The default is the number of CPUs available.
-race
enable data race detection.
Supported only on linux/amd64, freebsd/amd64, darwin/amd64 and windows/amd64.
-msan
enable interoperation with memory sanitizer.
Supported only on linux/amd64,
and only with Clang/LLVM as the host C compiler.
-v
print the names of packages as they are compiled.
-work
print the name of the temporary work directory and
do not delete it when exiting.
-x
print the commands.
-asmflags '[pattern=]arg list'
arguments to pass on each go tool asm invocation.
-buildmode mode
build mode to use. See 'go help buildmode' for more.
-compiler name
name of compiler to use, as in runtime.Compiler (gccgo or gc).
-gccgoflags '[pattern=]arg list'
arguments to pass on each gccgo compiler/linker invocation.
-gcflags '[pattern=]arg list'
arguments to pass on each go tool compile invocation.
-installsuffix suffix
a suffix to use in the name of the package installation directory,
in order to keep output separate from default builds.
If using the -race flag, the install suffix is automatically set to race
or, if set explicitly, has _race appended to it. Likewise for the -msan
flag. Using a -buildmode option that requires non-default compile flags
has a similar effect.
-ldflags '[pattern=]arg list'
arguments to pass on each go tool link invocation.
-linkshared
link against shared libraries previously created with
-buildmode=shared.
-pkgdir dir
install and load all packages from dir instead of the usual locations.
For example, when building with a non-standard configuration,
use -pkgdir to keep generated packages in a separate location.
-tags 'tag list'
a space-separated list of build tags to consider satisfied during the
build. For more information about build tags, see the description of
build constraints in the documentation for the go/build package.
-toolexec 'cmd args'
a program to use to invoke toolchain programs like vet and asm.
For example, instead of running asm, the go command will run
'cmd args /path/to/asm <arguments for asm>'.
...
參考
本系列示例程式碼
書籍
- Go併發程式設計實戰 第二版
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
3.19 請入門 Makefile
專案地址:https://github.com/EDDYCJY/go-gin-example
知識點
- 寫一個 Makefile
本文目標
含一定複雜度的軟體工程,基本上都是先編譯 A,再依賴 B,再編譯 C...,最後才執行構建。如果每次都人為編排,又或是每新來一個同事就問你專案 D 怎麼構建、重新構建需要注意什麼...等等情況,豈不是要崩潰?
我們常常會在開源專案中發現 Makefile,你是否有過疑問?
本章節會簡單介紹 Makefile 的使用方式,最後建議深入學習。
怎麼解決
對於構建編排,Docker 有 Dockerfile ,在 Unix 中有神器 Make ....
Make
是什麼
Make 是一個構建自動化工具,會在當前目錄下尋找 Makefile 或 makefile 檔案。如果存在,會依據 Makefile 的構建規則去完成構建
當然了,實際上 Makefile 內都是你根據 make 語法規則,自己編寫的特定 Shell 命令等
它是一個工具,規則也很簡單。在支援的範圍內,編譯 A, 依賴 B,再編譯 C,完全沒問題
規則
Makefile 由多條規則組成,每條規則都以一個 target(目標)開頭,後跟一個 : 冒號,冒號後是這一個目標的 prerequisites(前置條件)
緊接著新的一行,必須以一個 tab 作為開頭,後面跟隨 command(命令),也就是你希望這一個 target 所執行的構建命令
[target] ... : [prerequisites] ...
<tab>[command]
...
...
- target:一個目標代表一條規則,可以是一個或多個檔名。也可以是某個操作的名字(標籤),稱為偽目標(phony)
- prerequisites:前置條件,這一項是可選引數。通常是多個檔名、偽目標。它的作用是 target 是否需要重新構建的標準,如果前置條件不存在或有過更新(檔案的最後一次修改時間)則認為 target 需要重新構建
- command:構建這一個 target 的具體命令集
簡單的例子
本文將以 go-gin-example 去編寫 Makefile 檔案,請跨入 make 的大門
分析
在編寫 Makefile 前,需要先分析構建先後順序、依賴項,需要解決的問題等
編寫
.PHONY: build clean tool lint help
all: build
build:
go build -v .
tool:
go tool vet . |& grep -v vendor; true
gofmt -w .
lint:
golint ./...
clean:
rm -rf go-gin-example
go clean -i .
help:
@echo "make: compile packages and dependencies"
@echo "make tool: run specified go tool"
@echo "make lint: golint ./..."
@echo "make clean: remove object files and cached files"
1、在上述檔案中,使用了 .PHONY,其作用是宣告 build / clean / tool / lint / help 為偽目標,宣告為偽目標會怎麼樣呢?
- 宣告為偽目標後:在執行對應的命令時,make 就不會去檢查是否存在 build / clean / tool / lint / help 其對應的檔案,而是每次都會執行標籤對應的命令
- 若不宣告:恰好存在對應的檔案,則 make 將會認為 xx 檔案已存在,沒有重新構建的必要了
2、這塊比較簡單,在命令列執行即可看見效果,實作了以下功能:
- make: make 就是 make all
- make build: 編譯當前專案的包和依賴項
- make tool: 執行指定的 Go 工具集
- make lint: golint 一下
- make clean: 刪除物件檔案和快取檔案
- make help: help
為什麼會列印執行的命令
如果你實際操作過,可能會有疑問。明明只是執行命令,為什麼會列印到標準輸出上了?
原因
make 預設會列印每條命令,再執行。這個行為被定義為回聲
解決
可以在對應命令前加上 @,可指定該命令不被列印到標準輸出上
build:
@go build -v .
那麼還有其他的特殊符號嗎?有的,請課後去了解下 +、- 的用途 🤩
小結
這是一篇比較簡潔的文章,希望可以讓您對 Makefile 有一個基本瞭解。
參考
本系列示例程式碼
關於
修改記錄
- 第一版:2018年02月16日釋出文章
- 第二版:2019年10月01日修改文章
?
如果有任何疑問或錯誤,歡迎在 issues 進行提問或給予修正意見,如果喜歡或對你有所幫助,歡迎 Star,對作者是一種鼓勵和推進。
我的微信公眾號
第4課 grpc
- 4.1 gRPC及相關介紹
- 4.2 gRPC Client and Server
- 4.3 gRPC Streaming, Client and Server
- 4.4 TLS 證書認證
- 4.5 基於 CA 的 TLS 證書認證
- 4.6 Unary and Stream interceptor
- 4.7 讓你的服務同時提供 HTTP 介面
- 4.8 對 RPC 方法做自定義認證
- 4.9 gRPC Deadlines
- 4.10 分散式鏈路追蹤
4.1 gRPC及相關介紹
專案地址:https://github.com/EDDYCJY/go-grpc-example
作為開篇章,將會介紹 gRPC 相關的一些知識。簡單來講 gRPC 是一個 基於 HTTP/2 協議設計的 RPC 框架,它採用了 Protobuf 作為 IDL
你是否有過疑惑,它們都是些什麼?本文將會介紹一些常用的知識和概念,更詳細的會給出手冊地址去深入
一、RPC
什麼是 RPC
RPC 代指遠端過程呼叫(Remote Procedure Call),它的呼叫包含了傳輸協議和編碼(物件序列號)協議等等。允許運行於一臺計算機的程式呼叫另一臺計算機的子程式,而開發人員無需額外地為這個互動作用程式設計
實際場景:
有兩臺伺服器,分別是A、B。在 A 上的應用 C 想要呼叫 B 伺服器上的應用 D,它們可以直接本地呼叫嗎?
答案是不能的,但走 RPC 的話,十分方便。因此常有人稱使用 RPC,就跟本地呼叫一個函式一樣簡單
RPC 框架
我認為,一個完整的 RPC 框架,應包含負載均衡、服務註冊和發現、服務治理等功能,並具有可拓展性便於流量監控系統等接入
那麼它才算完整的,當然了。有些較單一的 RPC 框架,透過組合多元件也能達到這個標準
你認為呢?
常見 RPC 框架
比較一下
| \ | 跨語言 | 多 IDL | 服務治理 | 註冊中心 | 服務管理 |
|---|---|---|---|---|---|
| gRPC | √ | × | × | × | × |
| Thrift | √ | × | × | × | × |
| Rpcx | × | √ | √ | √ | √ |
| Dubbo | × | √ | √ | √ | √ |
為什麼要 RPC
簡單、通用、安全、效率
RPC 可以基於 HTTP 嗎
RPC 是代指遠端過程呼叫,是可以基於 HTTP 協議的
肯定會有人說效率優勢,我可以告訴你,那是基於 HTTP/1.1 來講的,HTTP/2 優化了許多問題(當然也存在新的問題),所以你看到了本文的主題 gRPC
二、Protobuf
介紹
Protocol Buffers 是一種與語言、平臺無關,可擴充套件的序列化結構化資料的方法,常用於通訊協議,資料儲存等等。相較於 JSON、XML,它更小、更快、更簡單,因此也更受開發人員的青眯
語法
syntax = "proto3";
service SearchService {
rpc Search (SearchRequest) returns (SearchResponse);
}
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
message SearchResponse {
...
}
1、第一行(非空的非註釋行)宣告使用 proto3 語法。如果不宣告,將預設使用 proto2 語法。同時我建議用 v2 還是 v3,都應當宣告其使用的版本
2、定義 SearchService RPC 服務,其包含 RPC 方法 Search,入參為 SearchRequest 訊息,出參為 SearchResponse 訊息
3、定義 SearchRequest、SearchResponse 訊息,前者定義了三個欄位,每一個欄位包含三個屬性:型別、欄位名稱、欄位編號
4、Protobuf 編譯器會根據選擇的語言不同,生成相應語言的 Service Interface Code 和 Stubs
最後,這裡只是簡單的語法介紹,詳細的請右拐 Language Guide (proto3)
資料型別
| .proto Type | C++ Type | Java Type | Go Type | PHP Type |
|---|---|---|---|---|
| double | double | double | float64 | float |
| float | float | float | float32 | float |
| int32 | int32 | int | int32 | integer |
| int64 | int64 | long | int64 | integer/string |
| uint32 | uint32 | int | uint32 | integer |
| uint64 | uint64 | long | uint64 | integer/string |
| sint32 | int32 | int | int32 | integer |
| sint64 | int64 | long | int64 | integer/string |
| fixed32 | uint32 | int | uint32 | integer |
| fixed64 | uint64 | long | uint64 | integer/string |
| sfixed32 | int32 | int | int32 | integer |
| sfixed64 | int64 | long | int64 | integer/string |
| bool | bool | boolean | bool | boolean |
| string | string | String | string | string |
| bytes | string | ByteString | []byte | string |
v2 和 v3 主要區別
- 刪除原始值欄位的欄位存在邏輯
- 刪除 required 欄位
- 刪除 optional 欄位,預設就是
- 刪除 default 欄位
- 刪除擴充套件特性,新增 Any 型別來替代它
- 刪除 unknown 欄位的支援
- 新增 JSON Mapping
- 新增 Map 型別的支援
- 修復 enum 的 unknown 型別
- repeated 預設使用 packed 編碼
- 引入了新的語言實作(C#,JavaScript,Ruby,Objective-C)
以上是日常涉及的常見功能,如果還想詳細瞭解可閱讀 Protobuf Version 3.0.0
相較 Protobuf,為什麼不使用XML?
- 更簡單
- 資料描述檔案只需原來的1/10至1/3
- 解析速度是原來的20倍至100倍
- 減少了二義性
- 生成了更易使用的資料訪問類
三、gRPC
介紹
gRPC 是一個高效能、開源和通用的 RPC 框架,面向移動和 HTTP/2 設計
多語言
- C++
- C#
- Dart
- Go
- Java
- Node.js
- Objective-C
- PHP
- Python
- Ruby
特點
1、HTTP/2
2、Protobuf
3、客戶端、服務端基於同一份 IDL
4、行動網路的良好支援
5、支援多語言
概覽
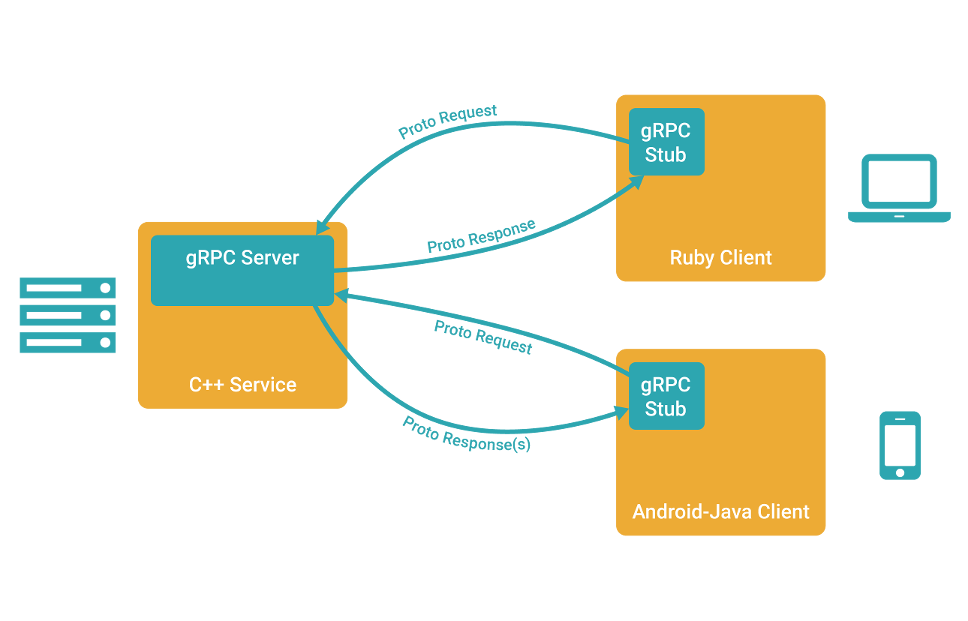
講解
1、客戶端(gRPC Sub)呼叫 A 方法,發起 RPC 呼叫
2、對請求資訊使用 Protobuf 進行物件序列化壓縮(IDL)
3、服務端(gRPC Server)接收到請求後,解碼請求體,進行業務邏輯處理並返回
4、對響應結果使用 Protobuf 進行物件序列化壓縮(IDL)
5、客戶端接受到服務端響應,解碼請求體。回撥被呼叫的 A 方法,喚醒正在等待響應(阻塞)的客戶端呼叫並返回響應結果
示例
在這一小節,將簡單的給大家展示 gRPC 的客戶端和服務端的示例程式碼,希望大家先有一個基礎的印象,將會在下一章節詳細介紹 🤔
構建和啟動服務端
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
grpcServer := grpc.NewServer()
...
pb.RegisterSearchServer(grpcServer, &SearchServer{})
grpcServer.Serve(lis)
1、監聽指定 TCP 埠,用於接受客戶端請求
2、建立 gRPC Server 的例項物件
3、gRPC Server 內部服務和路由的註冊
4、Serve() 呼叫伺服器以執行阻塞等待,直到程序被終止或被 Stop() 呼叫
建立客戶端
var opts []grpc.DialOption
...
conn, err := grpc.Dial(*serverAddr, opts...)
if err != nil {
log.Fatalf("fail to dial: %v", err)
}
defer conn.Close()
client := pb.NewSearchClient(conn)
...
1、建立 gRPC Channel 與 gRPC Server 進行通訊(需伺服器地址和埠作為引數)
2、設定 DialOptions 憑證(例如,TLS,GCE憑據,JWT憑證)
3、建立 Search Client Stub
4、呼叫對應的服務方法
思考題
1、什麼場景下不適合使用 Protobuf,而適合使用 JSON、XML?
2、Protobuf 一節中提到的 packed 編碼,是什麼?
總結
在開篇內容中,我利用了儘量簡短的描述給你介紹了接下來所必須、必要的知識點 希望你能夠有所收穫,建議能到我給的參考資料處進行深入學習,是最好的了
參考資料
4.2 gRPC Client and Server
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
本章節將使用 Go 來編寫 gRPC Server 和 Client,讓其互相通訊。在此之上會使用到如下庫:
- google.golang.org/grpc
- github.com/golang/protobuf/protoc-gen-go
安裝
gRPC
go get -u google.golang.org/grpc
Protocol Buffers v3
wget https://github.com/google/protobuf/releases/download/v3.5.1/protobuf-all-3.5.1.zip
unzip protobuf-all-3.5.1.zip
cd protobuf-3.5.1/
./configure
make
make install
檢查是否安裝成功
protoc --version
若出現以下錯誤,執行 ldconfig 命名就能解決這問題
protoc: error while loading shared libraries: libprotobuf.so.15: cannot open shared object file: No such file or directory
Protoc Plugin
go get -u github.com/golang/protobuf/protoc-gen-go
安裝環境若有問題,可參考我先前的文章 《介紹與環境安裝》 內有詳細介紹,不再贅述
gRPC
本小節開始正式編寫 gRPC 相關的程式,一起上車吧 😄
圖示
目錄結構
$ tree go-grpc-example
go-grpc-example
├── client
├── proto
│ └── search.proto
└── server.go
IDL
編寫
在 proto 資料夾下的 search.proto 檔案中,寫入如下內容:
syntax = "proto3";
package proto;
service SearchService {
rpc Search(SearchRequest) returns (SearchResponse) {}
}
message SearchRequest {
string request = 1;
}
message SearchResponse {
string response = 1;
}
生成
在 proto 資料夾下執行如下命令:
$ protoc --go_out=plugins=grpc:. *.proto
- plugins=plugin1+plugin2:指定要載入的子外掛列表
我們定義的 proto 檔案是涉及了 RPC 服務的,而預設是不會生成 RPC 程式碼的,因此需要給出 plugins 引數傳遞給 protoc-gen-go,告訴它,請支援 RPC(這裡指定了 gRPC)
- --go_out=.:設定 Go 程式碼輸出的目錄
該指令會載入 protoc-gen-go 外掛達到生成 Go 程式碼的目的,生成的檔案以 .pb.go 為檔案字尾
- : (冒號)
冒號充當分隔符的作用,後跟所需要的引數集。如果這處不涉及 RPC,命令可簡化為:
$ protoc --go_out=. *.proto
注:建議你看看兩條命令生成的 .pb.go 檔案,分別有什麼區別
生成後
執行完畢命令後,將得到一個 .pb.go 檔案,檔案內容如下:
type SearchRequest struct {
Request string `protobuf:"bytes,1,opt,name=request" json:"request,omitempty"`
XXX_NoUnkeyedLiteral struct{} `json:"-"`
XXX_unrecognized []byte `json:"-"`
XXX_sizecache int32 `json:"-"`
}
func (m *SearchRequest) Reset() { *m = SearchRequest{} }
func (m *SearchRequest) String() string { return proto.CompactTextString(m) }
func (*SearchRequest) ProtoMessage() {}
func (*SearchRequest) Descriptor() ([]byte, []int) {
return fileDescriptor_search_8b45f79ee13ff6a3, []int{0}
}
func (m *SearchRequest) GetRequest() string {
if m != nil {
return m.Request
}
return ""
}
透過閱讀這一部分程式碼,可以知道主要涉及如下方面:
- 欄位名稱從小寫下劃線轉換為大寫駝峰模式(欄位匯出)
- 生成一組 Getters 方法,能便於處理一些空指標取值的情況
- ProtoMessage 方法實作 proto.Message 的介面
- 生成 Rest 方法,便於將 Protobuf 結構體恢復為零值
- Repeated 轉換為切片
type SearchRequest struct {
Request string `protobuf:"bytes,1,opt,name=request" json:"request,omitempty"`
}
func (*SearchRequest) Descriptor() ([]byte, []int) {
return fileDescriptor_search_8b45f79ee13ff6a3, []int{0}
}
type SearchResponse struct {
Response string `protobuf:"bytes,1,opt,name=response" json:"response,omitempty"`
}
func (*SearchResponse) Descriptor() ([]byte, []int) {
return fileDescriptor_search_8b45f79ee13ff6a3, []int{1}
}
...
func init() { proto.RegisterFile("search.proto", fileDescriptor_search_8b45f79ee13ff6a3) }
var fileDescriptor_search_8b45f79ee13ff6a3 = []byte{
// 131 bytes of a gzipped FileDescriptorProto
0x1f, 0x8b, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0xff, 0xe2, 0xe2, 0x29, 0x4e, 0x4d, 0x2c,
0x4a, 0xce, 0xd0, 0x2b, 0x28, 0xca, 0x2f, 0xc9, 0x17, 0x62, 0x05, 0x53, 0x4a, 0x9a, 0x5c, 0xbc,
0xc1, 0x60, 0xe1, 0xa0, 0xd4, 0xc2, 0xd2, 0xd4, 0xe2, 0x12, 0x21, 0x09, 0x2e, 0xf6, 0x22, 0x08,
0x53, 0x82, 0x51, 0x81, 0x51, 0x83, 0x33, 0x08, 0xc6, 0x55, 0xd2, 0xe1, 0xe2, 0x83, 0x29, 0x2d,
0x2e, 0xc8, 0xcf, 0x2b, 0x4e, 0x15, 0x92, 0xe2, 0xe2, 0x28, 0x82, 0xb2, 0xa1, 0x8a, 0xe1, 0x7c,
0x23, 0x0f, 0x98, 0xc1, 0xc1, 0xa9, 0x45, 0x65, 0x99, 0xc9, 0xa9, 0x42, 0xe6, 0x5c, 0x6c, 0x10,
0x01, 0x21, 0x11, 0x88, 0x13, 0xf4, 0x50, 0x2c, 0x96, 0x12, 0x45, 0x13, 0x85, 0x98, 0xa3, 0xc4,
0x90, 0xc4, 0x06, 0x16, 0x37, 0x06, 0x04, 0x00, 0x00, 0xff, 0xff, 0xf3, 0xba, 0x74, 0x95, 0xc0,
0x00, 0x00, 0x00,
}
而這一部分程式碼主要是圍繞 fileDescriptor 進行,在這裡 fileDescriptor_search_8b45f79ee13ff6a3 表示一個編譯後的 proto 檔案,而每一個方法都包含 Descriptor 方法,代表著這一個方法在 fileDescriptor 中具體的 Message Field
Server
這一小節將編寫 gRPC Server 的基礎模板,完成一個方法的呼叫。對 server.go 寫入如下內容:
package main
import (
"context"
"log"
"net"
"google.golang.org/grpc"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
return &pb.SearchResponse{Response: r.GetRequest() + " Server"}, nil
}
const PORT = "9001"
func main() {
server := grpc.NewServer()
pb.RegisterSearchServiceServer(server, &SearchService{})
lis, err := net.Listen("tcp", ":"+PORT)
if err != nil {
log.Fatalf("net.Listen err: %v", err)
}
server.Serve(lis)
}
- 建立 gRPC Server 物件,你可以理解為它是 Server 端的抽象物件
- 將 SearchService(其包含需要被呼叫的服務端介面)註冊到 gRPC Server 的內部註冊中心。這樣可以在接受到請求時,透過內部的服務發現,發現該服務端介面並轉接進行邏輯處理
- 建立 Listen,監聽 TCP 埠
- gRPC Server 開始 lis.Accept,直到 Stop 或 GracefulStop
Client
接下來編寫 gRPC Go Client 的基礎模板,開啟 client/client.go 檔案,寫入以下內容:
package main
import (
"context"
"log"
"google.golang.org/grpc"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
const PORT = "9001"
func main() {
conn, err := grpc.Dial(":"+PORT, grpc.WithInsecure())
if err != nil {
log.Fatalf("grpc.Dial err: %v", err)
}
defer conn.Close()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(context.Background(), &pb.SearchRequest{
Request: "gRPC",
})
if err != nil {
log.Fatalf("client.Search err: %v", err)
}
log.Printf("resp: %s", resp.GetResponse())
}
- 建立與給定目標(服務端)的連線互動
- 建立 SearchService 的客戶端物件
- 傳送 RPC 請求,等待同步響應,得到回撥後返回響應結果
- 輸出響應結果
驗證
啟動 Server
$ pwd
$GOPATH/github.com/EDDYCJY/go-grpc-example
$ go run server.go
啟動 Client
$ pwd
$GOPATH/github.com/EDDYCJY/go-grpc-example/client
$ go run client.go
2018/09/23 11:06:23 resp: gRPC Server
總結
在本章節,我們對 Protobuf、gRPC Client/Server 分別都進行了介紹。希望你結合文中講述內容再寫一個 Demo 進行深入瞭解,肯定會更棒 🤔
參考
本系列示例程式碼
4.3 gRPC Streaming, Client and Server
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
本章節將介紹 gRPC 的流式,分為三種類型:
- Server-side streaming RPC:伺服器端流式 RPC
- Client-side streaming RPC:客戶端流式 RPC
- Bidirectional streaming RPC:雙向流式 RPC
流
任何技術,因為有痛點,所以才有了存在的必要性。如果您想要了解 gRPC 的流式呼叫,請繼續
圖
gRPC Streaming 是基於 HTTP/2 的,後續章節再進行詳細講解
為什麼不用 Simple RPC
流式為什麼要存在呢,是 Simple RPC 有什麼問題嗎?透過模擬業務場景,可得知在使用 Simple RPC 時,有如下問題:
- 資料包過大造成的瞬時壓力
- 接收資料包時,需要所有資料包都接受成功且正確後,才能夠回撥響應,進行業務處理(無法客戶端邊傳送,服務端邊處理)
為什麼用 Streaming RPC
- 大規模資料包
- 實時場景
模擬場景
每天早上 6 點,都有一批百萬級別的資料集要同從 A 同步到 B,在同步的時候,會做一系列操作(歸檔、資料分析、畫像、日誌等)。這一次性涉及的資料量確實大
在同步完成後,也有人馬上會去查閱資料,為了新的一天籌備。也符合實時性。
兩者相較下,這個場景下更適合使用 Streaming RPC
gRPC
在講解具體的 gRPC 流式程式碼時,會著重在第一節講解,因為三種模式其實是不同的組合。希望你能夠注重理解,舉一反三,其實都是一樣的知識點 👍
目錄結構
$ tree go-grpc-example
go-grpc-example
├── client
│ ├── simple_client
│ │ └── client.go
│ └── stream_client
│ └── client.go
├── proto
│ ├── search.proto
│ └── stream.proto
└── server
├── simple_server
│ └── server.go
└── stream_server
└── server.go
增加 stream_server、stream_client 存放服務端和客戶端檔案,proto/stream.proto 用於編寫 IDL
IDL
在 proto 資料夾下的 stream.proto 檔案中,寫入如下內容:
syntax = "proto3";
package proto;
service StreamService {
rpc List(StreamRequest) returns (stream StreamResponse) {};
rpc Record(stream StreamRequest) returns (StreamResponse) {};
rpc Route(stream StreamRequest) returns (stream StreamResponse) {};
}
message StreamPoint {
string name = 1;
int32 value = 2;
}
message StreamRequest {
StreamPoint pt = 1;
}
message StreamResponse {
StreamPoint pt = 1;
}
注意關鍵字 stream,宣告其為一個流方法。這裡共涉及三個方法,對應關係為
- List:伺服器端流式 RPC
- Record:客戶端流式 RPC
- Route:雙向流式 RPC
基礎模板 + 空定義
Server
package main
import (
"log"
"net"
"google.golang.org/grpc"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
type StreamService struct{}
const (
PORT = "9002"
)
func main() {
server := grpc.NewServer()
pb.RegisterStreamServiceServer(server, &StreamService{})
lis, err := net.Listen("tcp", ":"+PORT)
if err != nil {
log.Fatalf("net.Listen err: %v", err)
}
server.Serve(lis)
}
func (s *StreamService) List(r *pb.StreamRequest, stream pb.StreamService_ListServer) error {
return nil
}
func (s *StreamService) Record(stream pb.StreamService_RecordServer) error {
return nil
}
func (s *StreamService) Route(stream pb.StreamService_RouteServer) error {
return nil
}
寫程式碼前,建議先將 gRPC Server 的基礎模板和介面給空定義出來。若有不清楚可參見上一章節的知識點
Client
package main
import (
"log"
"google.golang.org/grpc"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
const (
PORT = "9002"
)
func main() {
conn, err := grpc.Dial(":"+PORT, grpc.WithInsecure())
if err != nil {
log.Fatalf("grpc.Dial err: %v", err)
}
defer conn.Close()
client := pb.NewStreamServiceClient(conn)
err = printLists(client, &pb.StreamRequest{Pt: &pb.StreamPoint{Name: "gRPC Stream Client: List", Value: 2018}})
if err != nil {
log.Fatalf("printLists.err: %v", err)
}
err = printRecord(client, &pb.StreamRequest{Pt: &pb.StreamPoint{Name: "gRPC Stream Client: Record", Value: 2018}})
if err != nil {
log.Fatalf("printRecord.err: %v", err)
}
err = printRoute(client, &pb.StreamRequest{Pt: &pb.StreamPoint{Name: "gRPC Stream Client: Route", Value: 2018}})
if err != nil {
log.Fatalf("printRoute.err: %v", err)
}
}
func printLists(client pb.StreamServiceClient, r *pb.StreamRequest) error {
return nil
}
func printRecord(client pb.StreamServiceClient, r *pb.StreamRequest) error {
return nil
}
func printRoute(client pb.StreamServiceClient, r *pb.StreamRequest) error {
return nil
}
一、Server-side streaming RPC:伺服器端流式 RPC
伺服器端流式 RPC,顯然是單向流,並代指 Server 為 Stream 而 Client 為普通 RPC 請求
簡單來講就是客戶端發起一次普通的 RPC 請求,服務端透過流式響應多次傳送資料集,客戶端 Recv 接收資料集。大致如圖:
Server
func (s *StreamService) List(r *pb.StreamRequest, stream pb.StreamService_ListServer) error {
for n := 0; n <= 6; n++ {
err := stream.Send(&pb.StreamResponse{
Pt: &pb.StreamPoint{
Name: r.Pt.Name,
Value: r.Pt.Value + int32(n),
},
})
if err != nil {
return err
}
}
return nil
}
在 Server,主要留意 stream.Send 方法。它看上去能傳送 N 次?有沒有大小限制?
type StreamService_ListServer interface {
Send(*StreamResponse) error
grpc.ServerStream
}
func (x *streamServiceListServer) Send(m *StreamResponse) error {
return x.ServerStream.SendMsg(m)
}
透過閱讀原始碼,可得知是 protoc 在生成時,根據定義生成了各式各樣符合標準的介面方法。最終再統一排程內部的 SendMsg 方法,該方法涉及以下過程:
- 訊息體(物件)序列化
- 壓縮序列化後的訊息體
- 對正在傳輸的訊息體增加 5 個位元組的 header
- 判斷壓縮+序列化後的訊息體總位元組長度是否大於預設的 maxSendMessageSize(預設值為
math.MaxInt32),若超出則提示錯誤 - 寫入給流的資料集
Client
func printLists(client pb.StreamServiceClient, r *pb.StreamRequest) error {
stream, err := client.List(context.Background(), r)
if err != nil {
return err
}
for {
resp, err := stream.Recv()
if err == io.EOF {
break
}
if err != nil {
return err
}
log.Printf("resp: pj.name: %s, pt.value: %d", resp.Pt.Name, resp.Pt.Value)
}
return nil
}
在 Client,主要留意 stream.Recv() 方法。什麼情況下 io.EOF ?什麼情況下存在錯誤資訊呢?
type StreamService_ListClient interface {
Recv() (*StreamResponse, error)
grpc.ClientStream
}
func (x *streamServiceListClient) Recv() (*StreamResponse, error) {
m := new(StreamResponse)
if err := x.ClientStream.RecvMsg(m); err != nil {
return nil, err
}
return m, nil
}
RecvMsg 會從流中讀取完整的 gRPC 訊息體,另外透過閱讀原始碼可得知:
(1)RecvMsg 是阻塞等待的
(2)RecvMsg 當流成功/結束(呼叫了 Close)時,會返回 io.EOF
(3)RecvMsg 當流出現任何錯誤時,流會被中止,錯誤資訊會包含 RPC 錯誤碼。而在 RecvMsg 中可能出現如下錯誤:
- io.EOF
- io.ErrUnexpectedEOF
- transport.ConnectionError
- google.golang.org/grpc/codes
同時需要注意,預設的 MaxReceiveMessageSize 值為 1024 1024 4,建議不要超出
驗證
執行 stream_server/server.go:
$ go run server.go
執行 stream_client/client.go:
$ go run client.go
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2018
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2019
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2020
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2021
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2022
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2023
2018/09/24 16:18:25 resp: pj.name: gRPC Stream Client: List, pt.value: 2024
二、Client-side streaming RPC:客戶端流式 RPC
客戶端流式 RPC,單向流,客戶端透過流式發起多次 RPC 請求給服務端,服務端發起一次響應給客戶端,大致如圖:
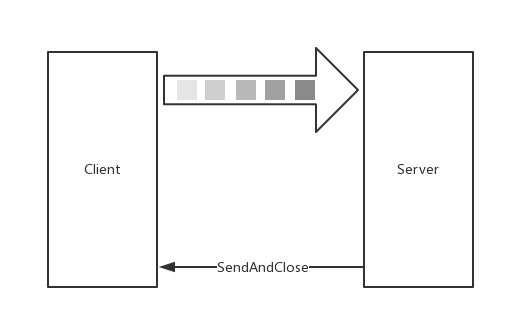
Server
func (s *StreamService) Record(stream pb.StreamService_RecordServer) error {
for {
r, err := stream.Recv()
if err == io.EOF {
return stream.SendAndClose(&pb.StreamResponse{Pt: &pb.StreamPoint{Name: "gRPC Stream Server: Record", Value: 1}})
}
if err != nil {
return err
}
log.Printf("stream.Recv pt.name: %s, pt.value: %d", r.Pt.Name, r.Pt.Value)
}
return nil
}
多了一個從未見過的方法 stream.SendAndClose,它是做什麼用的呢?
在這段程式中,我們對每一個 Recv 都進行了處理,當發現 io.EOF (流關閉) 後,需要將最終的響應結果傳送給客戶端,同時關閉正在另外一側等待的 Recv
Client
func printRecord(client pb.StreamServiceClient, r *pb.StreamRequest) error {
stream, err := client.Record(context.Background())
if err != nil {
return err
}
for n := 0; n < 6; n++ {
err := stream.Send(r)
if err != nil {
return err
}
}
resp, err := stream.CloseAndRecv()
if err != nil {
return err
}
log.Printf("resp: pj.name: %s, pt.value: %d", resp.Pt.Name, resp.Pt.Value)
return nil
}
stream.CloseAndRecv 和 stream.SendAndClose 是配套使用的流方法,相信聰明的你已經秒懂它的作用了
驗證
重啟 stream_server/server.go,再次執行 stream_client/client.go:
stream_client:
$ go run client.go
2018/09/24 16:23:03 resp: pj.name: gRPC Stream Server: Record, pt.value: 1
stream_server:
$ go run server.go
2018/09/24 16:23:03 stream.Recv pt.name: gRPC Stream Client: Record, pt.value: 2018
2018/09/24 16:23:03 stream.Recv pt.name: gRPC Stream Client: Record, pt.value: 2018
2018/09/24 16:23:03 stream.Recv pt.name: gRPC Stream Client: Record, pt.value: 2018
2018/09/24 16:23:03 stream.Recv pt.name: gRPC Stream Client: Record, pt.value: 2018
2018/09/24 16:23:03 stream.Recv pt.name: gRPC Stream Client: Record, pt.value: 2018
2018/09/24 16:23:03 stream.Recv pt.name: gRPC Stream Client: Record, pt.value: 2018
三、Bidirectional streaming RPC:雙向流式 RPC
雙向流式 RPC,顧名思義是雙向流。由客戶端以流式的方式發起請求,服務端同樣以流式的方式響應請求
首個請求一定是 Client 發起,但具體互動方式(誰先誰後、一次發多少、響應多少、什麼時候關閉)根據程式編寫的方式來確定(可以結合協程)
假設該雙向流是按順序傳送的話,大致如圖:
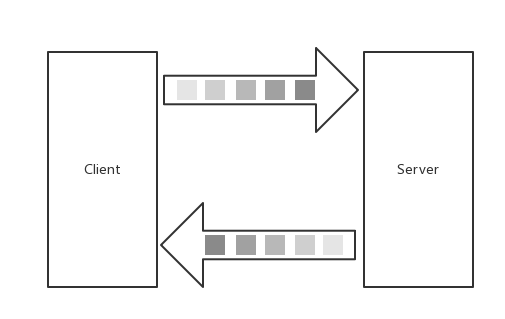
還是要強調,雙向流變化很大,因程式編寫的不同而不同。雙向流圖示無法適用不同的場景
Server
func (s *StreamService) Route(stream pb.StreamService_RouteServer) error {
n := 0
for {
err := stream.Send(&pb.StreamResponse{
Pt: &pb.StreamPoint{
Name: "gPRC Stream Client: Route",
Value: int32(n),
},
})
if err != nil {
return err
}
r, err := stream.Recv()
if err == io.EOF {
return nil
}
if err != nil {
return err
}
n++
log.Printf("stream.Recv pt.name: %s, pt.value: %d", r.Pt.Name, r.Pt.Value)
}
return nil
}
Client
func printRoute(client pb.StreamServiceClient, r *pb.StreamRequest) error {
stream, err := client.Route(context.Background())
if err != nil {
return err
}
for n := 0; n <= 6; n++ {
err = stream.Send(r)
if err != nil {
return err
}
resp, err := stream.Recv()
if err == io.EOF {
break
}
if err != nil {
return err
}
log.Printf("resp: pj.name: %s, pt.value: %d", resp.Pt.Name, resp.Pt.Value)
}
stream.CloseSend()
return nil
}
驗證
重啟 stream_server/server.go,再次執行 stream_client/client.go:
stream_server
$ go run server.go
2018/09/24 16:29:43 stream.Recv pt.name: gRPC Stream Client: Route, pt.value: 2018
2018/09/24 16:29:43 stream.Recv pt.name: gRPC Stream Client: Route, pt.value: 2018
2018/09/24 16:29:43 stream.Recv pt.name: gRPC Stream Client: Route, pt.value: 2018
2018/09/24 16:29:43 stream.Recv pt.name: gRPC Stream Client: Route, pt.value: 2018
2018/09/24 16:29:43 stream.Recv pt.name: gRPC Stream Client: Route, pt.value: 2018
2018/09/24 16:29:43 stream.Recv pt.name: gRPC Stream Client: Route, pt.value: 2018
stream_client
$ go run client.go
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 0
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 1
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 2
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 3
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 4
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 5
2018/09/24 16:29:43 resp: pj.name: gPRC Stream Client: Route, pt.value: 6
總結
在本文共介紹了三類流的互動方式,可以根據實際的業務場景去選擇合適的方式。會事半功倍哦 🎑
參考
本系列示例程式碼
4.4 TLS 證書認證
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
在前面的章節裡,我們介紹了 gRPC 的四種 API 使用方式。是不是很簡單呢 😀
此時存在一個安全問題,先前的例子中 gRPC Client/Server 都是明文傳輸的,會不會有被竊聽的風險呢?
從結論上來講,是有的。在明文通訊的情況下,你的請求就是裸奔的,有可能被第三方惡意篡改或者偽造為“非法”的資料
抓個包
嗯,明文傳輸無誤。這是有問題的,接下將改造我們的 gRPC,以便於解決這個問題 😤
證書生成
私鑰
openssl ecparam -genkey -name secp384r1 -out server.key
自籤公鑰
openssl req -new -x509 -sha256 -key server.key -out server.pem -days 3650
填寫資訊
Country Name (2 letter code) []:
State or Province Name (full name) []:
Locality Name (eg, city) []:
Organization Name (eg, company) []:
Organizational Unit Name (eg, section) []:
Common Name (eg, fully qualified host name) []:go-grpc-example
Email Address []:
生成完畢
生成證書結束後,將證書相關檔案放到 conf/ 下,目錄結構:
$ tree go-grpc-example
go-grpc-example
├── client
├── conf
│ ├── server.key
│ └── server.pem
├── proto
└── server
├── simple_server
└── stream_server
由於本文偏向 gRPC,詳解可參見 《製作證書》。後續番外可能會展開細節描述 👌
為什麼之前不需要證書
在 simple_server 中,為什麼“啥事都沒幹”就能在不需要證書的情況下執行呢?
Server
grpc.NewServer()
在服務端顯然沒有傳入任何 DialOptions
Client
conn, err := grpc.Dial(":"+PORT, grpc.WithInsecure())
在客戶端留意到 grpc.WithInsecure() 方法
func WithInsecure() DialOption {
return newFuncDialOption(func(o *dialOptions) {
o.insecure = true
})
}
在方法內可以看到 WithInsecure 返回一個 DialOption,並且它最終會透過讀取設定的值來停用安全傳輸
那麼它“最終”又是在哪裡處理的呢,我們把視線移到 grpc.Dial() 方法內
func DialContext(ctx context.Context, target string, opts ...DialOption) (conn *ClientConn, err error) {
...
for _, opt := range opts {
opt.apply(&cc.dopts)
}
...
if !cc.dopts.insecure {
if cc.dopts.copts.TransportCredentials == nil {
return nil, errNoTransportSecurity
}
} else {
if cc.dopts.copts.TransportCredentials != nil {
return nil, errCredentialsConflict
}
for _, cd := range cc.dopts.copts.PerRPCCredentials {
if cd.RequireTransportSecurity() {
return nil, errTransportCredentialsMissing
}
}
}
...
creds := cc.dopts.copts.TransportCredentials
if creds != nil && creds.Info().ServerName != "" {
cc.authority = creds.Info().ServerName
} else if cc.dopts.insecure && cc.dopts.authority != "" {
cc.authority = cc.dopts.authority
} else {
// Use endpoint from "scheme://authority/endpoint" as the default
// authority for ClientConn.
cc.authority = cc.parsedTarget.Endpoint
}
...
}
gRPC
接下來我們將正式開始編碼,在 gRPC Client/Server 上實作 TLS 證書認證的支援 🤔
TLS Server
package main
import (
"context"
"log"
"net"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
...
const PORT = "9001"
func main() {
c, err := credentials.NewServerTLSFromFile("../../conf/server.pem", "../../conf/server.key")
if err != nil {
log.Fatalf("credentials.NewServerTLSFromFile err: %v", err)
}
server := grpc.NewServer(grpc.Creds(c))
pb.RegisterSearchServiceServer(server, &SearchService{})
lis, err := net.Listen("tcp", ":"+PORT)
if err != nil {
log.Fatalf("net.Listen err: %v", err)
}
server.Serve(lis)
}
- credentials.NewServerTLSFromFile:根據服務端輸入的證書檔案和金鑰構造 TLS 憑證
func NewServerTLSFromFile(certFile, keyFile string) (TransportCredentials, error) {
cert, err := tls.LoadX509KeyPair(certFile, keyFile)
if err != nil {
return nil, err
}
return NewTLS(&tls.Config{Certificates: []tls.Certificate{cert}}), nil
}
- grpc.Creds():返回一個 ServerOption,用於設定伺服器連線的憑據。用於
grpc.NewServer(opt ...ServerOption)為 gRPC Server 設定連線選項
func Creds(c credentials.TransportCredentials) ServerOption {
return func(o *options) {
o.creds = c
}
}
經過以上兩個簡單步驟,gRPC Server 就建立起需證書認證的服務啦 🤔
TLS Client
package main
import (
"context"
"log"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
const PORT = "9001"
func main() {
c, err := credentials.NewClientTLSFromFile("../../conf/server.pem", "go-grpc-example")
if err != nil {
log.Fatalf("credentials.NewClientTLSFromFile err: %v", err)
}
conn, err := grpc.Dial(":"+PORT, grpc.WithTransportCredentials(c))
if err != nil {
log.Fatalf("grpc.Dial err: %v", err)
}
defer conn.Close()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(context.Background(), &pb.SearchRequest{
Request: "gRPC",
})
if err != nil {
log.Fatalf("client.Search err: %v", err)
}
log.Printf("resp: %s", resp.GetResponse())
}
- credentials.NewClientTLSFromFile():根據客戶端輸入的證書檔案和金鑰構造 TLS 憑證。serverNameOverride 為服務名稱
func NewClientTLSFromFile(certFile, serverNameOverride string) (TransportCredentials, error) {
b, err := ioutil.ReadFile(certFile)
if err != nil {
return nil, err
}
cp := x509.NewCertPool()
if !cp.AppendCertsFromPEM(b) {
return nil, fmt.Errorf("credentials: failed to append certificates")
}
return NewTLS(&tls.Config{ServerName: serverNameOverride, RootCAs: cp}), nil
}
- grpc.WithTransportCredentials():返回一個設定連線的 DialOption 選項。用於
grpc.Dial(target string, opts ...DialOption)設定連線選項
func WithTransportCredentials(creds credentials.TransportCredentials) DialOption {
return newFuncDialOption(func(o *dialOptions) {
o.copts.TransportCredentials = creds
})
}
驗證
請求
重新啟動 server.go 和執行 client.go,得到響應結果
$ go run client.go
2018/09/30 20:00:21 resp: gRPC Server
抓個包
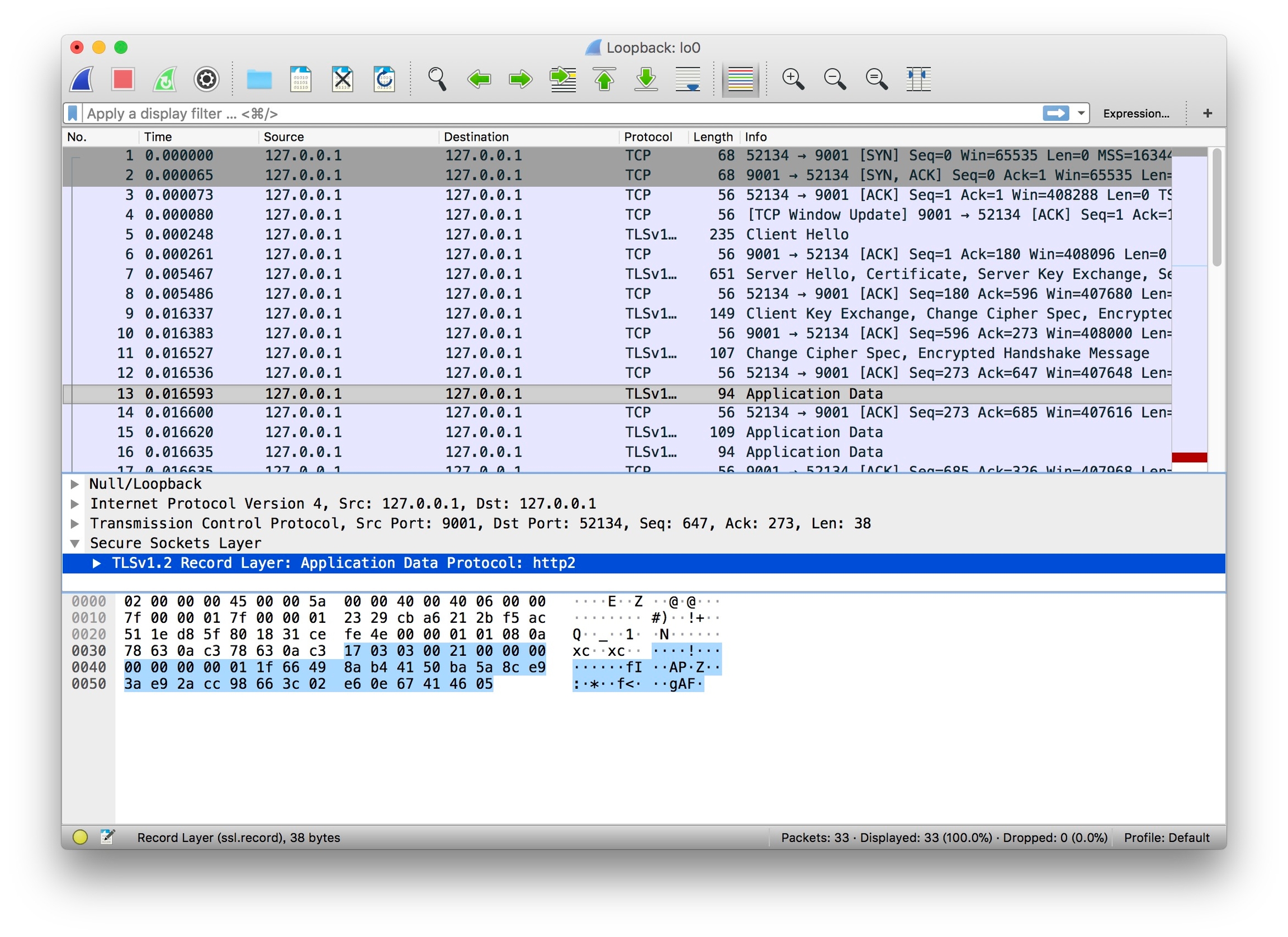
成功。
總結
在本章節我們實作了 gRPC TLS Client/Servert,你以為大功告成了嗎?我不 😤
問題
你仔細再看看,Client 是基於 Server 端的證書和服務名稱來建立請求的。這樣的話,你就需要將 Server 的證書透過各種手段給到 Client 端,否則是無法完成這項任務的
問題也就來了,你無法保證你的“各種手段”是安全的,畢竟現在的網路環境是很危險的,萬一被...
我們將在下一章節解決這個問題,保證其可靠性 🙂
參考
本系列示例程式碼
4.5 基於 CA 的 TLS 證書認證
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
在上一章節中,我們提出了一個問題。就是如何保證證書的可靠性和有效性?你如何確定你 Server、Client 的證書是對的呢?
CA
為了保證證書的可靠性和有效性,在這裡可引入 CA 頒發的根證書的概念。其遵守 X.509 標準
根證書
根證書(root certificate)是屬於根證書頒發機構(CA)的公鑰證書。我們可以透過驗證 CA 的簽名從而信任 CA ,任何人都可以得到 CA 的證書(含公鑰),用以驗證它所簽發的證書(客戶端、服務端)
它包含的檔案如下:
- 公鑰
- 金鑰
生成 Key
openssl genrsa -out ca.key 2048
生成金鑰
openssl req -new -x509 -days 7200 -key ca.key -out ca.pem
填寫資訊
Country Name (2 letter code) []:
State or Province Name (full name) []:
Locality Name (eg, city) []:
Organization Name (eg, company) []:
Organizational Unit Name (eg, section) []:
Common Name (eg, fully qualified host name) []:go-grpc-example
Email Address []:
Server
生成 CSR
openssl req -new -key server.key -out server.csr
填寫資訊
Country Name (2 letter code) []:
State or Province Name (full name) []:
Locality Name (eg, city) []:
Organization Name (eg, company) []:
Organizational Unit Name (eg, section) []:
Common Name (eg, fully qualified host name) []:go-grpc-example
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
CSR 是 Cerificate Signing Request 的英文縮寫,為證書請求檔案。主要作用是 CA 會利用 CSR 檔案進行簽名使得攻擊者無法偽裝或篡改原有證書
基於 CA 簽發
openssl x509 -req -sha256 -CA ca.pem -CAkey ca.key -CAcreateserial -days 3650 -in server.csr -out server.pem
Client
生成 Key
openssl ecparam -genkey -name secp384r1 -out client.key
生成 CSR
openssl req -new -key client.key -out client.csr
基於 CA 簽發
openssl x509 -req -sha256 -CA ca.pem -CAkey ca.key -CAcreateserial -days 3650 -in client.csr -out client.pem
整理目錄
至此我們生成了一堆檔案,請按照以下目錄結構存放:
$ tree conf
conf
├── ca.key
├── ca.pem
├── ca.srl
├── client
│ ├── client.csr
│ ├── client.key
│ └── client.pem
└── server
├── server.csr
├── server.key
└── server.pem
另外有一些檔案是不應該出現在倉庫內,應當保密或刪除的。但為了真實演示所以保留著(敲黑板)
gRPC
接下來將正式開始針對 gRPC 進行編碼,改造上一章節的程式碼。目標是基於 CA 進行 TLS 認證 🤫
Server
package main
import (
"context"
"log"
"net"
"crypto/tls"
"crypto/x509"
"io/ioutil"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
...
const PORT = "9001"
func main() {
cert, err := tls.LoadX509KeyPair("../../conf/server/server.pem", "../../conf/server/server.key")
if err != nil {
log.Fatalf("tls.LoadX509KeyPair err: %v", err)
}
certPool := x509.NewCertPool()
ca, err := ioutil.ReadFile("../../conf/ca.pem")
if err != nil {
log.Fatalf("ioutil.ReadFile err: %v", err)
}
if ok := certPool.AppendCertsFromPEM(ca); !ok {
log.Fatalf("certPool.AppendCertsFromPEM err")
}
c := credentials.NewTLS(&tls.Config{
Certificates: []tls.Certificate{cert},
ClientAuth: tls.RequireAndVerifyClientCert,
ClientCAs: certPool,
})
server := grpc.NewServer(grpc.Creds(c))
pb.RegisterSearchServiceServer(server, &SearchService{})
lis, err := net.Listen("tcp", ":"+PORT)
if err != nil {
log.Fatalf("net.Listen err: %v", err)
}
server.Serve(lis)
}
- tls.LoadX509KeyPair():從證書相關檔案中讀取和解析資訊,得到證書公鑰、金鑰對
func LoadX509KeyPair(certFile, keyFile string) (Certificate, error) {
certPEMBlock, err := ioutil.ReadFile(certFile)
if err != nil {
return Certificate{}, err
}
keyPEMBlock, err := ioutil.ReadFile(keyFile)
if err != nil {
return Certificate{}, err
}
return X509KeyPair(certPEMBlock, keyPEMBlock)
}
- x509.NewCertPool():建立一個新的、空的 CertPool
- certPool.AppendCertsFromPEM():嘗試解析所傳入的 PEM 編碼的證書。如果解析成功會將其加到 CertPool 中,便於後面的使用
- credentials.NewTLS:構建基於 TLS 的 TransportCredentials 選項
- tls.Config:Config 結構用於設定 TLS 客戶端或伺服器
在 Server,共使用了三個 Config 設定項:
(1)Certificates:設定證書鏈,允許包含一個或多個
(2)ClientAuth:要求必須校驗客戶端的證書。可以根據實際情況選用以下引數:
const (
NoClientCert ClientAuthType = iota
RequestClientCert
RequireAnyClientCert
VerifyClientCertIfGiven
RequireAndVerifyClientCert
)
(3)ClientCAs:設定根證書的集合,校驗方式使用 ClientAuth 中設定的模式
Client
package main
import (
"context"
"crypto/tls"
"crypto/x509"
"io/ioutil"
"log"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
const PORT = "9001"
func main() {
cert, err := tls.LoadX509KeyPair("../../conf/client/client.pem", "../../conf/client/client.key")
if err != nil {
log.Fatalf("tls.LoadX509KeyPair err: %v", err)
}
certPool := x509.NewCertPool()
ca, err := ioutil.ReadFile("../../conf/ca.pem")
if err != nil {
log.Fatalf("ioutil.ReadFile err: %v", err)
}
if ok := certPool.AppendCertsFromPEM(ca); !ok {
log.Fatalf("certPool.AppendCertsFromPEM err")
}
c := credentials.NewTLS(&tls.Config{
Certificates: []tls.Certificate{cert},
ServerName: "go-grpc-example",
RootCAs: certPool,
})
conn, err := grpc.Dial(":"+PORT, grpc.WithTransportCredentials(c))
if err != nil {
log.Fatalf("grpc.Dial err: %v", err)
}
defer conn.Close()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(context.Background(), &pb.SearchRequest{
Request: "gRPC",
})
if err != nil {
log.Fatalf("client.Search err: %v", err)
}
log.Printf("resp: %s", resp.GetResponse())
}
在 Client 中絕大部分與 Server 一致,不同點的地方是,在 Client 請求 Server 端時,Client 端會使用根證書和 ServerName 去對 Server 端進行校驗
簡單流程大致如下:
- Client 透過請求得到 Server 端的證書
- 使用 CA 認證的根證書對 Server 端的證書進行可靠性、有效性等校驗
- 校驗 ServerName 是否可用、有效
當然了,在設定了 tls.RequireAndVerifyClientCert 模式的情況下,Server 也會使用 CA 認證的根證書對 Client 端的證書進行可靠性、有效性等校驗。也就是兩邊都會進行校驗,極大的保證了安全性 👍
驗證
重新啟動 server.go 和執行 client.go,檢視響應結果是否正常
總結
在本章節,我們使用 CA 頒發的根證書對客戶端、服務端的證書進行了簽發。進一步的提高了兩者的通訊安全
這回是真的大功告成了!
參考
本系列示例程式碼
4.6 Unary and Stream interceptor
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
我想在每個 RPC 方法的前或後做某些事情,怎麼做?
本章節將要介紹的攔截器(interceptor),就能幫你在合適的地方實作這些功能。
有幾種方法
在 gRPC 中,大類可分為兩種 RPC 方法,與攔截器的對應關係是:
- 普通方法:一元攔截器(grpc.UnaryInterceptor)
- 流方法:流攔截器(grpc.StreamInterceptor)
看一看
grpc.UnaryInterceptor
func UnaryInterceptor(i UnaryServerInterceptor) ServerOption {
return func(o *options) {
if o.unaryInt != nil {
panic("The unary server interceptor was already set and may not be reset.")
}
o.unaryInt = i
}
}
函式原型:
type UnaryServerInterceptor func(ctx context.Context, req interface{}, info *UnaryServerInfo, handler UnaryHandler) (resp interface{}, err error)
透過檢視原始碼可得知,要完成一個攔截器需要實作 UnaryServerInterceptor 方法。形參如下:
- ctx context.Context:請求上下文
- req interface{}:RPC 方法的請求引數
- info *UnaryServerInfo:RPC 方法的所有資訊
- handler UnaryHandler:RPC 方法本身
grpc.StreamInterceptor
func StreamInterceptor(i StreamServerInterceptor) ServerOption
函式原型:
type StreamServerInterceptor func(srv interface{}, ss ServerStream, info *StreamServerInfo, handler StreamHandler) error
StreamServerInterceptor 與 UnaryServerInterceptor 形參的意義是一樣,不再贅述
如何實作多個攔截器
另外,可以發現 gRPC 本身居然只能設定一個攔截器,難道所有的邏輯都只能寫在一起?
關於這一點,你可以放心。採用開源專案 go-grpc-middleware 就可以解決這個問題,本章也會使用它。
import "github.com/grpc-ecosystem/go-grpc-middleware"
myServer := grpc.NewServer(
grpc.StreamInterceptor(grpc_middleware.ChainStreamServer(
...
)),
grpc.UnaryInterceptor(grpc_middleware.ChainUnaryServer(
...
)),
)
gRPC
從本節開始編寫 gRPC interceptor 的程式碼,我們會將實作以下攔截器:
- logging:RPC 方法的入參出參的日誌輸出
- recover:RPC 方法的異常保護和日誌輸出
實作 interceptor
logging
func LoggingInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (interface{}, error) {
log.Printf("gRPC method: %s, %v", info.FullMethod, req)
resp, err := handler(ctx, req)
log.Printf("gRPC method: %s, %v", info.FullMethod, resp)
return resp, err
}
recover
func RecoveryInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
defer func() {
if e := recover(); e != nil {
debug.PrintStack()
err = status.Errorf(codes.Internal, "Panic err: %v", e)
}
}()
return handler(ctx, req)
}
Server
import (
"context"
"crypto/tls"
"crypto/x509"
"errors"
"io/ioutil"
"log"
"net"
"runtime/debug"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
"google.golang.org/grpc/status"
"google.golang.org/grpc/codes"
"github.com/grpc-ecosystem/go-grpc-middleware"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
...
func main() {
c, err := GetTLSCredentialsByCA()
if err != nil {
log.Fatalf("GetTLSCredentialsByCA err: %v", err)
}
opts := []grpc.ServerOption{
grpc.Creds(c),
grpc_middleware.WithUnaryServerChain(
RecoveryInterceptor,
LoggingInterceptor,
),
}
server := grpc.NewServer(opts...)
pb.RegisterSearchServiceServer(server, &SearchService{})
lis, err := net.Listen("tcp", ":"+PORT)
if err != nil {
log.Fatalf("net.Listen err: %v", err)
}
server.Serve(lis)
}
驗證
logging
啟動 simple_server/server.go,執行 simple_client/client.go 發起請求,得到結果:
$ go run server.go
2018/10/02 13:46:35 gRPC method: /proto.SearchService/Search, request:"gRPC"
2018/10/02 13:46:35 gRPC method: /proto.SearchService/Search, response:"gRPC Server"
recover
在 RPC 方法中人為地製造執行時錯誤,再重複啟動 server/client.go,得到結果:
client
$ go run client.go
2018/10/02 13:19:03 client.Search err: rpc error: code = Internal desc = Panic err: assignment to entry in nil map
exit status 1
server
$ go run server.go
goroutine 23 [running]:
runtime/debug.Stack(0xc420223588, 0x1033da9, 0xc420001980)
/usr/local/Cellar/go/1.10.1/libexec/src/runtime/debug/stack.go:24 +0xa7
runtime/debug.PrintStack()
/usr/local/Cellar/go/1.10.1/libexec/src/runtime/debug/stack.go:16 +0x22
main.RecoveryInterceptor.func1(0xc420223a10)
...
檢查服務是否仍然執行,即可知道 Recovery 是否成功生效
總結
透過本章節,你可以學會最常見的攔截器使用方法。接下來其它“新”需求只要舉一反三即可。
參考
本系列示例程式碼
4.7 讓你的服務同時提供 HTTP 介面
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
- 介面需要提供給其他業務組訪問,但是 RPC 協議不同無法內調,對方問能否走 HTTP 介面,怎麼辦?
- 微信(公眾號、小程式)等第三方回撥介面只支援 HTTP 介面,怎麼辦
我相信你在實際工作中都會遇到如上問題,在 gRPC 中都是有解決方案的,本章節將會進行介紹 🤔
為什麼可以同時提供 HTTP 介面
關鍵一點,gRPC 的協議是基於 HTTP/2 的,因此應用程式能夠在單個 TCP 埠上提供 HTTP/1.1 和 gRPC 介面服務(兩種不同的流量)
怎麼同時提供 HTTP 介面
檢測協議
if r.ProtoMajor == 2 && strings.Contains(r.Header.Get("Content-Type"), "application/grpc") {
server.ServeHTTP(w, r)
} else {
mux.ServeHTTP(w, r)
}
流程
- 檢測請求協議是否為 HTTP/2
- 判斷 Content-Type 是否為 application/grpc(gRPC 的預設標識位)
- 根據協議的不同轉發到不同的服務處理
gRPC
TLS
在前面的章節,為了便於展示因此沒有簡單封裝
在本節需複用程式碼,重新封裝了,可詳見:go-grpc-example
目錄結構
新建 simple_http_client、simple_http_server 目錄,目錄結構如下:
go-grpc-example
├── client
│ ├── simple_client
│ ├── simple_http_client
│ └── stream_client
├── conf
├── pkg
│ └── gtls
├── proto
├── server
│ ├── simple_http_server
│ ├── simple_server
│ └── stream_server
Server
在 simple_http_server 目錄下新建 server.go,寫入檔案內容:
package main
import (
"context"
"log"
"net/http"
"strings"
"github.com/EDDYCJY/go-grpc-example/pkg/gtls"
pb "github.com/EDDYCJY/go-grpc-example/proto"
"google.golang.org/grpc"
)
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
return &pb.SearchResponse{Response: r.GetRequest() + " HTTP Server"}, nil
}
const PORT = "9003"
func main() {
certFile := "../../conf/server/server.pem"
keyFile := "../../conf/server/server.key"
tlsServer := gtls.Server{
CertFile: certFile,
KeyFile: keyFile,
}
c, err := tlsServer.GetTLSCredentials()
if err != nil {
log.Fatalf("tlsServer.GetTLSCredentials err: %v", err)
}
mux := GetHTTPServeMux()
server := grpc.NewServer(grpc.Creds(c))
pb.RegisterSearchServiceServer(server, &SearchService{})
http.ListenAndServeTLS(":"+PORT,
certFile,
keyFile,
http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.ProtoMajor == 2 && strings.Contains(r.Header.Get("Content-Type"), "application/grpc") {
server.ServeHTTP(w, r)
} else {
mux.ServeHTTP(w, r)
}
return
}),
)
}
func GetHTTPServeMux() *http.ServeMux {
mux := http.NewServeMux()
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("eddycjy: go-grpc-example"))
})
return mux
}
- http.NewServeMux:建立一個新的 ServeMux,ServeMux 本質上是一個路由表。它預設實作了 ServeHTTP,因此返回 Handler 後可直接透過 HandleFunc 註冊 pattern 和處理邏輯的方法
- http.ListenAndServeTLS:可簡單的理解為提供監聽 HTTPS 服務的方法,重點的協議判斷轉發,也在這裡面
其實,你理解後就會覺得很簡單,核心步驟:判斷 -> 轉發 -> 響應。我們改變了前兩步的預設邏輯,僅此而已
Client
在 simple_http_server 目錄下新建 client.go,寫入檔案內容:
package main
import (
"context"
"log"
"google.golang.org/grpc"
"github.com/EDDYCJY/go-grpc-example/pkg/gtls"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
const PORT = "9003"
func main() {
tlsClient := gtls.Client{
ServerName: "go-grpc-example",
CertFile: "../../conf/server/server.pem",
}
c, err := tlsClient.GetTLSCredentials()
if err != nil {
log.Fatalf("tlsClient.GetTLSCredentials err: %v", err)
}
conn, err := grpc.Dial(":"+PORT, grpc.WithTransportCredentials(c))
if err != nil {
log.Fatalf("grpc.Dial err: %v", err)
}
defer conn.Close()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(context.Background(), &pb.SearchRequest{
