Rust 是一門系統級編程語言,被設計為保證內存和線程安全,並防止段錯誤。作為系統級編程語言,它的基本理念是 “零開銷抽象”。理論上來說,它的速度與 C / C++ 同級。
Rust 可以被歸為通用的、多範式、編譯型的編程語言,類似 C 或者 C++。與這兩門編程語言不同的是,Rust 是線程安全的!
Rust 編程語言的目標是,創建一個高度安全和併發的軟件系統。它強調安全性、併發和內存控制。儘管 Rust 借用了 C 和 C++ 的語法,它不允許空指針和懸掛指針,二者是 C 和 C++ 中系統崩潰、內存洩露和不安全代碼的根源。
Rust 中有諸如 if else 和循環語句 for 和 while 的通用控制結構。和 C 和 C++ 風格的編程語言一樣,代碼段放在花括號中。
Rust 使用實現(implementation)、特徵(trait)和結構化類型(structured type)而不是類(class)。這點,與基於繼承的OO語言 C++, Java 有相當大的差異。而跟 Ocaml, Haskell 這類函數式語言更加接近。
Rust 做到了內存安全而無需 .NET 和 Java 編程語言中實現自動垃圾收集器的開銷,這是通過所有權/借用機制、生命週期、以及類型系統來達到的。
下面是一個代碼片段的例子,經典的 Hello World 應用:
fn main() { println!("hello, world"); }
影響了 Rust 的流行的編程語言包括 C, C++, C#, Erlang, Haskell, OCaml, Ruby, Scheme 和 Swift 等等。Rust 也影響了 C# 7, Elm, Idris, Swift。
Rust 提供了安裝程序,你只需要從官網下載並在相應的操作系統上運行安裝程序。安裝程序支持 Windows、Mac 和 Linux(通過腳本)上的32位和64位 CPU 體系架構,適用 Apache License 2.0 或者 MIT Licenses。
Rust 運行在以下操作系統上:Linux, OS X, Windows, FreeBSD, Android, iOS。
簡單提一下 Rust 的歷史。Rust 最早是 Mozilla 僱員 Graydon Hoare 的一個個人項目,從 2009 年開始,得到了 Mozilla 研究院的支助,2010 年項目對外公佈。2010 ~2011 年間實現的自舉。從此以後,Rust 經歷了巨大的設計變化和反覆(歷程極其艱辛),終於在 2015 年 5 月 15日發佈了 1.0 版。在這個研發過程中,Rust 建立了一個強大活躍的社區,形成了一整套完善穩定的項目貢獻機制(這是真正的可怕之處)。Rust 現在由 Rust 項目開發者社區(https://github.com/rust-lang/rust )維護。
自 15 年 5 月 1.0 發佈以來,湧現了大量優秀的項目(可以 github 上搜索 Rust 查找),大公司也逐漸積極參與 Rust 的應用開發,以及回饋開源社區。
本書(RustPrimer)旨在為中文 Rustaceans 初學者提供一個正確、最新、易懂的中文教程。本書會一直完善跟進,永不停歇。
本書是整個 Rust 中文社區共同努力的結果。其中,參與本書書寫及校訂的 Rustacean 有(排名不分先後):
- daogangtang(Mike貓)
- wayslog(貓貓反抗團團長)
- marvin-min
- tiansiyuan
- marvinguo
- ee0703
- fuyingfuying
- qdao
- JohnSmithX
- stormgbs (AX)
- tennix
- anzhihun
- zonyitoo(Elton, e貓)
- 42
- Naupio(N貓)
- F001(失落的神喵)
- wangyu190810
- domty
- MarisaKirisame(帥氣可愛魔理沙)
- Liqueur Librazy
- Knight42
- Ryan Kung
- lambdaplus
- doomsplayer
- lucklove
- veekxt
- lk-chen
- RyanKung
- arrowrowe
- marvin-min
- ghKelo
- wy193777
- domty
- xusss
- wangyu190810
- nextzhou
- zhongke
- ryuki
- codeworm96
- anzhihun
- lidashuang
- sceext2
- loggerhead
- twq0076262
- passchaos
- yyrust
- markgeek
- ts25504
- overvenus
- Akagi201
- theJian
- jqs7
- ahjdzx
- chareice
- chenshaobo
- marvinguo
- izgzhen
- ziqin
- peng1999
等。在此,向他們的辛苦工作和無私奉獻表示尊敬和感謝!
祝用 Rust 編程愉快!
安裝Rust
本章講解在三大平臺 Linux, MacOS, Windows 上分別安裝 Rust 的步驟。
Rust for Linux
Rust 支持主流的操作系統,Linux,Mac和 windows。
Rust 為Linux用戶提供了兩種安裝方式:
1、直接下載安裝包:
直接下載安裝包的話需要檢查一下你當前操作系統是64位還是32位,分別下載對應的安裝包。
查看操作系統請在終端執行如下命令:
uname -a
結果如下圖所示:

如上圖所示,如果是 x86_64 則證明是64位系統,需要下載64位安裝包;
如果是x86-32則需要下載32位安裝包
下載安裝包後解壓運行即可。在書寫本章時,最新的穩定版本為1.5.0,
解壓:tar -zxvf rust-1.5.0-x86_64-unknown-linux-gnu.tar.gz
解壓完進入對應的目錄:cd rust-1.5.0-x86_64-unknown-linux-gnu
執行 ./install.sh
上述命令執行完成後會打印: Rust is ready to roll. 表明安裝成功
此時執行: rustc --version, 你會看到對應的 rust 版本信息,如下圖所示:

2、命令行一鍵安裝:
Rust 提供簡單的一鍵安裝,命令如下:
curl -sSf https://static.rust-lang.org/rustup.sh | sh
打開終端執行如上命令即可。
注意
除了穩定版之外,Rust 還提供了 Beta 和 Nightly 版本,下載地址如下: https://www.rust-lang.org/zh-CN/other-installers.html
如果你不想安裝 Rust 在你的電腦上,但是你還是像嘗試一下 rust,那麼這裡有一個在線的環境:http://play.rust-lang.org/
中國科學技術大學鏡像源包含 rust-static,梯子暫時出問題的同學可以嘗試從這裡下載編譯器;除此之外。還有 Crates 源,詳見這裡的說明。
Rust for Mac OS
Rust 支持主流的操作系統,Linux,Mac 和 windows。
Rust 為 mac 用戶提供了兩種安裝方式:
1、直接下載安裝包:
直接下載安裝包的話需要檢查一下你當前操作系統是64位還是32位,分別下載對應的安裝包。 查看操作系統請在終端執行如下命令:
uname -a

如上圖紅色部分所示,如果是 x86_64 則證明是64位系統,需要下載64位安裝包; 如果是x86-32則需要下載32位安裝包
和安裝普通的軟件一樣,直接運行安裝包即可。
在書寫本章時,最新的穩定版本為1.5.0,
2、命令行一鍵安裝:
Rust 提供簡單的一鍵安裝,命令如下:
curl -sSf https://static.rust-lang.org/rustup.sh | sh
此過程,有可能需要你輸入幾次密碼
你只需打開你的命令行執行如上代碼就可以了。(注意,你可能需要一個梯子,否則會遇到一些類似Could not resolve host: static.rust-lang.org的錯誤)
3.驗證安裝:
如果你完成了上面任意一個步驟,請執行如下命令:
rustc --version
如果看到如下信息,表明你安裝成功:
rustc 1.5.0 (3d7cd77e4 2015-12-04)
如果提示沒有 rustc 命令,那麼請回顧你是否有某個地方操作不對,請回過頭來再看一遍文檔。
注意
除了穩定版之外,Rust 還提供了 Beta 和 Nightly 版本,下載地址如下: https://www.rust-lang.org/zh-CN/other-installers.html
如果你不想安裝 Rust 在你的電腦上,但是你還是像嘗試一下 rust,那麼這裡有一個在線的環境:http://play.rust-lang.org/
中國科學技術大學鏡像源包含 rust-static,梯子暫時出問題的同學可以嘗試從這裡下載編譯器;除此之外,還有 Crates 源,詳見這裡的說明。
Rust for Windows
Rust 支持主流的操作系統,Linux,Mac和 Windows。
Rust在Windows上的安裝和你在windows上安裝其它軟件一樣。
1、下載安裝包:
Rust提供了多個版本和多個平臺的安裝包,下載對應的即可,此處我們以1.6.0的穩定版為例。
2、安裝:
雙擊下載到的安裝包,如下圖所示:
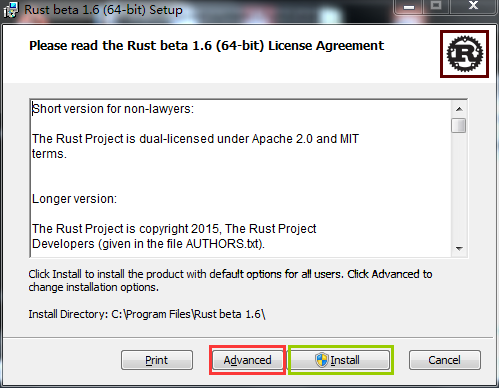
默認,rust將安裝到所有用戶下,選擇“Advanced”,可以指定安裝用戶和安裝路徑。然後點擊"install"等待幾分鐘即可(中間可能會有安全提示,點擊允許即可,如果你裝了360之類的,需要小心360阻止寫入註冊表)。
3.驗證安裝:
安裝完成後,運行windows命令行,然後輸入:
rustc --version
看到 以 rustc 1.6.0 開頭,說明你安裝成功了。
注意
中國科學技術大學鏡像源包含 rust-static,梯子暫時出問題的同學可以嘗試從這裡下載編譯器;除此之外。還有 Crates 源,詳見這裡的說明。
Rust 版本管理工具: rustup
rustup 是rust官方的版本管理工具。應當作為安裝 Rust 的首選。
項目主頁是: https://github.com/rust-lang-nursery/rustup.rs
Features
- 管理安裝多個官方版本的 Rust 二進制程序。
- 配置基於目錄的 Rust 工具鏈。
- 安裝和更新來自 Rust 的發佈通道: nightly, beta 和 stable。
- 接收來自發布通道更新的通知。
- 從官方安裝歷史版本的 nightly 工具鏈。
- 通過指定 stable 版本來安裝。
- 安裝額外的 std 用於交叉編譯。
- 安裝自定義的工具鏈。
- 獨立每個安裝的 Cargo metadata。
- 校驗下載的 hash 值。
- 校驗簽名 (如果 GPG 存在)。
- 斷點續傳。
- 只依賴 bash, curl 和常見 unix 工具。
- 支持 Linux, OS X, Windows(via MSYS2)。
安裝
Windows
在rustup的主頁下載並運行rustup-init.exe,並按照提示選擇選項。
Welcome to Rust!
This will download and install the official compiler for the Rust programming
language, and its package manager, Cargo.
It will add the cargo, rustc, rustup and other commands to Cargo's bin
directory, located at:
C:\Users\Liqueur Librazy\.cargo\bin
This path will then be added to your PATH environment variable by modifying the
HKEY_CURRENT_USER/Environment/PATH registry key.
You can uninstall at any time with rustup self uninstall and these changes will
be reverted.
Current installation options:
default host triple: x86_64-pc-windows-msvc
default toolchain: stable
modify PATH variable: yes
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
三個選項分別是
- 開始安裝(默認選項)
- 自定義安裝
- 取消
其中自定義安裝可以更改默認架構與工具鏈、是否添加 PATH。例如想要選擇 nightly 工具鏈可以進行以下自定義
I'm going to ask you the value of each these installation options.
You may simply press the Enter key to leave unchanged.
Default host triple?
Default toolchain? (stable/beta/nightly)
nightly
Modify PATH variable? (y/n)
設置完畢後,選擇 1 以開始安裝。
Linux & macOS
運行以下命令
curl https://sh.rustup.rs -sSf | sh
這個命令將會編譯和安裝 rustup, 安裝過程中可能會提示你輸入 sudo 的密碼。 然後, 他會下載和安裝 stable 版本的工具鏈, 當執行 rustc, rustdoc 和 cargo 時, 將會配置他為默認工具鏈。
Unix 上安裝後工具鏈會被安裝到 $HOME/.cargo/bin 目錄。
.cargo/bin 目錄會被添加到系統的 $PATH 環境變量,重新登錄後即可使用 rustc,cargo 等命令。
卸載
rustup self uninstall
用法
安裝後會得到一個 rustup 命令, 多使用命令自帶的幫助提示, 可以快速定位你需要功能。
幫助
運行 rustup -h 你將會得到如下提示:
❯ rustup -h
rustup 1.5.0 (92d0d1e9e 2017-06-24)
The Rust toolchain installer
USAGE:
rustup.exe [FLAGS] [SUBCOMMAND]
FLAGS:
-v, --verbose Enable verbose output
-h, --help Prints help information
-V, --version Prints version information
SUBCOMMANDS:
show Show the active and installed toolchains
update Update Rust toolchains and rustup
default Set the default toolchain
toolchain Modify or query the installed toolchains
target Modify a toolchain's supported targets
component Modify a toolchain's installed components
override Modify directory toolchain overrides
run Run a command with an environment configured for a given toolchain
which Display which binary will be run for a given command
doc Open the documentation for the current toolchain
self Modify the rustup installation
set Alter rustup settings
completions Generate completion scripts for your shell
help Prints this message or the help of the given subcommand(s)
DISCUSSION:
rustup installs The Rust Programming Language from the official
release channels, enabling you to easily switch between stable,
beta, and nightly compilers and keep them updated. It makes
cross-compiling simpler with binary builds of the standard library
for common platforms.
If you are new to Rust consider running `rustup doc --book` to
learn Rust.
根據提示, 使用 rust help <command> 來查看子命令的幫助。
rustup doc --book 會打開英文版的 The Rust Programming Language。
常用命令
rustup default <toolchain> 配置默認工具鏈。
rustup show 顯示當前安裝的工具鏈信息。
rustup update 檢查安裝更新。
rustup toolchain [SUBCOMMAND] 配置工具鏈
rustup toolchain install <toolchain>安裝工具鏈。rustup toolchain uninstall <toolchain>卸載工具鏈。rustup toolchain link <toolchain-name> "<toolchain-path>"設置自定義工具鏈。其中標準的
<toolchain>具有如下的形式`<channel>[-<date>][-<host>]` <channel> = stable|beta|nightly|<version> <date> = YYYY-MM-DD <host> = <target-triple>如
stable-x86_64-pc-windows-msvcnightly-2017-7-251.18.0等都是合法的toolchain名稱。
rustup override [SUBCOMMAND] 配置一個目錄以及其子目錄的默認工具鏈
使用
--path <path>指定目錄或在某個目錄下運行以下命令
rustup override set <toolchain>設置該目錄以及其子目錄的默認工具鏈。rustup override unset取消目錄以及其子目錄的默認工具鏈。使用
rustup override list查看已設置的默認工具鏈。
rustup target [SUBCOMMAND] 配置工具鏈的可用目標
rustup target add <target>安裝目標。rustup target remove <target>卸載目標。rustup target add --toolchain <toolchain> <target>為特定工具鏈安裝目標。
rustup component 配置 rustup 安裝的組件
rustup component add <component>安裝組件rustup component remove <component>卸載組件rustup component list列出可用組件常用組件:
- Rust 源代碼
rustup component add rust-src- Rust Langular Server (RLS)
rustup component add rls
編輯器
本章描述幾種常用編輯器針對 Rust 開發環境的配置。
前期準備
下載 Rust 源代碼(供 racer 使用)
從github下載
git clone https://github.com/rust-lang/rust.git
從官網下載源代碼包
下載地址: https://static.rust-lang.org/dist/rustc-nightly-src.tar.gz
使用rustup下載(推薦)
使用rustup獲取源碼最大的好處在於可以使用rustup update隨時獲取最新版源碼,~~而且特別省事,~~執行以下命令獲取源碼
rustup component add rust-src
racer
racer是一個由rust的愛好者提供的rust自動補全和語法分析工具,被用來提供基本的補全功能和定義跳轉功能。其本身完全由rust寫成,補全功能已經比較完善了。
我們可以通過如下的方式獲取它:
cargo自動安裝
在rust 1.5版本以後,其安裝包自帶的cargo工具已經支持了cargo install命令,這個命令可以幫助我們通過簡單的方式獲取到racer的最新版。
你可以通過以下命令安裝racer最新版,目前已知在Linux、Unix和Windows上適用
cargo install racer
編譯安裝
事實上我更推薦有條件的用戶通過這種方式安裝,因為自己實戰操作一遍總是有些收穫的。(帥氣可愛的DCjanus表示懷疑)
下載源碼
首先,我們需要下載racer的源碼
git clone https://github.com/phildawes/racer.git
進行編譯
然後,進入目錄然後進行編譯
cd racer && cargo build --release
這樣,我們會得到racer的二進制文件在 target/release/racer目錄
設置環境變量
為了對Rust標準庫進行補全,racer需要獲取Rust源碼路徑。
設置名為RUST_SRC_PATH的環境變量為[path_to_your_rust_source]/src
其中[path_to_your_rust_source]表示源碼所在文件夾,使用rustup獲取Rust源碼的情況下[path_to_your_rust_source]默認為~/.multirust/toolchains/[your-toolchain]/lib/rustlib/src/rust/src
測試
請重新打開終端,並進入到關閉之前的路徑。 執行如下代碼: linux:
./target/release/racer complete std::io::B
windows:
target\release\racer complete std::io::B
你將會看到racer的提示,這表示racer已經執行完成了。
安裝 rustfmt
cargo install rustfmt
Rust Langular Server (RLS)
Rust Langular Server(下文簡稱RLS)可以為很多IDE或編輯器提供包括不限於自動補全、跳轉定義、重命名、跳轉類型的功能支持。
使用rustup安裝步驟如下:
- 保證
rustup為最新版
rustup self update
- 升級工具鏈(並不要求設置
nightly為默認,但需要保證安裝了nightly工具鏈)
rustup update nightly
- 正式安裝RLS
rustup component add rls --toolchain nightly
rustup component add rust-analysis --toolchain nightly
rustup component add rust-src --toolchain nightly
- 設置環境變量
如果在安裝Racer時沒有設置名為
RUST_SRC_PATH的環境變量,請參考前文進行設置。
截至當前(2017年7月15日),RLS仍然處於alpha階段,隨著項目變動,安裝步驟可能會由較大變化,本文中提及的RLS安裝方法可能在較短的時間內過時,建議跟隨官方安裝指導進行安裝。
該項目託管地址:https://github.com/rust-lang-nursery/rls
vim/GVim安裝配置
本節介紹vim的Rust支持配置,在閱讀本節之前,我們假定你已經擁有了一個可執行的rustc程序,並編譯好了racer。
我的vim截圖
應邀而加
使用vundle
vundle是vim的一個插件管理工具,基本上算是本類當中最為易用的了。 首先我們需要安裝它
linux or OS X
mkdir -p ~/.vim/bundle/
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
windows
- 首先找到你的gvim的安裝路徑,然後在路徑下找到vimfiles文件夾
- 在這個文件夾中將vundle庫克隆到vimfiles/bundle/目錄下的Vundle.vim文件夾中
啟用rust支持
下載源碼
首先,你需要下載rust-lang的源碼文件,並將其解壓到一個路徑下。
這個源碼文件我們可以從rust官網下載到,請下載你對應平臺的文件。
然後將其解壓到一個目錄下,並找到其源碼文件中的src目錄。
比如我們解壓源碼包到C:\\rust-source\,那麼我們需要的路徑就是C:\\rust-source\src,記好這個路徑,我們將在下一步用到它。
修改vim配置
首先找到你的vimrc配置文件,然後在其中添加如下配置
set nocompatible
filetype off
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
Plugin 'VundleVim/Vundle.vim'
Plugin 'racer-rust/vim-racer'
Plugin 'rust-lang/rust.vim'
call vundle#end()
filetype on
然後為了讓配置生效,我們重啟我們的(g)vim,然後在vim裡執行如下命令
:PluginInstall
這裡vundle會自動的去倉庫里拉取我們需要的文件,這裡主要是vim-racer和rust.vim兩個庫。
更多的配置
為了讓我們的vim能正常的使用,我們還需要在vimrc配置文件里加入一系列配置,
"" 開啟rust的自動reformat的功能
let g:rustfmt_autosave = 1
"" 手動補全和定義跳轉
set hidden
"" 這一行指的是你編譯出來的racer所在的路徑
let g:racer_cmd = "<path-to-racer>/target/release/racer"
"" 這裡填寫的就是我們在1.2.1中讓你記住的目錄
let $RUST_SRC_PATH="<path-to-rust-srcdir>/src/"
使用 YouCompleteMe
YouCompleteMe 是 vim 下的智能補全插件, 支持 C-family, Python, Rust 等的語法補全, 整合了多種插件, 功能強大. Linux 各發行版的官方源裡基本都有軟件包, 可直接安裝. 如果有需要進行編譯安裝的話, 可參考官方教程
讓 YCM 支持 Rust 需要在安裝 YCM 過程中執行 ./install.py 時加上 --racer-completer, 並在 .vimrc 中添加如下設置
let g:ycm_rust_src_path="<path-to-rust-srcdir>/src/"
"" 一些方便的快捷鍵
""" 在 Normal 模式下, 敲 <leader>jd 跳轉到定義或聲明(支持跨文件)
nnoremap <leader>jd :YcmCompleter GoToDefinitionElseDeclaration<CR>
""" 在 Insert 模式下, 敲 <leader>; 補全
inoremap <leader>; <C-x><C-o>
總結
經過不多的配置,我們得到了如下功能:
- 基本的c-x c-o補全 (使用 YCM 後, 能做到自動補全)
- 語法著色
- gd跳轉到定義
總體來看支持度並不高。
額外的
Q1. 顏色好挫
A1. 我推薦一個配色,也是我自己用的 molokai
更詳細內容可以參見我的vimrc配置,當然,我這個用的是比較老的版本的vundle,僅供參考。
Have a nice Rust !
