3.2 函數和所生成的過程
譯者:飛龍
函數是計算過程的局部演化模式。它規定了過程的每個階段如何構建在之前的階段之上。我們希望能夠創建有關過程整體行為的語句,而過程的局部演化由一個或多個函數指定。這種分析通常非常困難,但是我們至少可以試圖描述一些典型的過程演化模式。
在這一章中,我們會檢測一些用於簡單函數所生成過程的通用“模型”。我們也會研究這些過程消耗重要的計算資源,例如時間和空間的比例。
3.2.1 遞歸函數
如果函數的函數體直接或者間接自己調用自己,那麼這個函數是遞歸的。也就是說,遞歸函數的執行過程可能需要再次調用這個函數。Python 中的遞歸函數不需要任何特殊的語法,但是它們的確需要一些注意來正確定義。
作為遞歸函數的介紹,我們以將英文單詞轉換為它的 Pig Latin 等價形式開始。Pig Latin 是一種隱語:對英文單詞使用一種簡單、確定的轉換來掩蓋單詞的含義。Thomas Jefferson 據推測是先行者。英文單詞的 Pig Latin 等價形式將輔音前綴(可能為空)從開頭移動到末尾,並且添加-ay元音。所以,pun會變成unpay,stout會變成outstay,all會變成allay。
>>> def pig_latin(w):
"""Return the Pig Latin equivalent of English word w."""
if starts_with_a_vowel(w):
return w + 'ay'
return pig_latin(w[1:] + w[0])
>>> def starts_with_a_vowel(w):
"""Return whether w begins with a vowel."""
return w[0].lower() in 'aeiou'
這個定義背後的想法是,一個以輔音開頭的字符串的 Pig Latin 變體和另一個字符串的 Pig Latin 變體相同:它通過將第一個字母移到末尾來創建。於是,sending的 Pig Latin 變體就和endings的變體(endingsay)相同。smother的 Pig Latin 變體和mothers的變體(othersmay)相同。而且,將輔音從開頭移動到末尾會產生帶有更少輔音前綴的更簡單的問題。在sending的例子中,將s移動到末尾會產生以元音開頭的單詞,我們的任務就完成了。
即使pig_latin函數在它的函數體中調用,pig_latin的定義是完整且正確的。
>>> pig_latin('pun')
'unpay'
能夠基於函數自身來定義函數的想法可能十分令人混亂:“循環”定義如何有意義,這看起來不是很清楚,更不用說讓計算機來執行定義好的過程。但是,我們能夠準確理解遞歸函數如何使用我們的計算環境模型來成功調用。環境的圖示和描述pig_latin('pun')求值的表達式樹展示在下面:
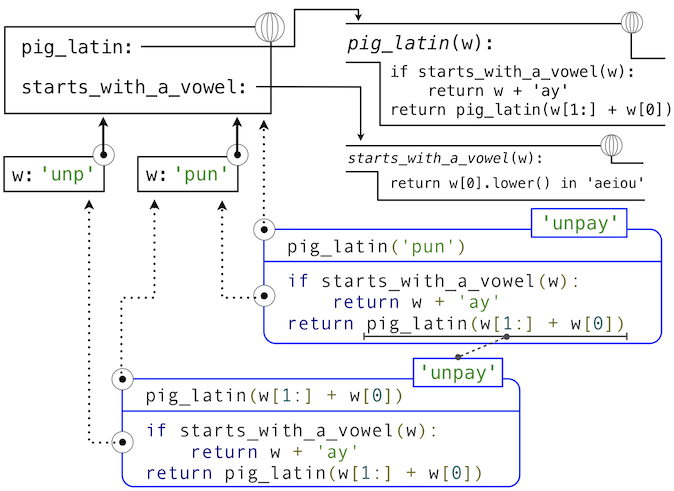
Python 求值過程的步驟產生如下結果:
pig_latin的def語句 被執行,其中:- 使用函數體創建新的
pig_latin函數對象,並且 - 將名稱
pig_latin在當前(全局)幀中綁定到這個函數上。
- 使用函數體創建新的
starts_with_a_vowel的def語句類似地執行。- 求出
pig_latin('pun')的調用表達式,通過- 求出運算符和操作數子表達式,通過