Request: "gRPC",
})
if err != nil {
log.Fatalf("client.Search err: %v", err)
}
log.Printf("resp: %s", resp.GetResponse())
}
驗證
gRPC Client
$ go run client.go
2018/10/04 14:56:56 resp: gRPC HTTP Server
HTTP/1.1 訪問
總結
透過本章節,表面上完成了同埠提供雙服務的功能,但實際上,應該是加深了 HTTP/2 的理解和使用,這才是本質
拓展
如果你有一個需求,是要同時提供 RPC 和 RESTful JSON API 兩種介面的,不要猶豫,點進去:gRPC + gRPC Gateway 實踐
問題
你以為這個方案就萬能了嗎,不。Envoy Proxy 的支援就不完美,無法同時監聽一個埠的兩種流量 😤
參考
本系列示例程式碼
4.8 對 RPC 方法做自定義認證
專案地址:https://github.com/EDDYCJY/go-grpc-example
前言
在前面的章節中,我們介紹了兩種(證書算一種)可全域性認證的方法:
而在實際需求中,常常會對某些模組的 RPC 方法做特殊認證或校驗。今天將會講解、實作這塊的功能點
課前知識
type PerRPCCredentials interface {
GetRequestMetadata(ctx context.Context, uri ...string) (map[string]string, error)
RequireTransportSecurity() bool
}
在 gRPC 中預設定義了 PerRPCCredentials,它就是本章節的主角,是 gRPC 預設提供用於自定義認證的介面,它的作用是將所需的安全認證資訊新增到每個 RPC 方法的上下文中。其包含 2 個方法:
- GetRequestMetadata:取得當前請求認證所需的元資料(metadata)
- RequireTransportSecurity:是否需要基於 TLS 認證進行安全傳輸
目錄結構
新建 simple_token_server/server.go 和 simple_token_client/client.go,目錄結構如下:
go-grpc-example
├── client
│ ├── simple_client
│ ├── simple_http_client
│ ├── simple_token_client
│ └── stream_client
├── conf
├── pkg
├── proto
├── server
│ ├── simple_http_server
│ ├── simple_server
│ ├── simple_token_server
│ └── stream_server
└── vendor
gRPC
Client
package main
import (
"context"
"log"
"google.golang.org/grpc"
"github.com/EDDYCJY/go-grpc-example/pkg/gtls"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
const PORT = "9004"
type Auth struct {
AppKey string
AppSecret string
}
func (a *Auth) GetRequestMetadata(ctx context.Context, uri ...string) (map[string]string, error) {
return map[string]string{"app_key": a.AppKey, "app_secret": a.AppSecret}, nil
}
func (a *Auth) RequireTransportSecurity() bool {
return true
}
func main() {
tlsClient := gtls.Client{
ServerName: "go-grpc-example",
CertFile: "../../conf/server/server.pem",
}
c, err := tlsClient.GetTLSCredentials()
if err != nil {
log.Fatalf("tlsClient.GetTLSCredentials err: %v", err)
}
auth := Auth{
AppKey: "eddycjy",
AppSecret: "20181005",
}
conn, err := grpc.Dial(":"+PORT, grpc.WithTransportCredentials(c), grpc.WithPerRPCCredentials(&auth))
...
}
在 Client 端,重點實作 type PerRPCCredentials interface 所需的方法,關注兩點即可:
- struct Auth:GetRequestMetadata、RequireTransportSecurity
- grpc.WithPerRPCCredentials
Server
package main
import (
"context"
"log"
"net"
"google.golang.org/grpc"
"google.golang.org/grpc/codes"
"google.golang.org/grpc/metadata"
"google.golang.org/grpc/status"
"github.com/EDDYCJY/go-grpc-example/pkg/gtls"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
type SearchService struct {
auth *Auth
}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
if err := s.auth.Check(ctx); err != nil {
return nil, err
}
return &pb.SearchResponse{Response: r.GetRequest() + " Token Server"}, nil
}
const PORT = "9004"
func main() {
...
}
type Auth struct {
appKey string
appSecret string
}
func (a *Auth) Check(ctx context.Context) error {
md, ok := metadata.FromIncomingContext(ctx)
if !ok {
return status.Errorf(codes.Unauthenticated, "自定义认证 Token 失败")
}
var (
appKey string
appSecret string
)
if value, ok := md["app_key"]; ok {
appKey = value[0]
}
if value, ok := md["app_secret"]; ok {
appSecret = value[0]
}
if appKey != a.GetAppKey() || appSecret != a.GetAppSecret() {
return status.Errorf(codes.Unauthenticated, "自定义认证 Token 无效")
}
return nil
}
func (a *Auth) GetAppKey() string {
return "eddycjy"
}
func (a *Auth) GetAppSecret() string {
return "20181005"
}
在 Server 端就更簡單了,實際就是呼叫 metadata.FromIncomingContext 從上下文中取得 metadata,再在不同的 RPC 方法中進行認證檢查
驗證
重新啟動 server.go 和 client.go,得到以下結果:
$ go run client.go
2018/10/05 20:59:58 resp: gRPC Token Server
修改 client.go 的值,製造兩者不一致,得到無效結果:
$ go run client.go
2018/10/05 21:00:05 client.Search err: rpc error: code = Unauthenticated desc = invalid token
exit status 1
一個個加太麻煩
我相信你肯定會問一個個加,也太麻煩了吧?有這個想法的你,應當把 type PerRPCCredentials interface 做成一個攔截器(interceptor)
總結
本章節比較簡單,主要是針對 RPC 方法的自定義認證進行了介紹,如果是想做全域性的,建議是舉一反三從攔截器下手哦。
參考
本系列示例程式碼
4.9 gRPC Deadlines
前言
在前面的章節中,已經介紹了 gRPC 的基本用法。那你想想,讓它這麼裸跑真的沒問題嗎?
那麼,肯定是有問題了。今天將介紹 gRPC Deadlines 的用法,這一個必備技巧。內容也比較簡單
Deadlines
Deadlines 意指截止時間,在 gRPC 中強調 TL;DR(Too long, Don't read)並建議始終設定截止日期,為什麼呢?
為什麼要設定
當未設定 Deadlines 時,將採用預設的 DEADLINE_EXCEEDED(這個時間非常大)
如果產生了阻塞等待,就會造成大量正在進行的請求都會被保留,並且所有請求都有可能達到最大超時
這會使服務面臨資源耗盡的風險,例如記憶體,這會增加服務的延遲,或者在最壞的情況下可能導致整個程序崩潰
gRPC
Client
func main() {
...
ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Duration(5 * time.Second)))
defer cancel()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(ctx, &pb.SearchRequest{
Request: "gRPC",
})
if err != nil {
statusErr, ok := status.FromError(err)
if ok {
if statusErr.Code() == codes.DeadlineExceeded {
log.Fatalln("client.Search err: deadline")
}
}
log.Fatalf("client.Search err: %v", err)
}
log.Printf("resp: %s", resp.GetResponse())
}
- context.WithDeadline:會返回最終上下文截止時間。第一個形參為父上下文,第二個形參為調整的截止時間。若父級時間早於子級時間,則以父級時間為準,否則以子級時間為最終截止時間
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {
if cur, ok := parent.Deadline(); ok && cur.Before(d) {
// The current deadline is already sooner than the new one.
return WithCancel(parent)
}
c := &timerCtx{
cancelCtx: newCancelCtx(parent),
deadline: d,
}
propagateCancel(parent, c)
dur := time.Until(d)
if dur <= 0 {
c.cancel(true, DeadlineExceeded) // deadline has already passed
return c, func() { c.cancel(true, Canceled) }
}
c.mu.Lock()
defer c.mu.Unlock()
if c.err == nil {
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded)
})
}
return c, func() { c.cancel(true, Canceled) }
}
- context.WithTimeout:很常見的另外一個方法,是便捷操作。實際上是對於 WithDeadline 的封裝
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}
- status.FromError:返回 GRPCStatus 的具體錯誤碼,若為非法,則直接返回
codes.Unknown
Server
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
for i := 0; i < 5; i++ {
if ctx.Err() == context.Canceled {
return nil, status.Errorf(codes.Canceled, "SearchService.Search canceled")
}
time.Sleep(1 * time.Second)
}
return &pb.SearchResponse{Response: r.GetRequest() + " Server"}, nil
}
func main() {
...
}
而在 Server 端,由於 Client 已經設定了截止時間。Server 勢必要去檢測它
否則如果 Client 已經結束掉了,Server 還傻傻的在那執行,這對資源是一種極大的浪費
因此在這裡需要用 ctx.Err() == context.Canceled 進行判斷,為了模擬場景我們加了迴圈和睡眠 🤔
驗證
重新啟動 server.go 和 client.go,得到結果:
$ go run client.go
2018/10/06 17:45:55 client.Search err: deadline
exit status 1
總結
本章節比較簡單,你需要知道以下知識點:
- 怎麼設定 Deadlines
- 為什麼要設定 Deadlines
你要清楚地明白到,gRPC Deadlines 是很重要的,否則這小小的功能點就會要了你生產的命 🤫
參考
本系列示例程式碼
資料
-
[gRPC and Deadlines
4.10 分散式鏈路追蹤
在實際應用中,你做了那麼多 Server 端,寫了 N 個 RPC 方法。想看看方法的指標,卻無處下手?
本文將透過 gRPC + Opentracing + Zipkin 搭建一個分散式鏈路追蹤系統來實作檢視整個系統的鏈路、效能等指標。
Opentracing
是什麼
OpenTracing 透過提供平臺無關、廠商無關的API,使得開發人員能夠方便的新增(或更換)追蹤系統的實作
不過 OpenTracing 並不是標準。因為 CNCF 不是官方標準機構,但是它的目標是致力為分散式追蹤建立更標準的 API 和工具
名詞解釋
Trace
一個 trace 代表了一個事務或者流程在(分散式)系統中的執行過程
Span
一個 span 代表在分散式系統中完成的單個工作單元。也包含其他 span 的 “引用”,這允許將多個 spans 組合成一個完整的 Trace
每個 span 根據 OpenTracing 規範封裝以下內容:
- 操作名稱
- 開始時間和結束時間
- key:value span Tags
- key:value span Logs
- SpanContext
Tags
Span tags(跨度標籤)可以理解為使用者自定義的 Span 註釋。便於查詢、過濾和理解跟蹤資料
Logs
Span logs(跨度日誌)可以記錄 Span 內特定時間或事件的日誌資訊。主要用於捕獲特定 Span 的日誌資訊以及應用程式本身的其他除錯或資訊輸出
SpanContext
SpanContext 代表跨越程序邊界,傳遞到子級 Span 的狀態。常在追蹤示意圖中建立上下文時使用
Baggage Items
Baggage Items 可以理解為 trace 全域性執行中額外傳輸的資料集合
一個案例
圖中可以看到以下內容:
- 執行時間的上下文
- 服務間的層次關係
- 服務間序列或並行呼叫鏈
結合以上資訊,在實際場景中我們可以透過整個系統的呼叫鏈的上下文、效能等指標資訊,一下子就能夠發現系統的痛點在哪兒
Zipkin
是什麼
Zipkin 是分散式追蹤系統。它的作用是收集解決微服務架構中的延遲問題所需的時序資料。它管理這些資料的收集和查詢
Zipkin 的設計基於 Google Dapper 論文。
執行
docker run -d -p 9411:9411 openzipkin/zipkin
其他方法安裝參見:https://github.com/openzipkin/zipkin
驗證
訪問 http://127.0.0.1:9411/zipkin/ 檢查 Zipkin 是否執行正常
gRPC + Opentracing + Zipkin
在前面的小節中,我們做了以下準備工作:
- 瞭解 Opentracing 是什麼
- 搭建 Zipkin 提供分散式追蹤系統的功能
接下來實作 gRPC 透過 Opentracing 標準 API 對接 Zipkin,再透過 Zipkin 去檢視資料
目錄結構
新建 simple_zipkin_client、simple_zipkin_server 目錄,目錄結構如下:
go-grpc-example
├── LICENSE
├── README.md
├── client
│ ├── ...
│ ├── simple_zipkin_client
├── conf
├── pkg
├── proto
├── server
│ ├── ...
│ ├── simple_zipkin_server
└── vendor
安裝
$ go get -u github.com/openzipkin/zipkin-go-opentracing
$ go get -u github.com/grpc-ecosystem/grpc-opentracing/go/otgrpc
gRPC
Server
package main
import (
"context"
"log"
"net"
"github.com/grpc-ecosystem/go-grpc-middleware"
"github.com/grpc-ecosystem/grpc-opentracing/go/otgrpc"
zipkin "github.com/openzipkin/zipkin-go-opentracing"
"google.golang.org/grpc"
"github.com/EDDYCJY/go-grpc-example/pkg/gtls"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
return &pb.SearchResponse{Response: r.GetRequest() + " Server"}, nil
}
const (
PORT = "9005"
SERVICE_NAME = "simple_zipkin_server"
ZIPKIN_HTTP_ENDPOINT = "http://127.0.0.1:9411/api/v1/spans"
ZIPKIN_RECORDER_HOST_PORT = "127.0.0.1:9000"
)
func main() {
collector, err := zipkin.NewHTTPCollector(ZIPKIN_HTTP_ENDPOINT)
if err != nil {
log.Fatalf("zipkin.NewHTTPCollector err: %v", err)
}
recorder := zipkin.NewRecorder(collector, true, ZIPKIN_RECORDER_HOST_PORT, SERVICE_NAME)
tracer, err := zipkin.NewTracer(
recorder, zipkin.ClientServerSameSpan(false),
)
if err != nil {
log.Fatalf("zipkin.NewTracer err: %v", err)
}
tlsServer := gtls.Server{
CaFile: "../../conf/ca.pem",
CertFile: "../../conf/server/server.pem",
KeyFile: "../../conf/server/server.key",
}
c, err := tlsServer.GetCredentialsByCA()
if err != nil {
log.Fatalf("GetTLSCredentialsByCA err: %v", err)
}
opts := []grpc.ServerOption{
grpc.Creds(c),
grpc_middleware.WithUnaryServerChain(
otgrpc.OpenTracingServerInterceptor(tracer, otgrpc.LogPayloads()),
),
}
...
}
- zipkin.NewHTTPCollector:建立一個 Zipkin HTTP 後端收集器
- zipkin.NewRecorder:建立一個基於 Zipkin 收集器的記錄器
- zipkin.NewTracer:建立一個 OpenTracing 跟蹤器(相容 Zipkin Tracer)
- otgrpc.OpenTracingClientInterceptor:返回 grpc.UnaryServerInterceptor,不同點在於該攔截器會在 gRPC Metadata 中查詢 OpenTracing SpanContext。如果找到則為該服務的 Span Context 的子節點
- otgrpc.LogPayloads:設定並返回 Option。作用是讓 OpenTracing 在雙向方向上記錄應用程式的有效載荷(payload)
總的來講,就是初始化 Zipkin,其又包含收集器、記錄器、跟蹤器。再利用攔截器在 Server 端實作 SpanContext、Payload 的雙向讀取和管理
Client
func main() {
// the same as zipkin server
// ...
conn, err := grpc.Dial(":"+PORT, grpc.WithTransportCredentials(c),
grpc.WithUnaryInterceptor(
otgrpc.OpenTracingClientInterceptor(tracer, otgrpc.LogPayloads()),
))
...
}
- otgrpc.OpenTracingClientInterceptor:返回 grpc.UnaryClientInterceptor。該攔截器的核心功能在於:
(1)OpenTracing SpanContext 注入 gRPC Metadata
(2)檢視 context.Context 中的上下文關係,若存在父級 Span 則建立一個 ChildOf 引用,得到一個子 Span
其他方面,與 Server 端是一致的,先初始化 Zipkin,再增加 Client 端特需的攔截器。就可以完成基礎工作啦
驗證
啟動 Server.go,執行 Client.go。檢視 http://127.0.0.1:9411/zipkin/ 的示意圖:
複雜點
來,自己實踐一下
總結
在多服務下的架構下,序列、並行、服務套服務是一個非常常見的情況,用常規的方案往往很難發現問題在哪裡(成本太大)。而這種情況就是分散式追蹤系統大展拳腳的機會了
希望你透過本章節的介紹和學習,能夠了解其概念和搭建且應用一個追蹤系統。
參考
本系列示例程式碼
資料
第5課 grpc-gateway
5.1 介紹與環境安裝
假定我們有一個專案需求,希望用Rpc作為內部API的通訊,同時也想對外提供Restful Api,寫兩套又太繁瑣不符合
於是我們想到了Grpc以及Grpc Gateway,這就是我們所需要的
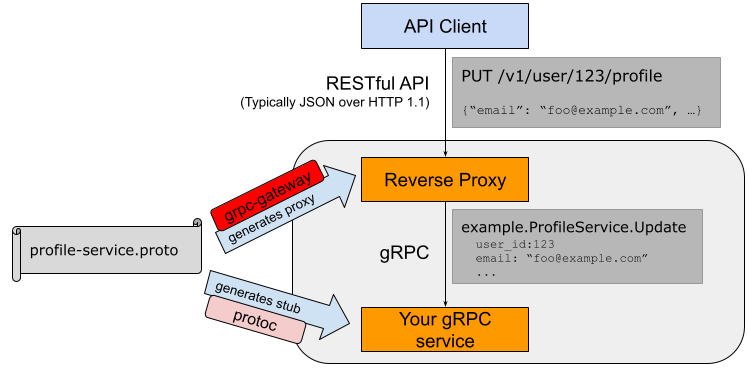
準備環節
在正式開始我們的Grpc+Grpc Gateway實踐前,我們需要先設定好我們的開發環境
- Grpc
- Protoc Plugin
- Protocol Buffers
- Grpc-gateway
Grpc
是什麼
Google對Grpc的定義:
A high performance, open-source universal RPC framework
也就是Grpc是一個高效能、開源的通用RPC框架,具有以下特性:
- 強大的
IDL,使用Protocol Buffers作為資料交換的格式,支援v2、v3(推薦v3) - 跨語言、跨平臺,也就是
Grpc支援多種平臺和語言 - 支援HTTP2,雙向傳輸、多路複用、認證等
安裝
1、官方推薦(需科學上網)
go get -u google.golang.org/grpc
2、透過github.com
進入到第一個$GOPATH目錄(因為go get 會預設安裝在第一個下)下,新建google.golang.org目錄,拉取golang在github上的映象庫:
cd /usr/local/go/path/src
mkdir google.golang.org
cd google.golang.org/
git clone https://github.com/grpc/grpc-go
mv grpc-go/ grpc/
目錄結構:
google.golang.org/
└── grpc
...
而在grpc下有許多常用的包,例如:
- metadata:定義了
grpc所支援的元資料結構,包中方法可以對MD進行取得和處理 - credentials:實作了
grpc所支援的各種認證憑據,封裝了客戶端對服務端進行身份驗證所需要的所有狀態,並做出各種斷言 - codes:定義了
grpc使用的標準錯誤碼,可通用
Protoc Plugin
是什麼
編譯器外掛
安裝
go get -u github.com/golang/protobuf/protoc-gen-go
將Protoc Plugin的可執行檔案從$GOPATH中移動到$GOBIN下
mv /usr/local/go/path/bin/protoc-gen-go /usr/local/go/bin/
Protocol Buffers v3
是什麼
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.
Protocol Buffers是Google推出的一種資料描述語言,支援多語言、多平臺,它是一種二進位制的格式,總得來說就是更小、更快、更簡單、更靈活,目前分別有v2、v3的版本,我們推薦使用v3
建議可以閱讀下官方文件的介紹,本系列會在使用時簡單介紹所涉及的內容
安裝
wget https://github.com/google/protobuf/releases/download/v3.5.1/protobuf-all-3.5.1.zip
unzip protobuf-all-3.5.1.zip
cd protobuf-3.5.1/
./configure
make
make install
檢查是否安裝成功
protoc --version
如果出現報錯
protoc: error while loading shared libraries: libprotobuf.so.15: cannot open shared object file: No such file or directory
則執行ldconfig後,再次執行即可成功
為什麼要執行ldconfig
我們透過控制檯輸出的資訊可以知道,Protocol Buffers Libraries的預設安裝路徑在/usr/local/lib
Libraries have been installed in:
/usr/local/lib
If you ever happen to want to link against installed libraries
in a given directory, LIBDIR, you must either use libtool, and
specify the full pathname of the library, or use the `-LLIBDIR'
flag during linking and do at least one of the following:
- add LIBDIR to the `LD_LIBRARY_PATH' environment variable
during execution
- add LIBDIR to the `LD_RUN_PATH' environment variable
during linking
- use the `-Wl,-rpath -Wl,LIBDIR' linker flag
- have your system administrator add LIBDIR to `/etc/ld.so.conf'
See any operating system documentation about shared libraries for
more information, such as the ld(1) and ld.so(8) manual pages.
而我們安裝了一個新的動態連結庫,ldconfig一般在系統啟動時執行,所以現在會找不到這個lib,因此我們要手動執行ldconfig,讓動態連結庫為系統所共享,它是一個動態連結庫管理命令,這就是ldconfig命令的作用
protoc使用
我們按照慣例執行protoc --help(檢視幫助文件),我們抽出幾個常用的命令進行講解
1、-IPATH, --proto_path=PATH:指定import搜尋的目錄,可指定多個,如果不指定則預設當前工作目錄
2、--go_out:生成golang原始檔
引數
若要將額外的引數傳遞給外掛,可使用從輸出目錄中分離出來的逗號分隔的引數列表:
protoc --go_out=plugins=grpc,import_path=mypackage:. *.proto
import_prefix=xxx:將指定字首新增到所有import路徑的開頭import_path=foo/bar:如果檔案沒有宣告go_package,則用作包。如果它包含斜槓,那麼最右邊的斜槓將被忽略。plugins=plugin1+plugin2:指定要載入的子外掛列表(我們所下載的repo中唯一的外掛是grpc)Mfoo/bar.proto=quux/shme:M引數,指定.proto檔案編譯後的包名(foo/bar.proto編譯後為包名為quux/shme)
Grpc支援
如果proto檔案指定了RPC服務,protoc-gen-go可以生成與grpc相相容的程式碼,我們僅需要將plugins=grpc引數傳遞給--go_out,就可以達到這個目的
protoc --go_out=plugins=grpc:. *.proto
Grpc-gateway
是什麼
grpc-gateway is a plugin of protoc. It reads gRPC service definition, and generates a reverse-proxy server which translates a RESTful JSON API into gRPC. This server is generated according to custom options in your gRPC definition.
grpc-gateway是protoc的一個外掛。它讀取gRPC服務定義,並生成一個反向代理伺服器,將RESTful JSON API轉換為gRPC。此伺服器是根據gRPC定義中的自定義選項生成的。
安裝
go get -u github.com/grpc-ecosystem/grpc-gateway/protoc-gen-grpc-gateway
如果出現以下報錯,我們分析錯誤提示可得知是連線超時(大概是被牆了)
package google.golang.org/genproto/googleapis/api/annotations: unrecognized import path "google.golang.org/genproto/googleapis/api/annotations" (https fetch: Get https://google.golang.org/genproto/googleapis/api/annotations?go-get=1: dial tcp 216.239.37.1:443: getsockopt: connection timed out)
有兩種解決方法,
1、科學上網
2、透過github.com
進入到第一個$GOTPATH目錄的google.golang.org目錄下,拉取genproto在github上的go-genproto映象庫:
cd /usr/local/go/path/src/google.golang.org
git clone https://github.com/google/go-genproto.git
mv go-genproto/ genproto/
在安裝完畢後,我們將grpc-gateway的可執行檔案從$GOPATH中移動到$GOBIN
mv /usr/local/go/path/bin/protoc-gen-grpc-gateway /usr/local/go/bin/
到這裡我們這節就基本完成了,建議多反覆看幾遍加深對各個元件的理解!
參考
示例程式碼
5.2 Hello World
這節將開始編寫一個複雜的Hello World,涉及到許多的知識,建議大家認真思考其中的概念
需求
由於本實踐偏向Grpc+Grpc Gateway的方面,我們的需求是同一個服務端支援Rpc和Restful Api,那麼就意味著http2、TLS等等的應用,功能方面就是一個服務端能夠接受來自grpc和Restful Api的請求並響應
一、初始化目錄
我們先在$GOPATH中新建grpc-hello-world資料夾,我們專案的初始目錄目錄如下:
grpc-hello-world/
├── certs
├── client
├── cmd
├── pkg
├── proto
│ ├── google
│ │ └── api
└── server
certs:證書憑證client:客戶端cmd:命令列pkg:第三方公共模組proto:protobuf的一些相關檔案(含.proto、pb.go、.pb.gw.go),google/api中用於存放annotations.proto、http.protoserver:服務端
二、製作證書
在服務端支援Rpc和Restful Api,需要用到TLS,因此我們要先製作證書
進入certs目錄,生成TLS所需的公鑰金鑰檔案
私鑰
openssl genrsa -out server.key 2048
openssl ecparam -genkey -name secp384r1 -out server.key
openssl genrsa:生成RSA私鑰,命令的最後一個引數,將指定生成金鑰的位數,如果沒有指定,預設512openssl ecparam:生成ECC私鑰,命令為橢圓曲線金鑰引數生成及操作,本文中ECC曲線選擇的是secp384r1
自簽名公鑰
openssl req -new -x509 -sha256 -key server.key -out server.pem -days 3650
openssl req:生成自簽名證書,-new指生成證書請求、-sha256指使用sha256加密、-key指定私鑰檔案、-x509指輸出證書、-days 3650為有效期,此後則輸入證書擁有者資訊
填寫資訊
Country Name (2 letter code) [XX]:
State or Province Name (full name) []:
Locality Name (eg, city) [Default City]:
Organization Name (eg, company) [Default Company Ltd]:
Organizational Unit Name (eg, section) []:
Common Name (eg, your name or your server's hostname) []:grpc server name
Email Address []:
三、proto
編寫
1、 google.api
我們看到proto目錄中有google/api目錄,它用到了google官方提供的兩個api描述檔案,主要是針對grpc-gateway的http轉換提供支援,定義了Protocol Buffer所擴充套件的HTTP Option
annotations.proto檔案:
// Copyright (c) 2015, Google Inc.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
syntax = "proto3";
package google.api;
import "google/api/http.proto";
import "google/protobuf/descriptor.proto";
option java_multiple_files = true;
option java_outer_classname = "AnnotationsProto";
option java_package = "com.google.api";
extend google.protobuf.MethodOptions {
// See `HttpRule`.
HttpRule http = 72295728;
}
http.proto檔案:
// Copyright 2016 Google Inc.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
syntax = "proto3";
package google.api;
option cc_enable_arenas = true;
option java_multiple_files = true;
option java_outer_classname = "HttpProto";
option java_package = "com.google.api";
// Defines the HTTP configuration for a service. It contains a list of
// [HttpRule][google.api.HttpRule], each specifying the mapping of an RPC method
// to one or more HTTP REST API methods.
message Http {
// A list of HTTP rules for configuring the HTTP REST API methods.
repeated HttpRule rules = 1;
}
// Use CustomHttpPattern to specify any HTTP method that is not included in the
// `pattern` field, such as HEAD, or "*" to leave the HTTP method unspecified for
// a given URL path rule. The wild-card rule is useful for services that provide
// content to Web (HTML) clients.
message HttpRule {
// Selects methods to which this rule applies.
//
// Refer to [selector][google.api.DocumentationRule.selector] for syntax details.
string selector = 1;
// Determines the URL pattern is matched by this rules. This pattern can be
// used with any of the {get|put|post|delete|patch} methods. A custom method
// can be defined using the 'custom' field.
oneof pattern {
// Used for listing and getting information about resources.
string get = 2;
// Used for updating a resource.
string put = 3;
// Used for creating a resource.
string post = 4;
// Used for deleting a resource.
string delete = 5;
// Used for updating a resource.
string patch = 6;
// Custom pattern is used for defining custom verbs.
CustomHttpPattern custom = 8;
}
// The name of the request field whose value is mapped to the HTTP body, or
// `*` for mapping all fields not captured by the path pattern to the HTTP
// body. NOTE: the referred field must not be a repeated field.
string body = 7;
// Additional HTTP bindings for the selector. Nested bindings must
// not contain an `additional_bindings` field themselves (that is,
// the nesting may only be one level deep).
repeated HttpRule additional_bindings = 11;
}
// A custom pattern is used for defining custom HTTP verb.
message CustomHttpPattern {
// The name of this custom HTTP verb.
string kind = 1;
// The path matched by this custom verb.
string path = 2;
}
hello.proto
這一小節將編寫Demo的.proto檔案,我們在proto目錄下新建hello.proto檔案,寫入檔案內容:
syntax = "proto3";
package proto;
import "google/api/annotations.proto";
service HelloWorld {
rpc SayHelloWorld(HelloWorldRequest) returns (HelloWorldResponse) {
option (google.api.http) = {
post: "/hello_world"
body: "*"
};
}
}
message HelloWorldRequest {
string referer = 1;
}
message HelloWorldResponse {
string message = 1;
}
在hello.proto檔案中,引用了google/api/annotations.proto,達到支援HTTP Option的效果
- 定義了一個
serviceRPC服務HelloWorld,在其內部定義了一個HTTP Option的POST方法,HTTP響應路徑為/hello_world - 定義
message型別HelloWorldRequest、HelloWorldResponse,用於響應請求和返回結果
編譯
在編寫完.proto檔案後,我們需要對其進行編譯,就能夠在server中使用
進入proto目錄,執行以下命令
# 编译google.api
protoc -I . --go_out=plugins=grpc,Mgoogle/protobuf/descriptor.proto=github.com/golang/protobuf/protoc-gen-go/descriptor:. google/api/*.proto
#编译hello_http.proto为hello_http.pb.proto
protoc -I . --go_out=plugins=grpc,Mgoogle/api/annotations.proto=grpc-hello-world/proto/google/api:. ./hello.proto
#编译hello_http.proto为hello_http.pb.gw.proto
protoc --grpc-gateway_out=logtostderr=true:. ./hello.proto
執行完畢後將生成hello.pb.go和hello.gw.pb.go,分別針對grpc和grpc-gateway的功能支援
四、命令列模組 cmd
介紹
這一小節我們編寫命令列模組,為什麼要獨立出來呢,是為了將cmd和server兩者解耦,避免混淆在一起。
我們採用 Cobra 來完成這項功能,Cobra既是建立強大的現代CLI應用程式的庫,也是生成應用程式和命令檔案的程式。提供了以下功能:
- 簡易的子命令列模式
- 完全相容posix的命令列模式(包括短和長版本)
- 巢狀的子命令
- 全域性、本地和級聯
flags - 使用
Cobra很容易的生成應用程式和命令,使用cobra create appname和cobra add cmdname - 智慧提示
- 自動生成commands和flags的幫助資訊
- 自動生成詳細的help資訊
-h,--help等等 - 自動生成的bash自動完成功能
- 為應用程式自動生成手冊
- 命令別名
- 定義您自己的幫助、用法等的靈活性。
- 可選與viper緊密整合的apps
編寫server
在編寫cmd時需要先用server進行測試關聯,因此這一步我們先寫server.go用於測試
在server模組下 新建server.go檔案,寫入測試內容:
package server
import (
"log"
)
var (
ServerPort string
CertName string
CertPemPath string
CertKeyPath string
)
func Serve() (err error){
log.Println(ServerPort)
log.Println(CertName)
log.Println(CertPemPath)
log.Println(CertKeyPath)
return nil
}
編寫cmd
在cmd模組下 新建root.go檔案,寫入內容:
package cmd
import (
"fmt"
"os"
"github.com/spf13/cobra"
)
var rootCmd = &cobra.Command{
Use: "grpc",
Short: "Run the gRPC hello-world server",
}
func Execute() {
if err := rootCmd.Execute(); err != nil {
fmt.Println(err)
os.Exit(-1)
}
}
新建server.go檔案,寫入內容:
package cmd
import (
"log"
"github.com/spf13/cobra"
"grpc-hello-world/server"
)
var serverCmd = &cobra.Command{
Use: "server",
Short: "Run the gRPC hello-world server",
Run: func(cmd *cobra.Command, args []string) {
defer func() {
if err := recover(); err != nil {
log.Println("Recover error : %v", err)
}
}()
server.Serve()
},
}
func init() {
serverCmd.Flags().StringVarP(&server.ServerPort, "port", "p", "50052", "server port")
serverCmd.Flags().StringVarP(&server.CertPemPath, "cert-pem", "", "./certs/server.pem", "cert pem path")
serverCmd.Flags().StringVarP(&server.CertKeyPath, "cert-key", "", "./certs/server.key", "cert key path")
serverCmd.Flags().StringVarP(&server.CertName, "cert-name", "", "grpc server name", "server's hostname")
rootCmd.AddCommand(serverCmd)
}
我們在grpc-hello-world/目錄下,新建檔案main.go,寫入內容:
package main
import (
"grpc-hello-world/cmd"
)
func main() {
cmd.Execute()
}
講解
要使用Cobra,按照Cobra標準要建立main.go和一個rootCmd檔案,另外我們有子命令server
1、rootCmd: rootCmd表示在沒有任何子命令的情況下的基本命令
2、&cobra.Command:
Use:Command的用法,Use是一個行用法訊息Short:Short是help命令輸出中顯示的簡短描述Run:執行:典型的實際工作功能。大多數命令只會實作這一點;另外還有PreRun、PreRunE、PostRun、PostRunE等等不同時期的執行命令,但比較少用,具體使用時再檢視亦可
3、rootCmd.AddCommand:AddCommand向這父命令(rootCmd)新增一個或多個命令
4、serverCmd.Flags().StringVarP():
一般來說,我們需要在init()函式中定義flags和處理設定,以serverCmd.Flags().StringVarP(&server.ServerPort, "port", "p", "50052", "server port")為例,我們定義了一個flag,值儲存在&server.ServerPort中,長命令為--port,短命令為-p,,預設值為50052,命令的描述為server port。這一種呼叫方式成為Local Flags
我們延伸一下,如果覺得每一個子命令都要設一遍覺得很麻煩,我們可以採用Persistent Flags:
rootCmd.PersistentFlags().BoolVarP(&Verbose, "verbose", "v", false, "verbose output")
作用:
flag是可以持久的,這意味著該flag將被分配給它所分配的命令以及該命令下的每個命令。對於全域性標記,將標記作為根上的持久標誌。
另外還有Local Flag on Parent Commands、Bind Flags with Config、Required flags等等,使用到再 傳送 瞭解即可
測試
回到grpc-hello-world/目錄下執行go run main.go server,檢視輸出是否為(此時應為預設值):
2018/02/25 23:23:21 50052
2018/02/25 23:23:21 dev
2018/02/25 23:23:21 ./certs/server.pem
2018/02/25 23:23:21 ./certs/server.key
執行go run main.go server --port=8000 --cert-pem=test-pem --cert-key=test-key --cert-name=test-name,檢驗命令列引數是否正確:
2018/02/25 23:24:56 8000
2018/02/25 23:24:56 test-name
2018/02/25 23:24:56 test-pem
2018/02/25 23:24:56 test-key
若都無誤,那麼恭喜你cmd模組的編寫正確了,下一部分開始我們的重點章節!
五、服務端模組 server
編寫hello.go
在server目錄下新建檔案hello.go,寫入檔案內容:
package server
import (
"golang.org/x/net/context"
pb "grpc-hello-world/proto"
)
type helloService struct{}
func NewHelloService() *helloService {
return &helloService{}
}
func (h helloService) SayHelloWorld(ctx context.Context, r *pb.HelloWorldRequest) (*pb.HelloWorldResponse, error) {
return &pb.HelloWorldResponse{
Message : "test",
}, nil
}
我們建立了helloService及其方法SayHelloWorld,對應.proto的rpc SayHelloWorld,這個方法需要有2個引數:ctx context.Context用於接受上下文引數、r *pb.HelloWorldRequest用於接受protobuf的Request引數(對應.proto的message HelloWorldRequest)
*編寫server.go
這一小章節,我們編寫最為重要的服務端程式部分,涉及到大量的grpc、grpc-gateway及一些網路知識的應用
1、在pkg下新建util目錄,新建grpc.go檔案,寫入內容:
package util
import (
"net/http"
"strings"
"google.golang.org/grpc"
)
func GrpcHandlerFunc(grpcServer *grpc.Server, otherHandler http.Handler) http.Handler {
if otherHandler == nil {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
grpcServer.ServeHTTP(w, r)
})
}
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.ProtoMajor == 2 && strings.Contains(r.Header.Get("Content-Type"), "application/grpc") {
grpcServer.ServeHTTP(w, r)
} else {
otherHandler.ServeHTTP(w, r)
}
})
}
GrpcHandlerFunc函式是用於判斷請求是來源於Rpc客戶端還是Restful Api的請求,根據不同的請求註冊不同的ServeHTTP服務;r.ProtoMajor == 2也代表著請求必須基於HTTP/2
2、在pkg下的util目錄下,新建tls.go檔案,寫入內容:
package util
import (
"crypto/tls"
"io/ioutil"
"log"
"golang.org/x/net/http2"
)
func GetTLSConfig(certPemPath, certKeyPath string) *tls.Config {
var certKeyPair *tls.Certificate
cert, _ := ioutil.ReadFile(certPemPath)
key, _ := ioutil.ReadFile(certKeyPath)
pair, err := tls.X509KeyPair(cert, key)
if err != nil {
log.Println("TLS KeyPair err: %v\n", err)
}
certKeyPair = &pair
return &tls.Config{
Certificates: []tls.Certificate{*certKeyPair},
NextProtos: []string{http2.NextProtoTLS},
}
}
GetTLSConfig函式是用於取得TLS設定,在內部,我們讀取了server.key和server.pem這類證書憑證檔案
tls.X509KeyPair:從一對PEM編碼的資料中解析公鑰/私鑰對。成功則返回公鑰/私鑰對http2.NextProtoTLS:NextProtoTLS是談判期間的NPN/ALPN協議,用於HTTP/2的TLS設定tls.Certificate:返回一個或多個證書,實質我們解析PEM呼叫的X509KeyPair的函式宣告就是func X509KeyPair(certPEMBlock, keyPEMBlock []byte) (Certificate, error),返回值就是Certificate
總的來說該函式是用於處理從證書憑證檔案(PEM),最終取得tls.Config作為HTTP2的使用引數
3、修改server目錄下的server.go檔案,該檔案是我們服務裡的核心檔案,寫入內容:
package server
import (
"crypto/tls"
"net"
"net/http"
"log"
"golang.org/x/net/context"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
"github.com/grpc-ecosystem/grpc-gateway/runtime"
pb "grpc-hello-world/proto"
"grpc-hello-world/pkg/util"
)
var (
ServerPort string
CertName string
CertPemPath string
CertKeyPath string
EndPoint string
)
func Serve() (err error){
EndPoint = ":" + ServerPort
conn, err := net.Listen("tcp", EndPoint)
if err != nil {
log.Printf("TCP Listen err:%v\n", err)
}
tlsConfig := util.GetTLSConfig(CertPemPath, CertKeyPath)
srv := createInternalServer(conn, tlsConfig)
log.Printf("gRPC and https listen on: %s\n", ServerPort)
if err = srv.Serve(tls.NewListener(conn, tlsConfig)); err != nil {
log.Printf("ListenAndServe: %v\n", err)
}
return err
}
func createInternalServer(conn net.Listener, tlsConfig *tls.Config) (*http.Server) {
var opts []grpc.ServerOption
// grpc server
creds, err := credentials.NewServerTLSFromFile(CertPemPath, CertKeyPath)
if err != nil {
log.Printf("Failed to create server TLS credentials %v", err)
}
opts = append(opts, grpc.Creds(creds))
grpcServer := grpc.NewServer(opts...)
// register grpc pb
pb.RegisterHelloWorldServer(grpcServer, NewHelloService())
// gw server
ctx := context.Background()
dcreds, err := credentials.NewClientTLSFromFile(CertPemPath, CertName)
if err != nil {
log.Printf("Failed to create client TLS credentials %v", err)
}
dopts := []grpc.DialOption{grpc.WithTransportCredentials(dcreds)}
gwmux := runtime.NewServeMux()
// register grpc-gateway pb
if err := pb.RegisterHelloWorldHandlerFromEndpoint(ctx, gwmux, EndPoint, dopts); err != nil {
log.Printf("Failed to register gw server: %v\n", err)
}
// http服务
mux := http.NewServeMux()
mux.Handle("/", gwmux)
return &http.Server{
Addr: EndPoint,
Handler: util.GrpcHandlerFunc(grpcServer, mux),
TLSConfig: tlsConfig,
}
}
server流程剖析
我們將這一大塊程式碼,分成以下幾個部分來理解
一、啟動監聽
net.Listen("tcp", EndPoint)用於監聽本地的網路地址通知,它的函式原型func Listen(network, address string) (Listener, error)
引數:network必須傳入tcp、tcp4、tcp6、unix、unixpacket,若address為空或為0則會自動選擇一個埠號 返回值:透過檢視原始碼我們可以得知其返回值為Listener,結構體原型:
type Listener interface {
Accept() (Conn, error)
Close() error
Addr() Addr
}
透過分析得知,最後net.Listen會返回一個監聽器的結構體,返回給接下來的動作,讓其執行下一步的操作,它可以執行三類操作
Accept:接受等待並將下一個連線返回給ListenerClose:關閉ListenerAddr:返回Listener的網路地址
二、取得TLS
透過util.GetTLSConfig解析得到tls.Config,傳達給http.Server服務的TLSConfig設定項使用
三、建立內部服務
createInternalServer函式,是整個服務端的核心流轉部分
程式採用的是HTT2、HTTPS也就是需要支援TLS,因此在啟動grpc.NewServer前,我們要將認證的中介軟體註冊進去
而前面所取得的tlsConfig僅能給HTTP使用,因此第一步我們要建立grpc的TLS認證憑證
1、建立grpc的TLS認證憑證
新增引用google.golang.org/grpc/credentials的第三方包,它實作了grpc庫支援的各種憑證,該憑證封裝了客戶機需要的所有狀態,以便與伺服器進行身份驗證並進行各種斷言,例如關於客戶機的身份,角色或是否授權進行特定的呼叫
我們呼叫NewServerTLSFromFile來達到我們的目的,它能夠從輸入證書檔案和伺服器的金鑰檔案構造TLS證書憑證
func NewServerTLSFromFile(certFile, keyFile string) (TransportCredentials, error) {
//LoadX509KeyPair读取并解析来自一对文件的公钥/私钥对
cert, err := tls.LoadX509KeyPair(certFile, keyFile)
if err != nil {
return nil, err
}
//NewTLS使用tls.Config来构建基于TLS的TransportCredentials
return NewTLS(&tls.Config{Certificates: []tls.Certificate{cert}}), nil
}
2、設定grpc ServerOption
以grpc.Creds(creds)為例,其原型為func Creds(c credentials.TransportCredentials) ServerOption,該函式返回ServerOption,它為伺服器連線設定憑據
3、建立grpc服務端
函式原型:
func NewServer(opt ...ServerOption) *Server
我們在此處建立了一個沒有註冊服務的grpc服務端,還沒有開始接受請求
grpcServer := grpc.NewServer(opts...)
4、註冊grpc服務
pb.RegisterHelloWorldServer(grpcServer, NewHelloService())
5、建立grpc-gateway關聯元件
ctx := context.Background()
dcreds, err := credentials.NewClientTLSFromFile(CertPemPath, CertName)
if err != nil {
log.Println("Failed to create client TLS credentials %v", err)
}
dopts := []grpc.DialOption{grpc.WithTransportCredentials(dcreds)}
context.Background:返回一個非空的空上下文。它沒有被登出,沒有值,沒有過期時間。它通常由主函式、初始化和測試使用,並作為傳入請求的頂級上下文credentials.NewClientTLSFromFile:從客戶機的輸入證書檔案構造TLS憑證grpc.WithTransportCredentials:設定一個連線級別的安全憑據(例:TLS、SSL),返回值為type DialOptiongrpc.DialOption:DialOption選項設定我們如何設定連線(其內部具體由多個的DialOption組成,決定其設定連線的內容)
6、建立HTTP NewServeMux及註冊grpc-gateway邏輯
gwmux := runtime.NewServeMux()
// register grpc-gateway pb
if err := pb.RegisterHelloWorldHandlerFromEndpoint(ctx, gwmux, EndPoint, dopts); err != nil {
log.Println("Failed to register gw server: %v\n", err)
}
// http服务
mux := http.NewServeMux()
mux.Handle("/", gwmux)
runtime.NewServeMux:返回一個新的ServeMux,它的內部對映是空的;ServeMux是grpc-gateway的一個請求多路複用器。它將http請求與模式匹配,並呼叫相應的處理程式RegisterHelloWorldHandlerFromEndpoint:如函式名,註冊HelloWorld服務的HTTP Handle到grpc端點http.NewServeMux:分配并返回一个新的ServeMuxmux.Handle:為給定模式註冊處理程式
(帶著疑問去看程式)為什麼gwmux可以放入mux.Handle中?
首先我們看看它們的原型是怎麼樣的
(1)http.NewServeMux()
func NewServeMux() *ServeMux {
return new(ServeMux)
}
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
(2)runtime.NewServeMux?
func NewServeMux(opts ...ServeMuxOption) *ServeMux {
serveMux := &ServeMux{
handlers: make(map[string][]handler),
forwardResponseOptions: make([]func(context.Context, http.ResponseWriter, proto.Message) error, 0),
marshalers: makeMarshalerMIMERegistry(),
}
...
return serveMux
}
(3)http.NewServeMux()的Handle方法
func (mux *ServeMux) Handle(pattern string, handler Handler)
透過分析可得知,兩者NewServeMux都是最終返回serveMux,Handler中匯出的方法僅有ServeHTTP,功能是用於響應HTTP請求
我們回到Handle interface中,可以得出結論就是任何結構體,只要實作了ServeHTTP方法,這個結構就可以稱為Handle,ServeMux會使用該Handler呼叫ServeHTTP方法處理請求,這也就是自定義Handler
而我們這裡正是將grpc-gateway中註冊好的HTTP Handler無縫的植入到net/http的Handle方法中
補充:在go中任何結構體只要實作了與介面相同的方法,就等同於實作了介面
7、註冊具體服務
if err := pb.RegisterHelloWorldHandlerFromEndpoint(ctx, gwmux, EndPoint, dopts); err != nil {
log.Println("Failed to register gw server: %v\n", err)
}
在這段程式碼中,我們利用了前幾小節的
- 上下文
gateway-grpc的請求多路複用器- 服務網路地址
- 設定好的安全憑據
註冊了HelloWorld這一個服務
四、建立tls.NewListener
func NewListener(inner net.Listener, config *Config) net.Listener {
l := new(listener)
l.Listener = inner
l.config = config
return l
}
NewListener將會建立一個Listener,它接受兩個引數,第一個是來自內部Listener的監聽器,第二個引數是tls.Config(必須包含至少一個證書)
五、服務開始接受請求
在最後我們呼叫srv.Serve(tls.NewListener(conn, tlsConfig)),可以得知它是http.Server的方法,並且需要一個Listener作為引數,那麼Serve內部做了些什麼事呢?
func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
...
baseCtx := context.Background() // base is always background, per Issue 16220
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, e := l.Accept()
...
c := srv.newConn(rw)
c.setState(c.rwc, StateNew) // before Serve can return
go c.serve(ctx)
}
}
粗略的看,它建立了一個context.Background()上下文物件,並呼叫Listener的Accept方法開始接受外部請求,在取得到連線資料後使用newConn建立連線物件,在最後使用goroutine的方式處理連線請求,達到其目的
補充:對於HTTP/2支援,在呼叫Serve之前,應將srv.TLSConfig初始化為提供的Listener的TLS設定。如果srv.TLSConfig非零,並且在Config.NextProtos中不包含字串h2,則不啟用HTTP/2支援
六、驗證功能
編寫測試客戶端
在grpc-hello-world/下新建目錄client,新建client.go檔案,新增內容:
package main
import (
"log"
"golang.org/x/net/context"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
pb "grpc-hello-world/proto"
)
func main() {
creds, err := credentials.NewClientTLSFromFile("../certs/server.pem", "dev")
if err != nil {
log.Println("Failed to create TLS credentials %v", err)
}
conn, err := grpc.Dial(":50052", grpc.WithTransportCredentials(creds))
defer conn.Close()
if err != nil {
log.Println(err)
}
c := pb.NewHelloWorldClient(conn)
context := context.Background()
body := &pb.HelloWorldRequest{
Referer : "Grpc",
}
r, err := c.SayHelloWorld(context, body)
if err != nil {
log.Println(err)
}
log.Println(r.Message)
}
由於客戶端只是展示測試用,就簡單的來了,原本它理應歸類到cobra的管控下,設定管理等等都應可控化
在看這篇文章的你,可以試試將測試客戶端歸類好
啟動服務端
回到grpc-hello-world/目錄下,啟動服務端go run main.go server,成功則僅返回
2018/02/26 17:19:36 gRPC and https listen on: 50052
執行測試客戶端
回到client目錄下,啟動客戶端go run client.go,成功則返回
2018/02/26 17:22:57 Grpc
執行測試Restful Api
curl -X POST -k https://localhost:50052/hello_world -d '{"referer": "restful_api"}'
成功則返回{"message":"restful_api"}
最終目錄結構
grpc-hello-world
├── certs
│ ├── server.key
│ └── server.pem
├── client
│ └── client.go
├── cmd
│ ├── root.go
│ └── server.go
├── main.go
├── pkg
│ └── util
│ ├── grpc.go
│ └── tls.go
├── proto
│ ├── google
│ │ └── api
│ │ ├── annotations.pb.go
│ │ ├── annotations.proto
│ │ ├── http.pb.go
│ │ └── http.proto
│ ├── hello.pb.go
│ ├── hello.pb.gw.go
│ └── hello.proto
└── server
├── hello.go
└── server.go
至此本節就結束了,推薦一下jergoo的文章,大家有時間可以看看
另外本節涉及了許多元件間的知識,值得大家細細的回味,非常有意義!
參考
示例程式碼
5.3 Swagger瞭解一下
在上一節,我們完成了一個服務端同時支援Rpc和RESTful Api後,你以為自己大功告成了,結果突然發現要寫Api文件和前端同事對接= = 。。。
你尋思有沒有什麼元件能夠自動化生成Api文件來解決這個問題,就在這時你發現了Swagger,一起了解一下吧!
介紹
Swagger
Swagger是全球最大的OpenAPI規範(OAS)API開發工具框架,支援從設計和文件到測試和部署的整個API生命週期的開發
Swagger是目前最受歡迎的RESTful Api文件生成工具之一,主要的原因如下
- 跨平臺、跨語言的支援
- 強大的社群
- 生態圈 Swagger Tools(Swagger Editor、Swagger Codegen、Swagger UI ...)
- 強大的控制檯
同時grpc-gateway也支援Swagger
[image]
OpenAPI規範
OpenAPI規範是Linux基金會的一個專案,試圖透過定義一種用來描述API格式或API定義的語言,來規範RESTful服務開發過程。OpenAPI規範幫助我們描述一個API的基本資訊,比如:
- 有關該API的一般性描述
- 可用路徑(/資源)
- 在每個路徑上的可用操作(取得/提交...)
- 每個操作的輸入/輸出格式
目前V2.0版本的OpenAPI規範(也就是SwaggerV2.0規範)已經發布並開源在github上。該文件寫的非常好,結構清晰,方便隨時查閱。
注:OpenAPI規範的介紹引用自原文
使用
生成Swagger的說明檔案
第一,我們需要檢查$GOBIN下是否包含protoc-gen-swagger可執行檔案
若不存在則需要執行:
go get -u github.com/grpc-ecosystem/grpc-gateway/protoc-gen-swagger
等待執行完畢後,可在$GOPATH/bin下發現該執行檔案,將其移動到$GOBIN下即可
第二,回到$GOPATH/src/grpc-hello-world/proto下,執行命令
protoc -I/usr/local/include -I. -I$GOPATH/src/grpc-hello-world/proto/google/api --swagger_out=logtostderr=true:. ./hello.proto
成功後執行ls即可看到hello.swagger.json檔案
下載Swagger UI檔案
Swagger提供視覺化的API管理平臺,就是Swagger UI
我們將其原始碼下載下來,並將其dist目錄下的所有檔案複製到我們專案中的$GOPATH/src/grpc-hello-world/third_party/swagger-ui去
將Swagger UI轉換為Go原始碼
在這裡我們使用的轉換工具是go-bindata
它支援將任何檔案轉換為可管理的Go原始碼。用於將二進位制資料嵌入到Go程式中。並且在將檔案資料轉換為原始位元組片之前,可以選擇壓縮檔案資料
安裝
go get -u github.com/jteeuwen/go-bindata/...
完成後,將$GOPATH/bin下的go-bindata移動到$GOBIN下
轉換
在專案下新建pkg/ui/data/swagger目錄,回到$GOPATH/src/grpc-hello-world/third_party/swagger-ui下,執行命令
go-bindata --nocompress -pkg swagger -o pkg/ui/data/swagger/datafile.go third_party/swagger-ui/...
檢查
回到pkg/ui/data/swagger目錄,檢查是否存在datafile.go檔案
Swagger UI檔案伺服器(對外提供服務)
在這一步,我們需要使用與其配套的go-bindata-assetfs
它能夠使用go-bindata所生成Swagger UI的Go程式碼,結合net/http對外提供服務
安裝
go get github.com/elazarl/go-bindata-assetfs/...
編寫
透過分析,我們得知生成的檔案提供了一個assetFS函式,該函式返回一個封裝了嵌入檔案的http.Filesystem,可以用其來提供一個HTTP服務
那麼我們來編寫Swagger UI的程式碼吧,主要是兩個部分,一個是swagger.json,另外一個是swagger-ui的響應
serveSwaggerFile
引用包strings、path
func serveSwaggerFile(w http.ResponseWriter, r *http.Request) {
if ! strings.HasSuffix(r.URL.Path, "swagger.json") {
log.Printf("Not Found: %s", r.URL.Path)
http.NotFound(w, r)
return
}
p := strings.TrimPrefix(r.URL.Path, "/swagger/")
p = path.Join("proto", p)
log.Printf("Serving swagger-file: %s", p)
http.ServeFile(w, r, p)
}
在函式中,我們利用r.URL.Path進行路徑字尾判斷
主要做了對swagger.json的檔案訪問支援(提供https://127.0.0.1:50052/swagger/hello.swagger.json的訪問)
serveSwaggerUI
引用包github.com/elazarl/go-bindata-assetfs、grpc-hello-world/pkg/ui/data/swagger
func serveSwaggerUI(mux *http.ServeMux) {
fileServer := http.FileServer(&assetfs.AssetFS{
Asset: swagger.Asset,
AssetDir: swagger.AssetDir,
Prefix: "third_party/swagger-ui",
})
prefix := "/swagger-ui/"
mux.Handle(prefix, http.StripPrefix(prefix, fileServer))
}
在函式中,我們使用了go-bindata-assetfs來排程先前生成的datafile.go,結合net/http來對外提供swagger-ui的服務
結合
在完成功能後,我們發現path.Join("proto", p)是寫死引數的,這樣顯然不對,我們應該將其匯出成外部引數,那麼我們來最終改造一番
首先我們在server.go新增包全域性變數SwaggerDir,修改cmd/server.go檔案:
package cmd
import (
"log"
"github.com/spf13/cobra"
"grpc-hello-world/server"
)
var serverCmd = &cobra.Command{
Use: "server",
Short: "Run the gRPC hello-world server",
Run: func(cmd *cobra.Command, args []string) {
defer func() {
if err := recover(); err != nil {
log.Println("Recover error : %v", err)
}
}()
server.Run()
},
}
func init() {
serverCmd.Flags().StringVarP(&server.ServerPort, "port", "p", "50052", "server port")
serverCmd.Flags().StringVarP(&server.CertPemPath, "cert-pem", "", "./conf/certs/server.pem", "cert-pem path")
serverCmd.Flags().StringVarP(&server.CertKeyPath, "cert-key", "", "./conf/certs/server.key", "cert-key path")
serverCmd.Flags().StringVarP(&server.CertServerName, "cert-server-name", "", "grpc server name", "server's hostname")
serverCmd.Flags().StringVarP(&server.SwaggerDir, "swagger-dir", "", "proto", "path to the directory which contains swagger definitions")
rootCmd.AddCommand(serverCmd)
}
修改path.Join("proto", p)為path.Join(SwaggerDir, p),這樣的話我們swagger.json的檔案路徑就可以根據外部情況去修改它
最終server.go檔案內容:
package server
import (
"crypto/tls"
"net"
"net/http"
"log"
"strings"
"path"
"golang.org/x/net/context"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
"github.com/grpc-ecosystem/grpc-gateway/runtime"
"github.com/elazarl/go-bindata-assetfs"
pb "grpc-hello-world/proto"
"grpc-hello-world/pkg/util"
"grpc-hello-world/pkg/ui/data/swagger"
)
var (
ServerPort string
CertServerName string
CertPemPath string
CertKeyPath string
SwaggerDir string
EndPoint string
tlsConfig *tls.Config
)
func Run() (err error) {
EndPoint = ":" + ServerPort
tlsConfig = util.GetTLSConfig(CertPemPath, CertKeyPath)
conn, err := net.Listen("tcp", EndPoint)
if err != nil {
log.Printf("TCP Listen err:%v\n", err)
}
srv := newServer(conn)
log.Printf("gRPC and https listen on: %s\n", ServerPort)
if err = srv.Serve(util.NewTLSListener(conn, tlsConfig)); err != nil {
log.Printf("ListenAndServe: %v\n", err)
}
return err
}
func newServer(conn net.Listener) (*http.Server) {
grpcServer := newGrpc()
gwmux, err := newGateway()
if err != nil {
panic(err)
}
mux := http.NewServeMux()
mux.Handle("/", gwmux)
mux.HandleFunc("/swagger/", serveSwaggerFile)
serveSwaggerUI(mux)
return &http.Server{
Addr: EndPoint,
Handler: util.GrpcHandlerFunc(grpcServer, mux),
TLSConfig: tlsConfig,
}
}
func newGrpc() *grpc.Server {
creds, err := credentials.NewServerTLSFromFile(CertPemPath, CertKeyPath)
if err != nil {
panic(err)
}
opts := []grpc.ServerOption{
grpc.Creds(creds),
}
server := grpc.NewServer(opts...)
pb.RegisterHelloWorldServer(server, NewHelloService())
return server
}
func newGateway() (http.Handler, error) {
ctx := context.Background()
dcreds, err := credentials.NewClientTLSFromFile(CertPemPath, CertServerName)
if err != nil {
return nil, err
}
dopts := []grpc.DialOption{grpc.WithTransportCredentials(dcreds)}
gwmux := runtime.NewServeMux()
if err := pb.RegisterHelloWorldHandlerFromEndpoint(ctx, gwmux, EndPoint, dopts); err != nil {
return nil, err
}
return gwmux, nil
}
func serveSwaggerFile(w http.ResponseWriter, r *http.Request) {
if ! strings.HasSuffix(r.URL.Path, "swagger.json") {
log.Printf("Not Found: %s", r.URL.Path)
http.NotFound(w, r)
return
}
p := strings.TrimPrefix(r.URL.Path, "/swagger/")
p = path.Join(SwaggerDir, p)
log.Printf("Serving swagger-file: %s", p)
http.ServeFile(w, r, p)
}
func serveSwaggerUI(mux *http.ServeMux) {
fileServer := http.FileServer(&assetfs.AssetFS{
Asset: swagger.Asset,
AssetDir: swagger.AssetDir,
Prefix: "third_party/swagger-ui",
})
prefix := "/swagger-ui/"
mux.Handle(prefix, http.StripPrefix(prefix, fileServer))
}
測試
訪問路徑https://127.0.0.1:50052/swagger/hello.swagger.json,檢視輸出內容是否為hello.swagger.json的內容,例如: [image]
訪問路徑https://127.0.0.1:50052/swagger-ui/,檢視內容 [image]
小結
至此我們這一章節就完畢了,Swagger和其生態圈十分的豐富,有興趣研究的小夥伴可以到其官網認真研究
而目前完成的程度也滿足了日常工作的需求了,可較自動化的生成RESTful Api文件,完成與介面對接
參考
示例程式碼
5.4 能不能不用證書?
如果你以前有涉獵過 gRPC+gRPC Gateway 這兩個元件,你肯定會遇到這個問題,就是 “為什麼非得開 TLS,才能夠實作同埠雙流量,能不能不開?” 又或是 “我不想用證書就實作這些功能,行不行?”。我被無數的人問過無數次這些問題,也說服過很多人,但說服歸說服,不代表放棄。前年不行,不代表今年不行,在今天我希望分享來龍去脈和具體的實作方式給你。