Emacs
本節介紹 Emacs (Version 24) 的 Rust 配置,假設你已經安裝好了 Emacs,並且有使用 Emacs 的經驗。具體的安裝和使用說明,見網上相關文檔,在此不贅述。
另外,本節的例子是在 Mac OS 上,在 Linux 上面基本一樣。
Windows的Emacs用戶僅作參考。
簡介
Emacs 的 rust-mode 提供了語法高亮顯示和 elisp 函數,可以圍繞 Rust 函數定義移動光標。有幾個插件提供了附加的功能,如自動補全和動態語法檢查。
安裝插件
首先,需要將 melpa 代碼庫添加到你的插件列表中,才能安裝 Rust 需要的插件。將下面的代碼片段加入你的~/.emacs.d/init.el 文件中。
;; Add melpa repository to archives
(add-to-list 'package-archives
'("melpa" . "http://melpa.milkbox.net/packages/") t)
;; Initialize packages
(package-initialize)
運行下面的命令,更新插件列表。
- M-x eval-buffer
- M-x package-refresh-contents
然後,就可以安裝插件,在 Emacs 中使用 Rust 了。運行 M-x package-list-packages,用 i 標記下述插件進行安裝,當所有的插件選擇好了之後,用 x 執行安裝。
- company
- company-racer
- racer
- flycheck
- flycheck-rust
- rust-mode
將下面的代碼片段加入你的~/.emacs.d/init.el 文件:
;; Enable company globally for all mode
(global-company-mode)
;; Reduce the time after which the company auto completion popup opens
(setq company-idle-delay 0.2)
;; Reduce the number of characters before company kicks in
(setq company-minimum-prefix-length 1)
;; Set path to racer binary
(setq racer-cmd "/usr/local/bin/racer")
;; Set path to rust src directory
(setq racer-rust-src-path "/Users/YOURUSERNAME/.rust/src/")
;; Load rust-mode when you open `.rs` files
(add-to-list 'auto-mode-alist '("\\.rs\\'" . rust-mode))
;; Setting up configurations when you load rust-mode
(add-hook 'rust-mode-hook
'(lambda ()
;; Enable racer
(racer-activate)
;; Hook in racer with eldoc to provide documentation
(racer-turn-on-eldoc)
;; Use flycheck-rust in rust-mode
(add-hook 'flycheck-mode-hook #'flycheck-rust-setup)
;; Use company-racer in rust mode
(set (make-local-variable 'company-backends) '(company-racer))
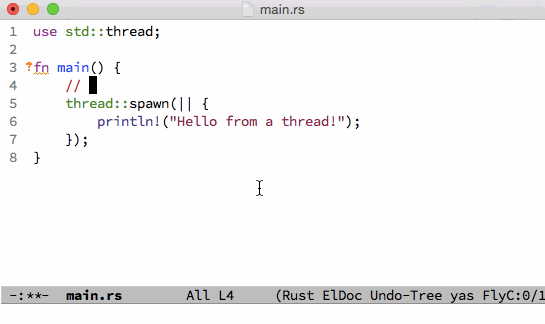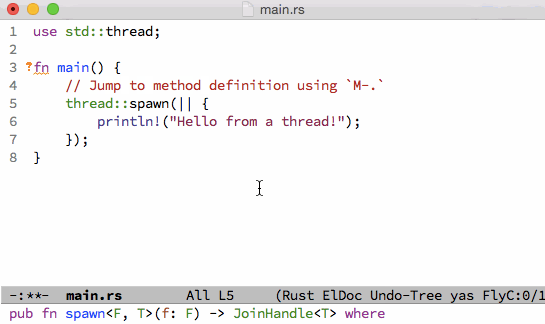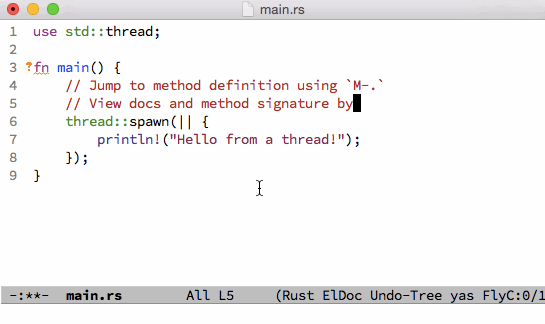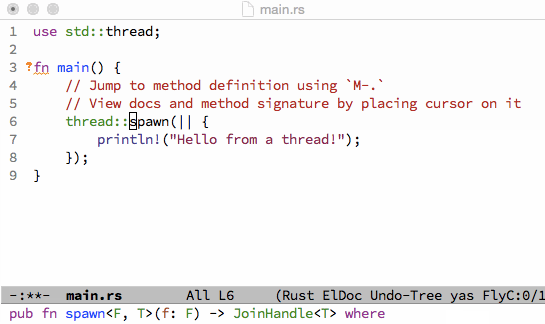
;; Key binding to jump to method definition
(local-set-key (kbd "M-.") #'racer-find-definition)
;; Key binding to auto complete and indent
(local-set-key (kbd "TAB") #'racer-complete-or-indent)))
配置 Racer
Racer 需要 Rust 的源代碼用於自動補全。
- git clone https://github.com/rust-lang/rust.git ~/.rust
- 重新啟動 Emacs 並打開一個 Rust 源代碼文件。
結論
現在,可以在 Emacs 中編輯 Rust 源代碼文件了。功能總結如下:
- 語法高亮顯示和自動縮進
- 自動補全
- 動態語法錯誤檢查
- 跳轉到函數定義
- 內嵌文檔
註釋
- 本節的內容適用於 Emacs Version 24;版本 23 的配置方法不同;版本 22 及以下不支持。
- MacOS 自帶的 Emacs 版本是 22,版本 24 可以從這裡下載。
VS Code 安裝配置
VS Code 是微軟出的一款開源代碼編輯器,秉承了微軟在IDE領域的一慣優秀基因,是一款潛力相當大的編輯器/IDE。
VScode 目前也對 Rust 也有良好的支持。
下載 VScode
請打開官網 https://code.visualstudio.com/ 下載編輯器。
依賴
如本章第一節所述,準備好 racer,rust 源代碼,rustfmt,rls 這四樣東西,並且配置好相應的環境變量,此不贅述。
安裝 Rust 擴展 Rust
- 打開 VScode 編輯器;
- 按 Ctrl + p 打開命令面板;
- 在編輯器中上部浮現出的輸入框中,輸入
ext install vscode-rust,會自動搜索可用的插件,搜索出來後,點擊進行安裝; - 使用
VScode打開任意一個.rs文件,插件首次啟動會自動引導用戶完成配置。
注:推薦使用RLS模式,即使用Rust Langular Server提供各項功能支持
Atom
本文是rust的Atom編輯器配置。 橫向對比一下,不得不說,Atom無論在易用性還是界面上都比前輩們要好的很多,對於Rust的配置,也是基本上可以做到開箱即用。 雖然本文獨佔一小節,但是其實能寫的東西也就了了。
自行配置
準備工作
首先,你需要一個可執行的rustc編譯器,一個cargo程序,一個已經編譯好的racer程序和一份已經解壓好的rust源碼。 我們假定你已經將這三個程序安裝完畢,並且能夠自由的從命令行裡調用他們。
另外,本文不講解如何安裝Atom,需要新安裝的同學請自行前往項目主頁安裝。
ps:無論是windows用戶還是*nix用戶都需要將以上三個程序加入你的PATH(Windows下叫Path)環境變量裡。
需要安裝的插件包
打開Atom,按Ctrl+Shift+p,搜索preference,打開Atom的配置中心,選擇install選項卡。
依次安裝rust-api-docs-helper/racer/language-rust/linter-rust/linter。
這裡要單獨說的一個就是linter,這是一個基礎的lint組件包,atom的很多以linter為前綴的包都會依賴這個包,但是Atom並不會為我們自動的安裝,因此需要我們自己去安裝。
一點配置
以上,我們安裝好了幾個組件包,但是不要著急去打開一個Rust文件。你可能還需要一點點的配置。這裡,我們在配置中心裡打開Packages選項卡,在Installed Packages裡搜索racer,並點擊其Setting。
這裡需要將racer的可執行文件的絕對路徑填入Path to the Racer executable裡。同時,我們還需要將rust源碼文件夾下的src目錄加入到Path to the Rust source code directory裡。
完成安裝
好了,就是這麼簡單。你現在可以打開任意一個rust文件就會發現源碼高亮已經默認打開了,編輯一下,racer也能自動補全,如果不能,嘗試一下用F3鍵來顯式地呼出racer的補全。
tokamak
tokamak 是一個使 atom 搖身一變為 rust IDE 的 atom 插件. 安裝後 atom 即具有語法高亮, 代碼補全與 Lint 等功能, 而且還有個不錯的界面, 看起來確實像個 IDE. 你可以在 atom 中搜索 tokamak 並安裝它.
Sublime
Sublime Text是一款非常有名的文本編輯器,其本身也具備強大的插件機制。通過配置各種插件可以在使用Sublime Text編輯rust代碼時獲得更加良好的支持。
本文主要展示在已經預裝rust的Windows環境下的安裝,如果您還沒有安裝rust,請先參照本書的安裝章節安裝rust。
安裝
Sublime Text3安裝
請在 Sublime Text3官網上選擇適合當前機器版本的Sublime Text版本進行下載和安裝。
rust的安裝
請在rust官網的下載頁面下載rust的源代碼壓縮包並在本地解壓縮安裝,在稍後的配置環節我們將會用到這個路徑。如果國內下載速度過慢,可以考慮使用中科大的鏡像下載rust源碼包。
下載Rust並編譯代碼提示插件racer
具體安裝和編譯內容請查看本章第一節的安裝準備,請牢記編譯後的racer.exe文件路徑,在稍後的配置環節中我們將用到它。
配置
Sublime Text3相關插件安裝
安裝Package Control
Sublime Text3在安裝各種插件前需要先安裝Package Control,如果您的編輯器已安裝Package Control請跳過本段直接安裝rust相關插件。
您可以查看Package Control官網學習如何安裝。
也可以直接在編輯器中使用 ctrl+~ 快捷鍵啟動控制檯,粘貼以下代碼並回車進行安裝。
import urllib.request,os,hashlib; h = '2915d1851351e5ee549c20394736b442' + '8bc59f460fa1548d1514676163dafc88'; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); by = urllib.request.urlopen( 'http://packagecontrol.io/' + pf.replace(' ', '%20')).read(); dh = hashlib.sha256(by).hexdigest(); print('Error validating download (got %s instead of %s), please try manual install' % (dh, h)) if dh != h else open(os.path.join( ipp, pf), 'wb' ).write(by)
rust相關插件
在編輯器下使用快捷鍵 ctrl+shift+p 啟動命令行工具,輸入Install Package按回車進入插件安裝,選擇或輸入插件名稱並回車即可完成插件的安裝。
使用上述方式安裝Rust插件(rust語法高亮)、RustAutoComplete(rust代碼提示和自動補全插件)。
此時安裝尚未完成,我們需要將本地的 racer.exe配置進RustAutoComplete插件中。打開編輯器頂端的Preferences選項卡,依次 Preferences->Package Settings->RustAutoComplete->Settings-User 來打開 RustAutoComplete 的配置文件,在文件中配置以下信息並保存。
{
"racer": "E:/soft/racer-master/target/release/racer.exe",
"search_paths": [ "E:/soft/rustc-1.7.0/src" ]
}
其中racer是編譯後的racer.exe程序的絕對路徑。search_paths是rust源碼文件下src目錄的絕對路徑。
編輯器重啟後插件即可生效。
快速編譯
Sublime本身支持多種編譯系統,在Tools選項卡下的Build System中選擇Rust或者Cargo作為編譯系統,選中後使用快捷鍵 ctrl+B 即可對代碼進行快速編譯。
Visual Studio
本文是使用VisualRust和VS GDB Debugger / VisualGDB 完成在VisualStudio中,編輯和調試Rust程序。
安裝Rust, Cargo
首先需要下載Rust, 下載地址https://www.rust-lang.org/downloads.html
這裡一定要下windows GNU ABI的版本, 因為我們要用GDB來調試.
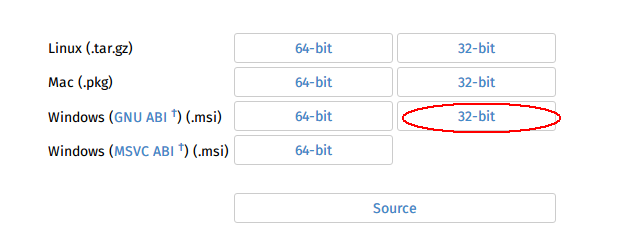
另外,機器上也需要安裝Visual Studio2013或2015。 安裝完Rust,打開命令行,執行 cargo install racer
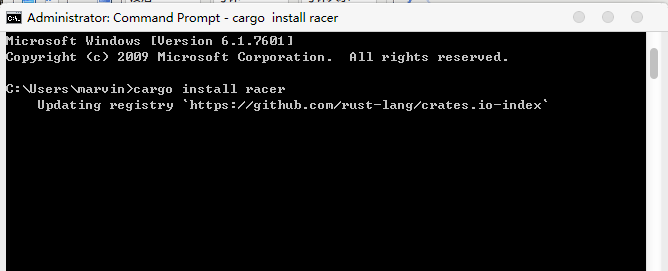
Racer是用來做Rust自動完成的,會在VisualRust使用。這裡我們使用rust編譯的racer, 並不用VisualRust裡自帶的racer,因為它太舊了. 另外需要下載Rust源代碼,設置 RUST_SRC_PATH為Rust源代碼src的目錄

安裝VisualRust和VS GDB Debugger
做完上述工作,就可以安裝VisualRust和VS GDB Debugger,在這裡下載 https://github.com/PistonDevelopers/VisualRust https://visualstudiogallery.msdn.microsoft.com/35dbae07-8c1a-4f9d-94b7-bac16cad9c01
VisualGDB可在這裡購買 http://www.visualgdb.com/
編譯Rust項目
新建Rust項目
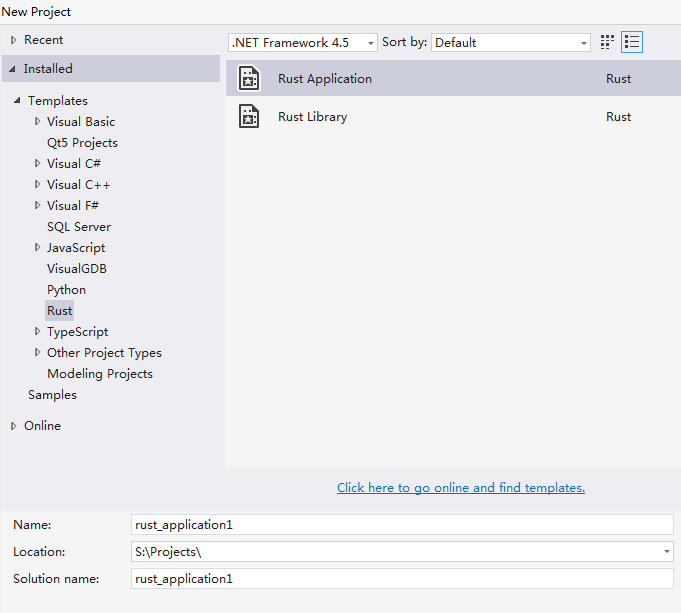 在tool, option裡設置racer和rust_src_path
在tool, option裡設置racer和rust_src_path
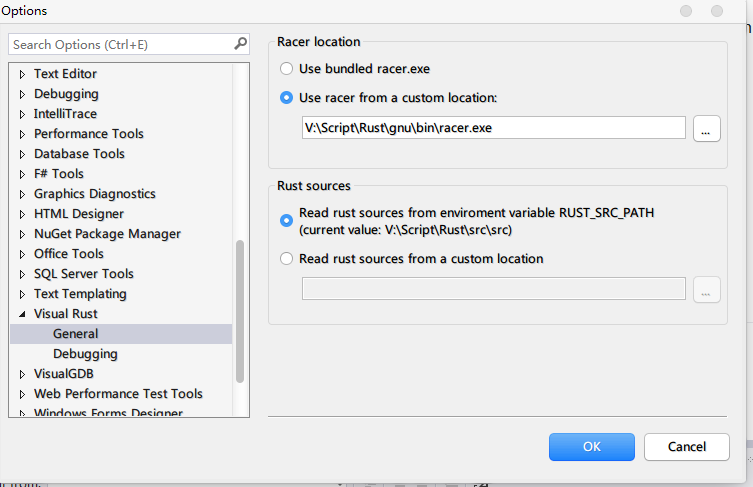 這時候就可以在寫代碼的時候就可以自動提示了。像下面這樣
這時候就可以在寫代碼的時候就可以自動提示了。像下面這樣
用VS GDB Debugger調試Rust項目
ok,愉快的開始你的Rust之旅吧。下面開始使用VS GDB Debugger調試Rust.
在解決方案中,添加GDB調試項目
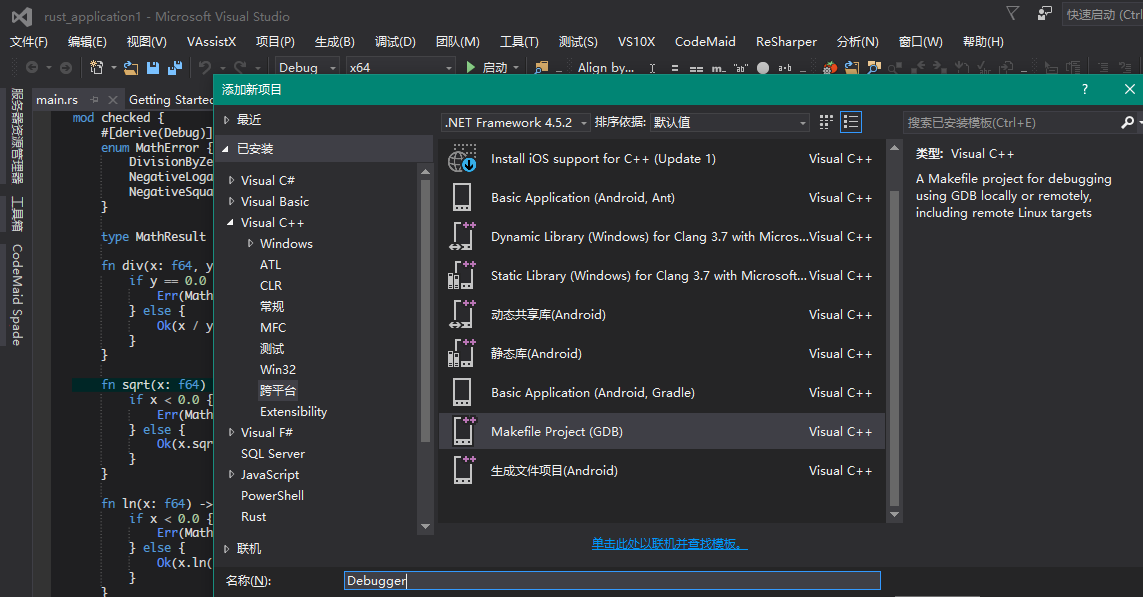
設置需要調試的程序所在的目錄和文件名
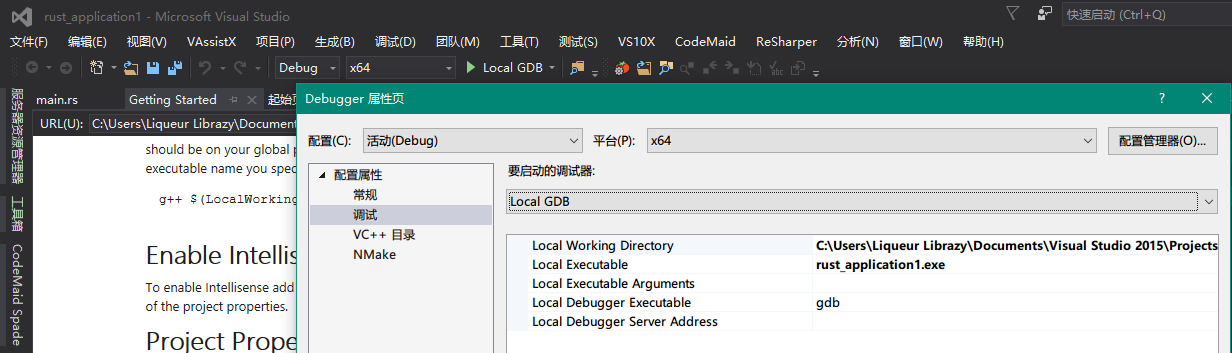
設置需要調試的程序的編譯命令,此處用rustc,也可以使用cargo編譯
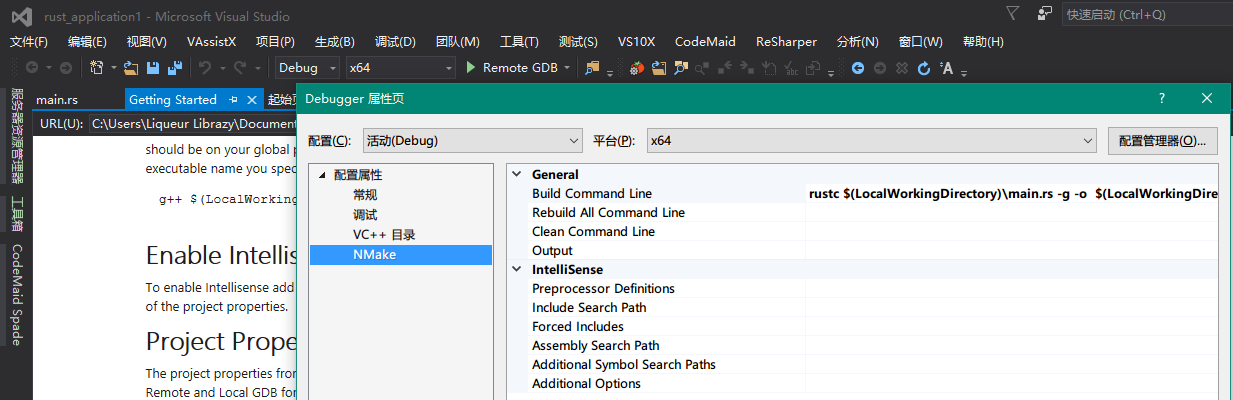
將需要調試的程序的源代碼添加到項目目錄下
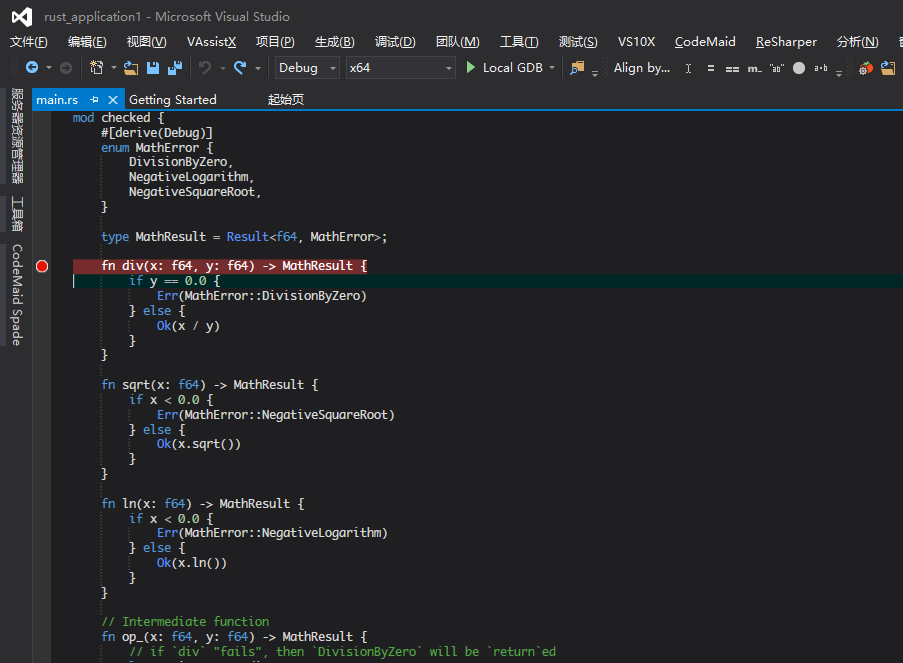
打開源代碼文件並設置斷點信息,將項目設置為啟動項目並選擇Local GDB即可開始調試
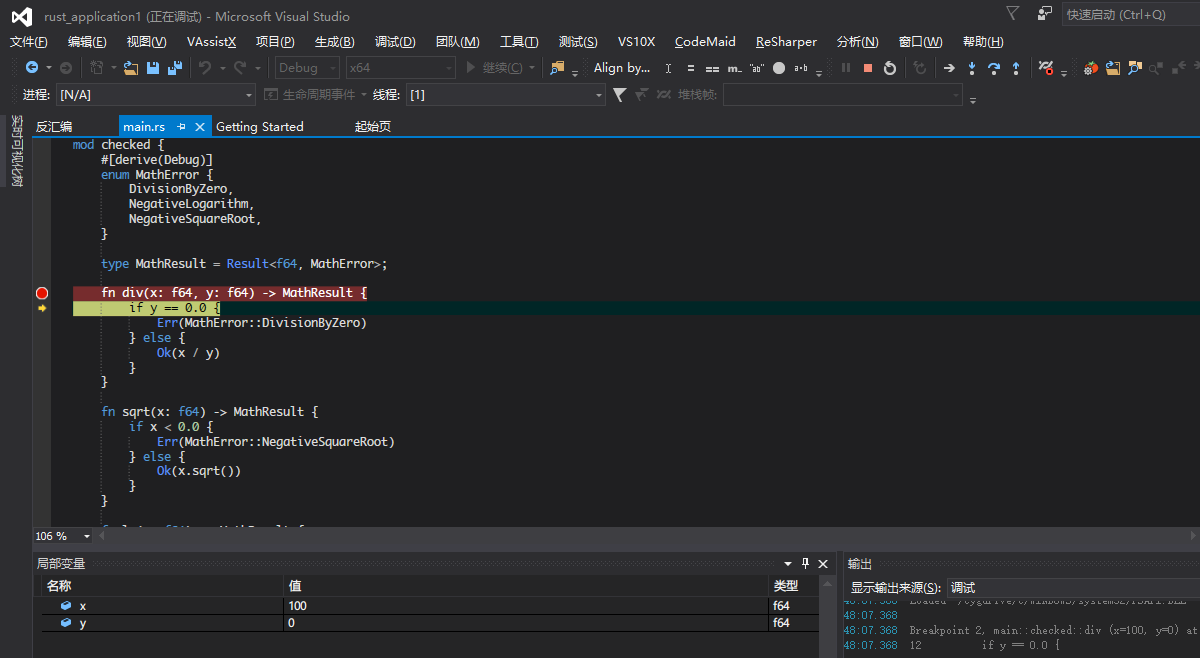
用VisualGDB調試Rust項目
Build完Rust程序,點擊debug, 選擇quick debug with gdb
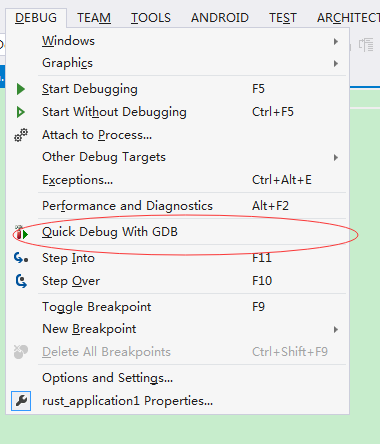
然後在裡面選擇MingW和exe的路徑
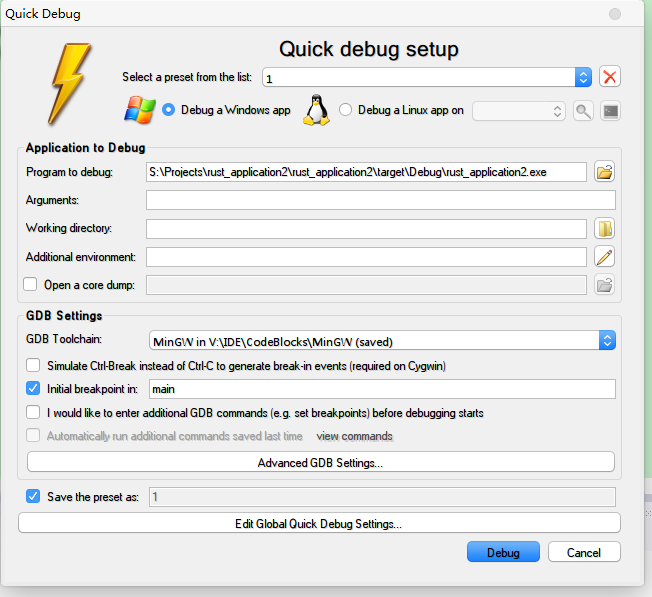
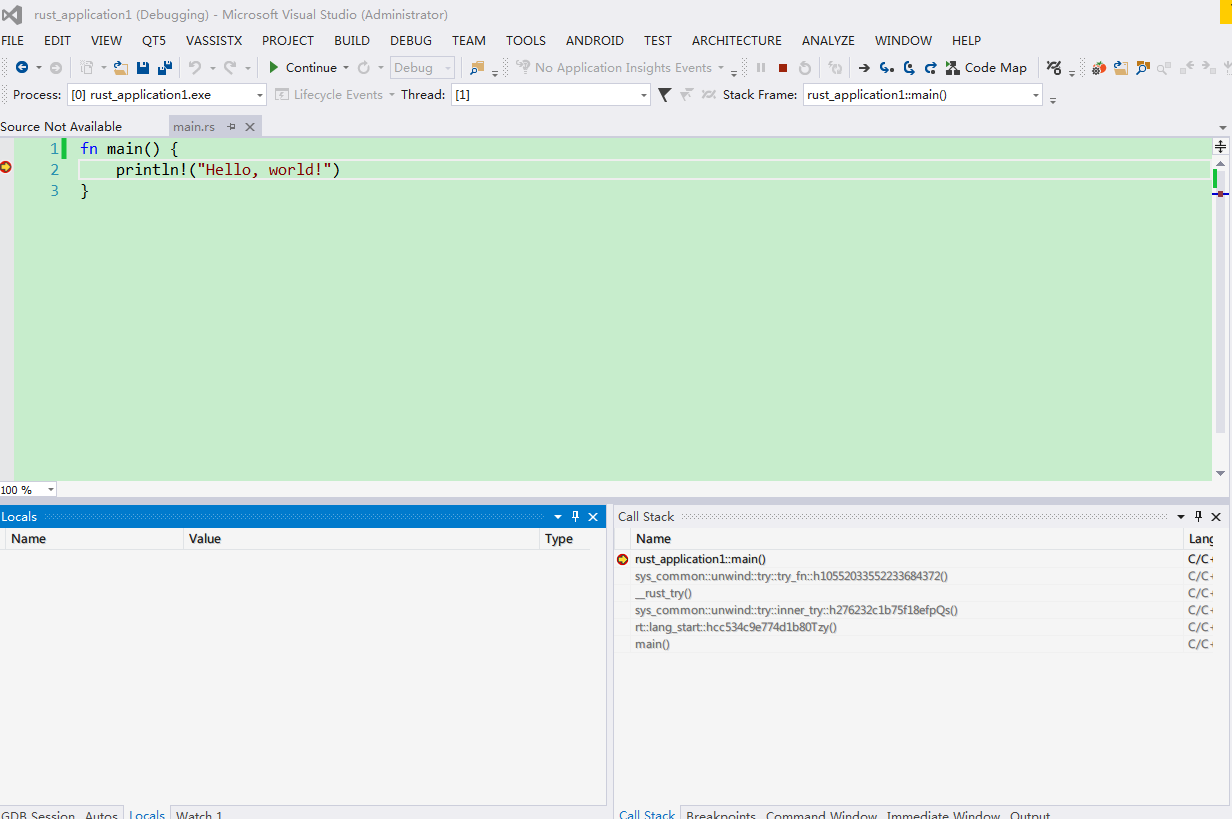
點擊Debug,開始你的調試生活吧
Spacemacs
spacemacs,是一個給vimer的Emacs。
簡介
spacemacs是一個專門給那些習慣vim的操作,同時又嚮往emacs的擴展能力的人。它非常適合我這種折騰過vim,配置過emacs的人,但同時也歡迎任何沒有基礎的新人使用。簡單來說,它是一個開箱即用的Emacs!這對一個比很多人年齡都大的軟件來說是一件極其不容易的事情。
安裝
由於筆者自己在linux平臺,並沒有windows平臺的經驗,所以在這裡便不獻醜了,期待各位補充。另外,windows平臺真的需要麼,斜眼瞅向了Visual Studio。
Emacs安裝
在*nix系統中,都不一定會默認安裝了Emacs,就算安裝了,也不一定是最新的版本。在這裡,我強烈建議各位卸載掉系統自帶的Emacs,因為你不知道系統給你安裝的是個什麼奇怪的存在,最遭心的,我碰見過只提供閹割版Emacs的linux發行版。
建議各位自己去emacs項目主頁下載Emacs-24.5(本書寫作時的最新版)極其以上版本,然後下載下來源碼。至於Emacs的安裝也非常簡單,linux平臺老三步。
./configure
make
sudo make install
什麼?你沒有make?沒有GCC?缺少依賴? 請安裝它們……
Spacemacs安裝
前面說了,Spacemacs就是個Emacs的配置文件庫,因此我們可以通過非常簡單的方式安裝它:
git clone https://github.com/syl20bnr/spacemacs ~/.emacs.d
mv ~/.emacs ~/_emacs.backup
cd ~/.emacs.d
echo $(git describe --tags $(git rev-list --tags --max-count=1)) | xargs git checkout
其中,後三行是筆者加的,這裡必須要吐槽一下的是,Spacemacs的master分支實際上是極其落後而且有錯誤的!其目前的release都是從develop分支上打的tag。
因此,一!定!不!要!用!主!分!支!
