Day 1:
- 原文:https://ithelp.ithome.com.tw/articles/10374851
- 發布日期:2025-09-11
2025/10/28 UPDATE:
Gthulhu 已加入 CNCF landscape,請參考:landscape.cncf.io
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
系列規劃概述
大家好,我是 Ian。我在今年年初受到大神 Andrea Righi 的演講「Crafting a Linux kernel scheduler in Rust」啟發,將 scx_rustland 移植到 golang 平台上運作,並且考慮 Cloud-Native 的應用場景打造了一款適用於雲原生的通用排程器「Gthulhu」。
該系列文會以系統性的方式帶你學習如何開發 eBPF 應用,從零開始逐步掌握 eBPF 技術,並最終實現一個完整的 Linux 排程器。整個系列分為六個階段,每個階段都建立在前一階段的基礎之上。
寫在開始之前
在 ChatGPT 問世以後,我在技術寫作上變得比以往要消極,因為我認為人們不在需要透過閱讀網路文章來學習「簡單的」基礎知識(看 StackOverflow 慘淡的流量就知道),語法怎麼用、特殊指令怎麼下已經不在需要逐篇文章翻閱才能得到答案了。所以過去一年多來我公開在個人 Medium 的文章基本上只會寫一些 ChatGPT、Perplexity 無法準確回答我的知識,經過了這些累積,我想也是時候來寫寫廢文了。
今年的系列文我會讓 GitHub Copilot Plus 基於我提供的 context 負責全部的編撰工作,並且由我本人驗證文章的正確性、適時的補充必要知識。
這麼做的原因如下:
我認為在 AI 工具爆炸式發展的年代,很大程度的顛覆了我們接受新知的方式,所以我們可以在社群媒體上看到很多非工程背景的人利用 Claude Code、Cursor、Copilot 等工具 Vibe 出非常厲害的系統。那麼,軟體工程師又要如何在最嚴峻的世代量化自己的價值呢?筆者個人的想法是:比起外行人只能 vibe coding,我們可以用更精確的 prompt(或是 context engineering)的方式高效的產出「就像是親手寫出來的程式碼」。
除了發表對 AI 工具發展的感想外,今年的挑戰對我來說也與以往十分不同。雖然我在開源社群混了些年,也貢獻過不少知名專案,但是從 0 到 60 認真打造一個開源軟體專案倒是頭一回。希望能藉由鐵人賽這個活動讓更多人認識 Gthulhu。
2025/09/21
我認為 Coding Agent 在產生部分文章的表現有待加強,所以在探討 scheduler 的部分會以我自己撰寫的內容為主。
目錄
eBPF 基礎
eBPF 網路程式基礎
eBPF 進階功能
scheduler extenstion 介紹
scx_goland 移植
- scx_goland_core 移植與挑戰(一):page fault
- scx_goland_core 移植與挑戰(二):watchdog failed to check in for default timeout
- scx_goland_core 移植與挑戰(三):data unsync
Gthulhu 開發與整合
- Gthulhu 系統設計
- Gthulhu API server 系統設計
- 使用 Kubernetes 部署 Gthulhu
- 搶佔式任務處理
- 整合 free5GC 實作低延遲資料層處理(上)
- 整合 free5GC 實作低延遲資料層處理(下)
- 實作自動化測試流水線
- AI 賦能的智慧排程器
- 可插拔式排程器
- 使用 plugin 模式實作簡易排程器
- 使用 perfetto 觀察排程器行為
- 結語
預期成果
完成這個系列後,讀者將能夠:
- 理解 eBPF 技術
- 使用 Golang 開發客製化的系統排程器
- 具備解決實際生產問題的能力
- 為開源社群做出有意義的貢獻
關於筆者
目前任職於禾薪科技,對核心網路與雲原生開發有一定的經驗與理解,目前也是 free5GC(a Linux Foundation project)的 TSC Member、現任微軟 MVP、書籍作家、大學兼任講師,同時跟女友一起經營寵物客製化用品的生意。
Day 2:
- 原文:https://ithelp.ithome.com.tw/articles/10377305
- 發布日期:2025-09-12
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
歡迎來到「30 篇文帶你用 eBPF 與 Golang 打造 Linux Scheduler」系列的第一篇!在這個系列中,我們將從零開始深入探索 eBPF(extended Berkeley Packet Filter)技術,並最終實現一個完整的 Linux 排程器。
eBPF 被譽為「Linux 內核的 JavaScript」,它革命性地改變了我們與 Linux 內核互動的方式。但要真正掌握 eBPF,我們必須先了解它的來龍去脈。今天,讓我們一起回顧 eBPF 的誕生與演進史,理解這項技術的設計哲學和發展脈絡。
理論基礎
Classic BPF 的誕生(1992年)
故事要從 1992 年說起。當時,Steven McCanne 和 Van Jacobson 在加州大學柏克萊分校發表了一篇名為「The BSD Packet Filter: A New Architecture for User-level Packet Capture」的論文,提出了 Berkeley Packet Filter(BPF)的概念。
Classic BPF 的設計目標很簡單:在內核空間提供一個安全、高效的封包過濾機制。它的核心思想包括:
-
虛擬機器架構:BPF 定義了一個簡單的虛擬機器,包含:
- 32 位累加器(A)
- 32 位索引暫存器(X)
- 16 個 32 位記憶體位置
- 程式計數器
-
有限的指令集:只支援基本的算術、邏輯和跳躍指令
-
安全性保證:
- 程式必須終止(不允許無限迴圈)
- 只能讀取封包資料,不能修改
- 記憶體存取範圍受限
從 Classic BPF 到 eBPF 的轉變
儘管 Classic BPF 在封包過濾方面表現出色,但隨著系統需求的複雜化,它的局限性也逐漸顯現:
- 功能受限:只能用於封包過濾
- 程式大小限制:最多 4096 條指令
- 缺乏現代特性:沒有函數呼叫、迴圈控制等
2013 年,Alexei Starovoitov 開始著手改造 BPF。他的目標是建立一個更強大、更通用的內核程式設計平台。
PLUMgrid 的貢獻
PLUMgrid 是一家專注於網路虛擬化的公司,他們需要在內核中實現複雜的網路功能。傳統的方法需要修改內核原始碼或載入內核模組,這在雲端環境中是不現實的。
PLUMgrid 團隊意識到,如果能夠擴展 BPF 的能力,就能在不修改內核的情況下實現複雜的網路邏輯。於是他們開發了 iovisor.ko,這是 eBPF 的前身。
Internal BPF 的誕生
2014 年,Alexei Starovoitov 將 PLUMgrid 的工作整合到 Linux 內核中,創造了 Internal BPF(也稱為 eBPF)。這個新的 BPF 虛擬機器有以下特點:
-
64 位架構:
- 10 個 64 位暫存器(r0-r9)
- 512 字節的堆疊空間
- 更大的程式空間
-
豐富的指令集:
- 支援 64 位算術運算
- 原子操作
- 函數呼叫
-
多種程式類型:
- 網路程式(XDP、TC)
- 追蹤程式(kprobe、tracepoint)
- 排程器程式(sched_ext)
筆者補充:
起初 eBPF 的應用偏向可觀測性以及網路封包處理,在近幾年才發展成可用於排程器程式,甚至是 TCP 壅塞演算法的開發。
eBPF 的技術突破
1. Verifier 機制
eBPF 最重要的創新是引入了 Verifier(驗證器)。Verifier 在程式載入時進行靜態分析,確保程式的安全性:
// Verifier 檢查的項目包括:
// 1. 程式必須終止
// 2. 記憶體存取安全
// 3. 函數呼叫合法性
// 4. 暫存器狀態追蹤
static int check_func_call(struct bpf_verifier_env *env,
struct bpf_insn *insn, int *insn_idx)
{
int subprog = find_subprog(env, *insn_idx + insn->imm + 1);
// 檢查函數是否存在
if (subprog < 0) {
verbose(env, "function not found\n");
return -EINVAL;
}
// 檢查呼叫堆疊深度
if (env->subprog_cnt >= BPF_MAX_SUBPROGS) {
verbose(env, "too many subprograms\n");
return -E2BIG;
}
return 0;
}
2. JIT 編譯
eBPF 程式在通過 Verifier 檢查後,會被 JIT(Just-In-Time)編譯器編譯成原生機器碼,實現接近原生程式碼的執行效能。
3. Maps 機制
eBPF Maps 提供了程式與使用者空間、程式與程式之間的資料共享機制:
// 定義一個 Hash Map
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10000);
__type(key, __u32);
__type(value, __u64);
} packet_count SEC(".maps");
eBPF 在 Linux Kernel 中的地位
核心子系統整合
eBPF 並不是一個獨立的功能,而是深度整合到 Linux 內核的各個子系統中:
-
網路子系統:
- XDP(eXpress Data Path)
- TC(Traffic Control)
- Socket filters
-
追蹤子系統:
- kprobes/kretprobes
- tracepoints
- perf events
-
安全子系統:
- LSM(Linux Security Modules)
- seccomp-bpf
-
排程子系統:
- sched_ext(Linux 6.12+)
設計哲學
eBPF 的設計遵循幾個重要原則:
- 安全第一:所有程式必須通過 Verifier 檢查
- 效能導向:JIT 編譯確保高效執行
- 通用性:一套機制支援多種應用場景
- 向後相容:與 Classic BPF 保持相容性
重要里程碑
讓我們梳理一下 eBPF 發展的重要時間點:
- 1992年:Classic BPF 論文發表
- 2013年:Alexei Starovoitov 開始 eBPF 開發
- 2014年:eBPF 合併到 Linux 3.15
- 2016年:XDP 框架引入(Linux 4.8)
- 2018年:BTF(BPF Type Format)引入
- 2019年:BPF_PROG_TYPE_TRACING 引入
- 2024年:sched_ext 合併到 Linux 6.12
實戰應用:觀察 eBPF 系統
雖然這篇文章主要是理論介紹,但讓我們透過一些簡單的命令來觀察現代 Linux 系統中的 eBPF:
檢查 eBPF 支援
# 檢查內核是否支援 eBPF
grep CONFIG_BPF /boot/config-$(uname -r)
# 檢查 BTF 支援
ls -la /sys/kernel/btf/vmlinux
# 檢查可用的 BPF 程式類型
cat /proc/kallsyms | grep bpf_prog_type
觀察已載入的 eBPF 程式
# 安裝 bpftool(如果尚未安裝)
sudo apt update && sudo apt install linux-tools-common linux-tools-generic
# 列出所有已載入的 eBPF 程式
sudo bpftool prog list
# 列出所有 eBPF Maps
sudo bpftool map list
# 檢視特定程式的詳細資訊
sudo bpftool prog show id <PROG_ID> --pretty
觀察 eBPF 系統統計
# 檢視 eBPF 相關的內核統計
cat /proc/kallsyms | grep -E "bpf_|ebpf_" | wc -l
# 檢查 eBPF 程式的輸出
sudo cat /sys/kernel/debug/tracing/trace_pipe
深度分析:為什麼 eBPF 如此重要?
1. 安全性與隔離性
傳統的內核模組開發需要管理員權限,並且一個錯誤可能導致整個系統崩潰。eBPF 透過 Verifier 提供了安全的內核程式設計環境:
// Verifier 確保這個程式是安全的
SEC("xdp")
int xdp_drop_packets(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
// Verifier 檢查邊界
if (eth + 1 > data_end)
return XDP_PASS;
// 只能返回預定義的值
if (eth->h_proto == bpf_htons(ETH_P_IP))
return XDP_DROP;
return XDP_PASS;
}
2. 效能優勢
eBPF 程式執行在內核空間,避免了使用者空間與內核空間的切換開銷:
- 零拷貝:直接在內核處理資料
- JIT 編譯:接近原生程式碼的效能
- 批次處理:可以批次處理多個事件
3. 可觀測性革命
eBPF 讓系統可觀測性達到了前所未有的程度:
// 追蹤系統呼叫,且開銷非常低
SEC("tracepoint/syscalls/sys_enter_openat")
int trace_openat(struct trace_event_raw_sys_enter *ctx)
{
char filename[256];
bpf_probe_read_user_str(filename, sizeof(filename),
(void *)ctx->args[1]);
bpf_printk("Process %d opening file: %s\n",
bpf_get_current_pid_tgid() >> 32, filename);
return 0;
}
筆者補充:
這邊 Copilot 給的範例比較古老,自 Linux v5.5 開始支援了更接近 zero overhead 的方式(利用 eBPF Trampolines),請參考:
總結
eBPF 的設計使它被多家科技公司採納,也因此得以在 kernel 社群中快速成長。我們可以預期 eBPF 在未來將被應用在 kernel 中的各個領域,以更安全、高效的方式提供給開發者一個全新的選擇。
在下一篇文章中,我們將深入探討 eBPF 的核心架構,包括虛擬機器、指令集、Verifier 機制等。這些知識將為我們後續的實作打下堅實的基礎。
Day 3:
- 原文:https://ithelp.ithome.com.tw/articles/10379593
- 發布日期:2025-09-13
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
在上一篇文章中,我們回顧了 eBPF 的誕生與演進史,了解了從 Classic BPF 到 eBPF 的技術發展脈絡。今天,我們將深入 eBPF 的核心架構,探討它的虛擬機器設計、指令集架構、Verifier 機制以及 JIT 編譯器的工作原理。
理解 eBPF 的架構設計對於後續的程式開發至關重要。只有掌握了這些底層機制,我們才能寫出高效、安全的 eBPF 程式。
理論基礎
eBPF 虛擬機器架構
eBPF 虛擬機器是一個 64 位的 RISC(精簡指令集)架構,專門設計用於在 Linux 內核中安全高效地執行使用者程式碼。
暫存器設計
eBPF VM 包含 11 個 64 位暫存器:
// eBPF 暫存器定義
enum {
BPF_REG_0 = 0, // 返回值暫存器
BPF_REG_1, // 函數參數 1 / 程式 context
BPF_REG_2, // 函數參數 2
BPF_REG_3, // 函數參數 3
BPF_REG_4, // 函數參數 4
BPF_REG_5, // 函數參數 5
BPF_REG_6, // 被呼叫者保存暫存器
BPF_REG_7, // 被呼叫者保存暫存器
BPF_REG_8, // 被呼叫者保存暫存器
BPF_REG_9, // 被呼叫者保存暫存器
BPF_REG_10, // 堆疊指標(Read Only)
__MAX_BPF_REG,
};
每個暫存器都有特定的用途:
- R0:存放函數返回值和程式退出碼
- R1-R5:函數參數傳遞
- R6-R9:被呼叫者保存暫存器(callee-saved)
- R10:堆疊指標,指向 512 字節的堆疊空間
記憶體模型
eBPF 程式的記憶體空間分為幾個部分:
- 程式記憶體:存放 eBPF 指令
- 堆疊記憶體:512 字節的堆疊空間
- Map 記憶體:透過 BPF Maps 存取的共享記憶體
- Context 記憶體:程式輸入參數(如封包資料)
eBPF 指令集架構
指令格式
每個 eBPF 指令都是 64 位(8 字節),格式如下:
struct bpf_insn {
__u8 code; // 操作碼
__u8 dst_reg:4; // 目標暫存器
__u8 src_reg:4; // 來源暫存器
__s16 off; // 偏移量
__s32 imm; // 立即數
};
指令分類
eBPF 指令可以分為以下幾類:
1. 算術指令
// 64 位加法:dst_reg += src_reg
BPF_ALU64 | BPF_ADD | BPF_X
// 32 位加法:dst_reg += imm
BPF_ALU | BPF_ADD | BPF_K
// 示例:計算兩個數的和
BPF_MOV64_IMM(BPF_REG_1, 10), // r1 = 10
BPF_MOV64_IMM(BPF_REG_2, 20), // r2 = 20
BPF_ALU64_REG(BPF_ADD, BPF_REG_1, BPF_REG_2), // r1 += r2
2. 跳躍指令
// 無條件跳躍
BPF_JMP | BPF_JA
// 條件跳躍:if (dst_reg == src_reg) goto pc + off
BPF_JMP | BPF_JEQ | BPF_X
// 示例:簡單的條件判斷
BPF_MOV64_IMM(BPF_REG_1, 42), // r1 = 42
BPF_JMP_IMM(BPF_JEQ, BPF_REG_1, 42, 2), // if r1 == 42 goto +2
BPF_MOV64_IMM(BPF_REG_0, 0), // r0 = 0 (false case)
BPF_EXIT_INSN(), // exit
BPF_MOV64_IMM(BPF_REG_0, 1), // r0 = 1 (true case)
BPF_EXIT_INSN(), // exit
3. 記憶體指令
// 載入指令:dst_reg = *(size *)(src_reg + off)
BPF_MEM | BPF_LDX | BPF_W // 載入 32 位
BPF_MEM | BPF_LDX | BPF_DW // 載入 64 位
// 儲存指令:*(size *)(dst_reg + off) = src_reg
BPF_MEM | BPF_STX | BPF_W // 儲存 32 位
BPF_MEM | BPF_STX | BPF_DW // 儲存 64 位
// 示例:存取堆疊變數
BPF_MOV64_IMM(BPF_REG_1, 123), // r1 = 123
BPF_STX_MEM(BPF_DW, BPF_REG_10, BPF_REG_1, -8), // *(u64*)(r10-8) = r1
BPF_LDX_MEM(BPF_DW, BPF_REG_2, BPF_REG_10, -8), // r2 = *(u64*)(r10-8)
4. 函數呼叫指令
// 呼叫 helper 函數
BPF_JMP | BPF_CALL
// 示例:呼叫 bpf_printk
BPF_LD_MAP_FD(BPF_REG_1, fmt_map_fd), // r1 = format string
BPF_MOV64_IMM(BPF_REG_2, 42), // r2 = 42
BPF_CALL_FUNC(BPF_FUNC_trace_printk), // call bpf_trace_printk(r1, r2)
eBPF Verifier 機制深度解析
Verifier 是 eBPF 安全性的核心,它在程式載入時進行靜態分析,確保程式不會對系統造成危害。
Verifier 的工作流程
// 簡化的 Verifier 檢查流程
int bpf_check(struct bpf_prog **prog, union bpf_attr *attr)
{
struct bpf_verifier_env *env;
int ret = -EINVAL;
// 1. 初始化驗證環境
env = kzalloc(sizeof(struct bpf_verifier_env), GFP_KERNEL);
// 2. 基本格式檢查
ret = check_cfg(env);
if (ret < 0)
goto err_free_env;
// 3. 指令層級檢查
ret = do_check(env);
if (ret < 0)
goto err_free_env;
// 4. 特權操作檢查
ret = check_map_access(env);
if (ret < 0)
goto err_free_env;
// 5. 最終最佳化
ret = convert_pseudo_ld_imm64(env);
err_free_env:
kfree(env);
return ret;
}
關鍵檢查項目
1. 控制流程檢查
Verifier 會檢查程式的所有執行路徑:
// 檢查無限迴圈
static int check_cfg(struct bpf_verifier_env *env)
{
int insn_cnt = env->prog->len;
bool *visited;
int ret = 0;
int i;
visited = kcalloc(insn_cnt, sizeof(bool), GFP_KERNEL);
if (!visited)
return -ENOMEM;
// 深度優先搜尋,檢查所有路徑
ret = visit_insn(env, 0, visited);
// 檢查是否有未訪問的指令(dead code)
for (i = 0; i < insn_cnt; i++) {
if (!visited[i]) {
verbose(env, "unreachable insn %d\n", i);
ret = -EINVAL;
break;
}
}
kfree(visited);
return ret;
}
2. 記憶體存取檢查
// 檢查記憶體存取的安全性
static int check_mem_access(struct bpf_verifier_env *env,
int regno, int off, int size,
enum bpf_access_type type)
{
struct bpf_reg_state *reg = &env->cur_state.regs[regno];
// 檢查暫存器類型
if (reg->type != PTR_TO_STACK &&
reg->type != PTR_TO_MAP_VALUE &&
reg->type != PTR_TO_CTX) {
verbose(env, "invalid read from register\n");
return -EACCES;
}
// 檢查存取邊界
if (off < reg->min_value || off + size > reg->max_value) {
verbose(env, "invalid memory access\n");
return -EACCES;
}
// 檢查對齊
if (off % size != 0) {
verbose(env, "misaligned memory access\n");
return -EACCES;
}
return 0;
}
3. 暫存器狀態追蹤
Verifier 會追蹤每個暫存器在程式執行過程中的狀態:
struct bpf_reg_state {
enum bpf_reg_type type; // 暫存器類型
s32 min_value; // 最小可能值
u32 max_value; // 最大可能值
u32 id; // 暫存器 ID
u32 ref_obj_id; // 引用物件 ID
struct tnum var_off; // 變數偏移
};
// 更新暫存器狀態
static void mark_reg_known(struct bpf_reg_state *reg, u64 imm)
{
reg->min_value = imm;
reg->max_value = imm;
reg->var_off = tnum_const(imm);
reg->type = SCALAR_VALUE;
}
JIT 編譯器原理
通過 Verifier 檢查的 eBPF 程式會被 JIT 編譯器編譯成原生機器碼。
JIT 編譯流程
// x86_64 JIT 編譯器的簡化流程
struct bpf_prog *bpf_int_jit_compile(struct bpf_prog *prog)
{
struct bpf_binary_header *header;
struct x64_jit_data *jit_data;
int proglen, oldproglen = 0;
u8 *image = NULL;
int pass;
// 多次遍歷最佳化
for (pass = 0; pass < 20; pass++) {
proglen = do_jit(prog, NULL, 0, &jit_data);
if (proglen <= 0) {
image = NULL;
goto out;
}
// 如果程式大小穩定,分配記憶體並生成程式碼
if (proglen == oldproglen) {
header = bpf_jit_binary_alloc(proglen, &image,
1, jit_fill_hole);
if (!header) {
prog = orig_prog;
goto out;
}
proglen = do_jit(prog, image, proglen, &jit_data);
break;
}
oldproglen = proglen;
}
out:
return prog;
}
指令翻譯示例
讓我們看看一個簡單的 eBPF 指令如何被翻譯成 x86_64 機器碼:
// eBPF 指令:r1 += r2
// BPF_ALU64_REG(BPF_ADD, BPF_REG_1, BPF_REG_2)
static int emit_add(u8 **pprog, u32 dst_reg, u32 src_reg)
{
u8 *prog = *pprog;
// 生成 x86_64 ADD 指令
// 對應 "add %rsi, %rdi" (假設 r1->rdi, r2->rsi)
*prog++ = 0x48; // REX prefix for 64-bit
*prog++ = 0x01; // ADD opcode
*prog++ = 0xfe; // ModR/M byte: add %rsi, %rdi
*pprog = prog;
return 0;
}
Hook 點與程式類型
eBPF 程式必須附加到特定的 Hook 點才能執行。不同的程式類型對應不同的 Hook 點和功能。
主要程式類型
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER, // Socket 過濾器
BPF_PROG_TYPE_KPROBE, // 內核 probe
BPF_PROG_TYPE_SCHED_CLS, // 排程分類器
BPF_PROG_TYPE_SCHED_ACT, // 排程動作
BPF_PROG_TYPE_TRACEPOINT, // 追蹤點
BPF_PROG_TYPE_XDP, // eXpress Data Path
BPF_PROG_TYPE_PERF_EVENT, // perf 事件
BPF_PROG_TYPE_CGROUP_SKB, // cgroup skb
BPF_PROG_TYPE_CGROUP_SOCK, // cgroup socket
BPF_PROG_TYPE_CGROUP_DEVICE, // cgroup 裝置
BPF_PROG_TYPE_SK_MSG, // socket message
BPF_PROG_TYPE_RAW_TRACEPOINT, // 原始追蹤點
BPF_PROG_TYPE_SOCK_OPS, // socket 操作
BPF_PROG_TYPE_SK_SKB, // socket skb
BPF_PROG_TYPE_STRUCT_OPS, // 結構操作
BPF_PROG_TYPE_EXT, // 擴展程式
BPF_PROG_TYPE_LSM, // Linux Security Module
BPF_PROG_TYPE_SK_LOOKUP, // socket lookup
BPF_PROG_TYPE_SYSCALL, // 系統呼叫
};
Context 類型
每種程式類型都有對應的 Context 結構:
// XDP 程式的 Context
struct xdp_md {
__u32 data; // 封包資料開始
__u32 data_end; // 封包資料結束
__u32 data_meta; // metadata 區域
__u32 ingress_ifindex; // 輸入介面索引
__u32 rx_queue_index; // 接收佇列索引
};
// 追蹤程式的 Context
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
// ... 其他暫存器
unsigned long rip; // 指令指標
unsigned long cs;
unsigned long eflags;
unsigned long rsp; // 堆疊指標
unsigned long ss;
};
實戰演練:解析 eBPF ByteCode
讓我們寫一個簡單的工具來解析 eBPF ByteCode:
// bytecode_analyzer.c
#include <stdio.h>
#include <stdint.h>
#include <linux/bpf.h>
// eBPF 指令操作碼定義
#define BPF_CLASS(code) ((code) & 0x07)
#define BPF_OP(code) ((code) & 0xf0)
#define BPF_SRC(code) ((code) & 0x08)
const char* get_opcode_name(uint8_t code)
{
uint8_t cls = BPF_CLASS(code);
uint8_t op = BPF_OP(code);
switch (cls) {
case BPF_ALU64:
switch (op) {
case BPF_ADD: return "add64";
case BPF_SUB: return "sub64";
case BPF_MUL: return "mul64";
case BPF_DIV: return "div64";
case BPF_MOV: return "mov64";
default: return "unknown_alu64";
}
case BPF_JMP:
switch (op) {
case BPF_JA: return "ja";
case BPF_JEQ: return "jeq";
case BPF_JNE: return "jne";
case BPF_JGT: return "jgt";
case BPF_EXIT: return "exit";
case BPF_CALL: return "call";
default: return "unknown_jmp";
}
case BPF_LD:
return "ld";
case BPF_LDX:
return "ldx";
case BPF_ST:
return "st";
case BPF_STX:
return "stx";
default:
return "unknown";
}
}
void disassemble_insn(struct bpf_insn *insn, int idx)
{
printf("%04d: %s", idx, get_opcode_name(insn->code));
// 根據指令類型顯示操作數
if (BPF_CLASS(insn->code) == BPF_ALU64 ||
BPF_CLASS(insn->code) == BPF_ALU) {
if (BPF_SRC(insn->code) == BPF_K) {
printf(" r%d, #%d", insn->dst_reg, insn->imm);
} else {
printf(" r%d, r%d", insn->dst_reg, insn->src_reg);
}
} else if (BPF_CLASS(insn->code) == BPF_JMP) {
if (insn->code == (BPF_JMP | BPF_CALL)) {
printf(" %d", insn->imm);
} else if (insn->code == (BPF_JMP | BPF_JA)) {
printf(" %+d", insn->off);
} else {
printf(" r%d, r%d, %+d", insn->dst_reg, insn->src_reg, insn->off);
}
}
printf("\n");
}
int main()
{
// 簡單的 eBPF 程式:return 42
struct bpf_insn program[] = {
BPF_MOV64_IMM(BPF_REG_0, 42), // r0 = 42
BPF_EXIT_INSN(), // exit
};
int insn_count = sizeof(program) / sizeof(program[0]);
printf("eBPF ByteCode 反組譯:\n");
printf("===================\n");
for (int i = 0; i < insn_count; i++) {
disassemble_insn(&program[i], i);
}
return 0;
}
編譯並執行:
# Makefile
CC = gcc
CFLAGS = -Wall -Wextra -std=c99
bytecode_analyzer: bytecode_analyzer.c
$(CC) $(CFLAGS) -o $@ $<
clean:
rm -f bytecode_analyzer
.PHONY: clean
make bytecode_analyzer
./bytecode_analyzer
預期輸出:
eBPF ByteCode 反組譯:
===================
0000: mov64 r0, #42
0001: exit
深度分析:eBPF 的設計權衡
1. 安全性 vs 效能
eBPF 在設計時面臨安全性和效能的權衡:
安全性措施:
- Verifier 靜態分析
- 有界迴圈檢查
- 記憶體存取限制
- 特權操作控制
效能最佳化:
- JIT 編譯
- 零拷貝操作
- 內聯 helper 函數
- 暫存器最佳化
2. 通用性 vs 特化
eBPF 既要支援多種應用場景,又要在特定領域有出色表現:
通用性特點:
- 統一的虛擬機器架構
- 標準化的指令集
- 一致的開發工具鏈
特化支援:
- 不同的程式類型
- 專用的 helper 函數
- 特定的 Context 結構
3. 簡潔性 vs 功能性
指令集設計的權衡:
簡潔性:
- 精簡指令集(RISC)
- 統一的指令格式
- 有限的暫存器數量
功能性:
- 64 位運算支援
- 原子操作
- 函數呼叫機制
總結
今天我們深入探討了 eBPF 的核心架構,包括:
- 虛擬機器設計:64 位 RISC 架構,11 個暫存器,512 字節堆疊
- 指令集架構:統一的 64 位指令格式,支援算術、跳躍、記憶體和函數呼叫
- Verifier 機制:多層次的安全檢查,確保程式安全性
- JIT 編譯:將 eBPF 程式編譯成高效的原生機器碼
- Hook 點系統:支援多種程式類型和執行環境
這些底層機制的理解對於編寫高效的 eBPF 程式至關重要。在下一篇文章中,我們將開始搭建 eBPF 開發環境,並實際編寫第一個 eBPF 程式。
Day 4:
- 原文:https://ithelp.ithome.com.tw/articles/10379882
- 發布日期:2025-09-14
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
在前兩篇文章中,我們了解了 eBPF 的歷史發展和核心架構。現在是時候動手實作了!但在開始編寫 eBPF 程式之前,我們需要搭建一個完整的開發環境。
eBPF 開發需要特定的內核支援、編譯工具鏈和函式庫。今天我們將一步步搭建這個環境,確保後續的開發工作能夠順利進行。
理論基礎
eBPF 開發環境需求
要進行 eBPF 開發,我們需要以下組件:
- Linux 內核:支援 eBPF 和 BTF 的現代內核(推薦 6.12+ 以使用 sched_ext)
- 編譯工具鏈:LLVM/Clang 17+,支援 eBPF 目標
- 開發函式庫:libbpf、libbpfgo
- 開發工具:bpftool、pahole
- 除錯工具:trace-cmd、perf
BTF(BPF Type Format)的重要性
BTF 是 eBPF 生態系統的重要組成部分,它提供:
- 型別資訊保存:將 C 結構體資訊嵌入內核
- CO-RE 支援:一次編譯,到處執行
- 除錯資訊:更好的除錯體驗
- 反射能力:執行時型別檢查
在 Ubuntu 25.04 上安裝 Gthulhu
為了節省各位的時間,我們直接跳過編譯 kernel 與安裝 kernel 的過程,使用直接支援 sched_ext 的 Ubuntu 25.04 。
讀者可以直接使用以下腳本安裝必要的套件:
sudo apt-get update
sudo apt-get install --yes bsdutils
sudo apt-get install --yes build-essential
sudo apt-get install --yes pkgconf
sudo apt-get install --yes llvm-17 clang-17 clang-format-17
sudo apt-get install --yes libbpf-dev libelf-dev libzstd-dev zlib1g-dev
sudo apt-get install --yes virtme-ng
sudo apt-get install --yes gcc-multilib
sudo apt-get install --yes systemtap-sdt-dev
sudo apt-get install --yes python3 python3-pip ninja-build
sudo apt-get install --yes libseccomp-dev protobuf-compiler
sudo apt-get install --yes meson cmake
for tool in "clang" "clang-format" "llc" "llvm-strip"
do
sudo rm -f /usr/bin/$tool
sudo ln -s /usr/bin/$tool-17 /usr/bin/$tool
done
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
這些套件包含了所有編譯 scx 的必要套件。
在編譯 Gthulhu 之前,我們還需要安裝 golang:
wget https://go.dev/dl/go1.24.2.linux-amd64.tar.gz
sudo tar -C /usr/local -xzf go1.24.2.linux-amd64.tar.gz
新增以下內容至 ~/.profile:
export GOROOT=/usr/local/go
export GOPATH=$HOME/go
export PATH=$GOROOT/bin:$GOPATH/bin:$PATH
新增後,記得使用 source ~/.profile 讓變更的內容生效。
安裝完必要套件後,安裝 Gthulhu:
git clone https://github.com/Gthulhu/Gthulhu.git
cd Gthulhu
make dep
git submodule init
git submodule sync
git submodule update
cd scx
meson setup build --prefix ~
meson compile -C build
cd ..
cd libbpfgo
make
cd ..
make
編譯完成後,Gthulhu 理應能順利執行在你的系統上:
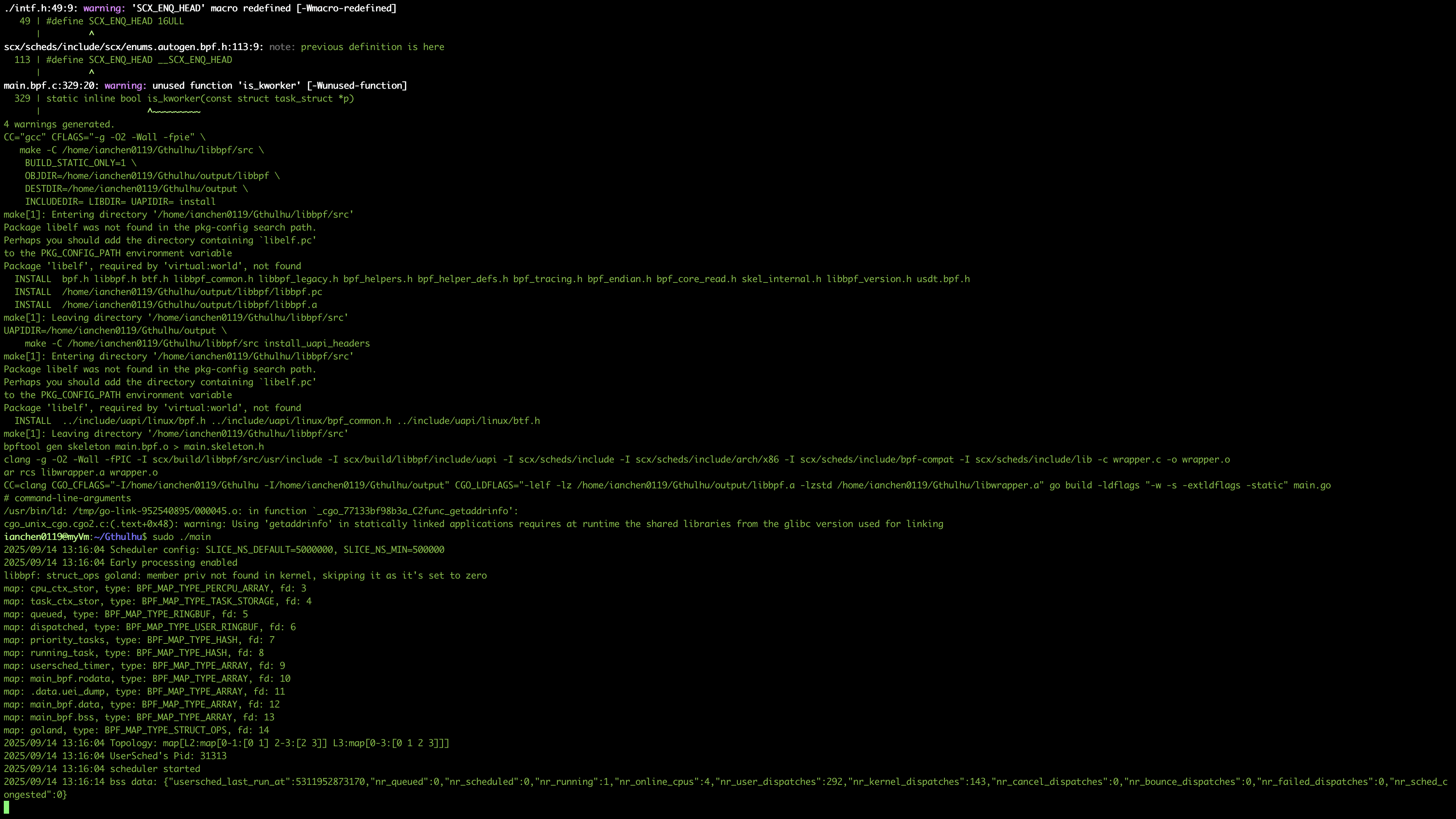
問題一:undefined reference to eu_search_tree_init
如果你遇到了類似的問題,是因為目前系統使用的是 elfutils 版的 libelf,你可以自行下載與編譯 libelf 來解決這個問題:
sudo apt remove --purge elfutils libelf-dev
cd ~
git clone https://github.com/arachsys/libelf.git
cd libelf
make
sudo make install
問題二:ERROR: Program 'clang' not found or not executable
如果你在執行 meson setup build --prefix ~ 命令時遇到該問題,可以嘗試以下命令:
sudo update-alternatives --install /usr/bin/clang clang /usr/bin/clang-17 100
sudo update-alternatives --install /usr/bin/llvm-strip llvm-strip /usr/bin/llvm-strip-17 100
深度分析:開發工具鏈的選擇
LLVM vs GCC
為什麼 eBPF 使用 LLVM 而不是 GCC?
