15|記憶體模型:Go 如何保證併發讀寫的順序?
你好,我是鳥窩。
本章導讀
記憶體模型(happens-before)示意
Goroutine A 同步事件 Goroutine B
┌──────────────┐ ┌────────────────┐ ┌──────────────┐
│ 寫入 shared x │ ───────> │ lock/unlock、 │ ───────> │ 讀取 shared x │
│ x = 1 │ │ channel send/recv│ │ 看到最新值? │
└──────────────┘ └────────────────┘ └──────────────┘
沒有同步事件 -> 可見性/順序不保證
Go 官方文件裡專門介紹了 Go 的記憶體模型,你不要誤解這裡的記憶體模型的含義,它並不是指 Go 物件的記憶體分配、記憶體回收和記憶體整理的規範,它描述的是併發環境中多 goroutine 讀相同變數的時候,變數的可見性條件。具體點說,就是指,在什麼條件下,goroutine 在讀取一個變數的值的時候,能夠看到其它 goroutine 對這個變數進行的寫的結果。
由於 CPU 指令重排和多級 Cache 的存在,保證多核訪問同一個變數這件事兒變得非常複雜。畢竟,不同 CPU 架構(x86/amd64、ARM、Power 等)的處理方式也不一樣,再加上編譯器的最佳化也可能對指令進行重排,所以程式語言需要一個規範,來明確多執行緒同時訪問同一個變數的可見性和順序( Russ Cox 在麻省理工學院 6.824 分散式系統 Distributed Systems 課程 的一課,專門介紹了相關的知識)。在程式語言中,這個規範被叫做記憶體模型。
除了 Go,Java、C++、C、C#、Rust 等程式語言也有記憶體模型。為什麼這些程式語言都要定義記憶體模型呢?在我看來,主要是兩個目的。
- 向廣大的程式設計師提供一種保證,以便他們在做設計和開發程式時,面對同一個資料同時被多個 goroutine 訪問的情況,可以做一些序列化訪問的控制,比如使用 Channel 或者 sync 包和 sync/atomic 包中的併發原語。
- 允許編譯器和硬體對程式做一些最佳化。這一點其實主要是為編譯器開發者提供的保證,這樣可以方便他們對 Go 的編譯器做最佳化。
既然記憶體模型這麼重要,今天,我們就來花一節課的時間學習一下。
首先,我們要先弄明白重排和可見性的問題,因為它們影響著程式實際執行的順序關係。
重排和可見性的問題
由於指令重排,程式碼並不一定會按照你寫的順序執行。
舉個例子,當兩個 goroutine 同時對一個資料進行讀寫時,假設 goroutine g1 對這個變數進行寫操作 w,goroutine g2 同時對這個變數進行讀操作 r,那麼,如果 g2 在執行讀操作 r 的時候,已經看到了 g1 寫操作 w 的結果,那麼,也不意味著 g2 能看到在 w 之前的其它的寫操作。這是一個反直觀的結果,不過的確可能會存在。
接下來,我再舉幾個具體的例子,帶你來感受一下,重排以及多核 CPU 併發執行導致程式的執行和程式碼的書寫順序不一樣的情況。
先看第一個例子,程式碼如下:
var a, b int
func f() {
a = 1 // w之前的寫操作
b = 2 // 寫操作w
}
func g() {
print(b) // 讀操作r
print(a) // ???