最後,之所以要加最後一行,這是筆者安裝的時候的release的一個小bug,沒有這個文件的話,emacs並不會順利的完成初始化。
好了,配置文件我們已經搞定了,接下來,啟動你的emacs,spacemacs會自動的去網上下載你需要的插件安裝包。另外,能自備梯子的最好,因為你要下的東西不大,但是這個網絡確實比較捉急。
前期準備
為了讓Spacemacs支持Rust,我們還需要一點小小的配置。首先,請參照前期準備,安裝好你的racer。
在這裡,強烈建議將racer的環境變量加入到系統變量中(通常他們在/etc/profile/裡進行配置)並重新啟動系統,因為真的有很多人直接點擊emacs的圖標啟動它的,這樣做很可能導致emacs並不繼承自己的環境變量,這是很令人無奈的。
完成配置
修改標準的Spacemacs配置。
Spacemacs文檔中提供了一份標準的spacemacs配置文件,你可以將其加入到你自己的~/.spacemacs文件中。
這裡,我們需要修改的是其關於自定義插件的部分:
(defun dotspacemacs/layers ()
"Configuration Layers declaration.
You should not put any user code in this function besides modifying the variable
values."
(setq-default
;; Base distribution to use. This is a layer contained in the directory
;; `+distribution'. For now available distributions are `spacemacs-base'
;; or `spacemacs'. (default 'spacemacs)
dotspacemacs-distribution 'spacemacs
;; List of additional paths where to look for configuration layers.
;; Paths must have a trailing slash (i.e. `~/.mycontribs/')
dotspacemacs-configuration-layer-path '()
;; List of configuration layers to load. If it is the symbol `all' instead
;; of a list then all discovered layers will be installed.
dotspacemacs-configuration-layers
'(
;; ----------------------------------------------------------------
;; Example of useful layers you may want to use right away.
;; Uncomment some layer names and press <SPC f e R> (Vim style) or
;; <M-m f e R> (Emacs style) to install them.
;; ----------------------------------------------------------------
auto-completion
better-defaults
git
spell-checking
syntax-checking
version-control
rust
)
;; List of additional packages that will be installed without being
;; wrapped in a layer. If you need some configuration for these
;; packages then consider to create a layer, you can also put the
;; configuration in `dotspacemacs/config'.
dotspacemacs-additional-packages '()
;; A list of packages and/or extensions that will not be install and loaded.
dotspacemacs-excluded-packages '()
;; If non-nil spacemacs will delete any orphan packages, i.e. packages that
;; are declared in a layer which is not a member of
;; the list `dotspacemacs-configuration-layers'. (default t)
dotspacemacs-delete-orphan-packages t))
;; ...
;; 以下配置文件內容省略
;; ...
注意dotspacemacs-configuration-layers的配置和標準配置文件的不同。
將配置文件保存,然後重啟你的emacs,當然,我們也可以按SPC f e R來完成重載配置文件的目的,然後你會發現emacs會開始下一輪下載,稍等其完成。
在上一步中,我們已經完成了對Racer的環境變量的配置,所以,現在你的Spacemacs已經配置完成了!這種簡便的配置形式,幾乎能和Atom抗衡了。
按鍵綁定
如下,spacemacs默認提供了幾種按鍵綁定,但是,筆者並不覺得這些很好用,還是更喜歡用命令行。
| Key Binding | Description |
|---|---|
| compile project with Cargo | |
| run tests with Cargo | |
| generate documentation with Cargo | |
| execute the project with Cargo |
嘗試
現在開始,我們可以打開一個Cargo項目,並且去使用它了。你會驚訝的發現racer/flycheck/company這三個插件配合在一起的時候是那麼的和諧簡單。
快速上手
本章的目的在於快速上手(Quickstart),對Rust語言建立初步的印象。 前面的章節中,我們已經安裝好了Rust,配置好了編輯器,相信你一定已經躍躍欲試了。 注意: 本章的一些概念只需要大概瞭解就行,後續的章節將會有詳細的講解,但是本章的例子請務必親自手敲並運行一遍。
下面,讓我們開始動手寫Rust程序吧!
ps:本章原始章節由 ee0703 書寫的。因為內容不太滿意,由 Naupio(N貓)重寫了整個章節,並加入大量的內容。特別鳴謝 photino 提供的 rust-notes 。本章也有大量內容編輯自 Naupio(N貓) 創作中的 Rust 新書的快速入門章節。
Rust旅程
HelloWorld
按照編程語言的傳統,學習第一門編程語言的第一個程序都是打印 Hello World! 下面根據我們的步驟創建 Rust 的 Hello World!程序:
下面的命令操作,如果沒有特別說明,都是在shell下運行。本文為了簡單統一,所有例子都在 win10 的 powershell 下運行,所有命令都運行在ps:標識符之後
- 創建一個 Doing 目錄和 helloworld.rs 文件
ps: mkdir ~/Doing
ps: cd ~/Doing
ps: notepad helloworld.rs # 作者偏向於使用 sublime 作為編輯器
ps: subl helloworld.rs # 本章以後使用 subl 代替 notepad
注意這裡用的後綴名是.rs,一般編程語言的代碼文件都有慣用的後綴名,比如: C語言是.c,java是.java,python是.py等等,請務必記住Rust語言的慣用後綴名是.rs(雖然用別的後綴名也能通過rustc的編譯)。
- 在 helloworld.rs 文件中輸入 Rust 代碼
fn main() { println!("Hello World!"); }
- 編譯 helloworld.rs 文件
ps: rustc helloworld.rs
ps: rustc helloworld.rs -O # 也可以選擇優化編譯
- 運行程序
ps: ./helloworld.exe # windows 平臺下需要加 .exe 後綴
Hello World!
沒有ps:前綴的表示為控制檯打印輸出。
我們已經用rust編寫第一個可執行程序,打印出了'hello world!',很酷,對吧! 但是這段代碼到底是什麼意思呢,作為新手的你一定雲裡霧裡吧,讓我們先看一下這個程序:
- 第一行中 fn 表示定義一個函數,main是這個函數的名字,花括號{}裡的語句則表示這個函數的內容。
- 名字叫做main的函數有特殊的用途,那就是作為程序的入口,也就是說程序每次都從這個函數開始運行。
- 函數中只有一句
println!("Hello World!");,這裡println!是一個Rust語言自帶的宏, 這個宏的功能就是打印文本(結尾會換行),而"Hello World!"這個用引號包起來的東西是一個字符串,就是我們要打印的文本。 - 你一定注意到了
;吧, 在Rust語言中,分號;用來把語句分隔開,也就是說語句的末尾一般用分號做為結束標誌。
HelloRust
- 創建項目 hellorust
ps: cargo new hellorust --bin
- 查看目錄結構
ps: tree # win10 powershell 自帶有 tree 查看文件目錄結構的功能
└─hellorust
----└─src
這裡顯示的目錄結構,在hellorust目錄下有 src 文件夾和 Cargo.toml 文件,同時這個目錄會初始化為 git 項目
- 查看Cargo.toml文件
ps: cat Cargo.toml
[package]
name = "hellorust"
version = "0.1."
authors = ["YourName"]
[dependencies]
- 編輯src目錄下的main.rs文件
ps: subl ./src/main.rs
cargo 創建的項目,在src目錄下會有一個初始化的main.rs文件,內容為:
fn main() { println!("Hello, world!"); }
現在我們編輯這個文件,改為:
fn main() { let rust = "Rust"; println!("Hello, {}!", rust); }
這裡的 let rust = "Rust" 是把 rust 變量綁定為 "Rust" ,
println!("Hello, {}!", rust);裡把 rust 變量的值代入到"Hello, {}!"中的{}。
- 編譯和運行
ps: cargo build
ps: cargo build --release # 這個屬於優化編譯
ps: ./target/debug/hellorust.exe
ps: ./target/release/hellorust.exe # 如果前面是優化編譯,則這樣運行
ps: cargo run # 編譯和運行合在一起
ps: cargo run --release # 同上,區別是是優化編譯的
變量綁定與原生類型
變量綁定
Rust 通過 let 關鍵字進行變量綁定。
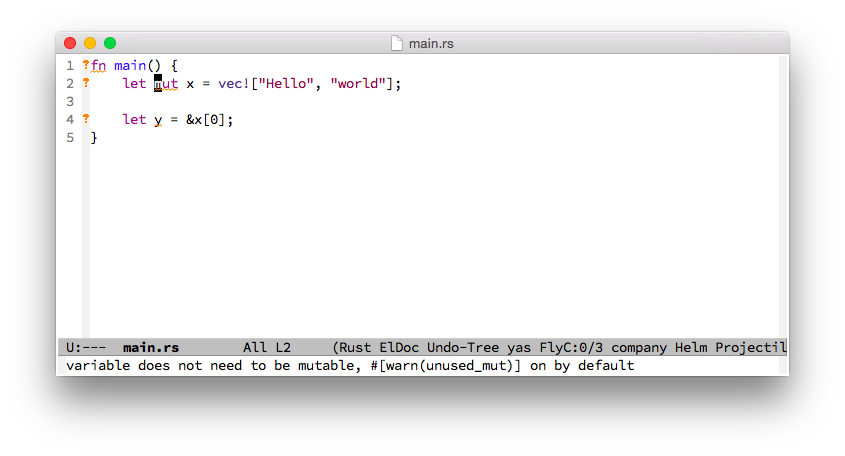
fn main() { let a1 = 5; let a2:i32 = 5; assert_eq!(a1, a2); //let 綁定 整數變量默認類型推斷是 i32 let b1:u32 = 5; //assert_eq!(a1, b1); //去掉上面的註釋會報錯,因為類型不匹配 //errer: mismatched types }
這裡的 assert_eq! 宏的作用是判斷兩個參數是不是相等的,但如果是兩個不匹配的類型,就算字面值相等也會報錯。
可變綁定
rust 在聲明變量時,在變量前面加入 mut 關鍵字,變量就會成為可變綁定的變量。
fn main() { let mut a: f64 = 1.0; let b = 2.0f32; //改變 a 的綁定 a = 2.0; println!("{:?}", a); //重新綁定為不可變 let a = a; //不能賦值 //a = 3.0; //類型不匹配 //assert_eq!(a, b); }
這裡的 b 變量,綁定了 2.0f32。這是 Rust 裡面值類型顯式標記的語法,規定為value+type的形式。
例如: 固定大小類型:
1u8 1i8
1u16 1i16
1u32 1i32
1u64 1i64
可變大小類型:
1usize 1isize
浮點類型:
1f32 1f64
let解構
為什麼在 Rust 裡面聲明一個變量的時候要採用 let 綁定表達式? 那是因為 let 綁定表達式的表達能力更強,而且 let 表達式實際上是一種模式匹配。
例如:
fn main() { let (a, mut b): (bool,bool) = (true, false); println!("a = {:?}, b = {:?}", a, b); //a 不可變綁定 //a = false; //b 可變綁定 b = true; assert_eq!(a, b); }
這裡使用了 bool,只有true和false兩個值,通常用來做邏輯判斷的類型。
原生類型
Rust內置的原生類型 (primitive types) 有以下幾類:
- 布爾類型:有兩個值
true和false。 - 字符類型:表示單個Unicode字符,存儲為4個字節。
- 數值類型:分為有符號整數 (
i8,i16,i32,i64,isize)、 無符號整數 (u8,u16,u32,u64,usize) 以及浮點數 (f32,f64)。 - 字符串類型:最底層的是不定長類型
str,更常用的是字符串切片&str和heap分配字符串String, 其中字符串切片是靜態分配的,有固定的大小,並且不可變,而heap分配字符串是可變的。 - 數組:具有固定大小,並且元素都是同種類型,可表示為
[T; N]。 - 切片:引用一個數組的部分數據並且不需要拷貝,可表示為
&[T]。 - 元組:具有固定大小的有序列表,每個元素都有自己的類型,通過解構或者索引來獲得每個元素的值。
- 指針:最底層的是裸指針
*const T和*mut T,但解引用它們是不安全的,必須放到unsafe塊裡。 - 函數:具有函數類型的變量實質上是一個函數指針。
- 元類型:即
(),其唯一的值也是()。
#![allow(unused)] fn main() { // boolean type let t = true; let f: bool = false; // char type let c = 'c'; // numeric types let x = 42; let y: u32 = 123_456; let z: f64 = 1.23e+2; let zero = z.abs_sub(123.4); let bin = 0b1111_0000; let oct = 0o7320_1546; let hex = 0xf23a_b049; // string types let str = "Hello, world!"; let mut string = str.to_string(); // arrays and slices let a = [0, 1, 2, 3, 4]; let middle = &a[1..4]; let mut ten_zeros: [i64; 10] = [0; 10]; // tuples let tuple: (i32, &str) = (50, "hello"); let (fifty, _) = tuple; let hello = tuple.1; // raw pointers let x = 5; let raw = &x as *const i32; let points_at = unsafe { *raw }; // functions fn foo(x: i32) -> i32 { x } let bar: fn(i32) -> i32 = foo; }
有幾點是需要特別注意的:
- 數值類型可以使用
_分隔符來增加可讀性。 - Rust還支持單字節字符
b'H'以及單字節字符串b"Hello",僅限制於ASCII字符。 此外,還可以使用r#"..."#標記來表示原始字符串,不需要對特殊字符進行轉義。 - 使用
&符號將String類型轉換成&str類型很廉價, 但是使用to_string()方法將&str轉換到String類型涉及到分配內存, 除非很有必要否則不要這麼做。 - 數組的長度是不可變的,動態的數組稱為Vec (vector),可以使用宏
vec!創建。 - 元組可以使用
==和!=運算符來判斷是否相同。 - 不多於32個元素的數組和不多於12個元素的元組在值傳遞時是自動複製的。
- Rust不提供原生類型之間的隱式轉換,只能使用
as關鍵字顯式轉換。 - 可以使用
type關鍵字定義某個類型的別名,並且應該採用駝峰命名法。
#![allow(unused)] fn main() { // explicit conversion let decimal = 65.4321_f32; let integer = decimal as u8; let character = integer as char; // type aliases type NanoSecond = u64; type Point = (u8, u8); }
數組、動態數組和字符串
數組和動態數組
數組 array
Rust 使用數組存儲相同類型的數據集。
[T; N]表示一個擁有 T 類型,N 個元素的數組。數組的大小是固定。
例子:
fn main() { let mut array: [i32; 3] = [0; 3]; array[1] = 1; array[2] = 2; assert_eq!([1, 2], &array[1..]); // This loop prints: 0 1 2 for x in &array { println!("{} ", x); } }
動態數組 Vec
動態數組是一種基於heap內存申請的連續動態數據類型,擁有 O(1) 時間複雜度的索引、壓入(push)、彈出(pop)。
例子:
#![allow(unused)] fn main() { //創建空Vec let v: Vec<i32> = Vec::new(); //使用宏創建空Vec let v: Vec<i32> = vec![]; //創建包含5個元素的Vec let v = vec![1, 2, 3, 4, 5]; //創建十個零 let v = vec![0; 10]; //創建可變的Vec,並壓入元素3 let mut v = vec![1, 2]; v.push(3); //創建擁有兩個元素的Vec,並彈出一個元素 let mut v = vec![1, 2]; let two = v.pop(); //創建包含三個元素的可變Vec,並索引一個值和修改一個值 let mut v = vec![1, 2, 3]; let three = v[2]; v[1] = v[1] + 5; }
字符串
Rust 裡面有兩種字符串類型。String 和 str。
&str
str 類型基本上不怎麼使用,通常使用 &str 類型,它其實是 [u8] 類型的切片形式 &[u8]。這是一種固定大小的字符串類型。
常見的的字符串字面值就是 &'static str 類型。這是一種帶有 'static 生命週期的 &str 類型。
例子:
#![allow(unused)] fn main() { // 字符串字面值 let hello = "Hello, world!"; // 附帶顯式類型標識 let hello: &'static str = "Hello, world!"; }
String
String 是一個帶有的 vec:Vec<u8> 成員的結構體,你可以理解為 str 類型的動態形式。
它們的關係相當於 [T] 和 Vec<T> 的關係。
顯然 String 類型也有壓入和彈出。
例子:
#![allow(unused)] fn main() { // 創建一個空的字符串 let mut s = String::new(); // 從 `&str` 類型轉化成 `String` 類型 let mut hello = String::from("Hello, "); // 壓入字符和壓入字符串切片 hello.push('w'); hello.push_str("orld!"); // 彈出字符。 let mut s = String::from("foo"); assert_eq!(s.pop(), Some('o')); assert_eq!(s.pop(), Some('o')); assert_eq!(s.pop(), Some('f')); assert_eq!(s.pop(), None); }
結構體與枚舉
結構體
結構體 (struct) 是一種記錄類型,所包含的每個域 (field) 都有一個名稱。
每個結構體也都有一個名稱,通常以大寫字母開頭,使用駝峰命名法。
元組結構體 (tuple struct) 是由元組和結構體混合構成,元組結構體有名稱,
但是它的域沒有。當元組結構體只有一個域時,稱為新類型 (newtype)。
沒有任何域的結構體,稱為類單元結構體 (unit-like struct)。
結構體中的值默認是不可變的,需要給結構體加上mut使其可變。
#![allow(unused)] fn main() { // structs struct Point { x: i32, y: i32, } let point = Point { x: 0, y: 0 }; // tuple structs struct Color(u8, u8, u8); let android_green = Color(0xa4, 0xc6, 0x39); let Color(red, green, blue) = android_green; // A tuple struct’s constructors can be used as functions. struct Digit(i32); let v = vec![0, 1, 2]; let d: Vec<Digit> = v.into_iter().map(Digit).collect(); // newtype: a tuple struct with only one element struct Inches(i32); let length = Inches(10); let Inches(integer_length) = length; // unit-like structs struct EmptyStruct; let empty = EmptyStruct; }
一個包含..的struct可以用來從其它結構體拷貝一些值或者在解構時忽略一些域:
#![allow(unused)] fn main() { #[derive(Default)] struct Point3d { x: i32, y: i32, z: i32, } let origin = Point3d::default(); let point = Point3d { y: 1, ..origin }; let Point3d { x: x0, y: y0, .. } = point; }
需要注意,Rust在語言級別不支持域可變性 (field mutability),所以不能這麼寫:
#![allow(unused)] fn main() { struct Point { mut x: i32, y: i32, } }
這是因為可變性是綁定的一個屬性,而不是結構體自身的。可以使用Cell<T>來模擬:
#![allow(unused)] fn main() { use std::cell::Cell; struct Point { x: i32, y: Cell<i32>, } let point = Point { x: 5, y: Cell::new(6) }; point.y.set(7); }
此外,結構體的域對其所在模塊 (mod) 之外默認是私有的,可以使用pub關鍵字將其設置成公開。
#![allow(unused)] fn main() { mod graph { #[derive(Default)] pub struct Point { pub x: i32, y: i32, } pub fn inside_fn() { let p = Point {x:1, y:2}; println!("{}, {}", p.x, p.y); } } fn outside_fn() { let p = graph::Point::default(); println!("{}", p.x); // println!("{}", p.y); // field `y` of struct `graph::Point` is private } }
枚舉
Rust有一個集合類型,稱為枚舉 (enum),代表一系列子數據類型的集合。
其中子數據結構可以為空-如果全部子數據結構都是空的,就等價於C語言中的enum。
我們需要使用::來獲得每個元素的名稱。
#![allow(unused)] fn main() { // enums enum Message { Quit, ChangeColor(i32, i32, i32), Move { x: i32, y: i32 }, Write(String), } let x: Message = Message::Move { x: 3, y: 4 }; }
與結構體一樣,枚舉中的元素默認不能使用關係運算符進行比較 (如==, !=, >=),
也不支持像+和*這樣的雙目運算符,需要自己實現,或者使用match進行匹配。
枚舉默認也是私有的,如果使用pub使其變為公有,則它的元素也都是默認公有的。
這一點是與結構體不同的:即使結構體是公有的,它的域仍然是默認私有的。這裡的共有/私有仍然
是針對其定義所在的模塊之外。此外,枚舉和結構體也可以是遞歸的 (recursive)。
控制流(control flow)
If
If是分支 (branch) 的一種特殊形式,也可以使用else和else if。
與C語言不同的是,邏輯條件不需要用小括號括起來,但是條件後面必須跟一個代碼塊。
Rust中的if是一個表達式 (expression),可以賦給一個變量:
#![allow(unused)] fn main() { let x = 5; let y = if x == 5 { 10 } else { 15 }; }
Rust是基於表達式的編程語言,有且僅有兩種語句 (statement):
- 聲明語句 (declaration statement),比如進行變量綁定的
let語句。 - 表達式語句 (expression statement),它通過在末尾加上分號
;來將表達式變成語句, 丟棄該表達式的值,一律返回unit()。
表達式如果返回,總是返回一個值,但是語句不返回值或者返回(),所以以下代碼會報錯:
#![allow(unused)] fn main() { let y = (let x = 5); let z: i32 = if x == 5 { 10; } else { 15; }; }
值得注意的是,在Rust中賦值 (如x = 5) 也是一個表達式,返回unit的值()。
For
Rust中的for循環與C語言的風格非常不同,抽象結構如下:
#![allow(unused)] fn main() { for var in expression { code } }
其中expression是一個迭代器 (iterator),具體的例子為0..10 (不包含最後一個值),
或者[0, 1, 2].iter()。
While
Rust中的while循環與C語言中的類似。對於無限循環,Rust有一個專用的關鍵字loop。
如果需要提前退出循環,可以使用關鍵字break或者continue,
還允許在循環的開頭設定標籤 (同樣適用於for循環):
#![allow(unused)] fn main() { 'outer: loop { println!("Entered the outer loop"); 'inner: loop { println!("Entered the inner loop"); break 'outer; } println!("This point will never be reached"); } println!("Exited the outer loop"); }
Match
Rust中的match表達式非常強大,首先看一個例子:
#![allow(unused)] fn main() { let day = 5; match day { 0 | 6 => println!("weekend"), 1 ... 5 => println!("weekday"), _ => println!("invalid"), } }
其中|用於匹配多個值,...匹配一個範圍 (包含最後一個值),並且_在這裡是必須的,
因為match強制進行窮盡性檢查 (exhaustiveness checking),必須覆蓋所有的可能值。
如果需要得到|或者...匹配到的值,可以使用@綁定變量:
#![allow(unused)] fn main() { let x = 1; match x { e @ 1 ... 5 => println!("got a range element {}", e), _ => println!("anything"), } }
使用ref關鍵字來得到一個引用:
#![allow(unused)] fn main() { let x = 5; let mut y = 5; match x { // the `r` inside the match has the type `&i32` ref r => println!("Got a reference to {}", r), } match y { // the `mr` inside the match has the type `&i32` and is mutable ref mut mr => println!("Got a mutable reference to {}", mr), } }
再看一個使用match表達式來解構元組的例子:
#![allow(unused)] fn main() { let pair = (0, -2); match pair { (0, y) => println!("x is `0` and `y` is `{:?}`", y), (x, 0) => println!("`x` is `{:?}` and y is `0`", x), _ => println!("It doesn't matter what they are"), } }
match的這種解構同樣適用於結構體或者枚舉。如果有必要,還可以使用..來忽略域或者數據:
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } let origin = Point { x: 0, y: 0 }; match origin { Point { x, .. } => println!("x is {}", x), } enum OptionalInt { Value(i32), Missing, } let x = OptionalInt::Value(5); match x { // 這裡是 match 的 if guard 表達式,我們將在以後的章節進行詳細介紹 OptionalInt::Value(i) if i > 5 => println!("Got an int bigger than five!"), OptionalInt::Value(..) => println!("Got an int!"), OptionalInt::Missing => println!("No such luck."), } }
此外,Rust還引入了if let和while let進行模式匹配:
#![allow(unused)] fn main() { let number = Some(7); let mut optional = Some(0); // If `let` destructures `number` into `Some(i)`, evaluate the block. if let Some(i) = number { println!("Matched {:?}!", i); } else { println!("Didn't match a number!"); } // While `let` destructures `optional` into `Some(i)`, evaluate the block. while let Some(i) = optional { if i > 9 { println!("Greater than 9, quit!"); optional = None; } else { println!("`i` is `{:?}`. Try again.", i); optional = Some(i + 1); } } }
函數與方法
函數
要聲明一個函數,需要使用關鍵字fn,後面跟上函數名,比如
#![allow(unused)] fn main() { fn add_one(x: i32) -> i32 { x + 1 } }
其中函數參數的類型不能省略,可以有多個參數,但是最多隻能返回一個值,
提前返回使用return關鍵字。Rust編譯器會對未使用的函數提出警告,
可以使用屬性#[allow(dead_code)]禁用無效代碼檢查。
Rust有一個特殊特性適用於發散函數 (diverging function),它不返回:
#![allow(unused)] fn main() { fn diverges() -> ! { panic!("This function never returns!"); } }
其中panic!是一個宏,使當前執行線程崩潰並打印給定信息。返回類型!可用作任何類型:
#![allow(unused)] fn main() { let x: i32 = diverges(); let y: String = diverges(); }
匿名函數
Rust使用閉包 (closure) 來創建匿名函數:
#![allow(unused)] fn main() { let num = 5; let plus_num = |x: i32| x + num; }
其中閉包plus_num借用了它作用域中的let綁定num。如果要讓閉包獲得所有權,
可以使用move關鍵字:
#![allow(unused)] fn main() { let mut num = 5; { let mut add_num = move |x: i32| num += x; // 閉包通過move獲取了num的所有權 add_num(5); } // 下面的num在被move之後還能繼續使用是因為其實現了Copy特性 // 具體可見所有權(Owership)章節 assert_eq!(5, num); }
高階函數
Rust 還支持高階函數 (high order function),允許把閉包作為參數來生成新的函數:
fn add_one(x: i32) -> i32 { x + 1 } fn apply<F>(f: F, y: i32) -> i32 where F: Fn(i32) -> i32 { f(y) * y } fn factory(x: i32) -> Box<Fn(i32) -> i32> { Box::new(move |y| x + y) } fn main() { let transform: fn(i32) -> i32 = add_one; let f0 = add_one(2i32) * 2; let f1 = apply(add_one, 2); let f2 = apply(transform, 2); println!("{}, {}, {}", f0, f1, f2); let closure = |x: i32| x + 1; let c0 = closure(2i32) * 2; let c1 = apply(closure, 2); let c2 = apply(|x| x + 1, 2); println!("{}, {}, {}", c0, c1, c2); let box_fn = factory(1i32); let b0 = box_fn(2i32) * 2; let b1 = (*box_fn)(2i32) * 2; let b2 = (&box_fn)(2i32) * 2; println!("{}, {}, {}", b0, b1, b2); let add_num = &(*box_fn); let translate: &Fn(i32) -> i32 = add_num; let z0 = add_num(2i32) * 2; let z1 = apply(add_num, 2); let z2 = apply(translate, 2); println!("{}, {}, {}", z0, z1, z2); }
方法
Rust通過impl關鍵字在struct、enum或者trait對象上實現方法調用語法 (method call syntax)。
關聯函數 (associated function) 的第一個參數通常為self參數,有3種變體:
self,允許實現者移動和修改對象,對應的閉包特性為FnOnce。&self,既不允許實現者移動對象也不允許修改,對應的閉包特性為Fn。&mut self,允許實現者修改對象但不允許移動,對應的閉包特性為FnMut。
不含self參數的關聯函數稱為靜態方法 (static method)。
struct Circle { x: f64, y: f64, radius: f64, } impl Circle { fn new(x: f64, y: f64, radius: f64) -> Circle { Circle { x: x, y: y, radius: radius, } } fn area(&self) -> f64 { std::f64::consts::PI * (self.radius * self.radius) } } fn main() { let c = Circle { x: 0.0, y: 0.0, radius: 2.0 }; println!("{}", c.area()); // use associated function and method chaining println!("{}", Circle::new(0.0, 0.0, 2.0).area()); }
特性
特性與接口
為了描述類型可以實現的抽象接口 (abstract interface), Rust引入了特性 (trait) 來定義函數類型簽名 (function type signature):
#![allow(unused)] fn main() { trait HasArea { fn area(&self) -> f64; } struct Circle { x: f64, y: f64, radius: f64, } impl HasArea for Circle { fn area(&self) -> f64 { std::f64::consts::PI * (self.radius * self.radius) } } struct Square { x: f64, y: f64, side: f64, } impl HasArea for Square { fn area(&self) -> f64 { self.side * self.side } } fn print_area<T: HasArea>(shape: T) { println!("This shape has an area of {}", shape.area()); } }
其中函數print_area()中的泛型參數T被添加了一個名為HasArea的特性約束 (trait constraint),
用以確保任何實現了HasArea的類型將擁有一個.area()方法。
如果需要多個特性限定 (multiple trait bounds),可以使用+:
#![allow(unused)] fn main() { use std::fmt::Debug; fn foo<T: Clone, K: Clone + Debug>(x: T, y: K) { x.clone(); y.clone(); println!("{:?}", y); } fn bar<T, K>(x: T, y: K) where T: Clone, K: Clone + Debug { x.clone(); y.clone(); println!("{:?}", y); } }
其中第二個例子使用了更靈活的where從句,它還允許限定的左側可以是任意類型,
而不僅僅是類型參數。
定義在特性中的方法稱為默認方法 (default method),可以被該特性的實現覆蓋。 此外,特性之間也可以存在繼承 (inheritance):
#![allow(unused)] fn main() { trait Foo { fn foo(&self); // default method fn bar(&self) { println!("We called bar."); } } // inheritance trait FooBar : Foo { fn foobar(&self); } struct Baz; impl Foo for Baz { fn foo(&self) { println!("foo"); } } impl FooBar for Baz { fn foobar(&self) { println!("foobar"); } } }
如果兩個不同特性的方法具有相同的名稱,可以使用通用函數調用語法 (universal function call syntax):
#![allow(unused)] fn main() { // short-hand form Trait::method(args); // expanded form <Type as Trait>::method(args); }
關於實現特性的幾條限制:
- 如果一個特性不在當前作用域內,它就不能被實現。
- 不管是特性還是
impl,都只能在當前的包裝箱內起作用。 - 帶有特性約束的泛型函數使用單態化實現 (monomorphization), 所以它是靜態派分的 (statically dispatched)。
下面列舉幾個非常有用的標準庫特性:
Drop提供了當一個值退出作用域後執行代碼的功能,它只有一個drop(&mut self)方法。Borrow用於創建一個數據結構時把擁有和借用的值看作等同。AsRef用於在泛型中把一個值轉換為引用。Deref<Target=T>用於把&U類型的值自動轉換為&T類型。Iterator用於在集合 (collection) 和惰性值生成器 (lazy value generator) 上實現迭代器。Sized用於標記運行時長度固定的類型,而不定長的切片和特性必須放在指針後面使其運行時長度已知, 比如&[T]和Box<Trait>。
泛型和多態
泛型 (generics) 在類型理論中稱作參數多態 (parametric polymorphism), 意為對於給定參數可以有多種形式的函數或類型。先看Rust中的一個泛型例子:
Option在rust標準庫中的定義:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Option的典型用法:
#![allow(unused)] fn main() { let x: Option<i32> = Some(5); let y: Option<f64> = Some(5.0f64); }
其中<T>部分表明它是一個泛型數據類型。當然,泛型參數也可以用於函數參數和結構體域:
#![allow(unused)] fn main() { // generic functions fn make_pair<T, U>(a: T, b: U) -> (T, U) { (a, b) } let couple = make_pair("man", "female"); // generic structs struct Point<T> { x: T, y: T, } let int_origin = Point { x: 0, y: 0 }; let float_origin = Point { x: 0.0, y: 0.0 }; }
對於多態函數,存在兩種派分 (dispatch) 機制:靜態派分和動態派分。
前者類似於C++的模板,Rust會生成適用於指定類型的特殊函數,然後在被調用的位置進行替換,
好處是允許函數被內聯調用,運行比較快,但是會導致代碼膨脹 (code bloat);
後者類似於Java或Go的interface,Rust通過引入特性對象 (trait object) 來實現,
在運行期查找虛表 (vtable) 來選擇執行的方法。特性對象&Foo具有和特性Foo相同的名稱,
通過轉換 (casting) 或者強制多態化 (coercing) 一個指向具體類型的指針來創建。
當然,特性也可以接受泛型參數。但是,往往更好的處理方式是使用關聯類型 (associated type):
#![allow(unused)] fn main() { // use generic parameters trait Graph<N, E> { fn has_edge(&self, &N, &N) -> bool; fn edges(&self, &N) -> Vec<E>; } fn distance<N, E, G: Graph<N, E>>(graph: &G, start: &N, end: &N) -> u32 { } // use associated types trait Graph { type N; type E; fn has_edge(&self, &Self::N, &Self::N) -> bool; fn edges(&self, &Self::N) -> Vec<Self::E>; } fn distance<G: Graph>(graph: &G, start: &G::N, end: &G::N) -> uint { } struct Node; struct Edge; struct SimpleGraph; impl Graph for SimpleGraph { type N = Node; type E = Edge; fn has_edge(&self, n1: &Node, n2: &Node) -> bool { } fn edges(&self, n: &Node) -> Vec<Edge> { } } let graph = SimpleGraph; let object = Box::new(graph) as Box<Graph<N=Node, E=Edge>>; }
註釋與文檔
註釋
在 Rust 裡面註釋分成兩種,行註釋和塊註釋。它的形式和 C 語言是一樣的。 兩種註釋分別是:
- 行註釋使用
//放在註釋前面。比如:
// I love Rust, but I hate Rustc.
- 塊註釋分別使用
/*和*/包裹需要註釋的內容。比如:
/* W-Cat 是個大胖貓,N-Cat 是個高度近視貓。*/
文檔
Rust 自帶有文檔功能的註釋,分別是///和//!。支持 Markdown 格式
///用來描述的它後面接著的項。//!用來描述包含它的項,一般用在模塊文件的頭部。 比如在 main.rs 文件中輸入以下內容:
//! # The first line
//! The second line
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let five = 5;
///
/// assert_eq!(6, add_one(5));
/// # fn add_one(x: i32) -> i32 {
/// # x + 1
/// # }
/// ```
fn add_one(x: i32) -> i32 {
x + 1
}
生成 html 文檔
rustdoc main.rs
或者
cargo doc
輸入輸出流
輸入輸出是人機交互的一種方式。最常見的輸入輸出是標準輸入輸出和文件輸入輸出(當然還有數據庫輸入輸出,本節不討論這部分)。
標準輸入
標準輸入也叫作控制檯輸入,是常見輸入的一種。
例子1:
use std::io; fn read_input() -> io::Result<()> { let mut input = String::new(); try!(io::stdin().read_line(&mut input)); println!("You typed: {}", input.trim()); Ok(()) } fn main() { read_input(); }
例子2:
use std::io; fn main() { let mut input = String::new(); io::stdin().read_line(&mut input).expect("WTF!"); println!("You typed: {}", input.trim()); }
這裡體現了常見的標準輸入的處理方式。兩個例子都是聲明瞭一個可變的字符串來保存輸入的數據。 他們的不同之處在在於處理潛在輸入異常的方式。
-
例子 1 使用了
try!宏。這個宏會返回Result<(), io::Error>類型,io::Result<()>就是這個類型的別名。所以例子 1 需要單獨使用一個read_input函數來接收這個類型,而不是在main函數里面,因為main函數並沒有接收io::Result<()>作為返回類型。 -
例子 2 使用了
Result<(), io::Error>類型的expect方法來接收io::stdin().read_line的返回類型。並處理可能潛在的 io 異常。
標準輸出
標準輸出也叫控制檯輸出,Rust 裡面常見的標準輸出宏有 print! 和 println!。它們的區別是後者比前者在末尾多輸出一個換行符。
例子1:
fn main() { print!("this "); print!("will "); print!("be "); print!("on "); print!("the "); print!("same "); print!("line "); print!("this string has a newline, why not choose println! instead?\n"); }
例子2:
fn main() { println!("hello there!"); println!("format {} arguments", "some"); }
這裡兩個例子都比較簡單。讀者可以運行一下查看輸出結果對比一下他們的區別。
值得注意的是例子 2 中,{ } 會被 "some" 所替換。這是 rust 裡面的一種格式化輸出。
標準化的輸出是行緩衝(line-buffered)的,這就導致標準化的輸出在遇到一個新行之前並不會被隱式刷新。
換句話說 print! 和 println! 二者的效果並不總是相同的。
如果說得更簡單明瞭一點就是,您不能把 print! 當做是C語言中的 printf 譬如:
use std::io; fn main() { print!("請輸入一個字符串:"); let mut input = String::new(); io::stdin() .read_line(&mut input) .expect("讀取失敗"); print!("您輸入的字符串是:{}\n", input); }
在這段代碼運行時則不會先出現預期的提示字符串,因為行沒有被刷新。 如果想要達到預期的效果就要顯示的刷新:
use std::io::{self, Write}; fn main() { print!("請輸入一個字符串:"); io::stdout().flush().unwrap(); let mut input = String::new(); io::stdin() .read_line(&mut input) .expect("讀取失敗"); print!("您輸入的字符串是:{}\n", input); }
文件輸入
文件輸入和標準輸入都差不多,除了輸入流指向了文件而不是控制檯。下面例子採用了模式匹配來處理潛在的輸入錯誤
例子:
use std::error::Error; use std::fs::File; use std::io::prelude::*; use std::path::Path; fn main() { // 創建一個文件路徑 let path = Path::new("hello.txt"); let display = path.display(); // 打開文件只讀模式, 返回一個 `io::Result<File>` 類型 let mut file = match File::open(&path) { // 處理打開文件可能潛在的錯誤 Err(why) => panic!("couldn't open {}: {}", display, Error::description(&why)), Ok(file) => file, }; // 文件輸入數據到字符串,並返回 `io::Result<usize>` 類型 let mut s = String::new(); match file.read_to_string(&mut s) { Err(why) => panic!("couldn't read {}: {}", display, Error::description(&why)), Ok(_) => print!("{} contains:\n{}", display, s), } }
文件輸出
文件輸出和標準庫輸出也差不多,只不過是把輸出流重定向到文件中。下面詳細看例子。
例子:
// 輸出文本 static LOREM_IPSUM: &'static str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. "; use std::error::Error; use std::io::prelude::*; use std::fs::File; use std::path::Path; fn main() { let path = Path::new("out/lorem_ipsum.txt"); let display = path.display(); // 用只寫模式打開一個文件,並返回 `io::Result<File>` 類型 let mut file = match File::create(&path) { Err(why) => panic!("couldn't create {}: {}", display, Error::description(&why)), Ok(file) => file, }; // 寫入 `LOREM_IPSUM` 字符串到文件中, 並返回 `io::Result<()>` 類型 match file.write_all(LOREM_IPSUM.as_bytes()) { Err(why) => { panic!("couldn't write to {}: {}", display, Error::description(&why)) }, Ok(_) => println!("successfully wrote to {}", display), } }
cargo簡介
曾幾何時,對於使用慣了C/C++語言的猿們來說,項目代碼的組織與管理絕對是一場噩夢。為了解決C/C++項目的管理問題,猿神們想盡了各種辦法,開發出了各種五花八門的項目管理工具,從一開始的automake到後來的cmake、qmake等等,但結果並不如人意,往往是解決了一些問題,卻引入了更多的問題,C/C++猿們經常會陷入在掌握語言本身的同時,還要掌握複雜的構建工具語法的窘境。無獨有偶,java的項目代碼組織與管理工具ant和maven也存在同樣的問題。複雜的項目管理配置參數,往往讓猿們不知所措。
作為一門現代語言,rust自然要摒棄石器時代項目代碼管理的方法和手段。rust項目組為各位猿提供了超級大殺器cargo,以解決項目代碼管理所帶來的干擾和困惑。用過node.js的猿們,應該對node.js中的神器npm、grunt、gulp等工具印象深刻。作為新一代靜態語言中的翹楚,rust官方參考了現有語言管理工具的優點,於是就產生了cargo。
言而總之,作為rust的代碼組織管理工具,cargo提供了一系列的工具,從項目的建立、構建到測試、運行直至部署,為rust項目的管理提供儘可能完整的手段。同時,與rust語言及其編譯器rustc本身的各種特性緊密結合,可以說既是語言本身的知心愛人,又是rust猿們的貼心小棉襖,誰用誰知道。
廢話就不多說了,直接上例子和各種高清無馬圖。
cargo入門
首先,當然還是廢話,要使用cargo,自然首先要安裝cargo。安裝cargo有三種方法,前兩種方法請參見rust的安裝方法,因為cargo工具是官方正統出身,當然包含在官方的分發包中。第三種方法即從cargo項目的源碼倉庫進行構建。Oh,My God。的確是廢話。
好了,假設各位已經安裝好了cargo,大家和我一起學一下起手式。當然了,猿的世界,起手式一般都千篇一律——那就是hello world大法。
在終端中輸入
$ cargo new hello_world --bin
上述命令使用cargo new在當前目錄下新建了基於cargo項目管理的rust項目,項目名稱為hello_world,--bin表示該項目將生成可執行文件。具體生成的項目目錄結構如下:
$ cd hello_world
$ tree .
.
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
大家可以在終端中輸入上述命令,敲出回車鍵之後即可看到上述結果,或者直接去編輯器或文件管理器中去觀察即可。 打開main.rs文件,可以看到,cargo new命令為我們自動生成了hello_world運行所必須的所有代碼:
fn main() { println!("Hello, world!"); }
好了,心急的猿們可能已經迫不及待的脫褲子了,好吧,我們先來構建並看看cargo有多神奇,在終端中輸入:
$ cargo build
稍等片刻,cargo會自動為我們構建好高清應用所需的一切,對於這個起手式來說,緩衝不會超過5秒,12秒88的選手要憋住了。
$ cargo run
Running `target/debug/hello_world`
Hello, world!
看到了什麼,看到了什麼,嚇尿了有木有,嚇尿了有木有。好了,cargo就是這麼簡單。
當然了,說cargo美,並不僅僅是簡單這麼簡單,cargo雖然簡單,但是很強大。有多麼強大??可以說,基本上rust開發管理中所需的手段,cargo都有。很小很強大,既強又有節操,不帶馬,學習曲線幾乎為零。
基於cargo的rust項目組織結構
這次不說廢話了,先上高清無馬圖:
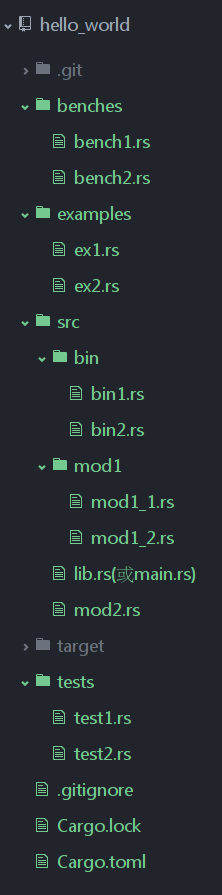
對上述cargo默認的項目結構解釋如下:
cargo.toml和cargo.lock文件總是位於項目根目錄下。
源代碼位於src目錄下。
默認的庫入口文件是src/lib.rs。
默認的可執行程序入口文件是src/main.rs。
其他可選的可執行文件位於src/bin/*.rs(這裡每一個rs文件均對應一個可執行文件)。
外部測試源代碼文件位於tests目錄下。
示例程序源代碼文件位於examples。
基準測試源代碼文件位於benches目錄下。
好了,大家一定謹記這些默認規則,最好按照這種模式來組織自己的rust項目。
cargo.toml和cargo.lock
cargo.toml和cargo.lock是cargo項目代碼管理的核心兩個文件,cargo工具的所有活動均基於這兩個文件。
cargo.toml是cargo特有的項目數據描述文件,對於猿們而言,cargo.toml文件存儲了項目的所有信息,它直接面向rust猿,猿們如果想讓自己的rust項目能夠按照期望的方式進行構建、測試和運行,那麼,必須按照合理的方式構建'cargo.toml'。
而cargo.lock文件則不直接面向猿,猿們也不需要直接去修改這個文件。lock文件是cargo工具根據同一項目的toml文件生成的項目依賴詳細清單文件,所以我們一般不用不管他,只需要對著cargo.toml文件擼就行了。
[package]
name = "hello_world"
version = "0.1.0"
authors = ["fuying"]
[dependencies]
toml文件是由諸如[package]或[dependencies]這樣的段落組成,每一個段落又由多個字段組成,這些段落和字段就描述了項目組織的基本信息,例如上述toml文件中的[package]段落描述了hello_world項目本身的一些信息,包括項目名稱(對應於name字段)、項目版本(對應於version字段)、作者列表(對應於authors字段)等;[dependencies]段落描述了hello_world項目的依賴項目有哪些。
下面我們來看看toml描述文件中常用段落和字段的意義。
package段落
[package]段落描述了軟件開發者對本項目的各種元數據描述信息,例如[name]字段定義了項目的名稱,[version]字段定義了項目的當前版本,[authors]定義了該項目的所有作者,當然,[package]段落不僅僅包含這些字段,[package]段落的其他可選字段詳見cargo參數配置章節。
定義項目依賴
使用cargo工具的最大優勢就在於,能夠對該項目的各種依賴項進行方便、統一和靈活的管理。這也是使用cargo對rust 的項目進行管理的重要目標之一。在cargo的toml文件描述中,主要通過各種依賴段落來描述該項目的各種依賴項。toml中常用的依賴段落包括一下幾種:
- 基於rust官方倉庫crates.io,通過版本說明來描述:
- 基於項目源代碼的git倉庫地址,通過URL來描述:
- 基於本地項目的絕對路徑或者相對路徑,通過類Unix模式的路徑來描述: 這三種形式具體寫法如下:
[dependencies]
typemap = "0.3"
plugin = "0.2*"
hammer = { version = "0.5.0"}
color = { git = "https://github.com/bjz/color-rs" }
geometry = { path = "crates/geometry" }
上述例子中,2-4行為方法一的寫法,第5行為方法二的寫法,第6行為方法三的寫法。 這三種寫法各有用處,如果項目需要使用crates.io官方倉庫來管理項目依賴項,推薦使用第一種方法。如果項目開發者更傾向於使用git倉庫中最新的源碼,可以使用方法二。方法二也經常用於當官方倉庫的依賴項編譯不通過時的備選方案。方法三主要用於源代碼位於本地的依賴項。
定義集成測試用例
cargo另一個重要的功能,即將軟件開發過程中必要且非常重要的測試環節進行集成,並通過代碼屬性聲明或者toml文件描述來對測試進行管理。其中,單元測試主要通過在項目代碼的測試代碼部分前用#[test]屬性來描述,而集成測試,則一般都會通過toml文件中的[[test]]段落進行描述。
例如,假設集成測試文件均位於tests文件夾下,則toml可以這樣來寫:
[[test]]
name = "testinit"
path = "tests/testinit.rs"
[[test]]
name = "testtime"
path = "tests/testtime.rs"
上述例子中,name字段定義了集成測試的名稱,path字段定義了集成測試文件相對於本toml文件的路徑。 看看,定義集成測試就是如此簡單。 需要注意的是:
- 如果沒有在Cargo.toml裡定義集成測試的入口,那麼tests目錄(不包括子目錄)下的每個rs文件被當作集成測試入口.
- 如果在Cargo.toml裡定義了集成測試入口,那麼定義的那些rs就是入口,不再默認指定任何集成測試入口.