過去
為什麼 h2 不行
因為 net/http2 僅支援 "h2" 標識,而 "h2" 標識 HTTP/2 必須使用傳輸層安全性(TLS)的協議,此識別符號用於 TLS 應用層協議協商欄位以及識別 HTTP/2 over TLS。
簡單來講,也就 net/http2 必須使用 TLS 來互動。通俗來講就要用證書,那麼理所當然,也就無法支援非 TLS 的情況了。
尋找 h2c
那這條路不行,我們再想想別的路?那就是 HTTP/2 規範中的 "h2c" 標識了,"h2c" 標識允許透過明文 TCP 執行 HTTP/2 的協議,此識別符號用於 HTTP/1.1 升級標頭欄位以及標識 HTTP/2 over TCP。
但是這條路,早在 2015 年就已經有在 issue 中進行討論,當時 @bradfitz 明確表示 “不打算支援 h2c,對僅支援 TLS 的情況非常滿意,一年後再問我一次”,原文回覆如下:
We do not plan to support h2c. I don't want to receive bug reports from users who get bitten by transparent proxies messing with h2c. Also, until there's widespread browser support, it's not interesting. I am also not interested in being the chicken or the egg to get browser support going. I'm very happy with the TLS-only situation, and things like https://LetsEncrypt.org/ will make TLS much easier (and automatic) soon.
Ask me again in one year.
琢磨其他方式
使用 cmux
基於多路複用器 soheilhy/cmux 的另類實作 Stoakes/grpc-gateway-example。若對 cmux 的實作方式感興趣,還可以看看 《Golang: Run multiple services on one port》。
使用第三方 h2
這種屬於自己實作了 h2c 的邏輯,以此達到效果。
現在
經過社群的不斷討論,最後在 2018 年 6 月,代表 "h2c" 標誌的 golang.org/x/net/http2/h2c 標準庫正式合併進來,自此我們就可以使用官方標準庫(h2c),這個標準庫實作了 HTTP/2 的未加密模式,因此我們就可以利用該標準庫在同個埠上既提供 HTTP/1.1 又提供 HTTP/2 的功能了。
使用標準庫 h2c
import (
...
"golang.org/x/net/http2"
"golang.org/x/net/http2/h2c"
"google.golang.org/grpc"
"github.com/grpc-ecosystem/grpc-gateway/runtime"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
...
func grpcHandlerFunc(grpcServer *grpc.Server, otherHandler http.Handler) http.Handler {
return h2c.NewHandler(http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.ProtoMajor == 2 && strings.Contains(r.Header.Get("Content-Type"), "application/grpc") {
grpcServer.ServeHTTP(w, r)
} else {
otherHandler.ServeHTTP(w, r)
}
}), &http2.Server{})
}
func main() {
server := grpc.NewServer()
pb.RegisterSearchServiceServer(server, &SearchService{})
mux := http.NewServeMux()
gwmux := runtime.NewServeMux()
dopts := []grpc.DialOption{grpc.WithInsecure()}
err := pb.RegisterSearchServiceHandlerFromEndpoint(context.Background(), gwmux, "localhost:"+PORT, dopts)
...
mux.Handle("/", gwmux)
http.ListenAndServe(":"+PORT, grpcHandlerFunc(server, mux))
}
我們可以看到關鍵之處在於呼叫了 h2c.NewHandler 方法進行了特殊處理,h2c.NewHandler 會返回一個 http.handler,主要的內部邏輯是攔截了所有 h2c 流量,然後根據不同的請求流量型別將其劫持並重定向到相應的 Hander 中去處理。
驗證
HTTP/1.1
$ curl -X GET 'http://127.0.0.1:9005/search?request=EDDYCJY'
{"response":"EDDYCJY"}
HTTP/2(gRPC)
...
func main() {
conn, err := grpc.Dial(":"+PORT, grpc.WithInsecure())
...
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(context.Background(), &pb.SearchRequest{
Request: "gRPC",
})
}
輸出結果:
$ go run main.go
2019/06/21 20:04:09 resp: gRPC h2c Server
總結
在本文中我介紹了大致的前因後果,且介紹了幾種解決方法,我建議你選擇官方的 h2c 標準庫去實作這個功能,也簡單。在最後,不管你是否曾經為這個問題煩惱過許久,又或者正在糾結,都希望這篇文章能夠幫到你。
參考
- https://github.com/golang/go/issues/13128
- https://github.com/golang/go/issues/14141
- https://github.com/golang/net/commit/c4299a1a0d8524c11563db160fbf9bddbceadb21
- https://go-review.googlesource.com/c/net/+/112997/
第6課 常用關鍵字
6.1 panic and recover
作為一個 gophper,我相信你對於 panic 和 recover 肯定不陌生,但是你有沒有想過。當我們執行了這兩條語句之後。底層到底發生了什麼事呢?前幾天和同事剛好聊到相關的話題,發現其實大家對這塊理解還是比較模糊的。希望這篇文章能夠從更深入的角度告訴你為什麼,它到底做了什麼事?
思考
一、為什麼會中止執行
func main() {
panic("EDDYCJY.")
}
輸出結果:
$ go run main.go
panic: EDDYCJY.
goroutine 1 [running]:
main.main()
/Users/eddycjy/go/src/github.com/EDDYCJY/awesomeProject/main.go:4 +0x39
exit status 2
請思考一下,為什麼執行 panic 後會導致應用程式執行中止?(而不是單單說執行了 panic 所以就結束了這麼含糊)
二、為什麼不會中止執行
func main() {
defer func() {
if err := recover(); err != nil {
log.Printf("recover: %v", err)
}
}()
panic("EDDYCJY.")
}
輸出結果:
$ go run main.go
2019/05/11 23:39:47 recover: EDDYCJY.
請思考一下,為什麼加上 defer + recover 組合就可以保護應用程式?
三、不設定 defer 行不
上面問題二是 defer + recover 組合,那我去掉 defer 是不是也可以呢?如下:
func main() {
if err := recover(); err != nil {
log.Printf("recover: %v", err)
}
panic("EDDYCJY.")
}
輸出結果:
$ go run main.go
panic: EDDYCJY.
goroutine 1 [running]:
main.main()
/Users/eddycjy/go/src/github.com/EDDYCJY/awesomeProject/main.go:10 +0xa1
exit status 2
竟然不行,啊呀畢竟入門教程都寫的 defer + recover 組合 “萬能” 捕獲。但是為什麼呢。去掉 defer 後為什麼就無法捕獲了?
請思考一下,為什麼需要設定 defer 後 recover 才能起作用?
同時你還需要仔細想想,我們設定 defer + recover 組合後就能無憂無慮了嗎,各種 “亂” 寫了嗎?
四、為什麼起個 goroutine 就不行
func main() {
go func() {
defer func() {
if err := recover(); err != nil {
log.Printf("recover: %v", err)
}
}()
}()
panic("EDDYCJY.")
}
輸出結果:
$ go run main.go
panic: EDDYCJY.
goroutine 1 [running]:
main.main()
/Users/eddycjy/go/src/github.com/EDDYCJY/awesomeProject/main.go:14 +0x51
exit status 2
請思考一下,為什麼新起了一個 Goroutine 就無法捕獲到異常了?到底發生了什麼事...
原始碼
接下來我們將帶著上述 4+1 個小思考題,開始對原始碼的剖析和分析,嘗試從閱讀原始碼中找到思考題的答案和更多為什麼
資料結構
type _panic struct {
argp unsafe.Pointer
arg interface{}
link *_panic
recovered bool
aborted bool
}
在 panic 中是使用 _panic 作為其基礎單元的,每執行一次 panic 語句,都會建立一個 _panic。它包含了一些基礎的欄位用於儲存當前的 panic 呼叫情況,涉及的欄位如下:
- argp:指向
defer延遲呼叫的引數的指標 - arg:
panic的原因,也就是呼叫panic時傳入的引數 - link:指向上一個呼叫的
_panic - recovered:
panic是否已經被處理,也就是是否被recover - aborted:
panic是否被中止
另外透過檢視 link 欄位,可得知其是一個連結串列的資料結構,如下圖:
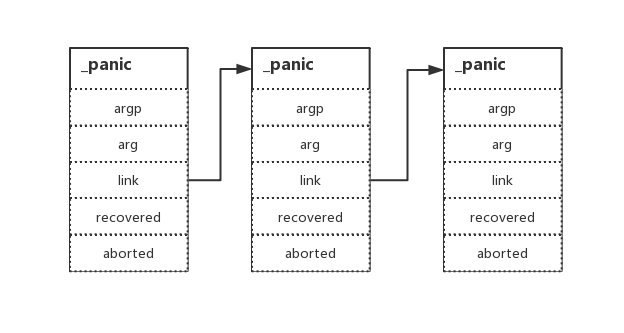
恐慌 panic
func main() {
panic("EDDYCJY.")
}
輸出結果:
$ go run main.go
panic: EDDYCJY.
goroutine 1 [running]:
main.main()
/Users/eddycjy/go/src/github.com/EDDYCJY/awesomeProject/main.go:4 +0x39
exit status 2
我們去反查一下 panic 處理具體邏輯的地方在哪,如下:
$ go tool compile -S main.go
"".main STEXT size=66 args=0x0 locals=0x18
0x0000 00000 (main.go:23) TEXT "".main(SB), ABIInternal, $24-0
0x0000 00000 (main.go:23) MOVQ (TLS), CX
0x0009 00009 (main.go:23) CMPQ SP, 16(CX)
...
0x002f 00047 (main.go:24) PCDATA $2, $0
0x002f 00047 (main.go:24) MOVQ AX, 8(SP)
0x0034 00052 (main.go:24) CALL runtime.gopanic(SB)
顯然彙編程式碼直指內部實作是 runtime.gopanic,我們一起來看看這個方法做了什麼事,如下(省略了部分):
func gopanic(e interface{}) {
gp := getg()
...
var p _panic
p.arg = e
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
d := gp._defer
if d == nil {
break
}
// defer...
...
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
p.argp = unsafe.Pointer(getargp(0))
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
p.argp = nil
// recover...
if p.recovered {
...
mcall(recovery)
throw("recovery failed") // mcall should not return
}
}
preprintpanics(gp._panic)
fatalpanic(gp._panic) // should not return
*(*int)(nil) = 0 // not reached
}
- 取得指向當前
Goroutine的指標 - 初始化一個
panic的基本單位_panic用作後續的操作 - 取得當前
Goroutine上掛載的_defer(資料結構也是連結串列) - 若當前存在
defer呼叫,則呼叫reflectcall方法去執行先前defer中延遲執行的程式碼,若在執行過程中需要執行recover將會呼叫gorecover方法 - 結束前,使用
preprintpanics方法打印出所涉及的panic訊息 - 最後呼叫
fatalpanic中止應用程式,實際是執行exit(2)進行最終退出行為的
透過對上述程式碼的執行分析,可得知 panic 方法實際上就是處理當前 Goroutine(g) 上所掛載的 ._panic 連結串列(所以無法對其他 Goroutine 的異常事件響應),然後對其所屬的 defer 連結串列和 recover 進行檢測並處理,最後呼叫退出命令中止應用程式
無法恢復的恐慌 fatalpanic
func fatalpanic(msgs *_panic) {
pc := getcallerpc()
sp := getcallersp()
gp := getg()
var docrash bool
systemstack(func() {
if startpanic_m() && msgs != nil {
...
printpanics(msgs)
}
docrash = dopanic_m(gp, pc, sp)
})
systemstack(func() {
exit(2)
})
*(*int)(nil) = 0
}
我們看到在異常處理的最後會執行該方法,似乎它承擔了所有收尾工作。實際呢,它是在最後對程式執行 exit 指令來達到中止執行的作用,但在結束前它會透過 printpanics 遞迴輸出所有的異常訊息及引數。程式碼如下:
func printpanics(p *_panic) {
if p.link != nil {
printpanics(p.link)
print("\t")
}
print("panic: ")
printany(p.arg)
if p.recovered {
print(" [recovered]")
}
print("\n")
}
所以不要以為所有的異常都能夠被 recover 到,實際上像 fatal error 和 runtime.throw 都是無法被 recover 到的,甚至是 oom 也是直接中止程式的,也有反手就給你來個 exit(2) 教做人。因此在寫程式碼時你應該要相對注意些,“恐慌” 是存在無法恢復的場景的
恢復 recover
func main() {
defer func() {
if err := recover(); err != nil {
log.Printf("recover: %v", err)
}
}()
panic("EDDYCJY.")
}
輸出結果:
$ go run main.go
2019/05/11 23:39:47 recover: EDDYCJY.
和預期一致,成功捕獲到了異常。但是 recover 是怎麼恢復 panic 的呢?再看看彙編程式碼,如下:
$ go tool compile -S main.go
"".main STEXT size=110 args=0x0 locals=0x18
0x0000 00000 (main.go:5) TEXT "".main(SB), ABIInternal, $24-0
...
0x0024 00036 (main.go:6) LEAQ "".main.func1·f(SB), AX
0x002b 00043 (main.go:6) PCDATA $2, $0
0x002b 00043 (main.go:6) MOVQ AX, 8(SP)
0x0030 00048 (main.go:6) CALL runtime.deferproc(SB)
...
0x0050 00080 (main.go:12) CALL runtime.gopanic(SB)
0x0055 00085 (main.go:12) UNDEF
0x0057 00087 (main.go:6) XCHGL AX, AX
0x0058 00088 (main.go:6) CALL runtime.deferreturn(SB)
...
0x0022 00034 (main.go:7) MOVQ AX, (SP)
0x0026 00038 (main.go:7) CALL runtime.gorecover(SB)
0x002b 00043 (main.go:7) PCDATA $2, $1
0x002b 00043 (main.go:7) MOVQ 16(SP), AX
0x0030 00048 (main.go:7) MOVQ 8(SP), CX
...
0x0056 00086 (main.go:8) LEAQ go.string."recover: %v"(SB), AX
...
0x0086 00134 (main.go:8) CALL log.Printf(SB)
...
透過分析底層呼叫,可得知主要是如下幾個方法:
- runtime.deferproc
- runtime.gopanic
- runtime.deferreturn
- runtime.gorecover
在上小節中,我們講述了簡單的流程,gopanic 方法會呼叫當前 Goroutine 下的 defer 連結串列,若 reflectcall 執行中遇到 recover 就會呼叫 gorecover 進行處理,該方法程式碼如下:
func gorecover(argp uintptr) interface{} {
gp := getg()
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
這程式碼,看上去挺簡單的,核心就是修改 recovered 欄位。該欄位是用於標識當前 panic 是否已經被 recover 處理。但是這和我們想象的並不一樣啊,程式是怎麼從 panic 流轉回去的呢?是不是在核心方法裡處理了呢?我們再看看 gopanic 的程式碼,如下:
func gopanic(e interface{}) {
...
for {
// defer...
...
pc := d.pc
sp := unsafe.Pointer(d.sp) // must be pointer so it gets adjusted during stack copy
freedefer(d)
// recover...
if p.recovered {
atomic.Xadd(&runningPanicDefers, -1)
gp._panic = p.link
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
if gp._panic == nil {
gp.sig = 0
}
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
mcall(recovery)
throw("recovery failed")
}
}
...
}
我們回到 gopanic 方法中再仔細看看,發現實際上是包含對 recover 流轉的處理程式碼的。恢復流程如下:
- 判斷當前
_panic中的recover是否已標註為處理 - 從
_panic連結串列中刪除已標註中止的panic事件,也就是刪除已經被恢復的panic事件 - 將相關需要恢復的棧幀資訊傳遞給
recovery方法的gp引數(每個棧幀對應著一個未執行完的函式。棧幀中儲存了該函式的返回地址和區域性變數) - 執行
recovery進行恢復動作
從流程來看,最核心的是 recovery 方法。它承擔了異常流轉控制的職責。程式碼如下:
func recovery(gp *g) {
sp := gp.sigcode0
pc := gp.sigcode1
if sp != 0 && (sp < gp.stack.lo || gp.stack.hi < sp) {
print("recover: ", hex(sp), " not in [", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n")
throw("bad recovery")
}
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
gp.sched.ret = 1
gogo(&gp.sched)
}
粗略一看,似乎就是很簡單的設定了一些值?但實際上設定的是編譯器中偽暫存器的值,常常被用於維護上下文等。在這裡我們需要結合 gopanic 方法一同觀察 recovery 方法。它所使用的棧指標 sp 和程式計數器 pc 是由當前 defer 在呼叫流程中的 deferproc 傳遞下來的,因此實際上最後是透過 gogo 方法跳回了 deferproc 方法。另外我們注意到:
gp.sched.ret = 1
在底層中程式將 gp.sched.ret 設定為了 1,也就是沒有實際呼叫 deferproc 方法,直接修改了其返回值。意味著預設它已經處理完成。直接轉移到 deferproc 方法的下一條指令去。至此為止,異常狀態的流轉控制就已經結束了。接下來就是繼續走 defer 的流程了
為了驗證這個想法,我們可以看一下核心的跳轉方法 gogo ,程式碼如下:
// void gogo(Gobuf*)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB),NOSPLIT,$8-4
MOVW buf+0(FP), R1
MOVW gobuf_g(R1), R0
BL setg<>(SB)
MOVW gobuf_sp(R1), R13 // restore SP==R13
MOVW gobuf_lr(R1), LR
MOVW gobuf_ret(R1), R0
MOVW gobuf_ctxt(R1), R7
MOVW $0, R11
MOVW R11, gobuf_sp(R1) // clear to help garbage collector
MOVW R11, gobuf_ret(R1)
MOVW R11, gobuf_lr(R1)
MOVW R11, gobuf_ctxt(R1)
MOVW gobuf_pc(R1), R11
CMP R11, R11 // set condition codes for == test, needed by stack split
B (R11)
透過檢視程式碼可得知其主要作用是從 Gobuf 恢復狀態。簡單來講就是將暫存器的值修改為對應 Goroutine(g) 的值,而在文中講了很多次的 Gobuf,如下:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr
}
講道理,其實它儲存的就是 Goroutine 切換上下文時所需要的一些東西
拓展
const(
OPANIC // panic(Left)
ORECOVER // recover()
...
)
...
func walkexpr(n *Node, init *Nodes) *Node {
...
switch n.Op {
default:
Dump("walk", n)
Fatalf("walkexpr: switch 1 unknown op %+S", n)
case ONONAME, OINDREGSP, OEMPTY, OGETG:
case OTYPE, ONAME, OLITERAL:
...
case OPANIC:
n = mkcall("gopanic", nil, init, n.Left)
case ORECOVER:
n = mkcall("gorecover", n.Type, init, nod(OADDR, nodfp, nil))
...
}
實際上在呼叫 panic 和 recover 關鍵字時,是在編譯階段先轉換為相應的 OPCODE 後,再由編譯器轉換為對應的執行時方法。並不是你所想像那樣一步到位,有興趣的小夥伴可以研究一下
總結
本文主要針對 panic 和 recover 關鍵字進行了深入原始碼的剖析,而開頭的 4+1 個思考題,就是希望您能夠帶著疑問去學習,達到事半功倍的功效
另外本文和 defer 有一定的關聯性,因此需要有一定的基礎知識。若剛剛看的時候這部分不理解,學習後可以再讀一遍加深印象
在最後,現在的你可以回答這幾個思考題了嗎?說出來了才是真的懂 :)
6.2 defer
在上一章節 《深入理解 Go panic and recover》 中,我們發現了 defer 與其關聯性極大,還是覺得非常有必要深入一下。希望透過本章節大家可以對 defer 關鍵字有一個深刻的理解,那麼我們開始吧。你先等等,請排好隊,我們這兒採取後進先出 LIFO 的出站方式...
特性
我們簡單的過一下 defer 關鍵字的基礎使用,讓大家先有一個基礎的認知
一、延遲呼叫
func main() {
defer log.Println("EDDYCJY.")
log.Println("end.")
}
輸出結果:
$ go run main.go
2019/05/19 21:15:02 end.
2019/05/19 21:15:02 EDDYCJY.
二、後進先出
func main() {
for i := 0; i < 6; i++ {
defer log.Println("EDDYCJY" + strconv.Itoa(i) + ".")
}
log.Println("end.")
}
輸出結果:
$ go run main.go
2019/05/19 21:19:17 end.
2019/05/19 21:19:17 EDDYCJY5.
2019/05/19 21:19:17 EDDYCJY4.
2019/05/19 21:19:17 EDDYCJY3.
2019/05/19 21:19:17 EDDYCJY2.
2019/05/19 21:19:17 EDDYCJY1.
2019/05/19 21:19:17 EDDYCJY0.
三、執行時間點
func main() {
func() {
defer log.Println("defer.EDDYCJY.")
}()
log.Println("main.EDDYCJY.")
}
輸出結果:
$ go run main.go
2019/05/22 23:30:27 defer.EDDYCJY.
2019/05/22 23:30:27 main.EDDYCJY.
四、異常處理
func main() {
defer func() {
if e := recover(); e != nil {
log.Println("EDDYCJY.")
}
}()
panic("end.")
}
輸出結果:
$ go run main.go
2019/05/20 22:22:57 EDDYCJY.
原始碼剖析
$ go tool compile -S main.go
"".main STEXT size=163 args=0x0 locals=0x40
...
0x0059 00089 (main.go:6) MOVQ AX, 16(SP)
0x005e 00094 (main.go:6) MOVQ $1, 24(SP)
0x0067 00103 (main.go:6) MOVQ $1, 32(SP)
0x0070 00112 (main.go:6) CALL runtime.deferproc(SB)
0x0075 00117 (main.go:6) TESTL AX, AX
0x0077 00119 (main.go:6) JNE 137
0x0079 00121 (main.go:7) XCHGL AX, AX
0x007a 00122 (main.go:7) CALL runtime.deferreturn(SB)
0x007f 00127 (main.go:7) MOVQ 56(SP), BP
0x0084 00132 (main.go:7) ADDQ $64, SP
0x0088 00136 (main.go:7) RET
0x0089 00137 (main.go:6) XCHGL AX, AX
0x008a 00138 (main.go:6) CALL runtime.deferreturn(SB)
0x008f 00143 (main.go:6) MOVQ 56(SP), BP
0x0094 00148 (main.go:6) ADDQ $64, SP
0x0098 00152 (main.go:6) RET
...
首先我們需要找到它,找到它實際對應什麼執行程式碼。透過彙編程式碼,可得知涉及如下方法:
- runtime.deferproc
- runtime.deferreturn
很顯然是執行時的方法,是對的人。我們繼續往下走看看都分別承擔了什麼行為
資料結構
在開始前我們需要先介紹一下 defer 的基礎單元 _defer 結構體,如下:
type _defer struct {
siz int32
started bool
sp uintptr // sp at time of defer
pc uintptr
fn *funcval
_panic *_panic // panic that is running defer
link *_defer
}
...
type funcval struct {
fn uintptr
// variable-size, fn-specific data here
}
- siz:所有傳入引數的總大小
- started:該
defer是否已經執行過 - sp:函式棧指標暫存器,一般指向當前函式棧的棧頂
- pc:程式計數器,有時稱為指令指標(IP),執行緒利用它來跟蹤下一個要執行的指令。在大多數處理器中,PC指向的是下一條指令,而不是當前指令
- fn:指向傳入的函式地址和引數
- _panic:指向
_panic連結串列 - link:指向
_defer連結串列
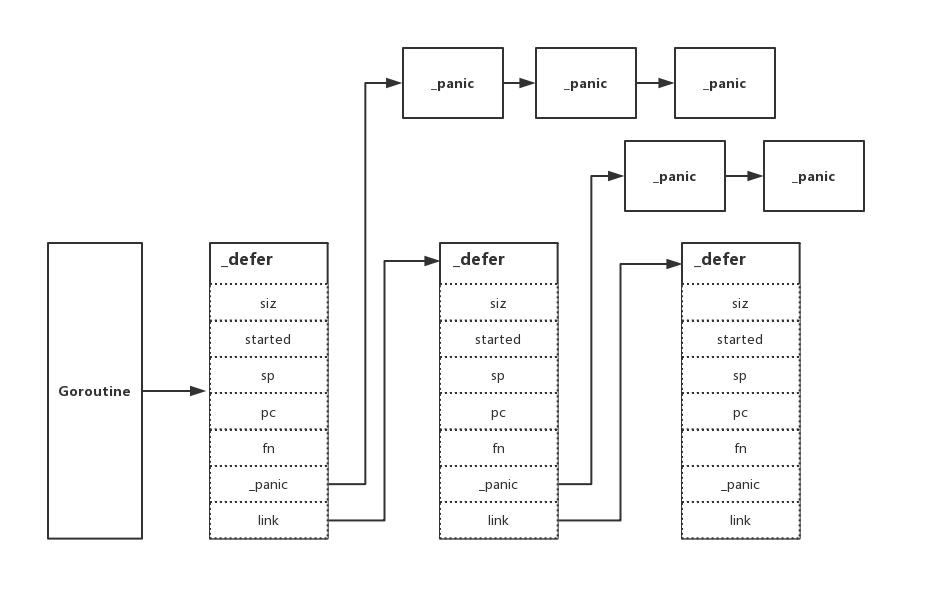
deferproc
func deferproc(siz int32, fn *funcval) {
...
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz)
...
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0()
}
- 取得呼叫
defer函式的函式棧指標、傳入函式的引數具體地址以及PC (程式計數器),也就是下一個要執行的指令。這些相當於是預備引數,便於後續的流轉控制 - 建立一個新的
defer最小單元_defer,填入先前準備的引數 - 呼叫
memmove將傳入的引數儲存到新_defer(當前使用)中去,便於後續的使用 - 最後呼叫
return0進行返回,這個函式非常重要。能夠避免在deferproc中又因為返回return,而誘發deferreturn方法的呼叫。其根本原因是一個停止panic的延遲方法會使deferproc返回 1,但在機制中如果deferproc返回不等於 0,將會總是檢查返回值並跳轉到函式的末尾。而return0返回的就是 0,因此可以防止重複呼叫
小結
在這個函式中會為新的 _defer 設定一些基礎屬性,並將呼叫函式的引數集傳入。最後透過特殊的返回方法結束函式呼叫。另外這一塊與先前 《深入理解 Go panic and recover》 的處理邏輯有一定關聯性,其實就是 gp.sched.ret 返回 0 還是 1 會分流至不同處理方式
newdefer
func newdefer(siz int32) *_defer {
var d *_defer
sc := deferclass(uintptr(siz))
gp := getg()
if sc < uintptr(len(p{}.deferpool)) {
pp := gp.m.p.ptr()
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
...
lock(&sched.deferlock)
d := sched.deferpool[sc]
unlock(&sched.deferlock)
}
...
}
if d == nil {
systemstack(func() {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (*_defer)(mallocgc(total, deferType, true))
})
...
}
d.siz = siz
d.link = gp._defer
gp._defer = d
return d
}
- 從池中取得可以使用的
_defer,則複用作為新的基礎單元 - 若在池中沒有取得到可用的,則呼叫
mallocgc重新申請一個新的 - 設定
defer的基礎屬性,最後修改當前Goroutine的_defer指向
透過這個方法我們可以注意到兩點,如下:
defer與Goroutine(g)有直接關係,所以討論defer時基本離不開g的關聯- 新的
defer總是會在現有的連結串列中的最前面,也就是defer的特性後進先出
小結
這個函式主要承擔了取得新的 _defer 的作用,它有可能是從 deferpool 中取得的,也有可能是重新申請的
deferreturn
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
sp := getcallersp()
if d.sp != sp {
return
}
switch d.siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
如果在一個方法中呼叫過 defer 關鍵字,那麼編譯器將會在結尾處插入 deferreturn 方法的呼叫。而該方法中主要做了如下事項:
- 清空當前節點
_defer被呼叫的函式呼叫資訊 - 釋放當前節點的
_defer的儲存資訊並放回池中(便於複用) - 跳轉到呼叫
defer關鍵字的呼叫函式處
在這段程式碼中,跳轉方法 jmpdefer 格外重要。因為它顯式的控制了流轉,程式碼如下:
// asm_amd64.s
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-16
MOVQ fv+0(FP), DX // fn
MOVQ argp+8(FP), BX // caller sp
LEAQ -8(BX), SP // caller sp after CALL
MOVQ -8(SP), BP // restore BP as if deferreturn returned (harmless if framepointers not in use)
SUBQ $5, (SP) // return to CALL again
MOVQ 0(DX), BX
JMP BX // but first run the deferred function
透過原始碼的分析,我們發現它做了兩個很 “奇怪” 又很重要的事,如下:
- MOVQ -8(SP), BP:
-8(BX)這個位置儲存的是deferreturn執行完畢後的地址 - SUBQ $5, (SP):
SP的地址減 5 ,其減掉的長度就恰好是runtime.deferreturn的長度
你可能會問,為什麼是 5?好吧。翻了半天最後看了一下彙編程式碼...嗯,相減的確是 5 沒毛病,如下:
0x007a 00122 (main.go:7) CALL runtime.deferreturn(SB)
0x007f 00127 (main.go:7) MOVQ 56(SP), BP
我們整理一下思緒,照上述邏輯的話,那 deferreturn 就是一個 “遞迴” 了哦。每次都會重新回到 deferreturn 函式,那它在什麼時候才會結束呢,如下:
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
...
}
也就是會不斷地進入 deferreturn 函式,判斷連結串列中是否還存著 _defer。若已經不存在了,則返回,結束掉它。簡單來講,就是處理完全部 defer 才允許你真的離開它。果真如此嗎?我們再看看上面的彙編程式碼,如下:
。..
0x0070 00112 (main.go:6) CALL runtime.deferproc(SB)
0x0075 00117 (main.go:6) TESTL AX, AX
0x0077 00119 (main.go:6) JNE 137
0x0079 00121 (main.go:7) XCHGL AX, AX
0x007a 00122 (main.go:7) CALL runtime.deferreturn(SB)
0x007f 00127 (main.go:7) MOVQ 56(SP), BP
0x0084 00132 (main.go:7) ADDQ $64, SP
0x0088 00136 (main.go:7) RET
0x0089 00137 (main.go:6) XCHGL AX, AX
0x008a 00138 (main.go:6) CALL runtime.deferreturn(SB)
...
的確如上述流程所分析一致,驗證完畢
小結
這個函式主要承擔了清空已使用的 defer 和跳轉到呼叫 defer 關鍵字的函式處,非常重要
總結
我們有提到 defer 關鍵字涉及兩個核心的函式,分別是 deferproc 和 deferreturn 函式。而 deferreturn 函式比較特殊,是當應用函式呼叫 defer 關鍵字時,編譯器會在其結尾處插入 deferreturn 的呼叫,它們倆一般都是成對出現的
但是當一個 Goroutine 上存在著多次 defer 行為(也就是多個 _defer)時,編譯器會進行利用一些小技巧, 重新回到 deferreturn 函式去消耗 _defer 連結串列,直到一個不剩才允許真正的結束
而新增的基礎單元 _defer,有可能是被複用的,也有可能是全新申請的。它最後都會被追加到 _defer 連結串列的表頭,從而設定了後進先出的呼叫特性
關聯
參考
第7課 資料結構
7.1 slice
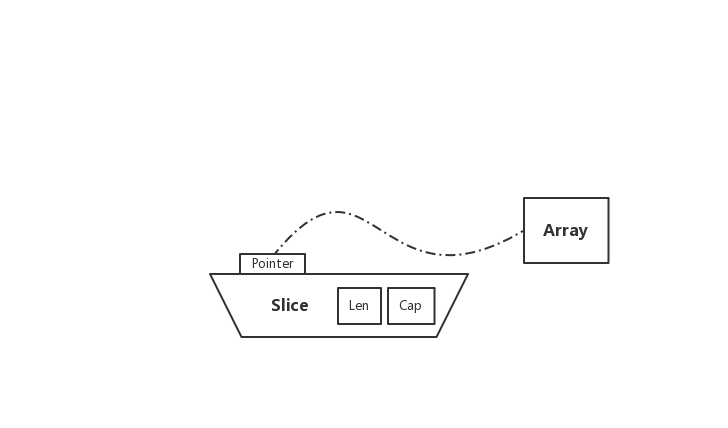
是什麼
在 Go 中,Slice(切片)是抽象在 Array(陣列)之上的特殊型別。為了更好地瞭解 Slice,第一步需要先對 Array 進行理解。深刻了解 Slice 與 Array 之間的區別後,就能更好的對其底層一番摸索 😄
用法
Array
func main() {
nums := [3]int{}
nums[0] = 1
n := nums[0]
n = 2
fmt.Printf("nums: %v\n", nums)
fmt.Printf("n: %d\n", n)
}
我們可得知在 Go 中,陣列型別需要指定長度和元素型別。在上述程式碼中,可得知 [3]int{} 表示 3 個整數的陣列,並進行了初始化。底層資料儲存為一段連續的記憶體空間,透過固定的索引值(下標)進行檢索
陣列在聲明後,其元素的初始值(也就是零值)為 0。並且該變數可以直接使用,不需要特殊操作
同時陣列的長度是固定的,它的長度是型別的一部分,因此 [3]int 和 [4]int 在型別上是不同的,不能稱為 “一個東西”
輸出結果
nums: [1 0 0]
n: 2
Slice
func main() {
nums := [3]int{}
nums[0] = 1
dnums := nums[:]
fmt.Printf("dnums: %v", dnums)
}
Slice 是對 Array 的抽象,型別為 []T。在上述程式碼中,dnums 變數透過 nums[:] 進行賦值。需要注意的是,Slice 和 Array 不一樣,它不需要指定長度。也更加的靈活,能夠自動擴容
資料結構
type slice struct {
array unsafe.Pointer
len int
cap int
}
Slice 的底層資料結構共分為三部分,如下:
- array:指向所引用的陣列指標(
unsafe.Pointer可以表示任何可定址的值的指標) - len:長度,當前引用切片的元素個數
- cap:容量,當前引用切片的容量(底層陣列的元素總數)
在實際使用中,cap 一定是大於或等於 len 的。否則會導致 panic
示例
為了更好的理解,我們回顧上小節的程式碼便於演示,如下:
func main() {
nums := [3]int{}
nums[0] = 1
dnums := nums[:]
fmt.Printf("dnums: %v", dnums)
}
在程式碼中,可觀察到 dnums := nums[:],這段程式碼確定了 Slice 的 Pointer 指向陣列,且 len 和 cap 都為陣列的基礎屬性。與圖示表達一致
len、cap 不同
func main() {
nums := [3]int{}
nums[0] = 1
dnums := nums[0:2]
fmt.Printf("dnums: %v, len: %d, cap: %d", dnums, len(dnums), cap(dnums))
}
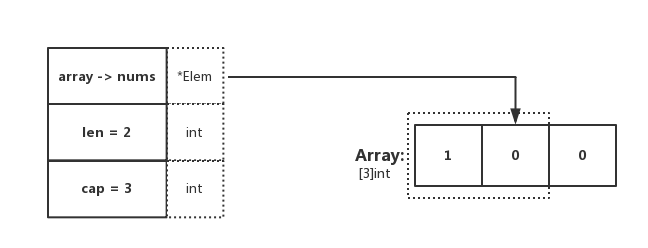
輸出結果
dnums: [1 0], len: 2, cap: 3
顯然,在這裡指定了 Slice[0:2],因此 len 為所引用元素的個數,cap 為所引用的陣列元素總個數。與期待一致 😄
建立
Slice 的建立有兩種方式,如下:
var []T或[]T{}func make([] T,len,cap)[] T
可以留意 make 函式,我們都知道 Slice 需要指向一個 Array。那 make 是怎麼做的呢?
它會在呼叫 make 的時候,分配一個數組並返回引用該陣列的 Slice
func makeslice(et *_type, len, cap int) slice {
maxElements := maxSliceCap(et.size)
if len < 0 || uintptr(len) > maxElements {
panic(errorString("makeslice: len out of range"))
}
if cap < len || uintptr(cap) > maxElements {
panic(errorString("makeslice: cap out of range"))
}
p := mallocgc(et.size*uintptr(cap), et, true)
return slice{p, len, cap}
}
- 根據傳入的 Slice 型別,取得其型別能夠申請的最大容量大小
- 判斷 len 是否合規,檢查是否在 0 < x < maxElements 範圍內
- 判斷 cap 是否合規,檢查是否在 len < x < maxElements 範圍內
- 申請 Slice 所需的記憶體空間物件。若為大型物件(大於 32 KB)則直接從堆中分配
- 返回申請成功的 Slice 記憶體地址和相關屬性(預設返回申請到的記憶體起始地址)
擴容
當使用 Slice 時,若儲存的元素不斷增長(例如透過 append)。當條件滿足擴容的策略時,將會觸發自動擴容
那麼分別是什麼規則呢?讓我們一起看看原始碼是怎麼說的 😄
zerobase
func growslice(et *_type, old slice, cap int) slice {
...
if et.size == 0 {
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
...
}
當 Slice size 為 0 時,若將要擴容的容量比原本的容量小,則丟擲異常(也就是不支援縮容操作)。否則,將重新生成一個新的 Slice 返回,其 Pointer 指向一個 0 byte 地址(不會保留老的 Array 指向)
擴容 - 計算策略
func growslice(et *_type, old slice, cap int) slice {
...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
...
}
}
...
}
- 若 Slice cap 大於 doublecap,則擴容後容量大小為 新 Slice 的容量(超了基準值,我就只給你需要的容量大小)
- 若 Slice len 小於 1024 個,在擴容時,增長因子為 1(也就是 3 個變 6 個)
- 若 Slice len 大於 1024 個,在擴容時,增長因子為 0.25(原本容量的四分之一)
注:也就是小於 1024 個時,增長 2 倍。大於 1024 個時,增長 1.25 倍
擴容 - 記憶體策略
func growslice(et *_type, old slice, cap int) slice {
...
var overflow bool
var lenmem, newlenmem, capmem uintptr
const ptrSize = unsafe.Sizeof((*byte)(nil))
switch et.size {
case 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > _MaxMem
newcap = int(capmem)
...
}
if cap < old.cap || overflow || capmem > _MaxMem {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.kind&kindNoPointers != 0 {
p = mallocgc(capmem, nil, false)
memmove(p, old.array, lenmem)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if !writeBarrier.enabled {
memmove(p, old.array, lenmem)
} else {
for i := uintptr(0); i < lenmem; i += et.size {
typedmemmove(et, add(p, i), add(old.array, i))
}
}
}
...
}
1、取得老 Slice 長度和計算假定擴容後的新 Slice 元素長度、容量大小以及指標地址(用於後續操作記憶體的一系列操作)
2、確定新 Slice 容量大於老 Sice,並且新容量記憶體小於指定的最大記憶體、沒有溢位。否則丟擲異常
3、若元素型別為 kindNoPointers,也就是非指標型別。則在老 Slice 後繼續擴容
- 第一步:根據先前計算的
capmem,在老 Slice cap 後繼續申請記憶體空間,其後用於擴容 - 第二步:將 old.array 上的 n 個 bytes(根據 lenmem)複製到新的記憶體空間上
- 第三步:新記憶體空間(p)加上新 Slice cap 的容量地址。最終得到完整的新 Slice cap 記憶體地址
add(p, newlenmem)(ptr) - 第四步:從 ptr 開始重新初始化 n 個 bytes(capmem-newlenmem)
注:那麼問題來了,為什麼要重新初始化這塊記憶體呢?這是因為 ptr 是未初始化的記憶體(例如:可重用的記憶體,一般用於新的記憶體分配),其可能包含 “垃圾”。因此在這裡應當進行 “清理”。便於後面實際使用(擴容)
4、不滿足 3 的情況下,重新申請並初始化一塊記憶體給新 Slice 用於儲存 Array
5、檢測當前是否正在執行 GC,也就是當前是否啟用 Write Barrier(寫屏障),若啟用則透過 typedmemmove 方法,利用指標運算迴圈複製。否則透過 memmove 方法採取整體複製的方式將 lenmem 個位元組從 old.array 複製到 ptr,以此達到更高的效率
注:一般會在 GC 標記階段啟用 Write Barrier,並且 Write Barrier 只針對指標啟用。那麼在第 5 點中,你就不難理解為什麼會有兩種截然不同的處理方式了
小結
這裡需要注意的是,擴容時的記憶體管理的選擇項,如下:
- 翻新擴充套件:當前元素為
kindNoPointers,將在老 Slice cap 的地址後繼續申請空間用於擴容 - 舉家搬遷:重新申請一塊記憶體地址,整體遷移並擴容
兩個小 “陷阱”
一、同根
func main() {
nums := [3]int{}
nums[0] = 1
fmt.Printf("nums: %v , len: %d, cap: %d\n", nums, len(nums), cap(nums))
dnums := nums[0:2]
dnums[0] = 5
fmt.Printf("nums: %v ,len: %d, cap: %d\n", nums, len(nums), cap(nums))
fmt.Printf("dnums: %v, len: %d, cap: %d\n", dnums, len(dnums), cap(dnums))
}
輸出結果:
nums: [1 0 0] , len: 3, cap: 3
nums: [5 0 0] ,len: 3, cap: 3
dnums: [5 0], len: 2, cap: 3
在未擴容前,Slice array 指向所引用的 Array。因此在 Slice 上的變更。會直接修改到原始 Array 上(兩者所引用的是同一個)
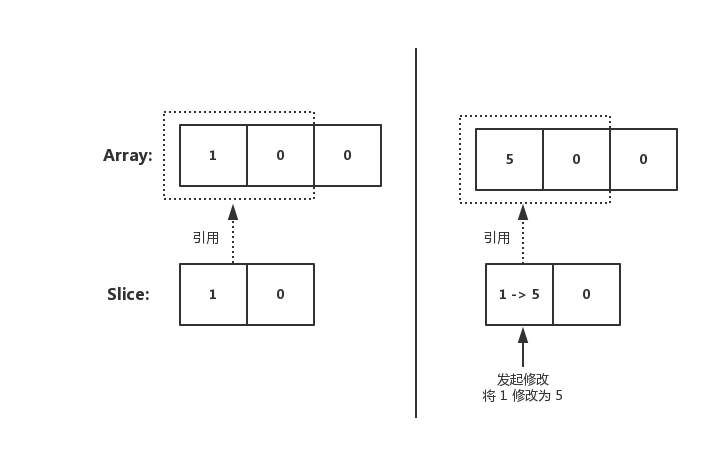
二、時過境遷
隨著 Slice 不斷 append,內在的元素越來越多,終於觸發了擴容。如下程式碼:
func main() {
nums := [3]int{}
nums[0] = 1
fmt.Printf("nums: %v , len: %d, cap: %d\n", nums, len(nums), cap(nums))
dnums := nums[0:2]
dnums = append(dnums, []int{2, 3}...)
dnums[1] = 1
fmt.Printf("nums: %v ,len: %d, cap: %d\n", nums, len(nums), cap(nums))
fmt.Printf("dnums: %v, len: %d, cap: %d\n", dnums, len(dnums), cap(dnums))
}
輸出結果:
nums: [1 0 0] , len: 3, cap: 3
nums: [1 0 0] ,len: 3, cap: 3
dnums: [1 1 2 3], len: 4, cap: 6
往 Slice append 元素時,若滿足擴容策略,也就是假設插入後,原本陣列的容量就超過最大值了
這時候內部就會重新申請一塊記憶體空間,將原本的元素複製一份到新的記憶體空間上。此時其與原本的陣列就沒有任何關聯關係了,再進行修改值也不會變動到原始陣列。這是需要注意的
複製
原型
func copy(dst,src [] T)int
copy 函式將資料從源 Slice複製到目標 Slice。它返回複製的元素數。
示例
func main() {
dst := []int{1, 2, 3}
src := []int{4, 5, 6, 7, 8}
n := copy(dst, src)
fmt.Printf("dst: %v, n: %d", dst, n)
}
copy 函式支援在不同長度的 Slice 之間進行復制,若出現長度不一致,在複製時會按照最少的 Slice 元素個數進行復制
那麼在原始碼中是如何完成複製這一個行為的呢?我們來一起看看原始碼的實作,如下:
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
if width == 0 {
return n
}
...
size := uintptr(n) * width
if size == 1 {
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
memmove(to.array, fm.array, size)
}
return n
}
- 若源 Slice 或目標 Slice 存在長度為 0 的情況,則直接返回 0(因為壓根不需要執行復制行為)
- 透過對比兩個 Slice,取得最小的 Slice 長度。便於後續操作
- 若 Slice 只有一個元素,則直接利用指標的特性進行轉換
- 若 Slice 大於一個元素,則從
fm.array複製size個位元組到to.array的地址處(會覆蓋原有的值)
"奇特"的初始化
在 Slice 中流傳著兩個傳說,分別是 Empty 和 Nil Slice,接下來讓我們看看它們的小區別 🤓
Empty
func main() {
nums := []int{}
renums := make([]int, 0)
fmt.Printf("nums: %v, len: %d, cap: %d\n", nums, len(nums), cap(nums))
fmt.Printf("renums: %v, len: %d, cap: %d\n", renums, len(renums), cap(renums))
}
輸出結果:
nums: [], len: 0, cap: 0
renums: [], len: 0, cap: 0
Nil
func main() {
var nums []int
}
輸出結果:
nums: [], len: 0, cap: 0
想一想
乍一看,Empty Slice 和 Nil Slice 好像一模一樣?不管是 len,還是 cap 都為 0。好像沒區別?我們再看看如下程式碼:
func main() {
var nums []int
renums := make([]int, 0)
if nums == nil {
fmt.Println("nums is nil.")
}
if renums == nil {
fmt.Println("renums is nil.")
}
}
你覺得輸出結果是什麼呢?你可能已經想到了,最終的輸出結果:
nums is nil.
為什麼
Empty
Nil
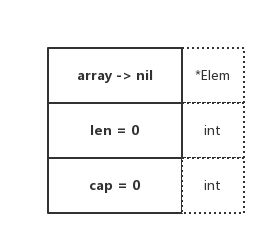
從圖示中可以看出來,兩者有本質上的區別。其底層陣列的指向指標是不一樣的,Nil Slice 指向的是 nil,Empty Slice 指向的是實際存在的空陣列地址
你可以認為,Nil Slice 代指不存在的 Slice,Empty Slice 代指空集合。兩者所代表的意義是完全不同的
總結
透過本文,可得知 Go Slice 相當靈活。不需要你手動擴容,也不需要你關注加多少減多少。對 Array 是動態引用,是 Go 型別的一個極大的補充,也因此在應用中使用的更多、更便捷
雖然有個別要注意的 “坑”,但其實是合理的。你覺得呢?😄
7.2 slice:最大容量大小是怎麼來的