}
func main() {
go f() //g1
g() //g2
}
可以看到,第 9 行是要列印 b 的值。需要注意的是,即使這裡打印出的值是 2,但是依然可能在列印 a 的值時,打印出初始值 0,而不是 1。這是因為,程式執行的時候,不能保證 g2 看到的 a 和 b 的賦值有先後關係。
再來看一個類似的例子。
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
在這段程式碼中,主 goroutine main 即使觀察到 done 變成 true 了,最後讀取到的 a 的值仍然可能為空。
更糟糕的情況是,main 根本就觀察不到另一個 goroutine 對 done 的寫操作,這就會導致 main 程式一直被 hang 住。甚至可能還會出現半初始化的情況,比如:
type T struct {
msg string
}
var g *T
func setup() {
t := new(T)
t.msg = "hello, world"
g = t
}
func main() {
go setup()
for g == nil {
}
print(g.msg)
}
即使 main goroutine 觀察到 g 不為 nil,也可能打印出空的 msg(第 17 行)。
看到這裡,你可能要說了,我都執行這個程式幾百萬次了,怎麼也沒有觀察到這種現象?我可以這麼告訴你,能不能觀察到和提供保證(guarantee)是兩碼事兒。由於 CPU 架構和 Go 編譯器的不同,即使你執行程式時沒有遇到這些現象,也不代表 Go 可以 100% 保證不會出現這些問題。
剛剛說了,程式在執行的時候,兩個操作的順序可能不會得到保證,那該怎麼辦呢?接下來,我要帶你瞭解一下 Go 記憶體模型中很重要的一個概念:happens-before,這是用來描述兩個時間的順序關係的。如果某些操作能提供 happens-before 關係,那麼,我們就可以 100% 保證它們之間的順序。
happens-before
在一個 goroutine 內部,程式的執行順序和它們的程式碼指定的順序是一樣的,即使編譯器或者 CPU 重排了讀寫順序,從行為上來看,也和程式碼指定的順序一樣。
這是一個非常重要的保證,我們一定要記住。
我們來看一個例子。在下面的程式碼中,即使編譯器或者 CPU 對 a、b、c 的初始化進行了重排,但是列印結果依然能保證是 1、2、3,而不會出現 1、0、0 或 1、0、1 等情況。
func foo() {
var a = 1
var b = 2
var c = 3
println(a)
println(b)
println(c)
}
但是,對於另一個 goroutine 來說,重排卻會產生非常大的影響。因為 Go 只保證 goroutine 內部重排對讀寫的順序沒有影響,比如剛剛我們在講“可見性”問題時提到的三個例子,那該怎麼辦呢?這就要用到 happens-before 關係了。
如果兩個 action(read 或者 write)有明確的 happens-before 關係,你就可以確定它們之間的執行順序(或者是行為表現上的順序)。
Go 記憶體模型透過 happens-before 定義兩個事件(讀、寫 action)的順序:如果事件 e1 happens before 事件 e2,那麼,我們就可以說事件 e2 在事件 e1 之後發生(happens after)。如果 e1 不是 happens before e2, 同時也不 happens after e2,那麼,我們就可以說事件 e1 和 e2 是同時發生的。
如果要保證對“變數 v 的讀操作 r”能夠觀察到一個對“變數 v 的寫操作 w”,並且 r 只能觀察到 w 對變數 v 的寫,沒有其它對 v 的寫操作,也就是說,我們要保證 r 絕對能觀察到 w 操作的結果,那麼就需要同時滿足兩個條件:
- w happens before r;
- 其它對 v 的寫操作(w2、w3、w4, …) 要麼 happens before w,要麼 happens after r,絕對不會和 w、r 同時發生,或者是在它們之間發生。
你可能會說,這是很顯然的事情啊,但我要和你說的是,這是一個非常嚴格、嚴謹的數學定義。
對於單個的 goroutine 來說,它有一個特殊的 happens-before 關係,Go 記憶體模型中是這麼講的:
Within a single goroutine, the happens-before order is the order expressed by the program.