- eBPF 後端支援:LLVM 率先支援 eBPF 目標架構
- 社群驅動:eBPF 社群主要圍繞 LLVM 生態發展
- 最佳化品質:LLVM 的 eBPF 後端最佳化更成熟
- 工具鏈整合:更好的工具鏈整合和除錯支援
libbpf vs 其他函式庫
libbpf 的優勢:
- 官方支援:Linux 內核官方維護
- 完整功能:支援所有 eBPF 功能
- 向前相容:與新內核功能同步更新
- CO-RE 支援:完整的 CO-RE 功能實現
BTF 的重要性
BTF 為什麼如此重要:
// 沒有 BTF 的時代,需要手動定義結構
struct task_struct_offsets {
int pid_offset;
int comm_offset;
int cred_offset;
};
// 有了 BTF,可以直接使用
#include "vmlinux.h"
// task_struct 定義自動可用,支援不同內核版本
除錯和監控工具設定
設定 trace-cmd
# 安裝 trace-cmd
sudo apt install -y trace-cmd
# 或從源碼編譯
git clone https://git.kernel.org/pub/scm/utils/trace-cmd/trace-cmd.git
cd trace-cmd
make -j$(nproc)
sudo make install
設定 perf 工具
# 安裝 perf
sudo apt install -y linux-perf
# 或從內核源碼編譯
cd linux/tools/perf
make -j$(nproc)
sudo make install
eBPF 除錯設定
# 掛載 debugfs(如果未掛載)
sudo mount -t debugfs none /sys/kernel/debug
# 掛載 bpffs(如果未掛載)
sudo mount -t bpf none /sys/fs/bpf
# 設定權限(可選,用於非 root 使用者)
sudo chown $USER:$USER /sys/fs/bpf
總結
今天我們完成了 eBPF 開發環境的搭建,包括:
- 內核準備:確保支援 eBPF 和 BTF 功能
- 工具鏈安裝:LLVM/Clang、bpftool、pahole
- 函式庫安裝:libbpf、libbpfgo
- 環境驗證:完整的檢查和測試流程
- 開發工作流程:專案結構和建置系統
一個正確配置的開發環境是成功進行 eBPF 開發的基礎。在下一篇文章中,我們將使用這個環境編寫第一個 eBPF 程式。
Day 5:
- 原文:https://ithelp.ithome.com.tw/articles/10380334
- 發布日期:2025-09-15
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
經過前面三篇文章的鋪墊,我們已經了解了 eBPF 的歷史、架構,並搭建好了完整的開發環境。現在終於到了最激動人心的時刻 —— 編寫第一個 eBPF 程式!
今天我們將從最簡單的 "Hello World" 開始,學習 eBPF 程式的基本結構、編譯流程,以及如何使用 Go 語言載入和管理 eBPF 程式。
理論基礎
eBPF 程式的生命週期
一個 eBPF 程式從編寫到執行需要經歷以下步驟:
- 編寫:使用 C 語言編寫 eBPF 程式
- 編譯:使用 Clang 編譯為 eBPF 字節碼
- 載入:透過系統呼叫載入到內核
- 驗證:內核 Verifier 檢查程式安全性
- JIT 編譯:編譯為原生機器碼
- 附加:附加到特定的 Hook 點
- 執行:響應系統事件執行程式
- 卸載:程式生命週期結束時清理
eBPF 程式的基本結構
每個 eBPF 程式都包含:
// 1. 標頭檔包含
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
// 2. 程式定義(使用 SEC 宏標記)
SEC("program_type")
int program_function(struct context *ctx) {
// 程式邏輯
return 0;
}
// 3. 授權聲明(必需)
char _license[] SEC("license") = "GPL";
實作演練:Hello World 程式
第一步:建立專案結構
mkdir -p ~/ebpf-hello-world/{src/kernel,src/userspace,headers,bin}
cd ~/ebpf-hello-world
# 建立專案結構
tree
預期結構:
ebpf-hello-world/
├── src/
│ ├── kernel/
│ └── userspace/
├── headers/
├── bin/
├── Makefile
└── go.mod
第二步:編寫 eBPF 程式
建立我們的第一個 eBPF 程式:
// src/kernel/hello.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// 定義一個字符映射,用於格式化輸出
char LICENSE[] SEC("license") = "GPL";
// 定義一個簡單的追蹤點程式
SEC("tp/syscalls/sys_enter_openat")
int trace_openat(struct trace_event_raw_sys_enter *ctx)
{
// 獲取當前程序的 PID 和 TID
u64 pid_tgid = bpf_get_current_pid_tgid();
u32 pid = pid_tgid >> 32;
u32 tid = pid_tgid & 0xffffffff;
// 獲取使用者 ID
u64 uid_gid = bpf_get_current_uid_gid();
u32 uid = uid_gid & 0xffffffff;
// 獲取程序名稱
char comm[16];
bpf_get_current_comm(&comm, sizeof(comm));
// 使用 bpf_printk 輸出資訊
bpf_printk("Hello from eBPF! PID=%d, TID=%d, UID=%d, COMM=%s\n",
pid, tid, uid, comm);
return 0;
}
// 定義一個更簡單的追蹤程式
SEC("tp/syscalls/sys_enter_write")
int trace_write(struct trace_event_raw_sys_enter *ctx)
{
// 簡單的計數輸出
static u64 count = 0;
count++;
bpf_printk("Write syscall #%llu\n", count);
return 0;
}
// 定義一個 kprobe 程式
SEC("kprobe/do_sys_openat2")
int kprobe_openat(struct pt_regs *ctx)
{
// 從暫存器獲取參數
int dfd = (int)PT_REGS_PARM1(ctx);
const char __user *filename = (const char __user *)PT_REGS_PARM2(ctx);
// 獲取檔案名(前 64 個字符)
char fname[64];
bpf_probe_read_user_str(fname, sizeof(fname), filename);
bpf_printk("Opening file: %s (dfd=%d)\n", fname, dfd);
return 0;
}
第三步:生成 vmlinux.h
# 生成包含所有內核型別定義的標頭檔
bpftool btf dump file /sys/kernel/btf/vmlinux format c > headers/vmlinux.h
# 檢查檔案大小(應該很大,幾MB)
ls -lh headers/vmlinux.h
第四步:建立 Makefile
# Makefile
CLANG := clang
LLVM_STRIP := llvm-strip
BPFTOOL := bpftool
GO := go
# 編譯器設定
CLANG_BPF_SYS_INCLUDES := $(shell $(CLANG) -v -E - </dev/null 2>&1 \
| sed -n '/<...> search starts here:/,/End of search list./{ //!p }')
BPF_CFLAGS := -g -O2 -Wall -Werror -target bpf -D__TARGET_ARCH_x86 \
$(foreach dir,$(CLANG_BPF_SYS_INCLUDES),-idirafter $(dir))
# 目錄定義
KERNEL_SRC := src/kernel
USERSPACE_SRC := src/userspace
HEADERS := headers
# 目標檔案
BPF_OBJ := hello.bpf.o
USERSPACE_BIN := bin/hello
.PHONY: all clean vmlinux.h userspace kernel
all: vmlinux.h kernel userspace
# 生成 vmlinux.h
vmlinux.h:
@echo "生成 vmlinux.h..."
$(BPFTOOL) btf dump file /sys/kernel/btf/vmlinux format c > $(HEADERS)/vmlinux.h
# 編譯 eBPF 程式
kernel: $(BPF_OBJ)
$(BPF_OBJ): $(KERNEL_SRC)/hello.bpf.c | vmlinux.h
@echo "編譯 eBPF 程式..."
$(CLANG) $(BPF_CFLAGS) -I$(HEADERS) -c $< -o $@
$(LLVM_STRIP) -g $@
# 編譯使用者空間程式
userspace: $(USERSPACE_BIN)
$(USERSPACE_BIN): $(USERSPACE_SRC)/main.go | $(BPF_OBJ)
@echo "編譯使用者空間程式..."
mkdir -p bin
$(GO) build -o $@ $<
# 執行程式
run: all
sudo ./$(USERSPACE_BIN)
# 檢視 eBPF 程式資訊
info: $(BPF_OBJ)
$(BPFTOOL) prog load $(BPF_OBJ) /sys/fs/bpf/hello_prog
$(BPFTOOL) prog show pinned /sys/fs/bpf/hello_prog
sudo rm -f /sys/fs/bpf/hello_prog
# 清理
clean:
rm -f *.o $(USERSPACE_BIN) $(HEADERS)/vmlinux.h
# 初始化 Go 模組
init:
$(GO) mod init ebpf-hello-world
$(GO) get github.com/aquasecurity/libbpfgo@latest
# 幫助
help:
@echo "可用目標:"
@echo " all - 編譯所有程式"
@echo " kernel - 編譯 eBPF 程式"
@echo " userspace - 編譯使用者空間程式"
@echo " run - 執行程式"
@echo " info - 顯示 eBPF 程式資訊"
@echo " clean - 清理建置檔案"
@echo " init - 初始化 Go 模組"
第五步:編寫 Go 載入程式
// src/userspace/main.go
package main
import (
"context"
"fmt"
"log"
"os"
"os/signal"
"syscall"
"time"
bpf "github.com/aquasecurity/libbpfgo"
)
func main() {
// 檢查 root 權限
if os.Geteuid() != 0 {
log.Fatal("此程式需要 root 權限執行")
}
// 載入 eBPF 程式
bpfModule, err := bpf.NewModuleFromFile("hello.bpf.o")
if err != nil {
log.Fatalf("載入 eBPF 模組失敗: %v", err)
}
defer bpfModule.Close()
// 載入程式到內核
if err := bpfModule.BPFLoadObject(); err != nil {
log.Fatalf("載入 eBPF 物件失敗: %v", err)
}
fmt.Println("✓ eBPF 程式載入成功")
// 獲取並附加追蹤點程式
progOpenat, err := bpfModule.GetProgram("trace_openat")
if err != nil {
log.Fatalf("獲取 trace_openat 程式失敗: %v", err)
}
progWrite, err := bpfModule.GetProgram("trace_write")
if err != nil {
log.Fatalf("獲取 trace_write 程式失敗: %v", err)
}
progKprobe, err := bpfModule.GetProgram("kprobe_openat")
if err != nil {
log.Fatalf("獲取 kprobe_openat 程式失敗: %v", err)
}
// 附加到追蹤點
linkOpenat, err := progOpenat.AttachTracepoint(&bpf.TracepointOpts{
Group: "syscalls",
Name: "sys_enter_openat",
})
if err != nil {
log.Fatalf("附加 openat 追蹤點失敗: %v", err)
}
defer linkOpenat.Close()
linkWrite, err := progWrite.AttachTracepoint(&bpf.TracepointOpts{
Group: "syscalls",
Name: "sys_enter_write",
})
if err != nil {
log.Fatalf("附加 write 追蹤點失敗: %v", err)
}
defer linkWrite.Close()
// 附加 kprobe
linkKprobe, err := progKprobe.AttachKprobe(&bpf.KprobeOpts{
Symbol: "do_sys_openat2",
})
if err != nil {
log.Fatalf("附加 kprobe 失敗: %v", err)
}
defer linkKprobe.Close()
fmt.Println("✓ 所有程式附加成功")
fmt.Println("正在追蹤系統呼叫...")
fmt.Println("請在另一個終端執行一些檔案操作,如:")
fmt.Println(" ls /tmp")
fmt.Println(" echo 'test' > /tmp/test.txt")
fmt.Println(" cat /tmp/test.txt")
fmt.Println()
fmt.Println("檢視輸出:sudo cat /sys/kernel/debug/tracing/trace_pipe")
fmt.Println("按 Ctrl+C 退出...")
// 設定信號處理
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
// 定期輸出統計資訊
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
startTime := time.Now()
for {
select {
case <-ctx.Done():
return
case sig := <-sigChan:
fmt.Printf("\n收到信號 %v,正在退出...\n", sig)
cancel()
case <-ticker.C:
uptime := time.Since(startTime)
fmt.Printf("程式運行時間: %v\n", uptime.Round(time.Second))
}
}
}
第六步:初始化和建置
# 初始化 Go 模組
make init
# 建置所有組件
make all
# 檢查建置結果
ls -la *.o bin/
第七步:執行程式
# 執行 Hello World 程式(需要 root 權限)
sudo make run
在另一個終端中,執行一些檔案操作來觸發追蹤:
# 在另一個終端執行
ls /tmp
echo "Hello eBPF!" > /tmp/test.txt
cat /tmp/test.txt
rm /tmp/test.txt
第八步:觀察輸出
在第三個終端中觀察 eBPF 程式的輸出:
# 觀察追蹤輸出
sudo cat /sys/kernel/debug/tracing/trace_pipe
你應該看到類似這樣的輸出:
bash-1234 [001] .... 12345.678901: bpf_trace_printk: Hello from eBPF! PID=1234, TID=1234, UID=1000, COMM=bash
bash-1234 [001] .... 12345.678902: bpf_trace_printk: Opening file: /tmp/test.txt (dfd=-100)
cat-1235 [002] .... 12345.678903: bpf_trace_printk: Write syscall #1
cat-1235 [002] .... 12345.678904: bpf_trace_printk: Hello from eBPF! PID=1235, TID=1235, UID=1000, COMM=cat
深度分析:Hello World 程式的工作原理
1. SEC() 宏的作用
SEC("tp/syscalls/sys_enter_openat")
SEC() 宏告訴編譯器和載入器:
- 這是一個 eBPF 程式
- 程式類型是追蹤點(tracepoint)
- 要附加到
syscalls/sys_enter_openat追蹤點
2. Context 結構
不同類型的 eBPF 程式有不同的 Context:
// 追蹤點程式的 Context
struct trace_event_raw_sys_enter *ctx
// kprobe 程式的 Context
struct pt_regs *ctx
// XDP 程式的 Context
struct xdp_md *ctx
3. Helper 函數的使用
我們使用了幾個重要的 helper 函數:
// 獲取程序 ID 和線程 ID
u64 pid_tgid = bpf_get_current_pid_tgid();
// 獲取程序名稱
bpf_get_current_comm(&comm, sizeof(comm));
// 讀取使用者空間字串
bpf_probe_read_user_str(fname, sizeof(fname), filename);
// 輸出除錯資訊
bpf_printk("格式化字串", 參數...);
4. Go 載入器的工作
Go 程式的主要職責:
- 載入模組:讀取 .o 檔案
- 載入物件:呼叫 BPF 系統呼叫
- 獲取程式:找到特定的 eBPF 程式
- 附加程式:將程式附加到 Hook 點
- 管理生命週期:處理信號和清理
實戰應用:改進和擴展
1. 新增 Maps 支援
讓我們改進程式,新增一個 Map 來統計檔案操作:
// src/kernel/hello_with_maps.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// 定義一個 Hash Map 來統計檔案操作
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10000);
__type(key, u32); // PID
__type(value, u64); // 計數
} file_ops_count SEC(".maps");
// 定義一個陣列 Map 來儲存統計資訊
struct file_stats {
u64 total_opens;
u64 total_writes;
u64 total_reads;
};
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 1);
__type(key, u32);
__type(value, struct file_stats);
} global_stats SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("tp/syscalls/sys_enter_openat")
int trace_openat_with_stats(struct trace_event_raw_sys_enter *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
u64 *count;
// 更新每個程序的計數
count = bpf_map_lookup_elem(&file_ops_count, &pid);
if (count) {
__sync_fetch_and_add(count, 1);
} else {
u64 initial_count = 1;
bpf_map_update_elem(&file_ops_count, &pid, &initial_count, BPF_ANY);
}
// 更新全局統計
u32 key = 0;
struct file_stats *stats = bpf_map_lookup_elem(&global_stats, &key);
if (stats) {
__sync_fetch_and_add(&stats->total_opens, 1);
} else {
struct file_stats initial_stats = {1, 0, 0};
bpf_map_update_elem(&global_stats, &key, &initial_stats, BPF_ANY);
}
// 獲取檔案名稱並輸出
char comm[16];
bpf_get_current_comm(&comm, sizeof(comm));
bpf_printk("PID %d (%s) opened file, total opens: %llu\n",
pid, comm, stats ? stats->total_opens : 1);
return 0;
}
對應的 Go 程式讀取 Map 資料:
// src/userspace/main_with_maps.go
package main
import (
"fmt"
"log"
"os"
"time"
"unsafe"
bpf "github.com/aquasecurity/libbpfgo"
)
type FileStats struct {
TotalOpens uint64
TotalWrites uint64
TotalReads uint64
}
func main() {
if os.Geteuid() != 0 {
log.Fatal("需要 root 權限")
}
// 載入程式
bpfModule, err := bpf.NewModuleFromFile("hello_with_maps.bpf.o")
if err != nil {
log.Fatalf("載入失敗: %v", err)
}
defer bpfModule.Close()
if err := bpfModule.BPFLoadObject(); err != nil {
log.Fatalf("載入物件失敗: %v", err)
}
// 附加程式
prog, err := bpfModule.GetProgram("trace_openat_with_stats")
if err != nil {
log.Fatalf("獲取程式失敗: %v", err)
}
link, err := prog.AttachTracepoint(&bpf.TracepointOpts{
Group: "syscalls",
Name: "sys_enter_openat",
})
if err != nil {
log.Fatalf("附加失敗: %v", err)
}
defer link.Close()
// 獲取 Maps
fileOpsMap, err := bpfModule.GetMap("file_ops_count")
if err != nil {
log.Fatalf("獲取 map 失敗: %v", err)
}
globalStatsMap, err := bpfModule.GetMap("global_stats")
if err != nil {
log.Fatalf("獲取 stats map 失敗: %v", err)
}
fmt.Println("eBPF 程式啟動,監控檔案操作...")
// 定期讀取統計資訊
ticker := time.NewTicker(3 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
fmt.Println("\n=== 統計資訊 ===")
// 讀取全局統計
key := uint32(0)
statsBytes, err := globalStatsMap.GetValue(unsafe.Pointer(&key))
if err == nil && len(statsBytes) == int(unsafe.Sizeof(FileStats{})) {
stats := (*FileStats)(unsafe.Pointer(&statsBytes[0]))
fmt.Printf("總檔案開啟次數: %d\n", stats.TotalOpens)
}
// 讀取前幾個程序的統計
fmt.Println("\n各程序檔案操作次數:")
iterator := fileOpsMap.Iterator()
count := 0
for iterator.Next() && count < 5 {
keyBytes := iterator.Key()
valueBytes, _ := iterator.Value()
if len(keyBytes) == 4 && len(valueBytes) == 8 {
pid := *(*uint32)(unsafe.Pointer(&keyBytes[0]))
ops := *(*uint64)(unsafe.Pointer(&valueBytes[0]))
fmt.Printf(" PID %d: %d 次操作\n", pid, ops)
count++
}
}
}
}
}
2. 新增過濾機制
我們可以新增過濾,只監控特定的程序:
// 只監控特定程序名稱
SEC("tp/syscalls/sys_enter_openat")
int trace_filtered_openat(struct trace_event_raw_sys_enter *ctx)
{
char comm[16];
bpf_get_current_comm(&comm, sizeof(comm));
// 只監控 bash 和 cat
if (comm[0] == 'b' && comm[1] == 'a' && comm[2] == 's' && comm[3] == 'h') {
// bash
} else if (comm[0] == 'c' && comm[1] == 'a' && comm[2] == 't') {
// cat
} else {
return 0; // 忽略其他程序
}
bpf_printk("Filtered: %s opened a file\n", comm);
return 0;
}
疑難排解指南
常見編譯錯誤
- 找不到 vmlinux.h
# 解決方法:重新生成
make vmlinux.h
- BPF helper 函數未定義
# 檢查 libbpf 版本
pkg-config --modversion libbpf
# 更新到最新版本
sudo apt update && sudo apt upgrade libbpf-dev
- 載入失敗
# 檢查內核支援
grep CONFIG_BPF /boot/config-$(uname -r)
# 檢查權限
sudo dmesg | grep bpf
除錯技巧
- 檢視 Verifier 日誌
# 啟用詳細 verifier 日誌
echo 2 | sudo tee /proc/sys/kernel/bpf_verbosity
- 使用 bpftool 除錯
# 檢視載入的程式
sudo bpftool prog list
# 檢視程式詳細資訊
sudo bpftool prog show id <ID> --pretty
# 反組譯程式
sudo bpftool prog dump xlated id <ID>
總結
今天我們成功編寫並執行了第一個 eBPF 程式!我們學習了:
- eBPF 程式結構:SEC() 宏、helper 函數、授權聲明
- 編譯流程:從 C 源碼到 eBPF 字節碼
- Go 載入器:使用 libbpfgo 管理 eBPF 程式
- 實際應用:系統呼叫追蹤和統計
- 進階特性:Maps 的使用和資料共享
這個 Hello World 程式為我們後續的學習奠定了基礎。在下一篇文章中,我們將深入探討 eBPF Maps,學習如何在內核和使用者空間之間高效地共享資料。
Day 6:
- 原文:https://ithelp.ithome.com.tw/articles/10381236
- 發布日期:2025-09-16
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
在上一篇文章中,我們成功編寫了第一個 eBPF 程式,並學會了基本的程式結構和載入流程。今天我們將深入探討 eBPF Maps——這個連接內核空間和使用者空間的重要橋樑。
eBPF Maps 不僅僅是簡單的資料結構,它們是 eBPF 程式持久化狀態、程式間通訊、以及與使用者空間互動的核心機制。
認識 eBPF Maps
eBPF Maps 的設計理念
eBPF Maps 解決了幾個核心問題:
Maps 的分類
eBPF Maps 可以按照不同維度分類:
按資料結構分類
- Array Maps:基於索引的陣列
- Hash Maps:基於鍵值的雜湊表
- Trie Maps:最長前綴匹配
- Stack/Queue Maps:堆疊和佇列結構
按使用場景分類
- 統計 Maps:Per-CPU Maps、Percpu Array/Hash
- 通訊 Maps:(User-)Ring Buffer、Perf Event Array
- 配置 Maps:Program Array、Map in Map
- 網路 Maps:Socket Maps、Device Maps
筆者補充:詳細的 Map 種類請參考:https://docs.ebpf.io/linux/map-type/
實作演練:深入探索各種 Maps
第一步:專案結構準備
mkdir -p ~/ebpf-maps-demo/{src/kernel,src/userspace,headers,bin}
cd ~/ebpf-maps-demo
# 建立 Makefile 和 Go module
cp ~/ebpf-hello-world/Makefile .
cp ~/ebpf-hello-world/go.mod .