前言
在《深入理解 Go Slice》中,我們提到了 “根據其型別大小去取得能夠申請的最大容量大小” 的處理邏輯。今天我們將更深入地去探究一下,底層到底做了什麼東西,涉及什麼知識點?
Go Slice 對應程式碼如下:
func makeslice(et *_type, len, cap int) slice {
maxElements := maxSliceCap(et.size)
if len < 0 || uintptr(len) > maxElements {
...
}
if cap < len || uintptr(cap) > maxElements {
...
}
p := mallocgc(et.size*uintptr(cap), et, true)
return slice{p, len, cap}
}
根據想要追尋的邏輯,定位到了 maxSliceCap 方法,它會根據當前型別的大小取得到了所允許的最大容量大小來進行閾值判斷,也就是安全檢查。這是淺層的瞭解,我們繼續追下去看看還做了些什麼?
maxSliceCap
func maxSliceCap(elemsize uintptr) uintptr {
if elemsize < uintptr(len(maxElems)) {
return maxElems[elemsize]
}
return maxAlloc / elemsize
}
maxElems
var maxElems = [...]uintptr{
^uintptr(0),
maxAlloc / 1, maxAlloc / 2, maxAlloc / 3, maxAlloc / 4,
maxAlloc / 5, maxAlloc / 6, maxAlloc / 7, maxAlloc / 8,
maxAlloc / 9, maxAlloc / 10, maxAlloc / 11, maxAlloc / 12,
maxAlloc / 13, maxAlloc / 14, maxAlloc / 15, maxAlloc / 16,
maxAlloc / 17, maxAlloc / 18, maxAlloc / 19, maxAlloc / 20,
maxAlloc / 21, maxAlloc / 22, maxAlloc / 23, maxAlloc / 24,
maxAlloc / 25, maxAlloc / 26, maxAlloc / 27, maxAlloc / 28,
maxAlloc / 29, maxAlloc / 30, maxAlloc / 31, maxAlloc / 32,
}
maxElems 是包含一些預定義的切片最大容量值的查詢表,索引是切片元素的型別大小。而值看起來 “奇奇怪怪” 不大眼熟,都是些什麼呢。主要是以下三個核心點:
- ^uintptr(0)
- maxAlloc
- maxAlloc / typeSize
^uintptr(0)
func main() {
log.Printf("uintptr: %v\n", uintptr(0))
log.Printf("^uintptr: %v\n", ^uintptr(0))
}
輸出結果:
2019/01/05 17:51:52 uintptr: 0
2019/01/05 17:51:52 ^uintptr: 18446744073709551615
我們留意一下輸出結果,比較神奇。取反之後為什麼是 18446744073709551615 呢?
uintptr 是什麼
在分析之前,我們要知道 uintptr 的本質(真面目),也就是它的型別是什麼,如下:
type uintptr uintptr
uintptr 的型別是自定義型別,接著找它的真面目,如下:
#ifdef _64BIT
typedef uint64 uintptr;
#else
typedef uint32 uintptr;
#endif
透過對以上程式碼的分析,可得出以下結論:
- 在 32 位系統下,uintptr 為 uint32 型別,佔用大小為 4 個位元組
- 在 64 位系統下,uintptr 為 uint64 型別,佔用大小為 8 個位元組
^uintptr 做了什麼事
^ 位運算子的作用是按位異或,如下:
func main() {
log.Println(^1)
log.Println(^uint64(0))
}
輸出結果:
2019/01/05 20:44:49 -2
2019/01/05 20:44:49 18446744073709551615
接下來我們分析一下,這兩段程式碼都做了什麼事情呢
^1
二進位制:0001
按位取反:1110
該數為有符號整數,最高位為符號位。低三位為表示數值。按位取反後為 1110,根據先前的說明,最高位為 1,因此表示為 -。取反後 110 對應十進位制 -2
^uint64(0)
二進位制:0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
按位取反:1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
該數為無符號整數,該位取反後得到十進位制值為:18446744073709551615
這個值是不是看起來很眼熟呢?沒錯,就是 ^uintptr(0) 的值。也印證了其底層資料型別為 uint64 的事實 (本機為 64 位)。同時它又代表如下:
- math.MaxUint64
- 2 的 64 次方減 1
maxAlloc
const GoarchMips = 0
const GoarchMipsle = 0
const GoarchWasm = 0
...
_64bit = 1 << (^uintptr(0) >> 63) / 2
heapAddrBits = (_64bit*(1-sys.GoarchWasm))*48 + (1-_64bit+sys.GoarchWasm)*(32-(sys.GoarchMips+sys.GoarchMipsle))
maxAlloc = (1 << heapAddrBits) - (1-_64bit)*1
maxAlloc 是允許使用者分配的最大虛擬記憶體空間。在 64 位,理論上可分配最大 1 << heapAddrBits 位元組。在 32 位,最大可分配小於 1 << 32 位元組
在本文,僅需瞭解它承載的是什麼就好了。具體的在以後記憶體管理的文章再講述
注:該變數在 go 10.1 為 _MaxMem,go 11.4 已改為 maxAlloc。相關的 heapAddrBits 計算方式也有所改變
maxAlloc / typeSize
我們再次回顧 maxSliceCap 的邏輯程式碼,這次重點放在控制邏輯,如下:
// func makeslice
maxElements := maxSliceCap(et.size)
...
// func maxSliceCap
if elemsize < uintptr(len(maxElems)) {
return maxElems[elemsize]
}
return maxAlloc / elemsize
透過這段程式碼和 Slice 上下文邏輯,可得知在想得到該型別的最大容量大小時。會根據對應的型別大小去查詢表查詢索引(索引為型別大小,擺放順序是有考慮原因的)。“迫不得已的情況下” 才會手動的計算它的值,最終計算得到的記憶體位元組大小都為該型別大小的整數倍
查詢表的設定,更像是一個最佳化邏輯。減少常用的計算開銷 :)
總結
透過本文的分析,可得出 Slice 所允許申請的最大容量大小,與當前值型別和當前平臺位數有直接關係
最後
本文與《有點不安全卻又一亮的 Go unsafe.Pointer》一同屬於《深入理解 Go Slice》的關聯章節。如果你在閱讀原始碼時,對這些片段有疑惑。記得想盡辦法深究下去,搞懂它
短短的一句話其實蘊含著不少知識點,希望這篇文章恰恰好可以幫你解惑
注:本文 Go 程式碼基於版本 11.4
7.3 map:初始化和訪問元素
從本文開始咱們一起探索 Go map 裡面的奧妙吧,看看它的內在是怎麼構成的,又分別有什麼值得留意的地方?
第一篇將探討初始化和訪問元素相關板塊,咱們帶著疑問去學習,例如:
- 初始化的時候會馬上分配記憶體嗎?
- 底層資料是如何儲存的?
- 底層是如何使用 key 去尋找資料的?
- 底層是用什麼方式解決雜湊衝突的?
- 資料型別那麼多,底層又是怎麼處理的呢?
...
資料結構
首先我們一起看看 Go map 的基礎資料結構,先有一個大致的印象
hmap
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
- count:map 的大小,也就是 len() 的值。代指 map 中的鍵值對個數
- flags:狀態標識,主要是 goroutine 寫入和擴容機制的相關狀態控制。併發讀寫的判斷條件之一就是該值
- B:桶,最大可容納的元素數量,值為 負載因子(預設 6.5) * 2 ^ B,是 2 的指數
- noverflow:溢位桶的數量
- hash0:雜湊因子
- buckets:儲存當前桶資料的指標地址(指向一段連續的記憶體地址,主要儲存鍵值對資料)
- oldbuckets,儲存舊桶的指標地址
- nevacuate:遷移進度
- extra:原有 buckets 滿載後,會發生擴容動作,在 Go 的機制中使用了增量擴容,如下為細項:
overflow為hmap.buckets(當前)溢位桶的指標地址oldoverflow為hmap.oldbuckets(舊)溢位桶的指標地址nextOverflow為空閒溢位桶的指標地址
在這裡我們要注意幾點,如下:
- 如果 keys 和 values 都不包含指標並且允許內聯的情況下。會將 bucket 標識為不包含指標,使用 extra 儲存溢位桶就可以避免 GC 掃描整個 map,節省不必要的開銷
- 在前面有提到,Go 用了增量擴容。而
buckets和oldbuckets也是與擴容相關的載體,一般情況下只使用buckets,oldbuckets是為空的。但如果正在擴容的話,oldbuckets便不為空,buckets的大小也會改變 - 當
hint大於 8 時,就會使用*mapextra做溢位桶。若小於 8,則儲存在 buckets 桶中
bmap
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
...
type bmap struct {
tophash [bucketCnt]uint8
}
- tophash:key 的 hash 值高 8 位
- keys:8 個 key
- values:8 個 value
- overflow:下一個溢位桶的指標地址(當 hash 衝突發生時)
實際 bmap 就是 buckets 中的 bucket,一個 bucket 最多儲存 8 個鍵值對
tophash
tophash 是個長度為 8 的陣列,代指桶最大可容納的鍵值對為 8。
儲存每個元素 hash 值的高 8 位,如果 tophash [0] <minTopHash,則 tophash [0] 表示為遷移進度
keys 和 values
在這裡我們留意到,儲存 k 和 v 的載體並不是用 k/v/k/v/k/v/k/v 的模式,而是 k/k/k/k/v/v/v/v 的形式去儲存。這是為什麼呢?
map[int64]int8
在這個例子中,如果按照 k/v/k/v/k/v/k/v 的形式存放的話,雖然每個鍵值對的值都只佔用 1 個位元組。但是卻需要 7 個填充位元組來補齊記憶體空間。最終就會造成大量的記憶體 “浪費”