- 查找綁定到
pig_latin函數的pig_latin名稱 - 對字符串對象
'pun'求出操作數字符串字面值
- 查找綁定到
- 在參數
'pun'上調用pig_latin函數,通過- 添加擴展自全局幀的局部幀
- 將形參
w綁定到當前幀的實參'pun'上。 - 在以當前幀起始的環境中執行
pig_latin的函數體- 最開始的條件語句沒有效果,因為頭部表達式求值為
False - 求出最後的返回表達式
pig_latin(w[1:] + w[0]),通過- 查找綁定到
pig_latin函數的pig_latin名稱 - 對字符串對象
'pun'求出操作數表達式 - 在參數
'unp'上調用pig_latin,它會從pig_latin函數體中的條件語句組返回預期結果。
- 查找綁定到
- 最開始的條件語句沒有效果,因為頭部表達式求值為
- 求出運算符和操作數子表達式,通過
就像這個例子所展示的那樣,雖然遞歸函數具有循環特徵,他仍舊正確調用。pig_latin函數調用了兩次,但是每次都帶有不同的參數。雖然第二個調用來自pig_latin自己的函數體,但由名稱查找函數會成功,因為名稱pig_latin在它的函數體執行前的環境中綁定。
這個例子也展示了 Python 的遞歸函數的求值過程如何與遞歸函數交互,來產生帶有許多嵌套步驟的複雜計算過程,即使函數定義本身可能包含非常少的代碼行數。
3.2.2 剖析遞歸函數
許多遞歸函數的函數體中都存在通用模式。函數體以基本條件開始,它是一個條件語句,為需要處理的最簡單的輸入定義函數行為。在pig_latin的例子中,基本條件對任何以元音開頭的單詞成立。這個時候,只需要返回末尾附加ay的參數。一些遞歸函數會有多重基本條件。
基本條件之後是一個或多個遞歸調用。遞歸調用有特定的特徵:它們必須簡化原始問題。在pig_latin的例子中,w中最開始輔音越多,就需要越多的處理工作。在遞歸調用pig_latin(w[1:] + w[0])中,我們在一個具有更少初始輔音的單詞上調用pig_latin -- 這就是更簡化的問題。每個成功的pig_latin調用都會更加簡化,直到滿足了基本條件:一個沒有初始輔音的單詞。
遞歸調用通過逐步簡化問題來表達計算。與我們在過去使用過的迭代方式相比,它們通常以不同方式來解決問題。考慮用於計算n的階乘的函數fact,其中fact(4)計算了4! = 4·3·2·1 = 24。
使用while語句的自然實現會通過將每個截至n的正數相乘來求出結果。
>>> def fact_iter(n):
total, k = 1, 1
while k <= n:
total, k = total * k, k + 1
return total
>>> fact_iter(4)
24
另一方面,階乘的遞歸實現可以以fact(n-1)(一個更簡單的問題)來表示fact(n)。遞歸的基本條件是問題的最簡形式:fact(1)是1。
>>> def fact(n):
if n == 1:
return 1
return n * fact(n-1)
>>> fact(4)
24
函數的正確性可以輕易通過階乘函數的標準數學定義來驗證。
(n − 1)! = (n − 1)·(n − 2)· ... · 1
n! = n·(n − 1)·(n − 2)· ... · 1
n! = n·(n − 1)!
