4.3 並行計算
計算機每一年都會變得越來越快。在 1965 年,英特爾聯合創始人戈登·摩爾預測了計算機將如何隨時間而變得越來越快。僅僅基於五個數據點,他推測,一個芯片中的晶體管數量每兩年將翻一倍。近50年後,他的預測仍驚人地準確,現在稱為摩爾定律。
儘管速度在爆炸式增長,計算機還是無法跟上可用數據的規模。根據一些估計,基因測序技術的進步將使可用的基因序列數據比處理器變得更快的速度還要快。換句話說,對於遺傳數據,計算機變得越來越不能處理每年需要處理的問題規模,即使計算機本身變得越來越快。
為了規避對單個處理器速度的物理和機械約束,製造商正在轉向另一種解決方案:多處理器。如果兩個,或三個,或更多的處理器是可用的,那麼許多程序可以更快地執行。當一個處理器在做一些計算的一個切面時,其他的可以在另一個切面工作。所有處理器都可以共享相同的數據,但工作並行執行。
為了能夠合作,多個處理器需要能夠彼此共享信息。這通過使用共享內存環境來完成。該環境中的變量、對象和數據結構對所有的進程可見。處理器在計算中的作用是執行編程語言的求值和執行規則。在一個共享內存模型中,不同的進程可能執行不同的語句,但任何語句都會影響共享環境。
4.3.1 共享狀態的問題
多個進程之間的共享狀態具有單一進程環境沒有的問題。要理解其原因,讓我們看看下面的簡單計算:
x = 5
x = square(x)
x = x + 1
x的值是隨時間變化的。起初它是 5,一段時間後它是 25,最後它是 26。在單一處理器的環境中,沒有時間依賴性的問題。x的值在結束時總是 26。但是如果存在多個進程,就不能這樣說了。假設我們並行執行了上面代碼的最後兩行:一個處理器執行x = square(x)而另一個執行x = x + 1。每一個這些賦值語句都包含查找當前綁定到x的值,然後使用新值更新綁定。讓我們假設x是共享的,同一時間只有一個進程讀取或寫入。即使如此,讀和寫的順序可能會有所不同。例如,下面的例子顯示了兩個進程的每個進程的一系列步驟,P1和P2。每一步都是簡要描述的求值過程的一部分,隨時間從上到下執行:
P1 P2
read x: 5
read x: 5
calculate 5*5: 25 calculate 5+1: 6
write 25 -> x
write x-> 6
在這個順序中,x的最終值為 6。如果我們不協調這兩個過程,我們可以得到另一個順序的不同結果:
P1 P2
read x: 5
read x: 5 calculate 5+1: 6
calculate 5*5: 25 write x->6
write 25 -> x
在這個順序中,x將是 25。事實上存在多種可能性,這取決於進程執行代碼行的順序。x的最終值可能最終為 5,25,或預期值 26。
前面的例子是無價值的。square(x)和x = x + 1是簡單快速的計算。我們強迫一條語句跑在另一條的後面,並不會失去太多的時間。但是什麼樣的情況下,並行化是必不可少的?這種情況的一個例子是銀行業。在任何給定的時間,可能有成千上萬的人想用他們的銀行賬戶進行交易:他們可能想在商店刷卡,存入支票,轉帳,或支付賬單。即使一個帳戶在同一時間也可能有活躍的多個交易。
讓我們看看第二章的make_withdraw函數,下面是修改過的版本,在更新餘額之後打印而不是返回它。我們感興趣的是這個函數將如何併發執行。
>>> def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
print('Insufficient funds')
else:
balance = balance - amount
print(balance)
return withdraw
現在想象一下,我們以 10 美元創建一個帳戶,讓我們想想,如果我們從帳戶中提取太多的錢會發生什麼。如果我們順序執行這些交易,我們會收到資金不足的消息。
>>> w = make_withdraw(10)
>>> w(8)
2
>>> w(7)
'Insufficient funds'
但是,在並行中可以有許多不同的結果。下面展示了一種可能性:
P1: w(8) P2: w(7)
read balance: 10
read amount: 8 read balance: 10
8 > 10: False read amount: 7