定義項目示例和可執行程序
上面我們介紹了cargo項目管理中常用的三個功能,還有兩個經常使用的功能:example用例的描述以及bin用例的描述。其描述方法和test用例描述方法類似。不過,這時候段落名稱'[[test]]'分別替換為:'[[example]]'或者'[[bin]]'。例如:
[[example]]
name = "timeout"
path = "examples/timeout.rs"
[[bin]]
name = "bin1"
path = "bin/bin1.rs"
對於'[[example]]'和'[[bin]]'段落中聲明的examples和bins,需要通過'cargo run --example NAME'或者'cargo run --bin NAME'來運行,其中NAME對應於你在name字段中定義的名稱。
構建、清理、更新以及安裝
領會了toml描述文件的寫法,是一個重要的方面。另一個重要的方面,就是cargo工具本身為我們程序猿提供的各種好用的工具。如果大家感興趣,自己在終端中輸入'cargo --help'查看即可。其中開發時最常用的命令就是'cargo build',用於構建項目。此外,'cargo clean'命令可以清理target文件夾中的所有內容;'cargo update'根據toml描述文件重新檢索並更新各種依賴項的信息,並寫入lock文件,例如依賴項版本的更新變化等等;'cargo install'可用於實際的生產部署。這些命令在實際的開發部署中均是非常有用的。
cargo更多詳細用法請參見'28. cargo參數配置'
基本程序結構
Rust 是多範式語言,當然支持命令式編程風格。本章講解 Rust 中的幾種基本程序結構。
註釋
Rust 代碼文件中,通常我們可以看到 3 種註釋。
- 行註釋
- 文檔註釋
- 模塊註釋
行註釋
// 後的,直到行尾,都屬於註釋,不會影響程序的行為。
#![allow(unused)] fn main() { // 創建一個綁定 let x = 5; let y = 6; // 創建另一個綁定 }
文檔註釋
文檔註釋使用 ///,一般用於函數或結構體(字段)的說明,置於要說明的對象上方。文檔註釋內部可使用markdown格式的標記語法,可用於 rustdoc 工具的自動文檔提取。
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let five = 5;
///
/// assert_eq!(6, add_one(5));
/// # fn add_one(x: i32) -> i32 {
/// # x + 1
/// # }
/// ```
fn add_one(x: i32) -> i32 {
x + 1
}
模塊註釋
模塊註釋使用 //!,用於說明本模塊的功能。一般置於模塊文件的頭部。
#![allow(unused)] fn main() { //! # The Rust Standard Library //! //! The Rust Standard Library provides the essential runtime //! functionality for building portable Rust software. }
PS: 相對於 ///, //! 用來註釋包含它的項(也就是說,crate,模塊或者函數),而不是位於它之後的項。
其它:兼容C語言的註釋
Rust 也支持兼容 C 的塊註釋寫法:/* */。但是不推薦使用,請儘量不要使用這種註釋風格(會被鄙視的)。
#![allow(unused)] fn main() { /* let x = 42; println!("{}", x); */ }
條件分支
- if
- if let
- match
if 表達式
Rust 中的 if 表達式基本就是如下幾種形式:
#![allow(unused)] fn main() { // 形式 1 if expr1 { } // 形式 2 if expr1 { } else { } // 形式 3 if expr1 { } else if expr2 { // else if 可多重 } else { } }
相對於 C 系語言,Rust 的 if 表達式的顯著特點是:
- 判斷條件不用小括號括起來;
- 它是表達式,而不是語句。
鑑於上述第二點,因為是表達式,所以我們可以寫出如下代碼:
#![allow(unused)] fn main() { let x = 5; let y = if x == 5 { 10 } else { 15 }; // y: i32 }
或者壓縮成一行:
#![allow(unused)] fn main() { let x = 5; let y = if x == 5 { 10 } else { 15 }; // y: i32 }
if let
我們在代碼中常常會看到 if let 成對出現,這實際上是一個 match 的簡化用法。直接舉例來說明:
#![allow(unused)] fn main() { let x = Some(5); if let Some(y) = x { println!("{}", y); // 這裡輸出為:5 } let z = if let Some(y) = x { y } else { 0 }; // z 值為 5 }
上面代碼等價於
#![allow(unused)] fn main() { let x = Some(5); match x { Some(y) => println!("{}", y), None => () } let z = match x { Some(y) => y, None => 0 }; }
設計這個特性的目的是,在條件判斷的時候,直接做一次模式匹配,方便代碼書寫,使代碼更緊湊。
match
Rust 中沒有類似於 C 的 switch 關鍵字,但它有用於模式匹配的 match,能實現同樣的功能,並且強大太多。
match 的使用非常簡單,舉例如下:
#![allow(unused)] fn main() { let x = 5; match x { 1 => { println!("one") }, 2 => println!("two"), 3 => println!("three"), 4 => println!("four"), 5 => println!("five"), _ => println!("something else"), } }
注意,match 也是一個表達式。match 後面會專門論述,請參見 模式匹配 這一章。
循環
- for
- while
- loop
- break 與 continue
- label
for
for 語句用於遍歷一個迭代器。
#![allow(unused)] fn main() { for var in iterator { code } }
Rust 迭代器返回一系列的元素,每個元素是循環中的一次重複。然後它的值與 var 綁定,它在循環體中有效。每當循環體執行完後,我們從迭代器中取出下一個值,然後我們再重複一遍。當迭代器中不再有值時,for 循環結束。
比如:
#![allow(unused)] fn main() { for x in 0..10 { println!("{}", x); // x: i32 } }
輸出
0
1
2
3
4
5
6
7
8
9
不熟悉迭代器概念的同學可能傻眼了,下面不妨用 C 形式的 for 語句做下對比:
#![allow(unused)] fn main() { // C 語言的 for 循環例子 for (x = 0; x < 10; x++) { printf( "%d\n", x ); } }
兩者輸出是相同的,那麼,為何 Rust 要這樣來設計 for 語句呢?
- 簡化邊界條件的確定,減少出錯;
- 減少運行時邊界檢查,提高性能。
即使對於有經驗的 C 語言開發者來說,要手動控制要循環的每個元素也都是複雜並且易於出錯的。
for 語句就是迭代器遍歷的語法糖。
上述迭代器的形式雖好,但是好像在循環過程中,少了索引信息。Rust 考慮到了這一點,當你需要記錄你已經循環了多少次了的時候,你可以使用 .enumerate() 函數。比如:
#![allow(unused)] fn main() { for (i,j) in (5..10).enumerate() { println!("i = {} and j = {}", i, j); } }
輸出:
i = 0 and j = 5
i = 1 and j = 6
i = 2 and j = 7
i = 3 and j = 8
i = 4 and j = 9
再比如:
#![allow(unused)] fn main() { let lines = "Content of line one Content of line two Content of line three Content of line four".lines(); for (linenumber, line) in lines.enumerate() { println!("{}: {}", linenumber, line); } }
輸出:
0: Content of line one
1: Content of line two
2: Content of line three
3: Content of line four
關於迭代器的知識,詳見 迭代器 章節。
while
Rust 提供了 while 語句,條件表達式為真時,執行語句體。當你不確定應該循環多少次時可選擇 while。
#![allow(unused)] fn main() { while expression { code } }
比如:
#![allow(unused)] fn main() { let mut x = 5; // mut x: i32 let mut done = false; // mut done: bool while !done { x += x - 3; println!("{}", x); if x % 5 == 0 { done = true; } } }
loop
有一種情況,我們經常會遇到,就是寫一個無限循環:
#![allow(unused)] fn main() { while true { // do something } }
針對這種情況,Rust 專門優化提供了一個語句 loop。
#![allow(unused)] fn main() { loop { // do something } }
loop 與 while true 的主要區別在編譯階段的靜態分析。
比如說,如下代碼:
#![allow(unused)] fn main() { let mut a; loop { a = 1; // ... break ... } do_something(a) }
如果是loop循環,編譯器會正確分析出變量a會被正確初始化,而如果換成while true,則會發生編譯錯誤。這個微小的區別也會影響生命週期分析。
break 和 continue
與 C 語言類似,Rust 也提供了 break 和 continue 兩個關鍵字用來控制循環的流程。
- break 用來跳出當前層的循環;
- continue 用來執行當前層的下一次迭代。
像上面那個 while 例子:
#![allow(unused)] fn main() { let mut x = 5; let mut done = false; while !done { x += x - 3; println!("{}", x); if x % 5 == 0 { done = true; } } }
可以優化成:
#![allow(unused)] fn main() { let mut x = 5; loop { x += x - 3; println!("{}", x); if x % 5 == 0 { break; } } }
這樣感覺更直觀一點。
下面這個例子演示 continue 的用法:
#![allow(unused)] fn main() { for x in 0..10 { if x % 2 == 0 { continue; } println!("{}", x); } }
它的作用是打印出 0~9 的奇數。結果如下:
1
3
5
7
9
label
你也許會遇到這樣的情形,當你有嵌套的循環而希望指定你的哪一個 break 或 continue 該起作用。就像大多數語言,默認 break 或 continue 將會作用於當前層的循環。當你想要一個 break 或 continue 作用於一個外層循環,你可以使用標籤來指定你的 break 或 continue 語句作用的循環。
如下代碼只會在 x 和 y 都為奇數時打印他們:
#![allow(unused)] fn main() { 'outer: for x in 0..10 { 'inner: for y in 0..10 { if x % 2 == 0 { continue 'outer; } // continues the loop over x if y % 2 == 0 { continue 'inner; } // continues the loop over y println!("x: {}, y: {}", x, y); } } }
類型、運算符和字符串
本章講解 Rust 中的類型相關基礎知識、運算符相關知識、和字符串的基本知識。
原生類型
像其他現代編程語言一樣,Rust提供了一系列基礎的類型,我們一般稱之為原生類型。其強大的類型系統就是建立在這些原生類型之上的,因此,在寫Rust代碼之前,必須要對Rust的原生類型有一定的瞭解。
bool
Rust自帶了bool類型,其可能值為true或者false。
我們可以通過這樣的方式去聲明它:
#![allow(unused)] fn main() { let is_she_love_me = false; let mut is_he_love_me: bool = true; }
當然,bool類型被用的最多的地方就是在if表達式裡了。
char
在Rust中,一個char類型表示一個Unicode字符,這也就意味著,在某些語言裡代表一個字符(8bit)的char,在Rust裡實際上是四個字節(32bit)。
同時,我們可以將各種奇怪的非中文字符隨心所欲的賦值給一個char類型。需要注意的是,Rust中我們要用'來表示一個char,如果用"的話你得到的實際上是一個&'static str。
#![allow(unused)] fn main() { let c = 'x'; let cc = '王'; }
數字類型
和其他類C系的語言不一樣,Rust用一種符號+位數的方式來表示其基本的數字類型。可能你習慣了int、double、float之類的表示法,Rust的表示法需要你稍微適應一下。
你可用的符號有 i、f、u
你可用的位數,當然了,都是2的n次冪,分別為8、16、32、64及size。
你可以將其組合起來,形成諸如i32,u16等類型。
當然了,這樣的組合並不自由,因為浮點類型最少只能用32位來表示,因此只能有f32和f64來表示。
自適應類型
看完上面你一定會對isize和usize很好奇。這兩個是來幹啥的。這兩個嘛,其實是取決於你的操作系統的位數。簡單粗暴一點比如64位電腦上就是64位,32位電腦上就是32位,16位……呵呵噠。
但是需要注意的是,你不能因為你的電腦是64位的,而強行將它等同於64,也就是說isize != i64,任何情況下你都需要強制轉換。
數組 array
Rust的數組是被表示為[T;N]。其中N表示數組大小,並且這個大小一定是個編譯時就能獲得的整數值,T表示泛型類型,即任意類型。我們可以這麼來聲明和使用一個數組:
#![allow(unused)] fn main() { let a = [8, 9, 10]; let b: [u8;3] = [8, 6, 5]; print!("{}", a[0]); }
和Golang一樣,Rust的數組中的N(大小)也是類型的一部分,即[u8; 3] != [u8; 4]。這麼設計是為了更安全和高效的使用內存,當然了,這會給第一次接觸類似概念的人帶來一點點困難,比如以下代碼。
fn show(arr: [u8;3]) { for i in &arr { print!("{} ", i); } } fn main() { let a: [u8; 3] = [1, 2, 3]; show(a); let b: [u8; 4] = [1, 2, 3, 4]; show(b); }
編譯運行它你將獲得一個編譯錯誤:
<anon>:11:10: 11:11 error: mismatched types:
expected `[u8; 3]`,
found `[u8; 4]`
(expected an array with a fixed size of 3 elements,
found one with 4 elements) [E0308]
<anon>:11 show(b);
^
<anon>:11:10: 11:11 help: see the detailed explanation for E0308
error: aborting due to previous error
這是因為你將一個4長度的數組賦值給了一個只需要3長度數組作為參數的函數。那麼如何寫一個通用的show方法來展現任意長度數組呢?請看下節Slice
Slice
Slice從直觀上講,是對一個Array的切片,通過Slice,你能獲取到一個Array的部分或者全部的訪問權限。和Array不同,Slice是可以動態的,但是呢,其範圍是不能超過Array的大小,這點和Golang是不一樣的。
一個Slice的表達式可以為如下: &[T] 或者 &mut [T]。
這裡&符號是一個難點,我們不妨放開這個符號,簡單的把它看成是Slice的甲魚臀部——規定。另外,同樣的,Slice也是可以通過下標的方式訪問其元素,下標也是從0開始的喲。
你可以這麼聲明並使用一個Slice:
#![allow(unused)] fn main() { let arr = [1, 2, 3, 4, 5, 6]; let slice_complete = &arr[..]; // 獲取全部元素 let slice_middle = &arr[1..4]; // 獲取中間元素,最後取得的Slice為 [2, 3, 4] 。切片遵循左閉右開原則。 let slice_right = &arr[1..]; // 最後獲得的元素為[2, 3, 4, 5, 6],長度為5。 let slice_left = &arr[..3]; // 最後獲得的元素為[1, 2, 3],長度為3。 }
怎麼樣,瞭解了吧。
那麼接下來我們用Slice來改造一下上面的函數
fn show(arr: &[u8]) { for i in arr { print!("{} ", i); } println!(""); } fn main() { let a: [u8; 3] = [1, 2, 3]; let slice_a = &a[..]; show(slice_a); let b: [u8; 4] = [1, 2, 3, 4]; show(&b[..]); }
輸出
1 2 3
1 2 3 4
動態數組 Vec
熟悉C++ STL的同學可能對C++的vector很熟悉,同樣的,Rust也提供了一個類似的東西。他叫Vec。
在基礎類型裡講Vec貌似是不太合適的,但在實際應用中的應用比較廣泛,所以說先粗略的介紹一下,在集合類型的章節會有詳細講述。
在Rust裡,Vec被表示為 Vec<T>, 其中T是一個泛型。
下面介紹幾種典型的Vec的用法:
#![allow(unused)] fn main() { let mut v1: Vec<i32> = vec![1, 2, 3]; // 通過vec!宏來聲明 let v2 = vec![0; 10]; // 聲明一個初始長度為10的值全為0的動態數組 println!("{}", v1[0]); // 通過下標來訪問數組元素 for i in &v1 { print!("{}", i); // &Vec<i32> 可以通過 Deref 轉換成 &[i32] } println!(""); for i in &mut v1 { *i = *i+1; print!("{}", i); // 可變訪問 } }
輸出結果:
1
123
234
最原生字符串 str
你可以用str來聲明一個字符串,事實上,Rust中,所有用""包裹起來的都可以稱為&str(注意這個&,這是難點,不用管他,不是麼?),但是這個類型被單獨用的情況很少,因此,我們將在下一節著重介紹字符串類型。
函數類型 Functions
函數同樣的是一個類型,這裡只給大家普及一些基本的概念,函數類型涉及到比較高階的應用,希望大家能在後面的閉包章節仔細參讀
下面是一個小例子
#![allow(unused)] fn main() { fn foo(x: i32) -> i32 { x+1 } let x: fn(i32) -> i32 = foo; assert_eq!(11, x(10)); }
複合類型
元組(Tuple)
在別的語言裡,你可能聽過元組這個詞,它表示一個大小、類型固定的有序數據組。在 Rust 中,情況並沒有什麼本質上的不同。不過 Rust 為我們提供了一系列簡單便利的語法來讓我們能更好的使用他。
#![allow(unused)] fn main() { let y = (2, "hello world"); let x: (i32, &str) = (3, "world hello"); // 然後呢,你能用很簡單的方式去訪問他們: // 用 let 表達式 let (w, z) = y; // w=2, z="hello world" // 用下標 let f = x.0; // f = 3 let e = x.1; // e = "world hello" }
結構體(struct)
在Rust中,結構體是一個跟 tuple 類似 的概念。我們同樣可以將一些常用的數據、屬性聚合在一起,就形成了一個結構體。
所不同的是,Rust的結構體有三種最基本的形式。
具名結構體
這種結構體呢,他可以大致看成這樣的一個聲明形式:
#![allow(unused)] fn main() { struct A { attr1: i32, atrr2: String, } }
內部每個成員都有自己的名字和類型。
元組類型結構體
元組類型結構體使用小括號,類似 tuple 。
#![allow(unused)] fn main() { struct B(i32, u16, bool); }
它可以看作是一個有名字的元組,具體使用方法和一般的元組基本類似。
空結構體
結構體內部也可以沒有任何成員。
#![allow(unused)] fn main() { struct D; }
空結構體的內存佔用為0。但是我們依然可以針對這樣的類型實現它的“成員函數”。
不過到目前為止,在 1.9 版本之前的版本,空結構體後面不能加大括號。 如果這麼寫,則會導致這部分的老編譯器編譯錯誤:
#![allow(unused)] fn main() { struct C { } }
實現結構體(impl)
Rust沒有繼承,它和Golang不約而同的選擇了trait(Golang叫Interface)作為其實現多態的基礎。可是,如果我們要想對一個結構體寫一些專門的成員函數那應該怎麼寫呢?
答: impl
talk is cheap ,舉個栗子:
struct Person { name: String, } impl Person { fn new(n: &str) -> Person { Person { name: n.to_string(), } } fn greeting(&self) { println!("{} say hello .", self.name); } } fn main() { let peter = Person::new("Peter"); peter.greeting(); }
看見了 self,Python程序員不厚道的笑了。
我們來分析一下,上面的impl中,new 被 Person 這個結構體自身所調用,其特徵是 :: 的調用,Java程序員站出來了:類函數! 而帶有 self 的 greeting ,更像是一個成員函數。
恩,回答正確,然而不加分。
關於各種ref的討論
Rust 對代碼有著嚴格的安全控制,因此對一個變量也就有了所有權和借用的概念。所有權同一時間只能一人持有,可變引用也只能同時被一個實例持有,不可變引用則可以被多個實例持有。同時所有權能被轉移,在Rust中被稱為 move 。
以上是所有權的基本概念,事實上,在整個軟件的運行週期內,所有權的轉換是一件極其惱人和煩瑣的事情,尤其對那些初學 Rust 的同學來說。同樣的,Rust 的結構體作為其類型系統的基石,也有著比較嚴格的所有權控制限制。具體來說,關於結構體的所有權,有兩種你需要考慮的情況。
字段的 ref 和 owner
在以上的結構體中,我們定義了不少結構體,但是如你所見,結構體的每個字段都是完整的屬於自己的。也就是說,每個字段的 owner 都是這個結構體。每個字段的生命週期最終都不會超過這個結構體。
但是有些時候,我只是想要持有一個(可變)引用的值怎麼辦? 如下代碼:
#![allow(unused)] fn main() { struct RefBoy { loc: &i32, } }
這時候你會得到一個編譯錯誤:
<anon>:6:14: 6:19 error: missing lifetime specifier [E0106]
<anon>:6 loc: & i32,
這種時候,你將持有一個值的引用,因為它本身的生命週期在這個結構體之外,所以對這個結構體而言,它無法準確的判斷獲知這個引用的生命週期,這在 Rust 編譯器而言是不被接受的。 因此,這個時候就需要我們給這個結構體人為的寫上一個生命週期,並顯式地表明這個引用的生命週期。寫法如下:
#![allow(unused)] fn main() { struct RefBoy<'a> { loc: &'a i32, } }
這裡解釋一下這個符號 <>,它表示的是一個 屬於 的關係,無論其中描述的是 生命週期 還是 泛型 。即: RefBoy in 'a 。最終我們可以得出個結論,RefBoy 這個結構體,其生命週期一定不能比 'a 更長才行。
寫到這裡,可能有的人還是對生命週期比較迷糊,不明白其中緣由,其實你只需要知道兩點即可:
- 結構體裡的引用字段必須要有顯式的生命週期
- 一個被顯式寫出生命週期的結構體,其自身的生命週期一定小於等於其顯式寫出的任意一個生命週期
關於第二點,其實生命週期是可以寫多個的,用 , 分隔。
注:生命週期和泛型都寫在 <> 裡,先生命週期後泛型,用,分隔。
impl中的三種self
前面我們知道,Rust中,通過impl可以對一個結構體添加成員方法。同時我們也看到了self這樣的關鍵字,同時,這個self也有好幾種需要你仔細記憶的情況。
impl中的self,常見的有三種形式:self、 &self、&mut self ,我們分別來說。
被move的self
正如上面例子中的impl,我們實現了一個以 self 為第一個參數的函數,但是這樣的函數實際上是有問題的。
問題在於Rust的所有權轉移機制。
我曾經見過一個關於Rust的笑話:"你調用了一下別人,然後你就不屬於你了"。
比如下面代碼就會報出一個錯誤:
struct A { a: i32, } impl A { pub fn show(self) { println!("{}", self.a); } } fn main() { let ast = A{a: 12i32}; ast.show(); println!("{}", ast.a); }
錯誤:
13:25 error: use of moved value: `ast.a` [E0382]
<anon>:13 println!("{}", ast.a);
為什麼呢?因為 Rust 本身,在你調用一個函數的時候,如果傳入的不是一個引用,那麼無疑,這個參數將被這個函數吃掉,即其 owner 將被 move 到這個函數的參數上。同理,impl 中的 self ,如果你寫的不是一個引用的話,也是會被默認的 move 掉喲!
那麼如何避免這種情況呢?答案是 Copy 和 Clone :
#![allow(unused)] fn main() { #[derive(Copy, Clone)] struct A { a: i32, } }
這麼寫的話,會使編譯通過。但是這麼寫實際上也是有其缺陷的。其缺陷就是: Copy 或者 Clone ,都會帶來一定的運行時開銷!事實上,被move的 self 其實是相對少用的一種情況,更多的時候,我們需要的是 ref 和 ref mut 。
ref 和 ref mut
關於 ref 和 mut ref 的寫法和被 move 的 self 寫法類似,只不過多了一個引用修飾符號,上面有例子,不多說。
需要注意的一點是,你不能在一個 &self 的方法裡調用一個 &mut ref ,任何情況下都不行!
但是,反過來是可以的。代碼如下:
#[derive(Copy, Clone)] struct A { a: i32, } impl A { pub fn show(&self) { println!("{}", self.a); // compile error: cannot borrow immutable borrowed content `*self` as mutable // self.add_one(); } pub fn add_two(&mut self) { self.add_one(); self.add_one(); self.show(); } pub fn add_one(&mut self) { self.a += 1; } } fn main() { let mut ast = A{a: 12i32}; ast.show(); ast.add_two(); }
需要注意的是,一旦你的結構體持有一個可變引用,你,只能在 &mut self 的實現裡去改變他!
Rust允許我們靈活的對一個 struct 進行你想要的實現,在編程的自由度上無疑有了巨大的提高。
至於更高級的關於 trait 和泛型的用法,我們將在以後的章節進行詳細介紹。
枚舉類型 enum
Rust的枚舉(enum)類型,跟C語言的枚舉有點接近,然而更強大,事實上它是一種代數數據類型(Algebraic Data Type)。
比如說,這是一個代表東南西北四個方向的枚舉:
#![allow(unused)] fn main() { enum Direction { West, North, South, East, } }
但是,rust 的枚舉能做到的,比 C 語言的更多。 比如,枚舉裡面居然能包含一些你需要的,特定的數據信息! 這是常規的枚舉所無法做到的,更像枚舉類,不是麼?
#![allow(unused)] fn main() { enum SpecialPoint { Point(i32, i32), Special(String), } }
你還可以給裡面的字段命名,如
#![allow(unused)] fn main() { enum SpecialPoint { Point { x: i32, y: i32, }, Special(String), } }
使用枚舉
和struct的成員訪問符號 . 不同的是,枚舉類型要想訪問其成員,幾乎無一例外的要用到模式匹配。並且, 你可以寫一個 Direction::West,但是你現在還不能寫成 Direction.West, 除非你顯式的 use 它 。雖然編譯器足夠聰明能發現你這個粗心的毛病。
關於模式匹配,我不會說太多,還是舉個栗子
enum SpecialPoint { Point(i32, i32), Special(String), } fn main() { let sp = SpecialPoint::Point(0, 0); match sp { SpecialPoint::Point(x, y) => { println!("I'am SpecialPoint(x={}, y={})", x, y); } SpecialPoint::Special(why) => { println!("I'am Special because I am {}", why); } } }
吶吶吶,這就是模式匹配取值啦。
當然了, enum 其實也是可以 impl 的,一般人我不告訴他!
對於帶有命名字段的枚舉,模式匹配時可指定字段名
#![allow(unused)] fn main() { match sp { SpecialPoint::Point { x: x, y: y } => { // ... }, SpecialPoint::Special(why) => {} } }
對於帶有字段名的枚舉類型,其模式匹配語法與匹配 struct 時一致。如
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } let point = Point { x: 1, y: 2 }; let Point { x: x, y: y } = point; // 或 let Point { x, y } = point; // 或 let Point { x: x, .. } = point; }
模式匹配的語法與 if let 和 let 是一致的,所以在後面的內容中看到的也支持同樣的語法。
String
這章我們來著重介紹一下字符串。
剛剛學習Rust的同學可能會被Rust的字符串搞混掉,比如str,String, OsStr, CStr,CString等等……
事實上,如果你不做FFI的話,常用的字符串類型就只有前兩種。我們就來著重研究一下Rust的前兩種字符串。
你要明白的是,Rust中的字符串實際上是被編碼成UTF-8的一個字節數組。這麼說比較拗口,簡單來說,Rust字符串內部存儲的是一個u8數組,但是這個數組是Unicode字符經過UTF-8編碼得來的。因此,可以看成Rust原生就支持Unicode字符集(Python2的碼農淚流滿面)。
str
首先我們先來看一下str, 從字面意思上,Rust的string被表達為: &'static str(看不懂這個表達式沒關係,&表示引用你知道吧,static表示靜態你知道吧,好了,齊了),即,你在代碼裡寫的,所有的用""包裹起來的字符串,都被聲明成了一個不可變,靜態的字符串。而我們的如下語句:
#![allow(unused)] fn main() { let x = "Hello"; let x:&'static str = "Hello"; }
實際上是將 "Hello" 這個靜態變量的引用傳遞給了x。同時,這裡的字符串不可變!