這兩個階乘函數在概念上不同。迭代的函數通過將每個式子,從基本條件1到最終的總數逐步相乘來構造結果。另一方面,遞歸函數直接從最終的式子n和簡化的問題fact(n-1)構造結果。
將fact函數應用於更簡單的問題實例,來展開遞歸的同時,結果最終由基本條件構建。下面的圖示展示了遞歸如何向fact傳入1而終止,以及每個調用的結果如何依賴於下一個調用,直到滿足了基本條件。
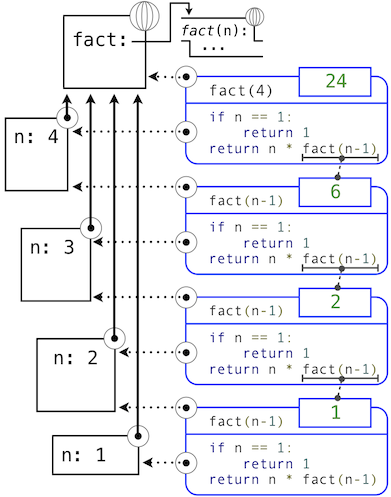
雖然我們可以使用我們的計算模型展開遞歸,通常把遞歸調用看做函數抽象更清晰一些。也就是說,我們不應該關心fact(n-1)如何在fact的函數體中實現;我們只需要相信它計算了n-1的階乘。將遞歸調用看做函數抽象叫做遞歸的“信仰飛躍”(leap of faith)。我們以函數自身來定義函數,但是僅僅相信更簡單的情況在驗證函數正確性時會正常工作。這個例子中我們相信,fact(n-1)會正確計算(n-1)!;我們只需要檢查,如果滿足假設n!是否正確計算。這樣,遞歸函數正確性的驗證就變成了一種歸納證明。
函數fact_iter和fact也不一樣,因為前者必須引入兩個額外的名稱,total和k,它們在遞歸實現中並不需要。通常,迭代函數必須維護一些局部狀態,它們會在計算過程中改變。在任何迭代的時間點上,狀態刻畫了已完成的結果,以及未完成的工作總量。例如,當k為3且total為2時,就還剩下兩個式子沒有處理,3和4。另一方面,fact由單一參數n來刻畫。計算的狀態完全包含在表達式樹的結果中,它的返回值起到total的作用,並且在不同的幀中將n綁定到不同的值上,而不是顯式跟蹤k。
遞歸函數可以更加依賴於解釋器本身,通過將計算狀態儲存為表達式樹和環境的一部分,而不是顯式使用局部幀中的名稱。出於這個原因,遞歸函數通常易於定義,因為我們不需要試著弄清必須在迭代中維護的局部狀態。另一方面,學會弄清由遞歸函數實現的計算過程,需要一些練習。
3.2.3 樹形遞歸
另一個遞歸的普遍模式叫做樹形遞歸。例如,考慮斐波那契序列的計算,其中每個數值都是前兩個的和。
>>> def fib(n):
if n == 1:
return 0
if n == 2:
return 1
return fib(n-2) + fib(n-1)
>>> fib(6)
5
這個遞歸定義和我們之前的嘗試有很大關係:它準確反映了斐波那契數的相似定義。考慮求出fib(6)所產生的計算模式,它展示在下面。為了計算fib(6),我們需要計算fib(5)和fib(4)。為了計算fib(5),我們需要計算fib(4)和fib(3)。通常,這個演化過程看起來像一棵樹(下面的圖並不是完整的表達式樹,而是簡化的過程描述;一個完整的表達式樹也擁有同樣的結構)。在遍歷這棵樹的過程中,每個藍點都表示斐波那契數的已完成計算。
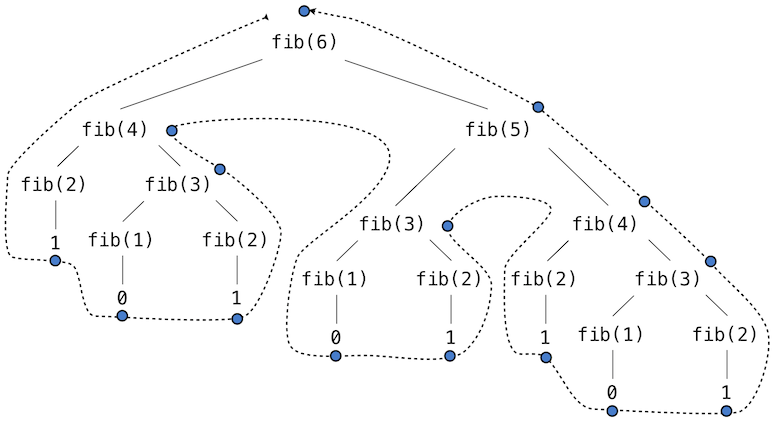
調用自身多次的函數叫做樹形遞歸。以樹形遞歸為原型編寫的函數十分有用,但是用於計算斐波那契數則非常糟糕,因為它做了很多重複的計算。要注意整個fib(4)的計算是重複的,它幾乎是一半的工作量。實際上,不難得出函數用於計算fib(1)和fib(2)(通常是樹中的葉子數量)的時間是fib(n+1)。為了弄清楚這有多糟糕,我們可以證明fib(n)的值隨著n以指數方式增長。所以,這個過程的步驟數量隨輸入以指數方式增長。
我們已經見過斐波那契數的迭代實現,出於便利在這裡貼出來:
>>> def fib_iter(n):
prev, curr = 1, 0 # curr is the first Fibonacci number.