我來解釋下這句話。它的意思是,在單個的 goroutine 內部, happens-before 的關係和程式碼編寫的順序是一致的。
其實,在這一章的開頭我已經用橙色把這句話標註出來了。我再具體解釋下。
在 goroutine 內部對一個區域性變數 v 的讀,一定能觀察到最近一次對這個區域性變數 v 的寫。如果要保證多個 goroutine 之間對一個共享變數的讀寫順序,在 Go 語言中,可以使用併發原語為讀寫操作建立 happens-before 關係,這樣就可以保證順序了。
說到這兒,我想先給你補充三個 Go 語言中和記憶體模型有關的小知識,掌握了這些,你就能更好地理解下面的內容。
- 在 Go 語言中,對變數進行零值的初始化就是一個寫操作。
- 如果對超過機器 word(64bit、32bit 或者其它)大小的值進行讀寫,那麼,就可以看作是對拆成 word 大小的幾個讀寫無序進行。
- Go 並不提供直接的 CPU 屏障(CPU fence)來提示編譯器或者 CPU 保證順序性,而是使用不同架構的記憶體屏障指令來實作統一的併發原語。
接下來,我就帶你學習下 Go 語言中提供的 happens-before 關係保證。
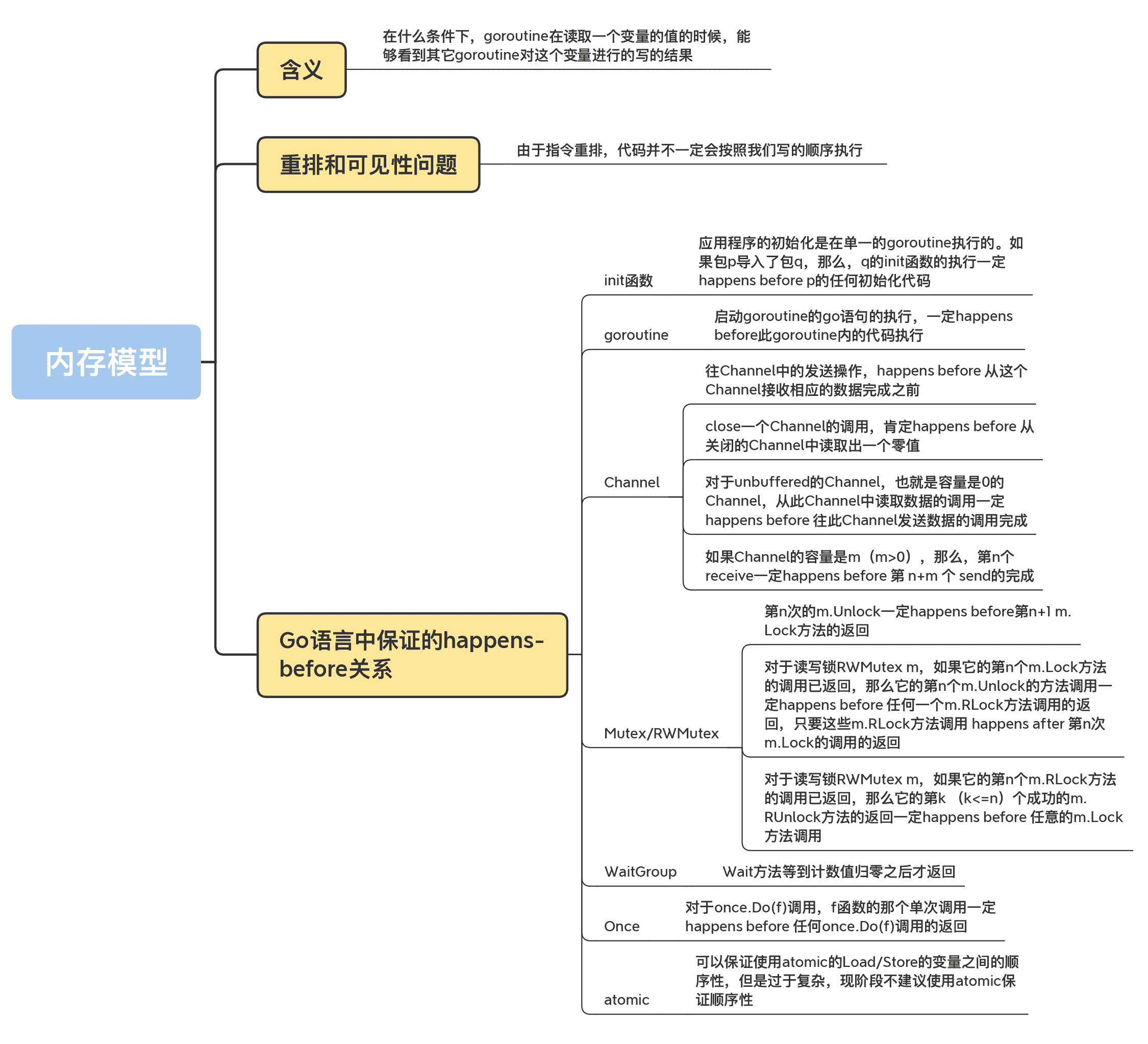
Go 語言中保證的 happens-before 關係
除了單個 goroutine 內部提供的 happens-before 保證,Go 語言中還提供了一些其它的 happens-before 關係的保證,下面我來一個一個介紹下。
init 函式
應用程式的初始化是在單一的 goroutine 執行的。如果包 p 匯入了包 q,那麼,q 的 init 函式的執行一定 happens before p 的任何初始化程式碼。
這裡有一個特殊情況需要你記住:main 函式一定在匯入的包的 init 函式之後執行。
包級別的變數在同一個檔案中是按照宣告順序逐個初始化的,除非初始化它的時候依賴其它的變數。同一個包下的多個檔案,會按照檔名的排列順序進行初始化。這個順序被定義在Go 語言規範中,而不是 Go 的記憶體模型規範中。你可以看看下面的例子中各個變數的值:
var (
a = c + b // == 9
b = f() // == 4
c = f() // == 5
d = 3 // == 5 全部初始化完成後
)
func f() int {
d++
return d
}
具體怎麼對這些變數進行初始化呢?Go 採用的是依賴分析技術。不過,依賴分析技術保證的順序只是針對同一包下的變數,而且,只有引用關係是本包變數、函式和非介面的方法,才能保證它們的順序性。
同一個包下可以有多個 init 函式,但是每個檔案最多隻能有一個 init 函式,多個 init 函式按照它們的檔名順序逐個初始化。
剛剛講的這些都是不同包的 init 函式執行順序,下面我舉一個具體的例子,把這些內容串起來,你一看就明白了。
這個例子是一個 main 程式,它依賴包 p1,包 p1 依賴包 p2,包 p2 依賴 p3。
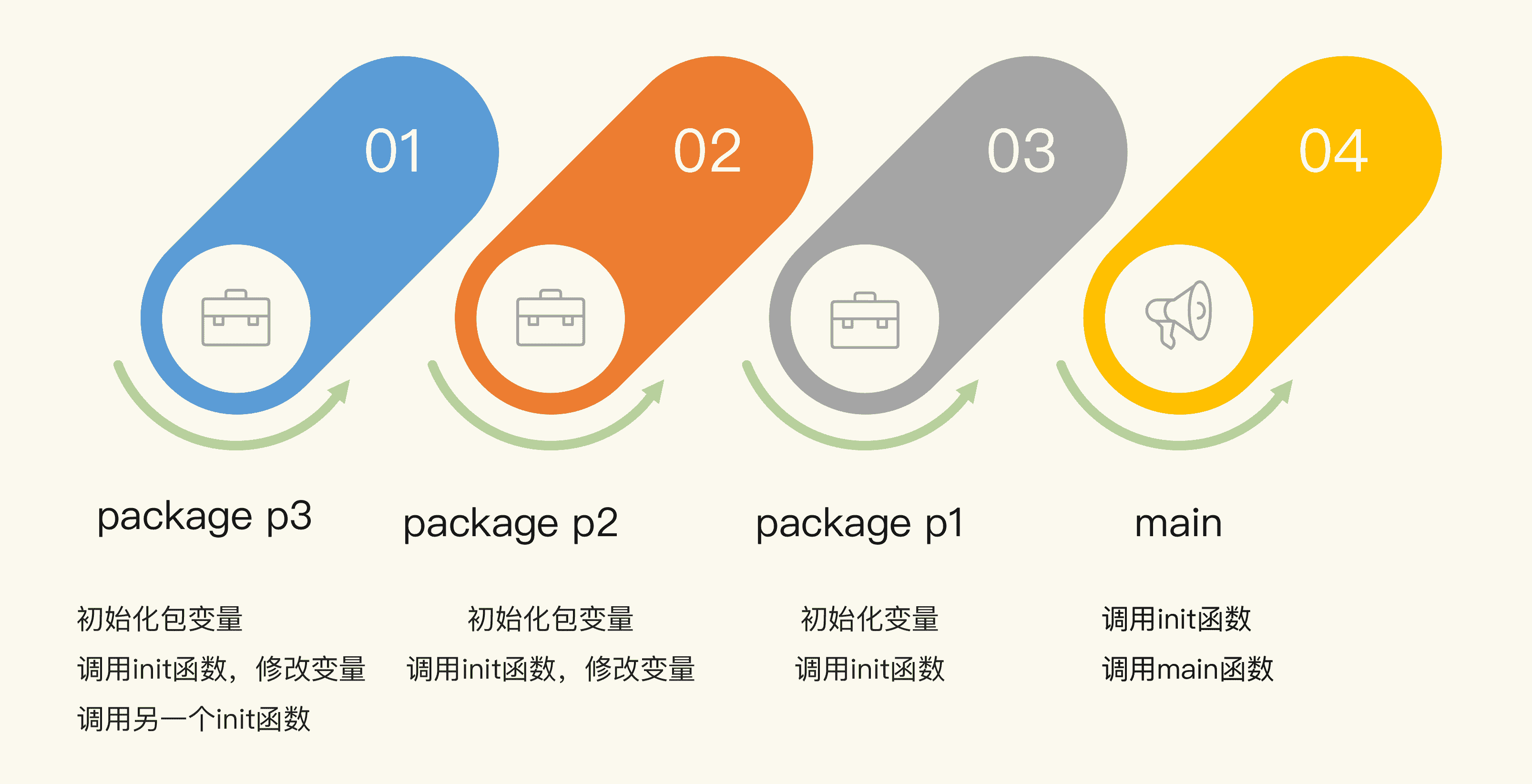
為了追蹤初始化過程,並輸出有意義的日誌,我定義了一個輔助方法,打印出日誌並返回一個用來初始化的整數值:
func Trace(t string, v int) int {
fmt.Println(t, ":", v)
return v
}
包 p3 包含兩個檔案,分別定義了一個 init 函式。第一個檔案中定義了兩個變數,這兩個變數的值還會在 init 函式中進行修改。
