原文多以 Go 1.13 為例;目前已補充 Go 1.26 的差異說明(尤其是模組與 go 指令行為)。
起步走
語言的起步走,需要的時間最好是長一些,因為慢一點才會快一點 ...
- Go 平台概要
在開始認識語言本身之前,先來瞭解 Go 提供的基本工具集,這是 Go 的一大特色。
- 型態、變數、常數、運算子
也許看似基本,然而沒你想像中的那麼簡單。
- 運算與流程控制
Go 有指標,switch 很有彈性,沒有 while,存在 goto ... XD
函式、結構與介面
封裝演算、定義行為、組織程式元件。
- 結構
把相關的東西放在一起。
- 介面
將行為定義出來。
常用 API
從常用 API 中學習如何撰寫 Go 程式碼。
- 基本 IO
從 io.Reader、io.Writer 開始認識。
- error 處理
到處都在 if err != nil?
- 資料結構
sort、list、heap 與 ring 套件。
- 文字
有關字串、位元組、規則表示式等的處理。
- 反射
探測資料的結構與相關數值。
- 並行
簡單的並行模型。
其他
一些雜七雜八的東西,暫時放這分類。
- 相依管理
go module 能終結混亂嗎?
- WebAssembly 支援
Go 也可以在瀏覽器裏跳舞?
附錄
我在這邊原本使用的是 Windows 中的 Go 1.13 版本;若你使用目前的 Go 1.26,可至 Go 的官方網站 下載安裝。
如果想來點不同的安裝方式,可以參考〈門外漢的 Go 輕量開發環境〉,在 Raspberry Pi 上的 Docker 容器中建立相關環境,就目前為止。
本文後半段會示範傳統 GOPATH 工作方式,這在 Go 1.26 仍有助於理解套件與建構流程,不過新專案通常會優先使用 Go 模組(go mod init,可搭配〈模組入門〉)。
使用官方安裝程式時,通常不需要手動設定 GOROOT(安裝程式會處理);實務上常見只要讓 Go 的 bin 目錄在 PATH 中即可。
go run
要撰寫第一個 Hello, World 程式,你可以建立一個 main.go,在當中撰寫以下的內容:
package main
import "fmt"
func main() {
fmt.Println("Hello, World")
fmt.Println("哈囉!世界!")
}
每個 .go 原始碼,都必須從 package 定義開始,而對於包括程式進入點 main 函式的 .go 原始碼,必須是在 package main 之中,為了要能輸出訊息,這邊使用了 fmt 套件(package)之中的 Println 函式,開頭的大寫 P 表示這是個公開的函式,可以在套件之外進行呼叫。
Go 的創建者之一也是 UTF-8 的創建者,因此,Go 可以直接處理多國語言,只要你確定編輯器編碼為 UTF-8 就可以了,如果你使用 vim,可以在 vim 的命令模式下輸入 :set encoding=utf-8,或者是在 .vimrc 之中增加一行 set encoding=utf-8。
Go 可以用直譯的方式來執行程式,第一個 Hello, World 程式就是這麼做的,執行 go run 指定你的原始碼檔名就可以了:
$ go run main.go
Hello, World
哈囉!世界!
package 與 GOPATH
以下示範的是傳統 GOPATH 目錄配置(src/、pkg/、bin/)。在 Go 1.26 的新專案中,通常不需要手動建立這種結構,也不需要把專案放在 GOPATH 內,改用模組即可。
那麼,一開始的 package 是怎麼回事?試著先來建立一個 hello.go:
package hello
import "fmt"
func HelloWorld() {
fmt.Println("Hello, World")
}
記得,package 中定義的函式,名稱必須是以大寫開頭,其他套件外的程式,才能進行呼叫,若函式名稱是小寫,那麼會是套件中才可以使用的函式。
接著,原本的 main.go 修改為:
package main
import "hello"
func main() {
hello.HelloWorld()
}
現在顯然地,main.go 中要用到方才建立的 hello 套件中的 HelloWorld 函式,這時 package 的設定就會發揮一下效用,你得將 hello.go 移到 src/hello 目錄之中,也就是目錄名稱必須符合 package 設定之名稱。
同樣地,你可以將 main.go 移到 src/main 目錄之中,以符合 package 的設定。
而 src 的位置,必須是在 GOROOT 或者是 GOPATH 的路徑中可以找到,當 Go 需要某套件中的元素時,會分別到這兩個環境變數的目錄之中,查看 src 中是否有相應於套件的原始碼存在。
為了方便,通常會設定 GOPATH,例如,指向目前的工作目錄:
set GOPATH=c:\workspace\go-exercise
如果沒有設定 GOPATH 的話,Go 預設會是使用者目錄的 go 目錄,雖然目前 GOPATH 中只一個目錄,不過 GOPATH 中可以設定數個目錄,現在我的 go-exercise 目錄底下會有這些東西:
go-exercise
└─src
├─hello
│ hello.go
│
└─main
main.go
接著在 go 目錄中執行指令 go run src/main/main.go 的話,你就會看到 Hello, World 了。
go build
如果想編譯原始碼為可執行檔,那麼可以使用 go build,例如,直接在 go 目錄中執行 go build src/main/main.go,就會在執行指令的目錄下,產生一個名稱為 main.exe 的可執行檔,可執行檔的名稱是來自己指定的原始碼檔案主檔名,執行產生出來的可執行檔就會顯示 Hello, World。
你也可以建立一個 bin 目錄,然後執行 go build -o bin/main.exe src/main/main.go,這樣產生出來的可執行檔,就會被放在 bin 底下。
go install
每次使用 go build,都是從原始碼編譯為可執行檔,這比較沒有效率,如果想要編譯時更有效率一些,可以使用 go install,例如,在目前既有的目錄與原始碼架構之下,於 go 目錄中執行 go install hello 的話,你就會發現有以下的內容:
go-exercise
├─bin
│ main.exe
│
├─pkg
│ └─windows_amd64
│ hello.a
│
└─src
├─hello
│ hello.go
│
└─main
main.go
go install packageName 表示要安裝指定名稱的套件,如果是 main 套件,那麼會在 bin 中產生可執行檔,如果是公用套件,那麼會在 pkg 目錄的 $GOOS_$GOARCH 目錄中產生 .a 檔案,你可以使用 go env 來查看 Go 使用到的環境變數,例如:
(補充:上面這段是以傳統 GOPATH 工作模式來理解;在現代模組模式下,編譯快取主要在 GOCACHE,模組原始碼快取在 GOMODCACHE,不一定會看到同樣的 pkg/$GOOS_$GOARCH/*.a 使用方式。)
set GO111MODULE=
set GOARCH=amd64
set GOBIN=
set GOCACHE=C:\Users\Justin\AppData\Local\go-build
set GOENV=C:\Users\Justin\AppData\Roaming\go\env
set GOEXE=.exe
set GOFLAGS=
set GOHOSTARCH=amd64
set GOHOSTOS=windows
set GONOPROXY=
set GONOSUMDB=
set GOOS=windows
set GOPATH=C:\Users\Justin\go
set GOPRIVATE=
set GOPROXY=https://proxy.golang.org,direct
set GOROOT=C:\Winware\Go
set GOSUMDB=sum.golang.org
set GOTMPDIR=
set GOTOOLDIR=C:\Winware\Go\pkg\tool\windows_amd64
set GCCGO=gccgo
set AR=ar
set CC=gcc
set CXX=g++
set CGO_ENABLED=1
set GOMOD=
set CGO_CFLAGS=-g -O2
set CGO_CPPFLAGS=
set CGO_CXXFLAGS=-g -O2
set CGO_FFLAGS=-g -O2
set CGO_LDFLAGS=-g -O2
set PKG_CONFIG=pkg-config
set GOGCCFLAGS=-m64 -mthreads -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=C:\Users\Justin\AppData\Local\Temp\go-build282125542=/tmp/go-build -gno-record-gcc-switches
.a 檔案是編譯過後的套件,因此,你看到的 hello.a,就是 hello.go 編譯之後的結果,如果編譯時需要某個套件,而對應的 .a 檔案存在,且原始碼自上次編譯後未曾經過修改,那麼就會直接使用 .a 檔案,而不是從原始碼開始編譯起。
os.Args
那麼,如果想在執行 Go 程式時使用命令列引數呢?可以使用 os 套件的 Args,例如,寫一個 main.go:
package main
import "os"
import "fmt"
func main() {
fmt.Printf("Command: %s\n", os.Args[0])
fmt.Printf("Hello, %s\n", os.Args[1])
}
os.Args 是個陣列,索引從 0 開始,索引 0 會是編譯後的可執行檔名稱,索引 1 開始會是你提供的引數,例如,在執行過 go build 或 go install 之後,如下直接執行編譯出來的執行檔,會產生的訊息是…
$ ./bin/main Justin
Command: ./bin/main
Hello, Justin
go doc
fmt 的 Printf,就像是 C 的 printf,可用的格式控制可參考 Package fmt 的說明。實際上,Go 本身附帶了說明文件,可以執行 go doc <pkg> <sym>[.<method>] 來查詢說明。例如:
$ go doc fmt.Printf
func Printf(format string, a ...interface{}) (n int, err error)
Printf formats according to a format specifier and writes to standard
output. It returns the number of bytes written and any write error
encountered.
本章主要是早期 GOPATH 時代的套件管理方式(歷史脈絡)。在 Go 1.26 的新專案中,通常會優先使用 Go 模組(go mod init、go mod tidy),可搭配〈模組入門〉閱讀。
在〈來個 Hello, World〉中,你已經看到 Go 開發中,一個 workspace 的基本樣貌,你可以看到,裏頭會有 src、pkg、bin 目錄,你會設置 GOPATH 環境變數指向這個目錄,這些都是當時的規範,正如〈How to Write Go Code〉中說到的:
The go tool is designed to work with open source code maintained in public repositories. Although you don't need to publish your code, the model for how the environment is set up works the same whether you do or not.
在〈來個 Hello, World〉已經稍微瞭解了 package 與 GOPATH 的關係,原始碼會是在 GOPATH 中設定的目錄之 src 中,並有著對照於 package 設定名稱之目錄包括著它,當 Go 的工具(go build、go install 等)需要原始碼時,會到 GOROOT 底下,或者是 GOPATH 底下,查看是否有相應於套件的原始碼存在,編譯出來的結果,會是在相對應的 pkg 或 bin 底下。
本地套件
在當時,為了簡化說明,原始碼主檔名故意與 package 設定的名稱同名,這不是必要的,一個相應於 package 的目錄底下,可以有許多個原始碼,而每個原始碼開頭,只要 package 設定的名稱都與目錄相符就可以了。例如,你可以有個原始碼是 hello.go,位於 src/goexample 底下:
package goexample
import "fmt"
func Hello() {
fmt.Println("Hello")
}
還可以有個 hi.go,位於 src/goexample 底下:
package goexample
import "fmt"
func Hi() {
fmt.Println("Hi")
}
也就是說,一個 package 可以有數個原始碼檔案,各自組織自己的任務,在執行 go install goexample 之後,上面兩個原始碼會在 pkg 目錄的 $GOOS_$GOARCH 目錄中產生 goexample.a 檔案。這包括了 goexample 套件編譯後的結果,如果想使用 goexample 套件的功能,只需要撰寫個 main.go:
package main
import "goexample"
func main() {
goexample.Hi()
goexample.Hello()
}
你可以在套件目錄之前增加父目錄,例如,可以建立一個 src/cc/openhome 目錄,然後將方才的 hello.go 與 hi.go 移至該目錄之中,接著執行 go install cc/openhome/goexample,那麼,在 pkg 目錄的 $GOOS_$GOARCH 目錄中,會產生對應的 cc/openhome 目錄,其中放置著 goexample.a 檔案,想要使用這個套件的話,可以撰寫個 main.go:
package main
import "cc/openhome/goexample"
func main() {
goexample.Hi()
goexample.Hello()
}
遠端套件
由於 Go 的 workspace 設置,都必須是如此規範,因此,若你想將原始碼發佈給他人使用時就很方便,例如,你可以建立 src/github.com/JustinSDK 目錄,然後將方才的 goexample 目錄移到 src/github.com/JustinSDK 當中,這麼一來,顯然地,你的 main.go 就要改成:
package main
import "github.com/JustinSDK/goexample"
func main() {
goexample.Hi()
goexample.Hello()
}
也就是說,你可以直接將 /src/github.com/JustinSDK/goexample 當作檔案庫(repository)發佈到 Github,那麼,其他人需要你的原始碼時,在當時常會使用 go get 指令。我將這個範例發佈在 Github 的 JustinSDK/goexample 了,因此,你可以執行以下指令:
go get github.com/JustinSDK/goexample
go get 會自行判斷該使用的協定,以這邊的例子來說,就會使用 git 來複製檔案庫至 src 目錄底下,結果就是 src/github.com/JustinSDK 底下,會有個 goexample 目錄,其中就是原始碼,go get 在下載原始碼之後,就會開始進行編譯,因此,你也會在 pkg 目錄中的 $GOOS_$GOARCH 目錄底下,github.com/JustinSDK 中找到編譯好的 .a 檔案。
補充(Go 1.26 現況):在模組模式下,go get 主要用於調整目前模組的依賴版本;若是安裝命令列工具,請改用 go install module/path/cmd@version(例如 @latest)。
接著,你就可以如上頭的程式撰寫 import "github.com/JustinSDK/goexample" 來使用這個套件。
當然,執行 go install main 的話,你的 pkg 目錄中的 $GOOS_$GOARCH 目錄,會有個 github.com/JustinSDK 目錄,裏頭放置著 goexample.a 檔案,而編譯出來的可執行檔,則會放置在 bin 目錄之中,此時,你的目錄應該會像是:
go-exercise
├─bin
│ main.exe
│
├─pkg
│ └─windows_amd64
│ └─github.com
│ └─JustinSDK
│ goexample.a
│
└─src
├─github.com
│ └─JustinSDK
│ └─goexample
│ .gitignore
│ hello.go
│ hi.go
│ LICENSE
│ README.md
│
└─main
main.go
GOPATH 中多個路徑
如果你在 GOPATH 中設定多個路徑,那麼,在哪個路徑底下的 src 找到套件的原始碼,編譯出來的 .a 檔案就會放在哪個路徑底下的 pkg 目錄之中。
如果是包括程式進入點的 main 套件,那麼執行 go install main 的話,預設會放在找到 main 套件原始碼的 bin 目錄之中。你可以設定 GOBIN,指定編譯出來的可執行檔放置的目錄。
如果你在 GOPATH 中設定多個路徑,那麼,go get 複製回來的原始碼,會被放置在 GOPATH 中設置的第一個目錄 src 之中,同理,對應的 .a 檔案,也會是 GOPATH 中設置的第一個目錄的 pkg 之中。
有關 import
在 import 時預設會使用套件名稱作為呼叫套件中函式等的前置名稱,你可以在 import 時指定別名。例如:
package main
import f "fmt"
func main() {
f.Println("哈囉!世界!")
}
若指定別名時使用 .,就不需要套件名稱作為前置名稱,例如:
package main
import . "fmt"
func main() {
Println("哈囉!世界!")
}
你不能只是 import x "x" 來試圖只執行套件的初始函式,因為 Go 編譯器不允許 import 了某個套件而不使用,然而若指定別名時使用 _,則不會導入套件,只會執行套件的初始函式,也就是套件中使用 func init() 定義的函式。
每個套件可以有多個 init 定義在各個不同的原始檔案中,套件被 import 時會執行,若是 main 套件,則會在所有 init 函式執行完畢後,再執行 main 函式,Go 執行套件初始化時,不會保證套件中多個 init 的執行順序。
如果你是個有點責任感的開發者,在新接觸一門語言的時候,應該會問一個問題:「我該用什麼格式寫程式?」所以了,在 Go 裏要用什麼格式寫程式?這個問題可以直接請 gofmt 來幫你解答。
使用 gofmt
使用 gofmt 最簡單的方式之一,就是直接執行 gofmt,這會接受你在標準輸入(Standard input)鍵入的的程式碼,輸入完成後按下 Ctrl + Z,gofmt 就會告訴你怎麼要用什麼格式,例如,來個 Hello, World:
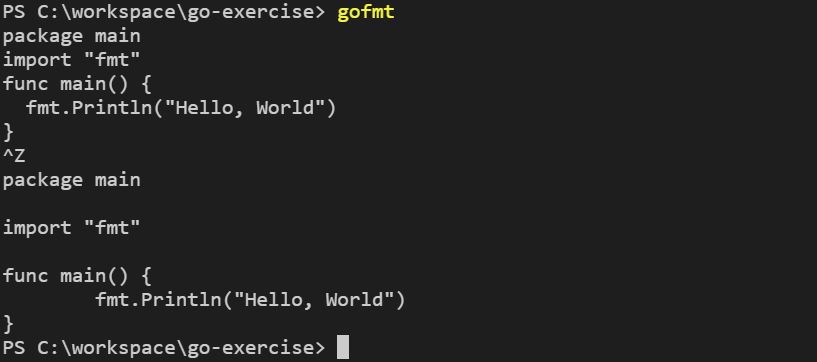
在上頭的例子中,我故意製作了一些其他的格式慣例,而從輸出中可以看到 gofmt 建議的格式會是什麼樣子,例如,Go 建議的格式是使用 Tab 縮排,你鍵入的程式碼不用是完整的程式,也可以只是個陳述句,例如:

你也可以指定檔案,格式化後的結果會輸出至標準輸出(Standard output),或者是一個目錄,這會遞迴地將其中的 .go 檔案讀入並格式化後,輸出至標準輸出,也可以加上 -w 指定以格式化後的結果重寫原有的 .go 文件。
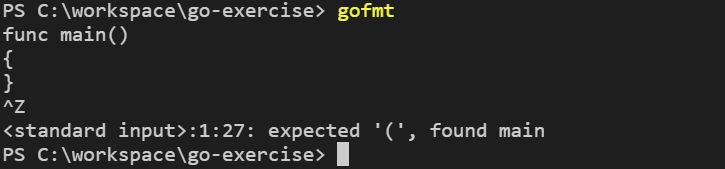
有些格式在 Go 中是強制的,例如,大括號 {} 必須是右上左下的形式,因此,如果你將大括號置於同一側,執行 gofmt 就會得到錯誤訊息:
gofmt 簡單重構
gofmt 也可以使用 -r 指定規則來實現簡單的重構,例如在〈Command gofmt〉文件說明中,有個 gofmt -r '(a) -> a' -l *.go 可以列出 .go 檔案中有多餘括號的檔案名稱(透過 -l 引數來列出名稱),要直接移除 .go 檔案中多餘的括號並重寫原有的 .go 檔案,可以使用 gofmt -r '(a) -> a' -w *.go。
-r 接受的規則是 pattern -> replacement,其中 pattern 與 replacement 必須是合法的 Go 語法,而單一、小寫的字元會被作為萬用字元(Wildcard),因此,如果有個原始碼內容是:
package goexample
func Hello(who string) {
var helloWho = ("Hello, ") + (who)
}
執行過後,會產生以下的結果:
package goexample
func Hello(who string) {
var helloWho = "Hello, " + who
}
再來看個無聊的例子,如果你的程式碼是:
package goexample
func Hello(who string) {
var helloWho = who + "Hello, "
}
若你想要 gofmt 幫你改成:
package goexample
func Hello(who string) {
var helloWho = "Hello, " + who
}
你可以執行 gofmt -r 'a + "Hello, " -> "Hello, " + a' -w *.go,甚至 gofmt -r 'a + b -> b + a' -w 來達到這個目的。
gofmt 還有個 -s 引數,可以嘗試為你簡化原始碼,你可以看看〈Command gofmt〉文件中的說明,瞭解它會做哪些簡化,文件中也談到,簡化後的 Go 原始碼,可能會與舊版的 Go 不相容。
至於方才提及的 goimports,在 Go 1.18+ / 1.26 的常見做法是使用 go install 搭配版本號來安裝,例如:
go install golang.org/x/tools/cmd/goimports@latest
go fmt
go 本身也可以附帶 fmt,也就是使用 go fmt 的方式來進行程式碼的格式化,go fmt 內部使用 gofmt,可以使用 -n 來顯示要被使用或已被使用的指令:
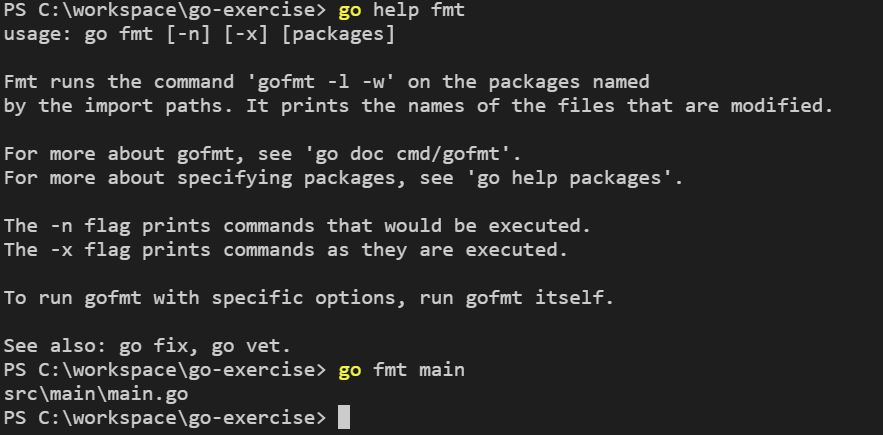
可以看到,go fmt 包裝了 gofmt -l -w 指令,簡化了常用的指令輸入,你只要指定套件就可以了。
如果你想查詢套件、函式等的說明,可以使用 go doc 指令。
查詢文件
如果你想要查詢套件的文件說明,可以使用 go doc packageName,例如 go doc fmt 可查詢 fmt 套件的說明,
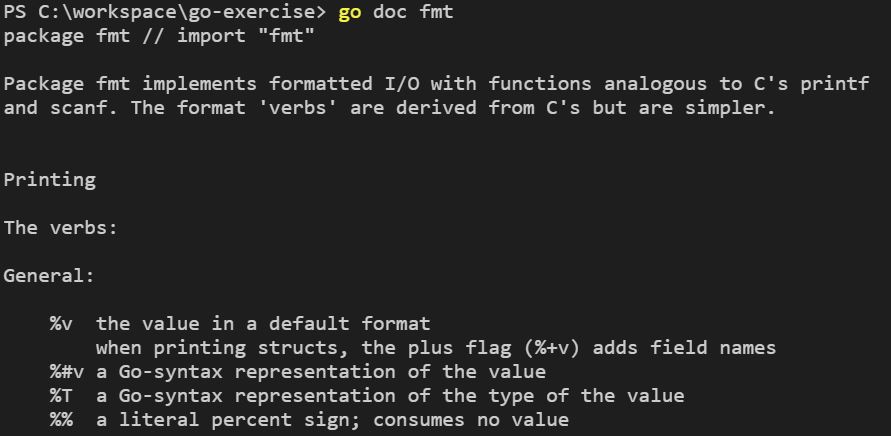
可以看到,這顯示了整個套件的說明,通常我們會想要查詢套件中某個函式,這可以使用 go doc packageName.funcName,例如,查詢 fmt 中的 Println,可以使用 go doc fmt.Println:
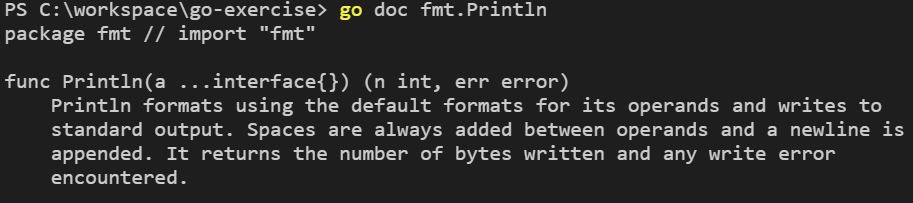
你也可以加上 -src 來查詢原始碼,雖然整個套件也可以查詢,不過我想,這直接開 Go 目錄的 src 中原始碼來看比較快,或許加上 -src 的機會,會是在查詢函式的原始碼時比較多:
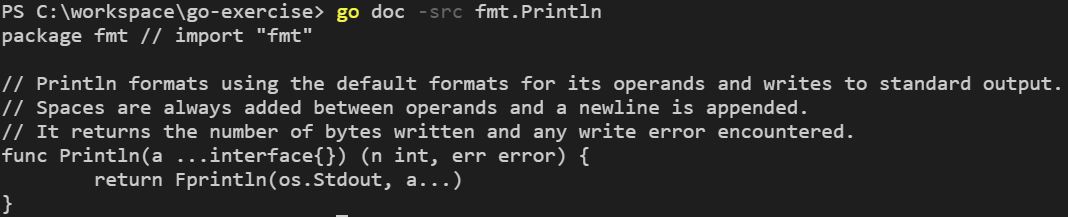
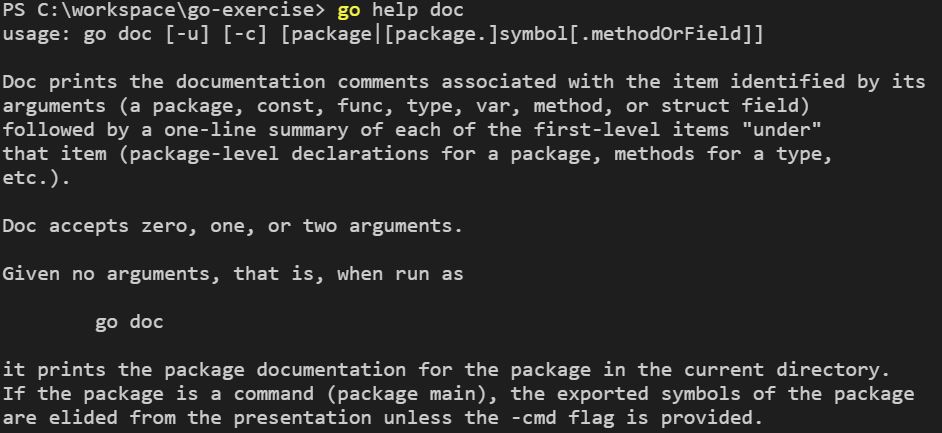
如同 go xxx 的指令說明,想要得到 go doc 的說明,可以使用 go help doc 指令。
註解即文件
實際上,go doc 的文件說明來自於原始碼中的註解,這樣的概念有點類似 Java 的 JavaDoc,或者是 Python 的 DocString,不過 Go 的理念是讓它更簡單,不使用特殊標記,不使用特別的格式,希望可以在沒有 go doc 的場合中,也可以藉由閱讀原始碼中的註解,輕易地得到文件說明。
當然,基本上還是要有一些約定,例如,在函式之前,緊接著函式的註解,中間沒有空白行,就是函式的文件說明來源。
類似地,在套件之前,緊接著套件的註解,就是套件的文件說明來源,通常,一個套件的文件說明,會是來自於套件中,一個 doc.go 中 package 宣告前的註解,例如,你可以在 fmt 的原始碼目錄 中,找到一個 doc.go,其中除了 package fmt 之外,沒有任何原始碼,剩下的只有註解。
除了函式、套件之外,最頂層的型態宣告、變數、常數等前緊接著的註解,都可以是文件的來源,不相鄰的註解則會被 godoc 忽略,如果有已知的 Bug,可以使用 BUG() 標示,例如 bytes.go 中有個:
// BUG(rsc): The rule Title uses for word boundaries does not handle Unicode punctuation properly.
func Title(s []byte) []byte {
....