第二步:Array Maps 實作
Array Maps 是最簡單的 Map 型別,適合存儲固定大小的陣列資料。
// src/kernel/array_maps_demo.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// 定義一個簡單的陣列 Map
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 256); // 最大 256 個元素
__type(key, __u32); // 鍵類型:32位整數(索引)
__type(value, __u64); // 值類型:64位整數(計數)
} syscall_count_array SEC(".maps");
// 定義一個 Per-CPU 陣列 Map
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
__uint(max_entries, 10);
__type(key, __u32);
__type(value, __u64);
} percpu_stats SEC(".maps");
// 定義統計結構
struct syscall_stats {
__u64 count;
__u64 total_time;
__u64 min_time;
__u64 max_time;
};
// 複雜的陣列 Map
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 512);
__type(key, __u32);
__type(value, struct syscall_stats);
} detailed_stats SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("tp/raw_syscalls/sys_enter")
int trace_syscall_enter(struct trace_event_raw_sys_enter *ctx)
{
__u32 syscall_nr = ctx->id;
__u64 *count;
__u64 timestamp = bpf_ktime_get_ns();
// 限制系統呼叫號範圍,避免越界
if (syscall_nr >= 256)
return 0;
// 更新簡單計數陣列
count = bpf_map_lookup_elem(&syscall_count_array, &syscall_nr);
if (count) {
__sync_fetch_and_add(count, 1);
} else {
__u64 initial = 1;
bpf_map_update_elem(&syscall_count_array, &syscall_nr, &initial, BPF_ANY);
}
// 更新 Per-CPU 統計(假設只統計前10個系統呼叫)
if (syscall_nr < 10) {
__u64 *percpu_count = bpf_map_lookup_elem(&percpu_stats, &syscall_nr);
if (percpu_count) {
*percpu_count += 1;
} else {
__u64 initial = 1;
bpf_map_update_elem(&percpu_stats, &syscall_nr, &initial, BPF_ANY);
}
}
// 更新詳細統計(限制範圍)
if (syscall_nr < 512) {
struct syscall_stats *stats = bpf_map_lookup_elem(&detailed_stats, &syscall_nr);
if (stats) {
__sync_fetch_and_add(&stats->count, 1);
if (stats->min_time == 0 || timestamp < stats->min_time) {
stats->min_time = timestamp;
}
if (timestamp > stats->max_time) {
stats->max_time = timestamp;
}
} else {
struct syscall_stats new_stats = {
.count = 1,
.total_time = 0,
.min_time = timestamp,
.max_time = timestamp
};
bpf_map_update_elem(&detailed_stats, &syscall_nr, &new_stats, BPF_ANY);
}
}
return 0;
}
第三步:Hash Maps 實作
Hash Maps 提供靈活的鍵值對存儲,適合動態資料。
// src/kernel/hash_maps_demo.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// 定義進程統計結構
struct process_stats {
__u64 file_opens;
__u64 memory_allocs;
__u64 network_ops;
__u64 first_seen;
__u64 last_seen;
char comm[16];
};
// PID -> 進程統計的 Hash Map
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10000);
__type(key, __u32); // PID
__type(value, struct process_stats);
} process_map SEC(".maps");
// 檔案名 Hash -> 存取次數
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1000);
__type(key, __u64); // 檔名雜湊
__type(value, __u64); // 存取次數
} file_access_map SEC(".maps");
// Per-CPU Hash Map 示例
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_HASH);
__uint(max_entries, 1000);
__type(key, __u32);
__type(value, __u64);
} percpu_process_stats SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
// 簡單的字串雜湊函數
static __always_inline __u64 hash_string(const char *str, int len)
{
__u64 hash = 5381;
for (int i = 0; i < len && i < 16; i++) {
if (str[i] == 0) break;
hash = ((hash << 5) + hash) + str[i];
}
return hash;
}
SEC("tp/syscalls/sys_enter_openat")
int trace_file_opens(struct trace_event_raw_sys_enter *ctx)
{
__u32 pid = bpf_get_current_pid_tgid() >> 32;
__u64 now = bpf_ktime_get_ns();
// 更新進程統計
struct process_stats *stats = bpf_map_lookup_elem(&process_map, &pid);
if (stats) {
__sync_fetch_and_add(&stats->file_opens, 1);
stats->last_seen = now;
} else {
struct process_stats new_stats = {
.file_opens = 1,
.memory_allocs = 0,
.network_ops = 0,
.first_seen = now,
.last_seen = now
};
bpf_get_current_comm(&new_stats.comm, sizeof(new_stats.comm));
bpf_map_update_elem(&process_map, &pid, &new_stats, BPF_ANY);
}
// 嘗試獲取檔案名並雜湊
char filename[64];
long ret = bpf_probe_read_user_str(filename, sizeof(filename),
(void *)ctx->args[1]);
if (ret > 0) {
__u64 file_hash = hash_string(filename, ret);
__u64 *count = bpf_map_lookup_elem(&file_access_map, &file_hash);
if (count) {
__sync_fetch_and_add(count, 1);
} else {
__u64 initial = 1;
bpf_map_update_elem(&file_access_map, &file_hash, &initial, BPF_ANY);
}
}
// 更新 Per-CPU 統計
__u64 *percpu_count = bpf_map_lookup_elem(&percpu_process_stats, &pid);
if (percpu_count) {
*percpu_count += 1;
} else {
__u64 initial = 1;
bpf_map_update_elem(&percpu_process_stats, &pid, &initial, BPF_ANY);
}
return 0;
}
第四步:Ring Buffer 實作
Ring Buffer 是現代 eBPF 推薦的事件通信機制。
// src/kernel/ringbuf_demo.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// 定義事件結構
struct file_event {
__u32 pid;
__u32 tgid;
__u32 uid;
__u64 timestamp;
__u32 filename_len;
char comm[16];
char filename[256];
};
// Ring Buffer Map
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024); // 256KB buffer
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("tp/syscalls/sys_enter_openat")
int trace_file_events(struct trace_event_raw_sys_enter *ctx)
{
struct file_event *event;
// 從 ring buffer 分配空間
event = bpf_ringbuf_reserve(&events, sizeof(*event), 0);
if (!event) {
return 0; // 分配失敗,buffer 可能已滿
}
// 填充事件資料
__u64 pid_tgid = bpf_get_current_pid_tgid();
event->pid = pid_tgid >> 32;
event->tgid = pid_tgid & 0xffffffff;
event->uid = bpf_get_current_uid_gid() & 0xffffffff;
event->timestamp = bpf_ktime_get_ns();
// 獲取進程名稱
bpf_get_current_comm(&event->comm, sizeof(event->comm));
// 讀取檔案名
long ret = bpf_probe_read_user_str(event->filename, sizeof(event->filename),
(void *)ctx->args[1]);
if (ret > 0) {
event->filename_len = ret;
} else {
event->filename_len = 0;
event->filename[0] = '\0';
}
// 提交事件到 ring buffer
bpf_ringbuf_submit(event, 0);
return 0;
}
第五步:Go 使用者空間程式
現在編寫一個完整的 Go 程式來操作所有這些 Maps:
// src/userspace/maps_demo.go
package main
import (
"bytes"
"context"
"encoding/binary"
"fmt"
"log"
"os"
"os/signal"
"sort"
"syscall"
"time"
"unsafe"
bpf "github.com/aquasecurity/libbpfgo"
)
// Go 結構對應 C 結構
type ProcessStats struct {
FileOpens uint64
MemoryAllocs uint64
NetworkOps uint64
FirstSeen uint64
LastSeen uint64
Comm [16]byte
}
type SyscallStats struct {
Count uint64
TotalTime uint64
MinTime uint64
MaxTime uint64
}
type FileEvent struct {
PID uint32
TGID uint32
UID uint32
Timestamp uint64
FilenameLen uint32
Comm [16]byte
Filename [256]byte
}
func main() {
if os.Geteuid() != 0 {
log.Fatal("需要 root 權限執行")
}
// 選擇要載入的程式
var objFile string
var progName string
if len(os.Args) > 1 {
switch os.Args[1] {
case "array":
objFile = "array_maps_demo.bpf.o"
progName = "trace_syscall_enter"
case "hash":
objFile = "hash_maps_demo.bpf.o"
progName = "trace_file_opens"
case "ringbuf":
objFile = "ringbuf_demo.bpf.o"
progName = "trace_file_events"
default:
fmt.Println("使用方法: ./maps_demo [array|hash|ringbuf]")
os.Exit(1)
}
} else {
objFile = "hash_maps_demo.bpf.o"
progName = "trace_file_opens"
}
fmt.Printf("載入 eBPF 程式: %s\n", objFile)
// 載入 eBPF 程式
bpfModule, err := bpf.NewModuleFromFile(objFile)
if err != nil {
log.Fatalf("載入 eBPF 模組失敗: %v", err)
}
defer bpfModule.Close()
if err := bpfModule.BPFLoadObject(); err != nil {
log.Fatalf("載入 eBPF 物件失敗: %v", err)
}
// 獲取並附加程式
prog, err := bpfModule.GetProgram(progName)
if err != nil {
log.Fatalf("獲取程式失敗: %v", err)
}
var link *bpf.BPFLink
if progName == "trace_syscall_enter" {
link, err = prog.AttachTracepoint(&bpf.TracepointOpts{
Group: "raw_syscalls",
Name: "sys_enter",
})
} else {
link, err = prog.AttachTracepoint(&bpf.TracepointOpts{
Group: "syscalls",
Name: "sys_enter_openat",
})
}
if err != nil {
log.Fatalf("附加程式失敗: %v", err)
}
defer link.Close()
fmt.Printf("✓ eBPF 程式 %s 附加成功\n", progName)
// 設定信號處理
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
// 根據程式類型執行不同的處理邏輯
switch os.Args[1] {
case "array":
runArrayDemo(ctx, bpfModule, sigChan)
case "hash":
runHashDemo(ctx, bpfModule, sigChan)
case "ringbuf":
runRingBufDemo(ctx, bpfModule, sigChan)
default:
runHashDemo(ctx, bpfModule, sigChan)
}
}
func runArrayDemo(ctx context.Context, module *bpf.Module, sigChan chan os.Signal) {
syscallCountMap, err := module.GetMap("syscall_count_array")
if err != nil {
log.Fatalf("獲取 syscall_count_array 失敗: %v", err)
}
detailedStatsMap, err := module.GetMap("detailed_stats")
if err != nil {
log.Fatalf("獲取 detailed_stats 失敗: %v", err)
}
ticker := time.NewTicker(3 * time.Second)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case sig := <-sigChan:
fmt.Printf("\n收到信號 %v,正在退出...\n", sig)
cancel()
case <-ticker.C:
fmt.Println("\n=== Array Maps 統計 ===")
// 顯示系統呼叫計數
fmt.Println("系統呼叫計數 (前10個):")
for i := uint32(0); i < 10; i++ {
valueBytes, err := syscallCountMap.GetValue(unsafe.Pointer(&i))
if err == nil && len(valueBytes) == 8 {
count := binary.LittleEndian.Uint64(valueBytes)
if count > 0 {
fmt.Printf(" syscall_%d: %d 次\n", i, count)
}
}
}
// 顯示詳細統計
fmt.Println("\n詳細統計 (有活動的系統呼叫):")
for i := uint32(0); i < 20; i++ {
valueBytes, err := detailedStatsMap.GetValue(unsafe.Pointer(&i))
if err == nil && len(valueBytes) == int(unsafe.Sizeof(SyscallStats{})) {
stats := (*SyscallStats)(unsafe.Pointer(&valueBytes[0]))
if stats.Count > 0 {
fmt.Printf(" syscall_%d: %d次, 最小時間: %d, 最大時間: %d\n",
i, stats.Count, stats.MinTime, stats.MaxTime)
}
}
}
}
}
}
func runHashDemo(ctx context.Context, module *bpf.Module, sigChan chan os.Signal) {
processMap, err := module.GetMap("process_map")
if err != nil {
log.Fatalf("獲取 process_map 失敗: %v", err)
}
fileAccessMap, err := module.GetMap("file_access_map")
if err != nil {
log.Fatalf("獲取 file_access_map 失敗: %v", err)
}
ticker := time.NewTicker(3 * time.Second)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case sig := <-sigChan:
fmt.Printf("\n收到信號 %v,正在退出...\n", sig)
cancel()
case <-ticker.C:
fmt.Println("\n=== Hash Maps 統計 ===")
// 顯示進程統計
fmt.Println("進程檔案操作統計:")
type ProcessInfo struct {
PID uint32
Stats ProcessStats
}
var processes []ProcessInfo
iterator := processMap.Iterator()
for iterator.Next() {
keyBytes := iterator.Key()
valueBytes, _ := iterator.Value()
if len(keyBytes) == 4 && len(valueBytes) == int(unsafe.Sizeof(ProcessStats{})) {
pid := binary.LittleEndian.Uint32(keyBytes)
stats := (*ProcessStats)(unsafe.Pointer(&valueBytes[0]))
processes = append(processes, ProcessInfo{PID: pid, Stats: *stats})
}
}
// 按檔案操作次數排序
sort.Slice(processes, func(i, j int) bool {
return processes[i].Stats.FileOpens > processes[j].Stats.FileOpens
})
// 顯示前10個進程
count := 10
if len(processes) < count {
count = len(processes)
}
for i := 0; i < count; i++ {
p := processes[i]
comm := string(bytes.TrimRight(p.Stats.Comm[:], "\x00"))
fmt.Printf(" PID %d (%s): %d 次檔案操作\n",
p.PID, comm, p.Stats.FileOpens)
}
// 顯示檔案存取統計
fmt.Println("\n檔案存取統計 (雜湊):")
fileIterator := fileAccessMap.Iterator()
fileCount := 0
for fileIterator.Next() && fileCount < 5 {
keyBytes := fileIterator.Key()
valueBytes, _ := fileIterator.Value()
if len(keyBytes) == 8 && len(valueBytes) == 8 {
hash := binary.LittleEndian.Uint64(keyBytes)
count := binary.LittleEndian.Uint64(valueBytes)
fmt.Printf(" Hash 0x%x: %d 次存取\n", hash, count)
fileCount++
}
}
}
}
}
func runRingBufDemo(ctx context.Context, module *bpf.Module, sigChan chan os.Signal) {
eventsMap, err := module.GetMap("events")
if err != nil {
log.Fatalf("獲取 events ringbuf 失敗: %v", err)
}
// 建立 ring buffer
rb, err := module.InitRingBuf("events", make(chan []byte, 100))
if err != nil {
log.Fatalf("初始化 ring buffer 失敗: %v", err)
}
defer rb.Close()
// 開始 polling
rb.Poll(300) // 300ms timeout
fmt.Println("開始監聽檔案事件 (Ring Buffer)...")
fmt.Println("執行一些檔案操作來觸發事件...")
eventCount := 0
for {
select {
case <-ctx.Done():
return
case sig := <-sigChan:
fmt.Printf("\n收到信號 %v,正在退出...\n", sig)
cancel()
case data := <-rb.EventsChannel:
if len(data) == int(unsafe.Sizeof(FileEvent{})) {
event := (*FileEvent)(unsafe.Pointer(&data[0]))
comm := string(bytes.TrimRight(event.Comm[:], "\x00"))
filename := string(bytes.TrimRight(event.Filename[:event.FilenameLen], "\x00"))
eventCount++
fmt.Printf("[%d] PID %d (%s) 開啟檔案: %s\n",
eventCount, event.PID, comm, filename)
}
}
}
}
第六步:編譯和測試
更新 Makefile 以支援多個程式:
# 更新 Makefile
BPF_PROGS := array_maps_demo.bpf.o hash_maps_demo.bpf.o ringbuf_demo.bpf.o
all: vmlinux.h $(BPF_PROGS) userspace
$(BPF_PROGS): %.bpf.o: $(KERNEL_SRC)/%.bpf.c | vmlinux.h
@echo "編譯 eBPF 程式: $<"
$(CLANG) $(BPF_CFLAGS) -I$(HEADERS) -c $< -o $@
$(LLVM_STRIP) -g $@
userspace: bin/maps_demo
bin/maps_demo: $(USERSPACE_SRC)/maps_demo.go
@echo "編譯使用者空間程式..."
mkdir -p bin
$(GO) build -o $@ $<
test-array: all
sudo ./bin/maps_demo array
test-hash: all
sudo ./bin/maps_demo hash
test-ringbuf: all
sudo ./bin/maps_demo ringbuf
編譯和測試:
# 編譯所有程式
make all
# 測試 Array Maps
make test-array
# 測試 Hash Maps
make test-hash
# 測試 Ring Buffer
make test-ringbuf
深度分析:Maps 的效能考量
1. Map 類型選擇
不同 Map 類型的效能特性:
| Map 類型 | 查找複雜度 | 記憶體使用 | 併發性能 | 適用場景 |
|---|---|---|---|---|
| Array | O(1) | 固定 | 優秀 | 固定索引、統計計數 |
| Hash | O(1) 平均 | 動態 | 良好 | 動態鍵值、進程追蹤 |
| LRU Hash | O(1) | 有界 | 良好 | 快取、最近使用 |
| Ring Buffer | O(1) | 環形 | 優秀 | 事件流、日誌 |
2. Per-CPU Maps 的優勢
// Per-CPU Maps 避免鎖爭用
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_HASH);
__uint(max_entries, 1000);
__type(key, __u32);
__type(value, __u64);
} percpu_map SEC(".maps");
// 在多核系統上,每個 CPU 有獨立的副本
SEC("tp/syscalls/sys_enter_write")
int count_writes(void *ctx)
{
__u32 pid = bpf_get_current_pid_tgid() >> 32;
__u64 *count = bpf_map_lookup_elem(&percpu_map, &pid);
if (count) {
*count += 1; // 無需原子操作,只在當前 CPU 上修改
}
return 0;
}
使用者空間需要聚合所有 CPU 的值:
// 讀取 Per-CPU Map 的值
func readPerCPUValue(m *bpf.BPFMap, key unsafe.Pointer) (uint64, error) {
values, err := m.GetValuePerCPU(key)
if err != nil {
return 0, err
}
var total uint64
for _, valueBytes := range values {
if len(valueBytes) == 8 {
val := binary.LittleEndian.Uint64(valueBytes)
total += val
}
}
return total, nil
}
3. 記憶體管理最佳化
// Map 大小設計原則
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10000); // 根據實際需求設定
__uint(map_flags, BPF_F_NO_PREALLOC); // 延遲分配記憶體
__type(key, __u32);
__type(value, struct large_value);
} optimized_map SEC(".maps");
疑難排解與最佳化
常見問題
- Map 滿了怎麼辦?
// 使用 LRU Map 自動淘汰舊項目
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, 1000);
__type(key, __u32);
__type(value, __u64);
} lru_map SEC(".maps");
- 如何處理 Map 更新衝突?
// 使用原子操作
__sync_fetch_and_add(&stats->counter, 1);
// 或使用 CAS 操作
__u64 old_val, new_val;
do {
old_val = stats->counter;
new_val = old_val + 1;
} while (!__sync_bool_compare_and_swap(&stats->counter, old_val, new_val));
- 監控 Map 使用情況
sudo bpftool map show
sudo bpftool map dump id <MAP_ID>
# 檢查 Map 統計
cat /proc/kallsyms | grep bpf_map
總結
今天我們深入探討了 eBPF Maps 的各個方面:
- Map 類型:Array、Hash、Ring Buffer 等不同類型的特點和用途
- 效能考量:Per-CPU Maps、記憶體管理、併發處理
- 實際應用:統計系統、配置管理、事件聚合
- 最佳實務:類型選擇、大小設定、錯誤處理
Maps 是 eBPF 程式設計的核心,掌握了 Maps 的使用,就掌握了 eBPF 開發的精髓。在下一篇文章中,我們將探索 XDP 網路程式設計,學習如何在最底層處理網路封包。
Day 7:
- 原文:https://ithelp.ithome.com.tw/articles/10382013
- 發布日期:2025-09-17
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
在前面的文章中,我們已經掌握了 eBPF 的基礎概念和 Maps 的使用方法。從本篇開始,我們將進入 eBPF 的實際應用領域。首先要介紹的是 XDP(eXpress Data Path),這是 eBPF 在網路程式設計中最重要的應用之一。
XDP 讓我們能夠在網路封包進入內核網路堆疊之前就進行處理,這帶來了前所未有的高效能網路處理能力。在本篇文章中,我們將深入理解 XDP 的工作原理,並實作一個簡單的封包過濾器。
XDP 技術概述
什麼是 XDP?
XDP(eXpress Data Path)是一種基於 eBPF 技術的高效能網路資料路徑。它的核心特點是:
- 極早期處理:在封包進入內核網路堆疊之前處理
- 零拷貝:直接在網卡驅動層面操作封包
- 高效能:接近 DPDK 的效能表現
- 靈活性:保持內核的完整網路功能
XDP 在網路堆疊中的位置
┌─────────────────┐
│ User Space │ ← 應用程式
└─────────────────┘
┌─────────────────┐
│ Socket Layer │ ← TCP/UDP Socket
└─────────────────┘
┌─────────────────┐
│ Network Stack │ ← IP/TCP/UDP 處理
└─────────────────┘
┌─────────────────┐
│ XDP Hook │ ← XDP 程式在這裡執行
└─────────────────┘
┌─────────────────┐
│ Network Driver │ ← 網卡驅動
└─────────────────┘
┌─────────────────┐
│ Network Card │ ← 硬體網卡
└─────────────────┘
XDP 程式的返回值
XDP 程式必須返回一個 action code,告訴內核如何處理封包:
// XDP action code
enum xdp_action {
XDP_ABORTED = 0, // 異常終止,丟棄封包並記錄
XDP_DROP, // 丟棄封包
XDP_PASS, // 將封包傳遞給網路堆疊
XDP_TX, // 從同一網卡傳送封包
XDP_REDIRECT, // 重定向到其他網卡或 CPU
};
action code 詳解
- XDP_DROP:最常用的動作,用於 DDoS 防護或惡意流量過濾
- XDP_PASS:允許封包正常進入網路堆疊
- XDP_TX:用於實現反射攻擊防護或負載均衡
- XDP_REDIRECT:用於流量轉發或負載分散
- XDP_ABORTED:錯誤處理,很少使用
實作:簡單的封包過濾器
讓我們實作一個簡單的 XDP 程式,用來過濾特定的 IP 位址。
eBPF 程式實作
首先建立 packet_filter.bpf.c:
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
// 統計 Map
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
__uint(max_entries, 256);
__type(key, __u32);
__type(value, __u64);
} stats_map SEC(".maps");
// 被阻擋的 IP 列表
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u8);
} blocked_ips SEC(".maps");
// 統計類型
enum {
STAT_RX_PACKETS = 0,
STAT_RX_BYTES,
STAT_DROPPED_PACKETS,
STAT_DROPPED_BYTES,
STAT_PASSED_PACKETS,
STAT_PASSED_BYTES,
};
static __always_inline void update_stats(__u32 key, __u64 bytes)
{
__u64 *value = bpf_map_lookup_elem(&stats_map, &key);
if (value) {
__sync_fetch_and_add(value, bytes);
}
}
SEC("xdp")
int packet_filter(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
// 檢查乙太網路標頭
struct ethhdr *eth = data;
if (data + sizeof(*eth) > data_end) {
return XDP_ABORTED;
}
// 只處理 IPv4 封包
if (bpf_ntohs(eth->h_proto) != ETH_P_IP) {
return XDP_PASS;
}
// 檢查 IP 標頭
struct iphdr *ip = data + sizeof(*eth);
if (data + sizeof(*eth) + sizeof(*ip) > data_end) {
return XDP_ABORTED;
}
__u32 packet_size = data_end - data;
__u32 src_ip = ip->saddr;
// 更新接收統計
update_stats(STAT_RX_PACKETS, 1);
update_stats(STAT_RX_BYTES, packet_size);
// 檢查是否為被阻擋的 IP
__u8 *blocked = bpf_map_lookup_elem(&blocked_ips, &src_ip);
if (blocked) {
// 更新丟棄統計
update_stats(STAT_DROPPED_PACKETS, 1);
update_stats(STAT_DROPPED_BYTES, packet_size);
bpf_printk("Blocked packet from IP: %pI4", &src_ip);
return XDP_DROP;
}
// 更新通過統計
update_stats(STAT_PASSED_PACKETS, 1);
update_stats(STAT_PASSED_BYTES, packet_size);
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";
Go 語言載入器實作
建立 main.go:
package main
import (
"fmt"
"log"
"net"
"os"
"os/signal"
"syscall"
"time"
"unsafe"
"github.com/aquasecurity/libbpfgo"
)
const (
STAT_RX_PACKETS = iota
STAT_RX_BYTES
STAT_DROPPED_PACKETS
STAT_DROPPED_BYTES
STAT_PASSED_PACKETS
STAT_PASSED_BYTES
)
type PacketFilter struct {
module *libbpfgo.Module
link *libbpfgo.BPFLink
}
func NewPacketFilter(objPath, ifaceName string) (*PacketFilter, error) {
// 載入 eBPF 物件
module, err := libbpfgo.NewModuleFromFile(objPath)
if err != nil {
return nil, fmt.Errorf("failed to load BPF object: %v", err)
}
if err := module.BPFLoadObject(); err != nil {
return nil, fmt.Errorf("failed to load BPF object: %v", err)
}
// 取得程式
prog, err := module.GetProgram("packet_filter")
if err != nil {
return nil, fmt.Errorf("failed to get BPF program: %v", err)
}
// 附加到網路介面
link, err := prog.AttachXDP(ifaceName)
if err != nil {
return nil, fmt.Errorf("failed to attach XDP program: %v", err)
}
return &PacketFilter{
module: module,
link: link,
}, nil
}
func (pf *PacketFilter) AddBlockedIP(ip string) error {
ipAddr := net.ParseIP(ip)
if ipAddr == nil {
return fmt.Errorf("invalid IP address: %s", ip)
}
// 轉換為 uint32 (little endian)
ipv4 := ipAddr.To4()
if ipv4 == nil {
return fmt.Errorf("not an IPv4 address: %s", ip)
}
ipUint32 := *(*uint32)(unsafe.Pointer(&ipv4[0]))
blockedMap, err := pf.module.GetMap("blocked_ips")
if err != nil {
return fmt.Errorf("failed to get blocked_ips map: %v", err)
}
key := ipUint32
value := uint8(1)
if err := blockedMap.Update(unsafe.Pointer(&key), unsafe.Pointer(&value)); err != nil {
return fmt.Errorf("failed to update blocked_ips map: %v", err)
}
fmt.Printf("Added blocked IP: %s\n", ip)
return nil
}
func (pf *PacketFilter) GetStats() (map[string]uint64, error) {
statsMap, err := pf.module.GetMap("stats_map")
if err != nil {
return nil, fmt.Errorf("failed to get stats_map: %v", err)
}
stats := make(map[string]uint64)
statNames := []string{
"rx_packets", "rx_bytes", "dropped_packets",
"dropped_bytes", "passed_packets", "passed_bytes",
}
for i, name := range statNames {
key := uint32(i)
value, err := statsMap.GetValue(unsafe.Pointer(&key))
if err != nil {
continue
}
// 對於 PERCPU_ARRAY,需要計算所有 CPU 的總和
cpuCount := len(value) / 8 // 每個 uint64 是 8 bytes
total := uint64(0)
for j := 0; j < cpuCount; j++ {
cpuValue := *(*uint64)(unsafe.Pointer(&value[j*8]))
total += cpuValue
}
stats[name] = total
}
return stats, nil
}
func (pf *PacketFilter) PrintStats() {
stats, err := pf.GetStats()
if err != nil {
log.Printf("Failed to get stats: %v", err)
return
}
fmt.Println("\n=== Packet Filter Statistics ===")
fmt.Printf("RX Packets: %d\n", stats["rx_packets"])
fmt.Printf("RX Bytes: %d\n", stats["rx_bytes"])
fmt.Printf("Dropped Packets: %d\n", stats["dropped_packets"])
fmt.Printf("Dropped Bytes: %d\n", stats["dropped_bytes"])
fmt.Printf("Passed Packets: %d\n", stats["passed_packets"])
fmt.Printf("Passed Bytes: %d\n", stats["passed_bytes"])
if stats["rx_packets"] > 0 {
dropRate := float64(stats["dropped_packets"]) / float64(stats["rx_packets"]) * 100
fmt.Printf("Drop Rate: %.2f%%\n", dropRate)
}
}
func (pf *PacketFilter) Close() {
if pf.link != nil {
pf.link.Destroy()
}
if pf.module != nil {
pf.module.Close()
}
}
func main() {
if len(os.Args) != 3 {
fmt.Printf("Usage: %s <interface> <blocked_ip>\n", os.Args[0])
fmt.Printf("Example: %s eth0 192.168.1.100\n", os.Args[0])
os.Exit(1)
}
ifaceName := os.Args[1]
blockedIP := os.Args[2]
// 建立封包過濾器
filter, err := NewPacketFilter("packet_filter.bpf.o", ifaceName)
if err != nil {
log.Fatalf("Failed to create packet filter: %v", err)
}
defer filter.Close()
// 新增被阻擋的 IP
if err := filter.AddBlockedIP(blockedIP); err != nil {
log.Fatalf("Failed to add blocked IP: %v", err)
}
fmt.Printf("XDP packet filter loaded on interface %s\n", ifaceName)
fmt.Printf("Blocking traffic from IP: %s\n", blockedIP)
fmt.Println("Press Ctrl+C to stop...")
// 設定信號處理
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
// 定期顯示統計資訊
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
filter.PrintStats()
case <-sigChan:
fmt.Println("\nShutting down...")
filter.PrintStats()
return
}
}
}
Makefile
建立 Makefile:
# XDP Packet Filter Makefile
CLANG ?= clang
LLVM_STRIP ?= llvm-strip
ARCH := x86_64
# 輸出檔案
BPF_OBJ = packet_filter.bpf.o
TARGET = packet_filter
# 編譯標誌
CFLAGS := -O2 -g -Wall -Werror
BPF_CFLAGS := -target bpf -D__TARGET_ARCH_$(ARCH)
# 包含路徑
INCLUDES := -I/usr/include/$(shell uname -m)-linux-gnu
.PHONY: all clean test
all: $(BPF_OBJ) $(TARGET)
# 編譯 eBPF 程式
$(BPF_OBJ): packet_filter.bpf.c
$(CLANG) $(BPF_CFLAGS) $(INCLUDES) $(CFLAGS) -c $< -o $@
$(LLVM_STRIP) -g $@
# 編譯 Go 程式
$(TARGET): main.go $(BPF_OBJ)
go build -o $(TARGET) main.go
# 測試 (需要 root 權限)
test: $(BPF_OBJ) $(TARGET)
@echo "Testing packet filter..."
@echo "Note: This requires root privileges and a valid network interface"
@echo "Run: sudo ./$(TARGET) <interface> <blocked_ip>"
# 安裝依賴
deps:
go mod init packet-filter
go get github.com/aquasecurity/libbpfgo
# 檢查程式
verify: $(BPF_OBJ)
bpftool prog show
bpftool map show
clean:
rm -f $(BPF_OBJ) $(TARGET)
rm -f go.mod go.sum
help:
@echo "Available targets:"
@echo " all - Build eBPF object and Go binary"
@echo " deps - Install Go dependencies"
@echo " test - Run test (requires root)"
@echo " verify - Verify loaded BPF programs"
@echo " clean - Clean build artifacts"
@echo " help - Show this help message"
使用與測試
編譯程式
# 安裝依賴
make deps
# 編譯
make all
執行測試
# 需要 root 權限
sudo ./packet_filter eth0 192.168.1.100
# 或者使用 loopback 介面測試
sudo ./packet_filter lo 127.0.0.1
測試封包過濾
在另一個終端機中:
# 測試正常流量 (應該通過)
ping 8.8.8.8
# 從被阻擋的 IP 發送流量 (如果可能的話)
# 或者使用 hping3 模擬
sudo hping3 -S -p 80 -a 192.168.1.100 target_ip
XDP 模式比較
XDP 支援多種載入模式:
-
Generic XDP (SKB 模式):
- 相容性最好,但效能較低
- 在網路堆疊中較晚執行
- Libbpf-go 目前尚不支援 attch Generic XDP type 的 eBPF program
-
Native XDP (驅動模式):
- 效能最好,在驅動層面執行
- 需要驅動支援
-
Offloaded XDP (硬體模式):
- 效能最高,在網卡硬體執行
- 需要特殊硬體支援
實戰應用場景
DDoS 防護
// 簡單的速率限制
struct rate_limit_key {
__u32 src_ip;
__u32 time_window;
};
// 實現每秒封包數限制
if (packet_count > MAX_PPS) {
return XDP_DROP;
}
負載均衡
// 基於 hash 的負載均衡
__u32 hash = jhash_2words(src_ip, dst_port, 0);
__u32 backend = hash % num_backends;
// 修改目標 IP
ip->daddr = backends[backend];
// 重新計算 checksum
return XDP_TX;
流量監控
// 記錄流量模式
struct flow_key {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u8 protocol;
};
// 更新流量統計
update_flow_stats(&flow_key, packet_size);
總結
在本篇文章中,我們深入學習了 XDP 技術:
- 理解了 XDP 的工作原理:在網路堆疊早期進行高效能封包處理
- 掌握了 XDP 程式的基本結構:動作代碼、封包解析、邊界檢查
- 實作了完整的封包過濾器:包含統計功能和動態配置
- 學習了效能最佳化技巧:記憶體存取、統計方法、原子操作
XDP 是 eBPF 在網路領域最重要的應用之一,為高效能網路處理打開了新的可能性。在下一篇文章中,我們將進一步實作一個完整的負載均衡器,展示 XDP 在實際應用中的強大能力。
在下一篇文章中,我們將使用 XDP 技術實作一個完整的 Tiny Load Balancer,學習如何修改封包內容並實現負載均衡功能。
Day 8:
- 原文:https://ithelp.ithome.com.tw/articles/10382716
- 發布日期:2025-09-18
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
在上一篇文章中,我們學習了 XDP 的基本概念和封包過濾技術。今天我們將進行一個稍具挑戰性的實戰專案:使用 XDP 技術打造一個完整的 Tiny Load Balancer。
該專案受 eBPF Summit 2021: An eBPF Load Balancer from scratch 啟發,並且修改自 lb-from-scratch 專案。
這個專案將帶領我們深入學習:
- 網路封包的解析與修改
- L2/L3/L4 層的封包處理
- 實作簡單的負載均衡演算法
- 完整的測試環境搭建
通過這個實戰專案,您將對 eBPF 在網路程式設計中的強大能力有更深刻的理解。
負載均衡器架構設計
整體架構
┌─────────────┐ ┌─────────────────┐ ┌─────────────┐
│ Client │───▶│ Load Balancer │───▶│ Backend A │
│192.17.0.4 │ │ 192.17.0.5 │ │192.17.0.2 │
└─────────────┘ │ │ └─────────────┘
│ XDP Hook │
│ │ ┌─────────────┐
└─────────────────┘───▶│ Backend B │
│192.17.0.3 │
└─────────────┘
負載均衡原理
我們的 TinyLB 工作原理:
- 入站處理:攔截發送到 LB IP 的封包
- 後端選擇:使用演算法選擇後端伺服器
- 封包修改:修改目標 IP 和 MAC 位址
- 轉發封包:將修改後的封包傳送出去
- 出站處理:修改返回封包的來源資訊
eBPF 程式實作
主程式檔案
建立 xdp_lb_kern.c:
#include "xdp_lb_kern.h"
#define IP_ADDRESS(x) (unsigned int)(192 + (17 << 8) + (0 << 16) + (x << 24))
#define BACKEND_A 2
#define BACKEND_B 3
#define CLIENT 4
#define LB 5
#define HTTP_PORT 80
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, __u32);
__type(value, __u32);
__uint(max_entries, 64);
} lb_map SEC(".maps");
SEC("xdp")
int tiny_lb(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if (data + sizeof(struct ethhdr) > data_end)
return XDP_ABORTED;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = data + sizeof(struct ethhdr);
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end)
return XDP_ABORTED;
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
struct tcphdr *tcph = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) + sizeof(struct tcphdr) > data_end)
return XDP_ABORTED;
__be32 ip_saddr = iph->saddr;
if (ip_saddr == IP_ADDRESS(CLIENT) &&
bpf_ntohs(tcph->dest) == HTTP_PORT)
{
bpf_printk("Got http request from %x", ip_saddr);
int dst = BACKEND_A;
if (bpf_ktime_get_ns() % 2)
dst = BACKEND_B;
__u32 *dst_ip = bpf_map_lookup_elem(&lb_map, &dst);
if (!dst_ip) {
bpf_printk("Error: Destination IP not found in the map");
return XDP_PASS;
}
iph->daddr = bpf_htonl(*dst_ip);
eth->h_dest[5] = dst;
} else if (iph->saddr == IP_ADDRESS(BACKEND_A) || iph->saddr == IP_ADDRESS(BACKEND_B))
{
bpf_printk("Got the http response from backend [%x]: forward to client %x", iph->saddr, iph->daddr);
int c = CLIENT;
__u32 *client_ip = bpf_map_lookup_elem(&lb_map, &c);
if (!client_ip) {
bpf_printk("Error: Client IP not found in the map");
return XDP_PASS;
}
iph->daddr = bpf_htonl(*client_ip);
eth->h_dest[5] = CLIENT;
}
iph->saddr = IP_ADDRESS(LB);
eth->h_source[5] = LB;
iph->check = iph_csum(iph);
bpf_printk("Forward from lb %x to client %x", iph->saddr, iph->daddr);
return XDP_TX;
}
char _license[] SEC("license") = "GPL";
參考上方的程式碼,XDP type program 允許接受 pointer to struct xdp_md 作為 program context。這個 context 本身就是 L2 以上的資料內容,所以我們可以做型別轉換來取得每一層的資料的起始位置:
SEC("xdp")
int tiny_lb(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if (data + sizeof(struct ethhdr) > data_end)
return XDP_ABORTED;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = data + sizeof(struct ethhdr);
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end)
return XDP_ABORTED;
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
struct tcphdr *tcph = data + sizeof(struct ethhdr) + sizeof(struct iphdr);
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) + sizeof(struct tcphdr) > data_end)
return XDP_ABORTED;
藉由這個方式,我們就能將不屬於 TCP 的網路封包過濾掉囉。
讓我們繼續向下追蹤,會發現範例程式使用 eBPF Maps 來管理 Load Balancer 後面 Backend Service 的 entity:
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, __u32);
__type(value, __u32);
__uint(max_entries, 64);
} lb_map SEC(".maps");
稍後會在 Golang 撰寫的管理程式看到操作 MAP 的程式碼。
若 Dst Port 為 80 且 Src IP 來自給定的 Client,那麼就根據當前的時間 %2 決定要將請求轉發到哪一個後端伺服器中:
if (ip_saddr == IP_ADDRESS(CLIENT) &&
bpf_ntohs(tcph->dest) == HTTP_PORT)
{
bpf_printk("Got http request from %x", ip_saddr);
int dst = BACKEND_A;
if (bpf_ktime_get_ns() % 2)
dst = BACKEND_B;
__u32 *dst_ip = bpf_map_lookup_elem(&lb_map, &dst);
if (!dst_ip) {
bpf_printk("Error: Destination IP not found in the map");
return XDP_PASS;
}
iph->daddr = bpf_htonl(*dst_ip);
eth->h_dest[5] = dst;
}
反之,若 Src IP 來自後端伺服器,我們就將請求的 Dst IP 設定為 Client IP:
else if (iph->saddr == IP_ADDRESS(BACKEND_A) || iph->saddr == IP_ADDRESS(BACKEND_B))
{
bpf_printk("Got the http response from backend [%x]: forward to client %x", iph->saddr, iph->daddr);
int c = CLIENT;
__u32 *client_ip = bpf_map_lookup_elem(&lb_map, &c);
if (!client_ip) {
bpf_printk("Error: Client IP not found in the map");
return XDP_PASS;
}
iph->daddr = bpf_htonl(*client_ip);
eth->h_dest[5] = CLIENT;
}
Go 語言負載均衡器管理程式
建立 main.go:
package main
import (
"os"
"time"
"unsafe"
bpf "github.com/aquasecurity/libbpfgo"
)
func IP_ADDRESS(d, c, b, a int) uint32 {
return uint32(a + b<<8 + c<<16 + d<<24)
}
func main() {
bpfModule, err := bpf.NewModuleFromFile("xdp_lb_kern.o")
if err != nil {
panic(err)
}
defer bpfModule.Close()
if err := bpfModule.BPFLoadObject(); err != nil {
panic(err)
}
prog, err := bpfModule.GetProgram("tiny_lb")
if err != nil {
panic(err)
}
// TODO: support xdpgeneric
// link, err := prog.AttachXDP("eth0")
// if err != nil {
// panic(err)
// }
// if link.FileDescriptor() == 0 {
// os.Exit(-1)
// }
prog_map, err := bpfModule.GetMap("lb_map")
if err != nil {
panic(err)
} else {
clientIP := IP_ADDRESS(192, 17, 0, 4)
backendAIP := IP_ADDRESS(192, 17, 0, 2)
backendBIP := IP_ADDRESS(192, 17, 0, 3)
lbIP := IP_ADDRESS(192, 17, 0, 5)
c := uint32(4)
a := uint32(2)
b := uint32(3)
lb := uint32(5)
prog_map.Update(unsafe.Pointer(&c), unsafe.Pointer(&clientIP))
prog_map.Update(unsafe.Pointer(&a), unsafe.Pointer(&backendAIP))
prog_map.Update(unsafe.Pointer(&b), unsafe.Pointer(&backendBIP))
prog_map.Update(unsafe.Pointer(&lb), unsafe.Pointer(&lbIP))
}
prog, err = bpfModule.GetProgram("capture_skb")
if err != nil {
panic(err)
}
link, err := prog.AttachGeneric()
if err != nil {
panic(err)
}
if link.FileDescriptor() == 0 {
os.Exit(-1)
}
for {
time.Sleep(10 * time.Second)
}
}
Docker Compose 測試環境
由於 Client、Backend A 與 Backend B 的 IP 在上面的範例中都是固定的,為了精簡測試環境的搭建,我們使用 docker-compose 部署測試必要的服務:
建立 docker-compose.yml:
version: '3.8'
services:
client:
container_name: client
image: ubuntu:20.04
command: bash -c "apt-get update && apt-get install -y curl iputils-ping && sleep infinity"
privileged: true
cap_add:
- NET_ADMIN
networks:
lbnet:
ipv4_address: 192.17.0.4
depends_on:
- lb
lb:
container_name: lb
image: ianchen0119/lb:latest
command: bash -c "make run"
privileged: true
cap_add:
- NET_ADMIN
volumes:
- ./xdp_lb_user:/ianchen/xdp_lb_user
- ./Makefile:/ianchen/Makefile
- ./xdp_lb_kern.h:/ianchen/xdp_lb_kern.h
- ./xdp_lb_kern.c:/ianchen/xdp_lb_kern.c
- ./vmlinux:/ianchen/vmlinux
- ./main:/ianchen/main
networks:
lbnet:
ipv4_address: 192.17.0.5
backend-a:
container_name: backend-a
image: nginxdemos/hello:plain-text
privileged: true
cap_add:
- NET_ADMIN
networks:
lbnet:
ipv4_address: 192.17.0.2
depends_on:
- lb
backend-b:
container_name: backend-b
image: nginxdemos/hello:plain-text
privileged: true
cap_add:
- NET_ADMIN
networks:
lbnet:
ipv4_address: 192.17.0.3
depends_on:
- lb
networks:
lbnet:
ipam:
driver: default
config:
- subnet: 192.17.0.0/24
driver_opts:
com.docker.network.bridge.name: br-lb
volumes:
dbdata:
測試與驗證
請參考 tinyLB README,內含詳細的說明。
這次的範例比起先前筆者發表於 StarBugs 的文章有些許的差異:
- 使用 Maps 讓 User Space 管理程式能夠指派 Backend server 的 IP
- 使用 libbpf-go 撰寫 User Space 管理程式
總結
在本篇文章中,我們實作了一個完整的 Tiny Load Balancer:
- 深入理解了負載均衡原理:從封包攔截到後端選擇的完整流程
- 掌握了封包修改技術:IP/MAC 地址修改和 checksum 重新計算
- 建立了完整的測試環境:Docker Compose 環境和自動化測試
這個實戰專案展示了 XDP 在實際網路應用中的強大能力,為後續學習更複雜的 eBPF 應用打下堅實基礎。
筆者的話:
Coding Agent 產出文章的品質還是有待加強,所以今日的內容我有手動修改一番。
XDP 雖然能高速、巨量的處理網路包,但完全早於 kernel 的網路堆疊也會造成一些問題:
- 若有 NAT 功能的需求,必須自行實作,否則因改用 TC type 的 eBPF。當然,這也會損失一些效能。
- XDP 與 TC 都沒辦法處理 IP Fragment 的問題,如果有這部分的需求得使用其他方法。
總而言之,XDP 非常適合打造 FireWall、LoadBalancer 這類網路功能,但如果有更複雜的封包處理要求,仍需要放棄 XDP 的吞吐量轉而使用更適合的 eBPF program type。
參考資源
Day 9:
- 原文:https://ithelp.ithome.com.tw/articles/10383530
- 發布日期:2025-09-19
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
在前面的文章中,我們體驗了 eBPF 程式的強大功能,但您可能已經注意到一個問題:eBPF 程式在不同的核心版本或系統配置上可能無法正常工作。這是因為核心資料結構在不同版本間可能發生變化,導致程式相容性問題。
今天我們將深入學習 CO-RE (Compile Once, Run Everywhere) 技術,這是解決 eBPF 程式可移植性問題的關鍵技術。通過 CO-RE,我們可以編寫一次 eBPF 程式,然後在任何支援的核心版本上運行。
筆者補充:
在 CO-RE 出現之前,我們可以使用 BCC 動態的載入 eBPF program 以解決 portability 的問題。但是對於 container-based service 來說,BCC 依賴的 tool chain 實在太大太雜了。因此,eBPF 社群就透過 relocation 的方式使 eBPF 能夠做到 Compile Once, Run Everywhere!但是使用 CO-RE 仍須注意 helper function、kfuncs 以及不同 program type 在跨版本支援度的問題唷。
什麼是 CO-RE?