字符串也支持轉義字符: 比如如下:
#![allow(unused)] fn main() { let z = "foo bar"; let w = "foo\nbar"; assert_eq!(z, w); }
也可以在字符串字面量前加上r來避免轉義
//沒有轉義序列
let d: &'static str = r"abc \n abc";
//等價於
let c: &'static str = "abc \\n abc";
String
光有str,確實不夠什麼卵用,畢竟我們在實際應用中要的更多的還是一個可變的,不定長的字符串。這時候,一種在heap上聲明的字符串String被設計了出來。
它能動態的去增長或者縮減,那麼怎麼聲明它呢?我們先介紹一種簡單的方式,從str中轉換:
#![allow(unused)] fn main() { let x:&'static str = "hello"; let mut y:String = x.to_string(); println!("{}", y); y.push_str(", world"); println!("{}", y); }
我知道你一定會問:——
那麼如何將一個String重新變成&str呢?
答:用 &* 符號
fn use_str(s: &str) { println!("I am: {}", s); } fn main() { let s = "Hello".to_string(); use_str(&*s); }
我們來分析一下,以下部分將涉及到部分Deref的知識,可能需要你預習一下,如果不能理解大可跳過下一段:
首先呢, &*是兩個符號&和*的組合,按照Rust的運算順序,先對String進行Deref,也就是*操作。
由於String實現了 impl Deref<Target=str> for String,這相當於一個運算符重載,所以你就能通過*獲得一個str類型。但是我們知道,單獨的str是不能在Rust裡直接存在的,因此,我們需要先給他進行&操作取得&str這個結果。
有人說了,我發現只要用&一個操作符就能將使上面的編譯通過。
這其實是一個編譯器的鍋,因為Rust的編譯器會在&後面插入足夠多的*來儘可能滿足Deref這個特性。這個特性會在某些情況下失效,因此,為了不給自己找麻煩,還是將操作符寫全為好。
需要知道的是,將String轉換成&str是非常輕鬆的,幾乎沒有任何開銷。但是反過來,將&str轉換成String是需要在heap上請求內存的,因此,要慎重。
我們還可以將一個UTF-8編碼的字節數組轉換成String,如
#![allow(unused)] fn main() { // 存儲在Vec裡的一些字節 let miao = vec![229,150,181]; // 我們知道這些字節是合法的UTF-8編碼字符串,所以直接unwrap() let meow = String::from_utf8(miao).unwrap(); assert_eq!("喵", meow); }
索引訪問
有人會把Rust中的字符串和其慣用的字符串等同起來,於是就出現瞭如下代碼
#![allow(unused)] fn main() { let x = "hello".to_string(); x[1]; //編譯錯誤! }
Rust的字符串實際上是不支持通過下標訪問的,但是呢,我們可以通過將其轉變成數組的方式訪問
#![allow(unused)] fn main() { let x = "哎喲我去".to_string(); for i in x.as_bytes() { print!("{} ", i); } println!(""); for i in x.chars() { print!("{}", i); } x.chars().nth(2); }
字符串切片
對字符串切片是一件非常危險的事,雖然Rust支持,但是我並不推薦。因為Rust的字符串Slice實際上是切的bytes。這也就造成了一個嚴重後果,如果你切片的位置正好是一個Unicode字符的內部,Rust會發生Runtime的panic,導致整個程序崩潰。 因為這個操作是如此的危險,所以我就不演示了……
操作符和格式化字符串
現在的Rust資料,無論是Book還是RustByExample都沒有統一而完全的介紹Rust的操作符。一個很重要的原因就是,Rust的操作符號和C++大部分都是一模一樣的。
一元操作符
顧名思義,一元操作符是專門對一個Rust元素進行操縱的操作符,主要包括以下幾個:
-: 取負,專門用於數值類型。*: 解引用。這是一個很有用的符號,和Deref(DerefMut)這個trait關聯密切。!: 取反。取反操作相信大家都比較熟悉了,不多說了。有意思的是,當這個操作符對數字類型使用的時候,會將其每一位都置反!也就是說,你對一個1u8進行!的話你將會得到一個254u8。&和&mut: 租借,borrow。向一個owner租借其使用權,分別是租借一個只讀使用權和讀寫使用權。
二元操作符
算數操作符
算數運算符都有對應的trait的,他們都在std::ops下:
+: 加法。實現了std::ops::Add。-: 減法。實現了std::ops::Sub。*: 乘法。實現了std::ops::Mul。/: 除法。實現了std::ops::Div。%: 取餘。實現了std::ops::Rem。
位運算符
和算數運算符差不多的是,位運算也有對應的trait。
&: 與操作。實現了std::ops::BitAnd。|: 或操作。實現了std::ops::BitOr。^: 異或。實現了std::ops::BitXor。<<: 左移運算符。實現了std::ops::Shl。>>: 右移運算符。實現了std::ops::Shr。
惰性boolean運算符
邏輯運算符有三個,分別是&&、||、!。其中前兩個叫做惰性boolean運算符,之所以叫這個名字。是因為在Rust裡也會出現其他類C語言的邏輯短路問題。所以取了這麼一個高大上然並卵的名字。
其作用和C語言裡的一毛一樣啊!哦,對了,有點不同的是Rust裡這個運算符只能用在bool類型變量上。什麼 1 && 1 之類的表達式給我死開。
比較運算符
比較運算符其實也是某些trait的語法糖啦,不同的是比較運算符所實現的trait只有兩個std::cmp::PartialEq和std::cmp::PartialOrd
其中, ==和!=實現的是PartialEq。
而,<、>、>=、<=實現的是PartialOrd。
邊看本節邊翻開標準庫(好習慣,鼓勵)的同學一定會驚奇的發現,不對啊,std::cmp這個mod下明明有四個trait,而且從肉眼上來看更符合邏輯的Ord和Eq豈不是更好?其實,Rust對於這四個trait的處理是很明確的。分歧主要存在於浮點類型。
熟悉IEEE的同學一定知道浮點數有一個特殊的值叫NaN,這個值表示未定義的一個浮點數。在Rust中可以用0.0f32 / 0.0f32來求得其值。那麼問題來了,這個數他是一個確定的值,但是它表示的是一個不確定的數!那麼 NaN != NaN 的結果是啥?標準告訴我們,是 true 。但是這麼寫又不符合Eq的定義裡total equal(每一位一樣兩個數就一樣)的定義。因此有了PartialEq這麼一個定義,我們只支持部分相等好吧,NaN這個情況我就給它特指了。
為了普適的情況,Rust的編譯器選擇了PartialOrd和PartialEq來作為其默認的比較符號的trait。我們也就和中央保持一致就好。
類型轉換運算符
其實這個並不算運算符,因為他是個單詞as。
這個就是C語言中各位熟悉的顯式類型轉換了。
show u the code:
#![allow(unused)] fn main() { fn avg(vals: &[f64]) -> f64 { let sum: f64 = sum(vals); let num: f64 = len(vals) as f64; sum / num } }
重載運算符
上面說了很多trait。有人會問了,你說這麼多幹啥?
答,為了運算符重載!
Rust是支持運算符重載的(某咖啡語言哭暈在廁所)。
關於這部分呢,在本書的第30節會有很詳細的敘述,因此在這裡我就不鋪開講了,上個栗子給大家,僅作參考:
use std::ops::{Add, Sub}; #[derive(Copy, Clone)] struct A(i32); impl Add for A { type Output = A; fn add(self, rhs: A) -> A { A(self.0 + rhs.0) } } impl Sub for A { type Output = A; fn sub(self, rhs: A) -> A{ A(self.0 - rhs.0) } } fn main() { let a1 = A(10i32); let a2 = A(5i32); let a3 = a1 + a2; println!("{}", (a3).0); let a4 = a1 - a2; println!("{}", (a4).0); }
output:
15
5
格式化字符串
說起格式化字符串,Rust採取了一種類似Python裡面format的用法,其核心組成是五個宏和兩個trait:format!、format_arg!、print!、println!、write!;Debug、Display。
相信你們在寫Rust版本的Hello World的時候用到了print!或者println!這兩個宏,但是其實最核心的是format!,前兩個宏只不過將format!的結果輸出到了console而已。
那麼,我們來探究一下format!這個神奇的宏吧。
在這裡呢,列舉format!的定義是沒卵用的,因為太複雜。我只為大家介紹幾種典型用法。學會了基本上就能覆蓋你平時80%的需求。
首先我們來分析一下format的一個典型調用
fn main() { let s = format!("{1}是個有著{0:>0width$}KG重,{height:?}cm高的大胖子", 81, "wayslog", width=4, height=178); // 我被逼的犧牲了自己了…… print!("{}", s); }
我們可以看到,format!宏調用的時候參數可以是任意類型,而且是可以position參數和key-value參數混合使用的。但是要注意的一點是,key-value的值只能出現在position值之後並且不佔position。例如例子裡你用3$引用到的絕對不是width,而是會報錯。
這裡面關於參數稍微有一個規則就是,參數類型必須要實現 std::fmt mod 下的某些trait。比如我們看到原生類型大部分都實現了Display和Debug這兩個宏,其中整數類型還會額外實現一個Binary,等等。
當然了,我們可以通過 {:type}的方式去調用這些參數。
比如這樣:
#![allow(unused)] fn main() { format!("{:b}", 2); // 調用 `Binary` trait // Get : 10 format!("{:?}", "Hello"); // 調用 `Debug` // Get : "Hello" }
另外請記住:type這個地方為空的話默認調用的是Display這個trait。
關於:號後面的東西其實還有更多式子,我們從上面的{0:>0width$}來分析它。
首先>是一個語義,它表示的是生成的字符串向右對齊,於是我們得到了 0081這個值。與之相對的還有<(向左對齊)和^(居中)。
再接下來0是一種特殊的填充語法,他表示用0補齊數字的空位,要注意的是,當0作用於負數的時候,比如上面例子中wayslog的體重是-81,那麼你最終將得到-0081;當然了,什麼都不寫表示用空格填充啦;在這一位上,還會出現+、#的語法,使用比較詭異,一般情況下用不上。
最後是一個組合式子width$,這裡呢,大家很快就能認出來是表示後面key-value值對中的width=4。你們沒猜錯,這個值表示格式化完成後字符串的長度。它可以是一個精確的長度數值,也可以是一個以$為結尾的字符串,$前面的部分可以寫一個key或者一個postion。
最後,你需要額外記住的是,在width和type之間會有一個叫精度的區域(可以省略不寫如例子),他們的表示通常是以.開始的,比如.4表示小數點後四位精度。最讓人遭心的是,你仍然可以在這個位置引用參數,只需要和上面width一樣,用.N$來表示一個position的參數,但是就是不能引用key-value類型的。這一位有一個特殊用法,那就是.*,它不表示一個值,而是表示兩個值!第一個值表示精確的位數,第二個值表示這個值本身。這是一種很尷尬的用法,而且極度容易匹配到其他參數。因此,我建議在各位能力或者時間不欠缺的時候儘量把格式化表達式用標準的形式寫的清楚明白。尤其在面對一個複雜的格式化字符串的時候。
好了好了,說了這麼多,估計你也頭昏腦漲的了吧,下面來跟我寫一下format宏的完整用法。仔細體會並提煉每一個詞的意思和位置。
format_string := <text> [ format <text> ] *
format := '{' [ argument ] [ ':' format_spec ] '}'
argument := integer | identifier
format_spec := [[fill]align][sign]['#'][0][width]['.' precision][type]
fill := character
align := '<' | '^' | '>'
sign := '+' | '-'
width := count
precision := count | '*'
type := identifier | ''
count := parameter | integer
parameter := integer '$'
最後,留個作業吧。
給出參數列表如下:
(500.0, 12, "ELTON", "QB", 4, CaiNiao="Mike")
請寫出能最後輸出一下句子並且將參數都被用過至少一遍的格式化字符串,並自己去play實驗一下。
rust.cc社區的唐Mike眼睛度數足有0500.0度卻還是每天辛苦碼代碼才能賺到100個QB。
但是ELTON卻只需睡 12 個小時就可以迎娶白富美了。
函數
儘管rust是一門多範式的編程語言,但rust的編程風格是更偏向於函數式的,函數在rust中是“一等公民”——first-class type。這意味著,函數是可以作為數據在程序中進行傳遞,如:作為函數的參數。跟C、C++一樣,rust程序也有一個唯一的程序入口-main函數。rust的main函數形式如下:
fn main() { //statements }
rust使用 fn 關鍵字來聲明和定義函數,fn 關鍵字隔一個空格後跟函數名,函數名後跟著一個括號,函數參數定義在括號內。rust使用snake_case風格來命名函數,即所有字母小寫並使用下劃線類分隔單詞,如:foo_bar。如果函數有返回值,則在括號後面加上箭頭 -> ,在箭頭後加上返回值的類型。
這一章我們將學習以下與函數相關的知識:
注:本章所有例子均在rustc1.4下編譯通過,且例子中說明的所有的編譯錯誤都是rustc1.4版本給出的。
函數參數
參數聲明
rust的函數參數聲明和一般的變量聲明相仿,也是參數名後加冒號,冒號後跟參數類型,不過不需要let關鍵字。需要注意的是,普通變量聲明(let語句)是可以省略變量類型的,而函數參數的聲明則不能省略參數類型。
來看一個簡單例子:
fn main() { say_hi("ruster"); } fn say_hi(name: &str) { println!("Hi, {}", name); }
上例中,say_hi函數擁有一個參數,名為name,類型為&str。
將函數作為參數
在rust中,函數是一等公民(可以儲存在變量/數據結構中,可以作為參數傳入函數,可以作為返回值),所以rust的函數參數不僅可以是一般的類型,也可以是函數。如:
fn main() { let xm = "xiaoming"; let xh = "xiaohong"; say_what(xm, hi); say_what(xh, hello); } fn hi(name: &str) { println!("Hi, {}.", name); } fn hello(name: &str) { println!("Hello, {}.", name); } fn say_what(name: &str, func: fn(&str)) { func(name) }
上例中,hi函數和hello函數都是隻有一個&str類型的參數且沒有返回值。而say_what函數則有兩個參數,一個是&str類型,另一個則是函數類型(function type),它是隻有一個&str類型參數且沒有返回值的函數類型。
模式匹配
支持模式匹配,讓rust平添了許多的靈活性,用起來也是十分的舒爽。模式匹配不僅可以用在變量聲明(let語句)中,也可以用在函數參數聲明中,如:
fn main() { let xm = ("xiaoming", 54); let xh = ("xiaohong", 66); print_id(xm); print_id(xh); print_name(xm); print_age(xh); print_name(xm); print_age(xh); } fn print_id((name, age): (&str, i32)) { println!("I'm {},age {}.", name, age); } fn print_age((_, age): (&str, i32)) { println!("My age is {}", age); } fn print_name((name,_): (&str, i32)) { println!("I am {}", name); }
上例是一個元組(Tuple)匹配的例子,當然也可以是其他可在let語句中使用的類型。參數的模式匹配跟let語句的匹配一樣,也可以使用下劃線來表示丟棄一個值。
函數返回值
在rust中,任何函數都有返回類型,當函數返回時,會返回一個該類型的值。我們先來看看main函數:
fn main() { //statements }
之前有說過,函數的返回值類型是在參數列表後,加上箭頭和類型來指定的。不過,一般我們看到的main函數的定義並沒有這麼做。這是因為main函數的返回值是(),在rust中,當一個函數返回()時,可以省略。main函數的完整形式如下:
fn main() -> () { //statements }
main函數的返回值類型是(),它是一個特殊的元組——沒有元素的元組,稱為unit,它表示一個函數沒有任何信息需要返回。在Rust Reference的Types中是的描述如下:
For historical reasons and convenience, the tuple type with no elements (
()) is often called ‘unit’ or ‘the unit type’.
()類型,其實類似於C/C++、Java、C#中的void類型。
下面來看一個有返回值的例子:
fn main() { let a = 3; println!("{}", inc(a)); } fn inc(n: i32) -> i32 { n + 1 }
上面的例子中,函數inc有一個i32類型的參數和返回值,作用是將參數加1返回。需要注意的是inc函數中只有n+1一個表達式,並沒有像C/C++或Java、C#等語言有顯式地return語句類返回一個值。這是因為,與其他基於語句的語言(如C語言)不同,rust是基於表達式的語言,函數中最後一個表達式的值,默認作為返回值。當然,rust中也有語句,關於rust的語句和表達式,請看下一節。
return關鍵字
rust也有return關鍵字,不過一般用於提前返回。來看一個簡單地例子:
fn main() { let a = [1,3,2,5,9,8]; println!("There is 7 in the array: {}", find(7, &a)); println!("There is 8 in the array: {}", find(8, &a)); } fn find(n: i32, a: &[i32]) -> bool { for i in a { if *i == n { return true; } } false }
上例中,find函數,接受一個i32類型n和一個i32類型的切片(slice)a,返回一個bool值,若n是a的元素,則返回true,否則返回false。可以看到,return關鍵字,用在for循環的if表達式中,若此時a的元素與n相等,則立刻返回true,剩下的循環不必再進行,否則一直循環檢測完整個切片(slice),最後返回false。當然,return語句也可以用在最後返回,像C/C++一樣使用:把find函數最後一句false改為return false;(注意分號不可省略)也是可以的,不過這就不是rust的編程風格了。這裡需要注意的是,for循環中的i,其類型為&i32,需要使用解引用操作符來變換為i32類型。另外,切片(slice)在這裡可以看作是對數組的引用,關於切片與數組的詳細解釋可以看Rust Reference和rustbyexample中的相關內容。
返回多個值
rust的函數不支持多返回值,但是我們可以利用元組來返回多個值,配合rust的模式匹配,使用起來十分靈活。先看例子:
fn main() { let (p2,p3) = pow_2_3(789); println!("pow 2 of 789 is {}.", p2); println!("pow 3 of 789 is {}.", p3); } fn pow_2_3(n: i32) -> (i32, i32) { (n*n, n*n*n) }
可以看到,上例中,pow_2_3函數接收一個i32類型的值,返回其二次方和三次方的值,這兩個值包裝在一個元組中返回。在main函數中,let語句就可以使用模式匹配將函數返回的元組進行解構,將這兩個返回值分別賦給p2和p3,從而可以得到789二次方的值和三次方的值。
發散函數
發散函數(diverging function)是rust中的一個特性。發散函數不返回,它使用感嘆號!作為返回類型表示:
fn main() { println!("hello"); diverging(); println!("world"); } fn diverging() -> ! { panic!("This function will never return"); }
由於發散函數不會返回,所以就算其後再有其他語句也是不會執行的。倘若其後還有其他語句,會出現如下編譯警告: 。當然了,我們要知道的是不發散的函數也是可以不返回的,比如無限循環之類的。
發散函數一般都以
。當然了,我們要知道的是不發散的函數也是可以不返回的,比如無限循環之類的。
發散函數一般都以panic!宏調用或其他調用其他發散函數結束,所以,調用發散函數會導致當前線程崩潰。Rust Reference 6.1.3.2 Diverging functions中的描述如下:
We call such functions "diverging" because they never return a value to the caller. Every control path in a diverging function must end with a panic!() or a call to another diverging function on every control path. The ! annotation does not denote a type.
語句和表達式
rust是一個基於表達式的語言,不過它也有語句。rust只有兩種語句:聲明語句和表達式語句,其他的都是表達式。基於表達式是函數式語言的一個重要特徵,表達式總是返回值。
聲明語句
rust的聲明語句可以分為兩種,一種為變量聲明語句,另一種為Item聲明語句。
- 變量聲明語句。主要是指
let語句,如:
#![allow(unused)] fn main() { let a = 8; let b: Vec<f64> = Vec::new(); let (a, c) = ("hi", false); }
由於let是語句,所以不能將let語句賦給其他值。如下形式是錯誤的:
#![allow(unused)] fn main() { let b = (let a = 8); }
rustc編譯器會給出錯誤信息:
- Item聲明。是指函數(function)、結構體(structure)、類型別名(type)、靜態變量(static)、特質(trait)、實現(implementation)或模塊(module)的聲明。這些聲明可以嵌套在任意塊(block)中。關於Item聲明,Rust Reference中的描述如下:
An item declaration statement has a syntactic form identical to an item declaration within a module. Declaring an item — a function, enumeration, structure, type, static, trait, implementation or module — locally within a statement block is simply a way of restricting its scope to a narrow region containing all of its uses; it is otherwise identical in meaning to declaring the item outside the statement block.
當然,這裡不能展開講這些Item都是如何聲明的,詳情請看RustPrimer的其他相關章節。
表達式語句
表達式語句,由一個表達式和一個分號組成,即在表達式後面加一個分號就將一個表達式轉變為了一個語句。所以,有多少種表達式,就有多少種表達式語句。
rust有許多種表達式:
- 字面表達式(literal expression)
#![allow(unused)] fn main() { (); // unit type "hello"; // string type '1'; // character type 15; // integer type }
- 元組表達式(Tuple expression):
#![allow(unused)] fn main() { (0.0, 4.5); ("a", 4usize, true); }
通常不使用一個元素的元組,不過如果你堅持的話,rust也是允許的,不過需要在元素後加一個逗號:
#![allow(unused)] fn main() { (0,); // single-element tuple (0); // zero in parentheses }
- 結構體表達式(structure expression) 由於結構體有多種形式,所以結構體表達式也有多種形式。
#![allow(unused)] fn main() { Point {x: 10.0, y: 20.0}; TuplePoint(10.0, 20.0); let u = game::User {name: "Joe", age: 35, score: 100_000}; some_fn::<Cookie>(Cookie); }
結構體表達式一般用於構造一個結構體對象,它除了以上從零構建的形式外,還可以在另一個對象的基礎上進行構建:
#![allow(unused)] fn main() { let base = Point3d {x: 1, y: 2, z: 3}; Point3d {y: 0, z: 10, .. base}; }
- 塊表達式(block expression):
塊表達式就是用花括號
{}括起來的一組表達式的集合,表達式間一般以分號分隔。塊表達式的值,就是最後一個表達式的值。
#![allow(unused)] fn main() { let x: i32 = { println!("Hello."); 5 }; }
如果以語句結尾,則塊表達式的值為():
#![allow(unused)] fn main() { let x: () = { println!("Hello."); }; }
- 範圍表達式(range expression):
可以使用範圍操作符
..來構建範圍對象(variant ofstd::ops::Range):
#![allow(unused)] fn main() { 1..2; // std::ops::Range 3..; // std::ops::RangeFrom ..4; // std::ops::RangeTo ..; // std::ops::RangeFull }
- if表達式(if expression):
#![allow(unused)] fn main() { let a = 9; let b = if a%2 == 0 {"even"} else {"odd"}; }
- 除了以上這些外,還有許多,如:
- path expression
- mehond-call expression
- field expression
- array expression
- index expression
- unary operator expression
- binary operator expression
- return expression
- grouped expression
- match expression
- if expression
- lambda expression
- ... ...
這裡無法詳細展開,讀者可以到[Rust Reference][1]去查看。 [1]:http://doc.rust-lang.org/reference.html#statements-and-expressions
以上表達式語句中的部分例子引用自Rust Reference
高階函數
高階函數與普通函數的不同在於,它可以使用一個或多個函數作為參數,可以將函數作為返回值。rust的函數是first class type,所以支持高階函數。而,由於rust是一個強類型的語言,如果要將函數作為參數或返回值,首先需要搞明白函數的類型。下面先說函數的類型,再說函數作為參數和返回值。
函數類型
前面說過,關鍵字fn可以用來定義函數。除此以外,它還用來構造函數類型。與函數定義主要的不同是,構造函數類型不需要函數名、參數名和函數體。在Rust Reference中的描述如下:
The function type constructor fn forms new function types. A function type consists of a possibly-empty set of function-type modifiers (such as unsafe or extern), a sequence of input types and an output type.