if False 7 > 10: False
10 - 8: 2 if False
write balance -> 2 10 - 7: 3
read balance: 2 write balance -> 3
print 2 read balance: 3
print 3
這個特殊的例子給出了一個不正確結果 3。就好像w(8)交易從來沒有發生過。其他可能的結果是 2,和'Insufficient funds'。這個問題的根源是:如果P2 在P1寫入值前讀取餘額,P2的狀態是不一致的(反之亦然)。P2所讀取的餘額值是過時的,因為P1打算改變它。P2不知道,並且會用不一致的值覆蓋它。
這個例子表明,並行化的代碼不像把代碼行分給多個處理器來執行那樣容易。變量讀寫的順序相當重要。
一個保證執行正確性的有吸引力的方式是,兩個修改共享數據的程序不能同時執行。不幸的是,對於銀行業這將意味著,一次只可以進行一個交易,因為所有的交易都修改共享數據。直觀地說,我們明白,讓 2 個不同的人同時進行完全獨立的帳戶交易應該沒有問題。不知何故,這兩個操作不互相干擾,但在同一帳戶上的相同方式的同時操作就相互干擾。此外,當進程不讀取或寫入時,讓它們同時運行就沒有問題。
4.3.2 並行計算的正確性
並行計算環境中的正確性有兩個標準。第一個是,結果應該總是相同。第二個是,結果應該和串行執行的結果一致。
第一個條件表明,我們必須避免在前面的章節中所示的變化,其中在不同的方式下的交叉讀寫會產生不同的結果。例子中,我們從 10 美元的帳戶取出了w(8)和w(7)。這個條件表明,我們必須始終返回相同的答案,獨立於P1和P2的指令執行順序。無論如何,我們必須以這樣一種方式來編寫我們的程序,無論他們如何相互交叉,他們應該總是產生同樣的結果。
第二個條件揭示了許多可能的結果中哪個是正確的。例子中,我們從 10 美元的帳戶取出了w(8)和w(7),這個條件表明結果必須總是餘額不足,而不是 2 或者 3。
當一個進程在程序的臨界區影響另一個進程時,並行計算中就會出現問題。這些都是需要執行的代碼部分,它們看似是單一的指令,但實際上由較小的語句組成。一個程序會以一系列原子硬件指令執行,由於處理器的設計,這些是不能被打斷或分割為更小單元的指令。為了在並行的情況下表現正確,程序代碼的臨界區需要具有原子性,保證他們不會被任何其他代碼中斷。
為了強制程序臨界區在併發下的原子性,需要能夠在重要的時刻將進程序列化或彼此同步。序列化意味著同一時間只運行一個進程 -- 這一瞬間就好像串行執行一樣。同步有兩種形式。首先是互斥,進程輪流訪問一個變量。其次是條件同步,在滿足條件(例如其他進程完成了它們的任務)之前進程一直等待,之後繼續執行。這樣,當一個程序即將進入臨界區時,其他進程可以一直等待到它完成,然後安全地執行。
4.3.3 保護共享狀態:鎖和信號量
在本節中討論的所有同步和序列化方法都使用相同的基本思想。它們在共享狀態中將變量用作信號,所有過程都會理解並遵守它。這是一個相同的理念,允許分佈式系統中的計算機協同工作 -- 它們通過傳遞消息相互協調,根據每一個參與者都理解和遵守的一個協議。
這些機制不是為了保護共享狀態而出現的物理障礙。相反,他們是建立相互理解的基礎上。和出現在十字路口的各種方向的車輛能夠安全通行一樣,是同一種相互理解。這裡沒有物理的牆壁阻止汽車相撞,只有遵守規則,紅色意味著“停止”,綠色意味著“通行”。同樣,沒有什麼可以保護這些共享變量,除非當一個特定的信號表明輪到某個進程了,進程才會訪問它們。
**鎖。**鎖,也被稱為互斥體(mutex),是共享對象,常用於發射共享狀態被讀取或修改的信號。不同的編程語言實現鎖的方式不同,但是在 Python 中,一個進程可以調用acquire()方法來嘗試獲得鎖的“所有權”,然後在使用完共享變量的時候調用release()釋放它。當進程獲得了一把鎖,任何試圖執行acquire()操作的其他進程都會自動等待到鎖被釋放。這樣,同一時間只有一個進程可以獲得一把鎖。
對於一把保護一組特定的變量的鎖,所有的進程都需要編程來遵循一個規則:一個進程不擁有特定的鎖就不能訪問相應的變量。實際上,所有進程都需要在鎖的acquire()和release()語句之間“包裝”自己對共享變量的操作。