但是如果以 k/k/k/k/v/v/v/v 的形式存放的話,就能夠解決因對齊所 "浪費" 的記憶體空間
因此這部分的拆分主要是考慮到記憶體對齊的問題,雖然相對會複雜一點,但依然值得如此設計

overflow
可能會有同學疑惑為什麼會有溢位桶這個東西?實際上在不存在雜湊衝突的情況下,去掉溢位桶,也就是隻需要桶、雜湊因子、雜湊演算法。也能實作一個簡單的 hash table。但是雜湊衝突(碰撞)是不可避免的...
而在 Go map 中當 hmap.buckets 滿了後,就會使用溢位桶接著儲存。我們結合分析可確定 Go 採用的是陣列 + 鏈地址法解決雜湊衝突
初始化
用法
m := make(map[int32]int32)
函式原型
透過閱讀原始碼可得知,初始化方法有好幾種。函式原型如下:
func makemap_small() *hmap
func makemap64(t *maptype, hint int64, h *hmap) *hmap
func makemap(t *maptype, hint int, h *hmap) *hmap
- makemap_small:當
hint小於 8 時,會呼叫makemap_small來初始化 hmap。主要差異在於是否會馬上初始化 hash table - makemap64:當
hint型別為 int64 時的特殊轉換及校驗處理,後續實質呼叫makemap - makemap:實作了標準的 map 初始化動作
原始碼
func makemap(t *maptype, hint int, h *hmap) *hmap {
if hint < 0 || hint > int(maxSliceCap(t.bucket.size)) {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
- 根據傳入的
bucket型別,取得其型別能夠申請的最大容量大小。並對其長度make(map[k]v, hint)進行邊界值檢驗 - 初始化 hmap
- 初始化雜湊因子
- 根據傳入的
hint,計算一個可以放下hint個元素的桶B的最小值 - 分配並初始化 hash table。如果
B為 0 將在後續懶惰分配桶,大於 0 則會馬上進行分配 - 返回初始化完畢的 hmap
在這裡可以注意到,(當 hint 大於等於 8 )第一次初始化 map 時,就會透過呼叫 makeBucketArray 對 buckets 進行分配。因此我們常常會說,在初始化時指定一個適當大小的容量。能夠提升效能。
若該容量過少,而新增的鍵值對又很多。就會導致頻繁的分配 buckets,進行擴容遷移等 rehash 動作。最終結果就是效能直接的下降(敲黑板)
而當 hint 小於 8 時,這種問題相對就不會凸顯的太明顯,如下:
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
圖示
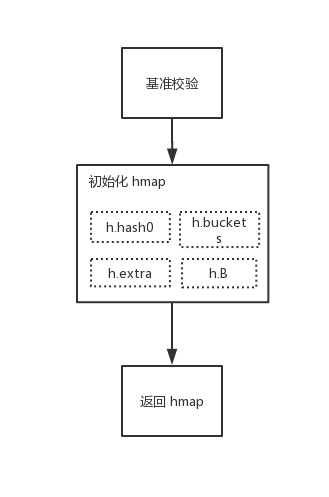
訪問
用法
v := m[i]
v, ok := m[i]
函式原型
在實作 map 元素訪問上有好幾種方法,主要是包含針對 32/64 位、string 型別的特殊處理,總的函式原型如下:
mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)
mapaccess1_fat(t *maptype, h *hmap, key, zero unsafe.Pointer) unsafe.Pointer
mapaccess2_fat(t *maptype, h *hmap, key, zero unsafe.Pointer) (unsafe.Pointer, bool)
mapaccess1_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer
mapaccess2_fast32(t *maptype, h *hmap, key uint32) (unsafe.Pointer, bool)
mapassign_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer
mapassign_fast32ptr(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer
...
mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer
...
- mapaccess1:返回
h[key]的指標地址,如果鍵不在map中,將返回對應型別的零值 - mapaccess2:返回
h[key]的指標地址,如果鍵不在map中,將返回零值和布林值用於判斷
原始碼
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
- 判斷 map 是否為 nil,長度是否為 0。若是則返回零值
- 判斷當前是否併發讀寫 map,若是則丟擲異常
- 根據 key 的不同型別呼叫不同的 hash 方法計算得出 hash 值
- 確定 key 在哪一個 bucket 中,並得到其位置
- 判斷是否正在發生擴容(h.oldbuckets 是否為 nil),若正在擴容,則到老的 buckets 中查詢(因為 buckets 中可能還沒有值,搬遷未完成),若該 bucket 已經搬遷完畢。則到 buckets 中繼續查詢
- 計算 hash 的 tophash 值(高八位)
- 根據計算出來的 tophash,依次迴圈對比 buckets 的 tophash 值(快速試錯)
- 如果 tophash 匹配成功,則計算 key 的所在位置,正式完整的對比兩個 key 是否一致
- 若查詢成功並返回,若不存在,則返回零值
在上述步驟三中,提到了根據不同的型別計算出 hash 值,另外會計算出 hash 值的高八位和低八位。低八位會作為 bucket index,作用是用於找到 key 所在的 bucket。而高八位會儲存在 bmap tophash 中
其主要作用是在上述步驟七中進行迭代快速定位。這樣子可以提高效能,而不是一開始就直接用 key 進行一致性對比
圖示
總結
在本章節,我們介紹了 map 型別的以下知識點:
- map 的基礎資料結構
- 初始化 map
- 訪問 map
從閱讀原始碼中,得知 Go 本身對於一些不同大小、不同型別的屬性,包括雜湊方法都有編寫特定方法去執行。總的來說,這塊的設計隱含較多的思路,有不少點值得細細品嚐 :)
注:本文基於 Go 1.11.5
7.4 map:賦值和擴容遷移
概要
在 上一章節 中,資料結構小節裡講解了大量基礎欄位,可能你會疑惑需要 #&(!……#(!¥! 來幹嘛?接下來我們一起簡單瞭解一下基礎概念。再開始研討今天文章的重點內容。我相信這樣你能更好的讀懂這篇文章
雜湊函式
雜湊函式,又稱雜湊演算法、雜湊函式。主要作用是透過特定演算法將資料根據一定規則組合重新生成得到一個雜湊值
而在雜湊表中,其生成的雜湊值常用於尋找其鍵對映到哪一個桶上。而一個好的雜湊函式,應當儘量少的出現雜湊衝突,以此保證操作雜湊表的時間複雜度(但是雜湊衝突在目前來講,是無法避免的。我們需要 “解決” 它)
鏈地址法
在雜湊操作中,相當核心的一個處理動作就是 “雜湊衝突” 的解決。而在 Go map 中採用的就是 "鏈地址法 " 去解決雜湊衝突,又稱 "拉鍊法"。其主要做法是陣列 + 連結串列的資料結構,其溢位節點的儲存記憶體都是動態申請的,因此相對更靈活。而每一個元素都是一個連結串列。如下圖:
桶/溢位桶
type hmap struct {
...
buckets unsafe.Pointer
...
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
在上章節中,我們介紹了 Go map 中的桶和溢位桶的概念,在其桶中只能儲存 8 個鍵值對元素。當超過 8 個時,將會使用溢位桶進行儲存或進行擴容
你可能會有疑問,hint 大於 8 又會怎麼樣?答案很明顯,效能問題,其時間複雜度改變(也就是執行效率出現問題)
前言
概要複習的差不多後,接下來我們將一同研討 Go map 的另外三個核心行為:賦值、擴容、遷移。正式開始我們的研討之旅吧 :)
賦值
m := make(map[int32]string)
m[0] = "EDDYCJY"
函式原型
在 map 的賦值動作中,依舊是針對 32/64 位、string、pointer 型別有不同的轉換處理,總的函式原型如下:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess1_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer
func mapaccess2_fast32(t *maptype, h *hmap, key uint32) (unsafe.Pointer, bool)
func mapassign_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer
func mapassign_fast32ptr(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer
func mapaccess2_fast64(t *maptype, h *hmap, key uint64) (unsafe.Pointer, bool)
func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer
func mapassign_fast64ptr(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer
func mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool)
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer
...
接下來我們將分成幾個部分去看看底層在賦值的時候,都做了些什麼處理?
原始碼
第一階段:校驗和初始化
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
...
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags |= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
...
}
- 判斷 hmap 是否已經初始化(是否為 nil)
- 判斷是否併發讀寫 map,若是則丟擲異常
- 根據 key 的不同型別呼叫不同的 hash 方法計算得出 hash 值
- 設定 flags 標誌位,表示有一個 goroutine 正在寫入資料。因為
alg.hash有可能出現panic導致異常 - 判斷 buckets 是否為 nil,若是則呼叫
newobject根據當前 bucket 大小進行分配(例如:上章節提到的makemap_small方法,就在初始化時沒有初始 buckets,那麼它在第一次賦值時就會對 buckets 分配)
第二階段:尋找可插入位和更新既有值
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == empty && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
if t.needkeyupdate {
typedmemmove(t.key, k, key)
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
...
- 根據低八位計算得到 bucket 的記憶體地址,並判斷是否正在擴容,若正在擴容中則先遷移再接著處理
- 計算並得到 bucket 的 bmap 指標地址,計算 key hash 高八位用於查詢 Key
- 迭代 buckets 中的每一個 bucket(共 8 個),對比
bucket.tophash與 top(高八位)是否一致 - 若不一致,判斷是否為空槽。若是空槽(有兩種情況,第一種是沒有插入過。第二種是插入後被刪除),則把該位置標識為可插入 tophash 位置。注意,這裡就是第一個可以插入資料的地方
- 若 key 與當前 k 不匹配則跳過。但若是匹配(也就是原本已經存在),則進行更新。最後跳出並返回 value 的記憶體地址
- 判斷是否迭代完畢,若是則結束迭代 buckets 並更新當前桶位置
- 若滿足三個條件:觸發最大
LoadFactor、存在過多溢位桶overflow buckets、沒有正在進行擴容。就會進行擴容動作(以確保後續的動作)
總的來講,這一塊邏輯做了兩件大事,第一是尋找空位,將位置其記錄在案,用於後續的插入動作。第二是判斷 Key 是否已經存在雜湊表中,存在則進行更新。而若是第二種場景,更新完畢後就會進行收尾動作,第一種將繼續執行下述的程式碼
第三階段:申請新的插入位和插入新值
...
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
if t.indirectkey {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
...
return val
經過前面迭代尋找動作,若沒有找到可插入的位置,意味著當前的所有桶都滿了,將重新分配一個新溢位桶用於插入動作。最後再在上一步申請的新插入位置,儲存鍵值對,返回該值的記憶體地址
第四階段:寫入
但是這裡又疑惑了?最後為什麼是返回記憶體地址。這是因為隱藏的最後一步寫入動作(將值複製到指定記憶體區域)是透過底層彙編配合來完成的,在 runtime 中只完成了絕大部分的動作
func main() {
m := make(map[int32]int32)
m[0] = 6666666
}
對應的彙編部分:
...
0x0099 00153 (test.go:6) CALL runtime.mapassign_fast32(SB)
0x009e 00158 (test.go:6) PCDATA $2, $2
0x009e 00158 (test.go:6) MOVQ 24(SP), AX
0x00a3 00163 (test.go:6) PCDATA $2, $0
0x00a3 00163 (test.go:6) MOVL $6666666, (AX)
這裡分為了幾個部位,主要是呼叫 mapassign 函式和拿到值存放的記憶體地址,再將 6666666 這個值存放進該記憶體地址中。另外我們看到 PCDATA 指令,主要是包含一些垃圾回收的資訊,由編譯器產生
小結
透過前面幾個階段的分析,我們可梳理出一些要點。例如:
- 不同型別對應雜湊函式不一樣
- 高八位用於定位 bucket
- 低八位用於定位 key,快速試錯後再進行完整對比
- buckets/overflow buckets 遍歷
- 可插入位的處理
- 最終寫入動作與底層彙編的互動
擴容
在所有動作中,擴容規則是大家較關注的點,也是賦值裡非常重要的一環。因此咱們將這節拉出來,對這塊細節進行研討
什麼時候擴容
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
在特定條件的情況下且當前沒有正在進行擴容動作(以判斷 hmap.oldbuckets != nil 為基準)。雜湊表在賦值、刪除的動作下會觸發擴容行為,條件如下:
- 觸發
load factor的最大值,負載因子已達到當前界限 - 溢位桶
overflow buckets過多
什麼時候受影響
那麼什麼情況下會對這兩個 “值” 有影響呢?如下:
- 負載因子
load factor,用途是評估雜湊表當前的時間複雜度,其與雜湊表當前包含的鍵值對數、桶數量等相關。如果負載因子越大,則說明空間使用率越高,但產生雜湊衝突的可能性更高。而負載因子越小,說明空間使用率低,產生雜湊衝突的可能性更低 - 溢位桶
overflow buckets的判定與 buckets 總數和 overflow buckets 總數相關聯
因子關係
| loadFactor | %overflow | bytes/entry | hitprobe | missprobe |
|---|---|---|---|---|
| 4.00 | 2.13 | 20.77 | 3.00 | 4.00 |
| 4.50 | 4.05 | 17.30 | 3.25 | 4.50 |
| 5.00 | 6.85 | 14.77 | 3.50 | 5.00 |
| 5.50 | 10.55 | 12.94 | 3.75 | 5.50 |
| 6.00 | 15.27 | 11.67 | 4.00 | 6.00 |
| 6.50 | 20.90 | 10.79 | 4.25 | 6.50 |
| 7.00 | 27.14 | 10.15 | 4.50 | 7.00 |
- loadFactor:負載因子
- %overflow:溢位率,具有溢位桶
overflow buckets的桶的百分比 - bytes/entry:每個鍵值對所的位元組數開銷
- hitprobe:查詢存在的 key 時,平均需要檢索的條目數量
- missprobe:查詢不存在的 key 時,平均需要檢索的條目數量
這一組資料能夠體現出不同的負載因子會給雜湊表的動作帶來怎麼樣的影響。而在上一章節我們有提到預設的負載因子是 6.5 (loadFactorNum/loadFactorDen),可以看出來是經過測試後取出的一個比較合理的因子。能夠較好的影響雜湊表的擴容動作的時機
原始碼剖析
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
...
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
第一階段:確定擴容容量規則
在上小節有講到擴容的依據有兩種,在 hashGrow 開頭就進行了劃分。如下:
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
若不是負載因子 load factor 超過當前界限,也就是屬於溢位桶 overflow buckets 過多的情況。因此本次擴容規則將是 sameSizeGrow,即是不改變大小的擴容動作。那要是前者的情況呢?
bigger := uint8(1)
...
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
結合程式碼分析可得出,若是負載因子 load factor 達到當前界限,將會動態擴容當前大小的兩倍作為其新容量大小
第二階段:初始化、交換新舊 桶/溢位桶
主要是針對擴容的相關資料前置處理,涉及 buckets/oldbuckets、overflow/oldoverflow 之類與儲存相關的欄位
...
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
h.B += bigger
...
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
...
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
...
h.extra.nextOverflow = nextOverflow
}
這裡注意到這段程式碼: newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)。第一反應是擴容的時候就馬上申請並初始化記憶體了嗎?假設涉及大量的記憶體分配,那挺耗費效能的...
然而並不,內部只會先進行預分配,當使用的時候才會真正的去初始化
第三階段:擴容
在原始碼中,發現第三階段的流轉並沒有顯式展示。這是因為流轉由底層去做控制了。但透過分析程式碼和註釋,可得知由第三階段涉及 growWork 和 evacuate 方法。如下:
func growWork(t *maptype, h *hmap, bucket uintptr) {
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
在該方法中,主要是兩個 evacuate 函式的呼叫。他們在呼叫上又分別有什麼區別呢?如下:
- evacuate(t, h, bucket&h.oldbucketmask()): 將 oldbucket 中的元素遷移 rehash 到擴容後的新 bucket
- evacuate(t, h, h.nevacuate): 如果當前正在進行擴容,則再進行多一次遷移
另外,在執行擴容動作的時候,可以發現都是以 bucket/oldbucket 為單位的,而不是傳統的 buckets/oldbuckets。再結合程式碼分析,可得知在 Go map 中擴容是採取增量擴容的方式,並非一步到位
為什麼是增量擴容?
如果是全量擴容的話,那問題就來了。假設當前 hmap 的容量比較大,直接全量擴容的話,就會導致擴容要花費大量的時間和記憶體,導致系統卡頓,最直觀的表現就是慢。顯然,不能這麼做
而增量擴容,就可以解決這個問題。它透過每一次的 map 操作行為去分攤總的一次性動作。因此有了 buckets/oldbuckets 的設計,它是逐步完成的,並且會在擴容完畢後才進行清空
小結
透過前面三個階段的分析,可以得知擴容的大致過程。我們階段性總結一下。主要如下:
- 根據需擴容的原因不同(overLoadFactor/tooManyOverflowBuckets),分為兩類容量規則方向,為等量擴容(不改變原有大小)或雙倍擴容
- 新申請的擴容空間(newbuckets/newoverflow)都是預分配,等真正使用的時候才會初始化
- 擴容完畢後(預分配),不會馬上就進行遷移。而是採取增量擴容的方式,當有訪問到具體 bukcet 時,才會逐漸的進行遷移(將 oldbucket 遷移到 bucket)
這時候又想到,既然遷移是逐步進行的。那如果在途中又要擴容了,怎麼辦?
again:
bucket := hash & bucketMask(h.B)
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
在這裡注意到 goto again 語句,結合上下文可得若正在進行擴容,就會不斷地進行遷移。待遷移完畢後才會開始進行下一次的擴容動作
遷移
在擴容的完整閉環中,包含著遷移的動作,又稱 “搬遷”。因此我們繼續深入研究 evacuate 函式。接下來一起開啟遷移世界的大門。如下:
type evacDst struct {
b *bmap
i int
k unsafe.Pointer
v unsafe.Pointer
}
evacDst 是遷移中的基礎資料結構,其包含如下欄位:
- b: 當前目標桶
- i: 當前目標桶儲存的鍵值對數量
- k: 指向當前 key 的記憶體地址
- v: 指向當前 value 的記憶體地址
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
}
for ; b != nil; b = b.overflow(t) {
...
}
if h.flags&oldIterator == 0 && t.bucket.kind&kindNoPointers == 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
- 計算並得到 oldbucket 的 bmap 指標地址
- 計算 hmap 在增長之前的桶數量
- 判斷當前的遷移(搬遷)狀態,以便流轉後續的操作。若沒有正在進行遷移
!evacuated(b),則根據擴容的規則的不同,當規則為等量擴容sameSizeGrow時,只使用一個evacDst桶用於分流。而為雙倍擴容時,就會使用兩個evacDst進行分流操作 - 當分流完畢後,需要遷移的資料都會透過
typedmemmove函式遷移到指定的目標桶上 - 若當前不存在 flags 使用標誌、使用 oldbucket 迭代器、bucket 不為指標型別。則取消連結溢位桶、清除鍵值
- 在最後
advanceEvacuationMark函式中會對遷移進度hmap.nevacuate進行累積計數,並呼叫bucketEvacuated對舊桶 oldbuckets 進行不斷的遷移。直至全部遷移完畢。那麼也就表示擴容完畢了,會對hmap.oldbuckets和h.extra.oldoverflow進行清空
總的來講,就是計算得到所需資料的位置。再根據當前的遷移狀態、擴容規則進行資料分流遷移。結束後進行清理,促進 GC 的回收
總結
在本章節我們主要研討了 Go map 的幾個核心動作,分別是:“賦值、擴容、遷移” 。而透過本次的閱讀,我們能夠更進一步的認識到一些要點,例如:
- 賦值的時候會觸發擴容嗎?
- 負載因子是什麼?過高會帶來什麼問題?它的變動會對雜湊表操作帶來什麼影響嗎?
- 溢位桶越多會帶來什麼問題?
- 是否要擴容的基準條件是什麼?
- 擴容的容量規則是怎麼樣的?
- 擴容的步驟是怎麼樣的?涉及到了哪些資料結構?
- 擴容是一次性擴容還是增量擴容?
- 正在擴容的時候又要擴容怎麼辦?
- 擴容時的遷移分流動作是怎麼樣的?
- 在擴容動作中,底層彙編承擔了什麼角色?做了什麼事?
- 在 buckets/overflow buckets 中尋找時,是如何 “快速” 定位值的?低八位、高八位的用途?
- 空槽有可能出現在任意位置嗎?假設已經沒有空槽了,但是又有新值要插入,底層會怎麼處理
最後希望你透過本文的閱讀,能更清楚地瞭解到 Go map 是怎麼樣運作的 :)
7.5 map:為什麼遍歷 map 是無序的
有的小夥伴沒留意過 Go map 輸出順序,以為它是穩定的有序的;有的小夥伴知道是無序的,但卻不知道為什麼?有的卻理解錯誤?今天我們將透過本文,揭開 for range map 的 “神秘” 面紗,看看它內部實作到底是怎麼樣的,輸出順序到底是怎麼樣?
前言
func main() {
m := make(map[int32]string)
m[0] = "EDDYCJY1"
m[1] = "EDDYCJY2"
m[2] = "EDDYCJY3"
m[3] = "EDDYCJY4"
m[4] = "EDDYCJY5"
for k, v := range m {
log.Printf("k: %v, v: %v", k, v)
}
}
假設執行這段程式碼,輸出結果是按順序?還是無序輸出呢?
2019/04/03 23:27:29 k: 3, v: EDDYCJY4
2019/04/03 23:27:29 k: 4, v: EDDYCJY5
2019/04/03 23:27:29 k: 0, v: EDDYCJY1
2019/04/03 23:27:29 k: 1, v: EDDYCJY2
2019/04/03 23:27:29 k: 2, v: EDDYCJY3
從輸出結果上來講,是非固定順序輸出的,也就是每次都不一樣(標題也講了)。但這是為什麼呢?
首先建議你先自己想想原因。其次我在面試時聽過一些說法。有人說因為是雜湊的所以就是無(亂)序等等說法。當時我是有點 ???
這也是這篇文章出現的原因,希望大家可以一起研討一下,理清這個問題 :)
看一下彙編
...
0x009b 00155 (main.go:11) LEAQ type.map[int32]string(SB), AX
0x00a2 00162 (main.go:11) PCDATA $2, $0
0x00a2 00162 (main.go:11) MOVQ AX, (SP)
0x00a6 00166 (main.go:11) PCDATA $2, $2
0x00a6 00166 (main.go:11) LEAQ ""..autotmp_3+24(SP), AX
0x00ab 00171 (main.go:11) PCDATA $2, $0
0x00ab 00171 (main.go:11) MOVQ AX, 8(SP)
0x00b0 00176 (main.go:11) PCDATA $2, $2
0x00b0 00176 (main.go:11) LEAQ ""..autotmp_2+72(SP), AX
0x00b5 00181 (main.go:11) PCDATA $2, $0
0x00b5 00181 (main.go:11) MOVQ AX, 16(SP)
0x00ba 00186 (main.go:11) CALL runtime.mapiterinit(SB)
0x00bf 00191 (main.go:11) JMP 207
0x00c1 00193 (main.go:11) PCDATA $2, $2
0x00c1 00193 (main.go:11) LEAQ ""..autotmp_2+72(SP), AX
0x00c6 00198 (main.go:11) PCDATA $2, $0
0x00c6 00198 (main.go:11) MOVQ AX, (SP)
0x00ca 00202 (main.go:11) CALL runtime.mapiternext(SB)
0x00cf 00207 (main.go:11) CMPQ ""..autotmp_2+72(SP), $0
0x00d5 00213 (main.go:11) JNE 193
...
我們大致看一下整體過程,重點處理 Go map 迴圈迭代的是兩個 runtime 方法,如下:
- runtime.mapiterinit
- runtime.mapiternext
但你可能會想,明明用的是 for range 進行迴圈迭代,怎麼出現了這兩個函式,怎麼回事?
看一下轉換後
var hiter map_iteration_struct
for mapiterinit(type, range, &hiter); hiter.key != nil; mapiternext(&hiter) {
index_temp = *hiter.key
value_temp = *hiter.val
index = index_temp
value = value_temp
original body
}
實際上編譯器對於 slice 和 map 的迴圈迭代有不同的實作方式,並不是 for 一扔就完事了,還做了一些附加動作進行處理。而上述程式碼就是 for range map 在編譯器展開後的偽實作
看一下原始碼
runtime.mapiterinit
func mapiterinit(t *maptype, h *hmap, it *hiter) {
...
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
if t.bucket.kind&kindNoPointers != 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
...
mapiternext(it)
}
透過對 mapiterinit 方法閱讀,可得知其主要用途是在 map 進行遍歷迭代時進行初始化動作。共有三個形參,用於讀取當前雜湊表的型別資訊、當前雜湊表的儲存資訊和當前遍歷迭代的資料
為什麼
咱們關注到原始碼中 fastrand 的部分,這個方法名,是不是迷之眼熟。沒錯,它是一個生成隨機數的方法。再看看上下文:
...
// decide where to start
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state
it.bucket = it.startBucket
在這段程式碼中,它生成了隨機數。用於決定從哪裡開始迴圈迭代。更具體的話就是根據隨機數,選擇一個桶位置作為起始點進行遍歷迭代
因此每次重新 for range map,你見到的結果都是不一樣的。那是因為它的起始位置根本就不固定!
runtime.mapiternext
func mapiternext(it *hiter) {
...
for ; i < bucketCnt; i++ {
...
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize))
...
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey || alg.equal(k, k)) {
...
it.key = k
it.value = v
} else {
rk, rv := mapaccessK(t, h, k)
if rk == nil {
continue // key has been deleted
}
it.key = rk
it.value = rv
}
it.bucket = bucket
if it.bptr != b {
it.bptr = b
}
it.i = i + 1
it.checkBucket = checkBucket
return
}
b = b.overflow(t)
i = 0
goto next
}
在上小節中,咱們已經選定了起始桶的位置。接下來就是透過 mapiternext 進行具體的迴圈遍歷動作。該方法主要涉及如下:
- 從已選定的桶中開始進行遍歷,尋找桶中的下一個元素進行處理
- 如果桶已經遍歷完,則對溢位桶
overflow buckets進行遍歷處理
透過對本方法的閱讀,可得知其對 buckets 的遍歷規則以及對於擴容的一些處理(這不是本文重點。因此沒有具體展開)
總結
在本文開始,咱們先提出核心討論點:“為什麼 Go map 遍歷輸出是不固定順序?”。而透過這一番分析,原因也很簡單明瞭。就是 for range map 在開始處理迴圈邏輯的時候,就做了隨機播種...
你想問為什麼要這麼做?當然是官方有意為之,因為 Go 在早期(1.0)的時候,雖是穩定迭代的,但從結果來講,其實是無法保證每個 Go 版本迭代遍歷規則都是一樣的。而這將會導致可移植性問題。因此,改之。也請不要依賴...
參考
第8課 標準庫
8.1 fmt
前言
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello World!")
}
標準開場見多了,那內部標準庫又是怎麼輸出這段英文的呢?今天一起來圍觀下原始碼吧 🤭
原型
func Print(a ...interface{}) (n int, err error) {
return Fprint(os.Stdout, a...)
}
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
func Printf(format string, a ...interface{}) (n int, err error) {
return Fprintf(os.Stdout, format, a...)
}
- Print:使用預設格式說明符列印格式並寫入標準輸出。當兩者都不是字串時,在運算元之間新增空格
- Println:同上,不同的地方是始終在運算元之間新增空格,並附加換行符
- Printf:根據格式說明符進行格式化並寫入標準輸出
以上三類就是最常見的格式化 I/O 的方法,我們將基於此去進行拆解描述
執行流程
案例一:Print
在這裡我們使用 Print 方法做一個分析,便於後面的加深理解 😄
func Print(a ...interface{}) (n int, err error) {
return Fprint(os.Stdout, a...)
}
Print 使用預設格式說明符列印格式並寫入標準輸出。另外當兩者都為非空字串時將插入一個空格
原型
func Fprint(w io.Writer, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrint(a)
n, err = w.Write(p.buf)
p.free()
return
}
該函式一共有兩個形參:
- w:輸出流,只要實作 io.Writer 就可以(抽象)為流的寫入
- a:任意型別的多個值
分析主幹流程
1、 p := newPrinter(): 申請一個臨時物件池(sync.Pool)
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.fmt.init(&p.buf)
return p
}
- ppFree.Get():基於 sync.Pool 實作 *pp 的臨時物件池,每次取得一定會返回一個新的 pp 物件用於接下來的處理
- *pp.panicking:用於解決無限遞迴的 panic、recover 問題,會根據該引數在 catchPanic 及時掐斷
- *pp.erroring:用於表示正在處理錯誤無效的 verb 識別符號,主要作用是防止呼叫 handleMethods 方法
- *pp.fmt.init(&p.buf):初始化 fmt 設定,會設定 buf 並且清空 fmtFlags 標誌位
2、 p.doPrint(a): 執行約定的格式化動作(引數間增加一個空格、最後一個引數增加換行符)
func (p *pp) doPrint(a []interface{}) {
prevString := false
for argNum, arg := range a {
true && false
isString := arg != nil && reflect.TypeOf(arg).Kind() == reflect.String
// Add a space between two non-string arguments.
if argNum > 0 && !isString && !prevString {
p.buf.WriteByte(' ')
}
p.printArg(arg, 'v')
prevString = isString
}
}
可以看到底層透過判斷該入參,同時滿足以下條件就會新增分隔符(空格):
- 當前入參為多個引數(例如:Slice)
- 當前入參不為 nil 且不為字串(透過反射確定)
- 當前入參不為首項或上一個入參不為字串
而在 Print 方法中,不需要指定格式符。實際上在該方法內直接指定為 v。也就是預設格式的值
p.printArg(arg, 'v')
- w.Write(p.buf): 寫入標準輸出(io.Writer)
- *pp.free(): 釋放已快取的內容。在使用完臨時物件後,會將 buf、arg、value 清空再重新存放到 ppFree 中。以便於後面再取出重用(利用 sync.Pool 的臨時物件特性)
案例二:Printf
識別符號
Verbs
%v the value in a default format
when printing structs, the plus flag (%+v) adds field names
%#v a Go-syntax representation of the value
%T a Go-syntax representation of the type of the value
%% a literal percent sign; consumes no value
%t the word true or false
Flags
+ always print a sign for numeric values;
guarantee ASCII-only output for %q (%+q)
- pad with spaces on the right rather than the left (left-justify the field)
# alternate format: add leading 0 for octal (%#o), 0x for hex (%#x);
0X for hex (%#X); suppress 0x for %p (%#p);
for %q, print a raw (backquoted) string if strconv.CanBackquote
returns true;
always print a decimal point for %e, %E, %f, %F, %g and %G;
do not remove trailing zeros for %g and %G;
write e.g. U+0078 'x' if the character is printable for %U (%#U).
' ' (space) leave a space for elided sign in numbers (% d);
put spaces between bytes printing strings or slices in hex (% x, % X)
0 pad with leading zeros rather than spaces;
for numbers, this moves the padding after the sign
詳細建議參見 Godoc
原型
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
p.free()
return
}
與 Print 相比,最大的不同就是 doPrintf 方法了。在這裡我們來詳細看看其程式碼,如下:
func (p *pp) doPrintf(format string, a []interface{}) {
end := len(format)
argNum := 0 // we process one argument per non-trivial format
afterIndex := false // previous item in format was an index like [3].
p.reordered = false
formatLoop:
for i := 0; i < end; {
p.goodArgNum = true
lasti := i
for i < end && format[i] != '%' {
i++
}
if i > lasti {
p.buf.WriteString(format[lasti:i])
}
if i >= end {
// done processing format string
break
}
// Process one verb
i++
// Do we have flags?
p.fmt.clearflags()
simpleFormat:
for ; i < end; i++ {
c := format[i]
switch c {
case '#': //'#'、'0'、'+'、'-'、' '
...
default:
if 'a' <= c && c <= 'z' && argNum < len(a) {
...
p.printArg(a[argNum], rune(c))
argNum++
i++
continue formatLoop
}
break simpleFormat
}
}
// Do we have an explicit argument index?
argNum, i, afterIndex = p.argNumber(argNum, format, i, len(a))
// Do we have width?
if i < end && format[i] == '*' {
...
}
// Do we have precision?
if i+1 < end && format[i] == '.' {
...
}
if !afterIndex {
argNum, i, afterIndex = p.argNumber(argNum, format, i, len(a))
}
if i >= end {
p.buf.WriteString(noVerbString)
break
}
...
switch {
case verb == '%': // Percent does not absorb operands and ignores f.wid and f.prec.
p.buf.WriteByte('%')
case !p.goodArgNum:
p.badArgNum(verb)
case argNum >= len(a): // No argument left over to print for the current verb.
p.missingArg(verb)
case verb == 'v':
...
fallthrough
default:
p.printArg(a[argNum], verb)
argNum++
}
}
if !p.reordered && argNum < len(a) {
...
}
}
分析主幹流程
- 寫入 % 之前的字元內容
- 如果所有標誌位處理完畢(到達字元尾部),則跳出處理邏輯
- (往後移)跳過 % ,開始處理其他 verb 標誌位
- 清空(重新初始化) fmt 設定
- 處理一些基礎的 verb 識別符號(simpleFormat)。如:'#'、'0'、'+'、'-'、' ' 以及簡單的 verbs 識別符號(不包含精度、寬度和引數索引)。需要注意的是,若當前字元為簡單 verb 識別符號。則直接進行處理。完成後會直接後移到下一個字元。其餘標誌位則變更 fmt 設定項,便於後續處理
- 處理引數索引(argument index)
- 處理引數寬度(width)
- 處理引數精度(precision)
- % 之後若不存在 verbs 識別符號則返回
noVerbString。值為 %!(NOVERB) - 處理特殊 verbs 識別符號(如:'%%'、'%#v'、'%+v')、錯誤情況(如:引數索引指定錯誤、引數集個數與 verbs 識別符號數量不匹配)或進行格式化引數集
- 常規流程處理完畢
在特殊情況下,若提供的引數集比 verb 識別符號多。fmt 將會貪婪檢查下去,將多出的引數集以特定的格式輸出,如下:
fmt.Printf("%d", 1, 2, 3)
// 1%!(EXTRA int=2, int=3)
- 約定字首額外標誌:%!(EXTRA
- 當前引數的型別
- 約定格式符:=
- 當前引數的值(預設以 %v 格式化)
- 約定格式符:)
值得注意的是,當指定了引數索引或實際處理的引數小於入參的引數集時,就不會進行貪婪匹配來展示
案例三:Println
原型
func Fprintln(w io.Writer, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrintln(a)
n, err = w.Write(p.buf)
p.free()
return
}
在這個方法中,最大的區別就是 doPrintln,我們一起來看看,如下:
func (p *pp) doPrintln(a []interface{}) {
for argNum, arg := range a {
if argNum > 0 {
p.buf.WriteByte(' ')
}
p.printArg(arg, 'v')
}
p.buf.WriteByte('\n')
}
分析主幹流程
- 迴圈入參的引數集,並以空格分隔
- 格式化當前引數,預設以
%v對引數進行格式化 - 在結尾新增
\n字元
如何格式化引數
在上例的執行流程分析中,可以看到格式化引數這一步是在 p.printArg(arg, verb) 執行的,我們一起來看看它都做了些什麼?
func (p *pp) printArg(arg interface{}, verb rune) {
p.arg = arg
p.value = reflect.Value{}
if arg == nil {
switch verb {
case 'T', 'v':
p.fmt.padString(nilAngleString)
default:
p.badVerb(verb)
}
return
}
switch verb {
case 'T':
p.fmt.fmt_s(reflect.TypeOf(arg).String())
return
case 'p':
p.fmtPointer(reflect.ValueOf(arg), 'p')
return
}
// Some types can be done without reflection.
switch f := arg.(type) {
case bool:
p.fmtBool(f, verb)
case float32:
p.fmtFloat(float64(f), 32, verb)
...
case reflect.Value:
if f.IsValid() && f.CanInterface() {
p.arg = f.Interface()
if p.handleMethods(verb) {
return
}
}
p.printValue(f, verb, 0)
default:
if !p.handleMethods(verb) {
p.printValue(reflect.ValueOf(f), verb, 0)
}
}
}
在小節程式碼中可以看見,fmt 本身對不同的型別做了不同的處理。這樣子就避免了透過反射確定。相對的提高了效能
其中有兩個特殊的方法,分別是 handleMethods 和 badVerb,接下來分別來看看他們的作用是什麼
1、badVerb
它主要用於格式化並處理錯誤的行為。我們可以一起來看看,程式碼如下:
func (p *pp) badVerb(verb rune) {
p.erroring = true
p.buf.WriteString(percentBangString)
p.buf.WriteRune(verb)
p.buf.WriteByte('(')
switch {
case p.arg != nil:
p.buf.WriteString(reflect.TypeOf(p.arg).String())
p.buf.WriteByte('=')
p.printArg(p.arg, 'v')
...
default:
p.buf.WriteString(nilAngleString)
}
p.buf.WriteByte(')')
p.erroring = false
}
在處理錯誤格式化時,我們可以對比以下例子:
fmt.Printf("%s", []int64{1, 2, 3})
// [%!s(int64=1) %!s(int64=2) %!s(int64=3)]%
在 badVerb 中可以看到錯誤字串的處理主要分為以下部分:
- 約定字首錯誤標誌:%!
- 當前的格式化運算子
- 約定格式符:(
- 當前引數的型別
- 約定格式符:=
- 當前引數的值(預設以 %v 格式化)
- 約定格式符:)
2、handleMethods
func (p *pp) handleMethods(verb rune) (handled bool) {
if p.erroring {
return
}
// Is it a Formatter?
if formatter, ok := p.arg.(Formatter); ok {
handled = true
defer p.catchPanic(p.arg, verb)
formatter.Format(p, verb)
return
}
// If we're doing Go syntax and the argument knows how to supply it, take care of it now.
...
return false
}
這個方法比較特殊,一般在自定義結構體和未知情況下進行呼叫。主要流程是:
- 若當前引數為錯誤 verb 識別符號,則直接返回
- 判斷是否實作了 Formatter
- 實作,則利用自定義 Formatter 格式化引數
- 未實作,則最大程度的利用 Go syntax 預設規則去格式化引數
拓展
在 fmt 標準庫中可以透過自定義結構體來實作方法的自定義,大致如下幾種
fmt.State
type State interface {
Write(b []byte) (n int, err error)
Width() (wid int, ok bool)
Precision() (prec int, ok bool)
Flag(c int) bool
}
State 用於取得標誌位的狀態值,涉及如下:
- Write:將格式化完畢的字元寫入緩衝區中,等待下一步處理
- Width:返回寬度資訊和是否被設定
- Precision:返回精度資訊和是否被設定
- Flag:返回特殊標誌符('#'、'0'、'+'、'-'、' ')是否被設定
fmt.Formatter
type Formatter interface {
Format(f State, c rune)
}
Formatter 用於實作自定義格式化方法。可透過在自定義結構體中實作 Format 方法來實作這個目的
另外,可以透過 f 取得到當前識別符號的寬度、精度等狀態值。c 為 verb 識別符號,可以得到其動作是什麼
fmt.Stringer
type Stringer interface {
String() string
}
當該物件為 String、Array、Slice 等型別時,將會呼叫 String() 方法對類字串進行格式化
fmt.GoStringer
type GoStringer interface {
GoString() string
}
當格式化特定 verb 識別符號(%v)時,將呼叫 GoString() 方法對其進行格式化
總結
透過本文對 fmt 標準庫的分析,可以發現它有以下特點:
- 在拓展性方面,可以自定義格式化方法等
- 在完整度方面,儘可能的貪婪匹配,輸出引數集
- 在效能方面,每種不同的引數型別,都實作了不同的格式化處理操作
- 在效能方面,儘可能的最短匹配,格式化引數集
總的來說,fmt 標準庫有許多值得推敲的細節,希望你能夠在本文學到 😄
8.2 log
日誌
輸出
2018/09/28 20:03:08 EDDYCJY Blog...
構成
[日期]<空格>[時分秒]<空格>[內容]<\n>
原始碼剖析
Logger
type Logger struct {
mu sync.Mutex
prefix string
flag int
out io.Writer
buf []byte
}
- mu:互斥鎖,用於確保原子的寫入
- prefix:每行需寫入的日誌字首內容
- flag:設定日誌輔助資訊(時間、檔名、行號)的寫入。可選如下標識位:
const (
Ldate = 1 << iota // value: 1
Ltime // value: 2
Lmicroseconds // value: 4
Llongfile // value: 8
Lshortfile // value: 16
LUTC // value: 32
LstdFlags = Ldate | Ltime // value: 3
)
- Ldate:當地時區的格式化日期:2009/01/23
- Ltime:當地時區的格式化時間:01:23:23
- Lmicroseconds:在 Ltime 的基礎上,增加微秒的時間數值顯示
- Llongfile:完整的檔名和行號:/a/b/c/d.go:23
- Lshortfile:當前檔名和行號:d.go:23,會覆蓋 Llongfile 標識
- LUTC:如果設定 Ldate 或 Ltime,且設定 LUTC,則優先使用 UTC 時區而不是本地時區
- LstdFlags:Logger 的預設初始值(Ldate 和 Ltime)
- out:io.Writer
- buf:用於儲存將要寫入的日誌內容
New
func New(out io.Writer, prefix string, flag int) *Logger {
return &Logger{out: out, prefix: prefix, flag: flag}
}
var std = New(os.Stderr, "", LstdFlags)
New 方法用於初始化 Logger,接受三個初始引數,可以定製化而在 log 包內預設會初始一個 std,它指向標準輸入流。而預設的標準輸出、標準錯誤就是顯示器(輸出到螢幕上),標準輸入就是鍵盤。輔助的時間資訊預設為 Ldate | Ltime,也就是 2009/01/23 01:23:23
// os
var (
Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")
Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")
Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr")
)
- Stdin:標準輸入
- Stdout:標準輸出
- Stderr:標準錯誤
Getter
- Flags
- Prefix
Setter
- SetFlags
- SetPrefix
- SetOutput
Print, Fatal, Panic*
func Print(v ...interface{}) {
std.Output(2, fmt.Sprint(v...))
}
func Printf(format string, v ...interface{}) {
std.Output(2, fmt.Sprintf(format, v...))
}
func Println(v ...interface{}) {
std.Output(2, fmt.Sprintln(v...))
}
func Fatal(v ...interface{}) {
std.Output(2, fmt.Sprint(v...))
os.Exit(1)
}
func Panic(v ...interface{}) {
s := fmt.Sprint(v...)
std.Output(2, s)
panic(s)
}
...
這一部分介紹最常用的日誌寫入方法,從原始碼可得知 Xrintln、Xrintf 函式 換行、可變引數都是透過 fmt 標準庫的方法去實作的
Fatal 和 Panic 是透過 os.Exit(1)、panic(s) 整合實作的。而具體的組裝邏輯是透過 Output 方法實作的
Logger.Output
func (l *Logger) Output(calldepth int, s string) error {
now := time.Now() // get this early.
var file string
var line int
l.mu.Lock()
defer l.mu.Unlock()
if l.flag&(Lshortfile|Llongfile) != 0 {
// Release lock while getting caller info - it's expensive.
l.mu.Unlock()
var ok bool
_, file, line, ok = runtime.Caller(calldepth)
if !ok {
file = "???"
line = 0
}
l.mu.Lock()
}
l.buf = l.buf[:0]
l.formatHeader(&l.buf, now, file, line)
l.buf = append(l.buf, s...)
if len(s) == 0 || s[len(s)-1] != '\n' {
l.buf = append(l.buf, '\n')
}
_, err := l.out.Write(l.buf)
return err
}
Output 方法,簡單來講就是將寫入的日誌事件資訊組裝並輸出,它會根據 flag 標識位的不同來使用 runtime.Caller 去取得當前 goroutine 所執行的函式檔案、行號等呼叫資訊(log 標準庫中預設深度為 2)。另外如果結尾不是換行符 \n,將自動補全一個換行
Logger.formatHeader
func (l *Logger) formatHeader(buf *[]byte, t time.Time, file string, line int) {
*buf = append(*buf, l.prefix...)
if l.flag&(Ldate|Ltime|Lmicroseconds) != 0 {
if l.flag&LUTC != 0 {
t = t.UTC()
}
if l.flag&Ldate != 0 {
year, month, day := t.Date()
itoa(buf, year, 4)
*buf = append(*buf, '/')
itoa(buf, int(month), 2)
*buf = append(*buf, '/')
itoa(buf, day, 2)
*buf = append(*buf, ' ')
}
if l.flag&(Ltime|Lmicroseconds) != 0 {
hour, min, sec := t.Clock()
itoa(buf, hour, 2)
*buf = append(*buf, ':')
itoa(buf, min, 2)
*buf = append(*buf, ':')
itoa(buf, sec, 2)
if l.flag&Lmicroseconds != 0 {
*buf = append(*buf, '.')
itoa(buf, t.Nanosecond()/1e3, 6)
}
*buf = append(*buf, ' ')
}
}
if l.flag&(Lshortfile|Llongfile) != 0 {
if l.flag&Lshortfile != 0 {
short := file
for i := len(file) - 1; i > 0; i-- {
if file[i] == '/' {
short = file[i+1:]
break
}
}
file = short
}
*buf = append(*buf, file...)
*buf = append(*buf, ':')
itoa(buf, line, -1)
*buf = append(*buf, ": "...)
}
}
該方法主要是用於格式化日誌頭(字首),根據入參不同的標識位,新增分隔符和對應的值到日誌資訊中。執行流程如下:
(1)如果不是空值,則將 prefix 寫入 buf
(2)如果設定 Ldate、Ltime、Lmicroseconds,則對應將日期和時間寫入 buf
(3)如果設定 Lshortfile、Llongfile,則對應將檔案和行號資訊寫入 buf
Logger.itoa
func itoa(buf *[]byte, i int, wid int) {
// Assemble decimal in reverse order.
var b [20]byte
bp := len(b) - 1
for i >= 10 || wid > 1 {
wid--
q := i / 10
b[bp] = byte('0' + i - q*10)
bp--
i = q
}
// i < 10
b[bp] = byte('0' + i)
*buf = append(*buf, b[bp:]...)
}
該方法主要用於將整數轉換為定長的十進位制 ASCII,同時給出負數寬度避免左側補 0。另外會以相反的順序組合十進位制
如何定製化 Logger
在標準庫內,可透過其開放的 New 方法來實作各種各樣的自定義 Logger 元件,但是為什麼也可以直接 log.Print* 等方法呢?
func New(out io.Writer, prefix string, flag int) *Logger
其實是在標準庫內,如果你剛剛細心的看了前面的小節,不難發現其預設實作了一個 Logger 元件
var std = New(os.Stderr, "", LstdFlags)
這也是一個小小的精妙之處 ⭕️
總結
透過查閱 log 標準庫的原始碼,可得知最簡單的一個日誌包應該如何編寫。另外 log 包是在所有涉及到 Logger 的地方都對 sync.Mutex 進行操作(以此解決原子問題),其餘邏輯均為組裝日誌資訊和轉換數值格式,該包較為經典,可以多讀幾遍 😄
問題
為什麼在呼叫 runtime.Caller 前要先解鎖,後再加鎖呢?
8.3 unsafe
在上一篇文章《深入理解 Go Slice》中,大家會發現其底層資料結構使用了 unsafe.Pointer。因此想著再介紹一下其關聯知識
前言
在大家學習 Go 的時候,肯定都學過 “Go 的指標是不支援指標運算和轉換” 這個知識點。為什麼呢?
首先,Go 是一門靜態語言,所有的變數都必須為標量型別。不同的型別不能夠進行賦值、計算等跨型別的操作。那麼指標也對應著相對的型別,也在 Compile 的靜態型別檢查的範圍內。同時靜態語言,也稱為強型別。也就是一旦定義了,就不能再改變它
錯誤示例
func main(){
num := 5
numPointer := &num
flnum := (*float32)(numPointer)
fmt.Println(flnum)
}
輸出結果:
# command-line-arguments
...: cannot convert numPointer (type *int) to type *float32
在示例中,我們建立了一個 num 變數,值為 5,型別為 int。取了其對於的指標地址後,試圖強制轉換為 *float32,結果失敗...
unsafe
針對剛剛的 “錯誤示例”,我們可以採用今天的男主角 unsafe 標準庫來解決。它是一個神奇的包,在官方的詮釋中,有如下概述:
- 圍繞 Go 程式記憶體安全及型別的操作
- 很可能會是不可移植的
- 不受 Go 1 相容性指南的保護
簡單來講就是,不怎麼推薦你使用。因為它是 unsafe(不安全的),但是在特殊的場景下,使用了它。可以打破 Go 的型別和記憶體安全機制,讓你獲得眼前一亮的驚喜效果 😄
Pointer
為了解決這個問題,需要用到 unsafe.Pointer。它表示任意型別且可定址的指標值,可以在不同的指標型別之間進行轉換(類似 C 語言的 void * 的用途)
其包含四種核心操作:
- 任何型別的指標值都可以轉換為 Pointer
- Pointer 可以轉換為任何型別的指標值
- uintptr 可以轉換為 Pointer
- Pointer 可以轉換為 uintptr
在這一部分,重點看第一點、第二點。你再想想怎麼修改 “錯誤示例” 讓它執行起來?
func main(){
num := 5
numPointer := &num
flnum := (*float32)(unsafe.Pointer(numPointer))
fmt.Println(flnum)
}
輸出結果:
0xc4200140b0
在上述程式碼中,我們小加改動。透過 unsafe.Pointer 的特性對該指標變數進行了修改,就可以完成任意型別(*T)的指標轉換
需要注意的是,這時還無法對變數進行操作或訪問。因為不知道該指標地址指向的東西具體是什麼型別。不知道是什麼型別,又如何進行解析呢。無法解析也就自然無法對其變更了
Offsetof
在上小節中,我們對普通的指標變數進行了修改。那麼它是否能做更復雜一點的事呢?
type Num struct{
i string
j int64
}
func main(){
n := Num{i: "EDDYCJY", j: 1}
nPointer := unsafe.Pointer(&n)
niPointer := (*string)(unsafe.Pointer(nPointer))
*niPointer = "煎鱼"
njPointer := (*int64)(unsafe.Pointer(uintptr(nPointer) + unsafe.Offsetof(n.j)))
*njPointer = 2
fmt.Printf("n.i: %s, n.j: %d", n.i, n.j)
}
輸出結果:
n.i: 煎鱼, n.j: 2
在剖析這段程式碼做了什麼事之前,我們需要了解結構體的一些基本概念:
- 結構體的成員變數在記憶體儲存上是一段連續的記憶體
- 結構體的初始地址就是第一個成員變數的記憶體地址
- 基於結構體的成員地址去計算偏移量。就能夠得出其他成員變數的記憶體地址
再回來看看上述程式碼,得出執行流程:
- 修改
n.i值:i為第一個成員變數。因此不需要進行偏移量計算,直接取出指標後轉換為Pointer,再強制轉換為字串型別的指標值即可 - 修改
n.j值:j為第二個成員變數。需要進行偏移量計算,才可以對其記憶體地址進行修改。在進行了偏移運算後,當前地址已經指向第二個成員變數。接著重複轉換賦值即可
需要注意的是,這裡使用瞭如下方法(來完成偏移計算的目標):
1、uintptr:uintptr 是 Go 的內建型別。返回無符號整數,可儲存一個完整的地址。後續常用於指標運算
type uintptr uintptr
2、unsafe.Offsetof:返回成員變數 x 在結構體當中的偏移量。更具體的講,就是返回結構體初始位置到 x 之間的位元組數。需要注意的是入參 ArbitraryType 表示任意型別,並非定義的 int。它實際作用是一個佔位符
func Offsetof(x ArbitraryType) uintptr
在這一部分,其實就是巧用了 Pointer 的第三、第四點特性。這時候就已經可以對變數進行操作了 😄
錯誤示例
func main(){
n := Num{i: "EDDYCJY", j: 1}
nPointer := unsafe.Pointer(&n)
...
ptr := uintptr(nPointer)
njPointer := (*int64)(unsafe.Pointer(ptr + unsafe.Offsetof(n.j)))
...
}
這裡存在一個問題,uintptr 型別是不能儲存在臨時變數中的。因為從 GC 的角度來看,uintptr 型別的臨時變數只是一個無符號整數,並不知道它是一個指標地址
因此當滿足一定條件後,ptr 這個臨時變數是可能被垃圾回收掉的,那麼接下來的記憶體操作,豈不成迷?
總結
簡潔回顧兩個知識點。第一是 unsafe.Pointer 可以讓你的變數在不同的指標型別轉來轉去,也就是表示為任意可定址的指標型別。第二是 uintptr 常用於與 unsafe.Pointer 打配合,用於做指標運算,巧妙地很
最後還是那句,沒有特殊必要的話。是不建議使用 unsafe 標準庫,它並不安全。雖然它常常能讓你眼前一亮 👌
第9課 工具
9.1 Go 大殺器之效能剖析 PProf
前言
寫了幾噸程式碼,實作了幾百個介面。功能測試也通過了,終於成功的部署上線了
結果,效能不佳,什麼鬼?😭
想做效能分析
PProf
想要進行效能最佳化,首先矚目在 Go 自身提供的工具鏈來作為分析依據,本文將帶你學習、使用 Go 後花園,涉及如下:
- runtime/pprof:採集程式(非 Server)的執行資料進行分析
- net/http/pprof:採集 HTTP Server 的執行時資料進行分析
是什麼
pprof 是用於視覺化和分析效能分析資料的工具
pprof 以 profile.proto 讀取分析樣本的集合,並生成報告以視覺化並幫助分析資料(支援文字和圖形報告)
profile.proto 是一個 Protocol Buffer v3 的描述檔案,它描述了一組 callstack 和 symbolization 資訊, 作用是表示統計分析的一組取樣的呼叫棧,是很常見的 stacktrace 設定檔案格式
支援什麼使用模式
- Report generation:報告生成
- Interactive terminal use:互動式終端使用
- Web interface:Web 介面
可以做什麼
- CPU Profiling:CPU 分析,按照一定的頻率採集所監聽的應用程式 CPU(含暫存器)的使用情況,可確定應用程式在主動消耗 CPU 週期時花費時間的位置
- Memory Profiling:記憶體分析,在應用程式進行堆分配時記錄堆疊跟蹤,用於監視當前和歷史記憶體使用情況,以及檢查記憶體洩漏
- Block Profiling:阻塞分析,記錄 goroutine 阻塞等待同步(包括定時器通道)的位置
- Mutex Profiling:互斥鎖分析,報告互斥鎖的競爭情況
一個簡單的例子
我們將編寫一個簡單且有點問題的例子,用於基本的程式初步分析
編寫 demo 檔案
(1)demo.go,檔案內容:
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"github.com/EDDYCJY/go-pprof-example/data"
)
func main() {
go func() {
for {
log.Println(data.Add("https://github.com/EDDYCJY"))
}
}()
http.ListenAndServe("0.0.0.0:6060", nil)
}
(2)data/d.go,檔案內容:
package data
var datas []string
func Add(str string) string {
data := []byte(str)
sData := string(data)
datas = append(datas, sData)
return sData
}
執行這個檔案,你的 HTTP 服務會多出 /debug/pprof 的 endpoint 可用於觀察應用程式的情況
分析
一、透過 Web 介面
檢視當前總覽:訪問 http://127.0.0.1:6060/debug/pprof/
/debug/pprof/
profiles:
0 block
5 goroutine
3 heap
0 mutex
9 threadcreate
full goroutine stack dump
這個頁面中有許多子頁面,咱們繼續深究下去,看看可以得到什麼?
- cpu(CPU Profiling):
$HOST/debug/pprof/profile,預設進行 30s 的 CPU Profiling,得到一個分析用的 profile 檔案 - block(Block Profiling):
$HOST/debug/pprof/block,檢視導致阻塞同步的堆疊跟蹤 - goroutine:
$HOST/debug/pprof/goroutine,檢視當前所有執行的 goroutines 堆疊跟蹤 - heap(Memory Profiling):
$HOST/debug/pprof/heap,檢視活動物件的記憶體分配情況 - mutex(Mutex Profiling):
$HOST/debug/pprof/mutex,檢視導致互斥鎖的競爭持有者的堆疊跟蹤 - threadcreate:
$HOST/debug/pprof/threadcreate,檢視建立新OS執行緒的堆疊跟蹤
二、透過互動式終端使用
(1)go tool pprof http://localhost:6060/debug/pprof/profile?seconds=60
$ go tool pprof http://localhost:6060/debug/pprof/profile\?seconds\=60
Fetching profile over HTTP from http://localhost:6060/debug/pprof/profile?seconds=60
Saved profile in /Users/eddycjy/pprof/pprof.samples.cpu.007.pb.gz
Type: cpu
Duration: 1mins, Total samples = 26.55s (44.15%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
執行該命令後,需等待 60 秒(可調整 seconds 的值),pprof 會進行 CPU Profiling。結束後將預設進入 pprof 的互動式命令模式,可以對分析的結果進行檢視或匯出。具體可執行 pprof help 檢視命令說明
(pprof) top10
Showing nodes accounting for 25.92s, 97.63% of 26.55s total
Dropped 85 nodes (cum <= 0.13s)
Showing top 10 nodes out of 21
flat flat% sum% cum cum%
23.28s 87.68% 87.68% 23.29s 87.72% syscall.Syscall
0.77s 2.90% 90.58% 0.77s 2.90% runtime.memmove
0.58s 2.18% 92.77% 0.58s 2.18% runtime.freedefer
0.53s 2.00% 94.76% 1.42s 5.35% runtime.scanobject
0.36s 1.36% 96.12% 0.39s 1.47% runtime.heapBitsForObject
0.35s 1.32% 97.44% 0.45s 1.69% runtime.greyobject
0.02s 0.075% 97.51% 24.96s 94.01% main.main.func1
0.01s 0.038% 97.55% 23.91s 90.06% os.(*File).Write
0.01s 0.038% 97.59% 0.19s 0.72% runtime.mallocgc
0.01s 0.038% 97.63% 23.30s 87.76% syscall.Write
- flat:給定函式上執行耗時
- flat%:同上的 CPU 執行耗時總比例
- sum%:給定函式累積使用 CPU 總比例
- cum:當前函式加上它之上的呼叫執行總耗時
- cum%:同上的 CPU 執行耗時總比例
最後一列為函式名稱,在大多數的情況下,我們可以透過這五列得出一個應用程式的執行情況,加以最佳化 🤔
(2)go tool pprof http://localhost:6060/debug/pprof/heap
$ go tool pprof http://localhost:6060/debug/pprof/heap
Fetching profile over HTTP from http://localhost:6060/debug/pprof/heap
Saved profile in /Users/eddycjy/pprof/pprof.alloc_objects.alloc_space.inuse_objects.inuse_space.008.pb.gz
Type: inuse_space
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 837.48MB, 100% of 837.48MB total
flat flat% sum% cum cum%
837.48MB 100% 100% 837.48MB 100% main.main.func1
- -inuse_space:分析應用程式的常駐記憶體佔用情況
- -alloc_objects:分析應用程式的記憶體臨時分配情況
(3) go tool pprof http://localhost:6060/debug/pprof/block
(4) go tool pprof http://localhost:6060/debug/pprof/mutex
三、PProf 視覺化介面
這是令人期待的一小節。在這之前,我們需要簡單的編寫好測試用例來跑一下
編寫測試用例
(1)新建 data/d_test.go,檔案內容:
package data
import "testing"
const url = "https://github.com/EDDYCJY"
func TestAdd(t *testing.T) {
s := Add(url)
if s == "" {
t.Errorf("Test.Add error!")
}
}
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
Add(url)
}
}
(2)執行測試用例
$ go test -bench=. -cpuprofile=cpu.prof
pkg: github.com/EDDYCJY/go-pprof-example/data
BenchmarkAdd-4 10000000 187 ns/op
PASS
ok github.com/EDDYCJY/go-pprof-example/data 2.300s
-memprofile 也可以瞭解一下
啟動 PProf 視覺化介面
方法一:
$ go tool pprof -http=:8080 cpu.prof
方法二:
$ go tool pprof cpu.prof
$ (pprof) web
如果出現 Could not execute dot; may need to install graphviz.,就是提示你要安裝 graphviz 了 (請右拐谷歌)
檢視 PProf 視覺化介面
(1)Top
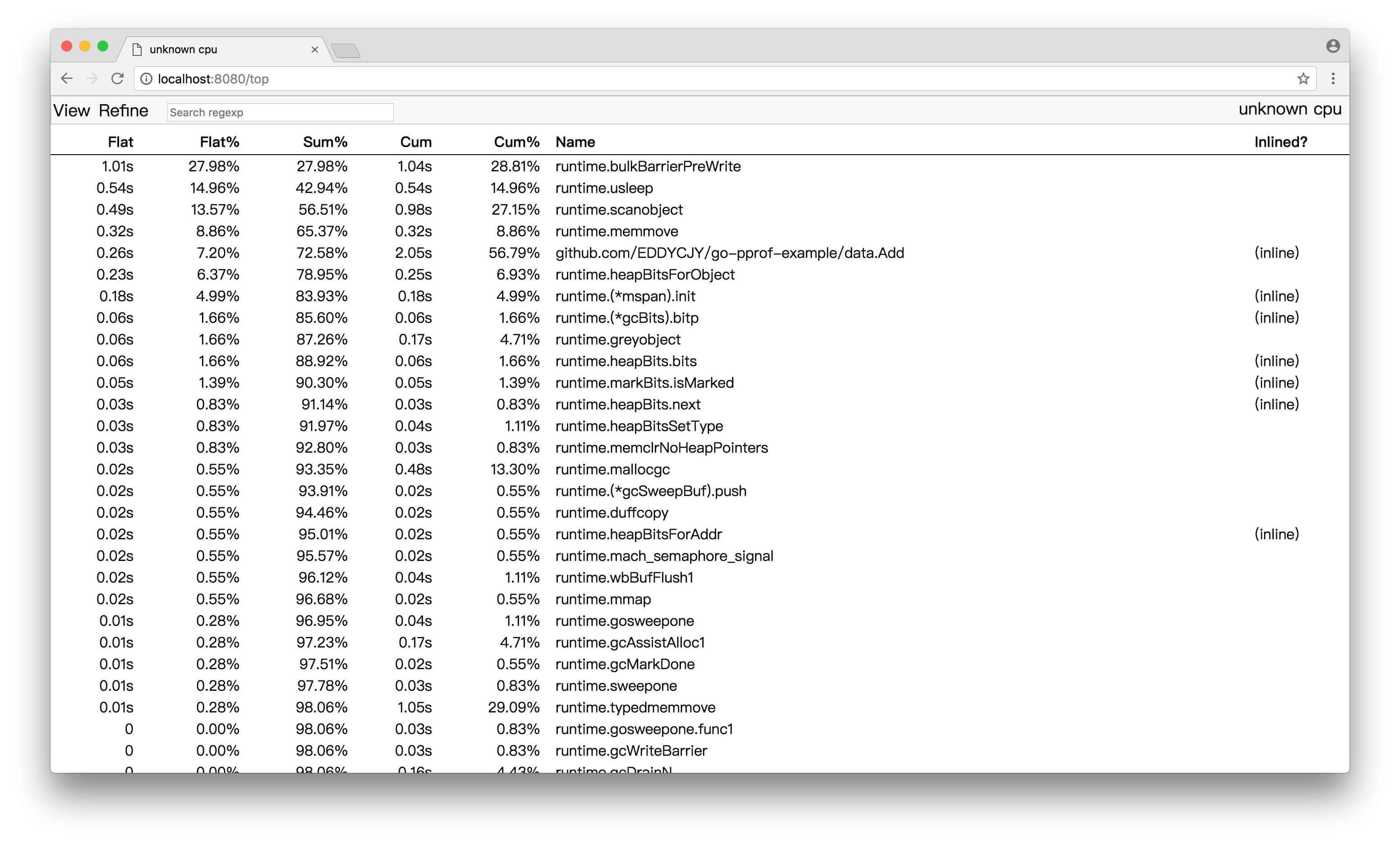
(2)Graph
框越大,線越粗代表它佔用的時間越大哦
(3)Peek
(4)Source
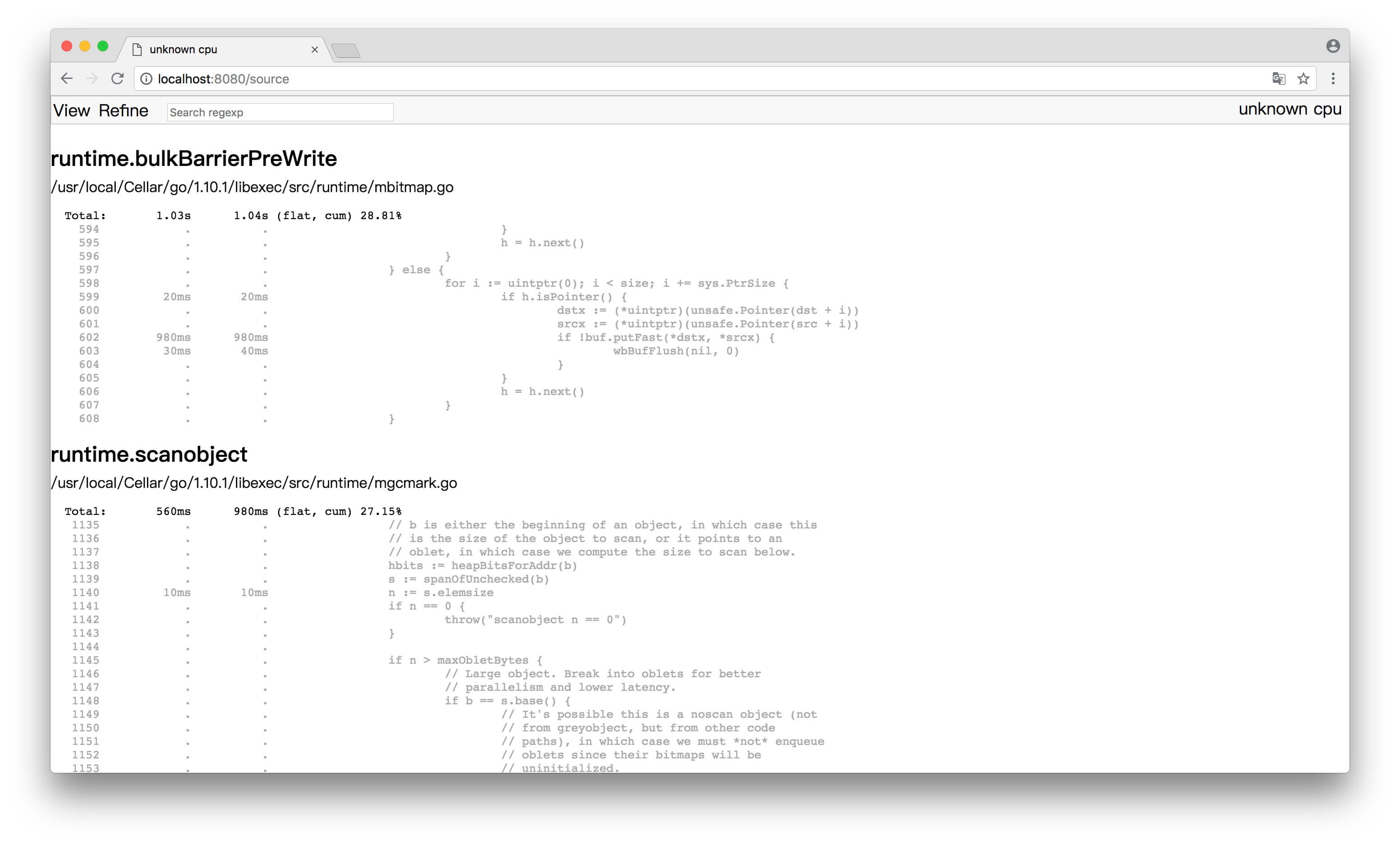
透過 PProf 的視覺化介面,我們能夠更方便、更直觀的看到 Go 應用程式的呼叫鏈、使用情況等,並且在 View 選單欄中,還支援如上多種方式的切換
你想想,在煩惱不知道什麼問題的時候,能用這些輔助工具來檢測問題,是不是瞬間效率翻倍了呢 👌
四、PProf 火焰圖
另一種視覺化資料的方法是火焰圖,需手動安裝原生 PProf 工具:
(1) 安裝 PProf
$ go get -u github.com/google/pprof
(2) 啟動 PProf 視覺化介面:
$ pprof -http=:8080 cpu.prof
(3) 檢視 PProf 視覺化介面
開啟 PProf 的視覺化介面時,你會明顯發現比官方工具鏈的 PProf 精緻一些,並且多了 Flame Graph(火焰圖)
它就是本次的目標之一,它的最大優點是動態的。呼叫順序由上到下(A -> B -> C -> D),每一塊代表一個函式,越大代表佔用 CPU 的時間更長。同時它也支援點選塊深入進行分析!
總結
在本章節,粗略地介紹了 Go 的效能利器 PProf。在特定的場景中,PProf 給定位、剖析問題帶了極大的幫助
希望本文對你有所幫助,另外建議能夠自己實際操作一遍,最好是可以深入琢磨一下,內含大量的用法、知識點 🤓
思考題
你很優秀的看到了最後,那麼有兩道簡單的思考題,希望拓展你的思路
(1)flat 一定大於 cum 嗎,為什麼?什麼場景下 cum 會比 flat 大?
(2)本章節的 demo 程式碼,有什麼效能問題?怎麼解決它?
9.2 Go 大殺器之跟蹤剖析 trace