我們來分別看下包 p3 的這兩個檔案:
// lib1.go in p3
var V1_p3 = trace.Trace("init v1_p3", 3)
var V2_p3 = trace.Trace("init v2_p3", 3)
func init() {
fmt.Println("init func in p3")
V1_p3 = 300
V2_p3 = 300
}
// lib2.go in p3
func init() {
fmt.Println("another init func in p3")
}
下面再來看看包 p2。包 p2 定義了變數和 init 函式。第一個變數初始化為 2,並在 init 函式中更改為 200。第二個變數是複製的 p3.V2_p3。
var V1_p2 = trace.Trace("init v1_p2", 2)
var V2_p2 = trace.Trace("init v2_p2", p3.V2_p3)
func init() {
fmt.Println("init func in p2")
V1_p2 = 200
}
包 p1 定義了變數和 init 函式。它的兩個變數的值是複製的 p2 對應的兩個變數值。
var V1_p1 = trace.Trace("init v1_p1", p2.V1_p2)
var V2_p1 = trace.Trace("init v2_p1", p2.V2_p2)
func init() {
fmt.Println("init func in p1")
}
main 定義了 init 函式和 main 函式。
func init() {
fmt.Println("init func in main")
}
func main() {
fmt.Println("V1_p1:", p1.V1_p1)
fmt.Println("V2_p1:", p1.V2_p1)
}
執行 main 函式會依次輸出 p3、p2、p1、main 的初始化變數時的日誌(變數初始化時的日誌和 init 函式呼叫時的日誌):
// 包p3的變數初始化
init v1_p3 : 3
init v2_p3 : 3
// p3的init函式
init func in p3
// p3的另一個init函式
another init func in p3
// 包p2的變數初始化
init v1_p2 : 2
init v2_p2 : 300
// 包p2的init函式
init func in p2
// 包p1的變數初始化
init v1_p1 : 200
init v2_p1 : 300
// 包p1的init函式
init func in p1
// 包main的init函式
init func in main
// main函式
V1_p1: 200
V2_p1: 300
下面,我們再來看看 goroutine 對 happens-before 關係的保證情況。
goroutine
首先,我們需要明確一個規則:啟動 goroutine 的 go 語句的執行,一定 happens before 此 goroutine 內的程式碼執行。
根據這個規則,我們就可以知道,如果 go 語句傳入的引數是一個函式執行的結果,那麼,這個函式一定先於 goroutine 內部的程式碼被執行。