我們可以把這個概念用於銀行餘額的例子中。該示例的臨界區是從餘額讀取到寫入的一組操作。我們看到,如果一個以上的進程同時執行這個區域,問題就會發生。為了保護臨界區,我們需要使用一把鎖。我們把這把鎖稱為balance_lock(雖然我們可以命名為任何我們喜歡的名字)。為了鎖定實際保護的部分,我們必須確保試圖進入這部分時調用acquire()獲取鎖,以及之後調用release()釋放鎖,這樣可以輪到別人。
>>> from threading import Lock
>>> def make_withdraw(balance):
balance_lock = Lock()
def withdraw(amount):
nonlocal balance
# try to acquire the lock
balance_lock.acquire()
# once successful, enter the critical section
if amount > balance:
print("Insufficient funds")
else:
balance = balance - amount
print(balance)
# upon exiting the critical section, release the lock
balance_lock.release()
如果我們建立和之前一樣的情形:
w = make_withdraw(10)
現在就可以並行執行w(8)和w(7)了:
P1 P2
acquire balance_lock: ok
read balance: 10 acquire balance_lock: wait
read amount: 8 wait
8 > 10: False wait
if False wait
10 - 8: 2 wait
write balance -> 2 wait
read balance: 2 wait
print 2 wait
release balance_lock wait
acquire balance_lock:ok
read balance: 2
read amount: 7
7 > 2: True
if True
print 'Insufficient funds'
release balance_lock
我們看到了,兩個進程同時進入臨界區是可能的。某個進程實例獲取到了balance_lock,另一個就得等待,直到那個進程退出了臨界區,它才能開始執行。
要注意程序不會自己終止,除非P1釋放了balance_lock。如果它沒有釋放balance_lock,P2永遠不可能獲取它,而是一直會等待。忘記釋放獲得的鎖是並行編程中的一個常見錯誤。
**信號量。**信號量是用於維持有限資源訪問的信號。它們和鎖類似,除了它們可以允許某個限制下的多個訪問。它就像電梯一樣只能夠容納幾個人。一旦達到了限制,想要使用資源的進程就必須等待。其它進程釋放了信號量之後,它才可以獲得。
例如,假設有許多進程需要讀取中心數據庫服務器的數據。如果過多的進程同時訪問它,它就會崩潰,所以限制連接數量就是個好主意。如果數據庫只能同時支持N=2的連接,我們就可以以初始值N=2來創建信號量。
>>> from threading import Semaphore
>>> db_semaphore = Semaphore(2) # set up the semaphore
>>> database = []
>>> def insert(data):
db_semaphore.acquire() # try to acquire the semaphore
database.append(data) # if successful, proceed
db_semaphore.release() # release the semaphore
>>> insert(7)
>>> insert(8)
>>> insert(9)
信號量的工作機制是,所有進程只在獲取了信號量之後才可以訪問數據庫。只有N=2個進程可以獲取信號量,其它的進程都需要等到其中一個進程釋放了信號量,之後在訪問數據庫之前嘗試獲取它。
P1 P2 P3
acquire db_semaphore: ok acquire db_semaphore: wait acquire db_semaphore: ok
read data: 7 wait read data: 9
