3.6 抽象語言的解釋器
譯者:飛龍
計算器語言提供了一種手段,來組合一些嵌套的調用表達式。然而,我們卻沒有辦法定義新的運算符,將值賦給名稱,或者表達通用的計算方法。總之,計算器並不以任何方式支持抽象。所以,它並不是特別強大或通用的編程語言。我們現在轉到定義一種通用編程語言的任務中,這門語言通過將名稱綁定到值以及定義新的操作來支持抽象。
我們並不是進一步擴展簡單的計算器語言,而是重新開始,並且為 Logo 語言開發解釋器。Logo 並不是為這門課發明的語言,而是一種經典的命令式語言,擁有許多解釋器實現和自己的開發者社區。
上一章,我們將完整的解釋器表示為 Python 源碼,這一章使用描述性的方式。某個配套工程需要你通過構建完整的 Logo 函數式解釋器來實現這裡展示的概念。
3.6.1 Scheme 語言
Scheme 是 Lisp 的一種方言,Lisp 是現在仍在廣泛使用的第二老(在 Fortran 之後)的編程語言。Scheme首次在 1975 年由 Gerald Sussman 和 Guy Steele 描述。Revised(4) Report on the Algorithmic Language Scheme 的引言中寫道:
編程語言不應該通過堆砌特性,而是應該通過移除那些使額外特性變得必要的缺點和限制來設計。Scheme 表明,用於組成表達式的非常少量的規則,在沒有組合方式的限制的情況下,足以組成實用並且高效的編程語言,它足夠靈活,在使用中可以支持多數當今的主流編程範式。
我們將這個報告推薦給你作為 Scheme 語言的詳細參考。我們這裡只會涉及重點。下面的描述中,我們會用到報告中的例子。
雖然 Scheme 非常簡單,但它是一種真正的編程語言,在許多地方都類似於 Python,但是“語法糖[1]”會盡量少。基本上,所有運算符都是函數調用的形式。這裡我們會描述完整的 Scheme 語言的在報告中描述的可展示的子集。
[1] 非常遺憾,這對於 Scheme 語言的最新版本並不成立,就像 Revised(6) Report 中的那樣。所以這裡我們僅僅針對之前的版本。
Scheme 有多種可用的實現,它們添加了額外的過程。在 UCB,我們使用Stk 解釋器的一個修改版,它也在我們的教學服務器上以stk提供。不幸的是,它並不嚴格遵守正式規範,但它可用於我們的目的。
**使用解釋器。**就像 Python 解釋器[2]那樣,向 Stk 鍵入的表達式會由“讀取-求值-打印”循環求值並打印:
>>> 3
3
>>> (- (/ (* (+ 3 7 10) (- 1000 8)) 992) 17)
3
>>> (define (fib n) (if (< n 2) n (+ (fib (- n 2)) (fib (- n 1)))))
fib
>>> '(1 (7 19))
(1 (7 19))
[2] 在我們的例子中,我們使用了和 Python 相同的符號
>>>和...,來表示解釋器的輸入行,和非前綴輸出的行。實際上,Scheme 解釋器使用不同的提示符。例如,Stk 以STk>來提示,並且不提示連續行。然而 Python 的慣例使輸入和輸出更加清晰。
**Scheme 中的值。**Scheme 中的值通常與 Python 對應。
布爾值
真值和假值,使用#t和#f來表示。Scheme 中唯一的假值(按照 Python 的含義)就是#f。
數值
這包括任意精度的整數、有理數、複數,和“不精確”(通常是浮點)數值。整數可用標準的十進制表示,或者通過在數字之前添加#o(八進制)、#x(十六進制)或#b(二進制),以其他進製表示。
符號
符號是一種字符串,但是不被引號包圍。有效的字符包括字母、數字和:
! $ % & * / : < = > ? ^ _ ~ + - . @
在使用read函數輸入時,它會讀取 Scheme 表達式(也是解釋器用於輸入程序文本的東西),不區分符號中的大小寫(在STk 實現中會轉為小寫)。兩個帶有相同表示的符號表示同一對象(並不是兩個碰巧擁有相同內容的對象)。
偶對和列表
偶對是含有兩個(任意類型)成員的對象,叫做它的car和cdr。car為A且cdr為B的偶對可表示為(A . B)。偶對(就像 Python 中的元組)可以表示列表、樹和任意的層次結構。
標準的 Scheme 列表包含空的列表值(記為()),或者包含一個偶對,它的car是列表第一個元素,cdr是列表的剩餘部分。所以,包含整數1, 2, 3的列表可表示為:
(1 . (2 . (3 . ())))
列表無處不在,Scheme 允許我們將(a . ())縮略為(a),將(a . (b ...))縮略為(a b ...)。所以,上面的列表通常寫為:
(1 2 3)
過程(函數)
就像 Python 中一樣,過程(或函數)值表示一些計算,它們可以通過向函數提供參數來調用。過程要麼是原始的,由 Scheme 的運行時系統提供,要麼從 Scheme 表達式和環境構造(就像 Python 中那樣)。沒有用於函數值的直接表示,但是有一些綁定到基本函數的預定義標識符,也有一些 Scheme 表達式,在求值時會產生新的過程值。
其它類型
Scheme 也支持字符和字符串(類似 Python 的字符串,除了 Scheme 區分字符和字符串),以及向量(就像 Python 的列表)。
**程序表示。**就像其它 Lisp 版本,Scheme 的數據值也用於表示程序。例如,下面的 Scheme 列表:
(+ x (* 10 y))
取決於如何使用,可表示為三個元素的列表(它的最後一個元素也是三個元素的列表),或者表達為用於計算x+10y的 Scheme 表達式。為了將 Scheme 值求值為程序,我們需要考慮值的類型,並按以下步驟求值:
- 整數、布爾值、字符、字符串和向量都求值為它們自己。所以,表達式
5求值為 5。 - 純符號看做變量。它們的值由當前被求值環境來決定,就像 Python 那樣。
- 非空列表以兩種方式解釋,取決於它們的第一個成員:
- 如果第一個成員是特殊形式的符號(在下面描述),求值由這個特殊形式的規則執行。
- 所有其他情況(叫做組合)中,列表的成員會以非特定的順序(遞歸)求值。第一個成員必須是函數值。這個值會被調用,以列表中剩餘成員的值作為參數。
- 其他 Scheme 值(特別是,不是列表的偶對)在程序中是錯誤的。
例如:
>>> 5 ; A literal.