核心概念
CO-RE 是 eBPF 生態系統中的一項革命性技術,它包含三個核心組件:
- BTF (BPF Type Format):核心資料結構的元資料描述
- Libbpf:使用者空間的重定位庫
- Compiler Built-ins:編譯器內建的幫助函數
傳統問題
在 CO-RE 之前,eBPF 程式面臨以下挑戰:
// 傳統方式:硬編碼偏移量
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
pid_t pid = *(pid_t *)((char *)task + 1248); // 偏移量在不同核心版本間可能改變
這種方式的問題:
- 偏移量隨核心版本變化
- 需要為每個核心版本重新編譯
- 維護成本極高
CO-RE 解決方案
// CO-RE 方式:使用 BPF_CORE_READ
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
pid_t pid = BPF_CORE_READ(task, pid); // 自動處理不同核心版本的差異
CO-RE 的優勢:
- 編譯一次,到處運行
- 自動處理核心版本差異
- 程式碼更簡潔易讀
BTF 詳解
BTF 格式
BTF 是一種緊湊的元資料格式,描述了 C 資料類型:
# 查看核心 BTF 資訊
bpftool btf dump file /sys/kernel/btf/vmlinux format c
# 查看特定結構體
bpftool btf dump file /sys/kernel/btf/vmlinux | grep "struct task_struct"
BTF 生成
# 從核心 DWARF 資訊生成 BTF
pahole --btf_encode_detached vmlinux vmlinux.btf
# 檢查 BTF 格式
bpftool btf dump file vmlinux.btf format raw
BTF 結構示例
// BTF 描述的 task_struct 結構
[1] STRUCT 'task_struct' size=8704 vlen=207
'state' type_id=2 bits_offset=0
'stack' type_id=3 bits_offset=64
'usage' type_id=4 bits_offset=128
'flags' type_id=5 bits_offset=160
'ptrace' type_id=5 bits_offset=192
'on_cpu' type_id=6 bits_offset=224
'wake_entry' type_id=7 bits_offset=256
'cpu' type_id=8 bits_offset=352
'recent_used_cpu' type_id=8 bits_offset=384
'pid' type_id=9 bits_offset=1056 // pid 在位置 1056
...
CO-RE 重定位機制
重定位類型
CO-RE 支持多種重定位類型:
- Field Offset:欄位偏移量
- Field Size:欄位大小
- Field Existence:欄位是否存在
- Type Size:類型大小
- Enum Value:列舉值
重定位範例
建立 core_example.bpf.c:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
// 傳統方式 vs CO-RE 方式比較
SEC("tp/sched/sched_process_exec")
int trace_exec_traditional(struct trace_event_raw_sched_process_exec *ctx)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
// 傳統方式:硬編碼偏移量(危險!)
// pid_t pid = *(pid_t *)((char *)task + 1056);
return 0;
}
SEC("tp/sched/sched_process_exec")
int trace_exec_core(struct trace_event_raw_sched_process_exec *ctx)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
// CO-RE 方式:自動重定位
pid_t pid = BPF_CORE_READ(task, pid);
// 檢查欄位是否存在
if (bpf_core_field_exists(task->pid)) {
bpf_printk("PID field exists: %d", pid);
}
// 取得欄位大小
size_t pid_size = bpf_core_field_size(task->pid);
bpf_printk("PID field size: %lu", pid_size);
return 0;
}
char _license[] SEC("license") = "GPL";
CO-RE 巨集詳解
BPF_CORE_READ 家族
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
SEC("tp/syscalls/sys_enter_openat")
int trace_openat(struct trace_event_raw_sys_enter *ctx)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
// 1. BPF_CORE_READ - 讀取單一欄位
pid_t pid = BPF_CORE_READ(task, pid);
pid_t tgid = BPF_CORE_READ(task, tgid);
// 2. BPF_CORE_READ_STR - 讀取字串
char comm[16];
BPF_CORE_READ_STR(comm, sizeof(comm), task, comm);
// 3. BPF_CORE_READ_INTO - 讀取到指定變數
pid_t local_pid;
BPF_CORE_READ_INTO(&local_pid, task, pid);
// 4. BPF_CORE_READ_USER - 讀取使用者空間資料
char __user *filename = (char __user *)ctx->args[1];
char filename_buf[256];
BPF_CORE_READ_USER_STR(filename_buf, sizeof(filename_buf), filename);
bpf_printk("Process %s (PID: %d, TGID: %d) opening: %s",
comm, pid, tgid, filename_buf);
return 0;
}
鏈式讀取
SEC("tp/sched/sched_process_fork")
int trace_fork(struct trace_event_raw_sched_process_fork *ctx)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
// 鏈式讀取:task->mm->mmap->vm_file->f_path->dentry->d_name->name
char *exe_name = BPF_CORE_READ(task, mm, exe_file, f_path.dentry, d_name.name);
// 多層指標讀取
struct mm_struct *mm = BPF_CORE_READ(task, mm);
if (mm) {
unsigned long start_brk = BPF_CORE_READ(mm, start_brk);
unsigned long brk = BPF_CORE_READ(mm, brk);
bpf_printk("Process heap: start=0x%lx, current=0x%lx", start_brk, brk);
}
return 0;
}
條件編譯與相容性
SEC("tp/sched/sched_process_exit")
int trace_exit(struct trace_event_raw_sched_process_exit *ctx)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
// 檢查欄位是否存在
if (bpf_core_field_exists(task->exit_code)) {
int exit_code = BPF_CORE_READ(task, exit_code);
bpf_printk("Process exit with code: %d", exit_code);
} else {
bpf_printk("exit_code field not available in this kernel");
}
// 取得類型大小
size_t task_size = bpf_core_type_size(struct task_struct);
bpf_printk("task_struct size: %lu bytes", task_size);
// 列舉值處理
if (bpf_core_enum_value_exists(enum pid_type, PIDTYPE_PID)) {
bpf_printk("PIDTYPE_PID value: %d",
bpf_core_enum_value(enum pid_type, PIDTYPE_PID));
}
return 0;
}
實戰範例:跨版本相容的程序監控器
程式結構設計
建立 process_monitor.h:
#ifndef __PROCESS_MONITOR_H__
#define __PROCESS_MONITOR_H__
#include <linux/types.h>
#define TASK_COMM_LEN 16
#define MAX_PATH_LEN 256
// 程序事件類型
enum event_type {
EVENT_EXEC = 1,
EVENT_EXIT,
EVENT_FORK,
EVENT_CLONE,
};
// 程序事件結構
struct process_event {
__u64 timestamp;
__u32 event_type;
__u32 pid;
__u32 ppid;
__u32 tid;
__u32 uid;
__u32 gid;
__s32 exit_code;
char comm[TASK_COMM_LEN];
char filename[MAX_PATH_LEN];
} __attribute__((packed));
// 程序統計
struct process_stats {
__u64 total_events;
__u64 exec_count;
__u64 exit_count;
__u64 fork_count;
__u64 clone_count;
} __attribute__((packed));
#endif /* __PROCESS_MONITOR_H__ */
eBPF 程式實作
建立 process_monitor.bpf.c:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_tracing.h>
#include "process_monitor.h"
// Ring Buffer for events
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024);
} events SEC(".maps");
// Statistics map
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
__uint(max_entries, 1);
__type(key, __u32);
__type(value, struct process_stats);
} stats_map SEC(".maps");
// 更新統計資訊
static __always_inline void update_stats(enum event_type type)
{
__u32 key = 0;
struct process_stats *stats = bpf_map_lookup_elem(&stats_map, &key);
if (!stats) {
return;
}
__sync_fetch_and_add(&stats->total_events, 1);
switch (type) {
case EVENT_EXEC:
__sync_fetch_and_add(&stats->exec_count, 1);
break;
case EVENT_EXIT:
__sync_fetch_and_add(&stats->exit_count, 1);
break;
case EVENT_FORK:
__sync_fetch_and_add(&stats->fork_count, 1);
break;
case EVENT_CLONE:
__sync_fetch_and_add(&stats->clone_count, 1);
break;
}
}
// 填充基本程序資訊
static __always_inline void fill_process_info(struct process_event *event)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
event->timestamp = bpf_ktime_get_ns();
// 使用 CO-RE 安全讀取
event->pid = BPF_CORE_READ(task, pid);
event->tid = BPF_CORE_READ(task, tgid);
// 讀取父程序 PID
struct task_struct *parent = BPF_CORE_READ(task, parent);
if (parent) {
event->ppid = BPF_CORE_READ(parent, pid);
}
// 讀取使用者資訊
kuid_t uid = BPF_CORE_READ(task, cred, uid);
kgid_t gid = BPF_CORE_READ(task, cred, gid);
event->uid = uid.val;
event->gid = gid.val;
// 讀取程序名稱
BPF_CORE_READ_STR(event->comm, sizeof(event->comm), task, comm);
}
// 取得執行檔路徑
static __always_inline int get_exe_path(char *buf, size_t size)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
// 檢查 mm 是否存在
if (!bpf_core_field_exists(task->mm) || !BPF_CORE_READ(task, mm)) {
return -1;
}
struct mm_struct *mm = BPF_CORE_READ(task, mm);
if (!mm) {
return -1;
}
// 檢查 exe_file 是否存在
if (!bpf_core_field_exists(mm->exe_file)) {
return -1;
}
struct file *exe_file = BPF_CORE_READ(mm, exe_file);
if (!exe_file) {
return -1;
}
// 讀取檔案路徑
struct path path = BPF_CORE_READ(exe_file, f_path);
struct dentry *dentry = BPF_CORE_READ(&path, dentry);
if (dentry) {
struct qstr d_name = BPF_CORE_READ(dentry, d_name);
BPF_CORE_READ_STR(buf, size, d_name.name);
return 0;
}
return -1;
}
// 程序執行事件
SEC("tp/sched/sched_process_exec")
int trace_exec(struct trace_event_raw_sched_process_exec *ctx)
{
struct process_event *event;
// 預留 Ring Buffer 空間
event = bpf_ringbuf_reserve(&events, sizeof(*event), 0);
if (!event) {
return 0;
}
// 初始化事件
__builtin_memset(event, 0, sizeof(*event));
event->event_type = EVENT_EXEC;
// 填充基本資訊
fill_process_info(event);
// 取得執行檔路徑
if (get_exe_path(event->filename, sizeof(event->filename)) != 0) {
// 如果無法取得路徑,使用程序名稱
__builtin_memcpy(event->filename, event->comm, sizeof(event->comm));
}
// 提交事件
bpf_ringbuf_submit(event, 0);
// 更新統計
update_stats(EVENT_EXEC);
return 0;
}
// 程序結束事件
SEC("tp/sched/sched_process_exit")
int trace_exit(struct trace_event_raw_sched_process_exit *ctx)
{
struct process_event *event;
event = bpf_ringbuf_reserve(&events, sizeof(*event), 0);
if (!event) {
return 0;
}
__builtin_memset(event, 0, sizeof(*event));
event->event_type = EVENT_EXIT;
fill_process_info(event);
// 讀取退出代碼
if (bpf_core_field_exists(((struct task_struct *)0)->exit_code)) {
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
event->exit_code = BPF_CORE_READ(task, exit_code);
}
bpf_ringbuf_submit(event, 0);
update_stats(EVENT_EXIT);
return 0;
}
// 程序 fork 事件
SEC("tp/sched/sched_process_fork")
int trace_fork(struct trace_event_raw_sched_process_fork *ctx)
{
struct process_event *event;
event = bpf_ringbuf_reserve(&events, sizeof(*event), 0);
if (!event) {
return 0;
}
__builtin_memset(event, 0, sizeof(*event));
event->event_type = EVENT_FORK;
fill_process_info(event);
bpf_ringbuf_submit(event, 0);
update_stats(EVENT_FORK);
return 0;
}
// kprobe 範例:監控 do_exit
SEC("kprobe/do_exit")
int kprobe_do_exit(struct pt_regs *ctx)
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
pid_t pid = BPF_CORE_READ(task, pid);
pid_t tgid = BPF_CORE_READ(task, tgid);
// 取得退出代碼參數
long exit_code = PT_REGS_PARM1(ctx);
bpf_printk("Process %d (tgid: %d) exiting with code: %ld",
pid, tgid, exit_code);
return 0;
}
char _license[] SEC("license") = "GPL";
Go 程式實作
建立 main.go:
package main
import (
"bytes"
"encoding/binary"
"fmt"
"log"
"os"
"os/signal"
"syscall"
"time"
"unsafe"
"github.com/aquasecurity/libbpfgo"
)
// 對應 C 結構體
type ProcessEvent struct {
Timestamp uint64
EventType uint32
PID uint32
PPID uint32
TID uint32
UID uint32
GID uint32
ExitCode int32
Comm [16]byte
Filename [256]byte
}
type ProcessStats struct {
TotalEvents uint64
ExecCount uint64
ExitCount uint64
ForkCount uint64
CloneCount uint64
}
// 事件類型常數
const (
EventExec = 1
EventExit = 2
EventFork = 3
EventClone = 4
)
type ProcessMonitor struct {
module *libbpfgo.Module
rb *libbpfgo.RingBuffer
}
func NewProcessMonitor(objPath string) (*ProcessMonitor, error) {
// 載入 eBPF 程式
module, err := libbpfgo.NewModuleFromFile(objPath)
if err != nil {
return nil, fmt.Errorf("failed to load BPF object: %v", err)
}
if err := module.BPFLoadObject(); err != nil {
return nil, fmt.Errorf("failed to load BPF object: %v", err)
}
// 附加 tracepoint 程式
execProg, err := module.GetProgram("trace_exec")
if err != nil {
return nil, fmt.Errorf("failed to get exec program: %v", err)
}
exitProg, err := module.GetProgram("trace_exit")
if err != nil {
return nil, fmt.Errorf("failed to get exit program: %v", err)
}
forkProg, err := module.GetProgram("trace_fork")
if err != nil {
return nil, fmt.Errorf("failed to get fork program: %v", err)
}
kprobeProg, err := module.GetProgram("kprobe_do_exit")
if err != nil {
return nil, fmt.Errorf("failed to get kprobe program: %v", err)
}
// 附加程式
if _, err := execProg.AttachTracepoint("sched", "sched_process_exec"); err != nil {
return nil, fmt.Errorf("failed to attach exec tracepoint: %v", err)
}
if _, err := exitProg.AttachTracepoint("sched", "sched_process_exit"); err != nil {
return nil, fmt.Errorf("failed to attach exit tracepoint: %v", err)
}
if _, err := forkProg.AttachTracepoint("sched", "sched_process_fork"); err != nil {
return nil, fmt.Errorf("failed to attach fork tracepoint: %v", err)
}
if _, err := kprobeProg.AttachKprobe("do_exit"); err != nil {
log.Printf("Warning: failed to attach kprobe: %v", err)
}
return &ProcessMonitor{
module: module,
}, nil
}
func (pm *ProcessMonitor) StartMonitoring() error {
// 取得 Ring Buffer
eventsMap, err := pm.module.GetMap("events")
if err != nil {
return fmt.Errorf("failed to get events map: %v", err)
}
pm.rb, err = pm.module.InitRingBuf("events", pm.handleEvent)
if err != nil {
return fmt.Errorf("failed to init ring buffer: %v", err)
}
// 開始處理事件
pm.rb.Start()
return nil
}
func (pm *ProcessMonitor) handleEvent(data []byte) {
// 解析事件
event := (*ProcessEvent)(unsafe.Pointer(&data[0]))
// 轉換字串
comm := nullTerminatedString(event.Comm[:])
filename := nullTerminatedString(event.Filename[:])
// 格式化時間
timestamp := time.Unix(0, int64(event.Timestamp))
// 格式化事件類型
eventTypeStr := map[uint32]string{
EventExec: "EXEC",
EventExit: "EXIT",
EventFork: "FORK",
EventClone: "CLONE",
}[event.EventType]
// 輸出事件
fmt.Printf("[%s] %s: PID=%d PPID=%d TID=%d UID=%d GID=%d",
timestamp.Format("15:04:05.000"),
eventTypeStr,
event.PID,
event.PPID,
event.TID,
event.UID,
event.GID)
if event.EventType == EventExit {
fmt.Printf(" ExitCode=%d", event.ExitCode)
}
fmt.Printf(" Comm=%s", comm)
if filename != "" && filename != comm {
fmt.Printf(" File=%s", filename)
}
fmt.Println()
}
func (pm *ProcessMonitor) GetStats() (*ProcessStats, error) {
statsMap, err := pm.module.GetMap("stats_map")
if err != nil {
return nil, fmt.Errorf("failed to get stats map: %v", err)
}
key := uint32(0)
value, err := statsMap.GetValue(unsafe.Pointer(&key))
if err != nil {
return nil, fmt.Errorf("failed to get stats: %v", err)
}
// 處理 Per-CPU 統計
stats := &ProcessStats{}
cpuCount := len(value) / int(unsafe.Sizeof(*stats))
for i := 0; i < cpuCount; i++ {
offset := i * int(unsafe.Sizeof(*stats))
cpuStats := (*ProcessStats)(unsafe.Pointer(&value[offset]))
stats.TotalEvents += cpuStats.TotalEvents
stats.ExecCount += cpuStats.ExecCount
stats.ExitCount += cpuStats.ExitCount
stats.ForkCount += cpuStats.ForkCount
stats.CloneCount += cpuStats.CloneCount
}
return stats, nil
}
func (pm *ProcessMonitor) PrintStats() {
stats, err := pm.GetStats()
if err != nil {
log.Printf("Failed to get stats: %v", err)
return
}
fmt.Println("\n=== Process Monitor Statistics ===")
fmt.Printf("Total Events: %d\n", stats.TotalEvents)
fmt.Printf("Exec Events: %d\n", stats.ExecCount)
fmt.Printf("Exit Events: %d\n", stats.ExitCount)
fmt.Printf("Fork Events: %d\n", stats.ForkCount)
fmt.Printf("Clone Events: %d\n", stats.CloneCount)
}
func (pm *ProcessMonitor) Close() {
if pm.rb != nil {
pm.rb.Stop()
pm.rb.Close()
}
if pm.module != nil {
pm.module.Close()
}
}
func nullTerminatedString(b []byte) string {
if i := bytes.IndexByte(b, 0); i >= 0 {
return string(b[:i])
}
return string(b)
}
func main() {
// 建立程序監控器
monitor, err := NewProcessMonitor("process_monitor.bpf.o")
if err != nil {
log.Fatalf("Failed to create process monitor: %v", err)
}
defer monitor.Close()
// 開始監控
if err := monitor.StartMonitoring(); err != nil {
log.Fatalf("Failed to start monitoring: %v", err)
}
fmt.Println("Process Monitor started. Press Ctrl+C to stop...")
fmt.Println("Monitoring process exec, exit, and fork events...")
// 設定信號處理
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
// 定期顯示統計資訊
ticker := time.NewTicker(30 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
monitor.PrintStats()
case <-sigChan:
fmt.Println("\nShutting down...")
monitor.PrintStats()
return
}
}
}
測試與驗證
編譯和執行
建立 Makefile:
# Process Monitor Makefile
CLANG ?= clang
LLVM_STRIP ?= llvm_strip
ARCH := x86_64
# 輸出檔案
BPF_OBJ = process_monitor.bpf.o
TARGET = process_monitor
# 編譯標誌
CFLAGS := -O2 -g -Wall -Werror
BPF_CFLAGS := -target bpf -D__TARGET_ARCH_$(ARCH)
# 包含路徑
INCLUDES := -I/usr/include/$(shell uname -m)-linux-gnu -I. -I./vmlinux
.PHONY: all clean test vmlinux
all: vmlinux $(BPF_OBJ) $(TARGET)
# 生成 vmlinux.h
vmlinux:
mkdir -p vmlinux
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux/vmlinux.h
# 編譯 eBPF 程式
$(BPF_OBJ): process_monitor.bpf.c process_monitor.h
$(CLANG) $(BPF_CFLAGS) $(INCLUDES) $(CFLAGS) -c $< -o $@
$(LLVM_STRIP) -g $@
# 編譯 Go 程式
$(TARGET): main.go $(BPF_OBJ)
go mod init process_monitor || true
go get github.com/aquasecurity/libbpfgo
go build -o $(TARGET) main.go
# 測試
test: $(TARGET)
@echo "Testing process monitor..."
