開篇詞|想真正學會 Go 併發,建議這樣學
你好,我是晁嶽攀(鳥窩),曾在微博研發平台架構中心擔任資深架構師,也是微服務框架 rpcx 的作者。歡迎來到這份《Go 併發程式設計實戰》學習內容。
這份內容的目標,不只是教你「會用 goroutine / channel」,而是幫你建立一套可以在實務專案裡穩定解題的併發思維。
為什麼要學 Go 併發?
我過去長期使用 Java 做專案開發,後來投入 Go,原因很直接:Go 在併發場景的開發體驗和執行效率,真的很有優勢。
Go 的特點大致有幾個:
- 語法相對精簡,程式碼比較容易維護
- 工具鏈完整,建置與部署方便
goroutine建立成本低,適合處理大量併發任務channel讓 goroutine 之間的資料傳遞更直觀
你可以很快寫出一個會動的併發程式,但要寫得穩、寫得準、寫得不踩坑,就是另一回事了。
多數人學 Go 併發時,常卡住的地方
我把常見問題整理成 5 類:
- 不知道該選哪一種併發原語(例如
Mutex、channel、WaitGroup)。 - 好幾種做法都能解,卻不知道哪個才是比較好的解法。
- 不知道怎麼做任務編排,導致流程順序失控。
- 程式會
panic、死鎖(deadlock)或卡住,但很難除錯。 - 現成原語不夠用時,程式越寫越複雜、可讀性越差。
這些問題很正常,幾乎每個開始深入學 Go 的工程師都會遇到。
這份內容的學習方式:兩條主線
我建議用「兩條主線」來學,才不會變成零散記憶。
1) 知識主線(你要有哪些工具)
課程核心分成 5 個模組:
- 基本併發原語
Mutex、RWMutex、WaitGroup、Cond、Pool、Context等
- 原子操作(atomic)
- 併發原語的基礎能力,理解後更容易看懂底層設計
- Channel
- Go 特有的資料傳遞機制,也是任務編排的核心工具之一
- 擴充併發原語
- 例如信號量(Semaphore)、
singleflight、循環柵欄(CyclicBarrier)、errgroup
- 例如信號量(Semaphore)、
- 分散式併發原語
- 例如 Leader 選舉、分散式鎖、分散式佇列等
你可以把它想成「武器庫」:工具越完整,面對不同併發情境時越不容易硬解。
2) 學習主線(每個工具要學到什麼程度)
每個模組都建議用同一套節奏學習:
- 基本用法
- 實作原理
- 常見踩坑情境
- 真實專案中的錯誤案例(Bug)
這樣學的好處是:你不只知道 API 怎麼呼叫,也知道它為什麼會壞、壞在哪裡、怎麼避開。
學習地圖(先建立全局觀)
Go 併發程式設計學習地圖
+--------------------+ +--------------------+
| 知識主線 | | 學習主線 |
| (你要有的工具庫) | | (每個工具怎麼學) |
+--------------------+ +--------------------+
| |
v v
+--------------------------------+ +------------------+
| 基本原語 / atomic / channel / | | 用法 |
| 擴充原語 / 分散式原語 | | 原理 |
+--------------------------------+ | 易錯情境 |
| | 真實 Bug 案例 |
+----------+----------+------------------+
|
v
+---------------------------+
| 實務上能選對工具、避開坑洞 |
+---------------------------+
實務上怎麼選工具?先用這個原則
剛開始學時,可以先用這個簡化判斷:
- 任務編排:優先考慮
channel - 共享資源保護:優先考慮傳統同步原語(例如
Mutex)
但這只是入門準則,不是萬用答案。
同一個問題,常常有不只一種可行方案;真正的關鍵是:
- 原語的底層機制是什麼
- 成本在哪裡(效能、複雜度、可維護性)
- 哪些情境容易出錯
所以,不建議「什麼都用 channel」;能不能用是一回事,適不適合是另一回事。
為什麼要看原始碼與真實 Bug?
如果你只停在 API 用法,遇到邊界情況通常會很痛苦。
深入看 Go 併發原語的原始碼,你會學到很多實戰價值很高的設計,例如:
Mutex在公平性與效能上的取捨sync.Map為了提升效能做的資料結構設計- 各種異常狀況(panic、競態、死鎖)是怎麼被觸發的
而真實專案的 Bug 案例更重要,因為它能幫你建立「避坑清單」。
最後的目標:不只會用,還能組合與設計
學到後面,你的能力應該分成 3 個層次:
- 會用:知道常見併發原語的用途與基本寫法。
- 會選:面對情境能選出更合適的做法,避免誤用。
- 會設計:能組合既有原語,甚至設計新的併發解法。
能力進階示意
[會用 API] -> [看懂原理與限制] -> [選對工具] -> [組合/設計新原語]
初學 進階 實務穩定 高階
例如:
- 你可以把多個原語組合成新的控制流程(例如限制併發數量 + 等待全部完成)
- 也可以依照需求設計出標準庫沒有直接提供的解法
建議你怎麼讀這份內容
- 想補基礎:從「基本併發原語」開始
- 對
channel不熟:先讀Channel相關章節 - 已熟悉標準庫:可先看「擴充併發原語」與「分散式併發原語」
- 想快速提升實戰能力:優先看每章的「易錯情境」與「真實 Bug」
結語
Go 併發世界很大,工具也很多。真正的差別不在於你背了多少 API,而在於:
- 你是否能理解原理
- 你是否能選對工具
- 你是否能在複雜場景裡穩定解題
把這份內容當成你的練功地圖,循序建立工具庫、補齊原理、累積避坑經驗,你的 Go 併發能力會進步得很快。
如果你是和同事、朋友一起學,效果通常更好,因為很多併發問題非常適合透過 code review 和討論來釐清。
01|Mutex:如何解決資源併發訪問問題?
你好,我是鳥窩。
本章導讀
┌──────────────┐ Lock() ┌──────────────┐
│ goroutine A │ ────────────────> │ Mutex 鎖 │
└──────────────┘ └──────┬───────┘
│ 取得鎖
v
┌──────────────┐
│ 臨界區/共享資源 │
└──────┬───────┘
│ Unlock()
┌──────────────┐ 等待/阻塞 │
│ goroutine B │ ──────────────────────────┘
└──────────────┘
今天是我們 Go 併發程式設計實戰課的第一講,我們就直接從解決併發訪問這個棘手問題入手。
說起併發訪問問題,真是太常見了,比如多個 goroutine 併發更新同一個資源,像計數器;同時更新使用者的賬戶資訊;秒殺系統;往同一個 buffer 中併發寫入資料等等。如果沒有互斥控制,就會出現一些異常情況,比如計數器的計數不準確、使用者的賬戶可能出現透支、秒殺系統出現超賣、buffer 中的資料混亂,等等,後果都很嚴重。
這些問題怎麼解決呢?對,用互斥鎖,那在 Go 語言裡,就是 Mutex。
這節課,我會帶你詳細瞭解互斥鎖的實作機制,以及 Go 標準庫的互斥鎖 Mutex 的基本使用方法。在後面的 3 節課裡,我還會講解 Mutex 的具體實作原理、易錯場景和一些拓展用法。
好了,我們先來看看互斥鎖的實作機制。
互斥鎖的實作機制
互斥鎖是併發控制的一個基本手段,是為了避免競爭而建立的一種併發控制機制。在學習它的具體實作原理前,我們要先搞懂一個概念,就是臨界區。
在併發程式設計中,如果程式中的一部分會被併發訪問或修改,那麼,為了避免併發訪問導致的意想不到的結果,這部分程式需要被保護起來,這部分被保護起來的程式,就叫做臨界區。
可以說,臨界區就是一個被共享的資源,或者說是一個整體的一組共享資源,比如對資料庫的訪問、對某一個共享資料結構的操作、對一個 I/O 裝置的使用、對一個連線池中的連線的呼叫,等等。
如果很多執行緒同步訪問臨界區,就會造成訪問或操作錯誤,這當然不是我們希望看到的結果。所以,我們可以使用互斥鎖,限定臨界區只能同時由一個執行緒持有。
當臨界區由一個執行緒持有的時候,其它執行緒如果想進入這個臨界區,就會返回失敗,或者是等待。直到持有的執行緒退出臨界區,這些等待執行緒中的某一個才有機會接著持有這個臨界區。
你看,互斥鎖就很好地解決了資源競爭問題,有人也把互斥鎖叫做排它鎖。那在 Go 標準庫中,它提供了 Mutex 來實作互斥鎖這個功能。
根據 2019 年第一篇全面分析 Go 併發 Bug 的論文Understanding Real-World Concurrency Bugs in Go,Mutex 是使用最廣泛的同步原語(Synchronization primitives,有人也叫做併發原語。我們在這個課程中根據英文直譯優先用同步原語,但是併發原語的指代範圍更大,還可以包括任務編排的型別,所以後面我們講 Channel 或者擴充套件型別時也會用併發原語)。關於同步原語,並沒有一個嚴格的定義,你可以把它看作解決併發問題的一個基礎的資料結構。
在這門課的前兩個模組,我會和你講互斥鎖 Mutex、讀寫鎖 RWMutex、併發編排 WaitGroup、條件變數 Cond、Channel 等同步原語。所以,在這裡,我先和你說一下同步原語的適用場景。
- 共享資源。併發地讀寫共享資源,會出現資料競爭(data race)的問題,所以需要 Mutex、RWMutex 這樣的併發原語來保護。
- 任務編排。需要 goroutine 按照一定的規律執行,而 goroutine 之間有相互等待或者依賴的順序關係,我們常常使用 WaitGroup 或者 Channel 來實作。
- 訊息傳遞。資訊交流以及不同的 goroutine 之間的執行緒安全的資料交流,常常使用 Channel 來實作。
今天這一講,咱們就從公認的使用最廣泛的 Mutex 開始學習吧。是騾子是馬咱得拉出來遛遛,看看我們到底可以怎麼使用 Mutex。
Mutex 的基本使用方法
在正式看 Mutex 用法之前呢,我想先給你交代一件事:Locker 介面。
在 Go 的標準庫中,package sync 提供了鎖相關的一系列同步原語,這個 package 還定義了一個 Locker 的介面,Mutex 就實作了這個介面。
Locker 的介面定義了鎖同步原語的方法集:
type Locker interface {
Lock()
Unlock()
}
可以看到,Go 定義的鎖介面的方法集很簡單,就是請求鎖(Lock)和釋放鎖(Unlock)這兩個方法,秉承了 Go 語言一貫的簡潔風格。
但是,這個介面在實際專案應用得不多,因為我們一般會直接使用具體的同步原語,而不是透過介面。
我們這一講介紹的 Mutex 以及後面會介紹的讀寫鎖 RWMutex 都實作了 Locker 介面,所以首先我把這個介面介紹了,讓你做到心中有數。
下面我們直接看 Mutex。
簡單來說,互斥鎖 Mutex 就提供兩個方法 Lock 和 Unlock:進入臨界區之前呼叫 Lock 方法,退出臨界區的時候呼叫 Unlock 方法:
func(m *Mutex)Lock()
func(m *Mutex)Unlock()
當一個 goroutine 透過呼叫 Lock 方法獲得了這個鎖的擁有權後, 其它請求鎖的 goroutine 就會阻塞在 Lock 方法的呼叫上,直到鎖被釋放並且自己獲取到了這個鎖的擁有權。
看到這兒,你可能會問,為啥一定要加鎖呢?別急,我帶你來看一個併發訪問場景中不使用鎖的例子,看看實作起來會出現什麼狀況。
在這個例子中,我們建立了 10 個 goroutine,同時不斷地對一個變數(count)進行加 1 操作,每個 goroutine 負責執行 10 萬次的加 1 操作,我們期望的最後計數的結果是 10 * 100000 = 1000000 (一百萬)。
import (
"fmt"
"sync"
)
func main() {
var count = 0
// 使用WaitGroup等待10個goroutine完成
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 對變數count執行10次加1
for j := 0; j < 100000; j++ {
count++
}
}()
}
// 等待10個goroutine完成
wg.Wait()
fmt.Println(count)
}
在這段程式碼中,我們使用 sync.WaitGroup 來等待所有的 goroutine 執行完畢後,再輸出最終的結果。sync.WaitGroup 這個同步原語我會在後面的課程中具體介紹,現在你只需要知道,我們使用它來控制等待一組 goroutine 全部做完任務。
但是,每次執行,你都可能得到不同的結果,基本上不會得到理想中的一百萬的結果。
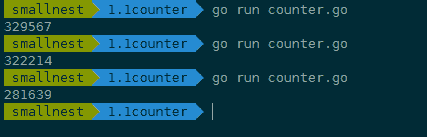
這是為什麼呢?
其實,這是因為,count++ 不是一個原子操作,它至少包含幾個步驟,比如讀取變數 count 的當前值,對這個值加 1,把結果再儲存到 count 中。因為不是原子操作,就可能有併發的問題。
比如,10 個 goroutine 同時讀取到 count 的值為 9527,接著各自按照自己的邏輯加 1,值變成了 9528,然後把這個結果再寫回到 count 變數。但是,實際上,此時我們增加的總數應該是 10 才對,這裡卻只增加了 1,好多計數都被“吞”掉了。這是併發訪問共享資料的常見錯誤。
// count++操作的彙編程式碼
MOVQ "".count(SB), AX
LEAQ 1(AX), CX
MOVQ CX, "".count(SB)
這個問題,有經驗的開發人員還是比較容易發現的,但是,很多時候,併發問題隱藏得非常深,即使是有經驗的人,也不太容易發現或者 Debug 出來。
針對這個問題,Go 提供了一個檢測併發訪問共享資源是否有問題的工具: race detector,它可以幫助我們自動發現程式有沒有 data race 的問題。
Go race detector 是基於 Google 的 C/C++ sanitizers 技術實作的,編譯器透過探測所有的記憶體訪問,加入程式碼能監視對這些記憶體地址的訪問(讀還是寫)。在程式碼執行的時候,race detector 就能監控到對共享變數的非同步訪問,出現 race 的時候,就會打印出警告資訊。
這個技術在 Google 內部幫了大忙,探測出了 Chromium 等程式碼的大量併發問題。Go 1.1 中就引入了這種技術,並且一下子就發現了標準庫中的 42 個併發問題。現在,race detector 已經成了 Go 持續整合過程中的一部分。
我們來看看這個工具怎麼用。
在編譯(compile)、測試(test)或者執行(run)Go 程式碼的時候,加上 race 引數,就有可能發現併發問題。比如在上面的例子中,我們可以加上 race 引數執行,檢測一下是不是有併發問題。如果你 go run -race counter.go,就會輸出警告資訊。
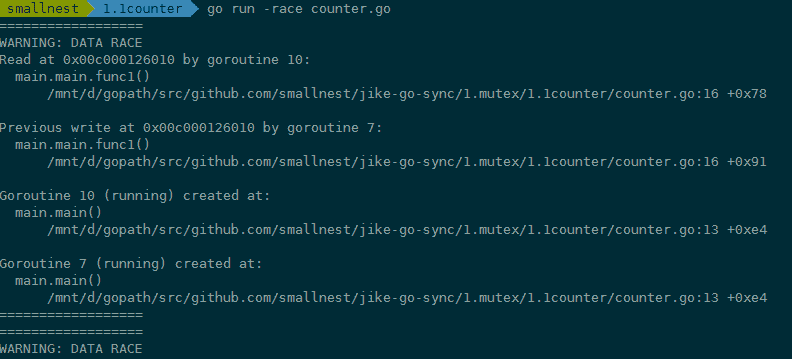
這個警告不但會告訴你有併發問題,而且還會告訴你哪個 goroutine 在哪一行對哪個變數有寫操作,同時,哪個 goroutine 在哪一行對哪個變數有讀操作,就是這些併發的讀寫訪問,引起了 data race。
例子中的 goroutine 10 對記憶體地址 0x00c000126010 有讀的操作(counter.go 檔案第 16 行),同時,goroutine 7 對記憶體地址 0x00c000126010 有寫的操作(counter.go 檔案第 16 行)。而且還可能有多個 goroutine 在同時進行讀寫,所以,警告資訊可能會很長。
雖然這個工具使用起來很方便,但是,因為它的實作方式,只能透過真正對實際地址進行讀寫訪問的時候才能探測,所以它並不能在編譯的時候發現 data race 的問題。而且,在執行的時候,只有在觸發了 data race 之後,才能檢測到,如果碰巧沒有觸發(比如一個 data race 問題只能在 2 月 14 號零點或者 11 月 11 號零點才出現),是檢測不出來的。
而且,把開啟了 race 的程式部署線上上,還是比較影響效能的。執行 go tool compile -race -S counter.go,可以檢視計數器例子的程式碼,重點關注一下 count++ 前後的編譯後的程式碼:
0x002a 00042 (counter.go:13) CALL runtime.racefuncenter(SB)
......
0x0061 00097 (counter.go:14) JMP 173
0x0063 00099 (counter.go:15) MOVQ AX, "".j+8(SP)
0x0068 00104 (counter.go:16) PCDATA $0, $1
0x0068 00104 (counter.go:16) MOVQ "".&count+128(SP), AX
0x0070 00112 (counter.go:16) PCDATA $0, $0
0x0070 00112 (counter.go:16) MOVQ AX, (SP)
0x0074 00116 (counter.go:16) CALL runtime.raceread(SB)
0x0079 00121 (counter.go:16) PCDATA $0, $1
0x0079 00121 (counter.go:16) MOVQ "".&count+128(SP), AX
0x0081 00129 (counter.go:16) MOVQ (AX), CX
0x0084 00132 (counter.go:16) MOVQ CX, ""..autotmp_8+16(SP)
0x0089 00137 (counter.go:16) PCDATA $0, $0
0x0089 00137 (counter.go:16) MOVQ AX, (SP)
0x008d 00141 (counter.go:16) CALL runtime.racewrite(SB)
0x0092 00146 (counter.go:16) MOVQ ""..autotmp_8+16(SP), AX
......
0x00b6 00182 (counter.go:18) CALL runtime.deferreturn(SB)
0x00bb 00187 (counter.go:18) CALL runtime.racefuncexit(SB)
0x00c0 00192 (counter.go:18) MOVQ 104(SP), BP
0x00c5 00197 (counter.go:18) ADDQ $112, SP
在編譯的程式碼中,增加了 runtime.racefuncenter、runtime.raceread、runtime.racewrite、runtime.racefuncexit 等檢測 data race 的方法。透過這些插入的指令,Go race detector 工具就能夠成功地檢測出 data race 問題了。
總結一下,透過在編譯的時候插入一些指令,在執行時透過這些插入的指令檢測併發讀寫從而發現 data race 問題,就是這個工具的實作機制。
既然這個例子存在 data race 問題,我們就要想辦法來解決它。這個時候,我們這節課的主角 Mutex 就要登場了,它可以輕鬆地消除掉 data race。
具體怎麼做呢?下面,我就結合這個例子,來具體給你講一講 Mutex 的基本用法。
我們知道,這裡的共享資源是 count 變數,臨界區是 count++,只要在臨界區前面獲取鎖,在離開臨界區的時候釋放鎖,就能完美地解決 data race 的問題了。
package main
import (
"fmt"
"sync"
)
func main() {
// 互斥鎖保護計數器
var mu sync.Mutex
// 計數器的值
var count = 0
// 輔助變數,用來確認所有的goroutine都完成
var wg sync.WaitGroup
wg.Add(10)
// 啟動10個gourontine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 累加10萬次
for j := 0; j < 100000; j++ {
mu.Lock()
count++
mu.Unlock()
}
}()
}
wg.Wait()
fmt.Println(count)
}
如果你再執行一下程式,就會發現,data race 警告沒有了,系統乾脆地輸出了 1000000:

怎麼樣,使用 Mutex 是不是非常高效?效果很驚喜。
這裡有一點需要注意:Mutex 的零值是還沒有 goroutine 等待的未加鎖的狀態,所以你不需要額外的初始化,直接宣告變數(如 var mu sync.Mutex)即可。
那 Mutex 還有哪些用法呢?
很多情況下,Mutex 會嵌入到其它 struct 中使用,比如下面的方式:
type Counter struct {
mu sync.Mutex
Count uint64
}
在初始化嵌入的 struct 時,也不必初始化這個 Mutex 欄位,不會因為沒有初始化出現空指標或者是無法獲取到鎖的情況。
有時候,我們還可以採用嵌入欄位的方式。透過嵌入欄位,你可以在這個 struct 上直接呼叫 Lock/Unlock 方法。
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100000; j++ {
counter.Lock()
counter.Count++
counter.Unlock()
}
}()
}
wg.Wait()
fmt.Println(counter.Count)
}
type Counter struct {
sync.Mutex
Count uint64
}
**如果嵌入的 struct 有多個欄位,我們一般會把 Mutex 放在要控制的欄位上面,然後使用空格把欄位分隔開來。**即使你不這樣做,程式碼也可以正常編譯,只不過,用這種風格去寫的話,邏輯會更清晰,也更易於維護。
甚至,你還可以把獲取鎖、釋放鎖、計數加一的邏輯封裝成一個方法,對外不需要暴露鎖等邏輯:
func main() {
// 封裝好的計數器
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
// 啟動10個goroutine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 執行10萬次累加
for j := 0; j < 100000; j++ {
counter.Incr() // 受到鎖保護的方法
}
}()
}
wg.Wait()
fmt.Println(counter.Count())
}
// 執行緒安全的計數器型別
type Counter struct {
CounterType int
Name string
mu sync.Mutex
count uint64
}
// 加1的方法,內部使用互斥鎖保護
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 得到計數器的值,也需要鎖保護
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}總結這節課,我介紹了併發問題的背景知識、標準庫中 Mutex 的使用和最佳實踐、透過 race detector 工具發現計數器程式的問題以及修復方法。相信你已經大致瞭解了 Mutex 這個同步原語。
在專案開發的初始階段,我們可能並沒有仔細地考慮資源的併發問題,因為在初始階段,我們還不確定這個資源是否被共享。經過更加深入的設計,或者新功能的增加、程式碼的完善,這個時候,我們就需要考慮共享資源的併發問題了。當然,如果你能在初始階段預見到資源會被共享併發訪問就更好了。
意識到共享資源的併發訪問的早晚不重要,重要的是,一旦你意識到這個問題,你就要及時透過互斥鎖等手段去解決。
比如 Docker issue 37583、35517、32826、30696等、kubernetes issue 72361、71617等,都是後來發現的 data race 而採用互斥鎖 Mutex 進行修復的。
思考題
你已經知道,如果 Mutex 已經被一個 goroutine 獲取了鎖,其它等待中的 goroutine 們只能一直等待。那麼,等這個鎖釋放後,等待中的 goroutine 中哪一個會優先獲取 Mutex 呢?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
02|Mutex:庖丁解牛看實作
你好,我是鳥窩。
本章導讀
Mutex 實作路徑(概念圖)
┌──────────────┐
│ Lock() │
└──────┬───────┘
│
┌───────▼────────┐
│ 快速路徑: CAS 成功 │───> 進入臨界區
└───────┬────────┘
│失敗
┌───────▼────────┐
│ 慢速路徑: 排隊/自旋 │
│ 休眠(wait sema) │
└───────┬────────┘
│
┌──────▼───────┐
│ Unlock() │
└──────┬───────┘
│喚醒/交棒
▼
下一個等待 goroutine
上一講我們一起體驗了 Mutex 的使用,竟是那麼簡單,只有簡簡單單兩個方法,Lock 和 Unlock,進入臨界區之前呼叫 Lock 方法,退出臨界區的時候呼叫 Unlock 方法。這個時候,你一定會有一絲好奇:“它的實作是不是也很簡單呢?”
其實不是的。如果你閱讀 Go 標準庫裡 Mutex 的原始碼,並且追溯 Mutex 的演進歷史,你會發現,從一個簡單易於理解的互斥鎖的實作,到一個非常複雜的資料結構,這是一個逐步完善的過程。Go 開發者們做了種種努力,精心設計。我自己每次看,都會被這種匠心和精益求精的精神打動。
所以,今天我就想帶著你一起去探索 Mutex 的實作及演進之路,希望你能和我一樣體驗到這種技術追求的美妙。我們從 Mutex 的一個簡單實作開始,看看它是怎樣逐步提升效能和公平性的。在這個過程中,我們可以學習如何逐步設計一個完善的同步原語,並能對複雜度、效能、結構設計的權衡考量有新的認識。經過這樣一個學習,我們不僅能通透掌握 Mutex,更好地使用這個工具,同時,對我們自己設計併發資料介面也非常有幫助。
那具體怎麼來講呢?我把 Mutex 的架構演進分成了四個階段,下面給你畫了一張圖來說明。
“初版”的 Mutex 使用一個 flag 來表示鎖是否被持有,實作比較簡單;後來照顧到新來的 goroutine,所以會讓新的 goroutine 也儘可能地先獲取到鎖,這是第二個階段,我把它叫作“給新人機會”;那麼,接下來就是第三階段“多給些機會”,照顧新來的和被喚醒的 goroutine;但是這樣會帶來飢餓問題,所以目前又加入了飢餓的解決方案,也就是第四階段“解決飢餓”。
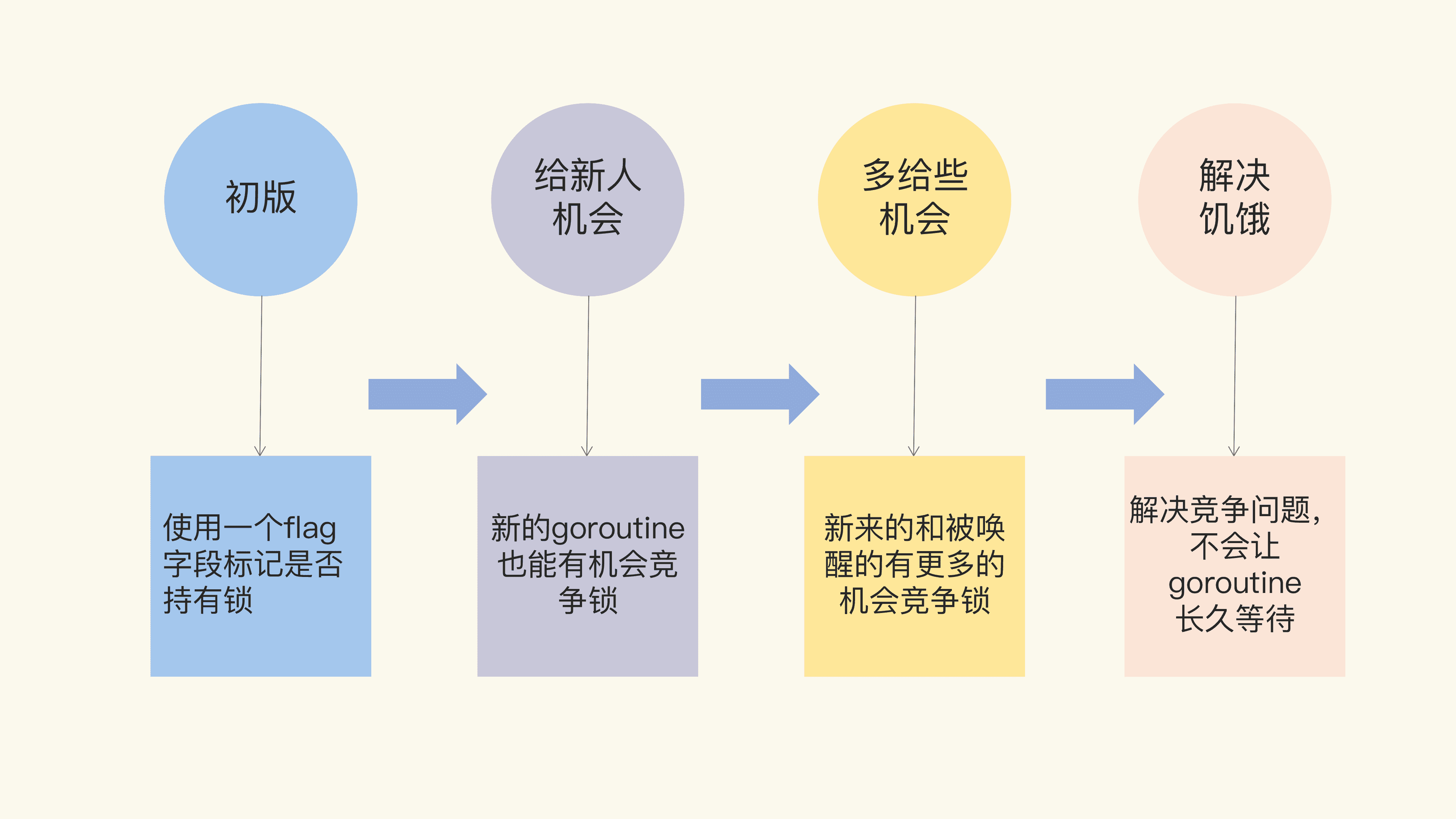
有了這四個階段,我們學習的路徑就清晰了,那接下來我會從程式碼層面帶你領略 Go 開發者這些大牛們是如何逐步解決這些問題的。
初版的互斥鎖
我們先來看怎麼實作一個最簡單的互斥鎖。在開始之前,你可以先想一想,如果是你,你會怎麼設計呢?
你可能會想到,可以透過一個 flag 變數,標記當前的鎖是否被某個 goroutine 持有。如果這個 flag 的值是 1,就代表鎖已經被持有,那麼,其它競爭的 goroutine 只能等待;如果這個 flag 的值是 0,就可以透過 CAS(compare-and-swap,或者 compare-and-set)將這個 flag 設定為 1,標識鎖被當前的這個 goroutine 持有了。
實際上,Russ Cox 在 2008 年提交的第一版 Mutex 就是這樣實作的。
// CAS操作,當時還沒有抽象出atomic包
func cas(val *int32, old, new int32) bool
func semacquire(*int32)
func semrelease(*int32)
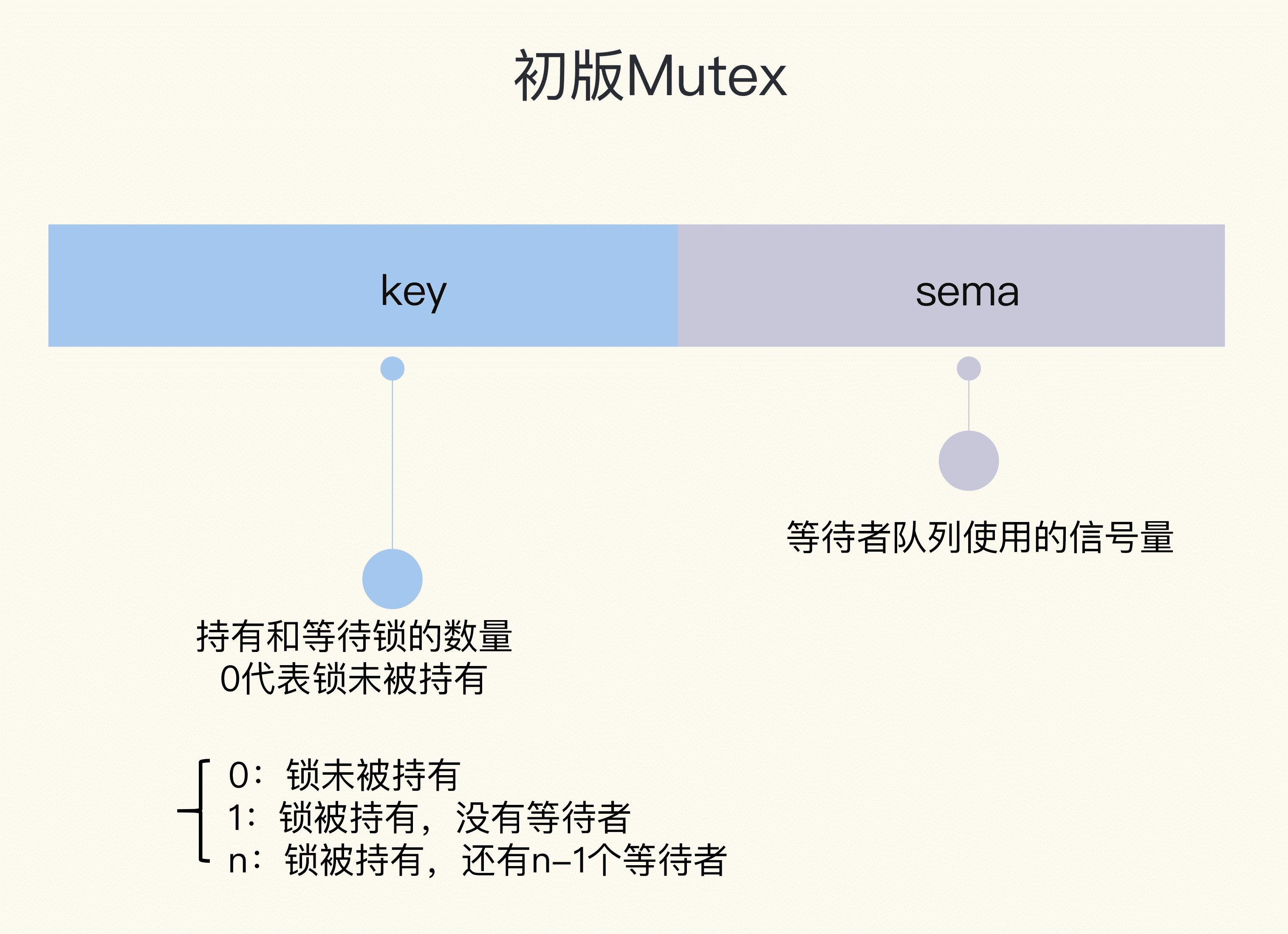
// 互斥鎖的結構,包含兩個欄位
type Mutex struct {
key int32 // 鎖是否被持有的標識
sema int32 // 訊號量專用,用以阻塞/喚醒goroutine
}
// 保證成功在val上增加delta的值
func xadd(val *int32, delta int32) (new int32) {
for {
v := *val
if cas(val, v, v+delta) {
return v + delta
}
}
panic("unreached")
}
// 請求鎖
func (m *Mutex) Lock() {
if xadd(&m.key, 1) == 1 { //標識加1,如果等於1,成功獲取到鎖
return
}
semacquire(&m.sema) // 否則阻塞等待
}
func (m *Mutex) Unlock() {
if xadd(&m.key, -1) == 0 { // 將標識減去1,如果等於0,則沒有其它等待者
return
}
semrelease(&m.sema) // 喚醒其它阻塞的goroutine
}
這裡呢,我先簡單補充介紹下剛剛提到的 CAS。
CAS 指令將給定的值和一個記憶體地址中的值進行比較,如果它們是同一個值,就使用新值替換記憶體地址中的值,這個操作是原子性的。那啥是原子性呢?如果你還不太理解這個概念,那麼在這裡只需要明確一點就行了,那就是原子性保證這個指令總是基於最新的值進行計算,如果同時有其它執行緒已經修改了這個值,那麼,CAS 會返回失敗。
CAS 是實作互斥鎖和同步原語的基礎,我們很有必要掌握它。
好了,我們繼續來分析下剛才的這段程式碼。
雖然當時的 Go 語法和現在的稍微有些不同,而且標準庫的佈局、實作和現在的也有很大的差異,但是,這些差異不會影響我們對程式碼的理解,因為最核心的結構體(struct)和函式、方法的定義幾乎是一樣的。
Mutex 結構體包含兩個欄位:
- **欄位 key:**是一個 flag,用來標識這個排外鎖是否被某個 goroutine 所持有,如果 key 大於等於 1,說明這個排外鎖已經被持有;
- **欄位 sema:**是個訊號量變數,用來控制等待 goroutine 的阻塞休眠和喚醒。
呼叫 Lock 請求鎖的時候,透過 xadd 方法進行 CAS 操作(第 24 行),xadd 方法透過迴圈執行 CAS 操作直到成功,保證對 key 加 1 的操作成功完成。如果比較幸運,鎖沒有被別的 goroutine 持有,那麼,Lock 方法成功地將 key 設定為 1,這個 goroutine 就持有了這個鎖;如果鎖已經被別的 goroutine 持有了,那麼,當前的 goroutine 會把 key 加 1,而且還會呼叫 semacquire 方法(第 27 行),使用訊號量將自己休眠,等鎖釋放的時候,訊號量會將它喚醒。
持有鎖的 goroutine 呼叫 Unlock 釋放鎖時,它會將 key 減 1(第 31 行)。如果當前沒有其它等待這個鎖的 goroutine,這個方法就返回了。但是,如果還有等待此鎖的其它 goroutine,那麼,它會呼叫 semrelease 方法(第 34 行),利用訊號量喚醒等待鎖的其它 goroutine 中的一個。
所以,到這裡,我們就知道了,初版的 Mutex 利用 CAS 原子操作,對 key 這個標誌量進行設定。key 不僅僅標識了鎖是否被 goroutine 所持有,還記錄了當前持有和等待獲取鎖的 goroutine 的數量。
Mutex 的整體設計非常簡潔,學習起來一點也沒有障礙。但是,注意,我要劃重點了。
Unlock 方法可以被任意的 goroutine 呼叫釋放鎖,即使是沒持有這個互斥鎖的 goroutine,也可以進行這個操作。這是因為,Mutex 本身並沒有包含持有這把鎖的 goroutine 的資訊,所以,Unlock 也不會對此進行檢查。Mutex 的這個設計一直保持至今。
這就帶來了一個有趣而危險的功能。為什麼這麼說呢?
你看,其它 goroutine 可以強制釋放鎖,這是一個非常危險的操作,因為在臨界區的 goroutine 可能不知道鎖已經被釋放了,還會繼續執行臨界區的業務操作,這可能會帶來意想不到的結果,因為這個 goroutine 還以為自己持有鎖呢,有可能導致 data race 問題。
所以,我們在使用 Mutex 的時候,必須要保證 goroutine 儘可能不去釋放自己未持有的鎖,一定要遵循“誰申請,誰釋放”的原則。在真實的實踐中,我們使用互斥鎖的時候,很少在一個方法中單獨申請鎖,而在另外一個方法中單獨釋放鎖,一般都會在同一個方法中獲取鎖和釋放鎖。
如果你接觸過其它語言(比如 Java 語言)的互斥鎖的實作,就會發現這一點和其它語言的互斥鎖不同,所以,如果是從其它語言轉到 Go 語言開發的同學,一定要注意。
以前,我們經常會基於效能的考慮,及時釋放掉鎖,所以在一些 if-else 分支中加上釋放鎖的程式碼,程式碼看起來很臃腫。而且,在重構的時候,也很容易因為誤刪或者是漏掉而出現死鎖的現象。
type Foo struct {
mu sync.Mutex
count int
}
func (f *Foo) Bar() {
f.mu.Lock()
if f.count < 1000 {
f.count += 3
f.mu.Unlock() // 此處釋放鎖
return
}
f.count++
f.mu.Unlock() // 此處釋放鎖
return
}
從 1.14 版本起,Go 對 defer 做了最佳化,採用更有效的內聯方式,取代之前的生成 defer 物件到 defer chain 中,defer 對耗時的影響微乎其微了,所以基本上修改成下面簡潔的寫法也沒問題:
func (f *Foo) Bar() {
f.mu.Lock()
defer f.mu.Unlock()
if f.count < 1000 {
f.count += 3
return
}
f.count++
return
}
這樣做的好處就是 Lock/Unlock 總是成對緊湊出現,不會遺漏或者多呼叫,程式碼更少。
但是,如果臨界區只是方法中的一部分,為了儘快釋放鎖,還是應該第一時間呼叫 Unlock,而不是一直等到方法返回時才釋放。
初版的 Mutex 實作之後,Go 開發組又對 Mutex 做了一些微調,比如把欄位型別變成了 uint32 型別;呼叫 Unlock 方法會做檢查;使用 atomic 包的同步原語執行原子操作等等,這些小的改動,都不是核心功能,你簡單知道就行了,我就不詳細介紹了。
但是,初版的 Mutex 實作有一個問題:請求鎖的 goroutine 會排隊等待獲取互斥鎖。雖然這貌似很公平,但是從效能上來看,卻不是最優的。因為如果我們能夠把鎖交給正在佔用 CPU 時間片的 goroutine 的話,那就不需要做上下文的切換,在高併發的情況下,可能會有更好的效能。
接下來,我們就繼續探索 Go 開發者是怎麼解決這個問題的。
給新人機會
Go 開發者在 2011 年 6 月 30 日的 commit 中對 Mutex 做了一次大的調整,調整後的 Mutex 實作如下:
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexWaiterShift = iota
)
雖然 Mutex 結構體還是包含兩個欄位,但是第一個欄位已經改成了 state,它的含義也不一樣了。
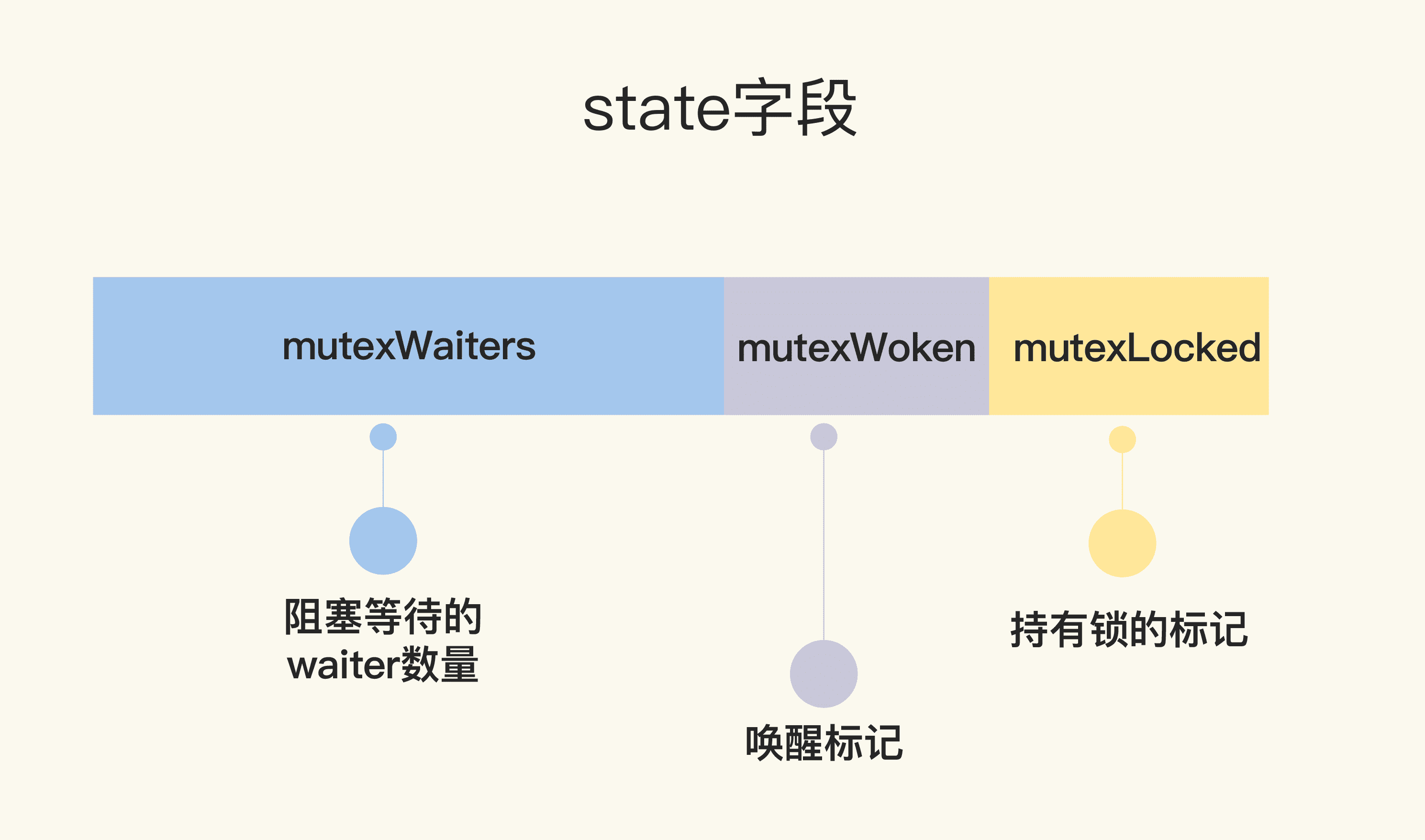
state 是一個複合型的欄位,一個欄位包含多個意義,這樣可以透過儘可能少的記憶體來實作互斥鎖。這個欄位的第一位(最小的一位)來表示這個鎖是否被持有,第二位代表是否有喚醒的 goroutine,剩餘的位數代表的是等待此鎖的 goroutine 數。所以,state 這一個欄位被分成了三部分,代表三個資料。
請求鎖的方法 Lock 也變得複雜了。複雜之處不僅僅在於對欄位 state 的操作難以理解,而且程式碼邏輯也變得相當複雜。
func (m *Mutex) Lock() {
// Fast path: 幸運case,能夠直接獲取到鎖
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
awoke := false
for {
old := m.state
new := old | mutexLocked // 新狀態加鎖
if old&mutexLocked != 0 {
new = old + 1<<mutexWaiterShift //等待者數量加一
}
if awoke {
// goroutine是被喚醒的,
// 新狀態清除喚醒標誌
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {//設定新狀態
if old&mutexLocked == 0 { // 鎖原狀態未加鎖
break
}
runtime.Semacquire(&m.sema) // 請求訊號量
awoke = true
}
}
}
首先是透過 CAS 檢測 state 欄位中的標誌(第 3 行),如果沒有 goroutine 持有鎖,也沒有等待持有鎖的 gorutine,那麼,當前的 goroutine 就很幸運,可以直接獲得鎖,這也是註釋中的 Fast path 的意思。
如果不夠幸運,state 不是零值,那麼就透過一個迴圈進行檢查。接下來的第 7 行到第 26 行這段程式碼雖然只有幾行,但是理解起來卻要費一番功夫,因為涉及到對 state 不同標誌位的操作。這裡的位操作以及操作後的結果和數值比較,並沒有明確的解釋,有時候你需要根據後續的處理進行推斷。所以說,如果你充分理解了這段程式碼,那麼對最新版的 Mutex 也會比較容易掌握了,因為你已經清楚了這些位操作的含義。
我們先前知道,如果想要獲取鎖的 goroutine 沒有機會獲取到鎖,就會進行休眠,但是在鎖釋放喚醒之後,它並不能像先前一樣直接獲取到鎖,還是要和正在請求鎖的 goroutine 進行競爭。這會給後來請求鎖的 goroutine 一個機會,也讓 CPU 中正在執行的 goroutine 有更多的機會獲取到鎖,在一定程度上提高了程式的效能。
for 迴圈是不斷嘗試獲取鎖,如果獲取不到,就透過 runtime.Semacquire(&m.sema) 休眠,休眠醒來之後 awoke 置為 true,嘗試爭搶鎖。
程式碼中的第 10 行將當前的 flag 設定為加鎖狀態,如果能成功地透過 CAS 把這個新值賦予 state(第 19 行和第 20 行),就代表搶奪鎖的操作成功了。
不過,需要注意的是,如果成功地設定了 state 的值,但是之前的 state 是有鎖的狀態,那麼,state 只是清除 mutexWoken 標誌或者增加一個 waiter 而已。
請求鎖的 goroutine 有兩類,一類是新來請求鎖的 goroutine,另一類是被喚醒的等待請求鎖的 goroutine。鎖的狀態也有兩種:加鎖和未加鎖。我用一張表格,來說明一下 goroutine 不同來源不同狀態下的處理邏輯。

剛剛說的都是獲取鎖,接下來,我們再來看看釋放鎖。釋放鎖的 Unlock 方法也有些複雜,我們來看一下。
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked) //去掉鎖標誌
if (new+mutexLocked)&mutexLocked == 0 { //本來就沒有加鎖
panic("sync: unlock of unlocked mutex")
}
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken) != 0 { // 沒有等待者,或者有喚醒的waiter,或者鎖原來已加鎖
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken // 新狀態,準備喚醒goroutine,並設定喚醒標誌
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime.Semrelease(&m.sema)
return
}
old = m.state
}
}
下面我來給你解釋一下這個方法。
第 3 行是嘗試將持有鎖的標識設定為未加鎖的狀態,這是透過減 1 而不是將標誌位置零的方式實作。第 4 到 6 行還會檢測原來鎖的狀態是否已經未加鎖的狀態,如果是 Unlock 一個未加鎖的 Mutex 會直接 panic。
不過,即使將加鎖置為未加鎖的狀態,這個方法也不能直接返回,還需要一些額外的操作,因為還可能有一些等待這個鎖的 goroutine(有時候我也把它們稱之為 waiter)需要透過訊號量的方式喚醒它們中的一個。所以接下來的邏輯有兩種情況。
第一種情況,如果沒有其它的 waiter,說明對這個鎖的競爭的 goroutine 只有一個,那就可以直接返回了;如果這個時候有喚醒的 goroutine,或者是又被別人加了鎖,那麼,無需我們操勞,其它 goroutine 自己幹得都很好,當前的這個 goroutine 就可以放心返回了。
第二種情況,如果有等待者,並且沒有喚醒的 waiter,那就需要喚醒一個等待的 waiter。在喚醒之前,需要將 waiter 數量減 1,並且將 mutexWoken 標誌設定上,這樣,Unlock 就可以返回了。
透過這樣複雜的檢查、判斷和設定,我們就可以安全地將一把互斥鎖釋放了。
相對於初版的設計,這次的改動主要就是,新來的 goroutine 也有機會先獲取到鎖,甚至一個 goroutine 可能連續獲取到鎖,打破了先來先得的邏輯。但是,程式碼複雜度也顯而易見。
雖然這一版的 Mutex 已經給新來請求鎖的 goroutine 一些機會,讓它參與競爭,沒有空閒的鎖或者競爭失敗才加入到等待佇列中。但是其實還可以進一步最佳化。我們接著往下看。
多給些機會
在 2015 年 2 月的改動中,如果新來的 goroutine 或者是被喚醒的 goroutine 首次獲取不到鎖,它們就會透過自旋(spin,透過迴圈不斷嘗試,spin 的邏輯是在runtime 實作的)的方式,嘗試檢查鎖是否被釋放。在嘗試一定的自旋次數後,再執行原來的邏輯。
func (m *Mutex) Lock() {
// Fast path: 幸運之路,正好獲取到鎖
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
awoke := false
iter := 0
for { // 不管是新來的請求鎖的goroutine, 還是被喚醒的goroutine,都不斷嘗試請求鎖
old := m.state // 先儲存當前鎖的狀態
new := old | mutexLocked // 新狀態設定加鎖標誌
if old&mutexLocked != 0 { // 鎖還沒被釋放
if runtime_canSpin(iter) { // 還可以自旋
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
continue // 自旋,再次嘗試請求鎖
}
new = old + 1<<mutexWaiterShift
}
if awoke { // 喚醒狀態
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}
new &^= mutexWoken // 新狀態清除喚醒標記
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&mutexLocked == 0 { // 舊狀態鎖已釋放,新狀態成功持有了鎖,直接返回
break
}
runtime_Semacquire(&m.sema) // 阻塞等待
awoke = true // 被喚醒
iter = 0
}
}
}
這次的最佳化,增加了第 13 行到 21 行、第 25 行到第 27 行以及第 36 行。我來解釋一下主要的邏輯,也就是第 13 行到 21 行。
如果可以 spin 的話,第 9 行的 for 迴圈會重新檢查鎖是否釋放。對於臨界區程式碼執行非常短的場景來說,這是一個非常好的最佳化。因為臨界區的程式碼耗時很短,鎖很快就能釋放,而搶奪鎖的 goroutine 不用透過休眠喚醒方式等待排程,直接 spin 幾次,可能就獲得了鎖。
解決飢餓
經過幾次最佳化,Mutex 的程式碼越來越複雜,應對高併發爭搶鎖的場景也更加公平。但是你有沒有想過,因為新來的 goroutine 也參與競爭,有可能每次都會被新來的 goroutine 搶到獲取鎖的機會,在極端情況下,等待中的 goroutine 可能會一直獲取不到鎖,這就是飢餓問題。
說到這兒,我突然想到了最近看到的一種叫做鸛的鳥。如果鸛媽媽尋找食物很艱難,找到的食物只夠一個幼鳥吃的,鸛媽媽就會把食物給最強壯的一隻,這樣一來,飢餓弱小的幼鳥總是得不到食物吃,最後就會被啄出巢去。
先前版本的 Mutex 遇到的也是同樣的困境,“悲慘”的 goroutine 總是得不到鎖。
Mutex 不能容忍這種事情發生。所以,2016 年 Go 1.9 中 Mutex 增加了飢餓模式,讓鎖變得更公平,不公平的等待時間限制在 1 毫秒,並且修復了一個大 Bug:總是把喚醒的 goroutine 放在等待佇列的尾部,會導致更加不公平的等待時間。
之後,2018 年,Go 開發者將 fast path 和 slow path 拆成獨立的方法,以便內聯,提高效能。2019 年也有一個 Mutex 的最佳化,雖然沒有對 Mutex 做修改,但是,對於 Mutex 喚醒後持有鎖的那個 waiter,排程器可以有更高的優先順序去執行,這已經是很細緻的效能優化了。
為了避免程式碼過多,這裡只列出當前的 Mutex 實作。想要理解當前的 Mutex,我們需要好好泡一杯茶,仔細地品一品了。
當然,現在的 Mutex 程式碼已經複雜得接近不可讀的狀態了,而且程式碼也非常長,刪減後佔了幾乎三頁紙。但是,作為第一個要詳細介紹的同步原語,我還是希望能更清楚地剖析 Mutex 的實作,向你展示它的演化和為了一個貌似很小的 feature 不得不將程式碼變得非常複雜的原因。
當然,你也可以暫時略過這一段,以後慢慢品,只需要記住,Mutex 絕不容忍一個 goroutine 被落下,永遠沒有機會獲取鎖。不拋棄不放棄是它的宗旨,而且它也儘可能地讓等待較長的 goroutine 更有機會獲取到鎖。
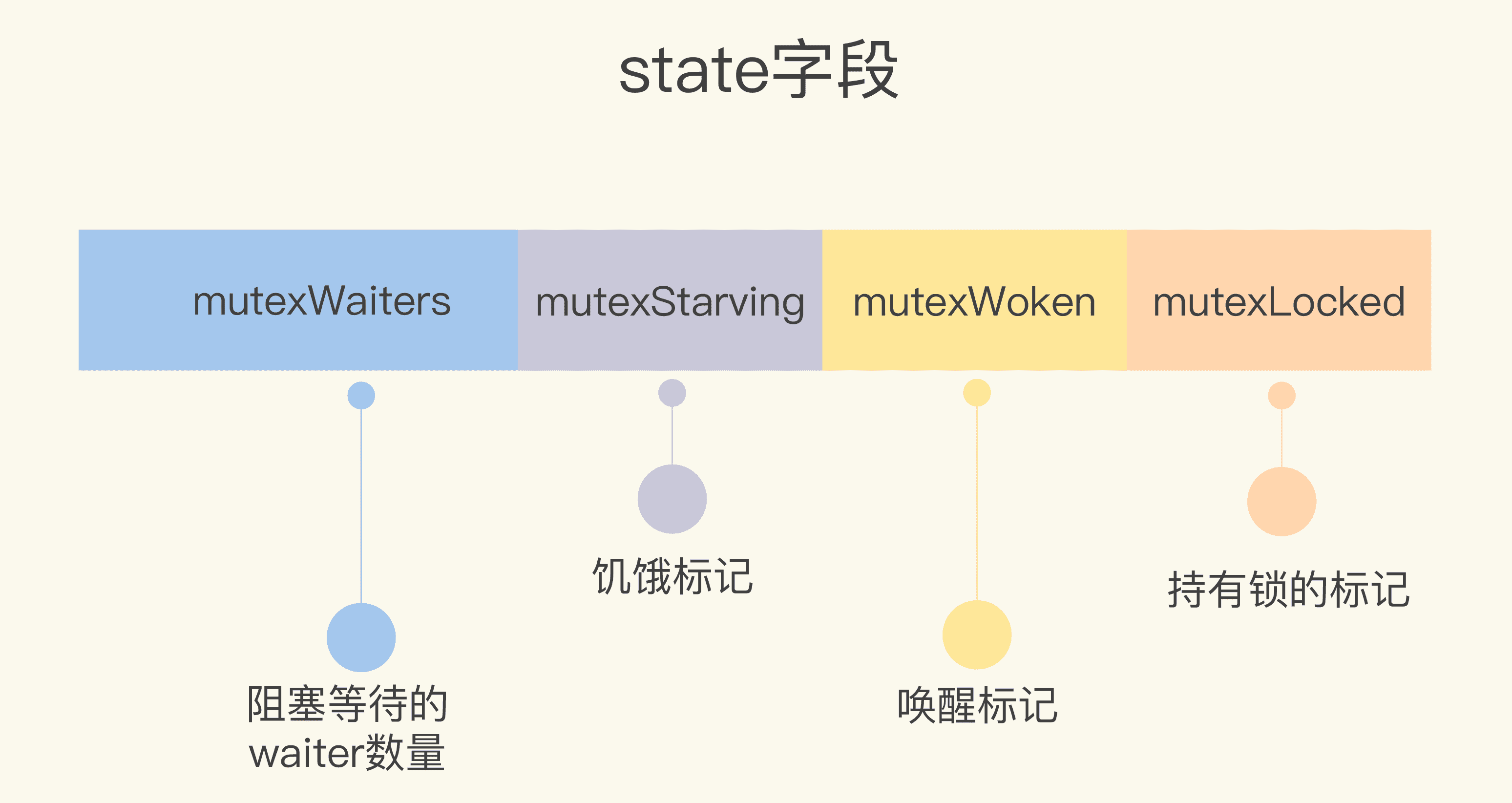
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving // 從state欄位中分出一個飢餓標記
mutexWaiterShift = iota
starvationThresholdNs = 1e6
)
func (m *Mutex) Lock() {
// Fast path: 幸運之路,一下就獲取到了鎖
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path:緩慢之路,嘗試自旋競爭或飢餓狀態下飢餓goroutine競爭
m.lockSlow()
}
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false // 此goroutine的飢餓標記
awoke := false // 喚醒標記
iter := 0 // 自旋次數
old := m.state // 當前的鎖的狀態
for {
// 鎖是非飢餓狀態,鎖還沒被釋放,嘗試自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state // 再次獲取鎖的狀態,之後會檢查是否鎖被釋放了
continue
}
new := old
if old&mutexStarving == 0 {
new |= mutexLocked // 非飢餓狀態,加鎖
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift // waiter數量加1
}
if starving && old&mutexLocked != 0 {
new |= mutexStarving // 設定飢餓狀態
}
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // 新狀態清除喚醒標記
}
// 成功設定新狀態
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 原來鎖的狀態已釋放,並且不是飢餓狀態,正常請求到了鎖,返回
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// 處理飢餓狀態
// 如果以前就在佇列裡面,加入到佇列頭
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 阻塞等待
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 喚醒之後檢查鎖是否應該處於飢餓狀態
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
// 如果鎖已經處於飢餓狀態,直接搶到鎖,返回
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 有點繞,加鎖並且將waiter數減1
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving // 最後一個waiter或者已經不飢餓了,清除飢餓標記
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
runtime_Semrelease(&m.sema, true, 1)
}
}
跟之前的實作相比,當前的 Mutex 最重要的變化,就是增加飢餓模式。第 12 行將飢餓模式的最大等待時間閾值設定成了 1 毫秒,這就意味著,一旦等待者等待的時間超過了這個閾值,Mutex 的處理就有可能進入飢餓模式,優先讓等待者先獲取到鎖,新來的同學主動謙讓一下,給老同志一些機會。
透過加入飢餓模式,可以避免把機會全都留給新來的 goroutine,保證了請求鎖的 goroutine 獲取鎖的公平性,對於我們使用鎖的業務程式碼來說,不會有業務一直等待鎖不被處理。
那麼,接下來的部分就是選學內容了。如果你還有精力,並且對飢餓模式很感興趣,那就跟著我一起繼續來挑戰吧。如果你現在理解起來覺得有困難,也沒關係,後面可以隨時回來複習。
飢餓模式和正常模式
Mutex 可能處於兩種操作模式下:正常模式和飢餓模式。
接下來我們分析一下 Mutex 對飢餓模式和正常模式的處理。
請求鎖時呼叫的 Lock 方法中一開始是 fast path,這是一個幸運的場景,當前的 goroutine 幸運地獲得了鎖,沒有競爭,直接返回,否則就進入了 lockSlow 方法。這樣的設計,方便編譯器對 Lock 方法進行內聯,你也可以在程式開發中應用這個技巧。
正常模式下,waiter 都是進入先入先出佇列,被喚醒的 waiter 並不會直接持有鎖,而是要和新來的 goroutine 進行競爭。新來的 goroutine 有先天的優勢,它們正在 CPU 中執行,可能它們的數量還不少,所以,在高併發情況下,被喚醒的 waiter 可能比較悲劇地獲取不到鎖,這時,它會被插入到佇列的前面。如果 waiter 獲取不到鎖的時間超過閾值 1 毫秒,那麼,這個 Mutex 就進入到了飢餓模式。
在飢餓模式下,Mutex 的擁有者將直接把鎖交給佇列最前面的 waiter。新來的 goroutine 不會嘗試獲取鎖,即使看起來鎖沒有被持有,它也不會去搶,也不會 spin,它會乖乖地加入到等待佇列的尾部。
如果擁有 Mutex 的 waiter 發現下面兩種情況的其中之一,它就會把這個 Mutex 轉換成正常模式:
- 此 waiter 已經是佇列中的最後一個 waiter 了,沒有其它的等待鎖的 goroutine 了;
- 此 waiter 的等待時間小於 1 毫秒。
正常模式擁有更好的效能,因為即使有等待搶鎖的 waiter,goroutine 也可以連續多次獲取到鎖。
飢餓模式是對公平性和效能的一種平衡,它避免了某些 goroutine 長時間的等待鎖。在飢餓模式下,優先對待的是那些一直在等待的 waiter。
接下來,我們逐步分析下 Mutex 程式碼的關鍵行,徹底搞清楚飢餓模式的細節。
我們從請求鎖(lockSlow)的邏輯看起。
第 9 行對 state 欄位又分出了一位,用來標記鎖是否處於飢餓狀態。現在一個 state 的欄位被劃分成了阻塞等待的 waiter 數量、飢餓標記、喚醒標記和持有鎖的標記四個部分。
第 25 行記錄此 goroutine 請求鎖的初始時間,第 26 行標記是否處於飢餓狀態,第 27 行標記是否是喚醒的,第 28 行記錄 spin 的次數。
第 31 行到第 40 行和以前的邏輯類似,只不過加了一個不能是飢餓狀態的邏輯。它會對正常狀態搶奪鎖的 goroutine 嘗試 spin,和以前的目的一樣,就是在臨界區耗時很短的情況下提高效能。
第 42 行到第 44 行,非飢餓狀態下搶鎖。怎麼搶?就是要把 state 的鎖的那一位,置為加鎖狀態,後續 CAS 如果成功就可能獲取到了鎖。
第 46 行到第 48 行,如果鎖已經被持有或者鎖處於飢餓狀態,我們最好的歸宿就是等待,所以 waiter 的數量加 1。
第 49 行到第 51 行,如果此 goroutine 已經處在飢餓狀態,並且鎖還被持有,那麼,我們需要把此 Mutex 設定為飢餓狀態。
第 52 行到第 57 行,是清除 mutexWoken 標記,因為不管是獲得了鎖還是進入休眠,我們都需要清除 mutexWoken 標記。
第 59 行就是嘗試使用 CAS 設定 state。如果成功,第 61 行到第 63 行是檢查原來的鎖的狀態是未加鎖狀態,並且也不是飢餓狀態的話就成功獲取了鎖,返回。
第 67 行判斷是否第一次加入到 waiter 佇列。到這裡,你應該就能明白第 25 行為什麼不對 waitStartTime 進行初始化了,我們需要利用它在這裡進行條件判斷。
第 72 行將此 waiter 加入到佇列,如果是首次,加入到隊尾,先進先出。如果不是首次,那麼加入到隊首,這樣等待最久的 goroutine 優先能夠獲取到鎖。此 goroutine 會進行休眠。
第 74 行判斷此 goroutine 是否處於飢餓狀態。注意,執行這一句的時候,它已經被喚醒了。
第 77 行到第 88 行是對鎖處於飢餓狀態下的一些處理。
第 82 行設定一個標誌,這個標誌稍後會用來加鎖,而且還會將 waiter 數減 1。
第 84 行,設定標誌,在沒有其它的 waiter 或者此 goroutine 等待還沒超過 1 毫秒,則會將 Mutex 轉為正常狀態。
第 86 行則是將這個標識應用到 state 欄位上。
釋放鎖(Unlock)時呼叫的 Unlock 的 fast path 不用多少,所以我們主要看 unlockSlow 方法就行。
如果 Mutex 處於飢餓狀態,第 123 行直接喚醒等待佇列中的 waiter。
如果 Mutex 處於正常狀態,如果沒有 waiter,或者已經有在處理的情況了,那麼釋放就好,不做額外的處理(第 112 行到第 114 行)。
否則,waiter 數減 1,mutexWoken 標誌設定上,透過 CAS 更新 state 的值(第 115 行到第 119 行)。
總結
“羅馬不是一天建成的”,Mutex 的設計也是從簡單設計到複雜處理逐漸演變的。初版的 Mutex 設計非常簡潔,充分展示了 Go 創始者的簡單、簡潔的設計哲學。但是,隨著大家的使用,逐漸暴露出一些缺陷,為了彌補這些缺陷,Mutex 不得不越來越複雜。
有一點值得我們學習的,同時也體現了 Go 創始者的哲學,就是他們強調 GO 語言和標準庫的穩定性,新版本要向下相容,用新的版本總能編譯老的程式碼。Go 語言從出生到現在已經 10 多年了,這個 Mutex 對外的介面卻沒有變化,依然向下相容,即使現在 Go 出了兩個版本,每個版本也會向下相容,保持 Go 語言的穩定性,你也能領悟他們軟體開發和設計的思想。
還有一點,你也可以觀察到,為了一個程式 20% 的特性,你可能需要新增 80% 的程式碼,這也是程式越來越複雜的原因。所以,最開始的時候,如果能夠有一個清晰而且易於擴充套件的設計,未來增加新特性時,也會更加方便。
思考題
最後,給你留兩個小問題:
- 目前 Mutex 的 state 欄位有幾個意義,這幾個意義分別是由哪些欄位表示的?
- 等待一個 Mutex 的 goroutine 數最大是多少?是否能滿足現實的需求?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
03|Mutex:4種易錯場景大盤點
你好,我是鳥窩。
本章導讀
Mutex 常見踩坑(問題定位圖)
┌────────────────┐
│ Lock / Unlock 使用 │
└───────┬────────┘
│
┌─────┼───────────────┬───────────────┬──────────────┐
▼ ▼ ▼ ▼ ▼
忘記解鎖 重複解鎖 重入鎖死鎖 複製已使用 Mutex 鎖範圍過大
│ │ │ │ │
└───────┴───────┬───────┴───────┬───────┴───────┬──────┘
▼ ▼ ▼
卡住/ panic 行為異常 效能下降/難除錯
上一講,我帶你一起領略了 Mutex 的架構演進之美,現在我們已經清楚 Mutex 的實作細節了。當前 Mutex 的實作貌似非常複雜,其實主要還是針對飢餓模式和公平性問題,做了一些額外處理。但是,我們在第一講中已經體驗過了,Mutex 使用起來還是非常簡單的,畢竟,它只有 Lock 和 Unlock 兩個方法,使用起來還能複雜到哪裡去?
正常使用 Mutex 時,確實是這樣的,很簡單,基本不會有什麼錯誤,即使出現錯誤,也是在一些複雜的場景中,比如跨函式呼叫 Mutex 或者是在重構或者修補 Bug 時誤操作。但是,我們使用 Mutex 時,確實會出現一些 Bug,比如說忘記釋放鎖、重入鎖、複製已使用了的 Mutex 等情況。那在這一講中,我們就一起來看看使用 Mutex 常犯的幾個錯誤,做到“Bug 提前知,後面早防範”。
常見的 4 種錯誤場景
我總結了一下,使用 Mutex 常見的錯誤場景有 4 類,分別是 Lock/Unlock 不是成對出現、Copy 已使用的 Mutex、重入和死鎖。下面我們一一來看。
Lock/Unlock 不是成對出現
Lock/Unlock 沒有成對出現,就意味著會出現死鎖的情況,或者是因為 Unlock 一個未加鎖的 Mutex 而導致 panic。
我們先來看看缺少 Unlock 的場景,常見的有三種情況:
- 程式碼中有太多的 if-else 分支,可能在某個分支中漏寫了 Unlock;
- 在重構的時候把 Unlock 給刪除了;
- Unlock 誤寫成了 Lock。
在這種情況下,鎖被獲取之後,就不會被釋放了,這也就意味著,其它的 goroutine 永遠都沒機會獲取到鎖。
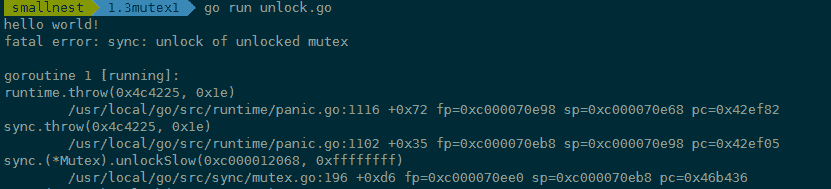
我們再來看缺少 Lock 的場景,這就很簡單了,一般來說就是誤操作刪除了 Lock。 比如先前使用 Mutex 都是正常的,結果後來其他人重構程式碼的時候,由於對程式碼不熟悉,或者由於開發者的馬虎,把 Lock 呼叫給刪除了,或者註釋掉了。比如下面的程式碼,mu.Lock() 一行程式碼被刪除了,直接 Unlock 一個未加鎖的 Mutex 會 panic:
func foo() {
var mu sync.Mutex
defer mu.Unlock()
fmt.Println("hello world!")
}
執行的時候 panic:
Copy 已使用的 Mutex
第二種誤用是 Copy 已使用的 Mutex。在正式分析這個錯誤之前,我先交代一個小知識點,那就是 Package sync 的同步原語在使用後是不能複製的。我們知道 Mutex 是最常用的一個同步原語,那它也是不能複製的。為什麼呢?
原因在於,Mutex 是一個有狀態的物件,它的 state 欄位記錄這個鎖的狀態。如果你要複製一個已經加鎖的 Mutex 給一個新的變數,那麼新的剛初始化的變數居然被加鎖了,這顯然不符合你的期望,因為你期望的是一個零值的 Mutex。關鍵是在併發環境下,你根本不知道要複製的 Mutex 狀態是什麼,因為要複製的 Mutex 是由其它 goroutine 併發訪問的,狀態可能總是在變化。
當然,你可能說,你說的我都懂,你的警告我都記下了,但是實際在使用的時候,一不小心就踩了這個坑,我們來看一個例子。
type Counter struct {
sync.Mutex
Count int
}
func main() {
var c Counter
c.Lock()
defer c.Unlock()
c.Count++
foo(c) // 複製鎖
}
// 這裡Counter的引數是透過複製的方式傳入的
func foo(c Counter) {
c.Lock()
defer c.Unlock()
fmt.Println("in foo")
}
第 12 行在呼叫 foo 函式的時候,呼叫者會複製 Mutex 變數 c 作為 foo 函式的引數,不幸的是,複製之前已經使用了這個鎖,這就導致,複製的 Counter 是一個帶狀態 Counter。
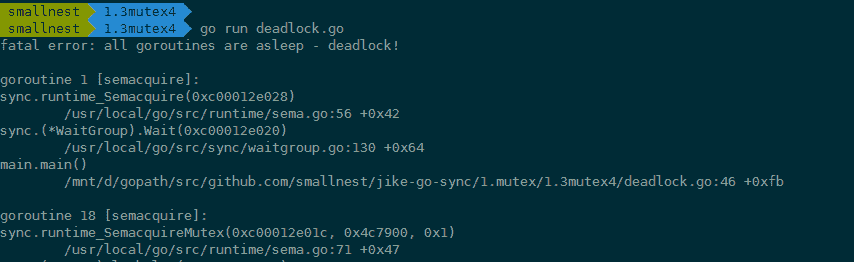
怎麼辦呢?Go 在執行時,有死鎖的檢查機制(checkdead() 方法),它能夠發現死鎖的 goroutine。這個例子中因為複製了一個使用了的 Mutex,導致鎖無法使用,程式處於死鎖的狀態。程式執行的時候,死鎖檢查機制能夠發現這種死鎖情況並輸出錯誤資訊,如下圖中錯誤資訊以及錯誤堆疊:
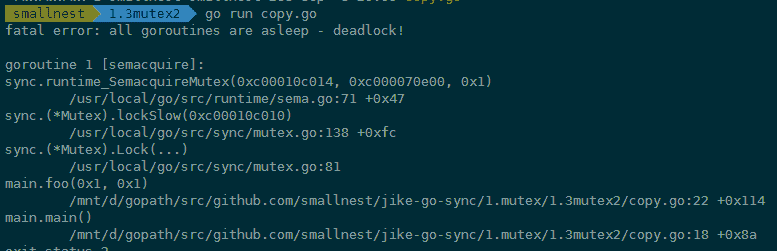
你肯定不想執行的時候才發現這個因為複製 Mutex 導致的死鎖問題,那麼你怎麼能夠及時發現問題呢?可以使用 vet 工具,把檢查寫在 Makefile 檔案中,在持續整合的時候跑一跑,這樣可以及時發現問題,及時修復。我們可以使用 go vet 檢查這個 Go 檔案:

你看,使用這個工具就可以發現 Mutex 複製的問題,錯誤資訊顯示得很清楚,是在呼叫 foo 函式的時候發生了 lock value 複製的情況,還告訴我們出問題的程式碼行數以及 copy lock 導致的錯誤。
那麼,vet 工具是怎麼發現 Mutex 複製使用問題的呢?我帶你簡單分析一下。
檢查是透過copylock分析器靜態分析實作的。這個分析器會分析函式呼叫、range 遍歷、複製、宣告、函式返回值等位置,有沒有鎖的值 copy 的情景,以此來判斷有沒有問題。可以說,只要是實作了 Locker 介面,就會被分析。我們看到,下面的程式碼就是確定什麼型別會被分析,其實就是實作了 Lock/Unlock 兩個方法的 Locker 介面:
var lockerType *types.Interface
// Construct a sync.Locker interface type.
func init() {
nullary := types.NewSignature(nil, nil, nil, false) // func()
methods := []*types.Func{
types.NewFunc(token.NoPos, nil, "Lock", nullary),
types.NewFunc(token.NoPos, nil, "Unlock", nullary),
}
lockerType = types.NewInterface(methods, nil).Complete()
}
其實,有些沒有實作 Locker 介面的同步原語(比如 WaitGroup),也能被分析。我先賣個關子,後面我們會介紹這種情況是怎麼實作的。
重入
接下來,我們來討論“重入”這個問題。在說這個問題前,我先解釋一下個概念,叫“可重入鎖”。
如果你學過 Java,可能會很熟悉 ReentrantLock,就是可重入鎖,這是 Java 併發包中非常常用的一個同步原語。它的基本行為和互斥鎖相同,但是加了一些擴充套件功能。
如果你沒接觸過 Java,也沒關係,這裡只是提一下,幫助會 Java 的同學對比來學。那下面我來具體講解可重入鎖是咋回事兒。
當一個執行緒獲取鎖時,如果沒有其它執行緒擁有這個鎖,那麼,這個執行緒就成功獲取到這個鎖。之後,如果其它執行緒再請求這個鎖,就會處於阻塞等待的狀態。但是,如果擁有這把鎖的執行緒再請求這把鎖的話,不會阻塞,而是成功返回,所以叫可重入鎖(有時候也叫做遞迴鎖)。只要你擁有這把鎖,你可以可著勁兒地呼叫,比如透過遞迴實作一些演算法,呼叫者不會阻塞或者死鎖。
瞭解了可重入鎖的概念,那我們來看 Mutex 使用的錯誤場景。劃重點了:Mutex 不是可重入的鎖。
想想也不奇怪,因為 Mutex 的實作中沒有記錄哪個 goroutine 擁有這把鎖。理論上,任何 goroutine 都可以隨意地 Unlock 這把鎖,所以沒辦法計算重入條件,畢竟,“臣妾做不到啊”!
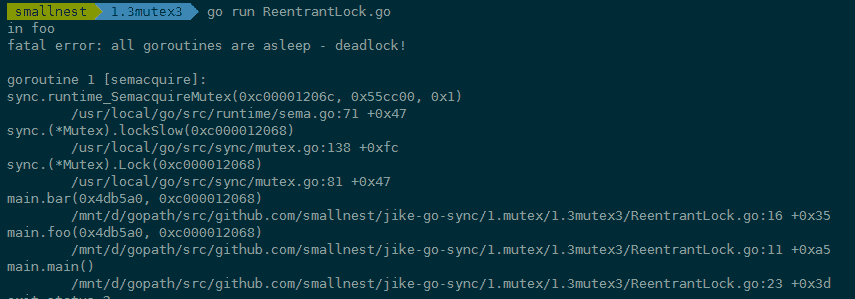
所以,一旦誤用 Mutex 的重入,就會導致報錯。下面是一個誤用 Mutex 的重入例子:
func foo(l sync.Locker) {
fmt.Println("in foo")
l.Lock()
bar(l)
l.Unlock()
}
func bar(l sync.Locker) {
l.Lock()
fmt.Println("in bar")
l.Unlock()
}
func main() {
l := &sync.Mutex{}
foo(l)
}
寫完這個 Mutex 重入的例子後,執行一下,你會發現類似下面的錯誤。程式一直在請求鎖,但是一直沒有辦法獲取到鎖,結果就是 Go 執行時發現死鎖了,沒有其它地方能夠釋放鎖讓程式執行下去,你透過下面的錯誤堆疊資訊就能定位到哪一行阻塞請求鎖:
學到這裡,你可能要問了,雖然標準庫 Mutex 不是可重入鎖,但是如果我就是想要實作一個可重入鎖,可以嗎?
可以,那我們就自己實作一個。這裡的關鍵就是,實作的鎖要能記住當前是哪個 goroutine 持有這個鎖。我來提供兩個方案。
- 方案一:透過 hacker 的方式獲取到 goroutine id,記錄下獲取鎖的 goroutine id,它可以實作 Locker 介面。
- 方案二:呼叫 Lock/Unlock 方法時,由 goroutine 提供一個 token,用來標識它自己,而不是我們透過 hacker 的方式獲取到 goroutine id,但是,這樣一來,就不滿足 Locker 介面了。
可重入鎖(遞迴鎖)解決了程式碼重入或者遞迴呼叫帶來的死鎖問題,同時它也帶來了另一個好處,就是我們可以要求,只有持有鎖的 goroutine 才能 unlock 這個鎖。這也很容易實作,因為在上面這兩個方案中,都已經記錄了是哪一個 goroutine 持有這個鎖。
下面我們具體來看這兩個方案怎麼實作。
方案一:goroutine id
這個方案的關鍵第一步是獲取 goroutine id,方式有兩種,分別是簡單方式和 hacker 方式。
簡單方式,就是透過 runtime.Stack 方法獲取棧幀資訊,棧幀資訊裡包含 goroutine id。你可以看看上面 panic 時候的貼圖,goroutine id 明明白白地顯示在那裡。runtime.Stack 方法可以獲取當前的 goroutine 資訊,第二個引數為 true 會輸出所有的 goroutine 資訊,資訊的格式如下:
goroutine 1 [running]:
main.main()
....../main.go:19 +0xb1
第一行格式為 goroutine xxx,其中 xxx 就是 goroutine id,你只要解析出這個 id 即可。解析的方法可以採用下面的程式碼:
func GoID() int {
var buf [64]byte
n := runtime.Stack(buf[:], false)
// 得到id字串
idField := strings.Fields(strings.TrimPrefix(string(buf[:n]), "goroutine "))[0]
id, err := strconv.Atoi(idField)
if err != nil {
panic(fmt.Sprintf("cannot get goroutine id: %v", err))
}
return id
}
瞭解了簡單方式,接下來我們來看 hacker 的方式,這也是我們方案一採取的方式。
首先,我們獲取執行時的 g 指標,反解出對應的 g 的結構。每個執行的 goroutine 結構的 g 指標儲存在當前 goroutine 的一個叫做 TLS 物件中。
第一步:我們先獲取到 TLS 物件;
第二步:再從 TLS 中獲取 goroutine 結構的 g 指標;
第三步:再從 g 指標中取出 goroutine id。
需要注意的是,不同 Go 版本的 goroutine 的結構可能不同,所以需要根據 Go 的不同版本進行調整。當然了,如果想要搞清楚各個版本的 goroutine 結構差異,所涉及的內容又過於底層而且複雜,學習成本太高。怎麼辦呢?我們可以重點關注一些庫。我們沒有必要重複發明輪子,直接使用第三方的庫來獲取 goroutine id 就可以了。
好訊息是現在已經有很多成熟的方法了,可以支援多個 Go 版本的 goroutine id,給你推薦一個常用的庫:petermattis/goid。
知道了如何獲取 goroutine id,接下來就是最後的關鍵一步了,我們實作一個可以使用的可重入鎖:
// RecursiveMutex 包裝一個Mutex,實作可重入
type RecursiveMutex struct {
sync.Mutex
owner int64 // 當前持有鎖的goroutine id
recursion int32 // 這個goroutine 重入的次數
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get()
// 如果當前持有鎖的goroutine就是這次呼叫的goroutine,說明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 獲得鎖的goroutine第一次呼叫,記錄下它的goroutine id,呼叫次數加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get()
// 非持有鎖的goroutine嘗試釋放鎖,錯誤的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 呼叫次數減1
m.recursion--
if m.recursion != 0 { // 如果這個goroutine還沒有完全釋放,則直接返回
return
}
// 此goroutine最後一次呼叫,需要釋放鎖
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
上面這段程式碼你可以拿來即用。我們一起來看下這個實作,真是非常巧妙,它相當於給 Mutex 打一個補丁,解決了記錄鎖的持有者的問題。可以看到,我們用 owner 欄位,記錄當前鎖的擁有者 goroutine 的 id;recursion 是輔助欄位,用於記錄重入的次數。
有一點,我要提醒你一句,儘管擁有者可以多次呼叫 Lock,但是也必須呼叫相同次數的 Unlock,這樣才能把鎖釋放掉。這是一個合理的設計,可以保證 Lock 和 Unlock 一一對應。
方案二:token
方案一是用 goroutine id 做 goroutine 的標識,我們也可以讓 goroutine 自己來提供標識。不管怎麼說,Go 開發者不期望你利用 goroutine id 做一些不確定的東西,所以,他們沒有暴露獲取 goroutine id 的方法。
下面的程式碼是第二種方案。呼叫者自己提供一個 token,獲取鎖的時候把這個 token 傳入,釋放鎖的時候也需要把這個 token 傳入。透過使用者傳入的 token 替換方案一中 goroutine id,其它邏輯和方案一一致。
// Token方式的遞迴鎖
type TokenRecursiveMutex struct {
sync.Mutex
token int64
recursion int32
}
// 請求鎖,需要傳入token
func (m *TokenRecursiveMutex) Lock(token int64) {
if atomic.LoadInt64(&m.token) == token { //如果傳入的token和持有鎖的token一致,說明是遞迴呼叫
m.recursion++
return
}
m.Mutex.Lock() // 傳入的token不一致,說明不是遞迴呼叫
// 搶到鎖之後記錄這個token
atomic.StoreInt64(&m.token, token)
m.recursion = 1
}
// 釋放鎖
func (m *TokenRecursiveMutex) Unlock(token int64) {
if atomic.LoadInt64(&m.token) != token { // 釋放其它token持有的鎖
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.token, token))
}
m.recursion-- // 當前持有這個鎖的token釋放鎖
if m.recursion != 0 { // 還沒有回退到最初的遞迴呼叫
return
}
atomic.StoreInt64(&m.token, 0) // 沒有遞迴呼叫了,釋放鎖
m.Mutex.Unlock()
}
死鎖接下來,我們來看第四種錯誤場景:死鎖。
我先解釋下什麼是死鎖。兩個或兩個以上的程式(或執行緒,goroutine)在執行過程中,因爭奪共享資源而處於一種互相等待的狀態,如果沒有外部干涉,它們都將無法推進下去,此時,我們稱系統處於死鎖狀態或系統產生了死鎖。
我們來分析一下死鎖產生的必要條件。如果你想避免死鎖,只要破壞這四個條件中的一個或者幾個,就可以了。
- 互斥: 至少一個資源是被排他性獨享的,其他執行緒必須處於等待狀態,直到資源被釋放。
- 持有和等待:goroutine 持有一個資源,並且還在請求其它 goroutine 持有的資源,也就是咱們常說的“吃著碗裡,看著鍋裡”的意思。
- 不可剝奪:資源只能由持有它的 goroutine 來釋放。
- 環路等待:一般來說,存在一組等待程式,P={P1,P2,…,PN},P1 等待 P2 持有的資源,P2 等待 P3 持有的資源,依此類推,最後是 PN 等待 P1 持有的資源,這就形成了一個環路等待的死結。
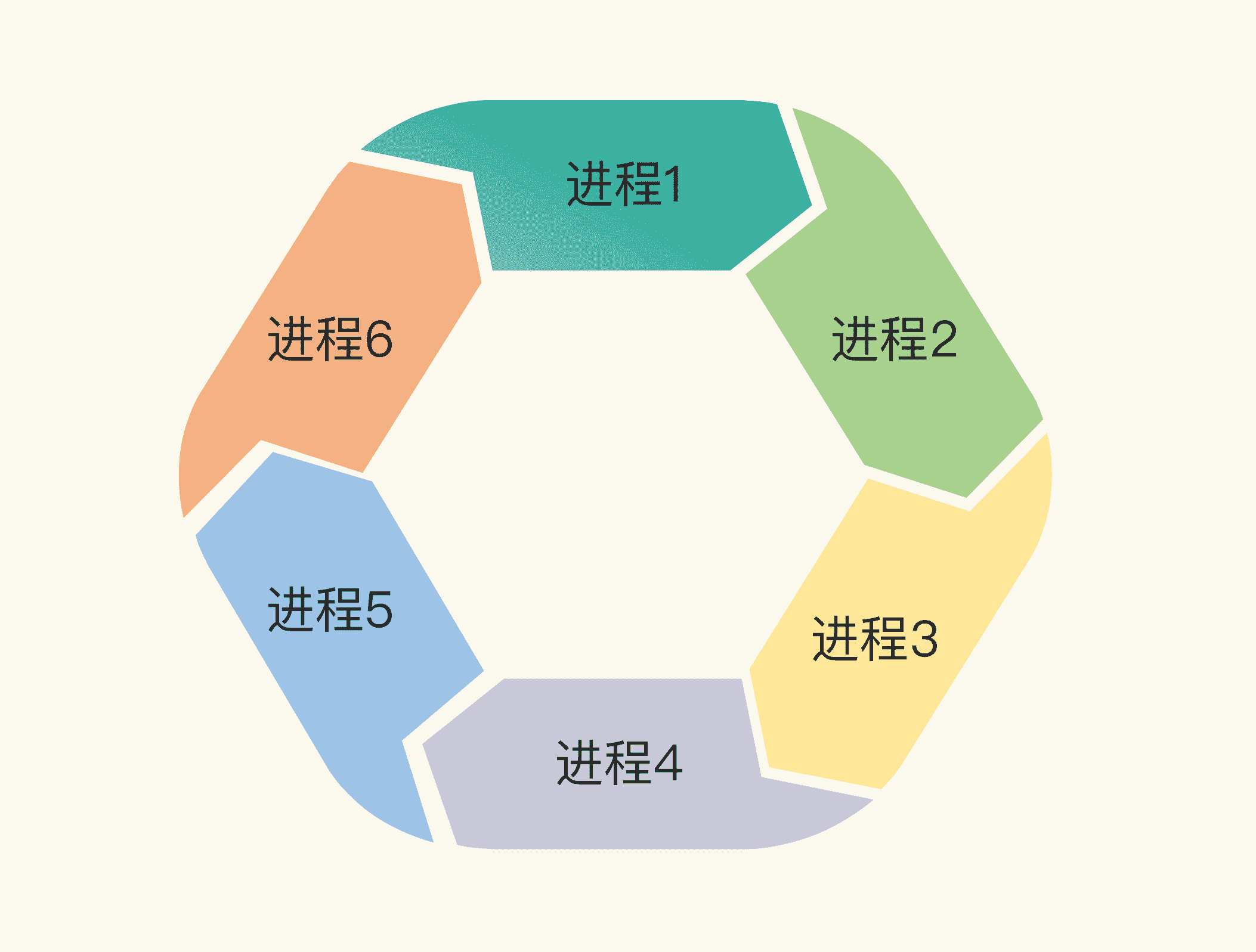
你看,死鎖問題還真是挺有意思的,所以有很多人研究這個事兒。一個經典的死鎖問題就是哲學家就餐問題,我不做介紹了,你可以點選連結進一步瞭解。其實,死鎖問題在現實生活中也比比皆是。
舉個例子。有一次我去派出所開證明,派出所要求物業先證明我是本物業的業主,但是,物業要我提供派出所的證明,才能給我開物業證明,結果就陷入了死鎖狀態。你可以把派出所和物業看成兩個 goroutine,派出所證明和物業證明是兩個資源,雙方都持有自己的資源而要求對方的資源,而且自己的資源自己持有,不可剝奪。
這是一個最簡單的只有兩個 goroutine 相互等待的死鎖的例子,轉化成程式碼如下:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
// 派出所證明
var psCertificate sync.Mutex
// 物業證明
var propertyCertificate sync.Mutex
var wg sync.WaitGroup
wg.Add(2) // 需要派出所和物業都處理
// 派出所處理goroutine
go func() {
defer wg.Done() // 派出所處理完成
psCertificate.Lock()
defer psCertificate.Unlock()
// 檢查材料
time.Sleep(5 * time.Second)
// 請求物業的證明
propertyCertificate.Lock()
propertyCertificate.Unlock()
}()
// 物業處理goroutine
go func() {
defer wg.Done() // 物業處理完成
propertyCertificate.Lock()
defer propertyCertificate.Unlock()
// 檢查材料
time.Sleep(5 * time.Second)
// 請求派出所的證明
psCertificate.Lock()
psCertificate.Unlock()
}()
wg.Wait()
fmt.Println("成功完成")
}
這個程式沒有辦法執行成功,因為派出所的處理和物業的處理是一個環路等待的死結。
Go 執行時,有死鎖探測的功能,能夠檢查出是否出現了死鎖的情況,如果出現了,這個時候你就需要調整策略來處理了。
你可以引入一個第三方的鎖,大家都依賴這個鎖進行業務處理,比如現在政府推行的一站式政務服務中心。或者是解決持有等待問題,物業不需要看到派出所的證明才給開物業證明,等等。
好了,到這裡,我給你講了使用 Mutex 常見的 4 類問題。你是不是覺得,哎呀,這幾類問題也太不應該了吧,真的會有人犯這麼基礎的錯誤嗎?
還真是有。雖然 Mutex 使用起來很簡單,但是,仍然可能出現使用錯誤的問題。而且,就連一些經驗豐富的開發人員,也會出現一些 Mutex 使用的問題。接下來,我就帶你圍觀幾個非常流行的 Go 開發專案,看看這些錯誤是怎麼產生和修復的。
流行的 Go 開發專案踩坑記
Docker
Docker 容器是一個開源的應用容器引擎,開發者可以以統一的方式,把他們的應用和依賴包打包到一個可移植的容器中,然後釋出到任何安裝了 docker 引擎的伺服器上。
Docker 是使用 Go 開發的,也算是 Go 的一個殺手級產品了,它的 Mutex 相關的 Bug 也不少,我們來看幾個典型的 Bug。
issue 36114
Docker 的issue 36114 是一個死鎖問題。
原因在於,hotAddVHDsAtStart 方法執行的時候,執行了加鎖 svm 操作。但是,在其中呼叫 hotRemoveVHDsAtStart 方法時,這個 hotRemoveVHDsAtStart 方法也是要加鎖 svm 的。很不幸,Go 標準庫中的 Mutex 是不可重入的,所以,程式碼執行到這裡,就出現了死鎖的現象。
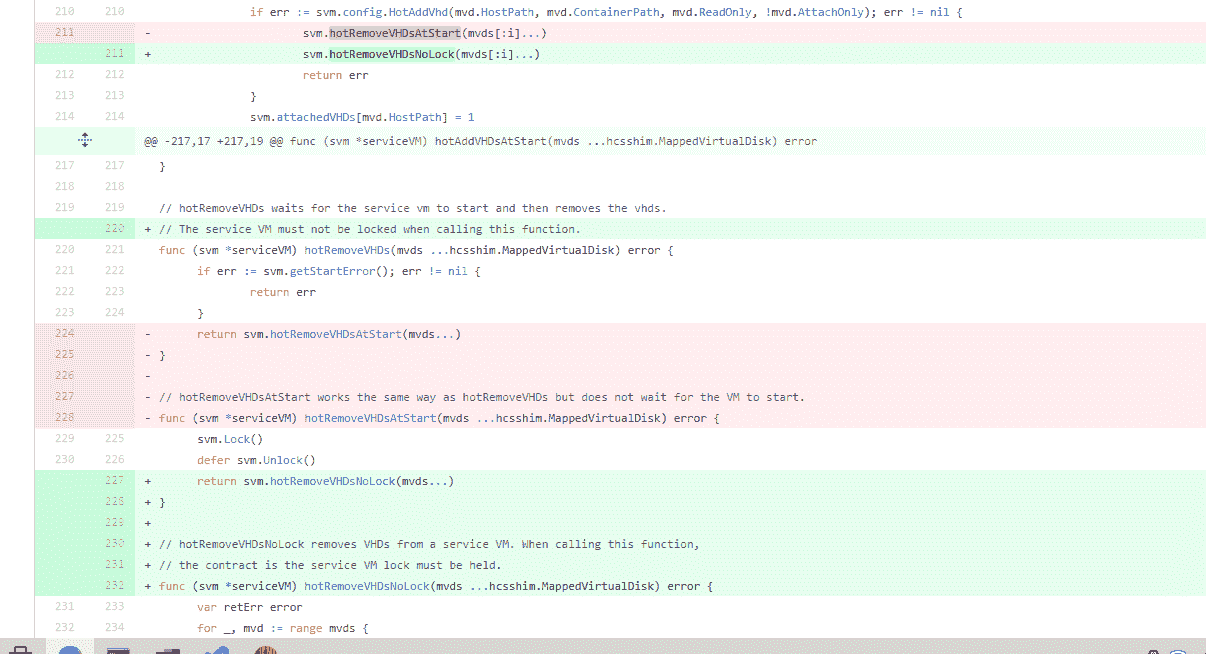
針對這個問題,解決辦法就是,再提供一個不需要鎖的 hotRemoveVHDsNoLock 方法,避免 Mutex 的重入。
issue 34881
issue 34881本來是修復 Docker 的一個簡單問題,如果節點在初始化的時候,發現自己不是一個 swarm mananger,就快速返回,這個修復就幾行程式碼,你看出問題來了嗎?
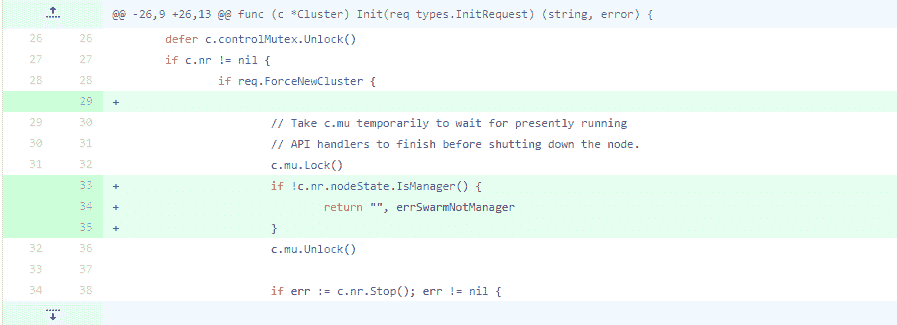
在第 34 行,節點發現不滿足條件就返回了,但是,c.mu 這個鎖沒有釋放!為什麼會出現這個問題呢?其實,這是在重構或者新增新功能的時候經常犯的一個錯誤,因為不太瞭解上下文,或者是沒有仔細看函式的邏輯,從而導致鎖沒有被釋放。現在的 Docker 當然已經沒有這個問題了。

這樣的 issue 還有很多,我就不一一列舉了。我給你推薦幾個關於 Mutex 的 issue 或者 pull request,你可以關注一下,分別是 36840、37583、35517、35482、33305、32826、30696、29554、29191、28912、26507 等。
Kubernetes
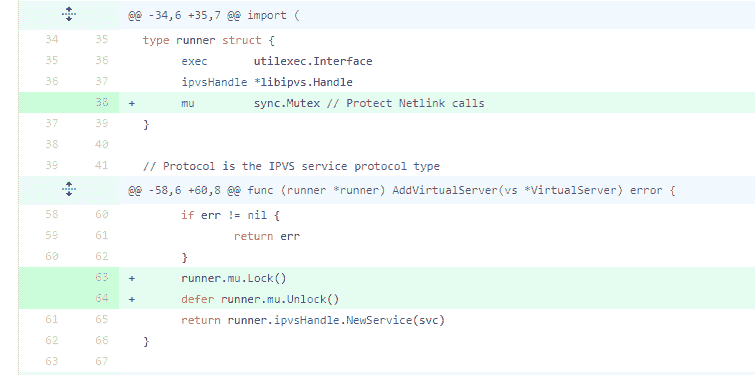
issue 72361
issue 72361 增加 Mutex 為了保護資源。這是為瞭解決 data race 問題而做的一個修復,修復方法也很簡單,使用互斥鎖即可,這也是我們解決 data race 時常用的方法。
issue 45192
issue 45192也是一個返回時忘記 Unlock 的典型例子,和 docker issue 34881 犯的錯誤都是一樣的。
兩大知名專案的開發者都犯了這個錯誤,所以,你就可以知道,引入這個 Bug 是多麼容易,記住晁老師這句話:保證 Lock/Unlock 成對出現,儘可能採用 defer mutex.Unlock 的方式,把它們成對、緊湊地寫在一起。
除了這些,我也建議你關注一下其它的 Mutex 相關的 issue,比如 71617、70605 等。
gRPC
gRPC 是 Google 發起的一個開源遠端過程呼叫 (Remote procedure call)系統。該系統基於 HTTP/2 協議傳輸,使用 Protocol Buffers 作為介面描述語言。它提供 Go 語言的實作。
即使是 Google 官方出品的系統,也有一些 Mutex 的 issue。
issue 795
issue 795是一個你可能想不到的 bug,那就是將 Unlock 誤寫成了 Lock。
關於這個專案,還有一些其他的為了保護共享資源而新增 Mutex 的 issue,比如 1318、2074、2542 等。
etcd
etcd 是一個非常知名的分散式一致性的 key-value 儲存技術, 被用來做配置共享和服務發現。
issue 10419
issue 10419是一個鎖重入導致的問題。 Store 方法內對請求了鎖,而呼叫的 Compact 的方法內又請求了鎖,這個時候,會導致死鎖,一直等待,解決辦法就是提供不需要加鎖的 Compact 方法。
總結
這節課,我們學習了 Mutex 的一些易錯場景,而且,我們還分析了流行的 Go 開源專案的錯誤,我也給你分享了我自己在開發中的經驗總結。需要強調的是,手誤和重入導致的死鎖,是最常見的使用 Mutex 的 Bug。
Go 死鎖探測工具只能探測整個程式是否因為死鎖而凍結了,不能檢測出一組 goroutine 死鎖導致的某一塊業務凍結的情況。你還可以透過 Go 執行時自帶的死鎖檢測工具,或者是第三方的工具(比如go-deadlock、go-tools)進行檢查,這樣可以儘早發現一些死鎖的問題。不過,有些時候,死鎖在某些特定情況下才會被觸發,所以,如果你的測試或者短時間的執行沒問題,不代表程式一定不會有死鎖問題。
併發程式最難跟蹤除錯的就是很難重現,因為併發問題不是按照我們指定的順序執行的,由於計算機排程的問題和事件觸發的時機不同,死鎖的 Bug 可能會在極端的情況下出現。透過搜尋日誌、檢視日誌,我們能夠知道程式有異常了,比如某個流程一直沒有結束。這個時候,可以透過 Go pprof 工具分析,它提供了一個 block profiler 監控阻塞的 goroutine。除此之外,我們還可以檢視全部的 goroutine 的堆疊資訊,透過它,你可以檢視阻塞的 groutine 究竟阻塞在哪一行哪一個物件上了。
思考題
查詢知名的資料庫系統 TiDB 的 issue,看看有沒有 Mutex 相關的 issue,看看它們都是哪些相關的 Bug。
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
04| Mutex:駭客程式設計,如何拓展額外功能?
你好,我是鳥窩。
本章導讀
以 Mutex 為核心做功能擴充(包裝器概念)
┌──────────────┐ 包裝/組合 ┌─────────────────────┐
│ sync.Mutex │ ─────────────────> │ 自訂鎖型別/工具函式 │
└──────────────┘ └─────────┬───────────┘
│
┌───────────────────────────────┼──────────────────────────────┐
▼ ▼ ▼
TryLock 風格能力 超時控制/取消 統計/除錯資訊
前面三講,我們學習了互斥鎖 Mutex 的基本用法、實作原理以及易錯場景,可以說是涵蓋了互斥鎖的方方面面。如果你能熟練掌握這些內容,那麼,在大多數的開發場景中,你都可以得心應手。
但是,在一些特定的場景中,這些基礎功能是不足以應對的。這個時候,我們就需要開發一些擴充套件功能了。我來舉幾個例子。
比如說,我們知道,如果互斥鎖被某個 goroutine 獲取了,而且還沒有釋放,那麼,其他請求這把鎖的 goroutine,就會阻塞等待,直到有機會獲得這把鎖。有時候阻塞並不是一個很好的主意,比如你請求鎖更新一個計數器,如果獲取不到鎖的話沒必要等待,大不了這次不更新,我下次更新就好了,如果阻塞的話會導致業務處理能力的下降。
再比如,如果我們要監控鎖的競爭情況,一個監控指標就是,等待這把鎖的 goroutine 數量。我們可以把這個指標推送到時間序列資料庫中,再透過一些監控系統(比如 Grafana)展示出來。要知道,鎖是效能下降的“罪魁禍首”之一,所以,有效地降低鎖的競爭,就能夠很好地提高效能。因此,監控關鍵互斥鎖上等待的 goroutine 的數量,是我們分析鎖競爭的激烈程度的一個重要指標。
實際上,不論是不希望鎖的 goroutine 繼續等待,還是想監控鎖,我們都可以基於標準庫中 Mutex 的實作,透過 Hacker 的方式,為 Mutex 增加一些額外的功能。這節課,我就來教你實作幾個擴充套件功能,包括實作 TryLock,獲取等待者的數量等指標,以及實作一個執行緒安全的佇列。
TryLock
我們可以為 Mutex 新增一個 TryLock 的方法,也就是嘗試獲取排外鎖。
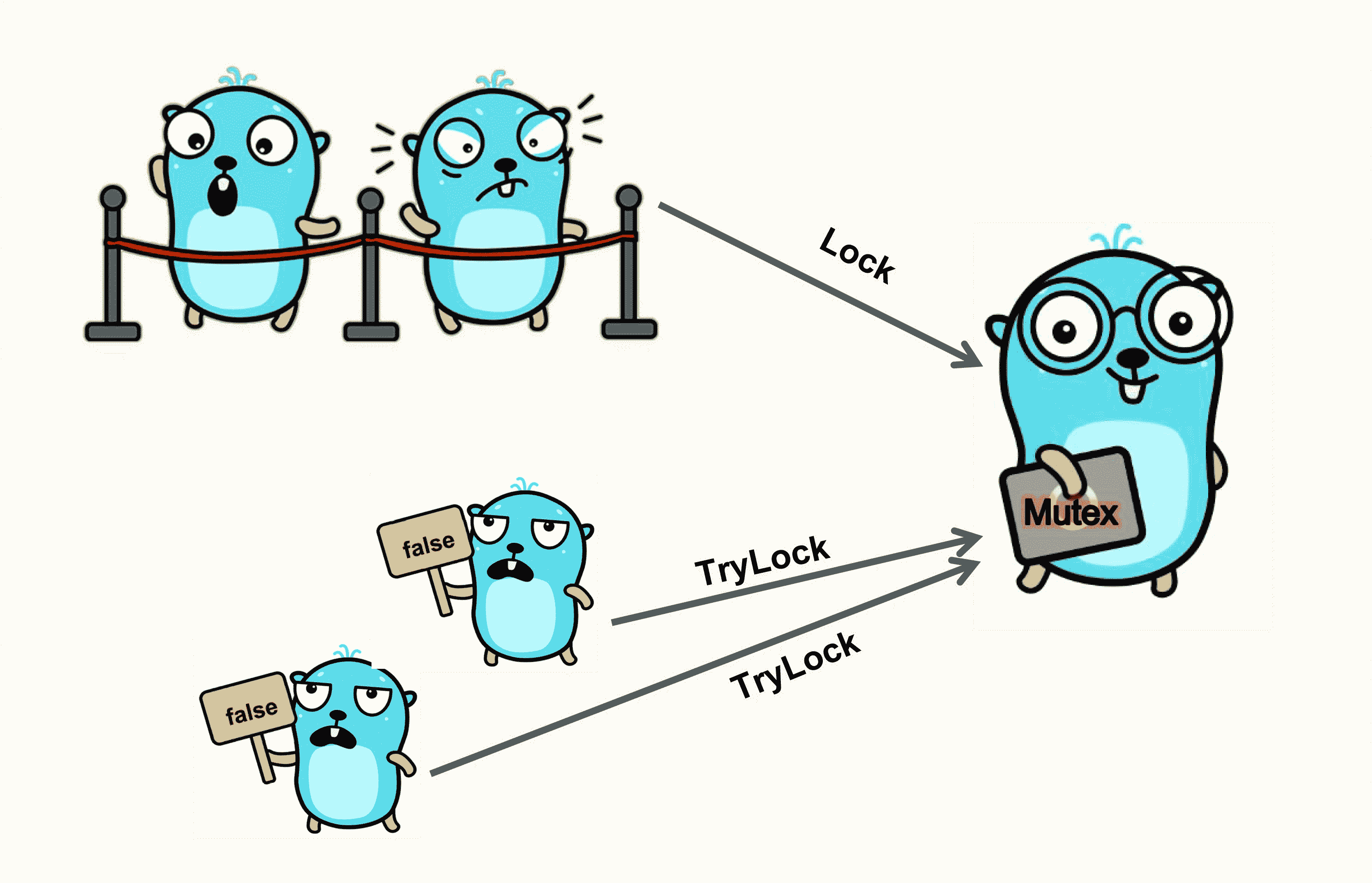
這個方法具體是什麼意思呢?我來解釋一下這裡的邏輯。當一個 goroutine 呼叫這個 TryLock 方法請求鎖的時候,如果這把鎖沒有被其他 goroutine 所持有,那麼,這個 goroutine 就持有了這把鎖,並返回 true;如果這把鎖已經被其他 goroutine 所持有,或者是正在準備交給某個被喚醒的 goroutine,那麼,這個請求鎖的 goroutine 就直接返回 false,不會阻塞在方法呼叫上。
如下圖所示,如果 Mutex 已經被一個 goroutine 持有,呼叫 Lock 的 goroutine 阻塞排隊等待,呼叫 TryLock 的 goroutine 直接得到一個 false 返回。
在實際開發中,如果要更新配置資料,我們通常需要加鎖,這樣可以避免同時有多個 goroutine 併發修改資料。有的時候,我們也會使用 TryLock。這樣一來,當某個 goroutine 想要更改配置資料時,如果發現已經有 goroutine 在更改了,其他的 goroutine 呼叫 TryLock,返回了 false,這個 goroutine 就會放棄更改。
很多語言(比如 Java)都為鎖提供了 TryLock 的方法,但是,Go 官方issue 6123有一個討論(後來一些 issue 中也提到過),標準庫的 Mutex 不會新增 TryLock 方法。雖然透過 Go 的 Channel 我們也可以實作 TryLock 的功能,但是基於 Channel 的實作我們會放在 Channel 那一講中去介紹,這一次我們還是基於 Mutex 去實作,畢竟大部分的程式設計師還是熟悉傳統的同步原語,而且傳統的同步原語也不容易出錯。所以這節課,還是希望帶你掌握基於 Mutex 實作的方法。
那怎麼實作一個擴充套件 TryLock 方法的 Mutex 呢?我們直接來看程式碼。
// 複製Mutex定義的常量
const (
mutexLocked = 1 << iota // 加鎖標識位置
mutexWoken // 喚醒標識位置
mutexStarving // 鎖飢餓標識位置
mutexWaiterShift = iota // 標識waiter的起始bit位置
)
// 擴充套件一個Mutex結構
type Mutex struct {
sync.Mutex
}
// 嘗試獲取鎖
func (m *Mutex) TryLock() bool {
// 如果能成功搶到鎖
if atomic.CompareAndSwapInt32((*int32)(unsafe.Pointer(&m.Mutex)), 0, mutexLocked) {
return true
}
// 如果處於喚醒、加鎖或者飢餓狀態,這次請求就不參與競爭了,返回false
old := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
if old&(mutexLocked|mutexStarving|mutexWoken) != 0 {
return false
}
// 嘗試在競爭的狀態下請求鎖
new := old | mutexLocked
return atomic.CompareAndSwapInt32((*int32)(unsafe.Pointer(&m.Mutex)), old, new)
}
第 17 行是一個 fast path,如果幸運,沒有其他 goroutine 爭這把鎖,那麼,這把鎖就會被這個請求的 goroutine 獲取,直接返回。
如果鎖已經被其他 goroutine 所持有,或者被其他喚醒的 goroutine 準備持有,那麼,就直接返回 false,不再請求,程式碼邏輯在第 23 行。
如果沒有被持有,也沒有其它喚醒的 goroutine 來競爭鎖,鎖也不處於飢餓狀態,就嘗試獲取這把鎖(第 29 行),不論是否成功都將結果返回。因為,這個時候,可能還有其他的 goroutine 也在競爭這把鎖,所以,不能保證成功獲取這把鎖。
我們可以寫一個簡單的測試程式,來測試我們的 TryLock 的機制是否工作。
這個測試程式的工作機制是這樣子的:程式執行時會啟動一個 goroutine 持有這把我們自己實作的鎖,經過隨機的時間才釋放。主 goroutine 會嘗試獲取這把鎖。如果前一個 goroutine 一秒內釋放了這把鎖,那麼,主 goroutine 就有可能獲取到這把鎖了,輸出“got the lock”,否則沒有獲取到也不會被阻塞,會直接輸出“can't get the lock”。
func try() {
var mu Mutex
go func() { // 啟動一個goroutine持有一段時間的鎖
mu.Lock()
time.Sleep(time.Duration(rand.Intn(2)) * time.Second)
mu.Unlock()
}()
time.Sleep(time.Second)
ok := mu.TryLock() // 嘗試獲取到鎖
if ok { // 獲取成功
fmt.Println("got the lock")
// do something
mu.Unlock()
return
}
// 沒有獲取到
fmt.Println("can't get the lock")
}獲取等待者的數量等指標接下來,我想和你聊聊怎麼獲取等待者數量等指標。
第二講中,我們已經學習了 Mutex 的結構。先來回顧一下 Mutex 的資料結構,如下面的程式碼所示。它包含兩個欄位,state 和 sema。前四個位元組(int32)就是 state 欄位。
type Mutex struct {
state int32
sema uint32
}
Mutex 結構中的 state 欄位有很多個含義,透過 state 欄位,你可以知道鎖是否已經被某個 goroutine 持有、當前是否處於飢餓狀態、是否有等待的 goroutine 被喚醒、等待者的數量等資訊。但是,state 這個欄位並沒有暴露出來,所以,我們需要想辦法獲取到這個欄位,並進行解析。
怎麼獲取未暴露的欄位呢?很簡單,我們可以透過 unsafe 的方式實作。我來舉一個例子,你一看就明白了。
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving
mutexWaiterShift = iota
)
type Mutex struct {
sync.Mutex
}
func (m *Mutex) Count() int {
// 獲取state欄位的值
v := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
v = v >> mutexWaiterShift //得到等待者的數值
v = v + (v & mutexLocked) //再加上鎖持有者的數量,0或者1
return int(v)
}
這個例子的第 14 行透過 unsafe 操作,我們可以得到 state 欄位的值。第 15 行我們右移三位(這裡的常量 mutexWaiterShift 的值為 3),就得到了當前等待者的數量。如果當前的鎖已經被其他 goroutine 持有,那麼,我們就稍微調整一下這個值,加上一個 1(第 16 行),你基本上可以把它看作是當前持有和等待這把鎖的 goroutine 的總數。
state 這個欄位的第一位是用來標記鎖是否被持有,第二位用來標記是否已經喚醒了一個等待者,第三位標記鎖是否處於飢餓狀態,透過分析這個 state 欄位我們就可以得到這些狀態資訊。我們可以為這些狀態提供查詢的方法,這樣就可以即時地知道鎖的狀態了。
// 鎖是否被持有
func (m *Mutex) IsLocked() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexLocked == mutexLocked
}
// 是否有等待者被喚醒
func (m *Mutex) IsWoken() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexWoken == mutexWoken
}
// 鎖是否處於飢餓狀態
func (m *Mutex) IsStarving() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexStarving == mutexStarving
}
我們可以寫一個程式測試一下,比如,在 1000 個 goroutine 併發訪問的情況下,我們可以把鎖的狀態資訊輸出出來:
func count() {
var mu Mutex
for i := 0; i < 1000; i++ { // 啟動1000個goroutine
go func() {
mu.Lock()
time.Sleep(time.Second)
mu.Unlock()
}()
}
time.Sleep(time.Second)
// 輸出鎖的資訊
fmt.Printf("waitings: %d, isLocked: %t, woken: %t, starving: %t\n", mu.Count(), mu.IsLocked(), mu.IsWoken(), mu.IsStarving())
}
有一點你需要注意一下,在獲取 state 欄位的時候,並沒有透過 Lock 獲取這把鎖,所以獲取的這個 state 的值是一個瞬態的值,可能在你解析出這個欄位之後,鎖的狀態已經發生了變化。不過沒關係,因為你檢視的就是呼叫的那一時刻的鎖的狀態。
使用 Mutex 實作一個執行緒安全的佇列
最後,我們來討論一下,如何使用 Mutex 實作一個執行緒安全的佇列。
為什麼要討論這個話題呢?因為 Mutex 經常會和其他非執行緒安全(對於 Go 來說,我們其實指的是 goroutine 安全)的資料結構一起,組合成一個執行緒安全的資料結構。新資料結構的業務邏輯由原來的資料結構提供,而 Mutex 提供了鎖的機制,來保證執行緒安全。
比如佇列,我們可以透過 Slice 來實作,但是透過 Slice 實作的佇列不是執行緒安全的,出隊(Dequeue)和入隊(Enqueue)會有 data race 的問題。這個時候,Mutex 就要隆重出場了,透過它,我們可以在出隊和入隊的時候加上鎖的保護。
type SliceQueue struct {
data []interface{}
mu sync.Mutex
}
func NewSliceQueue(n int) (q *SliceQueue) {
return &SliceQueue{data: make([]interface{}, 0, n)}
}
// Enqueue 把值放在隊尾
func (q *SliceQueue) Enqueue(v interface{}) {
q.mu.Lock()
q.data = append(q.data, v)
q.mu.Unlock()
}
// Dequeue 移去隊頭並返回
func (q *SliceQueue) Dequeue() interface{} {
q.mu.Lock()
if len(q.data) == 0 {
q.mu.Unlock()
return nil
}
v := q.data[0]
q.data = q.data[1:]
q.mu.Unlock()
return v
}
因為標準庫中沒有執行緒安全的佇列資料結構的實作,所以,你可以透過 Mutex 實作一個簡單的佇列。透過 Mutex 我們就可以為一個非執行緒安全的 data interface{}實作執行緒安全的訪問。
總結
好了,我們來做個總結。
Mutex 是 package sync 的基石,其他的一些同步原語也是基於它實作的,所以,我們“隆重”地用了四講來深度學習它。學到後面,你一定能感受到,多花些時間來完全掌握 Mutex 是值得的。
今天這一講我和你分享了幾個 Mutex 的拓展功能,這些方法是不是給你帶來了一種“駭客”的程式設計體驗呢,透過 Hacker 的方式,我們真的可以讓 Mutex 變得更強大。
我們學習了基於 Mutex 實作 TryLock,透過 unsafe 的方式讀取到 Mutex 內部的 state 欄位,這樣,我們就解決了開篇列舉的問題,一是不希望鎖的 goroutine 繼續等待,一是想監控鎖。
另外,使用 Mutex 組合成更豐富的資料結構是我們常見的場景,今天我們就實作了一個執行緒安全的佇列,未來我們還會講到實作執行緒安全的 map 物件。
到這裡,Mutex 我們就係統學習完了,最後給你總結了一張 Mutex 知識地圖,幫你複習一下。
思考題
你可以為 Mutex 獲取鎖時加上 Timeout 機制嗎?會有什麼問題嗎?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
05| RWMutex:讀寫鎖的實作原理及避坑指南
你好,我是鳥窩。
本章導讀
RWMutex 讀寫分流示意
讀 goroutine A ──RLock()──┐
讀 goroutine B ──RLock()──┼────> [共享讀取區](可同時多讀)
讀 goroutine C ──RLock()──┘
寫 goroutine W ──Lock()────────> [獨占寫入區](寫入時阻擋新讀/寫)
重點:讀多寫少時,RWMutex 通常比 Mutex 更能提升吞吐量
在前面的四節課中,我們學習了第一個同步原語,即 Mutex,我們使用它來保證讀寫共享資源的安全性。不管是讀還是寫,我們都透過 Mutex 來保證只有一個 goroutine 訪問共享資源,這在某些情況下有點“浪費”。比如說,在寫少讀多的情況下,即使一段時間內沒有寫操作,大量併發的讀訪問也不得不在 Mutex 的保護下變成了序列訪問,這個時候,使用 Mutex,對效能的影響就比較大。
怎麼辦呢?你是不是已經有思路了,對,就是區分讀寫操作。
我來具體解釋一下。如果某個讀操作的 goroutine 持有了鎖,在這種情況下,其它讀操作的 goroutine 就不必一直傻傻地等待了,而是可以併發地訪問共享變數,這樣我們就可以將序列的讀變成並行讀,提高讀操作的效能。當寫操作的 goroutine 持有鎖的時候,它就是一個排外鎖,其它的寫操作和讀操作的 goroutine,需要阻塞等待持有這個鎖的 goroutine 釋放鎖。
這一類併發讀寫問題叫作readers-writers 問題,意思就是,同時可能有多個讀或者多個寫,但是隻要有一個執行緒在執行寫操作,其它的執行緒都不能執行讀寫操作。
Go 標準庫中的 RWMutex(讀寫鎖)就是用來解決這類 readers-writers 問題的。所以,這節課,我們就一起來學習 RWMutex。我會給你介紹讀寫鎖的使用場景、實作原理以及容易掉入的坑,你一定要記住這些陷阱,避免在實際的開發中犯相同的錯誤。
什麼是 RWMutex?
我先簡單解釋一下讀寫鎖 RWMutex。標準庫中的 RWMutex 是一個 reader/writer 互斥鎖。RWMutex 在某一時刻只能由任意數量的 reader 持有,或者是隻被單個的 writer 持有。
RWMutex 的方法也很少,總共有 5 個。
- Lock/Unlock:寫操作時呼叫的方法。如果鎖已經被 reader 或者 writer 持有,那麼,Lock 方法會一直阻塞,直到能獲取到鎖;Unlock 則是配對的釋放鎖的方法。
- RLock/RUnlock:讀操作時呼叫的方法。如果鎖已經被 writer 持有的話,RLock 方法會一直阻塞,直到能獲取到鎖,否則就直接返回;而 RUnlock 是 reader 釋放鎖的方法。
- RLocker:這個方法的作用是為讀操作返回一個 Locker 介面的物件。它的 Lock 方法會呼叫 RWMutex 的 RLock 方法,它的 Unlock 方法會呼叫 RWMutex 的 RUnlock 方法。
RWMutex 的零值是未加鎖的狀態,所以,當你使用 RWMutex 的時候,無論是宣告變數,還是嵌入到其它 struct 中,都不必顯式地初始化。
我以計數器為例,來說明一下,如何使用 RWMutex 保護共享資源。計數器的 count++操作是寫操作,而獲取 count 的值是讀操作,這個場景非常適合讀寫鎖,因為讀操作可以並行執行,寫操作時只允許一個執行緒執行,這正是 readers-writers 問題。
在這個例子中,使用 10 個 goroutine 進行讀操作,每讀取一次,sleep 1 毫秒,同時,還有一個 gorotine 進行寫操作,每一秒寫一次,這是一個 1 writer-n reader 的讀寫場景,而且寫操作還不是很頻繁(一秒一次):
func main() {
var counter Counter
for i := 0; i < 10; i++ { // 10個reader
go func() {
for {
counter.Count() // 計數器讀操作
time.Sleep(time.Millisecond)
}
}()
}
for { // 一個writer
counter.Incr() // 計數器寫操作
time.Sleep(time.Second)
}
}
// 一個執行緒安全的計數器
type Counter struct {
mu sync.RWMutex
count uint64
}
// 使用寫鎖保護
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 使用讀鎖保護
func (c *Counter) Count() uint64 {
c.mu.RLock()
defer c.mu.RUnlock()
return c.count
}
可以看到,Incr 方法會修改計數器的值,是一個寫操作,我們使用 Lock/Unlock 進行保護。Count 方法會讀取當前計數器的值,是一個讀操作,我們使用 RLock/RUnlock 方法進行保護。
Incr 方法每秒才呼叫一次,所以,writer 競爭鎖的頻次是比較低的,而 10 個 goroutine 每毫秒都要執行一次查詢,透過讀寫鎖,可以極大提升計數器的效能,因為在讀取的時候,可以併發進行。如果使用 Mutex,效能就不會像讀寫鎖這麼好。因為多個 reader 併發讀的時候,使用互斥鎖導致了 reader 要排隊讀的情況,沒有 RWMutex 併發讀的效能好。
如果你遇到可以明確區分 reader 和 writer goroutine 的場景,且有大量的併發讀、少量的併發寫,並且有強烈的效能需求,你就可以考慮使用讀寫鎖 RWMutex 替換 Mutex。
在實際使用 RWMutex 的時候,如果我們在 struct 中使用 RWMutex 保護某個欄位,一般會把它和這個欄位放在一起,用來指示兩個欄位是一組欄位。除此之外,我們還可以採用匿名欄位的方式嵌入 struct,這樣,在使用這個 struct 時,我們就可以直接呼叫 Lock/Unlock、RLock/RUnlock 方法了,這和我們前面在01 講中介紹 Mutex 的使用方法很類似,你可以回去複習一下。
RWMutex 的實作原理
RWMutex 是很常見的併發原語,很多程式語言的庫都提供了類似的併發型別。RWMutex 一般都是基於互斥鎖、條件變數(condition variables)或者訊號量(semaphores)等併發原語來實作。Go 標準庫中的 RWMutex 是基於 Mutex 實作的。
readers-writers 問題一般有三類,基於對讀和寫操作的優先順序,讀寫鎖的設計和實作也分成三類。
- Read-preferring:讀優先的設計可以提供很高的併發性,但是,在競爭激烈的情況下可能會導致寫飢餓。這是因為,如果有大量的讀,這種設計會導致只有所有的讀都釋放了鎖之後,寫才可能獲取到鎖。
- Write-preferring:寫優先的設計意味著,如果已經有一個 writer 在等待請求鎖的話,它會阻止新來的請求鎖的 reader 獲取到鎖,所以優先保障 writer。當然,如果有一些 reader 已經請求了鎖的話,新請求的 writer 也會等待已經存在的 reader 都釋放鎖之後才能獲取。所以,寫優先順序設計中的優先權是針對新來的請求而言的。這種設計主要避免了 writer 的飢餓問題。
- 不指定優先順序:這種設計比較簡單,不區分 reader 和 writer 優先順序,某些場景下這種不指定優先順序的設計反而更有效,因為第一類優先順序會導致寫飢餓,第二類優先順序可能會導致讀飢餓,這種不指定優先順序的訪問不再區分讀寫,大家都是同一個優先順序,解決了飢餓的問題。
Go 標準庫中的 RWMutex 設計是 Write-preferring 方案。一個正在阻塞的 Lock 呼叫會排除新的 reader 請求到鎖。
RWMutex 包含一個 Mutex,以及四個輔助欄位 writerSem、readerSem、readerCount 和 readerWait:
type RWMutex struct {
w Mutex // 互斥鎖解決多個writer的競爭
writerSem uint32 // writer訊號量
readerSem uint32 // reader訊號量
readerCount int32 // reader的數量
readerWait int32 // writer等待完成的reader的數量
}
const rwmutexMaxReaders = 1 << 30
我來簡單解釋一下這幾個欄位。
- 欄位 w:為 writer 的競爭鎖而設計;
- 欄位 readerCount:記錄當前 reader 的數量(以及是否有 writer 競爭鎖);
- readerWait:記錄 writer 請求鎖時需要等待 read 完成的 reader 的數量;
- writerSem 和 readerSem:都是為了阻塞設計的訊號量。
這裡的常量 rwmutexMaxReaders,定義了最大的 reader 數量。
好了,知道了 RWMutex 的設計方案和具體欄位,下面我來解釋一下具體的方法實作。
RLock/RUnlock 的實作
首先,我們看一下移除了 race 等無關緊要的程式碼後的 RLock 和 RUnlock 方法:
func (rw *RWMutex) RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// rw.readerCount是負值的時候,意味著此時有writer等待請求鎖,因為writer優先順序高,所以把後來的reader阻塞休眠
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
func (rw *RWMutex) RUnlock() {
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
rw.rUnlockSlow(r) // 有等待的writer
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// 最後一個reader了,writer終於有機會獲得鎖了
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
第 2 行是對 reader 計數加 1。你可能比較困惑的是,readerCount 怎麼還可能為負數呢?其實,這是因為,readerCount 這個欄位有雙重含義:
- 沒有 writer 競爭或持有鎖時,readerCount 和我們正常理解的 reader 的計數是一樣的;
- 但是,如果有 writer 競爭鎖或者持有鎖時,那麼,readerCount 不僅僅承擔著 reader 的計數功能,還能夠標識當前是否有 writer 競爭或持有鎖,在這種情況下,請求鎖的 reader 的處理進入第 4 行,阻塞等待鎖的釋放。
呼叫 RUnlock 的時候,我們需要將 Reader 的計數減去 1(第 8 行),因為 reader 的數量減少了一個。但是,第 8 行的 AddInt32 的返回值還有另外一個含義。如果它是負值,就表示當前有 writer 競爭鎖,在這種情況下,還會呼叫 rUnlockSlow 方法,檢查是不是 reader 都釋放讀鎖了,如果讀鎖都釋放了,那麼可以喚醒請求寫鎖的 writer 了。
當一個或者多個 reader 持有鎖的時候,競爭鎖的 writer 會等待這些 reader 釋放完,才可能持有這把鎖。打個比方,在房地產行業中有條規矩叫做“買賣不破租賃”,意思是說,就算房東把房子賣了,新業主也不能把當前的租戶趕走,而是要等到租約結束後,才能接管房子。這和 RWMutex 的設計是一樣的。當 writer 請求鎖的時候,是無法改變既有的 reader 持有鎖的現實的,也不會強制這些 reader 釋放鎖,它的優先權只是限定後來的 reader 不要和它搶。
所以,rUnlockSlow 將持有鎖的 reader 計數減少 1 的時候,會檢查既有的 reader 是不是都已經釋放了鎖,如果都釋放了鎖,就會喚醒 writer,讓 writer 持有鎖。
Lock
RWMutex 是一個多 writer 多 reader 的讀寫鎖,所以同時可能有多個 writer 和 reader。那麼,為了避免 writer 之間的競爭,RWMutex 就會使用一個 Mutex 來保證 writer 的互斥。
一旦一個 writer 獲得了內部的互斥鎖,就會反轉 readerCount 欄位,把它從原來的正整數 readerCount(>=0) 修改為負數(readerCount-rwmutexMaxReaders),讓這個欄位保持兩個含義(既儲存了 reader 的數量,又表示當前有 writer)。
我們來看下下面的程式碼。第 5 行,還會記錄當前活躍的 reader 數量,所謂活躍的 reader,就是指持有讀鎖還沒有釋放的那些 reader。
func (rw *RWMutex) Lock() {
// 首先解決其他writer競爭問題
rw.w.Lock()
// 反轉readerCount,告訴reader有writer競爭鎖
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 如果當前有reader持有鎖,那麼需要等待
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
如果 readerCount 不是 0,就說明當前有持有讀鎖的 reader,RWMutex 需要把這個當前 readerCount 賦值給 readerWait 欄位儲存下來(第 7 行), 同時,這個 writer 進入阻塞等待狀態(第 8 行)。
每當一個 reader 釋放讀鎖的時候(呼叫 RUnlock 方法時),readerWait 欄位就減 1,直到所有的活躍的 reader 都釋放了讀鎖,才會喚醒這個 writer。
Unlock
當一個 writer 釋放鎖的時候,它會再次反轉 readerCount 欄位。可以肯定的是,因為當前鎖由 writer 持有,所以,readerCount 欄位是反轉過的,並且減去了 rwmutexMaxReaders 這個常數,變成了負數。所以,這裡的反轉方法就是給它增加 rwmutexMaxReaders 這個常數值。
既然 writer 要釋放鎖了,那麼就需要喚醒之後新來的 reader,不必再阻塞它們了,讓它們開開心心地繼續執行就好了。
在 RWMutex 的 Unlock 返回之前,需要把內部的互斥鎖釋放。釋放完畢後,其他的 writer 才可以繼續競爭這把鎖。
func (rw *RWMutex) Unlock() {
// 告訴reader沒有活躍的writer了
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 喚醒阻塞的reader們
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 釋放內部的互斥鎖
rw.w.Unlock()
}
在這段程式碼中,我刪除了 race 的處理和異常情況的檢查,總體看來還是比較簡單的。這裡有幾個重點,我要再提醒你一下。首先,你要理解 readerCount 這個欄位的含義以及反轉方式。其次,你還要注意欄位的更改和內部互斥鎖的順序關係。在 Lock 方法中,是先獲取內部互斥鎖,才會修改的其他欄位;而在 Unlock 方法中,是先修改的其他欄位,才會釋放內部互斥鎖,這樣才能保證欄位的修改也受到互斥鎖的保護。
好了,到這裡我們就完整學習了 RWMutex 的概念和實作原理。RWMutex 的應用場景非常明確,就是解決 readers-writers 問題。學完了今天的內容,之後當你遇到這類問題時,要優先想到 RWMutex。另外,Go 併發原語程式碼實作的質量都很高,非常精煉和高效,所以,你可以透過看它們的實作原理,學習一些程式設計的技巧。當然,還有非常重要的一點就是要知道 reader 或者 writer 請求鎖的時候,既有的 reader/writer 和後續請求鎖的 reader/writer 之間的(釋放鎖 / 請求鎖)順序關係。
有個很有意思的事兒,就是官方的文件對 RWMutex 介紹是錯誤的,或者說是不明確的,在下一個版本(Go 1.16)中,官方會更改對 RWMutex 的介紹,具體是這樣的:
A RWMutex is a reader/writer mutual exclusion lock.
The lock can be held by any number of readers or a single writer, and
a blocked writer also blocks new readers from acquiring the lock.
這個描述是相當精確的,它指出了 RWMutex 可以被誰持有,以及 writer 比後續的 reader 有獲取鎖的優先順序。
雖然 RWMutex 暴露的 API 也很簡單,使用起來也沒有複雜的邏輯,但是和 Mutex 一樣,在實際使用的時候,也會很容易踩到一些坑。接下來,我給你重點介紹 3 個常見的踩坑點。
RWMutex 的 3 個踩坑點
坑點 1:不可複製
前面剛剛說過,RWMutex 是由一個互斥鎖和四個輔助欄位組成的。我們很容易想到,互斥鎖是不可複製的,再加上四個有狀態的欄位,RWMutex 就更加不能複製使用了。
不能複製的原因和互斥鎖一樣。一旦讀寫鎖被使用,它的欄位就會記錄它當前的一些狀態。這個時候你去複製這把鎖,就會把它的狀態也給複製過來。但是,原來的鎖在釋放的時候,並不會修改你複製出來的這個讀寫鎖,這就會導致複製出來的讀寫鎖的狀態不對,可能永遠無法釋放鎖。
那該怎麼辦呢?其實,解決方案也和互斥鎖一樣。你可以藉助 vet 工具,在變數賦值、函式傳參、函式返回值、遍歷資料、struct 初始化等時,檢查是否有讀寫鎖隱式複製的情景。
坑點 2:重入導致死鎖
讀寫鎖因為重入(或遞迴呼叫)導致死鎖的情況更多。
我先介紹第一種情況。因為讀寫鎖內部基於互斥鎖實作對 writer 的併發訪問,而互斥鎖本身是有重入問題的,所以,writer 重入呼叫 Lock 的時候,就會出現死鎖的現象,這個問題,我們在學習互斥鎖的時候已經瞭解過了。
func foo(l *sync.RWMutex) {
fmt.Println("in foo")
l.Lock()
bar(l)
l.Unlock()
}
func bar(l *sync.RWMutex) {
l.Lock()
fmt.Println("in bar")
l.Unlock()
}
func main() {
l := &sync.RWMutex{}
foo(l)
}
執行這個程式,你就會得到死鎖的錯誤輸出,在 Go 執行的時候,很容易就能檢測出來。
第二種死鎖的場景有點隱蔽。我們知道,有活躍 reader 的時候,writer 會等待,如果我們在 reader 的讀操作時呼叫 writer 的寫操作(它會呼叫 Lock 方法),那麼,這個 reader 和 writer 就會形成互相依賴的死鎖狀態。Reader 想等待 writer 完成後再釋放鎖,而 writer 需要這個 reader 釋放鎖之後,才能不阻塞地繼續執行。這是一個讀寫鎖常見的死鎖場景。
第三種死鎖的場景更加隱蔽。
當一個 writer 請求鎖的時候,如果已經有一些活躍的 reader,它會等待這些活躍的 reader 完成,才有可能獲取到鎖,但是,如果之後活躍的 reader 再依賴新的 reader 的話,這些新的 reader 就會等待 writer 釋放鎖之後才能繼續執行,這就形成了一個環形依賴: writer 依賴活躍的 reader -> 活躍的 reader 依賴新來的 reader -> 新來的 reader 依賴 writer。
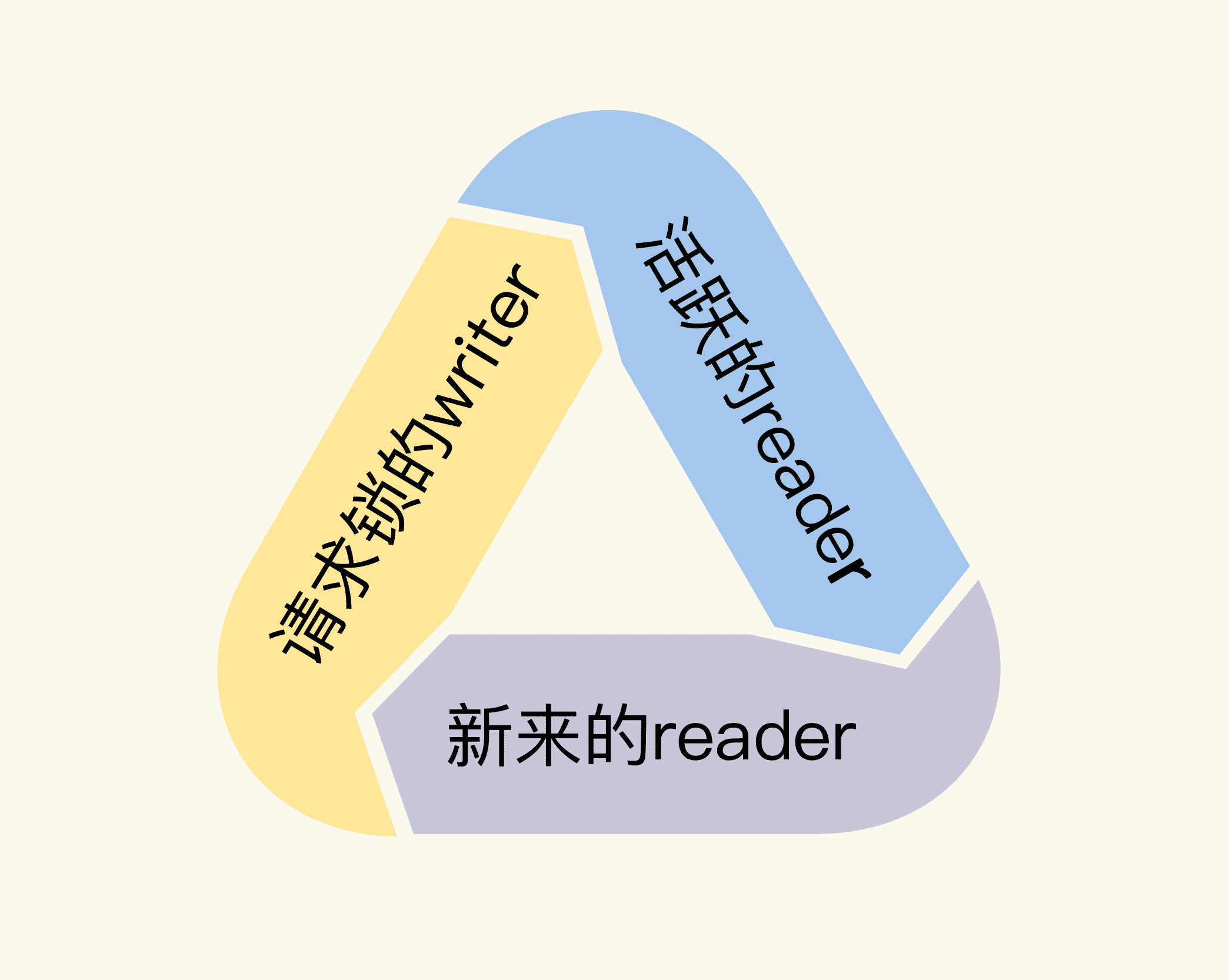
這個死鎖相當隱蔽,原因在於它和 RWMutex 的設計和實作有關。啥意思呢?我們來看一個計算階乘 (n!) 的例子:
func main() {
var mu sync.RWMutex
// writer,稍微等待,然後製造一個呼叫Lock的場景
go func() {
time.Sleep(200 * time.Millisecond)
mu.Lock()
fmt.Println("Lock")
time.Sleep(100 * time.Millisecond)
mu.Unlock()
fmt.Println("Unlock")
}()
go func() {
factorial(&mu, 10) // 計算10的階乘, 10!
}()
select {}
}
// 遞迴呼叫計算階乘
func factorial(m *sync.RWMutex, n int) int {
if n < 1 { // 階乘退出條件
return 0
}
fmt.Println("RLock")
m.RLock()
defer func() {
fmt.Println("RUnlock")
m.RUnlock()
}()
time.Sleep(100 * time.Millisecond)
return factorial(m, n-1) * n // 遞迴呼叫
}
factoria 方法是一個遞迴計算階乘的方法,我們用它來模擬 reader。為了更容易地製造出死鎖場景,我在這裡加上了 sleep 的呼叫,延緩邏輯的執行。這個方法會呼叫讀鎖(第 27 行),在第 33 行遞迴地呼叫此方法,每次呼叫都會產生一次讀鎖的呼叫,所以可以不斷地產生讀鎖的呼叫,而且必須等到新請求的讀鎖釋放,這個讀鎖才能釋放。
同時,我們使用另一個 goroutine 去呼叫 Lock 方法,來實作 writer,這個 writer 會等待 200 毫秒後才會呼叫 Lock,這樣在呼叫 Lock 的時候,factoria 方法還在執行中不斷呼叫 RLock。
這兩個 goroutine 互相持有鎖並等待,誰也不會退讓一步,滿足了“writer 依賴活躍的 reader -> 活躍的 reader 依賴新來的 reader -> 新來的 reader 依賴 writer”的死鎖條件,所以就導致了死鎖的產生。
所以,使用讀寫鎖最需要注意的一點就是儘量避免重入,重入帶來的死鎖非常隱蔽,而且難以診斷。
坑點 3:釋放未加鎖的 RWMutex
和互斥鎖一樣,Lock 和 Unlock 的呼叫總是成對出現的,RLock 和 RUnlock 的呼叫也必須成對出現。Lock 和 RLock 多餘的呼叫會導致鎖沒有被釋放,可能會出現死鎖,而 Unlock 和 RUnlock 多餘的呼叫會導致 panic。在生產環境中出現 panic 是大忌,你總不希望半夜爬起來處理生產環境程式崩潰的問題吧?所以,在使用讀寫鎖的時候,一定要注意,不遺漏不多餘。
流行的 Go 開發專案中的坑
好了,又到了泡一杯寧夏枸杞加新疆大灘棗的養生茶,靜靜地欣賞知名專案出現 Bug 的時候了,這次被拉出來的是 RWMutex 的 Bug。
Docker
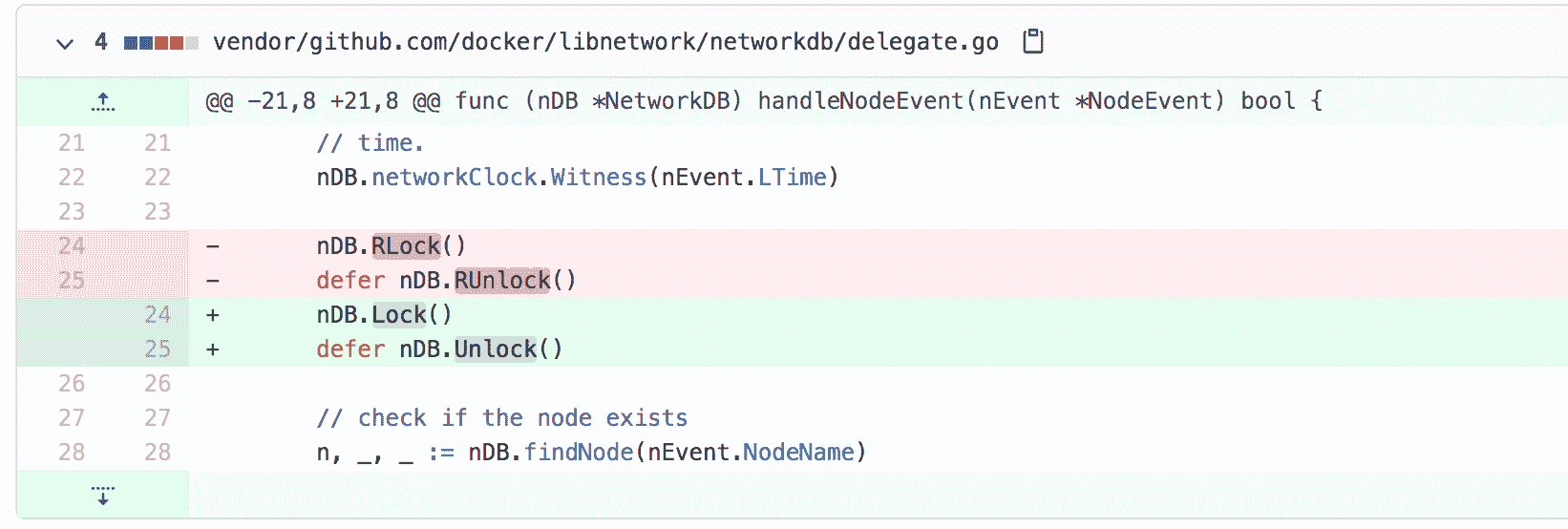
issue 36840
issue 36840修復的是錯誤地把 writer 當成 reader 的 Bug。 這個地方本來需要修改資料,需要呼叫的是寫鎖,結果用的卻是讀鎖。或許是被它緊挨著的 findNode 方法呼叫迷惑了,認為這只是一個讀操作。可實際上,程式碼後面還會有 changeNodeState 方法的呼叫,這是一個寫操作。修復辦法也很簡單,只需要改成 Lock/Unlock 即可。
Kubernetes
issue 62464
issue 62464就是讀寫鎖第二種死鎖的場景,這是一個典型的 reader 導致的死鎖的例子。知道墨菲定律吧?“凡是可能出錯的事,必定會出錯”。你可能覺得我前面講的 RWMutex 的坑絕對不會被人踩的,因為道理大家都懂,但是你看,Kubernetes 就踩了這個重入的坑。
這個 issue 在移除 pod 的時候可能會發生,原因就在於,GetCPUSetOrDefault 方法會請求讀鎖,同時,它還會呼叫 GetCPUSet 或 GetDefaultCPUSet 方法。當這兩個方法都請求寫鎖時,是獲取不到的,因為 GetCPUSetOrDefault 方法還沒有執行完,不會釋放讀鎖,這就形成了死鎖。