5
>>> (define x 3) ; A special form that creates a binding for symbol
x ; x.
>>> (+ 3 (* 10 x)) ; A combination. Symbol + is bound to the primitive
33 ; add function and * to primitive multiply.
**基本的特殊形式。**特殊形式將東西表示為 Python 中的控制結構、函數調用或者類的定義:在調用時,這些結構不會簡單地立即求值。
首先,一些通用的結構以這種形式使用:
EXPR-SEQ
只是表達式的序列,例如:
(+ 3 2) x (* y z)
當它出現在下面的定義中時,它指代從左到右求值的表達式序列,序列中最後一個表達式的值就是它的值。
BODY
一些結構擁有“主體”,它們是 EXPR-SEQ,就像上面一樣,可能由一個或多個定義處理。它們的值就是 EXPR-SEQ 的值。這些定義的解釋請見內部定義一節。
下面是這些特殊形式的代表性子集:
定義
定義可以出現在程序的頂層(也就是不包含在其它結構中)。
(define SYM EXPR)
求出EXPR並在當前環境將其值綁定到符號SYM上。
(define (SYM ARGUMENTS) BODY)
等價於(define SYM (lambda (ARGUMENTS) BODY))。
(lambda (ARGUMENTS) BODY)
求值為函數。ARGUMENTS 通常為(可能非空的)不同符號的列表,向函數提供參數名稱,並且表明它們的數量。ARGUMENTS也可能具有如下形式:
(sym1 sym2 ... symn . symr)
(也就是說,列表的末尾並不像普通列表那樣是空的,最後的cdr是個符號。)這種情況下,symr會綁定到列表的尾後參數值(後面的第 n+1 個參數)。
當產生的函數被調用時,ARGUMENTS在一個新的環境中綁定到形參的值上,新的環境擴展自lambda表達式求值的環境(就像 Python 那樣)。之後BODY會被求值,它的值會作為調用的值返回。
(if COND-EXPR TRUE-EXPR OPTIONAL-FALSE-EXPR)
求出COND-EXPR,如果它的值不是#f,那麼求出TRUE-EXPR,結果會作為if的值。如果COND-EXPR值為#f而且OPTIONAL-FALSE-EXPR存在,它會被求值為並作為if的值。如果它不存在,if值是未定義的。
(set! SYMBOL EXPR)
求出EXPR使用該值替換SYMBOL 的綁定。SYMBOL 必須已經綁定,否則會出現錯誤。和 Python 的默認情況不同,它會在定義它的第一個環境幀上替換綁定,而不總是最深處的幀。
(quote EXPR) 或 'EXPR
將 Scheme 數據結構用於程序表示的一個問題,是需要一種方式來表示打算被求值的程序文本。quote形式求值為EXPR自身,而不進行進一步的求值(替代的形式使用前導的單引號,由 Scheme 表達式讀取器轉換為第一種形式)。例如:
>>> (+ 1 2)
3
>>> '(+ 1 2)
(+ 1 2)
>>> (define x 3)
x
>>> x
3
>>> (quote x)
x
>>> '5
5
>>> (quote 'x)
(quote x)
派生的特殊形式
派生結構時可以翻譯為基本結構的結構。它們的目的是讓程序對於讀取器更加簡潔可讀。在 Scheme 中:
(begin EXPR-SEQ)
簡單地求值併產生EXPR-SEQ的值。這個結構是個簡單的方式,用於在需要單個表達式的上下文中執行序列或表達式。
(and EXPR1 EXPR2 ...)
每個EXPR從左到右執行,直到碰到了#f,或遍歷完EXPRs。值是最後求值的EXPR,如果EXPRs列表為空,那麼值為#t。例如:
>>> (and (= 2 2) (> 2 1))
#t
>>> (and (< 2 2) (> 2 1))
#f
>>> (and (= 2 2) '(a b))
(a b)
>>> (and)
#t
(or EXPR1 EXPR2 ...)
每個EXPR從左到右求值,直到碰到了不為#f的值,或遍歷完EXPRs。值為最後求值的EXPR,如EXPRs列表為空,那麼值為#f。例如:
>>> (or (= 2 2) (> 2 3))
#t
>>> (or (= 2 2) '(a b))
#t
>>> (or (> 2 2) '(a b))
(a b)
>>> (or (> 2 2) (> 2 3))
#f
>>> (or)
#f
(cond CLAUSE1 CLAUSE2 ...)
每個CLAUSEi都依次處理,直到其中一個處理成功,它的值就是cond的值。如果沒有子句處理成功,值是未定義的。每個子句都有三種可能的形式。
如果TEST-EXPR 求值為不為#f的值,(TEST-EXPR EXPR-SEQ)形式執行成功。這種情況下,它會求出EXPR-SEQ併產生它的值。EXPR-SEQ可以不寫,這種情況下值為TEST-EXPR本身。
最後一個子句可為(else EXPR-SEQ)的形式,它等價於(#t EXPR-SEQ)。
最後,如果(TEST_EXPR => EXPR)的形式在TEST_EXPR求值為不為#f的值(叫做V)時求值成功。如果求值成功,cond結構的值是由(EXPR V)返回的值。也就是說,EXPR必須求值為單參數的函數,在TEST_EXPR的值上調用。
例如:
>>> (cond ((> 3 2) 'greater)
... ((< 3 2) 'less)))
greater
>>> (cond ((> 3 3) 'greater)
... ((< 3 3) 'less)
... (else 'equal))
equal
>>> (cond ((if (< -2 -3) #f -3) => abs)
... (else #f))
3
(case KEY-EXPR CLAUSE1 CLAUSE2 ...)
KEY-EXPR的求值會產生一個值K。之後將K與每個CLAUSEi一次匹配,直到其中一個成功,並且返回該子句的值。如果沒有子句成功,值是未定義的。每個子句都擁有((DATUM1 DATUM2 ...) EXPR-SEQ)的形式。其中DATUMs是 Scheme 值(它們不會被求值)。如果K匹配了DATUM的值之一(由下面描述的eqv?函數判斷),子句就會求值成功,它的EXPR-SEQ就會被求值,並且它的值會作為case的值。最後的子句可為(else EXPR-SEQ)的形式,它總是會成功,例如:
>>> (case (* 2 3)
... ((2 3 5 7) 'prime)
... ((1 4 6 8 9) 'composite))
composite
>>> (case (car '(a . b))
... ((a c) 'd)
... ((b 3) 'e))
d
>>> (case (car '(c d))
... ((a e i o u) 'vowel)
... ((w y) 'semivowel)
... (else 'consonant))
consonant
(let BINDINGS BODY)
BINDINGS是偶對的列表,形式為:
( (VAR1 INIT1) (VAR2 INIT2) ...)