這會出現在文件的 Bugs 區段。
如果你想要從註解產生 HTML 文件(使用 -html 引數),那麼有幾個簡單的規則(用過 Markdown 的應該感覺有點熟悉),參考一下 Go 的原始碼,應該能很快地掌握。
基本上,go doc 會在 GOROOT 與 GOPATH 中的原始碼查詢註解作為文件,如果想改變查詢時的 Go 目錄,可以使用 -goroot 指定。
有關註解與文件間的關係,也可以進一步參考 Effective Go 的 Commentary。
godoc 文件伺服器
Go 1.2rc1 之後,曾經從 go doc 改用 godoc 指令了,不過,從 Go 1.5 Release Notes 中看到,Go 1.5 有個新的 go doc 指令,專門用於命令列模式下的文件查詢,這使得 godoc 主要剩下文件服器的功能,因而在 Go 1.13 中,godoc 被移除。
如果在一個網路受限的環境,又想要在網頁上查詢文件,還是可以安裝 godoc(來自 x/tools):
go install golang.org/x/tools/cmd/godoc@latest
這時執行安裝後的 godoc,並附帶一個 -http 引數指定連接埠,例如,godoc -http=:6060,這會在本機啟動一個 HTTP 伺服器,使用瀏覽器連接 http://localhost:6060(或 http://主機IP:6060)就可以查詢文件:
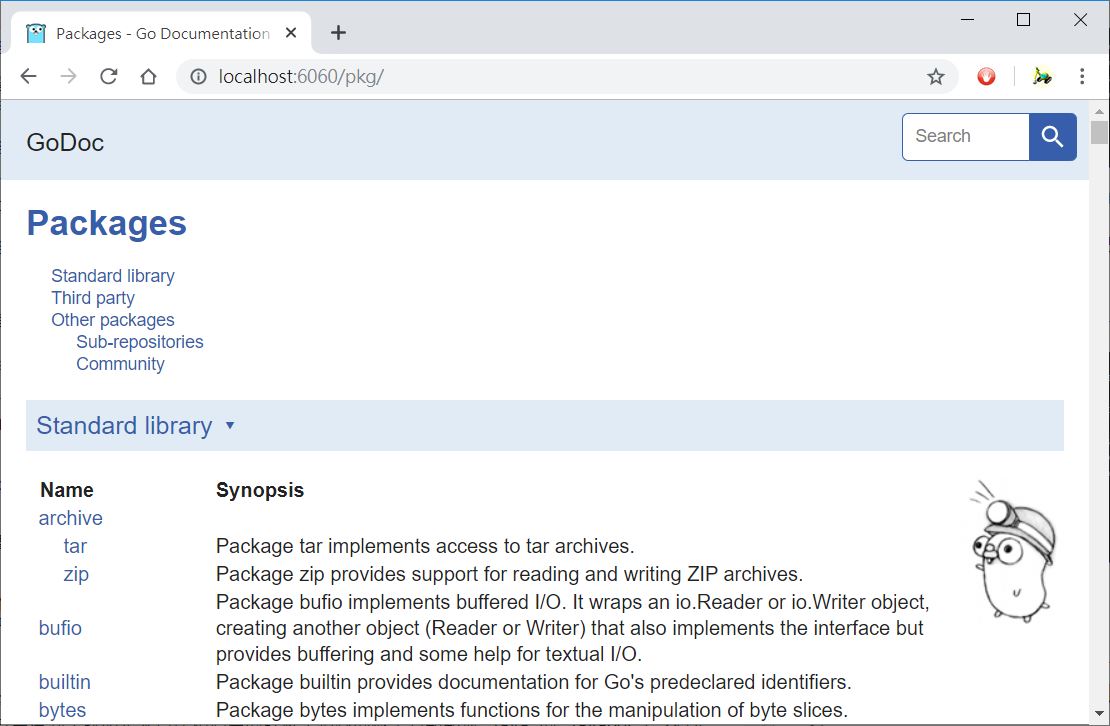
Go 本身附帶了 testing 套件,搭配 go test 指令,可以自動對套件中的程式碼進行測試,在套件中,測試程式碼必須是 _test.go 結尾,一個套件中可以有多個 _test.go,例如,fmt 套件的原始碼 中,可以看到 export_test.go、fmt_test.go 等,就是測試程式碼。
功能測試
想要使用 Go 的 testing 套件撰寫測試程式碼,必須 import "testing",在 _test.go 中撰寫形式 func TestXxx(t *testing.T) 的函式,Xxx 可以是任意名稱,例如,在 src/mymath 目錄中,寫個 basic_test.go:
package mymath
import "testing"
func TestSomething(t *testing.T) {
// write some test
}
接著只要執行 go test mymath,就會自動尋找 mymath 套件中的 _test.go 中 Test 開頭的函式並執行,由於目前沒撰寫任何測試內容,測試是以 PASS 結束。

如果函式中使用了 testing 的 Error、Fail 等與失敗相關的方法,那麼測試就會失敗,例如:
package mymath
import "testing"
func TestSomething(t *testing.T) {
t.Fail()
}

如果想要在測試失敗時,留下一些訊息,可以使用 Error 方法,例如:
package mymath
import "testing"
func TestSomething(t *testing.T) {
t.Error("something wrong")
}
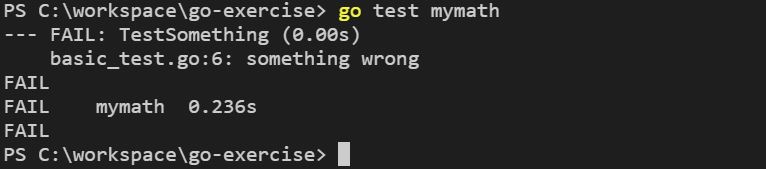
來實際寫個測試,例如,測試一個 Add 函式:
package mymath
import "testing"
func TestAdd(t *testing.T) {
if Add(1, 2) == 3 {
t.Log("mymath.Add PASS")
} else {
t.Error("mymath.Add FAIL")
}
}
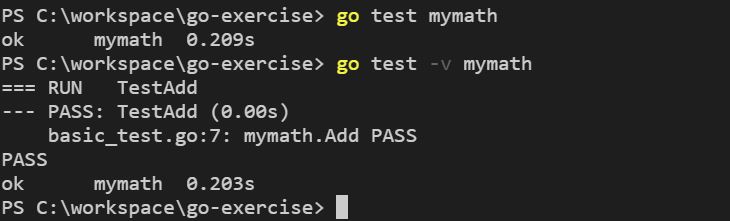
由於目前還沒有撰寫 Add 函式,因此若執行 go test mymath 的話,會以 [build failed] 收場,如果在 basic.go 撰寫了正確的 Add 函式:
package mymath
func Add(a, b int) int {
return a + b
}
不過,如果直接執行 go test mymath 的話,只會顯示 ok 等字眼,不會顯示 Log 的訊息,想看到 Log 的訊息的話,必須加上 -v 引數(代表 verbose),例如:
如果 Log 之後接上 Fail 函式,那麼不加上 -v,也會顯示 Log 的訊息,實際上,Error 函式就是相當於先以 Log 顯示指定的訊息,然後再接上 Fail 函式。
如果想要略過測試,那麼可以使用 Skip 函式,例如:
package mymath
import "testing"
func TestSomething(t *testing.T) {
t.Skip()
}
func TestAdd(t *testing.T) {
if Add(1, 2) == 3 {
t.Log("mymath.Add PASS")
} else {
t.Error("mymath.Add FAIL")
}
}
TestSomething 中如果沒有執行 Skip 會是兩個 PASS 的測試結果,若如上執行了 Skip,會是一個 SKIP 與一個 PASS 的測試結果。例如:
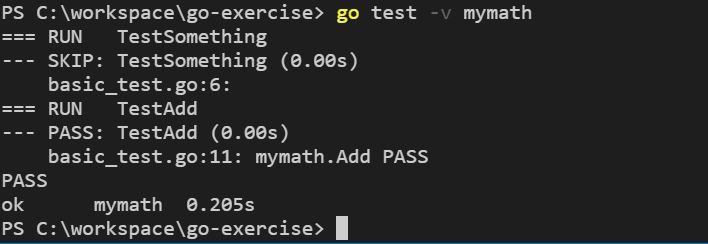
如果你想指定某個測試,可以使用 -run 引數,這接受一個正則表示式,例如,若只想執行 TestAdd,那麼可以如下:
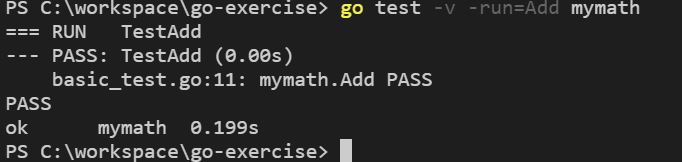
效能評測
如果想進行效能評測(Benchmark),那麼 _test.go 中,評測函式必須是 func BenchmarkXxx(b *testing.B) 形式,例如:
package mymath
import "testing"
func TestSomething(t *testing.T) {
t.Skip()
}
func TestAdd(t *testing.T) {
if Add(1, 2) == 3 {
t.Log("mymath.Add PASS")
} else {
t.Error("mymath.Add FAIL")
}
}
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
Add(1, 2)
}
}
為了進行評測,被測試的函式要執行多次,以求得每次執行的平均時間,要執行多次函式可以使用迴圈,並以 b.N 作為邊界,b.N 目標預設是 1000000000,評測預設會在一秒內,以越來越大的 b.N 執行迴圈,這是為了讓評測進入穩定狀態,以收集到可靠的評測資料;如果運行時間到了,b.N 目標值仍未達成,就以現有收集到的資料來回報評測結果。
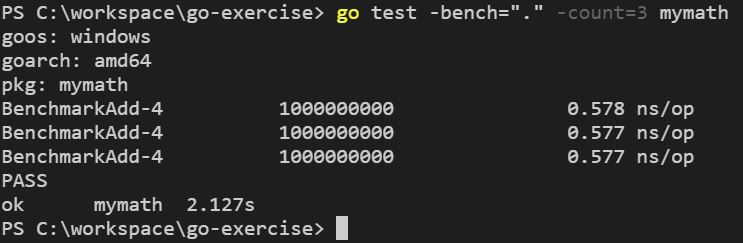
你可以在執行 go test 時,加上 -bench 引數,這個引數後可以使用正則表示式,來指定符合的評測函式名稱,例如,想執行所有評測函式,可以使用 -bench=".":
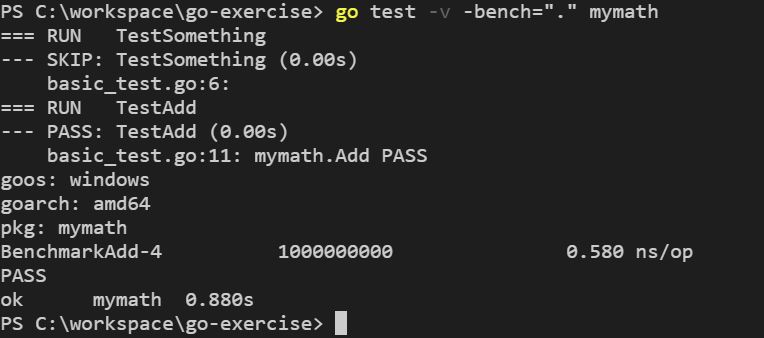
評測的結果中顯示,達到了 b.N 預設目標 100000000 次,平均每次迴圈花了 0.58 奈秒(nanosecond)。
如果只想進行效能評測,可以使用 -run 引數,這本來是用來指定要執行的測試函式,只要指定一個不符合任何測試函式的正則表示式,就可以略過所有測試,只執行評測函式了,例如:
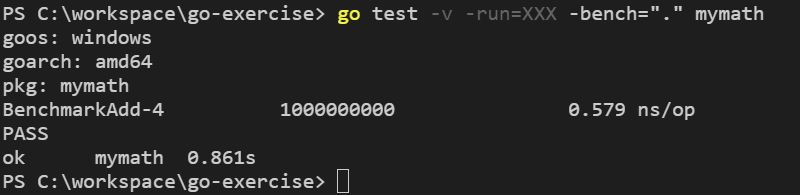
方才談到,評測預設的運行時間是一秒,如果在這個時間內,無法達到 b.N 的目標值,可以增加這個時間,這要使用 -benchtime 引數,指定的格式像是 1h30s,例如:
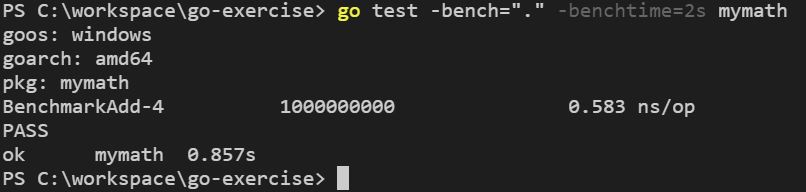
如果想固定 b.N 的值,Go 1.12 以後可以使用 x 後置,例如指定執行 100000000000 次(預設 b.N 目標的 10 倍)並收集結果:
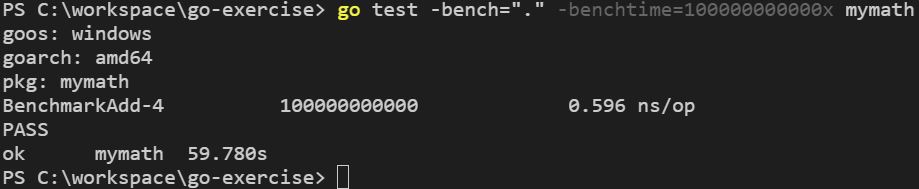
-count 可以指定評測重啟幾次:
想知道更多 Go 測試套件的細節,可以參考 Package testing 的說明。
Go 包括了一些預先定義型態(Pre-declared Type),這包括了布林、數字與字串型態。
布林型態
預定義型態也是具有名稱的型態(Named Type),布林型態名稱為 bool,只有兩個預先定義的常數 true 與 false,由於只有兩個值,因此在 Go 的規格書 中,並沒有明確提及 bool 的大小,雖然在 Go 官方網站的 The Go Playground 執行以下程式碼,會告訴你 bool 大小是 1:
package main
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(unsafe.Sizeof(true))
fmt.Println(unsafe.Sizeof(false))
}
附帶一提的是,Go 本身沒有提供 REPL 工具,不過 Go 官方網站的 The Go Playground 是個方便的介面,你也可以在 Does Go provide REPL? 找到一些其他開發者寫的 REPL。
數字型態
數字型態為整數與浮點數的集合,整數部份支援無號與有號整數,名稱分別為 uint 與 int,int 長度會與 uint 相同,而 uint 長度視平台實作而異,可能是 32 位元或是 64 位元。
如果想要長度固定,無號整數的型態名稱為 uint8、uint16、uint32、uint64,顧名思義,使用的長度分別為 8 位元、16 位元、32 位元與 64 位元,舉例來說,uint8 可儲存的整數範圍為 0 到 255,這也是開發者熟悉的位元組型態,而在 Go 中,byte 正是 uint8 的別名。
有號整數的型態名稱為 int8、int16、int32、int64,顧名思義,使用的長度分別為 8 位元、16 位元、32 位元與 64 位元,舉例來說,int32 可儲存的整數範圍為 -2147483648 到 2147483647,而 rune 為 int32 的別名,可用來儲存 Unicode 碼點(code point)。
如果直接寫下一個整數實字(literal),例如 10,在沒有程式上下文(context)的情況下,10 是未定型態(Untyped),未定義型態整數的預設型態(Default type)為 int 型態,在必須得到一個型態而程式上下文未提供時(例如變數宣告與賦值要進行型態推斷時),就會使用預設型態。
寫下 10 這樣的整數,預設是 10 進位制;可以在數字前加上 0,Go 1.13 後可使用 0o 來表示八進位制,加上 0x 表示 16 進位制,此時 a-f and A-F 都可以用來表示 10 到 15,例如 0xBadFace,Go 1.13 後可以使用 0x1.0p-1021 來表示浮點數。
Go 1.13 後,可以使用 0b 來定義二進位數字,例如 0b00101101;數字分隔底線在 Go 1.13 後可以使用,例如 1_000_000、0b_1010_0110 或 3.1415_9265。
math 模組上定義了一些常數,可以讓你得知各整數型態的儲存範圍,例如以下程式顯示了各整數型態的儲存範圍:
package main
import (
"fmt"
"math"
"reflect"
)
func main() {
fmt.Printf("uint8 : 0 ~ %d\n", math.MaxUint8)
fmt.Printf("uint16 : 0 ~ %d\n", math.MaxUint16)
fmt.Printf("uint32 : 0 ~ %d\n", math.MaxUint32)
fmt.Printf("uint64 : 0 ~ %d\n", uint64(math.MaxUint64))
fmt.Printf("int8 : %d ~ %d\n", math.MinInt8, math.MaxInt8)
fmt.Printf("int16 : %d ~ %d\n", math.MinInt16, math.MaxInt16)
fmt.Printf("int32 : %d ~ %d\n", math.MinInt32, math.MaxInt32)
fmt.Printf("int64 : %d ~ %d\n", math.MinInt64, math.MaxInt64)
fmt.Printf("整數預設型態: %s\n", reflect.TypeOf(1))
}
執行結果如下:
uint8 : 0 ~ 255
uint16 : 0 ~ 65535
uint32 : 0 ~ 4294967295
uint64 : 0 ~ 18446744073709551615
int8 : -128 ~ 127
int16 : -32768 ~ 32767
int32 : -2147483648 ~ 2147483647
int64 : -9223372036854775808 ~ 9223372036854775807
整數預設型態: int
注意到,程式中使用了 uint64 函式,對 math 的一些常數做了明確的型態轉換(Type conversion),這是因為在 Go 中,常數可以是未定型態(Untyped),實際型態會視當時程式環境而定,如果沒有可參考的環境資訊,會使用預設型態。
在這邊的例子中,若是拿掉 uint64,math.MaxUint64 就會採用 int 型態而發生 overflow 的錯誤,使用 uint64 函式進行型態轉換,讓常數有明確的環境資訊可以參考,就不會產生這個錯誤。
在 Go 中,不同型態之間也無法直接進行運算,就算都是整數也不行,例如以下會發生 mismatched types 錯誤:
package main
import "fmt"
func main() {
var x int32 = 10
var y int16 = 20
fmt.Println(x + y) // mismatched types error
}
想要避免錯誤,你必須明確進行型態轉換,例如寫為 x + int32(y)(或者是 int16(x) + y)。那麼,下面這個會不會發生錯誤呢?
package main
import "fmt"
func main() {
var x int8 = 10
fmt.Println(x + 20)
}
不會!結果會顯示 30,為什麼?正如先前談過,寫下 20 這個整數,它是未定型態,根據 x + 20,進行 int8 的運算,所以不會發生錯誤,不這樣的話,每次都得寫 x + int8(20),實在就夠煩的了!
在 Go 中並沒有字元對應的型態,只有碼點的概念,int32 或其別名 rune 可用來儲存 Unicode 碼點,你可以將單一文字包在單引號之中,例如 '林',這會以 int32 儲存為 26519,例如 fmt.Println('林') 會顯示 26519,若想顯示為文字,則要使用 fmt.Println(string('林'))。
浮點數的名稱為 float32、float64,分別為 IEEE-754 32 位元與 64 位元浮點數,如果直接寫下一個浮點數實字,預設型態是 float64 型態,可使用科學記號,例如 1.e+0、6.67428e-11 等,常數 math.MaxFloat32、math.MaxFloat64 分別代表著浮點數的最大儲存範圍。
Go 還有複數(Complex number),其中 complex64、complex128,可由一個實部數字,加上一個虛部數字與 i 來表示複數,例如 1 + 2i,寫下一個複數實字,預設型態為 complex128,虛數的部份,在 Go 1.13 後,之前談到的數字表示法都可以使用,有三個函式可以用來處理複數,即 complex、real 與 imag,可參考〈Manipulating complex numbers〉。
Go 還有個 uintptr,可以用來儲存指標值,這之後有機會再來談。
字串型態
Go 的字串在實作上使用 UTF-8,就目前必須先知道的是,當使用雙引號包裹一系列文字,會產生字串型態,預設型態為 string,例如,"Justin" 會建立一個字串。
如果對字串使用 len 函式,傳回的會是位元組數量,而不是 Unicode 碼點的數量;如果使用 [] 搭配索引,取得特定索引位置的值,那麼傳回的會是 byte(uint8)型態。
在 Go 中,可以對字串使用切片(slice)操作,傳回的型態會是 string 型態,例如,"Justin"[0:2] 會傳回字串 "Ju",不過,這是取得索引 0、1 處的位元組,再建立 string 傳回,因此,對於 "語言" 這個字串,如果想用切片操作取得 "語" 這個子字串,必須使用 "語言"[0:3],因為 Go 的字串在實作上使用 UTF-8,一個中文字基本上佔三個位元組。
Go 的字串還有許多值得說明的細節,這之後會再做詳細討論。
變數(Variable)是儲存值的位置,變數宣告可以給予識別名稱(Identifier)、型態與初始值,在 Go 中寫下的 10、3.14、true、"Justin" 等稱之為常數(Constant),常數宣告可給予這些常數識別名稱。
基本變數宣告
要在 Go 中進行變數宣告有多種形式,使用 var 是最基本的方式。例如,宣告一個 x 變數,型態為 int,初始值為 10:
var x int = 10
這麼一來,從 x 這個位置開始,儲存了 int 長度的值 10,在宣告變數時,型態是寫在名稱之後。你也可以同時建立多個變數並指定初值:
var x, y, z int = 10, 20, 30
這樣的話,x、y、z 的型態都是 int,值分別是 10、20、30。如果宣告多個變數時,想要指定不同的型態,可以使用批量宣告:
var (
x int = 10
y string = "Justin"
z bool = true
)
如果宣告變數時指定了型態,但未指定初值,那麼編輯器會提供預設初值,例如:
var (
a bool
b int32
c float32
d string
e complex128
)
在上面的宣告中,a、b、c、d、e 的值分別會是 false、0、0.0、"" 與 0 + 0i。在 Go 中,宣告了變數,程式中卻沒有取用的動作,那麼會發生 declared and not used 的編譯錯誤。
自動推斷型態
在 Go 中宣告變數並指定值時,可以不用提供型態,由編譯器自動推斷型態,例如:
var x = 10
上頭的 x 型態會是 int,而底下的宣告:
var x, y, z = 10, 3.14, "Justin"
x、y、z 的型態分別會是 int、float64 與 string,批量宣告時也可以自動推斷型態,例如:
var (
x = 10 // int 型態
y = 3.14 // float64 型態
z = "Justin" // string 型態
)
短變數宣告
在函式中,想要定義變數值的場合,可以使用短變數宣告,例如:
x := 10
y := 3.14
z := "Justin"
如果 x 是首次定義,就等於是宣告變數並指定值。上例也可以寫成一行:
x, y, z := 10, 3.14, "Justin"
由於 Go 的函式外,每個語法都必須以關鍵字開始,因此短變數宣告不能在函式外使用。
var 宣告的變數名稱不可重複,然而,短變數宣告時,若同一行內有新宣告了另一變數,就可以重複宣告已存在的變數,例如,以下是合法的,因為使用 := 時有一個新的 y 變數:
var x = 10
x, y := 20, 30
此時,並沒有建立一個新的 x 變數,只是將新值指定給 x 而已。
由於短變數宣告可以同時宣告變數並指定值,因此對於底下這類需求:
package main
import "fmt"
func main() {
var x = true
if x {
fmt.Println(x)
}
}
在上例,x 的範圍是整個 main,若改為底下,範圍就只會是 if 區塊:
package main
import "fmt"
func main() {
if x := true; x {
fmt.Println(x)
}
}
類似地,for 之類的語法,也常運用短變數宣告。
(在數學上 A := B 的寫法,涵義是藉由 B 來定義 A,例如數學上若已經定義 x 以及 f(x),x := f(x) 表示用舊的 x 定義新的 x,這反而像是程式語言中的 x = f(x) 指定的概念,當然,數學上的符號與程式語言中的符號是有出入的,Go 在這邊只是借用了 := 來作為另一種變數宣告符號。)
調換變數值
在 Go 中,要調換兩變數的值很簡單,例如底下的程式執行過後,x 會是 20,而 y 會是 10:
var x = 10
var y = 20
x, y = y, x
基本常數宣告
如一開始談到的,在 Go 中寫下的 10、3.14、true、"Justin" 等稱之為常數(Constant),常數宣告可給予這些常數識別名稱,要給予名稱時使用的是 const 關鍵字,例如:
const x = 10
正如〈認識預定義型態〉中談過的,10 會是一個整數常數,不過型態未定,如果要定義一個常數的型態,可以使用 int32()、int64() 之類的函式進行型態轉換,或者是在使用 const 宣告常數名稱時指定型態,例如:
const x int32 = 10
這邊的 10 就是 int32 型態了,注意,這邊的 x 並不是一個變數,而是一個識別名稱罷了,因此,會說 x 常數的型態是 int32,而不能說 x 變數的型態是 int32。
如果有多個常數要宣告,也可以批量宣告,例如:
const (
x = 10
y = 3.14
z = "Justin"
)
再次地,x、y、z 分別是未定型態的整數、浮點數與字串常數(而不是 int、float64、string 這三個 Go 中定義的型態),如果你想要讓他們為已定義型態的整數、浮點數與字串常數,可以在宣告時指定型態:
const (
x int = 10
y float32 = 3.14
z string = "Justin"
)
由於常數並非變數,因此,宣告了常數並不一定要用到,底下的程式不會發生錯誤:
package main
import "fmt"
func main() {
const (
x = 10
y = 3.14
z = "Justin"
)
fmt.Println(x)
fmt.Println(y)
}
常數運算式
由於常數可以是未定型態,因此一個有趣的地方就是,像 2 + 3.0、15 / 4、15 / 4.0 這樣的常數運算式,該怎麼在編譯時期決定它們的值?答案是根據運算式中的常數運算元是整數、rune(單引號括住的常數)、浮點數或複數來決定,如果運算式中包括了越後面的常數,就會用它來決定。
因此,2 + 3.0 會是未定型態的浮點數 5.0,15 / 4 會是未定型態的整數 3,然而,15 / 4.0,會是浮點數型態的 3.75,在規格書的〈Constant expressions〉中,列出了說明以及一些範例,例如:
const a = 2 + 3.0 // a == 5.0 (untyped floating-point constant)
const b = 15 / 4 // b == 3 (untyped integer constant)
const c = 15 / 4.0 // c == 3.75 (untyped floating-point constant)
const Θ float64 = 3/2 // Θ == 1.0 (type float64, 3/2 is integer division)
const Π float64 = 3/2. // Π == 1.5 (type float64, 3/2. is float division)
const d = 1 << 3.0 // d == 8 (untyped integer constant)
const e = 1.0 << 3 // e == 8 (untyped integer constant)
const f = int32(1) << 33 // illegal (constant 8589934592 overflows int32)
const g = float64(2) >> 1 // illegal (float64(2) is a typed floating-point constant)
const h = "foo" > "bar" // h == true (untyped boolean constant)
const j = true // j == true (untyped boolean constant)
const k = 'w' + 1 // k == 'x' (untyped rune constant)
const l = "hi" // l == "hi" (untyped string constant)
const m = string(k) // m == "x" (type string)
const Σ = 1 - 0.707i // (untyped complex constant)
const Δ = Σ + 2.0e-4 // (untyped complex constant)
const Φ = iota*1i - 1/1i // (untyped complex constant)
現在,應該能明白,〈認識預定義型態〉中 math.MaxInt64 若不加上 int64,何以會 overflow 的錯誤了。
附帶一提的是,在 Go 中,模組中定義的名稱若要能在模組外可見,必須是首字大寫,而對於像 math.MaxInt64 這類的公用常數,可以定義在一個 .go 檔案之中,例如 math.MaxInt64,就是定義在一個 const.go 之中。
使用 iota 列舉
如果要需要列舉一些常數時,可以使用 iota,它每遇到一次 const,就會重置為 0,若它在批量常數宣告中使用時,第一次出現時的預設值是 0,每出現一次就遞增 1,例如:
const (
x = iota // 0
y = iota // 1
z = iota // 2
)
因為 const 批量宣告時,若後面的值沒寫出,會使用前一個值設定,例如:
const (
x = 1
y // 1
z // 1
)
因此,如果是連續的列舉,只要寫一次 iota 就可以了,這表示後續的值,也都使用 iota,結果就是:
const (
x = iota // 0
y // 1
z // 2
)
其實也可以這麼寫來列舉常數,只是比較麻煩:
const x, y, z = iota, iota, iota
Go 1.20+ / 1.21+ / 1.26 補充
本章談變數、常數與型別轉換,這裡補充幾個較新的語法與內建函式。
Go 1.17 起可將 slice 轉成陣列指標,Go 1.20 起也可直接轉成陣列(長度不足時會 panic):
package main
import "fmt"
func main() {
s := []int{10, 20, 30}
ap := (*[3]int)(s) // Go 1.17+
a := [3]int(s) // Go 1.20+
ap[0] = 99
fmt.Println(s) // [99 20 30]
fmt.Println(a) // [10 20 30](a 是轉換當下的值複製)
}
Go 1.21 新增 min、max、clear 三個內建函式:
package main
import "fmt"
func main() {
nums := []int{3, 1, 2}
m := map[string]int{"a": 1, "b": 2}
fmt.Println(min(3, 1, 2)) // 1
fmt.Println(max(3, 1, 2)) // 3
clear(nums)
clear(m)
fmt.Println(nums) // [0 0 0]
fmt.Println(m) // map[]
}
Go 1.26 起,new 的運算元可以是運算式,能直接建立並初始化指標值:
package main
import "fmt"
func main() {
p := new(42)
q := new(int64(300))
fmt.Println(*p, *q) // 42 300
}
在〈認識預定義型態〉中略略談過字串,表面看來,用雙引號(")或反引號(`)括起來的文字就是字串,預設型態為 string,實際在 Go 中,字串是由唯讀的 UTF-8 編碼位元組所組成。
字串入門
先從簡單的開始,在 Go 原始碼中,如果你撰寫 "Go語言" 這麼一段文字,那麼會產生一個字串,預設型態為 string,字串是唯讀的,一旦建立,就無法改變字串內容。
使用 string 宣告變數若無指定初值,預設是空字串 "",可以使用 + 對兩個字串進行串接,由於字串是唯讀的,因此實際上串接的動作,會產生新的字串,如果想比較兩個字串的相等性,可以使用 ==、!=、<、<=、>、>= 依字典順序比較。
package main
import "fmt"
func main() {
text1 := "Go語言"
text2 := "Cool"
var text3 string
fmt.Println(text1 + text2) // Go語言Cool
fmt.Printf("%q\n", text3) // ""
fmt.Println(text1 > text2) // true
}
上面的例子中,由於使用 fmt.Println 顯示空字串時看不到什麼,因此改用 fmt.Printf,並使用 %q 來脫離無法顯示的字元。
使用 "" 時不可換行,如果你的字串想要換行,方法之一是分兩個字串,並用 + 串接。例如:
text := "Go語言" +
"Cool"
另一個方式是以重音符 ` 定義字串,例如:
package main
import "fmt"
func main() {
text := `Go語言
Cool`
fmt.Printf("%q\n", text) // "Go語言\n Cool"
}
使用 ` 定義的字串,會完全保留換行與空白,因此,在上頭你可以看到被保留的換行與空白字元,如果使用 fmt.Println(text),顯示時也會看到對應的換行與空白。使用 ` 定義的字串,也不會轉譯字元,例如:
package main
import "fmt"
func main() {
text := `Go語言\nCool`
fmt.Println(text) // Go語言\nCool
}
在這個例子中可以看到,使用 ` 時,不會對 \n 做轉譯的動作,因此,你會直接看到顯示了「Go語言\nCool」。
在 Go 中可以使用的轉譯有:
\a:U+0007,警示或響鈴\b:U+0008,倒退(backspace)\f:U+000C,饋頁(form feed)\n:U+000A,換行(newline)\r:U+000D,歸位(carriage return)\t:U+0009,水平 tab\v:U+000b,垂直 tab\\:U+005c,反斜線(backslash)\":U+0022,雙引號\ooo:位元組表示,o 為八進位數字\xhh:位元組表示,h 為十六進位數字\uhhhh:Unicode 點點表示,使用四個 16 進位數字\Uhhhhhhhh:Unicode 點點表示,使用八個 16 進位數字
唯讀位元組片段
那麼,想知道一個字串的長度該怎麼做呢?Go 中有個 len 函式,當它作用於字串時,結果可能會令一些從其他程式語言,像是 Java 過來的人感到訝異:
package main
import "fmt"
func main() {
fmt.Println(len("Go語言")) // 8
}
顯示的結果是 8 而不是 4,給個提示,Go 的字串實作使用 UTF-8,是的!len 傳回的是位元組長度,因為 Go 的字串,本質上是 UTF-8 編碼後的位元組組成,如果你使用 fmt.Printf("%x", "Go語言"),會顯示 476fe8aa9ee8a880,47 是「G」的位元組以 16 進位數字表示的結果,6f 是 o,e8aa9e 是「語」的三個位元組分別以 16 進位數字表示的結果,e8a880 是「言」。
不單是如此,Go 中可以使用 [] 與索引來取得字串的位元組資料,是的,位元組!傳回的型態是 byte(uint8),"Go語言"[0] 取得的是 G 的位元組資料,"Go語言"[1] 取得的是 o 的位元組資料,"Go語言"[2] 呢?取得的是「語」的 UTF-8 實作中,第一個位元組資料,也就是 e8。可以用以下這個程式片段來印證:
package main
import "fmt"
func main() {
text := "Go語言"
for i := 0; i < len(text); i++ {
fmt.Printf("%x ", text[i])
}
}
雖然還沒正確介紹 for 迴圈,不過程式應該很清楚,用迴圈遞增的 i 值來取得指定索引處的資料,結果是顯示「47 6f e8 aa 9e e8 a8 80 」。
這個位元組序列是怎麼決定的?當你寫下 "Go語言",你的 .go 原始碼檔案是什麼編碼呢?是的!UTF-8,Go 就是從這當中取得 "Go語言" 位元組序列,每個位元組就是 UTF-8 的一個碼元(code unit)。
雖說字串是唯讀的位元組片段,不過,實際的位元組是隱藏在字串底層,如果你想取得,必須轉為 []byte,例如:
package main
import "fmt"
func main() {
text1 := "Go語言"
bs := []byte(text1)
bs[0] = 103
text2 := string(bs)
fmt.Println(text1) // Go語言
fmt.Println(text2) // go語言
}
注意,你不是真的取得字串底層的位元組資料,只是取得複本,因此,在範例中可以看到,雖然對 text2 的位元組做了修改,text1 是不受影響的,記得,字串是唯讀的,一旦建立,沒有方式可以改變其內容。
string 與索引
實際上,Go 的字串支援片段操作,slice 操作時的索引是針對位元組,然而,傳回的型態還是 string,例如,"Go語言"[0:2],傳回 "Go",因為指定要切割出索引 0 開始,索引 2 結束(但不包括 2)的部份,也就是 47 與 6f 這兩個位元組,但是以 string 傳回。
那麼,如果是 "Go語言"[2:3] 呢?嗯,傳回的字串是 "\xe8"!這是什麼?事實上,Go 中的字串可以是任意位元組片段,因此,你可以如下定義字串:
package main
import "fmt"
func main() {
text := "\x47\x6f\xe8\xaa\x9e\xe8\xa8\x80"
fmt.Println(text) // Go語言
}
片段操作時,如果省略冒號之後的數字,則預設取得至字串尾端的子字串,例如 "Go語言"[3:] 會傳回 "\xaa\x9e\xe8\xa8\x80" 的字串,如果省略冒號之前的數字,預設從索引 0 開始,例如 "Go語言"[:2] 會取得 "Go" 的字串,也就是 "\x47\x6f" 的字串,如果是 "Go語言"[:],那麼就是取得全部字串內容了。
strings 套件 中有不少字串可用的方法,想做字串操作時,可以多加利用,不過要看清楚是針對什麼在操作。例如 strings.Index:
package main
import "fmt"
import "strings"
func main() {
text := "Go語言"
fmt.Printf("%d\n", strings.Index(text, "言")) // 5
}
傳回的索引值是 5 而不是 3,這是因為 "言" 的第一個位元組,是在 "Go語言" UTF-8 編碼後的位元組組成中第 5 個索引位置。
問題來了,如果對於 "Go語言",想逐一取得 'G'、'o'、'語'、'言' 該怎麼辦?當然不能用 text[n],這只會取得第 n 個位元組,可以將字串型態轉換為 []rune :
package main
import "fmt"
func main() {
text := "Go語言"
cs := []rune(text)
fmt.Printf("%c\n", cs[2]) // 語
fmt.Println(len(cs)) // 4
}
字串型態轉換為 []rune 時,會將 UTF-8 編碼的位元組,轉換為 Unicode 碼點,在這個例子中可以看到,cs[2] 確實地取得了第三個文字「語」,而 len 也確實取得數量 4。
如〈認識預定義型態〉中談過的,在 Go 中並沒有字元對應的型態,只有碼點的概念,rune 為 int32 的別名,可用來儲存 Unicode 碼點(code point),如果使用 fmt.Printf("%d\n", cs[2]),會顯示 35486,這就是「語」的 Unicode 碼點,35486 的 16 進位表示是 8a9e,因此,如果你寫 '\u8a9e',也會得到一個 rune 代表著「語」,fmt.Printf("%c", '\u8a9e') 也會顯示「語」,當然,直接寫 '語' 也是可以得到一個 rune。
想從 rune 得到一個 string,可以直接寫 string('語') 就可以了。如果想以 rune 為單位來走訪字串,而不是以位元組走訪,可以使用 for range,例如:
package main
import "fmt"
func main() {
text := "Go語言"
for index, runeValue := range text {
fmt.Printf("%#U 位元起始位置 %d\n", runeValue, index)
}
}
可以看到,for range 可以同時取得每個 rune 在字串中的位元起始位置,以及 rune 值,%U 可以用 16 進位顯示 rune,如果是 %#U,還會一併顯示碼點的列印形式。
這個程式的執行結果會顯示:
U+0047 'G' 位元起始位置 0
U+006F 'o' 位元起始位置 1
U+8A9E '語' 位元起始位置 2
U+8A00 '言' 位元起始位置 5
總而言之,Go 的字串是由 UTF-8 編碼的位元組構成,在〈Strings, bytes, runes and characters in Go〉談到了這麼設計的理由是,「字元」的定義太模稜兩可了,Go 為了避免模稜兩可,就將字串定義為 UTF-8 編碼的位元組構成,而 rune 用於儲存碼點。
PS. 這大概也是為何,我會整理出〈亂碼 1/2〉的原因 … XD
在 Go 中,陣列的長度固定,是個複合值,元素的型態及個數決定了陣列的型態,在記憶體中使用連續空間配置。
建立與存取陣列
建立陣列的方式是 [n]type,其中 n 為陣列的元素數量,type 是元素的型態。例如:
package main
import "fmt"
func main() {
var scores [10]int
scores[0] = 90
scores[1] = 89
fmt.Println(scores) // [90 89 0 0 0 0 0 0 0 0]
fmt.Println(len(scores)) // 10
}
在上面的程式中,建立了具有 10 個元素的陣列,可以用來儲存 int 型態的值,可透過 scores 變數指定索引來存取元素,scores 變數的型態為 [10]int,記得,長度也是陣列的型態的一部份,若一個陣列為 [10]int,而另一個陣列為 [5]int,這兩個陣列會是不同的型態,像上頭這樣宣告陣列,預設每個元素都會初始為 0。
陣列使用索引存取,如同其他語言的慣例,索引從 0 開始,len 函式可以取得陣列的長度,如果想在建立陣列時指定初始,可以如下:
package main
import "fmt"
func main() {
arr1 := [3]int{1, 2, 3}
arr2 := [5]int{1, 2, 3}
arr3 := [...]int{1, 2, 3, 4, 5}
fmt.Println(arr1) // [1 2 3]
fmt.Println(arr2) // [1 2 3 0 0]
fmt.Println(arr3) // [1 2 3 4 5]
}
在上頭可以看到,如果宣告的元素數量不足 [] 中指定的數量,那麼會自動給予初值,也可以使用 ...,或者只寫 [],讓編譯器自動判斷數量,如果宣告的元素數量超過 [] 中指定的數量,那麼會有 out of bounds 的編譯錯誤。
陣列指定與比較
在 Go 中,陣列指定會逐一複製值,例如:
package main
import "fmt"
func main() {
arr1 := [...]int{1, 2, 3}
arr2 := arr1
fmt.Println(arr1) // [1 2 3]
fmt.Println(arr2) // [1 2 3]
arr1[0] = 10
fmt.Println(arr1) // [10 2 3]
fmt.Println(arr2) // [1 2 3]
}
在呼叫函式時若傳遞陣列給參數,或者是傳回陣列,也是做複製的動作。陣列可以使用 == 與 != 進行比較,由於長度也是陣列型態的一部份,因此,只要長度與元素型態相同的陣列才可以做比較,如果將 [3]int 與 [5]int 做比較,會發生 mismatched types 編譯錯誤,同樣的,指定陣列給另一陣列時,也必須是相同型態的陣列。
巢狀陣列
Go 的陣列是線性的,如果想模擬多維,可以使用巢狀陣列。例如,建立一個二維陣列:
package main
import "fmt"
func main() {
var arr [2][3]int
fmt.Println(arr) // [[0 0 0] [0 0 0]]
}
顯然地,第一個 [] 中數字指定了陣列中會有兩個 [3]int 陣列,因此,若要同時宣告陣列中的元素,可以如下:
package main
import "fmt"
func change(arr [3]int) [3]int {
arr[0] = 10
return arr
}
func main() {
arr1 := [2][3]int{[3]int{1, 2, 3}, [3]int{4, 5, 6}}
fmt.Println(arr1) // [[1 2 3] [4 5 6]]
arr2 := [...][3]int{[...]int{1, 2, 3}, [...]int{4, 5, 6}}
fmt.Println(arr2) // [[1 2 3] [4 5 6]]
arr3 := [2][3]int{{1, 2, 3}, {4, 5, 6}}
fmt.Println(arr3) // [[1 2 3] [4 5 6]]
arr4 := [...][3]int{{1, 2, 3}, {4, 5, 6}}
fmt.Println(arr4) // [[1 2 3] [4 5 6]]
}
上頭一口氣示範了幾種巢狀陣列的宣告方式,基本上後兩種應該是比較容易撰寫的,由於陣列的長度是型態的一部份,必須在宣告時指定,因此,就二維陣列來說,一定都是方陣。
走訪陣列
想要逐一走訪陣列的話,基本上可以使用 for 迴圈,例如:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3}
for i := 0; i < len(arr); i++ {
fmt.Printf("%d\n", arr[i])
}
}
另一個方式是使用 for range:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3}
for index, element := range arr {
fmt.Printf("%d: %d\n", index, element)
}
}
在不需要索引的情況下,可以使用 _ 忽略傳回的索引值,例如:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3}
for _, element := range arr {
fmt.Printf("%d\n", element)
}
}
在〈身為複合值的陣列〉中看過陣列,有的場合需要陣列,然而,若只想處理陣列中某片區域,或者以更高階的觀點看待一片資料(而不是從固定長度的陣列觀點),那麼可以使用 slice。
建立一個 slice
如果需要一個 slice,可以使用 make 函式,舉個例子來說,可以如下建立一個長度與容量皆為 5 的 slice,並傳回 slice 的參考,型態為 []int:
package main
import "fmt"
func main() {
s1 := make([]int, 5)
s2 := s1
fmt.Println(s1) // [0 0 0 0 0]
fmt.Println(s2) // [0 0 0 0 0]
s1[0] = 1
fmt.Println(s1) // [1 0 0 0 0]
fmt.Println(s2) // [1 0 0 0 0]
s2[1] = 2
fmt.Println(s1) // [1 2 0 0 0]
fmt.Println(s2) // [1 2 0 0 0]
}
如上所示,s1、s2 會是個參考(Reference),型態是 []int,參考至同一個 slice 實例。
透過 s1 或 s2 操作時,操作的對象是變數參考之實例,就底層來說,make([]int, 5) 在記憶體某位置建立了 slice 實例,而 s1 儲存了該位置,如果改變了 s1 儲存的位址值,那透過 s1 操作時,就會是另一個 slice 實例了。
將變數的參考對象指定給另一個變數時,底層是將儲存的位址值指定給該變數,在上例中,s2 := s1,就是將 s1 儲存的位址值,指定給 s2,因此透過 s2 操作的對象,與 s1 操作的對象是相同的,透過其中一個名稱來改變 slice 的元素內容,透過另一個名稱取得 slice 的元素值,就會是改變後的值。
上例也可以寫為:
package main
import "fmt"
func main() {
var s1 []int = make([]int, 5)
var s2 []int // s2 這時是 nil
s2 = s1 // 將 s1 的參考對象指定給 s2
fmt.Println(s1) // [0 0 0 0 0]
fmt.Println(s2) // [0 0 0 0 0]
s1[0] = 1
fmt.Println(s1) // [1 0 0 0 0]
fmt.Println(s2) // [1 0 0 0 0]
s2[1] = 2
fmt.Println(s1) // [1 2 0 0 0]
fmt.Println(s2) // [1 2 0 0 0]
}
在 Go 中,參考的預設零值都是 nil。slice 無法進行 == 比較,slice 唯一可以用 == 比較的對象是 nil,儲存 slice 參考的變數也無法進行 == 比較,若真想知道兩個變數參考的是否同一 slice,可以如下透過反射機制來得知:
package main
import (
"fmt"
"reflect"
)
func main() {
s1 := make([]int, 5)
s2 := s1
fmt.Println(reflect.ValueOf(s1).Pointer() == reflect.ValueOf(s2).Pointer())
}
若事先知道 slice 的值,也可以使用 slice 字面常量:
package main
import (
"fmt"
"reflect"
)
func main() {
s1 := []int{1, 2, 3, 4, 5}
a1 := [...]int{1, 2, 3, 4, 5}
fmt.Println(reflect.TypeOf(s1)) // []int