來看一個簡單例子:
fn inc(n: i32) -> i32 {//函數定義 n + 1 } type IncType = fn(i32) -> i32;//函數類型 fn main() { let func: IncType = inc; println!("3 + 1 = {}", func(3)); }
上例首先使用fn定義了inc函數,它有一個i32類型參數,返回i32類型的值。然後再用fn定義了一個函數類型,這個函數類型有i32類型的參數和i32類型的返回值,並用type關鍵字定義了它的別名IncType。在main函數中定義了一個變量func,其類型就為IncType,並賦值為inc,然後在pirntln宏中調用:func(3)。可以看到,inc函數的類型其實就是IncType。
這裡有一個問題,我們將inc賦值給了func,而不是&inc,這樣是將inc函數的擁有權轉給了func嗎,賦值後還可以以inc()形式調用inc函數嗎?先來看一個例子:
fn main() { let func: IncType = inc; println!("3 + 1 = {}", func(3)); println!("3 + 1 = {}", inc(3)); } type IncType = fn(i32) -> i32; fn inc(n: i32) -> i32 { n + 1 }
我們將上例保存在rs源文件中,再用rustc編譯,發現並沒有報錯,並且運行也得到我們想要的結果:
3 + 1 = 4
3 + 1 = 4
這說明,賦值時,inc函數的所有權並沒有被轉移到func變量上,而是更像不可變引用。在rust中,函數的所有權是不能轉移的,我們給函數類型的變量賦值時,賦給的一般是函數的指針,所以rust中的函數類型,就像是C/C++中的函數指針,當然,rust的函數類型更安全。可見,rust的函數類型,其實應該是屬於指針類型(Pointer Type)。rust的Pointer Type有兩種,一種為引用(Reference&),另一種為原始指針(Raw pointer *),詳細內容請看Rust Reference 8.18 Pointer Types。而rust的函數類型應是引用類型,因為它是安全的,而原始指針則是不安全的,要使用原始指針,必須使用unsafe關鍵字聲明。
函數作為參數
函數作為參數,其聲明與普通參數一樣。看下例:
fn main() { println!("3 + 1 = {}", process(3, inc)); println!("3 - 1 = {}", process(3, dec)); } fn inc(n: i32) -> i32 { n + 1 } fn dec(n: i32) -> i32 { n - 1 } fn process(n: i32, func: fn(i32) -> i32) -> i32 { func(n) }
例子中,process就是一個高階函數,它有兩個參數,一個類型為i32的n,另一個類型為fn(i32)->i32的函數func,返回一個i32類型的參數;它在函數體內以n作為參數調用func函數,返回func函數的返回值。運行可以得到以下結果:
3 + 1 = 4
3 - 1 = 2
不過,這不是函數作為參數的唯一聲明方法,使用泛型函數配合特質(trait)也是可以的,因為rust的函數都會實現一個trait:FnOnce、Fn或FnMut。將上例中的process函數定義換成以下形式是等價的:
#![allow(unused)] fn main() { fn process<F>(n: i32, func: F) -> i32 where F: Fn(i32) -> i32 { func(n) } }
函數作為返回值
函數作為返回值,其聲明與普通函數的返回值類型聲明一樣。看例子:
fn main() { let a = [1,2,3,4,5,6,7]; let mut b = Vec::<i32>::new(); for i in &a { b.push(get_func(*i)(*i)); } println!("{:?}", b); } fn get_func(n: i32) -> fn(i32) -> i32 { fn inc(n: i32) -> i32 { n + 1 } fn dec(n: i32) -> i32 { n - 1 } if n % 2 == 0 { inc } else { dec } }
例子中的高階函數為get_func,它接收一個i32類型的參數,返回一個類型為fn(i32) -> i32的函數,若傳入的參數為偶數,返回inc,否則返回dec。這裡需要注意的是,inc函數和dec函數都定義在get_func內。在函數內定義函數在很多其他語言中是不支持的,不過rust支持,這也是rust靈活和強大的一個體現。不過,在函數中定義的函數,不能包含函數中(環境中)的變量,若要包含,應該閉包(詳看13章 閉包)。
所以下例:
fn main() { let f = get_func(); println!("{}", f(3)); } fn get_func() -> fn(i32)->i32 { let a = 1; fn inc(n:i32) -> i32 { n + a } inc }
使用rustc編譯,會出現如下錯誤:

模式匹配
除了我們常見的控制語句之外,Rust還提供了一個更加強大的關鍵字——match 。但是,需要指出的一點是,match只是匹配,要發揮其全部威力,還需要模式的配合。本章,我們就將的對Rust的模式匹配進行一番探索。
本章內容:
match關鍵字
模式匹配,多出現在函數式編程語言之中,為其複雜的類型系統提供一個簡單輕鬆的解構能力。比如從enum等數據結構中取出數據等等,但是在書寫上,相對比較複雜。我們來看一個例子:
enum Direction { East, West, North, South, } fn main() { let dire = Direction::South; match dire { Direction::East => println!("East"), Direction::North | Direction::South => { println!("South or North"); }, _ => println!("West"), }; }
這是一個沒什麼實際意義的程序,但是能清楚的表達出match的用法。看到這裡,你肯定能想起一個常見的控制語句——switch。沒錯,match可以起到和switch相同的作用。不過有幾點需要注意:
- match所羅列的匹配,必須窮舉出其所有可能。當然,你也可以用 _ 這個符號來代表其餘的所有可能性情況,就類似於switch中的
default語句。 - match的每一個分支都必須是一個表達式,並且,除非一個分支一定會觸發panic,這些分支的所有表達式的最終返回值類型必須相同。
關於第二點,有的同學可能不明白。這麼說吧,你可以把match整體視為一個表達式,既然是一個表達式,那麼就一定能求得它的結果。因此,這個結果當然就可以被賦予一個變量咯。 看代碼:
enum Direction { East, West, North, South, } fn main() { // let d_panic = Direction::South; let d_west = Direction::West; let d_str = match d_west { Direction::East => "East", Direction::North | Direction::South => { panic!("South or North"); }, _ => "West", }; println!("{}", d_str); }
解構初窺
match還有一個非常重要的作用就是對現有的數據結構進行解構,輕易的可以拿出其中的數據部分來。 比如,以下是比較常見的例子:
enum Action { Say(String), MoveTo(i32, i32), ChangeColorRGB(u16, u16, u16), } fn main() { let action = Action::Say("Hello Rust".to_string()); match action { Action::Say(s) => { println!("{}", s); }, Action::MoveTo(x, y) => { println!("point from (0, 0) move to ({}, {})", x, y); }, Action::ChangeColorRGB(r, g, _) => { println!("change color into '(r:{}, g:{}, b:0)', 'b' has been ignored", r, g, ); } } }
有人說了,從這來看也並不覺得match有多神奇啊!別急,請看下一小節——>模式
模式
模式,是Rust另一個強大的特性。它可以被用在let和match表達式裡面。相信大家應該還記得我們在複合類型中提到的關於在let表達式中解構元組的例子,實際上這就是一個模式。
#![allow(unused)] fn main() { let tup = (0u8, 1u8); let (x, y) = tup; }
而且我們需要知道的是,如果一個模式中出現了和當前作用域中已存在的同名的綁定,那麼它會覆蓋掉外部的綁定。比如:
#![allow(unused)] fn main() { let x = 1; let c = 'c'; match c { x => println!("x: {} c: {}", x, c), } println!("x: {}", x); }
它的輸出結果是:
x: c c: c
x: 1
在以上代碼中,match作用域裡的x這個綁定被覆蓋成了'c',而出了這個作用域,綁定x又恢復為1。這和變量綁定的行為是一致的。
更強大的解構
在上一節裡,我們初步瞭解了模式匹配在解構enum時候的便利性,事實上,在Rust中模式可以被用來對任何複合類型進行解構——struct/tuple/enum。現在我們要講述一個複雜點的例子,對struct進行解構。
首先,我們可以對一個結構體進行標準的解構:
#![allow(unused)] fn main() { struct Point { x: i64, y: i64, } let point = Point { x: 0, y: 0 }; match point { Point { x, y } => println!("({},{})", x, y), } }
最終,我們拿到了Point內部的值。有人說了,那我想改個名字怎麼辦?
很簡單,你可以使用 :來對一個struct的字段進行重命名,如下:
#![allow(unused)] fn main() { struct Point { x: i64, y: i64, } let point = Point { x: 0, y: 0 }; match point { Point { x: x1, y: y1} => println!("({},{})", x1, y1), } }
另外,有的時候我們其實只對某些字段感興趣,就可以用..來省略其他字段。
#![allow(unused)] fn main() { struct Point { x: i64, y: i64, } let point = Point { x: 0, y: 0 }; match point { Point { y, .. } => println!("y is {}", y), } }
忽略和內存管理
總結一下,我們遇到了兩種不同的模式忽略的情況——_和..。這裡要注意,模式匹配中被忽略的字段是不會被move的,而且實現Copy的也會優先被Copy而不是被move。
說的有點拗口,上代碼:
#![allow(unused)] fn main() { let tuple: (u32, String) = (5, String::from("five")); let (x, s) = tuple; // 以下行將導致編譯錯誤,因為String類型並未實現Copy, 所以tuple被整體move掉了。 // println!("Tuple is: {:?}", tuple); let tuple = (5, String::from("five")); // 忽略String類型,而u32實現了Copy,則tuple不會被move let (x, _) = tuple; println!("Tuple is: {:?}", tuple); }
範圍和多重匹配
模式匹配可以被用來匹配單種可能,當然也就能被用來匹配多種情況:
範圍
在模式匹配中,當我想要匹配一個數字(字符)範圍的時候,我們可以用...來表示:
#![allow(unused)] fn main() { let x = 1; match x { 1 ... 10 => println!("一到十"), _ => println!("其它"), } let c = 'w'; match c { 'a' ... 'z' => println!("小寫字母"), 'A' ... 'Z' => println!("大寫字母"), _ => println!("其他字符"), } }
多重匹配
當我們只是單純的想要匹配多種情況的時候,可以使用 | 來分隔多個匹配條件
#![allow(unused)] fn main() { let x = 1; match x { 1 | 2 => println!("一或二"), _ => println!("其他"), } }
ref 和 ref mut
前面我們瞭解到,當被模式匹配命中的時候,未實現Copy的類型會被默認的move掉,因此,原owner就不再持有其所有權。但是有些時候,我們只想要從中拿到一個變量的(可變)引用,而不想將其move出作用域,怎麼做呢?答:用ref或者ref mut。
#![allow(unused)] fn main() { let mut x = 5; match x { ref mut mr => println!("mut ref :{}", mr), } // 當然了……在let表達式裡也能用 let ref mut mrx = x; }
變量綁定
在模式匹配的過程內部,我們可以用@來綁定一個變量名,這在複雜的模式匹配中是再方便不過的,比如一個具名的範圍匹配如下:
#![allow(unused)] fn main() { let x = 1u32; match x { e @ 1 ... 5 | e @ 10 ... 15 => println!("get:{}", e), _ => (), } }
如代碼所示,e綁定了x的值。
當然,變量綁定是一個極其有用的語法,下面是一個來自官方doc裡的例子:
#![allow(unused)] fn main() { #[derive(Debug)] struct Person { name: Option<String>, } let name = "Steve".to_string(); let x: Option<Person> = Some(Person { name: Some(name) }); match x { Some(Person { name: ref a @ Some(_), .. }) => println!("{:?}", a), _ => {} } }
輸出:
Some("Steve")
後置條件
一個後置的if表達式可以被放在match的模式之後,被稱為match guards。例如如下代碼:
#![allow(unused)] fn main() { let x = 4; let y = false; match x { 4 | 5 if y => println!("yes"), _ => println!("no"), } }
猜一下上面代碼的輸出?
答案是no。因為guard是後置條件,是整個匹配的後置條件:所以上面的式子表達的邏輯實際上是:
// 偽代碼表示
IF y AND (x IN List[4, 5])
trait 和 trait對象
trait(特徵)類似於其他語言中的interface或者protocol,指定一個實際類型必須滿足的功能集合 與interface不同的地方在於,interface會隱藏具體實現類型,而trait不會。在rust中,隱藏實現類型可以由generic配合trait作出。
Rust中的trait:
10.1 trait關鍵字
trait與具體類型
使用trait定義一個特徵:
#![allow(unused)] fn main() { trait HasArea { fn area(&self) -> f64; } }
trait裡面的函數可以沒有函數體,實現代碼交給具體實現它的類型去補充:
struct Circle { x: f64, y: f64, radius: f64, } impl HasArea for Circle { fn area(&self) -> f64 { std::f64::consts::PI * (self.radius * self.radius) } } fn main() { let c = Circle { x: 0.0f64, y: 0.0f64, radius: 1.0f64, }; println!("circle c has an area of {}", c.area()); }
注: &self表示的是area這個函數會將調用者的借代引用作為參數
這個程序會輸出:
circle c has an area of 3.141592653589793
trait與泛型
我們瞭解了Rust中trait的定義和使用,接下來我們介紹一下它的使用場景,從中我們可以窺探出接口這特性帶來的驚喜
我們知道泛型可以指任意類型,但有時這不是我們想要的,需要給它一些約束。
泛型的trait約束
#![allow(unused)] fn main() { use std::fmt::Debug; fn foo<T: Debug>(s: T) { println!("{:?}", s); } }
Debug是Rust內置的一個trait,為"{:?}"實現打印內容,函數foo接受一個泛型作為參數,並且約定其需要實現Debug
多trait約束
可以使用多個trait對泛型進行約束:
#![allow(unused)] fn main() { use std::fmt::Debug; fn foo<T: Debug + Clone>(s: T) { s.clone(); println!("{:?}", s); } }
<T: Debug + Clone>中Debug和Clone使用+連接,標示泛型T需要同時實現這兩個trait。
where關鍵字
約束的trait增加後,代碼看起來就變得詭異了,這時候需要使用where從句:
#![allow(unused)] fn main() { use std::fmt::Debug; fn foo<T: Clone, K: Clone + Debug>(x: T, y: K) { x.clone(); y.clone(); println!("{:?}", y); } // where 從句 fn foo<T, K>(x: T, y: K) where T: Clone, K: Clone + Debug { x.clone(); y.clone(); println!("{:?}", y); } // 或者 fn foo<T, K>(x: T, y: K) where T: Clone, K: Clone + Debug { x.clone(); y.clone(); println!("{:?}", y); } }
trait與內置類型
內置類型如:i32, i64等也可以添加trait實現,為其定製一些功能:
#![allow(unused)] fn main() { trait HasArea { fn area(&self) -> f64; } impl HasArea for i32 { fn area(&self) -> f64 { *self as f64 } } 5.area(); }
這樣的做法是有限制的。Rust 有一個“孤兒規則”:當你為某類型實現某 trait 的時候,必須要求類型或者 trait 至少有一個是在當前 crate 中定義的。你不能為第三方的類型實現第三方的 trait 。
在調用 trait 中定義的方法的時候,一定要記得讓這個 trait 可被訪問。
#![allow(unused)] fn main() { let mut f = std::fs::File::open("foo.txt").ok().expect("Couldn’t open foo.txt"); let buf = b"whatever"; // buf: &[u8; 8] let result = f.write(buf); result.unwrap(); }
這裡是錯誤:
error: type `std::fs::File` does not implement any method in scope named `write`
let result = f.write(buf);
^~~~~~~~~~
我們需要先use這個Write trait:
#![allow(unused)] fn main() { use std::io::Write; let mut f = std::fs::File::open("foo.txt").expect("Couldn’t open foo.txt"); let buf = b"whatever"; let result = f.write(buf); result.unwrap(); // ignore the error }
這樣就能無錯誤地編譯了。
trait的默認方法
#![allow(unused)] fn main() { trait Foo { fn is_valid(&self) -> bool; fn is_invalid(&self) -> bool { !self.is_valid() } } }
is_invalid是默認方法,Foo的實現者並不要求實現它,如果選擇實現它,會覆蓋掉它的默認行為。
trait的繼承
#![allow(unused)] fn main() { trait Foo { fn foo(&self); } trait FooBar : Foo { fn foobar(&self); } }
這樣FooBar的實現者也要同時實現Foo:
#![allow(unused)] fn main() { struct Baz; impl Foo for Baz { fn foo(&self) { println!("foo"); } } impl FooBar for Baz { fn foobar(&self) { println!("foobar"); } } }
derive屬性
Rust提供了一個屬性derive來自動實現一些trait,這樣可以避免重複繁瑣地實現他們,能被derive使用的trait包括:Clone, Copy, Debug, Default, Eq, Hash, Ord, PartialEq, PartialOrd
#[derive(Debug)] struct Foo; fn main() { println!("{:?}", Foo); }
impl Trait
在版本1.26 開始,Rust提供了impl Trait的寫法,作為和Scala 對等的既存型別(Existential Type)的寫法。
在下面這個寫法中,fn foo()將返回一個實作了Trait的trait。
#![allow(unused)] fn main() { //before fn foo() -> Box<Trait> { // ... } //after fn foo() -> impl Trait { // ... } }
相較於1.25 版本以前的寫法,新的寫法會在很多場合中更有利於開發和執行效率。
impl Trait 的普遍用例
#![allow(unused)] fn main() { trait Trait { fn method(&self); } impl Trait for i32 { // implementation goes here } impl Trait for f32 { // implementation goes here } }
利用Box 會意味:即便回傳的內容是固定的,但也會使用到動態內存分配。利用impl Trait 的寫法可以避免便用Box。
#![allow(unused)] fn main() { //before fn foo() -> Box<Trait> { Box::new(5) as Box<Trait> } //after fn foo() -> impl Trait { 5 } }
其他受益的用例
閉包:
#![allow(unused)] fn main() { // before fn foo() -> Box<Fn(i32) -> i32> { Box::new(|x| x + 1) } // after fn foo() -> impl Fn(i32) -> i32 { |x| x + 1 } }
傳參:
#![allow(unused)] fn main() { // before fn foo<T: Trait>(x: T) { // after fn foo(x: impl Trait) { }
trait對象 (trait object)
trait對象在Rust中是指使用指針封裝了的 trait,比如 &SomeTrait 和 Box<SomeTrait>。
trait Foo { fn method(&self) -> String; } impl Foo for u8 { fn method(&self) -> String { format!("u8: {}", *self) } } impl Foo for String { fn method(&self) -> String { format!("string: {}", *self) } } fn do_something(x: &Foo) { x.method(); } fn main() { let x = "Hello".to_string(); do_something(&x); let y = 8u8; do_something(&y); }
x: &Foo其中x是一個trait對象,這裡用指針是因為x可以是任意實現Foo的類型實例,內存大小並不確定,但指針的大小是固定的。
trait對象的實現
&SomeTrait 類型和普通的指針類型&i32不同。它不僅包括指向真實對象的指針,還包括一個指向虛函數表的指針。它的內部實現定義在在std::raw模塊中:
#![allow(unused)] fn main() { pub struct TraitObject { pub data: *mut (), pub vtable: *mut (), } }
其中data是一個指向實際類型實例的指針, vtable是一個指向實際類型對於該trait的實現的虛函數表:
Foo的虛函數表類型:
#![allow(unused)] fn main() { struct FooVtable { destructor: fn(*mut ()), size: usize, align: usize, method: fn(*const ()) -> String, } }
之前的代碼可以解讀為:
#![allow(unused)] fn main() { // u8: // 這個函數只會被指向u8的指針調用 fn call_method_on_u8(x: *const ()) -> String { let byte: &u8 = unsafe { &*(x as *const u8) }; byte.method() } static Foo_for_u8_vtable: FooVtable = FooVtable { destructor: /* compiler magic */, size: 1, align: 1, method: call_method_on_u8 as fn(*const ()) -> String, }; // String: // 這個函數只會被指向String的指針調用 fn call_method_on_String(x: *const ()) -> String { let string: &String = unsafe { &*(x as *const String) }; string.method() } static Foo_for_String_vtable: FooVtable = FooVtable { destructor: /* compiler magic */, size: 24, align: 8, method: call_method_on_String as fn(*const ()) -> String, }; let a: String = "foo".to_string(); let x: u8 = 1; // let b: &Foo = &a; let b = TraitObject { // data存儲實際值的引用 data: &a, // vtable存儲實際類型實現Foo的方法 vtable: &Foo_for_String_vtable }; // let y: &Foo = x; let y = TraitObject { data: &x, vtable: &Foo_for_u8_vtable }; // b.method(); (b.vtable.method)(b.data); // y.method(); (y.vtable.method)(y.data); }
對象安全
並不是所有的trait都能作為trait對象使用的,比如:
#![allow(unused)] fn main() { let v = vec![1, 2, 3]; let o = &v as &Clone; }
會有一個錯誤:
error: cannot convert to a trait object because trait `core::clone::Clone` is not object-safe [E0038]
let o = &v as &Clone;
^~
note: the trait cannot require that `Self : Sized`
let o = &v as &Clone;
^~
讓我來分析一下錯誤的原因:
#![allow(unused)] fn main() { pub trait Clone: Sized { fn clone(&self) -> Self; fn clone_from(&mut self, source: &Self) { ... } } }
雖然Clone本身繼承了Sized這個trait,但是它的方法fn clone(&self) -> Self和fn clone_from(&mut self, source: &Self) { ... }含有Self類型,而在使用trait對象方法的時候Rust是動態派發的,我們根本不知道這個trait對象的實際類型,它可以是任何一個實現了該trait的類型的值,所以Self在這裡的大小不是Self: Sized的,這樣的情況在Rust中被稱為object-unsafe或者not object-safe,這樣的trait是不能成為trait對象的。
總結:
如果一個trait方法是object safe的,它需要滿足:
- 方法有
Self: Sized約束, 或者 - 同時滿足以下所有條件:
- 沒有泛型參數
- 不是靜態函數
- 除了
self之外的其它參數和返回值不能使用Self類型
如果一個trait是object-safe的,它需要滿足:
- 所有的方法都是
object-safe的,並且 - trait 不要求
Self: Sized約束
參考stackoverflow object safe rfc
泛型
我們在編程中,通常有這樣的需求,為多種類型的數據編寫一個功能相同的函數,如兩個數的加法,希望這個函數既支持i8、i16、 i32 ....float64等等,甚至自定義類型,在不支持泛型的編程語言中,我們通常要為每一種類型都編寫一個函數,而且通常情況下函數名還必須不同,例如:
fn add_i8(a:i8, b:i8) -> i8 { a + b } fn add_i16(a:i16, b:i16) -> i16 { a + b } fn add_f64(a:f64, b:f64) -> f64 { a + b } // 各種其他add函數 // ... fn main() { println!("add i8: {}", add_i8(2i8, 3i8)); println!("add i16: {}", add_i16(20i16, 30i16)); println!("add f64: {}", add_f64(1.23, 1.23)); }
如果有很多地方都需要支持多種類型,那麼代碼量就會非常大,而且代碼也會非常臃腫,編程就真的變成了苦逼搬磚的工作,枯燥而乏味:D。 學過C++的人也許很容易理解泛型,但本教程面向的是Rust初學者,所以不會拿C++的泛型、多態和Rust進行對比,以免增加學習的複雜度和不必要的困擾,從而讓Rust初學者更容易理解和接受Rust泛型。
概念
泛型程序設計是程序設計語言的一種風格或範式。允許程序員在強類型程序設計語言中編寫代碼時使用一些以後才指定的類型,在實例化時(instantiate)作為參數指明這些類型(在Rust中,有的時候類型還可以被編譯器推導出來)。各種程序設計語言和其編譯器、運行環境對泛型的支持均不一樣。Ada, Delphi, Eiffel, Java, C#, F#, Swift, and Visual Basic .NET稱之為泛型(generics);ML, Scala and Haskell稱之為參數多態(parametric polymorphism);C++與D稱之為模板。具有廣泛影響的1994年版的《Design Patterns》一書稱之為參數化類型(parameterized type)。
提示: 以上概念摘自《維基百科-泛型》
在編程的時候,我們經常利用多態。通俗的講,多態就是好比坦克的炮管,既可以發射普通彈藥,也可以發射制導炮彈(導彈),也可以發射貧鈾穿甲彈,甚至發射子母彈,大家都不想為每一種炮彈都在坦克上分別安裝一個專用炮管,即使生產商願意,炮手也不願意,累死人啊。所以在編程開發中,我們也需要這樣“通用的炮管”,這個“通用的炮管”就是多態。
需要知道的是,泛型就是一種多態。
泛型主要目的是為程序員提供了編程的便利,減少代碼的臃腫,同時極大豐富了語言本身的表達能力, 為程序員提供了一個合適的炮管。想想,一個函數,代替了幾十個,甚至數百個函數,是一件多麼讓人興奮的事情。 泛型,可以理解為具有某些功能共性的集合類型,如i8、i16、u8、f32等都可以支持add,甚至兩個struct Point類型也可以add形成一個新的Point。
先讓我們來看看標準庫中常見的泛型Option
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
T就是泛型參數,這裡的T可以換成A-Z任何你自己喜歡的字母。不過習慣上,我們用T表示Type,用E表示Error。T在具體使用的時候才會被實例化:
#![allow(unused)] fn main() { let a = Some(100.111f32); }
編譯器會自行推導出a為Option
當然,你也可以顯式聲明a的類型,但必須保證和右值的類型一樣,不然編譯器會報"mismatched types"類型不匹配錯誤。
#![allow(unused)] fn main() { let a:Option<f32> = Some(100.111); //編譯自動推導右值中的100.111為f32類型。 let b:Option<f32> = Some(100.111f32); let c:Option<f64> = Some(100.111); let d:Option<f64> = Some(100.111f64); }
泛型函數
至此,我們已經瞭解到泛型的定義和簡單的使用了。 現在讓我們用函數重寫add操作:
use std::ops::Add; fn add<T: Add<T, Output=T>>(a:T, b:T) -> T { a + b } fn main() { println!("{}", add(100i32, 1i32)); println!("{}", add(100.11f32, 100.22f32)); }
輸出: 101 200.33
add<T: Add<T, Output=T>>(a:T, b:T) -> T就是我們泛型函數,返回值也是泛型T,Add<>中的含義可以暫時忽略,大體意思就是隻要參數類型實現了Add trait,就可以被傳入到我們的add函數,因為我們的add函數中有相加+操作,所以要求傳進來的參數類型必須是可相加的,也就是必須實現了Add trait(具體參考std::ops::Add)。
自定義類型
上面的例子,add的都是語言內置的基礎數據類型,當然我們也可以為自己自定義的數據結構類型實現add操作。
use std::ops::Add; #[derive(Debug)] struct Point { x: i32, y: i32, } // 為Point實現Add trait impl Add for Point { type Output = Point; //執行返回值類型為Point fn add(self, p: Point) -> Point { Point{ x: self.x + p.x, y: self.y + p.y, } } } fn add<T: Add<T, Output=T>>(a:T, b:T) -> T { a + b } fn main() { println!("{}", add(100i32, 1i32)); println!("{}", add(100.11f32, 100.22f32)); let p1 = Point{x: 1, y: 1}; let p2 = Point{x: 2, y: 2}; println!("{:?}", add(p1, p2)); }
輸出: 101 200.33 Point { x: 3, y: 3 }
上面的例子稍微更復雜些了,只是我們增加了自定義的類型,然後讓add函數依然可以在上面工作。如果對trait不熟悉,請查閱trait相關章節。
大家可能會疑問,那我們是否可以讓Point也變成泛型的,這樣Point的x和y也能夠支持float類型或者其他類型,答案當然是可以的。
use std::ops::Add; #[derive(Debug)] struct Point<T: Add<T, Output = T>> { //限制類型T必須實現了Add trait,否則無法進行+操作。 x: T, y: T, } impl<T: Add<T, Output = T>> Add for Point<T> { type Output = Point<T>; fn add(self, p: Point<T>) -> Point<T> { Point{ x: self.x + p.x, y: self.y + p.y, } } } fn add<T: Add<T, Output=T>>(a:T, b:T) -> T { a + b } fn main() { let p1 = Point{x: 1.1f32, y: 1.1f32}; let p2 = Point{x: 2.1f32, y: 2.1f32}; println!("{:?}", add(p1, p2)); let p3 = Point{x: 1i32, y: 1i32}; let p4 = Point{x: 2i32, y: 2i32}; println!("{:?}", add(p3, p4)); }
輸出: Point { x: 3.2, y: 3.2 } Point { x: 3, y: 3 }
上面的列子更復雜了些,我們不僅讓自定義的Point類型支持了add操作,同時我們也為Point做了泛型化。
當let p1 = Point{x: 1.1f32, y: 1.1f32};時,Point的T推導為f32類型,這樣Point的x和y屬性均成了f32類型。因為p1.x+p2.x,所以T類型必須支持Add trait。
總結
上面區區幾十行的代碼,卻實現了非泛型語言百行甚至千行代碼才能達到的效果,足見泛型的強大。
習題
1. Generic lines iterator
問題描述
有時候我們可能做些文本分析工作, 數據可能來源於外部或者程序內置的文本.