其中VARs是(不同的)符號,而INITs是表達式。首先會求出INIT表達式,之後創建新的幀,將這些值綁定到VARs,再然後在新環境中求出BODY,返回它的值。換句話說,它等價於調用
((lambda (VAR1 VAR2 ...) BODY)
INIT1 INIT2 ...)
所以,任何INIT表達式中的VARs引用都指向這些符號在let結構外的定義(如果存在的話),例如:
>>> (let ((x 2) (y 3))
... (* x y))
6
>>> (let ((x 2) (y 3))
... (let ((x 7) (z (+ x y)))
... (* z x)))
35
(let* BINDINGS BODY)
BINDINGS 的語法和let相同。它等價於
(let ((VAR1 INIT1))
...
(let ((VARn INITn))
BODY))
也就是說,它就像let表達式那樣,除了VAR1的新綁定對INITs子序列以及BODY中可見,VAR2與之類似,例如:
>>> (define x 3)
x
>>> (define y 4)
y
>>> (let ((x 5) (y (+ x 1))) y)
4
>>> (let* ((x 5) (y (+ x 1))) y)
6
(letrec BINDINGS BODY)
同樣,語法類似於let。這裡,首先會創建新的綁定(帶有未定義的值),之後INITs被求值並賦給它們。如果某個INITs使用了某個VAR的值,並且沒有為其賦初始值,結果是未定義的。這個形式主要用於定義互相遞歸的函數(lambda 本身並不會使用它們提到過的值;這隻會在它們被調用時隨後發生)。例如:
(letrec ((even?
(lambda (n)
(if (zero? n)
#t
(odd? (- n 1)))))
(odd?
(lambda (n)
(if (zero? n)
#f
(even? (- n 1))))))
(even? 88))
**內部定義。**當BODY以define結構的序列開始時,它們被看作“內部定義”,並且在解釋上與頂層定義有些不同。特別是,它們就像letrec那樣。
- 首先,會為所有由
define語句定義的名稱創建綁定,一開始綁定到未定義的值上。 - 之後,值由定義來填充。
所以,內部函數定義的序列是互相遞歸的,就像 Python 中嵌套在函數中的def`語句那樣:
>>> (define (hard-even? x) ;; An outer-level definition
... (define (even? n) ;; Inner definition
... (if (zero? n)
... #t
... (odd? (- n 1))))
... (define (odd? n) ;; Inner definition
... (if (zero? n)
... #f
... (even? (- n 1))))
... (even? x))
>>> (hard-even? 22)
#t
**預定義函數。**預定義函數有很多,都在全局環境中綁定到名稱上,我們只會展示一小部分。其餘的會在 Revised(4) Scheme 報告中列出。函數調用並不是“特殊的”,因為它們都使用相同的完全統一的求值規則:遞歸求出所有項目(包括運算符),並且之後在操作數的值上調用運算符的值(它必須是個函數)。
-
**算數:**Scheme 提供了標準的算數運算符,許多都擁有熟悉的表示,雖然它們統一出現在操作數前面:
>>> ; Semicolons introduce one-line comments. >>> ; Compute (3+7+10)*(1000-8) // 992 - 17 >>> (- (quotient (* (+ 3 7 10) (- 1000 8))) 17) 3 >>> (remainder 27 4) 3 >>> (- 17) -17與之相似,存在通用的數學比較運算符,為可接受多於兩個參數而擴展:
>>> (< 0 5) #t >>> (>= 100 10 10 0) #t >>> (= 21 (* 7 3) (+ 19 2)) #t >>> (not (= 15 14)) #t >>> (zero? (- 7 7)) #t隨便提一下,
not是個函數,並不是and或or的特殊形式,因為他的運算符必須求值,所以不需要特殊對待。 -
**列表和偶對。**很多操作用於處理偶對和列表(它們同樣由偶對和空列表構建)。
>>> (cons 'a 'b) (a . b) >>> (list 'a 'b) (a b) >>> (cons 'a (cons 'b '())) (a b) >>> (car (cons 'a 'b)) a >>> (cdr (cons 'a 'b)) b >>> (cdr (list a b)) (b) >>> (cadr '(a b)) ; An abbreviation for (car (cdr '(a b))) b >>> (cddr '(a b)) ; Similarly, an abbreviation for (cdr (cdr '(a b))) () >>> (list-tail '(a b c) 0) (a b c) >>> (list-tail '(a b c) 1) (b c) >>> (list-ref '(a b c) 0) a >>> (list-ref '(a b c) 2) c >>> (append '(a b) '(c d) '() '(e)) (a b c d e) >>> ; All but the last list is copied. The last is shared, so: >>> (define L1 (list 'a 'b 'c)) >>> (define L2 (list 'd)) >>> (define L3 (append L1 L2)) >>> (set-car! L1 1) >>> (set-car! L2 2) >>> L3 (a b c 2) >>> (null? '()) #t >>> (list? '()) #t >>> (list? '(a b)) #t >>> (list? '(a . b)) #f -
相等性:
=運算符用於數值。通常對於值的相等性,Scheme 區分eq?(就像 Python 的is),eqv?(與之類似,但是和數值上的=一樣),和equal?(比較列表結構或字符串的內容)。通常來說,除了在比較符號、布爾值或者空列表的情況中,我們都使用eqv?和equal?。>>> (eqv? 'a 'a) #t >>> (eqv? 'a 'b) #f >>> (eqv? 100 (+ 50 50)) #t >>> (eqv? (list 'a 'b) (list 'a 'b)) #f >>> (equal? (list 'a 'b) (list 'a 'b)) #t -
**類型。**每個值的類型都只滿足一個基本的類型斷言。
>>> (boolean? #f) #t >>> (integer? 3) #t >>> (pair? '(a b)) #t >>> (null? '()) #t >>> (symbol? 'a) #t >>> (procedure? +) #t -