fmt.Println(reflect.TypeOf(a1)) // [5]int
}
注意到,建立 slice 時,方括號中是沒有 ... 的,如果方括號中有 ...,那會是個陣列,而不是個 slice,如上可看到的,s1 的型態會是 []int,然而,a1 的型態會是 [5]int,s1 是個參考,可以指向某個 slice 實例,s1 本身儲存的位址值可以改變,而 a1 本身就是陣列,從 a1 的位置開始,有連續 5 個 int 空間可用來儲存 int 值,a1 本身的位置是固定的,無法改變。
使用 slice 字面常量時,還可以初始特定索引處的值。例如:
slice := []int{10, 20, 30, 10: 100, 20: 200}
// 顯示 [10 20 30 0 0 0 0 0 0 0 100 0 0 0 0 0 0 0 0 0 200]
fmt.Println(slice)
在上面的例子中,索引 0、1、2 被初始為 10、20、30,之後指定索引 10 為 100,索引 20 為 200,其餘未指定處初始為 int 零值 0。
從陣列或 slice 建立 slice
如果有個現成的陣列,可以從陣列中建立 slice,例如,從陣列的索引 1 到 4(不包括)建立一個 slice 的話,可以如下:
package main
import (
"fmt"
"reflect"
)
func main() {
arr := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice := arr[1:4]
fmt.Println(reflect.TypeOf(arr)) // [10]int
fmt.Println(reflect.TypeOf(slice)) // []int
fmt.Println(len(slice)) // 3
fmt.Println(cap(slice)) // 9
fmt.Println(slice) // [2 3 4]
fmt.Println(arr) // [1 2 3 4 5 6 7 8 9 10]
slice[0] = 20
fmt.Println(slice) // [20 3 4]
fmt.Println(arr) // [1 20 3 4 5 6 7 8 9 10]
}
在這邊可以看到,slice 的長度可以使用 len 得知,而容量可以使用 cap 函式得知,如果從陣列中切出 slice,長度是 slice 可參考的元素長度,而容量預設為從 slice 索引 0 處起算的底層陣列元素長度,如圖所示:
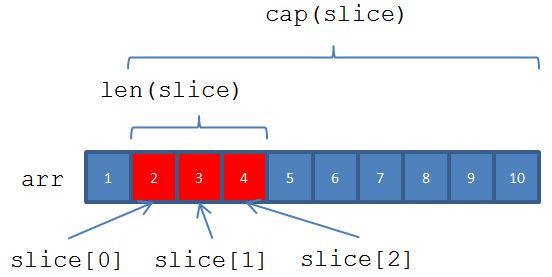
是的!slice 底層實際上還是個陣列,若兩個 slice 底層是共用同一個陣列,從一個 slice 操作,另一個 slice 取得的值也就會反映變化,也因此在上面的例子中,你透過 slice[0] 設定值為 20,底層的陣列也會因而反映出變化,透過 slice 指定索引取得元素值時,不能超出 slice 的長度,不然會出現 index out of range 的錯誤。
注意,單是宣告 var slice []int 的話,slice 預設零值會是 nil,也就是相當於 var slice []int = nil,也就是 slice 參考至 nil,此時 len(slice) 與 cap(slice) 的結果都會是 0,fmt.Println 的顯示會是 [],== 用於 slice 時,唯一能用來比較的就是 nil。
方才使用 make([]int, 5) 函式建立 slice 時,只指定了長度為 5,而容量就預設與長度相同,實際上,可以分別指定容量與長度,例如:
package main
import "fmt"
func main() {
slice := make([]int, 5, 10)
fmt.Println(slice) // [0 0 0 0 0]
fmt.Println(len(slice)) // 5
fmt.Println(cap(slice)) // 10
}
指定索引從陣列中產生 slice時,若省略冒號之後的數字,則建立的 slice,預設可取得至陣列尾端的元素,也就是長度將等於容量,例如,若 arr := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},那麼 arr[3:] 的話,取得的 slice 可以存取的元素為 {4, 5, 6, 7, 8, 9, 10},長度與容量皆為 7;如果省略冒號之前的數字,預設從索引 0 開始,例如 arr[:2] 會取得 {1, 2},長度為 2,容量為 10;如果是 arr[:],那麼就是取得全部陣列內容了,長度與容量皆為 10。
Go 1.2 開始,可以在 [] 中指定三個數字,以冒號區隔,第三個數字指定的是 slice 以原陣列哪個索引作為邊界。例如:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3, 4, 5}
slice1 := arr[0:2:4]
fmt.Println(slice1) // [1 2]
fmt.Println(len(slice1)) // 2
fmt.Println(cap(slice1)) // 4
}
第三個數字指定的索引不能超過陣列邊界,不然會發生 invalid slice index 的錯誤。
也可以從 slice 中產生 slice,產生的 slice 底層還是同一個陣列。例如:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice1 := arr[:5]
slice2 := slice1[:3]
fmt.Println(slice1) // [1 2 3 4 5]
fmt.Println(slice2) // [1 2 3]
slice2[0] = 10
fmt.Println(slice1) // [10 2 3 4 5]
fmt.Println(slice2) // [10 2 3]
fmt.Println(arr) // [10 2 3 4 5 6 7 8 9 10]
}
slice 的 append
可以使用 append 對 slice 附加元素,這會傳回一個 slice 的參考:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3, 4, 5}
slice1 := arr[:2]
fmt.Println(slice1) // [1 2]
fmt.Println(len(slice1)) // 2
fmt.Println(cap(slice1)) // 5
slice2 := append(slice1, 6)
fmt.Println(slice2) // [1 2 6]
fmt.Println(len(slice2)) // 3
fmt.Println(cap(slice2)) // 5
slice2[0] = 10
fmt.Println(slice1) // [10 2]
fmt.Println(slice2) // [10 2 6]
fmt.Println(arr) // [10 2 6 4 5]
}
只要附加的元素沒有超出 slice 的容量,傳回的 slice 參考就會是相同的,底層也是同一陣列,因此,改變了 slice2[0] 的值,slice1、arr 取得結果都有了變化。
如果 append 的時候,附加元素超出了 slice 的容量,那麼底層會建立一個新的陣列,容量為原 slice 容量的兩倍加 2,接著將舊陣列內容複製到新陣列,然後將指定的值附加上去,append 的結果也會傳回新的 slice 參考。例如:
package main
import "fmt"
func main() {
arr := [...]int{1, 2, 3, 4, 5}
slice1 := arr[:]
fmt.Println(slice1) // [1 2 3 4 5]
fmt.Println(len(slice1)) // 5
fmt.Println(cap(slice1)) // 5
slice2 := append(slice1, 6)
fmt.Println(slice2) // [1 2 3 4 5 6]
fmt.Println(len(slice2)) // 6
fmt.Println(cap(slice2)) // 12
slice2[0] = 10
fmt.Println(slice1) // [1 2 3 4 5]
fmt.Println(slice2) // [10 2 3 4 5 6]
fmt.Println(arr) // [1 2 3 4 5]
}
在上面的例子中,由於 slice2 底層的陣列,與 slice1 無關了,因此,透過 slice2[0] 修改了值,並不會影響到透過 slice1 或 arr 取得的值。
如果想用 append 來直接附加另一個 slice,可以使用 ...,將另一個 slice 擴展為一列引數,例如:
package main
import "fmt"
func main() {
slice1 := []int{1, 2, 3}
slice2 := []int{4, 5, 6}
fmt.Println(append(slice1, slice2...)) // [1 2 3 4 5 6]
}
slice 的 copy
可以使用 copy 函式,將一個 slice 的內容,複製至另一個 slice:
package main
import "fmt"
func main() {
src := []int{1, 2, 3, 4, 5}
dest := make([]int, len(src), (cap(src)+1)*2)
fmt.Println(copy(dest, src)) // 5
fmt.Println(src) // [1 2 3 4 5]
fmt.Println(dest) // [1 2 3 4 5]
src[0] = 10
fmt.Println(src) // [10 2 3 4 5]
fmt.Println(dest) // [1 2 3 4 5]
}
複製時,目的 slice 的容量必須足夠,否則會發生 cap out of range 的錯誤,copy 函式若執行成功,會傳回複製的元素個數。
先前提到,可以從 slice 中產生 slice,然而,由於從 slice 中產生 slice,底層仍會是同一個陣列,因此,要小心一些應用場合,對於一個很大的陣列,若不斷地切出新的 slice,底層參考的陣列還是那麼大,想避免這類問題,應自行使用 make 建立適當大小的 slice,然後從舊 slice 使用 copy 複製元素值,或者使用 append,將舊 slice 的內容附加至新 slice,以避免這類問題。
許多語言中都會有的成對鍵值資料結構,在 Go 中是以內建型態 map 來實作,格式為 map[keyType]valueType。
建立與初始 map
想要建立例一個 map 實例,但尚無任何鍵值對,可以使用 make 函式,例如:
package main
import "fmt"
func main() {
passwords := make(map[string]int)
fmt.Println(passwords) // map[]
fmt.Println(len(passwords)) // 0
passwords["caterpillar"] = 123456
passwords["monica"] = 54321
fmt.Println(passwords) // map[caterpillar:123456 monica:54321]
fmt.Println(len(passwords)) // 2
fmt.Println(passwords["caterpillar"]) // 123456
fmt.Println(passwords["monica"]) // 54321
}
在上例中,passwords 是個參考,指向 make(map[string]int) 建立的 map 實例。
類似一些語言(例如 Python),要設定一個鍵值對應時,使用 [] 與 = 指定,要取得鍵對應的值時,使用 [] 指定鍵,這會傳回對應的值,想知道 map 中的鍵數,可以使用 len 函式。
要注意的是,可用來做為鍵的值,必須是 comparable,就目前來說,你要先知道的 comparable 型態有布林、數字、字串、指標(pointer)、channel、interface、struct,或者含有這這些型態的陣列,這些是都可以使用 == 來比較的值;而 slice、map 與函式,就不能用來做為鍵。
如果已知 map 中會有的鍵值對,則可以如下建立 map:
package main
import "fmt"
func main() {
passwords := map[string]int{
"caterpillar": 123456,
"monica": 54321,
}
fmt.Println(passwords) // map[monica:54321 caterpillar:123456]
fmt.Println(len(passwords)) // 2
fmt.Println(passwords["caterpillar"]) // 12345
fmt.Println(passwords["monica"]) // 54321
}
如果 passwords 建立時,最後一個鍵值項目後不換行,那麼最後一個逗號就不需要,例如:
passwords := map[string]int {"caterpillar" : 123456, "monica" : 54321}
實際上,你也可以寫 passwords := map[string]int {},來建立一個沒有任何鍵值對的 map,這相當於寫 passwords := make(map[string]int),不過,若是 var passwords map[string]int 的話,只是建立一個參考名稱 passwords,預設零值是 nil,也就是相當於 var passwords map[string]int = nil 的意思。
也就是說,var passwords map[string]int 宣告了一個參考型態,兩個 map 型態的名稱,可以指向同一個 map 實例,透過其中一個名稱來改變 map 內容,從另一個名稱就可以獲得對應的修改:
package main
import "fmt"
func main() {
passwds1 := map[string]int{"caterpillar": 123456}
passwds2 := passwds1
fmt.Println(passwds1) // map[caterpillar:123456]
passwds2["monica"] = 54321
fmt.Println(passwds1) // map[monica:54321 caterpillar:123456]
}
鍵值存取、刪除
如方才所看到的,要設定一個鍵值對應時,使用 [] 與 = 指定,要取得鍵對應的值時,使用 [] 指定鍵,這會傳回對應的值,如果指定的鍵不存在,那麼會傳回值型態對應的零值,例如,若 passwords := map[string]int {"caterpillar" : 123456},那麼 passwords["monica"] 會傳回 0。
不過,更精確地說,使用 mapName[key] 時,會傳回兩個值(Go 中允許同時傳回多值),第一個是鍵對應的值,若沒有該鍵就傳回值型態的零值,第二個是布林值,指出鍵是否存在。例如:
package main
import "fmt"
func main() {
passwds := map[string]int{"caterpillar": 123456}
v, exists := passwds["monica"]
fmt.Printf("%d %t\n", v, exists) // 0 false
passwds["monica"] = 54321
v, exists = passwds["monica"]
fmt.Printf("%d %t\n", v, exists) // 54321 true
}
因此,若只是單純想測試鍵是否存在,只要用底線 _ 忽略傳回的值就可以了,例如:
package main
import "fmt"
func main() {
passwds := map[string]int{"caterpillar": 123456}
name := "caterpillar"
_, exists := passwds[name]
if exists {
fmt.Printf("%s's password is %d\n", name, passwds[name])
} else {
fmt.Printf("No password for %s\n", name)
}
}
exists 的指定與 if 的判斷也可以寫在同一行:
if _, exists := passwds[name]; exists {
fmt.Printf("%s's password is %d\n", name, passwds[name])
} else {
fmt.Printf("No password for %s\n", name)
}
如果想刪除某個鍵值,可以使用 delete 函式,例如 delete(passwds, "caterpillar")。
迭代鍵值
如果要迭代 map 的鍵值,可以使用 for range,例如:
package main
import "fmt"
func main() {
passwords := map[string]int{
"caterpillar": 123456,
"monica": 54321,
}
for name, passwd := range passwords {
fmt.Printf("%s : %d\n", name, passwd)
}
}
如果只是想迭代 map 的鍵,可以如下:
package main
import "fmt"
func main() {
passwords := map[string]int{
"caterpillar": 123456,
"monica": 54321,
}
for name := range passwords {
fmt.Printf("%s\n", name)
}
}
如果只想迭代 map 的值,可以如下:
package main
import "fmt"
func main() {
passwords := map[string]int{
"caterpillar": 123456,
"monica": 54321,
}
for _, passwd := range passwords {
fmt.Printf("%d\n", passwd)
}
}
如果想取得 map 中的鍵清單或者是值清單,方式之一是使用 slice 進行收集,例如:
package main
import "fmt"
func keys(m map[string]int) []string {
ks := make([]string, 0, len(m))
for k := range m {
ks = append(ks, k)
}
return ks
}
func values(m map[string]int) []int {
vs := make([]int, 0, len(m))
for _, v := range m {
vs = append(vs, v)
}
return vs
}
func main() {
passwords := map[string]int{
"caterpillar": 123456,
"monica": 54321,
}
fmt.Println(keys(passwords)) // [caterpillar monica]
fmt.Println(values(passwords)) // [123456 54321]
}
Go 的 map 在迭代時沒有一定的順序,如果想要有排序結果,必須自行處理,例如,針對鍵排序來進行迭代:
package main
import "sort"
import "fmt"
func main() {
passwords := map[string]int{
"caterpillar": 123456,
"monica": 54321,
"hamimi": 13579,
}
keys := make([]string, 0, len(passwords))
for key := range passwords {
keys = append(keys, key)
}
sort.Strings(keys)
for _, key := range keys {
fmt.Printf("%s : %d\n", key, passwords[key])
}
}
Go 語言中的運算子,大致上與 C 語系的語言中提供的運算子差不多,其中 &、* 也用來作為指標(Pointer)運算子。
算術運算子
算術運算子作用於數值,產生與第一個運算元相同型態的結果。+、-、*、/ 四個運算子,可用於整數、浮點數與複數;+ 也用於字串串接;% 餘除運算子,只用於整數,&、|、^、&^ 位元運算子只用於整數,<<、>> 位移運算子只用於整數。
+、-、*、/ 使用上應該沒什麼問題,主要就是注意運算的順序是先乘除後加減,必要時使用括號讓順序清楚,例如:
package main
import "fmt"
func main() {
fmt.Println(1 + 2*3) // 7
fmt.Println(2 + 2 + 8/4) // 6
fmt.Println((2 + 2 + 8) / 4) // 3
fmt.Println(10 % 3) // 1
}
%運算子計算的結果是除法後的餘數,例如上頭 10 % 3 會得到餘數 1。
對於遞增與遞減 1 的操作,Go 可以使用 ++ 與 -- 的操作,不過,++ 與 -- 只能置於變數後方,而且是個陳述,因此,對於 i := 1,你可以在一行陳述中寫 i++ 或 i--,不過,不能寫 fmt.Println(i++),這樣就能避免是要先傳回 i 值再遞增 i,還是先遞增 i 再傳回 1 的問題。
在二進位運算上有 AND、OR、XOR 等運算,底下是 Go 中的一些例子:
package main
import "fmt"
func main() {
fmt.Println("AND運算:")
fmt.Printf("0 AND 0 %5d\n", 0&1)
fmt.Printf("0 AND 1 %5d\n", 0&1)
fmt.Printf("1 AND 0 %5d\n", 1&0)
fmt.Printf("1 AND 1 %5d\n", 1&1)
fmt.Println("\nOR運算:")
fmt.Printf("0 OR 0 %6d\n", 0|0)
fmt.Printf("0 OR 1 %6d\n", 0|1)
fmt.Printf("1 OR 0 %6d\n", 1|0)
fmt.Printf("1 OR 1 %6d\n", 1|1)
fmt.Println("\nXOR運算:")
fmt.Printf("0 XOR 0 %5d\n", 0^0)
fmt.Printf("0 XOR 1 %5d\n", 0^1)
fmt.Printf("1 XOR 0 %5d\n", 1^0)
fmt.Printf("1 XOR 1 %5d\n", 1^1)
fmt.Println("\nAND NOT運算:")
fmt.Printf("0 AND NOT 0 %5d\n", 0&^0)
fmt.Printf("0 AND NOT 1 %5d\n", 0&^1)
fmt.Printf("1 AND NOT 0 %5d\n", 1&^0)
fmt.Printf("1 AND NOT 1 %5d\n", 1&^1)
}
執行結果如下:
AND運算:
0 AND 0 0
0 AND 1 0
1 AND 0 0
1 AND 1 1
OR運算:
0 OR 0 0
0 OR 1 1
1 OR 0 1
1 OR 1 1
XOR運算:
0 XOR 0 0
0 XOR 1 1
1 XOR 0 1
1 XOR 1 0
AND NOT運算:
0 AND NOT 0 0
0 AND NOT 1 0
1 AND NOT 0 1
1 AND NOT 1 0
位元運算是逐位元運算,例如 10010001 與 01000001 作 AND 運算,是一個一個位元對應運算,答案就是 00000001。補數運算是將所有位元 0 變 1,1 變 0。例如 00000001 經補數運算就會變為 11111110。Go 的補數運算子是 ^,例如:
package main
import "fmt"
func main() {
number := 0
fmt.Println(^number) // -1
}
上面的程式片段會顯示 -1,因為 number 在記憶體中全部位元都是 0,經補數運算全部位元就都變成 1,這個數在電腦中用整數表示則是 -1。
<< 左移運算子會將所有位元往左移指定位數,左邊被擠出去的位元會被丟棄,而右邊補上 0;>> 右移運算則是相反,會將所有位元往右移指定位數,右邊被擠出去的位元會被丟棄,至於最左邊補上原來的位元,如果左邊原來是 0 就補0,1 就補 1。
package main
import "fmt"
func main() {
number := 1
fmt.Printf("2 的 0 次方: %d\n", number) // 1
fmt.Printf("2 的 1 次方: %d\n", number << 1) // 2
fmt.Printf("2 的 2 次方: %d\n", number << 2) // 4
fmt.Printf("2 的 3 次方: %d\n", number << 3) // 8
}
實際來左移看看就知道為何可以如此作次方運算了:
00000001 -> 1
00000010 -> 2
00000100 -> 4
00001000 -> 8
對於一個算術運算 x = x op y,可以寫成 x op= y,op 是指算術運算子,例如 x = x + y,可以寫成 x += y,這也就是所謂的指定運算子。
比較運算
數學上有大於、等於、小於的比較運算,Go 中也提供了這些運算子,它們有大於(>)、不小於(>=)、小於(<)、不大於(<=)、等於(==)以及不等於(!=),比較條件成立時用 true 表示,比較條件不成立用 false 表示。以下程式片段示範了幾個比較運算的使用:
package main
import "fmt"
func main() {
fmt.Printf("10 > 5 結果 %t\n", 10 > 5) // true
fmt.Printf("10 >= 5 結果 %t\n", 10 >= 5) // true
fmt.Printf("10 < 5 結果 %t\n", 10 < 5) // false
fmt.Printf("10 <= 5 結果 %t\n", 10 <= 5) // false
fmt.Printf("10 == 5 結果 %t\n", 10 == 5) // false
fmt.Printf("10 != 5 結果 %t\n", 10 != 5) // true
}
== 與 != 只能用在 comparable 的運算元上,這有一套嚴格規則,Go 語言中哪些值是可以比較的,可以參考規格書中〈Comparison operators〉的說明。
Go 中沒有 ?: 三元條件運算子。
邏輯運算
在邏輯上有所謂的「且」、「或」與「反相」,在 Go 中提供對應的邏輯運算子(Logical operator),分別為 &&、||及 !。看看以下的程式片段會輸出什麼結果?
package main
import "fmt"
func main() {
number := 75
fmt.Println(number > 70 && number < 80) // true
fmt.Println(number > 80 || number < 75) // false
fmt.Println(!(number > 80 || number < 75)) // true
}
&& 與 || 有捷徑運算(Short-Circuit Evaluation)。因為 && 只要其中一個為假,就可以判定結果為假,所以只要左運算元評估為 false,就會直接傳回 false,不會再去運算右運算元。因為 || 只要其中一個為真,就可以判定結果為真,所以只要左運算元評估為 true,就會直接傳回 true,就不會再去運算右運算元。
來舉個運用捷徑運算的例子,在 Go 中兩個整數相除,若除數為 0 會發生 integer divide by zero 的錯誤,以下運用 && 捷徑運算避免了這個問題:
if(number2 != 0 && number1 / number2 > 1) {
fmt.Println(number1 / number2)
}
在這個程式片段中,變數 number1 與 number2 都是 int 型態,如果 number2 為 0 的話,&& 左邊運算元結果就是 false,直接判斷整個 && 的結果應是 false,不用再去評估右運算元,從而避免了 number1 / number2 而 number2 等於 0 時的除零錯誤。
指標
Go 語言中有指標(Pointer),你可以在宣告變數時於型態前加上 *,這表示建立一個指標,例如:
var i *int
這時 i 是個空指標,也就是值為 nil,上頭等同於 var i *int = nil,目前並沒有儲存任何位址,如果想讓它儲存另一個變數的記憶體位址,可以使用 & 取得變數位址並指定給 i,例如:
package main
import "fmt"
func main() {
var i *int
j := 1
i = &j
fmt.Println(i) // 0x104382e0 之類的值
fmt.Println(*i) // 1
j = 10
fmt.Println(*i) // 10
*i = 20
fmt.Println(j) // 20
}
j 的位置儲存了 1,那麼具體來說,j 的位置到底是在哪?這就是 & 取址運算的目的,&j 具體取得了 j 的位置,然後指定給 i。
如上所示,如果想存取指標位址處的變數儲存的值,可以使用 *,因而,你改變 j 的值,*i 取得的就是改變後的值,透過 *i 改變值,從 j 取得的也會是改變後的值。
其應用的實例之一是使用 fmt.Scanf 取得標準輸入時,例如:
package main
import "fmt"
func main() {
var input int
fmt.Printf("輸入數字")
fmt.Scanf("%d", &input)
fmt.Println(input)
}
這邊使用 &input 取出 input 的記憶體位址值,並傳入 fmt.Scanf 函式,函式中會取得使用者的標準輸入,並儲存至 input 變數的記憶體位址,因而,再度取得 input 的值時,就會是使用者輸入的值。
Go 雖然有指標,不過不能如同 C/C++ 那樣對指標做運算,之後有機會用到指標時,會再做相關說明。
在分支判斷的控制上,Go 提供了 if...else、switch 語法,相較於其他提供類似語法的語言,在 Go 中 if...else、switch 語法的相似性更高。
if..else 語法
直接來看個 if..else 的實例:
package main
import "fmt"
func main() {
input := 10
remain := input % 2
if remain == 1 {
fmt.Printf("%d 為奇數\n", input)
} else {
fmt.Printf("%d 為偶數\n", input)
}
}
在 Go 中,if 之後直接寫判斷式可以不用使用 () 括號,而 {} 是必要的,這樣應該是比較能避免 Apple 曾經發生某個函式中有兩個連續縮排而引發的問題:
...
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
...
Go 的 if 可以使用 := 宣告與指定變數值,與判斷式之間以分號區隔,因此方才的範例也可以寫成:
package main
import "fmt"
func main() {
input := 10
if remain := input % 2; remain == 1 {
fmt.Printf("%d 為奇數\n", input)
} else {
fmt.Printf("%d 為偶數\n", input)
}
}
這麼一來,remain 變數就只在 if..else 的區塊中有作用。如果要使用 := 宣告與指定多個變數值,可以寫成 if var1, var2 := 10, 20; cond 的形式。if...else 可以組成 if...else if...else 形式,例如:
package main
import "fmt"
func main() {
var level rune
if score := 88; score >= 90 {
level = 'A'
} else if score >= 80 && score < 90 {
level = 'B'
} else if score >= 70 && score < 80 {
level = 'C'
} else if score >= 60 && score < 70 {
level = 'D'
} else {
level = 'E'
}
fmt.Printf("得分等級:%c\n", level)
}
switch 語法
實際上,對於上頭的範例,可以改用 switch 來撰寫,程式會更為簡潔:
package main
import "fmt"
func main() {
var level rune
score := 88
switch score / 10 {
case 10, 9:
level = 'A'
case 8:
level = 'B'
case 7:
level = 'C'
case 6:
level = 'D'
default:
level = 'E'
}
fmt.Printf("得分等級:%c\n", level)
}
注意,與 C/C++ 或 Java 等語言不同的是,Go 的 switch 比對成功後,不會自動往下執行,因而不用撰寫 break,有多個條件想符合時,在同一 case 中使用逗號區隔。如果真的想在比對成功後,往下一個 case 中的陳述執行,可以使用 fallthrough,例如:
package main
import "fmt"
func main() {
var level rune
switch score := 100; score / 10 {
case 10:
fmt.Println("滿分喔!")
fallthrough
case 9:
level = 'A'
case 8:
level = 'B'
case 7:
level = 'C'
case 6:
level = 'D'
default:
level = 'E'
}
fmt.Printf("得分等級:%c\n", level)
}
在上面的例子中,如果沒有 fallthrough,那麼只會顯示 “滿分喔!“,而不會執行 case 9 中的 level = 'A',因此最後顯示得分等級時,不會有 A 的字眼。在上頭也可以看到,switch 中也可以使用 := 宣告與初始變數。
實際上,Go 的 switch 中, case 不用是常數,只要 switch 的值型態與 case 比對的型態符合,也可以是個變數或運算式,甚至還可以接受布林運算式,例如:
package main
import "fmt"
func main() {
var level rune
score := 88
switch {
case score >= 90:
level = 'A'
case score >= 80 && score < 90:
level = 'B'
case score >= 70 && score < 80:
level = 'C'
case score >= 60 && score < 70:
level = 'D'
default:
level = 'E'
}
fmt.Printf("得分等級:%c\n", level)
}
在上面的例子中,switch 沒有指定任何變數,此時等同於 switch true,這時的 case 可以接受布林運算式,可用來取代 if...else if...else 的風格。
在 Go 中唯一的迴圈語法是 for,然而,它也擔任了一些語言中 while 的功能,並可搭配 range 來使用。
有分號的 for
for 最基本的使用形式,與 C/C++、Java 等語言類似,具有初始式、條件式、後置式三個部份,中間使用分號加以區隔,不必使用 () 括號包住這三個式子,同樣地,for 迴圈本體一定要使用 {}。
初始式只執行一次,通常用來宣告或初始變數,若是宣告變數,可見範圍僅在 for 中。第一個分號後是每次執行迴圈本體前會執行一次,且必須是 true 或 false 的結果,true 就會執行迴圈本體,false 就會結束迴圈,第二個分號後,則是每次執行完迴圈本體後會執行一次。
實際來看個 for 迴圈範例,在文字模式下從 1 顯示到 10:
package main
import "fmt"
func main() {
for i := 1; i <= 10; i++ {
fmt.Println(i)
}
}
這個程式白話讀來,就是從 i 等於 1,只要 i 小於等於 10 就執行迴圈本體(顯示 i),然後遞增 i。在介紹 for 迴圈時,許多書籍或文件很喜歡用的範例就是顯示九九乘法表,這邊也用這個例子來示範巢狀迴圈:
package main
import "fmt"
func main() {
for i, j := 0, 0; i < 10; i, j = i+1, j+1 {
fmt.Printf("%d * %d = %2d\n", i, j, i*j)
}
}
for 中的各陳述是以分號區隔,若當中想寫兩個陳述則使用逗號區隔,例如:
package main
import "fmt"
func main() {
for i, j := 0, 0; i < 10; i, j = i+1, j+1 {
fmt.Printf("%d * %d = %2d\n", i, j, i*j)
}
}
初始式、後置式都可以省略,不過,分號必須保留,例如:
package main
import "fmt"
func foo(i int) {
for ; i < 10; i++ {
fmt.Println(i)
}
}
func multiplication_table() {
for i, j := 2, 1; j < 10; {
fmt.Printf("%d * %d = %2d ", i, j, i*j)
if i == 9 {
fmt.Println()
j++
i = (j+1)/j + 1
} else {
i++
}
}
}
func main() {
foo(1)
multiplication_table()
}
無分號的 for
在沒有初始式、後置式,只有條件式的情況,也就是 for ; cond; 的時候,可以只寫 for cond,這就是 C/C++、Java 中 while 迴圈的作用了:
package main
import "fmt"
func main() {
i := 1
for i < 10 {
fmt.Println(i)
i++
}
}
如果想製造個無窮迴圈,在 C/C++、Java 等語言中常見寫成 for(;;),在 Go 中是也可以寫 for ;;,因為條件式不寫預設就是 true,不過,可以只寫個 for 就可以了,底下是個很無聊的遊戲,看誰可以最久不撞到這個數字 5:
package main
import (
"fmt"
"math/rand"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func main() {
for {
number := random(1, 10)
fmt.Println(number)
if number == 5 {
break
}
time.Sleep(time.Second)
}
fmt.Println("I hit 5....Orz")
}
在 for 迴圈中如果執行到 break,會離開迴圈本體。
for range
Go 的 for 可以搭配 range,對 slice、陣列、string、map 和 channel(之後說明)進行迭代,range 視給定的形態不同,會有不同的傳回值。
對於 slice、陣列、string、map,在之前的〈位元組構成的字串〉、〈身為複合值的陣列〉、〈底層為陣列的 slice〉與〈成對鍵值的 map〉中,都有相關範例示範,這邊不再贅述。
Go 1.22+ 與 1.23+ 的 for 補充
從 Go 1.22 開始,for 迴圈中宣告的變數,會在每次迭代建立新的變數實例,這修正了過去常見的閉包捕捉問題。例如:
package main
import "fmt"
func main() {
funcs := []func(){}
for _, v := range []string{"a", "b", "c"} {
funcs = append(funcs, func() {
fmt.Println(v)
})
}
for _, f := range funcs {
f()
}
}
在 Go 1.22 之後,上例會依序印出 a、b、c(舊版本常會看到重複最後一個值)。
Go 1.22 也支援對整數直接使用 range,這相當於從 0 迭代到 n-1:
package main
import "fmt"
func main() {
for i := range 5 {
fmt.Println(i)
}
}
Go 1.23 更進一步支援對 iterator function 使用 range,常見型態之一是 func(func(T) bool):
package main
import "fmt"
func Counter(n int) func(func(int) bool) {
return func(yield func(int) bool) {
for i := range n {
if !yield(i) {
return
}
}
}
}
func main() {
for v := range Counter(3) {
fmt.Println(v)
}
}
這讓自訂容器或序列,也能自然地配合 for range 語法使用。
break 可以離開目前 switch、for 以及 select(之後介紹);continue 只用於 for 迴圈,略過之後陳述句,並回到迴圈開頭進行下一次迴圈,而不是離開迴圈。goto 可以在函式中,讓流程直接跳至指定標籤;實際上,break、continue 在迴圈中,也可以搭配標籤來使用。
break
在〈if … else、switch 條件式〉中說明過,switch 的 case 中不必特別使用 break,因為 switch 中預設不會 fallthrough,但 case 中若必要,還是可以使用 break,中斷 break 之後與下個 case 前的流程。
break 使用於 for 迴圈時,會結束迴圈,例如:
package main
import "fmt"
func main() {
for i := 1; i < 10; i++ {
if i == 5 {
break
}
fmt.Printf("i = %d\n", i)
}
}
這段程式會顯示 i = 1 到 i = 4,因為在 i 等於 5 時就會執行 break 而離開 for 迴圈。
break 可以配合標籤使用,例如本來 break 只會離開一層 for 迴圈,若設定標籤,並於 break 時指定標籤,就可以直接離開多層 for 迴圈:
package main
import "fmt"
func main() {
BACK:
for j := 1; j < 10; j++ {
for i := 1; i < 10; i++ {
if i == 5 {
break BACK
}
fmt.Printf("i = %d, j = %d\n", i, j)
}
fmt.Println("test")
}
}
你可以執行看看上面的範例,之後將 BACK: 與 BACK 拿掉看看,前者 break BACK 時會離開兩層 for 迴圈,後者只會離開內層 for 迴圈。
continue
continue 只用於 for 迴圈,略過之後陳述句,並回到迴圈開頭進行下一次迴圈,例如將先前第一個範例程式的 break 改成 continue:
package main
import "fmt"
func main() {
for i := 1; i < 10; i++ {
if i == 5 {
continue
}
fmt.Printf("i = %d\n", i)
}
}
這段程式會顯示 i = 1 到 4,以及 6 到 9,當 i 等於 5 時,會執行 continue 直接略過之後陳述句,也就是該次的 fmt.Printf() 該行並沒有被執行,直接從 for 開頭執行下一次迴圈,所以 i = 5 沒有被顯示。
continue 也有搭配標籤的用法:
package main
import "fmt"
func main() {
BACK:
for j := 1; j < 10; j++ {
for i := 1; i < 10; i++ {
if i == 5 {
continue BACK
}
fmt.Printf("i = %d, j = %d\n", i, j)
}
fmt.Println("test")
}
}
goto
在 C/C++ 中,goto 是一個很方便,但是常不建議使用的語法,因為濫用它的話,經常會破壞程式的架構、使得程式的邏輯混亂,然而,在 Go 中,亦有提供有 goto 語法。
相對於 break 與 continue 跳躍時,只能前往 for 迴圈開頭處設定的標籤,goto 可以在函式中,從某區塊內跳躍至區塊外任何位置,一個簡單的例子如下:
package main
import "fmt"
func main() {
var input int
RETRY:
fmt.Printf("輸入數字")
fmt.Scanf("%d", &input)
if input == 0 {
fmt.Println("除數不得為 0")
goto RETRY
}
fmt.Printf("100 / %d = %f\n", input, 100/float32(input))
}
如果你輸入 0,程式會顯示錯誤訊息後跳至 RETRY:,再執行一次提示與輸入。
注意,goto 可以在函式中,從某區塊內跳躍至區塊外任何位置,但不能從某區塊跳入另一區塊內,例如,以下是錯誤的,會發生 goto TEST jumps into block 的錯誤:
package main
import "fmt"
func main() {
var input int
RETRY:
fmt.Printf("輸入數字")
fmt.Scanf("%d", &input)
if input == 0 {
TEST:
fmt.Println("除數不得為 0")
goto RETRY
}
fmt.Printf("100 / %d = %f\n", input, 100/float32(input))
goto TEST
}
在 Go 中要定義函式,是使用 func 來定義,其基本格式如下:
func funcName(param1 type1, param2 type2) (return1 type1, return2 type2) {
// 一些程式碼...