for _ in range(n-1):
prev, curr = curr, prev + curr
return curr
這裡我們必須維護的狀態由當前值和上一個斐波那契數組成。for語句也顯式跟蹤了迭代數量。這個定義並沒有像遞歸方式那樣清晰反映斐波那契數的數學定義。但是,迭代實現中所需的計算總數只是線性,而不是指數於n的。甚至對於n的較小值,這個差異都非常大。
然而我們不應該從這個差異總結出,樹形遞歸的過程是沒有用的。當我們考慮層次數據結構,而不是數值上的操作時,我們發現樹形遞歸是自然而強大的工具。而且,樹形過程可以變得更高效。
**記憶。**用於提升重複計算的遞歸函數效率的機制叫做記憶。記憶函數會為任何之前接受的參數儲存返回值。fib(4)的第二次調用不會執行與第一次同樣的複雜過程,而是直接返回第一次調用的已儲存結果。
記憶函數可以自然表達為高階函數,也可以用作裝飾器。下面的定義為之前的已計算結果創建緩存,由被計算的參數索引。在這個實現中,這個字典的使用需要記憶函數的參數是不可變的。
>>> def memo(f):
"""Return a memoized version of single-argument function f."""
cache = {}
def memoized(n):
if n not in cache:
cache[n] = f(n)
return cache[n]
return memoized
>>> fib = memo(fib)
>>> fib(40)
63245986
由記憶函數節省的所需的計算時間總數在這個例子中是巨大的。被記憶的遞歸函數fib和迭代函數fib_iter都只需要線性於輸入n的時間總數。為了計算fib(40),fib的函數體只執行 40 次,而不是無記憶遞歸中的 102,334,155 次。
**空間。**為了理解函數所需的空間,我們必須在我們的計算模型中規定內存如何使用,保留和回收。在求解表達式過程中,我們必須保留所有活動環境和所有這些環境引用的值和幀。如果環境為表達式樹當前分支中的一些表達式提供求值上下文,那麼它就是活動環境。
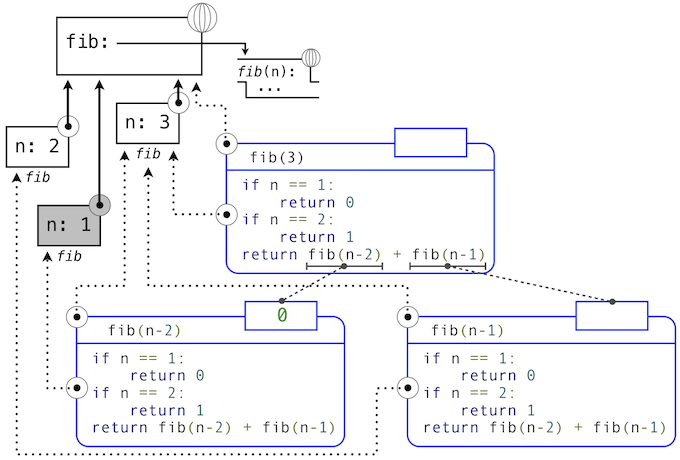
例如,當求值fib時,解釋器按序計算之前的每個值,遍歷樹形結構。為了這樣做,它只需要在計算的任何時間點,跟蹤樹中在當前節點之前的那些節點。用於求出剩餘節點的內存可以被回收,因為它不會影響未來的計算。通常,樹形遞歸所需空間與樹的深度成正比。
下面的圖示描述了由求解fib(3)生成的表達式樹。在求解fib最初調用的返回表達式的過程中,fib(n-2)被求值,產生值0。一旦這個值計算出來,對應的環境幀(標為灰色)就不再需要了:它並不是活動環境的一部分。所以,一個設計良好的解釋器會回收用於儲存這個幀的內存。另一方面,如果解釋器當前正在求解fib(n-1),那麼由這次fib調用(其中n為2)創建的環境是活動的。與之對應,最開始在3上調用fib所創建的環境也是活動的,因為這個值還沒有成功計算出來。
在memo的例子中,只要一些名稱綁定到了活動環境中的某個函數上,關聯到所返回函數(它包含cache)的環境必須保留。cache字典中的條目數量隨傳遞給fib的唯一參數數量線性增長,它的規模線性於輸入。另一方面,迭代實現只需要兩個數值來在計算過程中跟蹤:prev和curr,所以是常數大小。
我們使用記憶函數的例子展示了編程中的通用模式,即通常可以通過增加所用空間來減少計算時間,反之亦然。
3.2.4 示例:找零