@echo "Run: sudo ./$(TARGET)"
@echo "In another terminal, run some commands to generate events"
# 檢查 BTF 支援
check-btf:
@if [ ! -f /sys/kernel/btf/vmlinux ]; then \
echo "ERROR: BTF not supported on this kernel"; \
echo "Enable CONFIG_DEBUG_INFO_BTF=y in kernel config"; \
exit 1; \
fi
@echo "BTF support: OK"
# 清理
clean:
rm -f $(BPF_OBJ) $(TARGET)
rm -rf vmlinux/
rm -f go.mod go.sum
help:
@echo "Available targets:"
@echo " all - Build all components"
@echo " vmlinux - Generate vmlinux.h"
@echo " test - Run test"
@echo " check-btf - Check BTF support"
@echo " clean - Clean all artifacts"
@echo " help - Show this help"
測試執行
# 檢查 BTF 支援
make check-btf
# 編譯程式
make all
# 執行監控器
sudo ./process_monitor
測試案例
在另一個終端執行:
# 產生不同類型的事件
ls /tmp # exec 事件
sleep 1 # exec + exit 事件
bash -c "echo hello" # fork + exec + exit 事件
python3 -c "print('hi')" # exec + exit 事件
CO-RE 最佳實踐
1. 錯誤處理
// 總是檢查欄位是否存在
if (bpf_core_field_exists(task->some_field)) {
value = BPF_CORE_READ(task, some_field);
} else {
// 提供備選方案或跳過
bpf_printk("Field not available in this kernel version");
}
2. 向後相容性
// 使用條件編譯處理不同核心版本
#if __has_builtin(__builtin_preserve_access_index)
#define BPF_CORE_READ_BITFIELD_PROBED(dst, src) \
__builtin_preserve_access_index(({dst = src;}))
#else
#define BPF_CORE_READ_BITFIELD_PROBED(dst, src) \
bpf_probe_read(&dst, sizeof(dst), &src)
#endif
3. 效能最佳化
// 快取常用的資料結構大小
static const size_t task_struct_size = bpf_core_type_size(struct task_struct);
// 使用編譯時常數
#define PID_OFFSET bpf_core_field_offset(struct task_struct, pid)
4. 除錯技巧
// 除錯資訊
#ifdef DEBUG
bpf_printk("Field offset: %d, size: %d",
bpf_core_field_offset(struct task_struct, pid),
bpf_core_field_size(struct task_struct, pid));
#endif
常見問題與解決方案
1. BTF 不可用
# 檢查 BTF 支援
ls /sys/kernel/btf/vmlinux
# 如果不存在,檢查核心配置
zcat /proc/config.gz | grep BTF
2. 編譯錯誤
// 確保包含正確的標頭檔
#include "vmlinux.h" // 必須在其他 include 之前
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
3. 重定位失敗
# 檢查 BTF 資訊
bpftool btf dump file /sys/kernel/btf/vmlinux | grep "struct task_struct"
# 檢查程式載入資訊
bpftool prog load process_monitor.bpf.o /sys/fs/bpf/test
進階技巧
1. 自定義重定位
// 自定義存取巨集
#define CORE_READ_TASK_FIELD(task, field) ({ \
typeof(((struct task_struct *)0)->field) __val; \
BPF_CORE_READ_INTO(&__val, task, field); \
__val; \
})
2. 多架構支援
// 架構特定的處理
#if defined(__TARGET_ARCH_x86)
#define ARCH_SPECIFIC_OFFSET 8
#elif defined(__TARGET_ARCH_arm64)
#define ARCH_SPECIFIC_OFFSET 16
#else
#define ARCH_SPECIFIC_OFFSET 0
#endif
3. 版本檢查
// 核心版本檢查
#define KERNEL_VERSION(a,b,c) (((a) << 16) + ((b) << 8) + (c))
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5,8,0)
// 新版本特性
#else
// 舊版本相容性處理
#endif
總結
通過本篇文章,我們深入學習了 CO-RE 技術:
- 理解了 CO-RE 的核心概念:BTF、Libbpf、編譯器支援
- 掌握了 BPF_CORE_READ 家族巨集:安全讀取核心資料結構
- 學會了處理相容性問題:欄位存在檢查、條件編譯
- 實作了完整的監控程式:跨版本相容的程序監控器
- 了解了最佳實踐:錯誤處理、效能最佳化、除錯技巧
CO-RE 技術是現代 eBPF 開發的基石,讓我們能夠編寫真正可移植的 eBPF 程式。
Day 10:
- 原文:https://ithelp.ithome.com.tw/articles/10384032
- 發布日期:2025-09-20
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
前言
eBPF 的追蹤功能是其最強大的特性之一,能夠讓我們深入系統內核,監控和分析系統行為。不僅如此,學習使用 eBPF 進行動態追蹤也有助於我們之後使用 sched_ext 開發排程器。
今天我們將全面學習 eBPF 的各種追蹤機制,包括 kprobe、uprobe、tracepoint、fentry/fexit 等技術。
通過本篇文章,您將學會:
- 各種追蹤技術的原理和應用場景
- 如何選擇適合的追蹤方式
- 實戰開發系統追蹤工具
eBPF 追蹤技術概覽
追蹤技術分類
eBPF 追蹤技術
├── 核心空間追蹤
│ ├── kprobe/kretprobe - 動態核心函數追蹤
│ ├── tracepoint - 靜態追蹤點
│ ├── fentry/fexit - 高效能函數入口/出口追蹤
│ ├── raw_tracepoint - 原始追蹤點
│ └── perf_event - 效能事件追蹤
├── 使用者空間追蹤
│ ├── uprobe/uretprobe - 使用者程式函數追蹤
│ └── USDT - 使用者定義靜態追蹤點
└── 網路追蹤
├── socket filter - Socket 過濾追蹤
├── TC (Traffic Control) - 流量控制追蹤
└── XDP - 數據包處理追蹤
筆者補充
uretprobe 在一些情況下是不可用的,例如:golang 會動態的增減 goroutine 的 stack 大小,所以使用 uretprobe 對 golang 撰寫的特定函式時,就有可能導致程式 crash。詳細資訊請參考:https://www.cnxct.com/golang-uretprobe-tracing/
追蹤技術比較
| 技術 | 穩定性 | 效能 | 靈活性 | 使用場景 |
|---|---|---|---|---|
| tracepoint | 高 | 高 | 中 | 穩定的系統監控 |
| kprobe | 中 | 中 | 高 | 動態函數分析 |
| fentry/fexit | 高 | 最高 | 高 | 高效能追蹤 |
| uprobe | 中 | 低 | 高 | 應用程式分析 |
Kprobe/Kretprobe 深度剖析
基本原理
kprobe 通過在目標函數入口插入斷點,當函數被調用時觸發 eBPF 程式:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
// 追蹤系統調用統計
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u32);
__type(value, u64);
} syscall_count SEC(".maps");
// 函數執行時間統計
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 10240);
__type(key, u32);
__type(value, u64);
} function_time SEC(".maps");
// 追蹤 sys_openat
SEC("kprobe/do_sys_openat2")
int kprobe_openat_entry(struct pt_regs *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
u64 ts = bpf_ktime_get_ns();
// 記錄函數進入時間
bpf_map_update_elem(&function_time, &pid, &ts, BPF_ANY);
// 取得檔案路徑參數
int dfd = (int)PT_REGS_PARM1(ctx);
struct filename *filename = (struct filename *)PT_REGS_PARM2(ctx);
if (filename) {
char path[256];
BPF_CORE_READ_STR(path, sizeof(path), filename, name);
bpf_printk("PID %d opening: %s", pid, path);
}
return 0;
}
// 追蹤 sys_openat 返回
SEC("kretprobe/do_sys_openat2")
int kretprobe_openat_exit(struct pt_regs *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
u64 *start_ts = bpf_map_lookup_elem(&function_time, &pid);
if (start_ts) {
u64 end_ts = bpf_ktime_get_ns();
u64 duration = end_ts - *start_ts;
bpf_printk("PID %d openat duration: %llu ns", pid, duration);
// 清理時間記錄
bpf_map_delete_elem(&function_time, &pid);
// 更新系統調用計數
u64 *count = bpf_map_lookup_elem(&syscall_count, &pid);
if (count) {
(*count)++;
} else {
u64 initial = 1;
bpf_map_update_elem(&syscall_count, &pid, &initial, BPF_ANY);
}
}
// 取得返回值
long ret = PT_REGS_RC(ctx);
if (ret < 0) {
bpf_printk("PID %d openat failed: %ld", pid, ret);
}
return 0;
}
進階 kprobe 技巧
// 條件追蹤:只追蹤特定程序
SEC("kprobe/vfs_read")
int kprobe_vfs_read(struct pt_regs *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
// 只追蹤特定 PID
if (pid != TARGET_PID) {
return 0;
}
struct file *file = (struct file *)PT_REGS_PARM1(ctx);
size_t count = (size_t)PT_REGS_PARM3(ctx);
// 取得檔案資訊
struct dentry *dentry = BPF_CORE_READ(file, f_path.dentry);
if (dentry) {
char filename[64];
BPF_CORE_READ_STR(filename, sizeof(filename), dentry, d_name.name);
bpf_printk("Reading %zu bytes from %s", count, filename);
}
return 0;
}
// 參數過濾:只追蹤特定檔案類型
SEC("kprobe/vfs_open")
int kprobe_vfs_open(struct pt_regs *ctx)
{
struct path *path = (struct path *)PT_REGS_PARM1(ctx);
struct dentry *dentry = BPF_CORE_READ(path, dentry);
if (dentry) {
char filename[64];
BPF_CORE_READ_STR(filename, sizeof(filename), dentry, d_name.name);
// 只追蹤 .log 檔案
int len = bpf_probe_read_str(filename, sizeof(filename),
BPF_CORE_READ(dentry, d_name.name));
if (len > 4 &&
filename[len-4] == '.' &&
filename[len-3] == 'l' &&
filename[len-2] == 'o' &&
filename[len-1] == 'g') {
bpf_printk("Opening log file: %s", filename);
}
}
return 0;
}
Tracepoint 靜態追蹤
Tracepoint 基礎
Tracepoint 是核心中預定義的靜態追蹤點,效能高且穩定:
// 追蹤程序排程事件
SEC("tp/sched/sched_switch")
int trace_sched_switch(struct trace_event_raw_sched_switch *ctx)
{
// 取得切換資訊
u32 prev_pid = ctx->prev_pid;
u32 next_pid = ctx->next_pid;
char prev_comm[16], next_comm[16];
__builtin_memcpy(prev_comm, ctx->prev_comm, sizeof(prev_comm));
__builtin_memcpy(next_comm, ctx->next_comm, sizeof(next_comm));
bpf_printk("CPU switch: %s(%d) -> %s(%d)",
prev_comm, prev_pid, next_comm, next_pid);
return 0;
}
// 追蹤記憶體分配
SEC("tp/kmem/kmalloc")
int trace_kmalloc(struct trace_event_raw_kmalloc *ctx)
{
size_t bytes_req = ctx->bytes_req;
size_t bytes_alloc = ctx->bytes_alloc;
void *ptr = ctx->ptr;
if (bytes_req > 4096) { // 只追蹤大分配
bpf_printk("Large kmalloc: req=%zu alloc=%zu ptr=%p",
bytes_req, bytes_alloc, ptr);
}
return 0;
}
// 追蹤網路接收
SEC("tp/net/netif_receive_skb")
int trace_netif_receive_skb(struct trace_event_raw_netif_receive_skb *ctx)
{
char name[16];
__builtin_memcpy(name, ctx->name, sizeof(name));
bpf_printk("Network RX on %s: len=%d", name, ctx->len);
return 0;
}
系統調用追蹤
// 通用系統調用進入追蹤
SEC("tp/raw_syscalls/sys_enter")
int trace_sys_enter(struct trace_event_raw_sys_enter *ctx)
{
u64 syscall_id = ctx->id;
u32 pid = bpf_get_current_pid_tgid() >> 32;
// 只追蹤特定系統調用
switch (syscall_id) {
case 2: // open
case 257: // openat
case 3: // close
case 0: // read
case 1: // write
bpf_printk("PID %d syscall %lld", pid, syscall_id);
break;
default:
return 0;
}
return 0;
}
// 系統調用退出追蹤
SEC("tp/raw_syscalls/sys_exit")
int trace_sys_exit(struct trace_event_raw_sys_exit *ctx)
{
long ret = ctx->ret;
u32 pid = bpf_get_current_pid_tgid() >> 32;
if (ret < 0) {
bpf_printk("PID %d syscall failed: %ld", pid, ret);
}
return 0;
}
Fentry/Fexit 高效能追蹤
基本使用
fentry/fexit 是最新的追蹤技術,提供最佳效能:
// 函數入口追蹤
SEC("fentry/do_unlinkat")
int BPF_PROG(fentry_unlinkat, int dfd, struct filename *name)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
char filename[64];
BPF_CORE_READ_STR(filename, sizeof(filename), name, name);
bpf_printk("PID %d unlinking: %s", pid, filename);
return 0;
}
// 函數退出追蹤
SEC("fexit/do_unlinkat")
int BPF_PROG(fexit_unlinkat, int dfd, struct filename *name, long ret)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
if (ret == 0) {
char filename[64];
BPF_CORE_READ_STR(filename, sizeof(filename), name, name);
bpf_printk("PID %d successfully unlinked: %s", pid, filename);
} else {
bpf_printk("PID %d unlink failed: %ld", pid, ret);
}
return 0;
}
複雜參數處理
// 追蹤複雜結構體參數
SEC("fentry/tcp_sendmsg")
int BPF_PROG(fentry_tcp_sendmsg, struct sock *sk, struct msghdr *msg, size_t size)
{
// 取得 socket 資訊
u16 family = BPF_CORE_READ(sk, __sk_common.skc_family);
u16 sport = BPF_CORE_READ(sk, __sk_common.skc_num);
u16 dport = bpf_ntohs(BPF_CORE_READ(sk, __sk_common.skc_dport));
if (family == AF_INET) {
u32 saddr = BPF_CORE_READ(sk, __sk_common.skc_rcv_saddr);
u32 daddr = BPF_CORE_READ(sk, __sk_common.skc_daddr);
bpf_printk("TCP send: %pI4:%d -> %pI4:%d, size=%zu",
&saddr, sport, &daddr, dport, size);
}
return 0;
}
// 追蹤網路接收
SEC("fentry/tcp_recvmsg")
int BPF_PROG(fentry_tcp_recvmsg, struct sock *sk, struct msghdr *msg,
size_t len, int flags, int *addr_len)
{
u16 sport = BPF_CORE_READ(sk, __sk_common.skc_num);
u16 dport = bpf_ntohs(BPF_CORE_READ(sk, __sk_common.skc_dport));
bpf_printk("TCP recv: port %d<-%d, len=%zu", sport, dport, len);
return 0;
}
Uprobe 使用者空間追蹤
基本 Uprobe
// 追蹤 libc 函數
SEC("uprobe/libc.so.6:malloc")
int uprobe_malloc(struct pt_regs *ctx)
{
size_t size = (size_t)PT_REGS_PARM1(ctx);
u32 pid = bpf_get_current_pid_tgid() >> 32;
if (size > 1024) { // 只追蹤大分配
bpf_printk("PID %d malloc large: %zu bytes", pid, size);
}
return 0;
}
SEC("uretprobe/libc.so.6:malloc")
int uretprobe_malloc(struct pt_regs *ctx)
{
void *ptr = (void *)PT_REGS_RC(ctx);
u32 pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("PID %d malloc returned: %p", pid, ptr);
return 0;
}
// 追蹤 free
SEC("uprobe/libc.so.6:free")
int uprobe_free(struct pt_regs *ctx)
{
void *ptr = (void *)PT_REGS_PARM1(ctx);
u32 pid = bpf_get_current_pid_tgid() >> 32;
if (ptr) {
bpf_printk("PID %d freeing: %p", pid, ptr);
}
return 0;
}
追蹤 Go 程式
筆者補充
前面有提到 golang 開發的程式無法順利使用 uretprobe,不過 uprobe 仍是沒問題的。
// 追蹤 Go runtime
SEC("uprobe//usr/bin/myapp:runtime.mallocgc")
int uprobe_go_malloc(struct pt_regs *ctx)
{
u64 size = (u64)PT_REGS_PARM1(ctx);
u32 pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("Go PID %d mallocgc: %llu bytes", pid, size);
return 0;
}
// 追蹤 Go GC
SEC("uprobe//usr/bin/myapp:runtime.gcStart")
int uprobe_go_gc_start(struct pt_regs *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
u64 ts = bpf_ktime_get_ns();
bpf_printk("Go PID %d GC start at %llu", pid, ts);
return 0;
}
實戰演練:追蹤自定義的 kernel module
筆者在 Debug gtp5g kernel module using stacktrace and eBPF 一文中詳細的說明如何使用 eBPF 追蹤自定義的 kernel module,效果如下:
sudo cat /sys/kernel/debug/tracing/trace_pipe
<...>-236797 [009] b.s21 6141919.013036: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=236797, TGID=236797, CPU=9
<idle>-0 [009] b.s31 6141920.013210: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141921.014070: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141922.013615: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141923.013975: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141924.014871: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141925.013730: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
kubelite-3377186 [009] b.s21 6141926.013908: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=3377186, TGID=3376931, CPU=9
<idle>-0 [009] b.s31 6141927.014084: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141928.015013: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141929.014465: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141930.014600: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141931.013976: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141932.014142: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
<idle>-0 [009] b.s31 6141933.014331: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=9
感興趣的筆者可以點擊上方連結閱讀完整文章。
除錯與問題排查
1. 檢查追蹤點可用性
# 檢查 tracepoint 可用性
ls /sys/kernel/debug/tracing/events/sched/
# 檢查 kprobe 可用性
grep "do_sys_openat2" /proc/kallsyms
# 檢查 fentry 支援
bpftool feature | grep fentry
2. 追蹤程式除錯
// 使用 bpf_printk 除錯
SEC("kprobe/do_sys_openat2")
int debug_kprobe(struct pt_regs *ctx)
{
bpf_printk("kprobe triggered: PID=%d", bpf_get_current_pid_tgid() >> 32);
return 0;
}
# 檢視 debug 輸出
cat /sys/kernel/debug/tracing/trace_pipe
3. 效能分析
# 檢查 eBPF 程式統計
bpftool prog show
bpftool prog dump xlated id <ID>
# 檢查 Map 使用情況
bpftool map show
bpftool map dump id <ID>
總結
通過本篇文章,我們全面學習了 eBPF 追蹤技術:
- 掌握了各種追蹤機制:kprobe、tracepoint、fentry/fexit、uprobe
- 理解了技術選擇原則:穩定性、效能、靈活性的權衡
- 實作了完整的追蹤系統:多類型事件統一處理
這些追蹤技術是 eBPF 應用的核心,為後續學習調度器開發奠定了堅實基礎。
參考資源
Day 11:
- 原文:https://ithelp.ithome.com.tw/articles/10384582
- 發布日期:2025-09-21
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
libbpf 支援 skeleton 功能,讓開發者能夠透過 bpftool 產生對應的 skeleton file,相關指令如下:
$ bpftool gen skeleton main.bpf.o > main.skeleton.h
main.bpf.o為可載入的 BPF program 的 object file。main.skeleton.h為 bpftool 輸出的檔案,包含了許多高度封裝的 API。
讓我們觀察一下 main.skeleton.h 的檔案內容:
static void
main_bpf__destroy(struct main_bpf *obj)
{
if (!obj)
return;
if (obj->skeleton)
bpf_object__destroy_skeleton(obj->skeleton);
free(obj);
}
static inline int
main_bpf__create_skeleton(struct main_bpf *obj);
static inline struct main_bpf *
main_bpf__open_opts(const struct bpf_object_open_opts *opts)
{
struct main_bpf *obj;
int err;
obj = (struct main_bpf *)calloc(1, sizeof(*obj));
if (!obj) {
errno = ENOMEM;
return NULL;
}
err = main_bpf__create_skeleton(obj);
if (err)
goto err_out;
err = bpf_object__open_skeleton(obj->skeleton, opts);
if (err)
goto err_out;
obj->struct_ops.goland = (__typeof__(obj->struct_ops.goland))
bpf_map__initial_value(obj->maps.goland, NULL);
return obj;
err_out:
main_bpf__destroy(obj);
errno = -err;
return NULL;
}
我們會發現檔案包含了很多用來操作 struct main_bpf 指標的函式,這些函式封裝了 libbpf 提供的 APIs,讓使用者可以快速的在 user space 載入、更新給定的 eBPF program。
若我們細看 struct main_bpf 會發現,它封裝了 eBPF object 以及 rodata、data、bss 等 section。
若在 eBPF program 宣告全域變數,會根據不同的宣告方式將這些變數歸類在不同的 section:
int counter; // -> .bss
int init_value = 10; // -> .data
const int max = 100; // -> .rodata
若不使用 eBPF skeleton,當 eBPF program 載入後,我們可以用 BPF map 操作的方式來讀取這些 section 的資料。
反之,有了 skeleton file,讀取這些 section 都變的簡單不少:
#include "main.skeleton.h"
struct main_bpf *global_obj;
void *open_skel() {
struct main_bpf *obj = NULL;
obj = main_bpf__open();
main_bpf__create_skeleton(obj);
global_obj = obj;
return obj->obj;
}
u32 get_usersched_pid() {
return global_obj->bss->usersched_pid;
}
總結
skeleton 簡化了 User Space Program 和 BPF program 互動的方式,讓我們更輕易的存取 global variable。這對我們日後移植 scx_rustland 的實作有非常大的幫助,至於實際的用途我們將在接下來的文章向各位說明。
References
- https://lwn.net/Articles/806911/
- https://docs.ebpf.io/ebpf-library/libbpf/userspace/bpf_object__open_skeleton/
- https://github.com/aquasecurity/libbpfgo/pull/480/commits/8520bb199dd07b78b1503b62e84ffee15a674edb
- https://github.com/Gthulhu/scx_goland_core/pull/2/files#diff-16d86dfde6b5d79395d6ada5cd36dd32d217f2b34f9a426c00b894cebc56a5e0R41
Day 12:
- 原文:https://ithelp.ithome.com.tw/articles/10384828
- 發布日期:2025-09-22
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
sched_ext
Linux kernel 自 v6.12 開始支援 sched_ext(Scheduler Extesion)[1],它賦予了我們在 user space 動態插入系統排程器的能力:
- 以 eBPF program 的形式客製化熱插拔的 OS scheduler。
- Kernel 內建 watch dog 避免 deadlock 以及 starvation,如果 custom scheduler 沒辦法在一段時間為所有任務排程,那系統會將你注入的排程器剔除。
- BPF 保證了安全性(沒有記憶體錯誤、沒有 kernel panic)。
筆者補充:
Watch Dog 本身實作於 Linux 的 Concurrency Managed Workqueue(CMWQ)機制上,所以這個 task 本身會被 kworker 排程。若你實作的排程器沒辦法讓 task 對應的 kworker 在 scx 設定的 timeout 被分配到 CPU 且執行完畢,那麼你的 scheduler 就會被系統踢出。
BPF_STRUCT_OPS 的用途
/*
* Decide which CPU a task should be migrated to before being
* enqueued (either at wakeup, fork time, or exec time). If an
* idle core is found by the default ops.select_cpu() implementation,
* then insert the task directly into SCX_DSQ_LOCAL and skip the
* ops.enqueue() callback.
*
* Note that this implementation has exactly the same behavior as the
* default ops.select_cpu implementation. The behavior of the scheduler
* would be exactly same if the implementation just didn't define the
* simple_select_cpu() struct_ops prog.
*/
s32 BPF_STRUCT_OPS(simple_select_cpu, struct task_struct *p,
s32 prev_cpu, u64 wake_flags)
{
s32 cpu;
/* Need to initialize or the BPF verifier will reject the program */
bool direct = false;
cpu = scx_bpf_select_cpu_dfl(p, prev_cpu, wake_flags, &direct);
if (direct)
scx_bpf_dsq_insert(p, SCX_DSQ_LOCAL, SCX_SLICE_DFL, 0);
return cpu;
}
參考 Linux Kernel 官方文件 [3] 提供的範例,我們可以看到範例中的函式都使用了 BPF_STRUCT_OPS 這個 MACRO:
#define BPF_STRUCT_OPS(name, args...) \
SEC("struct_ops/"#name) \
BPF_PROG(name, ##args)
這個 MACRO 會將函式轉換為 BPF struct_ops(也就是 BPF_PROG_TYPE_STRUCT_OPS 類型的 eBPF program [6]),從 Linux Plumbers Conerference 的這場分享 [4] 可以得知 BPF struct_ops 是 Kernel 提供的一個方法,讓 Kernel 的子系統能夠使用者定義的函式:
來源:[4]
來源:[5]
實作 sched_ext 的 hook function
回到 scx_simple 這個範例:
SEC(".struct_ops")
struct sched_ext_ops simple_ops = {
.select_cpu = (void *)simple_select_cpu,
.enqueue = (void *)simple_enqueue,
.init = (void *)simple_init,
.exit = (void *)simple_exit,
.name = "simple",
};
最終我們會將前面定義好的 eBPF prog 以函式指標的方式指派到 sched_ext_ops 這個結構中。
而 sched_ext_ops 這個結構實際上是在 kernel source 定義好的 dummy interface,參考 kernel/sched/ext.c:
static struct sched_ext_ops __bpf_ops_sched_ext_ops = {
.select_cpu = select_cpu_stub,
.enqueue = enqueue_stub,
.dequeue = dequeue_stub,
.dispatch = dispatch_stub,
.tick = tick_stub,
.runnable = runnable_stub,
.running = running_stub,
.stopping = stopping_stub,
.quiescent = quiescent_stub,
.yield = yield_stub,
.core_sched_before = core_sched_before_stub,
.set_weight = set_weight_stub,
.set_cpumask = set_cpumask_stub,
.update_idle = update_idle_stub,
.cpu_acquire = cpu_acquire_stub,
.cpu_release = cpu_release_stub,
.init_task = init_task_stub,
.exit_task = exit_task_stub,
.enable = enable_stub,
.disable = disable_stub,
#ifdef CONFIG_EXT_GROUP_SCHED
.cgroup_init = cgroup_init_stub,
.cgroup_exit = cgroup_exit_stub,
.cgroup_prep_move = cgroup_prep_move_stub,
.cgroup_move = cgroup_move_stub,
.cgroup_cancel_move = cgroup_cancel_move_stub,
.cgroup_set_weight = cgroup_set_weight_stub,
#endif
.cpu_online = cpu_online_stub,
.cpu_offline = cpu_offline_stub,
.init = init_stub,
.exit = exit_stub,
.dump = dump_stub,
.dump_cpu = dump_cpu_stub,
.dump_task = dump_task_stub,
};
static struct bpf_struct_ops bpf_sched_ext_ops = {
.verifier_ops = &bpf_scx_verifier_ops,
.reg = bpf_scx_reg,
.unreg = bpf_scx_unreg,
.check_member = bpf_scx_check_member,
.init_member = bpf_scx_init_member,
.init = bpf_scx_init,
.update = bpf_scx_update,
.validate = bpf_scx_validate,
.name = "sched_ext_ops",
.owner = THIS_MODULE,
.cfi_stubs = &__bpf_ops_sched_ext_ops
};
最後在 scx_init 完成對該介面的註冊 ret = register_bpf_struct_ops(&bpf_sched_ext_ops, sched_ext_ops);。
上面的解說可能沒辦法讓大家完全理解 struct_ops,所以筆者使用 bpftool 來觀察當 eBPF scheduler attached 後,會出現哪些新的資訊:
> sudo bpftool map list
[sudo] password for ian:
6362: percpu_array name cpu_ctx_stor flags 0x0
key 4B value 24B max_entries 1 memlock 752B
btf_id 5965
pids main(791867)
6363: task_storage name task_ctx_stor flags 0x1
key 4B value 32B max_entries 0 memlock 912B
btf_id 5965
pids main(791867)
6364: ringbuf name queued flags 0x0
key 0B value 0B max_entries 262144 memlock 275736B
pids main(791867)
6365: user_ringbuf name dispatched flags 0x0
key 0B value 0B max_entries 262144 memlock 275736B
pids main(791867)
6366: hash name pid_mm_fault_ma flags 0x0
key 4B value 8B max_entries 4096 memlock 330656B
btf_id 5965
pids main(791867)
6367: array name usersched_timer flags 0x0
key 4B value 16B max_entries 1 memlock 280B
btf_id 5965
pids main(791867)
6369: array name main.rodata flags 0x480
key 4B value 504B max_entries 1 memlock 8192B
btf_id 5965 frozen
pids main(791867)
6370: array name .data.uei_dump flags 0x400
key 4B value 1B max_entries 1 memlock 8192B
btf_id 5965
pids main(791867)
6371: array name main.data flags 0x400
key 4B value 1425B max_entries 1 memlock 8192B
btf_id 5965
pids main(791867)
6372: array name main.bss flags 0x400
key 4B value 92B max_entries 1 memlock 8192B
btf_id 5965
pids main(791867)
6373: struct_ops name goland flags 0x2000
key 4B value 512B max_entries 1 memlock 6096B
btf_id 5965
pids main(791867)
6376: array name libbpf_global flags 0x0
key 4B value 32B max_entries 1 memlock 296B
6377: array name pid_iter.rodata flags 0x480
key 4B value 4B max_entries 1 memlock 8192B
btf_id 5976 frozen
pids bpftool(792421)
6378: array name libbpf_det_bind flags 0x0
key 4B value 32B max_entries 1 memlock 296B
只要是包含 pid main(791867) 資訊的 BPF MAP 都是由 eBPF scheduler 建立的 BPF MAP。接著,讓我們觀察 goland 的內容:
> sudo bpftool map dump name goland
[{
"value": {
"common": {
"refcnt": {
"refs": {
"counter": 1
}
},
"state": "BPF_STRUCT_OPS_STATE_READY"
},
"data": {
"select_cpu": "0x28aa",
"enqueue": "0x28ad",
"dequeue": "(nil)",
"dispatch": "0x28ae",
"tick": "(nil)",
"runnable": "(nil)",
"running": "0x28af",
"stopping": "0x28b0",
"quiescent": "(nil)",
"yield": "(nil)",
"core_sched_before": "(nil)",
"set_weight": "(nil)",
"set_cpumask": "0x28b2",
"update_idle": "0x28b1",
"cpu_acquire": "(nil)",
"cpu_release": "0x28b3",
"init_task": "0x28b4",
"exit_task": "(nil)",
"enable": "(nil)",
"disable": "(nil)",
"dump": "(nil)",
"dump_cpu": "(nil)",
"dump_task": "(nil)",
"cgroup_init": "(nil)",
"cgroup_exit": "(nil)",
"cgroup_prep_move": "(nil)",
"cgroup_move": "(nil)",
"cgroup_cancel_move": "(nil)",
"cgroup_set_weight": "(nil)",
"cpu_online": "(nil)",
"cpu_offline": "(nil)",
"init": "0x28b5",
"exit": "0x28b6",
"dispatch_max_batch": 512,
"flags": 3,
"timeout_ms": 5000,
"exit_dump_len": 0,
"hotplug_seq": 0,
"name": "goland"
}
}
}
]
我們就能找到每一個 scheduler ops 對應的函式指標位址囉。
總結
透過這篇文章可以得知:
- 使用 scx 開發自己的排程器需要遵守 struct_ops 的規範
- struct_ops 就像是用一個 member 都是 function pointer 的結構將每個排程器的 hook function 鏈結起來
- 將 struct_ops 對應的 Map 載入到系統後,kernel 就能得知每個 hook function 對應的記憶體位址,接著系統就會在排程的各個進入點呼叫對應的 hook function。
至於排程器的各個進入點是什麼?就交給明天的文章探討囉。
References
- https://www.phoronix.com/news/Linux-6.12-Lands-sched-ext
- Crafting a Linux kernel scheduler in Rust - Andrea Righi
- https://www.kernel.org/doc/html/v6.12/scheduler/sched-ext.html
- https://lpc.events/event/17/contributions/1607/attachments/1164/2407/lpc-struct_ops.pdf
- http://oldvger.kernel.org/bpfconf2024_material/struct_ops-lsfmmbpf-2024.pdf
- https://docs.ebpf.io/linux/program-type/BPF_PROG_TYPE_STRUCT_OPS/
Day 13:
- 原文:https://ithelp.ithome.com.tw/articles/10386212
- 發布日期:2025-09-23
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
在前一篇文章中我們介紹了 sched_ext 的概念,而本篇文章會聚焦在 Scheduling Cycle,讓各位了解透過 struct_ops 定義的 callback functions(eBPF programs)會在哪些時間點被呼叫。
Dispatch Queue
Kernel 在 sched_ext 引入 Dispatch Queue(DSQ)的概念,我們可以藉由多個 DSQ 達到 FIFO 或是 priority queue 的運作方式:
- 預設情況下,系統會有一個 global DSQ SCX_DSQ_GLOBAL 以及每個 CPU 分別持有一個 local DSQ SCX_DSQ_LOCAL 。
- BPF Scheduler 可以利用 scx_bpf_create_dsq() 建立其他 DSQ,並且使用 scx_bpf_destroy_dsq() 銷毀它們。
- CPU 永遠從 local DSQ 取得任務來執行,其他 DSQ 之中的任務要被執行需要將該任務移動到 local DSQ。
此外,還需要注意 DSQ 有兩種 policy,分別是 priority queue 以及 FIFO:
- FIFO DSQ 僅適用
scx_bpf_dsq_insert。 - priority queue DSQ 僅適用
scx_bpf_dsq_insert_vtime。
也就是說,若 DSQ 存在 FIFO task 則無法用 scx_bpf_dsq_insert_vtime 對該 DSQ 插入新任務。反之,若 DSQ 存在 priority queue task 則無法用 scx_bpf_dsq_insert 對該 DSQ 插入新任務。
若違反以上規定,eBPF scheduler 就會被 kernel 踢出。
進入正題
介紹完 Dispatch Queue 之後,讓我們重新回到 Scheduling Cycle 上:
- 當任務被喚醒,會進入到 select cpu 環節,這時
.select_cpu對應的 eBPF program 會被執行。如果這個步驟選擇的 CPU 為 idle,則會將該 CPU 喚醒。此外,如果 task 有 cpu_mask,這個選擇可能會無效。 - 選擇 target cpu 後,進入
.enqueue環節,這時.enqueue對應的 eBPF program 會被執行。該環節可以選擇將任務:- 呼叫
scx_bpf_dispatch()將任務插入 global DSQ SCX_DSQ_GLOBAL 或是 CPU 的 Local DSQ SCX_DSQ_LOCAL - 存入到自定義的資料結構中
- 將任務插入至自定義的 DSQ。
- 呼叫
- 當 CPU 準備好接受任務,會檢查自己持有的 Local DSQ,若有任務存在於 DSQ 將任務從 DSQ 取出並執行。若否,則檢查 Global DSQ,將任務取出並執行。
- 如果 Local DSQ 或 Global DSQ 都沒有可以執行的任務存在,會進入 dispatch 環節,執行 .dispatch 對應的 eBPF program。dispatch eBPF program 可以透過:
scx_bpf_dispatch將指定的任務派發至任一個 DSQ- 透過 scx_bpf_consume 將任務從指定的 DSQ 轉移到 local DSQ。
.dispatch結束後,會再次對 local DSQ 與 global DSQ 進行檢查,若有任務存在則將其取出並執行。- 如果步驟 4 有派發任務,會跳入
.enqueue環節嘗試取得任務。反之,如果前一個任務屬於 SCX task 且仍可被執行,則繼續執行該任務。最後,若前面的嘗試都失敗,則 cpu 進入 idle。
此外,kernel 的官方文件有提到:
The CPU selected by ops.select_cpu() is an optimization hint and not binding. The actual decision is made at the last step of scheduling. However, there is a small performance gain if the CPU ops.select_cpu() returns matches the CPU the task eventually runs on.
但沒有明確地指出為何會有 small performance gain,筆者猜測背後的原因是 select_cpu 通常會為 process 選擇一個當下最適合的 cpu(可能考慮 CPU Domain、Cache Domain 或是 workloads),如果最終執行 task 的 cpu 與當初選擇的不同,可能會有額外的開銷浪費 cpu 時間(如:cache miss)。
總結
到目前為止,我們已經學習了基本的 eBPF 開發技巧,以及開發 scx 排程器所需要的基本知識。
接下來我們會選擇幾個目前 scx 內建的排程器進行解說,讓大家對 scx 有更深刻的了解後,再進入 Gthulhu 的開發環節。
References
Day 14:
- 原文:https://ithelp.ithome.com.tw/articles/10387029
- 發布日期:2025-09-24
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
scx_simple 的原始程式碼收錄於 scx,採用 GPL 授權。本篇文章會講解該排程器的實作細節,方便大家近一步理解 sched_ext。
參考昨天的文章可以得知,當一個任務被喚醒會進入到 select cpu 環節,所以 simple_select_cpu 會被呼叫:
s32 BPF_STRUCT_OPS(simple_select_cpu, struct task_struct *p, s32 prev_cpu, u64 wake_flags)
{
bool is_idle = false;
s32 cpu;
cpu = scx_bpf_select_cpu_dfl(p, prev_cpu, wake_flags, &is_idle);
if (is_idle) {
stat_inc(0); /* count local queueing */
scx_bpf_dsq_insert(p, SCX_DSQ_LOCAL, SCX_SLICE_DFL, 0);
}
return cpu;
}
如果有找到處於 IDLE 狀態的 CPU,直接把 TASK 放到該 CPU 的 LOCAL DSQ。
否則,傳入 busy cpu 的代號,準備進入 enqueue:
void BPF_STRUCT_OPS(simple_enqueue, struct task_struct *p, u64 enq_flags)
{
stat_inc(1); /* count global queueing */
if (fifo_sched) {
scx_bpf_dsq_insert(p, SHARED_DSQ, SCX_SLICE_DFL, enq_flags);
} else {
u64 vtime = p->scx.dsq_vtime;
/*
* Limit the amount of budget that an idling task can accumulate
* to one slice.
*/
if (time_before(vtime, vtime_now - SCX_SLICE_DFL))
vtime = vtime_now - SCX_SLICE_DFL;
scx_bpf_dsq_insert_vtime(p, SHARED_DSQ, SCX_SLICE_DFL, vtime,
enq_flags);
}
}
進入 simple_enqueue,如果 FIFO(First In First Out)功能關閉,系統會更新 vtime(可以把它當成 virtual deadline),使用 scx_bpf_dsq_insert_vtime() 會根據 vtime 將任務插入到合適的位置,也就是屬於 priority queue DSQ 的操作。
假設 CPU 已經處理完當前的任務(假設是 cpu0),cpu0 進入到 kernel mode 準備處理下一個任務,首先 cpu0 會檢查自己持有的 Local DSQ,若有任務存在於 DSQ 將任務從 DSQ 取出並執行。若否,則檢查 Global DSQ,將任務取出並執行。
如果仍沒有任務,會進入 dispatch 環節:
void BPF_STRUCT_OPS(simple_dispatch, s32 cpu, struct task_struct *prev)
{
scx_bpf_dsq_move_to_local(SHARED_DSQ);
}
嘗試將 SHARED_DSQ 的任務移至 cpu0 的 Local DSQ,如果順利則執行該任務。否則 cpu0 進入 idle 狀態。
假設有任務成功被執行,這時候會進入到 running 環節:
void BPF_STRUCT_OPS(simple_running, struct task_struct *p)
{
if (fifo_sched)
return;
/*
* Global vtime always progresses forward as tasks start executing. The
* test and update can be performed concurrently from multiple CPUs and
* thus racy. Any error should be contained and temporary. Let's just
* live with it.