return value1, value2
}
定義函式
可以看到,Go 定義函式時,參數的型態宣告同樣地是放在名稱之後,如果多個參數有同樣的型態,那麼只要最右邊同型態的名稱右方加上型態就可以了,比較特別的地方在於,可以有兩個以上的傳回值,且傳回值可以設定名稱。
來看個簡單的函式定義,以下是個求最大公因數的函式定義:
package main
import "fmt"
func Gcd(m, n int) int {
if n == 0 {
return m
} else {
return Gcd(n, m%n)
}
}
func main() {
fmt.Printf("Gcd of 10 and 4: %d\n", Gcd(10, 4)) // 2
}
當只有一個傳回值且沒有宣告名稱時,傳回值的宣告可以不用使用 (),傳回值的名稱可以在函式中使用,傳回值名稱設定的值,會自動於函式 return 時傳回,例如:
package main
import "fmt"
func Gcd(m, n int) (gcd int) {
if n == 0 {
gcd = m
} else {
gcd = Gcd(n, m%n)
}
return
}
func main() {
fmt.Printf("Gcd of 10 and 4: %d\n", Gcd(10, 4)) // 2
}
官方的建議是要宣告傳回值名稱,令程式可讀性更高(當然程式會變得囉嗦一些),對那些公開給套件外使用的函式(也就是首字大寫的函式),最好是宣告傳回值名稱。
多個傳回值
Go 中允許多個傳回值,例如,定義一個函式,可搜尋 slice 的元素中是否指定的子字串,若有就傳回元素索引位置與字串,若無就傳回 -1 與空字串:
package main
import "fmt"
import "strings"
func FirstMatch(elems []string, substr string) (int, string) {
for index, elem := range elems {
if strings.Contains(elem, substr) {
return index, elem
}
}
return -1, ""
}
func main() {
names := []string{"Justin Lin", "Monica Huang", "Irene Lin"}
if index, name := FirstMatch(names, "Huang"); index == -1 {
fmt.Println("找不到任何東西")
} else {
fmt.Printf("在索引 %d 找到 \"%s\"\n", index, name)
}
}
傳回多值時,指定給變數時必須依順序,若不需要某個傳回值,可以使用 _ 略過:
_, name := FirstMatch(names, "Huang")
另一種多值傳回的場合之一是錯誤處理,例如:
package main
import "fmt"
import "errors"
func Div(x, y int) (int, error) {
if y == 0 {
return 0, errors.New("division by zero")
}
return x / y, nil
}
func main() {
if result, err := Div(10, 5); err == nil {
fmt.Printf("10 / 5 = %d\n", result)
} else {
fmt.Println(err)
}
}
若函式簽署上有傳回 error,應透過檢查其是否為 nil 來確認執行時是否有錯誤發生,這是 Go 的錯誤處理風格之一,例如,os.Open 的函式簽署是:
func Open(name string) (file *File, err error)
透過 os.Open 開啟檔案時的一個基本範例就是:
file, err := os.Open("file.go")
if err != nil {
log.Fatal(err)
}
可變參數
在呼叫方法時,若方法的引數個數事先無法決定該如何處理?在 Go 中支援不定長度引數(Variable-length Argument),可以輕鬆的解決這個問題。直接來看示範:
package main
import "fmt"
func Sum(numbers ...int) int {
var sum int
for _, number := range numbers {
sum += number
}
return sum
}
func main() {
fmt.Println(Sum(1, 2)) // 3
fmt.Println(Sum(1, 2, 3)) // 6
fmt.Println(Sum(1, 2, 3, 4)) // 10
fmt.Println(Sum(1, 2, 3, 4, 5)) // 15
}
可以看到,要使用不定長度引數,宣告參數時要於型態關鍵字前加上 ...,此參數本質上是個 slice,因此可以使用 for range 來走訪元素,可接受可變長度的參數只能有一個,而必須是最後一個參數。
雖然可接受可變長度引數的參數,本質上是個 slice,然而,若已經有個 slice,並不能直接傳遞給它,而必須使用 ... 展開,否則會發生錯誤:
package main
import "fmt"
func Sum(numbers ...int) int {
var sum int
for _, number := range numbers {
sum += number
}
return sum
}
func main() {
numbers := []int{1, 2, 3, 4, 5}
fmt.Println(Sum(numbers...)) // 15
}
函式與指標
Go 語言有指標,因此,在變數傳遞就多了一種選擇,直接來看個例子,以下的執行結果會顯示 1:
package main
import "fmt"
func add1To(n int) {
n = n + 1
}
func main() {
number := 1
add1To(number)
fmt.Println(number) // 1
}
這應該沒有問題,因為傳遞的是變數值給 n,函式中 n 的值加上 1 之後,再指定回給 n,這對 main 中的 number 變數毫無影響,因此函式結束後,顯示 number 的值,仍舊是 1。
那麼來看下面這個例子:
package main
import "fmt"
func add1To(n *int) {
*n = *n + 1
}
func main() {
number := 1
add1To(&number)
fmt.Println(number) // 2
}
這次使用了 &number 取得 number 的位址值再傳遞給 n,也就是傳遞了變數位址值給 n,函式中使用 *n 取得位址處的值,加上 1 後再將值存回原位址處,因此,透過 main 函式中的 number 取得的值,也會是加 1 後的值。
Go 1.18+:泛型函式補充
從 Go 1.18 開始,函式宣告可以帶有型別參數(type parameters),可讓同一個函式套用在多種型態上。例如,底下示範搜尋 slice 中第一個相等元素的位置:
package main
import "fmt"
func IndexOf[T comparable](elems []T, target T) int {
for i, elem := range elems {
if elem == target {
return i
}
}
return -1
}
func main() {
fmt.Println(IndexOf([]int{10, 20, 30}, 20)) // 1
fmt.Println(IndexOf([]string{"Go", "Rust"}, "Rust")) // 1
}
[T comparable] 表示 T 是型別參數,而 comparable 是型別條件(constraint);因為函式中用了 ==,所以要求 T 必須可比較。
多數情況下,編譯器可以根據引數自動推斷型別參數,因此通常不用寫成 IndexOf[int](...) 這麼完整。
如果你剛接觸泛型,建議搭配〈泛型入門(Go 1.18+)〉一起閱讀;該章也會補充 any、comparable、型別集合與 Go 1.24/1.26 的相關更新。
Go 1.21+:新的內建函式
雖然 min、max、clear 是內建函式(built-ins),不是一般套件函式,不過常會跟函式主題一起學習。從 Go 1.21 開始,可以直接使用:
package main
import "fmt"
func main() {
scores := []int{10, 20, 30}
fmt.Println(min(10, 3, 22)) // 3
fmt.Println(max(10, 3, 22)) // 22
clear(scores)
fmt.Println(scores) // [0 0 0]
}
clear 對 slice 的效果是「清為零值」,長度不變;對 map 的效果則是刪除全部鍵值對。
從 Go 1.18 開始,Go 支援泛型(Generics,也就是 type parameters)。這讓你可以用同一份程式碼,處理多種型態,而不用到處寫重複函式或依賴 interface{} 加型態斷言。
泛型函式
函式可以在名稱後面宣告型別參數,例如:
package main
import "fmt"
func First[T any](elems []T) (T, bool) {
if len(elems) == 0 {
var zero T
return zero, false
}
return elems[0], true
}
func main() {
if v, ok := First([]int{10, 20, 30}); ok {
fmt.Println(v) // 10
}
if v, ok := First([]string{"Go", "Rust"}); ok {
fmt.Println(v) // Go
}
}
T any 表示 T 可以是任何型態;any 是 interface{} 的別名(Go 1.18 新增)。
通常編譯器可以從引數推斷型別參數,因此呼叫時常不必寫成 First[int](...)。
型別條件(constraints)
如果泛型函式或泛型型別需要使用某些運算(例如 ==、<),就要限制型別參數可接受的型態範圍,這就是型別條件。
package main
import "fmt"
func IndexOf[T comparable](elems []T, target T) int {
for i, elem := range elems {
if elem == target {
return i
}
}
return -1
}
func main() {
fmt.Println(IndexOf([]int{1, 2, 3}, 2)) // 1
fmt.Println(IndexOf([]string{"Go", "C"}, "Rust")) // -1
}
comparable 也是 Go 1.18 新增的預定義識別名稱,只能用在型別條件中。從 Go 1.20 起,可比較(但可能在執行時比較時 panic)的型別,也能滿足 comparable 條件。
介面作為型別集合(type set)
Go 1.18 之後,介面不只描述方法集合,也可以描述型別集合(用於 constraint)。例如:
type Integer interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
~int 表示「底層型態是 int 的型態」,這讓自訂型別(例如 type MyInt int)也能符合條件。
這類帶有 union(|)或具體型別元素的介面,通常只能用在型別條件,不會拿來當一般執行期介面值使用。
泛型型別
不只函式可以用泛型,型別宣告也可以:
package main
import "fmt"
type Stack[T any] struct {
elems []T
}
func (s *Stack[T]) Push(v T) {
s.elems = append(s.elems, v)
}
func (s *Stack[T]) Pop() (T, bool) {
if len(s.elems) == 0 {
var zero T
return zero, false
}
i := len(s.elems) - 1
v := s.elems[i]
s.elems = s.elems[:i]
return v, true
}
func main() {
var s Stack[string]
s.Push("Go")
s.Push("1.26")
v, _ := s.Pop()
fmt.Println(v) // 1.26
}
Go 1.24:generic type aliases
Go 1.24 起,generic type aliases 完整支援,因此可像下面這樣寫:
type Set[T comparable] = map[T]struct{}
這在整理常用資料結構別名時很方便,例如 Set[string]、Set[int]。
Go 1.26:型別參數列表中的自我參照
Go 1.26 放寬了限制,泛型型別可在自己的型別參數列表中參照自己。這對某些泛型介面(特別是要求「輸入輸出都是自身型態」)會比較自然:
package main
import "fmt"
type Adder[A Adder[A]] interface {
Add(A) A
}
type MyInt int
func (x MyInt) Add(y MyInt) MyInt {
return x + y
}
func Algo[A Adder[A]](x, y A) A {
return x.Add(y)
}
func main() {
fmt.Println(Algo(MyInt(10), MyInt(20))) // 30
}
何時該用泛型?
泛型適合用在:
- 演算法或容器邏輯完全相同,只差元素型態(例如 stack、set、搜尋、走訪)
- 想避免
interface{}與型態斷言造成的樣板程式碼與執行期錯誤 - 需要在編譯期保留型態資訊,提高可讀性與型別安全
但如果某個邏輯本質上就是依賴行為(方法)而不是型態,傳統介面仍然常常是更直接的做法。
作為一門現代語言,Go 的特色之一是函式為一級函式(First-class function),可以作為值來進行傳遞。
函式作為值
例如你定義一個取最大值的函式 max,你可以將此函式作為值傳遞給 maximum:
package main
import "fmt"
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
maximum := max
fmt.Println(max(10, 5)) // 10
fmt.Println(maximum(10, 5)) // 10
}
可以看到,被 max 參考的函式,也被 maximum 參考著,因而,現在透過 max 或者 maximum,都可以呼叫函式。
因為 Go 型態推斷能力的關係,上頭的 maximum 並不用宣告型態,而可以直接參考 max 函式的型態,那麼,max 或者是 maximum 的型態是什麼呢?
package main
import "fmt"
import "reflect"
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
maximum := max
fmt.Println(reflect.TypeOf(max)) // func(int, int) int
fmt.Println(reflect.TypeOf(maximum)) // func(int, int) int
}
可以看到,函式的型態包括了 func、參數型態與傳回值型態,但不用宣告函式、參數與傳回值的名稱。
宣告函式變數
你可以僅宣告一個變數可用來參考特定型態的函式,例如:
package main
import "fmt"
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
var maximum func(int, int) int
fmt.Println(maximum) // nil
maximum = max
fmt.Println(maximum(10, 5)) // 10
}
若想先宣告一個 maximum 變數,可以在之後參考 max 函式,可以使用型態 func(int, int) int 來宣告,通常,宣告函式變數時,若想免於冗長的函式型態宣告,可以使用 type 來定義一個新的型態名稱:
package main
import "fmt"
type BiFunc func(int, int) int // 定義了新型態
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
var maximum BiFunc
fmt.Println(maximum) // nil
maximum = max
fmt.Println(maximum(10, 5)) // 10
}
在上例中,BiFunc 是個新的定義型態(defined type),底層型態(underlying type)為 func(int, int) int,Go 會認定兩者屬於不同型態,因為新的型態會擁有新的名稱,在 Go 1.9 前,這是避免冗長函式型態宣告的唯一方式。
不過,就這邊來說,實際上只是想要 func(int, int) int 能有個簡短一點的名稱,從 Go 1.9 開始,可以為型態取別名,別名就只是同一型態的另一個名稱,:
package main
import "fmt"
type BiFunc = func(int, int) int // 型態別名宣告
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
var maximum BiFunc
fmt.Println(maximum) // nil
maximum = max
fmt.Println(maximum(10, 5)) // 10
}
在這邊,BiFunc 只是 func(int, int) int 的另一個名稱,而不是新的型態。
函式變數既然是個變數,也就可以對它取指標,例如:
package main
import "fmt"
type BiFunc = func(int, int) int
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
var maximum BiFunc
fmt.Println(&maximum) // 0x1040a130
// fmt.Println(&max)
}
如上,你可以對 maximum 取指標,得到變數位址,不過,你不能對宣告的 max 取指標,去除程式中最後一個註解的話,會發生 cannot take the address of max 的錯誤。
回呼應用
因為函式可以當作值傳遞,因此,對於函式中流程幾乎相同,只有少數操作不同的情況,就可以將操作不同的部份以回呼(Callback)函式取代。例如,可以設計一個 filter 函式,用來過濾出符合特定條件的值:
package main
import "fmt"
type Predicate = func(int) bool
func filter(origin []int, predicate Predicate) []int {
filtered := []int{}
for _, elem := range origin {
if predicate(elem) {
filtered = append(filtered, elem)
}
}
return filtered
}
func greaterThan7(n int) bool {
return n > 7
}
func lessThan5(n int) bool {
return n < 5
}
func main() {
data := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println(filter(data, greaterThan7))
fmt.Println(filter(data, lessThan5))
}
在這個例子中,filter 函式重用了 for range 與 if 等流程,只要傳入過濾用的函式,就可以讓 filter 具有各種的過濾用途。
除了作為值傳遞之外,Go 的函式還可以是匿名函式,且具有閉包(Closure)的特性,這將在下一篇文件加以說明。
除了作為值傳遞之外,Go 的函式還可以是匿名函式,且具有閉包(Closure)的特性,由於 Go 具有指標,在理解閉包時反而容易一些了。
匿名函式
在〈一級函式〉中,我們看過函式可作為值傳遞的一個應用是,可將函式傳入另一函式作為回呼(Callback),除了傳遞具名的函式之外,有時會想要臨時建立一個函式進行傳遞,例如:
package main
import "fmt"
type Predicate = func(int) bool
func filter(origin []int, predicate Predicate) []int {
filtered := []int{}
for _, elem := range origin {
if predicate(elem) {
filtered = append(filtered, elem)
}
}
return filtered
}
func main() {
data := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println(filter(data, func(elem int) bool {
return elem > 5
}))
fmt.Println(filter(data, func(elem int) bool {
return elem <= 6
}))
}
這個函式與〈一級函式〉中最後一個範例的作用相同,不過這次傳遞了匿名函式給 filter,可以看到,匿名函式可使用 func 建立,同樣必須指定參數與傳回值型態。
在 Go 中,不允許在函式中又宣告函式,例如,以下是不允許的:
func funcA() {
func funcB() {
...
}
...
}
這會出現 “nested func not allowed” 的錯誤,然而,你可以建立匿名函式,然後將之指定給某個變數:
func funcA() {
funcB := func() {
...
}
...
}
你也可以在函式中建立匿名函式,並將之傳回:
package main
import "fmt"
type Func1 = func(int) int
func funcA() Func1 {
x := 10
return func(n int) int {
return x + n
}
}
func main() {
fmt.Println(funcA()(2)) // 12
}
在上面的範例中,執行 funcA 會傳回一個函式,這個傳回的函式會將接受的引數指定給參數 n,並與 x 的值進行相加,因此最後顯示結果為 12。
閉包
可以在函式中建立匿名函式,引發了一個有趣的事實,先來看個例子:
package main
import "fmt"
type Consumer = func(int)
func forEach(elems []int, consumer Consumer) {
for _, elem := range elems {
consumer(elem)
}
}
func main() {
numbers := []int{1, 2, 3, 4, 5}
sum := 0
forEach(numbers, func(elem int) {
sum += elem
})
fmt.Println(sum) // 15
}
乍看之下,似乎有點像是:
package main
import "fmt"
type Consumer = func(int)
func forEach(elems []int, consumer Consumer) {
for _, elem := range elems {
consumer(elem)
}
}
func main() {
numbers := []int{1, 2, 3, 4, 5}
sum := 0
for _, elem := range numbers {
sum += elem
}
fmt.Println(sum) // 15
}
然而意義完全不同。在使用 forEach 函式的範例中,sum 變數被匿名函式包覆並傳入 forEach 之中,在 forEach 執行迴圈的過程中,每次呼叫傳入的函式(被 consumer 參考),就會改變 sum 的值,因此,最後得到的是加總後的值 15。
實際上,使用 forEach 函式的範例中,建立了一個閉包,閉包本質上就是一個匿名函式,sum 變數被閉包包覆,讓 sum 變數可以存活於閉包的範疇中,其實,更之前從 funcA 傳回函式的範例中,也建立了閉包,funcA 的 x 區域變數被閉包包覆,因此,你執行傳回的函式時,即使 funcA 已執行完畢,x 變數依然是存活著在傳回的閉包範疇中,所以,你指定的引數總是會與 x 的值進行相加。
重點在於,閉包將變數本身關閉在自己的範疇中,而不是變數的值,可以用以下這個範例來做個示範:
package main
import "fmt"
type Getter = func() int
type Setter = func(int)
func x_getter_setter(x int) (Getter, Setter) {
getter := func() int {
return x
}
setter := func(n int) {
x = n
}
return getter, setter
}
func main() {
getX, setX := x_getter_setter(10)
fmt.Println(getX()) // 10
setX(20)
fmt.Println(getX()) // 20
}
對 x_getter_setter 來說,x 參數也是變數,x_getter_setter 傳回了兩個匿名函式,這兩個匿名函式都形成了閉包,將 x 變數關閉在自己的範疇中,因此,你使用了 setX(20) 改變了 x 的值,使用 getX() 時取得的值,就會是修改後的值。
閉包與指標
如果你寫過 JavaScript,對於方才的範例,應該不會陌生,也因為 JavaScript 的普及,現在開發者多半對閉包不會覺得神秘難解了,而對於「閉包將變數本身關閉在自己的範疇中,而不是變數的值」,也比較瞭解其應用所在。
由於 Go 語言有指標,我們可以將指標的值顯示出來,這代表著變數的位址值,來看看被閉包關閉的變數,到底是怎麼一回事好了:
package main
import "fmt"
type Getter = func() int
type Setter = func(int)
func x_getter_setter(x int) (Getter, Setter) {
fmt.Printf("the parameter :\tx (%p) = %d\n", &x, x)
getter := func() int {
fmt.Printf("getter invoked:\tx (%p) = %d\n", &x, x)
return x
}
setter := func(n int) {
x = n
fmt.Printf("setter invoked:\tx (%p) = %d\n", &x, x)
}
return getter, setter
}
func main() {
getX, setX := x_getter_setter(10)
fmt.Println(getX())
setX(20)
fmt.Println(getX())
}
這個範例與前一個範例類似,只不過呼叫函式時,都會顯示 x 變數的位址值與儲存值,一個執行結果是:
the parameter : x (0x104382e0) = 10
getter invoked: x (0x104382e0) = 10
10
setter invoked: x (0x104382e0) = 20
getter invoked: x (0x104382e0) = 20
20
看到了嗎?顯示的變數的位址值都是相同的,閉包將變數本身關閉在自己的範疇中,而不是變數的值,就是這麼一回事。
就許多現代語言而言,例外處理機制是基本特性之一,然而,例外處理是好是壞,一直以來存在著各種不同的意見,在 Go 語言中,沒有例外處理機制,取而代之的,是運用 defer、panic、recover 來滿足類似的處理需求。
defer 延遲執行
在 Go 語言中,可以使用 defer 指定某個函式延遲執行,那麼延遲到哪個時機?簡單來說,在函式 return 之前,例如:
package main
import "fmt"
func deferredFunc() {
fmt.Println("deferredFunc")
}
func main() {
defer deferredFunc()
fmt.Println("Hello, 世界")
}
這個範例執行時,deferredFunc() 前加上了 defer,因此,會在 main() 函式 return 前執行,結果就是先顯示了 "Hello, 世界",才顯示 "deferredFunc"。
如果有多個函式被 defer,那麼在函式 return 前,會依 defer 的相反順序執行,也就是 LIFO,例如:
package main
import "fmt"
func deferredFunc1() {
fmt.Println("deferredFunc1")
}
func deferredFunc2() {
fmt.Println("deferredFunc2")
}
func main() {
defer deferredFunc1()
defer deferredFunc2()
fmt.Println("Hello, 世界")
}
由於先 defer 了 deferredFunc1(),才 defer 了 deferredFunc2(),因此執行結果會是 "Hello, 世界"、"deferredFunc2"、"deferredFunc1" 的顯示順序。
上頭是為了清楚表示出 defer 與函式的關係,實際上,你也可以寫成這樣就好:
package main
import "fmt"
func main() {
defer fmt.Println("deffered 1")
defer fmt.Println("deffered 2")
fmt.Println("Hello, 世界")
}
執行結果會是 "Hello, 世界"、"deferred 2"、"deferred 1" 的顯示順序。
有趣的一點是,被 defer 的函式若有接受某變數作為引數,那麼會是被 defer 當時的變數值,例如:
package main
import "fmt"
func main() {
i := 10
defer fmt.Println(i)
i++
fmt.Println(i)
}
在上面的例子中,會顯示 11 與 10,這是因為第一個 fmt.Println(i) 被 defer 時,保有 i 當時的值 10。
使用 defer 清除資源
那麼要用在何處?記得 defer 的特性是在函式 return 前執行,而且一定會被執行,因此,對於以下的這個程式:
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/tmp/dat")
if err != nil {
fmt.Println(err)
} else {
b1 := make([]byte, 5)
n1, err := f.Read(b1)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("%d bytes: %s\n", n1, string(b1))
// 處理讀取的內容....
f.Close()
}
}
}
這是一個讀取檔案的例子,os.Open 與 f.Read 的風格是傳回兩個值,第二個值代表著有無錯誤發生,因此程式中進行了錯誤的檢查,在沒有錯誤的情況下才進行檔案的讀取與內容處理,而最後透過 f.Close() 關閉檔案。
基本上,這個範例的問題在於,f.Close() 不一定會被執行,因為 Go 語言中還有其他展現錯誤的方式,例如使用 panic 函式。假設在「處理讀取的內容」過程中因為呼叫了 panic 來表示有錯誤發生,那麼會立即中斷函式的執行(在這個例子就是直接離開 main 函式),這時 f.Close() 就不會被執行。
你可以使用 defer 來執行函式的關閉:
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/tmp/dat")
if err != nil {
fmt.Println(err)
return;
}
defer func() { // 延遲執行,而且函式 return 前一定會執行
if f != nil {
f.Close()
}
}()
b1 := make([]byte, 5)
n1, err := f.Read(b1)
if err != nil {
fmt.Printf("%d bytes: %s\n", n1, string(b1))
// 處理讀取的內容....
}
}
這麼一來,若 Read 發生錯誤,最後一定會執行被 defer 的函式,從而保證了 f.Close() 一定會關閉檔案。
(就某些意義來說,defer 的角色類似於例外處理機制中 finally 的機制,將資源清除的函式,藉由 defer 來處理,一方面大概也是為了在程式碼閱讀上,強調出資源清除的重要性吧!)
panic 恐慌中斷
方才稍微提過,如果在函式中執行 panic,那麼函式的流程就會中斷,若 A 函式呼叫了 B 函式,而 B 函式中呼叫了 panic,那麼 B 函式會從呼叫了 panic 的地方中斷,而 A 函式也會從呼叫了 B 函式的地方中斷,若有更深層的呼叫鏈,panic 的效應也會一路往回傳播。
(如果你有例外處理的經驗,這就相當於被拋出的例外都沒有處理的情況。)
可以將方才的範例改寫為以下:
package main
import (
"fmt"
"os"
)
func check(err error) {
if err != nil {
panic(err)
}
}
func main() {
f, err := os.Open("/tmp/dat")
check(err)
defer func() {
if f != nil {
f.Close()
}
}()
b1 := make([]byte, 5)
n1, err := f.Read(b1)
check(err)
fmt.Printf("%d bytes: %s\n", n1, string(b1))
}
如果在開啟檔案時,就發生了錯誤,假設這是在一個很深的呼叫層次中發生,若你直接想撰寫程式,將 os.Open 的 error 逐層傳回,那會是一件很麻煩的事,此時直接發出 panic,就可以達到想要的目的。
recover 恢復流程
如果發生了 panic,而你必須做一些處理,可以使用 recover,這個函式必須在被 defer 的函式中執行才有效果,若在被 defer 的函式外執行,recover 一定是傳回 nil。
如果有設置 defer 函式,在發生了 panic 的情況下,被 defer 的函式一定會被執行,若當中執行了 recover,那麼 panic 就會被捕捉並作為 recover 的傳回值,那麼 panic 就不會一路往回傳播,除非你又呼叫了 panic。
因此,雖然 Go 語言中沒有例外處理機制,也可使用 defer、panic 與 recover 來進行類似的錯誤處理。例如,將上頭的範例,再修改為:
package main
import (
"fmt"
"os"
)
func check(err error) {
if err != nil {
panic(err)
}
}
func main() {
f, err := os.Open("/tmp/dat")
check(err)
defer func() {
if err := recover(); err != nil {
fmt.Println(err) // 這已經是頂層的 UI 介面了,想以自己的方式呈現錯誤
}
if f != nil {
if err := f.Close(); err != nil {
panic(err) // 示範再拋出 panic
}
}
}()
b1 := make([]byte, 5)
n1, err := f.Read(b1)
check(err)
fmt.Printf("%d bytes: %s\n", n1, string(b1))
}
在這個例子中,假設已經是最頂層的 UI 介面了,因此使用 recover 嘗試捕捉 panic,並以自己的方式呈現錯誤,附帶一題的是,關閉檔案也有可能發生錯誤,程式中也檢查了 f.Close(),視需求而定,你可以像這邊重新拋出 panic,或者也可以單純地設計一個 UI 介面來呈現錯誤。
什麼時候該用 error?什麼時候該用 panic?在 Go 的慣例中,鼓勵你使用 error,明確地進行錯誤檢查,然而,就如方才所言,巢狀且深層的呼叫時,使用 panic 會比較便於傳播錯誤,就 Go 的慣例來說,是以套件為界限,於套件之中,必要時可以使用 panic,而套件公開的函式,建議以 error 來回報錯誤,若套件公開的函式可能會收到 panic,建議使用 recover 捕捉,並轉換為 error。
有些資料會有相關性,例如,一個 XY 平面上的點可以使用 (x, y) 座標來表示;名稱、郵件位址、電話可能代表著一張名片上的資訊。將相關聯的資料組織在一起,對於資料本身的可用性或者是程式碼的可讀性,都會有所幫助。
struct 組織資料
Go 語言中有 struct,可以用來將相關的資料組織在一起,如果你學過 C 語言,這對你應該不陌生。舉個例子來說,相對於個別地存取 x、y 變數:
package main
import "fmt"
func main() {
x := 10
y := 20
fmt.Printf("{%d %d}\n", x, y) // {10 20}
x = 20
y = 30
fmt.Printf("{%d %d}\n", x, y) // {20 30}
}
若 x 與 y 變數,相當於 XY 平面上的 (x, y) 座標,那麼將之組織在一起同時存取會比較好:
package main
import "fmt"
func main() {
point := struct{ x, y int }{10, 20}
fmt.Printf("{%d %d}\n", point.x, point.y) // {10 20}
point.x = 20
point.y = 30
fmt.Printf("{%d %d}\n", point.x, point.y) // {20 30}
}
實際上,fmt.Println 可以直接處理 struct,因此,上面的例子,可以直接使用 fmt.Println(point) 來得到相同的顯示結果。
在上面的例子中,struct 定義了一個結構,當中包括了 x 與 y 兩個值域(field),接著馬上用它來建立了一個實例,依順序指定了 x 與 y 的值是 10 與 20,可以看到,想要存取結構的值域,可以運過點運算子(.)。
基於結構定義新型態
上面的例子中,建立了一個匿名型態的結構,你可以使用 type 基於 struct 來定義新型態,例如:
package main
import "fmt"
type Point struct {
X, Y int
}
func main() {
point1 := Point{10, 20}
fmt.Println(point1) // {10 20}
point2 := Point{Y: 20, X: 30}
fmt.Println(point2) // {30 20}
}
在上面基於結構定義了新型態 Point,留意到名稱開頭的大小寫,若是大寫的話,就可以在其他套件中存取,這點對於結構的值域也是成立,大寫名稱的值域,才可以在其他套件中存取。在範例中也可以看到,建立並指定結構的值域時,可以直接指定值域名稱,而不一定要按照定義時的順序。
如果一開始不知道結構的值域數值為何,可以使用 var 宣告即可,那麼值域會依型態而有適當的預設值。例如:
package main
import "fmt"
type Point struct {
X, Y int
}
func main() {
var point Point
fmt.Println(point) // {0 0}
}
point 並不是參考,point 的位置開始,有一片可以儲存結構的空間,可以使用 & 來取得 point 的位址值,point 的位址值無法改變。
結構與指標
如果你建立了一個結構的實例,並將之指定給另一個結構變數,那麼會進行值域的複製。例如:
package main
import "fmt"
type Point struct {
X, Y int
}
func main() {
point1 := Point{X: 10, Y: 20}
point2 := point1
point1.X = 20
fmt.Println(point1) // {20, 20}
fmt.Println(point2) // {10 20}
}
這對於函式的參數傳遞也是一樣的:
package main
import "fmt"
type Point struct {
X, Y int
}
func changeX(point Point) {
point.X = 20
fmt.Println(point)
}
func main() {
point := Point{X: 10, Y: 20}
changeX(point) // {20 20}
fmt.Println(point) // {10 20}
}
point 的位置開始儲存了結構,可以對 point 使用 & 取值,將位址值指定給指標,因此若指定或傳遞結構時,不是想要複製值域,可以使用指標。例如:
package main
import "fmt"
type Point struct {
X, Y int
}
func main() {
point1 := Point{X: 10, Y: 20}
point2 := &point1
point1.X = 20
fmt.Println(point1) // {20, 20}
fmt.Println(point2) // &{20 20}
}
注意到 point2 := &point1 多了個 &,這取得了 point1 實例的指標值,並傳遞給 point2,point2 的型態是 *Point,也就是相當於 var point2 *Point = &point1,因此,當你透過 point1.X 改變了值,透過 point2 就能取得對應的改變。
類似地,也可以在傳遞參數給函式時使用指標:
package main
import "fmt"
type Point struct {
X, Y int
}
func changeX(point *Point) {
point.X = 20
fmt.Printf("&{%d %d}\n", point.X, point.Y)
}
func main() {
point := Point{X: 10, Y: 20}
changeX(&point) // &{20 20}
fmt.Println(point) // {20 20}
}
可以看到在 Go 語言中,即使是指標,也可以直接透過點運算子來存取值域,這是 Go 提供的語法糖,point.X 在編譯過後,會被轉換為 (*point).X。
你也可以透過 new 來建立結構實例,這會傳回結構實例的位址:
package main
import "fmt"
type Point struct {
X, Y int
}
func default_point() *Point {
point := new(Point)
point.X = 10
point.Y = 10
return point
}
func main() {
point := default_point()
fmt.Println(point) // &{10 10}
}
在這邊,point 是個指標,也就是 *Point 型態,儲存了結構實例的位址。
結構的值域也可以是指標型態,也可以是結構自身型態之指標,因此可實現鏈狀參考,例如:
package main
import "fmt"
type Point struct {
X, Y int
}
type Node struct {
point *Point
next *Node
}
func main() {
node := new(Node)
node.point = &Point{10, 20}
node.next = new(Node)
node.next.point = &Point{10, 30}
fmt.Println(node.point) // &{10 20}
fmt.Println(node.next.point) // &{10 30}
}
$T{} 的寫法與 new(T) 是等效的,使用 &Point{10, 20} 這類的寫法,可以同時指定結構的值域。
在〈結構入門〉中看過,有些資料會有相關性,相關聯的資料組織在一起,對於資料本身的可用性或者是程式碼的可讀性,都會有所幫助,實際上,有些資料與可處理它的函式也會有相關性,將相關聯的資料與函式組織在一起,對資料與函式本身的可用性或者是程式碼的可讀性,也有著極大的幫助。
建立方法
假設可能原本有如下的程式內容,負責銀行帳戶的建立、存款與提款:
package main
import (
"errors"
"fmt"
)
type Account struct {
id string
name string
balance float64
}
func Deposit(account *Account, amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
account.balance += amount
}
func Withdraw(account *Account, amount float64) error {
if amount > account.balance {
return errors.New("餘額不足")
}
account.balance -= amount
return nil
}
func String(account *Account) string {
return fmt.Sprintf("Account{%s %s %.2f}",
account.id, account.name, account.balance)
}
func main() {
account := &Account{"1234-5678", "Justin Lin", 1000}
Deposit(account, 500)
Withdraw(account, 200)
fmt.Println(String(account)) // Account{1234-5678 Justin Lin 1300.00}
}
實際上,Desposit、Withdraw、String 的函式操作,都是與傳入的 Account 實例有關,何不將它們組織在一起呢?這樣比較容易使用些,在 Go 語言中,你可以重新修改函式如下:
package main
import (
"errors"
"fmt"
)
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
func (ac *Account) String() string {
return fmt.Sprintf("Account{%s %s %.2f}",
ac.id, ac.name, ac.balance)
}
func main() {
account := &Account{"1234-5678", "Justin Lin", 1000}
account.Deposit(500)
account.Withdraw(200)
fmt.Println(account.String()) // Account{1234-5678 Justin Lin 1300.00}
}
簡單來說,只是將函式的第一個參數,移至方法名稱之前成為函式呼叫的接收者(Receiver),這麼一來,就可以使用 account.Deposit(500)、account.Withdraw(200)、account.String() 這樣的方式來呼叫函式,就像是物件導向程式語言中的方法(Method)。
注意到,在這邊使用的是 (ac *Account),也就是指標,如果你是如下使用 (ac Account):
func (ac Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
那麼執行像是 account.Deposit(500),就像是以 Deposit(*account, 500) 呼叫以下函式:
func Deposit(account Account, amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
account.balance += amount
}
也就是,相當於將 Account 實例以傳值方式複製給 Deposit 函式的參數。
某些程度上,可以將接收者想成是其他語言中的 this 或 self,Go 建議為接收者適當命名,而不是用 this、self 之類的名稱。接收者並沒有文件上記載的作用,命名時不用其他參數具有一定的描述性,只要能表達程式意圖就可以了,Go 建議是個一或兩個字母的名稱(某些程度上,也可以用來與其他參數區別)。
名稱相同的方法
之前談過,Go 語言中不允許方法重載(Overload),因此,對於以下的程式,是會發生 String 重複宣告的編譯錯誤:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
func String(account *Account) string {
return fmt.Sprintf("Account{%s %s %.2f}",
account.id, account.name, account.balance)
}
type Point struct {
x, y int
}
func String(point *Point) string { // String redeclared in this block 的編譯錯誤
return fmt.Sprintf("Point{%d %d}", point.x, point.y)
}
func main() {
account := &Account{"1234-5678", "Justin Lin", 1000}
point := &Point{10, 20}
fmt.Println(account.String())
fmt.Println(point.String())
}
然而,若是將函式定義為方法,就不會有這個問題,Go 可以從方法的接收者辨別,該使用哪個 String 方法:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
func (ac *Account) String() string {
return fmt.Sprintf("Account{%s %s %.2f}",
ac.id, ac.name, ac.balance)
}
type Point struct {
x, y int
}
func (p *Point) String() string {
return fmt.Sprintf("Point{%d %d}", p.x, p.y)
}
func main() {
account := &Account{"1234-5678", "Justin Lin", 1000}
point := &Point{10, 20}
fmt.Println(account.String()) // Account{1234-5678 Justin Lin 1000.00}
fmt.Println(point.String()) // Point{10 20}
}
方法作為值
在 Go 語言中,函式也可以作為值傳遞,那麼就產生了一個問題,方法呢?既然方法本質上也是個函式,那麼是否也可以作為值傳遞,答案是可以的,不過,以上面的程式為例,你不能直接以 String := String 這樣的方式傳遞,而必須使用方法運算式(Method expression)。例如:
package main
import (
"errors"
"fmt"
)
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
func (ac *Account) String() string {
return fmt.Sprintf("Account{%s %s %.2f}",
ac.id, ac.name, ac.balance)
}
func main() {
deposit := (*Account).Deposit
withdraw := (*Account).Withdraw
String := (*Account).String
account1 := &Account{"1234-5678", "Justin Lin", 1000}
deposit(account1, 500)
withdraw(account1, 200)
fmt.Println(String(account1)) // Account{1234-5678 Justin Lin 1300.00}
account2 := &Account{"5678-1234", "Monica Huang", 500}
deposit(account2, 250)
withdraw(account2, 150)
fmt.Println(String(account2)) // Account{5678-1234 Monica Huang 600.00}
}
可以看到,這樣取得的函式,就像是本文一開始的範例那樣,你可以傳入任何的 Account 實例。另一個取得方法的方式是方法值(Method value),這會保有取得方法當時的接收者:
package main
import (
"errors"
"fmt"
)
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
func (ac *Account) String() string {
return fmt.Sprintf("Account{%s %s %.2f}",
ac.id, ac.name, ac.balance)
}
func main() {
account1 := &Account{"1234-5678", "Justin Lin", 1000}
acct1Deposit := account1.Deposit
acct1Withdraw := account1.Withdraw
acct1String := account1.String
acct1Deposit(500)
acct1Withdraw(200)
fmt.Println(acct1String()) // Account{1234-5678 Justin Lin 1300.00}
account2 := &Account{"5678-1234", "Monica Huang", 500}
acct2Deposit := account2.Deposit
acct2Withdraw := account2.Withdraw
acct2String := account2.String
acct2Deposit(250)
acct2Withdraw(150)
fmt.Println(acct2String()) // Account{5678-1234 Monica Huang 600.00}
}
值都能有方法
實際上,不只是結構的實例可以定義方法,在 Go 語言中,只要是值,就可以定義方法,條件是必須是定義的型態(defined type),具體而言,就是使用 type 定義的新型態。
例如,以下的範例為 []int 定義了一個新的型態名稱,並定義了一個 ForEach 方法:
package main
import "fmt"
type IntList []int
type Funcint func(int)
func (lt IntList) ForEach(f Funcint) {
for _, ele := range lt {
f(ele)
}
}
func main() {
var lt IntList = []int{10, 20, 30, 40, 50}
lt.ForEach(func(ele int) {
fmt.Println(ele)
})
}
這個範例會顯示 10 到 50 作為結果,必須留意的是,type 定義了新型態 Funcint,因為 ForEach 是針對 Funcint 定義,而不是針對 []int,因此底下是行不通的:
lt2 := []int {10, 20, 30, 40, 50}
// lt2.ForEach undefined (type []int has no field or method ForEach)
lt2.ForEach(func(ele int) {
fmt.Println(ele)
})
編譯器認為 []int 並沒有定義 ForEach,因此發生錯誤,想要通過編譯的話,可以進行型態轉換:
lt2 := IntList([]int {10, 20, 30, 40, 50})
lt2.ForEach(func(ele int) {
fmt.Println(ele)
})
你甚至可以基於 int 等基本型態定義方法,同樣地,必須定義一個新的型態名稱:
package main
import (
"fmt"
)
type Int int
type FuncInt func(Int)
func (n Int) Times(f FuncInt) {
if n < 0 {
panic("必須是正數")
}
var i Int
for i = 0; i < n; i++ {
f(i)
}
}
func main() {
var x Int = 10
x.Times(func(n Int) {
fmt.Println(n)
})
}
像這樣基於某個基本型態定義新型態,並為其定義更多高階特性,在 Go 的領域是常見的做法。這個範例會顯示 0 到 9,看起來就像是指定函式,要求執行 x 次吧!…XD
nil 接收者
在 Go 中,接收者可以是 nil,這讓你有機會在方法中處理接收者為 nil 的情況,例如:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
func (ac *Account) String() string {
if ac == nil {
return "<nil>"
}
return fmt.Sprintf("Account{%s %s %.2f}",
ac.id, ac.name, ac.balance)
}
func findById(id string) *Account {
accts := []*Account{&Account{"123", "Justin Lin", 10000}, &Account{"456", "Monica", 10000}}
for i := 0; i < len(accts); i++ {
if accts[i].id == id {
return accts[i]
}
}
return nil
}
func main() {
fmt.Println(findById("123").String())
fmt.Println(findById("789").String())
}
如果是其他語言,例如 Java 的話,在 findById("789").String() 的地方會 NullPointerException,不過在 Go 中,可以針對接收者是否為 nil,來決定如何處理,例如這邊就實作了 nil safety 的概念。
模擬建構式、初始式
Go 沒有物件導向語言中建構式或初始式之類的概念,然而可以自行模擬,例如在 container/list 的原始碼可以看到 New 作為一個工廠函式,用來建立新的 List,初始的流程寫在 Init 方法之中:
...