在 Go 中有許許多多的分析工具,在之前我有寫過一篇 《Golang 大殺器之效能剖析 PProf》 來介紹 PProf,如果有小夥伴感興趣可以去我部落格看看。
但單單使用 PProf 有時候不一定足夠完整,因為在真實的程式中還包含許多的隱藏動作,例如 Goroutine 在執行時會做哪些操作?執行/阻塞了多長時間?在什麼時候阻止?在哪裡被阻止的?誰又鎖/解鎖了它們?GC 是怎麼影響到 Goroutine 的執行的?這些東西用 PProf 是很難分析出來的,但如果你又想知道上述的答案的話,你可以用本文的主角 go tool trace 來開啟新世界的大門。目錄如下:

初步瞭解
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
ch := make(chan string)
go func() {
ch <- "EDDYCJY"
}()
<-ch
}
生成跟蹤檔案:
$ go run main.go 2> trace.out
啟動視覺化介面:
$ go tool trace trace.out
2019/06/22 16:14:52 Parsing trace...
2019/06/22 16:14:52 Splitting trace...
2019/06/22 16:14:52 Opening browser. Trace viewer is listening on http://127.0.0.1:57321
檢視視覺化介面:

- View trace:檢視跟蹤
- Goroutine analysis:Goroutine 分析
- Network blocking profile:網路阻塞概況
- Synchronization blocking profile:同步阻塞概況
- Syscall blocking profile:系統呼叫阻塞概況
- Scheduler latency profile:排程延遲概況
- User defined tasks:使用者自定義任務
- User defined regions:使用者自定義區域
- Minimum mutator utilization:最低 Mutator 利用率
Scheduler latency profile
在剛開始檢視問題時,除非是很明顯的現象,否則不應該一開始就陷入細節,因此我們一般先檢視 “Scheduler latency profile”,我們能透過 Graph 看到整體的呼叫開銷情況,如下:
演示程式比較簡單,因此這裡就兩塊,一個是 trace 本身,另外一個是 channel 的收發。
Goroutine analysis
第二步看 “Goroutine analysis”,我們能透過這個功能看到整個執行過程中,每個函式塊有多少個有 Goroutine 在跑,並且觀察每個的 Goroutine 的執行開銷都花費在哪個階段。如下:

透過上圖我們可以看到共有 3 個 goroutine,分別是 runtime.main、runtime/trace.Start.func1、main.main.func1,那麼它都做了些什麼事呢,接下來我們可以透過點選具體細項去觀察。如下:

同時也可以看到當前 Goroutine 在整個呼叫耗時中的佔比,以及 GC 清掃和 GC 暫停等待的一些開銷。如果你覺得還不夠,可以把圖表下載下來分析,相當於把整個 Goroutine 執行時掰開來看了,這塊能夠很好的幫助我們對 Goroutine 執行階段做一個的剖析,可以得知到底慢哪,然後再決定下一步的排查方向。如下:
| 名稱 | 含義 | 耗時 |
|---|---|---|
| Execution Time | 執行時間 | 3140ns |
| Network Wait Time | 網路等待時間 | 0ns |
| Sync Block Time | 同步阻塞時間 | 0ns |
| Blocking Syscall Time | 呼叫阻塞時間 | 0ns |
| Scheduler Wait Time | 排程等待時間 | 14ns |
| GC Sweeping | GC 清掃 | 0ns |
| GC Pause | GC 暫停 | 0ns |
View trace
在對當前程式的 Goroutine 執行分佈有了初步瞭解後,我們再透過 “檢視跟蹤” 看看之間的關聯性,如下:
這個跟蹤圖粗略一看,相信有的小夥伴會比較懵逼,我們可以依據註解一塊塊檢視,如下:
- 時間線:顯示執行的時間單元,根據時間維度的不同可以調整區間,具體可執行
shift+?檢視幫助手冊。 - 堆:顯示執行期間的記憶體分配和釋放情況。
- 協程:顯示在執行期間的每個 Goroutine 執行階段有多少個協程在執行,其包含 GC 等待(GCWaiting)、可執行(Runnable)、執行中(Running)這三種狀態。
- OS 執行緒:顯示在執行期間有多少個執行緒在執行,其包含正在呼叫 Syscall(InSyscall)、執行中(Running)這兩種狀態。
- 虛擬處理器:每個虛擬處理器顯示一行,虛擬處理器的數量一般預設為系統核心數。
- 協程和事件:顯示在每個虛擬處理器上有什麼 Goroutine 正在執行,而連線行為代表事件關聯。
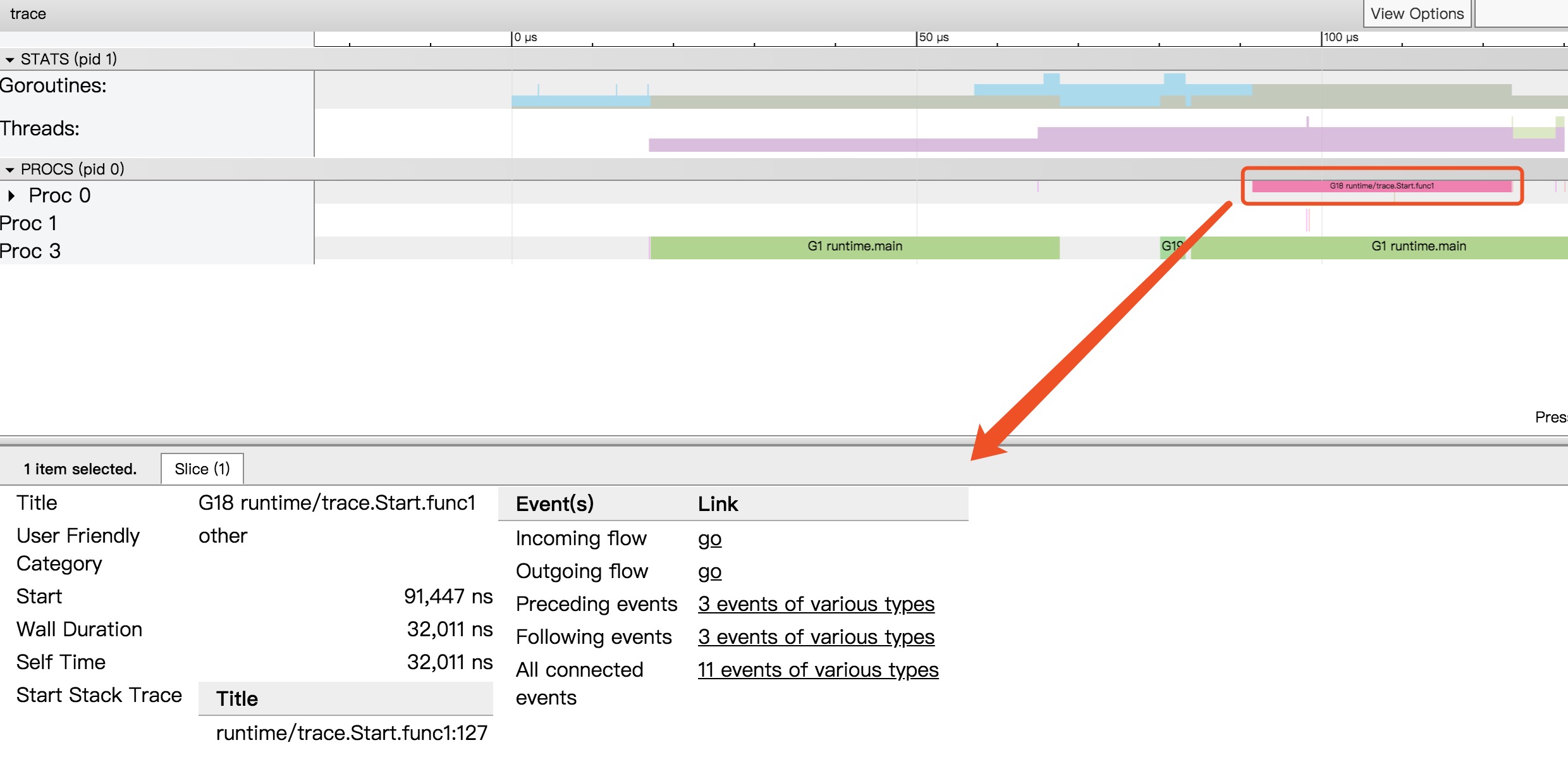
點選具體的 Goroutine 行為後可以看到其相關聯的詳細資訊,這塊很簡單,大家實際操作一下就懂了。文字解釋如下:
- Start:開始時間
- Wall Duration:持續時間
- Self Time:執行時間
- Start Stack Trace:開始時的堆疊資訊
- End Stack Trace:結束時的堆疊資訊
- Incoming flow:輸入流
- Outgoing flow:輸出流
- Preceding events:之前的事件
- Following events:之後的事件
- All connected:所有連線的事件
View Events
我們可以透過點選 View Options-Flow events、Following events 等方式,檢視我們應用執行中的事件流情況。如下:
透過分析圖上的事件流,我們可得知這程式從 G1 runtime.main 開始執行,在執行時建立了 2 個 Goroutine,先是建立 G18 runtime/trace.Start.func1,然後再是 G19 main.main.func1 。而同時我們可以透過其 Goroutine Name 去了解它的呼叫型別,如:runtime/trace.Start.func1 就是程式中在 main.main 呼叫了 runtime/trace.Start 方法,然後該方法又利用協程建立了一個閉包 func1 去進行呼叫。
在這裡我們結合開頭的程式碼去看的話,很明顯就是 ch 的輸入輸出的過程了。
結合實戰
今天生產環境突然出現了問題,機智的你早已埋好 _ "net/http/pprof" 這個神奇的工具,你麻利的執行了如下命令:
- curl http://127.0.0.1:6060/debug/pprof/trace\?seconds\=20 > trace.out
- go tool trace trace.out
View trace
你很快的看到了熟悉的 List 介面,然後不信邪點開了 View trace 介面,如下:
完全看懵的你,穩住,對著合適的區域執行快捷鍵 W 不斷地放大時間線,如下:
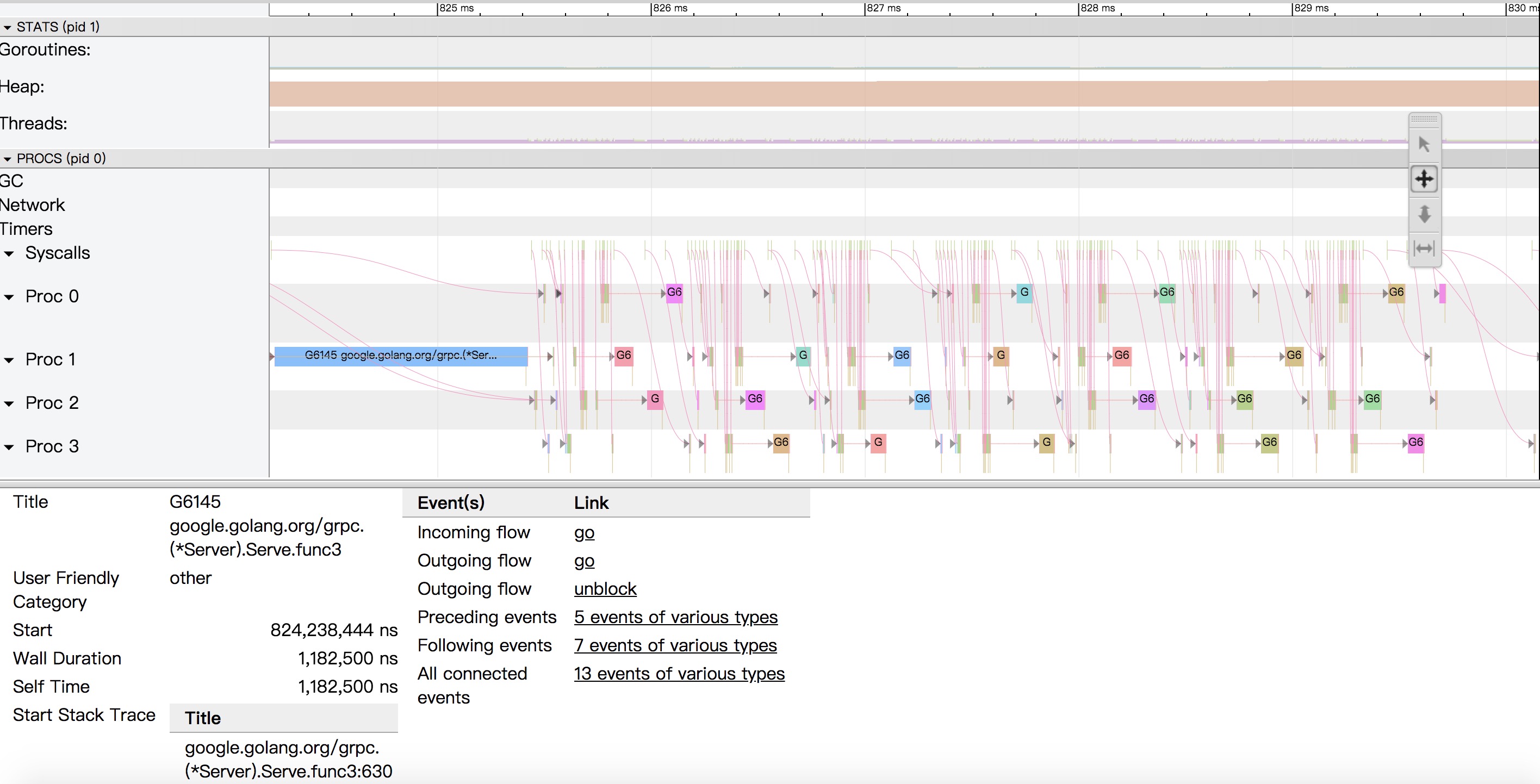
經過初步排查,你發現上述絕大部分的 G 竟然都和 google.golang.org/grpc.(*Server).Serve.func 有關,關聯的一大串也是 Serve 所觸發的相關動作。
這時候有經驗的你心裡已經有了初步結論,你可以繼續追蹤 View trace 深入進去,不過我建議先鳥瞰全貌,因此我們再往下看 “Network blocking profile” 和 “Syscall blocking profile” 所提供的資訊,如下:
Network blocking profile
Syscall blocking profile
透過對以上三項的跟蹤分析,加上這個洩露,這個阻塞的耗時,這個涉及的內部方法名,很明顯就是哪位又忘記關閉客戶端連線了,趕緊改改改。
總結
透過本文我們習得了 go tool trace 的武林秘籍,它能夠跟蹤捕獲各種執行中的事件,例如 Goroutine 的建立/阻塞/解除阻塞,Syscall 的進入/退出/阻止,GC 事件,Heap 的大小改變,Processor 啟動/停止等等。
希望你能夠用好 Go 的兩大殺器 pprof + trace 組合,此乃排查好搭檔,誰用誰清楚,即使他並不萬能。
參考
- https://about.sourcegraph.com/go/an-introduction-to-go-tool-trace-rhys-hiltner
- https://www.itcodemonkey.com/article/5419.html
- https://making.pusher.com/go-tool-trace/
- https://golang.org/cmd/trace/
- https://docs.google.com/document/d/1FP5apqzBgr7ahCCgFO-yoVhk4YZrNIDNf9RybngBc14/pub
- https://godoc.org/runtime/trace
9.3 用 GODEBUG 看排程跟蹤

讓 Go 更強大的原因之一莫過於它的 GODEBUG 工具,GODEBUG 的設定可以讓 Go 程式在執行時輸出除錯資訊,可以根據你的要求很直觀的看到你想要的排程器或垃圾回收等詳細資訊,並且還不需要加裝其它的外掛,非常方便,今天我們將先講解 GODEBUG 的排程器相關內容,希望對你有所幫助。
不過在開始前,沒接觸過的小夥伴得先補補如下前置知識,便於更好的瞭解偵錯程式輸出的資訊內容。
前置知識
Go scheduler 的主要功能是針對在處理器上執行的 OS 執行緒分發可執行的 Goroutine,而我們一提到排程器,就離不開三個經常被提到的縮寫,分別是:
- G:Goroutine,實際上我們每次呼叫
go func就是生成了一個 G。 - P:處理器,一般為處理器的核數,可以透過
GOMAXPROCS進行修改。 - M:OS 執行緒
這三者互動實際來源於 Go 的 M: N 排程模型,也就是 M 必須與 P 進行繫結,然後不斷地在 M 上迴圈尋找可執行的 G 來執行相應的任務,如果想具體瞭解可以詳細閱讀 《Go Runtime Scheduler》,我們抽其中的工作流程圖進行簡單分析,如下:
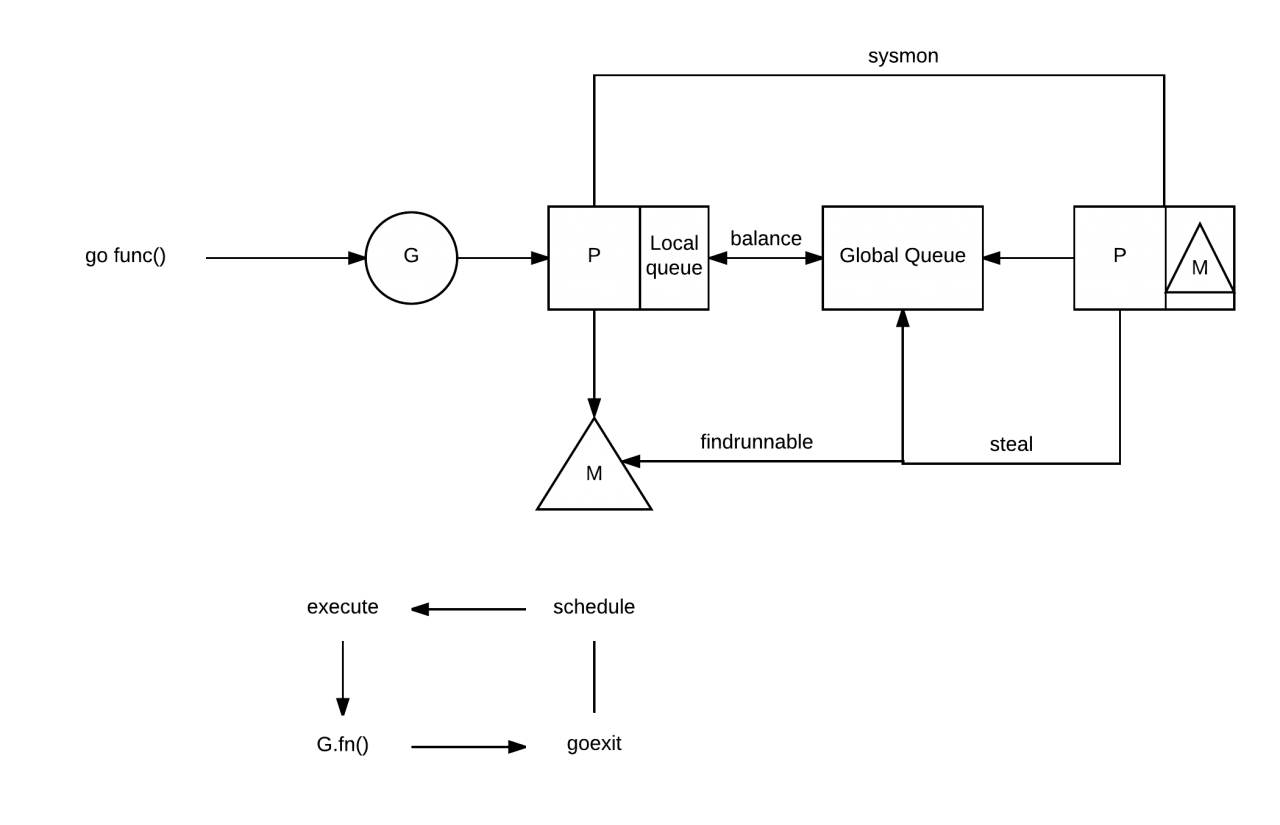
- 當我們執行
go func()時,實際上就是建立一個全新的 Goroutine,我們稱它為 G。 - 新建立的 G 會被放入 P 的本地佇列(Local Queue)或全域性佇列(Global Queue)中,準備下一步的動作。
- 喚醒或建立 M 以便執行 G。
- 不斷地進行事件迴圈
- 尋找在可用狀態下的 G 進行執行任務
- 清除後,重新進入事件迴圈
而在描述中有提到全域性和本地這兩類佇列,其實在功能上來講都是用於存放正在等待執行的 G,但是不同點在於,本地佇列有數量限制,不允許超過 256 個。並且在新建 G 時,會優先選擇 P 的本地佇列,如果本地佇列滿了,則將 P 的本地佇列的一半的 G 移動到全域性佇列,這其實可以理解為排程資源的共享和再平衡。
另外我們可以看到圖上有 steal 行為,這是用來做什麼的呢,我們都知道當你建立新的 G 或者 G 變成可執行狀態時,它會被推送加入到當前 P 的本地佇列中。但其實當 P 執行 G 完畢後,它也會 “幹活”,它會將其從本地佇列中彈出 G,同時會檢查當前本地佇列是否為空,如果為空會隨機的從其他 P 的本地佇列中嘗試竊取一半可執行的 G 到自己的名下。例子如下:
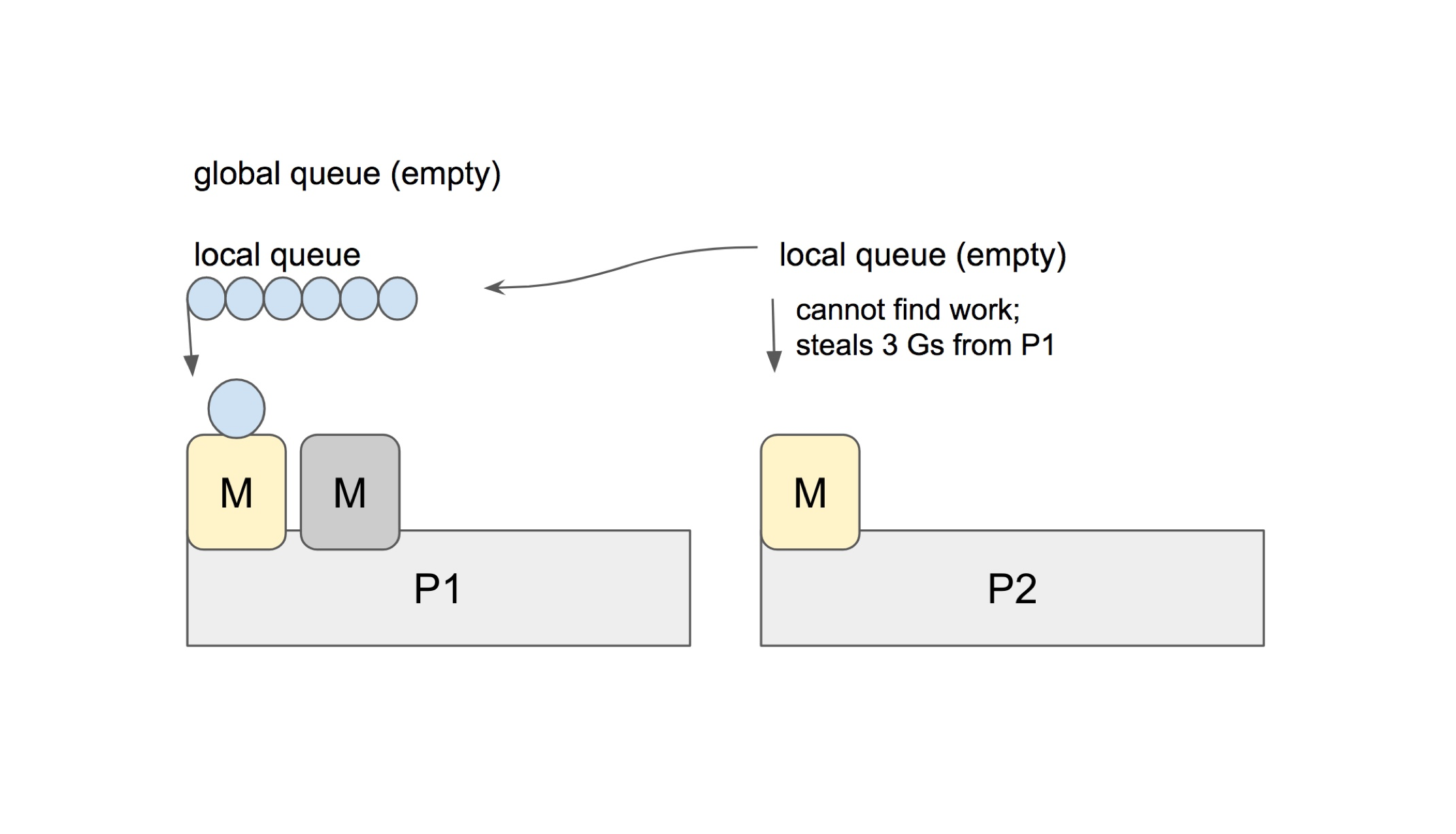
在這個例子中,P2 在本地佇列中找不到可以執行的 G,它會執行 work-stealing 排程演算法,隨機選擇其它的處理器 P1,並從 P1 的本地佇列中竊取了三個 G 到它自己的本地佇列中去。至此,P1、P2 都擁有了可執行的 G,P1 多餘的 G 也不會被浪費,排程資源將會更加平均的在多個處理器中流轉。
GODEBUG
GODEBUG 變數可以控制執行時內的除錯變數,引數以逗號分隔,格式為:name=val。本文著重點在排程器觀察上,將會使用如下兩個引數:
- schedtrace:設定
schedtrace=X引數可以使執行時在每 X 毫秒發出一行排程器的摘要資訊到標準 err 輸出中。 - scheddetail:設定
schedtrace=X和scheddetail=1可以使執行時在每 X 毫秒發出一次詳細的多行資訊,資訊內容主要包括排程程式、處理器、OS 執行緒 和 Goroutine 的狀態。
演示程式碼
func main() {
wg := sync.WaitGroup{}
wg.Add(10)
for i := 0; i < 10; i++ {
go func(wg *sync.WaitGroup) {
var counter int
for i := 0; i < 1e10; i++ {
counter++
}
wg.Done()
}(&wg)
}
wg.Wait()
}
schedtrace
$ GODEBUG=schedtrace=1000 ./awesomeProject
SCHED 0ms: gomaxprocs=4 idleprocs=1 threads=5 spinningthreads=1 idlethreads=0 runqueue=0 [0 0 0 0]
SCHED 1000ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 [1 2 2 1]
SCHED 2000ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 [1 2 2 1]
SCHED 3001ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 [1 2 2 1]
SCHED 4010ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 [1 2 2 1]
SCHED 5011ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 [1 2 2 1]
SCHED 6012ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 [1 2 2 1]
SCHED 7021ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 8023ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 9031ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 10033ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 11038ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 12044ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 13051ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=4 [0 1 1 0]
SCHED 14052ms: gomaxprocs=4 idleprocs=2 threads=5
...
- sched:每一行都代表排程器的除錯資訊,後面提示的毫秒數表示啟動到現在的執行時間,輸出的時間間隔受
schedtrace的值影響。 - gomaxprocs:當前的 CPU 核心數(GOMAXPROCS 的當前值)。
- idleprocs:空閒的處理器數量,後面的數字表示當前的空閒數量。
- threads:OS 執行緒數量,後面的數字表示當前正在執行的執行緒數量。
- spinningthreads:自旋狀態的 OS 執行緒數量。
- idlethreads:空閒的執行緒數量。
- runqueue:全域性佇列中中的 Goroutine 數量,而後面的 [0 0 1 1] 則分別代表這 4 個 P 的本地佇列正在執行的 Goroutine 數量。
在上面我們有提到 “自旋執行緒” 這個概念,如果你之前沒有了解過相關概念,一聽 “自旋” 肯定會比較懵,我們引用 《Head First of Golang Scheduler》 的內容來說明:
自旋執行緒的這個說法,是因為 Go Scheduler 的設計者在考慮了 “OS 的資源利用率” 以及 “頻繁的執行緒搶佔給 OS 帶來的負載” 之後,提出了 “Spinning Thread” 的概念。也就是當 “自旋執行緒” 沒有找到可供其排程執行的 Goroutine 時,並不會銷燬該執行緒 ,而是採取 “自旋” 的操作儲存了下來。雖然看起來這是浪費了一些資源,但是考慮一下 syscall 的情景就可以知道,比起 “自旋",執行緒間頻繁的搶佔以及頻繁的建立和銷燬操作可能帶來的危害會更大。
scheddetail
如果我們想要更詳細的看到排程器的完整資訊時,我們可以增加 scheddetail 引數,就能夠更進一步的檢視排程的細節邏輯,如下:
$ GODEBUG=scheddetail=1,schedtrace=1000 ./awesomeProject
SCHED 1000ms: gomaxprocs=4 idleprocs=0 threads=5 spinningthreads=0 idlethreads=0 runqueue=0 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0
P0: status=1 schedtick=2 syscalltick=0 m=3 runqsize=3 gfreecnt=0
P1: status=1 schedtick=2 syscalltick=0 m=4 runqsize=1 gfreecnt=0
P2: status=1 schedtick=2 syscalltick=0 m=0 runqsize=1 gfreecnt=0
P3: status=1 schedtick=1 syscalltick=0 m=2 runqsize=1 gfreecnt=0
M4: p=1 curg=18 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 spinning=false blocked=false lockedg=-1
M3: p=0 curg=22 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 spinning=false blocked=false lockedg=-1
M2: p=3 curg=24 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 spinning=false blocked=false lockedg=-1
M1: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 spinning=false blocked=false lockedg=-1
M0: p=2 curg=26 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 spinning=false blocked=false lockedg=-1
G1: status=4(semacquire) m=-1 lockedm=-1
G2: status=4(force gc (idle)) m=-1 lockedm=-1
G3: status=4(GC sweep wait) m=-1 lockedm=-1
G17: status=1() m=-1 lockedm=-1
G18: status=2() m=4 lockedm=-1
G19: status=1() m=-1 lockedm=-1
G20: status=1() m=-1 lockedm=-1
G21: status=1() m=-1 lockedm=-1
G22: status=2() m=3 lockedm=-1
G23: status=1() m=-1 lockedm=-1
G24: status=2() m=2 lockedm=-1
G25: status=1() m=-1 lockedm=-1
G26: status=2() m=0 lockedm=-1
在這裡我們抽取了 1000ms 時的除錯資訊來檢視,資訊量比較大,我們先從每一個欄位開始瞭解。如下:
G
- status:G 的執行狀態。
- m:隸屬哪一個 M。
- lockedm:是否有鎖定 M。
在第一點中我們有提到 G 的執行狀態,這對於分析內部流轉非常的有用,共涉及如下 9 種狀態:
| 狀態 | 值 | 含義 |
|---|---|---|
| _Gidle | 0 | 剛剛被分配,還沒有進行初始化。 |
| _Grunnable | 1 | 已經在執行佇列中,還沒有執行使用者程式碼。 |
| _Grunning | 2 | 不在執行佇列裡中,已經可以執行使用者程式碼,此時已經分配了 M 和 P。 |
| _Gsyscall | 3 | 正在執行系統呼叫,此時分配了 M。 |
| _Gwaiting | 4 | 在執行時被阻止,沒有執行使用者程式碼,也不在執行佇列中,此時它正在某處阻塞等待中。 |
| _Gmoribund_unused | 5 | 尚未使用,但是在 gdb 中進行了硬編碼。 |
| _Gdead | 6 | 尚未使用,這個狀態可能是剛退出或是剛被初始化,此時它並沒有執行使用者程式碼,有可能有也有可能沒有分配堆疊。 |
| _Genqueue_unused | 7 | 尚未使用。 |
| _Gcopystack | 8 | 正在複製堆疊,並沒有執行使用者程式碼,也不在執行佇列中。 |
在理解了各類的狀態的意思後,我們結合上述案例看看,如下:
G1: status=4(semacquire) m=-1 lockedm=-1
G2: status=4(force gc (idle)) m=-1 lockedm=-1
G3: status=4(GC sweep wait) m=-1 lockedm=-1
G17: status=1() m=-1 lockedm=-1
G18: status=2() m=4 lockedm=-1
在這個片段中,G1 的執行狀態為 _Gwaiting,並沒有分配 M 和鎖定。這時候你可能好奇在片段中括號裡的是什麼東西呢,其實是因為該 status=4 是表示 Goroutine 在執行時時被阻止,而阻止它的事件就是 semacquire 事件,是因為 semacquire 會檢查訊號量的情況,在合適的時機就呼叫 goparkunlock 函式,把當前 Goroutine 放進等待佇列,並把它設為 _Gwaiting 狀態。
那麼在實際執行中還有什麼原因會導致這種現象呢,我們一起看看,如下:
waitReasonZero // ""
waitReasonGCAssistMarking // "GC assist marking"
waitReasonIOWait // "IO wait"
waitReasonChanReceiveNilChan // "chan receive (nil chan)"
waitReasonChanSendNilChan // "chan send (nil chan)"
waitReasonDumpingHeap // "dumping heap"
waitReasonGarbageCollection // "garbage collection"
waitReasonGarbageCollectionScan // "garbage collection scan"
waitReasonPanicWait // "panicwait"
waitReasonSelect // "select"
waitReasonSelectNoCases // "select (no cases)"
waitReasonGCAssistWait // "GC assist wait"
waitReasonGCSweepWait // "GC sweep wait"
waitReasonChanReceive // "chan receive"
waitReasonChanSend // "chan send"
waitReasonFinalizerWait // "finalizer wait"
waitReasonForceGGIdle // "force gc (idle)"
waitReasonSemacquire // "semacquire"
waitReasonSleep // "sleep"
waitReasonSyncCondWait // "sync.Cond.Wait"
waitReasonTimerGoroutineIdle // "timer goroutine (idle)"
waitReasonTraceReaderBlocked // "trace reader (blocked)"
waitReasonWaitForGCCycle // "wait for GC cycle"
waitReasonGCWorkerIdle // "GC worker (idle)"
我們透過以上 waitReason 可以瞭解到 Goroutine 會被暫停執行的原因要素,也就是會出現在括號中的事件。
M
- p:隸屬哪一個 P。
- curg:當前正在使用哪個 G。
- runqsize:執行佇列中的 G 數量。
- gfreecnt:可用的G(狀態為 Gdead)。
- mallocing:是否正在分配記憶體。
- throwing:是否丟擲異常。
- preemptoff:不等於空字串的話,保持 curg 在這個 m 上執行。
P
- status:P 的執行狀態。
- schedtick:P 的排程次數。
- syscalltick:P 的系統呼叫次數。
- m:隸屬哪一個 M。
- runqsize:執行佇列中的 G 數量。
- gfreecnt:可用的G(狀態為 Gdead)。
| 狀態 | 值 | 含義 |
|---|---|---|
| _Pidle | 0 | 剛剛被分配,還沒有進行進行初始化。 |
| _Prunning | 1 | 當 M 與 P 繫結呼叫 acquirep 時,P 的狀態會改變為 _Prunning。 |
| _Psyscall | 2 | 正在執行系統呼叫。 |
| _Pgcstop | 3 | 暫停執行,此時系統正在進行 GC,直至 GC 結束後才會轉變到下一個狀態階段。 |
| _Pdead | 4 | 廢棄,不再使用。 |
總結
透過本文我們學習到了排程的一些基礎知識,再透過神奇的 GODEBUG 掌握了觀察排程器的方式方法,你想想,是不是可以和我上一篇文章的 go tool trace 來結合使用呢,在實際的使用中,類似的辦法有很多,組合巧用是重點。
參考
- Debugging performance issues in Go programs
- A whirlwind tour of Go’s runtime environment variables
- Go排程器系列(2)宏觀看排程器
- Go's work-stealing scheduler
- Scheduler Tracing In Go
- Head First of Golang Scheduler
- goroutine 的狀態切換
- Environment_Variables
9.4 用 GODEBUG 看GC