總結
在開發過程中,一開始考慮共享資源併發訪問問題的時候,我們就會想到互斥鎖 Mutex。因為剛開始的時候,我們還並不太瞭解併發的情況,所以,就會使用最簡單的同步原語來解決問題。等到系統成熟,真正到了需要效能最佳化的時候,我們就能靜下心來分析併發場景的可能性,這個時候,我們就要考慮將 Mutex 修改為 RWMutex,來壓榨系統的效能。
當然,如果一開始你的場景就非常明確了,比如我就要實作一個執行緒安全的 map,那麼,一開始你就可以考慮使用讀寫鎖。
正如我在前面提到的,如果你能意識到你要解決的問題是一個 readers-writers 問題,那麼你就可以毫不猶豫地選擇 RWMutex,不用考慮其它選擇。那在使用 RWMutex 時,最需要注意的一點就是儘量避免重入,重入帶來的死鎖非常隱蔽,而且難以診斷。
另外我們也可以擴充套件 RWMutex,不過實作方法和互斥鎖 Mutex 差不多,在技術上是一樣的,都是透過 unsafe 來實作,我就不再具體講了。課下你可以參照我們上節課學習的方法,實作一個擴充套件的 RWMutex。
這一講我們系統學習了讀寫鎖的相關知識,這裡提供給你一個知識地圖,幫助你複習本節課的知識。
思考題
請你寫一個擴充套件的讀寫鎖,比如提供 TryLock,查詢當前是否有 writer、reader 的數量等方法。
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
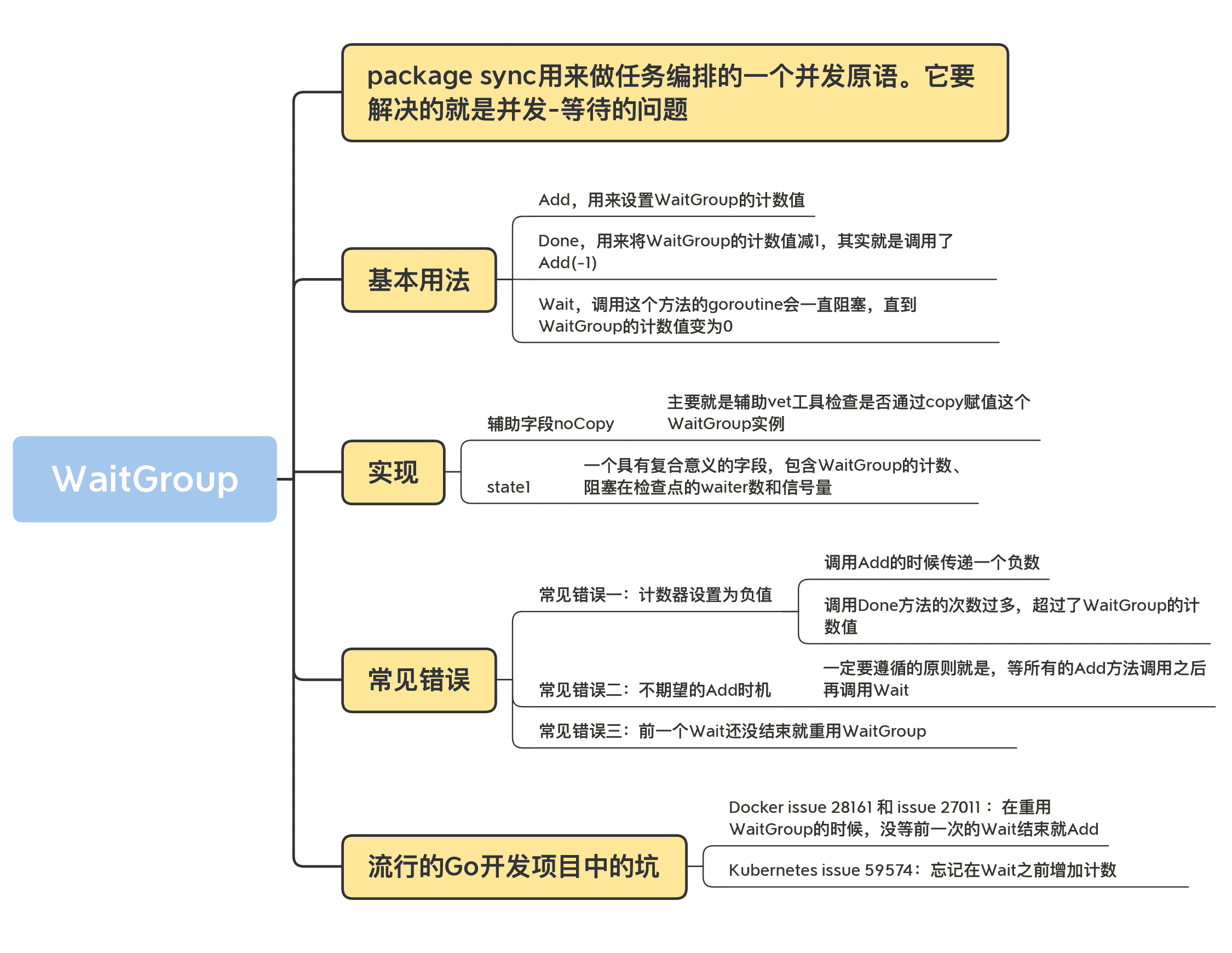
06|WaitGroup:協同等待,任務編排利器
你好,我是鳥窩。
本章導讀
WaitGroup 任務編排圖
主 goroutine
┌──────────────┐ Add(n) ┌──────────────────────┐
│ 啟動子任務群 │ ────────> │ WaitGroup 計數器 = n │
└──────┬───────┘ └──────────┬───────────┘
│ │
│ 啟動 n 個 goroutine │ Wait() 阻塞
▼ │
┌──────────────┐ Done() │
│ 子任務 #1 │ ─────────────────────┤
├──────────────┤ Done() │
│ 子任務 #2 │ ─────────────────────┤
├──────────────┤ ... │
│ 子任務 #n │ ─────────────────────┘
└──────────────┘
計數歸零 -> 主 goroutine 繼續
WaitGroup,我們以前都多多少少學習過,或者是使用過。其實,WaitGroup 很簡單,就是 package sync 用來做任務編排的一個併發原語。它要解決的就是併發 - 等待的問題:現在有一個 goroutine A 在檢查點(checkpoint)等待一組 goroutine 全部完成,如果在執行任務的這些 goroutine 還沒全部完成,那麼 goroutine A 就會阻塞在檢查點,直到所有 goroutine 都完成後才能繼續執行。
我們來看一個使用 WaitGroup 的場景。
比如,我們要完成一個大的任務,需要使用並行的 goroutine 執行三個小任務,只有這三個小任務都完成,我們才能去執行後面的任務。如果透過輪詢的方式定時詢問三個小任務是否完成,會存在兩個問題:一是,效能比較低,因為三個小任務可能早就完成了,卻要等很長時間才被輪詢到;二是,會有很多無謂的輪詢,空耗 CPU 資源。
那麼,這個時候使用 WaitGroup 併發原語就比較有效了,它可以阻塞等待的 goroutine。等到三個小任務都完成了,再即時喚醒它們。
其實,很多作業系統和程式語言都提供了類似的併發原語。比如,Linux 中的 barrier、Pthread(POSIX 執行緒)中的 barrier、C++ 中的 std::barrier、Java 中的 CyclicBarrier 和 CountDownLatch 等。由此可見,這個併發原語還是一個非常基礎的併發型別。所以,我們要認真掌握今天的內容,這樣就可以舉一反三,輕鬆應對其他場景下的需求了。
我們還是從 WaitGroup 的基本用法學起吧。
WaitGroup 的基本用法
Go 標準庫中的 WaitGroup 提供了三個方法,保持了 Go 簡潔的風格。
func (wg *WaitGroup) Add(delta int)
func (wg *WaitGroup) Done()
func (wg *WaitGroup) Wait()
我們分別看下這三個方法:
- Add,用來設定 WaitGroup 的計數值;
- Done,用來將 WaitGroup 的計數值減 1,其實就是呼叫了 Add(-1);
- Wait,呼叫這個方法的 goroutine 會一直阻塞,直到 WaitGroup 的計數值變為 0。
接下來,我們透過一個使用 WaitGroup 的例子,來看下 Add、Done、Wait 方法的基本用法。
在這個例子中,我們使用了以前實作的計數器 struct。我們啟動了 10 個 worker,分別對計數值加一,10 個 worker 都完成後,我們期望輸出計數器的值。
// 執行緒安全的計數器
type Counter struct {
mu sync.Mutex
count uint64
}
// 對計數值加一
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 獲取當前的計數值
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
// sleep 1秒,然後計數值加1
func worker(c *Counter, wg *sync.WaitGroup) {
defer wg.Done()
time.Sleep(time.Second)
c.Incr()
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10) // WaitGroup的值設定為10
for i := 0; i < 10; i++ { // 啟動10個goroutine執行加1任務
go worker(&counter, &wg)
}
// 檢查點,等待goroutine都完成任務
wg.Wait()
// 輸出當前計數器的值
fmt.Println(counter.Count())
}
我們一起來分析下這段程式碼。
- 第 28 行,宣告瞭一個 WaitGroup 變數,初始值為零。
- 第 29 行,把 WaitGroup 變數的計數值設定為 10。因為我們需要編排 10 個 goroutine(worker) 去執行任務,並且等待 goroutine 完成。
- 第 35 行,呼叫 Wait 方法阻塞等待。
- 第 32 行,啟動了 goroutine,並把我們定義的 WaitGroup 指標當作引數傳遞進去。goroutine 完成後,需要呼叫 Done 方法,把 WaitGroup 的計數值減 1。等 10 個 goroutine 都呼叫了 Done 方法後,WaitGroup 的計數值降為 0,這時,第 35 行的主 goroutine 就不再阻塞,會繼續執行,在第 37 行輸出計數值。
這就是我們使用 WaitGroup 編排這類任務的常用方式。而“這類任務”指的就是,需要啟動多個 goroutine 執行任務,主 goroutine 需要等待子 goroutine 都完成後才繼續執行。
熟悉了 WaitGroup 的基本用法後,我們再看看它具體是如何實作的吧。
WaitGroup 的實作
首先,我們看看 WaitGroup 的資料結構。它包括了一個 noCopy 的輔助欄位,一個 state1 記錄 WaitGroup 狀態的陣列。
- noCopy 的輔助欄位,主要就是輔助 vet 工具檢查是否透過 copy 賦值這個 WaitGroup 例項。我會在後面和你詳細分析這個欄位;
- state1,一個具有複合意義的欄位,包含 WaitGroup 的計數、阻塞在檢查點的 waiter 數和訊號量。
WaitGroup 的資料結構定義以及 state 資訊的獲取方法如下:
type WaitGroup struct {
// 避免複製使用的一個技巧,可以告訴vet工具違反了複製使用的規則
noCopy noCopy
// 64bit(8bytes)的值分成兩段,高32bit是計數值,低32bit是waiter的計數
// 另外32bit是用作訊號量的
// 因為64bit值的原子操作需要64bit對齊,但是32bit編譯器不支援,所以陣列中的元素在不同的架構中不一樣,具體處理看下面的方法
// 總之,會找到對齊的那64bit作為state,其餘的32bit做訊號量
state1 [3]uint32
}
// 得到state的地址和訊號量的地址
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// 如果地址是64bit對齊的,陣列前兩個元素做state,後一個元素做訊號量
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
// 如果地址是32bit對齊的,陣列後兩個元素用來做state,它可以用來做64bit的原子操作,第一個元素32bit用來做訊號量
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
因為對 64 位整數的原子操作要求整數的地址是 64 位對齊的,所以針對 64 位和 32 位環境的 state 欄位的組成是不一樣的。
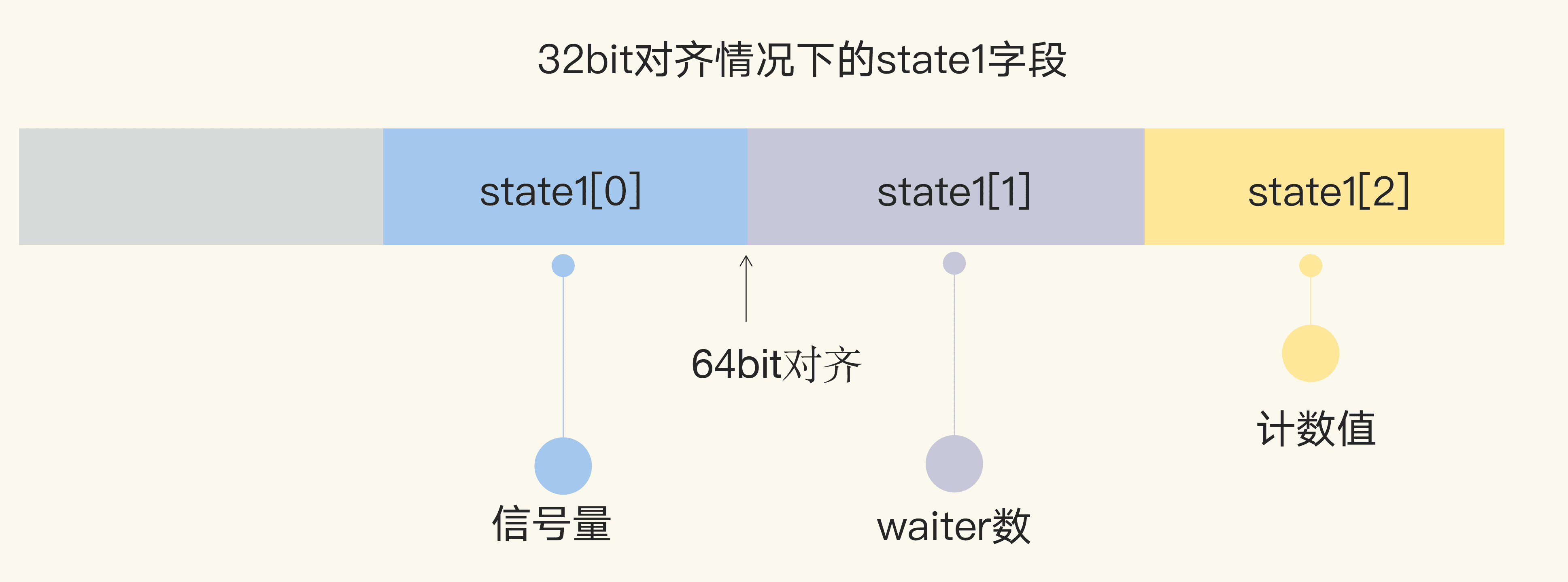
在 64 位環境下,state1 的第一個元素是 waiter 數,第二個元素是 WaitGroup 的計數值,第三個元素是訊號量。
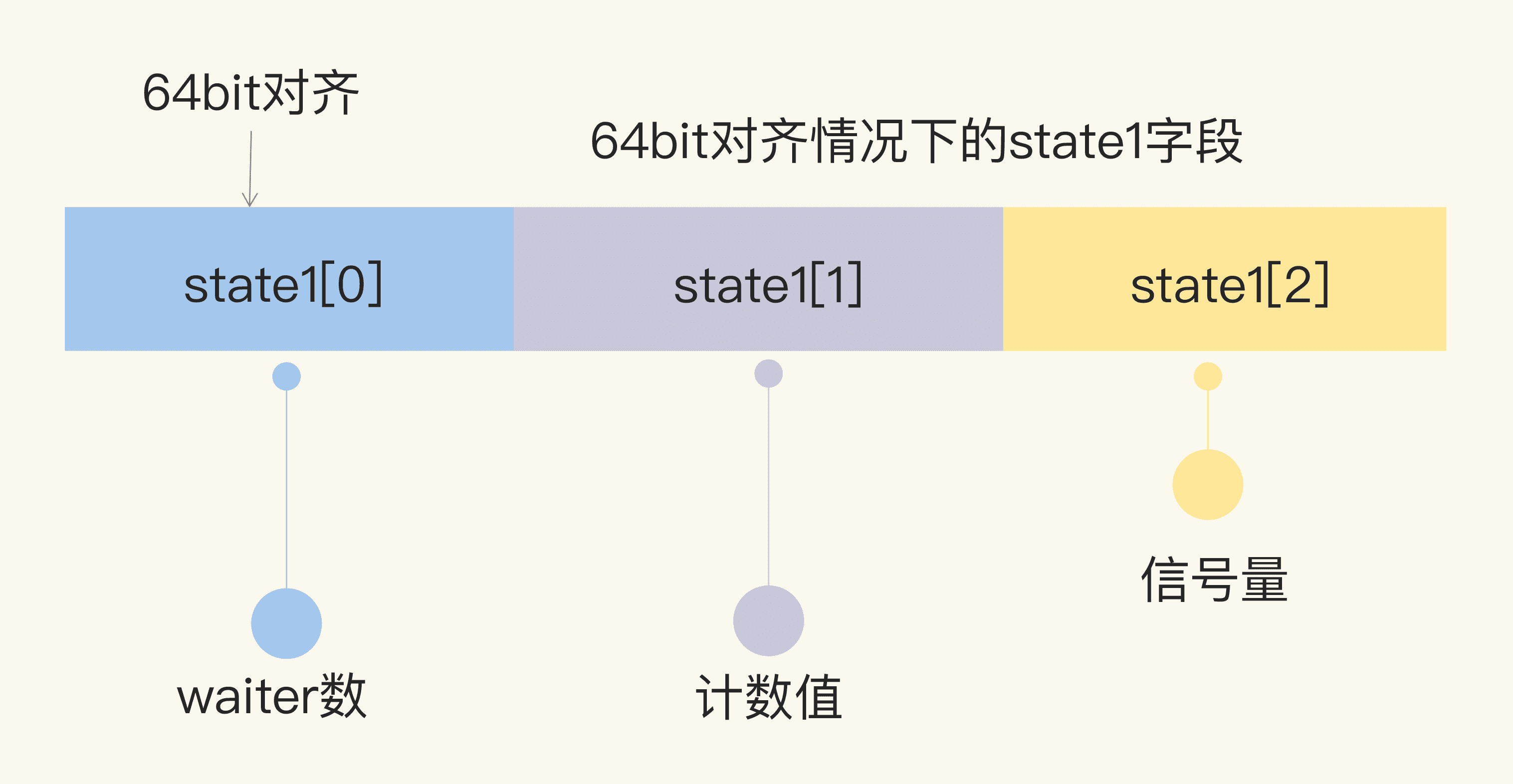
在 32 位環境下,如果 state1 不是 64 位對齊的地址,那麼 state1 的第一個元素是訊號量,後兩個元素分別是 waiter 數和計數值。
然後,我們繼續深入原始碼,看一下 Add、Done 和 Wait 這三個方法的實作。
在檢視這部分原始碼實作時,我們會發現,除了這些方法本身的實作外,還會有一些額外的程式碼,主要是 race 檢查和異常檢查的程式碼。其中,有幾個檢查非常關鍵,如果檢查不透過,會出現 panic,這部分內容我會在下一小節分析 WaitGroup 的錯誤使用場景時介紹。現在,我們先專注在 Add、Wait 和 Done 本身的實作程式碼上。
我先為你梳理下 Add 方法的邏輯。Add 方法主要操作的是 state 的計數部分。你可以為計數值增加一個 delta 值,內部透過原子操作把這個值加到計數值上。需要注意的是,這個 delta 也可以是個負數,相當於為計數值減去一個值,Done 方法內部其實就是透過 Add(-1) 實作的。
它的實作程式碼如下:
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
// 高32bit是計數值v,所以把delta左移32,增加到計數上
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32) // 當前計數值
w := uint32(state) // waiter count
if v > 0 || w == 0 {
return
}
// 如果計數值v為0並且waiter的數量w不為0,那麼state的值就是waiter的數量
// 將waiter的數量設定為0,因為計數值v也是0,所以它們倆的組合*statep直接設定為0即可。此時需要並喚醒所有的waiter
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
// Done方法實際就是計數器減1
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
Wait 方法的實作邏輯是:不斷檢查 state 的值。如果其中的計數值變為了 0,那麼說明所有的任務已完成,呼叫者不必再等待,直接返回。如果計數值大於 0,說明此時還有任務沒完成,那麼呼叫者就變成了等待者,需要加入 waiter 佇列,並且阻塞住自己。
其主幹實作程式碼如下:
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // 當前計數值
w := uint32(state) // waiter的數量
if v == 0 {
// 如果計數值為0, 呼叫這個方法的goroutine不必再等待,繼續執行它後面的邏輯即可
return
}
// 否則把waiter數量加1。期間可能有併發呼叫Wait的情況,所以最外層使用了一個for迴圈
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 阻塞休眠等待
runtime_Semacquire(semap)
// 被喚醒,不再阻塞,返回
return
}
}
}使用 WaitGroup 時的常見錯誤在分析 WaitGroup 的 Add、Done 和 Wait 方法的實作的時候,為避免幹擾,我刪除了異常檢查的程式碼。但是,這些異常檢查非常有用。
我們在開發的時候,經常會遇見或看到誤用 WaitGroup 的場景,究其原因就是沒有弄明白這些檢查的邏輯。所以接下來,我們就透過幾個小例子,一起學習下在開發時絕對要避免的 3 個問題。
常見問題一:計數器設定為負值
WaitGroup 的計數器的值必須大於等於 0。我們在更改這個計數值的時候,WaitGroup 會先做檢查,如果計數值被設定為負數,就會導致 panic。
一般情況下,有兩種方法會導致計數器設定為負數。
第一種方法是:呼叫 Add 的時候傳遞一個負數。如果你能保證當前的計數器加上這個負數後還是大於等於 0 的話,也沒有問題,否則就會導致 panic。
比如下面這段程式碼,計數器的初始值為 10,當第一次傳入 -10 的時候,計數值被設定為 0,不會有啥問題。但是,再緊接著傳入 -1 以後,計數值就被設定為負數了,程式就會出現 panic。
func main() {
var wg sync.WaitGroup
wg.Add(10)
wg.Add(-10)//將-10作為引數呼叫Add,計數值被設定為0
wg.Add(-1)//將-1作為引數呼叫Add,如果加上-1計數值就會變為負數。這是不對的,所以會觸發panic
}
第二個方法是:呼叫 Done 方法的次數過多,超過了 WaitGroup 的計數值。
使用 WaitGroup 的正確姿勢是,預先確定好 WaitGroup 的計數值,然後呼叫相同次數的 Done 完成相應的任務。比如,在 WaitGroup 變數宣告之後,就立即設定它的計數值,或者在 goroutine 啟動之前增加 1,然後在 goroutine 中呼叫 Done。
如果你沒有遵循這些規則,就很可能會導致 Done 方法呼叫的次數和計數值不一致,進而造成死鎖(Done 呼叫次數比計數值少)或者 panic(Done 呼叫次數比計數值多)。
比如下面這個例子中,多呼叫了一次 Done 方法後,會導致計數值為負,所以程式執行到這一行會出現 panic。
func main() {
var wg sync.WaitGroup
wg.Add(1)
wg.Done()
wg.Done()
}常見問題二:不期望的 Add 時機在使用 WaitGroup 的時候,你一定要遵循的原則就是,等所有的 Add 方法呼叫之後再呼叫 Wait,否則就可能導致 panic 或者不期望的結果。
我們構造這樣一個場景:只有部分的 Add/Done 執行完後,Wait 就返回。我們看一個例子:啟動四個 goroutine,每個 goroutine 內部呼叫 Add(1) 然後呼叫 Done(),主 goroutine 呼叫 Wait 等待任務完成。
func main() {
var wg sync.WaitGroup
go dosomething(100, &wg) // 啟動第一個goroutine
go dosomething(110, &wg) // 啟動第二個goroutine
go dosomething(120, &wg) // 啟動第三個goroutine
go dosomething(130, &wg) // 啟動第四個goroutine
wg.Wait() // 主goroutine等待完成
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
duration := millisecs * time.Millisecond
time.Sleep(duration) // 故意sleep一段時間
wg.Add(1)
fmt.Println("後臺執行, duration:", duration)
wg.Done()
}
在這個例子中,我們原本設想的是,等四個 goroutine 都執行完畢後輸出 Done 的資訊,但是它的錯誤之處在於,將 WaitGroup.Add 方法的呼叫放在了子 gorotuine 中。等主 goorutine 呼叫 Wait 的時候,因為四個任務 goroutine 一開始都休眠,所以可能 WaitGroup 的 Add 方法還沒有被呼叫,WaitGroup 的計數還是 0,所以它並沒有等待四個子 goroutine 執行完畢才繼續執行,而是立刻執行了下一步。
導致這個錯誤的原因是,沒有遵循先完成所有的 Add 之後才 Wait。要解決這個問題,一個方法是,預先設定計數值:
func main() {
var wg sync.WaitGroup
wg.Add(4) // 預先設定WaitGroup的計數值
go dosomething(100, &wg) // 啟動第一個goroutine
go dosomething(110, &wg) // 啟動第二個goroutine
go dosomething(120, &wg) // 啟動第三個goroutine
go dosomething(130, &wg) // 啟動第四個goroutine
wg.Wait() // 主goroutine等待
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
duration := millisecs * time.Millisecond
time.Sleep(duration)
fmt.Println("後臺執行, duration:", duration)
wg.Done()
}
另一種方法是在啟動子 goroutine 之前才呼叫 Add:
func main() {
var wg sync.WaitGroup
dosomething(100, &wg) // 呼叫方法,把計數值加1,並啟動任務goroutine
dosomething(110, &wg) // 呼叫方法,把計數值加1,並啟動任務goroutine
dosomething(120, &wg) // 呼叫方法,把計數值加1,並啟動任務goroutine
dosomething(130, &wg) // 呼叫方法,把計數值加1,並啟動任務goroutine
wg.Wait() // 主goroutine等待,程式碼邏輯保證了四次Add(1)都已經執行完了
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
wg.Add(1) // 計數值加1,再啟動goroutine
go func() {
duration := millisecs * time.Millisecond
time.Sleep(duration)
fmt.Println("後臺執行, duration:", duration)
wg.Done()
}()
}
可見,無論是怎麼修復,都要保證所有的 Add 方法是在 Wait 方法之前被呼叫的。
常見問題三:前一個 Wait 還沒結束就重用 WaitGroup
“前一個 Wait 還沒結束就重用 WaitGroup”這一點似乎不太好理解,我借用田徑比賽的例子和你解釋下吧。在田徑比賽的百米小組賽中,需要把選手分成幾組,一組選手比賽完之後,就可以進行下一組了。為了確保兩組比賽時間上沒有衝突,我們在模型化這個場景的時候,可以使用 WaitGroup。
WaitGroup 等一組比賽的所有選手都跑完後 5 分鐘,才開始下一組比賽。下一組比賽還可以使用這個 WaitGroup 來控制,因為 WaitGroup 是可以重用的。只要 WaitGroup 的計數值恢復到零值的狀態,那麼它就可以被看作是新建立的 WaitGroup,被重複使用。
但是,如果我們在 WaitGroup 的計數值還沒有恢復到零值的時候就重用,就會導致程式 panic。我們看一個例子,初始設定 WaitGroup 的計數值為 1,啟動一個 goroutine 先呼叫 Done 方法,接著就呼叫 Add 方法,Add 方法有可能和主 goroutine 併發執行。
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Millisecond)
wg.Done() // 計數器減1
wg.Add(1) // 計數值加1
}()
wg.Wait() // 主goroutine等待,有可能和第7行併發執行
}
在這個例子中,第 6 行雖然讓 WaitGroup 的計數恢復到 0,但是因為第 9 行有個 waiter 在等待,如果等待 Wait 的 goroutine,剛被喚醒就和 Add 呼叫(第 7 行)有併發執行的衝突,所以就會出現 panic。
總結一下:WaitGroup 雖然可以重用,但是是有一個前提的,那就是必須等到上一輪的 Wait 完成之後,才能重用 WaitGroup 執行下一輪的 Add/Wait,如果你在 Wait 還沒執行完的時候就呼叫下一輪 Add 方法,就有可能出現 panic。
noCopy:輔助 vet 檢查
我們剛剛在學習 WaitGroup 的資料結構時,提到了裡面有一個 noCopy 欄位。你還記得它的作用嗎?其實,它就是指示 vet 工具在做檢查的時候,這個資料結構不能做值複製使用。更嚴謹地說,是不能在第一次使用之後複製使用 ( must not be copied after first use)。
你可能會說了,為什麼要把 noCopy 欄位單獨拿出來講呢?一方面,把 noCopy 欄位穿插到 waitgroup 程式碼中講解,容易幹擾我們對 WaitGroup 整體的理解。另一方面,也是非常重要的原因,noCopy 是一個通用的計數技術,其他併發原語中也會用到,所以單獨介紹有助於你以後在實踐中使用這個技術。
我們在第 3 講學習 Mutex 的時候用到了 vet 工具。vet 會對實作 Locker 介面的資料型別做靜態檢查,一旦程式碼中有複製使用這種資料型別的情況,就會發出警告。但是,WaitGroup 同步原語不就是 Add、Done 和 Wait 方法嗎?vet 能檢查出來嗎?
其實是可以的。透過給 WaitGroup 新增一個 noCopy 欄位,我們就可以為 WaitGroup 實作 Locker 介面,這樣 vet 工具就可以做複製檢查了。而且因為 noCopy 欄位是未輸出型別,所以 WaitGroup 不會暴露 Lock/Unlock 方法。
noCopy 欄位的型別是 noCopy,它只是一個輔助的、用來幫助 vet 檢查用的型別:
type noCopy struct{}
// Lock is a no-op used by -copylocks checker from `go vet`.
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
如果你想要自己定義的資料結構不被複制使用,或者說,不能透過 vet 工具檢查出複製使用的報警,就可以透過嵌入 noCopy 這個資料型別來實作。
流行的 Go 開發專案中的坑
接下來又到了喝枸杞紅棗茶的時間了。你可以稍微休息一下,心態放輕鬆地跟我一起圍觀下知名專案犯過的錯,比如 copy Waitgroup、Add/Wait 併發執行問題、遺漏 Add 等 Bug。
有網友在 Go 的issue 28123中提了以下的例子,你能發現這段程式碼有什麼問題嗎?
type TestStruct struct {
Wait sync.WaitGroup
}
func main() {
w := sync.WaitGroup{}
w.Add(1)
t := &TestStruct{
Wait: w,
}
t.Wait.Done()
fmt.Println("Finished")
}
這段程式碼最大的一個問題,就是第 9 行 copy 了 WaitGroup 的例項 w。雖然這段程式碼能執行成功,但確實是違反了 WaitGroup 使用之後不要複製的規則。在專案中,我們可以透過 vet 工具檢查出這樣的錯誤。
Docker issue 28161 和 issue 27011 ,都是因為在重用 WaitGroup 的時候,沒等前一次的 Wait 結束就 Add 導致的錯誤。Etcd issue 6534 也是重用 WaitGroup 的 Bug,沒有等前一個 Wait 結束就 Add。
Kubernetes issue 59574 的 Bug 是忘記 Wait 之前增加計數了,這就屬於我們通常認為幾乎不可能出現的 Bug。
即使是開發 Go 語言的開發者自己,在使用 WaitGroup 的時候,也可能會犯錯。比如 issue 12813,因為 defer 的使用,Add 方法可能在 Done 之後才執行,導致計數負值的 panic。
總結
學完這一講,我們知道了使用 WaitGroup 容易犯的錯,是不是有些手腳被束縛的感覺呢?其實大可不必,只要我們不是特別複雜地使用 WaitGroup,就不用有啥心理負擔。
而關於如何避免錯誤使用 WaitGroup 的情況,我們只需要儘量保證下面 5 點就可以了:
- 不重用 WaitGroup。新建一個 WaitGroup 不會帶來多大的資源開銷,重用反而更容易出錯。
- 保證所有的 Add 方法呼叫都在 Wait 之前。
- 不傳遞負數給 Add 方法,只通過 Done 來給計數值減 1。
- 不做多餘的 Done 方法呼叫,保證 Add 的計數值和 Done 方法呼叫的數量是一樣的。
- 不遺漏 Done 方法的呼叫,否則會導致 Wait hang 住無法返回。
這一講我們詳細學習了 WaitGroup 的相關知識,這裡我整理了一份關於 WaitGroup 的知識地圖,方便你複習。
思考題
通常我們可以把 WaitGroup 的計數值,理解為等待要完成的 waiter 的數量。你可以試著擴充套件下 WaitGroup,來查詢 WaitGroup 的當前的計數值嗎?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
07|Cond:條件變數的實作機制及避坑指南
你好,我是鳥窩。
本章導讀
Cond 條件等待/通知圖
┌──────────────┐ 檢查條件(false) ┌──────────────┐
│ 等待 goroutine │ ────────────────> │ cond.Wait() │
└──────┬───────┘ └──────┬───────┘
│ (Wait 內部會先解鎖、睡眠) │
│ │ 被 Signal/Broadcast 喚醒
│ ▼
┌──────▼───────┐ 更新狀態 + 發通知 ┌──────────────┐
│ 生產/修改端 │ ──────────────────> │ Signal / │
│ (持有同一把鎖) │ │ Broadcast │
└──────────────┘ └──────────────┘
重點:醒來後要重新檢查條件(通常用 for)
在寫 Go 程式之前,我曾經寫了 10 多年的 Java 程式,也面試過不少 Java 程式設計師。在 Java 面試中,經常被問到的一個知識點就是等待 / 通知(wait/notify)機制。面試官經常會這樣考察候選人:請實作一個限定容量的佇列(queue),當佇列滿或者空的時候,利用等待 / 通知機制實作阻塞或者喚醒。
在 Go 中,也可以實作一個類似的限定容量的佇列,而且實作起來也比較簡單,只要用條件變數(Cond)併發原語就可以。Cond 併發原語相對來說不是那麼常用,但是在特定的場景使用會事半功倍,比如你需要在喚醒一個或者所有的等待者做一些檢查操作的時候。
那麼今天這一講,我們就學習下 Cond 這個併發原語。
Go 標準庫的 Cond
Go 標準庫提供 Cond 原語的目的是,為等待 / 通知場景下的併發問題提供支援。Cond 通常應用於等待某個條件的一組 goroutine,等條件變為 true 的時候,其中一個 goroutine 或者所有的 goroutine 都會被喚醒執行。
顧名思義,Cond 是和某個條件相關,這個條件需要一組 goroutine 協作共同完成,在條件還沒有滿足的時候,所有等待這個條件的 goroutine 都會被阻塞住,只有這一組 goroutine 透過協作達到了這個條件,等待的 goroutine 才可能繼續進行下去。
那這裡等待的條件是什麼呢?等待的條件,可以是某個變數達到了某個閾值或者某個時間點,也可以是一組變數分別都達到了某個閾值,還可以是某個物件的狀態滿足了特定的條件。總結來講,等待的條件是一種可以用來計算結果是 true 還是 false 的條件。
從開發實踐上,我們真正使用 Cond 的場景比較少,因為一旦遇到需要使用 Cond 的場景,我們更多地會使用 Channel 的方式(我會在第 12 和第 13 講展開 Channel 的用法)去實作,因為那才是更地道的 Go 語言的寫法,甚至 Go 的開發者有個“把 Cond 從標準庫移除”的提議(issue 21165)。而有的開發者認為,Cond 是唯一難以掌握的 Go 併發原語。至於其中原因,我先賣個關子,到這一講的後半部分我再和你解釋。
今天,這一講我們就帶你仔細地學一學 Cond 這個併發原語吧。
Cond 的基本用法
標準庫中的 Cond 併發原語初始化的時候,需要關聯一個 Locker 介面的例項,一般我們使用 Mutex 或者 RWMutex。
我們看一下 Cond 的實作:
type Cond
func NeWCond(l Locker) *Cond
func (c *Cond) Broadcast()
func (c *Cond) Signal()
func (c *Cond) Wait()
首先,Cond 關聯的 Locker 例項可以透過 c.L 訪問,它內部維護著一個先入先出的等待佇列。
然後,我們分別看下它的三個方法 Broadcast、Signal 和 Wait 方法。
Signal 方法,允許呼叫者 Caller 喚醒一個等待此 Cond 的 goroutine。如果此時沒有等待的 goroutine,顯然無需通知 waiter;如果 Cond 等待佇列中有一個或者多個等待的 goroutine,則需要從等待佇列中移除第一個 goroutine 並把它喚醒。在其他程式語言中,比如 Java 語言中,Signal 方法也被叫做 notify 方法。
呼叫 Signal 方法時,不強求你一定要持有 c.L 的鎖。
Broadcast 方法,允許呼叫者 Caller 喚醒所有等待此 Cond 的 goroutine。如果此時沒有等待的 goroutine,顯然無需通知 waiter;如果 Cond 等待佇列中有一個或者多個等待的 goroutine,則清空所有等待的 goroutine,並全部喚醒。在其他程式語言中,比如 Java 語言中,Broadcast 方法也被叫做 notifyAll 方法。
同樣地,呼叫 Broadcast 方法時,也不強求你一定持有 c.L 的鎖。
Wait 方法,會把呼叫者 Caller 放入 Cond 的等待佇列中並阻塞,直到被 Signal 或者 Broadcast 的方法從等待佇列中移除並喚醒。
呼叫 Wait 方法時必須要持有 c.L 的鎖。
Go 實作的 sync.Cond 的方法名是 Wait、Signal 和 Broadcast,這是電腦科學中條件變數的通用方法名。比如,C 語言中對應的方法名是 pthread_cond_wait、pthread_cond_signal 和 pthread_cond_broadcast。
知道了 Cond 提供的三個方法後,我們再透過一個百米賽跑開始時的例子,來學習下 Cond 的使用方法。10 個運動員進入賽場之後需要先做拉伸活動活動筋骨,向觀眾和粉絲招手致敬,在自己的賽道上做好準備;等所有的運動員都準備好之後,裁判員才會打響發令槍。
每個運動員做好準備之後,將 ready 加一,表明自己做好準備了,同時呼叫 Broadcast 方法通知裁判員。因為裁判員只有一個,所以這裡可以直接替換成 Signal 方法呼叫。呼叫 Broadcast 方法的時候,我們並沒有請求 c.L 鎖,只是在更改等待變數的時候才使用到了鎖。
裁判員會等待運動員都準備好(第 22 行)。雖然每個運動員準備好之後都喚醒了裁判員,但是裁判員被喚醒之後需要檢查等待條件是否滿足(運動員都準備好了)。可以看到,裁判員被喚醒之後一定要檢查等待條件,如果條件不滿足還是要繼續等待。
func main() {
c := sync.NewCond(&sync.Mutex{})
var ready int
for i := 0; i < 10; i++ {
go func(i int) {
time.Sleep(time.Duration(rand.Int63n(10)) * time.Second)
// 加鎖更改等待條件
c.L.Lock()
ready++
c.L.Unlock()
log.Printf("運動員#%d 已準備就緒\n", i)
// 廣播喚醒所有的等待者
c.Broadcast()
}(i)
}
c.L.Lock()
for ready != 10 {
c.Wait()
log.Println("裁判員被喚醒一次")
}
c.L.Unlock()
//所有的運動員是否就緒
log.Println("所有運動員都準備就緒。比賽開始,3,2,1, ......")
}
你看,Cond 的使用其實沒那麼簡單。它的複雜在於:一,這段程式碼有時候需要加鎖,有時候可以不加;二,Wait 喚醒後需要檢查條件;三,條件變數的更改,其實是需要原子操作或者互斥鎖保護的。所以,有的開發者會認為,Cond 是唯一難以掌握的 Go 併發原語。
我們繼續看看 Cond 的實作原理。
Cond 的實作原理
其實,Cond 的實作非常簡單,或者說複雜的邏輯已經被 Locker 或者 runtime 的等待佇列實作了。我們直接看看 Cond 的原始碼吧。
type Cond struct {
noCopy noCopy
// 當觀察或者修改等待條件的時候需要加鎖
L Locker
// 等待佇列
notify notifyList
checker copyChecker
}
func NewCond(l Locker) *Cond {
return &Cond{L: l}
}
func (c *Cond) Wait() {
c.checker.check()
// 增加到等待佇列中
t := runtime_notifyListAdd(&c.notify)
c.L.Unlock()
// 阻塞休眠直到被喚醒
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
}
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
這部分原始碼確實很簡單,我來帶你學習下其中比較關鍵的邏輯。
runtime_notifyListXXX 是執行時實作的方法,實作了一個等待 / 通知的佇列。如果你想深入學習這部分,可以再去看看 runtime/sema.go 程式碼中。
copyChecker 是一個輔助結構,可以在執行時檢查 Cond 是否被複制使用。
Signal 和 Broadcast 只涉及到 notifyList 資料結構,不涉及到鎖。
Wait 把呼叫者加入到等待佇列時會釋放鎖,在被喚醒之後還會請求鎖。在阻塞休眠期間,呼叫者是不持有鎖的,這樣能讓其他 goroutine 有機會檢查或者更新等待變數。
我們繼續看看使用 Cond 常見的兩個錯誤,一個是呼叫 Wait 的時候沒有加鎖,另一個是沒有檢查條件是否滿足程式就繼續執行了。
使用 Cond 的 2 個常見錯誤
我們先看 Cond 最常見的使用錯誤,也就是呼叫 Wait 的時候沒有加鎖。
以前面百米賽跑的程式為例,在呼叫 cond.Wait 時,把前後的 Lock/Unlock 註釋掉,如下面的程式碼中的第 20 行和第 25 行:
func main() {
c := sync.NewCond(&sync.Mutex{})
var ready int
for i := 0; i < 10; i++ {
go func(i int) {
time.Sleep(time.Duration(rand.Int63n(10)) * time.Second)
// 加鎖更改等待條件
c.L.Lock()
ready++
c.L.Unlock()
log.Printf("運動員#%d 已準備就緒\n", i)
// 廣播喚醒所有的等待者
c.Broadcast()
}(i)
}
// c.L.Lock()
for ready != 10 {
c.Wait()
log.Println("裁判員被喚醒一次")
}
// c.L.Unlock()
//所有的運動員是否就緒
log.Println("所有運動員都準備就緒。比賽開始,3,2,1, ......")
}
再執行程式,就會報釋放未加鎖的 panic:
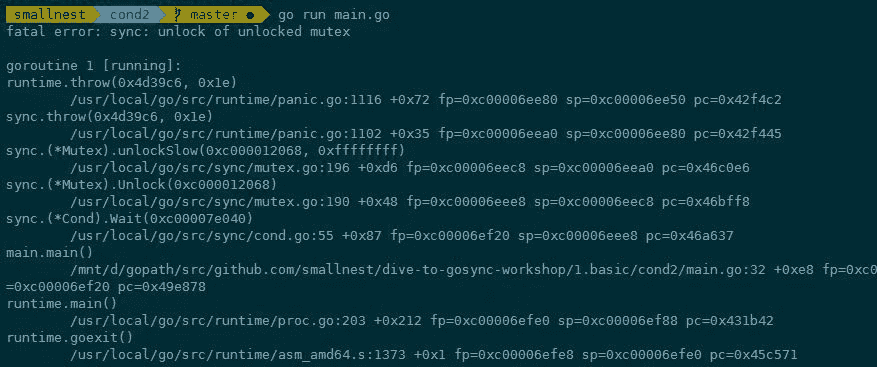
出現這個問題的原因在於,cond.Wait 方法的實作是,把當前呼叫者加入到 notify 佇列之中後會釋放鎖(如果不釋放鎖,其他 Wait 的呼叫者就沒有機會加入到 notify 佇列中了),然後一直等待;等呼叫者被喚醒之後,又會去爭搶這把鎖。如果呼叫 Wait 之前不加鎖的話,就有可能 Unlock 一個未加鎖的 Locker。所以切記,呼叫 cond.Wait 方法之前一定要加鎖。
使用 Cond 的另一個常見錯誤是,只呼叫了一次 Wait,沒有檢查等待條件是否滿足,結果條件沒滿足,程式就繼續執行了。出現這個問題的原因在於,誤以為 Cond 的使用,就像 WaitGroup 那樣呼叫一下 Wait 方法等待那麼簡單。比如下面的程式碼中,把第 21 行和第 24 行註釋掉:
func main() {
c := sync.NewCond(&sync.Mutex{})
var ready int
for i := 0; i < 10; i++ {
go func(i int) {
time.Sleep(time.Duration(rand.Int63n(10)) * time.Second)
// 加鎖更改等待條件
c.L.Lock()
ready++
c.L.Unlock()
log.Printf("運動員#%d 已準備就緒\n", i)
// 廣播喚醒所有的等待者
c.Broadcast()
}(i)
}
c.L.Lock()
// for ready != 10 {
c.Wait()
log.Println("裁判員被喚醒一次")
// }
c.L.Unlock()
//所有的運動員是否就緒
log.Println("所有運動員都準備就緒。比賽開始,3,2,1, ......")
}
執行這個程式,你會發現,可能只有幾個運動員準備好之後程式就執行完了,而不是我們期望的所有運動員都準備好才進行下一步。原因在於,每一個運動員準備好之後都會喚醒所有的等待者,也就是這裡的裁判員,比如第一個運動員準備好後就喚醒了裁判員,結果這個裁判員傻傻地沒做任何檢查,以為所有的運動員都準備好了,就繼續執行了。
所以,我們一定要記住,waiter goroutine 被喚醒不等於等待條件被滿足,只是有 goroutine 把它喚醒了而已,等待條件有可能已經滿足了,也有可能不滿足,我們需要進一步檢查。你也可以理解為,等待者被喚醒,只是得到了一次檢查的機會而已。
到這裡,我們小結下。如果你想在使用 Cond 的時候避免犯錯,只要時刻記住呼叫 cond.Wait 方法之前一定要加鎖,以及 waiter goroutine 被喚醒不等於等待條件被滿足這兩個知識點。
知名專案中 Cond 的使用
Cond 在實際專案中被使用的機會比較少,原因總結起來有兩個。
第一,同樣的場景我們會使用其他的併發原語來替代。Go 特有的 Channel 型別,有一個應用很廣泛的模式就是通知機制,這個模式使用起來也特別簡單。所以很多情況下,我們會使用 Channel 而不是 Cond 實作 wait/notify 機制。
第二,對於簡單的 wait/notify 場景,比如等待一組 goroutine 完成之後繼續執行餘下的程式碼,我們會使用 WaitGroup 來實作。因為 WaitGroup 的使用方法更簡單,而且不容易出錯。比如,上面百米賽跑的問題,就可以很方便地使用 WaitGroup 來實作。
所以,我在這一講開頭提到,Cond 的使用場景很少。先前的標準庫內部有幾個地方使用了 Cond,比如 io/pipe.go 等,後來都被其他的併發原語(比如 Channel)替換了,sync.Cond 的路越走越窄。但是,還是有一批忠實的“粉絲”堅持在使用 Cond,原因在於 Cond 有三點特性是 Channel 無法替代的:
- Cond 和一個 Locker 關聯,可以利用這個 Locker 對相關的依賴條件更改提供保護。
- Cond 可以同時支援 Signal 和 Broadcast 方法,而 Channel 只能同時支援其中一種。
- Cond 的 Broadcast 方法可以被重複呼叫。等待條件再次變成不滿足的狀態後,我們又可以呼叫 Broadcast 再次喚醒等待的 goroutine。這也是 Channel 不能支援的,Channel 被 close 掉了之後不支援再 open。
開源專案中使用 sync.Cond 的程式碼少之又少,包括標準庫原先一些使用 Cond 的程式碼也改成使用 Channel 實作了,所以別說找 Cond 相關的使用 Bug 了,想找到的一個使用的例子都不容易,我找了 Kubernetes 中的一個例子,我們一起看看它是如何使用 Cond 的。
Kubernetes 專案中定義了優先順序佇列 PriorityQueue 這樣一個資料結構,用來實作 Pod 的呼叫。它內部有三個 Pod 的佇列,即 activeQ、podBackoffQ 和 unschedulableQ,其中 activeQ 就是用來排程的活躍佇列(heap)。
Pop 方法呼叫的時候,如果這個佇列為空,並且這個佇列沒有 Close 的話,會呼叫 Cond 的 Wait 方法等待。
你可以看到,呼叫 Wait 方法的時候,呼叫者是持有鎖的,並且被喚醒的時候檢查等待條件(佇列是否為空)。
// 從佇列中取出一個元素
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
for p.activeQ.Len() == 0 { // 如果佇列為空
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
p.cond.Wait() // 等待,直到被喚醒
}
......
return pInfo, err
}
當 activeQ 增加新的元素時,會呼叫條件變數的 Boradcast 方法,通知被 Pop 阻塞的呼叫者。
// 增加元素到佇列中
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
pInfo := p.newQueuedPodInfo(pod)
if err := p.activeQ.Add(pInfo); err != nil {//增加元素到佇列中
klog.Errorf("Error adding pod %v to the scheduling queue: %v", nsNameForPod(pod), err)
return err
}
......
p.cond.Broadcast() //通知其它等待的goroutine,佇列中有元素了
return nil
}
這個優先順序佇列被關閉的時候,也會呼叫 Broadcast 方法,避免被 Pop 阻塞的呼叫者永遠 hang 住。
func (p *PriorityQueue) Close() {
p.lock.Lock()
defer p.lock.Unlock()
close(p.stop)
p.closed = true
p.cond.Broadcast() //關閉時通知等待的goroutine,避免它們永遠等待
}
你可以思考一下,這裡為什麼使用 Cond 這個併發原語,能不能換成 Channel 實作呢?
總結
好了,我們來做個總結。
Cond 是為等待 / 通知場景下的併發問題提供支援的。它提供了條件變數的三個基本方法 Signal、Broadcast 和 Wait,為併發的 goroutine 提供等待 / 通知機制。
在實踐中,處理等待 / 通知的場景時,我們常常會使用 Channel 替換 Cond,因為 Channel 型別使用起來更簡潔,而且不容易出錯。但是對於需要重複呼叫 Broadcast 的場景,比如上面 Kubernetes 的例子,每次往佇列中成功增加了元素後就需要呼叫 Broadcast 通知所有的等待者,使用 Cond 就再合適不過了。
使用 Cond 之所以容易出錯,就是 Wait 呼叫需要加鎖,以及被喚醒後一定要檢查條件是否真的已經滿足。你需要牢記這兩點。
雖然我們講到的百米賽跑的例子,也可以透過 WaitGroup 來實作,但是本質上 WaitGroup 和 Cond 是有區別的:WaitGroup 是主 goroutine 等待確定數量的子 goroutine 完成任務;而 Cond 是等待某個條件滿足,這個條件的修改可以被任意多的 goroutine 更新,而且 Cond 的 Wait 不關心也不知道其他 goroutine 的數量,只關心等待條件。而且 Cond 還有單個通知的機制,也就是 Signal 方法。
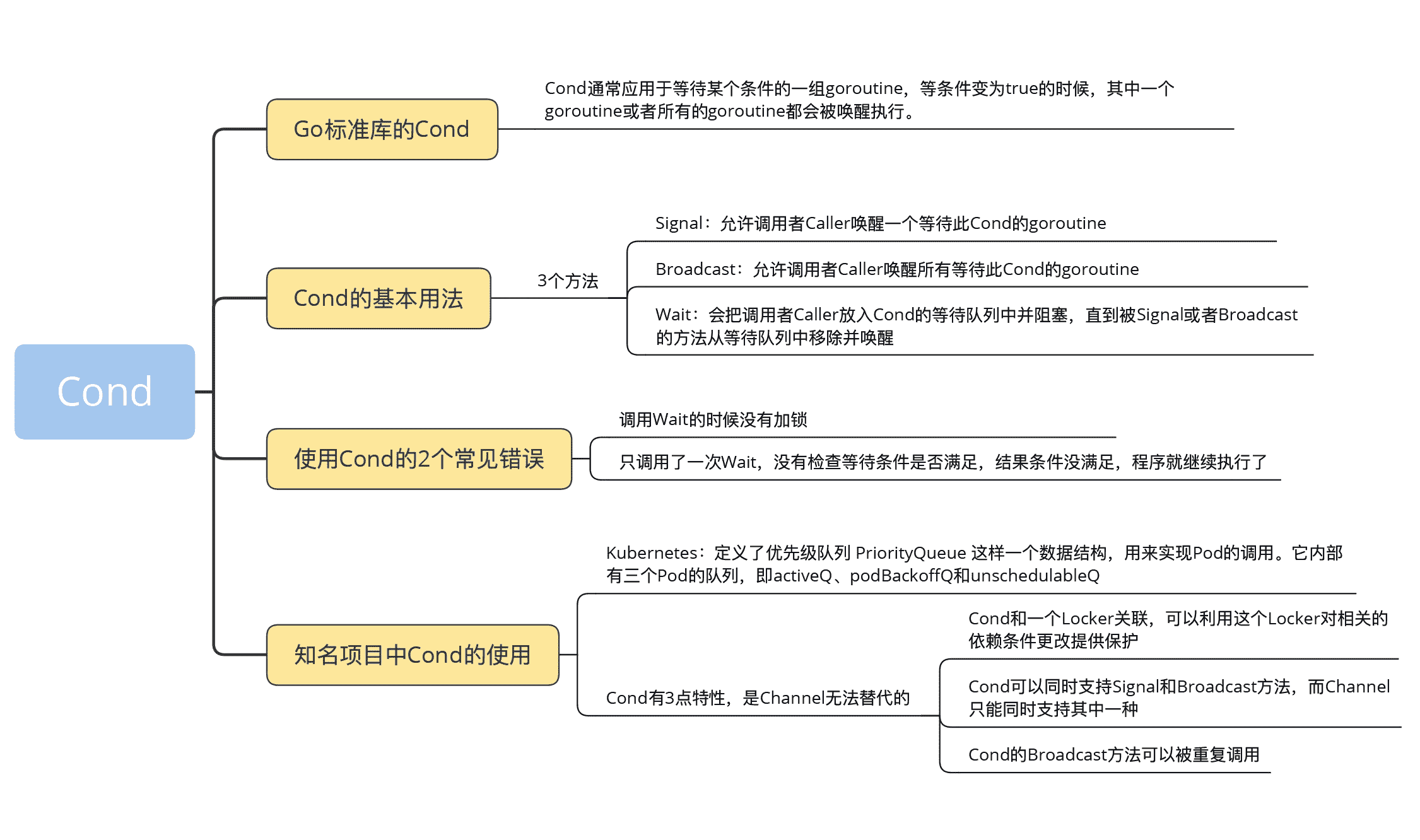
思考題
- 一個 Cond 的 waiter 被喚醒的時候,為什麼需要再檢查等待條件,而不是喚醒後進行下一步?
- 你能否利用 Cond 實作一個容量有限的 queue?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
08|Once:一個簡約而不簡單的併發原語
你好,我是鳥窩。
本章導讀
sync.Once 執行一次模型
多個 goroutine 同時呼叫 once.Do(init)
│
▼
┌──────────────┐
│ sync.Once │
└──────┬───────┘
│
┌───────┴──────────────┐
▼ ▼
第一次進入 後續進入
執行 init() 直接略過
│ │
└──────────┬───────────┘
▼
全部返回(初始化只做一次)
這一講我來講一個簡單的併發原語:Once。為什麼要學習 Once 呢?我先給你答案:Once 可以用來執行且僅僅執行一次動作,常常用於單例物件的初始化場景。
那這節課,我們就從對單例物件進行初始化這件事兒說起。
初始化單例資源有很多方法,比如定義 package 級別的變數,這樣程式在啟動的時候就可以初始化:
package abc
import time
var startTime = time.Now()
或者在 init 函式中進行初始化:
package abc
var startTime time.Time
func init() {
startTime = time.Now()
}
又或者在 main 函式開始執行的時候,執行一個初始化的函式:
package abc
var startTime time.Tim
func initApp() {
startTime = time.Now()
}
func main() {
initApp()
}
這三種方法都是執行緒安全的,並且後兩種方法還可以根據傳入的引數實作定製化的初始化操作。
但是很多時候我們是要延遲進行初始化的,所以有時候單例資源的初始化,我們會使用下面的方法:
package main
import (
"net"
"sync"
"time"
)
// 使用互斥鎖保證執行緒(goroutine)安全
var connMu sync.Mutex
var conn net.Conn
func getConn() net.Conn {
connMu.Lock()
defer connMu.Unlock()
// 返回已建立好的連線
if conn != nil {
return conn
}
// 建立連線
conn, _ = net.DialTimeout("tcp", "baidu.com:80", 10*time.Second)
return conn
}
// 使用連線
func main() {
conn := getConn()
if conn == nil {
panic("conn is nil")
}
}
這種方式雖然實作起來簡單,但是有效能問題。一旦連線建立好,每次請求的時候還是得競爭鎖才能讀取到這個連線,這是比較浪費資源的,因為連線如果建立好之後,其實就不需要鎖的保護了。怎麼辦呢?
這個時候就可以使用這一講要介紹的 Once 併發原語了。接下來我會詳細介紹 Once 的使用、實作和易錯場景。
Once 的使用場景
sync.Once 只暴露了一個方法 Do,你可以多次呼叫 Do 方法,但是隻有第一次呼叫 Do 方法時 f 引數才會執行,這裡的 f 是一個無引數無返回值的函式。
func (o *Once) Do(f func())
因為當且僅當第一次呼叫 Do 方法的時候引數 f 才會執行,即使第二次、第三次、第 n 次呼叫時 f 引數的值不一樣,也不會被執行,比如下面的例子,雖然 f1 和 f2 是不同的函式,但是第二個函式 f2 就不會執行。
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
// 第一個初始化函式
f1 := func() {
fmt.Println("in f1")
}
once.Do(f1) // 打印出 in f1
// 第二個初始化函式
f2 := func() {
fmt.Println("in f2")
}
once.Do(f2) // 無輸出
}
因為這裡的 f 引數是一個無引數無返回的函式,所以你可能會透過閉包的方式引用外面的引數,比如:
var addr = "baidu.com"
var conn net.Conn
var err error
once.Do(func() {
conn, err = net.Dial("tcp", addr)
})
而且在實際的使用中,絕大多數情況下,你會使用閉包的方式去初始化外部的一個資源。
你看,Once 的使用場景很明確,所以,在標準庫內部實作中也常常能看到 Once 的身影。
比如標準庫內部cache的實作上,就使用了 Once 初始化 Cache 資源,包括 defaultDir 值的獲取:
func Default() *Cache { // 獲取預設的Cache
defaultOnce.Do(initDefaultCache) // 初始化cache
return defaultCache
}
// 定義一個全域性的cache變數,使用Once初始化,所以也定義了一個Once變數
var (
defaultOnce sync.Once
defaultCache *Cache
)
func initDefaultCache() { //初始化cache,也就是Once.Do使用的f函式
......
defaultCache = c
}
// 其它一些Once初始化的變數,比如defaultDir
var (
defaultDirOnce sync.Once
defaultDir string
defaultDirErr error
)
還有一些測試的時候初始化測試的資源(export_windows_test):
// 測試window系統呼叫時區相關函式
func ForceAusFromTZIForTesting() {
ResetLocalOnceForTest()
// 使用Once執行一次初始化
localOnce.Do(func() { initLocalFromTZI(&aus) })
}
除此之外,還有保證只呼叫一次 copyenv 的 envOnce,strings 包下的 Replacer,time 包中的測試,Go 拉取庫時的proxy,net.pipe,crc64,Regexp,…,數不勝數。我給你重點介紹一下很值得我們學習的 math/big/sqrt.go 中實作的一個資料結構,它透過 Once 封裝了一個只初始化一次的值:
// 值是3.0或者0.0的一個資料結構
var threeOnce struct {
sync.Once
v *Float
}
// 返回此資料結構的值,如果還沒有初始化為3.0,則初始化
func three() *Float {
threeOnce.Do(func() { // 使用Once初始化
threeOnce.v = NewFloat(3.0)
})
return threeOnce.v
}
它將 sync.Once 和 *Float 封裝成一個物件,提供了只初始化一次的值 v。 你看它的 three 方法的實作,雖然每次都呼叫 threeOnce.Do 方法,但是引數只會被呼叫一次。
當你使用 Once 的時候,你也可以嘗試採用這種結構,將值和 Once 封裝成一個新的資料結構,提供只初始化一次的值。
總結一下 Once 併發原語解決的問題和使用場景:Once 常常用來初始化單例資源,或者併發訪問只需初始化一次的共享資源,或者在測試的時候初始化一次測試資源。
瞭解了 Once 的使用場景,那應該怎樣實作一個 Once 呢?
如何實作一個 Once?
很多人認為實作一個 Once 一樣的併發原語很簡單,只需使用一個 flag 標記是否初始化過即可,最多是用 atomic 原子操作這個 flag,比如下面的實作:
type Once struct {
done uint32
}
func (o *Once) Do(f func()) {
if !atomic.CompareAndSwapUint32(&o.done, 0, 1) {
return
}
f()
}
這確實是一種實作方式,但是,這個實作有一個很大的問題,就是如果引數 f 執行很慢的話,後續呼叫 Do 方法的 goroutine 雖然看到 done 已經設定為執行過了,但是獲取某些初始化資源的時候可能會得到空的資源,因為 f 還沒有執行完。
所以,一個正確的 Once 實作要使用一個互斥鎖,這樣初始化的時候如果有併發的 goroutine,就會進入doSlow 方法。互斥鎖的機制保證只有一個 goroutine 進行初始化,同時利用雙檢查的機制(double-checking),再次判斷 o.done 是否為 0,如果為 0,則是第一次執行,執行完畢後,就將 o.done 設定為 1,然後釋放鎖。
即使此時有多個 goroutine 同時進入了 doSlow 方法,因為雙檢查的機制,後續的 goroutine 會看到 o.done 的值為 1,也不會再次執行 f。
這樣既保證了併發的 goroutine 會等待 f 完成,而且還不會多次執行 f。
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
// 雙檢查
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
好了,到這裡我們就瞭解了 Once 的使用場景,很明確,同時呢,也感受到 Once 的實作也是相對簡單的。在實踐中,其實很少會出現錯誤使用 Once 的情況,但是就像墨菲定律說的,凡是可能出錯的事就一定會出錯。使用 Once 也有可能出現兩種錯誤場景,儘管非常罕見。我這裡提前講給你,咱打個預防針。
使用 Once 可能出現的 2 種錯誤
第一種錯誤:死鎖
你已經知道了 Do 方法會執行一次 f,但是如果 f 中再次呼叫這個 Once 的 Do 方法的話,就會導致死鎖的情況出現。這還不是無限遞迴的情況,而是的的確確的 Lock 的遞迴呼叫導致的死鎖。
func main() {
var once sync.Once
once.Do(func() {
once.Do(func() {
fmt.Println("初始化")
})
})
}
當然,想要避免這種情況的出現,就不要在 f 引數中呼叫當前的這個 Once,不管是直接的還是間接的。
第二種錯誤:未初始化
如果 f 方法執行的時候 panic,或者 f 執行初始化資源的時候失敗了,這個時候,Once 還是會認為初次執行已經成功了,即使再次呼叫 Do 方法,也不會再次執行 f。
比如下面的例子,由於一些防火牆的原因,googleConn 並沒有被正確的初始化,後面如果想當然認為既然執行了 Do 方法 googleConn 就已經初始化的話,會丟擲空指標的錯誤:
func main() {
var once sync.Once
var googleConn net.Conn // 到Google網站的一個連線
once.Do(func() {
// 建立到google.com的連線,有可能因為網路的原因,googleConn並沒有建立成功,此時它的值為nil
googleConn, _ = net.Dial("tcp", "google.com:80")
})
// 傳送http請求
googleConn.Write([]byte("GET / HTTP/1.1\r\nHost: google.com\r\n Accept: */*\r\n\r\n"))
io.Copy(os.Stdout, googleConn)
}
既然執行過 Once.Do 方法也可能因為函式執行失敗的原因未初始化資源,並且以後也沒機會再次初始化資源,那麼這種初始化未完成的問題該怎麼解決呢?
這裡我來告訴你一招獨家秘笈,我們可以自己實作一個類似 Once 的併發原語,既可以返回當前呼叫 Do 方法是否正確完成,還可以在初始化失敗後呼叫 Do 方法再次嘗試初始化,直到初始化成功才不再初始化了。
// 一個功能更加強大的Once
type Once struct {
m sync.Mutex
done uint32
}
// 傳入的函式f有返回值error,如果初始化失敗,需要返回失敗的error
// Do方法會把這個error返回給呼叫者
func (o *Once) Do(f func() error) error {
if atomic.LoadUint32(&o.done) == 1 { //fast path
return nil
}
return o.slowDo(f)
}
// 如果還沒有初始化
func (o *Once) slowDo(f func() error) error {
o.m.Lock()
defer o.m.Unlock()
var err error
if o.done == 0 { // 雙檢查,還沒有初始化
err = f()
if err == nil { // 初始化成功才將標記置為已初始化
atomic.StoreUint32(&o.done, 1)
}
}
return err
}
我們所做的改變就是 Do 方法和引數 f 函式都會返回 error,如果 f 執行失敗,會把這個錯誤資訊返回。
對 slowDo 方法也做了調整,如果 f 呼叫失敗,我們不會更改 done 欄位的值,這樣後續 degoroutine 還會繼續呼叫 f。如果 f 執行成功,才會修改 done 的值為 1。
可以說,真是一頓操作猛如虎,我們使用 Once 有點得心應手的感覺了。等等,還有個問題,我們怎麼查詢是否初始化過呢?
目前的 Once 實作可以保證你呼叫任意次數的 once.Do 方法,它只會執行這個方法一次。但是,有時候我們需要打一個標記。如果初始化後我們就去執行其它的操作,標準庫的 Once 並不會告訴你是否初始化完成了,只是讓你放心大膽地去執行 Do 方法,所以,你還需要一個輔助變數,自己去檢查是否初始化過了,比如透過下面的程式碼中的 inited 欄位:
type AnimalStore struct {once sync.Once;inited uint32}
func (a *AnimalStore) Init() // 可以被併發呼叫
a.once.Do(func() {
longOperationSetupDbOpenFilesQueuesEtc()
atomic.StoreUint32(&a.inited, 1)
})
}
func (a *AnimalStore) CountOfCats() (int, error) { // 另外一個goroutine
if atomic.LoadUint32(&a.inited) == 0 { // 初始化後才會執行真正的業務邏輯
return 0, NotYetInitedError
}
//Real operation
}
當然,透過這段程式碼,我們可以解決這類問題,但是,如果官方的 Once 型別有 Done 這樣一個方法的話,我們就可以直接使用了。這是有人在 Go 程式碼庫中提出的一個 issue(#41690)。對於這類問題,一般都會被建議採用其它型別,或者自己去擴充套件。我們可以嘗試擴充套件這個併發原語:
// Once 是一個擴充套件的sync.Once型別,提供了一個Done方法
type Once struct {
sync.Once
}
// Done 返回此Once是否執行過
// 如果執行過則返回true
// 如果沒有執行過或者正在執行,返回false
func (o *Once) Done() bool {
return atomic.LoadUint32((*uint32)(unsafe.Pointer(&o.Once))) == 1
}
func main() {
var flag Once
fmt.Println(flag.Done()) //false
flag.Do(func() {
time.Sleep(time.Second)
})
fmt.Println(flag.Done()) //true
}
好了,到這裡關於併發原語 Once 的內容我講得就差不多了。最後呢,和你分享一個 Once 的踩坑案例。
其實啊,使用 Once 真的不容易犯錯,想犯錯都很困難,因為很少有人會傻傻地在初始化函式 f 中遞迴呼叫 f,這種死鎖的現象幾乎不會發生。另外如果函式初始化不成功,我們一般會 panic,或者在使用的時候做檢查,會及早發現這個問題,在初始化函式中加強程式碼。
所以檢視大部分的 Go 專案,幾乎找不到 Once 的錯誤使用場景,不過我還是發現了一個。這個 issue 先從另外一個需求 (go#25955) 談起。
Once 的踩坑案例
go#25955 有網友提出一個需求,希望 Once 提供一個 Reset 方法,能夠將 Once 重置為初始化的狀態。比如下面的例子,St 透過兩個 Once 控制它的 Open/Close 狀態。但是在 Close 之後再呼叫 Open 的話,不會再執行 init 函式,因為 Once 只會執行一次初始化函式。
type St struct {
openOnce *sync.Once
closeOnce *sync.Once
}
func(st *St) Open(){
st.openOnce.Do(func() { ... }) // init
...
}
func(st *St) Close(){
st.closeOnce.Do(func() { ... }) // deinit
...
}
所以提交這個 Issue 的開發者希望 Once 增加一個 Reset 方法,Reset 之後再呼叫 once.Do 就又可以初始化了。
Go 的核心開發者 Ian Lance Taylor 給他了一個簡單的解決方案。在這個例子中,只使用一個 ponce *sync.Once 做初始化,Reset 的時候給 ponce 這個變數賦值一個新的 Once 例項即可 (ponce = new(sync.Once))。Once 的本意就是執行一次,所以 Reset 破壞了這個併發原語的本意。
這個解決方案一點都沒問題,可以很好地解決這位開發者的需求。Docker 較早的版本(1.11.2)中使用了它們的一個網路庫 libnetwork,這個網路庫在使用 Once 的時候就使用 Ian Lance Taylor 介紹的方法,但是不幸的是,它的 Reset 方法中又改變了 Once 指標的值,導致程式 panic 了。原始邏輯比較複雜,一個簡化版可重現的程式碼如下:
package main
import (
"fmt"
"sync"
"time"
)
// 一個組合的併發原語
type MuOnce struct {
sync.RWMutex
sync.Once
mtime time.Time
vals []string
}
// 相當於reset方法,會將m.Once重新複製一個Once
func (m *MuOnce) refresh() {
m.Lock()
defer m.Unlock()
m.Once = sync.Once{}
m.mtime = time.Now()
m.vals = []string{m.mtime.String()}
}
// 獲取某個初始化的值,如果超過某個時間,會reset Once
func (m *MuOnce) strings() []string {
now := time.Now()
m.RLock()
if now.After(m.mtime) {
defer m.Do(m.refresh) // 使用refresh函式重新初始化
}
vals := m.vals
m.RUnlock()
return vals
}
func main() {
fmt.Println("Hello, playground")
m := new(MuOnce)
fmt.Println(m.strings())
fmt.Println(m.strings())
}
如果你執行這段程式碼就會 panic:
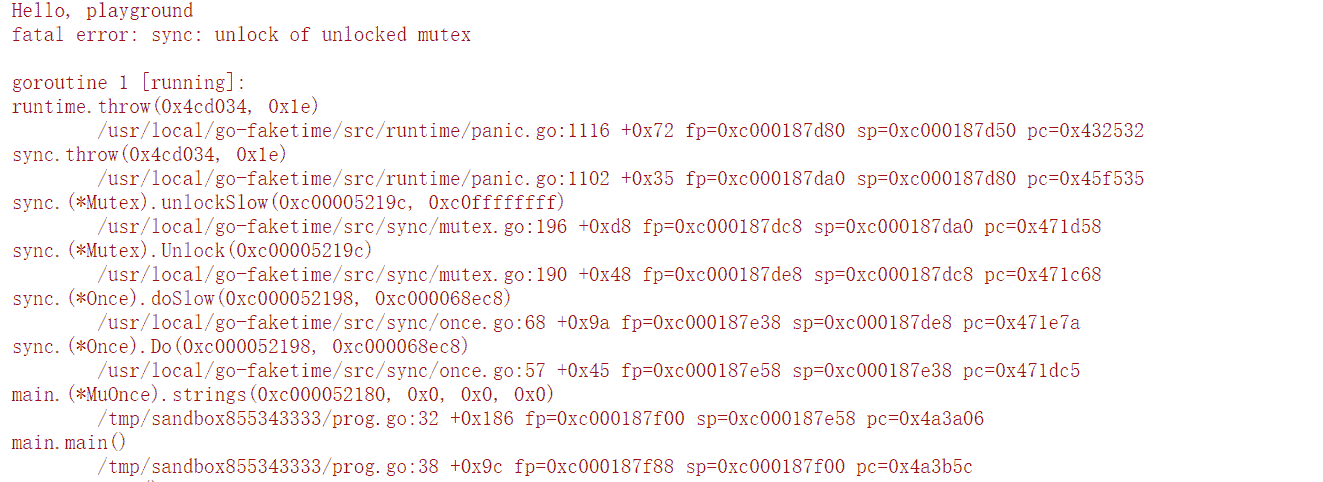
原因在於第 31 行執行 m.Once.Do 方法的時候,使用的是 m.Once 的指標,然後呼叫 m.refresh,在執行 m.refresh 的時候 Once 內部的 Mutex 首先會加鎖(可以再翻看一下這一講的 Once 的實作原理), 但是,在 refresh 中更改了 Once 指標的值之後,結果在執行完 refresh 釋放鎖的時候,釋放的是一個剛初始化未加鎖的 Mutex,所以就 panic 了。
如果你還不太明白,我再給你簡化成一個更簡單的例子:
package main
import (
"sync"
)
type Once struct {
m sync.Mutex
}
func (o *Once) doSlow() {
o.m.Lock()
defer o.m.Unlock()
// 這裡更新的o指標的值!!!!!!!, 會導致上一行Unlock出錯
*o = Once{}
}
func main() {
var once Once
once.doSlow()
}
doSlow 方法就演示了這個錯誤。Ian Lance Taylor 介紹的 Reset 方法沒有錯誤,但是你在使用的時候千萬別再初始化函式中 Reset 這個 Once,否則勢必會導致 Unlock 一個未加鎖的 Mutex 的錯誤。
總的來說,這還是對 Once 的實作機制不熟悉,又進行復雜使用導致的錯誤。不過最新版的 libnetwork 相關的地方已經去掉了 Once 的使用了。所以,我帶你一起來看這個案例,主要目的還是想鞏固一下我們對 Once 的理解。
總結
今天我們一起學習了 Once,我們常常使用它來實作單例模式。
單例是 23 種設計模式之一,也是常常引起爭議的設計模式之一,甚至有人把它歸為反模式。為什麼說它是反模式呢,我拿標準庫中的單例模式給你介紹下。
因為 Go 沒有 immutable 型別,導致我們宣告的全域性變數都是可變的,別的地方或者第三方庫可以隨意更改這些變數。比如 package io 中定義了幾個全域性變數,比如 io.EOF:
var EOF = errors.New("EOF")
因為它是一個 package 級別的變數,我們可以在程式中偷偷把它改了,這會導致一些依賴 io.EOF 這個變數做判斷的程式碼出錯。
io.EOF = errors.New("我們自己定義的EOF")
從我個人的角度來說,一些單例(全域性變數)的確很方便,比如 Buffer 池或者連線池,所以有時候我們也不要談虎色變。雖然有人把單例模式稱之為反模式,但畢竟只能代表一部分開發者的觀點,否則也不會把它列在 23 種設計模式中了。
如果你真的擔心這個 package 級別的變數被人修改,你可以不把它們暴露出來,而是提供一個只讀的 GetXXX 的方法,這樣別人就不會進行修改了。
而且,Once 不只應用於單例模式,一些變數在也需要在使用的時候做延遲初始化,所以也是可以使用 Once 處理這些場景的。
總而言之,Once 的應用場景還是很廣泛的。一旦你遇到只需要初始化一次的場景,首先想到的就應該是 Once 併發原語。
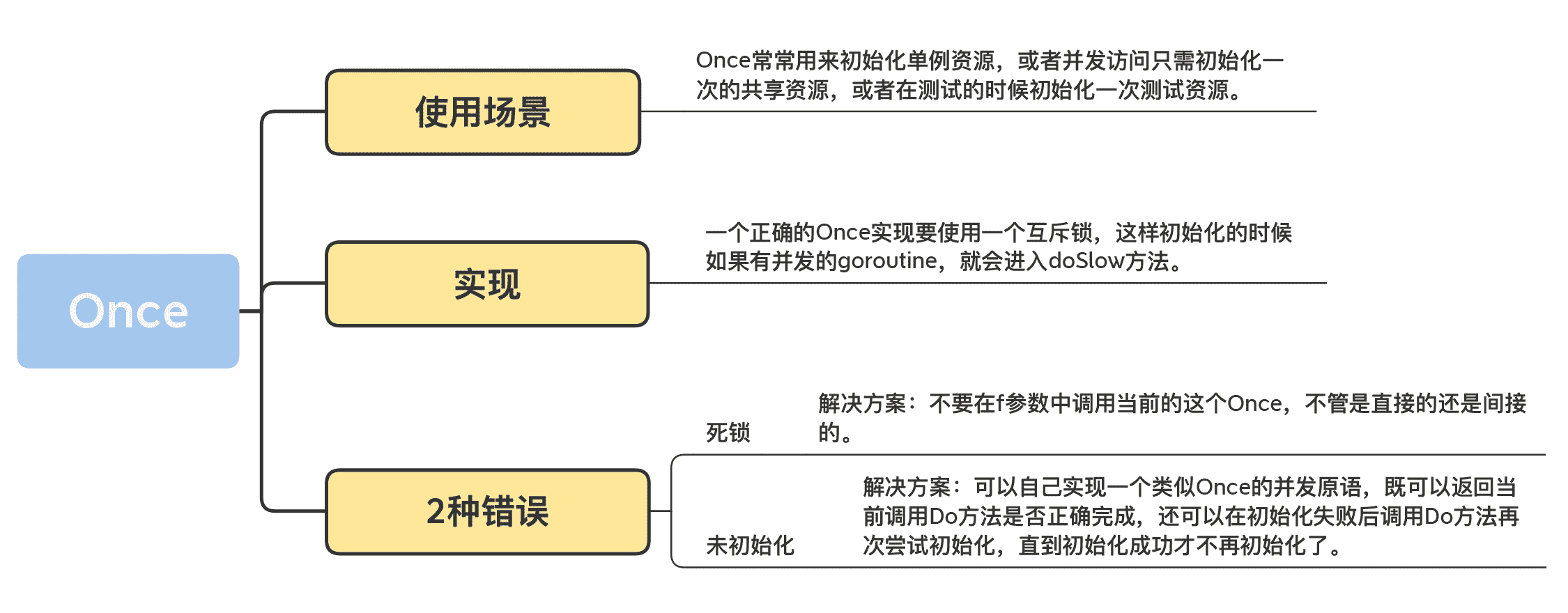
思考題
- 我已經分析了幾個併發原語的實作,你可能注意到總是有些 slowXXXX 的方法,從 XXXX 方法中單獨抽取出來,你明白為什麼要這麼做嗎,有什麼好處?
- Once 在第一次使用之後,還能複製給其它變數使用嗎?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
09|map:如何實作執行緒安全的map 型別?
你好,我是鳥窩。
本章導讀
併發 map 安全存取的常見做法
┌───────────────────────┐
│ 共享 map(非執行緒安全) │
└──────────┬────────────┘
│ 需要保護
┌──────────────┼──────────────┐
▼ ▼ ▼
Mutex + map RWMutex + map sync.Map
(簡單通用) (讀多寫少) (特定情境優勢)
雜湊表(Hash Table)這個資料結構,我們已經非常熟悉了。它實作的就是 key-value 之間的對映關係,主要提供的方法包括 Add、Lookup、Delete 等。因為這種資料結構是一個基礎的資料結構,每個 key 都會有一個唯一的索引值,透過索引可以很快地找到對應的值,所以使用雜湊表進行資料的插入和讀取都是很快的。Go 語言本身就內建了這樣一個資料結構,也就是 map 資料型別。
今天呢,我們就先來學習 Go 語言內建的這個 map 型別,瞭解它的基本使用方法和使用陷阱,然後再學習如何實作執行緒安全的 map 型別,最後我還會給你介紹 Go 標準庫中執行緒安全的 sync.Map 型別。學完了這節課,你可以學會幾種可以併發訪問的 map 型別。
map 的基本使用方法
Go 內建的 map 型別如下:
map[K]V
其中,key 型別的 K 必須是可比較的(comparable),也就是可以透過 == 和 != 運算子進行比較;value 的值和型別無所謂,可以是任意的型別,或者為 nil。
在 Go 語言中,bool、整數、浮點數、複數、字串、指標、Channel、介面都是可比較的,包含可比較元素的 struct 和陣列,這倆也是可比較的,而 slice、map、函式值都是不可比較的。
那麼,上面這些可比較的資料型別都可以作為 map 的 key 嗎?顯然不是。通常情況下,我們會選擇內建的基本型別,比如整數、字串做 key 的型別,因為這樣最方便。
這裡有一點需要注意,如果使用 struct 型別做 key 其實是有坑的,因為如果 struct 的某個欄位值修改了,查詢 map 時無法獲取它 add 進去的值,如下面的例子:
type mapKey struct {
key int
}
func main() {
var m = make(map[mapKey]string)
var key = mapKey{10}
m[key] = "hello"
fmt.Printf("m[key]=%s\n", m[key])
// 修改key的欄位的值後再次查詢map,無法獲取剛才add進去的值
key.key = 100
fmt.Printf("再次查詢m[key]=%s\n", m[key])
}
那該怎麼辦呢?如果要使用 struct 作為 key,我們要保證 struct 物件在邏輯上是不可變的,這樣才會保證 map 的邏輯沒有問題。
以上就是選取 key 型別的注意點了。接下來,我們看一下使用 map[key]函式時需要注意的一個知識點。在 Go 中,map[key]函式返回結果可以是一個值,也可以是兩個值,這是容易讓人迷惑的地方。原因在於,如果獲取一個不存在的 key 對應的值時,會返回零值。為了區分真正的零值和 key 不存在這兩種情況,可以根據第二個返回值來區分,如下面的程式碼的第 6 行、第 7 行:
func main() {
var m = make(map[string]int)
m["a"] = 0
fmt.Printf("a=%d; b=%d\n", m["a"], m["b"])
av, aexisted := m["a"]
bv, bexisted := m["b"]
fmt.Printf("a=%d, existed: %t; b=%d, existed: %t\n", av, aexisted, bv, bexisted)
}
map 是無序的,所以當遍歷一個 map 物件的時候,迭代的元素的順序是不確定的,無法保證兩次遍歷的順序是一樣的,也不能保證和插入的順序一致。那怎麼辦呢?如果我們想要按照 key 的順序獲取 map 的值,需要先取出所有的 key 進行排序,然後按照這個排序的 key 依次獲取對應的值。而如果我們想要保證元素有序,比如按照元素插入的順序進行遍歷,可以使用輔助的資料結構,比如orderedmap,來記錄插入順序。
好了,總結下關於 map 我們需要掌握的內容:map 的型別是 map[key],key 型別的 K 必須是可比較的,通常情況下,我們會選擇內建的基本型別,比如整數、字串做 key 的型別。如果要使用 struct 作為 key,我們要保證 struct 物件在邏輯上是不可變的。在 Go 中,map[key]函式返回結果可以是一個值,也可以是兩個值。map 是無序的,如果我們想要保證遍歷 map 時元素有序,可以使用輔助的資料結構,比如orderedmap。
使用 map 的 2 種常見錯誤
那接下來,我們來看使用 map 最常犯的兩個錯誤,就是未初始化和併發讀寫。
常見錯誤一:未初始化
和 slice 或者 Mutex、RWmutex 等 struct 型別不同,map 物件必須在使用之前初始化。如果不初始化就直接賦值的話,會出現 panic 異常,比如下面的例子,m 例項還沒有初始化就直接進行操作會導致 panic(第 3 行):
func main() {
var m map[int]int
m[100] = 100
}
解決辦法就是在第 2 行初始化這個例項(m := make(map[int]int))。
從一個 nil 的 map 物件中獲取值不會 panic,而是會得到零值,所以下面的程式碼不會報錯:
func main() {
var m map[int]int
fmt.Println(m[100])
}
這個例子很簡單,我們可以意識到 map 的初始化問題。但有時候 map 作為一個 struct 欄位的時候,就很容易忘記初始化了。
type Counter struct {
Website string
Start time.Time
PageCounters map[string]int
}
func main() {
var c Counter
c.Website = "baidu.com"
c.PageCounters["/"]++
}
所以,關於初始化這一點,我再強調一下,目前還沒有工具可以檢查,我們只能記住“別忘記初始化”這一條規則。
常見錯誤二:併發讀寫
對於 map 型別,另一個很容易犯的錯誤就是併發訪問問題。這個易錯點,相當令人討厭,如果沒有注意到併發問題,程式在執行的時候就有可能出現併發讀寫導致的 panic。
Go 內建的 map 物件不是執行緒(goroutine)安全的,併發讀寫的時候執行時會有檢查,遇到併發問題就會導致 panic。
我們一起看一個併發訪問 map 例項導致 panic 的例子:
func main() {
var m = make(map[int]int,10) // 初始化一個map
go func() {
for {
m[1] = 1 //設定key
}
}()
go func() {
for {
_ = m[2] //訪問這個map
}
}()
select {}
}
雖然這段程式碼看起來是讀寫 goroutine 各自操作不同的元素,貌似 map 也沒有擴容的問題,但是執行時檢測到同時對 map 物件有併發訪問,就會直接 panic。panic 資訊會告訴我們程式碼中哪一行有讀寫問題,根據這個錯誤資訊你就能快速定位出來是哪一個 map 物件在哪裡出的問題了。
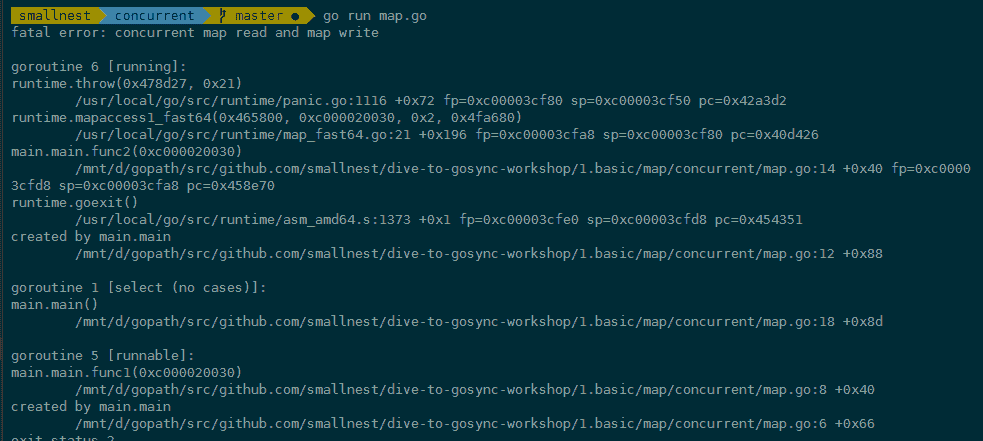
這個錯誤非常常見,是幾乎每個人都會踩到的坑。其實,不只是我們寫程式碼時容易犯這個錯,一些知名的專案中也是屢次出現這個問題,比如 Docker issue 40772,在刪除 map 物件的元素時忘記了加鎖:
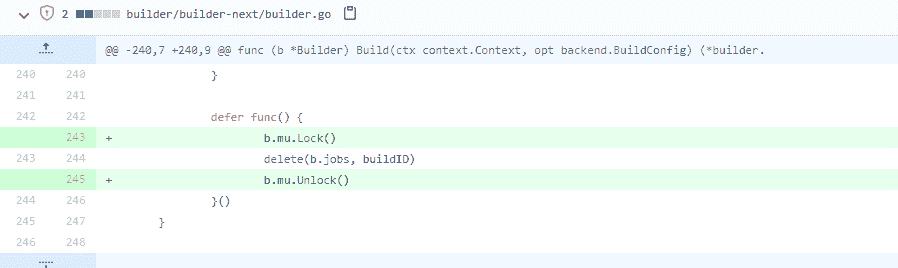
Docker issue 40772,Docker issue 35588、34540、39643 等等,也都有併發讀寫 map 的問題。
除了 Docker 中,Kubernetes 的 issue 84431、72464、68647、64484、48045、45593、37560 等,以及 TiDB 的 issue 14960 和 17494 等,也出現了這個錯誤。
這麼多人都會踩的坑,有啥解決方案嗎?肯定有,那接下來,我們就繼續來看如何解決內建 map 的併發讀寫問題。
如何實作執行緒安全的 map 型別?
避免 map 併發讀寫 panic 的方式之一就是加鎖,考慮到讀寫效能,可以使用讀寫鎖提供效能。
加讀寫鎖:擴充套件 map,支援併發讀寫
比較遺憾的是,目前 Go 還沒有正式釋出泛型特性,我們還不能實作一個通用的支援泛型的加鎖 map。但是,將要釋出的泛型方案已經可以驗證測試了,離釋出也不遠了,也許釋出之後 sync.Map 就支援泛型了。
當然了,如果沒有泛型支援,我們也能解決這個問題。我們可以透過 interface{}來模擬泛型,但還是要涉及介面和具體型別的轉換,比較複雜,還不如將要釋出的泛型方案更直接、效能更好。
這裡我以一個具體的 map 型別為例,來演示利用讀寫鎖實作執行緒安全的 map[int]int 型別:
type RWMap struct { // 一個讀寫鎖保護的執行緒安全的map
sync.RWMutex // 讀寫鎖保護下面的map欄位
m map[int]int
}
// 新建一個RWMap
func NewRWMap(n int) *RWMap {
return &RWMap{
m: make(map[int]int, n),
}
}
func (m *RWMap) Get(k int) (int, bool) { //從map中讀取一個值
m.RLock()
defer m.RUnlock()
v, existed := m.m[k] // 在鎖的保護下從map中讀取
return v, existed
}
func (m *RWMap) Set(k int, v int) { // 設定一個鍵值對
m.Lock() // 鎖保護
defer m.Unlock()
m.m[k] = v
}
func (m *RWMap) Delete(k int) { //刪除一個鍵
m.Lock() // 鎖保護
defer m.Unlock()
delete(m.m, k)
}
func (m *RWMap) Len() int { // map的長度
m.RLock() // 鎖保護
defer m.RUnlock()
return len(m.m)
}
func (m *RWMap) Each(f func(k, v int) bool) { // 遍歷map
m.RLock() //遍歷期間一直持有讀鎖
defer m.RUnlock()
for k, v := range m.m {
if !f(k, v) {
return
}
}
}
正如這段程式碼所示,對 map 物件的操作,無非就是增刪改查和遍歷等幾種常見操作。我們可以把這些操作分為讀和寫兩類,其中,查詢和遍歷可以看做讀操作,增加、修改和刪除可以看做寫操作。如例子所示,我們可以透過讀寫鎖對相應的操作進行保護。
分片加鎖:更高效的併發 map
雖然使用讀寫鎖可以提供執行緒安全的 map,但是在大量併發讀寫的情況下,鎖的競爭會非常激烈。我在第 4 講中提到過,鎖是效能下降的萬惡之源之一。
在併發程式設計中,我們的一條原則就是儘量減少鎖的使用。一些單執行緒單程式的應用(比如 Redis 等),基本上不需要使用鎖去解決併發執行緒訪問的問題,所以可以取得很高的效能。但是對於 Go 開發的應用程式來說,併發是常用的一個特性,在這種情況下,我們能做的就是,儘量減少鎖的粒度和鎖的持有時間。
你可以最佳化業務處理的程式碼,以此來減少鎖的持有時間,比如將序列的操作變成並行的子任務執行。不過,這就是另外的故事了,今天我們還是主要講對同步原語的最佳化,所以這裡我重點講如何減少鎖的粒度。
減少鎖的粒度常用的方法就是分片(Shard),將一把鎖分成幾把鎖,每個鎖控制一個分片。Go 比較知名的分片併發 map 的實作是orcaman/concurrent-map。
它預設採用 32 個分片,GetShard 是一個關鍵的方法,能夠根據 key 計算出分片索引。
var SHARD_COUNT = 32
// 分成SHARD_COUNT個分片的map
type ConcurrentMap []*ConcurrentMapShared
// 透過RWMutex保護的執行緒安全的分片,包含一個map
type ConcurrentMapShared struct {
items map[string]interface{}
sync.RWMutex // Read Write mutex, guards access to internal map.
}
// 建立併發map
func New() ConcurrentMap {
m := make(ConcurrentMap, SHARD_COUNT)
for i := 0; i < SHARD_COUNT; i++ {
m[i] = &ConcurrentMapShared{items: make(map[string]interface{})}
}
return m
}
// 根據key計算分片索引
func (m ConcurrentMap) GetShard(key string) *ConcurrentMapShared {
return m[uint(fnv32(key))%uint(SHARD_COUNT)]
}
增加或者查詢的時候,首先根據分片索引得到分片物件,然後對分片物件加鎖進行操作:
func (m ConcurrentMap) Set(key string, value interface{}) {
// 根據key計算出對應的分片
shard := m.GetShard(key)
shard.Lock() //對這個分片加鎖,執行業務操作
shard.items[key] = value
shard.Unlock()
}
func (m ConcurrentMap) Get(key string) (interface{}, bool) {
// 根據key計算出對應的分片
shard := m.GetShard(key)
shard.RLock()
// 從這個分片讀取key的值
val, ok := shard.items[key]
shard.RUnlock()
return val, ok
}
當然,除了 GetShard 方法,ConcurrentMap 還提供了很多其他的方法。這些方法都是透過計算相應的分片實作的,目的是保證把鎖的粒度限制在分片上。
好了,到這裡我們就學會瞭解決 map 併發 panic 的兩個方法:加鎖和分片。
在我個人使用併發 map 的過程中,加鎖和分片加鎖這兩種方案都比較常用,如果是追求更高的效能,顯然是分片加鎖更好,因為它可以降低鎖的粒度,進而提高訪問此 map 物件的吞吐。如果併發效能要求不是那麼高的場景,簡單加鎖方式更簡單。
接下來,我會繼續給你介紹 sync.Map,這是 Go 官方執行緒安全 map 的標準實作。雖然是官方標準,反而是不常用的,為什麼呢?一句話來說就是 map 要解決的場景很難描述,很多時候在做抉擇時根本就不知道該不該用它。但是呢,確實有一些特定的場景,我們需要用到 sync.Map 來實作,所以還是很有必要學習這個知識點。具體什麼場景呢,我慢慢給你道來。
應對特殊場景的 sync.Map
Go 內建的 map 型別不是執行緒安全的,所以 Go 1.9 中增加了一個執行緒安全的 map,也就是 sync.Map。但是,我們一定要記住,這個 sync.Map 並不是用來替換內建的 map 型別的,它只能被應用在一些特殊的場景裡。
那這些特殊的場景是啥呢?官方的文件中指出,在以下兩個場景中使用 sync.Map,會比使用 map+RWMutex 的方式,效能要好得多:
- 只會增長的快取系統中,一個 key 只寫入一次而被讀很多次;
- 多個 goroutine 為不相交的鍵集讀、寫和重寫鍵值對。
這兩個場景說得都比較籠統,而且,這些場景中還包含了一些特殊的情況。所以,官方建議你針對自己的場景做效能評測,如果確實能夠顯著提高效能,再使用 sync.Map。
這麼來看,我們能用到 sync.Map 的場景確實不多。即使是 sync.Map 的作者 Bryan C. Mills,也很少使用 sync.Map,即便是在使用 sync.Map 的時候,也是需要臨時查詢它的 API,才能清楚記住它的功能。所以,我們可以把 sync.Map 看成一個生產環境中很少使用的同步原語。
sync.Map 的實作
那 sync.Map 是怎麼實作的呢?它是如何解決併發問題提升效能的呢?其實 sync.Map 的實作有幾個最佳化點,這裡先列出來,我們後面慢慢分析。
- 空間換時間。透過冗餘的兩個資料結構(只讀的 read 欄位、可寫的 dirty),來減少加鎖對效能的影響。對只讀欄位(read)的操作不需要加鎖。
- 優先從 read 欄位讀取、更新、刪除,因為對 read 欄位的讀取不需要鎖。
- 動態調整。miss 次數多了之後,將 dirty 資料提升為 read,避免總是從 dirty 中加鎖讀取。
- double-checking。加鎖之後先還要再檢查 read 欄位,確定真的不存在才操作 dirty 欄位。
- 延遲刪除。刪除一個鍵值只是打標記,只有在提升 dirty 欄位為 read 欄位的時候才清理刪除的資料。
要理解 sync.Map 這些最佳化點,我們還是得深入到它的設計和實作上,去學習它的處理方式。
我們先看一下 map 的資料結構:
type Map struct {
mu Mutex
// 基本上你可以把它看成一個安全的只讀的map
// 它包含的元素其實也是透過原子操作更新的,但是已刪除的entry就需要加鎖操作了
read atomic.Value // readOnly
// 包含需要加鎖才能訪問的元素
// 包括所有在read欄位中但未被expunged(刪除)的元素以及新加的元素
dirty map[interface{}]*entry
// 記錄從read中讀取miss的次數,一旦miss數和dirty長度一樣了,就會把dirty提升為read,並把dirty置空
misses int
}
type readOnly struct {
m map[interface{}]*entry
amended bool // 當dirty中包含read沒有的資料時為true,比如新增一條資料
}
// expunged是用來標識此項已經刪掉的指標
// 當map中的一個專案被刪除了,只是把它的值標記為expunged,以後才有機會真正刪除此項
var expunged = unsafe.Pointer(new(interface{}))
// entry代表一個值
type entry struct {
p unsafe.Pointer // *interface{}
}
如果 dirty 欄位非 nil 的話,map 的 read 欄位和 dirty 欄位會包含相同的非 expunged 的項,所以如果透過 read 欄位更改了這個項的值,從 dirty 欄位中也會讀取到這個項的新值,因為本來它們指向的就是同一個地址。
dirty 包含重複專案的好處就是,一旦 miss 數達到閾值需要將 dirty 提升為 read 的話,只需簡單地把 dirty 設定為 read 物件即可。不好的一點就是,當建立新的 dirty 物件的時候,需要逐條遍歷 read,把非 expunged 的項複製到 dirty 物件中。
接下來,我們就深入到原始碼去看看 sync.map 的實作。在看這部分原始碼的過程中,我們只要重點關注 Store、Load 和 Delete 這 3 個核心的方法就可以了。
Store、Load 和 Delete 這三個核心函式的操作都是先從 read 欄位中處理的,因為讀取 read 欄位的時候不用加鎖。
Store 方法
我們先來看 Store 方法,它是用來設定一個鍵值對,或者更新一個鍵值對的。
func (m *Map) Store(key, value interface{}) {
read, _ := m.read.Load().(readOnly)
// 如果read欄位包含這個項,說明是更新,cas更新專案的值即可
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// read中不存在,或者cas更新失敗,就需要加鎖訪問dirty了
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok { // 雙檢查,看看read是否已經存在了
if e.unexpungeLocked() {
// 此專案先前已經被刪除了,透過將它的值設定為nil,標記為unexpunged
m.dirty[key] = e
}
e.storeLocked(&value) // 更新
} else if e, ok := m.dirty[key]; ok { // 如果dirty中有此項
e.storeLocked(&value) // 直接更新
} else { // 否則就是一個新的key
if !read.amended { //如果dirty為nil
// 需要建立dirty物件,並且標記read的amended為true,
// 說明有元素它不包含而dirty包含
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value) //將新值增加到dirty物件中
}
m.mu.Unlock()
}
可以看出,Store 既可以是新增元素,也可以是更新元素。如果運氣好的話,更新的是已存在的未被刪除的元素,直接更新即可,不會用到鎖。如果運氣不好,需要更新(重用)刪除的物件、更新還未提升的 dirty 中的物件,或者新增加元素的時候就會使用到了鎖,這個時候,效能就會下降。
所以從這一點來看,sync.Map 適合那些只會增長的快取系統,可以進行更新,但是不要刪除,並且不要頻繁地增加新元素。
新加的元素需要放入到 dirty 中,如果 dirty 為 nil,那麼需要從 read 欄位中複製出來一個 dirty 物件:
func (m *Map) dirtyLocked() {
if m.dirty != nil { // 如果dirty欄位已經存在,不需要建立了
return
}
read, _ := m.read.Load().(readOnly) // 獲取read欄位
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m { // 遍歷read欄位
if !e.tryExpungeLocked() { // 把非punged的鍵值對複製到dirty中
m.dirty[k] = e
}
}
}Load 方法Load 方法用來讀取一個 key 對應的值。它也是從 read 開始處理,一開始並不需要鎖。
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 首先從read處理
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended { // 如果不存在並且dirty不為nil(有新的元素)
m.mu.Lock()
// 雙檢查,看看read中現在是否存在此key
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {//依然不存在,並且dirty不為nil
e, ok = m.dirty[key]// 從dirty中讀取
// 不管dirty中存不存在,miss數都加1
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load() //返回讀取的物件,e既可能是從read中獲得的,也可能是從dirty中獲得的
}
如果幸運的話,我們從 read 中讀取到了這個 key 對應的值,那麼就不需要加鎖了,效能會非常好。但是,如果請求的 key 不存在或者是新加的,就需要加鎖從 dirty 中讀取。所以,讀取不存在的 key 會因為加鎖而導致效能下降,讀取還沒有提升的新值的情況下也會因為加鎖效能下降。
其中,missLocked 增加 miss 的時候,如果 miss 數等於 dirty 長度,會將 dirty 提升為 read,並將 dirty 置空。
func (m *Map) missLocked() {
m.misses++ // misses計數加一
if m.misses < len(m.dirty) { // 如果沒達到閾值(dirty欄位的長度),返回
return
}
m.read.Store(readOnly{m: m.dirty}) //把dirty欄位的記憶體提升為read欄位
m.dirty = nil // 清空dirty
m.misses = 0 // misses數重置為0
}Delete 方法sync.map 的第 3 個核心方法是 Delete 方法。在 Go 1.15 中歐長坤提供了一個 LoadAndDelete 的實作(go#issue 33762),所以 Delete 方法的核心改在了對 LoadAndDelete 中實作了。
同樣地,Delete 方法是先從 read 操作開始,原因我們已經知道了,因為不需要鎖。
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
// 雙檢查
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
// 這一行長坤在1.15中實作的時候忘記加上了,導致在特殊的場景下有些key總是沒有被回收
delete(m.dirty, key)
// miss數加1
m.missLocked()
}
m.mu.Unlock()
}
if ok {
return e.delete()
}
return nil, false
}
func (m *Map) Delete(key interface{}) {
m.LoadAndDelete(key)
}
func (e *entry) delete() (value interface{}, ok bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return nil, false
}
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return *(*interface{})(p), true
}
}
}
如果 read 中不存在,那麼就需要從 dirty 中尋找這個專案。最終,如果專案存在就刪除(將它的值標記為 nil)。如果專案不為 nil 或者沒有被標記為 expunged,那麼還可以把它的值返回。
最後,我補充一點,sync.map 還有一些 LoadAndDelete、LoadOrStore、Range 等輔助方法,但是沒有 Len 這樣查詢 sync.Map 的包含專案數量的方法,並且官方也不準備提供。如果你想得到 sync.Map 的專案數量的話,你可能不得不透過 Range 逐個計數。
總結
Go 內建的 map 型別使用起來很方便,但是它有一個非常致命的缺陷,那就是它存在著併發問題,所以如果有多個 goroutine 同時併發訪問這個 map,就會導致程式崩潰。所以 Go 官方 Blog 很早就提供了一種加鎖的方法,還有後來提供了適用特定場景的執行緒安全的 sync.Map,還有第三方實作的分片式的 map,這些方法都可以應用於併發訪問的場景。
這裡我給你的建議,也是 Go 開發者給的建議,就是透過效能測試,看看某種執行緒安全的 map 實作是否滿足你的需求。
當然還有一些擴充套件其它功能的 map 實作,比如帶有過期功能的timedmap、使用紅黑樹實作的 key 有序的treemap等,因為和併發問題沒有關係,就不詳細介紹了。這裡我給你提供了連結,你可以自己探索。
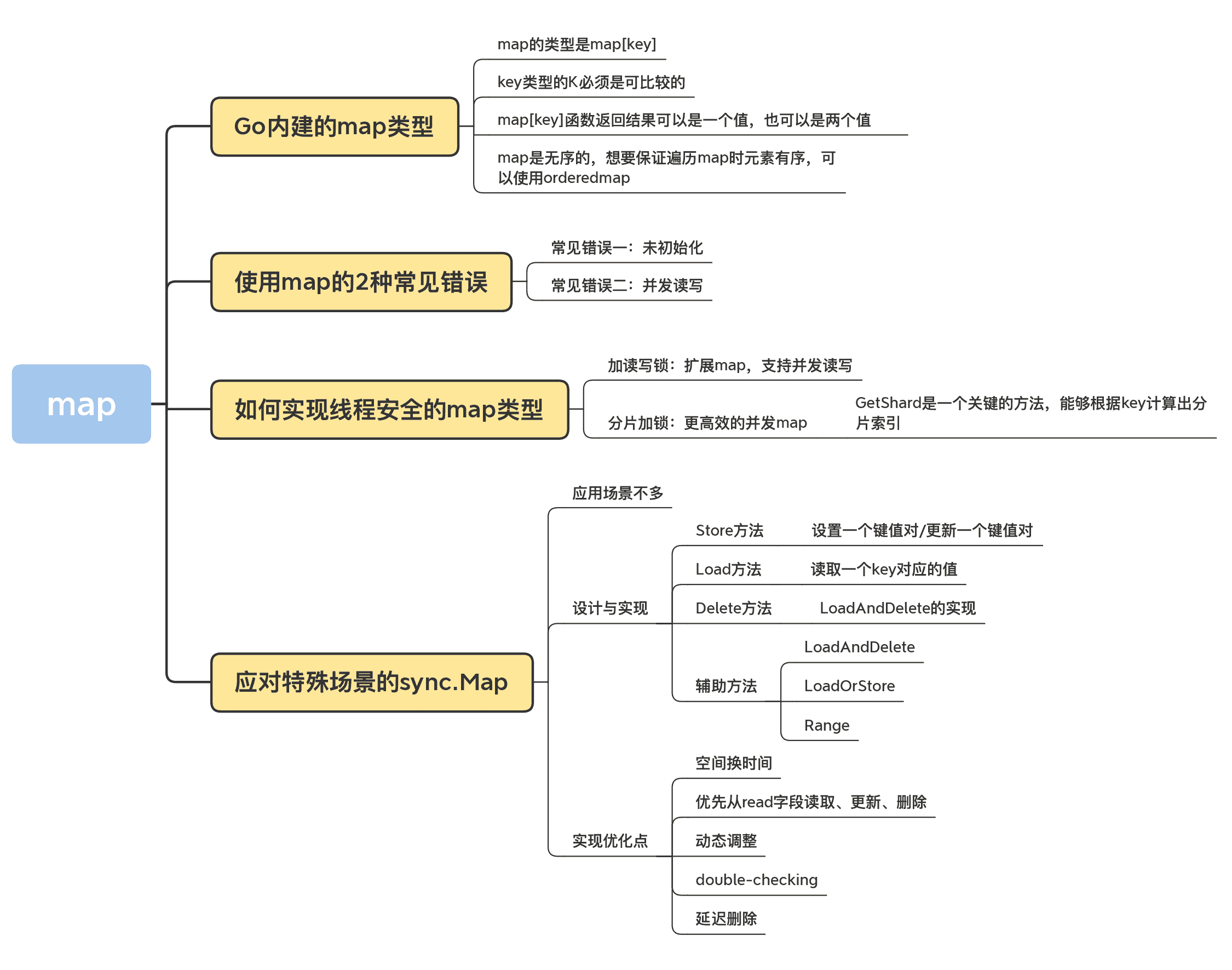
思考題
- 為什麼 sync.Map 中的集合核心方法的實作中,如果 read 中專案不存在,加鎖後還要雙檢查,再檢查一次 read?
- 你看到 sync.map 元素刪除的時候只是把它的值設定為 nil,那麼什麼時候這個 key 才會真正從 map 物件中刪除?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
10|Pool:效能提升大殺器
你好,我是鳥窩。
本章導讀
sync.Pool 物件重用流程
┌──────────────┐ Get() ┌──────────────┐
│ 業務程式碼 │ ──────────> │ sync.Pool │
└──────┬───────┘ └──────┬───────┘
│ │ 取到既有物件 / New() 建立
▼ ▼
使用物件 ----------------------> 完成後 Put() 放回池中
重點:減少短命物件配置,降低 GC 壓力(但不保證一定命中)
Go 是一個自動垃圾回收的程式語言,採用三色併發標記演算法標記物件並回收。和其它沒有自動垃圾回收的程式語言不同,使用 Go 語言建立物件的時候,我們沒有回收 / 釋放的心理負擔,想用就用,想建立就建立。
但是,如果你想使用 Go 開發一個高效能的應用程式的話,就必須考慮垃圾回收給效能帶來的影響,畢竟,Go 的自動垃圾回收機制還是有一個 STW(stop-the-world,程式暫停)的時間,而且,大量地建立在堆上的物件,也會影響垃圾回收標記的時間。
所以,一般我們做效能最佳化的時候,會採用物件池的方式,把不用的物件回收起來,避免被垃圾回收掉,這樣使用的時候就不必在堆上重新建立了。
不止如此,像資料庫連線、TCP 的長連線,這些連線在建立的時候是一個非常耗時的操作。如果每次都建立一個新的連線物件,耗時較長,很可能整個業務的大部分耗時都花在了建立連線上。
所以,如果我們能把這些連線儲存下來,避免每次使用的時候都重新建立,不僅可以大大減少業務的耗時,還能提高應用程式的整體效能。
Go 標準庫中提供了一個通用的 Pool 資料結構,也就是 sync.Pool,我們使用它可以建立池化的物件。這節課我會詳細給你介紹一下 sync.Pool 的使用方法、實作原理以及常見的坑,幫助你全方位地掌握標準庫的 Pool。
不過,這個型別也有一些使用起來不太方便的地方,就是它池化的物件可能會被垃圾回收掉,這對於資料庫長連線等場景是不合適的。所以在這一講中,我會專門介紹其它的一些 Pool,包括 TCP 連線池、資料庫連線池等等。
除此之外,我還會專門介紹一個池的應用場景: Worker Pool,或者叫做 goroutine pool,這也是常用的一種併發模式,可以使用有限的 goroutine 資源去處理大量的業務資料。
sync.Pool
首先,我們來學習下標準庫提供的 sync.Pool 資料型別。
sync.Pool 資料型別用來儲存一組可獨立訪問的臨時物件。請注意這裡加粗的“臨時”這兩個字,它說明瞭 sync.Pool 這個資料型別的特點,也就是說,它池化的物件會在未來的某個時候被毫無預兆地移除掉。而且,如果沒有別的物件引用這個被移除的物件的話,這個被移除的物件就會被垃圾回收掉。
因為 Pool 可以有效地減少新物件的申請,從而提高程式效能,所以 Go 內部庫也用到了 sync.Pool,比如 fmt 包,它會使用一個動態大小的 buffer 池做輸出快取,當大量的 goroutine 併發輸出的時候,就會建立比較多的 buffer,並且在不需要的時候回收掉。
有兩個知識點你需要記住:
- sync.Pool 本身就是執行緒安全的,多個 goroutine 可以併發地呼叫它的方法存取物件;
- sync.Pool 不可在使用之後再複製使用。
sync.Pool 的使用方法
知道了 sync.Pool 這個資料型別的特點,接下來,我們來學習下它的使用方法。其實,這個資料型別不難,它只提供了三個對外的方法:New、Get 和 Put。
1.New
Pool struct 包含一個 New 欄位,這個欄位的型別是函式 func() interface{}。當呼叫 Pool 的 Get 方法從池中獲取元素,沒有更多的空閒元素可返回時,就會呼叫這個 New 方法來建立新的元素。如果你沒有設定 New 欄位,沒有更多的空閒元素可返回時,Get 方法將返回 nil,表明當前沒有可用的元素。
有趣的是,New 是可變的欄位。這就意味著,你可以在程式執行的時候改變建立元素的方法。當然,很少有人會這麼做,因為一般我們建立元素的邏輯都是一致的,要建立的也是同一類的元素,所以你在使用 Pool 的時候也沒必要玩一些“花活”,在程式執行時更改 New 的值。
2.Get
如果呼叫這個方法,就會從 Pool取走一個元素,這也就意味著,這個元素會從 Pool 中移除,返回給呼叫者。不過,除了返回值是正常例項化的元素,Get 方法的返回值還可能會是一個 nil(Pool.New 欄位沒有設定,又沒有空閒元素可以返回),所以你在使用的時候,可能需要判斷。
3.Put
這個方法用於將一個元素返還給 Pool,Pool 會把這個元素儲存到池中,並且可以複用。但如果 Put 一個 nil 值,Pool 就會忽略這個值。
好了,瞭解了這幾個方法,下面我們看看 sync.Pool 最常用的一個場景:buffer 池(緩衝池)。
因為 byte slice 是經常被建立銷燬的一類物件,使用 buffer 池可以快取已經建立的 byte slice,比如,著名的靜態網站生成工具 Hugo 中,就包含這樣的實作bufpool,你可以看一下下面這段程式碼:
var buffers = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func GetBuffer() *bytes.Buffer {
return buffers.Get().(*bytes.Buffer)
}
func PutBuffer(buf *bytes.Buffer) {
buf.Reset()
buffers.Put(buf)
}
除了 Hugo,這段 buffer 池的程式碼非常常用。很可能你在閱讀其它專案的程式碼的時候就碰到過,或者是你自己實作 buffer 池的時候也會這麼去實作,但是請你注意了,這段程式碼是有問題的,你一定不要將上面的程式碼應用到實際的產品中。它可能會有記憶體洩漏的問題,下面我會重點講這個問題。
實作原理
瞭解了 sync.Pool 的基本使用方法,下面我們就來重點學習下它的實作。
Go 1.13 之前的 sync.Pool 的實作有 2 大問題:
1. 每次 GC 都會回收建立的物件。
如果快取元素數量太多,就會導致 STW 耗時變長;快取元素都被回收後,會導致 Get 命中率下降,Get 方法不得不新建立很多物件。
2. 底層實作使用了 Mutex,對這個鎖併發請求競爭激烈的時候,會導致效能的下降。
在 Go 1.13 中,sync.Pool 做了大量的最佳化。前幾講中我提到過,提高併發程式效能的最佳化點是儘量不要使用鎖,如果不得已使用了鎖,就把鎖 Go 的粒度降到最低。Go 對 Pool 的最佳化就是避免使用鎖,同時將加鎖的 queue 改成 lock-free 的 queue 的實作,給即將移除的元素再多一次“復活”的機會。
當前,sync.Pool 的資料結構如下圖所示:
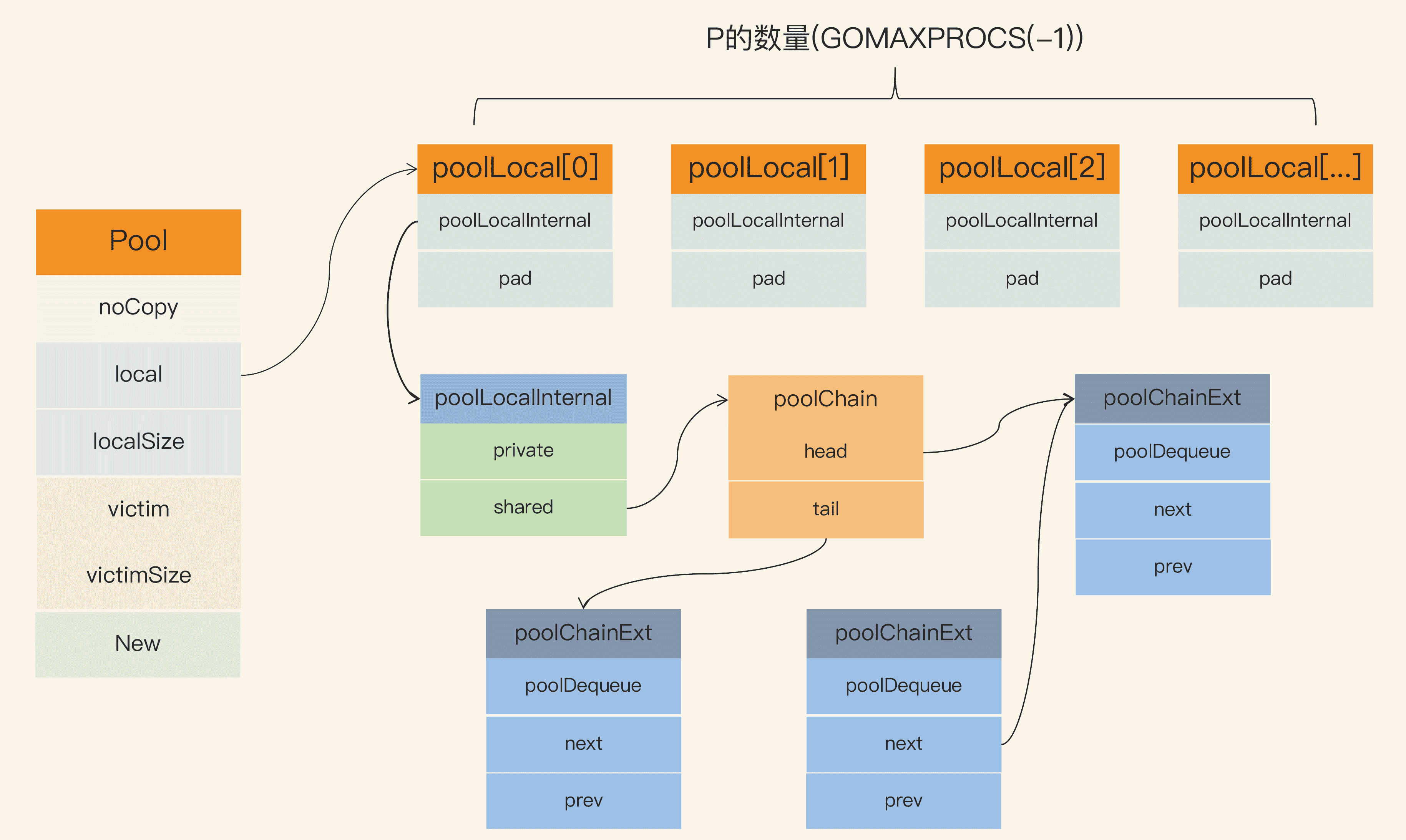
Pool 最重要的兩個欄位是 local 和 victim,因為它們兩個主要用來儲存空閒的元素。弄清楚這兩個欄位的處理邏輯,你就能完全掌握 sync.Pool 的實作了。下面我們來看看這兩個欄位的關係。
每次垃圾回收的時候,Pool 會把 victim 中的物件移除,然後把 local 的資料給 victim,這樣的話,local 就會被清空,而 victim 就像一個垃圾分揀站,裡面的東西可能會被當做垃圾丟棄了,但是裡面有用的東西也可能被撿回來重新使用。
victim 中的元素如果被 Get 取走,那麼這個元素就很幸運,因為它又“活”過來了。但是,如果這個時候 Get 的併發不是很大,元素沒有被 Get 取走,那麼就會被移除掉,因為沒有別人引用它的話,就會被垃圾回收掉。
下面的程式碼是垃圾回收時 sync.Pool 的處理邏輯:
func poolCleanup() {
// 丟棄當前victim, STW所以不用加鎖
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 將local複製給victim, 並將原local置為nil
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}
在這段程式碼中,你需要關注一下 local 欄位,因為所有當前主要的空閒可用的元素都存放在 local 欄位中,請求元素時也是優先從 local 欄位中查詢可用的元素。local 欄位包含一個 poolLocalInternal 欄位,並提供 CPU 快取對齊,從而避免 false sharing。
而 poolLocalInternal 也包含兩個欄位:private 和 shared。
- private,代表一個快取的元素,而且只能由相應的一個 P 存取。因為一個 P 同時只能執行一個 goroutine,所以不會有併發的問題。
- shared,可以由任意的 P 訪問,但是隻有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相當於只有一個本地的 P 作為生產者(Producer),多個 P 作為消費者(Consumer),它是使用一個 local-free 的 queue 列表實作的。
Get 方法
我們來看看 Get 方法的具體實作原理。
func (p *Pool) Get() interface{} {
// 把當前goroutine固定在當前的P上
l, pid := p.pin()
x := l.private // 優先從local的private欄位取,快速
l.private = nil
if x == nil {
// 從當前的local.shared彈出一個,注意是從head讀取並移除
x, _ = l.shared.popHead()
if x == nil { // 如果沒有,則去偷一個
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// 如果沒有獲取到,嘗試使用New函式生成一個新的
if x == nil && p.New != nil {
x = p.New()
}
return x
}
我來給你解釋下這段程式碼。首先,從本地的 private 欄位中獲取可用元素,因為沒有鎖,獲取元素的過程會非常快,如果沒有獲取到,就嘗試從本地的 shared 獲取一個,如果還沒有,會使用 getSlow 方法去其它的 shared 中“偷”一個。最後,如果沒有獲取到,就嘗試使用 New 函式建立一個新的。
這裡的重點是 getSlow 方法,我們來分析下。看名字也就知道了,它的耗時可能比較長。它首先要遍歷所有的 local,嘗試從它們的 shared 彈出一個元素。如果還沒找到一個,那麼,就開始對 victim 下手了。
在 vintim 中查詢可用元素的邏輯還是一樣的,先從對應的 victim 的 private 查詢,如果查不到,就再從其它 victim 的 shared 中查詢。
下面的程式碼是 getSlow 方法的主要邏輯:
func (p *Pool) getSlow(pid int) interface{} {
size := atomic.LoadUintptr(&p.localSize)
locals := p.local
// 從其它proc中嘗試偷取一個元素
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 如果其它proc也沒有可用元素,那麼嘗試從vintim中獲取
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil { // 同樣的邏輯,先從vintim中的local private獲取
l.private = nil
return x
}
for i := 0; i < int(size); i++ { // 從vintim其它proc嘗試偷取
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 如果victim中都沒有,則把這個victim標記為空,以後的查詢可以快速跳過了
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
這裡我沒列出 pin 程式碼的實作,你只需要知道,pin 方法會將此 goroutine 固定在當前的 P 上,避免查詢元素期間被其它的 P 執行。固定的好處就是查詢元素期間直接得到跟這個 P 相關的 local。有一點需要注意的是,pin 方法在執行的時候,如果跟這個 P 相關的 local 還沒有建立,或者執行時 P 的數量被修改了的話,就會新建立 local。
Put 方法
我們來看看 Put 方法的具體實作原理。
func (p *Pool) Put(x interface{}) {
if x == nil { // nil值直接丟棄
return
}
l, _ := p.pin()
if l.private == nil { // 如果本地private沒有值,直接設定這個值即可
l.private = x
x = nil
}
if x != nil { // 否則加入到本地佇列中
l.shared.pushHead(x)
}
runtime_procUnpin()
}
Put 的邏輯相對簡單,優先設定本地 private,如果 private 欄位已經有值了,那麼就把此元素 push 到本地佇列中。
sync.Pool 的坑
到這裡,我們就掌握了 sync.Pool 的使用方法和實作原理,接下來,我要再和你聊聊容易踩的兩個坑,分別是記憶體洩漏和記憶體浪費。
記憶體洩漏
這節課剛開始的時候,我講到,可以使用 sync.Pool 做 buffer 池,但是,如果用剛剛的那種方式做 buffer 池的話,可能會有記憶體洩漏的風險。為啥這麼說呢?我們來分析一下。
取出來的 bytes.Buffer 在使用的時候,我們可以往這個元素中增加大量的 byte 資料,這會導致底層的 byte slice 的容量可能會變得很大。這個時候,即使 Reset 再放回到池子中,這些 byte slice 的容量不會改變,所佔的空間依然很大。而且,因為 Pool 回收的機制,這些大的 Buffer 可能不被回收,而是會一直佔用很大的空間,這屬於記憶體洩漏的問題。
即使是 Go 的標準庫,在記憶體洩漏這個問題上也栽了幾次坑,比如 issue 23199、@dsnet提供了一個簡單的可重現的例子,演示了記憶體洩漏的問題。再比如 encoding、json 中類似的問題:將容量已經變得很大的 Buffer 再放回 Pool 中,導致記憶體洩漏。後來在元素放回時,增加了檢查邏輯,改成放回的超過一定大小的 buffer,就直接丟棄掉,不再放到池子中,如下所示:
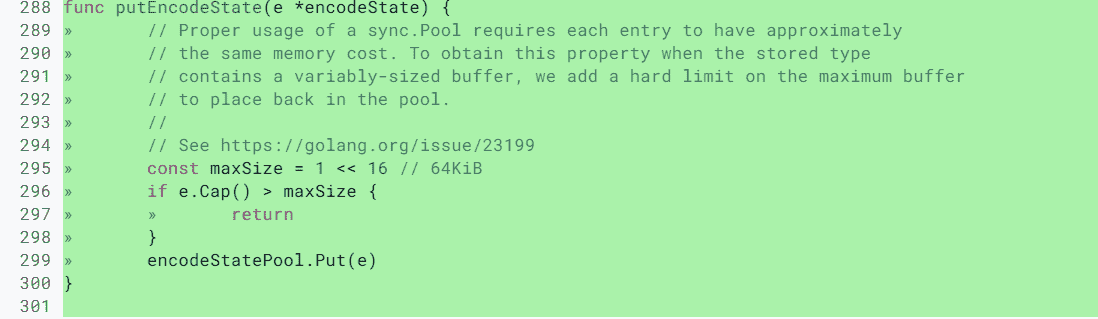
package fmt 中也有這個問題,修改方法是一樣的,超過一定大小的 buffer,就直接丟棄了:
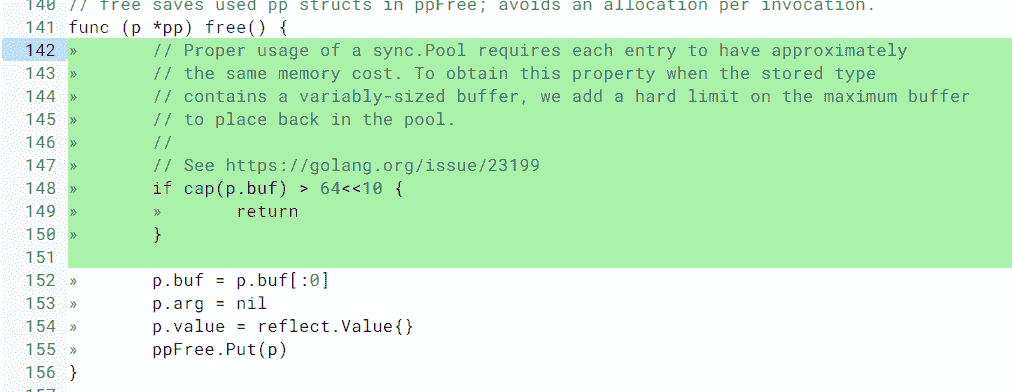
在使用 sync.Pool 回收 buffer 的時候,**一定要檢查回收的物件的大小。**如果 buffer 太大,就不要回收了,否則就太浪費了。
記憶體浪費
除了記憶體洩漏以外,還有一種浪費的情況,就是池子中的 buffer 都比較大,但在實際使用的時候,很多時候只需要一個小的 buffer,這也是一種浪費現象。接下來,我就講解一下這種情況的處理方法。
要做到物盡其用,儘可能不浪費的話,我們可以將 buffer 池分成幾層。首先,小於 512 byte 的元素的 buffer 佔一個池子;其次,小於 1K byte 大小的元素佔一個池子;再次,小於 4K byte 大小的元素佔一個池子。這樣分成幾個池子以後,就可以根據需要,到所需大小的池子中獲取 buffer 了。
在標準庫 net/http/server.go中的程式碼中,就提供了 2K 和 4K 兩個 writer 的池子。你可以看看下面這段程式碼:

YouTube 開源的知名專案 vitess 中提供了bucketpool的實作,它提供了更加通用的多層 buffer 池。你在使用的時候,只需要指定池子的最大和最小尺寸,vitess 就會自動計算出合適的池子數。而且,當你呼叫 Get 方法的時候,只需要傳入你要獲取的 buffer 的大小,就可以了。下面這段程式碼就描述了這個過程,你可以看看:

第三方庫
除了這種分層的為了節省空間的 buffer 設計外,還有其它的一些第三方的庫也會提供 buffer 池的功能。接下來我帶你熟悉幾個常用的第三方的庫。
1.bytebufferpool
這是 fasthttp 作者 valyala 提供的一個 buffer 池,基本功能和 sync.Pool 相同。它的底層也是使用 sync.Pool 實作的,包括會檢測最大的 buffer,超過最大尺寸的 buffer,就會被丟棄。
valyala 一向很擅長挖掘系統的效能,這個庫也不例外。它提供了校準(calibrate,用來動態調整建立元素的權重)的機制,可以“智慧”地調整 Pool 的 defaultSize 和 maxSize。一般來說,我們使用 buffer size 的場景比較固定,所用 buffer 的大小會集中在某個範圍裡。有了校準的特性,bytebufferpool 就能夠偏重於建立這個範圍大小的 buffer,從而節省空間。
2.oxtoacart/bpool
這也是比較常用的 buffer 池,它提供了以下幾種型別的 buffer。
- bpool.BufferPool: 提供一個固定元素數量的 buffer 池,元素型別是 bytes.Buffer,如果超過這個數量,Put 的時候就丟棄,如果池中的元素都被取光了,會新建一個返回。Put 回去的時候,不會檢測 buffer 的大小。
- bpool.BytesPool:提供一個固定元素數量的 byte slice 池,元素型別是 byte slice。Put 回去的時候不檢測 slice 的大小。
- bpool.SizedBufferPool: 提供一個固定元素數量的 buffer 池,如果超過這個數量,Put 的時候就丟棄,如果池中的元素都被取光了,會新建一個返回。Put 回去的時候,會檢測 buffer 的大小,超過指定的大小的話,就會建立一個新的滿足條件的 buffer 放回去。
bpool 最大的特色就是能夠保持池子中元素的數量,一旦 Put 的數量多於它的閾值,就會自動丟棄,而 sync.Pool 是一個沒有限制的池子,只要 Put 就會收進去。
bpool 是基於 Channel 實作的,不像 sync.Pool 為了提高效能而做了很多最佳化,所以,在效能上比不過 sync.Pool。不過,它提供了限制 Pool 容量的功能,所以,如果你想控制 Pool 的容量的話,可以考慮這個庫。
連線池
Pool 的另一個很常用的一個場景就是保持 TCP 的連線。一個 TCP 的連線建立,需要三次握手等過程,如果是 TLS 的,還會需要更多的步驟,如果加上身份認證等邏輯的話,耗時會更長。所以,為了避免每次通訊的時候都新建立連線,我們一般會建立一個連線的池子,預先把連線建立好,或者是逐步把連線放在池子中,減少連線建立的耗時,從而提高系統的效能。
事實上,我們很少會使用 sync.Pool 去池化連線物件,原因就在於,sync.Pool 會無通知地在某個時候就把連線移除垃圾回收掉了,而我們的場景是需要長久保持這個連線,所以,我們一般會使用其它方法來池化連線,比如接下來我要講到的幾種需要保持長連線的 Pool。
標準庫中的 http client 池
標準庫的 http.Client 是一個 http client 的庫,可以用它來訪問 web 伺服器。為了提高效能,這個 Client 的實作也是透過池的方法來快取一定數量的連線,以便後續重用這些連線。
http.Client 實作連線池的程式碼是在 Transport 型別中,它使用 idleConn 儲存持久化的可重用的長連線:

TCP 連線池
最常用的一個 TCP 連線池是 fatih 開發的fatih/pool,雖然這個專案已經被 fatih 歸檔(Archived),不再維護了,但是因為它相當穩定了,我們可以開箱即用。即使你有一些特殊的需求,也可以 fork 它,然後自己再做修改。
它的使用套路如下:
// 工廠模式,提供建立連線的工廠方法
factory := func() (net.Conn, error) { return net.Dial("tcp", "127.0.0.1:4000") }
// 建立一個tcp池,提供初始容量和最大容量以及工廠方法
p, err := pool.NewChannelPool(5, 30, factory)
// 獲取一個連線
conn, err := p.Get()
// Close並不會真正關閉這個連線,而是把它放回池子,所以你不必顯式地Put這個物件到池子中
conn.Close()
// 透過呼叫MarkUnusable, Close的時候就會真正關閉底層的tcp的連線了
if pc, ok := conn.(*pool.PoolConn); ok {
pc.MarkUnusable()
pc.Close()
}
// 關閉池子就會關閉=池子中的所有的tcp連線
p.Close()
// 當前池子中的連線的數量
current := p.Len()
雖然我一直在說 TCP,但是它管理的是更通用的 net.Conn,不侷限於 TCP 連線。
它透過把 net.Conn 包裝成 PoolConn,實作了攔截 net.Conn 的 Close 方法,避免了真正地關閉底層連線,而是把這個連線放回到池中:
type PoolConn struct {
net.Conn
mu sync.RWMutex
c *channelPool
unusable bool
}
//攔截Close
func (p *PoolConn) Close() error {
p.mu.RLock()
defer p.mu.RUnlock()
if p.unusable {
if p.Conn != nil {
return p.Conn.Close()
}
return nil
}
return p.c.put(p.Conn)
}
它的 Pool 是透過 Channel 實作的,空閒的連線放入到 Channel 中,這也是 Channel 的一個應用場景:
type channelPool struct {
// 儲存連線池的channel
mu sync.RWMutex
conns chan net.Conn
// net.Conn 的產生器
factory Factory
}資料庫連線池標準庫 sql.DB 還提供了一個通用的資料庫的連線池,透過 MaxOpenConns 和 MaxIdleConns 控制最大的連線數和最大的 idle 的連線數。預設的 MaxIdleConns 是 2,這個數對於資料庫相關的應用來說太小了,我們一般都會調整它。
DB 的 freeConn 儲存了 idle 的連線,這樣,當我們獲取資料庫連線的時候,它就會優先嚐試從 freeConn 獲取已有的連線(conn)。

Memcached Client 連線池
Brad Fitzpatrick 是知名快取庫 Memcached 的原作者,前 Go 團隊成員。gomemcache是他使用 Go 開發的 Memchaced 的客戶端,其中也用了連線池的方式池化 Memcached 的連線。接下來讓我們看看它的連線池的實作。
gomemcache Client 有一個 freeconn 的欄位,用來儲存空閒的連線。當一個請求使用完之後,它會呼叫 putFreeConn 放回到池子中,請求的時候,呼叫 getFreeConn 優先查詢 freeConn 中是否有可用的連線。它採用 Mutex+Slice 實作 Pool:
// 放回一個待重用的連線
func (c *Client) putFreeConn(addr net.Addr, cn *conn) {
c.lk.Lock()
defer c.lk.Unlock()
if c.freeconn == nil { // 如果物件為空,建立一個map物件
c.freeconn = make(map[string][]*conn)
}
freelist := c.freeconn[addr.String()] //得到此地址的連線列表
if len(freelist) >= c.maxIdleConns() {//如果連線已滿,關閉,不再放入
cn.nc.Close()
return
}
c.freeconn[addr.String()] = append(freelist, cn) // 加入到空閒列表中
}
// 得到一個空閒連線
func (c *Client) getFreeConn(addr net.Addr) (cn *conn, ok bool) {
c.lk.Lock()
defer c.lk.Unlock()
if c.freeconn == nil {
return nil, false
}
freelist, ok := c.freeconn[addr.String()]
if !ok || len(freelist) == 0 { // 沒有此地址的空閒列表,或者列表為空
return nil, false
}
cn = freelist[len(freelist)-1] // 取出尾部的空閒連線
c.freeconn[addr.String()] = freelist[:len(freelist)-1]
return cn, true
}
Worker Pool最後,我再講一個 Pool 應用得非常廣泛的場景。
你已經知道,goroutine 是一個很輕量級的“纖程”,在一個伺服器上可以建立十幾萬甚至幾十萬的 goroutine。但是“可以”和“合適”之間還是有區別的,你會在應用中讓幾十萬的 goroutine 一直跑嗎?基本上是不會的。
一個 goroutine 初始的棧大小是 2048 個位元組,並且在需要的時候可以擴充套件到 1GB(具體的內容你可以課下看看程式碼中的配置:不同的架構最大數會不同),所以,大量的 goroutine 還是很耗資源的。同時,大量的 goroutine 對於排程和垃圾回收的耗時還是會有影響的,因此,goroutine 並不是越多越好。
有的時候,我們就會建立一個 Worker Pool 來減少 goroutine 的使用。比如,我們實作一個 TCP 伺服器,如果每一個連線都要由一個獨立的 goroutine 去處理的話,在大量連線的情況下,就會建立大量的 goroutine,這個時候,我們就可以建立一個固定數量的 goroutine(Worker),由這一組 Worker 去處理連線,比如 fasthttp 中的Worker Pool。
Worker 的實作也是五花八門的:
- 有些是在後臺默默執行的,不需要等待返回結果;
- 有些需要等待一批任務執行完;
- 有些 Worker Pool 的生命週期和程式一樣長;
- 有些只是臨時使用,執行完畢後,Pool 就銷燬了。
大部分的 Worker Pool 都是透過 Channel 來快取任務的,因為 Channel 能夠比較方便地實作併發的保護,有的是多個 Worker 共享同一個任務 Channel,有些是每個 Worker 都有一個獨立的 Channel。
綜合下來,精挑細選,我給你推薦三款易用的 Worker Pool,這三個 Worker Pool 的 API 設計簡單,也比較相似,易於和專案整合,而且提供的功能也是我們常用的功能。
- gammazero/workerpool:gammazero/workerpool 可以無限制地提交任務,提供了更便利的 Submit 和 SubmitWait 方法提交任務,還可以提供當前的 worker 數和任務數以及關閉 Pool 的功能。
- ivpusic/grpool:grpool 建立 Pool 的時候需要提供 Worker 的數量和等待執行的任務的最大數量,任務的提交是直接往 Channel 放入任務。
- dpaks/goworkers:dpaks/goworkers 提供了更便利的 Submi 方法提交任務以及 Worker 數、任務數等查詢方法、關閉 Pool 的方法。它的任務的執行結果需要在 ResultChan 和 ErrChan 中去獲取,沒有提供阻塞的方法,但是它可以在初始化的時候設定 Worker 的數量和任務數。
類似的 Worker Pool 的實作非常多,比如還有panjf2000/ants、Jeffail/tunny 、benmanns/goworker、go-playground/pool、Sherifabdlnaby/gpool等第三方庫。pond也是一個非常不錯的 Worker Pool,關注度目前不是很高,但是功能非常齊全。
其實,你也可以自己去開發自己的 Worker Pool,但是,對於我這種“懶惰”的人來說,只要滿足我的實際需求,我還是傾向於從這個幾個常用的庫中選擇一個來使用。所以,我建議你也從常用的庫中進行選擇。
總結
Pool 是一個通用的概念,也是解決物件重用和預先分配的一個常用的最佳化手段。即使你自己沒在專案中直接使用過,但肯定在使用其它庫的時候,就享受到應用 Pool 的好處了,比如資料庫的訪問、http API 的請求等等。
我們一般不會在程式一開始的時候就開始考慮最佳化,而是等專案開發到一個階段,或者快結束的時候,才全面地考慮程式中的最佳化點,而 Pool 就是常用的一個最佳化手段。如果你發現程式中有一種 GC 耗時特別高,有大量的相同型別的臨時物件,不斷地被建立銷燬,這時,你就可以考慮看看,是不是可以透過池化的手段重用這些物件。
另外,在分散式系統或者微服務框架中,可能會有大量的併發 Client 請求,如果 Client 的耗時佔比很大,你也可以考慮池化 Client,以便重用。
如果你發現系統中的 goroutine 數量非常多,程式的記憶體資源佔用比較大,而且整體系統的耗時和 GC 也比較高,我建議你看看,是否能夠透過 Worker Pool 解決大量 goroutine 的問題,從而降低這些指標。
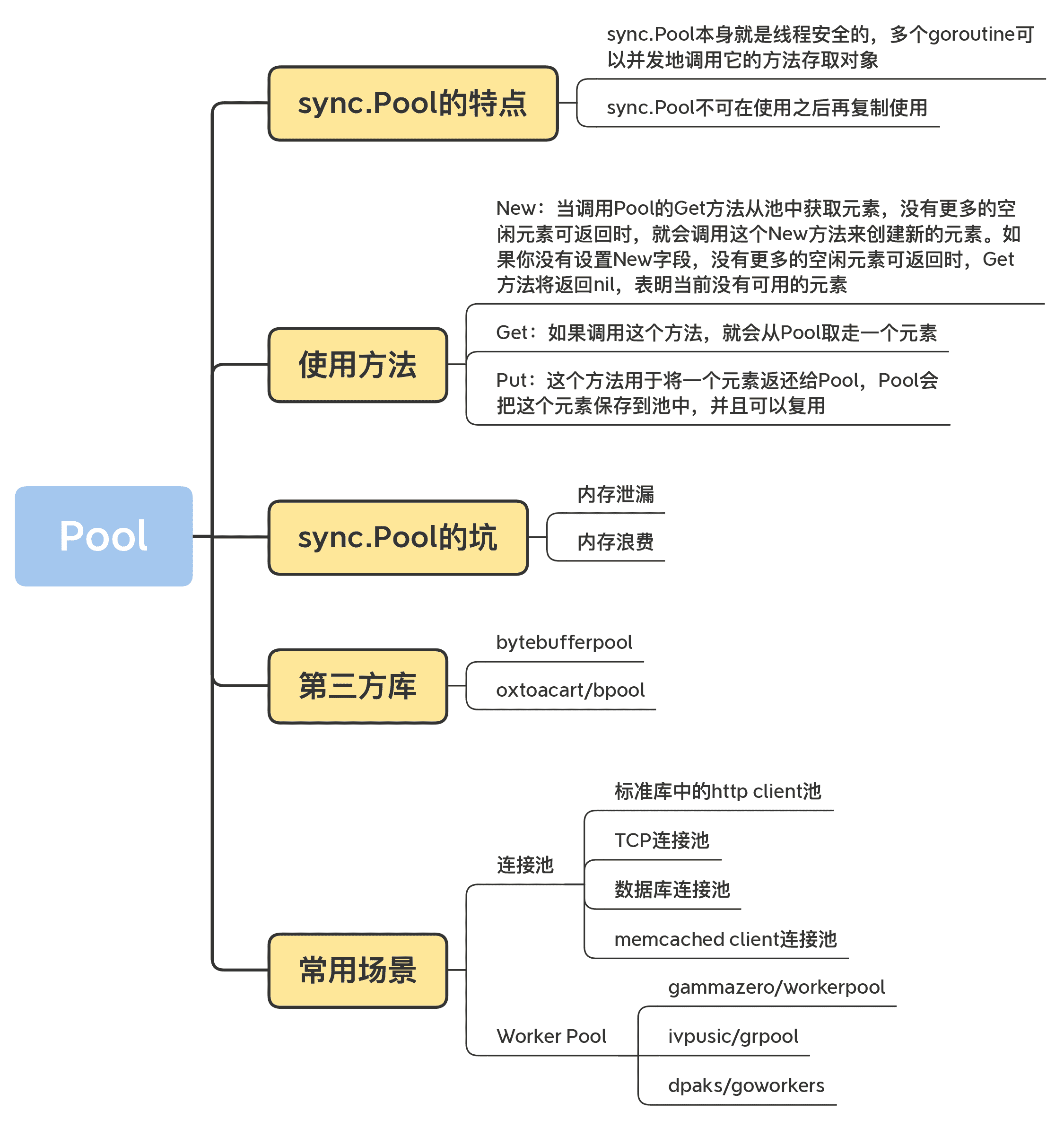
思考題
在標準庫 net/rpc 包中,Server 端需要解析大量客戶端的請求(Request),這些短暫使用的 Request 是可以重用的。請你檢查相關的程式碼,看看 Go 開發者都使用了什麼樣的方式來重用這些物件。
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
11|Context:資訊穿透上下文
你好,我是鳥窩。
本章導讀
Context 資訊/取消訊號傳遞圖
┌────────────────────┐
│ parent context │
│ deadline / cancel / │
│ values │
└─────────┬──────────┘
│ 衍生
┌─────────────┴─────────────┐
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ child context A │ │ child context B │
└─────────┬────────┘ └─────────┬────────┘
│ │
▼ ▼
goroutine A goroutine B
parent cancel -> 子層一起收到取消訊號
在這節課正式開始之前,我想先帶你看一個工作中的場景。
假設有一天你進入辦公室,突然同事們都圍住你,然後大喊“小王小王你最帥”,此時你可能一頭霧水,只能尷尬地笑笑。為啥呢?因為你缺少上下文的資訊,不知道之前發生了什麼。
但是,如果同事告訴你,由於你業績突出,一天之內就把雲服務化的主要架構寫好了,因此被評為 9 月份的工作之星,總經理還特意給你發 1 萬元的獎金,那麼,你心裡就很清楚了,原來同事恭喜你,是因為你的工作被表揚了,還獲得了獎金。同事告訴你的這些前因後果,就是上下文資訊,他把上下文傳遞給你,你接收後,就可以獲取之前不瞭解的資訊。
你看,上下文(Context)就是這麼重要。在我們的開發場景中,上下文也是不可或缺的,缺少了它,我們就不能獲取完整的程式資訊。那到底啥是上下文呢?其實,這就是指,在 API 之間或者方法呼叫之間,所傳遞的除了業務引數之外的額外資訊。
比如,服務端接收到客戶端的 HTTP 請求之後,可以把客戶端的 IP 地址和埠、客戶端的身份資訊、請求接收的時間、Trace ID 等資訊放入到上下文中,這個上下文可以在後端的方法呼叫中傳遞,後端的業務方法除了利用正常的引數做一些業務處理(如訂單處理)之外,還可以從上下文讀取到訊息請求的時間、Trace ID 等資訊,把服務處理的時間推送到 Trace 服務中。Trace 服務可以把同一 Trace ID 的不同方法的呼叫順序和呼叫時間展示成流程圖,方便跟蹤。
不過,Go 標準庫中的 Context 功能還不止於此,它還提供了超時(Timeout)和取消(Cancel)的機制,下面就讓我一一道來。
Context 的來歷
在學習 Context 的功能之前呢,我先帶你瞭解下它的來歷。畢竟,知道了它的來龍去脈,我們才能應用得更加得心應手一些。
Go 在 1.7 的版本中才正式把 Context 加入到標準庫中。在這之前,很多 Web 框架在定義自己的 handler 時,都會傳遞一個自定義的 Context,把客戶端的資訊和客戶端的請求資訊放入到 Context 中。Go 最初提供了 golang.org/x/net/context 庫用來提供上下文資訊,最終還是在 Go1.7 中把此庫提升到標準庫 context 包中。
為啥呢?這是因為,在 Go1.7 之前,有很多庫都依賴 golang.org/x/net/context 中的 Context 實作,這就導致 Go 1.7 釋出之後,出現了標準庫 Context 和 golang.org/x/net/context 並存的狀況。新的程式碼使用標準庫 Context 的時候,沒有辦法使用這個標準庫的 Context 去呼叫舊有的使用 x/net/context 實作的方法。
所以,在 Go1.9 中,還專門實作了一個叫做 type alias 的新特性,然後把 x/net/context 中的 Context 定義成標準庫 Context 的別名,以解決新舊 Context 型別衝突問題,你可以看一下下面這段程式碼:
// +build go1.9
package context
import "context"
type Context = context.Context
type CancelFunc = context.CancelFunc
Go 標準庫的 Context 不僅提供了上下文傳遞的資訊,還提供了 cancel、timeout 等其它資訊,這些資訊貌似和 context 這個包名沒關係,但是還是得到了廣泛的應用。所以,你看,context 包中的 Context 不僅僅傳遞上下文資訊,還有 timeout 等其它功能,是不是“名不副實”呢?
其實啊,這也是這個 Context 的一個問題,比較容易誤導人,Go 佈道師 Dave Cheney 還專門寫了一篇文章講述這個問題:Context isn’t for cancellation。
同時,也有一些批評者針對 Context 提出了批評:Context should go away for Go 2,這篇文章把 Context 比作病毒,病毒會傳染,結果把所有的方法都傳染上了病毒(加上 Context 引數),絕對是視覺汙染。
Go 的開發者也注意到了“關於 Context,存在一些爭議”這件事兒,所以,Go 核心開發者 Ian Lance Taylor 專門開了一個issue 28342,用來記錄當前的 Context 的問題:
- Context 包名導致使用的時候重複 ctx context.Context;
- Context.WithValue 可以接受任何型別的值,非型別安全;
- Context 包名容易誤導人,實際上,Context 最主要的功能是取消 goroutine 的執行;
- Context 漫天飛,函式汙染。
儘管有很多的爭議,但是,在很多場景下,使用 Context 其實會很方便,所以現在它已經在 Go 生態圈中傳播開來了,包括很多的 Web 應用框架,都切換成了標準庫的 Context。標準庫中的 database/sql、os/exec、net、net/http 等包中都使用到了 Context。而且,如果我們遇到了下面的一些場景,也可以考慮使用 Context:
- 上下文資訊傳遞 (request-scoped),比如處理 http 請求、在請求處理鏈路上傳遞資訊;
- 控制子 goroutine 的執行;
- 超時控制的方法呼叫;
- 可以取消的方法呼叫。
所以,我們需要掌握 Context 的具體用法,這樣才能在不影響主要業務流程實作的時候,實作一些通用的資訊傳遞,或者是能夠和其它 goroutine 協同工作,提供 timeout、cancel 等機制。
Context 基本使用方法
首先,我們來學習一下 Context 介面包含哪些方法,這些方法都是幹什麼用的。
包 context 定義了 Context 介面,Context 的具體實作包括 4 個方法,分別是 Deadline、Done、Err 和 Value,如下所示:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
下面我來具體解釋下這 4 個方法。
Deadline 方法會返回這個 Context 被取消的截止日期。如果沒有設定截止日期,ok 的值是 false。後續每次呼叫這個物件的 Deadline 方法時,都會返回和第一次呼叫相同的結果。
Done 方法返回一個 Channel 物件。在 Context 被取消時,此 Channel 會被 close,如果沒被取消,可能會返回 nil。後續的 Done 呼叫總是返回相同的結果。當 Done 被 close 的時候,你可以透過 ctx.Err 獲取錯誤資訊。Done 這個方法名其實起得並不好,因為名字太過籠統,不能明確反映 Done 被 close 的原因,因為 cancel、timeout、deadline 都可能導致 Done 被 close,不過,目前還沒有一個更合適的方法名稱。
關於 Done 方法,你必須要記住的知識點就是:如果 Done 沒有被 close,Err 方法返回 nil;如果 Done 被 close,Err 方法會返回 Done 被 close 的原因。
Value 返回此 ctx 中和指定的 key 相關聯的 value。
Context 中實作了 2 個常用的生成頂層 Context 的方法。
- context.Background():返回一個非 nil 的、空的 Context,沒有任何值,不會被 cancel,不會超時,沒有截止日期。一般用在主函式、初始化、測試以及建立根 Context 的時候。
- context.TODO():返回一個非 nil 的、空的 Context,沒有任何值,不會被 cancel,不會超時,沒有截止日期。當你不清楚是否該用 Context,或者目前還不知道要傳遞一些什麼上下文資訊的時候,就可以使用這個方法。
官方文件是這麼講的,你可能會覺得像沒說一樣,因為界限並不是很明顯。其實,你根本不用費腦子去考慮,可以直接使用 context.Background。事實上,它們兩個底層的實作是一模一樣的:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}
在使用 Context 的時候,有一些約定俗成的規則。
- 一般函式使用 Context 的時候,會把這個引數放在第一個引數的位置。
- 從來不把 nil 當做 Context 型別的引數值,可以使用 context.Background() 建立一個空的上下文物件,也不要使用 nil。
- Context 只用來臨時做函式之間的上下文透傳,不能持久化 Context 或者把 Context 長久儲存。把 Context 持久化到資料庫、本地檔案或者全域性變數、快取中都是錯誤的用法。
- key 的型別不應該是字串型別或者其它內建型別,否則容易在包之間使用 Context 時候產生衝突。使用 WithValue 時,key 的型別應該是自己定義的型別。
- 常常使用 struct{}作為底層型別定義 key 的型別。對於 exported key 的靜態型別,常常是介面或者指標。這樣可以儘量減少記憶體分配。
其實官方的文件也是比較搞笑的,文件中強調 key 的型別不要使用 string,結果接下來的例子中就是用 string 型別作為 key 的型別。你自己把握住這個要點就好,如果你能保證別人使用你的 Context 時不會和你定義的 key 衝突,那麼 key 的型別就比較隨意,因為你自己保證了不同包的 key 不會衝突,否則建議你儘量採用保守的 unexported 的型別。
建立特殊用途 Context 的方法
接下來,我會介紹標準庫中幾種建立特殊用途 Context 的方法:WithValue、WithCancel、WithTimeout 和 WithDeadline,包括它們的功能以及實作方式。
WithValue
WithValue 基於 parent Context 生成一個新的 Context,儲存了一個 key-value 鍵值對。它常常用來傳遞上下文。
WithValue 方法其實是建立了一個型別為 valueCtx 的 Context,它的型別定義如下:
type valueCtx struct {
Context
key, val interface{}
}
它持有一個 key-value 鍵值對,還持有 parent 的 Context。它覆蓋了 Value 方法,優先從自己的儲存中檢查這個 key,不存在的話會從 parent 中繼續檢查。
Go 標準庫實作的 Context 還實作了鏈式查詢。如果不存在,還會向 parent Context 去查詢,如果 parent 還是 valueCtx 的話,還是遵循相同的原則:valueCtx 會嵌入 parent,所以還是會查詢 parent 的 Value 方法的。
ctx = context.TODO()
ctx = context.WithValue(ctx, "key1", "0001")
ctx = context.WithValue(ctx, "key2", "0001")
ctx = context.WithValue(ctx, "key3", "0001")
ctx = context.WithValue(ctx, "key4", "0004")
fmt.Println(ctx.Value("key1"))

WithCancel
WithCancel 方法返回 parent 的副本,只是副本中的 Done Channel 是新建的物件,它的型別是 cancelCtx。
我們常常在一些需要主動取消長時間的任務時,建立這種型別的 Context,然後把這個 Context 傳給長時間執行任務的 goroutine。當需要中止任務時,我們就可以 cancel 這個 Context,這樣長時間執行任務的 goroutine,就可以透過檢查這個 Context,知道 Context 已經被取消了。
WithCancel 返回值中的第二個值是一個 cancel 函式。其實,這個返回值的名稱(cancel)和型別(Cancel)也非常迷惑人。
記住,不是隻有你想中途放棄,才去呼叫 cancel,只要你的任務正常完成了,就需要呼叫 cancel,這樣,這個 Context 才能釋放它的資源(通知它的 children 處理 cancel,從它的 parent 中把自己移除,甚至釋放相關的 goroutine)。很多同學在使用這個方法的時候,都會忘記呼叫 cancel,切記切記,而且一定儘早釋放。
我們來看下 WithCancel 方法的實作程式碼:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := newCancelCtx(parent)
propagateCancel(parent, &c)// 把c朝上傳播
return &c, func() { c.cancel(true, Canceled) }
}
// newCancelCtx returns an initialized cancelCtx.
func newCancelCtx(parent Context) cancelCtx {
return cancelCtx{Context: parent}
}
程式碼中呼叫的 propagateCancel 方法會順著 parent 路徑往上找,直到找到一個 cancelCtx,或者為 nil。如果不為空,就把自己加入到這個 cancelCtx 的 child,以便這個 cancelCtx 被取消的時候通知自己。如果為空,會新起一個 goroutine,由它來監聽 parent 的 Done 是否已關閉。
當這個 cancelCtx 的 cancel 函式被呼叫的時候,或者 parent 的 Done 被 close 的時候,這個 cancelCtx 的 Done 才會被 close。
cancel 是向下傳遞的,如果一個 WithCancel 生成的 Context 被 cancel 時,如果它的子 Context(也有可能是孫,或者更低,依賴子的型別)也是 cancelCtx 型別的,就會被 cancel,但是不會向上傳遞。parent Context 不會因為子 Context 被 cancel 而 cancel。
cancelCtx 被取消時,它的 Err 欄位就是下面這個 Canceled 錯誤:
var Canceled = errors.New("context canceled")WithTimeoutWithTimeout 其實是和 WithDeadline 一樣,只不過一個引數是超時時間,一個引數是截止時間。超時時間加上當前時間,其實就是截止時間,因此,WithTimeout 的實作是:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
// 當前時間+timeout就是deadline
return WithDeadline(parent, time.Now().Add(timeout))
}WithDeadlineWithDeadline 會返回一個 parent 的副本,並且設定了一個不晚於引數 d 的截止時間,型別為 timerCtx(或者是 cancelCtx)。
如果它的截止時間晚於 parent 的截止時間,那麼就以 parent 的截止時間為準,並返回一個型別為 cancelCtx 的 Context,因為 parent 的截止時間到了,就會取消這個 cancelCtx。
如果當前時間已經超過了截止時間,就直接返回一個已經被 cancel 的 timerCtx。否則就會啟動一個定時器,到截止時間取消這個 timerCtx。
綜合起來,timerCtx 的 Done 被 Close 掉,主要是由下面的某個事件觸發的:
- 截止時間到了;
- cancel 函式被呼叫;
- parent 的 Done 被 close。
下面的程式碼是 WithDeadline 方法的實作:
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {
// 如果parent的截止時間更早,直接返回一個cancelCtx即可
if cur, ok := parent.Deadline(); ok && cur.Before(d) {
return WithCancel(parent)
}
c := &timerCtx{
cancelCtx: newCancelCtx(parent),
deadline: d,
}
propagateCancel(parent, c) // 同cancelCtx的處理邏輯
dur := time.Until(d)
if dur <= 0 { //當前時間已經超過了截止時間,直接cancel
c.cancel(true, DeadlineExceeded)
return c, func() { c.cancel(false, Canceled) }
}
c.mu.Lock()
defer c.mu.Unlock()
if c.err == nil {
// 設定一個定時器,到截止時間後取消
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded)
})
}
return c, func() { c.cancel(true, Canceled) }
}
和 cancelCtx 一樣,WithDeadline(WithTimeout)返回的 cancel 一定要呼叫,並且要儘可能早地被呼叫,這樣才能儘早釋放資源,不要單純地依賴截止時間被動取消。正確的使用姿勢是啥呢?我們來看一個例子。
func slowOperationWithTimeout(ctx context.Context) (Result, error) {
ctx, cancel := context.WithTimeout(ctx, 100*time.Millisecond)
defer cancel() // 一旦慢操作完成就立馬呼叫cancel
return slowOperation(ctx)
}總結我們經常使用 Context 來取消一個 goroutine 的執行,這是 Context 最常用的場景之一,Context 也被稱為 goroutine 生命週期範圍(goroutine-scoped)的 Context,把 Context 傳遞給 goroutine。但是,goroutine 需要嘗試檢查 Context 的 Done 是否關閉了:
func main() {
ctx, cancel := context.WithCancel(context.Background())
go func() {
defer func() {
fmt.Println("goroutine exit")
}()
for {
select {
case <-ctx.Done():
return
default:
time.Sleep(time.Second)
}
}
}()
time.Sleep(time.Second)
cancel()
time.Sleep(2 * time.Second)
}
如果你要為 Context 實作一個帶超時功能的呼叫,比如訪問遠端的一個微服務,超時並不意味著你會通知遠端微服務已經取消了這次呼叫,大機率的實作只是避免客戶端的長時間等待,遠端的伺服器依然還執行著你的請求。
所以,有時候,Context 並不會減少對伺服器的請求負擔。如果在 Context 被 cancel 的時候,你能關閉和伺服器的連線,中斷和資料庫伺服器的通訊、停止對本地檔案的讀寫,那麼,這樣的超時處理,同時能減少對服務呼叫的壓力,但是這依賴於你對超時的底層處理機制。
思考題
使用 WithCancel 和 WithValue 寫一個級聯的使用 Context 的例子,驗證一下 parent Context 被 cancel 後,子 conext 是否也立刻被 cancel 了。
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
12|atomic:要保證原子操作,一定要使用這幾種方法
你好,我是鳥窩。
本章導讀
atomic 原子操作定位圖
┌─────────────────┐
│ 共享變數 x │
└────────┬────────┘
│ 併發存取
┌──────┼───────────────┐
▼ ▼ ▼
Load Store Add / CAS
(讀) (寫) (更新/比較交換)
目的:用不可分割操作避免資料競爭(適合小而簡單的共享狀態)
前面我們在學習 Mutex、RWMutex 等併發原語的實作時,你可以看到,最底層是透過 atomic 包中的一些原子操作來實作的。當時,為了讓你的注意力集中在這些原語的功能實作上,我並沒有展開介紹這些原子操作是幹什麼用的。
你可能會說,這些併發原語已經可以應對大多數的併發場景了,為啥還要學習原子操作呢?其實,這是因為,在很多場景中,使用併發原語實作起來比較複雜,而原子操作可以幫助我們更輕鬆地實作底層的最佳化。
所以,現在,我會專門用一節課,帶你仔細地瞭解一下什麼是原子操作,atomic 包都提供了哪些實作原子操作的方法。另外,我還會帶你實作一個基於原子操作的資料結構。好了,接下來我們先來學習下什麼是原子操作。
原子操作的基礎知識
Package sync/atomic 實作了同步演算法底層的原子的記憶體操作原語,我們把它叫做原子操作原語,它提供了一些實作原子操作的方法。
之所以叫原子操作,是因為一個原子在執行的時候,其它執行緒不會看到執行一半的操作結果。在其它執行緒看來,原子操作要麼執行完了,要麼還沒有執行,就像一個最小的粒子 - 原子一樣,不可分割。
CPU 提供了基礎的原子操作,不過,不同架構的系統的原子操作是不一樣的。
對於單處理器單核系統來說,如果一個操作是由一個 CPU 指令來實作的,那麼它就是原子操作,比如它的 XCHG 和 INC 等指令。如果操作是基於多條指令來實作的,那麼,執行的過程中可能會被中斷,並執行上下文切換,這樣的話,原子性的保證就被打破了,因為這個時候,操作可能只執行了一半。
在多處理器多核系統中,原子操作的實作就比較複雜了。
由於 cache 的存在,單個核上的單個指令進行原子操作的時候,你要確保其它處理器或者核不訪問此原子操作的地址,或者是確保其它處理器或者核總是訪問原子操作之後的最新的值。x86 架構中提供了指令字首 LOCK,LOCK 保證了指令(比如 LOCK CMPXCHG op1、op2)不會受其它處理器或 CPU 核的影響,有些指令(比如 XCHG)本身就提供 Lock 的機制。不同的 CPU 架構提供的原子操作指令的方式也是不同的,比如對於多核的 MIPS 和 ARM,提供了 LL/SC(Load Link/Store Conditional)指令,可以幫助實作原子操作(ARMLL/SC 指令 LDREX 和 STREX)。
因為不同的 CPU 架構甚至不同的版本提供的原子操作的指令是不同的,所以,要用一種程式語言實作支援不同架構的原子操作是相當有難度的。不過,還好這些都不需要你操心,因為 Go 提供了一個通用的原子操作的 API,將更底層的不同的架構下的實作封裝成 atomic 包,提供了修改型別的原子操作(atomic read-modify-write,RMW)和載入儲存型別的原子操作(Load 和 Store)的 API,稍後我會一一介紹。
有的程式碼也會因為架構的不同而不同。有時看起來貌似一個操作是原子操作,但實際上,對於不同的架構來說,情況是不一樣的。比如下面的程式碼的第 4 行,是將一個 64 位的值賦值給變數 i:
const x int64 = 1 + 1<<33
func main() {
var i = x
_ = i
}
如果你使用 GOARCH=386 的架構去編譯這段程式碼,那麼,第 5 行其實是被拆成了兩個指令,分別操作低 32 位和高 32 位(使用 GOARCH=386 go tool compile -N -l test.go;GOARCH=386 go tool objdump -gnu test.o 反編譯試試):

如果 GOARCH=amd64 的架構去編譯這段程式碼,那麼,第 5 行其中的賦值操作其實是一條指令:

所以,如果要想保證原子操作,切記一定要使用 atomic 提供的方法。
好了,瞭解了什麼是原子操作以及不同系統的不同原子操作,接下來,我來介紹下 atomic 原子操作的應用場景。
atomic 原子操作的應用場景
開篇我說過,使用 atomic 的一些方法,我們可以實作更底層的一些最佳化。如果使用 Mutex 等併發原語進行這些最佳化,雖然可以解決問題,但是這些併發原語的實作邏輯比較複雜,對效能還是有一定的影響的。
舉個例子:假設你想在程式中使用一個標誌(flag,比如一個 bool 型別的變數),來標識一個定時任務是否已經啟動執行了,你會怎麼做呢?
我們先來看看加鎖的方法。如果使用 Mutex 和 RWMutex,在讀取和設定這個標誌的時候加鎖,是可以做到互斥的、保證同一時刻只有一個定時任務在執行的,所以使用 Mutex 或者 RWMutex 是一種解決方案。
其實,這個場景中的問題不涉及到對資源複雜的競爭邏輯,只是會併發地讀寫這個標誌,這類場景就適合使用 atomic 的原子操作。具體怎麼做呢?你可以使用一個 uint32 型別的變數,如果這個變數的值是 0,就標識沒有任務在執行,如果它的值是 1,就標識已經有任務在完成了。你看,是不是很簡單呢?
再來看一個例子。假設你在開發應用程式的時候,需要從配置伺服器中讀取一個節點的配置資訊。而且,在這個節點的配置發生變更的時候,你需要重新從配置伺服器中拉取一份新的配置並更新。你的程式中可能有多個 goroutine 都依賴這份配置,涉及到對這個配置物件的併發讀寫,你可以使用讀寫鎖實作對配置物件的保護。在大部分情況下,你也可以利用 atomic 實作配置物件的更新和載入。
分析到這裡,可以看到,這兩個例子都可以使用基本併發原語來實作的,只不過,我們不需要這些基本併發原語裡面的複雜邏輯,而是隻需要其中的簡單原子操作,所以,這些場景可以直接使用 atomic 包中的方法去實作。
有時候,你也可以使用 atomic 實作自己定義的基本併發原語,比如 Go issue 有人提議的 CondMutex、Mutex.LockContext、WaitGroup.Go 等,我們可以使用 atomic 或者基於它的更高一級的併發原語去實作。我先前講的幾種基本併發原語的底層(比如 Mutex),就是基於透過 atomic 的方法實作的。
除此之外,atomic 原子操作還是實作 lock-free 資料結構的基石。
在實作 lock-free 的資料結構時,我們可以不使用互斥鎖,這樣就不會讓執行緒因為等待互斥鎖而阻塞休眠,而是讓執行緒保持繼續處理的狀態。另外,不使用互斥鎖的話,lock-free 的資料結構還可以提供併發的效能。
不過,lock-free 的資料結構實作起來比較複雜,需要考慮的東西很多,有興趣的同學可以看一位微軟專家寫的一篇經驗分享:Lockless Programming Considerations for Xbox 360 and Microsoft Windows,這裡我們不細談了。不過,這節課的最後我會帶你開發一個 lock-free 的 queue,來學習下使用 atomic 操作實作 lock-free 資料結構的方法,你可以拿它和使用互斥鎖實作的 queue 做效能對比,看看在效能上是否有所提升。
看到這裡,你是不是覺得 atomic 非常重要呢?不過,要想能夠靈活地應用 atomic,我們首先得知道 atomic 提供的所有方法。
atomic 提供的方法
目前的 Go 的泛型的特性還沒有釋出,Go 的標準庫中的很多實作會顯得非常囉嗦,多個型別會實作很多類似的方法,尤其是 atomic 包,最為明顯。相信泛型支援之後,atomic 的 API 會清爽很多。
atomic 為了支援 int32、int64、uint32、uint64、uintptr、Pointer(Add 方法不支援)型別,分別提供了 AddXXX、CompareAndSwapXXX、SwapXXX、LoadXXX、StoreXXX 等方法。不過,你也不要擔心,你只要記住了一種資料型別的方法的意義,其它資料型別的方法也是一樣的。
關於 atomic,還有一個地方你一定要記住,atomic 操作的物件是一個地址,你需要把可定址的變數的地址作為引數傳遞給方法,而不是把變數的值傳遞給方法。
好了,下面我就來給你介紹一下 atomic 提供的方法。掌握了這些,你就可以說完全掌握了 atomic 包。
Add
首先,我們來看 Add 方法的簽名:

其實,Add 方法就是給第一個引數地址中的值增加一個 delta 值。
對於有符號的整數來說,delta 可以是一個負數,相當於減去一個值。對於無符號的整數和 uinptr 型別來說,怎麼實作減去一個值呢?畢竟,atomic 並沒有提供單獨的減法操作。
我來跟你說一種方法。你可以利用計算機補碼的規則,把減法變成加法。以 uint32 型別為例:
AddUint32(&x, ^uint32(c-1)).
如果是對 uint64 的值進行操作,那麼,就把上面的程式碼中的 uint32 替換成 uint64。
尤其是減 1 這種特殊的操作,我們可以簡化為:
AddUint32(&x, ^uint32(0))
好了,我們再來看看 CAS 方法。
CAS (CompareAndSwap)
以 int32 為例,我們學習一下 CAS 提供的功能。在 CAS 的方法簽名中,需要提供要操作的地址、原資料值、新值,如下所示:
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
我們來看下這個方法的功能。
這個方法會比較當前 addr 地址裡的值是不是 old,如果不等於 old,就返回 false;如果等於 old,就把此地址的值替換成 new 值,返回 true。這就相當於“判斷相等才替換”。
如果使用偽程式碼來表示這個原子操作,程式碼如下:
if *addr == old {
*addr = new
return true
}
return false
它支援的型別和方法如圖所示:

Swap
如果不需要比較舊值,只是比較粗暴地替換的話,就可以使用 Swap 方法,它替換後還可以返回舊值,偽程式碼如下:
old = *addr
*addr = new
return old
它支援的資料型別和方法如圖所示:

Load
Load 方法會取出 addr 地址中的值,即使在多處理器、多核、有 CPU cache 的情況下,這個操作也能保證 Load 是一個原子操作。
它支援的資料型別和方法如圖所示:

Store
Store 方法會把一個值存入到指定的 addr 地址中,即使在多處理器、多核、有 CPU cache 的情況下,這個操作也能保證 Store 是一個原子操作。別的 goroutine 透過 Load 讀取出來,不會看到存取了一半的值。
它支援的資料型別和方法如圖所示:

Value 型別
剛剛說的都是一些比較常見的型別,其實,atomic 還提供了一個特殊的型別:Value。它可以原子地存取物件型別,但也只能存取,不能 CAS 和 Swap,常常用在配置變更等場景中。