我們來看一個例子。在下面的程式碼中,第 8 行 a 的賦值和第 9 行的 go 語句是在同一個 goroutine 中執行的,所以,在主 goroutine 看來,第 8 行肯定 happens before 第 9 行,又由於剛才的保證,第 9 行子 goroutine 的啟動 happens before 第 4 行的變數輸出,那麼,我們就可以推斷出,第 8 行 happens before 第 4 行。也就是說,在第 4 行列印 a 的值的時候,肯定會打印出“hello world”。
var a string
func f() {
print(a)
}
func hello() {
a = "hello, world"
go f()
}
剛剛說的是啟動 goroutine 的情況,goroutine 退出的時候,是沒有任何 happens-before 保證的。所以,如果你想觀察某個 goroutine 的執行效果,你需要使用同步機制建立 happens-before 關係,比如 Mutex 或者 Channel。接下來,我會講 Channel 的 happens-before 的關係保證。
Channel
Channel 是 goroutine 同步交流的主要方法。往一個 Channel 中傳送一條資料,通常對應著另一個 goroutine 從這個 Channel 中接收一條資料。
通用的 Channel happens-before 關係保證有 4 條規則,我分別來介紹下。
第 1 條規則是,往 Channel 中的傳送操作,happens before 從該 Channel 接收相應資料的動作完成之前,即第 n 個 send 一定 happens before 第 n 個 receive 的完成。
var ch = make(chan struct{}, 10) // buffered或者unbuffered
var s string
func f() {
s = "hello, world"
ch <- struct{}{}
}
func main() {
go f()
<-ch
print(s)
}
在這個例子中,s 的初始化(第 5 行)happens before 往 ch 中傳送資料, 往 ch 傳送資料 happens before 從 ch 中讀取出一條資料(第 11 行),第 12 行列印 s 的值 happens after 第 11 行,所以,列印的結果肯定是初始化後的 s 的值“hello world”。
第 2 條規則是,close 一個 Channel 的呼叫,肯定 happens before 從關閉的 Channel 中讀取出一個零值。
還是拿剛剛的這個例子來說,如果你把第 6 行替換成 close(ch),也能保證同樣的執行順序。因為第 11 行從關閉的 ch 中讀取出零值後,第 6 行肯定被呼叫了。
第 3 條規則是,對於 unbuffered 的 Channel,也就是容量是 0 的 Channel,從此 Channel 中讀取資料的呼叫一定 happens before 往此 Channel 傳送資料的呼叫完成。
所以,在上面的這個例子中呢,如果想保持同樣的執行順序,也可以寫成這樣:
var ch = make(chan int)
var s string
func f() {
s = "hello, world"
<-ch
}
func main() {
go f()
ch <- struct{}{}
print(s)
}
如果第 11 行傳送語句執行成功(完畢),那麼根據這個規則,第 6 行(接收)的呼叫肯定發生了(執行完成不完成不重要,重要的是這一句“肯定執行了”),那麼 s 也肯定初始化了,所以一定會打印出“hello world”。