什麼是 GC
在計算機科學中,垃圾回收(GC)是一種自動管理記憶體的機制,垃圾回收器會去嘗試回收程式不再使用的物件及其佔用的記憶體。而最早 John McCarthy 在 1959 年左右發明了垃圾回收,以簡化 Lisp 中的手動記憶體管理的機制(來自 wikipedia)。
為什麼要 GC
手動管理記憶體挺麻煩,管錯或者管漏記憶體也很糟糕,將會直接導致程式不穩定(持續洩露)甚至直接崩潰。
GC 帶來的問題
硬要說會帶來什麼問題的話,也就數大家最關注的 Stop The World(STW),STW 代指在執行某個垃圾回收演算法的某個階段時,需要將整個應用程式暫停去處理 GC 相關的工作事項。例如:
| 行為 | 會不會 STW | 為什麼 |
|---|---|---|
| 標記開始 | 會 | 在開始標記時,準備根物件的掃描,會開啟寫屏障(Write Barrier) 和 輔助GC(mutator assist),而回收器和應用程式是併發執行的,因此會暫停當前正在執行的所有 Goroutine。 |
| 併發標記中 | 不會 | 標記階段,主要目的是標記堆記憶體中仍在使用的值。 |
| 標記結束 | 會 | 在完成標記任務後,將重新掃描部分根物件,這時候會停用寫屏障(Write Barrier)和輔助GC(mutator assist),而標記階段和應用程式是併發執行的,所以在標記階段可能會有新的物件產生,因此在重新掃描時需要進行 STW。 |
如何調整 GC 頻率
可以透過 GOGC 變數設定初始垃圾收集器的目標百分比值,對比的規則為當新分配的數值與上一次收集後剩餘的實時數值的比例達到設定的目標百分比時,就會觸發 GC,預設值為 GOGC=100。如果將其設定為 GOGC=off 可以完全停用垃圾回收器,要不試試?
簡單來講就是,GOGC 的值設定的越大,GC 的頻率越低,但每次最終所觸發到 GC 的堆記憶體也會更大。
各版本 GC 情況
| 版本 | GC 演算法 | STW 時間 |
|---|---|---|
| Go 1.0 | STW(強依賴 tcmalloc) | 百ms到秒級別 |
| Go 1.3 | Mark STW, Sweep 並行 | 百ms級別 |
| Go 1.5 | 三色標記法, 併發標記清除。同時執行時從 C 和少量彙編,改為 Go 和少量彙編實作 | 10-50ms級別 |
| Go 1.6 | 1.5 中一些與併發 GC 不協調的地方更改,集中式的 GC 協調協程,改為狀態機實作 | 5ms級別 |
| Go 1.7 | GC 時由 mark 棧收縮改為併發,span 物件分配機制由 freelist 改為 bitmap 模式,SSA引入 | ms級別 |
| Go 1.8 | 混合寫屏障(hybrid write barrier), 消除 re-scanning stack | sub ms |
| Go 1.12 | Mark Termination 流程最佳化 | sub ms, 但幾乎減少一半 |
注:資料來源於 @boya 在深圳 Gopher Meetup 的分享。
GODEBUG
GODEBUG 變數可以控制執行時內的除錯變數,引數以逗號分隔,格式為:name=val。本文著重點在 GC 的觀察上,主要涉及 gctrace 引數,我們透過設定 gctrace=1 後就可以使得垃圾收集器向標準錯誤流發出 GC 執行資訊。
涉及術語
- mark:標記階段。
- markTermination:標記結束階段。
- mutator assist:輔助 GC,是指在 GC 過程中 mutator 執行緒會併發執行,而 mutator assist 機制會協助 GC 做一部分的工作。
- heap_live:在 Go 的記憶體管理中,span 是記憶體頁的基本單元,每頁大小為 8kb,同時 Go 會根據物件的大小不同而分配不同頁數的 span,而 heap_live 就代表著所有 span 的總大小。
- dedicated / fractional / idle:在標記階段會分為三種不同的 mark worker 模式,分別是 dedicated、fractional 和 idle,它們代表著不同的專注程度,其中 dedicated 模式最專注,是完整的 GC 回收行為,fractional 只會幹部分的 GC 行為,idle 最輕鬆。這裡你只需要瞭解它是不同專注程度的 mark worker 就好了,詳細介紹我們可以等後續的文章。
演示程式碼
func main() {
wg := sync.WaitGroup{}
wg.Add(10)
for i := 0; i < 10; i++ {
go func(wg *sync.WaitGroup) {
var counter int
for i := 0; i < 1e10; i++ {
counter++
}
wg.Done()
}(&wg)
}
wg.Wait()
}
gctrace
$ GODEBUG=gctrace=1 go run main.go
gc 1 @0.032s 0%: 0.019+0.45+0.003 ms clock, 0.076+0.22/0.40/0.80+0.012 ms cpu, 4->4->0 MB, 5 MB goal, 4 P
gc 2 @0.046s 0%: 0.004+0.40+0.008 ms clock, 0.017+0.32/0.25/0.81+0.034 ms cpu, 4->4->0 MB, 5 MB goal, 4 P
gc 3 @0.063s 0%: 0.004+0.40+0.008 ms clock, 0.018+0.056/0.32/0.64+0.033 ms cpu, 4->4->0 MB, 5 MB goal, 4 P
gc 4 @0.080s 0%: 0.004+0.45+0.016 ms clock, 0.018+0.15/0.34/0.77+0.065 ms cpu, 4->4->1 MB, 5 MB goal, 4 P
gc 5 @0.095s 0%: 0.015+0.87+0.005 ms clock, 0.061+0.27/0.74/1.8+0.023 ms cpu, 4->4->1 MB, 5 MB goal, 4 P
gc 6 @0.113s 0%: 0.014+0.69+0.002 ms clock, 0.056+0.23/0.48/1.4+0.011 ms cpu, 4->4->1 MB, 5 MB goal, 4 P
gc 7 @0.140s 1%: 0.031+2.0+0.042 ms clock, 0.12+0.43/1.8/0.049+0.17 ms cpu, 4->4->1 MB, 5 MB goal, 4 P
...
格式
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
含義
gc#:GC 執行次數的編號,每次疊加。@#s:自程式啟動後到當前的具體秒數。#%:自程式啟動以來在GC中花費的時間百分比。#+...+#:GC 的標記工作共使用的 CPU 時間佔總 CPU 時間的百分比。#->#-># MB:分別表示 GC 啟動時, GC 結束時, GC 活動時的堆大小.#MB goal:下一次觸發 GC 的記憶體佔用閾值。#P:當前使用的處理器 P 的數量。
案例
gc 7 @0.140s 1%: 0.031+2.0+0.042 ms clock, 0.12+0.43/1.8/0.049+0.17 ms cpu, 4->4->1 MB, 5 MB goal, 4 P
- gc 7:第 7 次 GC。
- @0.140s:當前是程式啟動後的 0.140s。
- 1%:程式啟動後到現在共花費 1% 的時間在 GC 上。
- 0.031+2.0+0.042 ms clock:
- 0.031:表示單個 P 在 mark 階段的 STW 時間。
- 2.0:表示所有 P 的 mark concurrent(併發標記)所使用的時間。
- 0.042:表示單個 P 的 markTermination 階段的 STW 時間。
- 0.12+0.43/1.8/0.049+0.17 ms cpu:
- 0.12:表示整個程序在 mark 階段 STW 停頓的時間。
- 0.43/1.8/0.049:0.43 表示 mutator assist 佔用的時間,1.8 表示 dedicated + fractional 佔用的時間,0.049 表示 idle 佔用的時間。
- 0.17ms:0.17 表示整個程序在 markTermination 階段 STW 時間。
- 4->4->1 MB:
- 4:表示開始 mark 階段前的 heap_live 大小。
- 4:表示開始 markTermination 階段前的 heap_live 大小。
- 1:表示被標記物件的大小。
- 5 MB goal:表示下一次觸發 GC 回收的閾值是 5 MB。
- 4 P:本次 GC 一共涉及多少個 P。
總結
透過本章節我們掌握了使用 GODEBUG 檢視應用程式 GC 執行情況的方法,只要用這種方法我們就可以觀測不同情況下 GC 的情況了,甚至可以做出非常直觀的對比圖,大家不妨嘗試一下。
關聯文章
參考
- Go GC打印出來的這些資訊都是什麼含義?
- GODEBUG之gctrace解析
- 關於Golang GC的一些誤解--真的比Java GC更領先嗎?
- @boya 深入淺出Golang Runtime PPT
第10課 爬蟲
9.1 爬取豆瓣電影 Top250
爬蟲是標配了,看資料那一刻很有趣。第一個就從最最最簡單最基礎的爬蟲開始寫起吧!
專案地址:https://github.com/go-crawler/douban-movie
目標
我們的目標站點是 豆瓣電影 Top250,估計大家都很眼熟了
本次爬取8個欄位,用於簡單的概括分析。具體的欄位如下:
簡單的分析一下目標源
- 一頁共25條
- 含分頁(共10頁)且分頁規則是正常的
- 每一項的資料欄位排序都是規則且不變
開始
由於量不大,我們的爬取步驟如下
- 分析頁面,取得所有的分頁
- 分析頁面,迴圈爬取所有頁面的電影資訊
- 爬取的電影資訊入庫
安裝
$ go get -u github.com/PuerkitoBio/goquery
執行
$ go run main.go
程式碼片段
1、取得所有分頁
func ParsePages(doc *goquery.Document) (pages []Page) {
pages = append(pages, Page{Page: 1, Url: ""})
doc.Find("#content > div > div.article > div.paginator > a").Each(func(i int, s *goquery.Selection) {
page, _ := strconv.Atoi(s.Text())
url, _ := s.Attr("href")
pages = append(pages, Page{
Page: page,
Url: url,
})
})
return pages
}
2、分析豆瓣電影資訊
func ParseMovies(doc *goquery.Document) (movies []Movie) {
doc.Find("#content > div > div.article > ol > li").Each(func(i int, s *goquery.Selection) {
title := s.Find(".hd a span").Eq(0).Text()
...
movieDesc := strings.Split(DescInfo[1], "/")
year := strings.TrimSpace(movieDesc[0])
area := strings.TrimSpace(movieDesc[1])
tag := strings.TrimSpace(movieDesc[2])
star := s.Find(".bd .star .rating_num").Text()
comment := strings.TrimSpace(s.Find(".bd .star span").Eq(3).Text())
compile := regexp.MustCompile("[0-9]")
comment = strings.Join(compile.FindAllString(comment, -1), "")
quote := s.Find(".quote .inq").Text()
...
log.Printf("i: %d, movie: %v", i, movie)
movies = append(movies, movie)
})
return movies
}
資料
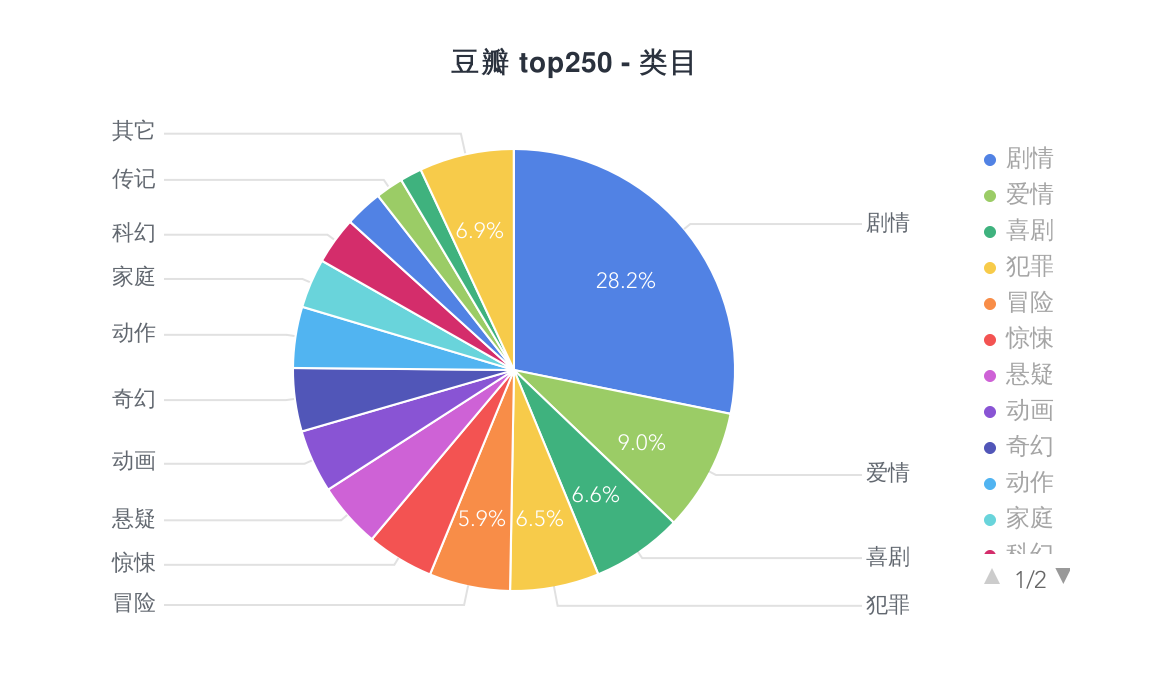

看到這些資料,你有什麼想法呢,真是好奇 :=)
9.2 爬取汽車之家 二手車產品庫
專案地址:https://github.com/go-crawler/car-prices
目標
最近經常有人在耳邊提起汽車之家,也好奇二手車在國內的價格是怎麼樣的,因此本次的目標站點是 汽車之家 的二手車產品庫
分析目標源:
- 一頁共24條
- 含分頁,但這個老產品庫,在100頁後會存在問題,因此我們爬取99頁
- 可以取得全部城市
- 共可爬取 19w+ 資料
開始
爬取步驟
- 取得全部的城市
- 拼裝全部城市URL入佇列
- 解析二手車頁面結構
- 下一頁URL入佇列
- 迴圈拉取所有分頁的二手車資料
- 迴圈拉取佇列中城市的二手車資料
- 等待,確定佇列中無新的 URL
- 爬取的二手車資料入庫
取得城市
透過頁面檢視,可發現在城市篩選區可得到全部的二手車城市列表,但是你仔細查閱程式碼。會發現它是JS載入進來的,城市也統一放在了一個變數中

有兩種提取方法
- 分析JS變數,提取出來
- 直接將
areaJson複製出來作為變數解析
在這裡我們直接將其複製粘貼出來即可,因為這是比較少變動的值
取得分頁
透過分析頁面可以得知分頁連結是有一定規律的,例如:/2sc/hangzhou/a0_0msdgscncgpi1ltocsp2exb4/,可以發現 sp%d,sp 後面為頁碼
按照常理,可以透過預測所有分頁連結,推入佇列後 go routine 一波 即可快速拉取
但是在這老產品庫存在一個問題,在超過 100 頁後,下一頁永遠是 101 頁
因此我們採取比較傳統的做法,透過拉取下一頁的連結去訪問,以便適應可能的分頁連結改變; 100 頁以後的分頁展示也很奇怪,先忽視
取得二手車資料
頁面結構較為固定,常規的清洗 HTML 即可
func GetCars(doc *goquery.Document) (cars []QcCar) {
cityName := GetCityName(doc)
doc.Find(".piclist ul li:not(.line)").Each(func(i int, selection *goquery.Selection) {
title := selection.Find(".title a").Text()
price := selection.Find(".detail .detail-r").Find(".colf8").Text()
kilometer := selection.Find(".detail .detail-l").Find("p").Eq(0).Text()
year := selection.Find(".detail .detail-l").Find("p").Eq(1).Text()
kilometer = strings.Join(compileNumber.FindAllString(kilometer, -1), "")
year = strings.Join(compileNumber.FindAllString(strings.TrimSpace(year), -1), "")
priceS, _ := strconv.ParseFloat(price, 64)
kilometerS, _ := strconv.ParseFloat(kilometer, 64)
yearS, _ := strconv.Atoi(year)
cars = append(cars, QcCar{
CityName: cityName,
Title: title,
Price: priceS,
Kilometer: kilometerS,
Year: yearS,
})
})
return cars
}
資料
在各城市的平均價格對比中,我們可以發現北上廣深裡的北京、上海、深圳都在榜單上,而近年勢頭較猛的杭州直接佔領了榜首,且後幾名都有一些距離
而其他城市大致都是梯級下降的趨勢,看來一線城市的二手車也是不便宜了,當然這只是均價
我們可以看到價格和公里數的對比,上海、成都、鄭州的等比差異是有點大,感覺有需求的話可以在價格和公里數上做一個衡量
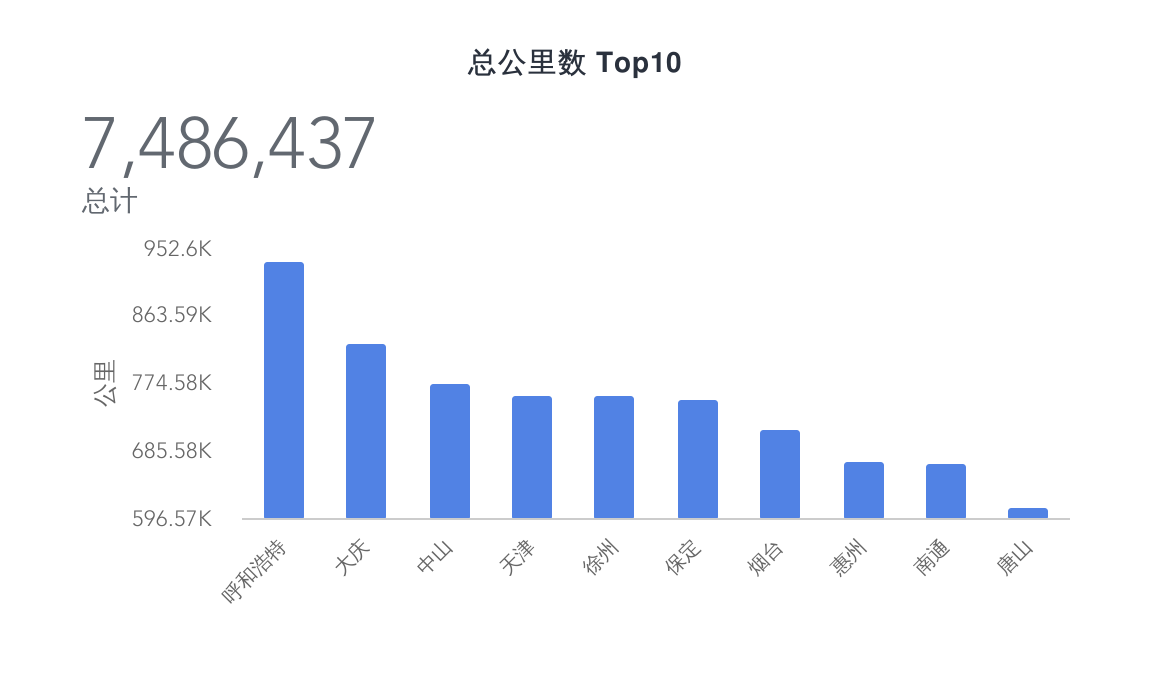
這圖有點兒有趣,粗略的統計了一下總公里數。在前幾張圖裡,平均價格排名較高的統統沒有出現在這裡,反倒是呼和浩特、大慶、中山等出現在了榜首
是否側面反應了一線城市的車輛更新換代較快,而較後的城市的車輛倒是換代較慢,公里數基本都槓槓的

透過對標題的分析,可以得知車輛產品庫的命名基本都是品牌名稱+自動/手動+XXXX款+屬性,看標題就能知道個概況了
參考
爬蟲專案地址
9.3 瞭解一下Golang的市場行情
專案地址:https://github.com/go-crawler/lagou_jobs
如果對你有所幫助,歡迎 Star,給文章來波贊,這樣可以讓更多的人看見 :)
目標
在工作中 Golang 已是一份子,想讓大家瞭解一下 Golang 的市場行情,也想讓更多的人熟悉它。因此主要是展示資料分析的結果
目標站點是 某招聘網站 的職位資料抓取和分析,爬取城市分別為 北京、上海、廣州、深圳、杭州、成都,再得出一個結論
分析
首先需要進行頁面分析,找到我們的抓取方向
搜尋 golang 關鍵字,開啟頁面 F12 就能看到它傳送了四個請求,留意 positionAjax.json 這個請求
我們仔細研判這個介面的入參和出參
入參
1、Query String Param
- city:請求的城市
- needAddtionalResult:是否需要補充額外的引數,這裡預設 false
2、Form Data
- first:是否首頁
- pn:頁碼
- kd:關鍵字
出參
就是它了,從返回結果可得出許多有用的資訊
- companyFullName:公司全稱
- companyLabelList:公司標籤
- companyShortName:公司簡稱
- companySize:公司規模
- education:學歷要求
- financeStage:融資階段
等等~
分頁
在上面兩張圖中,可以發現在 content 節點中包含 pageNo、pageSize 欄位,content.positionResult 節點有 totalCount 欄位,可以得知當前是第幾頁,每頁顯示多少條,當前的職位總條數
需要注意一下,分頁的計算是要向上取整的
模擬瀏覽器頭
User-Agent 可以用 fake-useragent 這個專案來隨機生成 UA 頭😄
資料
一、分佈圖
不同工作、工種,自然也會遍佈在不同的工作區域,我們先了解一下各個城市的 Golang 工程師都主要在哪個區上班,心裡留個底
北京
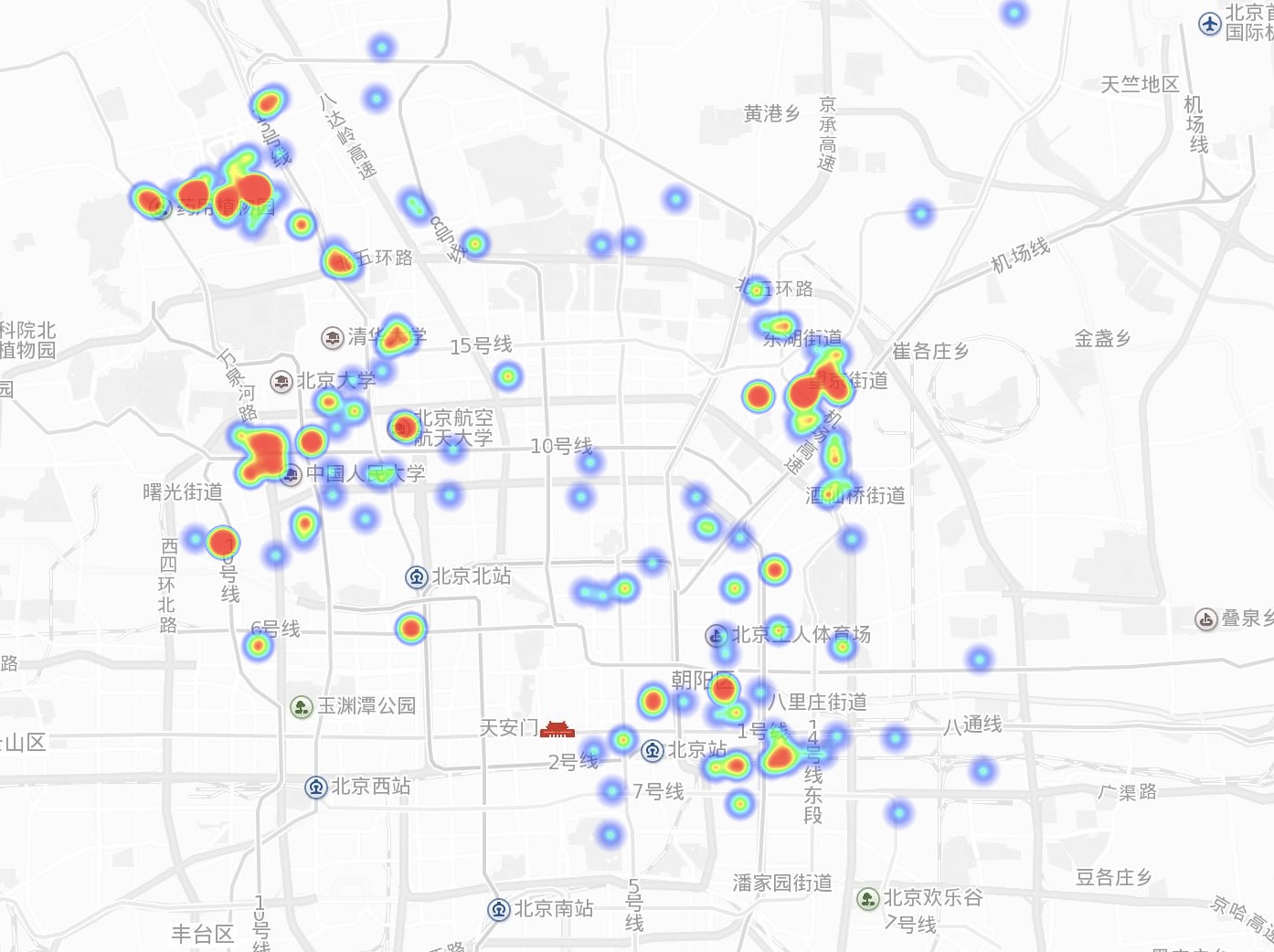
上海
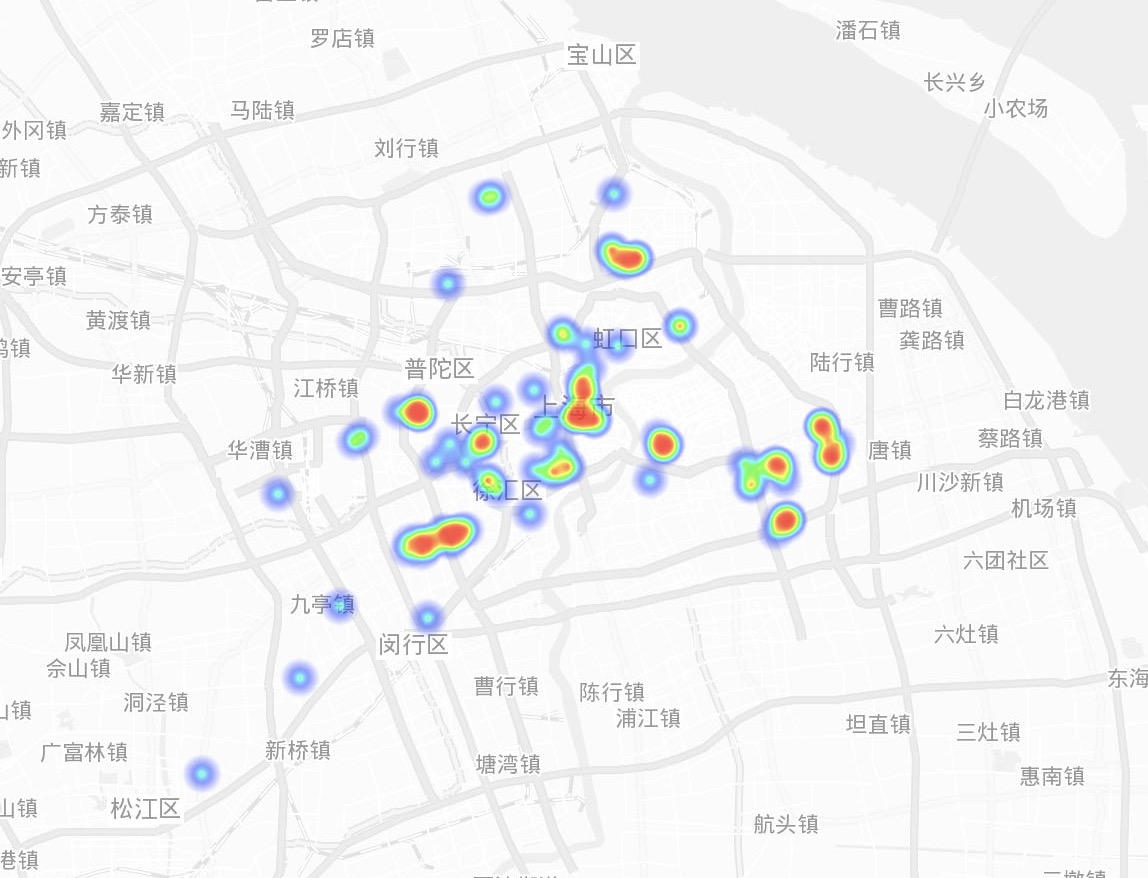
廣州
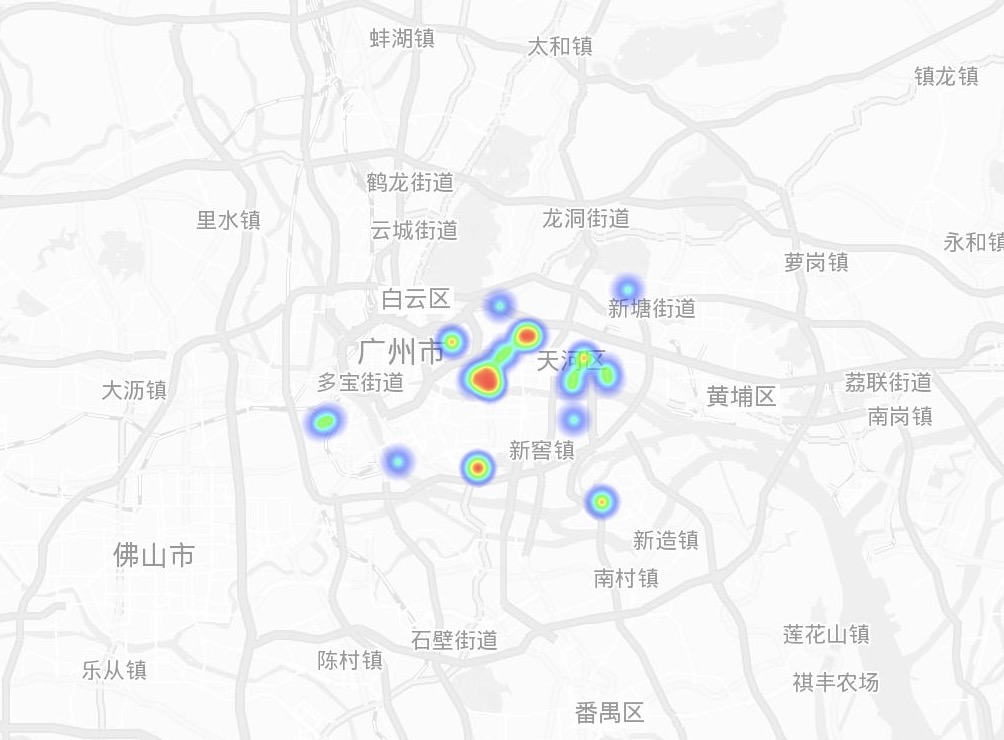
深圳
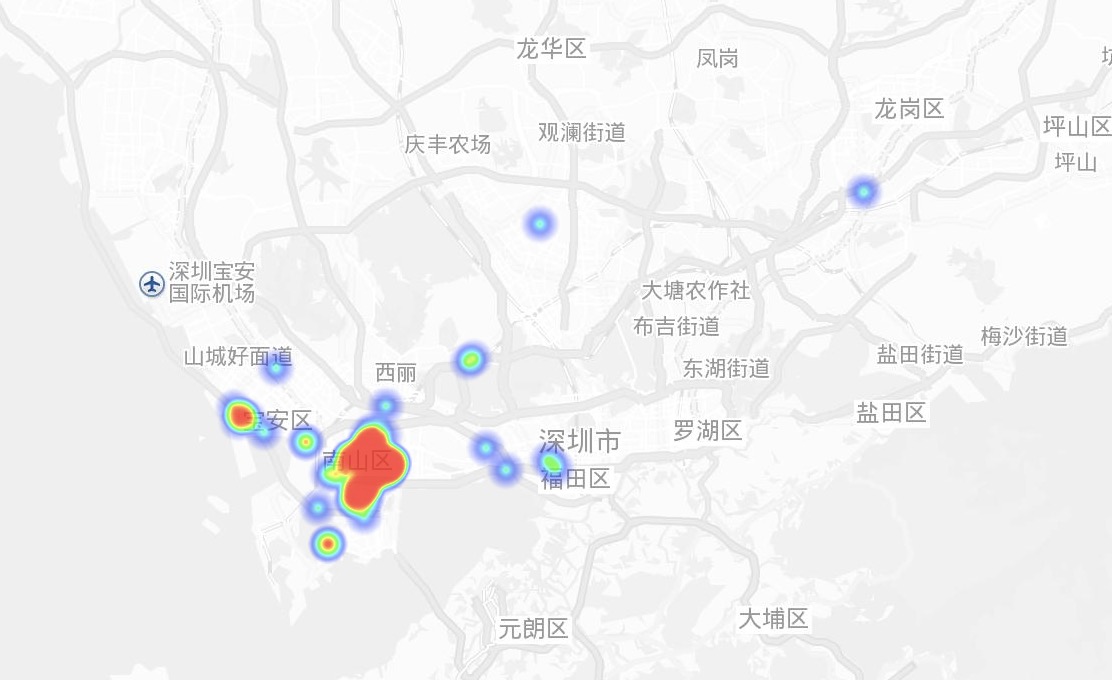
杭州
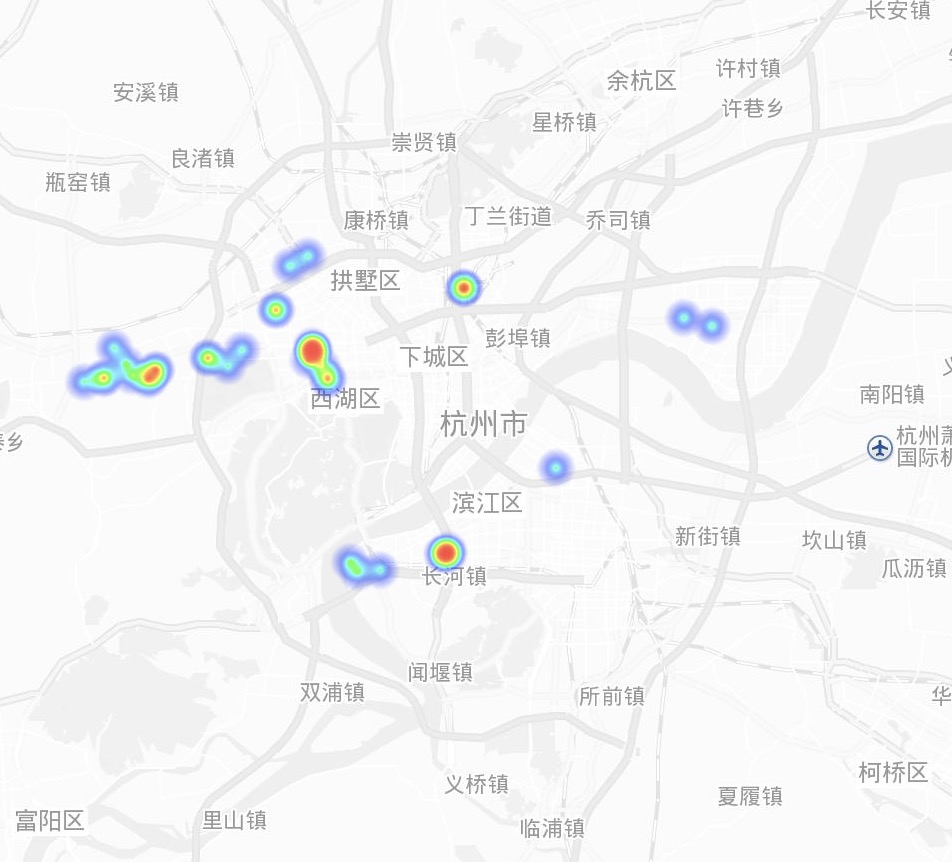
成都
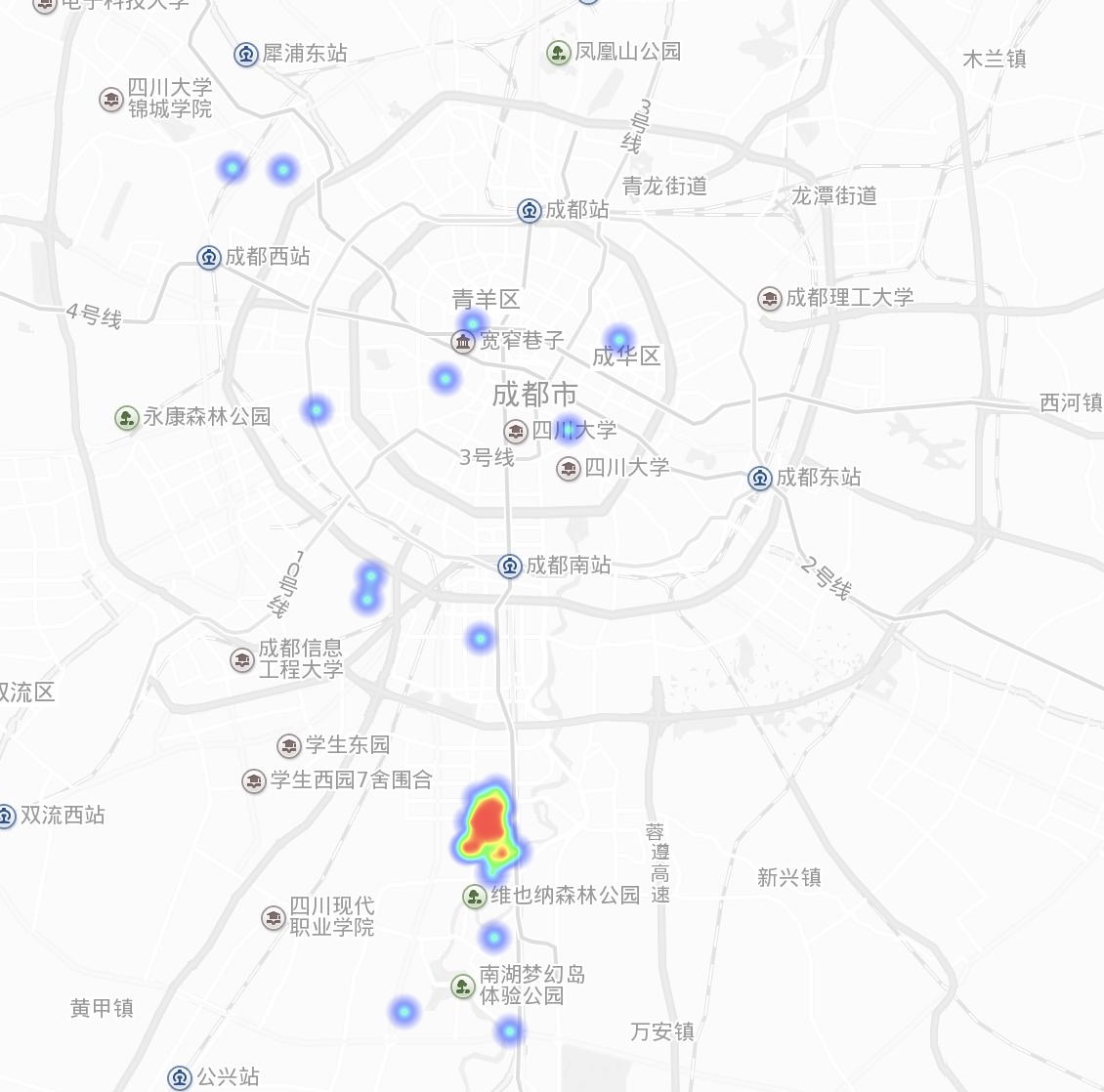
二、招聘與職位數量對比
透過分析圖中的資料,我們可以得知各城市的招聘職位數量
- 北京:348
- 上海:145
- 廣州:37
- 成都:49
- 杭州:45
- 深圳:108
總共招聘的職位數量為 732 個,數量順序分別為 北京 > 上海 > 深圳 > 成都 > 杭州 > 廣州
還有另外一個關注點,就是招聘公司數量與職位的數量對比,可以看到 北京 招聘的職位數量為 348 個,而招聘的公司數量為 191 個,約為 1.82 的比例,也就是一家公司能提供兩個 Golang 職位,它可能類別不同、(中級、中高階、高階)級別不同,具有一定可能性。而在廣州,為 31 對比 37,雖然差額不大,但仍然存在這種現象
可以得出結果,Golang 在市場上具有一定的伸縮空間,也就是具有上升空間,一家公司會將 Golang 應用在多個不同的應用場景,也就是方向不同,需要的級別人才也就不同了
但是需要注意的是,Golang 的市場招聘人數目前份額還是較低,六個城市總數僅為 732 個,與其他大熱語言相差有一定距離,需要謹慎
同時,面試 Golang 的人與其他大熱語言相比會少些,職位的爭奪是否小點呢?
三、招聘公司規模
透過檢視招聘 Golang 工程師的公司規模,可以很直觀的發現,微型公司使用 Golang 較少,其他類別的規模都有一定程度的應用,且差距不大。在 2000 人以上、50 - 150 人的公司規模中最受青睞
為什麼呢,我認為有以下可能
- 大型公司結合場景,想透過 Golang 的特性來解決一些痛點問題
- 在小型公司 Golang 這顆新星實施起來更便捷,有一定的應用場景
你覺得呢,是不是應該有更多的選擇它的原因?
四、學歷要求
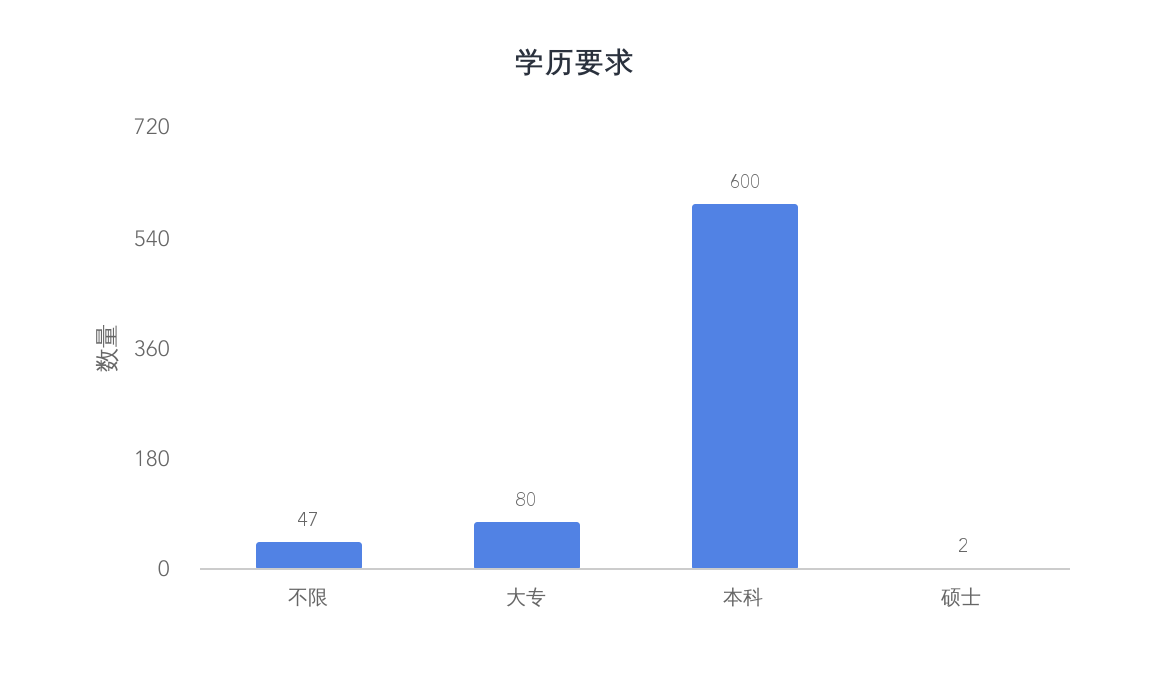
在招聘市場上,Golang 的招聘者更希望你是本科學歷,大專和不限也有一定的份額,但市場份額相差較大
碩士學歷要求的為兩個,可以得出,在市場上 Golang 招聘者們對高學歷的需求並不高,或者並不強制高學歷
五、行業領域
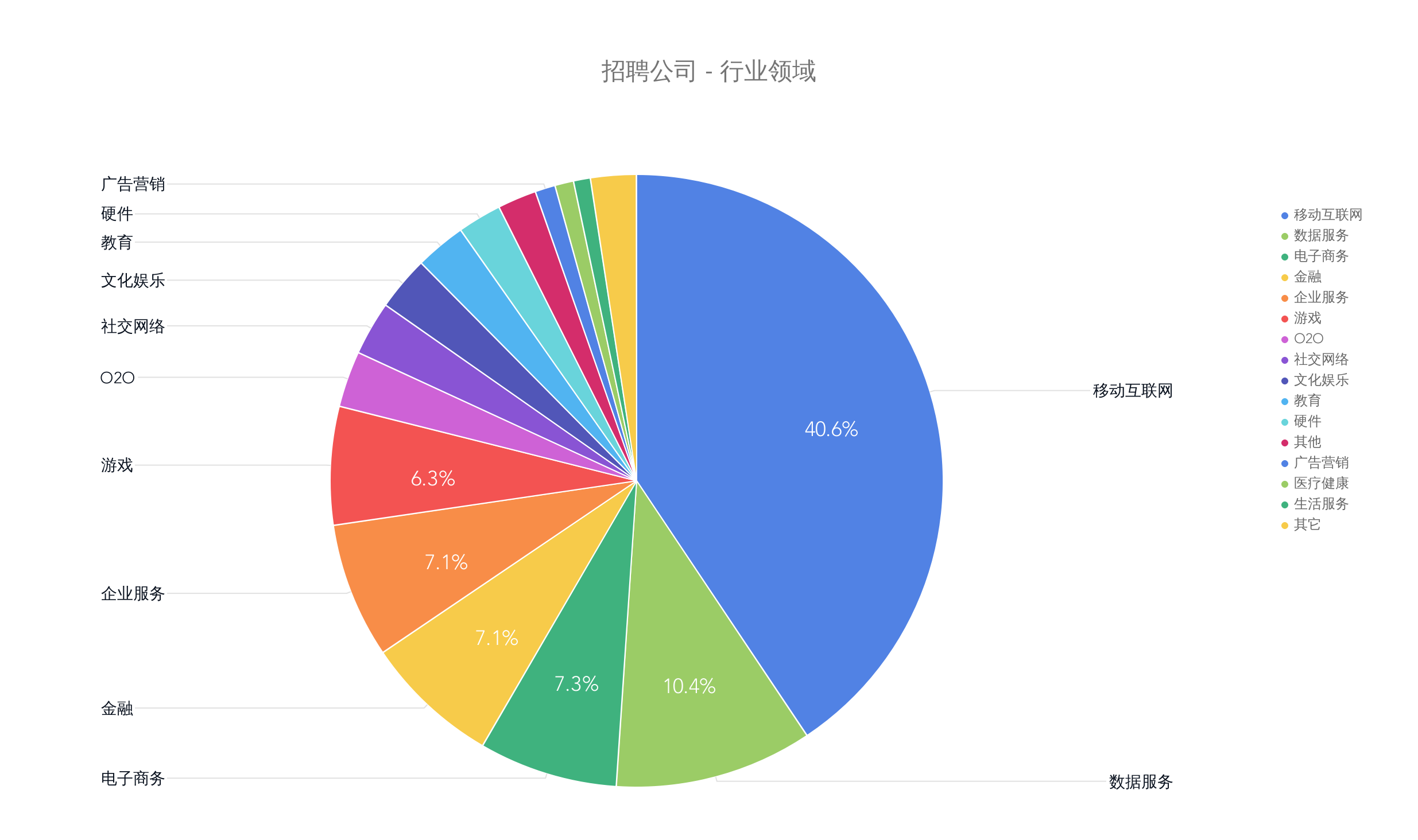
在這裡,重點關注 Golang 工程師的招聘公司都分別在什麼行業領域,大頭移動網際網路是不容置疑的了,還可以驚喜的發現
- 資料服務
- 電子商務
- 金融
- 企業服務
- 遊戲
Golang 在這幾個方面都有所應用,說明了在市場上,Golang 的路子是比較廣闊的,前景不錯
同時,如果可以涉及多個領域的內容,想必身為工程師的你,肯定很激動
六、職位誘惑