接下來,我以一個配置變更的例子,來演示 Value 型別的使用。這裡定義了一個 Value 型別的變數 config, 用來儲存配置資訊。
首先,我們啟動一個 goroutine,然後讓它隨機 sleep 一段時間,之後就變更一下配置,並透過我們前面學到的 Cond 併發原語,通知其它的 reader 去載入新的配置。
接下來,我們啟動一個 goroutine 等待配置變更的訊號,一旦有變更,它就會載入最新的配置。
透過這個例子,你可以瞭解到 Value 的 Store/Load 方法的使用,因為它只有這兩個方法,只要掌握了它們的使用,你就完全掌握了 Value 型別。
type Config struct {
NodeName string
Addr string
Count int32
}
func loadNewConfig() Config {
return Config{
NodeName: "北京",
Addr: "10.77.95.27",
Count: rand.Int31(),
}
}
func main() {
var config atomic.Value
config.Store(loadNewConfig())
var cond = sync.NewCond(&sync.Mutex{})
// 設定新的config
go func() {
for {
time.Sleep(time.Duration(5+rand.Int63n(5)) * time.Second)
config.Store(loadNewConfig())
cond.Broadcast() // 通知等待著配置已變更
}
}()
go func() {
for {
cond.L.Lock()
cond.Wait() // 等待變更訊號
c := config.Load().(Config) // 讀取新的配置
fmt.Printf("new config: %+v\n", c)
cond.L.Unlock()
}
}()
select {}
}
好了,關於標準庫的 atomic 提供的方法,到這裡我們就學完了。事實上,atomic 包提供了非常好的支援各種平臺的一致性的 API,絕大部分專案都是直接使用它。接下來,我再給你介紹一下第三方庫,幫助你稍微開拓一下思維。
第三方庫的擴充套件
其實,atomic 的 API 已經算是很簡單的了,它提供了包一級的函式,可以對幾種型別的資料執行原子操作。
不過有一點讓人覺得不爽的是,或者是讓熟悉面向物件程式設計的程式設計師不爽的是,函式呼叫有一點點麻煩。所以,有些人就對這些函式做了進一步的包裝,跟 atomic 中的 Value 型別類似,這些型別也提供了面向物件的使用方式,比如關注度比較高的uber-go/atomic,它定義和封裝了幾種與常見型別相對應的原子操作型別,這些型別提供了原子操作的方法。這些型別包括 Bool、Duration、Error、Float64、Int32、Int64、String、Uint32、Uint64 等。
比如 Bool 型別,提供了 CAS、Store、Swap、Toggle 等原子方法,還提供 String、MarshalJSON、UnmarshalJSON 等輔助方法,確實是一個精心設計的 atomic 擴充套件庫。關於這些方法,你一看名字就能猜出來它們的功能,我就不多說了。
其它的資料型別也和 Bool 型別相似,使用起來就像面向物件的程式設計一樣,你可以看下下面的這段程式碼。
var running atomic.Bool
running.Store(true)
running.Toggle()
fmt.Println(running.Load()) // false使用 atomic 實作 Lock-Free queueatomic 常常用來實作 Lock-Free 的資料結構,這次我會給你展示一個 Lock-Free queue 的實作。
Lock-Free queue 最出名的就是 Maged M. Michael 和 Michael L. Scott 1996 年發表的論文中的演算法,演算法比較簡單,容易實作,偽程式碼的每一行都提供了註釋,我就不在這裡貼出偽程式碼了,因為我們使用 Go 實作這個資料結構的程式碼幾乎和偽程式碼一樣:
package queue
import (
"sync/atomic"
"unsafe"
)
// lock-free的queue
type LKQueue struct {
head unsafe.Pointer
tail unsafe.Pointer
}
// 透過連結串列實作,這個資料結構代表連結串列中的節點
type node struct {
value interface{}
next unsafe.Pointer
}
func NewLKQueue() *LKQueue {
n := unsafe.Pointer(&node{})
return &LKQueue{head: n, tail: n}
}
// 入隊
func (q *LKQueue) Enqueue(v interface{}) {
n := &node{value: v}
for {
tail := load(&q.tail)
next := load(&tail.next)
if tail == load(&q.tail) { // 尾還是尾
if next == nil { // 還沒有新資料入隊
if cas(&tail.next, next, n) { //增加到隊尾
cas(&q.tail, tail, n) //入隊成功,移動尾巴指標
return
}
} else { // 已有新資料加到佇列後面,需要移動尾指標
cas(&q.tail, tail, next)
}
}
}
}
// 出隊,沒有元素則返回nil
func (q *LKQueue) Dequeue() interface{} {
for {
head := load(&q.head)
tail := load(&q.tail)
next := load(&head.next)
if head == load(&q.head) { // head還是那個head
if head == tail { // head和tail一樣
if next == nil { // 說明是空佇列
return nil
}
// 只是尾指標還沒有調整,嘗試調整它指向下一個
cas(&q.tail, tail, next)
} else {
// 讀取出隊的資料
v := next.value
// 既然要出隊了,頭指標移動到下一個
if cas(&q.head, head, next) {
return v // Dequeue is done. return
}
}
}
}
}
// 將unsafe.Pointer原子載入轉換成node
func load(p *unsafe.Pointer) (n *node) {
return (*node)(atomic.LoadPointer(p))
}
// 封裝CAS,避免直接將*node轉換成unsafe.Pointer
func cas(p *unsafe.Pointer, old, new *node) (ok bool) {
return atomic.CompareAndSwapPointer(
p, unsafe.Pointer(old), unsafe.Pointer(new))
}
我來給你介紹下這裡的主要邏輯。
這個 lock-free 的實作使用了一個輔助頭指標(head),頭指標不包含有意義的資料,只是一個輔助的節點,這樣的話,出隊入隊中的節點會更簡單。
入隊的時候,透過 CAS 操作將一個元素新增到隊尾,並且移動尾指標。
出隊的時候移除一個節點,並透過 CAS 操作移動 head 指標,同時在必要的時候移動尾指標。
總結
好了,我們來小結一下。這節課,我們學習了 atomic 的基本使用方法,以及它提供的幾種方法,包括 Add、CAS、Swap、Load、Store、Value 型別。除此之外,我還介紹了一些第三方庫,並且帶你實作了 Lock-free queue。到這裡,相信你已經掌握了 atomic 提供的各種方法,並且能夠應用到實踐中了。
最後,我還想和你討論一個額外的問題:對一個地址的賦值是原子操作嗎?
這是一個很有趣的問題,如果是原子操作,還要 atomic 包乾什麼?官方的文件中並沒有特意的介紹,不過,在一些 issue 或者論壇中,每當有人談到這個問題時,總是會被建議用 atomic 包。
Dave Cheney就談到過這個問題,講得非常好。我來給你總結一下他講的知識點,這樣你就比較容易理解使用 atomic 和直接記憶體操作的區別了。
在現在的系統中,write 的地址基本上都是對齊的(aligned)。 比如,32 位的作業系統、CPU 以及編譯器,write 的地址總是 4 的倍數,64 位的系統總是 8 的倍數(還記得 WaitGroup 針對 64 位系統和 32 位系統對 state1 的欄位不同的處理嗎)。對齊地址的寫,不會導致其他人看到只寫了一半的資料,因為它透過一個指令就可以實作對地址的操作。如果地址不是對齊的話,那麼,處理器就需要分成兩個指令去處理,如果執行了一個指令,其它人就會看到更新了一半的錯誤的資料,這被稱做撕裂寫(torn write) 。所以,你可以認為賦值操作是一個原子操作,這個“原子操作”可以認為是保證資料的完整性。
但是,對於現代的多處理多核的系統來說,由於 cache、指令重排,可見性等問題,我們對原子操作的意義有了更多的追求。在多核系統中,一個核對地址的值的更改,在更新到主記憶體中之前,是在多級快取中存放的。這時,多個核看到的資料可能是不一樣的,其它的核可能還沒有看到更新的資料,還在使用舊的資料。
多處理器多核心繫統為了處理這類問題,使用了一種叫做記憶體屏障(memory fence 或 memory barrier)的方式。一個寫記憶體屏障會告訴處理器,必須要等到它管道中的未完成的操作(特別是寫操作)都被重新整理到記憶體中,再進行操作。此操作還會讓相關的處理器的 CPU 快取失效,以便讓它們從主存中拉取最新的值。
atomic 包提供的方法會提供記憶體屏障的功能,所以,atomic 不僅僅可以保證賦值的資料完整性,還能保證資料的可見性,一旦一個核更新了該地址的值,其它處理器總是能讀取到它的最新值。但是,需要注意的是,因為需要處理器之間保證資料的一致性,atomic 的操作也是會降低效能的。
思考題
atomic.Value 只有 Load/Store 方法,你是不是感覺意猶未盡?你可以嘗試為 Value 型別增加 Swap 和 CompareAndSwap 方法(可以參考一下這份資料)。
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
13|Channel:另闢蹊徑,解決併發問題
你好,我是鳥窩。
本章導讀
Channel 基本通訊圖
Sender goroutine ── send ──> [ channel / buffer ] ── recv ──> Receiver goroutine
│
├─ 無 buffer:同步交握
└─ 有 buffer:可暫存資料、解耦速度
Channel 是 Go 語言內建的 first-class 型別,也是 Go 語言與眾不同的特性之一。Go 語言的 Channel 設計精巧簡單,以至於也有人用其它語言編寫了類似 Go 風格的 Channel 庫,比如docker/libchan、tylertreat/chan,但是並不像 Go 語言一樣把 Channel 內建到了語言規範中。從這一點,你也可以看出來,Channel 的地位在程式語言中的地位之高,比較罕見。
所以,這節課,我們就來學習下 Channel。
Channel 的發展
要想了解 Channel 這種 Go 程式語言中的特有的資料結構,我們要追溯到 CSP 模型,學習一下它的歷史,以及它對 Go 創始人設計 Channel 型別的影響。
CSP 是 Communicating Sequential Process 的簡稱,中文直譯為通訊順序程式,或者叫做交換資訊的循序程式,是用來描述併發系統中進行互動的一種模式。
CSP 最早出現於電腦科學家 Tony Hoare 在 1978 年發表的論文中(你可能不熟悉 Tony Hoare 這個名字,但是你一定很熟悉排序演算法中的 Quicksort 演算法,他就是 Quicksort 演算法的作者,圖靈獎的獲得者)。最初,論文中提出的 CSP 版本在本質上不是一種程式演算,而是一種併發程式語言,但之後又經過了一系列的改進,最終發展並精煉出 CSP 的理論。CSP 允許使用程式元件來描述系統,它們獨立執行,並且只通過訊息傳遞的方式通訊。
就像 Go 的創始人之一 Rob Pike 所說的:“每一個計算機程式設計師都應該讀一讀 Tony Hoare 1978 年的關於 CSP 的論文。”他和 Ken Thompson 在設計 Go 語言的時候也深受此論文的影響,並將 CSP 理論真正應用於語言本身(Russ Cox 專門寫了一篇文章記錄這個歷史),透過引入 Channel 這個新的型別,來實作 CSP 的思想。
Channel 型別是 Go 語言內建的型別,你無需引入某個包,就能使用它。雖然 Go 也提供了傳統的併發原語,但是它們都是透過庫的方式提供的,你必須要引入 sync 包或者 atomic 包才能使用它們,而 Channel 就不一樣了,它是內建型別,使用起來非常方便。
Channel 和 Go 的另一個獨特的特性 goroutine 一起為併發程式設計提供了優雅的、便利的、與傳統併發控制不同的方案,並演化出很多併發模式。接下來,我們就來看一看 Channel 的應用場景。
Channel 的應用場景
首先,我想先帶你看一條 Go 語言中流傳很廣的諺語:
Don’t communicate by sharing memory, share memory by communicating.
Go Proverbs by Rob Pike
這是 Rob Pike 在 2015 年的一次 Gopher 會議中提到的一句話,雖然有一點繞,但也指出了使用 Go 語言的哲學,我嘗試著來翻譯一下:“執行業務處理的 goroutine 不要透過共享記憶體的方式通訊,而是要透過 Channel 通訊的方式分享資料。”
“communicate by sharing memory”和“share memory by communicating”是兩種不同的併發處理模式。“communicate by sharing memory”是傳統的併發程式設計處理方式,就是指,共享的資料需要用鎖進行保護,goroutine 需要獲取到鎖,才能併發訪問資料。
“share memory by communicating”則是類似於 CSP 模型的方式,透過通訊的方式,一個 goroutine 可以把資料的“所有權”交給另外一個 goroutine(雖然 Go 中沒有“所有權”的概念,但是從邏輯上說,你可以把它理解為是所有權的轉移)。
從 Channel 的歷史和設計哲學上,我們就可以瞭解到,Channel 型別和基本併發原語是有競爭關係的,它應用於併發場景,涉及到 goroutine 之間的通訊,可以提供併發的保護,等等。
綜合起來,我把 Channel 的應用場景分為五種型別。這裡你先有個印象,這樣你可以有目的地去學習 Channel 的基本原理。下節課我會藉助具體的例子,來帶你掌握這幾種型別。
- 資料交流:當作併發的 buffer 或者 queue,解決生產者 - 消費者問題。多個 goroutine 可以併發當作生產者(Producer)和消費者(Consumer)。
- 資料傳遞:一個 goroutine 將資料交給另一個 goroutine,相當於把資料的擁有權 (引用) 託付出去。
- 訊號通知:一個 goroutine 可以將訊號 (closing、closed、data ready 等) 傳遞給另一個或者另一組 goroutine 。
- 任務編排:可以讓一組 goroutine 按照一定的順序併發或者序列的執行,這就是編排的功能。
- 鎖:利用 Channel 也可以實作互斥鎖的機制。
下面,我們來具體學習下 Channel 的基本用法。
Channel 基本用法
你可以往 Channel 中傳送資料,也可以從 Channel 中接收資料,所以,Channel 型別(為了說起來方便,我們下面都把 Channel 叫做 chan)分為只能接收、只能傳送、既可以接收又可以傳送三種型別。下面是它的語法定義:
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
相應地,Channel 的正確語法如下:
chan string // 可以傳送接收string
chan<- struct{} // 只能傳送struct{}
<-chan int // 只能從chan接收int
我們把既能接收又能傳送的 chan 叫做雙向的 chan,把只能傳送和只能接收的 chan 叫做單向的 chan。其中,“<-”表示單向的 chan,如果你記不住,我告訴你一個簡便的方法:這個箭頭總是射向左邊的,元素型別總在最右邊。如果箭頭指向 chan,就表示可以往 chan 中塞資料;如果箭頭遠離 chan,就表示 chan 會往外吐資料。
chan 中的元素是任意的型別,所以也可能是 chan 型別,我來舉個例子,比如下面的 chan 型別也是合法的:
chan<- chan int
chan<- <-chan int
<-chan <-chan int
chan (<-chan int)
可是,怎麼判定箭頭符號屬於哪個 chan 呢?其實,“<-”有個規則,總是儘量和左邊的 chan 結合(The <- operator associates with the leftmost chan possible:),因此,上面的定義和下面的使用括號的劃分是一樣的:
chan<- (chan int) // <- 和第一個chan結合
chan<- (<-chan int) // 第一個<-和最左邊的chan結合,第二個<-和左邊第二個chan結合
<-chan (<-chan int) // 第一個<-和最左邊的chan結合,第二個<-和左邊第二個chan結合
chan (<-chan int) // 因為括號的原因,<-和括號內第一個chan結合
透過 make,我們可以初始化一個 chan,未初始化的 chan 的零值是 nil。你可以設定它的容量,比如下面的 chan 的容量是 9527,我們把這樣的 chan 叫做 buffered chan;如果沒有設定,它的容量是 0,我們把這樣的 chan 叫做 unbuffered chan。
make(chan int, 9527)
如果 chan 中還有資料,那麼,從這個 chan 接收資料的時候就不會阻塞,如果 chan 還未滿(“滿”指達到其容量),給它傳送資料也不會阻塞,否則就會阻塞。unbuffered chan 只有讀寫都準備好之後才不會阻塞,這也是很多使用 unbuffered chan 時的常見 Bug。
還有一個知識點需要你記住:nil 是 chan 的零值,是一種特殊的 chan,對值是 nil 的 chan 的傳送接收呼叫者總是會阻塞。
下面,我來具體給你介紹幾種基本操作,分別是傳送資料、接收資料,以及一些其它操作。學會了這幾種操作,你就能真正地掌握 Channel 的用法了。
1. 傳送資料
往 chan 中傳送一個資料使用“ch<-”,傳送資料是一條語句:
ch <- 2000
這裡的 ch 是 chan int 型別或者是 chan <-int。
2. 接收資料
從 chan 中接收一條資料使用“<-ch”,接收資料也是一條語句:
x := <-ch // 把接收的一條資料賦值給變數x
foo(<-ch) // 把接收的一個的資料作為引數傳給函式
<-ch // 丟棄接收的一條資料
這裡的 ch 型別是 chan T 或者 <-chan T。
接收資料時,還可以返回兩個值。第一個值是返回的 chan 中的元素,很多人不太熟悉的是第二個值。第二個值是 bool 型別,代表是否成功地從 chan 中讀取到一個值,如果第二個引數是 false,chan 已經被 close 而且 chan 中沒有快取的資料,這個時候,第一個值是零值。所以,如果從 chan 讀取到一個零值,可能是 sender 真正傳送的零值,也可能是 closed 的並且沒有快取元素產生的零值。
3. 其它操作
Go 內建的函式 close、cap、len 都可以操作 chan 型別:close 會把 chan 關閉掉,cap 返回 chan 的容量,len 返回 chan 中快取的還未被取走的元素數量。
send 和 recv 都可以作為 select 語句的 case clause,如下面的例子:
func main() {
var ch = make(chan int, 10)
for i := 0; i < 10; i++ {
select {
case ch <- i:
case v := <-ch:
fmt.Println(v)
}
}
}
chan 還可以應用於 for-range 語句中,比如:
for v := range ch {
fmt.Println(v)
}
或者是忽略讀取的值,只是清空 chan:
for range ch {
}
好了,到這裡,Channel 的基本用法,我們就學完了。下面我從程式碼實作的角度分析 chan 型別的實作。畢竟,只有掌握了原理,你才能真正地用好它。
Channel 的實作原理
接下來,我會給你介紹 chan 的資料結構、初始化的方法以及三個重要的操作方法,分別是 send、recv 和 close。透過學習 Channel 的底層實作,你會對 Channel 的功能和異常情況有更深的理解。
chan 資料結構
chan 型別的資料結構如下圖所示,它的資料型別是runtime.hchan。
下面我來具體解釋各個欄位的意義。
- qcount:代表 chan 中已經接收但還沒被取走的元素的個數。內建函式 len 可以返回這個欄位的值。
- dataqsiz:佇列的大小。chan 使用一個迴圈佇列來存放元素,迴圈佇列很適合這種生產者 - 消費者的場景(我很好奇為什麼這個欄位省略 size 中的 e)。
- buf:存放元素的迴圈佇列的 buffer。
- elemtype 和 elemsize:chan 中元素的型別和 size。因為 chan 一旦宣告,它的元素型別是固定的,即普通型別或者指標型別,所以元素大小也是固定的。
- sendx:處理傳送資料的指標在 buf 中的位置。一旦接收了新的資料,指標就會加上 elemsize,移向下一個位置。buf 的總大小是 elemsize 的整數倍,而且 buf 是一個迴圈列表。
- recvx:處理接收請求時的指標在 buf 中的位置。一旦取出資料,此指標會移動到下一個位置。
- recvq:chan 是多生產者多消費者的模式,如果消費者因為沒有資料可讀而被阻塞了,就會被加入到 recvq 佇列中。
- sendq:如果生產者因為 buf 滿了而阻塞,會被加入到 sendq 佇列中。
初始化
Go 在編譯的時候,會根據容量的大小選擇呼叫 makechan64,還是 makechan。
下面的程式碼是處理 make chan 的邏輯,它會決定是使用 makechan 還是 makechan64 來實作 chan 的初始化:

我們只關注 makechan 就好了,因為 makechan64 只是做了 size 檢查,底層還是呼叫 makechan 實作的。makechan 的目標就是生成 hchan 物件。
那麼,接下來,就讓我們來看一下 makechan 的主要邏輯。主要的邏輯我都加上了註釋,它會根據 chan 的容量的大小和元素的型別不同,初始化不同的儲存空間:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 略去檢查程式碼
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
//
var c *hchan
switch {
case mem == 0:
// chan的size或者元素的size是0,不必建立buf
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素不是指標,分配一塊連續的記憶體給hchan資料結構和buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
// hchan資料結構後面緊接著就是buf
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指標,那麼單獨分配buf
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 元素大小、型別、容量都記錄下來
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
return c
}
最終,針對不同的容量和元素型別,這段程式碼分配了不同的物件來初始化 hchan 物件的欄位,返回 hchan 物件。
send
Go 在編譯傳送資料給 chan 的時候,會把 send 語句轉換成 chansend1 函式,chansend1 函式會呼叫 chansend,我們分段學習它的邏輯:
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 第一部分
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
......
}
最開始,第一部分是進行判斷:如果 chan 是 nil 的話,就把呼叫者 goroutine park(阻塞休眠), 呼叫者就永遠被阻塞住了,所以,第 11 行是不可能執行到的程式碼。
// 第二部分,如果chan沒有被close,並且chan滿了,直接返回
if !block && c.closed == 0 && full(c) {
return false
}
第二部分的邏輯是當你往一個已經滿了的 chan 例項傳送資料時,並且想不阻塞當前呼叫,那麼這裡的邏輯是直接返回。chansend1 方法在呼叫 chansend 的時候設定了阻塞引數,所以不會執行到第二部分的分支裡。
// 第三部分,chan已經被close的情景
lock(&c.lock) // 開始加鎖
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
第三部分顯示的是,如果 chan 已經被 close 了,再往裡面傳送資料的話會 panic。
// 第四部分,從接收佇列中出隊一個等待的receiver
if sg := c.recvq.dequeue(); sg != nil {
//
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
第四部分,如果等待佇列中有等待的 receiver,那麼這段程式碼就把它從佇列中彈出,然後直接把資料交給它(透過 memmove(dst, src, t.size)),而不需要放入到 buf 中,速度可以更快一些。
// 第五部分,buf還沒滿
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
第五部分說明當前沒有 receiver,需要把資料放入到 buf 中,放入之後,就成功返回了。
// 第六部分,buf滿。
// chansend1不會進入if塊裡,因為chansend1的block=true
if !block {
unlock(&c.lock)
return false
}
......
第六部分是處理 buf 滿的情況。如果 buf 滿了,傳送者的 goroutine 就會加入到傳送者的等待佇列中,直到被喚醒。這個時候,資料或者被取走了,或者 chan 被 close 了。
recv
在處理從 chan 中接收資料時,Go 會把程式碼轉換成 chanrecv1 函式,如果要返回兩個返回值,會轉換成 chanrecv2,chanrecv1 函式和 chanrecv2 會呼叫 chanrecv。我們分段學習它的邏輯:
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// 第一部分,chan為nil
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
chanrecv1 和 chanrecv2 傳入的 block 引數的值是 true,都是阻塞方式,所以我們分析 chanrecv 的實作的時候,不考慮 block=false 的情況。
第一部分是 chan 為 nil 的情況。和 send 一樣,從 nil chan 中接收(讀取、獲取)資料時,呼叫者會被永遠阻塞。
// 第二部分, block=false且c為空
if !block && empty(c) {
......
}
第二部分你可以直接忽略,因為不是我們這次要分析的場景。
// 加鎖,返回時釋放鎖
lock(&c.lock)
// 第三部分,c已經被close,且chan為空empty
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
第三部分是 chan 已經被 close 的情況。如果 chan 已經被 close 了,並且佇列中沒有快取的元素,那麼返回 true、false。
// 第四部分,如果sendq佇列中有等待傳送的sender
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
第四部分是處理 sendq 佇列中有等待者的情況。這個時候,如果 buf 中有資料,優先從 buf 中讀取資料,否則直接從等待佇列中彈出一個 sender,把它的資料複製給這個 receiver。
// 第五部分, 沒有等待的sender, buf中有資料
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// 第六部分, buf中沒有元素,阻塞
......
第五部分是處理沒有等待的 sender 的情況。這個是和 chansend 共用一把大鎖,所以不會有併發的問題。如果 buf 有元素,就取出一個元素給 receiver。
第六部分是處理 buf 中沒有元素的情況。如果沒有元素,那麼當前的 receiver 就會被阻塞,直到它從 sender 中接收了資料,或者是 chan 被 close,才返回。
close
透過 close 函式,可以把 chan 關閉,編譯器會替換成 closechan 方法的呼叫。
下面的程式碼是 close chan 的主要邏輯。如果 chan 為 nil,close 會 panic;如果 chan 已經 closed,再次 close 也會 panic。否則的話,如果 chan 不為 nil,chan 也沒有 closed,就把等待佇列中的 sender(writer)和 receiver(reader)從佇列中全部移除並喚醒。
下面的程式碼就是 close chan 的邏輯:
func closechan(c *hchan) {
if c == nil { // chan為nil, panic
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {// chan已經closed, panic
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
c.closed = 1
var glist gList
// 釋放所有的reader
for {
sg := c.recvq.dequeue()
......
gp := sg.g
......
glist.push(gp)
}
// 釋放所有的writer (它們會panic)
for {
sg := c.sendq.dequeue()
......
gp := sg.g
......
glist.push(gp)
}
unlock(&c.lock)
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
掌握了 Channel 的基本用法和實作原理,下面我再來給你講一講容易犯的錯誤。你一定要認真看,畢竟,這些可都是幫助你避坑的。
使用 Channel 容易犯的錯誤
根據 2019 年第一篇全面分析 Go 併發 Bug 的論文,那些知名的 Go 專案中使用 Channel 所犯的 Bug 反而比傳統的併發原語的 Bug 還要多。主要有兩個原因:一個是,Channel 的概念還比較新,程式設計師還不能很好地掌握相應的使用方法和最佳實踐;第二個是,Channel 有時候比傳統的併發原語更復雜,使用起來很容易顧此失彼。
使用 Channel 最常見的錯誤是 panic 和 goroutine 洩漏。
首先,我們來總結下會 panic 的情況,總共有 3 種:
- close 為 nil 的 chan;
- send 已經 close 的 chan;
- close 已經 close 的 chan。
goroutine 洩漏的問題也很常見,下面的程式碼也是一個實際專案中的例子:
func process(timeout time.Duration) bool {
ch := make(chan bool)
go func() {
// 模擬處理耗時的業務
time.Sleep((timeout + time.Second))
ch <- true // block
fmt.Println("exit goroutine")
}()
select {
case result := <-ch:
return result
case <-time.After(timeout):
return false
}
}
在這個例子中,process 函式會啟動一個 goroutine,去處理需要長時間處理的業務,處理完之後,會傳送 true 到 chan 中,目的是通知其它等待的 goroutine,可以繼續處理了。
我們來看一下第 10 行到第 15 行,主 goroutine 接收到任務處理完成的通知,或者超時後就返回了。這段程式碼有問題嗎?
如果發生超時,process 函式就返回了,這就會導致 unbuffered 的 chan 從來就沒有被讀取。我們知道,unbuffered chan 必須等 reader 和 writer 都準備好了才能交流,否則就會阻塞。超時導致未讀,結果就是子 goroutine 就阻塞在第 7 行永遠結束不了,進而導致 goroutine 洩漏。
解決這個 Bug 的辦法很簡單,就是將 unbuffered chan 改成容量為 1 的 chan,這樣第 7 行就不會被阻塞了。
Go 的開發者極力推薦使用 Channel,不過,這兩年,大家意識到,Channel 並不是處理併發問題的“銀彈”,有時候使用併發原語更簡單,而且不容易出錯。所以,我給你提供一套選擇的方法:
- 共享資源的併發訪問使用傳統併發原語;
- 複雜的任務編排和訊息傳遞使用 Channel;
- 訊息通知機制使用 Channel,除非只想 signal 一個 goroutine,才使用 Cond;
- 簡單等待所有任務的完成用 WaitGroup,也有 Channel 的推崇者用 Channel,都可以;
- 需要和 Select 語句結合,使用 Channel;
- 需要和超時配合時,使用 Channel 和 Context。
它們踩過的坑
接下來,我帶你圍觀下知名 Go 專案的 Channel 相關的 Bug。
etcd issue 6857是一個程式 hang 住的問題:在異常情況下,沒有往 chan 例項中填充所需的元素,導致等待者永遠等待。具體來說,Status 方法的邏輯是生成一個 chan Status,然後把這個 chan 交給其它的 goroutine 去處理和寫入資料,最後,Status 返回獲取的狀態資訊。
不幸的是,如果正好節點停止了,沒有 goroutine 去填充這個 chan,會導致方法 hang 在返回的那一行上(下面的截圖中的第 466 行)。解決辦法就是,在等待 status chan 返回元素的同時,也檢查節點是不是已經停止了(done 這個 chan 是不是 close 了)。
當前的 etcd 的程式碼就是修復後的程式碼,如下所示:
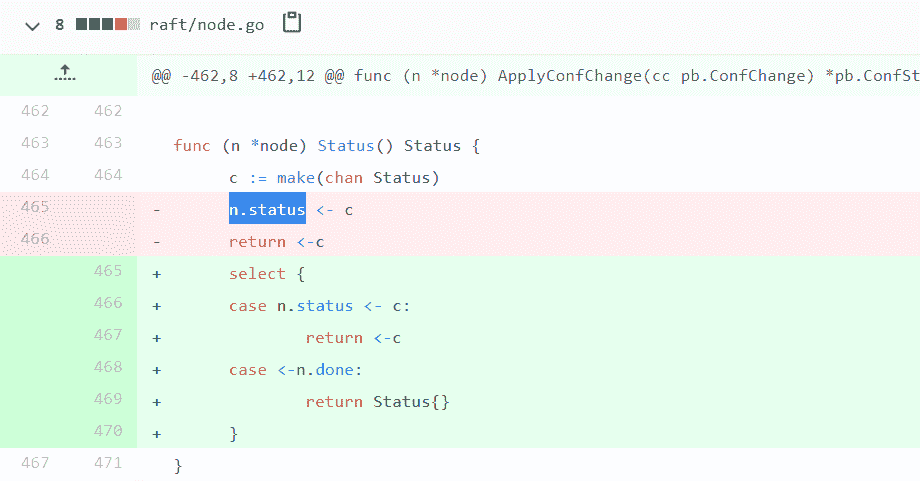
其實,我感覺這個修改還是有問題的。問題就在於,如果程式執行了 466 行,成功地把 c 寫入到 Status 待處理佇列後,執行到第 467 行時,如果停止了這個節點,那麼,這個 Status 方法還是會阻塞在第 467 行。你可以自己研究研究,看看是不是這樣。
etcd issue 5505 雖然沒有任何的 Bug 描述,但是從修復內容上看,它是一個往已經 close 的 chan 寫資料導致 panic 的問題。
etcd issue 11256 是因為 unbuffered chan goroutine 洩漏的問題。TestNodeProposeAddLearnerNode 方法中一開始定義了一個 unbuffered 的 chan,也就是 applyConfChan,然後啟動一個子 goroutine,這個子 goroutine 會在迴圈中執行業務邏輯,並且不斷地往這個 chan 中新增一個元素。TestNodeProposeAddLearnerNode 方法的末尾處會從這個 chan 中讀取一個元素。
這段程式碼在 for 迴圈中就往此 chan 中寫入了一個元素,結果導致 TestNodeProposeAddLearnerNode 從這個 chan 中讀取到元素就返回了。悲劇的是,子 goroutine 的 for 迴圈還在執行,阻塞在下圖中紅色的第 851 行,並且一直 hang 在那裡。
這個 Bug 的修復也很簡單,只要改動一下 applyConfChan 的處理邏輯就可以了:只有子 goroutine 的 for 迴圈中的主要邏輯完成之後,才往 applyConfChan 傳送一個元素,這樣,TestNodeProposeAddLearnerNode 收到通知繼續執行,子 goroutine 也不會被阻塞住了。
etcd issue 9956 是往一個已 close 的 chan 傳送資料,其實它是 grpc 的一個 bug(grpc issue 2695),修復辦法就是不 close 這個 chan 就好了:

總結
chan 的值和狀態有多種情況,而不同的操作(send、recv、close)又可能得到不同的結果,這是使用 chan 型別時經常讓人困惑的地方。
為了幫助你快速地瞭解不同狀態下各種操作的結果,我總結了一個表格,你一定要特別關注下那些 panic 的情況,另外還要掌握那些會 block 的場景,它們是導致死鎖或者 goroutine 洩露的罪魁禍首。
還有一個值得注意的點是,只要一個 chan 還有未讀的資料,即使把它 close 掉,你還是可以繼續把這些未讀的資料消費完,之後才是讀取零值資料。
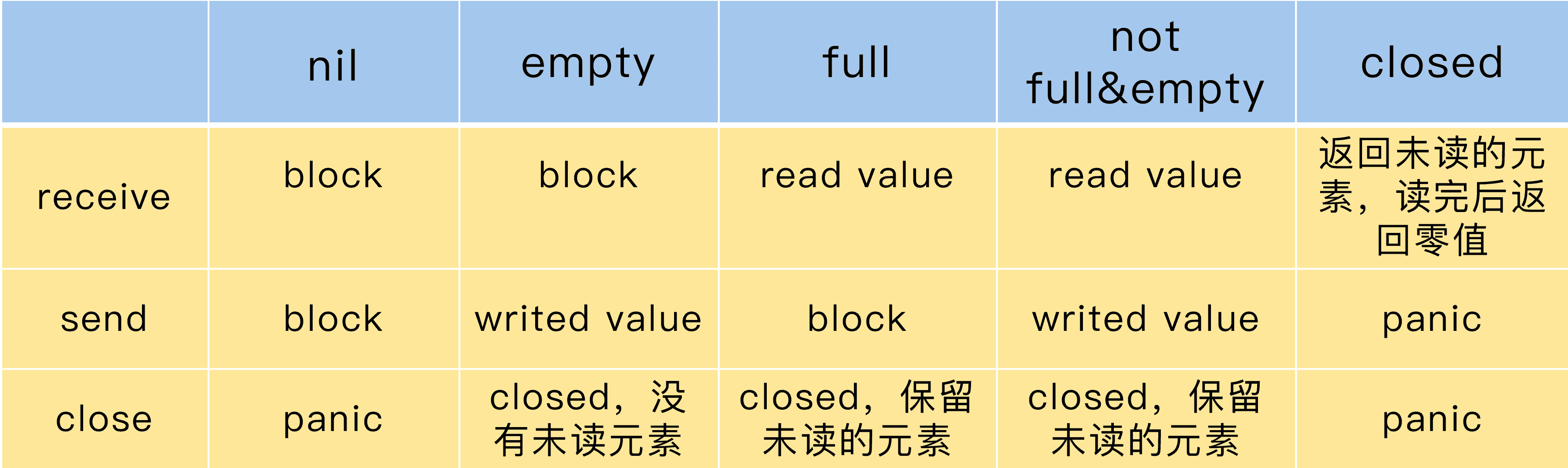
思考題
- 有一道經典的使用 Channel 進行任務編排的題,你可以嘗試做一下:有四個 goroutine,編號為 1、2、3、4。每秒鐘會有一個 goroutine 打印出它自己的編號,要求你編寫一個程式,讓輸出的編號總是按照 1、2、3、4、1、2、3、4、……的順序打印出來。
- chan T 是否可以給 <- chan T 和 chan<- T 型別的變數賦值?反過來呢?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
14|Channel:透過程式碼看典型的應用模式
你好,我是鳥窩。
本章導讀
Channel 常見應用模式(區塊圖)
[Producer] -> [stage1 workers] -> [stage2 workers] -> [Consumer]
│ │ │ │
└────── channel ─┴────── channel ──┴────── channel ─┘
可搭配:fan-out / fan-in / select / timeout / cancel
前一講,我介紹了 Channel 的基礎知識,並且總結了幾種應用場景。這一講,我將透過例項的方式,帶你逐個學習 Channel 解決這些問題的方法,幫你鞏固和完全掌握它的用法。
在開始上課之前,我先補充一個知識點:透過反射的方式執行 select 語句,在處理很多的 case clause,尤其是不定長的 case clause 的時候,非常有用。而且,在後面介紹任務編排的實作時,我也會採用這種方法,所以,我先帶你具體學習下 Channel 的反射用法。
使用反射操作 Channel
select 語句可以處理 chan 的 send 和 recv,send 和 recv 都可以作為 case clause。如果我們同時處理兩個 chan,就可以寫成下面的樣子:
select {
case v := <-ch1:
fmt.Println(v)
case v := <-ch2:
fmt.Println(v)
}
如果需要處理三個 chan,你就可以再新增一個 case clause,用它來處理第三個 chan。可是,如果要處理 100 個 chan 呢?一萬個 chan 呢?
或者是,chan 的數量在編譯的時候是不定的,在執行的時候需要處理一個 slice of chan,這個時候,也沒有辦法在編譯前寫成字面意義的 select。那該怎麼辦?
這個時候,就要“祭”出我們的反射大法了。
透過 reflect.Select 函式,你可以將一組執行時的 case clause 傳入,當作引數執行。Go 的 select 是偽隨機的,它可以在執行的 case 中隨機選擇一個 case,並把選擇的這個 case 的索引(chosen)返回,如果沒有可用的 case 返回,會返回一個 bool 型別的返回值,這個返回值用來表示是否有 case 成功被選擇。如果是 recv case,還會返回接收的元素。Select 的方法簽名如下:
func Select(cases []SelectCase) (chosen int, recv Value, recvOK bool)
下面,我來藉助一個例子,來演示一下,動態處理兩個 chan 的情形。因為這樣的方式可以動態處理 case 資料,所以,你可以傳入幾百幾千幾萬的 chan,這就解決了不能動態處理 n 個 chan 的問題。
首先,createCases 函式分別為每個 chan 生成了 recv case 和 send case,並返回一個 reflect.SelectCase 陣列。
然後,透過一個迴圈 10 次的 for 迴圈執行 reflect.Select,這個方法會從 cases 中選擇一個 case 執行。第一次肯定是 send case,因為此時 chan 還沒有元素,recv 還不可用。等 chan 中有了資料以後,recv case 就可以被選擇了。這樣,你就可以處理不定數量的 chan 了。
func main() {
var ch1 = make(chan int, 10)
var ch2 = make(chan int, 10)
// 建立SelectCase
var cases = createCases(ch1, ch2)
// 執行10次select
for i := 0; i < 10; i++ {
chosen, recv, ok := reflect.Select(cases)
if recv.IsValid() { // recv case
fmt.Println("recv:", cases[chosen].Dir, recv, ok)
} else { // send case
fmt.Println("send:", cases[chosen].Dir, ok)
}
}
}
func createCases(chs ...chan int) []reflect.SelectCase {
var cases []reflect.SelectCase
// 建立recv case
for _, ch := range chs {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(ch),
})
}
// 建立send case
for i, ch := range chs {
v := reflect.ValueOf(i)
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectSend,
Chan: reflect.ValueOf(ch),
Send: v,
})
}
return cases
}典型的應用場景瞭解剛剛的反射用法,我們就解決了今天的基礎知識問題,接下來,我就帶你具體學習下 Channel 的應用場景。
首先來看訊息交流。
訊息交流
從 chan 的內部實作看,它是以一個迴圈佇列的方式存放資料,所以,它有時候也會被當成執行緒安全的佇列和 buffer 使用。一個 goroutine 可以安全地往 Channel 中塞資料,另外一個 goroutine 可以安全地從 Channel 中讀取資料,goroutine 就可以安全地實作資訊交流了。
我們來看幾個例子。
第一個例子是 worker 池的例子。Marcio Castilho 在 使用 Go 每分鐘處理百萬請求 這篇文章中,就介紹了他們應對大併發請求的設計。他們將使用者的請求放在一個 chan Job 中,這個 chan Job 就相當於一個待處理任務佇列。除此之外,還有一個 chan chan Job 佇列,用來存放可以處理任務的 worker 的快取佇列。
dispatcher 會把待處理任務佇列中的任務放到一個可用的快取佇列中,worker 會一直處理它的快取佇列。透過使用 Channel,實作了一個 worker 池的任務處理中心,並且解耦了前端 HTTP 請求處理和後端任務處理的邏輯。
我在講 Pool 的時候,提到了一些第三方實作的 worker 池,它們全部都是透過 Channel 實作的,這是 Channel 的一個常見的應用場景。worker 池的生產者和消費者的訊息交流都是透過 Channel 實作的。
第二個例子是 etcd 中的 node 節點的實作,包含大量的 chan 欄位,比如 recvc 是訊息處理的 chan,待處理的 protobuf 訊息都扔到這個 chan 中,node 有一個專門的 run goroutine 處理這些訊息。

資料傳遞
“擊鼓傳花”的遊戲很多人都玩過,花從一個人手中傳給另外一個人,就有點類似流水線的操作。這個花就是資料,花在遊戲者之間流轉,這就類似程式設計中的資料傳遞。
還記得上節課我給你留了一道任務編排的題嗎?其實它就可以用資料傳遞的方式實作。
有 4 個 goroutine,編號為 1、2、3、4。每秒鐘會有一個 goroutine 打印出它自己的編號,要求你編寫程式,讓輸出的編號總是按照 1、2、3、4、1、2、3、4……這個順序打印出來。
為了實作順序的資料傳遞,我們可以定義一個令牌的變數,誰得到令牌,誰就可以列印一次自己的編號,同時將令牌傳遞給下一個 goroutine,我們嘗試使用 chan 來實作,可以看下下面的程式碼。
type Token struct{}
func newWorker(id int, ch chan Token, nextCh chan Token) {
for {
token := <-ch // 取得令牌
fmt.Println((id + 1)) // id從1開始
time.Sleep(time.Second)
nextCh <- token
}
}
func main() {
chs := []chan Token{make(chan Token), make(chan Token), make(chan Token), make(chan Token)}
// 建立4個worker
for i := 0; i < 4; i++ {
go newWorker(i, chs[i], chs[(i+1)%4])
}
//首先把令牌交給第一個worker
chs[0] <- struct{}{}
select {}
}
我來給你具體解釋下這個實作方式。
首先,我們定義一個令牌型別(Token),接著定義一個建立 worker 的方法,這個方法會從它自己的 chan 中讀取令牌。哪個 goroutine 取得了令牌,就可以打印出自己編號,因為需要每秒列印一次資料,所以,我們讓它休眠 1 秒後,再把令牌交給它的下家。
接著,在第 16 行啟動每個 worker 的 goroutine,並在第 20 行將令牌先交給第一個 worker。
如果你執行這個程式,就會在命令列中看到每一秒就會輸出一個編號,而且編號是以 1、2、3、4 這樣的順序輸出的。
這類場景有一個特點,就是當前持有資料的 goroutine 都有一個信箱,信箱使用 chan 實作,goroutine 只需要關注自己的信箱中的資料,處理完畢後,就把結果傳送到下一家的信箱中。
訊號通知
chan 型別有這樣一個特點:chan 如果為空,那麼,receiver 接收資料的時候就會阻塞等待,直到 chan 被關閉或者有新的資料到來。利用這個機制,我們可以實作 wait/notify 的設計模式。
傳統的併發原語 Cond 也能實作這個功能,但是,Cond 使用起來比較複雜,容易出錯,而使用 chan 實作 wait/notify 模式就方便很多了。
除了正常的業務處理時的 wait/notify,我們經常碰到的一個場景,就是程式關閉的時候,我們需要在退出之前做一些清理(doCleanup 方法)的動作。這個時候,我們經常要使用 chan。
比如,使用 chan 實作程式的 graceful shutdown,在退出之前執行一些連線關閉、檔案 close、快取落盤等一些動作。
func main() {
go func() {
...... // 執行業務處理
}()
// 處理CTRL+C等中斷訊號
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM)
<-termChan
// 執行退出之前的清理動作
doCleanup()
fmt.Println("優雅退出")
}
有時候,doCleanup 可能是一個很耗時的操作,比如十幾分鍾才能完成,如果程式退出需要等待這麼長時間,使用者是不能接受的,所以,在實踐中,我們需要設定一個最長的等待時間。只要超過了這個時間,程式就不再等待,可以直接退出。所以,退出的時候分為兩個階段:
- closing,代表程式退出,但是清理工作還沒做;
- closed,代表清理工作已經做完。
所以,上面的例子可以改寫如下:
func main() {
var closing = make(chan struct{})
var closed = make(chan struct{})
go func() {
// 模擬業務處理
for {
select {
case <-closing:
return
default:
// ....... 業務計算
time.Sleep(100 * time.Millisecond)
}
}
}()
// 處理CTRL+C等中斷訊號
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM)
<-termChan
close(closing)
// 執行退出之前的清理動作
go doCleanup(closed)
select {
case <-closed:
case <-time.After(time.Second):
fmt.Println("清理超時,不等了")
}
fmt.Println("優雅退出")
}
func doCleanup(closed chan struct{}) {
time.Sleep((time.Minute))
close(closed)
}鎖使用 chan 也可以實作互斥鎖。
在 chan 的內部實作中,就有一把互斥鎖保護著它的所有欄位。從外在表現上,chan 的傳送和接收之間也存在著 happens-before 的關係,保證元素放進去之後,receiver 才能讀取到(關於 happends-before 的關係,是指事件發生的先後順序關係,我會在下一講詳細介紹,這裡你只需要知道它是一種描述事件先後順序的方法)。
要想使用 chan 實作互斥鎖,至少有兩種方式。一種方式是先初始化一個 capacity 等於 1 的 Channel,然後再放入一個元素。這個元素就代表鎖,誰取得了這個元素,就相當於獲取了這把鎖。另一種方式是,先初始化一個 capacity 等於 1 的 Channel,它的“空槽”代表鎖,誰能成功地把元素髮送到這個 Channel,誰就獲取了這把鎖。
這是使用 Channel 實作鎖的兩種不同實作方式,我重點介紹下第一種。理解了這種實作方式,第二種方式也就很容易掌握了,我就不多說了。
// 使用chan實作互斥鎖
type Mutex struct {
ch chan struct{}
}
// 使用鎖需要初始化
func NewMutex() *Mutex {
mu := &Mutex{make(chan struct{}, 1)}
mu.ch <- struct{}{}
return mu
}
// 請求鎖,直到獲取到
func (m *Mutex) Lock() {
<-m.ch
}
// 解鎖
func (m *Mutex) Unlock() {
select {
case m.ch <- struct{}{}:
default:
panic("unlock of unlocked mutex")
}
}
// 嘗試獲取鎖
func (m *Mutex) TryLock() bool {
select {
case <-m.ch:
return true
default:
}
return false
}
// 加入一個超時的設定
func (m *Mutex) LockTimeout(timeout time.Duration) bool {
timer := time.NewTimer(timeout)
select {
case <-m.ch:
timer.Stop()
return true
case <-timer.C:
}
return false
}
// 鎖是否已被持有
func (m *Mutex) IsLocked() bool {
return len(m.ch) == 0
}
func main() {
m := NewMutex()
ok := m.TryLock()
fmt.Printf("locked v %v\n", ok)
ok = m.TryLock()
fmt.Printf("locked %v\n", ok)
}
你可以用 buffer 等於 1 的 chan 實作互斥鎖,在初始化這個鎖的時候往 Channel 中先塞入一個元素,誰把這個元素取走,誰就獲取了這把鎖,把元素放回去,就是釋放了鎖。元素在放回到 chan 之前,不會有 goroutine 能從 chan 中取出元素的,這就保證了互斥性。
在這段程式碼中,還有一點需要我們注意下:利用 select+chan 的方式,很容易實作 TryLock、Timeout 的功能。具體來說就是,在 select 語句中,我們可以使用 default 實作 TryLock,使用一個 Timer 來實作 Timeout 的功能。
任務編排
前面所說的訊息交流的場景是一個特殊的任務編排的場景,這個“擊鼓傳花”的模式也被稱為流水線模式。
在第 6 講,我們學習了 WaitGroup,我們可以利用它實作等待模式:啟動一組 goroutine 執行任務,然後等待這些任務都完成。其實,我們也可以使用 chan 實作 WaitGroup 的功能。這個比較簡單,我就不舉例子了,接下來我介紹幾種更復雜的編排模式。
這裡的編排既指安排 goroutine 按照指定的順序執行,也指多個 chan 按照指定的方式組合處理的方式。goroutine 的編排類似“擊鼓傳花”的例子,我們透過編排資料在 chan 之間的流轉,就可以控制 goroutine 的執行。接下來,我來重點介紹下多個 chan 的編排方式,總共 5 種,分別是 Or-Done 模式、扇入模式、扇出模式、Stream 和 Map-Reduce。
Or-Done 模式
首先來看 Or-Done 模式。Or-Done 模式是訊號通知模式中更寬泛的一種模式。這裡提到了“訊號通知模式”,我先來解釋一下。
我們會使用“訊號通知”實作某個任務執行完成後的通知機制,在實作時,我們為這個任務定義一個型別為 chan struct{}型別的 done 變數,等任務結束後,我們就可以 close 這個變數,然後,其它 receiver 就會收到這個通知。
這是有一個任務的情況,如果有多個任務,只要有任意一個任務執行完,我們就想獲得這個訊號,這就是 Or-Done 模式。
比如,你傳送同一個請求到多個微服務節點,只要任意一個微服務節點返回結果,就算成功,這個時候,就可以參考下面的實作:
func or(channels ...<-chan interface{}) <-chan interface{} {
// 特殊情況,只有零個或者1個chan
switch len(channels) {
case 0:
return nil
case 1:
return channels[0]
}
orDone := make(chan interface{})
go func() {
defer close(orDone)
switch len(channels) {
case 2: // 2個也是一種特殊情況
select {
case <-channels[0]:
case <-channels[1]:
}
default: //超過兩個,二分法遞迴處理
m := len(channels) / 2
select {
case <-or(channels[:m]...):
case <-or(channels[m:]...):
}
}
}()
return orDone
}
我們可以寫一個測試程式測試它:
func sig(after time.Duration) <-chan interface{} {
c := make(chan interface{})
go func() {
defer close(c)
time.Sleep(after)
}()
return c
}
func main() {
start := time.Now()
<-or(
sig(10*time.Second),
sig(20*time.Second),
sig(30*time.Second),
sig(40*time.Second),
sig(50*time.Second),
sig(01*time.Minute),
)
fmt.Printf("done after %v", time.Since(start))
}
這裡的實作使用了一個巧妙的方式,當 chan 的數量大於 2 時,使用遞迴的方式等待訊號。
在 chan 數量比較多的情況下,遞迴併不是一個很好的解決方式,根據這一講最開始介紹的反射的方法,我們也可以實作 Or-Done 模式:
func or(channels ...<-chan interface{}) <-chan interface{} {
//特殊情況,只有0個或者1個
switch len(channels) {
case 0:
return nil
case 1:
return channels[0]
}
orDone := make(chan interface{})
go func() {
defer close(orDone)
// 利用反射構建SelectCase
var cases []reflect.SelectCase
for _, c := range channels {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(c),
})
}
// 隨機選擇一個可用的case
reflect.Select(cases)
}()
return orDone
}
這是遞迴和反射兩種方法實作 Or-Done 模式的程式碼。反射方式避免了深層遞迴的情況,可以處理有大量 chan 的情況。其實最笨的一種方法就是為每一個 Channel 啟動一個 goroutine,不過這會啟動非常多的 goroutine,太多的 goroutine 會影響效能,所以不太常用。你只要知道這種用法就行了,不用重點掌握。
扇入模式
扇入借鑑了數位電路的概念,它定義了單個邏輯閘能夠接受的數字訊號輸入最大量的術語。一個邏輯閘可以有多個輸入,一個輸出。
在軟體工程中,模組的扇入是指有多少個上級模組呼叫它。而對於我們這裡的 Channel 扇入模式來說,就是指有多個源 Channel 輸入、一個目的 Channel 輸出的情況。扇入比就是源 Channel 數量比 1。
每個源 Channel 的元素都會傳送給目標 Channel,相當於目標 Channel 的 receiver 只需要監聽目標 Channel,就可以接收所有傳送給源 Channel 的資料。
扇入模式也可以使用反射、遞迴,或者是用最笨的每個 goroutine 處理一個 Channel 的方式來實作。
這裡我列舉下遞迴和反射的方式,幫你加深一下對這個技巧的理解。
反射的程式碼比較簡短,易於理解,主要就是構造出 SelectCase slice,然後傳遞給 reflect.Select 語句。
func fanInReflect(chans ...<-chan interface{}) <-chan interface{} {
out := make(chan interface{})
go func() {
defer close(out)
// 構造SelectCase slice
var cases []reflect.SelectCase
for _, c := range chans {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(c),
})
}
// 迴圈,從cases中選擇一個可用的
for len(cases) > 0 {
i, v, ok := reflect.Select(cases)
if !ok { // 此channel已經close
cases = append(cases[:i], cases[i+1:]...)
continue
}
out <- v.Interface()
}
}()
return out
}
遞迴模式也是在 Channel 大於 2 時,採用二分法遞迴 merge。
func fanInRec(chans ...<-chan interface{}) <-chan interface{} {
switch len(chans) {
case 0:
c := make(chan interface{})
close(c)
return c
case 1:
return chans[0]
case 2:
return mergeTwo(chans[0], chans[1])
default:
m := len(chans) / 2
return mergeTwo(
fanInRec(chans[:m]...),
fanInRec(chans[m:]...))
}
}
這裡有一個 mergeTwo 的方法,是將兩個 Channel 合併成一個 Channel,是扇入形式的一種特例(只處理兩個 Channel)。 下面我來藉助一段程式碼幫你理解下這個方法。
func mergeTwo(a, b <-chan interface{}) <-chan interface{} {
c := make(chan interface{})
go func() {
defer close(c)
for a != nil || b != nil { //只要還有可讀的chan
select {
case v, ok := <-a:
if !ok { // a 已關閉,設定為nil
a = nil
continue
}
c <- v
case v, ok := <-b:
if !ok { // b 已關閉,設定為nil
b = nil
continue
}
c <- v
}
}
}()
return c
}扇出模式有扇入模式,就有扇出模式,扇出模式是和扇入模式相反的。
扇出模式只有一個輸入源 Channel,有多個目標 Channel,扇出比就是 1 比目標 Channel 數的值,經常用在設計模式中的觀察者模式中(觀察者設計模式定義了物件間的一種一對多的組合關係。這樣一來,一個物件的狀態發生變化時,所有依賴於它的物件都會得到通知並自動重新整理)。在觀察者模式中,資料變動後,多個觀察者都會收到這個變更訊號。
下面是一個扇出模式的實作。從源 Channel 取出一個資料後,依次傳送給目標 Channel。在傳送給目標 Channel 的時候,可以同步傳送,也可以非同步傳送:
func fanOut(ch <-chan interface{}, out []chan interface{}, async bool) {
go func() {
defer func() { //退出時關閉所有的輸出chan
for i := 0; i < len(out); i++ {
close(out[i])
}
}()
for v := range ch { // 從輸入chan中讀取資料
v := v
for i := 0; i < len(out); i++ {
i := i
if async { //非同步
go func() {
out[i] <- v // 放入到輸出chan中,非同步方式
}()
} else {
out[i] <- v // 放入到輸出chan中,同步方式
}
}
}
}()
}
你也可以嘗試使用反射的方式來實作,我就不列相關程式碼了,希望你課後可以自己思考下。
Stream
這裡我來介紹一種把 Channel 當作流式管道使用的方式,也就是把 Channel 看作流(Stream),提供跳過幾個元素,或者是隻取其中的幾個元素等方法。
首先,我們提供建立流的方法。這個方法把一個資料 slice 轉換成流:
func asStream(done <-chan struct{}, values ...interface{}) <-chan interface{} {
s := make(chan interface{}) //建立一個unbuffered的channel
go func() { // 啟動一個goroutine,往s中塞資料
defer close(s) // 退出時關閉chan
for _, v := range values { // 遍歷陣列
select {
case <-done:
return
case s <- v: // 將陣列元素塞入到chan中
}
}
}()
return s
}
流建立好以後,該咋處理呢?下面我再給你介紹下實作流的方法。
- takeN:只取流中的前 n 個資料;
- takeFn:篩選流中的資料,只保留滿足條件的資料;
- takeWhile:只取前面滿足條件的資料,一旦不滿足條件,就不再取;
- skipN:跳過流中前幾個資料;
- skipFn:跳過滿足條件的資料;
- skipWhile:跳過前面滿足條件的資料,一旦不滿足條件,當前這個元素和以後的元素都會輸出給 Channel 的 receiver。
這些方法的實作很類似,我們以 takeN 為例來具體解釋一下。
func takeN(done <-chan struct{}, valueStream <-chan interface{}, num int) <-chan interface{} {
takeStream := make(chan interface{}) // 建立輸出流
go func() {
defer close(takeStream)
for i := 0; i < num; i++ { // 只讀取前num個元素
select {
case <-done:
return
case takeStream <- <-valueStream: //從輸入流中讀取元素
}
}
}()
return takeStream
}Map-Reducemap-reduce 是一種處理資料的方式,最早是由 Google 公司研究提出的一種面向大規模資料處理的平行計算模型和方法,開源的版本是 hadoop,前幾年比較火。
不過,我要講的並不是分散式的 map-reduce,而是單機單程式的 map-reduce 方法。
map-reduce 分為兩個步驟,第一步是對映(map),處理佇列中的資料,第二步是規約(reduce),把列表中的每一個元素按照一定的處理方式處理成結果,放入到結果佇列中。
就像做漢堡一樣,map 就是單獨處理每一種食材,reduce 就是從每一份食材中取一部分,做成一個漢堡。
我們先來看下 map 函式的處理邏輯:
func mapChan(in <-chan interface{}, fn func(interface{}) interface{}) <-chan interface{} {
out := make(chan interface{}) //建立一個輸出chan
if in == nil { // 異常檢查
close(out)
return out
}
go func() { // 啟動一個goroutine,實作map的主要邏輯
defer close(out)
for v := range in { // 從輸入chan讀取資料,執行業務操作,也就是map操作
out <- fn(v)
}
}()
return out
}
reduce 函式的處理邏輯如下:
func reduce(in <-chan interface{}, fn func(r, v interface{}) interface{}) interface{} {
if in == nil { // 異常檢查
return nil
}
out := <-in // 先讀取第一個元素
for v := range in { // 實作reduce的主要邏輯
out = fn(out, v)
}
return out
}
我們可以寫一個程式,這個程式使用 map-reduce 模式處理一組整數,map 函式就是為每個整數乘以 10,reduce 函式就是把 map 處理的結果累加起來:
// 生成一個資料流
func asStream(done <-chan struct{}) <-chan interface{} {
s := make(chan interface{})
values := []int{1, 2, 3, 4, 5}
go func() {
defer close(s)
for _, v := range values { // 從陣列生成
select {
case <-done:
return
case s <- v:
}
}
}()
return s
}
func main() {
in := asStream(nil)
// map操作: 乘以10
mapFn := func(v interface{}) interface{} {
return v.(int) * 10
}
// reduce操作: 對map的結果進行累加
reduceFn := func(r, v interface{}) interface{} {
return r.(int) + v.(int)
}
sum := reduce(mapChan(in, mapFn), reduceFn) //返回累加結果
fmt.Println(sum)
}總結這節課,我藉助程式碼示例,帶你學習了 Channel 的應用場景和應用模式。這幾種模式不是我們學習的終點,而是學習的起點。掌握了這幾種模式之後,我們可以延伸出更多的模式。
雖然 Channel 最初是基於 CSP 設計的用於 goroutine 之間的訊息傳遞的一種資料型別,但是,除了訊息傳遞這個功能之外,大家居然還演化出了各式各樣的應用模式。我不確定 Go 的創始人在設計這個型別的時候,有沒有想到這一點,但是,我確實被各位大牛利用 Channel 的各種點子折服了,比如有人實作了一個基於 TCP 網路的分散式的 Channel。
在使用 Go 開發程式的時候,你也不妨多考慮考慮是否能夠使用 chan 型別,看看你是不是也能創造出別具一格的應用模式。
思考題
想一想,我們在利用 chan 實作互斥鎖的時候,如果 buffer 設定的不是 1,而是一個更大的值,會出現什麼狀況嗎?能解決什麼問題嗎?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
15|記憶體模型:Go 如何保證併發讀寫的順序?
你好,我是鳥窩。
本章導讀
記憶體模型(happens-before)示意
Goroutine A 同步事件 Goroutine B
┌──────────────┐ ┌────────────────┐ ┌──────────────┐
│ 寫入 shared x │ ───────> │ lock/unlock、 │ ───────> │ 讀取 shared x │
│ x = 1 │ │ channel send/recv│ │ 看到最新值? │
└──────────────┘ └────────────────┘ └──────────────┘
沒有同步事件 -> 可見性/順序不保證
Go 官方文件裡專門介紹了 Go 的記憶體模型,你不要誤解這裡的記憶體模型的含義,它並不是指 Go 物件的記憶體分配、記憶體回收和記憶體整理的規範,它描述的是併發環境中多 goroutine 讀相同變數的時候,變數的可見性條件。具體點說,就是指,在什麼條件下,goroutine 在讀取一個變數的值的時候,能夠看到其它 goroutine 對這個變數進行的寫的結果。
由於 CPU 指令重排和多級 Cache 的存在,保證多核訪問同一個變數這件事兒變得非常複雜。畢竟,不同 CPU 架構(x86/amd64、ARM、Power 等)的處理方式也不一樣,再加上編譯器的最佳化也可能對指令進行重排,所以程式語言需要一個規範,來明確多執行緒同時訪問同一個變數的可見性和順序( Russ Cox 在麻省理工學院 6.824 分散式系統 Distributed Systems 課程 的一課,專門介紹了相關的知識)。在程式語言中,這個規範被叫做記憶體模型。
除了 Go,Java、C++、C、C#、Rust 等程式語言也有記憶體模型。為什麼這些程式語言都要定義記憶體模型呢?在我看來,主要是兩個目的。
- 向廣大的程式設計師提供一種保證,以便他們在做設計和開發程式時,面對同一個資料同時被多個 goroutine 訪問的情況,可以做一些序列化訪問的控制,比如使用 Channel 或者 sync 包和 sync/atomic 包中的併發原語。
- 允許編譯器和硬體對程式做一些最佳化。這一點其實主要是為編譯器開發者提供的保證,這樣可以方便他們對 Go 的編譯器做最佳化。
既然記憶體模型這麼重要,今天,我們就來花一節課的時間學習一下。
首先,我們要先弄明白重排和可見性的問題,因為它們影響著程式實際執行的順序關係。
重排和可見性的問題
由於指令重排,程式碼並不一定會按照你寫的順序執行。
舉個例子,當兩個 goroutine 同時對一個資料進行讀寫時,假設 goroutine g1 對這個變數進行寫操作 w,goroutine g2 同時對這個變數進行讀操作 r,那麼,如果 g2 在執行讀操作 r 的時候,已經看到了 g1 寫操作 w 的結果,那麼,也不意味著 g2 能看到在 w 之前的其它的寫操作。這是一個反直觀的結果,不過的確可能會存在。
接下來,我再舉幾個具體的例子,帶你來感受一下,重排以及多核 CPU 併發執行導致程式的執行和程式碼的書寫順序不一樣的情況。
先看第一個例子,程式碼如下:
var a, b int
func f() {
a = 1 // w之前的寫操作
b = 2 // 寫操作w
}
func g() {
print(b) // 讀操作r
print(a) // ???
}
func main() {
go f() //g1
g() //g2
}
可以看到,第 9 行是要列印 b 的值。需要注意的是,即使這裡打印出的值是 2,但是依然可能在列印 a 的值時,打印出初始值 0,而不是 1。這是因為,程式執行的時候,不能保證 g2 看到的 a 和 b 的賦值有先後關係。
再來看一個類似的例子。
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
在這段程式碼中,主 goroutine main 即使觀察到 done 變成 true 了,最後讀取到的 a 的值仍然可能為空。
更糟糕的情況是,main 根本就觀察不到另一個 goroutine 對 done 的寫操作,這就會導致 main 程式一直被 hang 住。甚至可能還會出現半初始化的情況,比如:
type T struct {
msg string
}
var g *T
func setup() {
t := new(T)
t.msg = "hello, world"
g = t
}
func main() {
go setup()
for g == nil {
}
print(g.msg)
}
即使 main goroutine 觀察到 g 不為 nil,也可能打印出空的 msg(第 17 行)。
看到這裡,你可能要說了,我都執行這個程式幾百萬次了,怎麼也沒有觀察到這種現象?我可以這麼告訴你,能不能觀察到和提供保證(guarantee)是兩碼事兒。由於 CPU 架構和 Go 編譯器的不同,即使你執行程式時沒有遇到這些現象,也不代表 Go 可以 100% 保證不會出現這些問題。
剛剛說了,程式在執行的時候,兩個操作的順序可能不會得到保證,那該怎麼辦呢?接下來,我要帶你瞭解一下 Go 記憶體模型中很重要的一個概念:happens-before,這是用來描述兩個時間的順序關係的。如果某些操作能提供 happens-before 關係,那麼,我們就可以 100% 保證它們之間的順序。
happens-before
在一個 goroutine 內部,程式的執行順序和它們的程式碼指定的順序是一樣的,即使編譯器或者 CPU 重排了讀寫順序,從行為上來看,也和程式碼指定的順序一樣。
這是一個非常重要的保證,我們一定要記住。
我們來看一個例子。在下面的程式碼中,即使編譯器或者 CPU 對 a、b、c 的初始化進行了重排,但是列印結果依然能保證是 1、2、3,而不會出現 1、0、0 或 1、0、1 等情況。
func foo() {
var a = 1
var b = 2
var c = 3
println(a)
println(b)
println(c)
}
但是,對於另一個 goroutine 來說,重排卻會產生非常大的影響。因為 Go 只保證 goroutine 內部重排對讀寫的順序沒有影響,比如剛剛我們在講“可見性”問題時提到的三個例子,那該怎麼辦呢?這就要用到 happens-before 關係了。
如果兩個 action(read 或者 write)有明確的 happens-before 關係,你就可以確定它們之間的執行順序(或者是行為表現上的順序)。
Go 記憶體模型透過 happens-before 定義兩個事件(讀、寫 action)的順序:如果事件 e1 happens before 事件 e2,那麼,我們就可以說事件 e2 在事件 e1 之後發生(happens after)。如果 e1 不是 happens before e2, 同時也不 happens after e2,那麼,我們就可以說事件 e1 和 e2 是同時發生的。
如果要保證對“變數 v 的讀操作 r”能夠觀察到一個對“變數 v 的寫操作 w”,並且 r 只能觀察到 w 對變數 v 的寫,沒有其它對 v 的寫操作,也就是說,我們要保證 r 絕對能觀察到 w 操作的結果,那麼就需要同時滿足兩個條件:
- w happens before r;
- 其它對 v 的寫操作(w2、w3、w4, …) 要麼 happens before w,要麼 happens after r,絕對不會和 w、r 同時發生,或者是在它們之間發生。
你可能會說,這是很顯然的事情啊,但我要和你說的是,這是一個非常嚴格、嚴謹的數學定義。
對於單個的 goroutine 來說,它有一個特殊的 happens-before 關係,Go 記憶體模型中是這麼講的:
Within a single goroutine, the happens-before order is the order expressed by the program.
我來解釋下這句話。它的意思是,在單個的 goroutine 內部, happens-before 的關係和程式碼編寫的順序是一致的。
其實,在這一章的開頭我已經用橙色把這句話標註出來了。我再具體解釋下。
在 goroutine 內部對一個區域性變數 v 的讀,一定能觀察到最近一次對這個區域性變數 v 的寫。如果要保證多個 goroutine 之間對一個共享變數的讀寫順序,在 Go 語言中,可以使用併發原語為讀寫操作建立 happens-before 關係,這樣就可以保證順序了。
說到這兒,我想先給你補充三個 Go 語言中和記憶體模型有關的小知識,掌握了這些,你就能更好地理解下面的內容。
- 在 Go 語言中,對變數進行零值的初始化就是一個寫操作。
- 如果對超過機器 word(64bit、32bit 或者其它)大小的值進行讀寫,那麼,就可以看作是對拆成 word 大小的幾個讀寫無序進行。
- Go 並不提供直接的 CPU 屏障(CPU fence)來提示編譯器或者 CPU 保證順序性,而是使用不同架構的記憶體屏障指令來實作統一的併發原語。
接下來,我就帶你學習下 Go 語言中提供的 happens-before 關係保證。
Go 語言中保證的 happens-before 關係
除了單個 goroutine 內部提供的 happens-before 保證,Go 語言中還提供了一些其它的 happens-before 關係的保證,下面我來一個一個介紹下。
init 函式
應用程式的初始化是在單一的 goroutine 執行的。如果包 p 匯入了包 q,那麼,q 的 init 函式的執行一定 happens before p 的任何初始化程式碼。
這裡有一個特殊情況需要你記住:main 函式一定在匯入的包的 init 函式之後執行。
包級別的變數在同一個檔案中是按照宣告順序逐個初始化的,除非初始化它的時候依賴其它的變數。同一個包下的多個檔案,會按照檔名的排列順序進行初始化。這個順序被定義在Go 語言規範中,而不是 Go 的記憶體模型規範中。你可以看看下面的例子中各個變數的值:
var (
a = c + b // == 9
b = f() // == 4
c = f() // == 5
d = 3 // == 5 全部初始化完成後
)
func f() int {
d++
return d
}
具體怎麼對這些變數進行初始化呢?Go 採用的是依賴分析技術。不過,依賴分析技術保證的順序只是針對同一包下的變數,而且,只有引用關係是本包變數、函式和非介面的方法,才能保證它們的順序性。
同一個包下可以有多個 init 函式,但是每個檔案最多隻能有一個 init 函式,多個 init 函式按照它們的檔名順序逐個初始化。
剛剛講的這些都是不同包的 init 函式執行順序,下面我舉一個具體的例子,把這些內容串起來,你一看就明白了。
這個例子是一個 main 程式,它依賴包 p1,包 p1 依賴包 p2,包 p2 依賴 p3。
為了追蹤初始化過程,並輸出有意義的日誌,我定義了一個輔助方法,打印出日誌並返回一個用來初始化的整數值:
func Trace(t string, v int) int {
fmt.Println(t, ":", v)
return v
}
包 p3 包含兩個檔案,分別定義了一個 init 函式。第一個檔案中定義了兩個變數,這兩個變數的值還會在 init 函式中進行修改。
我們來分別看下包 p3 的這兩個檔案:
// lib1.go in p3
var V1_p3 = trace.Trace("init v1_p3", 3)
var V2_p3 = trace.Trace("init v2_p3", 3)
func init() {
fmt.Println("init func in p3")
V1_p3 = 300
V2_p3 = 300
}
// lib2.go in p3
func init() {
fmt.Println("another init func in p3")
}
下面再來看看包 p2。包 p2 定義了變數和 init 函式。第一個變數初始化為 2,並在 init 函式中更改為 200。第二個變數是複製的 p3.V2_p3。
var V1_p2 = trace.Trace("init v1_p2", 2)
var V2_p2 = trace.Trace("init v2_p2", p3.V2_p3)
func init() {
fmt.Println("init func in p2")
V1_p2 = 200
}
包 p1 定義了變數和 init 函式。它的兩個變數的值是複製的 p2 對應的兩個變數值。
var V1_p1 = trace.Trace("init v1_p1", p2.V1_p2)
var V2_p1 = trace.Trace("init v2_p1", p2.V2_p2)
func init() {
fmt.Println("init func in p1")
}
main 定義了 init 函式和 main 函式。
func init() {
fmt.Println("init func in main")
}
func main() {
fmt.Println("V1_p1:", p1.V1_p1)
fmt.Println("V2_p1:", p1.V2_p1)
}
執行 main 函式會依次輸出 p3、p2、p1、main 的初始化變數時的日誌(變數初始化時的日誌和 init 函式呼叫時的日誌):
// 包p3的變數初始化
init v1_p3 : 3
init v2_p3 : 3
// p3的init函式
init func in p3
// p3的另一個init函式
another init func in p3
// 包p2的變數初始化
init v1_p2 : 2
init v2_p2 : 300
// 包p2的init函式
init func in p2
// 包p1的變數初始化
init v1_p1 : 200
init v2_p1 : 300
// 包p1的init函式
init func in p1
// 包main的init函式
init func in main
// main函式
V1_p1: 200
V2_p1: 300
下面,我們再來看看 goroutine 對 happens-before 關係的保證情況。
goroutine
首先,我們需要明確一個規則:啟動 goroutine 的 go 語句的執行,一定 happens before 此 goroutine 內的程式碼執行。
根據這個規則,我們就可以知道,如果 go 語句傳入的引數是一個函式執行的結果,那麼,這個函式一定先於 goroutine 內部的程式碼被執行。
我們來看一個例子。在下面的程式碼中,第 8 行 a 的賦值和第 9 行的 go 語句是在同一個 goroutine 中執行的,所以,在主 goroutine 看來,第 8 行肯定 happens before 第 9 行,又由於剛才的保證,第 9 行子 goroutine 的啟動 happens before 第 4 行的變數輸出,那麼,我們就可以推斷出,第 8 行 happens before 第 4 行。也就是說,在第 4 行列印 a 的值的時候,肯定會打印出“hello world”。
var a string
func f() {
print(a)
}
func hello() {
a = "hello, world"
go f()
}
剛剛說的是啟動 goroutine 的情況,goroutine 退出的時候,是沒有任何 happens-before 保證的。所以,如果你想觀察某個 goroutine 的執行效果,你需要使用同步機制建立 happens-before 關係,比如 Mutex 或者 Channel。接下來,我會講 Channel 的 happens-before 的關係保證。
Channel
Channel 是 goroutine 同步交流的主要方法。往一個 Channel 中傳送一條資料,通常對應著另一個 goroutine 從這個 Channel 中接收一條資料。
通用的 Channel happens-before 關係保證有 4 條規則,我分別來介紹下。
第 1 條規則是,往 Channel 中的傳送操作,happens before 從該 Channel 接收相應資料的動作完成之前,即第 n 個 send 一定 happens before 第 n 個 receive 的完成。
var ch = make(chan struct{}, 10) // buffered或者unbuffered
var s string
func f() {
s = "hello, world"
ch <- struct{}{}
}
func main() {
go f()
<-ch
print(s)
}
在這個例子中,s 的初始化(第 5 行)happens before 往 ch 中傳送資料, 往 ch 傳送資料 happens before 從 ch 中讀取出一條資料(第 11 行),第 12 行列印 s 的值 happens after 第 11 行,所以,列印的結果肯定是初始化後的 s 的值“hello world”。
第 2 條規則是,close 一個 Channel 的呼叫,肯定 happens before 從關閉的 Channel 中讀取出一個零值。
還是拿剛剛的這個例子來說,如果你把第 6 行替換成 close(ch),也能保證同樣的執行順序。因為第 11 行從關閉的 ch 中讀取出零值後,第 6 行肯定被呼叫了。
第 3 條規則是,對於 unbuffered 的 Channel,也就是容量是 0 的 Channel,從此 Channel 中讀取資料的呼叫一定 happens before 往此 Channel 傳送資料的呼叫完成。
所以,在上面的這個例子中呢,如果想保持同樣的執行順序,也可以寫成這樣:
var ch = make(chan int)
var s string
func f() {
s = "hello, world"
<-ch
}
func main() {
go f()
ch <- struct{}{}
print(s)
}
如果第 11 行傳送語句執行成功(完畢),那麼根據這個規則,第 6 行(接收)的呼叫肯定發生了(執行完成不完成不重要,重要的是這一句“肯定執行了”),那麼 s 也肯定初始化了,所以一定會打印出“hello world”。
這一條比較晦澀,但是,因為 Channel 是 unbuffered 的 Channel,所以這個規則也成立。
第 4 條規則是,如果 Channel 的容量是 m(m>0),那麼,第 n 個 receive 一定 happens before 第 n+m 個 send 的完成。
前一條規則是針對 unbuffered channel 的,這裡給出了更廣泛的針對 buffered channel 的保證。利用這個規則,我們可以實作訊號量(Semaphore)的併發原語。Channel 的容量相當於可用的資源,傳送一條資料相當於請求訊號量,接收一條資料相當於釋放訊號。關於訊號量這個併發原語,我會在下一講專門給你介紹一下,這裡你只需要知道它可以控制多個資源的併發訪問,就可以了。
Mutex/RWMutex
對於互斥鎖 Mutex m 或者讀寫鎖 RWMutex m,有 3 條 happens-before 關係的保證。
- 第 n 次的 m.Unlock 一定 happens before 第 n+1 m.Lock 方法的返回;
- 對於讀寫鎖 RWMutex m,如果它的第 n 個 m.Lock 方法的呼叫已返回,那麼它的第 n 個 m.Unlock 的方法呼叫一定 happens before 任何一個 m.RLock 方法呼叫的返回,只要這些 m.RLock 方法呼叫 happens after 第 n 次 m.Lock 的呼叫的返回。這就可以保證,只有釋放了持有的寫鎖,那些等待的讀請求才能請求到讀鎖。
- 對於讀寫鎖 RWMutex m,如果它的第 n 個 m.RLock 方法的呼叫已返回,那麼它的第 k (k<=n)個成功的 m.RUnlock 方法的返回一定 happens before 任意的 m.RUnlockLock 方法呼叫,只要這些 m.Lock 方法呼叫 happens after 第 n 次 m.RLock。
讀寫鎖的保證有點繞,我再帶你看看官方的描述:
對於讀寫鎖 l 的 l.RLock 方法呼叫,如果存在一個 n,這次的 l.RLock 呼叫 happens after 第 n 次的 l.Unlock,那麼,和這個 RLock 相對應的 l.RUnlock 一定 happens before 第 n+1 次 l.Lock。意思是,讀寫鎖的 Lock 必須等待既有的讀鎖釋放後才能獲取到。
我再舉個例子。在下面的程式碼中,第 6 行第一次的 Unlock 一定 happens before 第二次的 Lock(第 12 行),所以這也能保證正確地打印出“hello world”。
var mu sync.Mutex
var s string
func foo() {
s = "hello, world"
mu.Unlock()
}
func main() {
mu.Lock()
go foo()
mu.Lock()
print(s)WaitGroup接下來是 WaitGroup 的保證。
對於一個 WaitGroup 例項 wg,在某個時刻 t0 時,它的計數值已經不是零了,假如 t0 時刻之後呼叫了一系列的 wg.Add(n) 或者 wg.Done(),並且只有最後一次呼叫 wg 的計數值變為了 0,那麼,可以保證這些 wg.Add 或者 wg.Done() 一定 happens before t0 時刻之後呼叫的 wg.Wait 方法的返回。
這個保證的通俗說法,就是 Wait 方法等到計數值歸零之後才返回。
Once
我們在第 8 講學過 Once 了,相信你已經很熟悉它的功能了。它提供的保證是:對於 once.Do(f) 呼叫,f 函式的那個單次呼叫一定 happens before 任何 once.Do(f) 呼叫的返回。換句話說,就是函式 f 一定會在 Do 方法返回之前執行。
還是以 hello world 的例子為例,這次我們使用 Once 併發原語實作,可以看下下面的程式碼:
var s string
var once sync.Once
func foo() {
s = "hello, world"
}
func twoprint() {
once.Do(foo)
print(s)
}
第 5 行的執行一定 happens before 第 9 行的返回,所以執行到第 10 行的時候,sd 已經初始化了,所以會正確地列印“hello world”。
最後,我再來說說 atomic 的保證。
atomic
其實,Go 記憶體模型的官方文件並沒有明確給出 atomic 的保證,有一個相關的 issue go# 5045記錄了相關的討論。光看 issue 號,就知道這個討論由來已久了。Russ Cox 想讓 atomic 有一個弱保證,這樣可以為以後留下充足的可擴充套件空間,所以,Go 記憶體模型規範上並沒有嚴格的定義。
對於 Go 1.15 的官方實作來說,可以保證使用 atomic 的 Load/Store 的變數之間的順序性。
在下面的例子中,打印出的 a 的結果總是 1,但是官方並沒有做任何文件上的說明和保證。
依照 Ian Lance Taylor 的說法,Go 核心開發組的成員幾乎沒有關注這個方向上的研究,因為這個問題太複雜,有很多問題需要去研究,所以,現階段還是不要使用 atomic 來保證順序性。
func main() {
var a, b int32 = 0, 0
go func() {
atomic.StoreInt32(&a, 1)
atomic.StoreInt32(&b, 1)
}()
for atomic.LoadInt32(&b) == 0{
runtime.Gosched()
}
fmt.Println(atomic.LoadInt32(&a))
}總結Go 的記憶體模型規範中,一開始有這麼一段話:
If you must read the rest of this document to understand the behavior of your program, you are being too clever.
Don’t be clever.
我來說說我對這句話的理解:你透過學習這節課來理解你的程式的行為是聰明的,但是,不要自作聰明。
謹慎地使用這些保證,能夠讓你的程式按照設想的 happens-before 關係執行,但是不要以為完全理解這些概念和保證,就可以隨意地製造所謂的各種技巧,否則就很容易掉進“坑”裡,而且會給程式碼埋下了很多的“定時炸彈”。
比如,Go 裡面已經有值得信賴的互斥鎖了,如果沒有額外的需求,就不要使用 Channel 創造出自己的互斥鎖。
當然,我也不希望你畏手畏腳地把思想侷限住,我還是建議你去做一些有意義的嘗試,比如使用 Channel 實作訊號量等擴充套件併發原語。
思考題
我們知道,Channel 可以實作互斥鎖,那麼,我想請你思考一下,它是如何利用 happens-before 關係保證鎖的請求和釋放的呢?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
16|Semaphore:一篇文章搞懂訊號量
你好,我是鳥窩。
本章導讀
Semaphore 控制併發數量圖
可用許可數 = 3
任務1 ─Acquire─┐
任務2 ─Acquire─┼──> [執行中](最多 3 個)
任務3 ─Acquire─┘
任務4 ─Acquire────────> [等待許可]
任務完成 -> Release -> 等待中的任務取得許可繼續
在前面的課程裡,我們學習了標準庫的併發原語、原子操作和 Channel,掌握了這些,你就可以解決 80% 的併發程式設計問題了。但是,如果你要想進一步提升你的併發程式設計能力,就需要學習一些第三方庫。
所以,在接下來的幾節課裡,我會給你分享 Go 官方或者其他人提供的第三方庫,這節課我們先來學習訊號量,訊號量(Semaphore)是用來控制多個 goroutine 同時訪問多個資源的併發原語。
訊號量是什麼?都有什麼操作?
訊號量的概念是荷蘭電腦科學家 Edsger Dijkstra 在 1963 年左右提出來的,廣泛應用在不同的作業系統中。在系統中,會給每一個程式一個訊號量,代表每個程式目前的狀態。未得到控制權的程式,會在特定的地方被迫停下來,等待可以繼續進行的訊號到來。
最簡單的訊號量就是一個變數加一些併發控制的能力,這個變數是 0 到 n 之間的一個數值。當 goroutine 完成對此訊號量的等待(wait)時,該計數值就減 1,當 goroutine 完成對此訊號量的釋放(release)時,該計數值就加 1。當計數值為 0 的時候,goroutine 呼叫 wait 等待該訊號量是不會成功的,除非計數器又大於 0,等待的 goroutine 才有可能成功返回。
更復雜的訊號量型別,就是使用抽象資料型別代替變數,用來代表複雜的資源型別。實際上,大部分的訊號量都使用一個整型變數來表示一組資源,並沒有實作太複雜的抽象資料型別,所以你只要知道有更復雜的訊號量就行了,我們這節課主要是學習最簡單的訊號量。
說到這兒呢,我想借助一個生活中的例子,來幫你進一步理解訊號量。
舉個例子,圖書館新購買了 10 本《Go 併發程式設計的獨家秘籍》,有 1 萬個學生都想讀這本書,“僧多粥少”。所以,圖書館管理員先會讓這 1 萬個同學進行登記,按照登記的順序,借閱此書。如果書全部被借走,那麼,其他想看此書的同學就需要等待,如果有人還書了,圖書館管理員就會通知下一位同學來借閱這本書。這裡的資源是《Go 併發程式設計的獨家秘籍》這十本書,想讀此書的同學就是 goroutine,圖書管理員就是訊號量。
怎麼樣,現在是不是很好理解了?那麼,接下來,我們來學習下訊號量的 P/V 操作。
P/V 操作
Dijkstra 在他的論文中為訊號量定義了兩個操作 P 和 V。P 操作(descrease、wait、acquire)是減少訊號量的計數值,而 V 操作(increase、signal、release)是增加訊號量的計數值。
使用偽程式碼表示如下(中括號代表原子操作):
function V(semaphore S, integer I):
[S ← S + I]
function P(semaphore S, integer I):
repeat:
[if S ≥ I:
S ← S − I
break]
可以看到,初始化訊號量 S 有一個指定數量(n)的資源,它就像是一個有 n 個資源的池子。P 操作相當於請求資源,如果資源可用,就立即返回;如果沒有資源或者不夠,那麼,它可以不斷嘗試或者阻塞等待。V 操作會釋放自己持有的資源,把資源返還給訊號量。訊號量的值除了初始化的操作以外,只能由 P/V 操作改變。
現在,我們來總結下訊號量的實作。
- 初始化訊號量:設定初始的資源的數量。
- P 操作:將訊號量的計數值減去 1,如果新值已經為負,那麼呼叫者會被阻塞並加入到等待佇列中。否則,呼叫者會繼續執行,並且獲得一個資源。
- V 操作:將訊號量的計數值加 1,如果先前的計數值為負,就說明有等待的 P 操作的呼叫者。它會從等待佇列中取出一個等待的呼叫者,喚醒它,讓它繼續執行。
講到這裡,我想再稍微說一個題外話,我們在第 2 講提到過飢餓,就是說在高併發的極端場景下,會有些 goroutine 始終搶不到鎖。為了處理飢餓的問題,你可以在等待佇列中做一些“文章”。比如實作一個優先順序的佇列,或者先入先出的佇列,等等,保持公平性,並且照顧到優先順序。
在正式進入實作訊號量的具體實作原理之前,我想先講一個知識點,就是訊號量和互斥鎖的區別與聯絡,這有助於我們掌握接下來的內容。
其實,訊號量可以分為計數訊號量(counting semaphre)和二進位訊號量(binary semaphore)。剛剛所說的圖書館借書的例子就是一個計數訊號量,它的計數可以是任意一個整數。在特殊的情況下,如果計數值只能是 0 或者 1,那麼,這個訊號量就是二進位訊號量,提供了互斥的功能(要麼是 0,要麼是 1),所以,有時候互斥鎖也會使用二進位訊號量來實作。
我們一般用訊號量保護一組資源,比如資料庫連線池、一組客戶端的連線、幾個印表機資源,等等。如果訊號量蛻變成二進位訊號量,那麼,它的 P/V 就和互斥鎖的 Lock/Unlock 一樣了。
有人會很細緻地區分二進位訊號量和互斥鎖。比如說,有人提出,在 Windows 系統中,互斥鎖只能由持有鎖的執行緒釋放鎖,而二進位訊號量則沒有這個限制(Stack Overflow上也有相關的討論)。實際上,雖然在 Windows 系統中,它們的確有些區別,但是對 Go 語言來說,互斥鎖也可以由非持有的 goroutine 來釋放,所以,從行為上來說,它們並沒有嚴格的區別。
我個人認為,沒必要進行細緻的區分,因為互斥鎖並不是一個很嚴格的定義。實際在遇到互斥併發的問題時,我們一般選用互斥鎖。
好了,言歸正傳,剛剛我們掌握了訊號量的含義和具體操作方式,下面,我們就來具體瞭解下官方擴充套件庫的實作。
Go 官方擴充套件庫的實作
在執行時,Go 內部使用訊號量來控制 goroutine 的阻塞和喚醒。我們在學習基本併發原語的實作時也看到了,比如互斥鎖的第二個欄位:
type Mutex struct {
state int32
sema uint32
}
訊號量的 P/V 操作是透過函式實作的:
func runtime_Semacquire(s *uint32)
func runtime_SemacquireMutex(s *uint32, lifo bool, skipframes int)
func runtime_Semrelease(s *uint32, handoff bool, skipframes int)
遺憾的是,它是 Go 執行時內部使用的,並沒有封裝暴露成一個對外的訊號量併發原語,原則上我們沒有辦法使用。不過沒關係,Go 在它的擴充套件包中提供了訊號量semaphore,不過這個訊號量的型別名並不叫 Semaphore,而是叫 Weighted。
之所以叫做 Weighted,我想,應該是因為可以在初始化建立這個訊號量的時候設定權重(初始化的資源數),其實我覺得叫 Semaphore 或許會更好。