// Init initializes or clears list l.
func (l *List) Init() *List {
l.root.next = &l.root
l.root.prev = &l.root
l.len = 0
return l
}
// New returns an initialized list.
func New() *List { return new(List).Init() }
結構本身用來組織相關資料,可以將處理結構的相關函式定義為方法,類似物件導向程式語言中,使用類別定義值域與方法,那麼繼承呢?Go 語言並非以物件導向為主要典範的語言,沒有繼承的概念,不過可以使用組合代替繼承。
在組告之前
在〈結構與方法〉中使用 struct 定義了 Account,如果今天你想定義一個支票帳戶,方式之一是…
type CheckingAccount struct {
id string
name string
balance float64
overdraftlimit float64
}
這是個很尋常的作法,也許你想將 id、name 與 balance 組織在一起:
package main
import "fmt"
type CheckingAccount struct {
account struct {
id string
name string
balance float64
}
overdraftlimit float64
}
func main() {
checking := CheckingAccount{}
checking.account = struct {
id string
name string
balance float64
}{"1234-5678", "Justin Lin", 1000}
checking.overdraftlimit = 30000
fmt.Println(checking) // {{1234-5678 Justin Lin 1000} 30000}
fmt.Println(checking.account) // {1234-5678 Justin Lin 1000}
fmt.Println(checking.account.name) // Justin Lin
fmt.Println(checking.overdraftlimit) // 30000
}
這是一種方式,不過使用起來麻煩,或許你可以這麼做:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
type CheckingAccount struct {
account Account
overdraftlimit float64
}
func main() {
checking := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
fmt.Println(checking) // {{1234-5678 Justin Lin 1000} 30000}
fmt.Println(checking.account) // {1234-5678 Justin Lin 1000}
fmt.Println(checking.account.name) // Justin Lin
fmt.Println(checking.overdraftlimit) // 300000
}
看來還不錯,不過,如果想要 fmt.Println(checking.name) 就能取得名稱的話,這種寫法行不通!
結構值域的查找
在定義結構時,可以將另一已定義的結構直接內嵌:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func main() {
account := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
fmt.Println(account) // {{1234-5678 Justin Lin 1000} 30000}
fmt.Println(account.id) // 1234-5678
fmt.Println(account.name) // Justin
fmt.Println(account.balance) // 1000
fmt.Println(account.overdraftlimit) // 30000
}
這稱為型態內嵌(type embedding),Account 被稱為 CheckingAccount 的內部型態,反之,CheckingAccount 是 Account 的外部型態,雖然是透過 account.id、account.name、account.balance 來存取,不過內部型態提昇,令內部型態定義的值域為可見。
那麼,如果想要明確地透過 Account 的結構來存取呢?也是可以的:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func main() {
account := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
fmt.Println(account) // {{1234-5678 Justin Lin 1000} 30000}
fmt.Println(account.Account.id) // 1234-5678
fmt.Println(account.Account.name) // Justin
fmt.Println(account.Account.balance) // 1000
fmt.Println(account.overdraftlimit) // 30000
}
雖然內部型態會提昇,然而,若外部型態中定義了同名值域,就會直接取得外部型態的值域,因此,如果 CheckingAccount 定義了相同的值域 balance,如果透過 account.balance,結果會是找到 CheckingAccount 定義的 balance,如果想明確找到 Account 的 balance,可以指定 Account 作為前置:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
type CheckingAccount struct {
Account
balance float64
overdraftlimit float64
}
func main() {
account := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 2000, 30000}
fmt.Println(account.balance) // 2000
fmt.Println(account.Account.balance) // 1000
}
無論是結構值域或是方法,若來自兩個結構的值域或方法產生了同名衝突,Go 會有 ambiguous selector 的錯誤提示,此時你必須明確指定結構名稱,指定使用來自哪個結構的值域或方法。
方法的查找
如果內部型態原本定義了方法,這些方法也是查找時的對象:
package main
import (
"errors"
"fmt"
)
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func main() {
account := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
account.Deposit(2000)
account.Withdraw(500)
fmt.Println(account) // {{1234-5678 Justin Lin 2500} 30000}
}
類似地,若外部型態中定義了同名的方法,那麼就會使用該方法,這類似重新定義(Override)的概念:
package main
import (
"errors"
"fmt"
)
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func (ac *CheckingAccount) Withdraw(amount float64) error {
if amount > ac.balance+ac.overdraftlimit {
return errors.New("超出信用額度")
}
ac.balance -= amount
return nil
}
func main() {
account := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
account.Deposit(2000)
if err := account.Withdraw(50000); err != nil {
fmt.Println(err)
} else {
fmt.Println(account)
}
}
在上面的範例中,會顯示「超出信用額度」的訊息,拿掉 func (account *CheckingAccount) Withdraw(amount float64) 該函式的定義,則會顯示「餘額不足」的訊息。
如果想指定使用 Account 的 Withdraw 函式,也還是可以的:
func main() {
account := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
account.Deposit(2000)
if err := account.Account.Withdraw(50000); err != nil {
fmt.Println(err)
} else {
fmt.Println(account)
}
}
雖然可以實現方法重新定義的概念,不過,單純只是如上定義的話,並不支援多型的概念,因為一開始這麼指定就會出錯了:
// cannot use CheckingAccount literal (type CheckingAccount) as type Account in assignment
var account Account = CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
若想實作出多型的概念,必須使用 interface,這在之後的文件會加以說明。
在〈結構組合〉的最後討論到了多型,倘若現在需要有個函式,可以接受 Account 與 CheckingAccount 實例,或者是有個陣列或 slice,可以收集 Account 與 CheckingAccount實例,那該怎麼辦呢?
介面定義行為
在 Go 語言中,可以使用 interface 定義行為,舉例來說,若現在想要定義儲蓄的行為,可以如下:
type Savings interface {
Deposit(amount float64)
Withdraw(amount float64) error
}
注意,不必使用 func 關鍵字,也不用宣告接受者型態,只需要定義行為的名稱、參數與傳回值。接著該怎麼實現這個介面呢?實際上,就〈結構組合〉,已經實現了這個介面,也就是說,結構上不用任何關鍵字,只要有函式實現這兩個行為就可以了。
因此,現在可以寫個函式,同時接受 Account 與 CheckingAccount 實例,在提款後顯示餘額:
package main
import (
"errors"
"fmt"
)
type Savings interface {
Deposit(amount float64)
Withdraw(amount float64) error
}
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func (ac *CheckingAccount) Withdraw(amount float64) error {
if amount > ac.balance+ac.overdraftlimit {
return errors.New("超出信用額度")
}
ac.balance -= amount
return nil
}
func Withdraw(savings Savings) {
if err := savings.Withdraw(500); err != nil {
fmt.Println(err)
} else {
fmt.Println(savings)
}
}
func main() {
account1 := Account{"1234-5678", "Justin Lin", 1000}
account2 := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
Withdraw(&account1) // 顯示 &{1234-5678 Justin Lin 500}
Withdraw(&account2) // 顯示 &{{1234-5678 Justin Lin 500} 30000}
}
雖然沒有定義接收者為 *CheckingAccount 的 Deposit 方法,然而,作為內部型態的 Account 有定義 Deposit(並且沒有使用到 CheckingAccount 定義的值域),這個實現被提昇至外部型態,也就滿足了 Savings 要求的行為規範。
注意!由於在實作 Withdraw 與 Deposit 方法時,都是用指標 (ac *Account) 或 (ac *CheckingAccount) 宣告了接受者型態,因此傳遞實例給 func Withdraw(savings Savings) 時,也就必須傳遞指標。
如果在實作Withdraw 與 Deposit 方法時,是使用 (ac Account) 或 (ac CheckingAccount) 宣告了接受者型態,那麼傳遞實例給接受 Savings 的函式時,就可以不用取指標,例如:
package main
import (
"errors"
"fmt"
)
type Savings interface {
Deposit(amount float64)
Withdraw(amount float64) error
}
type Account struct {
id string
name string
balance float64
}
func (ac Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func (ac CheckingAccount) Withdraw(amount float64) error {
if amount > ac.balance+ac.overdraftlimit {
return errors.New("超出信用額度")
}
ac.balance -= amount
return nil
}
func Withdraw(savings Savings) {
if err := savings.Withdraw(500); err != nil {
fmt.Println(err)
} else {
fmt.Println(savings)
}
}
func main() {
account1 := Account{"1234-5678", "Justin Lin", 1000}
account2 := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
Withdraw(account1) // 顯示 {1234-5678 Justin Lin 1000}
Withdraw(account2) // 顯示 {{1234-5678 Justin Lin 1000} 30000}
}
當然,就這個例子來說,結果並不是正確的,就算改成 Withdraw(&account1) 與 &Withdraw(account2),也不會是正確的結果,因為就 Withdraw 與 Deposit 的接收者來說,會是複製結構的值域,而不是修改原結構實例的值域,這純綷只是示範。
介面實例的型態與值
如果你定義了一個變數:
var savings Savings
那麼 savings 變數儲存了什麼?技術上來說,savings 變數儲存兩個資訊:型態與值。就方才的savings 被指定為 nil 來說,代表著 savings 在底層儲存的型態為 nil,而值沒有指定,這樣的介面實例稱為 nil interface,因為沒有型態資訊,也就不能透過 nil interface 呼叫方法。
如果接收者是定義為 (ac *Account),而且有底下的程式,那麼 savings 底層儲存的型態會 *Account,而值是 Account 結構實例的位址值:
var savings Savings = &Account{"1234-5678", "Justin Lin", 1000}
當接收者是指標時,透過介面比對是否為 nil 時要留意,例如以下會是 true,這是因為 savings 在底層儲存的型態為 nil,而值沒有指定,介面宣告的變數只有在這個情況下,跟 nil 直接相等比較才會是 true:
var savings Savings = nil
fmt.Println(savings == nil)
然而以下會是 false,這是因為 savings 在底層儲存的型態為 *Account,而值是 nil(
這時透過 savings 是可以呼叫方法的,接收者會是 nil,就看你要不要在方法中處理 nil 了):
var acct *Account = nil
var savings Savings = acct
fmt.Println(savings == nil)
這是個 FAQ 了,在〈Why is my nil error value not equal to nil?〉就提到了個例子:
func returnsError() error {
var p *MyError = nil
if bad() {
p = ErrBad
}
return p
}
如果對 returnsError 傳回值進行 nil 比較,結果會是 false:
fmt.Println(returnsError() == nil) // false
因此如果傳回型態是個介面,值會是 nil,請記得直接傳 nil:
func returnsError() error {
if bad() {
return ErrBad
}
return nil // 直接傳 nil
}
如果接收者是定義為 (ac Account),而你有底下的程式:
var savings Savings = Account{"1234-5678", "Justin Lin", 1000}
這時 savings 在底層會儲存型態 Account,而值為結構實例,這時透過 Savings 來進行實例的指定時,底層也會是結構實例的指定,因此會發生複製:
var savings1 Savings = Account{"1234-5678", "Justin Lin", 1000}
var savings2 Savings = savings1
savings2.name = "Monica Huang"
fmt.Println(savings.name) // Justin Lin
Go 1.18+:介面也可作為型別條件
從 Go 1.18 開始,interface 除了用來描述物件要有哪些方法,也可以用來描述「型別集合(type set)」,作為泛型的型別條件(constraint)。
例如:
type StringKeyed interface {
~string
}
func HasKey[K StringKeyed, V any](m map[K]V, key K) bool {
_, ok := m[key]
return ok
}
上例中的 StringKeyed 並不是拿來做一般執行期介面值(例如 var x StringKeyed),而是拿來限制型別參數 K 的可用型別。
另外,Go 1.18 也新增了兩個常見的預定義識別名稱:
any:interface{}的別名。comparable:可用==、!=比較的型別集合(只能用在型別條件)。
Go 1.20 之後,像一般介面型別這類「可比較但可能在執行時 panic」的型別,也可以滿足 comparable 條件,因此像 Set[any] 這類泛型實例化會更容易成立;只是若實際比較到不可比較的動態值(例如內含 slice 的介面值),仍可能在執行時發生 panic。
異質陣列或 slice
Go 語言會檢查類型的實例,是否實現了介面中規範的行為,若是的話,就可以使用介面型態來接受不同型態實例的指定,因此,若要建立一個異質陣列或 slice,也是可以的:
package main
import (
"errors"
"fmt"
)
type Savings interface {
Deposit(amount float64)
Withdraw(amount float64) error
}
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) {
if amount <= 0 {
panic("必須存入正數")
}
ac.balance += amount
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func (ac *CheckingAccount) Withdraw(amount float64) error {
if amount > ac.balance+ac.overdraftlimit {
return errors.New("超出信用額度")
}
ac.balance -= amount
return nil
}
func main() {
savingsArray := [...]Savings{
&Account{"1234-5678", "Justin Lin", 1000},
&CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000},
}
for _, savings := range savingsArray {
fmt.Println(savings)
}
savingsSlice := []Savings{
&Account{"1234-5678", "Justin Lin", 1000},
&CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000},
}
for _, savings := range savingsSlice {
fmt.Println(savings)
}
}
在這邊雖然是以 Account 及 CheckingAccount 為例,不過,只要實現了 Savings 的行為,就算是一隻鴨子,也是可以的:
package main
import "fmt"
type Savings interface {
Deposit(amount float64)
Withdraw(amount float64) error
}
type Duck struct{}
func (d *Duck) Deposit(amount float64) {
fmt.Println("我是一隻鴨子,我沒帳戶")
}
func (d *Duck) Withdraw(amount float64) error {
fmt.Println("我是一隻鴨子,我沒錢")
return nil
}
func main() {
duckArray := [...]Savings{
&Duck{},
&Duck{},
}
for _, duck := range duckArray {
duck.Deposit(1000)
}
duckSlice := []Savings{
&Duck{},
&Duck{},
}
for _, duck := range duckSlice {
duck.Withdraw(500)
}
}
空介面
那麼,如果想要建立一個實例容器,可以收集各種類型的實例,要怎麼做呢?答案就是透過空介面,也就是沒有定義任何行為的 interface {}。
package main
import "fmt"
type Duck struct{}
func main() {
instances := [](interface{}){
&Duck{},
[...]int{1, 2, 3, 4, 5},
map[string]int{"caterpillar": 123456, "monica": 54321},
}
for _, instance := range instances {
fmt.Println(instance)
}
}
如果你查看 fmt.Println 的文件說明,可以發現,它的參數類型就是 interface {}:
func Print(a ...interface{}) (n int, err error)
func Printf(format string, a ...interface{}) (n int, err error)
func Println(a ...interface{}) (n int, err error)
順便一提的是,就目前來說,在使用 fmt.Println 顯示結構時,都是使用預設的字串格式,如果想自訂字串格式,必須實現 Stringer 這個介面,這定義在 fmt 的 print.go 之中:
type Stringer interface {
String() string
}
在需要字串的場合中,會呼叫 String() 方法。例如,若你想要帳號顯示時,可以出現 Account 或 CheckingAccount 字樣的話,可以如下實作:
package main
import "fmt"
type Account struct {
id string
name string
balance float64
}
func (ac *Account) String() string {
return fmt.Sprintf("Account(id = %s, name = %s, balance = %.2f)",
ac.id, ac.name, ac.balance)
}
type CheckingAccount struct {
Account
overdraftlimit float64
}
func (ac *CheckingAccount) String() string {
return fmt.Sprintf("CheckingAccount(id = %s, name = %s, balance = %.2f, overdraftlimit = %.2f)",
ac.id, ac.name, ac.balance, ac.overdraftlimit)
}
func main() {
account1 := Account{"1234-5678", "Justin Lin", 1000}
account2 := CheckingAccount{Account{"1234-5678", "Justin Lin", 1000}, 30000}
// 顯示 Account(id = 1234-5678, name = Justin Lin, balance = 1000.00)
fmt.Println(&account1)
// 顯示 CheckingAccount(id = 1234-5678, name = Justin Lin, balance = 1000.00, overdraftlimit = 30000.00)
fmt.Println(&account2)
}
實作某介面的型態有哪些?
來自 Java 之類語言的開發者,在認識 Go 的 interface 後可能會有些疑問,像是「如何知道某個介面的實現型態有哪些?」、「這個型態實現了哪些介面?」…並且會想在文件上尋找這類資訊,因為 Java 的文件中,會記錄某介面的實現類別有哪些。
這是因為 Java 中,介面型態與行為是結合在一起的。
在 Go 中不需要記錄這些,當開發者看到某 API 上定義可以接收某介面型態的值時,應該看看該介面定義了哪些行為,接著看看要傳入的值是否有實作這些行為,這樣就可以了,因為 Go 的介面重點是「行為」,不管 API 上定義的介面型態是什麼,只要行為符合都可以傳入。
也就是說 Go 中,介面型態與行為是分開的,應該重視的只有行為本身,本質上與動態定型語言中只重行為而非型態相同,因此「如何知道某個介面的實現型態有哪些?」、「這個型態實現了哪些介面?」這類問題也就不重要了!
宣告介面時使用的名稱,只是一個方便取用及閱讀的標示,最重要的是介面中定義的行為,以及實際的接收者型態。因此,若你打算從一個介面轉換至另一個介面,只要行為符合就可以了。例如以下是可行的:
package main
import "fmt"
type ATester interface {
test()
}
type BTester interface {
test()
}
type Subject struct {
name string
}
func (s *Subject) test() {
fmt.Println(s)
}
func main() {
var testerA ATester = &Subject{"Test"}
var testerB BTester = testerA
testerA.test()
testerB.test()
}
在第二個指定時,編譯器會檢查 testerA 的型態定義,也就是介面中,是否定義了 test() 行為,若是則可通過編譯,若否就編譯錯誤。例如以下的情況:
package main
import "fmt"
type ATester interface {
testA()
}
type BTester interface {
testB()
}
type Subject struct {
name string
}
func (s *Subject) testA() {
fmt.Println(s)
}
func (s *Subject) testB() {
fmt.Println(s)
}
func main() {
var testerA ATester = &Subject{"Test"}
var testerB BTester = testerA // 錯誤:ATester does not implement BTester
testerA.testA()
testerB.testB()
}
就算 testerA 儲存的結構實例,確實有實作testB() 這個方法,然而從編譯器的角度來看,testerA 的行為只有 testA(),而看不到它有 testB() 的行為,因此上面這個範例會編譯錯誤。
Comma-ok 型態斷言
如果真的要通過編譯,可以使用型態斷言(Type assertion):
...同前…略
func main() {
var testerA ATester = &Subject{"Test"}
var testerB BTester = testerA.(BTester)
testerA.testA()
testerB.testB()
}
x.(T) 這個語法,x 的型態是某介面,而 T 是預期的型態,或者是值實作的另一個介面名稱,在〈介面入門〉中談過,介面底層儲存了型態與值的資訊,x.(T) 是在告知編譯器,在執行時期再來斷言型態,也就是執行時期再來判斷 x 底層儲存的值,型態是否為 T,若是就傳回底層儲存的值。
型態斷言與型態轉換不同,型態轉換是將值的型態轉換為另一型態,編譯器會檢查兩個型態的資料結構是否相同,若否會發生編譯錯誤。
斷言是執行時期進行的,在底下的範例中,執行時期會斷言 value 底層儲存的值,其型態為 Duck:
package main
import "fmt"
type Duck struct {
name string
}
func main() {
values := [...](interface{}){
Duck{"Justin"},
Duck{"Monica"},
}
for _, value := range values {
duck := value.(Duck)
fmt.Println(duck.name)
}
}
如果 value 底層儲存的值,其型態為實際上不是 Duck 型態,那麼操作 duck 時會發生執行時期錯誤,為了避免這類錯誤發生,可以進行 Comma-ok 型態斷言,例如:
package main
import "fmt"
type Duck struct {
name string
}
func main() {
values := [...](interface{}){
Duck{"Justin"},
Duck{"Monica"},
[...]int{1, 2, 3, 4, 5},
map[string]int{"caterpillar": 123456, "monica": 54321},
}
for _, value := range values {
if duck, ok := value.(Duck); ok {
fmt.Println(duck.name)
}
}
}
第一個 duck 變數是 Duck 型態,若 value 底層儲存的值確實是 Duck 型態,ok 變數會是 true,否則 ok 會是 false,因此,在上面的例子中,只會針對 Duck 顯示其 name 的值。
在〈介面入門〉中談過,底下的範例會是 false:
var acct *Account = nil
var savings Savings = acct
fmt.Println(savings == nil) // false
實際上 savings 底層儲存的值確實是 nil,透過型態斷言的話可以取出。例如:
var acct *Account = nil
var savings Savings = acct
fmt.Println(savings.(*Account) == nil) // true
型態 switch 測試
依照上面的說明,如果想測試多個型態,可以用多個 if...else if,例如:
package main
import "fmt"
type Duck struct {
name string
}
func main() {
values := [...](interface{}){
Duck{"Justin"},
Duck{"Monica"},
[...]int{1, 2, 3, 4, 5},
map[string]int{"caterpillar": 123456, "monica": 54321},
10,
}
for _, value := range values {
if duck, ok := value.(Duck); ok {
fmt.Println(duck.name)
} else if arr, ok := value.([5]int); ok {
fmt.Println(arr)
} else if passwds, ok := value.(map[string]int); ok {
fmt.Println(passwds)
} else if i, ok := value.(int); ok {
fmt.Println(i)
} else {
fmt.Println("非預期之型態")
}
}
}
不過,針對這個情況,使用型態 switch 測試會更為適合:
package main
import "fmt"
type Duck struct {
name string
}
func main() {
values := [...](interface{}){
Duck{"Justin"},
Duck{"Monica"},
[...]int{1, 2, 3, 4, 5},
map[string]int{"caterpillar": 123456, "monica": 54321},
10,
}
for _, value := range values {
switch v := value.(type) {
case Duck:
fmt.Println(v.name)
case [5]int:
fmt.Println(v[0])
case map[string]int:
fmt.Println(v["caterpillar"])
case int:
fmt.Println(v)
default:
fmt.Println("非預期之型態")
}
}
}
value.(type) 這樣的語法,只能用在 switch 之中。
來看個實際的應用,在 Go 的 fmt 中,有個 print.go 的原始碼,其中有一段是針對傳入的引數,是實作了 Error 介面或 Stringer 介面,若實作了 Error 介面,則呼叫其 Error() 方法,若實作了 Stringer 介面,就呼叫其 String() 方法:
720 switch v := p.arg.(type) {
721 case error:
722 handled = true
723 defer p.catchPanic(p.arg, verb)
724 p.printArg(v.Error(), verb, depth)
725 return
726
727 case Stringer:
728 handled = true
729 defer p.catchPanic(p.arg, verb)
730 p.printArg(v.String(), verb, depth)
731 return
732 }
有時,可能會想要基於某個已定義的介面,並新增自己的行為,在 Go 中,這類似於結構中方法的查找,只要在定義介面時,內嵌想要的介面名稱就可以了。例如:
package main
import "fmt"
type ParentTester interface {
ptest()
}
type ChildTester interface {
ParentTester
ctest()
}
type Subject struct {
name string
}
func (s *Subject) ptest() {
fmt.Printf("ptest %s\n", s)
}
func (s *Subject) ctest() {
fmt.Printf("ctest %s\n", s)
}
func main() {
var tester ChildTester = &Subject{"Test"}
tester.ptest()
tester.ctest()
}
在上面,Subject 必須實作 ParentTester 與 ChildTest 中定義的全部行為,其實例才可以被指定 ChildTest。你也可以介面中包含多個介面:
package main
import "fmt"
type SuperTester interface {
stest()
}
type ParentTester interface {
ptest()
}
type ChildTester interface {
SuperTester
ParentTester
ctest()
}
type Subject struct {
name string
}
func (s *Subject) stest() {
fmt.Printf("stest %s\n", s)
}
func (s *Subject) ptest() {
fmt.Printf("ptest %s\n", s)
}
func (s *Subject) ctest() {
fmt.Printf("ctest %s\n", s)
}
func main() {
var tester ChildTester = &Subject{"Test"}
tester.stest()
tester.ptest()
tester.ctest()
}
如果多個介面間的行為重複定義了,就會出現 duplicate method 的錯誤。(這是個有爭議性的特性,因為許多人認為,實際上雖然在介面語法上確實重複定義了行為,然而就 Duck typing 的精神來看,結構上只要有實作行為就可以了,事實上在其他語言中,像是 Java 中,類似的情況並不會發生編譯錯誤,有關此議題,可參考 golang/go 的 此 issue)。
雖然說這像是介面有了繼承方面的語法,然而更精確地說,應該是行為的內嵌,因此,只要是有實現相關行為,就算沒有被包含在某個介面中,也可以做介面轉換:
package main
import "fmt"
type SuperTester interface {
stest()
}
type ParentTester interface {
ptest()
}
type ChildTester interface {
SuperTester
ParentTester
ctest()
}
type Tester interface {
stest()
ptest()
ctest()
}
type Subject struct {
name string
}
func (s *Subject) stest() {
fmt.Printf("stest %s\n", s)
}
func (s *Subject) ptest() {
fmt.Printf("ptest %s\n", s)
}
func (s *Subject) ctest() {
fmt.Printf("ctest %s\n", s)
}
func main() {
var ctester ChildTester = &Subject{"Test"}
var tester Tester = ctester
tester.stest()
tester.ptest()
tester.ctest()
}
有些文件會說,在介面有組合關係時,子介面的實例可以指定給父介面,反之就不行,這種說法不能說是錯,畢竟就上例來說,ChildTester 介面的實例,被指定給 ParentTester 介面時,從編譯器的角度來看,ChildTester 介面確實是有 ParentTester 介面的行為;反過來的話,ParentTester 介面被指定給 ChildTester 介面時,編譯器是看不到 ParentTester 介面上,會有 ChildTester 介面行為的,當然會發生錯誤。
更精確來說,Go 本身並非基於類別,沒有提供繼承語法,也就沒有父介面、子介面的概念,以上僅僅只是以行為的內嵌實現了繼承的概念,因而是就看不看得到相關的行為,來判斷是否可通過編譯。
Go 1.18+:型別條件中的介面組合
從 Go 1.18 開始,介面除了行為組合,也能在泛型中用來組合型別條件。這類介面通常不是拿來建立執行期介面值,而是用在型別參數限制上。
例如,可以先定義數值族群,再組合成更大的條件:
type Integer interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
type Unsigned interface {
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr
}
type Number interface {
Integer
Unsigned
~float32 | ~float64
}
這裡的 Number 是透過介面內嵌(組合)與 union type element(|)建立出來的型別條件。
Go 1.24 起,generic type aliases 完整支援,因此可以更自然地把這類條件用在 alias 上,例如:
type Set[T comparable] = map[T]struct{}
Go 1.26 也放寬了限制:泛型型別可以在自己的型別參數列表中參照自己,像是:
type Adder[A Adder[A]] interface {
Add(A) A
}
這對某些需要「與自身同型態運算」的泛型介面或資料結構定義會比較直接。
若要輸出訊息至主控台,可以透過 fmt 的 Print、Println、Printf 等函式,如果要從主控台讀取使用者輸入,可以透過 fmt 的 Scanf、Scanln 等函式。例如:
package main
import "fmt"
func main() {
fmt.Print("輸入名稱 年齡:")
var name string
var age int
fmt.Scanf("%s %d", &name, &age)
fmt.Printf("嗨!%s!今年 %d 歲了啊?", name, age)
}
%s、%d 是格式符號,在 Go 中稱為 verb,Go 可用的 verb 可以在 fmt 套件的文件中找到。
Scanf 就類似 C 語言中的 scanf,可以格式化地取得輸入,底下是個範例:
輸入名稱 年齡:Justin 45
嗨!Justin!今年 45 歲了啊?