**輸入和輸出:**Scheme 解釋器通常執行“讀取-求值-打印”循環,但是我們可以在程序控制下顯式輸出東西,使用與解釋器內部相同的函數:
>>> (begin (display 'a) (display 'b) (newline)) ab於是,
(display x)與 Python 的print(str(x), end="")相似,並且
(newline)類似於print()。對於輸入來說,
(read)從當前“端口”讀取 Scheme 表達式。它並不會解釋表達式,而是將其讀作數據:>>> (read) >>> (a b c) (a b c) -
求值。
apply函數提供了函數調用運算的直接訪問:>>> (apply cons '(1 2)) (1 . 2) >>> ;; Apply the function f to the arguments in L after g is >>> ;; applied to each of them >>> (define (compose-list f g L) ... (apply f (map g L))) >>> (compose-list + (lambda (x) (* x x)) '(1 2 3)) 14這個擴展允許開頭出現“固定”參數:
>>> (apply + 1 2 '(3 4 5)) 15下面的函數並不在 Revised(4) Scheme 中,但是存在於我們的解釋器版本中(警告:非標準的過程在 Scheme 的後續版本中並不以這種形式定義):
>>> (eval '(+ 1 2)) 3也就是說,
eval求解一塊 Scheme 數據,它表示正確的 Scheme 表達式。這個版本在全局環境中求解表達式的參數。我們的解釋器也提供了一種方式,來規定求值的特定環境:>>> (define (incr n) (lambda (x) (+ n x))) >>> (define add5 (incr 5)) >>> (add5 13) 18 >>> (eval 'n (procedure-environment add5)) 5
3.6.2 Logo 語言
Logo 是 Lisp 的另一種方言。它為教育用途而設計,所以 Logo 的許多設計決策是為了讓語言對新手更加友好。例如,多數 Logo 過程以前綴形式調用(首先是過程名稱,其次是參數),但是通用的算術運算符以普遍的中綴形式提供。Logo 的偉大之處是,它的簡單親切的語法仍舊為高級程序員提供了驚人的表現力。
Logo 的核心概念是,它的內建容器類型,也就是 Logo sentence (也叫作列表),可以輕易儲存 Logo 源碼,這也是它的強大表現力的來源。Logo 的程序可以編寫和執行 Logo 表達式,作為求值過程的一部分。許多動態語言都支持代碼生成,包括 Python,但是沒有語言像 Logo 一樣使代碼生成如此有趣和易用。
你可能希望下載完整的 Logo 解釋器來體驗這個語言。標準的實現是 Berkeley Logo(也叫做 UCBLogo),由 Brian Harvey 和他的 Berkeley 學生開發。對於蘋果用戶,ACSLogo 兼容 Mac OSX 的最新版本,並帶有一份介紹 Logo 語言許多特性的用戶指南。
**基礎。**Logo 設計為會話式。它的讀取-求值循環的提示符是一個問號(?),產生了“我下面應該做什麼?”的問題。我們自然想讓它打印數值:
? print 5
5
Logo 語言使用了非標準的調用表達式語法,完全不帶括號分隔符。上面,參數5轉給了print,它打印了它的參數。描述 Logo 程序結構的術語有些不同於 Python。Logo 擁有過程而不是 Python 中等價的函數,而且過程輸出值而不是返回值。和 python 類似,print過程總是輸出None,但也打印出參數的字符串表示作為副作用。(過程的參數在 Logo 中也通常叫做輸入,但是為了清晰起見,這篇文章中我們仍然稱之為參數。)
Logo 中最常見的數據類型是單詞,它是不帶空格的字符串。單詞用作可以表示數值、名稱和布爾值的通用值。可以解釋為數值或布爾值的記號,比如5,直接求值為單詞。另一方面,類似five的名稱解釋為過程調用:
? 5
You do not say what to do with 5.
? five
I do not know how to five.
5和five以不同方式解釋,Logo 的讀取-求值循環也以不同方式報錯。第一種情況的問題是,Logo 在頂層表達式不求值為 None 時報錯。這裡,我們看到了第一個 Logo 不同於計算器的結構;前者的接口是讀取-解釋循環,期待用戶來打印結果。後者使用更加通用的讀取-求值-打印循環,自動打印出返回值。Python 採取了混合的方式,非None的值使用repr強制轉換為字符串並自動打印。
Logo 的行可以順序包含多個表達式。解釋器會一次求出每個表達式。如果行中任何頂層表達式不求值為None,解釋器會報錯。一旦發生錯誤,行中其餘的表達式會被忽略。
? print 1 print 2
1
2
? 3 print 4
You do not say what to do with 3.
Logo 的調用表達式可以嵌套。在 Logo 的實現版本中,每個過程接受固定數量的參數。所以,當嵌套調用表達式的操作數完整時,Logo 解釋器能夠唯一地判斷。例如,考慮兩個過程sum和difference,它們相應輸出兩個參數的和或差。
? print sum 10 difference 7 3
14
我們可以從這個嵌套的例子中看到,分隔調用表達式的圓括號和逗號不是必須的。在計算器解釋器中,標點符號允許我們將表達式樹構建為純粹的句法操作,沒有任何運算符名稱的判斷。在 Logo 中,我們必須使用我們的知識,關於每個過程接受多少參數,來得出嵌套表達式的正確結構。下一節中,問題的細節會深入探討。
Logo 也支持中綴運算符,例如+和*。這些運算符的優先級根據代數的標準規則來解析。乘法和除法優於加法和減法:
? 2 + 3 * 4
14
如何實現運算符優先級和前綴運算符來生成正確的表達式樹的細節留做練習。對於下面的討論,我們會專注於使用前綴語法的調用表達式。
**引用。**一個名稱會被解釋為調用表達式的開始部分,但是我們也希望將單詞引用為數據。以雙引號開始的記號解釋為單詞字面值。要注意單詞字面值在 Logo 中並沒有尾後的雙引號。
? print "hello
hello
在 Lisp 的方言中(而 Logo 是它的方言),任何不被求值的表達式都叫做引用。這個引用的概念來自於事物之間的經典哲學。例如一隻狗,它可以到處亂跑和叫喚,而單詞“狗”只是用於指代這種事物的語言結構。當我們以引號使用“狗”的時候,我們並不是指特定的哪一隻,而是這個單詞。在語言中,引號允許我們談論語言自身,Logo 中也一樣。我們可以按照名稱引用sum過程,而不會實際調用它,通過這樣引用它:
? print "sum
sum
除了單詞,Logo 包含句子類型,可以叫做列表。句子由方括號包圍。print過程並不會打印方括號,以維持 Logo 的慣例風格,但是方括號可以使用show過程打印到輸出:
? print [hello world]
hello world
? show [hello world]
[hello world]
句子也可以使用三個不同的二元過程來構造。sentence過程將參數組裝為句子。它是多態過程,如果參數是單詞,會將它的參數放入新的句子中;如果參數是句子,則會將拼接參數。結果通常是一個句子:
? show sentence 1 2
[1 2]
? show sentence 1 [2 3]
[1 2 3]
? show sentence [1 2] 3
[1 2 3]
? show sentence [1 2] [3 4]
[1 2 3 4]
list過程從兩個元素創建句子,它允許用戶創建層次數據結構:
? show list 1 2
[1 2]
? show list 1 [2 3]
[1 [2 3]]
? show list [1 2] 3
[[1 2] 3]
? show list [1 2] [3 4]
[[1 2] [3 4]]
最後,fput過程從第一個元素和列表的剩餘部分創建列表,就像這一章之前的 Python RList構造器那樣:
? show fput 1 [2 3]
[1 2 3]
? show fput [1 2] [3 4]
[[1 2] 3 4]
我們在 Logo 中可以調用sentence、list和fput句子構造器。在 Logo 中將句子解構為first和剩餘部分(叫做butfirst)也非常直接,所以,我們也擁有一系列句子的選擇器過程。
? print first [1 2 3]
1
? print last [1 2 3]
3
? print butfirst [1 2 3]
[2 3]
**作為數據的表達式。**句子的內容可以直接當做未求值的引用。所以,我們可以打印出 Logo 表達式而不求值:
? show [print sum 1 2]
[print sum 1 2]
將 Logo 表示表達式表示為句子的目的通常不是打印它們,而是使用run過程來求值。
? run [print sum 1 2]
3
通過組合引用和句子構造器,以及run過程,我們獲得了一個非常通用的組合手段,它憑空構建 Logo 表達式並對其求值:
? run sentence "print [sum 1 2]
3
? print run sentence "sum sentence 10 run [difference 7 3]
14
最後一個例子的要點是為了展示,雖然sum和difference過程在 Logo 中並不是一等的構造器(它們不能直接放在句子中),它們的名稱是一等的,並且run過程可以將它們的名稱解析為所引用的過程。
將代碼表示為數據,並且稍後將其解釋為程序的一部分的功能,是 Lisp 風格語言的特性。程序可以重新編寫自己來執行是一個強大的概念,並且作為人工智能(AI)早期研究的基礎。Lisp 在數十年間都是 AI 研究者的首選語言。Lisp 語言由 John McCarthy 發明,他也發明了“人工智能”術語,並且在該領域的定義中起到關鍵作用。Lisp 方言的“代碼即數據”的特性,以及它們的簡潔和優雅,今天仍繼續吸引著 Lisp 程序員。
**海龜製圖(Turtle graphics)。**所有 Logo 的實現都基於 Logo 海龜 來完成圖形輸出。這個海龜以畫布的中點開始,基於過程移動和轉向,並且在它的軌跡上畫線。雖然海龜為鼓勵青少年實踐編程而發明,它對於高級程序員來說也是有趣的圖形化工具。
在執行 Logo 程序的任意時段,Logo 海龜都在畫布上擁有位置和朝向。類似於forward和right的一元過程能修改海龜的位置和朝向。常用的過程都有縮寫:forward也叫作fd,以及其它。下面的嵌套表達式畫出了每個端點帶有小星星的大星星:
? repeat 5 [fd 100 repeat 5 [fd 20 rt 144] rt 144]
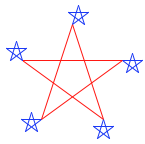
海龜過程的全部指令也內建於 Python 的turtle模塊中。這些函數的有限子集也在這一章的配套項目中提供。
**賦值。**Logo 支持綁定名稱和值。就像 Python 中那樣,Logo 環境由幀的序列組成,每個幀中的某個名稱都最多綁定到一個值上。名稱使用make過程來綁定,它接受名稱和值作為參數。
? make "x 2
任何以冒號起始的單詞,例如:x都叫做變量。變量求值為其名稱在當前環境中綁定的值。
make過程和 Python 的賦值語句具有不同的作用。傳遞給make的名稱要麼已經綁定了值,要麼當前未綁定。
- 如果名稱已經綁定,
make在找到它的第一幀中重新綁定該名稱。 - 如果沒有綁定,
make在全局幀中綁定名稱。
這個行為與 Python 賦值語句的語義很不同,後者總是在當前環境中的第一幀中綁定名稱。上面的第一條規則類似於遵循nonlocal語句的 Python 賦值。第二條類似於遵循global語句的全局賦值。
**過程。**Logo 支持用戶使用以to關鍵字開始的定義來定義過程。定義是 Logo 中的最後一個表達式類型,在調用表達式、基本表達式和引用表達式之後。定義的第一行提供了新過程的名稱,隨後是作為變量的形參。下面的行是過程的主體,它可以跨越多行,並且必須以只包含end記號的一行結束。Logo 的讀取-求值循環使用>連接符來提示用戶輸入過程體。用戶定義過程使用output過程來輸出一個值。
? to double :x
> output sum :x :x
> end
? print double 4
8
Logo 的用戶定義過程所產生的調用過程和 Python 中的過程類似。在一系列參數上調用過程以使用新的幀擴展當前環境,以及將過程的形參綁定到實參開始,之後在開始於新幀的環境中求出過程體的代碼行。
output的調用在 Logo 中與 Python 中的return語句有相同作用:它會中止過程體的執行,並返回一個值。Logo 過程可以通過調用stop來不帶任何值返回。
? to count
> print 1
> print 2
> stop
> print 3
> end
? count
1
2
**作用域。**Logo 是動態作用域語言。類似 Python 的詞法作用域語言並不允許一個函數的局部名稱影響另一個函數的求值,除非第二個函數顯式定義在第一個函數內。兩個頂層函數的形參完全是隔離的。在動態作用域的語言中,沒有這種隔離。當一個函數調用另一個函數時,綁定到第一個函數局部幀的名稱可在第二個函數的函數體中訪問:
? to print_last_x
> print :x
> end
? to print_x :x
> print_last_x
> end
? print_x 5
5
雖然名稱x並沒有在全局幀中綁定,而是在print_x的局部幀中,也就是首先調用的函數。Logo 的動態作用域規則允許函數print_last_x引用x,它被綁定到print_x的形式參數上。
動態作用域只需要一個對計算環境模型的簡單修改就能實現。由用戶函數調用創建的幀總是擴展自當前環境(調用處)。例如,上面的print_x調用引入了新的幀,它擴展自當前環境,當前環境中包含print_x的局部幀和全局幀。所以,在print_last_x的主體中查找x會發現局部幀中該名稱綁定到5。與之相似,在 Python 的詞法作用域下,print_last_x的幀只擴展自全局幀(定義處),而並不擴展自print_x的局部幀(調用處)。
動態作用域語言擁有一些好處,它的過程可能不需要接受許多參數。例如,print_last_x上面的過程沒有接受參數,但是它的行為仍然由內層作用域參數化。