考慮下面這個問題:如果給你半美元、四分之一美元、十美分、五美分和一美分,一美元有多少種找零的方式?更通常來說,我們能不能編寫一個函數,使用一系列貨幣的面額,計算有多少種方式為給定的金額總數找零?
這個問題可以用遞歸函數簡單解決。假設我們認為可用的硬幣類型以某種順序排列,假設從大到小排列。
使用n種硬幣找零的方式為:
- 使用所有除了第一種之外的硬幣為
a找零的方式,以及 - 使用
n種硬幣為更小的金額a - d找零的方式,其中d是第一種硬幣的面額。
為了弄清楚為什麼這是正確的,可以看出,找零方式可以分為兩組,不使用第一種硬幣的方式,和使用它們的方式。所以,找零方式的總數等於不使用第一種硬幣為該金額找零的方式數量,加上使用第一種硬幣至少一次的方式數量。而後者的數量等於在使用第一種硬幣之後,為剩餘的金額找零的方式數量。
因此,我們可以遞歸將給定金額的找零問題,歸約為使用更少種類的硬幣為更小的金額找零的問題。仔細考慮這個歸約原則,並且說服自己,如果我們規定了下列基本條件,我們就可以使用它來描述算法:
- 如果
a正好是零,那麼有一種找零方式。 - 如果
a小於零,那麼有零種找零方式。 - 如果
n小於零,那麼有零種找零方式。
我們可以輕易將這個描述翻譯成遞歸函數:
>>> def count_change(a, kinds=(50, 25, 10, 5, 1)):
"""Return the number of ways to change amount a using coin kinds."""
if a == 0:
return 1
if a < 0 or len(kinds) == 0:
return 0
d = kinds[0]
return count_change(a, kinds[1:]) + count_change(a - d, kinds)
>>> count_change(100)
292
count_change函數生成樹形遞歸過程,和fib的首個實現一樣,它是重複的。它會花費很長時間來計算出292,除非我們記憶這個函數。另一方面,設計迭代算法來計算出結果的方式並不是那麼明顯,我們將它留做一個挑戰。
3.2.5 增長度
前面的例子表明,不同過程在花費的時間和空間計算資源上有顯著差異。我們用於描述這個差異的便捷方式,就是使用增長度的概念,來獲得當輸入變得更大時,過程所需資源的大致度量。
令n為度量問題規模的參數,R(n)為處理規模為n的問題的過程所需的資源總數。在我們前面的例子中,我們將n看做給定函數所要計算出的數值。但是還有其他可能。例如,如果我們的目標是計算某個數值的平方根近似值,我們會將n看做所需的有效位數的數量。通常,有一些問題相關的特性可用於分析給定的過程。與之相似,R(n)可用於度量所用的內存總數,所執行的基本的機器操作數量,以及其它。在一次只執行固定數量操作的計算中,用於求解表達式的所需時間,與求值過程中執行的基本機器操作數量成正比。
我們說,R(n)具有Θ(f(n))的增長度,寫作R(n)=Θ(f(n))(讀作“theta f(n)”),如果存在獨立於n的常數k1和k2,那麼對於任何足夠大的n值:
k1·f(n) <= R(n) <= k2·f(n)
也就是說,對於較大的n,R(n)的值夾在兩個具有f(n)規模的值之間:
- 下界
k1·f(n),以及 - 上界
k2·f(n)。
例如,計算n!所需的步驟數量與n成正比,所以這個過程的所需步驟以Θ(n)增長。我們也看到了,遞歸實現fact的所需空間以Θ(n)增長。與之相反,迭代實現fact_iter 花費相似的步驟數量,但是所需的空間保持不變。這裡,我們說這個空間以Θ(1)增長。