*/
if (time_before(vtime_now, p->scx.dsq_vtime))
vtime_now = p->scx.dsq_vtime;
}
用於更新 global deadline vtime_now。
如果有新的任務被啟動(不是喚醒,是啟動),會進入 enable 環節:
void BPF_STRUCT_OPS(simple_enable, struct task_struct *p)
{
p->scx.dsq_vtime = vtime_now;
}
將該任務的 vtime 指派為當下的 global deadline。
總結
scx_simple 利用不到 150 行的程式碼就實作了一款排程器,藉由追蹤原始程式碼的方式我們也更加的了解 scx 的 scheduling cycle 如何在 kernel 實際的運作。
Day 15:
- 原文:https://ithelp.ithome.com.tw/articles/10387745
- 發布日期:2025-09-25
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
scx_rustland 是由任職於 NVIDIA 的大神 Andrea Righi 實作的排程器,它的設計理念是:
- 將排程器的決策 offload 到 user space,也就是在 user space 實作排程器。
- 排程器實作了一個基於 vruntime 的策略(類似於 CFS),並採用一些小技巧來檢測 interactive task 並稍微提高其優先級(透過查看 voluntary context switches 的數量來確定任務是否是 interactive task,未使用其分配的完整時間片就釋放 CPU 的任務很可能是 interactive task)。
- 排程器會根據目前排隊的任務數量來決定給定任務的 time slice。
補充:
起初 scx_rustland 是參考 voluntary context switches,但隨著 scx_rustland 的演化,現在是根據任務通過將停止執行與開始執行的時間戳相減取得實際的執行時間來取代原有的機制。
大致了解設計理念以後,稍微看一下技術細節(考慮的文章篇幅,這邊先不貼程式碼):
圖片來源:https://www.youtube.com/watch?v=L-39aeUQdS8
- 利用 eBPF Map(RingBuffer & UserRingBuffer)使 eBPF program 與 user space 排程器能夠傳遞任務。
- 將排程器實作在 user space 可以利用 rust 豐富的套件,在 user space 也比起在 kernel space 更容易探測到外部環境的改變。
- scx_rustland 會考慮 CPU topology 為任務選擇一個最合適的 CPU。
- 實作客製化的 memory allocator 改善 user-space scheduler 的效能(這部分後面的篇章會探討)
scx_rustland 可以大幅改善 interactive task 的響應時間,目前 scx 最大的作用是改善 Linux 上的遊戲體驗,這點從 scx 最初的 DEMO 影片就能得知。
References
Day 16:
- 原文:https://ithelp.ithome.com.tw/articles/10388468
- 發布日期:2025-09-26
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
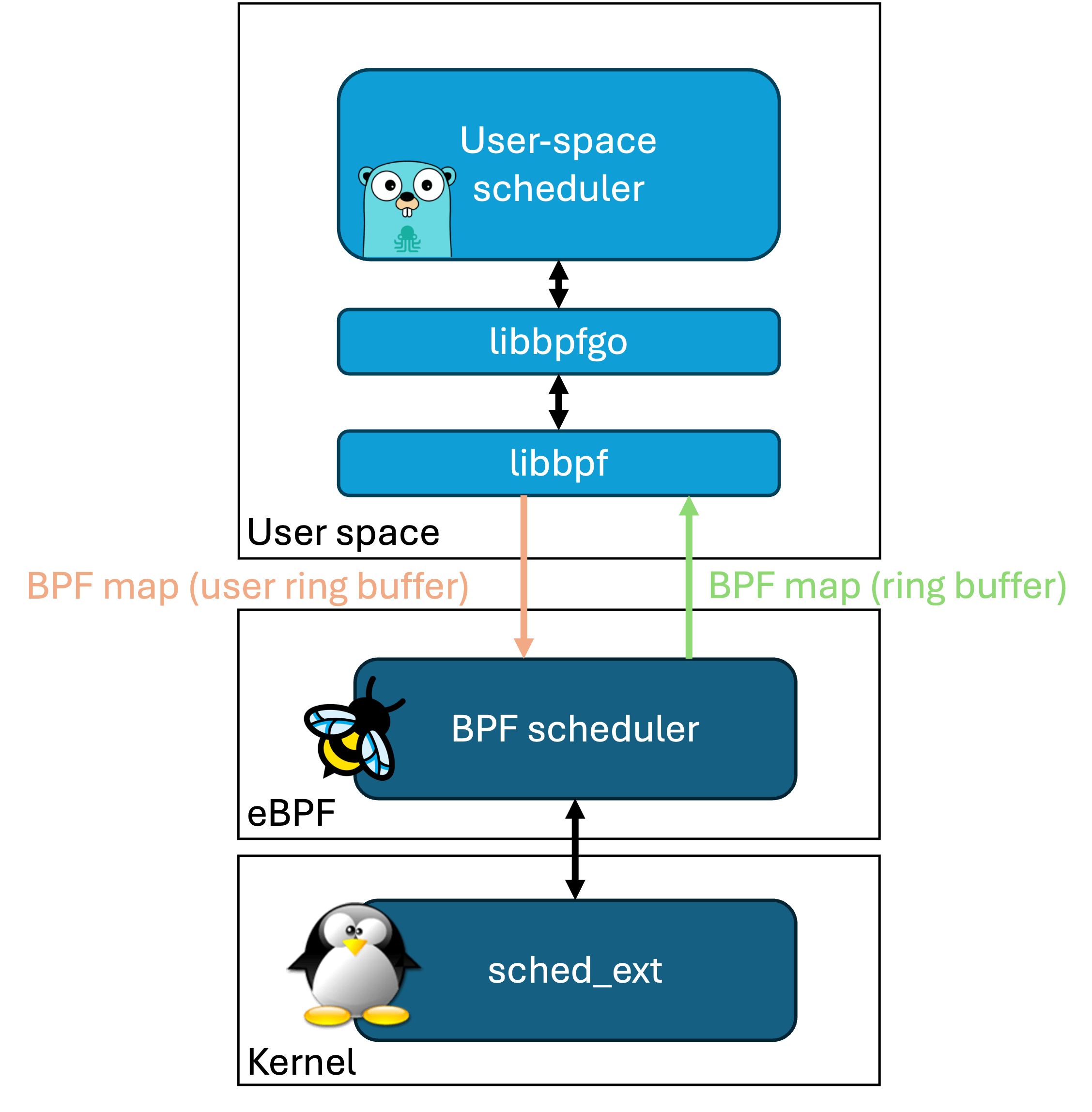
來源:https://github.com/Gthulhu/qumun/
昨天的文章中我們快速的導覽了 scx_rustland 的設計精神,起初,我決定用 golang 打造 Linux Scheduler 的原因也很單純,就是覺得如果能弄出來會很酷。
然而,即使 Golang 有 aqua security 包好的 libbpfgo,要移植 rustland 的成果仍會遇到非預期的問題。
這邊先撇開 libbpfgo 缺失的 API 實作,就談談我在移植的過程中忽略的第一件事。當我將缺失的 API 補足後,scx_rustland 的 eBPF program 確實能夠被我所實作的 user space app 載入至 kernel,但是只要程式一被載入後,系統就會停擺約 5 秒鐘,直到 scx_rustland 被 watch dog 剔除。
起初,我花費大量的心思在 user ring buffer 以及 ring buffer 的除錯,但後續使用了 syscall type 的 eBPF program 驗證兩者的功能性後才排除了這個問題。後來實在對這件事沒有頭緒,我才向 Andrea Righi 求助。
顯然,大神也被這個問題困擾過,因為他馬上給予我肯定的回答,且明確的指出是 page fault 造成的 deadlock。Andrea Righi 甚至為了解決 page fault 造成的“效能問題”實作了一個 buddy allocator。
值得一提的是,Page Fault 對 scx_rustland 的影響僅僅是「開銷變大」,但對於 scx_goland 是直接造成死機(deadlock)。兩者都使用同樣的 eBPF program 卻有截然不同的結果,經過一番研究後發現是 cgo 間接造成的問題:
- libbpfgo 本身是 libbpf 的 wrapper,每一個 function call 都是一次 cgo 呼叫,而 cgo 呼叫會產生額外的 goroutine。
- goroutine 本身會被 golang runtime 排程,最後執行的可能是不同的 thread entity。
而 scx_rustland 需要知道 user space scheduler 的 PID,讓 user space scheduler 能直接被 eBPF program 排程,不靠 user space scheduler 自己介入。這會導致 golang 產生的 thread 無法被 eBPF program 識別,因為 golang rutime 衍伸的 thread 的 PID 與 user space scheduler 的 PID 並不同。
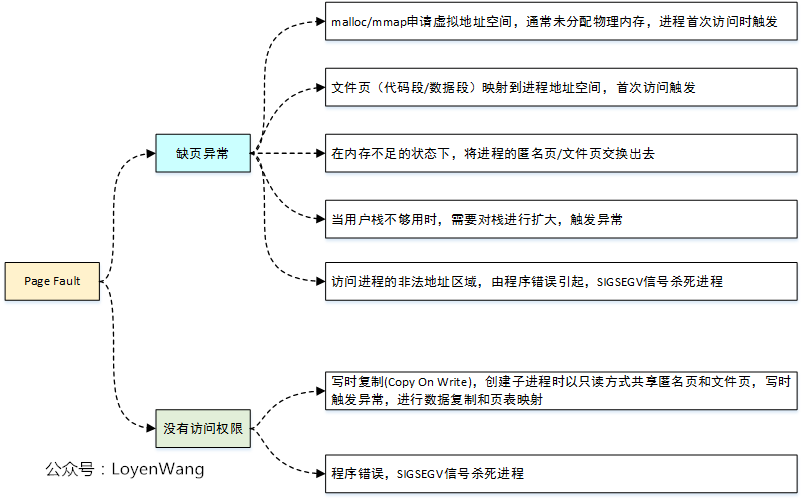
來源:https://www.cnblogs.com/LoyenWang/p/12116570.html
當 page fault 發生時,出問題的 process 會進入 kernel mode 來解決這個問題,這會讓 user space scheduler 對應的多個 thread entity 在發生 page fault 時無法排程自己生成的 goroutine,最後造成 deadlock。
這個問題的解法是改成識別 TGID,如果 process 的 TGID 等於 user space scheduler 的 PID,一律由 eBPF program 排程。
效能改善的部分則是盡可能使用 pre-allocated memory,且配合 Mlockall 減少 page fault 發生的頻率。
補充:
起初,scx_rustland 也會對處於 page fault 的 process 進行特殊處理,詳見:
- https://github.com/Gthulhu/qumun/blob/96cebdd3348b46ae96044d0269cd824213e56772/main.bpf.c#L854
- https://github.com/Gthulhu/qumun/blob/96cebdd3348b46ae96044d0269cd824213e56772/main.bpf.c#L277
後續又因為這個機制會讓沒有處於 page fault 的任務發生 starvation 而在該 commit 中移除。
Day 17:
- 原文:https://ithelp.ithome.com.tw/articles/10388823
- 發布日期:2025-09-27
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
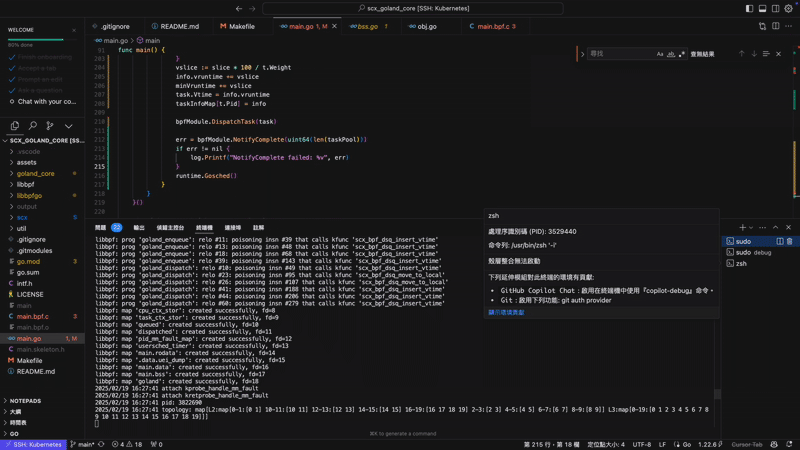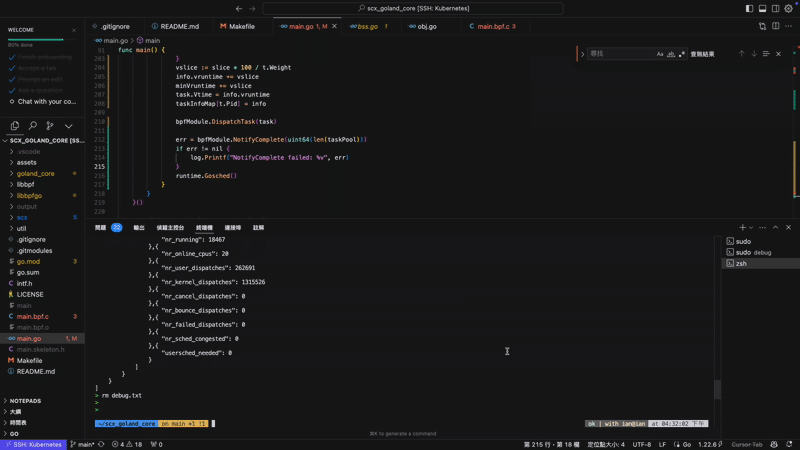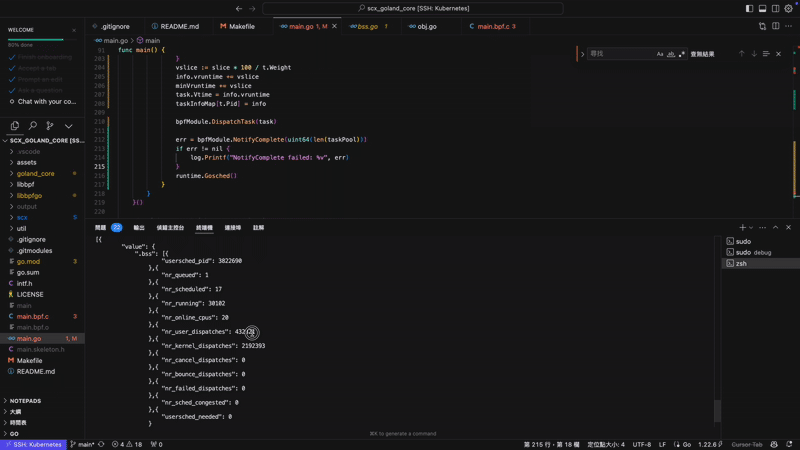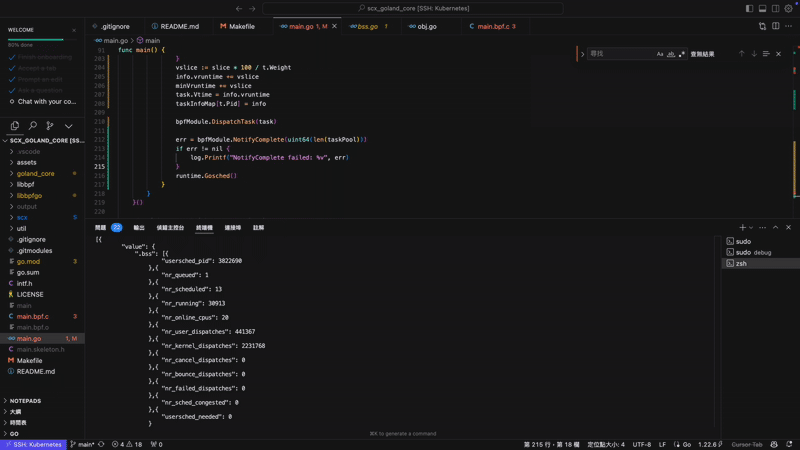
經過一系列的努力,總算是克服了 scheduler 死當的問題(page fault)。今天就來聊聊我在移植 scx_rustland 遇到的第二個問題。
補充:
我將 scx_rustland 以 golang 實作後將其命名為 scx_goland,後面採取了 jserv 的建議將其重新命名為 qunum(心臟的布農族語)。
我發現,當 qunum 運作一陣子後總是會被 watch dog 踢掉,而被踢掉的同時總是伴隨著 "runnable task stall" 的錯誤。這邊先科普一下 scx watch dog 的設計:
- Watch Dog 使用 Concurrency Managed Workqueue 機制運作,詳細資訊可參考 Linux 核心設計: Timer 及其管理機制以及 Linux 核心設計: Concurrency Managed Workqueue(CMWQ)。
- Watch Dog 會在 scheduler 無法在任務無法在設定的 timeout 時間內被排程時將其踢除。
- 第二點利用第一點達成,如果 Watch Dog 的檢查沒辦法在設定的 timeout 時間內完成,同樣會將 scheduler 踢除。
針對第三點,我一開始採取的 WORKAROUND 非常的暴力:
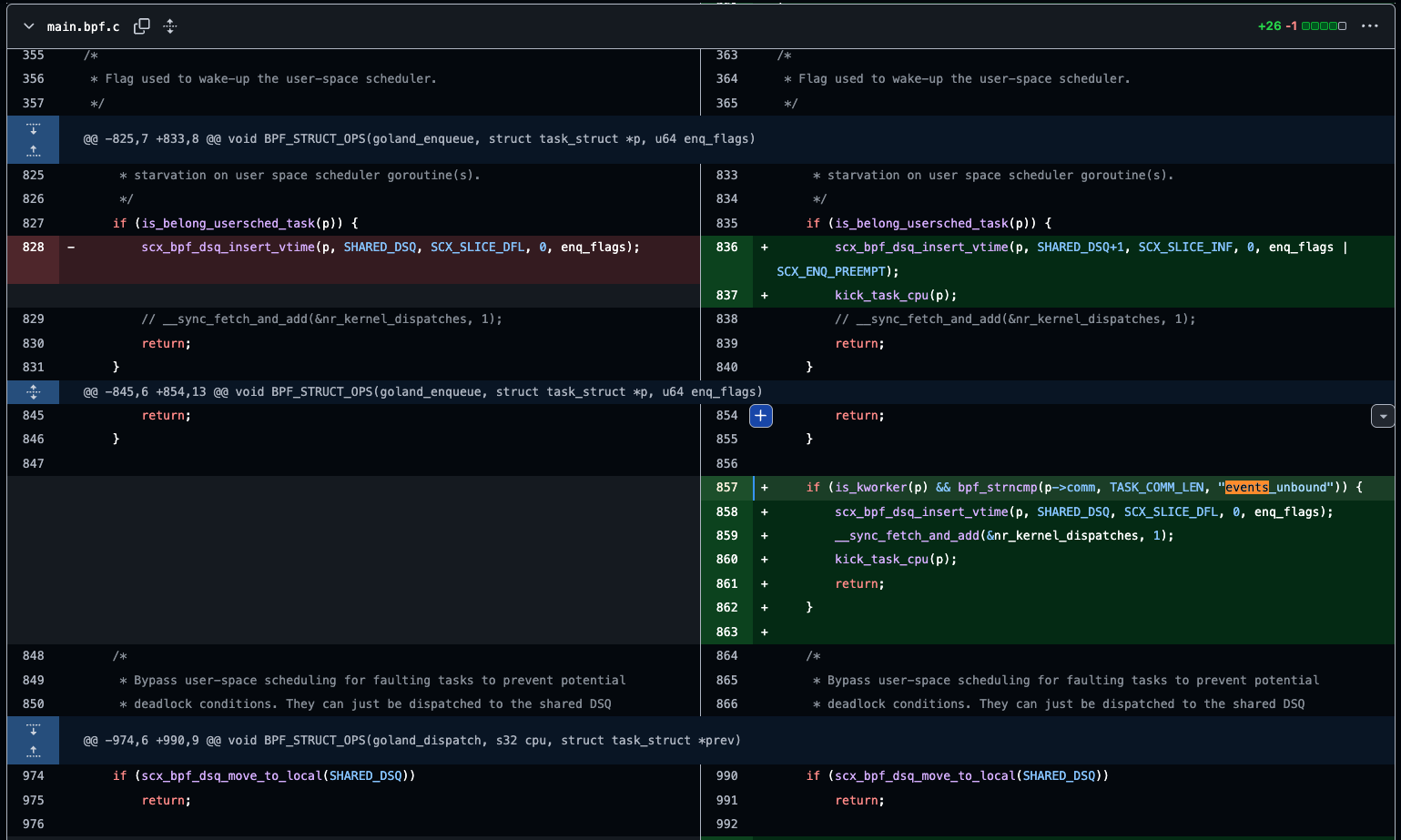
我讓運行 events_unbound 的 kworker(他會處理 cmwq 的任務)直接由 eBPF program 排程,避免 user space scheduler 將其給予過低的優先權,導致排程器被踢除。
這樣的手法有效,卻治標不治本,後來我重構了 user space scheduler 的排程迴圈:
for true {
select {
case <-ctx.Done():
log.Println("context done, exiting scheduler loop")
return
default:
}
bpfModule.DrainQueuedTask()
t = bpfModule.SelectQueuedTask()
if t == nil {
bpfModule.BlockTilReadyForDequeue(ctx)
} else if t.Pid != -1 {
task = core.NewDispatchedTask(t)
// Evaluate used task time slice.
nrWaiting := core.GetNrQueued() + core.GetNrScheduled() + 1
task.Vtime = t.Vtime
// Check if a custom execution time was set by a scheduling strategy
customTime := bpfModule.DetermineTimeSlice(t)
if customTime > 0 {
// Use the custom execution time from the scheduling strategy
task.SliceNs = min(customTime, (t.StopTs-t.StartTs)*11/10)
} else {
// No custom execution time, use default algorithm
task.SliceNs = max(SLICE_NS_DEFAULT/nrWaiting, SLICE_NS_MIN)
}
err, cpu = bpfModule.SelectCPU(t)
if err != nil {
log.Printf("SelectCPU failed: %v", err)
}
task.Cpu = cpu
err = bpfModule.DispatchTask(task)
if err != nil {
log.Printf("DispatchTask failed: %v", err)
continue
}
err = core.NotifyComplete(bpfModule.GetPoolCount())
if err != nil {
log.Printf("NotifyComplete failed: %v", err)
}
}
}
起初,為了避免這個迴圈佔滿 CPU,所以我會判斷當 task queue 有多個任務再進行排程,但這會導致排程的 delay 增加。後來我引入了 BlockTilReadyForDequeue 這個關鍵的函式:
func (s *Sched) BlockTilReadyForDequeue(ctx context.Context) {
select {
case t, ok := <-s.queue:
if !ok {
return
}
s.queue <- t
return
case <-ctx.Done():
return
}
}
想法非常簡單,如果我從 user ring buffer 拿到 eBPF program 派發的 task,我再向下執行,否則 block 整個迴圈。如此一來,我就能確保 scheduler 的 latency 盡可能地低,避免 watch dog 出現 starvation。這樣也就能夠把醜到爆炸的 WORKAROUND 移除了。
補充:
這裡的 latency 也是 Andrea Righi 在部落格中提到的 bubble,兩者都是要傳達一個任務從 runnable 到 running 所花的時間,這個 latency 對於一些低延遲需求的應用來說尤其重要。在後續我們將 Gthulhu 應用到 5G URLLC 的案例上也是優先處理了 latency 的問題。
Day 18:
- 原文:https://ithelp.ithome.com.tw/articles/10388827
- 發布日期:2025-09-28
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
克服了前面兩個巨大的挑戰後,基本上 Gthulhu 就已經有一定的穩定性了(至少在我的主力開發機器上熬過了漫長的 7x24 Hrs)。但是,還是有一個問題非常困擾我。
基本上,eBPF program 的全域變數會根據不同的宣告方式被歸類在不同的 segment:
struct {
struct bpf_map *cpu_ctx_stor;
struct bpf_map *task_ctx_stor;
struct bpf_map *queued;
struct bpf_map *dispatched;
struct bpf_map *priority_tasks;
struct bpf_map *running_task;
struct bpf_map *usersched_timer;
struct bpf_map *rodata;
struct bpf_map *data_uei_dump;
struct bpf_map *data;
struct bpf_map *bss;
struct bpf_map *goland;
} maps;
上方程式碼是由 bpftool 產生的 skeleton file 的一部分,可以發現 Gthulhu 使用的 eBPF program 就至少會有:
- bss
- data
- rodata
其中,bss 存放的資料非常重要:
struct main_bpf__bss {
u64 usersched_last_run_at;
u64 nr_queued;
u64 nr_scheduled;
u64 nr_running;
u64 nr_online_cpus;
u64 nr_user_dispatches;
u64 nr_kernel_dispatches;
u64 nr_cancel_dispatches;
u64 nr_bounce_dispatches;
u64 nr_failed_dispatches;
u64 nr_sched_congested;
} *bss;
這裡面的 nr_scheduled 以及 nr_queued 會影響 user space scheduler 為一個任務分配 time slice 的大小(呼應前面說的,scx_rustland 會根據待排程任務的數量決定 time slice)。
然而,libbpfgo 的 API 會將一個 bss section 視為一個 eBPF MAP,如果我今天先讀取後更新這份 MAP,在這個期間 eBPF program 只要對這個 MAP 裡面的資料增減,就會造成 DATA RACE 的問題。這類的問題如果出現在 DATABASE,就有點像是買超賣超的問題,不過在 DATABASE 的場景中使用 transaction 或是 DB Lock 就能解決這個問題了。
scx_rustland 本身會直接呼叫 skeleton API,所以能夠指定更新 bss map 的某一個欄位,為了克服這個惱人的問題,我的解法就是利用 eBPF skeleton!
// wrapper.c
#include "wrapper.h"
struct main_bpf *global_obj;
void *open_skel() {
struct main_bpf *obj = NULL;
obj = main_bpf__open();
main_bpf__create_skeleton(obj);
global_obj = obj;
return obj->obj;
}
u32 get_usersched_pid() {
return global_obj->rodata->usersched_pid;
}
void set_usersched_pid(u32 id) {
global_obj->rodata->usersched_pid = id;
}
void set_kugepagepid(u32 id) {
global_obj->rodata->khugepaged_pid = id;
}
void set_early_processing(bool enabled) {
global_obj->rodata->early_processing = enabled;
}
void set_default_slice(u64 t) {
global_obj->rodata->default_slice = t;
}
void set_debug(bool enabled) {
global_obj->rodata->debug = enabled;
}
void set_builtin_idle(bool enabled) {
global_obj->rodata->builtin_idle = enabled;
}
u64 get_nr_scheduled() {
return global_obj->bss->nr_scheduled;
}
u64 get_nr_queued() {
return global_obj->bss->nr_queued;
}
void notify_complete(u64 nr_pending) {
global_obj->bss->nr_scheduled = nr_pending;
}
void sub_nr_queued() {
if (global_obj->bss->nr_queued){
global_obj->bss->nr_queued--;
}
}
void destroy_skel(void*skel) {
main_bpf__destroy(skel);
}
golang 雖然無法像 rust 一樣直接使用 skeleton API,但我可以將這些 API 進行封裝,再利用 cgo 呼叫這些函式。
wrapper:
bpftool gen skeleton main.bpf.o > main.skeleton.h
clang -g -O2 -Wall -fPIC -I scx/build/libbpf/src/usr/include -I scx/build/libbpf/include/uapi -I scx/scheds/include -I scx/scheds/include/arch/x86 -I scx/scheds/include/bpf-compat -I scx/scheds/include/lib -c wrapper.c -o wrapper.o
ar rcs libwrapper.a wrapper.o
透過上面的方式,將 wrapper 變成靜態鏈結函式庫,供 Gthulhu 使用:
CGOFLAG = CC=clang CGO_CFLAGS="-I$(BASEDIR) -I$(BASEDIR)/$(OUTPUT)" CGO_LDFLAGS="-lelf -lz $(LIBBPF_OBJ) -lzstd $(BASEDIR)/libwrapper.a"
如此一來,就能夠在 golang 呼叫這些封裝過的 API 了:
func (s *Sched) AssignUserSchedPid(pid int) error {
C.set_kugepagepid(C.u32(KhugepagePid()))
C.set_usersched_pid(C.u32(pid))
return nil
}
func (s *Sched) SetDebug(enabled bool) {
C.set_debug(C.bool(enabled))
}
func (s *Sched) SetBuiltinIdle(enabled bool) {
C.set_builtin_idle(C.bool(enabled))
}
func (s *Sched) SetEarlyProcessing(enabled bool) {
C.set_early_processing(C.bool(enabled))
}
func (s *Sched) SetDefaultSlice(t uint64) {
C.set_default_slice(C.u64(t))
}
總結
截至目前為止,我們已經探討了將 scx_rustland 重新以 golang 實作時會遇到的“大問題”,接下來就可以將我多年泡在 free5GC 學到的奇怪知識與想法結合 Gthulhu,打造一款面向雲原生應用的排程器方案了👍
Day 19:
- 原文:https://ithelp.ithome.com.tw/articles/10389035
- 發布日期:2025-09-29
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
![]()
前三篇文章將焦點放在 qumun 誕生的歷程,今天就來談一下當初規劃 Gthulhu 這個專案時想到的設計要點:
- 直接利用 qumun 框架,打造一個面向雲端原生且穩定的排程器方案:
- 這部分已經達成,目前 Gthulhu 透過 git submodule + go replace 的方式直接使用 qumun 提供的 eBPF program 與相對應的 APIs。
- eBPF program 主要利用 scx_rustland,我們可以時時刻刻保持與 upstream 的聯繫,一邊發展自己的特色,同時也能站在巨人的肩膀上持續前進。
- 主要戰場定位在 Kubernetes 生態系,使用者提供意圖(intent),讓 Gthulhu 幫你完成!
- Gthulhu 需要提供與使用者之間的橋樑:
- 需要規劃一個 API Server,讓 Gthulhu 能夠與其溝通,取得使用者下達的排程器策略,實現 "Scheduling Policy As Configuration" 的概念。
- 如果可以,整合 MCP,使 Gthulhu 能夠與 Coding Agent 互動。
- Gthulhu 在進入正式的 Release 之前,至少需要有一個足夠強力的 PoC 來向展示潛在用戶展示雲端原生排程器的魅力:
- 選擇我熟悉的戰場,把 free5GC 與 Gthulhu 進行整合。
- 盡可能的容易安裝與部署:
- 利用 eBPF CORE 的特性,以 container image 的方式發布軟體。
- 提供 helm chart 讓用戶可以快速的部署 Gthulhu。
- 需考慮多節點叢集的架構
- 除了 API Server,最後仍需要一個管理系統管理所有節點的排程器與 API server。
- 需考慮權限問題。
- 需提供一定的可觀測性。
- 提供足夠資訊的官方文件
- 提供社群雙向交流的管道,在各大社群推廣,並且成立 Advisory Board。
- 先埋好 Search Console 與 GA,觀察活躍用戶的變化。
- 觀察 GitHub Traffic,觀察活躍用戶的變化。
Day 20:
- 原文:https://ithelp.ithome.com.tw/articles/10391332
- 發布日期:2025-09-30
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
在前一篇文章中有提到:
- 需要規劃一個 API Server,讓 Gthulhu 能夠與其溝通,取得使用者下達的排程器策略,實現 "Scheduling Policy As Configuration" 的概念。
- 如果可以,整合 MCP,使 Gthulhu 能夠與 Coding Agent 互動。
其實都已經順利達成了,所以今天的文章不會包含密密麻麻的實作細節還有程式碼,而是會從幾個面向來討論我當初實作 API server 時在想什麼。
考慮到 User-Space Scheduler 被分配到的 cpu time 應該不能有不必要的浪費(決定 cpu 與資源應該越快越好,才能提高排程器的吞吐量),任何不參與決策的雜事應該由其他的服務完成,像是:
- 處理使用者的意圖
- 根據意圖尋找對應的 Pod,以及對應的 PID
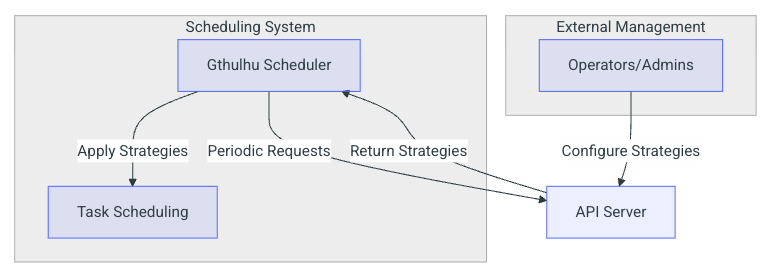
所以我決定額外開發一個 API Server 來處理這些東西,讓 User-Space scheduler 只有在必要時才需要處理 api server 交給他的決策。並且,考慮到如果使用者頻繁改變它的意圖,User-Space scheduler 不應該每次都即時的給予響應,所以我將 scheduler 與 api server 的互動模式設計成由 scheduler 每隔一段時間向 api server 索取新規則,而非當 api server 處理完客戶端的請求就直接將規則送往 scheduler。
透過這樣解耦合的方式,雖然有效避免 scheduler 浪費寶貴的 cpu quota,但會需要考慮溝通方式的安全性。
目前實作的暫解是:
- api server 有一對 rsa 密鑰
- scheduler 有 public key
- scheduler 詢問 api server 規則時,需要先向 api server 取得 JWT token
- scheduler 取得 JWT token 的過程中需要在請求中帶入 public key,方便 api server 使用 private key 驗證
- 若驗證成功,使用 private key 發行 JWT Token,並且給予合理的使用時效
基本上就是很簡單的系統設計,但可以暫時保證溝通層面的安全。
有了 api server,其實我們就讓排程器本身有機會提供更豐富的功能,舉例來說:我可以使用 MCP,Coding Agent 或是語言模型跟 api server 溝通,透過聊天的方式把 scheduling policy 聊出來。而且我也已經做到:
然而,考慮到 Gthulhu 想解決的場景是「多節點叢集」,所以要讓 api server 如何優雅的在多節點叢集下工作,也是個需要耗費腦力的挑戰!這部分我們就在下回分曉:)
Day 21:
- 原文:https://ithelp.ithome.com.tw/articles/10391888
- 發布日期:2025-10-01
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
為了方便 Kubernetes 部署所需要的文件(yaml),普遍的做法都是利用 helm 或是 kustomize 將不同 vendor 的設定給獨立出來。Gthulhu 則是使用筆者較為熟悉的 helm 來管理 k8s 部署,方便使用者快速的將 Gthulhu 運作在 k8s 上。
考慮到 Gthulhu 想解決的場景是「多節點叢集」環境,每一個節點其實都需要運作單獨的 Gthulhu 排程器,以及各自的 API Server。
每一個節點都需要運作單獨的 Gthulhu 排程器很好理解,就是每一個節點自己處理本身需要排程的任務們。至於 API Server 為何也需要這樣,則是受限於 PID 的關係。因此我們可以預期,如果要讓 Gthulhu 轉變成能夠運作在多節點叢集的解決方案,我們至少需要:
- 考慮 Pod Generator 的類型:常見的 Pod Generator 有 ReplicaSet / DaemonSet / StatefulSet,它們有各自不同的特性。對於「每一個節點都需要運作單獨的排程器與 API server」這個需求來說,DaemonSet 就是最佳人選。
- [TODO] 考慮 K8s 的 service discovery 機制:要讓 Gthulhu 永遠向同節點的 API server 溝通,這樣 Gthulhu 才能拿到正確的 Scheduling Policy(因為有 PID)。
- [TODO] 需要有一個 Operator 能夠管理每一個節點的 API Server,由它接受使用者的真正意圖,最後再向每一個節點的 API Server 更新規則。
第二點問題可以靠 Operator 來解決,只要:
- API server 啟動時透過 k8s service 向 Operator 進行註冊,並且於註冊時提供自己的 Cluster IP 以及 K8s Node Name
- Gthulhu Scheduler 嘗試向 API Server 抓取 scheduling policy 之前,向 Operator 詢問自己節點下的 API Server 的 Cluster IP 為何
- 如此一來,Scheduler 就能準確的找到位於同個節點下的 API Server。
Day 22:
- 原文:https://ithelp.ithome.com.tw/articles/10392369
- 發布日期:2025-10-02
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
今天來講一下搶佔式任務處理對 Gthulhu 為何重要?以及我們如何實作。
scx_rustland 和 Gthulhu 都是 vtime-based 的 scheduler,大家可以把 vtime 想像成 virtual deadline。而 Gthulhu 的 deadline 是這樣決定的:
func updatedEnqueueTask(t *models.QueuedTask) uint64 {
// Check if we have a specific strategy for this task
strategyApplied := ApplySchedulingStrategy(t)
if !strategyApplied {
// Default behavior if no specific strategy is found
if minVruntime < t.Vtime {
minVruntime = t.Vtime
}
minVruntimeLocal := util.SaturatingSub(minVruntime, SLICE_NS_DEFAULT)
if t.Vtime == 0 {
t.Vtime = minVruntimeLocal + (SLICE_NS_DEFAULT * 100 / t.Weight)
} else if t.Vtime < minVruntimeLocal {
t.Vtime = minVruntimeLocal
}
t.Vtime += (t.StopTs - t.StartTs) * t.Weight / 100
}
return 0
}
ApplySchedulingStrategy嘗試查找 API server 提供的 policy 中有沒有對的當前任務調整。- 如果沒有,根據上一輪的執行使間以及 task 本身的權重來決定 virtual deadline。
對於時間敏感的任務,如:5G 在 Ultra-Reliable and Low Latency Communications 場景的要求是:
- control plane 時延 10ms
- data plane 時延 0.5ms
如果只靠預設的排程器,很難保證在各種負載下滿足這樣的水準。
更甚者,即使將最高優先度的任務的 virtual deadline 設為 0,在系統有高負載的情況下,等到任務被排程也需要幾十個 ms。
解決辦法也很簡單,就是靠 preemption!