**常規編程。**我們的 Logo 之旅就到此為止了。我們還沒有介紹任何高級特性,例如,對象系統、高階過程,或者語句。學會在 Logo 中高效編程需要將語言的簡單特性組合為有效的整體。
Logo 中沒有條件表達式類型。過程if和ifelse使用調用表達式的求值規則。if的第一個參數是個布爾單詞,True或者False。第二個參數不是輸出值,而是一個句子,包含如果第一個參數為True時需要求值的代碼行。這個設計的重要結果是,第二個函數的內容如果不被用到就不會全部求值。
? 1/0
div raised a ZeroDivisionError: division by zero
? to reciprocal :x
> if not :x = 0 [output 1 / :x]
> output "infinity
> end
? print reciprocal 2
0.5
? print reciprocal 0
infinity
Logo 的條件語句不僅僅不需要特殊語法,而且它實際上可以使用word和run實現。ifelse的基本過程接受三個函數:布爾單詞、如果單詞為True需要求值的句子,和如果單詞為False需要求值的句子。通過適當命名形式參數,我們可以實現擁有相同行為的用戶定義過程ifelse2。
? to ifelse2 :predicate :True :False
> output run run word ": :predicate
> end
? print ifelse2 emptyp [] ["empty] ["full]
empty
遞歸過程不需要任何特殊語法,它們可以和run、sentence、first和butfirst一起使用,來定義句子上的通用序列操作。例如,我們可以通過構建二元句子並執行它,來在參數上調用過程。如果參數是個單詞,它必須被引用。
? to apply_fn :fn :arg
> output run list :fn ifelse word? :arg [word "" :arg] [:arg]
> end
下面,我們可以定義一個過程,它在句子:s上逐步映射函數:fn。
? to map_fn :fn :s
> if emptyp :s [output []]
> output fput apply_fn :fn first :s map_fn :fn butfirst :s
> end
? show map "double [1 2 3]
[2 4 6]
map_fn主體的第二行也可以使用圓括號編寫,表明調用表達式的嵌套結構。但是,圓括號表示了調用表達式的開始和末尾,而不是包圍在操作數和非運算符周圍。
> (output (fput (apply_fn :fn (first :s)) (map_fn :fn (butfirst :s))))
圓括號在 Logo 中並不必須,但是它們通常幫助程序員記錄嵌套表達式的結構。許多 Lisp 的方言都需要圓括號,所以就擁有了顯式嵌套的語法。
作為最後一個例子,Logo 可以以非常緊湊的形式使用海龜製圖來遞歸作圖。謝爾賓斯基三角是個分形圖形,它繪製每個三角形的同時還繪製鄰近的三個三角形,它們的頂點是包含它們的三角形的邊上的中點。它可以由這個 Logo 程序以有限的遞歸深度來繪製。
? to triangle :exp
> repeat 3 [run :exp lt 120]
> end
? to sierpinski :d :k
> triangle [ifelse :k = 1 [fd :d] [leg :d :k]]
> end
? to leg :d :k
> sierpinski :d / 2 :k - 1
> penup fd :d pendown
> end
triangle 過程是個通用方法,它重複三次繪製過程,並在每個重複之後左轉。sierpinski 過程接受長度和遞歸深度。如果深度為1,它畫出純三角形,否則它畫出由log的調用所組成的三角形。leg過程畫出謝爾賓斯基遞歸三角型的一條邊,通過遞歸調用sierpinski 填充這條邊長度的上一半,之後將海龜移動到另一個頂點上。過程up和down通過將筆拿起並在之後放下,在海龜移動過程中停止畫圖。sierpinski和leg之間的多重遞歸產生了如下結果:
? sierpinski 400 6

3.6.3 結構
這一節描述了 Logo 解釋器的通常結構。雖然這一章是獨立的,它也確實引用了配套項目。完成這個項目會從零製造出這一章描述的解釋器的有效實現。
Logo 的解釋器可以擁有和計算器解釋器相同的結構。解析器產生表達式數據結構,它們可由求值器來解釋。求值函數檢查表達式的形式,並且對於調用表達式,它在一些參數上調用函數來應用某個過程。但是,還是存在一些結構上的不同以適應 Logo 的特殊語法。
**行。**Logo 解析器並不讀取一行代碼,而是讀取可能按序包含多個表達式的整行代碼。它不返回表達式樹,而是返回 Logo 句子。
解析器實際上只做微小的語法分析。特別是,解析工作並不會將調用表達式的運算符和操作數子表達式區分為樹的不同枝幹。反之,調用表達式的組成部分順序排列,嵌套調用表達式表示為攤平的記號序列。最終,解析工作並不判斷基本表達式,例如數值的類型,因為 Logo 沒有豐富的類型系統。反之,每個元素都是單詞或句子。
>>> parse_line('print sum 10 difference 7 3')
['print', 'sum', '10', 'difference', '7', '3']
解析器做了很微小的分析,因為 Logo 的動態特性需要求值器解析嵌套表達式的結構。
解析器並不會弄清句子的嵌套結構,句子中的句子表示為 Python 的嵌套列表。
>>> parse_line('print sentence "this [is a [deep] list]')
['print', 'sentence', '"this', ['is', 'a', ['deep'], 'list']]
parse_line的完整實現在配套項目的logo_parser.py中。
**求值。**Logo 一次求值一行。求值器的一個框架實現定義在配套項目的logo.py中。從parse_line返回的句子傳給了eval_line函數,它求出行中的每個表達式。eval_line函數重複調用logo_eval,它求出行中的下一個完整的表達式,直到這一行全部求值完畢,之後返回最後一個值。logo_eval函數求出單個表達式。
![]()
logo_eval函數求出不同形式的表達式:基本、變量、定義、引用和調用表達式,我們已經在上一節中介紹過它們了。Logo 中多元素表達式的形式可以由檢查第一個元素來判斷。表達式的每個形式都有自己的求值規則。
- 基本表達式(可以解釋為數值、
True或False的單詞)求值為自身。 - 變量在環境中查找。環境會在下一節中詳細討論。
- 定義處理為特殊情況。用戶定義過程也在下一節中詳細討論。
- 引用表達式求值為引用的文本,它是個去掉前導引號的字符串。句子(表示為 Python 列表)也看做引用,它們求值為自身。
- 調用表達式在當前環境中查找運算符名稱,並且調用綁定到該名稱的過程。
下面是logo_apply的簡單實現。我們去掉了一些錯誤檢查,以專注於我們的討論。配套項目中有更加健壯的實現。
>>> def logo_eval(line, env):
"""Evaluate the first expression in a line."""