職位誘惑是投簡歷時必看的一點了,可以看到高頻詞條基本都是 IT 從業者關心的話題了,這裡你懂的...
重點,我看到了一個 “免費三餐” 的詞條命中 7 次,分別來自北京的海淀區、東城區、朝陽區,上海的黃浦區的七家不同的公司,辛苦了
七、行業、職位標籤
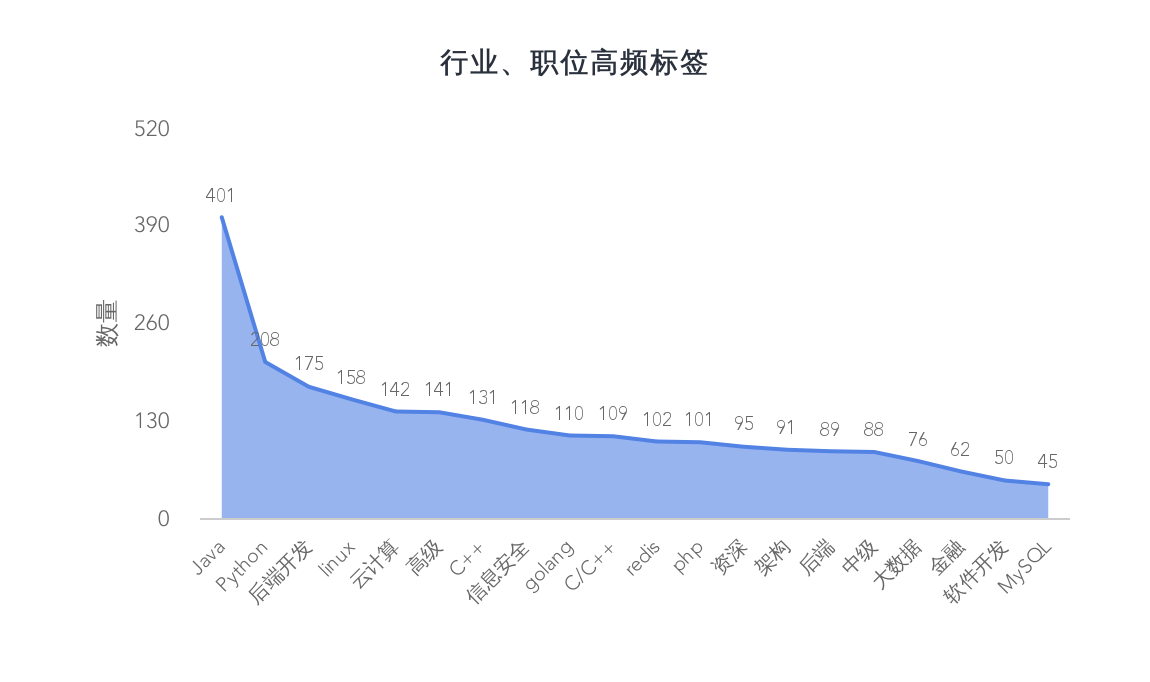
在招聘JD中,描述和標籤常用於給求職者瞭解這一職業的具體工作內容和其關聯性
在圖中你可以看到 Golang 常常和什麼內容搭上邊,這點很有意義哦
1、語言
- Java
- Python
- C/C++
- PHP
在圖中可以看出,Golang 與以上四種語言有一定關聯性,而 Java 和 Python 分別第一、第二名,可以說明市場上對複合型人才的渴望度更高,也許你不懂也行,但你懂了就最好(加分項)。需要你自身有多語言的經驗,也便於和其他人對接
同時 Golang 目前存在許多內部轉語言寫的情況,所以這一點可以參考
2、職稱
- 高階
- 資深
- 中級
特意將職稱放在第二位,可以發現在市場上 Golang 標籤的需求是 高階 > 資深 > 中級,關聯第一項 “語言關聯” 不難得出這個結論,因為語言只是解決問題的工具,到了中級及以上的工程師都是懂多門語言的居多,再採取不同的方案去解決應用場景上的問題
可得出結論,市場目前對 Golang 更期望是中高、高階、資深的人才,而中級的反而少一點點
大家可以努力再往上衝擊衝擊
3、元件
- Linux
- Redis
- Mysql
4、行業
- 雲計算
- 資訊保安
- 大資料
- 金融
- 軟體開發
八、薪資與工作年限
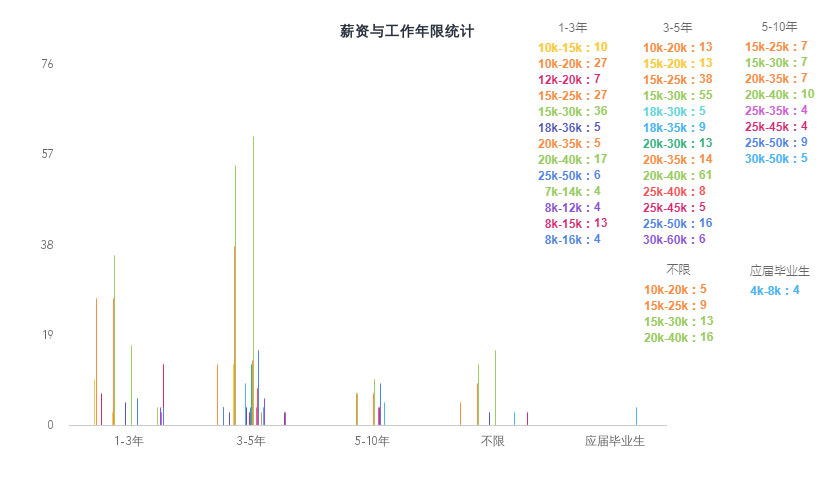
1、1-3年
一個(成長)特殊的階段,有個位數也有雙位數的,大頭可以到15-30k,20-40k,而初級的也有8-16k
2、3-5年
厚積待發的階段,薪酬範疇的跨度是較大,10-60k的薪酬都有,這充分說明能力決定你的上下
3、5-10年
核心,招聘網站上的招聘數量反而少,都會走內推或獵頭,不需要特別介紹了
小結
這一部分,相信是很多人關注的地方
在有的文章中會看到,他們的薪資部分是以平均值來展示的。我就很納悶,因為對平均值並不是很關心,重點是無法體現薪資幅度。因此這裡我會盡可能的把資料展現給你們看
(正文)從圖表來看,Golang 當前的薪酬水平還是很不錯的,市場能根據不同階段(水平)的人給出一個好的價位
(題外話)看完之後希望你能知道以下內容
- 你當前工作年限的最高、最低薪資範疇
- 你的下一階段的薪資範疇
- 為什麼有的人高,有的人低
- 在大頭部隊還是小頭,為什麼
- 不要滿足於平均值
九、融資階段
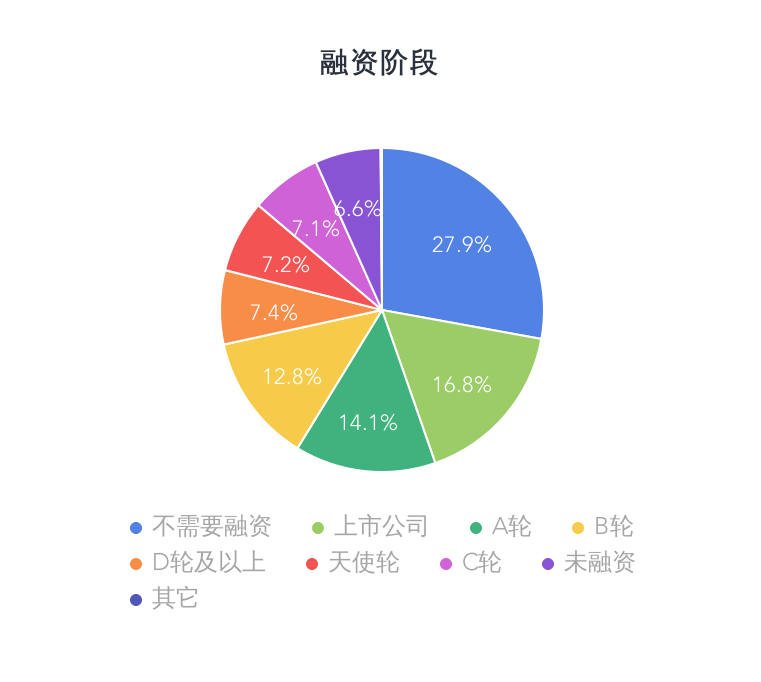
選用 Golang 的公司大多數都較為穩定,有一部分比較刺激 :)
融資階段與薪資範疇對比
不需要融資
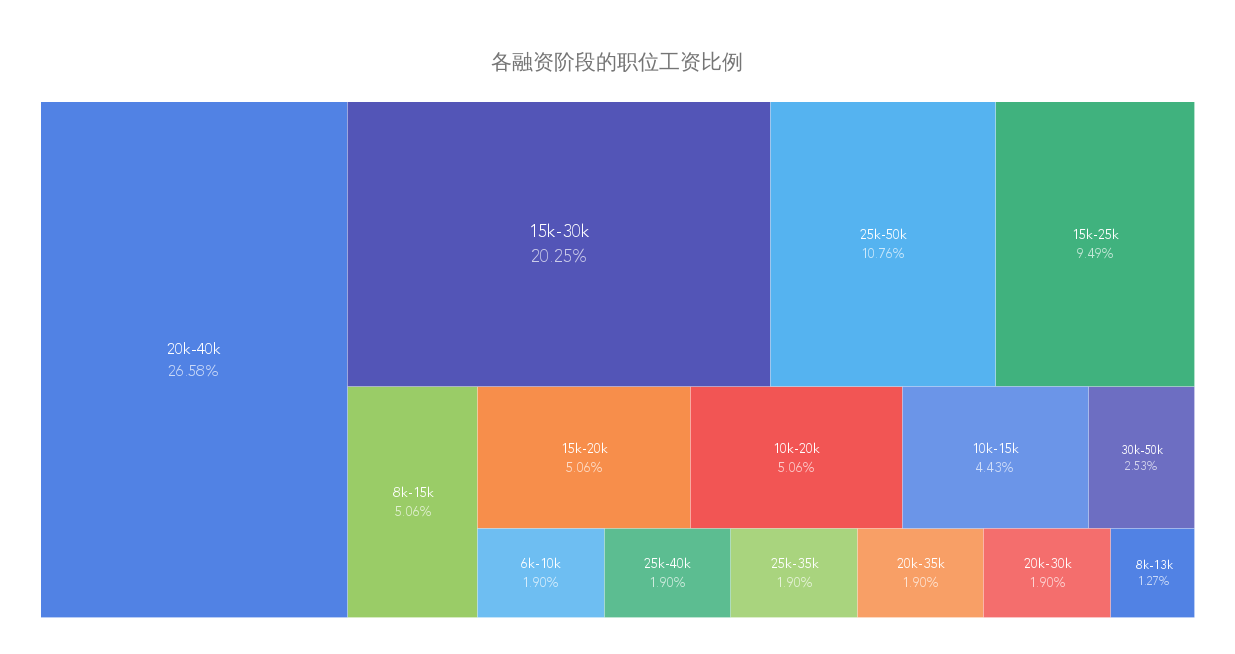
上市公司
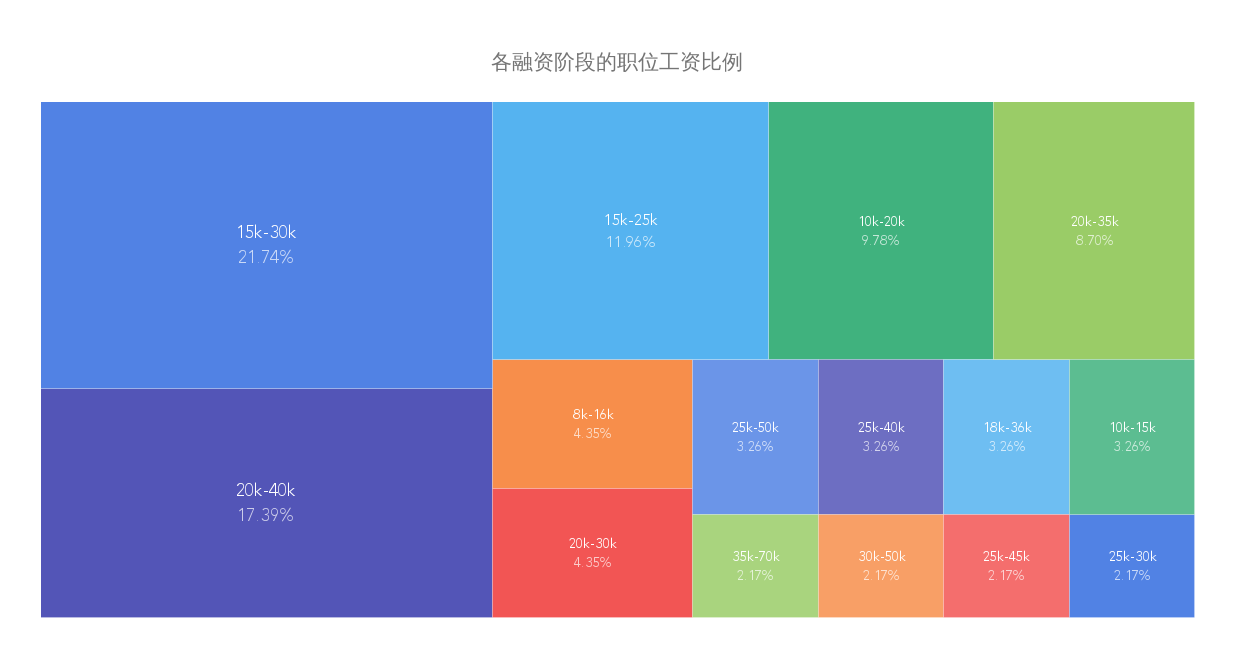
A輪
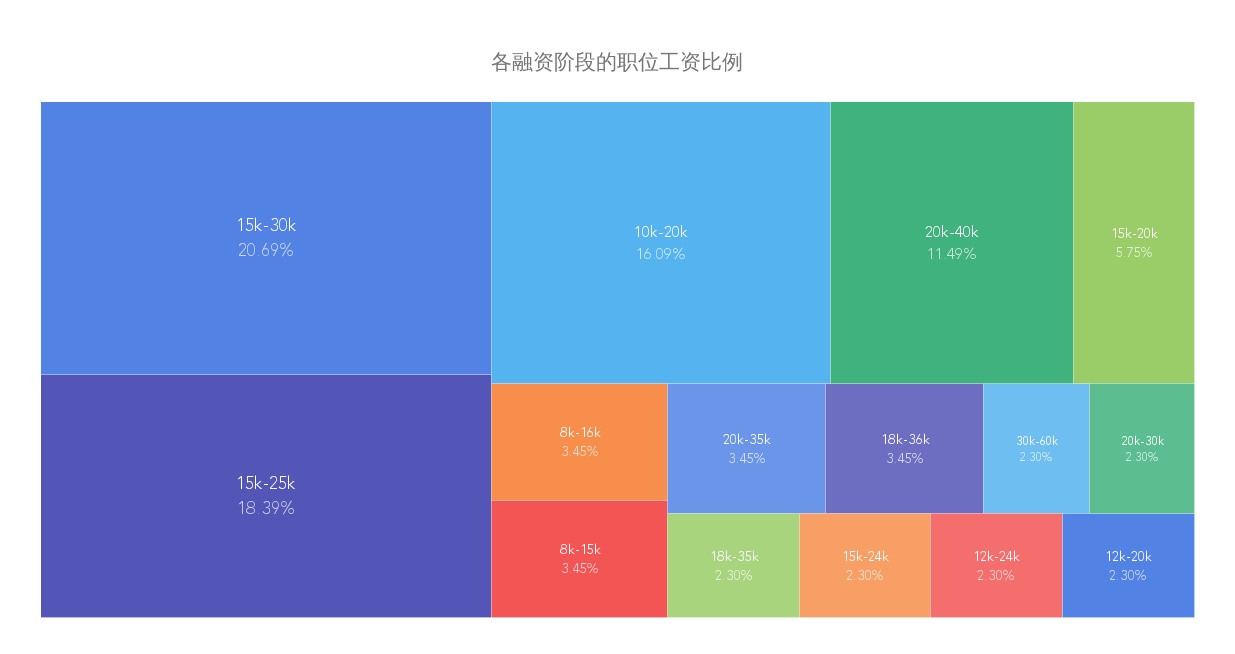
B輪
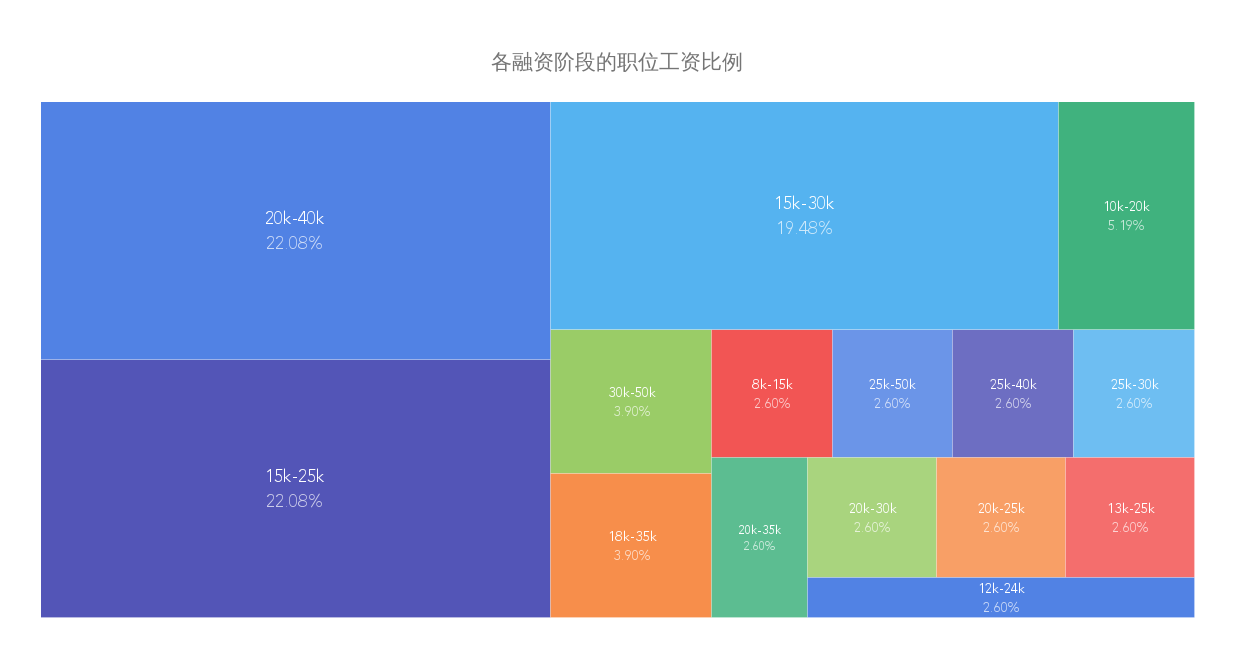
C輪
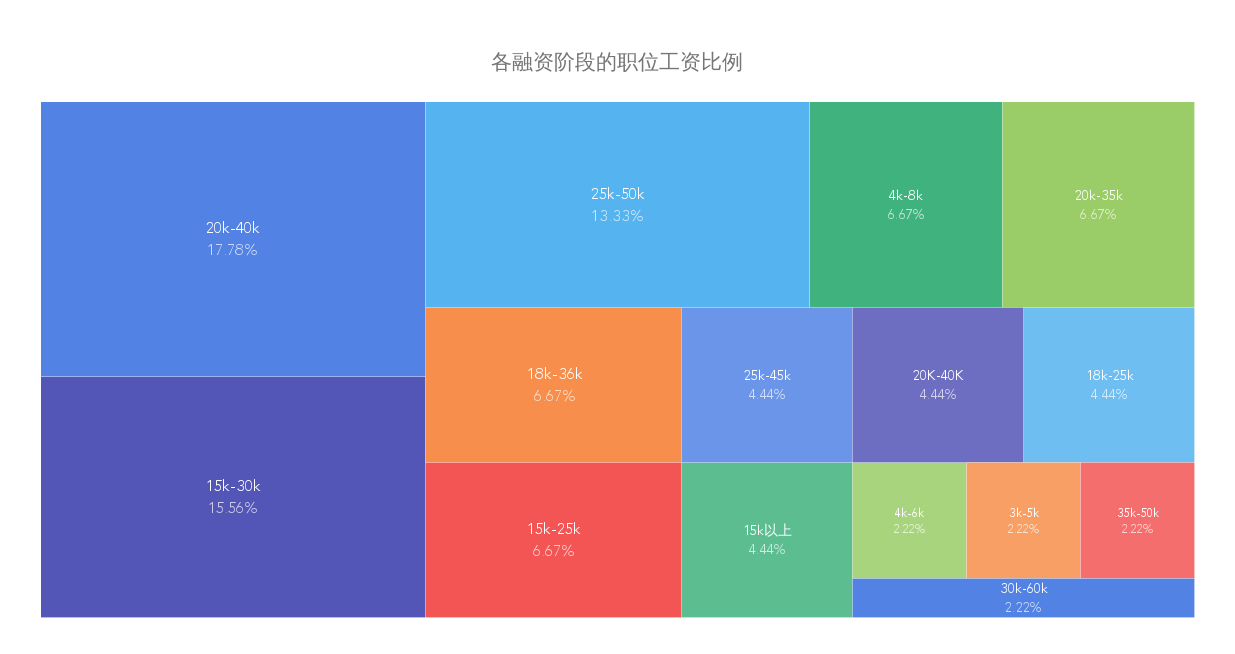
D輪以上
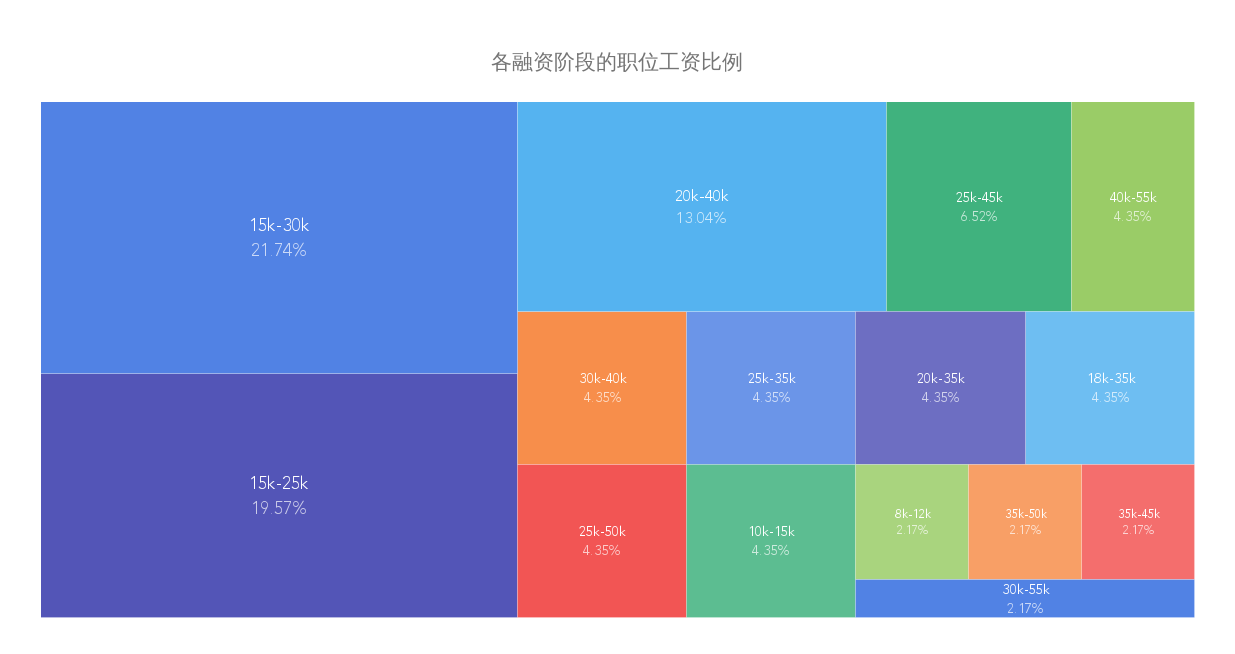
十、附近的地鐵
Golang 工程師都駐紮在什麼地鐵站附近呢
經常在地鐵上看到同行在看程式碼,來了解一下都分佈在哪 :)
北京
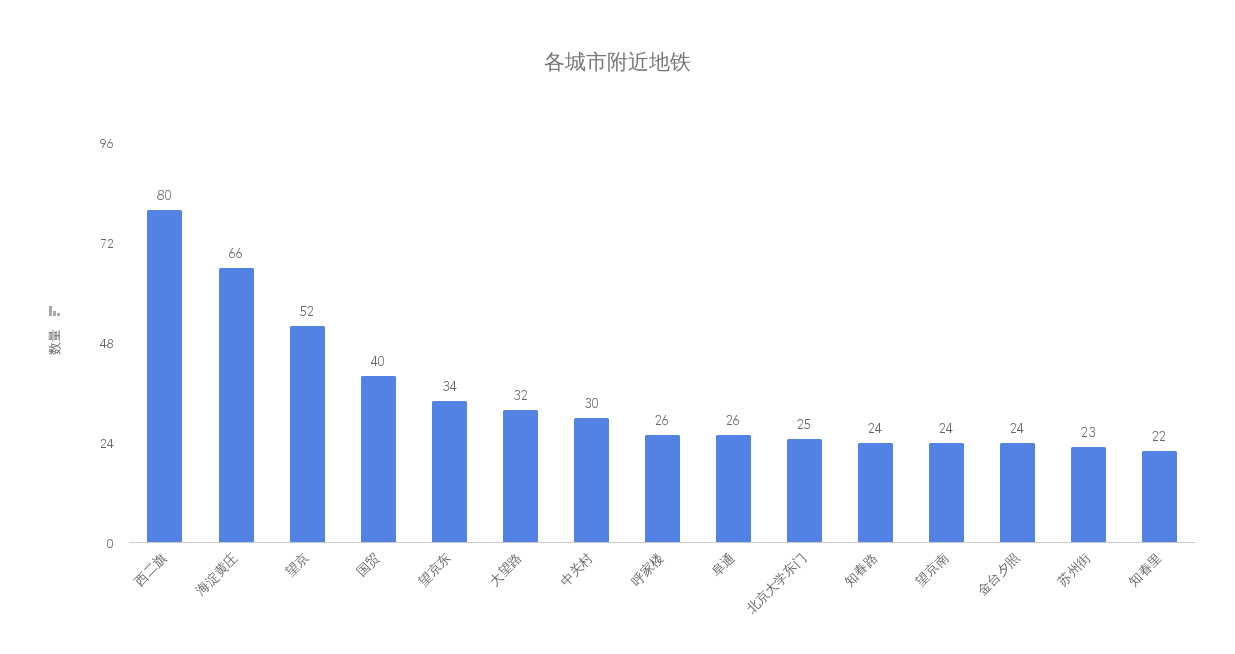
上海
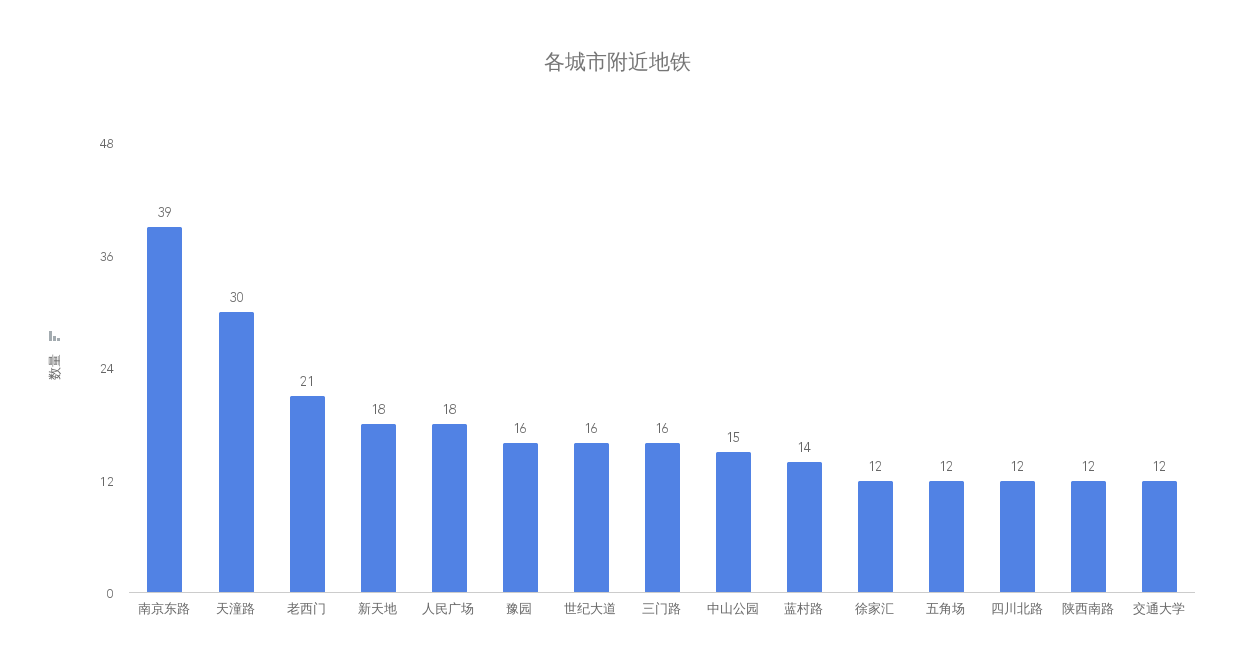
廣州
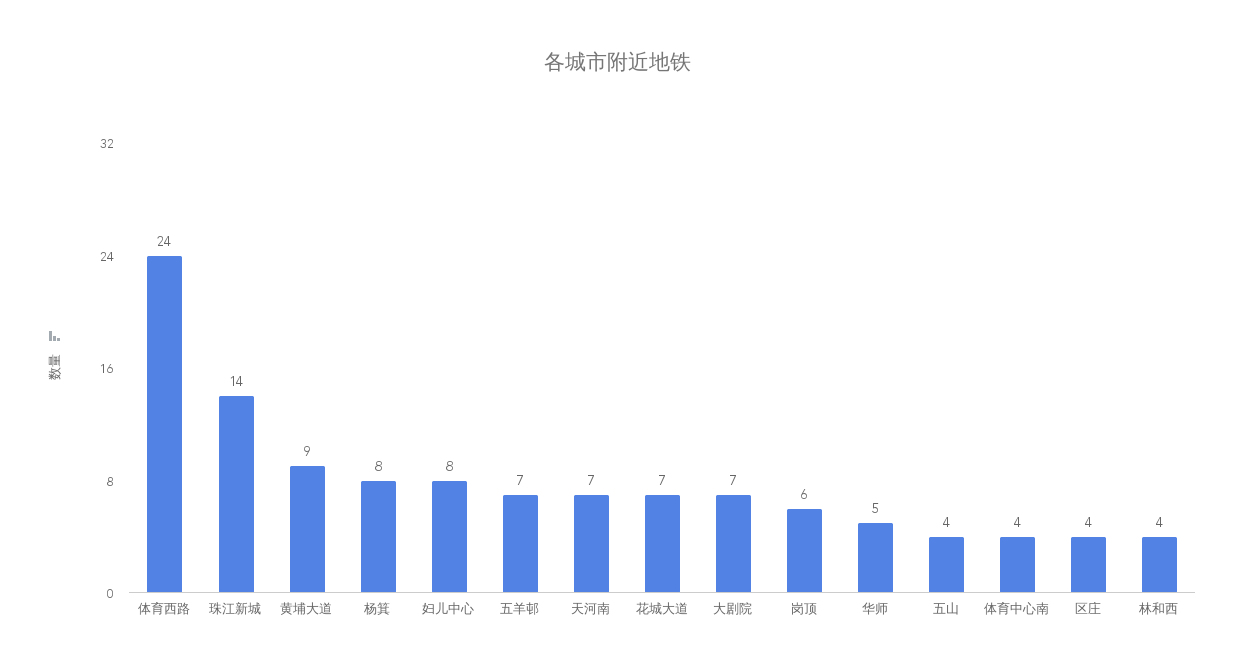
深圳
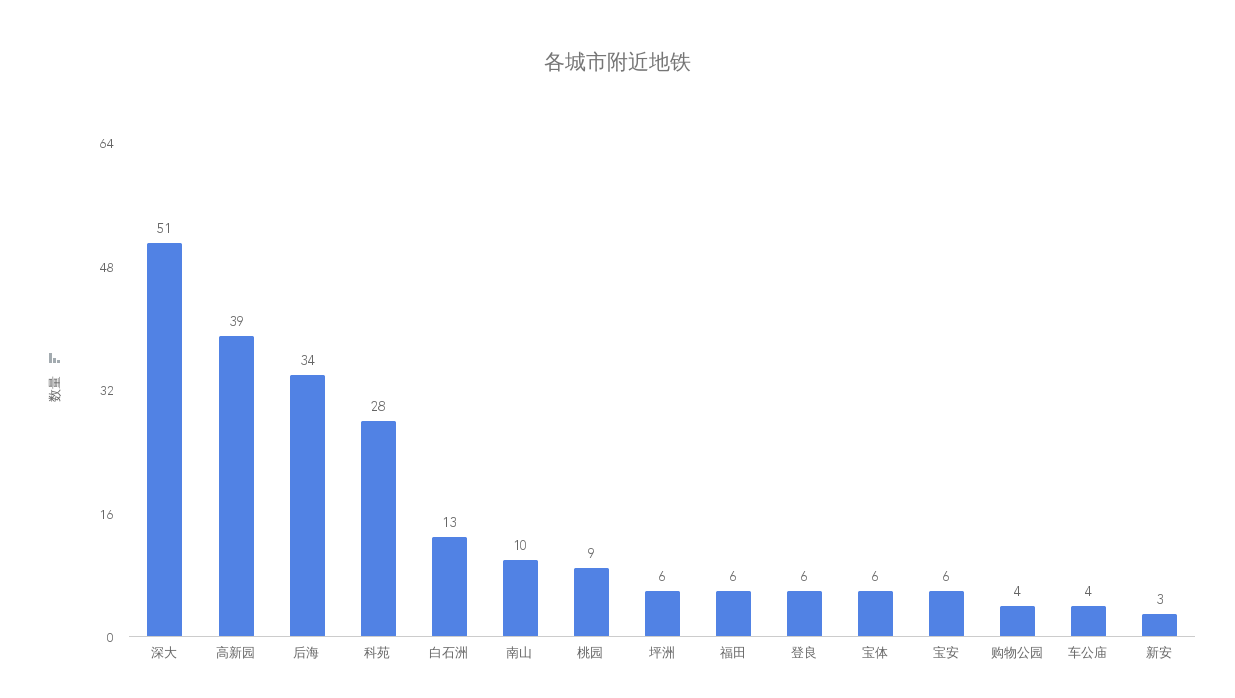
杭州
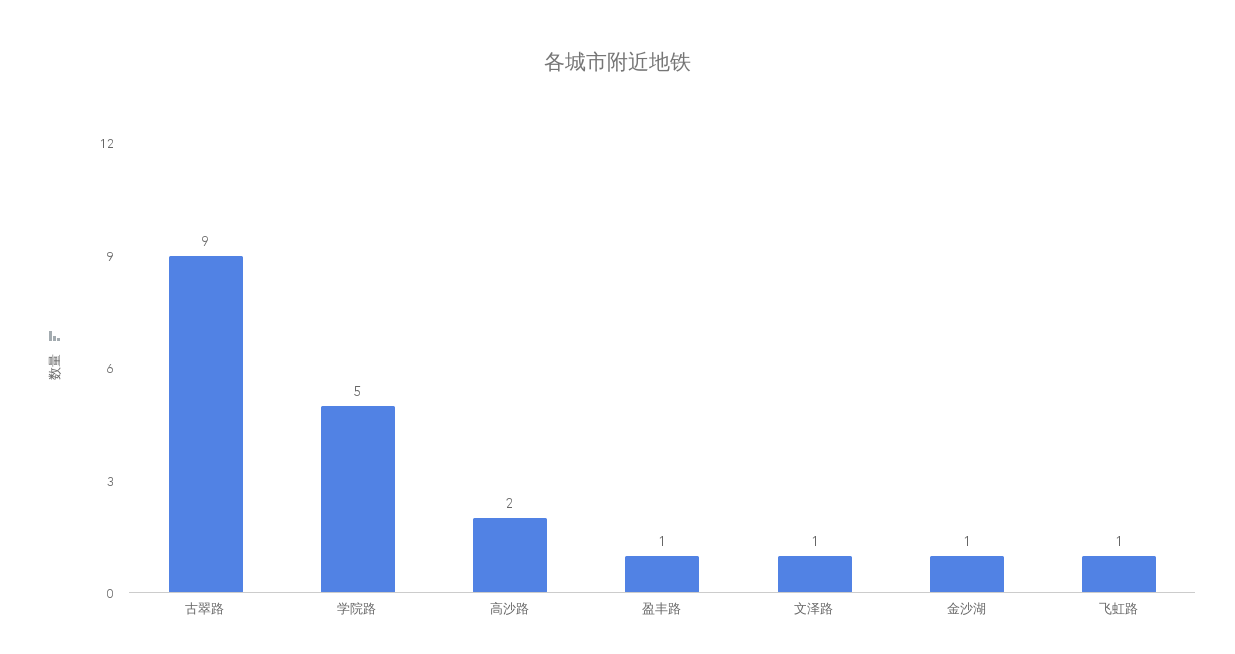
成都
結論
如同官方所說 "Go has been on an amazing journey over the last 8+ years",作為一門新生語言,一直在不斷地發展,缺點肯定是有的,你要去識別它
從數量來看
單從這個招聘網站上來看,數量方面,與大熱語言的招聘職位數量仍然有一定的差距,但 Golang 存在許多內部轉語言開發的情況,當前展現出來的資料,招聘數量不多,但質量不錯
從分佈圖來看
一線城市基本都有 Golang 的職位,雖然其他城市較少,但對於新語言來說是需要持續關注的過程,不能一刀切
從職稱級別來看
Golang 中高、高階、資深仍然是佔大頭,給的薪資也基本符合市場行情
從方向來看
Golang 涉及的行業領域廣泛,移動網際網路、資料服務、電子商務、金融、企業服務、雲計算等都是它的戰場之一
從開源專案來看
docker、k8s、etcd、consul 都挺穩
總的來說,Golang 處於一個發展的階段,市場行情也還行、應用場景較廣,不過招聘數量不多,你又怎麼看呢?
最後放上今天新發布的 Logo :)

如果對你有所幫助,歡迎 Star,給文章點個贊,這樣可以讓更多的人看見這篇文章