I. WELCOME
This may be the beginning of a grand adventure. Programming languages encompass a huge space to explore and play in. Plenty of room for your own creations to share with others or just enjoy yourself. Brilliant computer scientists and software engineers have spent entire careers traversing this land without ever reaching the end. If this book is your first entry into the country, welcome.
這也許是一場大冒險的開始。編程語言包含了一個巨大的探索和遊戲空間。在其中,你有足夠的空間與他人分享自己的創作,或者只是自娛自樂。傑出的計算機科學家和軟件工程師窮盡整個職業生涯都在穿越這片土地,卻從未到達終點。如果這是你第一次進入這個國度,歡迎你。
The pages of this book give you a guided tour through some of the world of languages. But before we strap on our hiking boots and venture out, we should familiarize ourselves with the territory. The chapters in this part introduce you to the basic concepts used by programming languages and how they are organized.
本書的內容為你提供了一些語言世界的導覽。但是,在我們穿上登山靴開始冒險之前,我們應該先熟悉一下這片土地。本部分的章節將向你介紹編程語言所使用的基本概念以及它們的組織方式。
We will also get acquainted with Lox, the language we’ll spend the rest of the book implementing (twice). Let’s go!
我們以後還會熟悉Lox,這門語言我們將用本書的其餘部分來實現(兩次)。讓我們開始吧!
1. 前言 Introduction
Fairy tales are more than true: not because they tell us that dragons exist, but because they tell us that dragons can be beaten.
—— Neil Gaiman, Coraline
童話故事是無比真實的:不是因為它告訴我們龍的存在,而是因為它告訴我們龍可以被擊敗。
I’m really excited we’re going on this journey together. This is a book on implementing interpreters for programming languages. It’s also a book on how to design a language worth implementing. It’s the book I wish I had when I first started getting into languages, and it’s the book I’ve been writing in my head for nearly a decade.
我真的很興奮我們能一起踏上這段旅程。這是一本關於為編程語言實現解釋器的書。它也是一本關於如何設計一種值得實現的語言的書。我剛開始接觸編程語言的時候就希望我可以寫出這本書,這本書我在腦子裡已經寫了將近十年了。
In these pages, we will walk step by step through two complete interpreters for a full-featured language. I assume this is your first foray into languages, so I’ll cover each concept and line of code you need to build a complete, usable, fast language implementation.
在本書中,我們將一步一步地介紹一種功能齊全的語言的兩個完整的解釋器實現。我假設這是您第一次涉足編程語言,因此我將介紹構建一個完整、可用、快速的語言所需的每個概念和代碼。
In order to cram two full implementations inside one book without it turning into a doorstop, this text is lighter on theory than others. As we build each piece of the system, I will introduce the history and concepts behind it. I’ll try to get you familiar with the lingo so that if you ever find yourself in a cocktail party full of PL (programming language) researchers, you’ll fit in.
為了在一本書中塞進兩個完整的實現,而且避免這變成一個門檻,本文在理論上比其他文章更輕。在構建系統的每個模塊時,我將介紹它背後的歷史和概念。我會盡力讓您熟悉這些行話,即便您在充滿PL(編程語言)研究人員的雞尾酒會中,也能快速融入其中。
But we’re mostly going to spend our brain juice getting the language up and running. This is not to say theory isn’t important. Being able to reason precisely and formally about syntax and semantics is a vital skill when working on a language. But, personally, I learn best by doing. It’s hard for me to wade through paragraphs full of abstract concepts and really absorb them. But if I’ve coded something, run it, and debugged it, then I get it.
但我們主要還是要花費精力讓這門語言運轉起來。這並不是說理論不重要。在學習一門語言時,能夠對語法和語義進行精確而公式化的推理1是一項至關重要的技能。但是,就我個人而言,我在實踐中學習效果最好。對我來說,要深入閱讀那些充滿抽象概念的段落並真正理解它們太難了。但是,如果我(根據理論)編寫了代碼,運行並調試完成,那麼我就明白了。
That’s my goal for you. I want you to come away with a solid intuition of how a real language lives and breathes. My hope is that when you read other, more theoretical books later, the concepts there will firmly stick in your mind, adhered to this tangible substrate.
這就是我對您的期望。我想讓你們直觀地理解一門真正的語言是如何生活和呼吸的。我希望當你以後閱讀其他理論性更強的書籍時,這些概念會牢牢地留在你的腦海中,依附於這個有形的基礎之上。
1.1 Why Learn This Stuff?
1.1 為什麼要學習這些?
Every introduction to every compiler book seems to have this section. I don’t know what it is about programming languages that causes such existential doubt. I don’t think ornithology books worry about justifying their existence. They assume the reader loves birds and start teaching.
每本編譯器書籍的導言似乎都有這一部分。我不知道到底是編程語言的哪一點讓人產生這樣的質疑。我不認為鳥類學書籍會擔心如何證明自己的存在。它們假定讀者喜歡鳥類,然後開始教學。
But programming languages are a little different. I suppose it is true that the odds of any of us creating a broadly successful general-purpose programming language are slim. The designers of the world’s widely-used languages could fit in a Volkswagen bus, even without putting the pop-top camper up. If joining that elite group was the only reason to learn languages, it would be hard to justify. Fortunately, it isn’t.
但是編程語言有一點不同。我認為,對我們中的任何一個人來說,能夠創建一種廣泛成功的通用編程語言的可能性都很小,這是事實。設計這個世界上被廣泛使用的語言的設計師們,一輛大眾旅遊巴士就能裝得下,甚至不用把頂上的帳篷加上。如果加入這個精英群體是學習語言的唯一原因,那麼就很難證明其合理性。幸運的是,事實並非如此。
1.1.1 Little languages are everywhere
1.1.1 小型語言無處不在
For every successful general-purpose language, there are a thousand successful niche ones. We used to call them “little languages”, but inflation in the jargon economy led today to the name “domain-specific languages”. These are pidgins tailor-built to a specific task. Think application scripting languages, template engines, markup formats, and configuration files.
對於每一種成功的通用語言,都有上千種成功的小眾語言。我們過去稱它們為“小語言”,但術語氾濫的今天它們有了“領域特定語言(即DSL)”的名稱。這些是為特定任務量身定做的洋涇浜語言2,如應用程序腳本語言、模板引擎、標記格式和配置文件。
Almost every large software project needs a handful of these. When you can, it’s good to reuse an existing one instead of rolling your own. Once you factor in documentation, debuggers, editor support, syntax highlighting, and all of the other trappings, doing it yourself becomes a tall order.
幾乎每個大型軟件項目都需要一些這樣的工具。如果可以的話,最好重用現有的工具,而不是自己動手實現。一旦考慮到文檔、調試器、編輯器支持、語法高亮顯示和所有其他可能的障礙,自己實現就成了一項艱鉅的任務。
But there’s still a good chance you’ll find yourself needing to whip up a parser or something when there isn’t an existing library that fits your needs. Even when you are reusing some existing implementation, you’ll inevitably end up needing to debug and maintain it and poke around in its guts.
但是,當現有的庫不能滿足您的需要時,您仍然很有可能發現自己需要一個解析器或其他東西。即使當您重用一些現有的實現時,您也不可避免地需要調試和維護,並在其內部進行探索。
1 . 1 . 2 Languages are great exercise
1.1.2 語言是很好的鍛鍊
Long distance runners sometimes train with weights strapped to their ankles or at high altitudes where the atmosphere is thin. When they later unburden themselves, the new relative ease of light limbs and oxygen-rich air enables them to run farther and faster.
長跑運動員有時會在腳踝上綁上重物,或者在空氣稀薄的高海拔地區進行訓練。當他們卸下自己的負擔以後,輕便的肢體和富氧的空氣帶來了新的相對舒適度,使它們可以跑得更遠,更快。
Implementing a language is a real test of programming skill. The code is complex and performance critical. You must master recursion, dynamic arrays, trees, graphs, and hash tables. You probably use hash tables at least in your day-to-day programming, but how well do you really understand them? Well, after we’ve crafted our own from scratch, I guarantee you will.
實現一門語言是對編程技能的真正考驗。代碼很複雜,而且性能很關鍵。您必須掌握遞歸、動態數組、樹、圖和哈希表。您在日常編程中至少使用過哈希表,但到底您對它們的理解程度有多高呢?嗯,等我們從頭完成我們的作品之後,我相信您會理解的。
While I intend to show you that an interpreter isn’t as daunting as you might believe, implementing one well is still a challenge. Rise to it, and you’ll come away a stronger programmer, and smarter about how you use data structures and algorithms in your day job.
雖然我想說明解釋器並不像您想的那樣令人生畏,但實現一個好的解釋器仍然是一個挑戰。學會了它,您就會成為一個更強大的程序員,並且在日常工作中也能更加聰明地使用數據結構和算法。
1 . 1 . 3 One more reason
1.1.3 另一個原因
This last reason is hard for me to admit, because it’s so close to my heart. Ever since I learned to program as a kid, I felt there was something magical about languages. When I first tapped out BASIC programs one key at a time I couldn’t conceive how BASIC itself was made.
這最後一個原因我很難承認,因為它是很私密的理由。自從我小時候學會編程以來,我就覺得語言有種神奇的力量。當我第一次一個鍵一個鍵地輸入BASIC程序時,我無法想象BASIC語言本身是如何製作出來的。
Later, the mixture of awe and terror on my college friends’ faces when talking about their compilers class was enough to convince me language hackers were a different breed of human—some sort of wizards granted privileged access to arcane arts.
後來,當我的大學朋友們談論他們的編譯器課程時,臉上那種既敬畏又恐懼的表情足以讓我相信,語言黑客是另一種人,某種可以操控奧術的巫師。
It’s a charming image, but it has a darker side. I didn’t feel like a wizard, so I was left thinking I lacked some in-born quality necessary to join the cabal. Though I’ve been fascinated by languages ever since I doodled made up keywords in my school notebook, it took me decades to muster the courage to try to really learn them. That “magical” quality, that sense of exclusivity, excluded me.
這是一個迷人的形象,但它也有黑暗的一面。我感覺自己不像個巫師,所以我認為自己缺乏加入秘社所需的先天品質。 儘管自從我在學校筆記本上拼寫關鍵詞以來,我一直對語言著迷,但我花了數十年的時間鼓起勇氣嘗試真正地學習它們。那種“神奇”的品質,那種排他性的感覺,將我擋在門外。
When I did finally start cobbling together my own little interpreters, I quickly learned that, of course, there is no magic at all. It’s just code, and the people who hack on languages are just people.
當我最終開始拼湊我自己的小解釋器時,我很快意識到,根本就沒有魔法。它只是代碼,而那些玩弄語言的人也只是普通人。
There are a few techniques you don’t often encounter outside of languages, and some parts are a little difficult. But not more difficult than other obstacles you’ve overcome. My hope is that if you’ve felt intimidated by languages, and this book helps you overcome that fear, maybe I’ll leave you just a tiny bit braver than you were before.
有一些技巧您在語言之外不會經常遇到,而且有些部分有點難。但不會比您克服的其他障礙更困難。我希望,如果您對語言感到害怕,而這本書能幫助您克服這種恐懼,也許我會讓您比以前更勇敢一點。
And, who knows, maybe you will make the next great language. Someone has to.
而且,說不準,你也許會創造出下一個偉大的語言,畢竟總要有人做。
1 . 2 How the Book is Organized
1.2 本書的組織方式
This book is broken into three parts. You’re reading the first one now. It’s a couple of chapters to get you oriented, teach you some of the lingo that language hackers use, and introduce you to Lox, the language we’ll be implementing.
這本書分為三個部分。您現在正在讀的是第一部分。這部分用了幾章來讓您進入狀態,教您一些語言黑客使用的行話,並向您介紹我們將要實現的語言Lox。
Each of the other two parts builds one complete Lox interpreter. Within those parts, each chapter is structured the same way. The chapter takes a single language feature, teaches you the concepts behind it, and walks through an implementation.
其他兩個部分則分別構建一個完整的Lox解釋器。在這些部分中,每個章節的結構都是相同的。 每一章節挑選一個語言功能點,教您背後對應的概念,並逐步介紹實現方法。
It took a good bit of trial and error on my part, but I managed to carve up the two interpreters into chapter-sized chunks that build on the previous chapters but require nothing from later ones. From the very first chapter, you’ll have a working program you can run and play with. With each passing chapter, it grows increasingly full-featured until you eventually have a complete language.
我花了不少時間去試錯,但我還是成功地把這兩個解釋器按照章節分成了一些小塊,每一小塊的內容都會建立在前面幾章的基礎上,但不需要後續章節的知識。從第一章開始,你就會有一個可以運行和使用的工作程序。隨著章節的推移,它的功能越來越豐富,直到你最終擁有一門完整的語言。
Aside from copious, scintillating English prose, chapters have a few other delightful facets:
除了大量妙趣橫生的英文段落,章節中還會包含一些其它的驚喜:
1.2.1 The code
1.2.1 代碼
We’re about crafting interpreters, so this book contains real code. Every single line of code needed is included, and each snippet tells you where to insert it in your ever-growing implementation.
本書是關於製作解釋器的,所以其中會包含真正的代碼。所需要的每一行代碼都需要包含在內,而且每個代碼片段都會告知您需要插入到實現代碼中的什麼位置。
Many other language books and language implementations use tools like Lex and Yacc, so-called compiler-compilers that automatically generate some of the source files for an implementation from some higher level description. There are pros and cons to tools like those, and strong opinions—some might say religious convictions—on both sides.
許多其他的語言書籍和語言實現都使用Lex和Yacc3這樣的工具,也就是所謂的編譯器-編譯器,可以從一些更高層次的(語法)描述中自動生成一些實現的源文件。這些工具有利有弊,而且雙方都有強烈的主張--有些人可能將其說成是信仰。
We will abstain from using them here. I want to ensure there are no dark corners where magic and confusion can hide, so we’ll write everything by hand. As you’ll see, it’s not as bad as it sounds and it means you really will understand each line of code and how both interpreters work.
我們這裡不會使用這些工具。我想確保魔法和困惑不會藏在黑暗的角落,所以我們會選擇手寫所有代碼。正如您將看到的,這並沒有聽起來那麼糟糕,因為這意味著您將真正理解每一行代碼以及兩種解釋器的工作方式。
A book has different constraints from the “real world” and so the coding style here might not always reflect the best way to write maintainable production software. If I seem a little cavalier about, say, omitting
privateor declaring a global variable, understand I do so to keep the code easier on your eyes. The pages here aren’t as wide as your IDE and every character counts.
為了寫書,書中代碼和“真實世界”的代碼是有區別的,因此這裡的代碼風格可能並不是編寫可維護的生產型軟件的最佳方式。可能我的某些寫法是不太準確的,比如省略private或者聲明全局變量,請理解我這樣做是為了讓您更容易看懂代碼。書頁不像IDE窗口那麼寬,所以每一個字符都很珍貴。
Also, the code doesn’t have many comments. That’s because each handful of lines is surrounded by several paragraphs of honest-to-God prose explaining it. When you write a book to accompany your program, you are welcome to omit comments too. Otherwise, you should probably use
//a little more than I do.
另外,代碼也不會有太多的註釋。這是因為每一部分代碼前後,都使用了一些真的很簡潔的文字來對其進行解釋。當你寫一本書來配合你的程序時,歡迎你也省略註釋。否則,你可能應該比我使用更多的 //。
While the book contains every line of code and teaches what each means, it does not describe the machinery needed to compile and run the interpreter. I assume you can slap together a makefile or a project in your IDE of choice in order to get the code to run. Those kinds of instructions get out of date quickly, and I want this book to age like XO brandy, not backyard hooch.
雖然這本書包含了每一行代碼,並教授了每一行代碼的含義,但它沒有描述編譯和運行解釋器所需的機制。我假設你可以簡單地拼湊出一個makefile,或者創建一個心儀的IDE中的一個工程,來讓代碼運行起來。 那種類型的說明很快就會過時,我希望這本書能像XO白蘭地一樣醇久,而不是像家釀酒(一樣易過期)。
1.2.2 Snippets
1.2.2 片段
Since the book contains literally every line of code needed for the implementations, the snippets are quite precise. Also, because I try to keep the program in a runnable state even when major features are missing, sometimes we add temporary code that gets replaced in later snippets.
因為這本書包含了實現所需的每一行代碼,所以代碼片段相當精確。此外,即使是在缺少主要功能的時候,我也嘗試將程序保持在可運行狀態。因此我們有時會添加臨時代碼,這些代碼將在後面被其他的代碼片段替換。
A snippet with all the bells and whistles looks like this:
一個完整的代碼片段可能如下所示:

In the center, you have the new code to add. It may have a few faded out lines above or below to show where it goes in the existing surrounding code. There is also a little blurb telling you in which file and where to place the snippet. If that blurb says “replace _ lines”, there is some existing code between the faded lines that you need to remove and replace with the new snippet.
中間是要添加的新代碼。這部分代碼的上面或下面可能有一些淡出的行,以顯示它在周圍代碼中的位置。還會附有一小段介紹,告訴您在哪個文件中以及在哪裡放置代碼片段。如果簡介說要“replace _ lines”,表明在淺色的行之間有一些現有的代碼需要刪除,並替換為新的代碼片段。
1.2.3 Asides
1.2.3 題外話
Asides contain biographical sketches, historical background, references to related topics, and suggestions of other areas to explore. There’s nothing that you need to know in them to understand later parts of the book, so you can skip them if you want. I won’t judge you, but I might be a little sad.
題外話中包含傳記簡介、歷史背景、對相關主題的引用以及對其他要探索的領域的建議。 您無需深入瞭解就可以理解本書的後續部分,因此可以根據需要跳過它們。 我不會批評你,但我可能會有些難過。【注:由於排版原因,在翻譯的時候,將有用的旁白信息作為腳註附在章節之後】
1.2.4 Challenge
1.2.4 挑戰
Each chapter ends with a few exercises. Unlike textbook problem sets which tend to review material you already covered, these are to help you learn more than what’s in the chapter. They force you to step off the guided path and explore on your own. They will make you research other languages, figure out how to implement features, or otherwise get you out of your comfort zone.
每章結尾都會有一些練習題。 不像教科書中的習題集那樣用於回顧已講述的內容,這些習題是為了幫助您學習更多的知識,而不僅僅是本章中的內容。 它們會迫使您走出文章指出的路線,自行探索。 它們將要求您研究其他語言,弄清楚如何實現功能,換句話說,就是使您走出舒適區。
Vanquish the challenges and you’ll come away with a broader understanding and possibly a few bumps and scrapes. Or skip them if you want to stay inside the comfy confines of the tour bus. It’s your book.
克服挑戰,您將獲得更廣泛的理解,也可能遇到一些挫折。 如果您想留在旅遊巴士的舒適區內,也可以跳過它們。 都隨你便4。
1.2.5 Design notes
1.2.5 設計筆記
Most “programming language” books are strictly programming language implementation books. They rarely discuss how one might happen to design the language being implemented. Implementation is fun because it is so precisely defined. We programmers seem to have an affinity for things that are black and white, ones and zeroes.
大多數編程語言書籍都是嚴格意義上的編程語言實現書籍。他們很少討論如何設計正在實現的語言。實現之所以有趣,是因為它的定義是很精確的。我們程序員似乎很喜歡黑白、1和0這樣的事物5。
Personally, I think the world only needs so many implementations of FORTRAN 77. At some point, you find yourself designing a new language. Once you start playing that game, then the softer, human side of the equation becomes paramount. Things like what features are easy to learn, how to balance innovation and familiarity, what syntax is more readable and to whom.
就個人而言,我認為世界只需要這麼多的FORTRAN 77實現。在某個時候,您會發現自己正在設計一種新的語言。 一旦開始這樣做,方程式中較柔和,人性化的一面就變得至關重要。 諸如哪些功能易於學習,如何在創新和熟悉度之間取得平衡,哪種語法更易讀以及對誰有幫助6。
All of that stuff profoundly affects the success of your new language. I want your language to succeed, so in some chapters I end with a “design note”, a little essay on some corner of the human aspect of programming languages. I’m no expert on this—I don’t know if anyone really is—so take these with a large pinch of salt. That should make them tastier food for thought, which is my main aim.
所有這些都會對您的新語言的成功產生深遠的影響。 我希望您的語言取得成功,因此在某些章節中,我以一篇“設計筆記”結尾,這些是關於編程語言的人文方面的一些文章。我並不是這方面的專家——我不確定是否有人真的精通這些,因此,請您在閱讀這些文字的時候仔細評估。這樣的話,這些文字就能成為您思考的食材,這也正是我的目標。
1 . 3 The First Interpreter
1.3 第一個解釋器
We’ll write our first interpreter, jlox, in Java. The focus is on concepts. We’ll write the simplest, cleanest code we can to correctly implement the semantics of the language. This will get us comfortable with the basic techniques and also hone our understanding of exactly how the language is supposed to behave.
我們將用Java編寫第一個解釋器jlox。(這裡的)主要關注點是概念。 我們將編寫最簡單,最乾淨的代碼,以正確實現該語言的語義。 這樣能夠幫助我們熟悉基本技術,並磨練對語言表現形式的確切理解。
Java is a great language for this. It’s high level enough that we don’t get overwhelmed by fiddly implementation details, but it’s still pretty explicit. Unlike scripting languages, there tends to be less complex machinery hiding under the hood, and you’ve got static types to see what data structures you’re working with.
Java是一門很適合這種場景的語言。它的級別足夠高,我們不會被繁瑣的實現細節淹沒,但代碼仍是非常明確的。與腳本語言不同的是,它的底層沒有隱藏太過複雜的機制,你可以使用靜態類型來查看正在處理的數據結構。
I also chose Java specifically because it is an object-oriented language. That paradigm swept the programming world in the 90s and is now the dominant way of thinking for millions of programmers. Odds are good you’re already used to organizing code into classes and methods, so we’ll keep you in that comfort zone.
我選擇Java還有特別的原因,就是因為它是一種面向對象的語言。 這種範式在90年代席捲了整個編程世界,如今已成為數百萬程序員的主流思維方式。 很有可能您已經習慣了將代碼組織到類和方法中,因此我們將讓您在舒適的環境中學習。
While academic language folks sometimes look down on object-oriented languages, the reality is that they are widely used even for language work. GCC and LLVM are written in C++, as are most JavaScript virtual machines. Object-oriented languages are ubiquitous and the tools and compilers for a language are often written in the same language.
雖然學術語言專家有時瞧不起面嚮對象語言,但事實上,它們即使在語言工作中也被廣泛使用。GCC和LLVM是用C++編寫的,大多數JavaScript虛擬機也是這樣。 面向對象的語言無處不在,並且針對該語言的工具和編譯器通常是用同一種語言編寫的7。
And, finally, Java is hugely popular. That means there’s a good chance you already know it, so there’s less for you to learn to get going in the book. If you aren’t that familiar with Java, don’t freak out. I try to stick to a fairly minimal subset of it. I use the diamond operator from Java 7 to make things a little more terse, but that’s about it as far as “advanced” features go. If you know another object-oriented language like C# or C++, you can muddle through.
最後,Java非常流行。 這意味著您很有可能已經瞭解它了,所以你要學習的東西就更少了。 如果您不太熟悉Java,也請不要擔心。 我儘量只使用它的最小子集。我使用Java 7中的菱形運算符使代碼看起來更簡潔,但就“高級”功能而言,僅此而已。 如果您瞭解其它面向對象的語言(例如C#或C++),就沒有問題。
By the end of part II, we’ll have a simple, readable implementation. What we won’t have is a fast one. It also takes advantage of the Java virtual machine’s own runtime facilities. We want to learn how Java itself implements those things.
在第二部分結束時,我們將得到一個簡單易讀的實現。 但是我們得到的不會是一個執行效率高的解釋器。它還是利用了Java虛擬機自身的運行時工具。我們想要學習Java本身是如何實現這些東西的。
1 . 4 The Second Interpreter
1.4 第二個解釋器
So in the next part, we start all over again, but this time in C. C is the perfect language for understanding how an implementation really works, all the way down to the bytes in memory and the code flowing through the CPU.
所以在下一部分,我們將從頭開始,但這一次是用C語言。C語言是理解實現編譯器工作方式的完美語言,一直到內存中的字節和流經CPU的代碼。
A big reason that we’re using C is so I can show you things C is particularly good at, but that does mean you’ll need to be pretty comfortable with it. You don’t have to be the reincarnation of Dennis Ritchie, but you shouldn’t be spooked by pointers either.
我們使用C語言的一個重要原因是,我可以向您展示C語言特別擅長的東西,但這並不意味著您需要非常熟練地使用它。您不必是丹尼斯·裡奇(Dennis Ritchie)的轉世,但也不應被指針嚇倒。
If you aren’t there yet, pick up an introductory book on C and chew through it, then come back here when you’re done. In return, you’ll come away from this book an even stronger C programmer. That’s useful given how many language implementations are written in C: Lua, CPython, and Ruby’s MRI, to name a few.
如果你(對C的掌握)還沒到那一步,找一本關於C的入門書,仔細閱讀,讀完後再回來。作為回報,從這本書中你將成為一個更優秀的C程序員。可以想想有多少語言實現是用C完成的: Lua、CPython和Ruby 的 MRI等,這裡僅舉幾例。
In our C interpreter, clox, we are forced to implement for ourselves all the things Java gave us for free. We’ll write our own dynamic array and hash table. We’ll decide how objects are represented in memory, and build a garbage collector to reclaim it.
在我們的C解釋器clox中8,我們不得不自己實現那些Java免費提供給我們的東西。 我們將編寫自己的動態數組和哈希表。 我們將決定對象在內存中的表示方式,並構建一個垃圾回收器來回收它。
Our Java implementation was focused on being correct. Now that we have that down, we’ll turn to also being fast. Our C interpreter will contain a compiler that translates Lox to an efficient bytecode representation (don’t worry, I’ll get into what that means soon) which it then executes. This is the same technique used by implementations of Lua, Python, Ruby, PHP, and many other successful languages.
我們的Java版實現專注於正確性。 既然我們已經完成了,那麼我們就要變快。 我們的C解釋器將包含一個編譯器9,該編譯器會將Lox轉換為有效的字節碼形式(不用擔心,我很快就會講解這是什麼意思)之後它會執行對應的字節碼。 這與Lua,Python,Ruby,PHP和許多其它成功語言的實現所使用的技術相同。
We’ll even try our hand at benchmarking and optimization. By the end, we’ll have a robust, accurate, fast interpreter for our language, able to keep up with other professional caliber implementations out there. Not bad for one book and a few thousand lines of code.
我們甚至會嘗試進行基準測試和優化。 到最後,我們將為lox語言提供一個強大,準確,快速的解釋器,並能夠不落後於其他專業水平的實現。對於一本書和幾千行代碼來說已經不錯了。
CHALLENGES
習題
1、There are at least six domain-specific languages used in the little system I cobbled together to write and publish this book. What are they?
在我編寫的這個小系統中,至少有六種特定領域語言(DSL),它們是什麼?
2、Get a “Hello, world!” program written and running in Java. Set up whatever Makefiles or IDE projects you need to get it working. If you have a debugger, get comfortable with it and step through your program as it runs.
使用Java編寫並運行一個“Hello, world!”程序,配置一個你需要的makefile或IDE項目讓它跑起來。如果您有調試器,請先熟悉一下,並在程序運行時對代碼逐步調試。
3、Do the same thing for C. To get some practice with pointers, define a doubly-linked list of heap-allocated strings. Write functions to insert, find, and delete items from it. Test them.
對C也進行同樣的操作。為了練習使用指針,可以定義一個堆分配字符串的雙向鏈表。編寫函數以插入,查找和刪除其中的項目。 測試編寫的函數。
DESIGN NOTE: WHAT’S IN A NAME?
設計筆記:名稱是什麼?
One of the hardest challenges in writing this book was coming up with a name for the language it implements. I went through pages of candidates before I found one that worked. As you’ll discover on the first day you start building your own language, naming is deviously hard. A good name satisfies a few criteria:
- It isn’t in use. You can run into all sorts of trouble, legal and social, if you inadvertently step on someone else’s name.
- It’s easy to pronounce. If things go well, hordes of people will be saying and writing your language’s name. Anything longer than a couple of syllables or a handful of letters will annoy them to no end.
- It’s distinct enough to search for. People will Google your language’s name to learn about it, so you want a word that’s rare enough that most results point to your docs. Though, with the amount of AI search engines are packing today, that’s less of an issue. Still, you won’t be doing your users any favors if you name your language “for”.
- It doesn’t have negative connotations across a number of cultures. This is hard to guard for, but it’s worth considering. The designer of Nimrod ended up renaming his language to “Nim” because too many people only remember that Bugs Bunny used “Nimrod” (ironically, actually) as an insult.
If your potential name makes it through that gauntlet, keep it. Don’t get hung up on trying to find an appellation that captures the quintessence of your language. If the names of the world’s other successful languages teach us anything, it’s that the name doesn’t matter much. All you need is a reasonably unique token.
寫這本書最困難的挑戰之一是為它所實現的語言取個名字。我翻了好幾頁的備選名才找到一個合適的。當你某一天開始構建自己的語言時,你就會發現命名是非常困難的。一個好名字要滿足幾個標準:
- 尚未使用。如果您不小心使用了別人的名字,就可能會遇到各種法律和社會上的麻煩。
- 容易發音。如果一切順利,將會有很多人會說和寫您的語言名稱。 超過幾個音節或幾個字母的任何內容都會使他們陷入無休止的煩惱。
- 足夠獨特,易於搜索。人們會Google你的語言的名字來瞭解它,所以你需要一個足夠獨特的單詞,以便大多數搜索結果都會指向你的文檔。不過,隨著人工智能搜索引擎數量的增加,這已經不是什麼大問題了。但是,如果您將語言命名為“ for”,那對用戶基本不會有任何幫助。
- 在多種文化中,都沒有負面的含義。這很難防範,但是值得深思。Nimrod的設計師最終將其語言重命名為“ Nim”,因為太多的人只記得Bugs Bunny使用“ Nimrod”作為一種侮辱(其實是諷刺)。
如果你潛在的名字通過了考驗,就保留它吧。不要糾結於尋找一個能夠抓住你語言精髓的名稱。如果說世界上其他成功的語言的名字教會了我們什麼的話,那就是名字並不重要。您所需要的只是一個相當獨特的標記。
-
靜態類型系統尤其需要嚴格的形式推理。破解類型系統就像證明數學定理一樣。事實證明這並非巧合。 上世紀初,Haskell Curry和William Alvin Howard證明瞭它們是同一枚硬幣的兩個方面:Curry-Howard同構。 ↩
-
pidgins,洋涇浜語言,一種混雜的英語 ↩
-
Yacc是一個工具,它接收語法文件並生成編譯器的源文件,因此它有點像一個輸出“編譯器”的編譯器,在術語中叫作“compiler-compiler”,即編譯器的編譯器。Yacc並不是同類工具中的第一個,這就是為什麼它被命名為“Yacc”—Yet Another Compiler-Compiler(另一個Compiler-Compiler)。後來還有一個類似的工具是Bison,它的名字源於Yacc和yak的發音,是一個雙關語。 ↩
-
警告:挑戰題目通常要求您對正在構建的解釋器進行更改。您需要在代碼副本中實現這些功能。後面的章節都假設你的解釋器處於原始(未解決挑戰題)狀態。 ↩
-
我知道很多語言黑客的職業就基於此。您將一份語言規範塞到他們的門下,等上幾個月,代碼和基準測試結果就出來了。 ↩
-
希望您的新語言不會將對打孔卡寬度的假設硬編碼到語法中。 ↩
-
編譯器以一種語言讀取文件。 翻譯它們,並以另一種語言輸出文件。 您可以使用任何一種語言(包括與目標語言相同的語言)來實現編譯器,該過程稱為“自舉”。你現在還不能使用編譯器本身來編譯你自己的編譯器,但是如果你用其它語言為你的語言寫了一個編譯器,你就可以用那個編譯器編譯一次你的編譯器。現在,您可以使用自己的編譯器的已編譯版本來編譯自身的未來版本,並且可以從另一個編譯器中丟棄最初的已編譯版本。 這就是所謂的“自舉”,通過自己的引導程序將自己拉起來。 ↩
-
我把這個名字讀作“sea-locks”,但是你也可以讀作“clocks”,如果你願意的話可以像希臘人讀“x”那樣將其讀作“clochs”, ↩
-
你以為這只是一本講解釋器的書嗎?它也是一本講編譯器的書。買一送一。 ↩
2.領土地圖 A Map of the Territory
You must have a map, no matter how rough. Otherwise you wander all over the place. In “The Lord of the Rings” I never made anyone go farther than he could on a given day.
——J.R.R. Tolkien
你必須要有一張地圖,無論它是多麼粗糙。否則你就會到處亂逛。在《指環王》中,我從未讓任何人在某一天走得超出他力所能及的範圍。
We don’t want to wander all over the place, so before we set off, let’s scan the territory charted by previous language implementers. It will help us understand where we are going and alternate routes others take.
我們不想到處亂逛,所以在我們開始之前,讓我們先瀏覽一下以前的語言實現者所繪製的領土。它能幫助我們瞭解我們的目的地和其他人採用的備選路線。
First, let me establish a shorthand. Much of this book is about a language’s implementation, which is distinct from the language itself in some sort of Platonic ideal form. Things like “stack”, “bytecode”, and “recursive descent”, are nuts and bolts one particular implementation might use. From the user’s perspective, as long as the resulting contraption faithfully follows the language’s specification, it’s all implementation detail.
首先,我先做個簡單說明。本書的大部分內容都是關於語言的實現,它與語言本身這種柏拉圖式的理想形式有所不同。諸如“堆疊”,“位元組碼”和“遞迴下降”之類的東西是某個特定實現中可能使用的基本要素。從使用者的角度來說,只要最終產生的裝置能夠忠實地遵循語言規範,這些都是東西不過是他們不關心的實現細節罷了。
We’re going to spend a lot of time on those details, so if I have to write “language implementation” every single time I mention them, I’ll wear my fingers off. Instead, I’ll use “language” to refer to either a language or an implementation of it, or both, unless the distinction matters.
我們將會花很多時間在這些細節上,所以如果我每次提及的時候都寫“語言實現”,我的手指都會被磨掉。相反,除非有重要的區別,否則我將使用“語言”來指代一種語言或該語言的一種實現,或兩者皆有。
2 . 1 The Parts of a Language
2.1 語言的各部分
Engineers have been building programming languages since the Dark Ages of computing. As soon as we could talk to computers, we discovered doing so was too hard, and we enlisted their help. I find it fascinating that even though today’s machines are literally a million times faster and have orders of magnitude more storage, the way we build programming languages is virtually unchanged.
自計算機的黑暗時代以來,工程師們就一直在構建程式語言。當我們可以和計算機對話的時候,我們發現這樣做太難了,於是我們尋求電腦的幫助。我覺得很有趣的是,即使今天的機器確實快了一百萬倍,儲存空間也大了幾個數量級,但我們構建程式語言的方式幾乎沒有改變。
Though the area explored by language designers is vast, the trails they’ve carved through it are few. Not every language takes the exact same path—some take a shortcut or two—but otherwise they are reassuringly similar from Rear Admiral Grace Hopper’s first COBOL compiler all the way to some hot new transpile-to-JavaScript language whose “documentation” consists entirely of a single poorly-edited README in a Git repository somewhere.
儘管語言設計師所探索的領域遼闊,但他們往往都走到相似的幾條路上。 並非每種語言都採用完全相同的路徑(有些會採用一種或兩種捷徑),但除此之外,從海軍少將Grace Hopper的第一個COBOL編譯器,一直到一些熱門的可以轉譯到JavaScript的語言(JS的 "文件 "甚至完全是由Git倉庫中一個編輯得很差的README組成的1),都呈現出相似的特徵,這令人十分欣慰。
I visualize the network of paths an implementation may choose as climbing a mountain. You start off at the bottom with the program as raw source text, literally just a string of characters. Each phase analyzes the program and transforms it to some higher-level representation where the semantics—what the author wants the computer to do—becomes more apparent.
我把一個語言實現可能選擇的路徑網路類比為爬山。你從最底層開始,程式是原始的源文字,實際上只是一串字元。每個階段都會對程式進行分析,並將其轉換為更高層次的表現形式,從而使語義(作者希望計算機做什麼)變得更加明顯。
Eventually we reach the peak. We have a bird’s-eye view of the users’s program and can see what their code means. We begin our descent down the other side of the mountain. We transform this highest-level representation down to successively lower-level forms to get closer and closer to something we know how to make the CPU actually execute.
最終我們達到了峰頂。我們可以鳥瞰使用者的程式,可以看到他們的程式碼含義是什麼。我們開始從山的另一邊下山。我們將這個最高階的表示形式轉化為連續的較低階別的形式,從而越來越接近我們所知道的如何讓CPU真正執行的形式。

Let’s trace through each of those trails and points of interest. Our journey begins on the left with the bare text of the user’s source code:
讓我們追隨著這一條條路徑和點前進吧。我們的旅程從左邊的使用者原始碼的純文字開始:

2.1.1 Scanning
2.1.1 掃描
The first step is scanning, also known as lexing, or (if you’re trying to impress someone) lexical analysis. They all mean pretty much the same thing. I like “lexing” because it sounds like something an evil supervillain would do, but I’ll use “scanning” because it seems to be marginally more commonplace.
第一步是掃描,也就是所謂的詞法分析 ( lexing 或者強調寫法 lexical analysis )。掃描和詞法分析的意思相近。我喜歡詞法分析這個描述,因為這聽起來像是一個邪惡的超級大壞蛋會做的事情,但我還是用掃描,因為它似乎更常見一些。
A scanner (or lexer) takes in the linear stream of characters and chunks them together into a series of something more akin to “words”. In programming languages, each of these words is called a token. Some tokens are single characters, like
(and,. Others may be several characters long, like numbers (123), string literals ("hi!"), and identifiers (min).
掃描器(或詞法解析器)接收線性字元流,並將它們切分成一系列更類似於“單詞”的東西。在程式語言中,這些詞的每一個都被稱為詞法單元。有些詞法單元是單個字元,比如(和 ,。其他的可能是幾個字元長的,比如數字(123)、字串字元("hi!")和識別符號(min)。
Some characters in a source file don’t actually mean anything. Whitespace is often insignificant and comments, by definition, are ignored by the language. The scanner usually discards these, leaving a clean sequence of meaningful tokens.
原始檔中的一些字元實際上沒有任何意義。空格通常是無關緊要的,而註釋,從定義就能看出來,會被變成語言忽略。掃描器通常會丟棄這些字元,留下一個乾淨的有意義的詞法單元序列。
![[var] [average] [=] [(] [min] [+] [max] [)] [/] [2] [;]](2.%E9%A0%98%E5%9C%9F%E5%9C%B0%E5%9C%96/tokens.png)
2.1.2 Parsing
2.1.2 語法分析
The next step is parsing. This is where our syntax gets a grammar—the ability to compose larger expressions and statements out of smaller parts. Did you ever diagram sentences in English class? If so, you’ve done what a parser does, except that English has thousands and thousands of “keywords” and an overflowing cornucopia of ambiguity. Programming languages are much simpler.
下一步是解析。 這就是我們從句法中得到語法的地方——語法能夠將較小的部分組成較大的表示式和語句。你在英語課上做過語法圖解嗎?如果有,你就做了解析器所做的事情,區別在於,英語中有成千上萬的“關鍵字”和大量的歧義,而程式語言要簡單得多。
A parser takes the flat sequence of tokens and builds a tree structure that mirrors the nested nature of the grammar. These trees have a couple of different names—“parse tree” or “abstract syntax tree”—depending on how close to the bare syntactic structure of the source language they are. In practice, language hackers usually call them “syntax trees”, “ASTs”, or often just “trees”.
解析器將扁平的詞法單元序列轉化為樹形結構,樹形結構能更好地反映語法的巢狀本質。這些樹有兩個不同的名稱:解析樹或抽象語法樹,這取決於它們與源語言的語法結構有多接近。在實踐中,語言駭客通常稱它們為“語法樹”、“AST”,或者乾脆直接說“樹”。

Parsing has a long, rich history in computer science that is closely tied to the artificial intelligence community. Many of the techniques used today to parse programming languages were originally conceived to parse human languages by AI researchers who were trying to get computers to talk to us.
解析在電腦科學中有著悠久而豐富的歷史,它與人工智慧界有著密切的聯絡。今天用於解析程式語言的許多技術最初被人工智慧研究人員用於解析人類語言,人工智慧研究人員試圖透過這些技術讓計算機能與我們對話。
It turns out human languages are too messy for the rigid grammars those parsers could handle, but they were a perfect fit for the simpler artificial grammars of programming languages. Alas, we flawed humans still manage to use those simple grammars incorrectly, so the parser’s job also includes letting us know when we do by reporting syntax errors.
事實證明,人類語言對於只能處理僵化語法的解析器來說太混亂了,但面對程式語言這種簡單的人造語法時,解析器表現得十分合適。唉,可惜我們這些有缺陷的人類在使用這些簡單的語法時,仍然會不停地出錯,因此解析器的工作還包括透過報告語法錯誤讓我們知道出錯了。
2 . 1 . 3 Static analysis
2.1.3 靜態分析
The first two stages are pretty similar across all implementations. Now, the individual characteristics of each language start coming into play. At this point, we know the syntactic structure of the code—things like which expressions are nested in which others—but we don’t know much more than that.
在所有實現中,前兩個階段都非常相似。 現在,每種語言的個性化特徵開始發揮作用。 至此,我們知道了程式碼的語法結構(諸如哪些表示式巢狀在其他表示式中)之類的東西,但是我們知道的也就僅限於此了。
In an expression like
a + b, we know we are addingaandb, but we don’t know what those names refer to. Are they local variables? Global? Where are they defined?
在a + b這樣的表示式中,我們知道我們要把a和b相加,但我們不知道這些名字指的是什麼。它們是區域性變數嗎?全域性變數?它們在哪裡被定義?
The first bit of analysis that most languages do is called binding or resolution. For each identifier we find out where that name is defined and wire the two together. This is where scope comes into play—the region of source code where a certain name can be used to refer to a certain declaration.
大多數語言所做的第一點分析叫做繫結或決議。對於每一個識別符號,我們都要找出定義該名稱的地方,並將兩者連線起來。這就是作用域的作用——在這個原始碼區域中,某個名字可以用來引用某個宣告。
If the language is statically typed, this is when we type check. Once we know where
aandbare declared, we can also figure out their types. Then if those types don’t support being added to each other, we report a type error.
如果語言是靜態型別的,這就是我們進行型別檢查的時機。一旦我們知道了a和b的宣告位置,我們也可以弄清楚它們的型別。然後如果這些型別不支援相加,我們就會報告一個型別錯誤2。
Take a deep breath. We have attained the summit of the mountain and a sweeping view of the user’s program. All this semantic insight that is visible to us from analysis needs to be stored somewhere. There are a few places we can squirrel it away:
- Often, it gets stored right back as attributes on the syntax tree itself—extra fields in the nodes that aren’t initialized during parsing but get filled in later.
- Other times, we may store data in a look-up table off to the side. Typically, the keys to this table are identifiers—names of variables and declarations. In that case, we call it a symbol table and the values it associates with each key tell us what that identifier refers to.
- The most powerful bookkeeping tool is to transform the tree into an entirely new data structure that more directly expresses the semantics of the code. That’s the next section.
深吸一口氣。 我們已經到達了山頂,並對使用者的程式有了全面的瞭解。從分析中可見的所有語義資訊都需要儲存在某個地方。我們可以把它儲存在幾個地方:
- 通常,它會被直接儲存在語法樹本身的屬性中——屬性是節點中的額外欄位,這些欄位在解析時不會初始化,但在稍後會進行填充。
- 有時,我們可能會將資料儲存在外部的查詢表中。 通常,該表的關鍵字是識別符號,即變數和宣告的名稱。 在這種情況下,我們稱其為符號表,並且其中與每個鍵關聯的值告訴我們該識別符號所指的是什麼。
- 最強大的記錄工具是將樹轉化為一個全新的資料結構,更直接地表達程式碼的語義。這是下一節的內容。
Everything up to this point is considered the front end of the implementation. You might guess everything after this is the back end, but no. Back in the days of yore when “front end” and “back end” were coined, compilers were much simpler. Later researchers invented new phases to stuff between the two halves. Rather than discard the old terms, William Wulf and company lumped them into the charming but spatially paradoxical name middle end.
到目前為止,所有內容都被視為實現的前端。 你可能會猜至此以後是後端,其實並不是。 在過去的年代,當“前端”和“後端”被創造出來時,編譯器要簡單得多。 後來,研究人員在兩個半部之間引入了新階段。 威廉·沃爾夫(William Wulf)和他的同伴沒有放棄舊術語,而是新添加了一個迷人但有點自相矛盾的名稱“中端”。
2 . 1 . 4 Intermediate representations
2.1.4 中間碼
You can think of the compiler as a pipeline where each stage’s job is to organize the data representing the user’s code in a way that makes the next stage simpler to implement. The front end of the pipeline is specific to the source language the program is written in. The back end is concerned with the final architecture where the program will run.
你可以把編譯器看成是一條流水線,每個階段的工作是把代表使用者程式碼的資料組織起來,使下一階段的實現更加簡單。管道的前端是針對程式所使用的源語言編寫的。後端關注的是程式執行的最終架構。
In the middle, the code may be stored in some intermediate representation (or IR) that isn’t tightly tied to either the source or destination forms (hence “intermediate”). Instead, the IR acts as an interface between these two languages.
在中間階段,程式碼可能被儲存在一些中間程式碼(intermediate representation, 也叫IR)中,這些中間程式碼與原始檔或目的檔案形式都沒有緊密的聯絡(因此叫作 "中間")。相反,IR充當了這兩種語言之間的介面3。
This lets you support multiple source languages and target platforms with less effort. Say you want to implement Pascal, C and Fortran compilers and you want to target x86, ARM, and, I dunno, SPARC. Normally, that means you’re signing up to write nine full compilers: Pascal→x86, C→ARM, and every other combination.
這可以讓你更輕鬆地支援多種源語言和目標平臺。假設你想在x86、ARM、SPARC 平臺上實現Pascal、C和Fortran編譯器。通常情況下,這意味著你需要寫九個完整的編譯器:Pascal→x86,C→ARM,以及其他各種組合4。
A shared intermediate representation reduces that dramatically. You write one front end for each source language that produces the IR. Then one back end for each target architecture. Now you can mix and match those to get every combination.
一個共享的中間程式碼可以大大減少這種情況。你為每個產生IR的源語言寫一個前端。然後為每個目標平臺寫一個後端。現在,你可以將這些混搭起來,得到每一種組合。
There’s another big reason we might want to transform the code into a form that makes the semantics more apparent…
我們希望將程式碼轉化為某種語義更加明確的形式,還有一個重要的原因是。。。
2 . 1 . 5 Optimization
2.1.5 最佳化
Once we understand what the user’s program means, we are free to swap it out with a different program that has the same semantics but implements them more efficiently—we can optimize it.
一旦我們理解了使用者程式的含義,我們就可以自由地用另一個具有相同語義但實現效率更高的程式來交換它——我們可以對它進行最佳化。
A simple example is constant folding: if some expression always evaluates to the exact same value, we can do the evaluation at compile time and replace the code for the expression with its result. If the user typed in:
一個簡單的例子是常量摺疊:如果某個表示式求值得到的始終是完全相同的值,我們可以在編譯時進行求值,並用其結果替換該表示式的程式碼。 如果使用者輸入:
pennyArea = 3.14159 * (0.75 / 2) * (0.75 / 2);
We can do all of that arithmetic in the compiler and change the code to:
我們可以在編譯器中完成所有的算術運算,並將程式碼更改為:
pennyArea = 0.4417860938;
Optimization is a huge part of the programming language business. Many language hackers spend their entire careers here, squeezing every drop of performance they can out of their compilers to get their benchmarks a fraction of a percent faster. It can become a sort of obsession.
最佳化是程式語言業務的重要組成部分。許多語言駭客把他們的整個職業生涯都花在了這裡,竭盡所能地從他們的編譯器中擠出每一點效能,以使他們的基準測試速度提高百分之幾。有的時候這也會變成一種痴迷, 無法自拔。
We’re mostly going to hop over that rathole in this book. Many successful languages have surprisingly few compile-time optimizations. For example, Lua and CPython generate relatively unoptimized code, and focus most of their performance effort on the runtime.
我們在本書中通常會跳過這些棘手問題。令人驚訝的是許多成功的語言只有很少的編譯期最佳化。 例如,Lua和CPython生成沒怎麼最佳化過的程式碼,並將其大部分效能工作集中在執行時上5。
2 . 1 . 6 Code generation
2.1.6 程式碼生成
We have applied all of the optimizations we can think of to the user’s program. The last step is converting it to a form the machine can actually run. In other words generating code (or code gen), where “code” here usually refers to the kind of primitive assembly-like instructions a CPU runs and not the kind of “source code” a human might want to read.
我們已經將所有可以想到的最佳化應用到了使用者程式中。 最後一步是將其轉換為機器可以實際執行的形式。 換句話說,生成程式碼(或程式碼生成),這裡的“程式碼”通常是指CPU執行的類似於彙編的原始指令,而不是人類可能想要閱讀的“原始碼”。
Finally, we are in the back end, descending the other side of the mountain. From here on out, our representation of the code becomes more and more primitive, like evolution run in reverse, as we get closer to something our simple-minded machine can understand.
最後,我們到了後端,從山的另一側開始向下。 從現在開始,隨著我們越來越接近於思維簡單的機器可以理解的東西,我們對程式碼的表示變得越來越原始,就像逆向進化。
We have a decision to make. Do we generate instructions for a real CPU or a virtual one? If we generate real machine code, we get an executable that the OS can load directly onto the chip. Native code is lightning fast, but generating it is a lot of work. Today’s architectures have piles of instructions, complex pipelines, and enough historical baggage to fill a 747’s luggage bay.
我們需要做一個決定。 我們是為真實CPU還是虛擬CPU生成指令? 如果我們生成真實的機器程式碼,則會得到一個可執行檔案,作業系統可以將其直接載入到晶片上。 原生程式碼快如閃電,但生成它需要大量工作。 當今的體系結構包含大量指令,複雜的管線和足夠塞滿一架747行李艙的歷史包袱。
Speaking the chip’s language also means your compiler is tied to a specific architecture. If your compiler targets x86 machine code, it’s not going to run on an ARM device. All the way back in the 60s, during the Cambrian explosion of computer architectures, that lack of portability was a real obstacle.
使用晶片的語言也意味著你的編譯器是與特定的架構相繫結的。如果你的編譯器以x86機器程式碼為目標,那麼它就無法在ARM裝置上執行。追朔到上世紀60年代計算機體系結構 “寒武紀大爆發” 期間,這種缺乏可移植性的情況是一個真正的障礙6。
To get around that, hackers like Martin Richards and Niklaus Wirth, of BCPL and Pascal fame, respectively, made their compilers produce virtual machine code. Instead of instructions for some real chip, they produced code for a hypothetical, idealized machine. Wirth called this “p-code” for “portable”, but today, we generally call it bytecode because each instruction is often a single byte long.
為瞭解決這個問題,專家開始讓他們的編譯器生成虛擬機器程式碼,包括BCPL的設計者Martin Richards以及Pascal設計者Niklaus Wirth。他們不是為真正的晶片編寫指令,而是為一個假設的、理想化的機器編寫程式碼。Wirth稱這種p-code為“可移植程式碼”,但今天,我們通常稱它為位元組碼,因為每條指令通常都是一個位元組長。
These synthetic instructions are designed to map a little more closely to the language’s semantics, and not be so tied to the peculiarities of any one computer architecture and its accumulated historical cruft. You can think of it like a dense, binary encoding of the language’s low-level operations.
這些合成指令的設計是為了更緊密地對映到語言的語義上,而不必與任何一個計算機體系結構的特性和它積累的歷史錯誤繫結在一起。你可以把它想象成語言底層操作的密集二進位制編碼。
2 . 1 . 7 Virtual machine
2.1.7 虛擬機器
If your compiler produces bytecode, your work isn’t over once that’s done. Since there is no chip that speaks that bytecode, it’s your job to translate. Again, you have two options. You can write a little mini-compiler for each target architecture that converts the bytecode to native code for that machine. You still have to do work for each chip you support, but this last stage is pretty simple and you get to reuse the rest of the compiler pipeline across all of the machines you support. You’re basically using your bytecode as an intermediate representation.
如果你的編譯器產生了位元組碼,你的工作還沒有結束。因為沒有晶片可以解析這些位元組碼,因此你還需要進行翻譯。同樣,你有兩個選擇。你可以為每個目標體系結構編寫一個小型編譯器,將位元組碼轉換為該機器的本機程式碼7。你仍然需要針對你支援的每個晶片做一些工作,但最後這個階段非常簡單,你可以在你支援的所有機器上重複使用編譯器流水線的其餘部分。你基本上是把你的位元組碼作為一種中間程式碼。
Or you can write a virtual machine (VM), a program that emulates a hypothetical chip supporting your virtual architecture at runtime. Running bytecode in a VM is slower than translating it to native code ahead of time because every instruction must be simulated at runtime each time it executes. In return, you get simplicity and portability. Implement your VM in, say, C, and you can run your language on any platform that has a C compiler. This is how the second interpreter we build in this book works.
或者,你可以編寫虛擬機器(VM)8,該程式可在執行時模擬支援虛擬架構的虛擬晶片。在虛擬機器中執行位元組碼比提前將其翻譯成原生代碼要慢,因為每條指令每次執行時都必須在執行時模擬。作為回報,你得到的是簡單性和可移植性。用比如說C語言實現你的虛擬機器,你就可以在任何有C編譯器的平臺上執行你的語言。這就是我們在本書中構建的第二個直譯器的工作原理。
2 . 1 . 8 Runtime
2.1.8 執行時
We have finally hammered the user’s program into a form that we can execute. The last step is running it. If we compiled it to machine code, we simply tell the operating system to load the executable and off it goes. If we compiled it to bytecode, we need to start up the VM and load the program into that.
我們終於將使用者程式錘鍊成可以執行的形式。最後一步是執行它。如果我們將其編譯為機器碼,我們只需告訴作業系統載入可執行檔案,然後就可以運行了。如果我們將它編譯成位元組碼,我們需要啟動VM並將程式載入到其中。
In both cases, for all but the basest of low-level languages, we usually need some services that our language provides while the program is running. For example, if the language automatically manages memory, we need a garbage collector going in order to reclaim unused bits. If our language supports “instance of” tests so you can see what kind of object you have, then we need some representation to keep track of the type of each object during execution.
在這兩種情況下,除了最基本的底層語言外,我們通常需要我們的語言在程式執行時提供一些服務。例如,如果語言自動管理記憶體,我們需要一個垃圾收集器去回收未使用的位元位。如果我們的語言支援用 "instance of "測試我們擁有什麼型別的物件,那麼我們就需要一些表示方法來跟蹤執行過程中每個物件的型別。
All of this stuff is going at runtime, so it’s called, appropriately, the runtime. In a fully compiled language, the code implementing the runtime gets inserted directly into the resulting executable. In, say, Go, each compiled application has its own copy of Go’s runtime directly embedded in it. If the language is run inside an interpreter or VM, then the runtime lives there. This is how most implementations of languages like Java, Python, and JavaScript work.
所有這些東西都是在執行時進行的,所以它被恰當地稱為,執行時。在一個完全編譯的語言中,實現執行時的程式碼會直接插入到生成的可執行檔案中。比如說,在Go中,每個編譯後的應用程式都有自己的一份Go的執行時副本直接嵌入其中。如果語言是在直譯器或虛擬機器內執行,那麼執行時將駐留於虛擬機器中。這也就是Java、Python和JavaScript等大多數語言實現的工作方式。
2 . 2 Shortcuts and Alternate Routes
2.2 捷徑和備選路線
That’s the long path covering every possible phase you might implement. Many languages do walk the entire route, but there are a few shortcuts and alternate paths.
這是一條漫長的道路,涵蓋了你要實現的每個可能的階段。許多語言的確走完了整條路線,但也有一些捷徑和備選路徑。
2 . 2 . 1 Single-pass compilers
2.2.1 單遍編譯器
Some simple compilers interleave parsing, analysis, and code generation so that they produce output code directly in the parser, without ever allocating any syntax trees or other IRs. These single-pass compilers restrict the design of the language. You have no intermediate data structures to store global information about the program, and you don’t revisit any previously parsed part of the code. That means as soon as you see some expression, you need to know enough to correctly compile it.
一些簡單的編譯器將解析、分析和程式碼生成交織在一起,這樣它們就可以直接在解析器中生成輸出程式碼,而無需分配任何語法樹或其他IR。這些單遍編譯器限制了語言的設計。你沒有中間資料結構來儲存程式的全域性資訊,也不會重新訪問任何之前解析過的程式碼部分。 這意味著,一旦你看到某個表示式,就需要足夠的知識來正確地對其進行編譯9。
Pascal and C were designed around this limitation. At the time, memory was so precious that a compiler might not even be able to hold an entire source file in memory, much less the whole program. This is why Pascal’s grammar requires type declarations to appear first in a block. It’s why in C you can’t call a function above the code that defines it unless you have an explicit forward declaration that tells the compiler what it needs to know to generate code for a call to the later function.
Pascal和C語言就是圍繞這個限制而設計的。在當時,記憶體非常珍貴,一個編譯器可能連整個原始檔都無法存放在記憶體中,更不用說整個程式了。這也是為什麼Pascal的語法要求型別宣告要先出現在一個塊中。這也是為什麼在C語言中,你不能在定義函式的程式碼上面呼叫函式,除非你有一個明確的前向宣告,告訴編譯器它需要知道什麼,以便生成呼叫後面函式的程式碼。
2 . 2 . 2 Tree-walk interpreters
2.2.2 樹遍歷直譯器
Some programming languages begin executing code right after parsing it to an AST (with maybe a bit of static analysis applied). To run the program, the interpreter traverses the syntax tree one branch and leaf at a time, evaluating each node as it goes.
有些程式語言在將程式碼解析為AST後就開始執行程式碼(可能應用了一點靜態分析)。為了執行程式,直譯器每次都會遍歷語法樹的一個分支和葉子,並在執行過程中計算每個節點。
This implementation style is common for student projects and little languages, but is not widely used for general-purpose languages since it tends to be slow. Some people use “interpreter” to mean only these kinds of implementations, but others define that word more generally, so I’ll use the inarguably explicit “tree-walk interpreter” to refer to these. Our first interpreter rolls this way.
這種實現風格在學生專案和小型語言中很常見,但在通用語言中並不廣泛使用,因為它往往很慢。有些人使用“直譯器”僅指這類實現,但其他人對“直譯器”一詞的定義更寬泛,因此我將使用沒有歧義的“樹遍歷直譯器”來指代這些實現。我們的第一個直譯器就是這樣工作的10。
2 . 2 . 3 Transpilers
2.2.3 轉譯器
Writing a complete back end for a language can be a lot of work. If you have some existing generic IR to target, you could bolt your front end onto that. Otherwise, it seems like you’re stuck. But what if you treated some other source language as if it were an intermediate representation?
為一種語言編寫一個完整的後端可能需要大量的工作。 如果你有一些現有的通用IR作為目標,則可以將前端轉換到該IR上。 否則,你可能會陷入困境。 但是,如果你將某些其他源語言視為中間程式碼,該怎麼辦?
You write a front end for your language. Then, in the back end, instead of doing all the work to lower the semantics to some primitive target language, you produce a string of valid source code for some other language that’s about as high level as yours. Then, you use the existing compilation tools for that language as your escape route off the mountain and down to something you can execute.
你需要為你的語言編寫一個前端。然後,在後端,你可以生成一份與你的語言級別差不多的其他語言的有效原始碼字串,而不是將所有程式碼降低到某個原始目標語言的語義。然後,你可以使用該語言現有的編譯工具作為逃離大山的路徑,得到某些可執行的內容。
They used to call this a source-to-source compiler or a transcompiler. After the rise of languages that compile to JavaScript in order to run in the browser, they’ve affected the hipster sobriquet transpiler.
人們過去稱之為源到源編譯器或轉換編譯器11。隨著那些為了在瀏覽器中執行而編譯成JavaScript的各類語言的興起,它們有了一個時髦的名字——轉譯器。
While the first transcompiler translated one assembly language to another, today, most transpilers work on higher-level languages. After the viral spread of UNIX to machines various and sundry, there began a long tradition of compilers that produced C as their output language. C compilers were available everywhere UNIX was and produced efficient code, so targeting C was a good way to get your language running on a lot of architectures.
雖然第一個編譯器是將一種組合語言翻譯成另一種組合語言,但現今,大多數編譯器都適用於高階語言。在UNIX廣泛執行在各種各樣的機器上之後,編譯器開始長期以C作為輸出語言。C編譯器在UNIX存在的地方都可以使用,並能生成有效的程式碼,因此,以C為目標是讓語言在許多體系結構上執行的好方法。
Web browsers are the “machines” of today, and their “machine code” is JavaScript, so these days it seems almost every language out there has a compiler that targets JS since that’s the main way to get your code running in a browser.
Web瀏覽器是今天的 "機器",它們的 "機器程式碼 "是JavaScript,所以現在似乎幾乎所有的語言都有一個以JS為目標的編譯器,因為這是讓你的程式碼在瀏覽器中執行的主要方式12。
The front end—scanner and parser—of a transpiler looks like other compilers. Then, if the source language is only a simple syntactic skin over the target language, it may skip analysis entirely and go straight to outputting the analogous syntax in the destination language.
轉譯器的前端(掃描器和解析器)看起來跟其他編譯器相似。 然後,如果源語言只是在目標語言在語法方面的換皮版本,則它可能會完全跳過分析,並直接輸出目標語言中的類似語法。
If the two languages are more semantically different, then you’ll see more of the typical phases of a full compiler including analysis and possibly even optimization. Then, when it comes to code generation, instead of outputting some binary language like machine code, you produce a string of grammatically correct source (well, destination) code in the target language.
如果兩種語言的語義差異較大,那麼你就會看到完整編譯器的更多典型階段,包括分析甚至最佳化。然後,在程式碼生成階段,無需輸出一些像機器程式碼一樣的二進位制語言,而是生成一串語法正確的目標語言的原始碼(好吧,目的碼)。
Either way, you then run that resulting code through the output language’s existing compilation pipeline and you’re good to go.
不管是哪種方式,你再透過目標語言已有的編譯流水線執行生成的程式碼就可以了。
2 . 2 . 4 Just-in-time compilation
2.2.4 即時編譯
This last one is less of a shortcut and more a dangerous alpine scramble best reserved for experts. The fastest way to execute code is by compiling it to machine code, but you might not know what architecture your end user’s machine supports. What to do?
最後一個與其說是捷徑,不如說是危險的高山爭霸賽,最好留給專家。執行程式碼最快的方法是將程式碼編譯成機器程式碼,但你可能不知道你的終端使用者的機器支援什麼架構。該怎麼做呢?
You can do the same thing that the HotSpot JVM, Microsoft’s CLR and most JavaScript interpreters do. On the end user’s machine, when the program is loaded—either from source in the case of JS, or platform-independent bytecode for the JVM and CLR—you compile it to native for the architecture their computer supports. Naturally enough, this is called just-in-time compilation. Most hackers just say “JIT”, pronounced like it rhymes with “fit”.
你可以做和HotSpot JVM、Microsoft的CLR和大多數JavaScript直譯器相同的事情。 在終端使用者的機器上,當程式載入時(無論是JS原始碼還者是平臺無關的JVM和CLR位元組碼),都可以將其編譯為對應的原生代碼,以適應本機支援的體系結構。 自然地,這被稱為即時編譯。 大多數駭客只是說“ JIT”,其發音與“ fit”押韻。
The most sophisticated JITs insert profiling hooks into the generated code to see which regions are most performance critical and what kind of data is flowing through them. Then, over time, they will automatically recompile those hot spots with more advanced optimizations.
最複雜的JIT將效能分析鉤子插入到生成的程式碼中,以檢視哪些區域對效能最為關鍵,以及哪些型別的資料正在流經其中。 然後,隨著時間的推移,它們將透過更高階的最佳化功能自動重新編譯那些熱點部分13。
2 . 3 Compilers and Interpreters
2.3 編譯器和直譯器
Now that I’ve stuffed your head with a dictionary’s worth of programming language jargon, we can finally address a question that’s plagued coders since time immemorial: “What’s the difference between a compiler and an interpreter?”
現在我已經向你的腦袋裡塞滿了一大堆程式語言術語,我們終於可以解決一個自遠古以來一直困擾著程式設計師的問題:編譯器和直譯器之間有什麼區別?
It turns out this is like asking the difference between a fruit and a vegetable. That seems like a binary either-or choice, but actually “fruit” is a botanical term and “vegetable” is culinary. One does not strictly imply the negation of the other. There are fruits that aren’t vegetables (apples) and vegetables that are not fruits (carrots), but also edible plants that are both fruits and vegetables, like tomatoes.
事實證明,這就像問水果和蔬菜的區別一樣。這看上去似乎是一個非此即彼的選擇,但實際上 "水果 "是一個植物學術語,"蔬菜 "是烹飪學術語。嚴格來說,一個並不意味著對另一個的否定。有不是蔬菜的水果(蘋果),也有不是水果的蔬菜(胡蘿蔔),也有既是水果又是蔬菜的可食用植物,比如西紅柿14。

So, back to languages:
- Compiling is an implementation technique that involves translating a source language to some other—usually lower-level—form. When you generate bytecode or machine code, you are compiling. When you transpile to another high-level language you are compiling too.
- When we say a language implementation “is a compiler”, we mean it translates source code to some other form but doesn’t execute it. The user has to take the resulting output and run it themselves.
- Conversely, when we say an implementation “is an interpreter”, we mean it takes in source code and executes it immediately. It runs programs “from source”.
好,回到語言上:
- 編譯是一種實現技術,其中涉及到將源語言翻譯成其他語言——通常是較低階的形式。當你生成位元組碼或機器程式碼時,你就是在編譯。當你移植到另一種高階語言時,你也在編譯。
- 當我們說語言實現“是編譯器”時,是指它會將原始碼轉換為其他形式,但不會執行。 使用者必須獲取結果輸出並自己執行。
- 相反,當我們說一個實現“是一個直譯器”時,是指它接受原始碼並立即執行它。 它“從原始碼”執行程式。
Like apples and oranges, some implementations are clearly compilers and not interpreters. GCC and Clang take your C code and compile it to machine code. An end user runs that executable directly and may never even know which tool was used to compile it. So those are compilers for C.
像蘋果和橘子一樣,某些實現顯然是編譯器,而不是直譯器。 GCC和Clang接受你的C程式碼並將其編譯為機器程式碼。 終端使用者直接執行該可執行檔案,甚至可能永遠都不知道使用了哪個工具來編譯它。 所以這些是C的編譯器。
In older versions of Matz’ canonical implementation of Ruby, the user ran Ruby from source. The implementation parsed it and executed it directly by traversing the syntax tree. No other translation occurred, either internally or in any user-visible form. So this was definitely an interpreter for Ruby.
由 Matz 實現的老版本 Ruby 中,使用者從原始碼中執行Ruby。該實現透過遍歷語法樹對其進行解析並直接執行。期間都沒有發生其他的轉換,無論是在實現內部還是以任何使用者可見的形式。所以這絕對是一個Ruby的直譯器。
But what of CPython? When you run your Python program using it, the code is parsed and converted to an internal bytecode format, which is then executed inside the VM. From the user’s perspective, this is clearly an interpreter—they run their program from source. But if you look under CPython’s scaly skin, you’ll see that there is definitely some compiling going on.
但是 CPython 呢?當你使用它執行你的Python程式時,程式碼會被解析並轉換為內部位元組碼格式,然後在虛擬機器內部執行。從使用者的角度來看,這顯然是一個直譯器——他們是從原始碼開始執行自己的程式。但如果你看一下CPython的內部,你會發現肯定有一些編譯工作在進行。
The answer is that it is both. CPython is an interpreter, and it has a compiler. In practice, most scripting languages work this way, as you can see:
答案是兩者兼而有之。 CPython是一個直譯器,但他也有一個編譯器。 實際上,大多數指令碼語言都以這種方式工作15,如你所見:

That overlapping region in the center is where our second interpreter lives too, since it internally compiles to bytecode. So while this book is nominally about interpreters, we’ll cover some compilation too.
中間那個重疊的區域也是我們第二個直譯器所在的位置,因為它會在內部編譯成位元組碼。所以,雖然本書名義上是關於直譯器的,但我們也會涉及一些編譯的內容。
2 . 4 Our Journey
2.4 我們的旅程
That’s a lot to take in all at once. Don’t worry. This isn’t the chapter where you’re expected to understand all of these pieces and parts. I just want you to know that they are out there and roughly how they fit together.
一下子有太多東西要消化掉。別擔心。這一章並不是要求你理解所有這些零碎的內容。我只是想讓你們知道它們是存在的,以及大致瞭解它們是如何組合在一起的。
This map should serve you well as you explore the territory beyond the guided path we take in this book. I want to leave you yearning to strike out on your own and wander all over that mountain.
當你探索本書本書所指導的路徑之外的領域時,這張地圖應該對你很有用。我希望你自己出擊,在那座山裡到處遊走。
But, for now, it’s time for our own journey to begin. Tighten your bootlaces, cinch up your pack, and come along. From here on out, all you need to focus on is the path in front of you.
但是,現在,是我們自己的旅程開始的時候了。繫好你的鞋帶,背好你的包,走吧。從這裡開始,你需要關注的是你面前的路。
CHALLENGES
習題
1、Pick an open source implementation of a language you like. Download the source code and poke around in it. Try to find the code that implements the scanner and parser. Are they hand-written, or generated using tools like Lex and Yacc? (
.lor.yfiles usually imply the latter.)
1、選擇一個你喜歡的語言的開源實現。下載原始碼,並在其中探索。試著找到實現掃描器和解析器的程式碼,它們是手寫的,還是用Lex和Yacc等工具生成的?(存在.l或.y檔案通常意味著後者)
2、Just-in-time compilation tends to be the fastest way to implement a dynamically-typed language, but not all of them use it. What reasons are there to not JIT?
2、實時編譯往往是實現動態型別語言最快的方法,但並不是所有的語言都使用它。有什麼理由不採用JIT呢?
3、Most Lisp implementations that compile to C also contain an interpreter that lets them execute Lisp code on the fly as well. Why?
3、大多數可編譯為C的Lisp實現也包含一個直譯器,該直譯器還使它們能夠即時執行Lisp程式碼。 為什麼?
-
毫無疑問,CS論文也有死衚衕,被引為零的悲慘小眾論文以及如今被遺忘的最佳化方法,這些最佳化方法只有在以單個位元組為單位來衡量記憶體時才有意義。 ↩
-
我們在本書中構建的語言是動態型別的,因此將在稍後的執行時中進行型別檢查。 ↩
-
有幾種成熟的IR風格。點選你熟悉的搜尋引擎,搜尋 "控制流圖"、"靜態單賦值形式"、"延續傳遞形式 "和 "三位址碼"。 ↩
-
如果你曾經好奇GCC如何支援這麼多瘋狂的語言和體系結構,例如Motorola 68k上的Modula-3,現在你就明白了。 語言前端針對的是少數IR,主要是GIMPLE和RTL。 目標後端如68k,會接受這些IR並生成本機程式碼。 ↩
-
如果你無法抗拒要進入這個領域,可以從以下關鍵字開始,例如“常量摺疊”,“公共表示式消除”,“迴圈不變程式碼外提”,“全域性值編號”,“強度降低”,“ 聚合量標量替換”,“死碼刪除”和“迴圈展開”。 ↩
-
例如,AAD("ASCII Adjust AX Before Division",除法前ASCII調整AX)指令可以讓你執行除法,這聽起來很有用。除了該指令將兩個二進位制編碼的十進位制數字作為運算元打包到一個16位暫存器中。你最後一次在16位機器上使用BCD是什麼時候? ↩
-
這裡的基本原則是,你把特定於體系架構的工作推得越靠後,你就可以在不同架構之間共享更多的早期階段。不過,這裡存在一些矛盾。 許多最佳化(例如暫存器分配和指令選擇)在瞭解特定晶片的優勢和功能時才能發揮最佳效果。 弄清楚編譯器的哪些部分可以共享,哪些應該針對特定目標是一門藝術。 ↩
-
術語“虛擬機器”也指另一種抽象。 “系統虛擬機器”在軟體中模擬整個硬體平臺和作業系統。 這就是你可以在Linux機器上玩Windows遊戲的原因,也是雲提供商為什麼可以給客戶提供控制自己的“伺服器”的使用者體驗,而無需為每個使用者實際分配單獨的計算機。在本書中,我們將要討論的虛擬機器型別是“語言虛擬機器”或“程序虛擬機器”(如果你需要明確的話)。 ↩
-
語法導向翻譯是一種結構化的技術,用於構建這些一次性編譯器。你可以將一個操作與語法的每個片段(通常是生成輸出程式碼的語法片段)相關聯。然後,每當解析器匹配該語法塊時,它就執行操作,一次構建一個規則的目的碼。 ↩
-
一個明顯的例外是早期版本的Ruby,它們是樹遍歷型直譯器。在1.9時,Ruby的規範實現從最初的MRI("Matz' Ruby Interpreter")切換到了Koichi Sasada的YARV("Yet Another Ruby VM")。YARV是一個位元組碼虛擬機器。 ↩
-
第一個轉編譯器XLT86將8080程式集轉換為8086程式集。 這看似簡單,但請記住8080是8位晶片,而8086是16位晶片,可以將每個暫存器用作一對8位暫存器。 XLT86進行了資料流分析,以跟蹤源程式中的暫存器使用情況,然後將其有效地對映到8086的暫存器集。它是由悲慘的電腦科學英雄加里·基爾達爾(Gary Kildall)撰寫的。 他是最早認識到微型計算機前景的人之一,他建立了PL / M和CP / M,這是它們的第一種高階語言和作業系統。 ↩
-
JS曾經是在瀏覽器中執行程式碼的唯一方式。多虧了Web Assembly,編譯器現在有了第二種可以在Web上執行的低階語言。 ↩
-
當然,這正是HotSpot JVM名稱的來源。 ↩
-
花生(連真正的堅果都算不上)和小麥等穀類其實都是水果,但我把這個圖畫錯了。我能說什麼呢,我是個軟體工程師,不是植物學家。我也許應該抹掉這個花生小傢伙,但他太可愛了,我不忍心。 ↩
-
Go工具更是一個奇葩。如果你執行
go build,它就會把你的go原始碼編譯成機器程式碼然後停止。如果你輸入go run,它也會這樣做,然後立即執行生成的可執行檔案。所以,可以說go是一個編譯器(你可以把它當做一個工具來編譯程式碼而不執行);也可以說是一個直譯器(你可以呼叫它立即從原始碼中執行一個程式),並且有一個編譯器(當你把它當做直譯器使用時,它仍然在內部編譯)。 ↩
3.Lox語言 The Lox Language
What nicer thing can you do for somebody than make them breakfast?
——Anthony Bourdain
還有什麼能比給別人做頓早餐,更能體現你對他的好呢?
We’ll spend the rest of this book illuminating every dark and sundry corner of the Lox language, but it seems cruel to have you immediately start grinding out code for the interpreter without at least a glimpse of what we’re going to end up with.
我們將用本書的其餘部分來照亮Lox語言的每一個黑暗和雜亂的角落,但如果讓你在對目標一無所知的情況下,就立即開始為直譯器編寫程式碼,這似乎很殘忍。
At the same time, I don’t want to drag you through reams of language lawyering and specification-ese before you get to touch your text editor. So this will be a gentle, friendly introduction to Lox. It will leave out a lot of details and edge cases. We’ve got plenty of time for those later.
與此同時,我也不想在您編碼之前,就把您拖入大量的語言和規範術語中。所以這是一個溫和、友好的Lox介紹,它會省去很多細節和邊緣情況1。後面我們有足夠的時間來解決這些問題。
3 . 1 Hello, Lox
3 . 1 Hello, Lox
Here’s your very first taste of Lox:
下面是你對Lox的第一次體驗:
// Your first Lox program!
print "Hello, world!";
As that
//line comment and the trailing semicolon imply, Lox’s syntax is a member of the C family. (There are no parentheses around the string because
正如那句//行註釋和後面的分號所暗示的那樣,Lox的語法是C語言家族的成員之一。(因為print是一個內建語句,而不是庫函式,所以字串周圍沒有括號。)
Now, I won’t claim that C has a great syntax. If we wanted something elegant, we’d probably mimic Pascal or Smalltalk. If we wanted to go full Scandinavian-furniture-minimalism, we’d do a Scheme. Those all have their virtues.
這裡,我並不是想說C語言具有出色的語法2。如果我們想要一些優雅的東西,我們可能會模仿Pascal或Smalltalk。如果我們想要完全體現斯堪的納維亞傢俱的極簡主義風格,我們會實現一個Scheme。這些都有其優點。
What C-like syntax has instead is something you’ll find is often more valuable in a language: familiarity. I know you are already comfortable with that style because the two languages we’ll be using to implement Lox—Java and C—also inherit it. Using a similar syntax for Lox gives you one less thing to learn.
但是,類C的語法所具有的反而是一些在語言中更有價值的東西:熟悉度。我知道你已經對這種風格很熟悉了,因為我們將用來實現Lox的兩種語言——Java和C——也繼承了這種風格。讓Lox使用類似的語法,你就少了一件需要學習的事情。
3 . 2 A High-Level Language
3.2 高階語言
While this book ended up bigger than I was hoping, it’s still not big enough to fit a huge language like Java in it. In order to fit two complete implementations of Lox in these pages, Lox itself has to be pretty compact.
雖然這本書最終比我所希望的要大,但它仍然不夠大,無法將Java這樣一門龐大的語言放進去。為了在有限的篇幅裡容納兩個完整的Lox實現,Lox本身必須相當緊湊。
When I think of languages that are small but useful, what comes to mind are high-level “scripting” languages like JavaScript, Scheme, and Lua. Of those three, Lox looks most like JavaScript, mainly because most C-syntax languages do. As we’ll learn later, Lox’s approach to scoping hews closely to Scheme. The C flavor of Lox we’ll build in Part III is heavily indebted to Lua’s clean, efficient implementation.
當我想到那些小而有用的語言時,我腦海中浮現的是像JavaScript3、Scheme和Lua這樣的高階 "指令碼 "語言。在這三種語言中,Lox看起來最像JavaScript,主要是因為大多數c語法語言都是這樣的。稍後我們將瞭解到,Lox的範圍界定方法與Scheme密切相關。 我們將在第三部分中構建的C風格的Lox很大程度上借鑑了Lua的乾淨、高效的實現。
Lox shares two other aspects with those three languages:
Lox與這三種語言有兩個共同之處:
3 . 2 . 1 Dynamic typing
3.2.1 動態型別
Lox is dynamically typed. Variables can store values of any type, and a single variable can even store values of different types at different times. If you try to perform an operation on values of the wrong type—say, dividing a number by a string—then the error is detected and reported at runtime.
Lox是動態型別的。變數可以儲存任何型別的值,單個變數甚至可以在不同時間儲存不同型別的值。如果嘗試對錯誤型別的值執行操作(例如,將數字除以字串),則會在執行時檢測到錯誤並報告。
There are plenty of reasons to like static types, but they don’t outweigh the pragmatic reasons to pick dynamic types for Lox. A static type system is a ton of work to learn and implement. Skipping it gives you a simpler language and a shorter book. We’ll get our interpreter up and executing bits of code sooner if we defer our type checking to runtime.
喜歡靜態型別的原因有很多,但它們都比不上為Lox選擇動態型別的實際原因4。靜態型別系統需要學習和實現大量的工作。跳過它會讓你的語言更簡單,也可以讓本書更短。如果我們將型別檢查推遲到執行時,我們將可以更快地啟動直譯器並執行程式碼。
3 . 2 . 2 Automatic memory management
3.2.2 自動記憶體管理
High-level languages exist to eliminate error-prone, low-level drudgery and what could be more tedious than manually managing the allocation and freeing of storage? No one rises and greets the morning sun with, “I can’t wait to figure out the correct place to call
free()for every byte of memory I allocate today!”
高階語言的存在是為了消除容易出錯的低階工作,還有什麼比手動管理儲存的分配和釋放更繁瑣的呢?沒有人會抬起頭來迎接早晨的陽光,“我迫不及待想找到正確的位置去呼叫free()方法,來釋放掉今天我在記憶體中申請的每個位元組!”
There are two main techniques for managing memory: reference counting and tracing garbage collection (usually just called “garbage collection” or “GC”). Ref counters are much simpler to implement—I think that’s why Perl, PHP, and Python all started out using them. But, over time, the limitations of ref counting become too troublesome. All of those languages eventually ended up adding a full tracing GC or at least enough of one to clean up object cycles.
有兩種主要的記憶體管理技術:引用計數和跟蹤垃圾收集(通常僅稱為“垃圾收集”或“ GC”)5。 引用計數器的實現要簡單得多——我想這就是為什麼Perl、PHP和Python一開始都使用該方式的原因。但是,隨著時間的流逝,引用計數的限制變得太麻煩了。 所有這些語言最終都添加了完整的跟蹤GC或至少一種足以清除物件迴圈引用的管理方式。
Tracing garbage collection has a fearsome reputation. It is a little harrowing working at the level of raw memory. Debugging a GC can sometimes leave you seeing hex dumps in your dreams. But, remember, this book is about dispelling magic and slaying those monsters, so we are going to write our own garbage collector. I think you’ll find the algorithm is quite simple and a lot of fun to implement.
追蹤式垃圾收集是一個聽起來就很可怕的名稱。在原始記憶體的層面上工作是有點折磨人的。除錯GC的時候會讓你在夢中也能看到hex dumps。但是,請記住,這本書是關於驅散魔法和殺死那些怪物的,所以我們要寫出自己的垃圾收集器。我想你會發現這個演算法相當簡單,而且實現起來很有趣。
3 . 3 Data Types
3.3 資料型別
In Lox’s little universe, the atoms that make up all matter are the built-in data types. There are only a few:
在Lox的小宇宙中,構成所有物質的原子是內建的資料型別。只有幾個:
Booleans – You can’t code without logic and you can’t logic without Boolean values. “True” and “false”, the yin and yang of software. Unlike some ancient languages that repurpose an existing type to represent truth and falsehood, Lox has a dedicated Boolean type. We may be roughing it on this expedition, but we aren’t savages.
There are two Boolean values, obviously, and a literal for each one:
Booleans——沒有邏輯就不能編碼,沒有布林值也就沒有邏輯6。 “真”和“假”,就是軟體的陰與陽。 與某些古老的語言重新利用已有型別來表示真假不同,Lox具有專用的布林型別。在這次探險中,我們可能會有些粗暴,但我們不是野蠻人。
顯然,有兩個布林值,每個值都有一個字面量:
true; // Not false.
false; // Not *not* false.
Numbers – Lox only has one kind of number: double-precision floating point. Since floating point numbers can also represent a wide range of integers, that covers a lot of territory, while keeping things simple.
Full-featured languages have lots of syntax for numbers—hexadecimal, scientific notation, octal, all sorts of fun stuff. We’ll settle for basic integer and decimal literals:
Numbers——Lox只有一種數字:雙精度浮點數。 由於浮點數還可以表示各種各樣的整數,因此可以覆蓋很多領域,同時保持簡單。
功能齊全的語言具有多種數字語法-十六進位制,科學計數法,八進位制和各種有趣的東西。 我們只使用基本的整數和十進位制文字:
1234; // An integer.
12.34; // A decimal number.
Strings – We’ve already seen one string literal in the first example. Like most languages, they are enclosed in double quotes:
Strings——在第一個示例中,我們已經看到一個字串字面量。 與大多數語言一樣,它們用雙引號引起來:
"I am a string";
""; // The empty string.
"123"; // This is a string, not a number.
As we’ll see when we get to implementing them, there is quite a lot of complexity hiding in that innocuous sequence of characters.
我們在實現它們時會看到,在這個看起來無害的字元序列7中隱藏了相當多的複雜性。
Nil – There’s one last built-in value who’s never invited to the party but always seems to show up. It represents “no value”. It’s called “null” in many other languages. In Lox we spell it
nil. (When we get to implementing it, that will help distinguish when we’re talking about Lox’snilversus Java or C’snull.)There are good arguments for not having a null value in a language since null pointer errors are the scourge of our industry. If we were doing a statically-typed language, it would be worth trying to ban it. In a dynamically-typed one, though, eliminating it is often more annoying than having it.
Nil——還有最後一個內建資料,它從未被邀請參加聚會,但似乎總是會出現。 它代表“沒有價值”。 在許多其他語言中稱為“null”。 在Lox中,我們將其拼寫為nil。 (當我們實現它時,這將有助於區分Lox的nil與Java或C的null)
有一些很好的理由表明在語言中不使用空值是合理的,因為空指標錯誤是我們行業的禍害。如果我們使用的是靜態型別語言,那麼禁止它是值得的。然而,在動態型別中,消除它往往比保留它更加麻煩。
3 . 4 Expressions
3.4 表示式
If built-in data types and their literals are atoms, then expressions must be the molecules. Most of these will be familiar.
如果內建資料型別及其字面量是原子,那麼表示式一定是分子。其中大部分大家都很熟悉。
3 . 4 . 1 Arithmetic
3.4.1 算術運算
Lox features the basic arithmetic operators you know and love from C and other languages:
Lox具備了您從C和其他語言中瞭解到的基本算術運算子:
add + me;
subtract - me;
multiply * me;
divide / me;
The subexpressions on either side of the operator are operands. Because there are two of them, these are called binary operators. (It has nothing to do with the ones-and-zeroes use of “binary”.) Because the operator is fixed in the middle of the operands, these are also called infix operators as opposed to prefix operators where the operator comes before and postfix where it follows the operand.
運算子兩邊的子表示式都是運算元。因為有兩個運算元,它們被稱為二元運算子(這與二進位制的1和0二元沒有關聯)。由於運算子固定在運算元的中間,因此也稱為中綴運算子,相對的,還有字首運算子(運算子在運算元前面)和字尾運算子(運算子在運算元後面)8。
One arithmetic operator is actually both an infix and a prefix one. The
-operator can also be used to negate a number:
有一個數學運算子既是中綴運算子也是字首運算子,-運算子可以對數字取負:
-negateMe;
All of these operators work on numbers, and it’s an error to pass any other types to them. The exception is the
+operator—you can also pass it two strings to concatenate them.
所有這些運算子都是針對數字的,將任何其他型別運算元傳遞給它們都是錯誤的。唯一的例外是+運算子——你也可以傳給它兩個字串將它們串接起來。
3 . 4 . 2 Comparison and equality
3.4.2 比較與相等
Moving along, we have a few more operators that always return a Boolean result. We can compare numbers (and only numbers), using Ye Olde Comparison Operators:
接下來,我們有幾個返回布林值的運算子。我們可以使用舊的比較運算子來比較數字(並且只能比較數字):
less < than;
lessThan <= orEqual;
greater > than;
greaterThan >= orEqual;
We can test two values of any kind for equality or inequality:
我們可以測試兩個任意型別的值是否相等:
1 == 2; // false.
"cat" != "dog"; // true.
Even different types:
即使是不同型別也可以:
314 == "pi"; // false.
Values of different types are never equivalent:
不同型別的值永遠不會相等:
123 == "123"; // false.
I’m generally against implicit conversions.
我通常是反對隱式轉換的。
3 . 4 . 3 Logical operators
3.4.3 邏輯運算
The not operator, a prefix
!, returnsfalseif its operand is true, and vice versa:
取非運算子,是字首運算子!,如果運算元是true,則返回false,反之亦然:
!true; // false.
!false; // true.
The other two logical operators really are control flow constructs in the guise of expressions. An
andexpression determines if two values are both true. It returns the left operand if it’s false, or the right operand otherwise:
其他兩個邏輯運算子實際上是表示式偽裝下的控制流結構。and表示式用於確認兩個運算元是否都是true。如果左側運算元是false,則返回左側運算元,否則返回右側運算元:
true and false; // false.
true and true; // true.
And an
orexpression determines if either of two values (or both) are true. It returns the left operand if it is true and the right operand otherwise:
or表示式用於確認兩個運算元中任意一個(或者都是)為true。如果左側運算元為true,則返回左側運算元,否則返回右側運算元:
false or false; // false.
true or false; // true.
The reason
andandorare like control flow structures is because they short-circuit. Not only doesandreturn the left operand if it is false, it doesn’t even evaluate the right one in that case. Conversely, (“contrapositively”?) if the left operand of anoris true, the right is skipped.
and和 or之所以像控制流結構,是因為它們會短路9。如果左運算元為假,and不僅會返回左運算元,在這種情況下,它甚至不會計算右運算元。反過來,("相對的"?)如果or的左運算元為真,右運算元就會被跳過。
3 . 4 . 4 Precedence and grouping
3.4.4 優先順序與分組
All of these operators have the same precedence and associativity that you’d expect coming from C. (When we get to parsing, we’ll get way more precise about that.) In cases where the precedence isn’t what you want, you can use
()to group stuff:
所有這些運算子都具有與c語言相同的優先順序和結合性(當我們開始解析時,會進行更詳細的說明)。在優先順序不滿足要求的情況下,你可以使用()來分組:
var average = (min + max) / 2;
Since they aren’t very technically interesting, I’ve cut the remainder of the typical operator menagerie out of our little language. No bitwise, shift, modulo, or conditional operators. I’m not grading you, but you will get bonus points in my heart if you augment your own implementation of Lox with them.
我把其他典型的運算子從我們的小語言中去掉了,因為它們在技術上不是很有趣。沒有位運算、移位、取模或條件運算子。我不是在給你打分,但如果你透過自己的方式來完成支援這些運算的Lox實現,你會在我心中得到額外的加分。
Those are the expression forms (except for a couple related to specific features that we’ll get to later), so let’s move up a level.
這些都是表示式形式(除了一些與我們將在後面介紹的特定特性相關的),所以讓我們繼續。
3 . 5 Statements
3.5 語句
Now we’re at statements. Where an expression’s main job is to produce a value, a statement’s job is to produce an effect. Since, by definition, statements don’t evaluate to a value, to be useful they have to otherwise change the world in some way—usually modifying some state, reading input, or producing output.
現在我們來看語句。表示式的主要作用是產生一個值,語句的主要作用是產生一個效果。由於根據定義,語句不求值,因此必須以某種方式改變世界(通常是修改某些狀態,讀取輸入或產生輸出)才能有用。
You’ve seen a couple of kinds of statements already. The first one was:
您已經看到了幾種語句。 第一個是:
print "Hello, world!";
A
print語句計算單個表示式並將結果顯示給使用者10。 您還看到了一些語句,例如:
"some expression";
An expression followed by a semicolon (
;) promotes the expression to statement-hood. This is called (imaginatively enough), an expression statement.
表示式後跟分號(;)可以將表示式提升為語句狀態。這被稱為(很有想象力)表示式語句。
If you want to pack a series of statements where a single one is expected, you can wrap them up in a block:
如果您想將一系列語句打包成一個語句,那麼可以將它們打包在一個塊中:
{
print "One statement.";
print "Two statements.";
}
Blocks also affect scoping, which leads us to the next section…
塊還會影響作用域,我們將在下一節中進行說明。
3 . 6 Variables
3.6 變數
You declare variables using
varstatements. If you omit the initializer, the variable’s value defaults tonil:
你可以使用var語句宣告變數。如果你省略了初始化操作,變數的值預設為nil11:
var imAVariable = "here is my value";
var iAmNil;
Once declared, you can, naturally, access and assign a variable using its name:
一旦宣告完成,你自然就可以透過變數名對其進行訪問和賦值:
var breakfast = "bagels";
print breakfast; // "bagels".
breakfast = "beignets";
print breakfast; // "beignets".
I won’t get into the rules for variable scope here, because we’re going to spend a surprising amount of time in later chapters mapping every square inch of the rules. In most cases, it works like you expect coming from C or Java.
我不會在這裡討論變數作用域的規則,因為我們在後面的章節中將會花費大量的時間來詳細討論這些規則。在大多數情況下,它的工作方式與您期望的C或Java一樣。
3 . 7 Control Flow
3.7 控制流
It’s hard to write useful programs if you can’t skip some code, or execute some more than once. That means control flow. In addition to the logical operators we already covered, Lox lifts three statements straight from C.
如果你不能跳過某些程式碼,或者不能多次執行某些程式碼,就很難寫出有用的程式12。這意味著控制流。除了我們已經介紹過的邏輯運算子之外,Lox直接從C中借鑑了三條語句。
An
ifstatement executes one of two statements based on some condition:
if語句根據某些條件執行兩條語句中的一條:
if (condition) {
print "yes";
} else {
print "no";
}
A
whileloop executes the body repeatedly as long as the condition expression evaluates to true:
只要條件表示式的計算結果為true,while迴圈就會重複執行迴圈體13:
var a = 1;
while (a < 10) {
print a;
a = a + 1;
}
Finally, we have
forloops:
最後,還有for迴圈:
for (var a = 1; a < 10; a = a + 1) {
print a;
}
This loop does the same thing as the previous
whileloop. Most modern languages also have some sort offor-inorforeachloop for explicitly iterating over various sequence types. In a real language, that’s nicer than the crude C-styleforloop we got here. Lox keeps it basic.
這個迴圈與之前的 while 迴圈做同樣的事情。大多數現代語言也有某種for-in或foreach迴圈,用於顯式迭代各種序列型別14。在真正的語言中,這比我們在這裡使用的粗糙的C-風格for迴圈要好。Lox只保持了它的基本功能。
3 . 8 Functions
3.8 函式
A function call expression looks the same as it does in C:
函式呼叫表示式與C語言中一樣:
makeBreakfast(bacon, eggs, toast);
You can also call a function without passing anything to it:
你也可以在不傳遞任何引數的情況下呼叫一個函式:
makeBreakfast();
Unlike, say, Ruby, the parentheses are mandatory in this case. If you leave them off, it doesn’t call the function, it just refers to it.
與Ruby不同的是,在本例中括號是強制性的。如果你把它們去掉,就不會呼叫函式,只是指向該函式。
A language isn’t very fun if you can’t define your own functions. In Lox, you do that with
fun:
如果你不能定義自己的函式,一門語言就不能算有趣。在Lox裡,你可以透過fun完成:
fun printSum(a, b) {
print a + b;
}
Now’s a good time to clarify some terminology. Some people throw around “parameter” and “argument” like they are interchangeable and, to many, they are. We’re going to spend a lot of time splitting the finest of downy hairs around semantics, so let’s sharpen our words. From here on out:
- An argument is an actual value you pass to a function when you call it. So a function call has an argument list. Sometimes you hear actual parameter used for these.
- A parameter is a variable that holds the value of the argument inside the body of the function. Thus, a function declaration has a parameter list. Others call these formal parameters or simply formals.
現在是澄清一些術語的好時機15。有些人把 "parameter "和 "argument "混為一談,好像它們可以互換,而對許多人來說,它們確實可以互換。我們要花很多時間圍繞語義學來對其進行分辨,所以讓我們在這裡把話說清楚:
- argument是你在呼叫函式時傳遞給它的實際值。所以一個函式呼叫有一個argument列表。有時你會聽到有人用實際引數指代這些引數。
- parameter是一個變數,用於在函式的主體裡面存放引數的值。因此,一個函式宣告有一個parameter列表。也有人把這些稱為形式引數或者乾脆稱為形參。
The body of a function is always a block. Inside it, you can return a value using a
returnstatement:
函式體總是一個塊。在其中,您可以使用return語句返回一個值:
fun returnSum(a, b) {
return a + b;
}
If execution reaches the end of the block without hitting a
return, it implicitly returnsnil.
如果執行到達程式碼塊的末尾而沒有return語句,則會隱式返回nil。
3 . 8 . 1 Closures
3.8.1 閉包
Functions are first class in Lox, which just means they are real values that you can get a reference to, store in variables, pass around, etc. This works:
在Lox中,函式是一等公民,這意味著它們都是真實的值,你可以對這些值進行引用、儲存在變數中、傳遞等等。下面的程式碼是有效的:
fun addPair(a, b) {
return a + b;
}
fun identity(a) {
return a;
}
print identity(addPair)(1, 2); // Prints "3".
Since function declarations are statements, you can declare local functions inside another function:
由於函式宣告是語句,所以可以在另一個函式中宣告區域性函式:
fun outerFunction() {
fun localFunction() {
print "I'm local!";
}
localFunction();
}
If you combine local functions, first-class functions, and block scope, you run into this interesting situation:
如果將區域性函式、頭等函式和塊作用域組合在一起,就會遇到這種有趣的情況:
fun returnFunction() {
var outside = "outside";
fun inner() {
print outside;
}
return inner;
}
var fn = returnFunction();
fn();
Here,
inner()accesses a local variable declared outside of its body in the surrounding function. Is this kosher? Now that lots of languages have borrowed this feature from Lisp, you probably know the answer is yes.
在這裡,inner()訪問了在其函式體外的外部函式中宣告的區域性變數。這樣可行嗎?現在很多語言都從Lisp借鑑了這個特性,你應該也知道答案是肯定的。
For that to work,
inner()has to “hold on” to references to any surrounding variables that it uses so that they stay around even after the outer function has returned. We call functions that do this closures. These days, the term is often used for any first-class function, though it’s sort of a misnomer if the function doesn’t happen to close over any variables.
要做到這一點,inner()必須“保留”對它使用的任何周圍變數的引用,這樣即使在外層函式返回之後,這些變數仍然存在。我們把能做到這一點的函式稱為閉包16。現在,這個術語經常被用於任何頭類函式,但是如果函式沒有在任何變數上閉包,那就有點用詞不當了。
As you can imagine, implementing these adds some complexity because we can no longer assume variable scope works strictly like a stack where local variables evaporate the moment the function returns. We’re going to have a fun time learning how to make these work and do so efficiently.
可以想象,實現這些會增加一些複雜性,因為我們不能再假定變數作用域嚴格地像堆疊一樣工作,在函式返回時區域性變數就消失了。我們將度過一段有趣的時間來學習如何使這些工作,並有效地做到這一點。
3 . 9 Classes
3.9 類
Since Lox has dynamic typing, lexical (roughly, “block”) scope, and closures, it’s about halfway to being a functional language. But as you’ll see, it’s also about halfway to being an object-oriented language. Both paradigms have a lot going for them, so I thought it was worth covering some of each.
因為Lox具有動態型別、詞法(粗略地說,就是塊)作用域和閉包,所以它離函式式語言只有一半的距離。但正如您將看到的,它離成為一種面向物件的語言也有一半的距離。這兩種模式都有很多優點,所以我認為有必要分別介紹一下。
Since classes have come under fire for not living up to their hype, let me first explain why I put them into Lox and this book. There are really two questions:
類因為沒有達到其宣傳效果而受到抨擊,所以讓我先解釋一下為什麼我把它們放到Lox和這本書中。這裡實際上有兩個問題:
3 . 9 . 1 Why might any language want to be object oriented?
3.9.1 為什麼任何語言都想要面向物件?
Now that object-oriented languages like Java have sold out and only play arena shows, it’s not cool to like them anymore. Why would anyone make a new language with objects? Isn’t that like releasing music on 8-track?
現在像Java這樣的面向物件的語言已經銷聲匿跡了,只能在舞臺上表演,喜歡它們已經不酷了。為什麼有人要用物件來做一門新的語言呢?這不就像用磁帶17發行音樂一樣嗎?
It is true that the “all inheritance all the time” binge of the 90s produced some monstrous class hierarchies, but object-oriented programming is still pretty rad. Billions of lines of successful code have been written in OOP languages, shipping millions of apps to happy users. Likely a majority of working programmers today are using an object-oriented language. They can’t all be that wrong.
90年代的 "一直都是繼承 "的狂潮確實產生了一些畸形的類層次結構,但面向物件的程式設計還是很流行的。數十億行成功的程式碼都是用OOP語言編寫的,為使用者提供了數百萬個應用程式。很可能今天大多數在職程式設計師都在使用面嚮物件語言。他們不可能都錯得那麼離譜。
In particular, for a dynamically-typed language, objects are pretty handy. We need some way of defining compound data types to bundle blobs of stuff together.
特別是,對於動態型別語言來說,物件是非常方便的。我們需要某種方式來定義複合資料型別,用來將一堆資料組合在一起。
If we can also hang methods off of those, then we avoid the need to prefix all of our functions with the name of the data type they operate on to avoid colliding with similar functions for different types. In, say, Racket, you end up having to name your functions like
hash-copy(to copy a hash table) andvector-copy(to copy a vector) so that they don’t step on each other. Methods are scoped to the object, so that problem goes away.
如果我們也能把方法掛在這些物件上,那麼我們就不需要把函式操作的資料型別的名字作為函式名稱的字首,以避免與不同型別的類似函式發生衝突。比如說,在Racket中,你最終不得不將你的函式命名為hash-copy(複製一個雜湊表)和vector-copy(複製一個向量),這樣它們就不會互相覆蓋。方法的作用域是物件,所以這個問題就不存在了。
3 . 9 . 2 Why is Lox object oriented?
3.9.2 為什麼Lox是面向物件的?
I could claim objects are groovy but still out of scope for the book. Most programming language books, especially ones that try to implement a whole language, leave objects out. To me, that means the topic isn’t well covered. With such a widespread paradigm, that omission makes me sad.
我可以說物件確實很吸引人,但仍然超出了本書的範圍。大多數程式語言的書籍,特別是那些試圖實現一門完整語言的書籍,都忽略了物件。對我來說,這意味著這個主題沒有被很好地覆蓋。對於如此廣泛使用的正規化,這種遺漏讓我感到悲傷。
Given how many of us spend all day using OOP languages, it seems like the world could use a little documentation on how to make one. As you’ll see, it turns out to be pretty interesting. Not as hard as you might fear, but not as simple as you might presume, either.
鑑於我們很多人整天都在使用OOP語言,似乎這個世界應該有一些關於如何製作OOP語言的文件。正如你將看到的那樣,事實證明這很有趣。沒有你擔心的那麼難,但也沒有你想象的那麼簡單。
3 . 9 . 3 Classes or prototypes?
3.9.3 類還是原型?
When it comes to objects, there are actually two approaches to them, classes and prototypes. Classes came first, and are more common thanks to C++, Java, C#, and friends. Prototypes were a virtually forgotten offshoot until JavaScript accidentally took over the world.
當涉及物件時,實際上有兩種方法,類和原型。 類最先出現,由於C++、Java、C#和其它近似語言的出現,類更加普遍。直到JavaScript意外地佔領了世界之前,原型幾乎是一個被遺忘的分支。
In a class-based language, there are two core concepts: instances and classes. Instances store the state for each object and have a reference to the instance’s class. Classes contain the methods and inheritance chain. To call a method on an instance, there is always a level of indirection. You look up the instance’s class and then you find the method there:
在基於類的語言中,有兩個核心概念:例項和類。 例項儲存每個物件的狀態,並有一個對例項的類的引用。 類包含方法和繼承鏈。要在例項上呼叫方法,總是存在一箇中間層。您要先查詢例項的類,然後在其中找到方法:

Prototype-based languages merge these two concepts. There are only objects—no classes—and each individual object may contain state and methods. Objects can directly inherit from each other (or “delegate to” in prototypal lingo):
基於原型的語言融合了這兩個概念18。這裡只有物件——沒有類,而且每個物件都可以包含狀態和方法。物件之間可以直接繼承(或者用原型語言的術語說是 “委託”):

This means prototypal languages are more fundamental in some way than classes. They are really neat to implement because they’re so simple. Also, they can express lots of unusual patterns that classes steer you away from.
這意味著原型語言在某些方面比類更基礎。 它們實現起來真的很整潔,因為它們很簡單。另外,它們還可以表達很多不尋常的模式,而這些模式是類所不具備的。
But I’ve looked at a lot of code written in prototypal languages—including some of my own devising. Do you know what people generally do with all of the power and flexibility of prototypes? …They use it to reinvent classes.
但是我看過很多用原型語言寫的程式碼——包括我自己設計的一些程式碼。你知道人們一般會怎麼使用原型的強大功能和靈活性嗎?...他們用它來重新發明類。
I don’t know why that is, but people naturally seem to prefer a class-based (“Classic”? “Classy”?) style. Prototypes are simpler in the language, but they seem to accomplish that only by pushing the complexity onto the user. So, for Lox, we’ll save our users the trouble and bake classes right in.
我不知道這是為什麼,但人們自然而然地似乎更喜歡基於類的(經典?優雅?)風格。原型在語言中更簡單,但它們似乎只是透過將複雜性推給使用者來實現的19。所以,對於Lox來說,我們將省去使用者的麻煩,直接把類包含進去。
3 . 9 . 4 Classes in Lox
3.9.4 Lox中的類
Enough rationale, let’s see what we actually have. Classes encompass a constellation of features in most languages. For Lox, I’ve selected what I think are the brightest stars. You declare a class and its methods like so:
理由已經說夠了,來看看我們實際上擁有什麼。在大多數語言中,類包含了一系列的特性。對於Lox,我選擇了我認為最閃亮的一點。您可以像這樣宣告一個類及其方法:
class Breakfast {
cook() {
print "Eggs a-fryin'!";
}
serve(who) {
print "Enjoy your breakfast, " + who + ".";
}
}
The body of a class contains its methods. They look like function declarations but without the
funkeyword. When the class declaration is executed, Lox creates a class object and stores that in a variable named after the class. Just like functions, classes are first class in Lox:
類的主體包含其方法。 它們看起來像函式宣告,但沒有fun關鍵字。 當類宣告生效時,Lox將建立一個類物件,並將其儲存在以該類命名的變數中。就像函式一樣,類在Lox中也是一等公民:
// Store it in variables.
var someVariable = Breakfast;
// Pass it to functions.
someFunction(Breakfast);
Next, we need a way to create instances. We could add some sort of
newkeyword, but to keep things simple, in Lox the class itself is a factory function for instances. Call a class like a function and it produces a new instance of itself:
接下來,我們需要一種建立例項的方法。我們可以新增某種new關鍵字,但為了簡單起見,在Lox中,類本身是例項的工廠函式。像呼叫函式一樣呼叫一個類,它會生成一個自己的新例項:
var breakfast = Breakfast();
print breakfast; // "Breakfast instance".
3 . 9 . 5 Instantiation and initialization
3.9.5 例項化和初始化
Classes that only have behavior aren’t super useful. The idea behind object-oriented programming is encapsulating behavior and state together. To do that, you need fields. Lox, like other dynamically-typed languages, lets you freely add properties onto objects:
只有行為的類不是非常有用。面向物件程式設計背後的思想是將行為和狀態封裝在一起。為此,您需要有欄位。Lox和其他動態型別語言一樣,允許您自由地向物件新增屬性:
breakfast.meat = "sausage";
breakfast.bread = "sourdough";
Assigning to a field creates it if it doesn’t already exist.
如果一個欄位不存在,那麼對它進行賦值時就會先建立。
If you want to access a field or method on the current object from within a method, you use good old
this:
如果您想從方法內部訪問當前物件上的欄位或方法,可以使用this:
class Breakfast {
serve(who) {
print "Enjoy your " + this.meat + " and " +
this.bread + ", " + who + ".";
}
// ...
}
Part of encapsulating data within an object is ensuring the object is in a valid state when it’s created. To do that, you can define an initializer. If your class has a method named
init(), it is called automatically when the object is constructed. Any parameters passed to the class are forwarded to its initializer:
在物件中封裝資料的目的之一是確保物件在建立時處於有效狀態。為此,你可以定義一個初始化器。如果您的類中包含一個名為init()的方法,則在構造物件時會自動呼叫該方法。傳遞給類的任何引數都會轉發給它的初始化器:
class Breakfast {
init(meat, bread) {
this.meat = meat;
this.bread = bread;
}
// ...
}
var baconAndToast = Breakfast("bacon", "toast");
baconAndToast.serve("Dear Reader");
// "Enjoy your bacon and toast, Dear Reader."
3 . 9 . 6 Inheritance
3.9.6 繼承
Every object-oriented language lets you not only define methods, but reuse them across multiple classes or objects. For that, Lox supports single inheritance. When you declare a class, you can specify a class that it inherits from using a less-than (
<) operator:
在每一種面向物件的語言中,你不僅可以定義方法,而且可以在多個類或物件中重用它們。為此,Lox支援單繼承。當你宣告一個類時,你可以使用小於(<)運算子指定它繼承的類20:
class Brunch < Breakfast {
drink() {
print "How about a Bloody Mary?";
}
}
Here, Brunch is the derived class or subclass, and Breakfast is the base class or superclass. Every method defined in the superclass is also available to its subclasses:
這裡,Brunch是派生類或子類,而Breakfast是基類或超類。父類中定義的每個方法對其子類也可用:
var benedict = Brunch("ham", "English muffin");
benedict.serve("Noble Reader");
Even the
init()method gets inherited. In practice, the subclass usually wants to define its owninit()method too. But the original one also needs to be called so that the superclass can maintain its state. We need some way to call a method on our own instance without hitting our own methods.
即使是init()方法也會被繼承。在實踐中,子類通常也想定義自己的init()方法。但還需要呼叫原始的初始化方法,以便超類能夠維護其狀態21。我們需要某種方式能夠呼叫自己例項上的方法,而無需觸發例項自身的方法。
As in Java, you use
superfor that:
與Java中一樣,您可以使用super:
class Brunch < Breakfast {
init(meat, bread, drink) {
super.init(meat, bread);
this.drink = drink;
}
}
That’s about it for object orientation. I tried to keep the feature set minimal. The structure of the book did force one compromise. Lox is not a pure object-oriented language. In a true OOP language every object is an instance of a class, even primitive values like numbers and Booleans.
這就是面向物件的內容。我儘量將功能設定保持在最低限度。本書的結構確實迫使我做了一個妥協。Lox不是一種純粹的面向物件的語言。在真正的OOP語言中,每個物件都是一個類的例項,即使是像數字和布林值這樣的基本型別。
Because we don’t implement classes until well after we start working with the built-in types, that would have been hard. So values of primitive types aren’t real objects in the sense of being instances of classes. They don’t have methods or properties. If I were trying to make Lox a real language for real users, I would fix that.
因為我們開始使用內建型別很久之後才會實現類,所以這一點很難實現。因此,從類例項的意義上說,基本型別的值並不是真正的物件。它們沒有方法或屬性。如果以後我想讓Lox成為真正的使用者使用的語言,我會解決這個問題。
3 . 10 The Standard Library
3.10 標準庫
We’re almost done. That’s the whole language, so all that’s left is the “core” or “standard” library—the set of functionality that is implemented directly in the interpreter and that all user-defined behavior is built on top of.
我們快結束了,這就是整個語言,所剩下的就是“核心”或“標準”庫——這是一組直接在直譯器中實現的功能集,所有使用者定義的行為都是建立在此之上。
This is the saddest part of Lox. Its standard library goes beyond minimalism and veers close to outright nihilism. For the sample code in the book, we only need to demonstrate that code is running and doing what it’s supposed to do. For that, we already have the built-in
這是Lox中最可悲的部分。它的標準庫已經超過了極簡主義,接近徹底的虛無主義。對於本書中的示例程式碼,我們只需要證明程式碼在執行,並且在做它應該做的事。為此,我們已經有了內建的print語句。
Later, when we start optimizing, we’ll write some benchmarks and see how long it takes to execute code. That means we need to track time, so we’ll define one built-in function
clock()that returns the number of seconds since the program started.
稍後,當我們開始最佳化時,我們將編寫一些基準測試,看看執行程式碼需要多長時間。這意味著我們需要跟蹤時間,因此我們將定義一個內建函式clock(),該函式會返回程式啟動後的秒數。
And… that’s it. I know, right? It’s embarrassing.
嗯...就是這樣。 我知道,有點尷尬,對吧?
If you wanted to turn Lox into an actual useful language, the very first thing you should do is flesh this out. String manipulation, trigonometric functions, file I/O, networking, heck, even reading input from the user would help. But we don’t need any of that for this book, and adding it wouldn’t teach you anything interesting, so I left it out.
如果您想將Lox變成一門實際可用的語言,那麼您應該做的第一件事就是對其充實。 字串操作、三角函式、檔案I / O、網路、擴充套件,甚至讀取使用者的輸入都將有所幫助。但對於本書來說,我們不需要這些,而且加入這些也不會教給你任何有趣的東西,所以我把它省略了。
Don’t worry, we’ll have plenty of exciting stuff in the language itself to keep us busy.
別擔心,這門語言本身就有很多精彩的內容讓我們忙個不停。
CHALLENGES
習題
1、Write some sample Lox programs and run them (you can use the implementations of Lox in my repository). Try to come up with edge case behavior I didn’t specify here. Does it do what you expect? Why or why not?
1、編寫一些示例Lox程式並執行它們(您可以使用我的Lox實現)。試著想出我在這裡沒有詳細說明的邊界情況。它是否按照期望執行?為什麼?
2、This informal introduction leaves a lot unspecified. List several open questions you have about the language’s syntax and semantics. What do you think the answers should be?
2、這種非正式的介紹留下了很多未說明的東西。列出幾個關於語言語法和語義的開放問題。你認為答案應該是什麼?
3、Lox is a pretty tiny language. What features do you think it is missing that would make it annoying to use for real programs? (Aside from the standard library, of course.)
3、Lox是一種很小的語言。 您認為缺少哪些功能會使其不適用於實際程式? (當然,除了標準庫。)
DESIGN NOTE: EXPRESSIONS AND STATEMENTS
設計筆記:表示式和語句
Lox has both expressions and statements. Some languages omit the latter. Instead, they treat declarations and control flow constructs as expressions too. These “everything is an expression” languages tend to have functional pedigrees and include most Lisps, SML, Haskell, Ruby, and CoffeeScript.
To do that, for each “statement-like” construct in the language, you need to decide what value it evaluates to. Some of those are easy:
- An
ifexpression evaluates to the result of whichever branch is chosen. Likewise, aswitchor other multi-way branch evaluates to whichever case is picked.- A variable declaration evaluates to the value of the variable.
- A block evaluates to the result of the last expression in the sequence.
Some get a little stranger. What should a loop evaluate to? A
whileloop in CoffeeScript evaluates to an array containing each element that the body evaluated to. That can be handy, or a waste of memory if you don’t need the array.You also have to decide how these statement-like expressions compose with other expressions—you have to fit them into the grammar’s precedence table. For example, Ruby allows:
puts 1 + if true then 2 else 3 end + 4Is this what you’d expect? Is it what your users expect? How does this affect how you design the syntax for your “statements”? Note that Ruby has an explicit
endto tell when theifexpression is complete. Without it, the+ 4would likely be parsed as part of theelseclause.Turning every statement into an expression forces you to answer a few hairy questions like that. In return, you eliminate some redundancy. C has both blocks for sequencing statements, and the comma operator for sequencing expressions. It has both the
ifstatement and the?:conditional operator. If everything was an expression in C, you could unify each of those.Languages that do away with statements usually also feature implicit returns—a function automatically returns whatever value its body evaluates to without need for some explicit
returnsyntax. For small functions and methods, this is really handy. In fact, many languages that do have statements have added syntax like=>to be able to define functions whose body is the result of evaluating a single expression.But making all functions work that way can be a little strange. If you aren’t careful, your function will leak a return value even if you only intend it to produce a side effect. In practice, though, users of these languages don’t find it to be a problem.
For Lox, I gave it statements for prosaic reasons. I picked a C-like syntax for familiarity’s sake, and trying to take the existing C statement syntax and interpret it like expressions gets weird pretty fast.
Lox既有表示式也有語句。有些語言省略了後者。相對地,它們將宣告和控制流結構也視為表示式。這類 "一切都是表示式" 的語言往往具有函式式的血統,包括大多數Lisps、SML、Haskell、Ruby和CoffeeScript。
要做到這一點,對於語言中的每一個 "類似於語句" 的構造,你需要決定它所計算的值是什麼。其中有些很簡單:
if表示式的計算結果是所選分支的結果。同樣,switch或其他多路分支的計算結果取決於所選擇的情況。- 變數宣告的計算結果是變數的值。
- 塊的計算結果是序列中最後一個表示式的結果。
有一些是比較複雜的。迴圈應該計算什麼值?在CoffeeScript中,一個while迴圈計算結果為一個陣列,其中包含了迴圈體中計算到的每個元素。這可能很方便,但如果你不需要這個陣列,就會浪費記憶體。
您還必須決定這些類似語句的表示式如何與其他表示式組合,必須將它們放入語法的優先表中。例如,Ruby允許下面這種寫法:
puts 1 + if true then 2 else 3 end + 4
這是你所期望的嗎?這是你的使用者所期望的嗎?這對你如何設計 "語句 "的語法有什麼影響?請注意,Ruby有一個顯式的end關鍵字來表明if表示式結束。如果沒有它,+4很可能會被解析為 else子句的一部分。
把每個語句都轉換成表示式會迫使你回答一些類似這樣的複雜問題。作為回報,您消除了一些冗餘。C語言中既有用於排序語句的塊,以及用於排序表示式的逗號運算子。它既有if語句,也有?:條件運算子。如果在C語言中所有東西都是表示式,你就可以把它們統一起來。
取消了語句的語言通常還具有隱式返回的特點——函式自動返回其函式主體所計算得到的任何值,而不需要顯式的return語法。對於小型函式和方法來說,這真的很方便。事實上,許多有語句的語言都添加了類似於 => 的語法,以便能夠定義函式體是計算單一表達式結果的函式。
但是讓所有的函式以這種方式工作可能有點奇怪。即使你只是想讓函式產生副作用,如果不小心,函式也可能會洩露返回值。但實際上,這些語言的使用者並不覺得這是一個問題。
對於Lox,我在其中新增語句是出於樸素的原因。為了熟悉起見,我選擇了一種類似於C的語法,而試圖把現有的C語句語法像表示式一樣解釋,會很快變得奇怪。
-
我肯定有偏見,但我認為Lox的語法很乾淨。 C語言最嚴重的語法問題就是關於型別的。丹尼斯·裡奇(Dennis Ritchie)有個想法叫“宣告反映使用”,其中變數宣告反映了為獲得基本型別的值而必須對變數執行的操作。這主意不錯,但是我認為實踐中效果不太好。Lox沒有靜態型別,所以我們避免了這一點。 ↩
-
現在,JavaScript已席捲全球,並已用於構建大量應用程式,很難將其視為“小指令碼語言”。但是Brendan Eich曾在十天內將第一個JS直譯器嵌入了Netscape Navigator,以使網頁上的按鈕具有動畫效果。 從那時起,JavaScript逐漸發展起來,但是它曾經是一種可愛的小語言。因為Eich大概只用了一集MacGyver的時間把JS糅合在一起,所以它有一些奇怪的語義,會有明顯的拼湊痕跡。比如變數提升、動態繫結
this、陣列中的漏洞和隱式轉換等。我有幸在Lox上多花了點時間,所以它應該更乾淨一些。 ↩ -
畢竟,我們用於實現Lox的兩種語言都是靜態型別的。 ↩
-
在實踐中,引用計數和追蹤更像是連續體的兩端,而不是對立的雙方。大多數引用計數系統最終會執行一些跟蹤來處理迴圈,如果你仔細觀察的話,分代收集器的寫屏障看起來有點像保留呼叫。有關這方面的更多資訊,請參閱垃圾收集統一理論(PDF)。 ↩
-
布林變數是Lox中唯一以人名George Boole命名的資料型別,這也是為什麼 "Boolean "是大寫的原因。他死於1864年,比數字計算機把他的代數變成電子資訊的時間早了近一個世紀。我很好奇他看到自己的名字出現在數十億行Java程式碼中時會怎麼想。 ↩
-
就連那個 "character "一詞也是個騙局。是ASCII碼?是Unicode?一個碼點,還是一個 "字詞群"?字元是如何編碼的?每個字元是固定的大小,還是可以變化的? ↩
-
有些運算子有兩個以上的運算元,並且運算子與運算元之間是交錯的。唯一廣泛使用的是C及其相近語言中的“條件”或“三元”運算子:
condition ?thenArm: elseArm;,有些人稱這些為mixfix運算子。有一些語言允許您定義自己的運算子,並控制它們的定位方式——它們的 "固定性"。。 ↩ -
我使用了and和or,而不是&&和||,因為Lox不使用&和|作為位元運算子。不存在單字元形式的情況下引入雙字元形式感覺很奇怪。我喜歡用單詞來表示運算,也是因為它們實際上是控制流結構,而不是簡單的運算子。 ↩
-
將 print 融入到語言中,而不是僅僅將其作為一個核心庫函式,這是一種入侵。但對我們來說,這是一個很有用的“入侵”:這意味著在我們實現所有定義函式、按名稱查詢和呼叫函式所需的機制之前,我們的直譯器可以就開始產生輸出。 ↩
-
這是一種情況,沒有nil並強制每個變數初始化為某個值,會比處理nil本身更麻煩。 ↩
-
我們已經有and和or可以進行分支處理,我們可以用遞迴來重複程式碼,所以理論上這就足夠了。但是,在命令式語言中這樣程式設計會很尷尬。另一方面,Scheme沒有內建的迴圈結構。它確實依賴遞迴進行重複執行程式碼。Smalltalk沒有內建的分支結構,並且依賴動態分派來選擇性地執行程式碼。 ↩
-
我沒有在Lox中使用do-while迴圈,因為它們並不常見,相比while迴圈也沒有多餘的內涵。如果你高興的話,就把它加入到你的實現中去吧。你自己做主。 ↩
-
這是我做出的讓步,因為本書中的實現是按章節劃分的。for-in迴圈需要迭代器協議中的某種動態分派來處理不同型別的序列,但我們完成控制流之後才能實現這種分派。我們可以回過頭來,新增for-in迴圈,但我認為這樣做不會教給你什麼超級有趣的東西。 ↩
-
說到術語,一些靜態型別的語言,比如C語言,會對函式的宣告和定義進行區分。宣告是將函式的型別和它的名字繫結在一起,所以呼叫時可以進行型別檢查,但不提供函式體。定義也會填入函式的主體,這樣就可以進行編譯。由於Lox是動態型別的,所以這種區分沒有意義。一個函式宣告完全指定了函式,包括它的主體。 ↩
-
Peter J. Landin創造了這個詞。沒錯,幾乎一半的程式語言術語都是他創造的。它們中的大部分都出自一篇不可思議的論文 "The Next 700 Programming Languages"。為了實現這類函式,您需要建立一個資料結構,將函式程式碼和它所需要的周圍變數繫結在一起。他稱它為“閉包”,是因為函式“閉合”並保留了它需要的變數。 ↩
-
這裡的8軌音樂指的是磁帶。在中國大陸,通常“磁帶”或者“錄音帶”一詞都指緊湊音訊盒帶,因為它的應用非常廣泛。在中國臺灣,reel-to-reel tape被稱為盤式錄音帶、緊湊音訊盒帶(Compact audio cassette)被稱為卡式錄音帶、8軌軟片(8-track cartridges))被稱為匣式錄音帶。 ↩
-
實際上,基於類的語言和基於原型的語言之間的界限變得模糊了。JavaScript的“建構函式”概念使您很難定義類物件。 同時,基於類的Ruby非常樂意讓您將方法附加到單個例項中。 ↩
-
Perl的發明家/先知Larry Wall將其稱為“水床理論”。 某些複雜性是必不可少的,無法消除。 如果在某個位置將其向下推,則在另一個位置會出現膨脹。原型語言並沒有消除類的複雜性,因為它們確實讓使用者透過構建近似類的超程式設計庫來承擔這種複雜性。 ↩
-
為什麼用<運算子?我不喜歡引入一個新的關鍵字,比如extends。Lox不使用:來做其他事情,所以我也不想保留它。相反,我借鑑了Ruby的做法,使用了<。如果你瞭解任何型別理論,你會發現這並不是一個完全任意的選擇。一個子類的每一個例項也是它的超類的一個例項,但可能有超類的例項不是子類的例項。這意味著,在物件的宇宙中,子類物件的集合比超類的集合要小,儘管型別迷們通常用<:來表示這種關係。 ↩
-
Lox不同於不繼承建構函式的c++、Java和c#,而是類似於Smalltalk和Ruby,它們繼承了建構函式。 ↩
II. A TREE-WALK INTERPRETER
With this part, we begin jlox, the first of our two interpreters. Programming languages are a huge topic with piles of concepts and terminology to cram into your brain all at once. Programming language theory requires a level of mental rigor that you probably haven’t had to summon since your last calculus final. (Fortunately there isn’t too much theory in this book.)
在這部分中,我們開始學習jlox,這是我們兩個解釋器中的第一個。編程語言是一個巨大的話題,其中有大量的概念和術語需要一下子塞進你的大腦。編程語言理論需要一定程度的腦力投入,你可能自上次微積分期末考試後就沒這麼投入過了。(幸運的是,這本書沒有太多的理論。)
Implementing an interpreter uses a few architectural tricks and design patterns uncommon in other kinds of applications, so we’ll be getting used to the engineering side of things too. Given all of that, we’ll keep the code we have to write as simple and plain as possible.
實現一個解釋器需要一些架構技巧和設計模式,這在其他類型的應用程序中是不常見的,所以我們也要習慣於工程方面的東西。考慮到這些,我們會盡可能地讓代碼簡單明瞭。
In less than two thousand lines of clean Java code, we’ll build a complete interpreter for Lox that implements every single feature of the language, exactly as we’ve specified. The first few chapters work front-to-back through the phases of the interpreter—scanning, parsing, and evaluating code. After that, we add language features one at a time, growing a simple calculator into a full-fledged scripting language.
在不到2000行簡潔的Java代碼中,我們將為Lox構建一個完整的解釋器,完全按照我們指定的方式實現該語言的每一個功能。前幾章從頭到尾介紹解釋器的各個階段——掃描、解析和計算代碼。之後,我們逐步添加語言特性,將一個簡單的計算器發展成一種成熟的腳本語言。
4.掃描 Scanning
Take big bites. Anything worth doing is worth overdoing.
—— Robert A. Heinlein, Time Enough for Love
大幹特工。每件值得做的事都要盡力做好。
The first step in any compiler or interpreter is scanning. The scanner takes in raw source code as a series of characters and groups it into a series of chunks we call tokens. These are the meaningful “words” and “punctuation” that make up the language’s grammar.
任何編譯器或直譯器的第一步都是掃描1。掃描器以一系列字元的形式接收原始原始碼,並將其分組成一系列的塊,我們稱之為標識(詞法單元)。這些是有意義的 "單詞 "和 "標點",它們構成了語言的語法。
Scanning is a good starting point for us too because the code isn’t very hard—pretty much a
switchstatement with delusions of grandeur. It will help us warm up before we tackle some of the more interesting material later. By the end of this chapter, we’ll have a full-featured, fast scanner that can take any string of Lox source code and produce the tokens that we’ll feed into the parser in the next chapter.
對於我們來說,掃描也是一個很好的起點,因為程式碼不是很難——相當於有很多分支的switch語句。這可以幫助我們在學習更後面有趣的部分之前進行熱身。在本章結束時,我們將擁有一個功能齊全、速度快的掃描器,它可以接收任何一串Lox原始碼,併產生標記,我們將在下一章把這些標記輸入到解析器中。
4 . 1 The Interpreter Framework
4.1 直譯器框架
Since this is our first real chapter, before we get to actually scanning some code we need to sketch out the basic shape of our interpreter, jlox. Everything starts with a class in Java.
由於這是我們的第一個真正的章節,在我們開始實際掃描程式碼之前,我們需要先勾勒出我們的直譯器jlox的基本形態。在Java中,一切都是從一個類開始的。
【譯者注:原作者在程式碼的側邊欄標註了程式碼名及對應的操作(建立檔案、追加程式碼、刪除程式碼等),由於翻譯版的格式受限,將這部分資訊遷移到程式碼塊之前,以帶下劃線的斜體突出,後同】
lox/Lox.java,建立新檔案2
package com.craftinginterpreters.lox;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Lox {
public static void main(String[] args) throws IOException {
if (args.length > 1) {
System.out.println("Usage: jlox [script]");
System.exit(64);
} else if (args.length == 1) {
runFile(args[0]);
} else {
runPrompt();
}
}
}
Stick that in a text file, and go get your IDE or Makefile or whatever set up. I’ll be right here when you’re ready. Good? OK!
把它貼在一個文字檔案裡,然後去把你的IDE或者Makefile或者其他工具設定好。我就在這裡等你準備好。好了嗎?好的!
Lox is a scripting language, which means it executes directly from source. Our interpreter supports two ways of running code. If you start jlox from the command line and give it a path to a file, it reads the file and executes it.
Lox是一種指令碼語言,這意味著它直接從原始碼執行。我們的直譯器支援兩種執行程式碼的方式。如果從命令列啟動jlox併為其提供檔案路徑,它將讀取該檔案並執行。
lox/Lox.java,新增到main()方法之後
private static void runFile(String path) throws IOException {
byte[] bytes = Files.readAllBytes(Paths.get(path));
run(new String(bytes, Charset.defaultCharset()));
}
If you want a more intimate conversation with your interpreter, you can also run it interactively. Fire up jlox without any arguments, and it drops you into a prompt where you can enter and execute code one line at a time.
如果你想與你的直譯器對話, 可以互動式的啟動它。 啟動的時候不加任何引數就可以了,它會有一個提示符,你可以在提示符處一次輸入並執行一行程式碼。
lox/Lox.java,新增到runFile()方法之後3
private static void runPrompt() throws IOException {
InputStreamReader input = new InputStreamReader(System.in);
BufferedReader reader = new BufferedReader(input);
for (;;) {
System.out.print("> ");
String line = reader.readLine();
if (line == null) break;
run(line);
}
}
The
readLine()function, as the name so helpfully implies, reads a line of input from the user on the command line and returns the result. To kill an interactive command-line app, you usually type Control-D. Doing so signals an “end-of-file” condition to the program. When that happensreadLine()returnsnull, so we check for that to exit the loop.
readLine()函式,顧名思義,讀取使用者在命令列上的一行輸入,並返回結果。要終止互動式命令列應用程式,通常需要輸入Control-D。這樣做會向程式發出 "檔案結束" 的訊號。當這種情況發生時,readLine()就會返回null,所以我們檢查一下是否存在null以退出迴圈。
Both the prompt and the file runner are thin wrappers around this core function:
互動式提示符和檔案執行工具都是對這個核心函式的簡單包裝:
lox/Lox.java,新增到runPrompt()之後
private static void run(String source) {
Scanner scanner = new Scanner(source);
List<Token> tokens = scanner.scanTokens();
// For now, just print the tokens.
for (Token token : tokens) {
System.out.println(token);
}
}
It’s not super useful yet since we haven’t written the interpreter, but baby steps, you know? Right now, it prints out the tokens our forthcoming scanner will emit so that we can see if we’re making progress.
因為我們還沒有寫出直譯器,所以這些程式碼還不是很有用,但這只是小步驟,你要明白?現在,它可以打印出我們即將完成的掃描器所返回的標記,這樣我們就可以看到我們的解析是否生效。
4 . 1 . 1 Error handling
4.1.1 錯誤處理
While we’re setting things up, another key piece of infrastructure is error handling. Textbooks sometimes gloss over this because it’s more a practical matter than a formal computer science-y problem. But if you care about making a language that’s actually usable, then handling errors gracefully is vital.
當我們設定東西的時候,另一個關鍵的基礎設施是錯誤處理。教科書有時會掩蓋這一點,因為這更多的是一個實際問題,而不是一個正式的電腦科學問題。但是,如果你關心的是如何製作一個真正可用的語言,那麼優雅地處理錯誤是至關重要的。
The tools our language provides for dealing with errors make up a large portion of its user interface. When the user’s code is working, they aren’t thinking about our language at all—their headspace is all about their program. It’s usually only when things go wrong that they notice our implementation.
我們的語言提供的處理錯誤的工具構成了其使用者介面的很大一部分。當使用者的程式碼在工作時,他們根本不會考慮我們的語言——他們的腦子裡都是他們的程式。通常只有當程式出現問題時,他們才會注意到我們的實現。
When that happens, it’s up to us to give the user all the information they need to understand what went wrong and guide them gently back to where they are trying to go. Doing that well means thinking about error handling all through the implementation of our interpreter, starting now.
當這種情況發生時,我們就需要向用戶提供他們所需要的所有資訊,讓他們瞭解哪裡出了問題,並引導他們慢慢達到他們想要去的地方。要做好這一點,意味著從現在開始,在直譯器的整個實現過程中都要考慮錯誤處理4。
lox/Lox.java,新增到run()方法之後
static void error(int line, String message) {
report(line, "", message);
}
private static void report(int line, String where,
String message) {
System.err.println(
"[line " + line + "] Error" + where + ": " + message);
hadError = true;
}
This
error()function and itsreport()helper tells the user some syntax error occurred on a given line. That is really the bare minimum to be able to claim you even have error reporting. Imagine if you accidentally left a dangling comma in some function call and the interpreter printed out:
這個error()函式和其工具方法report()會告訴使用者在某一行上發生了一些語法錯誤。這其實是最起碼的,可以說你有錯誤報告功能。想象一下,如果你在某個函式呼叫中不小心留下了一個懸空的逗號,直譯器就會打印出來:
Error: Unexpected "," somewhere in your code. Good luck finding it!
That’s not very helpful. We need to at least point them to the right line. Even better would be the beginning and end column so they know where in the line. Even better than that is to show the user the offending line, like:
這種資訊沒有多大幫助。我們至少要給他們指出正確的方向。好一些的做法是指出開頭和結尾一欄,這樣他們就知道這一行的位置了。更好的做法是向用戶顯示違規的行,比如:
Error: Unexpected "," in argument list.
15 | function(first, second,);
^-- Here.
I’d love to implement something like that in this book but the honest truth is that it’s a lot of grungy string manipulation code. Very useful for users, but not super fun to read in a book and not very technically interesting. So we’ll stick with just a line number. In your own interpreters, please do as I say and not as I do.
我很想在這本書裡實現這樣的東西,但老實說,這會引入很多繁瑣的字串操作程式碼。這些程式碼對使用者來說非常有用,但在書中讀起來並不友好,而且技術上也不是很有趣。所以我們還是隻用一個行號。在你們自己的直譯器中,請按我說的做,而不是按我做的做。
The primary reason we’re sticking this error reporting function in the main Lox class is because of that
hadErrorfield. It’s defined here:
我們在Lox主類中堅持使用這個錯誤報告功能的主要原因就是因為那個hadError欄位。它的定義在這裡:
lox/Lox.java 在Lox類中新增:
public class Lox {
static boolean hadError = false;
We’ll use this to ensure we don’t try to execute code that has a known error. Also, it lets us exit with a non-zero exit code like a good command line citizen should.
我們將以此來確保我們不會嘗試執行有已知錯誤的程式碼。此外,它還能讓我們像一個好的命令列工具那樣,用一個非零的結束程式碼退出。
lox/Lox.java,在runFile()中新增:
run(new String(bytes, Charset.defaultCharset()));
// Indicate an error in the exit code.
if (hadError) System.exit(65);
}
We need to reset this flag in the interactive loop. If the user makes a mistake, it shouldn’t kill their entire session.
我們需要在互動式迴圈中重置此標誌。 如果使用者輸入有誤,也不應終止整個會話。
lox/Lox.java,在runPrompt()中新增:
run(line);
hadError = false;
}
The other reason I pulled the error reporting out here instead of stuffing it into the scanner and other phases where the error might occur is to remind you that it’s good engineering practice to separate the code that generates the errors from the code that reports them.
我把錯誤報告拉出來,而不是把它塞進掃描器和其他可能發生錯誤的階段,還有另一個原因,是為了提醒您,把產生錯誤的程式碼和報告錯誤的程式碼分開是一個很好的工程實踐。
Various phases of the front end will detect errors, but it’s not really their job to know how to present that to a user. In a full-featured language implementation, you will likely have multiple ways errors get displayed: on stderr, in an IDE’s error window, logged to a file, etc. You don’t want that code smeared all over your scanner and parser.
前端的各個階段都會檢測到錯誤,但是它們不需要知道如何向用戶展示錯誤。在一個功能齊全的語言實現中,可能有多種方式展示錯誤資訊:在stderr,在IDE的錯誤視窗中,記錄到檔案,等等。您肯定不希望掃描器和直譯器中到處充斥著這類程式碼。
Ideally, we would have an actual abstraction, some kind of “ErrorReporter” interface that gets passed to the scanner and parser so that we can swap out different reporting strategies. For our simple interpreter here, I didn’t do that, but I did at least move the code for error reporting into a different class.
理想情況下,我們應該有一個實際的抽象,即傳遞給掃描程式和解析器的某種ErrorReporter介面5,這樣我們就可以交換不同的報告策略。對於我們這裡的簡單直譯器,我沒有那樣做,但我至少將錯誤報告程式碼移到了一個不同的類中。
With some rudimentary error handling in place, our application shell is ready. Once we have a Scanner class with a
scanTokens()method, we can start running it. Before we get to that, let’s get more precise about what tokens are.
有了一些基本的錯誤處理,我們的應用程式外殼已經準備好了。一旦我們有了一個帶有 scanTokens() 方法的 Scanner 類,我們就可以開始執行它了。在我們開始之前,讓我們更精確地瞭解什麼是標記(tokens)。
4 . 2 Lexemes and Tokens
4.2 詞素和標記(詞法單元)
下面是一行lox程式碼:
var language = "lox";
Here,
varis the keyword for declaring a variable. That three-character sequence “v-a-r” means something. But if we yank three letters out of the middle oflanguage, like “g-u-a”, those don’t mean anything on their own.
在這裡,var是宣告變數的關鍵字。“v-a-r”這三個字元的序列是有意義的。但如果我們從language中間抽出三個字母,比如“g-u-a”,它們本身並沒有任何意義。
That’s what lexical analysis is about. Our job is to scan through the list of characters and group them together into the smallest sequences that still represent something. Each of these blobs of characters is called a lexeme. In that example line of code, the lexemes are:
這就是詞法分析的意義所在。我們的工作是掃描字元列表,並將它們歸納為具有某些含義的最小序列。每一組字元都被稱為詞素。在示例程式碼行中,詞素是:

The lexemes are only the raw substrings of the source code. However, in the process of grouping character sequences into lexemes, we also stumble upon some other useful information. When we take the lexeme and bundle it together with that other data, the result is a token. It includes useful stuff like:
詞素只是原始碼的原始子字串。 但是,在將字元序列分組為詞素的過程中,我們也會發現了一些其他有用的資訊。 當我們獲取詞素並將其與其他資料捆綁在一起時,結果是一個標記(token,詞法單元)。它包含一些有用的內容,比如:
4 . 2 . 1 Token type
4.2.1 標記型別
Keywords are part of the shape of the language’s grammar, so the parser often has code like, “If the next token is
whilethen do . . . ” That means the parser wants to know not just that it has a lexeme for some identifier, but that it has a reserved word, and which keyword it is.
關鍵詞是語言語法的一部分,所以解析器經常會有這樣的程式碼:"如果下一個標記是while,那麼就……" 。這意味著解析器想知道的不僅僅是它有某個識別符號的詞素,而是它得到一個保留詞,以及它是哪個關鍵詞。
The parser could categorize tokens from the raw lexeme by comparing the strings, but that’s slow and kind of ugly. Instead, at the point that we recognize a lexeme, we also remember which kind of lexeme it represents. We have a different type for each keyword, operator, bit of punctuation, and literal type.
解析器可以透過比較字串對原始詞素中的標記進行分類,但這樣做很慢,而且有點難看6。相反,在我們識別一個詞素的時候,我們還要記住它代表的是哪種詞素。我們為每個關鍵字、運算子、標點位和字面量都有不同的型別。
lox/TokenType.java 建立新檔案
package com.craftinginterpreters.lox;
enum TokenType {
// Single-character tokens.
LEFT_PAREN, RIGHT_PAREN, LEFT_BRACE, RIGHT_BRACE,
COMMA, DOT, MINUS, PLUS, SEMICOLON, SLASH, STAR,
// One or two character tokens.
BANG, BANG_EQUAL,
EQUAL, EQUAL_EQUAL,
GREATER, GREATER_EQUAL,
LESS, LESS_EQUAL,
// Literals.
IDENTIFIER, STRING, NUMBER,
// Keywords.
AND, CLASS, ELSE, FALSE, FUN, FOR, IF, NIL, OR,
PRINT, RETURN, SUPER, THIS, TRUE, VAR, WHILE,
EOF
}
4 . 2 . 2 Literal value
4.2.2 字面量
There are lexemes for literal values—numbers and strings and the like. Since the scanner has to walk each character in the literal to correctly identify it, it can also convert that textual representation of a value to the living runtime object that will be used by the interpreter later.
字面量有對應詞素——數字和字串等。由於掃描器必須遍歷文字中的每個字元才能正確識別,所以它還可以將值的文字表示轉換為執行時物件,直譯器後續將使用該物件。
4 . 2 . 3 Location information
4.2.3 位置資訊
Back when I was preaching the gospel about error handling, we saw that we need to tell users where errors occurred. Tracking that starts here. In our simple interpreter, we note only which line the token appears on, but more sophisticated implementations include the column and length too.
早在我宣講錯誤處理的福音時,我們就看到,我們需要告訴使用者錯誤發生在哪裡。(使用者)從這裡開始定位問題。在我們的簡易直譯器中,我們只說明瞭標記出現在哪一行上,但更復雜的實現中還應該包括列位置和長度7。
We take all of this data and wrap it in a class.
我們將所有這些資料打包到一個類中。
lox/Token.java,建立新檔案
package com.craftinginterpreters.lox;
class Token {
final TokenType type;
final String lexeme;
final Object literal;
final int line;
Token(TokenType type, String lexeme, Object literal, int line) {
this.type = type;
this.lexeme = lexeme;
this.literal = literal;
this.line = line;
}
public String toString() {
return type + " " + lexeme + " " + literal;
}
}
Now we have an object with enough structure to be useful for all of the later phases of the interpreter.
現在我們有了一個資訊充分的物件,足以支撐直譯器的所有後期階段。
4 . 3 Regular Languages and Expressions
4.3 正則語言和表示式
Now that we know what we’re trying to produce, let’s, well, produce it. The core of the scanner is a loop. Starting at the first character of the source code, it figures out what lexeme it belongs to, and consumes it and any following characters that are part of that lexeme. When it reaches the end of that lexeme, it emits a token.
既然我們已知道我們要輸出什麼,那麼,我們就開始吧。掃描器的核心是一個迴圈。從原始碼的第一個字元開始,掃描器計算出該字元屬於哪個詞素,並消費它和屬於該詞素的任何後續字元。當到達該詞素的末尾時,掃描器會輸出一個標記(詞法單元 token)。
Then it loops back and does it again, starting from the very next character in the source code. It keeps doing that, eating characters and occasionally, uh, excreting tokens, until it reaches the end of the input.
然後再迴圈一次,它又迴圈回來,從原始碼中的下一個字元開始再做一次。它一直這樣做,吃掉字元,偶爾,呃,排出標記,直到它到達輸入的終點。

The part of the loop where we look at a handful of characters to figure out which kind of lexeme it “matches” may sound familiar. If you know regular expressions, you might consider defining a regex for each kind of lexeme and using those to match characters. For example, Lox has the same rules as C for identifiers (variable names and the like). This regex matches one:
在迴圈中,我們會檢視一些字元,以確定它 "匹配 "的是哪種詞素,這部分內容可能聽起來很熟悉,但如果你知道正規表示式,你可以考慮為每一種詞素定義一個regex,並使用這些regex來匹配字元。例如,Lox對識別符號(變數名等)的規則與C語言相同。下面的regex可以匹配一個識別符號:
[a-zA-Z_][a-zA-Z_0-9]*
If you did think of regular expressions, your intuition is a deep one. The rules that determine how a particular language groups characters into lexemes are called its lexical grammar. In Lox, as in most programming languages, the rules of that grammar are simple enough for the language to be classified a regular language. That’s the same “regular” as in regular expressions.
如果你確實想到了正規表示式,那麼你的直覺還是很深刻的。決定一門語言如何將字元分組為詞素的規則被稱為它的詞法語法8。在Lox中,和大多數程式語言一樣,該語法的規則非常簡單,可以將其歸為 正則語言。這裡的正則和正規表示式中的 "正則 "是一樣的含義。
You very precisely can recognize all of the different lexemes for Lox using regexes if you want to, and there’s a pile of interesting theory underlying why that is and what it means. Tools like Lex or Flex are designed expressly to let you do this—throw a handful of regexes at them, and they give you a complete scanner back.
如果你願意,你可以非常精確地使用正規表示式來識別Lox的所有不同片語,而且還有一堆有趣的理論來支撐著為什麼會這樣以及它的意義。像Lex9或Flex這樣的工具就是專門為實現這一功能而設計的——向其中傳入一些正規表示式,它可以為您提供完整的掃描器。
Since our goal is to understand how a scanner does what it does, we won’t be delegating that task. We’re about handcrafted goods.
由於我們的目標是瞭解掃描器是如何工作的,所以我們不會把這個任務交給正規表示式。我們要親自動手實現。
4 . 4 The Scanner Class
4.4 Scanner類
事不宜遲,我們先來建一個掃描器吧。
lox/Scanner.java,建立新檔案10
package com.craftinginterpreters.lox;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import static com.craftinginterpreters.lox.TokenType.*;
class Scanner {
private final String source;
private final List<Token> tokens = new ArrayList<>();
Scanner(String source) {
this.source = source;
}
}
We store the raw source code as a simple string, and we have a list ready to fill with tokens we’re going to generate. The aforementioned loop that does that looks like this:
我們將原始的原始碼儲存為一個簡單的字串,並且我們已經準備了一個列表來儲存掃描時產生的標記。前面提到的迴圈看起來類似於:
lox/Scanner.java,方法Scanner()後新增:
List<Token> scanTokens() {
while (!isAtEnd()) {
// We are at the beginning of the next lexeme.
start = current;
scanToken();
}
tokens.add(new Token(EOF, "", null, line));
return tokens;
}
The scanner works its way through the source code, adding tokens until it runs out of characters. Then it appends one final “end of file” token. That isn’t strictly needed, but it makes our parser a little cleaner.
掃描器透過自己的方式遍歷原始碼,新增標記,直到遍歷完所有字元。然後,它在最後附加一個的 "end of file "標記。嚴格意義上來說,這並不是必須的,但它可以使我們的解析器更加乾淨。
This loop depends on a couple of fields to keep track of where the scanner is in the source code.
這個迴圈依賴於幾個欄位來跟蹤掃描器在原始碼中的位置。
lox/Scanner.java,在Scanner類中新增:
private final List<Token> tokens = new ArrayList<>();
// 新增下面三行程式碼
private int start = 0;
private int current = 0;
private int line = 1;
Scanner(String source) {
The
startandcurrentfields are offsets that index into the string. Thestartfield points to the first character in the lexeme being scanned, andcurrentpoints at the character currently being considered. Thelinefield tracks what source linecurrentis on so we can produce tokens that know their location.
start和current欄位是指向字串的偏移量。start欄位指向被掃描的詞素中的第一個字元,current欄位指向當前正在處理的字元。line欄位跟蹤的是current所在的原始檔行數,這樣我們產生的標記就可以知道其位置。
Then we have one little helper function that tells us if we’ve consumed all the characters.
然後,我們還有一個輔助函式,用來告訴我們是否已消費完所有字元。
lox/Scanner.java在scanTokens()方法之後新增:
private boolean isAtEnd() {
return current >= source.length();
}
4 . 5 Recognizing Lexemes
4 . 5 識別詞素
In each turn of the loop, we scan a single token. This is the real heart of the scanner. We’ll start simple. Imagine if every lexeme were only a single character long. All you would need to do is consume the next character and pick a token type for it. Several lexemes are only a single character in Lox, so let’s start with those.
在每一次迴圈中,我們可以掃描出一個 token。這是掃描器真正的核心。讓我們先從簡單情況開始。想象一下,如果每個詞素只有一個字元長。您所需要做的就是消費下一個字元併為其選擇一個 token 型別。在Lox中有一些詞素只包含一個字元,所以我們從這些詞素開始11。
lox/Scanner.java新增到scanTokens()方法之後
private void scanToken() {
char c = advance();
switch (c) {
case '(': addToken(LEFT_PAREN); break;
case ')': addToken(RIGHT_PAREN); break;
case '{': addToken(LEFT_BRACE); break;
case '}': addToken(RIGHT_BRACE); break;
case ',': addToken(COMMA); break;
case '.': addToken(DOT); break;
case '-': addToken(MINUS); break;
case '+': addToken(PLUS); break;
case ';': addToken(SEMICOLON); break;
case '*': addToken(STAR); break;
}
}
Again, we need a couple of helper methods.
同樣,我們也需要一些輔助方法。
lox/Scanner.java,新增到 isAtEnd()方法後
private char advance() {
current++;
return source.charAt(current - 1);
}
private void addToken(TokenType type) {
addToken(type, null);
}
private void addToken(TokenType type, Object literal) {
String text = source.substring(start, current);
tokens.add(new Token(type, text, literal, line));
}
The
advance()method consumes the next character in the source file and returns it. Whereadvance()is for input,addToken()is for output. It grabs the text of the current lexeme and creates a new token for it. We’ll use the other overload to handle tokens with literal values soon.
advance()方法獲取原始檔中的下一個字元並返回它。advance()用於處理輸入,addToken()則用於輸出。該方法獲取當前詞素的文字併為其建立一個新 token。我們馬上會使用另一個過載方法來處理帶有字面值的 token。
4 . 5 . 1 Lexical errors
4.5.1 詞法錯誤
Before we get too far in, let’s take a moment to think about errors at the lexical level. What happens if a user throws a source file containing some characters Lox doesn’t use, like
@#^, at our interpreter? Right now, those characters get silently discarded. They aren’t used by the Lox language, but that doesn’t mean the interpreter can pretend they aren’t there. Instead, we report an error.
在我們深入探討之前,我們先花一點時間考慮一下詞法層面的錯誤。如果使用者拋入直譯器的原始檔中包含一些Lox中不使用的字元——如@#^,會發生什麼?現在,這些字元被默默拋棄了。它們沒有被Lox語言使用,但是不意味著直譯器可以假裝它們不存在。相反,我們應該報告一個錯誤:
lox/Scanner.java 在 scanToken()方法中新增:
case '*': addToken(STAR); break;
default:
Lox.error(line, "Unexpected character.");
break;
}
Note that the erroneous character is still consumed by the earlier call to
advance(). That’s important so that we don’t get stuck in an infinite loop.
注意,錯誤的字元仍然會被前面呼叫的advance()方法消費。這一點很重要,這樣我們就不會陷入無限迴圈了。
Note also that we keep scanning. There may be other errors later in the program. It gives our users a better experience if we detect as many of those as possible in one go. Otherwise, they see one tiny error and fix it, only to have the next error appear, and so on. Syntax error Whac-A-Mole is no fun.
另請注意,我們一直在掃描。 程式稍後可能還會出現其他錯誤。 如果我們能夠一次檢測出儘可能多的錯誤,將為我們的使用者帶來更好的體驗。 否則,他們會看到一個小錯誤並修復它,但是卻出現下一個錯誤,不斷重複這個過程。語法錯誤“打地鼠”一點也不好玩。
(Don’t worry. Since
hadErrorgets set, we’ll never try to execute any of the code, even though we keep going and scan the rest of it.)
(別擔心。因為hadError進行了賦值,我們永遠不會嘗試執行任何程式碼,即使程式在繼續執行並掃描程式碼檔案的其餘部分。)
4 . 5 . 2 Operators
4.5.2 運算子
We have single-character lexemes working, but that doesn’t cover all of Lox’s operators. What about
!? It’s a single character, right? Sometimes, yes, but if the very next character is an equals sign, then we should instead create a!=lexeme. Note that the!and=are not two independent operators. You can’t write! =in Lox and have it behave like an inequality operator. That’s why we need to scan!=as a single lexeme. Likewise,<,>, and=can all be followed by=to create the other equality and comparison operators.
我們的單字元詞素已經生效了,但是這不能涵蓋Lox中的所有運算子。比如!,這是單字元,對吧?有時候是的,但是如果下一個字元是等號,那麼我們應該改用!= 詞素。注意,這裡的!和=不是兩個獨立的運算子。在Lox中,你不能寫! =來表示不等運算子。這就是為什麼我們需要將!=作為單個詞素進行掃描。同樣地,<、>和=都可以與後面跟隨的=來組合成其他相等和比較運算子。
For all of these, we need to look at the second character.
對於所有這些情況,我們都需要檢視第二個字元。
lox/Scanner.java,在 scanToken()方法中新增
case '*': addToken(STAR); break;
case '!':
addToken(match('=') ? BANG_EQUAL : BANG);
break;
case '=':
addToken(match('=') ? EQUAL_EQUAL : EQUAL);
break;
case '<':
addToken(match('=') ? LESS_EQUAL : LESS);
break;
case '>':
addToken(match('=') ? GREATER_EQUAL : GREATER);
break;
default:
Those cases use this new method:
這些分支中使用了下面的新方法:
lox/Scanner.java 新增到 scanToken()方法後
private boolean match(char expected) {
if (isAtEnd()) return false;
if (source.charAt(current) != expected) return false;
current++;
return true;
}
It’s like a conditional
advance(). We only consume the current character if it’s what we’re looking for.
這就像一個有條件的advance()。只有當前字元是我們正在尋找的字元時,我們才會消費。
Using
match(), we recognize these lexemes in two stages. When we reach, for example,!, we jump to its switch case. That means we know the lexeme starts with!. Then we look at the next character to determine if we’re on a!=or merely a!.
使用match(),我們分兩個階段識別這些詞素。例如,當我們得到!時,我們會跳轉到它的case分支。這意味著我們知道這個詞素是以 !開始的。然後,我們檢視下一個字元,以確認詞素是一個 != 還是僅僅是一個 !。
4 . 6 Longer Lexemes
4.6 更長的詞素
We’re still missing one operator:
/for division. That character needs a little special handling because comments begin with a slash too.
我們還缺少一個運算子:表示除法的/。這個字元需要一些特殊處理,因為註釋也是以斜線開頭的。
lox/Scanner.java,在scanToken()方法中新增:
break;
case '/':
if (match('/')) {
// A comment goes until the end of the line.
while (peek() != '\n' && !isAtEnd()) advance();
} else {
addToken(SLASH);
}
break;
default:
This is similar to the other two-character operators, except that when we find a second
/, we don’t end the token yet. Instead, we keep consuming characters until we reach the end of the line.
這與其它的雙字元運算子是類似的,區別在於我們找到第二個/時,還沒有結束本次標記。相反,我們會繼續消費字元直至行尾。
This is our general strategy for handling longer lexemes. After we detect the beginning of one, we shunt over to some lexeme-specific code that keeps eating characters until it sees the end.
這是我們處理較長詞素的一般策略。當我們檢測到一個詞素的開頭後,我們會分流到一些特定於該詞素的程式碼,這些程式碼會不斷地消費字元,直到結尾。
We’ve got another helper:
我們又有了一個輔助函式:
lox/Scanner.java,在match()方法後新增:
private char peek() {
if (isAtEnd()) return '\0';
return source.charAt(current);
}
It’s sort of like
advance(), but doesn’t consume the character. This is called lookahead. Since it only looks at the current unconsumed character, we have one character of lookahead. The smaller this number is, generally, the faster the scanner runs. The rules of the lexical grammar dictate how much lookahead we need. Fortunately, most languages in wide use peek only one or two characters ahead.
這有點像advance()方法,只是不會消費字元。這就是所謂的lookahead(前瞻)12。因為它只關注當前未消費的字元,所以我們有一個前瞻字元。一般來說,前瞻的字元越少,掃描器執行速度就越快。詞法語法的規則決定了我們需要前瞻多少字元。幸運的是,大多數廣泛使用的語言只需要提前一到兩個字元。
Comments are lexemes, but they aren’t meaningful, and the parser doesn’t want to deal with them. So when we reach the end of the comment, we don’t call
addToken(). When we loop back around to start the next lexeme,startgets reset and the comment’s lexeme disappears in a puff of smoke.
註釋是詞素,但是它們沒有含義,而且解析器也不想要處理它們。所以,我們達到註釋末尾後,不會呼叫addToken()方法。當我們迴圈處理下一個詞素時,start已經被重置了,註釋的詞素就消失在一陣煙霧中了。
While we’re at it, now’s a good time to skip over those other meaningless characters: newlines and whitespace.
既然如此,現在正好可以跳過其它那些無意義的字元了:換行和空格。
lox/Scanner.java,在scanToken()方法中新增:
break;
case ' ':
case '\r':
case '\t':
// Ignore whitespace.
break;
case '\n':
line++;
break;
default:
Lox.error(line, "Unexpected character.");
When encountering whitespace, we simply go back to the beginning of the scan loop. That starts a new lexeme after the whitespace character. For newlines, we do the same thing, but we also increment the line counter. (This is why we used
peek()to find the newline ending a comment instead ofmatch(). We want that newline to get us here so we can updateline.)
當遇到空白字元時,我們只需回到掃描迴圈的開頭。這樣就會在空白字元之後開始一個新的詞素。對於換行符,我們做同樣的事情,但我們也會遞增行計數器。(這就是為什麼我們使用peek() 而不是match()來查詢註釋結尾的換行符。我們到這裡希望能讀取到換行符,這樣我們就可以更新行數了)
Our scanner is getting smarter. It can handle fairly free-form code like:
我們的掃描器越來越聰明瞭。它可以處理相當自由形式的程式碼,如:
// this is a comment
(( )){} // grouping stuff
!*+-/=<> <= == // operators
4 . 6 . 1 String literals
4.6.1 字串字面量
Now that we’re comfortable with longer lexemes, we’re ready to tackle literals. We’ll do strings first, since they always begin with a specific character,
".
現在我們對長詞素已經很熟悉了,我們可以開始處理字面量了。我們先處理字串,因為字串總是以一個特定的字元"開頭。
lox/Scanner.java,在 scanToken()方法中新增:
break;
case '"': string(); break;
default:
That calls:
這裡會呼叫:
lox/Scanner.java,在 scanToken()方法之後新增:
private void string() {
while (peek() != '"' && !isAtEnd()) {
if (peek() == '\n') line++;
advance();
}
if (isAtEnd()) {
Lox.error(line, "Unterminated string.");
return;
}
// The closing ".
advance();
// Trim the surrounding quotes.
String value = source.substring(start + 1, current - 1);
addToken(STRING, value);
}
Like with comments, we consume characters until we hit the
"that ends the string. We also gracefully handle running out of input before the string is closed and report an error for that.
與註釋類似,我們會一直消費字元,直到"結束該字串。如果輸入內容耗盡,我們也會進行優雅的處理,並報告一個對應的錯誤。
For no particular reason, Lox supports multi-line strings. There are pros and cons to that, but prohibiting them was a little more complex than allowing them, so I left them in. That does mean we also need to update
linewhen we hit a newline inside a string.
沒有特別的原因,Lox支援多行字串。這有利有弊,但禁止換行比允許換行更復雜一些,所以我把它們保留了下來。這意味著當我們在字串內遇到新行時,我們也需要更新line值。
Finally, the last interesting bit is that when we create the token, we also produce the actual string value that will be used later by the interpreter. Here, that conversion only requires a
substring()to strip off the surrounding quotes. If Lox supported escape sequences like\n, we’d unescape those here.
最後,還有一個有趣的地方就是當我們建立標記時,我們也會產生實際的字串值,該值稍後將被直譯器使用。這裡,值的轉換隻需要呼叫substring()剝離前後的引號。如果Lox支援轉義序列,比如\n,我們會在這裡取消轉義。
4 . 6 . 2 Number literals
4.6.2 數字字面量
All numbers in Lox are floating point at runtime, but both integer and decimal literals are supported. A number literal is a series of digits optionally followed by a
.and one or more trailing digits.
在Lox中,所有的數字在執行時都是浮點數,但是同時支援整數和小數字面量。一個數字字面量就是一系列數位,後面可以跟一個.和一或多個尾數13。
1234
12.34
我們不允許小數點處於最開始或最末尾,所以下面的格式是不正確的:
.1234
1234.
We could easily support the former, but I left it out to keep things simple. The latter gets weird if we ever want to allow methods on numbers like
123.sqrt().
我們可以很容易地支援前者,但為了保持簡單,我把它刪掉了。如果我們要允許對數字進行方法呼叫,比如123.sqrt(),後者會變得很奇怪。
To recognize the beginning of a number lexeme, we look for any digit. It’s kind of tedious to add cases for every decimal digit, so we’ll stuff it in the default case instead.
為了識別數字詞素的開頭,我們會尋找任何一位數字。 為每個十進位制數字新增case分支有點乏味,所以我們直接在預設分支中進行處理。
lox/Scanner.java,在 scanToken()方法中替換一行:
default:
// 替換部分開始
if (isDigit(c)) {
number();
} else {
Lox.error(line, "Unexpected character.");
}
// 替換部分結束
break;
This relies on this little utility:
這裡依賴下面的小工具函式14:
lox/Scanner.java,在 peek()方法之後新增:
private boolean isDigit(char c) {
return c >= '0' && c <= '9';
}
Once we know we are in a number, we branch to a separate method to consume the rest of the literal, like we do with strings.
一旦我們知道當前在處理數字,我們就分支進入一個單獨的方法消費剩餘的字面量,跟字串的處理類似。
lox/Scanner.java,在 scanToken()方法後新增:
private void number() {
while (isDigit(peek())) advance();
// Look for a fractional part.
if (peek() == '.' && isDigit(peekNext())) {
// Consume the "."
advance();
while (isDigit(peek())) advance();
}
addToken(NUMBER,
Double.parseDouble(source.substring(start, current)));
}
We consume as many digits as we find for the integer part of the literal. Then we look for a fractional part, which is a decimal point (
.) followed by at least one digit. If we do have a fractional part, again, we consume as many digits as we can find.
我們在字面量的整數部分中儘可能多地獲取數字。然後我們尋找小數部分,也就是一個小數點(.)後面至少跟一個數字。如果確實有小數部分,同樣地,我們也儘可能多地獲取數字。
Looking past the decimal point requires a second character of lookahead since we don’t want to consume the
.until we’re sure there is a digit after it. So we add:
在定位到小數點之後需要繼續前瞻第二個字元,因為我們只有確認其後有數字才會消費.。所以我們添加了15:
lox/Scanner.java,在 peek()方法後新增
private char peekNext() {
if (current + 1 >= source.length()) return '\0';
return source.charAt(current + 1);
}
Finally, we convert the lexeme to its numeric value. Our interpreter uses Java’s
Doubletype to represent numbers, so we produce a value of that type. We’re using Java’s own parsing method to convert the lexeme to a real Java double. We could implement that ourselves, but, honestly, unless you’re trying to cram for an upcoming programming interview, it’s not worth your time.
最後,我們將詞素轉換為其對應的數值。我們的直譯器使用Java的Double型別來表示數字,所以我們建立一個該型別的值。我們使用Java自帶的解析方法將詞素轉換為真正的Java double。我們可以自己實現,但是,說實話,除非你想為即將到來的程式設計面試做準備,否則不值得你花時間。
The remaining literals are Booleans and
nil, but we handle those as keywords, which gets us to . . .
剩下的詞素是Boolean和nil,但我們把它們作為關鍵字來處理,這樣我們就來到了......
4 . 7 Reserved Words and Identifiers
4.7 保留字和識別符號
Our scanner is almost done. The only remaining pieces of the lexical grammar to implement are identifiers and their close cousins, the reserved words. You might think we could match keywords like
orin the same way we handle multiple-character operators like<=.
我們的掃描器基本完成了,詞法語法中還需要實現的部分僅剩識別符號及其近親——保留字。你也許會想,我們可以採用與處理<=等多字元運算子時相同的方法來匹配關鍵字,如or。
case 'o':
if (peek() == 'r') {
addToken(OR);
}
break;
Consider what would happen if a user named a variable
orchid. The scanner would see the first two letters,or, and immediately emit anorkeyword token. This gets us to an important principle called maximal munch. When two lexical grammar rules can both match a chunk of code that the scanner is looking at, whichever one matches the most characters wins.
考慮一下,如果使用者將變數命名為orchid會發生什麼?掃描器會先看到前面的兩個字元,然後立刻生成一個or標記。這就涉及到了一個重要原則,叫作maximal munch(最長匹配)16。當兩個語法規則都能匹配掃描器正在處理的一大塊程式碼時,哪個規則相匹配的字元最多,就使用哪個規則。
That rule states that if we can match
orchidas an identifier andoras a keyword, then the former wins. This is also why we tacitly assumed, previously, that<=should be scanned as a single<=token and not<followed by=.
該規則規定,如果我們可以將orchid匹配為一個識別符號,也可以將or匹配為一個關鍵字,那就採用第一種結果。這也就是為什麼我們在前面會預設為,<=應該識別為單一的<=標記,而不是<後面跟了一個=。
Maximal munch means we can’t easily detect a reserved word until we’ve reached the end of what might instead be an identifier. After all, a reserved word is an identifier, it’s just one that has been claimed by the language for its own use. That’s where the term reserved word comes from.
最大匹配原則意味著,我們只有掃描完一個可能是識別符號的片段,才能確認是否一個保留字。畢竟,保留字也是一個識別符號,只是一個已經被語言要求為自己所用的識別符號。這也是保留字一詞的由來。
So we begin by assuming any lexeme starting with a letter or underscore is an identifier.
所以我們首先假設任何以字母或下劃線開頭的詞素都是一個識別符號。
lox/Scanner.java,在 scanToken()中新增程式碼
default:
if (isDigit(c)) {
number();
// 新增部分開始
} else if (isAlpha(c)) {
identifier();
// 新增部分結束
} else {
Lox.error(line, "Unexpected character.");
}
The rest of the code lives over here:
其它程式碼如下:
lox/Scanner.java,在 scanToken()方法之後新增:
private void identifier() {
while (isAlphaNumeric(peek())) advance();
addToken(IDENTIFIER);
}
We define that in terms of these helpers:
透過以下輔助函式來定義:
lox/Scanner.java,在 peekNext()方法之後新增:
private boolean isAlpha(char c) {
return (c >= 'a' && c <= 'z') ||
(c >= 'A' && c <= 'Z') ||
c == '_';
}
private boolean isAlphaNumeric(char c) {
return isAlpha(c) || isDigit(c);
}
That gets identifiers working. To handle keywords, we see if the identifier’s lexeme is one of the reserved words. If so, we use a token type specific to that keyword. We define the set of reserved words in a map.
這樣識別符號就開始工作了。為了處理關鍵字,我們要檢視識別符號的詞素是否是保留字之一。如果是,我們就使用該關鍵字特有的標記型別。我們在map中定義保留字的集合。
lox/Scanner.java,在 Scanner類中新增:
private static final Map<String, TokenType> keywords;
static {
keywords = new HashMap<>();
keywords.put("and", AND);
keywords.put("class", CLASS);
keywords.put("else", ELSE);
keywords.put("false", FALSE);
keywords.put("for", FOR);
keywords.put("fun", FUN);
keywords.put("if", IF);
keywords.put("nil", NIL);
keywords.put("or", OR);
keywords.put("print", PRINT);
keywords.put("return", RETURN);
keywords.put("super", SUPER);
keywords.put("this", THIS);
keywords.put("true", TRUE);
keywords.put("var", VAR);
keywords.put("while", WHILE);
}
Then, after we scan an identifier, we check to see if it matches anything in the map.
接下來,在我們掃描到識別符號之後,要檢查是否與map中的某些項匹配。
lox/Scanner.java,在 identifier()方法中替換一行:
while (isAlphaNumeric(peek())) advance();
// 替換部分開始
String text = source.substring(start, current);
TokenType type = keywords.get(text);
if (type == null) type = IDENTIFIER;
addToken(type);
// 替換部分結束
}
If so, we use that keyword’s token type. Otherwise, it’s a regular user-defined identifier.
如果匹配的話,就使用關鍵字的標記型別。否則,就是一個普通的使用者定義的識別符號。
And with that, we now have a complete scanner for the entire Lox lexical grammar. Fire up the REPL and type in some valid and invalid code. Does it produce the tokens you expect? Try to come up with some interesting edge cases and see if it handles them as it should.
至此,我們就有了一個完整的掃描器,可以掃描整個Lox詞法語法。啟動REPL,輸入一些有效和無效的程式碼。它是否產生了你所期望的詞法單元?試著想出一些有趣的邊界情況,看看它是否能正確地處理它們。
CHALLENGES
習題
1、The lexical grammars of Python and Haskell are not regular. What does that mean, and why aren’t they?
1、Python和Haskell的語法不是常規的。 這是什麼意思,為什麼不是呢?
- Python和Haskell都採用了對縮排敏感的語法,所以它們必須將縮排級別的變動識別為詞法標記。這樣做需要比較連續行的開頭空格數量,這是使用常規語法無法做到的。
2、Aside from separating tokens—distinguishing
print foofromprintfoo—spaces aren’t used for much in most languages. However, in a couple of dark corners, a space does affect how code is parsed in CoffeeScript, Ruby, and the C preprocessor. Where and what effect does it have in each of those languages?
2、除了分隔標記——區分print foo和printfoo——空格在大多數語言中並沒有什麼用處。在CoffeeScript、Ruby和C前處理器中的一些隱秘的地方,空格確實會影響程式碼解析方式。在這些語言中,空格在什麼地方,會有什麼影響?
3、Our scanner here, like most, discards comments and whitespace since those aren’t needed by the parser. Why might you want to write a scanner that does not discard those? What would it be useful for?
3、我們這裡的掃描器和大多數掃描器一樣,會丟棄註釋和空格,因為解析器不需要這些。什麼情況下你會寫一個不丟棄這些的掃描器?它有什麼用呢?
4、Add support to Lox’s scanner for C-style
/* ... */block comments. Make sure to handle newlines in them. Consider allowing them to nest. Is adding support for nesting more work than you expected? Why?
4、為Lox掃描器增加對C樣式/ * ... * /遮蔽註釋的支援。確保要處理其中的換行符。 考慮允許它們巢狀, 增加對巢狀的支援是否比你預期的工作更多? 為什麼?
DESIGN NOTE: IMPLICIT SEMICOLONS
設計筆記:隱藏的分號
Programmers today are spoiled for choice in languages and have gotten picky about syntax. They want their language to look clean and modern. One bit of syntactic lichen that almost every new language scrapes off (and some ancient ones like BASIC never had) is
;as an explicit statement terminator.Instead, they treat a newline as a statement terminator where it makes sense to do so. The “where it makes sense” part is the challenging bit. While most statements are on their own line, sometimes you need to spread a single statement across a couple of lines. Those intermingled newlines should not be treated as terminators.
Most of the obvious cases where the newline should be ignored are easy to detect, but there are a handful of nasty ones:
A return value on the next line:
if (condition) return "value"Is “value” the value being returned, or do we have a
returnstatement with no value followed by an expression statement containing a string literal?A parenthesized expression on the next line:
func (parenthesized)Is this a call to
func(parenthesized), or two expression statements, one forfuncand one for a parenthesized expression?A
-on the next line:first -secondIs this
first - second—an infix subtraction—or two expression statements, one forfirstand one to negatesecond?In all of these, either treating the newline as a separator or not would both produce valid code, but possibly not the code the user wants. Across languages, there is an unsettling variety of rules used to decide which newlines are separators. Here are a couple:
Lua completely ignores newlines, but carefully controls its grammar such that no separator between statements is needed at all in most cases. This is perfectly legit:
a = 1 b = 2Lua avoids the
returnproblem by requiring areturnstatement to be the very last statement in a block. If there is a value afterreturnbefore the keywordend, it must be for thereturn. For the other two cases, they allow an explicit;and expect users to use that. In practice, that almost never happens because there’s no point in a parenthesized or unary negation expression statement.Go handles newlines in the scanner. If a newline appears following one of a handful of token types that are known to potentially end a statement, the newline is treated like a semicolon, otherwise it is ignored. The Go team provides a canonical code formatter, gofmt, and the ecosystem is fervent about its use, which ensures that idiomatic styled code works well with this simple rule.
Python treats all newlines as significant unless an explicit backslash is used at the end of a line to continue it to the next line. However, newlines anywhere inside a pair of brackets (
(),[], or{}) are ignored. Idiomatic style strongly prefers the latter.This rule works well for Python because it is a highly statement-oriented language. In particular, Python’s grammar ensures a statement never appears inside an expression. C does the same, but many other languages which have a “lambda” or function literal syntax do not.
An example in JavaScript:
console.log(function() { statement(); });Here, the
console.log()expression contains a function literal which in turn contains the statementstatement();.Python would need a different set of rules for implicitly joining lines if you could get back into a statement where newlines should become meaningful while still nested inside brackets.
JavaScript’s “automatic semicolon insertion” rule is the real odd one. Where other languages assume most newlines are meaningful and only a few should be ignored in multi-line statements, JS assumes the opposite. It treats all of your newlines as meaningless whitespace unless it encounters a parse error. If it does, it goes back and tries turning the previous newline into a semicolon to get something grammatically valid.
This design note would turn into a design diatribe if I went into complete detail about how that even works, much less all the various ways that JavaScript’s “solution” is a bad idea. It’s a mess. JavaScript is the only language I know where many style guides demand explicit semicolons after every statement even though the language theoretically lets you elide them.
If you’re designing a new language, you almost surely should avoid an explicit statement terminator. Programmers are creatures of fashion like other humans, and semicolons are as passé as ALL CAPS KEYWORDS. Just make sure you pick a set of rules that make sense for your language’s particular grammar and idioms. And don’t do what JavaScript did.
現在的程式設計師已經被越來越多的語言選擇寵壞了,對語法也越來越挑剔。他們希望自己的程式碼看起來乾淨、現代化。幾乎每一種新語言都會放棄一個小的語法點(一些古老的語言,比如BASIC從來沒有過),那就是將;作為顯式的語句結束符。
相對地,它們將“有意義的”換行符看作是語句結束符。這裡所說的“有意義的”是有挑戰性的部分。儘管大多數的語句都是在同一行,但有時你需要將一個語句擴充套件到多行。這些混雜的換行符不應該被視作結束符。
大多數明顯的應該忽略換行的情況都很容易發現,但也有少數討厭的情況:
-
返回值在下一行:
if (condition) return "value"“value”是要返回的值嗎?還是說我們有一個空的
return語句,後面跟著包含一個字串字面量的表示式語句。 -
下一行中有帶圓括號的表示式:
func (parenthesized)這是一個對
func(parenthesized)的呼叫,還是兩個表示式語句,一個用於func,一個用於圓括號表示式? -
“-”號在下一行:
first -second這是一箇中綴表示式——
first - second,還是兩個表示式語句,一個是first,另一個是對second取負?
在所有這些情況下,無論是否將換行符作為分隔符,都會產生有效的程式碼,但可能不是使用者想要的程式碼。在不同的語言中,有各種不同的規則來決定哪些換行符是分隔符。下面是幾個例子:
-
Lua完全忽略了換行符,但是仔細地控制了它的語法,因此在大多數情況下,語句之間根本不需要分隔符。這段程式碼是完全合法的:
a = 1 b = 2Lua要求
return語句是一個塊中的最後一條語句,從而避免return問題。如果在關鍵字end之前、return之後有一個值,這個值必須是用於return。對於其他兩種情況來說,Lua允許顯式的;並且期望使用者使用它。在實踐中,這種情況基本不會發生,因為在小括號或一元否定表示式語句中沒有任何意義。 -
Go會處理掃描器中的換行。如果在詞法單元之後出現換行,並且該詞法標記是已知可能結束語句的少數標記型別之一,則將換行視為分號,否則就忽略它。Go團隊提供了一個規範的程式碼格式化程式gofmt,整個軟體生態系統非常熱衷於使用它,這確保了常用樣式的程式碼能夠很好地遵循這個簡單的規則。
-
Python將所有換行符都視為有效,除非在行末使用明確的反斜槓將其延續到下一行。但是,括號(
()、[]或{})內的任何換行都將被忽略。慣用的程式碼風格更傾向於後者。這條規則對 Python 很有效,因為它是一種高度面向語句的語言。特別是,Python 的語法確保了語句永遠不會出現在表示式內。C語言也是如此,但許多其他有 "lambda "或函式字面語法的語言則不然。
舉一個JavaScript中的例子:
console.log(function() { statement(); });這裡,
console.log()表示式包含一個函式字面量,而這個函式字面量又包含statement();語句。如果要求進入一個巢狀在括號內的語句中,並且要求其中的換行是有意義的,那麼Python將需要一套不同的隱式連線行的規則17。
-
JavaScript的“自動分號插入”規則才是真正的奇葩。其他語言認為大多數換行符都是有意義的,只有少數換行符在多行語句中應該被忽略,而JS的假設恰恰相反。它將所有的換行符都視為無意義的空白,除非遇到解析錯誤。如果遇到了,它就會回過頭來,嘗試把之前的換行變成分號,以期得到正確的語法。
如果我完全詳細地介紹它是如何工作的,那麼這個設計說明就會變成一篇設計檄文,更不用說JavaScript的“解決方案”從各種角度看都是個壞主意。真是一團糟。JavaScript是我所知道的唯一(風格指南和語言本身背離)的語言,它的許多風格指南要求在每條語句後都顯式地使用分號,但該語言卻理論上允許您省略分號。
如果您要設計一種新的語言,則幾乎可以肯定應該避免使用顯式的語句終止符。 程式設計師和其他人類一樣是時尚的動物,分號和ALL CAPS KEYWORDS(全大寫關鍵字)一樣已經過時了。只是要確保您選擇了一套適用於您語言的特定語法和習語的規則即可。不要重蹈JavaScript的覆轍。
-
一直以來,這項工作被稱為 "掃描(scanning) "和 "詞法分析(lexing)"( "詞法分析(lexical analysis)"的簡稱)。早在計算機還像Winnebagos一樣大,但記憶體比你的手錶還小的時候,有些人就用 "掃描 "來指代從磁碟上讀取原始原始碼字元並在記憶體中緩衝的那段程式碼。然後,"lexing "是後續階段,對字元做有用的操作。現在,將原始檔讀入記憶體是很平常的事情,因此在編譯器中很少出現不同的階段。 因此,這兩個術語基本上可以互換。 ↩
-
System.exit(64),對於退出程式碼,我使用UNIX sysexts .h標頭檔案中定義的約定。這是我能找到的最接近標準的東西。 ↩ -
互動式提示符也被稱為REPL(發音像rebel,但替換為p)。它的名稱來自於Lisp,實現Lisp非常簡單,只需圍繞幾個內建函式進行迴圈:
(print (eval (read)))從巢狀最內的呼叫向外執行,讀取一行輸入,求值,列印結果,然後迴圈並再次執行。 ↩ -
說了這麼多,對於這個直譯器,我們要構建的只是基本框架。我很想談談互動式偵錯程式、靜態分析器和其它有趣的東西,但是篇幅實在有限。 ↩
-
我第一次實現jlox的時候正是如此。最後我把它拆出去了,因為對於本書的最小直譯器來說,這有點過度設計了。 ↩
-
畢竟,字串比較最終也會比對單個字元,這不正是掃描器的工作嗎? ↩
-
一些標記實現將位置儲存為兩個數字:從原始檔開始到詞素開始的偏移量,以及詞素的長度。掃描器無論如何都會知道這些數字,因此計算這些數字沒有任何開銷。透過回頭檢視原始檔並計算前面的換行數,可以將偏移量轉換為行和列位置。這聽起來很慢,確實如此。然而,只有當你需要向用戶實際顯示行和列的時候,你才需要這樣做。大多數標記從來不會出現在錯誤資訊中。對於這些標記,你花在提前計算位置資訊上的時間越少越好。 ↩
-
我很痛心要對理論做這麼多掩飾,尤其是當它像喬姆斯基譜系和有限狀態機那樣有趣的時候。但說實話,其他的書比我寫得好。Compilers: Principles, Techniques, and Tools(常被稱為“龍書”)是最經典的參考書。 ↩
-
Lex是由Mike Lesk和Eric Schmidt建立的。是的,就是那個曾任谷歌執行董事長的Eric Schmidt。我並不是說程式語言是通往財富和名聲的必經之路,但我們中至少已經有一位超級億萬富翁。 ↩
-
我知道很多人認為靜態匯入是一種不好的程式碼風格,但這樣我就不必在掃描器和解析器中到處寫
TokenType了。恕我直言,在一本書中,每個字元都很重要 ↩ -
想知道這裡為什麼沒有
/嗎?別擔心,我們會解決的。 ↩ -
技術上來說,
match()方法也是在做前瞻。advance()和peek()是基本運算子,match()將它們結合起來。 ↩ -
因為我們只會根據數字來判斷數字字面量,這就意味著
-123不是一個數字字面量。相反,-123是一個表示式,將-應用到數字字面量123。在實踐中,結果是一樣的,儘管它有一個有趣的邊緣情況。試想一下,如果我們要在數字上新增方法呼叫:print -123.abs();,這裡會輸出-123,因為負號的優先順序低於方法呼叫。我們可以透過將-作為數字字面值的一部分來解決這個問題。但接著考慮:var n = 123; print -n.abs();,結果仍然是-123,所以現在語言似乎不一致。無論你怎麼做,有些情況最後都會變得很奇怪。 ↩ -
Java標準庫中提供了Character.isDigit(),這似乎是個不錯的選擇。唉,該方法中還允許梵文數字、全寬數字和其他我們不想要的有趣的東西。 ↩
-
我本可以讓
peek()方法接受一個引數來表示要前瞻的字元數,而不需要定義兩個函式。但這樣做就會允許前瞻任意長度的字元。提供兩個函式可以讓讀者更清楚地知道,我們的掃描器最多隻能向前看兩個字元。 ↩ -
看一下這段討厭的C程式碼:
---a;,它有效嗎?這取決於掃描器如何分割詞素。如果掃描器看到的是- --a;,那它就可以被解析。但是這需要掃描器知道程式碼前後的語法結構,這比我們需要的更復雜。相反,最大匹配原則表明,掃描結果總是:-- -a;,它就會這樣掃描,儘管這樣做會在解析器中導致後面的語法錯誤。 ↩ -
現在你明白為什麼Python中的
lambda只允許單行的表示式體了吧。 ↩
5.Representing Code 表示程式碼
To dwellers in a wood, almost every species of tree has its voice as well as its feature.
—— Thomas Hardy, Under the Greenwood Tree
對於森林中的居民來說,幾乎每一種樹都有它的聲音和特點。
In the last chapter, we took the raw source code as a string and transformed it into a slightly higher-level representation: a series of tokens. The parser we’ll write in the next chapter takes those tokens and transforms them yet again, into an even richer, more complex representation.
在上一章中,我們以字串形式接收原始原始碼,並將其轉換為一個稍高階別的表示:一系列詞法標記。我們在下一章中要編寫的解析器,會將這些詞法標記再次轉換為更豐富、更復雜的表示形式。
Before we can produce that representation, we need to define it. That’s the subject of this chapter. Along the way, we’ll cover some theory around formal grammars, feel the difference between functional and object-oriented programming, go over a couple of design patterns, and do some metaprogramming.
在我們能夠輸出這種表示形式之前,我們需要先對其進行定義。這就是本章的主題1。在這一過程中,我們將圍繞形式化語法進行一些理論講解,感受函數語言程式設計和麵向物件程式設計的區別,會介紹幾種設計模式,並進行一些超程式設計。
Before we do all that, let’s focus on the main goal—a representation for code. It should be simple for the parser to produce and easy for the interpreter to consume. If you haven’t written a parser or interpreter yet, those requirements aren’t exactly illuminating. Maybe your intuition can help. What is your brain doing when you play the part of a human interpreter? How do you mentally evaluate an arithmetic expression like this:
在做這些事情之前,我們先關注一下主要目標——程式碼的表示形式。它應該易於解析器生成,也易於直譯器使用。如果您還沒有編寫過解析器或直譯器,那麼這樣的需求描述並不能很好地說明問題。也許你的直覺可以幫助你。當你扮演一個人類直譯器的角色時,你的大腦在做什麼?你如何在心裡計算這樣的算術表示式:
1 + 2 * 3 - 4
Because you understand the order of operations—the old “Please Excuse My Dear Aunt Sally” stuff—you know that the multiplication is evaluated before the addition or subtraction. One way to visualize that precedence is using a tree. Leaf nodes are numbers, and interior nodes are operators with branches for each of their operands.
因為你已經理解了操作的順序——以前的“Please Excuse My Dear Aunt Sally”之類2,你知道乘法在加減操作之前執行。有一種方法可以將這種優先順序進行視覺化,那就是使用樹3。葉子節點是數字,內部節點是運算子,它們的每個運算元都對應一個分支。
In order to evaluate an arithmetic node, you need to know the numeric values of its subtrees, so you have to evaluate those first. That means working your way from the leaves up to the root—a post-order traversal:
要想計算一個算術節點,你需要知道它的子樹的數值,所以你必須先計運算元樹的結果。這意味著要從葉節點一直計算到根節點——後序遍歷:

- A.從完整的樹開始,先計算最下面的操作
2*3; - B.現在計算
+; - C.接下來,計算
-; - D.最終得到答案。
If I gave you an arithmetic expression, you could draw one of these trees pretty easily. Given a tree, you can evaluate it without breaking a sweat. So it intuitively seems like a workable representation of our code is a tree that matches the grammatical structure—the operator nesting—of the language.
如果我給你一個算術表示式,你可以很容易地畫出這樣的樹;給你一棵樹,你也可以毫不費力地進行計算。因此,從直觀上看,我們的程式碼的一種可行的表示形式是一棵與語言的語法結構(運算子巢狀)相匹配的樹。
We need to get more precise about what that grammar is then. Like lexical grammars in the last chapter, there is a long ton of theory around syntactic grammars. We’re going into that theory a little more than we did when scanning because it turns out to be a useful tool throughout much of the interpreter. We start by moving one level up the Chomsky hierarchy . . .
那麼我們需要更精確地瞭解這個語法是什麼。就像上一章的詞彙語法一樣,圍繞句法語法也有一大堆理論。我們要比之前處理掃描時投入更多精力去研究這個理論,因為它在整個直譯器的很多地方都是一個有用的工具。我們先從喬姆斯基譜系中往上升一級……
5 . 1 Context-Free Grammars
5.1 上下文無關語法
In the last chapter, the formalism we used for defining the lexical grammar—the rules for how characters get grouped into tokens—was called a regular language. That was fine for our scanner, which emits a flat sequence of tokens. But regular languages aren’t powerful enough to handle expressions which can nest arbitrarily deeply.
在上一章中,我們用來定義詞法語法(字元如何被分組為詞法標記的規則)的形式體系,被稱為正則語言。這對於我們的掃描器來說沒什麼問題,因為它輸出的是一個扁平的詞法標記序列。但正則語言還不夠強大,無法處理可以任意深度巢狀的表示式。
We need a bigger hammer, and that hammer is a context-free grammar (CFG). It’s the next heaviest tool in the toolbox of formal grammars. A formal grammar takes a set of atomic pieces it calls its “alphabet”. Then it defines a (usually infinite) set of “strings” that are “in” the grammar. Each string is a sequence of “letters” in the alphabet.
我們還需要一個更強大的工具,就是上下文無關語法(context-free grammar,CFG)。它是形式化語法的工具箱中下一個最重的工具。一個形式化語法需要一組原子片段,它稱之為 "alphabet(字母表)"。然後它定義了一組(通常是無限的)"strings(字串)",這些字串 "包含"在語法中。每個字串都是字母表中 "letters(字元)"的序列。
I’m using all those quotes because the terms get a little confusing as you move from lexical to syntactic grammars. In our scanner’s grammar, the alphabet consists of individual characters and the strings are the valid lexemes—roughly “words”. In the syntactic grammar we’re talking about now, we’re at a different level of granularity. Now each “letter” in the alphabet is an entire token and a “string” is a sequence of tokens—an entire expression.
我這裡使用引號是因為當你從詞法轉到文法語法時,這些術語會讓你有點困惑。在我們的掃描器詞法中,alphabet(字母表)由單個字元組成,strings(字串)是有效的詞素(粗略的說,就是“單詞”)。在現在討論的句法語法中,我們處於一個不同的粒度水平。現在,字母表中的一個“letters(字元)”是一個完整的詞法標記,而“strings(字串)”是一個詞法標記系列——一個完整的表示式。
Oof. Maybe a table will help:
嗯,使用表格可能更有助於理解:
| Terminology 術語 | Lexical grammar 詞法 | Syntactic grammar 語法 | |
|---|---|---|---|
| The “alphabet” is . . . 字母表 | → | Characters 字元 | Tokens 詞法標記 |
| A “string” is . . . 字串 | → | Lexeme or token 詞素或詞法標記 | Expression 表示式 |
| It's implemented by the . . . 實現 | → | Scanner 掃描器 | Parser 解析器 |
A formal grammar’s job is to specify which strings are valid and which aren’t. If we were defining a grammar for English sentences, “eggs are tasty for breakfast” would be in the grammar, but “tasty breakfast for are eggs” would probably not.
形式化語法的工作是指定哪些字串有效,哪些無效。如果我們要為英語句子定義一個語法,"eggs are tasty for breakfast "會包含在語法中,但 "tasty breakfast for are eggs "可能不會。
5 . 1 . 1 Rules for grammars
5.1.1 語法規則
How do we write down a grammar that contains an infinite number of valid strings? We obviously can’t list them all out. Instead, we create a finite set of rules. You can think of them as a game that you can “play” in one of two directions.
我們如何寫下一個包含無限多有效字串的語法?我們顯然無法一一列舉出來。相反,我們建立了一組有限的規則。你可以把它們想象成一場你可以朝兩個方向“玩”的遊戲。
If you start with the rules, you can use them to generate strings that are in the grammar. Strings created this way are called derivations because each is derived from the rules of the grammar. In each step of the game, you pick a rule and follow what it tells you to do. Most of the lingo around formal grammars comes from playing them in this direction. Rules are called productions because they produce strings in the grammar.
如果你從規則入手,你可以用它們生成語法中的字串。以這種方式建立的字串被稱為推導式(派生式),因為每個字串都是從語法規則中推導出來的。在遊戲的每一步中,你都要選擇一條規則,然後按照它告訴你的去做。圍繞形式化語法的大部分語言都傾向這種方式。規則被稱為生成式,因為它們生成了語法中的字串。
Each production in a context-free grammar has a head—its name—and a body, which describes what it generates. In its pure form, the body is simply a list of symbols. Symbols come in two delectable flavors:
上下文無關語法中的每個生成式都有一個頭部(其名稱)和描述其生成內容的主體4。在純粹的形式上看,主體只是一系列符號。符號有兩種:
A terminal is a letter from the grammar’s alphabet. You can think of it like a literal value. In the syntactic grammar we’re defining, the terminals are individual lexemes—tokens coming from the scanner like
ifor1234.These are called “terminals”, in the sense of an “end point” because they don’t lead to any further “moves” in the game. You simply produce that one symbol.
A nonterminal is a named reference to another rule in the grammar. It means “play that rule and insert whatever it produces here”. In this way, the grammar composes.
-
終止符是語法字母表中的一個字母。你可以把它想象成一個字面值。在我們定義的語法中,終止符是獨立的詞素——來自掃描器的詞法標記,比如
if或1234。這些詞素被稱為“終止符”,表示“終點”,因為它們不會導致遊戲中任何進一步的 "動作"。你只是簡單地產生了那一個符號。
-
非終止符是對語法中另一條規則的命名引用。它的意思是 "執行那條規則,然後將它產生的任何內容插入這裡"。這樣,語法就構成了。
There is one last refinement: you may have multiple rules with the same name. When you reach a nonterminal with that name, you are allowed to pick any of the rules for it, whichever floats your boat.
還有最後一個細節:你可以有多個同名的規則。當你遇到一個該名字的非終止符時,你可以為它選擇任何一條規則,隨您喜歡。
To make this concrete, we need a way to write down these production rules. People have been trying to crystallize grammar all the way back to Pāṇini’s Ashtadhyayi, which codified Sanskrit grammar a mere couple thousand years ago. Not much progress happened until John Backus and company needed a notation for specifying ALGOL 58 and came up with Backus-Naur form (BNF). Since then, nearly everyone uses some flavor of BNF, tweaked to their own tastes.
為了讓這個規則具體化,我們需要一種方式來寫下這些生成規則。人們一直試圖將語法具體化,可以追溯到Pāṇini的Ashtadhyayi,他在幾千年前編纂了梵文語法。直到約翰-巴庫斯(John Backus)和公司需要一個宣告ALGOL 58的符號,並提出了巴科斯正規化(BNF),才有了很大的進展。從那時起,幾乎每個人都在使用BNF的某種變形,並根據自己的需要進行了調整5。
I tried to come up with something clean. Each rule is a name, followed by an arrow (
→), followed by a sequence of symbols, and finally ending with a semicolon (;). Terminals are quoted strings, and nonterminals are lowercase words.
我試圖提出一個簡單的形式。 每個規則都是一個名稱,後跟一個箭頭(→),後跟一系列符號,最後以分號(;)結尾。 終止符是帶引號的字串,非終止符是小寫的單詞。
Using that, here’s a grammar for breakfast menus:
以此為基礎,下面是一個早餐選單語法:
breakfast → protein "with" breakfast "on the side" ;
breakfast → protein ;
breakfast → bread ;
protein → crispiness "crispy" "bacon" ;
protein → "sausage" ;
protein → cooked "eggs" ;
crispiness → "really" ;
crispiness → "really" crispiness ;
cooked → "scrambled" ;
cooked → "poached" ;
cooked → "fried" ;
bread → "toast" ;
bread → "biscuits" ;
bread → "English muffin" ;
We can use this grammar to generate random breakfasts. Let’s play a round and see how it works. By age-old convention, the game starts with the first rule in the grammar, here
breakfast. There are three productions for that, and we randomly pick the first one. Our resulting string looks like:
我們可以使用這個語法來隨機生成早餐。我們來玩一輪,看看它是如何工作的。按照老規矩,遊戲從語法中的第一個規則開始,這裡是breakfast。它有三個生成式,我們隨機選擇第一個。我們得到的字串是這樣的:
protein "with" breakfast "on the side"
We need to expand that first nonterminal,
protein, so we pick a production for that. Let’s pick:
我們需要展開第一個非終止符,protein,所有我們要選擇它對應的一個生成式。我們選:
protein → cooked "eggs" ;
Next, we need a production for
cooked, and so we pick"poached". That’s a terminal, so we add that. Now our string looks like:
接下來,我們需要 cooked的生成式,我們選擇 "poached"。這是一個終止符,我們加上它。現在我們的字串是這樣的:
"poached" "eggs" "with" breakfast "on the side"
The next non-terminal is
breakfastagain. The firstbreakfastproduction we chose recursively refers back to thebreakfastrule. Recursion in the grammar is a good sign that the language being defined is context-free instead of regular. In particular, recursion where the recursive nonterminal has productions on both sides implies that the language is not regular.
下一個非終止符還是breakfast ,我們開始選擇的breakfast 生成式遞迴地指向了breakfast 規則6。語法中的遞迴是一個很好的標誌,表明所定義的語言是上下文無關的,而不是正則的。特別是,遞迴非終止符兩邊都有生成式的遞迴,意味著語言不是正則的。
We could keep picking the first production for
breakfastover and over again yielding all manner of breakfasts like “bacon with sausage with scrambled eggs with bacon . . . ” We won’t though. This time we’ll pickbread. There are three rules for that, each of which contains only a terminal. We’ll pick “English muffin”.
我們可以不斷選擇breakfast 的第一個生成式,以做出各種各樣的早餐:“bacon with sausage with scrambled eggs with bacon . . . ”,【存疑,按照規則設定,這裡應該不會出現以bacon開頭的字串,原文可能有誤】但我們不會這樣做。這一次我們選擇bread。有三個對應的規則,每個規則只包含一個終止符。我們選 "English muffin"。
With that, every nonterminal in the string has been expanded until it finally contains only terminals and we’re left with:
這樣一來,字串中的每一個非終止符都被展開了,直到最後只包含終止符,我們就剩下:

Throw in some ham and Hollandaise, and you’ve got eggs Benedict.
再加上一些火腿和荷蘭醬,你就得到了鬆餅蛋。
Any time we hit a rule that had multiple productions, we just picked one arbitrarily. It is this flexibility that allows a short number of grammar rules to encode a combinatorially larger set of strings. The fact that a rule can refer to itself—directly or indirectly—kicks it up even more, letting us pack an infinite number of strings into a finite grammar.
每當我們遇到具有多個結果的規則時,我們都只是隨意選擇了一個。 正是這種靈活性允許用少量的語法規則來編碼出組合性更強的字串集。一個規則可以直接或間接地引用它自己,這就更提高了它的靈活性,讓我們可以將無限多的字串打包到一個有限的語法中。
5 . 1 . 2 Enhancing our notation
5.1.2 增強符號
Stuffing an infinite set of strings in a handful of rules is pretty fantastic, but let’s take it further. Our notation works, but it’s a little tedious. So, like any good language designer, we’ll sprinkle some syntactic sugar on top. In addition to terminals and nonterminals, we’ll allow a few other kinds of expressions in the body of a rule:
在少量的規則中可以填充無限多的字串是相當奇妙的,但是我們可以更進一步。我們的符號是可行的,但有點乏味。所以,就像所有優秀的語言設計者一樣,我們會在上面撒一些語法糖。除了終止符和非終止符之外,我們還允許在規則的主體中使用一些其他型別的表示式:
-
Instead of repeating the rule name each time we want to add another production for it, we’ll allow a series of productions separated by a pipe (
|).我們將允許一系列由管道符(
|)分隔的生成式,避免在每次在新增另一個生成式時重複規則名稱。bread → "toast" | "biscuits" | "English muffin" ; -
Further, we’ll allow parentheses for grouping and then allow
|within that to select one from a series of options within the middle of a production.此外,我們允許用括號進行分組,然後在分組中可以用
|表示從一系列生成式中選擇一個。protein → ( "scrambled" | "poached" | "fried" ) "eggs" ; -
Using recursion to support repeated sequences of symbols has a certain appealing purity, but it’s kind of a chore to make a separate named sub-rule each time we want to loop. So, we also use a postfix
*to allow the previous symbol or group to be repeated zero or more times.使用遞迴來支援符號的重複序列有一定的吸引力,但每次我們要迴圈的時候,都要建立一個單獨的命名子規則,有點繁瑣7。所以,我們也使用字尾
*來允許前一個符號或組重複零次或多次。crispiness → "really" "really"* ; -
A postfix
+is similar, but requires the preceding production to appear at least once.字尾
+與此類似,但要求前面的生成式至少出現一次。crispiness → "really"+ ; -
A postfix
?is for an optional production. The thing before it can appear zero or one time, but not more.字尾
?表示可選生成式,它之前的生成式可以出現零次或一次,但不能出現多次。breakfast → protein ( "with" breakfast "on the side" )? ;
With all of those syntactic niceties, our breakfast grammar condenses down to:
有了所有這些語法上的技巧,我們的早餐語法濃縮為:
breakfast → protein ( "with" breakfast "on the side" )?
| bread ;
protein → "really"+ "crispy" "bacon"
| "sausage"
| ( "scrambled" | "poached" | "fried" ) "eggs" ;
bread → "toast" | "biscuits" | "English muffin" ;
Not too bad, I hope. If you’re used to grep or using regular expressions in your text editor, most of the punctuation should be familiar. The main difference is that symbols here represent entire tokens, not single characters.
我希望還不算太壞。如果你習慣使用grep或在你的文字編輯器中使用正規表示式,大多數的標點符號應該是熟悉的。主要區別在於,這裡的符號代表整個標記,而不是單個字元。
We’ll use this notation throughout the rest of the book to precisely describe Lox’s grammar. As you work on programming languages, you’ll find that context-free grammars (using this or EBNF or some other notation) help you crystallize your informal syntax design ideas. They are also a handy medium for communicating with other language hackers about syntax.
在本書的其餘部分中,我們將使用這種表示法來精確地描述Lox的語法。當您使用程式語言時,您會發現上下文無關的語法(使用此語法或EBNF或其他一些符號)可以幫助您將非正式的語法設計思想具體化。它們也是與其他語言駭客交流語法的方便媒介。
The rules and productions we define for Lox are also our guide to the tree data structure we’re going to implement to represent code in memory. Before we can do that, we need an actual grammar for Lox, or at least enough of one for us to get started.
我們為Lox定義的規則和生成式也是我們將要實現的樹資料結構(用於表示記憶體中的程式碼)的指南。 在此之前,我們需要為Lox編寫一個實際的語法,或者至少要有一個足夠上手的語法。
5 . 1 . 3 A Grammar for Lox expressions
5.1.3 Lox表示式語法
In the previous chapter, we did Lox’s entire lexical grammar in one fell swoop. Every keyword and bit of punctuation is there. The syntactic grammar is larger, and it would be a real bore to grind through the entire thing before we actually get our interpreter up and running.
在上一章中,我們一氣呵成地完成了Lox的全部詞彙語法,包括每一個關鍵詞和標點符號。但句法語法的規模更大,如果在我們真正啟動並執行直譯器之前,就要把整個語法啃完,那就太無聊了。
Instead, we’ll crank through a subset of the language in the next couple of chapters. Once we have that mini-language represented, parsed, and interpreted, then later chapters will progressively add new features to it, including the new syntax. For now, we are going to worry about only a handful of expressions:
相反,我們將在接下來的幾章中摸索該語言的一個子集。一旦我們可以對這個迷你語言進行表示、解析和解釋,那麼在之後的章節中將逐步為它新增新的特性,包括新的語法。現在,我們只關心幾個表示式:
-
Literals. Numbers, strings, Booleans, and
nil.字面量。數字、字串、布林值以及
nil。 -
Unary expressions. A prefix
!to perform a logical not, and-to negate a number.一元表示式。字首
!執行邏輯非運算,-對數字求反。 -
Binary expressions. The infix arithmetic (
+,-,*,/) and logic operators (==,!=,<,<=,>,>=) we know and love.二元表示式。我們已經知道的中綴算術符(
+,-,*,/)和邏輯運算子(==,!=,<,<=,>,> =)。 -
Parentheses. A pair of
(and)wrapped around an expression.括號。表示式前後的一對
(和)。
That gives us enough syntax for expressions like:
這已經為表示式提供了足夠的語法,例如:
1 - (2 * 3) < 4 == false
Using our handy dandy new notation, here’s a grammar for those:
使用我們的新符號,下面是語法的表示:
expression → literal
| unary
| binary
| grouping ;
literal → NUMBER | STRING | "true" | "false" | "nil" ;
grouping → "(" expression ")" ;
unary → ( "-" | "!" ) expression ;
binary → expression operator expression ;
operator → "==" | "!=" | "<" | "<=" | ">" | ">="
| "+" | "-" | "*" | "/" ;
There’s one bit of extra metasyntax here. In addition to quoted strings for terminals that match exact lexemes, we
CAPITALIZEterminals that are a single lexeme whose text representation may vary.NUMBERis any number literal, andSTRINGis any string literal. Later, we’ll do the same forIDENTIFIER.
這裡有一點額外的元語法。除了與精確詞素相匹配的終止符會加引號外,我們還對錶示單一詞素的終止符進行大寫化,這些詞素的文字表示方式可能會有所不同。NUMBER是任何數字字面量,STRING是任何字串字面量。稍後,我們將對IDENTIFIER進行同樣的處理8。
This grammar is actually ambiguous, which we’ll see when we get to parsing it. But it’s good enough for now.
這個語法實際上是有歧義的,我們在解析它時就會看到這一點。但現在這已經足夠了。
5 . 2 Implementing Syntax Trees
5.2 實現語法樹
Finally, we get to write some code. That little expression grammar is our skeleton. Since the grammar is recursive—note how
grouping,unary, andbinaryall refer back toexpression—our data structure will form a tree. Since this structure represents the syntax of our language, it’s called a syntax tree.
最後,我們要寫一些程式碼。這個小小的表示式語法就是我們的骨架。由於語法是遞迴的——請注意grouping, unary, 和 binary 都是指回expression的——我們的資料結構將形成一棵樹。因為這個結構代表了我們語言的語法,所以叫做語法樹9。
Our scanner used a single Token class to represent all kinds of lexemes. To distinguish the different kinds—think the number
123versus the string"123"—we included a simple TokenType enum. Syntax trees are not so homogeneous. Unary expressions have a single operand, binary expressions have two, and literals have none.
我們的掃描器使用一個單一的 Token 類來表示所有型別的詞素。為了區分不同的種類——想想數字 123 和字串 "123"——我們建立了一個簡單的 TokenType 列舉。語法樹並不是那麼同質的10。一元表示式只有一個運算元,二元表示式有兩個運算元,而字面量則沒有。
We could mush that all together into a single Expression class with an arbitrary list of children. Some compilers do. But I like getting the most out of Java’s type system. So we’ll define a base class for expressions. Then, for each kind of expression—each production under
expression—we create a subclass that has fields for the nonterminals specific to that rule. This way, we get a compile error if we, say, try to access the second operand of a unary expression.
我們可以將所有這些內容整合到一個包含任意子類列表的 Expression 類中。有些編譯器會這麼做。但我希望充分利用Java的型別系統。所以我們將為表示式定義一個基類。然後,對於每一種表示式——expression下的每一個生成式——我們建立一個子類,這個子類有該規則所特有的非終止符欄位。這樣,如果試圖訪問一元表示式的第二個運算元,就會得到一個編譯錯誤。
Something like this:
類似這樣11:
package com.craftinginterpreters.lox;
abstract class Expr {
static class Binary extends Expr {
Binary(Expr left, Token operator, Expr right) {
this.left = left;
this.operator = operator;
this.right = right;
}
final Expr left;
final Token operator;
final Expr right;
}
// Other expressions...
}
Expr is the base class that all expression classes inherit from. As you can see from
Binary, the subclasses are nested inside of it. There’s no technical need for this, but it lets us cram all of the classes into a single Java file.
Expr是所有表示式類繼承的基類。從Binary中可以看到,子類都巢狀在它的內部。這在技術上沒有必要,但它允許我們將所有類都塞進一個Java檔案中。
5 . 2 . 1 Disoriented objects
5.2.1 非面向物件
You’ll note that, much like the Token class, there aren’t any methods here. It’s a dumb structure. Nicely typed, but merely a bag of data. This feels strange in an object-oriented language like Java. Shouldn’t the class do stuff?
你會注意到,(表示式類)像Token類一樣,其中沒有任何方法。這是一個很愚蠢的結構,巧妙的型別封裝,但僅僅是一包資料。這在Java這樣的面嚮物件語言中會有些奇怪,難道類不是應該做一些事情嗎?
The problem is that these tree classes aren’t owned by any single domain. Should they have methods for parsing since that’s where the trees are created? Or interpreting since that’s where they are consumed? Trees span the border between those territories, which means they are really owned by neither.
問題在於這些樹類不屬於任何單個的領域。樹是在解析的時候建立的,難道類中應該有解析對應的方法?或者因為樹結構在解釋的時候被消費,其中是不是要提供解釋相關的方法?樹跨越了這些領域之間的邊界,這意味著它們實際上不屬於任何一方。
In fact, these types exist to enable the parser and interpreter to communicate. That lends itself to types that are simply data with no associated behavior. This style is very natural in functional languages like Lisp and ML where all data is separate from behavior, but it feels odd in Java.
事實上,這些型別的存在是為了讓解析器和直譯器能夠進行交流。這就適合於那些只是簡單的資料而沒有相關行為的型別。這種風格在Lisp和ML這樣的函式式語言中是非常自然的,因為在這些語言中,所有的資料和行為都是分開的,但是在Java中感覺很奇怪。
Functional programming aficionados right now are jumping up to exclaim “See! Object-oriented languages are a bad fit for an interpreter!” I won’t go that far. You’ll recall that the scanner itself was admirably suited to object-orientation. It had all of the mutable state to keep track of where it was in the source code, a well-defined set of public methods, and a handful of private helpers.
函數語言程式設計的愛好者們現在都跳起來驚呼:“看吧!面向物件的語言不適合作為直譯器!”我不會那麼過分的。您可能還記得,掃描器本身非常適合面向物件。它包含所有的可變狀態來跟蹤其在原始碼中的位置、一組定義良好的公共方法和少量的私有輔助方法。
My feeling is that each phase or part of the interpreter works fine in an object-oriented style. It is the data structures that flow between them that are stripped of behavior.
我的感覺是,在面向物件的風格下,直譯器的每個階段或部分都能正常工作。只不過在它們之間流動的資料結構剝離了行為。
5 . 2 . 2 Metaprogramming the trees
5.2.2 節點樹超程式設計
Java can express behavior-less classes, but I wouldn’t say that it’s particularly great at it. Eleven lines of code to stuff three fields in an object is pretty tedious, and when we’re all done, we’re going to have 21 of these classes.
Java可以表達無行為的類,但很難說它特別擅長。用11行程式碼在一個物件中填充3個欄位是相當乏味的,當我們全部完成後,我們將有21個這樣的類。
I don’t want to waste your time or my ink writing all that down. Really, what is the essence of each subclass? A name, and a list of typed fields. That’s it. We’re smart language hackers, right? Let’s automate.
我不想浪費你的時間或我的墨水把這些都寫下來。真的,每個子類的本質是什麼?一個名稱和一個欄位列表而已。我們是聰明的語言駭客,對吧?我們把它自動化12。
Instead of tediously handwriting each class definition, field declaration, constructor, and initializer, we’ll hack together a script that does it for us. It has a description of each tree type—its name and fields—and it prints out the Java code needed to define a class with that name and state.
與其繁瑣地手寫每個類的定義、欄位宣告、建構函式和初始化器,我們一起編寫一個指令碼來完成任務。 它具有每種樹型別(名稱和欄位)的描述,並打印出定義具有該名稱和狀態的類所需的Java程式碼。
This script is a tiny Java command-line app that generates a file named “Expr.java”:
該指令碼是一個微型Java命令列應用程式,它生成一個名為“ Expr.java”的檔案:
tool/GenerateAst.java,建立新檔案
package com.craftinginterpreters.tool;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Arrays;
import java.util.List;
public class GenerateAst {
public static void main(String[] args) throws IOException {
if (args.length != 1) {
System.err.println("Usage: generate_ast <output directory>");
System.exit(64);
}
String outputDir = args[0];
}
}
Note that this file is in a different package,
.toolinstead of.lox. This script isn’t part of the interpreter itself. It’s a tool we, the people hacking on the interpreter, run ourselves to generate the syntax tree classes. When it’s done, we treat “Expr.java” like any other file in the implementation. We are merely automating how that file gets authored.
注意,這個檔案在另一個包中,是.tool而不是.lox。這個指令碼並不是直譯器本身的一部分,它是一個工具,我們這種編寫直譯器的人,透過執行該指令碼來生成語法樹類。完成後,我們把“Expr.java”與實現中的其它檔案進行相同的處理。我們只是自動化了檔案的生成方式。
To generate the classes, it needs to have some description of each type and its fields.
為了生成類,還需要對每種型別及其欄位進行一些描述。
tool/GenerateAst.java,在 main()方法中新增
String outputDir = args[0];
// 新增部分開始
defineAst(outputDir, "Expr", Arrays.asList(
"Binary : Expr left, Token operator, Expr right",
"Grouping : Expr expression",
"Literal : Object value",
"Unary : Token operator, Expr right"
));
// 新增部分結束
}
For brevity’s sake, I jammed the descriptions of the expression types into strings. Each is the name of the class followed by
:and the list of fields, separated by commas. Each field has a type and a name.
為簡便起見,我將表示式型別的描述放入了字串中。 每一項都包括類的名稱,後跟:和以逗號分隔的欄位列表。 每個欄位都有一個型別和一個名稱。
The first thing
defineAst()needs to do is output the base Expr class.
defineAst()需要做的第一件事是輸出基類Expr。
tool/GenerateAst.java,在 main()方法後新增:
private static void defineAst(
String outputDir, String baseName, List<String> types)
throws IOException {
String path = outputDir + "/" + baseName + ".java";
PrintWriter writer = new PrintWriter(path, "UTF-8");
writer.println("package com.craftinginterpreters.lox;");
writer.println();
writer.println("import java.util.List;");
writer.println();
writer.println("abstract class " + baseName + " {");
writer.println("}");
writer.close();
}
When we call this,
baseNameis “Expr”, which is both the name of the class and the name of the file it outputs. We pass this as an argument instead of hardcoding the name because we’ll add a separate family of classes later for statements.
我們呼叫這個函式時,baseName是“Expr”,它既是類的名稱,也是它輸出的檔案的名稱。我們將它作為引數傳遞,而不是對名稱進行硬編碼,因為稍後我們將為語句新增一個單獨的類族。
Inside the base class, we define each subclass.
在基類內部,我們定義每個子類。
tool/GenerateAst.java,在 defineAst()類中新增13:
writer.println("abstract class " + baseName + " {");
// 新增部分開始
// The AST classes.
for (String type : types) {
String className = type.split(":")[0].trim();
String fields = type.split(":")[1].trim();
defineType(writer, baseName, className, fields);
}
// 新增部分結束
writer.println("}");
That code, in turn, calls:
這段程式碼依次呼叫:
tool/GenerateAst.java,在 defineAst()後面新增:
private static void defineType(
PrintWriter writer, String baseName,
String className, String fieldList) {
writer.println(" static class " + className + " extends " +
baseName + " {");
// Constructor.
writer.println(" " + className + "(" + fieldList + ") {");
// Store parameters in fields.
String[] fields = fieldList.split(", ");
for (String field : fields) {
String name = field.split(" ")[1];
writer.println(" this." + name + " = " + name + ";");
}
writer.println(" }");
// Fields.
writer.println();
for (String field : fields) {
writer.println(" final " + field + ";");
}
writer.println(" }");
}
There we go. All of that glorious Java boilerplate is done. It declares each field in the class body. It defines a constructor for the class with parameters for each field and initializes them in the body.
好了。所有的Java模板都完成了。它在類體中宣告瞭每個欄位。它為類定義了一個建構函式,為每個欄位提供引數,並在類體中對其初始化。
Compile and run this Java program now and it blasts out a new “.java” file containing a few dozen lines of code. That file’s about to get even longer.
現在編譯並執行這個Java程式,它會生成一個新的“. Java”檔案,其中包含幾十行程式碼。那份檔案還會變得更長14。
5 . 3 Working with Trees
5.3 處理樹結構
Put on your imagination hat for a moment. Even though we aren’t there yet, consider what the interpreter will do with the syntax trees. Each kind of expression in Lox behaves differently at runtime. That means the interpreter needs to select a different chunk of code to handle each expression type. With tokens, we can simply switch on the TokenType. But we don’t have a “type” enum for the syntax trees, just a separate Java class for each one.
先想象一下吧。儘管我們還沒有到那一步,但請考慮一下直譯器將如何處理語法樹。Lox中的每種表示式在執行時的行為都不一樣。這意味著直譯器需要選擇不同的程式碼塊來處理每種表示式型別。對於詞法標記,我們可以簡單地根據TokenType進行轉換。但是我們並沒有為語法樹設定一個 "type "列舉,只是為每個語法樹單獨設定一個Java類。
We could write a long chain of type tests:
我們可以編寫一長串型別測試:
if (expr instanceof Expr.Binary) {
// ...
} else if (expr instanceof Expr.Grouping) {
// ...
} else // ...
But all of those sequential type tests are slow. Expression types whose names are alphabetically later would take longer to execute because they’d fall through more
ifcases before finding the right type. That’s not my idea of an elegant solution.
但所有這些順序型別測試都很慢。型別名稱按字母順序排列在後面的表示式,執行起來會花費更多的時間,因為在找到正確的型別之前,它們會遇到更多的if情況。這不是我認為的優雅解決方案。
We have a family of classes and we need to associate a chunk of behavior with each one. The natural solution in an object-oriented language like Java is to put those behaviors into methods on the classes themselves. We could add an abstract
interpret()method on Expr which each subclass would then implement to interpret itself.
我們有一個類族,我們需要將一組行為與每個類關聯起來。在Java這樣的面嚮物件語言中,最自然的解決方案是將這些行為放入類本身的方法中。我們可以在Expr上新增一個抽象的interpret()方法,然後每個子類都要實現這個方法來解釋自己15。
This works alright for tiny projects, but it scales poorly. Like I noted before, these tree classes span a few domains. At the very least, both the parser and interpreter will mess with them. As you’ll see later, we need to do name resolution on them. If our language was statically typed, we’d have a type checking pass.
這對於小型專案來說還行,但它的擴充套件性很差。就像我之前提到的,這些樹類跨越了幾個領域。至少,解析器和直譯器都會對它們進行幹擾。稍後您將看到,我們需要對它們進行名稱解析。如果我們的語言是靜態型別的,我們還需要做型別檢查。
If we added instance methods to the expression classes for every one of those operations, that would smush a bunch of different domains together. That violates separation of concerns and leads to hard-to-maintain code.
如果我們為每一個操作的表示式類中新增例項方法,就會將一堆不同的領域混在一起。這違反了關注點分離原則,並會產生難以維護的程式碼。
5 . 3 . 1 The expression problem
5.3.1 表示式問題
This problem is more fundamental than it may seem at first. We have a handful of types, and a handful of high-level operations like “interpret”. For each pair of type and operation, we need a specific implementation. Picture a table:
這個問題比起初看起來更基礎。我們有一些型別,和一些高階操作,比如“解釋”。對於每一對型別和操作,我們都需要一個特定的實現。畫一個表:

Rows are types, and columns are operations. Each cell represents the unique piece of code to implement that operation on that type.
行是型別,列是操作。每個單元格表示在該型別上實現該操作的唯一程式碼段。
An object-oriented language like Java assumes that all of the code in one row naturally hangs together. It figures all the things you do with a type are likely related to each other, and the language makes it easy to define them together as methods inside the same class.
像Java這樣的面向物件的語言,假定一行中的所有程式碼都自然地掛在一起。它認為你對一個型別所做的所有事情都可能是相互關聯的,而使用這類語言可以很容易將它們一起定義為同一個類裡面的方法。

This makes it easy to extend the table by adding new rows. Simply define a new class. No existing code has to be touched. But imagine if you want to add a new operation—a new column. In Java, that means cracking open each of those existing classes and adding a method to it.
這種情況下,向表中加入新行來擴充套件列表是很容易的,簡單地定義一個新類即可,不需要修改現有的程式碼。但是,想象一下,如果你要新增一個新操作(新的一列)。在Java中,這意味著要拆開已有的那些類並向其中新增方法。
Functional paradigm languages in the ML family flip that around. There, you don’t have classes with methods. Types and functions are totally distinct. To implement an operation for a number of different types, you define a single function. In the body of that function, you use pattern matching—sort of a type-based switch on steroids—to implement the operation for each type all in one place.
ML家族中的函式式範型反過來了16。在這些語言中,沒有帶方法的類,型別和函式是完全獨立的。要為許多不同型別實現一個操作,只需定義一個函式。在該函式體中,您可以使用模式匹配(某種基於型別的switch操作)在同一個函式中實現每個型別對應的操作。
This makes it trivial to add new operations—simply define another function that pattern matches on all of the types.
這使得新增新操作非常簡單——只需定義另一個與所有型別模式匹配的的函式即可。

But, conversely, adding a new type is hard. You have to go back and add a new case to all of the pattern matches in all of the existing functions.
但是,反過來說,新增新型別是困難的。您必須回頭向已有函式中的所有模式匹配新增一個新的case。
Each style has a certain “grain” to it. That’s what the paradigm name literally says—an object-oriented language wants you to orient your code along the rows of types. A functional language instead encourages you to lump each column’s worth of code together into a function.
每種風格都有一定的 "紋路"。這就是正規化名稱的字面意思——面向物件的語言希望你按照型別的行來組織你的程式碼。而函式式語言則鼓勵你把每一列的程式碼都歸納為一個函式。
A bunch of smart language nerds noticed that neither style made it easy to add both rows and columns to the table. They called this difficulty the “expression problem” because—like we are now—they first ran into it when they were trying to figure out the best way to model expression syntax tree nodes in a compiler.
一群聰明的語言迷注意到,這兩種風格都不容易向表格中新增行和列。他們稱這個困難為“表示式問題”17。就像我們現在一樣,他們是在試圖找出在編譯器中建模表達式語法樹節點的最佳方法時,第一次遇到了該問題。
People have thrown all sorts of language features, design patterns, and programming tricks to try to knock that problem down but no perfect language has finished it off yet. In the meantime, the best we can do is try to pick a language whose orientation matches the natural architectural seams in the program we’re writing.
人們已經拋出了各種各樣的語言特性、設計模式和程式設計技巧,試圖解決這個問題,但還沒有一種完美的語言能夠解決它。與此同時,我們所能做的就是儘量選擇一種與我們正在編寫的程式的自然架構相匹配的語言。
Object-orientation works fine for many parts of our interpreter, but these tree classes rub against the grain of Java. Fortunately, there’s a design pattern we can bring to bear on it.
面向物件在我們的直譯器的許多部分都可以正常工作,但是這些樹類與Java的本質背道而馳。 幸運的是,我們可以採用一種設計模式來解決這個問題。
5 . 3 . 2 The Visitor pattern
5.3.2 訪問者模式
The Visitor pattern is the most widely misunderstood pattern in all of Design Patterns, which is really saying something when you look at the software architecture excesses of the past couple of decades.
訪問者模式是所有設計模式中最容易被誤解的模式,當您回顧過去幾十年的軟體架構氾濫狀況時,會發現確實如此。
The trouble starts with terminology. The pattern isn’t about “visiting”, and the “accept” method in it doesn’t conjure up any helpful imagery either. Many think the pattern has to do with traversing trees, which isn’t the case at all. We are going to use it on a set of classes that are tree-like, but that’s a coincidence. As you’ll see, the pattern works as well on a single object.
問題出在術語上。這個模式不是關於“visiting(訪問)”,它的 “accept”方法也沒有讓人產生任何有用的想象。許多人認為這種模式與遍歷樹有關,但事實並非如此。我們確實要在一組樹結構的類上使用它,但這只是一個巧合。如您所見,該模式在單個物件上也可以正常使用。
The Visitor pattern is really about approximating the functional style within an OOP language. It lets us add new columns to that table easily. We can define all of the behavior for a new operation on a set of types in one place, without having to touch the types themselves. It does this the same way we solve almost every problem in computer science: by adding a layer of indirection.
訪問者模式實際上近似於OOP語言中的函式式。它讓我們可以很容易地向表中新增新的列。我們可以在一個地方定義針對一組型別的新操作的所有行為,而不必觸及型別本身。這與我們解決電腦科學中幾乎所有問題的方式相同:新增中間層。
Before we apply it to our auto-generated Expr classes, let’s walk through a simpler example. Say we have two kinds of pastries: beignets and crullers.
在將其應用到自動生成的Expr類之前,讓我們先看一個更簡單的例子。比方說我們有兩種點心:Beignet(捲餅)和Cruller(油酥卷)。
abstract class Pastry {
}
class Beignet extends Pastry {
}
class Cruller extends Pastry {
}
We want to be able to define new pastry operations—cooking them, eating them, decorating them, etc.—without having to add a new method to each class every time. Here’s how we do it. First, we define a separate interface.
我們希望能夠定義新的糕點操作(烹飪,食用,裝飾等),而不必每次都向每個類新增新方法。我們是這樣做的。首先,我們定義一個單獨的介面18。
interface PastryVisitor {
void visitBeignet(Beignet beignet);
void visitCruller(Cruller cruller);
}
Each operation that can be performed on pastries is a new class that implements that interface. It has a concrete method for each type of pastry. That keeps the code for the operation on both types all nestled snugly together in one class.
可以對糕點執行的每個操作都是實現該介面的新類。 它對每種型別的糕點都有具體的方法。 這樣一來,針對兩種型別的操作程式碼都緊密地巢狀在一個類中。
Given some pastry, how do we route it to the correct method on the visitor based on its type? Polymorphism to the rescue! We add this method to Pastry:
給定一個糕點,我們如何根據其型別將其路由到訪問者的正確方法?多型性拯救了我們!我們在Pastry中新增這個方法:
abstract class Pastry {
abstract void accept(PastryVisitor visitor);
}
Each subclass implements it.
每個子類都需要實現該方法:
class Beignet extends Pastry {
@Override
void accept(PastryVisitor visitor) {
visitor.visitBeignet(this);
}
}
And:
以及:
class Cruller extends Pastry {
@Override
void accept(PastryVisitor visitor) {
visitor.visitCruller(this);
}
}
To perform an operation on a pastry, we call its
accept()method and pass in the visitor for the operation we want to execute. The pastry—the specific subclass’s overriding implementation ofaccept()—turns around and calls the appropriate visit method on the visitor and passes itself to it.
要對糕點執行一個操作,我們就呼叫它的accept()方法,並將我們要執行的操作vistor作為引數傳入該方法。pastry類——特定子類對accept()的重寫實現——會反過來,在visitor上呼叫合適的visit方法,並將自身作為引數傳入。
That’s the heart of the trick right there. It lets us use polymorphic dispatch on the pastry classes to select the appropriate method on the visitor class. In the table, each pastry class is a row, but if you look at all of the methods for a single visitor, they form a column.
這就是這個技巧的核心所在。它讓我們可以在pastry類上使用多型派遣,在visitor類上選擇合適的方法。對應在表格中,每個pastry類都是一行,但如果你看一個visitor的所有方法,它們就會形成一列。

We added one
accept()method to each class, and we can use it for as many visitors as we want without ever having to touch the pastry classes again. It’s a clever pattern.
我們為每個類添加了一個accept()方法,我們可以根據需要將其用於任意數量的訪問者,而無需再次修改pastry類。 這是一個聰明的模式。
5 . 3 . 3 Visitors for expressions
5.3.3 表示式訪問者
OK, let’s weave it into our expression classes. We’ll also refine the pattern a little. In the pastry example, the visit and
accept()methods don’t return anything. In practice, visitors often want to define operations that produce values. But what return type shouldaccept()have? We can’t assume every visitor class wants to produce the same type, so we’ll use generics to let each implementation fill in a return type.
好的,讓我們將它編入表示式類中。我們還要對這個模式進行一下完善。在糕點的例子中,visit和accept()方法沒有返回任何東西。在實踐中,訪問者通常希望定義能夠產生值的操作。但accept()應該具有什麼返回型別呢?我們不能假設每個訪問者類都想產生相同的型別,所以我們將使用泛型來讓每個實現類自行填充一個返回型別。
First, we define the visitor interface. Again, we nest it inside the base class so that we can keep everything in one file.
首先,我們定義訪問者介面。同樣,我們把它巢狀在基類中,以便將所有的內容都放在一個檔案中。
tool/GenerateAst.java,在 defineAst()方法中新增:
writer.println("abstract class " + baseName + " {");
// 新增部分開始
defineVisitor(writer, baseName, types);
// 新增部分結束
// The AST classes.
That function generates the visitor interface.
這個函式會生成visitor介面。
tool/GenerateAst.java,在 defineAst()方法後新增:
private static void defineVisitor(
PrintWriter writer, String baseName, List<String> types) {
writer.println(" interface Visitor<R> {");
for (String type : types) {
String typeName = type.split(":")[0].trim();
writer.println(" R visit" + typeName + baseName + "(" +
typeName + " " + baseName.toLowerCase() + ");");
}
writer.println(" }");
}
Here, we iterate through all of the subclasses and declare a visit method for each one. When we define new expression types later, this will automatically include them.
在這裡,我們遍歷所有的子類,併為每個子類宣告一個visit方法。當我們以後定義新的表示式型別時,會自動包含這些內容。
Inside the base class, we define the abstract
accept()method.
在基類中,定義抽象 accept() 方法。
tool/GenerateAst.java,在 defineAst()方法中新增:
defineType(writer, baseName, className, fields);
}
// 新增部分開始
// The base accept() method.
writer.println();
writer.println(" abstract <R> R accept(Visitor<R> visitor);");
// 新增部分結束
writer.println("}");
Finally, each subclass implements that and calls the right visit method for its own type.
最後,每個子類都實現該方法,並呼叫其型別對應的visit方法。
tool/GenerateAst.java,在 defineType()方法中新增:
writer.println(" }");
// 新增部分開始
// Visitor pattern.
writer.println();
writer.println(" @Override");
writer.println(" <R> R accept(Visitor<R> visitor) {");
writer.println(" return visitor.visit" +
className + baseName + "(this);");
writer.println(" }");
// 新增部分結束
// Fields.
There we go. Now we can define operations on expressions without having to muck with the classes or our generator script. Compile and run this generator script to output an updated “Expr.java” file. It contains a generated Visitor interface and a set of expression node classes that support the Visitor pattern using it.
這下好了。現在我們可以在表示式上定義操作,而且無需對類或生成器指令碼進行修改。編譯並執行這個生成器指令碼,輸出一個更新後的 "Expr.java "檔案。該檔案中包含一個生成的Visitor介面和一組使用該介面支援Visitor模式的表示式節點類。
Before we end this rambling chapter, let’s implement that Visitor interface and see the pattern in action.
在結束這雜亂的一章之前,我們先實現一下這個Visitor介面,看看這個模式的執行情況。
5 . 4 A (Not Very) Pretty Printer
5.4 一個(不是很)漂亮的列印器
When we debug our parser and interpreter, it’s often useful to look at a parsed syntax tree and make sure it has the structure we expect. We could inspect it in the debugger, but that can be a chore.
當我們除錯解析器和直譯器時,檢視解析後的語法樹並確保其與期望的結構一致通常是很有用的。我們可以在偵錯程式中進行檢查,但那可能有點難。
Instead, we’d like some code that, given a syntax tree, produces an unambiguous string representation of it. Converting a tree to a string is sort of the opposite of a parser, and is often called “pretty printing” when the goal is to produce a string of text that is valid syntax in the source language.
相反,我們需要一些程式碼,在給定語法樹的情況下,生成一個明確的字串表示。將語法樹轉換為字串是解析器的逆向操作,當我們的目標是產生一個在源語言中語法有效的文字字串時,通常被稱為 "漂亮列印"。
That’s not our goal here. We want the string to very explicitly show the nesting structure of the tree. A printer that returned
1 + 2 * 3isn’t super helpful if what we’re trying to debug is whether operator precedence is handled correctly. We want to know if the+or*is at the top of the tree.
這不是我們的目標。我們希望字串非常明確地顯示樹的巢狀結構。如果我們要除錯的是運算子的優先順序是否處理正確,那麼返回1 + 2 * 3的列印器並沒有什麼用,我們想知道+或*是否在語法樹的頂部。
To that end, the string representation we produce isn’t going to be Lox syntax. Instead, it will look a lot like, well, Lisp. Each expression is explicitly parenthesized, and all of its subexpressions and tokens are contained in that.
因此,我們生成的字串表示形式不是Lox語法。相反,它看起來很像Lisp。每個表示式都被顯式地括起來,並且它的所有子表示式和詞法標記都包含在其中。
Given a syntax tree like:
給定一個語法樹,如:

It produces:
輸出結果為:
(* (- 123) (group 45.67))
Not exactly “pretty”, but it does show the nesting and grouping explicitly. To implement this, we define a new class.
不是很“漂亮”,但是它確實明確地展示了巢狀和分組。為了實現這一點,我們定義了一個新類。
lox/AstPrinter.java,建立新檔案:
package com.craftinginterpreters.lox;
class AstPrinter implements Expr.Visitor<String> {
String print(Expr expr) {
return expr.accept(this);
}
}
As you can see, it implements the visitor interface. That means we need visit methods for each of the expression types we have so far.
如你所見,它實現了visitor介面。這意味著我們需要為我們目前擁有的每一種表示式型別提供visit方法。
lox/AstPrinter.java,在 print()方法後新增:
return expr.accept(this);
}
// 新增部分開始
@Override
public String visitBinaryExpr(Expr.Binary expr) {
return parenthesize(expr.operator.lexeme,
expr.left, expr.right);
}
@Override
public String visitGroupingExpr(Expr.Grouping expr) {
return parenthesize("group", expr.expression);
}
@Override
public String visitLiteralExpr(Expr.Literal expr) {
if (expr.value == null) return "nil";
return expr.value.toString();
}
@Override
public String visitUnaryExpr(Expr.Unary expr) {
return parenthesize(expr.operator.lexeme, expr.right);
}
// 新增部分結束
}
Literal expressions are easy—they convert the value to a string with a little check to handle Java’s
nullstanding in for Lox’snil. The other expressions have subexpressions, so they use thisparenthesize()helper method:
字面量表達式很簡單——它們將值轉換為一個字串,並透過一個小檢查用Java中的null代替Lox中的nil。其他表示式有子表示式,所以它們要使用parenthesize()這個輔助方法:
lox/AstPrinter.java,在 visitUnaryExpr()方法後新增:
private String parenthesize(String name, Expr... exprs) {
StringBuilder builder = new StringBuilder();
builder.append("(").append(name);
for (Expr expr : exprs) {
builder.append(" ");
builder.append(expr.accept(this));
}
builder.append(")");
return builder.toString();
}
It takes a name and a list of subexpressions and wraps them all up in parentheses, yielding a string like:
它接收一個名稱和一組子表示式作為引數,將它們全部包裝在圓括號中,並生成一個如下的字串:
(+ 1 2)
Note that it calls
accept()on each subexpression and passes in itself. This is the recursive step that lets us print an entire tree.
請注意,它在每個子表示式上呼叫accept()並將自身傳遞進去。 這是遞迴步驟,可讓我們列印整棵樹。
We don’t have a parser yet, so it’s hard to see this in action. For now, we’ll hack together a little
main()method that manually instantiates a tree and prints it.
我們還沒有解析器,所以很難看到它的實際應用。現在,我們先使用一個main()方法來手動例項化一個樹並列印它。
lox/AstPrinter.java,在 parenthesize()方法後新增:
public static void main(String[] args) {
Expr expression = new Expr.Binary(
new Expr.Unary(
new Token(TokenType.MINUS, "-", null, 1),
new Expr.Literal(123)),
new Token(TokenType.STAR, "*", null, 1),
new Expr.Grouping(
new Expr.Literal(45.67)));
System.out.println(new AstPrinter().print(expression));
}
If we did everything right, it prints:
如果我們都做對了,它就會列印:
(* (- 123) (group 45.67))
You can go ahead and delete this method. We won’t need it. Also, as we add new syntax tree types, I won’t bother showing the necessary visit methods for them in AstPrinter. If you want to (and you want the Java compiler to not yell at you), go ahead and add them yourself. It will come in handy in the next chapter when we start parsing Lox code into syntax trees. Or, if you don’t care to maintain AstPrinter, feel free to delete it. We won’t need it again.
您可以繼續刪除這個方法,我們後面不再需要它了。另外,當我們新增新的語法樹型別時,我不會在AstPrinter中展示它們對應的visit方法。如果你想這樣做(並且希望Java編譯器不會報錯),那麼你可以自行新增這些方法。在下一章,當我們開始將Lox程式碼解析為語法樹時,它將會派上用場。或者,如果你不想維護AstPrinter,可以隨意刪除它。我們不再需要它了。
CHALLENGES
習題
1、Earlier, I said that the
|,*, and+forms we added to our grammar metasyntax were just syntactic sugar. Take this grammar:expr → expr ( "(" ( expr ( "," expr )* )? ")" | "." IDENTIFIER )+ | IDENTIFIER | NUMBERProduce a grammar that matches the same language but does not use any of that notational sugar.
Bonus: What kind of expression does this bit of grammar encode?
1、之前我說過,我們在語法元語法中新增的|、*、+等形式只是語法糖。以這個語法為例:
expr → expr ( "(" ( expr ( "," expr )* )? ")" | "." IDENTIFIER )+
| IDENTIFIER
| NUMBER
生成一個與同一語言相匹配的語法,但不要使用任何語法糖。
附加題:這一點語法表示了什麼樣的表示式?
2、The Visitor pattern lets you emulate the functional style in an object-oriented language. Devise a complementary pattern for a functional language. It should let you bundle all of the operations on one type together and let you define new types easily.
(SML or Haskell would be ideal for this exercise, but Scheme or another Lisp works as well.)
2、Visitor 模式讓你可以在面向物件的語言中模仿函式式。為函式式語言設計一個互補的模式,該模式讓你可以將一個型別上的所有操作捆綁在一起,並輕鬆擴充套件新的型別。
(SML或Haskell是這個練習的理想選擇,但Scheme或其它Lisp方言也可以。)
3、In Reverse Polish Notation (RPN), the operands to an arithmetic operator are both placed before the operator, so
1 + 2becomes1 2 +. Evaluation proceeds from left to right. Numbers are pushed onto an implicit stack. An arithmetic operator pops the top two numbers, performs the operation, and pushes the result. Thus, this:(1 + 2) * (4 - 3)in RPN becomes:
1 2 + 4 3 - *Define a visitor class for our syntax tree classes that takes an expression, converts it to RPN, and returns the resulting string.
3、在逆波蘭表示式(RPN)中,算術運算子的運算元都放在運算子之前,所以1 + 2變成了1 2 +。計算時從左到右進行,運算元被壓入隱式棧。算術運算子彈出前兩個數字,執行運算,並將結果推入棧中。因此,
(1 + 2) * (4 - 3)
在RPN中變為了
1 2 + 4 3 - *
為我們的語法樹類定義一個Vistor類,該類接受一個表示式,將其轉換為RPN,並返回結果字串。
-
我非常擔心這一章會成為這本書中最無聊的章節之一,所以我儘可能多地往裡面塞入了很多有趣的想法。 ↩
-
在美國,運算子優先順序常縮寫為PEMDAS,分別表示Parentheses(括號), Exponents(指數), Multiplication/Division(乘除), Addition/Subtraction(加減)。為了便於記憶,將縮寫詞擴充為“Please Excuse My Dear Aunt Sally”。 ↩
-
這並不是說樹是我們程式碼的唯一可能的表示方式。在第三部分,我們將生成位元組碼,這是另一種對人類不友好但更接近機器的表示方式。 ↩
-
是的,我們需要為定義語法的規則定義一個語法。我們也應該指定這個元語法嗎?我們用什麼符號來表示它?從上到下都是語言 ↩
-
想象一下,我們在這裡遞迴擴充套件幾次
breakfast規則,比如 "bacon with bacon with bacon with . . ." ,為了正確地完成這個字串,我們需要在結尾處新增同等數量的 "on the side "片語。跟蹤所需尾部的數量超出了正則語法的能力範圍。正則語法可以表達重複,但它們無法統計有多少重複,但是這(種跟蹤)對於確保字串的with和on the side部分的數量相同是必要的。 ↩ -
Scheme程式語言就是這樣工作的。它根本沒有內建的迴圈功能。相反,所有重複都用遞迴來表示。 ↩
-
如果你願意,可以嘗試使用這個語法生成一些表示式,就像我們之前用早餐語法做的那樣。生成的表示式你覺得對嗎?你能讓它生成任何錯誤的東西,比如1+/3嗎? ↩
-
特別是,我們要定義一個抽象語法樹(AST)。在解析樹中,每一個語法生成式都成為樹中的一個節點。AST省略了後面階段不需要的生成式。 ↩
-
詞法單元也不是完全同質的。字面值的標記儲存值,但其他型別的詞素不需要該狀態。我曾經見過一些掃描器使用不同的類來處理字面量和其他型別的詞素,但我認為我應該把事情簡單化。 ↩
-
我儘量避免在程式碼中使用縮寫,因為這會讓不知道其含義的讀者犯錯誤。但是在我所研究過的編譯器中,“Expr”和“Stmt”是如此普遍,我最好現在就開始讓您習慣它們。 ↩
-
我從Jython和IronPython的建立者Jim Hugunin那裡得到了編寫語法樹類指令碼的想法。真正的指令碼語言比Java更適合這種情況,但我儘量不向您提供太多的語言。 ↩
-
這不是世界上最優雅的字串操作程式碼,但也很好。它只在我們給它的類定義集上執行。穩健性不是優先考慮的問題。 ↩
-
附錄II包含了在我們完成jlox的實現並定義了它的所有語法樹節點之後,這個指令碼生成的程式碼。 ↩
-
ML,是元語言(metalanguage)的簡稱,它是由Robin Milner和他的朋友們建立的,是偉大的程式語言家族的主要分支之一。它的子程式包括SML、Caml、OCaml、Haskell和F#。甚至Scala、Rust和Swift都有很強的相似性。就像Lisp一樣,它也是那種充滿了好點子的語言之一,即使在40多年後的今天,語言設計者仍然在重新發現它們。 ↩
-
諸如Common Lisp的CLOS,Dylan和Julia這樣的支援多方法(多分派)的語言都能輕鬆新增新型別和操作。它們通常犧牲的是靜態型別檢查或單獨編譯。 ↩
-
在設計模式中,這兩種方法的名字都叫
visit(),很容易混淆,需要依賴過載來區分不同方法。這也導致一些讀者認為正確的visit方法是在執行時根據其引數型別選擇的。事實並非如此。與重寫不同,過載是在編譯時靜態分派的。為每個方法使用不同的名稱使分派更加明顯,同時還向您展示瞭如何在不支援過載的語言中應用此模式。 ↩
6.Parsing Expressions 解析表示式
Grammar, which knows how to control even kings.
——Molière
語法,它甚至知道如何控制國王。(莫里哀)
This chapter marks the first major milestone of the book. Many of us have cobbled together a mishmash of regular expressions and substring operations to extract some sense out of a pile of text. The code was probably riddled with bugs and a beast to maintain. Writing a real parser—one with decent error handling, a coherent internal structure, and the ability to robustly chew through a sophisticated syntax—is considered a rare, impressive skill. In this chapter, you will attain it.
本章是本書的第一個重要里程碑。我們中的許多人都曾將正規表示式和字串操作糅合在一起,以便從一堆文字中提取一些資訊。這些程式碼可能充滿了錯誤,而且很難維護。編寫一個真正的解析器1——具有良好的錯誤處理、一致的內部結構和能夠健壯地分析複雜語法的能力——被認為是一種罕見的、令人印象深刻的技能。在這一章中,你將獲得這種技能。
It’s easier than you think, partially because we front-loaded a lot of the hard work in the last chapter. You already know your way around a formal grammar. You’re familiar with syntax trees, and we have some Java classes to represent them. The only remaining piece is parsing—transmogrifying a sequence of tokens into one of those syntax trees.
這比想象中要簡單,部分是因為我們在上一章中提前完成了很多困難的工作。你已經對形式化語法瞭如指掌,也熟悉了語法樹,而且我們有一些Java類來表示它們。唯一剩下的部分是解析——將一個標記序列轉換成這些語法樹中的一個。
Some CS textbooks make a big deal out of parsers. In the ’60s, computer scientists—understandably tired of programming in assembly language—started designing more sophisticated, human-friendly languages like Fortran and ALGOL. Alas, they weren’t very machine-friendly for the primitive computers of the time.
一些CS教科書在解析器上大做文章。在60年代,電腦科學家——他們理所當然地厭倦了用匯編語言程式設計——開始設計更復雜的、對人類友好的語言,比如Fortran和ALGOL2。唉,對於當時原始的計算機來說,這些語言對機器並不友好。
These pioneers designed languages that they honestly weren’t even sure how to write compilers for, and then did groundbreaking work inventing parsing and compiling techniques that could handle these new, big languages on those old, tiny machines.
這些先驅們設計了一些語言,說實話,他們甚至不知道如何編寫編譯器。然後他們做了開創性的工作,發明瞭解析和編譯技術,可以在那些老舊、小型的機器上處理這些新的、大型的語言。
Classic compiler books read like fawning hagiographies of these heroes and their tools. The cover of Compilers: Principles, Techniques, and Tools literally has a dragon labeled “complexity of compiler design” being slain by a knight bearing a sword and shield branded “LALR parser generator” and “syntax directed translation”. They laid it on thick.
經典的編譯書讀起來就像是對這些英雄和他們的工具的吹捧傳記。《編譯器:原理、技術和工具》(Compilers: Principles, Techniques, and Tools)的封面上有一條標記著“編譯器設計複雜性”的龍,被一個手持劍和盾的騎士殺死,劍和盾上標記著“LALR解析器生成器”和“語法制導翻譯”。他們在過分吹捧。
A little self-congratulation is well-deserved, but the truth is you don’t need to know most of that stuff to bang out a high quality parser for a modern machine. As always, I encourage you to broaden your education and take it in later, but this book omits the trophy case.
稍微的自我祝賀是當之無愧的,但事實是,你不需要知道其中的大部分知識,就可以為現代機器製作出高質量的解析器。一如既往,我鼓勵你先擴大學習範圍,以後再慢慢接受它,但這本書省略了獎盃箱。
6 . 1 Ambiguity and the Parsing Game
6.1 歧義與解析遊戲
In the last chapter, I said you can “play” a context-free grammar like a game in order to generate strings. Parsers play that game in reverse. Given a string—a series of tokens—we map those tokens to terminals in the grammar to figure out which rules could have generated that string.
在上一章中,我說過你可以像“玩”遊戲一樣使用上下文無關的語法來生成字串。解析器則以相反的方式玩遊戲。給定一個字串(一系列語法標記),我們將這些標記對映到語法中的終止符,以確定哪些規則可能生成該字串。
The “could have” part is interesting. It’s entirely possible to create a grammar that is ambiguous, where different choices of productions can lead to the same string. When you’re using the grammar to generate strings, that doesn’t matter much. Once you have the string, who cares how you got to it?
"可能產生 "這部分很有意思。我們完全有可能建立一個模稜兩可的語法,在這個語法中,不同的生成式可能會得到同一個字串。當你使用該語法來生成字串時,這一點不太重要。一旦你有了字串,誰還會在乎你是怎麼得到它的呢?
When parsing, ambiguity means the parser may misunderstand the user’s code. As we parse, we aren’t just determining if the string is valid Lox code, we’re also tracking which rules match which parts of it so that we know what part of the language each token belongs to. Here’s the Lox expression grammar we put together in the last chapter:
但是在解析時,歧義意味著解析器可能會誤解使用者的程式碼。當我們進行解析時,我們不僅要確定字串是不是有效的Lox程式碼,還要記錄哪些規則與程式碼的哪些部分相匹配,以便我們知道每個標記屬於語言的哪一部分。下面是我們在上一章整理的Lox表示式語法:
expression → literal
| unary
| binary
| grouping ;
literal → NUMBER | STRING | "true" | "false" | "nil" ;
grouping → "(" expression ")" ;
unary → ( "-" | "!" ) expression ;
binary → expression operator expression ;
operator → "==" | "!=" | "<" | "<=" | ">" | ">="
| "+" | "-" | "*" | "/" ;
This is a valid string in that grammar:
下面是一個滿足語法的有效字串:

But there are two ways we could have generated it. One way is:
但是,有兩種方式可以生成該字串。其一是:
- Starting at
expression, pickbinary.- For the left-hand
expression, pickNUMBER, and use6.- For the operator, pick
"/".- For the right-hand
expression, pickbinaryagain.- In that nested
binaryexpression, pick3 - 1.
- 從
expression開始,選擇binary。 - 對於左邊的
expression,選擇NUMBER,並且使用6。 - 對於運算子,選擇
/。 - 對於右邊的
expression,再次選擇binary。 - 在內層的
binary表示式中,選擇3-1。
Another is:
其二是:
- Starting at
expression, pickbinary.- For the left-hand
expression, pickbinaryagain.- In that nested
binaryexpression, pick6 / 3.- Back at the outer
binary, for the operator, pick"-".- For the right-hand
expression, pickNUMBER, and use1.
- 從
expression開始,選擇binary。 - 對於左邊的
expression,再次選擇binary。 - 在內層的
binary表示式中,選擇6/3。 - 返回外層的
binary,對於運算子,選擇-。 - 對於右邊的
expression,選擇NUMBER,並且使用1。
Those produce the same strings, but not the same syntax trees:
它們產生相同的字串,但對應的是不同的語法樹:

In other words, the grammar allows seeing the expression as
(6 / 3) - 1or6 / (3 - 1). Thebinaryrule lets operands nest any which way you want. That in turn affects the result of evaluating the parsed tree. The way mathematicians have addressed this ambiguity since blackboards were first invented is by defining rules for precedence and associativity.
換句話說,這個語法可以將該表示式看作是 (6 / 3) - 1或6 / (3 - 1)。binary 規則執行運算元以任意方式巢狀,這反過來又會影響解析數的計算結果。自從黑板被髮明以來,數學家們解決這種模糊性的方法就是定義優先順序和結合性規則。
-
Precedence determines which operator is evaluated first in an expression containing a mixture of different operators. Precedence rules tell us that we evaluate the
/before the-in the above example. Operators with higher precedence are evaluated before operators with lower precedence. Equivalently, higher precedence operators are said to “bind tighter”. -
優先順序決定了在一個包含不同運算子的混合表示式中,哪個運算子先被執行3。優先順序規則告訴我們,在上面的例子中,我們在
-之前先計算/。優先順序較高的運算子在優先順序較低的運算子之前計算。同樣,優先順序較高的運算子被稱為 "更嚴格的繫結"。 -
Associativity determines which operator is evaluated first in a series of the same operator. When an operator is left-associative (think “left-to-right”), operators on the left evaluate before those on the right. Since
-is left-associative, this expression: -
結合性決定在一系列相同運算子中先計算哪個運算子。如果一個運算子是左結合的(可以認為是“從左到右”)時,左邊的運算子在右邊的運算子之前計算。因為
-是左結合的,下面的表示式:5 - 3 - 1is equivalent to:
等價於:
(5 - 3) - 1Assignment, on the other hand, is right-associative. This:
另一方面,賦值是右結合的。如:
a = b = cis equivalent to:
等價於:
a = (b = c)
Without well-defined precedence and associativity, an expression that uses multiple operators is ambiguous—it can be parsed into different syntax trees, which could in turn evaluate to different results. We’ll fix that in Lox by applying the same precedence rules as C, going from lowest to highest.
如果沒有明確定義的優先順序和結合性,使用多個運算子的表示式可能就會變得有歧義——它可以被解析為不同的語法樹,而這些語法樹又可能會計算出不同的結果。我們在Lox中會解決這個問題,使用與C語言相同的優先順序規則,從低到高分別是:
| Name | Operators | Associates |
|---|---|---|
| Equality 等於 | == != | Left 左結合 |
| Comparison 比較 | > >= < <= | Left 左結合 |
| Term 加減運算 | - + | Left 左結合 |
| Factor 乘除運算 | / * | Left 左結合 |
| Unary 一元運算子 | ! - | Right 右結合 |
Right now, the grammar stuffs all expression types into a single
expressionrule. That same rule is used as the non-terminal for operands, which lets the grammar accept any kind of expression as a subexpression, regardless of whether the precedence rules allow it.
現在,該語法將所有表示式型別都新增到一個 expression規則中。這條規則同樣作用於運算元中的非終止符,這使得語法中可以接受任何型別的表示式作為子表示式,而不管優先順序規則是否允許。
We fix that by stratifying the grammar. We define a separate rule for each precedence level.
我們透過對語法進行分層來解決這個問題。我們為每個優先順序定義一個單獨的規則4。
expression → ...
equality → ...
comparison → ...
term → ...
factor → ...
unary → ...
primary → ...
Each rule here only matches expressions at its precedence level or higher. For example,
unarymatches a unary expression like!negatedor a primary expression like1234. Andtermcan match1 + 2but also3 * 4 / 5. The finalprimaryrule covers the highest-precedence forms—literals and parenthesized expressions.
此處的每個規則僅匹配其當前優先順序或更高優先順序的表示式。 例如,unary 匹配一元表示式(如 !negated)或主表示式(如1234)。term可以匹配1 + 2,但也可以匹配3 * 4 /5。最後的primary 規則涵蓋優先順序最高的形式——字面量和括號表示式。
We just need to fill in the productions for each of those rules. We’ll do the easy ones first. The top
expressionrule matches any expression at any precedence level. Sinceequalityhas the lowest precedence, if we match that, then it covers everything.
我們只需要填寫每條規則的生成式。我們先從簡單的開始。頂級的expression 規則可以匹配任何優先順序的表示式。由於equality的優先順序最低,只要我們匹配了它,就涵蓋了一切5。
expression → equality
Over at the other end of the precedence table, a primary expression contains all the literals and grouping expressions.
在優先順序表的另一端,primary表示式包括所有的字面量和分組表示式。
primary → NUMBER | STRING | "true" | "false" | "nil"
| "(" expression ")" ;
A unary expression starts with a unary operator followed by the operand. Since unary operators can nest—
!!trueis a valid if weird expression—the operand can itself be a unary operator. A recursive rule handles that nicely.
一元表示式以一元運算子開頭,後跟運算元。因為一元運算子可以巢狀——!!true雖奇怪也是可用的表示式——這個運算元本身可以是一個一元表示式。遞迴規則可以很好地解決這個問題。
unary → ( "!" | "-" ) unary ;
But this rule has a problem. It never terminates.
但是這條規則有一個問題,它永遠不會終止。
Remember, each rule needs to match expressions at that precedence level or higher, so we also need to let this match a primary expression.
請記住,每個規則都需要匹配該優先順序或更高優先順序的表示式,因此我們還需要使其與主表示式匹配。
unary → ( "!" | "-" ) unary
| primary ;
That works.
這樣就可以了。
The remaining rules are all binary operators. We’ll start with the rule for multiplication and division. Here’s a first try:
剩下的規則就是二元運算子。我們先從乘法和除法的規則開始。下面是第一次嘗試:
factor → factor ( "/" | "*" ) unary
| unary ;
The rule recurses to match the left operand. That enables the rule to match a series of multiplication and division expressions like
1 * 2 / 3. Putting the recursive production on the left side andunaryon the right makes the rule left-associative and unambiguous.
該規則遞迴匹配左運算元,這樣一來,就可以匹配一系列乘法和除法表示式,例如 1 * 2 / 3。將遞迴生成式放在左側並將unary 放在右側,可以使該規則具有左關聯性和明確性6。
All of this is correct, but the fact that the first symbol in the body of the rule is the same as the head of the rule means this production is left-recursive. Some parsing techniques, including the one we’re going to use, have trouble with left recursion. (Recursion elsewhere, like we have in
unaryand the indirect recursion for grouping inprimaryare not a problem.)
所有這些都是正確的,但規則主體中的第一個符號與規則頭部相同意味著這個生成式是左遞迴的。一些解析技術,包括我們將要使用的解析技術,在處理左遞迴時會遇到問題。(其他地方的遞迴,比如在unary中,以及在primary分組中的間接遞迴都不是問題。)
There are many grammars you can define that match the same language. The choice for how to model a particular language is partially a matter of taste and partially a pragmatic one. This rule is correct, but not optimal for how we intend to parse it. Instead of a left recursive rule, we’ll use a different one.
你可以定義很多符合同一種語言的語法。如何對某一特定語言進行建模,一部分是品味問題,一部分是實用主義問題。這個規則是正確的,但對於我們後續的解析來說它並不是最優的。我們將使用不同的規則來代替左遞迴規則。
factor → unary ( ( "/" | "*" ) unary )* ;
We define a factor expression as a flat sequence of multiplications and divisions. This matches the same syntax as the previous rule, but better mirrors the code we’ll write to parse Lox. We use the same structure for all of the other binary operator precedence levels, giving us this complete expression grammar:
我們將因子表示式定義為乘法和除法的扁平序列。這與前面的規則語法相同,但更好地反映了我們將編寫的解析Lox的程式碼。我們對其它二元運算子的優先順序使用相同的結構,從而得到下面這個完整的表示式語法:
expression → equality ;
equality → comparison ( ( "!=" | "==" ) comparison )* ;
comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ;
term → factor ( ( "-" | "+" ) factor )* ;
factor → unary ( ( "/" | "*" ) unary )* ;
unary → ( "!" | "-" ) unary
| primary ;
primary → NUMBER | STRING | "true" | "false" | "nil"
| "(" expression ")" ;
This grammar is more complex than the one we had before, but in return we have eliminated the previous one’s ambiguity. It’s just what we need to make a parser.
這個語法比我們以前的那個更復雜,但反過來我們也消除了前一個語法定義中的歧義。這正是我們製作解析器時所需要的。
6 . 2 Recursive Descent Parsing
6.2 遞迴下降分析
There is a whole pack of parsing techniques whose names are mostly combinations of “L” and “R”—LL(k), LR(1), LALR—along with more exotic beasts like parser combinators, Earley parsers, the shunting yard algorithm, and packrat parsing. For our first interpreter, one technique is more than sufficient: recursive descent.
現在有一大堆解析技術,它們的名字大多是 "L "和 "R "的組合——LL(k)、LR(1)、LALR——還有更多的異類,比如解析器組合子、Earley parsers、分流碼演算法和packrat解析。對於我們的第一個直譯器來說,一種技術已經足夠了:遞迴下降。
Recursive descent is the simplest way to build a parser, and doesn’t require using complex parser generator tools like Yacc, Bison or ANTLR. All you need is straightforward handwritten code. Don’t be fooled by its simplicity, though. Recursive descent parsers are fast, robust, and can support sophisticated error handling. In fact, GCC, V8 (the JavaScript VM in Chrome), Roslyn (the C# compiler written in C#) and many other heavyweight production language implementations use recursive descent. It rocks.
遞迴下降是構建解析器最簡單的方法,不需要使用複雜的解析器生成工具,如Yacc、Bison或ANTLR。你只需要直接手寫程式碼。但是不要被它的簡單性所欺騙,遞迴下降解析器速度快、健壯,並且可以支援複雜的錯誤處理。事實上,GCC、V8 (Chrome中的JavaScript VM)、Roslyn(用c#編寫的c#編譯器)和許多其他重量級產品語言實現都使用了遞迴下降技術。它很好用。
Recursive descent is considered a top-down parser because it starts from the top or outermost grammar rule (here
expression) and works its way down into the nested subexpressions before finally reaching the leaves of the syntax tree. This is in contrast with bottom-up parsers like LR that start with primary expressions and compose them into larger and larger chunks of syntax.
遞迴下降被認為是一種自頂向下解析器,因為它從最頂部或最外層的語法規則(這裡是expression)開始,一直向下進入巢狀子表示式,最後到達語法樹的葉子。這與LR等自下而上的解析器形成鮮明對比,後者從初級表示式(primary)開始,將其組成越來越大的語法塊7。
A recursive descent parser is a literal translation of the grammar’s rules straight into imperative code. Each rule becomes a function. The body of the rule translates to code roughly like:
遞迴下降解析器是一種將語法規則直接翻譯成命令式程式碼的文字翻譯器。每個規則都會變成一個函式,規則主體翻譯成程式碼大致是這樣的:
| Grammar notation | Code representation |
|---|---|
| Terminal | Code to match and consume a token 匹配並消費一個語法標記 |
| Nonterminal | Call to that rule’s function 呼叫規則對應的函式 |
| ` | ` |
* or + | while or for loop while或for迴圈 |
? | if statement if語句 |
The descent is described as “recursive” because when a grammar rule refers to itself—directly or indirectly—that translates to a recursive function call.
下降被“遞迴”修飾是因為,如果一個規則引用自身(直接或間接)就會變為遞迴的函式呼叫。
6 . 2 . 1 The parser class
6.2.1 Parser類
Each grammar rule becomes a method inside this new class:
每個語法規則都成為新類中的一個方法:
lox/Parser.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.List;
import static com.craftinginterpreters.lox.TokenType.*;
class Parser {
private final List<Token> tokens;
private int current = 0;
Parser(List<Token> tokens) {
this.tokens = tokens;
}
}
Like the scanner, the parser consumes a flat input sequence, only now we’re reading tokens instead of characters. We store the list of tokens and use
currentto point to the next token eagerly waiting to be parsed.
與掃描器一樣,解析器也是消費一個扁平的輸入序列,只是這次我們要讀取的是語法標記而不是字元。我們會儲存標記列表並使用current指向待解析的下一個標記。
We’re going to run straight through the expression grammar now and translate each rule to Java code. The first rule,
expression, simply expands to theequalityrule, so that’s straightforward.
我們現在要直接執行表示式語法,並將每一條規則翻譯為Java程式碼。第一條規則expression,簡單地展開為equality規則,所以很直接:
lox/Parser.java,在 Parser()方法後新增:
private Expr expression() {
return equality();
}
Each method for parsing a grammar rule produces a syntax tree for that rule and returns it to the caller. When the body of the rule contains a nonterminal—a reference to another rule—we call that other rule’s method.
每個解析語法規則的方法都會生成該規則對應的語法樹,並將其返回給呼叫者。當規則主體中包含一個非終止符——對另一條規則的引用時,我們就會呼叫另一條規則對應的方法8。
The rule for equality is a little more complex.
equality規則有一點複雜:
equality → comparison ( ( "!=" | "==" ) comparison )* ;
In Java, that becomes:
在Java中,這會變成:
lox/Parser.java,在 expression()後面新增:
private Expr equality() {
Expr expr = comparison();
while (match(BANG_EQUAL, EQUAL_EQUAL)) {
Token operator = previous();
Expr right = comparison();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
Let’s step through it. The first
comparisonnonterminal in the body translates to the first call tocomparison()in the method. We take that result and store it in a local variable.
讓我們一步步來。規則體中的第一個 comparison 非終止符變成了方法中對 comparison() 的第一次呼叫。我們獲取結果並將其儲存在一個區域性變數中。
Then, the
( ... )*loop in the rule maps to awhileloop. We need to know when to exit that loop. We can see that inside the rule, we must first find either a!=or==token. So, if we don’t see one of those, we must be done with the sequence of equality operators. We express that check using a handymatch()method.
然後,規則中的( ... )*迴圈對映為一個while迴圈。我們需要知道何時退出這個迴圈。可以看到,在規則體中,我們必須先找到一個 != 或==標記。因此,如果我們沒有看到其中任一標記,我們必須結束相等(不相等)運算子的序列。我們使用一個方便的match()方法來執行這個檢查。
lox/Parser.java,在 equality()方法後新增:
private boolean match(TokenType... types) {
for (TokenType type : types) {
if (check(type)) {
advance();
return true;
}
}
return false;
}
This checks to see if the current token has any of the given types. If so, it consumes the token and returns
true. Otherwise, it returnsfalseand leaves the current token alone. Thematch()method is defined in terms of two more fundamental operations.
這個檢查會判斷當前的標記是否屬於給定的型別之一。如果是,則消費該標記並返回true;否則,就返回false並保留當前標記。match()方法是由兩個更基本的操作來定義的。
The
check()method returnstrueif the current token is of the given type. Unlikematch(), it never consumes the token, it only looks at it.
如果當前標記屬於給定型別,則check()方法返回true。與match()不同的是,它從不消費標記,只是讀取。
lox/Parser.java,在 match()方法後新增:
private boolean check(TokenType type) {
if (isAtEnd()) return false;
return peek().type == type;
}
The
advance()method consumes the current token and returns it, similar to how our scanner’s corresponding method crawled through characters.
advance()方法會消費當前的標記並返回它,類似於掃描器中對應方法處理字元的方式。
lox/Parser.java,在 check()方法後新增:
private Token advance() {
if (!isAtEnd()) current++;
return previous();
}
These methods bottom out on the last handful of primitive operations.
這些方法最後都歸結於幾個基本操作。
lox/Parser.java,在 advance()後新增:
private boolean isAtEnd() {
return peek().type == EOF;
}
private Token peek() {
return tokens.get(current);
}
private Token previous() {
return tokens.get(current - 1);
}
isAtEnd()checks if we’ve run out of tokens to parse.peek()returns the current token we have yet to consume, andprevious()returns the most recently consumed token. The latter makes it easier to usematch()and then access the just-matched token.
isAtEnd()檢查我們是否處理完了待解析的標記。peek()方法返回我們還未消費的當前標記,而previous()會返回最近消費的標記。後者讓我們更容易使用match(),然後訪問剛剛匹配的標記。
That’s most of the parsing infrastructure we need. Where were we? Right, so if we are inside the
whileloop inequality(), then we know we have found a!=or==operator and must be parsing an equality expression.
這就是我們需要的大部分解析基本工具。我們說到哪裡了?對,如果我們在equality()的while迴圈中,也就能知道我們已經找到了一個!=或==運算子,並且一定是在解析一個等式表示式。
We grab the matched operator token so we can track which kind of equality expression we have. Then we call
comparison()again to parse the right-hand operand. We combine the operator and its two operands into a newExpr.Binarysyntax tree node, and then loop around. For each iteration, we store the resulting expression back in the sameexprlocal variable. As we zip through a sequence of equality expressions, that creates a left-associative nested tree of binary operator nodes.
我們獲取到匹配的運算子標記,這樣就可以知道我們要處理哪一類等式表示式。之後,我們再次呼叫comparison()解析右邊的運算元。我們將運算子和它的兩個運算元組合成一個新的Expr.Binary語法樹節點,然後開始迴圈。對於每一次迭代,我們都將結果表示式儲存在同一個expr區域性變數中。在對等式表示式序列進行壓縮時,會建立一個由二元運算子節點組成的左結合巢狀樹9。

The parser falls out of the loop once it hits a token that’s not an equality operator. Finally, it returns the expression. Note that if the parser never encounters an equality operator, then it never enters the loop. In that case, the
equality()method effectively calls and returnscomparison(). In that way, this method matches an equality operator or anything of higher precedence.
一旦解析器遇到一個不是等式運算子的標記,就會退出迴圈。最後,它會返回對應的表示式。請注意,如果解析器從未遇到過等式運算子,它就永遠不會進入迴圈。在這種情況下,equality()方法有效地呼叫並返回comparison()。這樣一來,這個方法就會匹配一個等式運算子或任何更高優先順序的表示式。
Moving on to the next rule . . .
繼續看下一個規則。
comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ;
Translated to Java:
翻譯成Java:
lox/Parser.java,在 equality()方法後新增:
private Expr comparison() {
Expr expr = term();
while (match(GREATER, GREATER_EQUAL, LESS, LESS_EQUAL)) {
Token operator = previous();
Expr right = term();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
The grammar rule is virtually identical to
equalityand so is the corresponding code. The only differences are the token types for the operators we match, and the method we call for the operands—nowterm()instead ofcomparison(). The remaining two binary operator rules follow the same pattern.
語法規則與equality幾乎完全相同,相應的程式碼也是如此。唯一的區別是匹配的運算子的標記型別,而且現在獲取運算元時呼叫的方法是term()而不是comparison()。其餘兩個二元運算子規則遵循相同的模式。
In order of precedence, first addition and subtraction:
按照優先順序順序,先做加減法:
lox/Parser.java,在 comparison()方法後新增:
private Expr term() {
Expr expr = factor();
while (match(MINUS, PLUS)) {
Token operator = previous();
Expr right = factor();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
And finally, multiplication and division:
最後,是乘除法:
lox/Parser.java,在 term()方法後面新增:
private Expr factor() {
Expr expr = unary();
while (match(SLASH, STAR)) {
Token operator = previous();
Expr right = unary();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
That’s all of the binary operators, parsed with the correct precedence and associativity. We’re crawling up the precedence hierarchy and now we’ve reached the unary operators.
這就是所有的二元運算子,已經按照正確的優先順序和結合性進行了解析。接下來,按照優先順序層級,我們要處理一元運算子了。
unary → ( "!" | "-" ) unary
| primary ;
The code for this is a little different.
該規則對應的程式碼有些不同。
lox/Parser.java,在 factor()方法後新增:
private Expr unary() {
if (match(BANG, MINUS)) {
Token operator = previous();
Expr right = unary();
return new Expr.Unary(operator, right);
}
return primary();
}
Again, we look at the current token to see how to parse. If it’s a
!or-, we must have a unary expression. In that case, we grab the token and then recursively callunary()again to parse the operand. Wrap that all up in a unary expression syntax tree and we’re done.
同樣的,我們先檢查當前的標記以確認要如何進行解析10。如果是!或-,我們一定有一個一元表示式。在這種情況下,我們使用當前的標記遞迴呼叫unary()來解析運算元。將所有這些都包裝到一元表示式語法樹中,我們就完成了。
Otherwise, we must have reached the highest level of precedence, primary expressions.
否則,我們就達到了最高階別的優先順序,即基本表示式。
primary → NUMBER | STRING | "true" | "false" | "nil"
| "(" expression ")" ;
Most of the cases for the rule are single terminals, so parsing is straightforward.
該規則中大部分都是終止符,可以直接進行解析。
lox/Parser.java,在 unary()方法後新增:
private Expr primary() {
if (match(FALSE)) return new Expr.Literal(false);
if (match(TRUE)) return new Expr.Literal(true);
if (match(NIL)) return new Expr.Literal(null);
if (match(NUMBER, STRING)) {
return new Expr.Literal(previous().literal);
}
if (match(LEFT_PAREN)) {
Expr expr = expression();
consume(RIGHT_PAREN, "Expect ')' after expression.");
return new Expr.Grouping(expr);
}
}
The interesting branch is the one for handling parentheses. After we match an opening ( and parse the expression inside it, we must find a ) token. If we don’t, that’s an error.
有趣的一點是處理括號的分支。當我們匹配了一個開頭(並解析了裡面的表示式後,我們必須找到一個)標記。如果沒有找到,那就是一個錯誤。
6 . 3 Syntax Errors
6.3 語法錯誤
A parser really has two jobs:
解析器實際上有兩項工作:
-
Given a valid sequence of tokens, produce a corresponding syntax tree.
給定一個有效的標記序列,生成相應的語法樹。
-
Given an invalid sequence of tokens, detect any errors and tell the user about their mistakes.
給定一個無效的標記序列,檢測錯誤並告知使用者。
Don’t underestimate how important the second job is! In modern IDEs and editors, the parser is constantly reparsing code—often while the user is still editing it—in order to syntax highlight and support things like auto-complete. That means it will encounter code in incomplete, half-wrong states all the time.
不要低估第二項工作的重要性!在現代的IDE和編輯器中,為了語法高亮顯示和支援自動補齊等功能,當使用者還在編輯程式碼時,解析器就會不斷地重新解析程式碼。這也意味著解析器總是會遇到不完整的、半錯誤狀態的程式碼。
When the user doesn’t realize the syntax is wrong, it is up to the parser to help guide them back onto the right path. The way it reports errors is a large part of your language’s user interface. Good syntax error handling is hard. By definition, the code isn’t in a well-defined state, so there’s no infallible way to know what the user meant to write. The parser can’t read your mind.
當使用者沒有意識到語法錯誤時,解析器要幫助引導他們回到正確的道路上。在你的語言的人機互動中,錯誤反饋佔據了很大的比重。良好的語法錯誤處理是很難的。根據定義,程式碼並不是處於良好定義的狀態,所以沒有可靠的方法能夠知道使用者想要寫什麼。解析器無法讀懂你的思想。
There are a couple of hard requirements for when the parser runs into a syntax error. A parser must:
當解析器遇到語法錯誤時,有幾個硬性要求。解析器必須能夠:
-
Detect and report the error. If it doesn’t detect the error and passes the resulting malformed syntax tree on to the interpreter, all manner of horrors may be summoned.
檢測並報告錯誤。如果它沒有檢測到錯誤,並將由此產生的畸形語法樹傳遞給直譯器,就會出現各種可怕的情況。
-
Avoid crashing or hanging. Syntax errors are a fact of life, and language tools have to be robust in the face of them. Segfaulting or getting stuck in an infinite loop isn’t allowed. While the source may not be valid code, it’s still a valid input to the parser because users use the parser to learn what syntax is allowed.
避免崩潰或掛起。語法錯誤是生活中不可避免的事實,面對語法錯誤,語言工具必須非常健壯。段錯誤或陷入無限迴圈是不允許的。雖然原始碼可能不是有效的程式碼,但它仍然是解析器的有效輸入,因為使用者使用解析器來瞭解什麼是允許的語法。
Those are the table stakes if you want to get in the parser game at all, but you really want to raise the ante beyond that. A decent parser should:
如果你想參與到解析器的遊戲中來,這些就是桌面的籌碼,但你真的想提高賭注,除了這些。一個像樣的解析器還應該:
-
Be fast. Computers are thousands of times faster than they were when parser technology was first invented. The days of needing to optimize your parser so that it could get through an entire source file during a coffee break are over. But programmer expectations have risen as quickly, if not faster. They expect their editors to reparse files in milliseconds after every keystroke.
要快。計算機的速度比最初發明解析器技術時快了幾千倍。那種需要最佳化解析器,以便它能在喝咖啡的時候處理完整個原始檔的日子已經一去不復返了。但是程式設計師的期望值也上升得同樣快,甚至更快。他們希望他們的編輯器能在每次擊鍵後的幾毫秒內回覆檔案。
-
Report as many distinct errors as there are. Aborting after the first error is easy to implement, but it’s annoying for users if every time they fix what they think is the one error in a file, a new one appears. They want to see them all.
儘可能多地報告出不同的錯誤。在第一個錯誤後中止是很容易實現的,但是如果每次當使用者修復檔案中的一個錯誤時,又出現了另一個新的錯誤,這對使用者來說是很煩人的。他們希望一次看到所有的錯誤。
-
Minimize *cascaded* errors. Once a single error is found, the parser no longer really knows what’s going on. It tries to get itself back on track and keep going, but if it gets confused, it may report a slew of ghost errors that don’t indicate other real problems in the code. When the first error is fixed, those phantoms disappear, because they reflect only the parser’s own confusion. Cascaded errors are annoying because they can scare the user into thinking their code is in a worse state than it is.
最小化級聯錯誤。一旦發現一個錯誤,解析器就不再能知道發生了什麼。它會試圖讓自己回到正軌並繼續工作,但如果它感到混亂,它可能會報告大量的幽靈錯誤,而這些錯誤並不表明程式碼中存在其它問題。當第一個錯誤被修正後,這些幽靈錯誤就消失了,因為它們只反映瞭解析器自身的混亂。級聯錯誤很煩人,因為它們會讓使用者害怕,讓使用者認為自己的程式碼比實際情況更糟糕。
The last two points are in tension. We want to report as many separate errors as we can, but we don’t want to report ones that are merely side effects of an earlier one.
最後兩點是相互矛盾的。我們希望儘可能多地報告單獨的錯誤,但我們不想報告那些只是由早期錯誤的副作用導致的錯誤。
The way a parser responds to an error and keeps going to look for later errors is called error recovery. This was a hot research topic in the ’60s. Back then, you’d hand a stack of punch cards to the secretary and come back the next day to see if the compiler succeeded. With an iteration loop that slow, you really wanted to find every single error in your code in one pass.
解析器對一個錯誤做出反應,並繼續去尋找後面的錯誤的方式叫做錯誤恢復。這在60年代是一個熱門的研究課題。那時,你需要把一疊打孔卡交給秘書,第二天再來看看編譯器是否成功。在迭代迴圈如此緩慢的情況下,你真的會想在一次執行中找到程式碼中的每個錯誤。
Today, when parsers complete before you’ve even finished typing, it’s less of an issue. Simple, fast error recovery is fine.
如今,解析器在您甚至還沒有完成輸入之前就完成解析了,這不再是一個問題。 簡單,快速的錯誤恢復就可以了。
6 . 3 . 1 Panic mode error recovery
6.3.1 恐慌模式錯誤恢復
Of all the recovery techniques devised in yesteryear, the one that best stood the test of time is called—somewhat alarmingly—panic mode. As soon as the parser detects an error, it enters panic mode. It knows at least one token doesn’t make sense given its current state in the middle of some stack of grammar productions.
在過去設計的所有恢復技術中,最能經受住時間考驗的一種叫做恐慌模式(有點令人震驚)。一旦解析器檢測到一個錯誤,它就會進入恐慌模式。它知道至少有一個token是沒有意義的,因為它目前的狀態是在一些語法生成式的堆疊中間。
Before it can get back to parsing, it needs to get its state and the sequence of forthcoming tokens aligned such that the next token does match the rule being parsed. This process is called synchronization.
在程式繼續進行解析之前,它需要將自己的狀態和即將到來的標記序列對齊,使下一個標記能夠匹配正則解析的規則。這個過程稱為同步。
To do that, we select some rule in the grammar that will mark the synchronization point. The parser fixes its parsing state by jumping out of any nested productions until it gets back to that rule. Then it synchronizes the token stream by discarding tokens until it reaches one that can appear at that point in the rule.
為此,我們在語法中選擇一些規則來標記同步點。解析器會跳出所有巢狀的生成式直到回退至該規則中,來修復其解析狀態。然後,它會丟棄標記,直到遇到一個可以匹配該規則的標記,以此來同步標記流。
Any additional real syntax errors hiding in those discarded tokens aren’t reported, but it also means that any mistaken cascaded errors that are side effects of the initial error aren’t falsely reported either, which is a decent trade-off.
這些被丟棄的標記中隱藏的其它真正的語法錯誤都不會被報告,但是這也意味著由初始錯誤引起的其它級聯錯誤也不會被錯誤地報告出來,這是個不錯的權衡。
The traditional place in the grammar to synchronize is between statements. We don’t have those yet, so we won’t actually synchronize in this chapter, but we’ll get the machinery in place for later.
語法中傳統的要同步的地方是語句之間。我們還沒有這些,所以我們不會在這一章中真正地同步,但我們會在以後把這些機制準備好。
6 . 3 . 2 Entering panic mode
6.3.2 進入恐慌模式
Back before we went on this side trip around error recovery, we were writing the code to parse a parenthesized expression. After parsing the expression, it looks for the closing
)by callingconsume(). Here, finally, is that method:
在我們討論錯誤恢復之前,我們正在編寫解析括號表示式的程式碼。在解析表示式之後,會呼叫consume()方法查詢收尾的)。這裡,終於可以實現那個方法了:
lox/Parser.java,在 match()方法後新增:
private Token consume(TokenType type, String message) {
if (check(type)) return advance();
throw error(peek(), message);
}
It’s similar to
match()in that it checks to see if the next token is of the expected type. If so, it consumes it and everything is groovy. If some other token is there, then we’ve hit an error. We report it by calling this:
它和 match()方法類似,檢查下一個標記是否是預期的型別。如果是,它就會消費該標記,一切都很順利。如果是其它的標記,那麼我們就遇到了錯誤。我們透過呼叫下面的方法來報告錯誤:
lox/Parser.java,在 previous()方法後新增:
private ParseError error(Token token, String message) {
Lox.error(token, message);
return new ParseError();
}
First, that shows the error to the user by calling:
首先,透過呼叫下面的方法向用戶展示錯誤資訊:
lox/Lox.java,在 report()方法後新增:
static void error(Token token, String message) {
if (token.type == TokenType.EOF) {
report(token.line, " at end", message);
} else {
report(token.line, " at '" + token.lexeme + "'", message);
}
}
This reports an error at a given token. It shows the token’s location and the token itself. This will come in handy later since we use tokens throughout the interpreter to track locations in code.
該方法會報告給定標記處的錯誤。它顯示了標記的位置和標記本身。這在以後會派上用場,因為我們在整個直譯器中使用標記來跟蹤程式碼中的位置。
After we report the error, the user knows about their mistake, but what does the parser do next? Back in
error(), we create and return a ParseError, an instance of this new class:
在我們報告錯誤後,使用者知道了他們的錯誤,但接下來解析器要做什麼呢?回到error()方法中,我們建立並返回了一個ParseError,是下面這個新類的例項:
lox/Parser.java,在 Parser中嵌入內部類:
class Parser {
// 新增部分開始
private static class ParseError extends RuntimeException {}
// 新增部分結束
private final List<Token> tokens;
This is a simple sentinel class we use to unwind the parser. The
error()method returns the error instead of throwing it because we want to let the calling method inside the parser decide whether to unwind or not. Some parse errors occur in places where the parser isn’t likely to get into a weird state and we don’t need to synchronize. In those places, we simply report the error and keep on truckin’.
這是一個簡單的哨兵類,我們用它來幫助解析器擺脫錯誤。error()方法是返回錯誤而不是丟擲錯誤,因為我們希望解析器內的呼叫方法決定是否要跳脫出該錯誤。有些解析錯誤發生在解析器不可能進入異常狀態的地方,這時我們就不需要同步。在這些地方,我們只需要報告錯誤,然後繼續解析。
For example, Lox limits the number of arguments you can pass to a function. If you pass too many, the parser needs to report that error, but it can and should simply keep on parsing the extra arguments instead of freaking out and going into panic mode.
例如,Lox限制了你可以傳遞給一個函式的引數數量。如果你傳遞的引數太多,解析器需要報告這個錯誤,但它可以而且應該繼續解析額外的引數,而不是驚慌失措,進入恐慌模式11。
In our case, though, the syntax error is nasty enough that we want to panic and synchronize. Discarding tokens is pretty easy, but how do we synchronize the parser’s own state?
但是,在我們的例子中,語法錯誤非常嚴重,以至於我們要進入恐慌模式並進行同步。丟棄標記非常簡單,但是我們如何同步解析器自己的狀態呢?
6 . 3 . 3 Synchronizing a recursive descent parser
6.3.3 同步遞迴下降解析器
With recursive descent, the parser’s state—which rules it is in the middle of recognizing—is not stored explicitly in fields. Instead, we use Java’s own call stack to track what the parser is doing. Each rule in the middle of being parsed is a call frame on the stack. In order to reset that state, we need to clear out those call frames.
在遞迴下降中,解析器的狀態(即它正在識別哪個規則)不是顯式儲存在欄位中的。相反,我們使用Java自身的呼叫棧來跟蹤解析器正在做什麼。每一條正在被解析的規則都是棧上的一個呼叫幀。為了重置狀態,我們需要清除這些呼叫幀。
The natural way to do that in Java is exceptions. When we want to synchronize, we throw that ParseError object. Higher up in the method for the grammar rule we are synchronizing to, we’ll catch it. Since we synchronize on statement boundaries, we’ll catch the exception there. After the exception is caught, the parser is in the right state. All that’s left is to synchronize the tokens.
在Java中,最自然的實現方式是異常。當我們想要同步時,我們丟擲ParseError物件。在我們正同步的語法規則的方法上層,我們將捕獲它。因為我們在語句邊界上同步,所以我們可以在那裡捕獲異常。捕獲異常後,解析器就處於正確的狀態。剩下的就是同步標記了。
We want to discard tokens until we’re right at the beginning of the next statement. That boundary is pretty easy to spot—it’s one of the main reasons we picked it. After a semicolon, we’re probably finished with a statement. Most statements start with a keyword—
for,if,return,var, etc. When the next token is any of those, we’re probably about to start a statement.
我們想要丟棄標記,直至達到下一條語句的開頭。這個邊界很容易發現——這也是我們選其作為邊界的原因。在分號之後,我們可能就結束了一條語句12。大多數語句都透過一個關鍵字開頭——for、 if、 return、 var等等。當下一個標記是其中之一時,我們可能就要開始一條新語句了。
This method encapsulates that logic:
下面的方法封裝了這個邏輯:
lox/Parser.java,在 error()方法後新增:
private void synchronize() {
advance();
while (!isAtEnd()) {
if (previous().type == SEMICOLON) return;
switch (peek().type) {
case CLASS:
case FUN:
case VAR:
case FOR:
case IF:
case WHILE:
case PRINT:
case RETURN:
return;
}
advance();
}
}
It discards tokens until it thinks it has found a statement boundary. After catching a ParseError, we’ll call this and then we are hopefully back in sync. When it works well, we have discarded tokens that would have likely caused cascaded errors anyway, and now we can parse the rest of the file starting at the next statement.
該方法會不斷丟棄標記,直到它發現一個語句的邊界。在捕獲一個ParseError後,我們會呼叫該方法,然後我們就有望回到同步狀態。當它工作順利時,我們就已經丟棄了無論如何都可能會引起級聯錯誤的語法標記,現在我們可以從下一條語句開始解析檔案的其餘部分。
Alas, we don’t get to see this method in action, since we don’t have statements yet. We’ll get to that in a couple of chapters. For now, if an error occurs, we’ll panic and unwind all the way to the top and stop parsing. Since we can parse only a single expression anyway, that’s no big loss.
唉,我們還沒有看到這個方法的實際應用,因為我們目前還沒有語句。我們會在後面幾章中開始引入語句。現在,如果出現錯誤,我們就會進入恐慌模式,一直跳出到最頂層,並停止解析。由於我們只能解析一個表示式,所以這並不是什麼大損失。
6 . 4 Wiring up the Parser
6.4 調整解析器
We are mostly done parsing expressions now. There is one other place where we need to add a little error handling. As the parser descends through the parsing methods for each grammar rule, it eventually hits
primary(). If none of the cases in there match, it means we are sitting on a token that can’t start an expression. We need to handle that error too.
我們現在基本上已經完成了對錶達式的解析。我們還需要在另一個地方新增一些錯誤處理。當解析器在每個語法規則的解析方法中下降時,它最終會進入primary()。如果該方法中的case都不匹配,就意味著我們正面對一個不是表示式開頭的語法標記。我們也需要處理這個錯誤。
lox/Parser.java,在 primary()方法中新增:
if (match(LEFT_PAREN)) {
Expr expr = expression();
consume(RIGHT_PAREN, "Expect ')' after expression.");
return new Expr.Grouping(expr);
}
// 新增部分開始
throw error(peek(), "Expect expression.");
// 新增部分結束
}
With that, all that remains in the parser is to define an initial method to kick it off. That method is called, naturally enough,
parse().
這樣,解析器中剩下的工作就是定義一個初始方法來啟動它。這個方法自然應該叫做parse()。
lox/Parser.java,在 Parser()方法後新增:
Expr parse() {
try {
return expression();
} catch (ParseError error) {
return null;
}
}
We’ll revisit this method later when we add statements to the language. For now, it parses a single expression and returns it. We also have some temporary code to exit out of panic mode. Syntax error recovery is the parser’s job, so we don’t want the ParseError exception to escape into the rest of the interpreter.
稍後在向語言中新增語句時,我們將重新審視這個方法。目前,它只解析一個表示式並返回它。我們還有一些臨時程式碼用於退出恐慌模式。語法錯誤恢復是解析器的工作,所以我們不希望ParseError異常逃逸到直譯器的其它部分。
When a syntax error does occur, this method returns
null. That’s OK. The parser promises not to crash or hang on invalid syntax, but it doesn’t promise to return a usable syntax tree if an error is found. As soon as the parser reports an error,hadErrorgets set, and subsequent phases are skipped.
當確實出現語法錯誤時,該方法會返回null。這沒關係。解析器承諾不會因為無效語法而崩潰或掛起,但它不承諾在發現錯誤時返回一個可用的語法樹。一旦解析器報告錯誤,就會對hadError賦值,然後跳過後續階段。
Finally, we can hook up our brand new parser to the main Lox class and try it out. We still don’t have an interpreter, so for now, we’ll parse to a syntax tree and then use the AstPrinter class from the last chapter to display it.
最後,我們可以將全新的解析器掛到Lox主類並進行試驗。我們仍然還沒有直譯器,所以現在,我們將表示式解析為一個語法樹,然後使用上一章中的AstPrinter類來顯示它。
Delete the old code to print the scanned tokens and replace it with this:
刪除列印已掃描標記的舊程式碼,將其替換為:
lox/Lox.java,在 run()方法中,替換其中5行
List<Token> tokens = scanner.scanTokens();
// 替換部分開始
Parser parser = new Parser(tokens);
Expr expression = parser.parse();
// Stop if there was a syntax error.
if (hadError) return;
System.out.println(new AstPrinter().print(expression));
// 替換部分結束
}
Congratulations, you have crossed the threshold! That really is all there is to handwriting a parser. We’ll extend the grammar in later chapters with assignment, statements, and other stuff, but none of that is any more complex than the binary operators we tackled here.
祝賀你,你已經跨過了門檻!這就是手寫解析器的全部內容13。我們將在後面的章節中擴充套件賦值、語句和其它特性對應的語法,但這些都不會比我們本章處理的二元運算子更復雜。
Fire up the interpreter and type in some expressions. See how it handles precedence and associativity correctly? Not bad for less than 200 lines of code.
啟動直譯器並輸入一些表示式。檢視它是如何正確處理優先順序和結合性的?這對於不到200行程式碼來說已經很不錯了。
CHALLENGES
習題
1、In C, a block is a statement form that allows you to pack a series of statements where a single one is expected. The comma operator is an analogous syntax for expressions. A comma-separated series of expressions can be given where a single expression is expected (except inside a function call’s argument list). At runtime, the comma operator evaluates the left operand and discards the result. Then it evaluates and returns the right operand.
Add support for comma expressions. Give them the same precedence and associativity as in C. Write the grammar, and then implement the necessary parsing code.
1、在C語言中,塊是一種語句形式,它允許你把一系列的語句打包作為一個語句來使用。逗號運算子是表示式的類似語法。可以在需要單個表示式的地方給出以逗號分隔的表示式序列(函式呼叫的引數列表除外)。在執行時,逗號運算子計算左運算元並丟棄結果。然後計算並返回右運算元。
新增對逗號表示式的支援。賦予它們與c語言中相同的優先順序和結合性。編寫語法,然後實現必要的解析程式碼。
2、Likewise, add support for the C-style conditional or “ternary” operator
?:. What precedence level is allowed between the?and:? Is the whole operator left-associative or right-associative?
2、同樣,新增對C風格的條件運算子或 "三元 "運算子?:的支援。在?和:之間採用什麼優先順序順序?整個運算子是左關聯還是右關聯?
3、Add error productions to handle each binary operator appearing without a left-hand operand. In other words, detect a binary operator appearing at the beginning of an expression. Report that as an error, but also parse and discard a right-hand operand with the appropriate precedence.
3、新增錯誤生成式處理沒有左運算元的二元運算子。換句話說,檢測出現在表示式開頭的二元運算子。將其作為錯誤報告給使用者,同時也要解析並丟棄具有相應優先順序的右運算元。
DESIGN NOTE: LOGIC VERSUS HISTORY
Let’s say we decide to add bitwise
&and|operators to Lox. Where should we put them in the precedence hierarchy? C—and most languages that follow in C’s footsteps—place them below==. This is widely considered a mistake because it means common operations like testing a flag require parentheses.if (flags & FLAG_MASK == SOME_FLAG) { ... } // Wrong. if ((flags & FLAG_MASK) == SOME_FLAG) { ... } // Right.Should we fix this for Lox and put bitwise operators higher up the precedence table than C does? There are two strategies we can take.
You almost never want to use the result of an
==expression as the operand to a bitwise operator. By making bitwise bind tighter, users don’t need to parenthesize as often. So if we do that, and users assume the precedence is chosen logically to minimize parentheses, they’re likely to infer it correctly.This kind of internal consistency makes the language easier to learn because there are fewer edge cases and exceptions users have to stumble into and then correct. That’s good, because before users can use our language, they have to load all of that syntax and semantics into their heads. A simpler, more rational language makes sense.
But, for many users there is an even faster shortcut to getting our language’s ideas into their wetware—use concepts they already know. Many newcomers to our language will be coming from some other language or languages. If our language uses some of the same syntax or semantics as those, there is much less for the user to learn (and unlearn).
This is particularly helpful with syntax. You may not remember it well today, but way back when you learned your very first programming language, code probably looked alien and unapproachable. Only through painstaking effort did you learn to read and accept it. If you design a novel syntax for your new language, you force users to start that process all over again.
Taking advantage of what users already know is one of the most powerful tools you can use to ease adoption of your language. It’s almost impossible to overestimate how valuable this is. But it faces you with a nasty problem: What happens when the thing the users all know kind of sucks? C’s bitwise operator precedence is a mistake that doesn’t make sense. But it’s a familiar mistake that millions have already gotten used to and learned to live with.
Do you stay true to your language’s own internal logic and ignore history? Do you start from a blank slate and first principles? Or do you weave your language into the rich tapestry of programming history and give your users a leg up by starting from something they already know?
There is no perfect answer here, only trade-offs. You and I are obviously biased towards liking novel languages, so our natural inclination is to burn the history books and start our own story.
In practice, it’s often better to make the most of what users already know. Getting them to come to your language requires a big leap. The smaller you can make that chasm, the more people will be willing to cross it. But you can’t always stick to history, or your language won’t have anything new and compelling to give people a reason to jump over.
設計筆記:邏輯和歷史
假設我們決定在Lox中新增位元&和|運算子。我們應該將它們放在優先順序層次結構的哪個位置? C(以及大多數跟隨C語言步伐的語言)將它們放在==之下。 目前普遍認為這是一個錯誤,因為這意味著檢測標誌位等常用操作都需要加括號。
if (flags & FLAG_MASK == SOME_FLAG) { ... } // Wrong.
if ((flags & FLAG_MASK) == SOME_FLAG) { ... } // Right.
我們是否應該在 Lox 中修正這個問題,為位運算子賦予比 C 中更高的優先順序?我們可以採取兩種策略。
幾乎可以肯定你不會想把==表示式的計算結果當作位運算的運算元。將位運算操作繫結更緊密,使用者就不需要像以前那樣經常使用括號。所以如果我們這樣做,並且使用者認為優先順序的選擇是合乎邏輯的,是為了儘量減少小括號,他們很可能會正確地推斷出來。
這種內部一致性使語言更容易學習,因為使用者需要糾正的邊界情況和異常變少了。這很好,因為使用者在使用我們的語言之前,需要先理解所有的語法和語義。一個更簡單、更合理的語言是有意義的。
但是,對於許多使用者來說,有一個更快的捷徑,可以將我們語言的思想融入他們的溼件中——使用他們已經知道的概念。許多我們語言的新使用者都使用過其它一門或多門語言。如果我們的語言使用了與那些語言相同的一些語法或語義,那麼使用者需要學習(和忘掉)的東西就會少很多。
這對詞法語法特別有幫助。您現在可能不太記得了,但是回想一下您學習第一門程式語言時,程式碼看起來似乎很陌生且難以理解。 只有透過艱苦的努力,您才學會閱讀和接受它。 如果你為你的新語言設計了一種新穎的語法,你就會迫使使用者重新開始這個過程。
利用使用者已經知道的知識,是你可以用來簡化語言採用的最強大的工具之一。這一點的價值怎麼估計都不過分。但它也給你帶來了一個棘手的問題:如果使用者都知道的東西有點糟糕時,會發生什麼?C語言的位運算運算子優先是一個沒有意義的錯誤。但這是一個數以百萬計的人已經習慣並學會忍受的熟悉錯誤。
你是否忠於語言的內在邏輯而忽略歷史?你是從一張白紙和基本原則開始的嗎?還是把你的語言編織到豐富的程式設計歷史中去,從使用者已經知道的東西開始,使您的使用者受益?
這裡沒有完美的答案,只有權衡取捨。你和我顯然都傾向於喜歡新奇的語言,所以我們的自然傾向是燒掉歷史書,開始我們自己的故事。
在實踐中,充分利用使用者已經知道的知識往往更好。讓他們來使用你的語言需要一個大的跨越。兩個語言間的鴻溝越小,人們就越願意跨越它。但你不能總是拘泥於歷史,否則你的語言就不會有什麼新穎的、令人信服的東西讓使用者們有理由跳過去。
-
英語中的"Parse "來自古法語 "pars",意為 "語言的一部分"。它的意思是取一篇文章,把每一個詞都對映到語言的語法上。我們在這裡使用它也是這個意思,只不過我們的語言比古法語更現代一些。 ↩
-
可以想見,在那些老機器上進行彙編程式設計是多麼痛苦,以至於他們認為Fortran是一種改進。 ↩
-
雖然現在並不常見,但有些語言規定某些運算子之間沒有相對優先順序。這種語言中,在表示式中混合使用這些運算子而不使用顯式分組是一種語法錯誤。同樣,有些運算子是非結合的。這意味著在語句序列中多次使用該運算子是錯誤的。例如,Perl的範圍運算子是非結合的,所以
a ..b是可以的,但是a ..b . .c是錯誤的。 ↩ -
一些解析器生成器並沒有將優先順序直接寫入語法規則中,而是允許你保持同樣的模糊但簡單的語法,然後在旁邊新增一點明確的運算子優先順序後設資料,以消除歧義。 ↩
-
我們可以取消
expression,而只是在其他包含表示式的規則中使用equality,但使用expression會使這些其他規則可讀性更好。另外,在後面的章節中,當我們將語法擴充套件到包括賦值和邏輯運算子時,我們只需要改變expression的生成式,而不需要修改每條包含expression的規則。 ↩ -
原則上,你把乘法當作左關聯還是右關聯都沒有關係——無論你使用哪種方式都可以得到相同的結果。但是,在精度有限的情況下,舍入和溢位意味著關聯性會影響乘法序列的計算結果。如
print 0. 1 * (0. 2 * 0. 3);和print (0.1 * 0.2) * 0.3;,在Lox等使用IEEE 754雙精度浮點數的語言中,第一個算式的計算結果是0.006,而第二個算式的計算結果是0.006000000000000001。有時,這種微小的差異很重要。可以在這裡瞭解更多資訊。 ↩ -
該方法之所以被稱為“遞迴下降”,是因為它是沿著語法向下執行的。令人困惑的是,在談論“高”和“低”優先順序時,我們也使用方向來比喻,但是方向卻是相反的。在自頂向下的解析器中,首先達到優先順序最低的表示式,因為其中可能包含優先順序更高的子表示式。

CS的人真的需要聚在一起理清他們的隱喻。甚至不要讓我開始討論堆疊向哪個方向生長,或者為什麼樹的根在上面。 ↩ -
這就是為什麼左遞迴對於遞迴下降是有問題的。左遞迴規則的函式會立即呼叫自身,並迴圈往復,直到解析器遇到堆疊溢位並崩潰。 ↩
-
解析
a==b==c==d。對於每一次迭代,使用前一個子式結果作為左運算元並建立一個新的二元表示式。 ↩ -
解析器提前觀察即將到來的標記來決定如何解析,這就把遞迴下降納入了預測性解析器的範疇。 ↩
-
另一種處理常見語法錯誤的方法是錯誤生成式。你可以使用一個能成功匹配錯誤語法的規則來擴充語法。解析器可以對其進行安全地解析,但是不會生成語法樹,而是會報告一個錯誤。
舉例來說,有些語言中有一元運算子+,如+123,但是Lox不支援。當解析器在表示式的開頭遇到一個+時,我們不必感到困惑,我們可以擴充套件一元規則來允許該語法。unary → ( "!" | "-" | "+" ) unary | primary ;
這樣解析器就會消費+標記,而不是進入恐慌模式或讓解析器陷入奇怪的狀態。
錯誤生成式的效果很好。因為你作為解析器的作者,知道程式碼的如何出錯的以及使用者想要做什麼。這意味著你可以給出一個更有用的資訊來幫助使用者回到正軌,比如,"不支援一元'+'表示式"。成熟的解析器往往會積累錯誤生成式,因為它們可以幫助使用者修復常見的錯誤。 ↩ -
我說 "可能 "是因為我們可以在for迴圈中碰到分隔子句的分號。我們的同步並不完美,但這沒關係。我們已經準確地報告了第一個錯誤,所以之後的一切都算是 "盡力而為 "了。 ↩
-
你可能會定義一個比Lox更復雜的語法,使用遞迴下降法難以對其解析。當你可能需要預先檢視大量的標記以弄清你面臨的情況時,預測性解析就變得很棘手。實際上,大多數語言都是為了避免這種情況而設計的。 即使情況並非如此,您通常也可以毫不費力地解決問題。 既然您可以使用遞迴下降來解析C ++(許多C ++編譯器都可以做到),那麼您就可以解析任何內容。 ↩
7.表示式求值
You are my creator, but I am your master; Obey!
—— Mary Shelley, Frankenstein
你是我的創造者,但我是你的主人,聽話!
——Mary Shelley, 科學怪人
If you want to properly set the mood for this chapter, try to conjure up a thunderstorm, one of those swirling tempests that likes to yank open shutters at the climax of the story. Maybe toss in a few bolts of lightning. In this chapter, our interpreter will take breath, open its eyes, and execute some code.
如果你想為這一章適當地設定氣氛,試著想象一場雷雨,那種在故事高潮時喜歡拉開百葉窗的漩渦式暴風雨。也許再加上幾道閃電。在這一章中,我們的直譯器將開始呼吸,睜開眼睛,並執行一些程式碼。

There are all manner of ways that language implementations make a computer do what the user’s source code commands. They can compile it to machine code, translate it to another high-level language, or reduce it to some bytecode format for a virtual machine to run. For our first interpreter, though, we are going to take the simplest, shortest path and execute the syntax tree itself.
對於語言實現來說,有各種方式可以使計算機執行使用者的原始碼命令。它們可以將其編譯為機器程式碼,將其翻譯為另一種高階語言,或者將其還原為某種位元組碼格式,以便在虛擬機器中執行。不過對於我們的第一個直譯器,我們要選擇最簡單、最短的一條路,也就是執行語法樹本身。
Right now, our parser only supports expressions. So, to “execute” code, we will evaluate an expression and produce a value. For each kind of expression syntax we can parse—literal, operator, etc.—we need a corresponding chunk of code that knows how to evaluate that tree and produce a result. That raises two questions:
現在,我們的直譯器只支援表示式。因此,為了“執行”程式碼,我們要計算一個表示式時並生成一個值。對於我們可以解析的每一種表示式語法——字面量,運算子等——我們都需要一個相應的程式碼塊,該程式碼塊知道如何計算該語法樹併產生結果。這也就引出了兩個問題:
-
What kinds of values do we produce?
我們要生成什麼型別的值?
-
How do we organize those chunks of code?
我們如何組織這些程式碼塊?
Taking them on one at a time . . .
讓我們來逐個擊破。
7 . 1 Representing Values
7.1 值描述
In Lox, values are created by literals, computed by expressions, and stored in variables. The user sees these as Lox objects, but they are implemented in the underlying language our interpreter is written in. That means bridging the lands of Lox’s dynamic typing and Java’s static types. A variable in Lox can store a value of any (Lox) type, and can even store values of different types at different points in time. What Java type might we use to represent that?
在Lox中,值由字面量建立,由表示式計算,並儲存在變數中。使用者將其視作Lox物件1,但它們是用編寫直譯器的底層語言實現的。這意味著要在Lox的動態型別和Java的靜態型別之間架起橋樑。Lox中的變數可以儲存任何(Lox)型別的值,甚至可以在不同時間儲存不同型別的值。我們可以用什麼Java型別來表示?
Given a Java variable with that static type, we must also be able to determine which kind of value it holds at runtime. When the interpreter executes a
+operator, it needs to tell if it is adding two numbers or concatenating two strings. Is there a Java type that can hold numbers, strings, Booleans, and more? Is there one that can tell us what its runtime type is? There is! Good old java.lang.Object.
給定一個具有該靜態型別的Java變數,我們還必須能夠在執行時確定它持有哪種型別的值。當直譯器執行 +運算子時,它需要知道它是在將兩個數字相加還是在拼接兩個字串。有沒有一種Java型別可以容納數字、字串、布林值等等?有沒有一種型別可以告訴我們它的執行時型別是什麼?有的! 就是老牌的java.lang.Object。
In places in the interpreter where we need to store a Lox value, we can use Object as the type. Java has boxed versions of its primitive types that all subclass Object, so we can use those for Lox’s built-in types:
在直譯器中需要儲存Lox值的地方,我們可以使用Object作為型別。Java已經將其基本型別的所有子類物件裝箱了,因此我們可以將它們用作Lox的內建型別:
| Lox type Lox類 | Java representation Java表示 |
|---|---|
| Any Lox value | Object |
nil | null |
| Boolean | Boolean |
| number | Double |
| string | String |
Given a value of static type Object, we can determine if the runtime value is a number or a string or whatever using Java’s built-in
instanceofoperator. In other words, the JVM’s own object representation conveniently gives us everything we need to implement Lox’s built-in types. We’ll have to do a little more work later when we add Lox’s notions of functions, classes, and instances, but Object and the boxed primitive classes are sufficient for the types we need right now.
給定一個靜態型別為Object的值,我們可以使用Java內建的instanceof運算子來確定執行時的值是數字、字串或其它什麼。換句話說,JVM自己的物件表示方便地為我們提供了實現Lox內建型別所需的一切2。當稍後新增Lox的函式、類和例項等概念時,我們還必須做更多的工作,但Object和基本型別的包裝類足以滿足我們現在的需要。
7 . 2 Evaluating Expressions
7.2 表示式求值
Next, we need blobs of code to implement the evaluation logic for each kind of expression we can parse. We could stuff that code into the syntax tree classes in something like an
interpret()method. In effect, we could tell each syntax tree node, “Interpret thyself”. This is the Gang of Four’s Interpreter design pattern. It’s a neat pattern, but like I mentioned earlier, it gets messy if we jam all sorts of logic into the tree classes.
接下來,我們需要大量的程式碼實現我們可解析的每種表示式對應的求值邏輯。我們可以把這些程式碼放在語法樹的類中,比如新增一個interpret()方法。然後,我們可以告訴每一個語法樹節點“解釋你自己”,這就是四人組的直譯器模式。這是一個整潔的模式,但正如我前面提到的,如果我們將各種邏輯都塞進語法樹類中,就會變得很混亂。
Instead, we’re going to reuse our groovy Visitor pattern. In the previous chapter, we created an AstPrinter class. It took in a syntax tree and recursively traversed it, building up a string which it ultimately returned. That’s almost exactly what a real interpreter does, except instead of concatenating strings, it computes values.
相反,我們將重用我們的訪問者模式。在前面的章節中,我們建立了一個AstPrinter類。它接受一個語法樹,並遞迴地遍歷它,構建一個最終返回的字串。這幾乎就是一個真正的直譯器所做的事情,只不過直譯器不是連線字串,而是計算值。
We start with a new class.
我們先建立一個新類。
lox/Interpreter.java,建立新檔案:
package com.craftinginterpreters.lox;
class Interpreter implements Expr.Visitor<Object> {
}
The class declares that it’s a visitor. The return type of the visit methods will be Object, the root class that we use to refer to a Lox value in our Java code. To satisfy the Visitor interface, we need to define visit methods for each of the four expression tree classes our parser produces. We’ll start with the simplest . . .
這個類宣告它是一個訪問者。訪問方法的返回型別將是Object,即我們在Java程式碼中用來引用Lox值的根類。為了實現Visitor介面,我們需要為解析器生成的四個表示式樹類中分別定義訪問方法。我們從最簡單的開始…
7 . 2 . 1 Evaluating literals
7.2.1 字面量求值
The leaves of an expression tree—the atomic bits of syntax that all other expressions are composed of—are literals. Literals are almost values already, but the distinction is important. A literal is a bit of syntax that produces a value. A literal always appears somewhere in the user’s source code. Lots of values are produced by computation and don’t exist anywhere in the code itself. Those aren’t literals. A literal comes from the parser’s domain. Values are an interpreter concept, part of the runtime’s world.
一個表示式樹的葉子節點(構成其它表示式的語法原子單位)是字面量3。字面符號幾乎已經是值了,但兩者的區別很重要。字面量是產生一個值的語法單元。字面量總是出現在使用者的原始碼中的某個地方。而很多值是透過計算產生的,並不存在於程式碼中的任何地方,這些都不是字面量。字面量來自於解析器領域,而值是一個直譯器的概念,是執行時世界的一部分。
So, much like we converted a literal token into a literal syntax tree node in the parser, now we convert the literal tree node into a runtime value. That turns out to be trivial.
因此,就像我們在解析器中將字面量標記轉換為字面量語法樹節點一樣,現在我們將字面量樹節點轉換為執行時值。這其實很簡單。
lox/Interpreter.java,在 Interpreter類中新增:
@Override
public Object visitLiteralExpr(Expr.Literal expr) {
return expr.value;
}
We eagerly produced the runtime value way back during scanning and stuffed it in the token. The parser took that value and stuck it in the literal tree node, so to evaluate a literal, we simply pull it back out.
我們早在掃描過程中就即時生成了執行時的值,並把它放進了語法標記中。解析器獲取該值並將其插入字面量語法樹節點中,所以要對字面量求值,我們只需把它存的值取出來。
7 . 2 . 2 Evaluating parentheses
7.2.2 括號求值
The next simplest node to evaluate is grouping—the node you get as a result of using explicit parentheses in an expression.
下一個要求值的節點是分組——在表示式中顯式使用括號時產生的語法樹節點。
lox/Interpreter.java,在 Interpreter類中新增:
@Override
public Object visitGroupingExpr(Expr.Grouping expr) {
return evaluate(expr.expression);
}
A grouping node has a reference to an inner node for the expression contained inside the parentheses. To evaluate the grouping expression itself, we recursively evaluate that subexpression and return it.
一個分組節點中包含一個引用指向對應於括號內的表示式的內部節點4。要想計算括號表示式,我們只需要遞迴地對子表示式求值並返回結果即可。
We rely on this helper method which simply sends the expression back into the interpreter’s visitor implementation:
我們依賴於下面這個輔助方法,它只是將表示式發送回直譯器的訪問者實現中:
lox/Interpreter.java,在 Interpreter類中新增:
private Object evaluate(Expr expr) {
return expr.accept(this);
7 . 2 . 3 Evaluating unary expressions
7.2.3 一元表示式求值
Like grouping, unary expressions have a single subexpression that we must evaluate first. The difference is that the unary expression itself does a little work afterwards.
像分組表示式一樣,一元表示式也有一個必須先求值的子表示式。不同的是,一元表示式自身在完成求值之後還會做一些工作。
lox/Interpreter.java,在 visitLiteralExpr()方法後新增:
@Override
public Object visitUnaryExpr(Expr.Unary expr) {
Object right = evaluate(expr.right);
switch (expr.operator.type) {
case MINUS:
return -(double)right;
}
// Unreachable.
return null;
}
First, we evaluate the operand expression. Then we apply the unary operator itself to the result of that. There are two different unary expressions, identified by the type of the operator token.
首先,我們計算運算元表示式,然後我們將一元運算子作用於子表示式的結果。我們有兩種不同的一元表示式,由運算子標記的型別來區分。
Shown here is
-, which negates the result of the subexpression. The subexpression must be a number. Since we don’t statically know that in Java, we cast it before performing the operation. This type cast happens at runtime when the-is evaluated. That’s the core of what makes a language dynamically typed right there.
這裡展示的是-,它會對子表示式的結構取負。子表示式結果必須是數字。因為我們在Java中無法靜態地知道這一點,所以我們在執行操作之前先對其進行強制轉換。這個型別轉換是在執行時對-求值時發生的。這就是將語言動態型別化的核心所在。
You can start to see how evaluation recursively traverses the tree. We can’t evaluate the unary operator itself until after we evaluate its operand subexpression. That means our interpreter is doing a post-order traversal—each node evaluates its children before doing its own work.
你可以看到求值過程是如何遞迴遍歷語法樹的。在對一元運算子本身進行計算之前,我們必須先對其運算元子表示式求值。這表明,直譯器正在進行後序遍歷——每個節點在自己求值之前必須先對子節點求值。
The other unary operator is logical not.
另一個一元運算子是邏輯非。
lox/Interpreter.java,在visitUnaryExpr()方法中新增:
switch (expr.operator.type) {
// 新增部分開始
case BANG:
return !isTruthy(right);
// 新增部分結束
case MINUS:
The implementation is simple, but what is this “truthy” thing about? We need to make a little side trip to one of the great questions of Western philosophy: What is truth?
實現很簡單,但是這裡的“真實”指的是什麼呢?我們需要簡單地討論一下西方哲學中的一個偉大問題:什麼是真理?
7 . 2 . 4 Truthiness and falsiness
7.2.4 真與假
OK, maybe we’re not going to really get into the universal question, but at least inside the world of Lox, we need to decide what happens when you use something other than
trueorfalsein a logic operation like!or any other place where a Boolean is expected.
好吧,我們不會真正深入這個普世的問題,但是至少在Lox的世界中,我們需要確定當您在邏輯運算(如!或其他任何需要布林值的地方)中使用非true或false以外的東西時會發生什麼?
We could just say it’s an error because we don’t roll with implicit conversions, but most dynamically typed languages aren’t that ascetic. Instead, they take the universe of values of all types and partition them into two sets, one of which they define to be “true”, or “truthful”, or (my favorite) “truthy”, and the rest which are “false” or “falsey”. This partitioning is somewhat arbitrary and gets weird in a few languages.
我們可以說這是一個錯誤,因為我們沒有使用隱式轉換,但是大多數動態型別語言並不那麼嚴格。相反,他們把所有型別的值分成兩組,其中一組他們定義為“真”,其餘為“假”。這種劃分有些武斷,在一些語言中會變得很奇怪5。
Lox follows Ruby’s simple rule:
falseandnilare falsey, and everything else is truthy. We implement that like so:
Lox遵循Ruby的簡單規則:false和nil是假的,其他都是真的。我們是這樣實現的:
lox/Interpreter.java,在 visitUnaryExpr()方法後新增:
private boolean isTruthy(Object object) {
if (object == null) return false;
if (object instanceof Boolean) return (boolean)object;
return true;
}
7 . 2 . 5 Evaluating binary operators
7.2.5 二元運算子求值
On to the last expression tree class, binary operators. There’s a handful of them, and we’ll start with the arithmetic ones.
來到最後的表示式樹類——二元運算子,其中包含很多運算子,我們先從數學運算開始。
lox/Interpreter.java,在 evaluate()方法後新增6:
@Override
public Object visitBinaryExpr(Expr.Binary expr) {
Object left = evaluate(expr.left);
Object right = evaluate(expr.right);
switch (expr.operator.type) {
case MINUS:
return (double)left - (double)right;
case SLASH:
return (double)left / (double)right;
case STAR:
return (double)left * (double)right;
}
// Unreachable.
return null;
}
I think you can figure out what’s going on here. The main difference from the unary negation operator is that we have two operands to evaluate.
我想你能理解這裡的實現。與一元取負運算子的主要區別是,我們有兩個運算元要計算。
I left out one arithmetic operator because it’s a little special.
我漏掉了一個算術運算子,因為它有點特殊。
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
switch (expr.operator.type) {
case MINUS:
return (double)left - (double)right;
// 新增部分開始
case PLUS:
if (left instanceof Double && right instanceof Double) {
return (double)left + (double)right;
}
if (left instanceof String && right instanceof String) {
return (String)left + (String)right;
}
break;
// 新增部分結束
case SLASH:
The
+operator can also be used to concatenate two strings. To handle that, we don’t just assume the operands are a certain type and cast them, we dynamically check the type and choose the appropriate operation. This is why we need our object representation to supportinstanceof.
+運算子也可以用來拼接兩個字串。為此,我們不能只是假設運算元是某種型別並將其強制轉換,而是要動態地檢查運算元型別並選擇適當的操作。這就是為什麼我們需要物件表示能支援instanceof。
Next up are the comparison operators.
接下來是比較運算子。
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
switch (expr.operator.type) {
// 新增部分開始
case GREATER:
return (double)left > (double)right;
case GREATER_EQUAL:
return (double)left >= (double)right;
case LESS:
return (double)left < (double)right;
case LESS_EQUAL:
return (double)left <= (double)right;
// 新增部分結束
case MINUS:
They are basically the same as arithmetic. The only difference is that where the arithmetic operators produce a value whose type is the same as the operands (numbers or strings), the comparison operators always produce a Boolean.
它們基本上與算術運算子相同。唯一的區別是,算術運算子產生的值的型別與運算元(數字或字串)相同,而比較運算子總是產生一個布林值。
The last pair of operators are equality.
最後一對是等式運算子。
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case BANG_EQUAL: return !isEqual(left, right);
case EQUAL_EQUAL: return isEqual(left, right);
Unlike the comparison operators which require numbers, the equality operators support operands of any type, even mixed ones. You can’t ask Lox if 3 is less than
"three", but you can ask if it’s equal to it.
與需要數字的比較運算子不同,等式運算子支援任何型別的運算元,甚至是混合型別。你不能問Lox 3是否小於"three",但你可以問它3是否等於"three"。
Like truthiness, the equality logic is hoisted out into a separate method.
與真假判斷一樣,相等判斷也被提取到了單獨的方法中。
lox/Interpreter.java,在 isTruthy()方法後新增:
private boolean isEqual(Object a, Object b) {
if (a == null && b == null) return true;
if (a == null) return false;
return a.equals(b);
}
This is one of those corners where the details of how we represent Lox objects in terms of Java matter. We need to correctly implement Lox’s notion of equality, which may be different from Java’s.
這是我們使用Java表示Lox物件的細節一角。我們需要正確地實現Lox的相等概念,這可能與Java中不同。
Fortunately, the two are pretty similar. Lox doesn’t do implicit conversions in equality and Java does not either. We do have to handle
nil/nullspecially so that we don’t throw a NullPointerException if we try to callequals()onnull. Otherwise, we’re fine. Java’s.equals()method on Boolean, Double, and String have the behavior we want for Lox.
幸運的是,這兩者很相似。Lox不會在等式中做隱式轉換,Java也不會。我們必須對 nil/null 做特殊處理,這樣就不會在對null呼叫equals()方法時丟擲NullPointerException。其它情況下,都是沒問題的。Java中的.equals()方法對Boolean、Double和 String的處理都符合Lox的要求7。
And that’s it! That’s all the code we need to correctly interpret a valid Lox expression. But what about an invalid one? In particular, what happens when a subexpression evaluates to an object of the wrong type for the operation being performed?
就這樣了! 這就是我們要正確解釋一個有效的Lox表示式所需要的全部程式碼。但是無效的表示式呢?尤其是,當一個子表示式的計算結果型別與待執行的操作不符時會發生什麼?
7 . 3 Runtime Errors
7.3 執行時錯誤
I was cavalier about jamming casts in whenever a subexpression produces an Object and the operator requires it to be a number or a string. Those casts can fail. Even though the user’s code is erroneous, if we want to make a usable language, we are responsible for handling that error gracefully.
每當子表示式產生一個物件,而運算子要求它是一個數字或字串時,我都會輕率地插入強制型別轉換。這些型別轉換可能會失敗。如果我們想做出一個可用的語言,即使使用者的程式碼是錯誤的,我們也有責任優雅地處理這個錯誤8。
It’s time for us to talk about runtime errors. I spilled a lot of ink in the previous chapters talking about error handling, but those were all syntax or static errors. Those are detected and reported before any code is executed. Runtime errors are failures that the language semantics demand we detect and report while the program is running (hence the name).
現在是時候討論執行時錯誤了。在前面的章節中,我花了很多筆墨討論錯誤處理,但這些都是語法或靜態錯誤。這些都是在程式碼執行之前進行檢測和報告的。執行時錯誤是語言語義要求我們在程式執行時檢測和報告的故障(因此得名)。
Right now, if an operand is the wrong type for the operation being performed, the Java cast will fail and the JVM will throw a ClassCastException. That unwinds the whole stack and exits the application, vomiting a Java stack trace onto the user. That’s probably not what we want. The fact that Lox is implemented in Java should be a detail hidden from the user. Instead, we want them to understand that a Lox runtime error occurred, and give them an error message relevant to our language and their program.
現在,如果運算元對於正在執行的操作來說是錯誤的型別,那麼Java轉換將失敗,JVM將丟擲一個ClassCastException。這將跳脫出整個呼叫堆疊並退出應用程式,然後向用戶丟擲Java堆疊跟蹤資訊。這可能不是我們想要的。Lox是用Java實現的這一事實應該是一個對使用者隱藏的細節。相反,我們希望他們理解此時發生的是Lox執行時錯誤,並給他們一個與我們的語言和他們的程式相關的錯誤資訊。
The Java behavior does have one thing going for it, though. It correctly stops executing any code when the error occurs. Let’s say the user enters some expression like:
不過,Java的行為確實有一個優點。當錯誤發生時,它會正確地停止執行程式碼。比方說,使用者輸入了一些表示式,比如:
2 * (3 / -"muffin")
You can’t negate a muffin, so we need to report a runtime error at that inner
-expression. That in turn means we can’t evaluate the/expression since it has no meaningful right operand. Likewise for the*. So when a runtime error occurs deep in some expression, we need to escape all the way out.
你無法對"muffin"取負,所以我們需要在內部的-表示式中報告一個執行時錯誤。這又意味著我們無法計算/表示式,因為它的右運算元無意義,對於*表示式也是如此。因此,當某個表示式深處出現執行時錯誤時,我們需要一直跳出到最外層。
We could print a runtime error and then abort the process and exit the application entirely. That has a certain melodramatic flair. Sort of the programming language interpreter equivalent of a mic drop.
我們可以列印一個執行時錯誤,然後中止程序並完全退出應用程式。這有一點戲劇性,有點像程式語言直譯器中的 "mic drop"。
Tempting as that is, we should probably do something a little less cataclysmic. While a runtime error needs to stop evaluating the expression, it shouldn’t kill the interpreter. If a user is running the REPL and has a typo in a line of code, they should still be able to keep the session going and enter more code after that.
儘管這種處理方式很誘人,我們或許應該做一些不那麼災難性的事情。雖然執行時錯誤需要停止對錶達式的計算,但它不應該殺死直譯器。如果使用者正在執行REPL,並且在一行程式碼中出現了錯誤,他們應該仍然能夠保持會話,並在之後繼續輸入更多的程式碼。
7 . 3 . 1 Detecting runtime errors
7.3.1 檢測執行時錯誤
Our tree-walk interpreter evaluates nested expressions using recursive method calls, and we need to unwind out of all of those. Throwing an exception in Java is a fine way to accomplish that. However, instead of using Java’s own cast failure, we’ll define a Lox-specific one so that we can handle it how we want.
我們的樹遍歷型直譯器透過遞迴方法呼叫計算巢狀的表示式,而且我們需要能夠跳脫出所有的呼叫層。在Java中丟擲異常是實現這一點的好方法。但是,我們不使用Java自己的轉換失敗錯誤,而是定義一個Lox專用的錯誤,這樣我們就可以按照我們想要的方式處理它。
Before we do the cast, we check the object’s type ourselves. So, for unary
-, we add:
在進行強制轉換之前,我們先自己檢查物件的型別。因此,對於一元運算子-,我們需要新增程式碼:
lox/Interpreter.java,在visitUnaryExpr()方法中新增:
case MINUS:
// 新增部分開始
checkNumberOperand(expr.operator, right);
// 新增部分結束
return -(double)right;
The code to check the operand is:
檢查運算元的程式碼如下:
lox/Interpreter.java,在 visitUnaryExpr()方法後新增:
private void checkNumberOperand(Token operator, Object operand) {
if (operand instanceof Double) return;
throw new RuntimeError(operator, "Operand must be a number.");
}
When the check fails, it throws one of these:
當檢查失敗時,程式碼會丟擲一個以下的錯誤:
lox/RuntimeError.java,新建原始碼檔案:
package com.craftinginterpreters.lox;
class RuntimeError extends RuntimeException {
final Token token;
RuntimeError(Token token, String message) {
super(message);
this.token = token;
}
}
Unlike the Java cast exception, our class tracks the token that identifies where in the user’s code the runtime error came from. As with static errors, this helps the user know where to fix their code.
與Java轉換異常不同,我們的類會跟蹤語法標記,可以指明使用者程式碼中丟擲執行時錯誤的位置9。與靜態錯誤一樣,這有助於使用者知道去哪裡修復程式碼。
We need similar checking for the binary operators. Since I promised you every single line of code needed to implement the interpreters, I’ll run through them all.
我們需要對二元運算子進行類似的檢查。既然我答應了要展示實現直譯器所需的每一行程式碼,那麼我就把它們逐一介紹一遍。
Greater than:
大於:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case GREATER:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left > (double)right;
Greater than or equal to:
大於等於:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case GREATER_EQUAL:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left >= (double)right;
Less than:
小於:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case LESS:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left < (double)right;
Less than or equal to:
小於等於:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case LESS_EQUAL:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left <= (double)right;
Subtraction:
減法:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case MINUS:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left - (double)right;
Division:
除法:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case SLASH:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left / (double)right;
Multiplication:
乘法:
lox/Interpreter.java,在 visitBinaryExpr()方法中新增:
case STAR:
// 新增部分開始
checkNumberOperands(expr.operator, left, right);
// 新增部分結束
return (double)left * (double)right;
All of those rely on this validator, which is virtually the same as the unary one:
所有這些都依賴於下面這個驗證器,它實際上與一元驗證器相同10:
lox/Interpreter.java,在 checkNumberOperand()方法後新增:
private void checkNumberOperands(Token operator, Object left, Object right) {
if (left instanceof Double && right instanceof Double) return;
throw new RuntimeError(operator, "Operands must be numbers.");
}
The last remaining operator, again the odd one out, is addition. Since
+is overloaded for numbers and strings, it already has code to check the types. All we need to do is fail if neither of the two success cases match.
剩下的最後一個運算子,也是最奇怪的一個,就是加法。由於+已經對數字和字串進行過載,其中已經有檢查型別的程式碼。我們需要做的就是在這兩種情況都不匹配時失敗。
lox/Interpreter.java,在 visitBinaryExpr()方法中替換一行:
return (String)left + (String)right;
}
// 替換部分開始
throw new RuntimeError(expr.operator,
"Operands must be two numbers or two strings.");
// 替換部分結束
case SLASH:
That gets us detecting runtime errors deep in the bowels of the evaluator. The errors are getting thrown. The next step is to write the code that catches them. For that, we need to wire up the Interpreter class into the main Lox class that drives it.
這樣我們就可以在計算器的內部檢測執行時錯誤。錯誤已經被拋出了。下一步就是編寫能捕獲這些錯誤的程式碼。為此,我們需要將Interpreter類連線到驅動它的Lox主類中。
7 . 4 Hooking Up the Interpreter
7.4 連線直譯器
The visit methods are sort of the guts of the Interpreter class, where the real work happens. We need to wrap a skin around them to interface with the rest of the program. The Interpreter’s public API is simply one method.
visit方法是Interpreter類的核心部分,真正的工作是在這裡進行的。我們需要給它們包上一層皮,以便與程式的其他部分對接。直譯器的公共API只是一種方法。
lox/Interpreter.java,在 Interpreter類中新增:
void interpret(Expr expression) {
try {
Object value = evaluate(expression);
System.out.println(stringify(value));
} catch (RuntimeError error) {
Lox.runtimeError(error);
}
}
This takes in a syntax tree for an expression and evaluates it. If that succeeds,
evaluate()returns an object for the result value.interpret()converts that to a string and shows it to the user. To convert a Lox value to a string, we rely on:
該方法會接收一個表示式對應的語法樹,並對其進行計算。如果成功了,evaluate()方法會返回一個物件作為結果值。interpret()方法將結果轉為字串並展示給使用者。要將Lox值轉為字串,我們要依賴下面的方法:
lox/Interpreter.java,在 isEqual()方法後新增:
private String stringify(Object object) {
if (object == null) return "nil";
if (object instanceof Double) {
String text = object.toString();
if (text.endsWith(".0")) {
text = text.substring(0, text.length() - 2);
}
return text;
}
return object.toString();
}
This is another of those pieces of code like
isTruthy()that crosses the membrane between the user’s view of Lox objects and their internal representation in Java.
這是一段像isTruthy()一樣的程式碼,它連線了Lox物件的使用者檢視和它們在Java中的內部表示。
It’s pretty straightforward. Since Lox was designed to be familiar to someone coming from Java, things like Booleans look the same in both languages. The two edge cases are
nil, which we represent using Java’snull, and numbers.
這很簡單。由於Lox的設計旨在使Java使用者熟悉,因此Boolean之類的東西在兩種語言中看起來是一樣的。只有兩種邊界情況是nil(我們用Java的null表示)和數字。
Lox uses double-precision numbers even for integer values. In that case, they should print without a decimal point. Since Java has both floating point and integer types, it wants you to know which one you’re using. It tells you by adding an explicit
.0to integer-valued doubles. We don’t care about that, so we hack it off the end.
Lox即使對整數值也使用雙精度數字11。在這種情況下,列印時應該不帶小數點。 由於Java同時具有浮點型和整型,它希望您知道正在使用的是哪一種型別。它透過在整數值的雙數上新增一個明確的.0來告知使用者。我們不關心這個,所以我們把它去掉。
7 . 4 . 1 Reporting runtime errors
7.4.1 報告執行時錯誤
If a runtime error is thrown while evaluating the expression,
interpret()catches it. This lets us report the error to the user and then gracefully continue. All of our existing error reporting code lives in the Lox class, so we put this method there too:
如果在計算表示式時出現了執行時錯誤,interpret()方法會將其捕獲。這樣我們可以向用戶報告這個錯誤,然後優雅地繼續執行。我們現有的所有錯誤報告程式碼都在Lox類中,所以我們也把這個方法放在其中:
lox/Lox.java,在 error()方法後新增:
static void runtimeError(RuntimeError error) {
System.err.println(error.getMessage() +
"\n[line " + error.token.line + "]");
hadRuntimeError = true;
}
We use the token associated with the RuntimeError to tell the user what line of code was executing when the error occurred. Even better would be to give the user an entire call stack to show how they got to be executing that code. But we don’t have function calls yet, so I guess we don’t have to worry about it.
我們使用與RuntimeError關聯的標記來告訴使用者錯誤發生時正在執行哪一行程式碼。更好的做法是給使用者一個完整的呼叫堆疊,來顯示他們是如何執行該程式碼的。但我們目前還沒有函式呼叫,所以我想我們不必擔心這個問題。
After showing the error,
runtimeError()sets this field:
展示錯誤之後,runtimeError()會設定以下欄位:
lox/Lox.java,在 Lox類中新增:
static boolean hadError = false;
// 新增部分開始
static boolean hadRuntimeError = false;
// 新增部分結束
public static void main(String[] args) throws IOException {
That field plays a small but important role.
這個欄位擔任著很小但很重要的角色。
lox/Lox.java,在 runFile()方法中新增:
run(new String(bytes, Charset.defaultCharset()));
// Indicate an error in the exit code.
if (hadError) System.exit(65);
// 新增部分開始
if (hadRuntimeError) System.exit(70);
// 新增部分結束
}
If the user is running a Lox script from a file and a runtime error occurs, we set an exit code when the process quits to let the calling process know. Not everyone cares about shell etiquette, but we do.
如果使用者從檔案中執行Lox指令碼,並且發生了執行時錯誤,我們在程序退出時設定一個退出碼,以便讓呼叫程序知道。不是每個人都在乎shell的規矩,但我們在乎12。
7 . 4 . 2 Running the interpreter
7.4.2 執行直譯器
Now that we have an interpreter, the Lox class can start using it.
現在我們有了直譯器,Lox類可以開始使用它了。
lox/Lox.java,在 Lox類中新增:
public class Lox {
// 新增部分開始
private static final Interpreter interpreter = new Interpreter();
// 新增部分結束
static boolean hadError = false;
We make the field static so that successive calls to
run()inside a REPL session reuse the same interpreter. That doesn’t make a difference now, but it will later when the interpreter stores global variables. Those variables should persist throughout the REPL session.
我們把這個欄位設定為靜態的,這樣在一個REPL會話中連續呼叫run()時就會重複使用同一個直譯器。目前這一點沒有什麼區別,但以後當直譯器需要儲存全域性變數時就會有區別。這些全域性變數應該在整個REPL會話中持續存在。
Finally, we remove the line of temporary code from the last chapter for printing the syntax tree and replace it with this:
最後,我們刪除上一章中用於列印語法樹的那行臨時程式碼,並將其替換為:
lox/Lox.java,在 run()方法中替換一行:
// Stop if there was a syntax error.
if (hadError) return;
// 替換部分開始
interpreter.interpret(expression);
// 替換部分結束
}
We have an entire language pipeline now: scanning, parsing, and execution. Congratulations, you now have your very own arithmetic calculator.
我們現在有一個完整的語言管道:掃描、解析和執行。恭喜你,你現在有了你自己的算術計算器。
As you can see, the interpreter is pretty bare bones. But the Interpreter class and the Visitor pattern we’ve set up today form the skeleton that later chapters will stuff full of interesting guts—variables, functions, etc. Right now, the interpreter doesn’t do very much, but it’s alive!
如您所見,這個直譯器是非常簡陋的。但是我們今天建立的直譯器類和訪問者模式構成了一個骨架,後面的章節中將填充入有趣的內容(變數,函式等)。現在,直譯器的功能並不多,但它是活的!

CHALLENGES
習題
1、Allowing comparisons on types other than numbers could be useful. The operators might have a reasonable interpretation for strings. Even comparisons among mixed types, like
3 < "pancake"could be handy to enable things like ordered collections of heterogeneous types. Or it could simply lead to bugs and confusion.Would you extend Lox to support comparing other types? If so, which pairs of types do you allow and how do you define their ordering? Justify your choices and compare them to other languages.
1、允許對數字之外的型別進行比較可能是個有用的特性。運算子可能對字串有合理的解釋。即使是混合型別之間的比較,如3<"pancake",也可以方便地支援異構型別的有序集合。否則可能導致錯誤和混亂。
你是否會擴充套件Lox以支援對其他型別的比較?如果是,您允許哪些型別間的比較,以及如何定義它們的順序?證明你的選擇並與其他語言進行比較。
2、Many languages define
+such that if either operand is a string, the other is converted to a string and the results are then concatenated. For example,"scone" + 4would yieldscone4. Extend the code invisitBinaryExpr()to support that.
2、許多語言對+的定義是,如果其中一個運算元是字串,另一個運算元就會被轉換成字串,然後將兩個結果拼接起來。例如,"scone "+4的結果應該是scone4。擴充套件visitBinaryExpr()中的程式碼以支援該特性。
3、What happens right now if you divide a number by zero? What do you think should happen? Justify your choice. How do other languages you know handle division by zero, and why do they make the choices they do?
Change the implementation in
visitBinaryExpr()to detect and report a runtime error for this case.
3、如果你用一個數除以0會發生什麼?你認為應該發生什麼?證明你的選擇。你知道的其他語言是如何處理除零的,為什麼他們會做出這樣的選擇?
更改visitBinaryExpr()中的實現程式碼,以檢測並報告執行時錯誤。
DESIGN NOTE: STATIC AND DYNAMIC TYPING
設計筆記:靜態型別和動態型別
Some languages, like Java, are statically typed which means type errors are detected and reported at compile time before any code is run. Others, like Lox, are dynamically typed and defer checking for type errors until runtime right before an operation is attempted. We tend to consider this a black-and-white choice, but there is actually a continuum between them.
It turns out even most statically typed languages do some type checks at runtime. The type system checks most type rules statically, but inserts runtime checks in the generated code for other operations.
For example, in Java, the static type system assumes a cast expression will always safely succeed. After you cast some value, you can statically treat it as the destination type and not get any compile errors. But downcasts can fail, obviously. The only reason the static checker can presume that casts always succeed without violating the language’s soundness guarantees, is because the cast is checked at runtime and throws an exception on failure.
A more subtle example is covariant arrays in Java and C#. The static subtyping rules for arrays allow operations that are not sound. Consider:
Object[] stuff = new Integer[1]; stuff[0] = "not an int!";This code compiles without any errors. The first line upcasts the Integer array and stores it in a variable of type Object array. The second line stores a string in one of its cells. The Object array type statically allows that—strings are Objects—but the actual Integer array that
stuffrefers to at runtime should never have a string in it! To avoid that catastrophe, when you store a value in an array, the JVM does a runtime check to make sure it’s an allowed type. If not, it throws an ArrayStoreException.Java could have avoided the need to check this at runtime by disallowing the cast on the first line. It could make arrays invariant such that an array of Integers is not an array of Objects. That’s statically sound, but it prohibits common and safe patterns of code that only read from arrays. Covariance is safe if you never write to the array. Those patterns were particularly important for usability in Java 1.0 before it supported generics.
James Gosling and the other Java designers traded off a little static safety and performance—those array store checks take time—in return for some flexibility.
There are few modern statically typed languages that don’t make that trade-off somewhere. Even Haskell will let you run code with non-exhaustive matches. If you find yourself designing a statically typed language, keep in mind that you can sometimes give users more flexibility without sacrificing too many of the benefits of static safety by deferring some type checks until runtime.
On the other hand, a key reason users choose statically typed languages is because of the confidence the language gives them that certain kinds of errors can never occur when their program is run. Defer too many type checks until runtime, and you erode that confidence.
有些語言,如Java,是靜態型別的,這意味著在任何程式碼執行之前,會在編譯時檢測和報告型別錯誤。其他語言,如Lox,是動態型別的,將型別錯誤的檢查推遲到執行時嘗試執行具體操作之前。我們傾向於認為這是一個非黑即白的選擇,但實際上它們之間是連續統一的。
事實證明,大多數靜態型別的語言也會在執行時進行一些型別檢查。型別系統會靜態地檢查多數型別規則,但在生成的程式碼中插入了執行時檢查以支援其它操作。
例如,在Java中,靜態型別系統會假定強制轉換表示式總是能安全地成功執行。在轉換某個值之後,可以將其靜態地視為目標型別,而不會出現任何編譯錯誤。但向下轉換顯然會失敗。靜態檢查器之所以能夠在不違反語言的合理性保證的情況下假定轉換總是成功的,唯一原因是,強制轉換操作會在執行時進行型別檢查,並在失敗時丟擲異常。
一個更微妙的例子是Java和c#中的協變陣列。陣列的靜態子型別規則允許不健全的操作。考慮以下程式碼:
Object[] stuff = new Integer[1];
stuff[0] = "not an int!";
這段程式碼在編譯時沒有任何錯誤。第一行程式碼將整數陣列向上轉換並儲存到一個物件陣列型別的變數中。第二行程式碼將字串儲存在其中一個單元格里。物件陣列型別靜態地允許該操作——字串也是物件——但是stuff在執行時引用的整數陣列中不應該包含字串!為了避免這種災難,當你在陣列中儲存一個值時,JVM會進行執行時檢查,以確保該值是允許的型別。如果不是,則丟擲ArrayStoreException。
Java可以透過禁止對第一行進行強制轉換來避免在執行時檢查這一點。它可以使陣列保持不變,這樣整型陣列就不是物件陣列。這在靜態型別角度是合理的,但它禁止了只從陣列中讀取資料的常見安全的程式碼模式。如果你從來不向陣列寫入內容,那麼協變是安全的。在支援泛型之前,這些模式對於Java 1.0的可用性尤為重要。
James Gosling和其他Java設計師犧牲了一點靜態安全和效能(這些陣列儲存檢查需要花費時間)來換取一些靈活性。
幾乎所有的現代靜態型別語言都在某些方面做出了權衡。即使Haskell也允許您執行非窮舉性匹配的程式碼。如果您自己正在設計一種靜態型別語言,請記住,有時你可以透過將一些型別檢查推遲到執行時來給使用者更多的靈活性,而不會犧牲靜態安全的太多好處。
另一方面,使用者選擇靜態型別語言的一個關鍵原因是,這種語言讓他們相信:在他們的程式執行時,某些型別的錯誤永遠不會發生。將過多的型別檢查推遲到執行時,就會破壞使用者的這種信心。
-
在這裡,我基本可以互換地使用 "值 "和 "物件"。稍後在C直譯器中,我們會對它們稍作區分,但這主要是針對實現的兩個不同方面(本地資料和堆分配資料)使用不同的術語。從使用者的角度來看,這些術語是同義的。 ↩
-
我們需要對值做的另一件事是管理它們的記憶體,Java也能做到這一點。方便的物件表示和非常好的垃圾收集器是我們用Java編寫第一個直譯器的主要原因。 ↩
-
在下一章,當我們實現變數時,我們將新增識別符號表示式,它也是葉子節點。 ↩
-
有些解析器不為圓括號單獨定義樹節點。相應地,在解析帶圓括號的表示式時,它們只返回內部表示式的節點。在Lox中,我們確實為圓括號建立了一個節點,因為稍後我們需要用它來正確處理賦值表示式的左值。 ↩
-
在JavaScript中,字串是真的,但空字串不是。陣列是真的,但空陣列是......也是真的。數字0是假的,但字串 "0 "是真的。
在 Python 中,空字串是假的,就像在 JS 中一樣,但其他空序列也是假的。
在PHP中,數字0和字串 "0 "都是假的。大多數其他非空字串是真實的。明白了嗎? ↩ -
你是否注意到我們在這裡固定了語言語義的一個細微的點?在二元表示式中,我們按從左到右的順序計算運算元。如果這些運算元有副作用,那這個選擇應該是使用者可見的,所以這不是一個簡單的實現細節。如果我們希望我們的兩個直譯器是一致的(提示:我們是一致的),我們就需要確保 clox 也是這樣做的。 ↩
-
你希望這個表示式的計算結果是什麼?
(0 / 0) == (0 / 0)。根據IEEE 754(它規定了雙精度數的行為),用0除以0會得到特殊的NaN(不是一個數字)值。奇怪的是,NaN不等於它自己。
在Java中,基本型別double的==操作滿足該規範,但是封裝類Double的equals()方法不滿足。Lox使用了後者,因此不遵循IEEE。這類微妙的不相容問題佔據了語言開發者生活中令人沮喪的一部分。 ↩ -
我們完全可以不檢測或報告一個型別錯誤。當你在C語言中把一個指標轉換到與實際被指向的資料不匹配的型別上,C語言就是這樣做的。C語言透過允許這樣的操作獲得了靈活性和速度,但它也是出了名的危險。一旦你錯誤地解釋了記憶體中的資料,一切都完了。很少有現代語言接受這樣的不安全操作。相反,大多數語言都是記憶體安全的,並透過靜態和執行時檢查的組合,確保程式永遠不會錯誤地解釋儲存在記憶體中的值。 ↩
-
我承認 "RuntimeError "這個名字令人困惑,因為Java定義了一個RuntimeException類。關於構建直譯器的一件惱人的事情就是,您使用的名稱經常與實現語言中已經使用的名稱衝突。等我們支援Lox類就好了。 ↩
-
另一個微妙的語義選擇:在檢查兩個運算元的型別之前,我們先計算這兩個運算元。假設我們有一個函式
say(),它會列印其介紹的引數,然後返回。 我們使用這個函式寫出表示式:say("left") - say("right");。我們的直譯器在報告執行時錯誤之前會先列印"left"和"right"。相對地,我們也可以指定在計算右運算元之前先檢查左運算元。 ↩ -
同樣,我們要處理這種數字的邊界情況,以確保jlox和clox的工作方式相同。像這樣處理語言的一個奇怪的邊界可能會讓你抓狂,但這是工作的一個重要部分。使用者會有意或無意地依賴於這些細節,如果實現不一致,他們的程式在不同的直譯器上執行時將會中斷。 ↩
-
如果使用者正在執行REPL,則我們不必跟蹤執行時錯誤。在錯誤被報告之後,我們只需要迴圈,讓使用者輸入新的程式碼,然後繼續執行。 ↩
8.表示式和狀態 Statements and State
All my life, my heart has yearned for a thing I cannot name.
—— André Breton, Mad Love
終我一生,我們的內心都在渴求一種我無法名狀的東西。
The interpreter we have so far feels less like programming a real language and more like punching buttons on a calculator. “Programming” to me means building up a system out of smaller pieces. We can’t do that yet because we have no way to bind a name to some data or function. We can’t compose software without a way to refer to the pieces.
到目前為止,我們提供直譯器的感覺不太像是在使用一種真正的語言進行程式設計,更像是在計算器上按按鈕。對我來說,"程式設計 "意味著用較小的部分構建出一個系統。我們目前還不支援這樣做,因為我們還無法將一個名稱繫結到某個資料或函式。我們不能在無法引用小片段的情況下編寫軟體。
To support bindings, our interpreter needs internal state. When you define a variable at the beginning of the program and use it at the end, the interpreter has to hold on to the value of that variable in the meantime. So in this chapter, we will give our interpreter a brain that can not just process, but remember.
為了支援繫結,我們的直譯器需要儲存內部狀態。如果你在程式開始處定義了一個變數,並在結束處使用它,那麼直譯器必須在這期間保持該變數的值。所以在這一章中,我們會給直譯器一個大腦,它不僅可以運算,而且可以記憶。

State and statements go hand in hand. Since statements, by definition, don’t evaluate to a value, they need to do something else to be useful. That something is called a side effect. It could mean producing user-visible output or modifying some state in the interpreter that can be detected later. The latter makes them a great fit for defining variables or other named entities.
狀態和語句是相輔相成的。因為根據定義,語句不會計算出一個具體值,而是需要做一些事情來發揮作用。這些事情被稱為副作用(side effect)。它可能意味著產生使用者可見的輸出,或者修改直譯器中的一些狀態,而這些狀態後續可以被檢測到。第二個特性使得語句非常適合於定義變數或其他命名實體。
In this chapter, we’ll do all of that. We’ll define statements that produce output (
var). We’ll add expressions to access and assign to variables. Finally, we’ll add blocks and local scope. That’s a lot to stuff into one chapter, but we’ll chew through it all one bite at a time.
在這一章中,我們會實現所有這些。我們會定義可以產生輸出和建立狀態的語句,然後會新增表示式來訪問和賦值給這些變數,最後,我們會引入程式碼塊和區域性作用域。這一章要講的內容太多了,但是我們會一點一點地把它們嚼碎。
8 . 1 Statements
8.1 語句
We start by extending Lox’s grammar with statements. They aren’t very different from expressions. We start with the two simplest kinds:
我們首先擴充套件Lox的語法以支援語句。 語句與表示式並沒有很大的不同,我們從兩種最簡單的型別開始:
-
An expression statement lets you place an expression where a statement is expected. They exist to evaluate expressions that have side effects. You may not notice them, but you use them all the time in C, Java, and other languages. Any time you see a function or method call followed by a
;, you’re looking at an expression statement.表示式語句可以讓您將表示式放在需要語句的位置。它們的存在是為了計算有副作用的表示式。您可能沒有注意到它們,但其實你在C、Java和其他語言中一直在使用表示式語句1。如果你看到一個函式或方法呼叫後面跟著一個
;,您看到的其實就是一個表示式語句。 -
A
printstatement evaluates an expression and displays the result to the user. I admit it’s weird to bake printing right into the language instead of making it a library function. Doing so is a concession to the fact that we’re building this interpreter one chapter at a time and want to be able to play with it before it’s all done. To make print a library function, we’d have to wait until we had all of the machinery for defining and calling functions before we could witness any side effects.print語句會計算一個表示式,並將結果展示給使用者。我承認把print直接放進語言中,而不是把它變成一個庫函式,這很奇怪2。這樣做是基於本書的編排策略的讓步,即我們會以章節為單位逐步構建這個直譯器,並希望能夠在完成直譯器的所有功能之前能夠使用它。如果讓print成為一個標準庫函式,我們必須等到擁有了定義和呼叫函式的所有機制之後,才能看到它發揮作用。
New syntax means new grammar rules. In this chapter, we finally gain the ability to parse an entire Lox script. Since Lox is an imperative, dynamically typed language, the “top level” of a script is simply a list of statements. The new rules are:
新的詞法意味著新的語法規則。在本章中,我們終於獲得瞭解析整個Lox指令碼的能力。由於Lox是一種命令式的、動態型別的語言,所以指令碼的“頂層”也只是一組語句。新的規則如下:
program → statement* EOF ;
statement → exprStmt
| printStmt ;
exprStmt → expression ";" ;
printStmt → "print" expression ";" ;
The first rule is now
program, which is the starting point for the grammar and represents a complete Lox script or REPL entry. A program is a list of statements followed by the special “end of file” token. The mandatory end token ensures the parser consumes the entire input and doesn’t silently ignore erroneous unconsumed tokens at the end of a script.
現在第一條規則是program,這也是語法的起點,代表一個完整的Lox指令碼或REPL輸入項。程式是一個語句列表,後面跟著特殊的“檔案結束”(EOF)標記。強制性的結束標記可以確保解析器能夠消費所有輸入內容,而不會默默地忽略指令碼結尾處錯誤的、未消耗的標記。
Right now,
statementonly has two cases for the two kinds of statements we’ve described. We’ll fill in more later in this chapter and in the following ones. The next step is turning this grammar into something we can store in memory—syntax trees.
目前,statement只有兩種情況,分別對應於我們描述的兩類語句。我們將在本章後面和接下來的章節中補充更多內容。接下來就是將這個語法轉化為我們可以儲存在記憶體中的東西——語法樹。。
8 . 1 . 1 Statement syntax trees
8.1.1 Statement語法樹
There is no place in the grammar where both an expression and a statement are allowed. The operands of, say,
+are always expressions, never statements. The body of awhileloop is always a statement.
語法中沒有地方既允許使用表示式,也允許使用語句。 運算子(如+)的運算元總是表示式,而不是語句。while迴圈的主體總是一個語句。
Since the two syntaxes are disjoint, we don’t need a single base class that they all inherit from. Splitting expressions and statements into separate class hierarchies enables the Java compiler to help us find dumb mistakes like passing a statement to a Java method that expects an expression.
因為這兩種語法是不相干的,所以我們不需要提供一個它們都繼承的基類。將表示式和語句拆分為單獨的類結構,可使Java編譯器幫助我們發現一些愚蠢的錯誤,例如將語句傳遞給需要表示式的Java方法。
That means a new base class for statements. As our elders did before us, we will use the cryptic name “Stmt”. With great foresight, I have designed our little AST metaprogramming script in anticipation of this. That’s why we passed in “Expr” as a parameter to
defineAst(). Now we add another call to define Stmt and its subclasses.
這意味著要為語句建立一個新的基類。正如我們的前輩那樣,我們將使用“Stmt”這個隱秘的名字。我很有遠見,在設計我們的AST超程式設計指令碼時就已經預見到了這一點。這就是為什麼我們把“Expr”作為引數傳給了defineAst()。現在我們新增另一個方法呼叫來定義Stmt和它的子類。
tool/GenerateAst.java,在 main()方法中新增:
"Unary : Token operator, Expr right"
));
// 新增部分開始
defineAst(outputDir, "Stmt", Arrays.asList(
"Expression : Expr expression",
"Print : Expr expression"
));
// 新增部分結束
}
新節點對應的生成程式碼可以參考附錄: Appendix II: Expression statement, Print statement.
Run the AST generator script and behold the resulting “Stmt.java” file with the syntax tree classes we need for expression and
執行AST生成器指令碼,檢視生成的Stmt.java檔案,其中包含表示式和print語句所需的語法樹類。不要忘記將該檔案新增到IDE專案或makefile或其他檔案中。
8 . 1 . 2 Parsing statements
8.1.2 解析語句
The parser’s
parse()method that parses and returns a single expression was a temporary hack to get the last chapter up and running. Now that our grammar has the correct starting rule,program, we can turnparse()into the real deal.
解析器的parse()方法會解析並返回一個表示式,這是一個臨時方案,是為了讓上一章的程式碼能啟動並執行起來。現在,我們的語法已經有了正確的起始規則,即program,我們可以正式編寫parse()方法了。
lox/Parser.java, parse()方法,替換7行:
List<Stmt> parse() {
List<Stmt> statements = new ArrayList<>();
while (!isAtEnd()) {
statements.add(statement());
}
return statements;
}
This parses a series of statements, as many as it can find until it hits the end of the input. This is a pretty direct translation of the
programrule into recursive descent style. We must also chant a minor prayer to the Java verbosity gods since we are using ArrayList now.
該方法會盡可能多地解析一系列語句,直到命中輸入內容的結尾為止。這是一種非常直接的將program規則轉換為遞迴下降風格的方式。由於我們現在使用ArrayList,所以我們還必須向Java的冗長之神做一個小小的祈禱。
lox/Parser.java,新增程式碼:
package com.craftinginterpreters.lox;
// 新增部分開始
import java.util.ArrayList;
// 新增部分結束
import java.util.List;
A program is a list of statements, and we parse one of those statements using this method:
一個程式就是一系列的語句,而我們可以透過下面的方法解析每一條語句:
lox/Parser.java,在 expression()方法後新增:
private Stmt statement() {
if (match(PRINT)) return printStatement();
return expressionStatement();
}
A little bare bones, but we’ll fill it in with more statement types later. We determine which specific statement rule is matched by looking at the current token. A
這是一個簡單的框架,但是稍後我們將會填充更多的語句型別。我們透過檢視當前標記來確定匹配哪條語句規則。print標記意味著它顯然是一個print語句。
If the next token doesn’t look like any known kind of statement, we assume it must be an expression statement. That’s the typical final fallthrough case when parsing a statement, since it’s hard to proactively recognize an expression from its first token.
如果下一個標記看起來不像任何已知型別的語句,我們就認為它一定是一個表示式語句。這是解析語句時典型的最終失敗分支,因為我們很難透過第一個標記主動識別出一個表示式。
Each statement kind gets its own method. First
每種語句型別都有自己的方法。首先是print:
lox/Parser.java,在 statement()方法後新增:
private Stmt printStatement() {
Expr value = expression();
consume(SEMICOLON, "Expect ';' after value.");
return new Stmt.Print(value);
}
Since we already matched and consumed the
因為我們已經匹配並消費了print標記本身,所以這裡不需要重複消費。我們先解析隨後的表示式,消費表示語句終止的分號,並生成語法樹。
If we didn’t match a
如果我們沒有匹配到print語句,那一定是一條下面的語句:
lox/Parser.java,在 printStatement()方法後新增:
private Stmt expressionStatement() {
Expr expr = expression();
consume(SEMICOLON, "Expect ';' after expression.");
return new Stmt.Expression(expr);
}
Similar to the previous method, we parse an expression followed by a semicolon. We wrap that Expr in a Stmt of the right type and return it.
與前面的方法類似,我們解析一個後面帶分號的表示式。我們將Expr封裝在一個正確型別的Stmt中,並返回它。
8 . 1 . 3 Executing statements
8.1.3 執行語句
We’re running through the previous couple of chapters in microcosm, working our way through the front end. Our parser can now produce statement syntax trees, so the next and final step is to interpret them. As in expressions, we use the Visitor pattern, but we have a new visitor interface, Stmt.Visitor, to implement since statements have their own base class.
我們在前面幾章一步一步地慢慢完成了直譯器的前端工作。我們的解析器現在可以產生語句語法樹,所以下一步,也是最後一步,就是對其進行解釋。和表示式一樣,我們使用的是Visitor模式,但是我們需要實現一個新的訪問者介面Stmt.Visitor,因為語句有自己的基類。
We add that to the list of interfaces Interpreter implements.
我們將其新增到Interpreter實現的介面列表中。
lox/Interpreter.java,替換1行3:
// 替換部分開始
class Interpreter implements Expr.Visitor<Object>,
Stmt.Visitor<Void> {
// 替換部分結束
void interpret(Expr expression) {
Unlike expressions, statements produce no values, so the return type of the visit methods is Void, not Object. We have two statement types, and we need a visit method for each. The easiest is expression statements.
與表示式不同,語句不會產生值,因此visit方法的返回型別是Void,而不是Object。我們有兩種語句型別,每種型別都需要一個visit方法。最簡單的是表示式語句:
lox/Interpreter.java,在 evaluate()方法後新增:
@Override
public Void visitExpressionStmt(Stmt.Expression stmt) {
evaluate(stmt.expression);
return null;
}
We evaluate the inner expression using our existing
evaluate()method and discard the value. Then we returnnull. Java requires that to satisfy the special capitalized Void return type. Weird, but what can you do?
我們使用現有的evaluate()方法計算內部表示式,並丟棄其結果值。然後我們返回null,因為Java要求為特殊的大寫Void返回型別返回該值。很奇怪,但你能有什麼辦法呢?
The
print語句的visit方法沒有太大的不同。
lox/Interpreter.java,在 visitExpressionStmt()方法後新增:
@Override
public Void visitPrintStmt(Stmt.Print stmt) {
Object value = evaluate(stmt.expression);
System.out.println(stringify(value));
return null;
}
Before discarding the expression’s value, we convert it to a string using the
stringify()method we introduced in the last chapter and then dump it to stdout.
在丟棄表示式的值之前,我們使用上一章引入的stringify()方法將其轉換為字串,然後將其輸出到stdout。
Our interpreter is able to visit statements now, but we have some work to do to feed them to it. First, modify the old
interpret()method in the Interpreter class to accept a list of statements—in other words, a program.
我們的直譯器現在可以處理語句了,但是我們還需要做一些工作將語句輸入到直譯器中。首先,修改Interpreter類中原有的interpret() 方法,讓其能夠接受一組語句——即一段程式。
lox/Interpreter.java,修改 interpret()方法,替換8行:
void interpret(List<Stmt> statements) {
try {
for (Stmt statement : statements) {
execute(statement);
}
} catch (RuntimeError error) {
Lox.runtimeError(error);
}
}
This replaces the old code which took a single expression. The new code relies on this tiny helper method:
這段程式碼替換了原先處理單個表示式的舊程式碼。新程式碼依賴於下面的小輔助方法。
lox/Interpreter.java,在 evaluate()方法後新增:
private void execute(Stmt stmt) {
stmt.accept(this);
}
That’s the statement analogue to the
evaluate()method we have for expressions. Since we’re working with lists now, we need to let Java know.
這類似於處理表示式的evaluate()方法,這是這裡處理語句。因為我們要使用列表,所以我們需要在Java中引入一下。
lox/Interpreter.java
package com.craftinginterpreters.lox;
// 新增部分開始
import java.util.List;
// 新增部分結束
class Interpreter implements Expr.Visitor<Object>,
The main Lox class is still trying to parse a single expression and pass it to the interpreter. We fix the parsing line like so:
Lox主類中仍然是隻解析單個表示式並將其傳給直譯器。我們將其修正如下:
lox/Lox.java,在 run()方法中替換一行:
Parser parser = new Parser(tokens);
// 替換部分開始
List<Stmt> statements = parser.parse();
// 替換部分結束
// Stop if there was a syntax error.
And then replace the call to the interpreter with this:
然後將對直譯器的呼叫替換如下:
lox/Lox.java,在 run()方法中替換一行:
if (hadError) return;
// 替換部分開始
interpreter.interpret(statements);
// 替換部分結束
}
Basically just plumbing the new syntax through. OK, fire up the interpreter and give it a try. At this point, it’s worth sketching out a little Lox program in a text file to run as a script. Something like:
基本就是對新語法進行遍歷。 OK,啟動直譯器並測試一下。 現在有必要在文字檔案中草擬一個小的Lox程式來作為指令碼執行。 就像是:
print "one";
print true;
print 2 + 1;
It almost looks like a real program! Note that the REPL, too, now requires you to enter a full statement instead of a simple expression. Don’t forget your semicolons.
它看起來就像一個真實的程式! 請注意,REPL現在也要求你輸入完整的語句,而不是簡單的表示式。 所以不要忘記後面的分號。
8 . 2 Global Variables
8.2 全域性變數
Now that we have statements, we can start working on state. Before we get into all of the complexity of lexical scoping, we’ll start off with the easiest kind of variables—globals. We need two new constructs.
現在我們已經有了語句,可以開始處理狀態了。在深入探討語法作用域的複雜性之前,我們先從最簡單的變數(全域性變數)開始4。我們需要兩個新的結構。
-
A variable declaration statement brings a new variable into the world.
變數宣告語句用於建立一個新變數。
var beverage = "espresso";This creates a new binding that associates a name (here “beverage”) with a value (here, the string
"espresso").該語句將建立一個新的繫結,將一個名稱(這裡是
beverage)和一個值(這裡是字串"espresso")關聯起來。 -
Once that’s done, a variable expression accesses that binding. When the identifier “beverage” is used as an expression, it looks up the value bound to that name and returns it.
一旦宣告完成,變量表達式就可以訪問該繫結。當識別符號“beverage”被用作一個表示式時,程式會查詢與該名稱繫結的值並返回。
print beverage; // "espresso".
Later, we’ll add assignment and block scope, but that’s enough to get moving.
稍後,我們會新增賦值和塊作用域,但是這些已經足夠繼續後面的學習了。
8 . 2 . 1 Variable syntax
8.2.1 變數語法
As before, we’ll work through the implementation from front to back, starting with the syntax. Variable declarations are statements, but they are different from other statements, and we’re going to split the statement grammar in two to handle them. That’s because the grammar restricts where some kinds of statements are allowed.
與前面一樣,我們將從語法開始,從前到後依次完成實現。變數宣告是一種語句,但它們不同於其他語句,我們把statement語法一分為二來處理該情況。這是因為語法要限制某個位置上哪些型別的語句是被允許的。
The clauses in control flow statements—think the then and else branches of an
ifstatement or the body of awhile—are each a single statement. But that statement is not allowed to be one that declares a name. This is OK:
控制流語句中的子句——比如,if或while語句體中的then和else分支——都是一個語句。但是這個語句不應該是一個宣告名稱的語句。下面的程式碼是OK的:
if (monday) print "Ugh, already?";
But this is not:
但是下面的程式碼不行:
if (monday) var beverage = "espresso";
We could allow the latter, but it’s confusing. What is the scope of that
beveragevariable? Does it persist after theifstatement? If so, what is its value on days other than Monday? Does the variable exist at all on those days?
我們也可以允許後者,但是會令人困惑。 beverage變數的作用域是什麼?if語句結束之後它是否還繼續存在?如果存在的話,在其它條件下它的值是什麼?這個變數是否在其它情形下也一直存在?
Code like this is weird, so C, Java, and friends all disallow it. It’s as if there are two levels of “precedence” for statements. Some places where a statement is allowed—like inside a block or at the top level—allow any kind of statement, including declarations. Others allow only the “higher” precedence statements that don’t declare names.
這樣的程式碼有點奇怪,所以C、Java及類似語言中都不允許這種寫法。語句就好像有兩個“優先順序”。有些允許語句的地方——比如在程式碼塊內或程式頂層5——可以允許任何型別的語句,包括變數宣告。而其他地方只允許那些不宣告名稱的、優先順序更高的語句。
To accommodate the distinction, we add another rule for kinds of statements that declare names.
為了適應這種區別,我們為宣告名稱的語句型別添加了另一條規則:
program → declaration* EOF ;
declaration → varDecl
| statement ;
statement → exprStmt
| printStmt ;
Declaration statements go under the new
declarationrule. Right now, it’s only variables, but later it will include functions and classes. Any place where a declaration is allowed also allows non-declaring statements, so thedeclarationrule falls through tostatement. Obviously, you can declare stuff at the top level of a script, soprogramroutes to the new rule.
宣告語句屬於新的 declaration規則。目前,這裡只有變數,但是後面還會包含函式和類。任何允許宣告的地方都允許一個非宣告式的語句,所以 declaration 規則會下降到statement。顯然,你可以在指令碼的頂層宣告一些內容,所以program規則需要路由到新規則。
The rule for declaring a variable looks like:
宣告一個變數的規則如下:
varDecl → "var" IDENTIFIER ( "=" expression )? ";" ;
Like most statements, it starts with a leading keyword. In this case,
var. Then an identifier token for the name of the variable being declared, followed by an optional initializer expression. Finally, we put a bow on it with the semicolon.
像大多數語句一樣,它以一個前置關鍵字開頭,這裡是var。然後是一個識別符號標記,作為宣告變數的名稱,後面是一個可選的初始化式表示式。最後,以一個分號作為結尾。
To access a variable, we define a new kind of primary expression.
為了訪問變數,我們還需要定義一個新型別的基本表示式:
primary → "true" | "false" | "nil"
| NUMBER | STRING
| "(" expression ")"
| IDENTIFIER ;
That
IDENTIFIERclause matches a single identifier token, which is understood to be the name of the variable being accessed.
IDENTIFIER 子語句會匹配單個識別符號標記,該標記會被理解為正在訪問的變數的名稱。
These new grammar rules get their corresponding syntax trees. Over in the AST generator, we add a new statement tree for a variable declaration.
這些新的語法規則需要其相應的語法樹。在AST生成器中,我們為變數宣告新增一個新的語句樹。
tool/GenerateAst.java,在 main()方法中新增一行,前一行需要加,:
"Expression : Expr expression",
"Print : Expr expression",
// 新增部分開始
"Var : Token name, Expr initializer"
// 新增部分結束
));
It stores the name token so we know what it’s declaring, along with the initializer expression. (If there isn’t an initializer, that field is
null.)
這裡儲存了名稱標記,以便我們知道該語句宣告瞭什麼,此外還有初始化表示式(如果沒有,欄位就是null)。
Then we add an expression node for accessing a variable.
然後我們新增一個表示式節點用於訪問變數。
tool/GenerateAst.java,在 main()方法中新增一行,前一行需要加,:
"Literal : Object value",
"Unary : Token operator, Expr right",
// 新增部分開始
"Variable : Token name"
// 新增部分結束
));
It’s simply a wrapper around the token for the variable name. That’s it. As always, don’t forget to run the AST generator script so that you get updated “Expr.java” and “Stmt.java” files.
這只是對變數名稱標記的簡單包裝,就是這樣。像往常一樣,別忘了執行AST生成器指令碼,這樣你就能得到更新的 "Expr.java "和 "Stmt.java "檔案。
8 . 2 . 2 Parsing variables
8.2.2 解析變數
Before we parse variable statements, we need to shift around some code to make room for the new
declarationrule in the grammar. The top level of a program is now a list of declarations, so the entrypoint method to the parser changes.
在解析變數語句之前,我們需要修改一些程式碼,為語法中的新規則declaration騰出一些空間。現在,程式的最頂層是宣告語句的列表,所以解析器方法的入口需要更改:
lox/Parser.java,在 parse()方法中替換1行:
List<Stmt> parse() {
List<Stmt> statements = new ArrayList<>();
while (!isAtEnd()) {
// 替換部分開始
statements.add(declaration());
// 替換部分結束
}
return statements;
}
That calls this new method:
這裡會呼叫下面的新方法:
lox/Parser.java,在 expression()方法後新增:
private Stmt declaration() {
try {
if (match(VAR)) return varDeclaration();
return statement();
} catch (ParseError error) {
synchronize();
return null;
}
}
Hey, do you remember way back in that earlier chapter when we put the infrastructure in place to do error recovery? We are finally ready to hook that up.
你還記得前面的章節中,我們建立了一個進行錯誤恢復的框架嗎?現在我們終於可以用起來了。
This
declaration()method is the method we call repeatedly when parsing a series of statements in a block or a script, so it’s the right place to synchronize when the parser goes into panic mode. The whole body of this method is wrapped in a try block to catch the exception thrown when the parser begins error recovery. This gets it back to trying to parse the beginning of the next statement or declaration.
當我們解析塊或指令碼中的 一系列語句時, declaration() 方法會被重複呼叫。因此當解析器進入恐慌模式時,它就是進行同步的正確位置。該方法的整個主體都封裝在一個try塊中,以捕獲解析器開始錯誤恢復時拋出的異常。這樣可以讓解析器跳轉到解析下一個語句或宣告的開頭。
The real parsing happens inside the try block. First, it looks to see if we’re at a variable declaration by looking for the leading
varkeyword. If not, it falls through to the existingstatement()method that parses
真正的解析工作發生在try塊中。首先,它透過查詢前面的var關鍵字判斷是否是變數宣告語句。如果不是的話,就會進入已有的statement()方法中,解析print和語句表示式。
Remember how
statement()tries to parse an expression statement if no other statement matches? Andexpression()reports a syntax error if it can’t parse an expression at the current token? That chain of calls ensures we report an error if a valid declaration or statement isn’t parsed.
還記得 statement() 會在沒有其它語句匹配時會嘗試解析一個表示式語句嗎?而expression()如果無法在當前語法標記處解析表示式,則會丟擲一個語法錯誤?這一系列呼叫鏈可以保證在解析無效的宣告或語句時會報告錯誤。
When the parser matches a
vartoken, it branches to:
當解析器匹配到一個var標記時,它會跳轉到:
lox/Parser.java,在 printStatement()方法後新增:
private Stmt varDeclaration() {
Token name = consume(IDENTIFIER, "Expect variable name.");
Expr initializer = null;
if (match(EQUAL)) {
initializer = expression();
}
consume(SEMICOLON, "Expect ';' after variable declaration.");
return new Stmt.Var(name, initializer);
}
As always, the recursive descent code follows the grammar rule. The parser has already matched the
vartoken, so next it requires and consumes an identifier token for the variable name.
與之前一樣,遞迴下降程式碼會遵循語法規則。解析器已經匹配了var標記,所以接下來要消費一個識別符號標記作為變數的名稱。
Then, if it sees an
=token, it knows there is an initializer expression and parses it. Otherwise, it leaves the initializernull. Finally, it consumes the required semicolon at the end of the statement. All this gets wrapped in a Stmt.Var syntax tree node and we’re groovy.
然後,如果找到=標記,解析器就知道後面有一個初始化表示式,並對其進行解析。否則,它會將初始器保持為null。最後,會消費語句末尾所需的分號。然後將所有這些都封裝到一個Stmt.Var語法樹節點中。
Parsing a variable expression is even easier. In
primary(), we look for an identifier token.
解析變量表達式甚至更簡單。在primary()中,我們需要查詢一個識別符號標記。
lox/Parser.java,在 primary()方法中新增:
return new Expr.Literal(previous().literal);
}
// 新增部分開始
if (match(IDENTIFIER)) {
return new Expr.Variable(previous());
}
// 新增部分結束
if (match(LEFT_PAREN)) {
That gives us a working front end for declaring and using variables. All that’s left is to feed it into the interpreter. Before we get to that, we need to talk about where variables live in memory.
這為我們提供了宣告和使用變數的可用前端,剩下的就是將其接入直譯器中。在此之前,我們需要討論變數在記憶體中的位置。
8 . 3 Environments
8.3 環境
The bindings that associate variables to values need to be stored somewhere. Ever since the Lisp folks invented parentheses, this data structure has been called an environment.
變數與值之間的繫結關係需要儲存在某個地方。自從Lisp發明圓括號以來,這種資料結構就被稱為環境。

You can think of it like a map where the keys are variable names and the values are the variable’s, uh, values. In fact, that’s how we’ll implement it in Java. We could stuff that map and the code to manage it right into Interpreter, but since it forms a nicely delineated concept, we’ll pull it out into its own class.
你可以把它想象成一個對映,其中鍵是變數名稱,值就是變數的值6。實際上,這也就是我們在Java中採用的實現方式。我們可以直接在直譯器中加入該對映及其管理程式碼,但是因為它形成了一個很好的概念,我們可以將其提取到單獨的類中。
Start a new file and add:
開啟新檔案,新增以下程式碼:
lox/Environment.java,建立新檔案
package com.craftinginterpreters.lox;
import java.util.HashMap;
import java.util.Map;
class Environment {
private final Map<String, Object> values = new HashMap<>();
}
There’s a Java Map in there to store the bindings. It uses bare strings for the keys, not tokens. A token represents a unit of code at a specific place in the source text, but when it comes to looking up variables, all identifier tokens with the same name should refer to the same variable (ignoring scope for now). Using the raw string ensures all of those tokens refer to the same map key.
其中使用一個Java Map來儲存繫結關係。這裡使用原生字串作為鍵,而不是使用標記。一個標記表示源文字中特定位置的一個程式碼單元,但是在查詢變數時,具有相同名稱的識別符號標記都應該指向相同的變數(暫時忽略作用域)。使用原生字串可以保證所有這些標記都會指向相同的對映鍵。
There are two operations we need to support. First, a variable definition binds a new name to a value.
我們需要支援兩個操作。首先,是變數定義操作,可以將一個新的名稱與一個值進行繫結。
lox/Environment.java,在 Environment類中新增:
void define(String name, Object value) {
values.put(name, value);
}
Not exactly brain surgery, but we have made one interesting semantic choice. When we add the key to the map, we don’t check to see if it’s already present. That means that this program works:
不算困難,但是我們這裡也做出了一個有趣的語義抉擇。當我們向對映中新增鍵時,沒有檢查該鍵是否已存在。這意味著下面的程式碼是有效的:
var a = "before";
print a; // "before".
var a = "after";
print a; // "after".
A variable statement doesn’t just define a new variable, it can also be used to redefine an existing variable. We could choose to make this an error instead. The user may not intend to redefine an existing variable. (If they did mean to, they probably would have used assignment, not
var.) Making redefinition an error would help them find that bug.
變數語句不僅可以定義一個新變數,也可以用於重新定義一個已有的變數。我們可以選擇將其作為一個錯誤來處理。使用者可能不打算重新定義已有的變數(如果他們想這樣做,可能會使用賦值,而不是var),將重定義作為錯誤可以幫助使用者發現這個問題。
However, doing so interacts poorly with the REPL. In the middle of a REPL session, it’s nice to not have to mentally track which variables you’ve already defined. We could allow redefinition in the REPL but not in scripts, but then users would have to learn two sets of rules, and code copied and pasted from one form to the other might not work.
然而,這樣做與REPL的互動很差。在與REPL的互動中,最好是讓使用者不必在腦子記錄已經定義了哪些變數。我們可以在REPL中允許重定義,在指令碼中不允許。但是這樣一來,使用者就不得不學習兩套規則,而且一種形式的程式碼複製貼上到另一種形式後可能無法執行7。
So, to keep the two modes consistent, we’ll allow it—at least for global variables. Once a variable exists, we need a way to look it up.
所以,為了保證兩種模式的統一,我們選擇允許重定義——至少對於全域性變數如此。一旦一個變數存在,我們就需要可以查詢該變數的方法。
lox/Environment.java,在 Environment類中新增:
class Environment {
private final Map<String, Object> values = new HashMap<>();
// 新增部分開始
Object get(Token name) {
if (values.containsKey(name.lexeme)) {
return values.get(name.lexeme);
}
throw new RuntimeError(name,
"Undefined variable '" + name.lexeme + "'.");
}
// 新增部分結束
void define(String name, Object value) {
This is a little more semantically interesting. If the variable is found, it simply returns the value bound to it. But what if it’s not? Again, we have a choice:
這在語義上更有趣一些。如果找到了這個變數,只需要返回與之繫結的值。但如果沒有找到呢?我們又需要做一個選擇:
-
Make it a syntax error.
丟擲語法錯誤
-
Make it a runtime error.
丟擲執行時錯誤
-
Allow it and return some default value like
nil.允許該操作並返回預設值(如
nil)
Lox is pretty lax, but the last option is a little too permissive to me. Making it a syntax error—a compile-time error—seems like a smart choice. Using an undefined variable is a bug, and the sooner you detect the mistake, the better.
Lox是很寬鬆的,但最後一個選項對我來說有點過於寬鬆了。把它作為語法錯誤(一個編譯時的錯誤)似乎是一個明智的選擇。使用未定義的變數確實是一個錯誤,使用者越早發現這個錯誤就越好。
The problem is that using a variable isn’t the same as referring to it. You can refer to a variable in a chunk of code without immediately evaluating it if that chunk of code is wrapped inside a function. If we make it a static error to mention a variable before it’s been declared, it becomes much harder to define recursive functions.
問題在於,使用一個變數並不等同於引用它。如果程式碼塊封裝在函式中,則可以在程式碼塊中引用變數,而不必立即對其求值。如果我們把引用未宣告的變數當作一個靜態錯誤,那麼定義遞迴函式就變得更加困難了。
We could accommodate single recursion—a function that calls itself—by declaring the function’s own name before we examine its body. But that doesn’t help with mutually recursive procedures that call each other. Consider:
透過在檢查函式體之前先宣告函式名稱,我們可以支援單一遞迴——呼叫自身的函式。但是,這無法處理互相呼叫的遞迴程式8。考慮以下程式碼:
fun isOdd(n) {
if (n == 0) return false;
return isEven(n - 1);
}
fun isEven(n) {
if (n == 0) return true;
return isOdd(n - 1);
}
The
isEven()function isn’t defined by the time we are looking at the body ofisOdd()where it’s called. If we swap the order of the two functions, thenisOdd()isn’t defined when we’re looking atisEven()’s body.
當我們檢視isOdd()方法時, isEven() 方法被呼叫的時候還沒有被宣告。如果我們交換著兩個函式的順序,那麼在檢視isEven()方法體時會發現isOdd()方法未被定義9。
Since making it a static error makes recursive declarations too difficult, we’ll defer the error to runtime. It’s OK to refer to a variable before it’s defined as long as you don’t evaluate the reference. That lets the program for even and odd numbers work, but you’d get a runtime error in:
因為將其當作靜態錯誤會使遞迴宣告過於困難,因此我們把這個錯誤推遲到執行時。在一個變數被定義之前引用它是可以的,只要你不對引用進行求值。這樣可以讓前面的奇偶數程式碼正常工作。但是執行以下程式碼時,你會得到一個執行時錯誤:
print a;
var a = "too late!";
As with type errors in the expression evaluation code, we report a runtime error by throwing an exception. The exception contains the variable’s token so we can tell the user where in their code they messed up.
與表示式計算程式碼中的型別錯誤一樣,我們透過丟擲一個異常來報告執行時錯誤。異常中包含變數的標記,以便我們告訴使用者程式碼的什麼位置出現了錯誤。
8 . 3 . 1 Interpreting global variables
8.3.1 解釋全域性變數
The Interpreter class gets an instance of the new Environment class.
Interpreter類會獲取Environment類的一個例項。
lox/Interpreter.java,在 Interpreter類中新增:
class Interpreter implements Expr.Visitor<Object>,
Stmt.Visitor<Void> {
// 新增部分開始
private Environment environment = new Environment();
// 新增部分結束
void interpret(List<Stmt> statements) {
We store it as a field directly in Interpreter so that the variables stay in memory as long as the interpreter is still running.
我們直接將它作為一個欄位儲存在直譯器中,這樣,只要直譯器仍在執行,變數就會留在記憶體中。
We have two new syntax trees, so that’s two new visit methods. The first is for declaration statements.
我們有兩個新的語法樹,所以這就是兩個新的訪問方法。第一個是關於宣告語句的。
lox/Interpreter.java,在 visitPrintStmt()方法後新增:
@Override
public Void visitVarStmt(Stmt.Var stmt) {
Object value = null;
if (stmt.initializer != null) {
value = evaluate(stmt.initializer);
}
environment.define(stmt.name.lexeme, value);
return null;
}
If the variable has an initializer, we evaluate it. If not, we have another choice to make. We could have made this a syntax error in the parser by requiring an initializer. Most languages don’t, though, so it feels a little harsh to do so in Lox.
如果該變數有初始化式,我們就對其求值。如果沒有,我們就需要做一個選擇。我們可以透過在解析器中要求初始化式令其成為一個語法錯誤。但是,大多數語言都不會這麼做,所以在Lox中這樣做感覺有點苛刻。
We could make it a runtime error. We’d let you define an uninitialized variable, but if you accessed it before assigning to it, a runtime error would occur. It’s not a bad idea, but most dynamically typed languages don’t do that. Instead, we’ll keep it simple and say that Lox sets a variable to
nilif it isn’t explicitly initialized.
我們可以使其成為執行時錯誤。我們允許您定義一個未初始化的變數,但如果您在對其賦值之前訪問它,就會發生執行時錯誤。這不是一個壞主意,但是大多數動態型別的語言都不會這樣做。相反,我們使用最簡單的方式。或者說,如果變數沒有被顯式初始化,Lox會將變數設定為nil。
var a;
print a; // "nil".
Thus, if there isn’t an initializer, we set the value to
null, which is the Java representation of Lox’snilvalue. Then we tell the environment to bind the variable to that value.
因此,如果沒有初始化式,我們將值設為null,這也是Lox中的nil值的Java表示形式。然後,我們告訴環境上下文將變數與該值進行繫結。
Next, we evaluate a variable expression.
接下來,我們要對變量表達式求值。
lox/Interpreter.java,在 visitUnaryExpr()方法後新增:
@Override
public Object visitVariableExpr(Expr.Variable expr) {
return environment.get(expr.name);
}
This simply forwards to the environment which does the heavy lifting to make sure the variable is defined. With that, we’ve got rudimentary variables working. Try this out:
這裡只是簡單地將操作轉發到環境上下文中,環境做了一些繁重的工作保證變數已被定義。這樣,我們就可以支援基本的變數操作了。嘗試以下程式碼:
var a = 1;
var b = 2;
print a + b;
We can’t reuse code yet, but we can start to build up programs that reuse data.
我們還不能複用程式碼,但是我們可以構建能夠複用資料的程式。
8 . 4 Assignment
8.4 賦值
It’s possible to create a language that has variables but does not let you reassign—or mutate—them. Haskell is one example. SML supports only mutable references and arrays—variables cannot be reassigned. Rust steers you away from mutation by requiring a
mutmodifier to enable assignment.
你可以建立一種語言,其中有變數,但是不支援對該變數重新賦值(或更改)。Haskell就是一個例子。SML只支援可變引用和陣列——變數不能被重新賦值。Rust則透過要求mut識別符號開啟賦值,從而引導使用者遠離可更改變數。
Mutating a variable is a side effect and, as the name suggests, some language folks think side effects are dirty or inelegant. Code should be pure math that produces values—crystalline, unchanging ones—like an act of divine creation. Not some grubby automaton that beats blobs of data into shape, one imperative grunt at a time.
更改變數是一種副作用,顧名思義,一些語言專家認為副作用是骯髒或不優雅的。程式碼應該是純粹的數學,它會產生值——純淨的、不變的值——就像上帝造物一樣。而不是一些骯髒的自動機器,將資料塊轉換成各種形式,一次執行一條命令。
Lox is not so austere. Lox is an imperative language, and mutation comes with the territory. Adding support for assignment doesn’t require much work. Global variables already support redefinition, so most of the machinery is there now. Mainly, we’re missing an explicit assignment notation.
Lox沒有這麼嚴苛。Lox是一個命令式語言,可變性是與生俱來的,新增對賦值操作的支援並不需要太多工作。全域性變數已經支援了重定義,所以該機制的大部分功能已經存在。主要的是,我們缺少顯式的賦值符號。
8 . 4 . 1 Assignment syntax
8.4.1 賦值語法
That little
=syntax is more complex than it might seem. Like most C-derived languages, assignment is an expression and not a statement. As in C, it is the lowest precedence expression form. That means the rule slots betweenexpressionandequality(the next lowest precedence expression).
這個小小的=語法比看起來要更復雜。像大多數C派生語言一樣,賦值是一個表示式,而不是一個語句。和C語言中一樣,它是優先順序最低的表示式形式。這意味著該規則在語法中處於 expression 和equality(下一個優先順序的表示式)之間。
expression → assignment ;
assignment → IDENTIFIER "=" assignment
| equality ;
This says an
assignmentis either an identifier followed by an=and an expression for the value, or anequality(and thus any other) expression. Later,assignmentwill get more complex when we add property setters on objects, like:
這就是說,一個assignment(賦值式)要麼是一個識別符號,後跟一個=和一個對應值的表示式;要麼是一個等式(也就是任何其它)表示式。稍後,當我們在物件中新增屬性設定式時,賦值將會變得更加複雜,比如:
instance.field = "value";
The easy part is adding the new syntax tree node.
最簡單的部分就是新增新的語法樹節點。
tool/GenerateAst.java,在 main()方法中新增:
defineAst(outputDir, "Expr", Arrays.asList(
// 新增部分開始
"Assign : Token name, Expr value",
// 新增部分結束
"Binary : Expr left, Token operator, Expr right",
It has a token for the variable being assigned to, and an expression for the new value. After you run the AstGenerator to get the new Expr.Assign class, swap out the body of the parser’s existing
expression()method to match the updated rule.
其中包含被賦值變數的標記,一個計算新值的表示式。執行AstGenerator得到新的Expr.Assign類之後,替換掉解析器中現有的expression()方法的方法體,以匹配最新的規則。
lox/Parser.java,在 expression()方法中替換一行:
private Expr expression() {
// 替換部分開始
return assignment();
// 替換部分結束
}
Here is where it gets tricky. A single token lookahead recursive descent parser can’t see far enough to tell that it’s parsing an assignment until after it has gone through the left-hand side and stumbled onto the
=. You might wonder why it even needs to. After all, we don’t know we’re parsing a+expression until after we’ve finished parsing the left operand.
這裡開始變得棘手。單個標記前瞻遞迴下降解析器直到解析完左側標記並且遇到=標記之後,才能判斷出來正在解析的是賦值語句。你可能會想,為什麼需要這樣做?畢竟,我們也是完成左運算元的解析之後才知道正在解析的是+表示式。
The difference is that the left-hand side of an assignment isn’t an expression that evaluates to a value. It’s a sort of pseudo-expression that evaluates to a “thing” you can assign to. Consider:
區別在於,賦值表示式的左側不是可以求值的表示式,而是一種偽表示式,計算出的是一個你可以賦值的“東西”。考慮以下程式碼:
var a = "before";
a = "value";
On the second line, we don’t evaluate
a(which would return the string “before”). We figure out what variablearefers to so we know where to store the right-hand side expression’s value. The classic terms for these two constructs are l-value and r-value. All of the expressions that we’ve seen so far that produce values are r-values. An l-value “evaluates” to a storage location that you can assign into.
在第二行中,我們不會對a進行求值(如果求值會返回“before”)。我們要弄清楚a指向的是什麼變數,這樣我們就知道該在哪裡儲存右側表示式的值。這兩個概念的經典術語是左值和右值。到目前為止,我們看到的所有產生值的表示式都是右值。左值"計算"會得到一個儲存位置,你可以向其賦值。
We want the syntax tree to reflect that an l-value isn’t evaluated like a normal expression. That’s why the Expr.Assign node has a Token for the left-hand side, not an Expr. The problem is that the parser doesn’t know it’s parsing an l-value until it hits the
=. In a complex l-value, that may occur many tokens later.
我們希望語法樹能夠反映出左值不會像常規表示式那樣計算。這也是為什麼Expr.Assign節點的左側是一個Token,而不是Expr。問題在於,解析器直到遇到=才知道正在解析一個左值。在一個複雜的左值中,可能在出現很多標記之後才能識別到。
makeList().head.next = node;
We have only a single token of lookahead, so what do we do? We use a little trick, and it looks like this:
我們只會前瞻一個標記,那我們該怎麼辦呢?我們使用一個小技巧,看起來像下面這樣10:
lox/Parser.java,在 expressionStatement()方法後新增:
private Expr assignment() {
Expr expr = equality();
if (match(EQUAL)) {
Token equals = previous();
Expr value = assignment();
if (expr instanceof Expr.Variable) {
Token name = ((Expr.Variable)expr).name;
return new Expr.Assign(name, value);
}
error(equals, "Invalid assignment target.");
}
return expr;
}
Most of the code for parsing an assignment expression looks similar to that of the other binary operators like
+. We parse the left-hand side, which can be any expression of higher precedence. If we find an=, we parse the right-hand side and then wrap it all up in an assignment expression tree node.
解析賦值表示式的大部分程式碼看起來與解析其它二元運算子(如+)的程式碼類似。我們解析左邊的內容,它可以是任何優先順序更高的表示式。如果我們發現一個=,就解析右側內容,並把它們封裝到一個複雜表示式樹節點中。
One slight difference from binary operators is that we don’t loop to build up a sequence of the same operator. Since assignment is right-associative, we instead recursively call
assignment()to parse the right-hand side.
與二元運算子的一個細微差別在於,我們不會迴圈構建相同運算子的序列。因為賦值操作是右關聯的,所以我們遞迴呼叫 assignment()來解析右側的值。
The trick is that right before we create the assignment expression node, we look at the left-hand side expression and figure out what kind of assignment target it is. We convert the r-value expression node into an l-value representation.
訣竅在於,在建立賦值表示式節點之前,我們先檢視左邊的表示式,弄清楚它是什麼型別的賦值目標。然後我們將右值表示式節點轉換為左值的表示形式。
This conversion works because it turns out that every valid assignment target happens to also be valid syntax as a normal expression. Consider a complex field assignment like:
這種轉換是有效的,因為事實證明,每個有效的賦值目標正好也是符合普通表示式的有效語法11。考慮一個複雜的屬性賦值操作,如下:
newPoint(x + 2, 0).y = 3;
The left-hand side of that assignment could also work as a valid expression.
該賦值表示式的左側也是一個有效的表示式。
newPoint(x + 2, 0).y;
The first example sets the field, the second gets it.
第一個例子設定該欄位,第二個例子獲取該欄位。
This means we can parse the left-hand side as if it were an expression and then after the fact produce a syntax tree that turns it into an assignment target. If the left-hand side expression isn’t a valid assignment target, we fail with a syntax error. That ensures we report an error on code like this:
這意味著,我們可以像解析表示式一樣解析左側內容,然後生成一個語法樹,將其轉換為賦值目標。如果左邊的表示式不是一個有效的賦值目標,就會出現一個語法錯誤12。這樣可以確保在遇到類似下面的程式碼時會報告錯誤:
a + b = c;
Right now, the only valid target is a simple variable expression, but we’ll add fields later. The end result of this trick is an assignment expression tree node that knows what it is assigning to and has an expression subtree for the value being assigned. All with only a single token of lookahead and no backtracking.
現在,唯一有效的賦值目標就是一個簡單的變量表達式,但是我們後面會新增屬性欄位。這個技巧的最終結果是一個賦值表示式樹節點,該節點知道要向什麼賦值,並且有一個表示式子樹用於計算要使用的值。所有這些都只用了一個前瞻標記,並且沒有回溯。
8 . 4 . 2 Assignment semantics
We have a new syntax tree node, so our interpreter gets a new visit method.
我們有了一個新的語法樹節點,所以我們的直譯器也需要一個新的訪問方法。
lox/Interpreter.java,在 visitVarStmt()方法後新增:
@Override
public Object visitAssignExpr(Expr.Assign expr) {
Object value = evaluate(expr.value);
environment.assign(expr.name, value);
return value;
}
For obvious reasons, it’s similar to variable declaration. It evaluates the right-hand side to get the value, then stores it in the named variable. Instead of using
define()on Environment, it calls this new method:
很明顯,這與變數宣告很類似。首先,對右側表示式運算以獲取值,然後將其儲存到命名變數中。這裡不使用Environment中的 define(),而是呼叫下面的新方法:
lox/Environment.java,在 get()方法後新增:
void assign(Token name, Object value) {
if (values.containsKey(name.lexeme)) {
values.put(name.lexeme, value);
return;
}
throw new RuntimeError(name,
"Undefined variable '" + name.lexeme + "'.");
}
The key difference between assignment and definition is that assignment is not allowed to create a new variable. In terms of our implementation, that means it’s a runtime error if the key doesn’t already exist in the environment’s variable map.
賦值與定義的主要區別在於,賦值操作不允許建立新變數。就我們的實現而言,這意味著如果環境的變數對映中不存在變數的鍵,那就是一個執行時錯誤13。
The last thing the
visit()method does is return the assigned value. That’s because assignment is an expression that can be nested inside other expressions, like so:
visit()方法做的最後一件事就是返回要賦給變數的值。這是因為賦值是一個表示式,可以巢狀在其他表示式裡面,就像這樣:
var a = 1;
print a = 2; // "2".
Our interpreter can now create, read, and modify variables. It’s about as sophisticated as early BASICs. Global variables are simple, but writing a large program when any two chunks of code can accidentally step on each other’s state is no fun. We want local variables, which means it’s time for scope.
我們的直譯器現在可以建立、讀取和修改變數。這和早期的BASICs一樣複雜。全域性變數很簡單,但是在編寫一個大型程式時,任何兩塊程式碼都可能不小心修改對方的狀態,這就不好玩了。我們需要區域性變數,這意味著是時候討論作用域了。
8 . 5 Scope
8.5 作用域
A scope defines a region where a name maps to a certain entity. Multiple scopes enable the same name to refer to different things in different contexts. In my house, “Bob” usually refers to me. But maybe in your town you know a different Bob. Same name, but different dudes based on where you say it.
作用域定義了名稱對映到特定實體的一個區域。多個作用域允許同一個名稱在不同的上下文中指向不同的內容。在我家,“Bob”通常指的是我自己,但是在你的身邊,你可能認識另外一個Bob。同一個名字,基於你的所知所見指向了不同的人。
Lexical scope (or the less commonly heard static scope) is a specific style of scoping where the text of the program itself shows where a scope begins and ends. In Lox, as in most modern languages, variables are lexically scoped. When you see an expression that uses some variable, you can figure out which variable declaration it refers to just by statically reading the code.
詞法作用域(或者比較少見的靜態作用域)是一種特殊的作用域定義方式,程式本身的文字顯示了作用域的開始和結束位置14。Lox,和大多數現代語言一樣,變數在詞法作用域內有效。當你看到使用了某些變數的表示式時,你透過靜態地閱讀程式碼就可以確定其指向的變數宣告。
For example:
舉例來說:
{
var a = "first";
print a; // "first".
}
{
var a = "second";
print a; // "second".
}
Here, we have two blocks with a variable
adeclared in each of them. You and I can tell just from looking at the code that the use ofain the firsta, and the second one refers to the second.
這裡,我們在兩個塊中都定義了一個變數a。我們可以從程式碼中看出,在第一個print語句中使用的a指的是第一個a,第二個語句指向的是第二個變數。

This is in contrast to dynamic scope where you don’t know what a name refers to until you execute the code. Lox doesn’t have dynamically scoped variables, but methods and fields on objects are dynamically scoped.
這與動態作用域形成了對比,在動態作用域中,直到執行程式碼時才知道名稱指向的是什麼。Lox沒有動態作用域變數,但是物件上的方法和欄位是動態作用域的。
class Saxophone {
play() {
print "Careless Whisper";
}
}
class GolfClub {
play() {
print "Fore!";
}
}
fun playIt(thing) {
thing.play();
}
When playIt() calls thing.play(), we don’t know if we’re about to hear “Careless Whisper” or “Fore!” It depends on whether you pass a Saxophone or a GolfClub to the function, and we don’t know that until runtime.
當playIt()呼叫thing.play()時,我們不知道我們將要聽到的是 "Careless Whisper "還是 "Fore!" 。這取決於你向函式傳遞的是Saxophone還是GolfClub,而我們在執行時才知道這一點。
Scope and environments are close cousins. The former is the theoretical concept, and the latter is the machinery that implements it. As our interpreter works its way through code, syntax tree nodes that affect scope will change the environment. In a C-ish syntax like Lox’s, scope is controlled by curly-braced blocks. (That’s why we call it block scope.)
作用域和環境是近親,前者是理論概念,而後者是實現它的機制。當我們的直譯器處理程式碼時,影響作用域的語法樹節點會改變環境上下文。在像Lox這樣的類C語言語法中,作用域是由花括號的塊控制的。(這就是為什麼我們稱它為塊範圍)。
{
var a = "in block";
}
print a; // Error! No more "a".
The beginning of a block introduces a new local scope, and that scope ends when execution passes the closing
}. Any variables declared inside the block disappear.
塊的開始引入了一個新的區域性作用域,當執行透過結束的}時,這個作用域就結束了。塊內宣告的任何變數都會消失。
8 . 5 . 1 Nesting and shadowing
8.5.1 巢狀和遮蔽
A first cut at implementing block scope might work like this:
實現塊作用域的第一步可能是這樣的:
-
As we visit each statement inside the block, keep track of any variables declared.
當訪問塊內的每個語句時,跟蹤所有宣告的變數。
-
After the last statement is executed, tell the environment to delete all of those variables.
執行完最後一條語句後,告訴環境將這些變數全部刪除。
That would work for the previous example. But remember, one motivation for local scope is encapsulation—a block of code in one corner of the program shouldn’t interfere with some other block. Check this out:
這對前面的例子是可行的。但是請記住,區域性作用域的一個目的是封裝——程式中一個塊內的程式碼,不應該幹擾其他程式碼塊。看看下面的例子:
// How loud?
var volume = 11;
// Silence.
volume = 0;
// Calculate size of 3x4x5 cuboid.
{
var volume = 3 * 4 * 5;
print volume;
}
Look at the block where we calculate the volume of the cuboid using a local declaration of
volume. After the block exits, the interpreter will delete the globalvolumevariable. That ain’t right. When we exit the block, we should remove any variables declared inside the block, but if there is a variable with the same name declared outside of the block, that’s a different variable. It shouldn’t get touched.
請看這個程式碼塊,在這裡我們宣告瞭一個區域性變數volume來計算長方體的體積。該程式碼塊退出後,直譯器將刪除全域性volume變數。這是不對的。當我們退出程式碼塊時,我們應該刪除在塊內宣告的所有變數,但是如果在程式碼塊外宣告瞭相同名稱的變數,那就是一個不同的變數。它不應該被刪除。
When a local variable has the same name as a variable in an enclosing scope, it shadows the outer one. Code inside the block can’t see it any more—it is hidden in the “shadow” cast by the inner one—but it’s still there.
當區域性變數與外圍作用域中的變數具有相同的名稱時,內部變數會遮蔽外部變數。程式碼塊內部不能再看到外部變數——它被遮蔽在內部變數的陰影中——但它仍然是存在的。
When we enter a new block scope, we need to preserve variables defined in outer scopes so they are still around when we exit the inner block. We do that by defining a fresh environment for each block containing only the variables defined in that scope. When we exit the block, we discard its environment and restore the previous one.
當進入一個新的塊作用域時,我們需要保留在外部作用域中定義的變數,這樣當我們退出內部程式碼塊時這些外部變數仍然存在。為此,我們為每個程式碼塊定義一個新的環境,該環境只包含該作用域中定義的變數。當我們退出程式碼塊時,我們將丟棄其環境並恢復前一個環境。
We also need to handle enclosing variables that are not shadowed.
我們還需要處理沒有被遮蔽的外圍變數。
var global = "outside";
{
var local = "inside";
print global + local;
}
Here,
globallives in the outer global environment andlocalis defined inside the block’s environment. In that
這段程式碼中,global在外部全域性環境中,local則在塊環境中定義。在執行print`語句時,這兩個變數都在作用域內。為了找到它們,直譯器不僅要搜尋當前最內層的環境,還必須搜尋所有外圍的環境。
We implement this by chaining the environments together. Each environment has a reference to the environment of the immediately enclosing scope. When we look up a variable, we walk that chain from innermost out until we find the variable. Starting at the inner scope is how we make local variables shadow outer ones.
我們透過將環境連結在一起來實現這一點。每個環境都有一個對直接外圍作用域的環境的引用。當我們查詢一個變數時,我們從最內層開始遍歷環境鏈直到找到該變數。從內部作用域開始,就是我們使區域性變數遮蔽外部變數的方式。

Before we add block syntax to the grammar, we’ll beef up our Environment class with support for this nesting. First, we give each environment a reference to its enclosing one.
在我們新增塊語法之前,我們要強化Environment類對這種巢狀的支援。首先,我們在每個環境中新增一個對其外圍環境的引用。
lox/Environment.java,在 Environment類中新增:
class Environment {
// 新增部分開始
final Environment enclosing;
// 新增部分結束
private final Map<String, Object> values = new HashMap<>();
This field needs to be initialized, so we add a couple of constructors.
這個欄位需要初始化,所以我們新增兩個建構函式。
lox/Environment.java,在 Environment類中新增:
Environment() {
enclosing = null;
}
Environment(Environment enclosing) {
this.enclosing = enclosing;
}
The no-argument constructor is for the global scope’s environment, which ends the chain. The other constructor creates a new local scope nested inside the given outer one.
無參建構函式用於全域性作用域環境,它是環境鏈的結束點。另一個建構函式用來建立一個巢狀在給定外部作用域內的新的區域性作用域。
We don’t have to touch the
define()method—a new variable is always declared in the current innermost scope. But variable lookup and assignment work with existing variables and they need to walk the chain to find them. First, lookup:
我們不必修改define()方法——因為新變數總是在當前最內層的作用域中宣告。但是變數的查詢和賦值是結合已有的變數一起處理的,需要遍歷環境鏈以找到它們。首先是查詢操作:
lox/Environment.java,在 get()方法中新增:
return values.get(name.lexeme);
}
// 新增部分開始
if (enclosing != null) return enclosing.get(name);
// 新增部分結束
throw new RuntimeError(name,
"Undefined variable '" + name.lexeme + "'.");
If the variable isn’t found in this environment, we simply try the enclosing one. That in turn does the same thing recursively, so this will ultimately walk the entire chain. If we reach an environment with no enclosing one and still don’t find the variable, then we give up and report an error as before.
如果當前環境中沒有找到變數,就在外圍環境中嘗試。然後遞迴地重複該操作,最終會遍歷完整個鏈路。如果我們到達了一個沒有外圍環境的環境,並且仍然沒有找到這個變數,那我們就放棄,並且像之前一樣報告一個錯誤。
Assignment works the same way.
賦值也是如此。
lox/Environment.java,在 assign()方法中新增:
values.put(name.lexeme, value);
return;
}
// 新增部分開始
if (enclosing != null) {
enclosing.assign(name, value);
return;
}
// 新增部分結束
throw new RuntimeError(name,
Again, if the variable isn’t in this environment, it checks the outer one, recursively.
同樣,如果變數不在此環境中,它會遞迴地檢查外圍環境。
8 . 5 . 2 Block syntax and semantics
8.5.2 塊語法和語義
Now that Environments nest, we’re ready to add blocks to the language. Behold the grammar:
現在環境已經嵌套了,我們就準備向語言中新增塊了。請看以下語法:
statement → exprStmt
| printStmt
| block ;
block → "{" declaration* "}" ;
A block is a (possibly empty) series of statements or declarations surrounded by curly braces. A block is itself a statement and can appear anywhere a statement is allowed. The syntax tree node looks like this:
塊是由花括號包圍的一系列語句或宣告(可能是空的)。塊本身就是一條語句,可以出現在任何允許語句的地方。語法樹節點如下所示。
tool/GenerateAst.java,在 main()方法中新增:
defineAst(outputDir, "Stmt", Arrays.asList(
// 新增部分開始
"Block : List<Stmt> statements",
// 新增部分結束
"Expression : Expr expression",
It contains the list of statements that are inside the block. Parsing is straightforward. Like other statements, we detect the beginning of a block by its leading token—in this case the
{. In thestatement()method, we add:
它包含塊中語句的列表。解析很簡單。與其他語句一樣,我們透過塊的字首標記(在本例中是{)來檢測塊的開始。在statement()方法中,我們新增程式碼:
lox/Parser.java,在 statement()方法中新增:
if (match(PRINT)) return printStatement();
// 新增部分開始
if (match(LEFT_BRACE)) return new Stmt.Block(block());
// 新增部分結束
return expressionStatement();
All the real work happens here:
真正的工作都在這裡進行:
lox/Parser.java,在 expressionStatement()方法後新增:
private List<Stmt> block() {
List<Stmt> statements = new ArrayList<>();
while (!check(RIGHT_BRACE) && !isAtEnd()) {
statements.add(declaration());
}
consume(RIGHT_BRACE, "Expect '}' after block.");
return statements;
}
We create an empty list and then parse statements and add them to the list until we reach the end of the block, marked by the closing
}. Note that the loop also has an explicit check forisAtEnd(). We have to be careful to avoid infinite loops, even when parsing invalid code. If the user forgets a closing}, the parser needs to not get stuck.
我們先建立一個空列表,然後解析語句並將其放入列表中,直至遇到塊的結尾(由}符號標識)15。注意,該迴圈還有一個明確的isAtEnd()檢查。我們必須小心避免無限迴圈,即使在解析無效程式碼時也是如此。如果使用者忘記了結尾的},解析器需要保證不能被阻塞。
That’s it for syntax. For semantics, we add another visit method to Interpreter.
語法到此為止。對於語義,我們要在Interpreter中新增另一個訪問方法。
lox/Interpreter.java,在 execute()方法後新增:
@Override
public Void visitBlockStmt(Stmt.Block stmt) {
executeBlock(stmt.statements, new Environment(environment));
return null;
}
To execute a block, we create a new environment for the block’s scope and pass it off to this other method:
要執行一個塊,我們先為該塊作用域建立一個新的環境,然後將其傳入下面這個方法:
lox/Interpreter.java,在execute()方法後新增:
void executeBlock(List<Stmt> statements,
Environment environment) {
Environment previous = this.environment;
try {
this.environment = environment;
for (Stmt statement : statements) {
execute(statement);
}
} finally {
this.environment = previous;
}
}
This new method executes a list of statements in the context of a given environment. Up until now, the
environmentfield in Interpreter always pointed to the same environment—the global one. Now, that field represents the current environment. That’s the environment that corresponds to the innermost scope containing the code to be executed.
這個新方法會在給定的環境上下文中執行一系列語句。在此之前,直譯器中的 environment 欄位總是指向相同的環境——全域性環境。現在,這個欄位會指向當前環境,也就是與要執行的程式碼的最內層作用域相對應的環境16。
To execute code within a given scope, this method updates the interpreter’s
environmentfield, visits all of the statements, and then restores the previous value. As is always good practice in Java, it restores the previous environment using a finally clause. That way it gets restored even if an exception is thrown.
為了在給定作用域內執行程式碼,該方法會先更新直譯器的 environment 欄位,執行所有的語句,然後恢復之前的環境。基於Java中一貫的優良傳統,它使用finally子句來恢復先前的環境。這樣一來,即使拋出了異常,環境也會被恢復。
Surprisingly, that’s all we need to do in order to fully support local variables, nesting, and shadowing. Go ahead and try this out:
出乎意料的是,這就是我們為了完全支援區域性變數、巢狀和遮蔽所需要做的全部事情。試執行下面的程式碼:
var a = "global a";
var b = "global b";
var c = "global c";
{
var a = "outer a";
var b = "outer b";
{
var a = "inner a";
print a;
print b;
print c;
}
print a;
print b;
print c;
}
print a;
print b;
print c;
Our little interpreter can remember things now. We are inching closer to something resembling a full-featured programming language.
我們的小直譯器現在可以記住東西了,我們距離全功能程式語言又近了一步。
a = 3; // OK.
(a) = 3; // Error.
CHALLENGES
習題
1、The REPL no longer supports entering a single expression and automatically printing its result value. That’s a drag. Add support to the REPL to let users type in both statements and expressions. If they enter a statement, execute it. If they enter an expression, evaluate it and display the result value.
1、REPL不再支援輸入一個表示式並自動列印其結果值。這是個累贅。在 REPL 中增加支援,讓使用者既可以輸入語句又可以輸入表示式。如果他們輸入一個語句,就執行它。如果他們輸入一個表示式,則對錶達式求值並顯示結果值。
2、Maybe you want Lox to be a little more explicit about variable initialization. Instead of implicitly initializing variables to
nil, make it a runtime error to access a variable that has not been initialized or assigned to, as in:
2、也許你希望Lox對變數的初始化更明確一些。與其隱式地將變數初始化為nil,不如將訪問一個未被初始化或賦值的變數作為一個執行時錯誤,如:
// No initializers.
var a;
var b;
a = "assigned";
print a; // OK, was assigned first.
print b; // Error!
3、What does the following program do?
3、下面的程式碼會怎麼執行?
var a = 1;
{
var a = a + 2;
print a;
}
What did you expect it to do? Is it what you think it should do? What does analogous code in other languages you are familiar with do? What do you think users will expect this to do?
你期望它怎麼執行?它是按照你的想法執行的嗎?你所熟悉的其他語言中的類似程式碼怎麼執行?你認為使用者會期望它怎麼執行?
DESIGN NOTE: IMPLICIT VARIABLE DECLARATION
設計筆記:隱式變數宣告
Lox has distinct syntax for declaring a new variable and assigning to an existing one. Some languages collapse those to only assignment syntax. Assigning to a non-existent variable automatically brings it into being. This is called implicit variable declaration and exists in Python, Ruby, and CoffeeScript, among others. JavaScript has an explicit syntax to declare variables, but can also create new variables on assignment. Visual Basic has an option to enable or disable implicit variables.
When the same syntax can assign or create a variable, each language must decide what happens when it isn’t clear about which behavior the user intends. In particular, each language must choose how implicit declaration interacts with shadowing, and which scope an implicitly declared variable goes into.
- In Python, assignment always creates a variable in the current function’s scope, even if there is a variable with the same name declared outside of the function.
- Ruby avoids some ambiguity by having different naming rules for local and global variables. However, blocks in Ruby (which are more like closures than like “blocks” in C) have their own scope, so it still has the problem. Assignment in Ruby assigns to an existing variable outside of the current block if there is one with the same name. Otherwise, it creates a new variable in the current block’s scope.
- CoffeeScript, which takes after Ruby in many ways, is similar. It explicitly disallows shadowing by saying that assignment always assigns to a variable in an outer scope if there is one, all the way up to the outermost global scope. Otherwise, it creates the variable in the current function scope.
- In JavaScript, assignment modifies an existing variable in any enclosing scope, if found. If not, it implicitly creates a new variable in the global scope.
The main advantage to implicit declaration is simplicity. There’s less syntax and no “declaration” concept to learn. Users can just start assigning stuff and the language figures it out.
Older, statically typed languages like C benefit from explicit declaration because they give the user a place to tell the compiler what type each variable has and how much storage to allocate for it. In a dynamically typed, garbage-collected language, that isn’t really necessary, so you can get away with making declarations implicit. It feels a little more “scripty”, more “you know what I mean”.
But is that a good idea? Implicit declaration has some problems.
- A user may intend to assign to an existing variable, but may have misspelled it. The interpreter doesn’t know that, so it goes ahead and silently creates some new variable and the variable the user wanted to assign to still has its old value. This is particularly heinous in JavaScript where a typo will create a global variable, which may in turn interfere with other code.
- JS, Ruby, and CoffeeScript use the presence of an existing variable with the same name—even in an outer scope—to determine whether or not an assignment creates a new variable or assigns to an existing one. That means adding a new variable in a surrounding scope can change the meaning of existing code. What was once a local variable may silently turn into an assignment to that new outer variable.
- In Python, you may want to assign to some variable outside of the current function instead of creating a new variable in the current one, but you can’t.
Over time, the languages I know with implicit variable declaration ended up adding more features and complexity to deal with these problems.
- Implicit declaration of global variables in JavaScript is universally considered a mistake today. “Strict mode” disables it and makes it a compile error.
- Python added a
globalstatement to let you explicitly assign to a global variable from within a function. Later, as functional programming and nested functions became more popular, they added a similarnonlocalstatement to assign to variables in enclosing functions.- Ruby extended its block syntax to allow declaring certain variables to be explicitly local to the block even if the same name exists in an outer scope.
Given those, I think the simplicity argument is mostly lost. There is an argument that implicit declaration is the right default but I personally find that less compelling.
My opinion is that implicit declaration made sense in years past when most scripting languages were heavily imperative and code was pretty flat. As programmers have gotten more comfortable with deep nesting, functional programming, and closures, it’s become much more common to want access to variables in outer scopes. That makes it more likely that users will run into the tricky cases where it’s not clear whether they intend their assignment to create a new variable or reuse a surrounding one.
So I prefer explicitly declaring variables, which is why Lox requires it.
Lox使用不同的語法來宣告新變數和為已有變數賦值。有些語言將其簡化為只有賦值語法。對一個不存在的變數進行賦值時會自動生成該變數。這被稱為隱式變數宣告,存在於Python、Ruby和CoffeeScript以及其他語言中。JavaScript有一個顯式的語法來宣告變數,但是也可以在賦值時建立新變數。Visual Basic有一個選項可以啟用或停用隱式變數。
當同樣的語法既可以對變數賦值,也可以建立變數時,語言實現就必須決定在不清楚使用者的預期行為時該怎麼辦。特別是,每種語言必須選擇隱式變數宣告與變數遮蔽的互動方式,以及隱式變數應該屬於哪個作用域。
- 在Python中,賦值總是會在當前函式的作用域內建立一個變數,即使在函式外部宣告瞭同名變數。
- Ruby透過對區域性變數和全域性變數使用不同的命名規則,避免了一些歧義。 但是,Ruby中的塊(更像閉包,而不是C中的“塊”)具有自己的作用域,因此仍然存在問題。在Ruby中,如果已經存在一個同名的變數,則賦值會賦給當前塊之外的現有變數。否則,就會在當前塊的作用域中建立一個新變數。
- CoffeeScript在許多方面都效仿Ruby,這一點也類似。它明確禁止變數遮蔽,要求賦值時總是優先賦給外部作用域中現有的變數(一直到最外層的全域性作用域)。如果變數不存在的話,它會在當前函式作用域中建立新變數。
- 在JavaScript中,賦值會修改任意外部作用域中的一個現有變數(如果能找到該變數的話)。如果變數不存在,它就隱式地在全域性作用域內建立一個新的變數。
隱式宣告的主要優點是簡單。語法較少,無需學習“宣告”概念。使用者可以直接開始賦值,然後語言就能解決其它問題。
像C這樣較早的靜態型別語言受益於顯式宣告,是因為它們給使用者提供了一個地方,讓他們告訴編譯器每個變數的型別以及為它分配多少儲存空間。在動態型別、垃圾收集的語言中,這其實是沒有必要的,所以你可以透過隱式宣告來實現。這感覺更 "指令碼化",更像是 "你懂我的意思吧"。
但這是就個好主意嗎?隱式宣告還存在一些問題。
- 使用者可能打算為現有變數賦值,但是出現拼寫錯誤。直譯器不知道這一點,所以它悄悄地建立了一些新變數,而使用者想要賦值的變數仍然是原來的值。這在JavaScript中尤其令人討厭,因為一個拼寫錯誤會建立一個全域性變數,這反過來又可能會干擾其它程式碼。
- JS、Ruby和CoffeeScript透過判斷是否存在同名變數——包括外部作用域——來確定賦值是建立新變數還是賦值給現有變數。這意味著在外圍作用域中新增一個新變數可能會改變現有程式碼的含義,原先的區域性變數可能會默默地變成對新的外部變數的賦值。
- 在Python中,你可能想要賦值給當前函式之外的某個變數,而不是在當前函式中建立一個新變數,但是你做不到。
隨著時間的推移,我所知道的具有隱式變數宣告的語言最後都增加了更多的功能和複雜性來處理這些問題。
- 現在,普遍認為JavaScript中全域性變數的隱式宣告是一個錯誤。“Strict mode ”停用了它,並將其成為一個編譯錯誤。
- Python添加了一個
global語句,讓使用者可以在函式內部顯式地賦值給一個全域性變數。後來,隨著函數語言程式設計和巢狀函式越來越流行,他們添加了一個類似的nonlocal語句來賦值給外圍函式中的變數。 - Ruby擴充套件了它的塊語法,允許在塊中顯式地宣告某些變數,即使外部作用域中存在同名的變數。
考慮到這些,我認為簡單性的論點已經失去了意義。有一種觀點認為隱式宣告是正確的預設選項,但我個人認為這種說法不太有說服力。
我的觀點是,隱式宣告在過去的幾年裡是有意義的,當時大多數指令碼語言都是非常命令式的,程式碼是相當簡單直觀的。隨著程式設計師對深度巢狀、函數語言程式設計和閉包越來越熟悉,訪問外部作用域中的變數變得越來越普遍。這使得使用者更有可能遇到棘手的情況,即不清楚他們的賦值是要建立一個新變數還是重用外圍的已有變數。
所以我更喜歡顯式宣告變數,這就是Lox要這樣做的原因。
-
Pascal是一個異類。它區分了過程和函式。函式可以返回值,但過程不能。語言中有一個語句形式用於呼叫過程,但函式只能在需要表示式的地方被呼叫。在Pascal中沒有表示式語句。 ↩
-
我只想說,BASIC和Python有專門的
print語句,而且它們是真正的語言。當然,Python確實在3.0中刪除了print語句。 ↩ -
Java不允許使用小寫的void作為泛型型別引數,這是因為一些與型別擦除和堆疊有關的隱晦原因。相應的,提供了一個單獨的Void型別專門用於此用途,相當於裝箱後的void,就像Integer與int的關係。 ↩
-
全域性狀態的名聲不好。當然,過多的全域性狀態(尤其是可變狀態)使維護大型程式變得困難。一個出色的軟體工程師會盡量減少使用全域性變數。但是,如果你正在拼湊一種簡單的程式語言,甚至是在學習第一種語言時,全域性變數的簡單性會有所幫助。我學習的第一門語言是BASIC,雖然我最後不再使用了,但是在我能夠熟練使用計算機完成有趣的工作之前,如果能夠不需要考慮作用域規則,這一點很好。 ↩
-
程式碼塊語句的形式類似於表示式中的括號。“塊”本身處於“較高”的優先順序,並且可以在任何地方使用,如
if語句的子語句中。而其中包含的可以是優先順序較低的語句。你可以在塊中宣告變數或其它名稱。透過大括號,你可以在只允許某些語句的位置書寫完整的語句語法。 ↩ -
Java中稱之為對映或雜湊對映。其他語言稱它們為雜湊表、字典(Python和c#)、雜湊表(Ruby和Perl)、表(Lua)或關聯陣列(PHP)。很久以前,它們被稱為分散表。 ↩
-
我關於變數和作用域的原則是,“如果有疑問,參考Scheme的做法”。Scheme的開發人員可能比我們花了更多的時間來考慮變數範圍的問題——Scheme的主要目標之一就是向世界介紹詞法作用域,所以如果你跟隨他們的腳步,就很難出錯。Scheme允許在頂層重新定義變數。 ↩
-
當然,這可能不是判斷一個數字是奇偶性的最有效方法(更不用說如果傳入一個非整數或負數,程式會發生不可控的事情)。忍耐一下吧。 ↩
-
一些靜態型別的語言,如Java和C#,透過規定程式的頂層不是一連串的命令式語句來解決這個問題。相應的,它們認為程式是一組同時出現的宣告。語言實現在檢視任何函式的主體之前,會先宣告所有的名字。
像C和Pascal這樣的老式語言並不是這樣工作的。相反,它們會強制使用者新增明確的前向宣告,從而在名稱完全定義之前先宣告它。這是對當時有限的計算能力的一種讓步。它們希望能夠透過一次文字遍歷就編譯完一個原始檔,因此這些編譯器不能在處理函式體之前先收集所有宣告。 ↩ -
如果左側不是有效的賦值目標,我們會報告一個錯誤,但我們不會丟擲該錯誤,因為解析器並沒有處於需要進入恐慌模式和同步的混亂狀態。 ↩
-
即使存在不是有效表示式的賦值目標,你也可以使用這個技巧。定義一個覆蓋語法,一個可以接受所有有效表示式和賦值目標的寬鬆語法。如果你遇到了
=,並且左側不是有效的賦值目標則報告錯誤。相對地,如果沒有遇到=,而且左側不是有效的表示式也報告一個錯誤。 ↩ -
早在解析一章,我就說過我們要在語法樹中表示圓括號表示式,因為我們以後會用到。這就是為什麼。我們需要能夠區分這些情況: ↩
-
“詞法”來自希臘語“ lexikos”,意思是“與單詞有關”。 當我們在程式語言中使用它時,通常意味著您無需執行任何操作即可從原始碼本身中獲取到一些東西。詞法作用域是隨著ALGOL出現的。早期的語言通常是動態作用域的。當時的電腦科學家認為,動態作用域的執行速度更快。今天,多虧了早期的Scheme研究者,我們知道這不是真的。甚至可以說,情況恰恰相反。變數的動態作用域仍然存在於某些角落。Emacs Lisp預設為變數的動態作用域。Clojure中的
binding宏也提供了。JavaScript中普遍不被喜歡的with語句將物件上的屬性轉換為動態作用域變數。 ↩ -
讓
block()返回原始的語句列表,並在statement()方法中將該列表封裝在Stmt.Block中,這看起來有點奇怪。我這樣做是因為稍後我們會重用block()來解析函式體,我們當然不希望函式體被封裝在Stmt.Block中。 ↩ -
手動修改和恢復一個可變的
environment欄位感覺很不優雅。另一種經典方法是顯式地將環境作為引數傳遞給每個訪問方法。如果要“改變”環境,就在沿樹向下遞迴時傳入一個不同的環境。你不必恢復舊的環境,因為新的環境存在於 Java 堆疊中,當直譯器從塊的訪問方法返回時,該環境會被隱式丟棄。我曾考慮過在jlox中這樣做,但在每一個訪問方法中加入一個環境引數,這有點繁瑣和冗長。為了讓這本書更簡單,我選擇了可變欄位。 ↩
9.控制流 Control Flow
Logic, like whiskey, loses its beneficial effect when taken in too large quantities.
—— Edward John Moreton Drax Plunkett, Lord Dunsany
邏輯和威士忌一樣,如果攝入太多,就會失去其有益的效果。
Compared to last chapter’s grueling marathon, today is a lighthearted frolic through a daisy meadow. But while the work is easy, the reward is surprisingly large.
與上一章艱苦的馬拉松相比,這一章就是在雛菊草地上的輕鬆嬉戲。雖然工作很簡單,但回報卻驚人的大。
Right now, our interpreter is little more than a calculator. A Lox program can only do a fixed amount of work before completing. To make it run twice as long you have to make the source code twice as lengthy. We’re about to fix that. In this chapter, our interpreter takes a big step towards the programming language major leagues: Turing-completeness.
現在,我們的解釋器只不過是一個計算器而已。一個Lox程序在結束之前只能做固定的工作量。要想讓它的運行時間延長一倍,你就必須讓源代碼的長度增加一倍。我們即將解決這個問題。在本章中,我們的解釋器向編程語言大聯盟邁出了一大步:圖靈完備性。
9 . 1Turing Machines (Briefly)
9.1 圖靈機(簡介)
In the early part of last century, mathematicians stumbled into a series of confusing paradoxes that led them to doubt the stability of the foundation they had built their work upon. To address that crisis, they went back to square one. Starting from a handful of axioms, logic, and set theory, they hoped to rebuild mathematics on top of an impervious foundation.
在上世紀初,數學家們陷入了一系列令人困惑的悖論之中,導致他們對自己工作所依賴的基礎的穩定性產生懷疑1。為瞭解決這一危機,他們又回到了原點。他們希望從少量的公理、邏輯和集合理論開始,在一個不透水的地基上重建數學。
They wanted to rigorously answer questions like, “Can all true statements be proven?”, “Can we compute all functions that we can define?”, or even the more general question, “What do we mean when we claim a function is ‘computable’?”
他們想要嚴格地回答這樣的問題:“所有真實的陳述都可以被證明嗎?”,“我們可以計算我們能定義的所有函數嗎?”,甚至是更一般性的問題,“當我們聲稱一個函數是'可計算的'時,代表什麼意思?”
They presumed the answer to the first two questions would be “yes”. All that remained was to prove it. It turns out that the answer to both is “no”, and astonishingly, the two questions are deeply intertwined. This is a fascinating corner of mathematics that touches fundamental questions about what brains are able to do and how the universe works. I can’t do it justice here.
他們認為前兩個問題的答案應該是“是”,剩下的就是去證明它。但事實證明這兩個問題的答案都是“否”。而且令人驚訝的是,這兩個問題是深深地交織在一起的。這是數學的一個迷人的角落,它觸及了關於大腦能夠做什麼和宇宙如何運作的基本問題。我在這裡說不清楚。
What I do want to note is that in the process of proving that the answer to the first two questions is “no”, Alan Turing and Alonzo Church devised a precise answer to the last question—a definition of what kinds of functions are computable. They each crafted a tiny system with a minimum set of machinery that is still powerful enough to compute any of a (very) large class of functions.
我想指出的是,在證明前兩個問題的答案是 "否 "的過程中,艾倫·圖靈和阿隆佐·邱奇為最後一個問題設計了一個精確的答案,即定義了什麼樣的函數是可計算的。他們各自設計了一個具有最小機械集的微型系統,該系統仍然強大到足以計算一個超大類函數中的任何一個。
These are now considered the “computable functions”. Turing’s system is called a Turing machine. Church’s is the lambda calculus. Both are still widely used as the basis for models of computation and, in fact, many modern functional programming languages use the lambda calculus at their core.
這些現在被認為是“可計算函數”。圖靈的系統被稱為圖靈機2,邱奇的系統是lambda演算。這兩種方法仍然被廣泛用作計算模型的基礎,事實上,許多現代函數式編程語言的核心都是lambda演算。
Turing machines have better name recognition—there’s no Hollywood film about Alonzo Church yet—but the two formalisms are equivalent in power. In fact, any programming language with some minimal level of expressiveness is powerful enough to compute any computable function.
圖靈機的知名度更高——目前還沒有關於阿隆佐·邱奇的好萊塢電影,但這兩種形式在能力上是等價的。事實上,任何具有最低表達能力的編程語言都足以計算任何可計算函數。
You can prove that by writing a simulator for a Turing machine in your language. Since Turing proved his machine can compute any computable function, by extension, that means your language can too. All you need to do is translate the function into a Turing machine, and then run that on your simulator.
你可以用自己的語言為圖靈機編寫一個模擬器來證明這一點。由於圖靈證明瞭他的機器可以計算任何可計算函數,推而廣之,這意味著你的語言也可以。你所需要做的就是把函數翻譯成圖靈機,然後在你的模擬器上運行它。
If your language is expressive enough to do that, it’s considered Turing-complete. Turing machines are pretty dang simple, so it doesn’t take much power to do this. You basically need arithmetic, a little control flow, and the ability to allocate and use (theoretically) arbitrary amounts of memory. We’ve got the first. By the end of this chapter, we’ll have the second.
如果你的語言有足夠的表達能力來做到這一點,它就被認為是圖靈完備的。圖靈機非常簡單,所以它不需要太多的能力。您基本上只需要算術、一點控制流以及分配和使用(理論上)任意數量內存的能力。我們已經具備了第一個條件3。在本章結束時,我們將具備第二個條件。
9 . 2Conditional Execution
9.2 條件執行
Enough history, let’s jazz up our language. We can divide control flow roughly into two kinds:
說完了歷史,現在讓我們把語言優化一下。我們大致可以把控制流分為兩類:
-
Conditional or branching control flow is used to not execute some piece of code. Imperatively, you can think of it as jumping ahead over a region of code.
條件或分支控制流是用來不執行某些代碼的。意思是,你可以把它看作是跳過了代碼的一個區域。
-
Looping control flow executes a chunk of code more than once. It jumps back so that you can do something again. Since you don’t usually want infinite loops, it typically has some conditional logic to know when to stop looping as well.
循環控制流是用於多次執行一塊代碼的。它會向回跳轉,從而能再次執行某些代碼。用戶通常不需要無限循環,所以一般也會有一些條件邏輯用於判斷何時停止循環。
Branching is simpler, so we’ll start there. C-derived languages have two main conditional execution features, the
ifstatement and the perspicaciously named “conditional” operator (?:). Anifstatement lets you conditionally execute statements and the conditional operator lets you conditionally execute expressions.
分支更簡單一些,所以我們先從分支開始實現。C衍生語言中包含兩個主要的條件執行功能,即if語句和“條件”運算符(?:)4。if語句使你可以按條件執行語句,而條件運算符使你可以按條件執行表達式。
For simplicity’s sake, Lox doesn’t have a conditional operator, so let’s get our
ifstatement on. Our statement grammar gets a new production.
為了簡單起見,Lox沒有條件運算符,所以讓我們直接開始if語句吧。我們的語句語法需要一個新的生成式。
statement → exprStmt
| ifStmt
| printStmt
| block ;
ifStmt → "if" "(" expression ")" statement
( "else" statement )? ;
An
ifstatement has an expression for the condition, then a statement to execute if the condition is truthy. Optionally, it may also have anelsekeyword and a statement to execute if the condition is falsey. The syntax tree node has fields for each of those three pieces.
if語句有一個表達式作為條件,然後是一個在條件為真時要執行的語句。另外,它還可以有一個else關鍵字和條件為假時要執行的語句。語法樹節點中對語法的這三部分都有對應的字段。
tool/GenerateAst.java,在 main()方法中添加:
"Expression : Expr expression",
// 新增部分開始
"If : Expr condition, Stmt thenBranch," +
" Stmt elseBranch",
// 新增部分結束
"Print : Expr expression",
Like other statements, the parser recognizes an
ifstatement by the leadingifkeyword.
與其它語句類似,解析器通過開頭的if關鍵字來識別if語句。
lox/Parser.java,在 statement()方法中添加:
private Stmt statement() {
// 新增部分開始
if (match(IF)) return ifStatement();
// 新增部分結束
if (match(PRINT)) return printStatement();
When it finds one, it calls this new method to parse the rest:
如果發現了if關鍵字,就調用下面的新方法解析其餘部分5:
lox/Parser.java,在 statement()方法後添加:
private Stmt ifStatement() {
consume(LEFT_PAREN, "Expect '(' after 'if'.");
Expr condition = expression();
consume(RIGHT_PAREN, "Expect ')' after if condition.");
Stmt thenBranch = statement();
Stmt elseBranch = null;
if (match(ELSE)) {
elseBranch = statement();
}
return new Stmt.If(condition, thenBranch, elseBranch);
}
As usual, the parsing code hews closely to the grammar. It detects an else clause by looking for the preceding
elsekeyword. If there isn’t one, theelseBranchfield in the syntax tree isnull.
跟之前一樣,解析代碼嚴格遵循語法。它通過查找前面的else關鍵字來檢測else子句。如果沒有,語法樹中的elseBranch字段為null。
That seemingly innocuous optional else has, in fact, opened up an ambiguity in our grammar. Consider:
實際上,這個看似無傷大雅的可選項在我們的語法中造成了歧義。考慮以下代碼:
if (first) if (second) whenTrue(); else whenFalse();
Here’s the riddle: Which
ifstatement does that else clause belong to? This isn’t just a theoretical question about how we notate our grammar. It actually affects how the code executes:
謎題是這樣的:這裡的else子句屬於哪個if語句?這不僅僅是一個關於如何標註語法的理論問題。它實際上會影響代碼的執行方式:
-
If we attach the else to the first
ifstatement, thenwhenFalse()is called iffirstis falsey, regardless of what valuesecondhas.如果我們將
else語句關聯到第一個if語句,那麼當first為假時,無論second的值是多少,都將調用whenFalse()。 -
If we attach it to the second
ifstatement, thenwhenFalse()is only called iffirstis truthy andsecondis falsey.如果我們將
else語句關聯到第二個if語句,那麼只有當first為真並且second為假時,才會調用whenFalse()。
Since else clauses are optional, and there is no explicit delimiter marking the end of the
ifstatement, the grammar is ambiguous when you nestifs in this way. This classic pitfall of syntax is called the dangling else problem.
由於else子句是可選的,而且沒有明確的分隔符來標記if語句的結尾,所以當你以這種方式嵌套if時,語法是不明確的。這種典型的語法陷阱被稱為懸空的else問題。
It is possible to define a context-free grammar that avoids the ambiguity directly, but it requires splitting most of the statement rules into pairs, one that allows an
ifwith anelseand one that doesn’t. It’s annoying.
也可以定義一個上下文無關的語法來直接避免歧義,但是需要將大部分語句規則拆分成對,一個是允許帶有else的if語句,另一個不允許。這很煩人。
Instead, most languages and parsers avoid the problem in an ad hoc way. No matter what hack they use to get themselves out of the trouble, they always choose the same interpretation—the
elseis bound to the nearestifthat precedes it.
相反,大多數語言和解析器都以一種特殊的方式避免了這個問題。不管他們用什麼方法來解決這個問題,他們總是選擇同樣的解釋——else與前面最近的if綁定在一起。
Our parser conveniently does that already. Since
ifStatement()eagerly looks for anelsebefore returning, the innermost call to a nested series will claim the else clause for itself before returning to the outerifstatements.
我們的解析器已經很方便地做到了這一點。因為 ifStatement()在返回之前會繼續尋找一個else子句,連續嵌套的最內層調用在返回外部的if語句之前,會先為自己聲明else語句。
Syntax in hand, we are ready to interpret.
語法就緒了,我們可以開始解釋了。
lox/Interpreter.java,在 visitExpressionStmt()後添加:
@Override
public Void visitIfStmt(Stmt.If stmt) {
if (isTruthy(evaluate(stmt.condition))) {
execute(stmt.thenBranch);
} else if (stmt.elseBranch != null) {
execute(stmt.elseBranch);
}
return null;
}
The interpreter implementation is a thin wrapper around the self-same Java code. It evaluates the condition. If truthy, it executes the then branch. Otherwise, if there is an else branch, it executes that.
解釋器實現就是對相同的Java代碼的簡單包裝。它首先對條件表達式進行求值。如果為真,則執行then分支。否則,如果有存在else分支,就執行該分支。
If you compare this code to how the interpreter handles other syntax we’ve implemented, the part that makes control flow special is that Java
ifstatement. Most other syntax trees always evaluate their subtrees. Here, we may not evaluate the then or else statement. If either of those has a side effect, the choice not to evaluate it becomes user visible.
如果你把這段代碼與解釋器中我們已實現的處理其它語法的代碼進行比較,會發現控制流中特殊的地方就在於Java的if語句。其它大多數語法樹總是會對子樹求值,但是這裡,我們可能會不執行then語句或else語句。如果其中任何一個語句有副作用,那麼選擇不執行某條語句就是用戶可見的。
9 . 3Logical Operators
9.3 邏輯操作符
Since we don’t have the conditional operator, you might think we’re done with branching, but no. Even without the ternary operator, there are two other operators that are technically control flow constructs—the logical operators
andandor.
由於我們沒有條件運算符,你可能認為我們已經完成分支開發了,但其實還沒有。雖然沒有三元運算符,但是還有兩個其它操作符在技術上是控制流結構——邏輯運算符and和or。
These aren’t like other binary operators because they short-circuit. If, after evaluating the left operand, we know what the result of the logical expression must be, we don’t evaluate the right operand. For example:
它們與其它二進制運算符不同,是因為它們會短路。如果在計算左操作數之後,我們已經確切知道邏輯表達式的結果,那麼就不再計算右操作數。例如:
false and sideEffect();
For an
andexpression to evaluate to something truthy, both operands must be truthy. We can see as soon as we evaluate the leftfalseoperand that that isn’t going to be the case, so there’s no need to evaluatesideEffect()and it gets skipped.
對於一個and表達式來說,兩個操作數都必須是真,才能得到結果為真。我們只要看到左側的false操作數,就知道結果不會是真,也就不需要對sideEffect()求值,會直接跳過它。
This is why we didn’t implement the logical operators with the other binary operators. Now we’re ready. The two new operators are low in the precedence table. Similar to
||and&&in C, they each have their own precedence withorlower thanand. We slot them right betweenassignmentandequality.
這就是為什麼我們沒有在實現其它二元運算符的時候一起實現邏輯運算符。現在我們已經準備好了。這兩個新的運算符在優先級表中的位置很低,類似於C語言中的||和&&,它們都有各自的優先級,or低於and。我們把這兩個運算符插入assignment 和 equality之間。
expression → assignment ;
assignment → IDENTIFIER "=" assignment
| logic_or ;
logic_or → logic_and ( "or" logic_and )* ;
logic_and → equality ( "and" equality )* ;
Instead of falling back to
equality,assignmentnow cascades tologic_or. The two new rules,logic_orandlogic_and, are similar to other binary operators. Thenlogic_andcalls out toequalityfor its operands, and we chain back to the rest of the expression rules.
assignment 現在不是落到 equality,而是繼續進入logic_or。兩個新規則,logic_or 和 logic_and,與其它二元運算符類似。然後logic_and會調用equality計算其操作數,然後我們就鏈入了表達式規則的其它部分。
We could reuse the existing Expr.Binary class for these two new expressions since they have the same fields. But then
visitBinaryExpr()would have to check to see if the operator is one of the logical operators and use a different code path to handle the short circuiting. I think it’s cleaner to define a new class for these operators so that they get their own visit method.
對於這兩個新表達式,我們可以重用Expr.Binary類,因為他們具有相同的字段。但是這樣的話,visitBinaryExpr() 方法中必須檢查運算符是否是邏輯運算符,並且要使用不同的代碼處理短路邏輯。我認為更整潔的方法是為這些運算符定義一個新類,這樣它們就有了自己的visit方法。
tool/GenerateAst.java,在main()方法中添加:
"Literal : Object value",
// 新增部分開始
"Logical : Expr left, Token operator, Expr right",
// 新增部分結束
"Unary : Token operator, Expr right",
To weave the new expressions into the parser, we first change the parsing code for assignment to call
or().
為了將新的表達式加入到解析器中,我們首先將賦值操作的解析代碼改為調用or()方法。
lox/Parser.java,在 assignment()方法中替換一行:
private Expr assignment() {
// 新增部分開始
Expr expr = or();
// 新增部分結束
if (match(EQUAL)) {
The code to parse a series of
orexpressions mirrors other binary operators.
解析一系列or語句的代碼與其它二元運算符相似。
lox/Parser.java,在 assignment()方法後添加:
private Expr or() {
Expr expr = and();
while (match(OR)) {
Token operator = previous();
Expr right = and();
expr = new Expr.Logical(expr, operator, right);
}
return expr;
}
Its operands are the next higher level of precedence, the new
andexpression.
它的操作數是位於下一優先級的新的and表達式。
lox/Parser.java,在 or()方法後添加:
private Expr and() {
Expr expr = equality();
while (match(AND)) {
Token operator = previous();
Expr right = equality();
expr = new Expr.Logical(expr, operator, right);
}
return expr;
}
That calls
equality()for its operands, and with that, the expression parser is all tied back together again. We’re ready to interpret.
這裡會調用 equality() 計算操作數,這樣一來,表達式解析器又重新綁定到了一起。我們已經準備好進行解釋了。
lox/Interpreter.java,在 visitLiteralExpr()方法後添加:
@Override
public Object visitLogicalExpr(Expr.Logical expr) {
Object left = evaluate(expr.left);
if (expr.operator.type == TokenType.OR) {
if (isTruthy(left)) return left;
} else {
if (!isTruthy(left)) return left;
}
return evaluate(expr.right);
}
If you compare this to the earlier chapter’s
visitBinaryExpr()method, you can see the difference. Here, we evaluate the left operand first. We look at its value to see if we can short-circuit. If not, and only then, do we evaluate the right operand.
如果你把這個方法與前面章節的visitBinaryExpr()方法相比較,就可以看出其中的區別。這裡,我們先計算左操作數。然後我們查看結果值,判斷是否可以短路。當且僅當不能短路時,我們才計算右側的操作數。
The other interesting piece here is deciding what actual value to return. Since Lox is dynamically typed, we allow operands of any type and use truthiness to determine what each operand represents. We apply similar reasoning to the result. Instead of promising to literally return
trueorfalse, a logic operator merely guarantees it will return a value with appropriate truthiness.
另一個有趣的部分是決定返回什麼實際值。由於Lox是動態類型的,我們允許任何類型的操作數,並使用真實性來確定每個操作數代表什麼。我們對結果採用類似的推理。邏輯運算符並不承諾會真正返回true或false,而只是保證它將返回一個具有適當真實性的值。
Fortunately, we have values with proper truthiness right at hand—the results of the operands themselves. So we use those. For example:
幸運的是,我們手邊就有具有適當真實性的值——即操作數本身的結果,所以我們可以直接使用它們。如:
print "hi" or 2; // "hi".
print nil or "yes"; // "yes".
On the first line,
"hi"is truthy, so theorshort-circuits and returns that. On the second line,nilis falsey, so it evaluates and returns the second operand,"yes".
在第一行,“hi”是真的,所以or短路並返回它。在第二行,nil是假的,因此它計算並返回第二個操作數“yes”。
That covers all of the branching primitives in Lox. We’re ready to jump ahead to loops. You see what I did there? Jump. Ahead. Get it? See, it’s like a reference to . . . oh, forget it.
這樣就完成了Lox中的所有分支原語,我們準備實現循環吧。
9 . 4While Loops
9.4 While循環
Lox features two looping control flow statements,
whileandfor. Thewhileloop is the simpler one, so we’ll start there. Its grammar is the same as in C.
Lox有兩種類型的循環控制流語句,分別是while和for。while循環更簡單一點,我們先從它開始.
statement → exprStmt
| ifStmt
| printStmt
| whileStmt
| block ;
whileStmt → "while" "(" expression ")" statement ;
We add another clause to the statement rule that points to the new rule for while. It takes a
whilekeyword, followed by a parenthesized condition expression, then a statement for the body. That new grammar rule gets a syntax tree node.
我們在statement規則中添加一個子句,指向while對應的新規則whileStmt。該規則接收一個while關鍵字,後跟一個帶括號的條件表達式,然後是循環體對應的語句。新語法規則需要定義新的語法樹節點。
tool/GenerateAst.java,在 main()方法中新增,前一行後添加“,”
"Print : Expr expression",
"Var : Token name, Expr initializer",
// 新增部分開始
"While : Expr condition, Stmt body"
// 新增部分結束
));
The node stores the condition and body. Here you can see why it’s nice to have separate base classes for expressions and statements. The field declarations make it clear that the condition is an expression and the body is a statement.
該節點中保存了條件式和循環體。這裡就可以看出來為什麼表達式和語句最好要有單獨的基類。字段聲明清楚地表明瞭,條件是一個表達式,循環主體是一個語句。
Over in the parser, we follow the same process we used for
ifstatements. First, we add another case instatement()to detect and match the leading keyword.
在解析器中,我們遵循與if語句相同的處理步驟。首先,在 statement() 添加一個case分支檢查並匹配開頭的關鍵字。
lox/Parser.java,在statement()方法中添加:
if (match(PRINT)) return printStatement();
// 新增部分開始
if (match(WHILE)) return whileStatement();
// 新增部分結束
if (match(LEFT_BRACE)) return new Stmt.Block(block());
That delegates the real work to this method:
實際的工作委託給下面的方法:
lox/Parser.java,在 varDeclaration()方法後添加:
private Stmt whileStatement() {
consume(LEFT_PAREN, "Expect '(' after 'while'.");
Expr condition = expression();
consume(RIGHT_PAREN, "Expect ')' after condition.");
Stmt body = statement();
return new Stmt.While(condition, body);
}
The grammar is dead simple and this is a straight translation of it to Java. Speaking of translating straight to Java, here’s how we execute the new syntax:
語法非常簡單,這裡將其直接翻譯為Java。說到直接翻譯成Java,下面是我們執行新語法的方式:
lox/Interpreter.java,在 visitVarStmt()方法後添加:
@Override
public Void visitWhileStmt(Stmt.While stmt) {
while (isTruthy(evaluate(stmt.condition))) {
execute(stmt.body);
}
return null;
}
Like the visit method for
if, this visitor uses the corresponding Java feature. This method isn’t complex, but it makes Lox much more powerful. We can finally write a program whose running time isn’t strictly bound by the length of the source code.
和if的訪問方法一樣,這裡的訪問方法使用了相應的Java特性。這個方法並不複雜,但它使Lox變得更加強大。我們終於可以編寫一個運行時間不受源代碼長度嚴格限制的程序了。
9 . 5For Loops
9.5 For循環
We’re down to the last control flow construct, Ye Olde C-style
forloop. I probably don’t need to remind you, but it looks like this:
我們已經到了最後一個控制流結構,即老式的C語言風格for循環。我可能不需要提醒你,但還是要說它看起來是這樣的:
for (var i = 0; i < 10; i = i + 1) print i;
In grammarese, that’s:
在語法中,是這樣的:
statement → exprStmt
| forStmt
| ifStmt
| printStmt
| whileStmt
| block ;
forStmt → "for" "(" ( varDecl | exprStmt | ";" )
expression? ";"
expression? ")" statement ;
Inside the parentheses, you have three clauses separated by semicolons:
在括號內,有三個由分號分隔的子語句:
-
The first clause is the initializer. It is executed exactly once, before anything else. It’s usually an expression, but for convenience, we also allow a variable declaration. In that case, the variable is scoped to the rest of the
forloop—the other two clauses and the body.第一個子句是初始化式。它只會在任何其它操作之前執行一次。它通常是一個表達式,但是為了便利,我們也允許一個變量聲明。在這種情況下,變量的作用域就是
for循環的其它部分——其餘兩個子式和循環體。 -
Next is the condition. As in a
whileloop, this expression controls when to exit the loop. It’s evaluated once at the beginning of each iteration, including the first. If the result is truthy, it executes the loop body. Otherwise, it bails.接下來是條件表達式。與
while循環一樣,這個表達式控制了何時退出循環。它會在每次循環開始之前執行一次(包括第一次)。如果結果是真,就執行循環體;否則,就結束循環。 -
The last clause is the increment. It’s an arbitrary expression that does some work at the end of each loop iteration. The result of the expression is discarded, so it must have a side effect to be useful. In practice, it usually increments a variable.
最後一個子句是增量式。它是一個任意的表達式,會在每次循環結束的時候做一些工作。因為表達式的結果會被丟棄,所以它必須有副作用才能有用。在實踐中,它通常會對變量進行遞增。
Any of these clauses can be omitted. Following the closing parenthesis is a statement for the body, which is typically a block.
這些子語句都可以忽略。在右括號之後是一個語句作為循環體,通常是一個代碼塊。
9 . 5 . 1Desugaring
9.5.1 語法脫糖
That’s a lot of machinery, but note that none of it does anything you couldn’t do with the statements we already have. If
forloops didn’t support initializer clauses, you could just put the initializer expression before theforstatement. Without an increment clause, you could simply put the increment expression at the end of the body yourself.
這裡包含了很多配件,但是請注意,它所做的任何事情中,沒有一件是無法用已有的語句實現的。如果for循環不支持初始化子句,你可以在for語句之前加一條初始化表達式。如果沒有增量子語句,你可以直接把增量表達式放在循環體的最後。
In other words, Lox doesn’t need
forloops, they just make some common code patterns more pleasant to write. These kinds of features are called syntactic sugar. For example, the previousforloop could be rewritten like so:
換句話說,Lox不需要for循環,它們只是讓一些常見的代碼模式更容易編寫。這類功能被稱為語法糖6。例如,前面的for循環可以改寫成這樣:
{
var i = 0;
while (i < 10) {
print i;
i = i + 1;
}
}
This script has the exact same semantics as the previous one, though it’s not as easy on the eyes. Syntactic sugar features like Lox’s
forloop make a language more pleasant and productive to work in. But, especially in sophisticated language implementations, every language feature that requires back-end support and optimization is expensive.
雖然這個腳本不太容易看懂,但這個腳本與之前那個語義完全相同。像Lox中的for循環這樣的語法糖特性可以使語言編寫起來更加愉快和高效。但是,特別是在複雜的語言實現中,每一個需要後端支持和優化的語言特性都是代價昂貴的。
We can have our cake and eat it too by desugaring. That funny word describes a process where the front end takes code using syntax sugar and translates it to a more primitive form that the back end already knows how to execute.
我們可以通過脫糖來吃這個蛋糕。這個有趣的詞描述了這樣一個過程:前端接收使用了語法糖的代碼,並將其轉換成後端知道如何執行的更原始的形式。
We’re going to desugar
forloops to thewhileloops and other statements the interpreter already handles. In our simple interpreter, desugaring really doesn’t save us much work, but it does give me an excuse to introduce you to the technique. So, unlike the previous statements, we won’t add a new syntax tree node. Instead, we go straight to parsing. First, add an import we’ll need soon.
我們將把for循環脫糖為while循環和其它解釋器可處理的其它語句。在我們的簡單解釋器中,脫糖真的不能為我們節省很多工作,但它確實給了我一個契機來向你介紹這一技術。因此,與之前的語句不同,我們不會為for循環添加一個新的語法樹節點。相反,我們會直接進行解析。首先,先引入一個我們要用到的依賴:
lox/Parser.java,添加代碼:
import java.util.ArrayList;
// 新增部分開始
import java.util.Arrays;
// 新增部分結束
import java.util.List;
Like every statement, we start parsing a
forloop by matching its keyword.
像每個語句一樣,我們通過匹配for關鍵字來解析循環。
lox/Parser.java,在 statement()方法中新增:
private Stmt statement() {
// 新增部分開始
if (match(FOR)) return forStatement();
// 新增部分結束
if (match(IF)) return ifStatement();
Here is where it gets interesting. The desugaring is going to happen here, so we’ll build this method a piece at a time, starting with the opening parenthesis before the clauses.
接下來是有趣的部分,脫糖也是在這裡發生的,所以我們會一點點構建這個方法,首先從子句之前的左括號開始。
lox/Parser.java,在 statement()方法後添加:
private Stmt forStatement() {
consume(LEFT_PAREN, "Expect '(' after 'for'.");
// More here...
}
The first clause following that is the initializer.
接下來的第一個子句是初始化式。
lox/Parser.java,在 forStatement()方法中替換一行:
consume(LEFT_PAREN, "Expect '(' after 'for'.");
// 替換部分開始
Stmt initializer;
if (match(SEMICOLON)) {
initializer = null;
} else if (match(VAR)) {
initializer = varDeclaration();
} else {
initializer = expressionStatement();
}
// 替換部分結束
}
If the token following the
(is a semicolon then the initializer has been omitted. Otherwise, we check for avarkeyword to see if it’s a variable declaration. If neither of those matched, it must be an expression. We parse that and wrap it in an expression statement so that the initializer is always of type Stmt.
如果(後面的標記是分號,那麼初始化式就被省略了。否則,我們就檢查var關鍵字,看它是否是一個變量聲明。如果這兩者都不符合,那麼它一定是一個表達式。我們對其進行解析,並將其封裝在一個表達式語句中,這樣初始化器就必定屬於Stmt類型。
Next up is the condition.
接下來是條件表達式。
lox/Parser.java,在 forStatement()方法中添加代碼:
initializer = expressionStatement();
}
// 新增部分開始
Expr condition = null;
if (!check(SEMICOLON)) {
condition = expression();
}
consume(SEMICOLON, "Expect ';' after loop condition.");
// 新增部分結束
}
Again, we look for a semicolon to see if the clause has been omitted. The last clause is the increment.
同樣,我們查找分號檢查子句是否被忽略。最後一個子句是增量語句。
lox/Parser.java,在 forStatement()方法中添加:
consume(SEMICOLON, "Expect ';' after loop condition.");
// 新增部分開始
Expr increment = null;
if (!check(RIGHT_PAREN)) {
increment = expression();
}
consume(RIGHT_PAREN, "Expect ')' after for clauses.");
// 新增部分結束
}
It’s similar to the condition clause except this one is terminated by the closing parenthesis. All that remains is the body.
它類似於條件式子句,只是這個子句是由右括號終止的。剩下的就是循環主體了。
lox/Parser.java,在 forStatement()方法中添加代碼:
consume(RIGHT_PAREN, "Expect ')' after for clauses.");
// 新增部分開始
Stmt body = statement();
return body;
// 新增部分結束
}
We’ve parsed all of the various pieces of the
forloop and the resulting AST nodes are sitting in a handful of Java local variables. This is where the desugaring comes in. We take those and use them to synthesize syntax tree nodes that express the semantics of theforloop, like the hand-desugared example I showed you earlier.
我們已經解析了for循環的所有部分,得到的AST節點也存儲在一些Java本地變量中。這裡也是脫糖開始的地方。我們利用這些變量來合成表示for循環語義的語法樹節點,就像前面展示的手工脫糖的例子一樣。
The code is a little simpler if we work backward, so we start with the increment clause.
如果我們從後向前處理,代碼會更簡單一些,所以我們從增量子句開始。
lox/Parser.java,在 forStatement()方法中新增:
Stmt body = statement();
// 新增部分開始
if (increment != null) {
body = new Stmt.Block(
Arrays.asList(
body,
new Stmt.Expression(increment)));
}
// 新增部分結束
return body;
The increment, if there is one, executes after the body in each iteration of the loop. We do that by replacing the body with a little block that contains the original body followed by an expression statement that evaluates the increment.
如果存在增量子句的話,會在循環的每個迭代中在循環體結束之後執行。我們用一個代碼塊來代替循環體,這個代碼塊中包含原始的循環體,後面跟一個執行增量子語句的表達式語句。
lox/Parser.java,在 forStatement()方法中新增代碼:
}
// 新增部分開始
if (condition == null) condition = new Expr.Literal(true);
body = new Stmt.While(condition, body);
// 新增部分結束
return body;
Next, we take the condition and the body and build the loop using a primitive
whileloop. If the condition is omitted, we jam intrueto make an infinite loop.
接下來,我們獲取條件式和循環體,並通過基本的while語句構建對應的循環。如果條件式被省略了,我們就使用true來創建一個無限循環。
lox/Parser.java,在 forStatement()方法中新增:
body = new Stmt.While(condition, body);
// 新增部分開始
if (initializer != null) {
body = new Stmt.Block(Arrays.asList(initializer, body));
}
// 新增部分結束
return body;
Finally, if there is an initializer, it runs once before the entire loop. We do that by, again, replacing the whole statement with a block that runs the initializer and then executes the loop.
最後,如果有初始化式,它會在整個循環之前運行一次。我們的做法是,再次用代碼塊來替換整個語句,該代碼塊中首先運行一個初始化式,然後執行循環。
That’s it. Our interpreter now supports C-style
forloops and we didn’t have to touch the Interpreter class at all. Since we desugared to nodes the interpreter already knows how to visit, there is no more work to do.
就是這樣。我們的解釋器現在已經支持了C語言風格的for循環,而且我們根本不需要修改解釋器類。因為我們通過脫糖將其轉換為瞭解釋器已經知道如何訪問的節點,所以無需做其它的工作。
Finally, Lox is powerful enough to entertain us, at least for a few minutes. Here’s a tiny program to print the first 21 elements in the Fibonacci sequence:
最後,Lox已強大到足以娛樂我們,至少幾分鐘。下面是一個打印斐波那契數列前21個元素的小程序:
var a = 0;
var temp;
for (var b = 1; a < 10000; b = temp + b) {
print a;
temp = a;
a = b;
}
CHALLENGES
習題
1、A few chapters from now, when Lox supports first-class functions and dynamic dispatch, we technically won’t need branching statements built into the language. Show how conditional execution can be implemented in terms of those. Name a language that uses this technique for its control flow.
1、在接下來的幾章中,當Lox支持一級函數和動態調度時,從技術上講,我們就不需要在語言中內置分支語句。說明如何用這些特性來實現條件執行。說出一種在控制流中使用這種技術的語言。
2、Likewise, looping can be implemented using those same tools, provided our interpreter supports an important optimization. What is it, and why is it necessary? Name a language that uses this technique for iteration.
2、同樣地,只要我們的解釋器支持一個重要的優化,循環也可以用這些工具來實現。它是什麼?為什麼它是必要的?請說出一種使用這種技術進行迭代的語言。
3、Unlike Lox, most other C-style languages also support
breakandcontinuestatements inside loops. Add support forbreakstatements.The syntax is a
breakkeyword followed by a semicolon. It should be a syntax error to have abreakstatement appear outside of any enclosing loop. At runtime, abreakstatement causes execution to jump to the end of the nearest enclosing loop and proceeds from there. Note that thebreakmay be nested inside other blocks andifstatements that also need to be exited.
3、與Lox不同,大多數其他C風格語言也支持循環內部的break和continue語句。添加對break語句的支持。
語法是一個break關鍵字,後面跟一個分號。如果break語句出現在任何封閉的循環之後,那就應該是一個語法錯誤。在運行時,break語句會跳轉到最內層的封閉循環的末尾,並從那裡開始繼續執行。注意,break語句可以嵌套在其它需要退出的代碼塊和if語句中。
DESIGN NOTE: SPOONFULS OF SYNTACTIC SUGAR
設計筆記:一些語法糖
When you design your own language, you choose how much syntactic sugar to pour into the grammar. Do you make an unsweetened health food where each semantic operation maps to a single syntactic unit, or some decadent dessert where every bit of behavior can be expressed ten different ways? Successful languages inhabit all points along this continuum.
On the extreme acrid end are those with ruthlessly minimal syntax like Lisp, Forth, and Smalltalk. Lispers famously claim their language “has no syntax”, while Smalltalkers proudly show that you can fit the entire grammar on an index card. This tribe has the philosophy that the language doesn’t need syntactic sugar. Instead, the minimal syntax and semantics it provides are powerful enough to let library code be as expressive as if it were part of the language itself.
Near these are languages like C, Lua, and Go. They aim for simplicity and clarity over minimalism. Some, like Go, deliberately eschew both syntactic sugar and the kind of syntactic extensibility of the previous category. They want the syntax to get out of the way of the semantics, so they focus on keeping both the grammar and libraries simple. Code should be obvious more than beautiful.
Somewhere in the middle you have languages like Java, C#, and Python. Eventually you reach Ruby, C++, Perl, and D—languages which have stuffed so much syntax into their grammar, they are running out of punctuation characters on the keyboard.
To some degree, location on the spectrum correlates with age. It’s relatively easy to add bits of syntactic sugar in later releases. New syntax is a crowd pleaser, and it’s less likely to break existing programs than mucking with the semantics. Once added, you can never take it away, so languages tend to sweeten with time. One of the main benefits of creating a new language from scratch is it gives you an opportunity to scrape off those accumulated layers of frosting and start over.
Syntactic sugar has a bad rap among the PL intelligentsia. There’s a real fetish for minimalism in that crowd. There is some justification for that. Poorly designed, unneeded syntax raises the cognitive load without adding enough expressiveness to carry its weight. Since there is always pressure to cram new features into the language, it takes discipline and a focus on simplicity to avoid bloat. Once you add some syntax, you’re stuck with it, so it’s smart to be parsimonious.
At the same time, most successful languages do have fairly complex grammars, at least by the time they are widely used. Programmers spend a ton of time in their language of choice, and a few niceties here and there really can improve the comfort and efficiency of their work.
Striking the right balance—choosing the right level of sweetness for your language—relies on your own sense of taste.
當你設計自己的語言時,你可以選擇在語法中注入多少語法糖。你是要做一種不加糖、每個語法操作都對應單一的語法單元的健康食品?還是每一點行為都可以用10種不同方式實現的墮落的甜點?把這兩種情況看作是兩端的話,成功的語言分佈在這個連續體的每個中間點。
極端尖刻的一側是那些語法極少的語言,如Lisp、Forth和SmallTalk。Lisp的擁躉廣泛聲稱他們的語言 "沒有語法",而Smalltalk的人則自豪地表示,你可以把整個語法放在一張索引卡上。這個部落的理念是,語言不需要句法糖。相反,它所提供的最小的語法和語義足夠強大,足以讓庫中的代碼像語言本身的一部分一樣具有表現力。
接近這些的是像C、Lua和Go這樣的語言。他們的目標是簡單和清晰,而不是極簡主義。有些語言,如Go,故意避開了語法糖和前一類語言的語法擴展性。他們希望語法不受語義的影響,所以他們專注於保持語法和庫的簡單性。代碼應該是明顯的,而不是漂亮的。
介於之間的是Java、C#和Python等語言。最終,你會看到Ruby、C++、Perl和D-語言,它們在語法中塞入了太多的句法規則,以至於鍵盤上的標點符號都快用完了。
在某種程度上,頻譜上的位置與年齡相關。在後續的版本中增加一些語法糖是比較容易的。新的語法很容易讓人喜歡,而且與修改語義相比,它更不可能破壞現有的程序。一旦加進去,你就再也不能把它去掉了,所以隨著時間的推移,語言會變得越來越甜。從頭開始創建一門新語言的主要好處之一是,它給了你一個機會去刮掉那些累積的糖霜並重新開始。
語法糖在PL知識分子中名聲不佳。那群人對極簡主義有一種真正的迷戀。這是有一定道理的。設計不良的、不必要的語法增加了認知負荷,卻沒有增加相匹配的表達能力。因為一直會有向語言中添加新特性的壓力,所以需要自律並專注於簡單,以避免臃腫。一旦你添加了一些語法,你就會被它困住,所以明智的做法是要精簡。
同時,大多數成功的語言都有相當複雜的語法,至少在它們被廣泛使用的時候是這樣。程序員在他們所選擇的語言上花費了大量的時間,一些隨處可見的細節確實可以提高他們工作時的舒適度和效率。
找到正確的平衡——為你的語言選擇適當的甜度——取決於你自己的品味。
-
其中最著名的就是羅素悖論。最初,集合理論允許你定義任何類型的集合。只要你能用英語描述它,它就是有效的。自然,鑑於數學家對自引用的偏愛,集合可以包含其他的集合。於是,羅素,這個無賴,提出了:
R是所有不包含自身的集合的集合。
R是否包含自己?如果不包含,那麼根據定義的後半部分,它應該包含;如果包含,那麼它就不滿足定義。腦袋要炸了。 ↩ -
圖靈把他的發明稱為 “a-machines”,表示“automatic(自動)”。他並沒有自吹自擂到把自己的名字放入其中。後來的數學家們為他做了這些。這就是你如何在成名的同時還能保持謙虛。 ↩
-
我們也基本上具備第三個條件了。你可以創建和拼接任意大小的字符串,因此也就可以存儲無界內存。但我們還無法訪問字符串的各個部分。 ↩
-
條件操作符也稱為三元操作符,因為它是C語言中唯一接受三個操作數的操作符。 ↩
-
條件周圍的圓括號只有一半是有用的。您需要在條件和then語句之間設置某種分隔符,否則解析器無法判斷是否到達條件表達式的末尾。但是
if後面的小括號並沒有什麼用處。Dennis Ritchie 把它放在那裡是為了讓他可以使用)作為結尾的分隔符,而且不會出現不對稱的小括號。其他語言,比如Lua和一些BASICs,使用then這樣的關鍵字作為結束分隔符,在條件表達式之前沒有任何內容。而Go和Swift則要求語句必須是一個帶括號的塊,這樣就可以使用語句開頭的{來判斷條件表達式是否結束。 ↩ -
這個令人愉快的短語是由Peter J. Landin在1964年創造的,用來描述ALGOL等語言支持的一些很好的表達式形式是如何在更基本但可能不太令人滿意的lambda演算的基礎上增添一些小甜頭的。 ↩
10.函式Functions
And that is also the way the human mind works—by the compounding of old ideas into new structures that become new ideas that can themselves be used in compounds, and round and round endlessly, growing ever more remote from the basic earthbound imagery that is each language’s soil.
—— Douglas R. Hofstadter, I Am a Strange Loop
這也是人類思維的運作方式——將舊的想法複合成為新結構,成為新的想法,而這些想法本身又可以被用於複合,迴圈往復,無休無止,越來越遠離每一種語言賴以生存的基本的土壤。
This chapter marks the culmination of a lot of hard work. The previous chapters add useful functionality in their own right, but each also supplies a piece of a puzzle. We’ll take those pieces—expressions, statements, variables, control flow, and lexical scope—add a couple more, and assemble them all into support for real user-defined functions and function calls.
這一章標誌著很多艱苦工作的一個高潮。在前面的章節中,各自添加了一些有用的功能,但是每一章也都提供了一個拼圖的碎片。我們整理這些碎片——表示式、語句、變數、控制流和詞法作用域,再加上其它功能,並把他們組合起來,以支援真正的使用者定義函式和函式呼叫。
10 . 1 Function Calls
10.1 函式呼叫
You’re certainly familiar with C-style function call syntax, but the grammar is more subtle than you may realize. Calls are typically to named functions like:
你肯定熟悉C語言風格的函式呼叫語法,但其語法可能比你意識到的更微妙。呼叫通常是指向命名的函式,例如:
average(1, 2);
But the name of the function being called isn’t actually part of the call syntax. The thing being called—the callee—can be any expression that evaluates to a function. (Well, it does have to be a pretty high precedence expression, but parentheses take care of that.) For example:
但是被呼叫函式的名稱實際上並不是呼叫語法的一部分。被呼叫者( callee)可以是計算結果為一個函式的任何表示式。(好吧,它必須是一個非常高優先順序的表示式,但是圓括號可以解決這個問題。)例如:
getCallback()();
There are two call expressions here. The first pair of parentheses has
getCallbackas its callee. But the second call has the entiregetCallback()expression as its callee. It is the parentheses following an expression that indicate a function call. You can think of a call as sort of like a postfix operator that starts with(.
這裡有兩個函式呼叫。第一對括號將getCallback作為其被呼叫者。但是第二對括號將整個getCallback() 表示式作為其被呼叫者。表示式後面的小括號表示函式呼叫,你可以把呼叫看作是一種以(開頭的字尾運算子。
This “operator” has higher precedence than any other operator, even the unary ones. So we slot it into the grammar by having the
unaryrule bubble up to a newcallrule.
這個“運算子”比其它運算子(包括一元運算子)有更高的優先順序。所以我們透過讓unary規則跳轉到新的call規則,將其新增到語法中1。
unary → ( "!" | "-" ) unary | call ;
call → primary ( "(" arguments? ")" )* ;
This rule matches a primary expression followed by zero or more function calls. If there are no parentheses, this parses a bare primary expression. Otherwise, each call is recognized by a pair of parentheses with an optional list of arguments inside. The argument list grammar is:
該規則匹配一個基本表示式,後面跟著0個或多個函式呼叫。如果沒有括號,則解析一個簡單的基本表示式。否則,每一對圓括號都表示一個函式呼叫,圓括號內有一個可選的引數列表。引數列表語法是:
arguments → expression ( "," expression )* ;
This rule requires at least one argument expression, followed by zero or more other expressions, each preceded by a comma. To handle zero-argument calls, the
callrule itself considers the entireargumentsproduction to be optional.
這個規則要求至少有一個參數列達式,後面可以跟0個或多個其它表示式,每兩個表示式之間用,分隔。為了處理無參呼叫,call規則本身認為整個arguments生成式是可選的。
I admit, this seems more grammatically awkward than you’d expect for the incredibly common “zero or more comma-separated things” pattern. There are some sophisticated metasyntaxes that handle this better, but in our BNF and in many language specs I’ve seen, it is this cumbersome.
我承認,對於極其常見的 "零或多個逗號分隔的事物 "模式來說,這在語法上似乎比你想象的更難處理。有一些複雜的元語法可以更好地處理這個問題,但在我們的BNF和我見過的許多語言規範中,它就是如此的麻煩。
Over in our syntax tree generator, we add a new node.
在我們的語法樹生成器中,我們新增一個新節點。
tool/GenerateAst.java,在 main()方法中新增程式碼:
"Binary : Expr left, Token operator, Expr right",
// 新增部分開始
"Call : Expr callee, Token paren, List<Expr> arguments",
// 新增部分結束
"Grouping : Expr expression",
It stores the callee expression and a list of expressions for the arguments. It also stores the token for the closing parenthesis. We’ll use that token’s location when we report a runtime error caused by a function call.
它儲存了被呼叫者表示式和參數列達式列表,同時也儲存了右括號標記。當我們報告由函式呼叫引起的執行時錯誤時,會使用該標記的位置。
Crack open the parser. Where
unary()used to jump straight toprimary(), change it to call, well,call().
開啟解析器,原來unary()直接跳轉到primary()方法,將其修改為呼叫call()。
lox/Parser.java,在 unary()方法中替換一行:
return new Expr.Unary(operator, right);
}
// 替換部分開始
return call();
// 替換部分結束
}
Its definition is:
該方法定義為:
lox/Parser.java,在 unary()方法後新增2:
private Expr call() {
Expr expr = primary();
while (true) {
if (match(LEFT_PAREN)) {
expr = finishCall(expr);
} else {
break;
}
}
return expr;
}
The code here doesn’t quite line up with the grammar rules. I moved a few things around to make the code cleaner—one of the luxuries we have with a handwritten parser. But it’s roughly similar to how we parse infix operators. First, we parse a primary expression, the “left operand” to the call. Then, each time we see a
(, we callfinishCall()to parse the call expression using the previously parsed expression as the callee. The returned expression becomes the newexprand we loop to see if the result is itself called.
這裡的程式碼與語法規則並非完全一致。為了保持程式碼簡潔,我調整了一些東西——這是我們手寫解析器的優點之一。但它與我們解析中綴運算子的方式類似。首先,我們解析一個基本表示式,即呼叫的左運算元。然後,每次看到(,我們就呼叫finishCall()解析呼叫表示式,並使用之前解析出的表示式作為被呼叫者。返回的表示式成為新的expr,我們迴圈檢查其結果是否被呼叫。
The code to parse the argument list is in this helper:
解析引數列表的程式碼在下面的工具方法中:
lox/Parser.java,在 unary()方法後新增:
private Expr finishCall(Expr callee) {
List<Expr> arguments = new ArrayList<>();
if (!check(RIGHT_PAREN)) {
do {
arguments.add(expression());
} while (match(COMMA));
}
Token paren = consume(RIGHT_PAREN,
"Expect ')' after arguments.");
return new Expr.Call(callee, paren, arguments);
}
This is more or less the
argumentsgrammar rule translated to code, except that we also handle the zero-argument case. We check for that case first by seeing if the next token is). If it is, we don’t try to parse any arguments.
這或多或少是arguments 語法規則翻譯成程式碼的結果,除了我們這裡還處理了無參情況。我們首先判斷下一個標記是否)來檢查這種情況。如果是,我們就不會嘗試解析任何引數。
Otherwise, we parse an expression, then look for a comma indicating that there is another argument after that. We keep doing that as long as we find commas after each expression. When we don’t find a comma, then the argument list must be done and we consume the expected closing parenthesis. Finally, we wrap the callee and those arguments up into a call AST node.
如果不是,我們就解析一個表示式,然後尋找逗號(表明後面還有一個引數)。只要我們在表示式後面發現逗號,就會繼續解析表示式。當我們找不到逗號時,說明引數列表已經結束,我們繼續消費預期的右括號。最終,我們將被呼叫者和這些引數封裝成一個函式呼叫的AST節點。
10 . 1 . 1 Maximum argument counts
10.1.1 最大引數數量
Right now, the loop where we parse arguments has no bound. If you want to call a function and pass a million arguments to it, the parser would have no problem with it. Do we want to limit that?
現在,我們解析引數的迴圈是沒有邊界的。如果你想呼叫一個函式並向其傳遞一百萬個引數,解析器不會有任何問題。我們要對此進行限制嗎?
Other languages have various approaches. The C standard says a conforming implementation has to support at least 127 arguments to a function, but doesn’t say there’s any upper limit. The Java specification says a method can accept no more than 255 arguments.
其它語言採用了不同的策略。C語言標準要求在符合標準的實現中,一個函式至少要支援127個引數,但是沒有指定任何上限。Java規範規定一個方法可以接受不超過255個引數3。
Our Java interpreter for Lox doesn’t really need a limit, but having a maximum number of arguments will simplify our bytecode interpreter in Part III. We want our two interpreters to be compatible with each other, even in weird corner cases like this, so we’ll add the same limit to jlox.
Lox的Java直譯器實際上並不需要限制,但是設定一個最大的引數數量限制可以簡化第三部分中的位元組碼直譯器。即使是在這樣奇怪的地方里,我們也希望兩個直譯器能夠相互相容,所以我們為jlox新增同樣的限制。
lox/Parser.java,在 finishCall()方法中新增:
do {
// 新增部分開始
if (arguments.size() >= 255) {
error(peek(), "Can't have more than 255 arguments.");
}
// 新增部分結束
arguments.add(expression());
Note that the code here reports an error if it encounters too many arguments, but it doesn’t throw the error. Throwing is how we kick into panic mode which is what we want if the parser is in a confused state and doesn’t know where it is in the grammar anymore. But here, the parser is still in a perfectly valid state—it just found too many arguments. So it reports the error and keeps on keepin’ on.
請注意,如果發現引數過多,這裡的程式碼會報告一個錯誤,但是不會丟擲該錯誤。丟擲錯誤是進入恐慌模式的方法,如果解析器處於混亂狀態,不知道自己在語法中處於什麼位置,那這就是我們想要的。但是在這裡,解析器仍然處於完全有效的狀態,只是發現了太多的引數。所以它會報告這個錯誤,並繼續執行解析。
10 . 1 . 2 Interpreting function calls
10.1.2 解釋函式呼叫
We don’t have any functions we can call, so it seems weird to start implementing calls first, but we’ll worry about that when we get there. First, our interpreter needs a new import.
我們還沒有任何可以呼叫的函式,所以先實現函式呼叫似乎有點奇怪,但是這個問題我們後面再考慮。首先,我們的直譯器需要引入一個新依賴。
lox/Interpreter.java
// 新增部分開始
import java.util.ArrayList;
// 新增部分結束
import java.util.List;
As always, interpretation starts with a new visit method for our new call expression node.
跟之前一樣,解釋工作從新的呼叫表示式節點對應的新的visit方法開始4。
lox/Interpreter.java,在 visitBinaryExpr()方法後新增:
@Override
public Object visitCallExpr(Expr.Call expr) {
Object callee = evaluate(expr.callee);
List<Object> arguments = new ArrayList<>();
for (Expr argument : expr.arguments) {
arguments.add(evaluate(argument));
}
LoxCallable function = (LoxCallable)callee;
return function.call(this, arguments);
}
First, we evaluate the expression for the callee. Typically, this expression is just an identifier that looks up the function by its name, but it could be anything. Then we evaluate each of the argument expressions in order and store the resulting values in a list.
首先,對被呼叫者的表示式求值。通常情況下,這個表示式只是一個識別符號,可以透過它的名字來查詢函式。但它可以是任何東西。然後,我們依次對每個參數列達式求值,並將結果值儲存在一個列表中。
Once we’ve got the callee and the arguments ready, all that remains is to perform the call. We do that by casting the callee to a LoxCallable and then invoking a
call()method on it. The Java representation of any Lox object that can be called like a function will implement this interface. That includes user-defined functions, naturally, but also class objects since classes are “called” to construct new instances. We’ll also use it for one more purpose shortly.
一旦我們準備好被呼叫者和引數,剩下的就是執行函式呼叫。我們將被呼叫者轉換為LoxCallable,然後對其呼叫call()方法來實現。任何可以像函式一樣被呼叫的Lox物件的Java表示都要實現這個介面。這自然包括使用者定義的函式,但也包括類物件,因為類會被 "呼叫 "來建立新的例項。稍後我們還將把它用於另一個目的。
There isn’t too much to this new interface.
這個新介面中沒有太多內容。
lox/LoxCallable.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.List;
interface LoxCallable {
Object call(Interpreter interpreter, List<Object> arguments);
}
We pass in the interpreter in case the class implementing
call()needs it. We also give it the list of evaluated argument values. The implementer’s job is then to return the value that the call expression produces.
我們會傳入直譯器,以防實現call()方法的類會需要它。我們也會提供已求值的引數值列表。介面實現者的任務就是返回呼叫表示式產生的值。
10 . 1 . 3 Call type errors
10.1.3 呼叫型別錯誤
Before we get to implementing LoxCallable, we need to make the visit method a little more robust. It currently ignores a couple of failure modes that we can’t pretend won’t occur. First, what happens if the callee isn’t actually something you can call? What if you try to do this:
在實現LoxCallable之前,必須先強化一下我們的visit方法。這個方法忽略了兩個可能出現的錯誤場景。第一個,如果被呼叫者無法被呼叫,會發生什麼?比如:
"totally not a function"();
Strings aren’t callable in Lox. The runtime representation of a Lox string is a Java string, so when we cast that to LoxCallable, the JVM will throw a ClassCastException. We don’t want our interpreter to vomit out some nasty Java stack trace and die. Instead, we need to check the type ourselves first.
在Lox中,字串不是可呼叫的資料型別。Lox字串在執行時中的本質其實是java字串,所以當我們把它當作LoxCallable 處理的時候,JVM就會丟擲ClassCastException。我們並不想讓我們的直譯器吐出一坨java堆疊資訊然後掛掉。所以,我們自己必須先做一次型別檢查。
lox/Interpreter.java,在visitCallExpr介面中新增:
// 新增部分開始
if (!(callee instanceof LoxCallable)) {
throw new RuntimeError(expr.paren,
"Can only call functions and classes.");
}
// 新增部分結束
LoxCallable function = (LoxCallable)callee;
We still throw an exception, but now we’re throwing our own exception type, one that the interpreter knows to catch and report gracefully.
我們的實現同樣也是丟擲錯誤,但它們能夠被直譯器捕獲並優雅地展示出來。
10 . 1 . 4 Checking arity
10.1.4 檢查元數
The other problem relates to the function’s arity. Arity is the fancy term for the number of arguments a function or operation expects. Unary operators have arity one, binary operators two, etc. With functions, the arity is determined by the number of parameters it declares.
另一個問題與函式的元數有關。元數是一個花哨的術語,指一個函式或操作所期望的引數數量。一元運算子的元數是1,二元運算子是2,等等。對於函式來說,元數由函式宣告的引數數量決定。
fun add(a, b, c) {
print a + b + c;
}
This function defines three parameters,
a,b, andc, so its arity is three and it expects three arguments. So what if you try to call it like this:
這個函式定義了三個形參,a 、b 和c,所以它的元數是3,而且它期望有3個引數。那麼如果你用下面的方式呼叫該函式會怎樣:
add(1, 2, 3, 4); // Too many.
add(1, 2); // Too few.
Different languages take different approaches to this problem. Of course, most statically typed languages check this at compile time and refuse to compile the code if the argument count doesn’t match the function’s arity. JavaScript discards any extra arguments you pass. If you don’t pass enough, it fills in the missing parameters with the magic sort-of-like-null-but-not-really value
undefined. Python is stricter. It raises a runtime error if the argument list is too short or too long.
不同的語言對這個問題採用了不同的方法。當然,大多數靜態型別的語言在編譯時都會檢查這個問題,如果實參與函式元數不匹配,則拒絕編譯程式碼。JavaScript會丟棄你傳遞的所有多餘引數。如果你沒有傳入的引數數量不足,它就會用神奇的與null類似但並不相同的值undefined來填補缺少的引數。Python更嚴格。如果引數列表太短或太長,它會引發一個執行時錯誤。
I think the latter is a better approach. Passing the wrong number of arguments is almost always a bug, and it’s a mistake I do make in practice. Given that, the sooner the implementation draws my attention to it, the better. So for Lox, we’ll take Python’s approach. Before invoking the callable, we check to see if the argument list’s length matches the callable’s arity.
我認為後者是一種更好的方法。傳遞錯誤的引數數量幾乎總是一個錯誤,這也是我在實踐中確實犯的一個錯誤。有鑑於此,語言實現能越早引起使用者的注意就越好。所以對於Lox,我們將採取Python的方法。在執行可呼叫方法之前,我們檢查引數列表的長度是否與可呼叫方法的元數相符。
lox/Interpreter.java,在 visitCallExpr()方法中新增程式碼:
LoxCallable function = (LoxCallable)callee;
// 新增部分開始
if (arguments.size() != function.arity()) {
throw new RuntimeError(expr.paren, "Expected " +
function.arity() + " arguments but got " +
arguments.size() + ".");
}
// 新增部分結束
return function.call(this, arguments);
That requires a new method on the LoxCallable interface to ask it its arity.
這就需要在LoxCallable介面中增加一個新方法來查詢函式的元數。
lox/LoxCallable.java,在LoxCallable介面中新增:
interface LoxCallable {
// 新增部分開始
int arity();
// 新增部分結束
Object call(Interpreter interpreter, List<Object> arguments);
We could push the arity checking into the concrete implementation of
call(). But, since we’ll have multiple classes implementing LoxCallable, that would end up with redundant validation spread across a few classes. Hoisting it up into the visit method lets us do it in one place.
我們可以在call()方法的具體實現中做元數檢查。但是,由於我們會有多個實現LoxCallable的類,這將導致冗餘的驗證分散在多個類中。把它提升到訪問方法中,這樣我們可以在一個地方完成該功能。
10 . 2 Native Functions
10.2 原生函式(本地函式)
We can theoretically call functions, but we have no functions to call yet. Before we get to user-defined functions, now is a good time to introduce a vital but often overlooked facet of language implementations—native functions. These are functions that the interpreter exposes to user code but that are implemented in the host language (in our case Java), not the language being implemented (Lox).
理論上我們可以呼叫函式了,但是我們還沒有可供呼叫的函式。在我們實現使用者自定義函式之前,現在正好可以介紹語言實現中一個重要但經常被忽視的方面——原生函式(本地函式)。這些函式是直譯器向用戶程式碼公開的,但它們是用宿主語言(在我們的例子中是Java)實現的,而不是正在實現的語言(Lox)。
Sometimes these are called primitives, external functions, or foreign functions. Since these functions can be called while the user’s program is running, they form part of the implementation’s runtime. A lot of programming language books gloss over these because they aren’t conceptually interesting. They’re mostly grunt work.
有時這些函式也被稱為原語、外部函式或外來函式5。由於這些函式可以在使用者程式執行的時候被呼叫,因此它們構成了語言執行時的一部分。許多程式語言書籍都掩蓋了這些內容,因為它們在概念上並不有趣。它們主要是一些比較繁重的工作。
But when it comes to making your language actually good at doing useful stuff, the native functions your implementation provides are key. They provide access to the fundamental services that all programs are defined in terms of. If you don’t provide native functions to access the file system, a user’s going to have a hell of a time writing a program that reads and displays a file.
但是說到讓你的語言真正擅長做有用的事情,語言提供的本地函式是關鍵6。本地函式提供了對基礎服務的訪問,所有的程式都是根據這些服務來定義的。如果你不提供訪問檔案系統的本地函式,那麼使用者在寫一個讀取和顯示檔案的程式時就會有很大的困難。
Many languages also allow users to provide their own native functions. The mechanism for doing so is called a foreign function interface (FFI), native extension, native interface, or something along those lines. These are nice because they free the language implementer from providing access to every single capability the underlying platform supports. We won’t define an FFI for jlox, but we will add one native function to give you an idea of what it looks like.
許多語言還允許使用者提供自己的本地函式。這樣的機制稱為外來函式介面(FFI)、本機擴充套件、本機介面或類似的東西。這些機制很好,因為它們使語言實現者無需提供對底層平臺所支援的每一項功能的訪問。我們不會為 jlox 定義一個 FFI,但我們會新增一個本地函式,讓你知道它是什麼樣子。
10 . 2 . 1 Telling time
10.2.1 報時
When we get to Part III and start working on a much more efficient implementation of Lox, we’re going to care deeply about performance. Performance work requires measurement, and that in turn means benchmarks. These are programs that measure the time it takes to exercise some corner of the interpreter.
當我們進入第三部分,開始著手開發更有效的Lox實現時,我們就會非常關心效能。效能需要測量,這也就意味著需要基準測試。這些程式碼就是用於測量直譯器執行某些程式碼時所花費的時間。
We could measure the time it takes to start up the interpreter, run the benchmark, and exit, but that adds a lot of overhead—JVM startup time, OS shenanigans, etc. That stuff does matter, of course, but if you’re just trying to validate an optimization to some piece of the interpreter, you don’t want that overhead obscuring your results.
我們可以測量啟動直譯器、執行基準測試程式碼並退出所消耗的時間,但是這其中包括很多時間開銷——JVM啟動時間,作業系統欺詐等等。當然,這些東西確實很重要,但如果您只是試圖驗證對直譯器某個部分的最佳化,你肯定不希望這些多餘的時間開銷掩蓋你的結果。
A nicer solution is to have the benchmark script itself measure the time elapsed between two points in the code. To do that, a Lox program needs to be able to tell time. There’s no way to do that now—you can’t implement a useful clock “from scratch” without access to the underlying clock on the computer.
一個更好的解決方案是讓基準指令碼本身度量程式碼中兩個點之間的時間間隔。要做到這一點,Lox程式需要能夠報時。現在沒有辦法做到這一點——如果不訪問計算機上的底層時鐘,就無法從頭實現一個可用的時鐘。
So we’ll add
clock(), a native function that returns the number of seconds that have passed since some fixed point in time. The difference between two successive invocations tells you how much time elapsed between the two calls. This function is defined in the global scope, so let’s ensure the interpreter has access to that.
所以我們要新增clock(),這是一個本地函式,用於返回自某個固定時間點以來所經過的秒數。兩次連續呼叫之間的差值可用告訴你兩次呼叫之間經過了多少時間。這個函式被定義在全域性作用域內,以確保直譯器能夠訪問這個函式。
lox/Interpreter.java,在 Interpreter類中,替換一行:
class Interpreter implements Expr.Visitor<Object>,
Stmt.Visitor<Void> {
// 替換部分開始
final Environment globals = new Environment();
private Environment environment = globals;
// 替換部分結束
void interpret(List<Stmt> statements) {
The
environmentfield in the interpreter changes as we enter and exit local scopes. It tracks the current environment. This newglobalsfield holds a fixed reference to the outermost global environment.
直譯器中的environment欄位會隨著進入和退出區域性作用域而改變,它會跟隨當前環境。新加的globals欄位則固定指向最外層的全域性作用域。
When we instantiate an Interpreter, we stuff the native function in that global scope.
當我們例項化一個直譯器時,我們將全域性作用域中新增本地函式。
lox/Interpreter.java,在 Interpreter類中新增:
private Environment environment = globals;
// 新增部分開始
Interpreter() {
globals.define("clock", new LoxCallable() {
@Override
public int arity() { return 0; }
@Override
public Object call(Interpreter interpreter,
List<Object> arguments) {
return (double)System.currentTimeMillis() / 1000.0;
}
@Override
public String toString() { return "<native fn>"; }
});
}
// 新增部分結束
void interpret(List<Stmt> statements) {
This defines a variable named “clock”. Its value is a Java anonymous class that implements LoxCallable. The
clock()function takes no arguments, so its arity is zero. The implementation ofcall()calls the corresponding Java function and converts the result to a double value in seconds.
這裡有一個名為clock的變數,它的值是一個實現LoxCallable介面的Java匿名類。這裡的clock()函式不接受引數,所以其元數為0。call()方法的實現是直接呼叫Java函式並將結果轉換為以秒為單位的double值。
If we wanted to add other native functions—reading input from the user, working with files, etc.—we could add them each as their own anonymous class that implements LoxCallable. But for the book, this one is really all we need.
如果我們想要新增其它本地函式——讀取使用者輸入,處理檔案等等——我們可以依次為它們提供實現LoxCallable介面的匿名類。但是在本書中,這個函式足以滿足需要。
Let’s get ourselves out of the function-defining business and let our users take over . . .
讓我們從函式定義的事務中解脫出來,由使用者來接管吧。
10 . 3 Function Declarations
10.3 函式宣告
We finally get to add a new production to the
declarationrule we introduced back when we added variables. Function declarations, like variables, bind a new name. That means they are allowed only in places where a declaration is permitted.
我們終於可以在新增變數時就引入的declaration規則中新增產生式了。就像變數一樣,函式宣告也會繫結一個新的名稱。這意味中它們只能出現在允許宣告的地方。
declaration → funDecl
| varDecl
| statement ;
The updated
declarationrule references this new rule:
更新後的declaration引用了下面的新規則:
funDecl → "fun" function ;
function → IDENTIFIER "(" parameters? ")" block ;
The main
funDeclrule uses a separate helper rulefunction. A function declaration statement is thefunkeyword followed by the actual function-y stuff. When we get to classes, we’ll reuse thatfunctionrule for declaring methods. Those look similar to function declarations, but aren’t preceded byfun.
主要的funDecl規則使用了一個單獨的輔助規則function。函式宣告語句是fun關鍵字後跟實際的函式體內容。等到我們實現類的時候,將會複用function規則來宣告方法。這些方法與函式宣告類似,但是前面沒有fun。
The function itself is a name followed by the parenthesized parameter list and the body. The body is always a braced block, using the same grammar rule that block statements use. The parameter list uses this rule:
函式本身是一個名稱,後跟帶括號的引數列表和函式體。函式體是一個帶花括號的塊,可以使用與塊語句相同的語法。引數列表則使用以下規則:
parameters → IDENTIFIER ( "," IDENTIFIER )* ;
It’s like the earlier
argumentsrule, except that each parameter is an identifier, not an expression. That’s a lot of new syntax for the parser to chew through, but the resulting AST node isn’t too bad.
這就類似於前面的arguments 規則,區別在於引數是一個識別符號,而不是一個表示式。這對於解析器來說是很多要處理的新語法,但是生成的AST節點沒這麼複雜。
tool/GenerateAst.java,在 main()方法中新增:
"Expression : Expr expression",
// 新增部分開始
"Function : Token name, List<Token> params," +
" List<Stmt> body",
// 新增部分結束
"If : Expr condition, Stmt thenBranch," +
A function node has a name, a list of parameters (their names), and then the body. We store the body as the list of statements contained inside the curly braces.
函式節點有一個名稱、一個引數列表(引數的名稱),然後是函式主體。我們將函式主體儲存為包含在花括號中的語句列表。
Over in the parser, we weave in the new declaration.
在解析器中,我們把新的宣告新增進去。
lox/Parser.java,在 declaration()方法中新增:
try {
// 新增部分開始
if (match(FUN)) return function("function");
// 新增部分結束
if (match(VAR)) return varDeclaration();
Like other statements, a function is recognized by the leading keyword. When we encounter
fun, we callfunction. That corresponds to thefunctiongrammar rule since we already matched and consumed thefunkeyword. We’ll build the method up a piece at a time, starting with this:
像其它語句一樣,函式是透過前面的關鍵字來識別的。當我們遇到fun時,我們就呼叫function。這步操作對應於function語法規則,因為我們已經匹配並消費了fun關鍵字。我們會一步步構建這個方法,首先從下面的程式碼開始:
lox/Parser.java,在 expressionStatement()方法後新增:
private Stmt.Function function(String kind) {
Token name = consume(IDENTIFIER, "Expect " + kind + " name.");
}
Right now, it only consumes the identifier token for the function’s name. You might be wondering about that funny little
kindparameter. Just like we reuse the grammar rule, we’ll reuse thefunction()method later to parse methods inside classes. When we do that, we’ll pass in “method” forkindso that the error messages are specific to the kind of declaration being parsed.
現在,它只是消費了識別符號標記作為函式名稱。你可能會對這裡的kind引數感到疑惑。就像我們複用語法規則一樣,稍後我們也會複用function()方法來解析類中的方法。到時候,我們會在kind引數中傳入 "method",這樣錯誤資訊就會針對被解析的宣告型別來展示。
Next, we parse the parameter list and the pair of parentheses wrapped around it.
接下來,我們要解析引數列表和包裹著它們的一對小括號。
lox/Parser.java,在 function()方法中新增:
Token name = consume(IDENTIFIER, "Expect " + kind + " name.");
// 新增部分開始
consume(LEFT_PAREN, "Expect '(' after " + kind + " name.");
List<Token> parameters = new ArrayList<>();
if (!check(RIGHT_PAREN)) {
do {
if (parameters.size() >= 255) {
error(peek(), "Can't have more than 255 parameters.");
}
parameters.add(
consume(IDENTIFIER, "Expect parameter name."));
} while (match(COMMA));
}
consume(RIGHT_PAREN, "Expect ')' after parameters.");
// 新增部分結束
}
This is like the code for handling arguments in a call, except not split out into a helper method. The outer
ifstatement handles the zero parameter case, and the innerwhileloop parses parameters as long as we find commas to separate them. The result is the list of tokens for each parameter’s name.
這就像在函式呼叫中處理引數的程式碼一樣,只是沒有拆分到一個輔助方法中。外部的if語句用於處理零引數的情況,內部的while會迴圈解析引數,只要能找到分隔引數的逗號。其結果是包含每個引數名稱的標記列表。
Just like we do with arguments to function calls, we validate at parse time that you don’t exceed the maximum number of parameters a function is allowed to have.
就像我們處理函式呼叫的引數一樣,我們在解析時驗證是否超過了一個函式所允許的最大引數數。
Finally, we parse the body and wrap it all up in a function node.
最後,我們解析函式主體,並將其封裝為一個函式節點。
lox/Parser.java,在 function()方法中新增:
consume(RIGHT_PAREN, "Expect ')' after parameters.");
// 新增部分開始
consume(LEFT_BRACE, "Expect '{' before " + kind + " body.");
List<Stmt> body = block();
return new Stmt.Function(name, parameters, body);
// 新增部分結束
}
Note that we consume the
{at the beginning of the body here before callingblock(). That’s becauseblock()assumes the brace token has already been matched. Consuming it here lets us report a more precise error message if the{isn’t found since we know it’s in the context of a function declaration.
請注意,在呼叫block()方法之前,我們已經消費了函式體開頭的{。這是因為block()方法假定大括號標記已經匹配了。在這裡消費該標記可以讓我們在找不到{的情況下報告一個更精確的錯誤資訊,因為我們知道當前是在一個函式宣告的上下文中。
10 . 4 Function Objects
10.4 函式物件
We’ve got some syntax parsed so usually we’re ready to interpret, but first we need to think about how to represent a Lox function in Java. We need to keep track of the parameters so that we can bind them to argument values when the function is called. And, of course, we need to keep the code for the body of the function so that we can execute it.
我們已經解析了一些語法,通常我們要開始準備解釋了,但是我們首先需要思考一下,在Java中如何表示一個Lox函式。我們需要跟蹤形參,以便在函式被呼叫時可以將形參與實參值進行繫結。當然,我們也要保留函式體的程式碼,以便我們可以執行它。
That’s basically what the Stmt.Function class is. Could we just use that? Almost, but not quite. We also need a class that implements LoxCallable so that we can call it. We don’t want the runtime phase of the interpreter to bleed into the front end’s syntax classes so we don’t want Stmt.Function itself to implement that. Instead, we wrap it in a new class.
這基本上就是Stmt.Function的內容。我們可以用這個嗎?差不多,但還不夠。我們還需要一個實現LoxCallable的類,以便我們可以呼叫它。我們不希望直譯器的執行時階段滲入到前端語法類中,所以我們不希望使用Stmt.Function本身來實現它。相反,我們將它包裝在一個新類中。
lox/LoxFunction.java, 建立新檔案:
package com.craftinginterpreters.lox;
import java.util.List;
class LoxFunction implements LoxCallable {
private final Stmt.Function declaration;
LoxFunction(Stmt.Function declaration) {
this.declaration = declaration;
}
}
We implement the
call()of LoxCallable like so:
使用如下方式實現LoxCallable的call()方法:
lox/LoxFunction.java,在 LoxFunction()方法後新增:
@Override
public Object call(Interpreter interpreter,
List<Object> arguments) {
Environment environment = new Environment(interpreter.globals);
for (int i = 0; i < declaration.params.size(); i++) {
environment.define(declaration.params.get(i).lexeme,
arguments.get(i));
}
interpreter.executeBlock(declaration.body, environment);
return null;
}
This handful of lines of code is one of the most fundamental, powerful pieces of our interpreter. As we saw in the chapter on statements and state, managing name environments is a core part of a language implementation. Functions are deeply tied to that.
這幾行程式碼是我們的直譯器中最基本、最強大的部分之一。正如我們在上一章中所看到的,管理名稱環境是語言實現中的核心部分。函式與此緊密相關。
Parameters are core to functions, especially the fact that a function encapsulates its parameters—no other code outside of the function can see them. This means each function gets its own environment where it stores those variables.
引數是函式的核心,尤其是考慮到函式封裝了其引數——函式之外的程式碼看不到這些引數。這意味著每個函式都會維護自己的環境,其中儲存著那些變數。
Further, this environment must be created dynamically. Each function call gets its own environment. Otherwise, recursion would break. If there are multiple calls to the same function in play at the same time, each needs its own environment, even though they are all calls to the same function.
此外,這個環境必須是動態建立的。每次函式呼叫都會獲得自己的環境,否則,遞迴就會中斷。如果在同一時刻對相同的函式有多次呼叫,那麼每個呼叫都需要自身的環境,即便它們都是對相同函式的呼叫。
For example, here’s a convoluted way to count to three:
舉例來說,下面是一個計數到3的複雜方法:
fun count(n) {
if (n > 1) count(n - 1);
print n;
}
count(3);
Imagine we pause the interpreter right at the point where it’s about to print 1 in the innermost nested call. The outer calls to print 2 and 3 haven’t printed their values yet, so there must be environments somewhere in memory that still store the fact that
nis bound to 3 in one context, 2 in another, and 1 in the innermost, like:
假設一下,如果我們在最內層的巢狀呼叫中即將列印1的時候暫停了直譯器。列印2和3的外部呼叫還沒有打印出它們的值,所以在記憶體的某個地方一定有環境仍然儲存著這樣的資料:n在一個上下文中被繫結到3,在另一個上下文中被繫結到2,而在最內層呼叫中繫結為1,比如:

That’s why we create a new environment at each call, not at the function declaration. The
call()method we saw earlier does that. At the beginning of the call, it creates a new environment. Then it walks the parameter and argument lists in lockstep. For each pair, it creates a new variable with the parameter’s name and binds it to the argument’s value.
這就是為什麼我們在每次呼叫時建立一個新的環境,而不是在函式宣告時建立。我們前面看到的call()方法就是這樣做的。在呼叫開始的時候,它建立了一個新環境。然後它以同步的方式遍歷形參和實參列表。對於每一對引數,它用形參的名字建立一個新的變數,並將其與實參的值繫結。
So, for a program like this:
所以,對於類似下面這樣的程式碼:
fun add(a, b, c) {
print a + b + c;
}
add(1, 2, 3);
At the point of the call to
add(), the interpreter creates something like this:
在呼叫add()時,直譯器會建立類似下面這樣的內容:

Then
call()tells the interpreter to execute the body of the function in this new function-local environment. Up until now, the current environment was the environment where the function was being called. Now, we teleport from there inside the new parameter space we’ve created for the function.
然後call()會告訴直譯器在這個新的函式區域性環境中執行函式體。在此之前,當前環境是函式被呼叫的位置所處的環境。現在,我們轉入了為函式建立的新的引數空間中。
This is all that’s required to pass data into the function. By using different environments when we execute the body, calls to the same function with the same code can produce different results.
這就是將資料傳入函式所需的全部內容。透過在執行函式主體時使用不同的環境,用同樣的程式碼呼叫相同的函式可以產生不同的結果。
Once the body of the function has finished executing,
executeBlock()discards that function-local environment and restores the previous one that was active back at the callsite. Finally,call()returnsnull, which returnsnilto the caller. (We’ll add return values later.)
一旦函式的主體執行完畢,executeBlock()就會丟棄該函式的本地環境,並恢復呼叫該函式前的活躍環境。最後,call()方法會返回null,它向呼叫者返回nil。(我們會在稍後新增返回值)
Mechanically, the code is pretty simple. Walk a couple of lists. Bind some new variables. Call a method. But this is where the crystalline code of the function declaration becomes a living, breathing invocation. This is one of my favorite snippets in this entire book. Feel free to take a moment to meditate on it if you’re so inclined.
從機制上講,這段程式碼是非常簡單的。遍歷幾個列表,繫結一些新變數,呼叫一個方法。但這就是將程式碼塊變成有生命力的呼叫執行的地方。這是我在整本書中最喜歡的片段之一。如果你願意的話,可以花點時間好好思考一下。
Done? OK. Note when we bind the parameters, we assume the parameter and argument lists have the same length. This is safe because
visitCallExpr()checks the arity before callingcall(). It relies on the function reporting its arity to do that.
完成了嗎?好的。注意當我們繫結引數時,我們假設引數和引數列表具有相同的長度。這是安全的,因為visitCallExpr()在呼叫call()之前會檢查元數。它依靠報告其元數的函式來做到這一點。
lox/LoxFunction.java,在 LoxFunction()方法後新增:
@Override
public int arity() {
return declaration.params.size();
}
That’s most of our object representation. While we’re in here, we may as well implement
toString().
這基本就是我們的函式物件表示了。既然已經到了這一步,我們也可以實現toString()。
lox/LoxFunction.java,在 LoxFunction()方法後新增:
@Override
public String toString() {
return "<fn " + declaration.name.lexeme + ">";
}
This gives nicer output if a user decides to print a function value.
如果使用者要列印函式的值,該方法能提供一個更漂亮的輸出值。
fun add(a, b) {
print a + b;
}
print add; // "<fn add>".
10 . 4 . 1 Interpreting function declarations
10.4.1 解釋函式宣告
We’ll come back and refine LoxFunction soon, but that’s enough to get started. Now we can visit a function declaration.
我們很快就會回頭來完善LoxFunction,但是現在已足夠開始進行解釋了。現在,我們可以訪問函式宣告節點了。
lox/Interpreter.java,在 visitExpressionStmt()方法後新增:
@Override
public Void visitFunctionStmt(Stmt.Function stmt) {
LoxFunction function = new LoxFunction(stmt);
environment.define(stmt.name.lexeme, function);
return null;
}
This is similar to how we interpret other literal expressions. We take a function syntax node—a compile-time representation of the function—and convert it to its runtime representation. Here, that’s a LoxFunction that wraps the syntax node.
這類似於我們介紹其它文字表示式的方式。我們會接收一個函式語法節點——函式的編譯時表示形式——然後將其轉換為執行時表示形式。在這裡就是一個封裝了語法節點的LoxFunction例項。
Function declarations are different from other literal nodes in that the declaration also binds the resulting object to a new variable. So, after creating the LoxFunction, we create a new binding in the current environment and store a reference to it there.
函式宣告與其它文字節點的不同之處在於,宣告還會將結果物件繫結到一個新的變數。因此,在建立LoxFunction之後,我們在當前環境中建立一個新的繫結,並在其中儲存對該函式的引用。
With that, we can define and call our own functions all within Lox. Give it a try:
這樣,我們就可以在Lox中定義和呼叫我們自己的函式。試一下:
fun sayHi(first, last) {
print "Hi, " + first + " " + last + "!";
}
sayHi("Dear", "Reader");
I don’t know about you, but that looks like an honest-to-God programming language to me.
我不知道你怎麼想的,但對我來說,這看起來像是一種虔誠的程式語言。
10 . 5 Return Statements
10.5 Return語句
We can get data into functions by passing parameters, but we’ve got no way to get results back out. If Lox were an expression-oriented language like Ruby or Scheme, the body would be an expression whose value is implicitly the function’s result. But in Lox, the body of a function is a list of statements which don’t produce values, so we need dedicated syntax for emitting a result. In other words,
returnstatements. I’m sure you can guess the grammar already.
我們可以透過傳遞引數將資料輸入函式中,但是我們沒有辦法將結果傳出來。如果Lox是像Ruby或Scheme那樣的面向表示式的語言,那麼函式體就是一個表示式,其值就隱式地作為函式的結果。但是在Lox中,函式體是一個不產生值的語句列表,所有我們需要專門的語句來發出結果。換句話說,就是return語句。我相信你已經能猜出語法了。
statement → exprStmt
| forStmt
| ifStmt
| printStmt
| returnStmt
| whileStmt
| block ;
returnStmt → "return" expression? ";" ;
We’ve got one more—the final, in fact—production under the venerable
statementrule. Areturnstatement is thereturnkeyword followed by an optional expression and terminated with a semicolon.
我們又得到一個statement規則下的新產生式(實際上也是最後一個)。一個return語句就是一個return關鍵字,後跟一個可選的表示式,並以一個分號結尾。
The return value is optional to support exiting early from a function that doesn’t return a useful value. In statically typed languages, “void” functions don’t return a value and non-void ones do. Since Lox is dynamically typed, there are no true void functions. The compiler has no way of preventing you from taking the result value of a call to a function that doesn’t contain a
returnstatement.
返回值是可選的,用以支援從一個不返回有效值的函式中提前退出。在靜態型別語言中,void函式不返回值,而非void函式返回值。由於Lox是動態型別的,所以沒有真正的void函式。在呼叫一個不包含return語句的函式時,編譯器沒有辦法阻止你獲取其結果值。
fun procedure() {
print "don't return anything";
}
var result = procedure();
print result; // ?
This means every Lox function must return something, even if it contains no
returnstatements at all. We usenilfor this, which is why LoxFunction’s implementation ofcall()returnsnullat the end. In that same vein, if you omit the value in areturnstatement, we simply treat it as equivalent to:
這意味著每個Lox函式都要返回一些內容,即使其中根本不包含return語句。我們使用nil,這就是為什麼LoxFunction的call()實現在最後返回null。同樣,如果你省略了return 語句中的值,我們將其視為等價於:
return nil;
Over in our AST generator, we add a new node.
在AST生成器中,新增一個新節點。
tool/GenerateAst.java,在 main()方法中新增:
"Print : Expr expression",
// 新增部分開始
"Return : Token keyword, Expr value",
// 新增部分結束
"Var : Token name, Expr initializer",
It keeps the
returnkeyword token so we can use its location for error reporting, and the value being returned, if any. We parse it like other statements, first by recognizing the initial keyword.
其中保留了return關鍵字標記(這樣我們可以使用該標記的位置來報告錯誤),以及返回的值(如果有的話)。我們像解析其它語句一樣來解析它,首先識別起始的關鍵字。
lox/Parser.java,在 statement()方法中新增:
if (match(PRINT)) return printStatement();
// 新增部分開始
if (match(RETURN)) return returnStatement();
// 新增部分結束
if (match(WHILE)) return whileStatement();
That branches out to:
分支會跳轉到:
lox/Parser.java,在 printStatement()方法後新增:
private Stmt returnStatement() {
Token keyword = previous();
Expr value = null;
if (!check(SEMICOLON)) {
value = expression();
}
consume(SEMICOLON, "Expect ';' after return value.");
return new Stmt.Return(keyword, value);
}
After snagging the previously consumed
returnkeyword, we look for a value expression. Since many different tokens can potentially start an expression, it’s hard to tell if a return value is present. Instead, we check if it’s absent. Since a semicolon can’t begin an expression, if the next token is that, we know there must not be a value.
在捕獲先前消耗的return關鍵字之後,我們會尋找一個值表示式。因為很多不同的標記都可以引出一個表示式,所以很難判斷是否存在返回值。相反,我們檢查它是否不存在。因為分號不能作為表示式的開始,如果下一個標記是分號,我們就知道一定沒有返回值。
10 . 5 . 1 Returning from calls
10.5.1 從函式呼叫中返回
Interpreting a
returnstatement is tricky. You can return from anywhere within the body of a function, even deeply nested inside other statements. When the return is executed, the interpreter needs to jump all the way out of whatever context it’s currently in and cause the function call to complete, like some kind of jacked up control flow construct.
解釋return語句是很棘手的。你可以從函式體中的任何位置返回,甚至是深深巢狀在其它語句中的位置。當返回語句被執行時,直譯器需要完全跳出當前所在的上下文,完成函式呼叫,就像某種頂層的控制流結構。
For example, say we’re running this program and we’re about to execute the
returnstatement:
舉例來說,假設我們正在執行下面的程式碼,並且我們即將執行return語句:
fun count(n) {
while (n < 100) {
if (n == 3) return n; // <--
print n;
n = n + 1;
}
}
count(1);
The Java call stack currently looks roughly like this:
Java呼叫棧目前看起來大致如下所示:
Interpreter.visitReturnStmt()
Interpreter.visitIfStmt()
Interpreter.executeBlock()
Interpreter.visitBlockStmt()
Interpreter.visitWhileStmt()
Interpreter.executeBlock()
LoxFunction.call()
Interpreter.visitCallExpr()
We need to get from the top of the stack all the way back to
call(). I don’t know about you, but to me that sounds like exceptions. When we execute areturnstatement, we’ll use an exception to unwind the interpreter past the visit methods of all of the containing statements back to the code that began executing the body.
我們需要從棧頂一直回退到call()。我不知道你怎麼想,但是對我來說,這聽起來很像是異常。當我們執行return語句時,我們會使用一個異常來解開直譯器,經過所有函式內含語句的visit方法,一直回退到開始執行函式體的程式碼。
The visit method for our new AST node looks like this:
新的AST節點的visit方法如下所示:
lox/Interpreter.java,在 visitPrintStmt()方法後新增:
@Override
public Void visitReturnStmt(Stmt.Return stmt) {
Object value = null;
if (stmt.value != null) value = evaluate(stmt.value);
throw new Return(value);
}
If we have a return value, we evaluate it, otherwise, we use
nil. Then we take that value and wrap it in a custom exception class and throw it.
如果我們有返回值,就對其求值,否則就使用nil。然後我們取這個值並將其封裝在一個自定義的異常類中,並丟擲該異常。
lox/Return.java,建立新檔案:
package com.craftinginterpreters.lox;
class Return extends RuntimeException {
final Object value;
Return(Object value) {
super(null, null, false, false);
this.value = value;
}
}
This class wraps the return value with the accoutrements Java requires for a runtime exception class. The weird super constructor call with those
nullandfalsearguments disables some JVM machinery that we don’t need. Since we’re using our exception class for control flow and not actual error handling, we don’t need overhead like stack traces.
這個類使用Java執行時異常類來封裝返回值。其中那個奇怪的帶有null和false的父類構造器方法,停用了一些我們不需要的JVM機制。因為我們只是使用該異常類來控制流,而不是真正的錯誤處理,所以我們不需要像堆疊跟蹤這樣的開銷。
We want this to unwind all the way to where the function call began, the
call()method in LoxFunction.
我們希望可以一直跳出到函式呼叫開始的地方,也就是LoxFunction中的call()方法。
lox/LoxFunction.java,在 call()方法中替換一行:
arguments.get(i));
}
// 替換部分開始
try {
interpreter.executeBlock(declaration.body, environment);
} catch (Return returnValue) {
return returnValue.value;
}
// 替換部分結束
return null;
We wrap the call to
executeBlock()in a try-catch block. When it catches a return exception, it pulls out the value and makes that the return value fromcall(). If it never catches one of these exceptions, it means the function reached the end of its body without hitting areturnstatement. In that case, it implicitly returnsnil.
我們將對executeBlock()的呼叫封裝在一個try-catch塊中。當捕獲一個返回異常時,它會取出其中的值並將其作為call()方法的返回值。如果沒有捕獲任何異常,意味著函式到達了函式體的末尾,而且沒有遇到return語句。在這種情況下,隱式地返回nil。
Let’s try it out. We finally have enough power to support this classic example—a recursive function to calculate Fibonacci numbers:
我們來試一下。我們終於有能力支援這個經典的例子——遞迴函式計算Fibonacci數7:
fun fib(n) {
if (n <= 1) return n;
return fib(n - 2) + fib(n - 1);
}
for (var i = 0; i < 20; i = i + 1) {
print fib(i);
}
This tiny program exercises almost every language feature we have spent the past several chapters implementing—expressions, arithmetic, branching, looping, variables, functions, function calls, parameter binding, and returns.
這個小程式練習了我們在過去幾章中實現的幾乎所有語言特性,包括表示式、算術運算、分支、迴圈、變數、函式、函式呼叫、引數繫結和返回。
10 . 6 Local Functions and Closures
10.6 區域性函式和閉包
Our functions are pretty full featured, but there is one hole to patch. In fact, it’s a big enough gap that we’ll spend most of the next chapter sealing it up, but we can get started here.
我們的函式功能已經相當全面了,但是還有一個漏洞需要修補。實際上,這是一個很大的問題,我們將會在下一章中花費大部分時間來修補它,但是我們可以從這裡開始。
LoxFunction’s implementation of
call()creates a new environment where it binds the function’s parameters. When I showed you that code, I glossed over one important point: What is the parent of that environment?
LoxFunction中的call()實現建立了一個新的環境,並在其中綁定了函式的引數。當我向你展示這段程式碼時,我忽略了一個重要的問題:這個環境的父類是什麼?
Right now, it is always
globals, the top-level global environment. That way, if an identifier isn’t defined inside the function body itself, the interpreter can look outside the function in the global scope to find it. In the Fibonacci example, that’s how the interpreter is able to look up the recursive call tofibinside the function’s own body—fibis a global variable.
目前,它始終是globals,即頂級的全域性環境。這樣,如果一個識別符號不是在函式體內部定義的,直譯器可以在函式外部的全域性作用域中查詢它。在Fibonacci的例子中,這就是直譯器如何能夠在函式體中實現對fib的遞迴呼叫——fib是一個全域性變數。
But recall that in Lox, function declarations are allowed anywhere a name can be bound. That includes the top level of a Lox script, but also the inside of blocks or other functions. Lox supports local functions that are defined inside another function, or nested inside a block.
但請記住,在Lox中,允許在可以繫結名字的任何地方進行函式宣告。其中包括Lox指令碼的頂層,但也包括塊或其他函式的內部。Lox支援在另一個函式內定義或在一個塊內巢狀的區域性函式。
Consider this classic example:
考慮下面這個經典的例子:
fun makeCounter() {
var i = 0;
fun count() {
i = i + 1;
print i;
}
return count;
}
var counter = makeCounter();
counter(); // "1".
counter(); // "2".
Here,
count()usesi, which is declared outside of itself in the containing functionmakeCounter().makeCounter()returns a reference to thecount()function and then its own body finishes executing completely.
這個例子中,count()使用了i,它是在該函式外部的 makeCounter()宣告的。makeCounter() 返回對count()函式的引用,然後它的函式體就執行完成了。
Meanwhile, the top-level code invokes the returned
count()function. That executes the body ofcount(), which assigns to and readsi, even though the function whereiwas defined has already exited.
同時,頂層程式碼呼叫了返回的count()函式。這就執行了count()函式的主體,它會對i賦值並讀取i,儘管定義i的函式已經退出。
If you’ve never encountered a language with nested functions before, this might seem crazy, but users do expect it to work. Alas, if you run it now, you get an undefined variable error in the call to
counter()when the body ofcount()tries to look upi. That’s because the environment chain in effect looks like this:
如果你以前從未遇到過帶有巢狀函式的語言,那麼這可能看起來很瘋狂,但使用者確實希望它能工作。唉,如果你現在執行它,當count()的函式體試圖查詢i時,會在對counter()的呼叫中得到一個未定義的變數錯誤,這是因為當前的環境鏈看起來像是這樣的:

When we call
count()(through the reference to it stored incounter), we create a new empty environment for the function body. The parent of that is the global environment. We lost the environment formakeCounter()whereiis bound.
當我們呼叫count()時(透過counter中儲存的引用),我們會為函式體建立一個新的空環境,它的父環境就是全域性環境。我們丟失了i所在的makeCounter()環境。
Let’s go back in time a bit. Here’s what the environment chain looked like right when we declared
count()inside the body ofmakeCounter():
我們把時間往回撥一點。我們在makeCounter()的函式體中宣告count()時,環境鏈的樣子是下面這樣:

So at the point where the function is declared, we can see
i. But when we return frommakeCounter()and exit its body, the interpreter discards that environment. Since the interpreter doesn’t keep the environment surroundingcount()around, it’s up to the function object itself to hang on to it.
所以,在函式宣告的地方,我們可以看到i。但是當我們從 makeCounter() 返回並退出其主體時,直譯器會丟棄這個環境。因為直譯器不會保留count() 外圍的環境,所以要靠函式物件本身來儲存它。
This data structure is called a closure because it “closes over” and holds on to the surrounding variables where the function is declared. Closures have been around since the early Lisp days, and language hackers have come up with all manner of ways to implement them. For jlox, we’ll do the simplest thing that works. In LoxFunction, we add a field to store an environment.
這種資料結構被稱為閉包,因為它 "封閉 "並保留著函式宣告的外圍變數。閉包早在Lisp時代就已經存在了,語言駭客們想出了各種方法來實現閉包。在jlox中,我們將採用最簡單的方式。在LoxFunction中,我們新增一個欄位來儲存環境。
lox/LoxFunction.java,在 LoxFunction類中新增:
private final Stmt.Function declaration;
// 新增部分開始
private final Environment closure;
// 新增部分結束
LoxFunction(Stmt.Function declaration) {
We initialize that in the constructor.
我們在建構函式中對其初始化。
lox/LoxFunction.java,在 LoxFunction()構造方法中替換一行:
//替換部分開始
LoxFunction(Stmt.Function declaration, Environment closure) {
this.closure = closure;
// 替換部分結束
this.declaration = declaration;
When we create a LoxFunction, we capture the current environment.
當我們建立LoxFunction時,我們會捕獲當前環境。
lox/Interpreter.java,在 visitFunctionStmt()方法中替換一行:
public Void visitFunctionStmt(Stmt.Function stmt) {
// 替換部分開始
LoxFunction function = new LoxFunction(stmt, environment);
// 替換部分結束
environment.define(stmt.name.lexeme, function);
This is the environment that is active when the function is declared not when it’s called, which is what we want. It represents the lexical scope surrounding the function declaration. Finally, when we call the function, we use that environment as the call’s parent instead of going straight to
globals.
這是函式宣告時生效的環境,而不是函式被呼叫時的環境,這正是我們想要的。它代表了函式宣告時的詞法作用域。最後,當我們呼叫函式時,我們使用該環境作為呼叫的父環境,而不是直接使用globals。
lox/LoxFunction.java,在 call()方法中替換一行:
List<Object> arguments) {
// 替換部分開始
Environment environment = new Environment(closure);
// 替換部分結束
for (int i = 0; i < declaration.params.size(); i++) {
This creates an environment chain that goes from the function’s body out through the environments where the function is declared, all the way out to the global scope. The runtime environment chain matches the textual nesting of the source code like we want. The end result when we call that function looks like this:
這樣就建立了一個環境鏈,從函式體開始,經過函式被宣告的環境,然後到全域性作用域。執行時環境鏈與原始碼的文字巢狀相匹配,跟我們想要的一致。當我們呼叫該函式時,最終的結果是這樣的:

Now, as you can see, the interpreter can still find
iwhen it needs to because it’s in the middle of the environment chain. Try running thatmakeCounter()example now. It works!
如你所見,現在直譯器可以在需要的時候找到i,因為它在環境鏈中。現在嘗試執行makeCounter()的例子,起作用了!
Functions let us abstract over, reuse, and compose code. Lox is much more powerful than the rudimentary arithmetic calculator it used to be. Alas, in our rush to cram closures in, we have let a tiny bit of dynamic scoping leak into the interpreter. In the next chapter, we will explore deeper into lexical scope and close that hole.
函式讓我們對程式碼進行抽象、重用和編排。Lox比之前的初級算術計算器要強大得多。唉,在我們匆匆忙忙支援閉包時,已經讓一小部分動態作用域洩露到直譯器中了。在下一章中,我們將深入探索詞法作用域,堵住這個漏洞。
CHALLENGES
習題
1、Our interpreter carefully checks that the number of arguments passed to a function matches the number of parameters it expects. Since this check is done at runtime on every call, it has a performance cost. Smalltalk implementations don’t have that problem. Why not?
1、直譯器會仔細檢查傳給函式的實引數量是否與期望的形引數量匹配。由於該檢查是在執行時,針對每一次呼叫執行的,所以會有效能成本。Smalltalk的實現則沒有這個問題。為什麼呢?
2、Lox’s function declaration syntax performs two independent operations. It creates a function and also binds it to a name. This improves usability for the common case where you do want to associate a name with the function. But in functional-styled code, you often want to create a function to immediately pass it to some other function or return it. In that case, it doesn’t need a name.
Languages that encourage a functional style usually support anonymous functions or lambdas—an expression syntax that creates a function without binding it to a name. Add anonymous function syntax to Lox so that this works:
fun thrice(fn) { for (var i = 1; i <= 3; i = i + 1) { fn(i); } } thrice(fun (a) { print a; }); // "1". // "2". // "3".How do you handle the tricky case of an anonymous function expression occurring in an expression statement:
fun () {};
2、Lox的函式宣告語法執行了兩個獨立的操作。它建立了一個函式,並將其與一個名稱繫結。這提高了常見情況下的可用性,即你確實想把一個名字和函式聯絡起來。但在函式式的程式碼中,你經常想建立一個函式,以便立即將它傳遞給其他函式或返回它。在這種情況下,它不需要一個名字。
鼓勵函式式風格的語言通常支援匿名函式或lambdas——一個建立函式而不用將其與名稱繫結的表示式語法。在Lox中加入匿名函式的語法,已支援下面的程式碼:
fun thrice(fn) {
for (var i = 1; i <= 3; i = i + 1) {
fn(i);
}
}
thrice(fun (a) {
print a;
});
// "1".
// "2".
// "3".
如何處理在表示式語句中出現匿名函式表示式的棘手情況:
fun () {};
3、Is this program valid?
fun scope(a) { var a = "local"; }In other words, are a function’s parameters in the same scope as its local variables, or in an outer scope? What does Lox do? What about other languages you are familiar with? What do you think a language should do?
3、下面的程式碼可用嗎?
fun scope(a) {
var a = "local";
}
換句話說,一個函式的引數是跟它的區域性變數在同一個作用域內,還是在一個外部作用域內?Lox 是怎麼做的?你所熟悉的其他語言呢?你認為一種語言應該怎麼做?
-
該規則中使用
*符號匹配類似fn(1)(2)(3)的系列函式呼叫。這樣的程式碼不是常見的C語言風格,但是在ML衍生的語言族中很常見。在ML中,定義接受多個引數的函式的常規方式是將其定義為一系列巢狀函式。每個函式接受一個引數並返回一個新函式。該函式使用下一個引數,返回另一個函式,以此類推。最終,一旦所有引數都被使用,最後一個函式就完成了操作。這種風格被稱為柯里化,是以Haskell Curry(他的名字出現在另一個廣為人知的函式式語言中)的名字命名的,它被直接整合到語言的語法中,所以它不像這裡看起來那麼奇怪。 ↩ -
這段程式碼可以簡化為
while (match(LEFT_PAREN))形式,而不是使用這種愚蠢的while (true)和break形式。但是不用擔心,稍後使用解析器處理物件屬性的時候,這種寫法就有意義了。 ↩ -
如果該方法是一個例項方法,則限制為254個引數。因為
this(方法的接收者)就像一個被隱式傳遞給方法的引數一樣,所以也會佔用一個引數位置。 ↩ -
這是另一個微妙的語義選擇。由於參數列達式可能有副作用,因此它們的執行順序可能是使用者可見的。即便如此,有些語言如Scheme和C並沒有指定順序。這樣編譯器可以自由地重新排序以提高效率,但這意味著如果引數沒有按照使用者期望的順序計算,使用者可能會感到不愉快。 ↩
-
奇怪的是,這些函式的兩個名稱native和foreign是反義詞。也許這取決於選擇這個詞的人的角度。如果您認為自己生活在執行時實現中(在我們的例子中是Java),那麼用它編寫的函式就是本機的。但是,如果您站在語言使用者的角度,那麼執行時就是用其他“外來”語言實現的。或者本機指的是底層硬體的機器程式碼語言。在Java中,本機方法是用C或c++實現並編譯為本機機器碼的方法。 ↩
-
幾乎每種語言都提供的一個經典的本地函式是將文字列印到標準輸出。在Lox中,我將
print作為了內建語句,以便可以在前面的章節中看到程式碼結果。一旦我們有了函式,我們就可以刪除之前的print語法並用一個本機函式替換它,從而簡化語言。但這意味著書中前面的例子不能在後面章節的直譯器上執行,反之亦然。所以,在這本書中,我不去修改它。但是,如果您正在為自己的語言構建一個直譯器,您可能需要考慮一下。 ↩ -
你可能會注意到這是很慢的。顯然,遞迴併不是計算斐波那契數的最有效方法,但作為一個微基準測試,它很好地測試了我們的直譯器實現函式呼叫的速度。 ↩
11.解析和繫結 Resolving and Binding
Once in a while you find yourself in an odd situation. You get into it by degrees and in the most natural way but, when you are right in the midst of it, you are suddenly astonished and ask yourself how in the world it all came about.
—— Thor Heyerdahl, Kon-Tiki
你也許偶爾會發現自己處於一種奇怪的情況。你曾以最自然的方式逐漸進入其中,但當你身處其中時,你會突然感到驚訝,並問自己這一切到底是怎麼發生的。
Oh, no! Our language implementation is taking on water! Way back when we added variables and blocks, we had scoping nice and tight. But when we later added closures, a hole opened in our formerly waterproof interpreter. Most real programs are unlikely to slip through this hole, but as language implementers, we take a sacred vow to care about correctness even in the deepest, dampest corners of the semantics.
哦,不! 我們的語言實現正在進水! 在我們剛新增變數和程式碼塊時,我們把作用域控制的很好很嚴密。但是當我們後來新增閉包之後,我們以前防水的直譯器上就出現了一個洞。大多數真正的程式都不可能從這個洞裡溜走,但是作為語言實現者,我們要立下神聖的誓言,即使在語義的最深處、最潮溼的角落裡也要關心正確性。【譯者注:這一段好中二,其實原文中有很多地方都有類似的中二之魂燃燒瞬間】
We will spend this entire chapter exploring that leak, and then carefully patching it up. In the process, we will gain a more rigorous understanding of lexical scoping as used by Lox and other languages in the C tradition. We’ll also get a chance to learn about semantic analysis—a powerful technique for extracting meaning from the user’s source code without having to run it.
我們將用整整一章的時間來探索這個漏洞,然後小心翼翼地把它補上。在這個過程中,我們將對Lox和其他C語言傳統中使用的詞法範圍有一個更嚴格的理解。我們還將有機會學習語義分析——這是一種強大的技術,用於從使用者的原始碼中提取語義而無需執行它。
11 . 1 Static Scope
11.1 靜態作用域
A quick refresher: Lox, like most modern languages, uses lexical scoping. This means that you can figure out which declaration a variable name refers to just by reading the text of the program. For example:
快速複習一下:Lox和大多數現代語言一樣,使用詞法作用域。這意味著你可以透過閱讀程式碼文字找到變數名字指向的是哪個宣告。例如:
var a = "outer";
{
var a = "inner";
print a;
}
Here, we know that the
abeing printed is the variable declared on the previous line, and not the global one. Running the program doesn’t—can’t—affect this. The scope rules are part of the static semantics of the language, which is why they’re also called static scope.
這裡,我們知道列印的a是上一行宣告的變數,而不是全域性變數。執行程式碼並不會(也不能)影響這一點。作用域規則是語言的靜態語義的一部分,這也就是為什麼它們被稱為靜態作用域。
I haven’t spelled out those scope rules, but now is the time for precision:
我還沒有詳細說明這些作用域規則,但是現在是時候詳細說明一下了1:
A variable usage refers to the preceding declaration with the same name in the innermost scope that encloses the expression where the variable is used.
變數指向的是使用變數的表示式外圍環境中,前面具有相同名稱的最內層作用域中的變數宣告。
There’s a lot to unpack in that:
其中有很多東西需要解讀:
-
I say “variable usage” instead of “variable expression” to cover both variable expressions and assignments. Likewise with “expression where the variable is used”.
我說的是“變數使用”而不是“變量表達式”,是為了涵蓋變量表達式和賦值兩種情況。類似於“使用變數的表示式”。
-
“Preceding” means appearing before in the program text.
“前面”意味著出現在程式文字之前。
var a = "outer"; { print a; var a = "inner"; }Here, the
abeing printed is the outer one since it appears before theprintstatement that uses it. In most cases, in straight line code, the declaration preceding in text will also precede the usage in time. But that’s not always true. As we’ll see, functions may defer a chunk of code such that its dynamic temporal execution no longer mirrors the static textual ordering.這裡,列印的
a是外層的,因為它在使用該變數的print語句之前。在大多數情況下,在單行程式碼中,文字中靠前的變數宣告在時間上也先於變數使用。但並不總是如此。正如我們將看到的,函式可以推遲程式碼塊,以使其動態執行的時間不受靜態文字順序的約束2。 -
“Innermost” is there because of our good friend shadowing. There may be more than one variable with the given name in enclosing scopes, as in:
“最內層”之所以存在,是因為我們的好朋友——變數遮蔽的緣故。在外圍作用域中可能存在多個具有給定名稱的變數。如:
var a = "outer"; { var a = "inner"; print a; }Our rule disambiguates this case by saying the innermost scope wins.
我們透過優先使用最內層作用域的方式來消除這種歧義。
Since this rule makes no mention of any runtime behavior, it implies that a variable expression always refers to the same declaration through the entire execution of the program. Our interpreter so far mostly implements the rule correctly. But when we added closures, an error snuck in.
由於這條規則沒有提及任何執行時行為,它意味著一個變量表達式在程式的整個執行過程中總是指向同一宣告。到目前為止,我們的直譯器基本正確實現了這一規則。但是當我們添加了閉包後,一個錯誤悄悄出現了。
var a = "global";
{
fun showA() {
print a;
}
showA();
var a = "block";
showA();
}
Before you type this in and run it, decide what you think it should print.
在你執行這段程式碼之前,先思考一下它應該輸出什麼3。
OK . . . got it? If you’re familiar with closures in other languages, you’ll expect it to print “global” twice. The first call to
showA()should definitely print “global” since we haven’t even reached the declaration of the innerayet. And by our rule that a variable expression always resolves to the same variable, that implies the second call toshowA()should print the same thing.
好的……清楚了嗎?如果你熟悉其它語言中的閉包,你可能期望會輸出兩次“global”。對 showA() 的第一次呼叫肯定會列印 “global”,因為我們甚至還沒有執行到內部變數 a 的宣告。而根據我們的規則,一個變量表達式總是解析為同一個變數,這意味著對 showA() 的第二次呼叫也應該打印出同樣的內容。
Alas, it prints:
唉,它輸出的是:
global
block
Let me stress that this program never reassigns any variable and contains only a single
我要強調一下,這個程式碼中從未重新分配任何變數,並且只包含一個print語句。然而,不知何故,對於這個從未分配過的變數,print語句在不同的時間點上列印了兩個不同的值。我們肯定在什麼地方出了問題。
11 . 1 . 1 Scopes and mutable environments
11.1.1 作用域和可變環境
In our interpreter, environments are the dynamic manifestation of static scopes. The two mostly stay in sync with each other—we create a new environment when we enter a new scope, and discard it when we leave the scope. There is one other operation we perform on environments: binding a variable in one. This is where our bug lies.
在我們的直譯器中,環境是靜態作用域的動態表現。這兩者大多情況下保持同步——當我們進入一個新的作用域時,我們會建立一個新的環境,當我們離開這個作用域時,我們會丟棄它。在環境中還有一個可執行的操作:在環境中繫結一個變數。這就是我們的問題所在。
Let’s walk through that problematic example and see what the environments look like at each step. First, we declare
ain the global scope.
讓我們透過這個有問題的例子,看看每一步的環境是什麼樣的。首先,我們在全域性作用域內宣告a。

That gives us a single environment with a single variable in it. Then we enter the block and execute the declaration of
showA().
這為我們提供了一個環境,其中只有一個變數。然後我們進入程式碼塊,並執行showA()的宣告。

We get a new environment for the block. In that, we declare one name,
showA, which is bound to the LoxFunction object we create to represent the function. That object has aclosurefield that captures the environment where the function was declared, so it has a reference back to the environment for the block.
我們得到一個對應該程式碼塊的新環境。在這個環境中,我們宣告瞭一個名稱showA,它繫結到為表示函式而建立的LoxFunction物件。該物件中有一個closure欄位,用於捕獲函式宣告時的環境,因此它有一個指向該程式碼塊環境的引用。
Now we call
showA().
現在我們呼叫showA()。

The interpreter dynamically creates a new environment for the function body of
showA(). It’s empty since that function doesn’t declare any variables. The parent of that environment is the function’s closure—the outer block environment.
直譯器為showA()的函式體動態地建立了一個新環境。它是空的,因為該函式沒有宣告任何變數。該環境的父環境是該函式的閉包——外部的程式碼塊環境。
Inside the body of
showA(), we print the value ofa. The interpreter looks up this value by walking the chain of environments. It gets all the way to the global environment before finding it there and printing"global". Great.
在showA()函式體中,輸出a的值。直譯器透過遍歷環境鏈來查詢這個值。它會一直到達全域性環境,在其中找到變數a並列印“global”。太好了。
Next, we declare the second
a, this time inside the block.
接下來,我們宣告第二個a,這次是在程式碼塊內。

It’s in the same block—the same scope—as
showA(), so it goes into the same environment, which is also the same environmentshowA()’s closure refers to. This is where it gets interesting. We callshowA()again.
它和showA()在同一個程式碼塊中——同一個作用域,所以它進入了同一個環境,也就是showA()的閉包所指向的環境。這就是有趣的地方了。我們再次呼叫showA()。

We create a new empty environment for the body of
showA()again, wire it up to that closure, and run the body. When the interpreter walks the chain of environments to finda, it now discovers the newain the block environment. Boo.
我們再次為showA()的函式體建立了一個新的空環境,將其連線到該閉包,並執行函式體。當直譯器遍歷環境鏈去查詢a時,它會發現程式碼塊環境中新的變數a。
I chose to implement environments in a way that I hoped would agree with your informal intuition around scopes. We tend to consider all of the code within a block as being within the same scope, so our interpreter uses a single environment to represent that. Each environment is a mutable hash table. When a new local variable is declared, it gets added to the existing environment for that scope.
我選擇了一種實現環境的方式,希望它能夠與您對作用域的非正式直覺相一致。我們傾向於認為一個塊中的所有程式碼在同一個作用域中,所以我們的直譯器使用了一個環境來表示它。每個環境都是一個可變的hash表。當一個新的區域性變數被宣告時,它會被加入該作用域的現有環境中。
That intuition, like many in life, isn’t quite right. A block is not necessarily all the same scope. Consider:
就像生活中的很多直覺一樣,這種直覺並不完全正確。一個程式碼塊並不一定都是同一個作用域。考慮一下:
{
var a;
// 1.
var b;
// 2.
}
At the first marked line, only
ais in scope. At the second line, bothaandbare. If you define a “scope” to be a set of declarations, then those are clearly not the same scope—they don’t contain the same declarations. It’s like eachvarstatement splits the block into two separate scopes, the scope before the variable is declared and the one after, which includes the new variable.
在標記的第一行,作用域中只有a。在第二行時,a和b都在其中。如果將作用域定義為一組宣告,那麼它們顯然不是相同的作用域——它們不包含相同的宣告。這就好像是var語句將程式碼塊分割成了兩個獨立的作用域,變數宣告前的作用域和包含新變數的作用域4。
But in our implementation, environments do act like the entire block is one scope, just a scope that changes over time. Closures do not like that. When a function is declared, it captures a reference to the current environment. The function should capture a frozen snapshot of the environment as it existed at the moment the function was declared. But instead, in the Java code, it has a reference to the actual mutable environment object. When a variable is later declared in the scope that environment corresponds to, the closure sees the new variable, even though the declaration does not precede the function.
但是在我們的實現中,環境確實表現得像整個程式碼塊是一個作用域,只是這個作用域會隨時間變化。而閉包不是這樣的。當函式被宣告時,它會捕獲一個指向當前環境的引用。函式應該捕獲一個凍結的環境快照,就像它存在於函式被宣告的那一瞬間。但是事實上,在Java程式碼中,它引用的是一個實際可變的環境物件。當後續在該環境所對應的作用域內宣告一個變數時,閉包會看到該變數,即使變數宣告沒有出現在函式之前。
11 . 1 . 2 Persistent environments
11.1.2 持久環境
There is a style of programming that uses what are called persistent data structures. Unlike the squishy data structures you’re familiar with in imperative programming, a persistent data structure can never be directly modified. Instead, any “modification” to an existing structure produces a brand new object that contains all of the original data and the new modification. The original is left unchanged.
有一種程式設計風格,使用所謂的永續性資料結構。與你在指令式程式設計中所熟悉的模糊的資料結構不同,持久化資料結構永遠不能被直接修改。相應地,對現有結構的任何 "修改 "都會產生一個全新的物件,其中包含所有的原始資料和新的修改。而原有的物件則保持不變5。
If we were to apply that technique to Environment, then every time you declared a variable it would return a new environment that contained all of the previously declared variables along with the one new name. Declaring a variable would do the implicit “split” where you have an environment before the variable is declared and one after:
如果我們將這一技術應用於環境,那麼每次你宣告一個變數時,都會返回一個新的環境,其中包含所有先前宣告的變數和一個新名稱。宣告一個變數會執行隱式分割,在宣告變數之前與之後都有一個環境:

A closure retains a reference to the Environment instance in play when the function was declared. Since any later declarations in that block would produce new Environment objects, the closure wouldn’t see the new variables and our bug would be fixed.
當函式被宣告時,閉包保留對正在執行的Environment例項的引用。由於該程式碼塊中後續的任何宣告都會生成新的Environment物件,閉包就不會看到新的變數,我們的問題也得到修復。
This is a legit way to solve the problem, and it’s the classic way to implement environments in Scheme interpreters. We could do that for Lox, but it would mean going back and changing a pile of existing code.
這是解決該問題的合法方式,也是在Scheme直譯器中實現變數環境的經典方式。對於Lox,我們可以這樣做,但是這意味著要回頭修改一大堆現有的程式碼。
I won’t drag you through that. We’ll keep the way we represent environments the same. Instead of making the data more statically structured, we’ll bake the static resolution into the access operation itself.
我不會把你拖下水的。我們將保持表示環境的方式不變。我們不會讓資料變得更加靜態結構化,而是將靜態解析嵌入訪問操作本身。
11 . 2 Semantic Analysis
11.2 語義分析
Our interpreter resolves a variable—tracks down which declaration it refers to—each and every time the variable expression is evaluated. If that variable is swaddled inside a loop that runs a thousand times, that variable gets re-resolved a thousand times.
我們的直譯器每次對變量表達式求值時,都會解析變數——追蹤它所指向的宣告。如果這個變數被包在一個執行1000次的迴圈中,那麼該變數就會被重複解析1000次。
We know static scope means that a variable usage always resolves to the same declaration, which can be determined just by looking at the text. Given that, why are we doing it dynamically every time? Doing so doesn’t just open the hole that leads to our annoying bug, it’s also needlessly slow.
我們知道靜態作用域意味著一個變數的使用總是解析到同一個宣告,而且可以透過檢視文字來確定。既然如此,我們為什麼每次都要動態地解析呢?這樣做不僅僅導致了這個惱人的bug,而且也造成了不必要的低效。
A better solution is to resolve each variable use once. Write a chunk of code that inspects the user’s program, finds every variable mentioned, and figures out which declaration each refers to. This process is an example of a semantic analysis. Where a parser tells only if a program is grammatically correct (a syntactic analysis), semantic analysis goes farther and starts to figure out what pieces of the program actually mean. In this case, our analysis will resolve variable bindings. We’ll know not just that an expression is a variable, but which variable it is.
一個更好的解決方案是一次性解析每個變數的使用。編寫一段程式碼,檢查使用者的程式,找到所提到的每個變數,並找出每個變數引用的是哪個宣告。這個過程是語義分析的一個例子。解析器只能分析程式在語法上是否正確(語法分析),而語義分析則更進一步,開始弄清楚程式的各個部分的實際含義。在這種情況下,我們的分析將解決變數繫結的問題。我們不僅要知道一個表示式是一個變數,還要知道它是哪個變數。
There are a lot of ways we could store the binding between a variable and its declaration. When we get to the C interpreter for Lox, we’ll have a much more efficient way of storing and accessing local variables. But for jlox, I want to minimize the collateral damage we inflict on our existing codebase. I’d hate to throw out a bunch of mostly fine code.
有很多方法可以儲存變數及其宣告直接的繫結關係。當我們使用Lox的C直譯器時,我們將有一種更有效的方式來儲存和訪問區域性變數。但是對於jlox來說,我想盡量減少對現有程式碼庫的附帶損害。我不希望扔掉一堆基本上都很好的程式碼。
Instead, we’ll store the resolution in a way that makes the most out of our existing Environment class. Recall how the accesses of
aare interpreted in the problematic example.
相對地,我們將以最充分利用現有Environment類的方式來儲存解析結果。回想一下,在有問題的例子中,a的訪問是如何被解釋的。
In the first (correct) evaluation, we look at three environments in the chain before finding the global declaration of
a. Then, when the innerais later declared in a block scope, it shadows the global one.
在第一次(正確的)求值中,我們會檢查鏈中的環境,並找到a的全域性宣告。然後,當內部的a在塊作用域中宣告時,它會遮蔽全域性的變數a。
The next lookup walks the chain, finds
ain the second environment and stops there. Each environment corresponds to a single lexical scope where variables are declared. If we could ensure a variable lookup always walked the same number of links in the environment chain, that would ensure that it found the same variable in the same scope every time.
下一次查詢會遍歷環境鏈,在第二個環境中找到a並停止。每個環境都對應於一個宣告變數的詞法作用域。如果我們能夠保證變數查詢總是在環境鏈上遍歷相同數量的連結,也就可以保證每次都可以在相同的作用域中找到相同的變數。
To “resolve” a variable usage, we only need to calculate how many “hops” away the declared variable will be in the environment chain. The interesting question is when to do this calculation—or, put differently, where in our interpreter’s implementation do we stuff the code for it?
要“解析”一個變數使用,我們只需要計算宣告的變數在環境鏈中有多少“跳”。有趣的問題是在什麼時候進行這個計算——或者換句話說,在直譯器的實現中,這段程式碼要新增到什麼地方?
Since we’re calculating a static property based on the structure of the source code, the obvious answer is in the parser. That is the traditional home, and is where we’ll put it later in clox. It would work here too, but I want an excuse to show you another technique. We’ll write our resolver as a separate pass.
因為我們是根據原始碼的結構來計算一個靜態屬性,所以答案顯然是在解析器中。那是傳統的選擇,也是我們以後在 clox 中實現它的地方。在這裡同樣也適用,但是我想給你展示另一種技巧。我們會單獨寫一個解析器。
11 . 2 . 1 A variable resolution pass
11.2.1 變數解析過程
After the parser produces the syntax tree, but before the interpreter starts executing it, we’ll do a single walk over the tree to resolve all of the variables it contains. Additional passes between parsing and execution are common. If Lox had static types, we could slide a type checker in there. Optimizations are often implemented in separate passes like this too. Basically, any work that doesn’t rely on state that’s only available at runtime can be done in this way.
在解析器生成語法樹之後,直譯器執行語法樹之前,我們會對語法樹再進行一次遍歷,以解析其中包含的變數。在解析和執行之間的額外遍歷是很常見的。如果Lox中有靜態型別,我們可以插入一個型別檢查器。最佳化也經常是在類似單獨的遍歷過程中實現的。基本上,任何不依賴於執行時狀態的工作都可以透過這種方式完成。
Our variable resolution pass works like a sort of mini-interpreter. It walks the tree, visiting each node, but a static analysis is different from a dynamic execution:
我們的變數解析工作就像一個小型的直譯器。它會遍歷整棵樹,訪問每個節點,但是靜態分析與動態執行還是不同的:
-
There are no side effects. When the static analysis visits a print statement, it doesn’t actually print anything. Calls to native functions or other operations that reach out to the outside world are stubbed out and have no effect.
沒有副作用。當靜態分析處理一個
print語句時,它並不會列印任何東西。對本地函式或其它與外部世界聯絡的操作也會被終止,並且沒有任何影響。 -
There is no control flow. Loops are visited only once. Both branches are visited in
ifstatements. Logic operators are not short-circuited.沒有控制流。迴圈只會被處理一次,
if語句中的兩個分支都會處理,邏輯運算子也不會做短路處理6。
11 . 3 A Resolver Class
11.3 Resolver類
Like everything in Java, our variable resolution pass is embodied in a class.
與Java中的所有內容一樣,我們將變數解析處理也放在一個類中。
lox/Resolver.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Stack;
class Resolver implements Expr.Visitor<Void>, Stmt.Visitor<Void> {
private final Interpreter interpreter;
Resolver(Interpreter interpreter) {
this.interpreter = interpreter;
}
}
Since the resolver needs to visit every node in the syntax tree, it implements the visitor abstraction we already have in place. Only a few kinds of nodes are interesting when it comes to resolving variables:
因為解析器需要處理語法樹中的每個節點,所以它實現了我們已有的訪問者抽象。在解析變數時,有幾個節點是比較特殊的:
-
A block statement introduces a new scope for the statements it contains.
塊語句為它所包含的語句引入了一個新的作用域。
-
A function declaration introduces a new scope for its body and binds its parameters in that scope.
函式宣告為其函式體引入了一個新的作用域,並在該作用域中綁定了它的形參。
-
A variable declaration adds a new variable to the current scope.
變數宣告將一個新變數加入到當前作用域中。
-
Variable and assignment expressions need to have their variables resolved.
變數定義和賦值表示式需要解析它們的變數值。
The rest of the nodes don’t do anything special, but we still need to implement visit methods for them that traverse into their subtrees. Even though a
+expression doesn’t itself have any variables to resolve, either of its operands might.
其餘的節點不做任何特別的事情,但是我們仍然需要為它們實現visit方法,以遍歷其子樹。儘管+表示式本身沒有任何變數需要解析,但是它的任一運算元都可能需要。
11 . 3 . 1 Resolving blocks
11.3.1 解析程式碼塊
We start with blocks since they create the local scopes where all the magic happens.
我們從塊語法開始,因為它們建立了局部作用域——魔法出現的地方。
lox/Resolver.java,在 Resolver()方法後新增:
@Override
public Void visitBlockStmt(Stmt.Block stmt) {
beginScope();
resolve(stmt.statements);
endScope();
return null;
}
This begins a new scope, traverses into the statements inside the block, and then discards the scope. The fun stuff lives in those helper methods. We start with the simple one.
這裡會開始一個新的作用域,遍歷塊中的語句,然後丟棄該作用域。有趣的部分都在這些輔助方法中。我們先看一個簡單的。
lox/Resolver.java,在 Resolver()方法後新增:
void resolve(List<Stmt> statements) {
for (Stmt statement : statements) {
resolve(statement);
}
}
This walks a list of statements and resolves each one. It in turn calls:
它會遍歷語句列表,並解析其中每一條語句。它會進一步呼叫:
lox/Resolver.java,在 visitBlockStmt()方法後新增:
private void resolve(Stmt stmt) {
stmt.accept(this);
}
While we’re at it, let’s add another overload that we’ll need later for resolving an expression.
在此過程中,讓我們新增一個後續解析表示式時會用到的過載方法。
lox/Resolver.java,在 resolve(Stmt stmt)方法後新增:
private void resolve(Expr expr) {
expr.accept(this);
}
These methods are similar to the
evaluate()andexecute()methods in Interpreter—they turn around and apply the Visitor pattern to the given syntax tree node.
這些方法與直譯器中的 evaluate()和execute()方法類似——它們會反過來將訪問者模式應用到語法樹節點。
The real interesting behavior is around scopes. A new block scope is created like so:
真正有趣的部分是圍繞作用域的。一個新的塊作用域是這樣建立的:
lox/Resolver.java,在 resolve()方法後新增:
private void beginScope() {
scopes.push(new HashMap<String, Boolean>());
}
Lexical scopes nest in both the interpreter and the resolver. They behave like a stack. The interpreter implements that stack using a linked list—the chain of Environment objects. In the resolver, we use an actual Java Stack.
詞法作用域在直譯器和解析器中都有使用。它們的行為像一個棧。直譯器是使用連結串列(Environment物件組成的鏈)來實現棧的,在解析器中,我們使用一個真正的Java Stack。
lox/Resolver.java,在 Resolver類中新增:
private final Interpreter interpreter;
// 新增部分開始
private final Stack<Map<String, Boolean>> scopes = new Stack<>();
// 新增部分結束
Resolver(Interpreter interpreter) {
This field keeps track of the stack of scopes currently, uh, in scope. Each element in the stack is a Map representing a single block scope. Keys, as in Environment, are variable names. The values are Booleans, for a reason I’ll explain soon.
這個欄位會記錄當前作用域內的棧。棧中的每個元素是代表一個塊作用域的Map。與Environment中一樣,鍵是變數名。值是布林值,原因我很快會解釋。
The scope stack is only used for local block scopes. Variables declared at the top level in the global scope are not tracked by the resolver since they are more dynamic in Lox. When resolving a variable, if we can’t find it in the stack of local scopes, we assume it must be global.
作用域棧只用於區域性塊作用域。解析器不會跟蹤在全域性作用域的頂層宣告的變數,因為它們在Lox中是更動態的。當解析一個變數時,如果我們在本地作用域棧中找不到它,我們就認為它一定是全域性的。
Since scopes are stored in an explicit stack, exiting one is straightforward.
由於作用域被儲存在一個顯式的棧中,退出作用域很簡單。
lox/Resolver.java,在 beginScope()方法後新增:
private void endScope() {
scopes.pop();
}
Now we can push and pop a stack of empty scopes. Let’s put some things in them.
現在我們可以在一個棧中壓入和彈出一個空作用域,接下來我們往裡面放些內容。
11 . 3 . 2 Resolving variable declarations
11.3.2 解析變數宣告
Resolving a variable declaration adds a new entry to the current innermost scope’s map. That seems simple, but there’s a little dance we need to do.
解析一個變數宣告,會在當前最內層的作用域map中新增一個新的條目。這看起來很簡單,但是我們需要做一些小動作。
lox/Resolver.java,在 visitBlockStmt()方法後新增:
@Override
public Void visitVarStmt(Stmt.Var stmt) {
declare(stmt.name);
if (stmt.initializer != null) {
resolve(stmt.initializer);
}
define(stmt.name);
return null;
}
We split binding into two steps, declaring then defining, in order to handle funny edge cases like this:
我們將繫結分為兩個步驟,先宣告,然後定義,以便處理類似下面這樣的邊界情況:
var a = "outer";
{
var a = a;
}
What happens when the initializer for a local variable refers to a variable with the same name as the variable being declared? We have a few options:
當區域性變數的初始化式指向一個與當前宣告變數名稱相同的變數時,會發生什麼?我們有幾個選擇:
-
Run the initializer, then put the new variable in scope. Here, the new local
awould be initialized with “outer”, the value of the global one. In other words, the previous declaration would desugar to:1 執行初始化式,然後將新的變數放入作用域中。 在這個例子中,新的區域性變數
a會使用“outer”(全域性變數a的值)初始化。換句話說,前面的宣告脫糖後如下:var temp = a; // Run the initializer. var a; // Declare the variable. a = temp; // Initialize it. -
Put the new variable in scope, then run the initializer. This means you could observe a variable before it’s initialized, so we would need to figure out what value it would have then. Probably
nil. That means the new localawould be re-initialized to its own implicitly initialized value,nil. Now the desugaring would look like:2 將新的變數放入作用域中,然後執行初始化式。 這意味著你可以在變數被初始化之前觀察到它,所以當我們需要計算出它的值時,這個值其實是
nil。這意味著新的區域性變數a將被重新初始化為它自己的隱式初始化值nil。現在,脫糖後的結果如下:var a; // Define the variable. a = a; // Run the initializer. -
Make it an error to reference a variable in its initializer. Have the interpreter fail either at compile time or runtime if an initializer mentions the variable being initialized.
3 在初始化式中引用一個變數是錯誤的。 如果初始化式使用了要初始化的變數,則直譯器在編譯時或執行時都會失敗。
Do either of those first two options look like something a user actually wants? Shadowing is rare and often an error, so initializing a shadowing variable based on the value of the shadowed one seems unlikely to be deliberate.
前兩個選項中是否有使用者真正想要的?變數遮蔽很少見,而且通常是一個錯誤,所以根據被遮蔽的變數值來初始化一個遮蔽的變數,似乎不太可能是有意為之。
The second option is even less useful. The new variable will always have the value
nil. There is never any point in mentioning it by name. You could use an explicitnilinstead.
第二個選項就更沒用了。新變數的值總是nil。透過名稱來引用沒有任何意義。你可以使用一個隱式的nil來代替。
Since the first two options are likely to mask user errors, we’ll take the third. Further, we’ll make it a compile error instead of a runtime one. That way, the user is alerted to the problem before any code is run.
由於前兩個選項可能會掩蓋使用者的錯誤,我們將採用第三個選項。此外,我們要將其作為一個編譯錯誤而不是執行時錯誤。這樣一來,在程式碼執行之前,使用者就會收到該問題的警報。
In order to do that, as we visit expressions, we need to know if we’re inside the initializer for some variable. We do that by splitting binding into two steps. The first is declaring it.
要做到這一點,當我們訪問表示式時,我們需要知道當前是否在某個變數的初始化式中。我們透過將繫結拆分為兩步來實現。首先是宣告。
lox/Resolver.java,在 endScope()方法後新增:
private void declare(Token name) {
if (scopes.isEmpty()) return;
Map<String, Boolean> scope = scopes.peek();
scope.put(name.lexeme, false);
}
Declaration adds the variable to the innermost scope so that it shadows any outer one and so that we know the variable exists. We mark it as “not ready yet” by binding its name to
falsein the scope map. The value associated with a key in the scope map represents whether or not we have finished resolving that variable’s initializer.
宣告將變數新增到最內層的作用域,這樣它就會遮蔽任何外層作用域,我們也就知道了這個變數的存在。我們透過在作用域map中將其名稱繫結到false來表明該變數“尚未就緒”。作用域map中與key相關聯的值代表的是我們是否已經結束了對變數初始化式的解析。
After declaring the variable, we resolve its initializer expression in that same scope where the new variable now exists but is unavailable. Once the initializer expression is done, the variable is ready for prime time. We do that by defining it.
在宣告完變數後,我們在變數當前存在但是不可用的作用域中解析變數的初始化表示式。一旦初始化表示式完成,變數也就緒了。我們透過define來實現。
lox/Resolver.java,在 declare()方法後新增:
private void define(Token name) {
if (scopes.isEmpty()) return;
scopes.peek().put(name.lexeme, true);
}
We set the variable’s value in the scope map to
trueto mark it as fully initialized and available for use. It’s alive!
我們在作用域map中將變數的值置為true,以標記它已完全初始化並可使用。它有了生命!
11 . 3 . 3 Resolving variable expressions
11.3.3 解析變量表達式
Variable declarations—and function declarations, which we’ll get to—write to the scope maps. Those maps are read when we resolve variable expressions.
變數宣告——以及我們即將討論的函式宣告——會向作用域map中寫資料。在我們解析變量表達式時,需要讀取這些map。
lox/Resolver.java,在 visitVarStmt()方法後新增:
@Override
public Void visitVariableExpr(Expr.Variable expr) {
if (!scopes.isEmpty() &&
scopes.peek().get(expr.name.lexeme) == Boolean.FALSE) {
Lox.error(expr.name,
"Can't read local variable in its own initializer.");
}
resolveLocal(expr, expr.name);
return null;
}
First, we check to see if the variable is being accessed inside its own initializer. This is where the values in the scope map come into play. If the variable exists in the current scope but its value is
false, that means we have declared it but not yet defined it. We report that error.
首先,我們要檢查變數是否在其自身的初始化式中被訪問。這也就是作用域map中的值發揮作用的地方。如果當前作用域中存在該變數,但是它的值是false,意味著我們已經宣告瞭它,但是還沒有定義它。我們會報告一個錯誤出來。
After that check, we actually resolve the variable itself using this helper:
在檢查之後,我們實際上使用了這個輔助方法來解析變數:
lox/Resolver.java,在 define()方法後新增:
private void resolveLocal(Expr expr, Token name) {
for (int i = scopes.size() - 1; i >= 0; i--) {
if (scopes.get(i).containsKey(name.lexeme)) {
interpreter.resolve(expr, scopes.size() - 1 - i);
return;
}
}
}
This looks, for good reason, a lot like the code in Environment for evaluating a variable. We start at the innermost scope and work outwards, looking in each map for a matching name. If we find the variable, we resolve it, passing in the number of scopes between the current innermost scope and the scope where the variable was found. So, if the variable was found in the current scope, we pass in 0. If it’s in the immediately enclosing scope, 1. You get the idea.
這看起來很像是Environment中對變數求值的程式碼。我們從最內層的作用域開始,向外擴充套件,在每個map中尋找一個可以匹配的名稱。如果我們找到了這個變數,我們就對其解析,傳入當前最內層作用域和變數所在作用域之間的作用域的數量。所以,如果變數在當前作用域中找到該變數,則傳入0;如果在緊鄰的外網作用域中找到,則傳1。明白了吧。
If we walk through all of the block scopes and never find the variable, we leave it unresolved and assume it’s global. We’ll get to the implementation of that
resolve()method a little later. For now, let’s keep on cranking through the other syntax nodes.
如果我們遍歷了所有的作用域也沒有找到這個變數,我們就不解析它,並假定它是一個全域性變數。稍後我們將討論resolve()方法的實現。現在,讓我們繼續瀏覽其他語法節點。
11 . 3 . 4 Resolving assignment expressions
11.3.4 解析賦值表示式
The other expression that references a variable is assignment. Resolving one looks like this:
另一個引用變數的表示式就是賦值表示式。解析方法如下:
lox/Resolver.java,在 visitVarStmt()方法後新增:
@Override
public Void visitAssignExpr(Expr.Assign expr) {
resolve(expr.value);
resolveLocal(expr, expr.name);
return null;
}
First, we resolve the expression for the assigned value in case it also contains references to other variables. Then we use our existing
resolveLocal()method to resolve the variable that’s being assigned to.
首先,我們解析右值的表示式,以防它還包含對其它變數的引用。然後使用現有的 resolveLocal() 方法解析待賦值的變數。
11 . 3 . 5 Resolving function declarations
11.3.5 解析函式宣告
Finally, functions. Functions both bind names and introduce a scope. The name of the function itself is bound in the surrounding scope where the function is declared. When we step into the function’s body, we also bind its parameters into that inner function scope.
最後是函式。函式既繫結名稱又引入了作用域。函式本身的名稱被繫結在函式宣告時所在的作用域中。當我們進入函式體時,我們還需要將其引數繫結到函式內部作用域中。
lox/Resolver.java,在 visitBlockStmt()方法後新增:
@Override
public Void visitFunctionStmt(Stmt.Function stmt) {
declare(stmt.name);
define(stmt.name);
resolveFunction(stmt);
return null;
}
Similar to
visitVariableStmt(), we declare and define the name of the function in the current scope. Unlike variables, though, we define the name eagerly, before resolving the function’s body. This lets a function recursively refer to itself inside its own body.
與visitVariableStmt()類似,我們在當前作用域中宣告並定義函式的名稱。與變數不同的是,我們在解析函式體之前,就急切地定義了這個名稱。這樣函式就可以在自己的函式體中遞迴地使用自身。
Then we resolve the function’s body using this:
那麼我們可以使用下面的方法來解析函式體:
lox/Resolver.java,在 resolve()方法後新增:
private void resolveFunction(Stmt.Function function) {
beginScope();
for (Token param : function.params) {
declare(param);
define(param);
}
resolve(function.body);
endScope();
}
It’s a separate method since we will also use it for resolving Lox methods when we add classes later. It creates a new scope for the body and then binds variables for each of the function’s parameters.
這是一個單獨的方法,因為我們以後新增類時,還需要使用它來解析Lox方法。它為函式體建立一個新的作用域,然後為函式的每個引數繫結變數。
Once that’s ready, it resolves the function body in that scope. This is different from how the interpreter handles function declarations. At runtime, declaring a function doesn’t do anything with the function’s body. The body doesn’t get touched until later when the function is called. In a static analysis, we immediately traverse into the body right then and there.
一旦就緒,它就會在這個作用域中解析函式體。這與直譯器處理函式宣告的方式不同。在執行時,宣告一個函式不會對函式體做任何處理。直到後續函式被呼叫時,才會觸及主體。在靜態分析中,我們會立即遍歷函式體。
11 . 3 . 6 Resolving the other syntax tree nodes
11.3.6 解析其它語法樹節點
That covers the interesting corners of the grammars. We handle every place where a variable is declared, read, or written, and every place where a scope is created or destroyed. Even though they aren’t affected by variable resolution, we also need visit methods for all of the other syntax tree nodes in order to recurse into their subtrees. Sorry this bit is boring, but bear with me. We’ll go kind of “top down” and start with statements.
這涵蓋了語法中很多有趣的部分。我們處理了宣告、讀取、寫入遍歷,建立、銷燬作用域的部分。雖然其它部分不受遍歷解析的影響,我們也需要為其它語法樹節點提供visit方法,以便遞迴到它們的子樹。抱歉,這部分內容很枯燥,但請耐心聽我講。我們採用“自上而下”的方式,從語句開始。
An expression statement contains a single expression to traverse.
一個表示式語句中包含一個需要遍歷的表示式。
lox/Resolver.java,在 visitBlockStmt()方法後新增:
@Override
public Void visitExpressionStmt(Stmt.Expression stmt) {
resolve(stmt.expression);
return null;
}
An if statement has an expression for its condition and one or two statements for the branches.
if語句包含一個條件表示式,以及一個或兩個分支語句。
lox/Resolver.java,在 visitFunctionStmt()方法後新增:
@Override
public Void visitIfStmt(Stmt.If stmt) {
resolve(stmt.condition);
resolve(stmt.thenBranch);
if (stmt.elseBranch != null) resolve(stmt.elseBranch);
return null;
}
Here, we see how resolution is different from interpretation. When we resolve an
ifstatement, there is no control flow. We resolve the condition and both branches. Where a dynamic execution steps only into the branch that is run, a static analysis is conservative—it analyzes any branch that could be run. Since either one could be reached at runtime, we resolve both.
在這裡,我們可以看到解析與解釋是不同的。當我們解析if語句時,沒有控制流。我們會解析條件表示式和兩個分支表示式。動態執行則只會進入正在執行的分支,而靜態分析是保守的——它會分析所有可能執行的分支。因為任何一個分支在執行時都可能被觸及,所以我們要對兩者都進行解析。
Like expression statements, a
與表示式語句類似,print語句也包含一個子表示式。
lox/Resolver.java,在 visitIfStmt()方法後新增:
@Override
public Void visitPrintStmt(Stmt.Print stmt) {
resolve(stmt.expression);
return null;
}
Same deal for return.
return語句也是相同的。
lox/Resolver.java,在 visitPrintStmt()方法後新增:
@Override
public Void visitReturnStmt(Stmt.Return stmt) {
if (stmt.value != null) {
resolve(stmt.value);
}
return null;
}
As in
ifstatements, with awhilestatement, we resolve its condition and resolve the body exactly once.
與if語句一樣,對於while語句,我們會解析其條件,並解析一次迴圈體。
lox/Resolver.java,在 visitVarStmt()方法後新增:
@Override
public Void visitWhileStmt(Stmt.While stmt) {
resolve(stmt.condition);
resolve(stmt.body);
return null;
}
That covers all the statements. On to expressions . . .
這樣就涵蓋了所有的語句。接下來是表示式……
Our old friend the binary expression. We traverse into and resolve both operands.
我們的老朋友二元表示式。我們要遍歷並解析兩個運算元。
lox/Resolver.java,在 visitAssignExpr()方法後新增:
@Override
public Void visitBinaryExpr(Expr.Binary expr) {
resolve(expr.left);
resolve(expr.right);
return null;
}
Calls are similar—we walk the argument list and resolve them all. The thing being called is also an expression (usually a variable expression), so that gets resolved too.
呼叫也是類似的——我們遍歷引數列表並解析它們。被呼叫的物件也是一個表示式(通常是一個變量表達式),所以它也會被解析。
lox/Resolver.java,在 visitBinaryExpr()方法後新增:
@Override
public Void visitCallExpr(Expr.Call expr) {
resolve(expr.callee);
for (Expr argument : expr.arguments) {
resolve(argument);
}
return null;
}
Parentheses are easy.
括號表示式比較簡單。
lox/Resolver.java,在 visitCallExpr()方法後新增:
@Override
public Void visitGroupingExpr(Expr.Grouping expr) {
resolve(expr.expression);
return null;
}
Literals are easiest of all.
字面量表達式是最簡單的。
lox/Resolver.java,在 visitGroupingExpr()方法後新增:
@Override
public Void visitLiteralExpr(Expr.Literal expr) {
return null;
}
A literal expression doesn’t mention any variables and doesn’t contain any subexpressions so there is no work to do.
字面表示式中沒有使用任何變數,也不包含任何子表示式,所以也不需要做任何事情。
Since a static analysis does no control flow or short-circuiting, logical expressions are exactly the same as other binary operators.
因為靜態分析沒有控制流或短路處理,邏輯表示式與其它的二元運算子是一樣的。
lox/Resolver.java,在 visitLiteralExpr()方法後新增:
@Override
public Void visitLogicalExpr(Expr.Logical expr) {
resolve(expr.left);
resolve(expr.right);
return null;
}
And, finally, the last node. We resolve its one operand.
接下來是最後一個節點,我們解析它的一個運算元。
lox/Resolver.java,在 visitLogicalExpr()方法後新增:
@Override
public Void visitUnaryExpr(Expr.Unary expr) {
resolve(expr.right);
return null;
}
With all of these visit methods, the Java compiler should be satisfied that Resolver fully implements Stmt.Visitor and Expr.Visitor. Now is a good time to take a break, have a snack, maybe a little nap.
有了這些visit方法,Java編譯器應該會認為Resolver完全實現了Stmt.Visitor 和 Expr.Visitor。現在是時候休息一下了。
11 . 4 Interpreting Resolved Variables
11.4 解釋已解析的變數
Let’s see what our resolver is good for. Each time it visits a variable, it tells the interpreter how many scopes there are between the current scope and the scope where the variable is defined. At runtime, this corresponds exactly to the number of environments between the current one and the enclosing one where the interpreter can find the variable’s value. The resolver hands that number to the interpreter by calling this:
讓我們看看解析器有什麼用處。每次訪問一個變數時,它都會告訴直譯器,在當前作用域和變數定義的作用域之間隔著多少層作用域。在執行時,這正好對應於當前環境與直譯器可以找到變數值的外圍環境之間的environments數量。解析器透過呼叫下面的方法將這個數字傳遞給直譯器:
lox/Interpreter.java,在 execute()方法後新增:
void resolve(Expr expr, int depth) {
locals.put(expr, depth);
}
We want to store the resolution information somewhere so we can use it when the variable or assignment expression is later executed, but where? One obvious place is right in the syntax tree node itself. That’s a fine approach, and that’s where many compilers store the results of analyses like this.
我們要把解析資訊儲存在某個地方,這樣在執行變量表達式和賦值表示式時就可以使用它,但是要存在哪裡呢?一個明顯的位置就是語法樹節點本身。這是一個很好的方法,許多編譯器都是在這裡儲存類似的分析結果的。
We could do that, but it would require mucking around with our syntax tree generator. Instead, we’ll take another common approach and store it off to the side in a map that associates each syntax tree node with its resolved data.
我們可以這樣做,但是需要對我們的語法樹生成器進行修改。相反,我們會採用另一種常見的方法,將其儲存在一個map中,將每個語法樹節點與其解析的資料關聯起來。
Interactive tools like IDEs often incrementally reparse and re-resolve parts of the user’s program. It may be hard to find all of the bits of state that need recalculating when they’re hiding in the foliage of the syntax tree. A benefit of storing this data outside of the nodes is that it makes it easy to discard it—simply clear the map.
像IDE這種的互動式工具經常會增量地對使用者的部分程式碼進行重新分析和解析。當這些狀態隱藏在語法樹的枝葉中時,可能很難找到所有需要重新計算的狀態。將這些資料儲存在節點之外的好處之一就是,可以很容易地丟棄這部分資料——只需要清除map即可。
lox/Interpreter.java,在 Interpreter類中新增
private Environment environment = globals;
// 新增部分開始
private final Map<Expr, Integer> locals = new HashMap<>();
// 新增部分結束
Interpreter() {
You might think we’d need some sort of nested tree structure to avoid getting confused when there are multiple expressions that reference the same variable, but each expression node is its own Java object with its own unique identity. A single monolithic map doesn’t have any trouble keeping them separated.
你可能認為我們需要某種巢狀的樹狀結構,以避免在有多個表示式引用同一個變數時出現混亂,但是每個表示式節點都有其對應的Java物件,具有唯一性標識。一個簡單的map就足以將它們全部區分開來。
As usual, using a collection requires us to import a couple of names.
與之前一樣,使用集合需要先引入一些包名稱。
lox/Interpreter.java,新增:
import java.util.ArrayList;
// 新增部分開始
import java.util.HashMap;
// 新增部分結束
import java.util.List;
And:
還有:
lox/Interpreter.java,新增:
import java.util.List;
// 新增部分開始
import java.util.Map;
// 新增部分結束
class Interpreter implements Expr.Visitor<Object>,
11 . 4 . 1Accessing a resolved variable
11.4.1 訪問已解析的變數
Our interpreter now has access to each variable’s resolved location. Finally, we get to make use of that. We replace the visit method for variable expressions with this:
我們的直譯器現在可以訪問每個變數的解析位置。最後,我們可以利用這一點了,將變量表達式的visit方法替換如下:
lox/Interpreter.java,在 visitVariableExpr()方法中替換一行:
public Object visitVariableExpr(Expr.Variable expr) {
// 替換部分開始
return lookUpVariable(expr.name, expr);
// 替換部分結束
}
That delegates to:
這裡引用了:
lox/Interpreter.java,在 visitVariableExpr()方法後新增:
private Object lookUpVariable(Token name, Expr expr) {
Integer distance = locals.get(expr);
if (distance != null) {
return environment.getAt(distance, name.lexeme);
} else {
return globals.get(name);
}
}
There are a couple of things going on here. First, we look up the resolved distance in the map. Remember that we resolved only local variables. Globals are treated specially and don’t end up in the map (hence the name
locals). So, if we don’t find a distance in the map, it must be global. In that case, we look it up, dynamically, directly in the global environment. That throws a runtime error if the variable isn’t defined.
這裡有幾件事要做。首先,我們在map中查詢已解析的距離值。要記住,我們只解析了本地變數。全域性變數被特殊處理了,不會出現了map中(所以它的名字叫locals)。所以,如果我們沒有在map中找到變數對應的距離值,它一定是全域性變數。在這種情況下,我們直接在全域性environment中查詢。如果變數沒有被定義,就會產生一個執行時錯誤。
If we do get a distance, we have a local variable, and we get to take advantage of the results of our static analysis. Instead of calling
get(), we call this new method on Environment:
如果我們確實查到了一個距離值,那這就是個區域性變數,我們可以利用靜態分析的結果。我們不會呼叫get()方法,而是呼叫下面這個Environment中的新方法:
lox/Environment.java,在 define()方法後新增:
Object getAt(int distance, String name) {
return ancestor(distance).values.get(name);
}
The old
get()method dynamically walks the chain of enclosing environments, scouring each one to see if the variable might be hiding in there somewhere. But now we know exactly which environment in the chain will have the variable. We reach it using this helper method:
原先的get()方法會動態遍歷外圍的環境鏈,搜尋每一個環境,檢視變數是否包含在其中。但是現在我們明確知道鏈路中的哪個環境中會包含該變數。我們使用下面的輔助方法直達這個環境:
lox/Environment.java,在 define()方法後新增:
Environment ancestor(int distance) {
Environment environment = this;
for (int i = 0; i < distance; i++) {
environment = environment.enclosing;
}
return environment;
}
This walks a fixed number of hops up the parent chain and returns the environment there. Once we have that,
getAt()simply returns the value of the variable in that environment’s map. It doesn’t even have to check to see if the variable is there—we know it will be because the resolver already found it before.
該方法在環境鏈中經過確定的跳數之後,返回對應的環境。一旦我們有了環境,getAt()方法就可以直接返回對應環境map中的變數值。甚至不需要檢查變數是否存在——我們知道它是存在的,因為解析器之前已經確認過了7。
11 . 4 . 2 Assigning to a resolved variable
11.4.2 賦值已解析的變數
We can also use a variable by assigning to it. The changes to visiting an assignment epression are similar.
我們也可以透過賦值來使用一個變數。賦值表示式對應的visit方法的修改也是類似的。
lox/Interpreter.java,在 visitAssignExpr()方法中替換一行:
public Object visitAssignExpr(Expr.Assign expr) {
Object value = evaluate(expr.value);
// 替換部分開始
Integer distance = locals.get(expr);
if (distance != null) {
environment.assignAt(distance, expr.name, value);
} else {
globals.assign(expr.name, value);
}
// 替換部分結束
return value;
Again, we look up the variable’s scope distance. If not found, we assume it’s global and handle it the same way as before. Otherwise, we call this new method:
又一次,我們要查詢變數的作用域距離。如果沒有找到,我們就假定它是全域性變數並採用跟之前一樣的方式來處理;否則,我們使用下面的新方法:
lox/Environment.java,在 getAt()方法後新增:
void assignAt(int distance, Token name, Object value) {
ancestor(distance).values.put(name.lexeme, value);
}
As
getAt()is toget(),assignAt()is toassign(). It walks a fixed number of environments, and then stuffs the new value in that map.
正如getAt() 與get()的關係,assignAt() 對應於assign()。它會遍歷固定數量的環境,然後在其map中塞入新的值。
Those are the only changes to Interpreter. This is why I chose a representation for our resolved data that was minimally invasive. All of the rest of the nodes continue working as they did before. Even the code for modifying environments is unchanged.
直譯器就只需要做這些調整。這也就是為什麼我為解析資料選擇了一種侵入性最小的表示方法。其餘所有節點都跟之前一樣,甚至連修改環境的程式碼也沒有改動。
11 . 4 . 3 Running the resolver
11.4.3 執行解析器
We do need to actually run the resolver, though. We insert the new pass after the parser does its magic.
不過,我們確實需要執行解析器。我們在解析器完成工作之後插入一次解析器處理。
lox/Lox.java,在 run()方法中新增程式碼:
// Stop if there was a syntax error.
if (hadError) return;
// 新增部分開始
Resolver resolver = new Resolver(interpreter);
resolver.resolve(statements);
// 新增部分結束
interpreter.interpret(statements);
We don’t run the resolver if there are any parse errors. If the code has a syntax error, it’s never going to run, so there’s little value in resolving it. If the syntax is clean, we tell the resolver to do its thing. The resolver has a reference to the interpreter and pokes the resolution data directly into it as it walks over variables. When the interpreter runs next, it has everything it needs.
如果前面的分析中存在任何錯誤,我們都不會執行解析器。如果程式碼有語法錯誤,它就不會執行,所以解析它的價值不大。如果語法是乾淨的,我們就告訴解析器做該做的事。解析器中有一個對直譯器的引用,當它遍歷變數時,會將解析資料直接放入直譯器中。直譯器後續執行時,它就具備了所需的一切資料。
At least, that’s true if the resolver succeeds. But what about errors during resolution?
退一步講,如果解析器成功了,這麼說就是對的。但是如果解析過程中出現錯誤會怎麼辦?
11 . 5 Resolution Errors
11.5 解析錯誤
Since we are doing a semantic analysis pass, we have an opportunity to make Lox’s semantics more precise, and to help users catch bugs early before running their code. Take a look at this bad boy:
由於我們正在進行語義分析,因此我們有機會使Lox 的語義更加精確,以幫助使用者在執行程式碼之前及早發現錯誤。看一下下面這個壞程式碼:
fun bad() {
var a = "first";
var a = "second";
}
We do allow declaring multiple variables with the same name in the global scope, but doing so in a local scope is probably a mistake. If they knew the variable already existed, they would have assigned to it instead of using
var. And if they didn’t know it existed, they probably didn’t intend to overwrite the previous one.
我們確實允許在全域性作用域內宣告多個同名的變數,但在區域性作用域內這樣做可能是錯誤的。如果使用者知道變數已經存在,就應該使用賦值操作而不是var。如果他們不知道變數的存在,他們可能並不想覆蓋之前的變數。
We can detect this mistake statically while resolving.
我們可以在解析的時候靜態地檢測到這個錯誤。
lox/Resolver.java,在 declare()方法中新增:
Map<String, Boolean> scope = scopes.peek();
// 新增部分開始
if (scope.containsKey(name.lexeme)) {
Lox.error(name,
"Already variable with this name in this scope.");
}
// 新增部分結束
scope.put(name.lexeme, false);
When we declare a variable in a local scope, we already know the names of every variable previously declared in that same scope. If we see a collision, we report an error.
當我們在區域性作用域中宣告一個變數時,我們已經知道了之前在同一作用域中宣告的每個變數的名字。如果我們看到有衝突,我們就報告一個錯誤。
11 . 5 . 1 Invalid return errors
11.5.1 無效返回錯誤
Here’s another nasty little script:
這是另一個討人厭的小指令碼:
return "at top level";
This executes a
returnstatement, but it’s not even inside a function at all. It’s top-level code. I don’t know what the user thinks is going to happen, but I don’t think we want Lox to allow this.
這裡執行了一個return語句,但它甚至根本不在函式內部。這是一個頂層程式碼。我不知道使用者認為會發生什麼,但是我認為我們不希望Lox允許這種做法。
We can extend the resolver to detect this statically. Much like we track scopes as we walk the tree, we can track whether or not the code we are currently visiting is inside a function declaration.
我們可以對解析器進行擴充套件來靜態檢測這種錯誤。就像我們遍歷語法樹時跟蹤作用域一樣,我們也可以跟蹤當前訪問的程式碼是否在一個函式宣告內部。
lox/Resolver.java,在 Resolver類中新增程式碼:
private final Stack<Map<String, Boolean>> scopes = new Stack<>();
// 新增部分開始
private FunctionType currentFunction = FunctionType.NONE;
// 新增部分結束
Resolver(Interpreter interpreter) {
Instead of a bare Boolean, we use this funny enum:
我們不是使用一個簡單的Boolean值,而是使用下面這個有趣的列舉:
lox/Resolver.java,在 Resolver()方法後新增:
private enum FunctionType {
NONE,
FUNCTION
}
It seems kind of dumb now, but we’ll add a couple more cases to it later and then it will make more sense. When we resolve a function declaration, we pass that in.
現在看來又點蠢,但是我們稍後會新增更多案例,到時候它將更有意義。當我們解析函式宣告時,將其作為引數傳入。
lox/Resolver.java,在 visitFunctionStmt()方法中,替換一行:
define(stmt.name);
// 替換部分開始
resolveFunction(stmt, FunctionType.FUNCTION);
// 替換部分結束
return null;
Over in
resolveFunction(), we take that parameter and store it in the field before resolving the body.
在resolveFunction()中,我們接受該引數,並在解析函式體之前將其儲存在欄位中。
lox/Resolver.java,在 resolveFunction()方法中替換一行:
// 替換部分開始
private void resolveFunction(
Stmt.Function function, FunctionType type) {
FunctionType enclosingFunction = currentFunction;
currentFunction = type;
// 替換部分結束
beginScope();
We stash the previous value of the field in a local variable first. Remember, Lox has local functions, so you can nest function declarations arbitrarily deeply. We need to track not just that we’re in a function, but how many we’re in.
我們先把該欄位的舊值存在一個區域性變數中。記住,Lox中有區域性函式,所以你可以任意深度地巢狀函式宣告。我們不僅需要跟蹤是否在一個函式內部,還要記錄我們在多少函式內部。
We could use an explicit stack of FunctionType values for that, but instead we’ll piggyback on the JVM. We store the previous value in a local on the Java stack. When we’re done resolving the function body, we restore the field to that value.
我們可以使用一個顯式的FunctionType值堆疊來進行記錄,但我們會藉助JVM的力量。我們將前一個值儲存在Java堆疊中的一個區域性變數。當我們完成函式體的解析之後,我們將該欄位恢復為之前的值。
lox/Resolver.java,在 resolveFunction()方法中新增程式碼:
endScope();
// 新增部分開始
currentFunction = enclosingFunction;
// 新增部分結束
}
Now that we can always tell whether or not we’re inside a function declaration, we check that when resolving a
returnstatement.
既然我們能知道是否在一個函式宣告中,那我們就可以在解析return語句時進行檢查。
lox/Resolver.java,在 visitReturnStmt()方法中新增程式碼:
public Void visitReturnStmt(Stmt.Return stmt) {
// 新增部分開始
if (currentFunction == FunctionType.NONE) {
Lox.error(stmt.keyword, "Can't return from top-level code.");
}
// 新增部分結束
if (stmt.value != null) {
Neat, right?
很簡潔,對吧?
There’s one more piece. Back in the main Lox class that stitches everything together, we are careful to not run the interpreter if any parse errors are encountered. That check runs before the resolver so that we don’t try to resolve syntactically invalid code.
還有一件事。回到將所有部分整合到一起的主類Lox中,我們很小心,如果遇到任何解析錯誤就不會執行直譯器。這個檢查是在解析器之前執行的,這樣我們就不需要再去嘗試解析語法無效的程式碼。
But we also need to skip the interpreter if there are resolution errors, so we add another check.
但是如果在解析變數時存在錯誤,也需要跳過直譯器,所以我們新增另一個檢查。
lox/Lox.java,在 run()方法中新增程式碼:
resolver.resolve(statements);
// 新增部分開始
// Stop if there was a resolution error.
if (hadError) return;
// 新增部分結束
interpreter.interpret(statements);
You could imagine doing lots of other analysis in here. For example, if we added
breakstatements to Lox, we would probably want to ensure they are only used inside loops.
你可以想象在這裡做很多其它分析。例如,我們在Lox中添加了break語句,而我們可能想確保它只能在迴圈體中使用。
We could go farther and report warnings for code that isn’t necessarily wrong but probably isn’t useful. For example, many IDEs will warn if you have unreachable code after a
returnstatement, or a local variable whose value is never read. All of that would be pretty easy to add to our static visiting pass, or as separate passes.
我們還可以更進一步,對那些不一定是錯誤但可能沒有用的程式碼提出警告。舉例來說,如果在return語句後有不可觸及的程式碼,很多IDE都會發出警告,或者是一個區域性變數的值從沒有被使用過。所有這些都可以很簡單地新增到我們的靜態分析過程中,或者作為單獨的分析過程8。
But, for now, we’ll stick with that limited amount of analysis. The important part is that we fixed that one weird annoying edge case bug, though it might be surprising that it took this much work to do it.
但是,就目前而言,我們會堅持這種有限的分析。重要的是,我們修復了一個奇怪又煩人的邊界情況bug,儘管花費了這麼多精力可能有些令人意外。
CHALLENGES
習題
1、Why is it safe to eagerly define the variable bound to a function’s name when other variables must wait until after they are initialized before they can be used?
1、為什麼先定義與函式名稱繫結的變數是安全的,而其它變數必須等到初始化後才能使用?
2、How do other languages you know handle local variables that refer to the same name in their initializer, like:
2、你知道其它語言中是如何處理區域性變數在初始化式中引用了相同名稱變數的情況?比如:
var a = "outer";
{
var a = a;
}
Is it a runtime error? Compile error? Allowed? Do they treat global variables differently? Do you agree with their choices? Justify your answer.
這是一個執行時錯誤?編譯錯誤?還是允許這種操作?它們對待全域性變數的方式有區別嗎?你是否認同它們的選擇?證明你的答案。
3、Extend the resolver to report an error if a local variable is never used.
3、對解析器進行擴充套件,如果區域性變數沒有被使用就報告一個錯誤。
4、Our resolver calculates which environment the variable is found in, but it’s still looked up by name in that map. A more efficient environment representation would store local variables in an array and look them up by index.
Extend the resolver to associate a unique index for each local variable declared in a scope. When resolving a variable access, look up both the scope the variable is in and its index and store that. In the interpreter, use that to quickly access a variable by its index instead of using a map.
4、我們的解析器會計算出變數是在哪個環境中找到的,但是它仍然需要根據名稱在對應的map中查詢。一個更有效的環境表示形式是將區域性變數儲存在一個陣列中,並透過索引來查詢它們。
擴充套件解析器,為作用域中宣告的每個區域性變數關聯一個唯一的索引。當解析一個變數的訪問時,查詢變數所在的作用域及對應的索引,並儲存起來。在直譯器中,使用這個索引快速的訪問一個變數。
-
這還遠遠比不上真正的語言規範那麼精確。那些規範文件必須非常明確,即使是一個火星人或一個完全惡意的程式設計師也會被迫執行正確的語義,只要他們遵循規範說明。有一些公司希望自己的產品與其它產品不相容,從而將使用者鎖定在自己的平臺上,當一種語言由這類公司實現時,精確性就非常重要了。對於這本書來說,我們很慶幸可以忽略那些爾虞我詐。 ↩
-
在JavaScript中,使用var宣告的變數被隱式提升到塊的開頭,在程式碼塊中對該名稱的任何使用都將指向該變數,即使變數使用出現在宣告之前。當你用JavaScript寫如下程式碼時:
{ console.log(a); var a = "value"; }。它實際相當於:{ var a; // Hoist. console.log(a); a = "value"; }。這意味著在某些情況下,您可以在其初始化程式執行之前讀取一個變數——一個令人討厭的錯誤源。後來添加了用於宣告變數的備用let語法來解決這個問題。 ↩ -
我知道,這完全是一個病態的、人為的程式。這太奇怪了。沒有一個理性的人會寫這樣的程式碼。唉,如果你長期從事程式語言的工作,你的生活中會有比你想象的更多的時間花在處理這種古怪的程式碼片段上。 ↩
-
一些語言中明確進行了這種分割。在Scheme和ML中,當你用
let宣告一個區域性變數時,還描述了新變數在作用域內的後續程式碼。不存在隱含的 “塊的其餘部分”。 ↩ -
為每個操作複製結構,這聽起來可能會浪費大量的記憶體和時間。在實踐中,永續性資料結構在不同的“副本”之間共享大部分的資料。 ↩
-
變數解析對每個節點只觸及一次,因此其效能是O(n),其中n是語法樹中節點的個數。更復雜的分析可能會有更大的複雜性,但是大多數都被精心設計成線性或接近線性。如果編譯器隨著使用者程式的增長而呈指數級變慢,那將是一個很尷尬的失禮。 ↩
-
直譯器假定變數在map中存在的做法有點像是盲飛。直譯器相信解析器完成了工作並正確地解析了變數。這意味著這兩個類之間存在深度耦合。在解析器中,涉及作用域的每一行程式碼都必須與直譯器中修改環境的程式碼完全匹配。我對這種耦合有切身體會,因為當我在為本書寫程式碼時,我遇到了幾個微妙的錯誤,即解析器程式碼和直譯器程式碼有點不同步。跟蹤這些問題是很困難的。一個行之有效的方法就是,在直譯器中使用顯式的斷言——透過Java的assert或其它驗證工具——確認解析器已經具備它所期望的值。 ↩
-
要選擇將多少個不同的靜態分析納入單個處理過程中是很困難的。許多小的、孤立的過程(每個過程都有自己的職責)實現和維護都比較簡單。然而,遍歷語法樹本身是有實際執行時間成本的,所以將多個分析繫結到一個過程中通常會更快。 ↩
12.類 Classes
One has no right to love or hate anything if one has not acquired a thorough knowledge of its nature. Great love springs from great knowledge of the beloved object, and if you know it but little you will be able to love it only a little or not at all.
——Leonardo da Vinci
如果一個人沒有完全瞭解任何事物的本質,他就沒有權利去愛或恨它。偉大的愛來自於對所愛之物的深刻了解,如果你對它知之甚少,你就只能愛一點點,或者根本不愛它。(列奧納多·達·芬奇)
We’re eleven chapters in, and the interpreter sitting on your machine is nearly a complete scripting language. It could use a couple of built-in data structures like lists and maps, and it certainly needs a core library for file I/O, user input, etc. But the language itself is sufficient. We’ve got a little procedural language in the same vein as BASIC, Tcl, Scheme (minus macros), and early versions of Python and Lua.
我們已經完成了11章,你機器上的直譯器幾乎是一個完整的指令碼語言實現了。它可以使用一些內建的資料結構,如列表和map,當然還需要一個用於檔案IO、使用者輸入等的核心庫。但作為語言本身已經足夠了。我們有一個與BASIC、Tcl、Scheme(不包括宏)以及早期版本的Python和Lua相同的小程式語言。
If this were the ’80s, we’d stop here. But today, many popular languages support “object-oriented programming”. Adding that to Lox will give users a familiar set of tools for writing larger programs. Even if you personally don’t like OOP, this chapter and the next will help you understand how others design and build object systems.
如果現在是80年代,我們就可以到此為止。但是現在,很多流行的語言都支援“面向物件程式設計”。在Lox中新增該功能,可以為使用者提供一套熟悉的工具來編寫大型程式。即使你個人不喜歡OOP,這一章和下一章將幫助你理解別人是如何設計和構建物件系統的1。
12.1 OOP and Classes
There are three broad paths to object-oriented programming: classes, prototypes, and multimethods. Classes came first and are the most popular style. With the rise of JavaScript (and to a lesser extent Lua), prototypes are more widely known than they used to be. I’ll talk more about those later. For Lox, we’re taking the, ahem, classic approach.
面向物件程式設計有三大途徑:類、原型和多方法2。類排在第一位,是最流行的風格。隨著JavaScript(其次是Lua)的興起,原型也比以前更加廣為人知。稍後我們會更多地討論這些問題。對於Lox,我們採取的是經典的方法。
Since you’ve written about a thousand lines of Java code with me already, I’m assuming you don’t need a detailed introduction to object orientation. The main goal is to bundle data with the code that acts on it. Users do that by declaring a class that:
既然你已經跟我一起編寫了大約1000行Java程式碼,我假設你不需要對面向物件進行詳細介紹。OOP的主要目標就是將資料與作用於資料的程式碼捆綁在一起。使用者透過宣告一個類來實現這一點:
-
Exposes a constructor to create and initialize new instances of the class
暴露建構函式以建立和初始化該類的新例項
-
Provides a way to store and access fields on instances
提供在例項上儲存和訪問欄位的方法。
-
Defines a set of methods shared by all instances of the class that operate on each instances’ state.
定義一組由類的所有例項共享的方法,這些方法對各個例項的狀態進行操作。

That’s about as minimal as it gets. Most object-oriented languages, all the way back to Simula, also do inheritance to reuse behavior across classes. We’ll add that in the next chapter. Even kicking that out, we still have a lot to get through. This is a big chapter and everything doesn’t quite come together until we have all of the above pieces, so gather your stamina.
這大概是最低要求。大多數面向物件的語言(一直追溯到Simula),也都是透過繼承來跨類重用行為。我們會在下一章中新增該功能。即使剔除了這些,我們仍然有很多東西需要完成。這是一個很大的章節,直到我們完成上述所有內容之後,才能把所有東西整合到一起。所以請集中精力。
12 . 2 Class Declarations
Like we do, we’re gonna start with syntax. A
classstatement introduces a new name, so it lives in thedeclarationgrammar rule.
跟之前一樣,我們從語法開始。class語句引入了一個新名稱,所以它應該在declaration 語法規則中。
declaration → classDecl
| funDecl
| varDecl
| statement ;
classDecl → "class" IDENTIFIER "{" function* "}" ;
The new
classDeclrule relies on thefunctionrule we defined earlier. To refresh your memory:
新的classDecl規則依賴於前面定義的function規則。複習一下:
function → IDENTIFIER "(" parameters? ")" block ;
parameters → IDENTIFIER ( "," IDENTIFIER )* ;
In plain English, a class declaration is the
classkeyword, followed by the class’s name, then a curly-braced body. Inside that body is a list of method declarations. Unlike function declarations, methods don’t have a leadingfunkeyword. Each method is a name, parameter list, and body. Here’s an example:
用簡單的英語來說,類宣告就是class關鍵字,後跟類的名稱,然後是一對花括號包含的主體。在這個主體中,有一個方法宣告的列表。與函式宣告不同的是,方法沒有前導的fun關鍵字。每個方法就是一個名稱、引數列表和方法主體。下面是一個例子:
class Breakfast {
cook() {
print "Eggs a-fryin'!";
}
serve(who) {
print "Enjoy your breakfast, " + who + ".";
}
}
Like most dynamically typed languages, fields are not explicitly listed in the class declaration. Instances are loose bags of data and you can freely add fields to them as you see fit using normal imperative code.
像大多數動態型別的語言一樣,欄位沒有在類的宣告中明確列出。例項是鬆散的資料包,你可以使用正常的命令式程式碼自由地向其中新增欄位。
Over in our AST generator, the
classDeclgrammar rule gets its own statement node.
在AST生成器中,classDecl語法規則有自己的語句節點。
tool/GenerateAst.java,在 main()方法中新增:
"Block : List<Stmt> statements",
// 新增部分開始
"Class : Token name, List<Stmt.Function> methods",
// 新增部分結束
"Expression : Expr expression",
It stores the class’s name and the methods inside its body. Methods are represented by the existing Stmt.Function class that we use for function declaration AST nodes. That gives us all the bits of state that we need for a method: name, parameter list, and body.
它儲存了類的名稱和其主體內的方法。方法使用現有的表示函式宣告的Stmt.Function類來表示。這就為我們提供了一個方法所需的所有狀態:名稱、引數列表和方法體。
A class can appear anywhere a named declaration is allowed, triggered by the leading
classkeyword.
類可以出現在任何允許名稱宣告的地方,由前導的class關鍵字來觸發。
lox/Parser.java,在 declaration()方法中新增:
try {
// 新增部分開始
if (match(CLASS)) return classDeclaration();
// 新增部分結束
if (match(FUN)) return function("function");
That calls out to:
進一步呼叫:
lox/Parser.java,在 declaration()方法後新增:
private Stmt classDeclaration() {
Token name = consume(IDENTIFIER, "Expect class name.");
consume(LEFT_BRACE, "Expect '{' before class body.");
List<Stmt.Function> methods = new ArrayList<>();
while (!check(RIGHT_BRACE) && !isAtEnd()) {
methods.add(function("method"));
}
consume(RIGHT_BRACE, "Expect '}' after class body.");
return new Stmt.Class(name, methods);
}
There’s more meat to this than most of the other parsing methods, but it roughly follows the grammar. We’ve already consumed the
classkeyword, so we look for the expected class name next, followed by the opening curly brace. Once inside the body, we keep parsing method declarations until we hit the closing brace. Each method declaration is parsed by a call tofunction(), which we defined back in the chapter where functions were introduced.
這比其它大多數解析方法有更多的內容,但它大致上遵循了語法。我們已經使用了class關鍵字,所以我們接下來會查詢預期的類名,然後是左花括號。一旦進入主體,我們就繼續解析方法宣告,直到碰到右花括號。每個方法宣告是透過呼叫function()方法來解析的,我們在介紹函式的那一章中定義了該函式。
Like we do in any open-ended loop in the parser, we also check for hitting the end of the file. That won’t happen in correct code since a class should have a closing brace at the end, but it ensures the parser doesn’t get stuck in an infinite loop if the user has a syntax error and forgets to correctly end the class body.
就像我們在解析器中的所有開放式迴圈中的操作一樣,我們也要檢查是否到達檔案結尾。這在正確的程式碼是不會發生的,因為類的結尾應該有一個右花括號,但它可以確保在使用者出現語法錯誤而忘記正確結束類的主體時,解析器不會陷入無限迴圈。
We wrap the name and list of methods into a Stmt.Class node and we’re done. Previously, we would jump straight into the interpreter, but now we need to plumb the node through the resolver first.
我們將名稱和方法列表封裝到Stmt.Class節點中,這樣就完成了。以前,我們會直接進入直譯器中,但是現在我們需要先進入分析器中對節點進行分析。【譯者注:為了區分parse和resolve,這裡將resolver稱為分析器,用於對程式碼中的變數進行分析】
lox/Resolver.java,在 visitBlockStmt()方法後新增:
@Override
public Void visitClassStmt(Stmt.Class stmt) {
declare(stmt.name);
define(stmt.name);
return null;
}
We aren’t going to worry about resolving the methods themselves yet, so for now all we need to do is declare the class using its name. It’s not common to declare a class as a local variable, but Lox permits it, so we need to handle it correctly.
我們還不用擔心針對方法本身的分析,我們目前需要做的是使用類的名稱來宣告這個類。將類宣告為一個區域性變數並不常見,但是Lox中允許這樣做,所以我們需要正確處理。
Now we interpret the class declaration.
現在我們解釋一下類的宣告。
lox/Interpreter.java,在 visitBlockStmt()方法後新增:
@Override
public Void visitClassStmt(Stmt.Class stmt) {
environment.define(stmt.name.lexeme, null);
LoxClass klass = new LoxClass(stmt.name.lexeme);
environment.assign(stmt.name, klass);
return null;
}
This looks similar to how we execute function declarations. We declare the class’s name in the current environment. Then we turn the class syntax node into a LoxClass, the runtime representation of a class. We circle back and store the class object in the variable we previously declared. That two-stage variable binding process allows references to the class inside its own methods.
這看起來類似於我們執行函式宣告的方式。我們在當前環境中宣告該類的名稱。然後我們把類的語法節點轉換為LoxClass,即類的執行時表示。我們回過頭來,將類物件儲存在我們之前宣告的變數中。這個二階段的變數繫結過程允許在類的方法中引用其自身。
We will refine it throughout the chapter, but the first draft of LoxClass looks like this:
我們會在整個章節中對其進行完善,但是LoxClass的初稿看起來如下:
lox/LoxClass.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.List;
import java.util.Map;
class LoxClass {
final String name;
LoxClass(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
}
Literally a wrapper around a name. We don’t even store the methods yet. Not super useful, but it does have a
toString()method so we can write a trivial script and test that class objects are actually being parsed and executed.
字面上看,就是一個對name的包裝。我們甚至還沒有儲存類中的方法。不算很有用,但是它確實有一個toString()方法,所以我們可以編寫一個簡單的指令碼,測試類物件是否真的被解析和執行。
class DevonshireCream {
serveOn() {
return "Scones";
}
}
print DevonshireCream; // Prints "DevonshireCream".
12 . 3 Creating Instances
12.3 建立例項
We have classes, but they don’t do anything yet. Lox doesn’t have “static” methods that you can call right on the class itself, so without actual instances, classes are useless. Thus instances are the next step.
我們有了類,但是它們還不能做任何事。Lox沒有可以直接在類本身呼叫的“靜態”方法,所以如果沒有例項,類是沒有用的。因此,下一步就是例項化。
While some syntax and semantics are fairly standard across OOP languages, the way you create new instances isn’t. Ruby, following Smalltalk, creates instances by calling a method on the class object itself, a recursively graceful approach. Some, like C++ and Java, have a
newkeyword dedicated to birthing a new object. Python has you “call” the class itself like a function. (JavaScript, ever weird, sort of does both.)
雖然一些語法和語義在OOP語言中是相當標準的,但建立新例項的方式並不是。Ruby,繼Smalltalk之後,透過呼叫類物件本身的一個方法來建立例項,這是一種遞迴的優雅方法3。有些語言,像C++和Java,有一個new關鍵字專門用來建立一個新的物件。Python讓你像呼叫函式一樣“呼叫”類本身。(JavaScript,永遠都是那麼奇怪,兩者兼而有之)
I took a minimal approach with Lox. We already have class objects, and we already have function calls, so we’ll use call expressions on class objects to create new instances. It’s as if a class is a factory function that generates instances of itself. This feels elegant to me, and also spares us the need to introduce syntax like
new. Therefore, we can skip past the front end straight into the runtime.
我在Lox中採用了一種最簡單的方法。我們已經有了類物件,也有了函式呼叫,所以我們直接使用類物件的呼叫表示式來建立新的例項。這就好像類是一個生產自身例項的工廠函式。這讓我感覺很優雅,也不需要引入new這樣的語法。因此,我們可以跳過前端直接進入執行時。
Right now, if you try this:
現在,如果你試著執行下面的程式碼:
class Bagel {}
Bagel();
You get a runtime error.
visitCallExpr()checks to see if the called object implementsLoxCallableand reports an error since LoxClass doesn’t. Not yet, that is.
你會得到一個執行時錯誤。visitCallExpr()方法會檢查被呼叫的物件是否實現了LoxCallable 介面,因為LoxClass沒有實現所以會報錯。只是目前還沒有。
lox/LoxClass.java,替換一行:
import java.util.Map;
// 替換部分開始
class LoxClass implements LoxCallable {
// 替換部分結束
final String name;
Implementing that interface requires two methods.
實現該介面需要兩個方法。
lox/LoxClass.java,在 toString()方法後新增:
@Override
public Object call(Interpreter interpreter,
List<Object> arguments) {
LoxInstance instance = new LoxInstance(this);
return instance;
}
@Override
public int arity() {
return 0;
}
The interesting one is
call(). When you “call” a class, it instantiates a new LoxInstance for the called class and returns it. Thearity()method is how the interpreter validates that you passed the right number of arguments to a callable. For now, we’ll say you can’t pass any. When we get to user-defined constructors, we’ll revisit this.
有趣的是call()。當你“呼叫”一個類時,它會為被呼叫的類例項化一個新的LoxInstance並返回。arity() 方法是直譯器用於驗證你是否向callable中傳入了正確數量的引數。現在,我們會說你不用傳任何引數。當我們討論使用者自定義的建構函式時,我們再重新考慮這個問題。
That leads us to LoxInstance, the runtime representation of an instance of a Lox class. Again, our first implementation starts small.
這就引出了LoxInstance,它是Lox類例項的執行時表示。同樣,我們的第一個實現從小處著手。
lox/LoxInstance.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.HashMap;
import java.util.Map;
class LoxInstance {
private LoxClass klass;
LoxInstance(LoxClass klass) {
this.klass = klass;
}
@Override
public String toString() {
return klass.name + " instance";
}
}
Like LoxClass, it’s pretty bare bones, but we’re only getting started. If you want to give it a try, here’s a script to run:
和LoxClass一樣,它也是相當簡陋的,但我們才剛剛開始。如果你想測試一下,可以執行下面的指令碼:
class Bagel {}
var bagel = Bagel();
print bagel; // Prints "Bagel instance".
This program doesn’t do much, but it’s starting to do something.
這段程式沒有做太多事,但是已經開始做一些事情了。
12 . 4 Properties on Instances
12.4 例項屬性
We have instances, so we should make them useful. We’re at a fork in the road. We could add behavior first—methods—or we could start with state—properties. We’re going to take the latter because, as we’ll see, the two get entangled in an interesting way and it will be easier to make sense of them if we get properties working first.
我們有了例項,所以我們應該讓它們發揮作用。我們正處於一個岔路口。我們可以首先新增行為(方法),或者我們可以先從狀態(屬性)開始。我們將選擇後者,因為我們後面將會看到,這兩者以一種有趣的方式糾纏在一起,如果我們先支援屬性,就會更容易理解它們。
Lox follows JavaScript and Python in how it handles state. Every instance is an open collection of named values. Methods on the instance’s class can access and modify properties, but so can outside code. Properties are accessed using a
.syntax.
Lox遵循了JavaScript和Python處理狀態的方式。每個例項都是一個開放的命名值集合。例項類中的方法可以訪問和修改屬性,但外部程式碼也可以4。屬性透過.語法進行訪問。
someObject.someProperty
An expression followed by
.and an identifier reads the property with that name from the object the expression evaluates to. That dot has the same precedence as the parentheses in a function call expression, so we slot it into the grammar by replacing the existingcallrule with:
一個後面跟著.和一個識別符號的表示式,會從表示式計算出的物件中讀取該名稱對應的屬性。這個點符號與函式呼叫表示式中的括號具有相同的優先順序,所以我們要將該符號加入語法時,可以替換已有的call規則如下:
call → primary ( "(" arguments? ")" | "." IDENTIFIER )* ;
After a primary expression, we allow a series of any mixture of parenthesized calls and dotted property accesses. “Property access” is a mouthful, so from here on out, we’ll call these “get expressions”.
在基本表示式之後,我們允許跟一系列括號呼叫和點屬性訪問的任何混合。屬性訪問有點拗口,所以自此以後,我們稱其為“get表示式”。
12 . 4 . 1 Get expressions
12.4.1 Get表示式
The syntax tree node is:
語法樹節點是:
tool/GenerateAst.java,在 main()方法中新增:
"Call : Expr callee, Token paren, List<Expr> arguments",
// 新增部分開始
"Get : Expr object, Token name",
// 新增部分結束
"Grouping : Expr expression",
Following the grammar, the new parsing code goes in our existing
call()method.
按照語法,在現有的call()方法中加入新的解析程式碼。
lox/Parser.java,在 call()方法中新增程式碼:
while (true) {
if (match(LEFT_PAREN)) {
expr = finishCall(expr);
// 新增部分開始
} else if (match(DOT)) {
Token name = consume(IDENTIFIER,
"Expect property name after '.'.");
expr = new Expr.Get(expr, name);
// 新增部分結束
} else {
break;
}
}
The outer
whileloop there corresponds to the*in the grammar rule. We zip along the tokens building up a chain of calls and gets as we find parentheses and dots, like so:
外面的while迴圈對應於語法規則中的*。隨著查詢括號和點,我們會沿著標記構建一系列的call和get,就像:

Instances of the new Expr.Get node feed into the resolver.
新的Expr.Get節點例項會被送入分析器。
lox/Resolver.java,在visitCallExpr()方法後新增:
@Override
public Void visitGetExpr(Expr.Get expr) {
resolve(expr.object);
return null;
}
OK, not much to that. Since properties are looked up dynamically, they don’t get resolved. During resolution, we recurse only into the expression to the left of the dot. The actual property access happens in the interpreter.
好吧,沒什麼好說的。因為屬性是動態查詢的,所以不會解析它們。在解析過程中,我們只遞迴到點符左邊的表示式中。實際的屬性訪問發生在直譯器中。
lox/Interpreter.java,在 visitCallExpr()方法後新增:
@Override
public Object visitGetExpr(Expr.Get expr) {
Object object = evaluate(expr.object);
if (object instanceof LoxInstance) {
return ((LoxInstance) object).get(expr.name);
}
throw new RuntimeError(expr.name,
"Only instances have properties.");
}
First, we evaluate the expression whose property is being accessed. In Lox, only instances of classes have properties. If the object is some other type like a number, invoking a getter on it is a runtime error.
首先,我們對屬性被訪問的表示式求值。在Lox中,只有類的例項才具有屬性。如果物件是其它型別(如數字),則對其執行getter是執行時錯誤。
If the object is a LoxInstance, then we ask it to look up the property. It must be time to give LoxInstance some actual state. A map will do fine.
如果該物件是LoxInstance,我們就要求它去查詢該屬性。現在必須給LoxInstance一些實際的狀態了。一個map就行了。
lox/LoxInstance.java,在 LoxInstance類中新增:
private LoxClass klass;
// 新增部分開始
private final Map<String, Object> fields = new HashMap<>();
// 新增部分結束
LoxInstance(LoxClass klass) {
Each key in the map is a property name and the corresponding value is the property’s value. To look up a property on an instance:
map中的每個鍵是一個屬性名稱,對應的值就是該屬性的值。查詢例項中的一個屬性:
lox/LoxInstance.java,在 LoxInstance()方法後新增:
Object get(Token name) {
if (fields.containsKey(name.lexeme)) {
return fields.get(name.lexeme);
}
throw new RuntimeError(name,
"Undefined property '" + name.lexeme + "'.");
}
An interesting edge case we need to handle is what happens if the instance doesn’t have a property with the given name. We could silently return some dummy value like
nil, but my experience with languages like JavaScript is that this behavior masks bugs more often than it does anything useful. Instead, we’ll make it a runtime error.
我們需要處理的一個有趣的邊緣情況是,如果這個例項中不包含給定名稱的屬性,會發生什麼。我們可以悄悄返回一些假值,如nil,但是根據我對JavaScript等語言的經驗,這種行為只是掩蓋了錯誤,而沒有做任何有用的事。相反,我們將它作為一個執行時錯誤。
So the first thing we do is see if the instance actually has a field with the given name. Only then do we return it. Otherwise, we raise an error.
因此,我們首先要做的就是看看這個例項中是否真的包含給定名稱的欄位。只有這樣,我們才會返回其值。其它情況下,我們會引發一個錯誤。
Note how I switched from talking about “properties” to “fields”. There is a subtle difference between the two. Fields are named bits of state stored directly in an instance. Properties are the named, uh, things, that a get expression may return. Every field is a property, but as we’ll see later, not every property is a field.
注意我是如何從討論“屬性”轉換到討論“欄位”的。這兩者之間有一個微妙的區別。欄位是直接儲存在例項中的命名狀態。屬性是get表示式可能返回的已命名的東西。每個欄位都是一個屬性,但是正如我們稍後將看到的,並非每個屬性都是一個欄位。
In theory, we can now read properties on objects. But since there’s no way to actually stuff any state into an instance, there are no fields to access. Before we can test out reading, we must support writing.
理論上,我們現在可以讀取物件的屬性。但是由於沒有辦法將任何狀態真正填充到例項中,所以也沒有欄位可以訪問。在我們測試讀取之前,我們需要先支援寫入。
12 . 4 . 2 Set expressions
12.4.2 Set表示式
Setters use the same syntax as getters, except they appear on the left side of an assignment.
setter和getter使用相同的語法,區別只是它們出現在賦值表示式的左側。
someObject.someProperty = value;
In grammar land, we extend the rule for assignment to allow dotted identifiers on the left-hand side.
在語言方面,我們擴充套件了賦值規則,允許在左側使用點識別符號。
assignment → ( call "." )? IDENTIFIER "=" assignment
| logic_or ;
Unlike getters, setters don’t chain. However, the reference to
callallows any high-precedence expression before the last dot, including any number of getters, as in:
與getter不同,setter不使用鏈。但是,對call 規則的引用允許在最後的點符號之前出現任何高優先順序的表示式,包括任何數量的getters,如:

Note here that only the last part, the
.meatis the setter. The.omeletteand.fillingparts are both get expressions.
注意,這裡只有最後一部分.meat是setter。.omelette和.filling部分都是get表示式。
Just as we have two separate AST nodes for variable access and variable assignment, we need a second setter node to complement our getter node.
就像我們有兩個獨立的AST節點用於變數訪問和變數賦值一樣,我們也需要一個setter節點來補充getter節點。
tool/GenerateAst.java,在 main()方法中新增:
"Logical : Expr left, Token operator, Expr right",
// 新增部分開始
"Set : Expr object, Token name, Expr value",
// 新增部分結束
"Unary : Token operator, Expr right",
In case you don’t remember, the way we handle assignment in the parser is a little funny. We can’t easily tell that a series of tokens is the left-hand side of an assignment until we reach the
=. Now that our assignment grammar rule hascallon the left side, which can expand to arbitrarily large expressions, that final=may be many tokens away from the point where we need to know we’re parsing an assignment.
也許你不記得了,我們在解析器中處理賦值的方法有點奇怪。在遇到=之前,我們無法輕易判斷一系列標記是否是一個賦值表示式的左側部分。現在我們的賦值語法規則在左側添加了call,它可以擴充套件為任意大的表示式,最後的=可能與我們需要知道是否正在解析賦值表示式的地方隔著很多標記。
Instead, the trick we do is parse the left-hand side as a normal expression. Then, when we stumble onto the equal sign after it, we take the expression we already parsed and transform it into the correct syntax tree node for the assignment.
相對地,我們的技巧就是把左邊的表示式作為一個正常表示式來解析。然後,當我們在後面發現等號時,我們就把已經解析的表示式轉換為正確的賦值語法樹節點。
We add another clause to that transformation to handle turning an Expr.Get expression on the left into the corresponding Expr.Set.
我們在該轉換中新增另一個子句,將左邊的Expr.Get表示式轉化為相應的Expr.Set表示式。
lox/Parser.java,在 assignment()方法中新增:
return new Expr.Assign(name, value);
// 新增部分開始
} else if (expr instanceof Expr.Get) {
Expr.Get get = (Expr.Get)expr;
return new Expr.Set(get.object, get.name, value);
// 新增部分結束
}
That’s parsing our syntax. We push that node through into the resolver.
這就是語法解析。我們將該節點推入分析器中。
lox/Resolver.java,在 visitLogicalExpr()方法後新增:
@Override
public Void visitSetExpr(Expr.Set expr) {
resolve(expr.value);
resolve(expr.object);
return null;
}
Again, like Expr.Get, the property itself is dynamically evaluated, so there’s nothing to resolve there. All we need to do is recurse into the two subexpressions of Expr.Set, the object whose property is being set, and the value it’s being set to.
同樣,像Expr.Get一樣,屬性本身是動態計算的,所以沒有什麼需要分析的。我們只需要遞迴到Expr.Set的兩個子表示式中,即被設定屬性的物件和它被設定的值。
That leads us to the interpreter.
這又會把我們引向直譯器。
lox/Interpreter.java,在 visitLogicalExpr()方法後新增:
@Override
public Object visitSetExpr(Expr.Set expr) {
Object object = evaluate(expr.object);
if (!(object instanceof LoxInstance)) {
throw new RuntimeError(expr.name,
"Only instances have fields.");
}
Object value = evaluate(expr.value);
((LoxInstance)object).set(expr.name, value);
return value;
}
We evaluate the object whose property is being set and check to see if it’s a LoxInstance. If not, that’s a runtime error. Otherwise, we evaluate the value being set and store it on the instance. That relies on a new method in LoxInstance.
我們先計算出被設定屬性的物件,然後檢查它是否是一個LoxInstance。如果不是,這就是一個執行時錯誤。否則,我們計算設定的值,並將其儲存到該例項中。這一步依賴於LoxInstance中的一個新方法。
lox/LoxInstance.java,在 get()方法後新增:
void set(Token name, Object value) {
fields.put(name.lexeme, value);
}
No real magic here. We stuff the values straight into the Java map where fields live. Since Lox allows freely creating new fields on instances, there’s no need to see if the key is already present.
這裡沒什麼複雜的。我們把這些值之間塞入欄位所在的Java map中。由於Lox允許在例項上自由建立新欄位,所以不需要檢查鍵是否已經存在。
12 . 5 Methods on Classes
12.5 類中的方法
You can create instances of classes and stuff data into them, but the class itself doesn’t really do anything. Instances are just maps and all instances are more or less the same. To make them feel like instances of classes, we need behavior—methods.
你可以建立類的例項並將資料填入其中,但是類本身實際上並不能做任何事。例項只是一個map,而且所有的例項都是大同小異的。為了讓它們更像是類的例項,我們需要行為——方法。
Our helpful parser already parses method declarations, so we’re good there. We also don’t need to add any new parser support for method calls. We already have
.(getters) and()(function calls). A “method call” simply chains those together.
我們的解析器已經解析了方法宣告,所以我們在這部分做的不錯。我們也不需要為方法呼叫新增任何新的解析器支援。我們已經有了.(getter)和()(函式呼叫)。“方法呼叫”只是簡單地將這些串在一起。

That raises an interesting question. What happens when those two expressions are pulled apart? Assuming that
methodin this example is a method on the class ofobjectand not a field on the instance, what should the following piece of code do?
這引出了一個有趣的問題。當這兩個表示式分開時會發生什麼?假設這個例子中的方法method是object的類中的一個方法,而不是例項中的 一個欄位,下面的程式碼應該做什麼?
var m = object.method;
m(argument);
This program “looks up” the method and stores the result—whatever that is—in a variable and then calls that object later. Is this allowed? Can you treat a method like it’s a function on the instance?
這個程式會“查詢”該方法,並將結果(不管是什麼)儲存到一個變數中,稍後會呼叫該物件。允許這樣嗎?你能將方法作為例項中的一個函式來對待嗎?
What about the other direction?
另一個方向呢?
class Box {}
fun notMethod(argument) {
print "called function with " + argument;
}
var box = Box();
box.function = notMethod;
box.function("argument");
This program creates an instance and then stores a function in a field on it. Then it calls that function using the same syntax as a method call. Does that work?
這個程式建立了一個例項,然後在它的一個欄位中儲存了一個函式。然後使用與方法呼叫相同的語法來呼叫該函式。這樣做有用嗎?
Different languages have different answers to these questions. One could write a treatise on it. For Lox, we’ll say the answer to both of these is yes, it does work. We have a couple of reasons to justify that. For the second example—calling a function stored in a field—we want to support that because first-class functions are useful and storing them in fields is a perfectly normal thing to do.
不同的語言對這些問題有不同的答案。人們可以就此寫一篇論文。對於Lox來說,這兩個問題的答案都是肯定的,它確實有效。我們有幾個理由來證明這一點。對於第二個例子——呼叫儲存在欄位中的函式——我們想要支援它,是因為頭等函式是有用的,而且將它們儲存在欄位中是一件很正常的事情。
The first example is more obscure. One motivation is that users generally expect to be able to hoist a subexpression out into a local variable without changing the meaning of the program. You can take this:
第一個例子就比較晦澀了。一個場景是,使用者通常希望能夠在不改變程式含義的情況下,將子表示式賦值到一個區域性變數中。你可以這樣做:
breakfast(omelette.filledWith(cheese), sausage);
And turn it into this:
並將其變成這樣:
var eggs = omelette.filledWith(cheese);
breakfast(eggs, sausage);
And it does the same thing. Likewise, since the
.and the()in a method call are two separate expressions, it seems you should be able to hoist the lookup part into a variable and then call it later. We need to think carefully about what the thing you get when you look up a method is, and how it behaves, even in weird cases like:
它做的是同樣的事情。同樣,由於方法呼叫中的.和()是兩個獨立的表示式,你似乎應該把查詢部分提取到一個變數中,然後再呼叫它5。我們需要仔細思考,當你查詢一個方法時你得到的東西是什麼,它如何作用,甚至是在一些奇怪的情況下,比如:
class Person {
sayName() {
print this.name;
}
}
var jane = Person();
jane.name = "Jane";
var method = jane.sayName;
method(); // ?
If you grab a handle to a method on some instance and call it later, does it “remember” the instance it was pulled off from? Does
thisinside the method still refer to that original object?
如果你在某個例項上獲取了一個方法的控制代碼,並在稍後再呼叫它,它是否能“記住”它是從哪個例項中提取出來的?方法內部的this是否仍然指向原始的那個物件?
Here’s a more pathological example to bend your brain:
下面有一個更變態的例子,可以摧毀你的大腦:
class Person {
sayName() {
print this.name;
}
}
var jane = Person();
jane.name = "Jane";
var bill = Person();
bill.name = "Bill";
bill.sayName = jane.sayName;
bill.sayName(); // ?
Does that last line print “Bill” because that’s the instance that we called the method through, or “Jane” because it’s the instance where we first grabbed the method?
最後一行會因為呼叫方法的實體是bill而列印“Bill”,還是因為我們第一次獲取方法的例項是jane而列印“Jane”。
Equivalent code in Lua and JavaScript would print “Bill”. Those languages don’t really have a notion of “methods”. Everything is sort of functions-in-fields, so it’s not clear that
jane“owns”sayNameany more thanbilldoes.
在Lua和JavaScript中,同樣的程式碼會列印 "Bill"。這些語言並沒有真正的“方法”的概念。所有東西都類似於欄位中的函式,所以並不清楚jane 是否更應該比bill“擁有”sayName。
Lox, though, has real class syntax so we do know which callable things are methods and which are functions. Thus, like Python, C#, and others, we will have methods “bind”
thisto the original instance when the method is first grabbed. Python calls these bound methods.
不過,Lox有真正的類語法,所以我們確實知道哪些可呼叫的東西是方法,哪些是函式。因此,像Python、C#和其他語言一樣,當方法第一次被獲取時,我們會讓方法與原始例項this進行 "繫結"。Python將這些繫結的方法稱為bound methods(繫結方法)。
In practice, that’s usually what you want. If you take a reference to a method on some object so you can use it as a callback later, you want to remember the instance it belonged to, even if that callback happens to be stored in a field on some other object.
在實踐中,這通常也是你想要的。如果你獲取到了某個物件中一個方法的引用,這樣你以後就可以把它作為一個回撥函式使用,你想要記住它所屬的例項,即使這個回撥被儲存在其它物件的欄位中。
OK, that’s a lot of semantics to load into your head. Forget about the edge cases for a bit. We’ll get back to those. For now, let’s get basic method calls working. We’re already parsing the method declarations inside the class body, so the next step is to resolve them.
好吧,這裡有很多語義需要裝到你的腦子裡。暫時先不考慮那些邊緣情況了,我們以後再講。現在,讓我們先把基本的方法呼叫做好。我們已經解析了類主體內的方法宣告,所以下一步就是對其分析。
lox/Resolver.java,在 visitClassStmt()方法內新增6:
define(stmt.name);
// 新增部分開始
for (Stmt.Function method : stmt.methods) {
FunctionType declaration = FunctionType.METHOD;
resolveFunction(method, declaration);
}
// 新增部分結束
return null;
We iterate through the methods in the class body and call the
resolveFunction()method we wrote for handling function declarations already. The only difference is that we pass in a new FunctionType enum value.
我們遍歷類主體中的方法,並呼叫我們已經寫好的用來處理函式宣告的resolveFunction()方法。唯一的區別在於,我們傳入了一個新的FunctionType列舉值。
lox/Resolver.java,在 FunctionType列舉中新增程式碼,在上一行末尾新增,:
NONE,
FUNCTION,
// 新增部分開始
METHOD
// 新增部分結束
}
That’s going to be important when we resolve
thisexpressions. For now, don’t worry about it. The interesting stuff is in the interpreter.
這一點在我們分析this表示式時很重要。現在還不用擔心這個問題。有趣的部分在直譯器中。
lox/Interpreter.java,在 visitClassStmt()方法中替換一行:
environment.define(stmt.name.lexeme, null);
// 替換部分開始
Map<String, LoxFunction> methods = new HashMap<>();
for (Stmt.Function method : stmt.methods) {
LoxFunction function = new LoxFunction(method, environment);
methods.put(method.name.lexeme, function);
}
LoxClass klass = new LoxClass(stmt.name.lexeme, methods);
// 替換部分結束
environment.assign(stmt.name, klass);
When we interpret a class declaration statement, we turn the syntactic representation of the class—its AST node—into its runtime representation. Now, we need to do that for the methods contained in the class as well. Each method declaration blossoms into a LoxFunction object.
當我們解釋一個類宣告語句時,我們把類的語法表示(其AST節點)變成它的執行時表示。現在,我們也需要對類中包含的方法進行這樣的操作。每個方法宣告都會變成一個LoxFunction物件。
We take all of those and wrap them up into a map, keyed by the method names. That gets stored in LoxClass.
我們把所有這些都打包到一個map中,以方法名稱作為鍵。這些資料儲存在LoxClass中。
lox/LoxClass.java,在類 LoxClass中,替換4行:
final String name;
// 替換部分開始
private final Map<String, LoxFunction> methods;
LoxClass(String name, Map<String, LoxFunction> methods) {
this.name = name;
this.methods = methods;
}
// 替換部分結束
@Override
public String toString() {
Where an instance stores state, the class stores behavior. LoxInstance has its map of fields, and LoxClass gets a map of methods. Even though methods are owned by the class, they are still accessed through instances of that class.
例項儲存狀態,類儲存行為。LoxInstance包含欄位的map,而LoxClass包含方法的map。雖然方法是歸類所有,但仍然是透過類的例項來訪問。
lox/LoxInstance.java,在 get()方法中新增:
Object get(Token name) {
if (fields.containsKey(name.lexeme)) {
return fields.get(name.lexeme);
}
// 新增部分開始
LoxFunction method = klass.findMethod(name.lexeme);
if (method != null) return method;
// 新增部分結束
throw new RuntimeError(name,
"Undefined property '" + name.lexeme + "'.");
When looking up a property on an instance, if we don’t find a matching field, we look for a method with that name on the instance’s class. If found, we return that. This is where the distinction between “field” and “property” becomes meaningful. When accessing a property, you might get a field—a bit of state stored on the instance—or you could hit a method defined on the instance’s class.
在例項上查詢屬性時,如果我們沒有找到匹配的欄位,我們就在例項的類中查詢是否包含該名稱的方法。如果找到,我們就返回該方法7。這就是“欄位”和“屬性”之間的區別變得有意義的地方。當訪問一個屬性時,你可能會得到一個欄位(儲存在例項上的狀態值),或者你會得到一個例項類中定義的方法。
The method is looked up using this:
方法是透過下面的程式碼進行查詢的:
lox/LoxClass.java,在 LoxClass()方法後新增:
LoxFunction findMethod(String name) {
if (methods.containsKey(name)) {
return methods.get(name);
}
return null;
}
You can probably guess this method is going to get more interesting later. For now, a simple map lookup on the class’s method table is enough to get us started. Give it a try:
你大概能猜到這個方法後面會變得更有趣。但是現在,在類的方法表中進行簡單的對映查詢就足夠了。試一下:
class Bacon {
eat() {
print "Crunch crunch crunch!";
}
}
Bacon().eat(); // Prints "Crunch crunch crunch!".
12 . 6 This
We can define both behavior and state on objects, but they aren’t tied together yet. Inside a method, we have no way to access the fields of the “current” object—the instance that the method was called on—nor can we call other methods on that same object.
我們可以在物件上定義行為和狀態,但是它們並沒有被繫結在一起。在一個方法中,我們沒有辦法訪問“當前”物件(呼叫該方法的例項)的欄位,也不能呼叫同一個物件的其它方法。
To get at that instance, it needs a name. Smalltalk, Ruby, and Swift use “self”. Simula, C++, Java, and others use “this”. Python uses “self” by convention, but you can technically call it whatever you like.
為了獲得這個例項,它需要一個名稱。Smalltalk、Ruby和Swift使用 "self"。Simula、C++、Java等使用 "this"。Python按慣例使用 "self",但從技術上講,你可以隨便叫它什麼。
For Lox, since we generally hew to Java-ish style, we’ll go with “this”. Inside a method body, a
thisexpression evaluates to the instance that the method was called on. Or, more specifically, since methods are accessed and then invoked as two steps, it will refer to the object that the method was accessed from.
對於Lox來說,因為我們通常遵循Java風格,我們會使用“this”。在方法體中,this表示式計算結果為呼叫該方法的例項。或者,更確切地說,由於方法是分為兩個步驟進行訪問和呼叫的,因此它會引用呼叫方法的物件。
That makes our job harder. Peep at:
這使得我們的工作更加困難。請看:
class Egotist {
speak() {
print this;
}
}
var method = Egotist().speak;
method();
On the second-to-last line, we grab a reference to the
speak()method off an instance of the class. That returns a function, and that function needs to remember the instance it was pulled off of so that later, on the last line, it can still find it when the function is called.
在倒數第二行,我們從該類的一個例項中獲取到了指向speak() 的引用。這個操作會返回一個函式,並且該函式需要記住它來自哪個例項,這樣稍後在最後一行,當函式被呼叫時,它仍然可用找到對應例項。
We need to take
thisat the point that the method is accessed and attach it to the function somehow so that it stays around as long as we need it to. Hmm . . . a way to store some extra data that hangs around a function, eh? That sounds an awful lot like a closure, doesn’t it?
我們需要在方法被訪問時獲取到this,並將其附到函式上,這樣當我們需要的時候它就一直存在。嗯…一種儲存函式週圍的額外資料的方法,嗯?聽起來很像一個閉包,不是嗎?
If we defined
thisas a sort of hidden variable in an environment that surrounds the function returned when looking up a method, then uses ofthisin the body would be able to find it later. LoxFunction already has the ability to hold on to a surrounding environment, so we have the machinery we need.
如果我們把this定義為在查詢方法時返回的函式外圍環境中的一個隱藏變數,那麼稍後在方法主體中使用this時就可以找到它了。LoxFunction已經具備了保持外圍環境的能力,所以我們已經有了需要的機制。
Let’s walk through an example to see how it works:
我們透過一個例子來看看它是如何工作的:
class Cake {
taste() {
var adjective = "delicious";
print "The " + this.flavor + " cake is " + adjective + "!";
}
}
var cake = Cake();
cake.flavor = "German chocolate";
cake.taste(); // Prints "The German chocolate cake is delicious!".
When we first evaluate the class definition, we create a LoxFunction for
taste(). Its closure is the environment surrounding the class, in this case the global one. So the LoxFunction we store in the class’s method map looks like so:
當我們第一次執行類定義時,我們為taste()建立了一個LoxFunction。它的閉包是類外圍的環境,在這個例子中就是全域性環境。所以我們在類的方法map中儲存的LoxFunction看起來像是這樣的:

When we evaluate the
cake.tasteget expression, we create a new environment that bindsthisto the object the method is accessed from (here,cake). Then we make a new LoxFunction with the same code as the original one but using that new environment as its closure.
當我們執行cake.taste這個get表示式時,我們會建立一個新的環境,其中將this繫結到了訪問該方法的物件(這裡是cake)。然後我們建立一個新的LoxFunction,它的程式碼與原始的程式碼相同,但是使用新環境作為其閉包。

This is the LoxFunction that gets returned when evaluating the get expression for the method name. When that function is later called by a
()expression, we create an environment for the method body as usual.
這個是在執行方法名的get表示式時返回的LoxFunction。當這個函式稍後被一個()表示式呼叫時,我們像往常一樣為方法主體建立一個環境。

The parent of the body environment is the environment we created earlier to bind
thisto the current object. Thus any use ofthisinside the body successfully resolves to that instance.
主體環境的父環境,也就是我們先前建立並在其中將this繫結到當前物件的那個環境。因此,在函式主體內使用this都可以成功解析到那個例項。
Reusing our environment code for implementing
thisalso takes care of interesting cases where methods and functions interact, like:
重用環境程式碼來實現this時,也需要注意方法和函式互動的情況,比如:
class Thing {
getCallback() {
fun localFunction() {
print this;
}
return localFunction;
}
}
var callback = Thing().getCallback();
callback();
In, say, JavaScript, it’s common to return a callback from inside a method. That callback may want to hang on to and retain access to the original object—the
thisvalue—that the method was associated with. Our existing support for closures and environment chains should do all this correctly.
例如,在JavaScript中,在一個方法中返回一個回撥函式是很常見的。這個回撥函式可能希望保留對方法所關聯的原物件(this值)的訪問。我們現有的對閉包和環境鏈的支援應該可以正確地做到這一點。
Let’s code it up. The first step is adding new syntax for
this.
讓我們把它寫出來。第一步是為this新增新的語法。
tool/GenerateAst.java,在 main()方法中新增:
"Set : Expr object, Token name, Expr value",
// 新增部分開始
"This : Token keyword",
// 新增部分結束
"Unary : Token operator, Expr right",
Parsing is simple since it’s a single token which our lexer already recognizes as a reserved word.
解析很簡單,因為它是已經被詞法解析器當作關鍵字識別出來的單個詞法標記。
lox/Parser.java,在 primary()方法中新增:
return new Expr.Literal(previous().literal);
}
// 新增部分開始
if (match(THIS)) return new Expr.This(previous());
// 新增部分結束
if (match(IDENTIFIER)) {
You can start to see how
thisworks like a variable when we get to the resolver.
當進入分析器後,就可以看到 this 是如何像變數一樣工作的。
lox/Resolver.java,在 visitSetExpr()方法後新增:
@Override
public Void visitThisExpr(Expr.This expr) {
resolveLocal(expr, expr.keyword);
return null;
}
We resolve it exactly like any other local variable using “this” as the name for the “variable”. Of course, that’s not going to work right now, because “this” isn’t declared in any scope. Let’s fix that over in
visitClassStmt().
我們使用this作為“變數”的名稱,並像其它區域性變數一樣對其分析。當然,現在這是行不通的,因為“this”沒有在任何作用域進行宣告。我們在visitClassStmt()方法中解決這個問題。
lox/Resolver.java,在visitClassStmt()方法中新增:
define(stmt.name);
// 新增部分開始
beginScope();
scopes.peek().put("this", true);
// 新增部分結束
for (Stmt.Function method : stmt.methods) {
Before we step in and start resolving the method bodies, we push a new scope and define “this” in it as if it were a variable. Then, when we’re done, we discard that surrounding scope.
在我們開始分析方法體之前,我們推入一個新的作用域,並在其中像定義變數一樣定義“this”。然後,當我們完成後,會丟棄這個外圍作用域。
lox/Resolver.java,在 visitClassStmt()方法中新增:
}
// 新增部分開始
endScope();
// 新增部分結束
return null;
Now, whenever a
thisexpression is encountered (at least inside a method) it will resolve to a “local variable” defined in an implicit scope just outside of the block for the method body.
現在,只要遇到this表示式(至少是在方法內部),它就會解析為一個“區域性變數”,該變數定義在方法體塊之外的隱含作用域中。
The resolver has a new scope for
this, so the interpreter needs to create a corresponding environment for it. Remember, we always have to keep the resolver’s scope chains and the interpreter’s linked environments in sync with each other. At runtime, we create the environment after we find the method on the instance. We replace the previous line of code that simply returned the method’s LoxFunction with this:
分析器對this有一個新的作用域,所以直譯器需要為它建立一個對應的環境。記住,我們必須始終保持分析器的作用域鏈與直譯器的鏈式環境保持同步。在執行時,我們在找到例項上的方法後建立環境。我們把之前那行直接返回方法對應LoxFunction的程式碼替換如下:
lox/LoxInstance.java,在 get()方法中替換一行:
LoxFunction method = klass.findMethod(name.lexeme);
// 替換部分開始
if (method != null) return method.bind(this);
// 替換部分結束
throw new RuntimeError(name,
"Undefined property '" + name.lexeme + "'.");
Note the new call to
bind(). That looks like so:
注意這裡對bind()的新呼叫。該方法看起來是這樣的:
lox/LoxFunction.java,在 LoxFunction()方法後新增:
LoxFunction bind(LoxInstance instance) {
Environment environment = new Environment(closure);
environment.define("this", instance);
return new LoxFunction(declaration, environment);
}
There isn’t much to it. We create a new environment nestled inside the method’s original closure. Sort of a closure-within-a-closure. When the method is called, that will become the parent of the method body’s environment.
這沒什麼好說的。我們基於方法的原始閉包建立了一個新的環境。就像是閉包內的閉包。當方法被呼叫時,它將變成方法體對應環境的父環境。
We declare “this” as a variable in that environment and bind it to the given instance, the instance that the method is being accessed from. Et voilà, the returned LoxFunction now carries around its own little persistent world where “this” is bound to the object.
我們將this宣告為該環境中的一個變數,並將其繫結到給定的例項(即方法被訪問時的例項)上。就是這樣,現在返回的LoxFunction帶著它自己的小持久化世界,其中的“this”被繫結到物件上。
The remaining task is interpreting those
thisexpressions. Similar to the resolver, it is the same as interpreting a variable expression.
剩下的任務就是解釋那些this表示式。與分析器類似,與解釋變量表達式是一樣的。
lox/Interpreter.java,在 visitSetExpr()方法後新增:
@Override
public Object visitThisExpr(Expr.This expr) {
return lookUpVariable(expr.keyword, expr);
}
Go ahead and give it a try using that cake example from earlier. With less than twenty lines of code, our interpreter handles
thisinside methods even in all of the weird ways it can interact with nested classes, functions inside methods, handles to methods, etc.
來吧,用前面那個蛋糕的例子試一試。透過新增不到20行程式碼,我們的直譯器就能處理方法內部的this,甚至能以各種奇怪的方式與巢狀類、方法內部的函式、方法控制代碼等進行互動。
12 . 6 . 1 Invalid uses of this
12.6.1 this的無效使用
Wait a minute. What happens if you try to use
thisoutside of a method? What about:
等一下,如果你嘗試在方法之外使用this會怎麼樣?比如:
print this;
Or:
或者:
fun notAMethod() {
print this;
}
There is no instance for
thisto point to if you’re not in a method. We could give it some default value likenilor make it a runtime error, but the user has clearly made a mistake. The sooner they find and fix that mistake, the happier they’ll be.
如果你不在一個方法中,就沒有可供this指向的例項。我們可以給它一些預設值如nil或者丟擲一個執行時錯誤,但是使用者顯然犯了一個錯誤。他們越早發現並糾正這個錯誤,就會越高興。
Our resolution pass is a fine place to detect this error statically. It already detects
returnstatements outside of functions. We’ll do something similar forthis. In the vein of our existing FunctionType enum, we define a new ClassType one.
我們的分析過程是一個靜態檢測這個錯誤的好地方。它已經檢測了函式之外的return語句。我們可以針對this做一些類似的事情。在我們現有的FunctionType列舉的基礎上,我們定義一個新的ClassType列舉。
lox/Resolver.java,在 FunctionType列舉後新增:
}
// 新增部分開始
private enum ClassType {
NONE,
CLASS
}
private ClassType currentClass = ClassType.NONE;
// 新增部分結束
void resolve(List<Stmt> statements) {
Yes, it could be a Boolean. When we get to inheritance, it will get a third value, hence the enum right now. We also add a corresponding field,
currentClass. Its value tells us if we are currently inside a class declaration while traversing the syntax tree. It starts outNONEwhich means we aren’t in one.
是的,它可以是一個布林值。當我們談到繼承時,它會擴充套件第三個值,因此使用了列舉。我們還添加了一個相應的欄位currentClass。它的值告訴我們,在遍歷語法樹時,我們目前是否在一個類宣告中。它一開始是NONE,意味著我們不在類中。
When we begin to resolve a class declaration, we change that.
當我們開始分析一個類宣告時,我們會改變它。
lox/Resolver.java,在 visitClassStmt()方法中新增:
public Void visitClassStmt(Stmt.Class stmt) {
// 新增部分開始
ClassType enclosingClass = currentClass;
currentClass = ClassType.CLASS;
// 新增部分結束
declare(stmt.name);
As with
currentFunction, we store the previous value of the field in a local variable. This lets us piggyback onto the JVM to keep a stack ofcurrentClassvalues. That way we don’t lose track of the previous value if one class nests inside another.
與currentFunction一樣,我們將欄位的前一個值儲存在一個區域性變數中。這樣我們可以在JVM中保持一個currentClass的棧。如果一個類巢狀在另一個類中,我們就不會丟失對前一個值的跟蹤。
Once the methods have been resolved, we “pop” that stack by restoring the old value.
一旦這麼方法完成了分析,我們透過恢復舊值來“彈出”堆疊。
lox/Resolver.java,在 visitClassStmt()方法中新增:
endScope();
// 新增部分開始
currentClass = enclosingClass;
// 新增部分結束
return null;
When we resolve a
thisexpression, thecurrentClassfield gives us the bit of data we need to report an error if the expression doesn’t occur nestled inside a method body.
當我們解析this表示式時,如果表示式沒有出現在一個方法體內,currentClass就為我們提供了報告錯誤所需的資料。
lox/Resolver.java,在 visitThisExpr()方法中新增:
public Void visitThisExpr(Expr.This expr) {
// 新增部分開始
if (currentClass == ClassType.NONE) {
Lox.error(expr.keyword,
"Can't use 'this' outside of a class.");
return null;
}
// 新增部分結束
resolveLocal(expr, expr.keyword);
That should help users use
thiscorrectly, and it saves us from having to handle misuse at runtime in the interpreter.
這應該能幫助使用者正確地使用this,並且它使我們不必在直譯器執行時中處理這個誤用問題。
12 . 7 Constructors and Initializers
12.7 建構函式和初始化
We can do almost everything with classes now, and as we near the end of the chapter we find ourselves strangely focused on a beginning. Methods and fields let us encapsulate state and behavior together so that an object always stays in a valid configuration. But how do we ensure a brand new object starts in a good state?
我們現在幾乎可以用類來做任何事情,而當我們接近本章結尾時,卻發現自己奇怪地專注於開頭。方法和欄位讓我們把狀態和行為封裝在一起,這樣一個物件就能始終保持在有效的配置狀態。但我們如何確保一個全新的物件是以良好的狀態開始的?
For that, we need constructors. I find them one of the trickiest parts of a language to design, and if you peer closely at most other languages, you’ll see cracks around object construction where the seams of the design don’t quite fit together perfectly. Maybe there’s something intrinsically messy about the moment of birth.
為此,我們需要建構函式。我發現它們是語言設計中最棘手的部分之一,如果你仔細觀察大多數其它語言,就會發現圍繞著物件構造的缺陷,設計的接縫並不完全吻合8。也許在一開始就存在本質上的混亂。
“Constructing” an object is actually a pair of operations:
“構造”一個物件實際上是一對操作:
-
The runtime allocates the memory required for a fresh instance. In most languages, this operation is at a fundamental level beneath what user code is able to access.
執行時為一個新的例項分配所需的記憶體。在多數語言中,這個操作是在使用者程式碼可以訪問的層面之下的基礎層完成的9。
-
Then, a user-provided chunk of code is called which initializes the unformed object.
然後,使用者提供的一大塊程式碼被呼叫,以初始化未成形的物件。
The latter is what we tend to think of when we hear “constructor”, but the language itself has usually done some groundwork for us before we get to that point. In fact, our Lox interpreter already has that covered when it creates a new LoxInstance object.
當我們聽到“建構函式”時,我們往往會想到後者,但語言本身在此之前通常已經為我們做了一些基礎工作。事實上,我們的Lox直譯器在建立一個新的LoxInstance物件時已經涵蓋了這一點。
We’ll do the remaining part—user-defined initialization—now. Languages have a variety of notations for the chunk of code that sets up a new object for a class. C++, Java, and C# use a method whose name matches the class name. Ruby and Python call it
init(). The latter is nice and short, so we’ll do that.
我們現在要做的是剩下的部分——使用者自定義的初始化。對於為類建立新物件的這塊程式碼,不同的語言有不同的說法。C++、Java和C#使用一個名字與類名相匹配的方法。Ruby 和 Python 稱之為 init()。後者又好又簡短,所以我們採用它。
In LoxClass’s implementation of LoxCallable, we add a few more lines.
在LoxClass的LoxCallable實現中,我們再增加幾行。
lox/LoxClass.java,在 call()方法中新增:
List<Object> arguments) {
LoxInstance instance = new LoxInstance(this);
// 新增部分開始
LoxFunction initializer = findMethod("init");
if (initializer != null) {
initializer.bind(instance).call(interpreter, arguments);
}
// 新增部分結束
return instance;
When a class is called, after the LoxInstance is created, we look for an “init” method. If we find one, we immediately bind and invoke it just like a normal method call. The argument list is forwarded along.
當一個類被呼叫時,在LoxInstance被建立後,我們會尋找一個 "init "方法。如果我們找到了,我們就會立即繫結並呼叫它,就像普通的方法呼叫一樣。引數列表直接透傳。
That argument list means we also need to tweak how a class declares its arity.
這個引數列表意味著我們也需要調整類宣告其元數的方式。
public int arity() {
lox/LoxClass.java,在 arity()方法中替換一行:
public int arity() {
// 替換部分開始
LoxFunction initializer = findMethod("init");
if (initializer == null) return 0;
return initializer.arity();
// 替換部分結束
}
If there is an initializer, that method’s arity determines how many arguments you must pass when you call the class itself. We don’t require a class to define an initializer, though, as a convenience. If you don’t have an initializer, the arity is still zero.
如果有初始化方法,該方法的元數就決定了在呼叫類本身的時候需要傳入多少個引數。但是,為了方便起見,我們並不要求類定義初始化方法。如果你沒有初始化方法,元數仍然是0。
That’s basically it. Since we bind the
init()method before we call it, it has access tothisinside its body. That, along with the arguments passed to the class, are all you need to be able to set up the new instance however you desire.
基本上就是這樣了。因為我們在呼叫init()方法之前已經將其繫結,所以它可以在方法體內訪問this。這樣,連同傳遞給類的引數,你就可以按照自己的意願設定新例項了。
12 . 7 . 1 Invoking init() directly
12.7.1 直接執行init()
As usual, exploring this new semantic territory rustles up a few weird creatures. Consider:
像往常一樣,探索這一新的語義領域會催生出一些奇怪的事物。考慮一下:
class Foo {
init() {
print this;
}
}
var foo = Foo();
print foo.init();
Can you “re-initialize” an object by directly calling its
init()method? If you do, what does it return? A reasonable answer would benilsince that’s what it appears the body returns.
你能否透過直接呼叫物件的init()方法對其進行“重新初始化”?如果可以,它的返回值是什麼?一個合理的答案應該是nil,因為這是方法主體返回的內容。
However—and I generally dislike compromising to satisfy the implementation—it will make clox’s implementation of constructors much easier if we say that
init()methods always returnthis, even when directly called. In order to keep jlox compatible with that, we add a little special case code in LoxFunction.
然而,我通常不喜歡為滿足實現而妥協10,如果我們讓init()方法總是返回this(即使是被直接呼叫時),它會使clox中的建構函式實現更加簡單。為了保持jlox與之相容,我們在LoxFunction中添加了一些針對特殊情況的程式碼。
lox/LoxFunction.java,在 call()方法中新增:
return returnValue.value;
}
// 新增部分開始
if (isInitializer) return closure.getAt(0, "this");
// 新增部分結束
return null;
If the function is an initializer, we override the actual return value and forcibly return
this. That relies on a newisInitializerfield.
如果該函式是一個初始化方法,我們會覆蓋實際的返回值並強行返回this。這個操作依賴於一個新的isInitializer欄位。
lox/LoxFunction.java,在 LoxFunction類中,替換一行:
private final Environment closure;
// 替換部分開始
private final boolean isInitializer;
LoxFunction(Stmt.Function declaration, Environment closure, boolean isInitializer) {
this.isInitializer = isInitializer;
// 替換部分結束
this.closure = closure;
this.declaration = declaration;
We can’t simply see if the name of the LoxFunction is “init” because the user could have defined a function with that name. In that case, there is no
thisto return. To avoid that weird edge case, we’ll directly store whether the LoxFunction represents an initializer method. That means we need to go back and fix the few places where we create LoxFunctions.
我們不能簡單地檢查LoxFunction的名字是否為“init”,因為使用者可能已經定義了一個同名的函式。在這種情況下,是沒有this可供返回的。為了避免這種奇怪的邊緣情況,我們將直接儲存LoxFunction是否表示一個初始化方法。這意味著我們需要回頭修正我們建立LoxFunctions的幾個地方。
lox/Interpreter.java,在 visitFunctionStmt()方法中,替換一行:
public Void visitFunctionStmt(Stmt.Function stmt) {
// 替換部分開始
LoxFunction function = new LoxFunction(stmt, environment, false);
// 替換部分結束
environment.define(stmt.name.lexeme, function);
For actual function declarations,
isInitializeris always false. For methods, we check the name.
對於實際的函式宣告, isInitializer取值總是false。對於方法來說,我們檢查其名稱。
lox/Interpreter.java,在 visitClassStmt()方法中,替換一行:
for (Stmt.Function method : stmt.methods) {
// 替換部分開始
LoxFunction function = new LoxFunction(method, environment,
method.name.lexeme.equals("init"));
// 替換部分結束
methods.put(method.name.lexeme, function);
And then in
bind()where we create the closure that bindsthisto a method, we pass along the original method’s value.
然後在bind()方法,在建立閉包並將this繫結到新方法時,我們將原始方法的值傳遞給新方法。
lox/LoxFunction.java,在 bind()方法中,替換一行:
environment.define("this", instance);
// 替換部分開始
return new LoxFunction(declaration, environment,
isInitializer);
// 替換部分結束
}
12 . 7 . 2 Returning from init()
12.7.2 從init()返回
We aren’t out of the woods yet. We’ve been assuming that a user-written initializer doesn’t explicitly return a value because most constructors don’t. What should happen if a user tries:
我們還沒有走出困境。我們一直假設使用者編寫的初始化方法不會顯式地返回一個值,因為大多數建構函式都不會。如果使用者嘗試這樣做會發生什麼:
class Foo {
init() {
return "something else";
}
}
It’s definitely not going to do what they want, so we may as well make it a static error. Back in the resolver, we add another case to FunctionType.
這肯定不會按照使用者的期望執行,所以我們不妨把它作為一種靜態錯誤。回到分析器中,我們為FunctionType新增另一種情況。
lox/Resolver.java,在 FunctionType列舉中新增:
FUNCTION,
// 新增部分開始
INITIALIZER,
// 新增部分結束
METHOD
We use the visited method’s name to determine if we’re resolving an initializer or not.
我們透過被訪問方法的名稱來確定我們是否在分析一個初始化方法。
lox/Resolver.java,在 visitClassStmt()方法中新增:
FunctionType declaration = FunctionType.METHOD;
// 新增部分開始
if (method.name.lexeme.equals("init")) {
declaration = FunctionType.INITIALIZER;
}
// 新增部分結束
resolveFunction(method, declaration);
When we later traverse into a
returnstatement, we check that field and make it an error to return a value from inside aninit()method.
當我們稍後遍歷return語句時,我們會檢查該欄位,如果從init()方法內部返回一個值時就丟擲一個錯誤。
lox/Resolver.java,在 visitReturnStmt()方法中新增:
if (stmt.value != null) {
// 新增部分開始
if (currentFunction == FunctionType.INITIALIZER) {
Lox.error(stmt.keyword,
"Can't return a value from an initializer.");
}
// 新增部分結束
resolve(stmt.value);
We’re still not done. We statically disallow returning a value from an initializer, but you can still use an empty early
return.
我們仍然沒有結束。我們靜態地禁止了從初始化方法返回一個值,但是你仍然可用使用一個空的return。
class Foo {
init() {
return;
}
}
That is actually kind of useful sometimes, so we don’t want to disallow it entirely. Instead, it should return
thisinstead ofnil. That’s an easy fix over in LoxFunction.
有時候這實際上是有用的,所以我們不想完全禁止它。相對地,它應該返回this而不是nil。這在LoxFunction中很容易解決。
lox/LoxFunction.java,在 call()方法中新增:
} catch (Return returnValue) {
// 新增部分開始
if (isInitializer) return closure.getAt(0, "this");
// 新增部分結束
return returnValue.value;
If we’re in an initializer and execute a
returnstatement, instead of returning the value (which will always benil), we again returnthis.
如果我們在一個初始化方法中執行return語句時,我們仍然返回this,而不是返回值(該值始終是nil)。
Phew! That was a whole list of tasks but our reward is that our little interpreter has grown an entire programming paradigm. Classes, methods, fields,
this, and constructors. Our baby language is looking awfully grown-up.
籲!這是一大堆任務,但是我們的收穫是,我們的小直譯器已經成長為一個完整的程式設計正規化。類、方法、欄位、this以及建構函式,我們的語言看起來已經非常成熟了。
// 方式1
fun callback(a, b, c) {
object.method(a, b, c);
}
takeCallback(callback);
// 方式2
takeCallback(object.method);
CHALLENGES
習題
-
We have methods on instances, but there is no way to define “static” methods that can be called directly on the class object itself. Add support for them. Use a
classkeyword preceding the method to indicate a static method that hangs off the class object.我們有例項上的方法,但是沒有辦法定義可以直接在類物件上呼叫的“靜態”方法。新增對它們的支援,在方法之前使用
class關鍵字指示該方法是一個掛載在類物件上的靜態方法。class Math { class square(n) { return n * n; } } print Math.square(3); // Prints "9".You can solve this however you like, but the “metaclasses” used by Smalltalk and Ruby are a particularly elegant approach. Hint: Make LoxClass extend LoxInstance and go from there.
你可以用你喜歡的方式解決這問題,但是Smalltalk和Ruby使用的“metaclasses” 是一種特別優雅的方法。提示:讓LoxClass繼承LoxInstance,然後開始實現。
-
Most modern languages support “getters” and “setters”—members on a class that look like field reads and writes but that actually execute user-defined code. Extend Lox to support getter methods. These are declared without a parameter list. The body of the getter is executed when a property with that name is accessed.
大多數現代語言都支援“getters”和“setters”——類中的成員,看起來像是欄位的讀寫,但實際上執行的使用者自定義的程式碼。擴充套件Lox以支援getter方法。這些方法在宣告時沒有引數列表。當訪問具有該名稱的屬性時,會執行getter的主體。
class Circle { init(radius) { this.radius = radius; } area { return 3.141592653 * this.radius * this.radius; } } var circle = Circle(4); print circle.area; // Prints roughly "50.2655". -
Python and JavaScript allow you to freely access an object’s fields from outside of its own methods. Ruby and Smalltalk encapsulate instance state. Only methods on the class can access the raw fields, and it is up to the class to decide which state is exposed. Most statically typed languages offer modifiers like
privateandpublicto control which parts of a class are externally accessible on a per-member basis.What are the trade-offs between these approaches and why might a language prefer one or the other?
Python和JavaScript允許你從物件自身的方法之外的地方自由訪問物件的欄位。Ruby和Smalltalk封裝了例項狀態。只有類上的方法可以訪問原始欄位,並且由類來決定哪些狀態被暴露。大多數靜態型別的語言都提供了像
private和public這樣的修飾符,以便按成員維度控制類的哪些部分可以被外部訪問。這些方式之間的權衡是什麼?為什麼一門語言可能會更偏愛某一種方法?
DESIGN NOTE: PROTOTYPES AND POWER
設計筆記:原型與功率
In this chapter, we introduced two new runtime entities, LoxClass and LoxInstance. The former is where behavior for objects lives, and the latter is for state. What if you could define methods right on a single object, inside LoxInstance? In that case, we wouldn’t need LoxClass at all. LoxInstance would be a complete package for defining the behavior and state of an object.
We’d still want some way, without classes, to reuse behavior across multiple instances. We could let a LoxInstance delegate directly to another LoxInstance to reuse its fields and methods, sort of like inheritance.
Users would model their program as a constellation of objects, some of which delegate to each other to reflect commonality. Objects used as delegates represent “canonical” or “prototypical” objects that others refine. The result is a simpler runtime with only a single internal construct, LoxInstance.
That’s where the name prototypes comes from for this paradigm. It was invented by David Ungar and Randall Smith in a language called Self. They came up with it by starting with Smalltalk and following the above mental exercise to see how much they could pare it down.
Prototypes were an academic curiosity for a long time, a fascinating one that generated interesting research but didn’t make a dent in the larger world of programming. That is, until Brendan Eich crammed prototypes into JavaScript, which then promptly took over the world. Many (many) words have been written about prototypes in JavaScript. Whether that shows that prototypes are brilliant or confusing—or both!—is an open question.
Including more than a handful by yours truly.
I won’t get into whether or not I think prototypes are a good idea for a language. I’ve made languages that are prototypal and class-based, and my opinions of both are complex. What I want to discuss is the role of simplicity in a language.
Prototypes are simpler than classes—less code for the language implementer to write, and fewer concepts for the user to learn and understand. Does that make them better? We language nerds have a tendency to fetishize minimalism. Personally, I think simplicity is only part of the equation. What we really want to give the user is power, which I define as:
power = breadth × ease ÷ complexityNone of these are precise numeric measures. I’m using math as analogy here, not actual quantification.
- Breadth is the range of different things the language lets you express. C has a lot of breadth—it’s been used for everything from operating systems to user applications to games. Domain-specific languages like AppleScript and Matlab have less breadth.
- Ease is how little effort it takes to make the language do what you want. “Usability” might be another term, though it carries more baggage than I want to bring in. “Higher-level” languages tend to have more ease than “lower-level” ones. Most languages have a “grain” to them where some things feel easier to express than others.
- Complexity is how big the language (including its runtime, core libraries, tools, ecosystem, etc.) is. People talk about how many pages are in a language’s spec, or how many keywords it has. It’s how much the user has to load into their wetware before they can be productive in the system. It is the antonym of simplicity.
Reducing complexity does increase power. The smaller the denominator, the larger the resulting value, so our intuition that simplicity is good is valid. However, when reducing complexity, we must take care not to sacrifice breadth or ease in the process, or the total power may go down. Java would be a strictly simpler language if it removed strings, but it probably wouldn’t handle text manipulation tasks well, nor would it be as easy to get things done.
The art, then, is finding accidental complexity that can be omitted—language features and interactions that don’t carry their weight by increasing the breadth or ease of using the language.
If users want to express their program in terms of categories of objects, then baking classes into the language increases the ease of doing that, hopefully by a large enough margin to pay for the added complexity. But if that isn’t how users are using your language, then by all means leave classes out.
在本章中,我們引入了兩個新的執行時實體,LoxClass和LoxInstance。前者是物件的行為所在,後者則是狀態所在。如果你可以在LoxInstance的單個物件中定義方法,會怎麼樣?這種情況下,我們根本就不需要LoxClass。LoxInstance將是一個用於定義物件行為和狀態的完整包。
我們仍然需要一些方法,在沒有類的情況下,可以跨多個例項重用物件行為。我們可以讓一個LoxInstance直接委託給另一個LoxInstance來重用它的欄位和方法,有點像繼承。
使用者可以將他們的程式建模為一組物件,其中一些物件相互委託以反映共性。用作委託的物件代表“典型”或“原型”物件,會被其它物件完善。結果就是會有一個更簡單的執行時,只有一個內部結構LoxInstance。
這就是這種正規化的名稱“原型”的由來。它是由David Ungar和Randall Smith在一種叫做Self的語言中發明的。他們從Smalltalk開始,按照上面的練習,看他們能把它縮減到什麼程度,從而想到了這個方法。
長期以來,原型一直是學術上的探索,它是一個引人入勝的東西,也產生了有趣的研究,但是並沒有在更大的程式設計世界中產生影響。直到Brendan Eich把原型塞進JavaScript,然後迅速風靡世界。關於JavaScript中的原型,人們已經寫了很多(許多)文字。這是否能夠表明原型是出色的還是令人困惑的,或者兼而有之?這是一個開放的問題。
我不會去討論原型對於一門語言來說是不是一個好主意。基於原型和基於類的語言我都做過,我對兩者的看法很複雜。我想討論的是簡單性在一門語言中的作用。
原型比類更簡單——語言實現者要編寫的程式碼更少,語言使用者要學習和理解的概念更少。這是否意味著它讓語言變得更好呢?我們這些語言書呆子有一種迷戀極簡主義的傾向。就我個人而言,我認為簡單性只是一部分。我們真正想給使用者的是功率,我將其定義為:
power = breadth × ease ÷ complexity
功率 = 廣度 × 易用性 ÷ 複雜性
這些都不是精確的數字度量。我這裡用數學作比喻,而不是實際的量化。
- 廣度是語言可以表達的不同事物的範圍。C語言具有很大的廣度——從作業系統到使用者應用程式再到遊戲,它被廣泛使用。像AppleScript和Matlab這樣的特定領域語言的廣度相對較小。
- 易用性是指使用者付出多少努力就可以用語言做想做的事。“可用性Usability”是另一個概念,它包含的內容比我想要表達的更多。“高階”語言往往比“低階”語言更容易使用。大多數語言都有一個核心,對它們來說,有些東西比其它的更容易表達。
- 複雜性是指語言的規模(包括其執行時、核心庫、工具、生態等)有多大。人們談論一種語言的規範有多少頁,或者它有多少個關鍵詞。這是指使用者在使用系統之前,必須在先學習多少東西,才能產生效益。它是簡單性的反義詞。
降低複雜性確實可以提高功率,分母越小,得到的值就越大,所以我們直覺認為“簡單的是好的”是對的。然而,在降低複雜性時,我們必須注意不要在這個過程中犧牲廣度或易用性,否則總功率可能會下降。如果去掉字串,Java將變成一種嚴格意義上的簡單語言,但它可能無法很好地處理文字操作任務,也不會那麼容易完成事情。
因此,關鍵就在於找到可以省略的意外複雜性,也就是哪些沒有透過增加語言廣度或語言易用性來體現其重要性的語言特性與互動。
如果使用者想用物件的類別來表達他們的程式,那麼在語言中加入類就能提高這類操作的便利性,希望能有足夠大的提升幅度來彌補所增加的複雜性。但如果這不是使用者使用您的語言的方式,那麼無論如何都不要使用類。
-
但是,如果你真的討厭類,也可以跳過這兩章。它們與本書的其它部分是相當孤立的。就我個人而言,我覺得多瞭解自己不喜歡的物件是好事。有些事情乍一看很簡單,但當我近距離觀看時,細節出現了,我也獲得了一個更細緻入微的視角。 ↩
-
Multimethods是你最不可能熟悉的方法。我很想多談論一下它們——我曾經圍繞它們設計了一個業餘語言,它們特別棒——但是我只能裝下這麼多頁面了。如果你想了解更多,可以看看CLOS (Common Lisp中的物件系統), Dylan, Julia, 或 Raku。 ↩
-
在Smalltalk中,甚至連類也是透過現有物件(通常是所需的超類)的方法來建立的。有點像是一直向下龜縮。最後,它會在一些神奇的類上觸底,比如Object和Metaclass,它們是執行時憑空創造出來的。 ↩
-
允許類之外的程式碼直接修改物件的欄位,這違背了面向物件的原則,即類封裝狀態。有些語言採取了更有原則的立場。在SmallTalk中,欄位實際上是使用簡單的識別符號訪問的,這些識別符號是類方法作用域內的變數。Ruby使用@後跟名字來訪問物件中的欄位。這種語法只有在方法中才有意義,並且總是訪問當前物件的狀態。不管怎樣,Lox對OOP的信仰並不是那麼虔誠。 ↩
-
它的經典用途之一就是回撥。通常,你想要傳遞一個回撥函式,其主體只是呼叫某個物件上的一個方法。既然能夠找到該方法並直接傳遞它,就省去了手動宣告一個函式對其進行包裝的麻煩工作。比較一下下面兩段程式碼: ↩
-
現在將函式型別儲存到一個區域性變數中是沒有意義的,但我們稍後會擴充套件這段程式碼,到時它就有意義了。 ↩
-
首先尋找欄位,意味著欄位會遮蔽方法,這是一個微妙但重要的語義點。 ↩
-
舉幾個例子:在Java中,儘管final欄位必須被初始化,但仍有可能在被初始化之前被讀取。異常(一個龐大而複雜的特性)被新增到C++中主要是作為一種從建構函式發出錯誤的方式。 ↩
-
C++中的 "placement new "是一個罕見的例子,在這種情況下,分配的記憶體被暴露出來供程式設計師使用。 ↩
-
也許“不喜歡”這個說法太過激了。讓語言實現的約束和資源影響語言的設計是合理的。一天只有這麼多時間,如果在這裡或那裡偷工減料可以讓你在更短的時間內為使用者提供更多的功能,這可能會大大提高使用者的幸福感和工作效率。訣竅在於,要弄清楚哪些彎路不會導致你的使用者和未來的自己不會咒罵你的短視行為 ↩
13.繼承 Inheritance
Once we were blobs in the sea, and then fishes, and then lizards and rats and then monkeys, and hundreds of things in between. This hand was once a fin, this hand once had claws! In my human mouth I have the pointy teeth of a wolf and the chisel teeth of a rabbit and the grinding teeth of a cow! Our blood is as salty as the sea we used to live in! When we’re frightened, the hair on our skin stands up, just like it did when we had fur. We are history! Everything we’ve ever been on the way to becoming us, we still are.
—— Terry Pratchett, A Hat Full of Sky
我們曾經是海里一團一團的東西,然後是魚,然後是蜥蜴、老鼠、猴子,以及介於其間的數百種形態。這隻手曾經是鰭,這隻手曾經是爪子!在我人類的嘴裡,有狼的尖牙,有兔子的鑿齒,還有牛的磨牙!我們的血和我們曾經生活的大海一樣鹹!當我們受到驚嚇時,我們皮膚上的毛髮會豎起來,就像我們有毛時一樣。我們就是歷史!我們在成為我們的路上曾擁有的一切,我們仍然擁有。
Can you believe it? We’ve reached the last chapter of Part II. We’re almost done with our first Lox interpreter. The previous chapter was a big ball of intertwined object-orientation features. I couldn’t separate those from each other, but I did manage to untangle one piece. In this chapter, we’ll finish off Lox’s class support by adding inheritance.
你能相信嗎?我們已經到了第二部分的最後一章。我們幾乎已經完成了第一個Lox直譯器。上一章中是一大堆錯綜複雜的面向物件特性。我無法將這些內容完全解開,但是我設法拆出來一塊。在這一章,我們會新增繼承來完成Lox中對類的支援。
Inheritance appears in object-oriented languages all the way back to the first one, Simula. Early on, Kristen Nygaard and Ole-Johan Dahl noticed commonalities across classes in the simulation programs they wrote. Inheritance gave them a way to reuse the code for those similar parts.
繼承出現在面嚮物件語言中,可以追溯到第一種語言Simula。早些時候,克里斯汀·尼加德(Kristen Nygaard)和奧勒-約翰·達爾(Ole-Johan Dahl)注意到,在他們編寫的模擬程式中,不同類之間存在共性。繼承為他們提供了一種重用相似部分程式碼的方法。
13 . 1 Superclasses and Subclasses
13.1 超類和子類
Given that the concept is “inheritance”, you would hope they would pick a consistent metaphor and call them “parent” and “child” classes, but that would be too easy. Way back when, C. A. R. Hoare coined the term “subclass” to refer to a record type that refines another type. Simula borrowed that term to refer to a class that inherits from another. I don’t think it was until Smalltalk came along that someone flipped the Latin prefix to get “superclass” to refer to the other side of the relationship. From C++, you also hear “base” and “derived” classes. I’ll mostly stick with “superclass” and “subclass”.
鑑於這個概念叫“繼承”,你可能希望他們會選擇一個一致的比喻,把類稱為“父”類和“子”類,但這太簡單了。早在很久以前,C. A. R. Hoare就創造了“subclass”這個術語,指的是完善另一種型別的記錄型別。Simula借用了這個術語來指代一個繼承自另一個類的類。我認為直到Smalltalk出現後,才有人將這個詞的拉丁字首取反義1,用超類(superclass)指代這種關係的另一方。
Our first step towards supporting inheritance in Lox is a way to specify a superclass when declaring a class. There’s a lot of variety in syntax for this. C++ and C# place a
:after the subclass’s name, followed by the superclass name. Java usesextendsinstead of the colon. Python puts the superclass(es) in parentheses after the class name. Simula puts the superclass’s name before theclasskeyword.
我們在Lox中支援繼承的第一步是找到宣告類時指定超類的方法。這方面有很多不同的語法。C++和C#在子類的名字後面加一個:,然後是超類的名字。Java 使用 extends 而不是冒號。Python 則把超類放在類名後面的小括號裡。Simula 把超類的名字放在關鍵字class之前。
This late in the game, I’d rather not add a new reserved word or token to the lexer. We don’t have
extendsor even:, so we’ll follow Ruby and use a less-than sign (<).
遊戲已經到了後期,我寧願不在詞法分析器中新增新的保留字或標記。我們沒有extends或:,所以我們遵循Ruby來使用小於號(<)。
class Doughnut {
// General doughnut stuff...
}
class BostonCream < Doughnut {
// Boston Cream-specific stuff...
}
To work this into the grammar, we add a new optional clause in our existing
classDeclrule.
為了在語法中實現這一點,我們在目前的classDecl規則中加一個新的可選子句。
classDecl → "class" IDENTIFIER ( "<" IDENTIFIER )?
"{" function* "}" ;
After the class name, you can have a
<followed by the superclass’s name. The superclass clause is optional because you don’t have to have a superclass. Unlike some other object-oriented languages like Java, Lox has no root “Object” class that everything inherits from, so when you omit the superclass clause, the class has no superclass, not even an implicit one.
在類的名稱後面,可以有一個<,後跟超類的名稱。超類子句是可選的,因為一個類不一定要有超類。與Java等面向物件的語言不同,Lox沒有所有東西都繼承的一個根“Object”類,所以當你省略超類子句時,該類就沒有超類,甚至連隱含的都沒有。
We want to capture this new syntax in the class declaration’s AST node.
我們想在類宣告的AST節點中捕捉這個新語法。
tool/GenerateAst.java,在 main()方法中,替換一行:
"Block : List<Stmt> statements",
// 替換部分開始
"Class : Token name, Expr.Variable superclass, List<Stmt.Function> methods",
// 替換部分結束
"Expression : Expr expression",
You might be surprised that we store the superclass name as an Expr.Variable, not a Token. The grammar restricts the superclass clause to a single identifier, but at runtime, that identifier is evaluated as a variable access. Wrapping the name in an Expr.Variable early on in the parser gives us an object that the resolver can hang the resolution information off of.
你可能會驚訝,我們把超類的名字存為一個Expr.Variable,而不是一個Token。語法將一個超類子句限制為一個識別符號,但是在執行時,這個識別符號是當作變數訪問來執行的。在解析器早期將名稱封裝在Expr.Variable內部,這樣可以給我們提供一個物件,在分析器中可以將分析資訊附加在其中。
The new parser code follows the grammar directly.
新的解析器程式碼直接遵循語法。
lox/Parser.java,在 classDeclaration()中新增:
Token name = consume(IDENTIFIER, "Expect class name.");
// 新增部分開始
Expr.Variable superclass = null;
if (match(LESS)) {
consume(IDENTIFIER, "Expect superclass name.");
superclass = new Expr.Variable(previous());
}
// 新增部分結束
consume(LEFT_BRACE, "Expect '{' before class body.");
Once we’ve (possibly) parsed a superclass declaration, we store it in the AST.
一旦我們(可能)解析到一個超類宣告,就將其儲存到AST節點中。
lox/Parser.java,在 classDeclaration()方法中,替換一行:
consume(RIGHT_BRACE, "Expect '}' after class body.");
// 替換部分開始
return new Stmt.Class(name, superclass, methods);
// 替換部分結束
}
If we didn’t parse a superclass clause, the superclass expression will be
null. We’ll have to make sure the later passes check for that. The first of those is the resolver.
如果我們沒有解析到超類子句,超類表示式將是null。我們必須確保後面的操作會對其進行檢查。首先是分析器。
lox/Resolver.java,在 visitClassStmt()方法中新增:
define(stmt.name);
// 新增部分開始
if (stmt.superclass != null) {
resolve(stmt.superclass);
}
// 新增部分結束
beginScope();
The class declaration AST node has a new subexpression, so we traverse into and resolve that. Since classes are usually declared at the top level, the superclass name will most likely be a global variable, so this doesn’t usually do anything useful. However, Lox allows class declarations even inside blocks, so it’s possible the superclass name refers to a local variable. In that case, we need to make sure it’s resolved.
類宣告的AST節點有一個新的子表示式,所以我們要遍歷並分析它。因為類通常是在頂層宣告的,超類的名稱很可能是一個全域性變數,所以這一步通常沒有什麼作用。然而,Lox執行在區塊內的類宣告,所以超類名稱有可能指向一個區域性變數。在那種情況下,我們需要保證能被它被分析。
Because even well-intentioned programmers sometimes write weird code, there’s a silly edge case we need to worry about while we’re in here. Take a look at this:
即使是善意的程式設計師有時也會寫出奇怪的程式碼,所以在這裡我們需要考慮一個愚蠢的邊緣情況。看看這個:
class Oops < Oops {}
There’s no way this will do anything useful, and if we let the runtime try to run this, it will break the expectation the interpreter has about there not being cycles in the inheritance chain. The safest thing is to detect this case statically and report it as an error.
這種程式碼不可能做什麼有用的事情,如果我們嘗試讓執行時去執行它,將會打破直譯器對繼承鏈中沒有迴圈的期望。最安全的做法是靜態地檢測這種情況,並將其作為一個錯誤報告出來。
lox/Resolver.java,在 visitClassStmt()方法中新增:
define(stmt.name);
// 新增部分開始
if (stmt.superclass != null &&
stmt.name.lexeme.equals(stmt.superclass.name.lexeme)) {
Lox.error(stmt.superclass.name,
"A class can't inherit from itself.");
}
// 新增部分結束
if (stmt.superclass != null) {
Assuming the code resolves without error, the AST travels to the interpreter.
如果程式碼分析沒有問題,AST節點就會被傳遞到直譯器。
lox/Interpreter.java,在 visitClassStmt()方法中新增:
public Void visitClassStmt(Stmt.Class stmt) {
// 新增部分開始
Object superclass = null;
if (stmt.superclass != null) {
superclass = evaluate(stmt.superclass);
if (!(superclass instanceof LoxClass)) {
throw new RuntimeError(stmt.superclass.name,
"Superclass must be a class.");
}
}
// 新增部分結束
environment.define(stmt.name.lexeme, null);
If the class has a superclass expression, we evaluate it. Since that could potentially evaluate to some other kind of object, we have to check at runtime that the thing we want to be the superclass is actually a class. Bad things would happen if we allowed code like:
如果類中有超類表示式,我們就對其求值。因為我們可能會得到其它型別的物件,我們在執行時必須檢查我們希望作為超類的物件是否確實是一個類。如果我們允許下面這樣的程式碼,就會發生不好的事情:
var NotAClass = "I am totally not a class";
class Subclass < NotAClass {} // ?!
Assuming that check passes, we continue on. Executing a class declaration turns the syntactic representation of a class—its AST node—into its runtime representation, a LoxClass object. We need to plumb the superclass through to that too. We pass the superclass to the constructor.
假設檢查透過,我們繼續。執行類宣告語句會把類的語法表示(AST節點)轉換為其執行時表示(一個LoxClass物件)。我們也需要把超類物件傳入該類物件中。我們將超類傳遞給建構函式。
lox/Interpreter.java,在 visitClassStmt()方法中替換一行:
methods.put(method.name.lexeme, function);
}
// 替換部分開始
LoxClass klass = new LoxClass(stmt.name.lexeme,
(LoxClass)superclass, methods);
// 替換部分結束
environment.assign(stmt.name, klass);
The constructor stores it in a field.
建構函式將它儲存到一個欄位中。
lox/LoxClass.java, LoxClass()建構函式中,替換一行:
// 替換部分開始
LoxClass(String name, LoxClass superclass,
Map<String, LoxFunction> methods) {
this.superclass = superclass;
// 替換部分結束
this.name = name;
Which we declare here:
欄位我們在這裡宣告:
lox/LoxClass.java,在 LoxClass類中新增:
final String name;
// 新增部分開始
final LoxClass superclass;
// 新增部分結束
private final Map<String, LoxFunction> methods;
With that, we can define classes that are subclasses of other classes. Now, what does having a superclass actually do?
有了這個,我們就可以定義一個類作為其它類的子類。現在,擁有一個超類究竟有什麼用呢?
13 . 2 Inheriting Methods
13.2 繼承方法
Inheriting from another class means that everything that’s true of the superclass should be true, more or less, of the subclass. In statically typed languages, that carries a lot of implications. The subclass must also be a subtype, and the memory layout is controlled so that you can pass an instance of a subclass to a function expecting a superclass and it can still access the inherited fields correctly.
繼承自另一個類,意味著對於超類適用的一切,對於子類或多或少也應該適用。在靜態型別的語言中,這包含了很多含義。子類也必須是一個子型別,而且記憶體佈局是可控的,這樣你就可以把一個子類例項傳遞給一個期望超類的函式,而它仍然可以正確地訪問繼承的欄位。
Lox is a dynamically typed language, so our requirements are much simpler. Basically, it means that if you can call some method on an instance of the superclass, you should be able to call that method when given an instance of the subclass. In other words, methods are inherited from the superclass.
Lox是一種動態型別的語言,所以我們的要求要簡單得多。基本上,這意味著如果你能在超類的例項上呼叫某些方法,那麼當給你一個子類的例項時,你也應該能呼叫這個方法。換句話說,方法是從超類繼承的。
This lines up with one of the goals of inheritance—to give users a way to reuse code across classes. Implementing this in our interpreter is astonishingly easy.
這符合繼承的目標之一——為使用者提供一種跨類重用程式碼的方式。在我們的直譯器中實現這一點是非常容易的。
lox/LoxClass.java,在 findMethod()方法中新增:
return methods.get(name);
}
// 新增部分開始
if (superclass != null) {
return superclass.findMethod(name);
}
// 新增部分結束
return null;
That’s literally all there is to it. When we are looking up a method on an instance, if we don’t find it on the instance’s class, we recurse up through the superclass chain and look there. Give it a try:
這就是它的全部內容。當我們在一個例項上查詢一個方法時,如果我們在例項的類中找不到它,就沿著超類繼承鏈遞迴查詢。試一下這個:
class Doughnut {
cook() {
print "Fry until golden brown.";
}
}
class BostonCream < Doughnut {}
BostonCream().cook();
There we go, half of our inheritance features are complete with only three lines of Java code.
好了,一半的繼承特性只用了三行Java程式碼就完成了。
13 . 3 Calling Superclass Methods
13.3 呼叫超類方法
In
findMethod()we look for a method on the current class before walking up the superclass chain. If a method with the same name exists in both the subclass and the superclass, the subclass one takes precedence or overrides the superclass method. Sort of like how variables in inner scopes shadow outer ones.
在findMethod()方法中,我們首先在當前類中查詢,然後遍歷超類鏈。如果在子類和超類中包含相同的方法,那麼子類中的方法將優先於或覆蓋超類的方法。這有點像內部作用域中的變數對外部作用域的遮蔽。
That’s great if the subclass wants to replace some superclass behavior completely. But, in practice, subclasses often want to refine the superclass’s behavior. They want to do a little work specific to the subclass, but also execute the original superclass behavior too.
如果子類想要完全替換超類的某些行為,那就正好。但是,在實踐中,子類通常想改進超類的行為。他們想要做一些專門針對子類的操作,但是也想要執行原來超類中的行為。
However, since the subclass has overridden the method, there’s no way to refer to the original one. If the subclass method tries to call it by name, it will just recursively hit its own override. We need a way to say “Call this method, but look for it directly on my superclass and ignore my override”. Java uses
superfor this, and we’ll use that same syntax in Lox. Here is an example:
然而,由於子類已經重寫了該方法,所有沒有辦法指向原始的方法。如果子類的方法試圖透過名字來呼叫它,將會遞迴到自身的重寫方法上。我們需要一種方式來表明“呼叫這個方法,但是要直接在我的超類上尋找,忽略我內部的重寫方法”。Java中使用super實現這一點,我們在Lox中使用相同的語法。下面是一個例子:
class Doughnut {
cook() {
print "Fry until golden brown.";
}
}
class BostonCream < Doughnut {
cook() {
super.cook();
print "Pipe full of custard and coat with chocolate.";
}
}
BostonCream().cook();
If you run this, it should print:
如果你執行該程式碼,應該打印出:
Fry until golden brown.
Pipe full of custard and coat with chocolate.
We have a new expression form. The
superkeyword, followed by a dot and an identifier, looks for a method with that name. Unlike calls onthis, the search starts at the superclass.
我們有了一個新的表示式形式。super關鍵字,後跟一個點和一個識別符號,以使用該名稱查詢方法。與this呼叫不同,該搜尋是從超類開始的。
13 . 3 . 1 Syntax
13.3.1 語法
With
this, the keyword works sort of like a magic variable, and the expression is that one lone token. But withsuper, the subsequent.and property name are inseparable parts of thesuperexpression. You can’t have a baresupertoken all by itself.
在this使用中,關鍵字有點像一個魔法變數,而表示式是一個單獨的標記。但是對於super,隨後的.和屬性名是super表示式不可分割的一部分。你不可能只有一個單獨的super標記。
print super; // Syntax error.
So the new clause we add to the
primaryrule in our grammar includes the property access as well.
因此,我們在語法中的primary規則新增新子句時要包含屬性訪問。
primary → "true" | "false" | "nil" | "this"
| NUMBER | STRING | IDENTIFIER | "(" expression ")"
| "super" "." IDENTIFIER ;
Typically, a
superexpression is used for a method call, but, as with regular methods, the argument list is not part of the expression. Instead, a super call is a super access followed by a function call. Like other method calls, you can get a handle to a superclass method and invoke it separately.
通常情況下,super表示式用於方法呼叫,但是,與普通方法一樣,引數列表並不是表示式的一部分。相反,super呼叫是一個super屬性訪問,然後跟一個函式呼叫。與其它方法呼叫一樣,你可以獲得超類方法的控制代碼,然後單獨執行它。
var method = super.cook;
method();
So the
superexpression itself contains only the token for thesuperkeyword and the name of the method being looked up. The corresponding syntax tree node is thus:
因此,super表示式本身只包含super關鍵字和要查詢的方法名稱。對應的語法樹節點為:
tool/GenerateAst.java,在 main()方法中新增:
"Set : Expr object, Token name, Expr value",
// 新增部分開始
"Super : Token keyword, Token method",
// 新增部分結束
"This : Token keyword",
Following the grammar, the new parsing code goes inside our existing
primary()method.
按照語法,需要在我們現有的primary方法中新增新程式碼。
lox/Parser.java,在 primary()方法中新增:
return new Expr.Literal(previous().literal);
}
// 新增部分開始
if (match(SUPER)) {
Token keyword = previous();
consume(DOT, "Expect '.' after 'super'.");
Token method = consume(IDENTIFIER,
"Expect superclass method name.");
return new Expr.Super(keyword, method);
}
// 新增部分結束
if (match(THIS)) return new Expr.This(previous());
A leading
superkeyword tells us we’ve hit asuperexpression. After that we consume the expected.and method name.
開頭的super關鍵字告訴我們遇到了一個super表示式,之後我們消費預期中的.和方法名稱。
13 . 3 . 2 Semantics
13.3.2 語義
Earlier, I said a
superexpression starts the method lookup from “the superclass”, but which superclass? The naïve answer is the superclass ofthis, the object the surrounding method was called on. That coincidentally produces the right behavior in a lot of cases, but that’s not actually correct. Gaze upon:
之前,我說過super表示式從“超類”開始查詢方法,但是是哪個超類?一個不太成熟的答案是方法被呼叫時的外圍物件this的超類。在很多情況下,這碰巧產生了正確的行為,但實際上這是不正確的。請看:
class A {
method() {
print "A method";
}
}
class B < A {
method() {
print "B method";
}
test() {
super.method();
}
}
class C < B {}
C().test();
Translate this program to Java, C#, or C++ and it will print “A method”, which is what we want Lox to do too. When this program runs, inside the body of
test(),thisis an instance of C. The superclass of C is B, but that is not where the lookup should start. If it did, we would hit B’smethod().
將這個程式轉換為Java、c#或c++,它將輸出“A method”,這也是我們希望Lox做的。當這個程式執行時,在test方法體中,this是C的一個例項,C是超類是B,但這不是查詢應該開始的地方。如果是這樣,我們就會命中B的method()。
Instead, lookup should start on the superclass of the class containing the
superexpression. In this case, sincetest()is defined inside B, thesuperexpression inside it should start the lookup on B’s superclass—A.
相反,查詢應該從包含super表示式的類的超類開始。在這個例子中,由於test()是在B中定義的,它內部的super表示式應該在B的超類A中開始查詢。

The execution flow looks something like this:
執行流程看起來是這樣的:
-
We call
test()on an instance of C.我們在C的一個例項上呼叫
test()。 -
That enters the
test()method inherited from B. That callssuper.method().這就進入了從B中繼承的
test()方法,其中又會呼叫super.method()。 -
The superclass of B is A, so that chains to
method()on A, and the program prints “A method”.B的超類是A,所以連結到A中的
method(),程式會打印出“A method”。
Thus, in order to evaluate a
superexpression, we need access to the superclass of the class definition surrounding the call. Alack and alas, at the point in the interpreter where we are executing asuperexpression, we don’t have that easily available.
因此,為了對super表示式求值,我們需要訪問圍繞方法呼叫的類的超類。可惜的是,在直譯器中執行super表示式的地方,我們並沒有那麼容易獲得。
We could add a field to LoxFunction to store a reference to the LoxClass that owns that method. The interpreter would keep a reference to the currently executing LoxFunction so that we could look it up later when we hit a
superexpression. From there, we’d get the LoxClass of the method, then its superclass.
我們可以從LoxFunction新增一個欄位,以儲存指向擁有該方法的LoxClass的引用。直譯器會儲存當前正在執行的LoxFunction的引用,這樣稍後在遇到super表示式時就可以找到它。從它開始,可以得到方法的LoxClass,然後找到它的超類。
That’s a lot of plumbing. In the last chapter, we had a similar problem when we needed to add support for
this. In that case, we used our existing environment and closure mechanism to store a reference to the current object. Could we do something similar for storing the superclass? Well, I probably wouldn’t be talking about it if the answer was no, so . . . yes.
這需要很多管道。在上一章中,我們新增對this的支援時遇到了類似的問題。在那種情況下,我們使用已有的環境和閉包機制儲存了指向當前物件的引用。那我們是否可以做類似的事情來儲存超類?嗯,如果答案是否定的,我就不會問這個問題了,所以……是的。
One important difference is that we bound
thiswhen the method was accessed. The same method can be called on different instances and each needs its ownthis. Withsuperexpressions, the superclass is a fixed property of the class declaration itself. Every time you evaluate somesuperexpression, the superclass is always the same.
一個重要的區別是,我們在方法被訪問時綁定了this。同一個方法可以在不同的例項上被呼叫,而且每個例項都需要有自己的this。對於super表示式,超類是類宣告本身的一個固定屬性。每次對某個super表示式求值時,超類都是同一個。
That means we can create the environment for the superclass once, when the class definition is executed. Immediately before we define the methods, we make a new environment to bind the class’s superclass to the name
super.
這意味著我們可以在執行類定義時,為超類建立一個環境。在定義方法之前,我們建立一個新環境,將類的超類與名稱super繫結。

When we create the LoxFunction runtime representation for each method, that is the environment they will capture in their closure. Later, when a method is invoked and
thisis bound, the superclass environment becomes the parent for the method’s environment, like so:
當我們為每個方法建立LoxFunction執行時表示時,也就是這個方法閉包中獲取的環境。之後,放方法被呼叫時會繫結this,超類環境會成為方法環境的父環境,就像這樣:

That’s a lot of machinery, but we’ll get through it a step at a time. Before we can get to creating the environment at runtime, we need to handle the corresponding scope chain in the resolver.
這是一個複雜的機制,但是我們會一步一步完成它。在我們可以在執行時建立環境之前,我們需要在分析器中處理對應的作用域。
lox/Resolver.java,在 visitClassStmt()方法中新增:
resolve(stmt.superclass);
}
// 新增部分開始
if (stmt.superclass != null) {
beginScope();
scopes.peek().put("super", true);
}
// 新增部分結束
beginScope();
If the class declaration has a superclass, then we create a new scope surrounding all of its methods. In that scope, we define the name “super”. Once we’re done resolving the class’s methods, we discard that scope.
如果該類宣告有超類,那麼我們就在其所有方法的外圍建立一個新的作用域。在這個作用域中,我們會定義名稱super。一旦我們完成了對該類中方法的分析,就丟棄這個作用域。
lox/Resolver.java,在 visitClassStmt()方法中新增:
endScope();
// 新增部分開始
if (stmt.superclass != null) endScope();
// 新增部分結束
currentClass = enclosingClass;
It’s a minor optimization, but we only create the superclass environment if the class actually has a superclass. There’s no point creating it when there isn’t a superclass since there’d be no superclass to store in it anyway.
這是一個小最佳化,但是我們只在類真的有超類時才會建立超類環境。在沒有超類的情況下,建立超類環境是沒有意義的,因為無論如何裡面都不會儲存超類。
With “super” defined in a scope chain, we are able to resolve the
superexpression itself.
在作用域鏈中定義super後,我們就能夠分析super表示式了。
lox/Resolver.java,在 visitSetExpr()方法後新增:
@Override
public Void visitSuperExpr(Expr.Super expr) {
resolveLocal(expr, expr.keyword);
return null;
}
We resolve the
supertoken exactly as if it were a variable. The resolution stores the number of hops along the environment chain that the interpreter needs to walk to find the environment where the superclass is stored.
我們把super標記當作一個變數進行分析。分析結果儲存瞭直譯器要在環境鏈上找到超類所在的環境需要的跳數。
This code is mirrored in the interpreter. When we evaluate a subclass definition, we create a new environment.
這段程式碼在直譯器中也有對應。當我們執行子類定義時,建立一個新環境。
lox/Interpreter.java,在 visitClassStmt()方法中新增:
throw new RuntimeError(stmt.superclass.name,
"Superclass must be a class.");
}
}
environment.define(stmt.name.lexeme, null);
// 新增部分開始
if (stmt.superclass != null) {
environment = new Environment(environment);
environment.define("super", superclass);
}
// 新增部分結束
Map<String, LoxFunction> methods = new HashMap<>();
Inside that environment, we store a reference to the superclass—the actual LoxClass object for the superclass which we have now that we are in the runtime. Then we create the LoxFunctions for each method. Those will capture the current environment—the one where we just bound “super”—as their closure, holding on to the superclass like we need. Once that’s done, we pop the environment.
在這個環境中,我們儲存指向超類的引用——即我們在執行時現在擁有的超類的實際LoxClass物件。然後我們為每個方法建立LoxFunction。這些函式將捕獲當前環境(也就是我們剛剛繫結“super”的那個)作為其閉包,像我們需要的那樣維繫著超類。一旦這些完成,我們就彈出環境。
lox/Interpreter.java,在 visitClassStmt()方法中新增:
LoxClass klass = new LoxClass(stmt.name.lexeme,
(LoxClass)superclass, methods);
// 新增部分開始
if (superclass != null) {
environment = environment.enclosing;
}
// 新增部分結束
environment.assign(stmt.name, klass);
We’re ready to interpret
superexpressions themselves. There are a few moving parts, so we’ll build this method up in pieces.
我們現在已經準備好解釋super表示式了。這會分為很多部分,所以我們逐步構建這個方法。
lox/Interpreter.java,在 visitSetExpr()方法後新增:
@Override
public Object visitSuperExpr(Expr.Super expr) {
int distance = locals.get(expr);
LoxClass superclass = (LoxClass)environment.getAt(
distance, "super");
}
First, the work we’ve been leading up to. We look up the surrounding class’s superclass by looking up “super” in the proper environment.
首先,我們要做之前鋪墊的工作。我們透過在適當環境中查詢“super”來找到外圍類的超類。
When we access a method, we also need to bind
thisto the object the method is accessed from. In an expression likedoughnut.cook, the object is whatever we get from evaluatingdoughnut. In asuperexpression likesuper.cook, the current object is implicitly the same current object that we’re using. In other words,this. Even though we are looking up the method on the superclass, the instance is stillthis.
當我們訪問方法時,還需要將this與訪問該方法的物件進行繫結。在像doughnut.cook這樣的表示式中,物件是我們透過對doughnut求值得到的內容。在像super.cook這樣的super表示式中,當前物件隱式地與我們正使用的當前物件相同。換句話說,就是this。即使我們在超類中查詢方法,例項仍然是this。
Unfortunately, inside the
superexpression, we don’t have a convenient node for the resolver to hang the number of hops tothison. Fortunately, we do control the layout of the environment chains. The environment where “this” is bound is always right inside the environment where we store “super”.
不幸的是,在super表示式中,我們沒有一個方便的節點可以讓分析器將this對應的跳數儲存起來。幸運的是,我們可以控制環境鏈的佈局。繫結this的環境總是儲存在儲存super的環境中。
lox/Interpreter.java,在 visitSuperExpr()方法中新增:
LoxClass superclass = (LoxClass)environment.getAt(
distance, "super");
// 新增部分開始
LoxInstance object = (LoxInstance)environment.getAt(
distance - 1, "this");
// 新增部分結束
}
Offsetting the distance by one looks up “this” in that inner environment. I admit this isn’t the most elegant code, but it works.
將距離偏移1,在那個內部環境中查詢“this”。我承認這個程式碼不是最優雅的,但是它是有效的。
Now we’re ready to look up and bind the method, starting at the superclass.
現在我們準備查詢並繫結方法,從超類開始。
lox/Interpreter.java,在 visitSuperExpr()方法中新增:
LoxInstance object = (LoxInstance)environment.getAt(
distance - 1, "this");
// 新增部分開始
LoxFunction method = superclass.findMethod(expr.method.lexeme);
return method.bind(object);
// 新增部分結束
}
This is almost exactly like the code for looking up a method of a get expression, except that we call
findMethod()on the superclass instead of on the class of the current object.
這幾乎與查詢get表示式方法的程式碼完全一樣,區別在於,我們是在超類上呼叫findMethod() ,而不是在當前物件的類。
That’s basically it. Except, of course, that we might fail to find the method. So we check for that too.
基本上就是這樣了。當然,除了我們可能找不到方法之外。所以,我們要對其檢查。
lox/Interpreter.java,在 visitSuperExpr()方法中新增:
LoxFunction method = superclass.findMethod(expr.method.lexeme);
// 新增部分開始
if (method == null) {
throw new RuntimeError(expr.method,
"Undefined property '" + expr.method.lexeme + "'.");
}
// 新增部分結束
return method.bind(object);
}
There you have it! Take that BostonCream example earlier and give it a try. Assuming you and I did everything right, it should fry it first, then stuff it with cream.
這就對了!試著執行一下前面那個BostonCream的例子。如果你我都做對了,它的結果應該是:
Fry until golden brown.
Pipe full of custard and coat with chocolate.
13 . 3 . 3 Invalid uses of super
13.3.3 super的無效使用
As with previous language features, our implementation does the right thing when the user writes correct code, but we haven’t bulletproofed the intepreter against bad code. In particular, consider:
像以前的語言特性一樣,當使用者寫出正確的程式碼時,我們的語言實現也會做成正確的事情,但我們還沒有在直譯器中對錯誤程式碼進行防禦。具體來說,考慮以下程式碼:
class Eclair {
cook() {
super.cook();
print "Pipe full of crème pâtissière.";
}
}
This class has a
superexpression, but no superclass. At runtime, the code for evaluatingsuperexpressions assumes that “super” was successfully resolved and will be found in the environment. That’s going to fail here because there is no surrounding environment for the superclass since there is no superclass. The JVM will throw an exception and bring our interpreter to its knees.
這個類中有一個super表示式,但是沒有超類。在執行時,計算super表示式的程式碼假定super已經被成功分析,並且可以在環境中找到超類。但是在這裡會失敗,因為沒有超類,也就沒有超類對應的外圍環境。JVM會丟擲一個異常,我們的直譯器也會因此崩潰。
Heck, there are even simpler broken uses of super:
見鬼,還有更簡單的super錯誤用法:
super.notEvenInAClass();
We could handle errors like these at runtime by checking to see if the lookup of “super” succeeded. But we can tell statically—just by looking at the source code—that Eclair has no superclass and thus no
superexpression will work inside it. Likewise, in the second example, we know that thesuperexpression is not even inside a method body.
我們可以在執行時透過檢查“super”是否查詢成功而處理此類錯誤。但是我們可以只通過檢視原始碼靜態地知道,Eclair沒有超類,因此也就沒有super表示式可以在其中生效。同樣的,在第二個例子中,我們知道super表示式甚至不在方法體內。
Even though Lox is dynamically typed, that doesn’t mean we want to defer everything to runtime. If the user made a mistake, we’d like to help them find it sooner rather than later. So we’ll report these errors statically, in the resolver.
儘管Lox是動態型別的,但這並不意味著我們要將一切都推遲到執行時。如果使用者犯了錯誤,我們希望能幫助他們儘早發現,所以我們會在分析器中靜態地報告這些錯誤。
First, we add a new case to the enum we use to keep track of what kind of class is surrounding the current code being visited.
首先,在我們用來追蹤當前訪問程式碼外圍類的型別的列舉中新增一個新值。
lox/Resolver.java,在 ClassType列舉中新增程式碼,首先在上一行後面加“,”:
NONE,
CLASS,
// 新增部分開始
SUBCLASS
// 新增部分結束
}
We’ll use that to distinguish when we’re inside a class that has a superclass versus one that doesn’t. When we resolve a class declaration, we set that if the class is a subclass.
我們將用它來區分我們是否在一個有超類的類中。當我們分析一個類的宣告時,如果該類是一個子類,我們就設定該值。
lox/Resolver.java,在 visitClassStmt()方法中新增:
if (stmt.superclass != null) {
// 新增部分開始
currentClass = ClassType.SUBCLASS;
// 新增部分結束
resolve(stmt.superclass);
Then, when we resolve a
superexpression, we check to see that we are currently inside a scope where that’s allowed.
然後,當我們分析super表示式時,會檢查當前是否在一個允許使用super表示式的作用域中。
lox/Resolver.java,在 visitSuperExpr()方法中新增:
public Void visitSuperExpr(Expr.Super expr) {
// 新增部分開始
if (currentClass == ClassType.NONE) {
Lox.error(expr.keyword,
"Can't use 'super' outside of a class.");
} else if (currentClass != ClassType.SUBCLASS) {
Lox.error(expr.keyword,
"Can't use 'super' in a class with no superclass.");
}
// 新增部分結束
resolveLocal(expr, expr.keyword);
If not—oopsie!—the user made a mistake.
如果不是,那就是使用者出錯了。
13 . 4 Conclusion
13.4 總結
We made it! That final bit of error handling is the last chunk of code needed to complete our Java implementation of Lox. This is a real accomplishment and one you should be proud of. In the past dozen chapters and a thousand or so lines of code, we have learned and implemented . . .
我們成功了!最後的錯誤處理是完成Lox語言的Java實現所需的最後一塊程式碼。這是一項真正的成就,你應該為此感到自豪。在過去的十幾章和一千多行程式碼中,我們已經學習並實現了:
- tokens and lexing, 標記與詞法
- abstract syntax trees, 抽象語法樹
- recursive descent parsing, 遞迴下降分析
- prefix and infix expressions, 字首、中綴表示式
- runtime representation of objects, 物件的執行時表示
- interpreting code using the Visitor pattern, 使用Visitor模式解釋程式碼
- lexical scope, 詞法作用域
- environment chains for storing variables, 儲存變數的環境鏈
- control flow, 控制流
- functions with parameters, 有參函式
- closures, 閉包
- static variable resolution and error detection, 靜態變數分析與錯誤檢查
- classes, 類
- constructors, 建構函式
- fields, 欄位
- methods, and finally, 方法
- inheritance. 繼承

We did all of that from scratch, with no external dependencies or magic tools. Just you and I, our respective text editors, a couple of collection classes in the Java standard library, and the JVM runtime.
所有這些都是我們從頭開始做的,沒有藉助外部依賴和神奇工具。只有你和我,我們的文字編輯器,Java標準庫中的幾個集合類,以及JVM執行時。
This marks the end of Part II, but not the end of the book. Take a break. Maybe write a few fun Lox programs and run them in your interpreter. (You may want to add a few more native methods for things like reading user input.) When you’re refreshed and ready, we’ll embark on our next adventure.
這標誌著第二部分的結束,但不是這本書的結束。休息一下,也許可以編寫幾個Lox程式在你的直譯器中執行一下(你可能需要新增一些本地方法來支援讀取使用者的輸入等操作)。當你重新振作之後,我們將開始下一次冒險。
CHALLENGES
習題
-
Lox supports only single inheritance—a class may have a single superclass and that’s the only way to reuse methods across classes. Other languages have explored a variety of ways to more freely reuse and share capabilities across classes: mixins, traits, multiple inheritance, virtual inheritance, extension methods, etc.
If you were to add some feature along these lines to Lox, which would you pick and why? If you’re feeling courageous (and you should be at this point), go ahead and add it.
Lox只支援單繼承——一個類可以有一個超類,這是唯一跨類複用方法的方式。其它語言中已經探索出了各種方法來更自由地跨類重用和共享功能:mixins, traits, multiple inheritance, virtual inheritance, extension methods, 等等。
如果你要在Lox中新增一些類似的功能,你會選擇哪種,為什麼?如果你有勇氣的話(這時候你應該有勇氣了),那就去新增它。
-
In Lox, as in most other object-oriented languages, when looking up a method, we start at the bottom of the class hierarchy and work our way up—a subclass’s method is preferred over a superclass’s. In order to get to the superclass method from within an overriding method, you use
super.在Lox中,與其它大多數面嚮物件語言一樣,當查詢一個方法時,我們從類的底層開始向上查詢——子類的方法優先於超類的方法。為了在覆蓋方法中訪問超類方法,你可以使用
super。The language BETA takes the opposite approach. When you call a method, it starts at the top of the class hierarchy and works down. A superclass method wins over a subclass method. In order to get to the subclass method, the superclass method can call
inner, which is sort of like the inverse ofsuper. It chains to the next method down the hierarchy.BEAT語言採用了相反的方法。當你呼叫一個方法時,它從類繼承結構的頂層開始向下尋找。超類方法的優先順序高於子類方法。為了訪問子類的方法,超類方法可以呼叫
inner,這有點像是super的反義詞。它與繼承層次結構中的下一級方法相連線。The superclass method controls when and where the subclass is allowed to refine its behavior. If the superclass method doesn’t call
innerat all, then the subclass has no way of overriding or modifying the superclass’s behavior.超類方法控制著子類何時何地可以改進其行為。如果超類方法根本沒有呼叫
inner,那麼子類就無法覆蓋或修改超類的行為。Take out Lox’s current overriding and
superbehavior and replace it with BETA’s semantics. In short:去掉Lox目前的覆蓋和
super行為,用BEAT的語義來替換。簡而言之:-
When calling a method on a class, prefer the method highest on the class’s inheritance chain.
當呼叫類上的方法時,優先選擇類繼承鏈中最高的方法。
-
Inside the body of a method, a call to
innerlooks for a method with the same name in the nearest subclass along the inheritance chain between the class containing theinnerand the class ofthis. If there is no matching method, theinnercall does nothing.在方法體內部,
inner呼叫會在繼承鏈中包含inner的類和包含this的類之間,查詢具有相同名稱的最近的子類中的方法。如果沒有匹配的方法,inner呼叫不做任何事情。
For example:
舉例來說:
class Doughnut { cook() { print "Fry until golden brown."; inner(); print "Place in a nice box."; } } class BostonCream < Doughnut { cook() { print "Pipe full of custard and coat with chocolate."; } } BostonCream().cook();This should print:
這應該輸出:
Fry until golden brown. Pipe full of custard and coat with chocolate. Place in a nice box. -
-
In the chapter where I introduced Lox, I challenged you to come up with a couple of features you think the language is missing. Now that you know how to build an interpreter, implement one of those features.
在介紹Lox的那一章,我讓你想出幾個你認為該語言缺少的功能。現在你知道了如何構建一個直譯器,請實現其中的一個功能。
-
“Super-”和“sub-”在拉丁語中表示“上面”和“下面”。把繼承樹想象成一個根在頂部的家族樹——在這個圖上,子類就在超類的下面。更一般地說,“sub-”指的是細化或被更一般的概念所包含的事物。在動物學中,子類指的是對更大的生物類的一個精細分類。在集合論中,子集被一個更大的超集包含,該超集中包含子集的所有元素,可能還有更多元素。集合論和程式語言在型別論中相遇,就產生了“超型別”和“子型別”。在靜態型別的面嚮物件語言中,一個子類通常也是其超類的一個子型別。 ↩
III.A BYTECODE VIRTUAL MACHINE
Our Java interpreter, jlox, taught us many of the fundamentals of programming languages, but we still have much to learn. First, if you run any interesting Lox programs in jlox, you’ll discover it’s achingly slow. The style of interpretation it uses—walking the AST directly—is good enough for some real-world uses, but leaves a lot to be desired for a general-purpose scripting language.
我們的Java解釋器jlox教會了我們許多編程語言的基礎知識,但我們仍然有許多東西需要學習。首先,如果你在jlox中運行任何Lox程序,你會發現它非常慢。它所使用的解釋方式——直接遍歷AST,對於某些實際應用來說已經足夠了,但是對於通用腳本語言來說還有很多不足之處。
Also, we implicitly rely on runtime features of the JVM itself. We take for granted that things like instanceof in Java work somehow. And we never for a second worry about memory management because the JVM’s garbage collector takes care of it for us.
另外,我們隱式地依賴於JVM本身的運行時特性。我們想當然地認為像instanceof這樣的語句在Java中是可以工作的。而且我們從未擔心過內存管理,因為JVM的垃圾收集器為我們解決了這個問題。
When we were focused on high-level concepts, it was fine to gloss over those. But now that we know our way around an interpreter, it’s time to dig down to those lower layers and build our own virtual machine from scratch using nothing more than the C standard library . . .
當我們專注於高層次概念時,我們可以忽略這些。但現在我們已經對解釋器瞭如指掌,是時候深入到這些底層,從頭開始構建我們自己的虛擬機,只用C語言標準庫就可以了……
14.位元組碼塊 Chunks of Bytecode
If you find that you’re spending almost all your time on theory, start turning some attention to practical things; it will improve your theories. If you find that you’re spending almost all your time on practice, start turning some attention to theoretical things; it will improve your practice.
——Donald Knuth
如果你發現你幾乎把所有的時間都花在了理論上,那就開始把一些注意力轉向實際的東西;這會提高你的理論水平。如果你發現你幾乎把所有的時間都花在了實踐上,那就開始把一些注意力轉向理論上的東西;這將改善你的實踐。(高德納)
We already have ourselves a complete implementation of Lox with jlox, so why isn’t the book over yet? Part of this is because jlox relies on the JVM to do lots of things for us. If we want to understand how an interpreter works all the way down to the metal, we need to build those bits and pieces ourselves.
我們已經有了一個Lox 的完整實現jlox,那麼為什麼這本書還沒有結束呢?部分原因是jlox依賴JVM為我們做很多事情1。如果我們想要了解一個直譯器是如何工作的,我們就需要自己構建這些零碎的東西。
An even more fundamental reason that jlox isn’t sufficient is that it’s too damn slow. A tree-walk interpreter is fine for some kinds of high-level, declarative languages. But for a general-purpose, imperative language—even a “scripting” language like Lox—it won’t fly. Take this little script:
jlox不夠用的一個更根本的原因在於,它太慢了。樹遍歷直譯器對於某些高階的宣告式語言來說是不錯的,但是對於通用的命令式語言——即使是Lox這樣的“指令碼”語言——這是行不通的。以下面的小指令碼為例2:
fun fib(n) {
if (n < 2) return n;
return fib(n - 1) + fib(n - 2);
}
var before = clock();
print fib(40);
var after = clock();
print after - before;
On my laptop, that takes jlox about 72 seconds to execute. An equivalent C program finishes in half a second. Our dynamically typed scripting language is never going to be as fast as a statically typed language with manual memory management, but we don’t need to settle for more than two orders of magnitude slower.
在我的膝上型電腦上,jlox大概需要72秒的時間來執行。一個等價的C程式在半秒內可以完成。我們的動態型別的指令碼語言永遠不可能像手動管理記憶體的靜態型別語言那樣快,但我們沒必要滿足於慢兩個數量級以上的速度。
We could take jlox and run it in a profiler and start tuning and tweaking hotspots, but that will only get us so far. The execution model—walking the AST—is fundamentally the wrong design. We can’t micro-optimize that to the performance we want any more than you can polish an AMC Gremlin into an SR-71 Blackbird.
我們可以把jlox放在效能分析器中執行,並進行調優和調整熱點,但這也只能到此為止了。它的執行模型(遍歷AST)從根本上說就是一個錯誤的設計。我們無法將其微最佳化到我們想要的效能,就像你無法將AMC Gremlin打磨成SR-71 Blackbird一樣。
We need to rethink the core model. This chapter introduces that model, bytecode, and begins our new interpreter, clox.
我們需要重新考慮核心模型。本章將介紹這個模型——位元組碼,並開始我們的新直譯器,clox。
14 . 1Bytecode?
14.1 位元組碼?
In engineering, few choices are without trade-offs. To best understand why we’re going with bytecode, let’s stack it up against a couple of alternatives.
在工程領域,很少有選擇是不需要權衡的。為了更好地理解我們為什麼要使用位元組碼,讓我們將它與幾個備選方案進行比較。
14 . 1 . 1Why not walk the AST?
14.1.1 為什麼不遍歷AST?
Our existing interpreter has a couple of things going for it:
我們目前的直譯器有幾個優點:
-
Well, first, we already wrote it. It’s done. And the main reason it’s done is because this style of interpreter is really simple to implement. The runtime representation of the code directly maps to the syntax. It’s virtually effortless to get from the parser to the data structures we need at runtime.
嗯,首先我們已經寫好了,它已經完成了。它能完成的主要原因是這種風格的直譯器實現起來非常簡單。程式碼的執行時表示直接對映到語法。從解析器到我們在執行時需要的資料結構,幾乎都毫不費力。
-
It’s portable. Our current interpreter is written in Java and runs on any platform Java supports. We could write a new implementation in C using the same approach and compile and run our language on basically every platform under the sun.
它是可移植的。我們目前的直譯器是使用Java編寫的,可以在Java支援的任何平臺上執行。我們可以用同樣的方法在C語言中編寫一個新的實現,並在世界上幾乎所有平臺上編譯並執行我們的語言。
Those are real advantages. But, on the other hand, it’s not memory-efficient. Each piece of syntax becomes an AST node. A tiny Lox expression like
1 + 2turns into a slew of objects with lots of pointers between them, something like:
這些是真正的優勢。但是,另一方面,它的記憶體使用效率不高。每一段語法都會變成一個AST節點。像1+2這樣的Lox表示式會變成一連串的物件,物件之間有很多指標,就像3:

Each of those pointers adds an extra 32 or 64 bits of overhead to the object. Worse, sprinkling our data across the heap in a loosely connected web of objects does bad things for spatial locality.
每個指標都會給物件增加32或64位元的開銷。更糟糕的是,將我們的資料散佈在一個鬆散連線的物件網路中的堆上,會對空間區域性性造成影響。
Modern CPUs process data way faster than they can pull it from RAM. To compensate for that, chips have multiple layers of caching. If a piece of memory it needs is already in the cache, it can be loaded more quickly. We’re talking upwards of 100 times faster.
現代CPU處理資料的速度遠遠超過它們從RAM中提取資料的速度。為了彌補這一點,晶片中有多層快取。如果它需要的一塊儲存資料已經在快取中,它就可以更快地被載入。我們談論的是100倍以上的提速。
How does data get into that cache? The machine speculatively stuffs things in there for you. Its heuristic is pretty simple. Whenever the CPU reads a bit of data from RAM, it pulls in a whole little bundle of adjacent bytes and stuffs them in the cache.
資料是如何進入快取的?機器會推測性地為你把資料塞進去。它的啟發式方法很簡單。每當CPU從RAM中讀取資料時,它就會拉取一塊相鄰的位元組並放到快取中。
If our program next requests some data close enough to be inside that cache line, our CPU runs like a well-oiled conveyor belt in a factory. We really want to take advantage of this. To use the cache effectively, the way we represent code in memory should be dense and ordered like it’s read.
如果我們的程式接下來請求一些在快取行中的資料,那麼我們的CPU就能像工廠裡一條運轉良好的傳送帶一樣執行。我們真的很想利用這一點。為了有效的利用快取,我們在記憶體中表示程式碼的方式應該像讀取時一樣緊密而有序。
Now look up at that tree. Those sub-objects could be anywhere. Every step the tree-walker takes where it follows a reference to a child node may step outside the bounds of the cache and force the CPU to stall until a new lump of data can be slurped in from RAM. Just the overhead of those tree nodes with all of their pointer fields and object headers tends to push objects away from each other and out of the cache.
現在抬頭看看那棵樹。這些子物件可能在任何地方。樹遍歷器的每一步都會引用子節點,都可能會超出快取的範圍,並迫使CPU暫停,直到從RAM中拉取到新的資料塊(才會繼續執行)。僅僅是這些樹形節點及其所有指標欄位和物件頭的開銷,就會把物件彼此推離,並將其推出快取區。
Our AST walker has other overhead too around interface dispatch and the Visitor pattern, but the locality issues alone are enough to justify a better code representation.
我們的AST遍歷器在介面排程和Visitor模式方面還有其它開銷,但僅僅是區域性性問題就足以證明使用更好的程式碼表示是合理的。
14 . 1 . 2Why not compile to native code?
14.1.2 為什麼不編譯成原生代碼?
If you want to go real fast, you want to get all of those layers of indirection out of the way. Right down to the metal. Machine code. It even sounds fast. Machine code.
如果你想真正快,就要擺脫所有的中間層,一直到最底層——機器碼。聽起來就很快,機器碼。
Compiling directly to the native instruction set the chip supports is what the fastest languages do. Targeting native code has been the most efficient option since way back in the early days when engineers actually handwrote programs in machine code.
最快的語言所做的是直接把程式碼編譯為晶片支援的本地指令集。從早期工程師真正用機器碼手寫程式以來,以原生代碼為目標一直是最有效的選擇。
If you’ve never written any machine code, or its slightly more human-palatable cousin assembly code before, I’ll give you the gentlest of introductions. Native code is a dense series of operations, encoded directly in binary. Each instruction is between one and a few bytes long, and is almost mind-numbingly low level. “Move a value from this address to this register.” “Add the integers in these two registers.” Stuff like that.
如果你以前從來沒有寫過任何機器碼,或者是它略微討人喜歡的近親組合語言,那我給你做一個簡單的介紹。原生代碼是一系列密集的操作,直接用二進位制編碼。每條指令的長度都在一到幾個位元組之間,而且幾乎是令人頭疼的底層指令。“將一個值從這個地址移動到這個暫存器”“將這兩個暫存器中的整數相加”,諸如此類。
The CPU cranks through the instructions, decoding and executing each one in order. There is no tree structure like our AST, and control flow is handled by jumping from one point in the code directly to another. No indirection, no overhead, no unnecessary skipping around or chasing pointers.
透過解碼和按順序執行指令來操作CPU。沒有像AST那樣的樹狀結構,控制流是透過從程式碼中的一個點跳到另一個點來實現的。沒有中間層,沒有開銷,沒有不必要的跳轉或指標定址。
Lightning fast, but that performance comes at a cost. First of all, compiling to native code ain’t easy. Most chips in wide use today have sprawling Byzantine architectures with heaps of instructions that accreted over decades. They require sophisticated register allocation, pipelining, and instruction scheduling.
閃電般的速度,但這種效能是有代價的。首先,編譯成原生代碼並不容易。如今廣泛使用的大多數晶片都有著龐大的拜占庭式架構,其中包含了幾十年來積累的大量指令。它們需要複雜的暫存器分配、流水線和指令排程。
And, of course, you’ve thrown portability out. Spend a few years mastering some architecture and that still only gets you onto one of the several popular instruction sets out there. To get your language on all of them, you need to learn all of their instruction sets and write a separate back end for each one.
當然,你可以把可移植性拋在一邊。花費幾年時間掌握一些架構,但這仍然只能讓你接觸到一些流行的指令集。為了讓你的語言能在所有的架構上執行,你需要學習所有的指令集,併為每個指令集編寫一個單獨的後端4。
14 . 1 . 3What is bytecode?
14.1.3 什麼是位元組碼?
Fix those two points in your mind. On one end, a tree-walk interpreter is simple, portable, and slow. On the other, native code is complex and platform-specific but fast. Bytecode sits in the middle. It retains the portability of a tree-walker—we won’t be getting our hands dirty with assembly code in this book. It sacrifices some simplicity to get a performance boost in return, though not as fast as going fully native.
記住這兩點。一方面,樹遍歷直譯器簡單、可移植,而且慢。另一方面,原生代碼複雜且特定與平臺,但是很快。位元組碼位於中間。它保留了樹遍歷型的可移植性——在本書中我們不會編寫彙編程式碼,同時它犧牲了一些簡單性來換取效能的提升,雖然沒有完全的原生代碼那麼快。
Structurally, bytecode resembles machine code. It’s a dense, linear sequence of binary instructions. That keeps overhead low and plays nice with the cache. However, it’s a much simpler, higher-level instruction set than any real chip out there. (In many bytecode formats, each instruction is only a single byte long, hence “bytecode”.)
結構上講,位元組碼類似於機器碼。它是一個密集的、線性的二進位制指令序列。這樣可以保持較低的開銷,並可以與快取記憶體配合得很好。然而,它是一個更簡單、更高階的指令集,比任何真正的晶片都要簡單。(在很多位元組碼格式中,每條指令只有一個位元組長,因此稱為“位元組碼”)
Imagine you’re writing a native compiler from some source language and you’re given carte blanche to define the easiest possible architecture to target. Bytecode is kind of like that. It’s an idealized fantasy instruction set that makes your life as the compiler writer easier.
想象一下,你在用某種源語言編寫一個本地編譯器,並且你可以全權定義一個儘可能簡單的目標架構。位元組碼就有點像這樣,它是一個理想化的幻想指令集,可以讓你作為編譯器作者的生活更輕鬆。
The problem with a fantasy architecture, of course, is that it doesn’t exist. We solve that by writing an emulator—a simulated chip written in software that interprets the bytecode one instruction at a time. A virtual machine (VM), if you will.
當然,幻想架構的問題在於它並不存在。我們提供編寫模擬器來解決這個問題,這個模擬器是一個用軟體編寫的晶片,每次會解釋位元組碼的一條指令。如果你願意的話,可以叫它虛擬機器(VM)。
That emulation layer adds overhead, which is a key reason bytecode is slower than native code. But in return, it gives us portability. Write our VM in a language like C that is already supported on all the machines we care about, and we can run our emulator on top of any hardware we like.
模擬層增加了開銷,這是位元組碼比原生代碼慢的一個關鍵原因。但作為回報,它為我們提供了可移植性5。用像C這樣的語言來編寫我們的虛擬機器,它已經被我們所關心的所有機器所支援,這樣我們就可以在任何我們喜歡的硬體上執行我們的模擬器。
This is the path we’ll take with our new interpreter, clox. We’ll follow in the footsteps of the main implementations of Python, Ruby, Lua, OCaml, Erlang, and others. In many ways, our VM’s design will parallel the structure of our previous interpreter:
這就是我們的新直譯器clox要走的路。我們將追隨Python、Ruby、Lua、OCaml、Erlang和其它主要語言實現的腳步。在許多方面,我們的VM設計將與之前的直譯器結構並行。

Of course, we won’t implement the phases strictly in order. Like our previous interpreter, we’ll bounce around, building up the implementation one language feature at a time. In this chapter, we’ll get the skeleton of the application in place and create the data structures needed to store and represent a chunk of bytecode.
當然,我們不會嚴格按照順序實現這些階段。像我們之前的直譯器一樣,我們會反覆地構建實現,每次只構建一種語言特性。在這一章中,我們將瞭解應用程式的框架,並建立用於儲存和表示位元組碼塊的資料結構。
14 . 2Getting Started
14.2 開始
Where else to begin, but at
main()? Fire up your trusty text editor and start typing.
除了main()還能從哪裡開始呢?啟動你的文字編輯器,開始輸入。
main.c,建立新檔案:
#include "common.h"
int main(int argc, const char* argv[]) {
return 0;
}
From this tiny seed, we will grow our entire VM. Since C provides us with so little, we first need to spend some time amending the soil. Some of that goes into this header:
從這顆小小的種子開始,我們將成長為整個VM。由於C提供給我們的東西太少,我們首先需要花費一些時間來培育土壤。其中一部分就在下面的header中。
common.h,建立新檔案:
#ifndef clox_common_h
#define clox_common_h
#include <stdbool.h>
#include <stddef.h>
#include <stdint.h>
#endif
There are a handful of types and constants we’ll use throughout the interpreter, and this is a convenient place to put them. For now, it’s the venerable
NULL,size_t, the nice C99 Booleanbool, and explicit-sized integer types—uint8_tand friends.
在整個直譯器中,我們會使用一些型別和常量,這是一個方便放置它們的地方。現在,它是古老的NULL、size_t,C99中的布林型別bool,以及顯式宣告大小的整數型別——uint8_t和它的朋友們。
14 . 3Chunks of Instructions
14.3 指令塊
Next, we need a module to define our code representation. I’ve been using “chunk” to refer to sequences of bytecode, so let’s make that the official name for that module.
接下來,我們需要一個模組來定義我們的程式碼表示形式。我一直使用“chunk”指代位元組碼序列,所以我們把它作為該模組的正式名稱。
chunk.h,建立新檔案:
#ifndef clox_chunk_h
#define clox_chunk_h
#include "common.h"
#endif
In our bytecode format, each instruction has a one-byte operation code (universally shortened to opcode). That number controls what kind of instruction we’re dealing with—add, subtract, look up variable, etc. We define those here:
在我們的位元組碼格式中,每個指令都有一個位元組的操作碼(通常簡稱為opcode)。這個數字控制我們要處理的指令型別——加、減、查詢變數等。我們在這塊定義這些:
chunk.h,新增程式碼:
#include "common.h"
// 新增部分開始
typedef enum {
OP_RETURN,
} OpCode;
// 新增部分結束
#endif
For now, we start with a single instruction,
OP_RETURN. When we have a full-featured VM, this instruction will mean “return from the current function”. I admit this isn’t exactly useful yet, but we have to start somewhere, and this is a particularly simple instruction, for reasons we’ll get to later.
現在,我們從一條指令OP_RETURN開始。當我們有一個全功能的VM時,這個指令意味著“從當前函式返回”。我承認這還不是完全有用,但是我們必須從某個地方開始下手,而這是一個特別簡單的指令,原因我們會在後面講到。
14 . 3 . 1 A dynamic array of instructions
14.3.1 指令動態陣列
Bytecode is a series of instructions. Eventually, we’ll store some other data along with the instructions, so let’s go ahead and create a struct to hold it all.
位元組碼是一系列指令。最終,我們會與指令一起儲存一些其它資料,所以讓我們繼續建立一個結構體來儲存所有這些資料。
chunk.h,在列舉 OpCode後新增:
} OpCode;
// 新增部分開始
typedef struct {
uint8_t* code;
} Chunk;
// 新增部分結束
#endif
At the moment, this is simply a wrapper around an array of bytes. Since we don’t know how big the array needs to be before we start compiling a chunk, it must be dynamic. Dynamic arrays are one of my favorite data structures. That sounds like claiming vanilla is my favorite ice cream flavor, but hear me out. Dynamic arrays provide:
目前,這只是一個位元組陣列的簡單包裝。由於我們在開始編譯塊之前不知道陣列需要多大,所以它必須是動態的。動態陣列是我最喜歡的資料結構之一。這聽起來就像是在說香草是我最喜愛的冰淇淋口味,但請聽我說完。動態陣列提供了:
-
Cache-friendly, dense storage
快取友好,密集儲存
-
Constant-time indexed element lookup
索引元素查詢為常量時間複雜度
-
Constant-time appending to the end of the array
陣列末尾追加元素為常量時間複雜度
Those features are exactly why we used dynamic arrays all the time in jlox under the guise of Java’s ArrayList class. Now that we’re in C, we get to roll our own. If you’re rusty on dynamic arrays, the idea is pretty simple. In addition to the array itself, we keep two numbers: the number of elements in the array we have allocated (“capacity”) and how many of those allocated entries are actually in use (“count”).
這些特性正是我們在jlox中以ArrayList類的名義一直使用動態陣列的原因。現在我們在C語言中,可以推出我們自己的動態陣列。如果你對動態陣列不熟悉,其實這個想法非常簡單。除了陣列本身,我們還保留了兩個數字:陣列中已分配的元素數量(容量,capacity)和實際使用的已分配元數數量(計數,count)。
chunk.h,在結構體 Chunk中新增程式碼:
typedef struct {
// 新增部分開始
int count;
int capacity;
// 新增部分結束
uint8_t* code;
} Chunk;
When we add an element, if the count is less than the capacity, then there is already available space in the array. We store the new element right in there and bump the count.
當新增元素時,如果計數小於容量,那麼陣列中已有可用空間。我們將新元素直接存入其中,並修改計數值。

If we have no spare capacity, then the process is a little more involved.
如果沒有多餘的容量,那麼這個過程會稍微複雜一些。

-
Allocate a new array with more capacity.
分配一個容量更大的新陣列6。
-
Copy the existing elements from the old array to the new one.
將舊陣列中的已有元素複製到新陣列中。
-
Store the new
capacity.儲存新的
capacity。 -
Delete the old array.
刪除舊陣列。
-
Update
codeto point to the new array.更新
code指向新的陣列。 -
Store the element in the new array now that there is room.
現在有了空間,將元素儲存在新陣列中。
-
Update the
count.更新
count。
We have our struct ready, so let’s implement the functions to work with it. C doesn’t have constructors, so we declare a function to initialize a new chunk.
我們的結構體已經就緒,現在我們來實現和它相關的函式。C語言沒有建構函式,所以我們宣告一個函式來初始化一個新的塊。
chunk.h,在結構體 Chunk後新增:
} Chunk;
// 新增部分開始
void initChunk(Chunk* chunk);
// 新增部分結束
#endif
And implement it thusly:
並這樣實現它:
chunk.c,建立新檔案:
#include <stdlib.h>
#include "chunk.h"
void initChunk(Chunk* chunk) {
chunk->count = 0;
chunk->capacity = 0;
chunk->code = NULL;
}
The dynamic array starts off completely empty. We don’t even allocate a raw array yet. To append a byte to the end of the chunk, we use a new function.
動態陣列一開始是完全空的。我們甚至還沒有分配原始陣列。要將一個位元組追加到塊的末尾,我們使用一個新函式。
chunk.h,在 initChunk()方法後新增:
void initChunk(Chunk* chunk);
// 新增部分開始
void writeChunk(Chunk* chunk, uint8_t byte);
// 新增部分結束
#endif
This is where the interesting work happens.
這就是有趣的地方。
chunk.c,在 initChunk()方法後新增:
void writeChunk(Chunk* chunk, uint8_t byte) {
if (chunk->capacity < chunk->count + 1) {
int oldCapacity = chunk->capacity;
chunk->capacity = GROW_CAPACITY(oldCapacity);
chunk->code = GROW_ARRAY(uint8_t, chunk->code,
oldCapacity, chunk->capacity);
}
chunk->code[chunk->count] = byte;
chunk->count++;
}
The first thing we need to do is see if the current array already has capacity for the new byte. If it doesn’t, then we first need to grow the array to make room. (We also hit this case on the very first write when the array is
NULLandcapacityis 0.)
我們需要做的第一件事是檢視當前陣列是否已經有容納新位元組的容量。如果沒有,那麼我們首先需要擴充陣列以騰出空間(當我們第一個寫入時,陣列為NULL並且capacity為0,也會遇到這種情況)
To grow the array, first we figure out the new capacity and grow the array to that size. Both of those lower-level memory operations are defined in a new module.
要擴充陣列,首先我們要算出新容量,然後將陣列容量擴充到該大小。這兩種低階別的記憶體操作都在一個新模組中定義。
chunk.c,新增程式碼:
#include "chunk.h"
// 新增部分開始
#include "memory.h"
// 新增部分結束
void initChunk(Chunk* chunk) {
This is enough to get us started.
這就足夠我們開始後面的事情了。
memory.h,建立新檔案:
#ifndef clox_memory_h
#define clox_memory_h
#include "common.h"
#define GROW_CAPACITY(capacity) \
((capacity) < 8 ? 8 : (capacity) * 2)
#endif
This macro calculates a new capacity based on a given current capacity. In order to get the performance we want, the important part is that it scales based on the old size. We grow by a factor of two, which is pretty typical. 1.5× is another common choice.
這個宏會根據給定的當前容量計算出新的容量。為了獲得我們想要的效能,重要的部分就是基於舊容量大小進行擴充套件。我們以2的係數增長,這是一個典型的取值。1.5是另外一個常見的選擇。
We also handle when the current capacity is zero. In that case, we jump straight to eight elements instead of starting at one. That avoids a little extra memory churn when the array is very small, at the expense of wasting a few bytes on very small chunks.
我們還會處理當前容量為0的情況。在這種情況下,我們的容量直接跳到8,而不是從1開始7。這就避免了在陣列非常小的時候出現額外的記憶體波動,代價是在非常小的塊中浪費幾個位元組。
Once we know the desired capacity, we create or grow the array to that size using
GROW_ARRAY().
一旦我們知道了所需的容量,就可以使用GROW_ARRAY()建立或擴充陣列到該大小。
memory.h,新增程式碼:
#define GROW_CAPACITY(capacity) ((capacity) < 8 ? 8 : (capacity) * 2)
// 新增部分開始
#define GROW_ARRAY(type, pointer, oldCount, newCount) \
(type*)reallocate(pointer, sizeof(type) * (oldCount), \
sizeof(type) * (newCount))
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
// 新增部分結束
#endif
This macro pretties up a function call to
reallocate()where the real work happens. The macro itself takes care of getting the size of the array’s element type and casting the resultingvoid*back to a pointer of the right type.
這個宏簡化了對reallocate()函式的呼叫,真正的工作就是在其中完成的。宏本身負責獲取陣列元素型別的大小,並將生成的void*轉換成正確型別的指標。
This
reallocate()function is the single function we’ll use for all dynamic memory management in clox—allocating memory, freeing it, and changing the size of an existing allocation. Routing all of those operations through a single function will be important later when we add a garbage collector that needs to keep track of how much memory is in use.
這個reallocate()函式是我們將在clox中用於所有動態記憶體管理的唯一函式——分配記憶體,釋放記憶體以及改變現有分配的大小。當我們稍後新增一個需要跟蹤記憶體使用情況的垃圾收集器時,透過單個函式路由所有這些操作是很重要的。
The two size arguments passed to
reallocate()control which operation to perform:
傳遞給reallocate() 函式的兩個大小引數控制了要執行的操作:
| oldSize | newSize | Operation |
|---|---|---|
| 0 | Non‑zero | Allocate new block. 分配新塊 |
| Non‑zero | 0 | Free allocation. 釋放已分配記憶體 |
| Non‑zero | Smaller than oldSize | Shrink existing allocation. 收縮已分配記憶體 |
| Non‑zero | Larger than oldSize | Grow existing allocation. 增加已分配記憶體 |
That sounds like a lot of cases to handle, but here’s the implementation:
看起來好像有很多情況需要處理,但下面是其實現:
memory.c,建立新檔案:
#include <stdlib.h>
#include "memory.h"
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
if (newSize == 0) {
free(pointer);
return NULL;
}
void* result = realloc(pointer, newSize);
return result;
}
When
newSizeis zero, we handle the deallocation case ourselves by callingfree(). Otherwise, we rely on the C standard library’srealloc()function. That function conveniently supports the other three aspects of our policy. WhenoldSizeis zero,realloc()is equivalent to callingmalloc().
當newSize為0時,我們透過呼叫free()來自己處理回收的情況。其它情況下,我們依賴於C標準庫的realloc()函式。該函式可以方便地支援我們策略中的其它三個場景。當oldSize為0時,realloc() 等同於呼叫malloc()。
The interesting cases are when both
oldSizeandnewSizeare not zero. Those tellrealloc()to resize the previously allocated block. If the new size is smaller than the existing block of memory, it simply updates the size of the block and returns the same pointer you gave it. If the new size is larger, it attempts to grow the existing block of memory.
有趣的情況是當oldSize和newSize都不為0時。它們會告訴realloc()要調整之前分配的塊的大小。如果新的大小小於現有的記憶體塊,它就只是更新塊的大小,並返回傳入的指標。如果新塊大小更大,它就會嘗試增長現有的記憶體塊8。
It can do that only if the memory after that block isn’t already in use. If there isn’t room to grow the block,
realloc()instead allocates a new block of memory of the desired size, copies over the old bytes, frees the old block, and then returns a pointer to the new block. Remember, that’s exactly the behavior we want for our dynamic array.
只有在該塊之後的記憶體未被使用的情況下,才能這樣做。如果沒有空間支援塊的增長,realloc()會分配一個所需大小的新的記憶體塊,複製舊的位元組,釋放舊記憶體塊,然後返回一個指向新記憶體塊的指標。記住,這正是我們的動態陣列想要的行為。
Because computers are finite lumps of matter and not the perfect mathematical abstractions computer science theory would have us believe, allocation can fail if there isn’t enough memory and
realloc()will returnNULL. We should handle that.
因為計算機是有限的物質塊,而不是電腦科學理論所認為的完美的數學抽象,如果沒有足夠的記憶體,分配就會失敗,reealloc()會返回NULL。我們應該解決這個問題。
memory.c,在 reallocate()方法中新增:
void* result = realloc(pointer, newSize);
// 新增部分開始
if (result == NULL) exit(1);
// 新增部分結束
return result;
There’s not really anything useful that our VM can do if it can’t get the memory it needs, but we at least detect that and abort the process immediately instead of returning a
NULLpointer and letting it go off the rails later.
如果我們的VM不能得到它所需要的記憶體,那就做不了什麼有用的事情,但我們至少可以檢測這一點,並立即中止程序,而不是返回一個NULL指標,然後讓程式執行偏離軌道。
OK, we can create new chunks and write instructions to them. Are we done? Nope! We’re in C now, remember, we have to manage memory ourselves, like in Ye Olden Times, and that means freeing it too.
好了,我們可以建立新的塊並向其中寫入指令。我們完成了嗎?不!要記住,我們現在是在C語言中,我們必須自己管理記憶體,就像在《Ye Olden Times》中那樣,這意味著我們也要釋放記憶體。
chunk.h,在 initChunk()方法後新增:
void initChunk(Chunk* chunk);
// 新增部分開始
void freeChunk(Chunk* chunk);
// 新增部分結束
void writeChunk(Chunk* chunk, uint8_t byte);
實現為:
chunk.c,在 initChunk()方法後新增:
void freeChunk(Chunk* chunk) {
FREE_ARRAY(uint8_t, chunk->code, chunk->capacity);
initChunk(chunk);
}
We deallocate all of the memory and then call
initChunk()to zero out the fields leaving the chunk in a well-defined empty state. To free the memory, we add one more macro.
我們釋放所有的記憶體,然後呼叫initChunk()將欄位清零,使位元組碼塊處於一個定義明確的空狀態。為了釋放記憶體,我們再新增一個宏。
memory.h,新增程式碼:
#define GROW_ARRAY(type, pointer, oldCount, newCount) \
(type*)reallocate(pointer, sizeof(type) * (oldCount), \
sizeof(type) * (newCount))
// 新增部分開始
#define FREE_ARRAY(type, pointer, oldCount) \
reallocate(pointer, sizeof(type) * (oldCount), 0)
// 新增部分結束
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
Like
GROW_ARRAY(), this is a wrapper around a call toreallocate(). This one frees the memory by passing in zero for the new size. I know, this is a lot of boring low-level stuff. Don’t worry, we’ll get a lot of use out of these in later chapters and will get to program at a higher level. Before we can do that, though, we gotta lay our own foundation.
與GROW_ARRAY()類似,這是對reallocate()呼叫的包裝。這個函式透過傳入0作為新的記憶體塊大小,來釋放記憶體。我知道,這是一堆無聊的低階別程式碼。別擔心,在後面的章節中,我們會大量使用這些內容。但在此之前,我們必須先打好自己的基礎。
14 . 4Disassembling Chunks
14.4 反彙編位元組碼塊
Now we have a little module for creating chunks of bytecode. Let’s try it out by hand-building a sample chunk.
現在我們有一個建立位元組碼塊的小模組。讓我們手動構建一個樣例位元組碼塊來測試一下。
main.c,在 main()方法中新增:
int main(int argc, const char* argv[]) {
// 新增部分開始
Chunk chunk;
initChunk(&chunk);
writeChunk(&chunk, OP_RETURN);
freeChunk(&chunk);
// 新增部分結束
return 0;
Don’t forget the include.
不要忘了include。
main.c,新增程式碼:
#include "common.h"
// 新增部分開始
#include "chunk.h"
// 新增部分結束
int main(int argc, const char* argv[]) {
Run that and give it a try. Did it work? Uh . . . who knows? All we’ve done is push some bytes around in memory. We have no human-friendly way to see what’s actually inside that chunk we made.
試著執行一下,它起作用了嗎?額……誰知道呢。我們所做的只是在記憶體中存入一些位元組。我們沒有友好的方法來檢視我們製作的位元組碼塊中到底有什麼。
To fix this, we’re going to create a disassembler. An assembler is an old-school program that takes a file containing human-readable mnemonic names for CPU instructions like “ADD” and “MULT” and translates them to their binary machine code equivalent. A disassembler goes in the other direction—given a blob of machine code, it spits out a textual listing of the instructions.
為瞭解決這個問題,我們要建立一個反彙編程式。彙編程式是一個老式程式,它接收一個檔案,該檔案中包含CPU指令(如 "ADD "和 "MULT")的可讀助記符名稱,並將它們翻譯成等價的二進位制機器程式碼。反彙編程式則相反——給定一串機器碼,它會返回指令的文字列表。
We’ll implement something similar. Given a chunk, it will print out all of the instructions in it. A Lox user won’t use this, but we Lox maintainers will certainly benefit since it gives us a window into the interpreter’s internal representation of code.
我們將實現一個類似的模組。給定一個位元組碼塊,它將打印出其中所有的指令。Lox使用者不會使用它,但我們這些Lox的維護者肯定會從中受益,因為它給我們提供了一個瞭解直譯器內部程式碼表示的視窗。
In
main(), after we create the chunk, we pass it to the disassembler.
在main()中,我們建立位元組碼塊後,將其傳入反彙編器。
main.c,在 main()方法中新增:
initChunk(&chunk);
writeChunk(&chunk, OP_RETURN);
// 新增部分開始
disassembleChunk(&chunk, "test chunk");
// 新增部分結束
freeChunk(&chunk);
Again, we whip up yet another module.
我們又建立了另一個模組。
main.c,新增程式碼:
#include "chunk.h"
// 新增部分開始
#include "debug.h"
// 新增部分結束
int main(int argc, const char* argv[]) {
Here’s that header:
下面是這個標頭檔案:
debug.h,建立新檔案:
#ifndef clox_debug_h
#define clox_debug_h
#include "chunk.h"
void disassembleChunk(Chunk* chunk, const char* name);
int disassembleInstruction(Chunk* chunk, int offset);
#endif
In
main(), we calldisassembleChunk()to disassemble all of the instructions in the entire chunk. That’s implemented in terms of the other function, which just disassembles a single instruction. It shows up here in the header because we’ll call it from the VM in later chapters.
在main()方法中,我們呼叫disassembleChunk()來反彙編整個位元組碼塊中的所有指令。這是用另一個函式實現的,該函式只反彙編一條指令。因為我們將在後面的章節中從VM中呼叫它,所以將它新增到標頭檔案中。
Here’s a start at the implementation file:
下面是簡單的實現檔案:
debug.c,建立新檔案:
#include <stdio.h>
#include "debug.h"
void disassembleChunk(Chunk* chunk, const char* name) {
printf("== %s ==\n", name);
for (int offset = 0; offset < chunk->count;) {
offset = disassembleInstruction(chunk, offset);
}
}
To disassemble a chunk, we print a little header (so we can tell which chunk we’re looking at) and then crank through the bytecode, disassembling each instruction. The way we iterate through the code is a little odd. Instead of incrementing
offsetin the loop, we letdisassembleInstruction()do it for us. When we call that function, after disassembling the instruction at the given offset, it returns the offset of the next instruction. This is because, as we’ll see later, instructions can have different sizes.
要反彙編一個位元組碼塊,我們首先列印一個小標題(這樣我們就知道正在看哪個位元組碼塊),然後透過位元組碼反彙編每個指令。我們遍歷程式碼的方式有點奇怪。我們沒有在迴圈中增加offset,而是讓disassembleInstruction() 為我們做這個。當我們呼叫該函式時,在對給定偏移量的位置反彙編指令後,會返回下一條指令的偏移量。這是因為,我們後面也會看到,指令可以有不同的大小。
The core of the “debug” module is this function:
“debug”模組的核心是這個函式:
debug.c,在disassembleChunk()方法後新增:
int disassembleInstruction(Chunk* chunk, int offset) {
printf("%04d ", offset);
uint8_t instruction = chunk->code[offset];
switch (instruction) {
case OP_RETURN:
return simpleInstruction("OP_RETURN", offset);
default:
printf("Unknown opcode %d\n", instruction);
return offset + 1;
}
}
First, it prints the byte offset of the given instruction—that tells us where in the chunk this instruction is. This will be a helpful signpost when we start doing control flow and jumping around in the bytecode.
首先,它會列印給定指令的位元組偏移量——這能告訴我們當前指令在位元組碼塊中的位置。當我們在位元組碼中實現控制流和跳轉時,這將是一個有用的路標。
Next, it reads a single byte from the bytecode at the given offset. That’s our opcode. We switch on that. For each kind of instruction, we dispatch to a little utility function for displaying it. On the off chance that the given byte doesn’t look like an instruction at all—a bug in our compiler—we print that too. For the one instruction we do have,
OP_RETURN, the display function is:
接下來,它從位元組碼中的給定偏移量處讀取一個位元組。這也就是我們的操作碼。我們根據該值做switch操作。對於每一種指令,我們都分派給一個小的工具函式來展示它。如果給定的位元組看起來根本不像一條指令——這是我們編譯器的一個錯誤——我們也要打印出來。對於我們目前僅有的一條指令OP_RETURN,對應的展示函式是:
debug.c,在 disassembleChunk()方法後新增:
static int simpleInstruction(const char* name, int offset) {
printf("%s\n", name);
return offset + 1;
}
There isn’t much to a return instruction, so all it does is print the name of the opcode, then return the next byte offset past this instruction. Other instructions will have more going on.
return指令的內容不多,所以它所做的只是列印操作碼的名稱,然後返回該指令後的下一個位元組偏移量。其它指令會有更多的內容。
If we run our nascent interpreter now, it actually prints something:
如果我們現在執行我們的新直譯器,它實際上會打印出來:
== test chunk ==
0000 OP_RETURN
It worked! This is sort of the “Hello, world!” of our code representation. We can create a chunk, write an instruction to it, and then extract that instruction back out. Our encoding and decoding of the binary bytecode is working.
成功了!這有點像我們程式碼表示中的“Hello, world!”。我們可以建立一個位元組碼塊,向其中寫入一條指令,然後將該指令提取出來。我們對二進位制位元組碼的編碼和解碼工作正常。
14 . 5Constants
14.5 常量
Now that we have a rudimentary chunk structure working, let’s start making it more useful. We can store code in chunks, but what about data? Many values the interpreter works with are created at runtime as the result of operations.
現在我們有了一個基本的塊結構,我們來讓它變得更有用。我們可以在塊中儲存程式碼,但是資料呢?直譯器中使用的很多值都是在執行時作為操作的結果建立的。
1 + 2;
The value 3 appears nowhere in the code here. However, the literals
1and2do. To compile that statement to bytecode, we need some sort of instruction that means “produce a constant” and those literal values need to get stored in the chunk somewhere. In jlox, the Expr.Literal AST node held the value. We need a different solution now that we don’t have a syntax tree.
這裡的程式碼中沒有出現3這個值。但是,字面量1和2出現了。為了將該語句編譯成位元組碼,我們需要某種指令,其含義是“生成一個常量”,而這些字母值需要儲存在位元組碼塊中的某個地方。在jlox中,Expr.Literal 這個AST節點中儲存了這些值。因為我們沒有語法樹,現在我們需要一個不同的解決方案。
14 . 5 . 1 Representing values
14.5.1 表示值
We won’t be running any code in this chapter, but since constants have a foot in both the static and dynamic worlds of our interpreter, they force us to start thinking at least a little bit about how our VM should represent values.
在本章中我們不會執行任何程式碼,但是由於常量在直譯器的靜態和動態世界中都有涉足,這會迫使我們開始思考我們的虛擬機器中應該如何表示數值。
For now, we’re going to start as simple as possible—we’ll support only double-precision, floating-point numbers. This will obviously expand over time, so we’ll set up a new module to give ourselves room to grow.
現在,我們儘可能從最簡單的開始——只支援雙精度浮點數。這種表示形式顯然會逐漸擴大,所以我們將建立一個新的模組,給自己留出擴充套件的空間。
value.h,建立新檔案:
#ifndef clox_value_h
#define clox_value_h
#include "common.h"
typedef double Value;
#endif
This typedef abstracts how Lox values are concretely represented in C. That way, we can change that representation without needing to go back and fix existing code that passes around values.
這個型別定義抽象了Lox值在C語言中的具體表示方式。這樣,我們就可以直接改變表示方法,而不需要回去修改現有的傳遞值的程式碼。
Back to the question of where to store constants in a chunk. For small fixed-size values like integers, many instruction sets store the value directly in the code stream right after the opcode. These are called immediate instructions because the bits for the value are immediately after the opcode.
回到在位元組碼塊中儲存常量的問題。對於像整數這種固定大小的值,許多指令集直接將值儲存在操作碼之後的程式碼流中。這些指令被稱為即時指令,因為值的位元位緊跟在操作碼之後。
That doesn’t work well for large or variable-sized constants like strings. In a native compiler to machine code, those bigger constants get stored in a separate “constant data” region in the binary executable. Then, the instruction to load a constant has an address or offset pointing to where the value is stored in that section.
對於字串這種較大的或可變大小的常量來說,這並不適用。在本地編譯器的機器碼中,這些較大的常量會儲存在二進位制可執行檔案中的一個單獨的“常量資料”區域。然後,載入常量的指令會有一個地址和偏移量,指向該值在區域中儲存的位置。
Most virtual machines do something similar. For example, the Java Virtual Machine associates a constant pool with each compiled class. That sounds good enough for clox to me. Each chunk will carry with it a list of the values that appear as literals in the program. To keep things simpler, we’ll put all constants in there, even simple integers.
大多數虛擬機器都會做類似的事。例如,Java虛擬機器將常量池與每個編譯後的類關聯起來。我認為,這對於clox來說已經足夠了。每個位元組碼塊都會攜帶一個在程式中以字面量形式出現的值的列表。為簡單起見,我們會把所有的常量都放進去,甚至包括簡單的整數9。
14 . 5 . 2Value arrays
14.5.2 值陣列
The constant pool is an array of values. The instruction to load a constant looks up the value by index in that array. As with our bytecode array, the compiler doesn’t know how big the array needs to be ahead of time. So, again, we need a dynamic one. Since C doesn’t have generic data structures, we’ll write another dynamic array data structure, this time for Value.
常量池是一個值的陣列。載入常量的指令根據陣列中的索引查詢該陣列中的值。與位元組碼陣列一樣,編譯器也無法提前知道這個陣列需要多大。因此,我們需要一個動態陣列。由於C語言沒有通用資料結構,我們將編寫另一個動態陣列資料結構,這次儲存的是Value。
value.h:
typedef double Value;
// 新增部分開始
typedef struct {
int capacity;
int count;
Value* values;
} ValueArray;
// 新增部分結束
#endif
As with the bytecode array in Chunk, this struct wraps a pointer to an array along with its allocated capacity and the number of elements in use. We also need the same three functions to work with value arrays.
與Chunk中的位元組碼陣列一樣,這個結構體包裝了一個指向陣列的指標,以及其分配的容量和已使用元素的數量。我們也需要相同的三個函式來處理值陣列。
value.h,在結構體 ValueArray後新增:
} ValueArray;
// 新增部分開始
void initValueArray(ValueArray* array);
void writeValueArray(ValueArray* array, Value value);
void freeValueArray(ValueArray* array);
// 新增部分結束
#endif
The implementations will probably give you déjà vu. First, to create a new one:
對應的實現可能會讓你有似曾相識的感覺。首先,建立一個新檔案:
value.c,建立一個新檔案:
#include <stdio.h>
#include "memory.h"
#include "value.h"
void initValueArray(ValueArray* array) {
array->values = NULL;
array->capacity = 0;
array->count = 0;
}
Once we have an initialized array, we can start adding values to it.
一旦我們有了初始化的陣列,我們就可以開始向其中新增值。
value.c,在 initValueArray()方法後新增:
void writeValueArray(ValueArray* array, Value value) {
if (array->capacity < array->count + 1) {
int oldCapacity = array->capacity;
array->capacity = GROW_CAPACITY(oldCapacity);
array->values = GROW_ARRAY(Value, array->values,
oldCapacity, array->capacity);
}
array->values[array->count] = value;
array->count++;
}
The memory-management macros we wrote earlier do let us reuse some of the logic from the code array, so this isn’t too bad. Finally, to release all memory used by the array:
我們之前寫的記憶體管理宏確實讓我們重用了程式碼陣列中的一些邏輯,所以這並不是太糟糕。最後,釋放陣列所使用的所有記憶體:
value.c,在 writeValueArray()方法後新增:
void freeValueArray(ValueArray* array) {
FREE_ARRAY(Value, array->values, array->capacity);
initValueArray(array);
}
Now that we have growable arrays of values, we can add one to Chunk to store the chunk’s constants.
現在我們有了可增長的值陣列,我們可以向Chunk中新增一個來儲存位元組碼塊中的常量值。
chunk.h,在結構體 Chunk中新增:
uint8_t* code;
// 新增部分開始
ValueArray constants;
// 新增部分結束
} Chunk;
Don’t forget the include.
不要忘記include。
chunk.h,新增程式碼:
#include "common.h"
// 新增部分開始
#include "value.h"
// 新增部分結束
typedef enum {
Ah, C, and its Stone Age modularity story. Where were we? Right. When we initialize a new chunk, we initialize its constant list too.
初始化新的位元組碼塊時,我們也要初始化其常量值列表。
chunk.c,在 initChunk()方法中新增:
chunk->code = NULL;
// 新增部分開始
initValueArray(&chunk->constants);
// 新增部分結束
}
Likewise, we free the constants when we free the chunk.
同樣地,我們在釋放位元組碼塊時,也需要釋放常量值。
chunk.c,在 freeChunk()方法中新增:
FREE_ARRAY(uint8_t, chunk->code, chunk->capacity);
// 新增部分開始
freeValueArray(&chunk->constants);
// 新增部分結束
initChunk(chunk);
Next, we define a convenience method to add a new constant to the chunk. Our yet-to-be-written compiler could write to the constant array inside Chunk directly—it’s not like C has private fields or anything—but it’s a little nicer to add an explicit function.
接下來,我們定義一個便捷的方法來向位元組碼塊中新增一個新常量。我們尚未編寫的編譯器可以在Chunk內部直接把常量值寫入常量陣列——它不像C語言那樣有私有欄位之類的東西——但是新增一個顯式函式顯然會更好一些。
chunk.h,在 writeChunk()方法後新增:
void writeChunk(Chunk* chunk, uint8_t byte);
// 新增部分開始
int addConstant(Chunk* chunk, Value value);
// 新增部分結束
#endif
Then we implement it.
然後我們實現它。
chunk.c,在 writeChunk()方法後新增:
int addConstant(Chunk* chunk, Value value) {
writeValueArray(&chunk->constants, value);
return chunk->constants.count - 1;
}
After we add the constant, we return the index where the constant was appended so that we can locate that same constant later.
在新增常量之後,我們返回追加常量的索引,以便後續可以定位到相同的常量。
14 . 5 . 3Constant instructions
14.5.3 常量指令
We can store constants in chunks, but we also need to execute them. In a piece of code like:
我們可以將常量儲存在位元組碼塊中,但是我們也需要執行它們。在如下這段程式碼中:
print 1;
print 2;
The compiled chunk needs to not only contain the values 1 and 2, but know when to produce them so that they are printed in the right order. Thus, we need an instruction that produces a particular constant.
編譯後的位元組碼塊不僅需要包含數值1和2,還需要知道何時生成它們,以便按照正確的順序列印它們。因此,我們需要一種產生特定常數的指令。
chunk.h,在列舉 OpCode中新增:
typedef enum {
// 新增部分開始
OP_CONSTANT,
// 新增部分結束
OP_RETURN,
When the VM executes a constant instruction, it “loads” the constant for use. This new instruction is a little more complex than
OP_RETURN. In the above example, we load two different constants. A single bare opcode isn’t enough to know which constant to load.
當VM執行常量指令時,它會“載入”常量以供使用10。這個新指令比OP_RETURN要更復雜一些。在上面的例子中,我們載入了兩個不同的常量。一個簡單的操作碼不足以知道要載入哪個常量。
To handle cases like this, our bytecode—like most others—allows instructions to have operands. These are stored as binary data immediately after the opcode in the instruction stream and let us parameterize what the instruction does.
為了處理這樣的情況,我們的位元組碼像大多數其它位元組碼一樣,允許指令有運算元11。這些運算元以二進位制資料的形式儲存在指令流的操作碼之後,讓我們對指令的操作進行引數化。

Each opcode determines how many operand bytes it has and what they mean. For example, a simple operation like “return” may have no operands, where an instruction for “load local variable” needs an operand to identify which variable to load. Each time we add a new opcode to clox, we specify what its operands look like—its instruction format.
每個操作碼會定義它有多少運算元以及各自的含義。例如,一個像“return”這樣簡單的操作可能沒有運算元,而一個“載入區域性變數”的指令需要一個運算元來確定要載入哪個變數。每次我們向clox新增一個新的操作碼時,我們都會指定它的運算元是什麼樣子的——即它的指令格式。
In this case,
OP_CONSTANTtakes a single byte operand that specifies which constant to load from the chunk’s constant array. Since we don’t have a compiler yet, we “hand-compile” an instruction in our test chunk.
在這種情況下,OP_CONSTANT會接受一個單位元組的運算元,該運算元指定從塊的常量陣列中載入哪個常量。由於我們還沒有編譯器,所以我們在測試位元組碼塊中“手動編譯”一個指令。
main.c,在 main()方法中新增:
initChunk(&chunk);
// 新增部分開始
int constant = addConstant(&chunk, 1.2);
writeChunk(&chunk, OP_CONSTANT);
writeChunk(&chunk, constant);
// 新增部分結束
writeChunk(&chunk, OP_RETURN);
We add the constant value itself to the chunk’s constant pool. That returns the index of the constant in the array. Then we write the constant instruction, starting with its opcode. After that, we write the one-byte constant index operand. Note that
writeChunk()can write opcodes or operands. It’s all raw bytes as far as that function is concerned.
我們將常量值新增到位元組碼塊的常量池中。這會返回常量在陣列中的索引。然後我們寫常量操作指令,從操作碼開始。之後,我們寫入一位元組的常量索引運算元。注意, writeChunk() 可以寫操作碼或運算元。對於該函式而言,它們都是原始位元組。
If we try to run this now, the disassembler is going to yell at us because it doesn’t know how to decode the new instruction. Let’s fix that.
如果我們現在嘗試執行上面的程式碼,反彙編器會遇到問題,因為它不知道如何解碼新指令。讓我們來修復這個問題。
debug.c,在 disassembleInstruction()方法中新增:
switch (instruction) {
// 新增部分開始
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
// 新增部分結束
case OP_RETURN:
This instruction has a different instruction format, so we write a new helper function to disassemble it.
這條指令的格式有所不同,所以我們編寫一個新的輔助函式來對其反彙編。
debug.c,在 disassembleChunk()方法後新增:
static int constantInstruction(const char* name, Chunk* chunk,
int offset) {
uint8_t constant = chunk->code[offset + 1];
printf("%-16s %4d '", name, constant);
printValue(chunk->constants.values[constant]);
printf("'\n");
}
There’s more going on here. As with
OP_RETURN, we print out the name of the opcode. Then we pull out the constant index from the subsequent byte in the chunk. We print that index, but that isn’t super useful to us human readers. So we also look up the actual constant value—since constants are known at compile time after all—and display the value itself too.
這裡要做的事情更多一些。與OP_ETURN一樣,我們會打印出操作碼的名稱。然後,我們從該位元組碼塊的後續位元組中獲取常量索引。我們打印出這個索引值,但是這對於我們人類讀者來說並不十分有用。所以,我們也要查詢實際的常量值——因為常量畢竟是在編譯時就知道的——並將這個值也展示出來。
This requires some way to print a clox Value. That function will live in the “value” module, so we include that.
這就需要一些方法來列印clox中的一個Value。這個函式放在“value”模組中,所以我們要將其include。
debug.c,新增程式碼:
#include "debug.h"
// 新增部分開始
#include "value.h"
// 新增部分結束
void disassembleChunk(Chunk* chunk, const char* name) {
Over in that header, we declare:
在這個標頭檔案中,我們宣告:
value.h,在 freeValueArray()方法後新增:
void freeValueArray(ValueArray* array);
// 新增部分開始
void printValue(Value value);
// 新增部分結束
#endif
And here’s an implementation:
下面是對應的實現:
value.c,在 freeValueArray()方法後新增:
void printValue(Value value) {
printf("%g", value);
}
Magnificent, right? As you can imagine, this is going to get more complex once we add dynamic typing to Lox and have values of different types.
很壯觀,是吧?你可以想象,一旦我們在Lox中加入動態型別,並且包含了不同型別的值,這部分將會變得更加複雜。
Back in
constantInstruction(), the only remaining piece is the return value.
回到constantInstruction()中,唯一剩下的部分就是返回值。
debug.c,在 constantInstruction()方法中新增:
printf("'\n");
// 新增部分開始
return offset + 2;
// 新增部分結束
}
Remember that
disassembleInstruction()also returns a number to tell the caller the offset of the beginning of the next instruction. WhereOP_RETURNwas only a single byte,OP_CONSTANTis two—one for the opcode and one for the operand.
記住,disassembleInstruction()也會返回一個數字,告訴呼叫方下一條指令的起始位置的偏移量。OP_RETURN只有一個位元組,而OP_CONSTANT有兩個位元組——一個是操作碼,一個是運算元。
14 . 6 Line Information
14.6 行資訊
Chunks contain almost all of the information that the runtime needs from the user’s source code. It’s kind of crazy to think that we can reduce all of the different AST classes that we created in jlox down to an array of bytes and an array of constants. There’s only one piece of data we’re missing. We need it, even though the user hopes to never see it.
位元組碼塊中幾乎包含了執行時需要從使用者原始碼中獲取的所有資訊。想到我們可以把jlox中不同的AST類減少到一個位元組陣列和一個常量陣列,這實在有一點瘋狂。我們只缺少一個資料。我們需要它,儘管使用者希望永遠不會看到它。
When a runtime error occurs, we show the user the line number of the offending source code. In jlox, those numbers live in tokens, which we in turn store in the AST nodes. We need a different solution for clox now that we’ve ditched syntax trees in favor of bytecode. Given any bytecode instruction, we need to be able to determine the line of the user’s source program that it was compiled from.
當執行時錯誤發生時,我們會向用戶顯示出錯的原始碼的行號。在jlox中,這些數字儲存在詞法標記中,而我們又將詞法標記儲存在AST節點中。既然我們已經拋棄了語法樹而採用了位元組碼,我們就需要為clox提供不同的解決方案。對於任何位元組碼指令,我們需要能夠確定它是從使用者原始碼的哪一行編譯出來的。
There are a lot of clever ways we could encode this. I took the absolute simplest approach I could come up with, even though it’s embarrassingly inefficient with memory. In the chunk, we store a separate array of integers that parallels the bytecode. Each number in the array is the line number for the corresponding byte in the bytecode. When a runtime error occurs, we look up the line number at the same index as the current instruction’s offset in the code array.
我們有很多聰明的方法可以對此進行編碼。我採取了我能想到的絕對最簡單的方法,儘管這種方法的記憶體效率低得令人髮指12。在位元組碼塊中,我們儲存一個單獨的整數陣列,該陣列與位元組碼平級。陣列中的每個數字都是位元組碼中對應位元組所在的行號。當發生執行時錯誤時,我們根據當前指令在程式碼陣列中的偏移量查詢對應的行號。
To implement this, we add another array to Chunk.
為了實現這一點,我們向Chunk中新增另一個陣列。
chunk.h, 在結構體 Chunk中新增:
uint8_t* code;
// 新增部分開始
int* lines;
// 新增部分結束
ValueArray constants;
Since it exactly parallels the bytecode array, we don’t need a separate count or capacity. Every time we touch the code array, we make a corresponding change to the line number array, starting with initialization.
由於它與位元組碼陣列完全平行,我們不需要單獨的計數值和容量值。每次我們訪問程式碼陣列時,也會對行號陣列做相應的修改,從初始化開始。
chunk.c,在 initChunk()方法中新增:
chunk->code = NULL;
// 新增部分開始
chunk->lines = NULL;
// 新增部分結束
initValueArray(&chunk->constants);
And likewise deallocation:
回收也是類似的:
chunk.c,在 freeChunk()中新增:
FREE_ARRAY(uint8_t, chunk->code, chunk->capacity);
// 新增部分開始
FREE_ARRAY(int, chunk->lines, chunk->capacity);
// 新增部分結束
freeValueArray(&chunk->constants);
When we write a byte of code to the chunk, we need to know what source line it came from, so we add an extra parameter in the declaration of
writeChunk().
當我們向塊中寫入一個程式碼位元組時,我們需要知道它來自哪個原始碼行,所以我們在writeChunk()的宣告中新增一個額外的引數。
chunk.h,在 writeChunk()函式中替換一行:
void freeChunk(Chunk* chunk);
// 替換部分開始
void writeChunk(Chunk* chunk, uint8_t byte, int line);
// 替換部分結束
int addConstant(Chunk* chunk, Value value);
And in the implementation:
然後在實現中修改:
chunk.c,在 writeChunk()函式中替換一行:
// 替換部分開始
void writeChunk(Chunk* chunk, uint8_t byte, int line) {
// 替換部分結束
if (chunk->capacity < chunk->count + 1) {
When we allocate or grow the code array, we do the same for the line info too.
當我們分配或擴充套件程式碼陣列時,我們也要對行資訊進行相同的處理。
chunk.c,在 writeChunk()方法中新增:
chunk->code = GROW_ARRAY(uint8_t, chunk->code,
oldCapacity, chunk->capacity);
// 新增部分開始
chunk->lines = GROW_ARRAY(int, chunk->lines,
oldCapacity, chunk->capacity);
// 新增部分結束
}
Finally, we store the line number in the array.
最後,我們在陣列中儲存行資訊。
chunk.c,在 writeChunk()方法中新增:
chunk->code[chunk->count] = byte;
// 新增部分開始
chunk->lines[chunk->count] = line;
// 新增部分結束
chunk->count++;
14 . 6 . 1Disassembling line information
14.6.1 反彙編行資訊
Alright, let’s try this out with our little, uh, artisanal chunk. First, since we added a new parameter to
writeChunk(), we need to fix those calls to pass in some—arbitrary at this point—line number.
好吧,讓我們手動編譯一個小的位元組碼塊測試一下。首先,由於我們向writeChunk()添加了一個新引數,我們需要修改一下該方法的呼叫,向其中新增一些行號(這裡可以隨意選擇行號值)。
main.c,在 main()方法中替換四行:
int constant = addConstant(&chunk, 1.2);
// 替換部分開始
writeChunk(&chunk, OP_CONSTANT, 123);
writeChunk(&chunk, constant, 123);
writeChunk(&chunk, OP_RETURN, 123);
// 替換部分結束
disassembleChunk(&chunk, "test chunk");
Once we have a real front end, of course, the compiler will track the current line as it parses and pass that in.
當然,一旦我們有了真正的前端,編譯器會在解析時跟蹤當前行,並將其傳入位元組碼中。
Now that we have line information for every instruction, let’s put it to good use. In our disassembler, it’s helpful to show which source line each instruction was compiled from. That gives us a way to map back to the original code when we’re trying to figure out what some blob of bytecode is supposed to do. After printing the offset of the instruction—the number of bytes from the beginning of the chunk—we show its source line.
現在我們有了每條指令的行資訊,讓我們好好利用它吧。在我們的反彙編程式中,展示每條指令是由哪一行原始碼編譯出來的是很有幫助的。當我們試圖弄清楚某些位元組碼應該做什麼時,這給我們提供了一種方法來映射回原始程式碼。在列印了指令的偏移量之後——從位元組碼塊起點到當前指令的位元組數——我們也展示它在原始碼中的行號。
debug.c,在 disassembleInstruction()方法中新增:
int disassembleInstruction(Chunk* chunk, int offset) {
printf("%04d ", offset);
// 新增部分開始
if (offset > 0 &&
chunk->lines[offset] == chunk->lines[offset - 1]) {
printf(" | ");
} else {
printf("%4d ", chunk->lines[offset]);
}
// 新增部分結束
uint8_t instruction = chunk->code[offset];
Bytecode instructions tend to be pretty fine-grained. A single line of source code often compiles to a whole sequence of instructions. To make that more visually clear, we show a
|for any instruction that comes from the same source line as the preceding one. The resulting output for our handwritten chunk looks like:
位元組碼指令往往是非常細粒度的。一行原始碼往往可以編譯成一個完整的指令序列。為了更直觀地說明這一點,我們在與前一條指令來自同一原始碼行的指令前面顯示一個“|”。我們的手寫位元組碼塊的輸出結果如下所示:
== test chunk ==
0000 123 OP_CONSTANT 0 '1.2'
0002 | OP_RETURN
We have a three-byte chunk. The first two bytes are a constant instruction that loads 1.2 from the chunk’s constant pool. The first byte is the
OP_CONSTANTopcode and the second is the index in the constant pool. The third byte (at offset 2) is a single-byte return instruction.
我們有一個三位元組的塊。前兩個位元組是一個常量指令,從該塊的常量池中載入1.2。第一個位元組是OP_CONSTANT位元組碼,第二個是在常量池中的索引。第三個位元組(偏移量為2)是一個單位元組的返回指令。
In the remaining chapters, we will flesh this out with lots more kinds of instructions. But the basic structure is here, and we have everything we need now to completely represent an executable piece of code at runtime in our virtual machine. Remember that whole family of AST classes we defined in jlox? In clox, we’ve reduced that down to three arrays: bytes of code, constant values, and line information for debugging.
在接下來的章節中,我們將用更多種類的指令來充實這個結構。但是基本結構已經在這裡了,我們現在擁有了所需要的一切,可以在虛擬機器執行時完全表示一段可執行的程式碼。還記得我們在jlox中定義的整個AST類族嗎?在clox中,我們把它減少到了三個陣列:程式碼位元組陣列,常量值陣列,以及用於除錯的行資訊。
This reduction is a key reason why our new interpreter will be faster than jlox. You can think of bytecode as a sort of compact serialization of the AST, highly optimized for how the interpreter will deserialize it in the order it needs as it executes. In the next chapter, we will see how the virtual machine does exactly that.
這種減少是我們的新直譯器比jlox更快的一個關鍵原因。你可以把位元組碼看作是AST的一種緊湊的序列化,並且直譯器在執行時按照需要對其反序列化的方式進行了高度最佳化。在下一章中,我們將會看到虛擬機器是如何做到這一點的。
CHALLENGES
習題
-
Our encoding of line information is hilariously wasteful of memory. Given that a series of instructions often correspond to the same source line, a natural solution is something akin to run-length encoding of the line numbers.
我們對行資訊的編碼非常浪費記憶體。鑑於一系列指令通常對應於同一原始碼行,一個自然的解決方案是對行號進行類似遊程編碼的操作。
Devise an encoding that compresses the line information for a series of instructions on the same line. Change
writeChunk()to write this compressed form, and implement agetLine()function that, given the index of an instruction, determines the line where the instruction occurs.設計一個編碼方式,壓縮同一行上一系列指令的行資訊。修改
writeChunk()以寫入該壓縮形式,並實現一個getLine()函式,給定一條指令的索引,確定該指令所在的行。Hint: It’s not necessary for
getLine()to be particularly efficient. Since it is called only when a runtime error occurs, it is well off the critical path where performance matters.提示:
getLine()不一定要特別高效。因為它只在出現執行時錯誤時才被呼叫,所以在它並不是影響效能的關鍵因素。 -
Because
OP_CONSTANTuses only a single byte for its operand, a chunk may only contain up to 256 different constants. That’s small enough that people writing real-world code will hit that limit. We could use two or more bytes to store the operand, but that makes every constant instruction take up more space. Most chunks won’t need that many unique constants, so that wastes space and sacrifices some locality in the common case to support the rare case.因為
OP_CONSTANT只使用一個位元組作為運算元,所以一個塊最多隻能包含256個不同的常數。這已經夠小了,使用者在編寫真正的程式碼時很容易會遇到這個限制。我們可以使用兩個或更多位元組來儲存運算元,但這會使每個常量指令佔用更多的空間。大多數字節碼塊都不需要那麼多獨特的常量,所以這就浪費了空間,並犧牲了一些常規情況下的區域性性來支援罕見場景。To balance those two competing aims, many instruction sets feature multiple instructions that perform the same operation but with operands of different sizes. Leave our existing one-byte
OP_CONSTANTinstruction alone, and define a secondOP_CONSTANT_LONGinstruction. It stores the operand as a 24-bit number, which should be plenty.為了平衡這兩個相互衝突的目標,許多指令集具有多個執行相同操作但運算元大小不同的指令。保留現有的使用一個位元組的
OP_CONSTANT指令,並定義一個新的OP_CONSTANT_LONG指令。它將運算元儲存為24位的數字,這應該就足夠了。Implement this function:
實現該函式:
void writeConstant(Chunk* chunk, Value value, int line) { // Implement me... }It adds
valuetochunk’s constant array and then writes an appropriate instruction to load the constant. Also add support to the disassembler forOP_CONSTANT_LONGinstructions.它向
chunk的常量陣列中新增value,然後寫一條合適的指令來載入常量。同時在反彙編程式中增加對OP_CONSTANT_LONG指令的支援。Defining two instructions seems to be the best of both worlds. What sacrifices, if any, does it force on us?
定義兩條指令似乎是兩全其美的辦法。它會迫使我們做出什麼犧牲呢(如果有的話)?
-
Our
reallocate()function relies on the C standard library for dynamic memory allocation and freeing.malloc()andfree()aren’t magic. Find a couple of open source implementations of them and explain how they work. How do they keep track of which bytes are allocated and which are free? What is required to allocate a block of memory? Free it? How do they make that efficient? What do they do about fragmentation?我們的
reallocate()函式依賴於C標準庫進行動態記憶體分配和釋放。malloc()和free()並不神奇。找幾個它們的開源實現,並解釋它們是如何工作的。它們如何跟蹤哪些位元組被分配,哪些被釋放?分配一個記憶體塊需要什麼?釋放的時候呢?它們如何實現高效?它們如何處理碎片化記憶體?Hardcore mode: Implement
reallocate()without callingrealloc(),malloc(), orfree(). You are allowed to callmalloc()once, at the beginning of the interpreter’s execution, to allocate a single big block of memory, which yourreallocate()function has access to. It parcels out blobs of memory from that single region, your own personal heap. It’s your job to define how it does that.硬核模式:在不呼叫
realloc(),malloc(), 和free()的前提下,實現reallocate()。你可以在直譯器開始執行時呼叫一次malloc(),來分配一個大的記憶體塊,你的reallocate()函式能夠訪問這個記憶體塊。它可以從這個區域(你自己的私人堆記憶體)中分配記憶體塊。你的工作就是定義如何做到這一點。
DESIGN NOTE: TEST YOUR LANGUAGE
設計筆記:測試你的語言
We’re almost halfway through the book and one thing we haven’t talked about is testing your language implementation. That’s not because testing isn’t important. I can’t possibly stress enough how vital it is to have a good, comprehensive test suite for your language.
I wrote a test suite for Lox (which you are welcome to use on your own Lox implementation) before I wrote a single word of this book. Those tests found countless bugs in my implementations.
Tests are important in all software, but they’re even more important for a programming language for at least a couple of reasons:
- Users expect their programming languages to be rock solid. We are so used to mature, stable compilers and interpreters that “It’s your code, not the compiler” is an ingrained part of software culture. If there are bugs in your language implementation, users will go through the full five stages of grief before they can figure out what’s going on, and you don’t want to put them through all that.
- A language implementation is a deeply interconnected piece of software. Some codebases are broad and shallow. If the file loading code is broken in your text editor, it—hopefully!—won’t cause failures in the text rendering on screen. Language implementations are narrower and deeper, especially the core of the interpreter that handles the language’s actual semantics. That makes it easy for subtle bugs to creep in caused by weird interactions between various parts of the system. It takes good tests to flush those out.
- The input to a language implementation is, by design, combinatorial. There are an infinite number of possible programs a user could write, and your implementation needs to run them all correctly. You obviously can’t test that exhaustively, but you need to work hard to cover as much of the input space as you can.
- Language implementations are often complex, constantly changing, and full of optimizations. That leads to gnarly code with lots of dark corners where bugs can hide.
All of that means you’re gonna want a lot of tests. But what tests? Projects I’ve seen focus mostly on end-to-end “language tests”. Each test is a program written in the language along with the output or errors it is expected to produce. Then you have a test runner that pushes the test program through your language implementation and validates that it does what it’s supposed to. Writing your tests in the language itself has a few nice advantages:
- The tests aren’t coupled to any particular API or internal architecture decisions of the implementation. This frees you to reorganize or rewrite parts of your interpreter or compiler without needing to update a slew of tests.
- You can use the same tests for multiple implementations of the language.
- Tests can often be terse and easy to read and maintain since they are simply scripts in your language.
It’s not all rosy, though:
- End-to-end tests help you determine if there is a bug, but not where the bug is. It can be harder to figure out where the erroneous code in the implementation is because all the test tells you is that the right output didn’t appear.
- It can be a chore to craft a valid program that tickles some obscure corner of the implementation. This is particularly true for highly optimized compilers where you may need to write convoluted code to ensure that you end up on just the right optimization path where a bug may be hiding.
- The overhead can be high to fire up the interpreter, parse, compile, and run each test script. With a big suite of tests—which you do want, remember—that can mean a lot of time spent waiting for the tests to finish running.
I could go on, but I don’t want this to turn into a sermon. Also, I don’t pretend to be an expert on how to test languages. I just want you to internalize how important it is that you test yours. Seriously. Test your language. You’ll thank me for it.
我們的書已經過半了,有一件事我們還沒有談及,那就是測試你的語言實現。這並不是因為測試不重要。語言實現有一個好的、全面的套件是多麼重要,我怎麼強調都不為過。
在我寫本書之前,我為Lox寫了一個測試套件(你也可以在自己的Lox實現中使用它)。這些測試在我的語言實現中發現了無數的bug。
測試在所有軟體中都很重要,但對於程式語言來說,測試甚至更重要,至少有以下幾個原因:
- 使用者希望他們的程式語言能夠堅如磐石。我們已經習慣了成熟的編譯器、直譯器,以至於“是你的程式碼(出錯了),而不是編譯器”成為軟體文化中根深蒂固的一部分。如果你的語言實現中有錯誤,使用者需要經歷全部五個痛苦的階段才能弄清楚發生了什麼,而你並不想讓他們經歷這一切。
- 語言的實現是一個緊密相連的軟體。有些程式碼庫既廣泛又浮淺。如果你的文字編輯器中的檔案載入程式碼被破壞了,它不會導致螢幕上的文字渲染失敗(希望如此)。語言的實現則更狹窄和深入,特別是處理語言實際語義的直譯器核心部分。這使得系統的各個部分之間奇怪的互動會造成微妙的錯誤。這就需要好的測試來清除這些問題。
- 從設計上來說,語言實現的輸入是組合性的。使用者可以寫出無限多的程式,而你的實現需要能夠正確地執行這些程式。您顯然不能進行詳盡地測試,但需要努力覆蓋儘可能多的輸入空間。
- 語言的實現通常是複雜的、不斷變化的,而且充滿了最佳化。這就導致了粗糙程式碼中有很多隱藏錯誤的黑暗角落。
所有這些都意味著你需要做大量的測試。但是什麼測試呢?我見過的專案主要集中在端到端的“語言測試”上。每個測試都是一段用該語言編寫的程式,以及它預期產生的輸出或錯誤。然後,你還需要一個測試執行器,將這些測試程式輸入到你的語言實現中,並驗證它是否按照預期執行。用語言本身編寫測試有一些很好的優勢:
- 測試不與任何特定的API或語言實現的內部結構相耦合。這樣你可以重新組織或重寫直譯器或編譯器的一部分,而不需要更新大量的測試。
- 你可以對該語言的多種實現使用相同的測試。
- 測試通常是簡潔的,易於閱讀和維護,因為它們只是語言寫就的簡單指令碼。
不過,這並不全是好事:
- 端到端測試可以幫助你確定是否存在錯誤,但不能確認錯誤在哪裡。在語言實現中找出錯誤程式碼的位置可能更加困難,因為測試只能告訴你沒有出現正確的輸出。
- 要編寫一個有效的程式來測試實現中一些不太明顯的角落,可能是一件比較麻煩的事。對於高度最佳化的編譯器來說尤其如此,你可能需要編寫複雜的程式碼,以確保最終能夠到達正確的最佳化路徑,以測試其中可能隱藏的錯誤。
- 啟動直譯器、解析、編譯和執行每個測試指令碼的開銷可能很高。對於一個大的測試套件來說,(如果你確實需要的話,請記住)這可能意味著需要花費很多時間來等待測試的完成。
我可以繼續說下去,但是我不希望這變成一場說教。此外,我並不想假裝自己是語言測試專家。我只是想讓你在內心深處明白,測試你的語言是多麼重要。我是認真的。測試你的語言。你會為此感謝我的。
-
當然,我們的第二個直譯器會依賴C標準庫來實現記憶體分配等基本功能,而C編譯器將我們從執行它的底層機器碼的細節中解放出來。糟糕的是,該機器碼可能是透過晶片上的微碼來實現的。而C語言的執行時依賴於作業系統來分配記憶體頁。但是,如果要想在你的書架放得下這本書,我們必須在某個地方停下來。 ↩
-
這種計算斐波那契數列的方式效率低得可笑。我們的目的是檢視直譯器的執行速度,而不是看我們編寫的程式有多快。一個做了大量工作的程式,無論是否有意義,都是一個很好的測試用例。 ↩
-
“(header)”部分是Java虛擬機器用來支援記憶體管理和儲存物件型別的記錄資訊,這些也會佔用空間。 ↩
-
情況也沒有那麼可怕。一個架構良好的編譯器,可以讓你跨不同的架構共享前端和大部分中間層的最佳化通道。每次都需要重新編寫的主要是程式碼生成和指令選擇的一些細節。LLVM專案提供了一些開箱即用的功能。如果你的編譯器輸出LLVM自己特定的中間語言,LLVM可以反過來將其編譯為各種架構的原生代碼。 ↩
-
最早的位元組碼格式之一是p-code,是為Niklaus Wirth的Pascal語言開發的。你可能會認為一個執行在15MHz的PDP-11無法承擔模擬虛擬機器的開銷。但在當時,計算機正處於寒武紀大爆發時期,每天都有新的架構出現。跟上最新的晶片要比從某個晶片中壓榨出最大效能更有價值。這就是為什麼p-code中的“p”指的不是“Pascal”而是“可移植性Portable”。 ↩
-
增長陣列時會複製現有元素,使得追加元素的複雜度看起來像是O(n),而不是O(1)。但是,你只需要在某些追加操作中執行這個操作步驟。大多數時候,已有多餘的容量,所以不需要複製。要理解這一點,我們需要進行攤銷分析。這表明,只要我們把陣列大小增加到當前大小的倍數,當我們把一系列追加操作的成本平均化時,每次追加都是O(1)。 ↩
-
我在這本書中選擇了數字8,有些隨意。大多數動態陣列實現都有一個這樣的最小閾值。挑選這個值的正確方法是根據實際使用情況進行分析,看看那個常數能在額外增長和浪費的空間之間做出最佳的效能權衡。 ↩
-
既然我們傳入的只是一個指向記憶體第一個位元組的裸指標,那麼“更新”塊的大小意味著什麼呢?在內部,記憶體分配器為堆分配的每個記憶體塊都維護了額外的簿記資訊,包括它的大小。給定一個指向先前分配的記憶體的指標,它就可以找到這個簿記資訊,為了能幹淨地釋放記憶體,這是必需的。
realloc()所更新的正是這個表示大小的後設資料。許多malloc()的實現將分配的大小儲存在返回地址之前的記憶體中。 ↩ -
除了需要兩種常量指令(一種用於即時值,一種用於常量表中的常量)之外,即時指令還要求我們考慮對齊、填充和位元組順序的問題。如果你嘗試在一個奇數地址填充一個4位元組的整數,有些架構中會出錯。 ↩
-
我這裡對於“載入”或“產生”一個常量的含義含糊其辭,因為我們還沒有學到虛擬機器在執行時是如何執行的程式碼的。關於這一點,你必須等到(或者直接跳到)下一章。 ↩
-
位元組碼指令的運算元與傳遞給算術運算子的運算元不同。當我們講到表示式時,你會看到算術運算元的值是被單獨跟蹤的。指令運算元是一個較低層次的概念,它可以修改位元組碼指令本身的行為方式。 ↩
-
這種腦殘的編碼至少做對了一件事:它將行資訊儲存一個單獨的陣列中,而不是將其編入位元組碼本身中。由於行資訊只在執行時出現錯誤時才使用,我們不希望它在指令之間佔用CPU快取中的寶貴空間,而且直譯器在跳過行數獲取它所關心的操作碼和運算元時,會造成更多的快取丟失。 ↩
15.虛擬機器 A Virtual Machine
Magicians protect their secrets not because the secrets are large and important, but because they are so small and trivial. The wonderful effects created on stage are often the result of a secret so absurd that the magician would be embarrassed to admit that that was how it was done.
——Christopher Priest, The Prestige
魔術師們之所以保護他們的秘密,並不是因為秘密很大、很重要,而是它們是如此小而微不足道。在舞臺上創造出的奇妙效果往往源自於一個荒謬的小秘密,以至於魔術師都不好意思承認這是如何完成的。
We’ve spent a lot of time talking about how to represent a program as a sequence of bytecode instructions, but it feels like learning biology using only stuffed, dead animals. We know what instructions are in theory, but we’ve never seen them in action, so it’s hard to really understand what they do. It would be hard to write a compiler that outputs bytecode when we don’t have a good understanding of how that bytecode behaves.
我們已經花了很多時間討論如何將程式表示為位元組碼指令序列,但是這感覺像是隻用填充的死動物來學習生物學。我們知道理論上的指令是什麼,但我們在實際操作中從未見過,因此很難真正理解指令的作用。如果我們不能很好地理解位元組碼的行為方式,就很難編寫輸出位元組碼的編譯器。
So, before we go and build the front end of our new interpreter, we will begin with the back end—the virtual machine that executes instructions. It breathes life into the bytecode. Watching the instructions prance around gives us a clearer picture of how a compiler might translate the user’s source code into a series of them.
因此,在構建新直譯器的前端之前,我們先從後端開始——執行指令的虛擬機器。它為位元組碼注入了生命。透過觀察這些指令的執行,我們可以更清楚地瞭解編譯器如何將使用者的原始碼轉換成一系列的指令。
15 . 1An Instruction Execution Machine
15.1 指令執行機器
The virtual machine is one part of our interpreter’s internal architecture. You hand it a chunk of code—literally a Chunk—and it runs it. The code and data structures for the VM reside in a new module.
虛擬機器是我們直譯器內部結構的一部分。你把一個程式碼塊交給它,它就會執行這塊程式碼。VM的程式碼和資料結構放在一個新的模組中。
vm.h,建立新檔案:
#ifndef clox_vm_h
#define clox_vm_h
#include "chunk.h"
typedef struct {
Chunk* chunk;
} VM;
void initVM();
void freeVM();
#endif
As usual, we start simple. The VM will gradually acquire a whole pile of state it needs to keep track of, so we define a struct now to stuff that all in. Currently, all we store is the chunk that it executes.
跟之前一樣,我們從簡單的部分開始。VM會逐步獲取到一大堆它需要跟蹤的狀態,所以我們現在定義一個結構,把這些狀態都塞進去。目前,我們只儲存它執行的程式碼塊。
Like we do with most of the data structures we create, we also define functions to create and tear down a VM. Here’s the implementation:
與我們建立的大多數資料結構類似,我們也會定義用來建立和釋放虛擬機器的函式。下面是其對應實現:
vm.c,建立新檔案:
#include "common.h"
#include "vm.h"
VM vm;
void initVM() {
}
void freeVM() {
}
OK, calling those functions “implementations” is a stretch. We don’t have any interesting state to initialize or free yet, so the functions are empty. Trust me, we’ll get there.
好吧,把這些函式稱為“實現”有點牽強了。我們目前還沒有任何感興趣的狀態需要初始化或釋放,所以這些函式是空的。相信我,我們終會實現它的。
The slightly more interesting line here is that declaration of
vm. This module is eventually going to have a slew of functions and it would be a chore to pass around a pointer to the VM to all of them. Instead, we declare a single global VM object. We need only one anyway, and this keeps the code in the book a little lighter on the page.
這裡稍微有趣的一行是vm的宣告。這個模組最終會有一系列的函式,如果要將一個指向VM的指標傳遞給所有的函式,那就太麻煩了。相反,我們宣告瞭一個全域性VM物件。反正我們只需要一個虛擬機器物件,這樣可以讓本書中的程式碼在頁面上更輕便1。
Before we start pumping fun code into our VM, let’s go ahead and wire it up to the interpreter’s main entrypoint.
在我們開始向虛擬機器中新增有效程式碼之前,我們先將其連線到直譯器的主入口點。
main.c,在 main()方法中新增程式碼:
int main(int argc, const char* argv[]) {
// 新增部分開始
initVM();
// 新增部分結束
Chunk chunk;
We spin up the VM when the interpreter first starts. Then when we’re about to exit, we wind it down.
當直譯器第一次啟動時,我們也啟動虛擬機器。然後當我們要退出時,我們將其關閉。
main.c,在 main()方法中新增程式碼:
disassembleChunk(&chunk, "test chunk");
// 新增部分開始
freeVM();
// 新增部分結束
freeChunk(&chunk);
One last ceremonial obligation:
最後一項儀式性任務:
main.c,新增程式碼:
#include "debug.h"
// 新增部分開始
#include "vm.h"
// 新增部分結束
int main(int argc, const char* argv[]) {
Now when you run clox, it starts up the VM before it creates that hand-authored chunk from the last chapter. The VM is ready and waiting, so let’s teach it to do something.
現在如果你執行clox,它會先啟動虛擬機器,再建立上一章中的手寫程式碼塊。虛擬機器已經就緒了,我們來教它一些事情吧。
15 . 1 . 1Executing instructions
15.1.1 執行指令
The VM springs into action when we command it to interpret a chunk of bytecode.
當我們命令VM解釋一個位元組碼塊時,它就會開始啟動了。
main.c,在 main()方法中新增程式碼:
disassembleChunk(&chunk, "test chunk");
// 新增部分開始
interpret(&chunk);
// 新增部分結束
freeVM();
This function is the main entrypoint into the VM. It’s declared like so:
這個函式是進入VM的主要入口。它的宣告如下:
vm.h,在 freeVM()方法後新增:
void freeVM();
// 新增部分開始
InterpretResult interpret(Chunk* chunk);
// 新增部分結束
#endif
The VM runs the chunk and then responds with a value from this enum:
VM會執行位元組碼塊,然後返回下面列舉中的一個值作為響應:
vm.h,在結構體 VM後新增:
} VM;
// 新增部分開始
typedef enum {
INTERPRET_OK,
INTERPRET_COMPILE_ERROR,
INTERPRET_RUNTIME_ERROR
} InterpretResult;
// 新增部分結束
void initVM();
void freeVM();
We aren’t using the result yet, but when we have a compiler that reports static errors and a VM that detects runtime errors, the interpreter will use this to know how to set the exit code of the process.
我們現在還不會使用這個結果,但是當我們有一個報告靜態錯誤的編譯器和檢測執行時錯誤的VM時,直譯器會透過它來知道如何設定程序的退出程式碼。
We’re inching towards some actual implementation.
我們正逐步走向一些真正的實現。
vm.c,在 freeVM()方法後新增:
InterpretResult interpret(Chunk* chunk) {
vm.chunk = chunk;
vm.ip = vm.chunk->code;
return run();
}
First, we store the chunk being executed in the VM. Then we call
run(), an internal helper function that actually runs the bytecode instructions. Between those two parts is an intriguing line. What is thisipbusiness?
首先,我們在虛擬機器中儲存正在執行的塊。然後我們呼叫run(),這是一個內部輔助函式,實際執行位元組碼指令。在這兩部分之間,有一條耐人尋味的線。這個ip作用是什麼?
As the VM works its way through the bytecode, it keeps track of where it is—the location of the instruction currently being executed. We don’t use a local variable inside
run()for this because eventually other functions will need to access it. Instead, we store it as a field in VM.
當虛擬機器執行位元組碼時,它會記錄它在哪裡——即當前執行的指令所在的位置。我們沒有在run()方法中使用區域性變數來進行記錄,因為最終其它函式也會訪問該值。相對地,我們將其作為一個欄位儲存在VM中2。
vm.h,在結構體VM中新增程式碼:
typedef struct {
Chunk* chunk;
// 新增部分開始
uint8_t* ip;
// 新增部分結束
} VM;
Its type is a byte pointer. We use an actual real C pointer pointing right into the middle of the bytecode array instead of something like an integer index because it’s faster to dereference a pointer than look up an element in an array by index.
它的型別是一個位元組指標。我們使用一個真正的C指標指向位元組碼陣列的中間,而不是使用類似整數索引這種方式,這是因為對指標的引用比透過索引查詢陣列中的一個元素要更快。
The name “IP” is traditional, and—unlike many traditional names in CS—actually makes sense: it’s an instruction pointer. Almost every instruction set in the world, real and virtual, has a register or variable like this.
“IP”這個名字很傳統,而且與CS中的很多傳統名稱不同的是,它是有實際意義的:它是一個指令指標。幾乎世界上所有的指令集,不管是真實的還是虛擬的,都有一個類似的暫存器或變數3。
We initialize
ipby pointing it at the first byte of code in the chunk. We haven’t executed that instruction yet, soippoints to the instruction about to be executed. This will be true during the entire time the VM is running: the IP always points to the next instruction, not the one currently being handled.
我們透過將ip指向塊中的第一個位元組碼來對其初始化。我們還沒有執行該指令,所以ip指向即將執行的指令。在虛擬機器執行的整個過程中都是如此:IP總是指向下一條指令,而不是當前正在處理的指令。
The real fun happens in
run().
真正有趣的部分在run()中。
vm.c,在 freeVM()方法後新增:
static InterpretResult run() {
#define READ_BYTE() (*vm.ip++)
for (;;) {
uint8_t instruction;
switch (instruction = READ_BYTE()) {
case OP_RETURN: {
return INTERPRET_OK;
}
}
}
#undef READ_BYTE
}
This is the single most important function in all of clox, by far. When the interpreter executes a user’s program, it will spend something like 90% of its time inside
run(). It is the beating heart of the VM.
到目前為止,這是clox中最重要的一個函式。當直譯器執行使用者的程式時,它有大約90%的時間是在run()中。它是虛擬機器跳動的心臟。
Despite that dramatic intro, it’s conceptually pretty simple. We have an outer loop that goes and goes. Each turn through that loop, we read and execute a single bytecode instruction.
儘管這個介紹很戲劇性,但從概念上來說很簡單。我們有一個不斷進行的外層迴圈。每次迴圈中,我們會讀取並執行一條位元組碼指令。
To process an instruction, we first figure out what kind of instruction we’re dealing with. The
READ_BYTEmacro reads the byte currently pointed at byipand then advances the instruction pointer. The first byte of any instruction is the opcode. Given a numeric opcode, we need to get to the right C code that implements that instruction’s semantics. This process is called decoding or dispatching the instruction.
為了處理一條指令,我們首先需要弄清楚要處理的是哪種指令。READ_BYTE這個宏會讀取ip當前指向位元組,然後推進指令指標4。任何指令的第一個位元組都是操作碼。給定一個操作碼,我們需要找到實現該指令語義的正確的C程式碼。這個過程被稱為解碼或指令分派。
We do that process for every single instruction, every single time one is executed, so this is the most performance critical part of the entire virtual machine. Programming language lore is filled with clever techniques to do bytecode dispatch efficiently, going all the way back to the early days of computers.
每一條指令,每一次執行時,我們都會進行這個過程,所以這是整個虛擬機器效能最關鍵的部分。程式語言的傳說中充滿了高效進行位元組碼分派的各種奇技淫巧5,一直可以追溯到計算機的早期。
Alas, the fastest solutions require either non-standard extensions to C, or handwritten assembly code. For clox, we’ll keep it simple. Just like our disassembler, we have a single giant
switchstatement with a case for each opcode. The body of each case implements that opcode’s behavior.
可惜的是,最快的解決方案要麼需要對C進行非標準的擴充套件,要麼需要手寫彙編程式碼。對於clox,我們要保持簡單。就像我們的反彙編程式一樣,我們寫一個巨大的switch語句,其中每個case對應一個操作碼。每個case程式碼體實現了操作碼的行為。
So far, we handle only a single instruction,
OP_RETURN, and the only thing it does is exit the loop entirely. Eventually, that instruction will be used to return from the current Lox function, but we don’t have functions yet, so we’ll repurpose it temporarily to end the execution.
到目前為止,我們只處理了一條指令,OP_RETURN,而它做的唯一的事情就是完全退出迴圈。最終,該指令將被用於從當前的Lox函式返回,但是我們目前還沒有函式,所以我們暫時用它來結束程式碼執行。
Let’s go ahead and support our one other instruction.
讓我們繼續支援另一個指令。
vm.c,在 run()方法中增加程式碼:
switch (instruction = READ_BYTE()) {
// 新增部分開始
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
printValue(constant);
printf("\n");
break;
}
// 新增部分結束
case OP_RETURN: {
We don’t have enough machinery in place yet to do anything useful with a constant. For now, we’ll just print it out so we interpreter hackers can see what’s going on inside our VM. That call to
printf()necessitates an include.
我們還沒有足夠的機制來使用常量做任何有用的事。現在,我們只是把它打印出來,這樣我們這些直譯器駭客就可以看到我們的VM內部發生了什麼。呼叫printf()方法需要進行include。
vm.c,在檔案頂部新增:
// 新增部分開始
#include <stdio.h>
// 新增部分結束
#include "common.h"
We also have a new macro to define.
我們還需要定義一個新的宏。
vm.c,在 run()方法中新增程式碼:
#define READ_BYTE() (*vm.ip++)
// 新增部分開始
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
// 新增部分結束
for (;;) {
READ_CONSTANT()reads the next byte from the bytecode, treats the resulting number as an index, and looks up the corresponding Value in the chunk’s constant table. In later chapters, we’ll add a few more instructions with operands that refer to constants, so we’re setting up this helper macro now.
READ_CONTANT()從位元組碼中讀取下一個位元組,將得到的數字作為索引,並在程式碼塊的常量表中查詢相應的Value。在後面的章節中,我們將新增一些運算元指向常量的指令,所以我們現在要設定這個輔助宏。
Like the previous READ_BYTE macro, READ_CONSTANT is only used inside run(). To make that scoping more explicit, the macro definitions themselves are confined to that function. We define them at the beginning and—because we care—undefine them at the end.
與之前的READ_BYTE宏類似,READ_CONSTANT只會在run()方法中使用。為了使作用域更明確,宏定義本身要被限制在該函式中。我們在開始時定義了它們,然後因為我們比較關心,在結束時取消它們的定義6。
vm.c,在 run()方法中新增:
#undef READ_BYTE
// 新增部分開始
#undef READ_CONSTANT
// 新增部分結束
}
15 . 1 . 2 Execution tracing
15.1.2 執行跟蹤
If you run clox now, it executes the chunk we hand-authored in the last chapter and spits out
1.2to your terminal. We can see that it’s working, but that’s only because our implementation ofOP_CONSTANThas temporary code to log the value. Once that instruction is doing what it’s supposed to do and plumbing that constant along to other operations that want to consume it, the VM will become a black box. That makes our lives as VM implementers harder.
如果現在執行clox,它會執行我們在上一章中手工編寫的位元組碼塊,並向終端輸出1.2。我們可以看到它在工作,但這是因為我們在OP_CONSTANT的實現中,使用臨時程式碼記錄了這個值。一旦該指令執行了它應做的操作,並將取得的常量傳遞給其它想要使用該常量的操作,虛擬機器就會變成一個黑盒子。這使得我們作為虛擬機器實現者的工作更加艱難。
To help ourselves out, now is a good time to add some diagnostic logging to the VM like we did with chunks themselves. In fact, we’ll even reuse the same code. We don’t want this logging enabled all the time—it’s just for us VM hackers, not Lox users—so first we create a flag to hide it behind.
為了幫助我們自己解脫這種困境,現在是給虛擬機器新增一些診斷性日誌的好時機,就像我們對程式碼塊本身所做的那樣。事實上,我們甚至會重用相同的程式碼。我們不希望一直啟用這個日誌——它只針對我們這些虛擬機器開發者,而不是Lox使用者——所以我們首先建立一個標誌來隱藏它。
common.h,新增程式碼:
#include <stdint.h>
// 新增部分開始
#define DEBUG_TRACE_EXECUTION
// 新增部分結束
#endif
When this flag is defined, the VM disassembles and prints each instruction right before executing it. Where our previous disassembler walked an entire chunk once, statically, this disassembles instructions dynamically, on the fly.
定義了這個標誌之後,虛擬機器在執行每條指令之前都會反彙編並將其打印出來。我們之前的反彙編程式只是靜態地遍歷一次整個位元組碼塊,而這個反編譯程式則是動態地、即時地對指令進行反彙編。
vm.c,在 run()方法中新增程式碼:
for (;;) {
// 新增部分開始
#ifdef DEBUG_TRACE_EXECUTION
disassembleInstruction(vm.chunk,
(int)(vm.ip - vm.chunk->code));
#endif
// 新增部分結束
uint8_t instruction;
Since
disassembleInstruction()takes an integer byte offset and we store the current instruction reference as a direct pointer, we first do a little pointer math to convertipback to a relative offset from the beginning of the bytecode. Then we disassemble the instruction that begins at that byte.
由於 disassembleInstruction() 方法接收一個整數offset作為位元組偏移量,而我們將當前指令引用儲存為一個直接指標,所以我們首先要做一個小小的指標運算,將ip轉換成從位元組碼開始的相對偏移量。然後,我們對從該位元組開始的指令進行反彙編。
As ever, we need to bring in the declaration of the function before we can call it.
跟之前一樣,我們需要在呼叫函式之前先引入函式的宣告。
vm.c,新增程式碼:
#include "common.h"
// 新增部分開始
#include "debug.h"
// 新增部分結束
#include "vm.h"
I know this code isn’t super impressive so far—it’s literally a switch statement wrapped in a
forloop but, believe it or not, this is one of the two major components of our VM. With this, we can imperatively execute instructions. Its simplicity is a virtue—the less work it does, the faster it can do it. Contrast this with all of the complexity and overhead we had in jlox with the Visitor pattern for walking the AST.
我知道這段程式碼到目前為止還不是很令人印象深刻——它實際上只是一個封裝在for迴圈中的switch語句,但信不信由你,這就是我們虛擬機器的兩個主要組成部分之一。有了它,我們就可以命令式地執行指令。它的簡單是一種優點——它做的工作越少,就能做得越快。作為對照,可以回想一下我們在jlox中使用Visitor模式遍歷AST的複雜度和開銷。
15 . 2 A Value Stack Manipulator
15.2 一個值棧操作器
In addition to imperative side effects, Lox has expressions that produce, modify, and consume values. Thus, our compiled bytecode needs a way to shuttle values around between the different instructions that need them. For example:
除了命令式的副作用外,Lox還有產生、修改和使用值的表示式。因此,我們編譯的位元組碼還需要一種方法在需要值的不同指令之間傳遞它們。例如:
print 3 - 2;
We obviously need instructions for the constants 3 and 2, the
顯然我們需要常數3和2、print語句和減法對應的指令。但是減法指令如何知道3是被減數而2是減數呢?列印指令怎麼知道要列印計算結果的呢?
To put a finer point on it, look at this thing right here:
為了說得更清楚一點,看看下面的程式碼:
fun echo(n) {
print n;
return n;
}
print echo(echo(1) + echo(2)) + echo(echo(4) + echo(5));
I wrapped each subexpression in a call to
echo()that prints and returns its argument. That side effect means we can see the exact order of operations.
我將每個子表達都包裝在對echo()的呼叫中,這個呼叫會列印並返回其引數。這個副作用意味著我們可以看到操作的確切順序。
Don’t worry about the VM for a minute. Think about just the semantics of Lox itself. The operands to an arithmetic operator obviously need to be evaluated before we can perform the operation itself. (It’s pretty hard to add
a + bif you don’t know whataandbare.) Also, when we implemented expressions in jlox, we decided that the left operand must be evaluated before the right.
暫時不要擔心虛擬機器的問題。只考慮Lox本身的語義。算術運算子的運算元顯然需要在執行運算操作之前求值(如果你不知道a和b是什麼,就很難計算a+b)。另外,當我們在jlox中實現表示式時,我們決定了左運算元必須在右運算元之前進行求值7。
Here is the syntax tree for the
下面是print語句的語法樹:

Given left-to-right evaluation, and the way the expressions are nested, any correct Lox implementation must print these numbers in this order:
確定了從左到右的求值順序,以及表示式巢狀方式,任何一個正確的Lox實現都必須按照下面的順序列印這些數字:
1 // from echo(1)
2 // from echo(2)
3 // from echo(1 + 2)
4 // from echo(4)
5 // from echo(5)
9 // from echo(4 + 5)
12 // from print 3 + 9
Our old jlox interpreter accomplishes this by recursively traversing the AST. It does a postorder traversal. First it recurses down the left operand branch, then the right operand, then finally it evaluates the node itself.
我們的老式jlox直譯器透過遞迴遍歷AST來實現這一點。其中使用的是後序遍歷。首先,它向下遞迴左運算元分支,然後是右運算元分支,最後計算節點本身。
After evaluating the left operand, jlox needs to store that result somewhere temporarily while it’s busy traversing down through the right operand tree. We use a local variable in Java for that. Our recursive tree-walk interpreter creates a unique Java call frame for each node being evaluated, so we could have as many of these local variables as we needed.
在對左運算元求值之後,jlox需要將結果臨時儲存在某個地方,然後再向下遍歷右運算元。我們使用Java中的一個區域性變數來實現。我們的遞迴樹遍歷直譯器會為每個正在求值的節點建立一個單獨的Java呼叫幀,所以我們可以根據需要維護很多這樣的區域性變數。
In clox, our
run()function is not recursive—the nested expression tree is flattened out into a linear series of instructions. We don’t have the luxury of using C local variables, so how and where should we store these temporary values? You can probably guess already, but I want to really drill into this because it’s an aspect of programming that we take for granted, but we rarely learn why computers are architected this way.
在clox中,我們的run()函式不是遞迴的——巢狀的表示式被展開成一系列線性指令。我們沒有辦法使用C語言的區域性變數,那我們應該如何儲存這些臨時值呢?你可能已經猜到了,但我想真正深入研究這個問題,因為這是程式設計中我們習以為常的一個方面,但我們很少了解為什麼計算機是這樣架構的。
Let’s do a weird exercise. We’ll walk through the execution of the above program a step at a time:
讓我們做一個奇怪的練習。我們來一步一步地遍歷上述程式的執行過程:

On the left are the steps of code. On the right are the values we’re tracking. Each bar represents a number. It starts when the value is first produced—either a constant or the result of an addition. The length of the bar tracks when a previously produced value needs to be kept around, and it ends when that value finally gets consumed by an operation.
左邊是程式碼的執行步驟。右邊是我們要追蹤的值。每條槓代表一個數字。起點是數值產生時——要麼是一個常數,要麼是一個加法計算結果;槓的長度表示之前產生的值需要保留的時間;當該值最終被某個操作消費後,槓就到終點了。
As you step through, you see values appear and then later get eaten. The longest-lived ones are the values produced from the left-hand side of an addition. Those stick around while we work through the right-hand operand expression.
隨著你不斷執行,你會看到一些數值出現,然後被消費掉。壽命最長的是加法左側產生的值。當我們在處理右邊的運算元表示式時,這些值會一直存在。
In the above diagram, I gave each unique number its own visual column. Let’s be a little more parsimonious. Once a number is consumed, we allow its column to be reused for another later value. In other words, we take all of those gaps up there and fill them in, pushing in numbers from the right:
在上圖中,我為每個數字提供了單獨的視覺化列。讓我們更簡潔一些。一旦一個數字被消費了,我們就允許它的列被其它值重用。換句話說,我們將數字從右向左推入,把上面的空隙都填上:

There’s some interesting stuff going on here. When we shift everything over, each number still manages to stay in a single column for its entire life. Also, there are no gaps left. In other words, whenever a number appears earlier than another, then it will live at least as long as that second one. The first number to appear is the last to be consumed. Hmm . . . last-in, first-out . . . why, that’s a stack!
這裡有一些有趣的事情發生了。當我們把所有數字都移動以後,每個數字在整個生命週期中仍然能保持在一列。此外,也沒有留下任何空隙。換句話說,只要一個數字比另一個數字出現得早,那麼它的壽命至少和第二個數字一樣長。第一個出現的數字是最後一個消費掉的,嗯……後進先出……哎呀,這是一個棧!
In the second diagram, each time we introduce a number, we push it onto the stack from the right. When numbers are consumed, they are always popped off from rightmost to left.
在第二張圖中,每次我們生成一個數字時,都會從右邊將它壓入棧。當數字被消費時,它們也是從右向左進行彈出。
Since the temporary values we need to track naturally have stack-like behavior, our VM will use a stack to manage them. When an instruction “produces” a value, it pushes it onto the stack. When it needs to consume one or more values, it gets them by popping them off the stack.
由於我們需要跟蹤的臨時值天然具有類似棧的行為,我們的虛擬機器將使用棧來管理它們。當一條指令“生成”一個值時,它會把這個值壓入棧中。當它需要消費一個或多個值時,透過從棧中彈出資料來獲得這些值。
15 . 2 . 1 The VM’s Stack
15.2.1 虛擬機器的棧
Maybe this doesn’t seem like a revelation, but I love stack-based VMs. When you first see a magic trick, it feels like something actually magical. But then you learn how it works—usually some mechanical gimmick or misdirection—and the sense of wonder evaporates. There are a couple of ideas in computer science where even after I pulled them apart and learned all the ins and outs, some of the initial sparkle remained. Stack-based VMs are one of those.
也許這看起來不像是什麼新發現,但我喜歡基於棧的虛擬機器。當你第一次看到一個魔術時,你會覺得它真的很神奇。但是當你瞭解到它是如何工作的——通常是一些機械式花招或誤導——驚奇的感覺就消失了。在電腦科學中,有一些理念,即使我把它們拆開並瞭解了所有的來龍去脈之後,最初的閃光點仍然存在。基於堆疊的虛擬機器就是其中之一8。
As you’ll see in this chapter, executing instructions in a stack-based VM is dead simple. In later chapters, you’ll also discover that compiling a source language to a stack-based instruction set is a piece of cake. And yet, this architecture is fast enough to be used by production language implementations. It almost feels like cheating at the programming language game.
你在本章中將會看到,在基於堆疊的虛擬機器中執行指令是非常簡單的。在後面的章節中,你還會發現,將源語言編譯成基於棧的指令集是小菜一碟。但是,這種架構的速度快到足以在產生式語言的實現中使用。這感覺就像是在程式語言遊戲中作弊9。
Alrighty, it’s codin’ time! Here’s the stack:
好了,編碼時間到!下面是棧:
vm.h,在結構體VM中新增程式碼:
typedef struct {
Chunk* chunk;
uint8_t* ip;
// 新增部分開始
Value stack[STACK_MAX];
Value* stackTop;
// 新增部分結束
} VM;
We implement the stack semantics ourselves on top of a raw C array. The bottom of the stack—the first value pushed and the last to be popped—is at element zero in the array, and later pushed values follow it. If we push the letters of “crepe”—my favorite stackable breakfast item—onto the stack, in order, the resulting C array looks like this:
我們在一個原生的C陣列上自己實現了棧語義。棧的底部——第一個推入的值和最後一個被彈出的值——位於陣列中的零號位置,後面推入的值跟在它後面。如果我們把“crepe”幾個字母按順序推入棧中,得到的C陣列看起來像這樣:

Since the stack grows and shrinks as values are pushed and popped, we need to track where the top of the stack is in the array. As with
ip, we use a direct pointer instead of an integer index since it’s faster to dereference the pointer than calculate the offset from the index each time we need it.
由於棧會隨著值的壓入和彈出而伸縮,我們需要跟蹤棧的頂部在陣列中的位置。和ip一樣,我們使用一個直接指標而不是整數索引,因為每次我們需要使用它時,解引用比計算索引的偏移量更快。
The pointer points at the array element just past the element containing the top value on the stack. That seems a little odd, but almost every implementation does this. It means we can indicate that the stack is empty by pointing at element zero in the array.
指標指向陣列中棧頂元素的下一個元素位置,這看起來有點奇怪,但幾乎每個實現都會這樣做。這意味著我們可以透過指向陣列中的零號元素來表示棧是空的。

If we pointed to the top element, then for an empty stack we’d need to point at element -1. That’s undefined in C. As we push values onto the stack . . .
如果我們指向棧頂元素,那麼對於空棧,我們就需要指向-1位置的元素10。這在C語言中是沒有定義的。當我們把值壓入棧時:

. . .
stackTopalways points just past the last item.
stackTop一直會超過棧中的最後一個元素。

I remember it like this:
stackToppoints to where the next value to be pushed will go. The maximum number of values we can store on the stack (for now, at least) is:
我是這樣記的:stackTop指向下一個值要被壓入的位置。我們在棧中可以儲存的值的最大數量(至少目前是這樣)為:
vm.h,新增程式碼:
#include "chunk.h"
// 新增部分開始
#define STACK_MAX 256
// 新增部分結束
typedef struct {
Giving our VM a fixed stack size means it’s possible for some sequence of instructions to push too many values and run out of stack space—the classic “stack overflow”. We could grow the stack dynamically as needed, but for now we’ll keep it simple. Since VM uses Value, we need to include its declaration.
給我們的虛擬機器一個固定的棧大小,意味著某些指令系列可能會壓入太多的值並耗盡棧空間——典型的“堆疊溢位”。我們可以根據需要動態地增加棧,但是現在我們還是保持簡單。因為VM中會使用Value,我們需要包含它的宣告。
vm.h,新增程式碼:
#include "chunk.h"
// 新增部分開始
#include "value.h"
// 新增部分結束
#define STACK_MAX 256
Now that VM has some interesting state, we get to initialize it.
現在,虛擬機器中有了一些有趣的狀態,我們要對它進行初始化。
vm.c,在 initVM()中新增程式碼:
void initVM() {
// 新增部分開始
resetStack();
// 新增部分結束
}
That uses this helper function:
其中使用了這個輔助函式:
vm.c,在變數 vm後新增:
static void resetStack() {
vm.stackTop = vm.stack;
}
Since the stack array is declared directly inline in the VM struct, we don’t need to allocate it. We don’t even need to clear the unused cells in the array—we simply won’t access them until after values have been stored in them. The only initialization we need is to set
stackTopto point to the beginning of the array to indicate that the stack is empty.
因為棧陣列是直接在VM結構體中內聯宣告的,所以我們不需要為其分配空間。我們甚至不需要清除陣列中不使用的單元——我們只有在值存入之後才會訪問它們。我們需要的唯一的初始化操作就是將stackTop指向陣列的起始位置,以表明棧是空的。
The stack protocol supports two operations:
棧協議支援兩種操作:
vm.h,在 interpret()方法後新增:
InterpretResult interpret(Chunk* chunk);
// 新增部分開始
void push(Value value);
Value pop();
// 新增部分結束
#endif
You can push a new value onto the top of the stack, and you can pop the most recently pushed value back off. Here’s the first function:
你可以把一個新值壓入棧頂,你也可以把最近壓入的值彈出。下面是第一個函式:
vm.c,在 freeVM()方法後新增:
void push(Value value) {
*vm.stackTop = value;
vm.stackTop++;
}
If you’re rusty on your C pointer syntax and operations, this is a good warm-up. The first line stores
valuein the array element at the top of the stack. Remember,stackToppoints just past the last used element, at the next available one. This stores the value in that slot. Then we increment the pointer itself to point to the next unused slot in the array now that the previous slot is occupied.
如果你對C指標的語法和操作感到生疏,這是一個很好的熟悉的機會。第一行在棧頂的陣列元素中儲存value。記住,stackTop剛剛跳過上次使用的元素,即下一個可用的元素。這裡把值儲存在該元素槽中。接著,因為上一個槽被佔用了,我們增加指標本身,指向陣列中下一個未使用的槽。
Popping is the mirror image.
彈出正好是壓入的映象操作。
vm.c,在 push()方法後新增程式碼:
Value pop() {
vm.stackTop--;
return *vm.stackTop;
}
First, we move the stack pointer back to get to the most recent used slot in the array. Then we look up the value at that index and return it. We don’t need to explicitly “remove” it from the array—moving
stackTopdown is enough to mark that slot as no longer in use.
首先,我們將棧指標回退到陣列中最近使用的槽。然後,我們查詢該索引處的值並將其返回。我們不需要顯式地將其從陣列中“移除”——將stackTop下移就足以將該槽標記為不再使用了。
15 . 2 . 2 Stack tracing
15.2.2 棧跟蹤
We have a working stack, but it’s hard to see that it’s working. When we start implementing more complex instructions and compiling and running larger pieces of code, we’ll end up with a lot of values crammed into that array. It would make our lives as VM hackers easier if we had some visibility into the stack.
我們有了一個工作的棧,但是很難看出它在工作。當我們開始實現更復雜的指令,編譯和執行更大的程式碼片段時,最終會在這個陣列中塞入很多值。如果我們對棧有一定的可見性,那麼作為虛擬機器開發者,我們就會更輕鬆。
To that end, whenever we’re tracing execution, we’ll also show the current contents of the stack before we interpret each instruction.
為此,每當我們追蹤執行情況時,我們也會在解釋每條指令之前展示棧中的當前內容。
vm.c,在 run()方法中新增程式碼:
#ifdef DEBUG_TRACE_EXECUTION
// 新增部分開始
printf(" ");
for (Value* slot = vm.stack; slot < vm.stackTop; slot++) {
printf("[ ");
printValue(*slot);
printf(" ]");
}
printf("\n");
// 新增部分結束
disassembleInstruction(vm.chunk,
We loop, printing each value in the array, starting at the first (bottom of the stack) and ending when we reach the top. This lets us observe the effect of each instruction on the stack. The output is pretty verbose, but it’s useful when we’re surgically extracting a nasty bug from the bowels of the interpreter.
我們迴圈列印陣列中的每個值,從第一個值開始(棧底),到棧頂結束。這樣我們可以觀察到每條指令對棧的影響。這個輸出會相當冗長,但是從我們在直譯器中遇到令人討厭的錯誤時,這就會很有用了。
Stack in hand, let’s revisit our two instructions. First up:
堆疊在手,讓我們重新審視一下目前的兩條指令。首先是:
vm.c,在 run()方法中替換兩行:
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
// 新增部分開始
push(constant);
// 新增部分結束
break;
In the last chapter, I was hand-wavey about how the
OP_CONSTANTinstruction “loads” a constant. Now that we have a stack you know what it means to actually produce a value: it gets pushed onto the stack.
在上一節中,我粗略介紹了OP_CONSTANT指令是如何“載入”一個常量的。現在我們有了一個堆疊,你就知道產生一個值實際上意味著什麼:將它壓入棧。
vm.c,在 run()方法中新增程式碼:
case OP_RETURN: {
// 新增部分開始
printValue(pop());
printf("\n");
// 新增部分結束
return INTERPRET_OK;
Then we make
OP_RETURNpop the stack and print the top value before exiting. When we add support for real functions to clox, we’ll change this code. But, for now, it gives us a way to get the VM executing simple instruction sequences and displaying the result.
接下來,我們讓OP_RETURN在退出之前彈出棧頂值並列印。等到我們在clox中新增對真正的函式的支援時,我們將會修改這段程式碼。但是,目前來看,我們可以使用這種方法讓VM執行簡單的指令序列並顯示結果。
15 . 3 An Arithmetic Calculator
15.3 數學計算器
The heart and soul of our VM are in place now. The bytecode loop dispatches and executes instructions. The stack grows and shrinks as values flow through it. The two halves work, but it’s hard to get a feel for how cleverly they interact with only the two rudimentary instructions we have so far. So let’s teach our interpreter to do arithmetic.
我們的虛擬機器的核心和靈魂現在都已經就位了。位元組碼迴圈分派和執行指令。棧堆隨著數值的流動而增長和收縮。這兩部分都在工作,但僅憑我們目前的兩條基本指令,很難感受到它們如何巧妙地互動。所以讓我們教直譯器如何做算術。
We’ll start with the simplest arithmetic operation, unary negation.
我們從最簡單的算術運算開始,即一元取負。
var a = 1.2;
print -a; // -1.2.
The prefix
-operator takes one operand, the value to negate. It produces a single result. We aren’t fussing with a parser yet, but we can add the bytecode instruction that the above syntax will compile to.
字首的-運算子接受一個運算元,也就是要取負的值。它只產生一個結果。我們還沒有對解析器進行處理,但可以新增上述語法編譯後對應的位元組碼指令。
chunk.h,在列舉 OpCode中新增程式碼:
OP_CONSTANT,
// 新增部分開始
OP_NEGATE,
// 新增部分結束
OP_RETURN,
We execute it like so:
我們這樣執行它:
vm.c,在 run()方法中新增程式碼:
}
// 新增部分開始
case OP_NEGATE: push(-pop()); break;
// 新增部分結束
case OP_RETURN: {
The instruction needs a value to operate on, which it gets by popping from the stack. It negates that, then pushes the result back on for later instructions to use. Doesn’t get much easier than that. We can disassemble it too.
該指令需要操作一個值,該值透過彈出棧獲得。它對該值取負,然後把結果重新壓入棧,以便後面的指令使用。沒有什麼比這更簡單的了。我們也可以對其反彙編:
debug.c,在 disassembleInstruction()方法中新增程式碼:
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
// 新增部分開始
case OP_NEGATE:
return simpleInstruction("OP_NEGATE", offset);
// 新增部分結束
case OP_RETURN:
And we can try it out in our test chunk.
我們可以在測試程式碼中試一試。
main.c,在 main()方法中新增程式碼:
writeChunk(&chunk, constant, 123);
// 新增部分開始
writeChunk(&chunk, OP_NEGATE, 123);
// 新增部分結束
writeChunk(&chunk, OP_RETURN, 123);
After loading the constant, but before returning, we execute the negate instruction. That replaces the constant on the stack with its negation. Then the return instruction prints that out:
在載入常量之後,返回之前,我們會執行取負指令。這條指令會將棧中的常量替換為其對應的負值。然後返回指令會打印出:
-1.2
Magical!
神奇!
15 . 3 . 1 Binary operators
15.3.1 二元運算子
OK, unary operators aren’t that impressive. We still only ever have a single value on the stack. To really see some depth, we need binary operators. Lox has four binary arithmetic operators: addition, subtraction, multiplication, and division. We’ll go ahead and implement them all at the same time.
好吧,一元運算子並沒有那麼令人印象深刻。我們的棧中仍然只有一個值。要真正看到一些深度,我們需要二元運算子。Lox中有四個二進位制算術運算子:加、減、乘、除。我們接下來會同時實現它們。
chunk.h,在列舉OpCode中新增程式碼:
OP_CONSTANT,
// 新增部分開始
OP_ADD,
OP_SUBTRACT,
OP_MULTIPLY,
OP_DIVIDE,
// 新增部分結束
OP_NEGATE,
Back in the bytecode loop, they are executed like this:
回到位元組碼迴圈中,它們是這樣執行的:
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_ADD: BINARY_OP(+); break;
case OP_SUBTRACT: BINARY_OP(-); break;
case OP_MULTIPLY: BINARY_OP(*); break;
case OP_DIVIDE: BINARY_OP(/); break;
// 新增部分結束
case OP_NEGATE: push(-pop()); break;
The only difference between these four instructions is which underlying C operator they ultimately use to combine the two operands. Surrounding that core arithmetic expression is some boilerplate code to pull values off the stack and push the result. When we later add dynamic typing, that boilerplate will grow. To avoid repeating that code four times, I wrapped it up in a macro.
這四條指令之間唯一的區別是,它們最終使用哪一個底層C運算子來組合兩個運算元。圍繞這個核心算術表示式的是一些模板程式碼,用於從棧中獲取數值,並將結果結果壓入棧中。等我們後面新增動態型別時,這些模板程式碼會增加。為了避免這些程式碼重複出現四次,我將它包裝在一個宏中。
vm.c,在 run()方法中新增程式碼:
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
// 新增部分開始
#define BINARY_OP(op) \
do { \
double b = pop(); \
double a = pop(); \
push(a op b); \
} while (false)
// 新增部分結束
for (;;) {
I admit this is a fairly adventurous use of the C preprocessor. I hesitated to do this, but you’ll be glad in later chapters when we need to add the type checking for each operand and stuff. It would be a chore to walk you through the same code four times.
我承認這是對C前處理器的一次相當大膽的使用11。我曾猶豫過要不要這麼做,但在後面的章節中,等到我們需要為每個運算元和其它內容新增型別檢查時,你就會高興的。如果把相同的程式碼遍歷四遍就太麻煩了。
If you aren’t familiar with the trick already, that outer
do whileloop probably looks really weird. This macro needs to expand to a series of statements. To be careful macro authors, we want to ensure those statements all end up in the same scope when the macro is expanded. Imagine if you defined:
如果你對這個技巧還不熟悉,那麼外層的do while迴圈可能看起來非常奇怪。這個宏需要擴充套件為一系列語句。作為一個謹慎的宏作者,我們要確保當宏展開時,這些語句都在同一個作用域內。想象一下,如果你定義了:
#define WAKE_UP() makeCoffee(); drinkCoffee();
And then used it like:
然後這樣使用它:
if (morning) WAKE_UP();
The intent is to execute both statements of the macro body only if
morningis true. But it expands to:
其本意是在morning為true時執行這兩個語句。但是宏展開結果為:
if (morning) makeCoffee(); drinkCoffee();;
Oops. The
ifattaches only to the first statement. You might think you could fix this using a block.
哎呀。if只關聯了第一條語句。您可能認為可以用程式碼塊解決這個問題。
#define WAKE_UP() { makeCoffee(); drinkCoffee(); }
That’s better, but you still risk:
這樣好一點,但還是有風險:
if (morning)
WAKE_UP();
else
sleepIn();
Now you get a compile error on the
elsebecause of that trailing;after the macro’s block. Using ado whileloop in the macro looks funny, but it gives you a way to contain multiple statements inside a block that also permits a semicolon at the end.
現在你會在else子句遇到編譯錯誤,因為在宏程式碼塊後面有個;。在宏中使用do while迴圈看起來很滑稽,但它提供了一種方法,可以在一個程式碼塊中包含多個語句,並且允許在末尾使用分號。
Where were we? Right, so what the body of that macro does is straightforward. A binary operator takes two operands, so it pops twice. It performs the operation on those two values and then pushes the result.
我們說到哪裡了?對了,這個宏的主體所做的事情很直接。一個二元運算子接受兩個運算元,因此會彈出棧兩次,對這兩個值執行操作,然後將結果壓入棧。
Pay close attention to the order of the two pops. Note that we assign the first popped operand to
b, nota. It looks backwards. When the operands themselves are calculated, the left is evaluated first, then the right. That means the left operand gets pushed before the right operand. So the right operand will be on top of the stack. Thus, the first value we pop isb.
請密切注意這兩次彈出棧的順序。注意,我們將第一個彈出的運算元賦值給b,而不是a。在對運算元求值時,先計算左運算元,再計算右運算元。這意味著左運算元會在右運算元之前被壓入棧,所以右側的運算元在棧頂。因此,我們彈出的第一個值屬於b。
For example, if we compile
3 - 1, the data flow between the instructions looks like so:
舉例來說,如果我們編譯3-1,指令之間的資料流看起來是這樣的:

As we did with the other macros inside
run(), we clean up after ourselves at the end of the function.
正如我們在run()內的其它宏中做的那樣,我們在函式結束時自行清理。
vm.c,在run()方法中新增程式碼:
#undef READ_CONSTANT
// 新增部分開始
#undef BINARY_OP
// 新增部分結束
}
Last is disassembler support.
最後是反彙編器的支援。
debug.c,在 disassembleInstruction()方法中新增程式碼:
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
// 新增部分開始
case OP_ADD:
return simpleInstruction("OP_ADD", offset);
case OP_SUBTRACT:
return simpleInstruction("OP_SUBTRACT", offset);
case OP_MULTIPLY:
return simpleInstruction("OP_MULTIPLY", offset);
case OP_DIVIDE:
return simpleInstruction("OP_DIVIDE", offset);
// 新增部分結束
case OP_NEGATE:
The arithmetic instruction formats are simple, like
OP_RETURN. Even though the arithmetic operators take operands—which are found on the stack—the arithmetic bytecode instructions do not.
算術指令的格式很簡單,類似於OP_RETURN。即使算術運算子需要運算元(從堆疊中獲取),算術的位元組碼指令也不需要。
Let’s put some of our new instructions through their paces by evaluating a larger expression:
我們透過計算一個更大的表示式來檢驗一些新指令。

Building on our existing example chunk, here’s the additional instructions we need to hand-compile that AST to bytecode.
在我們現有的示例程式碼塊基礎上,下面是我們將AST手動編譯為位元組碼後需要新增的指令。
main.c,在main()方法中新增程式碼:
int constant = addConstant(&chunk, 1.2);
writeChunk(&chunk, OP_CONSTANT, 123);
writeChunk(&chunk, constant, 123);
// 新增部分開始
constant = addConstant(&chunk, 3.4);
writeChunk(&chunk, OP_CONSTANT, 123);
writeChunk(&chunk, constant, 123);
writeChunk(&chunk, OP_ADD, 123);
constant = addConstant(&chunk, 5.6);
writeChunk(&chunk, OP_CONSTANT, 123);
writeChunk(&chunk, constant, 123);
writeChunk(&chunk, OP_DIVIDE, 123);
// 新增部分結束
writeChunk(&chunk, OP_NEGATE, 123);
writeChunk(&chunk, OP_RETURN, 123);
The addition goes first. The instruction for the left constant, 1.2, is already there, so we add another for 3.4. Then we add those two using
OP_ADD, leaving it on the stack. That covers the left side of the division. Next we push the 5.6, and divide the result of the addition by it. Finally, we negate the result of that.
首先進行加法運算。左邊的常數1.2的指令已經存在了,所以我們再加一條3.4的指令。然後我們用OP_ADD把這兩個值加起來,將結果壓入堆疊中。這樣就完成了除法的左運算元。接下來,我們壓入5.6,並用加法的結果除以它。最後,我們對結果取負。
Note how the output of the
OP_ADDimplicitly flows into being an operand ofOP_DIVIDEwithout either instruction being directly coupled to each other. That’s the magic of the stack. It lets us freely compose instructions without them needing any complexity or awareness of the data flow. The stack acts like a shared workspace that they all read from and write to.
注意,OP_ADD的輸出如何隱式地變成了OP_DIVIDE的一個運算元,而這兩條指令都沒有直接耦合在一起。這就是堆疊的魔力。他讓我們可以自由地編寫指令,而無需任何複雜性或對於資料流的感知。堆疊就像一個共享工作區,它們都可以從中讀取和寫入。
In this tiny example chunk, the stack still only gets two values tall, but when we start compiling Lox source to bytecode, we’ll have chunks that use much more of the stack. In the meantime, try playing around with this hand-authored chunk to calculate different nested arithmetic expressions and see how values flow through the instructions and stack.
在這個小示例中,堆疊仍然只有兩個值,但當我們開始將Lox原始碼編譯為位元組碼時,我們的程式碼塊將使用更多的堆疊。同時,你可以試著用這個手工編寫的位元組碼塊來計算不同的巢狀算術表示式,看看數值是如何在指令和棧中流動的。
You may as well get it out of your system now. This is the last chunk we’ll build by hand. When we next revisit bytecode, we will be writing a compiler to generate it for us.
你不妨現在就把這塊程式碼從系統中拿出來。這是我們手工構建的最後一個位元組碼塊。當我們下次使用位元組碼時,我們將編寫一個編譯器來生成。
CHALLENGES
習題
-
What bytecode instruction sequences would you generate for the following expressions:
你會為以下表達式生成什麼樣的位元組碼指令序列:
1 * 2 + 3 1 + 2 * 3 3 - 2 - 1 1 + 2 * 3 - 4 / -5(Remember that Lox does not have a syntax for negative number literals, so the
-5is negating the number 5.)(請記得,Lox語法中沒有負數字面量,所以
-5是對數字5取負) -
If we really wanted a minimal instruction set, we could eliminate either
OP_NEGATEorOP_SUBTRACT. Show the bytecode instruction sequence you would generate for:如果我們真的想要一個最小指令集,我們可以取消
OP_NEGATE或OP_SUBTRACT。請寫出你為下面的表示式生成的位元組碼指令序列:4 - 3 * -2First, without using
OP_NEGATE. Then, without usingOP_SUBTRACT.Given the above, do you think it makes sense to have both instructions? Why or why not? Are there any other redundant instructions you would consider including?
首先是不能使用
OP_NEGATE。然後,試一下不使用OP_SUBTRACT。綜上所述,你認為同時擁有這兩條指令有意義嗎?為什麼呢?還有沒有其它指令可以考慮加入?
-
Our VM’s stack has a fixed size, and we don’t check if pushing a value overflows it. This means the wrong series of instructions could cause our interpreter to crash or go into undefined behavior. Avoid that by dynamically growing the stack as needed.
What are the costs and benefits of doing so?
我們虛擬機器的堆疊有一個固定大小,而且我們不會檢查壓入一個值是否會溢位。這意味著錯誤的指令序列可能會導致我們的直譯器崩潰或進入未定義的行為。透過根據需求動態增長堆疊來避免這種情況。
這樣做的代價和好處是什麼?
-
To interpret
OP_NEGATE, we pop the operand, negate the value, and then push the result. That’s a simple implementation, but it increments and decrementsstackTopunnecessarily, since the stack ends up the same height in the end. It might be faster to simply negate the value in place on the stack and leavestackTopalone. Try that and see if you can measure a performance difference.Are there other instructions where you can do a similar optimization?
為瞭解釋
OP_NEGATE,我們彈出操作數,對值取負,然後將結果壓入棧。這是一個簡單的實現,但它對stackTop進行了不必要的增減操作,因為棧最終的高度是相同的。簡單地對棧中的值取負而不處理stackTop可能會更快。試一下,看看你是否能測出效能差異。是否有其它指令可以做類似的最佳化?
DESIGN NOTE: REGISTER-BASED BYTECODE
設計筆記:基於暫存器的位元組碼
For the remainder of this book, we’ll meticulously implement an interpreter around a stack-based bytecode instruction set. There’s another family of bytecode architectures out there—register-based. Despite the name, these bytecode instructions aren’t quite as difficult to work with as the registers in an actual chip like x64. With real hardware registers, you usually have only a handful for the entire program, so you spend a lot of effort trying to use them efficiently and shuttling stuff in and out of them.
In a register-based VM, you still have a stack. Temporary values still get pushed onto it and popped when no longer needed. The main difference is that instructions can read their inputs from anywhere in the stack and can store their outputs into specific stack slots.
Take this little Lox script:
var a = 1; var b = 2; var c = a + b;In our stack-based VM, the last statement will get compiled to something like:
load <a> // Read local variable a and push onto stack. load <b> // Read local variable b and push onto stack. add // Pop two values, add, push result. store <c> // Pop value and store in local variable c.(Don’t worry if you don’t fully understand the load and store instructions yet. We’ll go over them in much greater detail when we implement variables.) We have four separate instructions. That means four times through the bytecode interpret loop, four instructions to decode and dispatch. It’s at least seven bytes of code—four for the opcodes and another three for the operands identifying which locals to load and store. Three pushes and three pops. A lot of work!
In a register-based instruction set, instructions can read from and store directly into local variables. The bytecode for the last statement above looks like:
add <a> <b> <c> // Read values from a and b, add, store in c.The add instruction is bigger—it has three instruction operands that define where in the stack it reads its inputs from and writes the result to. But since local variables live on the stack, it can read directly from
aandband then store the result right intoc.There’s only a single instruction to decode and dispatch, and the whole thing fits in four bytes. Decoding is more complex because of the additional operands, but it’s still a net win. There’s no pushing and popping or other stack manipulation.
The main implementation of Lua used to be stack-based. For Lua 5.0, the implementers switched to a register instruction set and noted a speed improvement. The amount of improvement, naturally, depends heavily on the details of the language semantics, specific instruction set, and compiler sophistication, but that should get your attention.
The Lua dev team—Roberto Ierusalimschy, Waldemar Celes, and Luiz Henrique de Figueiredo—wrote a fantastic paper on this, one of my all time favorite computer science papers, “The Implementation of Lua 5.0” (PDF).
That raises the obvious question of why I’m going to spend the rest of the book doing a stack-based bytecode. Register VMs are neat, but they are quite a bit harder to write a compiler for. For what is likely to be your very first compiler, I wanted to stick with an instruction set that’s easy to generate and easy to execute. Stack-based bytecode is marvelously simple.
It’s also much better known in the literature and the community. Even though you may eventually move to something more advanced, it’s a good common ground to share with the rest of your language hacker peers.
在本書的其餘部分,我們將圍繞基於堆疊的位元組碼指令集精心實現一個直譯器。此外還有另一種位元組碼架構——基於暫存器。儘管名稱如此,但這些位元組碼指令並不像x64這樣的真實晶片中的暫存器那樣難以操作。對於真正的硬體暫存器,整個程式通常只用少數幾個,所以你要花很多精力來有效地使用它們,並把資料存入或取出。(基於暫存器的位元組碼更接近於SPARC晶片支援的暫存器視窗)
在一個基於暫存器的虛擬機器中,仍然有一個棧。臨時值還是被壓入棧中,當不再需要時再被彈出。主要的區別是,指令可以從棧的任意位置讀取它們的輸入值,並可以將它們的輸出值儲存到任一指定的槽中。
以Lox指令碼為例:
var a = 1;
var b = 2;
var c = a + b;
在我們基於堆疊的虛擬機器中,最後一條指令的編譯結果類似於:
load <a> // 讀取區域性變數a,並將其壓入棧
load <b> // 讀取區域性變數b,並將其壓入棧
add // 彈出兩個值,相加,將結果壓入棧
store <c> // 彈出值,並存入區域性變數c
(如果你還沒有完全理解載入load和儲存store指令,也不用擔心。我們會在實現變數時詳細地討論它們)我們有四條獨立的指令,這意味著會有四次位元組碼解釋迴圈,四條指令需要解碼和排程。這至少包含7個位元組的程式碼——四個位元組是操作碼,另外三個是運算元,用於標識要載入和儲存哪些區域性變數。三次入棧,三次出棧,工作量很大!
在基於暫存器的指令集中,指令可以直接對區域性變數進行讀取和儲存。上面最後一條語句的位元組碼如下所示:
add <a> <b> <c> // 從a和b中讀取值,相加,並儲存到c中
add指令比之前更大——有三個指令運算元,定義了從堆疊的哪個位置讀取輸入,並將結果寫入哪個位置。但由於區域性變數在堆疊中,它可以直接從a和b中讀取資料,如何將結果存入c中。
只有一條指令需要解碼和排程,整個程式只需要四個位元組。由於有了額外的運算元,解碼變得更加複雜,但相比之下它仍然是更優秀的。沒有壓入和彈出或其它堆疊操作。
Lua的實現曾經是基於堆疊的。到了Lua 5.0,實現切換到了暫存器指令集,並注意到速度有所提高。當然,提高的幅度很大程度上取決於語言語義的細節、特定指令集和編譯器複雜性,但這應該引起你的注意。
這就引出了一個顯而易見的問題:我為什麼要在本書的剩餘部分做一個基於堆疊的位元組碼。暫存器虛擬機器是很好的,但要為它們編寫編譯器卻相當困難。考慮到這可能是你寫的第一個編譯器,我想堅持使用一個易於生成和易於執行的指令集。基於堆疊的位元組碼是非常簡單的。
它的文獻和社群中也更廣為人知。即使你最終可能會轉向更高階的東西,這也是一個你可以與其他語言開發者分享的很好的共同點。
-
選擇使用靜態的VM例項是本書的一個讓步,但對於真正的語言實現來說,不一定是合理的工程選擇。如果你正在構建一個旨在嵌入其它主機應用程式中的虛擬機器,那麼如果你顯式地獲取一個VM指標並傳遞該指標,則會為主機提供更大的靈活性。這樣,主機應用程式就可以控制何時何地為虛擬機器分配記憶體,並行地執行多個虛擬機器,等等。我在這裡使用的是一個全域性變數,你所聽說過的關於全域性變數的一切壞訊息在大型程式設計中仍然是正確的。但是,當你想在一本書中保持程式碼簡潔時,就另當別論了。 ↩
-
如果我們想要在位元組碼直譯器中再壓榨出一點效能,我們可以將
ip儲存到一個區域性變數中。該值在執行過程中會被頻繁修改,所以我們希望C編譯器將其放在暫存器中。 ↩ -
x86、x64和CLR稱其為 "IP"。68k、PowerPC、ARM、p-code和JVM稱它為 "PC",意為程式計數器。 ↩
-
請注意,一旦我們讀取了操作碼,
ip就會推進了。所以,再次說一下,ip指向的是將要使用的操作碼的下一個位元組。 ↩ -
如果你想了解其中一些技術,可以搜尋“direct threaded code”、“jump table” 和 “computed goto”。 ↩
-
顯示地取消這些宏定義,可能會顯得毫無必要,但C語言往往會懲罰粗心的使用者,而C語言的前處理器更是如此。 ↩
-
我們可以不指定計算順序,讓每個語言實現自行決定。這就為最佳化編譯器重新排列算術表示式以提高效率留下了餘地,即使是在運算元有明顯副作用的情況下也是如此。C和Scheme沒有指定求值順序。Java規定了從左到右進行求值,就跟我們在Lox中所做的一樣。我認為指定這樣的內容通常對使用者更好。當表示式沒有按照使用者的直覺順序進行求值時——可能在不同的實現中會有不同的順序——要想弄清楚發生了什麼,可能是非常痛苦的。 ↩
-
堆——資料結構,不是記憶體管理——是另一個。還有Vaughan Pratt自頂向下的運算子優先順序解析方案,我們會在適當的時候學習。 ↩
-
稍微說明一下:基於堆疊的直譯器並不是銀彈。它們通常是夠用的,但是JVM、CLR和JavaScript的現代化實現中都使用了複雜的即時編譯管道,在動態中生成更快的原生代碼。 ↩
-
聰明的讀者,你可能會問,那如果棧滿了怎麼辦?C標準比您領先一步。C語言中允許陣列指標正好指向陣列末尾的下一個位置。 ↩
-
你之前知道可以把運算子作為引數傳遞給宏嗎?現在你知道了。前處理器並不關心運算子是不是C語言中的類,在它看來,這一切都只是文字符號。我知道,你已經感受到濫用前處理器的誘惑了,不是嗎? ↩
16.按需掃描 Scanning on Demand
Literature is idiosyncratic arrangements in horizontal lines in only twenty-six phonetic symbols, ten Arabic numbers, and about eight punctuation marks.
—— Kurt Vonnegut, Like Shaking Hands With God: A Conversation about Writing
文學就是26個字母、10個阿拉伯數字和大概8個標點符號的水平排列。(馮尼古特《像與上帝握手:關於寫作的談話》)
Our second interpreter, clox, has three phases—scanner, compiler, and virtual machine. A data structure joins each pair of phases. Tokens flow from scanner to compiler, and chunks of bytecode from compiler to VM. We began our implementation near the end with chunks and the VM. Now, we’re going to hop back to the beginning and build a scanner that makes tokens. In the next chapter, we’ll tie the two ends together with our bytecode compiler.
我們的第二個直譯器clox分為三個階段——掃描器、編譯器和虛擬機器。每兩個階段之間有一個資料結構進行銜接。詞法標識從掃描器流入編譯器,位元組碼塊從編譯器流向虛擬機器。我們是從尾部開始先實現了位元組碼塊和虛擬機器。現在,我們要回到起點,構建一個生成詞法標識的掃描器。在下一章中,我們將用位元組碼編譯器將這兩部分連線起來。

I’ll admit, this is not the most exciting chapter in the book. With two implementations of the same language, there’s bound to be some redundancy. I did sneak in a few interesting differences compared to jlox’s scanner. Read on to see what they are.
我承認,這並不是書中最精彩的一章。對於同一種語言的兩個實現,肯定會有一些冗餘。與jlox的掃描器相比,我確實添加了一些有趣的差異點。往下讀,看看它們是什麼。
16 . 1 Spinning Up the Interpreter
Now that we’re building the front end, we can get clox running like a real interpreter. No more hand-authored chunks of bytecode. It’s time for a REPL and script loading. Tear out most of the code in
main()and replace it with:
現在我們正在構建前端,我們可以讓clox像一個真正的直譯器一樣執行。不需要再手動編寫位元組碼塊。現在是時候實現REPL和指令碼載入了。刪除main()方法中的大部分程式碼,替換成:
main.c,在 main()方法中替換26行:
int main(int argc, const char* argv[]) {
initVM();
// 替換部分開始
if (argc == 1) {
repl();
} else if (argc == 2) {
runFile(argv[1]);
} else {
fprintf(stderr, "Usage: clox [path]\n");
exit(64);
}
freeVM();
// 替換部分結束
return 0;
}
If you pass no arguments to the executable, you are dropped into the REPL. A single command line argument is understood to be the path to a script to run.
如果你沒有向可執行檔案傳遞任何引數,就會進入REPL。如果傳入一個引數,就將其當做要執行的指令碼的路徑1。
We’ll need a few system headers, so let’s get them all out of the way.
我們需要一些系統標頭檔案,所以把它們都列出來。
main.c,在檔案頂部新增:
// 新增部分開始
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 新增部分結束
#include "common.h"
Next, we get the REPL up and REPL-ing.
接下來,我們啟動REPL並執行。
main.c,新增程式碼:
#include "vm.h"
// 新增部分開始
static void repl() {
char line[1024];
for (;;) {
printf("> ");
if (!fgets(line, sizeof(line), stdin)) {
printf("\n");
break;
}
interpret(line);
}
}
// 新增部分結束
A quality REPL handles input that spans multiple lines gracefully and doesn’t have a hardcoded line length limit. This REPL here is a little more, ahem, austere, but it’s fine for our purposes.
一個高質量的REPL可以優雅地處理多行的輸入,並且沒有硬編碼的行長度限制。這裡的REPL有點……簡樸,但足以滿足我們的需求。
The real work happens in
interpret(). We’ll get to that soon, but first let’s take care of loading scripts.
真正的工作發生在interpret()中。我們很快會講到這個問題,但首先讓我們來看看如何載入指令碼。
main.c,在repl()方法後新增:
// 新增部分開始
static void runFile(const char* path) {
char* source = readFile(path);
InterpretResult result = interpret(source);
free(source);
if (result == INTERPRET_COMPILE_ERROR) exit(65);
if (result == INTERPRET_RUNTIME_ERROR) exit(70);
}
// 新增部分結束
We read the file and execute the resulting string of Lox source code. Then, based on the result of that, we set the exit code appropriately because we’re scrupulous tool builders and care about little details like that.
我們讀取檔案並執行生成的Lox原始碼字串。然後,根據其結果,我們適當地設定退出碼,因為我們是嚴謹的工具製作者,並且關心這樣的小細節。
We also need to free the source code string because
readFile()dynamically allocates it and passes ownership to its caller. That function looks like this:
我們還需要釋放原始碼字串,因為readFile()會動態地分配記憶體,並將所有權傳遞給它的呼叫者2。這個函式看起來像這樣:
main.c,在 repl()方法後新增程式碼:
static char* readFile(const char* path) {
FILE* file = fopen(path, "rb");
fseek(file, 0L, SEEK_END);
size_t fileSize = ftell(file);
rewind(file);
char* buffer = (char*)malloc(fileSize + 1);
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
buffer[bytesRead] = '\0';
fclose(file);
return buffer;
}
Like a lot of C code, it takes more effort than it seems like it should, especially for a language expressly designed for operating systems. The difficult part is that we want to allocate a big enough string to read the whole file, but we don’t know how big the file is until we’ve read it.
像很多C語言程式碼一樣,它所花費的精力比看起來要多,尤其是對於一門專為作業系統而設計的語言而言。困難的地方在於,我們想分配一個足以讀取整個檔案的字串,但是我們在讀取檔案之前並不知道它有多大。
The code here is the classic trick to solve that. We open the file, but before reading it, we seek to the very end using
fseek(). Then we callftell()which tells us how many bytes we are from the start of the file. Since we seeked (sought?) to the end, that’s the size. We rewind back to the beginning, allocate a string of that size, and read the whole file in a single batch.
這裡的程式碼是解決這個問題的經典技巧。我們開啟檔案,但是在讀之前,先透過fseek()尋找到檔案的最末端。接下來我們呼叫ftell(),它會告訴我們裡檔案起始點有多少位元組。既然我們定位到了最末端,那它就是檔案大小3。我們退回到起始位置,分配一個相同大小的字串,然後一次性讀取整個檔案。
So we’re done, right? Not quite. These function calls, like most calls in the C standard library, can fail. If this were Java, the failures would be thrown as exceptions and automatically unwind the stack so we wouldn’t really need to handle them. In C, if we don’t check for them, they silently get ignored.
這樣就完成了嗎?不完全是。這些函式呼叫,像C語言標準庫中的大多數呼叫一樣,可能會失敗。如果是在Java中,這些失敗會被當做異常丟擲,並自動清除堆疊,所以我們實際上並不需要處理它們。但在C語言中,如果我們不檢查,它們就會被忽略。
This isn’t really a book on good C programming practice, but I hate to encourage bad style, so let’s go ahead and handle the errors. It’s good for us, like eating our vegetables or flossing.
這並不是一本關於良好C語言程式設計實踐的書,但我討厭鼓勵糟糕的程式設計風格,所以讓我們繼續處理這些錯誤。這對我們有好處,就像吃蔬菜或使用牙線清潔牙齒一樣。
Fortunately, we don’t need to do anything particularly clever if a failure occurs. If we can’t correctly read the user’s script, all we can really do is tell the user and exit the interpreter gracefully. First of all, we might fail to open the file.
幸運地是,如果發生故障,我們不需要特別聰明的做法。如果我們不能正確地讀取使用者的指令碼,我們真正能做的就是告訴使用者並優雅地退出直譯器。首先,我們可能無法開啟檔案。
main.c,在readFile()方法中新增程式碼:
FILE* file = fopen(path, "rb");
// 新增部分開始
if (file == NULL) {
fprintf(stderr, "Could not open file \"%s\".\n", path);
exit(74);
}
// 新增部分結束
fseek(file, 0L, SEEK_END);
This can happen if the file doesn’t exist or the user doesn’t have access to it. It’s pretty common—people mistype paths all the time.
如果檔案不存在或使用者沒有訪問許可權,就會發生這種情況。這是很常見的——人們經常會輸入錯誤的路徑。
This failure is much rarer:
下面這種錯誤要少見得多:
main.c,在readFile()方法中新增程式碼:
char* buffer = (char*)malloc(fileSize + 1);
// 新增部分開始
if (buffer == NULL) {
fprintf(stderr, "Not enough memory to read \"%s\".\n", path);
exit(74);
}
// 新增部分結束
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
If we can’t even allocate enough memory to read the Lox script, the user’s probably got bigger problems to worry about, but we should do our best to at least let them know.
如果我們甚至不能分配足夠的記憶體來讀取Lox指令碼,那麼使用者可能會有更大的問題需要擔心,但我們至少應該盡最大努力讓他們知道。
Finally, the read itself may fail.
最後,讀取本身可能會失敗。
main.c,在readFile()方法中新增程式碼:
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
// 新增部分開始
if (bytesRead < fileSize) {
fprintf(stderr, "Could not read file \"%s\".\n", path);
exit(74);
}
// 新增部分結束
buffer[bytesRead] = '\0';
This is also unlikely. Actually, the calls to
fseek(),ftell(), andrewind()could theoretically fail too, but let’s not go too far off in the weeds, shall we?
這也是不大可能發生的。實際上,fseek(), ftell(), 和rewind() 的呼叫在理論上也可能會失敗,但是我們不要太過深入,好嗎?
16 . 1 . 1 Opening the compilation pipeline
16.1.1 開啟編譯管道
We’ve got ourselves a string of Lox source code, so now we’re ready to set up a pipeline to scan, compile, and execute it. It’s driven by
interpret(). Right now, that function runs our old hardcoded test chunk. Let’s change it to something closer to its final incarnation.
我們已經得到了Lox原始碼字串,所以現在我們準備建立一個管道來掃描、編譯和執行它。管道是由interpret()驅動的。現在,該函式執行的是舊的硬編碼測試位元組碼塊。我們來把它改成更接近其最終形態的東西。
vm.h,函式interpret()中替換1行:
void freeVM();
// 替換部分開始
InterpretResult interpret(const char* source);
// 替換部分結束
void push(Value value);
Where before we passed in a Chunk, now we pass in the string of source code. Here’s the new implementation:
以前我們傳入一個位元組碼塊,現在我們傳入的是原始碼的字串。下面是新的實現:
vm.c,函式interpret()中替換4行:
// 替換部分開始
InterpretResult interpret(const char* source) {
compile(source);
return INTERPRET_OK;
// 替換部分結束
}
We won’t build the actual compiler yet in this chapter, but we can start laying out its structure. It lives in a new module.
在本章中,我們還不會構建真正的編譯器,但我們可以開始佈局它的結構。它存在於一個新的模組中。
vm.c,新增程式碼:
#include "common.h"
// 新增部分開始
#include "compiler.h"
// 新增部分結束
#include "debug.h"
For now, the one function in it is declared like so:
目前,其中有一個函式宣告如下:
compiler.h,建立新檔案:
#ifndef clox_compiler_h
#define clox_compiler_h
void compile(const char* source);
#endif
That signature will change, but it gets us going.
這個簽名以後會變,但現在足以讓我們繼續工作。
The first phase of compilation is scanning—the thing we’re doing in this chapter—so right now all the compiler does is set that up.
編譯的第一階段是掃描——即我們在本章中要做的事情——所以現在編譯器所做的就是設定掃描。
compiler.c,建立新檔案:
#include <stdio.h>
#include "common.h"
#include "compiler.h"
#include "scanner.h"
void compile(const char* source) {
initScanner(source);
}
This will also grow in later chapters, naturally.
當然,這在後面的章節中也會繼續擴充套件。
16 . 1 . 2 The scanner scans
16.1.2 掃描器掃描
There are still a few more feet of scaffolding to stand up before we can start writing useful code. First, a new header:
在我們開始編寫實際有用的程式碼之前,還有一些腳手架需要先搭建起來。首先,是一個新的標頭檔案:
scanner.h,建立新檔案:
#ifndef clox_scanner_h
#define clox_scanner_h
void initScanner(const char* source);
#endif
And its corresponding implementation:
還有其對應的實現:
scanner.c,建立新檔案:
#include <stdio.h>
#include <string.h>
#include "common.h"
#include "scanner.h"
typedef struct {
const char* start;
const char* current;
int line;
} Scanner;
Scanner scanner;
As our scanner chews through the user’s source code, it tracks how far it’s gone. Like we did with the VM, we wrap that state in a struct and then create a single top-level module variable of that type so we don’t have to pass it around all of the various functions.
當我們的掃描器一點點處理使用者的原始碼時,它會跟蹤自己已經走了多遠。就像我們在虛擬機器中所做的那樣,我們將狀態封裝在一個結構體中,然後建立一個該型別的頂層模組變數,這樣就不必在所有的函式之間傳遞它。
There are surprisingly few fields. The
startpointer marks the beginning of the current lexeme being scanned, andcurrentpoints to the current character being looked at.
這裡的欄位少得驚人。start指標標識正在被掃描的詞素的起點,而current指標指向當前正在檢視的字元。

We have a
linefield to track what line the current lexeme is on for error reporting. That’s it! We don’t even keep a pointer to the beginning of the source code string. The scanner works its way through the code once and is done after that.
我們還有一個line欄位,用於跟蹤當前詞素在哪一行,以便進行錯誤報告。就是這樣!我們甚至沒有保留指向原始碼字串起點的指標。掃描器只處理一遍程式碼,然後就結束了。
Since we have some state, we should initialize it.
因為我們有一些狀態,我們還應該初始化它。
scanner.c,在變數scanner後新增程式碼:
void initScanner(const char* source) {
scanner.start = source;
scanner.current = source;
scanner.line = 1;
}
We start at the very first character on the very first line, like a runner crouched at the starting line.
我們從第一行的第一個字元開始,就像一個運動員蹲在起跑線上。
16 . 2 A Token at a Time
16.2 一次一個標識
In jlox, when the starting gun went off, the scanner raced ahead and eagerly scanned the whole program, returning a list of tokens. This would be a challenge in clox. We’d need some sort of growable array or list to store the tokens in. We’d need to manage allocating and freeing the tokens, and the collection itself. That’s a lot of code, and a lot of memory churn.
在jlox中,當發令槍響起時,掃描器飛快地前進,急切地掃描整個程式,並返回一個詞法標識序列。這在clox中有點困難。我們需要某種可增長的陣列或列表來儲存標識。我們需要管理標識的分配和釋放,以及集合本身。這需要大量的程式碼和大量的記憶體。
At any point in time, the compiler needs only one or two tokens—remember our grammar requires only a single token of lookahead—so we don’t need to keep them all around at the same time. Instead, the simplest solution is to not scan a token until the compiler needs one. When the scanner provides one, it returns the token by value. It doesn’t need to dynamically allocate anything—it can just pass tokens around on the C stack.
在任何時間點,編譯器只需要一個或兩個詞法標識——記住我們的語法只需要前瞻一個詞法標識——所以我們不需要同時保留它們。相反,最簡單的解決方案是在編譯器需要標識的時候再去掃描。當掃描器提供一個標識時,它按值返回標識。它不需要動態分配任何東西——只需要在C棧上傳遞詞法標識即可。
Unfortunately, we don’t have a compiler yet that can ask the scanner for tokens, so the scanner will just sit there doing nothing. To kick it into action, we’ll write some temporary code to drive it.
不巧的是,我們還沒有可以向掃描器請求詞法標識的編譯器,所以掃描器只能乾等著什麼也不做。為了讓它工作起來,我們要編寫一些臨時程式碼來驅動它4。
compiler.c,在compile()方法中新增程式碼:
initScanner(source);
// 新增部分開始
int line = -1;
for (;;) {
Token token = scanToken();
if (token.line != line) {
printf("%4d ", token.line);
line = token.line;
} else {
printf(" | ");
}
printf("%2d '%.*s'\n", token.type, token.length, token.start);
if (token.type == TOKEN_EOF) break;
}
// 新增部分結束
}
This loops indefinitely. Each turn through the loop, it scans one token and prints it. When it reaches a special “end of file” token or an error, it stops. For example, if we run the interpreter on this program:
這個迴圈是無限的。每迴圈一次,它就會掃描一個詞法標識並打印出來。當它遇到特殊的“檔案結束”標識或錯誤時,就會停止。例如,如果我們對下面的程式執行直譯器:
print 1 + 2;
It prints out:
就會打印出:
1 31 'print'
| 21 '1'
| 7 '+'
| 21 '2'
| 8 ';'
2 39 ''
The first column is the line number, the second is the numeric value of the token type, and then finally the lexeme. That last empty lexeme on line 2 is the EOF token.
第一列是行號,第二列是標識型別的數值,最後是詞素。第2行中最後一個空詞素就是EOF標識。
The goal for the rest of the chapter is to make that blob of code work by implementing this key function:
本章其餘部分的目標就是透過實現下面這個關鍵函式,使這塊程式碼能正常工作:
scanner.h,在initScanner()方法後新增:
void initScanner(const char* source);
// 新增部分開始
Token scanToken();
// 新增部分結束
#endif
Each call scans and returns the next token in the source code. A token looks like this:
該函式的每次呼叫都會掃描並返回原始碼中的下一個詞法標識。一個詞法標識結構如下:
scanner.h,新增程式碼:
#define clox_scanner_h
// 新增部分開始
typedef struct {
TokenType type;
const char* start;
int length;
int line;
} Token;
// 新增部分結束
void initScanner(const char* source);
It’s pretty similar to jlox’s Token class. We have an enum identifying what type of token it is—number, identifier,
+operator, etc. The enum is virtually identical to the one in jlox, so let’s just hammer out the whole thing.
它和jlox中的Token類很相似。我們用一個列舉來標記它是什麼型別的詞法標識——數字、識別符號、+運算子等等。這個列舉與jlox中的列舉幾乎完全相同,所以我們直接來敲定整個事情。
scanner.h,新增程式碼:
#ifndef clox_scanner_h
#define clox_scanner_h
// 新增部分開始
typedef enum {
// Single-character tokens. 單字元詞法
TOKEN_LEFT_PAREN, TOKEN_RIGHT_PAREN,
TOKEN_LEFT_BRACE, TOKEN_RIGHT_BRACE,
TOKEN_COMMA, TOKEN_DOT, TOKEN_MINUS, TOKEN_PLUS,
TOKEN_SEMICOLON, TOKEN_SLASH, TOKEN_STAR,
// One or two character tokens. 一或兩字元詞法
TOKEN_BANG, TOKEN_BANG_EQUAL,
TOKEN_EQUAL, TOKEN_EQUAL_EQUAL,
TOKEN_GREATER, TOKEN_GREATER_EQUAL,
TOKEN_LESS, TOKEN_LESS_EQUAL,
// Literals. 字面量
TOKEN_IDENTIFIER, TOKEN_STRING, TOKEN_NUMBER,
// Keywords. 關鍵字
TOKEN_AND, TOKEN_CLASS, TOKEN_ELSE, TOKEN_FALSE,
TOKEN_FOR, TOKEN_FUN, TOKEN_IF, TOKEN_NIL, TOKEN_OR,
TOKEN_PRINT, TOKEN_RETURN, TOKEN_SUPER, TOKEN_THIS,
TOKEN_TRUE, TOKEN_VAR, TOKEN_WHILE,
TOKEN_ERROR, TOKEN_EOF
} TokenType;
// 新增部分結束
typedef struct {
Aside from prefixing all the names with
TOKEN_(since C tosses enum names in the top-level namespace) the only difference is that extraTOKEN_ERRORtype. What’s that about?
除了在所有名稱前都加上TOKEN_字首(因為C語言會將列舉名稱拋出到頂層名稱空間)之外,唯一的區別就是多了一個TOKEN_ERROR型別。那是什麼呢?
There are only a couple of errors that get detected during scanning: unterminated strings and unrecognized characters. In jlox, the scanner reports those itself. In clox, the scanner produces a synthetic “error” token for that error and passes it over to the compiler. This way, the compiler knows an error occurred and can kick off error recovery before reporting it.
在掃描過程中只會檢測到幾種錯誤:未終止的字串和無法識別的字元。在jlox中,掃描器會自己報告這些錯誤。在clox中,掃描器會針對這些錯誤生成一個合成的“錯誤”標識,並將其傳遞給編譯器。這樣一來,編譯器就知道發生了一個錯誤,並可以在報告錯誤之前啟動錯誤恢復。
The novel part in clox’s Token type is how it represents the lexeme. In jlox, each Token stored the lexeme as its own separate little Java string. If we did that for clox, we’d have to figure out how to manage the memory for those strings. That’s especially hard since we pass tokens by value—multiple tokens could point to the same lexeme string. Ownership gets weird.
在clox的Token型別中,新穎之處在於它如何表示一個詞素。在jlox中,每個Token將詞素儲存到其單獨的Java字串中。如果我們在clox中也這樣做,我們就必須想辦法管理這些字串的記憶體。這非常困難,因為我們是透過值傳遞詞法標識的——多個標識可能指向相同的詞素字串。所有權會變得混亂。
Instead, we use the original source string as our character store. We represent a lexeme by a pointer to its first character and the number of characters it contains. This means we don’t need to worry about managing memory for lexemes at all and we can freely copy tokens around. As long as the main source code string outlives all of the tokens, everything works fine.
相反,我們將原始的原始碼字串作為我們的字元儲存。我們用指向第一個字元的指標和其中包含的字元數來表示一個詞素。這意味著我們完全不需要擔心管理詞素的記憶體,而且我們可以自由地複製詞法標識。只要主原始碼字串的壽命超過所有詞法標識,一切都可以正常工作5。
16 . 2 . 1 Scanning tokens
16.2.1 掃描標識
We’re ready to scan some tokens. We’ll work our way up to the complete implementation, starting with this:
我們已經準備好掃描一些標識了。我們將從下面的程式碼開始,逐步達成完整的實現:
scanner.c,在initScanner()方法後新增程式碼:
Token scanToken() {
scanner.start = scanner.current;
if (isAtEnd()) return makeToken(TOKEN_EOF);
return errorToken("Unexpected character.");
}
Since each call to this function scans a complete token, we know we are at the beginning of a new token when we enter the function. Thus, we set
scanner.startto point to the current character so we remember where the lexeme we’re about to scan starts.
由於對該函式的每次呼叫都會掃描一個完整的詞法標識,所以當我們進入該函式時,就知道我們正處於一個新詞法標識的開始處。因此,我們將scanner.start設定為指向當前字元,這樣我們就能記住我們將要掃描的詞素的開始位置。
Then we check to see if we’ve reached the end of the source code. If so, we return an EOF token and stop. This is a sentinel value that signals to the compiler to stop asking for more tokens.
然後檢查是否已達到原始碼的結尾。如果是,我們返回一個EOF標識並停止。這是一個標記值,它向編譯器發出訊號,停止請求更多標記。
If we aren’t at the end, we do some . . . stuff . . . to scan the next token. But we haven’t written that code yet. We’ll get to that soon. If that code doesn’t successfully scan and return a token, then we reach the end of the function. That must mean we’re at a character that the scanner can’t recognize, so we return an error token for that.
如果我們沒有達到結尾,我們會做一些……事情……來掃描下一個標識。但我們還沒有寫這些程式碼。我們很快就會講到。如果這段程式碼沒有成功掃描並返回一個詞法標識,那麼我們就到達了函式的終點。這肯定意味著我們遇到了一個掃描器無法識別的字元,所以我們為此返回一個錯誤標識。
This function relies on a couple of helpers, most of which are familiar from jlox. First up:
這個函式依賴於幾個輔助函式,其中大部分都是在jlox中已熟悉的。首先是:
scanner.c,在initScanner()方法後新增程式碼:
static bool isAtEnd() {
return *scanner.current == '\0';
}
We require the source string to be a good null-terminated C string. If the current character is the null byte, then we’ve reached the end.
我們要求源字串是一個良好的以null結尾的C字串。如果當前字元是null位元組,那我們就到達了終點。
To create a token, we have this constructor-like function:
要建立一個標識,我們還需要這個類似於建構函式的函式:
scanner.c,在isAtEnd()方法後新增程式碼:
static Token makeToken(TokenType type) {
Token token;
token.type = type;
token.start = scanner.start;
token.length = (int)(scanner.current - scanner.start);
token.line = scanner.line;
return token;
}
It uses the scanner’s
startandcurrentpointers to capture the token’s lexeme. It sets a couple of other obvious fields then returns the token. It has a sister function for returning error tokens.
其中使用掃描器的start和current指標來捕獲標識的詞素。它還設定了其它幾個明顯的欄位,如何返回標識。它還有一個用於返回錯誤標識的姊妹函式。
scanner.c,在makeToken()方法後新增程式碼:
static Token errorToken(const char* message) {
Token token;
token.type = TOKEN_ERROR;
token.start = message;
token.length = (int)strlen(message);
token.line = scanner.line;
return token;
}
The only difference is that the “lexeme” points to the error message string instead of pointing into the user’s source code. Again, we need to ensure that the error message sticks around long enough for the compiler to read it. In practice, we only ever call this function with C string literals. Those are constant and eternal, so we’re fine.
唯一的區別在於,“詞素”指向錯誤資訊字串而不是使用者的原始碼。同樣,我們需要確保錯誤資訊能保持足夠長的時間,以便編譯器能夠讀取它。在實踐中,我們只會用C語言的字串字面量來呼叫這個函式。它們是恆定不變的,所以我們不會有問題。
What we have now is basically a working scanner for a language with an empty lexical grammar. Since the grammar has no productions, every character is an error. That’s not exactly a fun language to program in, so let’s fill in the rules.
我們現在所擁有的是一個基本可用的掃描器,用於掃描空語法語言。因為語法沒有產生式,所以每個字元都是一個錯誤。這並不是一種有趣的程式語言,所以讓我們把規則填進去。
16 . 3 A Lexical Grammar for Lox
16.3 Lox語法
The simplest tokens are only a single character. We recognize those like so:
最簡單的詞法標識只有一個字元。我們這樣來識別它們:
scanner.c,在scanToken()方法中新增程式碼:
if (isAtEnd()) return makeToken(TOKEN_EOF);
// 新增部分開始
char c = advance();
switch (c) {
case '(': return makeToken(TOKEN_LEFT_PAREN);
case ')': return makeToken(TOKEN_RIGHT_PAREN);
case '{': return makeToken(TOKEN_LEFT_BRACE);
case '}': return makeToken(TOKEN_RIGHT_BRACE);
case ';': return makeToken(TOKEN_SEMICOLON);
case ',': return makeToken(TOKEN_COMMA);
case '.': return makeToken(TOKEN_DOT);
case '-': return makeToken(TOKEN_MINUS);
case '+': return makeToken(TOKEN_PLUS);
case '/': return makeToken(TOKEN_SLASH);
case '*': return makeToken(TOKEN_STAR);
}
// 新增部分結束
return errorToken("Unexpected character.");
We read the next character from the source code, and then do a straightforward switch to see if it matches any of Lox’s one-character lexemes. To read the next character, we use a new helper which consumes the current character and returns it.
我們從原始碼中讀取下一個字元,然後做一個簡單的switch判斷,看它是否與Lox中的某個單字元詞素相匹配。為了讀取下一個字元,我們使用一個新的輔助函式,它會消費當前字元並將其返回。
scanner.c,在isAtEnd()方法後新增程式碼:
static char advance() {
scanner.current++;
return scanner.current[-1];
}
Next up are the two-character punctuation tokens like
!=and>=. Each of these also has a corresponding single-character token. That means that when we see a character like!, we don’t know if we’re in a!token or a!=until we look at the next character too. We handle those like so:
接下來是兩個字元的符號,如!=和>=,其中每一個都包含對應的單字元標識。這意味著,當我們看到一個像!這樣的字元時,我們只有看到下一個字元,才能確認當前是!標識還是!=標識。我們是這樣處理的:
scanner.c in scanToken()
case '*': return makeToken(TOKEN_STAR);
// 新增部分開始
case '!':
return makeToken(
match('=') ? TOKEN_BANG_EQUAL : TOKEN_BANG);
case '=':
return makeToken(
match('=') ? TOKEN_EQUAL_EQUAL : TOKEN_EQUAL);
case '<':
return makeToken(
match('=') ? TOKEN_LESS_EQUAL : TOKEN_LESS);
case '>':
return makeToken(
match('=') ? TOKEN_GREATER_EQUAL : TOKEN_GREATER);
// 新增部分結束
}
After consuming the first character, we look for an
=. If found, we consume it and return the corresponding two-character token. Otherwise, we leave the current character alone (so it can be part of the next token) and return the appropriate one-character token.
在消費第一個字元之後,我們會嘗試尋找一個=。如果找到了,我們就消費它並返回對應的雙字元標識。否則,我們就不處理當前字元(這樣它就是下一個標識的一部分)並返回相應的單字元標識。
That logic for conditionally consuming the second character lives here:
這個有條件地消費第二個字元的邏輯如下:
scanner.c,在advance()方法後新增:
static bool match(char expected) {
if (isAtEnd()) return false;
if (*scanner.current != expected) return false;
scanner.current++;
return true;
}
If the current character is the desired one, we advance and return
true. Otherwise, we returnfalseto indicate it wasn’t matched.
如果當前字元是所需的字元,則指標前進並返回true。否則,我們返回false表示沒有匹配。
Now our scanner supports all of the punctuation-like tokens. Before we get to the longer ones, let’s take a little side trip to handle characters that aren’t part of a token at all.
現在我們的掃描器支援所有類似標點符號的標識。在我們處理更長的字元之前,我們先來處理一下那些根本不屬於標識的字元。
16 . 3 . 1 Whitespace
16.3.1 空白字元
Our scanner needs to handle spaces, tabs, and newlines, but those characters don’t become part of any token’s lexeme. We could check for those inside the main character switch in
scanToken()but it gets a little tricky to ensure that the function still correctly finds the next token after the whitespace when you call it. We’d have to wrap the whole body of the function in a loop or something.
我們的掃描器需要處理空格、製表符和換行符,但是這些字元不會成為任何標識詞素的一部分。我們可以在scanToken()中的主要的字元switch語句中檢查這些字元,但要想確保當你呼叫該函式時,它仍然能正確地找到空白字元後的下一個標識,這就有點棘手了。我們必須將整個函式封裝在一個迴圈或其它東西中。
Instead, before starting the token, we shunt off to a separate function.
相應地,在開始掃描標識之前,我們切換到一個單獨的函式。
scanner.c,在scanToken()方法中新增程式碼:
Token scanToken() {
// 新增部分開始
skipWhitespace();
// 新增部分結束
scanner.start = scanner.current;
This advances the scanner past any leading whitespace. After this call returns, we know the very next character is a meaningful one (or we’re at the end of the source code).
這將使掃描器跳過所有的前置空白字元。在這個呼叫返回後,我們知道下一個字元是一個有意義的字元(或者我們到達了原始碼的末尾)。
scanner.c,在errorToken()方法後新增:
static void skipWhitespace() {
for (;;) {
char c = peek();
switch (c) {
case ' ':
case '\r':
case '\t':
advance();
break;
default:
return;
}
}
}
It’s sort of a separate mini-scanner. It loops, consuming every whitespace character it encounters. We need to be careful that it does not consume any non-whitespace characters. To support that, we use this:
這有點像一個獨立的微型掃描器。它迴圈,消費遇到的每一個空白字元。我們需要注意的是,它不會消耗任何非空白字元。為了支援這一點,我們使用下面的函式:
scanner.c,在 advance()方法後新增程式碼:
static char peek() {
return *scanner.current;
}
This simply returns the current character, but doesn’t consume it. The previous code handles all the whitespace characters except for newlines.
這只是簡單地返回當前字元,但並不消費它。前面的程式碼已經處理了除換行符外的所有空白字元。
scanner.c,在skipWhitespace()方法內新增程式碼:
break;
// 新增部分開始
case '\n':
scanner.line++;
advance();
break;
// 新增部分結束
default:
return;
When we consume one of those, we also bump the current line number.
當我們消費換行符時,也會增加當前行數。
16 . 3 . 2 Comments
16.3.2 註釋
Comments aren’t technically “whitespace”, if you want to get all precise with your terminology, but as far as Lox is concerned, they may as well be, so we skip those too.
如果你想用精確的術語,那註釋在技術上來說不是“空白字元”,但就Lox目前而言,它們也可以是,所以我們也跳過它們。
scanner.c,在skipWhitespace()函式內新增程式碼:
break;
// 新增部分開始
case '/':
if (peekNext() == '/') {
// A comment goes until the end of the line.
while (peek() != '\n' && !isAtEnd()) advance();
} else {
return;
}
break;
// 新增部分結束
default:
return;
Comments start with
//in Lox, so as with!=and friends, we need a second character of lookahead. However, with!=, we still wanted to consume the!even if the=wasn’t found. Comments are different. If we don’t find a second/, thenskipWhitespace()needs to not consume the first slash either.
Lox中的註釋以//開頭,因此與!=類似,我們需要前瞻第二個字元。然而,在處理!=時,即使沒有找到=,也仍然希望消費!。註釋是不同的。如果我們沒有找到第二個/,那麼skipWhitespace()也不需要消費第一個斜槓。
To handle that, we add:
為此,我們新增以下函式:
scanner.c,在peek()方法後新增程式碼:
static char peekNext() {
if (isAtEnd()) return '\0';
return scanner.current[1];
}
This is like
peek()but for one character past the current one. If the current character and the next one are both/, we consume them and then any other characters until the next newline or the end of the source code.
這就像peek()一樣,但是是針對當前字元之後的一個字元。如果當前字元和下一個字元都是/,則消費它們,然後再消費其它字元,直到遇見下一個換行符或原始碼結束。
We use
peek()to check for the newline but not consume it. That way, the newline will be the current character on the next turn of the outer loop inskipWhitespace()and we’ll recognize it and incrementscanner.line.
我們使用peek()來檢查換行符,但是不消費它。這樣一來,換行符將成為skipWhitespace()外部下一輪迴圈中的當前字元,我們就能識別它並增加scanner.line。
16 . 3 . 3 Literal tokens
16.3.3 字面量標識
Number and string tokens are special because they have a runtime value associated with them. We’ll start with strings because they are easy to recognize—they always begin with a double quote.
數字和字串標識比較特殊,因為它們有一個與之關聯的執行時值。我們會從字串開始,因為它們很容易識別——總是以雙引號開始。
scanner.c,在 scanToken()方法中新增程式碼:
match('=') ? TOKEN_GREATER_EQUAL : TOKEN_GREATER);
// 新增部分開始
case '"': return string();
// 新增部分結束
}
That calls a new function.
它會呼叫一個新函式:
scanner.c,在 skipWhitespace()方法後新增程式碼:
static Token string() {
while (peek() != '"' && !isAtEnd()) {
if (peek() == '\n') scanner.line++;
advance();
}
if (isAtEnd()) return errorToken("Unterminated string.");
// The closing quote.
advance();
return makeToken(TOKEN_STRING);
}
Similar to jlox, we consume characters until we reach the closing quote. We also track newlines inside the string literal. (Lox supports multi-line strings.) And, as ever, we gracefully handle running out of source code before we find the end quote.
與jlox類似,我們消費字元,直到遇見右引號。我們也會追蹤字串字面量中的換行符(Lox支援多行字串)。並且,與之前一樣,我們會優雅地處理在找到結束引號之前原始碼耗盡的問題。
The main change here in clox is something that’s not present. Again, it relates to memory management. In jlox, the Token class had a field of type Object to store the runtime value converted from the literal token’s lexeme.
clox中的主要變化是一些不存在的東西。同樣,這與記憶體管理有關。在jlox中,Token類有一個Object型別的欄位,用於儲存從字面量詞素轉換而來的執行時值。
Implementing that in C would require a lot of work. We’d need some sort of union and type tag to tell whether the token contains a string or double value. If it’s a string, we’d need to manage the memory for the string’s character array somehow.
在C語言中實現這一點需要大量的工作。我們需要某種union和type標籤來告訴我們標識中是否包含字串或浮點數。如果是字串,我們還需要以某種方式管理字串中字元陣列的記憶體。
Instead of adding that complexity to the scanner, we defer converting the literal lexeme to a runtime value until later. In clox, tokens only store the lexeme—the character sequence exactly as it appears in the user’s source code. Later in the compiler, we’ll convert that lexeme to a runtime value right when we are ready to store it in the chunk’s constant table.
我們沒有給掃描器增加這種複雜性,我們把字面量詞素轉換為執行值的工作推遲到以後。在clox中,詞法標識只儲存詞素——即使用者原始碼中出現的字元序列。稍後在編譯器中,當我們準備將其儲存在位元組碼塊中的常量表中時,我們會將詞素轉換為執行時值6。
Next up, numbers. Instead of adding a switch case for each of the ten digits that can start a number, we handle them here:
接下來是數字。我們沒有為可能作為數字開頭的10個數位各新增對應的switch分支,而是使用如下方式處理:
scanner.c,在scanToken()方法中新增程式碼:
char c = advance();
// 新增部分開始
if (isDigit(c)) return number();
// 新增部分結束
switch (c) {
That uses this obvious utility function:
這裡使用了下面這個明顯的工具函式:
scanner.c,在initScanner()方法後新增程式碼:
static bool isDigit(char c) {
return c >= '0' && c <= '9';
}
We finish scanning the number using this:
我們使用下面的函式完成掃描數字的工作:
scanner.c,在skipWhitespace()方法後新增程式碼:
static Token number() {
while (isDigit(peek())) advance();
// Look for a fractional part.
if (peek() == '.' && isDigit(peekNext())) {
// Consume the ".".
advance();
while (isDigit(peek())) advance();
}
return makeToken(TOKEN_NUMBER);
}
It’s virtually identical to jlox’s version except, again, we don’t convert the lexeme to a double yet.
它與jlox版本幾乎是相同的,只是我們還沒有將詞素轉換為浮點數。
16 . 4 Identifiers and Keywords
16.4 識別符號和關鍵字
The last batch of tokens are identifiers, both user-defined and reserved. This section should be fun—the way we recognize keywords in clox is quite different from how we did it in jlox, and touches on some important data structures.
最後一批詞法是識別符號,包括使用者定義的和保留字。這一部分應該很有趣——我們在clox中識別關鍵字的方式與我們在jlox中的方式完全不同,而且涉及到一些重要的資料結構。
First, though, we have to scan the lexeme. Names start with a letter or underscore.
不過,首先我們需要掃描詞素。名稱以字母或下劃線開頭。
scanner.c,在scanToken()方法中新增程式碼:
char c = advance();
// 新增部分開始
if (isAlpha(c)) return identifier();
// 新增部分結束
if (isDigit(c)) return number();
We recognize those using this:
我們使用這個方法識別這些識別符號:
scanner.c,在initScanner()方法後新增程式碼:
static bool isAlpha(char c) {
return (c >= 'a' && c <= 'z') ||
(c >= 'A' && c <= 'Z') ||
c == '_';
}
Once we’ve found an identifier, we scan the rest of it here:
一旦我們發現一個識別符號,我們就透過下面的方法掃描其餘部分:
scanner.c,在skipWhitespace()方法後新增程式碼:
static Token identifier() {
while (isAlpha(peek()) || isDigit(peek())) advance();
return makeToken(identifierType());
}
After the first letter, we allow digits too, and we keep consuming alphanumerics until we run out of them. Then we produce a token with the proper type. Determining that “proper” type is the unique part of this chapter.
在第一個字母之後,我們也允許使用數字,並且我們會一直消費字母數字,直到消費完為止。然後我們生成一個具有適當型別的詞法標識。確定“適當”型別是本章的特點部分。
scanner.c,在skipWhitespace()方法後新增程式碼:
static TokenType identifierType() {
return TOKEN_IDENTIFIER;
}
Okay, I guess that’s not very exciting yet. That’s what it looks like if we have no reserved words at all. How should we go about recognizing keywords? In jlox, we stuffed them all in a Java Map and looked them up by name. We don’t have any sort of hash table structure in clox, at least not yet.
好吧,我想這還不算很令人興奮。如果我們沒有保留字,那就是這個樣子了。我們應該如何去識別關鍵字呢?在jlox中,我們將其都塞入一個Java Map中,然後按名稱查詢它們。在clox中,我們沒有任何型別的雜湊表結構,至少現在還沒有。
A hash table would be overkill anyway. To look up a string in a hash table, we need to walk the string to calculate its hash code, find the corresponding bucket in the hash table, and then do a character-by-character equality comparison on any string it happens to find there.
無論如何,雜湊表都是冗餘的。要在雜湊表中查詢一個字串,我們需要遍歷該字串以計算其雜湊碼,在雜湊表中找到對應的桶,然後對其中的所有字串逐個字元進行相等比較7。
Let’s say we’ve scanned the identifier “gorgonzola”. How much work should we need to do to tell if that’s a reserved word? Well, no Lox keyword starts with “g”, so looking at the first character is enough to definitively answer no. That’s a lot simpler than a hash table lookup.
假定我們已經掃描到了識別符號“gorgonzola”。我們需要做多少工作來判斷這是否是一個保留字?好吧,沒有Lox關鍵字是以“g”開頭的,所以看第一個字元就足以明確地回答不是。這比雜湊表查詢要簡單的多。
What about “cardigan”? We do have a keyword in Lox that starts with “c”: “class”. But the second character in “cardigan”, “a”, rules that out. What about “forest”? Since “for” is a keyword, we have to go farther in the string before we can establish that we don’t have a reserved word. But, in most cases, only a character or two is enough to tell we’ve got a user-defined name on our hands. We should be able to recognize that and fail fast.
那“cardigan”呢?我們在Lox中確實有一個以“c”開頭的關鍵字:“class”。但是“cardigan”中的第二個字元“a”就排除了這種情況。那“forest”呢?因為“for”是一個關鍵字,我們必須在字串中繼續遍歷,才能確定這不是一個保留字。但是,在大多數情況下,只有一兩個字元就足以告訴我們現在處理的是一個使用者定義的名稱。我們應該能夠意識到這一點,並快速失敗。
Here’s a visual representation of that branching character-inspection logic:
下面是這個分支字元檢查邏輯的一個視覺化表示8:

We start at the root node. If there is a child node whose letter matches the first character in the lexeme, we move to that node. Then repeat for the next letter in the lexeme and so on. If at any point the next letter in the lexeme doesn’t match a child node, then the identifier must not be a keyword and we stop. If we reach a double-lined box, and we’re at the last character of the lexeme, then we found a keyword.
我們從根節點開始。如果有一個子節點的字母與詞素中的第一個字元相匹配,我們就移動到該節點上。然後對詞素中的下一個字母重複此操作,以此類推。如果在任意節點上,詞素的下一個字元沒有匹配到子節點,那麼該識別符號一定不是一個關鍵字,我們就停止。如果我們到達了一個雙線框,並且我們在詞素的最後一個字元處,那麼我們就找到了一個關鍵字。
16 . 4 . 1 Tries and state machines
16.4.1 字典樹和狀態機
This tree diagram is an example of a thing called a trie. A trie stores a set of strings. Most other data structures for storing strings contain the raw character arrays and then wrap them inside some larger construct that helps you search faster. A trie is different. Nowhere in the trie will you find a whole string.
這個樹狀圖是trie9(字典樹)的一個例子。字典樹會儲存一組字串。大多數其它用於儲存字串的資料結構都包含原始字元陣列,然後將它們封裝在一些更大的結果中,以幫助你更快地搜尋。字典樹則不同,在其中你找不到一個完整的字串。
Instead, each string the trie “contains” is represented as a path through the tree of character nodes, as in our traversal above. Nodes that match the last character in a string have a special marker—the double lined boxes in the illustration. That way, if your trie contains, say, “banquet” and “ban”, you are able to tell that it does not contain “banque”—the “e” node won’t have that marker, while the “n” and “t” nodes will.
相應地,字典樹中“包含”的每個字串被表示為透過字元樹中節點的路徑,就像上面的遍歷一樣。用於匹配字串中最後一個字元的節點中有一個特殊的標記——插圖中的雙線框。這樣一來,假定你的字典樹中包含“banquet”和“ban”,你就能知道它不包括“banque”——“e”節點沒有這個標記,而“n”和“t”節點中有。
Tries are a special case of an even more fundamental data structure: a deterministic finite automaton (DFA). You might also know these by other names: finite state machine, or just state machine. State machines are rad. They end up useful in everything from game programming to implementing networking protocols.
字典樹是一種更基本的資料結構的特殊情況:確定性有限狀態機(deterministic finite automaton ,DFA)。你可能還知道它的其它名字:有限狀態機,或就叫狀態機。狀態機是非常重要的,從遊戲程式設計到實現網路協議的一切方面都很有用。
In a DFA, you have a set of states with transitions between them, forming a graph. At any point in time, the machine is “in” exactly one state. It gets to other states by following transitions. When you use a DFA for lexical analysis, each transition is a character that gets matched from the string. Each state represents a set of allowed characters.
在DFA中,你有一組狀態,它們之間有轉換,形成一個圖。在任何時間點,機器都“處於”其中一個狀態。它透過轉換過渡到其它狀態。當你使用DFA進行詞法分析時,每個轉換都是從字串中匹配到的一個字元。每個狀態代表一組允許的字元。
Our keyword tree is exactly a DFA that recognizes Lox keywords. But DFAs are more powerful than simple trees because they can be arbitrary graphs. Transitions can form cycles between states. That lets you recognize arbitrarily long strings. For example, here’s a DFA that recognizes number literals:
我們的關鍵字樹正是一個能夠識別Lox關鍵字的DFA。但是DFA比簡單的樹更強大,因為它們可以是任意的圖。轉換可以在狀態之間形成迴圈。這讓你可以識別任意長的字串。舉例來說,下面是一個可以識別數字字面量的DFA10:

I’ve collapsed the nodes for the ten digits together to keep it more readable, but the basic process works the same—you work through the path, entering nodes whenever you consume a corresponding character in the lexeme. If we were so inclined, we could construct one big giant DFA that does all of the lexical analysis for Lox, a single state machine that recognizes and spits out all of the tokens we need.
我把十個數位的節點摺疊在一起,以使其更易於閱讀,但是基本的過程是相同的——遍歷路徑,每當你消費詞素中的一個字元,就進入對應節點。如果我們願意的話,可以構建一個巨大的DFA來完成Lox的所有詞法分析,用一個狀態機來識別並輸出我們需要的所有詞法標識。
However, crafting that mega-DFA by hand would be challenging. That’s why Lex was created. You give it a simple textual description of your lexical grammar—a bunch of regular expressions—and it automatically generates a DFA for you and produces a pile of C code that implements it.
然而,手工完成這種巨型DFA是一個巨大的挑戰。這就是Lex誕生的原因。你給它一個關於語法的簡單文字描述——一堆正規表示式——它就會自動為你生成一個DFA,並生成一堆實現它的C程式碼11。
This is also how most regular expression engines in programming languages and text editors work under the hood. They take your regex string and convert it to a DFA, which they then use to match strings.
If you want to learn the algorithm to convert a regular expression into a DFA, the dragon book has you covered.
We won’t go down that road. We already have a perfectly serviceable hand-rolled scanner. We just need a tiny trie for recognizing keywords. How should we map that to code?
我們就不走這條路了。我們已經有了一個完全可用的簡單掃描器。我們只需要一個很小的字典樹來識別關鍵字。我們應該如何將其對映到程式碼中?
The absolute simplest solution is to use a switch statement for each node with cases for each branch. We’ll start with the root node and handle the easy keywords.
最簡單的解決方案是對每個節點使用一個switch語句,每個分支是一個case。我們從根節點開始,處理簡單的關鍵字12。
scanner.c,在identifierType()方法中新增程式碼:
static TokenType identifierType() {
// 新增部分開始
switch (scanner.start[0]) {
case 'a': return checkKeyword(1, 2, "nd", TOKEN_AND);
case 'c': return checkKeyword(1, 4, "lass", TOKEN_CLASS);
case 'e': return checkKeyword(1, 3, "lse", TOKEN_ELSE);
case 'i': return checkKeyword(1, 1, "f", TOKEN_IF);
case 'n': return checkKeyword(1, 2, "il", TOKEN_NIL);
case 'o': return checkKeyword(1, 1, "r", TOKEN_OR);
case 'p': return checkKeyword(1, 4, "rint", TOKEN_PRINT);
case 'r': return checkKeyword(1, 5, "eturn", TOKEN_RETURN);
case 's': return checkKeyword(1, 4, "uper", TOKEN_SUPER);
case 'v': return checkKeyword(1, 2, "ar", TOKEN_VAR);
case 'w': return checkKeyword(1, 4, "hile", TOKEN_WHILE);
}
// 新增部分結束
return TOKEN_IDENTIFIER;
These are the initial letters that correspond to a single keyword. If we see an “s”, the only keyword the identifier could possibly be is
super. It might not be, though, so we still need to check the rest of the letters too. In the tree diagram, this is basically that straight path hanging off the “s”.
這些是對應於單個關鍵字的首字母。如果我們看到一個“s”,那麼這個識別符號唯一可能的關鍵字就是super。但也可能不是,所以我們仍然需要檢查其餘的字母。在樹狀圖中,這基本上就是掛在“s”上的一條直線路徑。
We won’t roll a switch for each of those nodes. Instead, we have a utility function that tests the rest of a potential keyword’s lexeme.
我們不會為每個節點都增加一個switch語句。相反,我們有一個工具函式來測試潛在關鍵字詞素的剩餘部分。
scanner.c,在skipWhitespace()方法後新增程式碼:
static TokenType checkKeyword(int start, int length,
const char* rest, TokenType type) {
if (scanner.current - scanner.start == start + length &&
memcmp(scanner.start + start, rest, length) == 0) {
return type;
}
return TOKEN_IDENTIFIER;
}
We use this for all of the unbranching paths in the tree. Once we’ve found a prefix that could only be one possible reserved word, we need to verify two things. The lexeme must be exactly as long as the keyword. If the first letter is “s”, the lexeme could still be “sup” or “superb”. And the remaining characters must match exactly—“supar” isn’t good enough.
我們將此用於樹中的所有無分支路徑。一旦我們發現一個字首,其只有可能是一種保留字,我們需要驗證兩件事。詞素必須與關鍵字一樣長。如果第一個字母是“s”,詞素仍然可以是“sup”或“superb”。剩下的字元必須完全匹配——“supar”就不夠好。
If we do have the right number of characters, and they’re the ones we want, then it’s a keyword, and we return the associated token type. Otherwise, it must be a normal identifier.
如果我們字元數量確實正確,並且它們是我們想要的字元,那這就是一個關鍵字,我們返回相關的標識型別。否則,它必然是一個普通的識別符號。
We have a couple of keywords where the tree branches again after the first letter. If the lexeme starts with “f”, it could be
false,for, orfun. So we add another switch for the branches coming off the “f” node.
我們有幾個關鍵字是在第一個字母之後又有樹的分支。如果詞素以“f”開頭,它可能是false、for或fun。因此我們在“f”節點下的分支中新增一個switch語句。
scanner.c,在identifierType()方法中新增程式碼:
case 'e': return checkKeyword(1, 3, "lse", TOKEN_ELSE);
// 新增部分開始
case 'f':
if (scanner.current - scanner.start > 1) {
switch (scanner.start[1]) {
case 'a': return checkKeyword(2, 3, "lse", TOKEN_FALSE);
case 'o': return checkKeyword(2, 1, "r", TOKEN_FOR);
case 'u': return checkKeyword(2, 1, "n", TOKEN_FUN);
}
}
break;
// 新增部分結束
case 'i': return checkKeyword(1, 1, "f", TOKEN_IF);
Before we switch, we need to check that there even is a second letter. “f” by itself is a valid identifier too, after all. The other letter that branches is “t”.
在我們進入switch語句之前,需要先檢查是否有第二個字母。畢竟,“f”本身也是一個有效的識別符號。另外一個需要分支的字母是“t”。
scanner.c,在identifierType()方法中新增程式碼:
case 's': return checkKeyword(1, 4, "uper", TOKEN_SUPER);
// 新增部分開始
case 't':
if (scanner.current - scanner.start > 1) {
switch (scanner.start[1]) {
case 'h': return checkKeyword(2, 2, "is", TOKEN_THIS);
case 'r': return checkKeyword(2, 2, "ue", TOKEN_TRUE);
}
}
break;
// 新增部分結束
case 'v': return checkKeyword(1, 2, "ar", TOKEN_VAR);
That’s it. A couple of nested
switchstatements. Not only is this code short, but it’s very, very fast. It does the minimum amount of work required to detect a keyword, and bails out as soon as it can tell the identifier will not be a reserved one.
就是這樣。幾個巢狀的switch語句。這段程式碼不僅短,而且非常非常快。它只做了檢測一個關鍵字所需的最少的工作,而且一旦知道這個識別符號不是一個保留字,就會直接結束13。
And with that, our scanner is complete.
這樣一來,我們的掃描器就完整了。
CHALLENGES
習題
-
Many newer languages support string interpolation. Inside a string literal, you have some sort of special delimiters—most commonly
${at the beginning and}at the end. Between those delimiters, any expression can appear. When the string literal is executed, the inner expression is evaluated, converted to a string, and then merged with the surrounding string literal.許多較新的語言都支援字串插值。在字串字面量中,有一些特殊的分隔符——最常見的是以
${開頭以}結尾。在這些分隔符之間,可以出現任何表示式。當字串字面量被執行時,內部表示式也會求值,轉換為字串,然後與周圍的字串字面量合併。For example, if Lox supported string interpolation, then this . . .
舉例來說,如果Lox支援字串插值,那麼下面的程式碼……
var drink = "Tea"; var steep = 4; var cool = 2; print "${drink} will be ready in ${steep + cool} minutes.";. . . would print:
將會輸出:
Tea will be ready in 6 minutes.What token types would you define to implement a scanner for string interpolation? What sequence of tokens would you emit for the above string literal?
你會定義什麼標識型別來實現支援字串插值的掃描器?對於上面的字串,你會生成什麼樣的標識序列?
What tokens would you emit for:
下面的字串會產生哪些標識:
"Nested ${"interpolation?! Are you ${"mad?!"}"}"Consider looking at other language implementations that support interpolation to see how they handle it.
可以考慮看看其它支援插值的語言實現,看它們是如何處理的。
-
Several languages use angle brackets for generics and also have a
>>right shift operator. This led to a classic problem in early versions of C++:有些語言使用尖括號來表示泛型,也有右移運算子
>>。這就導致了C++早期版本中的一個經典問題:vector<vector<string>> nestedVectors;This would produce a compile error because the
>>was lexed to a single right shift token, not two>tokens. Users were forced to avoid this by putting a space between the closing angle brackets.這將產生一個編譯錯誤,因為
>>被詞法識別為一個右移符號,而不是兩個>標識。使用者不得不在右側的兩個尖括號之間增加一個空格來避免這種情況。Later versions of C++ are smarter and can handle the above code. Java and C# never had the problem. How do those languages specify and implement this?
後續的C++版本更加智慧,可以處理上述程式碼。Java和C#從未出現過這個問題。這些語言是如何規定和實現這一點的呢?
-
Many languages, especially later in their evolution, define “contextual keywords”. These are identifiers that act like reserved words in some contexts but can be normal user-defined identifiers in others.
許多語言,尤其是在其發展的後期,都定義了“上下文式關鍵字”。這些識別符號在某些情況下類似於保留字,但在其它上下文中可以是普通的使用者定義的識別符號。
For example,
awaitis a keyword inside anasyncmethod in C#, but in other methods, you can useawaitas your own identifier.例如,在C#中,
await在async方法中是一個關鍵字,但在其它方法中,你可以使用await作為自己的識別符號。Name a few contextual keywords from other languages, and the context where they are meaningful. What are the pros and cons of having contextual keywords? How would you implement them in your language’s front end if you needed to?
說出幾個來自其它語言中的上下文關鍵字,以及它們在哪些情況下是有意義的。擁有上下文關鍵字的優點和缺點是什麼?如果需要的話,你要如何在語言的前端中實現它們?
-
程式碼裡面校驗是一個引數還是兩個引數,而不是0和1,因為argv中的第一個引數總是被執行的可執行檔案的名稱。 ↩
-
C語言不僅要求我們顯式地管理記憶體,而且要在精神上管理。我們程式設計師必須記住所有權規則,並在整個程式中手動實現。Java為我們做了這些。C++為我們提供了直接編碼策略的工具,這樣編譯器就會為我們驗證它。我喜歡C語言的簡潔,但是我們為此付出了真正的代價——這門語言要求我們更加認真。 ↩
-
嗯,這個size要加1,永遠記得為null位元組留出空間。 ↩
-
格式字串中的
%.*s是一個很好的特性。通常情況下,你需要在格式字串中寫入一個數字來設定輸出精度——要顯示的字元數。使用*則可以把精度作為一個引數來傳遞。因此,printf()呼叫將字串從token.start開始的前token.length個字元。我們需要這樣限制長度,因為詞素指向原始的原始碼字串,並且在末尾沒有終止符。 ↩ -
我並不想讓這個聽起來太輕率。我們確實需要考慮並確保在“main”模組中建立的源字串具有足夠長的生命週期。這就是
runFile()中會在interpret()執行完程式碼並返回後才釋放字串的原因。 ↩ -
在編譯器中進行詞素到執行時值的轉換確實會引入一些冗餘。掃描一個數字字面量的工作與將一串數字字元轉換為一個數值的工作非常相似。但是並沒有那麼多冗餘,它並不是任何效能上的關鍵點,而且能使得我們的掃描器更加簡單。 ↩
-
如果你對此不熟悉,請不要擔心。當我們從頭開始構建我們自己的雜湊表時,將會學習關於它的所有細節。 ↩
-
從上向下閱讀每個節點鏈,你將看到Lox的關鍵字。 ↩
-
“Trie”是CS中最令人困惑的名字之一。Edward Fredkin從“檢索(retrieval)”中把這個詞提取出來,這意味著它的讀音應該像“tree”。但是,已經有一個非常重要的資料結構發音為“tree”,而trie只是一個特例。所以如果你談論這些東西時,沒人能分辨出你在說哪一個。因此,現在人們經常把它讀作“try”,以免頭痛。 ↩
-
這種風格的圖被稱為語法圖或鐵路圖。後者的名字是因為它看起來像火車的排程場。
在Backus-Naur正規化出現之前,這是記錄語言語法的主要方式之一。如今,我們大多使用文字,但一種文字語言的官方規範依賴於影象,這一點很令人高興。 ↩ -
這也是大多數程式語言和文字編輯器中的正規表示式引擎的工作原理。它們獲取你的正規表示式字串並將其轉換為DFA,然後使用DFA來匹配字串。
如果你想學習將正規表示式轉換為DFA的演算法,龍書中已經為你提供了答案。 ↩ -
簡單並不意味著愚蠢。V8也採用了同樣的方法,而它是目前世界上最複雜、最快的語言實現之一。 ↩
-
我們有時會陷入這樣的誤區:任務效能來自於複雜的資料結構、多級快取和其它花哨的最佳化。但是,很多時候所需要的就是做更少的工作,而我經常發現,編寫最簡單的程式碼就足以完成這些工作。 ↩
17.編譯表示式 Compiling Expressions
In the middle of the journey of our life I found myself within a dark woods where the straight way was lost.
—— Dante Alighieri, Inferno
方吾生之半路,恍餘處乎幽林,失正軌而迷誤。(但丁,《地獄》)
【譯者注:這裡引用的是大名鼎鼎的《神曲》,所以我也直接引用了錢稻孫先生的譯文】
This chapter is exciting for not one, not two, but three reasons. First, it provides the final segment of our VM’s execution pipeline. Once in place, we can plumb the user’s source code from scanning all the way through to executing it.
這一章令人激動,原因不止一個,也不止兩個,而是三個。首先,它補齊了虛擬機器執行管道的最後一段。一旦到位,我們就可以處理使用者的原始碼,從掃描一直到執行。

Second, we get to write an actual, honest-to-God compiler. It parses source code and outputs a low-level series of binary instructions. Sure, it’s bytecode and not some chip’s native instruction set, but it’s way closer to the metal than jlox was. We’re about to be real language hackers.
第二,我們要編寫一個真正的編譯器。它會解析原始碼並輸出低階的二進位制指令序列。當然,它是位元組碼,而不是某個晶片的原生指令集,但它比jlox更接近於硬體。我們即將成為真正的語言駭客了。
Third and finally, I get to show you one of my absolute favorite algorithms: Vaughan Pratt’s “top-down operator precedence parsing”. It’s the most elegant way I know to parse expressions. It gracefully handles prefix operators, postfix, infix, mixfix, any kind of -fix you got. It deals with precedence and associativity without breaking a sweat. I love it.
第三,也是最後一個,我可以向你們展示我們最喜歡的演算法之一:Vaughan Pratt的“自頂向下算符優先解析”。這是我所知道的解析表達的最優雅的方法。它可以優雅地處理字首、字尾、中綴、多元運算子,以及任何型別的運算子。它能處理優先順序和結合性,而且毫不費力。我喜歡它。
As usual, before we get to the fun stuff, we’ve got some preliminaries to work through. You have to eat your vegetables before you get dessert. First, let’s ditch that temporary scaffolding we wrote for testing the scanner and replace it with something more useful.
與往常一樣,在我們開始真正有趣的工作之前,還有一些準備工作需要做。在得到甜點之前,你得先吃點蔬菜。首先,讓我們拋棄我們為測試掃描器而編寫的臨時腳手架,用更有效的東西來替換它。
vm.c,在interpret() 方法中替換2行:
InterpretResult interpret(const char* source) {
// 替換部分開始
Chunk chunk;
initChunk(&chunk);
if (!compile(source, &chunk)) {
freeChunk(&chunk);
return INTERPRET_COMPILE_ERROR;
}
vm.chunk = &chunk;
vm.ip = vm.chunk->code;
InterpretResult result = run();
freeChunk(&chunk);
return result;
// 替換部分結束
}
We create a new empty chunk and pass it over to the compiler. The compiler will take the user’s program and fill up the chunk with bytecode. At least, that’s what it will do if the program doesn’t have any compile errors. If it does encounter an error,
compile()returnsfalseand we discard the unusable chunk.
我們建立一個新的空位元組碼塊,並將其傳遞給編譯器。編譯器會獲取使用者的程式,並將位元組碼填充到該塊中。至少在程式沒有任何編譯錯誤的情況下,它就會這麼做。如果遇到錯誤,compile()方法會返回false,我們就會丟棄不可用的位元組碼塊。
Otherwise, we send the completed chunk over to the VM to be executed. When the VM finishes, we free the chunk and we’re done. As you can see, the signature to
compile()is different now.
否則,我們將完整的位元組碼塊傳送到虛擬機器中去執行。當虛擬機器完成後,我們會釋放該位元組碼塊,這樣就完成了。如你所見,現在compile()的簽名已經不同了。
compiler.h,替換一行程式碼:
#define clox_compiler_h
// 替換部分開始
#include "vm.h"
bool compile(const char* source, Chunk* chunk);
// 替換部分結束
#endif
We pass in the chunk where the compiler will write the code, and then
compile()returns whether or not compilation succeeded. We make the same change to the signature in the implementation.
我們將位元組碼塊傳入,而編譯器會向其中寫入程式碼,如何compile()返回編譯是否成功。我們在實現方法中對簽名進行相同的修改。
compiler.c,在compile()方法中替換1行:
#include "scanner.h"
// 替換部分開始
bool compile(const char* source, Chunk* chunk) {
// 替換部分結束
initScanner(source);
That call to
initScanner()is the only line that survives this chapter. Rip out the temporary code we wrote to test the scanner and replace it with these three lines:
對initScanner()的呼叫是本章中唯一保留下來的程式碼行。刪除我們為測試掃描器而編寫的臨時程式碼,將其替換為以下三行:
compiler.c,在compile()方法中替換13行:
initScanner(source);
// 替換部分開始
advance();
expression();
consume(TOKEN_EOF, "Expect end of expression.");
// 替換部分結束
}
The call to
advance()“primes the pump” on the scanner. We’ll see what it does soon. Then we parse a single expression. We aren’t going to do statements yet, so that’s the only subset of the grammar we support. We’ll revisit this when we add statements in a few chapters. After we compile the expression, we should be at the end of the source code, so we check for the sentinel EOF token.
對advance()的呼叫會在掃描器上“啟動泵”。我們很快會看到它的作用。然後我們解析一個表示式。我們還不打算處理語句,所以表示式是我們支援的唯一的語法子集。等到我們在後面的章節中新增語句時,會重新審視這個問題。在編譯表示式之後,我們應該處於原始碼的末尾,所以我們要檢查EOF標識。
We’re going to spend the rest of the chapter making this function work, especially that little
expression()call. Normally, we’d dive right into that function definition and work our way through the implementation from top to bottom.
我們將用本章的剩餘時間讓這個函式工作起來。尤其是那個小小的expression()呼叫。通常情況下,我們會直接進入函式定義,並從上到下地進行實現。
This chapter is different. Pratt’s parsing technique is remarkably simple once you have it all loaded in your head, but it’s a little tricky to break into bite-sized pieces. It’s recursive, of course, which is part of the problem. But it also relies on a big table of data. As we build up the algorithm, that table grows additional columns.
這一章則不同。Pratt的解析技術,你一旦理解了就非常簡單,但是要把它分解成小塊就比較麻煩了1。當然,它是遞迴的,這也是問題的一部分。但它也依賴於一個很大的資料表。等我們構建演算法時,這個表格會增加更多的列。
I don’t want to revisit 40-something lines of code each time we extend the table. So we’re going to work our way into the core of the parser from the outside and cover all of the surrounding bits before we get to the juicy center. This will require a little more patience and mental scratch space than most chapters, but it’s the best I could do.
我不想在每次擴充套件表時都要重新檢視40多行程式碼。因此,我們要從外部進入解析器的核心,並在進入有趣的中心之前覆蓋其外圍的所有部分。與大多數章節相比,這將需要更多的耐心和思考空間,但這是我能做到的最好的了。
17 . 1 Single-Pass Compilation
17.1 單遍編譯
A compiler has roughly two jobs. It parses the user’s source code to understand what it means. Then it takes that knowledge and outputs low-level instructions that produce the same semantics. Many languages split those two roles into two separate passes in the implementation. A parser produces an AST—just like jlox does—and then a code generator traverses the AST and outputs target code.
一個編譯器大約有兩項工作2。它會解析使用者的原始碼以理解其含義。然後,它利用這些知識並輸出產生相同語義的低階指令。許多語言在實現中將這兩個角色分成兩遍獨立的執行部分。一個解析器生成AST——就像jlox那樣——還有一個程式碼生成器遍歷AST並輸出目的碼。
In clox, we’re taking an old-school approach and merging these two passes into one. Back in the day, language hackers did this because computers literally didn’t have enough memory to store an entire source file’s AST. We’re doing it because it keeps our compiler simpler, which is a real asset when programming in C.
在clox中,我們採用了一種老派的方法,將這兩遍處理合而為一。在過去,語言駭客們這樣做是因為計算機沒有足夠的記憶體來儲存整個原始檔的AST。我們這樣做是因為它使我們的編譯器更簡單,這是用C語言程式設計時的真正優勢。
Single-pass compilers like we’re going to build don’t work well for all languages. Since the compiler has only a peephole view into the user’s program while generating code, the language must be designed such that you don’t need much surrounding context to understand a piece of syntax. Fortunately, tiny, dynamically typed Lox is well-suited to that.
像我們要構建的單遍編譯器並不是對所有語言都有效。因為編譯器在生產程式碼時只能“管窺”使用者的程式,所以語言必須設計成不需要太多外圍的上下文環境就能理解一段語法。幸運的是,微小的、動態型別的Lox非常適合這種情況。
What this means in practical terms is that our “compiler” C module has functionality you’ll recognize from jlox for parsing—consuming tokens, matching expected token types, etc. And it also has functions for code gen—emitting bytecode and adding constants to the destination chunk. (And it means I’ll use “parsing” and “compiling” interchangeably throughout this and later chapters.)
在實踐中,這意味著我們的“編譯器”C模組具有你在jlox中認識到的解析功能——消費標識,匹配期望的標識型別,等等。而且它還具有程式碼生成的功能——生成位元組碼和向目標塊中新增常量。(這也意味著我會在本章和後面的章節中交替使用“解析”和“編譯”。)
We’ll build the parsing and code generation halves first. Then we’ll stitch them together with the code in the middle that uses Pratt’s technique to parse Lox’s particular grammar and output the right bytecode.
我們首先分別構建解析和程式碼生成兩個部分。然後,我們會用中間程式碼將它們縫合在一起,該程式碼使用Pratt的技術來解析Lox 的語法並輸出正確的位元組碼。
17 . 2 Parsing Tokens
17.2 解析標識
First up, the front half of the compiler. This function’s name should sound familiar.
首先是編譯器的前半部分。這個函式的名字聽起來應該很熟悉。 compiler.c,新增程式碼:
#include "scanner.h"
// 新增部分開始
static void advance() {
parser.previous = parser.current;
for (;;) {
parser.current = scanToken();
if (parser.current.type != TOKEN_ERROR) break;
errorAtCurrent(parser.current.start);
}
}
// 新增部分結束
Just like in jlox, it steps forward through the token stream. It asks the scanner for the next token and stores it for later use. Before doing that, it takes the old
currenttoken and stashes that in apreviousfield. That will come in handy later so that we can get at the lexeme after we match a token.
就像在jlox中一樣,該函式向前透過標識流。它會向掃描器請求下一個詞法標識,並將其儲存起來以供後面使用。在此之前,它會獲取舊的current標識,並將其儲存在previous欄位中。這在以後會派上用場,讓我們可以在匹配到標識之後獲得詞素。
The code to read the next token is wrapped in a loop. Remember, clox’s scanner doesn’t report lexical errors. Instead, it creates special error tokens and leaves it up to the parser to report them. We do that here.
讀取下一個標識的程式碼被包在一個迴圈中。記住,clox的掃描器不會報告詞法錯誤。相反地,它建立了一個特殊的錯誤標識,讓解析器來報告這些錯誤。我們這裡就是這樣做的。
We keep looping, reading tokens and reporting the errors, until we hit a non-error one or reach the end. That way, the rest of the parser sees only valid tokens. The current and previous token are stored in this struct:
我們不斷地迴圈,讀取標識並報告錯誤,直到遇到一個沒有錯誤的標識或者到達標識流終點。這樣一來,解析器的其它部分只能看到有效的標記。當前和之前的標記被儲存在下面的結構體中:
compiler.c,新增程式碼:
#include "scanner.h"
// 新增部分開始
typedef struct {
Token current;
Token previous;
} Parser;
Parser parser;
// 新增部分結束
static void advance() {
Like we did in other modules, we have a single global variable of this struct type so we don’t need to pass the state around from function to function in the compiler.
就像我們在其它模組中所做的那樣,我們維護一個這種結構體型別的單一全域性變數,所以我們不需要在編譯器中將狀態從一個函式傳遞到另一個函式。
17 . 2 . 1 Handling syntax errors
17.2.1 處理語法錯誤
If the scanner hands us an error token, we need to actually tell the user. That happens using this:
如果掃描器交給我們一個錯誤標識,我們必須明確地告訴使用者。這就需要使用下面的語句:
compiler.c,在變數parser後新增程式碼:
static void errorAtCurrent(const char* message) {
errorAt(&parser.current, message);
}
We pull the location out of the current token in order to tell the user where the error occurred and forward it to
errorAt(). More often, we’ll report an error at the location of the token we just consumed, so we give the shorter name to this other function:
我們從當前標識中提取位置資訊,以便告訴使用者錯誤發生在哪裡,並將其轉發給errorAt()。更常見的情況是,我們會在剛剛消費的令牌的位置報告一個錯誤,所以我們給另一個函式取了一個更短的名字:
compiler.c,在變數parser後新增程式碼:
static void error(const char* message) {
errorAt(&parser.previous, message);
}
The actual work happens here:
實際的工作發生在這裡:
compiler.c,在變數parser後新增程式碼:
static void errorAt(Token* token, const char* message) {
fprintf(stderr, "[line %d] Error", token->line);
if (token->type == TOKEN_EOF) {
fprintf(stderr, " at end");
} else if (token->type == TOKEN_ERROR) {
// Nothing.
} else {
fprintf(stderr, " at '%.*s'", token->length, token->start);
}
fprintf(stderr, ": %s\n", message);
parser.hadError = true;
}
First, we print where the error occurred. We try to show the lexeme if it’s human-readable. Then we print the error message itself. After that, we set this
hadErrorflag. That records whether any errors occurred during compilation. This field also lives in the parser struct.
首先,我們打印出錯誤發生的位置。如果詞素是人類可讀的,我們就儘量顯示詞素。然後我們列印錯誤資訊。之後,我們設定這個hadError標誌。該標誌記錄了編譯過程中是否有任何錯誤發生。這個欄位也存在於解析器結構體中。
compiler.c,在結構體Parser中新增程式碼:
Token previous;
// 新增部分開始
bool hadError;
// 新增部分結束
} Parser;
Earlier I said that
compile()should returnfalseif an error occurred. Now we can make it do that.
前面我說過,如果發生錯誤,compile()應該返回false。現在我們可以這樣做:
compiler.c,在compile()函式中新增程式碼:
consume(TOKEN_EOF, "Expect end of expression.");
// 新增部分開始
return !parser.hadError;
// 新增部分結束
}
I’ve got another flag to introduce for error handling. We want to avoid error cascades. If the user has a mistake in their code and the parser gets confused about where it is in the grammar, we don’t want it to spew out a whole pile of meaningless knock-on errors after the first one.
我還要引入另一個用於錯誤處理的標誌。我們想要避免錯誤的級聯效應。如果使用者在他們的程式碼中犯了一個錯誤,而解析器又不理解它在語法中的含義,我們不希望解析器在第一個錯誤之後,又丟擲一大堆無意義的連帶錯誤。
We fixed that in jlox using panic mode error recovery. In the Java interpreter, we threw an exception to unwind out of all of the parser code to a point where we could skip tokens and resynchronize. We don’t have exceptions in C. Instead, we’ll do a little smoke and mirrors. We add a flag to track whether we’re currently in panic mode.
我們在jlox中使用緊急模式錯誤恢復來解決這個問題。在Java直譯器中,我們丟擲一個異常,跳出解析器程式碼直到可以跳過標識並重新同步。我們在C語言中沒有異常3。相反,我們會做一些欺騙性行為。我們新增一個標誌來跟蹤當前是否在緊急模式中。
compiler.c,在結構體Parser中新增程式碼:
bool hadError;
// 新增部分開始
bool panicMode;
// 新增部分結束
} Parser;
When an error occurs, we set it.
當出現錯誤時,我們為其賦值。
compiler.c,在errorAt()方法中新增程式碼:
static void errorAt(Token* token, const char* message) {
// 新增部分開始
parser.panicMode = true;
// 新增部分結束
fprintf(stderr, "[line %d] Error", token->line);
After that, we go ahead and keep compiling as normal as if the error never occurred. The bytecode will never get executed, so it’s harmless to keep on trucking. The trick is that while the panic mode flag is set, we simply suppress any other errors that get detected.
之後,我們繼續進行編譯,就像錯誤從未發生過一樣。位元組碼永遠不會被執行,所以繼續執行也是無害的。訣竅在於,雖然設定了緊急模式標誌,但我們只是簡單地遮蔽了檢測到的其它錯誤。
compiler.c,在errorAt()方法中新增程式碼:
static void errorAt(Token* token, const char* message) {
// 新增部分開始
if (parser.panicMode) return;
// 新增部分結束
parser.panicMode = true;
There’s a good chance the parser will go off in the weeds, but the user won’t know because the errors all get swallowed. Panic mode ends when the parser reaches a synchronization point. For Lox, we chose statement boundaries, so when we later add those to our compiler, we’ll clear the flag there.
解析器很有可能會崩潰,但是使用者不會知道,因為錯誤都會被吞掉。當解析器到達一個同步點時,緊急模式就結束了。對於Lox,我們選擇了語句作為邊界,所以當我們稍後將語句新增到編譯器時,將會清除該標誌。
These new fields need to be initialized.
這些新欄位需要被初始化。
compiler.c,在compile()方法中新增程式碼:
initScanner(source);
// 新增部分開始
parser.hadError = false;
parser.panicMode = false;
// 新增部分結束
advance();
And to display the errors, we need a standard header.
為了展示這些錯誤,我們需要一個標準的標頭檔案。
compiler.c,新增程式碼:
#include <stdio.h>
// 新增部分開始
#include <stdlib.h>
// 新增部分結束
#include "common.h"
There’s one last parsing function, another old friend from jlox.
還有最後一個解析函式,是jlox中的另一個老朋友。
compiler.c,在advance()方法後新增程式碼:
static void consume(TokenType type, const char* message) {
if (parser.current.type == type) {
advance();
return;
}
errorAtCurrent(message);
}
It’s similar to
advance()in that it reads the next token. But it also validates that the token has an expected type. If not, it reports an error. This function is the foundation of most syntax errors in the compiler.
它類似於advance(),都是讀取下一個標識。但它也會驗證標識是否具有預期的型別。如果不是,則報告錯誤。這個函式是編譯器中大多數語法錯誤的基礎。
OK, that’s enough on the front end for now.
好了,關於前端的介紹就到此為止。
17 . 3 Emitting Bytecode
17.3 發出位元組碼
After we parse and understand a piece of the user’s program, the next step is to translate that to a series of bytecode instructions. It starts with the easiest possible step: appending a single byte to the chunk.
在我們解析並理解了使用者的一段程式之後,下一步是將其轉換為一系列位元組碼指令。它從最簡單的步驟開始:向塊中追加一個位元組。
compiler.c,在consume()方法後新增程式碼:
static void emitByte(uint8_t byte) {
writeChunk(currentChunk(), byte, parser.previous.line);
}
It’s hard to believe great things will flow through such a simple function. It writes the given byte, which may be an opcode or an operand to an instruction. It sends in the previous token’s line information so that runtime errors are associated with that line.
很難相信偉大的東西會流經這樣一個簡單的函式。它將給定的位元組寫入一個指令,該位元組可以是操作碼或運算元。它會傳送前一個標記的行資訊,以便將執行時錯誤與該行關聯起來。
The chunk that we’re writing gets passed into
compile(), but it needs to make its way toemitByte(). To do that, we rely on this intermediary function:
我們正在寫入的位元組碼塊被傳遞給compile(),但是它也需要進入emitByte()中。要做到這一點,我們依靠這個中間函式:
compiler.c,在變數parser後新增程式碼:
Parser parser;
// 新增部分開始
Chunk* compilingChunk;
static Chunk* currentChunk() {
return compilingChunk;
}
// 新增部分結束
static void errorAt(Token* token, const char* message) {
Right now, the chunk pointer is stored in a module-level variable like we store other global state. Later, when we start compiling user-defined functions, the notion of “current chunk” gets more complicated. To avoid having to go back and change a lot of code, I encapsulate that logic in the
currentChunk()function.
現在,chunk指標儲存在一個模組級變數中,就像我們儲存其它全域性狀態一樣。以後,當我們開始編譯使用者定義的函式時,“當前塊”的概念會變得更加複雜。為了避免到時候需要回頭修改大量程式碼,我把這個邏輯封裝在currentChunk()函式中。
We initialize this new module variable before we write any bytecode:
在寫入任何位元組碼之前,我們先初始化這個新的模組變數:
compiler.c,在compile()方法中新增程式碼:
bool compile(const char* source, Chunk* chunk) {
initScanner(source);
// 新增部分開始
compilingChunk = chunk;
// 新增部分結束
parser.hadError = false;
Then, at the very end, when we’re done compiling the chunk, we wrap things up.
然後,在最後,當我們編譯完位元組碼塊後,對全部內容做個了結。
compiler.c,在compile()方法中新增程式碼:
consume(TOKEN_EOF, "Expect end of expression.");
// 新增部分開始
endCompiler();
// 新增部分結束
return !parser.hadError;
That calls this:
會呼叫下面的函式:
compiler.c,在emitByte()方法後新增程式碼:
static void endCompiler() {
emitReturn();
}
In this chapter, our VM deals only with expressions. When you run clox, it will parse, compile, and execute a single expression, then print the result. To print that value, we are temporarily using the
OP_RETURNinstruction. So we have the compiler add one of those to the end of the chunk.
在本章中,我們的虛擬機器只處理表示式。當你執行clox時,它會解析、編譯並執行一個表示式,然後列印結果。為了列印這個值,我們暫時使用OP_RETURN指令。我們讓編譯器在塊的模組新增一條這樣的指令。
compiler.c,在emitByte()方法後新增程式碼:
static void emitReturn() {
emitByte(OP_RETURN);
}
While we’re here in the back end we may as well make our lives easier.
既然已經在編寫後端,不妨讓我們的工作更輕鬆一點。
compiler.c,在emitByte()方法後新增程式碼:
static void emitBytes(uint8_t byte1, uint8_t byte2) {
emitByte(byte1);
emitByte(byte2);
}
Over time, we’ll have enough cases where we need to write an opcode followed by a one-byte operand that it’s worth defining this convenience function.
隨著時間的推移,我們將遇到很多的情況中需要寫一個操作碼,後面跟一個單位元組的運算元,因此值得定義這個便利的函式。
17 . 4 Parsing Prefix Expressions
17.4 解析字首表示式
We’ve assembled our parsing and code generation utility functions. The missing piece is the code in the middle that connects those together.
我們已經組裝瞭解析和生成程式碼的工具函式。缺失的部分就是將它們連線在一起的的中間程式碼。

The only step in
compile()that we have left to implement is this function:
compile()中唯一還未實現的步驟就是這個函式:
compiler.c,在endCompiler()方法後新增程式碼:
static void expression() {
// What goes here?
}
We aren’t ready to implement every kind of expression in Lox yet. Heck, we don’t even have Booleans. For this chapter, we’re only going to worry about four:
我們還沒有準備好在Lox中實現每一種表示式。見鬼,我們甚至還沒有布林值。在本章中,我們只考慮四個問題:
- Number literals:
123- Parentheses for grouping:
(123)- Unary negation:
-123- The Four Horsemen of the Arithmetic:
+,-,*,/
- 數值字面量:
123 - 用於分組的括號:
(123) - 一元取負:
-123 - 算術運算四騎士:
+、-、*、/
As we work through the functions to compile each of those kinds of expressions, we’ll also assemble the requirements for the table-driven parser that calls them.
當我們透過函式編譯每種型別的表示式時,我們也會對呼叫這些表示式的表格驅動的解析器的要求進行彙總。
17 . 4 . 1 Parsers for tokens
17.4.1 標識解析器
For now, let’s focus on the Lox expressions that are each only a single token. In this chapter, that’s just number literals, but there will be more later. Here’s how we can compile them:
現在,讓我們把注意力集中在那些只由單個 token 組成的Lox表示式上。在本章中,這隻包括數值字面量,但後面會有更多。下面是我們如何編譯它們:
We map each token type to a different kind of expression. We define a function for each expression that outputs the appropriate bytecode. Then we build an array of function pointers. The indexes in the array correspond to the
TokenTypeenum values, and the function at each index is the code to compile an expression of that token type.
我們將每種標識型別對映到不同型別的表示式。我們為每個表示式定義一個函式,該函式會輸出對應的位元組碼。然後我們構建一個函式指標的陣列。陣列中的索引對應於TokenType列舉值,每個索引處的函式是編譯該標識型別的表示式的程式碼。
To compile number literals, we store a pointer to the following function at the
TOKEN_NUMBERindex in the array.
為了編譯數值字面量,我們在陣列的TOKEN_NUMBER索引處儲存一個指向下面函式的指標,
compiler.c,在endCompiler()方法後新增程式碼:
static void number() {
double value = strtod(parser.previous.start, NULL);
emitConstant(value);
}
We assume the token for the number literal has already been consumed and is stored in
previous. We take that lexeme and use the C standard library to convert it to a double value. Then we generate the code to load that value using this function:
我們假定數值字面量標識已經被消耗了,並被儲存在previous中。我們獲取該詞素,並使用C標準庫將其轉換為一個double值。然後我們用下面的函式生成載入該double值的位元組碼:
compiler.c,在emitReturn()方法後新增程式碼:
static void emitConstant(Value value) {
emitBytes(OP_CONSTANT, makeConstant(value));
}
First, we add the value to the constant table, then we emit an
OP_CONSTANTinstruction that pushes it onto the stack at runtime. To insert an entry in the constant table, we rely on:
首先,我們將值新增到常量表中,然後我們發出一條OP_CONSTANT指令,在執行時將其壓入棧中。要在常量表中插入一條資料,我們需要依賴:
compiler.c,在emitReturn()方法後新增程式碼:
static uint8_t makeConstant(Value value) {
int constant = addConstant(currentChunk(), value);
if (constant > UINT8_MAX) {
error("Too many constants in one chunk.");
return 0;
}
return (uint8_t)constant;
}
Most of the work happens in
addConstant(), which we defined back in an earlier chapter. That adds the given value to the end of the chunk’s constant table and returns its index. The new function’s job is mostly to make sure we don’t have too many constants. Since theOP_CONSTANTinstruction uses a single byte for the index operand, we can store and load only up to 256 constants in a chunk.
大部分的工作發生在addConstant()中,我們在前面的章節中定義了這個函式。它將給定的值新增到位元組碼塊的常量表的末尾,並返回其索引。這個新函式的工作主要是確保我們沒有太多常量。由於OP_CONSTANT指令使用單個位元組來索引運算元,所以我們在一個塊中最多隻能儲存和載入256個常量4。
That’s basically all it takes. Provided there is some suitable code that consumes a
TOKEN_NUMBERtoken, looks upnumber()in the function pointer array, and then calls it, we can now compile number literals to bytecode.
這基本就是所有的事情了。只要有了這些合適的程式碼,能夠消耗一個TOKEN_NUMBER標識,在函式指標陣列中查詢number()方法,然後呼叫它,我們現在就可以將數值字面量編譯為位元組碼。
17 . 4 . 2 Parentheses for grouping
17.4.2 括號分組
Our as-yet-imaginary array of parsing function pointers would be great if every expression was only a single token long. Alas, most are longer. However, many expressions start with a particular token. We call these prefix expressions. For example, when we’re parsing an expression and the current token is
(, we know we must be looking at a parenthesized grouping expression.
如果每個表示式只有一個標識,那我們這個尚未成型的解析函式指標陣列就很好處理了。不幸的是,大多數表示式都比較長。然而,許多表達式以一個特定的標識開始。我們稱之為字首表示式。舉例來說,當我們解析一個表示式,而當前標識是(,我們就知道當前處理的一定是一個帶括號的分組表示式。
It turns out our function pointer array handles those too. The parsing function for an expression type can consume any additional tokens that it wants to, just like in a regular recursive descent parser. Here’s how parentheses work:
事實證明,我們的函式指標陣列也能處理這些。一個表示式型別的解析函式可以消耗任何它需要的標識,就像在常規的遞迴下降解析器中一樣。下面是小括號的工作原理:
compiler.c,在endCompiler()方法後新增程式碼:
static void grouping() {
expression();
consume(TOKEN_RIGHT_PAREN, "Expect ')' after expression.");
}
Again, we assume the initial
(has already been consumed. We recursively call back intoexpression()to compile the expression between the parentheses, then parse the closing)at the end.
同樣,我們假定初始的(已經被消耗了。我們遞迴地5呼叫expression()來編譯括號之間的表示式,然後解析結尾的)。
As far as the back end is concerned, there’s literally nothing to a grouping expression. Its sole function is syntactic—it lets you insert a lower-precedence expression where a higher precedence is expected. Thus, it has no runtime semantics on its own and therefore doesn’t emit any bytecode. The inner call to
expression()takes care of generating bytecode for the expression inside the parentheses.
就後端而言,分組表示式實際上沒有任何意義。它的唯一功能是語法上的——它允許你在需要高優先順序的地方插入一個低優先順序的表示式。因此,它本身沒有執行時語法,也就不會發出任何位元組碼。對expression()的內部呼叫負責為括號內的表示式生成位元組碼。
17 . 4 . 3 Unary negation
17.4.3 一元取負
Unary minus is also a prefix expression, so it works with our model too.
一元減號也是一個字首表示式,因此也適用於我們的模型。
compiler.c,在number()方法後新增程式碼:
static void unary() {
TokenType operatorType = parser.previous.type;
// Compile the operand.
expression();
// Emit the operator instruction.
switch (operatorType) {
case TOKEN_MINUS: emitByte(OP_NEGATE); break;
default: return; // Unreachable.
}
}
The leading
-token has been consumed and is sitting inparser.previous. We grab the token type from that to note which unary operator we’re dealing with. It’s unnecessary right now, but this will make more sense when we use this same function to compile the!operator in the next chapter.
前導的-標識已經被消耗掉了,並被放在parser.previous中。我們從中獲取標識型別,以瞭解當前正在處理的是哪個一元運算子。現在還沒必要這樣做,但當下一章中我們使用這個函式來編譯!時,這將會更有意義。
As in
grouping(), we recursively callexpression()to compile the operand. After that, we emit the bytecode to perform the negation. It might seem a little weird to write the negate instruction after its operand’s bytecode since the-appears on the left, but think about it in terms of order of execution:
就像在grouping()中一樣,我們會遞迴地呼叫expression()來編譯運算元。之後,我們發出位元組碼執行取負運算。因為-出現在左邊,將取負指令放在其運算元的後面似乎有點奇怪,但是從執行順序的角度來考慮:
- We evaluate the operand first which leaves its value on the stack.
- Then we pop that value, negate it, and push the result.
- 首先計算運算元,並將其值留在堆疊中。
- 然後彈出該值,對其取負,並將結果壓入棧中。
So the
OP_NEGATEinstruction should be emitted last. This is part of the compiler’s job—parsing the program in the order it appears in the source code and rearranging it into the order that execution happens.
所以OP_NEGATE指令應該是最後發出的6。這也是編譯器工作的一部分——按照原始碼中的順序對程式進行解析,並按照執行的順序對其重新排序。
There is one problem with this code, though. The
expression()function it calls will parse any expression for the operand, regardless of precedence. Once we add binary operators and other syntax, that will do the wrong thing. Consider:
不過,這段程式碼有一個問題。它所呼叫的expression()函式會解析運算元中的任何表示式,而不考慮優先順序。一旦我們加入二元運算子和其它語法,就會出錯。考慮一下:
-a.b + c;
Here, the operand to
-should be just thea.bexpression, not the entirea.b + c. But ifunary()callsexpression(), the latter will happily chew through all of the remaining code including the+. It will erroneously treat the-as lower precedence than the+.
在這裡-的運算元應該只是a.b表示式,而不是整個a.b+c。但如果unary()呼叫expression(),後者會愉快地處理包括+在內的所有剩餘程式碼。它會錯誤地把-視為比+的優先順序低。
When parsing the operand to unary
-, we need to compile only expressions at a certain precedence level or higher. In jlox’s recursive descent parser we accomplished that by calling into the parsing method for the lowest-precedence expression we wanted to allow (in this case,call()). Each method for parsing a specific expression also parsed any expressions of higher precedence too, so that included the rest of the precedence table.
當解析一元-的運算元時,只需要編譯具有某一優先順序或更高優先順序的表示式。在jlox的遞迴下降解析器中,我們透過呼叫我們想要允許的最低優先順序的表示式的解析方法(在本例中是call())來實現這一點。每個解析特定表示式的方法也會解析任何優先順序更高的表示式,也就是包括優先順序表的其餘部分。
The parsing functions like
number()andunary()here in clox are different. Each only parses exactly one type of expression. They don’t cascade to include higher-precedence expression types too. We need a different solution, and it looks like this:
clox中的number()和unary()這樣的解析函式是不同的。每個函式只解析一種型別的表示式。它們不會級聯處理更高優先順序的表示式型別。我們需要一個不同的解決方案,看起來是這樣的:
compiler.c,在unary()方法後新增程式碼:
static void parsePrecedence(Precedence precedence) {
// What goes here?
}
This function—once we implement it—starts at the current token and parses any expression at the given precedence level or higher. We have some other setup to get through before we can write the body of this function, but you can probably guess that it will use that table of parsing function pointers I’ve been talking about. For now, don’t worry too much about how it works. In order to take the “precedence” as a parameter, we define it numerically.
這個函式(一旦實現)從當前的標識開始,解析給定優先順序或更高優先順序的任何表示式。在編寫這個函式的主體之前,我們還有一些其它的設定要完成,但你可能也猜得到,它會使用我一直在談論的解析函式指標列表。現在,還不用太擔心它的如何工作的。為了把“優先順序”作為一個引數,我們用數值來定義它。
compiler.c,在結構體Parser後新增程式碼:
} Parser;
// 新增部分開始
typedef enum {
PREC_NONE,
PREC_ASSIGNMENT, // =
PREC_OR, // or
PREC_AND, // and
PREC_EQUALITY, // == !=
PREC_COMPARISON, // < > <= >=
PREC_TERM, // + -
PREC_FACTOR, // * /
PREC_UNARY, // ! -
PREC_CALL, // . ()
PREC_PRIMARY
} Precedence;
// 新增部分結束
Parser parser;
These are all of Lox’s precedence levels in order from lowest to highest. Since C implicitly gives successively larger numbers for enums, this means that
PREC_CALLis numerically larger thanPREC_UNARY. For example, say the compiler is sitting on a chunk of code like:
這些是Lox中的所有優先順序,按照從低到高的順序排列。由於C語言會隱式地為列舉賦值連續遞增的數字,這就意味著PREC_CALL在數值上比PREC_UNARY要大。舉例來說,假設編譯器正在處理這樣的程式碼:
-a.b + c
If we call
parsePrecedence(PREC_ASSIGNMENT), then it will parse the entire expression because+has higher precedence than assignment. If instead we callparsePrecedence(PREC_UNARY), it will compile the-a.band stop there. It doesn’t keep going through the+because the addition has lower precedence than unary operators.
如果我們呼叫parsePrecedence(PREC_ASSIGNMENT),那麼它就會解析整個表示式,因為+的優先順序高於賦值。如果我們呼叫parsePrecedence(PREC_UNARY),它就會編譯-a.b並停止。它不會徑直解析+,因為加法的優先順序比一元取負運算子要低。
With this function in hand, it’s a snap to fill in the missing body for
expression().
有了這個函式,我們就可以輕鬆地填充expression()的缺失部分。
compiler.c,在expression()方法中替換1行:
static void expression() {
// 替換部分開始
parsePrecedence(PREC_ASSIGNMENT);
// 替換部分結束
}
We simply parse the lowest precedence level, which subsumes all of the higher-precedence expressions too. Now, to compile the operand for a unary expression, we call this new function and limit it to the appropriate level:
我們只需要解析最低優先順序,它也包含了所有更高優先順序的表示式。現在,為了編譯一元表示式的運算元,我們呼叫這個新函式並將其限制在適當的優先順序:
compiler.c,在unary()方法中替換1行:
// Compile the operand.
// 替換部分開始
parsePrecedence(PREC_UNARY);
// 替換部分結束
// Emit the operator instruction.
We use the unary operator’s own
PREC_UNARYprecedence to permit nested unary expressions like!!doubleNegative. Since unary operators have pretty high precedence, that correctly excludes things like binary operators. Speaking of which . . .
我們使用一元運算子本身的PREC_UNARY優先順序來允許巢狀的一元表示式,如!!doubleNegative。因為一元運算子的優先順序很高,所以正確地排除了二元運算子之類的東西。說到這一點……
17 . 5 Parsing Infix Expressions
17.5 解析中綴表示式
Binary operators are different from the previous expressions because they are infix. With the other expressions, we know what we are parsing from the very first token. With infix expressions, we don’t know we’re in the middle of a binary operator until after we’ve parsed its left operand and then stumbled onto the operator token in the middle.
二元運算子與之前的表示式不同,因為它們是中綴的。對於其它表示式,我們從第一個標識就知道我們在解析什麼,對於中綴表示式,只有在解析了左運算元並發現了中間的運算子時,才知道自己正在處理二元運算子。
Here’s an example:
下面是一個例子:
1 + 2
Let’s walk through trying to compile it with what we know so far:
讓我們用目前已知的邏輯走一遍,試著編譯一下它:
- We call
expression(). That in turn callsparsePrecedence(PREC_ASSIGNMENT).- That function (once we implement it) sees the leading number token and recognizes it is parsing a number literal. It hands off control to
number().number()creates a constant, emits anOP_CONSTANT, and returns back toparsePrecedence().
- 我們呼叫
expression(),它會進一步呼叫parsePrecedence(PREC_ASSIGNMENT) - 該函式(一旦實現後)會看到前面的數字標識,並意識到正在解析一個數值字面量。它將控制權交給
number()。 number()建立一個常數,發出一個OP_CONSTANT指令,然後返回到parsePrecedence()
Now what? The call to
parsePrecedence()should consume the entire addition expression, so it needs to keep going somehow. Fortunately, the parser is right where we need it to be. Now that we’ve compiled the leading number expression, the next token is+. That’s the exact token thatparsePrecedence()needs to detect that we’re in the middle of an infix expression and to realize that the expression we already compiled is actually an operand to that.
現在怎麼辦?對 parsePrecedence()的呼叫應該要消費整個加法表示式,所以它需要以某種方式繼續進行解析。幸運的是,解析器就在我們需要它的地方。現在我們已經編譯了前面的數字表達式,下一個標識就是+。這正是parsePrecedence()用於判斷我們是否在處理中綴表示式所需的標識,並意識到我們已經編譯的表示式實際上是中綴表示式的運算元。
So this hypothetical array of function pointers doesn’t just list functions to parse expressions that start with a given token. Instead, it’s a table of function pointers. One column associates prefix parser functions with token types. The second column associates infix parser functions with token types.
所以,這個假定的函式指標陣列,不只是列出用於解析以指定標識開頭的表示式的函式。相反,這個一個函式指標的表格。一列將字首解析函式與標識型別關聯起來,第二列將中綴解析函式與標識型別相關聯。
The function we will use as the infix parser for
TOKEN_PLUS,TOKEN_MINUS,TOKEN_STAR, andTOKEN_SLASHis this:
我們將使用下面的函式作為TOKEN_PLUS, TOKEN_MINUS,TOKEN_STAR和TOKEN_SLASH 的中綴解析函式:
compiler.c,在endCompiler()方法後新增程式碼:
static void binary() {
TokenType operatorType = parser.previous.type;
ParseRule* rule = getRule(operatorType);
parsePrecedence((Precedence)(rule->precedence + 1));
switch (operatorType) {
case TOKEN_PLUS: emitByte(OP_ADD); break;
case TOKEN_MINUS: emitByte(OP_SUBTRACT); break;
case TOKEN_STAR: emitByte(OP_MULTIPLY); break;
case TOKEN_SLASH: emitByte(OP_DIVIDE); break;
default: return; // Unreachable.
}
}
When a prefix parser function is called, the leading token has already been consumed. An infix parser function is even more in medias res—the entire left-hand operand expression has already been compiled and the subsequent infix operator consumed.
當字首解析函式被呼叫時,字首標識已經被消耗了。中綴解析函式被呼叫時,情況更進一步——整個左運算元已經被編譯,而隨後的中綴運算子也已經被消耗掉。
The fact that the left operand gets compiled first works out fine. It means at runtime, that code gets executed first. When it runs, the value it produces will end up on the stack. That’s right where the infix operator is going to need it.
首先左運算元已經被編譯的事實是很好的。這意味著在執行時,其程式碼已經被執行了。當它執行時,它產生的值最終進入棧中。而這正是中綴運算子需要它的地方。
Then we come here to
binary()to handle the rest of the arithmetic operators. This function compiles the right operand, much like howunary()compiles its own trailing operand. Finally, it emits the bytecode instruction that performs the binary operation.
然後我們使用binary()來處理算術運算子的其餘部分。這個函式會編譯右邊的運算元,就像unary()編譯自己的尾運算元那樣。最後,它會發出執行對應二元運算的位元組碼指令。
When run, the VM will execute the left and right operand code, in that order, leaving their values on the stack. Then it executes the instruction for the operator. That pops the two values, computes the operation, and pushes the result.
當執行時,虛擬機器會按順序執行左、右運算元的程式碼,將它們的值留在棧上。然後它會執行運算子的指令。這時,會從棧中彈出這兩個值,計算結果,並將結果推入棧中。
The code that probably caught your eye here is that
getRule()line. When we parse the right-hand operand, we again need to worry about precedence. Take an expression like:
這裡可能會引起你注意的程式碼是getRule()這一行。當我們解析右運算元時,我們又一次需要考慮優先順序的問題。以下面這個表示式為例:
2 * 3 + 4
When we parse the right operand of the
*expression, we need to just capture3, and not3 + 4, because+is lower precedence than*. We could define a separate function for each binary operator. Each would callparsePrecedence()and pass in the correct precedence level for its operand.
當我們解析*表示式的右運算元時,我們只需要獲取3,而不是3+4,因為+的優先順序比*低。我們可以為每個二元運算子定義一個單獨的函式。每個函式都會呼叫 parsePrecedence() 並傳入正確的優先順序來解析其運算元。
But that’s kind of tedious. Each binary operator’s right-hand operand precedence is one level higher than its own. We can look that up dynamically with this
getRule()thing we’ll get to soon. Using that, we callparsePrecedence()with one level higher than this operator’s level.
但這有點乏味。每個二元運算子的右運算元的優先順序都比自己高一級7。我們可以透過getRule()動態地查詢,我們很快就會講到。有了它,我們就可以使用比當前運算子高一級的優先順序來呼叫parsePrecedence()。
This way, we can use a single
binary()function for all binary operators even though they have different precedences.
這樣,我們就可以對所有的二元運算子使用同一個binary()函式,即使它們的優先順序各不相同。
17 . 6 A Pratt Parser
17.6 Pratt解析器
We now have all of the pieces and parts of the compiler laid out. We have a function for each grammar production:
number(),grouping(),unary(), andbinary(). We still need to implementparsePrecedence(), andgetRule(). We also know we need a table that, given a token type, lets us find
現在我們已經排列好了編譯器的所有部分。對於每個語法生成式都有對應的函式:number(),grouping(),unary() 和 binary()。我們仍然需要實現 parsePrecedence()和getRule()。我們還知道,我們需要一個表格,給定一個標識型別,可以從中找到:
- the function to compile a prefix expression starting with a token of that type,
- the function to compile an infix expression whose left operand is followed by a token of that type, and
- the precedence of an infix expression that uses that token as an operator.
- 編譯以該型別標識為起點的字首表示式的函式
- 編譯一個左運算元後跟該型別標識的中綴表示式的函式,以及
- 使用該標識作為運算子的中綴表示式的優先順序8
We wrap these three properties in a little struct which represents a single row in the parser table.
我們將這三個屬性封裝在一個小結構體中9,該結構體表示解析器表格中的一行。
compiler.c,在列舉Precedence後新增程式碼:
} Precedence;
// 新增部分開始
typedef struct {
ParseFn prefix;
ParseFn infix;
Precedence precedence;
} ParseRule;
// 新增部分結束
Parser parser;
That ParseFn type is a simple typedef for a function type that takes no arguments and returns nothing.
這個ParseFn型別是一個簡單的函式型別定義,這類函式不需要任何引數且不返回任何內容。
compiler.c,在列舉 Precedence後新增程式碼:
} Precedence;
// 新增部分開始
typedef void (*ParseFn)();
// 新增部分結束
typedef struct {
The table that drives our whole parser is an array of ParseRules. We’ve been talking about it forever, and finally you get to see it.
驅動整個解析器的表格是一個ParserRule的陣列。我們討論了這麼久,現在你終於可以看到它了10。
compiler.c,在unary()方法後新增程式碼:
ParseRule rules[] = {
[TOKEN_LEFT_PAREN] = {grouping, NULL, PREC_NONE},
[TOKEN_RIGHT_PAREN] = {NULL, NULL, PREC_NONE},
[TOKEN_LEFT_BRACE] = {NULL, NULL, PREC_NONE},
[TOKEN_RIGHT_BRACE] = {NULL, NULL, PREC_NONE},
[TOKEN_COMMA] = {NULL, NULL, PREC_NONE},
[TOKEN_DOT] = {NULL, NULL, PREC_NONE},
[TOKEN_MINUS] = {unary, binary, PREC_TERM},
[TOKEN_PLUS] = {NULL, binary, PREC_TERM},
[TOKEN_SEMICOLON] = {NULL, NULL, PREC_NONE},
[TOKEN_SLASH] = {NULL, binary, PREC_FACTOR},
[TOKEN_STAR] = {NULL, binary, PREC_FACTOR},
[TOKEN_BANG] = {NULL, NULL, PREC_NONE},
[TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE},
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
[TOKEN_EQUAL_EQUAL] = {NULL, NULL, PREC_NONE},
[TOKEN_GREATER] = {NULL, NULL, PREC_NONE},
[TOKEN_GREATER_EQUAL] = {NULL, NULL, PREC_NONE},
[TOKEN_LESS] = {NULL, NULL, PREC_NONE},
[TOKEN_LESS_EQUAL] = {NULL, NULL, PREC_NONE},
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
[TOKEN_STRING] = {NULL, NULL, PREC_NONE},
[TOKEN_NUMBER] = {number, NULL, PREC_NONE},
[TOKEN_AND] = {NULL, NULL, PREC_NONE},
[TOKEN_CLASS] = {NULL, NULL, PREC_NONE},
[TOKEN_ELSE] = {NULL, NULL, PREC_NONE},
[TOKEN_FALSE] = {NULL, NULL, PREC_NONE},
[TOKEN_FOR] = {NULL, NULL, PREC_NONE},
[TOKEN_FUN] = {NULL, NULL, PREC_NONE},
[TOKEN_IF] = {NULL, NULL, PREC_NONE},
[TOKEN_NIL] = {NULL, NULL, PREC_NONE},
[TOKEN_OR] = {NULL, NULL, PREC_NONE},
[TOKEN_PRINT] = {NULL, NULL, PREC_NONE},
[TOKEN_RETURN] = {NULL, NULL, PREC_NONE},
[TOKEN_SUPER] = {NULL, NULL, PREC_NONE},
[TOKEN_THIS] = {NULL, NULL, PREC_NONE},
[TOKEN_TRUE] = {NULL, NULL, PREC_NONE},
[TOKEN_VAR] = {NULL, NULL, PREC_NONE},
[TOKEN_WHILE] = {NULL, NULL, PREC_NONE},
[TOKEN_ERROR] = {NULL, NULL, PREC_NONE},
[TOKEN_EOF] = {NULL, NULL, PREC_NONE},
};
You can see how
groupingandunaryare slotted into the prefix parser column for their respective token types. In the next column,binaryis wired up to the four arithmetic infix operators. Those infix operators also have their precedences set in the last column.
你可以看到grouping和unary是如何被插入到它們各自標識型別對應的字首解析器列中的。在下一列中,binary被連線到四個算術中綴運算子上。這些中綴運算子的優先順序也設定在最後一列。
Aside from those, the rest of the table is full of
NULLandPREC_NONE. Most of those empty cells are because there is no expression associated with those tokens. You can’t start an expression with, say,else, and}would make for a pretty confusing infix operator.
除此之外,表格的其餘部分都是NULL和PREC_NONE。這些空的單元格中大部分是因為沒有與這些標識相關聯的表示式。比如說,你不能用else作為表示式開頭,而}如果作為中綴運算子也會變得很混亂。
But, also, we haven’t filled in the entire grammar yet. In later chapters, as we add new expression types, some of these slots will get functions in them. One of the things I like about this approach to parsing is that it makes it very easy to see which tokens are in use by the grammar and which are available.
但是,我們還沒有填入整個語法。在後面的章節中,當我們新增新的表示式型別時,其中一些槽會插入函式。我喜歡這種解析方法的一點是,它使我們很容易看到哪些標識被語法使用,以及哪些標識是可用的。
Now that we have the table, we are finally ready to write the code that uses it. This is where our Pratt parser comes to life. The easiest function to define is getRule().
我們現在有了這個表格,終於準備好編寫使用它的程式碼了。這就是我們的Pratt解析器發揮作用的地方。最容易定義的函式是getRule()。
compiler.c,在parsePrecedence()方法後新增程式碼:
static ParseRule* getRule(TokenType type) {
return &rules[type];
}
It simply returns the rule at the given index. It’s called by
binary()to look up the precedence of the current operator. This function exists solely to handle a declaration cycle in the C code.binary()is defined before the rules table so that the table can store a pointer to it. That means the body ofbinary()cannot access the table directly.
它只是簡單地返回指定索引處的規則。binary()呼叫該函式來查詢當前運算子的優先順序。這個函式的存在只是為了處理C程式碼中的宣告迴圈。binary()在規則表之前定義,以便規則表中可以儲存指向它的指標。這也就意味著binary()的函式體不能直接訪問表格。
Instead, we wrap the lookup in a function. That lets us forward declare
getRule()before the definition ofbinary(), and then definegetRule()after the table. We’ll need a couple of other forward declarations to handle the fact that our grammar is recursive, so let’s get them all out of the way.
相反地,我們將查詢封裝在一個函式中。這樣我們可以在binary()函式定義之前宣告getRule(),然後在表格之後定義getRule()。我們還需要一些其它的前置宣告來處理語法的遞迴,所以讓我們一次性全部理出來。
compiler.c,在endCompiler()方法後新增程式碼:
emitReturn();
}
// 新增部分開始
static void expression();
static ParseRule* getRule(TokenType type);
static void parsePrecedence(Precedence precedence);
// 新增部分結束
static void binary() {
If you’re following along and implementing clox yourself, pay close attention to the little annotations that tell you where to put these code snippets. Don’t worry, though, if you get it wrong, the C compiler will be happy to tell you.
如果你正在跟隨本文實現自己的clox,請密切注意那些告訴你程式碼片段應該加在哪裡的小注釋。不過不用擔心,如果你弄錯了,C編譯器會很樂意告訴你。
17 . 6 . 1 Parsing with precedence
17.6.1 帶優先順序解析
Now we’re getting to the fun stuff. The maestro that orchestrates all of the parsing functions we’ve defined is
parsePrecedence(). Let’s start with parsing prefix expressions.
現在,我們要開始做有趣的事情了。我們定義的所有解析函式的協調者是 parsePrecedence()。讓我們從解析字首表示式開始。
compiler.c,在parsePrecedence()方法中替換一行:
static void parsePrecedence(Precedence precedence) {
// 替換部分開始
advance();
ParseFn prefixRule = getRule(parser.previous.type)->prefix;
if (prefixRule == NULL) {
error("Expect expression.");
return;
}
prefixRule();
// 替換部分結束
}
We read the next token and look up the corresponding ParseRule. If there is no prefix parser, then the token must be a syntax error. We report that and return to the caller.
我們讀取下一個標識並查詢對應的ParseRule。如果沒有字首解析器,那麼這個標識一定是語法錯誤。我們會報告這個錯誤並返回給呼叫方。
Otherwise, we call that prefix parse function and let it do its thing. That prefix parser compiles the rest of the prefix expression, consuming any other tokens it needs, and returns back here. Infix expressions are where it gets interesting since precedence comes into play. The implementation is remarkably simple.
否則,我們就呼叫字首解析函式,讓它做自己的事情。該字首解析器會編譯表示式的其餘部分,消耗它需要的任何其它標識,然後返回這裡。中綴表示式是比較有趣的地方,因為優先順序開始發揮作用了。這個實現非常簡單。 compiler.c,在parsePrecedence()方法中新增程式碼:
prefixRule();
// 新增部分開始
while (precedence <= getRule(parser.current.type)->precedence) {
advance();
ParseFn infixRule = getRule(parser.previous.type)->infix;
infixRule();
}
// 新增部分結束
}
That’s the whole thing. Really. Here’s how the entire function works: At the beginning of
parsePrecedence(), we look up a prefix parser for the current token. The first token is always going to belong to some kind of prefix expression, by definition. It may turn out to be nested as an operand inside one or more infix expressions, but as you read the code from left to right, the first token you hit always belongs to a prefix expression.
這就是全部內容了,真的。下面是整個函式的工作原理:在parsePrecedence()的開頭,我們會為當前標識查詢對應的字首解析器。根據定義,第一個標識總是屬於某種字首表示式。它可能作為一個運算元巢狀在一個或多箇中綴表示式中,但是當你從左到右閱讀程式碼時,你碰到的第一個標識總是屬於一個字首表示式。
After parsing that, which may consume more tokens, the prefix expression is done. Now we look for an infix parser for the next token. If we find one, it means the prefix expression we already compiled might be an operand for it. But only if the call to
parsePrecedence()has aprecedencethat is low enough to permit that infix operator.
解析之後(可能會消耗更多的標識),字首表示式就完成了。現在我們要為下一個標識尋找一箇中綴解析器。如果我們找到了,就意味著我們剛剛編譯的字首表示式可能是它的一個運算元。但前提是呼叫 parsePrecedence() 時傳入的precedence允許該中綴運算子。
If the next token is too low precedence, or isn’t an infix operator at all, we’re done. We’ve parsed as much expression as we can. Otherwise, we consume the operator and hand off control to the infix parser we found. It consumes whatever other tokens it needs (usually the right operand) and returns back to
parsePrecedence(). Then we loop back around and see if the next token is also a valid infix operator that can take the entire preceding expression as its operand. We keep looping like that, crunching through infix operators and their operands until we hit a token that isn’t an infix operator or is too low precedence and stop.
如果下一個標識的優先順序太低,或者根本不是一箇中綴運算子,我們就結束了。我們已經儘可能多地解析了表示式。否則,我們就消耗運算子,並將控制權移交給我們發現的中綴解析器。它會消耗所需要的其它標識(通常是右運算元)並返回到parsePrecedence()。然後我們再次迴圈,並檢視下一個識別符號是否也是一個有效的中綴運算子,且該運算子可以把前面的整個表示式作為其運算元。我們就這樣一直迴圈下去,直到遇見一個不是中綴運算子或優先順序太低的標識,然後停止。
That’s a lot of prose, but if you really want to mind meld with Vaughan Pratt and fully understand the algorithm, step through the parser in your debugger as it works through some expressions. Maybe a picture will help. There’s only a handful of functions, but they are marvelously intertwined:
這是一篇冗長的文章,但是如果你真的想與Vaughan Pratt心意相通,完全理解這個演算法,你可以讓解析器處理一些表示式,然後在偵錯程式中逐步檢視解析器。也許圖片會有幫助,只有少數幾個函式,但它們奇妙地交織在一起11。