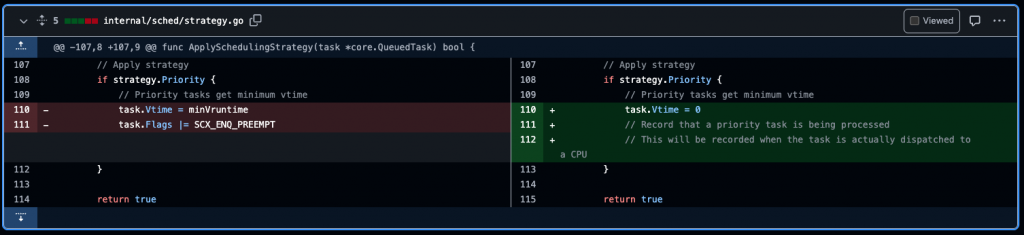
假設任務是高優先度的任務,我們先在 user space 將他的 vtime 設置為 0。我們會將 vtime 為 0 的任務的 pid 存入 priority_tasks 這個 eBPF MAP:
/*
* Helper function to update priority tasks map based on vtime.
* If vtime == 0, add PID to map. If vtime != 0, remove PID from map.
*/
static void update_priority_task_map(u32 pid, u64 vtime)
{
if (vtime == 0) {
u8 val = 1;
bpf_map_update_elem(&priority_tasks, &pid, &val, BPF_ANY);
} else {
bpf_map_delete_elem(&priority_tasks, &pid);
}
}
接著在 .enqueue 時直接處理高優先度的任務:
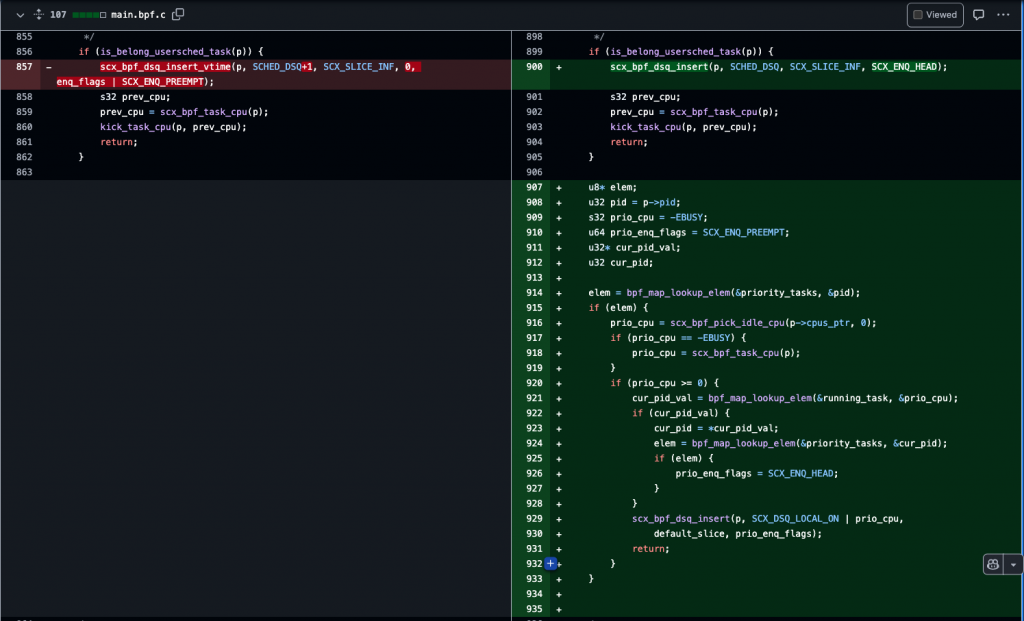
首先,先為需要排程的任務尋找一個 idle cpu,如果找不到,就選擇前一次服務該任務的 cpu。
接著我們會看這個 cpu 上正在執行的任務:
- 如果運行中的任務也是高優先度的任務,那們我們不會做 preemption,而是把需要排程的任務放入該 CPU 自己所有的 DSQ 的最前端。
- 如果運行中的任務不是高優先度的任務,則使用
SCX_ENQ_PREEMPT觸發 preemption。
詳細的更動請參考 PR #15
讓 Gthulhu 支援 preemption 之後,我們就有能力對延遲敏感的任務進行最佳調整。但是,下一個挑戰來了,我們要如何挑選出 The One(需要被調整的 Process)呢?讓我們在未來兩篇文章揭曉。
Day 23:
- 原文:https://ithelp.ithome.com.tw/articles/10392928
- 發布日期:2025-10-03
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
5G 核心網路將所有的 Data-Plane traffic 都交給 UPF 網路元件處理。在 free5GC 中,我們又再將 UPF 分成兩個部分實作:
- application:負責處理 N4 介面的控制訊號,將訊號轉為封包處理規則送往 kernel space。
- kernel module:實作一個 virtual network device,將封包處理的所有任務保留在 kernel space 來提高吞吐量。
結合我們先前的研究成果,要整合 free5GC 的困難度在於:
- Linux kernel 的網路堆疊很複雜
- 如果使用 kubernetes 部署 free5GC,我們要考慮 data-plane traffic 的流向(來自同節點還是跨節點、送往同節點還是跨節點?)
這些因素會導致我們無法直接告訴 API server 只要降低 UPF process 的 latency 即可,因為 kernel module 在處理封包時並不是使用 UPF process 的 context。
為了有效的識別出那個 destiny(誰接收了封包、又是誰把封包送出去),我們就需要想辦法觀察 kernel module(gtp5g)的行為。
而 eBPF 本身就是 observability 的利器,所以我利用 BTF export 出 gtp5g 中的 self-defined structure,並且觀察有哪些函式能夠被 ftrace 觀測到。抓出 gtp5g 之中明確的 uplink 與 downlink 進入點,我就能用 eBPF 進行觀測了:)
- 程式碼可參考 gtp5g-tracer
- 當初實作 gtp5g-tracer 撰寫的文章:https://free5gc.org/blog/20241224/
- 更 detail 的文章:https://free5gc.org/blog/20250913/20250913/
我在這邊先總結一下觀察到的結果:
- Uplink 會綁著收進封包的 context,比如說,N3 的封包從某個網卡收進來,那麼 Uplink 會由那張網卡的 irq 處理。經過處理後送往 N6 則是看 N6 對應的是哪張網卡,會有對應的 irq 處理。
- Downlinkk 同樣看綁著收進封包的 context,比如說,N6 的封包從某個網卡收進來,那麼就由這張網卡的 irq 處理。
- 如果所有的通訊都在一個 node 裡面(UERANSIM, DN server 都在同一個機器上),那麼就會吃到 nr-ue(因為用來測試的 ICMP 是由 nr-ue 送出的)這個 process 的 context。
Day 24:
- 原文:https://ithelp.ithome.com.tw/articles/10393308
- 發布日期:2025-10-04
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
對於 5G 與 scx 的結合,已經有些許討論 [1] [2] [3]。然而,考慮到現代 Cloud-Native App (5G Core Network) 的特性,目前尚沒有相關案例探討 scx 如何在雲原生架構上運作。
圖一:API 架構
對此,筆者提出了一個初步的想法,基於 scx_goland_core 框架開發了一個可在雲原生環境中運行的自訂排程器 Gthulhu,它可以部署於 Kubernetes 群集中,透過部署的方式管理叢集中大量節點的排程策略。
我們可以透過 Restful API 對 Gthulhu API server 下達排程策略,讓 API server 為我們找出需要調整的 workloads。與此同時,Gthulhu 會定期向 API server 發送心跳訊息,並在必要時更新排程策略。
關於 Gthulhu 的詳細資訊,請參考 Gthulhu Docs。
牛刀小試:觀察 Gthulhu 載入後資料層的效能差異
在本次實驗中,筆者的機器運作 在 Ubuntu 24.04 LTS 上,使用 Linux Kernel 6.12。實驗的目的是觀察 Gthulhu 在載入後對資料層效能的影響。
試驗環境如下:
- VM1 (Ubuntu 24.04 LTS, Linux Kernel 6.12)
- 部署 free5GC v4.0.1
- VM2 (Ubuntu 20.04 LTS, Linux Kernel 5.4.0)
- 部署 UERANSIM
待 PDU Session 建立後,筆者使用 ping 工具對 UPF N6 介面進行測試,並觀察在載入 Gthulhu 前後的延遲變化。
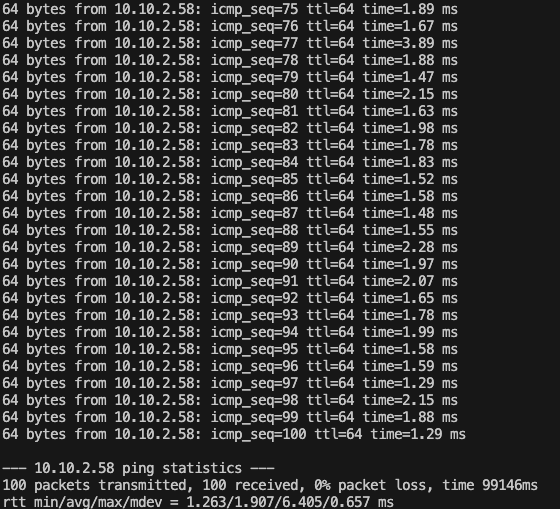
載入前,Linux 預設的排程器為 EEVDF,RTT 相關參數如下:
- rtt min = 1.263 ms
- rtt avg = 1.907 ms
- rtt max = 6.405 ms
- rtt mdev = 0.657 ms
rtt min/avg/max/mdev = 1.222/1.864/3.771/0.433 ms
載入 Gthulhu 後,RTT 參數變化如下:
- rtt min = 1.222 ms
- rtt avg = 1.864 ms
- rtt max = 3.771 ms
- rtt mdev = 0.433 ms
由此可見,載入 Gthulhu 後,RTT 的平均值和最大值均有所下降,顯示出 Gthulhu 在資料層的排程上確實有助於降低延遲。
對 GTP5G 進行最佳化排程
根據前面的實驗結果可以得知,在不對排程器進行任何調整的前提下,Gthulhu 確實有效的降低 RTT 的表現。那麼,我們有機會利用網路子系統的知識結合 Gthulhu 更進一步對 GTP5G 進行調教嗎?
[!Note]
實驗環境如下:
- 5GC on kubernetes
- N3/N6 使用 Multus CNI 建立 macvlan interfaces(N6 綁定 enp7s0,N3 介面綁定 dummy interface)
觀察 Downlink 由哪一個 cpu 負責處理
$ grep enp7s0 /proc/interrupts
159: 116096 131508 763166 532207 4697697 3924514 24589811 5660340 29315073 11862910 25971964 8494127 1935719 2420802 5149765 948266 6835920 2126158 1825640 1044404 IR-PCI-MSIX-0000:07:00.0 0-edge enp7s0
透過上方執行的命令可以得知 enp7s0 對應的 IRQ 為 159,接著利用 cat /proc/irq/${IRQ}/smp_affinity_list 可以得知 IRQ 159 綁定的 CPU:
$ cat /proc/irq/159/smp_affinity_list
11
當 enp7s0 收到來自 Data Network 的封包,會接封包送往 UPF Container 對應的 n6 interface,而 N6 interface 會將 downlink 封包轉送至虛擬介面 gtp5g 內。
因此,處理 gtp5g downlink 流量的 CPU 應該是 CPU 11,這一點可以透過 eBPF program 驗證。
在筆者先前撰寫的 Debug gtp5g kernel module using stacktrace and eBPF 一文中已經探討過使用 eBPF 追蹤 kernel module 的可能性,只要追蹤一下 gtp5g 的 source code 便可以得知 downlink 封包最後會進入 gtp5g_xmit_skb_ipv4,使用 sudo cat /sys/kernel/tracing/available_filter_functions | grep gtp5g 也可得知該函式在 available_filter_functions 清單內。
SEC("fentry/gtp5g_xmit_skb_ipv4")
int BPF_PROG(capture_skb, struct sk_buff *skb, struct gtp5g_pktinfo *pktinfo)
{
__u64 pid_tgid = bpf_get_current_pid_tgid();
__u32 pid = pid_tgid & 0xFFFFFFFF;
__u32 tgid = pid_tgid >> 32;
__u32 cpu = bpf_get_smp_processor_id();
bpf_printk("gtp5g_xmit_skb_ipv4: PID=%u, TGID=%u, CPU=%u", pid, tgid, cpu);
return 0;
}
將上述的 eBPF 程式載入到核心後,利用 UERANSIM 建立 PDU Session 向 8.8.8.8 發送 ICMP 封包時,我們即可觀察 eBPF 程式的輸出:
gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156182.987076: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156183.987343: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156184.986858: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156185.987004: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156186.987574: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156187.987330: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156188.987722: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156189.988054: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156190.988038: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
kubelite-3377186 [011] b.s21 6156191.987614: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=3377186, TGID=3376931, CPU=11
<idle>-0 [011] b.s31 6156192.987963: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156193.987763: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156194.988095: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
從 eBPF 程式的輸出可得知,gtp5g 的 downlink 流量確實由 CPU 11 負責處理,與先前的猜測相同。
當我使用 echo "12" | sudo tee /proc/irq/159/smp_affinity_list 修改 IRQ 159 綁定的 CPU 後,eBPF 程式的輸出也會馬上改變:
gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156445.013125: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156446.012413: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156447.012498: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156448.013280: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156449.012909: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156450.013119: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156451.013496: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
補充:
IRQ 綁定的 CPU 有可能會被 irqbalance 動態的更新,建議可以用$ sudo systemctl stop irqbalance暫時關閉 irqbalance。
話說回來,即使將 irqbalance 關閉,eBPF 程式的輸出仍有可能出現非預期情況。
當我將 ICMP 的目標從外部 IP 改為 UPF container 本身 N6 網卡的 IP 時,eBPF 程式的輸出如下:
nr-gnb-168420 [016] b.s41 6158463.012636: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=16
nr-gnb-168420 [016] b.s41 6158464.012282: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=16
nr-gnb-168420 [017] b.s41 6158465.012408: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=17
nr-gnb-168420 [017] b.s41 6158466.012551: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=17
nr-gnb-168420 [016] b.s41 6158467.012401: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=16
nr-gnb-168420 [006] b.s41 6158468.012565: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158469.012700: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158470.012549: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158471.012763: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158472.012862: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
基本上執行 gtp5g_xmit_skb_ipv4 的 CPU 一定會是 scheduler 為 nr-gnb process 分配的 CPU。原因也很簡單,因為送往 N6 網卡的封包會在 Container 內處理完畢,不會經過 enp7s0 網卡,所以封包從 UERANSIM 傳出一路到 N6 返回都會在同一個上下文內處理完畢。
了解 Linux 核心處理封包的行為後,我們可以實驗看看當系統滿載的情況下,UERANSIM 透過 uesimtun0 向 UPF N6 IP 發送 ICMP echo request 的表現。
Gthulhu 的組態設定
在本次實驗中,組態的設定固定如下:
# Gthulhu Scheduler Configuration
# This configuration file allows you to adjust scheduler parameters before eBPF program loading
scheduler:
# Default time slice in nanoseconds (default: 5000000 = 5ms)
slice_ns_default: 2000000
# Minimum time slice in nanoseconds (default: 500000 = 0.5ms)
slice_ns_min: 500000
api:
enabled: false
url: http://127.0.0.1:8080
interval: 5
debug: false
early_processing: false
builtin_idle: false
使用 stress-ng 產生負載
$ stress-ng -c 20 --timeout 60s --metrics-brief
使用 ping 進行測試
Gthulhu scheduler 借鑑了 scx_rustland 的設計,因此,在本實驗中我們使用 scx_rustland 作為對照組:
/UERANSIM # taskset -c 5 ping 10.10.2.60 -I uesimtun0 -c 10
PING 10.10.2.60 (10.10.2.60): 56 data bytes
64 bytes from 10.10.2.60: seq=0 ttl=64 time=75.589 ms
64 bytes from 10.10.2.60: seq=1 ttl=64 time=75.917 ms
64 bytes from 10.10.2.60: seq=2 ttl=64 time=63.919 ms
64 bytes from 10.10.2.60: seq=3 ttl=64 time=71.934 ms
64 bytes from 10.10.2.60: seq=4 ttl=64 time=72.005 ms
64 bytes from 10.10.2.60: seq=5 ttl=64 time=64.108 ms
64 bytes from 10.10.2.60: seq=6 ttl=64 time=83.945 ms
64 bytes from 10.10.2.60: seq=7 ttl=64 time=100.525 ms
64 bytes from 10.10.2.60: seq=8 ttl=64 time=59.987 ms
64 bytes from 10.10.2.60: seq=9 ttl=64 time=63.940 ms
--- 10.10.2.60 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 59.987/73.186/100.525 ms
我們可以觀察出:當系統的每個 CPU 滿載時,scx_rustland 在處理封包的效率上非常糟糕。這個問題在 Gthulhu 排程器上亦然:
/UERANSIM # taskset -c 5 ping 10.10.2.60 -I uesimtun0 -c 10
PING 10.10.2.60 (10.10.2.60): 56 data bytes
64 bytes from 10.10.2.60: seq=0 ttl=64 time=22.085 ms
64 bytes from 10.10.2.60: seq=1 ttl=64 time=59.904 ms
64 bytes from 10.10.2.60: seq=2 ttl=64 time=96.299 ms
64 bytes from 10.10.2.60: seq=3 ttl=64 time=20.349 ms
64 bytes from 10.10.2.60: seq=4 ttl=64 time=71.244 ms
64 bytes from 10.10.2.60: seq=5 ttl=64 time=28.001 ms
64 bytes from 10.10.2.60: seq=6 ttl=64 time=74.964 ms
64 bytes from 10.10.2.60: seq=7 ttl=64 time=59.977 ms
64 bytes from 10.10.2.60: seq=8 ttl=64 time=32.617 ms
64 bytes from 10.10.2.60: seq=9 ttl=64 time=90.945 ms
--- 10.10.2.60 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 20.349/55.638/96.299 ms
接著,讓我們嘗試以下做法,看能不能降低 round-trip-time:
- 將某個 CPU(這裡使用 CPU 5)給 UERANSIM、
icmp工具 - 若其他任務被分配到 CPU 5,則隨機為它分配其他 CPU
相關改動請參考:
// ...
log.Println("scheduler started")
+ var specialPid int32 = 168420 // Special case for PID 168420
+ var specialPidCpu int32 = 5
for true {
select {
case <-ctx.Done():
log.Println("context done, exiting scheduler loop")
return
default:
}
sched.DrainQueuedTask(bpfModule)
t = sched.GetTaskFromPool()
if t == nil {
bpfModule.BlockTilReadyForDequeue(ctx)
} else if t.Pid != -1 {
task = core.NewDispatchedTask(t)
err, cpu = bpfModule.SelectCPU(t)
if err != nil {
log.Printf("SelectCPU failed: %v", err)
}
+ if t.Pid == specialPid {
+ if specialPidCpu == -1 && cpu != core.RL_CPU_ANY {
+ specialPidCpu = cpu
+ } else {
+ cpu = specialPidCpu
+ }
+ } else {
+ if cpu == core.RL_CPU_ANY {
+ // ramdom select cpu 0-19
+ cpu = int32(rand.Intn(20))
+ }
+ if specialPidCpu == cpu {
+ if (cpu & 1) == 1 {
+ cpu = cpu - 1
+ } else {
+ cpu = cpu + 1
+ }
+ }
+ }
// Evaluate used task time slice.
nrWaiting := core.GetNrQueued() + core.GetNrScheduled() + 1
task.Vtime = t.Vtime
Special pid 168420 是透過 eBPF 程式觀察出負責執行 gtp5g_xmit_skb_ipv4() 的 process id:
nr-gnb-770208 [005] b.s41 6233538.456200: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233711.301750: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233712.346565: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233713.312931: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233714.314609: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233715.340537: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233716.337300: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233717.389852: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233718.387986: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233719.368526: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233720.396073: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
完成修改後,讓我們嘗試重新執行 Gthulhu 並再次測試:
/UERANSIM # taskset -c 5 ping 10.10.2.60 -I uesimtun0 -c 10
PING 10.10.2.60 (10.10.2.60): 56 data bytes
64 bytes from 10.10.2.60: seq=0 ttl=64 time=0.767 ms
64 bytes from 10.10.2.60: seq=1 ttl=64 time=1.150 ms
64 bytes from 10.10.2.60: seq=2 ttl=64 time=1.120 ms
64 bytes from 10.10.2.60: seq=3 ttl=64 time=0.968 ms
64 bytes from 10.10.2.60: seq=4 ttl=64 time=1.002 ms
64 bytes from 10.10.2.60: seq=5 ttl=64 time=0.601 ms
64 bytes from 10.10.2.60: seq=6 ttl=64 time=1.132 ms
64 bytes from 10.10.2.60: seq=7 ttl=64 time=0.833 ms
64 bytes from 10.10.2.60: seq=8 ttl=64 time=0.666 ms
64 bytes from 10.10.2.60: seq=9 ttl=64 time=0.795 ms
--- 10.10.2.60 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 0.601/0.903/1.150 ms
從結果來看,修改後的 Gthulhu 排程器在高負載的情況下使 UPF 能在短時間內處理來自 UERANSIM 的封包。這樣的表現與我們預期的一致。
透過自定義組態降低 RTT
前面的的實驗中,我們為特定的 process 分配了專用的 CPU,這樣的做法確實能夠在高負載的情況下提升 RTT 的表現。然而,這種方法並不通用,因為每個系統的負載情況和工作負載可能會有所不同。
因此,Gthulhu 發展出一套自定義的組態設定,讓使用者能夠根據自己的需求調整排程策略,專案原始碼請參考 Gthulhu/api。
{
"server": {
"port": ":8080",
"read_timeout": 15,
"write_timeout": 15,
"idle_timeout": 60
},
"logging": {
"level": "info",
"format": "text"
},
"jwt": {
"private_key_path": "./config/jwt_private_key.key",
"token_duration": 24
},
"strategies": {
"default": [
{
"priority": true,
"execution_time": 20000,
"selectors": [
{
"key": "app",
"value": "ueransim-macvlan"
}
],
"command_regex": "nr-gnb|nr-ue|ping"
}
]
}
}
透過上方的 json 檔案,api server 能夠找出對應的 processes,並將這些 process 的排程策略更新至 Gthulhu。
如果該任務的 "priority": true,則該任務本身能夠搶佔其他非 "priority": true 的任務,大大的降低任務從 runnable 到 running 的時間。
在 free5GC 的整合案例中,降低 ueransim 的排程延遲代表著 UPF 能夠更快的處理來自 RAN 的封包,進而降低整體的 RTT。
上方影片展示了在高負載的情況下,Gthulhu 如何透過自定義的排程策略顯著降低 RTT 的表現。
此外,Gthulhu 也支援簡易的 WEB GUI,讓使用者能夠更直觀地管理和監控排程策略。
結論
5G 提出了網路切片的概念,期待透過將實體網路切分成多個虛擬網路來提供不同的服務品質。有了 Gthulhu 這樣的自訂排程器,我們可以更靈活地管理和優化這些虛擬網路的性能,將不同業務需求的 UPF 部署在不同的節點上,並根據實際需求調整排程策略。
Day 25:
- 原文:https://ithelp.ithome.com.tw/articles/10393310
- 發布日期:2025-10-05
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
對於一個成熟的開源專案來說,測試覆蓋率也是相當重要的指標。在人力有限的情況下,至少需要確保新的更動至少不會影響 Gthulhu 的運作。最快速的方式就是將相關測試整合至 CI/CD pipeline 中,由於 Gthulhu 與相關的套件目前都託管在 GitHub 平台進行管理,而 GitHub Actions 提供的 Runner 目前也沒有 Linux Kernel 6.12+ 的版本可以使用(即使有,它也不一定允許我們使用 sched_ext 抽換預設的排程器)。
因此,我們會在 Actions 中使用到 virtme-ng 這套工具,它能夠利用 QEMU 建立一個輕量化的 Linux 測試環境,kernel 本身能夠與 Host 隔離,加上使用 Host 的系統充做 copy-on-write snapshot,所以它能夠在非常短的時間內啟動一個虛擬機器。
首先,我們將必要的 dependency 安裝步驟整合進 ./.github/actions/build-dependencies/action.yaml 之中:
name: Build Dependencies
description: |
Install build dependencies to test and compile tracee artifacts
inputs:
go-version:
description: go version
default: "1.21"
runs:
using: composite
steps:
- name: Setup Go
uses: actions/setup-go@cdcb36043654635271a94b9a6d1392de5bb323a7 # v5.0.1
with:
go-version: "${{ inputs.go-version }}"
- name: Install Compilers & Formatters
run: |
sudo apt-get update
sudo apt-get install --yes bsdutils
sudo apt-get install --yes build-essential
sudo apt-get install --yes pkgconf
sudo apt-get install --yes llvm-17 clang-17 clang-format-17
sudo apt-get install --yes libbpf-dev libelf-dev libzstd-dev zlib1g-dev
sudo apt-get install --yes virtme-ng
sudo apt-get install --yes gcc-multilib
sudo apt-get install --yes systemtap-sdt-dev
sudo apt-get install --yes python3 python3-pip ninja-build
sudo apt-get install --yes libseccomp-dev protobuf-compiler
pip3 install --user meson
for tool in "clang" "clang-format" "llc" "llvm-strip"
do
sudo rm -f /usr/bin/$tool
sudo ln -s /usr/bin/$tool-17 /usr/bin/$tool
done
shell: bash
這個 yaml 檔案會讓 Actions Runner 啟動時先將編譯 scx 所需要的工具鏈以及 virtme-ng 準備好,再進入測試環節:
name: Go
on:
push:
branches: [ main ]
pull_request:
branches:
- main
workflow_call:
jobs:
analyze-code:
name: Analyze Code
runs-on: ubuntu-24.04
steps:
- name: Checkout Code
uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
- name: Install Dependencies
uses: ./.github/actions/build-dependencies
- name: Lint
run: |
if test -z "$(gofmt -l .)"; then
echo "Congrats! There is nothing to fix."
else
echo "The following lines should be fixed."
gofmt -s -d .
exit 1
fi
shell: bash
- name: Lint (vet)
run: |
make dep
git submodule init
git submodule sync
git submodule update
cd scx
meson setup build --prefix ~
meson compile -C build
cd ..
cd libbpfgo
make
cd ..
make lint
shell: bash
self-tests:
name: Selftests
runs-on: ubuntu-24.04
strategy:
matrix:
go-version: [ 'stable' ]
steps:
- name: Checkout Code
uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
- name: Install Dependencies
uses: ./.github/actions/build-dependencies
with:
go-version: ${{ matrix.go-version }}
- name: Static Selftests
run: |
make dep
git submodule init
git submodule sync
git submodule update
cd scx
meson setup build --prefix ~
meson compile -C build
cd ..
cd libbpfgo
make
cd ..
make build
make test
shell: bash
有了能夠執行 vng 以及 scx 的環境後,將 Gthulhu 的 submodule scx 以及 libbpfgo 進行編譯,完成後使用 make test 進入測試環節:
test: build
vng -r v6.12.2 -- timeout 15 bash -c "./main" || true
如此一來,我們就能在 Actions Runner 上啟動 Gthulhu 了!