token = line.pop()
if isprimitive(token):
return token
elif isvariable(token):
return env.lookup_variable(variable_name(token))
elif isdefinition(token):
return eval_definition(line, env)
elif isquoted(token):
return text_of_quotation(token)
else:
procedure = env.procedures.get(token, None)
return apply_procedure(procedure, line, env)
上面的最後情況調用了第二個過程,表達為函數apply_procedure。為了調用由運算符記號命名的過程,這個運算符會在當前環境中查找。在上面的定義中,env是Environment 類的實例,會在下一節中描述。env.procedures屬性是個儲存運算符名稱和過程之間映射的字典。在 Logo 中,環境擁有單詞的這種映射,並且沒有局部定義的過程。而且,Logo 為過程名稱和變量名稱維護分離的映射,叫做分離的命名空間。但是,以這種方式複用名稱並不推薦。
**過程調用。**過程調用以調用apply_procedure函數開始,它被傳入由logo_apply查找到的函數,並帶有代碼的當前行和當前環境。Logo 中過程調用的過程比計算器中的calc_apply更加通用。特別是,apply_procedure必須檢查打算調用的過程,以便在求解n個運算符表達式之前,判斷它的參數數量n。這裡我們會看到,為什麼 Logo 解析器不能僅僅由語法分析構建表達式樹,因為樹的結構由過程決定。
apply_procedure函數調用collect_args 函數,它必須重複調用logo_eval來求解行中的下n個表達式。之後,計算完過程的參數之後,apply_procedure調用了logo_apply,實際上這個函數在參數上調用過程。下面的調用圖示展示了這個過程。
![]()
最終的函數 logo_apply接受兩種參數:基本過程和用戶定義的過程,二者都是Procedure的實例。Procedure是一個 Python 對象,它擁有過程的名稱、參數數量、主體和形式參數作為實例屬性。body屬性可以擁有不同類型。基本過程在 Python 中已經實現,所以它的body就是 Python 函數。用戶定義的過程(非基本)定義在 Logo 中,所以它的 body就是 Logo 代碼行的列表。Procedure也擁有兩個布爾值屬性。一個用於表明是否是基本過程,另一個用於表明是否需要訪問當前環境。
>>> class Procedure():
def __init__(self, name, arg_count, body, isprimitive=False,
needs_env=False, formal_params=None):
self.name = name
self.arg_count = arg_count
self.body = body
self.isprimitive = isprimitive
self.needs_env = needs_env
self.formal_params = formal_params
基本過程通過在參數列表上調用主體,並返回它的返回值作為過程輸出來應用。
>>> def logo_apply(proc, args):
"""Apply a Logo procedure to a list of arguments."""
if proc.isprimitive:
return proc.body(*args)
else:
"""Apply a user-defined procedure"""
用戶定義過程的主體是代碼行的列表,每一行都是 Logo 句子。為了在參數列表上調用過程,我們在新的環境中求出主體的代碼行。為了構造這個環境,我們向當前環境中添加新的幀,過程的形式參數在裡面綁定到實參上。這個過程的重要結構化抽象是,求出用戶定義過程的主體的代碼行,需要遞歸調用eval_line。
**求值/應用遞歸。**實現求值過程的函數,eval_line 和logo_eval,以及實現函數應用過程的函數,apply_procedure、collect_args和logo_apply,是互相遞歸的。無論何時調用表達式被發現,求值操作都需要調用它。應用操作使用求值來求出實參中的操作數表達式,以及求出用戶定義過程的主體。這個互相遞歸過程的通用結構在解釋器中非常常見:求值以應用定義,應用又使用求值定義。
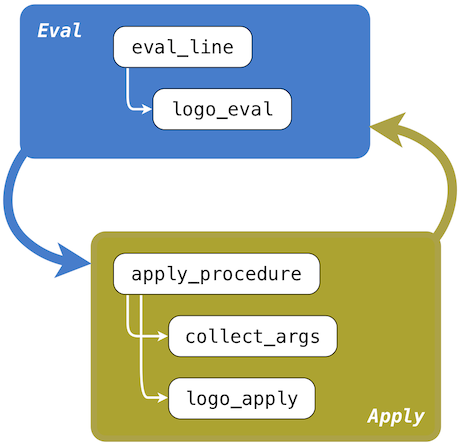
這個遞歸循環終止於語言的基本類型。求值的基本條件是,求解基本表達式、變量、引用表達式或定義。函數調用的基本條件是調用基本過程。這個互相遞歸的結構,在處理表達式形式的求值函數,和處理函數及其參數的應用之間,構成了求值過程的本質。
3.6.4 環境
既然我們已經描述了 Logo 解釋器的結構,我們轉而實現Environment 類,便於讓它使用動態作用域正確支持賦值、過程定義和變量查找。Environment實例表示名稱綁定的共有集合,可以在程序執行期間的某一點上訪問。綁定在幀中組織,而幀以 Python 字典實現。幀包含變量的名稱綁定,但不包含過程。運算符名稱和Procedure實例之間的綁定在 Logo 中是單獨儲存的。在這個實現中,包含變量名稱綁定的幀儲存為字典的列表,位於Environment的_frames屬性中,而過程名稱綁定儲存在值為字典的procedures屬性中。
幀不能直接訪問,而是通過兩個Environment的方法:lookup_variable和set_variable_value。前者實現了一個過程,與我們在第一章的計算環境模型中引入的查找過程相同。名稱在當前環境第一幀(最新添加)中與值匹配。如果它被找到,所綁定的值會被返回。如果沒有找到,會在被當前幀擴展的幀中尋找。