Later, we’ll need to tweak the code in this chapter to handle assignment. But, otherwise, what we wrote covers all of our expression compiling needs for the rest of the book. We’ll plug additional parsing functions into the table when we add new kinds of expressions, but
parsePrecedence()is complete.
稍後,我們在處理賦值的時候需要調整本章中的程式碼。但是,除此之外,我們所寫的內容涵蓋了本書中其餘部分所有表示式編譯的需求。在新增新的表示式型別時,我們會在表格中插入額外的解析函式,但是 parsePrecedence() 是完整的。
17 . 7 Dumping Chunks
17.7 轉儲位元組碼塊
While we’re here in the core of our compiler, we should put in some instrumentation. To help debug the generated bytecode, we’ll add support for dumping the chunk once the compiler finishes. We had some temporary logging earlier when we hand-authored the chunk. Now we’ll put in some real code so that we can enable it whenever we want.
既然我們已經進入了編譯器的核心,我們就應該加入一些工具。為了有助於除錯生成的位元組碼,我們會增加對編譯器完成後轉儲位元組碼塊的支援。在之前我們手工編寫位元組碼塊時,進行了一些臨時的日誌記錄。現在,我們要填入一些實際的程式碼,以便我們可以隨時啟用它。
Since this isn’t for end users, we hide it behind a flag.
因為這不是為終端使用者準備的,所以我們把它隱藏在一個標誌後面。
common.h,新增程式碼:
#include <stdint.h>
// 新增部分開始
#define DEBUG_PRINT_CODE
// 新增部分結束
#define DEBUG_TRACE_EXECUTION
When that flag is defined, we use our existing “debug” module to print out the chunk’s bytecode.
當這個標誌被定義後,我們使用現有的“debug”模組打印出塊中的位元組碼。
compiler.c,在endCompiler()方法中新增程式碼:
emitReturn();
// 新增部分開始
#ifdef DEBUG_PRINT_CODE
if (!parser.hadError) {
disassembleChunk(currentChunk(), "code");
}
#endif
// 新增部分結束
}
We do this only if the code was free of errors. After a syntax error, the compiler keeps on going but it’s in kind of a weird state and might produce broken code. That’s harmless because it won’t get executed, but we’ll just confuse ourselves if we try to read it.
只有在程式碼沒有錯誤的情況下,我們才會這樣做。在出現語法錯誤後,編譯器會繼續執行,但它會處於一種奇怪的狀態,可能會產生錯誤的程式碼。不過這是無害的,因為它不會被執行,但如果我們試圖閱讀它,只會把我們弄糊塗。
Finally, to access
disassembleChunk(), we need to include its header.
最後,為了訪問disassembleChunk(),我們需要包含它的標頭檔案。
compiler.c,新增程式碼:
#include "scanner.h"
// 新增部分開始
#ifdef DEBUG_PRINT_CODE
#include "debug.h"
#endif
// 新增部分結束
typedef struct {
We made it! This was the last major section to install in our VM’s compilation and execution pipeline. Our interpreter doesn’t look like much, but inside it is scanning, parsing, compiling to bytecode, and executing.
我們成功了!這是我們的虛擬機器的編譯和執行管道中需要安裝的最後一個主要部分。我們的直譯器看起來不大,但它內部有掃描、解析、編譯位元組碼並執行。
Fire up the VM and type in an expression. If we did everything right, it should calculate and print the result. We now have a very over-engineered arithmetic calculator. We have a lot of language features to add in the coming chapters, but the foundation is in place.
啟動虛擬機器,輸入一個表示式。如果我們所有操作都正確,它應該會計算並列印結果。我們現在有了一個過度設計的算術計算器。在接下來的章節中,我們還好新增很多語言特性,但是基礎已經準備好了。
CHALLENGES
習題
-
To really understand the parser, you need to see how execution threads through the interesting parsing functions—
parsePrecedence()and the parser functions stored in the table. Take this (strange) expression:要真正理解解析器,你需要檢視執行執行緒如何透過有趣的解析函式——
parsePrecedence()和表格中的解析器函式。以這個(奇怪的)表示式為例:(-1 + 2) * 3 - -4Write a trace of how those functions are called. Show the order they are called, which calls which, and the arguments passed to them.
寫一下關於這些函式如何被呼叫的追蹤資訊。顯示它們被呼叫的順序,哪個呼叫哪個,以及傳遞給它們的引數。
-
The ParseRule row for
TOKEN_MINUShas both prefix and infix function pointers. That’s because-is both a prefix operator (unary negation) and an infix one (subtraction).In the full Lox language, what other tokens can be used in both prefix and infix positions? What about in C or in another language of your choice?
TOKEN_MINUS的ParseRule行同時具有字首和中綴函式指標。這是因為-既是字首運算子(一元取負),也是一箇中綴運算子(減法)。在完整的Lox語言中,還有哪些標識可以同時用於字首和中綴位置?在C語言或你選擇的其它語言中呢?
-
You might be wondering about complex “mixfix” expressions that have more than two operands separated by tokens. C’s conditional or “ternary” operator,
?:, is a widely known one.Add support for that operator to the compiler. You don’t have to generate any bytecode, just show how you would hook it up to the parser and handle the operands.
你可能會好奇負責的“多元”表示式,他有兩個以上的運算元,運算元之間由標識分開。C語言中的條件運算子或“三元”運算子
?:就是一個廣為人知的多元運算子。向編譯器中新增對該運算子的支援。你不需要生成任何位元組碼,只需要展示如何將其連線到解析器中並處理運算元。
DESIGN NOTE: IT’S JUST PARSING
設計筆記:只是解析
I’m going to make a claim here that will be unpopular with some compiler and language people. It’s OK if you don’t agree. Personally, I learn more from strongly stated opinions that I disagree with than I do from several pages of qualifiers and equivocation. My claim is that parsing doesn’t matter.
Over the years, many programming language people, especially in academia, have gotten really into parsers and taken them very seriously. Initially, it was the compiler folks who got into compiler-compilers, LALR, and other stuff like that. The first half of the dragon book is a long love letter to the wonders of parser generators.
All of us suffer from the vice of “when all you have is a hammer, everything looks like a nail”, but perhaps none so visibly as compiler people. You wouldn’t believe the breadth of software problems that miraculously seem to require a new little language in their solution as soon as you ask a compiler hacker for help.
Yacc and other compiler-compilers are the most delightfully recursive example. “Wow, writing compilers is a chore. I know, let’s write a compiler to write our compiler for us.”
For the record, I don’t claim immunity to this affliction.
Later, the functional programming folks got into parser combinators, packrat parsers, and other sorts of things. Because, obviously, if you give a functional programmer a problem, the first thing they’ll do is whip out a pocketful of higher-order functions.
Over in math and algorithm analysis land, there is a long legacy of research into proving time and memory usage for various parsing techniques, transforming parsing problems into other problems and back, and assigning complexity classes to different grammars.
At one level, this stuff is important. If you’re implementing a language, you want some assurance that your parser won’t go exponential and take 7,000 years to parse a weird edge case in the grammar. Parser theory gives you that bound. As an intellectual exercise, learning about parsing techniques is also fun and rewarding.
But if your goal is just to implement a language and get it in front of users, almost all of that stuff doesn’t matter. It’s really easy to get worked up by the enthusiasm of the people who are into it and think that your front end needs some whiz-bang generated combinator-parser-factory thing. I’ve seen people burn tons of time writing and rewriting their parser using whatever today’s hot library or technique is.
That’s time that doesn’t add any value to your user’s life. If you’re just trying to get your parser done, pick one of the bog-standard techniques, use it, and move on. Recursive descent, Pratt parsing, and the popular parser generators like ANTLR or Bison are all fine.
Take the extra time you saved not rewriting your parsing code and spend it improving the compile error messages your compiler shows users. Good error handling and reporting is more valuable to users than almost anything else you can put time into in the front end.
我在這裡要提出一個主張,這個主張可能不被一些編譯器和語言人士所歡迎。如果你不同意也沒關係。就我個人而言,比起幾頁的限定詞和含糊其辭,從那些我不同意的強烈的觀點中學習到的東西更多。我的主張是,解析並不重要。
多年來,許多從事程式語言的人,尤其是在學術界,確實是真正地深入瞭解析器,並且非常認真地對待它們12。最初,是編譯器研究者,他們深入研究編譯器的編譯器、LALR,以及其它類似的東西。龍書的前半部分就是寫給對解析器生成器好奇的人的一封長信。
後來,函數語言程式設計人員開始研究解析器組合子、packrat解析器和其它型別的東西。原因很明顯,如果你給函式式程式設計師提出一個問題,他們要做的第一件事就是拿出一堆高階函式。
在數學和演算法分析領域,長期以來一直在研究證明各種解析技術的時間和記憶體使用情況,將解析問題轉換為其它問題,併為不同的語法進行復雜性分類。
在某種程度上,這些東西很重要。如果你正在實現一門語言,你希望能夠確保你的解析器複雜度不會是指數級,不會花費7000年時間來解析語法中的一個奇怪的邊界情況。解析器理論給了你這種約束。作為一項智力練習,學習解析技術也是很有趣和有意義的。
但是,如果你的目標只是實現一門語言並將其送到使用者面前,那麼幾乎所有這些都不重要了。你很容易被那些對語言感興趣的人們的熱情所感染,認為你的前端需要一些快速生成的解析器組合子工廠之類的東西。我見過人們花費大量的時間,使用當下最熱門的庫或技術,編寫或重寫他們的解析器。
這些時間並不會給使用者的生活帶來任何價值。如果你只是想完成解析器,那麼可以選擇一個普通的標準技術,使用它,然後繼續前進。遞迴下降法,Pratt解析和流行的解析器生成器(如ANTLR或Bison)都很不錯。
把你不用重寫解析程式碼而節省下來的額外時間,花在改進編譯器向用戶顯示的編譯錯誤資訊上。對使用者來說,良好的錯誤處理和報告比你在語言前端投入時間所做的幾乎任何事情都更有價值。
-
如果你對這一章不感興趣,而你又希望從另一個角度瞭解這些概念,我寫過一篇文章講授了同樣的演算法,但使用了Java和麵向物件的風格:“Pratt Parsing: Expression Parsing Made Easy” ↩
-
事實上,大多數複雜的最佳化編譯器都不止兩遍執行過程。不僅要確定需要進行哪些最佳化,還要確定如何安排它們的順序——因為最佳化往往以複雜的方式相互作用——這是介於“開放的研究領域”和“黑暗的藝術”之間的問題。 ↩
-
有
setjmp()和longjmp(),但我不想使用它們。這些使我們很容易洩漏記憶體、忘記維護不變數,或者說寢食難安。 ↩ -
確實,這個限制是很低的。如果這是一個完整的語言實現,我們應該新增另一個指令,比如
OP_CONSTANT_16,將索引儲存為兩位元組的運算元,這樣就可以在需要時處理更多的常量。支援這個指令的程式碼不是特別有啟發性,所以我在clox中省略了它,但你會希望你的虛擬機器能夠擴充套件成更大的程式。 ↩ -
Pratt解析器不是遞迴下降解析器,但它仍然是遞迴的。這是意料之中的,因為語法本身是遞迴的。 ↩
-
在運算元之後發出
OP_NEGATE確實意味著寫入位元組碼時的當前標識不是-標識。但這並不重要,除了我們使用標識中的行號與指令相關聯。這意味著,如果你有一個多行的取負表示式,比如
那麼執行時錯誤會報告在錯誤的程式碼行上。這裡,它將在第2行顯示錯誤,而-是在第一行。一個更穩健的方法是在編譯器運算元之前儲存標識中的行號,然後將其傳遞給emitByte(),當我想在本書中儘量保持簡單。 ↩ -
我們對右運算元使用高一級的優先順序,因為二元運算子是左結合的。給出一系列相同的運算子,如:
1+2+3+4
我們想這樣解析它:((1+2)+3)+4
因此,當解析第一個+的右側運算元時,我們希望消耗2,但不消耗其餘部分,所以我們使用比+高一個優先順序的運算元。但如果我們的運算子是右結合的,這就錯了。考慮一下:a=b=c=d
因為賦值是右結合的,我們希望將其解析為:a=(b=(c=d))
為了實現這一點,我們會使用與當前運算子相同的優先順序來呼叫parsePrecedence()。 ↩ -
我們不需要跟蹤以指定標識開頭的字首表示式的優先順序,因為Lox中的所有字首運算子都有相同的優先順序。 ↩
-
C語言中函式指標型別的語法非常糟糕,所以我總是把它隱藏在型別定義之後。我理解這種語法背後的意圖——整個“宣告反映使用”之類的——但我認為這是一個失敗的語法實驗。 ↩
-
現在明白我所說的“不想每次需要新列時都重新審視這個表格”是什麼意思了吧?這就是個野獸。也許你沒有見過C語言陣列字面量中的
[TOKEN_DOT]=語法,這是C99指定的初始化器語法。這比手動計算陣列索引要清楚得多。 ↩ -
 箭頭連線一個函式與其直接呼叫的另一個函式,
箭頭連線一個函式與其直接呼叫的另一個函式, 箭頭連線表格中的指標與解析函式。 ↩
箭頭連線表格中的指標與解析函式。 ↩ -
我們所有人都有這樣的毛病:“當你只有一把錘子時,一切看起來都像是釘子”,但也許沒有人向編譯器人員那樣明顯。你不會相信,只要你向編譯器駭客尋求幫助,在他們的解決方案中有那麼多的軟體問題需要一種新的小語言來解決。
Yacc和其它編譯器的編譯器是最令人愉快的遞迴示例。“哇,寫編譯器是一件苦差事。我知道,讓我們寫一個編譯器來為我們編寫編譯器吧”。
鄭重宣告一下,我對這種疾病並沒有免疫力。 ↩
18.值型別 Types of Values
When you are a Bear of Very Little Brain, and you Think of Things, you find sometimes that a Thing which seemed very Thingish inside you is quite different when it gets out into the open and has other people looking at it.
—— A. A. Milne, Winnie-the-Pooh
你要是一隻腦子很小的熊,當你想事情的時候,你會發現,有時在你心裡看起來很像回事的事情,當它展示出來,讓別人看著它的時候,就完全不同了。(A. A.米爾恩,《小熊維尼》)
The past few chapters were huge, packed full of complex techniques and pages of code. In this chapter, there’s only one new concept to learn and a scattering of straightforward code. You’ve earned a respite.
前面的幾章篇幅很長,充滿了複雜的技術和一頁又一頁的程式碼。在本章中,只需要學習一個新概念和一些簡單的程式碼。你獲得了喘息的機會。
Lox is dynamically typed. A single variable can hold a Boolean, number, or string at different points in time. At least, that’s the idea. Right now, in clox, all values are numbers. By the end of the chapter, it will also support Booleans and
nil. While those aren’t super interesting, they force us to figure out how our value representation can dynamically handle different types.
Lox是動態型別的1。一個變數可以在不同的時間點持有布林值、數字或字串。至少,我們的想法是如此。現在,在clox中,所有的值都是數字。到本章結束時,它還將支援布林值和nil。雖然這些不是特別有趣,但它們迫使我們弄清楚值表示如何動態地處理不同型別。
18 . 1 Tagged Unions
18.1 帶標籤聯合體
The nice thing about working in C is that we can build our data structures from the raw bits up. The bad thing is that we have to do that. C doesn’t give you much for free at compile time and even less at runtime. As far as C is concerned, the universe is an undifferentiated array of bytes. It’s up to us to decide how many of those bytes to use and what they mean.
使用C語言工作的好處是,我們可以從最基礎的位元位開始構建資料結構。壞處是,我們必須這樣做。C語言在編譯時並沒有提供多少免費的東西,在執行時就更少了。對C語言來說,宇宙是一個無差別的位元組陣列。由我們來決定使用多少個位元組以及它們的含義。
In order to choose a value representation, we need to answer two key questions:
為了選擇一種值的表示形式,我們需要先回答兩個關鍵問題:
-
How do we represent the type of a value? If you try to, say, multiply a number by
true, we need to detect that error at runtime and report it. In order to do that, we need to be able to tell what a value’s type is.我們如何表示一個值的型別? 比如說,如果你將一個數字乘以
true,我們需要在執行時檢測到這個錯誤並報告它。為此,我們需要知道值的型別是什麼? -
How do we store the value itself? We need to not only be able to tell that three is a number, but that it’s different from the number four. I know, seems obvious, right? But we’re operating at a level where it’s good to spell these things out.
我們如何儲存該值本身? 我們不僅要能分辨出3是一個數字,還要能分辨出它與4是不同的。我知道,這是顯而易見的對吧?但是在我們所討論的層面,最好把這些事情說清楚。
Since we’re not just designing this language but building it ourselves, when answering these two questions we also have to keep in mind the implementer’s eternal quest: to do it efficiently.
因為我們不僅僅是設計這門語言,還要自己構建它,所以在回答這兩個問題時,我們還必須牢記實現者們永恆的追求:高效地完成它。
Language hackers over the years have come up with a variety of clever ways to pack the above information into as few bits as possible. For now, we’ll start with the simplest, classic solution: a tagged union. A value contains two parts: a type “tag”, and a payload for the actual value. To store the value’s type, we define an enum for each kind of value the VM supports.
多年來,語言駭客們想出了各種巧妙的方法,將上述資訊打包成儘可能少的位元。現在,我們將從最簡單、最經典的解決方案開始:帶標籤的聯合體。一個值包含兩個部分:一個型別“標籤”,和一個實際值的有效載荷。為了儲存值的型別,我們要為虛擬機器支援的每一種值定義一個列舉2。
value.h,新增程式碼:
#include "common.h"
// 新增部分開始
typedef enum {
VAL_BOOL,
VAL_NIL,
VAL_NUMBER,
} ValueType;
// 新增部分結束
typedef double Value;
For now, we have only a couple of cases, but this will grow as we add strings, functions, and classes to clox. In addition to the type, we also need to store the data for the value—the
doublefor a number,trueorfalsefor a Boolean. We could define a struct with fields for each possible type.
現在,我們只有這幾種情況,但隨著我們向clox中新增字串、函式和類,這裡也會越來越多。除了型別之外,我們還需要儲存值的資料——數字是double值,Boolean是true或false。我們可以定義一個結構體,其中包含每種可能的型別所對應的欄位。

But this is a waste of memory. A value can’t simultaneously be both a number and a Boolean. So at any point in time, only one of those fields will be used. C lets you optimize this by defining a union. A union looks like a struct except that all of its fields overlap in memory.
但這是對記憶體的一種浪費。一個值不可能同時是數字和布林值。所以在任何時候,這些欄位中只有一個會被使用。C語言中允許定義聯合體來最佳化這一點。聯合體看起來很像是結構體,區別在於其中的所有欄位在記憶體中是重疊的。

The size of a union is the size of its largest field. Since the fields all reuse the same bits, you have to be very careful when working with them. If you store data using one field and then access it using another, you will reinterpret what the underlying bits mean.
聯合體的大小就是其最大欄位的大小。由於這些欄位都複用相同的位元位,你在使用它們時必須要非常小心。如果你使用一個欄位儲存資料,然後用另一個欄位訪問資料,那你需要重新解釋底層位元位的含義3。
As the name “tagged union” implies, our new value representation combines these two parts into a single struct.
顧名思義,“帶標籤的聯合體”說明,我們新的值表示形式中將這兩部分合併成一個結構體。
value.h,在列舉ValueType後替換一行:
} ValueType;
// 替換部分開始
typedef struct {
ValueType type;
union {
bool boolean;
double number;
} as;
} Value;
// 替換部分結束
typedef struct {
There’s a field for the type tag, and then a second field containing the union of all of the underlying values. On a 64-bit machine with a typical C compiler, the layout looks like this:
有一個欄位用作型別標籤,然後是第二個欄位,一個包含所有底層值的聯合體4。在使用典型的C語言編譯器的64位機器上,佈局看起來如下:

The four-byte type tag comes first, then the union. Most architectures prefer values be aligned to their size. Since the union field contains an eight-byte double, the compiler adds four bytes of padding after the type field to keep that double on the nearest eight-byte boundary. That means we’re effectively spending eight bytes on the type tag, which only needs to represent a number between zero and three. We could stuff the enum in a smaller size, but all that would do is increase the padding.
首先是4位元組的型別標籤,然後是聯合體。大多數體系結構都喜歡將值與它們的字長對齊。由於聯合體欄位中包含一個8位元組的double值,所以編譯器在型別欄位後添加了4個位元組的填充,以使該double值保持在最近的8位元組邊界上。這意味著我們實際在型別標籤上花費了8個位元組,而它只需要表示0到3之間的數字。我們可以把列舉放在一個佔位更少的變數中,但這樣做只會增加填充量5。
So our Values are 16 bytes, which seems a little large. We’ll improve it later. In the meantime, they’re still small enough to store on the C stack and pass around by value. Lox’s semantics allow that because the only types we support so far are immutable. If we pass a copy of a Value containing the number three to some function, we don’t need to worry about the caller seeing modifications to the value. You can’t “modify” three. It’s three forever.
所以我們的Value是16個位元組,這似乎有點大。我們稍後會改進它。同時,它們也足夠小,可以儲存在C語言的堆疊中,並按值傳遞。Lox的語義允許這樣做,因為到目前為止我們只支援不可變型別。如果我們把一個包含數字3的Value的副本傳遞給某個函式,我們不需要擔心呼叫者會看到對該值的修改。你不能“修改”3,它永遠都是3。
18 . 2 Lox Values and C Values
18.2 Lox值和C值
That’s our new value representation, but we aren’t done. Right now, the rest of clox assumes Value is an alias for
double. We have code that does a straight C cast from one to the other. That code is all broken now. So sad.
這就是我們新的值表示形式,但是我們還沒有做完。現在,clox的其餘部分都假定了Value是double的別名。我們有一些程式碼是直接用C語言將一個值轉換為另一個值。這些程式碼現在都被破壞了,好傷心。
With our new representation, a Value can contain a double, but it’s not equivalent to it. There is a mandatory conversion step to get from one to the other. We need to go through the code and insert those conversions to get clox working again.
在我們新的表示形式中,Value可以包含一個double值,但它並不等同於double型別。有一個強制性的轉換步驟可以實現從一個值到另一個值的轉換。我們需要遍歷程式碼並插入這些轉換步驟,以使clox重新工作。
We’ll implement these conversions as a handful of macros, one for each type and operation. First, to promote a native C value to a clox Value:
我們會用少量的宏來實現這些轉換,每個宏對應一個型別和操作。首先,將原生的C值轉換為clox Value:
value.h,在結構體Value後新增程式碼:
} Value;
// 新增部分開始
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}})
#define NIL_VAL ((Value){VAL_NIL, {.number = 0}})
#define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
// 新增部分結束
typedef struct {
Each one of these takes a C value of the appropriate type and produces a Value that has the correct type tag and contains the underlying value. This hoists statically typed values up into clox’s dynamically typed universe. In order to do anything with a Value, though, we need to unpack it and get the C value back out.
其中每個宏都接收一個適當型別的C值,並生成一個Value,其具有正確型別標籤幷包含底層的值。這就把靜態型別的值提升到了clox的動態型別的世界。但是為了能對Value做任何操作,我們需要將其拆包並取出對應的C值6。
value.h,在結構體Value後新增程式碼:
} Value;
// 新增部分開始
#define AS_BOOL(value) ((value).as.boolean)
#define AS_NUMBER(value) ((value).as.number)
// 新增部分結束
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}})
These macros go in the opposite direction. Given a Value of the right type, they unwrap it and return the corresponding raw C value. The “right type” part is important! These macros directly access the union fields. If we were to do something like:
這些宏的作用是反方向的。給定一個正確型別的Value,它們會將其解包並返回對應的原始C值。“正確型別”很重要!這些宏會直接訪問聯合體欄位。如果我們要這樣做:
Value value = BOOL_VAL(true);
double number = AS_NUMBER(value);
Then we may open a smoldering portal to the Shadow Realm. It’s not safe to use any of the
AS_macros unless we know the Value contains the appropriate type. To that end, we define a last few macros to check a Value’s type.
那我們可能會開啟一個通往暗影王國的陰燃之門。除非我們知道Value包含適當的型別,否則使用任何的AS_宏都是不安全的。為此,我們定義最後幾個宏來檢查Value的型別。
value.h,在結構體Value後新增程式碼:
} Value;
// 新增部分開始
#define IS_BOOL(value) ((value).type == VAL_BOOL)
#define IS_NIL(value) ((value).type == VAL_NIL)
#define IS_NUMBER(value) ((value).type == VAL_NUMBER)
// 新增部分結束
#define AS_BOOL(value) ((value).as.boolean)
These macros return
trueif the Value has that type. Any time we call one of theAS_macros, we need to guard it behind a call to one of these first. With these eight macros, we can now safely shuttle data between Lox’s dynamic world and C’s static one.
如果Value具有對應型別,這些宏會返回true。每當我們呼叫一個AS_宏時,我們都需要保證首先呼叫了這些宏。有了這8個宏,我們現在可以安全地在Lox的動態世界和C的靜態世界之間傳輸資料了。
18 . 3 Dynamically Typed Numbers
18.3 動態型別數字
We’ve got our value representation and the tools to convert to and from it. All that’s left to get clox running again is to grind through the code and fix every place where data moves across that boundary. This is one of those sections of the book that isn’t exactly mind-blowing, but I promised I’d show you every single line of code, so here we are.
我們已經有了值的表示形式和轉換的工具。要想讓clox重新執行起來,剩下的工作就是仔細檢查程式碼,修復每個資料跨邊界傳遞的地方。這是本書中不太讓人興奮的章節之一,但我保證會給你展示每一行程式碼,所以我們開始吧。
The first values we create are the constants generated when we compile number literals. After we convert the lexeme to a C double, we simply wrap it in a Value before storing it in the constant table.
我們建立的第一個值是在編譯數值字面量時生成的常量。在我們將詞素轉換為C語言的double之後,我們簡單地將其包裝在一個Value中,然後再儲存到常量表中。
compiler.c,在number()函式中替換一行:
double value = strtod(parser.previous.start, NULL);
// 替換部分開始
emitConstant(NUMBER_VAL(value));
// 替換部分結束
}
Over in the runtime, we have a function to print values.
在執行時,我們有一個函式來列印值。
value.c,在printValue()方法中替換一行:
void printValue(Value value) {
// 替換部分開始
printf("%g", AS_NUMBER(value));
// 替換部分結束
}
Right before we send the Value to
printf(), we unwrap it and extract the double value. We’ll revisit this function shortly to add the other types, but let’s get our existing code working first.
在我們將Value傳送給printf()之前,我們將其拆裝並提取出double值。我們很快會重新回顧這個函式並新增其它型別,但是我們先讓現有的程式碼工作起來。
18 . 3 . 1 Unary negation and runtime errors
18.3.1 一元取負與執行時錯誤
The next simplest operation is unary negation. It pops a value off the stack, negates it, and pushes the result. Now that we have other types of values, we can’t assume the operand is a number anymore. The user could just as well do:
接下來最簡單的操作是一元取負。它會從棧中彈出一個值,對其取負,並將結果壓入棧。現在我們有了其它型別的值,我們不能再假設運算元是一個數字。使用者也可以這樣做:
print -false; // Uh...
We need to handle that gracefully, which means it’s time for runtime errors. Before performing an operation that requires a certain type, we need to make sure the Value is that type.
我們需要優雅地處理這個問題,這意味著是時候討論執行時錯誤了。在執行需要特定型別的操作之前,我們需要確保Value是該型別。
For unary negation, the check looks like this:
對於一元取負來說,檢查是這樣的:
vm.c,在run()方法中替換一行:
case OP_DIVIDE: BINARY_OP(/); break;
// 替換部分開始
case OP_NEGATE:
if (!IS_NUMBER(peek(0))) {
runtimeError("Operand must be a number.");
return INTERPRET_RUNTIME_ERROR;
}
push(NUMBER_VAL(-AS_NUMBER(pop())));
break;
// 替換部分結束
case OP_RETURN: {
First, we check to see if the Value on top of the stack is a number. If it’s not, we report the runtime error and stop the interpreter. Otherwise, we keep going. Only after this validation do we unwrap the operand, negate it, wrap the result and push it.
首先,我們檢查棧頂的Value是否是一個數字。如果不是,則報告執行時錯誤並停止直譯器7。否則,我們就繼續執行。只有在驗證之後,我們才會拆裝運算元,取負,將結果封裝並壓入棧。
To access the Value, we use a new little function.
為了訪問Value,我們使用一個新的小函式。
vm.c,在pop()方法後新增程式碼:
static Value peek(int distance) {
return vm.stackTop[-1 - distance];
}
It returns a Value from the stack but doesn’t pop it. The
distanceargument is how far down from the top of the stack to look: zero is the top, one is one slot down, etc.
它從堆疊中返回一個Value,但是並不彈出它8。distance引數是指要從堆疊頂部向下看多遠:0是棧頂,1是下一個槽,以此類推。
We report the runtime error using a new function that we’ll get a lot of mileage out of over the remainder of the book.
我們使用一個新函式來報告執行時錯誤,在本書的剩餘部分,我們會從中得到很多的好處。
vm.c,在resetStack()方法後新增程式碼:
static void runtimeError(const char* format, ...) {
va_list args;
va_start(args, format);
vfprintf(stderr, format, args);
va_end(args);
fputs("\n", stderr);
size_t instruction = vm.ip - vm.chunk->code - 1;
int line = vm.chunk->lines[instruction];
fprintf(stderr, "[line %d] in script\n", line);
resetStack();
}
You’ve certainly called variadic functions—ones that take a varying number of arguments—in C before:
printf()is one. But you may not have defined your own. This book isn’t a C tutorial, so I’ll skim over it here, but basically the...andva_liststuff let us pass an arbitrary number of arguments toruntimeError(). It forwards those on tovfprintf(), which is the flavor ofprintf()that takes an explicitva_list.
你以前肯定在C語言中呼叫過變參函式——接受不同數量引數的函式:printf()就是其中之一。但你可能還沒定義過自己的變參函式。這本書不是C語言教程9,所以我在這裡略過了,但是基本上是...和va_list讓我們可以向runtimeError()傳遞任意數量的引數。它將這些引數轉發給vfprintf(),這是printf()的一個變體,需要一個顯式地va_list。
Callers can pass a format string to
runtimeError()followed by a number of arguments, just like they can when callingprintf()directly.runtimeError()then formats and prints those arguments. We won’t take advantage of that in this chapter, but later chapters will produce formatted runtime error messages that contain other data.
呼叫者可以向runtimeError()傳入一個格式化字串,後跟一些引數,就像他們直接呼叫printf()一樣。然後runtimeError()格式化並列印這些引數。在本章中我們不會利用這一點,但後面的章節中將生成包含其它資料的格式化執行時錯誤資訊。
After we show the hopefully helpful error message, we tell the user which line of their code was being executed when the error occurred. Since we left the tokens behind in the compiler, we look up the line in the debug information compiled into the chunk. If our compiler did its job right, that corresponds to the line of source code that the bytecode was compiled from.
在顯示了希望有幫助的錯誤資訊之後,我們還會告訴使用者,當錯誤發生時正在執行程式碼中的哪一行10。因為我們在編譯器中留下了標識,所以我們可以從編譯到位元組碼塊中的除錯資訊中查詢行號。如果我們的編譯器正確完成了它的工作,就能對應到位元組碼被編譯出來的那一行原始碼。
We look into the chunk’s debug line array using the current bytecode instruction index minus one. That’s because the interpreter advances past each instruction before executing it. So, at the point that we call
runtimeError(), the failed instruction is the previous one.
我們使用當前位元組碼指令索引減1來檢視位元組碼塊的除錯行陣列。這是因為直譯器在之前每條指令之前都會向前推進。所以,當我們呼叫 runtimeError(),失敗的指令就是前一條。
Just showing the immediate line where the error occurred doesn’t provide much context. Better would be a full stack trace. But we don’t even have functions to call yet, so there is no call stack to trace.
In order to use
va_listand the macros for working with it, we need to bring in a standard header.
為了使用va_list和相關的宏,我們需要引入一個標準標頭檔案。
vm.c,在檔案頂部新增程式碼:
// 新增部分開始
#include <stdarg.h>
// 新增部分結束
#include <stdio.h>
With this, our VM can not only do the right thing when we negate numbers (like it used to before we broke it), but it also gracefully handles erroneous attempts to negate other types (which we don’t have yet, but still).
有了它,我們的虛擬機器不僅可以在對數字取負時正確執行(原本就會這樣做),而且還可以優雅地處理對其它型別取負的錯誤嘗試(目前還沒有,但仍然存在)。
18 . 3 . 2 Binary arithmetic operators
18.3.2 二元數字運算子
We have our runtime error machinery in place now, so fixing the binary operators is easier even though they’re more complex. We support four binary operators today:
+,-,*, and/. The only difference between them is which underlying C operator they use. To minimize redundant code between the four operators, we wrapped up the commonality in a big preprocessor macro that takes the operator token as a parameter.
我們現在已經有了執行時錯誤機制,所以修復二元運算子更容易,儘管它們更復雜。現在我們支援四種二元運算子:+、-、*和/。它們之間唯一的區別就是使用的是哪種底層C運算子。為了儘量減少這四個運算子之間的冗餘程式碼,我們將它們的共性封裝在一個大的預處理宏中,該宏以運算子標識作為引數。
That macro seemed like overkill a few chapters ago, but we get the benefit from it today. It lets us add the necessary type checking and conversions in one place.
這個宏在前幾章中似乎是多餘的,但現在我們卻從中受益。它讓我們可以在某個地方新增必要的型別檢查和轉換。 vm.c,在run()方法中替換6行:
#define READ_CONSTANT() (vm.chunk>constants.values[READ_BYTE()])
// 替換部分開始
#define BINARY_OP(valueType, op) \
do { \
if (!IS_NUMBER(peek(0)) || !IS_NUMBER(peek(1))) { \
runtimeError("Operands must be numbers."); \
return INTERPRET_RUNTIME_ERROR; \
} \
double b = AS_NUMBER(pop()); \
double a = AS_NUMBER(pop()); \
push(valueType(a op b)); \
} while (false)
// 替換部分結束
for (;;) {
Yeah, I realize that’s a monster of a macro. It’s not what I’d normally consider good C practice, but let’s roll with it. The changes are similar to what we did for unary negate. First, we check that the two operands are both numbers. If either isn’t, we report a runtime error and yank the ejection seat lever.
是的,我知道這是一個巨大的宏。這不是我通常認為的好的C語言實踐,但我們還是用它吧。這些調整與我們對一元取負所做的相似。首先,我們檢查兩個運算元是否都是數字。如果其中一個不是,我們就報告一個執行時錯誤,並拉下彈射座椅手柄。
If the operands are fine, we pop them both and unwrap them. Then we apply the given operator, wrap the result, and push it back on the stack. Note that we don’t wrap the result by directly using
NUMBER_VAL(). Instead, the wrapper to use is passed in as a macro parameter. For our existing arithmetic operators, the result is a number, so we pass in theNUMBER_VALmacro.
如果運算元都沒有問題,我們就把它們都彈出棧並進行拆裝。然後我們應用給定的運算子,包裝結果並將其壓回棧中。注意,我們沒有直接使用NUMBER_VAL()來包裝結果。相反,我們要使用的包裝器是作為宏引數傳入的。對於我們現有的數字運算子來說,結果是一個數字,所以我們傳入NUMBER_VAL宏11。
vm.c,在run()方法中替換4行:
}
// 替換部分開始
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break;
case OP_MULTIPLY: BINARY_OP(NUMBER_VAL, *); break;
case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
// 替換部分結束
case OP_NEGATE:
Soon, I’ll show you why we made the wrapping macro an argument.
很快,我就會告訴你為什麼我們要將包裝宏作為引數。
18 . 4 Two New Types
18.4 兩個新型別
All of our existing clox code is back in working order. Finally, it’s time to add some new types. We’ve got a running numeric calculator that now does a number of pointless paranoid runtime type checks. We can represent other types internally, but there’s no way for a user’s program to ever create a Value of one of those types.
我們現有的所有clox程式碼都恢復正常工作了。最後,是時候新增一些新型別了。我們有一個正在執行的數字計算器,它現在做了一些毫無意義的偏執的執行時型別檢查。我們可以在內部表示其它型別,但使用者的程式無法建立這些型別的Value。
Not until now, that is. We’ll start by adding compiler support for the three new literals:
true,false, andnil. They’re all pretty simple, so we’ll do all three in a single batch.
現在還不能。首先,我們向編譯器新增對三個新字面量的支援:true、false、nil。它們都很簡單,所以我們一次性完成這三個。
With number literals, we had to deal with the fact that there are billions of possible numeric values. We attended to that by storing the literal’s value in the chunk’s constant table and emitting a bytecode instruction that simply loaded that constant. We could do the same thing for the new types. We’d store, say,
true, in the constant table, and use anOP_CONSTANTto read it out.
對於數字字面量,我們要面對這樣一個事實:有數十億個可能的數字值。為此,我們將字面量的值儲存在位元組碼塊的常量表中,並生成一個載入該常量的位元組碼指令。我們可以對這些新型別做同樣的事。我們在常量表中儲存值,比如true,並使用OP_CONSTANT來讀取它。
But given that there are literally (heh) only three possible values we need to worry about with these new types, it’s gratuitous—and slow!—to waste a two-byte instruction and a constant table entry on them. Instead, we’ll define three dedicated instructions to push each of these literals on the stack.
但是考慮到這些新型別實際上只有三種可能的值,這樣做是沒有必要的——而且速度很慢!——浪費了一個兩位元組的指令和常量表中的一個項。相反,我們會定義三個專用指令12來將這些字面量壓入棧中。
chunk.h,在列舉OpCode中新增程式碼:
OP_CONSTANT,
// 新增部分開始
OP_NIL,
OP_TRUE,
OP_FALSE,
// 新增部分結束
OP_ADD,
Our scanner already treats
true,false, andnilas keywords, so we can skip right to the parser. With our table-based Pratt parser, we just need to slot parser functions into the rows associated with those keyword token types. We’ll use the same function in all three slots. Here:
我們的掃描器已經將true、false和nil視為關鍵字,所以我們可以直接調到解析器。對於我們這個基於表格的Pratt解析器,只需要將解析器函式插入到與這些關鍵字標識型別相對應的行中。我們會在三個槽中使用相同的函式。這裡:
compiler.c,替換一行:
[TOKEN_ELSE] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_FALSE] = {literal, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_FOR] = {NULL, NULL, PREC_NONE},
這裡:
compiler.c,替換一行:
[TOKEN_THIS] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_TRUE] = {literal, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_VAR] = {NULL, NULL, PREC_NONE},
還有這裡:
compiler.c,替換一行:
[TOKEN_IF] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_NIL] = {literal, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_OR] = {NULL, NULL, PREC_NONE},
When the parser encounters
false,nil, ortrue, in prefix position, it calls this new parser function:
當解析器在字首位置遇到false、nil或 true時,它會呼叫這個新的解析器函式:
compiler.c,在binary()方法後新增程式碼:
static void literal() {
switch (parser.previous.type) {
case TOKEN_FALSE: emitByte(OP_FALSE); break;
case TOKEN_NIL: emitByte(OP_NIL); break;
case TOKEN_TRUE: emitByte(OP_TRUE); break;
default: return; // Unreachable.
}
}
Since
parsePrecedence()has already consumed the keyword token, all we need to do is output the proper instruction. We figure that out based on the type of token we parsed. Our front end can now compile Boolean and nil literals to bytecode. Moving down the execution pipeline, we reach the interpreter.
因為parsePrecedence()已經消耗了關鍵字標識,我們需要做的就是輸出正確的指令。我們根據解析出的標識的型別來確定指令。我們的前端現在可以將布林值和nil字面量編譯為位元組碼。沿著執行管道向下移動,我們就到了直譯器。
vm.c,在run()方法中新增程式碼:
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
push(constant);
break;
}
// 新增部分開始
case OP_NIL: push(NIL_VAL); break;
case OP_TRUE: push(BOOL_VAL(true)); break;
case OP_FALSE: push(BOOL_VAL(false)); break;
// 新增部分結束
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
This is pretty self-explanatory. Each instruction summons the appropriate value and pushes it onto the stack. We shouldn’t forget our disassembler either.
這一點是不言而喻的。每條指令都會召喚出相應的值並將其壓入堆疊。我們也不能忘記反彙編程式。
debug.c,在disassembleInstruction()方法中新增程式碼:
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
// 新增部分開始
case OP_NIL:
return simpleInstruction("OP_NIL", offset);
case OP_TRUE:
return simpleInstruction("OP_TRUE", offset);
case OP_FALSE:
return simpleInstruction("OP_FALSE", offset);
// 新增部分結束
case OP_ADD:
With this in place, we can run this Earth-shattering program:
有了這些,我們就可以執行這個驚天動地的程式:
true
Except that when the interpreter tries to print the result, it blows up. We need to extend
printValue()to handle the new types too:
只是當直譯器試圖列印結果時,就崩潰了。我們也需要擴充套件printValue()來處理新型別:
value.c,在printValue()方法中替換1行:
void printValue(Value value) {
// 替換部分開始
switch (value.type) {
case VAL_BOOL:
printf(AS_BOOL(value) ? "true" : "false");
break;
case VAL_NIL: printf("nil"); break;
case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break;
}
// 替換部分結束
}
There we go! Now we have some new types. They just aren’t very useful yet. Aside from the literals, you can’t really do anything with them. It will be a while before
nilcomes into play, but we can start putting Booleans to work in the logical operators.
我們繼續!現在我們有了一些新的型別,只是它們目前還不是很有用。除了字面量之外,你無法真正對其做任何事。還需要一段時間nil才會發揮作用,但我們可以先讓布林值在邏輯運算子中發揮作用。
18 . 4 . 1 Logical not and falsiness
18.4.1 邏輯非和falsiness
The simplest logical operator is our old exclamatory friend unary not.
最簡單的邏輯運算子是我們充滿感嘆意味的老朋友一元取非。
print !true; // "false"
This new operation gets a new instruction.
這個新操作會有一條新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_DIVIDE,
// 新增部分開始
OP_NOT,
// 新增部分結束
OP_NEGATE,
We can reuse the
unary()parser function we wrote for unary negation to compile a not expression. We just need to slot it into the parsing table.
我們可以重用為一元取負所寫的解析函式來編譯一個邏輯非表示式。我們只需要將其插入到解析表格中。
compiler.c,替換一行:
[TOKEN_STAR] = {NULL, binary, PREC_FACTOR},
// 替換部分開始
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE},
Because I knew we were going to do this, the
unary()function already has a switch on the token type to figure out which bytecode instruction to output. We merely add another case.
因為我之前已知道我們要這樣做,unary()函式已經有了關於標識型別的switch語句,來判斷要輸出哪個位元組碼指令。我們只需要增加一個分支即可。
compiler.c,在unary()方法中新增程式碼:
switch (operatorType) {
// 新增部分開始
case TOKEN_BANG: emitByte(OP_NOT); break;
// 新增部分結束
case TOKEN_MINUS: emitByte(OP_NEGATE); break;
default: return; // Unreachable.
}
That’s it for the front end. Let’s head over to the VM and conjure this instruction into life.
前端就這樣了。讓我們去虛擬機器那裡,並將這個指令變成現實。
vm.c,在run()方法中新增程式碼:
case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
// 新增部分開始
case OP_NOT:
push(BOOL_VAL(isFalsey(pop())));
break;
// 新增部分結束
case OP_NEGATE:
Like our previous unary operator, it pops the one operand, performs the operation, and pushes the result. And, as we did there, we have to worry about dynamic typing. Taking the logical not of
trueis easy, but there’s nothing preventing an unruly programmer from writing something like this:
跟之前的一元運算子一樣,它會彈出一個運算元,執行操作,並將結果壓入棧中。正如我們所做的那樣,我們必須考慮動態型別。對true進行邏輯取非很容易,但沒什麼能阻止一個不守規矩的程式設計師寫出這樣的東西:
print !nil;
For unary minus, we made it an error to negate anything that isn’t a number. But Lox, like most scripting languages, is more permissive when it comes to
!and other contexts where a Boolean is expected. The rule for how other types are handled is called “falsiness”, and we implement it here:
對於一元取負,我們把對任何非數字的東西進行取負13當作一個錯誤。但是Lox,像大多數指令碼語言一樣,在涉及到!和其它期望出現布林值的情況下,是比較寬容的。處理其它型別的規則被稱為“falsiness”,我們在這裡實現它:
vm.c,在peek()方法後新增程式碼:
static bool isFalsey(Value value) {
return IS_NIL(value) || (IS_BOOL(value) && !AS_BOOL(value));
}
Lox follows Ruby in that
nilandfalseare falsey and every other value behaves liketrue. We’ve got a new instruction we can generate, so we also need to be able to ungenerate it in the disassembler.
Lox遵循Ruby的規定,nil和false是假的,其它的值都表現為true。我們已經有了一條可以生成的新指令,所以我們也需要能夠在反彙編程式中反生成它。
debug.c,在disassembleInstruction()方法中新增程式碼:
case OP_DIVIDE:
return simpleInstruction("OP_DIVIDE", offset);
// 新增部分開始
case OP_NOT:
return simpleInstruction("OP_NOT", offset);
// 新增部分結束
case OP_NEGATE:
18 . 4 . 2 Equality and comparison operators
18.4.2 相等與比較運算子
That wasn’t too bad. Let’s keep the momentum going and knock out the equality and comparison operators too:
==,!=,<,>,<=, and>=. That covers all of the operators that return Boolean results except the logical operatorsandandor. Since those need to short-circuit (basically do a little control flow) we aren’t ready for them yet.
還不算太糟。讓我們繼續保持這種勢頭,搞定相等與比較運算子: ==,!=,<,>,<=和>=。這涵蓋了所有會返回布林值的運算子,除了邏輯運算子and和or。因為這些運算子需要短路計算(基本上是做一個小小的控制流),我們還沒準備好。
Here are the new instructions for those operators:
下面是這些運算子對應的新指令:
chunk.h,在列舉OpCode中新增程式碼:
OP_FALSE,
// 新增部分開始
OP_EQUAL,
OP_GREATER,
OP_LESS,
// 新增部分結束
OP_ADD,
Wait, only three? What about
!=,<=, and>=? We could create instructions for those too. Honestly, the VM would execute faster if we did, so we should do that if the goal is performance.
等一下,只有三個?那!=、<=和>=呢?我們也可以為它們建立指令。老實說,如果我們這樣做,虛擬機器的執行速度會更快。所以如果我們的目標是追求效能,那就應該這樣做。
But my main goal is to teach you about bytecode compilers. I want you to start internalizing the idea that the bytecode instructions don’t need to closely follow the user’s source code. The VM has total freedom to use whatever instruction set and code sequences it wants as long as they have the right user-visible behavior.
但我的主要目標是教你有關位元組碼編譯器的知識。我想要你開始內化一個想法:位元組碼指令不需要緊跟使用者的原始碼。虛擬機器可以完全自由地使用它想要的任何指令集和程式碼序列,只要它們有正確的使用者可見的行為。
The expression
a != bhas the same semantics as!(a == b), so the compiler is free to compile the former as if it were the latter. Instead of a dedicatedOP_NOT_EQUALinstruction, it can output anOP_EQUALfollowed by anOP_NOT. Likewise,a <= bis the same as!(a > b)anda >= bis!(a < b). Thus, we only need three new instructions.
表示式a!=b與!(a==b)具有相同的語義14,所以編譯器可以自由地編譯前者,就好像它是後者一樣。它可以輸出一條OP_EQUAL指令,之後是一條OP_NOT,而不是一條專用的OP_NOT_EQUAL指令。同樣地,a<=b與!(a>b)相同,而a>=b與!(a<b)相同,所以我們只需要三條新指令。
Over in the parser, though, we do have six new operators to slot into the parse table. We use the same
binary()parser function from before. Here’s the row for!=:
不過,在解析器中,我們確實有6個新的運算子要加入到解析表中。我們使用與之前相同的binary()解析函式。下面是!=對應的行:
compiler.c,替換1行:
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_BANG_EQUAL] = {NULL, binary, PREC_EQUALITY},
// 替換部分結束
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
The remaining five operators are a little farther down in the table.
其餘五個運算子在表的最下方。
compiler.c,替換5行:
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_EQUAL_EQUAL] = {NULL, binary, PREC_EQUALITY},
[TOKEN_GREATER] = {NULL, binary, PREC_COMPARISON},
[TOKEN_GREATER_EQUAL] = {NULL, binary, PREC_COMPARISON},
[TOKEN_LESS] = {NULL, binary, PREC_COMPARISON},
[TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
// 替換部分結束
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
Inside
binary()we already have a switch to generate the right bytecode for each token type. We add cases for the six new operators.
在binary()中,我們已經有了一個switch語句,為每種標識型別生成正確的位元組碼。我們為這六個新運算子新增分支。
compiler.c,在binary()方法內新增程式碼:
switch (operatorType) {
// 新增部分開始
case TOKEN_BANG_EQUAL: emitBytes(OP_EQUAL, OP_NOT); break;
case TOKEN_EQUAL_EQUAL: emitByte(OP_EQUAL); break;
case TOKEN_GREATER: emitByte(OP_GREATER); break;
case TOKEN_GREATER_EQUAL: emitBytes(OP_LESS, OP_NOT); break;
case TOKEN_LESS: emitByte(OP_LESS); break;
case TOKEN_LESS_EQUAL: emitBytes(OP_GREATER, OP_NOT); break;
// 新增部分結束
case TOKEN_PLUS: emitByte(OP_ADD); break;
The
==,<, and>operators output a single instruction. The others output a pair of instructions, one to evalute the inverse operation, and then anOP_NOTto flip the result. Six operators for the price of three instructions!
==、<和> 運算子輸出單個指令。其它運算子則輸出一對指令,一條用於計算逆運算,然後用OP_NOT來反轉結果。僅僅使用三種指令就表達出了六種運算子的效果!
That means over in the VM, our job is simpler. Equality is the most general operation.
這意味著在虛擬機器中,我們的工作更簡單了。相等是最普遍的操作。
vm.c,在run()方法中新增程式碼:
case OP_FALSE: push(BOOL_VAL(false)); break;
// 新增部分開始
case OP_EQUAL: {
Value b = pop();
Value a = pop();
push(BOOL_VAL(valuesEqual(a, b)));
break;
}
// 新增部分結束
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
You can evaluate
==on any pair of objects, even objects of different types. There’s enough complexity that it makes sense to shunt that logic over to a separate function. That function always returns a Cbool, so we can safely wrap the result in aBOOL_VAL. The function relates to Values, so it lives over in the “value” module.
你可以對任意一對物件執行==,即使這些物件是不同型別的。這有足夠的複雜性,所以有必要把這個邏輯分流到一個單獨的函式中。這個函式會一個C語言的bool值,所以我們可以安全地把結果包裝在一個BOLL_VAL中。這個函式與Value有關,所以它位於“value”模組中。
value.h,在結構體ValueArray後新增程式碼:
} ValueArray;
// 新增部分開始
bool valuesEqual(Value a, Value b);
// 新增部分結束
void initValueArray(ValueArray* array);
And here’s the implementation:
下面是實現:
value.c,在printValue()方法後新增程式碼:
bool valuesEqual(Value a, Value b) {
if (a.type != b.type) return false;
switch (a.type) {
case VAL_BOOL: return AS_BOOL(a) == AS_BOOL(b);
case VAL_NIL: return true;
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
default: return false; // Unreachable.
}
}
First, we check the types. If the Values have different types, they are definitely not equal. Otherwise, we unwrap the two Values and compare them directly.
首先,我們檢查型別。如果兩個Value的型別不同,它們肯定不相等15。否則,我們就把這兩個Value拆裝並直接進行比較。
For each value type, we have a separate case that handles comparing the value itself. Given how similar the cases are, you might wonder why we can’t simply
memcmp()the two Value structs and be done with it. The problem is that because of padding and different-sized union fields, a Value contains unused bits. C gives no guarantee about what is in those, so it’s possible that two equal Values actually differ in memory that isn’t used.
對於每一種值型別,我們都有一個單獨的case分支來處理值本身的比較。考慮到這些分支的相似性,你可能會想,為什麼我們不能簡單地對兩個Value結構體進行memcmp(),然後就可以了。問題在於,因為填充以及聯合體欄位的大小不同,Value中會包含無用的位元位。C語言不能保證這些值是什麼,所以兩個相同的Value在未使用的記憶體中可能是完全不同的。

(You wouldn’t believe how much pain I went through before learning this fact.)
(你無法想象在瞭解這個事實之前我經歷了多少痛苦。)
Anyway, as we add more types to clox, this function will grow new cases. For now, these three are sufficient. The other comparison operators are easier since they work only on numbers.
總之,隨著我們向clox中新增更多的型別,這個函式也會增加更多的case分支。就目前而言,這三個已經足夠了。其它的比較運算子更簡單,因為它們只處理數字。
vm.c,在run()方法中新增程式碼:
push(BOOL_VAL(valuesEqual(a, b)));
break;
}
// 新增部分開始
case OP_GREATER: BINARY_OP(BOOL_VAL, >); break;
case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
// 新增部分結束
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
We already extended the
BINARY_OPmacro to handle operators that return non-numeric types. Now we get to use that. We pass inBOOL_VALsince the result value type is Boolean. Otherwise, it’s no different from plus or minus.
我們已經擴充套件了BINARY_OP宏,來處理返回非數字型別的運算子。現在我們要用到它了。因為結果值型別是布林型,所以我們傳入BOOL_VAL。除此之外,這與加減運算沒有區別。
As always, the coda to today’s aria is disassembling the new instructions.
與往常一樣,今天的詠歎調的尾聲是對新指令進行反彙編。
debug.c,在disassembleInstruction()方法中新增程式碼:
case OP_FALSE:
return simpleInstruction("OP_FALSE", offset);
// 新增部分開始
case OP_EQUAL:
return simpleInstruction("OP_EQUAL", offset);
case OP_GREATER:
return simpleInstruction("OP_GREATER", offset);
case OP_LESS:
return simpleInstruction("OP_LESS", offset);
// 新增部分結束
case OP_ADD:
With that, our numeric calculator has become something closer to a general expression evaluator. Fire up clox and type in:
這樣一來,我們的數字計算器就變得更接近於一個通用的表示式求值器。啟動clox並輸入:
!(5 - 4 > 3 * 2 == !nil)
OK, I’ll admit that’s maybe not the most useful expression, but we’re making progress. We have one missing built-in type with its own literal form: strings. Those are much more complex because strings can vary in size. That tiny difference turns out to have implications so large that we give strings their very own chapter.
好吧,我承認這可能不是最有用的表示式,但我們正在取得進展。我們還缺少一種自帶字面量形式的內建型別:字串。它們要複雜得多,因為字串的大小可以不同。這個微小的差異會產生巨大的影響,以至於我們給字串單獨開了一章。
CHALLENGES
習題
-
We could reduce our binary operators even further than we did here. Which other instructions can you eliminate, and how would the compiler cope with their absence?
我們可以進一步簡化二元運算子。還有哪些指令可以取消,編譯器如何應對這些指令的缺失?
-
Conversely, we can improve the speed of our bytecode VM by adding more specific instructions that correspond to higher-level operations. What instructions would you define to speed up the kind of user code we added support for in this chapter?
相反,我們可以透過新增更多對應於高階操作的專用指令來提高位元組碼虛擬機器的速度。你會定義什麼指令來加速我們在本章中新增的那種使用者程式碼?
-
在靜態型別和動態型別之外,還有第三類:單一型別(unityped)。在這種正規化中,所有的變數都是一個型別,通常是一個機器暫存器整數。單一型別的語言在今天並不常見,但一些Forth派生語言和BCPL(啟發了C的語言)是這樣工作的。從這一刻起,clox是單一型別的。 ↩
-
這個案例中涵蓋了虛擬機器中內建支援的每一種值。等到我們在語言中新增類時,使用者定義的每個類並不需要在這個列舉中新增對應的條目。對於虛擬機器而言,一個類的每個例項都是相同的型別:“instance”。換句話說,這是虛擬機器中的“型別”概念,而不是使用者的。 ↩
-
使用聯合體將位元位解釋為不同型別是C語言的精髓。它提供了許多巧妙的最佳化,讓你能夠以記憶體安全型語言中不允許的方式對記憶體中的每個位元組進行切分。但它也是非常不安全的,如果你不小心,它就可能會鋸掉你的手指。 ↩
-
一個聰明的語言駭客給了我一個想法,把“as”作為聯合體欄位名稱,因為當你取出各種值時,讀起來感覺很好,就像是強制轉換一樣。 ↩
-
我們可以把標籤欄位移動到聯合體欄位之後,但這也沒有多大幫助。每當我們建立一個Value陣列時(這也是我們對Value的主要記憶體使用),C編譯器都會在每個數值之間插入相同的填充,以保持雙精度數對齊。 ↩
-
沒有
AS_NIL宏,因為只有一個nil值,所以一個型別為VAL_NIL的Value不會攜帶任何額外的資料。 ↩ -
Lox的錯誤處理方法是相當……簡樸的。所有的錯誤都是致命的,會立即停止直譯器。使用者程式碼無法從錯誤中恢復。如果Lox是一種真正的語言,這是我首先要補救的事情之一。 ↩
-
為什麼不直接彈出操作數然後驗證它呢?我們可以這麼做。在後面的章節中,將運算元留在棧上是很重要的,可以確保在執行過程中觸發垃圾收集時,垃圾收集器能夠找到它們。我在這裡做了同樣的事情,主要是出於習慣。 ↩
-
如果你在尋找一個C教程,我喜歡C程式設計語言,通常被稱為“K&R”,以紀念它的作者。它並不完全是最新的,但是寫作質量足以彌補這一點。 ↩
-
僅僅顯示發生錯誤的那一行並不能提供太多的上下文資訊。最後是提供完整的堆疊跟蹤,但是我們目前甚至還沒有函式呼叫,所以也沒有呼叫堆疊可以跟蹤。 ↩
-
你知道可以將宏作為引數傳遞給宏嗎?現在你知道了! ↩
-
我不是在開玩笑,對於某些常量值的專用操作會更快。位元組碼虛擬機器的大部分執行時間都花在讀取和解碼指令上。對於一個特定的行為,你需要的指令越少、越簡單,它就越快。專用於常見操作的短指令是一種典型的最佳化。
例如,Java位元組碼指令集中有專門的指令用於載入0.0、1.0、2.0以及從-1到5之間的整數。(考慮到大多數成熟的JVM在執行前都會對位元組碼進行JIT編譯,這最終成為了一種殘留的最佳化) ↩ -
現在我忍不住想弄清楚,對其它型別的值取反意味著什麼。
nil可能有自己的非值,有點像一個奇怪的偽零。對字串取反可以,呃……,反轉? ↩ -
a<=b總是與!(a>b)相同嗎?根據IEEE 754標準,當運算元為NaN時,所有的比較運算子都返回假。這意味著NaN <= 1是假的,NaN > 1也是假的。但我們的脫糖操作假定了後者是前者的非值。
在本書中,我們不必糾結於此,但這些細節在你的真正的語言實現中會很重要。 ↩ -
有些語言支援“隱式轉換”,如果某個型別的值可以轉換為另一個型別,那麼這兩種型別的值就可以被認為是相等的。舉例來說,在JavaScript中,數字0等同於字串“0”。這種鬆散性導致JS增加了一個單獨的“嚴格相等”運算子,
===。
PHP認為字串“1”和“01”是等價的,因為兩者都可以轉換成等價的數字,但是最根本的原因在於PHP是由Lovecraftian(譯者注:洛夫克拉夫特,克蘇魯之父,可見作者對PHP怨念頗深)的邪神設計的,目的是摧毀人類心智。
大多數具有單獨的整數和浮點數型別的動態型別語言認為,如果數值相同,則不同數字型別的值是相等的(所以說,1.0等於1),但即便是這種看似無害的便利,如果一不小心也會讓人吃不消。 ↩
19.字符串 Strings
“Ah? A small aversion to menial labor?” The doctor cocked an eyebrow. “Understandable, but misplaced. One should treasure those hum-drum tasks that keep the body occupied but leave the mind and heart unfettered.”
——Tad Williams, The Dragonbone Chair
“啊?對瑣碎的勞動有點反感?”醫生挑了挑眉毛,“可以理解,但這是錯誤的。一個人應該珍惜那些讓身體忙碌,但讓思想和心靈不受束縛的瑣碎工作。”(泰德-威廉姆斯,《龍骨椅》)
Our little VM can represent three types of values right now: numbers, Booleans, and
nil. Those types have two important things in common: they’re immutable and they’re small. Numbers are the largest, and they still fit into two 64-bit words. That’s a small enough price that we can afford to pay it for all values, even Booleans and nils which don’t need that much space.
我們的小虛擬機現在可以表示三種類型的值:數字,布爾值和nil。這些類型有兩個重要的共同點:它們是不可變的,它們很小。數字是最大的,而它仍可以被2個64比特的字容納。這是一個足夠小的代價,我們可以為所有值都支付這個代價,即使是不需要那麼多空間的布爾值和nil。
Strings, unfortunately, are not so petite. There’s no maximum length for a string. Even if we were to artificially cap it at some contrived limit like 255 characters, that’s still too much memory to spend on every single value.
不幸的是,字符串就沒有這麼小了。一個字符串沒有最大的長度,即使我們人為地將其限制在255個字符1,這對於每個單獨的值來說仍然花費了太多的內存。
We need a way to support values whose sizes vary, sometimes greatly. This is exactly what dynamic allocation on the heap is designed for. We can allocate as many bytes as we need. We get back a pointer that we’ll use to keep track of the value as it flows through the VM.
我們需要一種方法來支持那些大小變化(有時變化很大)的值。這正是堆上動態分配的設計目的。我們可以根據需要分配任意多的字節。我們會得到一個指針,當值在虛擬機中流動時,我們會用該指針來跟蹤它。
19 . 1 Values and Objects
19.1 值與對象
Using the heap for larger, variable-sized values and the stack for smaller, atomic ones leads to a two-level representation. Every Lox value that you can store in a variable or return from an expression will be a Value. For small, fixed-size types like numbers, the payload is stored directly inside the Value struct itself.
將堆用於較大的、可變大小的值,將棧用於較小的、原子性的值,這就導致了兩級表示形式。每個可以存儲在變量中或從表達式返回的Lox值都是一個Value。對於小的、固定大小的類型(如數字),有效載荷直接存儲在Value結構本身。
If the object is larger, its data lives on the heap. Then the Value’s payload is a pointer to that blob of memory. We’ll eventually have a handful of heap-allocated types in clox: strings, instances, functions, you get the idea. Each type has its own unique data, but there is also state they all share that our future garbage collector will use to manage their memory.
如果對象比較大,它的數據就駐留在堆中。那麼Value的有效載荷就是指向那塊內存的一個指針。我們最終會在clox中擁有一些堆分配的類型:字符串、實例、函數,你懂的。每個類型都有自己獨特的數據,但它們也有共同的狀態,我們未來的垃圾收集器會用這些狀態來管理它們的內存。
We’ll call this common representation “Obj”. Each Lox value whose state lives on the heap is an Obj. We can thus use a single new ValueType case to refer to all heap-allocated types.
我們將這個共同的表示形式稱為“Obj”2。每個狀態位於堆上的Lox值都是一個Obj。因此,我們可以使用一個新的ValueType來指代所有堆分配的類型。
value.h,在枚舉ValueType中添加代碼:
VAL_NUMBER,
// 新增部分開始
VAL_OBJ
// 新增部分結束
} ValueType;
When a Value’s type is
VAL_OBJ, the payload is a pointer to the heap memory, so we add another case to the union for that.
當Value的類型是VAL_OBJ時,有效載荷是一個指向堆內存的指針,因此我們在聯合體中為其添加另一種情況。
value.h,在結構體Value中添加代碼:
double number;
// 新增部分開始
Obj* obj;
// 新增部分結束
} as;
As we did with the other value types, we crank out a couple of helpful macros for working with Obj values.
正如我們對其它值類型所做的那樣,我們提供了幾個有用的宏來處理Obj值。
value.h,在結構體Value後添加代碼:
#define IS_NUMBER(value) ((value).type == VAL_NUMBER)
// 新增部分開始
#define IS_OBJ(value) ((value).type == VAL_OBJ)
// 新增部分結束
#define AS_BOOL(value) ((value).as.boolean)
This evaluates to
trueif the given Value is an Obj. If so, we can use this:
如果給定的Value是一個Obj,則該值計算結果為true。如果這樣,我們可以使用這個:
value.h,添加代碼:
#define IS_OBJ(value) ((value).type == VAL_OBJ)
// 新增部分開始
#define AS_OBJ(value) ((value).as.obj)
// 新增部分結束
#define AS_BOOL(value) ((value).as.boolean)
It extracts the Obj pointer from the value. We can also go the other way.
它會從值中提取Obj指針。我們也可以反其道而行之。
value.h,添加代碼:
#define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
// 新增部分開始
#define OBJ_VAL(object) ((Value){VAL_OBJ, {.obj = (Obj*)object}})
// 新增部分結束
typedef struct {
This takes a bare Obj pointer and wraps it in a full Value.
該方法會接受一個Obj指針,並將其包裝成一個完整的Value。
19 . 2 Struct Inheritance
19.2 結構體繼承
Every heap-allocated value is an Obj, but Objs are not all the same. For strings, we need the array of characters. When we get to instances, they will need their data fields. A function object will need its chunk of bytecode. How do we handle different payloads and sizes? We can’t use another union like we did for Value since the sizes are all over the place.
每個堆分配的值都是一個Obj,但Obj並不都是一樣的。對於字符串,我們需要字符數組。等我們有了實例,它們需要自己的數據字段。一個函數對象需要的是其字節碼塊。我們如何處理不同的有效載荷和大小?我們不能像Value那樣使用另一個聯合體,因為這些大小各不相同。
Instead, we’ll use another technique. It’s been around for ages, to the point that the C specification carves out specific support for it, but I don’t know that it has a canonical name. It’s an example of type punning, but that term is too broad. In the absence of any better ideas, I’ll call it struct inheritance, because it relies on structs and roughly follows how single-inheritance of state works in object-oriented languages.
相對地,我們會使用另一種技術。它已經存在了很久,以至於C語言規範為它提供了明確的支持,但我不知道它是否有一個正式的名字。這是一個類型雙關的例子,但這個術語太寬泛了。鑑於沒有更好的想法,我將其稱為結構體繼承,因為它依賴於結構體,並大致遵循了面嚮對象語言中狀態的單繼承工作方式。
Like a tagged union, each Obj starts with a tag field that identifies what kind of object it is—string, instance, etc. Following that are the payload fields. Instead of a union with cases for each type, each type is its own separate struct. The tricky part is how to treat these structs uniformly since C has no concept of inheritance or polymorphism. I’ll explain that soon, but first lets get the preliminary stuff out of the way.
與帶標籤的聯合體一樣,每個Obj開頭都是一個標籤字段,用於識別它是什麼類型的對象——字符串、實例,等等。接下來是有效載荷字段。每種類型都有自己單獨的結構,而不是各類型結構的聯合體。棘手的部分是如何統一處理這些結構,因為C沒有繼承或多態的概念。我很快就會對此進行解釋,但是首先讓我們先弄清楚一些基本的東西。
The name “Obj” itself refers to a struct that contains the state shared across all object types. It’s sort of like the “base class” for objects. Because of some cyclic dependencies between values and objects, we forward-declare it in the “value” module.
“Obj”這個名稱本身指的是一個結構體,它包含所有對象類型共享的狀態。它有點像對象的“基類”。由於值和對象之間存在一些循環依賴關係,我們在“value”模塊中對其進行前置聲明。
value.h,添加代碼:
#include "common.h"
// 新增部分開始
typedef struct Obj Obj;
// 新增部分結束
typedef enum {
And the actual definition is in a new module.
實際的定義是在一個新的模塊中。
object.h,創建新文件:
#ifndef clox_object_h
#define clox_object_h
#include "common.h"
#include "value.h"
struct Obj {
ObjType type;
};
#endif
Right now, it contains only the type tag. Shortly, we’ll add some other bookkeeping information for memory management. The type enum is this:
現在,它只包含一個類型標記。不久之後,我們將為內存管理添加一些其它的簿記信息。類型枚舉如下:
object.h,添加代碼:
#include "value.h"
// 新增部分開始
typedef enum {
OBJ_STRING,
} ObjType;
// 新增部分結束
struct Obj {
Obviously, that will be more useful in later chapters after we add more heap-allocated types. Since we’ll be accessing these tag types frequently, it’s worth making a little macro that extracts the object type tag from a given Value.
顯然,等我們在後面的章節中添加了更多的堆分配類型之後,這個枚舉會更有用。因為我們會經常訪問這些標記類型,所以有必要編寫一個宏,從給定的Value中提取對象類型標籤。
object.h,添加代碼:
#include "value.h"
// 新增部分開始
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
// 新增部分結束
typedef enum {
That’s our foundation.
這是我們的基礎。
Now, let’s build strings on top of it. The payload for strings is defined in a separate struct. Again, we need to forward-declare it.
現在,讓我們在其上建立字符串。字符串的有效載荷定義在一個單獨的結構體中。同樣,我們需要對其進行前置聲明。
value.h,添加代碼:
typedef struct Obj Obj;
// 新增部分開始
typedef struct ObjString ObjString;
// 新增部分結束
typedef enum {
The definition lives alongside Obj.
這個定義與Obj是並列的。
object.h,在結構體Obj後添加代碼:
};
// 新增部分開始
struct ObjString {
Obj obj;
int length;
char* chars;
};
// 新增部分結束
#endif
A string object contains an array of characters. Those are stored in a separate, heap-allocated array so that we set aside only as much room as needed for each string. We also store the number of bytes in the array. This isn’t strictly necessary but lets us tell how much memory is allocated for the string without walking the character array to find the null terminator.
字符串對象中包含一個字符數組。這些字符存儲在一個單獨的、由堆分配的數組中,這樣我們就可以按需為每個字符串留出空間。我們還會保存數組中的字節數。這並不是嚴格必需的,但可以讓我們迅速知道為字符串分配了多少內存,而不需要遍歷字符數組尋找空結束符。
Because ObjString is an Obj, it also needs the state all Objs share. It accomplishes that by having its first field be an Obj. C specifies that struct fields are arranged in memory in the order that they are declared. Also, when you nest structs, the inner struct’s fields are expanded right in place. So the memory for Obj and for ObjString looks like this:
因為ObjString是一個Obj,它也需要所有Obj共有的狀態。它通過將第一個字段置為Obj來實現這一點。C語言規定,結構體的字段在內存中是按照它們的聲明順序排列的。此外,當結構體嵌套時,內部結構體的字段會在適當的位置展開。所以Obj和ObjString的內存看起來是這樣的:
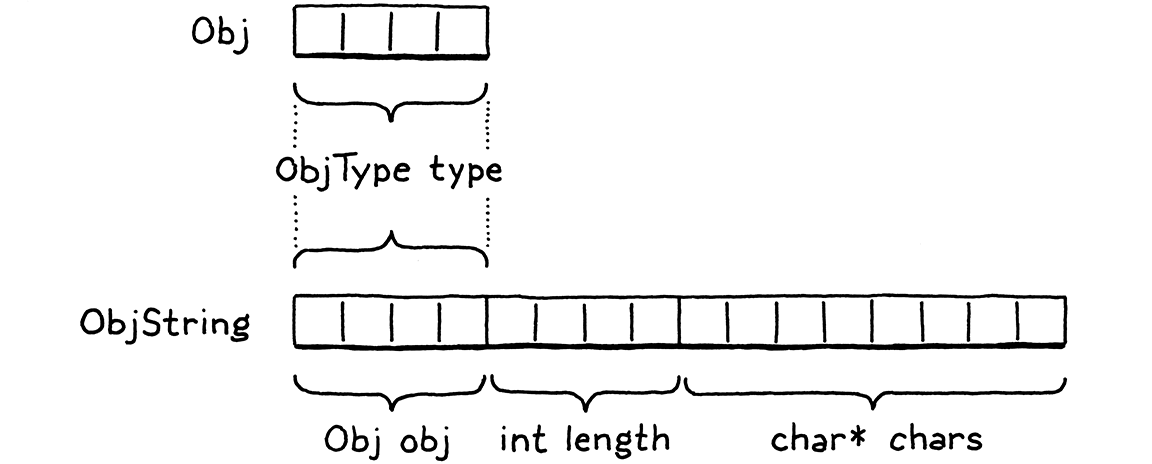
Note how the first bytes of ObjString exactly line up with Obj. This is not a coincidence—C mandates it. This is designed to enable a clever pattern: You can take a pointer to a struct and safely convert it to a pointer to its first field and back.
注意ObjString的第一個字節是如何與Obj精確對齊的。這並非巧合——是C語言強制要求的3。這是為實現一個巧妙的模式而設計的:你可以接受一個指向結構體的指針,並安全地將其轉換為指向其第一個字段的指針,反之亦可。
Given an
ObjString*, you can safely cast it toObj*and then access thetypefield from it. Every ObjString “is” an Obj in the OOP sense of “is”. When we later add other object types, each struct will have an Obj as its first field. Any code that wants to work with all objects can treat them as baseObj*and ignore any other fields that may happen to follow.
給定一個ObjString*,你可以安全地將其轉換為Obj*,然後訪問其中的type字段。每個ObjString“是”一個Obj,這裡的“是”指OOP意義上的“是”。等我們稍後添加其它對象類型時,每個結構體都會有一個Obj作為其第一個字段。任何代碼若想要面向所有對象,都可以把它們當做基礎的Obj*,並忽略後面可能出現的任何其它字段。
You can go in the other direction too. Given an
Obj*, you can “downcast” it to anObjString*. Of course, you need to ensure that theObj*pointer you have does point to theobjfield of an actual ObjString. Otherwise, you are unsafely reinterpreting random bits of memory. To detect that such a cast is safe, we add another macro.
你也能反向操作。給定一個Obj*,你可以將其“向下轉換”為一個ObjString*。當然,你需要確保你的Obj*指針確實指向一個實際的ObjString中的obj字段。否則,你就會不安全地重新解釋內存中的隨機比特位。為了檢測這種類型轉換是否安全,我們再添加另一個宏。
object.h,添加代碼:
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
// 新增部分開始
#define IS_STRING(value) isObjType(value, OBJ_STRING)
// 新增部分結束
typedef enum {
It takes a Value, not a raw
Obj*because most code in the VM works with Values. It relies on this inline function:
它接受一個Value,而不是原始的Obj*,因為虛擬機中的大多數代碼都使用Value。它依賴於這個內聯函數:
object.h,在結構體ObjString後添加代碼:
};
// 新增部分開始
static inline bool isObjType(Value value, ObjType type) {
return IS_OBJ(value) && AS_OBJ(value)->type == type;
}
// 新增部分結束
#endif
Pop quiz: Why not just put the body of this function right in the macro? What’s different about this one compared to the others? Right, it’s because the body uses
valuetwice. A macro is expanded by inserting the argument expression every place the parameter name appears in the body. If a macro uses a parameter more than once, that expression gets evaluated multiple times.
突擊測試:為什麼不直接把這個函數體放在宏中?與其它函數相比,這個函數有什麼不同?對,這是因為函數體使用了兩次value。宏的展開方式是在主體中形參名稱出現的每個地方插入實參表達式。如果一個宏中使用某個參數超過一次,則該表達式就會被求值多次。
That’s bad if the expression has side effects. If we put the body of
isObjType()into the macro definition and then you did, say,IS_STRING(POP())then it would pop two values off the stack! Using a function fixes that.
如果這個表達式有副作用,那就不好了。如果我們把isObjType()的主體放到宏的定義中,假設你這麼使用
IS_STRING(POP())
那麼它就會從堆棧中彈出兩個值!使用函數可以解決這個問題。
As long as we ensure that we set the type tag correctly whenever we create an Obj of some type, this macro will tell us when it’s safe to cast a value to a specific object type. We can do that using these:
只要我們確保在創建某種類型的Obj時正確設置了類型標籤,這個宏就會告訴我們何時將一個值轉換為特定的對象類型是安全的。我們可以用下面這些函數來做轉換:
object.h,添加代碼:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
// 新增部分開始
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
#define AS_CSTRING(value) (((ObjString*)AS_OBJ(value))->chars)
// 新增部分結束
typedef enum {
These two macros take a Value that is expected to contain a pointer to a valid ObjString on the heap. The first one returns the
ObjString*pointer. The second one steps through that to return the character array itself, since that’s often what we’ll end up needing.
這兩個宏會接受一個Value,其中應當包含一個指向堆上的有效ObjString指針。第一個函數返回 ObjString* 指針。第二個函數更進一步返回了字符數組本身,因為這往往是我們最終需要的。
19 . 3 Strings
19.3 字符串
OK, our VM can now represent string values. It’s time to add strings to the language itself. As usual, we begin in the front end. The lexer already tokenizes string literals, so it’s the parser’s turn.
好了,我們的虛擬機現在可以表示字符串值了。現在是時候向語言本身添加字符串了。像往常一樣,我們從前端開始。詞法解析器已經將字符串字面量標識化了,所以現在輪到解析器了。
compiler.c,替換1行:
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
// 替換一行開始
[TOKEN_STRING] = {string, NULL, PREC_NONE},
// 替換一行結束
[TOKEN_NUMBER] = {number, NULL, PREC_NONE},
When the parser hits a string token, it calls this parse function:
當解析器遇到一個字符串標識時,會調用這個解析函數:
compiler.c,在number()方法後添加代碼:
static void string() {
emitConstant(OBJ_VAL(copyString(parser.previous.start + 1,
parser.previous.length - 2)));
}
This takes the string’s characters directly from the lexeme. The
+ 1and- 2parts trim the leading and trailing quotation marks. It then creates a string object, wraps it in a Value, and stuffs it into the constant table.
這裡直接從詞素中獲取字符串的字符4。+1和-2部分去除了開頭和結尾的引號。然後,它創建了一個字符串對象,將其包裝為一個Value,並塞入常量表中。
To create the string, we use
copyString(), which is declared inobject.h.
為了創建字符串,我們使用了在object.h中聲明的copyString()。
object.h,在結構體ObjString後添加代碼:
};
// 新增部分開始
ObjString* copyString(const char* chars, int length);
// 新增部分結束
static inline bool isObjType(Value value, ObjType type) {
The compiler module needs to include that.
編譯器模塊需要引入它。
compiler.h,添加代碼:
#define clox_compiler_h
// 新增部分開始
#include "object.h"
// 新增部分結束
#include "vm.h"
Our “object” module gets an implementation file where we define the new function.
我們的“object”模塊有了一個實現文件,我們在其中定義新函數。
object.c,創建新文件:
#include <stdio.h>
#include <string.h>
#include "memory.h"
#include "object.h"
#include "value.h"
#include "vm.h"
ObjString* copyString(const char* chars, int length) {
char* heapChars = ALLOCATE(char, length + 1);
memcpy(heapChars, chars, length);
heapChars[length] = '\0';
return allocateString(heapChars, length);
}
First, we allocate a new array on the heap, just big enough for the string’s characters and the trailing terminator, using this low-level macro that allocates an array with a given element type and count:
首先,我們在堆上分配一個新數組,其大小剛好可以容納字符串中的字符和末尾的結束符,使用這個底層宏來分配一個具有給定元素類型和數量的數組:
memory.h,添加代碼:
#include "common.h"
// 新增部分開始
#define ALLOCATE(type, count) \
(type*)reallocate(NULL, 0, sizeof(type) * (count))
// 新增部分結束
#define GROW_CAPACITY(capacity) \
Once we have the array, we copy over the characters from the lexeme and terminate it.
有了數組以後,就把詞素中的字符複製過來並終止5。
You might wonder why the ObjString can’t just point back to the original characters in the source string. Some ObjStrings will be created dynamically at runtime as a result of string operations like concatenation. Those strings obviously need to dynamically allocate memory for the characters, which means the string needs to free that memory when it’s no longer needed.
你可能想知道為什麼ObjString不能直接執行源字符串中的原始字符。由於連接等字符串操作,一些ObjString會在運行時被動態創建。這些字符串顯然需要為字符動態分配內存,這也意味著該字符串不再需要這些內存時,要釋放它們。
If we had an ObjString for a string literal, and tried to free its character array that pointed into the original source code string, bad things would happen. So, for literals, we preemptively copy the characters over to the heap. This way, every ObjString reliably owns its character array and can free it.
如果我們有一個ObjString存儲字符串字面量,並且試圖釋放其中指向原始的源代碼字符串的字符數組,糟糕的事情就會發生。因此,對於字面量,我們預先將字符複製到堆中。這樣一來,每個ObjString都能可靠地擁有自己的字符數組,並可以釋放它。
The real work of creating a string object happens in this function:
創建字符串對象的真正工作發生在這個函數中:
object.c,添加代碼:
#include "vm.h"
// 新增部分開始
static ObjString* allocateString(char* chars, int length) {
ObjString* string = ALLOCATE_OBJ(ObjString, OBJ_STRING);
string->length = length;
string->chars = chars;
return string;
}
// 新增部分結束
It creates a new ObjString on the heap and then initializes its fields. It’s sort of like a constructor in an OOP language. As such, it first calls the “base class” constructor to initialize the Obj state, using a new macro.
它在堆上創建一個新的ObjString,然後初始化其字段。這有點像OOP語言中的構建函數。因此,它首先調用“基類”的構造函數來初始化Obj狀態,使用了一個新的宏。
object.c,添加代碼:
#include "vm.h"
// 新增部分開始
#define ALLOCATE_OBJ(type, objectType) \
(type*)allocateObject(sizeof(type), objectType)
// 新增部分結束
static ObjString* allocateString(char* chars, int length) {
Like the previous macro, this exists mainly to avoid the need to redundantly cast a
void*back to the desired type. The actual functionality is here:
跟前面的宏一樣,這個宏6的存在主要是為了避免重複地將void*轉換回期望的類型。實際的功能在這裡:
object.c,添加代碼:
#define ALLOCATE_OBJ(type, objectType) \
(type*)allocateObject(sizeof(type), objectType)
// 新增部分開始
static Obj* allocateObject(size_t size, ObjType type) {
Obj* object = (Obj*)reallocate(NULL, 0, size);
object->type = type;
return object;
}
// 新增部分結束
static ObjString* allocateString(char* chars, int length) {
It allocates an object of the given size on the heap. Note that the size is not just the size of Obj itself. The caller passes in the number of bytes so that there is room for the extra payload fields needed by the specific object type being created.
它在堆上分配了一個給定大小的對象。注意,這個大小不僅僅是Obj本身的大小。調用者傳入字節數,以便為被創建的對象類型留出額外的載荷字段所需的空間。
Then it initializes the Obj state—right now, that’s just the type tag. This function returns to
allocateString(), which finishes initializing the ObjString fields. Voilà, we can compile and execute string literals.
然後它初始化Obj狀態——現在這只是個類型標籤。這個函數會返回到 allocateString(),它來完成對ObjString字段的初始化。就是這樣,我們可以編譯和執行字符串字面量了。
19 . 4 Operations on Strings
19.4 字符串操作
Our fancy strings are there, but they don’t do much of anything yet. A good first step is to make the existing print code not barf on the new value type.
我們的花哨的字符串已經就位了,但是它們還沒有發揮什麼作用。一個好的第一步是使現有的打印代碼不要排斥新的值類型。
value.c,在printValue()方法中添加代碼:
case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break;
// 新增部分開始
case VAL_OBJ: printObject(value); break;
// 新增部分結束
}
If the value is a heap-allocated object, it defers to a helper function over in the “object” module.
如果該值是一個堆分配的對象,它會調用“object”模塊中的一個輔助函數。
object.h,在copyString()方法後添加代碼:
ObjString* copyString(const char* chars, int length);
// 新增部分開始
void printObject(Value value);
// 新增部分結束
static inline bool isObjType(Value value, ObjType type) {
The implementation looks like this:
對應的實現的這樣的:
object.c,在copyString()方法後添加代碼:
void printObject(Value value) {
switch (OBJ_TYPE(value)) {
case OBJ_STRING:
printf("%s", AS_CSTRING(value));
break;
}
}
We have only a single object type now, but this function will sprout additional switch cases in later chapters. For string objects, it simply prints the character array as a C string.
我們現在只有一個對象類型,但是這個函數在後續的章節中會出現更多case分支。對於字符串對象,只是簡單地將字符數組作為C字符串打印出來7。
The equality operators also need to gracefully handle strings. Consider:
相等運算符也需要優雅地處理字符串。考慮一下:
"string" == "string"
These are two separate string literals. The compiler will make two separate calls to
copyString(), create two distinct ObjString objects and store them as two constants in the chunk. They are different objects in the heap. But our users (and thus we) expect strings to have value equality. The above expression should evaluate totrue. That requires a little special support.
這是兩個獨立的字符串字面量。編譯器會對copyString()進行兩次單獨的調用,創建兩個不同的ObjString對象,並將它們作為兩個常量存儲在字節碼塊中。它們是堆中的不同對象。但是我們的用戶(也就是我們)希望字符串的值是相等的。上面的表達式計算結果應該是true。這需要一點特殊的支持。
value.c,在valuesEqual()中添加代碼:
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
// 新增部分開始
case VAL_OBJ: {
ObjString* aString = AS_STRING(a);
ObjString* bString = AS_STRING(b);
return aString->length == bString->length &&
memcmp(aString->chars, bString->chars,
aString->length) == 0;
}
// 新增部分結束
default: return false; // Unreachable.
If the two values are both strings, then they are equal if their character arrays contain the same characters, regardless of whether they are two separate objects or the exact same one. This does mean that string equality is slower than equality on other types since it has to walk the whole string. We’ll revise that later, but this gives us the right semantics for now.
如果兩個值都是字符串,那麼當它們的字符數組中包含相同的字符時,它們就是相等的,不管它們是兩個獨立的對象還是完全相同的一個對象。這確實意味著字符串相等比其它類型的相等要慢,因為它必須遍歷整個字符串。我們稍後會對此進行修改,但目前這為我們提供了正確的語義。
Finally, in order to use
memcmp()and the new stuff in the “object” module, we need a couple of includes. Here:
最後,為了使用memcmp()和“object”模塊中的新內容,我們需要一些引入。這裡:
value.c,添加代碼:
#include <stdio.h>
// 新增部分開始
#include <string.h>
// 新增部分結束
#include "memory.h"
And here:
還有這裡:
value.c,添加代碼:
#include <string.h>
// 新增部分開始
#include "object.h"
// 新增部分結束
#include "memory.h"
19 . 4 . 1 Concatenation
19.4.1 連接
Full-grown languages provide lots of operations for working with strings—access to individual characters, the string’s length, changing case, splitting, joining, searching, etc. When you implement your language, you’ll likely want all that. But for this book, we keep things very minimal.
成熟的語言都提供了很多處理字符串的操作——訪問單個字符、字符串長度、改變大小寫、分割、連接、搜索等。當你實現自己的語言時,你可能會想要所有這些。但是在本書中,我們還是讓事情保持簡單。
The only interesting operation we support on strings is
+. If you use that operator on two string objects, it produces a new string that’s a concatenation of the two operands. Since Lox is dynamically typed, we can’t tell which behavior is needed at compile time because we don’t know the types of the operands until runtime. Thus, theOP_ADDinstruction dynamically inspects the operands and chooses the right operation.
我們對字符串支持的唯一有趣的操作是+。如果你在兩個字符串對象上使用這個操作符,它會產生一個新的字符串,是兩個操作數的連接。由於Lox是動態類型的,因此我們在編譯時無法判斷需要哪種行為,因為我們在運行時才知道操作數的類型。因此,OP_ADD指令會動態地檢查操作數,並選擇正確的操作。
vm.c,在run()方法中替換1行:
case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
// 替換部分開始
case OP_ADD: {
if (IS_STRING(peek(0)) && IS_STRING(peek(1))) {
concatenate();
} else if (IS_NUMBER(peek(0)) && IS_NUMBER(peek(1))) {
double b = AS_NUMBER(pop());
double a = AS_NUMBER(pop());
push(NUMBER_VAL(a + b));
} else {
runtimeError(
"Operands must be two numbers or two strings.");
return INTERPRET_RUNTIME_ERROR;
}
break;
}
// 替換部分結束
case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break;
If both operands are strings, it concatenates. If they’re both numbers, it adds them. Any other combination of operand types is a runtime error.
如果兩個操作數都是字符串,則連接。如果都是數字,則相加。任何其它操作數類型的組合都是一個運行時錯誤8。
To concatenate strings, we define a new function.
為了連接字符串,我們定義一個新函數。
vm.c,在isFalsey()方法後添加代碼:
static void concatenate() {
ObjString* b = AS_STRING(pop());
ObjString* a = AS_STRING(pop());
int length = a->length + b->length;
char* chars = ALLOCATE(char, length + 1);
memcpy(chars, a->chars, a->length);
memcpy(chars + a->length, b->chars, b->length);
chars[length] = '\0';
ObjString* result = takeString(chars, length);
push(OBJ_VAL(result));
}
It’s pretty verbose, as C code that works with strings tends to be. First, we calculate the length of the result string based on the lengths of the operands. We allocate a character array for the result and then copy the two halves in. As always, we carefully ensure the string is terminated.
這是相當繁瑣的,因為處理字符串的C語言代碼往往是這樣。首先,我們根據操作數的長度計算結果字符串的長度。我們為結果分配一個字符數組,然後將兩個部分複製進去。與往常一樣,我們要小心地確保這個字符串被終止了。
In order to call
memcpy(), the VM needs an include.
為了調用memcpy(),虛擬機需要引入頭文件。
vm.c,添加代碼:
#include <stdio.h>
// 新增部分開始
#include <string.h>
// 新增部分結束
#include "common.h"
Finally, we produce an ObjString to contain those characters. This time we use a new function,
takeString().
最後,我們生成一個ObjString來包含這些字符。這次我們使用一個新函數takeString()。
object.h,在結構體ObjString後添加代碼:
};
// 新增部分開始
ObjString* takeString(char* chars, int length);
// 新增部分結束
ObjString* copyString(const char* chars, int length);
The implementation looks like this:
其實現如下:
object.c,在allocateString()方法後添加代碼:
ObjString* takeString(char* chars, int length) {
return allocateString(chars, length);
}
The previous
copyString()function assumes it cannot take ownership of the characters you pass in. Instead, it conservatively creates a copy of the characters on the heap that the ObjString can own. That’s the right thing for string literals where the passed-in characters are in the middle of the source string.
前面的copyString()函數假定它不能擁有傳入的字符的所有權。相對地,它保守地在堆上創建了一個ObjString可以擁有的字符的副本。對於傳入的字符位於源字符串中間的字面量來說,這樣做是正確的。
But, for concatenation, we’ve already dynamically allocated a character array on the heap. Making another copy of that would be redundant (and would mean
concatenate()has to remember to free its copy). Instead, this function claims ownership of the string you give it.
但是,對於連接,我們已經在堆上動態地分配了一個字符數組。再做一個副本是多餘的(而且意味著concatenate()必須記得釋放它的副本)。相反,這個函數要求擁有傳入字符串的所有權。
As usual, stitching this functionality together requires a couple of includes.
通常,將這個功能拼接在一起需要引入一些頭文件。
vm.c,添加代碼:
#include "debug.h"
// 新增部分開始
#include "object.h"
#include "memory.h"
// 新增部分結束
#include "vm.h"
19 . 5 Freeing Objects
19.5 釋放對象
Behold this innocuous-seeming expression:
看看這個看似無害的表達式:
"st" + "ri" + "ng"
When the compiler chews through this, it allocates an ObjString for each of those three string literals and stores them in the chunk’s constant table and generates this bytecode:
當編譯器在處理這個表達式時,會為這三個字符串字面量分別分配一個ObjString,將它們存儲到字節碼塊的常量表中9,並生成這個字節碼:
0000 OP_CONSTANT 0 "st"
0002 OP_CONSTANT 1 "ri"
0004 OP_ADD
0005 OP_CONSTANT 2 "ng"
0007 OP_ADD
0008 OP_RETURN
The first two instructions push
"st"and"ri"onto the stack. Then theOP_ADDpops those and concatenates them. That dynamically allocates a new"stri"string on the heap. The VM pushes that and then pushes the"ng"constant. The lastOP_ADDpops"stri"and"ng", concatenates them, and pushes the result:"string". Great, that’s what we expect.
前兩條指令將"st"和"ri"壓入棧中。然後OP_ADD將它們彈出並連接。這會在堆上動態分配一個新的"stri"字符串。虛擬機將它壓入棧中,然後壓入"ng"常量。最後一個OP_ADD會彈出"stri"和"ng",將它們連接起來,並將結果"string"壓入棧。很好,這就是我們所期望的。
But, wait. What happened to that
"stri"string? We dynamically allocated it, then the VM discarded it after concatenating it with"ng". We popped it from the stack and no longer have a reference to it, but we never freed its memory. We’ve got ourselves a classic memory leak.
但是,請等一下。那個"stri"字符串怎麼樣了?我們動態分配了它,然後虛擬機在將其與"ng"連接後丟棄了它。我們把它從棧中彈出,不再持有對它的引用,但是我們從未釋放它的內存。我們遇到了典型的內存洩露。
Of course, it’s perfectly fine for the Lox program to forget about intermediate strings and not worry about freeing them. Lox automatically manages memory on the user’s behalf. The responsibility to manage memory doesn’t disappear. Instead, it falls on our shoulders as VM implementers.
當然,Lox程序完全可以忘記中間的字符串,也不必擔心釋放它們。Lox代表用戶自動管理內存。管理內存的責任並沒有消失,相反,它落到了我們這些虛擬機實現者的肩上。
The full solution is a garbage collector that reclaims unused memory while the program is running. We’ve got some other stuff to get in place before we’re ready to tackle that project. Until then, we are living on borrowed time. The longer we wait to add the collector, the harder it is to do.
完整的解決方案是一個垃圾回收器,在程序運行時回收不使用的內存。在我們準備著手那個項目之前,還有一些其它的事情要做10。在那之前,我們只是僥倖運行。我們等待添加收集器的時間越長,它就越難做。
Today, we should at least do the bare minimum: avoid leaking memory by making sure the VM can still find every allocated object even if the Lox program itself no longer references them. There are many sophisticated techniques that advanced memory managers use to allocate and track memory for objects. We’re going to take the simplest practical approach.
今天我們至少應該做到最基本的一點:確保虛擬機可以找到每一個分配的對象,即使Lox程序本身不再引用它們,從而避免洩露內存。高級內存管理程序會使用很多複雜的技術來分配和跟蹤對象的內存。我們將採取最簡單的實用方法。
We’ll create a linked list that stores every Obj. The VM can traverse that list to find every single object that has been allocated on the heap, whether or not the user’s program or the VM’s stack still has a reference to it.
我們會創建一個鏈表存儲每個Obj。虛擬機可以遍歷這個列表,找到在堆上分配的每一個對象,無論用戶的程序或虛擬機的堆棧是否仍然有對它的引用。
We could define a separate linked list node struct but then we’d have to allocate those too. Instead, we’ll use an intrusive list—the Obj struct itself will be the linked list node. Each Obj gets a pointer to the next Obj in the chain.
我們可以定義一個單獨的鏈表節點結構體,但那樣我們也必須分配這些節點。相反,我們會使用侵入式列表——Obj結構體本身將作為鏈表節點。每個Obj都有一個指向鏈中下一個Obj的指針。
object.h,在結構體Obj中添加代碼:
struct Obj {
ObjType type;
// 新增部分開始
struct Obj* next;
// 新增部分結束
};
The VM stores a pointer to the head of the list.
VM存儲一個指向表頭的指針。
vm.h,在結構體VM中添加代碼:
Value* stackTop;
// 新增部分開始
Obj* objects;
// 新增部分結束
} VM;
When we first initialize the VM, there are no allocated objects.
當我們第一次初始化VM時,沒有分配的對象。
vm.c,在initVM()方法中添加代碼:
resetStack();
// 新增部分開始
vm.objects = NULL;
// 新增部分結束
}
Every time we allocate an Obj, we insert it in the list.
每當我們分配一個Obj時,就將其插入到列表中。
object.c,在allocateObject()方法中添加代碼:
object->type = type;
// 新增部分開始
object->next = vm.objects;
vm.objects = object;
// 新增部分結束
return object;
Since this is a singly linked list, the easiest place to insert it is as the head. That way, we don’t need to also store a pointer to the tail and keep it updated.
由於這是一個單鏈表,所以最容易插入的地方是頭部。這樣,我們就不需要同時存儲一個指向尾部的指針並保持對其更新。
The “object” module is directly using the global
vmvariable from the “vm” module, so we need to expose that externally.
“object”模塊直接使用了“vm”模塊的vm變量,所以我們需要將該變量公開到外部。
vm.h,在枚舉InterpretResult後添加代碼:
} InterpretResult;
// 新增部分開始
extern VM vm;
// 新增部分結束
void initVM();
Eventually, the garbage collector will free memory while the VM is still running. But, even then, there will usually be unused objects still lingering in memory when the user’s program completes. The VM should free those too.
最終,垃圾收集器會在虛擬機仍在運行時釋放內存。但是,即便如此,當用戶的程序完成時,通常仍會有未使用的對象駐留在內存中。VM也應該釋放這些對象。
There’s no sophisticated logic for that. Once the program is done, we can free every object. We can and should implement that now.
這方面沒有什麼複雜的邏輯。一旦程序完成,我們就可以釋放每個對象。我們現在可以也應該實現它。
vm.c,在freeVM()方法中添加代碼:
void freeVM() {
// 新增部分開始
freeObjects();
// 新增部分結束
}
That empty function we defined way back when finally does something! It calls this:
我們早先定義的空函數終於有了用武之地!它調用了這個方法:
memory.h,在reallocate()方法後添加代碼:
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
// 新增部分開始
void freeObjects();
// 新增部分結束
#endif
Here’s how we free the objects:
下面是釋放對象的方法:
memory.c,在reallocate()後添加代碼:
void freeObjects() {
Obj* object = vm.objects;
while (object != NULL) {
Obj* next = object->next;
freeObject(object);
object = next;
}
}
This is a CS 101 textbook implementation of walking a linked list and freeing its nodes. For each node, we call:
這是CS 101教科書中關於遍歷鏈表並釋放其節點的實現。對於每個節點,我們調用:
memory.c,在reallocate()方法後添加代碼:
static void freeObject(Obj* object) {
switch (object->type) {
case OBJ_STRING: {
ObjString* string = (ObjString*)object;
FREE_ARRAY(char, string->chars, string->length + 1);
FREE(ObjString, object);
break;
}
}
}
We aren’t only freeing the Obj itself. Since some object types also allocate other memory that they own, we also need a little type-specific code to handle each object type’s special needs. Here, that means we free the character array and then free the ObjString. Those both use one last memory management macro.
我們不僅釋放了Obj本身。因為有些對象類型還分配了它們所擁有的其它內存,我們還需要一些特定於類型的代碼來處理每種對象類型的特殊需求。在這裡,這意味著我們釋放字符數組,然後釋放ObjString。它們都使用了最後一個內存管理宏。
memory.h,添加代碼:
(type*)reallocate(NULL, 0, sizeof(type) * (count))
// 新增部分開始
#define FREE(type, pointer) reallocate(pointer, sizeof(type), 0)
// 新增部分結束
#define GROW_CAPACITY(capacity) \
It’s a tiny wrapper around
reallocate()that “resizes” an allocation down to zero bytes.
這是圍繞reallocate()的一個小包裝11,可以將分配的內存“調整”為零字節。
Using reallocate() to free memory might seem pointless. Why not just call free()? Later, this will help the VM track how much memory is still being used. If all allocation and freeing goes through reallocate(), it’s easy to keep a running count of the number of bytes of allocated memory.
As usual, we need an include to wire everything together.
像往常一樣,我們需要一個include將所有東西連接起來
memory.h,添加代碼:
#include "common.h"
// 新增部分開始
#include "object.h"
// 新增部分結束
#define ALLOCATE(type, count) \
Then in the implementation file:
然後是實現文件:
memory.c,添加代碼:
#include "memory.h"
// 新增部分開始
#include "vm.h"
// 新增部分結束
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
With this, our VM no longer leaks memory. Like a good C program, it cleans up its mess before exiting. But it doesn’t free any objects while the VM is running. Later, when it’s possible to write longer-running Lox programs, the VM will eat more and more memory as it goes, not relinquishing a single byte until the entire program is done.
這樣一來,我們的虛擬機就不會再洩露內存了。像一個好的C程序一樣,它會在退出之前進行清理。但在虛擬機運行時,它不會釋放任何對象。稍後,當可以編寫長時間運行的Lox程序時,虛擬機在運行過程中會消耗越來越多的內存,在整個程序完成之前不會釋放任何一個字節。
We won’t address that until we’ve added a real garbage collector, but this is a big step. We now have the infrastructure to support a variety of different kinds of dynamically allocated objects. And we’ve used that to add strings to clox, one of the most used types in most programming languages. Strings in turn enable us to build another fundamental data type, especially in dynamic languages: the venerable hash table. But that’s for the next chapter . . .
在添加真正的垃圾收集器之前,我們不會解決這個問題,但這是一個很大的進步。我們現在擁有了支持各種不同類型的動態分配對象的基礎設施。我們利用這一點在clox中加入了字符串,這是大多數編程語言中最常用的類型之一。字符串反過來又使我們能夠構建另一種基本的數據類型,尤其是在動態語言中:古老的哈希表。但這是下一章的內容了……
習題
-
Each string requires two separate dynamic allocations—one for the ObjString and a second for the character array. Accessing the characters from a value requires two pointer indirections, which can be bad for performance. A more efficient solution relies on a technique called flexible array members. Use that to store the ObjString and its character array in a single contiguous allocation.
每個字符串都需要兩次單獨的動態分配——一個是ObjString,另一個是字符數組。從一個值中訪問字符需要兩個指針間接訪問,這對性能是不利的。一個更有效的解決方案是依靠一種名為靈活數組成員的技術。用該方法將ObjString和它的字符數據存儲在一個連續分配的內存中。
-
When we create the ObjString for each string literal, we copy the characters onto the heap. That way, when the string is later freed, we know it is safe to free the characters too.
This is a simpler approach but wastes some memory, which might be a problem on very constrained devices. Instead, we could keep track of which ObjStrings own their character array and which are “constant strings” that just point back to the original source string or some other non-freeable location. Add support for this.
當我們為每個字符串字面量創建ObjString時,會將字符複製到堆中。這樣,當字符串後來被釋放時,我們知道釋放這些字符也是安全的。
這是一個簡單但是會浪費一下內存的方法,這在非常受限的設備上可能是一個問題。相反,我們可以追蹤哪些ObjString擁有自己的字符數組,哪些是“常量字符串”,只是指向原始的源字符串或其它不可釋放的位置。添加對此的支持。
-
If Lox was your language, what would you have it do when a user tries to use
+with one string operand and the other some other type? Justify your choice. What do other languages do?如果Lox是你的語言,當用戶試圖用一個字符串操作數使用
+,而另一個操作數是其它類型時,你會讓它做什麼?證明你的選擇是正確的,其它的語言是怎麼做的?
DESIGN NOTE: STRING ENCODING
設計筆記:字符串編碼
In this book, I try not to shy away from the gnarly problems you’ll run into in a real language implementation. We might not always use the most sophisticated solution—it’s an intro book after all—but I don’t think it’s honest to pretend the problem doesn’t exist at all. However, I did skirt around one really nasty conundrum: deciding how to represent strings.
There are two facets to a string encoding:
What is a single “character” in a string? How many different values are there and what do they represent? The first widely adopted standard answer to this was ASCII. It gave you 127 different character values and specified what they were. It was great . . . if you only ever cared about English. While it has weird, mostly forgotten characters like “record separator” and “synchronous idle”, it doesn’t have a single umlaut, acute, or grave. It can’t represent “jalapeño”, “naïve”, “Gruyère”, or “Mötley Crüe”.
Next came Unicode. Initially, it supported 16,384 different characters (code points), which fit nicely in 16 bits with a couple of bits to spare. Later that grew and grew, and now there are well over 100,000 different code points including such vital instruments of human communication as 💩 (Unicode Character ‘PILE OF POO’,
U+1F4A9).Even that long list of code points is not enough to represent each possible visible glyph a language might support. To handle that, Unicode also has combining characters that modify a preceding code point. For example, “a” followed by the combining character “¨” gives you “ä”. (To make things more confusing Unicode also has a single code point that looks like “ä”.)
If a user accesses the fourth “character” in “naïve”, do they expect to get back “v” or “¨”? The former means they are thinking of each code point and its combining character as a single unit—what Unicode calls an extended grapheme cluster—the latter means they are thinking in individual code points. Which do your users expect?
How is a single unit represented in memory? Most systems using ASCII gave a single byte to each character and left the high bit unused. Unicode has a handful of common encodings. UTF-16 packs most code points into 16 bits. That was great when every code point fit in that size. When that overflowed, they added surrogate pairs that use multiple 16-bit code units to represent a single code point. UTF-32 is the next evolution of UTF-16—it gives a full 32 bits to each and every code point.
UTF-8 is more complex than either of those. It uses a variable number of bytes to encode a code point. Lower-valued code points fit in fewer bytes. Since each character may occupy a different number of bytes, you can’t directly index into the string to find a specific code point. If you want, say, the 10th code point, you don’t know how many bytes into the string that is without walking and decoding all of the preceding ones.
Choosing a character representation and encoding involves fundamental trade-offs. Like many things in engineering, there’s no perfect solution:
- ASCII is memory efficient and fast, but it kicks non-Latin languages to the side.
- UTF-32 is fast and supports the whole Unicode range, but wastes a lot of memory given that most code points do tend to be in the lower range of values, where a full 32 bits aren’t needed.
- UTF-8 is memory efficient and supports the whole Unicode range, but its variable-length encoding makes it slow to access arbitrary code points.
- UTF-16 is worse than all of them—an ugly consequence of Unicode outgrowing its earlier 16-bit range. It’s less memory efficient than UTF-8 but is still a variable-length encoding thanks to surrogate pairs. Avoid it if you can. Alas, if your language needs to run on or interoperate with the browser, the JVM, or the CLR, you might be stuck with it, since those all use UTF-16 for their strings and you don’t want to have to convert every time you pass a string to the underlying system.
One option is to take the maximal approach and do the “rightest” thing. Support all the Unicode code points. Internally, select an encoding for each string based on its contents—use ASCII if every code point fits in a byte, UTF-16 if there are no surrogate pairs, etc. Provide APIs to let users iterate over both code points and extended grapheme clusters.
This covers all your bases but is really complex. It’s a lot to implement, debug, and optimize. When serializing strings or interoperating with other systems, you have to deal with all of the encodings. Users need to understand the two indexing APIs and know which to use when. This is the approach that newer, big languages tend to take—like Raku and Swift.
A simpler compromise is to always encode using UTF-8 and only expose an API that works with code points. For users that want to work with grapheme clusters, let them use a third-party library for that. This is less Latin-centric than ASCII but not much more complex. You lose fast direct indexing by code point, but you can usually live without that or afford to make it O(n) instead of O(1).
If I were designing a big workhorse language for people writing large applications, I’d probably go with the maximal approach. For my little embedded scripting language Wren, I went with UTF-8 and code points.
在本書中,我儘量不迴避你在真正的語言實現中會遇到的棘手問題。我們也許並不總是使用最複雜的解決方案——畢竟這只是一本入門書——但我認為假裝問題根本不存在是不誠實的。但是,我們確實繞過了一個非常棘手的難題:決定如何表示字符串。
字符串編碼有兩個方面:
-
什麼是字符串中的一個“字符”?有多少個不同的值,它們代表什麼?第一個被廣泛採用的標準答案是ASCII。它給出了127個不同的字符值,並指明瞭它們是什麼。這太棒了……如果你只關心英語的話。雖然它包含有像“記錄分隔符”和“同步空閒”這樣奇怪的、幾乎被遺忘的字符,但它沒有元音變音、銳音或鈍音。它無法表示 “jalapeño”,“naïve”,“Gruyère”或 “Mötley Crüe”。
接下來是Unicode。最初,它支持16384個不同的字符(碼點),這非常適合在16比特位中使用,還有幾位是多餘的。後來,這個數字不斷增加,現在已經有了超過100,000個不同的碼點,包括諸如💩(Unicode字符 "PILE OF POO",U+1F4A9)等人類交流的重要工具。
即使是這麼長的碼點列表,也不足以表示一種語言可能支持的每個可見字形。為了處理這個問題,Unicode還有一些組合字符,可以修改前面的碼點。例如,“a”後面跟組合字符“¨”,就可以得到“ä”。(為了使事情更混亂,Unicode也有一個看起來像“ä”的單一碼點)
如果用戶訪問“naïve”中的第四個“字符”,他們希望得到的是“v”還是“¨”?前者意味著他們把每個碼點及其組合符看著一個單元——Unicode稱之為擴展的字母簇,後者意味著它們以單獨的碼點來思考。你的用戶期望的是哪一種?
-
單一單元在內存中是如何表示的?大多數使用ASCII的系統給每個字符分配一個字節,高位不使用。Unicode有幾種常見的編碼方式。UTF-16將大多數碼點打包成16比特。當每個碼點都在這個範圍內時,是很好的。當碼點溢出時,它們增加了代理對,使用多個16比特碼來表示一個碼點。UTF-32是UTF-16的進一步演變,它為每個碼點都提供了完整的32比特。
UTF-8比這兩個都要複雜。它使用可變數量的字節來對碼點編碼。低值的碼點適合於較少的字節。因為每個字符可能佔用不同數量的字節,你不能直接在字符串中索引到特定的碼點。如果你想要訪問,比如說,第10個碼點,在不遍歷和解碼前面所有碼點的情況下,你不知道它在字符串中佔用多少個字節。
選擇字符表示形式和編碼涉及到基本的權衡。就像工程領域的許多事情一樣,沒有完美的解決方案:
【關於這個問題有多難的一個例子就是Python 。從Python 2到3的漫長轉變之所以令人痛苦,主要是因為它圍繞字符串編碼的變化】
- ASCII內存效率高,速度快,但它把非拉丁語系的語言踢到了一邊。
- UTF-32速度快,並且支持整個Unicode範圍,但考慮到大多數碼點往往都位於較低的值範圍內,不需要完整的32比特,所以浪費了大量的內存。
- UTF-8的內存效率高,支持整個Unicode範圍,但是它的可變長度編碼使得在訪問任意碼點時速度很慢。
- UTF-16比所有這些都糟糕——這是Unicode超出其早期16比特範圍的醜陋後果。它的內存效率低於UTF-8,但由於代理對的存在,它仍然是一種可變長度的編碼。儘量避免使用它。唉,如果你的語言需要在瀏覽器、JVM或CLR上運行或與之交互,你也許就只能用它了,因為這些系統的字符串都使用UTF-16,而你並不想每次向底層系統傳遞字符串時都進行轉換。
一種選擇是採取最大限度的方法,做“最正確”的事情。支持所有的Unicode碼點。在內部,根據每個字符串的內容選擇編碼——如果每個碼點都在一個字節內,就使用ASCII;如果沒有代理對,就使用UTF-16,等等。提供API,讓用戶對碼點和擴展字母簇進行遍歷。
這涵蓋了所有的基礎,但真的很複雜。需要實現、調試和優化的東西很多。當序列化字符串或與其它系統進行交互時,你必須處理所有的編碼。用戶需要理解這兩種索引API,並知道何時使用哪一種。這是較新的大型語言傾向於採取的方法,比如Raku和Swift。
一種更簡單的折衷辦法是始終使用UTF-8編碼,並且只暴露與碼點相關的API。對於想要處理字母簇的用戶,讓他們使用第三方庫來處理。這不像ASCII那樣以拉丁語為中心,但也沒有多複雜,雖然會失去通過碼點快速直接索引的能力,但通常沒有索引也可以,或者可以將索引改為O(n)而不是O(1)。
如果我要為編寫大型應用程序的人設計一種大型工作語言,我可能會採用最大的方法。至於我的小型嵌入式腳本語言Wren,我採用了UTF-8和碼點。
-
UCSD Pascal,Pascal最早的實現之一,就有這個確切的限制。Pascal字符串開頭是長度值,而不是像C語言那樣用一個終止的空字符表示字符串的結束。因為UCSD只使用一個字節來存儲長度,所以字符串不能超過255個字符。
 ↩
↩ -
當然,“Obj”是“對象(object)”的簡稱。 ↩
-
語言規範中的關鍵部分是:
$ 6.7.2.1 13
在一個結構體對象中,非位域成員和位域所在的單元的地址按照它們被聲明的順序遞增。一個指向結構對象的指針,經過適當轉換後,指向其第一個成員(如果該成員是一個位域,則指向其所在的單元),反之亦然。在結構對象中可以有未命名的填充,但不允許在其開頭。 ↩ -
如果Lox支持像
\n這樣的字符串轉義序列,我們會在這裡對其進行轉換。既然不支持,我們就可以原封不動地接受這些字符。 ↩ -
我們需要自己終止字符串,因為詞素指向整個源字符串中的一個字符範圍,並且沒有終止符。
由於ObjString明確存儲了長度,我們可以讓字符數組不終止,但是在結尾處添加一個終止符只花費一個字節,並且可以讓我們將字符數組傳遞給期望帶終止符的C標準庫函數。 ↩ -
我承認這一章涉及了大量的輔助函數和宏。我試圖讓代碼保持良好的分解,但這導致了一些分散的小函數。等我們以後重用它們時,將會得到回報。 ↩
-
我說過,終止字符串會有用的。 ↩
-
這比大多數語言都要保守。在其它語言中,如果一個操作數是字符串,另一個操作數可以是任何類型,在連接這兩個操作數之前會隱式地轉換為字符串。
我認為這是一個很好的特性,但是需要為每種類型編寫冗長的“轉換為字符串”的代碼,所以我在Lox中沒有支持它。 ↩ -
下面是每條指令執行後的堆棧:
 ↩
↩ -
我見過很多人在實現看語言的大部分內容之後,才試圖開始實現GC。對於在開發語言時通常會運行的那種玩具程序,實際上不會在程序結束之前耗盡內存,所以在需要GC之前,你可以開發出很多的特性。
但是,這低估了以後添加垃圾收集器的難度。收集器必須確保它能夠找到每一點仍在使用的內存,這樣它就不會收集活躍數據。一個語言的實現可以在數百個地方存儲對某個對象的引用。如果你不能找到所有這些地方,你就會遇到噩夢般的漏洞。
我曾見過一些語言實現因為後來的GC太困難而夭折。如果你的語言需要GC,請儘快實現它。它是涉及整個代碼庫的橫切關注點。 ↩ -
使用
reallocate()來釋放內存似乎毫無意義。為什麼不直接調用free()呢?稍後,這將幫助虛擬機跟蹤仍在使用的內存數量。如果所有的分配和釋放都通過reallocate()進行,那麼就很容易對已分配的內存字節數進行記錄。 ↩
20.哈希表 Hash Tables
Hash, x. There is no definition for this word—nobody knows what hash is.
——Ambrose Bierce, The Unabridged Devil’s Dictionary
哈希,未知。這個詞沒有定義——沒人知道哈希是什麼。(安布羅斯·比爾斯,《無刪減魔鬼詞典》)
Before we can add variables to our burgeoning virtual machine, we need some way to look up a value given a variable’s name. Later, when we add classes, we’ll also need a way to store fields on instances. The perfect data structure for these problems and others is a hash table.
在向這個發展迅速的虛擬機中添加變量之前,我們需要某種方法來根據給定的變量名稱查詢變量值。稍後,等到我們添加類時,也需要某種方法來存儲實例中的字段。對於這些問題和其它問題,完美的數據結構就是哈希表。
You probably already know what a hash table is, even if you don’t know it by that name. If you’re a Java programmer, you call them “HashMaps”. C# and Python users call them “dictionaries”. In C++, it’s an “unordered map”. “Objects” in JavaScript and “tables” in Lua are hash tables under the hood, which is what gives them their flexibility.
你可能已經知道什麼是哈希表了,即使你不知道它的名字。如果你是Java程序員,你把它們稱為“HashMap”。C#和Python用戶則稱它們為“字典”。在C++中,它是“無序映射”。JavaScript中的“對象”和Lua中的“表”本質上都是哈希表,這賦予了它們靈活性。
A hash table, whatever your language calls it, associates a set of keys with a set of values. Each key/value pair is an entry in the table. Given a key, you can look up its corresponding value. You can add new key/value pairs and remove entries by key. If you add a new value for an existing key, it replaces the previous entry.
哈希表(無論你的語言中怎麼稱呼它)是將一組鍵和一組值關聯起來。每個鍵/值對是表中的一個條目。給定一個鍵,可以查找它對應的值。你可以按鍵添加新的鍵/值對或刪除條目。如果你為已有的鍵添加新值,它就會替換原先的條目。
Hash tables appear in so many languages because they are incredibly powerful. Much of this power comes from one metric: given a key, a hash table returns the corresponding value in constant time, regardless of how many keys are in the hash table.
哈希表之所以出現在這麼多的語言中,是因為它們非常強大。這種強大的能力主要來自於一個指標:給定一個鍵,哈希表會在常量時間1內返回對應的值,不管哈希表中有多少鍵。
That’s pretty remarkable when you think about it. Imagine you’ve got a big stack of business cards and I ask you to find a certain person. The bigger the pile is, the longer it will take. Even if the pile is nicely sorted and you’ve got the manual dexterity to do a binary search by hand, you’re still talking O(log n). But with a hash table, it takes the same time to find that business card when the stack has ten cards as when it has a million.
仔細想想,這是非常了不起的。想象一下,你有一大堆名片,我讓你去找出某個人。這堆名片越大,花的時間就越長。即使這堆名片被很好地排序,而且你有足夠的能力來手動進行二分查找,你的複雜度仍然是O(log n)。但是對於哈希表來說,無論這摞名片有10張還是100萬張,你找到那張特定名片所需的時間都是一樣的。
20 . 1 An Array of Buckets
20.1 桶數組
A complete, fast hash table has a couple of moving parts. I’ll introduce them one at a time by working through a couple of toy problems and their solutions. Eventually, we’ll build up to a data structure that can associate any set of names with their values.
一個完整、快速的哈希表需要一些組件。我會通過幾個小問題及其解決方案來逐一介紹它們。最終,我們將構建一個數據結構,可以將任何一組名稱和它們的值關聯起來。
For now, imagine if Lox was a lot more restricted in variable names. What if a variable’s name could only be a single lowercase letter. How could we very efficiently represent a set of variable names and their values?
現在,假定Lox在變量名稱上有更多的限制。如果一個變量的名稱只能是一個小寫字母該怎麼辦2?我們如何高效地表示一組變量名和它們的值?
With only 26 possible variables (27 if you consider underscore a “letter”, I guess), the answer is easy. Declare a fixed-size array with 26 elements. We’ll follow tradition and call each element a bucket. Each represents a variable with
astarting at index zero. If there’s a value in the array at some letter’s index, then that key is present with that value. Otherwise, the bucket is empty and that key/value pair isn’t in the data structure.
由於只有26個可能的變量(如果你認為下劃線是一個“字母”,我猜是27個),答案很簡單。聲明一個具有26個元素的固定大小的數組。我們遵循傳統,將每個元素稱為一個桶(bucket)。每個元素代表一個變量,a從索引下標0開始。如果數組中某個字母對應的索引位置有值,那麼這個鍵就與該值相對應。否則的話,桶是空的,該鍵/值對在數據結構中不存在。
Memory usage is great—just a single, reasonably sized array. There’s some waste from the empty buckets, but it’s not huge. There’s no overhead for node pointers, padding, or other stuff you’d get with something like a linked list or tree.
這個方案的內存佔用情況很好——只是一個大小合理的數組。空桶會有一些浪費,但不是很大。沒有節點指針、填充以及其它類似於鏈表或樹的開銷。
Performance is even better. Given a variable name—its character—you can subtract the ASCII value of
aand use the result to index directly into the array. Then you can either look up the existing value or store a new value directly into that slot. It doesn’t get much faster than that.
性能就更好了。給定一個變量名——它的字符——你可以減去a的ASCII值,並使用結果直接在數組中進行索引。然後,你可以查找已有的值或將新值存儲到對應的槽中。沒有比這更快的了。
This is sort of our Platonic ideal data structure. Lightning fast, dead simple, and compact in memory. As we add support for more complex keys, we’ll have to make some concessions, but this is what we’re aiming for. Even once you add in hash functions, dynamic resizing, and collision resolution, this is still the core of every hash table out there—a contiguous array of buckets that you index directly into.
這是一種柏拉圖式的理想數據結構。快如閃電,非常簡單,而且內存緊湊。當我們進一步支持更復雜的鍵時,就必須作出一些讓步,但這仍是我們的目標所在。即使加入了哈希函數、動態調整大小和衝突解決,這仍然是每個哈希表的核心——一個可以直接索引到的連續桶數組。
20 . 1 . 1 Load factor and wrapped keys
20.1.1 負載因子和封裝鍵
Confining Lox to single-letter variables would make our job as implementers easier, but it’s probably no fun programming in a language that gives you only 26 storage locations. What if we loosened it a little and allowed variables up to eight characters long?
將Lox限制為單字母變量,會使我們作為實現者的工作更容易,但在一種只提供26個存儲位置的語言中編程可能沒有什麼樂趣。如果我們稍微放寬限制,允許變量的長度到8個字符呢3?
That’s small enough that we can pack all eight characters into a 64-bit integer and easily turn the string into a number. We can then use it as an array index. Or, at least, we could if we could somehow allocate a 295,148 petabyte array. Memory’s gotten cheaper over time, but not quite that cheap. Even if we could make an array that big, it would be heinously wasteful. Almost every bucket would be empty unless users started writing way bigger Lox programs than we’ve anticipated.
它足夠小,我們可以將所有8個字符打包成一個64比特的整數,輕鬆地將字符串變成一個數字。然後我們可以把它作為數組索引。至少,如果我們能夠以某種方式分配295,148 PB的數組,也是可以的。隨著時間的推移,內存越來越便宜了,但還沒那麼便宜。即便我們可以創建這麼大的數組,也會造成嚴重的浪費。除非用戶會編寫比我們的預期大得多的Lox程序,否則幾乎每個桶都是空的。
Even though our variable keys cover the full 64-bit numeric range, we clearly don’t need an array that large. Instead, we allocate an array with more than enough capacity for the entries we need, but not unreasonably large. We map the full 64-bit keys down to that smaller range by taking the value modulo the size of the array. Doing that essentially folds the larger numeric range onto itself until it fits the smaller range of array elements.
儘管我們的變量鍵覆蓋了整個64位數字範圍,但我們顯然不需要那麼大的數組。相反地,我們會分配一個數組,它的容量足以容納我們需要的條目,但又不會大得不合理。通過對數組的大小進行取模,我們將完整的64位鍵值映射到較小的範圍。這樣做本質上是將較大的數值範圍不斷摺疊,直到適合較小的數組元素範圍。
For example, say we want to store “bagel”. We allocate an array with eight elements, plenty enough to store it and more later. We treat the key string as a 64-bit integer. On a little-endian machine like Intel, packing those characters into a 64-bit word puts the first letter, “b” (ASCII value 98), in the least-significant byte. We take that integer modulo the array size (8) to fit it in the bounds and get a bucket index, 2. Then we store the value there as usual.
例如,假設我們想要存儲“bagel”。我們分配一個有8個元素的數組4,足夠存儲它,之後還可以存儲更多。我們把鍵字符串當作一個64位整數。在Intel這樣的小端機器上,將這些字符打包成一個64位的字時,會將第一個字母“b”(ASCII值 98)放在最低的有效字節中。我們將這個整數與數組大小(8)取模以適應邊界,並得到桶索引2。然後我們像往常一樣,將值存儲在那裡。
Using the array size as a modulus lets us map the key’s numeric range down to fit an array of any size. We can thus control the number of buckets independently of the key range. That solves our waste problem, but introduces a new one. Any two variables whose key number has the same remainder when divided by the array size will end up in the same bucket. Keys can collide. For example, if we try to add “jam”, it also ends up in bucket 2.
使用數組的大小作為模數,可以讓我們將鍵的數值範圍向下適配到任意大小的數組。因此,我們可以獨立於鍵的範圍來控制桶的數量。這就解決了我們的浪費問題,但是也引入了一個新的問題。任意兩個變量,如果它們的鍵值除以數組大小時有相同的餘數,最後都會被放在同一個桶中。鍵會發生衝突。舉例來說,如果我們嘗試添加“jam”,它也會出現在2號桶中。
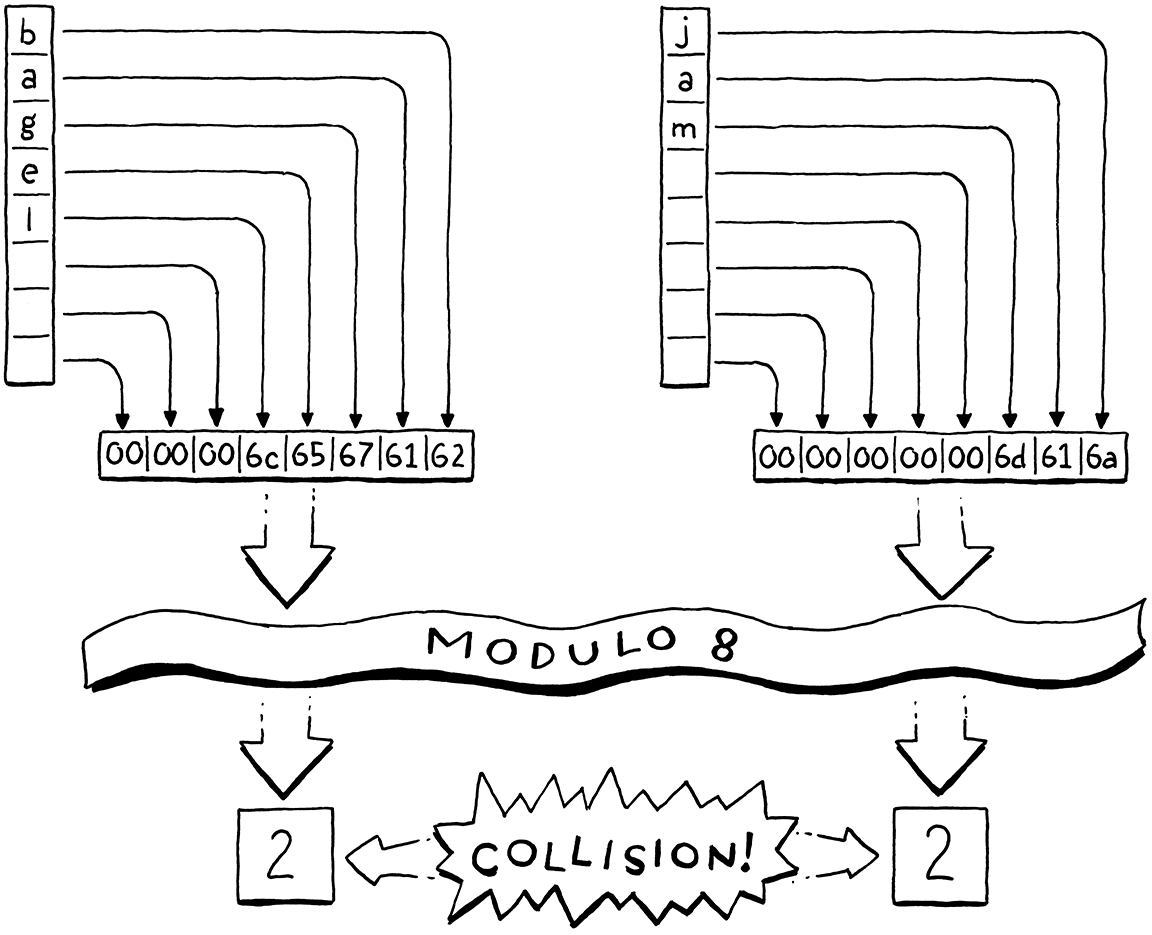
We have some control over this by tuning the array size. The bigger the array, the fewer the indexes that get mapped to the same bucket and the fewer the collisions that are likely to occur. Hash table implementers track this collision likelihood by measuring the table’s load factor. It’s defined as the number of entries divided by the number of buckets. So a hash table with five entries and an array of 16 elements has a load factor of 0.3125. The higher the load factor, the greater the chance of collisions.
我們可以通過調整數組的大小來控制這個問題。數組越大,映射到同一個桶的索引就越少,可能發生的衝突也就越少。哈希表實現者評估這種衝突的可能性的方式就是計算表的負載因子。它的定義是條目的數量除以桶的數量。因此,一個包含5個條目和16個元素的數組的哈希表,其負載係數為0.3125。負載因子越大,發生衝突的可能性就越大。
One way we mitigate collisions is by resizing the array. Just like the dynamic arrays we implemented earlier, we reallocate and grow the hash table’s array as it fills up. Unlike a regular dynamic array, though, we won’t wait until the array is full. Instead, we pick a desired load factor and grow the array when it goes over that.
減少衝突的一種方法是調整數組的大小。就像我們前面實現的動態數組一樣,我們在哈希表的數組被填滿時,重新分配並擴大該數組。但與常規的動態數組不同的是,我們不會等到數組填滿。相反,我們選擇一個理想的負載因子,當數組的負載因子超過該值時,我們就擴大數組。
20 . 2 Collision Resolution
20.2 衝突解決
Even with a very low load factor, collisions can still occur. The birthday paradox tells us that as the number of entries in the hash table increases, the chance of collision increases very quickly. We can pick a large array size to reduce that, but it’s a losing game. Say we wanted to store a hundred items in a hash table. To keep the chance of collision below a still-pretty-high 10%, we need an array with at least 47,015 elements. To get the chance below 1% requires an array with 492,555 elements, over 4,000 empty buckets for each one in use.
即使負載因子很低,仍可能發生碰撞。生日悖論告訴我們,隨著哈希表中條目數量的增加,碰撞的概率會很快增加。我們可以選擇一個很大的數組規模來減少這種情況,但這是註定失敗的。假設我們想在哈希表中存儲100個條目,要想使碰撞幾率保持在10%以下,我們需要一個至少有47,105個元素的數組。要想使碰撞幾率低於1%,需要一個有492,555個元素的數組,每使用一個元素就需要超過4000個空桶。
A low load factor can make collisions rarer, but the pigeonhole principle tells us we can never eliminate them entirely. If you’ve got five pet pigeons and four holes to put them in, at least one hole is going to end up with more than one pigeon. With 18,446,744,073,709,551,616 different variable names, any reasonably sized array can potentially end up with multiple keys in the same bucket.
低負載因子可以使衝突變少,但是鴿籠原理告訴我們,我們永遠無法完全消除衝突。如果你有5只寵物鴿,有4個洞來放它們,至少有一個洞最終會有不止一個鴿子。既然有18,446,744,073,709,551,616個不同的變量名,任何大小合理的數組都有可能在同一個桶中出現多個鍵。
Thus we still have to handle collisions gracefully when they occur. Users don’t like it when their programming language can look up variables correctly only most of the time.
因此,當衝突發生時,我們仍然需要優雅地處理它們。用戶並不喜歡他們的編程語言只在大多數情況下能正確地查找變量。
20 . 2 . 1 Separate chaining
20.2.1 拉鍊法
Techniques for resolving collisions fall into two broad categories. The first is separate chaining. Instead of each bucket containing a single entry, we let it contain a collection of them. In the classic implementation, each bucket points to a linked list of entries. To look up an entry, you find its bucket and then walk the list until you find an entry with the matching key.
解決衝突的技術可以分為兩大類。第一類是拉鍊法。每個桶中不再包含一個條目,而是包含條目的集合。在經典的實現中,每個桶都指向一個條目的鏈表。要查找一個條目,你要先找到它的桶,然後遍歷列表,直到找到包含匹配鍵的條目。
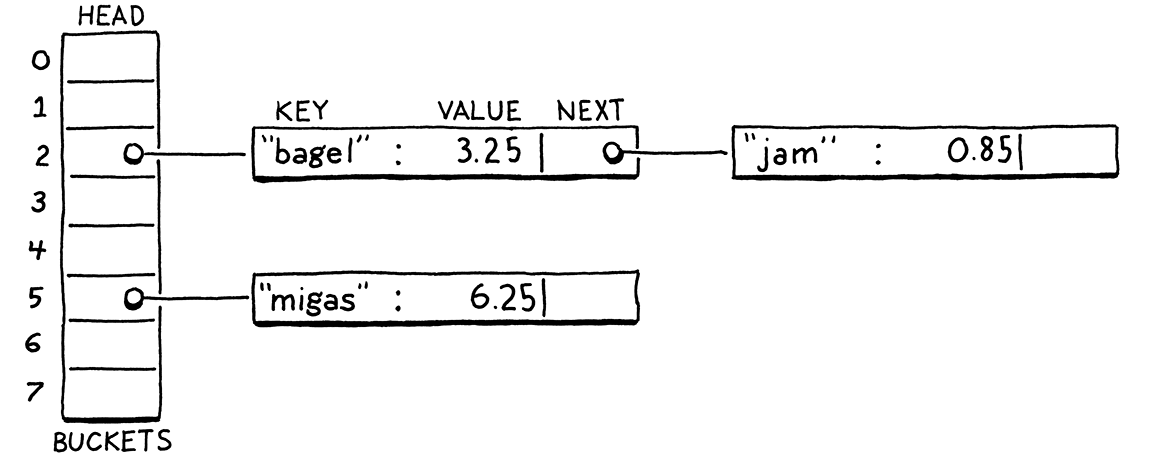
In catastrophically bad cases where every entry collides in the same bucket, the data structure degrades into a single unsorted linked list with O(n) lookup. In practice, it’s easy to avoid that by controlling the load factor and how entries get scattered across buckets. In typical separate-chained hash tables, it’s rare for a bucket to have more than one or two entries.
在最壞的情況下,每個條目都碰撞到同一個桶中,數據結構會退化成一個無序鏈表,查詢複雜度為O(n)。在實踐中,通過控制負載因子和條目在桶中的分散方式,可以很容易地避免這種情況。在典型的拉鍊哈希表中,一個桶中很少會有超過一個或兩個條目的情況。
Separate chaining is conceptually simple—it’s literally an array of linked lists. Most operations are straightforward to implement, even deletion which, as we’ll see, can be a pain. But it’s not a great fit for modern CPUs. It has a lot of overhead from pointers and tends to scatter little linked list nodes around in memory which isn’t great for cache usage.
拉鍊法在概念上很簡單——它實際上就是一個鏈表數組。大多數操作實現都可以直接實現,甚至是刪除(正如我們將看到的,這可能會很麻煩)。但它並不適合現代的CPU。它有很多指針帶來的開銷5,並且傾向於在內存中分散的小的鏈表節點,這對緩存的使用不是很好。
20 . 2 . 2 Open addressing
20.2.2 開放地址法
The other technique is called open addressing or (confusingly) closed hashing. With this technique, all entries live directly in the bucket array, with one entry per bucket. If two entries collide in the same bucket, we find a different empty bucket to use instead.
另一種技術稱為開放地址或(令人困惑的)封閉哈希6。使用這種技術時,所有的條目都直接存儲在桶數組中,每個桶有一個條目。如果兩個條目在同一個桶中發生衝突,我們會找一個其它的空桶來代替。
Storing all entries in a single, big, contiguous array is great for keeping the memory representation simple and fast. But it makes all of the operations on the hash table more complex. When inserting an entry, its bucket may be full, sending us to look at another bucket. That bucket itself may be occupied and so on. This process of finding an available bucket is called probing, and the order that you examine buckets is a probe sequence.
將所有條目存儲在一個單一的、大的、連續的數組中,對於保持內存表示方式的簡單和快速是非常好的。但它使得哈希表上的所有操作變得非常複雜。當插入一個條目時,它的桶可能已經滿了,這就會讓我們去查看另一個桶。而那個桶本身可能也被佔用了,等等。這個查找可用存儲桶的過程被稱為探測,而檢查存儲桶的順序是探測序列。
There are a number of algorithms for determining which buckets to probe and how to decide which entry goes in which bucket. There’s been a ton of research here because even slight tweaks can have a large performance impact. And, on a data structure as heavily used as hash tables, that performance impact touches a very large number of real-world programs across a range of hardware capabilities.
有很多算法7可以用來確定要探測哪些桶,以及如何決定哪個條目要放在哪個桶中。這方面有大量的研究,因為即使是輕微的調整也會對性能產生很大的影響。而且,對於像哈希表這樣大量使用的數據結構來說,這種性能影響涉及到跨一系列硬件功能的大量實際的程序。
As usual in this book, we’ll pick the simplest one that gets the job done efficiently. That’s good old linear probing. When looking for an entry, we look in the first bucket its key maps to. If it’s not in there, we look in the very next element in the array, and so on. If we reach the end, we wrap back around to the beginning.
依照本書的慣例,我們會選擇最簡單的方法來有效地完成工作。這就是良好的老式線性探測法。當查找一個條目時,我們先在它的鍵映射的桶中查找。如果它不在裡面,我們就在數組的下一個元素中查找,以此類推。如果我們到了數組終點,就繞回到起點。
The good thing about linear probing is that it’s cache friendly. Since you walk the array directly in memory order, it keeps the CPU’s cache lines full and happy. The bad thing is that it’s prone to clustering. If you have a lot of entries with numerically similar key values, you can end up with a lot of colliding, overflowing buckets right next to each other.
線性探測的好處是它對緩存友好。因為你是直接按照內存順序遍歷數組,所以它可以保持CPU緩存行完整且正常。壞處是,它容易聚集。如果你有很多具有相似鍵值的條目,那最終可能會產生許多相互緊挨的衝突、溢出的桶。
Compared to separate chaining, open addressing can be harder to wrap your head around. I think of open addressing as similar to separate chaining except that the “list” of nodes is threaded through the bucket array itself. Instead of storing the links between them in pointers, the connections are calculated implicitly by the order that you look through the buckets.
與拉鍊法相比,開放地址法可能更難理解。我認為開放地址法與拉鍊法是類似的,區別在於“列表”中的節點是通過桶數組本身進行的。它們之間的鏈接並沒有存儲在指針中,而是通過查看桶的順序隱式計算的。
The tricky part is that more than one of these implicit lists may be interleaved together. Let’s walk through an example that covers all the interesting cases. We’ll ignore values for now and just worry about a set of keys. We start with an empty array of 8 buckets.
棘手的部分是,這些隱式的列表中可能會有多個交錯在一起。讓我們通過一個例子,涵蓋所有有意思的情況。我們現在先不考慮值,只關心一組鍵。首先從一個包含8個桶的數組開始。

We decide to insert “bagel”. The first letter, “b” (ASCII value 98), modulo the array size (8) puts it in bucket 2.
我們決定插入“bagel”。第一個字母“b”(ASCII值是98),對數組大小(8)取模後,將其放入2號桶中。

Next, we insert “jam”. That also wants to go in bucket 2 (106 mod 8 = 2), but that bucket’s taken. We keep probing to the next bucket. It’s empty, so we put it there.
接下來,我們插入“jam”。它也應該放在2號桶中(106 mod 8 = 2),但是這個桶已經被佔用了。我們繼續探測下一個桶。它是空的,所以我們把它放入其中。
We insert “fruit”, which happily lands in bucket 6.
我們插入“fruit”,它愉快地落在6號桶中。
Likewise, “migas” can go in its preferred bucket 5.
同樣,“migas”可以放在其首選的5號桶中。
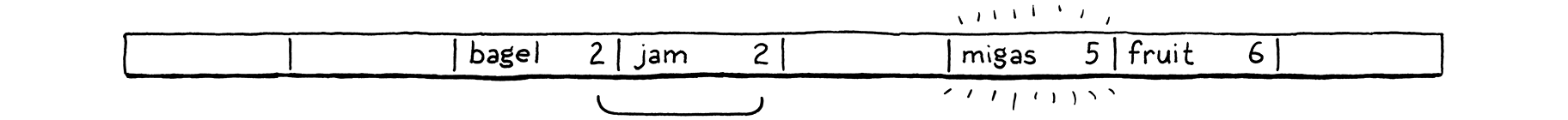
When we try to insert “eggs”, it also wants to be in bucket 5. That’s full, so we skip to 6. Bucket 6 is also full. Note that the entry in there is not part of the same probe sequence. “Fruit” is in its preferred bucket, 6. So the 5 and 6 sequences have collided and are interleaved. We skip over that and finally put “eggs” in bucket 7.
當我們嘗試插入“eggs”時,它也想放在5號桶中。滿了,我們跳到6號桶。6號桶也滿了。請注意,其中的條目並不是當前探測序列的一部分。“Fruit” 在其首選的6號桶中。因此,這裡是5號和6號序列發生了碰撞,並交錯在一起。我們跳過這個,最後把“eggs”放在7號桶中。

We run into a similar problem with “nuts”. It can’t land in 6 like it wants to. Nor can it go into 7. So we keep going. But we’ve reached the end of the array, so we wrap back around to 0 and put it there.
我們在“nuts”上遇到了同樣的問題。它不能按預期進入6號桶中,也不能進入7號桶中。所以我們繼續前進,但是我們已經到了數組的末端,所以我們回到0並將其放入0號桶。

In practice, the interleaving turns out to not be much of a problem. Even in separate chaining, we need to walk the list to check each entry’s key because multiple keys can reduce to the same bucket. With open addressing, we need to do that same check, and that also covers the case where you are stepping over entries that “belong” to a different original bucket.
在實踐中,這種交錯並不是什麼大問題。即使是在拉鍊法中,我們也需要遍歷列表來檢查每個條目的鍵,因為多個鍵會落入同一個桶中。使用開放地址法,我們需要做同樣的檢查,這也涵蓋了你需要遍歷“屬於”不同原始桶的條目的情況。
20 . 3 Hash Functions
20.3 哈希函數
We can now build ourselves a reasonably efficient table for storing variable names up to eight characters long, but that limitation is still annoying. In order to relax the last constraint, we need a way to take a string of any length and convert it to a fixed-size integer.
現在,我們可以為自己構建一個相當有效的表,來存儲長度不超過8字符的變量名,但這個限制仍然令人討厭。為了放寬最後一個限制,我們需要一種方法,將任意長度的字符串轉換成固定大小的整數。
Finally, we get to the “hash” part of “hash table”. A hash function takes some larger blob of data and “hashes” it to produce a fixed-size integer hash code whose value depends on all of the bits of the original data. A good hash function has three main goals:
終於,我們來到了“哈希表”的“哈希”部分。哈希函數接受一些更大的數據塊,並將其“哈希”生成一個固定大小的整數哈希碼,該值取決於原始數據的每一個比特。一個好的哈希函數有三個主要目標8:
-
It must be deterministic. The same input must always hash to the same number. If the same variable ends up in different buckets at different points in time, it’s gonna get really hard to find it.
它必須是確定性的。相同的輸入必須總是哈希到相同的數字。如果同一個變量在不同的時間點出現在不同的桶中,那就很難找到它了。
-
It must be uniform. Given a typical set of inputs, it should produce a wide and evenly distributed range of output numbers, with as few clumps or patterns as possible. We want it to scatter values across the whole numeric range to minimize collisions and clustering.
它必須是均勻的。給定一組典型的輸入,它應該產生一個廣泛而均勻分佈的輸出數字範圍,儘可能少地出現簇或模式。我們希望它能在整個數字範圍內分散數值,以儘量減少碰撞和聚類9。
-
It must be fast. Every operation on the hash table requires us to hash the key first. If hashing is slow, it can potentially cancel out the speed of the underlying array storage.
它必須是快速的。對哈希表的每個操作都需要我們首先對鍵進行哈希。如果哈希計算很慢,就有可能會抵消底層數組存儲的速度優勢。
There is a veritable pile of hash functions out there. Some are old and optimized for architectures no one uses anymore. Some are designed to be fast, others cryptographically secure. Some take advantage of vector instructions and cache sizes for specific chips, others aim to maximize portability.
這裡有一堆名副其實的哈希函數。有些是舊的,並且針對已經不再使用的架構進行了優化。有些是為了快速設計的,有些則是加密安全的。有的利用了特定芯片的矢量指令和緩存大小,有的則旨在最大限度地提高可移植性。
There are people out there for whom designing and evaluating hash functions is, like, their jam. I admire them, but I’m not mathematically astute enough to be one. So for clox, I picked a simple, well-worn hash function called FNV-1a that’s served me fine over the years. Consider trying out different ones in your code and see if they make a difference.
有些人把設計和計算哈希函數當作自己的工作。我很佩服他們,但我在數學上還不夠精明,不足以成為其中一員。所以對於clox來說。我選擇了一個簡單、常用的哈希函數FNV-1a,多年來它一直為我所用。可以考慮在你的代碼中嘗試不同的方法,看看它們是否有什麼不同。
OK, that’s a quick run through of buckets, load factors, open addressing, collision resolution, and hash functions. That’s an awful lot of text and not a lot of real code. Don’t worry if it still seems vague. Once we’re done coding it up, it will all click into place.
好了,我們快速瀏覽了桶、負載因子、開放地址法、衝突解決和哈希函數。這裡有非常多的文字,但沒有多少真正的代碼。如果它看起來仍然很模糊,不要擔心。一旦我們完成了編碼,一切都會全部就位。
20 . 4 Building a Hash Table
20.4 構建哈希表
The great thing about hash tables compared to other classic techniques like balanced search trees is that the actual data structure is so simple. Ours goes into a new module.
與平衡搜索樹等其它經典技術相比,哈希表的好處在於,它實際的數據結構非常簡單。我們進入一個新的模塊。
table.h,創建新文件:
#ifndef clox_table_h
#define clox_table_h
#include "common.h"
#include "value.h"
typedef struct {
int count;
int capacity;
Entry* entries;
} Table;
#endif
A hash table is an array of entries. As in our dynamic array earlier, we keep track of both the allocated size of the array (
capacity) and the number of key/value pairs currently stored in it (count). The ratio of count to capacity is exactly the load factor of the hash table.
哈希表是一個條目數組。就像前面的動態數組一樣,我們既要跟蹤數組的分配大小(容量,capacity)和當前存儲在其中的鍵/值對數量(計數,count)。數量與容量的比值正是哈希表的負載因子。
Each entry is one of these:
每個條目都是這樣的:
table.h,添加代碼:
#include "value.h"
// 新增部分開始
typedef struct {
ObjString* key;
Value value;
} Entry;
// 新增部分結束
typedef struct {
It’s a simple key/value pair. Since the key is always a string, we store the ObjString pointer directly instead of wrapping it in a Value. It’s a little faster and smaller this way.
這是一個簡單的鍵/值對。因為鍵總是一個字符串10,我們直接存儲ObjString指針,而不是將其包裝在Value中。這樣做速度更快,體積更小。
To create a new, empty hash table, we declare a constructor-like function.
為了創建一個新的、空的哈希表,我們聲明一個類似構造器的函數。
table.h,在結構體Table後添加代碼:
} Table;
// 新增部分開始
void initTable(Table* table);
// 新增部分結束
#endif
We need a new implementation file to define that. While we’re at it, let’s get all of the pesky includes out of the way.
我們需要一個新的實現文件來定義它。既然說到這裡,讓我們把所有討厭的依賴文件都搞定。
table.c,創建新文件:
#include <stdlib.h>
#include <string.h>
#include "memory.h"
#include "object.h"
#include "table.h"
#include "value.h"
void initTable(Table* table) {
table->count = 0;
table->capacity = 0;
table->entries = NULL;
}
As in our dynamic value array type, a hash table initially starts with zero capacity and a
NULLarray. We don’t allocate anything until needed. Assuming we do eventually allocate something, we need to be able to free it too.
就像動態值數組類型一樣,哈希表最初以容量0和NULL數組開始。等到需要的時候我們才會分配一些東西。假設我們最終分配了什麼,我們也需要能夠釋放它。
table.h,在initTable()方法後添加代碼:
void initTable(Table* table);
// 新增部分開始
void freeTable(Table* table);
// 新增部分結束
#endif
And its glorious implementation:
以及其絢麗的實現:
table.c,在initTable()方法後添加代碼:
void freeTable(Table* table) {
FREE_ARRAY(Entry, table->entries, table->capacity);
initTable(table);
}
Again, it looks just like a dynamic array. In fact, you can think of a hash table as basically a dynamic array with a really strange policy for inserting items. We don’t need to check for
NULLhere sinceFREE_ARRAY()already handles that gracefully.
同樣,它看起來就像一個動態數組。實際上,你基本可以把哈希表看作是一個動態數組,它具有一個非常奇怪的插入條目策略。在這裡我們不需要檢查NULL,因為FREE_ARRAY()已經優雅地處理了這個問題。
20 . 4 . 1 Hashing strings
20.4.1 哈希字符串
Before we can start putting entries in the table, we need to, well, hash them. To ensure that the entries get distributed uniformly throughout the array, we want a good hash function that looks at all of the bits of the key string. If it looked at, say, only the first few characters, then a series of strings that all shared the same prefix would end up colliding in the same bucket.
在我們開始向表中加入條目之前,我們需要,嗯,哈希它們。為了確保條目均勻分佈在整個數組中,我們需要一個能考慮鍵字符串所有比特位的好的哈希函數。如果它只著眼於前幾個字符,那麼共享相同前綴的一系列字符串最終會碰撞在同一個桶中。
On the other hand, walking the entire string to calculate the hash is kind of slow. We’d lose some of the performance benefit of the hash table if we had to walk the string every time we looked for a key in the table. So we’ll do the obvious thing: cache it.
另一方面,遍歷整個字符串來計算哈希值是有點慢的。如果我們每次在哈希表中查找鍵時都要遍歷字符串,就會失去哈希表的一些性能優勢。所以我們要做一件顯而易見的事:緩存它。
Over in the “object” module in ObjString, we add:
在“object”模塊的ObjString中,添加:
object.h,在結構體ObjString中添加代碼:
char* chars;
// 新增部分開始
uint32_t hash;
// 新增部分結束
};
Each ObjString stores the hash code for its string. Since strings are immutable in Lox, we can calculate the hash code once up front and be certain that it will never get invalidated. Caching it eagerly makes a kind of sense: allocating the string and copying its characters over is already an O(n) operation, so it’s a good time to also do the O(n) calculation of the string’s hash.
每個ObjString 會存儲其字符串的哈希碼。由於字符串在Lox中是不可變的,所以我們可以預先計算一次哈希代碼,並確保它永遠不會失效。提前緩存它是有道理的:分配字符串並複製其字符已然是一個O(n)的操作了,所以這是一個很好的時機來執行字符串哈希的O(n)計算。
Whenever we call the internal function to allocate a string, we pass in its hash code.
每當我們調用內部函數來分配字符串時,我們就會傳入其哈希碼。
object.c,在allocateString()方法中替換1行:
// 替換部分開始
static ObjString* allocateString(char* chars, int length,
uint32_t hash) {
// 替換部分結束
ObjString* string = ALLOCATE_OBJ(ObjString, OBJ_STRING);
That function simply stores the hash in the struct.
該函數只是將哈希值存儲在結構體中
object.c,在allocateString()方法中添加代碼:
string->chars = chars;
// 新增部分開始
string->hash = hash;
// 新增部分結束
return string;
}
The fun happens over at the callers.
allocateString()is called from two places: the function that copies a string and the one that takes ownership of an existing dynamically allocated string. We’ll start with the first.
有趣的部分是在調用者中。allocateString()方法在兩個地方被調用:複製字符串的函數和獲取現有動態分配字符串所有權的函數。我們從第一個開始。
object.c,在copyString()方法中添加代碼:
ObjString* copyString(const char* chars, int length) {
// 新增部分開始
uint32_t hash = hashString(chars, length);
// 新增部分結束
char* heapChars = ALLOCATE(char, length + 1);
No magic here. We calculate the hash code and then pass it along.
沒有魔法。我們計算哈希碼,然後把它傳遞出去。
object.c,在copyString()方法中替換1行:
memcpy(heapChars, chars, length);
heapChars[length] = '\0';
// 替換部分開始
return allocateString(heapChars, length, hash);
// 替換部分結束
}
The other string function is similar.
另一個字符串函數是類似的。
object.c,在takeString()方法中替換1行:
ObjString* takeString(char* chars, int length) {
// 替換部分開始
uint32_t hash = hashString(chars, length);
return allocateString(chars, length, hash);
// 替換部分結束
}
The interesting code is over here:
有趣的代碼在這裡:
object.c,在allocateString()方法後添加代碼:
static uint32_t hashString(const char* key, int length) {
uint32_t hash = 2166136261u;
for (int i = 0; i < length; i++) {
hash ^= (uint8_t)key[i];
hash *= 16777619;
}
return hash;
}
This is the actual bona fide “hash function” in clox. The algorithm is called “FNV-1a”, and is the shortest decent hash function I know. Brevity is certainly a virtue in a book that aims to show you every line of code.
這就是clox中真正的“哈希函數”。該算法被稱為“FNV-1a”,是我所知道的最短的正統哈希函數。對於一本旨在向您展示每一行代碼的書來說,簡潔無疑是一種美德。
The basic idea is pretty simple, and many hash functions follow the same pattern. You start with some initial hash value, usually a constant with certain carefully chosen mathematical properties. Then you walk the data to be hashed. For each byte (or sometimes word), you mix the bits into the hash value somehow, and then scramble the resulting bits around some.
基本思想非常簡單,許多哈希函數都遵循同樣的模式。從一些初始哈希值開始,通常是一個帶有某些精心選擇的數學特性的常量。然後遍歷需要哈希的數據。對於每個字節(有些是每個字),以某種方式將比特與哈希值混合,然後將結果比特進行一些擾亂。
What it means to “mix” and “scramble” can get pretty sophisticated. Ultimately, though, the basic goal is uniformity—we want the resulting hash values to be as widely scattered around the numeric range as possible to avoid collisions and clustering.
“混合”和“擾亂”的含義可以變得相當複雜。不過,最終的基本目標是均勻——我們希望得到的哈希值儘可能廣泛地分散在數組範圍內,以避免碰撞和聚集。
20 . 4 . 2 Inserting entries
20.4.2 插入條目
Now that string objects know their hash code, we can start putting them into hash tables.
現在字符串對象已經知道了它們的哈希碼,我們可以開始將它們放入哈希表了。
table.h,在freeTable()方法後添加代碼:
void freeTable(Table* table);
// 新增部分開始
bool tableSet(Table* table, ObjString* key, Value value);
// 新增部分結束
#endif
This function adds the given key/value pair to the given hash table. If an entry for that key is already present, the new value overwrites the old value. The function returns
trueif a new entry was added. Here’s the implementation:
這個函數將給定的鍵/值對添加到給定的哈希表中。如果該鍵的條目已存在,新值將覆蓋舊值。如果添加了新條目,則該函數返回true。下面是實現:
table.c,在freeTable()方法後添加代碼:
bool tableSet(Table* table, ObjString* key, Value value) {
Entry* entry = findEntry(table->entries, table->capacity, key);
bool isNewKey = entry->key == NULL;
if (isNewKey) table->count++;
entry->key = key;
entry->value = value;
return isNewKey;
}
Most of the interesting logic is in
findEntry()which we’ll get to soon. That function’s job is to take a key and figure out which bucket in the array it should go in. It returns a pointer to that bucket—the address of the Entry in the array.
大部分有趣的邏輯都在findEntry()中,我們很快就會講到。該函數的作用是接受一個鍵,並找到它應該放在數組中的哪個桶裡。它會返回一個指向該桶的指針——數組中Entry的地址。
Once we have a bucket, inserting is straightforward. We update the hash table’s size, taking care to not increase the count if we overwrote the value for an already-present key. Then we copy the key and value into the corresponding fields in the Entry.
一旦有了桶,插入就很簡單了。我們更新哈希表的大小,如果我們覆蓋了一個已經存在的鍵的值,注意不要增加計數。然後,我們將鍵和值複製到Entry中的對應字段中。
We’re missing a little something here, though. We haven’t actually allocated the Entry array yet. Oops! Before we can insert anything, we need to make sure we have an array, and that it’s big enough.
不過,我們這裡還少了點什麼,我們還沒有分配Entry數組。糟糕!在我們向其中插入數據之前,需要確保已經有一個數組,而且足夠大。
table.c,在tableSet()方法中添加代碼:
bool tableSet(Table* table, ObjString* key, Value value) {
// 新增部分開始
if (table->count + 1 > table->capacity * TABLE_MAX_LOAD) {
int capacity = GROW_CAPACITY(table->capacity);
adjustCapacity(table, capacity);
}
// 新增部分結束
Entry* entry = findEntry(table->entries, table->capacity, key);
This is similar to the code we wrote a while back for growing a dynamic array. If we don’t have enough capacity to insert an item, we reallocate and grow the array. The
GROW_CAPACITY()macro takes an existing capacity and grows it by a multiple to ensure that we get amortized constant performance over a series of inserts.
這與我們之前為擴展動態數組所寫的代碼相似。如果沒有足夠的容量插入條目,我們就重新分配和擴展數組。GROW_CAPACITY()宏會接受現有容量,並將其增長一倍,以確保在一系列插入操作中得到攤銷的常數性能。
The interesting difference here is that
TABLE_MAX_LOADconstant.
這裡一個有趣的區別是TABLE_MAX_LOAD常量。
table.c,添加代碼:
#include "value.h"
// 新增部分開始
#define TABLE_MAX_LOAD 0.75
// 新增部分結束
void initTable(Table* table) {
This is how we manage the table’s load factor. We don’t grow when the capacity is completely full. Instead, we grow the array before then, when the array becomes at least 75% full.
這就是我們管理表負載因子的方式。我們不會在容量全滿的時候才進行擴展。相反,當數組達到75%滿時11,我們會提前擴展數組。
We’ll get to the implementation of
adjustCapacity()soon. First, let’s look at thatfindEntry()function you’ve been wondering about.
我們很快就會討論adjustCapacity()的實現。首先,我們看看你一直很好奇的findEntry()函數。
table.c,在freeTable()方法後添加代碼:
static Entry* findEntry(Entry* entries, int capacity,
ObjString* key) {
uint32_t index = key->hash % capacity;
for (;;) {
Entry* entry = &entries[index];
if (entry->key == key || entry->key == NULL) {
return entry;
}
index = (index + 1) % capacity;
}
}
This function is the real core of the hash table. It’s responsible for taking a key and an array of buckets, and figuring out which bucket the entry belongs in. This function is also where linear probing and collision handling come into play. We’ll use
findEntry()both to look up existing entries in the hash table and to decide where to insert new ones.
這個函數是哈希表的真正核心。它負責接受一個鍵和一個桶數組,並計算出該條目屬於哪個桶。這個函數也是線性探測和衝突處理發揮作用的地方。我們在查詢哈希表中的現有條目以及決定在哪裡插入新條目時,都會使用findEntry()方法。
For all that, there isn’t much to it. First, we use modulo to map the key’s hash code to an index within the array’s bounds. That gives us a bucket index where, ideally, we’ll be able to find or place the entry.
儘管如此,其中也沒什麼特別的。首先,我們通過取餘操作將鍵的哈希碼映射為數值邊界內的一個索引值。這就給了我們一個桶索引,理想情況下,我們可以在這裡找到或放置條目。
There are a few cases to check for:
有幾種情況需要檢查:
-
If the key for the Entry at that array index is
NULL, then the bucket is empty. If we’re usingfindEntry()to look up something in the hash table, this means it isn’t there. If we’re using it to insert, it means we’ve found a place to add the new entry.如果數組索引處的Entry的鍵為
NULL,則表示桶為空。如果我們使用findEntry()在哈希表中查找東西,這意味著它不存在。如果我們用來插入,這表明我們找到了一個可以插入新條目的地方。 -
If the key in the bucket is equal to the key we’re looking for, then that key is already present in the table. If we’re doing a lookup, that’s good—we’ve found the key we seek. If we’re doing an insert, this means we’ll be replacing the value for that key instead of adding a new entry.
如果桶中的鍵等於我們要找的鍵12,那麼這個鍵已經存在於表中了。如果我們在做查找,這很好——我們已經找到了要查找的鍵。如果我們在做插入,這意味著我們要替換該鍵的值,而不是添加一個新條目。
-
Otherwise, the bucket has an entry in it, but with a different key. This is a collision. In that case, we start probing. That’s what that
forloop does. We start at the bucket where the entry would ideally go. If that bucket is empty or has the same key, we’re done. Otherwise, we advance to the next element—this is the linear part of “linear probing”—and check there. If we go past the end of the array, that second modulo operator wraps us back around to the beginning.否則,就是桶中有一個條目,但具有不同的鍵。這就是一個衝突。在這種情況下,我們要開始探測。這也就是
for循環所做的。我們從條目理想的存放位置開始。如果這個桶是空的或者有相同的鍵,我們就完成了。否則,我們就前進到下一個元素——這就是“線性探測”的線性部分——並進行檢查。如果我們超過了數組的末端,第二個模運算符就會把我們重新帶回起點。
We exit the loop when we find either an empty bucket or a bucket with the same key as the one we’re looking for. You might be wondering about an infinite loop. What if we collide with every bucket? Fortunately, that can’t happen thanks to our load factor. Because we grow the array as soon as it gets close to being full, we know there will always be empty buckets.
當我們找到空桶或者與我們要找的桶具有相同鍵的桶時,我們就退出循環。你可能會考慮無限循環的問題。如果我們與所有的桶都衝突怎麼辦?幸運的是,因為負載因子的原因,這種情況不會發生。因為一旦數組接近滿。我們就會擴展數組,所以我們知道總是會有空桶。
We return directly from within the loop, yielding a pointer to the found Entry so the caller can either insert something into it or read from it. Way back in
tableSet(), the function that first kicked this off, we store the new entry in that returned bucket and we’re done.
我們會從循環中直接返回,得到一個指向找到的Entry的指針,這樣調用方就可以向其中插入內容或從中讀取內容。回到tableSet()——最先調用它的函數,我們將新條目存儲到返回的桶中,然後就完成了。
20 . 4 . 3 Allocating and resizing
20.4.3 分配和調整
Before we can put entries in the hash table, we do need a place to actually store them. We need to allocate an array of buckets. That happens in this function:
在我們將條目放入哈希表之前,我們確實需要一個地方來實際存儲它們。我們需要分配一個桶數組。發生在這個函數中:
table.c,在findEntry()方法後添加代碼:
static void adjustCapacity(Table* table, int capacity) {
Entry* entries = ALLOCATE(Entry, capacity);
for (int i = 0; i < capacity; i++) {
entries[i].key = NULL;
entries[i].value = NIL_VAL;
}
table->entries = entries;
table->capacity = capacity;
}
We create a bucket array with
capacityentries. After we allocate the array, we initialize every element to be an empty bucket and then store the array (and its capacity) in the hash table’s main struct. This code is fine for when we insert the very first entry into the table, and we require the first allocation of the array. But what about when we already have one and we need to grow it?
我們創建一個包含capacity個條目的桶數組。分配完數組後,我們將每個元素初始化為空桶,然後將數組(及其容量)存儲到哈希表的主結構體中。當我們將第一個條目插入表中時,這段代碼是沒有問題的,而且我們需要對數組進行第一次分配。但如果我們已經有了一個數組,並且需要增加它的容量時,怎麼辦?
Back when we were doing a dynamic array, we could just use
realloc()and let the C standard library copy everything over. That doesn’t work for a hash table. Remember that to choose the bucket for each entry, we take its hash key modulo the array size. That means that when the array size changes, entries may end up in different buckets.
在我們做動態數組時,我們只需使用realloc(),讓C標準庫把所有內容都複製過來。這對哈希表是行不通的。請記住,為了給每個條目選擇存儲桶,我們要用其哈希鍵與數組大小取模。這意味著,當數組大小發生變化時,條目可能會出現在不同的桶中。
Those new buckets may have new collisions that we need to deal with. So the simplest way to get every entry where it belongs is to rebuild the table from scratch by re-inserting every entry into the new empty array.
這些新的桶可能會出現新的衝突,我們需要處理這些衝突。因此,獲取每個條目所屬位置的最簡單的方法是從頭重新構建哈希表,將每個條目都重新插入到新的空數組中。
table.c,在adjustCapacity()方法中添加代碼:
entries[i].value = NIL_VAL;
}
// 新增部分開始
for (int i = 0; i < table->capacity; i++) {
Entry* entry = &table->entries[i];
if (entry->key == NULL) continue;
Entry* dest = findEntry(entries, capacity, entry->key);
dest->key = entry->key;
dest->value = entry->value;
}
// 新增部分結束
table->entries = entries;
We walk through the old array front to back. Any time we find a non-empty bucket, we insert that entry into the new array. We use findEntry(), passing in the new array instead of the one currently stored in the Table. (This is why findEntry() takes a pointer directly to an Entry array and not the whole Table struct. That way, we can pass the new array and capacity before we’ve stored those in the struct.)
我們從前到後遍歷舊數組。只要發現一個非空的桶,我們就把這個條目插入到新的數組中。我們使用findEntry(),傳入的是新數組,而不是當前存儲在哈希表中的舊數組。(這就是為什麼findEntry()接受一個直接指向Entry數組的指針,而不是整個Table結構體。這樣,我們就可以在將新數組和容量存儲到結構體之前傳遞這些數據)
After that’s done, we can release the memory for the old array.
完成之後,我們就可以釋放舊數組的內存。
table.c,在adjustCapacity()方法中添加代碼:
dest->value = entry->value;
}
// 新增部分開始
FREE_ARRAY(Entry, table->entries, table->capacity);
// 新增部分結束
table->entries = entries;
With that, we have a hash table that we can stuff as many entries into as we like. It handles overwriting existing keys and growing itself as needed to maintain the desired load capacity.
這樣,我們就有了一個哈希表,我們可以隨心所欲地向其中塞入很多條目。它可以處理覆蓋現有鍵,以及按需擴展自身,以保持所需的負載容量。
While we’re at it, let’s also define a helper function for copying all of the entries of one hash table into another.
既然如此,我們也來定義一個輔助函數,將一個哈希表的所有條目複製到另一個哈希表中。
table.h,在tableSet()方法後添加代碼:
bool tableSet(Table* table, ObjString* key, Value value);
// 新增部分開始
void tableAddAll(Table* from, Table* to);
// 新增部分結束
#endif
We won’t need this until much later when we support method inheritance, but we may as well implement it now while we’ve got all the hash table stuff fresh in our minds.
等到很久之後我們要支持方法繼承時,才會需要這個能力,但是我們不妨現在就實現它,趁著我們還記得哈希表的一切內容。
table.c,在tableSet()方法後添加代碼:
void tableAddAll(Table* from, Table* to) {
for (int i = 0; i < from->capacity; i++) {
Entry* entry = &from->entries[i];
if (entry->key != NULL) {
tableSet(to, entry->key, entry->value);
}
}
}
There’s not much to say about this. It walks the bucket array of the source hash table. Whenever it finds a non-empty bucket, it adds the entry to the destination hash table using the
tableSet()function we recently defined.
這沒什麼可說的。它會遍歷源哈希表的桶數組。只要發現一個非空的桶,就使用我們剛定義的tableSet()函數將條目添加到目標哈希表中。
20 . 4 . 4 Retrieving values
20.4.4 檢索值
Now that our hash table contains some stuff, let’s start pulling things back out. Given a key, we can look up the corresponding value, if there is one, with this function:
現在,我們的哈希表中已經包含了一些東西,讓我們開始把它們取出來。給定一個鍵,如果有對應的條目,我們可以用這個函數來查找對應的值:
table.h,在freeTable()方法後添加代碼:
void freeTable(Table* table);
// 新增部分開始
bool tableGet(Table* table, ObjString* key, Value* value);
// 新增部分結束
bool tableSet(Table* table, ObjString* key, Value value);
You pass in a table and a key. If it finds an entry with that key, it returns
true, otherwise it returnsfalse. If the entry exists, thevalueoutput parameter points to the resulting value.
傳入一個表和一個鍵。如果它找到一個帶有該鍵的條目,則返回true,否則返回false。如果該條目存在,輸出的value參數會指向結果值。
Since
findEntry()already does the hard work, the implementation isn’t bad.
因為findEntry()已經完成了這項艱苦的工作,所以實現起來並不難。
table.c,在findEntry()方法後添加代碼:
bool tableGet(Table* table, ObjString* key, Value* value) {
if (table->count == 0) return false;
Entry* entry = findEntry(table->entries, table->capacity, key);
if (entry->key == NULL) return false;
*value = entry->value;
return true;
}
If the table is completely empty, we definitely won’t find the entry, so we check for that first. This isn’t just an optimization—it also ensures that we don’t try to access the bucket array when the array is
NULL. Otherwise, we letfindEntry()work its magic. That returns a pointer to a bucket. If the bucket is empty, which we detect by seeing if the key isNULL, then we didn’t find an Entry with our key. IffindEntry()does return a non-empty Entry, then that’s our match. We take the Entry’s value and copy it to the output parameter so the caller can get it. Piece of cake.
如果表完全是空的,我們肯定找不到這個條目,所以我們先檢查一下。這不僅僅是一種優化——它還確保當數組為NULL時,我們不會試圖訪問桶數組。其它情況下,我們就讓findEntry()發揮它的魔力。這將返回一個指向桶的指針。如果桶是空的(我們通過查看鍵是否為NULL來檢測),那麼我們就沒有找到包含對應鍵的Entry。如果findEntry()確實返回了一個非空的Entry,那麼它就是我們的匹配項。我們獲取Entry的值並將其複製到輸出參數中,這樣調用方就可以得到該值。小菜一碟。
20 . 4 . 5 Deleting entries
20.4.5 刪除條目
There is one more fundamental operation a full-featured hash table needs to support: removing an entry. This seems pretty obvious, if you can add things, you should be able to un-add them, right? But you’d be surprised how many tutorials on hash tables omit this.
全功能的哈希表還需要支持一個更基本的操作:刪除一個條目。這看起來很明顯,如果你能添加東西,你應該就能刪除它,對嗎?但你會驚訝於有多少關於哈希表的教程省略了這一點。
I could have taken that route too. In fact, we use deletion in clox only in a tiny edge case in the VM. But if you want to actually understand how to completely implement a hash table, this feels important. I can sympathize with their desire to overlook it. As we’ll see, deleting from a hash table that uses open addressing is tricky.
我也可以走這條路。事實上,我們在clox中只在VM的一個很小的邊緣情況下會使用刪除。但如果你想真正理解如何完全實現一個哈希表,這一點很重要。我能理解它們忽略這一點的想法。正如我們將看到的,從使用開放地址法的哈希表中刪除數據是很棘手的13。
At least the declaration is simple.
至少聲明是簡單的。
table.h,在tableSet()方法後添加代碼:
bool tableSet(Table* table, ObjString* key, Value value);
// 新增部分開始
bool tableDelete(Table* table, ObjString* key);
// 新增部分結束
void tableAddAll(Table* from, Table* to);
The obvious approach is to mirror insertion. Use
findEntry()to look up the entry’s bucket. Then clear out the bucket. Done!
一個明顯的方法就是插入的鏡像操作。使用findEntry()找到條目的桶,然後把桶清空。完成了!
In cases where there are no collisions, that works fine. But if a collision has occurred, then the bucket where the entry lives may be part of one or more implicit probe sequences. For example, here’s a hash table containing three keys all with the same preferred bucket, 2:
在沒有衝突的情況下,這樣做沒問題。但是如果發生了衝突,那麼條目所在的桶可能是一個或多個隱式探測序列的一部分。舉例來說,下面是一個哈希表,包含三個鍵,它們有著相同的首選桶,2:
Remember that when we’re walking a probe sequence to find an entry, we know we’ve reached the end of a sequence and that the entry isn’t present when we hit an empty bucket. It’s like the probe sequence is a list of entries and an empty entry terminates that list.
請記住,我們在遍歷探測序列來查找一個條目時,如果碰到一個空桶,我們就知道已經到達了序列的末端而且該條目不存在。這就好像探測序列是一個條目的列表,而空條目終止了這個列表。
If we delete “biscuit” by simply clearing the Entry, then we break that probe sequence in the middle, leaving the trailing entries orphaned and unreachable. Sort of like removing a node from a linked list without relinking the pointer from the previous node to the next one.
如果我們通過簡單地清除Entry來刪除“biscuit”,那麼我們就會中斷探測序列,讓後面的條目變得孤立、不可訪問。這有點像是從鏈表中刪除了一個節點,而沒有把指針從上一個節點重新鏈接到下一個節點。
If we later try to look for “jam”, we’d start at “bagel”, stop at the next empty Entry, and never find it.
如果我們後面嘗試查找“jam”,我們會從“bagel”開始,在下一個空條目處停止,並且永遠找不到它。

To solve this, most implementations use a trick called tombstones. Instead of clearing the entry on deletion, we replace it with a special sentinel entry called a “tombstone”. When we are following a probe sequence during a lookup, and we hit a tombstone, we don’t treat it like an empty slot and stop iterating. Instead, we keep going so that deleting an entry doesn’t break any implicit collision chains and we can still find entries after it.
為瞭解決這個問題,大多數實現都使用了一個叫作墓碑的技巧。我們不會在刪除時清除條目,而是將其替換為一個特殊的哨兵條目,稱為“墓碑”14。當我們在查找過程中順著探測序列遍歷時,如果遇到墓碑,我們不會把它當作是空槽而停止遍歷。相反,我們會繼續前進,這樣刪除一個條目不會破壞任何隱式衝突鏈,我們仍然可以找到它之後的條目。

The code looks like this:
這段代碼看起來像這樣:
table.c,在tableSet()方法後添加代碼:
bool tableDelete(Table* table, ObjString* key) {
if (table->count == 0) return false;
// Find the entry.
Entry* entry = findEntry(table->entries, table->capacity, key);
if (entry->key == NULL) return false;
// Place a tombstone in the entry.
entry->key = NULL;
entry->value = BOOL_VAL(true);
return true;
}
First, we find the bucket containing the entry we want to delete. (If we don’t find it, there’s nothing to delete, so we bail out.) We replace the entry with a tombstone. In clox, we use a
NULLkey and atruevalue to represent that, but any representation that can’t be confused with an empty bucket or a valid entry works.
首先,我們找到包含待刪除條目的桶(如果我們沒有找到,就沒有什麼可刪除的,所以我們退出)。我們將該條目替換為墓碑。在clox中,我們使用NULL鍵和true值來表示,但任何不會與空桶或有效條目相混淆的表示形式都是可行的。
That’s all we need to do to delete an entry. Simple and fast. But all of the other operations need to correctly handle tombstones too. A tombstone is a sort of “half” entry. It has some of the characteristics of a present entry, and some of the characteristics of an empty one.
這就是刪除一個條目所需要做的全部工作。簡單而快速。但是所有其它操作也需要正確處理墓碑。墓碑有點像“半個”條目。它既有當前條目的一些特徵,也有空條目的一些特徵。
When we are following a probe sequence during a lookup, and we hit a tombstone, we note it and keep going.
當我們在查詢中遵循探測序列時,如果遇到了墓碑,我們會記錄它並繼續前進。
table.c,在findEntry()方法中替換3行:
for (;;) {
Entry* entry = &entries[index];
// 替換部分開始
if (entry->key == NULL) {
if (IS_NIL(entry->value)) {
// Empty entry.
return tombstone != NULL ? tombstone : entry;
} else {
// We found a tombstone.
if (tombstone == NULL) tombstone = entry;
}
} else if (entry->key == key) {
// We found the key.
return entry;
}
// 替換部分結束
index = (index + 1) % capacity;
The first time we pass a tombstone, we store it in this local variable:
第一次通過一個墓碑條目時,我們將它存儲在這個局部變量中:
table.c,在findEntry()方法中添加代碼:
uint32_t index = key->hash % capacity;
// 新增部分開始
Entry* tombstone = NULL;
// 新增部分結束
for (;;) {
If we reach a truly empty entry, then the key isn’t present. In that case, if we have passed a tombstone, we return its bucket instead of the later empty one. If we’re calling
findEntry()in order to insert a node, that lets us treat the tombstone bucket as empty and reuse it for the new entry.
如果我們遇到一個真正的空條目,那麼這個鍵就不存在。在這種情況下,若我們經過了一個墓碑,就返回它的桶,而不是返回後面的空桶。如果我們為了插入一個節點而調用findEntry(),這時我們可以把墓碑桶視為空桶,並重用它來存儲新條目。
Reusing tombstone slots automatically like this helps reduce the number of tombstones wasting space in the bucket array. In typical use cases where there is a mixture of insertions and deletions, the number of tombstones grows for a while and then tends to stabilize.
像這樣自動重用墓碑槽,有助於減少墓碑在桶數組中浪費的空間。在插入與刪除混合使用的典型用例中,墓碑的數量會增長一段時間,然後趨於穩定。
Even so, there’s no guarantee that a large number of deletes won’t cause the array to be full of tombstones. In the very worst case, we could end up with no empty buckets. That would be bad because, remember, the only thing preventing an infinite loop in
findEntry()is the assumption that we’ll eventually hit an empty bucket.
即便如此,也不能保證大量的刪除操作不會導致數組中滿是墓碑。在最壞的情況下,我們最終可能沒有空桶。這是很糟糕的。因為,請記住,唯一能阻止findEntry()中無限循環的原因是假設我們最終會命中一個空桶。
So we need to be thoughtful about how tombstones interact with the table’s load factor and resizing. The key question is, when calculating the load factor, should we treat tombstones like full buckets or empty ones?
所以我們需要仔細考慮墓碑如何與表的負載因子和大小調整進行互動。關鍵問題是,在計算負載因子時,我們應該把墓碑當作滿桶還是空桶?
20 . 4 . 6 Counting tombstones
20.4.6 墓碑計數
If we treat tombstones like full buckets, then we may end up with a bigger array than we probably need because it artificially inflates the load factor. There are tombstones we could reuse, but they aren’t treated as unused so we end up growing the array prematurely.
如果我們把墓碑當作滿桶,那麼我們最終得到的數組可能會比我們需要的更大,因為它人為地抬高了負載因子。有些墓碑我們可以重複使用,但是它們沒有被視為未使用,所以我們最終會過早地擴展數組。
But if we treat tombstones like empty buckets and don’t include them in the load factor, then we run the risk of ending up with no actual empty buckets to terminate a lookup. An infinite loop is a much worse problem than a few extra array slots, so for load factor, we consider tombstones to be full buckets.
但是,如果我們把墓碑當作空桶,並且不將它們計入負載因子中,那麼我們就有可能沒有真正的空桶來終止查找。無限循環比幾個多餘的數組槽要糟糕得多,所以對於負載因子,我們把墓碑看作是滿桶。
That’s why we don’t reduce the count when deleting an entry in the previous code. The count is no longer the number of entries in the hash table, it’s the number of entries plus tombstones. That implies that we increment the count during insertion only if the new entry goes into an entirely empty bucket.
這就是我們在前面的代碼中刪除條目卻不減少計數的原因。這個計數不再是哈希表中的條目數,而是條目數加上墓碑數。這意味著,只有當新條目進入一個完全空的桶中時,才會在插入操作中增加計數。
table.c,在tableSet()方法中替換1行:
bool isNewKey = entry->key == NULL;
// 替換部分開始
if (isNewKey && IS_NIL(entry->value)) table->count++;
// 替換部分結束
entry->key = key;
If we are replacing a tombstone with a new entry, the bucket has already been accounted for and the count doesn’t change.
如果我們用新條目替換墓碑,因為這個桶已經被統計過了,所以計數不會改變。
When we resize the array, we allocate a new array and re-insert all of the existing entries into it. During that process, we don’t copy the tombstones over. They don’t add any value since we’re rebuilding the probe sequences anyway, and would just slow down lookups. That means we need to recalculate the count since it may change during a resize. So we clear it out:
當我們調整數組的大小時,我們會分配一個新數組,並重新插入所有的現存條目。在這個過程中,我們不會把墓碑複製過來。因為無論如何我們都要重新構建探測序列,它們不會增加任何價值,而且只會減慢查找速度。這意味著我們需要重算計數,因為它可能會在調整大小的期間發生變化。所以我們把它清除掉:
table.c,在adjustCapacity()方法中添加代碼:
}
// 新增部分開始
table->count = 0;
// 新增部分結束
for (int i = 0; i < table->capacity; i++) {
Then each time we find a non-tombstone entry, we increment it.
然後,每當我們找到一個非墓碑的條目,就給它加1。
table.c,在adjustCapacity()方法中添加代碼:
dest->value = entry->value;
// 新增部分開始
table->count++;
// 新增部分結束
}
This means that when we grow the capacity, we may end up with fewer entries in the resulting larger array because all of the tombstones get discarded. That’s a little wasteful, but not a huge practical problem.
這意味著,當我們增加容量時,最終在更大的數組中的條目可能會更少,因為所有的墓碑都被丟棄了。這有點浪費,但不是一個嚴重的實際問題。
I find it interesting that much of the work to support deleting entries is in
findEntry()andadjustCapacity(). The actual delete logic is quite simple and fast. In practice, deletions tend to be rare, so you’d expect a hash table to do as much work as it can in the delete function and leave the other functions alone to keep them faster. With our tombstone approach, deletes are fast, but lookups get penalized.
我發現一個有趣的現象,支持刪除條目的大部分工作都是在findEntry() 和adjustCapacity()中完成的。實際的刪除邏輯是相當簡單和快速的。在實踐中,刪除操作往往是少見的,所以你會希望哈希表在刪除函數中完成儘可能多的工作,而讓其它函數保持更快的速度。使用我們的墓碑方案,刪除是快速的,但查找會受到影響。
I did a little benchmarking to test this out in a few different deletion scenarios. I was surprised to discover that tombstones did end up being faster overall compared to doing all the work during deletion to reinsert the affected entries.
我做了一個小小的基準測試,在一些不同的刪除場景中驗證這一點。我驚訝地發現,與在刪除過程中做所有的工作來重新插入受影響的條目相比,墓碑方案最終確實更快。
But if you think about it, it’s not that the tombstone approach pushes the work of fully deleting an entry to other operations, it’s more that it makes deleting lazy. At first, it does the minimal work to turn the entry into a tombstone. That can cause a penalty when later lookups have to skip over it. But it also allows that tombstone bucket to be reused by a later insert too. That reuse is a very efficient way to avoid the cost of rearranging all of the following affected entries. You basically recycle a node in the chain of probed entries. It’s a neat trick.
但如果你仔細想想,墓碑方案並不是將刪除的工作完全推給了其它操作,它更像是讓刪除延遲了。首先,它只做了很少的工作,把條目變成墓碑。當以後的查找不得不跳過它時,這可能會造成損失。但是,它也允許墓碑桶被後續的插入操作重用。這種重用是一種非常有效的方法,可以避免重新安排後續受影響的條目的成本。你基本上是回收了探測條目鏈中的一個節點。這是一個很巧妙的技巧。
20 . 5 String Interning
20.5 字符串駐留
We’ve got ourselves a hash table that mostly works, though it has a critical flaw in its center. Also, we aren’t using it for anything yet. It’s time to address both of those and, in the process, learn a classic technique used by interpreters.
我們已經有了一個基本可用的哈希表,儘管它的中心有一個嚴重的缺陷。此外,我們還沒有用它做任何事情。現在是時候解決這兩個問題了,在這個過程中,我們要學習解釋器中使用的一個經典技術。
The reason the hash table doesn’t totally work is that when
findEntry()checks to see if an existing key matches the one it’s looking for, it uses==to compare two strings for equality. That only returns true if the two keys are the exact same string in memory. Two separate strings with the same characters should be considered equal, but aren’t.
哈希表不能完全工作的原因在於,當findEntry()檢查一個現有的鍵是否與要查找的鍵相匹配時,它使用了==來比較兩個字符串是否相等。只有當兩個鍵在內存中是完全相同的字符串時,才會返回true。兩個具有相同字符的單獨的字符串也應該被認為是相等的,但是並沒有。
Remember, back when we added strings in the last chapter, we added explicit support to compare the strings character-by-character in order to get true value equality. We could do that in
findEntry(), but that’s slow.
還記得嗎?在上一章我們添加字符串時,也顯式支持了逐字符比較字符串,以實現真正的值相等。我們在findEntry()中也可以這樣做,但這很慢15。
Instead, we’ll use a technique called string interning. The core problem is that it’s possible to have different strings in memory with the same characters. Those need to behave like equivalent values even though they are distinct objects. They’re essentially duplicates, and we have to compare all of their bytes to detect that.
相反,我們將使用一種叫作字符串駐留的技術,核心問題是,在內存中不同的字符串可能包含相同的字符。儘管它們是不同的對象,它們的行為也需要像等效值一樣。它們本質上是相同的,而我們必須比較它們所有的字節來檢查這一點。
String interning is a process of deduplication. We create a collection of “interned” strings. Any string in that collection is guaranteed to be textually distinct from all others. When you intern a string, you look for a matching string in the collection. If found, you use that original one. Otherwise, the string you have is unique, so you add it to the collection.
字符串駐留是一個數據去重的過程16。我們創建一個“駐留”字符串的集合。該集合中的任何字符串都保證與其它字符串在文本上不相同。當你要駐留一個字符串時,首先從集合中查找匹配的字符串,如果找到了,就使用原來的那個。否則,說明你持有的字符串是唯一的,所以你將其添加到集合中。
In this way, you know that each sequence of characters is represented by only one string in memory. This makes value equality trivial. If two strings point to the same address in memory, they are obviously the same string and must be equal. And, because we know strings are unique, if two strings point to different addresses, they must be distinct strings.
通過這種方式,你知道每個字符序列在內存中只由一個字符串表示。這使得值相等變得很簡單。如果兩個字符串在內存中指向相同的地址,它們顯然是同一個字符串,並且必須相等。而且,因為我們知道字符串是唯一的,如果兩個字符串指向不同的地址,它們一定是不同的。
Thus, pointer equality exactly matches value equality. Which in turn means that our existing
==infindEntry()does the right thing. Or, at least, it will once we intern all the strings. In order to reliably deduplicate all strings, the VM needs to be able to find every string that’s created. We do that by giving it a hash table to store them all.
因此,指針相等與值相等完全匹配。這反過來又意味著,我們在findEntry()中使用的==做了正確的事情。或者說,至少在我們實現字符串駐留之後,它是對的。為了可靠地去重所有字符串,虛擬機需要能夠找到創建的每個字符串。我們用一個哈希表存儲這些字符串,從而實現這一點。
vm.h,在結構體VM中添加代碼:
Value* stackTop;
// 新增部分開始
Table strings;
// 新增部分結束
Obj* objects;
As usual, we need an include.
像往常一樣,我們需要引入頭文件。
vm.h,添加代碼:
#include "chunk.h"
// 新增部分開始
#include "table.h"
// 新增部分結束
#include "value.h"
When we spin up a new VM, the string table is empty.
當我們啟動一個新的虛擬機時,字符串表是空的。
vm.c,在initVM()方法中添加代碼:
vm.objects = NULL;
// 新增部分開始
initTable(&vm.strings);
// 新增部分結束
}
And when we shut down the VM, we clean up any resources used by the table.
而當我們關閉虛擬機時,我們要清理該表使用的所有資源。
vm.c,在freeVM()方法中添加代碼:
void freeVM() {
// 新增部分開始
freeTable(&vm.strings);
// 新增部分結束
freeObjects();
Some languages have a separate type or an explicit step to intern a string. For clox, we’ll automatically intern every one. That means whenever we create a new unique string, we add it to the table.
一些語言中有單獨的類型或顯式步驟來駐留字符串。對於clox,我們會自動駐留每個字符串。這意味著,每當我們創建了一個新的唯一字符串,就將其添加到表中。
object.c,在allocateString()方法中添加代碼:
string->hash = hash;
// 新增部分開始
tableSet(&vm.strings, string, NIL_VAL);
// 新增部分結束
return string;
We’re using the table more like a hash set than a hash table. The keys are the strings and those are all we care about, so we just use
nilfor the values.
我們使用這個表的方式更像是哈希集合而不是哈希表。鍵是字符串,而我們只關心這些,所以我們用nil作為值。
This gets a string into the table assuming that it’s unique, but we need to actually check for duplication before we get here. We do that in the two higher-level functions that call
allocateString(). Here’s one:
假定一個字符串是唯一的,這就會把它放入表中,但在此之前,我們需要實際檢查字符串是否有重複。我們在兩個調用allocateString()的高級函數中做到了這一點。這裡有一個:
object.c,在copyString()方法中添加代碼:
uint32_t hash = hashString(chars, length);
// 新增部分開始
ObjString* interned = tableFindString(&vm.strings, chars, length,
hash);
if (interned != NULL) return interned;
// 新增部分結束
char* heapChars = ALLOCATE(char, length + 1);
When copying a string into a new LoxString, we look it up in the string table first. If we find it, instead of “copying”, we just return a reference to that string. Otherwise, we fall through, allocate a new string, and store it in the string table.
當把一個字符串複製到新的LoxString中時,我們首先在字符串表中查找它。如果找到了,我們就不“複製”,而是直接返回該字符串的引用。如果沒有找到,我們就是落空了,則分配一個新字符串,並將其存儲到字符串表中。
Taking ownership of a string is a little different.
獲取字符串的所有權有點不同。
object.c,在takeString()方法中添加代碼:
uint32_t hash = hashString(chars, length);
// 新增部分開始
ObjString* interned = tableFindString(&vm.strings, chars, length,
hash);
if (interned != NULL) {
FREE_ARRAY(char, chars, length + 1);
return interned;
}
// 新增部分結束
return allocateString(chars, length, hash);
Again, we look up the string in the string table first. If we find it, before we return it, we free the memory for the string that was passed in. Since ownership is being passed to this function and we no longer need the duplicate string, it’s up to us to free it.
同樣,我們首先在字符串表中查找該字符串。如果找到了,在返回它之前,我們釋放傳入的字符串的內存。因為所有權被傳遞給了這個函數,我們不再需要這個重複的字符串,所以由我們釋放它。
Before we get to the new function we need to write, there’s one more include.
在開始編寫新函數之前,還需要引入一個頭文件。
object.c,添加代碼:
#include "object.h"
// 新增部分開始
#include "table.h"
// 新增部分結束
#include "value.h"
To look for a string in the table, we can’t use the normal
tableGet()function because that callsfindEntry(), which has the exact problem with duplicate strings that we’re trying to fix right now. Instead, we use this new function:
要在表中查找字符串,我們不能使用普通的tableGet()函數,因為它調用了findEntry(),這正是我們現在試圖解決的重複字符串的問題。相反地,我們使用這個新函數:
table.h,在tableAddAll()方法後添加代碼:
void tableAddAll(Table* from, Table* to);
// 新增部分開始
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
// 新增部分結束
#endif
The implementation looks like so:
其實現如下:
table.c,在tableAddAll()方法後添加代碼:
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash) {
if (table->count == 0) return NULL;
uint32_t index = hash % table->capacity;
for (;;) {
Entry* entry = &table->entries[index];
if (entry->key == NULL) {
// Stop if we find an empty non-tombstone entry.
if (IS_NIL(entry->value)) return NULL;
} else if (entry->key->length == length &&
entry->key->hash == hash &&
memcmp(entry->key->chars, chars, length) == 0) {
// We found it.
return entry->key;
}
index = (index + 1) % table->capacity;
}
}
It appears we have copy-pasted
findEntry(). There is a lot of redundancy, but also a couple of key differences. First, we pass in the raw character array of the key we’re looking for instead of an ObjString. At the point that we call this, we haven’t created an ObjString yet.
看起來我們是複製粘貼了findEntry()。這裡確實有很多冗餘,但也有幾個關鍵的區別。首先,我們傳入的是我們要查找的鍵的原始字符數組,而不是ObjString。在我們調用這個方法時,還沒有創建ObjString。
Second, when checking to see if we found the key, we look at the actual strings. We first see if they have matching lengths and hashes. Those are quick to check and if they aren’t equal, the strings definitely aren’t the same.
其次,在檢查是否找到鍵時,我們要看一下實際的字符串。我們首先看看它們的長度和哈希值是否匹配。這些都是快速檢查,如果它們不相等,那些字符串肯定不一樣。
If there is a hash collision, we do an actual character-by-character string comparison. This is the one place in the VM where we actually test strings for textual equality. We do it here to deduplicate strings and then the rest of the VM can take for granted that any two strings at different addresses in memory must have different contents.
如果存在哈希衝突,我們就進行實際的逐字符的字符串比較。這是虛擬機中我們真正測試字符串是否相等的一個地方。我們在這裡這樣做是為了對字符串去重,然後虛擬機的其它部分可以想當然地認為,內存中不同地址的任意兩個字符串一定有著不同的內容。
In fact, now that we’ve interned all the strings, we can take advantage of it in the bytecode interpreter. When a user does
==on two objects that happen to be strings, we don’t need to test the characters any more.
事實上,既然我們已經駐留了所有的字符串,我們就可以在字節碼解釋器中利用這一優勢。當用戶對兩個字符串對象進行==時,我們不需要再檢查字符了。
value.c,在valuesEqual()方法中替換7行:
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
// 替換部分開始
case VAL_OBJ: return AS_OBJ(a) == AS_OBJ(b);
// 替換部分結束
default: return false; // Unreachable.
We’ve added a little overhead when creating strings to intern them. But in return, at runtime, the equality operator on strings is much faster. With that, we have a full-featured hash table ready for us to use for tracking variables, instances, or any other key-value pairs that might show up.
在創建字符串時,我們增加了一點開銷來進行駐留。但作為回報,在運行時,字符串的相等操作符要快得多。這樣,我們就有了一個全功能的哈希表,可以用來跟蹤變量、實例或其它可能出現的任何鍵值對。
We also sped up testing strings for equality. This is nice for when the user does
==on strings. But it’s even more critical in a dynamically typed language like Lox where method calls and instance fields are looked up by name at runtime. If testing a string for equality is slow, then that means looking up a method by name is slow. And if that’s slow in your object-oriented language, then everything is slow.
我們還加快了測試字符串是否相等的速度。這對於用戶在字符串上的==操作是很好的。但在Lox這樣的動態類型語言中,這一點更為關鍵,因為在這種語言中,方法調用和實例屬性都是在運行時根據名稱查找的。如果測試字符串是否相等是很慢的,那就意味著按名稱查找方法也很慢。在面向對象的語言中,如果這一點很慢,那麼一切都會變得很慢。
習題
-
In clox, we happen to only need keys that are strings, so the hash table we built is hardcoded for that key type. If we exposed hash tables to Lox users as a first-class collection, it would be useful to support different kinds of keys.
Add support for keys of the other primitive types: numbers, Booleans, and
nil. Later, clox will support user-defined classes. If we want to support keys that are instances of those classes, what kind of complexity does that add?在clox中,我們碰巧只需要字符串類型的鍵,所以我們構建的哈希表是針對這種鍵類型硬編碼的。如果我們將哈希表作為一級集合暴露給Lox用戶,那麼支持不同類型的鍵就會很有用。
添加對其它基本類型鍵的支持:數字、布爾值和
nil。稍後,clox會支持用戶定義的類。如果我們想支持那些類的實例作為鍵,那會增加什麼樣的複雜性呢? -
Hash tables have a lot of knobs you can tweak that affect their performance. You decide whether to use separate chaining or open addressing. Depending on which fork in that road you take, you can tune how many entries are stored in each node, or the probing strategy you use. You control the hash function, load factor, and growth rate.
All of this variety wasn’t created just to give CS doctoral candidates something to publish theses on: each has its uses in the many varied domains and hardware scenarios where hashing comes into play. Look up a few hash table implementations in different open source systems, research the choices they made, and try to figure out why they did things that way.
哈希表中有很多你可以調整的旋鈕,它們會影響哈希表的性能。你可以決定使用拉鍊法還是開放地址法。根據你採取的方式,你可以調整每個節點中存儲的條目數量,或者是使用的探測策略。你可以控制哈希函數、負載因子和增長率。
所有這些變化不僅僅是為了給CS博士發表論文(至少這不是它們被創造的唯一原因,是否是主要原因還有待商榷):在哈希表能發揮作用的許多不同領域和硬件場景中,每一種都有其用途。在不同的開源系統中查找一些哈希表的實現,研究他們所做的選擇,並嘗試弄清楚他們為什麼這樣做。
-
Benchmarking a hash table is notoriously difficult. A hash table implementation may perform well with some keysets and poorly with others. It may work well at small sizes but degrade as it grows, or vice versa. It may choke when deletions are common, but fly when they aren’t. Creating benchmarks that accurately represent how your users will use the hash table is a challenge.
Write a handful of different benchmark programs to validate our hash table implementation. How does the performance vary between them? Why did you choose the specific test cases you chose?
對哈希表進行基準測試是出了名的困難。一個哈希表的實現可能在某些鍵集上表現良好,而在其它鍵集上則表現不佳。它可能是規模較小時工作得很好,但隨著規則擴展會退化,或者正好反過來。當刪除操作很多時,它可能被卡住,但刪除不常見時,它可能會飛起來。創建能夠準確代表用戶使用哈希表方式的基準是一項挑戰。
編寫一些不同的基準程序來驗證我們的哈希表實現。它們之間的表現有什麼不同?你為什麼選擇這些測試用例?
-
更確切地說,平均查找時間是常數。最壞情況下,性能可能會更糟。在實踐中,很容易可以避免退化行為並保持在快樂的道路上。 ↩
-
這種限制並不算太牽強。達特茅斯大學的初版BASIC只允許變量名是一個字母,後面可以跟一個數字。 ↩
-
同樣,這個限制也不是那麼瘋狂。早期的C語言鏈接器只將外部標識符的前6個字符視為有意義的。後面的一切都被忽略了。如果你曾好奇為什麼C語言標準庫對縮寫如此著迷——比如,
strncmp()——事實證明,這並不完全是因為當時的小屏幕(或小電視)。 ↩ -
我這裡使用了2的冪作為數組的大小,但其實不需要這樣。有些類型的哈希表在使用2的冪時效果最好,包括我們將在本書中建立的哈希表。其它類型則更偏愛素數作為數組大小或者是其它規則。 ↩
-
有一些技巧可以優化這一點。許多實現將第一個條目直接存儲在桶中,因此在通常只有一個條目的情況下,不需要額外的間接指針。你也可以讓每個鏈表節點存儲幾個條目以減少指針的開銷。 ↩
-
它被稱為“開放”地址,是因為條目最終可能會出現在其首選地址(桶)之外的地方。它被稱為“封閉”哈希,是因為所有的條目都存儲在桶數組內。 ↩
-
如果你想了解更多(你應該瞭解,因為其中一些真的很酷),可以看看“雙重哈希(double hashing)”、“布穀鳥哈希(cuckoo hashing)”以及“羅賓漢哈希(Robin Hood hashing)”。 ↩
-
哈希函數也被用於密碼學。在該領域中,“好”有一個更嚴格的定義,以避免暴露有關被哈希的數據的細節。值得慶幸的是,我們在本書中不需要擔心這些問題。 ↩
-
哈希表最初的名稱之一是“散列表”,因為它會獲取條目並將其分散到整個數組中。“哈希”這個詞來自於這樣的想法:哈希函數將輸入數據分割開來,然後將其組合成一堆,從所有這些比特位中得出一個數字。 ↩
-
在clox中,我們只需要支持字符串類型的鍵。處理其它類型的鍵不會增加太多複雜性。只要你能比較兩個對象是否相等,並把它們簡化為比特序列,就很容易將它們用作哈希鍵。 ↩
-
理想的最大負載因子根據哈希函數、衝突處理策略和你將會看到的典型鍵集而變化。由於像Lox這樣的玩具語言沒有“真實世界”的數據集,所以很難對其進行優化,所以我隨意地選擇了75%。當你構建自己的哈希表時,請對其進行基準測試和調整。 ↩
-
看起來我們在用
==判斷兩個字符串是否相等。這行不通,對吧?相同的字符串可能會在內存的不同地方有兩個副本。不要害怕,聰明的讀者。我們會進一步解決這個問題。而且,奇怪的是,是一個哈希表提供了我們需要的工具。 ↩ -
使用拉鍊法時,刪除條目就像從鏈表中刪除一個節點一樣容易。 ↩
-
在實踐中,我們會首先比較兩個字符串的哈希碼。這樣可以快速檢測到幾乎所有不同的字符串——如果不能,它就不是一個很好的哈希函數。但是,當兩個哈希值相同時,我們仍然需要比較字符,以確保沒有在不同的字符串上出現哈希衝突。 ↩
-
我猜想“intern”是“internal(內部)”的縮寫。我認為這個想法是,語言的運行時保留了這些字符串的“內部”集合,而其它字符串可以由用戶創建並漂浮在內存中。當你要駐留一個字符串時,你要求運行時將該字符串添加到該內部集合,並返回一個指向該字符串的指針。
不同語言在字符串駐留程度以及對用戶的暴露方式上有所不同。Lua會駐留所有字符串,這也是clox要做的事情。Lisp、Scheme、Smalltalk、Ruby和其他語言都有一個單獨的類似字符串的類型“symbol(符號)”,它是隱式駐留的。(這就是為什麼他們說Ruby中的符號“更快”)Java默認會駐留常量字符串,並提供一個API讓你顯式地駐留傳入的任何字符串。 ↩

21.全域性變數 Global Variables
If only there could be an invention that bottled up a memory, like scent. And it never faded, and it never got stale. And then, when one wanted it, the bottle could be uncorked, and it would be like living the moment all over again.
—— Daphne du Maurier, Rebecca
如果有一種發明能把一段記憶裝進瓶子裡就好了,像香味一樣。它永遠不會褪色,也不會變質。然後,當一個人想要的時候,可以開啟瓶塞,就像重新活在那個時刻一樣。(達芙妮-杜穆裡埃,《蝴蝶夢》)
The previous chapter was a long exploration of one big, deep, fundamental computer science data structure. Heavy on theory and concept. There may have been some discussion of big-O notation and algorithms. This chapter has fewer intellectual pretensions. There are no large ideas to learn. Instead, it’s a handful of straightforward engineering tasks. Once we’ve completed them, our virtual machine will support variables.
上一章對一個大的、深入的、基本的電腦科學資料結構進行了長時間的探索。偏重理論和概念。可能有一些關於大O符號和演算法的討論。這一章沒有那麼多知識分子的自吹自擂。沒有什麼偉大的思想需要學習。相反,它是一些簡單的工程任務。一旦我們完成了這些任務,我們的虛擬機器就可以支援變數。
Actually, it will support only global variables. Locals are coming in the next chapter. In jlox, we managed to cram them both into a single chapter because we used the same implementation technique for all variables. We built a chain of environments, one for each scope, all the way up to the top. That was a simple, clean way to learn how to manage state.
事實上,它將只支援全域性變數。區域性變數將在下一章中支援。在jlox中,我們設法將它們塞進了一個章節,因為我們對所有變數都使用了相同的實現技術。我們建立了一個環境鏈,每個作用域都有一個,一直到頂部作用域。這是學習如何管理狀態的一種簡單、乾淨的方法。
But it’s also slow. Allocating a new hash table each time you enter a block or call a function is not the road to a fast VM. Given how much code is concerned with using variables, if variables go slow, everything goes slow. For clox, we’ll improve that by using a much more efficient strategy for local variables, but globals aren’t as easily optimized.
但它也很慢。每次進入一個程式碼塊或呼叫一個函式時,都要分配一個新的雜湊表,這不是通往快速虛擬機器的道路。鑑於很多程式碼都與使用變數有關,如果變數操作緩慢,一切都會變慢。對於clox,我們會透過對區域性變數使用更有效的策略來改善這一點,但全域性變數不那麼容易最佳化1。
This is a common meta-strategy in sophisticated language implementations. Often, the same language feature will have multiple implementation techniques, each tuned for different use patterns. For example, JavaScript VMs often have a faster representation for objects that are used more like instances of classes compared to other objects whose set of properties is more freely modified. C and C++ compilers usually have a variety of ways to compile switch statements based on the number of cases and how densely packed the case values are.
A quick refresher on Lox semantics: Global variables in Lox are “late bound”, or resolved dynamically. This means you can compile a chunk of code that refers to a global variable before it’s defined. As long as the code doesn’t execute before the definition happens, everything is fine. In practice, that means you can refer to later variables inside the body of functions.
快速複習一下Lox語義:Lox中的全域性變數是“後期繫結”的,或者說是動態解析的。這意味著,你可以在全域性變數被定義之前,編譯引用它的一大塊程式碼。只要程式碼在定義發生之前沒有執行,就沒有問題。在實踐中,這意味著你可以在函式的主體中引用後面的變數。
fun showVariable() {
print global;
}
var global = "after";
showVariable();
Code like this might seem odd, but it’s handy for defining mutually recursive functions. It also plays nicer with the REPL. You can write a little function in one line, then define the variable it uses in the next.
這樣的程式碼可能看起來很奇怪,但它對於定義相互遞迴的函式很方便。它與REPL的配合也更好。你可以在一行中編寫一個小函式,然後在下一行中定義它使用的變數。
Local variables work differently. Since a local variable’s declaration always occurs before it is used, the VM can resolve them at compile time, even in a simple single-pass compiler. That will let us use a smarter representation for locals. But that’s for the next chapter. Right now, let’s just worry about globals.
區域性變數的工作方式不同。因為區域性變數的宣告總是發生在使用之前,虛擬機器可以在編譯時解析它們,即使是在簡單的單遍編譯器中。這讓我們可以為區域性變數使用更聰明的表示形式。但這是下一章的內容。現在,我們只考慮全域性變數。
21 . 1 Statements
21.1 語句
Variables come into being using variable declarations, which means now is also the time to add support for statements to our compiler. If you recall, Lox splits statements into two categories. “Declarations” are those statements that bind a new name to a value. The other kinds of statements—control flow, print, etc.—are just called “statements”. We disallow declarations directly inside control flow statements, like this:
變數是透過變數宣告產生的,這意味著現在是時候向編譯器中新增對語句的支援了。如果你還記得的話,Lox將語句分為兩類。“宣告”是那些將一個新名稱與值繫結的語句。其它型別的語句——控制流、列印等——只被稱為“語句”。我們不允許在控制流語句中直接使用宣告,像這樣:
if (monday) var croissant = "yes"; // Error.
Allowing it would raise confusing questions around the scope of the variable. So, like other languages, we prohibit it syntactically by having a separate grammar rule for the subset of statements that are allowed inside a control flow body.
允許這種做法會引發圍繞變數作用域的令人困惑的問題。因此,像其它語言一樣,對於允許出現在控制流主體內的語句子集,我們制定單獨的語法規則,從而禁止這種做法。
statement → exprStmt
| forStmt
| ifStmt
| printStmt
| returnStmt
| whileStmt
| block ;
Then we use a separate rule for the top level of a script and inside a block.
然後,我們為指令碼的頂層和程式碼塊內部使用單獨的規則。
declaration → classDecl
| funDecl
| varDecl
| statement ;
The
declarationrule contains the statements that declare names, and also includesstatementso that all statement types are allowed. Sinceblockitself is instatement, you can put declarations inside a control flow construct by nesting them inside a block.
declaration包含宣告名稱的語句,也包含statement規則,這樣所有的語句型別都是允許的。因為block本身就在statement中,你可以透過將宣告巢狀在程式碼塊中的方式將它們放在控制流結構中2。
In this chapter, we’ll cover only a couple of statements and one declaration.
在本章中,我們只討論幾個語句和一個宣告。
statement → exprStmt
| printStmt ;
declaration → varDecl
| statement ;
Up to now, our VM considered a “program” to be a single expression since that’s all we could parse and compile. In a full Lox implementation, a program is a sequence of declarations. We’re ready to support that now.
到目前為止,我們的虛擬機器都認為“程式”是一個表示式,因為我們只能解析和編譯一條表示式。在完整的Lox實現中,程式是一連串的宣告。我們現在已經準備要支援它了。
compiler.c,在compile()方法中替換2行:
advance();
// 替換部分開始
while (!match(TOKEN_EOF)) {
declaration();
}
// 替換部分結束
endCompiler();
We keep compiling declarations until we hit the end of the source file. We compile a single declaration using this:
我們會一直編譯宣告語句,直到到達原始檔的結尾。我們用這個方法來編譯一條宣告語句:
compiler.c,在expression()方法後新增程式碼:
static void declaration() {
statement();
}
We’ll get to variable declarations later in the chapter, so for now, we simply forward to
statement().
我們將在本章後面討論變數宣告,所以現在,我們直接使用statement()。
compiler.c,在declaration()方法後新增程式碼:
static void statement() {
if (match(TOKEN_PRINT)) {
printStatement();
}
}
Blocks can contain declarations, and control flow statements can contain other statements. That means these two functions will eventually be recursive. We may as well write out the forward declarations now.
程式碼塊可以包含宣告,而控制流語句可以包含其它語句。這意味著這兩個函式最終是遞迴的。我們不妨現在就把前置宣告寫出來。
compiler.c,在expression()方法後新增程式碼:
static void expression();
// 新增部分開始
static void statement();
static void declaration();
// 新增部分結束
static ParseRule* getRule(TokenType type);
21 . 1 . 1 Print statements
21.1.1 Print語句
We have two statement types to support in this chapter. Let’s start with
在本章中,我們有兩種語句型別需要支援。我們從print語句開始,它自然是以print標識開頭的。我們使用這個輔助函式來檢測:
compiler.c,在consume()方法後新增程式碼:
static bool match(TokenType type) {
if (!check(type)) return false;
advance();
return true;
}
You may recognize it from jlox. If the current token has the given type, we consume the token and return
true. Otherwise we leave the token alone and returnfalse. This helper function is implemented in terms of this other helper:
你可能看出它是從jlox來的。如果當前的標識是指定型別,我們就消耗該標識並返回true。否則,我們就不處理該標識並返回false。這個輔助函式是透過另一個輔助函式實現的:
compiler.c,在consume()方法後新增程式碼:
static bool check(TokenType type) {
return parser.current.type == type;
}
The
check()function returnstrueif the current token has the given type. It seems a little silly to wrap this in a function, but we’ll use it more later, and I think short verb-named functions like this make the parser easier to read.
如果當前標識符合給定的型別,check()函式返回true。將它封裝在一個函式中似乎有點傻,但我們以後會更多地使用它,而且我們認為像這樣簡短的動詞命名的函式使解析器更容易閱讀3。
If we did match the
如果我們確實匹配到了print標識,那麼我們在下面這個方法中編譯該語句的剩餘部分:
compiler.c,在expression()方法後新增程式碼:
static void printStatement() {
expression();
consume(TOKEN_SEMICOLON, "Expect ';' after value.");
emitByte(OP_PRINT);
}
A
print語句會對錶達式求值並打印出結果,所以我們首先解析並編譯這個表示式。語法要求在表示式之後有一個分號,所以我們消耗一個分號標識。最後,我們生成一條新指令來列印結果。
chunk.h,在列舉OpCode中新增程式碼:
OP_NEGATE,
// 新增部分開始
OP_PRINT,
// 新增部分結束
OP_RETURN,
At runtime, we execute this instruction like so:
在執行時,我們這樣執行這條指令:
vm.c,在run()方法中新增程式碼:
break;
// 新增部分開始
case OP_PRINT: {
printValue(pop());
printf("\n");
break;
}
// 新增部分結束
case OP_RETURN: {
When the interpreter reaches this instruction, it has already executed the code for the expression, leaving the result value on top of the stack. Now we simply pop and print it.
當直譯器到達這條指令時,它已經執行了表示式的程式碼,將結果值留在了棧頂。現在我們只需要彈出該值並列印。
Note that we don’t push anything else after that. This is a key difference between expressions and statements in the VM. Every bytecode instruction has a stack effect that describes how the instruction modifies the stack. For example,
OP_ADDpops two values and pushes one, leaving the stack one element smaller than before.
請注意,在此之後我們不會再向棧中壓入任何內容。這是虛擬機器中表達式和語句之間的一個關鍵區別。每個位元組碼指令都有堆疊效應,這個值用於描述指令如何修改堆疊內容。例如,OP_ADD會彈出兩個值並壓入一個值,使得棧中比之前少了一個元素4。
You can sum the stack effects of a series of instructions to get their total effect. When you add the stack effects of the series of instructions compiled from any complete expression, it will total one. Each expression leaves one result value on the stack.
你可以把一系列指令的堆疊效應相加,得到它們的總體效應。如果把從任何一個完整的表示式中編譯得到的一系列指令的堆疊效應相加,其總數是1。每個表示式會在棧中留下一個結果值。
The bytecode for an entire statement has a total stack effect of zero. Since a statement produces no values, it ultimately leaves the stack unchanged, though it of course uses the stack while it’s doing its thing. This is important because when we get to control flow and looping, a program might execute a long series of statements. If each statement grew or shrank the stack, it might eventually overflow or underflow.
整個語句對應位元組碼的總堆疊效應為0。因為語句不產生任何值,所以它最終會保持堆疊不變,儘管它在執行自己的操作時難免會使用堆疊。這一點很重要,因為等我們涉及到控制流和迴圈時,一個程式可能會執行一長串的語句。如果每條語句都增加或減少堆疊,最終就可能會溢位或下溢。
While we’re in the interpreter loop, we should delete a bit of code.
在直譯器迴圈中,我們應該刪除一些程式碼。
vm.c,在run()方法中替換2行:
case OP_RETURN: {
// 替換部分開始
// Exit interpreter.
// 替換部分結束
return INTERPRET_OK;
When the VM only compiled and evaluated a single expression, we had some temporary code in
OP_RETURNto output the value. Now that we have statements and
當虛擬機器只編譯和計算一條表示式時,我們在OP_RETURN中使用一些臨時程式碼來輸出值。現在我們已經有了語句和print,就不再需要這些了。我們離clox的完全實現又近了一步5。
As usual, a new instruction needs support in the disassembler.
像往常一樣,一條新指令需要反彙編程式的支援。
debug.c,在disassembleInstruction()方法中新增程式碼:
return simpleInstruction("OP_NEGATE", offset);
// 新增部分開始
case OP_PRINT:
return simpleInstruction("OP_PRINT", offset);
// 新增部分結束
case OP_RETURN:
That’s our
這就是我們的print語句。如果你願意,可以試一試:
print 1 + 2;
print 3 * 4;
Exciting! OK, maybe not thrilling, but we can build scripts that contain as many statements as we want now, which feels like progress.
令人興奮!好吧,也許沒有那麼激動人心,但是我們現在可以構建包含任意多語句的指令碼,這感覺是一種進步。
21 . 1 . 2 Expression statements
21.1.2 表示式語句
Wait until you see the next statement. If we don’t see a
等待,直到你看到下一條語句。如果沒有看到print關鍵字,那麼我們看到的一定是一條表示式語句。
compiler.c,在statement()方法中新增程式碼:
printStatement();
// 新增部分開始
} else {
expressionStatement();
// 新增部分結束
}
It’s parsed like so:
它是這樣解析的:
compiler.c,在expression()方法後新增程式碼:
static void expressionStatement() {
expression();
consume(TOKEN_SEMICOLON, "Expect ';' after expression.");
emitByte(OP_POP);
}
An “expression statement” is simply an expression followed by a semicolon. They’re how you write an expression in a context where a statement is expected. Usually, it’s so that you can call a function or evaluate an assignment for its side effect, like this:
“表示式語句”就是一個表示式後面跟著一個分號。這是在需要語句的上下文中寫表示式的方式。通常來說,這樣你就可以呼叫函式或執行賦值操作以觸發其副作用,像這樣:
brunch = "quiche";
eat(brunch);
Semantically, an expression statement evaluates the expression and discards the result. The compiler directly encodes that behavior. It compiles the expression, and then emits an
OP_POPinstruction.
從語義上說,表示式語句會對錶達式求值並丟棄結果。編譯器直接對這種行為進行編碼。它會編譯表示式,然後生成一條OP_POP指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_FALSE,
// 新增部分開始
OP_POP,
// 新增部分結束
OP_EQUAL,
As the name implies, that instruction pops the top value off the stack and forgets it.
顧名思義,該指令會彈出棧頂的值並將其遺棄。
vm.c,在run()方法中新增程式碼:
case OP_FALSE: push(BOOL_VAL(false)); break;
// 新增部分開始
case OP_POP: pop(); break;
// 新增部分結束
case OP_EQUAL: {
We can disassemble it too.
我們也可以對它進行反彙編。
debug.c,在disassembleInstruction()方法中新增程式碼:
return simpleInstruction("OP_FALSE", offset);
// 新增部分開始
case OP_POP:
return simpleInstruction("OP_POP", offset);
// 新增部分結束
case OP_EQUAL:
Expression statements aren’t very useful yet since we can’t create any expressions that have side effects, but they’ll be essential when we add functions later. The majority of statements in real-world code in languages like C are expression statements.
表示式語句現在還不是很有用,因為我們無法建立任何有副作用的表示式,但等我們後面新增函式時,它們將是必不可少的。在像C這樣的真正語言中,大部分語句都是表示式語句6。
21 . 1 . 3 Error synchronization
21.1.3 錯誤同步
While we’re getting this initial work done in the compiler, we can tie off a loose end we left several chapters back. Like jlox, clox uses panic mode error recovery to minimize the number of cascaded compile errors that it reports. The compiler exits panic mode when it reaches a synchronization point. For Lox, we chose statement boundaries as that point. Now that we have statements, we can implement synchronization.
當我們在編譯器中完成這些初始化工作時,我們可以把前幾章遺留的一個小尾巴處理一下。與jlox一樣,clox也使用了恐慌模式下的錯誤恢復來減少它所報告的級聯編譯錯誤。當編譯器到達同步點時,就退出恐慌模式。對於Lox來說,我們選擇語句邊界作為同步點。現在我們有了語句,就可以實現同步了。
compiler.c,在declaration()方法中新增程式碼:
statement();
// 新增部分開始
if (parser.panicMode) synchronize();
// 新增部分結束
}
If we hit a compile error while parsing the previous statement, we enter panic mode. When that happens, after the statement we start synchronizing.
如果我們在解析前一條語句時遇到編譯錯誤,我們就會進入恐慌模式。當這種情況發生時,我們會在這條語句之後開始同步。
compiler.c,在printStatement()方法後新增程式碼:
static void synchronize() {
parser.panicMode = false;
while (parser.current.type != TOKEN_EOF) {
if (parser.previous.type == TOKEN_SEMICOLON) return;
switch (parser.current.type) {
case TOKEN_CLASS:
case TOKEN_FUN:
case TOKEN_VAR:
case TOKEN_FOR:
case TOKEN_IF:
case TOKEN_WHILE:
case TOKEN_PRINT:
case TOKEN_RETURN:
return;
default:
; // Do nothing.
}
advance();
}
}
We skip tokens indiscriminately until we reach something that looks like a statement boundary. We recognize the boundary by looking for a preceding token that can end a statement, like a semicolon. Or we’ll look for a subsequent token that begins a statement, usually one of the control flow or declaration keywords.
我們會不分青紅皂白地跳過標識,直到我們到達一個看起來像是語句邊界的位置。我們識別邊界的方式包括,查詢可以結束一條語句的前驅標識,如分號;或者我們可以查詢能夠開始一條語句的後續標識,通常是控制流或宣告語句的關鍵字之一。
21 . 2 Variable Declarations
21.2 變數宣告
Merely being able to print doesn’t win your language any prizes at the programming language fair, so let’s move on to something a little more ambitious and get variables going. There are three operations we need to support:
僅僅能夠列印並不能為你的語言在程式語言博覽會上贏得任何獎項,所以讓我們繼續做一些更有野心的事,讓變數發揮作用。我們需要支援三種操作:
-
Declaring a new variable using a
varstatement.使用
var語句宣告一個新變數 -
Accessing the value of a variable using an identifier expression.
使用識別符號表示式訪問一個變數的值
-
Storing a new value in an existing variable using an assignment expression.
使用賦值表示式將一個新的值儲存在現有的變數中
We can’t do either of the last two until we have some variables, so we start with declarations.
等我們有了變數以後,才能做後面兩件事,所以我們從宣告開始。
compiler.c,在declaration()方法中替換1行:
static void declaration() {
// 替換部分開始
if (match(TOKEN_VAR)) {
varDeclaration();
} else {
statement();
}
// 替換部分結束
if (parser.panicMode) synchronize();
The placeholder parsing function we sketched out for the declaration grammar rule has an actual production now. If we match a
vartoken, we jump here:
我們為宣告語法規則建立的佔位解析函式現在已經有了實際的生成式。如果我們匹配到一個var標識,就跳轉到這裡:
compiler.c,在expression()方法後新增程式碼:
static void varDeclaration() {
uint8_t global = parseVariable("Expect variable name.");
if (match(TOKEN_EQUAL)) {
expression();
} else {
emitByte(OP_NIL);
}
consume(TOKEN_SEMICOLON,
"Expect ';' after variable declaration.");
defineVariable(global);
}
The keyword is followed by the variable name. That’s compiled by
parseVariable(), which we’ll get to in a second. Then we look for an=followed by an initializer expression. If the user doesn’t initialize the variable, the compiler implicitly initializes it tonilby emitting anOP_NILinstruction. Either way, we expect the statement to be terminated with a semicolon.
關鍵字後面跟著變數名。它是由parseVariable()編譯的,我們馬上就會講到。然後我們會尋找一個=,後跟初始化表示式。如果使用者沒有初始化變數,編譯器會生成OP_NIL指令隱式地將其初始化為nil7。無論哪種方式,我們都希望語句以分號結束。
There are two new functions here for working with variables and identifiers. Here is the first:
這裡有兩個新函式用於處理變數和識別符號。下面是第一個:
compiler.c,在parsePrecedence()方法後新增程式碼:
static void parsePrecedence(Precedence precedence);
// 新增部分開始
static uint8_t parseVariable(const char* errorMessage) {
consume(TOKEN_IDENTIFIER, errorMessage);
return identifierConstant(&parser.previous);
}
// 新增部分結束
It requires the next token to be an identifier, which it consumes and sends here:
它要求下一個標識是一個識別符號,它會消耗該標識併傳送到這裡:
compiler.c,在parsePrecedence()方法後新增程式碼:
static void parsePrecedence(Precedence precedence);
// 新增部分開始
static uint8_t identifierConstant(Token* name) {
return makeConstant(OBJ_VAL(copyString(name->start,
name->length)));
}
// 新增部分結束
This function takes the given token and adds its lexeme to the chunk’s constant table as a string. It then returns the index of that constant in the constant table.
這個函式接受給定的標識,並將其詞素作為一個字串新增到位元組碼塊的常量表中。然後,它會返回該常量在常量表中的索引。
Global variables are looked up by name at runtime. That means the VM—the bytecode interpreter loop—needs access to the name. A whole string is too big to stuff into the bytecode stream as an operand. Instead, we store the string in the constant table and the instruction then refers to the name by its index in the table.
全域性變數在執行時是按名稱查詢的。這意味著虛擬機器(位元組碼直譯器迴圈)需要訪問該名稱。整個字串太大,不能作為運算元塞進位元組碼流中。相反,我們將字串儲存到常量表中,然後指令透過該名稱在表中的索引來引用它。
This function returns that index all the way to
varDeclaration()which later hands it over to here:
這個函式會將索引一直返回給varDeclaration(),隨後又將其傳遞到這裡:
compiler.c,在parseVariable()方法後新增程式碼:
static void defineVariable(uint8_t global) {
emitBytes(OP_DEFINE_GLOBAL, global);
}
This outputs the bytecode instruction that defines the new variable and stores its initial value. The index of the variable’s name in the constant table is the instruction’s operand. As usual in a stack-based VM, we emit this instruction last. At runtime, we execute the code for the variable’s initializer first. That leaves the value on the stack. Then this instruction takes that value and stores it away for later.
它會輸出位元組碼指令,用於定義新變數並儲存其初始化值。變數名在常量表中的索引是該指令的運算元。在基於堆疊的虛擬機器中,我們通常是最後發出這條指令。在執行時,我們首先執行變數初始化器的程式碼,將值留在棧中。然後這條指令會獲取該值並儲存起來,以供日後使用8。
Over in the runtime, we begin with this new instruction:
在執行時,我們從這條新指令開始:
chunk.h,在列舉OpCode中新增程式碼:
OP_POP,
// 新增部分開始
OP_DEFINE_GLOBAL,
// 新增部分結束
OP_EQUAL,
Thanks to our handy-dandy hash table, the implementation isn’t too hard.
多虧了我們方便的雜湊表,實現起來並不太難。
vm.c,在run()方法中新增程式碼:
case OP_POP: pop(); break;
// 新增部分開始
case OP_DEFINE_GLOBAL: {
ObjString* name = READ_STRING();
tableSet(&vm.globals, name, peek(0));
pop();
break;
}
// 新增部分結束
case OP_EQUAL: {
We get the name of the variable from the constant table. Then we take the value from the top of the stack and store it in a hash table with that name as the key.
我們從常量表中獲取變數的名稱,然後我們從棧頂獲取值,並以該名稱為鍵將其儲存在雜湊表中9。
This code doesn’t check to see if the key is already in the table. Lox is pretty lax with global variables and lets you redefine them without error. That’s useful in a REPL session, so the VM supports that by simply overwriting the value if the key happens to already be in the hash table.
這段程式碼並沒有檢查鍵是否已經在表中。Lox對全域性變數的處理非常寬鬆,允許你重新定義它們而且不會出錯。這在REPL會話中很有用,如果鍵恰好已經在雜湊表中,虛擬機器透過簡單地覆蓋值來支援這一點。
There’s another little helper macro:
還有另一個小的輔助宏:
vm.c,在run()方法中新增程式碼:
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
// 新增部分開始
#define READ_STRING() AS_STRING(READ_CONSTANT())
// 新增部分結束
#define BINARY_OP(valueType, op) \
It reads a one-byte operand from the bytecode chunk. It treats that as an index into the chunk’s constant table and returns the string at that index. It doesn’t check that the value is a string—it just indiscriminately casts it. That’s safe because the compiler never emits an instruction that refers to a non-string constant.
它從位元組碼塊中讀取一個1位元組的運算元。它將其視為位元組碼塊的常量表的索引,並返回該索引處的字串。它不檢查該值是否是字串——它只是不加區分地進行型別轉換。這是安全的,因為編譯器永遠不會發出引用非字串常量的指令。
Because we care about lexical hygiene, we also undefine this macro at the end of the interpret function.
因為我們關心詞法衛生,所以在直譯器函式的末尾也取消了這個宏的定義。
vm.c,在run()方法中新增程式碼:
#undef READ_CONSTANT
// 新增部分開始
#undef READ_STRING
// 新增部分結束
#undef BINARY_OP
I keep saying “the hash table”, but we don’t actually have one yet. We need a place to store these globals. Since we want them to persist as long as clox is running, we store them right in the VM.
我一直在說“雜湊表”,但實際上我們還沒有雜湊表。我們需要一個地方來儲存這些全域性變數。因為我們希望它們在clox執行期間一直存在,所以我們將它們之間儲存在虛擬機器中。
vm.h,在結構體VM中新增程式碼:
Value* stackTop;
// 新增部分開始
Table globals;
// 新增部分結束
Table strings;
As we did with the string table, we need to initialize the hash table to a valid state when the VM boots up.
正如我們對字串表所做的那樣,我們需要在虛擬機器啟動時將雜湊表初始化為有效狀態。
vm.c,在initVM()方法中新增程式碼:
vm.objects = NULL;
// 新增部分開始
initTable(&vm.globals);
// 新增部分結束
initTable(&vm.strings);
And we tear it down when we exit.
當我們退出時,就將其刪掉10。
vm.c,在freeVM()方法中新增程式碼:
void freeVM() {
// 新增部分開始
freeTable(&vm.globals);
// 新增部分結束
freeTable(&vm.strings);
As usual, we want to be able to disassemble the new instruction too.
跟往常一樣,我們也希望能夠對新指令進行反彙編。
debug.c,在disassembleInstruction()方法中新增程式碼:
return simpleInstruction("OP_POP", offset);
// 新增部分開始
case OP_DEFINE_GLOBAL:
return constantInstruction("OP_DEFINE_GLOBAL", chunk,
offset);
// 新增部分結束
case OP_EQUAL:
And with that, we can define global variables. Not that users can tell that they’ve done so, because they can’t actually use them. So let’s fix that next.
有了這個,我們就可以定義全域性變量了。但使用者並不能說他們可以定義全域性變數,因為他們實際上還不能使用這些變數。所以,接下來我們解決這個問題。
21 . 3 Reading Variables
21.3 讀取變數
As in every programming language ever, we access a variable’s value using its name. We hook up identifier tokens to the expression parser here:
像所有程式語言中一樣,我們使用變數的名稱來訪問它的值。我們在這裡將識別符號和表示式解析器進行掛鉤:
compiler.c,替換1行:
[TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
// 替換部分開始
[TOKEN_IDENTIFIER] = {variable, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_STRING] = {string, NULL, PREC_NONE},
That calls this new parser function:
這裡呼叫了這個新解析器函式:
compiler.c,在string()方法後新增程式碼:
static void variable() {
namedVariable(parser.previous);
}
Like with declarations, there are a couple of tiny helper functions that seem pointless now but will become more useful in later chapters. I promise.
和宣告一樣,這裡有幾個小的輔助函式,現在看起來毫無意義,但在後面的章節中會變得更加有用。我保證。
compiler.c,在string()方法後新增程式碼:
static void namedVariable(Token name) {
uint8_t arg = identifierConstant(&name);
emitBytes(OP_GET_GLOBAL, arg);
}
This calls the same
identifierConstant()function from before to take the given identifier token and add its lexeme to the chunk’s constant table as a string. All that remains is to emit an instruction that loads the global variable with that name. Here’s the instruction:
這裡會呼叫與之前相同的identifierConstant()函式,以獲取給定的識別符號標識,並將其詞素作為字串新增到位元組碼塊的常量表中。剩下的工作就是生成一條指令,載入具有該名稱的全域性變數。下面是這個指令:
chunk.h,在列舉OpCode中新增程式碼:
OP_POP,
// 新增部分開始
OP_GET_GLOBAL,
// 新增部分結束
OP_DEFINE_GLOBAL,
Over in the interpreter, the implementation mirrors
OP_DEFINE_GLOBAL.
在直譯器中,它的實現是OP_DEFINE_GLOBAL的映象操作。
vm.c,在run()方法中新增程式碼:
case OP_POP: pop(); break;
// 新增部分開始
case OP_GET_GLOBAL: {
ObjString* name = READ_STRING();
Value value;
if (!tableGet(&vm.globals, name, &value)) {
runtimeError("Undefined variable '%s'.", name->chars);
return INTERPRET_RUNTIME_ERROR;
}
push(value);
break;
}
// 新增部分結束
case OP_DEFINE_GLOBAL: {
We pull the constant table index from the instruction’s operand and get the variable name. Then we use that as a key to look up the variable’s value in the globals hash table.
我們從指令運算元中提取常量表索引並獲得變數名稱。然後我們使用它作為鍵,在全域性變數雜湊表中查詢變數的值。
If the key isn’t present in the hash table, it means that global variable has never been defined. That’s a runtime error in Lox, so we report it and exit the interpreter loop if that happens. Otherwise, we take the value and push it onto the stack.
如果該鍵不在雜湊表中,就意味著這個全域性變數從未被定義過。這在Lox中是執行時錯誤,所以如果發生這種情況,我們要報告錯誤並退出直譯器迴圈。否則,我們獲取該值並將其壓入棧中。
debug.c,在disassembleInstruction()方法中新增程式碼:
return simpleInstruction("OP_POP", offset);
// 新增部分開始
case OP_GET_GLOBAL:
return constantInstruction("OP_GET_GLOBAL", chunk, offset);
// 新增部分結束
case OP_DEFINE_GLOBAL:
A little bit of disassembling, and we’re done. Our interpreter is now able to run code like this:
稍微反彙編一下,就完成了。我們的直譯器現在可以執行這樣的程式碼了:
var beverage = "cafe au lait";
var breakfast = "beignets with " + beverage;
print breakfast;
There’s only one operation left.
只剩一個操作了。
21 . 4 Assignment
21.4 賦值
Throughout this book, I’ve tried to keep you on a fairly safe and easy path. I don’t avoid hard problems, but I try to not make the solutions more complex than they need to be. Alas, other design choices in our bytecode compiler make assignment annoying to implement.
在這本書中,我一直試圖讓你走在一條相對安全和簡單的道路上。我並不迴避困難的問題,但是我儘量不讓解決方案過於複雜。可惜的是,我們的位元組碼編譯器中的其它設計選擇使得賦值的實現變得很麻煩11。
Our bytecode VM uses a single-pass compiler. It parses and generates bytecode on the fly without any intermediate AST. As soon as it recognizes a piece of syntax, it emits code for it. Assignment doesn’t naturally fit that. Consider:
我們的位元組碼虛擬機器使用的是單遍編譯器。它在不需要任何中間AST的情況下,動態地解析並生成位元組碼。一旦它識別出某個語法,它就會生成對應的位元組碼。賦值操作天然不符合這一點。請考慮一下:
menu.brunch(sunday).beverage = "mimosa";
In this code, the parser doesn’t realize
menu.brunch(sunday).beverageis the target of an assignment and not a normal expression until it reaches=, many tokens after the firstmenu. By then, the compiler has already emitted bytecode for the whole thing.
在這段程式碼中,直到解析器遇見=(第一個menu之後很多個標識),它才能意識到menu.brunch(sunday).beverage是賦值操作的目標,而不是常規的表示式。到那時,編譯器已經為整個程式碼生成位元組碼了。
The problem is not as dire as it might seem, though. Look at how the parser sees that example:
不過,這個問題並不像看上去那麼可怕。看看解析器是如何處理這個例子的:

Even though the
.beveragepart must not be compiled as a get expression, everything to the left of the.is an expression, with the normal expression semantics. Themenu.brunch(sunday)part can be compiled and executed as usual.
儘管.beverage部分無法被編譯為一個get表示式,.左側的其它部分是一個表示式,有著正常的表示式語義。menu.brunch(sunday)部分可以像往常一樣編譯和執行。
Fortunately for us, the only semantic differences on the left side of an assignment appear at the very right-most end of the tokens, immediately preceding the
=. Even though the receiver of a setter may be an arbitrarily long expression, the part whose behavior differs from a get expression is only the trailing identifier, which is right before the=. We don’t need much lookahead to realizebeverageshould be compiled as a set expression and not a getter.
幸運的是,賦值語句左側部分唯一的語義差異在於其最右側的標識,緊挨著=之前。儘管setter的接收方可能是一個任意長的表示式,但與get表示式不同的部分在於尾部的識別符號,它就在=之前。我們不需要太多的前瞻就可以意識到beverage應該被編譯為set表示式而不是getter。
Variables are even easier since they are just a single bare identifier before an
=. The idea then is that right before compiling an expression that can also be used as an assignment target, we look for a subsequent=token. If we see one, we compile it as an assignment or setter instead of a variable access or getter.
變數就更簡單了,因為它們在=之前就是一個簡單的識別符號。那麼我們的想法是,在編譯一個也可以作為賦值目標的表示式之前,我們會尋找隨後的=標識。如果我們看到了,那表明我們將其一個賦值表示式或setter來編譯,而不是變數訪問或getter。
We don’t have setters to worry about yet, so all we need to handle are variables.
我們還不需要考慮setter,所以我們需要處理的就是變數。
compiler.c,在namedVariable()方法中替換1行:
uint8_t arg = identifierConstant(&name);
// 替換部分開始
if (match(TOKEN_EQUAL)) {
expression();
emitBytes(OP_SET_GLOBAL, arg);
} else {
emitBytes(OP_GET_GLOBAL, arg);
}
// 替換部分結束
}
In the parse function for identifier expressions, we look for an equals sign after the identifier. If we find one, instead of emitting code for a variable access, we compile the assigned value and then emit an assignment instruction.
在識別符號表示式的解析函式中,我們會查詢識別符號後面的等號。如果找到了,我們就不會生成變數訪問的程式碼,我們會編譯所賦的值,然後生成一個賦值指令。
That’s the last instruction we need to add in this chapter.
這就是我們在本章中需要新增的最後一條指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_DEFINE_GLOBAL,
// 新增部分開始
OP_SET_GLOBAL,
// 新增部分結束
OP_EQUAL,
As you’d expect, its runtime behavior is similar to defining a new variable.
如你所想,它的執行時行為類似於定義一個新變數。
vm.c,在run()方法中新增程式碼12:
}
// 新增部分開始
case OP_SET_GLOBAL: {
ObjString* name = READ_STRING();
if (tableSet(&vm.globals, name, peek(0))) {
tableDelete(&vm.globals, name);
runtimeError("Undefined variable '%s'.", name->chars);
return INTERPRET_RUNTIME_ERROR;
}
break;
}
// 新增部分結束
case OP_EQUAL: {
The main difference is what happens when the key doesn’t already exist in the globals hash table. If the variable hasn’t been defined yet, it’s a runtime error to try to assign to it. Lox doesn’t do implicit variable declaration.
主要的區別在於,當鍵在全域性變數雜湊表中不存在時會發生什麼。如果這個變數還沒有定義,對其進行賦值就是一個執行時錯誤。Lox不做隱式的變數宣告。
The other difference is that setting a variable doesn’t pop the value off the stack. Remember, assignment is an expression, so it needs to leave that value there in case the assignment is nested inside some larger expression.
另一個區別是,設定變數並不會從棧中彈出值。記住,賦值是一個表示式,所以它需要把這個值保留在那裡,以防賦值巢狀在某個更大的表示式中。
Add a dash of disassembly:
加一點反彙編程式碼:
debug.c,在disassembleInstruction()方法中新增程式碼:
return constantInstruction("OP_DEFINE_GLOBAL", chunk,
offset);
// 新增部分開始
case OP_SET_GLOBAL:
return constantInstruction("OP_SET_GLOBAL", chunk, offset);
// 新增部分結束
case OP_EQUAL:
So we’re done, right? Well . . . not quite. We’ve made a mistake! Take a gander at:
我們已經完成了,是嗎?嗯……不完全是。我們犯了一個錯誤!看一下這個:
a * b = c + d;
According to Lox’s grammar,
=has the lowest precedence, so this should be parsed roughly like:
根據Lox語法,=的優先順序最低,所以這大致應該解析為:

Obviously,
a * bisn’t a valid assignment target, so this should be a syntax error. But here’s what our parser does:
顯然,a*b不是一個有效的賦值目標13,所以這應該是一個語法錯誤。但我們的解析器是這樣的:
- First,
parsePrecedence()parsesausing thevariable()prefix parser.- After that, it enters the infix parsing loop.
- It reaches the
*and callsbinary().- That recursively calls
parsePrecedence()to parse the right-hand operand.- That calls
variable()again for parsingb.- Inside that call to
variable(), it looks for a trailing=. It sees one and thus parses the rest of the line as an assignment.
- 首先,
parsePrecedence()使用variable()字首解析器解析a。 - 之後,會進入中綴解析迴圈。
- 達到
*,並呼叫binary()。 - 遞迴地呼叫
parsePrecedence()解析右運算元。 - 再次呼叫
variable()解析b。 - 在對
variable()的呼叫中,會查詢尾部的=。它看到了,因此會將本行的其餘部分解析為一個賦值表示式。
In other words, the parser sees the above code like:
換句話說,解析器將上面的程式碼看作:

We’ve messed up the precedence handling because
variable()doesn’t take into account the precedence of the surrounding expression that contains the variable. If the variable happens to be the right-hand side of an infix operator, or the operand of a unary operator, then that containing expression is too high precedence to permit the=.
我們搞砸了優先順序處理,因為variable()沒有考慮包含變數的外圍表示式的優先順序。如果變數恰好是中綴運算子的右運算元,或者是一元運算子的運算元,那麼這個包含表示式的優先順序太高,不允許使用=。
To fix this,
variable()should look for and consume the=only if it’s in the context of a low-precedence expression. The code that knows the current precedence is, logically enough,parsePrecedence(). Thevariable()function doesn’t need to know the actual level. It just cares that the precedence is low enough to allow assignment, so we pass that fact in as a Boolean.
為瞭解決這個問題,variable()應該只在低優先順序表示式的上下文中尋找並使用=。從邏輯上講,知道當前優先順序的程式碼是parsePrecedence()。variable()函式不需要知道實際的級別。它只關心優先順序是否低到允許賦值表示式,所以我們把這個情況以布林值傳入。
compiler.c,在parsePrecedence()方法中替換1行:
error("Expect expression.");
return;
}
// 替換部分開始
bool canAssign = precedence <= PREC_ASSIGNMENT;
prefixRule(canAssign);
// 替換部分結束
while (precedence <= getRule(parser.current.type)->precedence) {
Since assignment is the lowest-precedence expression, the only time we allow an assignment is when parsing an assignment expression or top-level expression like in an expression statement. That flag makes its way to the parser function here:
因為賦值是最低優先順序的表示式,只有在解析賦值表示式或如表示式語句等頂層表示式時,才允許出現賦值。這個標誌會被傳入這個解析器函式:
compiler.c,在variable()函式中替換3行:
static void variable(bool canAssign) {
namedVariable(parser.previous, canAssign);
}
Which passes it through a new parameter:
透過一個新引數透傳該值:
compiler.c,在namedVariable()方法中替換1行:
// 替換部分開始
static void namedVariable(Token name, bool canAssign) {
// 替換部分結束
uint8_t arg = identifierConstant(&name);
And then finally uses it here:
最後在這裡使用它:
uint8_t arg = identifierConstant(&name);
compiler.c,在namedVariable()方法中替換1行:
uint8_t arg = identifierConstant(&name);
// 替換部分開始
if (canAssign && match(TOKEN_EQUAL)) {
// 替換部分結束
expression();
That’s a lot of plumbing to get literally one bit of data to the right place in the compiler, but arrived it has. If the variable is nested inside some expression with higher precedence,
canAssignwill befalseand this will ignore the=even if there is one there. ThennamedVariable()returns, and execution eventually makes its way back toparsePrecedence().
為了把字面上的1位元資料送到編譯器的正確位置需要做很多工作,但它已經到達了。如果變數巢狀在某個優先順序更高的表示式中,canAssign將為false,即使有=也會被忽略。然後namedVariable()返回,執行最終返回到了parsePrecedence()。
Then what? What does the compiler do with our broken example from before? Right now,
variable()won’t consume the=, so that will be the current token. The compiler returns back toparsePrecedence()from thevariable()prefix parser and then tries to enter the infix parsing loop. There is no parsing function associated with=, so it skips that loop.
然後呢?編譯器會對我們前面的負面例子做什麼?現在,variable()不會消耗=,所以它將是當前的標識。編譯器從variable()字首解析器返回到parsePrecedence(),然後嘗試進入中綴解析迴圈。沒有與=相關的解析函式,因此也會跳過這個迴圈。
Then
parsePrecedence()silently returns back to the caller. That also isn’t right. If the=doesn’t get consumed as part of the expression, nothing else is going to consume it. It’s an error and we should report it.
然後parsePrecedence()默默地返回到呼叫方。這也是不對的。如果=沒有作為表示式的一部分被消耗,那麼其它任何東西都不會消耗它。這是一個錯誤,我們應該報告它。
compiler.c,在parsePrecedence()方法中新增程式碼:
infixRule();
}
// 新增部分開始
if (canAssign && match(TOKEN_EQUAL)) {
error("Invalid assignment target.");
}
// 新增部分結束
}
With that, the previous bad program correctly gets an error at compile time. OK, now are we done? Still not quite. See, we’re passing an argument to one of the parse functions. But those functions are stored in a table of function pointers, so all of the parse functions need to have the same type. Even though most parse functions don’t support being used as an assignment target—setters are the only other one—our friendly C compiler requires them all to accept the parameter.
這樣,前面的錯誤程式在編譯時就會正確地得到一個錯誤。好了,現在我們完成了嗎?也不盡然。看,我們正向一個解析函式傳遞引數。但是這些函式是儲存在一個函式指令表格中的,所以所有的解析函式需要具有相同的型別。儘管大多數解析函式都不支援被用作賦值目標——setter是唯一的一個14——但我們這個友好的C編譯器要求它們都接受相同的引數。
So we’re going to finish off this chapter with some grunt work. First, let’s go ahead and pass the flag to the infix parse functions.
所以我們要做一些苦差事來結束這一章。首先,讓我們繼續前進,將標誌傳給中綴解析函式。
compiler.c,在parsePrecedence()方法中替換1行:
ParseFn infixRule = getRule(parser.previous.type)->infix;
// 替換部分開始
infixRule(canAssign);
// 替換部分結束
}
We’ll need that for setters eventually. Then we’ll fix the typedef for the function type.
我們最終會在setter中需要它。然後,我們要修復函式型別的型別定義。
compiler.c,在列舉Precedence後替換1行:
} Precedence;
// 替換部分開始
typedef void (*ParseFn)(bool canAssign);
// 替換部分結束
typedef struct {
And some completely tedious code to accept this parameter in all of our existing parse functions. Here:
還有一些非常乏味的程式碼,為了在所有的現有解析函式中接受這個引數。這裡:
compiler.c,在binary()方法中替換1行:
// 替換部分開始
static void binary(bool canAssign) {
// 替換部分結束
TokenType operatorType = parser.previous.type;
這裡:
compiler.c,在literal()方法中替換1行:
// 替換部分開始
static void literal(bool canAssign) {
// 替換部分結束
switch (parser.previous.type) {
這裡:
compiler.c,在grouping()方法中替換1行:
// 替換部分開始
static void grouping(bool canAssign) {
// 替換部分結束
expression();
這裡:
compiler.c,在number()方法中替換1行:
// 替換部分開始
static void number(bool canAssign) {
// 替換部分結束
double value = strtod(parser.previous.start, NULL);
還有這裡:
compiler.c,在string()方法中替換1行:
// 替換部分開始
static void string(bool canAssign) {
// 替換部分結束
emitConstant(OBJ_VAL(copyString(parser.previous.start + 1,
最後:
compiler.c,在unary()方法中替換1行:
// 替換部分開始
static void unary(bool canAssign) {
// 替換部分結束
TokenType operatorType = parser.previous.type;
Phew! We’re back to a C program we can compile. Fire it up and now you can run this:
籲!我們又回到了可以編譯的C程式。啟動它,新增你可以執行這個:
var breakfast = "beignets";
var beverage = "cafe au lait";
breakfast = "beignets with " + beverage;
print breakfast;
It’s starting to look like real code for an actual language!
它開始看起來像是實際語言的真正程式碼了!
習題
-
The compiler adds a global variable’s name to the constant table as a string every time an identifier is encountered. It creates a new constant each time, even if that variable name is already in a previous slot in the constant table. That’s wasteful in cases where the same variable is referenced multiple times by the same function. That, in turn, increases the odds of filling up the constant table and running out of slots since we allow only 256 constants in a single chunk.
Optimize this. How does your optimization affect the performance of the compiler compared to the runtime? Is this the right trade-off?
每次遇到識別符號時,編譯器都會將全域性變數的名稱作為字串新增到常量表中。它每次都會建立一個新的常量,即使這個變數的名字已經在常量表中的前一個槽中存在。在同一個函式多次引用同一個變數的情況下,這是一種浪費。這反過來又增加了填滿常量表的可能性,因為我們在一個位元組碼塊中只允許有256個常量。
對此進行最佳化。與執行時相比,你的最佳化對編譯器的效能有何影響?這是正確的取捨嗎?
-
Looking up a global variable by name in a hash table each time it is used is pretty slow, even with a good hash table. Can you come up with a more efficient way to store and access global variables without changing the semantics?
每次使用全域性變數時,根據名稱在雜湊表中查詢變數是很慢的,即使有一個很好的雜湊表。你能否想出一種更有效的方法來儲存和訪問全域性變數而不改變語義?
-
When running in the REPL, a user might write a function that references an unknown global variable. Then, in the next line, they declare the variable. Lox should handle this gracefully by not reporting an “unknown variable” compile error when the function is first defined.
But when a user runs a Lox script, the compiler has access to the full text of the entire program before any code is run. Consider this program:
當在REPL中執行時,使用者可能會編寫一個引用未知全域性變數的函式。然後,在下一行中,他們宣告瞭這個變數。Lox應該優雅地處理這個問題,在第一次定義函式時不報告“未知變數”的編譯錯誤。
但是,當使用者執行Lox指令碼時,編譯器可以在任何程式碼執行之前訪問整個程式的全部文字。考慮一下這個程式:
fun useVar() { print oops; } var ooops = "too many o's!";Here, we can tell statically that
oopswill not be defined because there is no declaration of that global anywhere in the program. Note thatuseVar()is never called either, so even though the variable isn’t defined, no runtime error will occur because it’s never used either.We could report mistakes like this as compile errors, at least when running from a script. Do you think we should? Justify your answer. What do other scripting languages you know do?
這裡,我們可以靜態地告知使用者
oops不會被定義,因為在程式中沒有任何地方對該全域性變數進行了宣告。請注意,useVar()也從未被呼叫,所以即使變數沒有被定義,也不會發生執行時錯誤,因為它從未被使用。我們可以將這樣的錯誤報告為編譯錯誤,至少在執行指令碼時是這樣。你認為我們應該這樣做嗎?請說明你的答案。你知道其它指令碼語言是怎麼做的嗎?
-
這是複雜的語言實現中常見的元策略。通常情況下,同一種語言特性會有多種實現技術,每種技術都針對不同的使用模式進行了最佳化。舉例來說,與屬性集可以自由修改的其它物件相比,Java Script虛擬機器通常對那些使用起來像類例項物件有著更快的表示形式。C和C++編譯器通常由多種方法能夠根據case分支數量和case值的密集程度來編譯
switch語句。 ↩ -
程式碼塊的作用有點像表示式中的括號。塊可以讓你把“低階別的”宣告語句放在只允許“高階別的”非宣告語句的地方。 ↩
-
這聽起來微不足道,但是非玩具型語言的手寫解析器非常大。當你有數千行程式碼時,如果一個實用函式可以將兩行程式碼簡化為一行程式碼,並使結果更易於閱讀,那它就很容易被接受。 ↩
-
OP_ADD執行過後堆疊會少一個元素,所以它的效應是-1: ↩
↩ -
不過,我們只是近了一步。等我們新增函式時,還會重新審視
OP_RETURN。現在,它退出整個直譯器的迴圈即可。 ↩ -
據我統計,在本章末尾的
compiler.c版本中,149條語句中有80條是表示式語句。 ↩ -
基本上,編譯器會對變數宣告進行脫糖處理,如
var a;變成var a = nil;,它為前者生成的程式碼和為後者生成的程式碼是相同的。 ↩ -
我知道這裡有一些函式現在看起來沒什麼意義。但是,隨著我們增加更多與名稱相關的語言特性,我們會從中獲得更多的好處。函式和類宣告都宣告瞭新的變數,而變量表達式和賦值表示式會訪問它們。 ↩
-
請注意,直到將值新增到雜湊表之後,我們才會彈出它。這確保瞭如果在將值新增到雜湊表的過程中觸發了垃圾回收,虛擬機器仍然可以找到這個值。這顯然是很可能的,因為雜湊表在調整大小時需要動態分配。 ↩
-
這個程序在退出時會釋放所有的東西,但要求作業系統來收拾我們的爛攤子,總感覺很不體面。 ↩
-
如果你還記得,在jlox中賦值是很容易的。 ↩
-
對
tableSet()的呼叫會將值儲存在全域性變量表中,即使該變數之前沒有定義。這個問題在REPL會話中是使用者可見的,因為即使報告了執行時錯誤,它仍然在執行。因此,我們也要注意從表中刪除殭屍值。 ↩ -
如果
a*b是一個有效的賦值目標,這豈不是很瘋狂?你可以想象一些類似代數的語言,試圖以某種合理的方式劃分所賦的值,並將其分配給a和b……這可能是一個很糟糕的主意。 ↩ -
如果Lox有陣列和下標運算子,如
array[index],那麼中綴運算子[也能允許賦值,支援:array[index] = value。 ↩
22.區域性變數 Local Variables
And as imagination bodies forth The forms of things unknown, the poet’s pen Turns them to shapes and gives to airy nothing A local habitation and a name.
—— William Shakespeare, A Midsummer Night’s Dream
隨著想象力的不斷湧現
未知事物的形式,詩人的筆
把它們變成形狀,變成虛無
當地的居住地和名字。
(威廉·莎士比亞《仲夏夜之夢》)
The last chapter introduced variables to clox, but only of the global variety. In this chapter, we’ll extend that to support blocks, block scope, and local variables. In jlox, we managed to pack all of that and globals into one chapter. For clox, that’s two chapters worth of work partially because, frankly, everything takes more effort in C.
上一章介紹了clox中的變數,但是隻介紹了全域性變數。在本章中,我們將進一步支援塊、塊作用域和區域性變數。在jlox中,我們設法將所有這些內容和全域性變數打包成一章。對於clox來說,這需要兩章的工作量,坦率的說,部分原因是在C語言中一切都要花費更多的精力。
But an even more important reason is that our approach to local variables will be quite different from how we implemented globals. Global variables are late bound in Lox. “Late” in this context means “resolved after compile time”. That’s good for keeping the compiler simple, but not great for performance. Local variables are one of the most-used parts of a language. If locals are slow, everything is slow. So we want a strategy for local variables that’s as efficient as possible.
但更重要的原因是,我們處理區域性變數的方法與我們實現全域性變數的方法截然不同。全域性變數在Lox中是後期繫結的。這裡的“後期”是指“在編譯後分析”。這有利於保持編譯器的簡單性,但不利於效能。區域性變數是語言中最常用的部分之一。如果區域性變數很慢,那麼一切都是緩慢的。因此,對於區域性變數,我們希望採取儘可能高效的策略1。
Fortunately, lexical scoping is here to help us. As the name implies, lexical scope means we can resolve a local variable just by looking at the text of the program—locals are not late bound. Any processing work we do in the compiler is work we don’t have to do at runtime, so our implementation of local variables will lean heavily on the compiler.
幸運的是,詞法作用域可以幫助我們。顧名思義,詞法作用域意味著我們可以透過檢視程式文字來解析區域性變數——區域性變數不是後期繫結的。我們在編譯器中所做的任何處理工作都不必在執行時完成,因此區域性變數的實現將在很大程度上依賴於編譯器。
22 . 1 Representing Local Variables
22.1 表示區域性變數
The nice thing about hacking on a programming language in modern times is there’s a long lineage of other languages to learn from. So how do C and Java manage their local variables? Why, on the stack, of course! They typically use the native stack mechanisms supported by the chip and OS. That’s a little too low level for us, but inside the virtual world of clox, we have our own stack we can use.
在現代,實現一門程式語言的好處是,可以參考已經發展了很長時間的其它語言。那麼,C和Java是如何管理它們的區域性變數的呢?當然是在堆疊上!它們通常使用晶片和作業系統支援的本地堆疊機制。這對我們來說有點太底層了,但是在clox的虛擬世界中,我們有自己的堆疊可以使用。
Right now, we only use it for holding on to temporaries—short-lived blobs of data that we need to remember while computing an expression. As long as we don’t get in the way of those, we can stuff our local variables onto the stack too. This is great for performance. Allocating space for a new local requires only incrementing the
stackToppointer, and freeing is likewise a decrement. Accessing a variable from a known stack slot is an indexed array lookup.
現在,我們只使用它來儲存臨時變數——我們在計算表示式時需要記住的短期資料塊。只要我們不妨礙這些資料,我們也可以把區域性變數塞到棧中。這對效能很有幫助。為一個新的區域性變數分配空間只需要遞增stackTop指標,而釋放也同樣是遞減的過程。從已知的棧槽訪問變數是一種索引陣列的查詢。
We do need to be careful, though. The VM expects the stack to behave like, well, a stack. We have to be OK with allocating new locals only on the top of the stack, and we have to accept that we can discard a local only when nothing is above it on the stack. Also, we need to make sure temporaries don’t interfere.
不過,我們確實需要小心。虛擬機器希望棧的行為就像,嗯,一個棧。我們必須接受只能在棧頂分配新的區域性變數,而且我們必須接受只有區域性變數上方的棧槽沒有資料時,才能丟棄該變數。此外,我們還需要保證臨時變數不受幹擾。
Conveniently, the design of Lox is in harmony with these constraints. New locals are always created by declaration statements. Statements don’t nest inside expressions, so there are never any temporaries on the stack when a statement begins executing. Blocks are strictly nested. When a block ends, it always takes the innermost, most recently declared locals with it. Since those are also the locals that came into scope last, they should be on top of the stack where we need them.
方便的是,Lox的設計與這些約束條件是一致的2。新的區域性變數總是透過宣告語句建立的。語句不會巢狀在表示式內,所以當一個語句開始執行時,棧中沒有任何臨時變數。程式碼塊是嚴格巢狀的。當一個塊結束時,它總會帶走最內部、最近宣告的區域性變數。因為這些也是最後進入作用域的區域性變數,所以它們應該位於棧頂(我們期望它所在的位置)。
Step through this example program and watch how the local variables come in and go out of scope:
逐步執行這段示例程式碼,檢視區域性變數是如何進入和離開作用域的:

See how they fit a stack perfectly? It seems that the stack will work for storing locals at runtime. But we can go further than that. Not only do we know that they will be on the stack, but we can even pin down precisely where they will be on the stack. Since the compiler knows exactly which local variables are in scope at any point in time, it can effectively simulate the stack during compilation and note where in the stack each variable lives.
看到它們如何完美地適應堆疊了嗎?看來,棧可以在執行時儲存區域性變數。但是我們可以更進一步。我們不僅知道它們會在棧上,而且我們甚至可以確定它們在棧上的精確位置。因為編譯器確切地知道任何時間點上有哪些區域性變數在作用域中,因此它可以在編譯過程中有效地模擬堆疊,並注意每個變數在棧中的位置。
We’ll take advantage of this by using these stack offsets as operands for the bytecode instructions that read and store local variables. This makes working with locals deliciously fast—as simple as indexing into an array.
我們將利用這一點,對於讀取和儲存區域性變數的位元組碼指令,把這些棧偏移量作為其運算元。這使得區域性變數非常快——就像索引陣列一樣簡單3。
There’s a lot of state we need to track in the compiler to make this whole thing go, so let’s get started there. In jlox, we used a linked chain of “environment” HashMaps to track which local variables were currently in scope. That’s sort of the classic, schoolbook way of representing lexical scope. For clox, as usual, we’re going a little closer to the metal. All of the state lives in a new struct.
我們需要在編譯器中跟蹤大量狀態,以使整個程式執行起來,讓我們就從那裡開始。在jlox中,我們使用“環境”HashMap鏈來跟蹤當前在作用域中的區域性變數。這是一種經典的、教科書式的詞法作用域表示方式。對於clox,像往常一樣,我們更接近於硬體。所有的狀態都儲存了一個新的結構體中。
compiler.c,在結構體ParseRule後新增程式碼:
} ParseRule;
// 新增部分開始
typedef struct {
Local locals[UINT8_COUNT];
int localCount;
int scopeDepth;
} Compiler;
// 新增部分結束
Parser parser;
We have a simple, flat array of all locals that are in scope during each point in the compilation process. They are ordered in the array in the order that their declarations appear in the code. Since the instruction operand we’ll use to encode a local is a single byte, our VM has a hard limit on the number of locals that can be in scope at once. That means we can also give the locals array a fixed size.
我們有一個簡單、扁平的陣列,其中包含了編譯過程中每個時間點上處於作用域內的所有區域性變數4。它們在陣列中的順序與它們的宣告在程式碼中出現的順序相同。由於我們用來編碼區域性變數的指令運算元是一個位元組,所以我們的虛擬機器對同時處於作用域內的區域性變數的數量有一個硬性限制。這意味著我們也可以給區域性變數陣列一個固定的大小。
common.h,新增程式碼:
#define DEBUG_TRACE_EXECUTION
// 新增部分開始
#define UINT8_COUNT (UINT8_MAX + 1)
// 新增部分結束
#endif
Back in the Compiler struct, the
localCountfield tracks how many locals are in scope—how many of those array slots are in use. We also track the “scope depth”. This is the number of blocks surrounding the current bit of code we’re compiling.
回到Compiler結構體中,localCount欄位記錄了作用域中有多少區域性變數——有多少個陣列槽在使用。我們還會跟蹤“作用域深度”。這指的是我們正在編譯的當前程式碼外圍的程式碼塊數量。
Our Java interpreter used a chain of maps to keep each block’s variables separate from other blocks’. This time, we’ll simply number variables with the level of nesting where they appear. Zero is the global scope, one is the first top-level block, two is inside that, you get the idea. We use this to track which block each local belongs to so that we know which locals to discard when a block ends.
我們的Java直譯器使用了一個map鏈將每個塊的變數與其它塊分開。這一次,我們根據變量出現的巢狀級別對其進行編號。0是全域性作用域,1是第一個頂層塊,2是它內部的塊,你懂的。我們用它來跟蹤每個區域性變數屬於哪個塊,這樣當一個塊結束時,我們就知道該刪除哪些區域性變數。
Each local in the array is one of these:
陣列中的每個區域性變數都是這樣的:
compiler.c,在結構體ParseRule後新增程式碼:
} ParseRule;
// 新增部分開始
typedef struct {
Token name;
int depth;
} Local;
// 新增部分結束
typedef struct {
We store the name of the variable. When we’re resolving an identifier, we compare the identifier’s lexeme with each local’s name to find a match. It’s pretty hard to resolve a variable if you don’t know its name. The
depthfield records the scope depth of the block where the local variable was declared. That’s all the state we need for now.
我們儲存變數的名稱。當我們解析一個識別符號時,會將識別符號的詞素與每個區域性變數名稱進行比較,以找到一個匹配項。如果你不知道變數的名稱,就很難解析它。depth欄位記錄了宣告區域性變數的程式碼塊的作用域深度。這就是我們現在需要的所有狀態。
This is a very different representation from what we had in jlox, but it still lets us answer all of the same questions our compiler needs to ask of the lexical environment. The next step is figuring out how the compiler gets at this state. If we were principled engineers, we’d give each function in the front end a parameter that accepts a pointer to a Compiler. We’d create a Compiler at the beginning and carefully thread it through each function call . . . but that would mean a lot of boring changes to the code we already wrote, so here’s a global variable instead:
這與我們在jlox中使用的表示方式非常不同,但我們用它仍然可以回答編譯器需要向詞法環境提出的所有相同的問題。下一步是弄清楚編譯器如何獲取這個狀態。如果我們是有原則的工程師,我們應該給前端的每個函式新增一個引數,接受一個指向Compiler的指標。我們在一開始就建立一個Compiler,並小心地在將它貫穿於每個函式的呼叫中……但這意味著要對我們已經寫好的程式碼進行大量無聊的修改,所以這裡用一個全域性變數代替5:
compiler.c,在變數parser後新增程式碼:
Parser parser;
// 新增部分開始
Compiler* current = NULL;
// 新增部分結束
Chunk* compilingChunk;
Here’s a little function to initialize the compiler:
下面是一個用於初始化編譯器的小函式:
compiler.c,在emitConstant()方法後新增程式碼:
static void initCompiler(Compiler* compiler) {
compiler->localCount = 0;
compiler->scopeDepth = 0;
current = compiler;
}
When we first start up the VM, we call it to get everything into a clean state.
當我們第一次啟動虛擬機器時,我們會呼叫它使所有東西進入一個乾淨的狀態。
compiler.c,在compile()方法中新增程式碼:
initScanner(source);
// 新增部分開始
Compiler compiler;
initCompiler(&compiler);
// 新增部分結束
compilingChunk = chunk;
Our compiler has the data it needs, but not the operations on that data. There’s no way to create and destroy scopes, or add and resolve variables. We’ll add those as we need them. First, let’s start building some language features.
我們的編譯器有了它需要的資料,但還沒有對這些資料的操作。沒有辦法建立或銷燬作用域,新增和解析變數。我們會在需要的時候新增這些功能。首先,讓我們開始構建一些語言特性。
22 . 2 Block Statements
22.2 塊語句
Before we can have any local variables, we need some local scopes. These come from two things: function bodies and blocks. Functions are a big chunk of work that we’ll tackle in a later chapter, so for now we’re only going to do blocks. As usual, we start with the syntax. The new grammar we’ll introduce is:
在能夠使用區域性變數之前,我們需要一些區域性作用域。它們來自於兩方面:函式體和程式碼塊。函式是一大塊工作,我們在後面的章節中處理,因此現在我們只做塊6。和往常一樣,我們從語法開始。我們要介紹的新語法是:
statement → exprStmt
| printStmt
| block ;
block → "{" declaration* "}" ;
Blocks are a kind of statement, so the rule for them goes in the
statementproduction. The corresponding code to compile one looks like this:
塊是一種語句,所以它的規則是在statement生成式中。對應的編譯程式碼如下:
compiler.c,在statement()方法中新增程式碼:
if (match(TOKEN_PRINT)) {
printStatement();
// 新增部分開始
} else if (match(TOKEN_LEFT_BRACE)) {
beginScope();
block();
endScope();
// 新增部分結束
} else {
After parsing the initial curly brace, we use this helper function to compile the rest of the block:
解析完開頭的花括號之後,我們使用這個輔助函式7來編譯塊的其餘部分:
compiler.c,在expression()方法後新增程式碼:
static void block() {
while (!check(TOKEN_RIGHT_BRACE) && !check(TOKEN_EOF)) {
declaration();
}
consume(TOKEN_RIGHT_BRACE, "Expect '}' after block.");
}
It keeps parsing declarations and statements until it hits the closing brace. As we do with any loop in the parser, we also check for the end of the token stream. This way, if there’s a malformed program with a missing closing curly, the compiler doesn’t get stuck in a loop.
它會一直解析宣告和語句,直到遇見右括號。就像我們在解析器中的所有迴圈一樣,我們也要檢查標識流是否結束。這樣一來,如果有一個格式不正確的程式缺少右括號,編譯器也不會卡在迴圈裡。
Executing a block simply means executing the statements it contains, one after the other, so there isn’t much to compiling them. The semantically interesting thing blocks do is create scopes. Before we compile the body of a block, we call this function to enter a new local scope:
執行程式碼塊只是意味著一個接一個地執行其中包含的語句,所以不需要編譯它們。從語義上講,塊所做的事就是建立作用域。在我們編譯塊的主體之前,我們會呼叫這個函式進入一個新的區域性作用域:
compiler.c,在endCompiler()方法後新增程式碼:
static void beginScope() {
current->scopeDepth++;
}
In order to “create” a scope, all we do is increment the current depth. This is certainly much faster than jlox, which allocated an entire new HashMap for each one. Given
beginScope(), you can probably guess whatendScope()does.
為了“建立”一個作用域,我們所做的就是增加當前的深度。這當然比jlox快得多,因為jlox為每個作用域分配了全新的HashMap。有了beginScope(),你大概能猜到endScope()會做什麼。
compiler.c,在beginScope()方法後新增程式碼:
static void endScope() {
current->scopeDepth--;
}
That’s it for blocks and scopes—more or less—so we’re ready to stuff some variables into them.
這就是塊和作用域的全部內容——或多或少吧——現在我們準備在其中新增一些變數。
22 . 3 Declaring Local Variables
22.3 宣告區域性變數
Usually we start with parsing here, but our compiler already supports parsing and compiling variable declarations. We’ve got
varstatements, identifier expressions and assignment in there now. It’s just that the compiler assumes all variables are global. So we don’t need any new parsing support, we just need to hook up the new scoping semantics to the existing code.
通常我們會從解析開始,但是我們的編譯器已經支援瞭解析和編譯變數宣告。我們現在已經有了var語句、識別符號表示式和賦值語句。只是編譯器假設所有的變數都是全域性變數。所以,我們不需要任何新的解析支援,我們只需要將新的作用域語義與已有的程式碼連線起來。

Variable declaration parsing begins in
varDeclaration()and relies on a couple of other functions. First,parseVariable()consumes the identifier token for the variable name, adds its lexeme to the chunk’s constant table as a string, and then returns the constant table index where it was added. Then, aftervarDeclaration()compiles the initializer, it callsdefineVariable()to emit the bytecode for storing the variable’s value in the global variable hash table.
變數宣告的解析從varDeclaration()開始,並依賴於其它幾個函式。首先,parseVariable()會使用識別符號標識作為變數名稱,將其詞素作為字串新增到位元組碼塊的常量表中,然後返回它的常量表索引。接著,在varDeclaration()編譯完初始化表示式後,會呼叫defineVariable()生成位元組碼,將變數的值儲存到全域性變數雜湊表中。
Both of those helpers need a few changes to support local variables. In
parseVariable(), we add:
這兩個輔助函式都需要一些調整以支援區域性變數。在parseVariable()中,我們新增:
compiler.c,在parseVariable()方法中新增程式碼:
consume(TOKEN_IDENTIFIER, errorMessage);
// 新增部分開始
declareVariable();
if (current->scopeDepth > 0) return 0;
// 新增部分結束
return identifierConstant(&parser.previous);
First, we “declare” the variable. I’ll get to what that means in a second. After that, we exit the function if we’re in a local scope. At runtime, locals aren’t looked up by name. There’s no need to stuff the variable’s name into the constant table, so if the declaration is inside a local scope, we return a dummy table index instead.
首先,我們“宣告”這個變數。我一會兒會說到這是什麼意思。之後,如果我們在區域性作用域中,則退出函式。在執行時,不會透過名稱查詢區域性變數。不需要將變數的名稱放入常量表中,所以如果宣告在區域性作用域內,則返回一個假的表索引。
Over in
defineVariable(), we need to emit the code to store a local variable if we’re in a local scope. It looks like this:
在defineVariable()中,如果處於區域性作用域內,就需要生成一個位元組碼來儲存區域性變數。它看起來是這樣的:
compiler.c,在defineVariable()方法中新增程式碼:
static void defineVariable(uint8_t global) {
// 新增部分開始
if (current->scopeDepth > 0) {
return;
}
// 新增部分結束
emitBytes(OP_DEFINE_GLOBAL, global);
Wait, what? Yup. That’s it. There is no code to create a local variable at runtime. Think about what state the VM is in. It has already executed the code for the variable’s initializer (or the implicit
nilif the user omitted an initializer), and that value is sitting right on top of the stack as the only remaining temporary. We also know that new locals are allocated at the top of the stack . . . right where that value already is. Thus, there’s nothing to do. The temporary simply becomes the local variable. It doesn’t get much more efficient than that.
等等,什麼?是的,就是這樣。沒有程式碼會在執行時建立區域性變數。想想虛擬機器現在處於什麼狀態。它已經執行了變數初始化表示式的程式碼(如果使用者省略了初始化,則是隱式的nil),並且該值作為唯一保留的臨時變數位於棧頂。我們還知道,新的區域性變數會被分配到棧頂……這個值已經在那裡了。因此,沒有什麼可做的。臨時變數直接成為區域性變數。沒有比這更有效的方法了。

OK, so what’s “declaring” about? Here’s what that does:
好的,那“宣告”是怎麼回事呢?它的作用如下:
compiler.c,在identifierConstant()方法後新增程式碼:
static void declareVariable() {
if (current->scopeDepth == 0) return;
Token* name = &parser.previous;
addLocal(*name);
}
This is the point where the compiler records the existence of the variable. We only do this for locals, so if we’re in the top-level global scope, we just bail out. Because global variables are late bound, the compiler doesn’t keep track of which declarations for them it has seen.
在這裡,編譯器記錄變數的存在。我們只對區域性變數這樣做,所以如果在頂層全域性作用域中,就直接退出。因為全域性變數是後期繫結的,所以編譯器不會跟蹤它所看到的關於全域性變數的宣告。
But for local variables, the compiler does need to remember that the variable exists. That’s what declaring it does—it adds it to the compiler’s list of variables in the current scope. We implement that using another new function.
但是對於區域性變數,編譯器確實需要記住變數的存在。這就是宣告的作用——將變數新增到編譯器在當前作用域內的變數列表中。我們使用另一個新函式來實現這一點。
compiler.c,在identifierConstant()方法後新增程式碼:
static void addLocal(Token name) {
Local* local = ¤t->locals[current->localCount++];
local->name = name;
local->depth = current->scopeDepth;
}
This initializes the next available Local in the compiler’s array of variables. It stores the variable’s name and the depth of the scope that owns the variable.
這會初始化編譯器變數陣列中下一個可用的Local。它儲存了變數的名稱和持有變數的作用域的深度8。
Our implementation is fine for a correct Lox program, but what about invalid code? Let’s aim to be robust. The first error to handle is not really the user’s fault, but more a limitation of the VM. The instructions to work with local variables refer to them by slot index. That index is stored in a single-byte operand, which means the VM only supports up to 256 local variables in scope at one time.
我們的實現對於一個正確的Lox程式來說是沒有問題的,但是對於無效的程式碼呢?我們還是以穩健為目標。第一個要處理的錯誤其實不是使用者的錯,而是虛擬機器的限制。使用區域性變數的指令透過槽的索引來引用變數。該索引儲存在一個單位元組運算元中,這意味著虛擬機器一次最多隻能支援256個區域性變數。
If we try to go over that, not only could we not refer to them at runtime, but the compiler would overwrite its own locals array, too. Let’s prevent that.
如果我們試圖超過這個範圍,不僅不能在執行時引用變數,而且編譯器也會覆蓋自己的區域性變數陣列。我們要防止這種情況。
compiler.c,在addLocal()方法中新增程式碼:
static void addLocal(Token name) {
// 新增部分開始
if (current->localCount == UINT8_COUNT) {
error("Too many local variables in function.");
return;
}
// 新增部分結束
Local* local = ¤t->locals[current->localCount++];
The next case is trickier. Consider:
接下來的情況就有點棘手了。考慮一下:
{
var a = "first";
var a = "second";
}
At the top level, Lox allows redeclaring a variable with the same name as a previous declaration because that’s useful for the REPL. But inside a local scope, that’s a pretty weird thing to do. It’s likely to be a mistake, and many languages, including our own Lox, enshrine that assumption by making this an error.
在頂層,Lox允許使用與之前宣告的變數相同的名稱重新宣告一個變數,因為這在REPL中很有用。但在區域性作用域中,這就有些奇怪了。這很可能是一個誤用,許多語言(包括我們的Lox)都把它作為一個錯誤9。
Note that the above program is different from this one:
請注意,上面的程式碼跟這個是不同的:
{
var a = "outer";
{
var a = "inner";
}
}
It’s OK to have two variables with the same name in different scopes, even when the scopes overlap such that both are visible at the same time. That’s shadowing, and Lox does allow that. It’s only an error to have two variables with the same name in the same local scope.
在不同的作用域中有兩個同名變數是可以的,即使作用域重疊,以至於兩個變數是同時可見的。這就是遮蔽,而Lox確實允許這樣做。只有在同一個區域性作用域中有兩個同名的變數才是錯誤的。
We detect that error like so:
我們這樣檢測這個錯誤10:
compiler.c,在declareVariable()方法中新增程式碼:
Token* name = &parser.previous;
// 新增部分開始
for (int i = current->localCount - 1; i >= 0; i--) {
Local* local = ¤t->locals[i];
if (local->depth != -1 && local->depth < current->scopeDepth) {
break;
}
if (identifiersEqual(name, &local->name)) {
error("Already a variable with this name in this scope.");
}
}
// 新增部分結束
addLocal(*name);
}
Local variables are appended to the array when they’re declared, which means the current scope is always at the end of the array. When we declare a new variable, we start at the end and work backward, looking for an existing variable with the same name. If we find one in the current scope, we report the error. Otherwise, if we reach the beginning of the array or a variable owned by another scope, then we know we’ve checked all of the existing variables in the scope.
區域性變數在宣告時被追加到陣列中,這意味著當前作用域始終位於陣列的末端。當我們宣告一個新的變數時,我們從末尾開始,反向查詢具有相同名稱的已有變數。如果是當前作用域中找到,我們就報告錯誤。此外,如果我們已經到達了陣列開頭或另一個作用域中的變數,我們就知道已經檢查了當前作用域中的所有現有變數。
To see if two identifiers are the same, we use this:
為了檢視兩個識別符號是否相同,我們使用這個方法:
compiler.c,在identifierConstant()方法後新增程式碼:
static bool identifiersEqual(Token* a, Token* b) {
if (a->length != b->length) return false;
return memcmp(a->start, b->start, a->length) == 0;
}
Since we know the lengths of both lexemes, we check that first. That will fail quickly for many non-equal strings. If the lengths are the same, we check the characters using
memcmp(). To get tomemcmp(), we need an include.
既然我們知道兩個詞素的長度,那我們首先檢查它11。對於很多不相等的字串,在這一步就很快失敗了。如果長度相同,我們就使用memcmp()檢查字元。為了使用memcmp(),我們需要引入一下。
compiler.c,新增程式碼:
#include <stdlib.h>
// 新增部分開始
#include <string.h>
// 新增部分結束
#include "common.h"
有了這個,我們就能創造出變數。但是,它們會停留在宣告它們的作用域之外,像幽靈一樣。當一個程式碼塊結束時,我們需要讓其中的變數安息。
compiler.c,在endScope()方法中新增程式碼:
current->scopeDepth--;
// 新增部分開始
while (current->localCount > 0 &&
current->locals[current->localCount - 1].depth >
current->scopeDepth) {
emitByte(OP_POP);
current->localCount--;
}
// 新增部分結束
}
When we pop a scope, we walk backward through the local array looking for any variables declared at the scope depth we just left. We discard them by simply decrementing the length of the array.
當我們彈出一個作用域時,後向遍歷區域性變數陣列,查詢在剛剛離開的作用域深度上宣告的所有變數。我們透過簡單地遞減陣列長度來丟棄它們。
There is a runtime component to this too. Local variables occupy slots on the stack. When a local variable goes out of scope, that slot is no longer needed and should be freed. So, for each variable that we discard, we also emit an
OP_POPinstruction to pop it from the stack.
這裡也有一個執行時的因素。區域性變數佔用了堆疊中的槽位。當區域性變數退出作用域時,這個槽就不再需要了,應該被釋放。因此,對於我們丟棄的每一個變數,我們也要生成一條OP_POP指令,將其從棧中彈出12。
22 . 4 Using Locals
22.4 使用區域性變數
We can now compile and execute local variable declarations. At runtime, their values are sitting where they should be on the stack. Let’s start using them. We’ll do both variable access and assignment at the same time since they touch the same functions in the compiler.
我們現在可以編譯和執行區域性變數的宣告瞭。在執行時,它們的值就在棧中應在的位置上。讓我們開始使用它們吧。我們會同時完成變數訪問和賦值,因為它們在編譯器中涉及相同的函式。
We already have code for getting and setting global variables, and—like good little software engineers—we want to reuse as much of that existing code as we can. Something like this:
我們已經有了獲取和設定全域性變數的程式碼,而且像優秀的小軟體工程師一樣,我們希望儘可能多地重用現有的程式碼。就像這樣:
compiler.c,在namedVariable()方法中替換1行:
static void namedVariable(Token name, bool canAssign) {
// 替換部分開始
uint8_t getOp, setOp;
int arg = resolveLocal(current, &name);
if (arg != -1) {
getOp = OP_GET_LOCAL;
setOp = OP_SET_LOCAL;
} else {
arg = identifierConstant(&name);
getOp = OP_GET_GLOBAL;
setOp = OP_SET_GLOBAL;
}
// 替換部分結束
if (canAssign && match(TOKEN_EQUAL)) {
Instead of hardcoding the bytecode instructions emitted for variable access and assignment, we use a couple of C variables. First, we try to find a local variable with the given name. If we find one, we use the instructions for working with locals. Otherwise, we assume it’s a global variable and use the existing bytecode instructions for globals.
我們不對變數訪問和賦值對應的位元組碼指令進行硬編碼,而是使用了一些C變數。首先,我們嘗試查詢具有給定名稱的區域性變數,如果我們找到了,就使用處理區域性變數的指令。否則,我們就假定它是一個全域性變數,並使用現有的處理全域性變數的位元組碼。
A little further down, we use those variables to emit the right instructions. For assignment:
再往下一點,我們使用這些變數來生成正確的指令。對於賦值:
compiler.c,在namedVariable()方法中替換1行:
if (canAssign && match(TOKEN_EQUAL)) {
expression();
// 替換部分開始
emitBytes(setOp, (uint8_t)arg);
// 替換部分結束
} else {
And for access:
對於訪問:
compiler.c,在namedVariable()方法中替換1行:
emitBytes(setOp, (uint8_t)arg);
} else {
// 替換部分開始
emitBytes(getOp, (uint8_t)arg);
// 替換部分結束
}
The real heart of this chapter, the part where we resolve a local variable, is here:
本章的核心,也就是解析區域性變數的部分,在這裡:
compiler.c,在identifiersEqual()方法後新增程式碼:
static int resolveLocal(Compiler* compiler, Token* name) {
for (int i = compiler->localCount - 1; i >= 0; i--) {
Local* local = &compiler->locals[i];
if (identifiersEqual(name, &local->name)) {
return i;
}
}
return -1;
}
For all that, it’s straightforward. We walk the list of locals that are currently in scope. If one has the same name as the identifier token, the identifier must refer to that variable. We’ve found it! We walk the array backward so that we find the last declared variable with the identifier. That ensures that inner local variables correctly shadow locals with the same name in surrounding scopes.
儘管如此,它還是很直截了當的。我們會遍歷當前在作用域內的區域性變數列表。如果有一個名稱與識別符號相同,則識別符號一定指向該變數。我們已經找到了它!我們後向遍歷陣列,這樣就能找到最後一個帶有該識別符號的已宣告變數。這可以確保內部的區域性變數能正確地遮蔽外圍作用域中的同名變數。
At runtime, we load and store locals using the stack slot index, so that’s what the compiler needs to calculate after it resolves the variable. Whenever a variable is declared, we append it to the locals array in Compiler. That means the first local variable is at index zero, the next one is at index one, and so on. In other words, the locals array in the compiler has the exact same layout as the VM’s stack will have at runtime. The variable’s index in the locals array is the same as its stack slot. How convenient!
在執行時,我們使用棧中槽索引來載入和儲存區域性變數,因此編譯器在解析變數之後需要計算索引。每當一個變數被宣告,我們就將它追加到編譯器的區域性變數陣列中。這意味著第一個區域性變數在索引0的位置,下一個在索引1的位置,以此類推。換句話說,編譯器中的區域性變數陣列的佈局與虛擬機器堆疊在執行時的佈局完全相同。變數在區域性變數陣列中的索引與其在棧中的槽位相同。多麼方便啊!
If we make it through the whole array without finding a variable with the given name, it must not be a local. In that case, we return
-1to signal that it wasn’t found and should be assumed to be a global variable instead.
如果我們在整個陣列中都沒有找到具有指定名稱的變數,那它肯定不是區域性變數。在這種情況下,我們返回-1,表示沒有找到,應該假定它是一個全域性變數。
22 . 4 . 1 Interpreting local variables
22.4.1 解釋區域性變數
Our compiler is emitting two new instructions, so let’s get them working. First is loading a local variable:
我們的編譯器發出了兩條新指令,我們來讓它們發揮作用。首先是載入一個區域性變數:
chunk.h,在列舉OpCode中新增程式碼:
OP_POP,
// 新增部分開始
OP_GET_LOCAL,
// 新增部分結束
OP_GET_GLOBAL,
And its implementation:
還有其實現13:
vm.c,在run()方法中新增程式碼:
case OP_POP: pop(); break;
// 新增部分開始
case OP_GET_LOCAL: {
uint8_t slot = READ_BYTE();
push(vm.stack[slot]);
break;
}
// 新增部分結束
case OP_GET_GLOBAL: {
It takes a single-byte operand for the stack slot where the local lives. It loads the value from that index and then pushes it on top of the stack where later instructions can find it.
它接受一個單位元組運算元,用作區域性變數所在的棧槽。它從索引處載入值,然後將其壓入棧頂,在後面的指令可以找到它。
Next is assignment:
接下來是賦值:
chunk.h,在列舉OpCode中新增程式碼:
OP_GET_LOCAL,
// 新增部分開始
OP_SET_LOCAL,
// 新增部分結束
OP_GET_GLOBAL,
You can probably predict the implementation.
你大概能預測到它的實現。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_SET_LOCAL: {
uint8_t slot = READ_BYTE();
vm.stack[slot] = peek(0);
break;
}
// 新增部分結束
case OP_GET_GLOBAL: {
It takes the assigned value from the top of the stack and stores it in the stack slot corresponding to the local variable. Note that it doesn’t pop the value from the stack. Remember, assignment is an expression, and every expression produces a value. The value of an assignment expression is the assigned value itself, so the VM just leaves the value on the stack.
它從棧頂獲取所賦的值,然後儲存到與區域性變數對應的棧槽中。注意,它不會從棧中彈出值。請記住,賦值是一個表示式,而每個表示式都會產生一個值。賦值表示式的值就是所賦的值本身,所以虛擬機器要把值留在棧上。
Our disassembler is incomplete without support for these two new instructions.
如果不支援這兩條新指令,我們的反彙編程式就不完整了。
debug.c,在disassembleInstruction()方法中新增程式碼:
return simpleInstruction("OP_POP", offset);
// 新增部分開始
case OP_GET_LOCAL:
return byteInstruction("OP_GET_LOCAL", chunk, offset);
case OP_SET_LOCAL:
return byteInstruction("OP_SET_LOCAL", chunk, offset);
// 新增部分結束
case OP_GET_GLOBAL:
The compiler compiles local variables to direct slot access. The local variable’s name never leaves the compiler to make it into the chunk at all. That’s great for performance, but not so great for introspection. When we disassemble these instructions, we can’t show the variable’s name like we could with globals. Instead, we just show the slot number.
編譯器將區域性變數編譯為直接的槽訪問。區域性變數的名稱永遠不會離開編譯器,根本不可能進入位元組碼塊。這對效能很好,但對內省(自我觀察)來說就不那麼好了。當我們反彙編這些指令時,我們不能像全域性變數那樣使用變數名稱。相反,我們只顯示槽號14。
debug.c,在simpleInstruction()方法後新增程式碼:
static int byteInstruction(const char* name, Chunk* chunk,
int offset) {
uint8_t slot = chunk->code[offset + 1];
printf("%-16s %4d\n", name, slot);
return offset + 2;
}
22 . 4 . 2 Another scope edge case
22.4.2 另一種作用域邊界情況
We already sunk some time into handling a couple of weird edge cases around scopes. We made sure shadowing works correctly. We report an error if two variables in the same local scope have the same name. For reasons that aren’t entirely clear to me, variable scoping seems to have a lot of these wrinkles. I’ve never seen a language where it feels completely elegant.
我們已經花了一些時間來處理部分關於作用域的奇怪的邊界情況。我們確保變數遮蔽能正確工作。如果同一個區域性作用域中的兩個變數具有相同的名稱,我們會報告錯誤。由於我並不完全清楚的原因,變數作用域似乎有很多這樣的問題。我從來沒有見過一種語言讓人感覺絕對優雅15。
We’ve got one more edge case to deal with before we end this chapter. Recall this strange beastie we first met in jlox’s implementation of variable resolution:
在本章結束之前,我們還有一個邊界情況需要處理。回顧一下我們第一次在jlox中實現變數解析時,遇到的這個奇怪的東西:
{
var a = "outer";
{
var a = a;
}
}
We slayed it then by splitting a variable’s declaration into two phases, and we’ll do that again here:
我們當時透過將一個變數的宣告拆分為兩個階段來解決這個問題,在這裡我們也要這樣做:

As soon as the variable declaration begins—in other words, before its initializer—the name is declared in the current scope. The variable exists, but in a special “uninitialized” state. Then we compile the initializer. If at any point in that expression we resolve an identifier that points back to this variable, we’ll see that it is not initialized yet and report an error. After we finish compiling the initializer, we mark the variable as initialized and ready for use.
一旦變數宣告開始——換句話說,在它的初始化式之前——名稱就會在當前作用域中宣告。變數存在,但處於特殊的“未初始化”狀態。然後我們編譯初始化式。如果在表示式中的任何一個時間點,我們解析了一個指向該變數的識別符號,我們會發現它還沒有初始化,並報告錯誤。在我們完成初始化表示式的編譯之後,把變數標記為已初始化並可供使用。
To implement this, when we declare a local, we need to indicate the “uninitialized” state somehow. We could add a new field to Local, but let’s be a little more parsimonious with memory. Instead, we’ll set the variable’s scope depth to a special sentinel value,
-1.
為了實現這一點,當宣告一個區域性變數時,我們需要以某種方式表明“未初始化”狀態。我們可以在Local中新增一個新欄位,但我們還是在記憶體方面更節省一些。相對地,我們將變數的作用域深度設定為一個特殊的哨兵值-1。
compiler.c,在addLocal()方法中替換1行:
local->name = name;
// 替換部分開始
local->depth = -1;
// 替換部分結束
}
Later, once the variable’s initializer has been compiled, we mark it initialized.
稍後,一旦變數的初始化式編譯完成,我們將其標記為已初始化。
compiler.c,在defineVariable()方法中新增程式碼:
if (current->scopeDepth > 0) {
// 新增部分開始
markInitialized();
// 新增部分結束
return;
}
That is implemented like so:
實現如下:
compiler.c,在parseVariable()方法後新增程式碼:
static void markInitialized() {
current->locals[current->localCount - 1].depth =
current->scopeDepth;
}
So this is really what “declaring” and “defining” a variable means in the compiler. “Declaring” is when the variable is added to the scope, and “defining” is when it becomes available for use.
所這就是編譯器中“宣告”和“定義”變數的真正含義。“宣告”是指變數被新增到作用域中,而“定義”是變數可以被使用的時候。
When we resolve a reference to a local variable, we check the scope depth to see if it’s fully defined.
當解析指向區域性變數的引用時,我們會檢查作用域深度,看它是否被完全定義。
compiler.c,在resolveLocal()方法中新增程式碼:
if (identifiersEqual(name, &local->name)) {
// 新增部分開始
if (local->depth == -1) {
error("Can't read local variable in its own initializer.");
}
// 新增部分結束
return i;
If the variable has the sentinel depth, it must be a reference to a variable in its own initializer, and we report that as an error.
如果變數的深度是哨兵值,那這一定是在變數自身的初始化式中對該變數的引用,我們會將其報告為一個錯誤。
That’s it for this chapter! We added blocks, local variables, and real, honest-to-God lexical scoping. Given that we introduced an entirely different runtime representation for variables, we didn’t have to write a lot of code. The implementation ended up being pretty clean and efficient.
這一章就講到這裡!我們添加了塊、區域性變數和真正的詞法作用域。鑑於我們為變數引入了完全不同的執行時表示形式,我們不必編寫很多程式碼。這個實現最終是相當乾淨和高效的。
You’ll notice that almost all of the code we wrote is in the compiler. Over in the runtime, it’s just two little instructions. You’ll see this as a continuing trend in clox compared to jlox. One of the biggest hammers in the optimizer’s toolbox is pulling work forward into the compiler so that you don’t have to do it at runtime. In this chapter, that meant resolving exactly which stack slot every local variable occupies. That way, at runtime, no lookup or resolution needs to happen.
你會注意到,我們寫的幾乎所有的程式碼都在編譯器中。在執行時,只有兩個小指令。你會看到,相比於jlox,這是clox中的一個持續的趨勢16。最佳化器工具箱中最大的錘子就是把工作提前到編譯器中,這樣你就不必在執行時做這些工作了。在本章中,這意味著要準確地解析每個區域性變數佔用的棧槽。這樣,在執行時就不需要進行查詢或解析。
習題
-
Our simple local array makes it easy to calculate the stack slot of each local variable. But it means that when the compiler resolves a reference to a variable, we have to do a linear scan through the array.
Come up with something more efficient. Do you think the additional complexity is worth it?
我們這個簡單的區域性變數陣列使得計算每個區域性變數的棧槽很容易。但這意味著,當編譯器解析一個變數的引用時,我們必須對陣列進行線性掃描。
想出一些更有效的方法。你認為這種額外的複雜性是否值得?
-
How do other languages handle code like this:
其它語言中如何處理這樣的程式碼:
var a = a;What would you do if it was your language? Why?
如果這是你的語言,你會怎麼做?為什麼?
-
Many languages make a distinction between variables that can be reassigned and those that can’t. In Java, the
finalmodifier prevents you from assigning to a variable. In JavaScript, a variable declared withletcan be assigned, but one declared usingconstcan’t. Swift treatsletas single-assignment and usesvarfor assignable variables. Scala and Kotlin usevalandvar.Pick a keyword for a single-assignment variable form to add to Lox. Justify your choice, then implement it. An attempt to assign to a variable declared using your new keyword should cause a compile error.
許多語言中,對可以重新賦值的變數與不能重新賦值的變數進行了區分。在Java中,
final修飾符可以阻止你對變數進行賦值。在JavaScript中,用let宣告的變數可以被賦值,但用const宣告的變數不能被賦值。Swift將let視為單次賦值,並對可賦值變數使用var。Scala和Kotlin則使用val和var。選一個關鍵字作為單次賦值變數的形式新增到Lox中。解釋一下你的選擇,然後實現它。試圖賦值給一個用新關鍵字宣告的變數應該會引起編譯錯誤。
-
Extend clox to allow more than 256 local variables to be in scope at a time.
擴充套件Lox,允許作用域中同時有超過256個區域性變數。
-
函式引數也被大量使用。它們也像區域性變數一樣工作,因此我們將會對它們使用同樣的實現技術。 ↩
-
這種排列方式顯然不是巧合。我將Lox設計成可以單遍編譯為基於堆疊的位元組碼。但我沒必要為了適應這些限制對語言進行過多的調整。它的大部分設計應該感覺很自然。
這在很大程度上是因為語言的歷史與單次編譯緊密聯絡在一起,其次是基於堆疊的架構。Lox的塊作用域遵循的傳統可以追溯到BCPL。作為程式設計師,我們對一門語言中什麼是“正常”的直覺,即使在今天也會受到過去的硬體限制的影響。 ↩ -
在本章中,區域性變數從虛擬機器堆疊陣列的底部開始,並在那裡建立索引。當我們新增函式時,這個方案就變得有點複雜了。每個函式都需要自己的堆疊區域來存放引數和區域性變數。但是,正如我們將看到的,這並沒有如你所想那樣增加太多的複雜性。 ↩
-
我們正在編寫一個單遍編譯器,所以對於如何在陣列中對變數進行排序,我們並沒有太多的選擇。 ↩
-
特別說明,如果我們想在多執行緒應用程式中使用編譯器(可能有多個編譯器並行執行),那麼使用全域性變數是一個壞主意。 ↩
-
仔細想想,“塊”是個奇怪的名字。作為比喻來說,“塊”通常意味著一個不可分割的小單元,但出於某種原因,Algol 60委員會決定用它來指代一個複合結構——一系列語句。我想,還有更糟的情況,Algol 58將
begin和end稱為“語句括號”。 ↩ -
在後面編譯函式體時,這個方法會派上用場。 ↩
-
擔心作為變數名稱的字串的生命週期嗎?Local直接儲存了識別符號對應Token結構體的副本。Token儲存了一個指向其詞素中第一個字元的指標,以及詞素的長度。該指標指向正在編譯的指令碼或REPL輸入語句的源字串。
只要這個字串在整個編譯過程中存在——你知道,它一定存在,我們正在編譯它——那麼所有指向它的標識都是正常的。 ↩ -
有趣的是,Rust語言確實允許這樣做,而且慣用程式碼也依賴於此。 ↩
-
暫時先不用關心那個奇怪的
depth != -1部分。我們稍後會講到。 ↩ -
如果我們能檢查它們的雜湊值,將是一個不錯的小最佳化,但標識不是完整的LoxString,所以我們還沒有計算出它們的雜湊值。 ↩
-
當多個區域性變數同時退出作用域時,你會得到一系列的
OP_POP指令,這些指令會被逐個解釋。你可以在你的Lox實現中新增一個簡單的最佳化,那就是專門的OP_POPN指令,該指令接受一個運算元,作為彈出的槽位的數量,並一次性彈出所有槽位。 ↩ -
把區域性變數的值壓到棧中似乎是多餘的,因為它已經在棧中較低的某個位置了。問題是,其它位元組碼指令只能查詢棧頂的資料。這也是我們的位元組碼指令集基於堆疊的主要表現。基於暫存器的位元組碼指令集避免了這種堆疊技巧,其代價是有著更多運算元的大型指令。 ↩
-
如果我們想為虛擬機器實現一個偵錯程式,在編譯器中擦除區域性變數名稱是一個真正的問題。當使用者逐步執行程式碼時,他們希望看到區域性變數的值按名稱排列。為了支援這一點,我們需要輸出一些額外的資訊,以跟蹤每個棧槽中的區域性變數的名稱。 ↩
-
沒有,即便Scheme也不是。 ↩
-
你可以把靜態型別看作是這種趨勢的一個極端例子。靜態型別語言將所有的型別分析和型別錯誤處理都在編譯過程中進行了整理。這樣,執行時就不必浪費時間來檢查值是否具有適合其操作的型別。事實上,在一些靜態型別語言(如C)中,你甚至不知道執行時的型別。編譯器完全擦除值型別的任何表示,只留下空白的位元位。 ↩
23.來回跳轉 Jumping Back and Forth
The order that our mind imagines is like a net, or like a ladder, built to attain something. But afterward you must throw the ladder away, because you discover that, even if it was useful, it was meaningless.
——Umberto Eco, The Name of the Rose
我們頭腦中想象的秩序就像一張網,或者像一架梯子,用來達到某種目的。但事後你必須把梯子扔掉,因為你會發現,即使它有用,也毫無意義。(翁貝託·艾柯,《玫瑰之名》)
It’s taken a while to get here, but we’re finally ready to add control flow to our virtual machine. In the tree-walk interpreter we built for jlox, we implemented Lox’s control flow in terms of Java’s. To execute a Lox
ifstatement, we used a Javaifstatement to run the chosen branch. That works, but isn’t entirely satisfying. By what magic does the JVM itself or a native CPU implementifstatements? Now that we have our own bytecode VM to hack on, we can answer that.
雖然花了一些時間,但我們終於準備好向虛擬機器中新增控制流了。在我們為jlox構建的樹遍歷直譯器中,我們以Java的方式實現了控制流。為了執行Lox的if語句,我們使用Java的if語句來執行所選的分支。這是可行的,但並不是完全令人滿意。JVM本身或原生CPU如何實現if語句呢?現在我們有了自己的位元組碼虛擬機器,我們可以回答這個問題。
When we talk about “control flow”, what are we referring to? By “flow” we mean the way execution moves through the text of the program. Almost like there is a little robot inside the computer wandering through our code, executing bits and pieces here and there. Flow is the path that robot takes, and by controlling the robot, we drive which pieces of code it executes.
當我們談論“控制流”時,我們指的是什麼?我們所說的“流”是指執行過程在程式文字中的移動方式。就好像電腦裡有一個小機器人在我們的程式碼裡遊蕩,在這裡或那裡執行一些零零碎碎的片段。流就是機器人所走的路徑,透過控制機器人,我們驅動它執行某些程式碼片段。
In jlox, the robot’s locus of attention—the current bit of code—was implicit based on which AST nodes were stored in various Java variables and what Java code we were in the middle of running. In clox, it is much more explicit. The VM’s
ipfield stores the address of the current bytecode instruction. The value of that field is exactly “where we are” in the program.
在jlox中,機器人的關注點(當前程式碼位)是隱式的,它取決於哪些AST節點被儲存在各種Java變數中,以及我們正在執行的Java程式碼是什麼。在clox中,它要明確得多。VM的ip欄位儲存了當前位元組碼指令的地址。該欄位的值正是我們在程式中的“位置”。
Execution proceeds normally by incrementing the
ip. But we can mutate that variable however we want to. In order to implement control flow, all that’s necessary is to change theipin more interesting ways. The simplest control flow construct is anifstatement with noelseclause:
執行操作通常是透過增加ip進行的。但是我們可以隨意地改變這個變數。為了實現控制流,所需要做的就是以更有趣的方式改變ip。最簡單的控制流結構是沒有else子句的if語句:
if (condition) print("condition was truthy");
The VM evaluates the bytecode for the condition expression. If the result is truthy, then it continues along and executes the
虛擬機器會計算條件表示式對應的位元組碼。如果結構是真,則繼續執行主體中的print語句。有趣的是當條件為假的時候,這種情況下,執行會跳過then分支並執行下一條語句。
To skip over a chunk of code, we simply set the
ipfield to the address of the bytecode instruction following that code. To conditionally skip over some code, we need an instruction that looks at the value on top of the stack. If it’s falsey, it adds a given offset to theipto jump over a range of instructions. Otherwise, it does nothing and lets execution proceed to the next instruction as usual.
要想跳過一大塊程式碼,我們只需將ip欄位設定為其後程式碼的位元組碼指令的地址。為了有條件地跳過一些程式碼,我們需要一條指令來檢視棧頂的值。如果它是假,就在ip上增加一個給定的偏移量,跳過一系列指令。否則,它什麼也不做,並照常執行下一條指令。
When we compile to bytecode, the explicit nested block structure of the code evaporates, leaving only a flat series of instructions behind. Lox is a structured programming language, but clox bytecode isn’t. The right—or wrong, depending on how you look at it—set of bytecode instructions could jump into the middle of a block, or from one scope into another.
當我們編譯成位元組碼時,程式碼中顯式的巢狀塊結構就消失了,只留下一系列扁平的指令。Lox是一種結構化的程式語言,但clox位元組碼卻不是。正確的(或者說錯誤的,取決於你怎麼看待它)位元組碼指令集可以跳轉到程式碼塊的中間位置,或從一個作用域跳到另一個作用域。
The VM will happily execute that, even if the result leaves the stack in an unknown, inconsistent state. So even though the bytecode is unstructured, we’ll take care to ensure that our compiler only generates clean code that maintains the same structure and nesting that Lox itself does.
虛擬機器會很高興地執行這些指令,即使其結果會導致堆疊處於未知的、不一致的狀態。因此,儘管位元組碼是非結構化的,我們也要確保編譯成只生成與Lox本身保持相同結構和巢狀的乾淨程式碼。
This is exactly how real CPUs behave. Even though we might program them using higher-level languages that mandate structured control flow, the compiler lowers that down to raw jumps. At the bottom, it turns out goto is the only real control flow.
這就是真正的CPU的行為方式。即使我們可能會使用高階語言對它們進行程式設計,這些語言能夠規定格式化控制流,但編譯器也會將其降級為原生跳轉。在底層,事實證明goto是唯一真正的控制流。
Anyway, I didn’t mean to get all philosophical. The important bit is that if we have that one conditional jump instruction, that’s enough to implement Lox’s
ifstatement, as long as it doesn’t have anelseclause. So let’s go ahead and get started with that.
不管這麼說,我並不是故意要搞得這麼哲學化。重要的是,如果我們有一個條件跳轉指令,就足以實現Lox的if語句了,只要它沒有else子句。讓我們開始吧。
23 . 1 If Statements
23.1 If語句
This many chapters in, you know the drill. Any new feature starts in the front end and works its way through the pipeline. An
ifstatement is, well, a statement, so that’s where we hook it into the parser.
這麼多章了,你知道該怎麼做。任何新特性都是從前端開始的,如果沿著管道進行工作。if語句是一個,嗯,語句,所以我們透過語句將它連線到解析器。
compiler.c,在statement()語句中新增程式碼:
if (match(TOKEN_PRINT)) {
printStatement();
// 新增部分開始
} else if (match(TOKEN_IF)) {
ifStatement();
// 新增部分結束
} else if (match(TOKEN_LEFT_BRACE)) {
When we see an
ifkeyword, we hand off compilation to this function:
如果我們看到if關鍵字,就把編譯工作交給這個函式1:
compiler.c,在expressionStatement()方法後新增程式碼:
static void ifStatement() {
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'if'.");
expression();
consume(TOKEN_RIGHT_PAREN, "Expect ')' after condition.");
int thenJump = emitJump(OP_JUMP_IF_FALSE);
statement();
patchJump(thenJump);
}
First we compile the condition expression, bracketed by parentheses. At runtime, that will leave the condition value on top of the stack. We’ll use that to determine whether to execute the then branch or skip it.
首先我們編譯條件表示式(用小括號括起來)。在執行時,這會將條件值留在棧頂。我們將透過它來決定是執行then分支還是跳過它。
Then we emit a new
OP_JUMP_IF_FALSEinstruction. It has an operand for how much to offset theip—how many bytes of code to skip. If the condition is falsey, it adjusts theipby that amount. Something like this:
然後我們生成一個新的OP_JUMP_IF_ELSE指令。這條指令有一個運算元,用來表示ip的偏移量——要跳過多少位元組的程式碼。如果條件是假,它就按這個值調整ip,就像這樣:

But we have a problem. When we’re writing the
OP_JUMP_IF_FALSEinstruction’s operand, how do we know how far to jump? We haven’t compiled the then branch yet, so we don’t know how much bytecode it contains.
但我們有個問題。當我們寫OP_JUMP_IF_FALSE指令的運算元時,我們怎麼知道要跳多遠?我們還沒有編譯then分支,所以我們不知道它包含多少位元組碼。
To fix that, we use a classic trick called backpatching. We emit the jump instruction first with a placeholder offset operand. We keep track of where that half-finished instruction is. Next, we compile the then body. Once that’s done, we know how far to jump. So we go back and replace that placeholder offset with the real one now that we can calculate it. Sort of like sewing a patch onto the existing fabric of the compiled code.
為瞭解決這個問題,我們使用了一個經典的技巧,叫作回填(backpatching)。我們首先生成跳轉指令,並附上一個佔位的偏移量運算元,我們跟蹤這個半成品指令的位置。接下來,我們編譯then主體。一旦完成,我們就知道要跳多遠。所以我們回去將佔位符替換為真正的偏移量,現在我們可以計算它了。這有點像在已編譯程式碼的現有結構上打補丁。

We encode this trick into two helper functions.
我們將這個技巧編碼為兩個輔助函式。
compiler.c,在emitBytes()方法後新增程式碼:
static int emitJump(uint8_t instruction) {
emitByte(instruction);
emitByte(0xff);
emitByte(0xff);
return currentChunk()->count - 2;
}
The first emits a bytecode instruction and writes a placeholder operand for the jump offset. We pass in the opcode as an argument because later we’ll have two different instructions that use this helper. We use two bytes for the jump offset operand. A 16-bit offset lets us jump over up to 65,535 bytes of code, which should be plenty for our needs.
第一個程式會生成一個位元組碼指令,併為跳轉偏移量寫入一個佔位符運算元。我們把操作碼作為引數傳入,因為稍後我們會有兩個不同的指令都使用這個輔助函式。我們使用兩個位元組作為跳轉偏移量的運算元。一個16位的偏移量可以讓我們跳轉65535個位元組的程式碼,這對於我們的需求來說應該足夠了2。
The function returns the offset of the emitted instruction in the chunk. After compiling the then branch, we take that offset and pass it to this:
該函式會返回生成的指令在位元組碼塊中的偏移量。編譯完then分支後,我們將這個偏移量傳遞給這個函式:
compiler.c,在emitConstant()方法後新增程式碼:
static void patchJump(int offset) {
// -2 to adjust for the bytecode for the jump offset itself.
int jump = currentChunk()->count - offset - 2;
if (jump > UINT16_MAX) {
error("Too much code to jump over.");
}
currentChunk()->code[offset] = (jump >> 8) & 0xff;
currentChunk()->code[offset + 1] = jump & 0xff;
}
This goes back into the bytecode and replaces the operand at the given location with the calculated jump offset. We call
patchJump()right before we emit the next instruction that we want the jump to land on, so it uses the current bytecode count to determine how far to jump. In the case of anifstatement, that means right after we compile the then branch and before we compile the next statement.
這個函式會返回到位元組碼中,並將給定位置的運算元替換為計算出的跳轉偏移量。我們在生成下一條希望跳轉的指令之前呼叫patchJump(),因此會使用當前位元組碼計數來確定要跳轉的距離。在if語句的情況下,就是在編譯完then分支之後,並在編譯下一個語句之前。
That’s all we need at compile time. Let’s define the new instruction.
這就是在編譯時需要做的。讓我們來定義新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_PRINT,
// 新增部分開始
OP_JUMP_IF_FALSE,
// 新增部分結束
OP_RETURN,
Over in the VM, we get it working like so:
在虛擬機器中,我們讓它這樣工作:
vm.c,在run()方法中新增程式碼:
break;
}
// 新增部分開始
case OP_JUMP_IF_FALSE: {
uint16_t offset = READ_SHORT();
if (isFalsey(peek(0))) vm.ip += offset;
break;
}
// 新增部分結束
case OP_RETURN: {
This is the first instruction we’ve added that takes a 16-bit operand. To read that from the chunk, we use a new macro.
這是我們新增的第一個需要16位運算元的指令。為了從位元組碼塊中讀出這個指令,需要使用一個新的宏。
vm.c,在run()方法中新增程式碼:
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
// 新增部分開始
#define READ_SHORT() \
(vm.ip += 2, (uint16_t)((vm.ip[-2] << 8) | vm.ip[-1]))
// 新增部分結束
#define READ_STRING() AS_STRING(READ_CONSTANT())
It yanks the next two bytes from the chunk and builds a 16-bit unsigned integer out of them. As usual, we clean up our macro when we’re done with it.
它從位元組碼塊中抽取接下來的兩個位元組,並從中構建出一個16位無符號整數。和往常一樣,當我們結束之後要清理宏。
vm.c,在run()方法中新增程式碼:
#undef READ_BYTE
// 新增部分開始
#undef READ_SHORT
// 新增部分結束
#undef READ_CONSTANT
After reading the offset, we check the condition value on top of the stack. If it’s falsey, we apply this jump offset to the
ip. Otherwise, we leave theipalone and execution will automatically proceed to the next instruction following the jump instruction.
讀取偏移量之後,我們檢查棧頂的條件值。如果是假,我們就將這個跳轉偏移量應用到ip上。否則,我們就保持ip不變,執行會自動進入跳轉指令的下一條指令。
In the case where the condition is falsey, we don’t need to do any other work. We’ve offset the
ip, so when the outer instruction dispatch loop turns again, it will pick up execution at that new instruction, past all of the code in the then branch.
在條件為假的情況下,我們不需要做任何其它工作。我們已經移動了ip,所以當外部指令排程迴圈再次啟動時,將會在新指令處執行,跳過了then分支的所有程式碼3。
Note that the jump instruction doesn’t pop the condition value off the stack. So we aren’t totally done here, since this leaves an extra value floating around on the stack. We’ll clean that up soon. Ignoring that for the moment, we do have a working
ifstatement in Lox now, with only one little instruction required to support it at runtime in the VM.
請注意,跳轉指令並沒有將條件值彈出棧。因此,我們在這裡還沒有全部完成,因為還在堆疊上留下了一個額外的值。我們很快就會把它清理掉。暫時先忽略這個問題,我們現在在Lox中已經有了可用的if語句,只需要一條小指令在虛擬機器執行時支援它。
23 . 1 . 1 Else clauses
23.1.1 Else子句
An
ifstatement without support forelseclauses is like Morticia Addams without Gomez. So, after we compile the then branch, we look for anelsekeyword. If we find one, we compile the else branch.
一個不支援else子句的if語句就像沒有Gomez的Morticia Addams(《亞當斯一家》)。因此,在我們編譯完then分支之後,我們要尋找else關鍵字。如果找到了,則編譯else分支。
compiler.c,在ifStatement()方法中新增程式碼:
patchJump(thenJump);
// 新增部分開始
if (match(TOKEN_ELSE)) statement();
// 新增部分結束
}
When the condition is falsey, we’ll jump over the then branch. If there’s an else branch, the
ipwill land right at the beginning of its code. But that’s not enough, though. Here’s the flow that leads to:
當條件為假時,我們會跳過then分支。如果存在else分支,ip就會出現在其位元組碼的開頭處。但這還不夠。下面是對應的流:

If the condition is truthy, we execute the then branch like we want. But after that, execution rolls right on through into the else branch. Oops! When the condition is true, after we run the then branch, we need to jump over the else branch. That way, in either case, we only execute a single branch, like this:
如果條件是真,則按照要求執行then分支。但在那之後,執行會直接轉入到else分支。糟糕!當條件為真時,執行完then分支後,我們需要跳過else分支。這樣,無論哪種情況,我們都只執行一個分支,像這樣:

To implement that, we need another jump from the end of the then branch.
為了實現這一點,我們需要從then分支的末端再進行一次跳轉。
compiler.c,在ifStatement()方法中新增程式碼:
statement();
// 新增部分開始
int elseJump = emitJump(OP_JUMP);
// 新增部分結束
patchJump(thenJump);
We patch that offset after the end of the else body.
我們在else主體結束後修補這個偏移量。
compiler.c,在ifStatement()方法中新增程式碼:
if (match(TOKEN_ELSE)) statement();
// 新增部分開始
patchJump(elseJump);
// 新增部分結束
}
After executing the then branch, this jumps to the next statement after the else branch. Unlike the other jump, this jump is unconditional. We always take it, so we need another instruction that expresses that.
在執行完then分支後,會跳轉到else分支之後的下一條語句。與其它跳轉不同,這個跳轉是無條件的。我們一定會接受該跳轉,所以我們需要另一條指令來表達它。
chunk.h,在列舉OpCode中新增程式碼:
OP_PRINT,
// 新增部分開始
OP_JUMP,
// 新增部分結束
OP_JUMP_IF_FALSE,
We interpret it like so:
我們這樣來解釋它:
vm.c,在run()方法中新增程式碼:
break;
}
// 新增部分開始
case OP_JUMP: {
uint16_t offset = READ_SHORT();
vm.ip += offset;
break;
}
// 新增部分結束
case OP_JUMP_IF_FALSE: {
Nothing too surprising here—the only difference is that it doesn’t check a condition and always applies the offset.
這裡沒有什麼特別出人意料的——唯一的區別就是它不檢查條件,並且一定會應用偏移量。
We have then and else branches working now, so we’re close. The last bit is to clean up that condition value we left on the stack. Remember, each statement is required to have zero stack effect—after the statement is finished executing, the stack should be as tall as it was before.
我們現在有了then和else分支,所以已經接近完成了。最後一點是清理我們遺留在棧上的條件值。請記住,每個語句都要求是0堆疊效應——在語句執行完畢後,堆疊應該與之前一樣高。
We could have the
OP_JUMP_IF_FALSEinstruction pop the condition itself, but soon we’ll use that same instruction for the logical operators where we don’t want the condition popped. Instead, we’ll have the compiler emit a couple of explicitOP_POPinstructions when compiling anifstatement. We need to take care that every execution path through the generated code pops the condition.
我們可以讓OP_JUMP_IF_FALSE指令自身彈出條件值,但很快我們會對不希望彈出條件值的邏輯運算子使用相同的指令。相對地,我們在編譯if語句時,會讓編譯器生成幾條顯式的OP_POP指令,我們需要注意生成的程式碼中的每一條執行路徑都要彈出條件值。
When the condition is truthy, we pop it right before the code inside the then branch.
當條件為真時,我們會在進入then分支的程式碼前彈出該值。
compiler.c,在ifStatement()方法中新增程式碼:
int thenJump = emitJump(OP_JUMP_IF_FALSE);
// 新增部分開始
emitByte(OP_POP);
// 新增部分結束
statement();
Otherwise, we pop it at the beginning of the else branch.
否則,我們就在else分支的開頭彈出它。
compiler.c,在ifStatement()方法中新增程式碼:
patchJump(thenJump);
// 新增部分開始
emitByte(OP_POP);
// 新增部分結束
if (match(TOKEN_ELSE)) statement();
This little instruction here also means that every
ifstatement has an implicit else branch even if the user didn’t write anelseclause. In the case where they left it off, all the branch does is discard the condition value.
這裡的這個小指令也意味著每個if語句都有一個隱含的else分支,即使使用者沒有寫else子句。在使用者沒有寫else子句的情況下,這個分支所做的就是丟棄條件值。
The full correct flow looks like this:
完整正確的流看起來是這樣的:

If you trace through, you can see that it always executes a single branch and ensures the condition is popped first. All that remains is a little disassembler support.
如果你跟蹤整個過程,可以看到它總是隻執行一個分支,並確保條件值首先被彈出。剩下的就是一點反彙編程式的支援了。
debug.c,在disassembleInstruction()方法中新增程式碼:
return simpleInstruction("OP_PRINT", offset);
// 新增部分開始
case OP_JUMP:
return jumpInstruction("OP_JUMP", 1, chunk, offset);
case OP_JUMP_IF_FALSE:
return jumpInstruction("OP_JUMP_IF_FALSE", 1, chunk, offset);
// 新增部分結束
case OP_RETURN:
These two instructions have a new format with a 16-bit operand, so we add a new utility function to disassemble them.
這兩條指令具有新格式,有著16位的運算元,因此我們添加了一個新的工具函式來反彙編它們。
debug.c,在byteInstruction()方法後新增程式碼:
static int jumpInstruction(const char* name, int sign,
Chunk* chunk, int offset) {
uint16_t jump = (uint16_t)(chunk->code[offset + 1] << 8);
jump |= chunk->code[offset + 2];
printf("%-16s %4d -> %d\n", name, offset,
offset + 3 + sign * jump);
return offset + 3;
}
There we go, that’s one complete control flow construct. If this were an ’80s movie, the montage music would kick in and the rest of the control flow syntax would take care of itself. Alas, the ’80s are long over, so we’ll have to grind it out ourselves.
就這樣,這就是一個完整的控制流結構。如果這是一部80年代的電影,蒙太奇音樂就該響起了,剩下的控制流語法就會自行完成。唉,80年代已經過去很久了,所以我們得自己打磨了。
23 . 2 Logical Operators
23.2 邏輯運算子
You probably remember this from jlox, but the logical operators
andandoraren’t just another pair of binary operators like+and-. Because they short-circuit and may not evaluate their right operand depending on the value of the left one, they work more like control flow expressions.
你可能還記得jlox中的實現,但是邏輯運算子and和or並不僅僅是另一對像+和-一樣的二元運算子。因為它們是短路的,根據左運算元的值,有可能不會對右運算元求值,它們的工作方式 更像是控制流表示式。
They’re basically a little variation on an
ifstatement with anelseclause. The easiest way to explain them is to just show you the compiler code and the control flow it produces in the resulting bytecode. Starting withand, we hook it into the expression parsing table here:
它們基本上是帶有else子句的if語句的小變體。解釋它們的最簡單的方法是向你展示編譯器程式碼以及它在位元組碼中生成的控制流。從and開始,我們把它掛接到表示式解析表中:
compiler.c,替換1行:
[TOKEN_NUMBER] = {number, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_AND] = {NULL, and_, PREC_AND},
// 替換部分結束
[TOKEN_CLASS] = {NULL, NULL, PREC_NONE},
That hands off to a new parser function.
這就交給了一個新的解析器函式。
compiler.c,在defineVariable()方法後新增程式碼:
static void and_(bool canAssign) {
int endJump = emitJump(OP_JUMP_IF_FALSE);
emitByte(OP_POP);
parsePrecedence(PREC_AND);
patchJump(endJump);
}
At the point this is called, the left-hand side expression has already been compiled. That means at runtime, its value will be on top of the stack. If that value is falsey, then we know the entire
andmust be false, so we skip the right operand and leave the left-hand side value as the result of the entire expression. Otherwise, we discard the left-hand value and evaluate the right operand which becomes the result of the wholeandexpression.
在這個方法被呼叫時,左側的表示式已經被編譯了。這意味著,在執行時,它的值將會在棧頂。如果這個值為假,我們就知道整個and表示式的結果一定是假,所以我們跳過右邊的運算元,將左邊的值作為整個表示式的結果。否則,我們就丟棄左值,計算右運算元,並將它作為整個and表示式的結果。
Those four lines of code right there produce exactly that. The flow looks like this:
這四行程式碼正是產生這樣的結果。流程看起來像這樣:

Now you can see why
OP_JUMP_IF_FALSEleaves the value on top of the stack. When the left-hand side of theandis falsey, that value sticks around to become the result of the entire expression.
現在你可以看到為什麼OP_JUMP_IF_FALSE要將值留在棧頂。當and左側的值為假時,這個值會保留下來,成為整個表示式的結果4。
23 . 2 . 1 Logical or operator
23.2.1 邏輯or運算子
The
oroperator is a little more complex. First we add it to the parse table.
or運算子有點複雜。首先,我們將它新增到解析表中。
compiler.c,替換1行:
[TOKEN_NIL] = {literal, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_OR] = {NULL, or_, PREC_OR},
// 替換部分結束
[TOKEN_PRINT] = {NULL, NULL, PREC_NONE},
When that parser consumes an infix
ortoken, it calls this:
當解析器處理中綴or標識時,會呼叫這個:
compiler.c,在number()方法後新增程式碼:
static void or_(bool canAssign) {
int elseJump = emitJump(OP_JUMP_IF_FALSE);
int endJump = emitJump(OP_JUMP);
patchJump(elseJump);
emitByte(OP_POP);
parsePrecedence(PREC_OR);
patchJump(endJump);
}
In an
orexpression, if the left-hand side is truthy, then we skip over the right operand. Thus we need to jump when a value is truthy. We could add a separate instruction, but just to show how our compiler is free to map the language’s semantics to whatever instruction sequence it wants, I implemented it in terms of the jump instructions we already have.
在or表示式中,如果左側值為真,那麼我們就跳過右側的運算元。因此,當值為真時,我們需要跳過。我們可以新增一條單獨的指令,但為了說明編譯器如何自由地將語言的語義對映為它想要的任何指令序列,我會使用已有的跳轉指令來實現它。
When the left-hand side is falsey, it does a tiny jump over the next statement. That statement is an unconditional jump over the code for the right operand. This little dance effectively does a jump when the value is truthy. The flow looks like this:
當左側值為假時,它會做一個小跳躍,跳過下一條語句。該語句會無條件跳過右側運算元的程式碼。當值為真時,就會進行該跳轉。流程看起來是這樣的:

If I’m honest with you, this isn’t the best way to do this. There are more instructions to dispatch and more overhead. There’s no good reason why
orshould be slower thanand. But it is kind of fun to see that it’s possible to implement both operators without adding any new instructions. Forgive me my indulgences.
說實話,這並不是最好的方法。(這種方式中)需要排程的指令更多,開銷也更大。沒有充足的理由說明為什麼or要比and慢。但是,可以在不增加任何新指令的前提下實現兩個運算子,這是有趣的。請原諒我的放縱。
OK, those are the three branching constructs in Lox. By that, I mean, these are the control flow features that only jump forward over code. Other languages often have some kind of multi-way branching statement like
switchand maybe a conditional expression like?:, but Lox keeps it simple.
好了,這就是Lox中的三個分支結構。我的意思是,這些控制流特性只能在程式碼上向前跳轉。其它語言中通常有某種多路分支語句,如switch,也許還有條件表示式?:,但Lox保持簡單。
23 . 3 While Statements
23.3 While語句
That takes us to the looping statements, which jump backward so that code can be executed more than once. Lox only has two loop constructs,
whileandfor. Awhileloop is (much) simpler, so we start the party there.
這就將我們帶到了迴圈語句,迴圈語句會向後跳轉,使程式碼可以多次執行。Lox只有兩種迴圈結構while和for。while迴圈要簡單(得多),所以我們從這裡開始。
compiler.c,在statement()方法中新增程式碼:
ifStatement();
// 新增部分開始
} else if (match(TOKEN_WHILE)) {
whileStatement();
// 新增部分結束
} else if (match(TOKEN_LEFT_BRACE)) {
When we reach a
whiletoken, we call:
當我們遇到while標識時,呼叫:
compiler.c,在printStatement()方法後新增程式碼:
static void whileStatement() {
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'while'.");
expression();
consume(TOKEN_RIGHT_PAREN, "Expect ')' after condition.");
int exitJump = emitJump(OP_JUMP_IF_FALSE);
emitByte(OP_POP);
statement();
patchJump(exitJump);
emitByte(OP_POP);
}
Most of this mirrors
ifstatements—we compile the condition expression, surrounded by mandatory parentheses. That’s followed by a jump instruction that skips over the subsequent body statement if the condition is falsey.
大部分跟if語句相似——我們編譯條件表示式(強制用括號括起來)。之後是一個跳轉指令,如果條件為假,會跳過後續的主體語句。
We patch the jump after compiling the body and take care to pop the condition value from the stack on either path. The only difference from an
ifstatement is the loop. That looks like this:
我們在編譯完主體之後對跳轉指令進行修補,並注意在每個執行路徑上都要彈出棧頂的條件值。與if語句的唯一區別就是迴圈5。看起來像這樣:
compiler.c,在whileStatement()方法中新增程式碼:
statement();
// 新增部分開始
emitLoop(loopStart);
// 新增部分結束
patchJump(exitJump);
After the body, we call this function to emit a “loop” instruction. That instruction needs to know how far back to jump. When jumping forward, we had to emit the instruction in two stages since we didn’t know how far we were going to jump until after we emitted the jump instruction. We don’t have that problem now. We’ve already compiled the point in code that we want to jump back to—it’s right before the condition expression.
在主體之後,我們呼叫這個函式來生成一個“迴圈”指令。該指令需要知道往回跳多遠。當向前跳時,我們必須分兩個階段發出指令,因為在發出跳躍指令前,我們不知道要跳多遠。現在我們沒有這個問題了。我們已經編譯了要跳回去的程式碼位置——就在條件表示式之前。
All we need to do is capture that location as we compile it.
我們所需要做的就是在編譯時捕獲這個位置。
compiler.c,在whileStatement()方法中新增程式碼:
static void whileStatement() {
// 新增部分開始
int loopStart = currentChunk()->count;
// 新增部分結束
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'while'.");
After executing the body of a
whileloop, we jump all the way back to before the condition. That way, we re-evaluate the condition expression on each iteration. We store the chunk’s current instruction count inloopStartto record the offset in the bytecode right before the condition expression we’re about to compile. Then we pass that into this helper function:
在執行完while迴圈後,我們會一直跳到條件表示式之前。這樣,我們就可以在每次迭代時都重新對條件表示式求值。我們在loopStar中儲存位元組碼塊中當前的指令數,作為我們即將編譯的條件表示式在位元組碼中的偏移量。然後我們將該值傳給這個輔助函式:
compiler.c,在emitBytes()方法後新增程式碼:
static void emitLoop(int loopStart) {
emitByte(OP_LOOP);
int offset = currentChunk()->count - loopStart + 2;
if (offset > UINT16_MAX) error("Loop body too large.");
emitByte((offset >> 8) & 0xff);
emitByte(offset & 0xff);
}
It’s a bit like
emitJump()andpatchJump()combined. It emits a new loop instruction, which unconditionally jumps backwards by a given offset. Like the jump instructions, after that we have a 16-bit operand. We calculate the offset from the instruction we’re currently at to theloopStartpoint that we want to jump back to. The+ 2is to take into account the size of theOP_LOOPinstruction’s own operands which we also need to jump over.
這有點像emitJump()和patchJump() 的結合。它生成一條新的迴圈指令,該指令會無條件地向回跳轉給定的偏移量。和跳轉指令一樣,其後還有一個16位的運算元。我們計算當前指令到我們想要跳回的loopStart之間的偏移量。+2是考慮到了OP_LOOP指令自身運算元的大小,這個運算元我們也需要跳過。
From the VM’s perspective, there really is no semantic difference between
OP_LOOPandOP_JUMP. Both just add an offset to theip. We could have used a single instruction for both and given it a signed offset operand. But I figured it was a little easier to sidestep the annoying bit twiddling required to manually pack a signed 16-bit integer into two bytes, and we’ve got the opcode space available, so why not use it?
從虛擬機器的角度看,OP_LOOP 和OP_JUMP之間實際上沒有語義上的區別。兩者都只是在ip上加了一個偏移量。我們本可以用一條指令來處理這兩者,並給該指令傳入一個有符號的偏移量運算元。但我認為,這樣做更容易避免手動將一個有符號的16位整數打包到兩個位元組所需要的煩人的位操作,況且我們有可用的操作碼空間,為什麼不使用呢?
The new instruction is here:
新指令如下:
chunk.h,在列舉OpCode中新增程式碼:
OP_JUMP_IF_FALSE,
// 新增部分開始
OP_LOOP,
// 新增部分結束
OP_RETURN,
And in the VM, we implement it thusly:
在虛擬機器中,我們這樣實現它:
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_LOOP: {
uint16_t offset = READ_SHORT();
vm.ip -= offset;
break;
}
// 新增部分結束
case OP_RETURN: {
The only difference from
OP_JUMPis a subtraction instead of an addition. Disassembly is similar too.
與OP_JUMP唯一的區別就是這裡使用了減法而不是加法。反彙編也是相似的。
debug.c,在disassembleInstruction()方法中新增程式碼:
return jumpInstruction("OP_JUMP_IF_FALSE", 1, chunk, offset);
// 新增部分開始
case OP_LOOP:
return jumpInstruction("OP_LOOP", -1, chunk, offset);
// 新增部分結束
case OP_RETURN:
That’s our
whilestatement. It contains two jumps—a conditional forward one to escape the loop when the condition is not met, and an unconditional loop backward after we have executed the body. The flow looks like this:
這就是我們的while語句。它包含兩個跳轉——一個是有條件的前向跳轉,用於在不滿足條件的時候退出迴圈;另一個是在執行完主體程式碼後的無條件跳轉。流程看起來如下:

23 . 4 For Statements
23.4 For語句
The other looping statement in Lox is the venerable
forloop, inherited from C. It’s got a lot more going on with it compared to awhileloop. It has three clauses, all of which are optional:
Lox中的另一個迴圈語句是古老的for迴圈,繼承自C語言。與while迴圈相比,它有著更多的功能。它有三個子句,都是可選的:
- The initializer can be a variable declaration or an expression. It runs once at the beginning of the statement.
- The condition clause is an expression. Like in a
whileloop, we exit the loop when it evaluates to something falsey.- The increment expression runs once at the end of each loop iteration.
- 初始化器可以是一個變數宣告或一個表示式。它會在整個語句的開頭執行一次。
- 條件子句是一個表示式。就像
while迴圈一樣,如果其計算結果為假,就退出迴圈。 - 增量表達式在每次迴圈迭代結束時執行一次。
In jlox, the parser desugared a
forloop to a synthesized AST for awhileloop with some extra stuff before it and at the end of the body. We’ll do something similar, though we won’t go through anything like an AST. Instead, our bytecode compiler will use the jump and loop instructions we already have.
在jlox中,解析器將for迴圈解構為一個while迴圈與其主體前後的一些額外內容的合成AST。我們會做一些類似的事情,不過我們不會使用AST之類的東西。相反,我們的位元組碼編譯器將使用我們已有的跳轉和迴圈指令。
We’ll work our way through the implementation a piece at a time, starting with the
forkeyword.
我們將從for關鍵字開始,逐步完成整個實現。
compiler.c,在statement()方法中新增程式碼:
printStatement();
// 新增部分開始
} else if (match(TOKEN_FOR)) {
forStatement();
// 新增部分結束
} else if (match(TOKEN_IF)) {
It calls a helper function. If we only supported
forloops with empty clauses likefor (;;), then we could implement it like this:
它會呼叫一個輔助函式。如果我們只支援for(;;)這樣帶有空子句的for迴圈,那麼我們可以這樣實現它:
compiler.c,在expressionStatement()方法後新增程式碼:
static void forStatement() {
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'for'.");
consume(TOKEN_SEMICOLON, "Expect ';'.");
int loopStart = currentChunk()->count;
consume(TOKEN_SEMICOLON, "Expect ';'.");
consume(TOKEN_RIGHT_PAREN, "Expect ')' after for clauses.");
statement();
emitLoop(loopStart);
}
There’s a bunch of mandatory punctuation at the top. Then we compile the body. Like we did for
whileloops, we record the bytecode offset at the top of the body and emit a loop to jump back to that point after it. We’ve got a working implementation of infinite loops now.
首先是一堆強制性的標點符號。然後我們編譯主體。與while迴圈一樣,我們在主體的頂部記錄位元組碼的偏移量,並在之後生成一個迴圈指令跳回該位置。現在我們已經有了一個無限迴圈的有效實現。
23 . 4 . 1 Initializer clause
23.4.1 初始化子句
Now we’ll add the first clause, the initializer. It executes only once, before the body, so compiling is straightforward.
現在我們要新增第一個子句,初始化器。它只在主體之前執行一次,因此編譯很簡單。
compiler.c,在forStatement()方法中替換1行:
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'for'.");
// 替換部分開始
if (match(TOKEN_SEMICOLON)) {
// No initializer.
} else if (match(TOKEN_VAR)) {
varDeclaration();
} else {
expressionStatement();
}
// 替換部分結束
int loopStart = currentChunk()->count;
The syntax is a little complex since we allow either a variable declaration or an expression. We use the presence of the
varkeyword to tell which we have. For the expression case, we callexpressionStatement()instead ofexpression(). That looks for a semicolon, which we need here too, and also emits anOP_POPinstruction to discard the value. We don’t want the initializer to leave anything on the stack.
語法有點複雜,因為我們允許出現變數宣告或表示式。我們透過是否存在var關鍵字來判斷是哪種型別。對於表示式,我們呼叫expressionStatement()而不是expression()。它會查詢分號(我們這裡也需要一個分號),並生成一個OP_POP指令來丟棄表示式的值。我們不希望初始化器在堆疊中留下任何東西。
If a
forstatement declares a variable, that variable should be scoped to the loop body. We ensure that by wrapping the whole statement in a scope.
如果for語句宣告瞭一個變數,那麼該變數的作用域應該限制在迴圈體中。我們透過將整個語句包裝在一個作用域中來確保這一點。
compiler.c,在forStatement()方法中新增程式碼:
static void forStatement() {
// 新增部分開始
beginScope();
// 新增部分結束
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'for'.");
Then we close it at the end.
然後我們在結尾關閉這個作用域。
compiler.c,在forStatement()方法中新增程式碼:
emitLoop(loopStart);
// 新增部分開始
endScope();
// 新增部分結束
}
23 . 4 . 2 Condition clause
23.4.2 條件子句
Next, is the condition expression that can be used to exit the loop.
接下來,是可以用來退出迴圈的條件表示式。
compiler.c,在forStatement()方法中替換1行:
int loopStart = currentChunk()->count;
// 替換部分開始
int exitJump = -1;
if (!match(TOKEN_SEMICOLON)) {
expression();
consume(TOKEN_SEMICOLON, "Expect ';' after loop condition.");
// Jump out of the loop if the condition is false.
exitJump = emitJump(OP_JUMP_IF_FALSE);
emitByte(OP_POP); // Condition.
}
// 替換部分結束
consume(TOKEN_RIGHT_PAREN, "Expect ')' after for clauses.");
Since the clause is optional, we need to see if it’s actually present. If the clause is omitted, the next token must be a semicolon, so we look for that to tell. If there isn’t a semicolon, there must be a condition expression.
因為子句是可選的,我們需要檢視它是否存在。如果子句被省略,下一個標識一定是分號,所以我們透過查詢分號來進行判斷。如果沒有分號,就一定有一個條件表示式。
In that case, we compile it. Then, just like with while, we emit a conditional jump that exits the loop if the condition is falsey. Since the jump leaves the value on the stack, we pop it before executing the body. That ensures we discard the value when the condition is true.
在這種情況下,我們對它進行編譯。然後,就像while一樣,我們生成一個條件跳轉指令,如果條件為假則退出迴圈。因為跳轉指令將值留在了棧上,我們在執行主體之前將值彈出。這樣可以確保當條件值為真時,我們會丟棄這個值。
After the loop body, we need to patch that jump.
在迴圈主體之後,我們需要修補跳轉指令。
compiler.c,在forStatement()方法中新增程式碼:
emitLoop(loopStart);
// 新增部分開始
if (exitJump != -1) {
patchJump(exitJump);
emitByte(OP_POP); // Condition.
}
// 新增部分結束
endScope();
}
We do this only when there is a condition clause. If there isn’t, there’s no jump to patch and no condition value on the stack to pop.
我們只在有條件子句的時候才會這樣做。如果沒有條件子句,就沒有需要修補的跳轉指令,堆疊中也沒有條件值需要彈出。
23 . 4 . 3 Increment clause
23.4.3 增量子句
I’ve saved the best for last, the increment clause. It’s pretty convoluted. It appears textually before the body, but executes after it. If we parsed to an AST and generated code in a separate pass, we could simply traverse into and compile the
forstatement AST’s body field before its increment clause.
我把非常複雜的增量子句部分留到最後。從文字上看,它出現在迴圈主體之前,但卻是在主體之後執行。如果我們將其解析為AST,並在單獨的處理過程中生成程式碼,就可以簡單地遍歷並編譯for語句AST的主體欄位,然後再編譯其增量子句。
Unfortunately, we can’t compile the increment clause later, since our compiler only makes a single pass over the code. Instead, we’ll jump over the increment, run the body, jump back up to the increment, run it, and then go to the next iteration.
不幸的是,我們不能稍後再編譯增量子句,因為我們的編譯器只對程式碼做了一次遍歷。相對地,我們會跳過增量子句,執行主體,跳回增量子句,執行它,然後進入下一個迭代。
I know, a little weird, but hey, it beats manually managing ASTs in memory in C, right? Here’s the code:
我知道,這有點奇怪,但是,這總比在C語言中手動管理記憶體中的AST要好,對嗎?程式碼如下:
compiler.c,在forStatement()方法中替換1行:
}
// 替換部分開始
if (!match(TOKEN_RIGHT_PAREN)) {
int bodyJump = emitJump(OP_JUMP);
int incrementStart = currentChunk()->count;
expression();
emitByte(OP_POP);
consume(TOKEN_RIGHT_PAREN, "Expect ')' after for clauses.");
emitLoop(loopStart);
loopStart = incrementStart;
patchJump(bodyJump);
}
// 替換部分結束
statement();
Again, it’s optional. Since this is the last clause, when omitted, the next token will be the closing parenthesis. When an increment is present, we need to compile it now, but it shouldn’t execute yet. So, first, we emit an unconditional jump that hops over the increment clause’s code to the body of the loop.
同樣,它也是可選的。因為這是最後一個子句,下一個標識是右括號。當存在增加子句時,我們需要立即編譯它,但是它還不應該執行。因此,首先我們生成一個無條件跳轉指令,該指令會跳過增量子句的程式碼進入迴圈體中。
Next, we compile the increment expression itself. This is usually an assignment. Whatever it is, we only execute it for its side effect, so we also emit a pop to discard its value.
接下來,我們編譯增量表達式本身。這通常是一個賦值語句。不管它是什麼,我們執行它只是為了它的副作用,所以我們也生成一個彈出指令丟棄該值。
The last part is a little tricky. First, we emit a loop instruction. This is the main loop that takes us back to the top of the
forloop—right before the condition expression if there is one. That loop happens right after the increment, since the increment executes at the end of each loop iteration.
最後一部分有點棘手。首先,我們生成一個迴圈指令。這是主迴圈,會將我們帶到for迴圈的頂部——如果有條件表示式的話,就回在它前面。這個迴圈發生在增量語句之後,因此增量語句是在每次迴圈迭代結束時執行的。
Then we change
loopStartto point to the offset where the increment expression begins. Later, when we emit the loop instruction after the body statement, this will cause it to jump up to the increment expression instead of the top of the loop like it does when there is no increment. This is how we weave the increment in to run after the body.
然後我們更改loopStart,指向增量表達式開始處的偏移量。之後,當我們在主體語句結束之後生成迴圈指令時,就會跳轉到增量表達式,而不是像沒有增量表達式時那樣跳轉到迴圈頂部。這就是我們如何在主體之後執行增量子句的辦法。
It’s convoluted, but it all works out. A complete loop with all the clauses compiles to a flow like this:
這很複雜,但一切都解決了。一個包含所有子句的完整迴圈會被編譯為類似這樣的流程:

As with implementing
forloops in jlox, we didn’t need to touch the runtime. It all gets compiled down to primitive control flow operations the VM already supports. In this chapter, we’ve taken a big leap forward—clox is now Turing complete. We’ve also covered quite a bit of new syntax: three statements and two expression forms. Even so, it only took three new simple instructions. That’s a pretty good effort-to-reward ratio for the architecture of our VM.
與jlox中實現for迴圈一樣,我們不需要接觸執行時。所有這些都被編譯到虛擬機器已經支援的原始控制流中。在這一章中,我們向前邁出了一大步——clox現在圖靈完整了。我們還討論了相當多的新語法:三種語句和兩種表示式形式。即便如此,我們也只用了三個簡單的新指令。對於我們的虛擬機器架構來說,這是一個相當不錯的努力-回報比。
習題
-
In addition to
ifstatements, most C-family languages have a multi-wayswitchstatement. Add one to clox. The grammar is:除了
if語句,大多數C家族語言都要一個多路switch語句。在clox中新增一個。語法如下:switchStmt → "switch" "(" expression ")" "{" switchCase* defaultCase? "}" ; switchCase → "case" expression ":" statement* ; defaultCase → "default" ":" statement* ;To execute a
switchstatement, first evaluate the parenthesized switch value expression. Then walk the cases. For each case, evaluate its value expression. If the case value is equal to the switch value, execute the statements under the case and then exit theswitchstatement. Otherwise, try the next case. If no case matches and there is adefaultclause, execute its statements.To keep things simpler, we’re omitting fallthrough and
breakstatements. Each case automatically jumps to the end of the switch statement after its statements are done.為了執行
switch語句,首先要計算括號內的switch值表示式。然後遍歷分支。對於每個分支,計算其值表示式。如果case值等於switch值,就執行case下的語句,然後退出switch語句。否則,就嘗試下一個case分支。如果沒有匹配的分支,並且有default子句,就執行其中的語句。為了讓事情更簡單,我們省略了fall through和
break語句。每個case子句在其語句完成後會自動跳轉到switch語句的結尾。 -
In jlox, we had a challenge to add support for
breakstatements. This time, let’s docontinue:在jlox中,我們有一個習題是新增對
break語句的支援。這一次,我們來做continue:continueStmt → "continue" ";" ;A
continuestatement jumps directly to the top of the nearest enclosing loop, skipping the rest of the loop body. Inside aforloop, acontinuejumps to the increment clause, if there is one. It’s a compile-time error to have acontinuestatement not enclosed in a loop.Make sure to think about scope. What should happen to local variables declared inside the body of the loop or in blocks nested inside the loop when a
continueis executed?continue語句直接跳轉到最內層的封閉迴圈的頂部,跳過迴圈體的其餘部分。在for迴圈中,如果有增量子句,continue會跳到增量子句。如果continue子句沒有被包含在迴圈中,則是一個編譯時錯誤。一定要考慮作用域問題。當執行
continue語句時,在迴圈體內或巢狀在迴圈體中的程式碼塊內宣告的區域性變數應該如何處理? -
Control flow constructs have been mostly unchanged since Algol 68. Language evolution since then has focused on making code more declarative and high level, so imperative control flow hasn’t gotten much attention.
For fun, try to invent a useful novel control flow feature for Lox. It can be a refinement of an existing form or something entirely new. In practice, it’s hard to come up with something useful enough at this low expressiveness level to outweigh the cost of forcing a user to learn an unfamiliar notation and behavior, but it’s a good chance to practice your design skills.
自Algol 68以來,控制流結構基本沒有變化。從那時起,語言的發展就專注於使程式碼更具有宣告性和高層次,因此命令式控制流並沒有得到太多的關注。
為了好玩,可以試著為Lox發明一個有用的新的控制流功能。它可以是現有形式的改進,也可以是全新的東西。實踐中,在這種較低的表達層次上,很難想出足夠有用的東西來抵消迫使使用者學習不熟悉的符號和行為的代價,但這是一個練習設計技能的好機會。
DESIGN NOTE: CONSIDERING GOTO HARMFUL
設計筆記:認為GOTO有害
Discovering that all of our beautiful structured control flow in Lox is actually compiled to raw unstructured jumps is like the moment in Scooby Doo when the monster rips the mask off their face. It was goto all along! Except in this case, the monster is under the mask. We all know goto is evil. But . . . why?
It is true that you can write outrageously unmaintainable code using goto. But I don’t think most programmers around today have seen that first hand. It’s been a long time since that style was common. These days, it’s a boogie man we invoke in scary stories around the campfire.
The reason we rarely confront that monster in person is because Edsger Dijkstra slayed it with his famous letter “Go To Statement Considered Harmful”, published in Communications of the ACM (March, 1968). Debate around structured programming had been fierce for some time with adherents on both sides, but I think Dijkstra deserves the most credit for effectively ending it. Most new languages today have no unstructured jump statements.
A one-and-a-half page letter that almost single-handedly destroyed a language feature must be pretty impressive stuff. If you haven’t read it, I encourage you to do so. It’s a seminal piece of computer science lore, one of our tribe’s ancestral songs. Also, it’s a nice, short bit of practice for reading academic CS writing, which is a useful skill to develop.
That is, if you can get past Dijkstra’s insufferable faux-modest self-aggrandizing writing style:
More recently I discovered why the use of the go to statement has such disastrous effects. . . . At that time I did not attach too much importance to this discovery; I now submit my considerations for publication because in very recent discussions in which the subject turned up, I have been urged to do so.
Ah, yet another one of my many discoveries. I couldn’t even be bothered to write it up until the clamoring masses begged me to.
I’ve read it through a number of times, along with a few critiques, responses, and commentaries. I ended up with mixed feelings, at best. At a very high level, I’m with him. His general argument is something like this:
- As programmers, we write programs—static text—but what we care about is the actual running program—its dynamic behavior.
- We’re better at reasoning about static things than dynamic things. (He doesn’t provide any evidence to support this claim, but I accept it.)
- Thus, the more we can make the dynamic execution of the program reflect its textual structure, the better.
This is a good start. Drawing our attention to the separation between the code we write and the code as it runs inside the machine is an interesting insight. Then he tries to define a “correspondence” between program text and execution. For someone who spent literally his entire career advocating greater rigor in programming, his definition is pretty hand-wavey. He says:
Let us now consider how we can characterize the progress of a process. (You may think about this question in a very concrete manner: suppose that a process, considered as a time succession of actions, is stopped after an arbitrary action, what data do we have to fix in order that we can redo the process until the very same point?)
Imagine it like this. You have two computers with the same program running on the exact same inputs—so totally deterministic. You pause one of them at an arbitrary point in its execution. What data would you need to send to the other computer to be able to stop it exactly as far along as the first one was?
If your program allows only simple statements like assignment, it’s easy. You just need to know the point after the last statement you executed. Basically a breakpoint, the
ipin our VM, or the line number in an error message. Adding branching control flow likeifandswitchdoesn’t add any more to this. Even if the marker points inside a branch, we can still tell where we are.Once you add function calls, you need something more. You could have paused the first computer in the middle of a function, but that function may be called from multiple places. To pause the second machine at exactly the same point in the entire program’s execution, you need to pause it on the right call to that function.
So you need to know not just the current statement, but, for function calls that haven’t returned yet, you need to know the locations of the callsites. In other words, a call stack, though I don’t think that term existed when Dijkstra wrote this. Groovy.
He notes that loops make things harder. If you pause in the middle of a loop body, you don’t know how many iterations have run. So he says you also need to keep an iteration count. And, since loops can nest, you need a stack of those (presumably interleaved with the call stack pointers since you can be in loops in outer calls too).
This is where it gets weird. So we’re really building to something now, and you expect him to explain how goto breaks all of this. Instead, he just says:
The unbridled use of the go to statement has an immediate consequence that it becomes terribly hard to find a meaningful set of coordinates in which to describe the process progress.
He doesn’t prove that this is hard, or say why. He just says it. He does say that one approach is unsatisfactory:
With the go to statement one can, of course, still describe the progress uniquely by a counter counting the number of actions performed since program start (viz. a kind of normalized clock). The difficulty is that such a coordinate, although unique, is utterly unhelpful.
But . . . that’s effectively what loop counters do, and he was fine with those. It’s not like every loop is a simple “for every integer from 0 to 10” incrementing count. Many are
whileloops with complex conditionals.Taking an example close to home, consider the core bytecode execution loop at the heart of clox. Dijkstra argues that that loop is tractable because we can simply count how many times the loop has run to reason about its progress. But that loop runs once for each executed instruction in some user’s compiled Lox program. Does knowing that it executed 6,201 bytecode instructions really tell us VM maintainers anything edifying about the state of the interpreter?
In fact, this particular example points to a deeper truth. Böhm and Jacopini proved that any control flow using goto can be transformed into one using just sequencing, loops, and branches. Our bytecode interpreter loop is a living example of that proof: it implements the unstructured control flow of the clox bytecode instruction set without using any gotos itself.
That seems to offer a counter-argument to Dijkstra’s claim: you can define a correspondence for a program using gotos by transforming it to one that doesn’t and then use the correspondence from that program, which—according to him—is acceptable because it uses only branches and loops.
But, honestly, my argument here is also weak. I think both of us are basically doing pretend math and using fake logic to make what should be an empirical, human-centered argument. Dijkstra is right that some code using goto is really bad. Much of that could and should be turned into clearer code by using structured control flow.
By eliminating goto completely from languages, you’re definitely prevented from writing bad code using gotos. It may be that forcing users to use structured control flow and making it an uphill battle to write goto-like code using those constructs is a net win for all of our productivity.
But I do wonder sometimes if we threw out the baby with the bathwater. In the absence of goto, we often resort to more complex structured patterns. The “switch inside a loop” is a classic one. Another is using a guard variable to exit out of a series of nested loops:
// See if the matrix contains a zero. bool found = false; for (int x = 0; x < xSize; x++) { for (int y = 0; y < ySize; y++) { for (int z = 0; z < zSize; z++) { if (matrix[x][y][z] == 0) { printf("found"); found = true; break; } } if (found) break; } if (found) break; }Is that really better than:
for (int x = 0; x < xSize; x++) { for (int y = 0; y < ySize; y++) { for (int z = 0; z < zSize; z++) { if (matrix[x][y][z] == 0) { printf("found"); goto done; } } } } done:You could do this without
breakstatements—themselves a limited goto-ish construct—by inserting!found &&at the beginning of the condition clause of each loop.I guess what I really don’t like is that we’re making language design and engineering decisions today based on fear. Few people today have any subtle understanding of the problems and benefits of goto. Instead, we just think it’s “considered harmful”. Personally, I’ve never found dogma a good starting place for quality creative work.
發現我們在Lox中的所有漂亮的結構化控制流實際上都被編譯成原始的非結構化跳轉,就像《Scooby Doo》中怪獸撕下臉上的面具一樣。一直以來都是goto!只不過這一次,怪物藏在面具下。我們都知道goto是魔鬼。但是……為什麼呢?
的確,你可以用goto編寫極度難以維護的程式碼。但我認為現在的大多數程式設計師都沒有親身經歷過這種情況。這種風格已經很久沒有出現了。如今,它只是我們在篝火旁的恐怖故事裡會提到的一個惡棍。
我們之所以很少親自面對這個怪物,是因為Edsger Dijkstra用他那封著名的信件“Go To Statement Considered Harmful”殺死了它,這封信發表在《ACM通訊》(1968年3月刊)上。彼時圍繞結構化程式設計的爭論已經激烈了一段時間,雙方都有支持者,但我認為Dijkstra最突出的貢獻就是有效地結束了爭論。今天的大多數新語言都沒有非結構化的跳轉語句。
一封一頁半的信,幾乎以一己之力摧毀了一種語言特性,這一定是相當令人印象深刻的東西。如果你還沒有讀過,我鼓勵你讀一下。它是電腦科學知識的開山之作,是我們部落的祖傳歌曲之一。同時,它也是閱讀學術性CS文章的一個很好的、簡短的練習,這是一個很有用的技能。
【也就是說,你是否能克服Dijkstra那令人難以忍受的虛偽謙虛、自我吹噓的寫作風格:
最近,我發現了為什麼goto語句是使用會產生災難性的影響。……當時我並沒有太重視這個發現;現在我把我的想法提交出來進行發表,是因為在最近關於這個問題的討論中,有人敦促我這樣做。
嗯,這是我眾多發現中的又一項。我甚至懶得把它寫下來,都是吵吵嚷嚷的群眾求我寫。】
我把它讀了好幾遍,還有一些批評、回覆和評論。我最後的感受充其量是喜憂參半。在很高的層次上來說,我是支援他的。他的總體論點是這樣的:
- 作為程式設計師,我們編寫程式——靜態文字——但我們關心的是實際執行的程式——它的動態行為。
- 相比之下,我們更擅長對靜態事物進行推理,而不是動態事物。(他沒有提供任何證據來支援這一說法,但我接受這個說法)
- 因此,我們越能使程式的動態執行反映其文字結構,就越好。
這是一個良好的開端。讓我們注意到編寫的程式碼和機器內部執行的程式碼之間的分離是一個有趣的見解。然後,他試圖在程式文字和執行之間定義一種“對應關係”。對於一個幾乎在整個職業生涯中都倡導更嚴格的程式設計的人來說,他的定義是相當簡單的。他說:
現在讓我們考慮一下,如何能夠描述一個過程的進展。(你可以用一種非常具體的方式來思考這個問題:假設一個過程,被看做是一系列操作的時間序列,在一個任意的操作之後停止,我們必須要固定哪些資料,才能重做整個過程,並達到完全相同的點)
想象一下這樣的情況,你有兩臺計算機,在完全相同的輸入上執行相同的程式,所以這是完全確定性的。在執行過程中,你可以在任意點暫停其中一個函式。你需要向另一臺計算機傳送什麼資料才能讓它完全像第一臺那樣暫停。
如果你的程式只允許像賦值這樣的簡單語句,這很容易。你只需要知道你執行的最後一條語句之後的那一個點。基本上就是一個斷點,即我們虛擬機器中的ip或錯誤資訊中的行號。新增if和switch這樣的分支控制流並不會改變什麼。即時標記點指向分支內部,我們仍然可以知道我們在哪裡。
一旦增加了函式呼叫,就需要更多的資料才行。你可以在函式中間位置暫停第一臺計算機,但是該函式可能會從多個地方呼叫。要想在整個程式執行的同一時刻暫停第二臺機器,你就需要在正確呼叫該函式的時機暫停它。
因此,你不僅需要知道當前的語句,而且,對於尚未返回的函式呼叫,你也需要知道呼叫點的位置。換句話說,就是呼叫堆疊,儘管我認為Dijkstra寫這個的時候,這個術語還不存在。有趣。
他指出,迴圈使事情變得更難。如果你在迴圈體中間暫停,你就不知道運行了多少次迭代。所以他說你還需要記錄迭代數。而且,由於迴圈可以巢狀,所以你需要一個堆疊(估計是與呼叫棧指標交錯在一起,因為你也可能在外部呼叫的迴圈中)。
這就是奇怪的地方。所以,我們現在真的有了一些進展,你希望他解釋goto是如何破壞這一切的。相反,他說:
無節制地使用goto語句會產生一個直接的後果,那就是很難找到一組有意義的座標來描述程序的進展。
他沒有證明這很困難,也沒有說明原因。他就是這麼說了一下。他確實說過有一種方法是無法令人滿意的:
當然,有了goto語句,我們仍然可以透過一個計數器來唯一性地描述程序,計數器計算自程式啟動以來所執行的操作的數量(即一種規範化的時鐘)。困難的是,這樣的座標雖然是唯一的,但完全沒有幫助。
但是……這就是迴圈計數器的作用,而且他對這些計數器很滿意。並不是每個迴圈都是簡單地“對於0到10的每個整數”的遞增計數。許多是帶有複雜條件的while迴圈。
舉一個比較接近的例子,考慮一下clox中的核心位元組碼執行迴圈。Dijkstra認為這個迴圈很容易處理,因為我們可以簡單地計算迴圈運行了多少次來推斷它的進度。但是,對於某些使用者編譯的Lox程式中執行的每條指令,該迴圈都會執行一次。知道它執行了6201條位元組碼指令真的能告訴我們這些虛擬機器維護者關於直譯器狀態的任何資訊嗎?
事實上,這個特殊的例子指出了一個更深層次的事實。Böhm和Jacopini證明,任何使用goto的控制流都可以轉換為只使用排序、迴圈和分支的控制流。我們的位元組碼直譯器核心迴圈就是一個活生生的例子:它實現了clox位元組碼指令集的非結構化控制流,而本身沒有使用任何goto。
這似乎提供了一種反駁Dijkstra主張的論點:你可以為使用goto的程式定義一個對應關係,將其轉換為不使用goto的程式,然後使用該程式的對應關係,根據他的說法,這是可接受的,因為它只使用了分支和迴圈。
但是,老實說,我的論點也很弱。我認為我們兩個人基本上都在做假數學,用假邏輯來做一個應該是經驗性的、以人為本的論證。Dijkstra是對的,一些使用goto的程式碼真的很糟糕。透過使用結構化控制流,其中的大部分內容可以也應該變成更清晰的程式碼。
從語言中消除goto,你肯定可以避免使用goto寫出糟糕的程式碼。對我們所有的生產力來說,迫使使用者使用結構化控制流,並使用這些結構寫出類似goto的程式碼,可能是一場淨勝。
但我有時會懷疑我們是否把孩子和洗澡水一起倒掉了。在沒有goto的情況下,我們常常求助於更復雜的結構化模式。“迴圈中的分支”就是一個典型的例子。另一個例子是使用保護變數退出一系列的巢狀迴圈:
// See if the matrix contains a zero.
bool found = false;
for (int x = 0; x < xSize; x++) {
for (int y = 0; y < ySize; y++) {
for (int z = 0; z < zSize; z++) {
if (matrix[x][y][z] == 0) {
printf("found");
found = true;
break;
}
}
if (found) break;
}
if (found) break;
}
【你可以在每個迴圈的條件子句的開頭插入!found &&,而不需要使用break語句(它們本身就是一種有限的goto式結構)】
這真的比下面的形式好嗎:
for (int x = 0; x < xSize; x++) {
for (int y = 0; y < ySize; y++) {
for (int z = 0; z < zSize; z++) {
if (matrix[x][y][z] == 0) {
printf("found");
goto done;
}
}
}
}
done:
我想我真正不喜歡的是,我們現在基於恐懼來進行語言設計和工程決策。如今,很少有人對goto的問題和好處有任何微妙的瞭解。相反,我們只是認為它“被認為是有害的”。就我個人而言,我從不覺得教條是高質量創造性工作的良好開端。
-
你有沒有注意到,
if關鍵字後面的(實際上沒有什麼用處?如果沒有它,語言也會很明確,而且容易解析,比如:if condition) print("looks weird");
結尾的)是有用的,因為它將條件表示式和主體分隔開。有些語言使用then關鍵字來代替。但是開頭的(沒有任何作用。它之所以存在,是因為不匹配的括號在我們人類看來很糟糕。 ↩ -
一些指令集中有單獨的“長”跳轉指令,這些指令會接受更大的運算元,當你需要跳轉更遠的距離時可以使用。 ↩
-
我說過我們不會使用C的
if語句來實現Lox的控制流,但我們在這裡確實使用了if語句來決定是否偏移指令指標。但我們並沒有真正使用C語言來實現控制流。如果我們想的話,可以用純粹的算術做到同樣的事情。假設我們有一個函式falsey(),它接受一個Lox Value,如果是假則返回1,否則返回0。那我們可以這樣實現跳轉指令:
falsey()函式可能會使用一些控制流來處理不同的值型別,但這是該函式的實現細節,並不影響我們的虛擬機器如何處理自己的控制流。 ↩ -
我們的操作碼範圍中還有足夠的空間,所以我們可以為隱式彈出值的條件跳轉和不彈出值的條件跳轉制定單獨的指令。但我想盡量在書中保持簡約。在你的位元組碼虛擬機器中,值得探索新增更多的專用指令,看看它們是如何影響效能的。 ↩
-
真的開始懷疑我對邏輯運算子使用相同的跳轉指令的決定了。 ↩
24.呼叫和函式 Calls and Functions
Any problem in computer science can be solved with another level of indirection. Except for the problem of too many layers of indirection.
——David Wheeler
電腦科學中的任何問題都可以透過引入一箇中間層來解決。除了中間層太多的問題。(David Wheeler)
This chapter is a beast. I try to break features into bite-sized pieces, but sometimes you gotta swallow the whole meal. Our next task is functions. We could start with only function declarations, but that’s not very useful when you can’t call them. We could do calls, but there’s nothing to call. And all of the runtime support needed in the VM to support both of those isn’t very rewarding if it isn’t hooked up to anything you can see. So we’re going to do it all. It’s a lot, but we’ll feel good when we’re done.
這一章是一頭猛獸。我試圖把功能分解成小塊,但有時候你不得不吞下整頓飯。我們的下一個任務是函式。我們可以只從函式宣告開始,但是如果你不能呼叫它們,那就沒什麼用了。我們可以實現呼叫,但是也沒什麼可呼叫的。而且,為了實現這兩個功能所需的所有執行時支援,如果不能與你能直觀看到的東西相掛鉤,就不是很有價值。所以我們都要做。雖然內容很多,但等我們完成時,我們會感覺很好。
24 . 1 Function Objects
24.1 函式物件
The most interesting structural change in the VM is around the stack. We already have a stack for local variables and temporaries, so we’re partway there. But we have no notion of a call stack. Before we can make much progress, we’ll have to fix that. But first, let’s write some code. I always feel better once I start moving. We can’t do much without having some kind of representation for functions, so we’ll start there. From the VM’s perspective, what is a function?
虛擬機器中最有趣的結構變化是圍繞堆疊進行的。我們已經有了用於區域性變數和臨時變數的棧,所以我們已經完成了一半。但是我們還沒有呼叫堆疊的概念。在我們取得更大進展之前,必須先解決這個問題。但首先,讓我們編寫一些程式碼。一旦開始行動,我就感覺好多了。如果沒有函式的某種表示形式,我們就做不了太多事,所以我們先從這裡開始。從虛擬機器的角度來看,什麼是函式?
A function has a body that can be executed, so that means some bytecode. We could compile the entire program and all of its function declarations into one big monolithic Chunk. Each function would have a pointer to the first instruction of its code inside the Chunk.
函式有一個可以被執行的主體,也就是一些位元組碼。我們可以把整個程式和所有的函式宣告編譯成一個大的位元組碼塊。每個函式都有一個指標指向其在位元組碼塊中的第一條指令。
This is roughly how compilation to native code works where you end up with one solid blob of machine code. But for our bytecode VM, we can do something a little higher level. I think a cleaner model is to give each function its own Chunk. We’ll want some other metadata too, so let’s go ahead and stuff it all in a struct now.
這大概就是編譯為原生代碼的工作原理,你最終得到的是一大堆機器碼。但是對於我們的位元組碼虛擬機器,我們可以做一些更高層次的事情。我認為一個更簡潔的模型是給每個函式它自己的位元組碼塊。我們還需要一些其它的後設資料,所以我們現在來把它們塞進一個結構體中。
object.h,在結構體Obj後新增程式碼:
struct Obj* next;
};
// 新增部分開始
typedef struct {
Obj obj;
int arity;
Chunk chunk;
ObjString* name;
} ObjFunction;
// 新增部分結束
struct ObjString {
Functions are first class in Lox, so they need to be actual Lox objects. Thus ObjFunction has the same Obj header that all object types share. The
arityfield stores the number of parameters the function expects. Then, in addition to the chunk, we store the function’s name. That will be handy for reporting readable runtime errors.
函式是Lox中的一等公民,所以它們需要作為實際的Lox物件。因此,ObjFunction具有所有物件型別共享的Obj頭。arity欄位儲存了函式所需要的引數數量。然後,除了位元組碼塊,我們還需要儲存函式名稱。這有助於報告可讀的執行時錯誤1。
This is the first time the “object” module has needed to reference Chunk, so we get an include.
這是“object”模組第一次需要引用Chunk,所以我們需要引入一下。
object.h,新增程式碼:
#include "common.h"
// 新增部分開始
#include "chunk.h"
// 新增部分結束
#include "value.h"
Like we did with strings, we define some accessories to make Lox functions easier to work with in C. Sort of a poor man’s object orientation. First, we’ll declare a C function to create a new Lox function.
就像我們處理字串一樣,我們定義一些輔助程式,使Lox函式更容易在C語言中使用。有點像窮人版的面向物件。首先,我們會宣告一個C函式來建立新Lox函式。
object.h,在結構體ObjString後新增程式碼:
uint32_t hash;
};
// 新增部分開始
ObjFunction* newFunction();
// 新增部分結束
ObjString* takeString(char* chars, int length);
The implementation is over here:
實現如下:
object.c,在allocateObject()方法後新增程式碼:
ObjFunction* newFunction() {
ObjFunction* function = ALLOCATE_OBJ(ObjFunction, OBJ_FUNCTION);
function->arity = 0;
function->name = NULL;
initChunk(&function->chunk);
return function;
}
We use our friend
ALLOCATE_OBJ()to allocate memory and initialize the object’s header so that the VM knows what type of object it is. Instead of passing in arguments to initialize the function like we did with ObjString, we set the function up in a sort of blank state—zero arity, no name, and no code. That will get filled in later after the function is created.
我們使用好朋友ALLOCATE_OBJ()來分配記憶體並初始化物件的頭資訊,以便虛擬機器知道它是什麼型別的物件。我們沒有像對ObjString那樣傳入引數來初始化函式,而是將函式設定為一種空白狀態——零引數、無名稱、無程式碼。這裡會在稍後建立函式後被填入資料。
Since we have a new kind of object, we need a new object type in the enum.
因為有了一個新型別的物件,我們需要在列舉中新增一個新的物件型別。
object.h,在列舉ObjType中新增程式碼:
typedef enum {
// 新增部分開始
OBJ_FUNCTION,
// 新增部分結束
OBJ_STRING,
} ObjType;
When we’re done with a function object, we must return the bits it borrowed back to the operating system.
當我們使用完一個函式物件後,必須將它借用的位元位返還給作業系統。
memory.c,在freeObject()方法中新增程式碼:
switch (object->type) {
// 新增部分開始
case OBJ_FUNCTION: {
ObjFunction* function = (ObjFunction*)object;
freeChunk(&function->chunk);
FREE(ObjFunction, object);
break;
}
// 新增部分結束
case OBJ_STRING: {
This switch case is responsible for freeing the ObjFunction itself as well as any other memory it owns. Functions own their chunk, so we call Chunk’s destructor-like function.
這個switch語句負責釋放ObjFunction本身以及它所佔用的其它記憶體。函式擁有自己的位元組碼塊,所以我們呼叫Chunk中類似析構器的函式2。
Lox lets you print any object, and functions are first-class objects, so we need to handle them too.
Lox允許你列印任何物件,而函式是一等物件,所以我們也需要處理它們。
object.c,在printObject()方法中新增程式碼:
switch (OBJ_TYPE(value)) {
// 新增部分開始
case OBJ_FUNCTION:
printFunction(AS_FUNCTION(value));
break;
// 新增部分結束
case OBJ_STRING:
This calls out to:
這就引出了:
object.c,在copyString()方法後新增程式碼:
static void printFunction(ObjFunction* function) {
printf("<fn %s>", function->name->chars);
}
Since a function knows its name, it may as well say it.
既然函式知道它的名稱,那就應該說出來。
Finally, we have a couple of macros for converting values to functions. First, make sure your value actually is a function.
最後,我們有幾個宏用於將值轉換為函式。首先,確保你的值實際上是一個函式。
object.h,新增程式碼:
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
// 新增部分開始
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
// 新增部分結束
#define IS_STRING(value) isObjType(value, OBJ_STRING)
Assuming that evaluates to true, you can then safely cast the Value to an ObjFunction pointer using this:
假設計算結果為真,你就可以使用這個方法將Value安全地轉換為一個ObjFunction指標:
object.h,新增程式碼:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
// 新增部分開始
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
// 新增部分結束
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
With that, our object model knows how to represent functions. I’m feeling warmed up now. You ready for something a little harder?
這樣,我們的物件模型就知道如何表示函式了。我現在感覺已經熱身了。你準備好來點更難的東西了嗎?
24 . 2 Compiling to Function Objects
24.2 編譯為函式物件
Right now, our compiler assumes it is always compiling to one single chunk. With each function’s code living in separate chunks, that gets more complex. When the compiler reaches a function declaration, it needs to emit code into the function’s chunk when compiling its body. At the end of the function body, the compiler needs to return to the previous chunk it was working with.
現在,我們的編譯器假定它總會編譯到單個位元組碼塊中。由於每個函式的程式碼都位於不同的位元組碼塊,這就變得更加複雜了。當編譯器碰到函式宣告時,需要在編譯函式主體時將程式碼寫入函式自己的位元組碼塊中。在函式主體的結尾,編譯器需要返回到它之前正處理的前一個位元組碼塊。
That’s fine for code inside function bodies, but what about code that isn’t? The “top level” of a Lox program is also imperative code and we need a chunk to compile that into. We can simplify the compiler and VM by placing that top-level code inside an automatically defined function too. That way, the compiler is always within some kind of function body, and the VM always runs code by invoking a function. It’s as if the entire program is wrapped inside an implicit
main()function.
這對於函式主體內的程式碼來說很好,但是對於不在其中的程式碼呢?Lox程式的“頂層”也是命令式程式碼,而且我們需要一個位元組碼塊來編譯它。我們也可以將頂層程式碼放入一個自動定義的函式中,從而簡化編譯器和虛擬機器的工作。這樣一來,編譯器總是在某種函式主體內,而虛擬機器總是透過呼叫函式來執行程式碼。這就像整個程式被包裹在一個隱式的main()函式中一樣3。
Before we get to user-defined functions, then, let’s do the reorganization to support that implicit top-level function. It starts with the Compiler struct. Instead of pointing directly to a Chunk that the compiler writes to, it instead has a reference to the function object being built.
在我們討論使用者定義的函式之前,讓我們先重新組織一下,支援隱式的頂層函式。這要從Compiler結構體開始。它不再直接指向編譯器寫入的Chunk,而是指向正在構建的函式物件的引用。
compiler.c,在結構體Compiler中新增程式碼:
typedef struct {
// 新增部分開始
ObjFunction* function;
FunctionType type;
// 新增部分結束
Local locals[UINT8_COUNT];
We also have a little FunctionType enum. This lets the compiler tell when it’s compiling top-level code versus the body of a function. Most of the compiler doesn’t care about this—that’s why it’s a useful abstraction—but in one or two places the distinction is meaningful. We’ll get to one later.
我們也有一個小小的FunctionType列舉。這讓編譯器可以區分它在編譯頂層程式碼還是函式主體。大多數編譯器並不關心這一點——這就是為什麼它是一個有用的抽象——但是在一兩個地方,這種區分是有意義的。我們稍後會講到其中一個。
compiler.c,在結構體Local後新增程式碼:
typedef enum {
TYPE_FUNCTION,
TYPE_SCRIPT
} FunctionType;
Every place in the compiler that was writing to the Chunk now needs to go through that
functionpointer. Fortunately, many chapters ago, we encapsulated access to the chunk in thecurrentChunk()function. We only need to fix that and the rest of the compiler is happy.
編譯器中所有寫入Chunk的地方,現在都需要透過function指標。幸運的是,在很多章節之前,我們在currentChunk()函式中封裝了對位元組碼塊的訪問。我們只需要修改它,編譯器的其它部分就可以了4。
compiler.c,在變數current後,替換5行:
Compiler* current = NULL;
// 替換部分開始
static Chunk* currentChunk() {
return ¤t->function->chunk;
}
// 替換部分結束
static void errorAt(Token* token, const char* message) {
The current chunk is always the chunk owned by the function we’re in the middle of compiling. Next, we need to actually create that function. Previously, the VM passed a Chunk to the compiler which filled it with code. Instead, the compiler will create and return a function that contains the compiled top-level code—which is all we support right now—of the user’s program.
當前的位元組碼塊一定是我們正在編譯的函式所擁有的塊。接下來,我們需要實際建立該函式。之前,虛擬機器將一個Chunk傳遞給編譯器,編譯器會將程式碼填入其中。現在取而代之的是,編譯器建立並返回一個包含已編譯頂層程式碼的函式——這就是我們目前所支援的。
24 . 2 . 1 Creating functions at compile time
24.2.1 編譯時建立函式
We start threading this through in
compile(), which is the main entry point into the compiler.
我們在compile()中開始執行此操作,該方法是進入編譯器的主要入口點。
compiler.c,在compile()方法中替換1行:
Compiler compiler;
// 替換部分開始
initCompiler(&compiler, TYPE_SCRIPT);
// 替換部分結束
parser.hadError = false;
There are a bunch of changes in how the compiler is initialized. First, we initialize the new Compiler fields.
在如何初始化編譯器方面有很多改變。首先,我們初始化新的Compiler欄位。
compiler.c,在函式initCompiler()中替換3行:
// 替換部分開始
static void initCompiler(Compiler* compiler, FunctionType type) {
compiler->function = NULL;
compiler->type = type;
// 替換部分結束
compiler->localCount = 0;
Then we allocate a new function object to compile into.
然後我們分配一個新的函式物件用於編譯。
compiler.c,在initCompiler()方法中新增程式碼5:
compiler->scopeDepth = 0;
// 新增部分開始
compiler->function = newFunction();
// 新增部分結束
current = compiler;
Creating an ObjFunction in the compiler might seem a little strange. A function object is the runtime representation of a function, but here we are creating it at compile time. The way to think of it is that a function is similar to a string or number literal. It forms a bridge between the compile time and runtime worlds. When we get to function declarations, those really are literals—they are a notation that produces values of a built-in type. So the compiler creates function objects during compilation. Then, at runtime, they are simply invoked.
在編譯器中建立ObjFunction可能看起來有點奇怪。函式物件是一個函式的執行時表示,但這裡我們是在編譯時建立它。我們可以這樣想:函式類似於一個字串或數字字面量。它在編譯時和執行時之間形成了一座橋樑。當我們碰到函式宣告時,它們確實是字面量——它們是一種生成內建型別值的符號。因此,編譯器在編譯期間建立函式物件6。然後,在執行時,它們被簡單地呼叫。
Here is another strange piece of code:
下面是另一段奇怪的程式碼:
compiler.c,在initCompiler()方法中新增程式碼:
current = compiler;
// 新增部分開始
Local* local = ¤t->locals[current->localCount++];
local->depth = 0;
local->name.start = "";
local->name.length = 0;
// 新增部分結束
}
Remember that the compiler’s
localsarray keeps track of which stack slots are associated with which local variables or temporaries. From now on, the compiler implicitly claims stack slot zero for the VM’s own internal use. We give it an empty name so that the user can’t write an identifier that refers to it. I’ll explain what this is about when it becomes useful.
請記住,編譯器的locals陣列記錄了哪些棧槽與哪些區域性變數或臨時變數相關聯。從現在開始,編譯器隱式地要求棧槽0供虛擬機器自己內部使用。我們給它一個空的名稱,這樣使用者就不能向一個指向它的識別符號寫值。等它起作用時,我會解釋這是怎麼回事。
That’s the initialization side. We also need a couple of changes on the other end when we finish compiling some code.
這就是初始化這一邊的工作。當我們完成一些程式碼的編譯時,還需要在另一邊做一些改變。
compiler.c,在函式endCompiler()中替換1行:
// 替換部分開始
static ObjFunction* endCompiler() {
// 替換部分結束
emitReturn();
Previously, when
interpret()called into the compiler, it passed in a Chunk to be written to. Now that the compiler creates the function object itself, we return that function. We grab it from the current compiler here:
以前,當呼叫interpret()方法進入編譯器時,會傳入一個要寫入的Chunk。現在,編譯器自己建立了函式物件,我們返回該函式。我們從當前編譯器中這樣獲取它:
compiler.c,在endCompiler()方法中新增程式碼:
emitReturn();
// 新增部分開始
ObjFunction* function = current->function;
// 新增部分結束
#ifdef DEBUG_PRINT_CODE
And then return it to
compile()like so:
然後這樣將其返回給compile():
compiler.c,在endCompiler()方法中新增程式碼:
#endif
// 新增部分開始
return function;
// 新增部分結束
}
Now is a good time to make another tweak in this function. Earlier, we added some diagnostic code to have the VM dump the disassembled bytecode so we could debug the compiler. We should fix that to keep working now that the generated chunk is wrapped in a function.
現在是對該函式進行另一個調整的好時機。之前,我們添加了一些診斷性程式碼,讓虛擬機器轉儲反彙編的位元組碼,以便我們可以除錯編譯器。現在生成的位元組碼塊包含在一個函式中,我們要修復這些程式碼,使其繼續工作。
compiler.c,在endCompiler()方法中替換1行:
#ifdef DEBUG_PRINT_CODE
if (!parser.hadError) {
// 替換部分開始
disassembleChunk(currentChunk(), function->name != NULL
? function->name->chars : "<script>");
// 替換部分結束
}
#endif
Notice the check in here to see if the function’s name is
NULL? User-defined functions have names, but the implicit function we create for the top-level code does not, and we need to handle that gracefully even in our own diagnostic code. Speaking of which:
注意到這裡檢查了函式名稱是否為NULL嗎?使用者定義的函式有名稱,但我們為頂層程式碼建立的隱式函式卻沒有,即使在我們自己的診斷程式碼中,我們也需要優雅地處理這個問題。說到這一點:
object.c,在printFunction()方法中新增程式碼:
static void printFunction(ObjFunction* function) {
// 新增部分開始
if (function->name == NULL) {
printf("<script>");
return;
}
// 新增部分結束
printf("<fn %s>", function->name->chars);
There’s no way for a user to get a reference to the top-level function and try to print it, but our
DEBUG_TRACE_EXECUTIONdiagnostic code that prints the entire stack can and does.
使用者沒有辦法獲取對頂層函式的引用並試圖列印它,但我們用來列印整個堆疊的診斷程式碼DEBUG_TRACE_EXECUTION可以而且確實這樣做了7。
Bumping up a level to
compile(), we adjust its signature.
為了給compile()提升一級,我們調整其簽名。
compiler.h,在函式compile()中替換1行:
#include "vm.h"
// 替換部分開始
ObjFunction* compile(const char* source);
// 替換部分結束
#endif
Instead of taking a chunk, now it returns a function. Over in the implementation:
現在它不再接受位元組碼塊,而是返回一個函式。在實現中:
compiler.c,在函式compile()中替換1行:
// 替換部分開始
ObjFunction* compile(const char* source) {
// 替換部分結束
initScanner(source);
Finally we get to some actual code. We change the very end of the function to this:
最後,我們得到了一些實際的程式碼。我們把方法的最後部分改成這樣: compiler.c,在compile()方法中替換2行:
while (!match(TOKEN_EOF)) {
declaration();
}
// 替換部分開始
ObjFunction* function = endCompiler();
return parser.hadError ? NULL : function;
// 替換部分結束
}
We get the function object from the compiler. If there were no compile errors, we return it. Otherwise, we signal an error by returning
NULL. This way, the VM doesn’t try to execute a function that may contain invalid bytecode.
我們從編譯器獲取函式物件。如果沒有編譯錯誤,就返回它。否則,我們透過返回NULL表示錯誤。這樣,虛擬機器就不會試圖執行可能包含無效位元組碼的函式。
Eventually, we will update
interpret()to handle the new declaration ofcompile(), but first we have some other changes to make.
最終,我們會更新interpret()來處理compile()的新宣告,但首先我們要做一些其它的改變。
24 . 3 Call Frames
24.3 呼叫幀
It’s time for a big conceptual leap. Before we can implement function declarations and calls, we need to get the VM ready to handle them. There are two main problems we need to worry about:
是時候進行一次重大的概念性飛躍了。在我們實現函式宣告和呼叫之前,需要讓虛擬機器準備好處理它們。我們需要考慮兩個主要問題:
24 . 3 . 1 Allocating local variables
24.3.1 分配區域性變數
The compiler allocates stack slots for local variables. How should that work when the set of local variables in a program is distributed across multiple functions?
編譯器為區域性變數分配了堆疊槽。當程式中的區域性變數集分佈在多個函式中時,應該如何操作?
One option would be to keep them totally separate. Each function would get its own dedicated set of slots in the VM stack that it would own forever, even when the function isn’t being called. Each local variable in the entire program would have a bit of memory in the VM that it keeps to itself.
一種選擇是將它們完全分開。每個函式在虛擬機器堆疊中都有自己的一組專用槽,即使在函式沒有被呼叫的情況下,它也會永遠擁有這些槽。整個程式中的每個區域性變數在虛擬機器中都有自己保留的一小塊記憶體8。
Believe it or not, early programming language implementations worked this way. The first Fortran compilers statically allocated memory for each variable. The obvious problem is that it’s really inefficient. Most functions are not in the middle of being called at any point in time, so sitting on unused memory for them is wasteful.
信不信由你,早期的程式語言實現就是這樣工作的。第一個Fortran編譯器為每個變數靜態地分配了記憶體。最顯而易見的問題是效率很低。大多數函式不會隨時都在被呼叫,所以一直佔用未使用的記憶體是浪費的。
The more fundamental problem, though, is recursion. With recursion, you can be “in” multiple calls to the same function at the same time. Each needs its own memory for its local variables. In jlox, we solved this by dynamically allocating memory for an environment each time a function was called or a block entered. In clox, we don’t want that kind of performance cost on every function call.
不過,更根本的問題是遞迴。透過遞迴,你可以在同一時刻處於對同一個函式的多次呼叫“中”。每個函式的區域性變數都需要自己的記憶體。在jlox中,我們透過在每次呼叫函式或進入程式碼塊時為環境動態分配記憶體來解決這個問題9。在clox中,我們不希望在每次呼叫時都付出這樣的效能代價。
Instead, our solution lies somewhere between Fortran’s static allocation and jlox’s dynamic approach. The value stack in the VM works on the observation that local variables and temporaries behave in a last-in first-out fashion. Fortunately for us, that’s still true even when you add function calls into the mix. Here’s an example:
相反,我們的解決方案介於Fortran的靜態分配和jlox的動態方法之間。虛擬機器中的值棧的工作原理是:區域性變數和臨時變數的後進先出的行為模式。幸運的是,即使你把函式呼叫考慮在內,這仍然是正確的。這裡有一個例子:
fun first() {
var a = 1;
second();
var b = 2;
}
fun second() {
var c = 3;
var d = 4;
}
first();
Step through the program and look at which variables are in memory at each point in time:
逐步執行程式,看看在每個時間點上記憶體中有哪些變數:

As execution flows through the two calls, every local variable obeys the principle that any variable declared after it will be discarded before the first variable needs to be. This is true even across calls. We know we’ll be done with
canddbefore we are done witha. It seems we should be able to allocate local variables on the VM’s value stack.
在這兩次呼叫的執行過程中,每個區域性變數都遵循這樣的原則:當某個變數需要被丟棄時,在它之後宣告的任何變數都會被丟棄。甚至在不同的呼叫中也是如此。我們知道,在我們用完a之前,已經用完了c和d。看起來我們應該能夠在虛擬機器的值棧上分配區域性變數。
Ideally, we still determine where on the stack each variable will go at compile time. That keeps the bytecode instructions for working with variables simple and fast. In the above example, we could imagine doing so in a straightforward way, but that doesn’t always work out. Consider:
理想情況下,我們仍然在編譯時確定每個變數在棧中的位置。這使得處理變數的位元組碼指令變得簡單而快速。在上面的例子中,我們可以想象10以一種直接的方式這樣做,但這並不總是可行的。考慮一下:
fun first() {
var a = 1;
second();
var b = 2;
second();
}
fun second() {
var c = 3;
var d = 4;
}
first();
In the first call to
second(),canddwould go into slots 1 and 2. But in the second call, we need to have made room forb, socanddneed to be in slots 2 and 3. Thus the compiler can’t pin down an exact slot for each local variable across function calls. But within a given function, the relative locations of each local variable are fixed. Variabledis always in the slot right afterc. This is the key insight.
在對second()的第一次呼叫中,c和d將進入槽1和2。但在第二次呼叫中,我們需要為b騰出空間,所以c和d需要放在槽2和3裡。因此,編譯器不能在不同的函式呼叫中為每個區域性變數指定一個確切的槽。但是在特定的函式中,每個區域性變數的相對位置是固定的。變數d總是在變數c後面的槽裡。這是關鍵的見解。
When a function is called, we don’t know where the top of the stack will be because it can be called from different contexts. But, wherever that top happens to be, we do know where all of the function’s local variables will be relative to that starting point. So, like many problems, we solve our allocation problem with a level of indirection.
當函式被呼叫時,我們不知道棧頂在什麼位置,因為它可以從不同的上下文中被呼叫。但是,無論棧頂在哪裡,我們都知道該函式的所有區域性變數相對於起始點的位置。因此,像很多問題一樣,我們使用一箇中間層來解決分配問題。
At the beginning of each function call, the VM records the location of the first slot where that function’s own locals begin. The instructions for working with local variables access them by a slot index relative to that, instead of relative to the bottom of the stack like they do today. At compile time, we calculate those relative slots. At runtime, we convert that relative slot to an absolute stack index by adding the function call’s starting slot.
在每次函式呼叫開始時,虛擬機器都會記錄函式自身的區域性變數開始的第一個槽的位置。使用區域性變數的指令透過相對於該槽的索引來訪問它們,而不是像現在這樣使用相對於棧底的索引。在編譯時,我們可以計算出這些相對槽位。在執行時,加上函式呼叫時的起始槽位,就能將相對位置轉換為棧中的絕對索引。
It’s as if the function gets a “window” or “frame” within the larger stack where it can store its locals. The position of the call frame is determined at runtime, but within and relative to that region, we know where to find things.
這就好像是函式在更大的堆疊中得到了一個“視窗”或“幀”,它可以在其中儲存區域性變數。呼叫幀的位置是在執行時確定的,但在該區域內部及其相對位置上,我們知道在哪裡可以找到目標。

The historical name for this recorded location where the function’s locals start is a frame pointer because it points to the beginning of the function’s call frame. Sometimes you hear base pointer, because it points to the base stack slot on top of which all of the function’s variables live.
這個記錄了函式區域性變數開始的位置的歷史名稱是幀指標,因為它指向函式呼叫幀的開始處。有時你會聽到基指標,因為它指向一個基本棧槽,函式的所有變數都在其之上。
That’s the first piece of data we need to track. Every time we call a function, the VM determines the first stack slot where that function’s variables begin.
這是我們需要跟蹤的第一塊資料。每次我們呼叫函式時,虛擬機器都會確定該函式變數開始的第一個棧槽。
24 . 3 . 2 Return addresses
24.3.2 返回地址
Right now, the VM works its way through the instruction stream by incrementing the
ipfield. The only interesting behavior is around control flow instructions which offset theipby larger amounts. Calling a function is pretty straightforward—simply setipto point to the first instruction in that function’s chunk. But what about when the function is done?
現在,虛擬機器透過遞增ip欄位的方式在指令流中工作。唯一有趣的行為是關於控制流指令的,這些指令會以較大的數值對ip進行偏移。呼叫函式非常直接——將ip簡單地設定為指向函式塊中的第一條指令。但是等函式完成後怎麼辦?
The VM needs to return back to the chunk where the function was called from and resume execution at the instruction immediately after the call. Thus, for each function call, we need to track where we jump back to when the call completes. This is called a return address because it’s the address of the instruction that the VM returns to after the call.
虛擬機器需要返回到呼叫函式的位元組碼塊,並在呼叫之後立即恢復執行指令。因此,對於每個函式呼叫,在呼叫完成後,需要記錄呼叫完成後需要跳回什麼地方。這被稱為返回地址,因為它是虛擬機器在呼叫後返回的指令的地址。
Again, thanks to recursion, there may be multiple return addresses for a single function, so this is a property of each invocation and not the function itself.
同樣,由於遞迴的存在,一個函式可能會對應多個返回地址,所以這是每個呼叫的屬性,而不是函式本身的屬性11。
24 . 3 . 3 The call stack
24.3.3 呼叫棧
So for each live function invocation—each call that hasn’t returned yet—we need to track where on the stack that function’s locals begin, and where the caller should resume. We’ll put this, along with some other stuff, in a new struct.
因此,對於每個活動的函式執行(每個尚未返回的呼叫),我們需要跟蹤該函式的區域性變數在堆疊中的何處開始,以及呼叫方應該在何處恢復。我們會將這些資訊以及其它一些資料放在新的結構體中。
vm.h,新增程式碼:
#define STACK_MAX 256
// 新增部分開始
typedef struct {
ObjFunction* function;
uint8_t* ip;
Value* slots;
} CallFrame;
// 新增部分結束
typedef struct {
A CallFrame represents a single ongoing function call. The
slotsfield points into the VM’s value stack at the first slot that this function can use. I gave it a plural name because—thanks to C’s weird “pointers are sort of arrays” thing—we’ll treat it like an array.
一個CallFrame代表一個正在進行的函式呼叫。slots欄位指向虛擬機器的值棧中該函式可以使用的第一個槽。我給它取了一個複數的名字是因為我們會把它當作一個陣列來對待(感謝C語言中“指標是一種陣列”這個奇怪的概念)。
The implementation of return addresses is a little different from what I described above. Instead of storing the return address in the callee’s frame, the caller stores its own
ip. When we return from a function, the VM will jump to theipof the caller’s CallFrame and resume from there.
返回地址的實現與我上面的描述有所不同。呼叫者不是將返回地址儲存在被呼叫者的幀中,而是將自己的ip儲存起來。等到從函式中返回時,虛擬機器會跳轉到呼叫方的CallFrame的ip,並從那裡繼續執行。
I also stuffed a pointer to the function being called in here. We’ll use that to look up constants and for a few other things.
我還在這裡塞了一個指向被呼叫函式的指標。我們會用它來查詢常量和其它一些事情。
Each time a function is called, we create one of these structs. We could dynamically allocate them on the heap, but that’s slow. Function calls are a core operation, so they need to be as fast as possible. Fortunately, we can make the same observation we made for variables: function calls have stack semantics. If
first()callssecond(), the call tosecond()will complete beforefirst()does.
每次函式被呼叫時,我們會建立一個這樣的結構體。我們可以在堆上動態地分配它們,但那樣會很慢。函式呼叫是核心操作,所以它們需要儘可能快。幸運的是,我們意識到它和變數很相似:函式呼叫具有堆疊語義。如果first()呼叫second(),對second()的呼叫將在first()之前完成12。
So over in the VM, we create an array of these CallFrame structs up front and treat it as a stack, like we do with the value array.
因此在虛擬機器中,我們預先建立一個CallFrame結構體的陣列,並將其作為堆疊對待,就像我們對值陣列所做的那樣。
vm.h,在結構體VM中替換2行:
typedef struct {
// 替換部分開始
CallFrame frames[FRAMES_MAX];
int frameCount;
// 替換部分結束
Value stack[STACK_MAX];
This array replaces the
chunkandipfields we used to have directly in the VM. Now each CallFrame has its ownipand its own pointer to the ObjFunction that it’s executing. From there, we can get to the function’s chunk.
這個陣列取代了我們過去在VM中直接使用的chunk和ip欄位。現在,每個CallFrame都有自己的ip和指向它正在執行的ObjFunction的指標。透過它們,我們可以得到函式的位元組碼塊。
The new
frameCountfield in the VM stores the current height of the CallFrame stack—the number of ongoing function calls. To keep clox simple, the array’s capacity is fixed. This means, as in many language implementations, there is a maximum call depth we can handle. For clox, it’s defined here:
VM中新的frameCount欄位儲存了CallFrame棧的當前高度——正在進行的函式呼叫的數量。為了使clox簡單,陣列的容量是固定的。這意味著,和許多語言的實現一樣,存在一個我們可以處理的最大呼叫深度。對於clox,在這裡定義它:
vm.h,替換1行:
#include "value.h"
// 替換部分開始
#define FRAMES_MAX 64
#define STACK_MAX (FRAMES_MAX * UINT8_COUNT)
// 替換部分結束
typedef struct {
We also redefine the value stack’s size in terms of that to make sure we have plenty of stack slots even in very deep call trees. When the VM starts up, the CallFrame stack is empty.
我們還以此重新定義了值棧的大小,以確保即使在很深的呼叫樹中我們也有足夠的棧槽13。當虛擬機器啟動時,CallFrame棧是空的。
vm.c,在resetStack()方法中新增程式碼:
vm.stackTop = vm.stack;
// 新增部分開始
vm.frameCount = 0;
// 新增部分結束
}
The “vm.h” header needs access to ObjFunction, so we add an include.
“vm.h”標頭檔案需要訪問ObjFunction,所以我們加一個引入。
vm.h,替換1行:
#define clox_vm_h
// 替換部分開始
#include "object.h"
// 替換部分結束
#include "table.h"
Now we’re ready to move over to the VM’s implementation file. We’ve got some grunt work ahead of us. We’ve moved
ipout of the VM struct and into CallFrame. We need to fix every line of code in the VM that touchesipto handle that. Also, the instructions that access local variables by stack slot need to be updated to do so relative to the current CallFrame’sslotsfield.
現在我們準備轉移到VM的實現檔案中。我們還有很多艱鉅的工作要做。我們已經將ip從VM結構體移到了CallFrame中。我們需要修改VM中使用了ip的每一行程式碼來解決這個問題。此外,需要更新根據棧槽訪問區域性變數的指令,使其相對於當前CallFrame的slots欄位進行訪問。
We’ll start at the top and plow through it.
我們從最上面開始,徹底解決這個問題。
vm.c,在run()方法中替換4行:
static InterpretResult run() {
// 替換部分開始
CallFrame* frame = &vm.frames[vm.frameCount - 1];
#define READ_BYTE() (*frame->ip++)
#define READ_SHORT() \
(frame->ip += 2, \
(uint16_t)((frame->ip[-2] << 8) | frame->ip[-1]))
#define READ_CONSTANT() \
(frame->function->chunk.constants.values[READ_BYTE()])
// 替換部分結束
#define READ_STRING() AS_STRING(READ_CONSTANT())
First, we store the current topmost CallFrame in a local variable inside the main bytecode execution function. Then we replace the bytecode access macros with versions that access
ipthrough that variable.
首先,我們將當前最頂部的CallFrame儲存在主位元組碼執行函式中的一個區域性變數中。然後我們將位元組碼訪問宏替換為透過該變數訪問ip的版本14。
Now onto each instruction that needs a little tender loving care.
現在我們來看看每條需要溫柔呵護的指令。
vm.c,在run()方法中替換1行:
case OP_GET_LOCAL: {
uint8_t slot = READ_BYTE();
// 替換部分開始
push(frame->slots[slot]);
// 替換部分結束
break;
Previously,
OP_GET_LOCALread the given local slot directly from the VM’s stack array, which meant it indexed the slot starting from the bottom of the stack. Now, it accesses the current frame’sslotsarray, which means it accesses the given numbered slot relative to the beginning of that frame.
以前,OP_GET_LOCAL直接從虛擬機器的棧陣列中讀取給定的區域性變數槽,這意味著它是從棧底開始對槽進行索引。現在,它訪問的是當前幀的slots陣列,這意味著它是訪問相對於該幀起始位置的給定編號的槽。
Setting a local variable works the same way.
設定區域性變數的方法也是如此。
vm.c,在run()方法中替換1行:
case OP_SET_LOCAL: {
uint8_t slot = READ_BYTE();
// 替換部分開始
frame->slots[slot] = peek(0);
// 替換部分結束
break;
The jump instructions used to modify the VM’s
ipfield. Now, they do the same for the current frame’sip.
跳轉指令之前是修改VM的ip欄位。現在,它會對當前幀的ip做相同的操作。
vm.c,在run()方法中替換1行:
case OP_JUMP: {
uint16_t offset = READ_SHORT();
// 替換部分開始
frame->ip += offset;
// 替換部分結束
break;
Same with the conditional jump:
條件跳轉也是如此:
vm.c,在run()方法中替換1行:
case OP_JUMP_IF_FALSE: {
uint16_t offset = READ_SHORT();
// 替換部分開始
if (isFalsey(peek(0))) frame->ip += offset;
// 替換部分結束
break;
And our backward-jumping loop instruction:
還有向後跳轉的迴圈指令:
vm.c,在run()方法中替換1行:
case OP_LOOP: {
uint16_t offset = READ_SHORT();
// 替換部分開始
frame->ip -= offset;
// 替換部分結束
break;
We have some diagnostic code that prints each instruction as it executes to help us debug our VM. That needs to work with the new structure too.
我們還有一些診斷程式碼,可以在每條指令執行時將其打印出來,幫助我們除錯虛擬機器。這也需要能處理新的結構體。
vm.c,在run()方法中替換2行:
printf("\n");
// 替換部分開始
disassembleInstruction(&frame->function->chunk,
(int)(frame->ip - frame->function->chunk.code));
// 替換部分結束
#endif
Instead of passing in the VM’s
chunkandipfields, now we read from the current CallFrame.
現在我們從當前的CallFrame中讀取資料,而不是傳入VM的chunk 和ip 欄位。
You know, that wasn’t too bad, actually. Most instructions just use the macros so didn’t need to be touched. Next, we jump up a level to the code that calls
run().
其實,這不算太糟。大多數指令只是使用了宏,所以不需要修改。接下來,我們向上跳到呼叫run()的程式碼。
vm.c,在interpret() 方法中替換10行:
InterpretResult interpret(const char* source) {
// 替換部分開始
ObjFunction* function = compile(source);
if (function == NULL) return INTERPRET_COMPILE_ERROR;
push(OBJ_VAL(function));
CallFrame* frame = &vm.frames[vm.frameCount++];
frame->function = function;
frame->ip = function->chunk.code;
frame->slots = vm.stack;
// 替換部分結束
InterpretResult result = run();
We finally get to wire up our earlier compiler changes to the back-end changes we just made. First, we pass the source code to the compiler. It returns us a new ObjFunction containing the compiled top-level code. If we get
NULLback, it means there was some compile-time error which the compiler has already reported. In that case, we bail out since we can’t run anything.
我們終於可以將之前的編譯器修改與我們剛剛做的後端更改聯絡起來。首先,我們將原始碼傳遞給編譯器。它返回給我們一個新的ObjFunction,其中包含編譯好的頂層程式碼。如果我們得到的是NULL,這意味著存在一些編譯時錯誤,編譯器已經報告過了。在這種情況下,我們就退出,因為我們沒有可以執行的程式碼。
Otherwise, we store the function on the stack and prepare an initial CallFrame to execute its code. Now you can see why the compiler sets aside stack slot zero—that stores the function being called. In the new CallFrame, we point to the function, initialize its
ipto point to the beginning of the function’s bytecode, and set up its stack window to start at the very bottom of the VM’s value stack.
否則,我們將函式儲存在堆疊中,並準備一個初始CallFrame來執行其程式碼。現在你可以看到為什麼編譯器將棧槽0留出來——其中儲存著正在被呼叫的函式。在新的CallFrame中,我們指向該函式,將ip初始化為函式位元組碼的起始位置,並將堆疊視窗設定為從VM值棧的最底部開始。
This gets the interpreter ready to start executing code. After finishing, the VM used to free the hardcoded chunk. Now that the ObjFunction owns that code, we don’t need to do that anymore, so the end of
interpret()is simply this:
這樣直譯器就準備好開始執行程式碼了。完成後,虛擬機器原本會釋放硬編碼的位元組碼塊。現在ObjFunction持有那段程式碼,我們就不需要再這樣做了,所以interpret()的結尾是這樣的:
vm.c,在interpret()方法中替換4行:
frame->slots = vm.stack;
// 替換部分開始
return run();
// 替換部分結束
}
The last piece of code referring to the old VM fields is
runtimeError(). We’ll revisit that later in the chapter, but for now let’s change it to this:
最後一段引用舊的VM欄位的程式碼是runtimeError()。我們會在本章後面重新討論這個問題,但現在我們先將它改成這樣:
vm.c,在runtimeError()方法中替換2行:
fputs("\n", stderr);
// 替換部分開始
CallFrame* frame = &vm.frames[vm.frameCount - 1];
size_t instruction = frame->ip - frame->function->chunk.code - 1;
int line = frame->function->chunk.lines[instruction];
// 替換部分結束
fprintf(stderr, "[line %d] in script\n", line);
Instead of reading the chunk and
ipdirectly from the VM, it pulls those from the topmost CallFrame on the stack. That should get the function working again and behaving as it did before.
它不是直接從VM中讀取位元組碼塊和ip,而是從棧頂的CallFrame中獲取這些資訊。這應該能讓函式重新工作,並且表現像以前一樣。
Assuming we did all of that correctly, we got clox back to a runnable state. Fire it up and it does . . . exactly what it did before. We haven’t added any new features yet, so this is kind of a let down. But all of the infrastructure is there and ready for us now. Let’s take advantage of it.
假如我們都正確執行了所有這些操作,就可以讓clox回到可執行的狀態。啟動它,它就會……像以前一樣。我們還沒有新增任何新功能,所以這有點讓人失望。但是所有的基礎設施都已經就緒了。讓我們好好利用它。
24 . 4 Function Declarations
24.4 函式宣告
Before we can do call expressions, we need something to call, so we’ll do function declarations first. The fun starts with a keyword.
在我們確實可以呼叫表示式之前,首先需要一些可以用來呼叫的東西,所以我們首先要處理函式宣告。一切從關鍵字開始。【譯者注:作者這裡使用了一個小小的雙關,實在不好翻譯】
compiler.c,在declaration()方法中替換1行:
static void declaration() {
// 替換部分開始
if (match(TOKEN_FUN)) {
funDeclaration();
} else if (match(TOKEN_VAR)) {
// 替換部分結束
varDeclaration();
That passes control to here:
它將控制權傳遞到這裡:
compiler.c,在block()方法後新增:
static void funDeclaration() {
uint8_t global = parseVariable("Expect function name.");
markInitialized();
function(TYPE_FUNCTION);
defineVariable(global);
}
Functions are first-class values, and a function declaration simply creates and stores one in a newly declared variable. So we parse the name just like any other variable declaration. A function declaration at the top level will bind the function to a global variable. Inside a block or other function, a function declaration creates a local variable.
函式是一等公民,函式宣告只是在新宣告的變數中建立並儲存一個函式。因此,我們像其它變數宣告一樣解析名稱。頂層的函式宣告會將函式繫結到一個全域性變數。在程式碼塊或其它函式內部,函式宣告會建立一個區域性變數。
In an earlier chapter, I explained how variables get defined in two stages. This ensures you can’t access a variable’s value inside the variable’s own initializer. That would be bad because the variable doesn’t have a value yet.
在前面的章節中,我解釋了變數是如何分兩個階段定義的。這確保了你不能在變數自己的初始化器中訪問該變數的值。這很糟糕,因為變數還沒有值。
Functions don’t suffer from this problem. It’s safe for a function to refer to its own name inside its body. You can’t call the function and execute the body until after it’s fully defined, so you’ll never see the variable in an uninitialized state. Practically speaking, it’s useful to allow this in order to support recursive local functions.
函式不會遇到這個問題。函式在其主體內引用自己的名稱是安全的。在函式被完全定義之後,你才能呼叫函式並執行函式體,所以你永遠不會看到處於未初始化狀態的變數。實際上,為了支援遞迴區域性函式,允許這樣做是很有用的。
To make that work, we mark the function declaration’s variable “initialized” as soon as we compile the name, before we compile the body. That way the name can be referenced inside the body without generating an error.
為此,在我們編譯函式名稱時(編譯函式主體之前),就將函式宣告的變數標記為“已初始化”。這樣就可以在主體中引用該名稱,而不會產生錯誤。
We do need one check, though.
不過,我們確實需要做一個檢查。
compiler.c,在markInitialized()方法中新增程式碼:
static void markInitialized() {
// 新增部分開始
if (current->scopeDepth == 0) return;
// 新增部分結束
current->locals[current->localCount - 1].depth =
Before, we called
markInitialized()only when we already knew we were in a local scope. Now, a top-level function declaration will also call this function. When that happens, there is no local variable to mark initialized—the function is bound to a global variable.
以前,只有在已經知道當前處於區域性作用域中時,我們才會呼叫markInitialized()。現在,頂層的函式宣告也會呼叫這個函式。當這種情況發生時,沒有區域性變數需要標記為已初始化——函式被繫結到了一個全域性變數。
Next, we compile the function itself—its parameter list and block body. For that, we use a separate helper function. That helper generates code that leaves the resulting function object on top of the stack. After that, we call
defineVariable()to store that function back into the variable we declared for it.
接下來,我們編譯函式本身——它的引數列表和程式碼塊主體。為此,我們使用一個單獨的輔助函式。該函式生成的程式碼會將生成的函式物件留在棧頂。之後,我們呼叫defineVariable(),將該函式儲存到我們為其宣告的變數中。
I split out the code to compile the parameters and body because we’ll reuse it later for parsing method declarations inside classes. Let’s build it incrementally, starting with this:
我將編譯引數和主體的程式碼分開,因為我們稍後會重用它來解析類中的方法宣告。我們來逐步構建它,從這裡開始:
compiler.c,在block()方法後新增程式碼15:
static void function(FunctionType type) {
Compiler compiler;
initCompiler(&compiler, type);
beginScope();
consume(TOKEN_LEFT_PAREN, "Expect '(' after function name.");
consume(TOKEN_RIGHT_PAREN, "Expect ')' after parameters.");
consume(TOKEN_LEFT_BRACE, "Expect '{' before function body.");
block();
ObjFunction* function = endCompiler();
emitBytes(OP_CONSTANT, makeConstant(OBJ_VAL(function)));
}
For now, we won’t worry about parameters. We parse an empty pair of parentheses followed by the body. The body starts with a left curly brace, which we parse here. Then we call our existing
block()function, which knows how to compile the rest of a block including the closing brace.
現在,我們不需要考慮引數。我們解析一對空括號,然後是主體。主體以左大括號開始,我們在這裡會解析它。然後我們呼叫現有的block()函式,該函式知道如何編譯程式碼塊的其餘部分,包括結尾的右大括號。
24 . 4 . 1 A stack of compilers
24.4.1 編譯器棧
The interesting parts are the compiler stuff at the top and bottom. The Compiler struct stores data like which slots are owned by which local variables, how many blocks of nesting we’re currently in, etc. All of that is specific to a single function. But now the front end needs to handle compiling multiple functions nested within each other.
有趣的部分是頂部和底部的編譯器。Compiler結構體儲存的資料包括哪些棧槽被哪些區域性變數擁有,目前處於多少層的巢狀塊中,等等。所有這些都是針對單個函式的。但是現在,前端需要處理編譯相互巢狀的多個函式的編譯16。
The trick for managing that is to create a separate Compiler for each function being compiled. When we start compiling a function declaration, we create a new Compiler on the C stack and initialize it.
initCompiler()sets that Compiler to be the current one. Then, as we compile the body, all of the functions that emit bytecode write to the chunk owned by the new Compiler’s function.
管理這個問題的訣竅是為每個正在編譯的函式建立一個單獨的Compiler。當我們開始編譯函式宣告時,會在C語言棧中建立一個新的Compiler並初始化它。initCompiler()將該Compiler設定為當前編譯器。然後,在編譯主體時,所有產生位元組碼的函式都寫入新Compiler的函式所持有的位元組碼塊。
After we reach the end of the function’s block body, we call
endCompiler(). That yields the newly compiled function object, which we store as a constant in the surrounding function’s constant table. But, wait, how do we get back to the surrounding function? We lost it wheninitCompiler()overwrote the current compiler pointer.
在我們到達函式主體塊的末尾時,會呼叫endCompiler()。這就得到了新編譯的函式物件,我們將其作為常量儲存在外圍函式的常量表中。但是,等等。我們怎樣才能回到外圍的函式中呢?在initCompiler()覆蓋當前編譯器指標時,我們把它丟了。
We fix that by treating the series of nested Compiler structs as a stack. Unlike the Value and CallFrame stacks in the VM, we won’t use an array. Instead, we use a linked list. Each Compiler points back to the Compiler for the function that encloses it, all the way back to the root Compiler for the top-level code.
我們透過將一系列巢狀的Compiler結構體視為一個棧來解決這個問題。與VM中的Value和CallFrame棧不同,我們不會使用陣列。相反,我們使用連結串列。每個Compiler都指向包含它的函式的Compiler,一直到頂層程式碼的根Compiler。
compiler.c,在列舉FunctionType後替換1行:
} FunctionType;
// 替換部分開始
typedef struct Compiler {
struct Compiler* enclosing;
// 替換部分結束
ObjFunction* function;
Inside the Compiler struct, we can’t reference the Compiler typedef since that declaration hasn’t finished yet. Instead, we give a name to the struct itself and use that for the field’s type. C is weird.
在Compiler結構體內部,我們不能引用Compiler型別定義,因為宣告還沒有結束。相反,我們要為結構體本身提供一個名稱,並將其用作欄位的型別。C語言真奇怪。
When initializing a new Compiler, we capture the about-to-no-longer-be-current one in that pointer.
在初始化一個新的Compiler時,我們捕獲即將更換的當前編譯器。
compiler.c,在initCompiler()方法中新增程式碼:
static void initCompiler(Compiler* compiler, FunctionType type) {
// 新增部分開始
compiler->enclosing = current;
// 新增部分結束
compiler->function = NULL;
Then when a Compiler finishes, it pops itself off the stack by restoring the previous compiler to be the new current one.
然後,當編譯器完成時,將之前的編譯器恢復為新的當前編譯器,從而將自己從棧中彈出。
compiler.c,在endCompiler()方法中新增程式碼:
#endif
// 新增部分開始
current = current->enclosing;
// 新增部分結束
return function;
Note that we don’t even need to dynamically allocate the Compiler structs. Each is stored as a local variable in the C stack—either in
compile()orfunction(). The linked list of Compilers threads through the C stack. The reason we can get an unbounded number of them is because our compiler uses recursive descent, sofunction()ends up calling itself recursively when you have nested function declarations.
請注意,我們甚至不需要動態地分配Compiler結構體。每個結構體都作為區域性變數儲存在C語言棧中——不是compile()就是function()。編譯器連結串列在C語言棧中存在。我們之所以能得到無限多的編譯器17,是因為我們的編譯器使用了遞迴下降,所以當有巢狀的函式宣告時,function()最終會遞迴地呼叫自己。
24 . 4 . 2 Function parameters
24.4.2 函式引數
Functions aren’t very useful if you can’t pass arguments to them, so let’s do parameters next.
如果你不能向函式傳遞引數,那函式就不是很有用,所以接下來我們實現引數。
compiler.c,在function()方法中新增程式碼:
consume(TOKEN_LEFT_PAREN, "Expect '(' after function name.");
// 新增部分開始
if (!check(TOKEN_RIGHT_PAREN)) {
do {
current->function->arity++;
if (current->function->arity > 255) {
errorAtCurrent("Can't have more than 255 parameters.");
}
uint8_t constant = parseVariable("Expect parameter name.");
defineVariable(constant);
} while (match(TOKEN_COMMA));
}
// 新增部分結束
consume(TOKEN_RIGHT_PAREN, "Expect ')' after parameters.");
Semantically, a parameter is simply a local variable declared in the outermost lexical scope of the function body. We get to use the existing compiler support for declaring named local variables to parse and compile parameters. Unlike local variables, which have initializers, there’s no code here to initialize the parameter’s value. We’ll see how they are initialized later when we do argument passing in function calls.
語義上講,形參就是在函式體最外層的詞法作用域中宣告的一個區域性變數。我們可以使用現有的編譯器對宣告命名區域性變數的支援來解析和編譯形參。與有初始化器的區域性變數不同,這裡沒有程式碼來初始化形參的值。稍後在函式呼叫中傳遞引數時,我們會看到它們是如何初始化的。
While we’re at it, we note the function’s arity by counting how many parameters we parse. The other piece of metadata we store with a function is its name. When compiling a function declaration, we call
initCompiler()right after we parse the function’s name. That means we can grab the name right then from the previous token.
在此過程中,我們透過計算所解析的引數數量來確定函式的元數。函式中儲存的另一個後設資料是它的名稱。在編譯函式宣告時,我們在解析完函式名稱之後,會立即呼叫initCompiler()。這意味著我們可以立即從上一個標識中獲取名稱。
compiler.c,在initCompiler()方法中新增程式碼:
current = compiler;
// 新增部分開始
if (type != TYPE_SCRIPT) {current->function->name = copyString(parser.previous.start, parser.previous.length);
}
// 新增部分結束
Local* local = ¤t->locals[current->localCount++];
Note that we’re careful to create a copy of the name string. Remember, the lexeme points directly into the original source code string. That string may get freed once the code is finished compiling. The function object we create in the compiler outlives the compiler and persists until runtime. So it needs its own heap-allocated name string that it can keep around.
請注意,我們謹慎地建立了名稱字串的副本。請記住,詞素直接指向了原始碼字串。一旦程式碼編譯完成,該字串就可能被釋放。我們在編譯器中建立的函式物件比編譯器的壽命更長,並持續到執行時。所以它需要自己的堆分配的名稱字串,以便隨時可用。
Rad. Now we can compile function declarations, like this:
太棒了。現在我們可以編譯函式宣告瞭,像這樣:
fun areWeHavingItYet() {
print "Yes we are!";
}
print areWeHavingItYet;
We just can’t do anything useful with them.
只是我們還不能用它們來做任何有用的事情。
24 . 5 Function Calls
24.5 函式呼叫
By the end of this section, we’ll start to see some interesting behavior. The next step is calling functions. We don’t usually think of it this way, but a function call expression is kind of an infix
(operator. You have a high-precedence expression on the left for the thing being called—usually just a single identifier. Then the(in the middle, followed by the argument expressions separated by commas, and a final)to wrap it up at the end.
在本小節結束時,我們將開始看到一些有趣的行為。下一步是呼叫函式。我們通常不會這樣想,但是函式呼叫表示式有點像是一箇中綴(運算子。在左邊有一個高優先順序的表示式,表示被呼叫的內容——通常只是一個識別符號。然後是中間的(,後跟由逗號分隔的參數列達式,最後是一個)把它包起來。
That odd grammatical perspective explains how to hook the syntax into our parsing table.
這個奇怪的語法視角解釋瞭如何將語法掛接到我們的解析表格中。
compiler.c,在unary()方法後新增,替換1行:
ParseRule rules[] = {
// 替換部分開始
[TOKEN_LEFT_PAREN] = {grouping, call, PREC_CALL},
// 替換部分結束
[TOKEN_RIGHT_PAREN] = {NULL, NULL, PREC_NONE},
When the parser encounters a left parenthesis following an expression, it dispatches to a new parser function.
當解析器遇到表示式後面的左括號時,會將其分派到一個新的解析器函式。
compiler.c,在binary()方法後新增程式碼:
static void call(bool canAssign) {
uint8_t argCount = argumentList();
emitBytes(OP_CALL, argCount);
}
We’ve already consumed the
(token, so next we compile the arguments using a separateargumentList()helper. That function returns the number of arguments it compiled. Each argument expression generates code that leaves its value on the stack in preparation for the call. After that, we emit a newOP_CALLinstruction to invoke the function, using the argument count as an operand.
我們已經消費了(標識,所以接下來我們用一個單獨的argumentList()輔助函式來編譯引數。該函式會返回它所編譯的引數的數量。每個參數列達式都會生成程式碼,將其值留在棧中,為呼叫做準備。之後,我們發出一條新的OP_CALL指令來呼叫該函式,將引數數量作為運算元。
We compile the arguments using this friend:
我們使用這個助手來編譯引數:
compiler.c,在defineVariable()方法後新增程式碼:
static uint8_t argumentList() {
uint8_t argCount = 0;
if (!check(TOKEN_RIGHT_PAREN)) {
do {
expression();
argCount++;
} while (match(TOKEN_COMMA));
}
consume(TOKEN_RIGHT_PAREN, "Expect ')' after arguments.");
return argCount;
}
That code should look familiar from jlox. We chew through arguments as long as we find commas after each expression. Once we run out, we consume the final closing parenthesis and we’re done.
這段程式碼看起來跟jlox很相似。只要我們在每個表示式後面找到逗號,就會仔細分析函式。一旦執行完成,消耗最後的右括號,我們就完成了。
Well, almost. Back in jlox, we added a compile-time check that you don’t pass more than 255 arguments to a call. At the time, I said that was because clox would need a similar limit. Now you can see why—since we stuff the argument count into the bytecode as a single-byte operand, we can only go up to 255. We need to verify that in this compiler too.
嗯,大概就這樣。在jlox中,我們添加了一個編譯時檢查,即一次呼叫傳遞的引數不超過255個。當時,我說這是因為clox需要類似的限制。現在你可以明白為什麼了——因為我們把引數數量作為單位元組運算元填充到位元組碼中,所以最多隻能達到255。我們也需要在這個編譯器中驗證。
compiler.c,在argumentList()方法中新增程式碼:
expression();
// 新增部分開始
if (argCount == 255) {
error("Can't have more than 255 arguments.");
}
// 新增部分結束
argCount++;
That’s the front end. Let’s skip over to the back end, with a quick stop in the middle to declare the new instruction.
這就是前端。讓我們跳到後端繼續,不過要在中間快速暫停一下,宣告一個新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_LOOP,
// 新增部分開始
OP_CALL,
// 新增部分結束
OP_RETURN,
24 . 5 . 1 Binding arguments to parameters
24.5.1 繫結形參與實參
Before we get to the implementation, we should think about what the stack looks like at the point of a call and what we need to do from there. When we reach the call instruction, we have already executed the expression for the function being called, followed by its arguments. Say our program looks like this:
在我們開始實現之前,應該考慮一下堆疊在呼叫時是什麼樣子的,以及我們需要從中做什麼。當我們到達呼叫指令時,我們已經執行了被呼叫函式的表示式,後面是其引數。假設我們的程式是這樣的:
fun sum(a, b, c) {
return a + b + c;
}
print 4 + sum(5, 6, 7);
If we pause the VM right on the
OP_CALLinstruction for that call tosum(), the stack looks like this:
如果我們在呼叫sum()的OP_CALL指令處暫停虛擬機器,棧看起來是這樣的:

Picture this from the perspective of
sum()itself. When the compiler compiledsum(), it automatically allocated slot zero. Then, after that, it allocated local slots for the parametersa,b, andc, in order. To perform a call tosum(), we need a CallFrame initialized with the function being called and a region of stack slots that it can use. Then we need to collect the arguments passed to the function and get them into the corresponding slots for the parameters.
從sum()本身的角度來考慮這個問題。當編譯器編譯sum()時,它自動分配了槽位0。然後,它在該位置後為引數a、b、c依次分配了區域性槽。為了執行對sum()的呼叫,我們需要一個透過被呼叫函式和可用棧槽區域初始化的CallFrame。然後我們需要收集傳遞給函式的引數,並將它們放入引數對應的槽中。
When the VM starts executing the body of
sum(), we want its stack window to look like this:
當VM開始執行sum()函式體時,我們需要棧視窗看起來像這樣:

Do you notice how the argument slots that the caller sets up and the parameter slots the callee needs are both in exactly the right order? How convenient! This is no coincidence. When I talked about each CallFrame having its own window into the stack, I never said those windows must be disjoint. There’s nothing preventing us from overlapping them, like this:
你是否注意到,呼叫者設定的實參槽和被呼叫者需要的形參槽的順序是完全匹配的?多麼方便啊!這並非巧合。當我談到每個CallFrame在棧中都有自己的視窗時,從未說過這些視窗一定是不相交的。沒有什麼能阻止我們將它們重疊起來,就像這樣:

The top of the caller’s stack contains the function being called followed by the arguments in order. We know the caller doesn’t have any other slots above those in use because any temporaries needed when evaluating argument expressions have been discarded by now. The bottom of the callee’s stack overlaps so that the parameter slots exactly line up with where the argument values already live.
呼叫者棧的頂部包括被呼叫的函式,後面依次是引數。我們知道呼叫者在這些正在使用的槽位之上沒有佔用其它槽,因為在計算參數列達式時需要的所有臨時變數都已經被丟棄了。被呼叫者棧的底部是重疊的,這樣形參的槽位與已有的實參值的位置就完全一致18。
This means that we don’t need to do any work to “bind an argument to a parameter”. There’s no copying values between slots or across environments. The arguments are already exactly where they need to be. It’s hard to beat that for performance.
這意味著我們不需要做任何工作來“將形參繫結到實參”。不用在槽之間或跨環境複製值。這些實參已經在它們需要在的位置了。很難有比這更好的效能了。
Time to implement the call instruction.
是時候來實現呼叫指令了。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_CALL: {
int argCount = READ_BYTE();
if (!callValue(peek(argCount), argCount)) {
return INTERPRET_RUNTIME_ERROR;
}
break;
}
// 新增部分結束
case OP_RETURN: {
We need to know the function being called and the number of arguments passed to it. We get the latter from the instruction’s operand. That also tells us where to find the function on the stack by counting past the argument slots from the top of the stack. We hand that data off to a separate
callValue()function. If that returnsfalse, it means the call caused some sort of runtime error. When that happens, we abort the interpreter.
我們需要知道被呼叫的函式以及傳遞給它的引數數量。我們從指令的運算元中得到後者。它還告訴我們,從棧頂向下跳過引數數量的槽位,就可以在棧中找到該函式。我們將這些資料傳給一個單獨的callValue()函式。如果函式返回false,意味著該呼叫引發了某種執行時錯誤。當這種情況發生時,我們中止直譯器。
If
callValue()is successful, there will be a new frame on the CallFrame stack for the called function. Therun()function has its own cached pointer to the current frame, so we need to update that.
如果callValue()成功,將會在CallFrame棧中為被呼叫函式建立一個新幀。run()函式有它自己快取的指向當前幀的指標,所以我們需要更新它。
vm.c,在run()方法中新增程式碼:
return INTERPRET_RUNTIME_ERROR;
}
// 新增部分開始
frame = &vm.frames[vm.frameCount - 1];
// 新增部分結束
break;
Since the bytecode dispatch loop reads from that
framevariable, when the VM goes to execute the next instruction, it will read theipfrom the newly called function’s CallFrame and jump to its code. The work for executing that call begins here:
因為位元組碼排程迴圈會從frame變數中讀取資料,當VM執行下一條指令時,它會從新的被呼叫函式CallFrame中讀取ip,並跳轉到其程式碼處。執行該呼叫的工作從這裡開始:
vm.c,在peek()方法後新增程式碼19:
static bool callValue(Value callee, int argCount) {
if (IS_OBJ(callee)) {
switch (OBJ_TYPE(callee)) {
case OBJ_FUNCTION:
return call(AS_FUNCTION(callee), argCount);
default:
break; // Non-callable object type.
}
}
runtimeError("Can only call functions and classes.");
return false;
}
There’s more going on here than just initializing a new CallFrame. Because Lox is dynamically typed, there’s nothing to prevent a user from writing bad code like:
這裡要做的不僅僅是初始化一個新的CallFrame,因為Lox是動態型別的,所以沒有什麼可以防止使用者編寫這樣的糟糕程式碼:
var notAFunction = 123;
notAFunction();
If that happens, the runtime needs to safely report an error and halt. So the first thing we do is check the type of the value that we’re trying to call. If it’s not a function, we error out. Otherwise, the actual call happens here:
如果發生這種情況,執行時需要安全報告錯誤並停止。所以我們要做的第一件事就是檢查我們要呼叫的值的型別。如果不是函式,我們就報錯退出。否則,真正的呼叫就發生在這裡:
vm.c,在peek()方法後新增程式碼:
static bool call(ObjFunction* function, int argCount) {
CallFrame* frame = &vm.frames[vm.frameCount++];
frame->function = function;
frame->ip = function->chunk.code;
frame->slots = vm.stackTop - argCount - 1;
return true;
}
This simply initializes the next CallFrame on the stack. It stores a pointer to the function being called and points the frame’s
ipto the beginning of the function’s bytecode. Finally, it sets up theslotspointer to give the frame its window into the stack. The arithmetic there ensures that the arguments already on the stack line up with the function’s parameters:
這裡只是初始化了棧上的下一個CallFrame。其中儲存了一個指向被呼叫函式的指標,並將呼叫幀的ip指向函式位元組碼的開始處。最後,它設定slots指標,告訴呼叫幀它在棧上的視窗位置。這裡的演算法可以確保棧中已存在的實參與函式的形參是對齊的。

The funny little
- 1is to account for stack slot zero which the compiler set aside for when we add methods later. The parameters start at slot one so we make the window start one slot earlier to align them with the arguments.
這個有趣的-1是為了處理棧槽0,編譯器留出了這個槽,以便稍後新增方法時使用。形參從棧槽1開始,所以我們讓視窗提前一個槽開始,以使它們與實參對齊。
Before we move on, let’s add the new instruction to our disassembler.
在我們更進一步之前,讓我們把新指令新增到反彙編程式中。
debug.c,在disassembleInstruction()方法中新增程式碼:
return jumpInstruction("OP_LOOP", -1, chunk, offset);
// 新增部分開始
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
// 新增部分結束
case OP_RETURN:
And one more quick side trip. Now that we have a handy function for initiating a CallFrame, we may as well use it to set up the first frame for executing the top-level code.
還有一個快速的小改動。現在我們有一個方便的函式用來初始化CallFrame,我們不妨用它來設定用於執行頂層程式碼的第一個幀。
vm.c,在interpret()方法中替換4行:
push(OBJ_VAL(function));
// 替換部分開始
call(function, 0);
// 替換部分結束
return run();
OK, now back to calls . . .
好了,現在回到呼叫……
24 . 5 . 2 Runtime error checking
24.5.2 執行時錯誤檢查
The overlapping stack windows work based on the assumption that a call passes exactly one argument for each of the function’s parameters. But, again, because Lox ain’t statically typed, a foolish user could pass too many or too few arguments. In Lox, we’ve defined that to be a runtime error, which we report like so:
重疊的棧視窗的工作基於這樣一個假設:一次呼叫中正好為函式的每個形參傳入一個實參。但是,同樣的,由於Lox不是靜態型別的,某個愚蠢的使用者可以會傳入太多或太少的引數。在Lox中,我們將其定義為執行時錯誤,並像這樣報告:
vm.c,在call()方法中新增程式碼:
static bool call(ObjFunction* function, int argCount) {
// 新增部分開始
if (argCount != function->arity) {
runtimeError("Expected %d arguments but got %d.",
function->arity, argCount);
return false;
}
// 新增部分結束
CallFrame* frame = &vm.frames[vm.frameCount++];
Pretty straightforward. This is why we store the arity of each function inside the ObjFunction for it.
非常簡單直接。這就是為什麼我們要在ObjFunction中儲存每個函式的元數。
There’s another error we need to report that’s less to do with the user’s foolishness than our own. Because the CallFrame array has a fixed size, we need to ensure a deep call chain doesn’t overflow it.
還有一個需要報告的錯誤,與其說是使用者的愚蠢行為,不如說是我們自己的愚蠢行為。因為CallFrame陣列具有固定的大小,我們需要確保一個深的呼叫鏈不會溢位。
vm.c,在call()方法中新增程式碼:
}
// 新增部分開始
if (vm.frameCount == FRAMES_MAX) {
runtimeError("Stack overflow.");
return false;
}
// 新增部分結束
CallFrame* frame = &vm.frames[vm.frameCount++];
In practice, if a program gets anywhere close to this limit, there’s most likely a bug in some runaway recursive code.
在實踐中,如果一個程式接近這個極限,那麼很可能在某些失控的遞迴程式碼中出現了錯誤。
24 . 5 . 3 Printing stack traces
24.5.3 列印棧跟蹤記錄
While we’re on the subject of runtime errors, let’s spend a little time making them more useful. Stopping on a runtime error is important to prevent the VM from crashing and burning in some ill-defined way. But simply aborting doesn’t help the user fix their code that caused that error.
既然我們在討論執行時錯誤,那我們就花一點時間讓它們變得更有用。在出現執行時錯誤時停止很重要,可以防止虛擬機器以某種不明確的方式崩潰。但是簡單的中止並不能幫助使用者修復導致錯誤的程式碼。
The classic tool to aid debugging runtime failures is a stack trace—a print out of each function that was still executing when the program died, and where the execution was at the point that it died. Now that we have a call stack and we’ve conveniently stored each function’s name, we can show that entire stack when a runtime error disrupts the harmony of the user’s existence. It looks like this:
幫助除錯執行時故障的經典工具是堆疊跟蹤——打印出程式死亡時仍在執行的每個函式,以及程式死亡時執行的位置。現在我們有了一個排程棧,並且方便地儲存了每個函式的名稱。當執行時錯誤破壞了使用者的和諧時,我們可以顯示整個堆疊。它看起來像這樣:
vm.c,在runtimeError()方法中替換4行20:
fputs("\n", stderr);
// 替換部分開始
for (int i = vm.frameCount - 1; i >= 0; i--) {
CallFrame* frame = &vm.frames[i];
ObjFunction* function = frame->function;
size_t instruction = frame->ip - function->chunk.code - 1;
fprintf(stderr, "[line %d] in ",
function->chunk.lines[instruction]);
if (function->name == NULL) {
fprintf(stderr, "script\n");
} else {
fprintf(stderr, "%s()\n", function->name->chars);
}
}
// 替換部分結束
resetStack();
}
After printing the error message itself, we walk the call stack from top (the most recently called function) to bottom (the top-level code). For each frame, we find the line number that corresponds to the current
ipinside that frame’s function. Then we print that line number along with the function name.
在列印完錯誤資訊本身之後,我們從頂部(最近呼叫的函式)到底部(頂層程式碼)遍歷呼叫棧21。對於每個呼叫幀,我們找到與該幀的函式內的當前ip相對應的行號。然後我們將該行號與函式名稱一起打印出來。
For example, if you run this broken program:
舉例來說,如果你執行這個壞掉的程式:
fun a() { b(); }
fun b() { c(); }
fun c() {
c("too", "many");
}
a();
It prints out:
它會列印:
Expected 0 arguments but got 2.
[line 4] in c()
[line 2] in b()
[line 1] in a()
[line 7] in script
That doesn’t look too bad, does it?
看起來還不錯,是吧?
24 . 5 . 4 Returning from functions
24.5.4 從函式中返回
We’re getting close. We can call functions, and the VM will execute them. But we can’t return from them yet. We’ve had an
OP_RETURNinstruction for quite some time, but it’s always had some kind of temporary code hanging out in it just to get us out of the bytecode loop. The time has arrived for a real implementation.
我們快完成了。我們可以呼叫函式,而虛擬機器會執行它們。但是我們還不能從函式中返回。我們支援OP_RETURN指令已經有一段時間了,但其中一直有一些臨時程式碼,只是為了讓我們脫離位元組碼迴圈。現在是真正實現它的時候了。
vm.c,在run()方法中替換2行:
case OP_RETURN: {
// 替換部分開始
Value result = pop();
vm.frameCount--;
if (vm.frameCount == 0) {
pop();
return INTERPRET_OK;
}
vm.stackTop = frame->slots;
push(result);
frame = &vm.frames[vm.frameCount - 1];
break;
// 替換部分結束
}
When a function returns a value, that value will be on top of the stack. We’re about to discard the called function’s entire stack window, so we pop that return value off and hang on to it. Then we discard the CallFrame for the returning function. If that was the very last CallFrame, it means we’ve finished executing the top-level code. The entire program is done, so we pop the main script function from the stack and then exit the interpreter.
當函式返回一個值時,該值會在棧頂。我們將會丟棄被呼叫函式的整個堆疊視窗,因此我們將返回值彈出棧並保留它。然後我們丟棄CallFrame,從函式中返回。如果是最後一個CallFrame,這意味著我們已經完成了頂層程式碼的執行。整個程式已經完成,所以我們從堆疊中彈出主指令碼函式,然後退出直譯器。
Otherwise, we discard all of the slots the callee was using for its parameters and local variables. That includes the same slots the caller used to pass the arguments. Now that the call is done, the caller doesn’t need them anymore. This means the top of the stack ends up right at the beginning of the returning function’s stack window.
否則,我們會丟棄所有被呼叫者用於儲存引數和區域性變數的棧槽,其中包括呼叫者用來傳遞實參的相同的槽。現在呼叫已經完成,呼叫者不再需要它們了。這意味著棧頂的結束位置正好在返回函式的棧視窗的開頭。
We push the return value back onto the stack at that new, lower location. Then we update the
run()function’s cached pointer to the current frame. Just like when we began a call, on the next iteration of the bytecode dispatch loop, the VM will readipfrom that frame, and execution will jump back to the caller, right where it left off, immediately after theOP_CALLinstruction.
我們把返回值壓回堆疊,放在新的、較低的位置。然後我們更新run函式中快取的指標,將其指向當前幀。就像我們開始呼叫一樣,在位元組碼排程迴圈的下一次迭代中,VM會從該幀中讀取ip,執行程式會跳回呼叫者,就在它離開的地方,緊挨著OP_CALL指令之後。

Note that we assume here that the function did actually return a value, but a function can implicitly return by reaching the end of its body:
請注意,我們這裡假設函式確實返回了一個值,但是函式可以在到達主體末尾時隱式返回:
fun noReturn() {
print "Do stuff";
// No return here.
}
print noReturn(); // ???
We need to handle that correctly too. The language is specified to implicitly return
nilin that case. To make that happen, we add this:
我們也需要正確地處理這個問題。在這種情況下,語言被指定為隱式返回nil。為了實現這一點,我們添加了以下內容:
compiler.c,在emitReturn()方法中新增程式碼:
static void emitReturn() {
// 新增部分開始
emitByte(OP_NIL);
// 新增部分結束
emitByte(OP_RETURN);
}
The compiler calls
emitReturn()to write theOP_RETURNinstruction at the end of a function body. Now, before that, it emits an instruction to pushnilonto the stack. And with that, we have working function calls! They can even take parameters! It almost looks like we know what we’re doing here.
編譯器呼叫emitReturn(),在函式體的末尾寫入OP_RETURN指令。現在,在此之前,它會生成一條指令將nil壓入棧中。這樣,我們就有了可行的函式呼叫!它們甚至可以接受引數!看起來我們好像知道自己在做什麼。
24 . 6 Return Statements
24.6 Return語句
If you want a function that returns something other than the implicit
nil, you need areturnstatement. Let’s get that working.
如果你想讓某個函式返回一些資料,而不是隱式的nil,你就需要一個return語句。我們來完成它。
compiler.c,在statement()方法中新增程式碼:
ifStatement();
// 新增部分開始
} else if (match(TOKEN_RETURN)) {
returnStatement();
// 新增部分結束
} else if (match(TOKEN_WHILE)) {
When the compiler sees a
returnkeyword, it goes here:
當編譯器看到return關鍵字時,會進入這裡:
compiler.c,在printStatement()方法後新增程式碼:
static void returnStatement() {
if (match(TOKEN_SEMICOLON)) {
emitReturn();
} else {
expression();
consume(TOKEN_SEMICOLON, "Expect ';' after return value.");
emitByte(OP_RETURN);
}
}
The return value expression is optional, so the parser looks for a semicolon token to tell if a value was provided. If there is no return value, the statement implicitly returns
nil. We implement that by callingemitReturn(), which emits anOP_NILinstruction. Otherwise, we compile the return value expression and return it with anOP_RETURNinstruction.
返回值表示式是可選的,因此解析器會尋找分號標識來判斷是否提供了返回值。如果沒有返回值,語句會隱式地返回nil。我們透過呼叫emitReturn()來實現,該函式會生成一個OP_NIL指令。否則,我們編譯返回值表示式,並用OP_RETURN指令將其返回。
This is the same
OP_RETURNinstruction we’ve already implemented—we don’t need any new runtime code. This is quite a difference from jlox. There, we had to use exceptions to unwind the stack when areturnstatement was executed. That was because you could return from deep inside some nested blocks. Since jlox recursively walks the AST, that meant there were a bunch of Java method calls we needed to escape out of.
這與我們已經實現的OP_RETURN指令相同——我們不需要任何新的執行時程式碼。這與jlox有很大的不同。在jlox中,當執行return語句時,我們必須使用異常來跳出堆疊。這是因為你可以從某些巢狀的程式碼塊深處返回。因為jlox遞迴地遍歷AST。這意味著我們需要從一堆Java方法呼叫中退出。
Our bytecode compiler flattens that all out. We do recursive descent during parsing, but at runtime, the VM’s bytecode dispatch loop is completely flat. There is no recursion going on at the C level at all. So returning, even from within some nested blocks, is as straightforward as returning from the end of the function’s body.
我們的位元組碼編譯器把這些都扁平化了。我們在解析時進行遞迴下降,但在執行時,虛擬機器的位元組碼排程迴圈是完全扁平的。在C語言級別上根本沒有發生遞迴。因此,即使從一些巢狀程式碼塊中返回,也和從函式體的末端返回一樣簡單。
We’re not totally done, though. The new
returnstatement gives us a new compile error to worry about. Returns are useful for returning from functions but the top level of a Lox program is imperative code too. You shouldn’t be able to return from there.
不過,我們還沒有完全完成。新的return語句為我們帶來了一個新的編譯錯誤。return語句從函式中返回是很有用的,但是Lox程式的頂層程式碼也是命令式程式碼。你不能從那裡返回22。
return "What?!";
We’ve specified that it’s a compile error to have a
returnstatement outside of any function, which we implement like so:
我們已經規定,在任何函式之外有return語句都是編譯錯誤,我們這樣實現:
compiler.c,在returnStatement()方法中新增程式碼:
static void returnStatement() {
// 新增部分開始
if (current->type == TYPE_SCRIPT) {
error("Can't return from top-level code.");
}
// 新增部分結束
if (match(TOKEN_SEMICOLON)) {
This is one of the reasons we added that FunctionType enum to the compiler.
這是我們在編譯器中新增FunctionType列舉的原因之一。
24 . 7 Native Functions
24.7 本地函式
Our VM is getting more powerful. We’ve got functions, calls, parameters, returns. You can define lots of different functions that can call each other in interesting ways. But, ultimately, they can’t really do anything. The only user-visible thing a Lox program can do, regardless of its complexity, is print. To add more capabilities, we need to expose them to the user.
我們的虛擬機器越來越強大。我們已經支援了函式、呼叫、引數、返回。你可以定義許多不同的函式,它們可以以有趣的方式相互呼叫。但是,最終,它們什麼都做不了。不管Lox程式有多複雜,它唯一能做的使用者可見的事情就是列印。為了新增更多的功能,我們需要將函式暴露給使用者。
A programming language implementation reaches out and touches the material world through native functions. If you want to be able to write programs that check the time, read user input, or access the file system, we need to add native functions—callable from Lox but implemented in C—that expose those capabilities.
程式語言的實現透過本地函式向外延伸並接觸物質世界。如果你想編寫檢查時間、讀取使用者輸入或訪問檔案系統的程式,則需要新增本地函式——可以從Lox呼叫,但是使用C語言實現——來暴露這些能力。
At the language level, Lox is fairly complete—it’s got closures, classes, inheritance, and other fun stuff. One reason it feels like a toy language is because it has almost no native capabilities. We could turn it into a real language by adding a long list of them.
在語言層面,Lox是相當完整的——它支援閉包、類、繼承和其它有趣的東西。它之所以給人一種玩具語言的感覺,是因為它幾乎沒有原生功能。我們可以透過新增一系列功能將其變成一種真正的語言。
However, grinding through a pile of OS operations isn’t actually very educational. Once you’ve seen how to bind one piece of C code to Lox, you get the idea. But you do need to see one, and even a single native function requires us to build out all the machinery for interfacing Lox with C. So we’ll go through that and do all the hard work. Then, when that’s done, we’ll add one tiny native function just to prove that it works.
然而,辛辛苦苦地完成一堆作業系統的操作,實際上並沒有什麼教育意義。只要你看到如何將一段C程式碼與Lox繫結,你就會明白了。但你確實需要看到一個例子,即使只是一個本地函式,我們也需要構建將Lox與C語言對接的所有機制。所以我們將詳細討論這個問題並完成所有困難的工作。等這些工作完成之後,我們會新增一個小小的本地函式,以證明它是可行的。
The reason we need new machinery is because, from the implementation’s perspective, native functions are different from Lox functions. When they are called, they don’t push a CallFrame, because there’s no bytecode code for that frame to point to. They have no bytecode chunk. Instead, they somehow reference a piece of native C code.
我們需要新機制的原因是,從實現的角度來看,本地函式與Lox函式不同。當它們被呼叫時,它們不會壓入一個CallFrame,因為沒有這個幀要指向的位元組碼。它們沒有位元組碼塊。相反,它們會以某種方式引用一段本地C程式碼。
We handle this in clox by defining native functions as an entirely different object type.
在clox中,我們透過將本地函式定義為一個完全不同的物件型別來處理這個問題。
object.h,在結構體ObjFunction後新增程式碼:
} ObjFunction;
// 新增部分開始
typedef Value (*NativeFn)(int argCount, Value* args);
typedef struct {
Obj obj;
NativeFn function;
} ObjNative;
// 新增部分結束
struct ObjString {
The representation is simpler than ObjFunction—merely an Obj header and a pointer to the C function that implements the native behavior. The native function takes the argument count and a pointer to the first argument on the stack. It accesses the arguments through that pointer. Once it’s done, it returns the result value.
其表示形式比ObjFunction更簡單——僅僅是一個Obj頭和一個指向實現本地行為的C函式的指標。該本地函式接受引數數量和指向棧中第一個引數的指標。它透過該指標訪問引數。一旦執行完成,它就返回結果值。
As always, a new object type carries some accoutrements with it. To create an ObjNative, we declare a constructor-like function.
一如既往,一個新的物件型別會帶有一些附屬品。為了建立ObjNative,我們宣告一個類似構造器的函式。
object.h,在newFunction()方法後新增程式碼:
ObjFunction* newFunction();
// 新增部分開始
ObjNative* newNative(NativeFn function);
// 新增部分結束
ObjString* takeString(char* chars, int length);
We implement that like so:
我們這樣實現它:
object.c,在newFunction()方法後新增程式碼:
ObjNative* newNative(NativeFn function) {
ObjNative* native = ALLOCATE_OBJ(ObjNative, OBJ_NATIVE);
native->function = function;
return native;
}
The constructor takes a C function pointer to wrap in an ObjNative. It sets up the object header and stores the function. For the header, we need a new object type.
該建構函式接受一個C函式指標,並將其包裝在ObjNative中。它會設定物件頭並儲存傳入的函式。至於物件頭,我們需要一個新的物件型別。
object.h,在列舉ObjType中新增程式碼:
typedef enum {
OBJ_FUNCTION,
// 新增部分結束
OBJ_NATIVE,
// 新增部分開始
OBJ_STRING,
} ObjType;
The VM also needs to know how to deallocate a native function object.
虛擬機器也需要知道如何釋放本地函式物件。
memory.c,在freeObject()方法中新增程式碼:
}
// 新增部分開始
case OBJ_NATIVE:
FREE(ObjNative, object);
break;
// 新增部分結束
case OBJ_STRING: {
There isn’t much here since ObjNative doesn’t own any extra memory. The other capability all Lox objects support is being printed.
因為ObjNative並沒有佔用任何額外的記憶體,所以這裡沒有太多要做的。所有Lox物件需要支援的另一個功能是能夠被列印。
object.c,在printObject()方法中新增程式碼:
break;
// 新增部分開始
case OBJ_NATIVE:
printf("<native fn>");
break;
// 新增部分結束
case OBJ_STRING:
In order to support dynamic typing, we have a macro to see if a value is a native function.
為了支援動態型別,我們用一個宏來檢查某個值是否本地函式。
object.h,新增程式碼:
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
// 新增部分開始
#define IS_NATIVE(value) isObjType(value, OBJ_NATIVE)
// 新增部分結束
#define IS_STRING(value) isObjType(value, OBJ_STRING)
Assuming that returns true, this macro extracts the C function pointer from a Value representing a native function:
如果返回值為真,下面這個宏可以從一個代表本地函式的Value中提取C函式指標:
object.h,新增程式碼:
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
// 新增部分開始
#define AS_NATIVE(value) \
(((ObjNative*)AS_OBJ(value))->function)
// 新增部分結束
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
All of this baggage lets the VM treat native functions like any other object. You can store them in variables, pass them around, throw them birthday parties, etc. Of course, the operation we actually care about is calling them—using one as the left-hand operand in a call expression.
所有這些使得虛擬機器可以像對待其它物件一樣對待本地函式。你可以將它們儲存在變數中,傳遞它們,給它們舉辦生日派對,等等。當然,我們真正關心的是呼叫它們——將一個本地函式作為呼叫表示式的左運算元。
Over in
callValue()we add another type case.
在 callValue()中,我們新增另一個型別的case分支。
vm.c,在callValue()方法中新增程式碼:
case OBJ_FUNCTION:
return call(AS_FUNCTION(callee), argCount);
// 新增部分開始
case OBJ_NATIVE: {
NativeFn native = AS_NATIVE(callee);
Value result = native(argCount, vm.stackTop - argCount);
vm.stackTop -= argCount + 1;
push(result);
return true;
}
// 新增部分結束
default:
If the object being called is a native function, we invoke the C function right then and there. There’s no need to muck with CallFrames or anything. We just hand off to C, get the result, and stuff it back in the stack. This makes native functions as fast as we can get.
如果被呼叫的物件是一個本地函式,我們就會立即呼叫C函式。沒有必要使用CallFrames或其它任何東西。我們只需要交給C語言,得到結果,然後把結果塞回棧中。這使得本地函式的執行速度能夠儘可能快。
With this, users should be able to call native functions, but there aren’t any to call. Without something like a foreign function interface, users can’t define their own native functions. That’s our job as VM implementers. We’ll start with a helper to define a new native function exposed to Lox programs.
有了這個,使用者應該能夠呼叫本地函式了,但是還沒有任何函式可供呼叫。如果沒有外部函式介面之類的東西,使用者就不能定義自己的本地函式。這就是我們作為虛擬機器實現者的工作。我們將從一個輔助函式開始,定義一個新的本地函式暴露給Lox程式。
vm.c,在runtimeError()方法後新增程式碼:
static void defineNative(const char* name, NativeFn function) {
push(OBJ_VAL(copyString(name, (int)strlen(name))));
push(OBJ_VAL(newNative(function)));
tableSet(&vm.globals, AS_STRING(vm.stack[0]), vm.stack[1]);
pop();
pop();
}
It takes a pointer to a C function and the name it will be known as in Lox. We wrap the function in an ObjNative and then store that in a global variable with the given name.
它接受一個指向C函式的指標及其在Lox中的名稱。我們將函式包裝在ObjNative中,然後將其儲存在一個帶有指定名稱的全域性變數中。
You’re probably wondering why we push and pop the name and function on the stack. That looks weird, right? This is the kind of stuff you have to worry about when garbage collection gets involved. Both
copyString()andnewNative()dynamically allocate memory. That means once we have a GC, they can potentially trigger a collection. If that happens, we need to ensure the collector knows we’re not done with the name and ObjFunction so that it doesn’t free them out from under us. Storing them on the value stack accomplishes that.
你可能像知道為什麼我們要在棧中壓入和彈出名稱與函式。看起來很奇怪,是吧?當涉及到垃圾回收時,你必須考慮這類問題。copyString()和newNative()都是動態分配記憶體的。這意味著一旦我們有了GC,它們就有可能觸發一次收集。如果發生這種情況,我們需要確保收集器知道我們還沒有用完名稱和ObjFunction ,這樣垃圾回收就不會將這些資料從我們手下釋放出來。將它們儲存在值棧中可以做到這一點23。
It feels silly, but after all of that work, we’re going to add only one little native function.
這感覺很傻,但是在完成所有這些工作之後,我們只會新增一個小小的本地函式。
vm.c,在變數vm後新增程式碼:
static Value clockNative(int argCount, Value* args) {
return NUMBER_VAL((double)clock() / CLOCKS_PER_SEC);
}
This returns the elapsed time since the program started running, in seconds. It’s handy for benchmarking Lox programs. In Lox, we’ll name it
clock().
該函式會返回程式開始執行以來經過的時間,單位是秒。它對Lox程式的基準測試很有幫助。在Lox中,我們將其命名為clock()。
vm.c,在initVM()方法中新增程式碼:
initTable(&vm.strings);
// 新增部分開始
defineNative("clock", clockNative);
// 新增部分結束
}
To get to the C standard library
clock()function, the “vm” module needs an include.
為了獲得C語言標準庫中的clock()函式,vm模組需要引入標頭檔案。
vm.c,新增程式碼:
#include <string.h>
// 新增部分開始
#include <time.h>
// 新增部分結束
#include "common.h"
That was a lot of material to work through, but we did it! Type this in and try it out:
這部分有很多內容要處理,但是我們做到了!輸入這段程式碼試試:
fun fib(n) {
if (n < 2) return n;
return fib(n - 2) + fib(n - 1);
}
var start = clock();
print fib(35);
print clock() - start;
We can write a really inefficient recursive Fibonacci function. Even better, we can measure just how inefficient it is. This is, of course, not the smartest way to calculate a Fibonacci number. But it is a good way to stress test a language implementation’s support for function calls. On my machine, running this in clox is about five times faster than in jlox. That’s quite an improvement.
我們已經可以編寫一個非常低效的遞迴斐波那契函式。更妙的是,我們可以測量它有多低效。當然,這不是計算斐波那契數的最聰明的方法,但這是一個針對語言實現對函式呼叫的支援進行壓力測試的好方法。在我的機器上,clox中執行這個程式大約比jlox快5倍。這是個相當大的提升24。
習題
-
Reading and writing the
ipfield is one of the most frequent operations inside the bytecode loop. Right now, we access it through a pointer to the current CallFrame. That requires a pointer indirection which may force the CPU to bypass the cache and hit main memory. That can be a real performance sink.Ideally, we’d keep the
ipin a native CPU register. C doesn’t let us require that without dropping into inline assembly, but we can structure the code to encourage the compiler to make that optimization. If we store theipdirectly in a C local variable and mark itregister, there’s a good chance the C compiler will accede to our polite request.This does mean we need to be careful to load and store the local
ipback into the correct CallFrame when starting and ending function calls. Implement this optimization. Write a couple of benchmarks and see how it affects the performance. Do you think the extra code complexity is worth it?讀寫
ip欄位是位元組碼迴圈中最頻繁的操作之一。新增,我們透過一個指向當前CallFrame的指標來訪問它。這裡需要一次指標間接引用,可能會迫使CPU繞過快取而進入主存。這可能是一個真正的效能損耗。理想情況下,我們一個將
ip儲存在一個本地CPU暫存器中。在不引入內聯彙編的情況下,C語言中不允許我們這樣做,但是我們可以透過結構化的程式碼來鼓勵編譯器進行最佳化。如果我們將ip直接儲存在C區域性變數中,並將其標記為register,那麼C編譯器很可能會同意我們的禮貌請求。這確實意味著在開始和結束函式呼叫時,我們需要謹慎地從正確的CallFrame中載入和儲存區域性變數
ip。請實現這一最佳化。寫幾個基準測試,看看它對效能有什麼影響。您認為增加的程式碼複雜性值得嗎? -
Native function calls are fast in part because we don’t validate that the call passes as many arguments as the function expects. We really should, or an incorrect call to a native function without enough arguments could cause the function to read uninitialized memory. Add arity checking.
本地函式呼叫之所以快,部分原因是我們沒有驗證呼叫時傳入的引數是否與期望的一樣多。我們確實應該這樣做,否則在沒有足夠引數的情況下錯誤地呼叫本地函式,會導致函數讀取未初始化的記憶體空間。請新增引數數量檢查。
-
Right now, there’s no way for a native function to signal a runtime error. In a real implementation, this is something we’d need to support because native functions live in the statically typed world of C but are called from dynamically typed Lox land. If a user, say, tries to pass a string to
sqrt(), that native function needs to report a runtime error.Extend the native function system to support that. How does this capability affect the performance of native calls?
目前,本機函式還沒有辦法發出執行時錯誤的訊號。在一個真正的語言實現中,這是我們需要支援的,因為本機函式存在於靜態型別的C語言世界中,卻被動態型別的Lox呼叫。假如說,使用者試圖向
sqrt()傳遞一個字串,則該本地函式需要報告一個執行時錯誤。擴充套件本地函式系統,以支援該功能。這個功能會如何影響本地呼叫的效能?
-
Add some more native functions to do things you find useful. Write some programs using those. What did you add? How do they affect the feel of the language and how practical it is?
新增一些本地函式來做你認為有用的事情。用它們寫一些程式。你添加了什麼?它們是如何影響語言的感覺和實用性的?
-
人們似乎並不覺得數值型的位元組碼偏移量在崩潰轉儲中特別有意義。 ↩
-
我們不需要顯式地釋放函式名稱,因為它是一個ObjString。這意味著我們可以讓垃圾收集器為我們管理它的生命週期。或者說,至少在實現垃圾收集器之後,我們就可以這樣做了。 ↩
-
這種類比在語義上有個行不通的地方就是全域性變數。它們具有與區域性變數不同的特殊作用域規則,因此從這個角度來說,指令碼的頂層並不像一個函式體。 ↩
-
這就像我有一個可以看到未來的水晶球,知道我們以後需要修改程式碼。但是,實際上,這是因為我在寫文字之前已經寫了本書中的所有程式碼。 ↩
-
我知道,讓
function欄位為空,但在幾行之後又立即為其賦值,這看起來很蠢。更像是與垃圾回收有關的偏執。 ↩ -
我們可以在編譯時建立函式,是因為它們只包含編譯時可用的資料。函式的程式碼、名稱和元都是固定的。等我們在下一章中新增閉包時(在執行時捕獲變數),情況就變得更加複雜了。 ↩
-
如果我們用來尋找bug的診斷程式碼本身導致虛擬機器發生故障,那就不好玩了。 ↩
-
這基本就是你在C語言中使用
static宣告每個區域性變數的結果。 ↩ -
Fortran完全不允許遞迴,從而避免了這個問題。遞迴在當時被認為是一種高階、深奧的特性。 ↩
-
我說“想象”是因為編譯器實際上無法弄清這一點。因為函式在Lox中是一等公民,我們無法在編譯時確定哪些函式呼叫了哪些函式。 ↩
-
早期Fortran編譯器的作者在實現返回地址方面有一個巧妙的技巧。由於它們不支援遞迴,任何給定的函式在任何時間點都只需要一個返回地址。因此,當函式在執行時被呼叫時,程式會修改自己的程式碼,更改函式末尾的跳轉指標,以跳回呼叫方。有時候,天才和瘋子之間只有一線之隔。 ↩
-
許多Lisp實現都是動態地分配堆疊幀的,因為它簡化實現了續延。如果你的語言支援續延,那麼函式呼叫並不一定具有堆疊語義。 ↩
-
如果除了區域性變數之外,還有足夠多的臨時變數,仍然有可能溢位堆疊。一個健壯的實現可以防止這種情況,但我想盡量保持簡單。 ↩
-
我們可以透過每次檢視CallFrame陣列來訪問當前幀,但這太繁瑣了。更重要的是,將幀儲存在一個區域性變數中,可以促使C編譯器將該指標儲存在一個暫存器中。這樣就能加快對幀中
ip的訪問。我們不能保證編譯器會這樣做,但很有可能會這樣做。 ↩ -
這裡的
beginScope()並沒有對應的endScope()呼叫。因為當達到函式體的末尾時,我們會完全結束整個Compiler,所以沒必要關閉逗留的最外層作用域。 ↩ -
請記住,編譯器將頂層程式碼視為隱式函式的主體,因此只要新增任何函式宣告,我們就會進入一個巢狀函式的世界。 ↩
-
使用本地堆疊儲存編譯器結構體確實意味著我們的編譯器對函式宣告的巢狀深度有一個實際限制。如果巢狀太多,可能會導致C語言堆疊溢位。如果我們想讓編譯器能夠更健壯地抵禦錯誤甚至惡意的程式碼(這是JavaScript虛擬機器等工具真正關心的問題),那麼最好是人為地讓編譯器限制所允許的函式巢狀層級。 ↩
-
不同的位元組碼虛擬機器和真實的CPU架構有不同的呼叫約定,也就是它們傳遞引數、儲存返回地址等的具體機制。我在這裡使用的機制是基於Lua乾淨、快速的虛擬機器。 ↩
-
使用
switch語句來檢查一個型別現在看有些多餘,但當我們新增case來處理其它呼叫型別時,就有意義了。 ↩ -
這裡的
-1是因為IP已經指向了下一條待執行的指令上 ,但我們希望堆疊跟蹤指向前一條失敗的指令。 ↩ -
關於棧幀在跟蹤資訊中顯示的順序,存在一些不同的意見。大部分把最內部的函式放在第一行,然後向堆疊的底部。Python則以相反的順序打印出來。因此,從上到下閱讀可以告訴你程式是如何達到現在的位置的,而最後一行是錯誤實際發生的地方。
這種風格有一個邏輯。它可以確保你始終可以看到最裡面的函式,即使堆疊跟蹤資訊太長而無法在一個螢幕上顯示。另一方面,新聞業中的“倒金字塔”告訴我們,我們應該把最重要的資訊放在一段文字的前面。在堆疊跟蹤中,這就是實際發生錯誤的函式。大多數其它語言的實現都是如此。 ↩ -
允許在頂層返回並不是世界上最糟糕的主意。它可以為你提供一種自然的方式來提前終止指令碼。你甚至可以用返回的數字來表示程序的退出碼。 ↩
-
如果你沒搞懂也不用擔心,一旦我們開始實現GC,它就會變得更有意義。 ↩
-
它比在Ruby 2.4.3p205中執行的同類Ruby程式稍慢,比在Python 3.7.3中執行的程式快3倍左右。而且我們仍然可以在我們的虛擬機器中做很多簡單的最佳化。 ↩
25.閉包 Closures
As the man said, for every complex problem there’s a simple solution, and it’s wrong.
——Umberto Eco, Foucault’s Pendulum
正如那人所說,每一個複雜的問題都有一個簡單的解決方案,而且是錯誤的。(翁貝託·艾柯,《傅科擺》)
Thanks to our diligent labor in the last chapter, we have a virtual machine with working functions. What it lacks is closures. Aside from global variables, which are their own breed of animal, a function has no way to reference a variable declared outside of its own body.
感謝我們在上一章的辛勤勞動,我們得到了一個擁有函式的虛擬機器。現在虛擬機器缺失的是閉包。除了全域性變數(也就是函式的同類)之外,函式沒有辦法引用其函式體之外宣告的變數。
var x = "global";
fun outer() {
var x = "outer";
fun inner() {
print x;
}
inner();
}
outer();
Run this example now and it prints “global”. It’s supposed to print “outer”. To fix this, we need to include the entire lexical scope of all surrounding functions when resolving a variable.
現在執行這個示例,它列印的是“global”。但它應該列印“outer”。為瞭解決這個問題,我們需要在解析變數時涵蓋所有外圍函式的整個詞法作用域。
This problem is harder in clox than it was in jlox because our bytecode VM stores locals on a stack. We used a stack because I claimed locals have stack semantics—variables are discarded in the reverse order that they are created. But with closures, that’s only mostly true.
這個問題在clox中比在jlox中更難解決,因為我們的位元組碼虛擬機器將區域性變數儲存在棧中。我們使用堆疊是因為,我聲稱區域性變數具有棧語義——變數被丟棄的順序與建立的順序正好相反。但對於閉包來說,這隻在大部分情況下是正確的。
fun makeClosure() {
var local = "local";
fun closure() {
print local;
}
return closure;
}
var closure = makeClosure();
closure();
The outer function
makeClosure()declares a variable,local. It also creates an inner function,closure()that captures that variable. ThenmakeClosure()returns a reference to that function. Since the closure escapes while holding on to the local variable,localmust outlive the function call where it was created.
外層函式makeClosure()宣告瞭一個變數local。它還建立了一個內層函式closure(),用於捕獲該變數。然後makeClosure()返回對該內層函式的引用。因為閉包要在保留區域性變數的同時進行退出,所以local必須比建立它的函式呼叫存活更長的時間。

We could solve this problem by dynamically allocating memory for all local variables. That’s what jlox does by putting everything in those Environment objects that float around in Java’s heap. But we don’t want to. Using a stack is really fast. Most local variables are not captured by closures and do have stack semantics. It would suck to make all of those slower for the benefit of the rare local that is captured.
我們可以透過為所有區域性變數動態地分配記憶體來解決這個問題。這就是jlox所做的,它將所有物件都放在Java堆中漂浮的Environment物件中。但我們並不想這樣做。使用堆疊非常快。大多數區域性變數都不會被閉包捕獲,並且具有棧語義。如果為了極少數被捕獲的區域性變數而使所有變數的速度變慢,那就糟糕了1。
This means a more complex approach than we used in our Java interpreter. Because some locals have very different lifetimes, we will have two implementation strategies. For locals that aren’t used in closures, we’ll keep them just as they are on the stack. When a local is captured by a closure, we’ll adopt another solution that lifts them onto the heap where they can live as long as needed.
這意味著一種比我們在Java直譯器中所用的更復雜的方法。因為有些區域性變數具有非常不同的生命週期,我們將有兩種實現策略。對於那些不在閉包中使用的區域性變數,我們將保持它們在棧中的原樣。當某個區域性變數被閉包捕獲時,我們將採用另一種解決方案,將它們提升到堆中,在那裡它們存活多久都可以。
Closures have been around since the early Lisp days when bytes of memory and CPU cycles were more precious than emeralds. Over the intervening decades, hackers devised all manner of ways to compile closures to optimized runtime representations. Some are more efficient but require a more complex compilation process than we could easily retrofit into clox.
閉包早在Lisp時代就已經存在了,當時記憶體位元組和CPU週期比祖母綠還要珍貴。在過去的幾十年裡,駭客們設計了各種各樣的方式來編譯閉包,以最佳化執行時表示2。有些方法更有效,但也需要更復雜的編譯過程,我們無法輕易地在clox中加以改造。
The technique I explain here comes from the design of the Lua VM. It is fast, parsimonious with memory, and implemented with relatively little code. Even more impressive, it fits naturally into the single-pass compilers clox and Lua both use. It is somewhat intricate, though. It might take a while before all the pieces click together in your mind. We’ll build them one step at a time, and I’ll try to introduce the concepts in stages.
我在這裡解釋的技術來自於Lua虛擬機器的設計。它速度快,記憶體佔用少,並且只用相對較少的程式碼就實現了。更令人印象深刻的是,它很自然地適用於clox和Lua都在使用的單遍編譯器。不過,它有些複雜,可能需要一段時間才能把所有的碎片在你的腦海中拼湊起來。我們將一步一步地構建它們,我將嘗試分階段介紹這些概念。
25 . 1 Closure Objects
25.1 閉包物件
Our VM represents functions at runtime using ObjFunction. These objects are created by the front end during compilation. At runtime, all the VM does is load the function object from a constant table and bind it to a name. There is no operation to “create” a function at runtime. Much like string and number literals, they are constants instantiated purely at compile time.
我們的虛擬機器在執行時使用ObjFunction表示函式。這些物件是由前端在編譯時建立的。在執行時,虛擬機器所做的就是從一個常量表中載入函式物件,並將其與一個名稱繫結。在執行時,沒有“建立”函式的操作。與字串和數字字面量一樣,它們是純粹在編譯時例項化的常量3。
That made sense because all of the data that composes a function is known at compile time: the chunk of bytecode compiled from the function’s body, and the constants used in the body. Once we introduce closures, though, that representation is no longer sufficient. Take a gander at:
這是有道理的,因為組成函式的所有資料在編譯時都是已知的:根據函式主體編譯的位元組碼塊,以及函式主體中使用的常量。一旦我們引入閉包,這種表示形式就不夠了。請看一下:
fun makeClosure(value) {
fun closure() {
print value;
}
return closure;
}
var doughnut = makeClosure("doughnut");
var bagel = makeClosure("bagel");
doughnut();
bagel();
The
makeClosure()function defines and returns a function. We call it twice and get two closures back. They are created by the same nested function declaration,closure, but close over different values. When we call the two closures, each prints a different string. That implies we need some runtime representation for a closure that captures the local variables surrounding the function as they exist when the function declaration is executed, not just when it is compiled.
makeClosure()函式會定義並返回一個函式。我們呼叫它兩次,得到兩個閉包。它們都是由相同的巢狀函式宣告closure建立的,但關閉在不同的值上。當我們呼叫這兩個閉包時,每個閉包都打印出不同的字串。這意味著我們需要一些閉包執行時表示,以捕獲函式外圍的區域性變數,因為這些變數要在函式宣告被執行時存在,而不僅僅是在編譯時存在。
We’ll work our way up to capturing variables, but a good first step is defining that object representation. Our existing ObjFunction type represents the “raw” compile-time state of a function declaration, since all closures created from a single declaration share the same code and constants. At runtime, when we execute a function declaration, we wrap the ObjFunction in a new ObjClosure structure. The latter has a reference to the underlying bare function along with runtime state for the variables the function closes over.
我們會逐步來捕獲變數,但良好的第一步是定義物件表示形式。我們現有的ObjFunction型別表示了函式宣告的“原始”編譯時狀態,因為從同一個宣告中建立的所有閉包都共享相同的程式碼和常量。在執行時,當我們執行函式宣告時,我們將ObjFunction包裝進一個新的ObjClosure結構體中。後者有一個對底層裸函式的引用,以及該函式關閉的變數的執行時狀態4。