append 7 to database wait append 9 to database
release db_semaphore: ok acquire db_semaphore: ok release db_semaphore: ok
read data: 8
append 8 to database
release db_semaphore: ok
值為 1 的信號量的行為和鎖一樣。
4.3.4 保持同步:條件變量
條件變量在並行計算由一系列步驟組成時非常有用。進程可以使用條件變量,來用信號告知它完成了特定的步驟。之後,等待信號的其它進程就會開始它們的任務。一個需要逐步計算的例子就是大規模向量序列的計算。在計算生物學,Web 範圍的計算,和圖像處理及圖形學中,常常需要處理非常大型(百萬級元素)的向量和矩陣。想象下面的計算:
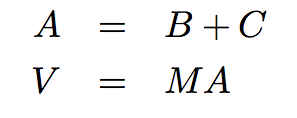
我們可以通過將矩陣和向量按行拆分,並把每一行分配到單獨的線程上,來並行處理每一步。作為上面的計算的一個實例,想象下面的簡單值:
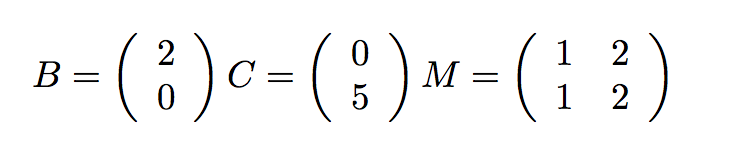
我們將前一半(這裡是第一行)分配給一個線程,後一半(第二行)分配給另一個線程:
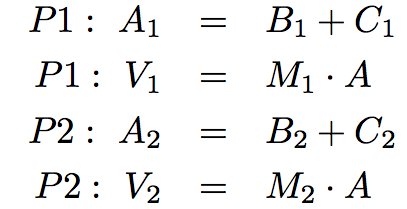
在偽代碼中,計算是這樣的:
def do_step_1(index):
A[index] = B[index] + C[index]
def do_step_2(index):
V[index] = M[index] . A
進程 1 執行了:
do_step_1(1)
do_step_2(1)
進程 2 執行了:
do_step_1(2)
do_step_2(2)
如果允許不帶同步處理,就造成下面的不一致性:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
read M1: (1 2) read C2: 5
read A: (2 0) calculate 5+0: 5
calculate (1 2).(2 0): 2 write 5 -> A2
write 2 -> V1 read M2: (1 2)
read A: (2 5)
calculate (1 2).(2 5):12
write 12 -> V2
問題就是V直到所有元素計算出來時才會計算出來。但是,P1在A的所有元素計算出來之前,完成A = B+C並且移到V = MA。所以它與M相乘時使用了A的不一致的值。
我們可以使用條件變量來解決這個問題。
條件變量是表現為信號的對象,信號表示某個條件被滿足。它們通常被用於協調進程,這些進程需要在繼續執行之前等待一些事情的發生。需要滿足一定條件的進程可以等待一個條件變量,直到其它進程修改了條件變量來告訴它們繼續執行。
Python 中,任何數量的進程都可以使用condition.wait()方法,用信號告知它們正在等待某個條件。在調用該方法之後,它們會自動等待到其它進程調用了condition.notify()或condition.notifyAll()函數。notify()方法值喚醒一個進程,其它進程仍舊等待。notifyAll()方法喚醒所有等待中的進程。每個方法在不同情形中都很實用。
由於條件變量通常和決定條件是否為真的共享變量相聯繫,它們也提供了acquire()和release()方法。這些方法應該在修改可能改變條件狀態的變量時使用。任何想要用信號告知條件已經改變的進程,必須首先使用acquire()來訪問它。
在我們的例子中,在執行第二步之前必須滿足的條件是,兩個進程都必須完成了第一步。我們可以跟蹤已經完成第一步的進程數量,以及條件是否被滿足,通過引入下面兩個變量:
step1_finished = 0
start_step2 = Condition()
我們在do_step_2的開頭插入start_step_2().wait()。每個進程都會在完成步驟 1 之後自增step1_finished,但是我們只會在step_1_finished = 2時發送信號。下面的偽代碼展示了它:
step1_finished = 0
start_step2 = Condition()