在按下 Enter 鍵後,實際上還有個 CR(carriage return)字元還未掃描,如果只是要取得空白分隔的輸入,並以換行作為結束,可以使用 Scanln:
package main
import "fmt"
func main() {
fmt.Print("輸入空白分隔的文字")
var text1, text2 string
fmt.Scanln(&text1, &text2)
fmt.Println(text1)
fmt.Println(text2)
}
如果是 Scan 的話,也是掃描以空白區隔的輸入,按下 Enter 鍵的 CR 字元,也會被視為空白。
Println、Printf 會使用標準輸出(Standout),如果想使用標準錯誤(Standard err)呢?可以透過 Fprint、Fprintln、Fprintf 等函式,第一個引數指定 os.Stderr。例如:
package main
import (
"fmt"
"os"
)
func main() {
fmt.Fprintln(os.Stderr, "輸出至標準錯誤")
}
os 套件的 Stderr 代表標準錯誤,而 Stdin、Stdout 代表標準輸入與輸出,它們的型態是 *os.File,若願意的話,也可以直接操作它們,例如 File 定義了 Read 與 Write 方法,可以指定一個型態為 byte[] 的 slice,Read 會讀入同樣長度的資料至 slice,後者可以將同等長度的資料輸出。例如:
package main
import "os"
func main() {
buf := make([]byte, 5);
os.Stdout.Write([]byte("輸入五個數字:"))
os.Stdin.Read(buf)
os.Stdout.Write(buf)
}
實際上,os.File 可用的方法不只有 Read、Write,先留意這兩個方法的目的在於,這兩個方法分別符合 io.Reader、io.Writer 定義的行為:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
如果察看 fmt 的 Fprint、Fprintln、Fprintf 等函式,可以發現它們第一個參數宣告的型態並不是 *os.File,而是 io.Writer:
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Fprintln(w io.Writer, a ...interface{}) (n int, err error)
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
類似地,Fscan 字樣開頭的幾個函式,第一個參數接受的是 io.Reader:
func Fscan(r io.Reader, a ...interface{}) (n int, err error)
func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error)
func Fscanln(r io.Reader, a ...interface{}) (n int, err error)
這表示,fmt 套件中這些函式,並不只能用於標準輸入、輸出或錯誤,例如,strings.NewReader 函式,可以指定字串,傳回 *Reader,這表示 fmt 的 Fscanf 等函式,可以從字串讀取輸入。例如:
package main
import (
"fmt"
"io"
"strings"
)
func main() {
data := `Justin 45
Monica 42
Irene 12`
r := strings.NewReader(data)
var name string
var age int
for {
if _, err := fmt.Fscanln(r, &name, &age); err == io.EOF {
break
}
fmt.Printf("%s: %d\n", name, age)
}
}
Fscanln 會傳回掃描的筆數,如果筆數少於指定的掃描數量,err 會指出原因,在檔案讀取結束(End of file)時,err 會是 io.EOF,在上例中,資料來源是個格式確定的字串,因此僅簡單地判斷 err 是否為 io.EOF 來結束掃描。
os.File 不過是具有 io.Reader、io.Writer 的行為罷了,os.File 代表檔案,也就是說 Fprint、Fprintln、Fprintf、Fscan、Fscanln、Fscanf 等函式,也可以用在檔案讀寫,其實標準輸入、輸出、錯誤等,也是被視為檔案的,這在 os 的 file.go 可以看到:
var (
Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")
Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")
Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr")
)
因此 IO 之類的操作,在 Go 中非常靈活,一切都看 API 上可接受行為而定,不受型態之限制,這之後再從實際的例子中來談。
在〈從標準輸入、輸出認識 io〉中談到了 io.Reader、io.Writer,在 Go 中,這兩個介面抽象化了輸入、輸出,認識這兩個介面分別定義的 Read、Write 行為,是掌握 Go 中輸入、輸出的基礎。
io.Reader 定義的 Read 行為,可以在 type Reader 查看:
type Reader interface {
Read(p []byte) (n int, err error)
}
對於呼叫者來說,Read 會將資料讀入 p,並傳回讀入的位元組數 n,n 會是 0 到不大於 len(p) 的整數,如果 n 不是 0 但不足 len(p),應該先處理已讀取的位元組,這時 err 可能不是 nil(例如檔案結尾,可能會傳回 io.EOF),無論如何,在這之後 Read,n 會是 0 而 err 會是 io.EOF。
例如,若要讀取一個文字檔案,其中以 UTF-8 儲存中文,可以如下:
package main
import (
"fmt"
"io"
"os"
)
func printUTF8TC(r io.Reader) (err error) {
var (
buf = make([]byte, 3)
n int
)
for err == nil {
n, err = r.Read(buf)
fmt.Print(string(buf[:n]))
}
if err == io.EOF {
err = nil
}
return
}
func main() {
fmt.Print("檔案來源:")
var filename string
fmt.Scanf("%s", &filename)
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
printUTF8TC(f)
}
io.Writer 定義的 Write 行為,可以在 type Writer 查看:
type Writer interface {
Write(p []byte) (n int, err error)
}
Write 會將 p 輸出並傳回實際輸出的位元組,n 會是 0 到不大於 len(p) 的整數,如果 n < len(p),那麼 err 不會是 nil。
來寫個 Copy 函式好了,可以將 io.Reader 的資料直接寫到 io.Writer:
package main
import (
"fmt"
"io"
"os"
)
func write(w io.Writer, buf []byte, n int) (err error) {
nw, ew := w.Write(buf[:n])
if ew != nil {
return ew
}
if n != nw {
return io.ErrShortWrite
}
return nil
}
func Copy(w io.Writer, r io.Reader) (err error) {
buf := make([]byte, 32 * 1024)
for {
nr, er := r.Read(buf)
if nr > 0 {
err = write(w, buf, nr)
if err != nil {
return
}
}
if er != nil {
if er != io.EOF {
err = er
}
return
}
}
}
func main() {
fmt.Print("檔案來源:")
var filename string
fmt.Scanf("%s", &filename)
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
Copy(os.Stdout, f)
}
在這個例子中,可以將指定的檔案讀入並顯示在主控台中,這是因為 os.Stdout 具有 io.Writer 的行為。實際上,io.Copy 就提供了這個功能:
package main
import (
"fmt"
"io"
"os"
)
func main() {
fmt.Print("檔案來源:")
var filename string
fmt.Scanf("%s", &filename)
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
io.Copy(os.Stdout, f)
}
io.Reader、io.Writer 定義了基於位元組的讀寫行為,然而許多情況下,你會想要基於字串、行來進行讀寫,這可以透過 bufio 套件的 bufio.Reader、bufio.Writer 等達到。
bufio.Reader 可以透過 NewReader、NewReaderSize 指定 io.Reader 來建立實例,前者指定預設緩衝區大小 4096 位元組呼叫後者,bufio.Reader 在讀取來源時會從底層的 io.Reader 將資料讀入,在建立 bufio.Reader 實例之後,可以使用的方法有:
func (b *Reader) Buffered() int
func (b *Reader) Discard(n int) (discarded int, err error)
func (b *Reader) Peek(n int) ([]byte, error)
func (b *Reader) Read(p []byte) (n int, err error)
func (b *Reader) ReadByte() (byte, error)
func (b *Reader) ReadBytes(delim byte) ([]byte, error)
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error)
func (b *Reader) ReadRune() (r rune, size int, err error)
func (b *Reader) ReadSlice(delim byte) (line []byte, err error)
func (b *Reader) ReadString(delim byte) (string, error)
func (b *Reader) Reset(r io.Reader)
func (b *Reader) Size() int
func (b *Reader) UnreadByte() error
func (b *Reader) UnreadRune() error
func (b *Reader) WriteTo(w io.Writer) (n int64, err error)
因此對於逐行讀取一個 UTF-8 文字檔案來說,可以簡單地撰寫如下:
package main
import (
"bufio"
"os"
"fmt"
"io"
)
func printFile(f *os.File) (err error){
var (
r = bufio.NewReader(f)
line string
)
for err == nil {
line, err = r.ReadString('\n')
fmt.Println(line)
}
if err == io.EOF {
err = nil
}
return
}
func main() {
var filename string
fmt.Print("檔案名稱:")
fmt.Scanf("%s", &filename);
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
printFile(f)
}
如果實際上是要讀取之後寫到另一個輸出,使用 WriteTo 方法更為方便:
package main
import (
"bufio"
"os"
"fmt"
)
func main() {
var filename string
fmt.Print("檔案名稱:")
fmt.Scanf("%s", &filename);
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
bufio.NewReader(f).WriteTo(os.Stdout)
}
Go 在 io.WriteTo 介面定義了 WriteTo 行為:
type WriterTo interface {
WriteTo(w Writer) (n int64, err error)
}
實際上 bufio.Reader 實作了 io 中一些介面,io.WriteTo 只是其中之一;類似地,如果要建立 bufio.Writer 實例,可以透過 NewWriter、NewWriterSize 函式,建立之後可用的方法如下:
func (b *Writer) Available() int
func (b *Writer) Buffered() int
func (b *Writer) Flush() error
func (b *Writer) ReadFrom(r io.Reader) (n int64, err error)
func (b *Writer) Reset(w io.Writer)
func (b *Writer) Size() int
func (b *Writer) Write(p []byte) (nn int, err error)
func (b *Writer) WriteByte(c byte) error
func (b *Writer) WriteRune(r rune) (size int, err error)
func (b *Writer) WriteString(s string) (int, error)
bufio.Writer 實作了 io 中一些介面,像是 io.ReadFrom,因此,也可以如下在標準輸出中,顯示讀入的的檔案內容:
package main
import (
"bufio"
"os"
"fmt"
)
func main() {
var filename string
fmt.Print("檔案名稱:")
fmt.Scanf("%s", &filename);
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
w := bufio.NewWriter(os.Stdout)
w.ReadFrom(f)
w.Flush()
}
NewWriter 預設的緩衝區為 4096 位元組,由於這邊使用標準輸出,在緩衝區未滿前,資料不會寫出,可以使用 Flush 來出清緩衝區中的資料。
事實上,對於需要逐行讀取的需求,使用 bufio.Scanner 會比較方便,可以使用 NewScanner 來建立實例,建立之後有以下的方法可以使用:
func (s *Scanner) Buffer(buf []byte, max int)
func (s *Scanner) Bytes() []byte
func (s *Scanner) Err() error
func (s *Scanner) Scan() bool
func (s *Scanner) Split(split SplitFunc)
func (s *Scanner) Text() string
來看看讀取文字檔案的例子:
package main
import (
"bufio"
"os"
"fmt"
)
func main() {
var filename string
fmt.Print("檔案名稱:")
fmt.Scanf("%s", &filename);
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
if err := scanner.Err(); err != nil {
panic(err)
}
}
想要進行目錄、檔案等的操作,基本上就是查看 os 套件,可以使用的函式很多,逐一談好像也沒太大意義,基本上若對目錄、檔案以及權限等有所認識,應該查查文件、搜尋一些範例,大致就知道怎麼用吧!
無論如何,輸入輸出中最基本的就是檔案讀寫,至今為止看過,要開啟檔案進行讀取的話,使用的是 os.Open 函式,這會以唯讀方式開啟既有的檔案(否則會有 PathError):
func Open(name string) (*File, error)
如果要指定讀寫方式與權限的話,要使用 os.OpenFile:
func OpenFile(name string, flag int, perm FileMode) (*File, error)
flag 可以指定的常數有:
const (
// 必須指定 O_RDONLY、O_WRONLY 或 O_RDWR
O_RDONLY int = syscall.O_RDONLY // 唯讀
O_WRONLY int = syscall.O_WRONLY // 唯寫
O_RDWR int = syscall.O_RDWR // 讀寫
// 接下來這些可以用 | 的方式附加行為
O_APPEND int = syscall.O_APPEND // 寫入時使用附加方式
O_CREATE int = syscall.O_CREAT // 檔案不存在時建立新檔
O_EXCL int = syscall.O_EXCL // 與 O_CREATE 併用,檔案必須不存在
O_SYNC int = syscall.O_SYNC // 以同步 I/O 開啟
O_TRUNC int = syscall.O_TRUNC // 檔案開啟時清空文件
)
perm 的話是檔案八進位權限,例如 0777;另外,還有個 os.Create,實現上就是使用 OpenFile 以 0666 的方式建立可讀寫的檔案(清空文件):
func Create(name string) (*File, error) {
return OpenFile(name, O_RDWR|O_CREATE|O_TRUNC, 0666)
}
Open、OpenFile 或 Create 都會傳回 *os.File;另外還有個 NewFile,多數情況下用不到,主要是在將檔案描述(File descriptor)以 *os.File 來表示,例如,os.Stdin、os.Stdout、os.Stderr,在〈從標準輸入、輸出認識 io〉看過它的使用:
var (
Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")
Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")
Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr")
)
syscall.Stdin、syscall.Stdout、syscall.Stderr 分別是標準輸入、輸出、錯誤的檔案描述,這在 syscall 的文件可以看到:
var (
Stdin = 0
Stdout = 1
Stderr = 2
)
os.File 實作了 io.Reader、io.Writer 等行為,因此只要知道〈io.Reader、io.Writer〉,剩下的就是查詢文件,看看有哪些方法可以使用,沒什麼特別需要示範的了,倒是若需要簡單的檔案讀寫,可以看看 ioutil 套件(歷史 API),其中有些簡便的函式:
func NopCloser(r io.Reader) io.ReadCloser
func ReadAll(r io.Reader) ([]byte, error)
func ReadDir(dirname string) ([]os.FileInfo, error)
func ReadFile(filename string) ([]byte, error)
func TempDir(dir, prefix string) (name string, err error)
func TempFile(dir, pattern string) (f *os.File, err error)
func WriteFile(filename string, data []byte, perm os.FileMode) error
ReadFile、WriteFile 只要指定檔案名稱等,程式碼上不需要自行建立檔案、緩衝區之類的,這些函式在 ioutil 套件 的文件中,都有範例可以參考。
補充(Go 1.16+):ioutil 已棄用(deprecated),功能多已移到 io 與 os:
ioutil.ReadAll -> io.ReadAll
ioutil.ReadFile -> os.ReadFile
ioutil.WriteFile -> os.WriteFile
ioutil.TempDir -> os.MkdirTemp
ioutil.TempFile -> os.CreateTemp
對於錯誤,Go 不採取例外處理機制,而是透過傳回 error 值來表示是否發生了什麼錯誤,最基本的做法就是:
if err != nil {
// 做些什麼
}
然而,接觸 Go 不用多久就會發現,若要認真地檢查、處理錯誤,if err != nil 之類的程式碼就會到處充斥,特別是在進行 IO 之類的操作時更是如此,單純地 if err != nil 寫法最後會寫到懷疑人生,這麼寫真的是對的嗎?
這時可能會做的選擇之一是:就別檢查了吧!如果寫的是特定目的之程式、不太需要考慮太多狀況、不用考慮過多的穩固性、想要很快地寫出原型之類的,這個選擇可能是正確的,畢竟真要認真寫 Go 中的錯誤檢查,某些程度上就像 Java 中常被人嫌的受檢例外(Checked exception)一樣囉嗦,還好 Go 可以選擇不檢查…XD
只不過,如果想寫出較通用、具有穩固性的程式,錯誤檢查就是必需的,Go 也鼓勵開發者積極地檢查錯誤;那麼…乾脆全 panic 好了?
func check(err) {
if err != nil {
panic(err)
}
}
這麼一來,遇到要檢查錯誤時,就呼叫 check 來檢查,這樣就能少寫些 if err != nil 了吧!這種做法其實並不建議,因為 panic 是 panic,error 是 error,panic 的場合,應該用在適用 panic 的場合,也就是那些實際上真的無法處理的錯誤,發生這類錯誤最重要的引發開發者恐慌,讓開發者知道要修改程式的演算,避免發生 panic。
panic 就像 Java 中發生 RuntimeException,其實不建議捕捉,而是停下程式,修正演算上的錯誤。
不過,可以想想為什麼會有人想在發生錯誤時,一律引發 panic,因為可以從目前的執行處中斷,就像例外處理機制中例外發生時,後續程式碼就不會執行那樣。
這就是以檢查是否有錯誤的方式,沒辦法直接做到的事,因為不在檢查出錯誤的時候進行 return、break 之類的動作,程式碼就會往下執行。
為了能在錯誤發生時中斷流程,就有可能寫出這類的程式碼:
_, err = fd.Write(p0[a:b])
if err != nil {
return err
}
_, err = fd.Write(p1[c:d])
if err != nil {
return err
}
_, err = fd.Write(p2[e:f])
if err != nil {
return err
}
// 諸如此類
這段程式碼摘自〈Errors are values〉,該文章中提到一個解決的方式是:
var err error
write := func(buf []byte) {
if err != nil {
return
}
_, err = w.Write(buf)
}
write(p0[a:b])
write(p1[c:d])
write(p2[e:f])
// 諸如此類
if err != nil {
return err
}
這麼一來,每一次 write 呼叫時,就都會檢查 err 是否為 nil,如果不是 nil 就 return,實際上也就不會執行 w.Write,雖然程式碼上呼叫了 write 多次;然而,某次呼叫若發生了錯誤,後續的 write 並不會真正執行寫出的動作,而透過這個方式,可以將發生錯誤時要進行的動作,統整在最後檢查並執行。
匿名函式的方式建立了 Closure,捕捉了 err 變數,這麼一來就得做些迴避同名變數的問題,另外匿名函式的寫法也不是那麼簡明,因此文章中定義了:
type errWriter struct {
w io.Writer
err error
}
func (ew *errWriter) write(buf []byte) {
if ew.err != nil {
return
}
_, ew.err = ew.w.Write(buf)
}
這麼一來,每個 io.Writer 可以有個別的 err 可以使用,而原本的程式就可以改寫為:
ew := &errWriter{w: fd}
ew.write(p0[a:b])
ew.write(p1[c:d])
ew.write(p2[e:f])
// 諸如此類
if ew.err != nil {
return ew.err
}
在〈bufio 套件〉中看過的 bufio.Writer 就是這類的設計:
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}
...略
func (b *Writer) Write(p []byte) (nn int, err error) {
for len(p) > b.Available() && b.err == nil {
var n int
if b.Buffered() == 0 {
// Large write, empty buffer.
// Write directly from p to avoid copy.
n, b.err = b.wr.Write(p)
} else {
n = copy(b.buf[b.n:], p)
b.n += n
b.Flush()
}
nn += n
p = p[n:]
}
if b.err != nil {
return nn, b.err
}
n := copy(b.buf[b.n:], p)
b.n += n
nn += n
return nn, nil
}
... 略
func (b *Writer) Flush() error {
if b.err != nil {
return b.err
}
if b.n == 0 {
return nil
}
n, err := b.wr.Write(b.buf[0:b.n])
if n < b.n && err == nil {
err = io.ErrShortWrite
}
if err != nil {
if n > 0 && n < b.n {
copy(b.buf[0:b.n-n], b.buf[n:b.n])
}
b.n -= n
b.err = err
return err
}
b.n = 0
return nil
}
在 b.err 不為 nil 的情況下,實際上不會有實際的寫出,而 Flush 時,若 b.err 不為 nil 就會被 return,因此在使用 bufio.Writer 時,可以如下撰寫,在最後檢查
b := bufio.NewWriter(fd)
b.Write(p0[a:b])
b.Write(p1[c:d])
b.Write(p2[e:f])
// 諸如此類
if b.Flush() != nil {
return b.Flush()
}
這個模式可以進一步應用,例如在〈bufio 套件〉中看過 bufio.Scanner 的使用,語意上比較高階:
scanner := bufio.NewScanner(f)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
if err := scanner.Err(); err != nil {
panic(err)
}
scanner.Scan() 傳回布林值,表示是否掃描到下一行,沒有下一行或中途發生錯誤,就會傳回 false;然而迴圈檢查就只在乎有沒有下一行,離開迴圈後再來檢查錯誤,兩個程式區塊各司其職。
bufio.Scanner 本身的組成中有 io.Reader 與 err:
type Scanner struct {
r io.Reader
...略
err error
...略
}
若你查看 Scan 方法的實作,會傳回 false 的情況之一,就是 Scanner 的 err 不是 nil:
...略
if s.err != nil {
// Shut it down.
s.start = 0
s.end = 0
return false
}
...略
Go 不以特定語法處理錯誤(例如 Java 使用 try..catch),正因為錯誤發生是傳回錯誤,也就會有許多方式可以檢查錯誤,這邊只是談到幾個可用的設計,重點在於觀察程式碼的需求,適時地重構,看看如何以設計的方式,優雅地處理錯誤,而不是避免檢查錯誤,如果一開始沒什麼方向,可以多觀察 Go 程式庫的原始碼實作中是怎麼處理錯誤的。
如果函式或方法傳回錯誤,要比對的不單只是 nil 與否,例如,讀取檔案時,會需要判斷傳回的錯誤是否為 io.EOF,那麼 io.EOF 這些錯誤是什麼呢?在 io 套件的 io.go 原始碼中可以看到,它們就是個 errors.New 建出的值罷了:
var ErrShortWrite = errors.New("short write")
var ErrShortBuffer = errors.New("short buffer")
var EOF = errors.New("EOF")
var ErrUnexpectedEOF = errors.New("unexpected EOF")
var ErrNoProgress = errors.New("multiple Read calls return no data or error")
在 errors 套件的 errors.go 可以看到,errors.New 建立的是個結構值,只有一個 string 欄位,並且實作了 Error 方法:
func New(text string) error {
return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
字串是可以比較的(Comparable),errorString 結構也是個可以比較的,因此可以直接使用 == 來比較錯誤是否為 io.EOF 等,在開發自己的應用程式或程式庫時,對於通用、簡單的錯誤,也可以如上定義。
errors.New 建立的實例,能攜帶的資訊就只是字串罷了,如果錯誤發生時,需要傳遞更多的環境資訊,怎麼辦呢?
在方法宣告傳回錯誤時的 error 其實是個內建的介面,定義的正是 Error 方法:
type error interface {
Error() string
}
也就是說,只要有實作 Error 方法,都可以作為 error 實例傳回,例如,os.PathError 在 os 套件的 error.go 是這麼定義的:
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }
func (e *PathError) Unwrap() error { return e.Err }
func (e *PathError) Timeout() bool {
t, ok := e.Err.(timeout)
return ok && t.Timeout()
}
也就是說,若錯誤是 PathError 實例,可以有透過欄位或者是方法來取得更多資訊,例如:
if e, ok := err.(*PathError); ok {
// 透過 e 取得欄位或呼叫方法
}
若要多種類型要判斷,可以使用型態 switch 語法,例如 os 套件的 error.go 內部實作就有個例子:
func underlyingError(err error) error {
switch err := err.(type) {
case *PathError:
return err.Err
case *LinkError:
return err.Err
case *SyscallError:
return err.Err
}
return err
}
像 PathError 中還包含了 Err 欄位,這並非必要,其應用的情境是在呼叫某函式時檢查到錯誤,除了建立另一個錯誤實例收集當時的環境資訊之外,你可能會想要包裹來源的錯誤實例,以便後續呼叫者可以進一步檢視錯誤根源。
然而,當某個錯誤包裹了另一個錯誤,也就表示後續呼叫者得知道該錯誤的細節,如果這些細節來自另一個底層,而你不想曝露,就不要直接包裹它,這時在目前應用程式或程式庫的抽象層面中,抽取出來源錯誤中的資訊,包裝為目前層次的錯誤就可以了。
在 Go 1.13 之前,errors 套件只公開了 New 函式,從 Go 1.13 之後,增加了 Is、As、與 Unwrap 函式。
Is 函式是用於取代 == 判斷錯誤的場合,例如以下的程式片段:
if err == io.EOF {
...
}
可以改用 Is 函式:
if errors.Is(err, io.EOF) {
...
}
Is 也可以用於判斷 nil,err 若有實作 Is 方法,也可以使用 Is 函式來判斷,因為 Is 函式的原始碼是這麼實作的:
func Is(err, target error) bool {
if target == nil {
return err == target
}
isComparable := reflectlite.TypeOf(target).Comparable()
for {
if isComparable && err == target {
return true
}
if x, ok := err.(interface{ Is(error) bool }); ok && x.Is(target) {
return true
}
// TODO: consider supporing target.Is(err). This would allow
// user-definable predicates, but also may allow for coping with sloppy
// APIs, thereby making it easier to get away with them.
if err = Unwrap(err); err == nil {
return false
}
}
}
(從原始碼中的註解可以看到,未來可能進一步支援 target 實作 Is 方法的情況。)
As 函式是用於取代型態斷言判斷錯誤類型的場合,例如以下的程式片段:
if e, ok := err.(*PathError); ok {
...
}
可以改用 As 函式:
var e *PathError
if errors.As(err, &e) {
...
}
來看看 As 函式的實作:
func As(err error, target interface{}) bool {
if target == nil {
panic("errors: target cannot be nil")
}
val := reflectlite.ValueOf(target)
typ := val.Type()
if typ.Kind() != reflectlite.Ptr || val.IsNil() {
panic("errors: target must be a non-nil pointer")
}
if e := typ.Elem(); e.Kind() != reflectlite.Interface && !e.Implements(errorType) {
panic("errors: *target must be interface or implement error")
}
targetType := typ.Elem()
for err != nil {
if reflectlite.TypeOf(err).AssignableTo(targetType) {
val.Elem().Set(reflectlite.ValueOf(err))
return true
}
if x, ok := err.(interface{ As(interface{}) bool }); ok && x.As(target) {
return true
}
err = Unwrap(err)
}
return false
}
target 若不是指標就會 panic;另外,err 可以是個實作 As 方法的實例。
在 Is 與 As 的實作中,都看到了 Unwrap 函式:
func Unwrap(err error) error {
u, ok := err.(interface {
Unwrap() error
})
if !ok {
return nil
}
return u.Unwrap()
}
從 Go 1.13 開始,錯誤可以實作 Unwrap 方法,如果 e1.Unwrap() 可以得到 e2,那麼 e1 實例包裹了 e2,因此,對於需要包含根源錯誤的情況,保存根源錯誤的欄位不需要是公開的,可以透過 Unwrap 來傳回,Unwrap 為取得包裹的錯誤提供了統一的名稱。
fmt 套件有個 Errorf 函式,可以格式化字串並傳回 error 實例,在 Go 1.13 之前的版本,就只是將格式化後的字串傳給 errors.New;從 Go 1.13 開始,Errorf 支援 %w,這會令傳回的 error 實例會包裹指定的錯誤,並具有 Unwrap 方法。
Go 提供了 sort 套件來協助排序、搜尋任務,對於 []int、[]float64 與 []string,可以透過 Ints、Float64s、Strings 來由小而大排序,可以使用 IntsAreSorted、Float64sAreSorted、StringsAreSorted 來看看是否已經排序。
若想在已由小而大排序的 []int、[]float64 與 []string 中進行搜尋,可以使用 SearchInts、SearchFloat64s、SearchStrings 函式,搜尋結果將傳回找到搜尋值的索引位置,沒有搜尋到的話,傳回的會是可以安插搜尋值的索引位置。例如:
package main
import (
"fmt"
"sort"
)
func main() {
s := []int{8, 2, 6, 3, 1, 4}
sort.Ints(s)
fmt.Println(sort.IntsAreSorted(s)) // true
fmt.Println(s) // [1 2 3 4 6 8]
fmt.Println(sort.SearchInts(s, 7)) // 5
}
如果想要由大而小排序呢?可以透過 Slice、SliceStable,指定一個 less 函式,該函式接受兩個索引,你要傳回布林值表示 i 處的值順序上是否小於 j:
package main
import (
"fmt"
"sort"
)
func main() {
s := []int{8, 2, 6, 3, 1, 4}
sort.Slice(s, func(i, j int) bool {
return s[i] > s[j]
})
fmt.Println(s) // [8 6 4 3 2 1]
}
實際上,Slice、SliceStable 可用於任意的結構,例如:
package main
import (
"fmt"
"sort"
)
func main() {
family := []struct {
Name string
Age int
} {{"Irene", 12}, {"Justin", 45}, {"Monica", 42}}
// 依年齡由小而大排序
sort.SliceStable(family, func(i, j int) bool {
return family[i].Age < family[j].Age
})
fmt.Println(family) // [{Irene 12} {Monica 42} {Justin 45}]
}
那麼怎麼搜尋上面的 family 呢?例如,找出年齡 45 歲的資料?這可以用 Search,例如:
package main
import (
"fmt"
"sort"
)
func main() {
family := []struct {
Name string
Age int
} {{"Irene", 12}, {"Justin", 45}, {"Monica", 42}}
// 依年齡由小而大排序
sort.SliceStable(family, func(i, j int) bool {
return family[i].Age < family[j].Age
})
fmt.Println(family) // [{Irene 12} {Monica 42} {Justin 45}]
idx := sort.Search(len(family), func (i int) bool {
return family[i].Age == 45
})
fmt.Println(idx)
}
Search 會使用二分搜尋,第二個參數指定的函式要傳回布林值,表示是否符合搜尋條件,若找到第一個符合的話傳回索引位置,否則傳回第一個參數指定的值。
在 Search 說明中,還有個猜數字的有趣範例,由程式猜出你心中想的數字:
func GuessingGame() {
var s string
fmt.Printf("Pick an integer from 0 to 100.\n")
answer := sort.Search(100, func(i int) bool {
fmt.Printf("Is your number <= %d? ", i)
fmt.Scanf("%s", &s)
return s != "" && s[0] == 'y'
})
fmt.Printf("Your number is %d.\n", answer)
}
sort 還提供了 Sort、Stable 函式,乍看很奇怪:
func Sort(data Interface)
func Stable(data Interface)
Interface 的定義是:
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
這是給有序、具索引的資料結構實現的行為,任何具有 Interface 行為的資料結構,都可以透過 Sort、Stable 函式排序,sort 套件提供的實作有 IntSlice、Float64Slice、StringSlice,以 IntSlice 的原始碼實現為例:
type IntSlice []int
func (p IntSlice) Len() int { return len(p) }
func (p IntSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p IntSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
因此,若要對整數排序,也可以如下:
package main
import (
"fmt"
"sort"
)
func main() {
s := sort.IntSlice([]int{8, 2, 6, 3, 1, 4})
sort.Sort(s)
fmt.Println(s) // [1 2 3 4 6 8]
}
實際上,Ints、Float64s、Strings 函式,內部也只是轉換為 IntSlice、Float64Slice、StringSlice,然後呼叫 Sort 罷了:
func Ints(a []int) { Sort(IntSlice(a)) }
func Float64s(a []float64) { Sort(Float64Slice(a)) }
func Strings(a []string) { Sort(StringSlice(a)) }
對於一個實現了 Interface 的資料結構,除了可以使用 Sort、Stable 函式外,若需要反向排序,可以有個簡單方式,透過 Reverse 來包裹。例如:
package main
import (
"fmt"
"sort"
)
func main() {
s := sort.IntSlice([]int{8, 2, 6, 3, 1, 4})
sort.Sort(sort.Reverse(s))
fmt.Println(s) // [8 6 4 3 2 1]
}
有趣的是 Reverse 的實作,它不過就是將給原本資料結構 Less 方法的 i、j 對調罷了:
type reverse struct {
Interface
}
func (r reverse) Less(i, j int) bool {
return r.Interface.Less(j, i)
}
func Reverse(data Interface) Interface {
return &reverse{data}
}
來自己實現一下 Interface,使用家人的年齡來排序:
package main
import (
"fmt"
"sort"
)
type Person struct {
Name string
Age int
}
type Family []Person
func (f Family) Len() int {
return len(f)
}
func (f Family) Less(i, j int) bool {
return f[i].Age < f[j].Age
}
func (f Family) Swap(i, j int) {
f[i], f[j] = f[j], f[i]
}
func main() {
family := Family{{"Irene", 12}, {"Justin", 45}, {"Monica", 42}}
sort.Sort(family)
fmt.Println(family) // [{Irene 12} {Monica 42} {Justin 45}]
sort.Sort(sort.Reverse(family))
fmt.Println(family) // [{Justin 45} {Monica 42} {Irene 12}]
}
如果想連續地看待一組資料,可以使用 slice,優點是可以透過索引快速存取,透過 append 也可以附加元素,若偶而需要安插、刪除元素,可以透過切片等操作來實現。
然而,如果經常性地需要安插、刪除元素,透過 slice 實現缺乏效率時,Go 提供了 container/list 套件,可讓開發者基於雙向鏈結的 list.List 實作來達成需求。
想要建立 list.List 實例,可以透過 list.New,實例可使用的方法有:
func (l *List) Back() *Element
func (l *List) Front() *Element
func (l *List) Init() *List
func (l *List) InsertAfter(v interface{}, mark *Element) *Element
func (l *List) InsertBefore(v interface{}, mark *Element) *Element
func (l *List) Len() int
func (l *List) MoveAfter(e, mark *Element)
func (l *List) MoveBefore(e, mark *Element)
func (l *List) MoveToBack(e *Element)
func (l *List) MoveToFront(e *Element)
func (l *List) PushBack(v interface{}) *Element
func (l *List) PushBackList(other *List)
func (l *List) PushFront(v interface{}) *Element
func (l *List) PushFrontList(other *List)
func (l *List) Remove(e *Element) interface{}
從 PushBack、PushFront 方法的參數型態 interface{} 就能知道,list.List 可以保存任意型態的資料,它們會傳回 *Element,Element 是個結構,公開的欄位有 Value,公開的方法為 Next 與 Prev:
type Element struct {
Value interface{}
}
func (e *Element) Next() *Element
func (e *Element) Prev() *Element
因此,若你保留傳回的 *Element,可以透過 Value 取得放入 list.List 的值,必要時也可以透過 Next 或 Prev 方法,往後探尋下一元素或往前探尋前一元素,Next 與 Prev 方法傳回的也是 *Element,因此隨時可以往前探尋元素前或後全部的清單。
Back、Front 方法,分別傳回 list.List 最後、最前一個元素,因此,若要從清單頭走訪至尾,基本的模式就是:
package main
import (
"fmt"
"container/list"
)
func printAll(lt *list.List) {
for e := lt.Front(); e != nil; e = e.Next() {
fmt.Println(e.Value)
}
}
func main() {
lt := list.New()
for i := 1; i <= 10; i++ {
lt.PushBack(i)
}
printAll(lt)
}
你可能會有問題,Element 的 Value 型態是 interface{},那麼想操作保存的元素值上的欄位、方法時,不就要知道型態嗎?這裡仍然需要透過型態斷言:
補充(Go 1.18+):Go 已支援泛型,不過 container/list 本身仍是舊有 API 風格(實務上可視為 any / interface{} 容器),因此若你需要型別安全的清單結構,常見做法是自行包一層泛型型別。
package main
import (
"fmt"
"container/list"
)
type Person struct {
Name string
Age int
}
func printAllPerson(persons *list.List) {
for e := persons.Front(); e != nil; e = e.Next() {
p := e.Value.(*Person)
fmt.Printf("姓名:%s\t年齡:%d\n", p.Name, p.Age)
}
}
func main() {
persons := list.New()
persons.PushBack(&Person{"Irene", 12})
persons.PushBack(&Person{"Justin", 45})
persons.PushBack(&Person{"Monica", 42})
printAllPerson(persons)
}
你可能還會有其他問題,例如 list.List 怎麼不支援索引?要怎麼進行排序等?…唔…list.List 提供的方法怎麼這麼少?