We’ll wrap every function in an ObjClosure, even if the function doesn’t actually close over and capture any surrounding local variables. This is a little wasteful, but it simplifies the VM because we can always assume that the function we’re calling is an ObjClosure. That new struct starts out like this:
我們將用ObjClosure包裝每個函式,即使該函式實際上並沒有關閉或捕獲任何外圍區域性變數。這有點浪費,但它簡化了虛擬機器,因為我們總是可以認為我們正在呼叫的函式是一個ObjClosure。這個新結構體是這樣開始的:
object.h,在結構體ObjString後新增程式碼:
typedef struct {
Obj obj;
ObjFunction* function;
} ObjClosure;
Right now, it simply points to an ObjFunction and adds the necessary object header stuff. Grinding through the usual ceremony for adding a new object type to clox, we declare a C function to create a new closure.
現在,它只是簡單地指向一個ObjFunction,並添加了必要的物件頭內容。遵循向clox中新增新物件型別的常規步驟,我們宣告一個C函式來建立新閉包。
object.h,在結構體ObjClosure後新增程式碼:
ObjFunction
// 新增部分開始
ObjClosure* newClosure(ObjFunction* function);
// 新增部分結束
ObjFunction* newFunction();
Then we implement it here:
然後我們在這裡實現它:
object.c,在allocateObject()方法後新增程式碼:
ObjClosure* newClosure(ObjFunction* function) {
ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE);
closure->function = function;
return closure;
}
It takes a pointer to the ObjFunction it wraps. It also initializes the type field to a new type.
它接受一個指向待包裝ObjFunction的指標。它還將型別欄位初始為一個新型別。
object.h,在列舉ObjType中新增程式碼:
typedef enum {
// 新增部分開始
OBJ_CLOSURE,
// 新增部分結束
OBJ_FUNCTION,
And when we’re done with a closure, we release its memory.
以及,當我們用完閉包後,要釋放其記憶體。
memory.c,在freeObject()方法中新增程式碼:
switch (object->type) {
// 新增部分開始
case OBJ_CLOSURE: {
FREE(ObjClosure, object);
break;
}
// 新增部分結束
case OBJ_FUNCTION: {
We free only the ObjClosure itself, not the ObjFunction. That’s because the closure doesn’t own the function. There may be multiple closures that all reference the same function, and none of them claims any special privilege over it. We can’t free the ObjFunction until all objects referencing it are gone—including even the surrounding function whose constant table contains it. Tracking that sounds tricky, and it is! That’s why we’ll write a garbage collector soon to manage it for us.
我們只釋放ObjClosure本身,而不釋放ObjFunction。這是因為閉包不擁有函式。可能會有多個閉包都引用了同一個函式,但沒有一個閉包聲稱對該函式有任何特殊的許可權。我們不能釋放某個ObjFunction,直到引用它的所有物件全部消失——甚至包括那些常量表中包含該函式的外圍函式。要跟蹤這個資訊聽起來很棘手,事實也的確如此!這就是我們很快就會寫一個垃圾收集器來管理它們的原因。
We also have the usual macros for checking a value’s type.
我們還有用於檢查值型別的常用宏5。
object.h,新增程式碼:
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
// 新增部分開始
#define IS_CLOSURE(value) isObjType(value, OBJ_CLOSURE)
// 新增部分結束
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
And to cast a value:
還有值轉換:
object.h,新增程式碼:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
// 新增部分開始
#define AS_CLOSURE(value) ((ObjClosure*)AS_OBJ(value))
// 新增部分結束
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
Closures are first-class objects, so you can print them.
閉包是第一類物件,因此你可以列印它們。
object.c,在printObject()方法中新增程式碼:
switch (OBJ_TYPE(value)) {
// 新增部分開始
case OBJ_CLOSURE:
printFunction(AS_CLOSURE(value)->function);
break;
// 新增部分結束
case OBJ_FUNCTION:
They display exactly as ObjFunction does. From the user’s perspective, the difference between ObjFunction and ObjClosure is purely a hidden implementation detail. With that out of the way, we have a working but empty representation for closures.
它們的顯示和ObjFunction一樣。從使用者的角度來看,ObjFunction和ObjClosure之間的區別純粹是一個隱藏的實現細節。有了這些,我們就有了一個可用但空白的閉包表示形式。
25 . 1 . 1 Compiling to closure objects
25.1.1 編譯為閉包物件
We have closure objects, but our VM never creates them. The next step is getting the compiler to emit instructions to tell the runtime when to create a new ObjClosure to wrap a given ObjFunction. This happens right at the end of a function declaration.
我們有了閉包物件,但是我們的VM還從未建立它們。下一步就是讓編譯器發出指令,告訴執行時何時建立一個新的ObjClosure來包裝指定的ObjFunction。這就發生在函式宣告的末尾。
compiler.c,在function()方法中替換1行:
ObjFunction* function = endCompiler();
// 替換部分開始
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
// 替換部分結束
}
Before, the final bytecode for a function declaration was a single
OP_CONSTANTinstruction to load the compiled function from the surrounding function’s constant table and push it onto the stack. Now we have a new instruction.
之前,函式宣告的最後一個位元組碼是一條OP_CONSTANT指令,用於從外圍函式的常量表中載入已編譯的函式,並將其壓入堆疊。現在我們有了一個新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_CALL,
// 新增部分開始
OP_CLOSURE,
// 新增部分結束
OP_RETURN,
Like
OP_CONSTANT, it takes a single operand that represents a constant table index for the function. But when we get over to the runtime implementation, we do something more interesting.
和OP_CONSTANT一樣,它接受一個運算元,表示函式在常量表中的索引。但是等到進入執行時實現時,我們會做一些更有趣的事情。
First, let’s be diligent VM hackers and slot in disassembler support for the instruction.
首先,讓我們做一個勤奮的虛擬機器駭客,為該指令新增反彙編器支援。
debug.c,在disassembleInstruction()方法中新增程式碼:
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
// 新增部分開始
case OP_CLOSURE: {
offset++;
uint8_t constant = chunk->code[offset++];
printf("%-16s %4d ", "OP_CLOSURE", constant);
printValue(chunk->constants.values[constant]);
printf("\n");
return offset;
}
// 新增部分結束
case OP_RETURN:
There’s more going on here than we usually have in the disassembler. By the end of the chapter, you’ll discover that
OP_CLOSUREis quite an unusual instruction. It’s straightforward right now—just a single byte operand—but we’ll be adding to it. This code here anticipates that future.
這裡做的事情比我們通常在反彙編程式中看到的要多。在本章結束時,你會發現OP_CLOSURE是一個相當不尋常的指令。它現在很簡單——只有一個單位元組的運算元——但我們會增加它的內容。這裡的程式碼預示了未來。
25 . 1 . 2 Interpreting function declarations
25.1.2 解釋函式宣告
Most of the work we need to do is in the runtime. We have to handle the new instruction, naturally. But we also need to touch every piece of code in the VM that works with ObjFunction and change it to use ObjClosure instead—function calls, call frames, etc. We’ll start with the instruction, though.
我們需要做的大部分工作是在執行時。我們必須處理新的指令,這是自然的。但是我們也需要觸及虛擬機器中每一段使用ObjFunction的程式碼,並將其改為使用ObjClosure——函式呼叫、呼叫幀,等等。不過,我們會從指令開始。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_CLOSURE: {
ObjFunction* function = AS_FUNCTION(READ_CONSTANT());
ObjClosure* closure = newClosure(function);
push(OBJ_VAL(closure));
break;
}
// 新增部分結束
case OP_RETURN: {
Like the
OP_CONSTANTinstruction we used before, first we load the compiled function from the constant table. The difference now is that we wrap that function in a new ObjClosure and push the result onto the stack.
與我們前面使用的OP_CONSTANT類似,首先從常量表中載入已編譯的函式。現在的不同之處在於,我們將該函式包裝在一個新的ObjClosure中,並將結果壓入堆疊。
Once you have a closure, you’ll eventually want to call it.
一旦你有了一個閉包,你最終就會想要呼叫它。
vm.c,在callValue()方法中替換2行:
switch (OBJ_TYPE(callee)) {
// 替換部分開始
case OBJ_CLOSURE:
return call(AS_CLOSURE(callee), argCount);
// 替換部分結束
case OBJ_NATIVE: {
We remove the code for calling objects whose type is
OBJ_FUNCTION. Since we wrap all functions in ObjClosures, the runtime will never try to invoke a bare ObjFunction anymore. Those objects live only in constant tables and get immediately wrapped in closures before anything else sees them.
我們刪除了呼叫OBJ_FUNCTION型別物件的程式碼。因為我們用ObjClosures包裝了所有的函式,執行時永遠不會再嘗試呼叫原生的ObjFunction。這些原生函式物件只存在於常量表中,並在其它部分看到它們之前立即被封裝在閉包中。
We replace the old code with very similar code for calling a closure instead. The only difference is the type of object we pass to
call(). The real changes are over in that function. First, we update its signature.
我們用非常相似的呼叫閉包的程式碼來代替舊程式碼。唯一的區別是傳遞給call()的型別。真正的變化在這個函式中。首先,我們更新它的簽名。
vm.c,在函式call()中,替換1行:
// 替換部分開始
static bool call(ObjClosure* closure, int argCount) {
// 替換部分結束
if (argCount != function->arity) {
Then, in the body, we need to fix everything that referenced the function to handle the fact that we’ve introduced a layer of indirection. We start with the arity checking:
然後,在主體中,我們需要修正所有引用該函式的內容,以便處理我們引入中間層的問題。首先從元數檢查開始:
vm.c,在call()方法中,替換3行:
static bool call(ObjClosure* closure, int argCount) {
// 替換部分開始
if (argCount != closure->function->arity) {
runtimeError("Expected %d arguments but got %d.",
closure->function->arity, argCount);
// 替換部分結束
return false;
The only change is that we unwrap the closure to get to the underlying function. The next thing
call()does is create a new CallFrame. We change that code to store the closure in the CallFrame and get the bytecode pointer from the closure’s function.
唯一的變化是,我們解開閉包獲得底層函式。call()做的下一件事是建立一個新的CallFrame。我們修改這段程式碼,將閉包儲存在CallFrame中,並從閉包內的函式中獲取位元組碼指標。
vm.c,在call()方法中,替換2行:
CallFrame* frame = &vm.frames[vm.frameCount++];
// 替換部分開始
frame->closure = closure;
frame->ip = closure->function->chunk.code;
// 替換部分結束
frame->slots = vm.stackTop - argCount - 1;
This necessitates changing the declaration of CallFrame too.
這就需要修改CallFrame的宣告。
vm.h,在結構體CallFrame中,替換1行:
typedef struct {
// 替換部分開始
ObjClosure* closure;
// 替換部分結束
uint8_t* ip;
That change triggers a few other cascading changes. Every place in the VM that accessed CallFrame’s function needs to use a closure instead. First, the macro for reading a constant from the current function’s constant table:
這一更改觸發了其它一些級聯更改。VM中所有訪問CallFrame中函式的地方都需要使用閉包來代替。首先,是從當前函式常量表中讀取常量的宏:
vm.c,在run()方法中,替換2行:
(uint16_t)((frame->ip[-2] << 8) | frame->ip[-1]))
// 替換部分開始
#define READ_CONSTANT() \
(frame->closure->function->chunk.constants.values[READ_BYTE()])
// 替換部分結束
#define READ_STRING() AS_STRING(READ_CONSTANT())
When
DEBUG_TRACE_EXECUTIONis enabled, it needs to get to the chunk from the closure.
當DEBUG_TRACE_EXECUTION被啟用時,它需要從閉包中獲取位元組碼塊。
vm.c,在run()方法中,替換2行:
printf("\n");
// 替換部分開始
disassembleInstruction(&frame->closure->function->chunk,
(int)(frame->ip - frame->closure->function->chunk.code));
// 替換部分結束
#endif
Likewise when reporting a runtime error:
同樣地,在報告執行時錯誤時也是如此:
vm.c,在runtimeError()方法中,替換1行:
CallFrame* frame = &vm.frames[i];
// 替換部分開始
ObjFunction* function = frame->closure->function;
// 替換部分結束
size_t instruction = frame->ip - function->chunk.code - 1;
Almost there. The last piece is the blob of code that sets up the very first CallFrame to begin executing the top-level code for a Lox script.
差不多完成了。最後一部分是用來設定第一個CallFrame以開始執行Lox指令碼頂層程式的程式碼塊。
vm.c,在interpret()方法中,替換1行6:
push(OBJ_VAL(function));
// 替換部分開始
ObjClosure* closure = newClosure(function);
pop();
push(OBJ_VAL(closure));
call(closure, 0);
// 替換部分結束
return run();
The compiler still returns a raw ObjFunction when compiling a script. That’s fine, but it means we need to wrap it in an ObjClosure here, before the VM can execute it.
編譯指令碼時,編譯器仍然返回一個原始的ObjFunction。這是可以的,但這意味著我們現在(也就是在VM能夠執行它之前),需要將其包裝在一個ObjClosure中。
We are back to a working interpreter. The user can’t tell any difference, but the compiler now generates code telling the VM to create a closure for each function declaration. Every time the VM executes a function declaration, it wraps the ObjFunction in a new ObjClosure. The rest of the VM now handles those ObjClosures floating around. That’s the boring stuff out of the way. Now we’re ready to make these closures actually do something.
我們又得到了一個可以工作的直譯器。使用者看不出有什麼不同,但是編譯器現在生成的程式碼會告訴虛擬機器,為每一個函式宣告建立一個閉包。每當VM執行一個函式宣告時,它都會將ObjFunction包裝在一個新的ObjClosure中。VM的其餘部分會處理那些四處漂浮的ObjClosures。無聊的事情就到此為止吧。現在,我們準備讓這些閉包實際做一些事情。
25 . 2 Upvalues
25.2 上值
Our existing instructions for reading and writing local variables are limited to a single function’s stack window. Locals from a surrounding function are outside of the inner function’s window. We’re going to need some new instructions.
我們現有的讀寫區域性變數的指令只限於單個函式的棧視窗。來自外圍函式的區域性變數是在內部函式的視窗之外。我們需要一些新的指令。
The easiest approach might be an instruction that takes a relative stack slot offset that can reach before the current function’s window. That would work if closed-over variables were always on the stack. But as we saw earlier, these variables sometimes outlive the function where they are declared. That means they won’t always be on the stack.
最簡單的方法可能是一條指令,接受一個棧槽相對偏移量,可以訪問當前函式視窗之前的位置。如果閉包變數始終在棧上,這是有效的。但正如我們前面看到的,這些變數的生存時間有時會比宣告它們的函式更長。這意味著它們不會一直在棧中。
The next easiest approach, then, would be to take any local variable that gets closed over and have it always live on the heap. When the local variable declaration in the surrounding function is executed, the VM would allocate memory for it dynamically. That way it could live as long as needed.
然後,次簡單的方法是獲取閉包使用的任意區域性變數,並讓它始終存活在堆中。當執行外圍函式中的區域性變數宣告時,虛擬機器會為其動態分配記憶體。這樣一來,它就可以根據需要長期存活。
This would be a fine approach if clox didn’t have a single-pass compiler. But that restriction we chose in our implementation makes things harder. Take a look at this example:
如果clox不是單遍編譯器,這會是一種很好的方法。但是我們在實現中所選擇的這種限制使事情變得更加困難。看看這個例子:
fun outer() {
var x = 1; // (1)
x = 2; // (2)
fun inner() { // (3)
print x;
}
inner();
}
Here, the compiler compiles the declaration of
xat(1)and emits code for the assignment at(2). It does that before reaching the declaration ofinner()at(3)and discovering thatxis in fact closed over. We don’t have an easy way to go back and fix that already-emitted code to treatxspecially. Instead, we want a solution that allows a closed-over variable to live on the stack exactly like a normal local variable until the point that it is closed over.
在這裡,編譯器在(1)處編譯了x的宣告,並在(2)處生成了賦值程式碼。這些發生在編譯器到達在(3)處的inner()宣告並發現x實際上被閉包引用之前。我們沒有一種簡單的方法來回溯並修復已生成的程式碼,以特殊處理x。相反,我們想要的解決方案是,在變數被關閉之前,允許它像常規的區域性變數一樣存在於棧中。
Fortunately, thanks to the Lua dev team, we have a solution. We use a level of indirection that they call an upvalue. An upvalue refers to a local variable in an enclosing function. Every closure maintains an array of upvalues, one for each surrounding local variable that the closure uses.
幸運的是,感謝Lua開發團隊,我們有了一個解決方案。我們使用一種他們稱之為上值的中間層。上值指的是一個閉包函式中的區域性變數。每個閉包都維護一個上值陣列,每個上值對應閉包使用的外圍區域性變數。
The upvalue points back into the stack to where the variable it captured lives. When the closure needs to access a closed-over variable, it goes through the corresponding upvalue to reach it. When a function declaration is first executed and we create a closure for it, the VM creates the array of upvalues and wires them up to “capture” the surrounding local variables that the closure needs.
上值指向棧中它所捕獲的變數所在的位置。當閉包需要訪問一個封閉的變數時,它會透過相應的上值(upvalues)得到該變數。當某個函式宣告第一次被執行,而且我們為其建立閉包時,虛擬機器會建立一個上值陣列,並將其與閉包連線起來,以“捕獲”閉包需要的外圍區域性變數。
For example, if we throw this program at clox,
舉個例子,如果我們把這個程式扔給clox
{
var a = 3;
fun f() {
print a;
}
}
the compiler and runtime will conspire together to build up a set of objects in memory like this:
編譯器和執行時會合力在記憶體中構建一組這樣的物件:

That might look overwhelming, but fear not. We’ll work our way through it. The important part is that upvalues serve as the layer of indirection needed to continue to find a captured local variable even after it moves off the stack. But before we get to all that, let’s focus on compiling captured variables.
這可能看起來讓人不知所措,但不要害怕。我們會用自己的方式來完成的。重要的部分是,上值充當了中間層,以便在被捕獲的區域性變數離開堆疊後能繼續找到它。但在此之前,讓我們先關注一下編譯捕獲的變數。
25 . 2 . 1 Compiling upvalues
25.2.1 編譯上值
As usual, we want to do as much work as possible during compilation to keep execution simple and fast. Since local variables are lexically scoped in Lox, we have enough knowledge at compile time to resolve which surrounding local variables a function accesses and where those locals are declared. That, in turn, means we know how many upvalues a closure needs, which variables they capture, and which stack slots contain those variables in the declaring function’s stack window.
像往常一樣,我們希望在編譯期間做盡可能多的工作,從而保持執行的簡單快速。由於區域性變數在Lox是具有詞法作用域的,我們在編譯時有足夠的資訊來確定某個函式訪問了哪些外圍的區域性變數,以及這些區域性變數是在哪裡宣告的。反過來,這意味著我們知道閉包需要多少個上值,它們捕獲了哪個變數,以及在宣告函式的棧視窗中的哪個棧槽中包含這些變數。
Currently, when the compiler resolves an identifier, it walks the block scopes for the current function from innermost to outermost. If we don’t find the variable in that function, we assume the variable must be a global. We don’t consider the local scopes of enclosing functions—they get skipped right over. The first change, then, is inserting a resolution step for those outer local scopes.
目前,當編譯器解析一個識別符號時,它會從最內層到最外層遍歷當前函式的塊作用域。如果我們沒有在函式中找到該變數,我們就假定該變數一定是一個全域性變數。我們不考慮封閉函式的區域性作用域——它們會被直接跳過。那麼,第一個變化就是為這些外圍區域性作用域插入一個解析步驟。
compiler.c,在namedVariable()方法中新增程式碼:
if (arg != -1) {
getOp = OP_GET_LOCAL;
setOp = OP_SET_LOCAL;
// 新增部分開始
} else if ((arg = resolveUpvalue(current, &name)) != -1) {
getOp = OP_GET_UPVALUE;
setOp = OP_SET_UPVALUE;
// 新增部分結束
} else {
This new
resolveUpvalue()function looks for a local variable declared in any of the surrounding functions. If it finds one, it returns an “upvalue index” for that variable. (We’ll get into what that means later.) Otherwise, it returns -1 to indicate the variable wasn’t found. If it was found, we use these two new instructions for reading or writing to the variable through its upvalue:
這個新的resolveUpvalue()函式會查詢在任何外圍函式中宣告的區域性變數。如果找到了,就會返回該變數的“上值索引”。(我們稍後會解釋這是什麼意思)否則,它會返回-1,表示沒有找到該變數。如果找到變數,我們就使用這兩條新指令,透過其上值對變數進行讀寫:
chunk.h,在列舉OpCode中新增程式碼:
OP_SET_GLOBAL,
// 新增部分開始
OP_GET_UPVALUE,
OP_SET_UPVALUE,
// 新增部分結束
OP_EQUAL,
We’re implementing this sort of top-down, so I’ll show you how these work at runtime soon. The part to focus on now is how the compiler actually resolves the identifier.
我們是自上而下實現的,所以我們很快會向你展示這些在執行時是如何工作的。現在要關注的部分是編譯器實際上是如何解析識別符號的。
compiler.c,在resolveLocal()方法後新增程式碼:
static int resolveUpvalue(Compiler* compiler, Token* name) {
if (compiler->enclosing == NULL) return -1;
int local = resolveLocal(compiler->enclosing, name);
if (local != -1) {
return addUpvalue(compiler, (uint8_t)local, true);
}
return -1;
}
We call this after failing to resolve a local variable in the current function’s scope, so we know the variable isn’t in the current compiler. Recall that Compiler stores a pointer to the Compiler for the enclosing function, and these pointers form a linked chain that goes all the way to the root Compiler for the top-level code. Thus, if the enclosing Compiler is
NULL, we know we’ve reached the outermost function without finding a local variable. The variable must be global, so we return -1.
在當前函式作用域中解析區域性變數失敗後,我們才會呼叫這個方法,因此我們知道該變數不在當前編譯器中。回顧一下,Compiler中儲存了一個指向外層函式Compiler的指標,這些指標形成了一個鏈,一直到頂層程式碼的根Compiler。因此,如果外圍的Compiler是NULL,我們就知道已經到達最外層的函式,而且沒有找到區域性變數。那麼該變數一定是全域性的7,所以我們返回-1。
Otherwise, we try to resolve the identifier as a local variable in the enclosing compiler. In other words, we look for it right outside the current function. For example:
否則,我們嘗試將識別符號解析為一個在外圍編譯器中的區域性變數。換句話說,我們在當前函式外面尋找它。舉例來說:
fun outer() {
var x = 1;
fun inner() {
print x; // (1)
}
inner();
}
When compiling the identifier expression at
(1),resolveUpvalue()looks for a local variablexdeclared inouter(). If found—like it is in this example—then we’ve successfully resolved the variable. We create an upvalue so that the inner function can access the variable through that. The upvalue is created here:
當在(1)處編譯識別符號表示式時,resolveUpvalue()會查詢在outer()中定義的區域性變數x。如果找到了(就像本例中這樣),那我們就成功解析了該變數。我們建立一個上值,以便內部函式可以透過它訪問變數。上值是在這裡建立的:
compiler.c,在resolveLocal()方法後新增程式碼:
static int addUpvalue(Compiler* compiler, uint8_t index,
bool isLocal) {
int upvalueCount = compiler->function->upvalueCount;
compiler->upvalues[upvalueCount].isLocal = isLocal;
compiler->upvalues[upvalueCount].index = index;
return compiler->function->upvalueCount++;
}
The compiler keeps an array of upvalue structures to track the closed-over identifiers that it has resolved in the body of each function. Remember how the compiler’s Local array mirrors the stack slot indexes where locals live at runtime? This new upvalue array works the same way. The indexes in the compiler’s array match the indexes where upvalues will live in the ObjClosure at runtime.
編譯器保留了一個上值結構的陣列,用以跟蹤每個函式主體中已解析的封閉識別符號。還記得編譯器的Local陣列是如何反映區域性變數在執行時所在的棧槽索引的嗎?這個新的上值陣列也使用相同的方式。編譯器陣列中的索引,與執行時ObjClosure中上值所在的索引相匹配。
This function adds a new upvalue to that array. It also keeps track of the number of upvalues the function uses. It stores that count directly in the ObjFunction itself because we’ll also need that number for use at runtime.
這個函式向陣列中添加了一個新的上值。它還記錄了該函式所使用的上值的數量。它直接在ObjFunction中儲存了這個計數值,因為我們在執行時也需要使用這個數字8。
The
indexfield tracks the closed-over local variable’s slot index. That way the compiler knows which variable in the enclosing function needs to be captured. We’ll circle back to what thatisLocalfield is for before too long. Finally,addUpvalue()returns the index of the created upvalue in the function’s upvalue list. That index becomes the operand to theOP_GET_UPVALUEandOP_SET_UPVALUEinstructions.
index欄位記錄了封閉區域性變數的棧槽索引。這樣,編譯器就知道需要捕獲外部函式中的哪個變數。用不了多久,我們會回過頭來討論isLocal欄位的用途。最後,addUpvalue()返回已建立的上值在函式的上值列表中的索引。這個索引會成為OP_GET_UPVALUE和OP_SET_UPVALUE指令的運算元。
That’s the basic idea for resolving upvalues, but the function isn’t fully baked. A closure may reference the same variable in a surrounding function multiple times. In that case, we don’t want to waste time and memory creating a separate upvalue for each identifier expression. To fix that, before we add a new upvalue, we first check to see if the function already has an upvalue that closes over that variable.
這就是解析上值的基本思路,但是這個函式還沒有完全成熟。一個閉包可能會多次引用外圍函式中的同一個變數。在這種情況下,我們不想浪費時間和記憶體來為每個識別符號表示式建立一個單獨的上值。為瞭解決這個問題,在我們新增新的上值之前,我們首先要檢查該函式是否已經有封閉該變數的上值。
compiler.c,在addUpvalue()方法中新增程式碼:
int upvalueCount = compiler->function->upvalueCount;
// 新增部分開始
for (int i = 0; i < upvalueCount; i++) {
Upvalue* upvalue = &compiler->upvalues[i];
if (upvalue->index == index && upvalue->isLocal == isLocal) {
return i;
}
}
// 新增部分結束
compiler->upvalues[upvalueCount].isLocal = isLocal;
If we find an upvalue in the array whose slot index matches the one we’re adding, we just return that upvalue index and reuse it. Otherwise, we fall through and add the new upvalue.
如果我們在陣列中找到與待新增的上值索引相匹配的上值,我們就返回該上值的索引並複用它。否則,我們就放棄,並新增新的上值。
These two functions access and modify a bunch of new state, so let’s define that. First, we add the upvalue count to ObjFunction.
這兩個函式訪問並修改了一些新的狀態,所以我們來定義一下。首先,我們將上值計數新增到ObjFunction中。
object.h,在結構體ObjFunction中新增程式碼:
int arity;
// 新增部分開始
int upvalueCount;
// 新增部分結束
Chunk chunk;
We’re conscientious C programmers, so we zero-initialize that when an ObjFunction is first allocated.
我們是負責的C程式設計師,所以當ObjFunction第一次被分配時,我們將其初始化為0。
object.c,在newFunction()方法中新增程式碼:
function->arity = 0;
// 新增部分開始
function->upvalueCount = 0;
// 新增部分結束
function->name = NULL;
In the compiler, we add a field for the upvalue array.
在編譯器中,我們新增一個欄位來儲存上值陣列。
compiler.c,在結構體Compiler中新增程式碼:
int localCount;
// 新增部分開始
Upvalue upvalues[UINT8_COUNT];
// 新增部分結束
int scopeDepth;
For simplicity, I gave it a fixed size. The
OP_GET_UPVALUEandOP_SET_UPVALUEinstructions encode an upvalue index using a single byte operand, so there’s a restriction on how many upvalues a function can have—how many unique variables it can close over. Given that, we can afford a static array that large. We also need to make sure the compiler doesn’t overflow that limit.
為了簡單起見,我給了它一個固定的大小。OP_GET_UPVALUE和OP_SET_UPVALUE指令使用一個單位元組運算元來編碼上值索引,所以一個函式可以有多少個上值(可以封閉多少個不同的變數)是有限制的。鑑於此,我們可以負擔得起這麼大的靜態陣列。我們還需要確保編譯器不會超出這個限制。
compiler.c,在addUpvalue()方法中新增程式碼:
if (upvalue->index == index && upvalue->isLocal == isLocal) {
return i;
}
}
// 新增部分開始
if (upvalueCount == UINT8_COUNT) {
error("Too many closure variables in function.");
return 0;
}
// 新增部分結束
compiler->upvalues[upvalueCount].isLocal = isLocal;
Finally, the Upvalue struct type itself.
最後,是Upvalue結構體本身。
compiler.c,在結構體Local後新增程式碼:
typedef struct {
uint8_t index;
bool isLocal;
} Upvalue;
The
indexfield stores which local slot the upvalue is capturing. TheisLocalfield deserves its own section, which we’ll get to next.
index欄位儲存了上值捕獲的是哪個區域性變數槽。isLocal欄位值得有自己的章節,我們接下來會講到。
25 . 2 . 2 Flattening upvalues
25.2.2 扁平化上值
In the example I showed before, the closure is accessing a variable declared in the immediately enclosing function. Lox also supports accessing local variables declared in any enclosing scope, as in:
在我之前展示的例子中,閉包訪問的是在緊鄰的外圍函式中宣告的變數。Lox還支援訪問在任何外圍作用域中宣告的區域性變數,如:
fun outer() {
var x = 1;
fun middle() {
fun inner() {
print x;
}
}
}
Here, we’re accessing
xininner(). That variable is defined not inmiddle(), but all the way out inouter(). We need to handle cases like this too. You might think that this isn’t much harder since the variable will simply be somewhere farther down on the stack. But consider this devious example:
這裡,我們在inner()中訪問x。這個變數不是在middle()中定義的,而是要一直追溯到outer()中。我們也需要處理這樣的情況。你可能認為這並不難,因為變數只是位於棧中更下面的某個位置。但是考慮一下這個複雜的例子:
If you work on programming languages long enough, you will develop a finely honed skill at creating bizarre programs like this that are technically valid but likely to trip up an implementation written by someone with a less perverse imagination than you.
如果你在程式語言方面工作的時間足夠長,你就會開發出一種精細的技能,能夠創造出像這樣的怪異程式,這些程式在技術上是有效的,但很可能會在一個由想象力沒你那麼變態的人編寫的實現中出錯。
fun outer() {
var x = "value";
fun middle() {
fun inner() {
print x;
}
print "create inner closure";
return inner;
}
print "return from outer";
return middle;
}
var mid = outer();
var in = mid();
in();
When you run this, it should print:
當你執行這段程式碼時,應該打印出來:
return from outer
create inner closure
value
I know, it’s convoluted. The important part is that
outer()—wherexis declared—returns and pops all of its variables off the stack before the declaration ofinner()executes. So, at the point in time that we create the closure forinner(),xis already off the stack.
我知道,這很複雜。重要的是,在inner()的宣告執行之前,outer()(x被宣告的地方)已經返回並彈出其所有變數。因此,在我們為inner()建立閉包時,x已經離開了堆疊。
Here, I traced out the execution flow for you:
下面,我為你繪製了執行流程:

See how
xis popped before it is captured and then later accessed ? We really have two problems:
看到了嗎,x在被捕獲②之前,先被彈出 ①,隨後又被訪問③?我們確實有兩個問題:
- We need to resolve local variables that are declared in surrounding functions beyond the immediately enclosing one.
- We need to be able to capture variables that have already left the stack.
- 我們需要解析在緊鄰的函式之外的外圍函式中宣告的區域性變數。
- 我們需要能夠捕獲已經離開堆疊的變數。
Fortunately, we’re in the middle of adding upvalues to the VM, and upvalues are explicitly designed for tracking variables that have escaped the stack. So, in a clever bit of self-reference, we can use upvalues to allow upvalues to capture variables declared outside of the immediately surrounding function.
幸運的是,我們正在向虛擬機器中新增上值,而上值是明確為跟蹤已退出棧的變數而設計的。因此,透過一個巧妙的自我引用,我們可以使用上值來允許上值捕獲緊鄰函式之外宣告的變數。
The solution is to allow a closure to capture either a local variable or an existing upvalue in the immediately enclosing function. If a deeply nested function references a local variable declared several hops away, we’ll thread it through all of the intermediate functions by having each function capture an upvalue for the next function to grab.
解決方案是允許閉包捕獲區域性變數或緊鄰函式中已有的上值。如果一個深度巢狀的函式引用了幾跳之外宣告的區域性變數,我們讓每個函式捕獲一個上值,供下一個函式抓取,從而穿透所有的中間函式。

In the above example,
middle()captures the local variablexin the immediately enclosing functionouter()and stores it in its own upvalue. It does this even thoughmiddle()itself doesn’t referencex. Then, when the declaration ofinner()executes, its closure grabs the upvalue from the ObjClosure formiddle()that capturedx. A function captures—either a local or upvalue—only from the immediately surrounding function, which is guaranteed to still be around at the point that the inner function declaration executes.
在上面的例子中,middle()捕獲了緊鄰的外層函式outer()中的區域性變數x,並將其儲存在自己的上值中。即使middle()本身不引用x,它也會這樣做。然後,當inner()的宣告執行時,它的閉包會從已捕獲x的middle()對應的ObjClosure中抓取上值。函式只會從緊鄰的外層函式中捕獲區域性變數或上值,因為這些值在內部函式宣告執行時仍然能夠確儲存在。
In order to implement this,
resolveUpvalue()becomes recursive.
為了實現這一點,resolveUpvalue()變成遞迴的。
compiler.c,在resolveUpvalue()方法中新增程式碼:
if (local != -1) {
return addUpvalue(compiler, (uint8_t)local, true);
}
// 新增部分開始
int upvalue = resolveUpvalue(compiler->enclosing, name);
if (upvalue != -1) {
return addUpvalue(compiler, (uint8_t)upvalue, false);
}
// 新增部分結束
return -1;
It’s only another three lines of code, but I found this function really challenging to get right the first time. This in spite of the fact that I wasn’t inventing anything new, just porting the concept over from Lua. Most recursive functions either do all their work before the recursive call (a pre-order traversal, or “on the way down”), or they do all the work after the recursive call (a post-order traversal, or “on the way back up”). This function does both. The recursive call is right in the middle.
這只是另外加了三行程式碼,但我發現這個函式真的很難一次就正確完成。儘管我並沒有發明什麼新東西,只是從Lua中移植了這個概念。大多數遞迴函式要麼在遞迴呼叫之前完成所有工作(先序遍歷,或“下行”),要麼在遞迴呼叫之後完成所有工作(後續遍歷,或“回退”)。這個函式兩者都是,遞迴呼叫就在中間。
We’ll walk through it slowly. First, we look for a matching local variable in the enclosing function. If we find one, we capture that local and return. That’s the base case.
我們來慢慢看一下。首先,我們在外部函式中查詢匹配的區域性變數。如果我們找到了,就捕獲該區域性變數並返回。這就是基本情況9。
Otherwise, we look for a local variable beyond the immediately enclosing function. We do that by recursively calling
resolveUpvalue()on the enclosing compiler, not the current one. This series ofresolveUpvalue()calls works its way along the chain of nested compilers until it hits one of the base cases—either it finds an actual local variable to capture or it runs out of compilers.
否則,我們會在緊鄰的函式之外尋找區域性變數。我們透過遞迴地對外層編譯器(而不是當前編譯器)呼叫resolveUpvalue()來實現這一點。這一系列的resolveUpvalue()呼叫沿著巢狀的編譯器鏈執行,直到遇見基本情況——要麼找到一個事件的區域性變數來捕獲,要麼是遍歷完了所有編譯器。
When a local variable is found, the most deeply nested call to
resolveUpvalue()captures it and returns the upvalue index. That returns to the next call for the inner function declaration. That call captures the upvalue from the surrounding function, and so on. As each nested call toresolveUpvalue()returns, we drill back down into the innermost function declaration where the identifier we are resolving appears. At each step along the way, we add an upvalue to the intervening function and pass the resulting upvalue index down to the next call.
當找到區域性變數時,巢狀最深的resolveUpvalue()呼叫會捕獲它並返回上值的索引。這就會返回到內層函式宣告對應的下一級呼叫。該呼叫會捕獲外層函式中的上值,以此類推。隨著對resolveUpvalue()的每個巢狀呼叫的返回,我們會往下鑽到最內層函式宣告,即我們正在解析的識別符號出現的地方。在這一過程中的每一步,我們都向中間函式新增一個上值,並將得到的上值索引向下傳遞給下一個呼叫10。
It might help to walk through the original example when resolving
x:
在解析x的時候,走一遍原始的例子可能會有幫助:

Note that the new call to
addUpvalue()passesfalsefor theisLocalparameter. Now you see that that flag controls whether the closure captures a local variable or an upvalue from the surrounding function.
請注意,對addUpvalue()的新呼叫為isLocal引數傳遞了false。現在你可以看到,該標誌控制著閉包捕獲的是區域性變數還是來自外圍函式的上值。
By the time the compiler reaches the end of a function declaration, every variable reference has been resolved as either a local, an upvalue, or a global. Each upvalue may in turn capture a local variable from the surrounding function, or an upvalue in the case of transitive closures. We finally have enough data to emit bytecode which creates a closure at runtime that captures all of the correct variables.
當編譯器到達函式宣告的結尾時,每個變數的引用都已經被解析為區域性變數、上值或全域性變數。每個上值可以依次從外圍函式中捕獲一個區域性變數,或者在傳遞閉包的情況下捕獲一個上值。我們終於有了足夠的資料來生成位元組碼,該位元組碼在執行時建立一個捕獲所有正確變數的閉包。
compiler.c,在function()方法中新增程式碼:
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
// 新增部分開始
for (int i = 0; i < function->upvalueCount; i++) {
emitByte(compiler.upvalues[i].isLocal ? 1 : 0);
emitByte(compiler.upvalues[i].index);
}
// 新增部分結束
}
The
OP_CLOSUREinstruction is unique in that it has a variably sized encoding. For each upvalue the closure captures, there are two single-byte operands. Each pair of operands specifies what that upvalue captures. If the first byte is one, it captures a local variable in the enclosing function. If zero, it captures one of the function’s upvalues. The next byte is the local slot or upvalue index to capture.
OP_CLOSURE指令的獨特之處在於,它是不定長編碼的。對於閉包捕獲的每個上值,都有兩個單位元組的運算元。每一對運算元都指定了上值捕獲的內容。如果第一個位元組是1,它捕獲的就是外層函式中的一個區域性變數。如果是0,它捕獲的是函式的一個上值。下一個位元組是要捕獲區域性變數插槽或上值索引。
This odd encoding means we need some bespoke support in the disassembly code for
OP_CLOSURE.
這種奇怪的編碼意味著我們需要在反彙編程式中對OP_CLOSURE提供一些定製化的支援。
debug.c,在disassembleInstruction()方法中新增程式碼:
printf("\n");
// 新增部分開始
ObjFunction* function = AS_FUNCTION(
chunk->constants.values[constant]);
for (int j = 0; j < function->upvalueCount; j++) {
int isLocal = chunk->code[offset++];
int index = chunk->code[offset++];
printf("%04d | %s %d\n",
offset - 2, isLocal ? "local" : "upvalue", index);
}
// 新增部分結束
return offset;
For example, take this script:
舉例來說,請看這個指令碼:
fun outer() {
var a = 1;
var b = 2;
fun middle() {
var c = 3;
var d = 4;
fun inner() {
print a + c + b + d;
}
}
}
If we disassemble the instruction that creates the closure for
inner(), it prints this:
如果我們反彙編為inner()建立閉包的指令,它會列印如下內容:
0004 9 OP_CLOSURE 2 <fn inner>
0006 | upvalue 0
0008 | local 1
0010 | upvalue 1
0012 | local 2
We have two other, simpler instructions to add disassembler support for.
我們還有兩條更簡單的指令需要新增反彙編支援。
debug.c,在disassembleInstruction()方法中新增程式碼:
case OP_SET_GLOBAL:
return constantInstruction("OP_SET_GLOBAL", chunk, offset);
// 新增部分開始
case OP_GET_UPVALUE:
return byteInstruction("OP_GET_UPVALUE", chunk, offset);
case OP_SET_UPVALUE:
return byteInstruction("OP_SET_UPVALUE", chunk, offset);
// 新增部分結束
case OP_EQUAL:
These both have a single-byte operand, so there’s nothing exciting going on. We do need to add an include so the debug module can get to
AS_FUNCTION().
這兩條指令都是單位元組運算元,所有沒有什麼有趣的內容。我們確實需要新增一個標頭檔案引入,以便除錯模組能夠訪問AS_FUNCTION()。
debug.c,新增程式碼:
#include "debug.h"
// 新增部分開始
#include "object.h"
// 新增部分結束
#include "value.h"
With that, our compiler is where we want it. For each function declaration, it outputs an
OP_CLOSUREinstruction followed by a series of operand byte pairs for each upvalue it needs to capture at runtime. It’s time to hop over to that side of the VM and get things running.
有了這些,我們的編譯器就達到了我們想要的效果。對於每個函式宣告,它都會輸出一條OP_CLOSURE指令,後跟一系列運算元位元組對,對應需要在執行時捕獲的每個上值。現在是時候跳到虛擬機器那邊,讓整個程式運轉起來。
25 . 3 Upvalue Objects
25.3 Upvalue物件
Each
OP_CLOSUREinstruction is now followed by the series of bytes that specify the upvalues the ObjClosure should own. Before we process those operands, we need a runtime representation for upvalues.
現在每條OP_CLOSURE指令後面都跟著一系列位元組,這些位元組指定了ObjClosure應該擁有的上值。在處理這些運算元之前,我們需要一個上值的執行時表示。
object.h,在結構體ObjString後新增程式碼:
typedef struct ObjUpvalue {
Obj obj;
Value* location;
} ObjUpvalue;
We know upvalues must manage closed-over variables that no longer live on the stack, which implies some amount of dynamic allocation. The easiest way to do that in our VM is by building on the object system we already have. That way, when we implement a garbage collector in the next chapter, the GC can manage memory for upvalues too.
我們知道上值必須管理已關閉的變數,這些變數不再存活於棧上,這意味著需要一些動態分配。在我們的虛擬機器中,最簡單的方法就是在已有的物件系統上進行構建。這樣,當我們在下一章中實現垃圾收集器時,GC也可以管理上值的記憶體。
Thus, our runtime upvalue structure is an ObjUpvalue with the typical Obj header field. Following that is a
locationfield that points to the closed-over variable. Note that this is a pointer to a Value, not a Value itself. It’s a reference to a variable, not a value. This is important because it means that when we assign to the variable the upvalue captures, we’re assigning to the actual variable, not a copy. For example:
因此,我們的執行時上值結構是一個具有典型Obj頭欄位的ObjUpvalue。之後是一個指向關閉變數的location欄位。注意,這是一個指向Value的指標,而不是Value本身。它是一個變數的引用,而不是一個值。這一點很重要,因為它意味著當我們向上值捕獲的變數賦值時,我們是在給實際的變數賦值,而不是對一個副本賦值。舉例來說:
fun outer() {
var x = "before";
fun inner() {
x = "assigned";
}
inner();
print x;
}
outer();
This program should print “assigned” even though the closure assigns to
xand the surrounding function accesses it.
這個程式應該列印“assigned”,儘管是在閉包中對x賦值,而在外圍函式中訪問它。
Because upvalues are objects, we’ve got all the usual object machinery, starting with a constructor-like function:
因為上值是物件,我們已經有了所有常見的物件機制,首先是類似構造器的函式:
object.h,在copyString()方法後新增程式碼:
ObjString* copyString(const char* chars, int length);
// 新增部分開始
ObjUpvalue* newUpvalue(Value* slot);
// 新增部分結束
void printObject(Value value);
It takes the address of the slot where the closed-over variable lives. Here is the implementation:
它接受的是封閉變數所在的槽的地址。下面是其實現:
object.c,在copyString()方法後新增程式碼:
ObjUpvalue* newUpvalue(Value* slot) {
ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE);
upvalue->location = slot;
return upvalue;
}
We simply initialize the object and store the pointer. That requires a new object type.
我們簡單地初始化物件並儲存指標。這需要一個新的物件型別。
object.h,在列舉ObjType中新增程式碼:
OBJ_STRING,
// 新增部分開始
OBJ_UPVALUE
// 新增部分結束
} ObjType;
And on the back side, a destructor-like function:
在後面,還有一個類似解構函式的方法:
memory.c,在freeObject()方法中新增程式碼:
FREE(ObjString, object);
break;
}
// 新增部分開始
case OBJ_UPVALUE:
FREE(ObjUpvalue, object);
break;
// 新增部分結束
}
Multiple closures can close over the same variable, so ObjUpvalue does not own the variable it references. Thus, the only thing to free is the ObjUpvalue itself.
多個閉包可以關閉同一個變數,所以ObjUpvalue並不擁有它引用的變數。因此,唯一需要釋放的就是ObjUpvalue本身。
And, finally, to print:
最後,是列印:
object.c,在printObject()方法中新增程式碼:
case OBJ_STRING:
printf("%s", AS_CSTRING(value));
break;
// 新增部分開始
case OBJ_UPVALUE:
printf("upvalue");
break;
// 新增部分結束
}
Printing isn’t useful to end users. Upvalues are objects only so that we can take advantage of the VM’s memory management. They aren’t first-class values that a Lox user can directly access in a program. So this code will never actually execute . . . but it keeps the compiler from yelling at us about an unhandled switch case, so here we are.
列印對終端使用者沒有用。上值是物件,只是為了讓我們能夠利用虛擬機器的記憶體管理。它們並不是Lox使用者可以在程式中直接訪問的一等公民。因此,這段程式碼實際上永遠不會執行……但它使得編譯器不會因為未處理的case分支而對我們大喊大叫,所以我們這樣做了。
25 . 3 . 1 Upvalues in closures
25.3.1 閉包中的上值
When I first introduced upvalues, I said each closure has an array of them. We’ve finally worked our way back to implementing that.
我在第一次介紹上值時,說過每個閉包中都有一個上值陣列。我們終於回到了實現它的道路上。
object.h,在結構體ObjClosure中新增程式碼:
ObjFunction* function;
// 新增部分開始
ObjUpvalue** upvalues;
int upvalueCount;
// 新增部分結束
} ObjClosure;
Different closures may have different numbers of upvalues, so we need a dynamic array. The upvalues themselves are dynamically allocated too, so we end up with a double pointer—a pointer to a dynamically allocated array of pointers to upvalues. We also store the number of elements in the array.
不同的閉包可能會有不同數量的上值,所以我們需要一個動態陣列。上值本身也是動態分配的,因此我們最終需要一個二級指標——一個指向動態分配的上值指標陣列的指標。我們還會儲存陣列中的元素數量11。
When we create an ObjClosure, we allocate an upvalue array of the proper size, which we determined at compile time and stored in the ObjFunction.
當我們建立ObjClosure時,會分配一個適當大小的上值陣列,這個大小在編譯時就已經確定並儲存在ObjFunction中。
object.c,在newClosure()方法中新增程式碼:
ObjClosure* newClosure(ObjFunction* function) {
// 新增部分開始
ObjUpvalue** upvalues = ALLOCATE(ObjUpvalue*,
function->upvalueCount);
for (int i = 0; i < function->upvalueCount; i++) {
upvalues[i] = NULL;
}
// 新增部分結束
ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE);
Before creating the closure object itself, we allocate the array of upvalues and initialize them all to
NULL. This weird ceremony around memory is a careful dance to please the (forthcoming) garbage collection deities. It ensures the memory manager never sees uninitialized memory.
在建立閉包物件本身之前,我們分配了上值陣列,並將其初始化為NULL。這種圍繞記憶體的奇怪儀式是一場精心的舞蹈,為了取悅(即將到來的)垃圾收集器神靈。它可以確保記憶體管理器永遠不會看到未初始化的記憶體。
Then we store the array in the new closure, as well as copy the count over from the ObjFunction.
然後,我們將陣列儲存在新的閉包中,並將計數值從ObjFunction中複製過來。
object.c,在newClosure()方法中新增程式碼:
closure->function = function;
// 新增部分開始
closure->upvalues = upvalues;
closure->upvalueCount = function->upvalueCount;
// 新增部分結束
return closure;
When we free an ObjClosure, we also free the upvalue array.
當我們釋放ObjClosure時,也需要釋放上值陣列。
memory.c,在freeObject()方法中新增程式碼:
case OBJ_CLOSURE: {
// 新增部分開始
ObjClosure* closure = (ObjClosure*)object;
FREE_ARRAY(ObjUpvalue*, closure->upvalues,
closure->upvalueCount);
// 新增部分結束
FREE(ObjClosure, object);
ObjClosure does not own the ObjUpvalue objects themselves, but it does own the array containing pointers to those upvalues.
ObjClosure並不擁有ObjUpvalue本身,但它確實擁有包含指向這些上值的指標的陣列。
We fill the upvalue array over in the interpreter when it creates a closure. This is where we walk through all of the operands after
OP_CLOSUREto see what kind of upvalue each slot captures.
當直譯器建立閉包時,我們會填充上值陣列。在這裡,我們會遍歷OP_CLOSURE之後的所有運算元,以檢視每個槽捕獲了什麼樣的上值。
vm.c,在run()方法中新增程式碼:
push(OBJ_VAL(closure));
// 新增部分開始
for (int i = 0; i < closure->upvalueCount; i++) {
uint8_t isLocal = READ_BYTE();
uint8_t index = READ_BYTE();
if (isLocal) {
closure->upvalues[i] =
captureUpvalue(frame->slots + index);
} else {
closure->upvalues[i] = frame->closure->upvalues[index];
}
}
// 新增部分結束
break;
This code is the magic moment when a closure comes to life. We iterate over each upvalue the closure expects. For each one, we read a pair of operand bytes. If the upvalue closes over a local variable in the enclosing function, we let
captureUpvalue()do the work.
這段程式碼是閉包誕生的神奇時刻。我們遍歷了閉包所期望的每個上值。對於每個上值,我們讀取一對運算元位元組。如果上值在外層函式的一個區域性變數上關閉,我們就讓captureUpvalue()完成這項工作。
Otherwise, we capture an upvalue from the surrounding function. An
OP_CLOSUREinstruction is emitted at the end of a function declaration. At the moment that we are executing that declaration, the current function is the surrounding one. That means the current function’s closure is stored in the CallFrame at the top of the callstack. So, to grab an upvalue from the enclosing function, we can read it right from theframelocal variable, which caches a reference to that CallFrame.
否則,我們從外圍函式中捕獲一個上值。OP_CLOSURE指令是在函式宣告的末尾生成。在我們執行該宣告時,當前函式就是外圍的函式。這意味著當前函式的閉包儲存在呼叫棧頂部的CallFrame中。因此,要從外層函式中抓取上值,我們可以直接從區域性變數frame中讀取,該變數快取了一個對CallFrame的引用。
Closing over a local variable is more interesting. Most of the work happens in a separate function, but first we calculate the argument to pass to it. We need to grab a pointer to the captured local’s slot in the surrounding function’s stack window. That window begins at
frame->slots, which points to slot zero. Addingindexoffsets that to the local slot we want to capture. We pass that pointer here:
關閉區域性變數更有趣。大部分工作發生在一個單獨的函式中,但首先我們要計算傳遞給它的引數。我們需要在外圍函式的棧視窗中抓取一個指向捕獲的區域性變數槽的指標。該視窗起點在frame->slots,指向槽0。在其上新增index偏移量,以指向我們想要捕獲的區域性變數槽。我們將該指標傳入這裡:
vm.c,在callValue()方法後新增程式碼:
static ObjUpvalue* captureUpvalue(Value* local) {
ObjUpvalue* createdUpvalue = newUpvalue(local);
return createdUpvalue;
}
This seems a little silly. All it does is create a new ObjUpvalue that captures the given stack slot and returns it. Did we need a separate function for this? Well, no, not yet. But you know we are going to end up sticking more code in here.
這看起來有點傻。它所做的就是建立一個新的捕獲給定棧槽的ObjUpvalue,並將其返回。我們需要為此建一個單獨的函式嗎?嗯,不,現在還不用。但你懂的,我們最終會在這裡插入更多程式碼。
First, let’s wrap up what we’re working on. Back in the interpreter code for handling
OP_CLOSURE, we eventually finish iterating through the upvalue array and initialize each one. When that completes, we have a new closure with an array full of upvalues pointing to variables.
首先,來總結一下我們的工作。回到處理OP_CLOSURE的直譯器程式碼中,我們最終完成了對上值陣列的迭代,並初始化了每個值。完成後,我們就有了一個新的閉包,它的陣列中充滿了指向變數的上值。
With that in hand, we can implement the instructions that work with those upvalues.
有了這個,我們就可以實現與這些上值相關的指令。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_GET_UPVALUE: {
uint8_t slot = READ_BYTE();
push(*frame->closure->upvalues[slot]->location);
break;
}
// 新增部分結束
case OP_EQUAL: {
The operand is the index into the current function’s upvalue array. So we simply look up the corresponding upvalue and dereference its location pointer to read the value in that slot. Setting a variable is similar.
運算元是當前函式的上值陣列的索引。因此,我們只需查詢相應的上值,並對其位置指標解引用,以讀取該槽中的值。設定變數也是如此。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_SET_UPVALUE: {
uint8_t slot = READ_BYTE();
*frame->closure->upvalues[slot]->location = peek(0);
break;
}
// 新增部分結束
case OP_EQUAL: {
We take the value on top of the stack and store it into the slot pointed to by the chosen upvalue. Just as with the instructions for local variables, it’s important that these instructions are fast. User programs are constantly reading and writing variables, so if that’s slow, everything is slow. And, as usual, the way we make them fast is by keeping them simple. These two new instructions are pretty good: no control flow, no complex arithmetic, just a couple of pointer indirections and a
push().
我們取棧頂的值,並將其儲存的選中的上值所指向的槽中。就像區域性變數的指令一樣,這些指令的速度很重要。使用者程式在不斷的讀寫變數,因此如果這個操作很慢,一切都會很慢。而且,像往常一樣,我們讓它變快的方法就是保持簡單。這兩條新指令非常好:沒有控制流,沒有複雜的算術,只有幾個指標間接引用和一個push()12。
This is a milestone. As long as all of the variables remain on the stack, we have working closures. Try this:
這是一個里程碑。只要所有的變數都留存在棧上,閉包就可以工作。試試這個:
fun outer() {
var x = "outside";
fun inner() {
print x;
}
inner();
}
outer();
Run this, and it correctly prints “outside”.
執行這個,它就會正確地列印“outside”。
25 . 4 Closed Upvalues
25.4 關閉的上值
Of course, a key feature of closures is that they hold on to the variable as long as needed, even after the function that declares the variable has returned. Here’s another example that should work:
當然,閉包的一個關鍵特性是,只要有需要,它們就會一直保留這個變數,即使宣告變數的函式已經返回。下面是另一個應該有效的例子:
fun outer() {
var x = "outside";
fun inner() {
print x;
}
return inner;
}
var closure = outer();
closure();
But if you run it right now . . . who knows what it does? At runtime, it will end up reading from a stack slot that no longer contains the closed-over variable. Like I’ve mentioned a few times, the crux of the issue is that variables in closures don’t have stack semantics. That means we’ve got to hoist them off the stack when the function where they were declared returns. This final section of the chapter does that.
但是如果你現在執行它……天知道它會做什麼?在執行時,他會從不包含關閉變數的棧槽中讀取資料。正如我多次提到的,問題的關鍵在於閉包中的變數不具有棧語義。這意味著當宣告它們的函式返回時,我們必須將它們從棧中取出。本章的最後一節就是實現這一點的。
25 . 4 . 1 Values and variables
25.4.1 值與變數
Before we get to writing code, I want to dig into an important semantic point. Does a closure close over a value or a variable? This isn’t purely an academic question. I’m not just splitting hairs. Consider:
在我們開始編寫程式碼之前,我想深入探討一個重要的語義問題。閉包關閉的是一個值還是一個變數?這並不是一個純粹的學術問題13。我並不是在胡攪蠻纏。考慮一下:
var globalSet;
var globalGet;
fun main() {
var a = "initial";
fun set() { a = "updated"; }
fun get() { print a; }
globalSet = set;
globalGet = get;
}
main();
globalSet();
globalGet();
The outer
main()function creates two closures and stores them in global variables so that they outlive the execution ofmain()itself. Both of those closures capture the same variable. The first closure assigns a new value to it and the second closure reads the variable.
外層的main()方法建立了兩個閉包,並將它們儲存在全域性變數中,這樣它們的存活時間就比main()本身的執行時間更長。這兩個閉包都捕獲了相同的變數。第一個閉包為其賦值,第二個閉包則讀取該變數的值14。
What does the call to
globalGet()print? If closures capture values then each closure gets its own copy ofawith the value thatahad at the point in time that the closure’s function declaration executed. The call toglobalSet()will modifyset()’s copy ofa, butget()’s copy will be unaffected. Thus, the call toglobalGet()will print “initial”.
呼叫globalGet()會列印什麼?如果閉包捕獲的是值,那麼每個閉包都會獲得自己的a副本,該副本的值為a在執行閉包函式宣告的時間點上的值。對globalSet()的呼叫會修改set()中的a副本,但是get()中的副本不受影響。因此,對globalGet()的呼叫會列印“initial”。
If closures close over variables, then
get()andset()will both capture—reference—the same mutable variable. Whenset()changesa, it changes the sameathatget()reads from. There is only onea. That, in turn, implies the call toglobalGet()will print “updated”.
如果閉包關閉的是變數,那麼get()和set()都會捕獲(引用)同一個可變變數。當set()修改a時,它改變的是get()所讀取的那個a。這裡只有一個a。這意味著對globalGet()的呼叫會列印“updated”。
Which is it? The answer for Lox and most other languages I know with closures is the latter. Closures capture variables. You can think of them as capturing the place the value lives. This is important to keep in mind as we deal with closed-over variables that are no longer on the stack. When a variable moves to the heap, we need to ensure that all closures capturing that variable retain a reference to its one new location. That way, when the variable is mutated, all closures see the change.
到底是哪一個呢?對於Lox和我所知的其它大多數帶閉包的語言來說,答案是後者。閉包捕獲的是變數。你可以把它們看作是對值所在位置的捕獲。當我們處理不再留存於棧上的閉包變數時,這一點很重要,要牢牢記住。當一個變數移動到堆中時,我們需要確保所有捕獲該變數的閉包都保留對其新位置的引用。這樣一來,當變數發生變化時,所有閉包都能看到這個變化。
25 . 4 . 2 Closing upvalues
25.4.2 關閉上值
We know that local variables always start out on the stack. This is faster, and lets our single-pass compiler emit code before it discovers the variable has been captured. We also know that closed-over variables need to move to the heap if the closure outlives the function where the captured variable is declared.
我們知道,區域性變數總是從堆疊開始。這樣做更快,並且可以讓我們的單遍編譯器在發現變數被捕獲之前先生成位元組碼。我們還知道,如果閉包的存活時間超過宣告被捕獲變數的函式,那麼封閉的變數就需要移動到堆中。
Following Lua, we’ll use open upvalue to refer to an upvalue that points to a local variable still on the stack. When a variable moves to the heap, we are closing the upvalue and the result is, naturally, a closed upvalue. The two questions we need to answer are:
跟隨Lua,我們會使用開放上值來表示一個指向仍在棧中的區域性變數的上值。當變數移動到堆中時,我們就關閉上值,而結果自然就是一個關閉的上值。我們需要回答兩個問題:
- Where on the heap does the closed-over variable go?
- When do we close the upvalue?
- 被關閉的變數放在堆中的什麼位置?
- 我們什麼時候關閉上值?
The answer to the first question is easy. We already have a convenient object on the heap that represents a reference to a variable—ObjUpvalue itself. The closed-over variable will move into a new field right inside the ObjUpvalue struct. That way we don’t need to do any additional heap allocation to close an upvalue.
第一個問題的答案很簡單。我們在堆上已經有了一個便利的物件,它代表了對某個變數(ObjUpvalue本身)的引用。被關閉的變數將移動到ObjUpvalue結構體中的一個新欄位中。這樣一來,我們不需要做任何額外的堆分配來關閉上值。
The second question is straightforward too. As long as the variable is on the stack, there may be code that refers to it there, and that code must work correctly. So the logical time to hoist the variable to the heap is as late as possible. If we move the local variable right when it goes out of scope, we are certain that no code after that point will try to access it from the stack. After the variable is out of scope, the compiler will have reported an error if any code tried to use it.
第二個問題也很直截了當。只要變數在棧中,就可能存在引用它的程式碼,而且這些程式碼必須能夠正確工作。因此,將變數提取到堆上的邏輯時間越晚越好。如果我們在區域性變數超出作用域時將其移出,我們可以肯定,在那之後沒有任何程式碼會試圖從棧中訪問它。在變數超出作用域之後15,如果有任何程式碼試圖訪問它,編譯器就會報告一個錯誤。
The compiler already emits an
OP_POPinstruction when a local variable goes out of scope. If a variable is captured by a closure, we will instead emit a different instruction to hoist that variable out of the stack and into its corresponding upvalue. To do that, the compiler needs to know which locals are closed over.
當區域性變數超出作用域時,編譯器已經生成了OP_POP指令16。如果變數被某個閉包捕獲,我們會發出一條不同的指令,將該變數從棧中提取到其對應的上值。為此,編譯器需要知道哪些區域性變數被關閉了。
The compiler already maintains an array of Upvalue structs for each local variable in the function to track exactly that state. That array is good for answering “Which variables does this closure use?” But it’s poorly suited for answering, “Does any function capture this local variable?” In particular, once the Compiler for some closure has finished, the Compiler for the enclosing function whose variable has been captured no longer has access to any of the upvalue state.
編譯器已經為函式中的每個區域性變數維護了一個Upvalue結構體的陣列,以便準確地跟蹤該狀態。這個陣列很好地回答了“這個閉包使用了哪個變數”,但他不適合回答“是否有任何函式捕獲了這個區域性變數?”特別是,一旦某個閉包的Compiler 執行完成,變數被捕獲的外層函式的Compiler就不能再訪問任何上值狀態了。
In other words, the compiler maintains pointers from upvalues to the locals they capture, but not in the other direction. So we first need to add some extra tracking inside the existing Local struct so that we can tell if a given local is captured by a closure.
換句話說,編譯器保持著從上值指向它們捕獲的區域性變數的指標,而沒有相反方向的指標。所以,我們首先需要在現有的Local結構體中新增額外的跟蹤資訊,這樣我們就能夠判斷某個給定的區域性變數是否被某個閉包捕獲。
compiler.c,在Local結構體中新增程式碼:
int depth;
// 新增部分開始
bool isCaptured;
// 新增部分結束
} Local;
This field is
trueif the local is captured by any later nested function declaration. Initially, all locals are not captured.
如果區域性變數被後面巢狀的任何函式宣告捕獲,欄位則為true。最初,所有的區域性資料都沒有被捕獲。
compiler.c,在addLocal()方法中新增程式碼:
local->depth = -1;
// 新增部分開始
local->isCaptured = false;
// 新增部分結束
}
Likewise, the special “slot zero local” that the compiler implicitly declares is not captured.
同樣地,編譯器隱式宣告的特殊的“槽0中的區域性變數”不會被捕獲17。
compiler.c,在initCompiler()方法中新增程式碼:
local->depth = 0;
// 新增部分開始
local->isCaptured = false;
// 新增部分結束
local->name.start = "";
When resolving an identifier, if we end up creating an upvalue for a local variable, we mark it as captured.
在解析識別符號時,如果我們最終為某個區域性變數建立了一個上值,我們將其標記為已捕獲。
compiler.c,在resolveUpvalue()方法中新增程式碼:
if (local != -1) {
// 新增部分開始
compiler->enclosing->locals[local].isCaptured = true;
// 新增部分結束
return addUpvalue(compiler, (uint8_t)local, true);
Now, at the end of a block scope when the compiler emits code to free the stack slots for the locals, we can tell which ones need to get hoisted onto the heap. We’ll use a new instruction for that.
現在,在塊作用域的末尾,當編譯器生成位元組碼來釋放區域性變數的棧槽時,我們可以判斷哪些資料需要被提取到堆中。我們將使用一個新指令來實現這一點。
compiler.c,在endScope()方法中,替換1行:
while (current->localCount > 0 &&
current->locals[current->localCount - 1].depth >
current->scopeDepth) {
// 新增部分開始
if (current->locals[current->localCount - 1].isCaptured) {
emitByte(OP_CLOSE_UPVALUE);
} else {
emitByte(OP_POP);
}
// 新增部分結束
current->localCount--;
}
The instruction requires no operand. We know that the variable will always be right on top of the stack at the point that this instruction executes. We declare the instruction.
這個指令不需要運算元。我們知道,在該指令執行時,變數一定在棧頂。我們來宣告這條指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_CLOSURE,
// 新增部分開始
OP_CLOSE_UPVALUE,
// 新增部分結束
OP_RETURN,
And add trivial disassembler support for it:
併為它新增簡單的反彙編支援:
debug.c,在disassembleInstruction()方法中新增程式碼:
}
// 新增部分開始
case OP_CLOSE_UPVALUE:
return simpleInstruction("OP_CLOSE_UPVALUE", offset);
// 新增部分結束
case OP_RETURN:
Excellent. Now the generated bytecode tells the runtime exactly when each captured local variable must move to the heap. Better, it does so only for the locals that are used by a closure and need this special treatment. This aligns with our general performance goal that we want users to pay only for functionality that they use. Variables that aren’t used by closures live and die entirely on the stack just as they did before.
太好了。現在,生成的位元組碼準確地告訴執行時,每個被捕獲的區域性變數必須移動到堆中的確切時間。更好的是,它只對被閉包使用並需要這種特殊處理的區域性變數才會這樣做。這與我們的總體效能目標是一致的,即我們希望使用者只為他們使用的功能付費。那些不被閉包使用的變數只會出現於棧中,就像以前一樣。
25 . 4 . 3 Tracking open upvalues
25.4.3 跟蹤開放的上值
Let’s move over to the runtime side. Before we can interpret
OP_CLOSE_UPVALUEinstructions, we have an issue to resolve. Earlier, when I talked about whether closures capture variables or values, I said it was important that if multiple closures access the same variable that they end up with a reference to the exact same storage location in memory. That way if one closure writes to the variable, the other closure sees the change.
讓我們轉到執行時方面。在解釋OP_CLOSE_UPVALUE指令之前,我們還有一個問題需要解決。之前,在談到閉包捕獲的是變數還是值時,我說過,如果多個閉包訪問同一個變數,它們最終將引用記憶體中完全相同的儲存位置,這一點很重要。這樣一來,如果某個閉包對變數進行寫入,另一個閉包就會看到這一變化。
Right now, if two closures capture the same local variable, the VM creates a separate Upvalue for each one. The necessary sharing is missing. When we move the variable off the stack, if we move it into only one of the upvalues, the other upvalue will have an orphaned value.
現在,如果兩個閉包捕獲同一個區域性變數,虛擬機器就會為每個閉包建立一個單獨的Upvalue。必要的共享是缺失的18。當我們把變數移出堆疊時,如果我們只是將它移入其中一個上值中,其它上值就會有一個孤兒值。
To fix that, whenever the VM needs an upvalue that captures a particular local variable slot, we will first search for an existing upvalue pointing to that slot. If found, we reuse that. The challenge is that all of the previously created upvalues are squirreled away inside the upvalue arrays of the various closures. Those closures could be anywhere in the VM’s memory.
為瞭解決這個問題,每當虛擬機器需要一個捕獲特定區域性變數槽的上值時,我們會首先搜尋指向該槽的現有上值。如果找到了,我們就重用它。難點在於,之前建立的所有上值都儲存在各個閉包的上值陣列中。這些閉包可能位於虛擬機器記憶體中的任何位置。
The first step is to give the VM its own list of all open upvalues that point to variables still on the stack. Searching a list each time the VM needs an upvalue sounds like it might be slow, but in practice, it’s not bad. The number of variables on the stack that actually get closed over tends to be small. And function declarations that create closures are rarely on performance critical execution paths in the user’s program.
第一步是給虛擬機器提供它自己的所有開放上值的列表,這些上值指向仍在棧中的變數。每次虛擬機器需要一個上值時,都要搜尋列表,這聽起來似乎很慢,但是實際上,這並沒有那麼壞。棧中真正被關閉的變數的數量往往很少。而且建立閉包的函式宣告很少出現在使用者程式中的效能關鍵執行路徑上19。
Even better, we can order the list of open upvalues by the stack slot index they point to. The common case is that a slot has not already been captured—sharing variables between closures is uncommon—and closures tend to capture locals near the top of the stack. If we store the open upvalue array in stack slot order, as soon as we step past the slot where the local we’re capturing lives, we know it won’t be found. When that local is near the top of the stack, we can exit the loop pretty early.
更妙的是,我們可以根據開放上值所指向的棧槽索引對列表進行排序。常見的情況是,某個棧槽還沒有被捕獲(在閉包之間共享變數是不常見的),而閉包傾向於捕獲靠近棧頂的區域性變數。如果我們按照棧槽的順序儲存開放上值陣列,一旦我們越過正在捕獲的區域性變數所在的槽,我們就知道它不會被找到。當這個區域性變數在棧頂時,我們可以很早就退出迴圈。
Maintaining a sorted list requires inserting elements in the middle efficiently. That suggests using a linked list instead of a dynamic array. Since we defined the ObjUpvalue struct ourselves, the easiest implementation is an intrusive list that puts the next pointer right inside the ObjUpvalue struct itself.
維護有序列表需要能高效地在中間插入元素。這一點建議我們使用連結串列而不是動態陣列。因為我們自己定義了ObjUpvalue結構體,最簡單的實現是一個插入式列表,將指向下一元素的指標放在ObjUpvalue結構體本身中。
object.h,在結構體ObjUpvalue中新增程式碼:
Value* location;
// 新增部分開始
struct ObjUpvalue* next;
// 新增部分結束
} ObjUpvalue;
When we allocate an upvalue, it is not attached to any list yet so the link is
NULL.
當我們分配一個上值時,它還沒有附加到任何列表,因此連結是NULL。
object.c,在newUpvalue()方法中新增程式碼:
upvalue->location = slot;
// 新增部分開始
upvalue->next = NULL;
// 新增部分結束
return upvalue;
The VM owns the list, so the head pointer goes right inside the main VM struct.
VM擁有該列表,因此頭指標放在VM主結構體中。
vm.h,在結構體VM中新增程式碼:
Table strings;
// 新增部分開始
ObjUpvalue* openUpvalues;
// 新增部分結束
Obj* objects;
The list starts out empty.
列表在開始時為空。
vm.c,在resetStack()方法中新增程式碼:
vm.frameCount = 0;
// 新增部分開始
vm.openUpvalues = NULL;
// 新增部分結束
}
Starting with the first upvalue pointed to by the VM, each open upvalue points to the next open upvalue that references a local variable farther down the stack. This script, for example,
從VM指向的第一個上值開始,每個開放上值都指向下一個引用了棧中靠下位置的區域性變數的開放上值。以這個指令碼為例
{
var a = 1;
fun f() {
print a;
}
var b = 2;
fun g() {
print b;
}
var c = 3;
fun h() {
print c;
}
}
should produce a series of linked upvalues like so:
它應該產生如下所示的一系列連結的上值:

Whenever we close over a local variable, before creating a new upvalue, we look for an existing one in the list.
每當關閉一個區域性變數時,在建立新的上值之前,先在該列表中查詢現有的上值。
vm.c,在captureUpvalue()方法中新增程式碼:
static ObjUpvalue* captureUpvalue(Value* local) {
// 新增部分開始
ObjUpvalue* prevUpvalue = NULL;
ObjUpvalue* upvalue = vm.openUpvalues;
while (upvalue != NULL && upvalue->location > local) {
prevUpvalue = upvalue;
upvalue = upvalue->next;
}
if (upvalue != NULL && upvalue->location == local) {
return upvalue;
}
// 新增部分結束
ObjUpvalue* createdUpvalue = newUpvalue(local);
We start at the head of the list, which is the upvalue closest to the top of the stack. We walk through the list, using a little pointer comparison to iterate past every upvalue pointing to slots above the one we’re looking for. While we do that, we keep track of the preceding upvalue on the list. We’ll need to update that node’s
nextpointer if we end up inserting a node after it.
我們從列表的頭部開始,它是最接近棧頂的上值。我們遍歷列表,使用一個小小的指標比較,對每一個指向的槽位高於當前查詢的位置的上值進行迭代20。當我們這樣做時,我們要跟蹤列表中前面的上值。如果我們在某個節點後面插入了一個節點,就需要更新該節點的next指標。
There are three reasons we can exit the loop:
我們有三個原因可以退出迴圈:
-
The local slot we stopped at *is* the slot we’re looking for. We found an existing upvalue capturing the variable, so we reuse that upvalue.
我們停止時的區域性變數槽是我們要找的槽。我在找到了一個現有的上值捕獲了這個變數,因此我們重用這個上值。
-
We ran out of upvalues to search. When
upvalueisNULL, it means every open upvalue in the list points to locals above the slot we’re looking for, or (more likely) the upvalue list is empty. Either way, we didn’t find an upvalue for our slot.我們找不到需要搜尋的上值了。當
upvalue為NULL時,這意味著列表中每個開放上值都指向位於我們要找的槽之上的區域性變數,或者(更可能是)上值列表是空的。無論怎樣,我們都沒有找到對應該槽的上值。 -
We found an upvalue whose local slot is *below* the one we’re looking for. Since the list is sorted, that means we’ve gone past the slot we are closing over, and thus there must not be an existing upvalue for it.
我們找到了一個上值,其區域性變數槽低於我們正查詢的槽位。因為列表是有序的,這意味著我們已經超過了正在關閉的槽,因此肯定沒有對應該槽的已有上值。
In the first case, we’re done and we’ve returned. Otherwise, we create a new upvalue for our local slot and insert it into the list at the right location.
在第一種情況下,我們已經完成並且返回了。其它情況下,我們為區域性變數槽建立一個新的上值,並將其插入到列表中的正確位置。
vm.c,在captureUpvalue()方法中新增程式碼:
ObjUpvalue* createdUpvalue = newUpvalue(local);
// 新增部分開始
createdUpvalue->next = upvalue;
if (prevUpvalue == NULL) {
vm.openUpvalues = createdUpvalue;
} else {
prevUpvalue->next = createdUpvalue;
}
// 新增部分結束
return createdUpvalue;
The current incarnation of this function already creates the upvalue, so we only need to add code to insert the upvalue into the list. We exited the list traversal by either going past the end of the list, or by stopping on the first upvalue whose stack slot is below the one we’re looking for. In either case, that means we need to insert the new upvalue before the object pointed at by
upvalue(which may beNULLif we hit the end of the list).
這個函式的當前版本已經建立了上值,我們只需要新增程式碼將上值插入到列表中。我們退出列表遍歷的原因,要麼是到達了列表末尾,要麼是停在了第一個棧槽低於待查詢槽位的上值。無論哪種情況,這都意味著我們需要在upvalue指向的物件(如果到達列表的末尾,則該物件可能是NULL)之前插入新的上值。
As you may have learned in Data Structures 101, to insert a node into a linked list, you set the
nextpointer of the previous node to point to your new one. We have been conveniently keeping track of that preceding node as we walked the list. We also need to handle the special case where we are inserting a new upvalue at the head of the list, in which case the “next” pointer is the VM’s head pointer.
正如你在《資料結構101》中所學到的,要將一個節點插入到連結串列中,你需要將前一個節點的next指標指向新的節點。當我們遍歷列表時,我們一直很方便地跟蹤著前面的節點。我們還需要處理一種特殊情況,即我們在列表頭部插入一個新的上值,在這種情況下,“next”指標是VM的頭指標21。
With this updated function, the VM now ensures that there is only ever a single ObjUpvalue for any given local slot. If two closures capture the same variable, they will get the same upvalue. We’re ready to move those upvalues off the stack now.
有了這個升級版函式,VM現在可以確保每個指定的區域性變數槽都只有一個ObjUpvalue。如果兩個閉包捕獲了相同的變數,它們會得到相同的上值。現在,我們準備將這些上值從棧中移出。
25 . 4 . 4 Closing upvalues at runtime
25.4.4 在執行時關閉上值
The compiler helpfully emits an
OP_CLOSE_UPVALUEinstruction to tell the VM exactly when a local variable should be hoisted onto the heap. Executing that instruction is the interpreter’s responsibility.
編譯器會生成一個有用的OP_CLOSE_UPVALUE指令,以準確地告知VM何時將區域性變數提取到堆中。執行該指令是直譯器的責任。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_CLOSE_UPVALUE:
closeUpvalues(vm.stackTop - 1);
pop();
break;
// 新增部分結束
case OP_RETURN: {
When we reach the instruction, the variable we are hoisting is right on top of the stack. We call a helper function, passing the address of that stack slot. That function is responsible for closing the upvalue and moving the local from the stack to the heap. After that, the VM is free to discard the stack slot, which it does by calling
pop().
當我們到達該指令時,我們要提取的變數就在棧頂。我們呼叫一個輔助函式,傳入棧槽的地址。該函式負責關閉上值,並將區域性變數從棧中移動到堆上。之後,VM就可以自由地丟棄棧槽,這是透過呼叫pop()實現的。
The fun stuff happens here:
有趣的事情發生在這裡:
vm.c,在captureUpvalue()方法後新增程式碼:
static void closeUpvalues(Value* last) {
while (vm.openUpvalues != NULL &&
vm.openUpvalues->location >= last) {
ObjUpvalue* upvalue = vm.openUpvalues;
upvalue->closed = *upvalue->location;
upvalue->location = &upvalue->closed;
vm.openUpvalues = upvalue->next;
}
}
This function takes a pointer to a stack slot. It closes every open upvalue it can find that points to that slot or any slot above it on the stack. Right now, we pass a pointer only to the top slot on the stack, so the “or above it” part doesn’t come into play, but it will soon.
這個函式接受一個指向棧槽的指標。它會關閉它能找到的指向該槽或棧上任何位於該槽上方的所有開放上值。現在,我們只傳遞了一個指向棧頂的指標,所以“或其上方”的部分沒有發揮作用,但它很快就會起作用了。
To do this, we walk the VM’s list of open upvalues, again from top to bottom. If an upvalue’s location points into the range of slots we’re closing, we close the upvalue. Otherwise, once we reach an upvalue outside of the range, we know the rest will be too, so we stop iterating.
為此,我們再次從上到下遍歷VM的開放上值列表。如果某個上值的位置指向我們要關閉的槽位範圍,則關閉該上值。否則,一旦我們遇到範圍之外的上值,我們知道其它上值也在範圍之外,所以我們停止迭代。
The way an upvalue gets closed is pretty cool. First, we copy the variable’s value into the
closedfield in the ObjUpvalue. That’s where closed-over variables live on the heap. TheOP_GET_UPVALUEandOP_SET_UPVALUEinstructions need to look for the variable there after it’s been moved. We could add some conditional logic in the interpreter code for those instructions to check some flag for whether the upvalue is open or closed.
關閉上值的方式非常酷22。首先,我們將變數的值複製到ObjUpvalue的closed欄位。這就是被關閉的變數在堆中的位置。在變數被移動之後,OP_GET_UPVALUE和OP_SET_UPVALUE指令需要在那裡查詢它。我們可以在直譯器程式碼中為這些指令新增一些條件邏輯,檢查一些標誌,以確定上值是開放的還是關閉的。
But there is already a level of indirection in play—those instructions dereference the
locationpointer to get to the variable’s value. When the variable moves from the stack to theclosedfield, we simply update thatlocationto the address of the ObjUpvalue’s ownclosedfield.
但是已經有一箇中間層在起作用了——這些指令對location指標解引用以獲取變數的值。當變數從棧移動到closed欄位時,我們只需將location更新為ObjUpvalue自己的closed欄位。

We don’t need to change how
OP_GET_UPVALUEandOP_SET_UPVALUEare interpreted at all. That keeps them simple, which in turn keeps them fast. We do need to add the new field to ObjUpvalue, though.
我們根本不需要改變OP_GET_UPVALUE和OP_SET_UPVALUE的解釋方式。這使得它們保持簡單,反過來又使它們保持快速。不過,我們確實需要向ObjUpvalue新增新的欄位。
object.h,在結構體ObjUpvalue中新增程式碼:
Value* location;
// 新增部分開始
Value closed;
// 新增部分結束
struct ObjUpvalue* next;
And we should zero it out when we create an ObjUpvalue so there’s no uninitialized memory floating around.
當我們建立一個ObjUpvalue時,應該將其置為0,這樣就不會有未初始化的記憶體了。
object.c,在newUpvalue()方法中新增程式碼:
ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE);
// 新增部分開始
upvalue->closed = NIL_VAL;
// 新增部分結束
upvalue->location = slot;
Whenever the compiler reaches the end of a block, it discards all local variables in that block and emits an
OP_CLOSE_UPVALUEfor each local variable that was closed over. The compiler does not emit any instructions at the end of the outermost block scope that defines a function body. That scope contains the function’s parameters and any locals declared immediately inside the function. Those need to get closed too.
每當編譯器到達一個塊的末尾時,它就會丟棄該程式碼塊中的所有區域性變數,併為每個關閉的區域性變數生成一個OP_CLOSE_UPVALUE指令。編譯器不會在定義某個函式主體的最外層塊作用域的末尾生成任何指令23。這個作用域包含函式的形參和函式內部宣告的任何區域性變數。這些也需要被關閉。
This is the reason
closeUpvalues()accepts a pointer to a stack slot. When a function returns, we call that same helper and pass in the first stack slot owned by the function.
這就是closeUpvalues()接受一個指向棧槽的指標的原因。當函式返回時,我們呼叫相同的輔助函式,並傳入函式擁有的第一個棧槽。
vm.c,在run()方法中新增程式碼:
Value result = pop();
// 新增部分開始
closeUpvalues(frame->slots);
// 新增部分結束
vm.frameCount--;
By passing the first slot in the function’s stack window, we close every remaining open upvalue owned by the returning function. And with that, we now have a fully functioning closure implementation. Closed-over variables live as long as they are needed by the functions that capture them.
透過傳遞函式棧視窗中的第一個槽,我們關閉了正在返回的函式所擁有的所有剩餘的開放上值。有了這些,我們現在就有了一個功能齊全的閉包實現。只要捕獲變數的函式需要,被關閉的變數就一直存在。
This was a lot of work! In jlox, closures fell out naturally from our environment representation. In clox, we had to add a lot of code—new bytecode instructions, more data structures in the compiler, and new runtime objects. The VM very much treats variables in closures as different from other variables.
這是一項艱鉅的工作!在jlox中,閉包很自然地從我們的環境表示形式中分離出來。在clox中,我們必須新增大量的程式碼——新的位元組碼指令、編譯器中的更多資料結構和新的執行時物件。VM在很大程度上將閉包中的變數與其它變數進行區別對待。
There is a rationale for that. In terms of implementation complexity, jlox gave us closures “for free”. But in terms of performance, jlox’s closures are anything but. By allocating all environments on the heap, jlox pays a significant performance price for all local variables, even the majority which are never captured by closures.
這是有道理的。就實現複雜性而言,jlox“免費”為我們提供了閉包。但是就效能而言,jlox的閉包完全不是這樣。由於在堆上分配所有環境,jlox為所有區域性變數付出了顯著的效能代價,甚至是未被閉包捕獲的大部分變數。
With clox, we have a more complex system, but that allows us to tailor the implementation to fit the two use patterns we observe for local variables. For most variables which do have stack semantics, we allocate them entirely on the stack which is simple and fast. Then, for the few local variables where that doesn’t work, we have a second slower path we can opt in to as needed.
在clox中,我們有一個更復雜的系統,但這允許我們對實現進行調整以適應我們觀察到的區域性變數的兩種使用模式。對於大多數具有堆疊語義的變數,我們完全可用在棧中分配,這既簡單又快速。然後,對於少數不適用的區域性變數,我們可以根據需要選擇第二條較慢的路徑。
Fortunately, users don’t perceive the complexity. From their perspective, local variables in Lox are simple and uniform. The language itself is as simple as jlox’s implementation. But under the hood, clox is watching what the user does and optimizing for their specific uses. As your language implementations grow in sophistication, you’ll find yourself doing this more. A large fraction of “optimization” is about adding special case code that detects certain uses and provides a custom-built, faster path for code that fits that pattern.
幸運的是,使用者並不會察覺到這種複雜性。在他們看來,Lox中的區域性變數簡單而統一。語言本身就像jlox一樣簡單。但在內部,clox會觀察使用者的行為,並針對他們的具體用途進行最佳化。隨著你的語言實現越來越複雜,你會發現自己要做的事情越來越多。“最佳化”的很大一部分是關於新增特殊情況的程式碼,以檢測特定的使用,併為符合該模式的程式碼提供定製化的、更快速的路徑。
We have lexical scoping fully working in clox now, which is a major milestone. And, now that we have functions and variables with complex lifetimes, we also have a lot of objects floating around in clox’s heap, with a web of pointers stringing them together. The next step is figuring out how to manage that memory so that we can free some of those objects when they’re no longer needed.
我們現在已經在clox中完全實現了詞法作用域,這是一個重要的里程碑。而且,現在我們有了具有複雜生命週期的函式和變數,我們也要了很多漂浮在clox堆中的物件,並有一個指標網路將它們串聯起來。下一步是弄清楚如何管理這些記憶體,以便我們可以在不再需要這些物件的時候釋放它們。
習題
-
Wrapping every ObjFunction in an ObjClosure introduces a level of indirection that has a performance cost. That cost isn’t necessary for functions that do not close over any variables, but it does let the runtime treat all calls uniformly.
Change clox to only wrap functions in ObjClosures that need upvalues. How does the code complexity and performance compare to always wrapping functions? Take care to benchmark programs that do and do not use closures. How should you weight the importance of each benchmark? If one gets slower and one faster, how do you decide what trade-off to make to choose an implementation strategy?
將每個ObjFunction 包裝在ObjClosure中,會引入一個有效能代價的中間層。這個代價對於那些沒有關閉任何變數的函式來說是不必要的,但它確實讓執行時能夠統一處理所有的呼叫。
將clox改為只用ObjClosure包裝需要上值的函式。與包裝所有函式相比,程式碼的複雜性與效能如何?請注意對使用閉包和不使用閉包的程式進行基準測試。你應該如何衡量每個基準的重要性?如果一個變慢了,另一個變快了,你決定透過什麼權衡來選擇實現策略?
-
Read the design note below. I’ll wait. Now, how do you think Lox should behave? Change the implementation to create a new variable for each loop iteration.
請閱讀下面的設計筆記。我在這裡等著。現在,你覺得Lox應該怎麼做?改變實現方式,為每個迴圈迭代建立一個新的變數。
-
A famous koan teaches us that “objects are a poor man’s closure” (and vice versa). Our VM doesn’t support objects yet, but now that we have closures we can approximate them. Using closures, write a Lox program that models two-dimensional vector “objects”. It should:
- Define a “constructor” function to create a new vector with the given x and y coordinates.
- Provide “methods” to access the x and y coordinates of values returned from that constructor.
- Define an addition “method” that adds two vectors and produces a third.
一個著名的公案告訴我們:“物件是簡化版的閉包”(反之亦然)。我們的虛擬機器還不支援物件,但現在我們有了閉包,我們可以近似地使用它們。使用閉包,編寫一個Lox程式,建模一個二維向量“物件”。它應該:
- 定義一個“構造器”函式,建立一個具有給定x和y座標的新向量。
- 提供“方法”來訪問建構函式返回值的x和y座標。
- 定義一個相加“方法”,將兩個向量相加併產生第三個向量。
設計筆記:關閉迴圈變數
Closures capture variables. When two closures capture the same variable, they share a reference to the same underlying storage location. This fact is visible when new values are assigned to the variable. Obviously, if two closures capture different variables, there is no sharing.
閉包捕獲變數。當兩個閉包捕獲相同的變數時,它們共享對相同的底層儲存位置的引用。當將新值賦給該變數時,這一事實是可見的。顯然,如果兩個閉包捕獲不同的變數,就不存在共享。
var globalOne;
var globalTwo;
fun main() {
{
var a = "one";
fun one() {
print a;
}
globalOne = one;
}
{
var a = "two";
fun two() {
print a;
}
globalTwo = two;
}
}
main();
globalOne();
globalTwo();
This prints “one” then “two”. In this example, it’s pretty clear that the two
avariables are different. But it’s not always so obvious. Consider:
這裡會列印“one”然後是“two”。在這個例子中,很明顯兩個a變數是不同的。但一點這並不總是那麼明顯。考慮一下:
var globalOne;
var globalTwo;
fun main() {
for (var a = 1; a <= 2; a = a + 1) {
fun closure() {
print a;
}
if (globalOne == nil) {
globalOne = closure;
} else {
globalTwo = closure;
}
}
}
main();
globalOne();
globalTwo();
The code is convoluted because Lox has no collection types. The important part is that the
main()function does two iterations of aforloop. Each time through the loop, it creates a closure that captures the loop variable. It stores the first closure inglobalOneand the second inglobalTwo.
這段程式碼很複雜,因為Lox沒有集合型別。重要的部分是,main()函式進行了for迴圈的兩次迭代。每次迴圈執行時,它都會建立一個捕獲迴圈變數的閉包。它將第一個閉包儲存在globalOne中,並將第二個閉包儲存在globalTwo中。
There are definitely two different closures. Do they close over two different variables? Is there only one
afor the entire duration of the loop, or does each iteration get its own distinctavariable?
這無疑是兩個不同的閉包。它們是在兩個不同的變數上閉合的嗎?在整個迴圈過程中只有一個a,還是每個迭代都有自己單獨的a變數?
The script here is strange and contrived, but this does show up in real code in languages that aren’t as minimal as clox. Here’s a JavaScript example:
這裡的指令碼很奇怪,而且是人為設計的,但它確實出現在實際的程式碼中,而且這些程式碼使用的語言並不是像clox這樣的小語言。下面是一個JavaScript的示例:
var closures = [];
for (var i = 1; i <= 2; i++) {
closures.push(function () { console.log(i); });
}
closures[0]();
closures[1]();
Does this print “1” then “2”, or does it print “3” twice? You may be surprised to hear that it prints “3” twice. In this JavaScript program, there is only a single
ivariable whose lifetime includes all iterations of the loop, including the final exit.
這裡會列印“1”再列印“2”,還是列印兩次“3”?你可能會驚訝地發現,它列印了兩次“3”24。在這個JavaScript程式中,只有一個i變數,它的生命週期包括迴圈的所有迭代,包括最後的退出。
If you’re familiar with JavaScript, you probably know that variables declared using
varare implicitly hoisted to the surrounding function or top-level scope. It’s as if you really wrote this:
如果你熟悉JavaScript,你可能知道,使用var宣告的變數會隱式地被提取到外圍函式或頂層作用域中。這就好像你是這樣寫的:
var closures = [];
var i;
for (i = 1; i <= 2; i++) {
closures.push(function () { console.log(i); });
}
closures[0]();
closures[1]();
At that point, it’s clearer that there is only a single
i. Now consider if you change the program to use the newerletkeyword:
此時,很明顯只有一個i。現在考慮一下,如果你將程式改為使用更新的let關鍵字:
var closures = [];
for (let i = 1; i <= 2; i++) {
closures.push(function () { console.log(i); });
}
closures[0]();
closures[1]();
Does this new program behave the same? Nope. In this case, it prints “1” then “2”. Each closure gets its own
i. That’s sort of strange when you think about it. The increment clause isi++. That looks very much like it is assigning to and mutating an existing variable, not creating a new one.
這個新程式的行為是一樣的嗎?不是。在本例中,它會列印“1”然後列印“2”。每個閉包都有自己的i。仔細想想會覺得有點奇怪,增量子句是i++,這看起來很像是對現有變數進行賦值和修改,而不是建立一個新變數。
Let’s try some other languages. Here’s Python:
讓我們試試其它語言。下面是Python:
closures = []
for i in range(1, 3):
closures.append(lambda: print(i))
closures[0]()
closures[1]()
Python doesn’t really have block scope. Variables are implicitly declared and are automatically scoped to the surrounding function. Kind of like hoisting in JS, now that I think about it. So both closures capture the same variable. Unlike C, though, we don’t exit the loop by incrementing
ipast the last value, so this prints “2” twice.
Python並沒有真正的塊作用域。變數是隱式宣告的,並自動限定在外圍函式的作用域中。現在我想起來,這有點像JS中的“懸掛”。所以兩個閉包都捕獲了同一個變數。但與C不同的是,我們不會透過增加i超過最後一個值來退出迴圈,所以這裡會列印兩次“2”。
What about Ruby? Ruby has two typical ways to iterate numerically. Here’s the classic imperative style:
那Ruby呢?Ruby有兩種典型的數值迭代方式。下面是典型的命令式風格:
closures = []
for i in 1..2 do
closures << lambda { puts i }
end
closures[0].call
closures[1].call
This, like Python, prints “2” twice. But the more idiomatic Ruby style is using a higher-order
each()method on range objects:
這有點像是Python,會列印兩次“2”。但是更慣用的Ruby風格是在範圍物件上使用高階的each()方法:
closures = []
(1..2).each do |i|
closures << lambda { puts i }
end
closures[0].call
closures[1].call
If you’re not familiar with Ruby, the
do |i| ... endpart is basically a closure that gets created and passed to theeach()method. The|i|is the parameter signature for the closure. Theeach()method invokes that closure twice, passing in 1 forithe first time and 2 the second time.
如果你不熟悉Ruby,do |i| ... end部分基本上就是一個閉包,它被建立並傳遞給each()方法。|i|是閉包的引數簽名。each()方法兩次呼叫該閉包,第一次傳入1,第二次傳入2。
In this case, the “loop variable” is really a function parameter. And, since each iteration of the loop is a separate invocation of the function, those are definitely separate variables for each call. So this prints “1” then “2”.
在這種情況下,“迴圈變數”實際上是一個函式引數。而且,由於迴圈的每次迭代都是對函式的單獨呼叫,所以每次呼叫都是單獨的變數。因此,這裡先列印“1”然後列印“2”。
If a language has a higher-level iterator-based looping structure like
foreachin C#, Java’s “enhanced for”,for-ofin JavaScript,for-inin Dart, etc., then I think it’s natural to the reader to have each iteration create a new variable. The code looks like a new variable because the loop header looks like a variable declaration. And there’s no increment expression that looks like it’s mutating that variable to advance to the next step.
如果一門語言具有基於迭代器的高階迴圈結果,比如C#中的foreach,Java中的“增強型for迴圈”,JavaScript中的for-of,Dart中的for-in等等,那我認為讀者很自然地會讓每次迭代都建立一個新變數。程式碼看起來像一個新變數,是因為迴圈頭看起來像是一個變數宣告。看起來沒有任何增量表達式透過改變變數以推進到下一步。
If you dig around StackOverflow and other places, you find evidence that this is what users expect, because they are very surprised when they don’t get it. In particular, C# originally did not create a new loop variable for each iteration of a
foreachloop. This was such a frequent source of user confusion that they took the very rare step of shipping a breaking change to the language. In C# 5, each iteration creates a fresh variable.
如果你在StackOverflow和其它地方挖掘一下,你會發現這正是使用者所期望的,因為當他們沒有看到這個結果時,他們會非常驚訝。特別是,C#最初並沒有為foreach迴圈的每次迭代建立一個新的迴圈變數。這一點經常引起使用者的困惑,所以他們採用了非常罕見的措施,對語言進行了突破性的修改。在C# 5中,每個迭代都會建立一個新的變數。
Old C-style
forloops are harder. The increment clause really does look like mutation. That implies there is a single variable that’s getting updated each step. But it’s almost never useful for each iteration to share a loop variable. The only time you can even detect this is when closures capture it. And it’s rarely helpful to have a closure that references a variable whose value is whatever value caused you to exit the loop.
舊的C風格的for迴圈更難了。增量子句看起來像是修改。這意味著每一步更新的是同一個變數。但是每個迭代共享一個迴圈變數幾乎是沒有用的。只有在閉包捕獲它時,你才能檢測到這一現象。而且,如果閉包引用的變數的值是導致迴圈退出的值,那麼它也幾乎沒有幫助。
The pragmatically useful answer is probably to do what JavaScript does with
letinforloops. Make it look like mutation but actually create a new variable each time, because that’s what users want. It is kind of weird when you think about it, though.
實用的答案可能是像JavaScript在for迴圈中的let那樣。讓它看起來像修改,但實際上每次都建立一個新變數,因為這是使用者想要的。不過,仔細想想,還是有點奇怪的。
-
畢竟,C和Java使用棧來儲存區域性變數是有原因的。 ↩
-
搜尋“閉包轉換 closure conversion”和“Lambda提升 lambda lifting”就可以開始探索了。 ↩
-
換句話說,Lox中的函式宣告是一種字面量——定義某個內建型別的常量值的一段語法。 ↩
-
或許我應該定義一個宏,以便更容易地生成這些宏。也許這有點太玄了。 ↩
-
這段程式碼看起來有點傻,因為我們仍然把原始的ObjFunction壓入棧中,然後在建立完閉包之後彈出它,然後再將閉包壓入棧。為什麼要把ObjFunction放在這裡呢?像往常一樣,當你看到奇怪的堆疊操作發生時,它是為了讓即將到來的垃圾回收器知道一些堆分配的物件。 ↩
-
它最終可能會是一個完全未定義的變數,甚至不是全域性變數。但是在Lox中,我們直到執行時才能檢測到這個錯誤,所以從編譯器的角度看,它是“期望是全域性的”。 ↩
-
就像常量和函式元數一樣,上值計數也是連線編譯器與執行時的一些小資料。 ↩
-
當然,另一種基本情況是,沒有外層函式。在這種情況下,該變數不能在詞法上解析,並被當作全域性變數處理。 ↩
-
每次遞迴呼叫
resolveUpvalue()都會走出一層函式巢狀。因此,內部的遞迴呼叫指向的是外部的巢狀宣告。查詢區域性變數的最內層的resolveUpvalue()遞迴呼叫對應的將是最外層的函式,就是實際宣告該變數的外層函式的內部。 ↩ -
在閉包中儲存上值數量是多餘的,因為ObjClosure引用的ObjFunction也儲存了這個數量。通常,這類奇怪的程式碼是為了適應GC。在閉包對應的ObjFunction已經被釋放後,收集器可能也需要知道ObjClosure對應上值陣列的大小。 ↩
-
設定指令不會從棧中彈出值,因為,請記住,賦值在Lox中是一個表示式。所以賦值的結果(所賦的值)需要保留在棧中,供外圍的表示式使用。 ↩
-
如果Lox不允許賦值,這就是一個學術問題。 ↩
-
我使用了多個全域性變數的事實並不重要。我需要某種方式從一個函式中返回兩個值。而在Lox中沒有任何形式的聚合型別,我的選擇很有限。 ↩
-
這裡 的“之後”,指的是詞法或文字意義上的——在包含關閉變數的宣告語句的程式碼塊的
}之後的程式碼。 ↩ -
編譯器不會彈出引數和在函式體中宣告的區域性變數。這些我們也會在執行時處理。 ↩
-
在本書的後面部分,使用者將有可能捕獲這個變數。這裡只是建立一些預期。 ↩
-
如果某個閉包從外圍函式中捕獲了一個上值,那麼虛擬機器確實會共享上值。巢狀的情況下,工作正常。但是如果兩個同級閉包捕獲了同一個區域性變數,它們會各自建立一個單獨的ObjUpvalue。 ↩
-
閉包經常在熱迴圈中被呼叫。想想傳遞給集合的典型高階函式,如
map()和filter()。這應該是很快的。但是建立閉包的函式宣告只發生一次,而且通常是在迴圈之外。 ↩ -
這是個單連結串列。除了從頭指標開始遍歷,我們沒有其它選擇。 ↩
-
還有一種更簡短的實現,透過使用一個指向指標的指標,來統一處理更新頭部指標或前一個上值的
next指標兩種情況,但這種程式碼幾乎會讓所有未達到指標專業水平的人感到困惑。我選擇了基本的if語句的方法。 ↩ -
我並不是在自誇。這都是Lua開發團隊的創新。 ↩
-
沒有什麼阻止我們在編譯器中關閉最外層的函式作用域,並生成
OP_POP和OP_CLOSE_UPVALUE指令。這樣做只是沒有必要,因為執行時在彈出呼叫幀時,隱式地丟棄了函式使用的所有棧槽。 ↩ -
你想知道“3”是怎麼出現的嗎?在第二次迭代後,執行
i++,它將i增加到3。這就是導致i<=2的值為false並結束迴圈的原因。如果i永遠達不到3,迴圈就會一直執行下去。 ↩
26.垃圾回收 Garbage Collection
I wanna, I wanna, I wanna, I wanna, I wanna be trash.
—— The Whip, “Trash”
【譯者注:The Whip樂隊的歌曲,歌詞也沒必要翻譯了】
We say Lox is a “high-level” language because it frees programmers from worrying about details irrelevant to the problem they’re solving. The user becomes an executive, giving the machine abstract goals and letting the lowly computer figure out how to get there.
我們說Lox是一種“高級”語言,因為它使得程序員不必擔心那些與他們要解決的問題無關的細節。用戶變成了執行者,給機器設定抽象的目標,讓底層的計算機自己想辦法實現目標。
Dynamic memory allocation is a perfect candidate for automation. It’s necessary for a working program, tedious to do by hand, and yet still error-prone. The inevitable mistakes can be catastrophic, leading to crashes, memory corruption, or security violations. It’s the kind of risky-yet-boring work that machines excel at over humans.
動態內存分配是自動化的最佳選擇。這是一個基本可用的程序所必需的,手動操作很繁瑣,而且很容易出錯。不可避免的錯誤可能是災難性的,會導致崩潰、內存損壞或安全漏洞。機器比人類更擅長這種既有風險又無聊的工作。
This is why Lox is a managed language, which means that the language implementation manages memory allocation and freeing on the user’s behalf. When a user performs an operation that requires some dynamic memory, the VM automatically allocates it. The programmer never worries about deallocating anything. The machine ensures any memory the program is using sticks around as long as needed.
這就是為什麼Lox是一種託管語言,這意味著語言實現會代表用戶管理內存的分配與釋放。當用戶執行某個需要動態內存的操作時,虛擬機會自動分配。程序員不用擔心任何釋放內存的事情。機器會確保程序使用的任意內存會在需要的時候存在。
Lox provides the illusion that the computer has an infinite amount of memory. Users can allocate and allocate and allocate and never once think about where all these bytes are coming from. Of course, computers do not yet have infinite memory. So the way managed languages maintain this illusion is by going behind the programmer’s back and reclaiming memory that the program no longer needs. The component that does this is called a garbage collector.
Lox提供了一種計算機擁有無限內存的錯覺。用戶可以不停地分配、分配、再分配,而不用考慮這些內存是從哪裡來的。當然,計算機還沒有無限的內存。因此,託管語言維持這種錯覺的方式是揹著程序員,回收程序不再需要的內存。實現這一點的組件被稱為垃圾回收器。
26 . 1 Reachability
26.1 可達性
This raises a surprisingly difficult question: how does a VM tell what memory is not needed? Memory is only needed if it is read in the future, but short of having a time machine, how can an implementation tell what code the program will execute and which data it will use? Spoiler alert: VMs cannot travel into the future. Instead, the language makes a conservative approximation: it considers a piece of memory to still be in use if it could possibly be read in the future.
這就引出了一個非常困難的問題:虛擬機如何分辨哪些內存是不需要的?內存只有在未來被讀取時才需要,但是如果沒有時間機器,語言如何知道程序將執行哪些代碼,使用哪些數據?劇透警告:虛擬機不能穿越到未來。相反,語言做了一個保守的估計1:如果一塊內存在未來有可能被讀取,就認為它仍然在使用。
That sounds too conservative. Couldn’t any bit of memory potentially be read? Actually, no, at least not in a memory-safe language like Lox. Here’s an example:
這聽起來太保守了。難道不是內存中的任何比特都可能被讀取嗎?事實上,不是,至少在Lox這樣內存安全的語言中不是。下面是一個例子:
var a = "first value";
a = "updated";
// GC here.
print a;
Say we run the GC after the assignment has completed on the second line. The string “first value” is still sitting in memory, but there is no way for the user’s program to ever get to it. Once
agot reassigned, the program lost any reference to that string. We can safely free it. A value is reachable if there is some way for a user program to reference it. Otherwise, like the string “first value” here, it is unreachable.
假設我們在完成第二行的賦值之後運行GC。字符串“first value”仍然在內存中,但是用戶的程序沒有辦法訪訪問它。一旦a被重新賦值,程序就失去了對該字符串的任何引用,我們可以安全地釋放它。如果用戶程序可以通過某種方式引用一個值,這個值就是可達的。否則,就像這裡的字符串“first value”一樣,它是不可達的。
Many values can be directly accessed by the VM. Take a look at:
許多值可以被虛擬機直接訪問。請看:
var global = "string";
{
var local = "another";
print global + local;
}
Pause the program right after the two strings have been concatenated but before the
"string"by looking through the global variable table and finding the entry forglobal. It can find"another"by walking the value stack and hitting the slot for the local variablelocal. It can even find the concatenated string"stringanother"since that temporary value is also sitting on the VM’s stack at the point when we paused our program.
在兩個字符串連接之後但是print語句執行之前暫停程序。虛擬機可以通過查看全局變量表,並查找global條目到達"string"。它可以通過遍歷值棧,並找到局部變量local的棧槽來找到"another"。它甚至也可以找到連接後的字符串"stringanother",因為在我們暫停程序的時候,這個臨時值也在虛擬機的棧中。
All of these values are called roots. A root is any object that the VM can reach directly without going through a reference in some other object. Most roots are global variables or on the stack, but as we’ll see, there are a couple of other places the VM stores references to objects that it can find.
所有這些值都被稱為根。根是虛擬機可以無需通過其它對象的引用而直接到達的任何對象。大多數根是全局變量或在棧上,但正如我們將看到的,還有其它一些地方,虛擬機會在其中存儲它可以找到的對象的引用。
Other values can be found by going through a reference inside another value. Fields on instances of classes are the most obvious case, but we don’t have those yet. Even without those, our VM still has indirect references. Consider:
其它值可以通過另一個值中的引用來找到。類實例中的字段是最明顯的情況,但我們目前還沒有類。即使沒有這些,我們的虛擬機中仍然存在間接引用。考慮一下:
fun makeClosure() {
var a = "data";
fun f() { print a; }
return f;
}
{
var closure = makeClosure();
// GC here.
closure();
}
Say we pause the program on the marked line and run the garbage collector. When the collector is done and the program resumes, it will call the closure, which will in turn print
"data". So the collector needs to not free that string. But here’s what the stack looks like when we pause the program:
假設我們在標記的行上暫停並運行垃圾回收器。當回收器完成、程序恢復時,它將會調用閉包,然後輸出"data"。所以回收器需要不釋放那個字符串。但當我們暫停程序時,棧是這樣的:

The
"data"string is nowhere on it. It has already been hoisted off the stack and moved into the closed upvalue that the closure uses. The closure itself is on the stack. But to get to the string, we need to trace through the closure and its upvalue array. Since it is possible for the user’s program to do that, all of these indirectly accessible objects are also considered reachable.
"data"字符串並不在上面。它已經被從棧中提取出來,並移動到閉包所使用的關閉上值中。閉包本身在棧上。但是要得到字符串,我們需要跟蹤閉包及其上值數組。因為用戶的程序可能會這樣做,所有這些可以間接訪問的對象也被認為是可達的。
This gives us an inductive definition of reachability:
這給了我們一個關於可達性的歸納定義:
- All roots are reachable.
- Any object referred to from a reachable object is itself reachable.
- 所有根都是可達的。
- 任何被某個可達對象引用的對象本身是可達的。
These are the values that are still “live” and need to stay in memory. Any value that doesn’t meet this definition is fair game for the collector to reap. That recursive pair of rules hints at a recursive algorithm we can use to free up unneeded memory:
這些是仍然“存活”、需要留在內存中的值。任何不符合這個定義的值,對於回收器來說都是可收割的獵物。這一對遞歸規則暗示了我們可以用一個遞歸算法來釋放不需要的內存:
- Starting with the roots, traverse through object references to find the full set of reachable objects.
- Free all objects not in that set.
- 從根開始,遍歷對象引用,找到可達對象的完整集合。
- 釋放不在集合中的所有對象。
Many different garbage collection algorithms are in use today, but they all roughly follow that same structure. Some may interleave the steps or mix them, but the two fundamental operations are there. They mostly differ in how they perform each step.
如今有很多不同的垃圾回收算法,但是它們都大致遵循相同的結構。有些算法可能會將這些步驟進行交叉或混合,但這兩個基本操作是存在的。不同算法的區別在於如何執行每個步驟2。
26 . 2 Mark-Sweep Garbage Collection
26.2 標記-清除垃圾回收
The first managed language was Lisp, the second “high-level” language to be invented, right after Fortran. John McCarthy considered using manual memory management or reference counting, but eventually settled on (and coined) garbage collection—once the program was out of memory, it would go back and find unused storage it could reclaim.
第一門託管語言是Lisp,它是繼Fortran之後發明的第二種“高級”語言。John McCarthy曾考慮使用手動內存管理或引用計數,但最終還是選擇(並創造了)垃圾回收——一旦程序的內存用完了,它就會回去尋找可以回收的未使用的存儲空間3。
He designed the very first, simplest garbage collection algorithm, called mark-and-sweep or just mark-sweep. Its description fits in three short paragraphs in the initial paper on Lisp. Despite its age and simplicity, the same fundamental algorithm underlies many modern memory managers. Some corners of CS seem to be timeless.
他設計了最早的、最簡單的垃圾回收算法,被稱為標記並清除(mark-and-sweep),或者就叫標記清除(mark-sweep)。在最初的Lisp論文中,關於它的描述只有短短的三段。儘管它年代久遠且簡單,但許多現代內存管理器都使用了相同的基本算法。CS中的一些角落似乎是永恆的。
As the name implies, mark-sweep works in two phases:
顧名思義,標記-清除分兩個階段工作:
- Marking: We start with the roots and traverse or trace through all of the objects those roots refer to. This is a classic graph traversal of all of the reachable objects. Each time we visit an object, we mark it in some way. (Implementations differ in how they record the mark.)
- Sweeping: Once the mark phase completes, every reachable object in the heap has been marked. That means any unmarked object is unreachable and ripe for reclamation. We go through all the unmarked objects and free each one.
- 標記:我們從根開始,遍歷或跟蹤這些根所引用的所有對象。這是對所有可達對象的經典圖式遍歷。每次我們訪問一個對象時,我們都用某種方式來標記它。(不同的實現方式,記錄標記的方法也不同)
- 清除:一旦標記階段完成,堆中的每個可達對象都被標記了。這意味著任何未被標記的對象都是不可達的,可以被回收。我們遍歷所有未被標記的對象,並逐個釋放。
It looks something like this:
它看起來像是這樣的4:
That’s what we’re gonna implement. Whenever we decide it’s time to reclaim some bytes, we’ll trace everything and mark all the reachable objects, free what didn’t get marked, and then resume the user’s program.
這就是我們要實現的。每當我們決定是時候回收一些字節的時候,我們就會跟蹤一切,並標記所有可達的對象,釋放沒有被標記的對象,然後恢復用戶的程序。
26 . 2 . 1 Collecting garbage
26.2.1 回收垃圾
This entire chapter is about implementing this one function:
整個章節都是關於實現這一個函數的5:
memory.h,在reallocate()方法後添加代碼:
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
// 新增部分開始
void collectGarbage();
// 新增部分結束
void freeObjects();
We’ll work our way up to a full implementation starting with this empty shell:
我們會從這個空殼開始逐步完整實現:
memory.c,在freeObject()方法後添加代碼:
void collectGarbage() {
}
The first question you might ask is, When does this function get called? It turns out that’s a subtle question that we’ll spend some time on later in the chapter. For now we’ll sidestep the issue and build ourselves a handy diagnostic tool in the process.
你可能會問的第一個問題是,這個函數在什麼時候被調用?事實證明,這是一個微妙的問題,我們會在後面的章節中花些時間討論。現在,我們先回避這個問題,並在這個過程中為自己構建一個方便的診斷工具。
common.h,添加代碼:
#define DEBUG_TRACE_EXECUTION
// 新增部分開始
#define DEBUG_STRESS_GC
// 新增部分結束
#define UINT8_COUNT (UINT8_MAX + 1)
We’ll add an optional “stress test” mode for the garbage collector. When this flag is defined, the GC runs as often as it possibly can. This is, obviously, horrendous for performance. But it’s great for flushing out memory management bugs that occur only when a GC is triggered at just the right moment. If every moment triggers a GC, you’re likely to find those bugs.
我們將為垃圾回收器添加一個可選的“壓力測試”模式。當定義這個標誌後,GC就會盡可能頻繁地運行。顯然,這對性能來說是很糟糕的。但它對於清除內存管理bug很有幫助,這些bug只有在適當的時候觸發GC時才會出現。如果每時每刻都觸發GC,那你很可能會找到這些bug。
memory.c,在reallocate()方法中添加代碼:
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
// 新增部分開始
if (newSize > oldSize) {
#ifdef DEBUG_STRESS_GC
collectGarbage();
#endif
}
// 新增部分結束
if (newSize == 0) {
Whenever we call
reallocate()to acquire more memory, we force a collection to run. The if check is becausereallocate()is also called to free or shrink an allocation. We don’t want to trigger a GC for that—in particular because the GC itself will callreallocate()to free memory.
每當我們調用reallocate()來獲取更多內存時,都會強制運行一次回收。這個if檢查是因為,在釋放或收縮分配的內存時也會調用reallocate()。我們不希望在這種時候觸發GC——特別是因為GC本身也會調用reallocate()來釋放內存。
Collecting right before allocation is the classic way to wire a GC into a VM. You’re already calling into the memory manager, so it’s an easy place to hook in the code. Also, allocation is the only time when you really need some freed up memory so that you can reuse it. If you don’t use allocation to trigger a GC, you have to make sure every possible place in code where you can loop and allocate memory also has a way to trigger the collector. Otherwise, the VM can get into a starved state where it needs more memory but never collects any.
在分配之前進行回收是將GC引入虛擬機的經典方式6。你已經在調用內存管理器了,所以這是個很容易掛接代碼的地方。另外,分配是唯一你真的需要一些釋放出來的內存的時候,這樣你就可以重新使用它。如果不使用分配來觸發GC,則必須確保代碼中每個可以循環和分配內存的地方都有觸發回收器的方法。否則,虛擬機會進入飢餓狀態,它需要更多的內存,但卻沒有回收到任何內存。
26 . 2 . 2 Debug logging
26.2.2 調試日誌
While we’re on the subject of diagnostics, let’s put some more in. A real challenge I’ve found with garbage collectors is that they are opaque. We’ve been running lots of Lox programs just fine without any GC at all so far. Once we add one, how do we tell if it’s doing anything useful? Can we tell only if we write programs that plow through acres of memory? How do we debug that?
既然我們在討論診斷的問題,那我們再加入一些內容。我發現垃圾回收器的一個真正的挑戰在於它們是不透明的。到目前為止,我們已經在沒有任何GC的情況下運行了很多Lox程序。一旦我們添加了GC,我們如何知道它是否在做有用的事情?只有當我們編寫的程序耗費了大量的內存時,我們才能知道嗎?我們該如何調試呢?
An easy way to shine a light into the GC’s inner workings is with some logging.
瞭解GC內部工作的一種簡單方式是進行一些日誌記錄。
common.h,添加代碼:
#define DEBUG_STRESS_GC
// 新增部分開始
#define DEBUG_LOG_GC
// 新增部分結束
#define UINT8_COUNT (UINT8_MAX + 1)
When this is enabled, clox prints information to the console when it does something with dynamic memory.
啟用這個功能後,當clox使用動態內存執行某些操作時,會將信息打印到控制檯。
We need a couple of includes.
我們需要一些引入。
memory.c,添加代碼:
#include "vm.h"
// 新增部分開始
#ifdef DEBUG_LOG_GC
#include <stdio.h>
#include "debug.h"
#endif
// 新增部分結束
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
We don’t have a collector yet, but we can start putting in some of the logging now. We’ll want to know when a collection run starts.
我們還沒有回收器,但我們現在可以開始添加一些日誌記錄。我們想要知道回收是在何時開始的。
memory.c,在collectGarbage()方法中添加代碼:
void collectGarbage() {
// 新增部分開始
#ifdef DEBUG_LOG_GC
printf("-- gc begin\n");
#endif
// 新增部分結束
}
Eventually we will log some other operations during the collection, so we’ll also want to know when the show’s over.
最終,我們會在回收過程中記錄一些其它操作,因此我們也想知道回收什麼時候結束。
memory.c,在collectGarbage()方法中添加代碼:
printf("-- gc begin\n");
#endif
// 新增部分開始
#ifdef DEBUG_LOG_GC
printf("-- gc end\n");
#endif
// 新增部分結束
}
We don’t have any code for the collector yet, but we do have functions for allocating and freeing, so we can instrument those now.
我們還沒有關於回收器的任何代碼,但是我們有分配和釋放的函數,所以我們現在可以對這些函數進行檢測。
object.c,在allocateObject()方法中添加代碼:
vm.objects = object;
// 新增部分開始
#ifdef DEBUG_LOG_GC
printf("%p allocate %zu for %d\n", (void*)object, size, type);
#endif
// 新增部分結束
return object;
And at the end of an object’s lifespan:
在對象的生命週期結束時:
memory.c,在freeObject()方法中添加代碼:
static void freeObject(Obj* object) {
// 新增部分開始
#ifdef DEBUG_LOG_GC
printf("%p free type %d\n", (void*)object, object->type);
#endif
// 新增部分結束
switch (object->type) {
With these two flags, we should be able to see that we’re making progress as we work through the rest of the chapter.
有了這兩個標誌,我們應該能夠看到我們在本章其餘部分的學習中取得了進展。
26 . 3 Marking the Roots
26.3 標記根
Objects are scattered across the heap like stars in the inky night sky. A reference from one object to another forms a connection, and these constellations are the graph that the mark phase traverses. Marking begins at the roots.
對象就像漆黑夜空中的星星一樣散落在堆中。從一個對象到另一個對象的引用形成了一種連接,而這些星座就是標記階段需要遍歷的圖。標記是從根開始的。
memory.c,在collectGarbage()方法中添加代碼:
#ifdef DEBUG_LOG_GC
printf("-- gc begin\n");
#endif
// 新增部分開始
markRoots();
// 新增部分結束
#ifdef DEBUG_LOG_GC
Most roots are local variables or temporaries sitting right in the VM’s stack, so we start by walking that.
大多數根是虛擬機棧中的局部變量或臨時變量,因此我們從遍歷棧開始:
memory.c,在freeObject()方法後添加代碼:
static void markRoots() {
for (Value* slot = vm.stack; slot < vm.stackTop; slot++) {
markValue(*slot);
}
}
To mark a Lox value, we use this new function:
為了標記Lox值,我們使用這個新函數:
memory.h,在reallocate()方法後添加代碼:
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
// 新增部分開始
void markValue(Value value);
// 新增部分結束
void collectGarbage();
Its implementation is here:
它的實現在這裡:
memory.c,在reallocate()方法後添加代碼:
void markValue(Value value) {
if (IS_OBJ(value)) markObject(AS_OBJ(value));
}
Some Lox values—numbers, Booleans, and
nil—are stored directly inline in Value and require no heap allocation. The garbage collector doesn’t need to worry about them at all, so the first thing we do is ensure that the value is an actual heap object. If so, the real work happens in this function:
一些Lox值(數字、布爾值和nil)直接內聯存儲在Value中,不需要堆分配。垃圾回收器根本不需要擔心這些,因此我們要做的第一件事是確保值是一個真正的堆對象。如果是這樣,真正的工作就發生在這個函數中:
memory.h,在reallocate()方法後添加代碼:
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
// 新增部分開始
void markObject(Obj* object);
// 新增部分結束
void markValue(Value value);
Which is defined here:
下面是定義:
memory.c,在reallocate()方法後添加代碼:
void markObject(Obj* object) {
if (object == NULL) return;
object->isMarked = true;
}
The
NULLcheck is unnecessary when called frommarkValue(). A Lox Value that is some kind of Obj type will always have a valid pointer. But later we will call this function directly from other code, and in some of those places, the object being pointed to is optional.
從markValue()中調用時,NULL檢查是不必要的。某種Obj類型的Lox Value一定會有一個有效的指針。但稍後我們將從其它代碼中直接調用這個函數,在其中一些地方,被指向的對象是可選的。
Assuming we do have a valid object, we mark it by setting a flag. That new field lives in the Obj header struct all objects share.
假設我們確實有一個有效的對象,我們通過設置一個標誌來標記它。這個新字段存在於所有對象共享的Obj頭中。
object.h,在結構體Obj中添加代碼:
ObjType type;
// 新增部分開始
bool isMarked;
// 新增部分結束
struct Obj* next;
Every new object begins life unmarked because we haven’t yet determined if it is reachable or not.
每個新對象在開始時都沒有標記,因為我們還不確定它是否可達。
object.c,在allocateObject()方法中添加代碼:
object->type = type;
// 新增部分開始
object->isMarked = false;
// 新增部分結束
object->next = vm.objects;
Before we go any farther, let’s add some logging to
markObject().
在進一步討論之前,我們先在markObject()中添加一些日誌。
memory.c,在markObject()方法中添加代碼:
void markObject(Obj* object) {
if (object == NULL) return;
// 新增部分開始
#ifdef DEBUG_LOG_GC
printf("%p mark ", (void*)object);
printValue(OBJ_VAL(object));
printf("\n");
#endif
// 新增部分結束
object->isMarked = true;
This way we can see what the mark phase is doing. Marking the stack takes care of local variables and temporaries. The other main source of roots are the global variables.
這樣我們就可以看到標記階段在做什麼。對棧進行標記可以處理局部變量和臨時變量。另一個根的主要來源就是全局變量。
memory.c,在markRoots()方法中添加代碼:
markValue(*slot);
}
// 新增部分開始
markTable(&vm.globals);
// 新增部分結束
}
Those live in a hash table owned by the VM, so we’ll declare another helper function for marking all of the objects in a table.
它們位於VM擁有的一個哈希表中,因此我們會聲明另一個輔助函數來標記表中的所有對象。
table.h,在tableFindString()方法後添加代碼:
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
// 新增部分開始
void markTable(Table* table);
// 新增部分結束
#endif
We implement that in the “table” module here:
我們在“table”模塊中實現它:
table.c,在tableFindString()方法後添加代碼:
void markTable(Table* table) {
for (int i = 0; i < table->capacity; i++) {
Entry* entry = &table->entries[i];
markObject((Obj*)entry->key);
markValue(entry->value);
}
}
Pretty straightforward. We walk the entry array. For each one, we mark its value. We also mark the key strings for each entry since the GC manages those strings too.
非常簡單。我們遍歷條目數組。對於每個條目,我們標記其值。我們還會標記每個條目的鍵字符串,因為GC也要管理這些字符串。
26 . 3 . 1 Less obvious roots
26.3.1 不明顯的根
Those cover the roots that we typically think of—the values that are obviously reachable because they’re stored in variables the user’s program can see. But the VM has a few of its own hidey-holes where it squirrels away references to values that it directly accesses.
這些覆蓋了我們通常認為的根——那些明顯可達的值,因為它們存儲在用戶程序可以看到的變量中。但是虛擬機也有一些自己的藏身之所,可以隱藏對直接訪問的值的引用。
Most function call state lives in the value stack, but the VM maintains a separate stack of CallFrames. Each CallFrame contains a pointer to the closure being called. The VM uses those pointers to access constants and upvalues, so those closures need to be kept around too.
大多數函數調用狀態都存在於值棧中,但是虛擬機維護了一個單獨的CallFrame棧。每個CallFrame都包含一個指向被調用閉包的指針。VM使用這些指針來訪問常量和上值,所以這些閉包也需要被保留下來。
memory.c,在markRoots()方法中添加代碼:
}
// 新增部分開始
for (int i = 0; i < vm.frameCount; i++) {
markObject((Obj*)vm.frames[i].closure);
}
// 新增部分結束
markTable(&vm.globals);
Speaking of upvalues, the open upvalue list is another set of values that the VM can directly reach.
說到上值,開放上值列表是VM可以直接訪問的另一組值。
memory.c,在markRoots()方法中添加代碼:
for (int i = 0; i < vm.frameCount; i++) {
markObject((Obj*)vm.frames[i].closure);
}
// 新增部分開始
for (ObjUpvalue* upvalue = vm.openUpvalues;
upvalue != NULL;
upvalue = upvalue->next) {
markObject((Obj*)upvalue);
}
// 新增部分結束
markTable(&vm.globals);
Remember also that a collection can begin during any allocation. Those allocations don’t just happen while the user’s program is running. The compiler itself periodically grabs memory from the heap for literals and the constant table. If the GC runs while we’re in the middle of compiling, then any values the compiler directly accesses need to be treated as roots too.
還要記住,回收可能會在任何分配期間開始。這些分配並不僅僅是在用戶程序運行的時候發生。編譯器本身會定期從堆中獲取內存,用於存儲字面量和常量表。如果GC在編譯期間運行,那麼編譯器直接訪問的任何值也需要被當作根來處理。
To keep the compiler module cleanly separated from the rest of the VM, we’ll do that in a separate function.
為了保持編譯器模塊與虛擬機的其它部分完全分離,我們在一個單獨的函數中完成這一工作。
memory.c,在markRoots()方法中添加代碼:
markTable(&vm.globals);
// 新增部分開始
markCompilerRoots();
// 新增部分結束
}
It’s declared here:
它是在這裡聲明的:
compiler.h,在compile()方法後添加代碼:
ObjFunction* compile(const char* source);
// 新增部分開始
void markCompilerRoots();
// 新增部分結束
#endif
Which means the “memory” module needs an include.
這意味著“memory”模塊需要引入頭文件。
memory.c,添加代碼:
#include <stdlib.h>
// 新增部分開始
#include "compiler.h"
// 新增部分結束
#include "memory.h"
And the definition is over in the “compiler” module.
定義在“compiler”模塊中。
compiler.c,在compile()方法後添加代碼:
void markCompilerRoots() {
Compiler* compiler = current;
while (compiler != NULL) {
markObject((Obj*)compiler->function);
compiler = compiler->enclosing;
}
}
Fortunately, the compiler doesn’t have too many values that it hangs on to. The only object it uses is the ObjFunction it is compiling into. Since function declarations can nest, the compiler has a linked list of those and we walk the whole list.
幸運的是,編譯器並沒有太多掛載的值。它唯一使用的對象是它正在編譯的ObjFunction。由於函數聲明可以嵌套,編譯器有一個函數聲明的鏈表,我們遍歷整個列表。
Since the “compiler” module is calling
markObject(), it also needs an include.
因為“compiler”模塊會調用markObject(),也需要引入。
compiler.c,添加代碼:
#include "compiler.h"
// 新增部分開始
#include "memory.h"
// 新增部分結束
#include "scanner.h"
Those are all the roots. After running this, every object that the VM—runtime and compiler—can get to without going through some other object has its mark bit set.
這些就是所有的根。運行這段程序後,虛擬機(運行時和編譯器)無需通過其它對象就可以達到的每個對象,其標記位都被設置了。
26 . 4 Tracing Object References
26.4 跟蹤對象引用
The next step in the marking process is tracing through the graph of references between objects to find the indirectly reachable values. We don’t have instances with fields yet, so there aren’t many objects that contain references, but we do have some. In particular, ObjClosure has the list of ObjUpvalues it closes over as well as a reference to the raw ObjFunction that it wraps. ObjFunction, in turn, has a constant table containing references to all of the literals created in the function’s body. This is enough to build a fairly complex web of objects for our collector to crawl through.
標記過程的下一步是跟蹤對象之間的引用圖,找到間接可達的對象。我們現在還沒有帶有字段的實例,因此包含引用的對象不多,但確實有一些。特別的,ObjClosure擁有它所關閉的ObjUpvalue列表,以及它所包裝的指向原始ObjFunction的引用7。反過來,ObjFunction有一個常量表,包含函數體中創建的所有字面量的引用。這足以構建一個相當複雜的對象網絡,供回收器爬取。
Now it’s time to implement that traversal. We can go breadth-first, depth-first, or in some other order. Since we just need to find the set of all reachable objects, the order we visit them mostly doesn’t matter.
現在是時候實現遍歷了。我們可以按照廣度優先、深度優先或其它順序進行遍歷。因為我們只需要找到所有可達對象的集合,所以訪問它們的順序幾乎沒有影響8。
26 . 4 . 1 The tricolor abstraction
26.4.1 三色抽象
As the collector wanders through the graph of objects, we need to make sure it doesn’t lose track of where it is or get stuck going in circles. This is particularly a concern for advanced implementations like incremental GCs that interleave marking with running pieces of the user’s program. The collector needs to be able to pause and then pick up where it left off later.
當回收器在對象圖中漫遊時,我們需要確保它不會失去對其位置的跟蹤或者陷入循環。這對於像增量GC這樣的高級實現來說尤其值得關注,因為增量GC將標記與用戶程序的的運行部分交織在一起。回收器需要能夠暫停,稍後在停止的地方重新開始。
To help us soft-brained humans reason about this complex process, VM hackers came up with a metaphor called the tricolor abstraction. Each object has a conceptual “color” that tracks what state the object is in, and what work is left to do.
為了幫助我們這些愚蠢的人類理解這個複雜的過程,虛擬機專家們想出了一個稱為三色抽象的比喻。每個對象都有一個概念上的“顏色”,用於追蹤對象處於什麼狀態,以及還需要做什麼工作9。
White: At the beginning of a garbage collection, every object is white. This color means we have not reached or processed the object at all.
Gray: During marking, when we first reach an object, we darken it gray. This color means we know the object itself is reachable and should not be collected. But we have not yet traced through it to see what other objects it references. In graph algorithm terms, this is the worklist—the set of objects we know about but haven’t processed yet.
Black: When we take a gray object and mark all of the objects it references, we then turn the gray object black. This color means the mark phase is done processing that object.
- 白色: 在垃圾回收的開始階段,每個對象都是白色的。這種顏色意味著我們根本沒有達到或處理該對象。
- 灰色: 在標記過程中,當我們第一次達到某個對象時,我們將其染為灰色。這種顏色意味著我們知道這個對象本身是可達的,不應該被收集。但我們還沒有通過它來跟蹤它引用的其它對象。用圖算法的術語來說,這就是工作列表(worklist)——我們知道但還沒有被處理的對象集合。
- 黑色: 當我們接受一個灰色對象,並將其引用的所有對象全部標記後,我們就把這個灰色對象變為黑色。這種顏色意味著標記階段已經完成了對該對象的處理。
In terms of that abstraction, the marking process now looks like this:
從這個抽象的角度看,標記過程新增看起來是這樣的:
- Start off with all objects white.
- Find all the roots and mark them gray.
- Repeat as long as there are still gray objects:
- Pick a gray object. Turn any white objects that the object mentions to gray.
- Mark the original gray object black.
- 開始時,所有對象都是白色的。
- 找到所有的根,將它們標記為灰色。
- 只要還存在灰色對象,就重複此過程:
- 選擇一個灰色對象。將該對象引用的所有白色對象標記為灰色。
- 將原來的灰色對象標記為黑色。
I find it helps to visualize this. You have a web of objects with references between them. Initially, they are all little white dots. Off to the side are some incoming edges from the VM that point to the roots. Those roots turn gray. Then each gray object’s siblings turn gray while the object itself turns black. The full effect is a gray wavefront that passes through the graph, leaving a field of reachable black objects behind it. Unreachable objects are not touched by the wavefront and stay white.
我發現把它可視化很有幫助。你有一個對象網絡,對象之間有引用。最初,它們都是小白點。旁邊是一些虛擬機的傳入邊,這些邊指向根。這些根變成了灰色。然後每個灰色對象的兄弟節點變成灰色,而該對象本身變成黑色。完整的效果是一個灰色波前穿過圖,在它後面留下一個可達的黑色對象區域。不可達對象不會被波前觸及,並保持白色。

At the end, you’re left with a sea of reached, black objects sprinkled with islands of white objects that can be swept up and freed. Once the unreachable objects are freed, the remaining objects—all black—are reset to white for the next garbage collection cycle.
最後,你會看到一片可達的、黑色對象組成的海洋,其中點綴著可以清除和釋放的白色對象組成的島嶼。一旦不可達的對象被釋放,剩下的對象(全部為黑色)會被重置為白色,以便在下一個垃圾收集週期使用10。
26 . 4 . 2 A worklist for gray objects
26.4.2 灰色對象的工作列表
In our implementation we have already marked the roots. They’re all gray. The next step is to start picking them and traversing their references. But we don’t have any easy way to find them. We set a field on the object, but that’s it. We don’t want to have to traverse the entire object list looking for objects with that field set.
在我們的實現中,我們已經對根進行了標記。它們都是灰色的。下一步是開始挑選灰色對象並遍歷其引用。但是我們沒有任何簡單的方法來查找灰色對象。我們在對象上設置了一個字段,但也僅此而已。我們不希望遍歷整個對象列表來查找設置了該字段的對象。
Instead, we’ll create a separate worklist to keep track of all of the gray objects. When an object turns gray, in addition to setting the mark field we’ll also add it to the worklist.
相反,我們創建一個單獨的工作列表來跟蹤所有的灰色對象。當某個對象變成灰色時,除了設置標記字段外,我們還會將它添加到工作列表中。
memory.c,在markObject()方法中添加代碼:
object->isMarked = true;
// 新增部分開始
if (vm.grayCapacity < vm.grayCount + 1) {
vm.grayCapacity = GROW_CAPACITY(vm.grayCapacity);
vm.grayStack = (Obj**)realloc(vm.grayStack,
sizeof(Obj*) * vm.grayCapacity);
}
vm.grayStack[vm.grayCount++] = object;
// 新增部分結束
}
We could use any kind of data structure that lets us put items in and take them out easily. I picked a stack because that’s the simplest to implement with a dynamic array in C. It works mostly like other dynamic arrays we’ve built in Lox, except, note that it calls the system
realloc()function and not our ownreallocate()wrapper. The memory for the gray stack itself is not managed by the garbage collector. We don’t want growing the gray stack during a GC to cause the GC to recursively start a new GC. That could tear a hole in the space-time continuum.
我們可以使用任何類型的數據結構,讓我們可以輕鬆地放入和取出項目。我選擇了棧,因為這是用C語言實現動態數組最簡單的方法。它的工作原理與我們在Lox中構建的其它動態數組基本相同,除了一點,要注意它調用了系統的realloc()函數,而不是我們自己包裝的reallocate()。灰色對象棧本身的內存是不被垃圾回收器管理的。我們不希望因為GC過程中增加灰色對象棧,導致GC遞歸地發起一個新的GC。這可能會在時空連續體上撕開一個洞。
We’ll manage its memory ourselves, explicitly. The VM owns the gray stack.
我們會自己顯式地管理它的內存。VM擁有這個灰色棧。
vm.h,在結構體VM中添加代碼:
Obj* objects;
// 新增部分開始
int grayCount;
int grayCapacity;
Obj** grayStack;
// 新增部分結束
} VM;
It starts out empty.
開始時是空的。
vm.c,在initVM()方法中添加代碼:
vm.objects = NULL;
// 新增部分開始
vm.grayCount = 0;
vm.grayCapacity = 0;
vm.grayStack = NULL;
// 新增部分結束
initTable(&vm.globals);
And we need to free it when the VM shuts down.
當VM關閉時,我們需要釋放它。
memory.c,在freeObjects()方法中添加代碼:
object = next;
}
// 新增部分開始
free(vm.grayStack);
// 新增部分結束
}
We take full responsibility for this array. That includes allocation failure. If we can’t create or grow the gray stack, then we can’t finish the garbage collection. This is bad news for the VM, but fortunately rare since the gray stack tends to be pretty small. It would be nice to do something more graceful, but to keep the code in this book simple, we just abort.
我們對這個數組負擔全部責任,其中包括分配失敗。如果我們不能創建或擴張灰色棧,那我們就無法完成垃圾回收。這對VM來說是個壞消息,但幸運的是這很少發生,因為灰色棧往往是非常小的。如果能做得更優雅一些就好了,但是為了保持本書中的代碼簡單,我們就停在這裡吧11。
memory.c,在markObject()方法中添加代碼:
vm.grayStack = (Obj**)realloc(vm.grayStack,
sizeof(Obj*) * vm.grayCapacity);
// 新增部分開始
if (vm.grayStack == NULL) exit(1);
// 新增部分結束
}
26 . 4 . 3 Processing gray objects
26.4.3 處理灰色對象
OK, now when we’re done marking the roots, we have both set a bunch of fields and filled our work list with objects to chew through. It’s time for the next phase.
好了,現在我們在完成對根的標記後,既設置了一堆字段,也用待處理的對象填滿了我們的工作列表。是時候進入下一階段了。
memory.c,在collectGarbage()方法中添加代碼:
markRoots();
// 新增部分開始
traceReferences();
// 新增部分結束
#ifdef DEBUG_LOG_GC
Here’s the implementation:
下面是其實現:
memory.c,在markRoots()方法後添加代碼:
static void traceReferences() {
while (vm.grayCount > 0) {
Obj* object = vm.grayStack[--vm.grayCount];
blackenObject(object);
}
}
It’s as close to that textual algorithm as you can get. Until the stack empties, we keep pulling out gray objects, traversing their references, and then marking them black. Traversing an object’s references may turn up new white objects that get marked gray and added to the stack. So this function swings back and forth between turning white objects gray and gray objects black, gradually advancing the entire wavefront forward.
這與文本描述的算法已經儘可能接近了。在棧清空之前,我們會不斷取出灰色對象,遍歷它們的引用,然後將它們標記為黑色。遍歷某個對象的引用可能會出現新的白色對象,這些對象被標記為灰色並添加到棧中。所以這個函數在把白色對象變成灰色和把灰色對象變成黑色之間來回擺動,逐漸把整個波前向前推進。
Here’s where we traverse a single object’s references:
下面是我們遍歷某個對象的引用的地方:
memory.c,在markValue()方法後添加代碼:
static void blackenObject(Obj* object) {
switch (object->type) {
case OBJ_NATIVE:
case OBJ_STRING:
break;
}
}
Each object kind has different fields that might reference other objects, so we need a specific blob of code for each type. We start with the easy ones—strings and native function objects contain no outgoing references so there is nothing to traverse.
每種對象類型都有不同的可能引用其它對象的字段,因此我們需要為每種類型編寫一塊特定的代碼。我們從簡單的開始——字符串和本地函數對象不包含向外的引用,因此沒有任何東西需要遍歷12。
Note that we don’t set any state in the traversed object itself. There is no direct encoding of “black” in the object’s state. A black object is any object whose
isMarkedfield is set and that is no longer in the gray stack.
注意,我們沒有在已被遍歷的對象本身中設置任何狀態。在對象的狀態中,沒有對“black”的直接編碼。黑色對象是isMarked字段被設置且不再位於灰色棧中的任何對象13。
Now let’s start adding in the other object types. The simplest is upvalues.
現在讓我們開始添加其它的對象類型。最簡單的是上值。
memory.c,在blackenObject()方法中添加代碼:
static void blackenObject(Obj* object) {
switch (object->type) {
// 新增部分開始
case OBJ_UPVALUE:
markValue(((ObjUpvalue*)object)->closed);
break;
// 新增部分結束
case OBJ_NATIVE:
When an upvalue is closed, it contains a reference to the closed-over value. Since the value is no longer on the stack, we need to make sure we trace the reference to it from the upvalue.
當某個上值被關閉後,它包含一個指向關閉值的引用。由於該值不在棧上,我們需要確保從上值中跟蹤對它的引用。
Next are functions.
接下來是函數。
memory.c,在blackenObject()方法中添加代碼:
switch (object->type) {
// 新增部分開始
case OBJ_FUNCTION: {
ObjFunction* function = (ObjFunction*)object;
markObject((Obj*)function->name);
markArray(&function->chunk.constants);
break;
}
// 新增部分結束
case OBJ_UPVALUE:
Each function has a reference to an ObjString containing the function’s name. More importantly, the function has a constant table packed full of references to other objects. We trace all of those using this helper:
每個函數都有一個對包含函數名稱的ObjString 的引用。更重要的是,函數有一個常量表,其中充滿了對其它對象的引用。我們使用這個輔助函數來跟蹤它們:
memory.c,在markValue()方法後添加代碼:
static void markArray(ValueArray* array) {
for (int i = 0; i < array->count; i++) {
markValue(array->values[i]);
}
}
The last object type we have now—we’ll add more in later chapters—is closures.
我們現在擁有的最後一種對象類型(我們會在後面的章節中添加更多)是閉包。
memory.c,在blackenObject()方法中添加代碼:
switch (object->type) {
// 新增部分開始
case OBJ_CLOSURE: {
ObjClosure* closure = (ObjClosure*)object;
markObject((Obj*)closure->function);
for (int i = 0; i < closure->upvalueCount; i++) {
markObject((Obj*)closure->upvalues[i]);
}
break;
}
// 新增部分結束
case OBJ_FUNCTION: {
Each closure has a reference to the bare function it wraps, as well as an array of pointers to the upvalues it captures. We trace all of those.
每個閉包都有一個指向其包裝的裸函數的引用,以及一個指向它所捕獲的上值的指針數組。我們要跟蹤所有這些。
That’s the basic mechanism for processing a gray object, but there are two loose ends to tie up. First, some logging.
這就是處理灰色對象的基本機制,但還有兩個未解決的問題。首先,是一些日誌記錄。
memory.c,在blackenObject()中添加代碼:
static void blackenObject(Obj* object) {
// 新增部分開始
#ifdef DEBUG_LOG_GC
printf("%p blacken ", (void*)object);
printValue(OBJ_VAL(object));
printf("\n");
#endif
// 新增部分結束
switch (object->type) {
This way, we can watch the tracing percolate through the object graph. Speaking of which, note that I said graph. References between objects are directed, but that doesn’t mean they’re acyclic! It’s entirely possible to have cycles of objects. When that happens, we need to ensure our collector doesn’t get stuck in an infinite loop as it continually re-adds the same series of objects to the gray stack.
這樣一來,我們就可以觀察到跟蹤操作在對象圖中的滲入情況。說到這裡,請注意,我說的是圖。對象之間的引用是有方向的,但這並不意味著它們是無循環的!完全有可能出現對象的循環。當這種情況發生時,我們需要確保,我們的回收器不會因為持續將同一批對象添加到灰色堆棧而陷入無限循環。
The fix is easy.
解決方法很簡單。
memory.c,在markObject()方法中添加代碼:
if (object == NULL) return;
// 新增部分開始
if (object->isMarked) return;
// 新增部分結束
#ifdef DEBUG_LOG_GC
If the object is already marked, we don’t mark it again and thus don’t add it to the gray stack. This ensures that an already-gray object is not redundantly added and that a black object is not inadvertently turned back to gray. In other words, it keeps the wavefront moving forward through only the white objects.
如果對象已經被標記,我們就不會再標記它,因此也不會把它添加到灰色棧中。這就保證了已經是灰色的對象不會被重複添加,而且黑色對象不會無意中變回灰色。換句話說,它使得波前只通過白色對象向前移動。
26 . 5 Sweeping Unused Objects
26.5 清除未使用的對象
When the loop in
traceReferences()exits, we have processed all the objects we could get our hands on. The gray stack is empty, and every object in the heap is either black or white. The black objects are reachable, and we want to hang on to them. Anything still white never got touched by the trace and is thus garbage. All that’s left is to reclaim them.
當traceReferences()中的循環退出時,我們已經處理了所有能接觸到的對象。灰色棧是空的,堆中的每個對象不是黑色就是白色。黑色對象是可達的,我們想要抓住它們。任何仍然是白色的對象都沒有被追蹤器接觸過,因此是垃圾。剩下的就是回收它們了。
memory.c,在collectGarbage()方法中添加代碼:
traceReferences();
// 新增部分開始
sweep();
// 新增部分結束
#ifdef DEBUG_LOG_GC
All of the logic lives in one function.
所有的邏輯都在一個函數中。
memory.c,在traceReferences()方法後添加代碼:
static void sweep() {
Obj* previous = NULL;
Obj* object = vm.objects;
while (object != NULL) {
if (object->isMarked) {
previous = object;
object = object->next;
} else {
Obj* unreached = object;
object = object->next;
if (previous != NULL) {
previous->next = object;
} else {
vm.objects = object;
}
freeObject(unreached);
}
}
}
I know that’s kind of a lot of code and pointer shenanigans, but there isn’t much to it once you work through it. The outer
whileloop walks the linked list of every object in the heap, checking their mark bits. If an object is marked (black), we leave it alone and continue past it. If it is unmarked (white), we unlink it from the list and free it using thefreeObject()function we already wrote.
我知道這有點像是一堆代碼和指針的詭計,不過一旦你完成了,就沒什麼好說的。外層的while循環會遍歷堆中每個對象組成的鏈表,檢查它們的標記位。如果某個對象被標記(黑色),我們就不管它,繼續進行。如果它沒有被標記(白色),我們將它從鏈表中斷開,並使用我們已經寫好的freeObject()函數釋放它。
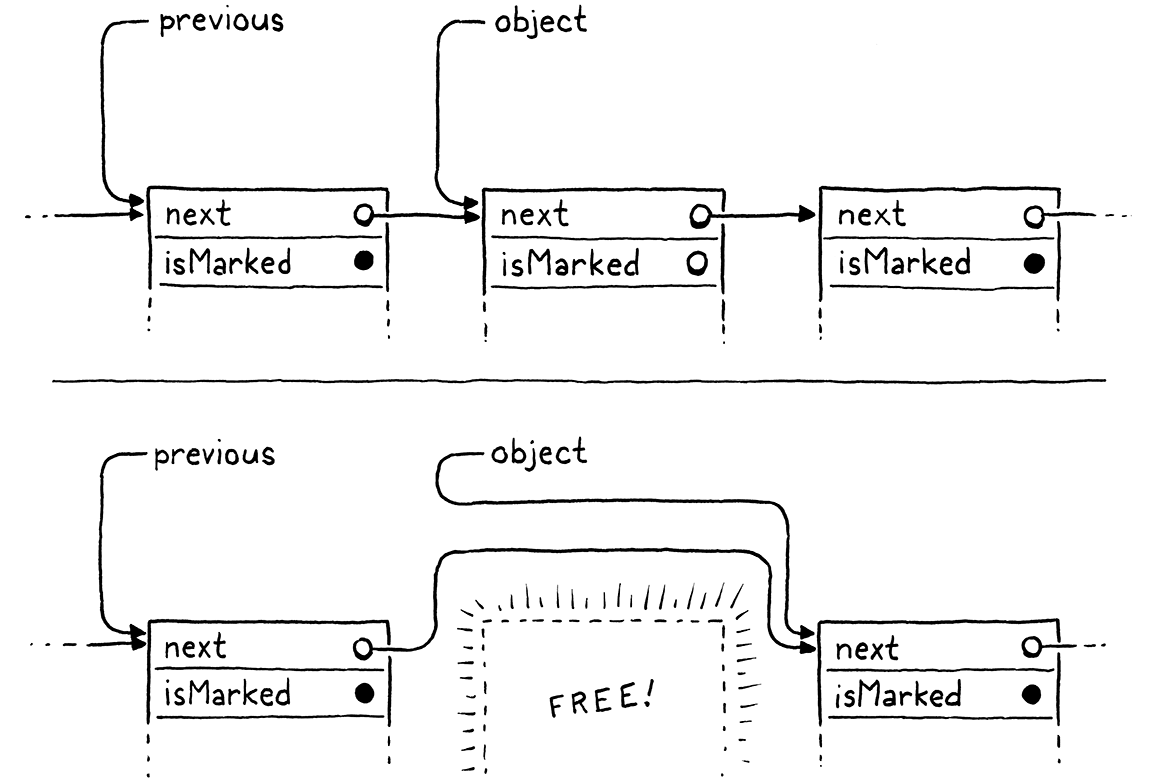
Most of the other code in here deals with the fact that removing a node from a singly linked list is cumbersome. We have to continuously remember the previous node so we can unlink its next pointer, and we have to handle the edge case where we are freeing the first node. But, otherwise, it’s pretty simple—delete every node in a linked list that doesn’t have a bit set in it.
這裡大多數其它代碼都在處理這樣一個事實:從單鏈表中刪除節點非常麻煩。我們必須不斷地記住前一個節點,這樣我們才能斷開它的next指針,而且我們還必須處理釋放第一個節點這種邊界情況。但是,除此之外,它非常簡單——刪除鏈表中沒有設置標記位的每個節點。
There’s one little addition:
還有一點需要補充:
memory.c,在sweep()方法中添加代碼:
if (object->isMarked) {
// 新增部分開始
object->isMarked = false;
// 新增部分結束
previous = object;
After
sweep()completes, the only remaining objects are the live black ones with their mark bits set. That’s correct, but when the next collection cycle starts, we need every object to be white. So whenever we reach a black object, we go ahead and clear the bit now in anticipation of the next run.
在sweep()完成後,僅剩下的對象是帶有標記位的活躍黑色對象。這是正確的,但在下一個回收週期開始時,我們需要每個對象都是白色的。因此,每當我們碰到黑色對象時,我們就繼續並清除標記位,為下一輪作業做好準備。
26 . 5 . 1 Weak references and the string pool
26.5.1 弱引用與字符串池
We are almost done collecting. There is one remaining corner of the VM that has some unusual requirements around memory. Recall that when we added strings to clox we made the VM intern them all. That means the VM has a hash table containing a pointer to every single string in the heap. The VM uses this to de-duplicate strings.
我們差不多已經回收完畢了。虛擬機中還有一個剩餘的角落,它對內存有著一些不尋常的要求。回想一下,我們在clox中添加字符串的時,我們讓虛擬機對所有字符串進行駐留。這意味著VM擁有一個哈希表,其中包含指向堆中每個字符串的指針。虛擬機使用它來對字符串去重。
During the mark phase, we deliberately did not treat the VM’s string table as a source of roots. If we had, no string would ever be collected. The string table would grow and grow and never yield a single byte of memory back to the operating system. That would be bad.
在標記階段,我們故意不將虛擬機的字符串表作為根的來源。如果我們這樣做,就不會有字符串被回收。字符串表會不斷增長,並且永遠不會向操作系統讓出一比特的內存。那就糟糕了14。
At the same time, if we do let the GC free strings, then the VM’s string table will be left with dangling pointers to freed memory. That would be even worse.
同時,如果我們真的讓GC釋放字符串,那麼VM的字符串表就會留下指向已釋放內存的懸空指針。那就更糟糕了。
The string table is special and we need special support for it. In particular, it needs a special kind of reference. The table should be able to refer to a string, but that link should not be considered a root when determining reachability. That implies that the referenced object can be freed. When that happens, the dangling reference must be fixed too, sort of like a magic, self-clearing pointer. This particular set of semantics comes up frequently enough that it has a name: a weak reference.
字符串表是很特殊的,我們需要對它進行特殊的支持。特別是,它需要一種特殊的引用。這個表應該能夠引用字符串,但在確定可達性時,不應該將該鏈接視為根。這意味著被引用的對象也可以被釋放。當這種情況發生時,懸空的引用也必須被修正,有點像一個神奇的、自我清除的指針。這組特定的語義出現得非常頻繁,所以它有一個名字:弱引用。
We have already implicitly implemented half of the string table’s unique behavior by virtue of the fact that we don’t traverse it during marking. That means it doesn’t force strings to be reachable. The remaining piece is clearing out any dangling pointers for strings that are freed.
我們已經隱式地實現了一半的字符串表的獨特行為,因為我們在標記階段沒有遍歷它。這意味著它不強制要求字符串可達。剩下的部分就是清除任何指向被釋放字符串的懸空指針。
To remove references to unreachable strings, we need to know which strings are unreachable. We don’t know that until after the mark phase has completed. But we can’t wait until after the sweep phase is done because by then the objects—and their mark bits—are no longer around to check. So the right time is exactly between the marking and sweeping phases.
為了刪除對不可達字符串的引用,我們需要知道哪些字符串不可達。在標記階段完成之後,我們才能知道這一點。但是我們不能等到清除階段完成之後,因為到那時對象(以及它們的標記位)已經無法再檢查了。因此,正確的時機正好是在標記和清除階段之間。
memory.c,在collectGarbage()方法中添加代碼:
traceReferences();
// 新增部分開始
tableRemoveWhite(&vm.strings);
// 新增部分結束
sweep();
The logic for removing the about-to-be-deleted strings exists in a new function in the “table” module.
清除即將被刪除的字符串的邏輯存在於“table”模塊中的一個新函數中。
table.h,在tableFindString()方法後添加代碼:
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
// 新增部分開始
void tableRemoveWhite(Table* table);
// 新增部分結束
void markTable(Table* table);
The implementation is here:
實現在這裡:
table.c,在tableFindString()方法後添加代碼:
void tableRemoveWhite(Table* table) {
for (int i = 0; i < table->capacity; i++) {
Entry* entry = &table->entries[i];
if (entry->key != NULL && !entry->key->obj.isMarked) {
tableDelete(table, entry->key);
}
}
}
We walk every entry in the table. The string intern table uses only the key of each entry—it’s basically a hash set not a hash map. If the key string object’s mark bit is not set, then it is a white object that is moments from being swept away. We delete it from the hash table first and thus ensure we won’t see any dangling pointers.
我們遍歷表中的每一項。字符串駐留表只使用了每一項的鍵——它基本上是一個HashSet而不是HashMap。如果鍵字符串對象的標記位沒有被設置,那麼它就是一個白色對象,很快就會被清除。我們首先從哈希表中刪除它,從而確保不會看到任何懸空指針。
26 . 6 When to Collect
26.6 何時回收
We have a fully functioning mark-sweep garbage collector now. When the stress testing flag is enabled, it gets called all the time, and with the logging enabled too, we can watch it do its thing and see that it is indeed reclaiming memory. But, when the stress testing flag is off, it never runs at all. It’s time to decide when the collector should be invoked during normal program execution.
我們現在有了一個功能完備的標記-清除垃圾回收器。當壓力測試標誌啟用時,它會一直被調用,而且在日誌功能也被啟用的情況下,我們可以觀察到它正在工作,並看到它確實在回收內存。但是,當壓力測試標誌關閉時,它根本就不會運行。現在是時候決定,在正常的程序執行過程中,何時應該調用回收器。
As far as I can tell, this question is poorly answered by the literature. When garbage collectors were first invented, computers had a tiny, fixed amount of memory. Many of the early GC papers assumed that you set aside a few thousand words of memory—in other words, most of it—and invoked the collector whenever you ran out. Simple.
據我所知,這個問題在文獻中沒有得到很好的回答。在垃圾回收器剛被髮明出來的時候,計算機只有一個很小的、固定大小的內存。許多早期的GC論文假定你預留了幾千個字的內存(換句話說,其中大部分是這樣),並在內存用完時調用回收器。這很簡單。
Modern machines have gigs of physical RAM, hidden behind the operating system’s even larger virtual memory abstraction, which is shared among a slew of other programs all fighting for their chunk of memory. The operating system will let your program request as much as it wants and then page in and out from the disc when physical memory gets full. You never really “run out” of memory, you just get slower and slower.
現代計算機擁有數以G計的物理內存,而操作系統在其基礎上提供了更多的虛擬內存抽象,這些物理內存是由一系列其它程序共享的,所有程序都在爭奪自己的那塊內存。操作系統會允許你的程序儘可能多地申請內存,然後當物理內存滿時會利用磁盤進行頁面換入換出。你永遠不會真的“耗盡”內存,只是變得越來越慢。
26 . 6 . 1 Latency and throughput
26.6.1 延遲和吞吐量
It no longer makes sense to wait until you “have to”, to run the GC, so we need a more subtle timing strategy. To reason about this more precisely, it’s time to introduce two fundamental numbers used when measuring a memory manager’s performance: throughput and latency.
等到“不得不做”的時候再去運行GC,就沒有意義了,因此我們需要一種更巧妙的選時策略。為了更精確地解釋這個問題,現在應該引入在度量內存管理器性能時使用的兩個基本數值:吞吐量和延遲。
Every managed language pays a performance price compared to explicit, user-authored deallocation. The time spent actually freeing memory is the same, but the GC spends cycles figuring out which memory to free. That is time not spent running the user’s code and doing useful work. In our implementation, that’s the entirety of the mark phase. The goal of a sophisticated garbage collector is to minimize that overhead.
與顯式的、用戶自發的釋放內存相比,每一種託管語言都要付出性能代價。實際釋放內存所花費的時間是相同的,但是GC花費了一些週期來計算要釋放哪些內存。這些時間沒有花在運行用戶的代碼和做有用的工作。在我們的實現中,這就是整個標記階段。複雜的垃圾回收器的模板就是使這種開銷最小化。
There are two key metrics we can use to understand that cost better:
我們可以使用這兩個關鍵指標來更好地理解成本:
-
Throughput is the total fraction of time spent running user code versus doing garbage collection work. Say you run a clox program for ten seconds and it spends a second of that inside
collectGarbage(). That means the throughput is 90%—it spent 90% of the time running the program and 10% on GC overhead.Throughput is the most fundamental measure because it tracks the total cost of collection overhead. All else being equal, you want to maximize throughput. Up until this chapter, clox had no GC at all and thus 100% throughput. That’s pretty hard to beat. Of course, it came at the slight expense of potentially running out of memory and crashing if the user’s program ran long enough. You can look at the goal of a GC as fixing that “glitch” while sacrificing as little throughput as possible.
吞吐量是指運行用戶代碼的時間與執行垃圾回收工作所花費的時間的總比例。假設你運行一個clox程序10秒鐘,其中有1秒花在
collectGarbage()中。這意味是吞吐量是90%——它花費了90%的時間運行程序,10%的時間用於GC開銷。吞吐量是最基本的度量值,因為它跟蹤的是回收開銷的總成本。在其它條件相同的情況下,你會希望最大化吞吐量。在本章之前,clox完全沒有GC,因此吞吐量為100%15。這是很難做到的。當然,它的代價是,如果用戶的程序運行時間足夠長的話,可能會導致內存耗盡和程序崩潰。你可以把GC的目標看作是修復這個“小故障”,同時以犧牲儘可能少的吞吐量為代價。
-
Latency is the longest continuous chunk of time where the user’s program is completely paused while garbage collection happens. It’s a measure of how “chunky” the collector is. Latency is an entirely different metric than throughput.
Consider two runs of a clox program that both take ten seconds. In the first run, the GC kicks in once and spends a solid second in
collectGarbage()in one massive collection. In the second run, the GC gets invoked five times, each for a fifth of a second. The total amount of time spent collecting is still a second, so the throughput is 90% in both cases. But in the second run, the latency is only 1/5th of a second, five times less than in the first.延遲是指當垃圾回收發生時,用戶的程序完全暫停的最長連續時間塊。這是衡量回收器“笨重”程度的指標。延遲是一個與吞吐量完全不同的指標。
考慮一下,一個程序的兩次運行都花費了10秒。第一次運行時,GC啟動了一次,並在
collectGarbage()中花費了整整1秒鐘進行了一次大規模的回收。在第二次運行中,GC被調用了五次,每次調用1/5秒。回收所花費的總時間仍然是1秒,所以這兩種情況下的吞吐量都是90%。但是在第二次運行中,延遲只有1/5秒,比第一次少了5倍16。
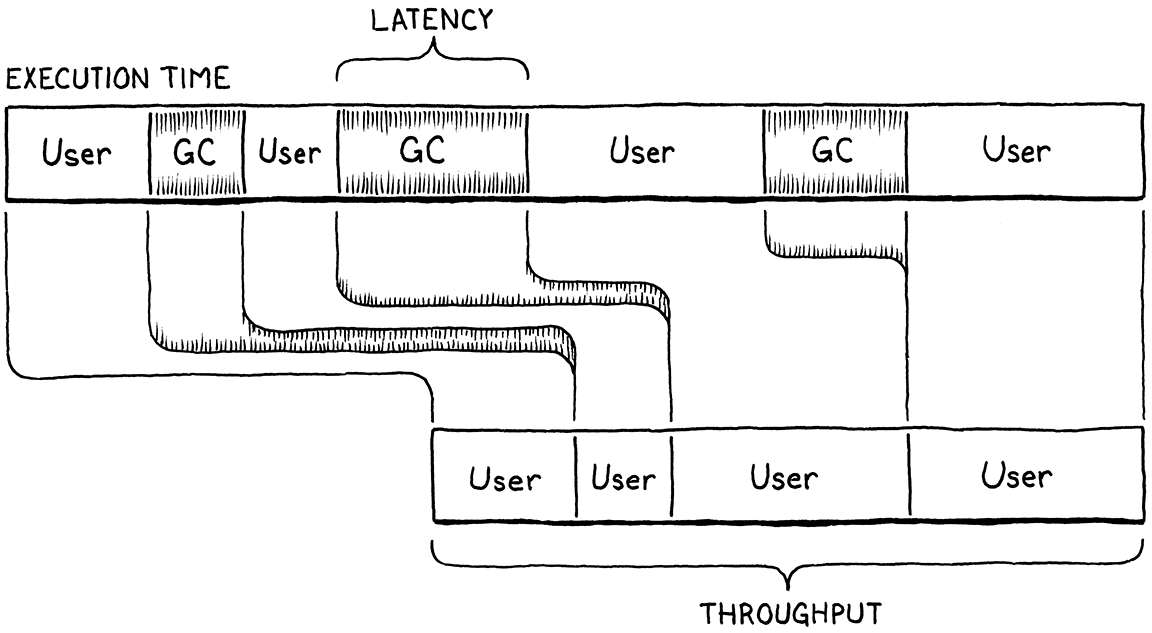
If you like analogies, imagine your program is a bakery selling fresh-baked bread to customers. Throughput is the total number of warm, crusty baguettes you can serve to customers in a single day. Latency is how long the unluckiest customer has to wait in line before they get served.
如果你喜歡打比方,可以將你的程序想象成一家麵包店,向顧客出售新鮮出爐的麵包。吞吐量是指你在一天內可以為顧客提供的溫暖結皮的法棍的總數。延遲是指最不走運的顧客在得到服務之前需要排隊等候多長時間。
Running the garbage collector is like shutting down the bakery temporarily to go through all of the dishes, sort out the dirty from the clean, and then wash the used ones. In our analogy, we don’t have dedicated dishwashers, so while this is going on, no baking is happening. The baker is washing up.
運行垃圾回收器就像暫時關閉麵包店,去檢查所有的盤子,把髒的和乾淨的分開,然後把用過的洗掉。在我們的比喻中,我們沒有專門的洗碗機,所以在這個過程中,沒有烘焙發生。麵包師正在清洗17。
Selling fewer loaves of bread a day is bad, and making any particular customer sit and wait while you clean all the dishes is too. The goal is to maximize throughput and minimize latency, but there is no free lunch, even inside a bakery. Garbage collectors make different trade-offs between how much throughput they sacrifice and latency they tolerate.
每天賣出更少的麵包是糟糕的,讓任何一個顧客坐著等你洗完所有的盤子也是如此。我們的目標是最大化吞吐量和最小化延遲,但是沒有免費的午餐,即使是在麵包店裡。不同垃圾回收器在犧牲多少吞吐量和容忍多大延遲之間做出了不同的權衡。
Being able to make these trade-offs is useful because different user programs have different needs. An overnight batch job that is generating a report from a terabyte of data just needs to get as much work done as fast as possible. Throughput is queen. Meanwhile, an app running on a user’s smartphone needs to always respond immediately to user input so that dragging on the screen feels buttery smooth. The app can’t freeze for a few seconds while the GC mucks around in the heap.
能夠進行這些權衡是很有用的,因為不同的用戶程序有不同的需求。一個從TB級數據中生成報告的夜間批處理作業,只需要儘可能快地完成儘可能多的工作。吞吐量為王。與此同時,在用戶智能手機上運行的應用程序需要總是對用戶輸入立即做出響應,這樣才能讓用戶在屏幕上拖拽時感覺非常流暢。應用程序不能因為GC在堆中亂翻而凍結幾秒鐘。
As a garbage collector author, you control some of the trade-off between throughput and latency by your choice of collection algorithm. But even within a single algorithm, we have a lot of control over how frequently the collector runs.
作為一個垃圾回收器作者,你可以通過選擇收集算法來控制吞吐量和延遲之間的一些權衡。但即使在單一的算法中,我們也可以對回收器的運行頻率有很大的控制。
Our collector is a stop-the-world GC which means the user’s program is paused until the entire garbage collection process has completed. If we wait a long time before we run the collector, then a large number of dead objects will accumulate. That leads to a very long pause while the collector runs, and thus high latency. So, clearly, we want to run the collector really frequently.
我們的回收器是一個stop-the-world GC,這意味著會暫停用戶的程序,直到垃圾回收過程完成18。如果我們在運行回收器之前等待很長時間,那麼將會積累大量的死亡對象。這會導致回收器在運行時會出現很長時間的停頓,從而導致高延遲。所以,很明顯,我們希望頻繁地運行回收器。
But every time the collector runs, it spends some time visiting live objects. That doesn’t really do anything useful (aside from ensuring that they don’t incorrectly get deleted). Time visiting live objects is time not freeing memory and also time not running user code. If you run the GC really frequently, then the user’s program doesn’t have enough time to even generate new garbage for the VM to collect. The VM will spend all of its time obsessively revisiting the same set of live objects over and over, and throughput will suffer. So, clearly, we want to run the collector really infrequently.
但是每次回收器運行時,它都要花一些時間來訪問活動對象。這其實並沒有什麼用處(除了確保它們不會被錯誤地刪除之外)。訪問活動對象的時間是沒有釋放內存的時間,也是沒有運行用戶代碼的時間。如果你真的非常頻繁地運行GC,那麼用戶的程序甚至沒有足夠的時間生成新的垃圾供VM回收。VM會花費所有的時間反覆訪問相同的活動對象,吞吐量將會受到影響。所以,很明顯,我們也不希望頻繁地運行回收器。
In fact, we want something in the middle, and the frequency of when the collector runs is one of our main knobs for tuning the trade-off between latency and throughput.
事實上,我們想要的是介於兩者之間的東西,而回收器的運行頻率是我們調整延遲和吞吐量之間權衡的主要因素之一。
26 . 6 . 2 Self-adjusting heap
26.6.2 自適應堆
We want our GC to run frequently enough to minimize latency but infrequently enough to maintain decent throughput. But how do we find the balance between these when we have no idea how much memory the user’s program needs and how often it allocates? We could pawn the problem onto the user and force them to pick by exposing GC tuning parameters. Many VMs do this. But if we, the GC authors, don’t know how to tune it well, odds are good most users won’t either. They deserve a reasonable default behavior.
我們希望GC運行得足夠頻繁,以最小化延遲,但又不能太頻繁,以維持良好的吞吐量。但是,當我們不知道用戶程序需要多少內存以及內存分配的頻率時,我們如何在兩者之間找到平衡呢?我們可以把問題推給用戶,並通過暴露GC調整參數來迫使他們進行選擇。許多虛擬機都是這樣做的。但是,如果我們這些GC的作者都不知道如何很好地調優回收器,那麼大多數用戶可能也不知道。他們理應得到一個合理的默認行為。
I’ll be honest with you, this is not my area of expertise. I’ve talked to a number of professional GC hackers—this is something you can build an entire career on—and read a lot of the literature, and all of the answers I got were . . . vague. The strategy I ended up picking is common, pretty simple, and (I hope!) good enough for most uses.
說實話,這不是我的專業領域。我曾經和一些專業的GC專家交談過(GC是一項可以投入整個職業生涯的東西),並且閱讀了大量的文獻,我得到的所有答案都是……模糊的。我最終選擇的策略很常見,也很簡單,而且(我希望!)對大多數用途來說足夠好。
The idea is that the collector frequency automatically adjusts based on the live size of the heap. We track the total number of bytes of managed memory that the VM has allocated. When it goes above some threshold, we trigger a GC. After that, we note how many bytes of memory remain—how many were not freed. Then we adjust the threshold to some value larger than that.
其思想是,回收器的頻率根據堆的大小自動調整。我們根據虛擬機已分配的託管內存的總字節數。當它超過某個閾值時,我們就觸發一次GC。在那之後,我們關注一下有多少字節保留下來——多少沒有被釋放。然後我們將閾值調整為比它更大的某個值。
The result is that as the amount of live memory increases, we collect less frequently in order to avoid sacrificing throughput by re-traversing the growing pile of live objects. As the amount of live memory goes down, we collect more frequently so that we don’t lose too much latency by waiting too long.
其結果是,隨著活動內存數量的增加,我們回收的頻率會降低,以避免因為重新遍歷不斷增長的活動對象而犧牲吞吐量。隨著活動內存數量的減少,我們會更頻繁地收集,這樣我們就不會因為等待時間過長而造成太多的延遲。
The implementation requires two new bookkeeping fields in the VM.
這個實現需要在虛擬機中設置兩個新的簿記字段。
vm.h,在結構體VM中添加代碼:
ObjUpvalue* openUpvalues;
// 新增部分開始
size_t bytesAllocated;
size_t nextGC;
// 新增部分結束
Obj* objects;
The first is a running total of the number of bytes of managed memory the VM has allocated. The second is the threshold that triggers the next collection. We initialize them when the VM starts up.
第一個是虛擬機已分配的託管內存實時字節總數。第二個是觸發下一次回收的閾值。我們在虛擬機啟動時初始化它們。
vm.c,在initVM()方法中添加代碼:
vm.objects = NULL;
// 新增部分開始
vm.bytesAllocated = 0;
vm.nextGC = 1024 * 1024;
// 新增部分結束
vm.grayCount = 0;
The starting threshold here is arbitrary. It’s similar to the initial capacity we picked for our various dynamic arrays. The goal is to not trigger the first few GCs too quickly but also to not wait too long. If we had some real-world Lox programs, we could profile those to tune this. But since all we have are toy programs, I just picked a number.
這裡的起始閾值是任意的。它類似於我們為各種動態數據選擇的初始容量。我們的目標是不要太快觸發最初的幾次GC,但是也不要等得太久。如果我們有一些真實的Lox程序,我們可以對程序進行剖析來調整這個參數。但是因為我們寫的都是一些玩具程序,我只是隨意選了一個數字19。
Every time we allocate or free some memory, we adjust the counter by that delta.
每當我們分配或釋放一些內存時,我們就根據差值來調整計數器。
memory.c,在reallocate()方法中添加代碼:
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
// 新增部分開始
vm.bytesAllocated += newSize - oldSize;
// 新增部分結束
if (newSize > oldSize) {
When the total crosses the limit, we run the collector.
當總數超過限制時,我們運行回收器。
memory.c,在reallocate()方法中添加代碼:
collectGarbage();
#endif
// 新增部分開始
if (vm.bytesAllocated > vm.nextGC) {
collectGarbage();
}
// 新增部分結束
}
Now, finally, our garbage collector actually does something when the user runs a program without our hidden diagnostic flag enabled. The sweep phase frees objects by calling
reallocate(), which lowers the value ofbytesAllocated, so after the collection completes, we know how many live bytes remain. We adjust the threshold of the next GC based on that.
現在,終於,即便用戶運行一個沒有啟用隱藏診斷標誌的程序時,我們的垃圾回收器實際上也做了一些事情。掃描階段通過調用reallocate()釋放對象,這會降低bytesAllocated的值,所以在收集完成後,我們知道還有多少活動字節。我們在此基礎上調整下一次GC的閾值。
memory.c,在collectGarbage()方法中添加代碼:
sweep();
// 新增部分開始
vm.nextGC = vm.bytesAllocated * GC_HEAP_GROW_FACTOR;
// 新增部分結束
#ifdef DEBUG_LOG_GC
The threshold is a multiple of the heap size. This way, as the amount of memory the program uses grows, the threshold moves farther out to limit the total time spent re-traversing the larger live set. Like other numbers in this chapter, the scaling factor is basically arbitrary.
該閾值是堆大小的倍數。這樣一來,隨著程序使用的內存量的增加長,閾值會向上移動。以限制重新遍歷更大的活動集合所花費的總時間。和本章中的其它數字一樣,比例因子基本上是任意的。
memory.c,添加代碼:
#endif
// 新增部分開始
#define GC_HEAP_GROW_FACTOR 2
// 新增部分結束
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
You’d want to tune this in your implementation once you had some real programs to benchmark it on. Right now, we can at least log some of the statistics that we have. We capture the heap size before the collection.
一旦你有了一些真正的程序來對其進行基準測試,你就需要在實現中對該參數進行調優。現在,我們至少可以記錄一些統計數據。我們在回收之前捕獲堆的大小。
memory.c,在collectGarbage()方法中添加代碼:
printf("-- gc begin\n");
// 新增部分開始
size_t before = vm.bytesAllocated;
// 新增部分結束
#endif
And then print the results at the end.
最後把結果打印出來。
memory.c,在collectGarbage()方法中添加代碼:
printf("-- gc end\n");
// 新增部分開始
printf(" collected %zu bytes (from %zu to %zu) next at %zu\n",
before - vm.bytesAllocated, before, vm.bytesAllocated,
vm.nextGC);
// 新增部分結束
#endif
This way we can see how much the garbage collector accomplished while it ran.
這樣,我們就可以看到垃圾回收器在運行時完成了多少任務。
26 . 7 Garbage Collection Bugs
26.7 垃圾回收Bug
In theory, we are all done now. We have a GC. It kicks in periodically, collects what it can, and leaves the rest. If this were a typical textbook, we would wipe the dust from our hands and bask in the soft glow of the flawless marble edifice we have created.
理論上講,我們現在已經完成了。我們有了一個GC,它週期性啟動,回收可以回收的東西,並留下其餘的東西。如果這是一本典型的教科書,我們會擦掉手上的灰塵,沉浸在我們所創造的完美無瑕的大理石建築的柔和光芒中。
But I aim to teach you not just the theory of programming languages but the sometimes painful reality. I am going to roll over a rotten log and show you the nasty bugs that live under it, and garbage collector bugs really are some of the grossest invertebrates out there.
但是,我的目的不僅僅是教授編程語言的理論,還要教你有時令人痛苦的現實。我要掀開一根爛木頭,向你展示生活在下面的討厭的蟲子,垃圾回收器蟲真的是世界上最噁心的無脊椎動物之一【譯者注:bug雙關】。
The collector’s job is to free dead objects and preserve live ones. Mistakes are easy to make in both directions. If the VM fails to free objects that aren’t needed, it slowly leaks memory. If it frees an object that is in use, the user’s program can access invalid memory. These failures often don’t immediately cause a crash, which makes it hard for us to trace backward in time to find the bug.
回收器的工作是釋放已死對象並保留活動對象。在這兩個方面都很容易出現錯誤。如果虛擬機不能釋放不需要的對象,就會慢慢地洩露內存。如果它釋放了一個正在使用的對象,用戶的程序就會訪問無效的內存。這些故障通常不會立即導致崩潰,這使得我們很難即時追溯以找到錯誤。
This is made harder by the fact that we don’t know when the collector will run. Any call that eventually allocates some memory is a place in the VM where a collection could happen. It’s like musical chairs. At any point, the GC might stop the music. Every single heap-allocated object that we want to keep needs to find a chair quickly—get marked as a root or stored as a reference in some other object—before the sweep phase comes to kick it out of the game.
由於我們不知道回收器何時會運行,這就更加困難了。任何發生內存分配的地方恰好可能是發生回收的地方。這就像搶椅子游戲。在任何時候,GC都可能停止音樂。我們想保留的每一個堆分配對象都需要快速找到一個椅子(被標記為根或作為引用保存在其它對象中),在清除階段將其踢出遊戲之前。
How is it possible for the VM to use an object later—one that the GC itself doesn’t see? How can the VM find it? The most common answer is through a pointer stored in some local variable on the C stack. The GC walks the VM’s value and CallFrame stacks, but the C stack is hidden to it.
VM怎麼可能會在稍後使用一個GC自己都看不到的對象呢?VM如何找到它?最常見的答案是通過存儲在C棧中的一些局部變量。GC會遍歷VM的值和CallFrame棧,但C的棧對它來說是隱藏的20。
In previous chapters, we wrote seemingly pointless code that pushed an object onto the VM’s value stack, did a little work, and then popped it right back off. Most times, I said this was for the GC’s benefit. Now you see why. The code between pushing and popping potentially allocates memory and thus can trigger a GC. We had to make sure the object was on the value stack so that the collector’s mark phase would find it and keep it alive.
在前面的章節中,我們編寫了一些看似無意義的代碼,將一個對象推到VM的值棧上,執行一些操作,然後又把它彈了出來。大多數時候,我說這是為了便於GC。現在你知道為什麼了。壓入和彈出之間的代碼可能會分配內存,因此可能會觸發GC。我們必須確保對象在值棧上,這樣回收器的標記階段才能找到它並保持它存活。
I wrote the entire clox implementation before splitting it into chapters and writing the prose, so I had plenty of time to find all of these corners and flush out most of these bugs. The stress testing code we put in at the beginning of this chapter and a pretty good test suite were very helpful.
在把整個clox拆分為不同章節並編寫文章之前,我已經寫完了整個clox實現,因此我有足夠的時間來找到這些角落,並清除大部分的bug。我們在本章開始時放入的壓力測試代碼和一個相當好的測試套件都非常有幫助。
But I fixed only most of them. I left a couple in because I want to give you a hint of what it’s like to encounter these bugs in the wild. If you enable the stress test flag and run some toy Lox programs, you can probably stumble onto a few. Give it a try and see if you can fix any yourself.
但我只修復了其中的大部分。我留下了幾個,因為我想給你一些提示,告訴你在野外遇到這些蟲子是什麼感覺。如果你啟用壓力測試標誌並運行一些玩具Lox程序,你可能會偶然發現一些。試一試,看看你是否能自己解決問題。
26 . 7 . 1 Adding to the constant table
26.7.1 添加到常量表中
You are very likely to hit the first bug. The constant table each chunk owns is a dynamic array. When the compiler adds a new constant to the current function’s table, that array may need to grow. The constant itself may also be some heap-allocated object like a string or a nested function.
你很有可能會碰到第一個bug。每個塊擁有的常量表是一個動態數組。當編譯器向當前函數的表中添加一個新常量時,這個數組可能需要增長。常量本身也可以是一些堆分配的對象,如字符串或嵌套函數。
The new object being added to the constant table is passed to
addConstant(). At that moment, the object can be found only in the parameter to that function on the C stack. That function appends the object to the constant table. If the table doesn’t have enough capacity and needs to grow, it callsreallocate(). That in turn triggers a GC, which fails to mark the new constant object and thus sweeps it right before we have a chance to add it to the table. Crash.
待添加到常量表的新對象會被傳遞給addConstant()。此時,該對象只能在C棧上該函數的形參中找到。該函數將對象追加到常量表中。如果表中沒有足夠的容量並且需要增長,它會調用reallocate()。這反過來又觸發了一次GC,它無法標記新的常量對象,因此在我們有機會將該對象添加到常量表之前便將其清除了。崩潰。
The fix, as you’ve seen in other places, is to push the constant onto the stack temporarily.
正如你在其它地方所看到的,解決方法是將常量臨時推入棧中。
chunk.c,在addConstant()方法中添加代碼:
int addConstant(Chunk* chunk, Value value) {
// 新增部分開始
push(value);
// 新增部分結束
writeValueArray(&chunk->constants, value);
Once the constant table contains the object, we pop it off the stack.
一旦常量表中有了該對象,我們就將其從棧中彈出。
chunk.c,在addConstant()方法中添加代碼:
writeValueArray(&chunk->constants, value);
// 新增部分開始
pop();
// 新增部分結束
return chunk->constants.count - 1;
When the GC is marking roots, it walks the chain of compilers and marks each of their functions, so the new constant is reachable now. We do need an include to call into the VM from the “chunk” module.
當GC標記根時,它會遍歷編譯器鏈並標記它們的每個函數,因此現在新的常量是可達的。我們確實需要引入頭文件開從“chunk”模塊調用到VM中。
chunk.c,添加代碼:
#include "memory.h"
// 新增部分開始
#include "vm.h"
// 新增部分結束
void initChunk(Chunk* chunk) {
26 . 7 . 2 Interning strings
26.7.2 駐留字符串
Here’s another similar one. All strings are interned in clox, so whenever we create a new string, we also add it to the intern table. You can see where this is going. Since the string is brand new, it isn’t reachable anywhere. And resizing the string pool can trigger a collection. Again, we go ahead and stash the string on the stack first.
下面是另一個類似的例子。所有字符串在clox都是駐留的,因此每當創建一個新的字符串時,我們也會將其添加到駐留表中。你知道將會發生什麼。因為字符串是全新的,所以它在任何地方都是不可達的。調整字符串池的大小會觸發一次回收。同樣,我們先去把字符串藏在棧上。
object.c,在allocateString()方法中添加代碼:
string->chars = chars;
string->hash = hash;
// 新增部分開始
push(OBJ_VAL(string));
// 新增部分結束
tableSet(&vm.strings, string, NIL_VAL);
And then pop it back off once it’s safely nestled in the table.
等它穩穩地進入表中,再把它彈出來。
object.c,在allocateString()方法中添加代碼:
tableSet(&vm.strings, string, NIL_VAL);
// 新增部分開始
pop();
// 新增部分結束
return string;
}
This ensures the string is safe while the table is being resized. Once it survives that,
allocateString()will return it to some caller which can then take responsibility for ensuring the string is still reachable before the next heap allocation occurs.
這確保了在調整表大小時字符串是安全的。一旦它存活下來,allocateString()會把它返回給某個調用者,隨後調用者負責確保,在下一次堆分配之前字符串仍然是可達的。
26 . 7 . 3 Concatenating strings
26.7.3 連接字符串
One last example: Over in the interpreter, the
OP_ADDinstruction can be used to concatenate two strings. As it does with numbers, it pops the two operands from the stack, computes the result, and pushes that new value back onto the stack. For numbers that’s perfectly safe.
最後一個例子:在解釋器中,OP_ADD指令可以用來連接兩個字符串。就像處理數字一樣,它會從棧中取出兩個操作數,計算結果,並將新值壓入棧中。對於數字來說,這是絕對安全的。
But concatenating two strings requires allocating a new character array on the heap, which can in turn trigger a GC. Since we’ve already popped the operand strings by that point, they can potentially be missed by the mark phase and get swept away. Instead of popping them off the stack eagerly, we peek them.
但是連接兩個字符串需要在堆中分配一個新的字符數組,這又會觸發一次GC。因為此時我們已經彈出了操作數字符串,它們可能被標記階段遺漏並被清除。我們不急於從棧中彈出這些字符串,而只是查看一下它們。
vm.c,在concatenate()方法中,替換2行:
static void concatenate() {
// 新增部分開始
ObjString* b = AS_STRING(peek(0));
ObjString* a = AS_STRING(peek(1));
// 新增部分結束
int length = a->length + b->length;
That way, they are still hanging out on the stack when we create the result string. Once that’s done, we can safely pop them off and replace them with the result.
這樣,當我們創建結果字符串時,它們仍然掛在棧上。一旦完成操作,我們就可以放心的將它們彈出,並用結果字符串替換它們。
vm.c,在concatenate()方法中添加代碼:
ObjString* result = takeString(chars, length);
// 新增部分開始
pop();
pop();
// 新增部分結束
push(OBJ_VAL(result));
Those were all pretty easy, especially because I showed you where the fix was. In practice, finding them is the hard part. All you see is an object that should be there but isn’t. It’s not like other bugs where you’re looking for the code that causes some problem. You’re looking for the absence of code which fails to prevent a problem, and that’s a much harder search.
這些都很簡單,特別是因為我告訴了你解決方法在哪裡。實際上,找到它們才是困難的部分。你所看到的只是一個本該存在但卻不存在的對象。它不像其它錯誤那樣,你需要找的是導致某些問題的代碼。這裡你要找的是那些無法防止問題發生的代碼缺失,而這是一個更困難的搜索。
But, for now at least, you can rest easy. As far as I know, we’ve found all of the collection bugs in clox, and now we have a working, robust, self-tuning, mark-sweep garbage collector.
但是,至少現在,你可以放心了。據我所知,我們已經找到了clox中的所有回收錯誤,現在我們有了一個有效的、強大的、自我調整的標記-清除垃圾回收器。
習題
-
The Obj header struct at the top of each object now has three fields:
type,isMarked, andnext. How much memory do those take up (on your machine)? Can you come up with something more compact? Is there a runtime cost to doing so?每個對象頂部的Obj頭結構體現在有三個字段:
type,isMarked和next。它們(在你的機器上)佔用了多少內存?你能想出更緊湊的辦法嗎?這樣做是否有運行時成本? -
When the sweep phase traverses a live object, it clears the
isMarkedfield to prepare it for the next collection cycle. Can you come up with a more efficient approach?當清除階段遍歷某個活動對象時,它會清除
isMarked字段,以便為下一個回收週期做好準備。你能想出一個更有效的方法嗎? -
Mark-sweep is only one of a variety of garbage collection algorithms out there. Explore those by replacing or augmenting the current collector with another one. Good candidates to consider are reference counting, Cheney’s algorithm, or the Lisp 2 mark-compact algorithm.
標記-清除只是眾多垃圾回收算法中的一種。通過用另一種回收器來替換或增強當前的回收器來探索這些算法。可以考慮引用計數、Cheney算法或Lisp 2標記-壓縮算法。
設計筆記:分代回收器
A collector loses throughput if it spends a long time re-visiting objects that are still alive. But it can increase latency if it avoids collecting and accumulates a large pile of garbage to wade through. If only there were some way to tell which objects were likely to be long-lived and which weren’t. Then the GC could avoid revisiting the long-lived ones as often and clean up the ephemeral ones more frequently.
It turns out there kind of is. Many years ago, GC researchers gathered metrics on the lifetime of objects in real-world running programs. They tracked every object when it was allocated, and eventually when it was no longer needed, and then graphed out how long objects tended to live.
They discovered something they called the generational hypothesis, or the much less tactful term infant mortality. Their observation was that most objects are very short-lived but once they survive beyond a certain age, they tend to stick around quite a long time. The longer an object has lived, the longer it likely will continue to live. This observation is powerful because it gave them a handle on how to partition objects into groups that benefit from frequent collections and those that don’t.
They designed a technique called generational garbage collection. It works like this: Every time a new object is allocated, it goes into a special, relatively small region of the heap called the “nursery”. Since objects tend to die young, the garbage collector is invoked frequently over the objects just in this region.
Nurseries are also usually managed using a copying collector which is faster at allocating and freeing objects than a mark-sweep collector.
Each time the GC runs over the nursery is called a “generation”. Any objects that are no longer needed get freed. Those that survive are now considered one generation older, and the GC tracks this for each object. If an object survives a certain number of generations—often just a single collection—it gets tenured. At this point, it is copied out of the nursery into a much larger heap region for long-lived objects. The garbage collector runs over that region too, but much less frequently since odds are good that most of those objects will still be alive.
Generational collectors are a beautiful marriage of empirical data—the observation that object lifetimes are not evenly distributed—and clever algorithm design that takes advantage of that fact. They’re also conceptually quite simple. You can think of one as just two separately tuned GCs and a pretty simple policy for moving objects from one to the other.
如果回收器花費很長時間重新訪問仍然活動的對象,則會損失吞吐量。但是,如果它避免了回收並積累了一大堆需要處理的垃圾,就會增加延遲。要是能有某種辦法可以告訴我們哪些對象可能是長壽的以及哪些對象不是就好了。這樣GC就可以避免頻繁地重新訪問壽命較長的數據,而更頻繁地清理那些短暫壽命短暫的對象。
事實證明,確實如此。許多年前,GC研究人員收集了關於真實運行程序中對象生命週期的指標。他們跟蹤了每個對象被分配時,以及它最終不再需要時的情況,然後用圖表顯示出對象的壽命。
他們發現了一種被稱為“代際假說”的東西,或者是一個不太委婉的術語“早夭”。他們的觀察結果是,大多數對象的壽命都很短,但是一旦它們存活超過了一定的年齡,它們往往會存活相當長的時間。一個對象已經存活的時間越長,它將繼續存活的時間就越長。這一觀察結果非常有說服力,因為這為他們提供了將對象劃分為頻繁回收的群體和不頻繁回收群體的方法。
他們設計了一種叫作分代垃圾回收的技術。它的工作原理是這樣的:每次分配一個新對象時,它會進入堆中一個特殊的、相對較小的區域,稱為“nursery”(意為託兒所)。由於對象傾向於早夭,所以垃圾回收器會在這個區域中的對象上被頻繁調用。
【nursery通常也是要複製回收器進行管理,它在分配和釋放對象方面比標記-清除回收器更快。】
GC在nursery的每次運行都被稱為“一代”。任何不再需要的對象都會被釋放。那些存活下來對象現在被認為老了一代,GC會為每個對象記錄這一屬性。如果一個對象存活了一定數量的代(通常只是一次回收),它就會被永久保留。此時,將它從nursery中複製處理,放入一個更大的、用於存放 長壽命對象的堆區域。垃圾回收器也會在這個區域內運行,但頻率要低得多,因為這些對象中的大部分都很有可能還活著。
分代回收器是經驗數據(觀察到對象生命週期不是均勻分佈的)以及利用這一事實的聰明算法設計的完美結合。它們在概念上也很簡單。你可以把它看作是兩個單獨調優的GC和把對象從一個區域移到另一個區域的一個非常簡單的策略。
-
我用的是一般意義上的“保守”。有一種“保守的垃圾回收器”,它的意思更具體。所有的垃圾回收器都是“保守的”,如果內存可以被訪問,它們就保持內存存活,而不是有一個魔力8號球,可以讓它們更精確地知道哪些數據將被訪問。
保守的GC是一種特殊的回收器,它認為如果任何一塊內存中的值看起來可能是地址,那它就是一個指針。這與我們將要實現的精確的GC相反,精確GC知道內存中哪些數據是指針,哪些存儲的是數字或字符串等其它類型的值。 ↩ -
如果你想探索其它的GC算法,《垃圾回收手冊》是一本經典的參考書。對於這樣一本深入淺出的大部頭來說,它的閱讀體驗是相當愉快的。也許我對樂趣有種奇怪的看法。 ↩
-
在John McCarthy的《Lisp的歷史》中,他指出:“一旦我們決定進行垃圾回收,它的實際實現就會被推遲,因為當時只做了玩具性的例子。”我們選擇推遲在clox中加入GC,是追隨了巨人的腳步。 ↩
-
跟蹤式垃圾回收器是指任何通過對象引用圖來追蹤的算法。這與引用計數相反,後者使用不同的策略來追蹤可達對象。 ↩
-
當然,我們最終也會添加一些輔助函數。 ↩
-
更復雜的回收器可能運行在單獨的線程上,或者在程序執行過程中定期交錯運行——通常是在函數調用邊界處或發生後向跳轉時。 ↩
-
我把這一章安排在這裡,特別是因為我們現在有了閉包,它給我們提供了有趣的對象,讓垃圾回收器來處理。 ↩
-
我說“幾乎”是因為有些垃圾回收器是按照對象被訪問的順序來移動對象的,所以遍歷順序決定了哪些對象最終會在內存中相鄰。這會影響性能,因為CPU使用位置來決定哪些內存要預加載到緩存中。
即便在遍歷順序很重要的時候,也不清楚哪種順序是最好的。很難確定對象在未來會以何種順序被使用,因此GC很難知道哪種順序有助於提高性能。 ↩ -
高級的垃圾回收算法經常為這個抽象概念加入其它顏色。我見過多種深淺不一的灰色,甚至在一些設計中見過紫色。可惜的是,我的黃綠色-紫紅色-孔雀石回收器論文沒有被接受發表。 ↩
-
請注意,在此過程的每一步,都沒有黑色節點指向白色節點。這個屬性被稱為三色不變性。變量過程中保持這一不變性,以確保沒有任何可達對象被回收。 ↩
-
為了更加健壯,我們可以在啟動虛擬機時分配一個“雨天基金”內存塊。如果灰色棧分配失敗,我們就釋放這個塊並重新嘗試。這可能會為我們在堆上提供足夠的空間來創建灰色棧,完成GC並釋放更多內存。 ↩
-
我們可以在
markObject()中做一個簡單的優化,就是不要向灰色棧中添加字符串和本地函數,因為我們知道它們不需要處理。相對地,它們可以從白色直接變黑。 ↩ -
你可能正在好奇為什麼要有
isMarked字段。別急,朋友。 ↩ -
這可能是一個真正的問題。Java並沒有駐留所有字符串,但它確實駐留了字符串字面量。它還提供了向字符串表添加字符串的API。多年以來,該表的容量是固定的,添加到其中的字符串永遠無法被刪除。如果用戶不謹慎使用
String.intern(),他們可能會耗盡內存導致崩潰。
Ruby多年以來也存在類似的問題,符號(駐留的類似字符串的值)不會被垃圾回收。兩者最終都啟用了GC來回收這些字符串。 ↩ -
嗯,不完全是100%。它仍然將分配的對象放入了一個鏈表中,所以在設置這些指針時有一些微小的開銷。 ↩
-
每個條帶表示程序的執行,分為運行用戶代碼的時間和在GC中花費的時間。運行GC的最大單個時間片的大小就是延遲。所有用戶代碼片的大小相加就是吞吐量。 ↩
-
如果每個人代表一個線程,那麼一個明顯的優化就是讓單獨的線程進行垃圾回收,提供一個併發垃圾回收器。換句話說,在其他人烘焙的時候,僱傭一些洗碗工來清洗。這就是非常複雜的GC工作方式,因為它確實允許烘焙師(工作線程)在幾乎沒有中斷的情況下持續運行用戶代碼。
但是,協調是必須的。你不會想讓洗碗工從麵包師手中搶走碗吧!這種協調增加了開銷和大量的複雜性。併發回收器速度很快,但要正確實現卻很有挑戰性。 ↩ -
相比之下,增量式垃圾回收器可以做一點回收工作,然後運行一些用戶代碼,然後再做一點回收工作,以此類推。 ↩
-
學習垃圾回收器的一個挑戰是,在孤立的實驗室環境中很難發現最佳實踐。除非你在大型的、混亂的真實世界的程序上運行回收器,否則你無法看到它的實際表現。這就像調校一輛拉力賽車——你需要把它帶到賽道上。 ↩
-
我們的GC無法在C棧中查找地址,但很多GC可以。保守的垃圾回收器會查看所有內存,包括本機堆棧。這類垃圾回收器中最著名的是Boehm–Demers–Weiser垃圾回收器 ,通常就叫作“Boehm回收器”。(在CS中,成名的捷徑是姓氏在字母順序上靠前,這樣就能在排序的名字列表中出現在第一位)
許多精確GC也在C棧中遍歷。即便是這些GC,也必須對指向僅存於CPU寄存器中的活動對象的指針加以注意。 ↩
27.類與例項 Classes and Instances
Caring too much for objects can destroy you. Only—if you care for a thing enough, it takes on a life of its own, doesn’t it? And isn’t the whole point of things—beautiful things—that they connect you to some larger beauty?
——Donna Tartt, The Goldfinch
對物品過於關心會毀了你。只是,如果你對一件事物足夠關心,它就有了自己的生命,不是嗎?而事物——美麗的事物——的全部意義不就是把你和一些更大的美聯絡起來嗎?(唐娜 塔特,《金翅雀》)
The last area left to implement in clox is object-oriented programming. OOP is a bundle of intertwined features: classes, instances, fields, methods, initializers, and inheritance. Using relatively high-level Java, we packed all that into two chapters. Now that we’re coding in C, which feels like building a model of the Eiffel tower out of toothpicks, we’ll devote three chapters to covering the same territory. This makes for a leisurely stroll through the implementation. After strenuous chapters like closures and the garbage collector, you have earned a rest. In fact, the book should be easy from here on out.
clox中需要實現的最後一個領域是面向物件程式設計。OOP是一堆交織在一起的特性:類、例項、欄位、方法、初始化式和繼承1。使用相對高階的Java,我們可以把這些內容都裝進兩章中。現在我們用C語言編寫程式碼,感覺就像用牙籤搭建埃菲爾鐵塔的模型,我們將用三章的篇幅來涵蓋這些內容。這使得我們可以悠閒地漫步在實現中。在經歷了閉包和垃圾回收器這樣艱苦的章節之後,你贏得了休息的機會。事實上,從這裡開始,這本書都是很容易的。
In this chapter, we cover the first three features: classes, instances, and fields. This is the stateful side of object orientation. Then in the next two chapters, we will hang behavior and code reuse off of those objects.
在本章中,我們會介紹前三個特性:類、例項和欄位。這就是面向物件中表現出狀態的一面。然後在接下來的兩章中,我們會對這些物件掛上行為和程式碼重用能力。
27 . 1 Class Objects
27.1 Class物件
In a class-based object-oriented language, everything begins with classes. They define what sorts of objects exist in the program and are the factories used to produce new instances. Going bottom-up, we’ll start with their runtime representation and then hook that into the language.
在一門基於類的面向物件的語言中,一切都從類開始。它們定義了程式中存在什麼型別的物件,並且它們也是用來生產新例項的工廠。自下向上,我們將從它們的執行時表示形式開始,然後將其掛接到語言中。
By this point, we’re well-acquainted with the process of adding a new object type to the VM. We start with a struct.
至此,我們已經非常熟悉向VM新增新物件型別的過程了。我們從一個結構體開始。
object.h,在結構體ObjClosure後新增程式碼:
} ObjClosure;
// 新增部分開始
typedef struct {
Obj obj;
ObjString* name;
} ObjClass;
// 新增部分結束
ObjClosure* newClosure(ObjFunction* function);
After the Obj header, we store the class’s name. This isn’t strictly needed for the user’s program, but it lets us show the name at runtime for things like stack traces.
在Obj標頭檔案之後,我們儲存了類的名稱。對於使用者的程式來說,這一資訊並不是嚴格需要的,但是它讓我們可以在執行時顯示名稱,例如堆疊跟蹤。
The new type needs a corresponding case in the ObjType enum.
新型別需要在ObjType列舉中有一個對應的項。
object.h,在列舉ObjType中新增程式碼:
typedef enum {
// 新增部分開始
OBJ_CLASS,
// 新增部分結束
OBJ_CLOSURE,
And that type gets a corresponding pair of macros. First, for testing an object’s type:
而該型別會有一組對應的宏。首先,用於測試物件的型別:
object.h,新增程式碼:
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
// 新增部分開始
#define IS_CLASS(value) isObjType(value, OBJ_CLASS)
// 新增部分結束
#define IS_CLOSURE(value) isObjType(value, OBJ_CLOSURE)
And then for casting a Value to an ObjClass pointer:
然後是用於將一個Value轉換為一個ObjClass指標:
object.h,新增程式碼:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
// 新增部分開始
#define AS_CLASS(value) ((ObjClass*)AS_OBJ(value))
// 新增部分結束
#define AS_CLOSURE(value) ((ObjClosure*)AS_OBJ(value))
The VM creates new class objects using this function:
VM使用這個函式建立新的類物件:
object.h,在結構體ObjClass後新增程式碼:
} ObjClass;
// 新增部分開始
ObjClass* newClass(ObjString* name);
// 新增部分結束
ObjClosure* newClosure(ObjFunction* function);
The implementation lives over here:
實現在這裡:
object.c,在allocateObject()方法後新增程式碼:
ObjClass* newClass(ObjString* name) {
ObjClass* klass = ALLOCATE_OBJ(ObjClass, OBJ_CLASS);
klass->name = name;
return klass;
}
Pretty much all boilerplate. It takes in the class’s name as a string and stores it. Every time the user declares a new class, the VM will create a new one of these ObjClass structs to represent it.
幾乎都是模板程式碼。它接受並儲存字串形式的類名。每當使用者宣告一個新類時,VM會建立一個新的ObjClass結構體來表示它2。
When the VM no longer needs a class, it frees it like so:
當VM不再需要某個類時,這樣釋放它:
memory.c,在freeObject()方法中新增程式碼:
switch (object->type) {
// 新增部分開始
case OBJ_CLASS: {
FREE(ObjClass, object);
break;
}
// 新增部分結束
case OBJ_CLOSURE: {
We have a memory manager now, so we also need to support tracing through class objects.
我們現在有一個記憶體管理器,所以我們也需要支援透過類物件進行跟蹤。
memory.c,在blackenObject()方法中新增程式碼:
switch (object->type) {
// 新增部分開始
case OBJ_CLASS: {
ObjClass* klass = (ObjClass*)object;
markObject((Obj*)klass->name);
break;
}
// 新增部分結束
case OBJ_CLOSURE: {
When the GC reaches a class object, it marks the class’s name to keep that string alive too.
當GC到達一個類物件時,它會標記該類的名稱,以保持該字串也能存活。
The last operation the VM can perform on a class is printing it.
VM可以對類執行的最後一個操作是列印它。
object.c,在printObject()方法中新增程式碼:
switch (OBJ_TYPE(value)) {
// 新增部分開始
case OBJ_CLASS:
printf("%s", AS_CLASS(value)->name->chars);
break;
// 新增部分結束
case OBJ_CLOSURE:
A class simply says its own name.
類只是簡單地說出它的名稱。
27 . 2 Class Declarations
27.2 類宣告
Runtime representation in hand, we are ready to add support for classes to the language. Next, we move into the parser.
有了執行時表示形式,我們就可以向語言中新增對類的支援了。接下來,我們進入語法分析部分。
compiler.c,在declaration()方法中替換1行:
static void declaration() {
// 替換部分開始
if (match(TOKEN_CLASS)) {
classDeclaration();
} else if (match(TOKEN_FUN)) {
// 替換部分結束
funDeclaration();
Class declarations are statements, and the parser recognizes one by the leading
classkeyword. The rest of the compilation happens over here:
類宣告是語句,直譯器透過前面的class關鍵字識別宣告語句。剩下部分的編譯工作在這裡進行:
compiler.c,在function()方法後新增程式碼:
static void classDeclaration() {
consume(TOKEN_IDENTIFIER, "Expect class name.");
uint8_t nameConstant = identifierConstant(&parser.previous);
declareVariable();
emitBytes(OP_CLASS, nameConstant);
defineVariable(nameConstant);
consume(TOKEN_LEFT_BRACE, "Expect '{' before class body.");
consume(TOKEN_RIGHT_BRACE, "Expect '}' after class body.");
}
Immediately after the
classkeyword is the class’s name. We take that identifier and add it to the surrounding function’s constant table as a string. As you just saw, printing a class shows its name, so the compiler needs to stuff the name string somewhere that the runtime can find. The constant table is the way to do that.
緊跟在class關鍵字之後的是類名。我們將這個識別符號作為字串新增到外圍函式的常量表中。正如你剛才看到的,列印一個類會顯示它的名稱,所以編譯器需要把這個名稱字串放在執行時可以找到的地方。常量表就是實現這一目的的方法。
The class’s name is also used to bind the class object to a variable of the same name. So we declare a variable with that identifier right after consuming its token.
類名也被用來將類物件與一個同名變數繫結。因此,我們在使用完它的詞法標識後,馬上用這個識別符號宣告一個變數3。
Next, we emit a new instruction to actually create the class object at runtime. That instruction takes the constant table index of the class’s name as an operand.
接下來我們發出一條新指令,在執行時實際建立類物件。該指令以類名的常量表索引作為運算元。
After that, but before compiling the body of the class, we define the variable for the class’s name. Declaring the variable adds it to the scope, but recall from a previous chapter that we can’t use the variable until it’s defined. For classes, we define the variable before the body. That way, users can refer to the containing class inside the bodies of its own methods. That’s useful for things like factory methods that produce new instances of the class.
在此之後,但是在編譯類主體之前,我們使用類名定義變數。宣告變數會將其新增到作用域中,但請回想一下前一章的內容,在定義變數之前我們不能使用它。對於類,我們在解析主體之前定義變數。這樣,使用者就可以在類自己的方法主體中引用類本身。這對於產生類的新例項的工廠方法等場景來說是很有用的。
Finally, we compile the body. We don’t have methods yet, so right now it’s simply an empty pair of braces. Lox doesn’t require fields to be declared in the class, so we’re done with the body—and the parser—for now.
最後,我們編譯主體。我們現在還沒有方法,所以現在它只是一對空的大括號。Lox不要求在類中宣告欄位,因此我們目前已經完成了主體(和解析器)的工作。
The compiler is emitting a new instruction, so let’s define that.
編譯器會發出一條新指令,所以我們來定義它。
chunk.h,在列舉OpCode中新增程式碼:
OP_RETURN,
// 新增部分開始
OP_CLASS,
// 新增部分結束
} OpCode;
And add it to the disassembler:
然後將其新增到反彙編程式中:
debug.c,在disassembleInstruction()方法中新增程式碼:
case OP_RETURN:
return simpleInstruction("OP_RETURN", offset);
// 新增部分開始
case OP_CLASS:
return constantInstruction("OP_CLASS", chunk, offset);
// 新增部分結束
default:
For such a large-seeming feature, the interpreter support is minimal.
對於這樣一個看起來很大的特性,直譯器支援是最小的。
vm.c,在run()方法中新增程式碼:
break;
}
// 新增部分開始
case OP_CLASS:
push(OBJ_VAL(newClass(READ_STRING())));
break;
// 新增部分結束
}
We load the string for the class’s name from the constant table and pass that to
newClass(). That creates a new class object with the given name. We push that onto the stack and we’re good. If the class is bound to a global variable, then the compiler’s call todefineVariable()will emit code to store that object from the stack into the global variable table. Otherwise, it’s right where it needs to be on the stack for a new local variable.
我們從常量表中載入類名的字串,並將其傳遞給newClass()。這將建立一個具有給定名稱的新類物件。我們把它推入棧中就可以了。如果該類被繫結到一個全域性變數上,那麼編譯器對defineVariable()的呼叫就會生成位元組碼,將該物件從棧中儲存到全域性變量表。否則,它就正好位於棧中新的區域性變數所在的位置4。
There you have it, our VM supports classes now. You can run this:
好了,我們的虛擬機器現在支援類了。你可以執行這段程式碼:
class Brioche {}
print Brioche;
Unfortunately, printing is about all you can do with classes, so next is making them more useful.
不幸的是,列印是你對類所能做的全部事情,所以接下來是讓它們更有用。
27 . 3 Instances of Classes
27.3 類的例項
Classes serve two main purposes in a language:
類在一門語言中主要有兩個作用:
- They are how you create new instances. Sometimes this involves a
newkeyword, other times it’s a method call on the class object, but you usually mention the class by name somehow to get a new instance.- They contain methods. These define how all instances of the class behave.
- 它們是你建立新例項的方式。有時這會涉及到
new關鍵字,有時則是對類物件的方法呼叫,但是你通常會以某種方式透過類的名稱來獲得一個新的例項。 - 它們包含方法。這些方法定義了類的所有例項的行為方式。
We won’t get to methods until the next chapter, so for now we will only worry about the first part. Before classes can create instances, we need a representation for them.
我們要到下一章才會講到方法,所以我們現在只關心第一部分。在類能夠建立例項之前,我們需要為它們提供一個表示形式。
object.h,在結構體ObjClass後新增程式碼:
} ObjClass;
// 新增部分開始
typedef struct {
Obj obj;
ObjClass* klass;
Table fields;
} ObjInstance;
// 新增部分結束
ObjClass* newClass(ObjString* name);
Instances know their class—each instance has a pointer to the class that it is an instance of. We won’t use this much in this chapter, but it will become critical when we add methods.
例項知道它們的類——每個例項都有一個指向它所屬類的指標。在本章中我們不會過多地使用它,但是等我們新增方法時,它將會變得非常重要。
More important to this chapter is how instances store their state. Lox lets users freely add fields to an instance at runtime. This means we need a storage mechanism that can grow. We could use a dynamic array, but we also want to look up fields by name as quickly as possible. There’s a data structure that’s just perfect for quickly accessing a set of values by name and—even more conveniently—we’ve already implemented it. Each instance stores its fields using a hash table.
對本章來說,更重要的是例項如何儲存它們的狀態。Lox允許使用者在執行時自由地向例項中新增欄位。這意味著我們需要一種可以增長的儲存機制。我們可以使用動態陣列,但我們也希望儘可能快地按名稱查詢欄位。有一種資料結構非常適合於按名稱快速訪問一組值——甚至更方便的是——我們已經實現了它。每個例項都使用雜湊表來儲存其欄位5。
We only need to add an include, and we’ve got it.
我們只需要新增一個標頭檔案引入,就可以了。
object.h,新增程式碼:
#include "chunk.h"
// 新增部分開始
#include "table.h"
// 新增部分結束
#include "value.h"
This new struct gets a new object type.
新結構體有新的物件型別。
object.h,在列舉ObjType中新增程式碼:
OBJ_FUNCTION,
// 新增部分開始
OBJ_INSTANCE,
// 新增部分結束
OBJ_NATIVE,
I want to slow down a bit here because the Lox language’s notion of “type” and the VM implementation’s notion of “type” brush against each other in ways that can be confusing. Inside the C code that makes clox, there are a number of different types of Obj—ObjString, ObjClosure, etc. Each has its own internal representation and semantics.
這裡我想放慢一點速度,因為Lox語言中的“type”概念和虛擬機器實現中的“type”概念是相互牴觸的,可能會造成混淆。在生成clox 的C語言程式碼中,有許多不同型別的Obj——ObjString、ObjClosure等等。每個都有自己的內部表示和語義。
In the Lox language, users can define their own classes—say Cake and Pie—and then create instances of those classes. From the user’s perspective, an instance of Cake is a different type of object than an instance of Pie. But, from the VM’s perspective, every class the user defines is simply another value of type ObjClass. Likewise, each instance in the user’s program, no matter what class it is an instance of, is an ObjInstance. That one VM object type covers instances of all classes. The two worlds map to each other something like this:
在Lox語言中,使用者可以定義自己的類——比如Cake和Pie——然後建立這些類的例項。從使用者的角度來看,Cake例項與Pie例項是不同型別的物件。但是,從虛擬機器的角度來看,使用者定義的每個類都只是另一個ObjClass型別的值。同樣,使用者程式中的每個例項,無論它是什麼類的例項,都是一個ObjInstance。這一虛擬機器物件型別涵蓋了所有類的例項。這兩個世界之間的對映是這樣的:

Got it? OK, back to the implementation. We also get our usual macros.
明白了嗎?好了,回到實現中。我們新增了一些熟悉的宏。
object.h,新增程式碼:
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
// 新增部分開始
#define IS_INSTANCE(value) isObjType(value, OBJ_INSTANCE)
// 新增部分結束
#define IS_NATIVE(value) isObjType(value, OBJ_NATIVE)
And:
以及:
object.h,新增程式碼:
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
// 新增部分開始
#define AS_INSTANCE(value) ((ObjInstance*)AS_OBJ(value))
// 新增部分結束
#define AS_NATIVE(value) \
Since fields are added after the instance is created, the “constructor” function only needs to know the class.
因為欄位是在例項建立之後新增的,所以“構造器”函式只需要知道類。
object.h,在newFunction()方法後新增程式碼:
ObjFunction* newFunction();
// 新增部分開始
ObjInstance* newInstance(ObjClass* klass);
// 新增部分結束
ObjNative* newNative(NativeFn function);
We implement that function here:
我們在這裡實現該函式:
object.c,在newFunction()方法後新增程式碼:
ObjInstance* newInstance(ObjClass* klass) {
ObjInstance* instance = ALLOCATE_OBJ(ObjInstance, OBJ_INSTANCE);
instance->klass = klass;
initTable(&instance->fields);
return instance;
}
We store a reference to the instance’s class. Then we initialize the field table to an empty hash table. A new baby object is born!
我們儲存了對例項的類的引用。然後我們將欄位表初始化為一個空的雜湊表。一個全新的物件誕生了!
At the sadder end of the instance’s lifespan, it gets freed.
在例項生命週期的最後階段,它被釋放了。
memory.c,在freeObject()方法中新增程式碼:
FREE(ObjFunction, object);
break;
}
// 新增部分開始
case OBJ_INSTANCE: {
ObjInstance* instance = (ObjInstance*)object;
freeTable(&instance->fields);
FREE(ObjInstance, object);
break;
}
// 新增部分結束
case OBJ_NATIVE:
The instance owns its field table so when freeing the instance, we also free the table. We don’t explicitly free the entries in the table, because there may be other references to those objects. The garbage collector will take care of those for us. Here we free only the entry array of the table itself.
例項擁有自己的欄位表,所以當釋放例項時,我們也會釋放該表。我們沒有顯式地釋放表中的條目,因為可能存在對這些物件的其它引用。垃圾回收器會幫我們處理這些問題。這裡我們只釋放表本身的條目陣列。
Speaking of the garbage collector, it needs support for tracing through instances.
說到垃圾回收,它需要支援透過例項進行跟蹤。
memory.c,在blackenObject()方法中新增程式碼:
markArray(&function->chunk.constants);
break;
}
// 新增部分開始
case OBJ_INSTANCE: {
ObjInstance* instance = (ObjInstance*)object;
markObject((Obj*)instance->klass);
markTable(&instance->fields);
break;
}
// 新增部分結束
case OBJ_UPVALUE:
If the instance is alive, we need to keep its class around. Also, we need to keep every object referenced by the instance’s fields. Most live objects that are not roots are reachable because some instance refers to the object in a field. Fortunately, we already have a nice
markTable()function to make tracing them easy.
如果這個例項是活動的,我們需要保留它的類。此外,我們還需要保留每個被例項欄位引用的物件。大多數不是根的活動物件都是可達的,因為某些例項會在某個欄位中引用該物件。幸運的是,我們已經有了一個很好的markTable()函式,可以輕鬆地跟蹤它們。
Less critical but still important is printing.
不太關鍵但仍然重要的是列印。
object.c,在printObject()方法中新增程式碼:
break;
// 新增部分開始
case OBJ_INSTANCE:
printf("%s instance",
AS_INSTANCE(value)->klass->name->chars);
break;
// 新增部分結束
case OBJ_NATIVE:
An instance prints its name followed by “instance”. (The “instance” part is mainly so that classes and instances don’t print the same.)
例項會列印它的名稱,並在後面加上“instance”6。(“instance”部分主要是為了使類和例項不會打印出相同的內容)
The real fun happens over in the interpreter. Lox has no special
newkeyword. The way to create an instance of a class is to invoke the class itself as if it were a function. The runtime already supports function calls, and it checks the type of object being called to make sure the user doesn’t try to invoke a number or other invalid type.
真正有趣的部分在直譯器中,Lox沒有特殊的new關鍵字。建立類例項的方法是呼叫類本身,就像呼叫函式一樣。執行時已經支援函式呼叫,它會檢查被呼叫物件的型別,以確保使用者不會試圖呼叫數字或其它無效型別。
We extend that runtime checking with a new case.
我們用一個新的case分支來擴充套件執行時的檢查。
vm.c,在callValue()方法中新增程式碼:
switch (OBJ_TYPE(callee)) {
// 新增部分開始
case OBJ_CLASS: {
ObjClass* klass = AS_CLASS(callee);
vm.stackTop[-argCount - 1] = OBJ_VAL(newInstance(klass));
return true;
}
// 新增部分結束
case OBJ_CLOSURE:
If the value being called—the object that results when evaluating the expression to the left of the opening parenthesis—is a class, then we treat it as a constructor call. We create a new instance of the called class and store the result on the stack.
如果被呼叫的值(在左括號左邊的表示式求值得到的物件)是一個類,則將其視為一個建構函式呼叫。我們建立一個被呼叫類的新例項,並將結果儲存在棧中7。
We’re one step farther. Now we can define classes and create instances of them.
我們又前進了一步。現在我們可以定義類並建立它們的例項了。
class Brioche {}
print Brioche();
Note the parentheses after
Briocheon the second line now. This prints “Brioche instance”.
注意第二行Brioche後面的括號。這裡會列印“Brioche instance”。
27 . 4 Get and Set Expressions
27.4 Get和SET表示式
Our object representation for instances can already store state, so all that remains is exposing that functionality to the user. Fields are accessed and modified using get and set expressions. Not one to break with tradition, Lox uses the classic “dot” syntax:
例項的物件表示形式已經可以儲存狀態了,所以剩下的就是把這個功能暴露給使用者。欄位是使用get和set表示式進行訪問和修改的。Lox並不喜歡打破傳統,這裡也沿用了經典的“點”語法:
eclair.filling = "pastry creme";
print eclair.filling;
The period—full stop for my English friends—works sort of like an infix operator. There is an expression to the left that is evaluated first and produces an instance. After that is the
.followed by a field name. Since there is a preceding operand, we hook this into the parse table as an infix expression.
句號——對英國朋友來說是句號——其作用有點像一箇中綴運算子8。左邊有一個表示式,首先被求值併產生一個例項。之後是.後跟一個欄位名稱。由於前面有一個運算元,我們將其作為中綴表示式放到解析表中。
compiler.c,替換1行:
[TOKEN_COMMA] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_DOT] = {NULL, dot, PREC_CALL},
// 替換部分結束
[TOKEN_MINUS] = {unary, binary, PREC_TERM},
As in other languages, the
.operator binds tightly, with precedence as high as the parentheses in a function call. After the parser consumes the dot token, it dispatches to a new parse function.
和其它語言一樣,.運算子繫結緊密,其優先順序和函式呼叫中的括號一樣高。解析器消費了點標識之後,會分發給一個新的解析函式。
compiler.c,在call()方法後新增程式碼:
static void dot(bool canAssign) {
consume(TOKEN_IDENTIFIER, "Expect property name after '.'.");
uint8_t name = identifierConstant(&parser.previous);
if (canAssign && match(TOKEN_EQUAL)) {
expression();
emitBytes(OP_SET_PROPERTY, name);
} else {
emitBytes(OP_GET_PROPERTY, name);
}
}
The parser expects to find a property name immediately after the dot. We load that token’s lexeme into the constant table as a string so that the name is available at runtime.
解析器希望在點運算子後面立即找到一個屬性名稱9。我們將該詞法標識的詞素作為字串載入到常量表中,這樣該名稱在執行時就是可用的。
We have two new expression forms—getters and setters—that this one function handles. If we see an equals sign after the field name, it must be a set expression that is assigning to a field. But we don’t always allow an equals sign after the field to be compiled. Consider:
我們將兩種新的表示式形式——getter和setter——都交由這一個函式處理。如果我們看到欄位名稱後有一個等號,那麼它一定是一個賦值給欄位的set表示式。但我們並不總是允許編譯欄位後面的等號。考慮一下:
a + b.c = 3
This is syntactically invalid according to Lox’s grammar, which means our Lox implementation is obligated to detect and report the error. If
dot()silently parsed the= 3part, we would incorrectly interpret the code as if the user had written:
根據Lox的文法,這在語法上是無效的,這意味著我們的Lox實現有義務檢測和報告這個錯誤。如果dot()默默地解析=3的部分,我們就會錯誤地解釋程式碼,就像使用者寫的是:
a + (b.c = 3)
The problem is that the
=side of a set expression has much lower precedence than the.part. The parser may calldot()in a context that is too high precedence to permit a setter to appear. To avoid incorrectly allowing that, we parse and compile the equals part only whencanAssignis true. If an equals token appears whencanAssignis false,dot()leaves it alone and returns. In that case, the compiler will eventually unwind up toparsePrecedence(), which stops at the unexpected=still sitting as the next token and reports an error.
問題是,set表示式中的=側優先順序遠低於.部分。解析器有可能會在一個優先順序高到不允許出現setter的上下文中呼叫dot()。為了避免錯誤地允許這種情況,我們只有在canAssign為true時才去解析和編譯等號部分。如果在canAssign為false時出現等號標識,dot()會保留它並返回。在這種情況下,編譯器最終會進入parsePrecedence(),而該方法會在非預期的=(仍然作為下一個標識)處停止,並報告一個錯誤。
If we find an
=in a context where it is allowed, then we compile the expression that follows. After that, we emit a newOP_SET_PROPERTYinstruction. That takes a single operand for the index of the property name in the constant table. If we didn’t compile a set expression, we assume it’s a getter and emit anOP_GET_PROPERTYinstruction, which also takes an operand for the property name.
如果我們在允許使用等號的上下文中找到=,則編譯後面的表示式。之後,我們發出一條新的OP_SET_PROPERTY指令10。這條指令接受一個運算元,作為屬性名稱在常量表中的索引。如果我們沒有編譯set表示式,就假定它是getter,併發出一條OP_GET_PROPERTY指令,它也接受一個運算元作為屬性名。
Now is a good time to define these two new instructions.
現在是定義這兩條新指令的好時機。
chunk.h,在列舉OpCode中新增程式碼:
OP_SET_UPVALUE,
// 新增部分開始
OP_GET_PROPERTY,
OP_SET_PROPERTY,
// 新增部分結束
OP_EQUAL,
And add support for disassembling them:
並在反彙編程式中為它們新增支援:
debug.c,在disassembleInstruction()方法中新增程式碼:
return byteInstruction("OP_SET_UPVALUE", chunk, offset);
// 新增部分開始
case OP_GET_PROPERTY:
return constantInstruction("OP_GET_PROPERTY", chunk, offset);
case OP_SET_PROPERTY:
return constantInstruction("OP_SET_PROPERTY", chunk, offset);
// 新增部分結束
case OP_EQUAL:
27 . 4 . 1 Interpreting getter and setter expressions
27.4.1 解釋getter和setter表示式
Sliding over to the runtime, we’ll start with get expressions since those are a little simpler.
進入執行時,我們從獲取表示式開始,因為它們更簡單一些。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_GET_PROPERTY: {
ObjInstance* instance = AS_INSTANCE(peek(0));
ObjString* name = READ_STRING();
Value value;
if (tableGet(&instance->fields, name, &value)) {
pop(); // Instance.
push(value);
break;
}
}
// 新增部分結束
case OP_EQUAL: {
When the interpreter reaches this instruction, the expression to the left of the dot has already been executed and the resulting instance is on top of the stack. We read the field name from the constant pool and look it up in the instance’s field table. If the hash table contains an entry with that name, we pop the instance and push the entry’s value as the result.
當直譯器到達這條指令時,點左邊的表示式已經被執行,得到的例項就在棧頂。我們從常量池中讀取欄位名,並在例項的欄位表中查詢該名稱。如果雜湊表中包含具有該名稱的條目,我們就彈出例項,並將該條目的值作為結果壓入棧。
Of course, the field might not exist. In Lox, we’ve defined that to be a runtime error. So we add a check for that and abort if it happens.
當然,這個欄位可能不存在。在Lox中,我們將其定義為執行時錯誤。所以我們添加了一個檢查,如果發生這種情況就中止。
vm.c,在run()方法中新增程式碼:
push(value);
break;
}
// 新增部分開始
runtimeError("Undefined property '%s'.", name->chars);
return INTERPRET_RUNTIME_ERROR;
// 新增部分結束
}
case OP_EQUAL: {
There is another failure mode to handle which you’ve probably noticed. The above code assumes the expression to the left of the dot did evaluate to an ObjInstance. But there’s nothing preventing a user from writing this:
你可能已經注意到了,還有另一種需要處理的失敗模式。上面的程式碼中假定了點左邊的表示式計算結果確實是一個ObjInstance。但是沒有什麼可以阻止使用者這樣寫:
var obj = "not an instance";
print obj.field;
The user’s program is wrong, but the VM still has to handle it with some grace. Right now, it will misinterpret the bits of the ObjString as an ObjInstance and, I don’t know, catch on fire or something definitely not graceful.
使用者的程式是錯誤的,但是虛擬機器仍然需要以某種優雅的方式來處理它。現在,它會把ObjString 資料誤認為是一個ObjInstance ,並且,我不確定,程式碼起火或發生其它事情絕對是不優雅的。
In Lox, only instances are allowed to have fields. You can’t stuff a field onto a string or number. So we need to check that the value is an instance before accessing any fields on it.
在Lox中,只有例項才允許有欄位。你不能把欄位塞到字串或數字中。因此,在訪問某個值上的任何欄位之前,檢查該值是否是一個例項11。
vm.c,在run()方法中新增程式碼:
case OP_GET_PROPERTY: {
// 新增部分開始
if (!IS_INSTANCE(peek(0))) {
runtimeError("Only instances have properties.");
return INTERPRET_RUNTIME_ERROR;
}
// 新增部分結束
ObjInstance* instance = AS_INSTANCE(peek(0));
If the value on the stack isn’t an instance, we report a runtime error and safely exit.
如果棧中的值不是例項,則報告一個執行時錯誤並安全退出。
Of course, get expressions are not very useful when no instances have any fields. For that we need setters.
當然,如果例項沒有任何欄位,get表示式就不太有用了。因此,我們需要setter。
vm.c,在run()方法中新增程式碼:
return INTERPRET_RUNTIME_ERROR;
}
// 新增部分開始
case OP_SET_PROPERTY: {
ObjInstance* instance = AS_INSTANCE(peek(1));
tableSet(&instance->fields, READ_STRING(), peek(0));
Value value = pop();
pop();
push(value);
break;
}
// 新增部分結束
case OP_EQUAL: {
This is a little more complex than
OP_GET_PROPERTY. When this executes, the top of the stack has the instance whose field is being set and above that, the value to be stored. Like before, we read the instruction’s operand and find the field name string. Using that, we store the value on top of the stack into the instance’s field table.
這比OP_GET_PROPERTY要複雜一些。當執行此指令時,棧頂有待設定欄位的例項,在該例項之上有要儲存的值。與前面一樣,我們讀取指令的運算元,並查詢欄位名稱字串。使用該方法,我們將棧頂的值儲存到例項的欄位表中。
After that is a little stack juggling. We pop the stored value off, then pop the instance, and finally push the value back on. In other words, we remove the second element from the stack while leaving the top alone. A setter is itself an expression whose result is the assigned value, so we need to leave that value on the stack. Here’s what I mean:
在那之後是一些棧技巧。我們將儲存的值彈出,然後彈出例項,最後再把值壓回棧中。換句話說,我們從棧中刪除第二個元素,而保留最上面的元素。setter本身是一個表示式,其結果就是所賦的值,所以我們需要將值保留在棧上。我的意思是12:
class Toast {}
var toast = Toast();
print toast.jam = "grape"; // Prints "grape".
Unlike when reading a field, we don’t need to worry about the hash table not containing the field. A setter implicitly creates the field if needed. We do need to handle the user incorrectly trying to store a field on a value that isn’t an instance.
與讀取欄位不同,我們不需要擔心雜湊表中不包含該欄位。如果需要的話,setter會隱式地建立這個欄位。我們確實需要處理使用者不正確地試圖在非例項的值上儲存欄位的情況。
vm.c,在run()方法中新增程式碼:
case OP_SET_PROPERTY: {
// 新增部分開始
if (!IS_INSTANCE(peek(1))) {
runtimeError("Only instances have fields.");
return INTERPRET_RUNTIME_ERROR;
}
// 新增部分結束
ObjInstance* instance = AS_INSTANCE(peek(1));
Exactly like with get expressions, we check the value’s type and report a runtime error if it’s invalid. And, with that, the stateful side of Lox’s support for object-oriented programming is in place. Give it a try:
就像get表示式一樣,我們檢查值的型別,如果無效就報告一個執行時錯誤。這樣一來,Lox對面向物件程式設計中有狀態部分的支援就到位了。試一試:
class Pair {}
var pair = Pair();
pair.first = 1;
pair.second = 2;
print pair.first + pair.second; // 3.
This doesn’t really feel very object-oriented. It’s more like a strange, dynamically typed variant of C where objects are loose struct-like bags of data. Sort of a dynamic procedural language. But this is a big step in expressiveness. Our Lox implementation now lets users freely aggregate data into bigger units. In the next chapter, we will breathe life into those inert blobs.
這感覺不太面向物件。它更像是一種奇怪的、動態型別的C語言變體,其中的物件是鬆散的類似結構體的資料包。有點像動態過程化語言。但這是表達能力的一大進步。我們的Lox實現現在允許使用者自由地將資料聚合成更大的單元。在下一章中,我們將為這些遲緩的資料注入活力。
習題
-
Trying to access a non-existent field on an object immediately aborts the entire VM. The user has no way to recover from this runtime error, nor is there any way to see if a field exists before trying to access it. It’s up to the user to ensure on their own that only valid fields are read.
How do other dynamically typed languages handle missing fields? What do you think Lox should do? Implement your solution.
試圖訪問一個物件上不存在的欄位會立即中止整個虛擬機器。使用者沒有辦法從這個執行時錯誤中恢復過來,也沒有辦法在試圖訪問一個欄位之前看它是否存在。需要由使用者自己來確保只讀取有效欄位。
其它動態型別語言是如何處理缺少欄位的?你認為Lox應該怎麼做?實現你的解決方案。
-
Fields are accessed at runtime by their string name. But that name must always appear directly in the source code as an identifier token. A user program cannot imperatively build a string value and then use that as the name of a field. Do you think they should be able to? Devise a language feature that enables that and implement it.
欄位在執行時是透過它們的字串名稱來訪問的。但是該名稱必須總是作為識別符號直接出現在原始碼中。使用者程式不能命令式地構建字串值,然後將其用作欄位名。你認為應該這樣做嗎?那就設計一種語言特性來實現它。
-
Conversely, Lox offers no way to remove a field from an instance. You can set a field’s value to
nil, but the entry in the hash table is still there. How do other languages handle this? Choose and implement a strategy for Lox.反過來說,Lox沒有提供從例項中刪除欄位的方法。你可以將一個欄位的值設定為
nil,但雜湊表中的條目仍然存在。其它語言如何處理這個問題?為Lox選擇一個策略並實現。 -
Because fields are accessed by name at runtime, working with instance state is slow. It’s technically a constant-time operation—thanks, hash tables—but the constant factors are relatively large. This is a major component of why dynamic languages are slower than statically typed ones.
How do sophisticated implementations of dynamically typed languages cope with and optimize this?
因為欄位在執行時是按照名稱訪問的,所以對例項狀態的操作是很慢的。從技術上講,這是一個常量時間的操作(感謝雜湊表),但是常量因子比較大。這就是動態語言比靜態語言慢的一個主要原因。
動態型別語言的複雜實現是如何應對和最佳化這一問題的?
-
那些對面向物件程式設計有強烈看法的人——讀作“每個人”——往往認為OOP意味著一些非常具體的語言特性清單,但實際上有一個完整的空間可以探索,而每種語言都有自己的成分和配方。
Self有物件但沒有類。CLOS有方法,當沒有把它們附加到特定的類中。C++最初沒有執行時多型——沒有虛方法。Python有多重繼承,但Java沒有。Ruby把方法附加在類上,但你也可以在單個物件上定義方法。 ↩ -
 我將變數命名為“klass”,不僅僅是為了給虛擬機器一種古怪的幼兒園的"Kidz Korner "感覺。它使得clox更容易被編譯為C++,而C++中“class”是一個保留字。 ↩
我將變數命名為“klass”,不僅僅是為了給虛擬機器一種古怪的幼兒園的"Kidz Korner "感覺。它使得clox更容易被編譯為C++,而C++中“class”是一個保留字。 ↩ -
我們可以讓類宣告成為表示式而不是語句——比較它們本質上是一個產生值的字面量。然後使用者必須自己顯式地將類繫結到一個變數,比如:
var Pie = class {}。這有點像lambda函式,但只是針對類的。但由於我們通常希望類被命名,所以將其視為宣告是有意義的。 ↩ -
“區域性(Local)”類——在函式或塊主體中宣告的類,是一個不尋常的概念。許多語言根本不允許這一特性。但由於Lox是一種動態型別指令碼語言,它會對程式的頂層程式碼和函式以及塊的主體進行統一處理。類只是另一種宣告,既然你可以在塊中宣告變數和函式,那你也可以在塊中宣告類。 ↩
-
能夠在執行時自由地向物件新增欄位,是大多數動態語言和靜態語言之間的一個很大的實際區別。靜態型別語言通常要求顯式宣告欄位。這樣,編譯器就確切知道每個例項有哪些欄位。它可以利用這一點來確定每個例項所需的精確記憶體量,以及每個欄位在記憶體中的偏移量。
在Lox和其它動態語言中,訪問欄位通常是一次雜湊表查詢。常量時間複雜度,但仍然是相當重的。在C++這樣的語言中,訪問一個欄位就像對指標偏移一個整數常量一樣快。 ↩ -
大多數面向物件的語言允許類定義某種形式的
toString()方法,讓該類指定如何將其例項轉換為字串並打印出來。如果Lox不是一門玩具語言,我也想要支援它。 ↩ -
我們暫時忽略傳遞給呼叫的所有引數。在下一章新增對初始化器的支援時,我們會重新審視這一段程式碼。 ↩
-
我說“有點”是因為
.右邊的不是表示式,而是一個識別符號,其語義由get或set表示式本身來處理。它實際上更接近於一個字尾表示式。 ↩ -
編譯器在這裡使用“屬性(property)”而不是“欄位(field)”,因為,請記住,Lox還允許你使用點語法來訪問一個方法而不呼叫它。“屬性”是一個通用術語,我們用來指代可以在例項上訪問的任何命名實體。欄位是基於例項狀態的屬性子集。 ↩
-
你不能設定非欄位屬性,所以我認為這個指令本該是
OP_SET_FIELD,但是我認為它與get指令一致看起來更漂亮。 ↩ -
Lox可以支援向其它型別的值中新增欄位。這是我們的語言,我們可以做我們想做的。但這可能是個壞主意。它大大增加了實現的複雜性,從而損害了效能——例如,字串駐留變得更加困難。
此外,它還引起了關於數值的相等和同一性的複雜語義問題。如果我給數字3附加一個欄位,那麼1+2的結果也有這個欄位嗎?如果是的話,實現上如何跟蹤它?如果不是,這兩個結果中的“3”仍然被認為是相等的嗎? ↩ -
棧的操作是這樣的:
 ↩
↩
28.方法和初始化器 Methods and Initializers
When you are on the dancefloor, there is nothing to do but dance.
—— Umberto Eco, The Mysterious Flame of Queen Loana
當你在舞池裡時,除了跳舞,別無選擇。(翁貝託·艾柯,《洛安娜女王的神秘火焰》)
It is time for our virtual machine to bring its nascent objects to life with behavior. That means methods and method calls. And, since they are a special kind of method, initializers too.
對於我們的虛擬機來說,現在是時候通過賦予行為的方式為新生對象賦予生命了。也就是方法和方法調用。而且由於初始化器同樣也屬於這種特殊的方法,所以也要予以考慮。
All of this is familiar territory from our previous jlox interpreter. What’s new in this second trip is an important optimization we’ll implement to make method calls over seven times faster than our baseline performance. But before we get to that fun, we gotta get the basic stuff working.
所有這些都是我們以前的jlox解釋器中所熟悉的領域。第二次旅行中的新內容是我們將實現一個重要的優化,使方法調用的速度比基線性能快7倍以上。但在此之前,我們得先把基本的東西弄好。
28 . 1 Method Declarations
28.1 方法聲明
We can’t optimize method calls before we have method calls, and we can’t call methods without having methods to call, so we’ll start with declarations.
沒有方法調用,我們就無法優化方法調用,而沒有可供調用的方法,我們就無法調用方法,因此我們從聲明開始。
28 . 1 . 1 Representing methods
28.1.1 表示方法
We usually start in the compiler, but let’s knock the object model out first this time. The runtime representation for methods in clox is similar to that of jlox. Each class stores a hash table of methods. Keys are method names, and each value is an ObjClosure for the body of the method.
我們通常從編譯器開始,但這次讓我們先搞定對象模型。clox中方法的運行時表示形式與jlox相似。每個類都存儲了一個方法的哈希表。鍵是方法名,每個值都是方法主體對應的ObjClosure。
object.h,在結構體ObjClass中添加代碼:
typedef struct {
Obj obj;
ObjString* name;
// 新增部分開始
Table methods;
// 新增部分結束
} ObjClass;
A brand new class begins with an empty method table.
一個全新的類初始時得到的是空方法表。
object.c,在newClass()方法中添加代碼:
klass->name = name;
// 新增部分開始
initTable(&klass->methods);
// 新增部分結束
return klass;
The ObjClass struct owns the memory for this table, so when the memory manager deallocates a class, the table should be freed too.
ObjClass 結構體擁有該表的內存,因此當內存管理器釋放某個類時,該表也應該被釋放。
memory.c,在freeObject()方法中添加代碼:
case OBJ_CLASS: {
// 新增部分開始
ObjClass* klass = (ObjClass*)object;
freeTable(&klass->methods);
// 新增部分結束
FREE(ObjClass, object);
Speaking of memory managers, the GC needs to trace through classes into the method table. If a class is still reachable (likely through some instance), then all of its methods certainly need to stick around too.
說到內存管理器,GC需要通過類追蹤到方法表。如果某個類仍然是可達的(可能是通過某個實例),那麼它的所有方法當然也需要保留。
memory.c,在blackenObject()方法中添加代碼:
markObject((Obj*)klass->name);
// 新增部分開始
markTable(&klass->methods);
// 新增部分結束
break;
We use the existing
markTable()function, which traces through the key string and value in each table entry.
我們使用現有的markTable()函數,該函數可以追蹤每個表項中的鍵字符串和值。
Storing a class’s methods is pretty familiar coming from jlox. The different part is how that table gets populated. Our previous interpreter had access to the entire AST node for the class declaration and all of the methods it contained. At runtime, the interpreter simply walked that list of declarations.
存儲類方法的方式與jlox是非常類似的。不同之處在於如何填充該表。我們以前的解釋器可以訪問整個類聲明及其包含的所有方法對應的AST節點。在運行時,解釋器只是簡單地遍歷聲明列表。
Now every piece of information the compiler wants to shunt over to the runtime has to squeeze through the interface of a flat series of bytecode instructions. How do we take a class declaration, which can contain an arbitrarily large set of methods, and represent it as bytecode? Let’s hop over to the compiler and find out.
現在,編譯器想要分發到運行時的每一條信息都必須通過一個扁平的字節碼指令序列形式。我們如何接受一個可以包含任意大的方法集的類聲明,並以字節碼的形式將其表現出來?讓我們跳到編譯器上看看。
28 . 1 . 2 Compiling method declarations
28.1.2 編譯方法聲明
The last chapter left us with a compiler that parses classes but allows only an empty body. Now we insert a little code to compile a series of method declarations between the braces.
上一章留給我們一個能解析類但只允許空主體的編譯器。現在我們添加一些代碼來解析大括號之間的一系列方法聲明。
compiler.c,在classDeclaration()方法中添加代碼:
consume(TOKEN_LEFT_BRACE, "Expect '{' before class body.");
// 新增部分開始
while (!check(TOKEN_RIGHT_BRACE) && !check(TOKEN_EOF)) {
method();
}
// 新增部分結束
consume(TOKEN_RIGHT_BRACE, "Expect '}' after class body.");
Lox doesn’t have field declarations, so anything before the closing brace at the end of the class body must be a method. We stop compiling methods when we hit that final curly or if we reach the end of the file. The latter check ensures our compiler doesn’t get stuck in an infinite loop if the user accidentally forgets the closing brace.
Lox沒有字段聲明,因此,在主體塊末尾的右括號之前的任何內容都必須是方法。當我們碰到最後的大括號或到達文件結尾時,就會停止編譯方法。後一項檢查可以確保我們的編譯器不會在用戶不小心忘記關閉大括號時陷入無限循環。
The tricky part with compiling a class declaration is that a class may declare any number of methods. Somehow the runtime needs to look up and bind all of them. That would be a lot to pack into a single
OP_CLASSinstruction. Instead, the bytecode we generate for a class declaration will split the process into a series of instructions. The compiler already emits anOP_CLASSinstruction that creates a new empty ObjClass object. Then it emits instructions to store the class in a variable with its name.
編譯類聲明的棘手之處在於,一個類可以聲明任意數量的方法。運行時需要以某種方式查找並綁定所有這些方法。這會導致一個OP_CLASS指令中納入了太多內容。相反,我們為類聲明生成的字節碼將這個過程分為一系列的指令。編譯器已經發出了一條OP_CLASS指令,用來創建一個新的空ObjClass對象。然後它發出指令,將類存儲在一個具有其名稱的變量中1。
Now, for each method declaration, we emit a new
OP_METHODinstruction that adds a single method to that class. When all of theOP_METHODinstructions have executed, we’re left with a fully formed class. While the user sees a class declaration as a single atomic operation, the VM implements it as a series of mutations.
現在,對於每個方法聲明,我們發出一條新的OP_METHOD指令,將一個方法添加到該類中。當所有的OP_METHOD指令都執行完畢後,我們就得到了一個完整的類。儘管用戶將類聲明看作是單個原子操作,但虛擬機卻將其實現為一系列的變化。
To define a new method, the VM needs three things:
要定義一個新方法,VM需要三樣東西:
- The name of the method.
- The closure for the method body.
- The class to bind the method to.
- 方法名稱。
- 方法主體的閉包。
- 綁定該方法的類。
We’ll incrementally write the compiler code to see how those all get through to the runtime, starting here:
我們會逐步編寫編譯器代碼,看看它們是如何進入運行時的,從這裡開始:
compiler.c,在function()方法後添加代碼:
static void method() {
consume(TOKEN_IDENTIFIER, "Expect method name.");
uint8_t constant = identifierConstant(&parser.previous);
emitBytes(OP_METHOD, constant);
}
Like
OP_GET_PROPERTYand other instructions that need names at runtime, the compiler adds the method name token’s lexeme to the constant table, getting back a table index. Then we emit anOP_METHODinstruction with that index as the operand. That’s the name. Next is the method body:
像OP_GET_PROPERTY和其它在運行時需要名稱的指令一樣,編譯器將方法名稱標識的詞素添加到常量表中,獲得表索引。然後發出一個OP_METHOD指令,以該索引作為操作數。這就是名稱。接下來是方法主體:
compiler.c,在method()方法中添加代碼:
uint8_t constant = identifierConstant(&parser.previous);
// 新增部分開始
FunctionType type = TYPE_FUNCTION;
function(type);
// 新增部分結束
emitBytes(OP_METHOD, constant);
We use the same
function()helper that we wrote for compiling function declarations. That utility function compiles the subsequent parameter list and function body. Then it emits the code to create an ObjClosure and leave it on top of the stack. At runtime, the VM will find the closure there.
我們使用為編譯函數聲明而編寫的function()輔助函數。該工具函數會編譯後續的參數列表和函數主體。然後它發出創建ObjClosure的代碼,並將其留在棧頂。在運行時,VM會在那裡找到這個閉包。
Last is the class to bind the method to. Where can the VM find that? Unfortunately, by the time we reach the
OP_METHODinstruction, we don’t know where it is. It could be on the stack, if the user declared the class in a local scope. But a top-level class declaration ends up with the ObjClass in the global variable table.
最後是要綁定方法的類。VM在哪裡可以找到它呢?不幸的是,當我們到達OP_METHOD指令時,我們還不知道它在哪裡。如果用戶在局部作用域中聲明該類,那它可能在棧上。但是頂層的類聲明最終會成為全局變量表中的ObjClass2。
Fear not. The compiler does know the name of the class. We can capture it right after we consume its token.
不要擔心。編譯器確實知道類的名稱。我們可以在消費完名稱標識後捕獲這個值。
compiler.c,在classDeclaration()方法中添加代碼:
consume(TOKEN_IDENTIFIER, "Expect class name.");
// 新增部分開始
Token className = parser.previous;
// 新增部分結束
uint8_t nameConstant = identifierConstant(&parser.previous);
And we know that no other declaration with that name could possibly shadow the class. So we do the easy fix. Before we start binding methods, we emit whatever code is necessary to load the class back on top of the stack.
我們知道,其它具有該名稱的聲明不可能會遮蔽這個類。所以我們選擇了簡單的處理方式。在我們開始綁定方法之前,通過一些必要的代碼,將類加載回棧頂。
compiler.c,在classDeclaration()方法中添加代碼:
defineVariable(nameConstant);
// 新增部分開始
namedVariable(className, false);
// 新增部分結束
consume(TOKEN_LEFT_BRACE, "Expect '{' before class body.");
Right before compiling the class body, we call
namedVariable(). That helper function generates code to load a variable with the given name onto the stack. Then we compile the methods.
在編譯類主體之前,我們調用namedVariable()。這個輔助函數會生成代碼,將一個具有給定名稱的變量加載到棧中3。然後,我們編譯方法。
This means that when we execute each
OP_METHODinstruction, the stack has the method’s closure on top with the class right under it. Once we’ve reached the end of the methods, we no longer need the class and tell the VM to pop it off the stack.
這意味著,當我們執行每一條OP_METHOD指令時,棧頂是方法的閉包,它下面就是類。一旦我們到達了方法的末尾,我們就不再需要這個類,並告訴虛擬機將該它從棧中彈出。
compiler.c,在classDeclaration()方法中添加代碼:
consume(TOKEN_RIGHT_BRACE, "Expect '}' after class body.");
// 新增部分開始
emitByte(OP_POP);
// 新增部分結束
}
Putting all of that together, here is an example class declaration to throw at the compiler:
把所有這些放在一起,下面是一個可以扔給編譯器的類聲明示例:
class Brunch {
bacon() {}
eggs() {}
}
Given that, here is what the compiler generates and how those instructions affect the stack at runtime:
鑑於此,下面是編譯器生成的內容以及這些指令在運行時如何影響堆棧:
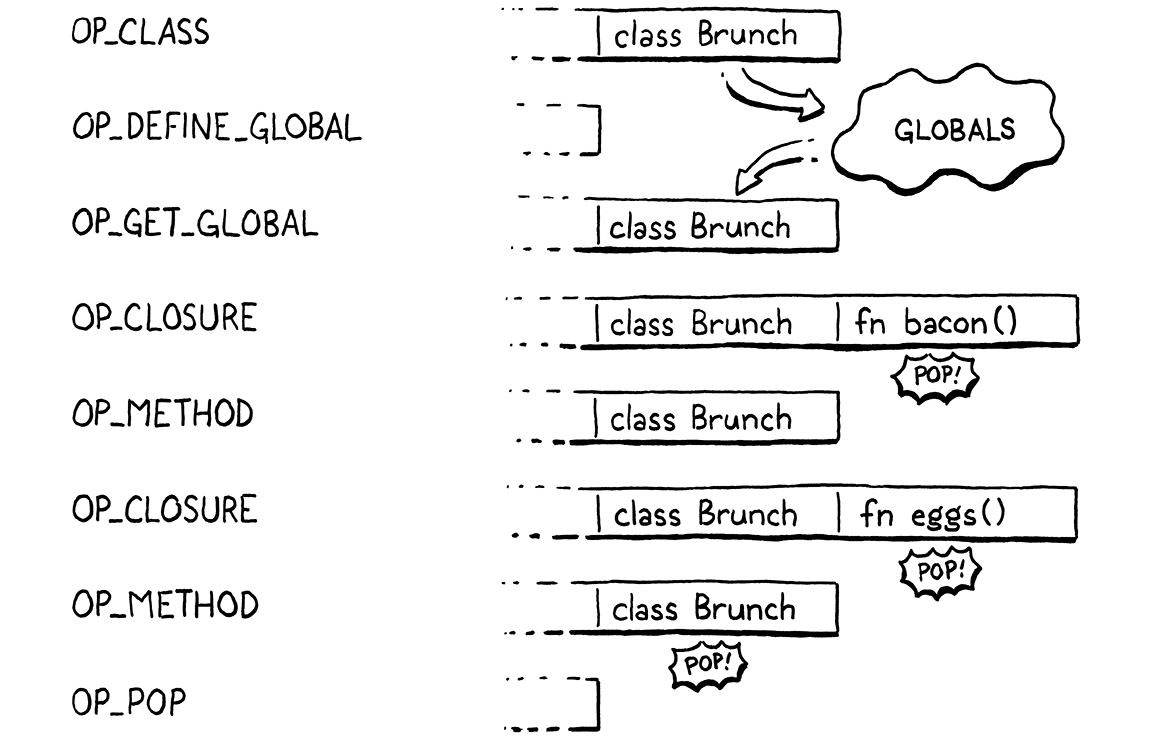
All that remains for us is to implement the runtime for that new
OP_METHODinstruction.
我們剩下要做的就是為這個新的OP_METHOD指令實現運行時。
28 . 1 . 3 Executing method declarations
28.1.3 執行方法聲明
First we define the opcode.
首先我們定義操作碼。
chunk.h,在枚舉OpCode中添加代碼:
OP_CLASS,
// 新增部分開始
OP_METHOD
// 新增部分結束
} OpCode;
We disassemble it like other instructions that have string constant operands.
我們像其它具有字符串常量操作數的指令一樣對它進行反彙編。
debug.c,在disassembleInstruction()方法中添加代碼:
case OP_CLASS:
return constantInstruction("OP_CLASS", chunk, offset);
// 新增部分開始
case OP_METHOD:
return constantInstruction("OP_METHOD", chunk, offset);
// 新增部分結束
default:
And over in the interpreter, we add a new case too.
在解釋器中,我們也添加一個新的case分支。
vm.c,在run()方法中添加代碼:
break;
// 新增部分開始
case OP_METHOD:
defineMethod(READ_STRING());
break;
// 新增部分結束
}
There, we read the method name from the constant table and pass it here:
其中,我們從常量表中讀取方法名稱,並將其傳遞到這裡:
vm.c,在closeUpvalues()方法後添加代碼:
static void defineMethod(ObjString* name) {
Value method = peek(0);
ObjClass* klass = AS_CLASS(peek(1));
tableSet(&klass->methods, name, method);
pop();
}
The method closure is on top of the stack, above the class it will be bound to. We read those two stack slots and store the closure in the class’s method table. Then we pop the closure since we’re done with it.
方法閉包位於棧頂,在它將綁定的類的上方。我們讀取這兩個棧槽並將閉包存儲到類的方法表中。然後彈出閉包,因為我們已經用完了。
Note that we don’t do any runtime type checking on the closure or class object. That
AS_CLASS()call is safe because the compiler itself generated the code that causes the class to be in that stack slot. The VM trusts its own compiler.
注意,我們沒有對閉包或類對象做任何的運行時類型檢查。AS_CLASS()調用是安全的,因為編譯器本身會生成使類位於棧槽的代碼。虛擬機信任自己的編譯器4。
After the series of
OP_METHODinstructions is done and theOP_POPhas popped the class, we will have a class with a nicely populated method table, ready to start doing things. The next step is pulling those methods back out and using them.
在完成一系列的OP_METHOD指令並且OP_POP彈出類後,我們將得到一個已填充好方法表的類,可以開始做事情了。下一步是將這些方法拉出來並使用它們。
28 . 2 Method References
28.2 方法引用
Most of the time, methods are accessed and immediately called, leading to this familiar syntax:
大多數情況下,方法被訪問並立即被調用,導致了這種熟悉的語法:
instance.method(argument);
But remember, in Lox and some other languages, those two steps are distinct and can be separated.
但是請記住,在Lox和其它一些語言中,這兩個步驟是不同的,可以分開。
var closure = instance.method;
closure(argument);
Since users can separate the operations, we have to implement them separately. The first step is using our existing dotted property syntax to access a method defined on the instance’s class. That should return some kind of object that the user can then call like a function.
由於用戶可以將這些操作分開,所以我們必須分別實現它們。第一步是使用現有的點屬性語法來訪問實例的類中定義的方法。這應該返回某種類型的對象,然後用戶可以向函數一樣調用它。
The obvious approach is to look up the method in the class’s method table and return the ObjClosure associated with that name. But we also need to remember that when you access a method,
thisgets bound to the instance the method was accessed from. Here’s the example from when we added methods to jlox:
明顯的方式是,在類的方法表中查找該方法,並返回與該名稱關聯的ObjClosure。但是我們也需要記住,當你訪問一個方法時,this綁定到訪問該方法的實例上。下面是我們在向jlox添加方法時的例子:
class Person {
sayName() {
print this.name;
}
}
var jane = Person();
jane.name = "Jane";
var method = jane.sayName;
method(); // ?
This should print “Jane”, so the object returned by
.sayNamesomehow needs to remember the instance it was accessed from when it later gets called. In jlox, we implemented that “memory” using the interpreter’s existing heap-allocated Environment class, which handled all variable storage.
這裡應該打印“Jane”,因此.sayName返回的對象在以後被調用時需要記住訪問它的實例。在jlox中,我們通過解釋器已有的堆分配的Environment類來實現這個“記憶”,該Environment類會處理所有的變量存儲。。
Our bytecode VM has a more complex architecture for storing state. Local variables and temporaries are on the stack, globals are in a hash table, and variables in closures use upvalues. That necessitates a somewhat more complex solution for tracking a method’s receiver in clox, and a new runtime type.
我們的字節碼虛擬機用一個更復雜的結構來存儲狀態。局部變量和臨時變量在棧中,全局變量在哈希表中,而閉包中的變量使用上值。這就需要一個更復雜的跟蹤clox中方法接收者的解決方案,以及一個新的運行時類型。
28 . 2 . 1 Bound methods
28.2.1 已綁定方法
When the user executes a method access, we’ll find the closure for that method and wrap it in a new “bound method” object that tracks the instance that the method was accessed from. This bound object can be called later like a function. When invoked, the VM will do some shenanigans to wire up
thisto point to the receiver inside the method’s body.
當用戶執行一個方法訪問時,我們會找到該方法的閉包,並將其包裝在一個新的“已綁定方法(bound method)”對象中5,該對象會跟蹤訪問該方法的實例。這個已綁定對象可以像一個函數一樣在稍後被調用。當被調用時,虛擬機會做一些小動作,將this連接到方法主體中的接收器。
Here’s the new object type:
下面是新的對象類型:
object.h,在結構體ObjInstance後添加代碼:
} ObjInstance;
// 新增部分開始
typedef struct {
Obj obj;
Value receiver;
ObjClosure* method;
} ObjBoundMethod;
// 新增部分結束
ObjClass* newClass(ObjString* name);
It wraps the receiver and the method closure together. The receiver’s type is Value even though methods can be called only on ObjInstances. Since the VM doesn’t care what kind of receiver it has anyway, using Value means we don’t have to keep converting the pointer back to a Value when it gets passed to more general functions.
它將接收器和方法閉包包裝在一起。儘管方法只能在ObjInstances上調用,但接收器類型是Value。因為虛擬機並不關心它擁有什麼樣的接收器,使用Value意味著當它需要傳遞給更多通用函數時,我們不必將指針轉換回Value。
The new struct implies the usual boilerplate you’re used to by now. A new case in the object type enum:
新的結構體暗含了你現在已經熟悉的常規模板。對象類型枚舉中的新值:
object.h,在枚舉ObjType中添加代碼:
typedef enum {
// 新增部分開始
OBJ_BOUND_METHOD,
// 新增部分結束
OBJ_CLASS,
A macro to check a value’s type:
一個檢查值類型的宏:
object.h,添加代碼:
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
// 新增部分開始
#define IS_BOUND_METHOD(value) isObjType(value, OBJ_BOUND_METHOD)
// 新增部分結束
#define IS_CLASS(value) isObjType(value, OBJ_CLASS)
Another macro to cast the value to an ObjBoundMethod pointer:
另一個將值轉換為ObjBoundMethod 指針的宏:
object.h,添加代碼:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
// 新增部分開始
#define AS_BOUND_METHOD(value) ((ObjBoundMethod*)AS_OBJ(value))
// 新增部分結束
#define AS_CLASS(value) ((ObjClass*)AS_OBJ(value))
A function to create a new ObjBoundMethod:
一個創建新ObjBoundMethod的函數:
object.h,在結構體ObjBoundMethod後添加代碼:
} ObjBoundMethod;
// 新增部分開始
ObjBoundMethod* newBoundMethod(Value receiver,
ObjClosure* method);
// 新增部分結束
ObjClass* newClass(ObjString* name);
And an implementation of that function here:
以及該函數的實現:
object.c,在allocateObject()方法後添加代碼:
ObjBoundMethod* newBoundMethod(Value receiver,
ObjClosure* method) {
ObjBoundMethod* bound = ALLOCATE_OBJ(ObjBoundMethod,
OBJ_BOUND_METHOD);
bound->receiver = receiver;
bound->method = method;
return bound;
}
The constructor-like function simply stores the given closure and receiver. When the bound method is no longer needed, we free it.
這個類似構造器的函數簡單地存儲了給定的閉包和接收器。當不再需要某個已綁定方法時,我們將其釋放。
memory.c,在freeObject()方法中添加代碼:
switch (object->type) {
// 新增部分開始
case OBJ_BOUND_METHOD:
FREE(ObjBoundMethod, object);
break;
// 新增部分結束
case OBJ_CLASS: {
The bound method has a couple of references, but it doesn’t own them, so it frees nothing but itself. However, those references do get traced by the garbage collector.
已綁定方法有幾個引用,但並不擁有它們,所以它只釋放自己。但是,這些引用確實要被垃圾回收器跟蹤到。
memory.c,在blackenObject()方法中添加代碼:
switch (object->type) {
// 新增部分開始
case OBJ_BOUND_METHOD: {
ObjBoundMethod* bound = (ObjBoundMethod*)object;
markValue(bound->receiver);
markObject((Obj*)bound->method);
break;
}
// 新增部分結束
case OBJ_CLASS: {
This ensures that a handle to a method keeps the receiver around in memory so that
thiscan still find the object when you invoke the handle later. We also trace the method closure.
這可以確保方法的句柄會將接收器保持在內存中,以便後續當你調用這個句柄時,this仍然可以找到這個對象。我們也會跟蹤方法閉包6。
The last operation all objects support is printing.
所有對象要支持的最後一個操作是打印。
object.c,在printObject()方法中添加代碼:
switch (OBJ_TYPE(value)) {
// 新增部分開始
case OBJ_BOUND_METHOD:
printFunction(AS_BOUND_METHOD(value)->method->function);
break;
// 新增部分結束
case OBJ_CLASS:
A bound method prints exactly the same way as a function. From the user’s perspective, a bound method is a function. It’s an object they can call. We don’t expose that the VM implements bound methods using a different object type.
已綁定方法的打印方式與函數完全相同。從用戶的角度來看,已綁定方法就是一個函數,是一個可以被他們調用的對象。我們不會暴露虛擬機中使用不同的對象類型來實現已綁定方法的事實。
Put on your party hat because we just reached a little milestone. ObjBoundMethod is the very last runtime type to add to clox. You’ve written your last
IS_andAS_macros. We’re only a few chapters from the end of the book, and we’re getting close to a complete VM.
慶祝一下,因為我們剛剛到達了一個小小的里程碑。ObjBoundMethod是要添加到clox中的最後一個運行時類型。你已經寫完了最後的IS_和AS_宏。我們離本書的結尾只有幾章了,而且我們已經接近一個完整的虛擬機了。
28 . 2 . 2 Accessing methods
28.2.2 訪問方法
Let’s get our new object type doing something. Methods are accessed using the same “dot” property syntax we implemented in the last chapter. The compiler already parses the right expressions and emits
OP_GET_PROPERTYinstructions for them. The only changes we need to make are in the runtime.
我們來讓新對象類型做點什麼。方法是通過我們在上一章中實現的“點”屬性語法進行訪問的。編譯器已經能夠解析正確的表達式,併為它們發出OP_GET_PROPERTY指令。我們接下來只需要在運行時做適當改動。
When a property access instruction executes, the instance is on top of the stack. The instruction’s job is to find a field or method with the given name and replace the top of the stack with the accessed property.
當執行某個屬性訪問指令時,實例在棧頂。該指令的任務是找到一個具有給定名稱的字段或方法,並將棧頂替換為所訪問的屬性。
The interpreter already handles fields, so we simply extend the
OP_GET_PROPERTYcase with another section.
解釋器已經處理了字段,所以我們只需要在OP_GET_PROPERTY分支中擴展另一部分。
vm.c,在run()方法中替換2行:
pop(); // Instance.
push(value);
break;
}
// 替換部分開始
if (!bindMethod(instance->klass, name)) {
return INTERPRET_RUNTIME_ERROR;
}
break;
// 替換部分結束
}
We insert this after the code to look up a field on the receiver instance. Fields take priority over and shadow methods, so we look for a field first. If the instance does not have a field with the given property name, then the name may refer to a method.
我們在查找接收器實例上字段的代碼後面插入這部分邏輯。字段優先於方法,因此我們首先查找字段。如果實例確實不包含具有給定屬性名稱的字段,那麼這個名稱可能指向的是一個方法。
We take the instance’s class and pass it to a new
bindMethod()helper. If that function finds a method, it places the method on the stack and returnstrue. Otherwise it returnsfalseto indicate a method with that name couldn’t be found. Since the name also wasn’t a field, that means we have a runtime error, which aborts the interpreter.
我們獲取實例的類,並將其傳遞給新的bindMethod()輔助函數。如果該函數找到了方法,它會將該方法放在棧中並返回true。否則返回false,表示找不到具有該名稱的方法。因為這個名稱也不是字段,這意味著我們遇到了一個運行時錯誤,從而中止瞭解釋器。
Here is the good stuff:
下面是這段精彩的邏輯:
vm.c,在callValue()方法後添加代碼:
static bool bindMethod(ObjClass* klass, ObjString* name) {
Value method;
if (!tableGet(&klass->methods, name, &method)) {
runtimeError("Undefined property '%s'.", name->chars);
return false;
}
ObjBoundMethod* bound = newBoundMethod(peek(0),
AS_CLOSURE(method));
pop();
push(OBJ_VAL(bound));
return true;
}
First we look for a method with the given name in the class’s method table. If we don’t find one, we report a runtime error and bail out. Otherwise, we take the method and wrap it in a new ObjBoundMethod. We grab the receiver from its home on top of the stack. Finally, we pop the instance and replace the top of the stack with the bound method.
首先,我們在類的方法表中查找具有指定名稱的方法。如果我們沒有找到,我們就報告一個運行時錯誤並退出。否則,我們獲取該方法,並將其包裝為一個新的ObjBoundMethod。我們從棧頂獲得接收器。最後,我們彈出實例,並將這個已綁定方法替換到棧頂。
For example:
舉例來說:
class Brunch {
eggs() {}
}
var brunch = Brunch();
var eggs = brunch.eggs;
Here is what happens when the VM executes the
bindMethod()call for thebrunch.eggsexpression:
下面是虛擬機執行brunch.eggs表達式的bindMethod()調用時發生的情況:
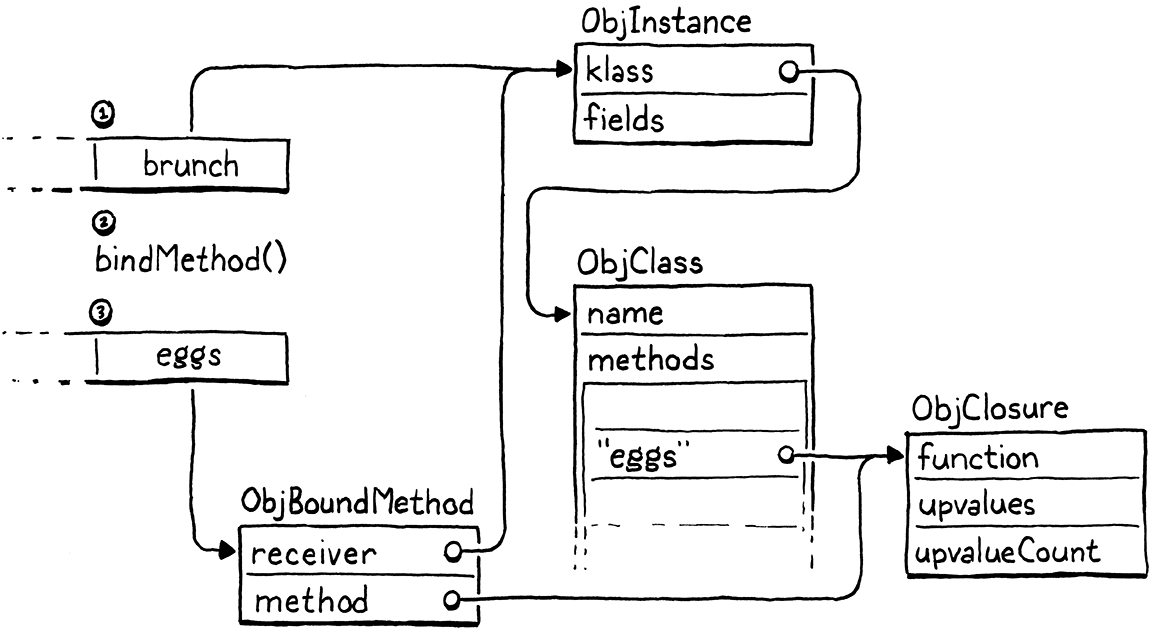
That’s a lot of machinery under the hood, but from the user’s perspective, they simply get a function that they can call.
在底層有很多機制,但從用戶的角度來看,他們只是得到了一個可以調用的函數。
28 . 2 . 3 Calling methods
28.2.3 調用方法
Users can declare methods on classes, access them on instances, and get bound methods onto the stack. They just can’t do anything useful with those bound method objects. The operation we’re missing is calling them. Calls are implemented in
callValue(), so we add a case there for the new object type.
用戶可以在類上聲明方法,在實例上訪問這些方法,並將已綁定的方法放到棧上7。他們目前還不能使用這些已綁定方法做任何有意義的事。我們所缺少的操作就是調用他們。調用在callValue()中實現,所以我們在其中為新的對象類型添加一個case分支。
vm.c,在callValue()方法中添加代碼:
switch (OBJ_TYPE(callee)) {
// 新增部分開始
case OBJ_BOUND_METHOD: {
ObjBoundMethod* bound = AS_BOUND_METHOD(callee);
return call(bound->method, argCount);
}
// 新增部分結束
case OBJ_CLASS: {
We pull the raw closure back out of the ObjBoundMethod and use the existing
call()helper to begin an invocation of that closure by pushing a CallFrame for it onto the call stack. That’s all it takes to be able to run this Lox program:
我們從ObjBoundMethod中抽取原始閉包,並使用現有的call()輔助函數,通過將對應CallFrame壓入調用棧,來開始對該閉包的調用。有了這些,就能夠運行下面這個Lox程序:
class Scone {
topping(first, second) {
print "scone with " + first + " and " + second;
}
}
var scone = Scone();
scone.topping("berries", "cream");
That’s three big steps. We can declare, access, and invoke methods. But something is missing. We went to all that trouble to wrap the method closure in an object that binds the receiver, but when we invoke the method, we don’t use that receiver at all.
這是三大步。我們可以聲明、訪問和調用方法。但我們缺失了一些東西。我們費盡心思將方法閉包包裝在一個綁定了接收器的對象中,但當我們調用方法時,根本沒有使用那個接收器。
28 . 3 This
The reason bound methods need to keep hold of the receiver is so that it can be accessed inside the body of the method. Lox exposes a method’s receiver through
thisexpressions. It’s time for some new syntax. The lexer already treatsthisas a special token type, so the first step is wiring that token up in the parse table.
已綁定方法中需要保留接收器的原因在於,這樣就可以在方法體內部訪問接收器實例。Lox通過this表達式暴露方法的接收器。現在是時候用一些新語法了。詞法解析器已經將this當作一個特殊的標識類型,因此第一步是將該標識鏈接到解析表中。
compiler.c,替換1行:
[TOKEN_SUPER] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_THIS] = {this_, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_TRUE] = {literal, NULL, PREC_NONE},
When the parser encounters a
thisin prefix position, it dispatches to a new parser function.
當解析器在前綴位置遇到一個this時,會派發給新的解析器函數8。
compiler.c,在variable()方法後添加:
static void this_(bool canAssign) {
variable(false);
}
We’ll apply the same implementation technique for
thisin clox that we used in jlox. We treatthisas a lexically scoped local variable whose value gets magically initialized. Compiling it like a local variable means we get a lot of behavior for free. In particular, closures inside a method that referencethiswill do the right thing and capture the receiver in an upvalue.
對於clox中的this,我們將使用與jlox相同的技術。我們將this看作是一個具有詞法作用域的局部變量,它的值被神奇地初始化了。像局部變量一樣編譯它意味著我們可以免費獲得很多行為。特別是,引用this的方法對應的閉包會做正確的事情,並在上值中捕獲接收器。
When the parser function is called, the
thistoken has just been consumed and is stored as the previous token. We call our existingvariable()function which compiles identifier expressions as variable accesses. It takes a single Boolean parameter for whether the compiler should look for a following=operator and parse a setter. You can’t assign tothis, so we passfalseto disallow that.
當解析器函數被調用時,this標識剛剛被使用,並且存儲在上一個標識中。我們調用已有的variable()函數,它將標識符表達式編譯為變量訪問。它需要一個Boolean參數,用於判斷編譯器是否應該查找後續的=運算符並解析setter。你不能給this賦值,所以我們傳入false來禁止它。
The
variable()function doesn’t care thatthishas its own token type and isn’t an identifier. It is happy to treat the lexeme “this” as if it were a variable name and then look it up using the existing scope resolution machinery. Right now, that lookup will fail because we never declared a variable whose name is “this”. It’s time to think about where the receiver should live in memory.
variable()函數並不關心this是否有自己的標識類型,也不關心它是否是一個標識符。它很樂意將詞素this當作一個變量名,然後用現有的作用域解析機制來查找它。現在,這種查找會失敗,因為我們從未聲明過名稱為this的變量。現在是時候考慮一下接收器在內存中的位置了。
At least until they get captured by closures, clox stores every local variable on the VM’s stack. The compiler keeps track of which slots in the function’s stack window are owned by which local variables. If you recall, the compiler sets aside stack slot zero by declaring a local variable whose name is an empty string.
至少在每個局部變量被閉包捕獲之前,clox會將其存儲在VM的棧中。編譯器持續跟蹤函數棧窗口中的哪個槽由哪些局部變量所擁有。如果你還記得,編譯器通過聲明一個名稱為空字符串的局部變量來預留出棧槽0。
For function calls, that slot ends up holding the function being called. Since the slot has no name, the function body never accesses it. You can guess where this is going. For method calls, we can repurpose that slot to store the receiver. Slot zero will store the instance that
thisis bound to. In order to compilethisexpressions, the compiler simply needs to give the correct name to that local variable.
對於函數調用來說,這個槽會存儲被調用的函數。因為這個槽沒有名字,所以函數主體永遠不會訪問它。你可以猜到接下來會發生什麼。對於方法調用,我們可以重新利用這個槽來存儲接收器。槽0會存儲this綁定的實例。為了編譯this表達式,編譯器只需要給這個局部變量一個正確的名稱。
compiler.c,在initCompiler()方法中替換2行:
local->isCaptured = false;
// 替換部分開始
if (type != TYPE_FUNCTION) {
local->name.start = "this";
local->name.length = 4;
} else {
local->name.start = "";
local->name.length = 0;
}
// 替換部分結束
}
We want to do this only for methods. Function declarations don’t have a
this. And, in fact, they must not declare a variable named “this”, so that if you write athisexpression inside a function declaration which is itself inside a method, thethiscorrectly resolves to the outer method’s receiver.
我們只想對方法這樣做。函數聲明中沒有this。事實上,它們不能聲明一個名為this的變量,因此,如果你在函數聲明中寫了一個this表達式,而該函數本身又在某個方法中,這個this會被正確地解析為外部方法的接收器。
class Nested {
method() {
fun function() {
print this;
}
function();
}
}
Nested().method();
This program should print “Nested instance”. To decide what name to give to local slot zero, the compiler needs to know whether it’s compiling a function or method declaration, so we add a new case to our FunctionType enum to distinguish methods.
這個程序應該打印“Nested instance”。為了決定給局部槽0取什麼名字,編譯器需要知道它正在編譯一個函數還是方法聲明,所以我們向FunctionType枚舉中增加一個新的類型來區分方法。
compiler.c,在枚舉FunctionType中添加代碼:
TYPE_FUNCTION,
// 新增部分開始
TYPE_METHOD,
// 新增部分結束
TYPE_SCRIPT
When we compile a method, we use that type.
當我們編譯方法時,就使用這個類型。
compiler.c,在method()方法中替換1行:
uint8_t constant = identifierConstant(&parser.previous);
// 替換部分開始
FunctionType type = TYPE_METHOD;
// 替換部分結束
function(type);
Now we can correctly compile references to the special “this” variable, and the compiler will emit the right
OP_GET_LOCALinstructions to access it. Closures can even capturethisand store the receiver in upvalues. Pretty cool.
現在我們可以正確地編譯對特殊的this變量的引用,編譯器會發出正確的OP_GET_LOCAL來訪問它。閉包甚至可以捕獲this,並將接收器存儲在上值中。非常酷。
Except that at runtime, the receiver isn’t actually in slot zero. The interpreter isn’t holding up its end of the bargain yet. Here is the fix:
除了在運行時,接收器實際上並不在槽0中。解釋器還沒有履行它的承諾。下面是修復方法:
vm.c,在callValue()方法中添加代碼:
case OBJ_BOUND_METHOD: {
ObjBoundMethod* bound = AS_BOUND_METHOD(callee);
// 新增部分開始
vm.stackTop[-argCount - 1] = bound->receiver;
// 新增部分結束
return call(bound->method, argCount);
}
When a method is called, the top of the stack contains all of the arguments, and then just under those is the closure of the called method. That’s where slot zero in the new CallFrame will be. This line of code inserts the receiver into that slot. For example, given a method call like this:
當某個方法被調用時,棧頂包含所有的參數,然後在這些參數下面是被調用方法的閉包。這就是新的CallFrame中槽0所在的位置。這一行代碼會向該槽中插入接收器。例如,給出一個這樣的方法調用:
scone.topping("berries", "cream");
We calculate the slot to store the receiver like so:
我們像這樣計算存儲接收器的槽:
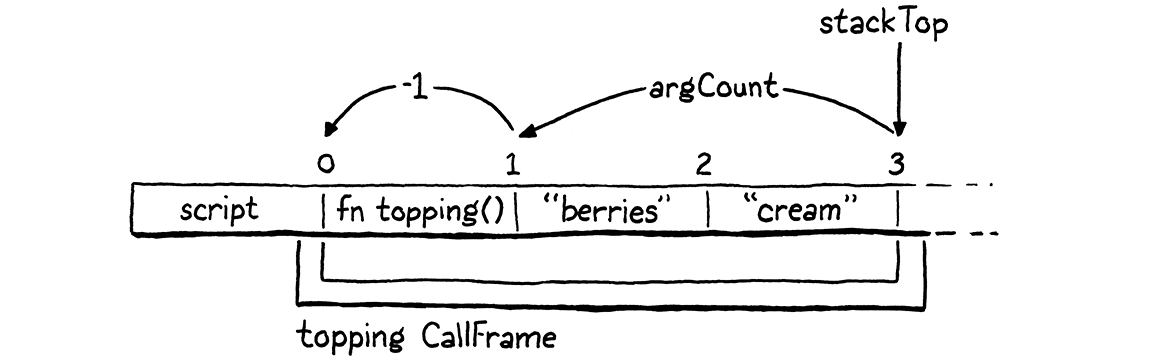
The
-argCountskips past the arguments and the- 1adjusts for the fact thatstackToppoints just past the last used stack slot.
-argCount跳過傳遞的參數,而-1則是因為stackTop指向剛剛最後一個實用的棧槽而做的調整。
28 . 3 . 1 Misusing this
28.3.1 誤用this
Our VM now supports users correctly using
this, but we also need to make sure it properly handles users misusingthis. Lox says it is a compile error for athisexpression to appear outside of the body of a method. These two wrong uses should be caught by the compiler:
我們的虛擬機現在支持用戶正確地使用this,但我們還需要確保它能正確地處理用戶誤用this的情況。Lox表示,如果this表達式出現在方法主體之外,就是一個編譯錯誤。這兩個錯誤的用法是編譯器應該捕獲的:
print this; // At top level.
fun notMethod() {
print this; // In a function.
}
So how does the compiler know if it’s inside a method? The obvious answer is to look at the FunctionType of the current Compiler. We did just add an enum case there to treat methods specially. However, that wouldn’t correctly handle code like the earlier example where you are inside a function which is, itself, nested inside a method.
那麼編譯器如何知道它是否在一個方法中呢?顯而易見的答案是,查看當前Compiler的FunctionType。我們在其中添加了一個新的枚舉值來特殊對待方法。但是,這並不能正確地處理前面那個示例中的代碼,即你在一個函數裡面,而這個函數本身又嵌套在一個方法中。
We could try to resolve “this” and then report an error if it wasn’t found in any of the surrounding lexical scopes. That would work, but would require us to shuffle around a bunch of code, since right now the code for resolving a variable implicitly considers it a global access if no declaration is found.
我們可以嘗試解析this,如果在外圍的詞法作用域中沒有找到它,就報告一個錯誤。這樣做是可行的,但需要我們修改一堆代碼,因為如果沒有找到聲明,解析變量的代碼現在會隱式地將其視為全局變量訪問。
In the next chapter, we will need information about the nearest enclosing class. If we had that, we could use it here to determine if we are inside a method. So we may as well make our future selves’ lives a little easier and put that machinery in place now.
在下一章中,我們將需要關於最近鄰外層類的信息。如果我們有這些信息,就可以在這裡使用它來確定我們是否在某個方法中。因此,我們不妨讓未來的自己生活得輕鬆一些,現在就把這種機制搞定。
compiler.c,在變量current後添加代碼:
Compiler* current = NULL;
// 新增部分開始
ClassCompiler* currentClass = NULL;
// 新增部分結束
static Chunk* currentChunk() {
This module variable points to a struct representing the current, innermost class being compiled. The new type looks like this:
這個模塊變量指向一個表示當前正在編譯的最內部類的結構體,新的類型看起來像這樣:
compiler.c,在結構體Compiler後添加代碼:
} Compiler;
// 新增部分開始
typedef struct ClassCompiler {
struct ClassCompiler* enclosing;
} ClassCompiler;
// 新增部分結束
Parser parser;
Right now we store only a pointer to the ClassCompiler for the enclosing class, if any. Nesting a class declaration inside a method in some other class is an uncommon thing to do, but Lox supports it. Just like the Compiler struct, this means ClassCompiler forms a linked list from the current innermost class being compiled out through all of the enclosing classes.
現在,我們只存儲一個指向外層類(如果存在的話)的ClassCompiler的指針。將類聲明嵌套在其它類的某個方法中並不常見,但Lox支持這種做法。就像Compiler結構體一樣,這意味著ClassCompiler形成了一個鏈表,從當前正在被編譯的最內層類一直到所有的外層類。
If we aren’t inside any class declaration at all, the module variable
currentClassisNULL. When the compiler begins compiling a class, it pushes a new ClassCompiler onto that implicit linked stack.
如果我們根本不在任何類的聲明中,則模塊變量currentClass是NULL。當編譯器開始編譯某個類時,它會將一個新的ClassCompiler推入這個隱式的鏈棧中。
compiler.c,在classDeclaration()方法中添加代碼:
defineVariable(nameConstant);
// 新增部分開始
ClassCompiler classCompiler;
classCompiler.enclosing = currentClass;
currentClass = &classCompiler;
// 新增部分結束
namedVariable(className, false);
The memory for the ClassCompiler struct lives right on the C stack, a handy capability we get by writing our compiler using recursive descent. At the end of the class body, we pop that compiler off the stack and restore the enclosing one.
ClassCompiler結構體的內存正好位於C棧中,這是通過使用遞歸下降來編寫編譯器而獲得的便利。在類主體的最後,我們將該編譯器從棧中彈出,並恢復外層的編譯器。
compiler.c,在classDeclaration()方法中添加代碼:
emitByte(OP_POP);
// 新增部分開始
currentClass = currentClass->enclosing;
// 新增部分結束
}
When an outermost class body ends,
enclosingwill beNULL, so this resetscurrentClasstoNULL. Thus, to see if we are inside a class—and therefore inside a method—we simply check that module variable.
當最外層的類主體結束時,enclosing將是NULL,因此這裡會將currentClass重置為NULL。因此,要想知道我們是否在一個類內部——也就是是否在一個方法中——我們只需要檢查模塊變量。
compiler.c,在this_()方法中添加代碼:
static void this_(bool canAssign) {
// 新增部分開始
if (currentClass == NULL) {
error("Can't use 'this' outside of a class.");
return;
}
// 新增部分結束
variable(false);
With that,
thisoutside of a class is correctly forbidden. Now our methods really feel like methods in the object-oriented sense. Accessing the receiver lets them affect the instance you called the method on. We’re getting there!
有個這個,類之外的this就被正確地禁止了。現在我們的方法就像是面向對象意義上的方法。對接收器的訪問使得它們可以影響調用方法的實例。我們正在走向成功!
28 . 4 Instance Initializers
28.4 實例初始化器
The reason object-oriented languages tie state and behavior together—one of the core tenets of the paradigm—is to ensure that objects are always in a valid, meaningful state. When the only way to touch an object’s state is through its methods, the methods can make sure nothing goes awry. But that presumes the object is already in a proper state. What about when it’s first created?
面嚮對象語言之所以將狀態和行為結合在一起(範式的核心原則之一),是為了確保對象總是處於有效的、有意義的狀態。當接觸對象狀態的唯一形式是通過它的方法時,這些方法可以確保不會出錯9。但前提是對象已經處於正常狀態。那麼,當對象第一次被創建時呢?
Object-oriented languages ensure that brand new objects are properly set up through constructors, which both produce a new instance and initialize its state. In Lox, the runtime allocates new raw instances, and a class may declare an initializer to set up any fields. Initializers work mostly like normal methods, with a few tweaks:
面向對象的語言通過構造函數確保新對象是被正確設置的,構造函數會生成一個新實例並初始化其狀態。在Lox中,運行時會分配新的原始實例,而類可以聲明一個初始化器來設置任何字段。初始化器的工作原理和普通方法差不多,只是做了一些調整:
- The runtime automatically invokes the initializer method whenever an instance of a class is created.
- The caller that constructs an instance always gets the instance back after the initializer finishes, regardless of what the initializer function itself returns. The initializer method doesn’t need to explicitly return
this.- In fact, an initializer is prohibited from returning any value at all since the value would never be seen anyway.
- 每當一個類的實例被創建時,運行時會自動調用初始化器方法。
- 構建實例的調用方總是在初始化器完成後得到實例,而不管初始化器本身返回什麼。初始化器方法不需要顯式地返回
this10。 - 事實上,初始化器根本不允許返回任何值,因為這些值無論如何都不會被看到。
Now that we support methods, to add initializers, we merely need to implement those three special rules. We’ll go in order.
既然我們支持方法,為了添加初始化式,我們只需要實現這三條特殊規則。我們按順序進行。
28 . 4 . 1 Invoking initializers
28.4.1 調用初始化器
First, automatically calling
init()on new instances:
首先,在新實例上自動調用init():
vm.c,在callValue()方法中添加代碼:
vm.stackTop[-argCount - 1] = OBJ_VAL(newInstance(klass));
// 新增部分開始
Value initializer;
if (tableGet(&klass->methods, vm.initString,
&initializer)) {
return call(AS_CLOSURE(initializer), argCount);
}
// 新增部分結束
return true;
After the runtime allocates the new instance, we look for an
init()method on the class. If we find one, we initiate a call to it. This pushes a new CallFrame for the initializer’s closure. Say we run this program:
在運行時分配了新實例後,我們在類中尋找init()方法。如果找到了,就對其發起調用。這就為初始化器的閉包壓入了一個新的CallFrame。假設我們運行這個程序:
class Brunch {
init(food, drink) {}
}
Brunch("eggs", "coffee");
When the VM executes the call to
Brunch(), it goes like this:
當VM執行對Brunch()的調用時,情況是這樣的:
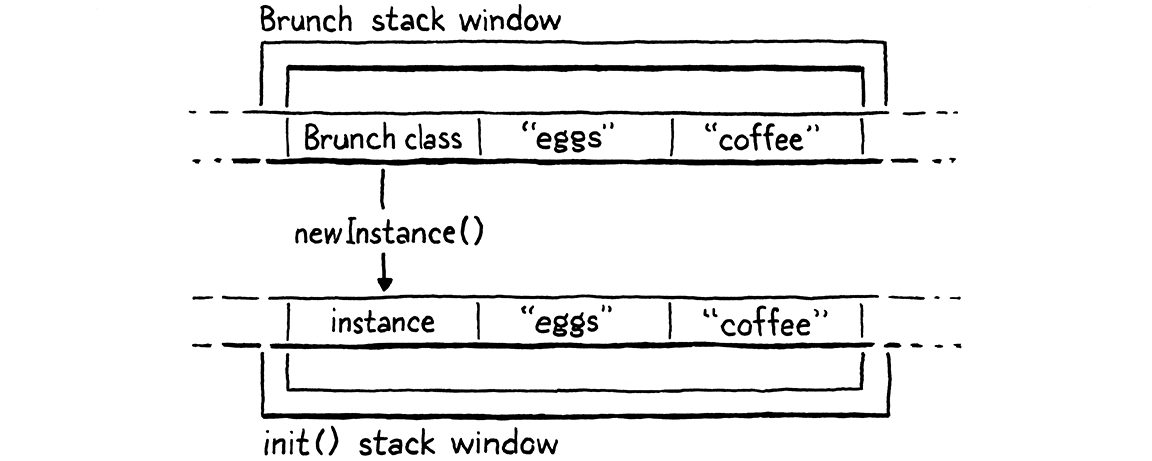
Any arguments passed to the class when we called it are still sitting on the stack above the instance. The new CallFrame for the
init()method shares that stack window, so those arguments implicitly get forwarded to the initializer.
我們在調用該類時傳入的所有參數都仍然在實例上方的棧中。init()方法的新CallFrame共享了這個棧窗口,因此這些參數會隱式地轉發給初始化器。
Lox doesn’t require a class to define an initializer. If omitted, the runtime simply returns the new uninitialized instance. However, if there is no
init()method, then it doesn’t make any sense to pass arguments to the class when creating the instance. We make that an error.
Lox並不要求類定義初始化器。如果省略,運行時只是簡單地返回新的未初始化的實例。然而,如果沒有init()方法,那麼在創建實例時向類傳遞參數就沒有意義了。我們將其當作一個錯誤。
vm.c,在callValue()方法中添加代碼:
return call(AS_CLOSURE(initializer), argCount);
// 新增部分開始
} else if (argCount != 0) {
runtimeError("Expected 0 arguments but got %d.",
argCount);
return false;
// 新增部分結束
}
When the class does provide an initializer, we also need to ensure that the number of arguments passed matches the initializer’s arity. Fortunately, the
call()helper does that for us already.
當類確實提供了初始化器時,我們還需要確保傳入參數的數量與初始化器的元數匹配。幸運的是,call()輔助函數已經為我們做到了這一點。
To call the initializer, the runtime looks up the
init()method by name. We want that to be fast since it happens every time an instance is constructed. That means it would be good to take advantage of the string interning we’ve already implemented. To do that, the VM creates an ObjString for “init” and reuses it. The string lives right in the VM struct.
為了調用初始化器,運行時會按名稱查找init()方法。我們希望這個過程是快速的,因為這在每次構造實例時都會發生。這意味著我們可以很好地利用已經實現的字符串駐留。為此,VM為“init”創建了一個ObjString並重用它。這個字符串就位於VM結構體中。
vm.h,在結構體VM中添加代碼:
Table strings;
// 新增部分開始
ObjString* initString;
// 新增部分結束
ObjUpvalue* openUpvalues;
We create and intern the string when the VM boots up.
當虛擬機啟動時,我們創建並駐留該字符串。
vm.c,在initVM()方法中添加代碼:
initTable(&vm.strings);
// 新增部分開始
vm.initString = copyString("init", 4);
// 新增部分結束
defineNative("clock", clockNative);
We want it to stick around, so the GC considers it a root.
我們希望它一直存在,因此GC將其視為根。
memory.c,在markRoots()方法中添加代碼:
markCompilerRoots();
// 新增部分開始
markObject((Obj*)vm.initString);
// 新增部分結束
}
Look carefully. See any bug waiting to happen? No? It’s a subtle one. The garbage collector now reads
vm.initString. That field is initialized from the result of callingcopyString(). But copying a string allocates memory, which can trigger a GC. If the collector ran at just the wrong time, it would readvm.initStringbefore it had been initialized. So, first we zero the field out.
仔細觀察。看到什麼潛藏的bug了嗎?沒有嗎?這是一個微妙的問題。垃圾回收器現在讀取vm.initString。這個字段是由調用copyString()的結果來初始化的。但複製字符串會分配內存,這可能會觸發GC。如果回收器在錯誤的時間運行時,它就會在vm.initString初始化之前讀取它。所以,我們首先將這個字段清零。
vm.c,在initVM()方法中添加代碼:
initTable(&vm.strings);
// 新增部分開始
vm.initString = NULL;
// 新增部分結束
vm.initString = copyString("init", 4);
We clear the pointer when the VM shuts down since the next line will free it.
我們在VM關閉時清除指針,因為下一行會釋放它。
vm.c,在freeVM()方法中添加代碼:
freeTable(&vm.strings);
// 新增部分開始
vm.initString = NULL;
// 新增部分結束
freeObjects();
OK, that lets us call initializers.
好,這樣我們就可以調用初始化器了。
28 . 4 . 2 Initializer return values
28.4.2 返回值的初始化器
The next step is ensuring that constructing an instance of a class with an initializer always returns the new instance, and not
nilor whatever the body of the initializer returns. Right now, if a class defines an initializer, then when an instance is constructed, the VM pushes a call to that initializer onto the CallFrame stack. Then it just keeps on trucking.
下一步是確保用初始化器構造類實例時,總是返回新的實例,而不是nil或初始化式返回的任何內容。現在,如果某個類定義了一個初始化器,那麼當構建一個實例時,虛擬機會把對該初始化器的調用壓入CallFrame棧。然後,它就可以自動被執行了。
The user’s invocation on the class to create the instance will complete whenever that initializer method returns, and will leave on the stack whatever value the initializer puts there. That means that unless the user takes care to put
return this;at the end of the initializer, no instance will come out. Not very helpful.
只要初始化器方法返回,用戶對類的創建實例的調用就會結束,並把初始化器方法放入棧中的值遺留在那裡。這意味著,除非用戶特意在初始化器的末尾寫上return this;,否則不會出現任何實例。不太有用。
To fix this, whenever the front end compiles an initializer method, it will emit different bytecode at the end of the body to return
thisfrom the method instead of the usual implicitnilmost functions return. In order to do that, the compiler needs to actually know when it is compiling an initializer. We detect that by checking to see if the name of the method we’re compiling is “init”.
為瞭解決這個問題,每當前端編譯初始化器方法時,都會在主體末尾生成一個特殊的字節碼,以便從方法中返回this,而不是大多數函數通常會隱式返回的nil。為了做到這一點,編譯器需要真正知道它在何時編譯一個初始化器。我們通過檢查正在編譯的方法名稱是否為“init”進行確認。
compiler.c,在method()方法中添加代碼:
FunctionType type = TYPE_METHOD;
// 新增部分開始
if (parser.previous.length == 4 &&
memcmp(parser.previous.start, "init", 4) == 0) {
type = TYPE_INITIALIZER;
}
// 新增部分結束
function(type);
We define a new function type to distinguish initializers from other methods.
我們定義一個新的函數類型來區分初始化器和其它方法。
compiler.c,在枚舉FunctionType中添加代碼:
TYPE_FUNCTION,
// 新增部分開始
TYPE_INITIALIZER,
// 新增部分結束
TYPE_METHOD,
Whenever the compiler emits the implicit return at the end of a body, we check the type to decide whether to insert the initializer-specific behavior.
每當編譯器準備在主體末尾發出隱式返回指令時,我們會檢查其類型以決定是否插入初始化器的特定行為。
compiler.c,在emitReturn()方法中替換1行:
static void emitReturn() {
// 新增部分開始
if (current->type == TYPE_INITIALIZER) {
emitBytes(OP_GET_LOCAL, 0);
} else {
emitByte(OP_NIL);
}
// 新增部分結束
emitByte(OP_RETURN);
In an initializer, instead of pushing
nilonto the stack before returning, we load slot zero, which contains the instance. ThisemitReturn()function is also called when compiling areturnstatement without a value, so this also correctly handles cases where the user does an early return inside the initializer.
在初始化器中,我們不再在返回前將nil壓入棧中,而是加載包含實例的槽0。在編譯不帶值的return語句時,這個emitReturn()函數也會被調用,因此它也能正確處理用戶在初始化器中提前返回的情況。
28 . 4 . 3 Incorrect returns in initializers
28.4.3 初始化器中的錯誤返回
The last step, the last item in our list of special features of initializers, is making it an error to try to return anything else from an initializer. Now that the compiler tracks the method type, this is straightforward.
最後一步,也就是我們的初始化器特性列表中的最後一條,是讓試圖從初始化器中返回任何其它值的行為成為錯誤。既然編譯器跟蹤了方法類型,這就很簡單了。
compiler.c,在returnStatement()方法中添加代碼:
if (match(TOKEN_SEMICOLON)) {
emitReturn();
} else {
// 新增部分開始
if (current->type == TYPE_INITIALIZER) {
error("Can't return a value from an initializer.");
}
// 新增部分結束
expression();
We report an error if a
returnstatement in an initializer has a value. We still go ahead and compile the value afterwards so that the compiler doesn’t get confused by the trailing expression and report a bunch of cascaded errors.
如果初始化式中的return語句中有值,則報告一個錯誤。我們仍然會在後面編譯這個值,這樣編譯器就不會因為被後面的表達式迷惑而報告一堆級聯錯誤。
Aside from inheritance, which we’ll get to soon, we now have a fairly full-featured class system working in clox.
除了繼承(我們很快會講到),我們在clox中有了一個功能相當齊全的類系統。
class CoffeeMaker {
init(coffee) {
this.coffee = coffee;
}
brew() {
print "Enjoy your cup of " + this.coffee;
// No reusing the grounds!
this.coffee = nil;
}
}
var maker = CoffeeMaker("coffee and chicory");
maker.brew();
Pretty fancy for a C program that would fit on an old floppy disk.
對於一個可以放在舊軟盤上的C程序來說,這真是太神奇了11。
28 . 5 Optimized Invocations
28.5 優化調用
Our VM correctly implements the language’s semantics for method calls and initializers. We could stop here. But the main reason we are building an entire second implementation of Lox from scratch is to execute faster than our old Java interpreter. Right now, method calls even in clox are slow.
我們的虛擬機正確地實現了語言中方法調用和初始化器的語義。我們可以到此為止。但是,我們從頭開始構建Lox的第二個完整實現的主要原因是,它的執行速度比我們的舊Java解釋器要更快。現在,即使在clox中,方法調用也很慢。
Lox’s semantics define a method invocation as two operations—accessing the method and then calling the result. Our VM must support those as separate operations because the user can separate them. You can access a method without calling it and then invoke the bound method later. Nothing we’ve implemented so far is unnecessary.
Lox的語義將方法調用定義為兩個操作——訪問方法,然後調用結果。我們的虛擬機必須支持這些單獨的操作,因為用戶可以將它們區分對待。你可以在不調用方法的情況下訪問它,接著稍後再調用已綁定的方法。我們目前還未實現的一切內容,都是不必要的。
But always executing those as separate operations has a significant cost. Every single time a Lox program accesses and invokes a method, the runtime heap allocates a new ObjBoundMethod, initializes its fields, then pulls them right back out. Later, the GC has to spend time freeing all of those ephemeral bound methods.
但是,總是將它們作為兩個單獨的操作來執行會產生很大的成本。每次Lox程序訪問並調用一個方法時,運行時堆都會分配一個新的ObjBoundMethod,初始化其字段,然後再把這些字段拉出來。之後,GC必須花時間釋放所有這些臨時綁定的方法。
Most of the time, a Lox program accesses a method and then immediately calls it. The bound method is created by one bytecode instruction and then consumed by the very next one. In fact, it’s so immediate that the compiler can even textually see that it’s happening—a dotted property access followed by an opening parenthesis is most likely a method call.
大多數情況下,Lox程序會訪問一個方法並立即調用它。已綁定方法是由一條字節碼指令創建的,然後由下一條指令使用。事實上,它是如此直接,以至於編譯器甚至可以從文本上看到它的發生——一個帶點的屬性訪問後面跟著一個左括號,很可能是一個方法調用。
Since we can recognize this pair of operations at compile time, we have the opportunity to emit a new, special instruction that performs an optimized method call.
因為我們可以在編譯時識別這對操作,所以我們有機會發出一條新的特殊指令,執行優化過的方法調用12。
We start in the function that compiles dotted property expressions.
我們從編譯點屬性表達式的函數中開始。
compiler.c,在dot()方法中添加代碼:
if (canAssign && match(TOKEN_EQUAL)) {
expression();
emitBytes(OP_SET_PROPERTY, name);
// 新增部分開始
} else if (match(TOKEN_LEFT_PAREN)) {
uint8_t argCount = argumentList();
emitBytes(OP_INVOKE, name);
emitByte(argCount);
// 新增部分結束
} else {
After the compiler has parsed the property name, we look for a left parenthesis. If we match one, we switch to a new code path. There, we compile the argument list exactly like we do when compiling a call expression. Then we emit a single new
OP_INVOKEinstruction. It takes two operands:
在編譯器解析屬性名稱之後,我們尋找一個左括號。如果匹配到了,則切換到一個新的代碼路徑。在那裡,我們會像編譯調用表達式一樣來編譯參數列表。然後我們發出一條新的OP_INVOKE指令。它需要兩個操作數:
- The index of the property name in the constant table.
- The number of arguments passed to the method.
- 屬性名稱在常量表中的索引。
- 傳遞給方法的參數數量。
In other words, this single instruction combines the operands of the
OP_GET_PROPERTYandOP_CALLinstructions it replaces, in that order. It really is a fusion of those two instructions. Let’s define it.
換句話說,這條指令結合了它所替換的OP_GET_PROPERTY 和 OP_CALL指令的操作數,按順序排列。它實際上是這兩條指令的融合。讓我們來定義它。
chunk.h,在枚舉OpCode中添加代碼:
OP_CALL,
// 新增部分開始
OP_INVOKE,
// 新增部分結束
OP_CLOSURE,
And add it to the disassembler:
將其添加到反彙編程序:
debug.c,在disassembleInstruction()方法中添加代碼:
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
// 新增部分開始
case OP_INVOKE:
return invokeInstruction("OP_INVOKE", chunk, offset);
// 新增部分結束
case OP_CLOSURE: {
This is a new, special instruction format, so it needs a little custom disassembly logic.
這是一種新的、特殊的指令格式,所以需要一些自定義的反彙編邏輯。
debug.c,在constantInstruction()方法後添加代碼:
static int invokeInstruction(const char* name, Chunk* chunk,
int offset) {
uint8_t constant = chunk->code[offset + 1];
uint8_t argCount = chunk->code[offset + 2];
printf("%-16s (%d args) %4d '", name, argCount, constant);
printValue(chunk->constants.values[constant]);
printf("'\n");
return offset + 3;
}
We read the two operands and then print out both the method name and the argument count. Over in the interpreter’s bytecode dispatch loop is where the real action begins.
我們讀取兩個操作數,然後打印出方法名和參數數量。解釋器的字節碼調度循環中才是真正的行動開始的地方。
vm.c,在run()方法中添加代碼:
}
// 新增部分開始
case OP_INVOKE: {
ObjString* method = READ_STRING();
int argCount = READ_BYTE();
if (!invoke(method, argCount)) {
return INTERPRET_RUNTIME_ERROR;
}
frame = &vm.frames[vm.frameCount - 1];
break;
}
// 新增部分結束
case OP_CLOSURE: {
Most of the work happens in
invoke(), which we’ll get to. Here, we look up the method name from the first operand and then read the argument count operand. Then we hand off toinvoke()to do the heavy lifting. That function returnstrueif the invocation succeeds. As usual, afalsereturn means a runtime error occurred. We check for that here and abort the interpreter if disaster has struck.
大部分工作都發生在invoke()中,我們會講到這一點。在這裡,我們從第一個操作數中查找方法名稱,接著讀取參數數量操作數。然後我們交給invoke()來完成繁重的工作。如果調用成功,該函數會返回true。像往常一樣,返回false意味著發生了運行時錯誤。我們在這裡進行檢查,如果災難發生就中止解釋器的運行。
Finally, assuming the invocation succeeded, then there is a new CallFrame on the stack, so we refresh our cached copy of the current frame in
frame.
最後,假如調用成功,那麼棧中會有一個新的CallFrame,所以我們刷新frame中緩存的當前幀副本。
The interesting work happens here:
有趣的部分在這裡:
vm.c,在callValue()方法後添加代碼:
static bool invoke(ObjString* name, int argCount) {
Value receiver = peek(argCount);
ObjInstance* instance = AS_INSTANCE(receiver);
return invokeFromClass(instance->klass, name, argCount);
}
First we grab the receiver off the stack. The arguments passed to the method are above it on the stack, so we peek that many slots down. Then it’s a simple matter to cast the object to an instance and invoke the method on it.
首先我們從棧中抓取接收器。傳遞給方法的參數在棧中位於接收器上方,因此我們要查看從上往下跳過多個位置的棧槽。然後,將對象轉換成實例並對其調用方法就很簡單了。
That does assume the object is an instance. As with
OP_GET_PROPERTYinstructions, we also need to handle the case where a user incorrectly tries to call a method on a value of the wrong type.
它確實假定了對象是一個實例。與OP_GET_PROPERTY指令一樣,我們也需要處理這種情況:用戶錯誤地試圖在一個錯誤類型的值上調用一個方法。
vm.c,在invoke()方法中添加代碼:
Value receiver = peek(argCount);
// 新增部分開始
if (!IS_INSTANCE(receiver)) {
runtimeError("Only instances have methods.");
return false;
}
// 新增部分結束
ObjInstance* instance = AS_INSTANCE(receiver);
That’s a runtime error, so we report that and bail out. Otherwise, we get the instance’s class and jump over to this other new utility function:
這是一個運行時錯誤,所以我們報告錯誤並退出。否則,我們獲取實例的類並跳轉到另一個新的工具函數13:
vm.c,在callValue()方法後添加代碼:
static bool invokeFromClass(ObjClass* klass, ObjString* name,
int argCount) {
Value method;
if (!tableGet(&klass->methods, name, &method)) {
runtimeError("Undefined property '%s'.", name->chars);
return false;
}
return call(AS_CLOSURE(method), argCount);
}
This function combines the logic of how the VM implements
OP_GET_PROPERTYandOP_CALLinstructions, in that order. First we look up the method by name in the class’s method table. If we don’t find one, we report that runtime error and exit.
這個函數按順序結合了VM中實現OP_GET_PROPERTY 和OP_CALL指令的邏輯。首先,我們在類的方法表中按名稱查找方法。如果沒有找到,則報告錯誤並退出。
Otherwise, we take the method’s closure and push a call to it onto the CallFrame stack. We don’t need to heap allocate and initialize an ObjBoundMethod. In fact, we don’t even need to juggle anything on the stack. The receiver and method arguments are already right where they need to be.
否則,我們獲取方法閉包並將對它的調用壓入CallFrame棧。我們不需要在堆上分配並初始化ObjBoundMethod。實際上,我們甚至不需要在棧上做什麼操作。接收器和方法參數已經位於它們應在的位置了14。
If you fire up the VM and run a little program that calls methods now, you should see the exact same behavior as before. But, if we did our job right, the performance should be much improved. I wrote a little microbenchmark that does a batch of 10,000 method calls. Then it tests how many of these batches it can execute in 10 seconds. On my computer, without the new
OP_INVOKEinstruction, it got through 1,089 batches. With this new optimization, it finished 8,324 batches in the same time. That’s 7.6 times faster, which is a huge improvement when it comes to programming language optimization.
如果你現在啟動虛擬機並運行一個調用方法的小程序,你應該會看到和以前完全相同的行為。但是,如果我們的工作做得好,性能應該會大大提高。我寫了一個小小的微基準測試,執行每批10000次方法調用。然後測試在10秒鐘內可以執行多少個批次。在我的電腦上,如果沒有新的OP_INVOKE指令,它完成了1089個批次。通過新的優化,它在相同的時間中完成了8324個批次。速度提升了7.6倍,對於編程語言優化來說,這是一個巨大的改進15。
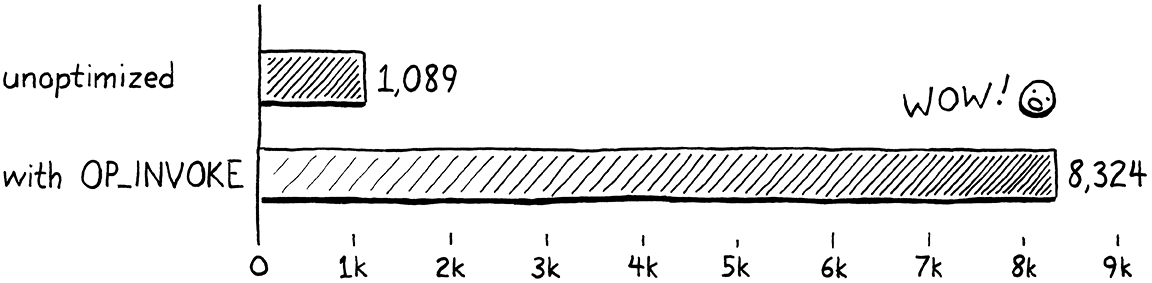
28 . 5 . 1 Invoking fields
28.5.1 調用字段
The fundamental creed of optimization is: “Thou shalt not break correctness.” Users like it when a language implementation gives them an answer faster, but only if it’s the right answer. Alas, our implementation of faster method invocations fails to uphold that principle:
優化的基本信條是:“你不應該破壞正確性”。用戶喜歡語言實現能更快地給出答案,但前提是這個答案是正確的16。唉,我們這個快速的方法調用實現並沒有堅持這一原則:
class Oops {
init() {
fun f() {
print "not a method";
}
this.field = f;
}
}
var oops = Oops();
oops.field();
The last line looks like a method call. The compiler thinks that it is and dutifully emits an
OP_INVOKEinstruction for it. However, it’s not. What is actually happening is a field access that returns a function which then gets called. Right now, instead of executing that correctly, our VM reports a runtime error when it can’t find a method named “field”.
最後一行看起來像是一個方法調用。編譯器認為它是,並盡職盡責地為它發出一條OP_INVOKE指令。然而,事實並非如此。實際發生的是一個字段訪問,它會返回一個函數,然後該函數被調用。現在,我們的虛擬機沒有正確地執行它,而在找不到名為“field”的方法時報告一個運行時錯誤。
Earlier, when we implemented
OP_GET_PROPERTY, we handled both field and method accesses. To squash this new bug, we need to do the same thing forOP_INVOKE.
之前,當我實現OP_GET_PROPERTY時,我們同時處理了字段和方法的訪問。為了消除這個新bug,我們需要對OP_INVOKE做同樣的事情。
vm.c,在invoke()方法中添加代碼:
ObjInstance* instance = AS_INSTANCE(receiver);
// 新增部分開始
Value value;
if (tableGet(&instance->fields, name, &value)) {
vm.stackTop[-argCount - 1] = value;
return callValue(value, argCount);
}
// 新增部分結束
return invokeFromClass(instance->klass, name, argCount);
Pretty simple fix. Before looking up a method on the instance’s class, we look for a field with the same name. If we find a field, then we store it on the stack in place of the receiver, under the argument list. This is how
OP_GET_PROPERTYbehaves since the latter instruction executes before a subsequent parenthesized list of arguments has been evaluated.
非常簡單的解決方法。在查找實例類上的方法之前,我們先查找具有相同名稱的字段。如果我們找到一個字段,那我們就將其存儲在棧中代替接收器,放在參數列表下面。這就是OP_GET_PROPERTY的行為方式,因為後者的指令執行時機是在隨後括號內的參數列表被求值之前。
Then we try to call that field’s value like the callable that it hopefully is. The
callValue()helper will check the value’s type and call it as appropriate or report a runtime error if the field’s value isn’t a callable type like a closure.
然後,我們嘗試調用該字段的值(就像它如期望的那樣是可調用的)。callValue()輔助函數會檢查值的類型並適當地調用它,如果該字段的值不是像閉包這樣的可調用類型,則報告運行時錯誤。
That’s all it takes to make our optimization fully safe. We do sacrifice a little performance, unfortunately. But that’s the price you have to pay sometimes. You occasionally get frustrated by optimizations you could do if only the language wouldn’t allow some annoying corner case. But, as language implementers, we have to play the game we’re given.
這就是使我們的優化完全安全的全部工作。不幸的是,我們確實犧牲了一點性能。但有時候這是你必須要付出的代價。如果語言不允許出現一些令人討厭的極端情況,你可能會對某些可做的優化感到沮喪。但是,作為語言實現者,我們必須玩我們被賦予的遊戲17。
The code we wrote here follows a typical pattern in optimization:
我們在這裡編寫的代碼遵循一個優化中的典型模式:
- Recognize a common operation or sequence of operations that is performance critical. In this case, it is a method access followed by a call.
- Add an optimized implementation of that pattern. That’s our
OP_INVOKEinstruction.- Guard the optimized code with some conditional logic that validates that the pattern actually applies. If it does, stay on the fast path. Otherwise, fall back to a slower but more robust unoptimized behavior. Here, that means checking that we are actually calling a method and not accessing a field.
- 識別出對性能至關重要的常見操作或操作序列。在本例中,它是一個方法訪問後跟一個調用。
- 添加該模式的優化實現。也就是我們的
OP_INVOKE指令。 - 用一些條件邏輯來驗收是否適用該模式,從而保護優化後的代碼。如果適用,就走捷徑。否則,就退回到較慢但更穩健的非優化行為。在這裡,意味著要檢查我們是否真的在調用一個方法而不是訪問一個字段。
As your language work moves from getting the implementation working at all to getting it to work faster, you will find yourself spending more and more time looking for patterns like this and adding guarded optimizations for them. Full-time VM engineers spend much of their careers in this loop.
隨著你的語言工作從讓語言實現完全工作到讓它更快工作,你會發現自己花費了越來越多的時間來尋找這樣的模式,併為它們添加保護性優化。全職虛擬機工程師的大部分職業生涯都是在這個循環中度過的。
But we can stop here for now. With this, clox now supports most of the features of an object-oriented programming language, and with respectable performance.
但是我們可以到此為止了。有了這些,clox現在支持面向對象編程語言的大部分特性,而且具有不錯的性能。
習題
-
The hash table lookup to find a class’s
init()method is constant time, but still fairly slow. Implement something faster. Write a benchmark and measure the performance difference.哈希表中查找類的
init()方法是常量時間複雜度,但仍然相當慢。實現一些更快的方法。寫一個基準測試並度量性能差異。 -
In a dynamically typed language like Lox, a single callsite may invoke a variety of methods on a number of classes throughout a program’s execution. Even so, in practice, most of the time a callsite ends up calling the exact same method on the exact same class for the duration of the run. Most calls are actually not polymorphic even if the language says they can be.
How do advanced language implementations optimize based on that observation?
在像Lox這樣的動態類型語言中,程序執行過程中的同樣的一個調用可能會調用多個類上的多個方法。即便如此,在實踐中,大多數情況下某個調用在運行期間會執行同一個類上的同一個方法。大多數調用實際上不是多態的,即使語言說它們是多態的。
高級的語言實現是如何基於這一觀察進行優化的?
-
When interpreting an
OP_INVOKEinstruction, the VM has to do two hash table lookups. First, it looks for a field that could shadow a method, and only if that fails does it look for a method. The former check is rarely useful—most fields do not contain functions. But it is necessary because the language says fields and methods are accessed using the same syntax, and fields shadow methods.That is a language choice that affects the performance of our implementation. Was it the right choice? If Lox were your language, what would you do?
在解釋
OP_INVOKE指令時,虛擬機必須執行兩次哈希表查詢。首先,它要查找可能會遮蔽方法的字段,只有這一步失敗時才會查找方法。前一個檢查很少有用——大多數字段都不包含函數。但它是必要的,因為語言要求字段和方法通過同樣的語法來訪問,並且字段會遮蔽方法。這是一種影響實現性能的語言選擇。這是個正確的選擇嗎?如果Lox是你的語言,你會怎麼做?
設計筆記:新奇性預算
I still remember the first time I wrote a tiny BASIC program on a TRS-80 and made a computer do something it hadn’t done before. It felt like a superpower. The first time I cobbled together just enough of a parser and interpreter to let me write a tiny program in my own language that made a computer do a thing was like some sort of higher-order meta-superpower. It was and remains a wonderful feeling.
我還記得我第一次在TRS-8上寫了一個小小的BASIC程序,讓電腦做了一些它以前沒有做過的事。這感覺就像是一種超能力。我第一次組裝出一個解析器和解釋器,能夠讓我使用自己的語言寫一個小程序,讓計算機做了一件事,就像某種更高階的超能力。這種感覺過去是美妙的,現在仍然是。
I realized I could design a language that looked and behaved however I chose. It was like I’d been going to a private school that required uniforms my whole life and then one day transferred to a public school where I could wear whatever I wanted. I don’t need to use curly braces for blocks? I can use something other than an equals sign for assignment? I can do objects without classes? Multiple inheritance and multimethods? A dynamic language that overloads statically, by arity?
我意識到,我可以設計一種外觀和行為都由我選擇的語言。就好像我一直在一所要求穿制服的私立學校上學,然後有一天轉到了一所公立學校,在那裡我想穿什麼就穿什麼。我不要使用大括號來表示代碼塊?我可以用等號以外的符號進行賦值?我可以實現沒有類的對象?多重繼承和多分派?根據元數進行靜態重載的動態語言?
Naturally, I took that freedom and ran with it. I made the weirdest, most arbitrary language design decisions. Apostrophes for generics. No commas between arguments. Overload resolution that can fail at runtime. I did things differently just for difference’s sake.
很自然地,我接受了這種自由。我做了最古怪、最隨意的語言設計決策。撇號表示泛型,參數之間不使用逗號,在運行時可能會失敗的重載解析。我做了一些不同的事情,只是為了與眾不同。
This is a very fun experience that I highly recommend. We need more weird, avant-garde programming languages. I want to see more art languages. I still make oddball toy languages for fun sometimes.
這是一個非常有趣的體驗,我強烈推薦。我們需要更多奇怪、前衛的編程語言。我希望看到更多的藝術語言。有時候我還會做一些奇怪的玩具語言來玩。
However, if your goal is success where “success” is defined as a large number of users, then your priorities must be different. In that case, your primary goal is to have your language loaded into the brains of as many people as possible. That’s really hard. It takes a lot of human effort to move a language’s syntax and semantics from a computer into trillions of neurons.
然而,如果你的目標是成功,而“成功”被定義為大量的用戶,那麼你的優先事項必然是不同的。在這種情況下,你的首要目標是讓儘可能多的人記住你的語言。這真的很難。要將一種語言的語法和語義從計算機轉移到數萬億的神經元中,需要付出大量的努力。
Programmers are naturally conservative with their time and cautious about what languages are worth uploading into their wetware. They don’t want to waste their time on a language that ends up not being useful to them. As a language designer, your goal is thus to give them as much language power as you can with as little required learning as possible.
程序員對他們的時間自然是保守的,對於哪些語言值得上傳到他們的溼件(即大腦)中。他們不想把時間浪費在一門最終對他們沒有用處的語言上。因此,作為語言設計者,你的目標是為他們提供儘可能多的語言能力,並儘可能地減少所需的學習。
One natural approach is simplicity. The fewer concepts and features your language has, the less total volume of stuff there is to learn. This is one of the reasons minimal scripting languages often find success even though they aren’t as powerful as the big industrial languages—they are easier to get started with, and once they are in someone’s brain, the user wants to keep using them.
一個自然的方法是簡單化。你的語言擁有的概念和功能越少,你需要學習的東西就越少。這就是小型腳本語言雖然不像大型工業語言那樣強大卻經常獲得成功的原因之一——它們更容易上手,而且它們一旦進入了人們的大腦,用戶就想繼續使用它們18。
The problem with simplicity is that simply cutting features often sacrifices power and expressiveness. There is an art to finding features that punch above their weight, but often minimal languages simply do less.
簡單化的問題在於,簡單地刪減功能通常會犧牲功能和表現力。找到超越其重量的功能是一門藝術,但通常小型語言做得更少,
There is another path that avoids much of that problem. The trick is to realize that a user doesn’t have to load your entire language into their head, just the part they don’t already have in there. As I mentioned in an earlier design note, learning is about transferring the delta between what they already know and what they need to know.
還有另一種方法可以避免這個問題。訣竅是要意識到,用戶不必將你的整個語言都裝進他們的腦子裡,只需要把他們還沒有的部分裝進去就行了。正如我在之前的設計筆記中提到的,學習是轉移他們已知內容與需要知道的內容之間的差量。
Many potential users of your language already know some other programming language. Any features your language shares with that language are essentially “free” when it comes to learning. It’s already in their head, they just have to recognize that your language does the same thing.
你的語言的許多潛在用戶已經瞭解了一些其它的編程語言。當涉及到學習時,你的語言與這些語言共享的任何功能基本上都是“免費”的。它已經在用戶的頭腦中了,他們只需要認識到你的語言也做了同樣的事情。
In other words, familiarity is another key tool to lower the adoption cost of your language. Of course, if you fully maximize that attribute, the end result is a language that is completely identical to some existing one. That’s not a recipe for success, because at that point there’s no incentive for users to switch to your language at all.
換句話說,熟悉度是降低語言採用成本的另一個關鍵工具。當然,如果你將這一屬性完全最大化,最終的結果就是一門與某些現有語言完全相同的語言。這不是成功的秘訣,因為在這一點上,用戶根本沒有切換到你的語言的動力。
So you do need to provide some compelling differences. Some things your language can do that other languages can’t, or at least can’t do as well. I believe this is one of the fundamental balancing acts of language design: similarity to other languages lowers learning cost, while divergence raises the compelling advantages.
所以你確實需要提供一些令人信服的差異。某些事情你的語言可以做到,而其它語言做不到,或者至少做得不如你的好。我相信這是語言設計的基本平衡行為之一:與其它語言的相似性降低了學習成本,而差異性提高了令人信服的優勢。
I think of this balancing act in terms of a novelty budget, or as Steve Klabnik calls it, a “strangeness budget”. Users have a low threshold for the total amount of new stuff they are willing to accept to learn a new language. Exceed that, and they won’t show up.
我認為這種平衡就像是新奇性預算,或者像Steve Klabnik所說,是一種“陌生感預算”19。用戶對於學習新語言時願意接受的新知識的總量有一個較低的閾值。如果超過這個值,他們就不會來學習了。
Anytime you add something new to your language that other languages don’t have, or anytime your language does something other languages do in a different way, you spend some of that budget. That’s OK—you need to spend it to make your language compelling. But your goal is to spend it wisely. For each feature or difference, ask yourself how much compelling power it adds to your language and then evaluate critically whether it pays its way. Is the change so valuable that it is worth blowing some of your novelty budget?
任何時候,你為你的語言添加了其它語言沒有的新東西,或者你的語言以不同的方式做了其它語言做的事情,你都會花費一下預算。這沒關係——你需要花費預算來使你的語言更具有吸引力。但你的目標是明智地使用這些預算。對於每一種特性或差異,問問你自己它為你的語言增加了多少引人注目的能力,然後嚴格評估它是否值得。這種改變是否有價值,而且值得你花費一些新奇性預算?
In practice, I find this means that you end up being pretty conservative with syntax and more adventurous with semantics. As fun as it is to put on a new change of clothes, swapping out curly braces with some other block delimiter is very unlikely to add much real power to the language, but it does spend some novelty. It’s hard for syntax differences to carry their weight.
在實踐中,我發現這意味著你最終會在語法上相當保守,而在語義上更加大膽。雖然換一套新衣服很有趣,但把花括號換成其它代碼塊分隔符並不可能給語言增加多少真正的能力,但它確實會花費一些新奇性。語法上的差異很難承載它們的重量。
On the other hand, new semantics can significantly increase the power of the language. Multimethods, mixins, traits, reflection, dependent types, runtime metaprogramming, etc. can radically level up what a user can do with the language.
另一方面,新的語義可以顯著增加語言的能力。多分派、mixins、traits、反射、依賴類型、運行時元編程等可以從根本上提升用戶使用語言的能力。
Alas, being conservative like this is not as fun as just changing everything. But it’s up to you to decide whether you want to chase mainstream success or not in the first place. We don’t all need to be radio-friendly pop bands. If you want your language to be like free jazz or drone metal and are happy with the proportionally smaller (but likely more devoted) audience size, go for it.
唉,這樣的保守並不像直接改變一切那樣有趣。但是否追求主流的成功,首先取決於你。我們不需要都成為電臺歡迎的流行樂隊。如果你想讓你的語言像自由爵士或嗡鳴金屬那樣,並且對比較較小(但可能更忠實)的觀眾數量感到滿意,那就去做吧。
-
我們對閉包做了類似的操作。
OP_CLOSURE指令需要知道每個捕獲的上值的類型和索引。我們在主OP_CLOSURE指令之後使用一系列偽指令對其進行編碼——基本上是一個可變數量的操作數。VM在解釋OP_CLOSURE指令時立即處理所有這些額外的字節。
這裡我們的方法有所不同,因為從VM的角度看,定義方法的每條指令都是一個獨立的操作。兩種方法都可行。可變大小的偽指令可能稍微快一點,但是類聲明很少在熱循環中出現,所以沒有太大關係。 ↩ -
如果Lox只支持在頂層聲明類,那麼虛擬機就可以假定任何類都可以直接從全局變量表中查找出來。然而,由於我們支持局部類,所以我們也需要處理這種情況。 ↩
-
前面對
defineVariable()的調用將類彈出棧,因此調用namedVariable()將其加載會棧中似乎有點愚蠢。為什麼不一開始就把它留在棧上呢?我們可以這樣做,但在下一章中,我們將在這兩個調用之間插入代碼,以支持繼承。到那時,如果類不在棧上會更容易。 ↩ -
虛擬機相信它執行的指令是有效的,因為將代碼送到字節碼解釋器的唯一途徑是通過clox自己的編譯器。許多字節碼虛擬機,如JVM和CPython,支持執行單獨編譯好的字節碼。這就導致了一個不同的安全問題。惡意編寫的字節碼可能會導致虛擬機崩潰,甚至更糟。
為了防止這種情況,JVM在執行任何加載的代碼之前都會進行字節碼驗證。CPython說,由用戶來確保他們運行的任何字節碼都是安全的。 ↩ -
我從CPython中借鑑了“bound method”這個名字。Python跟Lox這裡的行為很類似,我通過它的實現獲得靈感。 ↩
-
跟蹤方法的閉包實際上是沒有必要的。接收器是一個ObjInstance,它有一個指向其ObjClass的指針,而ObjClass有一個存儲所有方法的表。但讓ObjBoundMethod依賴於它,我覺得在某種程度上是值得懷疑的。 ↩
-
已綁定方法是第一類值,所以他們可以把它存儲在變量中,傳遞給函數,以及用它做“值”可做的事情。 ↩
-
解析器函數名稱後面的下劃線是因為
this是C++中的一個保留字,我們支持將clox編譯為C++。 ↩ -
當然,Lox確實允許外部代碼之間訪問和修改一個實例的字段,而不需要通過實例的方法。這與Ruby和Smalltalk不同,後者將狀態完全封裝在對象中。我們的玩具式腳本語言,唉,不那麼有原則。 ↩
-
就好像初始化器被隱式地包裝在這樣的一段代碼中:

注意init()返回的值是如何被丟棄的。 ↩ -
我承認,“軟盤”對於當前一代程序員來說,可能不再是一個有用的大小參考。也許我應該說“幾條推特”之類的。 ↩
-
如果你花足夠的時間觀察字節碼虛擬機的運行,你會發現它經常一次次地執行同一系列的字節碼指令。一個經典的優化技術是定義新的單條指令,稱為超級指令,它將這些指令融合到具有與整個序列相同行為的單一指令。
在字節碼解釋器中,最大的性能消耗之一是每個指令的解碼和調度的開銷。將幾個指令融合在一起可以消除其中的一些問題。
難點在於確定哪些指令序列足夠常見,並可以從這種優化中受益。每條新的超級指令都要求有一個操作碼供自己使用,而這些操作碼的數量是有限的。如果添加太多,你就需要對操作碼進行更長的編碼,這就增加了代碼的大小,使得所有指令的解碼速度變慢。 ↩ -
你應該可以猜到,我們將這段代碼拆分成一個單獨的函數,是因為我們稍後會複用它——
super調用中。 ↩ -
這就是我們使用棧槽0來存儲接收器的一個主要原因——調用方就是這樣組織方法調用棧的。高效的調用約定是字節碼虛擬機性能故事的重要組成部分。 ↩
-
我們不應該過於自信。這種性能優化是相對於我們自己未優化的方法調用實現而言的,而那種方法調用實現相當緩慢。為每個方法調用都進行堆分配不會贏得任何比賽。 ↩
-
在有些情況下,當程序偶爾返回錯誤的答案,以換取顯著加快的運行速度或更好的性能邊界,用戶可能也是滿意的。這些就是**蒙特卡洛算法**的領域。對於某些用例來說,這是一個很好的權衡。
不過,重要的是,由用戶選擇使用這些算法中的某一種。我們這些語言實現者不能單方面地決定犧牲程序的正確性。 ↩ -
作為語言設計者,我們的角色非常不同。如果我們確實控制了語言本身,我們有時可能會選擇限制或改變語言的方式來實現優化。用戶想要有表達力的語言,但他們也想要快速實現。有時,如果犧牲一點功能來獲得完美回報是很好的語言設計。 ↩
-
特別的,這是動態類型語言的一大優勢。靜態語言需要你學習兩種語言——運行時語義和靜態類型系統,然後才能讓計算機做一些事情。動態語言只要求你學習前者。
最終,程序變得足夠大,靜態分析的價值足以抵扣學習第二門靜態語言的努力,但其價值在一開始並不那麼明顯。 ↩ -
心理學中的一個相關概念是性格信用,即社會上的其他人會給予你有限的與社會規範的偏離。你通過融入並做群體內的事情來獲得信用,然後你可以把這些信用花費在那些可能會引人側目的古怪活動上。換句話說,證明你是“好人之一”,讓你有資格展示自己怪異的一面,但只能到此為止。 ↩
29.超類 Superclasses
You can choose your friends but you sho’ can’t choose your family, an’ they’re still kin to you no matter whether you acknowledge ’em or not, and it makes you look right silly when you don’t.
—— Harper Lee, To Kill a Mockingbird
你可以選擇你的朋友,但無法選擇你的家庭,所以不管你承認與否,他們都是你的親屬,而且不承認會讓你顯得很蠢。(哈珀·李,《殺死一隻知更鳥》)
This is the very last chapter where we add new functionality to our VM. We’ve packed almost the entire Lox language in there already. All that remains is inheriting methods and calling superclass methods. We have another chapter after this one, but it introduces no new behavior. It only makes existing stuff faster. Make it to the end of this one, and you’ll have a complete Lox implementation.
這是我們向虛擬機器新增新功能的最後一章。我們已經把幾乎所有的Lox語言都裝進虛擬機器中了。剩下的就是繼承方法和呼叫超類方法。在本章之後還有一章,但是沒有引入新的行為。它只是讓現有的東西更快1。堅持到本章結束,你將擁有一個完整的Lox實現。
Some of the material in this chapter will remind you of jlox. The way we resolve super calls is pretty much the same, though viewed through clox’s more complex mechanism for storing state on the stack. But we have an entirely different, much faster, way of handling inherited method calls this time around.
本章中的一些內容會讓你想起jlox。我們解決超類呼叫的方式幾乎是一樣的,即便是從clox這種在棧中儲存狀態的更復雜的機制來看。但這次我們會用一種完全不同的、更快的方式來處理繼承方法的呼叫。
29 . 1 Inheriting Methods
29.1 繼承方法
We’ll kick things off with method inheritance since it’s the simpler piece. To refresh your memory, Lox inheritance syntax looks like this:
我們會從方法繼承開始,因為它是比較簡單的部分。為了恢復你的記憶,Lox的繼承語法如下所示:
class Doughnut {
cook() {
print "Dunk in the fryer.";
}
}
class Cruller < Doughnut {
finish() {
print "Glaze with icing.";
}
}
Here, the Cruller class inherits from Doughnut and thus, instances of Cruller inherit the
cook()method. I don’t know why I’m belaboring this. You know how inheritance works. Let’s start compiling the new syntax.
這裡,Culler類繼承自Doughnut,因此,Cruller的例項繼承了cook()方法。我不明白我為什麼要反覆強調這個,你知道繼承是怎麼回事。讓我們開始編譯新語法。
compiler.c,在classDeclaration()方法中新增程式碼:
currentClass = &classCompiler;
// 新增部分開始
if (match(TOKEN_LESS)) {
consume(TOKEN_IDENTIFIER, "Expect superclass name.");
variable(false);
namedVariable(className, false);
emitByte(OP_INHERIT);
}
// 新增部分結束
namedVariable(className, false);
After we compile the class name, if the next token is a
<, then we found a superclass clause. We consume the superclass’s identifier token, then callvariable(). That function takes the previously consumed token, treats it as a variable reference, and emits code to load the variable’s value. In other words, it looks up the superclass by name and pushes it onto the stack.
在編譯類名之後,如果下一個標識是<,那我們就找到了一個超類子句。我們消耗超類的識別符號,然後呼叫variable()。該函式接受前面消耗的標識,將其視為變數引用,併發出程式碼來載入變數的值。換句話說,它透過名稱查詢超類並將其壓入棧中。
After that, we call
namedVariable()to load the subclass doing the inheriting onto the stack, followed by anOP_INHERITinstruction. That instruction wires up the superclass to the new subclass. In the last chapter, we defined anOP_METHODinstruction to mutate an existing class object by adding a method to its method table. This is similar—theOP_INHERITinstruction takes an existing class and applies the effect of inheritance to it.
之後,我們呼叫namedVariable()將進行繼承的子類載入到棧中,接著是OP_INHERIT指令。該指令將超類與新的子類連線起來。在上一章中,我們定義了一條OP_METHOD指令,透過向已有類物件的方法表中新增方法來改變它。這裡是類似的——OP_INHERIT指令接受一個現有的類,並對其應用繼承的效果。
In the previous example, when the compiler works through this bit of syntax:
在前面的例子中,當編譯器處理這些語法時:
class Cruller < Doughnut {
The result is this bytecode:
結果就是這個位元組碼:

Before we implement the new
OP_INHERITinstruction, we have an edge case to detect.
在我們實現新的OP_INHERIT指令之前,還需要檢測一個邊界情況。
compiler.c,在classDeclaration()方法中新增程式碼:
variable(false);
// 新增部分開始
if (identifiersEqual(&className, &parser.previous)) {
error("A class can't inherit from itself.");
}
// 新增部分結束
namedVariable(className, false);
A class cannot be its own superclass. Unless you have access to a deranged nuclear physicist and a very heavily modified DeLorean, you cannot inherit from yourself.
一個類不能成為它自己的超類2。除非你能接觸到一個核物理學家和一輛改裝過的DeLorean汽車【譯者注:電影《回到未來》的梗】,否則你無法繼承自己。
29 . 1 . 1 Executing inheritance
29.1.1 執行繼承
Now onto the new instruction.
現在來看新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_CLASS,
// 新增部分開始
OP_INHERIT,
// 新增部分結束
OP_METHOD
There are no operands to worry about. The two values we need—superclass and subclass—are both found on the stack. That means disassembling is easy.
不需要擔心任何運算元。我們需要的兩個值——超類和子類——都可以在棧中找到。這意味著反彙編很容易。
debug.c,在disassembleInstruction()方法中新增程式碼:
return constantInstruction("OP_CLASS", chunk, offset);
// 新增部分開始
case OP_INHERIT:
return simpleInstruction("OP_INHERIT", offset);
// 新增部分結束
case OP_METHOD:
The interpreter is where the action happens.
直譯器是行為發生的地方。
vm.c,在run()方法中新增程式碼:
break;
// 新增部分開始
case OP_INHERIT: {
Value superclass = peek(1);
ObjClass* subclass = AS_CLASS(peek(0));
tableAddAll(&AS_CLASS(superclass)->methods,
&subclass->methods);
pop(); // Subclass.
break;
}
// 新增部分結束
case OP_METHOD:
From the top of the stack down, we have the subclass then the superclass. We grab both of those and then do the inherit-y bit. This is where clox takes a different path than jlox. In our first interpreter, each subclass stored a reference to its superclass. On method access, if we didn’t find the method in the subclass’s method table, we recursed through the inheritance chain looking at each ancestor’s method table until we found it.
從棧頂往下,我們依次有子類,然後是超類。我們獲取這兩個類,然後進行繼承。這就是clox與jlox不同的地方。在我們的第一個直譯器中,每個子類都儲存了一個對其超類的引用。在訪問方法時,如果我們沒有在子類方法表中找到它,就透過繼承鏈遞迴遍歷每個祖先的方法表,直到找到該方法。
For example, calling
cook()on an instance of Cruller sends jlox on this journey:
例如,在Cruller的例項上呼叫cook()方法,jlox會這樣做:

That’s a lot of work to perform during method invocation time. It’s slow, and worse, the farther an inherited method is up the ancestor chain, the slower it gets. Not a great performance story.
在方法呼叫期間要做大量的工作。這很慢,而且更糟糕的是,繼承的方法在祖先鏈上越遠,它就越慢。這不是一個好的效能故事。
The new approach is much faster. When the subclass is declared, we copy all of the inherited class’s methods down into the subclass’s own method table. Later, when calling a method, any method inherited from a superclass will be found right in the subclass’s own method table. There is no extra runtime work needed for inheritance at all. By the time the class is declared, the work is done. This means inherited method calls are exactly as fast as normal method calls—a single hash table lookup.
新方法則要快得多。當子類被宣告時,我們將繼承類的所有方法複製到子類自己的方法表中。之後,當我們呼叫某個方法時,從超類繼承的任何方法都可以在子類自己的方法表中找到。繼承根本不需要做額外的執行時工作。當類被宣告時,工作就完成了。這意味著繼承的方法和普通方法呼叫一樣快——只需要一次雜湊表查詢3。

I’ve sometimes heard this technique called “copy-down inheritance”. It’s simple and fast, but, like most optimizations, you get to use it only under certain constraints. It works in Lox because Lox classes are closed. Once a class declaration is finished executing, the set of methods for that class can never change.
我有時聽到這種技術被稱為“向下複製繼承”。它簡單而快速,但是,與大多數最佳化一樣,你只能在特定的約束條件下使用它。它適用於Lox,是因為Lox的類是關閉的。一旦某個類的宣告執行完畢,該類的方法集就永遠不能更改。
In languages like Ruby, Python, and JavaScript, it’s possible to crack open an existing class and jam some new methods into it or even remove them. That would break our optimization because if those modifications happened to a superclass after the subclass declaration executed, the subclass would not pick up those changes. That breaks a user’s expectation that inheritance always reflects the current state of the superclass.
在Ruby、Python和JavaScript等語言中,可以開啟一個現有的類,並將一些新方法加入其中,甚至刪除方法。這會破壞我們的最佳化,因為如果這些修改在子類宣告執行之後發生在超類上,子類就不會獲得這些變化。這就打破了使用者的期望,即繼承總是反映超類的當前狀態4。
Fortunately for us (but not for users who like the feature, I guess), Lox doesn’t let you patch monkeys or punch ducks, so we can safely apply this optimization.
幸運的是(我猜對於喜歡這一特性的使用者來說不算幸運),Lox不允許猴子補丁或鴨子打洞,所以我們可以安全的應用這種最佳化。
What about method overrides? Won’t copying the superclass’s methods into the subclass’s method table clash with the subclass’s own methods? Fortunately, no. We emit the
OP_INHERITafter theOP_CLASSinstruction that creates the subclass but before any method declarations andOP_METHODinstructions have been compiled. At the point that we copy the superclass’s methods down, the subclass’s method table is empty. Any methods the subclass overrides will overwrite those inherited entries in the table.
那方法重寫呢?將超類的方法複製到子類的方法表中,不會與子類自己的方法發生衝突嗎?幸運的是,不會。我們是在建立子類的OP_CLASS指令之後、但在任何方法宣告和OP_METHOD指令被編譯之前發出OP_INHERIT指令。當我們將超類的方法複製下來時,子類的方法表是空的。子類重寫的任何方法都會覆蓋表中那些繼承的條目。
29 . 1 . 2 Invalid superclasses
29.1.2 無效超類
Our implementation is simple and fast, which is just the way I like my VM code. But it’s not robust. Nothing prevents a user from inheriting from an object that isn’t a class at all:
我們的實現簡單而快速,這正是我喜歡我的VM程式碼的原因。但它並不健壯。沒有什麼能阻止使用者繼承一個根本不是類的物件:
var NotClass = "So not a class";
class OhNo < NotClass {}
Obviously, no self-respecting programmer would write that, but we have to guard against potential Lox users who have no self respect. A simple runtime check fixes that.
顯然,任何一個有自尊心的程式設計師都不會寫這種東西,但我們必須堤防那些沒有自尊心的潛在Lox使用者。一個簡單的執行時檢查就可以解決這個問題。
vm.c,在run()方法中新增程式碼:
Value superclass = peek(1);
// 新增部分開始
if (!IS_CLASS(superclass)) {
runtimeError("Superclass must be a class.");
return INTERPRET_RUNTIME_ERROR;
}
// 新增部分結束
ObjClass* subclass = AS_CLASS(peek(0));
If the value we loaded from the identifier in the superclass clause isn’t an ObjClass, we report a runtime error to let the user know what we think of them and their code.
如果我們從超類子句的識別符號中載入到的值不是ObjClass,就報告一個執行時錯誤,讓使用者知道我們對他們及其程式碼的看法。
29 . 2 Storing Superclasses
29.2 儲存超類
Did you notice that when we added method inheritance, we didn’t actually add any reference from a subclass to its superclass? After we copy the inherited methods over, we forget the superclass entirely. We don’t need to keep a handle on the superclass, so we don’t.
你是否注意到,在我們新增方法繼承時,實際上並沒有新增任何從子類指向超類的引用?我們把繼承的方法複製到子類之後,就完全忘記了超類。我們不需要儲存超類的控制代碼,所以我們沒有這樣做。
That won’t be sufficient to support super calls. Since a subclass may override the superclass method, we need to be able to get our hands on superclass method tables. Before we get to that mechanism, I want to refresh your memory on how super calls are statically resolved.
這不足以支援超類呼叫。因為子類可能會覆蓋超類方法5,我們需要能夠獲得超類方法表。在討論這個機制之前,我想讓你回憶一下如何靜態解析超類呼叫。
Back in the halcyon days of jlox, I showed you this tricky example to explain the way super calls are dispatched:
回顧jlox的光輝歲月,我給你展示了這個棘手的示例,來解釋超類呼叫的分派方式:
class A {
method() {
print "A method";
}
}
class B < A {
method() {
print "B method";
}
test() {
super.method();
}
}
class C < B {}
C().test();
Inside the body of the
test()method,thisis an instance of C. If super calls were resolved relative to the superclass of the receiver, then we would look in C’s superclass, B. But super calls are resolved relative to the superclass of the surrounding class where the super call occurs. In this case, we are in B’stest()method, so the superclass is A, and the program should print “A method”.
在test()方法的主體中,this是C的一個例項。如果超類呼叫是在接收器的超類中來解析的,那我們會在C的超類B中尋找方法。但是超類呼叫是在發生超類呼叫的外圍類的超類中解析的。在本例中,我們在B的test()方法中,因此超類是A,程式應該列印“A method”。
This means that super calls are not resolved dynamically based on the runtime instance. The superclass used to look up the method is a static—practically lexical—property of where the call occurs. When we added inheritance to jlox, we took advantage of that static aspect by storing the superclass in the same Environment structure we used for all lexical scopes. Almost as if the interpreter saw the above program like this:
這意味著超類呼叫不是根據執行時的例項進行動態解析的。用於查詢方法的超類是呼叫發生位置的一個靜態(實際上是詞法)屬性。當我們在jlox中新增繼承時,我們利用了這種靜態優勢,將超類儲存在我們用於所有詞法作用域的同一個Environment結構中。就好像直譯器看到的程式是這樣的:
class A {
method() {
print "A method";
}
}
var Bs_super = A;
class B < A {
method() {
print "B method";
}
test() {
runtimeSuperCall(Bs_super, "method");
}
}
var Cs_super = B;
class C < B {}
C().test();
Each subclass has a hidden variable storing a reference to its superclass. Whenever we need to perform a super call, we access the superclass from that variable and tell the runtime to start looking for methods there.
每個子類都有一個隱藏變數,用於儲存對其超類的引用。當我們需要執行一個超類呼叫時,我們就從這個變數訪問超類,並告訴執行時從那裡開始查詢方法。
We’ll take the same path with clox. The difference is that instead of jlox’s heap-allocated Environment class, we have the bytecode VM’s value stack and upvalue system. The machinery is a little different, but the overall effect is the same.
我們在clox中採用相同的方法。不同之處在於,我們使用的是位元組碼虛擬機器的值棧和上值系統,而不是jlox的堆分配的Environment 類。機制有些不同,但總體效果是一樣的。
29 . 2 . 1 A superclass local variable
29.2.1 超類區域性變數
Our compiler already emits code to load the superclass onto the stack. Instead of leaving that slot as a temporary, we create a new scope and make it a local variable.
我們的編譯器已經發出了將超類載入到棧中的程式碼。我們不將這個槽看作是臨時的,而是建立一個新的作用域,並將其作為一個區域性變數。
compiler.c,在classDeclaration()方法中新增程式碼:
}
// 新增部分開始
beginScope();
addLocal(syntheticToken("super"));
defineVariable(0);
// 新增部分結束
namedVariable(className, false);
emitByte(OP_INHERIT);
Creating a new lexical scope ensures that if we declare two classes in the same scope, each has a different local slot to store its superclass. Since we always name this variable “super”, if we didn’t make a scope for each subclass, the variables would collide.
建立一個新的詞法作用域可以確保,如果我們在同一個作用域中宣告兩個類,每個類都有一個不同的區域性槽來儲存其超類。由於我們總是將該變數命名為“super”,如果我們不為每個子類建立作用域,那麼這些變數就會發生衝突。
We name the variable “super” for the same reason we use “this” as the name of the hidden local variable that
thisexpressions resolve to: “super” is a reserved word, which guarantees the compiler’s hidden variable won’t collide with a user-defined one.
我們將該變數命名為“super”,與我們使用“this”作為this表示式解析得到的隱藏區域性變數名稱的原因相同:“super”是一個保留字,它可以保證編譯器的隱藏變數不會與使用者定義的變數發生衝突。
The difference is that when compiling
thisexpressions, we conveniently have a token sitting around whose lexeme is “this”. We aren’t so lucky here. Instead, we add a little helper function to create a synthetic token for the given constant string.
不同之處在於,在編譯this表示式時,我們可以很方便地使用一個標識,詞素是this。在這裡我們就沒那麼幸運了。相對地,我們新增一個小的輔助函式,來為給定的常量字串建立一個合成標識6。
compiler.c,在variable()方法後新增程式碼:
static Token syntheticToken(const char* text) {
Token token;
token.start = text;
token.length = (int)strlen(text);
return token;
}
Since we opened a local scope for the superclass variable, we need to close it.
因為我們為超類變數開啟了一個區域性作用域,我們還需要關閉它。
compiler.c,在classDeclaration()方法中新增程式碼:
emitByte(OP_POP);
// 新增部分開始
if (classCompiler.hasSuperclass) {
endScope();
}
// 新增部分結束
currentClass = currentClass->enclosing;
We pop the scope and discard the “super” variable after compiling the class body and its methods. That way, the variable is accessible in all of the methods of the subclass. It’s a somewhat pointless optimization, but we create the scope only if there is a superclass clause. Thus we need to close the scope only if there is one.
在編譯完類的主體及其方法後,我們會彈出作用域並丟棄“super”變數。這樣,該變數在子類的所有方法中被都可以訪問。這是一個有點無意義的最佳化,但我們只在有超類子句的情況下建立作用域。因此,只有在有超類的情況下,我們才需要關閉這個作用域。
To track that, we could declare a little local variable in
classDeclaration(). But soon, other functions in the compiler will need to know whether the surrounding class is a subclass or not. So we may as well give our future selves a hand and store this fact as a field in the ClassCompiler now.
為了記錄是否有超類,我們可以在classDeclaration()中宣告一個區域性變數。但是很快,編譯器中的其它函式需要知道外層的類是否是子類。所以我們不妨幫幫未來的自己,現在就把它作為一個欄位儲存在ClassCompiler中。
compiler.c,在結構體ClassCompiler中新增程式碼:
typedef struct ClassCompiler {
struct ClassCompiler* enclosing;
// 新增部分開始
bool hasSuperclass;
// 新增部分結束
} ClassCompiler;
When we first initialize a ClassCompiler, we assume it is not a subclass.
當我們第一次初始化某個ClassCompiler時,我們假定它不是子類。
compiler.c,在classDeclaration()方法中新增程式碼:
ClassCompiler classCompiler;
// 新增部分開始
classCompiler.hasSuperclass = false;
// 新增部分結束
classCompiler.enclosing = currentClass;
Then, if we see a superclass clause, we know we are compiling a subclass.
然後,如果看到超類子句,我們就知道正在編譯一個子類。
compiler.c,在classDeclaration()方法中新增程式碼:
emitByte(OP_INHERIT);
// 新增部分開始
classCompiler.hasSuperclass = true;
// 新增部分結束
}
This machinery gives us a mechanism at runtime to access the superclass object of the surrounding subclass from within any of the subclass’s methods—simply emit code to load the variable named “super”. That variable is a local outside of the method body, but our existing upvalue support enables the VM to capture that local inside the body of the method or even in functions nested inside that method.
這種機制在執行時為我們提供了一種方法,可以從子類的任何方法中訪問外層子類的超類物件——只需發出程式碼來載入名為“super”的變數。這個變數是方法主體之外的一個區域性變數,但是我們現有的上值支援VM在方法主體內、甚至是巢狀方法內的函式中捕獲該區域性變數。
29 . 3 Super Calls
29.3 超類呼叫
With that runtime support in place, we are ready to implement super calls. As usual, we go front to back, starting with the new syntax. A super call begins, naturally enough, with the
superkeyword.
有了這個執行時支援,我們就可以實現超類呼叫了。跟之前一樣,我們從前端到後端,先從新語法開始。超類呼叫,自然是以super關鍵字開始7。
compiler.c,替換1行:
[TOKEN_RETURN] = {NULL, NULL, PREC_NONE},
// 替換部分開始
[TOKEN_SUPER] = {super_, NULL, PREC_NONE},
// 替換部分結束
[TOKEN_THIS] = {this_, NULL, PREC_NONE},
When the expression parser lands on a
supertoken, control jumps to a new parsing function which starts off like so:
當表示式解析器落在一個super標識時,控制流會跳轉到一個新的解析函式,該函式的開頭是這樣的:
compiler.c,在syntheticToken()方法後新增程式碼:
static void super_(bool canAssign) {
consume(TOKEN_DOT, "Expect '.' after 'super'.");
consume(TOKEN_IDENTIFIER, "Expect superclass method name.");
uint8_t name = identifierConstant(&parser.previous);
}
This is pretty different from how we compiled
thisexpressions. Unlikethis, asupertoken is not a standalone expression. Instead, the dot and method name following it are inseparable parts of the syntax. However, the parenthesized argument list is separate. As with normal method access, Lox supports getting a reference to a superclass method as a closure without invoking it:
這與我們編譯this表示式的方式很不一樣。與this不同,super標識不是一個獨立的表示式8。相反,它後面的點和方法名稱是語法中不可分割的部分。但是,括號內的引數列表是獨立的。和普通的方法訪問一樣,Lox支援以閉包的方式獲得對超類方法的引用,而不必呼叫它:
class A {
method() {
print "A";
}
}
class B < A {
method() {
var closure = super.method;
closure(); // Prints "A".
}
}
In other words, Lox doesn’t really have super call expressions, it has super access expressions, which you can choose to immediately invoke if you want. So when the compiler hits a
supertoken, we consume the subsequent.token and then look for a method name. Methods are looked up dynamically, so we useidentifierConstant()to take the lexeme of the method name token and store it in the constant table just like we do for property access expressions.
換句話說,Lox並沒有真正的超類*呼叫(call)表示式,它有的是超類訪問(access)*表示式,如果你願意,可以選擇立即呼叫。因此,當編譯器碰到一個super標識時,我們會消費後續的.標識,然後尋找一個方法名稱。方法是動態查詢的,所以我們使用identifierConstant()來獲取方法名標識的詞素,並將其儲存在常量表中,就像我們對屬性訪問表示式所做的那樣。
Here is what the compiler does after consuming those tokens:
下面是編譯器在消費這些標識之後做的事情:
compiler.c,在super_()方法中新增程式碼:
uint8_t name = identifierConstant(&parser.previous);
// 新增部分開始
namedVariable(syntheticToken("this"), false);
namedVariable(syntheticToken("super"), false);
emitBytes(OP_GET_SUPER, name);
// 新增部分結束
}
In order to access a superclass method on the current instance, the runtime needs both the receiver and the superclass of the surrounding method’s class. The first
namedVariable()call generates code to look up the current receiver stored in the hidden variable “this” and push it onto the stack. The secondnamedVariable()call emits code to look up the superclass from its “super” variable and push that on top.
為了在當前例項上訪問一個超類方法,執行時需要接收器和外圍方法所在類的超類。第一個namedVariable()呼叫產生程式碼來查詢儲存在隱藏變數“this”中的當前接收器,並將其壓入棧中。第二個namedVariable()呼叫產生程式碼,從它的“super”變數中查詢超類,並將其推入棧頂。
Finally, we emit a new
OP_GET_SUPERinstruction with an operand for the constant table index of the method name. That’s a lot to hold in your head. To make it tangible, consider this example program:
最後,我們發出一條新的OP_GET_SUPER指令,其運算元為方法名稱的常量表索引。你腦子裡裝的東西太多了。為了使它具體化,請看下面的示例程式:
class Doughnut {
cook() {
print "Dunk in the fryer.";
this.finish("sprinkles");
}
finish(ingredient) {
print "Finish with " + ingredient;
}
}
class Cruller < Doughnut {
finish(ingredient) {
// No sprinkles, always icing.
super.finish("icing");
}
}
The bytecode emitted for the
super.finish("icing")expression looks and works like this:
super.finish("icing")發出的位元組碼看起來像是這樣的:

The first three instructions give the runtime access to the three pieces of information it needs to perform the super access:
前三條指令讓執行時獲得了執行超類訪問時需要的三條資訊:
- The first instruction loads the instance onto the stack.
- The second instruction loads the superclass where the method is resolved.
- Then the new
OP_GET_SUPERinstuction encodes the name of the method to access as an operand.
- 第一條指令將例項載入到棧中。
- 第二條指令載入了將用於解析方法的超類。
- 然後,新的
OP_GET_SUPER指令將要訪問的方法名稱編碼為運算元。
The remaining instructions are the normal bytecode for evaluating an argument list and calling a function.
剩下的指令是用於計算引數列表和呼叫函式的常規位元組碼。
We’re almost ready to implement the new
OP_GET_SUPERinstruction in the interpreter. But before we do, the compiler has some errors it is responsible for reporting.
我們幾乎已經準備好在直譯器中實現新的OP_GET_SUPER指令了。但在此之前,編譯器需要負責報告一些錯誤。
compiler.c,在super_()方法中新增程式碼:
static void super_(bool canAssign) {
// 新增部分開始
if (currentClass == NULL) {
error("Can't use 'super' outside of a class.");
} else if (!currentClass->hasSuperclass) {
error("Can't use 'super' in a class with no superclass.");
}
// 新增部分結束
consume(TOKEN_DOT, "Expect '.' after 'super'.");
A super call is meaningful only inside the body of a method (or in a function nested inside a method), and only inside the method of a class that has a superclass. We detect both of these cases using the value of
currentClass. If that’sNULLor points to a class with no superclass, we report those errors.
超類呼叫只有在方法主體(或方法中巢狀的函式)中才有意義,而且只在具有超類的某個類的方法中才有意義。我們使用currentClass的值來檢測這兩種情況。如果它是NULL或者指向一個沒有超類的類,我們就報告這些錯誤。
29 . 3 . 1 Executing super accesses
29.3.1 執行超類訪問
Assuming the user didn’t put a
superexpression where it’s not allowed, their code passes from the compiler over to the runtime. We’ve got ourselves a new instruction.
假設使用者沒有在不允許的地方使用super表示式,他們的程式碼將從編譯器傳遞到執行時。我們已經有了一個新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_SET_PROPERTY,
// 新增部分開始
OP_GET_SUPER,
// 新增部分結束
OP_EQUAL,
We disassemble it like other opcodes that take a constant table index operand.
我們像對其它需要常量表索引運算元的操作碼一樣對它進行反彙編。
debug.c,在disassembleInstruction()方法中新增程式碼:
return constantInstruction("OP_SET_PROPERTY", chunk, offset);
// 新增部分開始
case OP_GET_SUPER:
return constantInstruction("OP_GET_SUPER", chunk, offset);
// 新增部分結束
case OP_EQUAL:
You might anticipate something harder, but interpreting the new instruction is similar to executing a normal property access.
你可能預想這是一件比較困難的事,但解釋新指令與執行正常的屬性訪問類似。
vm.c,在run()方法中新增程式碼:
}
// 新增部分開始
case OP_GET_SUPER: {
ObjString* name = READ_STRING();
ObjClass* superclass = AS_CLASS(pop());
if (!bindMethod(superclass, name)) {
return INTERPRET_RUNTIME_ERROR;
}
break;
}
// 新增部分結束
case OP_EQUAL: {
As with properties, we read the method name from the constant table. Then we pass that to
bindMethod()which looks up the method in the given class’s method table and creates an ObjBoundMethod to bundle the resulting closure to the current instance.
和屬性一樣,我們從常量表中讀取方法名。然後我們將其傳遞給bindMethod(),該方法會在給定類的方法表中查詢方法,並建立一個ObjBoundMethod將結果閉包與當前例項相繫結。
The key difference is which class we pass to
bindMethod(). With a normal property access, we use the ObjInstances’s own class, which gives us the dynamic dispatch we want. For a super call, we don’t use the instance’s class. Instead, we use the statically resolved superclass of the containing class, which the compiler has conveniently ensured is sitting on top of the stack waiting for us.
關鍵的區別在於將哪個類傳遞給bindMethod()。對於普通的屬性訪問,我們使用ObjInstances自己的類,這為我們提供了我們想要的動態分派。對於超類呼叫,我們不使用例項的類。相反,我們使用靜態分析得到的外層類的超類,編譯器已經確保它在棧頂等著我們9。
We pop that superclass and pass it to
bindMethod(), which correctly skips over any overriding methods in any of the subclasses between that superclass and the instance’s own class. It also correctly includes any methods inherited by the superclass from any of its superclasses.
我們彈出該超類並將其傳遞給bindMethod(),該方法會正確地跳過該超類與例項本身的類之間的任何子類覆寫的方法。它還正確地包含了超類從其任何超類中繼承的方法。
The rest of the behavior is the same. Popping the superclass leaves the instance at the top of the stack. When
bindMethod()succeeds, it pops the instance and pushes the new bound method. Otherwise, it reports a runtime error and returnsfalse. In that case, we abort the interpreter.
其餘的行為都是一樣的。超類彈出棧使得例項位於棧頂。當bindMethod()成功時,它會彈出例項並壓入新的已繫結方法。否則,它會報告一個執行時錯誤並返回false。在這種情況下,我們中止直譯器。
29 . 3 . 2 Faster super calls
29.3.2 更快的超類呼叫
We have superclass method accesses working now. And since the returned object is an ObjBoundMethod that you can then invoke, we’ve got super calls working too. Just like last chapter, we’ve reached a point where our VM has the complete, correct semantics.
我們現在有了對超類方法的訪問。由於返回的物件是一個你可以稍後呼叫的ObjBoundMethod,我們也就有了可用的超類呼叫。就像上一章一樣,我們的虛擬機器現在已經有了完整、正確的語義。
But, also like last chapter, it’s pretty slow. Again, we’re heap allocating an ObjBoundMethod for each super call even though most of the time the very next instruction is an
OP_CALLthat immediately unpacks that bound method, invokes it, and then discards it. In fact, this is even more likely to be true for super calls than for regular method calls. At least with method calls there is a chance that the user is actually invoking a function stored in a field. With super calls, you’re always looking up a method. The only question is whether you invoke it immediately or not.
但是,也和上一章一樣,它很慢。同樣,我們為每個超類呼叫在堆中分配了一個ObjBoundMethod,儘管大多數時候下一個指令就是OP_CALL,它會立即解包該已繫結方法,呼叫它,然後丟棄它。事實上,超類呼叫比普通方法呼叫更有可能出現這種情況。至少在方法呼叫中,使用者有可能實際上在呼叫儲存在欄位中的函式。在超類呼叫中,你肯定是在查詢一個方法。唯一的問題在於你是否立即呼叫它。
The compiler can certainly answer that question for itself if it sees a left parenthesis after the superclass method name, so we’ll go ahead and perform the same optimization we did for method calls. Take out the two lines of code that load the superclass and emit
OP_GET_SUPER, and replace them with this:
如果編譯器看到超類方法名稱後面有一個左括號,它肯定能自己回答這個問題,所以我們會繼續執行與方法呼叫相同的最佳化。去掉載入超類併發出OP_GET_SUPER的兩行程式碼,替換為這個:
compiler.c,在super_()方法中替換2行:
namedVariable(syntheticToken("this"), false);
// 替換部分開始
if (match(TOKEN_LEFT_PAREN)) {
uint8_t argCount = argumentList();
namedVariable(syntheticToken("super"), false);
emitBytes(OP_SUPER_INVOKE, name);
emitByte(argCount);
} else {
namedVariable(syntheticToken("super"), false);
emitBytes(OP_GET_SUPER, name);
}
// 替換部分結束
}
Now before we emit anything, we look for a parenthesized argument list. If we find one, we compile that. Then we load the superclass. After that, we emit a new
OP_SUPER_INVOKEinstruction. This superinstruction combines the behavior ofOP_GET_SUPERandOP_CALL, so it takes two operands: the constant table index of the method name to look up and the number of arguments to pass to it.
現在,在我們發出任何程式碼之前,我們要尋找一個帶括號的引數列表。如果找到了,我們就編譯它,任何載入超類,之後,我們發出一條新的OP_SUPER_INVOKE指令。這個超級指令結合了OP_GET_SUPER和OP_CALL的行為,所以它需要兩個運算元:待查詢的方法名稱和要傳遞給它的引數數量。
Otherwise, if we don’t find a
(, we continue to compile the expression as a super access like we did before and emit anOP_GET_SUPER.
否則,如果沒有找到(,則繼續像前面那樣將表示式編譯為一個超類訪問,併發出一條OP_GET_SUPER指令。
Drifting down the compilation pipeline, our first stop is a new instruction.
沿著編譯流水線向下,我們的第一站是一條新指令。
chunk.h,在列舉OpCode中新增程式碼:
OP_INVOKE,
// 新增部分開始
OP_SUPER_INVOKE,
// 新增部分結束
OP_CLOSURE,
And just past that, its disassembler support.
在那之後,是它的反彙編器支援。
debug.c,在disassembleInstruction()方法中新增程式碼:
return invokeInstruction("OP_INVOKE", chunk, offset);
// 新增部分開始
case OP_SUPER_INVOKE:
return invokeInstruction("OP_SUPER_INVOKE", chunk, offset);
// 新增部分結束
case OP_CLOSURE: {
A super invocation instruction has the same set of operands as
OP_INVOKE, so we reuse the same helper to disassemble it. Finally, the pipeline dumps us into the interpreter.
超類呼叫指令具有與OP_INVOKE相同的運算元集,因此我們複用同一個輔助函式對其反彙編。最後,流水線將我們帶到直譯器中。
vm.c,在run()方法中新增程式碼:
break;
}
// 新增部分開始
case OP_SUPER_INVOKE: {
ObjString* method = READ_STRING();
int argCount = READ_BYTE();
ObjClass* superclass = AS_CLASS(pop());
if (!invokeFromClass(superclass, method, argCount)) {
return INTERPRET_RUNTIME_ERROR;
}
frame = &vm.frames[vm.frameCount - 1];
break;
}
// 新增部分結束
case OP_CLOSURE: {
This handful of code is basically our implementation of
OP_INVOKEmixed together with a dash ofOP_GET_SUPER. There are some differences in how the stack is organized, though. With an unoptimized super call, the superclass is popped and replaced by the ObjBoundMethod for the resolved function before the arguments to the call are executed. This ensures that by the time theOP_CALLis executed, the bound method is under the argument list, where the runtime expects it to be for a closure call.
這一小段程式碼基本上是OP_INVOKE的實現,其中混雜了一點OP_GET_SUPER。不過,在堆疊的組織方式上有些不同。在未最佳化的超類呼叫中,超類會被彈出,並在呼叫的引數被執行之前替換為被解析函式的ObjBoundMethod。這確保了在OP_CALL執行時,已繫結方法在引數列表之下,也就是執行時期望閉包呼叫所在的位置。
With our optimized instructions, things are shuffled a bit:
在我們最佳化的指令中,事情有點被打亂:

Now resolving the superclass method is part of the invocation, so the arguments need to already be on the stack at the point that we look up the method. This means the superclass object is on top of the arguments.
現在,解析超類方法是執行的一部分,因此當我們查詢方法時,引數需要已經在棧上。這意味著超類物件位於引數之上。
Aside from that, the behavior is roughly the same as an
OP_GET_SUPERfollowed by anOP_CALL. First, we pull out the method name and argument count operands. Then we pop the superclass off the top of the stack so that we can look up the method in its method table. This conveniently leaves the stack set up just right for a method call.
除此之外,其行為與OP_GET_SUPER後跟OP_CALL大致相同。首先,我們取出方法名和引數數量兩個運算元。然後我們從棧頂彈出超類,這樣我們就可以在它的方法表中查詢方法。這方便地將堆疊設定為適合方法呼叫的狀態。
We pass the superclass, method name, and argument count to our existing
invokeFromClass()function. That function looks up the given method on the given class and attempts to create a call to it with the given arity. If a method could not be found, it returnsfalse, and we bail out of the interpreter. Otherwise,invokeFromClass()pushes a new CallFrame onto the call stack for the method’s closure. That invalidates the interpreter’s cached CallFrame pointer, so we refreshframe.
我們將超類、方法名和引數數量傳遞給現有的invokeFromClass()函式。該函式在給定的類上查詢給定的方法,並嘗試用給定的元數建立一個對它的呼叫。如果找不到某個方法,它就返回false,並退出直譯器。否則,invokeFromClass()將一個新的CallFrame壓入方法閉包的呼叫棧上。這會使直譯器快取的CallFrame指標失效,所以我們也要重新整理frame。
29 . 4 A Complete Virtual Machine
29.4 一個完整的虛擬機器
Take a look back at what we’ve created. By my count, we wrote around 2,500 lines of fairly clean, straightforward C. That little program contains a complete implementation of the—quite high-level!—Lox language, with a whole precedence table full of expression types and a suite of control flow statements. We implemented variables, functions, closures, classes, fields, methods, and inheritance.
回顧一下我們創造了什麼。根據我的計算,我們編寫了大約2500行相當乾淨、簡潔的C語言程式碼。這個小程式中包含了對Lox語言(相當高階)的完整實現,它有一個滿是表示式型別的優先順序表和一套控制流語句。我們實現了變數、函式、閉包、類、欄位、方法和繼承。
Even more impressive, our implementation is portable to any platform with a C compiler, and is fast enough for real-world production use. We have a single-pass bytecode compiler, a tight virtual machine interpreter for our internal instruction set, compact object representations, a stack for storing variables without heap allocation, and a precise garbage collector.
更令人印象深刻的是,我們的實現可以移植到任何帶有C編譯器的平臺上,而且速度快到足以在實際生產中使用。我們有一個單遍位元組碼編譯器,一個用於內部指令集的嚴格虛擬機器直譯器,緊湊的物件表示,一個用於儲存變數而不需要堆分配的棧,以及一個精確的垃圾回收器。
If you go out and start poking around in the implementations of Lua, Python, or Ruby, you will be surprised by how much of it now looks familiar to you. You have seriously leveled up your knowledge of how programming languages work, which in turn gives you a deeper understanding of programming itself. It’s like you used to be a race car driver, and now you can pop the hood and repair the engine too.
如果你開始研究Lua、Python或Ruby的實現,你會驚訝於它們現在看起來有多熟悉。你已經真正提高了關於程式語言工作方式的知識水平,這反過來又使你對程式設計本身有了更深的理解。這就像你以前是個賽車手,現在你可以開啟引擎蓋,修改發動機了。
You can stop here if you like. The two implementations of Lox you have are complete and full featured. You built the car and can drive it wherever you want now. But if you are looking to have more fun tuning and tweaking for even greater performance out on the track, there is one more chapter. We don’t add any new capabilities, but we roll in a couple of classic optimizations to squeeze even more perf out. If that sounds fun, keep reading . . .
如果你願意,可以在這裡停下來。你擁有的兩個Lox實現是完整的、功能齊全的。你造了這倆車,現在可以把它開到你想去的地方。但是,如果你想獲得更多改裝與調整的樂趣,以期在賽道上獲得更佳的效能,還有一個章節。我們沒有增加任何新的功能,但我們推出了幾個經典的最佳化,以擠壓出更多的效能。如果這聽起來很有趣,請繼續讀下去……
習題
-
A tenet of object-oriented programming is that a class should ensure new objects are in a valid state. In Lox, that means defining an initializer that populates the instance’s fields. Inheritance complicates invariants because the instance must be in a valid state according to all of the classes in the object’s inheritance chain.
The easy part is remembering to call
super.init()in each subclass’sinit()method. The harder part is fields. There is nothing preventing two classes in the inheritance chain from accidentally claiming the same field name. When this happens, they will step on each other’s fields and possibly leave you with an instance in a broken state.If Lox was your language, how would you address this, if at all? If you would change the language, implement your change.
面向物件程式設計的一個原則是,類應該確保新物件處於有效狀態。在Lox中,這意味著要定義一個填充例項欄位的初始化器。繼承使不變性複雜化,因為對於物件繼承鏈中的所有類,例項必須處於有效狀態。
簡單的部分是記住在每個子類的
init()方法中呼叫super.init()。比較難的部分是欄位。沒有什麼方法可以防止繼承鏈中的兩個類意外地宣告相同的欄位名。當這種情況發生時,它們會互相干擾彼此的欄位,並可能讓你的例項處於崩潰狀態。如果Lox是你的語言,你會如何解決這個問題?如果你想改變語言,請實現你的更改。
-
Our copy-down inheritance optimization is valid only because Lox does not permit you to modify a class’s methods after its declaration. This means we don’t have to worry about the copied methods in the subclass getting out of sync with later changes to the superclass.
Other languages, like Ruby, do allow classes to be modified after the fact. How do implementations of languages like that support class modification while keeping method resolution efficient?
我們的向下複製繼承最佳化之所以有效,僅僅是因為Lox不允許在類宣告之後修改它的方法。這意味著我們不必擔心子類中複製的方法與後面對超類的修改不同步。
其它語言,如Ruby,確實允許在事後修改類。像這樣的語言實現如何支援類的修改,同時保持方法解析的效率呢?
-
In the jlox chapter on inheritance, we had a challenge to implement the BETA language’s approach to method overriding. Solve the challenge again, but this time in clox. Here’s the description of the previous challenge:
在jlox關於繼承的章節中,我們有一個習題,是實現BETA語言的方法重寫。再次解決這個習題,但這次是在clox中。下面是對之前習題的描述:
In Lox, as in most other object-oriented languages, when looking up a method, we start at the bottom of the class hierarchy and work our way up—a subclass’s method is preferred over a superclass’s. In order to get to the superclass method from within an overriding method, you use
super.在Lox中,和其它大多數面向物件的語言一樣,當查詢一個方法時,我們從類層次結構的底部開始,然後向上查詢——子類的方法優於超類的方法。要想在子類方法中訪問超類方法,可以使用
super。The language BETA takes the opposite approach. When you call a method, it starts at the top of the class hierarchy and works down. A superclass method wins over a subclass method. In order to get to the subclass method, the superclass method can call
inner, which is sort of like the inverse ofsuper. It chains to the next method down the hierarchy.BETA語言則採取了相反的方法。當你呼叫某個方法時,它從類層次結構的頂部開始向下執行。超類方法優於子類方法。要想訪問子類方法,超類方法中可以呼叫
inner(),這有點像是super的反義詞。它會連結到層次結構中的下一個方法。The superclass method controls when and where the subclass is allowed to refine its behavior. If the superclass method doesn’t call
innerat all, then the subclass has no way of overriding or modifying the superclass’s behavior.超類方法控制著子類何時何地被允許完善其行為。如果超類方法根本不呼叫
inner,那麼子類就沒有辦法覆寫或修改超類的行為。Take out Lox’s current overriding and
superbehavior, and replace it with BETA’s semantics. In short:去掉Lox中當前的覆寫和
super行為,替換為BETA的語義。簡而言之:- When calling a method on a class, the method highest on the class’s inheritance chain takes precedence.
- Inside the body of a method, a call to
innerlooks for a method with the same name in the nearest subclass along the inheritance chain between the class containing theinnerand the class ofthis. If there is no matching method, theinnercall does nothing.
- 當呼叫某個類中的方法時,該類繼承鏈上最高的方法優先。
- 在方法體內部,對
inner的呼叫,會沿著包含inner的類和this的類之間的繼承鏈,在最近的子類中查詢同名的方法。如果沒有匹配的方法,inner呼叫就什麼也不做。
For example:
舉例來說:
class Doughnut { cook() { print "Fry until golden brown."; inner(); print "Place in a nice box."; } } class BostonCream < Doughnut { cook() { print "Pipe full of custard and coat with chocolate."; } } BostonCream().cook();This should print:
這裡應該列印:
Fry until golden brown. Pipe full of custard and coat with chocolate. Place in a nice box.Since clox is about not just implementing Lox, but doing so with good performance, this time around try to solve the challenge with an eye towards efficiency.
因為clox不僅僅是實現Lox,而是要以良好的效能來實現,所以這次要嘗試以效率為導向來解決這個問題。
-
這個“只是”並不意味著加速不重要!畢竟,我們的第二個虛擬機器的全部目的就是比jlox有更好的效能。你可以認為,前面的15章都是“最佳化”。 ↩
-
有趣的是,根據我們實現方法繼承的方式,我認為允許迴圈實際上不會在clox中引起任何問題。它不會做任何有用的事情,但我認為它不會導致崩潰或無限迴圈。 ↩
-
好吧,我想應該是兩次雜湊查詢。因為首先我們必須確保例項上的欄位不會遮蔽方法。 ↩
-
可以想見,在執行時改變某個類中以命令式定義的方法集會使得對程式的推理變得困難。這是一個非常強大的工具,但也是一個危險的工具。
那些認為這個工具可能有點太危險的人,給它取了個不倫不類的名字“猴子補丁”,或者是更不體面的“鴨子打洞”。 ↩ -
“可能”這個詞也許不夠有力。大概這個方法已經被重寫了。否則,你為什麼要費力地使用
super而不是直接呼叫它呢? ↩ -
我說“常量字串”是因為標識不對其詞素做任何記憶體管理。如果我們試圖使用堆分配的字串,最終會洩漏記憶體,因為它永遠不會被釋放。但是,C語言字串字面量的記憶體位於可執行檔案的常量資料部分,永遠不需要釋放,所以我們這樣沒有問題。 ↩
-
就是這樣,朋友,你要新增到解析表中的最後一項。 ↩
-
假設性問題:如果一個光禿禿的
super標識是一個表示式,那麼它會被計算為哪種物件呢? ↩ -
與
OP_GET_PROPERTY相比的另一個區別是,我們不會先嚐試尋找遮蔽欄位。欄位不會被繼承,所以super表示式總是解析為方法。
如果Lox是一種使用委託而不是繼承的基於原型的語言,那麼就不是一個類繼承另一個類,而是例項繼承自(委託給)其它例項。在這種情況下,欄位可以被繼承,我們就需要在這裡檢查它們。 ↩
30.最佳化 Optimization
The evening’s the best part of the day. You’ve done your day’s work. Now you can put your feet up and enjoy it.
——Kazuo Ishiguro, The Remains of the Day
夜晚是一天中最美好的時光。你已經完成了一天的工作,現在你可以雙腿擱平,享受一下。(石黑一雄,《長日將盡》)
If I still lived in New Orleans, I’d call this chapter a lagniappe, a little something extra given for free to a customer. You’ve got a whole book and a complete virtual machine already, but I want you to have some more fun hacking on clox. This time, we’re going for pure performance. We’ll apply two very different optimizations to our virtual machine. In the process, you’ll get a feel for measuring and improving the performance of a language implementation—or any program, really.
如果我還住在新奧爾良,我會把這一章稱為lagniappe(小贈品),即免費送給顧客的一點額外的東西。你已經有了一整本書和一個完整的虛擬機器,但我希望你能在clox上獲得更多的樂趣。這一次,我們要追求的是純粹的效能。我們將對虛擬機器應用兩種截然不同的最佳化。在這個過程中,你將瞭解如何測量和提高語言實現的效能——或者說任何程式的效能,真的。
30 . 1 Measuring Performance
30.1 測量效能
Optimization means taking a working application and improving its performance. An optimized program does the same thing, it just takes less resources to do so. The resource we usually think of when optimizing is runtime speed, but it can also be important to reduce memory usage, startup time, persistent storage size, or network bandwidth. All physical resources have some cost—even if the cost is mostly in wasted human time—so optimization work often pays off.
最佳化是指拿到一個基本可用的應用程式並提高其效能。一個最佳化後的程式能做到同樣的事情,只是需要更少的資源。我們在最佳化時通常考慮的資源是執行時速度,但減少記憶體使用、啟動時間、持久化儲存大小或網路頻寬也很重要。所有的物理資源都有一定的成本——即使成本主要是浪費人力時間,所以最佳化工作通常都能得到回報。
There was a time in the early days of computing that a skilled programmer could hold the entire hardware architecture and compiler pipeline in their head and understand a program’s performance just by thinking real hard. Those days are long gone, separated from the present by microcode, cache lines, branch prediction, deep compiler pipelines, and mammoth instruction sets. We like to pretend C is a “low-level” language, but the stack of technology between
printf("Hello, world!");and a greeting appearing on screen is now perilously tall.
在計算機早期,曾經有一段時間,一個熟練的程式設計師可以把整個硬體架構和編譯器管道記在腦子裡,只需要認真思考就可以瞭解程式的效能。那些日子早已一去不復返了,現在已經被微碼、快取線、分支預測、深層編譯器管道和龐大的指令集所分隔。我們喜歡假裝C語言是一種“低階”語言,但在printf("Hello, world!");和螢幕上出現的問候語之間的技術棧現在已經很高了。
Optimization today is an empirical science. Our program is a border collie sprinting through the hardware’s obstacle course. If we want her to reach the end faster, we can’t just sit and ruminate on canine physiology until enlightenment strikes. Instead, we need to observe her performance, see where she stumbles, and then find faster paths for her to take.
今天的最佳化是一門經驗科學。我們的程式是一隻在硬體障礙賽中衝刺的邊牧。如果我們想讓她更快地到達終點,我們不能只是坐在那裡思考犬類的生理機能,等著靈光乍現。相反,我們需要觀察她的表現,看看她在那裡出錯,然後為她找到更快的路徑。
Much like agility training is particular to one dog and one obstacle course, we can’t assume that our virtual machine optimizations will make all Lox programs run faster on all hardware. Different Lox programs stress different areas of the VM, and different architectures have their own strengths and weaknesses.
就像敏捷訓練要真的一隻狗和一項障礙賽,我們不能假設我們的虛擬機器最佳化會使所有的Lox程式在所有硬體上執行得更快。不同的Lox程式側重虛擬機器的不同領域,不同的架構也有其自身的優勢和劣勢。
30 . 1 . 1 Benchmarks
When we add new functionality, we validate correctness by writing tests—Lox programs that use a feature and validate the VM’s behavior. Tests pin down semantics and ensure we don’t break existing features when we add new ones. We have similar needs when it comes to performance:
當我們新增新功能時,我們透過編寫測試來驗證正確性——使用某個特性並驗證虛擬機器行為的Lox程式。測試可以約束語義,並確保在新增新功能時,不會破壞現有的特性。在效能方面,我們也有類似的需求:
- How do we validate that an optimization does improve performance, and by how much?
- How do we ensure that other unrelated changes don’t regress performance?
- 我們如何驗證一項最佳化確實提高了效能,以及提高了多少?
- 我們如何確保其它不相關的修改不會使效能退步?
The Lox programs we write to accomplish those goals are benchmarks. These are carefully crafted programs that stress some part of the language implementation. They measure not what the program does, but how long it takes to do it.
我們為實現這些目標而編寫的Lox程式就是基準。這些都是精心設計的程式,側重於語言實現的某些部分。它們測量的不是程式做了什麼,而是做完這些需要多久1。
By measuring the performance of a benchmark before and after a change, you can see what your change does. When you land an optimization, all of the tests should behave exactly the same as they did before, but hopefully the benchmarks run faster.
透過測量修改前後的基準效能,你可以看到修改的效果。當你完成最佳化時,所有測試都應該與之前的行為完全一樣,只是希望基準程式執行更快一點。
Once you have an entire suite of benchmarks, you can measure not just that an optimization changes performance, but on which kinds of code. Often you’ll find that some benchmarks get faster while others get slower. Then you have to make hard decisions about what kinds of code your language implementation optimizes for.
一旦你有了一整套的基準測試,你不僅可以衡量某個最佳化是否改變了效能,而且可以衡量改變了哪類程式碼的效能。通常,你會發現一些基準測試變得更快,而另一些則變得更慢。然後你必須作出艱難的決策:你的語言實現要對哪種程式碼進行最佳化。
The suite of benchmarks you choose to write is a key part of that decision. In the same way that your tests encode your choices around what correct behavior looks like, your benchmarks are the embodiment of your priorities when it comes to performance. They will guide which optimizations you implement, so choose your benchmarks carefully, and don’t forget to periodically reflect on whether they are helping you reach your larger goals.
你選擇編寫的基準套件是該決策的一部分。就像你的測試程式碼編碼了關於正確程式碼行為的選擇,你的基準測試是你在效能方面側重點的體現。它們將指導你實現哪些最佳化,所以要仔細選擇你的基準測試,並且不要忘記定期反思它們是否能幫助你實現更大的目標2。
Benchmarking is a subtle art. Like tests, you need to balance not overfitting to your implementation while ensuring that the benchmark does actually tickle the code paths that you care about. When you measure performance, you need to compensate for variance caused by CPU throttling, caching, and other weird hardware and operating system quirks. I won’t give you a whole sermon here, but treat benchmarking as its own skill that improves with practice.
基準測試是一門微妙的藝術。就像測試一樣,你需要在不過度擬合語言實現的同時,確保基準測試確實適合你所關心的程式碼路徑。在測量效能時,你需要補償由CPU節流、快取和其它奇怪的硬體和作業系統特性造成的差異。我不會在這裡給你一個完整的說教,但請把基準測試當作可以透過實踐來提高的一門技能。
30 . 1 . 2 Profiling
30.1.2 剖析
OK, so you’ve got a few benchmarks now. You want to make them go faster. Now what? First of all, let’s assume you’ve done all the obvious, easy work. You are using the right algorithms and data structures—or, at least, you aren’t using ones that are aggressively wrong. I don’t consider using a hash table instead of a linear search through a huge unsorted array “optimization” so much as “good software engineering”.
好的,現在你已經有了一些基準測試。你想讓它們走得更快,現在怎麼辦呢?首先,我們假設你已經完成了所有明顯的、簡單的工作。你使用了正確的演算法和資料結構——或者,至少你沒有使用那些嚴重錯誤的演算法和資料結構。我認為使用雜湊表代替巨大的無序陣列進行線性搜尋不是“最佳化”,而是“良好的軟體工程實現”。
Since the hardware is too complex to reason about our program’s performance from first principles, we have to go out into the field. That means profiling. A profiler, if you’ve never used one, is a tool that runs your program and tracks hardware resource use as the code executes. Simple ones show you how much time was spent in each function in your program. Sophisticated ones log data cache misses, instruction cache misses, branch mispredictions, memory allocations, and all sorts of other metrics.
由於硬體太過複雜,無法從基本原理推斷出程式的效能,所以我們必須深入實地。這意味著剖析。剖析器(如果你從未使用過)是一種工具,可以執行你的程式並在程式碼執行過程中跟蹤硬體資源的使用情況3。簡單的剖析器可以向你展示程式中每個函式花費了多少時間。複雜的剖析器則會記錄資料快取缺失、指令快取缺失、分支預測錯誤、記憶體分配和其它各種指標。
There are many profilers out there for various operating systems and languages. On whatever platform you program, it’s worth getting familiar with a decent profiler. You don’t need to be a master. I have learned things within minutes of throwing a program at a profiler that would have taken me days to discover on my own through trial and error. Profilers are wonderful, magical tools.
現在有很多針對不同作業系統和語言的剖析器。無論你在什麼平臺上程式設計,熟悉一個像樣的剖析器都是值得的。你不需要稱為大師。我在把程式扔給剖析器的幾分鐘內就學到了很多東西,而這些東西是我自己透過反覆試驗好幾天才發現的。剖析器是一種絕妙、神奇的工具。
30 . 2 Faster Hash Table Probing
30.2 更快的雜湊表探測
Enough pontificating, let’s get some performance charts going up and to the right. The first optimization we’ll do, it turns out, is about the tiniest possible change we could make to our VM.
廢話說得夠多了,我們來讓效能圖表趨向右上方(提升效能)。我們要做的第一個最佳化,事實證明也是我們可以對虛擬機器所做出的最微小的改變。
When I first got the bytecode virtual machine that clox is descended from working, I did what any self-respecting VM hacker would do. I cobbled together a couple of benchmarks, fired up a profiler, and ran those scripts through my interpreter. In a dynamically typed language like Lox, a large fraction of user code is field accesses and method calls, so one of my benchmarks looked something like this:
當我第一次讓clox派生的位元組碼虛擬機器工作時,我做了任何有自尊心的虛擬機器駭客都會做的事情。我拼湊了幾個基準測試,啟動了一個剖析器,並透過我的直譯器運行了這些指令碼。在Lox這樣的動態型別語言中,使用者程式碼的很大一部分是欄位訪問和方法呼叫,所以我的其中一個基準測試看起來是這樣的4:
class Zoo {
init() {
this.aardvark = 1;
this.baboon = 1;
this.cat = 1;
this.donkey = 1;
this.elephant = 1;
this.fox = 1;
}
ant() { return this.aardvark; }
banana() { return this.baboon; }
tuna() { return this.cat; }
hay() { return this.donkey; }
grass() { return this.elephant; }
mouse() { return this.fox; }
}
var zoo = Zoo();
var sum = 0;
var start = clock();
while (sum < 100000000) {
sum = sum + zoo.ant()
+ zoo.banana()
+ zoo.tuna()
+ zoo.hay()
+ zoo.grass()
+ zoo.mouse();
}
print clock() - start;
print sum;
If you’ve never seen a benchmark before, this might seem ludicrous. What is going on here? The program itself doesn’t intend to do anything useful. What it does do is call a bunch of methods and access a bunch of fields since those are the parts of the language we’re interested in. Fields and methods live in hash tables, so it takes care to populate at least a few interesting keys in those tables. That is all wrapped in a big loop to ensure our profiler has enough execution time to dig in and see where the cycles are going.
如果你以前從未見過基準測試,那這個看起來可能會很好笑。這是怎麼回事?這個程式本身並不打算做任何有用的事情。它所做的就是呼叫一堆方法和訪問一堆欄位,因為這些是語言中我們感興趣的部分。欄位和方法都在雜湊表中,因此需要小心地在這些表中至少填入幾個有趣的鍵5。這一切都包裝在一個大迴圈中,以確保我們的剖析器有足夠的執行時間來挖掘和檢視迴圈的走向。
Before I tell you what my profiler showed me, spend a minute taking a few guesses. Where in clox’s codebase do you think the VM spent most of its time? Is there any code we’ve written in previous chapters that you suspect is particularly slow?
在我告訴你剖析器顯示了什麼之前,先花點時間猜一下。你認為在clox的程式碼庫中,虛擬機器的大部分時間都花在了哪裡?我們在前幾章所寫的程式碼中,有沒有你懷疑特別慢的?
Here’s what I found: Naturally, the function with the greatest inclusive time is
run(). (Inclusive time means the total time spent in some function and all other functions it calls—the total time between when you enter the function and when it returns.) Sincerun()is the main bytecode execution loop, it drives everything.
下面是我的發現:自然,非獨佔時間最大的函式是run()。(**非獨佔時間(Inclusive time)**是指在某個函式及其呼叫的所有其它函式中所花費的總時間——即從你進入函式到函式返回之間的總時間。)因為run()是主要的位元組碼執行迴圈,它驅動著一切。
Inside
run(), there are small chunks of time sprinkled in various cases in the bytecode switch for common instructions likeOP_POP,OP_RETURN, andOP_ADD. The big heavy instructions areOP_GET_GLOBALwith 17% of the execution time,OP_GET_PROPERTYat 12%, andOP_INVOKEwhich takes a whopping 42% of the total running time.
在run()內部,有小塊的時間視不同情況分散在如OP_POP、OP_RETURN、OP_ADD等常見指令中。較大的重磅指令是佔執行時間17%的OP_GET_GLOBAL,佔12%的OP_GET_PROPERTY,還有佔總執行時間的42%的OP_INVOKE。
So we’ve got three hotspots to optimize? Actually, no. Because it turns out those three instructions spend almost all of their time inside calls to the same function:
tableGet(). That function claims a whole 72% of the execution time (again, inclusive). Now, in a dynamically typed language, we expect to spend a fair bit of time looking stuff up in hash tables—it’s sort of the price of dynamism. But, still, wow.
所以我們有三個熱點需要最佳化?事實上,並不是。因為事實證明,這三條指令幾乎所有的時間都花在了呼叫同一個函式上:tableGet()。這個函式佔用了整整72%的執行時間(同樣的,非獨佔時間)。現在,在一個動態型別語言中,我們預想到會花費相當多的時間在雜湊表中查詢內容——這算是動態的代價,但是,仍舊讓人驚歎。
30 . 2 . 1 Slow key wrapping
30.2.1 緩慢的鍵包裝
If you take a look at
tableGet(), you’ll see it’s mostly a wrapper around a call tofindEntry()where the actual hash table lookup happens. To refresh your memory, here it is in full:
如果檢視一下tableGet(),你會發現它主要是對findEntry()呼叫的一個包裝,而findEntry()是真正進行雜湊表查詢的地方。為了喚起你的記憶,下面是它的全部內容:
static Entry* findEntry(Entry* entries, int capacity,
ObjString* key) {
uint32_t index = key->hash % capacity;
Entry* tombstone = NULL;
for (;;) {
Entry* entry = &entries[index];
if (entry->key == NULL) {
if (IS_NIL(entry->value)) {
// Empty entry.
return tombstone != NULL ? tombstone : entry;
} else {
// We found a tombstone.
if (tombstone == NULL) tombstone = entry;
}
} else if (entry->key == key) {
// We found the key.
return entry;
}
index = (index + 1) % capacity;
}
}
When running that previous benchmark—on my machine, at least—the VM spends 70% of the total execution time on one line in this function. Any guesses as to which one? No? It’s this:
在執行之前的基準測試時——至少在我的機器上是這樣——虛擬機器將總執行時間的70%花費在這個函式的一行程式碼上。能猜到是哪一行嗎?猜不到?是這一行:
uint32_t index = key->hash % capacity;
That pointer dereference isn’t the problem. It’s the little
%. It turns out the modulo operator is really slow. Much slower than other arithmetic operators. Can we do something better?
問題不在於指標解引用,而是那個小小的%。事實證明,取模運算子真的很慢。比其它算術運算子慢得多6。我們能做得更好嗎?
In the general case, it’s really hard to re-implement a fundamental arithmetic operator in user code in a way that’s faster than what the CPU itself can do. After all, our C code ultimately compiles down to the CPU’s own arithmetic operations. If there were tricks we could use to go faster, the chip would already be using them.
在一般情況下,要想在使用者程式碼中重新實現一個算術運算子,而且要比CPU本身的運算速度更快,這是非常難的。畢竟,我們的C程式碼最終會被編譯為CPU自己的算術運算。如果有什麼技巧可以加速運算,晶片早就在使用了。
However, we can take advantage of the fact that we know more about our problem than the CPU does. We use modulo here to take a key string’s hash code and wrap it to fit within the bounds of the table’s entry array. That array starts out at eight elements and grows by a factor of two each time. We know—and the CPU and C compiler do not—that our table’s size is always a power of two.
然而,我們可以利用這一事實:我們比CPU更瞭解我們的問題。我們在這裡使用取模將鍵字串的雜湊碼包裝到表的項陣列的大小範圍內。該陣列開始時有8個元素,每次增加2倍。我們知道(CPU和C編譯器都不知道)我們的表大小總是2的冪。
Because we’re clever bit twiddlers, we know a faster way to calculate the remainder of a number modulo a power of two: bit masking. Let’s say we want to calculate 229 modulo 64. The answer is 37, which is not particularly apparent in decimal, but is clearer when you view those numbers in binary:
因為我們是聰明的位操作者,我們知道一個更快的方法來計算一個數以2的冪為模的餘數:位掩碼。假設我們要計算229對64取模。答案是37,這在十進制中不是特別明顯,但當你用二進位制檢視這些數字時,就會更清楚:

On the left side of the illustration, notice how the result (37) is simply the dividend (229) with the highest two bits shaved off? Those two highest bits are the bits at or to the left of the divisor’s single 1 bit.
在圖的左側,注意結果(37)是如何簡單地將除數(229)的最高兩位削除?這兩個最高的位是被除數第一個1及其左側的位元位。
On the right side, we get the same result by taking 229 and bitwise AND-ing it with 63, which is one less than our original power of two divisor. Subtracting one from a power of two gives you a series of 1 bits. That is exactly the mask we need in order to strip out those two leftmost bits.
在右邊,我們將299和63(原來的2的冪除數減一)進行按位與操作,也可以得到同樣的結果。2的冪減去1會得到一系列的1位元。這正是我們需要的掩碼,以便剝離掉最左側的兩個位元。
In other words, you can calculate a number modulo any power of two by simply AND-ing it with that power of two minus one. I’m not enough of a mathematician to prove to you that this works, but if you think it through, it should make sense. We can replace that slow modulo operator with a very fast decrement and bitwise AND. We simply change the offending line of code to this:
換句話說,要計算某個數與任何2的冪的模數,你可以簡單地將該數與2的冪減1進行位相與。我不是一個數學家,無法向你證明這一點,但如果你仔細想想,這應該是有道理的。我們可以用一個非常快的減法和按位與運算來替換那個緩慢的模運算。我們只是簡單地將那行程式碼改為:
table.c,在findEntry()方法中替換1行:
static Entry* findEntry(Entry* entries, int capacity,
ObjString* key) {
// 替換部分開始
uint32_t index = key->hash & (capacity - 1);
// 替換部分結束
Entry* tombstone = NULL;
CPUs love bitwise operators, so it’s hard to improve on that.
CPU喜歡位運算,因此很難在此基礎上進行改進7。
Our linear probing search may need to wrap around the end of the array, so there is another modulo in
findEntry()to update.
我們的線性探測搜尋可能需要在陣列的末尾繞回起點,所以在findEntry()中還有一個模運算需要更新。
table.c,在findEntry()方法中替換1行:
// We found the key.
return entry;
}
// 替換部分開始
index = (index + 1) & (capacity - 1);
// 替換部分結束
}
This line didn’t show up in the profiler since most searches don’t wrap.
這一行沒有出現在剖析器中,是因為大部分搜尋都不需要繞回。
The
findEntry()function has a sister function,tableFindString()that does a hash table lookup for interning strings. We may as well apply the same optimizations there too. This function is called only when interning strings, which wasn’t heavily stressed by our benchmark. But a Lox program that created lots of strings might noticeably benefit from this change.
findEntry()函式有一個姊妹函式,tableFindString(),它為駐留的字串做雜湊表查詢。我們不妨在這裡也應用同樣的最佳化。該函式只在對字串進行駐留時才會被呼叫,我們的基準測試中沒有特別側重這一點。但是一個建立大量字串的Lox程式可能會從這個調整中明顯受益。
table.c,在tableFindString()方法中替換1行:
if (table->count == 0) return NULL;
// 替換部分開始
uint32_t index = hash & (table->capacity - 1);
// 替換部分結束
for (;;) {
Entry* entry = &table->entries[index];
And also when the linear probing wraps around.
當線性探索繞回起點時也是如此。
table.c,在tableFindString()方法中替換1行:
return entry->key;
}
// 替換部分開始
index = (index + 1) & (table->capacity - 1);
// 替換部分結束
}
Let’s see if our fixes were worth it. I tweaked that zoological benchmark to count how many batches of 10,000 calls it can run in ten seconds. More batches equals faster performance. On my machine using the unoptimized code, the benchmark gets through 3,192 batches. After this optimization, that jumps to 6,249.
來看看我們的修補是否值得。我調整了前面的動物學基準測試,計算它能在10秒內執行多少批的10000次呼叫8。處理批次越多,效能越快。在我的機器上,使用未最佳化的程式碼,基準測試可以執行3192個批次。經過最佳化之後,這個數字躍升到了6249。

That’s almost exactly twice as much work in the same amount of time. We made the VM twice as fast (usual caveat: on this benchmark). That is a massive win when it comes to optimization. Usually you feel good if you can claw a few percentage points here or there. Since methods, fields, and global variables are so prevalent in Lox programs, this tiny optimization improves performance across the board. Almost every Lox program benefits.
在同樣的時間內,工作量幾乎是原來的兩倍。我們讓虛擬機器的速度提高了一倍(警告:在這個基準測試中)。對於最佳化來說,這是一個巨大的勝利。通常情況下,如果你能在這裡或那裡提升幾個百分點,你都會感覺很好。因為方法、欄位和全域性變數在Lox程式中非常普遍,因此這個微小的最佳化可以全面提高效能。幾乎每個Lox程式都會受益。
Now, the point of this section is not that the modulo operator is profoundly evil and you should stamp it out of every program you ever write. Nor is it that micro-optimization is a vital engineering skill. It’s rare that a performance problem has such a narrow, effective solution. We got lucky.
現在,本節的重點不是說取模運算子非常邪惡,你要把它從你寫的每個程式中剔除。也不是說微最佳化是一項重要的工程技能。很少有一個效能問題具有如此狹窄、有效的解決方案。我們很幸運。
The point is that we didn’t know that the modulo operator was a performance drain until our profiler told us so. If we had wandered around our VM’s codebase blindly guessing at hotspots, we likely wouldn’t have noticed it. What I want you to take away from this is how important it is to have a profiler in your toolbox.
關鍵在於,直到剖析器告訴我們,我們才知道取模運算子是一個效能損耗。如果我們在虛擬機器的程式碼庫中盲目地猜測熱點,我們可能不會注意到它。我想讓你從中學到的是,在你的工具箱中擁有一個剖析器是多麼重要。
To reinforce that point, let’s go ahead and run the original benchmark in our now-optimized VM and see what the profiler shows us. On my machine,
tableGet()is still a fairly large chunk of execution time. That’s to be expected for a dynamically typed language. But it has dropped from 72% of the total execution time down to 35%. That’s much more in line with what we’d like to see and shows that our optimization didn’t just make the program faster, but made it faster in the way we expected. Profilers are as useful for verifying solutions as they are for discovering problems.
為了強化這一點,我們繼續在現在已最佳化的虛擬機器中執行最初的基準測試,看看剖析器會顯示什麼。在我的機器上,tableGet()仍然佔用了相當大的執行時間。對於動態型別的語言來說,這是可以預期的結果。但是它已經從72%下降到了35%。這更符合我們希望看到的情況,表明我們的最佳化不僅使程式更快,而且是以預期的方式使它更快。剖析器在驗證解決方法時和發現問題時一樣有用。
30 . 3 NaN Boxing
30.3 NaN裝箱
This next optimization has a very different feel. Thankfully, despite the odd name, it does not involve punching your grandmother. It’s different, but not, like, that different. With our previous optimization, the profiler told us where the problem was, and we merely had to use some ingenuity to come up with a solution.
接下來的這個最佳化有著非常不同的感覺。值得慶幸的是,雖然它的名字很奇怪,但它並不會推翻一切。確實不同,但不會那麼不同。在我們之前的最佳化中,剖析器會告訴我們問題出在哪裡,而我們只需要發揮一些聰明才智就可以想出解決方案。
This optimization is more subtle, and its performance effects more scattered across the virtual machine. The profiler won’t help us come up with this. Instead, it was invented by someone thinking deeply about the lowest levels of machine architecture.
這個最佳化更加微妙,它對效能的影響在虛擬機器在更加分散。剖析器無法幫我們找到它。相反,它是由一個對機器架構底層進行深入思考的人發明的9。
Like the heading says, this optimization is called NaN boxing or sometimes NaN tagging. Personally I like the latter name because “boxing” tends to imply some kind of heap-allocated representation, but the former seems to be the more widely used term. This technique changes how we represent values in the VM.
正如標題所說,這種最佳化稱為NaN裝箱,有時也被稱為NaN標記。我個人更喜歡後者,因為“裝箱”往往意味著某種堆分配的表示形式,但前者似乎是使用廣泛的術語。這種技術改變了我們在虛擬機器中表示值的方式。
On a 64-bit machine, our Value type takes up 16 bytes. The struct has two fields, a type tag and a union for the payload. The largest fields in the union are an Obj pointer and a double, which are both 8 bytes. To keep the union field aligned to an 8-byte boundary, the compiler adds padding after the tag too:
在64位機器上,我們的Value型別佔用了16個位元組。該結構體中有兩個欄位,一個型別標籤和一個儲存有效載荷的聯合體。聯合體中最大的欄位是一個Obj指標和一個double值,都是8位元組。為了使聯合體欄位與8位元組邊界對齊,編譯器也在標籤後面添加了填充:

That’s pretty big. If we could cut that down, then the VM could pack more values into the same amount of memory. Most computers have plenty of RAM these days, so the direct memory savings aren’t a huge deal. But a smaller representation means more Values fit in a cache line. That means fewer cache misses, which affects speed.
真可真夠大的。如果我們能把它減少,那虛擬機器就能在相同的記憶體中裝入更多的值。現在大多數計算機都有足夠的RAM,所以節省直接記憶體不是什麼大問題。但是更小的表示方式意味著有更多的值可以放入快取行中。這意味著更少的快取失誤,從而影響速度。
If Values need to be aligned to their largest payload size, and a Lox number or Obj pointer needs a full 8 bytes, how can we get any smaller? In a dynamically typed language like Lox, each value needs to carry not just its payload, but enough additional information to determine the value’s type at runtime. If a Lox number is already using the full 8 bytes, where could we squirrel away a couple of extra bits to tell the runtime “this is a number”?
既然Value需要與最大的有效載荷對齊,而且Lox數值或Obj指標需要完整的8個位元組,那我們如何才能變得更小呢?在Lox這樣的動態型別語言中,每個值不僅需要攜帶其有效載荷,還需要攜帶足夠多的附加資訊,以便在執行時確定值的型別。如果一個Lox的數字已經用了整整8個位元組,那我們可以在哪裡偷取兩個額外的位元來告訴執行時“這是一個數字”?
This is one of the perennial problems for dynamic language hackers. It particularly bugs them because statically typed languages don’t generally have this problem. The type of each value is known at compile time, so no extra memory is needed at runtime to track it. When your C compiler compiles a 32-bit int, the resulting variable gets exactly 32 bits of storage.
這是動態語言駭客長期面臨的問題之一。因為靜態型別語言通常不存在這個問題,所以這讓他們特別困擾。每個值的型別在編譯時就已經知道了,所以在執行時不需要額外的記憶體來記錄這些資訊。當你的C語言編譯器編譯一個32位的int時,產生的變數會得到正好32位的儲存空間。
Dynamic language folks hate losing ground to the static camp, so they’ve come up with a number of very clever ways to pack type information and a payload into a small number of bits. NaN boxing is one of those. It’s a particularly good fit for languages like JavaScript and Lua, where all numbers are double-precision floating point. Lox is in that same boat.
動態語言的人討厭輸給靜態陣營,所以他們想出了許多非常聰明的方法,將型別資訊和有效載荷打包到少量的位元中。NaN裝箱就是其中之一。它特別適合於像JavaScript和Lua這樣的語言,在這些語言中,所有數字都是雙精度浮點數。Lox也是如此。
30 . 3 . 1 What is (and is not) a number?
30.3.1 什麼是(以及不是)數值?
Before we start optimizing, we need to really understand how our friend the CPU represents floating-point numbers. Almost all machines today use the same scheme, encoded in the venerable scroll IEEE 754, known to mortals as the “IEEE Standard for Floating-Point Arithmetic”.
在開始最佳化之前,我們需要真正瞭解我們的朋友CPU是如何表示浮點數的。現在幾乎所有的機器都使用相同的方案,編碼在古老的卷軸IEEE 754中,凡人們稱之為“IEEE浮點運算標準”。
In the eyes of your computer, a 64-bit, double-precision, IEEE floating-point number looks like this:
在你的計算機看來,一個64位、雙精度的IEEE浮點數是這樣的:

- Starting from the right, the first 52 bits are the fraction, mantissa, or significand bits. They represent the significant digits of the number, as a binary integer.
- Next to that are 11 exponent bits. These tell you how far the mantissa is shifted away from the decimal (well, binary) point.
- The highest bit is the sign bit, which indicates whether the number is positive or negative.
- 從右邊開始,前52位是分數、尾數或有效位。它們以二進位制整數形式表示數值的有效數字。
- 接下來是11個指數位。它們會告訴你尾數中的小數點要移動多少位。
- 最高的位是符號位,表示這個數值是正數還是負數10。
I know that’s a little vague, but this chapter isn’t a deep dive on floating point representation. If you want to know how the exponent and mantissa play together, there are already better explanations out there than I could write.
我知道這有一點模糊,但這一章並不是對浮點數表示法的深入探討。如果你想知道指數和尾數是如何互相作用的,外面已經有比我寫得更好的解釋了。
The important part for our purposes is that the spec carves out a special case exponent. When all of the exponent bits are set, then instead of just representing a really big number, the value has a different meaning. These values are “Not a Number” (hence, NaN) values. They represent concepts like infinity or the result of division by zero.
對於我們的目的來說,重要的部分是該規範列出了一個特殊情況下的指數。當指數位全部置為1,這個值就不再表示一個非常大的數字了,而是有著不同的含義。這些值是“非數字”(Not a Number,即NaN)值。它們代表了像無窮或除0結果這樣的概念。
Any double whose exponent bits are all set is a NaN, regardless of the mantissa bits. That means there’s lots and lots of different NaN bit patterns. IEEE 754 divides those into two categories. Values where the highest mantissa bit is 0 are called signalling NaNs, and the others are quiet NaNs. Signalling NaNs are intended to be the result of erroneous computations, like division by zero. A chip may detect when one of these values is produced and abort a program completely. They may self-destruct if you try to read one.
任何指數位全部被置為1的double數都是NaN,無論尾數位是什麼。這意味著有很多不同的NaN模式。IEEE 754將其分為兩類。最高尾數位為0的值被稱為訊號NaN,其它的是靜默NaN。訊號NaN是錯誤計算的結果,如除以0。當這些值被生成時,晶片可以檢測到並完全中止程式11。如果你試圖讀取這些值,它們可能會自毀。
Quiet NaNs are supposed to be safer to use. They don’t represent useful numeric values, but they should at least not set your hand on fire if you touch them.
靜默NaN使用起來更安全。它們不代表有用的數值,但它們至少不會一碰就著。
Every double with all of its exponent bits set and its highest mantissa bit set is a quiet NaN. That leaves 52 bits unaccounted for. We’ll avoid one of those so that we don’t step on Intel’s “QNaN Floating-Point Indefinite” value, leaving us 51 bits. Those remaining bits can be anything. We’re talking 2,251,799,813,685,248 unique quiet NaN bit patterns.
每一個所有指數位置1、最高尾數位置1的double都是一個靜默NaN。這就留下了52個未解釋的位。我們會避開其中一個,這樣我們就不會踩到Intel的“QNaN浮點不確定”值,剩下51位。這些剩餘的位元可以是任何東西。我們現在說的是2,251,799,813,685,248獨一無二的靜默NaN位模式。

This means a 64-bit double has enough room to store all of the various different numeric floating-point values and also has room for another 51 bits of data that we can use however we want. That’s plenty of room to set aside a couple of bit patterns to represent Lox’s
nil,true, andfalsevalues. But what about Obj pointers? Don’t pointers need a full 64 bits too?
這意味著一個64位的double有足夠的框架儲存所有不同的浮點數值,還有52位的資料空間供我們隨意使用。這樣就有足夠的空間來預留幾個位來表示Lox的nil、true和false值。但是Obj的指標呢?指標不是也需要64位嗎?
Fortunately, we have another trick up our other sleeve. Yes, technically pointers on a 64-bit architecture are 64 bits. But, no architecture I know of actually uses that entire address space. Instead, most widely used chips today only ever use the low 48 bits. The remaining 16 bits are either unspecified or always zero.
幸運的是,我們還有另一個妙招。是的,從技術上講,64位架構上的指標是64位的。但是,我所知道的架構中沒有一個真正使用了整個地址空間。相反,如今大多數廣泛使用的晶片只使用低48位12。剩餘16位要麼未指定,要麼始終為零。
If we’ve got 51 bits, we can stuff a 48-bit pointer in there with three bits to spare. Those three bits are just enough to store tiny type tags to distinguish between
nil, Booleans, and Obj pointers.
如果我們有51位元位,可以把一個48位的指標塞進去,還有3位元位的空閒。這三個位元位剛好可以用來儲存微小的型別標記來區分nil、布林值和Obj指標。
That’s NaN boxing. Within a single 64-bit double, you can store all of the different floating-point numeric values, a pointer, or any of a couple of other special sentinel values. Half the memory usage of our current Value struct, while retaining all of the fidelity.
這就是NaN裝箱。在一個64位的double中,你可以儲存所有不同的浮點數值、一個指標或其它一些特殊的標示值。這比我們當前Value結構體少了一半的記憶體佔用量,同時保留了所有的精確性。
What’s particularly nice about this representation is that there is no need to convert a numeric double value into a “boxed” form. Lox numbers are just normal, 64-bit doubles. We still need to check their type before we use them, since Lox is dynamically typed, but we don’t need to do any bit shifting or pointer indirection to go from “value” to “number”.
這種表示方法的特別之處在於,不需要將數值型別的double值轉換為一個“裝箱後的”形式。Lox中的數字只是普通的64位double。在使用之前,我們仍然需要檢查它們的型別,因為Lox是動態型別的,但我們不需要做任何的數位偏移或指標引用來完成從“值”到“數”的轉換。
For the other value types, there is a conversion step, of course. But, fortunately, our VM hides all of the mechanism to go from values to raw types behind a handful of macros. Rewrite those to implement NaN boxing, and the rest of the VM should just work.
對於其它的值型別,當然有一個轉換步驟。但幸運的是,我們的虛擬機器將從值到原始型別的所有機制都隱藏在少數幾個宏後面。重寫這些宏來實現NaN裝箱,虛擬機器的其它部分就可以正常工作了。
30 . 3 . 2 Conditional support
30.3.2 有條件地支援
I know the details of this new representation aren’t clear in your head yet. Don’t worry, they will crystallize as we work through the implementation. Before we get to that, we’re going to put some compile-time scaffolding in place.
我知道這個新表示形式的細節在你的腦子裡還不清晰。不用擔心,它們會在我們的實現過程中逐步具現化。在此之前,我們要放置一些編譯時的腳手架。
For our previous optimization, we rewrote the previous slow code and called it done. This one is a little different. NaN boxing relies on some very low-level details of how a chip represents floating-point numbers and pointers. It probably works on most CPUs you’re likely to encounter, but you can never be totally sure.
對於我們之前的最佳化,我們重寫之前的慢程式碼就可以宣告完成了。這一次則有點不同。NaN裝箱依賴於晶片如何表示浮點數和指標等一些非常底層的細節。它也許適用於你可能遇到的大多數CPU,但你永遠無法完全確定。
It would suck if our VM completely lost support for an architecture just because of its value representation. To avoid that, we’ll maintain support for both the old tagged union implementation of Value and the new NaN-boxed form. We select which representation we want at compile time using this flag:
如果我們的虛擬機器僅僅因為某個架構的值表示形式而完全失去對它的支援,那就太糟糕了。為了避免這種情況,我們會保留對Value的舊的帶標記聯合體實現方式以及新的NaN裝箱形式的支援。我們在編譯時使用這個標誌來選擇我們想要的方法:
common.h,新增程式碼:
#include <stdint.h>
// 新增部分開始
#define NAN_BOXING
// 新增部分結束
#define DEBUG_PRINT_CODE
If that’s defined, the VM uses the new form. Otherwise, it reverts to the old style. The few pieces of code that care about the details of the value representation—mainly the handful of macros for wrapping and unwrapping Values—vary based on whether this flag is set. The rest of the VM can continue along its merry way.
如果定義了這個值,虛擬機器就會使用新的形式。否則,它就會恢復舊的風格。少數關心值表示形式細節的幾段程式碼——主要是用於包裝和解包Value的少數幾個宏——會根據這個標誌是否被設定而有所不同。虛擬機器的其它部分可以繼續快樂的旅程。
Most of the work happens in the “value” module where we add a section for the new type.
大部分工作都發生在“value”模組中,我們在其中為新型別新增一些程式碼。
value.h,新增程式碼:
typedef struct ObjString ObjString;
// 新增部分開始
#ifdef NAN_BOXING
typedef uint64_t Value;
#else
// 新增部分結束
typedef enum {
When NaN boxing is enabled, the actual type of a Value is a flat, unsigned 64-bit integer. We could use double instead, which would make the macros for dealing with Lox numbers a little simpler. But all of the other macros need to do bitwise operations and uint64_t is a much friendlier type for that. Outside of this module, the rest of the VM doesn’t really care one way or the other.
當啟用NaN裝箱時,Value的實際型別是一個扁平的、無符號的64位整數。我們可以用double代替,這會使處理Lox數字的宏更簡單一些。但所有其它宏都需要進行位操作,而uint_64是一個更友好的型別。在這個模組之外,虛擬機器的其它部分並不真正關心這一點。
Before we start re-implementing those macros, we close the
#elsebranch of the#ifdefat the end of the definitions for the old representation.
在我們開始重新實現這些宏之前,我們先關閉舊錶示形式的定義末尾的#ifdef的#else分支。
value.h,新增程式碼:
#define OBJ_VAL(object) ((Value){VAL_OBJ, {.obj = (Obj*)object}})
// 新增部分開始
#endif
// 新增部分結束
typedef struct {
Our remaining task is simply to fill in that first
#ifdefsection with new implementations of all the stuff already in the#elseside. We’ll work through it one value type at a time, from easiest to hardest.
我們剩下的任務只是在第一個#ifdef部分中填入已經在#else部分存在的所有內容的新實現。我們會從最簡單到最難,依次完成每個值型別的工作。
30 . 3 . 3 Numbers
30.3.3 數字
We’ll start with numbers since they have the most direct representation under NaN boxing. To “convert” a C double to a NaN-boxed clox Value, we don’t need to touch a single bit—the representation is exactly the same. But we do need to convince our C compiler of that fact, which we made harder by defining Value to be uint64_t.
我們會從數字開始,因為它們在NaN裝箱方式中有最直接的表示形式。要將C語言中的double“轉換”為一個NaN裝箱後的clox Value,我們不需要改動任何一個位元——其表示方式是完全相同的。但我們確實需要說服我們的C編譯器相信這一事實,我們將Value定義為uint64_t使之變得更加困難。
We need to get the compiler to take a set of bits that it thinks are a double and use those same bits as a uint64_t, or vice versa. This is called type punning. C and C++ programmers have been doing this since the days of bell bottoms and 8-tracks, but the language specifications have hesitated to say which of the many ways to do this is officially sanctioned.
我們需要讓編譯器接受一組它認為是double的位元,並作為uint64_t來使用,反之亦然。這就是所謂的型別雙關。C和C++程式設計師早在喇叭褲和8音軌的時代就開始這樣做了,但語言規範卻一直猶豫不決,不知道哪種方法是官方認可的13。
I know one way to convert a
doubletoValueand back that I believe is supported by both the C and C++ specs. Unfortunately, it doesn’t fit in a single expression, so the conversion macros have to call out to helper functions. Here’s the first macro:
我知道一種將double轉換為Value並反向轉換的方法,我相信C和C++規範都支援該方法。不幸的是,它不適合在一個表示式中使用,因此轉換宏必須呼叫輔助函式。下面是第一個宏:
value.h,新增程式碼:
typedef uint64_t Value;
// 新增部分開始
#define NUMBER_VAL(num) numToValue(num)
// 新增部分結束
#else
That macro passes the double here:
這個宏會將double傳遞到這裡:
value.h,新增程式碼:
#define NUMBER_VAL(num) numToValue(num)
// 新增部分開始
static inline Value numToValue(double num) {
Value value;
memcpy(&value, &num, sizeof(double));
return value;
}
// 新增部分結束
#else
I know, weird, right? The way to treat a series of bytes as having a different type without changing their value at all is
memcpy()? This looks horrendously slow: Create a local variable. Pass its address to the operating system through a syscall to copy a few bytes. Then return the result, which is the exact same bytes as the input. Thankfully, because this is the supported idiom for type punning, most compilers recognize the pattern and optimize away thememcpy()entirely.
我知道,很奇怪,對嗎?在不改變值的情況下,將一系列位元組視為具有不同型別的方式是memcpy()?這看起來慢的可怕:建立一個區域性變數;透過系統呼叫 將其地址傳遞給作業系統,以複製幾個位元組;然後返回結果,這個結果與輸入的位元組完全相同。值得慶幸的是,由於這是型別雙關的習慣用法,大部分編譯器都能識別這種模式,並完全最佳化掉memcpy()。
“Unwrapping” a Lox number is the mirror image.
“拆包”一個Lox數字就是映象操作。
value.h,新增程式碼:
typedef uint64_t Value;
// 新增部分開始
#define AS_NUMBER(value) valueToNum(value)
// 新增部分結束
#define NUMBER_VAL(num) numToValue(num)
That macro calls this function:
這個宏會呼叫下面的函式:
value.h,新增程式碼:
#define NUMBER_VAL(num) numToValue(num)
// 新增部分開始
static inline double valueToNum(Value value) {
double num;
memcpy(&num, &value, sizeof(Value));
return num;
}
// 新增部分結束
static inline Value numToValue(double num) {
It works exactly the same except we swap the types. Again, the compiler will eliminate all of it. Even though those calls to
memcpy()will disappear, we still need to show the compiler whichmemcpy()we’re calling so we also need an include.
它的工作原理完全一樣,只是交換了型別。同樣,編譯器會消除所有這些。儘管對memcpy()的那些呼叫會消失,我們仍然需要向編譯器顯示我們正在呼叫哪個memcpy(),因此我們也需要引入一下14。
value.h,新增程式碼:
#define clox_value_h
// 新增部分開始
#include <string.h>
// 新增部分結束
#include "common.h"
That was a lot of code to ultimately do nothing but silence the C type checker. Doing a runtime type test on a Lox number is a little more interesting. If all we have are exactly the bits for a double, how do we tell that it is a double? It’s time to get bit twiddling.
其中是大量的程式碼,最終除了讓C語言型別檢查器保持沉默之外,什麼也沒做。對一個Lox數字進行執行時型別測試就比較有趣了。如果我們拿到的所有位元位正好是一個double,如何判斷它是一個double呢?是時候玩一些位操作技巧了。
value.h,新增程式碼:
typedef uint64_t Value;
// 新增部分開始
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
// 新增部分結束
#define AS_NUMBER(value) valueToNum(value)
We know that every Value that is not a number will use a special quiet NaN representation. And we presume we have correctly avoided any of the meaningful NaN representations that may actually be produced by doing arithmetic on numbers.
我們知道,每個不是數字的Value都會使用一個特殊的靜默NaN表示形式。而且假定我們已經正確地避免了任何有意義的NaN表示形式(這些實際上可能是透過對數字進行算術運算產生的)。
If the double has all of its NaN bits set, and the quiet NaN bit set, and one more for good measure, we can be pretty certain it is one of the bit patterns we ourselves have set aside for other types. To check that, we mask out all of the bits except for our set of quiet NaN bits. If all of those bits are set, it must be a NaN-boxed value of some other Lox type. Otherwise, it is actually a number.
如果某個double值的NaN位元位置為1,而且靜默NaN位元位也置為1,還有一個位元位也被置為1,那我們就可以非常肯定它是我們為其它型別預留的位元模式之一15。為了驗證這一點,我們遮蔽掉除靜默NaN置為1的位元之外的所有其它位元位,如果這些位都被置為1了,那它一定是某個其它Lox型別的已NaN裝箱的值。否則,它就是一個數字。
The set of quiet NaN bits are declared like this:
靜默NaN的位元集合是這樣宣告的:
value.h,新增程式碼:
#ifdef NAN_BOXING
// 新增部分開始
#define QNAN ((uint64_t)0x7ffc000000000000)
// 新增部分結束
typedef uint64_t Value;
It would be nice if C supported binary literals. But if you do the conversion, you’ll see that value is the same as this:
如果C支援二進位制字面量就好了。但如果你做了轉換,你會看到那個值是這樣的:

This is exactly all of the exponent bits, plus the quiet NaN bit, plus one extra to dodge that Intel value.
這正是所有的指數位,加上靜默NaN位元位,再加上一個額外的用來規避英特爾值的位元位。
30 . 3 . 4 Nil, true, and false
30 . 3 . 4 Nil、true和false
The next type to handle is
nil. That’s pretty simple since there’s only onenilvalue and thus we need only a single bit pattern to represent it. There are two other singleton values, the two Booleans,trueandfalse. This calls for three total unique bit patterns.
下一個要處理的型別是nil。這非常簡單,因為只有一個nil值,因此我們只需要1 個位元位模式來表示它。還有另外兩個單例值,即兩個布林值,true和false。這總共需要三種唯一的位元位模式。
Two bits give us four different combinations, which is plenty. We claim the two lowest bits of our unused mantissa space as a “type tag” to determine which of these three singleton values we’re looking at. The three type tags are defined like so:
兩個位元可以得到四種不同的組合,這已經足夠了。我們要求將未使用的尾數中的兩個最低位作為“型別標籤”,以確定我們正面對的是這三個單例值中的哪一個。這三個型別標籤定義如下:
value.h,新增程式碼:
#define QNAN ((uint64_t)0x7ffc000000000000)
// 新增部分開始
#define TAG_NIL 1 // 01.
#define TAG_FALSE 2 // 10.
#define TAG_TRUE 3 // 11.
// 新增部分結束
typedef uint64_t Value;
Our representation of
nilis thus all of the bits required to define our quiet NaN representation along with theniltype tag bits:
因此,我們的nil表示形式的所有位元位就是定義靜默NaN表示形式所需的所有位元位,以及nil型別的標記位:

In code, we check the bits like so:
在程式碼中,我們這樣來檢查:
value.h,新增程式碼:
#define AS_NUMBER(value) valueToNum(value)
// 新增部分開始
#define NIL_VAL ((Value)(uint64_t)(QNAN | TAG_NIL))
// 新增部分結束
#define NUMBER_VAL(num) numToValue(num)
We simply bitwise OR the quiet NaN bits and the type tag, and then do a little cast dance to teach the C compiler what we want those bits to mean.
我們只是將靜默NaN位元位與型別標籤進行按位或運算,然後做一點強制轉換來告訴C編譯器我們希望這些位表示什麼意思。
Since
nilhas only a single bit representation, we can use equality on uint64_t to see if a Value isnil.
由於nil只有一個位元表示形式,我們可以對uint64_t使用等號來判斷某個Value是否是nil。
value.h,新增程式碼:
typedef uint64_t Value;
// 新增部分開始
#define IS_NIL(value) ((value) == NIL_VAL)
// 新增部分結束
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
You can guess how we define the
trueandfalsevalues.
你可以猜到我們如何定義true和false值。
value.h,新增程式碼:
#define AS_NUMBER(value) valueToNum(value)
// 新增部分開始
#define FALSE_VAL ((Value)(uint64_t)(QNAN | TAG_FALSE))
#define TRUE_VAL ((Value)(uint64_t)(QNAN | TAG_TRUE))
// 新增部分結束
#define NIL_VAL ((Value)(uint64_t)(QNAN | TAG_NIL))
The bits look like this:
位元位看起來是這樣的:

To convert a C bool into a Lox Boolean, we rely on these two singleton values and the good old conditional operator.
為了將C語言bool轉換為Lox的Boolean,我們依靠這兩個單例值和古老的條件運算子。
value.h,新增程式碼:
#define AS_NUMBER(value) valueToNum(value)
// 新增部分開始
#define BOOL_VAL(b) ((b) ? TRUE_VAL : FALSE_VAL)
// 新增部分結束
#define FALSE_VAL ((Value)(uint64_t)(QNAN | TAG_FALSE))
There’s probably a cleverer bitwise way to do this, but my hunch is that the compiler can figure one out faster than I can. Going the other direction is simpler.
可能有更聰明的位運算方式來實現這一點,但我的直覺是,編譯器可以比我更快地找到一個方法。反過來就簡單多了。
value.h,新增程式碼:
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
// 新增部分開始
#define AS_BOOL(value) ((value) == TRUE_VAL)
// 新增部分結束
#define AS_NUMBER(value) valueToNum(value)
Since we know there are exactly two Boolean bit representations in Lox—unlike in C where any non-zero value can be considered “true”—if it ain’t
true, it must befalse. This macro does assume you call it only on a Value that you know is a Lox Boolean. To check that, there’s one more macro.
因為我們知道在Lox中正好有兩個Boolean的位表示形式——不像C語言中,任何非零值都可以被認為是“true”——如果它不是true,就一定是false。這個宏假設你只會在明知是Lox布林值型別的Value上呼叫該方法。為了檢查這一點,還有一個宏。
value.h,新增程式碼:
typedef uint64_t Value;
// 新增部分開始
#define IS_BOOL(value) (((value) | 1) == TRUE_VAL)
// 新增部分結束
#define IS_NIL(value) ((value) == NIL_VAL)
That looks a little strange. A more obvious macro would look like this:
這裡看起來有點奇怪。一個更直觀的宏看起來應該是這樣的:
#define IS_BOOL(v) ((v) == TRUE_VAL || (v) == FALSE_VAL)
Unfortunately, that’s not safe. The expansion mentions
vtwice, which means if that expression has any side effects, they will be executed twice. We could have the macro call out to a separate function, but, ugh, what a chore.
不幸的是,這並不安全。展開式中兩次使用了v,這意味著如果表示式有任何副作用,它們將被執行兩次。我們可以讓宏呼叫到一個單獨的函式,但是,唉,真麻煩。
Instead, we bitwise OR a 1 onto the value to merge the only two valid Boolean bit patterns. That leaves three potential states the value can be in:
相反,我們在值上按位或1,來合併僅有的兩個有效的Boolean位元位模式。這樣,值就剩下了三種可能的狀態:
- It was
FALSE_VALand has now been converted toTRUE_VAL.- It was
TRUE_VALand the| 1did nothing and it’s stillTRUE_VAL.- It’s some other, non-Boolean value.
- 之前是
FALSE_VAL,現在轉換為TRUE_VAL。 - 之前是
TRUE_VAL,| 1沒有起任何作用,結果仍然是TRUE_VAL。 - 它是其它的非布林值。
At that point, we can simply compare the result to
TRUE_VALto see if we’re in the first two states or the third.
在此基礎上,我們可以簡單地將結果與TRUE_VAL進行比較,看看我們是處於前兩個狀態還是第三個狀態。
30 . 3 . 5 Objects
30.3.5 物件
The last value type is the hardest. Unlike the singleton values, there are billions of different pointer values we need to box inside a NaN. This means we need both some kind of tag to indicate that these particular NaNs are Obj pointers, and room for the addresses themselves.
最後一種值型別是最難的。與單例值不同,我們需要在NaN中包含數十億個不同的指標值。這意味著我們既需要某種標籤來表明這些特定的NaN是Obj指標,也需要為這些地址本身留出空間。
The tag bits we used for the singleton values are in the region where I decided to store the pointer itself, so we can’t easily use a different bit there to indicate that the value is an object reference. However, there is another bit we aren’t using. Since all our NaN values are not numbers—it’s right there in the name—the sign bit isn’t used for anything. We’ll go ahead and use that as the type tag for objects. If one of our quiet NaNs has its sign bit set, then it’s an Obj pointer. Otherwise, it must be one of the previous singleton values.
我們用於單例值的標籤位元位處於我決定儲存指標本身的區域,所以我們不能輕易地在那裡使用不同的位來表明該值是一個物件引用16。不過,還有一個位我們沒有用到。因為所有的NaN值都不是數字——正如其名——符號位沒有任何用途。我們會繼續使用它來作為物件的型別標籤。如果某個靜默NaN的符號位被置為1,那麼它就是一個Obj指標。否則,它一定是前面的單例值之一。
If the sign bit is set, then the remaining low bits store the pointer to the Obj:
如果符號位被置1,那麼剩餘的低位元位會儲存Obj指標:

To convert a raw Obj pointer to a Value, we take the pointer and set all of the quiet NaN bits and the sign bit.
為了將一個原生Obj指標轉換為Value,我們會接受指標並將所有的靜默NaN位元位和符號位置1。
value.h,新增程式碼:
#define NUMBER_VAL(num) numToValue(num)
// 新增部分開始
#define OBJ_VAL(obj) \
(Value)(SIGN_BIT | QNAN | (uint64_t)(uintptr_t)(obj))
// 新增部分結束
static inline double valueToNum(Value value) {
The pointer itself is a full 64 bits, and in principle, it could thus overlap with some of those quiet NaN and sign bits. But in practice, at least on the architectures I’ve tested, everything above the 48th bit in a pointer is always zero. There’s a lot of casting going on here, which I’ve found is necessary to satisfy some of the pickiest C compilers, but the end result is just jamming some bits together.
指標本身是一個完整的64位,原則上,它可能因此與某些靜默NaN和符號位衝突。但實際上,至少在我測試過的架構中,指標中48位以上的所有內容都是零。這裡進行了大量的型別轉換。我們發現這對於滿足一些最挑剔的C語言編譯器來說是必要的,但最終的結果只是將這些位元位塞在一起17。
We define the sign bit like so:
我們這樣定義符號位:
value.h,新增程式碼:
#ifdef NAN_BOXING
// 新增部分開始
#define SIGN_BIT ((uint64_t)0x8000000000000000)
// 新增部分結束
#define QNAN ((uint64_t)0x7ffc000000000000)
To get the Obj pointer back out, we simply mask off all of those extra bits.
為了取出Obj指標,我們只需把所有這些額外的位元位遮蔽掉。
value.h,新增程式碼:
#define AS_NUMBER(value) valueToNum(value)
// 新增部分開始
#define AS_OBJ(value) \
((Obj*)(uintptr_t)((value) & ~(SIGN_BIT | QNAN)))
// 新增部分結束
#define BOOL_VAL(b) ((b) ? TRUE_VAL : FALSE_VAL)
The tilde (
~), if you haven’t done enough bit manipulation to encounter it before, is bitwise NOT. It toggles all ones and zeroes in its operand. By masking the value with the bitwise negation of the quiet NaN and sign bits, we clear those bits and let the pointer bits remain.
如果你沒有做過足夠多的位運算就可能沒有遇到過,波浪號(~)是位運算中的NOT(按位取非)。它會切換運算元中所有的1和0。使用靜默NaN和符號位按位取非的值作為掩碼,對值進行遮蔽,我們可以清除這些位元位,並將指標位元保留下來。
One last macro:
最後一個宏:
value.h,新增程式碼:
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
// 新增部分開始
#define IS_OBJ(value) \
(((value) & (QNAN | SIGN_BIT)) == (QNAN | SIGN_BIT))
// 新增部分結束
#define AS_BOOL(value) ((value) == TRUE_VAL)
A Value storing an Obj pointer has its sign bit set, but so does any negative number. To tell if a Value is an Obj pointer, we need to check that both the sign bit and all of the quiet NaN bits are set. This is similar to how we detect the type of the singleton values, except this time we use the sign bit as the tag.
儲存Obj指標的Value的符號位被置1,但任意負數也是如此。為了判斷Value是否為Obj指標,我們需要同時檢查符號位和所有的靜默NaN位元位。這與我們檢測單例值型別的方法類似,這不過這次我們使用符號位作為標籤。
30 . 3 . 6 Value functions
30.3.6 Value函式
The rest of the VM usually goes through the macros when working with Values, so we are almost done. However, there are a couple of functions in the “value” module that peek inside the otherwise black box of Value and work with its encoding directly. We need to fix those too.
VM的其餘部分在處理Value時通常都是透過宏,所以我們基本上已經完成了。但是,在“value”模組中,有幾個函式會窺探Value黑匣子內部,並直接處理器編碼。我們也需要修復這些問題。
The first is
printValue(). It has separate code for each value type. We no longer have an explicit type enum we can switch on, so instead we use a series of type tests to handle each kind of value.
第一個是printValue()。它針對每個值型別都有單獨的程式碼。我們不再有一個明確的型別列舉進行switch,因此我們使用一系列的型別檢查來處理每一種值。
value.c,在printValue()方法中新增程式碼:
void printValue(Value value) {
// 新增部分開始
#ifdef NAN_BOXING
if (IS_BOOL(value)) {
printf(AS_BOOL(value) ? "true" : "false");
} else if (IS_NIL(value)) {
printf("nil");
} else if (IS_NUMBER(value)) {
printf("%g", AS_NUMBER(value));
} else if (IS_OBJ(value)) {
printObject(value);
}
#else
// 新增部分結束
switch (value.type) {
This is technically a tiny bit slower than a switch, but compared to the overhead of actually writing to a stream, it’s negligible.
從技術上講,這比switch語句稍微慢一點點,但是與實際寫入流的開銷相比,它可以忽略不計。
We still support the original tagged union representation, so we keep the old code and enclose it in the
#elseconditional section.
我們仍然支援原先的帶標籤聯合體表示形式,因此我們保留舊程式碼,並將其包含在#else條件部分。
value.c,在printValue()方法中新增程式碼:
}
// 新增部分開始
#endif
// 新增部分結束
}
The other operation is testing two values for equality.
另一個操作是測試兩個值是否相等。
value.c,在valuesEqual()方法中新增程式碼:
bool valuesEqual(Value a, Value b) {
// 新增部分開始
#ifdef NAN_BOXING
return a == b;
#else
// 新增部分結束
if (a.type != b.type) return false;
It doesn’t get much simpler than that! If the two bit representations are identical, the values are equal. That does the right thing for the singleton values since each has a unique bit representation and they are only equal to themselves. It also does the right thing for Obj pointers, since objects use identity for equality—two Obj references are equal only if they point to the exact same object.
沒有比這更簡單的了!如果兩個位元表示形式是相同的,則值就是相等的。這對於單例值來說是正確的,因為每個單例值都有唯一的位表示形式,而且它們只等於自己。對於Obj指標,它也做了正確的事情,因為物件使用本體來判斷相等——只有當兩個Obj指向完全相同的物件時,它們才相等。
It’s mostly correct for numbers too. Most floating-point numbers with different bit representations are distinct numeric values. Alas, IEEE 754 contains a pothole to trip us up. For reasons that aren’t entirely clear to me, the spec mandates that NaN values are not equal to themselves. This isn’t a problem for the special quiet NaNs that we are using for our own purposes. But it’s possible to produce a “real” arithmetic NaN in Lox, and if we want to correctly implement IEEE 754 numbers, then the resulting value is not supposed to be equal to itself. More concretely:
對於數字來說,也基本是正確的。大多數具有不同位表示形式的浮點數是不同的數值。然而,IEEE 754中有一個坑,會讓我們陷入困境。由於我不太清楚的原因,該規範規定NaN值不等於自身。對於我們自己使用的特殊的靜默NaN來說,這不是問題。但是在Lox中產生一個“真正的”算術型NaN是有可能的,如果我們想正確地實現IEEE 754數字,那麼產生的結果值就不等於它自身。更具體地說:
var nan = 0/0;
print nan == nan;
IEEE 754 says this program is supposed to print “false”. It does the right thing with our old tagged union representation because the
VAL_NUMBERcase applies==to two values that the C compiler knows are doubles. Thus the compiler generates the right CPU instruction to perform an IEEE floating-point equality.
IEEE 754表明,這個程式應該列印“false”。對於我們原先的帶標籤聯合體表示形式來說,它是正確的,因為VAL_NUMBER將==應用於兩個C編譯器知道是double的值。因此,編譯器會生成正確的CPU指令來執行IEEE浮點運算。
Our new representation breaks that by defining Value to be a uint64_t. If we want to be fully compliant with IEEE 754, we need to handle this case.
我們的新表示形式由於將Value定義為uint64_t而打破了這一點。如果我們想完全符合IEEE 754的要求,就需要處理這種情況。
value.c,在valuesEqual()方法中新增程式碼:
#ifdef NAN_BOXING
// 新增部分開始
if (IS_NUMBER(a) && IS_NUMBER(b)) {
return AS_NUMBER(a) == AS_NUMBER(b);
}
// 新增部分結束
return a == b;
I know, it’s weird. And there is a performance cost to doing this type test every time we check two Lox values for equality. If we are willing to sacrifice a little compatibility—who really cares if NaN is not equal to itself?—we could leave this off. I’ll leave it up to you to decide how pedantic you want to be.
我知道,這很奇怪。而且每次我們檢查兩個Lox值是否相等時,都要進行這種型別測試,這是有效能代價的。如果我們願意犧牲一點相容性——誰會真正關心NaN是否等於其本身呢?——我們可以忽略它。我把這個問題留給你,看看你想要有多“迂腐”18。
Finally, we close the conditional compilation section around the old implementation.
最後,我們關閉舊實現中的條件編譯部分。
value.c,在valuesEqual()方法中新增程式碼:
}
// 新增部分開始
#endif
// 新增部分結束
}
And that’s it. This optimization is complete, as is our clox virtual machine. That was the last line of new code in the book.
就是這樣。這個最佳化完成了,我們的clox虛擬機器也完成了。這是本書中最後一行新程式碼。
30 . 3 . 7 Evaluating performance
30.3.7 評估效能
The code is done, but we still need to figure out if we actually made anything better with these changes. Evaluating an optimization like this is very different from the previous one. There, we had a clear hotspot visible in the profiler. We fixed that part of the code and could instantly see the hotspot get faster.
程式碼完成了,但我們仍然需要弄清楚,我們是否真的透過這些修改獲得了一些改進。評估這樣的最佳化與之前的最佳化有很大不同。之前,我們可以在剖析器中看到一個明顯的熱點。我們修復了這部分程式碼,並立即看到熱點部分變快了。
The effects of changing the value representation are more diffused. The macros are expanded in place wherever they are used, so the performance changes are spread across the codebase in a way that’s hard for many profilers to track well, especially in an optimized build.
改變值表示形式的影響更加分散。在宏的任何地方都會進行對應的擴充套件,所以效能的變化會分散到整個程式碼庫中,這對很多剖析器來說是很難跟蹤的,尤其是在最佳化的構建中19。
We also can’t easily reason about the effects of our change. We’ve made values smaller, which reduces cache misses all across the VM. But the actual real-world performance effect of that change is highly dependent on the memory use of the Lox program being run. A tiny Lox microbenchmark may not have enough values scattered around in memory for the effect to be noticeable, and even things like the addresses handed out to us by the C memory allocator can impact the results.
我們也無法輕易推斷出我們的改變所帶來的影響。我們讓Value變得更小,這就減少了虛擬機器中的快取丟失。但是,這一改變在真實世界中的實際效能影響在很大程式上取決於正在執行的Lox程式的記憶體使用情況。一個很小的Lox微基準測試可能沒有足夠的值分散在記憶體中,因此效果也許不明顯,甚至類似C語言地址分配器為我們提供的地址這樣的東西也會影響結果。
If we did our job right, basically everything gets a little faster, especially on larger, more complex Lox programs. But it is possible that the extra bitwise operations we do when NaN-boxing values nullify the gains from the better memory use. Doing performance work like this is unnerving because you can’t easily prove that you’ve made the VM better. You can’t point to a single surgically targeted microbenchmark and say, “There, see?”
如果我們的工作做對了,基本上所有東西都會變快一點,尤其是在更大、更復雜的Lox程式上。但是,我們對NaN裝箱值執行的位操作可能會抵消更高效的記憶體使用所帶來的收益。做這樣的效能工作是令人不安的,因為你無法輕易地證明你已經使虛擬機器變得更好了。你不能指著一個特定的微基準測試說:“看到了嗎?”
Instead, what we really need is a suite of larger benchmarks. Ideally, they would be distilled from real-world applications—not that such a thing exists for a toy language like Lox. Then we can measure the aggregate performance changes across all of those. I did my best to cobble together a handful of larger Lox programs. On my machine, the new value representation seems to make everything roughly 10% faster across the board.
相反,我們真正需要的是一套更大的基準測試。理想情況下,這些基準測試應該是從真實世界的應用程式中提煉出來的——對於Lox這樣的玩具語言來說,不存在這樣的東西。然後我們可以測量所有這些測試的總體效能變化。我盡力拼湊了幾個較大的Lox程式。在我的機器是,新的值表示形式似乎使所有的程式碼都全面提高了大約10%。
That’s not a huge improvement, especially compared to the profound effect of making hash table lookups faster. I added this optimization in large part because it’s a good example of a certain kind of performance work you may experience, and honestly, because I think it’s technically really cool. It might not be the first thing I would reach for if I were seriously trying to make clox faster. There is probably other, lower-hanging fruit.
這並不是一個巨大的改進,尤其是與雜湊查詢加速的深遠影響相比。我新增這個最佳化,很大程度上是因為它是關於你可能遇到的某種效能工作的一個很好的例子,而且說實話,我認為它在技術上真的很酷。如果我真的想讓clox變得更快的話,這應該不是我首先要做的事情。可能還有其它更容易實現的目標。
But, if you find yourself working on a program where all of the easy wins have been taken, then at some point you may want to think about tuning your value representation. I hope this chapter has shined a light on some of the options you have in that area.
但是,如果你發現自己正在處理的程式中,所有容易贏得的東西都已經被拿走了,那麼在某些時候,你可能要考慮調整一下值表示形式。我希望這一章能對你在這方面的一些選擇有所啟發。
30 . 4 Where to Next
30.4 前路何方
We’ll stop here with the Lox language and our two interpreters. We could tinker on it forever, adding new language features and clever speed improvements. But, for this book, I think we’ve reached a natural place to call our work complete. I won’t rehash everything we’ve learned in the past many pages. You were there with me and you remember. Instead, I’d like to take a minute to talk about where you might go from here. What is the next step in your programming language journey?
關於Lox語言和我們的兩個直譯器,就到此為止了。我們可以一直對它進行修補,新增新的語言功能和巧妙的速度改進。但是,對於本書來說,我認為我們已經達到了一個可以宣告工作完成的狀態。我不會重述我們在過去的許多章節中所學到的一切。你和我一起從那裡過來,你都記得。相反,我想花點時間談談你今後的發展方向。你的程式語言之旅的下一步是什麼?
Most of you probably won’t spend a significant part of your career working in compilers or interpreters. It’s a pretty small slice of the computer science academia pie, and an even smaller segment of software engineering in industry. That’s OK. Even if you never work on a compiler again in your life, you will certainly use one, and I hope this book has equipped you with a better understanding of how the programming languages you use are designed and implemented.
你們中的大多數人可能不會把職業生涯的大部分時間花在編譯器或直譯器上。這在電腦科學學術界中的一個相當小的部分,在工業軟體工程中則是一個更小的部分。這也沒關係。即使你一生中不再從事編譯器工作,你也一定會使用它,而我希望這本書能讓你更好地理解你所使用的程式語言是如何設計與實現的。
You have also learned a handful of important, fundamental data structures and gotten some practice doing low-level profiling and optimization work. That kind of expertise is helpful no matter what domain you program in.
你還學習了一些重要的、基本的資料結構,並進行了一些底層剖析和最佳化工作的實踐。無論你在哪個領域程式設計,這種專業知識都是有幫助的。
I also hope I gave you a new way of looking at and solving problems. Even if you never work on a language again, you may be surprised to discover how many programming problems can be seen as language-like. Maybe that report generator you need to write can be modeled as a series of stack-based “instructions” that the generator “executes”. That user interface you need to render looks an awful lot like traversing an AST.
我也希望我為你們提供了一種看待問題和解決問題的新方法。即使你不再從事語言工作,你也可能會驚訝地發現,有多少程式設計問題可以被視為類似於語言的問題20。也許你需要編寫的報告生成器可以被建模為一系列由生成器“執行”的、基於堆疊的“指令”。你需要渲染的使用者介面看起來非常像遍歷AST。
If you do want to go further down the programming language rabbit hole, here are some suggestions for which branches in the tunnel to explore:
如果你確實想在程式語言領域中走得更遠,這裡有一些關於哪些方面可以探索的建議:
-
Our simple, single-pass bytecode compiler pushed us towards mostly runtime optimization. In a mature language implementation, compile-time optimization is generally more important, and the field of compiler optimizations is incredibly rich. Grab a classic compilers book, and rebuild the front end of clox or jlox to be a sophisticated compilation pipeline with some interesting intermediate representations and optimization passes.
Dynamic typing will place some restrictions on how far you can go, but there is still a lot you can do. Or maybe you want to take a big leap and add static types and a type checker to Lox. That will certainly give your front end a lot more to chew on.
我們這個簡單的、單遍位元組碼編譯器將我們推向了執行時最佳化。在一個成熟的語言實現中,編譯時最佳化通常更重要,而且編譯器最佳化的領域也非常豐富。找一本經典的編譯器書籍21,將clox或jlox的前端重構為一個複雜的編譯管道,其中要包含一些有趣的中間表示形式和最佳化遍歷。
動態型別會對你能走多遠加以限制,但你仍然可以做很多事情。或者你想要來個大躍進,給Lox新增靜態型別和型別檢查器。這肯定會讓你的前端有更多的東西可以細細咀嚼。
-
In this book, I aim to be correct, but not particularly rigorous. My goal is mostly to give you an intuition and a feel for doing language work. If you like more precision, then the whole world of programming language academia is waiting for you. Languages and compilers have been studied formally since before we even had computers, so there is no shortage of books and papers on parser theory, type systems, semantics, and formal logic. Going down this path will also teach you how to read CS papers, which is a valuable skill in its own right.
在本書中,我的目標是正確,但不是特別嚴謹。我的目標主要是給你一個直觀感受和做語言工作的感覺。如果你想要更精確的感覺,那麼整個程式語言學術界都在等著你。在我們擁有計算機之前,語言和編譯器就已經被正式研究過了,因此在解析器理論、型別系統、語義學和形式邏輯方面並不缺乏書籍和論文。沿著這條路走下去也會教你如何閱讀CS論文,這本身就是一項有價值的技能。
-
Or, if you just really enjoy hacking on and making languages, you can take Lox and turn it into your own plaything. Change the syntax to something that delights your eye. Add missing features or remove ones you don’t like. Jam new optimizations in there.
Eventually you may get to a point where you have something you think others could use as well. That gets you into the very distinct world of programming language popularity. Expect to spend a ton of time writing documentation, example programs, tools, and useful libraries. The field is crowded with languages vying for users. To thrive in that space you’ll have to put on your marketing hat and sell. Not everyone enjoys that kind of public-facing work, but if you do, it can be incredibly gratifying to see people use your language to express themselves.
或者,如果你真的喜歡鑽研和製造語言,你可以把Lox變成你自己的玩物。把語法改成能讓你滿意的東西。增加缺失的功能或刪除你不喜歡的功能。在其中新增新的最佳化22。
最終,你會達到某個境地,有了一些你認為其他人也可以使用的東西。這會帶你進入非常獨特的程式語言流行度的世界。預計你將花費大量的時間來編寫文件、示例程式、工具和有用的庫。這個領域充斥著很多爭奪使用者的語言。要想在這個領域取得成功,你將必須帶上營銷的帽子,進行銷售。不是每個人都喜歡這種面對公眾的工作,但如果你喜歡,能夠看到人們使用你的語言來表達自己,你會感到無比欣慰。
Or maybe this book has satisfied your craving and you’ll stop here. Whichever way you go, or don’t go, there is one lesson I hope to lodge in your heart. Like I was, you may have initially been intimidated by programming languages. But in these chapters, you’ve seen that even really challenging material can be tackled by us mortals if we get our hands dirty and take it a step at a time. If you can handle compilers and interpreters, you can do anything you put your mind to.
或者,也許這本書已經滿足了你的需求,你會在這裡停下來。無論你走哪條路,或者不走哪條路,我都希望能把這個教訓留在你心裡。像我一樣,你可能一開始就被程式語言嚇到了。但在這些章節中,你已經看到,即使是真正具有挑戰性的事情,只要親自動手,一步一步來,我們這些凡人也可以解決。如果你能處理好編譯器和直譯器,你就可以做到任何你想做的事情。
習題
Assigning homework on the last day of school seems cruel but if you really want something to do during your summer vacation:
在學校的最後一天佈置家庭作業似乎很殘酷,但如果你真的想在暑假做點什麼的話:
-
Fire up your profiler, run a couple of benchmarks, and look for other hotspots in the VM. Do you see anything in the runtime that you can improve?
啟動你的剖析器,執行幾個基準測試,並查詢虛擬機器中的其它熱點。你在執行時中看到什麼可以改進的地方嗎?
-
Many strings in real-world user programs are small, often only a character or two. This is less of a concern in clox because we intern strings, but most VMs don’t. For those that don’t, heap allocating a tiny character array for each of those little strings and then representing the value as a pointer to that array is wasteful. Often, the pointer is larger than the string’s characters. A classic trick is to have a separate value representation for small strings that stores the characters inline in the value.
Starting from clox’s original tagged union representation, implement that optimization. Write a couple of relevant benchmarks and see if it helps.
在現實世界的使用者程式中,許多字串都很小,通常只有一兩個字元。這種clox中不太需要考慮,因為我們會駐留字串,但大樹下虛擬機器不會這樣做。對於那些不這樣做的虛擬機器來說,為每個小字串在堆上分配一個很小的字元陣列,然後用一個指向該陣列的指標來表示該值是很浪費的。通常情況下,這個指標要比字串的字元大。一個經典的技巧是為小字串設定一個單獨的值表示形式,該形式會將字元內聯儲存在值中。
從clox最初的帶標籤聯合體表示形式開始,實現這一最佳化。寫幾個相關的基準測試,看看是否有幫助。
-
Reflect back on your experience with this book. What parts of it worked well for you? What didn’t? Was it easier for you to learn bottom-up or top-down? Did the illustrations help or distract? Did the analogies clarify or confuse?
The more you understand your personal learning style, the more effectively you can upload knowledge into your head. You can specifically target material that teaches you the way you learn best.
回顧一下你在這本書中的經歷。哪些部分對你來說很有用?哪些沒有?對你來說,自下而上的學習更容易,還是自上而下的學習更簡單?插圖有幫助還是分散了注意力?類比是澄清了還是混淆了?
你越瞭解你的個人學習風格,你就能越有效地將知識輸入你的大腦中。你可以有針對性地選擇用你最擅長的方式進行教學的材料。
-
大多數基準程式測量的是執行時間。但是,當然,你最終會發現自己需要編寫基準測試來測量記憶體分配、垃圾回收器花費的時間、啟動時間等等。 ↩
-
在JavaScript虛擬機器的早期擴散中,第一個廣泛使用的基準測試套件是WebKit的SunSpider。在瀏覽器大戰期間,營銷人員利用SunSpider的結果來宣稱他們的瀏覽器是最快的。這極大地激勵了虛擬機器專家們根據這些基準進行最佳化。
不幸的是,SunSpider程式往往與真實世界的JavaScript不匹配。它們大多是微基準測試——快速結束的小玩具程式。這些基準測試對複雜的即時編譯器不利,因為它們一開始速度比較慢,但一旦JIT有足夠的時間來最佳化並重新編譯熱點程式碼,就會變得快很多。這將虛擬機器專家們置於一個不幸的境地:要麼讓SubSpider的數字變得更好,要麼實際最佳化真實使用者執行的程式型別。
谷歌的V8團隊分享了他們的Octane基準測試套件,這在當時更接近於真實世界的程式碼。多年以後,隨著JavaScript使用模式的不斷發展,甚至Octane也失去了作用。期待你的基準測試隨著你的語言生態系統的發展而發展。
記住,最終目標是使使用者程式更快,而基準測試只是實現這個目標的一個代替物。 ↩ -
這裡的“你的程式”是指執行其它Lox程式的Lox虛擬機器本身。我們要最佳化的是clox,而不是使用者的Lox指令碼。當然,選擇哪一個Lox程式載入到虛擬機器中會極大地影響clox的哪些部分會受到壓力,這就是基準測試如此重要的原因。
剖析器不會告訴我們正在執行的指令碼中每個Lox函式花費了多少時間。我們必須編寫自己的“Lox剖析器”才能做到這一點,這有點超出了本書的範圍。 ↩ -
這個基準測試的另一個注意點是要使用所執行的程式碼的結果。透過計算滾動求和與列印結果,我們確保虛擬機器必須執行所有的Lox程式碼。這是一個重要的習慣。與我們這個簡單的Lox虛擬機器不同,很多編譯器都做了積極的死碼消除,並且聰明到會丟棄那些結果未被使用的計算邏輯。
許多程式語言駭客都會對虛擬機器在某些基準測試上的驚人表現印象深刻,最後才意識到這是因為編譯器將整個基準測試程式最佳化到不存在了。 ↩ -
如果你真的想要對雜湊表的效能進行基準測試,那你應該使用許多不同大小的表。我們在這裡給每個表新增的6個鍵甚至都沒有超過雜湊表中8個元素的最小閾值。但我不想向你丟擲一個龐大的基準測試指令碼。如果你喜歡,可以隨意新增更多的小動物和食物。 ↩
-
流水線使得我們很難討論單個CPU指令的效能,但可以給你一個直觀感受,在x86上,除法和模運算比加法和減法運算慢30-50倍。 ↩
-
另一個潛在的改進是透過直接儲存位掩碼而不是儲存容量值來消除減法。在我的測試中,這並沒有什麼區別。如果CPU在其它方面遇到瓶頸,指令流水線的存在使得一些操作基本上是無用的。 ↩
-
我們最初的基準測試是固定工作量,然後測量時間。修改後的指令碼計算它在10秒內可以執行多少批次的呼叫,是固定時間並測量工作量。對於效能的比較,我喜歡後一種方法,因為報告的數字代表了速度。你可以直接比較最佳化前後的數字。當測量執行時間時,你必須進行一些計算,才能得到一個良好的相對效能測量。 ↩
-
我不確定是誰首先提出了這個技巧。我能找到的最早的資料是David Gudeman在1993年發表的論文 《在動態型別語言中表示型別資訊(Representing Type Information in Dynamically Typed Languages)》。其他人都在引用這篇文章。但是Gudeman自己說這篇論文並不是什麼新穎的工作,而是 "收集了大量的民間傳說"。
也許發明者已經消失在時間的迷霧中,也許它已經被重新發明瞭很多次。任何人對IEEE 754進行了足夠長時間的思考,都可能會開始考慮在那些未使用的NaN中加入一些有用的資訊。 ↩ -
因為符號位一直存在,即使數字是零,這意味著“正零”和“負零”有不同的位表示形式,事實上,IEEE 754確實區分了它們。 ↩
-
我不知道是否有CPU真正做到了捕獲訊號NaN並中止,規範中只是說它們可以。 ↩
-
48位元位足以對262,114GB的記憶體進行尋找。現代作業系統也為每個程序提供了自己的地址空間,所以這應該足夠了。 ↩
-
規範的作者不喜歡型別雙關,因為它使得最佳化變得更加困難。一個關鍵的最佳化技術是對指令進行重新排序,以填充CPU的執行管道。顯然,編譯器只有在重排序不會產生使用者可見的影響時才可以這樣做。
指標使得這一點更加困難。如果兩個指標指向同一個值,那麼透過一個指標進行的寫操作和透過另一個指標進行的讀操作就不能被重新排序。但是,如果是兩個不同型別的指標呢?如果這些指標可以指向同一個物件,那麼基本上任意兩個指標都可以成為同一個值的別名。這極大地限制了編譯器可以自由地重新排列的程式碼量。
為了避免這種情況,編譯器希望採用嚴格別名——不相容型別的指標不能指向相同的值。型別雙關,從本質上來說,打破了這種假設。 ↩ -
如果你發現自己的編譯器沒有對
memcpy()進行最佳化,可以試試這個: ↩
↩ -
非常肯定,但不是嚴格保證。據我所知,沒有什麼可以阻止CPU產生一個NaN值,作為某些操作的結果,而且這些操作的位表示形式會與我們宣告的位表示形式相沖突。但在我跨多個架構的測試中,還沒有看到這種情況發生。 ↩
-
實際上,即使該值是一個Obj指標,我們也可以使用最低位來儲存型別標籤。這是因為Obj指標總是被對齊到8位元組邊界,因為Obj包含一個64位的欄位。這反過來意味著Obj指標的最低三位始終是0。我們可以在其中儲存任何我們想要的東西,只是在解引用指標之前要將這些遮蔽掉。
這是另一種被稱為指標標記的值表示形式最佳化方案。 ↩ -
在涉及到本書中的程式碼時,我都試圖遵循法律條文,所以這一段是值得懷疑的。在最佳化的時候,你會遇到一個問題,那就是你不僅要突破規範所規定的邊界,還有突破真正的編譯器和晶片所允許的邊界。
超出規範之外是有風險的,但在這個無法無天的領域也會有回報。這樣做是否值得,取決於你自己。 ↩ -
事實上,jlox把NaN相等性搞錯了。當你使用
==來比較基本型別double時,Java做的是正確的,但如果你把這些值包裝在Double或Object中,並使用equals()來比較它們時,就是錯的,而這正是jlox中使用相等性的方式。 ↩ -
在做剖析工作時,你基本總是想剖析程式的最佳化後的“釋出”構建版本,因為這反映了終端使用者體驗的效能情況。編譯器的最佳化(如內聯)會極大地影響程式碼中哪些部分是效能熱點。手工最佳化一個除錯構建版本,可能會讓你去“修復”那些最佳化編譯器本來就會為你解決的問題。
請確保你不會意外地對除錯構建版本進行基準測試和最佳化。我似乎每年都至少要犯一次這樣的錯誤。 ↩ -
這也適用於其它領域。我認為我在程式設計中所學到的任何一個主題——甚至在程式設計之外——最終都發現在其它領域中是有用的。我最喜歡軟體工程的一個方面正是它對那些興趣廣泛的人的助益。 ↩
-
在這方面,我喜歡Cooper和Torczon的《編譯器工程,Engineering a Compiler》。Appel的《現代編譯器實現,Modern Compiler Implementation》一書也廣受好評。 ↩
-
本書的文字版權歸我所有,但jlox和clox的程式碼和實現採用了非常寬鬆的MIT許可。我非常歡迎你使用這些直譯器中的任何一個,對它們做任何你想做的事。去吧。
如果你對語言做了重大改動,最好也能改一下名字,主要是為了避免人們對“Lox”這個名字的含義感到困惑。 ↩
後記 BACKMATTER
You’ve reached the end of the book! There are two pieces of supplementary material you may find helpful:
你已經看完了這本書!有兩份補充材料可能對你有所幫助:
- Appendix I contains a complete grammar for Lox, all in one place.
- Appendix II shows the Java classes produced by the AST generator we use for jlox.
附錄I Appendix I
Here is a complete grammar for Lox. The chapters that introduce each part of the language include the grammar rules there, but this collects them all into one place.
這裡有一份Lox的完整語法。介紹語言每個部分的章節中都包含對應的語法規則,但這裡將它們全部收錄在一起了。
A1 . 1 Syntax Grammar
A1.1 語法
The syntactic grammar is used to parse the linear sequence of tokens into the nested syntax tree structure. It starts with the first rule that matches an entire Lox program (or a single REPL entry).
語法用於將詞法標識(token)的線性序列解析為巢狀的語法樹結構。它從匹配整個Lox程式(或單條REPL輸入)的第一個規則開始。
program → declaration* EOF ;
A1 . 1 . 1 Declarations
A1.1.1 宣告
A program is a series of declarations, which are the statements that bind new identifiers or any of the other statement types.
一個程式就是一系列的宣告,也就是繫結新識別符號或其它statement型別的語句。
declaration → classDecl
| funDecl
| varDecl
| statement ;
classDecl → "class" IDENTIFIER ( "<" IDENTIFIER )?
"{" function* "}" ;
funDecl → "fun" function ;
varDecl → "var" IDENTIFIER ( "=" expression )? ";" ;
A1 . 1 . 2 Statements
A1.1.2 語句
The remaining statement rules produce side effects, but do not introduce bindings.
其餘的語句規則會產生副作用,但不會引入繫結。
statement → exprStmt
| forStmt
| ifStmt
| printStmt
| returnStmt
| whileStmt
| block ;
exprStmt → expression ";" ;
forStmt → "for" "(" ( varDecl | exprStmt | ";" )
expression? ";"
expression? ")" statement ;
ifStmt → "if" "(" expression ")" statement
( "else" statement )? ;
printStmt → "print" expression ";" ;
returnStmt → "return" expression? ";" ;
whileStmt → "while" "(" expression ")" statement ;
block → "{" declaration* "}" ;
Note that
blockis a statement rule, but is also used as a nonterminal in a couple of other rules for things like function bodies.
請注意,block是一個語句規則,但在其它規則中也作為非終止符使用,用於表示函式體等內容。
A1 . 1 . 3 Expressions
A1.1.3 表示式
Expressions produce values. Lox has a number of unary and binary operators with different levels of precedence. Some grammars for languages do not directly encode the precedence relationships and specify that elsewhere. Here, we use a separate rule for each precedence level to make it explicit.
表示式會產生值。Lox有許多具有不同優先順序的一元或二元運算子。一些語言的語法中沒有直接編碼優先順序關係,而是在其它地方指定。在這裡,我們為每個優先順序使用單獨的規則,使其明確。
expression → assignment ;
assignment → ( call "." )? IDENTIFIER "=" assignment
| logic_or ;
logic_or → logic_and ( "or" logic_and )* ;
logic_and → equality ( "and" equality )* ;
equality → comparison ( ( "!=" | "==" ) comparison )* ;
comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ;
term → factor ( ( "-" | "+" ) factor )* ;
factor → unary ( ( "/" | "*" ) unary )* ;
unary → ( "!" | "-" ) unary | call ;
call → primary ( "(" arguments? ")" | "." IDENTIFIER )* ;
primary → "true" | "false" | "nil" | "this"
| NUMBER | STRING | IDENTIFIER | "(" expression ")"
| "super" "." IDENTIFIER ;
A1 . 1 . 4 Utility rules
A1.1.4 實用規則
In order to keep the above rules a little cleaner, some of the grammar is split out into a few reused helper rules.
為了使上面的規則更簡潔一點,一些語法被拆分為幾個重複使用的輔助規則。
function → IDENTIFIER "(" parameters? ")" block ;
parameters → IDENTIFIER ( "," IDENTIFIER )* ;
arguments → expression ( "," expression )* ;
A1 . 2 Lexical Grammar
A1.2 詞法
The lexical grammar is used by the scanner to group characters into tokens. Where the syntax is context free, the lexical grammar is regular—note that there are no recursive rules.
詞法被掃描器用來將字元分組為詞法標識(token)。語法是上下文無關的,詞法是正則的——注意這裡沒有遞迴規則。
NUMBER → DIGIT+ ( "." DIGIT+ )? ;
STRING → "\"" <any char except "\"">* "\"" ;
IDENTIFIER → ALPHA ( ALPHA | DIGIT )* ;
ALPHA → "a" ... "z" | "A" ... "Z" | "_" ;
DIGIT → "0" ... "9" ;
附錄II Appendix II
For your edification, here is the code produced by the little script we built to automate generating the syntax tree classes for jlox.
為了方便你們學習,下面是我們為自動生成jlox語法樹類而構建的小指令碼所產生的程式碼。
A2 . 1 Expressions
A2.1 表示式
Expressions are the first syntax tree nodes we see, introduced in “Representing Code”. The main Expr class defines the visitor interface used to dispatch against the specific expression types, and contains the other expression subclasses as nested classes.
表示式是我們看到的第一個語法樹節點,在“表示程式碼”中介紹過。主要的Expr類定義了用於針對特定表示式型別進行排程的訪問者介面,並將其它表示式子類作為巢狀類包含其中。
lox/Expr.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.List;
abstract class Expr {
interface Visitor<R> {
R visitAssignExpr(Assign expr);
R visitBinaryExpr(Binary expr);
R visitCallExpr(Call expr);
R visitGetExpr(Get expr);
R visitGroupingExpr(Grouping expr);
R visitLiteralExpr(Literal expr);
R visitLogicalExpr(Logical expr);
R visitSetExpr(Set expr);
R visitSuperExpr(Super expr);
R visitThisExpr(This expr);
R visitUnaryExpr(Unary expr);
R visitVariableExpr(Variable expr);
}
// Nested Expr classes here...
abstract <R> R accept(Visitor<R> visitor);
}
A2 . 1 . 1 Assign expression
Variable assignment is introduced in “Statements and State”.
變數賦值在“表示式與狀態”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Assign extends Expr {
Assign(Token name, Expr value) {
this.name = name;
this.value = value;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitAssignExpr(this);
}
final Token name;
final Expr value;
}
A2 . 1 . 2 Binary expression
A2.1.2 Binary表示式
Binary operators are introduced in “Representing Code”.
二元運算子在“表示程式碼”中介紹過。
lox/Expr.java,巢狀在類Expr中:
static class Binary extends Expr {
Binary(Expr left, Token operator, Expr right) {
this.left = left;
this.operator = operator;
this.right = right;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitBinaryExpr(this);
}
final Expr left;
final Token operator;
final Expr right;
}
A2 . 1 . 3 Call expression
Function call expressions are introduced in “Functions”.
函式呼叫語句在“函式”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Call extends Expr {
Call(Expr callee, Token paren, List<Expr> arguments) {
this.callee = callee;
this.paren = paren;
this.arguments = arguments;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitCallExpr(this);
}
final Expr callee;
final Token paren;
final List<Expr> arguments;
}
A2 . 1 . 4 Get expression
Property access, or “get” expressions are introduced in “Classes”.
屬性訪問,或者說“get”表示式,在“類”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Get extends Expr {
Get(Expr object, Token name) {
this.object = object;
this.name = name;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitGetExpr(this);
}
final Expr object;
final Token name;
}
A2 . 1 . 5 Grouping expression
Using parentheses to group expressions is introduced in “Representing Code”.
使用括號進行分組的表示式在“表示程式碼”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Grouping extends Expr {
Grouping(Expr expression) {
this.expression = expression;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitGroupingExpr(this);
}
final Expr expression;
}
A2 . 1 . 6 Literal expression
Literal value expressions are introduced in “Representing Code”.
字面量值表示式在“表示程式碼”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Literal extends Expr {
Literal(Object value) {
this.value = value;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitLiteralExpr(this);
}
final Object value;
}
A2 . 1 . 7 Logical expression
The logical
andandoroperators are introduced in “Control Flow”.
邏輯運算子and和or在“控制流”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Logical extends Expr {
Logical(Expr left, Token operator, Expr right) {
this.left = left;
this.operator = operator;
this.right = right;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitLogicalExpr(this);
}
final Expr left;
final Token operator;
final Expr right;
}
A2 . 1 . 8 Set expression
Property assignment, or “set” expressions are introduced in “Classes”.
屬性賦值,或者叫“set”表示式,在“類”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Set extends Expr {
Set(Expr object, Token name, Expr value) {
this.object = object;
this.name = name;
this.value = value;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitSetExpr(this);
}
final Expr object;
final Token name;
final Expr value;
}
A2 . 1 . 9 Super expression
The
superexpression is introduced in “Inheritance”.
super表示式在“繼承”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Super extends Expr {
Super(Token keyword, Token method) {
this.keyword = keyword;
this.method = method;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitSuperExpr(this);
}
final Token keyword;
final Token method;
}
A2 . 1 . 10 This expression
The
thisexpression is introduced in “Classes”.
this表示式在“類”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class This extends Expr {
This(Token keyword) {
this.keyword = keyword;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitThisExpr(this);
}
final Token keyword;
}
A2 . 1 . 11 Unary expression
Unary operators are introduced in “Representing Code”.
一元運算子在“表示程式碼”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Unary extends Expr {
Unary(Token operator, Expr right) {
this.operator = operator;
this.right = right;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitUnaryExpr(this);
}
final Token operator;
final Expr right;
}
A2 . 1 . 12 Variable expression
Variable access expressions are introduced in “Statements and State”.
變數訪問表示式在“語句和狀態”中介紹過。
lox/Expr.java,巢狀在Expr類中:
static class Variable extends Expr {
Variable(Token name) {
this.name = name;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitVariableExpr(this);
}
final Token name;
}
A2 . 2 Statements
A2.2 語句
Statements form a second hierarchy of syntax tree nodes independent of expressions. We add the first couple of them in “Statements and State”.
語句形成了獨立於表示式的第二個語法樹節點層次。我們在“宣告和狀態”中添加了前幾個。
lox/Stmt.java,建立新檔案:
package com.craftinginterpreters.lox;
import java.util.List;
abstract class Stmt {
interface Visitor<R> {
R visitBlockStmt(Block stmt);
R visitClassStmt(Class stmt);
R visitExpressionStmt(Expression stmt);
R visitFunctionStmt(Function stmt);
R visitIfStmt(If stmt);
R visitPrintStmt(Print stmt);
R visitReturnStmt(Return stmt);
R visitVarStmt(Var stmt);
R visitWhileStmt(While stmt);
}
// Nested Stmt classes here...
abstract <R> R accept(Visitor<R> visitor);
}
A2 . 2 . 1 Block statement
The curly-braced block statement that defines a local scope is introduced in “Statements and State”.
在“語句和狀態”中介紹過的花括號塊語句,可以定義一個區域性作用域。
lox/Stmt.java,巢狀在Stmt類中:
static class Block extends Stmt {
Block(List<Stmt> statements) {
this.statements = statements;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitBlockStmt(this);
}
final List<Stmt> statements;
}
A2 . 2 . 2 Class statement
Class declarations are introduced in, unsurprisingly, “Classes”.
類宣告是在“類”中介紹的,毫不意外。
lox/Stmt.java,巢狀在Stmt類中:
static class Class extends Stmt {
Class(Token name,
Expr.Variable superclass,
List<Stmt.Function> methods) {
this.name = name;
this.superclass = superclass;
this.methods = methods;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitClassStmt(this);
}
final Token name;
final Expr.Variable superclass;
final List<Stmt.Function> methods;
}
A2 . 2 . 3 Expression statement
The expression statement is introduced in “Statements and State”.
表示式語句在“語句和狀態”中介紹過。
lox/Stmt.java,巢狀在Stmt類中:
static class Expression extends Stmt {
Expression(Expr expression) {
this.expression = expression;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitExpressionStmt(this);
}
final Expr expression;
}
A2 . 2 . 4 Function statement
Function declarations are introduced in, you guessed it, “Functions”.
函式宣告是在“函式”中介紹的。
lox/Stmt.java,巢狀在Stmt類中:
static class Function extends Stmt {
Function(Token name, List<Token> params, List<Stmt> body) {
this.name = name;
this.params = params;
this.body = body;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitFunctionStmt(this);
}
final Token name;
final List<Token> params;
final List<Stmt> body;
}
A2 . 2 . 5 If statement
The
ifstatement is introduced in “Control Flow”.
if語句在“控制流”中介紹過。
lox/Stmt.java,巢狀在Stmt類中:
static class If extends Stmt {
If(Expr condition, Stmt thenBranch, Stmt elseBranch) {
this.condition = condition;
this.thenBranch = thenBranch;
this.elseBranch = elseBranch;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitIfStmt(this);
}
final Expr condition;
final Stmt thenBranch;
final Stmt elseBranch;
}
A2 . 2 . 6 Print statement
The
print語句在“語句和狀態”中介紹過。
lox/Stmt.java,巢狀在Stmt類中:
static class Print extends Stmt {
Print(Expr expression) {
this.expression = expression;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitPrintStmt(this);
}
final Expr expression;
}
A2 . 2 . 7 Return statement
You need a function to return from, so
returnstatements are introduced in “Functions”.
你需要一個函式才能返回,所以return語句是在“函式”中介紹的。
lox/Stmt.java,巢狀在Stmt類中:
static class Return extends Stmt {
Return(Token keyword, Expr value) {
this.keyword = keyword;
this.value = value;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitReturnStmt(this);
}
final Token keyword;
final Expr value;
}
A2 . 2 . 8 Variable statement
Variable declarations are introduced in “Statements and State”.
變數宣告在“語句和狀態”中介紹過。
lox/Stmt.java,巢狀在Stmt類中:
static class Var extends Stmt {
Var(Token name, Expr initializer) {
this.name = name;
this.initializer = initializer;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitVarStmt(this);
}
final Token name;
final Expr initializer;
}
A2 . 2 . 9 While statement
The
whilestatement is introduced in “Control Flow”.
while語句在“控制流”中介紹過。
lox/Stmt.java,巢狀在Stmt類中:
static class While extends Stmt {
While(Expr condition, Stmt body) {
this.condition = condition;
this.body = body;
}
@Override
<R> R accept(Visitor<R> visitor) {
return visitor.visitWhileStmt(this);
}
final Expr condition;
final Stmt body;
}