set_variable_value 也會尋找與變量名稱匹配的綁定。如果找到了,它會更新為新的值,如果沒有找到,那麼會在全局幀上創建新的綁定。這些方法的實現留做配套項目中的練習。
lookup_variable 方法在求解變量名稱時由logo_eval調用。set_variable_value 由logo_make函數調用,它用作 Logo 中make基本過程的主體。
除了變量和make基本過程之外,我們的解釋器支持它的第一種抽象手段:將名稱綁定到值上。在 Logo 中,我們現在可以重複我們第一章中的第一種抽象步驟。
? make "radius 10
? print 2 * :radius
20
賦值只是抽象的一種有限形式。我們已經從這門課的開始看到,即使對於不是很大的程序,用戶定義函數也是管理複雜性的關鍵工具。我們需要兩個改進來實現 Logo 中的用戶定義過程。首先,我們必須描述eval_definition的實現,如果當前行是定義,logo_eval會調用這個 Python 函數。其次,我們需要在logo_apply中完成我們的描述,它在一些參數上調用用戶過程。這兩個改動都需要利用上一節定義的Procedure類。
定義通過創建新的Procedure實例來求值,它表示用戶定義的過程。考慮下面的 Logo 過程定義:
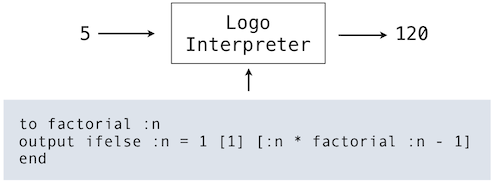
? to factorial :n
> output ifelse :n = 1 [1] [:n * factorial :n - 1]
> end
? print fact 5
120
定義的第一行提供了過程的名稱factorial和形參n。隨後的一些行組成了過程體。這些行並不會立即求值,而是為將來使用而儲存。也就是說,這些行由eval_definition讀取並解析,但是並不傳遞給eval_line。主體中的行一直讀取,直到出現了只包含end的行。在 Logo 中,end並不是需要求值的過程,也不是過程體的一部分。它是個函數定義末尾的語法標記。
Procedure實例從這個過程的名稱、形參列表以及主體中創建,並且在環境中的procedures的字典屬性中註冊。不像 Python,在 Logo 中,一旦過程綁定到一個名稱,其它定義都不能複用這個名稱。
logo_apply將Procedure實例應用於一些參數,它是表示為字符串的 Logo 值(對於單詞),或列表(對於句子)。對於用戶定義過程,logo_apply創建了新的幀,它是一個字典對象,鍵是過程的形參,值是實參。在動態作用域語言例如 Logo 中,這個新的幀總是擴展自過程調用處的當前環境。所以,我們將新創建的幀附加到當前環境上。之後,主體中的每一行都依次傳遞給eval_line 。最後,在主體完成求值後,我們可以從環境中移除新創建的幀。由於 Logo 並不支持高階或一等過程,在程序執行期間,我們並不需要一次跟蹤多於一個環境。
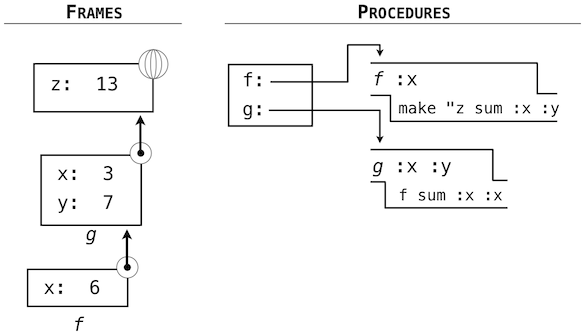
下面的例子演示了幀的列表和動態作用域規則,它們由調用這兩個 Logo 用戶定義過程產生:
? to f :x
> make "z sum :x :y
> end
? to g :x :y
> f sum :x :x
> end
? g 3 7
? print :z
13
由這些表達式的求值創建的環境分為過程和幀,它們維護在分離的命名空間中。幀的順序由調用順序決定。
3.6.5 數據即程序
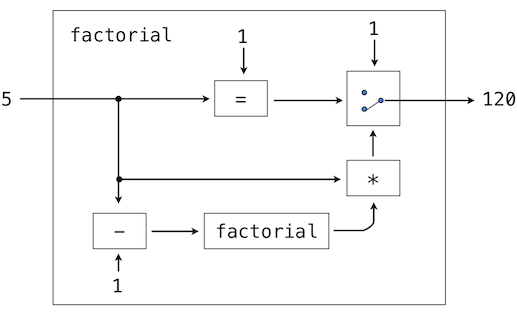
在思考求值 Logo 表達式的程序時,一個類比可能很有幫助。程序含義的一個可取觀點是,程序是抽象機器的描述。例如,再次思考下面的計算階乘的過程:
? to factorial :n
> output ifelse :n = 1 [1] [:n * factorial :n - 1]
> end
我們可以在 Python 中表達為等價的程序,使用傳統的表達式。
>>> def factorial(n):
return 1 if n == 1 else n * factorial(n - 1)
我們可能將這個程序看做機器的描述,它包含幾個部分,減法、乘法和相等性測試,並帶有兩相開關和另一個階乘機器(階乘機器是無限的,因為它在其中包含另一個階乘機器)。下面的圖示是一個階乘機器的流程圖,展示了這些部分是怎麼組合到一起的。
與之相似,我們可以將 Logo 解釋器看做非常特殊的機器,它接受機器的描述作為輸入。給定這個輸入,解釋器就能配置自己來模擬描述的機器。例如,如果我們向解釋器中輸入階乘的定義,解釋器就可以計算階乘。
從這個觀點得出,我們的 Logo 解釋器可以看做通用的機器。當輸入以 Logo 程序描述時,它就能模擬其它機器。它在由我們的編程語言操作的數據對象,和編程語言自身之間起到銜接作用。想象一下,一個用戶在我們正在運行的 Logo 解釋器中輸入了 Logo 表達式。從用戶的角度來看,類似sum 2 2的輸入表達式是編程語言中的表達式,解釋器應該對其求值。但是,從解釋器的角度來看,表達式只是單詞組成的句子,可以根據定義好的一系列規則來操作它。
用戶的程序是解釋器的數據,這不應該是混亂的原因。實際上,有時候忽略這個差異會更方便,以及讓用戶能夠顯式將數據對象求值為表達式。在 Logo 中,無論我們何時使用run 過程,我們都使用了這種能力。Python 中也存在相似的函數:eval函數會求出 Python 表達式,exec函數會求出 Python 語句,所以:
>>> eval('2+2')
4
和
>>> 2+2
4
返回了相同的結果。求解構造為指令的一部分的表達式是動態編程語言的常見和強大的特性。這個特性在 Logo 中十分普遍,很少語言是這樣,但是在程序執行期間構造和求解表達式的能力,對任何程序員來說都是有價值的工具。