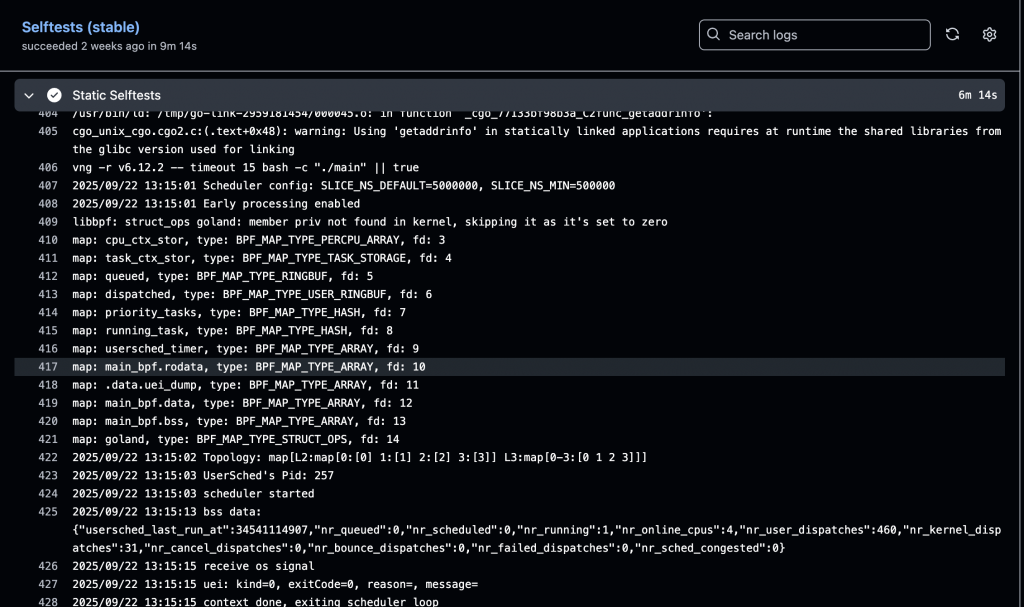
Day 26:
- 原文:https://ithelp.ithome.com.tw/articles/10393317
- 發布日期:2025-10-06
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
在先前整合 free5GC 實作 5G URLLC 的實驗中讓我意識到,要讓每一個使用者深入的理解 kernel 的行為,並以此基礎找出正確的排程器策略。 是很困難的。換句話說,如果使用者對系統有深刻的了解,那麼他也能考慮自己開發排程器了。
我們的目標是打造一個能夠被廣泛使用的雲原生排程器方案,因此,將 LLM 或 AI 結合一直是我有在思考的可能方案之一。MCP(Model Context Protoco)的出現很大程度地解決了我的問題,因為它讓我能夠:
- 不需要從頭打造一個 LLM 應用,甚至是專屬的 AI Agent。
- MCP 廣泛的被現行的 Agents 採用,只要開發一次,就能在多個平台上運作。
- MCP 的生態圈相當開放,這也意味著 AI Agent 能夠幫我除錯、測試,甚至是開發 MCP 工具。
因此,我透過 GitHub Copilot 加上 SDD(Spec-driven development)的方式為 Gthulhu 快速的打造了一款專屬的 MCP 工具,讓 LLM 與排程器溝通不再只是紙上談兵:
上面的 DEMO 影片呈現了幾個重點:
- 一開始 API server 並沒有任何的 scheduling policy 存在
- 我透過與 Copilot 聊天的方式,請他幫我根據提供的條件提出一個 scheduling policy
- Gthulhu MCP 成功地與 API Server 溝通,下達了符合我期望的 scheduling policy
因此我們可以預期,當使用者提供給模型足夠完整的 Context,Agent 能夠根據這些資訊推斷我們的系統架構的瓶頸在哪,後續可以再利用 k8s-mcp 等工具篩選出對應的 Pod,最後將匹配的 scheduling policy 套用至 API Server,使 Gthulhu 大大的提供易用性。
Day 27:
- 原文:https://ithelp.ithome.com.tw/articles/10394539
- 發布日期:2025-10-07
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
sched_ext 的衍生物基本上都使用 GPL 授權,因為 GPL 授權較為嚴格,許多公司可能會因為不想揭露其商業機密而不採用 sched_ext 或是 Gthulhu。
為了克服這個問題,我採納了 Jserv 老師的提議,將 Gthulhu 於 User-Space 的核心實作抽離出來,改以更為寬鬆的 Apache 2.0 授權。這讓使用者需要一定程度客製化私有排程器時不需要將修改的部分開放大眾存取。
type CustomScheduler interface {
// Drain the queued task from eBPF and return the number of tasks drained
DrainQueuedTask(s Sched) int
// Select a task from the queued tasks and return it
SelectQueuedTask(s Sched) *models.QueuedTask
// Select a CPU for the given queued task, After selecting the CPU, the task will be dispatched to that CPU by Scheduler
SelectCPU(s Sched, t *models.QueuedTask) (error, int32)
// Determine the time slice for the given task
DetermineTimeSlice(s Sched, t *models.QueuedTask) uint64
// Get the number of objects in the pool (waiting to be dispatched)
// GetPoolCount will be called by the scheduler to notify the number of tasks waiting to be dispatched (NotifyComplete)
GetPoolCount() uint64
}
只要滿足以上 interface 的定義,就能替換掉 Gthulhu 的預設排程行為(vtime-based scheduler)。
需要注意的是,上列的幾個 API 需要傳入 Sched instance:
type Sched interface {
DequeueTask(task *models.QueuedTask)
DefaultSelectCPU(t *models.QueuedTask) (error, int32)
}
DequeueTask由 Gthulhu 實作,負責從 eBPF Map 將待排程的任務取出。DefaultSelectCPU則會呼叫預設的 select cpu hook,這部分可自行替換。
此外,因為將核心實作抽離了,plugin 這個套件本身並不依賴 libbpfgo/scx/libbpf,也不需要 cgo。
這讓測試變得更加容易:
// MockScheduler implements the plugin.Sched interface for testing
type MockScheduler struct {
taskQueue []*models.QueuedTask
queueIndex int
cpuAllocated map[int32]int32 // PID -> CPU mapping
defaultCPU int32
dequeueCount int
selectCPUCall int
}
// Compile-time check that MockScheduler implements plugin.Sched
var _ plugin.Sched = (*MockScheduler)(nil)
// NewMockScheduler creates a new mock scheduler for testing
func NewMockScheduler() *MockScheduler {
return &MockScheduler{
taskQueue: make([]*models.QueuedTask, 0),
queueIndex: 0,
cpuAllocated: make(map[int32]int32),
defaultCPU: 0,
}
}
// EnqueueTask adds a task to the mock scheduler's queue
func (m *MockScheduler) EnqueueTask(task *models.QueuedTask) {
m.taskQueue = append(m.taskQueue, task)
}
// DequeueTask implements plugin.Sched.DequeueTask
func (m *MockScheduler) DequeueTask(task *models.QueuedTask) {
m.dequeueCount++
if m.queueIndex >= len(m.taskQueue) {
// No more tasks, return sentinel value
task.Pid = -1
return
}
// Copy the task from queue
qt := m.taskQueue[m.queueIndex]
*task = *qt
m.queueIndex++
}
// DefaultSelectCPU implements plugin.Sched.DefaultSelectCPU
func (m *MockScheduler) DefaultSelectCPU(t *models.QueuedTask) (error, int32) {
m.selectCPUCall++
// Simple round-robin CPU selection
cpu := m.defaultCPU
m.defaultCPU = (m.defaultCPU + 1) % 4 // Assume 4 CPUs
m.cpuAllocated[t.Pid] = cpu
return nil, cpu
}
// Reset resets the mock scheduler state
func (m *MockScheduler) Reset() {
m.taskQueue = make([]*models.QueuedTask, 0)
m.queueIndex = 0
m.cpuAllocated = make(map[int32]int32)
m.defaultCPU = 0
m.dequeueCount = 0
m.selectCPUCall = 0
}
在測試檔案中,我們預先定義好 MockScheduler 的行為,便能夠在沒有 eBPF 程式載入的前提下對 Gthulhu plugin 進行測試:
func TestXXX(t *testing.T) {
// Create plugin instance
gthulhuPlugin := NewGthulhuPlugin(5000*1000, 500*1000)
// Create mock scheduler
mockSched := NewMockScheduler()
t.Run("MultipleTasksWorkflow", func(t *testing.T) {
mockSched.Reset()
gthulhuPlugin = NewGthulhuPlugin(5000*1000, 500*1000) // Reset plugin
// Create multiple tasks with different priorities
tasks := []*models.QueuedTask{
{Pid: 100, Weight: 100, Vtime: 0, Tgid: 100, StartTs: 1000, StopTs: 2000},
{Pid: 200, Weight: 150, Vtime: 0, Tgid: 200, StartTs: 1500, StopTs: 2500},
{Pid: 300, Weight: 80, Vtime: 0, Tgid: 300, StartTs: 2000, StopTs: 3000},
}
// Enqueue all tasks
for _, task := range tasks {
mockSched.EnqueueTask(task)
}
// Drain all tasks
drained := gthulhuPlugin.DrainQueuedTask(mockSched)
if drained != 3 {
t.Errorf("DrainQueuedTask = %d; want 3", drained)
}
// Verify pool count
if gthulhuPlugin.GetPoolCount() != 3 {
t.Errorf("GetPoolCount = %d; want 3", gthulhuPlugin.GetPoolCount())
}
// Process all tasks
processedTasks := make([]*models.QueuedTask, 0)
for gthulhuPlugin.GetPoolCount() > 0 {
task := gthulhuPlugin.SelectQueuedTask(mockSched)
if task == nil {
t.Fatal("SelectQueuedTask returned nil while pool count > 0")
}
// Select CPU and determine time slice
err, cpu := gthulhuPlugin.SelectCPU(mockSched, task)
if err != nil {
t.Errorf("SelectCPU error: %v", err)
}
if cpu < 0 {
t.Errorf("Invalid CPU selected: %d", cpu)
}
_ = gthulhuPlugin.DetermineTimeSlice(mockSched, task)
processedTasks = append(processedTasks, task)
}
// Verify all tasks were processed
if len(processedTasks) != 3 {
t.Errorf("Processed tasks = %d; want 3", len(processedTasks))
}
// Verify pool is empty
if gthulhuPlugin.GetPoolCount() != 0 {
t.Errorf("Final GetPoolCount = %d; want 0", gthulhuPlugin.GetPoolCount())
}
})
}
plugin pattern 為 Gthulhu 帶來了多變的靈活性。我們將在下一篇文章中嘗試實作一個簡易的 scheduler!
Day 28:
- 原文:https://ithelp.ithome.com.tw/articles/10394875
- 發布日期:2025-10-08
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
在前一篇文章中,我們探討了 Gthulhu 如何利用 plugin 擴充實作上的靈活性。在這篇文章中,我們會嘗試實作一個符合 plugin 介面的簡易排程器。
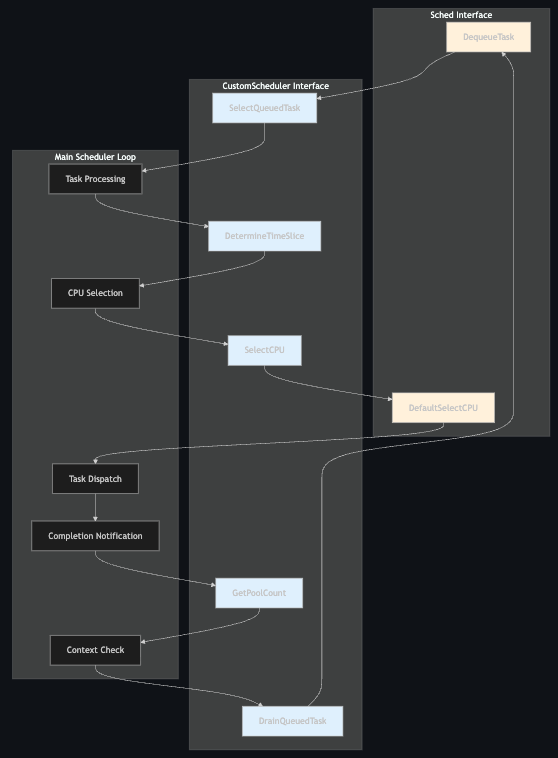
Gthulhu 的 eBPF 排程器有兩種 DSQ,分別是:
- SHARED DSQ:所有 CPU 共享這個 DSQ,優先權較 LOCAL DSQ 更低。
- LOCAL DSQ:每一個 CPU 都會有一個。
我們可以利用 SHARED DSQ 實作 FIFO 或是簡單的 weighted deadline 排程器。
type CustomScheduler interface {
// Drain the queued task from eBPF and return the number of tasks drained
DrainQueuedTask(s Sched) int
// Select a task from the queued tasks and return it
SelectQueuedTask(s Sched) *models.QueuedTask
// Select a CPU for the given queued task, After selecting the CPU, the task will be dispatched to that CPU by Scheduler
SelectCPU(s Sched, t *models.QueuedTask) (error, int32)
// Determine the time slice for the given task
DetermineTimeSlice(s Sched, t *models.QueuedTask) uint64
// Get the number of objects in the pool (waiting to be dispatched)
// GetPoolCount will be called by the scheduler to notify the number of tasks waiting to be dispatched (NotifyComplete)
GetPoolCount() uint64
}
讓我們逐一探討該如何實作這些 Hook:
// DrainQueuedTask drains tasks from the scheduler queue into the task pool
func (s *SimplePlugin) DrainQueuedTask(sched plugin.Sched) int {
count := 0
// Keep draining until the pool is full or no more tasks available
for {
var queuedTask models.QueuedTask
sched.DequeueTask(&queuedTask)
// Validate task before processing to prevent corruption
if queuedTask.Pid <= 0 {
// Skip invalid tasks
return count
}
// Create task and enqueue it
task := s.enqueueTask(&queuedTask)
s.insertTaskToPool(task)
count++
s.globalQueueCount++
}
}
將任務從 RingBuffer eBPF Map 取出,直到沒有可被排程的任務(queuedTask.Pid <= 0)可以取得。
取出來的任務會被按順序插入至 global slice,如此一來,當 Scheduler 呼叫 SelectQueuedTask() 時就能按插入順序取得任務,也就實現了 FIFO 的效果:
// getTaskFromPool retrieves the next task from the pool
func (s *SimplePlugin) getTaskFromPool() *models.QueuedTask {
if len(s.taskPool) == 0 {
return nil
}
// Get the first task
task := &s.taskPool[0]
// Remove the first task from slice
selectedTask := task.QueuedTask
s.taskPool = s.taskPool[1:]
// Update running task vtime (for weighted vtime scheduling)
if !s.fifoMode {
// Ensure task vtime is never 0 before updating global vtime
if selectedTask.Vtime == 0 {
selectedTask.Vtime = 1
}
s.updateRunningTask(selectedTask)
}
return selectedTask
}
再來就是選擇 CPU 的部分,我希望將任務都放入 SHARED DSQ 之中,讓空閑的 CPU 能夠從 SHARED DSQ 取得任務,所以 CPU selection 一率會回應 ANY CPU(1<<20):
// SelectCPU selects a CPU for the given task
func (s *SimplePlugin) SelectCPU(sched plugin.Sched, task *models.QueuedTask) (error, int32) {
return nil, 1 << 20
}
再來看為任務分配 time slice 的部分,simple scheduler 一率會回應預設的 time slice:
// DetermineTimeSlice determines the time slice for the given task
func (s *SimplePlugin) DetermineTimeSlice(sched plugin.Sched, task *models.QueuedTask) uint64 {
// Always return default slice
return s.sliceDefault
}
總結
透過 plugin 的機制,我們只要使用約 200 行的程式碼即可實作一個排程器,並且不需要撰寫任何一行 eBPF code。如果大家有興趣也歡迎一同參與貢獻!
Day 29:
- 原文:https://ithelp.ithome.com.tw/articles/10395281
- 發布日期:2025-10-09
如果覺得文章對你有所啟發,可以考慮用 🌟 支持 Gthulhu 專案,短期目標是集齊 300 個 🌟 藉此被 CNCF Landscape 採納 [ref]。
Perfetto 是由 Google 維護的專案,可以用於 System profiling 、 app tracing 以及 trace analysis。這對我們在分析排程器行為時非常有幫助。
將 Perfetto 編譯後,可以使用以下命令擷取系統的排程事件:
out/linux/tracebox -o out.perfetto-trace --txt -c test/configs/scheduling.cfg
它會在運作數秒後結束執行,並且將紀錄存放至 out.perfetto-trace。
接著,我們就可以打開 Perfetto 提供的 Trace Viewer 將檔案匯入:
我匯入的範例是在使用 stress-test 進行壓力測試時錄製的,因此,可以預期所有 CPU 都會被佔滿:
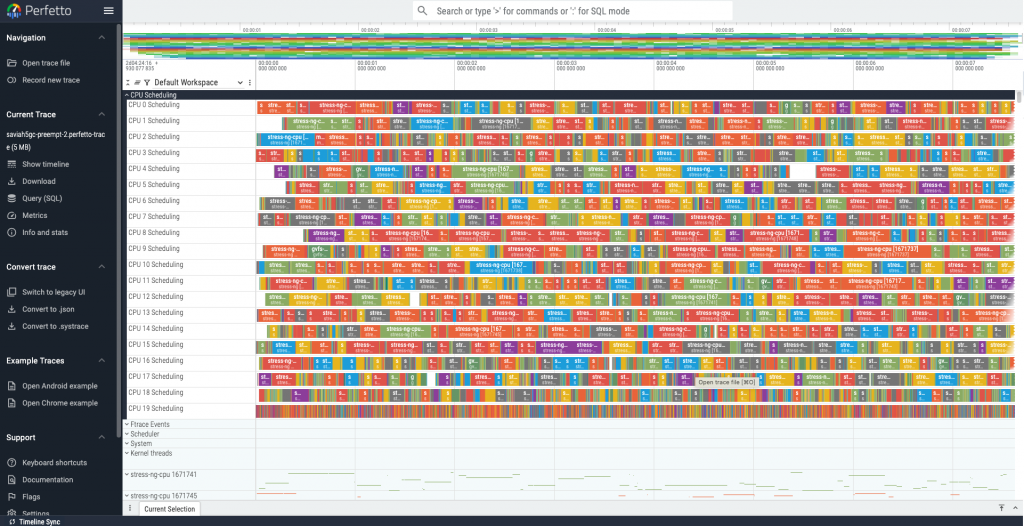
我們可以使用 W 與 S 在畫面上進行縮放:
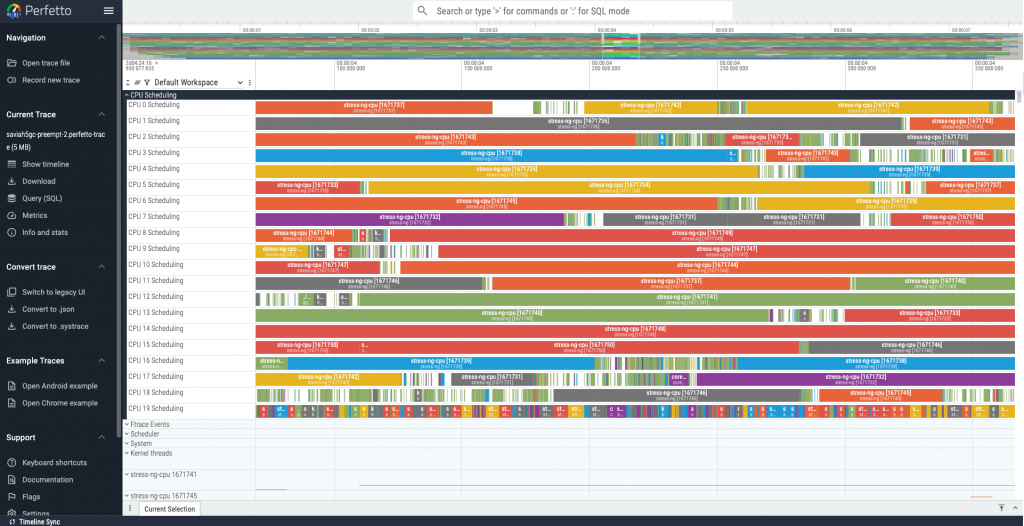
使用 A 與 D 在時間線上移動:
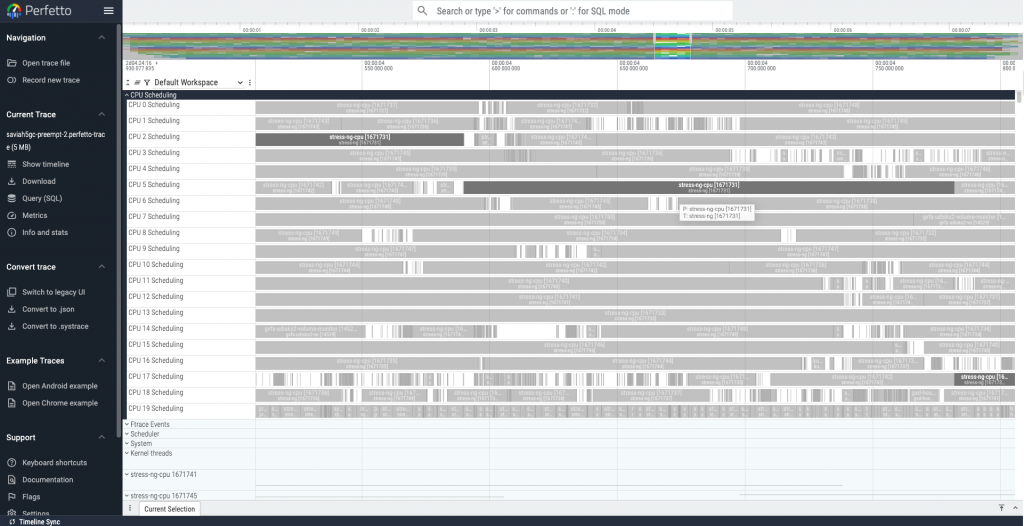
接著讓我們鎖定 UERANSIM 提供的 UE 模擬器 nr-ue 進行觀察:
我們可以將 nr-ue 下的所有 thread 釘選,方便觀察 nr-ue 的行為:
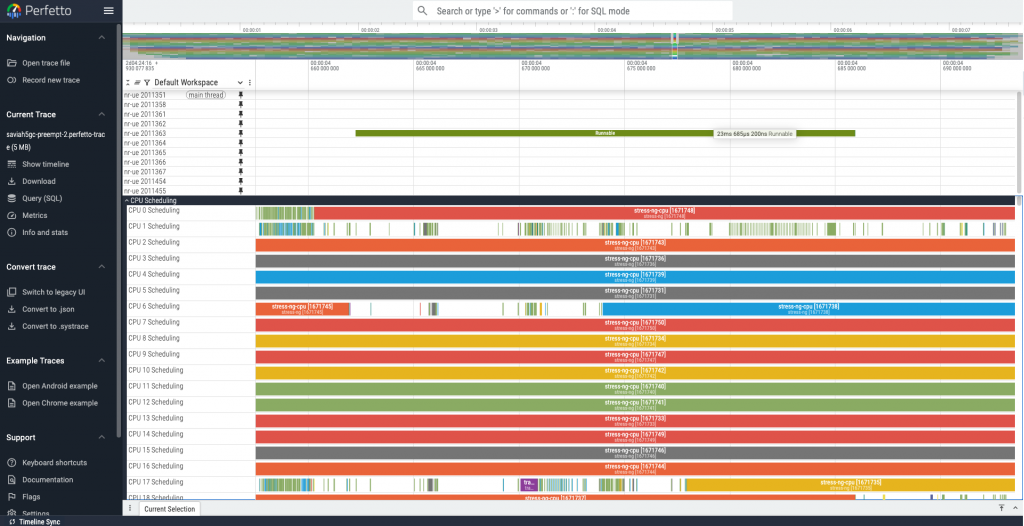
上方的圖片是當我快速的在時間線上移動,找到 nr-ue 被排程的足跡。我們可以發現該 thread 處於 RUNNABLE 的時間非常長,高達 23ms!
這也意味著因為排程器的關係,如果 nr-ue 這時候需要收送封包,其延遲至少就會再加上 23ms。
如果我們在對畫面進行放大,可以觀察 nr-ue 進入 RUNNING 後是因為什麼原因結束執行、被排程到哪一個 CPU 上:
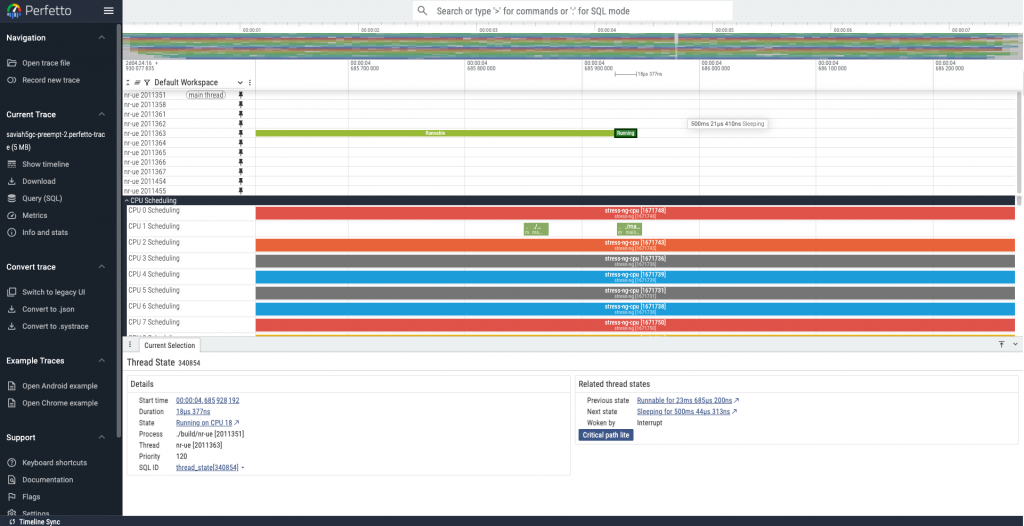
若上述的使用方式無法滿足分析需求,也可以利用 Trace Viewer 提供的 SQL 功能對資料快速查詢:
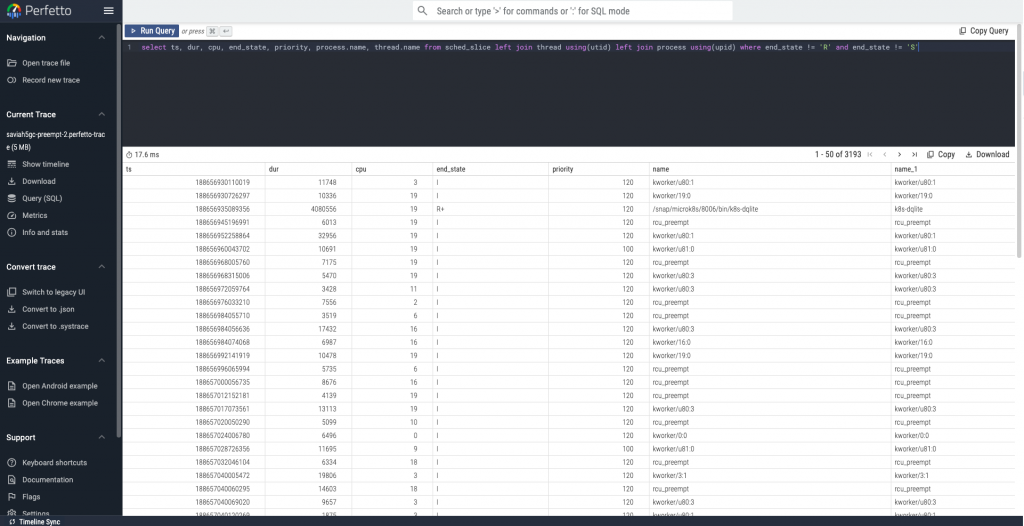
總結
有了 Perfetto,我們就能觀察客製的排程器在運作時是否符合我們的預想。透過 Perfetto 我能馬上觀察目標 process 的 scheduling latency,以及前後任務的 end state,這對我嘗試降低 5G 核心網路的 latency 時也提供了非常大的幫助。
如果讀者想嘗試使用 Plugin 實作排程器,也可以使用 Perfetto 分析系統行爲唷。
Day 30:
- 原文:https://ithelp.ithome.com.tw/articles/10395355
- 發布日期:2025-10-10
從 2023 年碩士班畢業後,我就接下了老闆交給我的任務,試著讓 free5GC 能夠變得更加 community-driven,在有限的時間內我也做了很多有趣的嘗試:
- 翻新官網內容,帶領團隊撰寫更多 design document,讓有貢獻能力的志願者不需要耗費大量的時間才能搞懂 source code
- 推動技術部落格專區,制定相關規則
- 發起 free5GLabs 讓沒有背景的意願者可以一步一步了解 5GC 開發的必要知識
- 參與捐贈至 Linux 基金會的相關程序
- 跟各種開源專案的維護人聊聊,弄一些有趣的開源整合案例
- 參加各種研討會 promote free5GC,幫團隊與 ITHome 牽線促成了一個大型專題報導
- 與 Linux 基金會籌備 free online course "Introduction to free5GC"
- 在陽明交大開設「開源核心網路設計與實作」課程,從頭到尾撰寫教材、設計課程與專案作業
很感謝過程中一起貢獻參與的 Lab 成員以及其他開源社群的貢獻者,大家的參與都讓 free5GC 被更多人看見。
然而,我還是不滿足於這段有趣的經歷,畢竟 free5GC 在我加入時就已經是相當成熟的專案,我只不過是用熱忱跟一些創新的想法讓專案的一部分變得更有趣而已。所以我常常在想,能不能從 0 開始建置一個專案,再運用在 free5GC 的經驗,打造一個世界級的專案呢?
今年對我來說是個充滿挑戰、象徵性的一年,我在年初看到 scx_rustland 的時候就知道這是一個會在開源世界佔有一席之地的基礎設施,剛好我也可以發揮我薄弱的專業在這個 topics 做一些事情,所以大家才會在今年看見這個系列文。
從年初開始 porting scx_rustland 弄到崩潰、第一次能夠"運作"的 golang 排程器、能夠運作 7x24 的時間、能夠接收使用者意圖,再到整合 free5GC 做到一些真實應用、整合 MCP 提供一個 AI 賦能排程器的想像。
除了技術相關的議題,還需要花非常多時間宣傳專案,讓大家了解專案的使命與操作方法,以及觀察專案的流量:
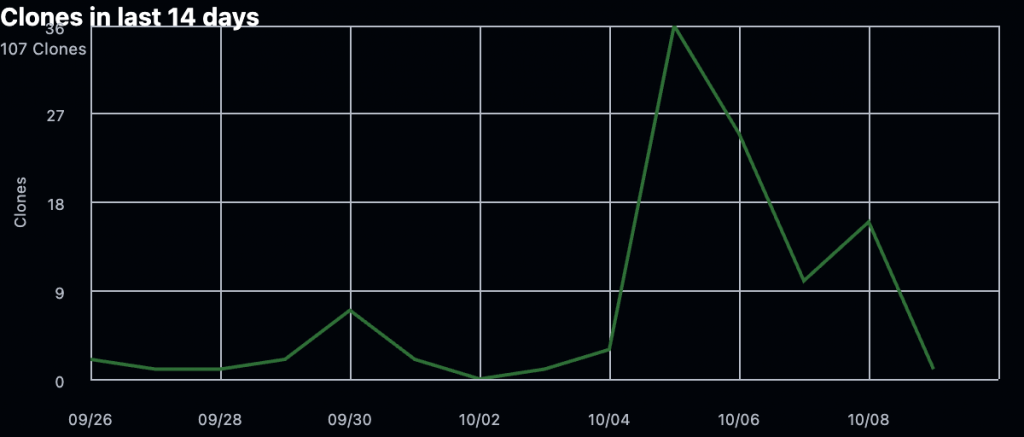
埋 GA,觀察潛在用戶:
從今年 6 月專案 launch 後,GitHub Stars 的成長趨勢:
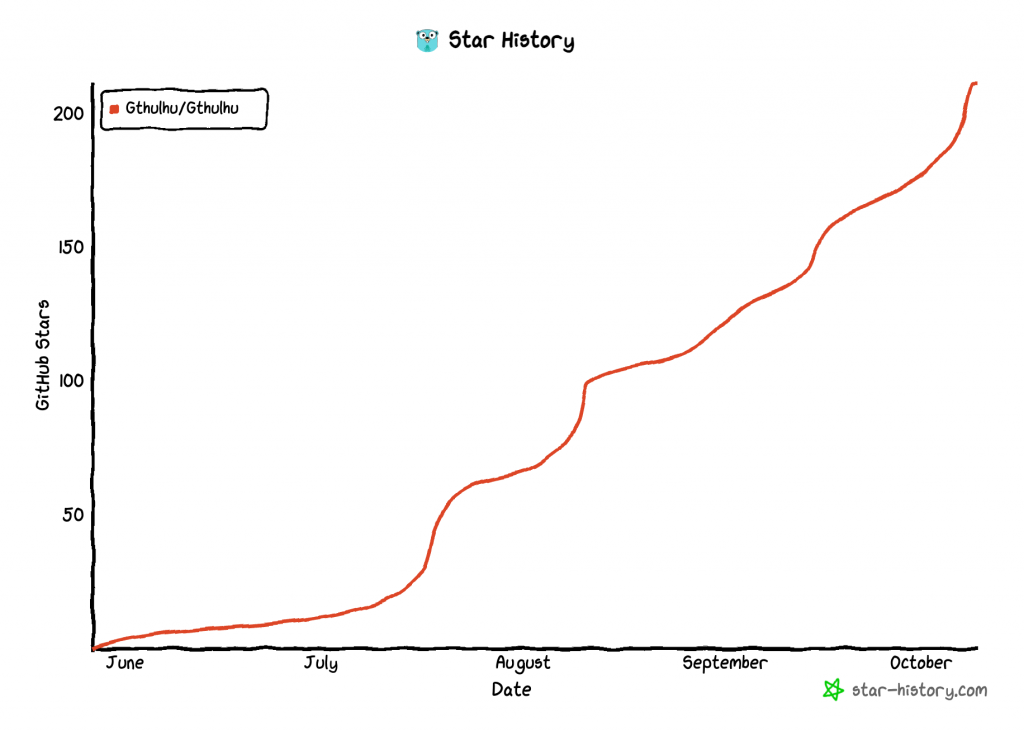
短短四個月內有如此這樣的數據對我而言是非常開心的(但我當然希望有更多的 visitor、user 甚至是 contributor)。但在 linux distribution 對 sched_ext 的支援尚不普及時,我們也只能再等一會兒,先讓專案集滿 300 個 Stars 收錄至 CNCF landscape 後,再來考量有沒有可能讓 Gthulhu 專案進入 CNCF 下進行專案的治理。後續的故事我也會更新在個人的 Medium,對進展有興趣的人歡迎訂閱:)
最後的最後,感謝有人(?)耐心的系列文看完,這也許是我最後一次參加鐵人賽也說不定,畢竟學生時期的作家夢也圓了,接下來就是看看發起一個世界級專案的心願能不能實現(打臉 Google 前執行長 Eric Schmidt 在一場活動中說的:「台灣雖然是個很棒的國家,但軟體卻一團糟。」)...