嚴格來說,不會直接使用 list.List 來保存資料,而是如果某資料結構底層需要雙向鏈結的特性,可以透過 list.List 來實現。例如,實現一個 PersonQueue:
package main
import (
"fmt"
"container/list"
)
type Person struct {
Name string
Age int
}
type PersonQueue struct {
list *list.List
}
func NewPersonQueue() *PersonQueue {
return &PersonQueue{list.New()}
}
func (q *PersonQueue) Len() int {
return q.list.Len()
}
func (q *PersonQueue) Offer(p *Person) {
q.list.PushBack(p)
}
func (q *PersonQueue) Peek() *Person {
if q.list.Len() == 0 {
return nil
}
e := q.list.Remove(q.list.Front())
return e.(*Person)
}
func main() {
q := NewPersonQueue()
q.Offer(&Person{"Irene", 12})
q.Offer(&Person{"Justin", 45})
q.Offer(&Person{"Monica", 42})
for p := q.Peek(); p != nil; p = q.Peek() {
fmt.Printf("姓名:%s\t年齡:%d\n", p.Name, p.Age)
}
}
因此,並不是 list.List 不常用,而是你可能很少自行實現資料結構(都拿別人寫好的來用?);另一種說法「每當想使用 list.List 時,都該思考一下是否優先使用 slice。」的說法也不是完全正確…
若想使用 list.List,應該問的是,你的資料結構在實現上需要雙向鏈結的特性嗎?例如,也許你會需要有個具索引的資料結構,同時底層實現必須是雙向鏈結(像是 Java 的 LinkedList)?那麼就可以考慮透過 list.List 來實現。
如果在收集元素的過程中,想要一併排序,方式之一是使用堆積排序,對於這個需求,Go 提供了 heap 套件作為實現上的輔助。
heap 套件提供的是最小堆積樹演算,底層的資料結構必須實現 heap.Interface:
type Interface interface {
sort.Interface
Push(x interface{})
Pop() interface{}
}
也就是說,除了實現 sort.Interface 的 Len、Less、Swap 方法之外,還要實現 Push 與 Pop 的行為,在 heap 的 Go 官方文件說明 有個簡單範例:
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
實現了 heap.Interface 的資料結構,就可以透過 heap 套件中的 Init、Push、Pop 等函式來進行操作:
h := &IntHeap{2, 1, 5}
heap.Init(h)
heap.Push(h, 3)
fmt.Printf("minimum: %d\n", (*h)[0])
for h.Len() > 0 {
fmt.Printf("%d ", heap.Pop(h))
}
在 Push、Pop 過程中有關堆積樹的調整,就都由 heap.Push、heap.Pop 等函式來處理了。
官方文件提供的範例是可以簡單示範 heap 套件的使用,不過,一下子使用 heap.Xxx,一下子又是使用 h.Xxx 的混合風格,看來蠻怪的,可以來改變一下:
package main
import (
"container/heap"
"fmt"
)
// IntSlice 實現了 heap.Interface
type IntSlice []int
func (s IntSlice) Len() int { return len(s) }
func (s IntSlice) Less(i, j int) bool { return s[i] < s[j] }
func (s IntSlice) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
func (s *IntSlice) Push(x interface{}) {
*s = append(*s, x.(int))
}
func (s *IntSlice) Pop() interface{} {
old := *s
n := len(old)
x := old[n-1]
*s = old[0 : n-1]
return x
}
// IntHeap 封裝了 IntSlice
type IntHeap struct {
elems IntSlice
}
// 實現相關函式或方法時,透過 heap 提供的函式
func NewIntHeap(numbers ...int) *IntHeap {
h := &IntHeap{IntSlice(numbers)}
heap.Init(&(h.elems))
return h
}
func (h *IntHeap) Push(n int) {
heap.Push(&(h.elems), n)
}
func (h *IntHeap) Pop() int {
return heap.Pop(&(h.elems)).(int)
}
func (h *IntHeap) Len() int {
return len(h.elems)
}
// 一律透過 h 來操作
func main() {
h := NewIntHeap(2, 1, 5)
h.Push(3)
for h.Len() > 0 {
fmt.Printf("%d ", h.Pop())
}
}
官方文件提供的範例中,還有個 PriorityQueue 的實現,類似地,該範例是簡單示範,混合了兩種操作風格,你也可以試著自行把 heap.Xxx 的操作給封裝起來。
對於環狀資料結構,Go 提供了 container/ring 套件,Ring 結構有 Value 欄位,可以使用 New 指定元素數量來建立實例,可用的方法有:
func (r *Ring) Do(f func(interface{})) // 走訪每個元素並傳入 f
func (r *Ring) Len() int // 元素數量
func (r *Ring) Link(s *Ring) *Ring // 銜接另一個 Ring
func (r *Ring) Move(n int) *Ring // 移動 n 個元素,n 可正或負
func (r *Ring) Next() *Ring // 下一個鏈(也就是下一個元素)
func (r *Ring) Prev() *Ring // 上一個鏈(也就是上一個元素)
func (r *Ring) Unlink(n int) *Ring // 解除指定數量的 Ring,傳回被解除的子鏈
因為是環狀結構,每個元素都可視為一個鏈的開頭或結尾,因此 Link 等操作都傳回 *Ring。底下是個建立 Ring 並設值的簡單範例:
package main
import (
"fmt"
"container/ring"
)
func main() {
numbers := ring.New(10)
for i := 0; i < numbers.Len(); i++ {
numbers.Value = i
numbers = numbers.Next()
}
numbers.Do(func(n interface{}) {
fmt.Printf("%d ", n.(int))
})
}
ring 的官方文件有相關方法的範例,這邊就不重複列出了,實際應用上,ring 可以用來管理有限筆數的歷史記錄、輪播等。
這邊的話拿來解一下 約瑟夫問題(Josephus Problem) 好了:
package main
import (
"fmt"
"container/ring"
)
type Person struct {
Number int
}
func main() {
persons := ring.New(41)
// 給每個人編號
for i := 1; i <= persons.Len(); i++ {
persons.Value = &Person{i}
persons = persons.Next()
}
persons = persons.Prev()
// 最後只留下兩人
for persons.Len() > 2 {
for i := 1; i <= 2; i++ {
persons = persons.Next()
}
// 報數 3 Out
persons.Unlink(1)
}
fmt.Print("安全位置:")
persons.Do(func(p interface{}) {
person := p.(*Person)
fmt.Printf("%d ", person.Number)
})
}
Go 的字串基本上是個 []byte,在程式語言強弱型別的光譜中,Go 位於強型別的一端,對於字串與其他型態之間的轉換,往往得自行處理,在這方面,strconv 套件就提供了不少的函式。
例如,最常用的是將字串剖析為某個型態:
func ParseBool(str string) (bool, error)
func ParseFloat(s string, bitSize int) (float64, error)
func ParseInt(s string, base int, bitSize int) (i int64, err error)
func ParseUint(s string, base int, bitSize int) (uint64, error)
若是剖析失敗,傳回的錯誤會是 *NumError:
type NumError struct {
Func string // 來源函式(ParseBool、ParseInt、ParseUint、ParseFloat)
Num string // 輸入字串
Err error // 失敗的源由(ErrRange、ErrSyntax 等)
}
如果要將其他型態附加至字串,可以使用 Append 名稱開頭的函式:
func AppendBool(dst []byte, b bool) []byte
func AppendFloat(dst []byte, f float64, fmt byte, prec, bitSize int) []byte
func AppendInt(dst []byte, i int64, base int) []byte
func AppendQuote(dst []byte, s string) []byte
func AppendQuoteRune(dst []byte, r rune) []byte
func AppendQuoteRuneToASCII(dst []byte, r rune) []byte
func AppendQuoteRuneToGraphic(dst []byte, r rune) []byte
func AppendQuoteToASCII(dst []byte, s string) []byte
func AppendQuoteToGraphic(dst []byte, s string) []byte
func AppendUint(dst []byte, i uint64, base int) []byte
以上的附加函式設計上接收 []byte,Go 字串本質上是個 []byte,呼叫這些函式時只要明確型態轉換就可以了,例如:
b := []byte("bool:")
b = strconv.AppendBool(b, true)
fmt.Println(string(b))
對於大量的字串附加處理,可以使用 strings 套件的 Builder,一來操作上比較方便,二來可看看是否可取得較好的效能表現:
type Builder
func (b *Builder) Cap() int
func (b *Builder) Grow(n int)
func (b *Builder) Len() int
func (b *Builder) Reset()
func (b *Builder) String() string
func (b *Builder) Write(p []byte) (int, error)
func (b *Builder) WriteByte(c byte) error
func (b *Builder) WriteRune(r rune) (int, error)
func (b *Builder) WriteString(s string) (int, error)
例如,來個簡單的評測:
package mypackage
import (
"testing"
"strings"
)
func plusAppend() string {
c := ""
for i := 0; i < 100000; i++ {
c += "test"
}
return c
}
func buliderAppend() string {
var b strings.Builder
for i := 0; i < 100000; i++ {
b.WriteString("test")
}
return b.String()
}
func BenchmarkPlusAppend(b *testing.B) {
for i := 0; i < b.N; i++ {
plusAppend()
}
}
func BenchmarkBuilderAppend(b *testing.B) {
for i := 0; i < b.N; i++ {
buliderAppend()
}
}
看一下效能上是否有差異:
C:\workspace\go-exercise>go test -bench="." mypackage
goos: windows
goarch: amd64
pkg: mypackage
BenchmarkPlusAppend-4 1 4162865000 ns/op
BenchmarkBuilderAppend-4 1946 655490 ns/op
PASS
ok mypackage 6.614s
如果想將字串當成是個 io.Reader 來源,可以使用 strings.Reader:
type Reader
func NewReader(s string) *Reader
func (r *Reader) Len() int
func (r *Reader) Read(b []byte) (n int, err error)
func (r *Reader) ReadAt(b []byte, off int64) (n int, err error)
func (r *Reader) ReadByte() (byte, error)
func (r *Reader) ReadRune() (ch rune, size int, err error)
func (r *Reader) Reset(s string)
func (r *Reader) Seek(offset int64, whence int) (int64, error)
func (r *Reader) Size() int64
func (r *Reader) UnreadByte() error
func (r *Reader) UnreadRune() error
func (r *Reader) WriteTo(w io.Writer) (n int64, err error)
strings 還有個 Replacer,用於一對一的字串取代:
type Replacer
func NewReplacer(oldnew ...string) *Replacer
func (r *Replacer) Replace(s string) string
func (r *Replacer) WriteString(w io.Writer, s string) (n int, err error)
什麼是一對一的取代呢?看看官方文件中提到的範例就知道了:
package main
import (
"fmt"
"strings"
)
func main() {
r := strings.NewReplacer("<", "<", ">", ">")
fmt.Println(r.Replace("This is <b>HTML</b>!"))
}
其他對於字串的比較、分割、大小寫轉換等處理,strings 中提供了一系列的函式,strings 套件的文件中都有程式碼示範。
Go 字串的本質是 []byte,如果想基於位元組來處理字串,或者是想處理其他來源的 []byte,可以使用 bytes 套件。
因為 Go 字串本質上就是一組 Unicode 碼點的 UTF-8 編碼位元組,bytes 與 strings 套件中提供的函式,有著很大的相似性,只不過前者針對 []byte,後者針對 string…唔…好像在說廢話…也就是說…儘管兩者提供的函式在名稱上有重疊,除了函式上的參數或傳回型態不同之外,兩者處理的粒度等也不同,例如 Compare,一個是逐一比較位元組,另一個是逐一比較 Unicode 碼點。
類似地,對於頻繁性的字串操作,可以使用 strings.Builder,對於對於頻繁性的位元組操作,可以使用 bytes.Buffer:
type Buffer
func NewBuffer(buf []byte) *Buffer
func NewBufferString(s string) *Buffer
func (b *Buffer) Bytes() []byte
func (b *Buffer) Cap() int
func (b *Buffer) Grow(n int)
func (b *Buffer) Len() int
func (b *Buffer) Next(n int) []byte
func (b *Buffer) Read(p []byte) (n int, err error)
func (b *Buffer) ReadByte() (byte, error)
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error)
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error)
func (b *Buffer) ReadRune() (r rune, size int, err error)
func (b *Buffer) ReadString(delim byte) (line string, err error)
func (b *Buffer) Reset()
func (b *Buffer) String() string
func (b *Buffer) Truncate(n int)
func (b *Buffer) UnreadByte() error
func (b *Buffer) UnreadRune() error
func (b *Buffer) Write(p []byte) (n int, err error)
func (b *Buffer) WriteByte(c byte) error
func (b *Buffer) WriteRune(r rune) (n int, err error)
func (b *Buffer) WriteString(s string) (n int, err error)
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error)
建立 Buffer 時可以使用 NewBuffer 指定初始的位元組大小,如果你想要處理的是字串的 UTF-8 位元組,可以使用 NewBufferString。例如,來簡單地針對中文做百分比編碼:
package main
import (
"fmt"
"bytes"
"strings"
)
func encodeURI(s string) string {
buf := bytes.NewBufferString(s)
var builder strings.Builder
for {
b, e := buf.ReadByte()
if e != nil {
break
}
builder.WriteString(fmt.Sprintf("%%%X", b))
}
return builder.String()
}
func main() {
fmt.Println(encodeURI("良葛格")) // %E8%89%AF%E8%91%9B%E6%A0%BC
}
類似地,你也可以透過 bytes.Reader,將 []byte 作為來源讀取:
type Reader
func NewReader(b []byte) *Reader
func (r *Reader) Len() int
func (r *Reader) Read(b []byte) (n int, err error)
func (r *Reader) ReadAt(b []byte, off int64) (n int, err error)
func (r *Reader) ReadByte() (byte, error)
func (r *Reader) ReadRune() (ch rune, size int, err error)
func (r *Reader) Reset(b []byte)
func (r *Reader) Seek(offset int64, whence int) (int64, error)
func (r *Reader) Size() int64
func (r *Reader) UnreadByte() error
func (r *Reader) UnreadRune() error
func (r *Reader) WriteTo(w io.Writer) (n int64, err error)
unicode、unicode/utf8、unicode/utf16 是用來判斷、處理 Unicode 以及 UTF-8、UTF-16 編碼的套件,在使用這些套件之前,要先知道的是,Go 認為「字元」的定義過於模糊,在 Go 中使用 rune 儲存 Unicode 碼點(Code point),而 Go 中字串是 UTF-8 編碼的位元組組成。
unicode 套件主要用來判斷 Unicode 碼點的特性(properties),在 Unicode 規範中,每個碼點會被指定某些特性,具有相同特性的一組碼點構成一個集合,以便於理解、判斷這組碼點。
例如,General Category 特性有 Letter/L 代表字母、Number/N 代表數字等,在 Go 的 unicode 套件文件的 Variables 一開頭,列出的就是這類特性的變數:
var (
...
Digit = _Nd // 十進位數字的集合
Letter = _L // 字母集合
L = _L
...
Number = _N // 數字集合
N = _N
...
}
每個變數的型態都是 *RangeTable,由碼點的範圍等欄位組成:
type RangeTable struct {
R16 []Range16 // 用 uint16 記錄碼點低位至高位
R32 []Range32 // 記錄 R16 無法表示的範圍,用 uint32 記錄碼點低位至高位
LatinOffset int
}
碼點範圍表可以在 tables.go 找到。舉例來說,字母集合的碼點範圍:
var _L = &RangeTable{
R16: []Range16{
{0x0041, 0x005a, 1},
{0x0061, 0x007a, 1},
{0x00aa, 0x00b5, 11},
很長的清單...
透過指定 RangeTable,就可以簡單地判斷碼點是否有某特性,例如,²³¹¼½¾𝟏𝟐𝟑𝟜𝟝𝟞𝟩𝟪𝟫𝟬𝟭𝟮𝟯𝟺𝟻𝟼㉛㉜㉝ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩⅪⅫⅬⅭⅮⅯⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹⅺⅻⅼⅽⅾⅿ 都是數字:
package main
import (
"fmt"
"unicode"
)
func allNumbers(s string) bool {
for _, r := range []rune(s) {
if !unicode.Is(unicode.Number, r) {
return false
}
}
return true
}
func main() {
// true
fmt.Println(allNumbers("²³¹¼½¾𝟏𝟐𝟑𝟜𝟝𝟞𝟩𝟪𝟫𝟬𝟭𝟮𝟯𝟺𝟻𝟼㉛㉜㉝ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩⅪⅫⅬⅭⅮⅯⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹⅺⅻⅼⅽⅾⅿ"))
}
Unicode 將希臘文、漢字等以文字(Script)特性標示,在 Go 的 unicode 套件文件的 Variables 第二組列出的變數清單,就是對應的 RangeTable,例如 unicode.Han 是正體中文、簡體中文,以及日、韓、越南文的全部漢字範圍。
另外還有一些其他特性,列在 Go 的 unicode 套件文件的 Variables 第三組變數清單,例如 unicode.White_Space 代表被標示為空白特性的碼點,這包括了半形、全形、Tab 等。
如果想要使用多個 RangeTable,可以透過 IsOneOf:
func IsOneOf(ranges []*RangeTable, r rune) bool
unicode 也提供了一些常用的判斷函式:
func IsControl(r rune) bool
func IsDigit(r rune) bool
func IsGraphic(r rune) bool
func IsLetter(r rune) bool
func IsLower(r rune) bool
func IsMark(r rune) bool
func IsNumber(r rune) bool
func IsPrint(r rune) bool
func IsPunct(r rune) bool
func IsSpace(r rune) bool
func IsSymbol(r rune) bool
func IsTitle(r rune) bool
func IsUpper(r rune) bool
在大小寫或特定轉換上,有以下的函式:
func To(_case int, r rune) rune
func ToLower(r rune) rune
func ToTitle(r rune) rune
func ToUpper(r rune) rune
基本上,這可以應付大多數語言的轉換,像是全形字母的大小寫或首字母大寫等,To 可使用的常數有:
const (
UpperCase = iota
LowerCase
TitleCase
MaxCase
)
例如,unicode.To(unicode.UpperCase, rune('a')) 可以得到 'A'。
unicode/utf8、unicode/utf16 套件
unicode/utf8 套件提供的函式,主要是進行 rune 與 UTF-8 編碼之間的處理。例如驗證是否為合法的 UTF-8 []byte 或字串:
func Valid(p []byte) bool
func ValidString(s string) bool
驗證 rune 可否編碼為 UTF-8:
func ValidRune(r rune) bool
在 rune 與 UTF-8 編碼之間轉換:
func DecodeLastRune(p []byte) (r rune, size int)
func DecodeLastRuneInString(s string) (r rune, size int)
func DecodeRune(p []byte) (r rune, size int)
func DecodeRuneInString(s string) (r rune, size int)
func EncodeRune(p []byte, r rune) int
unicode/utf16 主要是進行 rune 與 UTF-16 編碼之間的處理,只不過目前函式只有幾個:
func Decode(s []uint16) []rune
func DecodeRune(r1, r2 rune) rune
func Encode(s []rune) []uint16
func EncodeRune(r rune) (r1, r2 rune)
func IsSurrogate(r rune) bool
UTF-8 編碼下,碼元(code unit)是 8 個位元,Go 中使用 byte 也就是 uint8 來儲存,UTF-16 編碼下,碼元(code unit)是 16 個位元,Go 中使用 uint16 來儲存。
來看個簡單的範例,使用 unicode/utf8 與 unicode/utf16 套件來顯示「Hello, 世界」的 UTF-16 碼元:
package main
import (
"fmt"
"unicode/utf8"
"unicode/utf16"
)
func main() {
b := []byte("Hello, 世界")
for len(b) > 0 {
r, size := utf8.DecodeRune(b)
u16 := utf16.Encode([]rune{r})
fmt.Printf("%#U:\n Code unit %04X\n", r, u16)
b = b[size:]
}
}
顯示結果如下:
U+0048 'H':
Code unit [0048]
U+0065 'e':
Code unit [0065]
U+006C 'l':
Code unit [006C]
U+006C 'l':
Code unit [006C]
U+006F 'o':
Code unit [006F]
U+002C ',':
Code unit [002C]
U+0020 ' ':
Code unit [0020]
U+4E16 '世':
Code unit [4E16]
U+754C '界':
Code unit [754C]
Unicode 碼點號碼與碼元顯示剛好一樣對吧?這就是為什麼常有人會亂說「Unicode 使用 16 位元儲存」的原因之一吧!… XD
不論從哪個面向,都可以看出 Go 獨厚 UTF-8,這可能是因為 Go 的設計者之一 Ken Thompson,也曾經參與了 UTF-8 的設計。
如果文字資料的來源並非 UTF-8 呢?例如,儲存時並非使用 UTF-8 的檔案?解決的方法之一,是將檔案另行儲存為 UTF-8,再使用 Go 來讀取,當然,並非所有的的場合都可以這麼做,另一個方式是,使用 golang.org/x/text 套件。
Go 除了本身自帶的標準套件之外,還有另外一系列官方的擴充套件(常稱 x/ repos),這些套件也是 Go 專案的一部份,只不過在相容性的維護上比較沒那麼嚴格。
在官方擴充套件中,golang.org/x/text 主要包含了文字編碼、轉換、國際化、本地化等文字性任務的套件。若是在模組專案中使用,通常直接 import 後執行 go mod tidy 即可;若要手動加入依賴,也可以使用:
go get golang.org/x/text@latest
文字編碼的轉換主要由 golang.org/x/text/transform 套件來處理,看看其中的函式或結構方法,都會需要 Transformer 介面的實現,例如最基本的 String:
func String(t Transformer, s string) (result string, n int, err error)
Transformer 定義的主要是 Transform 方法,代表著編碼的轉換:
type Transformer interface {
Transform(dst, src []byte, atEOF bool) (nDst, nSrc int, err error)
Reset()
}
dst、src 代表著同一文字兩個不同編碼的位元組,由於 Go 使用 UTF-8,從 UTF-8 轉換為其他編碼,這個動作稱為 Encode,從其他編碼轉換為 UTF-8,這個動作稱為 Decode。
Encode、Decode 的動作,分別由 golang.org/x/text/encoding 套件的 Encoder、Decoder 來處理,它們都是 transform.Transformer 的實現:
type Encoder struct {
transform.Transformer
...
}
type Decoder struct {
transform.Transformer
...
}
為了便於使用,encoding 定義了 Encoding 的行為:
type Encoding interface {
NewDecoder() *Decoder
NewEncoder() *Encoder
}
golang.org/x/text/encoding 套件之中,定義了不同的編碼轉換套件,例如,想處理 Big5(Code Page 950) 編碼轉換的話,需要 golang.org/x/text/encoding/traditionalchinese 套件,它的 Big5 就實現了 Encoding,因此想要獲得 UTF-8 <-> Big5 的 Encoder、Decoder,可以如下:
utf8ToBig5 := traditionalchinese.Big5.NewEncoder()
big5ToUtf8 := traditionalchinese.Big5.NewDecoder()
因此,若要讀取一個底層為 Big5 編碼的字串,轉換為 UTF-8 編碼字串,可以如下:
package main
import (
"golang.org/x/text/encoding/traditionalchinese"
"golang.org/x/text/transform"
"fmt"
)
func main() {
big5ToUTF8 := traditionalchinese.Big5.NewDecoder()
big5Test := "\xb4\xfa\xb8\xd5" // 測試的 Big5 編碼
utf8, _, _ := transform.String(big5ToUTF8, big5Test)
fmt.Println(utf8) // 顯示「測試」
}
要將一個 UTF-8 編碼字串,轉換為 Big5 編碼的字串,可以如下:
package main
import (
"golang.org/x/text/encoding/traditionalchinese"
"golang.org/x/text/transform"
"fmt"
)
func main() {
utf8ToBig5 := traditionalchinese.Big5.NewEncoder()
big5, _, _ := transform.String(utf8ToBig5, "測試")
fmt.Printf("%q", big5) // 顯示 "\xb4\xfa\xb8\xd5"
}
transform 也定義了 Reader、Writer,可以用來將 Transformer 與 io.Reader、io.Writer 包裹在一起:
type Reader
func NewReader(r io.Reader, t Transformer) *Reader
func (r *Reader) Read(p []byte) (int, error)
type Writer
func NewWriter(w io.Writer, t Transformer) *Writer
func (w *Writer) Close() error
func (w *Writer) Write(data []byte) (n int, err error)
例如,想要讀取 Big5 文件的話,底下是個示範:
package main
import (
"golang.org/x/text/encoding/traditionalchinese"
"golang.org/x/text/transform"
"fmt"
"io"
"os"
)
func printBig5(r io.Reader) error {
var big5R = transform.NewReader(r, traditionalchinese.Big5.NewDecoder())
b, err := io.ReadAll(big5R)
fmt.Println(string(b))
return err
}
func main() {
fmt.Print("檔案來源:")
var filename string
fmt.Scanf("%s", &filename)
f, err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
printBig5(f)
}
反射(Reflection)是探知資料自身結構的一種能力,不同的語言提供不同的反射機制,在 Go 語言中,反射的能力主要由 reflect 套件提供。
資料的 Type
在先前的文件中,有時會用到 reflect.TypeOf() 來顯示資料的型態名稱,實際上,reflect.TypeOf() 傳回 Type 的實例,Type 是個介面定義,目前包含了以下的方法定義:
type Type interface {
Align() int
FieldAlign() int
Method(int) Method
MethodByName(string) (Method, bool)
NumMethod() int
Name() string
PkgPath() string
Size() uintptr
String() string
Kind() Kind
Implements(u Type) bool
AssignableTo(u Type) bool
ConvertibleTo(u Type) bool
Comparable() bool
Bits() int
ChanDir() ChanDir
IsVariadic() bool
Elem() Type
Field(i int) StructField
FieldByIndex(index []int) StructField
FieldByName(name string) (StructField, bool)
FieldByNameFunc(match func(string) bool) (StructField, bool)
In(i int) Type
Key() Type
Len() int
NumField() int
NumIn() int
NumOut() int
Out(i int) Type
}
因此,你可以透過 Type 的方法定義,取得某個型態的相關結構資訊,舉例來說:
package main
import (
"fmt"
"reflect"
)
type Account struct {
id string
name string
balance float64
}
func main() {
account := Account{"X123", "Justin Lin", 1000}
t := reflect.TypeOf(account)
fmt.Println(t.Kind()) // struct
fmt.Println(t.String()) // main.Account
/*
底下顯示
id string
name string
balance float64
*/
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
fmt.Println(f.Name, f.Type)
}
}
如果 reflect.TypeOf() 接受的是個指標,因為指標實際上只是個位址值,必須要透過 Type 的 Elem 方法取得指標的目標 Type,才能取得型態的相關成員:
package main
import (
"errors"
"fmt"
"reflect"
)
type Savings interface {
Deposit(amount float64) error
Withdraw(amount float64) error
}
type Account struct {
id string
name string
balance float64
}
func (ac *Account) Deposit(amount float64) error {
if amount <= 0 {
return errors.New("必須存入正數")
}
ac.balance += amount
return nil
}
func (ac *Account) Withdraw(amount float64) error {
if amount > ac.balance {
return errors.New("餘額不足")
}
ac.balance -= amount
return nil
}
func main() {
var savings Savings = &Account{"X123", "Justin Lin", 1000}
t := reflect.TypeOf(savings)
for i, n := 0, t.NumMethod(); i < n; i++ {
f := t.Method(i)
fmt.Println(f.Name, f.Type)
}
if t.Kind() == reflect.Ptr {
t = t.Elem()
}
fmt.Println(t.Kind())
fmt.Println(t.String())
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
fmt.Println(f.Name, f.Type)
}
}
有上面的範例中,也示範了如何取得介面定義的方法資訊,這個範例會顯示以下的結果:
Deposit func(*main.Account, float64) error
Withdraw func(*main.Account, float64) error
struct
main.Account
id string
name string
資料的 Kind
上面的範例中,使用了 Type 的 Kind() 方法,這會傳回 Kind 列舉值:
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
以下是個簡單的型態測試:
package main
import (
"fmt"
"reflect"
)
type Duck struct {
name string
}
func main() {
values := [...](interface{}){
Duck{"Justin"},
Duck{"Monica"},
[...]int{1, 2, 3, 4, 5},
map[string]int{"caterpillar": 123456, "monica": 54321},
10,
}
for _, value := range values {
switch t := reflect.TypeOf(value); t.Kind() {
case reflect.Struct:
fmt.Println("it's a struct.")
case reflect.Array:
fmt.Println("it's a array.")
case reflect.Map:
fmt.Println("it's a map.")
case reflect.Int:
fmt.Println("it's a integer.")
default:
fmt.Println("非預期之型態")
}
}
}
資料的 Value
如果想實際獲得資料的值,可以使用 reflect.ValueOf() 函式,這會傳回 Value 實例,Value 是個結構,定義了一些方法可以使用,可用來取得實際的值,例如:
package main
import (
"fmt"
"reflect"
)
type Account struct {
id string
name string
balance float64
}
func main() {
x := 10
vx := reflect.ValueOf(x)
fmt.Printf("x = %d\n", vx.Int())
account := Account{"X123", "Justin Lin", 1000}
vacct := reflect.ValueOf(account)
fmt.Printf("id = %s\n", vacct.FieldByName("id").String())
fmt.Printf("name = %s\n", vacct.FieldByName("name").String())
fmt.Printf("balance = %.2f\n", vacct.FieldByName("balance").Float())
}
如果是個指標,一樣也是要透過 Elem() 方法取得目標值,例如:
package main
import (
"fmt"
"reflect"
)
type Account struct {
id string
name string
balance float64
}
func main() {
x := 10
vx := reflect.ValueOf(&x)
fmt.Printf("x = %d\n", vx.Elem().Int())
account := &Account{"X123", "Justin Lin", 1000}
vacct := reflect.ValueOf(account).Elem()
fmt.Printf("id = %s\n", vacct.FieldByName("id").String())
fmt.Printf("name = %s\n", vacct.FieldByName("name").String())
fmt.Printf("balance = %.2f\n", vacct.FieldByName("balance").Float())
}
可以透過 Value 對值進行變動,不過,Value 必須是可定址的,具體來說,就是 reflect.ValueOf() 必須接受指標:
package main
import (
"fmt"
"reflect"
)
type Account struct {
id string
name string
balance float64
}
func main() {
x := 10
vx := reflect.ValueOf(&x).Elem()
fmt.Printf("x = %d\n", vx.Int()) // x = 10
vx.SetInt(20)
fmt.Printf("x = %d\n", x) // x = 20
}
上面的例子若改成以下,就會出現錯誤:
package main
import (
"fmt"
"reflect"
)
type Account struct {
id string
name string
balance float64
}
func main() {
x := 10
vx := reflect.ValueOf(x)
fmt.Printf("x = %d\n", vx.Int())
vx.SetInt(20) // panic: reflect: reflect.Value.SetInt using unaddressable value
fmt.Printf("x = %d\n", x)
}
技術上來說,上面的例子,只是傳了 x 的值複本給 reflect.ValueOf(),因此,對其設值並無意義。
若對反射想進一步研究,可以參考〈The Laws of Reflection〉。
對於 JSON 或 XML 等具有結構性的資料,在 Go 中經常會使用 struct 定義資料結構,例如,底下這個程式可以將簡單的結構轉為 JSON:
package main
import (
"fmt"
"reflect"
"strings"
)
type Customer struct {
Name string
City string
}
func ToJSON(obj interface{}) string {
t := reflect.TypeOf(obj)
v := reflect.ValueOf(obj)
var b []string
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
b = append(b, fmt.Sprintf(`"%s": "%s"`, f.Name, v.FieldByName(f.Name)))
}
return fmt.Sprintf("{%s}", strings.Join(b, ","))
}
func main() {
cust := Customer{"Justin", "Kaohsiung"}
// 顯示 {"Name": "Justin","City": "Kaohsiung"}
fmt.Println(ToJSON(cust))
}
然而,Go 的慣例中,公開的結構欄位名稱通常是大寫的,如果你的 JSON 要求的是小寫的欄位名稱,或者是其他名稱,可以使用欄位標籤(Field tag)。例如:
package main
import (
"fmt"
"reflect"
"strings"
)
type Customer struct {
Name string `name`
City string `city`
}
func ToJSON(obj interface{}) string {
t := reflect.TypeOf(obj)
v := reflect.ValueOf(obj)
var b []string
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
b = append(b, fmt.Sprintf(`"%s": "%s"`, f.Tag, v.FieldByName(f.Name)))
}
return fmt.Sprintf("{%s}", strings.Join(b, ","))
}
func main() {
cust := Customer{"Justin", "Kaohsiung"}
// 顯示 {"name": "Justin","city": "Kaohsiung"}
fmt.Println(ToJSON(cust))
}
欄位標籤可以在反射時,使用 Field 的 Tag 來取得,雖然欄位標籤可以是任意格式字串,然而慣例上,會由 key: "value" 的格式組成,符合此格式的話,可以使用 Tag 的 Lookup 來查找 value,它傳回兩個值,第一個值是 value,第二個值指出是否有對應的名稱,例如:
package main
import (
"fmt"
"reflect"
"strings"
)
type Customer struct {
Name string `json:"name"`
City string `json:"city"`
}
func ToJSON(obj interface{}) string {
t := reflect.TypeOf(obj)
v := reflect.ValueOf(obj)
var b []string
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
fv, _ := f.Tag.Lookup("json")
b = append(b, fmt.Sprintf(`"%s": "%s"`, fv, v.FieldByName(f.Name)))
}
return fmt.Sprintf("{%s}", strings.Join(b, ","))
}
func main() {
cust := Customer{"Justin", "Kaohsiung"}
// 顯示 {"name": "Justin","city": "Kaohsiung"}
fmt.Println(ToJSON(cust))
}
實際上,如果要將結構轉為 JSON 格式字串,可以使用 encoding/json,例如:
package main
import (
"encoding/json"
"fmt"
)
type Customer struct {
Name string `json:"name"`
City string `json:"city"`
}
func main() {
cust := Customer{"Justin", "Kaohsiung"}
b, _ := json.Marshal(cust)
// 顯示 {"name": "Justin","city": "Kaohsiung"}
fmt.Println(string(b))
}
在 Go 中要讓指定的流程並行執行非常簡單,只需要將流程寫在函式中,並在函式加個 go 就可以了,這樣我們稱之為啟動一個 Goroutine。
使用 Goroutine
先來看個沒有啟用 Goroutine,卻要寫個龜兔賽跑遊戲的例子,你可能是這麼寫的:
package main
import (
"fmt"
"math/rand"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func main() {
flags := [...]bool{true, false}
totalStep := 10
tortoiseStep := 0
hareStep := 0
fmt.Println("龜兔賽跑開始...")
for tortoiseStep < totalStep && hareStep < totalStep {
tortoiseStep++
fmt.Printf("烏龜跑了 %d 步...\n", tortoiseStep)
isHareSleep := flags[random(1, 10)%2]
if isHareSleep {
fmt.Println("兔子睡著了zzzz")
} else {
hareStep += 2
fmt.Printf("兔子跑了 %d 步...\n", hareStep)
}
}
}
由於程式只有一個流程,所以只能將烏龜與兔子的行為混雜在這個流程中撰寫,而且為什麼每次都先遞增烏龜再遞增兔子步數呢?這樣對兔子很不公平啊!如果可以撰寫程式再啟動兩個流程,一個是烏龜流程,一個兔子流程,程式邏輯會比較清楚。
你可以將烏龜的流程與兔子的流程分別寫在一個函式中,並用 go 啟動執行:
package main
import (
"fmt"
"math/rand"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func tortoise(totalStep int) {
for step := 1; step <= totalStep; step++ {
fmt.Printf("烏龜跑了 %d 步...\n", step)
}
}
func hare(totalStep int) {
flags := [...]bool{true, false}
step := 0
for step < totalStep {
isHareSleep := flags[random(1, 10)%2]
if isHareSleep {
fmt.Println("兔子睡著了zzzz")
} else {
step += 2
fmt.Printf("兔子跑了 %d 步...\n", step)
}
}
}
func main() {
totalStep := 10
go tortoise(totalStep)
go hare(totalStep)
time.Sleep(5 * time.Second) // 給予時間等待 Goroutine 完成
}
現在烏龜的流程與兔子的流程都清楚多了,程式的最後使用 time.Sleep() 讓主流程沉睡了五秒鐘,這是因為主流程一結束,所有的 Goroutine 就會停止。
使用 sync.WaitGroup
有沒有辦法知道 Goroutine 執行結束呢?實際上沒有任何方法可以得知,除非你主動設計一種機制,可以在 Goroutine 結束時執行通知,使用 Channel 是一種方式,這在之後的文件再說明,這邊先說明另一種方式,也就是使用 sync.WaitGroup。
sync.WaitGroup 可以用來等待一組 Goroutine 的完成,主流程中建立 sync.WaitGroup,並透過 Add 告知要等待的 Goroutine 數量,並使用 Wait 等待 Goroutine 結束,而每個 Goroutine 結束前,必須執行 sync.WaitGroup 的 Done 方法。
重點是,Add 的數字代表「之後會呼叫 Done() 的 Goroutine 數量」,不是程式總共會跑幾步或迴圈會執行幾次。
Add設太小:可能提早結束,甚至在多呼叫Done()時發生panic: sync: negative WaitGroup counterAdd設太大:wg.Wait()會一直卡住不返回
因此,我們可以使用 sync.WaitGroup 來改寫以上的範例:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func tortoise(totalStep int, wg *sync.WaitGroup) {
defer wg.Done()
for step := 1; step <= totalStep; step++ {
fmt.Printf("烏龜跑了 %d 步...\n", step)
}
}
func hare(totalStep int, wg *sync.WaitGroup) {
defer wg.Done()
flags := [...]bool{true, false}
step := 0
for step < totalStep {
isHareSleep := flags[random(1, 10)%2]
if isHareSleep {
fmt.Println("兔子睡著了zzzz")
} else {
step += 2
fmt.Printf("兔子跑了 %d 步...\n", step)
}
}
}
func main() {
wg := new(sync.WaitGroup)
wg.Add(2)
totalStep := 10
go tortoise(totalStep, wg)
go hare(totalStep, wg)
wg.Wait()
}
有個 runtime.GOMAXPROCS() 函式,可以設定 Go 同時間能使用的 CPU 數量,它會傳回上一次設定的數字,如果傳入小於 1 的值,不會改變任何設定,因此,可以使用 runtime.GOMAXPROCS(0) 知道目前的設定值。想在執行時期得知可用的 CPU 數量,可以使用 runtime.NumCPU() 函式,因此,為了確保 Go 會使用全部的 CPU 來運行,可以這麼撰寫:
runtime.GOMAXPROCS(runtime.NumCPU())
除了透過 runtime.GOMAXPROCS() 設定之外,也可以透過環境變數 GOMAXPROCS 來設置,實際上,Go 1.5 已經預設會使用所有的 CPU 核心,不過,仍可以透過 runtime.GOMAXPROCS() 函式或環境變數來改變設定。
在〈Goroutine〉中提到,想要通知主流程 Goroutine 已經結束,使用 Channel 是一種方式,實際上,Channel 是 Groutine 間的溝通管道。
使用 Channel
Channel 就像是個佇列,可以對它發送值,也可以從它上頭取得值,想要建立一個 Channel,要在型態之前加上個 chan,每個 chan 都要宣告可容納的型態。
舉例來說,使用 Channel 來修改之前的龜兔賽跑程式:
package main
import (
"fmt"
"math/rand"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func tortoise(totalStep int, goal chan string) {
for step := 1; step <= totalStep; step++ {
fmt.Printf("烏龜跑了 %d 步...\n", step)
}
goal <- "烏龜"
}
func hare(totalStep int, goal chan string) {
flags := [...]bool{true, false}
step := 0
for step < totalStep {
isHareSleep := flags[random(1, 10)%2]
if isHareSleep {
fmt.Println("兔子睡著了zzzz")
} else {
step += 2
fmt.Printf("兔子跑了 %d 步...\n", step)
}
}
goal <- "兔子"
}
func main() {
goal := make(chan string)
totalStep := 10
go tortoise(totalStep, goal)
go hare(totalStep, goal)
fmt.Printf("%s 抵達終點\n", <-goal)
fmt.Printf("%s 抵達終點\n", <-goal)
}
在這個範例中,使用 make 建立了一個 Channel,當烏龜或兔子抵達終點時,使用 goal <- 發送一個字串至 Channel 中,而在主流程中,使用 <- goal 從 Channel 取得字串,若 Channel 中無法取得資料,這時會發生阻斷,直到可從 Channel 中取得字串為止。實際上,使用 goal <- 發送資料至 Channel 時,若 Channel 中已有資料,也會發生阻斷,直到該資料被取走為止。
Buffered Channel
上頭的範例建立 Channel 時並沒有指定 Channel 中可以容納多少資料,Channel 中預設只能容納一個資料,你可以在建立 Channel 時指定當中可以容納的資料數量。例如,建立一個生產者、消費者的程式:
package main
import "fmt"
func producer(clerk chan int) {
fmt.Println("生產者開始生產整數......")