我們的樹形遞歸的斐波那契數計算函數fib 的步驟數量,隨輸入n指數增長。尤其是,我們可以發現,第 n 個斐波那契數是距離φ^(n-2)/√5的最近整數,其中φ是黃金比例:
φ = (1 + √5)/2 ≈ 1.6180
我們也表示,步驟數量隨返回值增長而增長,所以樹形遞歸過程需要Θ(φ^n)的步驟,它的一個隨n指數增長的函數。
增長度只提供了過程行為的大致描述。例如,需要n^2個步驟的過程和需要1000·n^2個步驟的過程,以及需要3·n^2+10·n+17個步驟的過程都擁有Θ(n^2)的增長度。在特定的情況下,增長度的分析過於粗略,不能在函數的兩個可能實現中做出判斷。
但是,增長度提供了實用的方法,來表示在改變問題規模的時候,我們應如何預期過程行為的改變。對於Θ(n)(線性)的過程,使規模加倍只會使所需的資源總數加倍。對於指數的過程,每一點問題規模的增長都會使所用資源以固定因數翻倍。接下來的例子展示了一個增長度為對數的算法,所以使問題規模加倍,只會使所需資源以固定總數增加。
3.2.6 示例:求冪
考慮對給定數值求冪的問題。我們希望有一個函數,它接受底數b和正整數指數n作為參數,並計算出b^n。一種方式就是通過遞歸定義:
b^n = b·b^(n-1)
b^0 = 1
這可以翻譯成遞歸函數:
>>> def exp(b, n):
if n == 0:
return 1
return b * exp(b, n-1)
這是個線性的遞歸過程,需要Θ(n)的步驟和空間。就像階乘那樣,我們可以編寫等價的線性迭代形式,它需要相似的步驟數量,但只需要固定的空間。
>>> def exp_iter(b, n):
result = 1
for _ in range(n):
result = result * b
return result
我們可以以更少的步驟求冪,通過逐次平方。例如,我們這樣計算b^8:
b·(b·(b·(b·(b·(b·(b·b))))))
我們可以使用三次乘法來計算它:
b^2 = b·b
b^4 = b^2·b^2
b^8 = b^4·b^4
這個方法對於 2 的冪的指數工作良好。我們也可以使用這個遞歸規則,在求冪中利用逐步平方的優點:
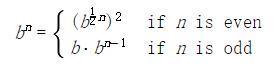
我們同樣可以將這個方式表達為遞歸函數:
>>> def square(x):
return x*x
>>> def fast_exp(b, n):
if n == 0:
return 1
if n % 2 == 0:
return square(fast_exp(b, n//2))
else:
return b * fast_exp(b, n-1)
>>> fast_exp(2, 100)
1267650600228229401496703205376
fast_exp所生成的過程的空間和步驟數量隨n以對數方式增長。為了弄清楚它,可以看出,使用fast_exp計算b^2n比計算b^n只需要一步額外的乘法操作。於是,我們能夠計算的指數大小,在每次新的乘法操作時都會(近似)加倍。所以,計算n的指數所需乘法操作的數量,增長得像以2為底n的對數那樣慢。這個過程擁有Θ(log n)的增長度。Θ(log n)和Θ(n)之間的差異在n非常大時變得顯著。例如,n為1000時,fast_exp 僅僅需要14個乘法操作,而不是1000。