這一條比較晦澀,但是,因為 Channel 是 unbuffered 的 Channel,所以這個規則也成立。
第 4 條規則是,如果 Channel 的容量是 m(m>0),那麼,第 n 個 receive 一定 happens before 第 n+m 個 send 的完成。
前一條規則是針對 unbuffered channel 的,這裡給出了更廣泛的針對 buffered channel 的保證。利用這個規則,我們可以實作訊號量(Semaphore)的併發原語。Channel 的容量相當於可用的資源,傳送一條資料相當於請求訊號量,接收一條資料相當於釋放訊號。關於訊號量這個併發原語,我會在下一講專門給你介紹一下,這裡你只需要知道它可以控制多個資源的併發訪問,就可以了。
Mutex/RWMutex
對於互斥鎖 Mutex m 或者讀寫鎖 RWMutex m,有 3 條 happens-before 關係的保證。
- 第 n 次的 m.Unlock 一定 happens before 第 n+1 m.Lock 方法的返回;
- 對於讀寫鎖 RWMutex m,如果它的第 n 個 m.Lock 方法的呼叫已返回,那麼它的第 n 個 m.Unlock 的方法呼叫一定 happens before 任何一個 m.RLock 方法呼叫的返回,只要這些 m.RLock 方法呼叫 happens after 第 n 次 m.Lock 的呼叫的返回。這就可以保證,只有釋放了持有的寫鎖,那些等待的讀請求才能請求到讀鎖。
- 對於讀寫鎖 RWMutex m,如果它的第 n 個 m.RLock 方法的呼叫已返回,那麼它的第 k (k<=n)個成功的 m.RUnlock 方法的返回一定 happens before 任意的 m.RUnlockLock 方法呼叫,只要這些 m.Lock 方法呼叫 happens after 第 n 次 m.RLock。
讀寫鎖的保證有點繞,我再帶你看看官方的描述:
對於讀寫鎖 l 的 l.RLock 方法呼叫,如果存在一個 n,這次的 l.RLock 呼叫 happens after 第 n 次的 l.Unlock,那麼,和這個 RLock 相對應的 l.RUnlock 一定 happens before 第 n+1 次 l.Lock。意思是,讀寫鎖的 Lock 必須等待既有的讀鎖釋放後才能獲取到。
我再舉個例子。在下面的程式碼中,第 6 行第一次的 Unlock 一定 happens before 第二次的 Lock(第 12 行),所以這也能保證正確地打印出“hello world”。
var mu sync.Mutex
var s string
func foo() {
s = "hello, world"
mu.Unlock()
}
func main() {
mu.Lock()
go foo()
mu.Lock()
print(s)WaitGroup接下來是 WaitGroup 的保證。
對於一個 WaitGroup 例項 wg,在某個時刻 t0 時,它的計數值已經不是零了,假如 t0 時刻之後呼叫了一系列的 wg.Add(n) 或者 wg.Done(),並且只有最後一次呼叫 wg 的計數值變為了 0,那麼,可以保證這些 wg.Add 或者 wg.Done() 一定 happens before t0 時刻之後呼叫的 wg.Wait 方法的返回。
這個保證的通俗說法,就是 Wait 方法等到計數值歸零之後才返回。