我們來分析下這個訊號量的幾個實作方法。
- Acquire 方法:相當於 P 操作,你可以一次獲取多個資源,如果沒有足夠多的資源,呼叫者就會被阻塞。它的第一個引數是 Context,這就意味著,你可以透過 Context 增加超時或者 cancel 的機制。如果是正常獲取了資源,就返回 nil;否則,就返回 ctx.Err(),訊號量不改變。
- Release 方法:相當於 V 操作,可以將 n 個資源釋放,返還給訊號量。
- TryAcquire 方法:嘗試獲取 n 個資源,但是它不會阻塞,要麼成功獲取 n 個資源,返回 true,要麼一個也不獲取,返回 false。
知道了訊號量的實作方法,在實際的場景中,我們應該怎麼用呢?我來舉個 Worker Pool 的例子,來幫助你理解。
我們建立和 CPU 核數一樣多的 Worker,讓它們去處理一個 4 倍數量的整數 slice。每個 Worker 一次只能處理一個整數,處理完之後,才能處理下一個。
當然,這個問題的解決方案有很多種,這一次我們使用訊號量,程式碼如下:
var (
maxWorkers = runtime.GOMAXPROCS(0) // worker數量
sema = semaphore.NewWeighted(int64(maxWorkers)) //訊號量
task = make([]int, maxWorkers*4) // 任務數,是worker的四倍
)
func main() {
ctx := context.Background()
for i := range task {
// 如果沒有worker可用,會阻塞在這裡,直到某個worker被釋放
if err := sema.Acquire(ctx, 1); err != nil {
break
}
// 啟動worker goroutine
go func(i int) {
defer sema.Release(1)
time.Sleep(100 * time.Millisecond) // 模擬一個耗時操作
task[i] = i + 1
}(i)
}
// 請求所有的worker,這樣能確保前面的worker都執行完
if err := sema.Acquire(ctx, int64(maxWorkers)); err != nil {
log.Printf("獲取所有的worker失敗: %v", err)
}
fmt.Println(task)
}
在這段程式碼中,main goroutine 相當於一個 dispacher,負責任務的分發。它先請求訊號量,如果獲取成功,就會啟動一個 goroutine 去處理計算,然後,這個 goroutine 會釋放這個訊號量(有意思的是,訊號量的獲取是在 main goroutine,訊號量的釋放是在 worker goroutine 中),如果獲取不成功,就等到有訊號量可以使用的時候,再去獲取。
需要提醒你的是,其實,在這個例子中,還有一個值得我們學習的知識點,就是最後的那一段處理(第 25 行)。如果在實際應用中,你想等所有的 Worker 都執行完,就可以獲取最大計數值的訊號量。
Go 擴充套件庫中的訊號量是使用互斥鎖 +List 實作的。互斥鎖實作其它欄位的保護,而 List 實作了一個等待佇列,等待者的通知是透過 Channel 的通知機制實作的。
我們來看一下訊號量 Weighted 的資料結構:
type Weighted struct {
size int64 // 最大資源數
cur int64 // 當前已被使用的資源
mu sync.Mutex // 互斥鎖,對欄位的保護
waiters list.List // 等待佇列
}
在訊號量的幾個實作方法裡,Acquire 是程式碼最複雜的一個方法,它不僅僅要監控資源是否可用,而且還要檢測 Context 的 Done 是否已關閉。我們來看下它的實作程式碼。
func (s *Weighted) Acquire(ctx context.Context, n int64) error {
s.mu.Lock()
// fast path, 如果有足夠的資源,都不考慮ctx.Done的狀態,將cur加上n就返回
if s.size-s.cur >= n && s.waiters.Len() == 0 {
s.cur += n
s.mu.Unlock()
return nil
}
// 如果是不可能完成的任務,請求的資源數大於能提供的最大的資源數
if n > s.size {
s.mu.Unlock()
// 依賴ctx的狀態返回,否則一直等待
<-ctx.Done()
return ctx.Err()
}
// 否則就需要把呼叫者加入到等待佇列中
// 建立了一個ready chan,以便被通知喚醒
ready := make(chan struct{})
w := waiter{n: n, ready: ready}
elem := s.waiters.PushBack(w)
s.mu.Unlock()
// 等待
select {
case <-ctx.Done(): // context的Done被關閉
err := ctx.Err()
s.mu.Lock()
select {
case <-ready: // 如果被喚醒了,忽略ctx的狀態
err = nil
default: 通知waiter
isFront := s.waiters.Front() == elem
s.waiters.Remove(elem)
// 通知其它的waiters,檢查是否有足夠的資源
if isFront && s.size > s.cur {
s.notifyWaiters()
}
}
s.mu.Unlock()
return err
case <-ready: // 被喚醒了
return nil
}
}
其實,為了提高效能,這個方法中的 fast path 之外的程式碼,可以抽取成 acquireSlow 方法,以便其它 Acquire 被內聯。
Release 方法將當前計數值減去釋放的資源數 n,並喚醒等待佇列中的呼叫者,看是否有足夠的資源被獲取。
func (s *Weighted) Release(n int64) {
s.mu.Lock()
s.cur -= n
if s.cur < 0 {
s.mu.Unlock()
panic("semaphore: released more than held")
}
s.notifyWaiters()
s.mu.Unlock()
}
notifyWaiters 方法就是逐個檢查等待的呼叫者,如果資源不夠,或者是沒有等待者了,就返回:
func (s *Weighted) notifyWaiters() {
for {
next := s.waiters.Front()
if next == nil {
break // No more waiters blocked.
}
w := next.Value.(waiter)
if s.size-s.cur < w.n {
//避免飢餓,這裡還是按照先入先出的方式處理
break
}
s.cur += w.n
s.waiters.Remove(next)
close(w.ready)
}
}
notifyWaiters 方法是按照先入先出的方式喚醒呼叫者。當釋放 100 個資源的時候,如果第一個等待者需要 101 個資源,那麼,佇列中的所有等待者都會繼續等待,即使有的等待者只需要 1 個資源。這樣做的目的是避免飢餓,否則的話,資源可能總是被那些請求資源數小的呼叫者獲取,這樣一來,請求資源數巨大的呼叫者,就沒有機會獲得資源了。
好了,到這裡,你就知道了官方擴充套件庫的訊號量實作方法,接下來你就可以使用訊號量了。不過,在此之前呢,我想給你講幾個使用時的常見錯誤。這部分內容可是幫助你避坑的,我建議你好好學習。
使用訊號量的常見錯誤
保證訊號量不出錯的前提是正確地使用它,否則,公平性和安全性就會受到損害,導致程式 panic。
在使用訊號量時,最常見的幾個錯誤如下:
- 請求了資源,但是忘記釋放它;
- 釋放了從未請求的資源;
- 長時間持有一個資源,即使不需要它;
- 不持有一個資源,卻直接使用它。
不過,即使你規避了這些坑,在同時使用多種資源,不同的訊號量控制不同的資源的時候,也可能會出現死鎖現象,比如哲學家就餐問題。
就 Go 擴充套件庫實作的訊號量來說,在呼叫 Release 方法的時候,你可以傳遞任意的整數。但是,如果你傳遞一個比請求到的數量大的錯誤的數值,程式就會 panic。如果傳遞一個負數,會導致資源永久被持有。如果你請求的資源數比最大的資源數還大,那麼,呼叫者可能永遠被阻塞。
所以,使用訊號量遵循的原則就是請求多少資源,就釋放多少資源。你一定要注意,必須使用正確的方法傳遞整數,不要“耍小聰明”,而且,請求的資源數一定不要超過最大資源數。
其它訊號量的實作
除了官方擴充套件庫的實作,實際上,我們還有很多方法實作訊號量,比較典型的就是使用 Channel 來實作。
根據之前的 Channel 型別的介紹以及 Go 記憶體模型的定義,你應該能想到,使用一個 buffer 為 n 的 Channel 很容易實作訊號量,比如下面的程式碼,我們就是使用 chan struct{}型別來實作的。
在初始化這個訊號量的時候,我們設定它的初始容量,代表有多少個資源可以使用。它使用 Lock 和 Unlock 方法實作請求資源和釋放資源,正好實作了 Locker 介面。
// Semaphore 資料結構,並且還實作了Locker介面
type semaphore struct {
sync.Locker
ch chan struct{}
}
// 建立一個新的訊號量
func NewSemaphore(capacity int) sync.Locker {
if capacity <= 0 {
capacity = 1 // 容量為1就變成了一個互斥鎖
}
return &semaphore{ch: make(chan struct{}, capacity)}
}
// 請求一個資源
func (s *semaphore) Lock() {
s.ch <- struct{}{}
}
// 釋放資源
func (s *semaphore) Unlock() {
<-s.ch
}
當然,你還可以自己擴充套件一些方法,比如在請求資源的時候使用 Context 引數(Acquire(ctx))、實作 TryLock 等功能。
看到這裡,你可能會問,這個訊號量的實作看起來非常簡單,而且也能應對大部分的訊號量的場景,為什麼官方擴充套件庫的訊號量的實作不採用這種方法呢?其實,具體是什麼原因,我也不知道,但是我必須要強調的是,官方的實作方式有這樣一個功能:它可以一次請求多個資源,這是透過 Channel 實作的訊號量所不具備的。
除了 Channel,marusama/semaphore也實作了一個可以動態更改資源容量的訊號量,也是一個非常有特色的實作。如果你的資源數量並不是固定的,而是動態變化的,我建議你考慮一下這個訊號量庫。
總結
這是一個很奇怪的現象:標準庫中實作基本併發原語(比如 Mutex)的時候,強烈依賴訊號量實作等待佇列和通知喚醒,但是,標準庫中卻沒有把這個實作直接暴露出來放到標準庫,而是透過第三庫提供。
不管怎樣,訊號量這個併發原語在多資源共享的併發控制的場景中被廣泛使用,有時候也會被 Channel 型別所取代,因為一個 buffered chan 也可以代表 n 個資源。
但是,官方擴充套件的訊號量也有它的優勢,就是可以一次獲取多個資源。在批次獲取資源的場景中,我建議你嘗試使用官方擴充套件的訊號量。
思考題
- 你能用 Channel 實作訊號量併發原語嗎?你能想到幾種實作方式?
- 為什麼訊號量的資源數設計成 int64 而不是 uint64 呢?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
17|SingleFlight 和 CyclicBarrier:請求合併和迴圈柵欄該怎麼用?
你好,我是鳥窩。
本章導讀
SingleFlight + CyclicBarrier(兩種不同用途)
A. SingleFlight(請求合併)
請求A ─┐
請求B ─┼──> [同一 key] -> 只執行 1 次 -> 結果廣播給等待者
請求C ─┘
B. CyclicBarrier(分批同步)
worker1 ─┐
worker2 ─┼──> [barrier 點] -> 全員到齊 -> 一起往下執行(可重複使用)
worker3 ─┘
這節課,我來給你介紹兩個非常重要的擴充套件併發原語:SingleFlight 和 CyclicBarrier。SingleFlight 的作用是將併發請求合併成一個請求,以減少對下層服務的壓力;而 CyclicBarrier 是一個可重用的柵欄併發原語,用來控制一組請求同時執行的資料結構。
其實,它們兩個並沒有直接的關係,只是內容相對來說比較少,所以我打算用最短的時間帶你掌握它們。一節課就能掌握兩個“武器”,是不是很高效?
請求合併 SingleFlight
SingleFlight 是 Go 開發組提供的一個擴充套件併發原語。它的作用是,在處理多個 goroutine 同時呼叫同一個函式的時候,只讓一個 goroutine 去呼叫這個函式,等到這個 goroutine 返回結果的時候,再把結果返回給這幾個同時呼叫的 goroutine,這樣可以減少併發呼叫的數量。
這裡我想先回答一個問題:標準庫中的 sync.Once 也可以保證併發的 goroutine 只會執行一次函式 f,那麼,SingleFlight 和 sync.Once 有什麼區別呢?
其實,sync.Once 不是隻在併發的時候保證只有一個 goroutine 執行函式 f,而是會保證永遠只執行一次,而 SingleFlight 是每次呼叫都重新執行,並且在多個請求同時呼叫的時候只有一個執行。它們兩個面對的場景是不同的,sync.Once 主要是用在單次初始化場景中,而 SingleFlight 主要用在合併併發請求的場景中,尤其是快取場景。
如果你學會了 SingleFlight,在面對秒殺等大併發請求的場景,而且這些請求都是讀請求時,你就可以把這些請求合併為一個請求,這樣,你就可以將後端服務的壓力從 n 降到 1。尤其是在面對後端是資料庫這樣的服務的時候,採用 SingleFlight 可以極大地提高效能。那麼,話不多說,就讓我們開始學習 SingleFlight 吧。
實作原理
SingleFlight 使用互斥鎖 Mutex 和 Map 來實作。Mutex 提供併發時的讀防寫,Map 用來儲存同一個 key 的正在處理(in flight)的請求。
SingleFlight 的資料結構是 Group,它提供了三個方法。

- Do:這個方法執行一個函式,並返回函式執行的結果。你需要提供一個 key,對於同一個 key,在同一時間只有一個在執行,同一個 key 併發的請求會等待。第一個執行的請求返回的結果,就是它的返回結果。函式 fn 是一個無參的函式,返回一個結果或者 error,而 Do 方法會返回函式執行的結果或者是 error,shared 會指示 v 是否返回給多個請求。
- DoChan:類似 Do 方法,只不過是返回一個 chan,等 fn 函式執行完,產生了結果以後,就能從這個 chan 中接收這個結果。
- Forget:告訴 Group 忘記這個 key。這樣一來,之後這個 key 請求會執行 f,而不是等待前一個未完成的 fn 函式的結果。
下面,我們來看具體的實作方法。
首先,SingleFlight 定義一個輔助物件 call,這個 call 就代表正在執行 fn 函式的請求或者是已經執行完的請求。Group 代表 SingleFlight。
// 代表一個正在處理的請求,或者已經處理完的請求
type call struct {
wg sync.WaitGroup
// 這個欄位代表處理完的值,在waitgroup完成之前只會寫一次
// waitgroup完成之後就讀取這個值
val interface{}
err error
// 指示當call在處理時是否要忘掉這個key
forgotten bool
dups int
chans []chan<- Result
}
// group代表一個singleflight物件
type Group struct {
mu sync.Mutex // protects m
m map[string]*call // lazily initialized
}
我們只需要檢視一個 Do 方法,DoChan 的處理方法是類似的。
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {//如果已經存在相同的key
c.dups++
g.mu.Unlock()
c.wg.Wait() //等待這個key的第一個請求完成
return c.val, c.err, true //使用第一個key的請求結果
}
c := new(call) // 第一個請求,建立一個call
c.wg.Add(1)
g.m[key] = c //加入到key map中
g.mu.Unlock()
g.doCall(c, key, fn) // 呼叫方法
return c.val, c.err, c.dups > 0
}
doCall 方法會實際呼叫函式 fn:
func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
if !c.forgotten { // 已呼叫完,刪除這個key
delete(g.m, key)
}
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
g.mu.Unlock()
}
在這段程式碼中,你要注意下第 7 行。在預設情況下,forgotten==false,所以第 8 行預設會被呼叫,也就是說,第一個請求完成後,後續的同一個 key 的請求又重新開始新一次的 fn 函式的呼叫。
Go 標準庫的程式碼中就有一個 SingleFlight 的實作,而擴充套件庫中的 SingleFlight 就是在標準庫的程式碼基礎上改的,邏輯幾乎一模一樣,我就不多說了。
應用場景
瞭解了 SingleFlight 的實作原理,下面我們來看看它都應用於什麼場景中。
Go 程式碼庫中有兩個地方用到了 SingleFlight。
第一個是在net/lookup.go中,如果同時有查詢同一個 host 的請求,lookupGroup 會把這些請求 merge 到一起,只需要一個請求就可以了:
// lookupGroup merges LookupIPAddr calls together for lookups for the same
// host. The lookupGroup key is the LookupIPAddr.host argument.
// The return values are ([]IPAddr, error).
lookupGroup singleflight.Group
第二個是 Go 在查詢倉庫版本資訊時,將併發的請求合併成 1 個請求:
func metaImportsForPrefix(importPrefix string, mod ModuleMode, security web.SecurityMode) (*urlpkg.URL, []metaImport, error) {
// 使用快取儲存請求結果
setCache := func(res fetchResult) (fetchResult, error) {
fetchCacheMu.Lock()
defer fetchCacheMu.Unlock()
fetchCache[importPrefix] = res
return res, nil
// 使用 SingleFlight請求
resi, _, _ := fetchGroup.Do(importPrefix, func() (resi interface{}, err error) {
fetchCacheMu.Lock()
// 如果快取中有資料,那麼直接從快取中取
if res, ok := fetchCache[importPrefix]; ok {
fetchCacheMu.Unlock()
return res, nil
}
fetchCacheMu.Unlock()
......
需要注意的是,這裡涉及到了快取的問題。上面的程式碼會把結果放在快取中,這也是常用的一種解決快取擊穿的例子。
設計快取問題時,我們常常需要解決快取穿透、快取雪崩和快取擊穿問題。快取擊穿問題是指,在平常高併發的系統中,大量的請求同時查詢一個 key 時,如果這個 key 正好過期失效了,就會導致大量的請求都打到資料庫上。這就是快取擊穿。
用 SingleFlight 來解決快取擊穿問題再合適不過了。因為,這個時候,只要這些對同一個 key 的併發請求的其中一個到資料庫中查詢,就可以了,這些併發的請求可以共享同一個結果。因為是快取查詢,不用考慮冪等性問題。
事實上,在 Go 生態圈知名的快取框架 groupcache 中,就使用了較早的 Go 標準庫的 SingleFlight 實作。接下來,我就來給你介紹一下 groupcache 是如何使用 SingleFlight 解決快取擊穿問題的。
groupcache 中的 SingleFlight 只有一個方法:
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error)
SingleFlight 的作用是,在載入一個快取項的時候,合併對同一個 key 的 load 的併發請求:
type Group struct {
。。。。。。
// loadGroup ensures that each key is only fetched once
// (either locally or remotely), regardless of the number of
// concurrent callers.
loadGroup flightGroup
......
}
func (g *Group) load(ctx context.Context, key string, dest Sink) (value ByteView, destPopulated bool, err error) {
viewi, err := g.loadGroup.Do(key, func() (interface{}, error) {
// 從cache, peer, local嘗試查詢cache
return value, nil
})
if err == nil {
value = viewi.(ByteView)
}
return
}
其它的知名專案如 Cockroachdb(小強資料庫)、CoreDNS(DNS 伺服器)等都有 SingleFlight 應用,你可以檢視這些專案的程式碼,加深對 SingleFlight 的理解。
總結來說,使用 SingleFlight 時,可以透過合併請求的方式降低對下游服務的併發壓力,從而提高系統的效能,常常用於快取系統中。最後,我想給你留一個思考題,你覺得,SingleFlight 能不能合併併發的寫操作呢?
迴圈柵欄 CyclicBarrier
接下來,我再給你介紹另外一個併發原語:迴圈柵欄(CyclicBarrier),它常常應用於重複進行一組 goroutine 同時執行的場景中。
CyclicBarrier允許一組 goroutine 彼此等待,到達一個共同的執行點。同時,因為它可以被重複使用,所以叫迴圈柵欄。具體的機制是,大家都在柵欄前等待,等全部都到齊了,就抬起柵欄放行。
事實上,這個 CyclicBarrier 是參考Java CyclicBarrier和C# Barrier的功能實作的。Java 提供了 CountDownLatch(倒計時器)和 CyclicBarrier(迴圈柵欄)兩個類似的用於保證多執行緒到達同一個執行點的類,只不過前者是到達 0 的時候放行,後者是到達某個指定的數的時候放行。C# Barrier 功能也是類似的,你可以檢視連結,瞭解它的具體用法。
你可能會覺得,CyclicBarrier 和 WaitGroup 的功能有點類似,確實是這樣。不過,CyclicBarrier 更適合用在“固定數量的 goroutine 等待同一個執行點”的場景中,而且在放行 goroutine 之後,CyclicBarrier 可以重複利用,不像 WaitGroup 重用的時候,必須小心翼翼避免 panic。
處理可重用的多 goroutine 等待同一個執行點的場景的時候,CyclicBarrier 和 WaitGroup 方法呼叫的對應關係如下:
可以看到,如果使用 WaitGroup 實作的話,呼叫比較複雜,不像 CyclicBarrier 那麼清爽。更重要的是,如果想重用 WaitGroup,你還要保證,將 WaitGroup 的計數值重置到 n 的時候不會出現併發問題。
WaitGroup 更適合用在“一個 goroutine 等待一組 goroutine 到達同一個執行點”的場景中,或者是不需要重用的場景中。
好了,瞭解了 CyclicBarrier 的應用場景和功能,下面我們來學習下它的具體實作。
實作原理
CyclicBarrier 有兩個初始化方法:
- 第一個是 New 方法,它只需要一個引數,來指定迴圈柵欄參與者的數量;
- 第二個方法是 NewWithAction,它額外提供一個函式,可以在每一次到達執行點的時候執行一次。具體的時間點是在最後一個參與者到達之後,但是其它的參與者還未被放行之前。我們可以利用它,做放行之前的一些共享狀態的更新等操作。
這兩個方法的簽名如下:
func New(parties int) CyclicBarrier
func NewWithAction(parties int, barrierAction func() error) CyclicBarrier
CyclicBarrier 是一個介面,定義的方法如下:
type CyclicBarrier interface {
// 等待所有的參與者到達,如果被ctx.Done()中斷,會返回ErrBrokenBarrier
Await(ctx context.Context) error
// 重置迴圈柵欄到初始化狀態。如果當前有等待者,那麼它們會返回ErrBrokenBarrier
Reset()
// 返回當前等待者的數量
GetNumberWaiting() int
// 參與者的數量
GetParties() int
// 迴圈柵欄是否處於中斷狀態
IsBroken() bool
}
迴圈柵欄的使用也很簡單。迴圈柵欄的參與者只需呼叫 Await 等待,等所有的參與者都到達後,再執行下一步。當執行下一步的時候,迴圈柵欄的狀態又恢復到初始的狀態了,可以迎接下一輪同樣多的參與者。
有一道非常經典的併發程式設計的題目,非常適合使用迴圈柵欄,下面我們來看一下。
併發趣題:一氧化二氫製造工廠
題目是這樣的:
有一個名叫大自然的搬運工的工廠,生產一種叫做一氧化二氫的神秘液體。這種液體的分子是由一個氧原子和兩個氫原子組成的,也就是水。
這個工廠有多條生產線,每條生產線負責生產氧原子或者是氫原子,每條生產線由一個 goroutine 負責。
這些生產線會透過一個柵欄,只有一個氧原子生產線和兩個氫原子生產線都準備好,才能生成出一個水分子,否則所有的生產線都會處於等待狀態。也就是說,一個水分子必須由三個不同的生產線提供原子,而且水分子是一個一個按照順序產生的,每生產一個水分子,就會打印出 HHO、HOH、OHH 三種形式的其中一種。HHH、OOH、OHO、HOO、OOO 都是不允許的。
生產線中氫原子的生產線為 2N 條,氧原子的生產線為 N 條。
你可以先想一下,我們怎麼來實作呢?
首先,我們來定義一個 H2O 輔助資料型別,它包含兩個訊號量的欄位和一個迴圈柵欄。
- semaH 訊號量:控制氫原子。一個水分子需要兩個氫原子,所以,氫原子的空槽數資源數設定為 2。
- semaO 訊號量:控制氧原子。一個水分子需要一個氧原子,所以資源數的空槽數設定為 1。
- 迴圈柵欄:等待兩個氫原子和一個氧原子填補空槽,直到任務完成。
我們來看下具體的程式碼:
package water
import (
"context"
"github.com/marusama/cyclicbarrier"
"golang.org/x/sync/semaphore"
)
// 定義水分子合成的輔助資料結構
type H2O struct {
semaH *semaphore.Weighted // 氫原子的訊號量
semaO *semaphore.Weighted // 氧原子的訊號量
b cyclicbarrier.CyclicBarrier // 迴圈柵欄,用來控制合成
}
func New() *H2O {
return &H2O{
semaH: semaphore.NewWeighted(2), //氫原子需要兩個
semaO: semaphore.NewWeighted(1), // 氧原子需要一個
b: cyclicbarrier.New(3), // 需要三個原子才能合成
}
}
接下來,我們看看各條流水線的處理情況。
流水線分為氫原子處理流水線和氧原子處理流水線,首先,我們先看一下氫原子的流水線:如果有可用的空槽,氫原子的流水線的處理方法是 hydrogen,hydrogen 方法就會佔用一個空槽(h2o.semaH.Acquire),輸出一個 H 字元,然後等待柵欄放行。等其它的 goroutine 填補了氫原子的另一個空槽和氧原子的空槽之後,程式才可以繼續進行。
func (h2o *H2O) hydrogen(releaseHydrogen func()) {
h2o.semaH.Acquire(context.Background(), 1)
releaseHydrogen() // 輸出H
h2o.b.Await(context.Background()) //等待柵欄放行
h2o.semaH.Release(1) // 釋放氫原子空槽
}
然後是氧原子的流水線。氧原子的流水線處理方法是 oxygen, oxygen 方法是等待氧原子的空槽,然後輸出一個 O,就等待柵欄放行。放行後,釋放氧原子空槽位。
func (h2o *H2O) oxygen(releaseOxygen func()) {
h2o.semaO.Acquire(context.Background(), 1)
releaseOxygen() // 輸出O
h2o.b.Await(context.Background()) //等待柵欄放行
h2o.semaO.Release(1) // 釋放氫原子空槽
}
在柵欄放行之前,只有兩個氫原子的空槽位和一個氧原子的空槽位。只有等柵欄放行之後,這些空槽位才會被釋放。柵欄放行,就意味著一個水分子組成成功。
這個演算法是不是正確呢?我們來編寫一個單元測試檢測一下。
package water
import (
"math/rand"
"sort"
"sync"
"testing"
"time"
)
func TestWaterFactory(t *testing.T) {
//用來存放水分子結果的channel
var ch chan string
releaseHydrogen := func() {
ch <- "H"
}
releaseOxygen := func() {
ch <- "O"
}
// 300個原子,300個goroutine,每個goroutine併發的產生一個原子
var N = 100
ch = make(chan string, N*3)
h2o := New()
// 用來等待所有的goroutine完成
var wg sync.WaitGroup
wg.Add(N * 3)
// 200個氫原子goroutine
for i := 0; i < 2*N; i++ {
go func() {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
h2o.hydrogen(releaseHydrogen)
wg.Done()
}()
}
// 100個氧原子goroutine
for i := 0; i < N; i++ {
go func() {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
h2o.oxygen(releaseOxygen)
wg.Done()
}()
}
//等待所有的goroutine執行完
wg.Wait()
// 結果中肯定是300個原子
if len(ch) != N*3 {
t.Fatalf("expect %d atom but got %d", N*3, len(ch))
}
// 每三個原子一組,分別進行檢查。要求這一組原子中必須包含兩個氫原子和一個氧原子,這樣才能正確組成一個水分子。
var s = make([]string, 3)
for i := 0; i < N; i++ {
s[0] = <-ch
s[1] = <-ch
s[2] = <-ch
sort.Strings(s)
water := s[0] + s[1] + s[2]
if water != "HHO" {
t.Fatalf("expect a water molecule but got %s", water)
}
}
}總結每一個併發原語都有它存在的道理,也都有它應用的場景。
如果你沒有學習 CyclicBarrier,你可能只會想到,用 WaitGroup 來實作這個水分子製造工廠的例子。
type H2O struct {
semaH *semaphore.Weighted
semaO *semaphore.Weighted
wg sync.WaitGroup //將迴圈柵欄替換成WaitGroup
}
func New() *H2O {
var wg sync.WaitGroup
wg.Add(3)
return &H2O{
semaH: semaphore.NewWeighted(2),
semaO: semaphore.NewWeighted(1),
wg: wg,
}
}
func (h2o *H2O) hydrogen(releaseHydrogen func()) {
h2o.semaH.Acquire(context.Background(), 1)
releaseHydrogen()
// 標記自己已達到,等待其它goroutine到達
h2o.wg.Done()
h2o.wg.Wait()
h2o.semaH.Release(1)
}
func (h2o *H2O) oxygen(releaseOxygen func()) {
h2o.semaO.Acquire(context.Background(), 1)
releaseOxygen()
// 標記自己已達到,等待其它goroutine到達
h2o.wg.Done()
h2o.wg.Wait()
//都到達後重置wg
h2o.wg.Add(3)
h2o.semaO.Release(1)
}
你一看程式碼就知道了,使用 WaitGroup 非常複雜,而且,重用和 Done 方法的呼叫有併發的問題,程式可能 panic,遠遠沒有使用迴圈柵欄更加簡單直接。
所以,我建議你多瞭解一些併發原語,甚至是從其它程式語言、作業系統中學習更多的併發原語,這樣可以讓你的知識庫更加豐富,在面對併發場景的時候,你也能更加遊刃有餘。
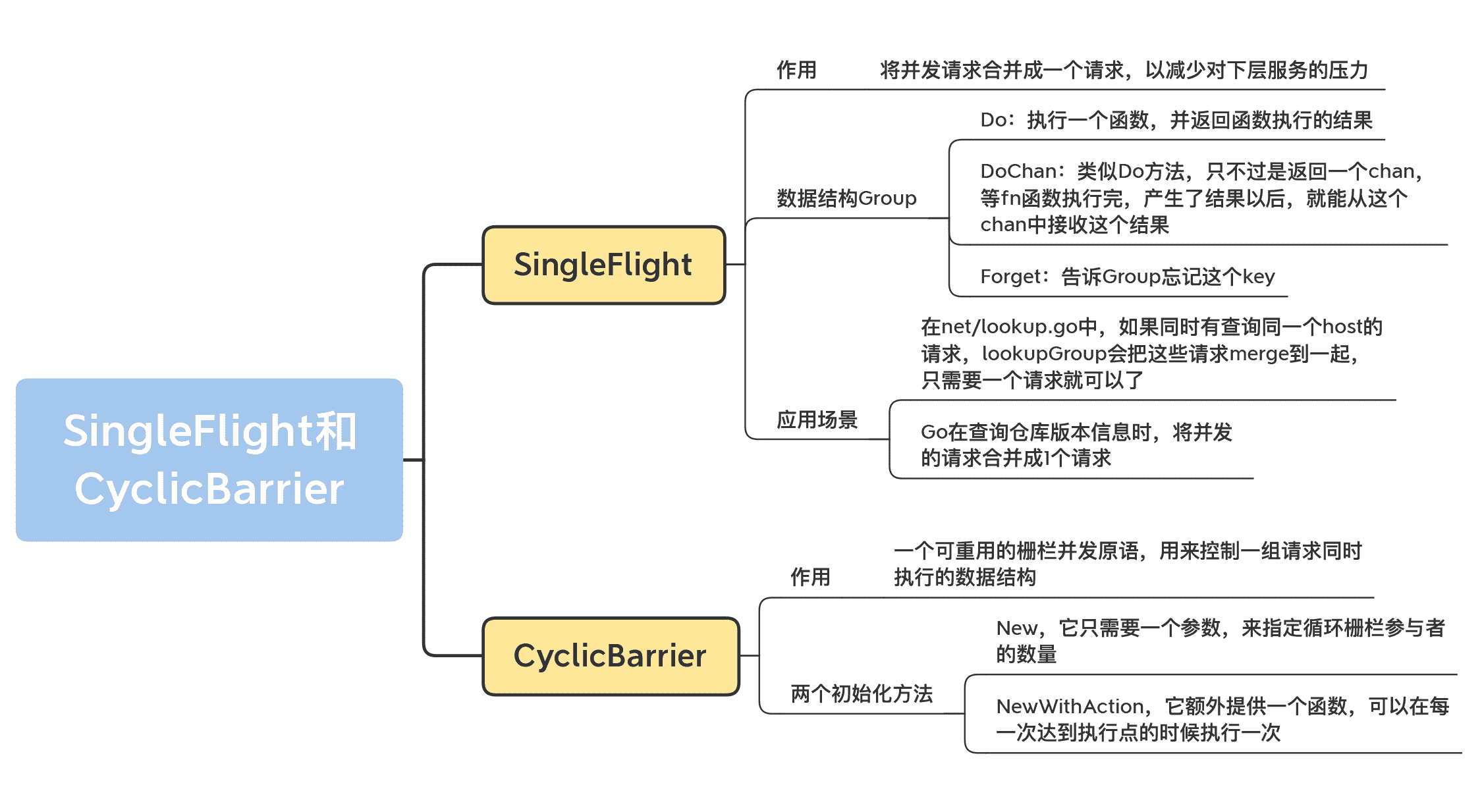
思考題
如果大自然的搬運工工廠生產的液體是雙氧水(雙氧水分子是兩個氫原子和兩個氧原子),你又該怎麼實作呢?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
18|分組操作:處理一組子任務,該用什麼併發原語?
你好,我是鳥窩。
本章導讀
分組任務處理(group orchestration)
┌──────────────────────────┐
│ 一批子任務(可並行) │
└──────────┬───────────────┘
│ 啟動/收斂結果
┌─────────────┼─────────────┐
▼ ▼ ▼
errgroup rollback/補償 結果收集
(錯誤收斂) (失敗回復) (彙整輸出)
│
▼
主流程決策(成功/失敗)
共享資源保護、任務編排和訊息傳遞是 Go 併發程式設計中常見的場景,而分組執行一批相同的或類似的任務則是任務編排中一類情形,所以,這節課,我專門來介紹一下分組編排的一些常用場景和併發原語,包括 ErrGroup、gollback、Hunch 和 schedgroup。
我們先來學習一類非常常用的併發原語,那就是 ErrGroup。
ErrGroup
ErrGroup是 Go 官方提供的一個同步擴充套件庫。我們經常會碰到需要將一個通用的父任務拆成幾個小任務併發執行的場景,其實,將一個大的任務拆成幾個小任務併發執行,可以有效地提高程式的併發度。就像你在廚房做飯一樣,你可以在蒸米飯的同時炒幾個小菜,米飯蒸好了,菜同時也做好了,很快就能吃到可口的飯菜。
ErrGroup 就是用來應對這種場景的。它和 WaitGroup 有些類似,但是它提供功能更加豐富:
- 和 Context 整合;
- error 向上傳播,可以把子任務的錯誤傳遞給 Wait 的呼叫者。
接下來,我來給你介紹一下 ErrGroup 的基本用法和幾種應用場景。
基本用法
golang.org/x/sync/errgroup 包下定義了一個 Group struct,它就是我們要介紹的 ErrGroup 併發原語,底層也是基於 WaitGroup 實作的。
在使用 ErrGroup 時,我們要用到三個方法,分別是 WithContext、Go 和 Wait。
1.WithContext
在建立一個 Group 物件時,需要使用 WithContext 方法:
func WithContext(ctx context.Context) (*Group, context.Context)
這個方法返回一個 Group 例項,同時還會返回一個使用 context.WithCancel(ctx) 生成的新 Context。一旦有一個子任務返回錯誤,或者是 Wait 呼叫返回,這個新 Context 就會被 cancel。
Group 的零值也是合法的,只不過,你就沒有一個可以監控是否 cancel 的 Context 了。
注意,如果傳遞給 WithContext 的 ctx 引數,是一個可以 cancel 的 Context 的話,那麼,它被 cancel 的時候,並不會終止正在執行的子任務。
2.Go
我們再來學習下執行子任務的 Go 方法:
func (g *Group) Go(f func() error)
傳入的子任務函式 f 是型別為 func() error 的函式,如果任務執行成功,就返回 nil,否則就返回 error,並且會 cancel 那個新的 Context。
一個任務可以分成好多個子任務,而且,可能有多個子任務執行失敗返回 error,不過,Wait 方法只會返回第一個錯誤,所以,如果想返回所有的錯誤,需要特別的處理,我先留個小懸念,一會兒再講。
3.Wait
類似 WaitGroup,Group 也有 Wait 方法,等所有的子任務都完成後,它才會返回,否則只會阻塞等待。如果有多個子任務返回錯誤,它只會返回第一個出現的錯誤,如果所有的子任務都執行成功,就返回 nil:
func (g *Group) Wait() errorErrGroup 使用例子好了,知道了基本用法,下面我來給你介紹幾個例子,幫助你全面地掌握 ErrGroup 的使用方法和應用場景。簡單例子:返回第一個錯誤先來看一個簡單的例子。在這個例子中,啟動了三個子任務,其中,子任務 2 會返回執行失敗,其它兩個執行成功。在三個子任務都執行後,group.Wait 才會返回第 2 個子任務的錯誤。
package main
import (
"errors"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
var g errgroup.Group
// 啟動第一個子任務,它執行成功
g.Go(func() error {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
return nil
})
// 啟動第二個子任務,它執行失敗
g.Go(func() error {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
return errors.New("failed to exec #2")
})
// 啟動第三個子任務,它執行成功
g.Go(func() error {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
return nil
})
// 等待三個任務都完成
if err := g.Wait(); err == nil {
fmt.Println("Successfully exec all")
} else {
fmt.Println("failed:", err)
}
}
如果執行下面的這個程式,會顯示三個任務都執行了,而 Wait 返回了子任務 2 的錯誤:

更進一步,返回所有子任務的錯誤
Group 只能返回子任務的第一個錯誤,後續的錯誤都會被丟棄。但是,有時候我們需要知道每個任務的執行情況。怎麼辦呢?這個時候,我們就可以用稍微有點曲折的方式去實作。我們使用一個 result slice 儲存子任務的執行結果,這樣,透過查詢 result,就可以知道每一個子任務的結果了。
下面的這個例子,就是使用 result 記錄每個子任務成功或失敗的結果。其實,你不僅可以使用 result 記錄 error 資訊,還可以用它記錄計算結果。
package main
import (
"errors"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
var g errgroup.Group
var result = make([]error, 3)
// 啟動第一個子任務,它執行成功
g.Go(func() error {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
result[0] = nil // 儲存成功或者失敗的結果
return nil
})
// 啟動第二個子任務,它執行失敗
g.Go(func() error {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
result[1] = errors.New("failed to exec #2") // 儲存成功或者失敗的結果
return result[1]
})
// 啟動第三個子任務,它執行成功
g.Go(func() error {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
result[2] = nil // 儲存成功或者失敗的結果
return nil
})
if err := g.Wait(); err == nil {
fmt.Printf("Successfully exec all. result: %v\n", result)
} else {
fmt.Printf("failed: %v\n", result)
}
}任務執行流水線 PipelineGo 官方文件中還提供了一個 pipeline 的例子。這個例子是說,由一個子任務遍歷資料夾下的檔案,然後把遍歷出的檔案交給 20 個 goroutine,讓這些 goroutine 平行計算檔案的 md5。
這個例子中的計算邏輯你不需要重點掌握,我來把這個例子簡化一下(如果你想看原始的程式碼,可以看這裡):
package main
import (
......
"golang.org/x/sync/errgroup"
)
// 一個多階段的pipeline.使用有限的goroutine計算每個檔案的md5值.
func main() {
m, err := MD5All(context.Background(), ".")
if err != nil {
log.Fatal(err)
}
for k, sum := range m {
fmt.Printf("%s:\t%x\n", k, sum)
}
}
type result struct {
path string
sum [md5.Size]byte
}
// 遍歷根目錄下所有的檔案和子資料夾,計算它們的md5的值.
func MD5All(ctx context.Context, root string) (map[string][md5.Size]byte, error) {
g, ctx := errgroup.WithContext(ctx)
paths := make(chan string) // 檔案路徑channel
g.Go(func() error {
defer close(paths) // 遍歷完關閉paths chan
return filepath.Walk(root, func(path string, info os.FileInfo, err error) error {
...... //將檔案路徑放入到paths
return nil
})
})
// 啟動20個goroutine執行計算md5的任務,計算的檔案由上一階段的檔案遍歷子任務生成.
c := make(chan result)
const numDigesters = 20
for i := 0; i < numDigesters; i++ {
g.Go(func() error {
for path := range paths { // 遍歷直到paths chan被關閉
...... // 計算path的md5值,放入到c中
}
return nil
})
}
go func() {
g.Wait() // 20個goroutine以及遍歷檔案的goroutine都執行完
close(c) // 關閉收集結果的chan
}()
m := make(map[string][md5.Size]byte)
for r := range c { // 將md5結果從chan中讀取到map中,直到c被關閉才退出
m[r.path] = r.sum
}
// 再次呼叫Wait,依然可以得到group的error資訊
if err := g.Wait(); err != nil {
return nil, err
}
return m, nil
}
透過這個例子,你可以學習到多階段 pipeline 的實作(這個例子是遍歷資料夾和計算 md5 兩個階段),還可以學習到如何控制執行子任務的 goroutine 數量。
很多公司都在使用 ErrGroup 處理併發子任務,比如 Facebook、bilibili 等公司的一些專案,但是,這些公司在使用的時候,發現了一些不方便的地方,或者說,官方的 ErrGroup 的功能還不夠豐富。所以,他們都對 ErrGroup 進行了擴充套件。接下來呢,我就帶你看看幾個擴充套件庫。
擴充套件庫
bilibili/errgroup
如果我們無限制地直接呼叫 ErrGroup 的 Go 方法,就可能會創建出非常多的 goroutine,太多的 goroutine 會帶來排程和 GC 的壓力,而且也會佔用更多的記憶體資源。就像go#34457指出的那樣,當前 Go 執行時建立的 g 物件只會增長和重用,不會回收,所以在高併發的情況下,也要儘可能減少 goroutine 的使用。
常用的一個手段就是使用 worker pool(goroutine pool),或者是類似containerd/stargz-snapshotter的方案,使用前面我們講的訊號量,訊號量的資源的數量就是可以並行的 goroutine 的數量。但是在這一講,我來介紹一些其它的手段,比如下面介紹的 bilibili 實作的 errgroup。
bilibili 實作了一個擴充套件的 ErrGroup,可以使用一個固定數量的 goroutine 處理子任務。如果不設定 goroutine 的數量,那麼每個子任務都會比較“放肆地”建立一個 goroutine 併發執行。
這個連結裡的文件已經很詳細地介紹了它的幾個擴充套件功能,所以我就不透過示例的方式來進行講解了。
除了可以控制併發 goroutine 的數量,它還提供了 2 個功能:
- cancel,失敗的子任務可以 cancel 所有正在執行任務;
- recover,而且會把 panic 的堆疊資訊放到 error 中,避免子任務 panic 導致的程式崩潰。
但是,有一點不太好的地方就是,一旦你設定了併發數,超過併發數的子任務需要等到呼叫者呼叫 Wait 之後才會執行,而不是隻要 goroutine 空閒下來,就去執行。如果不注意這一點的話,可能會出現子任務不能及時處理的情況,這是這個庫可以最佳化的一點。
另外,這個庫其實是有一個併發問題的。在高併發的情況下,如果任務數大於設定的 goroutine 的數量,並且這些任務被集中加入到 Group 中,這個庫的處理方式是把子任務加入到一個陣列中,但是,這個陣列不是執行緒安全的,有併發問題,問題就在於,下面圖片中的標記為 96 行的那一行,這一行對 slice 的 append 操作不是執行緒安全的:

我們可以寫一個簡單的程式來測試這個問題:
package main
import (
"context"
"fmt"
"sync/atomic"
"time"
"github.com/bilibili/kratos/pkg/sync/errgroup"
)
func main() {
var g errgroup.Group
g.GOMAXPROCS(1) // 只使用一個goroutine處理子任務
var count int64
g.Go(func(ctx context.Context) error {
time.Sleep(time.Second) //睡眠5秒,把這個goroutine佔住
return nil
})
total := 10000
for i := 0; i < total; i++ { // 併發一萬個goroutine執行子任務,理論上這些子任務都會加入到Group的待處理列表中
go func() {
g.Go(func(ctx context.Context) error {
atomic.AddInt64(&count, 1)
return nil
})
}()
}
// 等待所有的子任務完成。理論上10001個子任務都會被完成
if err := g.Wait(); err != nil {
panic(err)
}
got := atomic.LoadInt64(&count)
if got != int64(total) {
panic(fmt.Sprintf("expect %d but got %d", total, got))
}
}
執行這個程式的話,你就會發現死鎖問題,因為我們的測試程式是一個簡單的命令列工具,程式退出的時候,Go runtime 能檢測到死鎖問題。如果是一直執行的伺服器程式,死鎖問題有可能是檢測不出來的,程式一直會 hang 在 Wait 的呼叫上。
neilotoole/errgroup
neilotoole/errgroup 是今年年中新出現的一個 ErrGroup 擴充套件庫,它可以直接替換官方的 ErrGroup,方法都一樣,原有功能也一樣,只不過增加了可以控制併發 goroutine 的功能。它的方法集如下:
type Group
func WithContext(ctx context.Context) (*Group, context.Context)
func WithContextN(ctx context.Context, numG, qSize int) (*Group, context.Context)
func (g *Group) Go(f func() error)
func (g *Group) Wait() error
新增加的方法 WithContextN,可以設定併發的 goroutine 數,以及等待處理的子任務佇列的大小。當佇列滿的時候,如果呼叫 Go 方法,就會被阻塞,直到子任務可以放入到佇列中才返回。如果你傳給這兩個引數的值不是正整數,它就會使用 runtime.NumCPU 代替你傳入的引數。
當然,你也可以把 bilibili 的 recover 功能擴充套件到這個庫中,以避免子任務的 panic 導致程式崩潰。
facebookgo/errgroup
Facebook 提供的這個 ErrGroup,其實並不是對 Go 擴充套件庫 ErrGroup 的擴充套件,而是對標準庫 WaitGroup 的擴充套件。不過,因為它們的名字一樣,處理的場景也類似,所以我把它也列在了這裡。
標準庫的 WaitGroup 只提供了 Add、Done、Wait 方法,而且 Wait 方法也沒有返回子 goroutine 的 error。而 Facebook 提供的 ErrGroup 提供的 Wait 方法可以返回 error,而且可以包含多個 error。子任務在呼叫 Done 之前,可以把自己的 error 資訊設定給 ErrGroup。接著,Wait 在返回的時候,就會把這些 error 資訊返回給呼叫者。
我們來看下 Group 的方法:
type Group
func (g *Group) Add(delta int)
func (g *Group) Done()
func (g *Group) Error(e error)
func (g *Group) Wait() error
關於 Wait 方法,我剛剛已經介紹了它和標準庫 WaitGroup 的不同,我就不多說了。這裡還有一個不同的方法,就是 Error 方法,
我舉個例子演示一下 Error 的使用方法。
在下面的這個例子中,第 26 行的子 goroutine 設定了 error 資訊,第 39 行會把這個 error 資訊輸出出來。
package main
import (
"errors"
"fmt"
"time"
"github.com/facebookgo/errgroup"
)
func main() {
var g errgroup.Group
g.Add(3)
// 啟動第一個子任務,它執行成功
go func() {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
g.Done()
}()
// 啟動第二個子任務,它執行失敗
go func() {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
g.Error(errors.New("failed to exec #2"))
g.Done()
}()
// 啟動第三個子任務,它執行成功
go func() {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
g.Done()
}()
// 等待所有的goroutine完成,並檢查error
if err := g.Wait(); err == nil {
fmt.Println("Successfully exec all")
} else {
fmt.Println("failed:", err)
}
}
關於 ErrGroup,你掌握這些就足夠了,接下來,我再介紹幾種有趣而實用的 Group 併發原語。這些併發原語都是控制一組子 goroutine 執行的面向特定場景的併發原語,當你遇見這些特定場景時,就可以參考這些庫。
其它實用的 Group 併發原語
SizedGroup/ErrSizedGroup
go-pkgz/syncs提供了兩個 Group 併發原語,分別是 SizedGroup 和 ErrSizedGroup。
SizedGroup 內部是使用訊號量和 WaitGroup 實作的,它透過訊號量控制併發的 goroutine 數量,或者是不控制 goroutine 數量,只控制子任務併發執行時候的數量(透過)。
它的程式碼實作非常簡潔,你可以到它的程式碼庫中瞭解它的具體實作,你一看就明白了,我就不多說了。下面我重點說說它的功能。
預設情況下,SizedGroup 控制的是子任務的併發數量,而不是 goroutine 的數量。在這種方式下,每次呼叫 Go 方法都不會被阻塞,而是新建一個 goroutine 去執行。
如果想控制 goroutine 的數量,你可以使用 syncs.Preemptive 設定這個併發原語的可選項。如果設定了這個可選項,但在呼叫 Go 方法的時候沒有可用的 goroutine,那麼呼叫者就會等待,直到有 goroutine 可以處理這個子任務才返回,這個控制在內部是使用訊號量實作的。
我們來看一個使用 SizedGroup 的例子:
package main
import (
"context"
"fmt"
"sync/atomic"
"time"
"github.com/go-pkgz/syncs"
)
func main() {
// 設定goroutine數是10
swg := syncs.NewSizedGroup(10)
// swg := syncs.NewSizedGroup(10, syncs.Preemptive)
var c uint32
// 執行1000個子任務,只會有10個goroutine去執行
for i := 0; i < 1000; i++ {
swg.Go(func(ctx context.Context) {
time.Sleep(5 * time.Millisecond)
atomic.AddUint32(&c, 1)
})
}
// 等待任務完成
swg.Wait()
// 輸出結果
fmt.Println(c)
}
ErrSizedGroup 為 SizedGroup 提供了 error 處理的功能,它的功能和 Go 官方擴充套件庫的功能一樣,就是等待子任務完成並返回第一個出現的 error。不過,它還提供了額外的功能,我來介紹一下。
第一個額外的功能,就是可以控制併發的 goroutine 數量,這和 SizedGroup 的功能一樣。
第二個功能是,如果設定了 termOnError,子任務出現第一個錯誤的時候會 cancel Context,而且後續的 Go 呼叫會直接返回,Wait 呼叫者會得到這個錯誤,這相當於是遇到錯誤快速返回。如果沒有設定 termOnError,Wait 會返回所有的子任務的錯誤。
不過,ErrSizedGroup 和 SizedGroup 設計得不太一致的地方是,SizedGroup 可以把 Context 傳遞給子任務,這樣可以透過 cancel 讓子任務中斷執行,但是 ErrSizedGroup 卻沒有實作。我認為,這是一個值得加強的地方。
總體來說,syncs 包提供的併發原語的質量和功能還是非常讚的。不過,目前的 star 只有十幾個,這和它的功能嚴重不匹配,我建議你 star 這個專案,支援一下作者。
好了,關於 ErrGroup,你掌握這些就足夠了,下面我再來給你介紹一些非 ErrGroup 的併發原語,它們用來編排子任務。
gollback
gollback也是用來處理一組子任務的執行的,不過它解決了 ErrGroup 收集子任務返回結果的痛點。使用 ErrGroup 時,如果你要收到子任務的結果和錯誤,你需要定義額外的變數收集執行結果和錯誤,但是這個庫可以提供更便利的方式。
我剛剛在說官方擴充套件庫 ErrGroup 的時候,舉了一些例子(返回第一個錯誤的例子和返回所有子任務錯誤的例子),在例子中,如果想得到每一個子任務的結果或者 error,我們需要額外提供一個 result slice 進行收集。使用 gollback 的話,就不需要這些額外的處理了,因為它的方法會把結果和 error 資訊都返回。
接下來,我們看一下它提供的三個方法,分別是 All、Race 和 Retry。
All 方法
All 方法的簽名如下:
func All(ctx context.Context, fns ...AsyncFunc) ([]interface{}, []error)
它會等待所有的非同步函式(AsyncFunc)都執行完才返回,而且返回結果的順序和傳入的函式的順序保持一致。第一個返回引數是子任務的執行結果,第二個引數是子任務執行時的錯誤資訊。
其中,非同步函式的定義如下:
type AsyncFunc func(ctx context.Context) (interface{}, error)
可以看到,ctx 會被傳遞給子任務。如果你 cancel 這個 ctx,可以取消子任務。
我們來看一個使用 All 方法的例子:
package main
import (
"context"
"errors"
"fmt"
"github.com/vardius/gollback"
"time"
)
func main() {
rs, errs := gollback.All( // 呼叫All方法
context.Background(),
func(ctx context.Context) (interface{}, error) {
time.Sleep(3 * time.Second)
return 1, nil // 第一個任務沒有錯誤,返回1
},
func(ctx context.Context) (interface{}, error) {
return nil, errors.New("failed") // 第二個任務返回一個錯誤
},
func(ctx context.Context) (interface{}, error) {
return 3, nil // 第三個任務沒有錯誤,返回3
},
)
fmt.Println(rs) // 輸出子任務的結果
fmt.Println(errs) // 輸出子任務的錯誤資訊
}
Race 方法
Race 方法跟 All 方法類似,只不過,在使用 Race 方法的時候,只要一個非同步函式執行沒有錯誤,就立馬返回,而不會返回所有的子任務資訊。如果所有的子任務都沒有成功,就會返回最後一個 error 資訊。
Race 方法簽名如下:
func Race(ctx context.Context, fns ...AsyncFunc) (interface{}, error)
如果有一個正常的子任務的結果返回,Race 會把傳入到其它子任務的 Context cancel 掉,這樣子任務就可以中斷自己的執行。
Race 的使用方法也跟 All 方法類似,我就不再舉例子了,你可以把 All 方法的例子中的 All 替換成 Race 方式測試下。
Retry 方法
Retry 不是執行一組子任務,而是執行一個子任務。如果子任務執行失敗,它會嘗試一定的次數,如果一直不成功 ,就會返回失敗錯誤 ,如果執行成功,它會立即返回。如果 retires 等於 0,它會永遠嘗試,直到成功。
func Retry(ctx context.Context, retires int, fn AsyncFunc) (interface{}, error)
再來看一個使用 Retry 的例子:
package main
import (
"context"
"errors"
"fmt"
"github.com/vardius/gollback"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 嘗試5次,或者超時返回
res, err := gollback.Retry(ctx, 5, func(ctx context.Context) (interface{}, error) {
return nil, errors.New("failed")
})
fmt.Println(res) // 輸出結果
fmt.Println(err) // 輸出錯誤資訊
} HunchHunch提供的功能和 gollback 類似,不過它提供的方法更多,而且它提供的和 gollback 相應的方法,也有一些不同。我來一一介紹下。
它定義了執行子任務的函式,這和 gollback 的 AyncFunc 是一樣的,它的定義如下:
type Executable func(context.Context) (interface{}, error)
All 方法
All 方法的簽名如下:
func All(parentCtx context.Context, execs ...Executable) ([]interface{}, error)
它會傳入一組可執行的函式(子任務),返回子任務的執行結果。和 gollback 的 All 方法不一樣的是,一旦一個子任務出現錯誤,它就會返回錯誤資訊,執行結果(第一個返回引數)為 nil。
Take 方法
Take 方法的簽名如下:
func Take(parentCtx context.Context, num int, execs ...Executable) ([]interface{}, error)
你可以指定 num 引數,只要有 num 個子任務正常執行完沒有錯誤,這個方法就會返回這幾個子任務的結果。一旦一個子任務出現錯誤,它就會返回錯誤資訊,執行結果(第一個返回引數)為 nil。
Last 方法
Last 方法的簽名如下:
func Last(parentCtx context.Context, num int, execs ...Executable) ([]interface{}, error)
它只返回最後 num 個正常執行的、沒有錯誤的子任務的結果。一旦一個子任務出現錯誤,它就會返回錯誤資訊,執行結果(第一個返回引數)為 nil。
比如 num 等於 1,那麼,它只會返回最後一個無錯的子任務的結果。
Retry 方法
Retry 方法的簽名如下:
func Retry(parentCtx context.Context, retries int, fn Executable) (interface{}, error)
它的功能和 gollback 的 Retry 方法的功能一樣,如果子任務執行出錯,就會不斷嘗試,直到成功或者是達到重試上限。如果達到重試上限,就會返回錯誤。如果 retries 等於 0,它會不斷嘗試。
Waterfall 方法
Waterfall 方法簽名如下:
func Waterfall(parentCtx context.Context, execs ...ExecutableInSequence) (interface{}, error)
它其實是一個 pipeline 的處理方式,所有的子任務都是序列執行的,前一個子任務的執行結果會被當作引數傳給下一個子任務,直到所有的任務都完成,返回最後的執行結果。一旦一個子任務出現錯誤,它就會返回錯誤資訊,執行結果(第一個返回引數)為 nil。
gollback 和 Hunch 是屬於同一類的併發原語,對一組子任務的執行結果,可以選擇一個結果或者多個結果,這也是現在熱門的微服務常用的服務治理的方法。
schedgroup
接下來,我再介紹一個和時間相關的處理一組 goroutine 的併發原語 schedgroup。
schedgroup是 Matt Layher 開發的 worker pool,可以指定任務在某個時間或者某個時間之後執行。Matt Layher 也是一個知名的 Gopher,經常在一些會議上分享一些他的 Go 開發經驗,他在 GopherCon Europe 2020 大會上專門介紹了這個併發原語:schedgroup: a timer-based goroutine concurrency primitive ,課下你可以點開這個連結看一下,下面我來給你介紹一些重點。
這個併發原語包含的方法如下:
type Group
func New(ctx context.Context) *Group
func (g *Group) Delay(delay time.Duration, fn func())
func (g *Group) Schedule(when time.Time, fn func())
func (g *Group) Wait() error
我來介紹下這些方法。
先說 Delay 和 Schedule。
它們的功能其實是一樣的,都是用來指定在某個時間或者之後執行一個函式。只不過,Delay 傳入的是一個 time.Duration 引數,它會在 time.Now()+delay 之後執行函式,而 Schedule 可以指定明確的某個時間執行。
再來說說 Wait 方法。
這個方法呼叫會阻塞呼叫者,直到之前安排的所有子任務都執行完才返回。如果 Context 被取消,那麼,Wait 方法會返回這個 cancel error。
在使用 Wait 方法的時候,有 2 點需要注意一下。
第一點是,如果呼叫了 Wait 方法,你就不能再呼叫它的 Delay 和 Schedule 方法,否則會 panic。
第二點是,Wait 方法只能呼叫一次,如果多次呼叫的話,就會 panic。
你可能認為,簡單地使用 timer 就可以實作這個功能。其實,如果只有幾個子任務,使用 timer 不是問題,但一旦有大量的子任務,而且還要能夠 cancel,那麼,使用 timer 的話,CPU 資源消耗就比較大了。所以,schedgroup 在實作的時候,就使用 container/heap,按照子任務的執行時間進行排序,這樣可以避免使用大量的 timer,從而提高效能。
我們來看一個使用 schedgroup 的例子,下面程式碼會依次輸出 1、2、3:
sg := schedgroup.New(context.Background())
// 設定子任務分別在100、200、300之後執行
for i := 0; i < 3; i++ {
n := i + 1
sg.Delay(time.Duration(n)*100*time.Millisecond, func() {
log.Println(n) //輸出任務編號
})
}
// 等待所有的子任務都完成
if err := sg.Wait(); err != nil {
log.Fatalf("failed to wait: %v", err)
}總結這節課,我給你介紹了幾種常見的處理一組子任務的併發原語,包括 ErrGroup、gollback、Hunch、schedgroup,等等。這些常見的業務場景共性處理方式的總結,你可以把它們加入到你的知識庫中,等以後遇到相同的業務場景時,你就可以考慮使用這些併發原語。
當然,類似的併發原語還有別的,比如go-waitgroup等,而且,我相信還會有新的併發原語不斷出現。所以,你不僅僅要掌握這些併發原語,而且還要透過學習這些併發原語,學會構造新的併發原語來處理應對你的特有場景,實作程式碼重用和業務邏輯簡化。
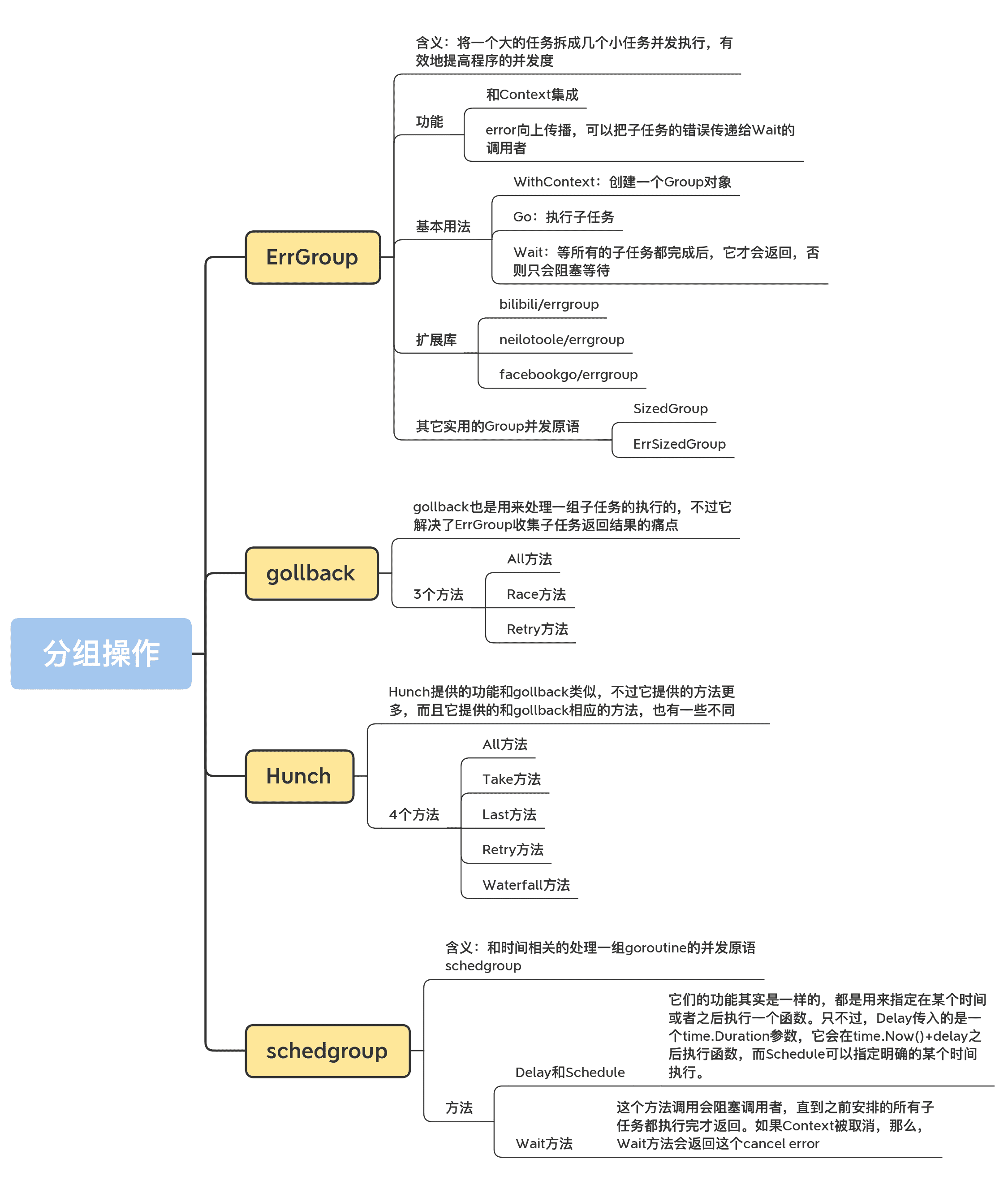
思考題
這節課,我講的官方擴充套件庫 ErrGroup 沒有實作可以取消子任務的功能,請你課下可以自己去實作一個子任務可取消的 ErrGroup。
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
19|在分散式環境中,Leader 選舉、互斥鎖和讀寫鎖該如何實作?
你好,我是鳥窩。
本章導讀
etcd 分散式併發原語:Leader / Lock / RWLock
┌──────────┐ lease/session ┌──────────────┐
│ 節點 A │ ────────────────────> │ etcd │
├──────────┤ └──────┬───────┘
│ 節點 B │ ─────────────────────────────┤
├──────────┤ │
│ 節點 C │ ─────────────────────────────┘
└──────────┘ │
▼
[選主 / 鎖競爭 / 讀寫鎖]
重點:把協調一致性工作交給 etcd,業務端專注流程控制
在前面的課程裡,我們學習的併發原語都是在行程內使用的,也就是我們常見的一個執行程式為了控制共享資源、實作任務編排和進行訊息傳遞而提供的控制型別。在接下來的這兩節課裡,我要講的是幾個分散式的併發原語,它們控制的資源或編排的任務分佈在不同行程、不同機器上。
分散式的併發原語實作更加複雜,因為在分散式環境中,網路狀況、服務狀態都是不可控的。不過還好有相應的軟體系統去做這些事情。這些軟體系統會專門去處理這些節點之間的協調和異常情況,並且保證資料的一致性。我們要做的就是在它們的基礎上實作我們的業務。
常用來做協調工作的軟體系統是 Zookeeper、etcd、Consul 之類的軟體,Zookeeper 為 Java 生態群提供了豐富的分散式併發原語(透過 Curator 庫),但是缺少 Go 相關的併發原語庫。Consul 在提供分散式併發原語這件事兒上不是很積極,而 etcd 就提供了非常好的分散式併發原語,比如分散式互斥鎖、分散式讀寫鎖、Leader 選舉,等等。所以,今天,我就以 etcd 為基礎,給你介紹幾種分散式併發原語。
既然我們依賴 etcd,那麼,在生產環境中要有一個 etcd 叢集,而且應該保證這個 etcd 叢集是 7*24 工作的。在學習過程中,你可以使用一個 etcd 節點進行測試。
這節課我要介紹的就是 Leader 選舉、互斥鎖和讀寫鎖。
Leader 選舉
Leader 選舉常常用在主從架構的系統中。主從架構中的服務節點分為主(Leader、Master)和從(Follower、Slave)兩種角色,實際節點包括 1 主 n 從,一共是 n+1 個節點。
主節點常常執行寫操作,從節點常常執行讀操作,如果讀寫都在主節點,從節點只是提供一個備份功能的話,那麼,主從架構就會退化成主備模式架構。
主從架構中最重要的是如何確定節點的角色,也就是,到底哪個節點是主,哪個節點是從?
在同一時刻,系統中不能有兩個主節點,否則,如果兩個節點都是主,都執行寫操作的話,就有可能出現資料不一致的情況,所以,我們需要一個選主機制,選擇一個節點作為主節點,這個過程就是 Leader 選舉。
當主節點宕機或者是不可用時,就需要新一輪的選舉,從其它的從節點中選擇出一個節點,讓它作為新主節點,宕機的原主節點恢復後,可以變為從節點,或者被摘掉。
我們可以透過 etcd 基礎服務來實作 leader 選舉。具體點說,我們可以將 Leader 選舉的邏輯交給 etcd 基礎服務,這樣,我們只需要把重心放在業務開發上。etcd 基礎服務可以透過多節點的方式保證 7*24 服務,所以,我們也不用擔心 Leader 選舉不可用的問題。如下圖所示:
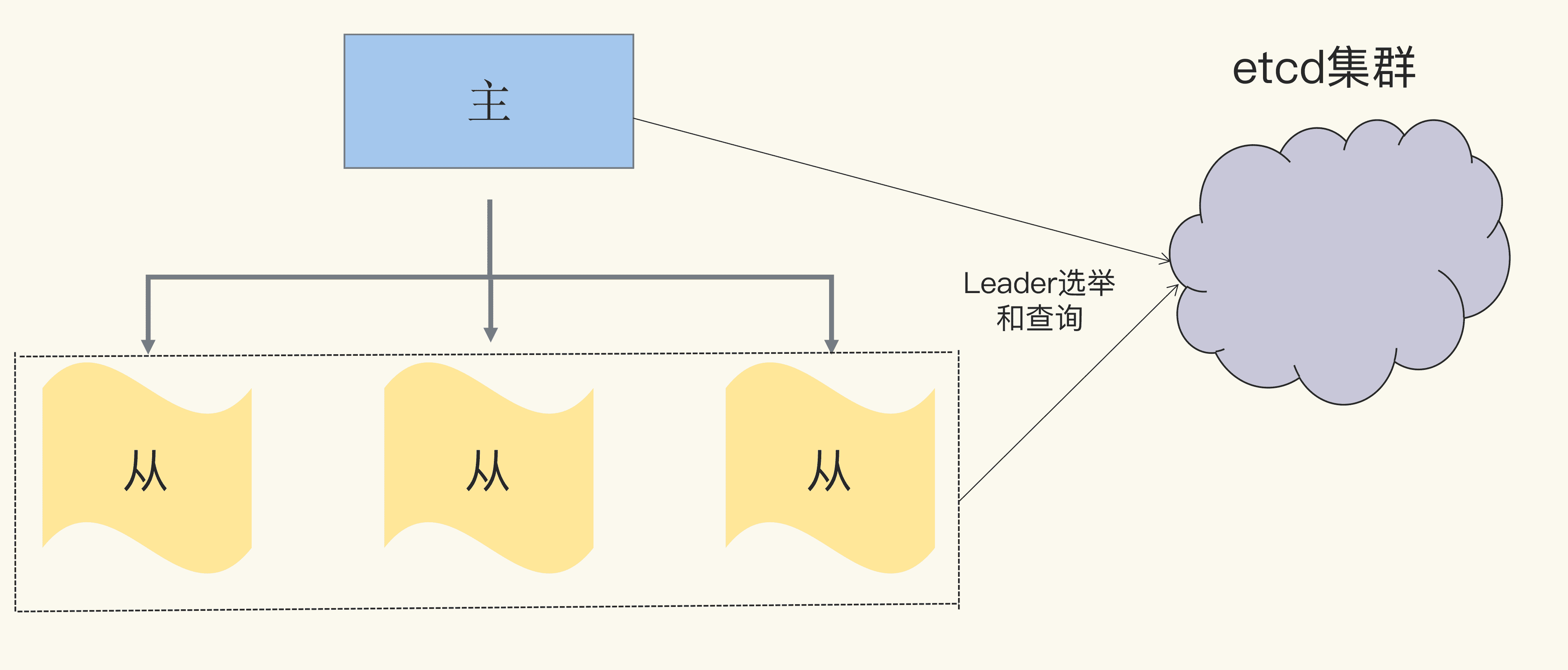
接下來,我會給你介紹業務開發中跟 Leader 選舉相關的選舉、查詢、Leader 變動監控等功能。
我要先提醒你一句,如果你想執行我下面講到的測試程式碼,就要先部署一個 etcd 的叢集,或者部署一個 etcd 節點做測試。
首先,我們來實作一個測試分散式程式的框架:它會先從命令列中讀取命令,然後再執行相應的命令。你可以開啟兩個視窗,模擬不同的節點,分別執行不同的命令。
這個測試程式如下:
package main
// 匯入所需的庫
import (
"bufio"
"context"
"flag"
"fmt"
"log"
"os"
"strconv"
"strings"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
)
// 可以設定一些引數,比如節點ID
var (
nodeID = flag.Int("id", 0, "node ID")
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
electName = flag.String("name", "my-test-elect", "election name")
)
func main() {
flag.Parse()
// 將etcd的地址解析成slice of string
endpoints := strings.Split(*addr, ",")
// 生成一個etcd的clien
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 建立session,如果程式宕機導致session斷掉,etcd能檢測到
session, err := concurrency.NewSession(cli)
defer session.Close()
// 生成一個選舉物件。下面主要使用它進行選舉和查詢等操作
// 另一個方法ResumeElection可以使用既有的leader初始化Election
e1 := concurrency.NewElection(session, *electName)
// 從命令列讀取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
switch action {
case "elect": // 選舉命令
go elect(e1, *electName)
case "proclaim": // 只更新leader的value
proclaim(e1, *electName)
case "resign": // 辭去leader,重新選舉
resign(e1, *electName)
case "watch": // 監控leader的變動
go watch(e1, *electName)
case "query": // 查詢當前的leader
query(e1, *electName)
case "rev":
rev(e1, *electName)
default:
fmt.Println("unknown action")
}
}
}
部署完以後,我們就可以開始選舉了。
選舉
如果你的業務叢集還沒有主節點,或者主節點宕機了,你就需要發起新一輪的選主操作,主要會用到 Campaign 和 Proclaim。如果你需要主節點放棄主的角色,讓其它從節點有機會成為主節點,就可以呼叫 Resign 方法。
這裡我提到了三個和選主相關的方法,下面我來介紹下它們的用法。
第一個方法是 Campaign。它的作用是,把一個節點選舉為主節點,並且會設定一個值。它的簽名如下所示:
func (e *Election) Campaign(ctx context.Context, val string) error
需要注意的是,這是一個阻塞方法,在呼叫它的時候會被阻塞,直到滿足下面的三個條件之一,才會取消阻塞。
- 成功當選為主;
- 此方法返回錯誤;
- ctx 被取消。
第二個方法是 Proclaim。它的作用是,重新設定 Leader 的值,但是不會重新選主,這個方法會返回新值設定成功或者失敗的資訊。方法簽名如下所示:
func (e *Election) Proclaim(ctx context.Context, val string) error
第三個方法是 Resign:開始新一次選舉。這個方法會返回新的選舉成功或者失敗的資訊。它的簽名如下所示:
func (e *Election) Resign(ctx context.Context) (err error)
這三個方法的測試程式碼如下。你可以使用測試程式進行測試,具體做法是,啟動兩個節點,執行和這三個方法相關的命令。
var count int
// 選主
func elect(e1 *concurrency.Election, electName string) {
log.Println("acampaigning for ID:", *nodeID)
// 呼叫Campaign方法選主,主的值為value-<主節點ID>-<count>
if err := e1.Campaign(context.Background(), fmt.Sprintf("value-%d-%d", *nodeID, count)); err != nil {
log.Println(err)
}
log.Println("campaigned for ID:", *nodeID)
count++
}
// 為主設定新值
func proclaim(e1 *concurrency.Election, electName string) {
log.Println("proclaiming for ID:", *nodeID)
// 呼叫Proclaim方法設定新值,新值為value-<主節點ID>-<count>
if err := e1.Proclaim(context.Background(), fmt.Sprintf("value-%d-%d", *nodeID, count)); err != nil {
log.Println(err)
}
log.Println("proclaimed for ID:", *nodeID)
count++
}
// 重新選主,有可能另外一個節點被選為了主
func resign(e1 *concurrency.Election, electName string) {
log.Println("resigning for ID:", *nodeID)
// 呼叫Resign重新選主
if err := e1.Resign(context.TODO()); err != nil {
log.Println(err)
}
log.Println("resigned for ID:", *nodeID)
}查詢除了選舉 Leader,程式在啟動的過程中,或者在執行的時候,還有可能需要查詢當前的主節點是哪一個節點?主節點的值是什麼?版本是多少?不光是主從節點需要查詢和知道哪一個節點,在分散式系統中,還有其它一些節點也需要知道叢集中的哪一個節點是主節點,哪一個節點是從節點,這樣它們才能把讀寫請求分別發往相應的主從節點上。
etcd 提供了查詢當前 Leader 的方法 Leader,如果當前還沒有 Leader,就返回一個錯誤,你可以使用這個方法來查詢主節點資訊。這個方法的簽名如下:
func (e *Election) Leader(ctx context.Context) (*v3.GetResponse, error)
每次主節點的變動都會生成一個新的版本號,你還可以查詢版本號資訊(Rev 方法),瞭解主節點變動情況:
func (e *Election) Rev() int64
你可以在測試完選主命令後,測試查詢命令(query、rev),程式碼如下:
// 查詢主的資訊
func query(e1 *concurrency.Election, electName string) {
// 呼叫Leader返回主的資訊,包括key和value等資訊
resp, err := e1.Leader(context.Background())
if err != nil {
log.Printf("failed to get the current leader: %v", err)
}
log.Println("current leader:", string(resp.Kvs[0].Key), string(resp.Kvs[0].Value))
}
// 可以直接查詢主的rev資訊
func rev(e1 *concurrency.Election, electName string) {
rev := e1.Rev()
log.Println("current rev:", rev)
}監控有了選舉和查詢方法,我們還需要一個監控方法。畢竟,如果主節點變化了,我們需要得到最新的主節點資訊。
我們可以透過 Observe 來監控主的變化,它的簽名如下:
func (e *Election) Observe(ctx context.Context) <-chan v3.GetResponse
它會返回一個 chan,顯示主節點的變動資訊。需要注意的是,它不會返回主節點的全部歷史變動資訊,而是隻返回最近的一條變動資訊以及之後的變動資訊。
它的測試程式碼如下:
func watch(e1 *concurrency.Election, electName string) {
ch := e1.Observe(context.TODO())
log.Println("start to watch for ID:", *nodeID)
for i := 0; i < 10; i++ {
resp := <-ch
log.Println("leader changed to", string(resp.Kvs[0].Key), string(resp.Kvs[0].Value))
}
}
etcd 提供了選主的邏輯,而你要做的就是利用這些方法,讓它們為你的業務服務。在使用的過程中,你還需要做一些額外的設定,比如查詢當前的主節點、啟動一個 goroutine 阻塞呼叫 Campaign 方法,等等。雖然你需要做一些額外的工作,但是跟自己實作一個分散式的選主邏輯相比,大大地減少了工作量。
接下來,我們繼續看 etcd 提供的分散式併發原語:互斥鎖。
互斥鎖
互斥鎖是非常常用的一種併發原語,我專門花了 4 講的時間,重點介紹了互斥鎖的功能、原理和易錯場景。
不過,前面說的互斥鎖都是用來保護同一行程內的共享資源的,今天,我們要掌握的是分散式環境中的互斥鎖。我們要重點學習下分佈在不同機器中的不同行程內的 goroutine,如何利用分散式互斥鎖來保護共享資源。
互斥鎖的應用場景和主從架構的應用場景不太一樣。使用互斥鎖的不同節點是沒有主從這樣的角色的,所有的節點都是一樣的,只不過在同一時刻,只允許其中的一個節點持有鎖。
下面,我們就來學習下互斥鎖相關的兩個原語,即 Locker 和 Mutex。
Locker
etcd 提供了一個簡單的 Locker 原語,它類似於 Go 標準庫中的 sync.Locker 介面,也提供了 Lock/UnLock 的機制:
func NewLocker(s *Session, pfx string) sync.Locker
可以看到,它的返回值是一個 sync.Locker,因為你對標準庫的 Locker 已經非常瞭解了,而且它只有 Lock/Unlock 兩個方法,所以,接下來使用這個鎖就非常容易了。下面的程式碼是一個使用 Locker 併發原語的例子:
package main
import (
"flag"
"log"
"math/rand"
"strings"
"time"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
lockName = flag.String("name", "my-test-lock", "lock name")
)
func main() {
flag.Parse()
rand.Seed(time.Now().UnixNano())
// etcd地址
endpoints := strings.Split(*addr, ",")
// 生成一個etcd client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
useLock(cli) // 測試鎖
}
func useLock(cli *clientv3.Client) {
// 為鎖生成session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
//得到一個分散式鎖
locker := concurrency.NewLocker(s1, *lockName)
// 請求鎖
log.Println("acquiring lock")
locker.Lock()
log.Println("acquired lock")
// 等待一段時間
time.Sleep(time.Duration(rand.Intn(30)) * time.Second)
locker.Unlock() // 釋放鎖
log.Println("released lock")
}
你可以同時在兩個終端中執行這個測試程式。可以看到,它們獲得鎖是有先後順序的,一個節點釋放了鎖之後,另外一個節點才能獲取到這個分散式鎖。
Mutex
事實上,剛剛說的 Locker 是基於 Mutex 實作的,只不過,Mutex 提供了查詢 Mutex 的 key 的資訊的功能。測試程式碼也類似:
func useMutex(cli *clientv3.Client) {
// 為鎖生成session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
m1 := concurrency.NewMutex(s1, *lockName)
//在請求鎖之前查詢key
log.Printf("before acquiring. key: %s", m1.Key())
// 請求鎖
log.Println("acquiring lock")
if err := m1.Lock(context.TODO()); err != nil {
log.Fatal(err)
}
log.Printf("acquired lock. key: %s", m1.Key())
//等待一段時間
time.Sleep(time.Duration(rand.Intn(30)) * time.Second)
// 釋放鎖
if err := m1.Unlock(context.TODO()); err != nil {
log.Fatal(err)
}
log.Println("released lock")
}
可以看到,Mutex 並沒有實作 sync.Locker 介面,它的 Lock/Unlock 方法需要提供一個 context.Context 例項做引數,這也就意味著,在請求鎖的時候,你可以設定超時時間,或者主動取消請求。
讀寫鎖
學完了分散式 Locker 和互斥鎖 Mutex,你肯定會聯想到讀寫鎖 RWMutex。是的,etcd 也提供了分散式的讀寫鎖。不過,互斥鎖 Mutex 是在 github.com/coreos/etcd/clientv3/concurrency 包中提供的,讀寫鎖 RWMutex 卻是在 github.com/coreos/etcd/contrib/recipes 包中提供的。
etcd 提供的分散式讀寫鎖的功能和標準庫的讀寫鎖的功能是一樣的。只不過,etcd 提供的讀寫鎖,可以在分散式環境中的不同的節點使用。它提供的方法也和標準庫中的讀寫鎖的方法一致,分別提供了 RLock/RUnlock、Lock/Unlock 方法。下面的程式碼是使用讀寫鎖的例子,它從命令列中讀取命令,執行讀寫鎖的操作:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"math/rand"
"os"
"strings"
"time"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
lockName = flag.String("name", "my-test-lock", "lock name")
action = flag.String("rw", "w", "r means acquiring read lock, w means acquiring write lock")
)
func main() {
flag.Parse()
rand.Seed(time.Now().UnixNano())
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 建立etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 建立session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
m1 := recipe.NewRWMutex(s1, *lockName)
// 從命令列讀取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
switch action {
case "w": // 請求寫鎖
testWriteLocker(m1)
case "r": // 請求讀鎖
testReadLocker(m1)
default:
fmt.Println("unknown action")
}
}
}
func testWriteLocker(m1 *recipe.RWMutex) {
// 請求寫鎖
log.Println("acquiring write lock")
if err := m1.Lock(); err != nil {
log.Fatal(err)
}
log.Println("acquired write lock")
// 等待一段時間
time.Sleep(time.Duration(rand.Intn(10)) * time.Second)
// 釋放寫鎖
if err := m1.Unlock(); err != nil {
log.Fatal(err)
}
log.Println("released write lock")
}
func testReadLocker(m1 *recipe.RWMutex) {
// 請求讀鎖
log.Println("acquiring read lock")
if err := m1.RLock(); err != nil {
log.Fatal(err)
}
log.Println("acquired read lock")
// 等待一段時間
time.Sleep(time.Duration(rand.Intn(10)) * time.Second)
// 釋放寫鎖
if err := m1.RUnlock(); err != nil {
log.Fatal(err)
}
log.Println("released read lock")
}總結自己實作分散式環境的併發原語,是相當困難的一件事,因為你需要考慮網路的延遲和異常、節點的可用性、資料的一致性等多種情況。
所以,我們可以藉助 etcd 這樣成熟的框架,基於它提供的分散式併發原語處理分散式的場景。需要注意的是,在使用這些分散式併發原語的時候,你需要考慮異常的情況,比如網路斷掉等。同時,分散式併發原語需要網路之間的通訊,所以會比使用標準庫中的併發原語耗時更長。
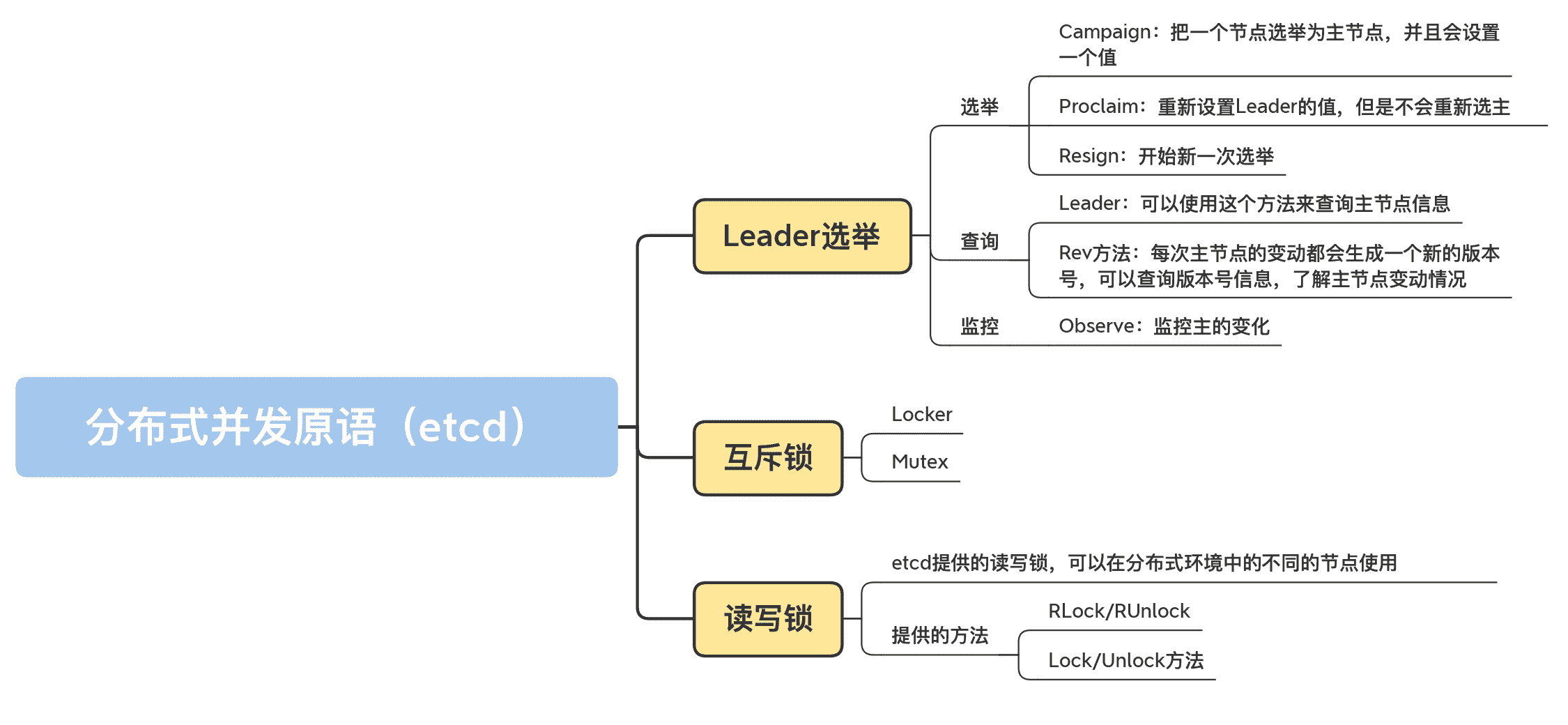
好了,這節課就到這裡,下節課,我會帶你繼續學習其它的分散式併發原語,包括佇列、柵欄和 STM,敬請期待。
思考題
- 如果持有互斥鎖或者讀寫鎖的節點意外宕機了,它持有的鎖會不會被釋放?
- etcd 提供的讀寫鎖中的讀和寫有沒有優先順序?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
20|在分散式環境中,佇列、柵欄和STM該如何實作?
你好,我是鳥窩。
本章導讀
etcd 分散式佇列 / 柵欄 / STM(交易)示意
客戶端/節點 ──> [etcd KV + Txn + Watch] ──> 分散式控制語義
│
┌───────────────┼────────────────┐
▼ ▼ ▼
佇列(enqueue/ 柵欄(等到條件) STM(讀改寫交易)
dequeue) 再放行) 一致性提交)
上一講,我已經帶你認識了基於 etcd 實作的 Leader 選舉、互斥鎖和讀寫鎖,今天,我們來學習下基於 etcd 的分散式佇列、柵欄和 STM。
只要你學過計算機演算法和資料結構相關的知識, 佇列這種資料結構你一定不陌生,它是一種先進先出的型別,有出隊(dequeue)和入隊(enqueue)兩種操作。在第 12 講中,我專門講到了一種叫做 lock-free 的佇列。佇列在單機的應用程式中常常使用,但是在分散式環境中,多節點如何併發地執行入隊和出隊的操作呢?這一講,我會帶你認識一下基於 etcd 實作的分散式佇列。
除此之外,我還會講用分散式柵欄編排一組分散式節點同時執行的方法,以及簡化多個 key 的操作並且提供事務功能的 STM(Software Transactional Memory,軟體事務記憶體)。
分散式佇列和優先順序佇列
前一講我也講到,我們並不是從零開始實作一個分散式佇列,而是站在 etcd 的肩膀上,利用 etcd 提供的功能實作分散式佇列。
etcd 叢集的可用性由 etcd 叢集的維護者來保證,我們不用擔心網路分割槽、節點宕機等問題。我們可以把這些通通交給 etcd 的運維人員,把我們自己的關注點放在使用上。
下面,我們就來瞭解下 etcd 提供的分散式佇列。etcd 透過 github.com/coreos/etcd/contrib/recipes 包提供了分散式佇列這種資料結構。
建立分散式佇列的方法非常簡單,只有一個,即 NewQueue,你只需要傳入 etcd 的 client 和這個佇列的名字,就可以了。程式碼如下:
func NewQueue(client *v3.Client, keyPrefix string) *Queue
這個佇列只有兩個方法,分別是出隊和入隊,佇列中的元素是字串型別。這兩個方法的簽名如下所示:
// 入隊
func (q *Queue) Enqueue(val string) error
//出隊
func (q *Queue) Dequeue() (string, error)
需要注意的是,如果這個分散式佇列當前為空,呼叫 Dequeue 方法的話,會被阻塞,直到有元素可以出隊才返回。
既然是分散式的佇列,那就意味著,我們可以在一個節點將元素放入佇列,在另外一個節點把它取出。
在我接下來講的例子中,你就可以啟動兩個節點,一個節點往佇列中放入元素,一個節點從佇列中取出元素,看看是否能正常取出來。etcd 的分散式佇列是一種多讀多寫的佇列,所以,你也可以啟動多個寫節點和多個讀節點。
下面我們來藉助程式碼,看一下如何實作分散式佇列。
首先,我們啟動一個程式,它會從命令列讀取你的命令,然後執行。你可以輸入push <value>,將一個元素入隊,輸入pop,將一個元素彈出。另外,你還可以使用這個程式啟動多個例項,用來模擬分散式的環境:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strings"
"github.com/coreos/etcd/clientv3"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
queueName = flag.String("name", "my-test-queue", "queue name")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 建立etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 建立/獲取佇列
q := recipe.NewQueue(cli, *queueName)
// 從命令列讀取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "push": // 加入佇列
if len(items) != 2 {
fmt.Println("must set value to push")
continue
}
q.Enqueue(items[1]) // 入隊
case "pop": // 從佇列彈出
v, err := q.Dequeue() // 出隊
if err != nil {
log.Fatal(err)
}
fmt.Println(v) // 輸出出隊的元素
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
我們可以開啟兩個終端,分別執行這個程式。在第一個終端中執行入隊操作,在第二個終端中執行出隊操作,並且觀察一下出隊、入隊是否正常。
除了剛剛說的分散式佇列,etcd 還提供了優先順序佇列(PriorityQueue)。
它的用法和佇列類似,也提供了出隊和入隊的操作,只不過,在入隊的時候,除了需要把一個值加入到佇列,我們還需要提供 uint16 型別的一個整數,作為此值的優先順序,優先順序高的元素會優先出隊。
優先順序佇列的測試程式如下,你可以在一個節點輸入一些不同優先順序的元素,在另外一個節點讀取出來,看看它們是不是按照優先順序順序彈出的:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strconv"
"strings"
"github.com/coreos/etcd/clientv3"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
queueName = flag.String("name", "my-test-queue", "queue name")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 建立etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 建立/獲取佇列
q := recipe.NewPriorityQueue(cli, *queueName)
// 從命令列讀取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "push": // 加入佇列
if len(items) != 3 {
fmt.Println("must set value and priority to push")
continue
}
pr, err := strconv.Atoi(items[2]) // 讀取優先順序
if err != nil {
fmt.Println("must set uint16 as priority")
continue
}
q.Enqueue(items[1], uint16(pr)) // 入隊
case "pop": // 從佇列彈出
v, err := q.Dequeue() // 出隊
if err != nil {
log.Fatal(err)
}
fmt.Println(v) // 輸出出隊的元素
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
你看,利用 etcd 實作分散式佇列和分散式優先佇列,就是這麼簡單。所以,在實際專案中,如果有這類需求的話,你就可以選擇用 etcd 實作。
不過,在使用分散式併發原語時,除了需要考慮可用性和資料一致性,還需要考慮分散式設計帶來的效能損耗問題。所以,在使用之前,你一定要做好效能的評估。
分散式柵欄
在第 17 講中,我們學習了迴圈柵欄 CyclicBarrier,它和第 6 講的標準庫中的 WaitGroup,本質上是同一類併發原語,都是等待同一組 goroutine 同時執行,或者是等待同一組 goroutine 都完成。
在分散式環境中,我們也會遇到這樣的場景:一組節點協同工作,共同等待一個訊號,在訊號未出現前,這些節點會被阻塞住,而一旦訊號出現,這些阻塞的節點就會同時開始繼續執行下一步的任務。
etcd 也提供了相應的分散式併發原語。
- Barrier:分散式柵欄。如果持有 Barrier 的節點釋放了它,所有等待這個 Barrier 的節點就不會被阻塞,而是會繼續執行。
- DoubleBarrier:計數型柵欄。在初始化計數型柵欄的時候,我們就必須提供參與節點的數量,當這些數量的節點都 Enter 或者 Leave 的時候,這個柵欄就會放開。所以,我們把它稱為計數型柵欄。
Barrier:分散式柵欄
我們先來學習下分散式 Barrier。
分散式 Barrier 的建立很簡單,你只需要提供 etcd 的 Client 和 Barrier 的名字就可以了,如下所示:
func NewBarrier(client *v3.Client, key string) *Barrier
Barrier 提供了三個方法,分別是 Hold、**Release 和 Wait,**程式碼如下:
func (b *Barrier) Hold() error
func (b *Barrier) Release() error
func (b *Barrier) Wait() error
- Hold 方法是建立一個 Barrier。如果 Barrier 已經建立好了,有節點呼叫它的 Wait 方法,就會被阻塞。
- Release 方法是釋放這個 Barrier,也就是開啟柵欄。如果使用了這個方法,所有被阻塞的節點都會被放行,繼續執行。
- Wait 方法會阻塞當前的呼叫者,直到這個 Barrier 被 release。如果這個柵欄不存在,呼叫者不會被阻塞,而是會繼續執行。
學習併發原語最好的方式就是使用它。下面我們就來藉助一個例子,來看看 Barrier 該怎麼用。
你可以在一個終端中執行這個程式,執行"hold""release"命令,模擬柵欄的持有和釋放。在另外一個終端中執行這個程式,不斷呼叫"wait"方法,看看是否能正常地跳出阻塞繼續執行:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strings"
"github.com/coreos/etcd/clientv3"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
barrierName = flag.String("name", "my-test-queue", "barrier name")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 建立etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 建立/獲取柵欄
b := recipe.NewBarrier(cli, *barrierName)
// 從命令列讀取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "hold": // 持有這個barrier
b.Hold()
fmt.Println("hold")
case "release": // 釋放這個barrier
b.Release()
fmt.Println("released")
case "wait": // 等待barrier被釋放
b.Wait()
fmt.Println("after wait")
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}DoubleBarrier:計數型柵欄etcd 還提供了另外一種柵欄,叫做 DoubleBarrier,這也是一種非常有用的柵欄。這個柵欄初始化的時候需要提供一個計數 count,如下所示:
func NewDoubleBarrier(s *concurrency.Session, key string, count int) *DoubleBarrier
同時,它還提供了兩個方法,分別是 Enter 和 Leave,程式碼如下:
func (b *DoubleBarrier) Enter() error
func (b *DoubleBarrier) Leave() error
我來解釋下這兩個方法的作用。
當呼叫者呼叫 Enter 時,會被阻塞住,直到一共有 count(初始化這個柵欄的時候設定的值)個節點呼叫了 Enter,這 count 個被阻塞的節點才能繼續執行。所以,你可以利用它編排一組節點,讓這些節點在同一個時刻開始執行任務。
同理,如果你想讓一組節點在同一個時刻完成任務,就可以呼叫 Leave 方法。節點呼叫 Leave 方法的時候,會被阻塞,直到有 count 個節點,都呼叫了 Leave 方法,這些節點才能繼續執行。
我們再來看一下 DoubleBarrier 的使用例子。你可以起兩個節點,同時執行 Enter 方法,看看這兩個節點是不是先阻塞,之後才繼續執行。然後,你再執行 Leave 方法,也觀察一下,是不是先阻塞又繼續執行的。
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strings"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
barrierName = flag.String("name", "my-test-doublebarrier", "barrier name")
count = flag.Int("c", 2, "")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 建立etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 建立session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
// 建立/獲取柵欄
b := recipe.NewDoubleBarrier(s1, *barrierName, *count)
// 從命令列讀取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "enter": // 持有這個barrier
b.Enter()
fmt.Println("enter")
case "leave": // 釋放這個barrier
b.Leave()
fmt.Println("leave")
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
好了,我們先來簡單總結一下。我們在第 17 講學習的迴圈柵欄,控制的是同一個程式中的不同 goroutine 的執行,而分散式柵欄和計數型柵欄控制的是不同節點、不同行程的執行。當你需要協調一組分散式節點在某個時間點同時執行的時候,可以考慮 etcd 提供的這組併發原語。
STM
提到事務,你肯定不陌生。在開發基於資料庫的應用程式的時候,我們經常用到事務。事務就是要保證一組操作要麼全部成功,要麼全部失敗。
在學習 STM 之前,我們要先了解一下 etcd 的事務以及它的問題。
etcd 提供了在一個事務中對多個 key 的更新功能,這一組 key 的操作要麼全部成功,要麼全部失敗。etcd 的事務實作方式是基於 CAS 方式實作的,融合了 Get、Put 和 Delete 操作。
etcd 的事務操作如下,分為條件塊、成功塊和失敗塊,條件塊用來檢測事務是否成功,如果成功,就執行 Then(...),如果失敗,就執行 Else(...):
Txn().If(cond1, cond2, ...).Then(op1, op2, ...,).Else(op1’, op2’, …)
我們來看一個利用 etcd 的事務實作轉賬的小例子。我們從賬戶 from 向賬戶 to 轉賬 amount,程式碼如下:
func doTxnXfer(etcd *v3.Client, from, to string, amount uint) (bool, error) {
// 一個查詢事務
getresp, err := etcd.Txn(ctx.TODO()).Then(OpGet(from), OpGet(to)).Commit()
if err != nil {
return false, err
}
// 獲取轉賬賬戶的值
fromKV := getresp.Responses[0].GetRangeResponse().Kvs[0]
toKV := getresp.Responses[1].GetRangeResponse().Kvs[1]
fromV, toV := toUInt64(fromKV.Value), toUint64(toKV.Value)
if fromV < amount {
return false, fmt.Errorf(“insufficient value”)
}
// 轉賬事務
// 條件塊
txn := etcd.Txn(ctx.TODO()).If(
v3.Compare(v3.ModRevision(from), “=”, fromKV.ModRevision),
v3.Compare(v3.ModRevision(to), “=”, toKV.ModRevision))
// 成功塊
txn = txn.Then(
OpPut(from, fromUint64(fromV - amount)),
OpPut(to, fromUint64(toV + amount))
//提交事務
putresp, err := txn.Commit()
// 檢查事務的執行結果
if err != nil {
return false, err
}
return putresp.Succeeded, nil
}
從剛剛的這段程式碼中,我們可以看到,雖然可以利用 etcd 實作事務操作,但是邏輯還是比較複雜的。
因為事務使用起來非常麻煩,所以 etcd 又在這些基礎 API 上進行了封裝,新增了一種叫做 STM 的操作,提供了更加便利的方法。
下面我們來看一看 STM 怎麼用。
要使用 STM,你需要先編寫一個 apply 函式,這個函式的執行是在一個事務之中的:
apply func(STM) error
這個方法包含一個 STM 型別的引數,它提供了對 key 值的讀寫操作。
STM 提供了 4 個方法,分別是 Get、Put、Receive 和 Delete,程式碼如下:
type STM interface {
Get(key ...string) string
Put(key, val string, opts ...v3.OpOption)
Rev(key string) int64
Del(key string)
}
使用 etcd STM 的時候,我們只需要定義一個 apply 方法,比如說轉賬方法 exchange,然後透過 concurrency.NewSTM(cli, exchange),就可以完成轉賬事務的執行了。
STM 咋用呢?我們還是藉助一個例子來學習下。
下面這個例子建立了 5 個銀行賬號,然後隨機選擇一些賬號兩兩轉賬。在轉賬的時候,要把源賬號一半的錢要轉給目標賬號。這個例子啟動了 10 個 goroutine 去執行這些事務,每個 goroutine 要完成 100 個事務。
為了確認事務是否出錯了,我們最後要校驗每個賬號的錢數和總錢數。總錢數不變,就代表執行成功了。這個例子的程式碼如下:
package main
import (
"context"
"flag"
"fmt"
"log"
"math/rand"
"strings"
"sync"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 設定5個賬戶,每個賬號都有100元,總共500元
totalAccounts := 5
for i := 0; i < totalAccounts; i++ {
k := fmt.Sprintf("accts/%d", i)
if _, err = cli.Put(context.TODO(), k, "100"); err != nil {
log.Fatal(err)
}
}
// STM的應用函式,主要的事務邏輯
exchange := func(stm concurrency.STM) error {
// 隨機得到兩個轉賬賬號
from, to := rand.Intn(totalAccounts), rand.Intn(totalAccounts)
if from == to {
// 自己不和自己轉賬
return nil
}
// 讀取賬號的值
fromK, toK := fmt.Sprintf("accts/%d", from), fmt.Sprintf("accts/%d", to)
fromV, toV := stm.Get(fromK), stm.Get(toK)
fromInt, toInt := 0, 0
fmt.Sscanf(fromV, "%d", &fromInt)
fmt.Sscanf(toV, "%d", &toInt)
// 把源賬號一半的錢轉賬給目標賬號
xfer := fromInt / 2
fromInt, toInt = fromInt-xfer, toInt+xfer
// 把轉賬後的值寫回
stm.Put(fromK, fmt.Sprintf("%d", fromInt))
stm.Put(toK, fmt.Sprintf("%d", toInt))
return nil
}
// 啟動10個goroutine進行轉賬操作
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100; j++ {
if _, serr := concurrency.NewSTM(cli, exchange); serr != nil {
log.Fatal(serr)
}
}
}()
}
wg.Wait()
// 檢查賬號最後的數目
sum := 0
accts, err := cli.Get(context.TODO(), "accts/", clientv3.WithPrefix()) // 得到所有賬號
if err != nil {
log.Fatal(err)
}
for _, kv := range accts.Kvs { // 遍歷賬號的值
v := 0
fmt.Sscanf(string(kv.Value), "%d", &v)
sum += v
log.Printf("account %s: %d", kv.Key, v)
}
log.Println("account sum is", sum) // 總數
}
總結一下,當你利用 etcd 做儲存時,是可以利用 STM 實作事務操作的,一個事務可以包含多個賬號的資料更改操作,事務能夠保證這些更改要麼全成功,要麼全失敗。
總結
如果我們把眼光放得更寬廣一些,其實並不只是 etcd 提供了這些併發原語,比如我上節課一開始就提到了,Zookeeper 很早也提供了類似的併發原語,只不過只提供了 Java 的庫,並沒有提供合適的 Go 庫。另外,根據 Consul 官方的反饋,他們並沒有開發這些併發原語的計劃,所以,從目前來看,etcd 是個不錯的選擇。
當然,也有一些其它不太知名的分散式原語庫,但是活躍度不高,可用性低,所以我們也不需要去了解了。
其實,你也可以使用 Redis 實作分散式鎖,或者是基於 MySQL 實作分散式鎖,這也是常用的選擇。對於大廠來說,選擇起來是非常簡單的,只需要看看廠內提供了哪個基礎服務,哪個更穩定些。對於沒有 etcd、Redis 這些基礎服務的公司來說,很重要的一點,就是自己搭建一套這樣的基礎服務,並且運維好,這就需要考察你們對 etcd、Redis、MySQL 的技術把控能力了,哪個用得更順手,就用哪個。
一般來說,我不建議你自己去實作分散式原語,最好是直接使用 etcd、Redis 這些成熟的軟體提供的功能,這也意味著,我們將程式的風險轉嫁到了這些基礎服務上,這些基礎服務必須要能夠提供足夠的服務保障。
思考題
- 部署一個 3 節點的 etcd 叢集,測試一下分散式佇列的效能。
- etcd 提供的 STM 是分散式事務嗎?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。
結束語|再聊Go 併發程式設計的價值和精進之路
你好,我是鳥窩。
本章導讀
課程收尾與能力進階路徑
[學會 API] -> [理解原理] -> [避坑除錯] -> [實務選型] -> [組合新解法]
| | | | |
會寫 看得懂底層 知道風險 做對取捨 能處理複雜場景
很高興和你一起度過了一個多月的時間,到了和你說再見的時候了。
在過去的這些年裡,我一直在研究 Go 併發程式設計,時間越久,越覺得,掌握 Go 併發原語是一件很有意思的事情。
很多剛開始學習併發原語的同學給我留言說:“使用 Go 寫併發程式很容易啊,為啥要學這麼多併發原語呢?”
如果你也有這樣的疑問,我的答案就是在這節課的封面圖中寫的那句話:“併發原語,初識時簡單,深交時複雜,熟識時又覺簡單。”這是我的真實體會。
如果你處於剛開始接觸併發原語的階段,你可能會覺得:“這挺好理解的呀,我一看就會了。”但是隨著學習的不斷深入,你會看到各種複雜的用法,各種潛在的坑,這些東西打破了初印象,你會陷入到“千頭萬緒”的境地。只要你不畏困難,持續學習,最後你就可以輕鬆地使用這些併發原語了。如果說最初的“簡單”是“初生牛犢不怕虎”的“簡單”,那麼“熟識”後的“簡單”,就是“撥雲見霧”的“簡單”。這也是,我在這門課裡想要帶你達到的狀態。
總之,使用 Go 寫併發程式很容易,使用 Go 寫好併發程式很不容易。
遺憾的是,很多人都沒有意識併發程式設計的複雜性,甚至還沒有意識到,併發程式設計錯誤帶來的嚴重後果。所以,我想跟你分享關於併發程式設計 Bug 的兩個小故事。
第一個故事,是我剛剛看到的澳大利亞交易所(ASX)的新系統在上線後崩潰的故事。
11 月 16 日中午,ASX 釋出宣告說,當天將休市,會在次日的正常時間重新開放。官方給出的關閉原因是“侷限於單個交易指令中交易多種證券(組合交易)的軟體問題,導致了市場資料不準確。”
雖然我並沒有看到這個 Bug 的細節,但是,從官方提供的關閉原因中,我們可以簡單地推斷出是“單個指令中交易多種證券的問題”,大機率是一個併發問題的 Bug。雖然經過一天的排查和修復,第二天這個交易所就恢復上線了。但是,耽誤一天的時間,損失也是非常大的。
類似的軟體 Bug,尤其是併發問題的 Bug,即使經過很長時間的測試,也不一定能被觸發和發現。可是一旦出現,就可能是一個一級的 Bug。
如果看完這個故事,你還沒有意識到併發程式設計的複雜性和併發問題的危害,我再給你講一個故事。
1997 年 7 月,NASA 的 Mars Pathfinder(火星探路者)在降落火星表面後不久,就因併發軟體中的一個缺陷受到了威脅。這是在飛行前的測試中發現的,但因為它只發生在某些沒有預料到的過載條件下,所以被給予了較低的優先順序。
但是,飛船開始採集氣象資料的時候,它所使用的 vxWorks 作業系統就出現了問題,不斷地重啟。這是經典的優先順序反轉的併發 Bug。
幸好工程師上傳了一小段 C 語言程式給飛船,在執行的時候,將優先順序繼承的互斥標誌從 false 改成了 true,才成功地解決了這個 Bug。
這次人為的忽視,險些釀成慘劇。所以,學好併發程式設計,是我們的重要責任。
那麼,該怎麼在編寫 Go 程式時,避免併發程式設計的 Bug 呢?在開篇詞裡,我講到了“兩大主線”,現在學完了所有內容之後,你會發現,其實可以抽象成“三部曲”:
- 全面地掌握 Go 併發程式設計的知識,不遺漏任何的知識點;
- 熟悉每一個併發原語的功能和實作,在面對併發場景時,能夠高效地選出最適合的併發原語;
- 多看看別人踩的坑,避免自己再掉進相同的坑裡。
在前面的課程中,我講的所有內容,都是為了幫助你輕鬆地完成這三個目標。在課程的最後,我還想再給你多交代幾句。
學完這門課,並不代表你已經掌握了 Go 併發程式設計的知識。Go 併發程式設計的知識廣、內容深,現在你再回顧前面的知識,可能已經遺忘了一大半了。即使你現在記得很清楚,等過一段時間,再提到這些知識點,你也可能答不上來。
所以,學完這門課並不是一件一勞永逸的事情,你要在空閒的時候多複習下前面的內容。怎麼複習呢?你可能也注意到了,每講完一個併發原語,課程裡都有一張知識導圖,這些圖既可以幫助你梳理知識主線,也可以幫助你高效地複習。
你可以對照著圖中的核心要點,去回顧我們學習的重要內容,如果感覺有些地方比較陌生了,就及時回去複習下。另外,你也可以做一些摘錄,並且寫上你自己的收穫和思考。學習過不等於能輸出,你一定要記住這句話。
另外,這門課的核心是講 Go 併發原語的知識,並沒有涉及到 Go 併發模型和排程的事情。這不是說,我認為這部分內容不重要,而是很多大牛已經把這些內容寫得很清楚、很明白了。如果你對這方面的知識還不太熟悉,可以搜尋關鍵字“golang gpm schedule”,你會看到很多資料。你讀幾篇,就明白了。如果要推薦的話,我建議你重點讀一讀歐長坤的 《Go 語言原本》的 併發排程,這一篇的邏輯非常順暢,能看出非常多的經驗。
當然,我還想再給你推薦一些補充資料,如果你還有餘力,可以再擴充套件一下知識面。
首先是一本書,名字是“Concurrency in Go”。這是第一本全面介紹 Go 併發程式設計的圖書。書中介紹了併發程式設計的背景知識、常見的原語和併發模式。我印象最深的,就是書裡對 Channel 的介紹,比如 Channel 是粘合 goroutine 的膠水,而 select 是粘合 Channel 的膠水。這樣形象的說法,可以幫助你快速地學到精髓。
除此之外,Go 官方部落格列出的一些技術分享,比如Go Concurrency Patterns、Advanced Go Concurrency Patterns,都是不錯的閱讀材料,我建議你好好讀一讀。
好了,關於結課後的學習方法,我就說到這裡。在這節課的最後,我特別想再和你分享我自己的兩個心得。
第一,開放的心態,可以拓展你的人生邊界。
我始終認為,一個人衰老的標誌,不是指他的容貌經歷了太多歲月的刻畫,而是他的內心封閉了,不再接收新的知識、新的事物。
在一些技術交流會上,我聽到一些開發者說,Go 併發程式設計很簡單,有什麼可學的?遇到這種不是技術討論的話題,我一般只會說:“你說得對。”
我當然認同我們應該把核心精力用在眼下有價值的事情上,在自己擅長的領域裡深耕,但是我更相信,開放心會讓你的人生與眾不同。如果你碰見了新技術的發展,即使不需要深入地學習,也要儘量花時間去了解一下,也許這些新的東西,就是你人生的轉折點。
我之前就是一直使用 Java、Scala,後來才開始瞭解 Go,但是,很顯然,Go 給我的人生帶來了不一樣的東西。如果不是深入研究 Go,我就沒有機會開設這麼一門課了。
第二,無數人想要你的注意力,但只有你能決定你把它放在哪裡。
我們總說這個時代是資訊爆炸的時代,其實,資訊爆炸就意味著千萬的資訊傳送者想要佔用你的注意力。你一定要保持謹慎,不要毫無感知地把你的時間扔給無價值、無意義的資訊。
如果說上一條是讓你延伸注意力的觸角,那麼這一條,就是讓你收縮注意力的觸角,但這兩者並不矛盾,因為側重點不同。“延伸”還是“收縮”,取決於你自己想要擁有的人生的樣子,只有你能決定。我能做的,就是提醒你,要開放,也要謹慎。
雖然很捨不得,但還是要跟你說再見了。在課程的最後,我給你準備一份結課問卷,希望你花 1 分鐘時間,點選下面的圖片填寫一下。如果你的建議被採納,我將會給你贈送一個護腕墊或者價值 99 元的課程閱碼。期待你的暢所欲言。