for product := 1; product <= 10; product++ {
clerk <- product
fmt.Printf("生產了 (%d)\n", product)
}
}
func consumer(clerk chan int) {
fmt.Println("消費者開始消耗整數......")
for i := 1; i <= 10; i++ {
fmt.Printf("消費了 (%d)\n", <-clerk)
}
}
func main() {
clerk := make(chan int, 2)
go producer(clerk)
consumer(clerk)
}
在這個程式中,建立的 Channel 的容量為 2,因此在 Channel 的容量未滿前,發送數據至 Channel 並不會發生阻斷。
close 與 range
在這篇文件的第一個範例中,由於預期只會從 Channel 中收到兩個字串,因此主流程中使用了兩次 <- goal,然而有時,我們無法事先知道,能從 Channel 得到幾筆資料。
舉例來說,你也許想寫個猜數字遊戲,在隨機猜測數字的情況下,你無法事先知道要猜幾次才會猜中,而你想將先前猜測的數字透過 Channel 傳送:
package main
import (
"fmt"
"math/rand"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func guess(n int, ch chan int) {
for {
number := random(1, 10)
ch <- number
if number == n {
close(ch)
}
time.Sleep(time.Second)
}
}
func main() {
ch := make(chan int)
go guess(5, ch)
for i := range ch {
fmt.Println(i)
}
fmt.Println("I hit 5....Orz")
}
在這個範例中,每次猜測的數字,都會使用 ch <- number 傳至 Channel 中,而最後猜中數字時,使用 close() 關閉 Channel,Go 的 range 可以搭配 Channel 使用,在 Channel 尚未關閉前,搭配 for 就可以持續從 Channel 中取出資料。
select
如果有多個 Channel 需要協調,可以使用 select,直接來看個多個生產者與一個消費者的例子:
package main
import "fmt"
func producer(clerk chan int) {
fmt.Println("生產者開始生產整數......")
for product := 1; product <= 10; product++ {
clerk <- product
fmt.Printf("生產了 (%d)\n", product)
}
}
func consumer(clerk1 chan int, clerk2 chan int) {
fmt.Println("消費者開始消耗整數......")
for i := 1; i <= 20; i++ {
select {
case p1 := <-clerk1:
fmt.Printf("消費了生產者一的 (%d)\n", p1)
case p2 := <-clerk2:
fmt.Printf("消費了生產者二的 (%d)\n", p2)
}
}
}
func main() {
clerk1 := make(chan int)
clerk2 := make(chan int)
go producer(clerk1)
go producer(clerk2)
consumer(clerk1, clerk2)
}
在 select 的 case 中,會監看哪個 Channel 可以取得資料(或發送資料至 Channel),如果都有資料的話,就會隨機選取,如果都無法取得資料(或發送資料至 Channel)就會發生 panic,這可以設置 default 來解決,也就是監看的 Channel 中都沒有資料的話就會執行,或者利用 select 來做些超時設定。例如:
package main
import (
"fmt"
"math/rand"
"time"
)
func random(min, max int) int {
rand.Seed(time.Now().Unix())
return rand.Intn(max-min) + min
}
func producer(clerk chan int) {
fmt.Println("生產者開始生產整數......")
for product := 1; product <= 10; product++ {
time.After(time.Duration(random(1, 5)) * time.Second)
clerk <- product
fmt.Printf("生產了 (%d)\n", product)
}
}
func consumer(clerk1 chan int, clerk2 chan int) {
fmt.Println("消費者開始消耗整數......")
for i := 1; i <= 20; i++ {
select {
case p1 := <-clerk1:
fmt.Printf("消費了生產者一的 (%d)\n", p1)
case p2 := <-clerk2:
fmt.Printf("消費了生產者二的 (%d)\n", p2)
case <-time.After(3 * time.Second):
fmt.Printf("消費者抱怨中…XD")
}
}
}
func main() {
clerk1 := make(chan int)
clerk2 := make(chan int)
go producer(clerk1)
go producer(clerk2)
consumer(clerk1, clerk2)
}
如果過了 3 秒鐘,另兩個 Channel 都還是阻斷,case <- time.After(3 * time.Second) 該行就會成立,因此就可以看到消費者的抱怨了…XD
在 select 中若有相同的 Channel,會隨機選取。例如底下會顯示哪個結果是不一定的:
package main
import "fmt"
func main() {
ch := make(chan int, 1)
ch <- 1
select {
case <-ch:
fmt.Println("隨機任務 1")
case <-ch:
fmt.Println("隨機任務 2")
case <-ch:
fmt.Println("隨機任務 3")
}
}
單向 Channel
可以將 Channel 轉為只可發送或只可取值的 Channel,例如:
package main
import "fmt"
func producer(clerk chan<- int) {
fmt.Println("生產者開始生產整數......")
for product := 1; product <= 10; product++ {
clerk <- product
fmt.Printf("生產了 (%d)\n", product)
}
}
func consumer(clerk <-chan int) {
fmt.Println("消費者開始消耗整數......")
for i := 1; i <= 10; i++ {
fmt.Printf("消費了 (%d)\n", <-clerk)
}
}
func main() {
clerk := make(chan int, 2)
go producer(clerk)
consumer(clerk)
}
clerk chan<- int 是只能發送的 Channel,而 clerk <-chan int 是只能接收的 Channel,從一個只能發送的 Channel 接收資料,或者是對一個只能接收的 Channel 發送資料,都會引發 invalid operation 的錯誤。
透過 Channel 來作為 Goroutine 間的溝通機制,是 Go 中比較建議的方式,如果你真的不想要透過 Channel,而想要直接共用某些資料結構,就必須注意有無 Race condition的問題,若必要,可透過鎖定資源的方式來避免相關問題,有關鎖定的方式,可以參考 sync.Mutex 的使用。
在只有一個專案的情況下,GOPATH 非常合情合理而且簡單,如果有多個專案,各個專案的原始碼也可以放在同一個 GOPATH 之中,有著各自的套件結構,使用著來自 GOPATH 的非標準套件,此時整個 GOPATH 目錄就是一個巨大的 repository,具稱 Google 內部就是這樣的場景,才會有 GOPATH 這樣的設計,Go 社群中也有著「如果必須切換 GOPATH,大概有哪些地方不對了」的說法。
問題在於,這並不是社群或其他公司中使用 Go 的方式,如果個別專案有個別的套件,比較單純的做法是各個專案有個專用的 GOPATH,想要開發哪個專案,就切換至該專案使用的 GOPATH,然而很快地,如果有專案相依在這些個別專案上呢?將它們組織為巨大的 repository 是個做法,或者是令 GOPATH=prj1:prj2:prj3,prjx 是指向各專案原始碼的路徑,也就是說 GOPATH 會是一大串路徑結合後的產物。
在上述的設定中,維持了一個 GOPATH 不用切換,新專案可以加入至 GOPATH 最前頭,go get 的第三方套件會下載到最前面的路徑中,然而,若需要 prj2 也在開發中,若 prj2 需要新的第三方套件時,go get 卻會下載到新專案之中;在各自不同的情境中,無論怎麼調整 GOPATH 的順序,總是會有各自不同的問題發生。
另一方面,GOPATH 本身不涉及套件來源的版本問題,因此,若專案依賴的 repository 被修改了,日後建構專案就會受到影響,對依賴於Github之類來源,而且第三方套件本身非常活躍的專案來說,重新建構專案時無法有穩定的結果,這顯然是個大問題。
例如在〈Go 套件管理〉中看過的例子,使用 go get github.com/JustinSDK/goexample,然後撰寫底下的程式:
package main
import "github.com/JustinSDK/goexample"
func main() {
goexample.Hi()
goexample.Hello()
}
這簡單的程式被發佈為一個範例了,某年某月的某一天,我修改了 goexample 的內容,讓 Hi、Hello 顯示中文並發佈到 Github 上的檔案庫,有位讀者,依舊照著〈Go 套件管理〉中的說明進行操作,然而看到的不是英文,而是中文的招呼。
為了避免這個問題,通常會將下載的檔案庫複製出來,例如放到 deps 中:
project
└─src
├─deps
│ └─src
│ └─github.com
│ └─JustinSDK
│ └─goexample
│ .gitignore
│ hello.go
│ hi.go
│ LICENSE
│ README.md
│
└─main
main.go
問題是放到 deps 的檔案庫該怎麼用呢?其中一個方式是修改 import:
package main
import "deps/src/github.com/JustinSDK/goexample"
func main() {
goexample.Hi()
goexample.Hello()
}
另一個方式是透過工具修改 GOPATH 自動包含 deps 目錄,這類的概念主要成為了 godep 等工具早期在管理 Go 套件時的思考出發點。
Go 在 1.5 時實驗性地加入了 vendor,需要透過 GO15VENDOREXPERIMENT="1" 來啟用,1.6 預設 GO15VENDOREXPERIMENT="1",1.7 拿掉 GO15VENDOREXPERIMENT 環境變數,使得vendor成為正式的內建特性。
簡單來說,如果你的套件中有個 vendor 資料夾,例如:
project
└─src
└─main
│ main.go
│
└─vender
└─github.com
└─JustinSDK
└─goexample
.gitignore
hello.go
hi.go
LICENSE
README.md
對於 import "github.com/JustinSDK/goexample" 來說,尋找相依套件的順序會變成 vendor -> GOROOT 的 src -> GOPATH 的 src。
在 vendor 推出後,godep 也改使用 vendor了,而 glide 等工具,也都基於 vendor 了。
Go 在 1.11 時內建了實驗性的模組管理功能,並藉由 GO111MODULE 來決定是否啟用,可設定的值是 auto(1.11 ~ 1.15 的常見預設)、on 與 off。
若使用 Go 1.13,當設定值是 auto,執行建構指令時,會看看是否有個 go.mod 檔案(用來定義依賴的模組),若有就使用 Go 模組功能;沒有 go.mod 時,則仍可能採用舊式 GOPATH / vendor 的工作方式。
不過,在現代版本(例如 Go 1.26)中,模組已是標準做法。從 Go 1.16 起,模組模式預設啟用;日常開發通常不需要特別設定 GO111MODULE,直接使用 go mod init / go mod tidy 即可。
當設定值為 on 時,就是始終使用 Go 模組功能(從 1.12 之後,go.mod 可以在必要時再新增),模組下載內容會放在模組快取(預設位於 GOPATH/pkg/mod)。
在 Go 1.13 之後,go.mod 可以位於 GOPATH 之內或之外;新專案通常直接放在版本控制目錄下即可,不必刻意配合 GOPATH。
設定值為 off 時就是使用舊式 GOPATH 模式(僅建議維護舊專案時使用)。
例如,現在有個 pkgfoo 釋出了 v1.0.0 版,而你打算基於它寫個 go-exercise,go-exercise 資料夾中有個 src/main/main.go:
package main
import "github.com/JustinSDK/pkgfoo"
func main() {
pkgfoo.Hi()
pkgfoo.Hello()
}
現在進入你的 go-exercise 資料夾底下,執行 go mod init go-exercise,這會建立一個 go.mod;go 指令寫入的版本號會依實際安裝版本而異。在 Go 1.26 中,go mod init 預設會寫入較低的相容版本(例如 1.25.0),而不是直接寫成 1.26:
module go-exercise
go 1.25.0
從 Go 1.12 開始,預設的 go.mod 中會有版本字段,放置了 go.mod 的資料夾稱為模組根(module root)目錄,通常就是一個 repository 的根目錄,該目錄下的全部套件都屬於該模組(除了那些本身包含 go.mod 檔案的子目錄之外)。
在 Go 1.13 時,go build 常會一邊找出 import 陳述、一邊下載套件並更新 go.mod。不過從 Go 1.16 開始,go build / go test 預設不再自動改寫 go.mod 與 go.sum。在 Go 1.26 中,較常見的做法是先執行 go mod tidy(或 go get 調整依賴),再執行建構。
另外,因為 pkgfoo 現在最新版本可能已經不是 v1.0.0,如果你想重現本頁後面「從 v1.0.0 昇級到 v1.0.1」的過程,可以先明確指定版本:
go get github.com/JustinSDK/pkgfoo@v1.0.0
例如,先執行 go mod tidy 時,會看到類似訊息:
go: finding module for package github.com/JustinSDK/pkgfoo
go: downloading github.com/JustinSDK/pkgfoo v1.0.0
go: found github.com/JustinSDK/pkgfoo in github.com/JustinSDK/pkgfoo v1.0.0
而 go.mod 也有了底下內容:
module go-exercise
go 1.25.0
require github.com/JustinSDK/pkgfoo v1.0.0
go.mod 定義了相依的套件與版本,你也可以自行編輯 go.mod 的內容,來取得想要的版本;另外你也會發現多了個 go.sum,其中包含了套件的 hash 等訊息,這用來確認取得的是正確的版本。實務上常以 go mod tidy 來同步整理 go.mod 與 go.sum:
github.com/JustinSDK/pkgfoo v1.0.0 h1:XOi67njsT9pcRrsT40Oi3LCA3b1TyIxHd6+9ceGwa0U=
github.com/JustinSDK/pkgfoo v1.0.0/go.mod h1:5PAHGmqvfj2XbzxxOeiJJjOflE/p6zTVRFfaiEeSn1w=
接著在執行建構出來的可執行檔時會看到:
Hi
Helo
喔!Hello 少了一個小寫的 l,這是一個小 bug,在修正之後,發佈了 v1.0.1:
現在 appfoo 為了要能取得更新,可以使用 go get -u,這會昇級到最新的 MINOR 或 PATCH 版本,像是從 1.0.0 到 1.0.1,或者是 1.0.0 到 1.1.0,是的,這採用的是 Semantic Versioning;若是使用 go get -u=patch all,會將用到的套件昇級至最新的 PATCH 版本,像是從 1.0.0 到 1.0.1;若是使用 go get package@version,可以指定昇級至某個版本號,例如 go get github.com/JustinSDK/pkgfoo@v1.0.1,然而,不建議以此方式昇級至新的 MAJOR 版本,原因後述。
補充(Go 1.26 現況):這裡的 go get 是在「目前模組內管理依賴版本」。如果是安裝命令列工具,請改用 go install module/path/cmd@version(例如 @latest);從 Go 1.18 起,go get 不再負責建構/安裝可執行檔。
在這邊因為只是小 bug 更新,就使用 go get -u=patch all,這會看到類似底下的訊息:
go: finding github.com/JustinSDK/pkgfoo v1.0.1
go: downloading github.com/JustinSDK/pkgfoo v1.0.1
go: extracting github.com/JustinSDK/pkgfoo v1.0.1
go.mod 的內容也更新了(go.sum 也會更新):
module go-exercise
go 1.25.0
require github.com/JustinSDK/pkgfoo v1.0.1
重新執行 go build,就會顯示正確的訊息了:
Hi
Hello
假設現在 pkgfoo 中的訊息都改成中文,並更新為 v2.0.0 了,雖然可以使用 go get github.com/JustinSDK/pkgfoo@v2.0.0 來下載最新版本,然而會出現 +incompatible 字樣:
go: finding github.com/JustinSDK/pkgfoo v2.0.0
go: downloading github.com/JustinSDK/pkgfoo v2.0.0+incompatible
雖然可以順利建構,執行時也會是最新版本的結果,然而,若要昇級至最新的 MAJOR 版本,依賴的套件,必須明確地屬於某個模組,因此,pkgfoo 中必須有個 go.mod,並定義版本資訊:
module github.com/JustinSDK/pkgfoo/v2
go.mod 在加入了 pkgfoo 之後,發佈了 v2.0.0 ,現在 appfoo 打算使用這 v2.0.0,可以在 import 時指定:
package main
import "github.com/JustinSDK/pkgfoo/v2"
func main() {
pkgfoo.Hi()
pkgfoo.Hello()
}
直接 go build -o bin/main.exe src/main/main.go,就會看到類似底下下載 v2.0.0 的訊息:
go: finding github.com/JustinSDK/pkgfoo/v2 v2.0.0
go: downloading github.com/JustinSDK/pkgfoo/v2 v2.0.0
go: extracting github.com/JustinSDK/pkgfoo/v2 v2.0.0
而且你可以看到 appfoo 的 go.mod 更新為:
module go-exercise
go 1.25.0
require (
github.com/JustinSDK/pkgfoo v1.0.1
github.com/JustinSDK/pkgfoo/v2 v2.0.0
)
補充(Go 1.18+):如果你同時維護多個模組(例如 app 與數個本地 library),可以使用 go work init / go work use 建立 workspace,避免在本機開發時大量寫 replace 指令。
現在它依賴在…兩個版本?是的,事實上,你也可以同時在 appfoo 中使用:
package main
import "github.com/JustinSDK/pkgfoo/v2"
import pkgfooV1 "github.com/JustinSDK/pkgfoo"
func main() {
pkgfoo.Hi()
pkgfoo.Hello()
pkgfooV1.Hi()
pkgfooV1.Hello()
}
不同模組版本的套件,被視為不同的套件,上面的程式執行過時會顯示:
嗨
哈囉
Hi
Hello
Go 1.11 當時以實驗性功能加入了 WebAssembly 支援;在現代版本(例如 Go 1.26)中,js/wasm 已是常見目標之一,你可以使用 Go 來撰寫程式碼,然後令其在網頁中執行,也可以與瀏覽器互動,像是瀏覽器的 JavaScript 環境、DOM 操作等。
對 Go 開發者而言,理想的狀況下,若 Go 封裝的好,最好是可以完全忽略 JavaScript、瀏覽器環境等事實,也不需要知道 WebAssembly 的細節;不過,若能認識 JavaScript、瀏覽器、WebAssembly 的特性,對使用 Go 撰寫程式並編譯為 WebAssembly 來說,仍有很大的幫助。
如果對 JavaScript、瀏覽器的細節有興趣,建議參考〈ECMAScript 本質部份〉,如果對 WebAssembly 的細節有興趣,建議參考〈WebAssembly〉文件。
無論如何,來看個簡單的 Go 程式如何編譯為 WebAssembly,首先,來個簡單的 Go 程式:
package main
func main() {
println("Hello, WebAssembly")
}
再簡單也不過,在編譯為 WebAssembly 之後,println 的輸出預設會是瀏覽器主控台(console),接下來,若要編譯為 WebAssembly,環境變數 GOOS 必須設定為 js,GOARCH 必須設定為 wasm。
如果你是使用 Visual Studio Code,安裝了 vscode-go 擴充,可以在 settings.json 中設定:
{
"go.toolsEnvVars": {"GOOS":"js", "GOARCH": "wasm"}
}
如果是要在 Visual Studio Code 開啟的終端機中設定環境變數,因為它是基於 Power Shell,可以如下設定環境變數:
$env:GOOS="js"
$env:GOARCH="wasm"
如果是在 Windows 的命令提示字元,就是使用 set 了:
SET GOOS=js
SET GOARCH=wasm
接下來,可以執行建構:
go build -o test.wasm main.go
test.wasm 是編譯出來的 WebAssembly 模組位元組碼。體積會依 Go 版本、程式內容與最佳化方式而異;早期 Go 1.11 的 wasm hello world 常見約數 MB 等級(壓縮後可明顯降低),現代版本的結果也仍建議搭配壓縮與快取策略評估。
接下來就是開個 HTML 檔案,在當中使用 JavaScript,運用 Fetch API、WebAssembly API 等,取得、編譯、初始化 WebAssembly 模組,這些細節在〈WebAssembly〉文件都有談到。
如果想要直接有個現成的載入頁面可以使用,在 Go 1.26 可從 Go 安裝目錄的 lib/wasm 取得 wasm_exec.html 與 wasm_exec.js(舊版文件常見 misc/wasm 路徑)。wasm_exec.html 裏頭寫的 JavaScript,會使用 Fetch API 來取得 test.wasm,這也是為什麼,方才編譯時指定輸出檔案名稱為 test.wasm 的原因。
如果你有安裝 Node.js,Go 1.26 也可使用 go_js_wasm_exec(或參考 lib/wasm/wasm_exec_node.js)來運行 test.wasm。舊版文件常見直接搭配 wasm_exec.js 的方式,實際可用性會依版本而異:
node wasm_exec.js test.wasm
如果要在瀏覽器中運行,你需要有個 HTTP 伺服器,例如 Node.js 的 http-server,在啟動之後,請求你的 http://localhost:8080/wasm_exec.html。
這會看到一個 Run 按鈕,開啟你瀏覽器上的開發者工具,然後按下網頁中的 Run 按鈕,你就會看到開發者工具中的主控台顯示了文字:
要注意的是,在執行完 Go 的 main 之後,程式就結束了,就網頁中 Run 按鈕的事件來說,每按一次是會重新跑一次 WebAssembly 模組實例,也就是重新跑一次 main 流程,有時這不會是你想要的,這時就要在 Go 中以某種方式,阻斷 main 的流程,這之後還會看到。
這只是個體驗,之後的文件還會談到,如何操作瀏覽器中的 JavaScript、DOM,以及 Go 中定義的函式,如何能被 JavaScript 取得呼叫。
Go 社群中有不少人直言,Go 支援 WebAssembly 就是要取代 Javascript,雖然我個人覺得,這就姑且當成是個崇高的理想就好,不過這也表示,在編譯為 WebAssembly 之後,可以呼叫 JavaScript 或操作 DOM,自然也是 Go 應該照料之事。syscall/js 在 Go 1.11 時期以實驗性姿態登場,而在現代版本(例如 Go 1.26)的 js/wasm 開發中,仍是重要的橋接套件。
Go 與 JavaScript 畢竟是兩個不同的語言,各擁有不同的資料型態與結構,因而必須先知道,兩個語言間的型態如何對應,這主要定義在 syscall/js 套件的 js.go 中。
例如,js.Value 結構代表 JavaScript 中的值,定義有 Get 與 Set 方法,可以對物件上的特性存取;若想存取的對象實際上是陣列,可以使用 Index、SetIndex 並指定索引;若對象是個函式,可以使用 Invoke 指定引數來呼叫,若想呼叫的是物件上的方法,可以使用 Call 指定方法名稱與呼叫時的引數等。
在 js.go 中預先定義了一些 js.Value 的實例,可以透過公開的 js.Undefined、js.Null、js.Global 等函式呼叫取得。
因而,你可以開啟〈哈囉!WebAssembly!〉中談到的 wasm_exec.html,在 <button onClick="run();" id="runButton" disabled>Run</button> 標籤底下加上 <div id="c1">Hello, WebAssembly!</div>:
<!doctype html>
<!--
Copyright 2018 The Go Authors. All rights reserved.
Use of this source code is governed by a BSD-style
license that can be found in the LICENSE file.
-->
<html>
<head>
<meta charset="utf-8">
<title>Go wasm</title>
</head>
<body>
<script src="wasm_exec.js"></script>
<script>
WebAssembly API 等... 略
</script>
<button onClick="run();" id="runButton" disabled>Run</button>
<div id="c1">Hello, WebAssembly!</div>
</body>
</html>
若想撰寫 Go 來取得對應的 DOM 物件,並在主控台顯示 innerHTML 特性值,可以如下撰寫:
package main
import "syscall/js"
func main() {
window := js.Global() // 取得全域的 window
doc := window.Get("document") // 相當於 window.document
c1 := doc.Call("getElementById", "c1") // 相當於 document.getElementById('c1')
innerHTML := c1.Get("innerHTML").String() // 相當於 c1.innerHTML
println(innerHTML)
}
這邊特意使用數個變數,代逐一對照取得的各是哪個 JavaScript 值,實際上當然可以直接寫成底下:
package main
import "syscall/js"
func main() {
innerHTML :=
js.Global().
Get("document").
Call("getElementById", "c1").
Get("innerHTML").
String()
println(innerHTML)
}
也就是相當於在 JavaScript 中撰寫 document.getElementById("c1").innerHTML;在編譯為 WebAssembly、使用瀏覽器連線至網頁之後,按下 Run 按鈕,就可以取得目標 c1 的 innerHTML:
類似地,如果想在 Go 中呼叫瀏覽器提供的 alert 全域函式,可以如下撰寫:
package main
import "syscall/js"
func main() {
alert := js.Global().Get("alert")
// 相當於 alert('Hello, WebAssembly!')
alert.Invoke("Hello, WebAssembly!")
}
在編譯為 WebAssembly、使用瀏覽器連線至網頁之後,按下 Run 按鈕,會令瀏覽器出現警示對話方塊:
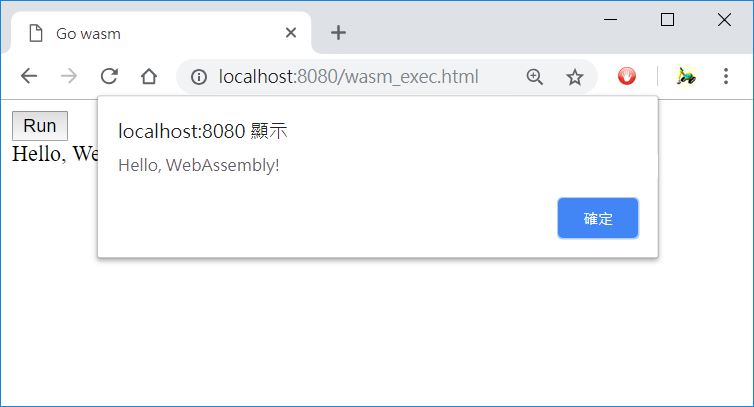
因此,如果有個自定義的 JavaScript 函式,而你想在 Go 中呼叫它,就是看看,那個函式是在哪個物件之上,想辦法取得該物件,之後就可以加以呼叫了,例如:
<!doctype html>
<!--
Copyright 2018 The Go Authors. All rights reserved.
Use of this source code is governed by a BSD-style
license that can be found in the LICENSE file.
-->
<html>
<head>
<meta charset="utf-8">
<title>Go wasm</title>
</head>
<body>
<script src="wasm_exec.js"></script>
<script>
WebAssembly API 等... 略
</script>
<script>
function hi_wasm(name) {
document.getElementById('c1').innerHTML = 'Hi, ' + name;
}
</script>
<button onClick="run();" id="runButton" disabled>Run</button>
<div id="c1">Hello, WebAssembly!</div>
</body>
</html>
在上例中,hi_wasm 函式實際上是 window 的一個特性,因此在 Go 中可以這麼呼叫:
package main
import "syscall/js"
func main() {
hi_wasm := js.Global().Get("hi_wasm")
hi_wasm.Invoke("WebAssembly")
}
在編譯為 WebAssembly、使用瀏覽器連線至網頁之後,按下 Run 按鈕,就會將 c1 的文字改變為 Hi, WebAssembly。
如果自訂的 JavaScript 函式有傳回值的話,那會成為 Invoke 方法的傳回值,然而記得,JavaScript 的值在 Go 中是對應至 js.Value,Invoke 的傳回型態正是 js.Value,取得之後,就看它代表著什麼 JavaScript 值(數值、字串、陣列、函式?),再進一步操作。
在〈Go 呼叫 JavaScript〉看過如何在 Go 中取得 JavaScript 的函式,然後予以呼叫,若你曾稍微瞭解過〈WebAssembly〉,就會發覺,這跟 WebAssembly 匯入函式至 WebAssembly 的方式不同。
這是 JavaScript 的 wasm_exec.js 以及 Go 的 syscall/js 居中之緣故,在 wasm_exec.html 中你也可以看到載入、編譯、實例化 WebAssembly 的過程:
if (!WebAssembly.instantiateStreaming) { // polyfill
WebAssembly.instantiateStreaming = async (resp, importObject) => {
const source = await (await resp).arrayBuffer();
return await WebAssembly.instantiate(source, importObject);
};
}
const go = new Go();
let mod, inst;
WebAssembly.instantiateStreaming(fetch("test.wasm"), go.importObject).then((result) => {
mod = result.module;
inst = result.instance;
document.getElementById("runButton").disabled = false;
});
async function run() {
console.clear();
await go.run(inst);
inst = await WebAssembly.instantiate(mod, go.importObject); // reset instance
}
Go 有自己的匯入物件,也就是 go.importObject,這個物件主要是 JavaScript 環境與 Go 編譯出來的 WebAssembly 之橋樑,將 JavaScript 的值與 Go 的結構實例作了個對應,因此,不用自己匯入某個函式,只要取得某個作為名稱空間的 JavaScript 物件,取得上頭對應的特性,像是函式,就可以在 Go 中操作。
也就是說,如果想要在 Go 中定義函式,然後在 JavaScript 中呼叫,就是將 Go 中定義的函式,設定給某個對應的 JavaScript 物件,之後就可以在 JavaScript 環境中使用了,只不過在定義時,必須留意 JavaScript 與 Go 的型態對應。
在現代版本(例如 Go 1.26)中,可以被 JavaScript 環境呼叫的 Go 函式,通常會使用 js.Func 搭配 js.FuncOf 來包裝;這個值可以設定到 JavaScript 物件上,之後由 JavaScript 呼叫。
要能被 JavaScript 呼叫的 Go 函式,常見簽章為 func(this js.Value, args []js.Value) any,其中 args 是呼叫函式時傳入的引數,你可以想像 JavaScript 函式中 arguments 的對應型態。
例如,顯示加總至某個指定 DOM 物件的函式,可以如下定義:
package main
import "syscall/js"
func main() {
// 註冊在 JavaScript 全域
js.Global().Set("printSumTo", js.FuncOf(printSum))
// 阻斷 main 流程
select {}
}
func printSum(this js.Value, args []js.Value) any {
c1 := args[0] // 結果顯示到這個 div
numbers := args[1:] // 接下來是要加總的數字
c1.Set("innerHTML", sum(numbers))
return nil
}
func sum(numbers []js.Value) int {
var sum int
for _, val := range numbers {
sum += val.Int()
}
return sum
}
js.FuncOf 的回呼可傳回值(會轉為對應的 JavaScript 值),不過像事件處理器這類場合,通常仍以副作用方式實現比較常見,例如改變某個 JavaScript 物件的狀態,像是這邊是改變某個 DOM 的 innerHTML。
因為 Go 的 main 執行完,模組的程式就結束了,這樣 Go 中定義的函式就沒有了,然而,事件會是在之後才發生,因而要被回呼的函式必須存活著,為了這個目的,範例中使用 select {} 來阻斷流程,視需求而定,你也可以用別的方式來設計某種阻斷。
至於 JavaScript 的部份,來稍微修改一下 wasm_exec.html:
<!doctype html>
<!--
Copyright 2018 The Go Authors. All rights reserved.
Use of this source code is governed by a BSD-style
license that can be found in the LICENSE file.
-->
<html>
<head>
<meta charset="utf-8">
<title>Go wasm</title>
</head>
<body>
<script src="wasm_exec.js"></script>
<script>
if (!WebAssembly.instantiateStreaming) { // polyfill
WebAssembly.instantiateStreaming = async (resp, importObject) => {
const source = await (await resp).arrayBuffer();
return await WebAssembly.instantiate(source, importObject);
};
}
const go = new Go();
let mod, inst;
WebAssembly.instantiateStreaming(fetch("test.wasm"), go.importObject).then((result) => {
mod = result.module;
inst = result.instance;
document.getElementById("runButton").disabled = false;
}).then(_ => { // 實例化模組之後就執行
console.clear();
go.run(inst);
});
</script>
<script>
function run() {
// 呼叫 Go 定義的回呼函式
printSumTo(document.getElementById('c1'),
1, 2, 3, 4, 5);
}
</script>
<button onClick="run();" id="runButton" disabled>Run</button>
<div id="c1"></div>
</body>
</body>
</html>
按下 Run 之後,會呼叫 runAndPrintSum,這會先執行 run 函式,執行 WebAssembly 模組實例,對應的就是執行 Go 定義的 main,因為 run 是非同步的,接下來就會執行 printSumTo,因此 1 到 5 的加總結果,就會顯示到 id 為 c1 的 div 元素之中。
至於 WebAssembly API 的調整,想要瞭解這部份的話,可以看看〈WebAssembly〉中前三篇的說明。
故且不討論 WebAssembly API 怎麼寫,在自定義的 JavaScript 程式碼中,想要呼叫 Go 中定義的函式,其實感覺就是多了些額外的手續,而且不自然。
如果把一切都帶到 Go 中做,將 Go 中定義的函式,當成是某事件的回呼,會比較單純一些,例如:
package main
import (
"strconv"
"syscall/js"
)
func main() {
// 註冊按鈕事件
dom("runButton").Call("addEventListener", "click", js.FuncOf(cal))
select {}
}
// 根據 id 取得 DOM 物件
func dom(id string) js.Value {
return js.Global().Get("document").Call("getElementById", id)
}
// 按下 Run 的事件處理器
func cal(this js.Value, args []js.Value) any {
n1, _ := inputValue("n1")
n2, _ := inputValue("n2")
dom("r").Set("innerHTML", n1+n2)
return nil
}
// 取得輸入欄位值
func inputValue(id string) (int, error) {
return strconv.Atoi(dom(id).Get("value").String())
}
至於 wasm_exec.html 可以如下調整:
<!doctype html>
<!--
Copyright 2018 The Go Authors. All rights reserved.
Use of this source code is governed by a BSD-style
license that can be found in the LICENSE file.
-->
<html>
<head>
<meta charset="utf-8">
<title>Go wasm</title>
</head>
<body>
<input id="n1"> + <input id="n2"> = <span id="r"></span><br>
<button id="runButton" disabled>Run</button>
<script src="wasm_exec.js"></script>
<script>
if (!WebAssembly.instantiateStreaming) { // polyfill
WebAssembly.instantiateStreaming = async (resp, importObject) => {
const source = await (await resp).arrayBuffer();
return await WebAssembly.instantiate(source, importObject);
};
}
const go = new Go();
let mod, inst;
WebAssembly.instantiateStreaming(fetch("test.wasm"), go.importObject).then((result) => {
mod = result.module;
inst = result.instance;
document.getElementById("runButton").disabled = false;
}).then(_ => {
console.clear();
go.run(inst);
});
</script>
</body>
</html>
這樣就可以進行頁面操作,就是個簡單的加法器:
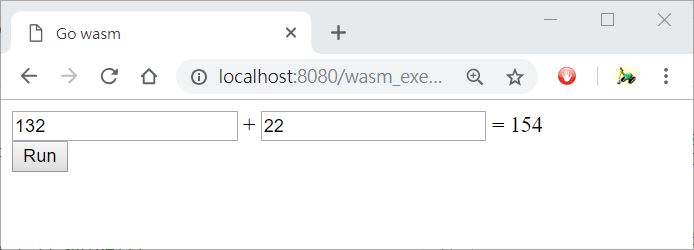
(這也許才是 Go 希望的,要你把東西都帶入 Go 中來做,JavaScript 環境的事件會呼叫 Go 的函式,然後在 Go 中計算,在 Go 中改變物件狀態、畫面等。)