Once
我們在第 8 講學過 Once 了,相信你已經很熟悉它的功能了。它提供的保證是:對於 once.Do(f) 呼叫,f 函式的那個單次呼叫一定 happens before 任何 once.Do(f) 呼叫的返回。換句話說,就是函式 f 一定會在 Do 方法返回之前執行。
還是以 hello world 的例子為例,這次我們使用 Once 併發原語實作,可以看下下面的程式碼:
var s string
var once sync.Once
func foo() {
s = "hello, world"
}
func twoprint() {
once.Do(foo)
print(s)
}
第 5 行的執行一定 happens before 第 9 行的返回,所以執行到第 10 行的時候,sd 已經初始化了,所以會正確地列印“hello world”。
最後,我再來說說 atomic 的保證。
atomic
其實,Go 記憶體模型的官方文件並沒有明確給出 atomic 的保證,有一個相關的 issue go# 5045記錄了相關的討論。光看 issue 號,就知道這個討論由來已久了。Russ Cox 想讓 atomic 有一個弱保證,這樣可以為以後留下充足的可擴充套件空間,所以,Go 記憶體模型規範上並沒有嚴格的定義。
對於 Go 1.15 的官方實作來說,可以保證使用 atomic 的 Load/Store 的變數之間的順序性。
在下面的例子中,打印出的 a 的結果總是 1,但是官方並沒有做任何文件上的說明和保證。
依照 Ian Lance Taylor 的說法,Go 核心開發組的成員幾乎沒有關注這個方向上的研究,因為這個問題太複雜,有很多問題需要去研究,所以,現階段還是不要使用 atomic 來保證順序性。
func main() {
var a, b int32 = 0, 0
go func() {
atomic.StoreInt32(&a, 1)
atomic.StoreInt32(&b, 1)
}()
for atomic.LoadInt32(&b) == 0{
runtime.Gosched()
}
fmt.Println(atomic.LoadInt32(&a))
}總結Go 的記憶體模型規範中,一開始有這麼一段話:
If you must read the rest of this document to understand the behavior of your program, you are being too clever.
Don’t be clever.
我來說說我對這句話的理解:你透過學習這節課來理解你的程式的行為是聰明的,但是,不要自作聰明。
謹慎地使用這些保證,能夠讓你的程式按照設想的 happens-before 關係執行,但是不要以為完全理解這些概念和保證,就可以隨意地製造所謂的各種技巧,否則就很容易掉進“坑”裡,而且會給程式碼埋下了很多的“定時炸彈”。
比如,Go 裡面已經有值得信賴的互斥鎖了,如果沒有額外的需求,就不要使用 Channel 創造出自己的互斥鎖。
當然,我也不希望你畏手畏腳地把思想侷限住,我還是建議你去做一些有意義的嘗試,比如使用 Channel 實作訊號量等擴充套件併發原語。
思考題
我們知道,Channel 可以實作互斥鎖,那麼,我想請你思考一下,它是如何利用 happens-before 關係保證鎖的請求和釋放的呢?
歡迎在留言區寫下你的思考和答案,我們一起交流討論。如果你覺得有所收穫,也歡迎你把今天的內容分享給你的朋友或同事。