def do_step_1(index):
A[index] = B[index] + C[index]
# access the shared state that determines the condition status
start_step2.acquire()
step1_finished += 1
if(step1_finished == 2): # if the condition is met
start_step2.notifyAll() # send the signal
#release access to shared state
start_step2.release()
def do_step_2(index):
# wait for the condition
start_step2.wait()
V[index] = M[index] . A
在引入條件變量之後,兩個進程會一起進入步驟 2,像下面這樣:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
acquire start_step2: ok read C2: 5
write 1 -> step1_finished calculate 5+0: 5
step1_finished == 2: false write 5-> A2
release start_step2: ok acquire start_step2: ok
start_step2: wait write 2-> step1_finished
wait step1_finished == 2: true
wait notifyAll start_step_2: ok
start_step2: ok start_step2:ok
read M1: (1 2) read M2: (1 2)
read A:(2 5)
calculate (1 2). (2 5): 12 read A:(2 5)
write 12->V1 calculate (1 2). (2 5): 12
write 12->V2
在進入do_step_2的時候,P1需要在start_step_2之前等待,直到P2自增了step1_finished,發現了它等於 2,之後向條件發送信號。
4.3.5 死鎖
雖然同步方法對保護共享狀態十分有效,但它們也帶來了麻煩。因為它們會導致一個進程等待另一個進程,這些進程就有死鎖的風險。死鎖是一種情形,其中兩個或多個進程被卡住,互相等待對方完成。我們已經提到了忘記釋放某個鎖如何導致進程無限卡住。但是即使acquire()和release()調用的數量正確,程序仍然會構成死鎖。
死鎖的來源是循環等待,像下面展示的這樣。沒有進程能夠繼續執行,因為它們正在等待其它進程,而其它進程也在等待它完成。
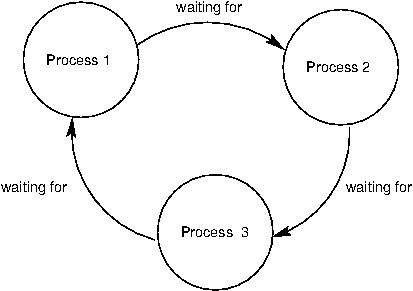
作為一個例子,我們會建立兩個進程的死鎖。假設有兩把鎖,x_lock和y_lock,並且它們像這樣使用:
>>> x_lock = Lock()
>>> y_lock = Lock()
>>> x = 1
>>> y = 0
>>> def compute():
x_lock.acquire()
y_lock.acquire()
y = x + y
x = x * x
y_lock.release()
x_lock.release()
>>> def anti_compute():
y_lock.acquire()
x_lock.acquire()
y = y - x
x = sqrt(x)
x_lock.release()
y_lock.release()
如果compute()和anti_compute()並行執行,並且恰好像下面這樣互相交錯:
P1 P2
acquire x_lock: ok acquire y_lock: ok
acquire y_lock: wait acquire x_lock: wait
wait wait
wait wait
wait wait
... ...
所產生的情形就是死鎖。P1和P2每個都持有一把鎖,但是它們需要兩把鎖來執行。P1正在等待P2釋放y_lock,而P2正在等待P1釋放x_lock。所以,沒有進程能夠繼續執行。