請實現一個 parse 函數, 只接收一個 lines iterator 為參數, 並輸出每行.
要求既能輸出內置的文本, 也能輸出文件內容.
調用方式及輸出參考
let lines = "some\nlong\ntext".lines()
parse(do_something_or_nothing(lines))
some
long
text
use std::fs:File;
use std::io::prelude::*;
use std::io::BufReader;
let lines = BufReader::new(File::open("/etc/hosts").unwrap()).lines()
parse(do_some_other_thing_or_nothing(lines))
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
...
Hint
本書類型系統中的幾個常見 trait章節中介紹的 AsRef, Borrow 等 trait 應該能派上用場.
所有權系統
概述
所有權系統(Ownership System)是Rust語言最基本最獨特也是最重要的特性之一。
Rust追求的目標是內存安全與運行效率,但是它卻沒有golang, java, python等語言的內存垃圾回收機制GC。
Rust語言號稱,只要編譯通過就不會崩潰(內存安全);擁有著零或者極小的運行時開銷(運行效率)。這些優點也都得益於Rust的所有權系統。
所有權系統,包括三個重要的組成部分:
- Ownership(所有權)
- Borrowing(借用)
- Lifetimes(生命週期)
這三個特性之間相互關聯,後面章節會依次全面講解。
提示: Rust的所有權系統對很多初學者來說,可能會覺得難以理解,Rust的內存檢查是在編譯階段完成,這個檢查是非常嚴謹的,所以初學者在編譯代碼的時候,剛開始可能很難一次編譯通過。
不過不要害怕:),當你一旦瞭解熟悉它後你會喜歡上它,並且在日後的編程中受益頗多。所有權系統需要讀者慢慢體會其中的奧秘,學習過程中也可以參考官方文檔。
所有權(Ownership)
在進入正題之前,大家先回憶下一般的編程語言知識。 對於一般的編程語言,通常會先聲明一個變量,然後初始化它。 例如在C語言中:
int* foo() {
int a; // 變量a的作用域開始
a = 100;
char *c = "xyz"; // 變量c的作用域開始
return &a;
} // 變量a和c的作用域結束
儘管可以編譯通過,但這是一段非常糟糕的代碼,現實中我相信大家都不會這麼去寫。變量a和c都是局部變量,函數結束後將局部變量a的地址返回,但局部變量a存在stack中,在離開作用域後,局部變量所申請的stack上內存都會被系統回收,從而造成了Dangling Pointer的問題。這是一個非常典型的內存安全問題。很多編程語言都存在類似這樣的內存安全問題。再來看變量c,c的值是常量字符串,存儲於常量區,可能這個函數我們只調用了一次,我們可能不再想使用這個字符串,但xyz只有當整個程序結束後系統才能回收這片內存,這點讓程序員是不是也很無奈?
備註:對於
xyz,可根據實際情況,通過heap的方式,手動管理(申請和釋放)內存。
所以,內存安全和內存管理通常是程序員眼中的兩大頭疼問題。令人興奮的是,Rust卻不再讓你擔心內存安全問題,也不用再操心內存管理的麻煩,那Rust是如何做到這一點的?請往下看。
綁定(Binding)
重要:首先必須強調下,準確地說Rust中並沒有變量這一概念,而應該稱為標識符,目標資源(內存,存放value)綁定到這個標識符:
#![allow(unused)] fn main() { { let x: i32; // 標識符x, 沒有綁定任何資源 let y: i32 = 100; // 標識符y,綁定資源100 } }
好了,我們繼續看下以下一段Rust代碼:
#![allow(unused)] fn main() { { let a: i32; println!("{}", a); } }
上面定義了一個i32類型的標識符a,如果你直接println!,你會收到一個error報錯:
error: use of possibly uninitialized variable:
a
這是因為Rust並不會像其他語言一樣可以為變量默認初始化值,Rust明確規定變量的初始值必須由程序員自己決定。
正確的做法:
#![allow(unused)] fn main() { { let a: i32; a = 100; //必須初始化a println!("{}", a); } }
其實,let關鍵字並不只是聲明變量的意思,它還有一層特殊且重要的概念-綁定。通俗的講,let關鍵字可以把一個標識符和一段內存區域做“綁定”,綁定後,這段內存就被這個標識符所擁有,這個標識符也成為這段內存的唯一所有者。
所以,a = 100發生了這麼幾個動作,首先在stack內存上分配一個i32的資源,並填充值100,隨後,把這個資源與a做綁定,讓a成為資源的所有者(Owner)。
作用域
像C語言一樣,Rust通過{}大括號定義作用域:
#![allow(unused)] fn main() { { { let a: i32 = 100; } println!("{}", a); } }
編譯後會得到如下error錯誤:
b.rs:3:20: 3:21 error: unresolved name
a[E0425] b.rs:3 println!("{}", a);
像C語言一樣,在局部變量離開作用域後,變量隨即會被銷燬;但不同是,Rust會連同變量綁定的內存,不管是否為常量字符串,連同所有者變量一起被銷燬釋放。所以上面的例子,a銷燬後再次訪問a就會提示無法找到變量a的錯誤。這些所有的一切都是在編譯過程中完成的。
移動語義(move)
先看如下代碼:
#![allow(unused)] fn main() { { let a: String = String::from("xyz"); let b = a; println!("{}", a); } }
編譯後會得到如下的報錯:
c.rs:4:20: 4:21 error: use of moved value:
a[E0382] c.rs:4 println!("{}", a);
錯誤的意思是在println中訪問了被moved的變量a。那為什麼會有這種報錯呢?具體含義是什麼?
在Rust中,和“綁定”概念相輔相成的另一個機制就是“轉移move所有權”,意思是,可以把資源的所有權(ownership)從一個綁定轉移(move)成另一個綁定,這個操作同樣通過let關鍵字完成,和綁定不同的是,=兩邊的左值和右值均為兩個標識符:
#![allow(unused)] fn main() { 語法: let 標識符A = 標識符B; // 把“B”綁定資源的所有權轉移給“A” }
move前後的內存示意如下:
Before move:
a <=> 內存(地址:A,內容:"xyz")
After move:
a
b <=> 內存(地址:A,內容:"xyz")
被move的變量不可以繼續被使用。否則提示錯誤error: use of moved value。
這裡有些人可能會疑問,move後,如果變量A和變量B離開作用域,所對應的內存會不會造成“Double Free”的問題?答案是否定的,Rust規定,只有資源的所有者銷燬後才釋放內存,而無論這個資源是否被多次move,同一時刻只有一個owner,所以該資源的內存也只會被free一次。
通過這個機制,就保證了內存安全。是不是覺得很強大?
Copy特性
有讀者仿照“move”小節中的例子寫了下面一個例子,然後說“a被move後是可以訪問的”:
#![allow(unused)] fn main() { let a: i32 = 100; let b = a; println!("{}", a); }
編譯確實可以通過,輸出為100。這是為什麼呢,是不是跟move小節裡的結論相悖了?
其實不然,這其實是根據變量類型是否實現Copy特性決定的。對於實現Copy特性的變量,在move時會拷貝資源到新內存區域,並把新內存區域的資源binding為b。
Before move:
a <=> 內存(地址:A,內容:100)
After move:
a <=> 內存(地址:A,內容:100)
b <=> 內存(地址:B,內容:100)
move前後的a和b對應資源內存的地址不同。
在Rust中,基本數據類型(Primitive Types)均實現了Copy特性,包括i8, i16, i32, i64, usize, u8, u16, u32, u64, f32, f64, (), bool, char等等。其他支持Copy的數據類型可以參考官方文檔的Copy章節。
淺拷貝與深拷貝
前面例子中move String和i32用法的差異,其實和很多面向對象編程語言中“淺拷貝”和“深拷貝”的區別類似。對於基本數據類型來說,“深拷貝”和“淺拷貝“產生的效果相同。對於引用對象類型來說,”淺拷貝“更像僅僅拷貝了對象的內存地址。
如果我們想實現對String的”深拷貝“怎麼辦? 可以直接調用String的Clone特性實現對內存的值拷貝而不是簡單的地址拷貝。
#![allow(unused)] fn main() { { let a: String = String::from("xyz"); let b = a.clone(); // <-注意此處的clone println!("{}", a); } }
這個時候可以編譯通過,並且成功打印"xyz"。
clone後的效果等同如下:
Before move:
a <=> 內存(地址:A,內容:"xyz")
After move:
a <=> 內存(地址:A,內容:"xyz")
b <=> 內存(地址:B,內容:"xyz")
注意,然後a和b對應的資源值相同,但是內存地址並不一樣。
可變性
通過上面,我們已經已經瞭解了變量聲明、值綁定、以及移動move語義等等相關知識,但是還沒有進行過修改變量值這麼簡單的操作,在其他語言中看似簡單到不值得一提的事卻在Rust中暗藏玄機。 按照其他編程語言思維,修改一個變量的值:
#![allow(unused)] fn main() { let a: i32 = 100; a = 200; }
很抱歉,這麼簡單的操作依然還會報錯:
error: re-assignment of immutable variable
a[E0384]:3 a = 200;
不能對不可變綁定賦值。如果要修改值,必須用關鍵字mut聲明綁定為可變的:
#![allow(unused)] fn main() { let mut a: i32 = 100; // 通過關鍵字mut聲明a是可變的 a = 200; }
想到“不可變”我們第一時間想到了const常量,但不可變綁定與const常量是完全不同的兩種概念;首先,“不可變”準確地應該稱為“不可變綁定”,是用來約束綁定行為的,“不可變綁定”後不能通過原“所有者”更改資源內容。
例如:
#![allow(unused)] fn main() { let a = vec![1, 2, 3]; //不可變綁定, a <=> 內存區域A(1,2,3) let mut a = a; //可變綁定, a <=> 內存區域A(1,2,3), 注意此a已非上句a,只是名字一樣而已 a.push(4); println!("{:?}", a); //打印:[1, 2, 3, 4] }
“可變綁定”後,目標內存還是同一塊,只不過,可以通過新綁定的a去修改這片內存了。
#![allow(unused)] fn main() { let mut a: &str = "abc"; //可變綁定, a <=> 內存區域A("abc") a = "xyz"; //綁定到另一內存區域, a <=> 內存區域B("xyz") println!("{:?}", a); //打印:"xyz" }
上面這種情況不要混淆了,a = "xyz"表示a綁定目標資源發生了變化。
其實,Rust中也有const常量,常量不存在“綁定”之說,和其他語言的常量含義相同:
#![allow(unused)] fn main() { const PI:f32 = 3.14; }
可變性的目的就是嚴格區分綁定的可變性,以便編譯器可以更好的優化,也提高了內存安全性。
高級Copy特性
在前面的小節有簡單瞭解Copy特性,接下來我們來深入瞭解下這個特性。 Copy特性定義在標準庫std::marker::Copy中:
#![allow(unused)] fn main() { pub trait Copy: Clone { } }
一旦一種類型實現了Copy特性,這就意味著這種類型可以通過的簡單的位(bits)拷貝實現拷貝。從前面知識我們知道“綁定”存在move語義(所有權轉移),但是,一旦這種類型實現了Copy特性,會先拷貝內容到新內存區域,然後把新內存區域和這個標識符做綁定。
哪些情況下我們自定義的類型(如某個Struct等)可以實現Copy特性? 只要這種類型的屬性類型都實現了Copy特性,那麼這個類型就可以實現Copy特性。 例如:
#![allow(unused)] fn main() { struct Foo { //可實現Copy特性 a: i32, b: bool, } struct Bar { //不可實現Copy特性 l: Vec<i32>, } }
因為Foo的屬性a和b的類型i32和bool均實現了Copy特性,所以Foo也是可以實現Copy特性的。但對於Bar來說,它的屬性l是Vec<T>類型,這種類型並沒有實現Copy特性,所以Bar也是無法實現Copy特性的。
那麼我們如何來實現Copy特性呢?
有兩種方式可以實現。
-
通過
derive讓Rust編譯器自動實現#![allow(unused)] fn main() { #[derive(Copy, Clone)] struct Foo { a: i32, b: bool, } }編譯器會自動檢查
Foo的所有屬性是否實現了Copy特性,一旦檢查通過,便會為Foo自動實現Copy特性。 -
手動實現
Clone和Copytrait#[derive(Debug)] struct Foo { a: i32, b: bool, } impl Copy for Foo {} impl Clone for Foo { fn clone(&self) -> Foo { Foo{a: self.a, b: self.b} } } fn main() { let x = Foo{ a: 100, b: true}; let mut y = x; y.b = false; println!("{:?}", x); //打印:Foo { a: 100, b: true } println!("{:?}", y); //打印:Foo { a: 100, b: false } }從結果我們發現
let mut y = x後,x並沒有因為所有權move而出現不可訪問錯誤。 因為Foo繼承了Copy特性和Clone特性,所以例子中我們實現了這兩個特性。
高級move
我們從前面的小節瞭解到,let綁定會發生所有權轉移的情況,但ownership轉移卻因為資源類型是否實現Copy特性而行為不同:
#![allow(unused)] fn main() { let x: T = something; let y = x; }
- 類型
T沒有實現Copy特性:x所有權轉移到y。 - 類型
T實現了Copy特性:拷貝x所綁定的資源為新資源,並把新資源的所有權綁定給y,x依然擁有原資源的所有權。
move關鍵字
move關鍵字常用在閉包中,強制閉包獲取所有權。
例子1:
fn main() { let x: i32 = 100; let some_closure = move |i: i32| i + x; let y = some_closure(2); println!("x={}, y={}", x, y); }
結果: x=100, y=102
注意: 例子1是比較特別的,使不使用 move 對結果都沒什麼影響,因為x綁定的資源是i32類型,屬於 primitive type,實現了 Copy trait,所以在閉包使用 move 的時候,是先 copy 了x ,在 move 的時候是 move 了這份 clone 的 x,所以後面的 println!引用 x 的時候沒有報錯。
例子2:
fn main() { let mut x: String = String::from("abc"); let mut some_closure = move |c: char| x.push(c); let y = some_closure('d'); println!("x={:?}", x); }
報錯: error: use of moved value:
x[E0382]:5 println!("x={:?}", x);
這是因為move關鍵字,會把閉包中的外部變量的所有權move到包體內,發生了所有權轉移的問題,所以println訪問x會如上錯誤。如果我們去掉println就可以編譯通過。
那麼,如果我們想在包體外依然訪問x,即x不失去所有權,怎麼辦?
fn main() { let mut x: String = String::from("abc"); { let mut some_closure = |c: char| x.push(c); some_closure('d'); } println!("x={:?}", x); //成功打印:x="abcd" }
我們只是去掉了move,去掉move後,包體內就會對x進行了可變借用,而不是“剝奪”x的所有權,細心的同學還注意到我們在前後還加了{}大括號作用域,是為了作用域結束後讓可變借用失效,這樣println才可以成功訪問並打印我們期待的內容。
關於“Borrowing借用”知識我們會在下一個大節中詳細講解。
引用&借用(References&Borrowing)
如上所示,Owership讓我們改變一個變量的值變得“複雜”,那能否像其他編程語言那樣隨意改變變量的值呢?答案是有的。
所有權系統允許我們通過“Borrowing”的方式達到這個目的。這個機制非常像其他編程語言中的“讀寫鎖”,即同一時刻,只能擁有一個“寫鎖”,或只能擁有多個“讀鎖”,不允許“寫鎖”和“讀鎖”在同一時刻同時出現。當然這也是數據讀寫過程中保障一致性的典型做法。只不過Rust是在編譯中完成這個(Borrowing)檢查的,而不是在運行時,這也就是為什麼其他語言程序在運行過程中,容易出現死鎖或者野指針的問題。
通過**&**符號完成Borrowing:
fn main() { let x: Vec<i32> = vec!(1i32, 2, 3); let y = &x; println!("x={:?}, y={:?}", x, y); }
Borrowing(&x)並不會發生所有權moved,所以println可以同時訪問x和y。 通過引用,就可以對普通類型完成修改。
fn main() { let mut x: i32 = 100; { let y: &mut i32 = &mut x; *y += 2; } println!("{}", x); }
###借用與引用的區別
借用與引用是一種相輔相成的關係,若B是對A的引用,也可稱之為B借用了A。
很相近對吧,但是借用一詞本意為要歸還。所以在Rust用引用時,一定要注意應該在何處何時正確的“歸回”借用/引用。 最後面的“高級”小節會詳細舉例。
###規則
- 同一作用域,特定數據最多隻有一個可變借用(&mut T),或者2。
- 同一作用域,特定數據可有0個或多個不可變借用(&T),但不能有任何可變借用。
- 借用在離開作用域後釋放。
- 在可變借用釋放前不可訪問源變量。
###可變性 Borrowing也分“不可變借用”(默認,&T)和“可變借用”(&mut T)。
顧名思義,“不可變借用”是隻讀的,不可更新被引用的內容。
fn main() { let x: Vec<i32> = vec!(1i32, 2, 3); //可同時有多個不可變借用 let y = &x; let z = &x; let m = &x; //ok println!("{:?}, {:?}, {:?}, {:?}", x, y, z, m); }
再次強調下,同一作用域下只能有一個可變借用(&mut T),且被借用的變量本身必須有可變性 :
fn main() { //源變量x可變性 let mut x: Vec<i32> = vec!(1i32, 2, 3); //只能有一個可變借用 let y = &mut x; // let z = &mut x; //錯誤 y.push(100); //ok println!("{:?}", y); //錯誤,可變借用未釋放,源變量不可訪問 // println!("{:?}", x); } //y在此處銷燬
###高級例子 下面的複雜例子,進行了詳細的註釋,即使看不懂也沒關係,可以在完成Lifetimes(生命週期)的學習後再仔細思考本例子。
fn main() { let mut x: Vec<i32> = vec!(1i32, 2, 3); //更新數組 //push中對數組進行了可變借用,並在push函數退出時銷燬這個借用 x.push(10); { //可變借用1 let mut y = &mut x; y.push(100); //可變借用2,注意:此處是對y的借用,不可再對x進行借用, //因為y在此時依然存活。 let z = &mut y; z.push(1000); println!("{:?}", z); //打印: [1, 2, 3, 10, 100, 1000] } //y和z在此處被銷燬,並釋放借用。 //訪問x正常 println!("{:?}", x); //打印: [1, 2, 3, 10, 100, 1000] }
####總結
- 借用不改變內存的所有者(Owner),借用只是對源內存的臨時引用。
- 在借用週期內,借用方可以讀寫這塊內存,所有者被禁止讀寫內存;且所有者保證在有“借用”存在的情況下,不會釋放或轉移內存。
- 失去所有權的變量不可以被借用(訪問)。
- 在租借期內,內存所有者保證不會釋放/轉移/可變租借這塊內存,但如果是在非可變租借的情況下,所有者是允許繼續非可變租借出去的。
- 借用週期滿後,所有者收回讀寫權限
- 借用週期小於被借用者(所有者)的生命週期。
備註: 借用週期,指的是借用的有效時間段。
生命週期( Lifetime )
下面是一個資源借用的例子:
fn main() { let a = 100_i32; { let x = &a; } // x 作用域結束 println!("{}", x); }
編譯時,我們會看到一個嚴重的錯誤提示:
error: unresolved name
x.
錯誤的意思是“無法解析 x 標識符”,也就是找不到 x , 這是因為像很多編程語言一樣,Rust中也存在作用域概念,當資源離開離開作用域後,資源的內存就會被釋放回收,當借用/引用離開作用域後也會被銷燬,所以 x 在離開自己的作用域後,無法在作用域之外訪問。
上面的涉及到幾個概念:
- Owner: 資源的所有者
a - Borrower: 資源的借用者
x - Scope: 作用域,資源被借用/引用的有效期
強調下,無論是資源的所有者還是資源的借用/引用,都存在在一個有效的存活時間或區間,這個時間區間稱為生命週期, 也可以直接以Scope作用域去理解。
所以上例子代碼中的生命週期/作用域圖示如下:
{ a { x } * }
所有者 a: |________________________|
借用者 x: |____| x = &a
訪問 x: | 失敗:訪問 x
可以看到,借用者 x 的生命週期是資源所有者 a 的生命週期的子集。但是 x 的生命週期在第一個 } 時結束並銷燬,在接下來的 println! 中再次訪問便會發生嚴重的錯誤。
我們來修正上面的例子:
fn main() { let a = 100_i32; { let x = &a; println!("{}", x); } // x 作用域結束 }
這裡我們僅僅把 println! 放到了中間的 {}, 這樣就可以在 x的生命週期內正常的訪問 x ,此時的Lifetime圖示如下:
{ a { x * } }
所有者 a: |________________________|
借用者 x: |_________| x = &a
訪問 x: | OK:訪問 x
隱式Lifetime
我們經常會遇到參數或者返回值為引用類型的函數:
#![allow(unused)] fn main() { fn foo(x: &str) -> &str { x } }
上面函數在實際應用中並沒有太多用處,foo 函數僅僅接受一個 &str 類型的參數(x為對某個string類型資源Something的借用),並返回對資源Something的一個新的借用。
實際上,上面函數包含該了隱性的生命週期命名,這是由編譯器自動推導的,相當於:
#![allow(unused)] fn main() { fn foo<'a>(x: &'a str) -> &'a str { x } }
在這裡,約束返回值的Lifetime必須大於或等於參數x的Lifetime。下面函數寫法也是合法的:
#![allow(unused)] fn main() { fn foo<'a>(x: &'a str) -> &'a str { "hello, world!" } }
為什麼呢?這是因為字符串"hello, world!"的類型是&'static str,我們知道static類型的Lifetime是整個程序的運行週期,所以她比任意傳入的參數的Lifetime'a都要長,即'static >= 'a滿足。
在上例中Rust可以自動推導Lifetime,所以並不需要程序員顯式指定Lifetime 'a 。
'a是什麼呢?它是Lifetime的標識符,這裡的a也可以用b、c、d、e、...,甚至可以用this_is_a_long_name等,當然實際編程中並不建議用這種冗長的標識符,這樣會嚴重降低程序的可讀性。foo後面的<'a>為Lifetime的聲明,可以聲明多個,如<'a, 'b>等等。
另外,除非編譯器無法自動推導出Lifetime,否則不建議顯式指定Lifetime標識符,會降低程序的可讀性。
顯式Lifetime
當輸入參數為多個借用/引用時會發生什麼呢?
#![allow(unused)] fn main() { fn foo(x: &str, y: &str) -> &str { if true { x } else { y } } }
這時候再編譯,就沒那麼幸運了:
error: missing lifetime specifier [E0106]
fn foo(x: &str, y: &str) -> &str {
^~~~
編譯器告訴我們,需要我們顯式指定Lifetime標識符,因為這個時候,編譯器無法推導出返回值的Lifetime應該是比 x長,還是比y長。雖然我們在函數中中用了 if true 確認一定可以返回x,但是要知道,編譯器是在編譯時候檢查,而不是運行時,所以編譯期間會同時檢查所有的輸入參數和返回值。
修復後的代碼如下:
#![allow(unused)] fn main() { fn foo<'a>(x: &'a str, y: &'a str) -> &'a str { if true { x } else { y } } }
Lifetime推導
要推導Lifetime是否合法,先明確兩點:
- 輸出值(也稱為返回值)依賴哪些輸入值
- 輸入值的Lifetime大於或等於輸出值的Lifetime (準確來說:子集,而不是大於或等於)
Lifetime推導公式: 當輸出值R依賴輸入值X Y Z ...,當且僅當輸出值的Lifetime為所有輸入值的Lifetime交集的子集時,生命週期合法。
Lifetime(R) ⊆ ( Lifetime(X) ∩ Lifetime(Y) ∩ Lifetime(Z) ∩ Lifetime(...) )
對於例子1:
#![allow(unused)] fn main() { fn foo<'a>(x: &'a str, y: &'a str) -> &'a str { if true { x } else { y } } }
因為返回值同時依賴輸入參數x和y,所以
Lifetime(返回值) ⊆ ( Lifetime(x) ∩ Lifetime(y) )
即:
'a ⊆ ('a ∩ 'a) // 成立
定義多個Lifetime標識符
那我們繼續看個更復雜的例子,定義多個Lifetime標識符:
#![allow(unused)] fn main() { fn foo<'a, 'b>(x: &'a str, y: &'b str) -> &'a str { if true { x } else { y } } }
先看下編譯,又報錯了:
<anon>:5:3: 5:4 error: cannot infer an appropriate lifetime for automatic coercion due to conflicting requirements [E0495]
<anon>:5 y
^
<anon>:1:1: 7:2 help: consider using an explicit lifetime parameter as shown: fn foo<'a>(x: &'a str, y: &'a str) -> &'a str
<anon>:1 fn bar<'a, 'b>(x: &'a str, y: &'b str) -> &'a str {
<anon>:2 if true {
<anon>:3 x
<anon>:4 } else {
<anon>:5 y
<anon>:6 }
編譯器說自己無法正確地推導返回值的Lifetime,讀者可能會疑問,“我們不是已經指定返回值的Lifetime為'a了嗎?"。
這兒我們同樣可以通過生命週期推導公式推導:
因為返回值同時依賴x和y,所以
Lifetime(返回值) ⊆ ( Lifetime(x) ∩ Lifetime(y) )
即:
'a ⊆ ('a ∩ 'b) //不成立
很顯然,上面我們根本沒法保證成立。
所以,這種情況下,我們可以顯式地告訴編譯器'b比'a長('a是'b的子集),只需要在定義Lifetime的時候, 在'b的後面加上: 'a, 意思是'b比'a長,'a是'b的子集:
fn foo<'a, 'b: 'a>(x: &'a str, y: &'b str) -> &'a str {
if true {
x
} else {
y
}
}
這裡我們根據公式繼續推導:
條件:Lifetime(x) ⊆ Lifetime(y)
推導:Lifetime(返回值) ⊆ ( Lifetime(x) ∩ Lifetime(y) )
即:
條件: 'a ⊆ 'b
推導:'a ⊆ ('a ∩ 'b) // 成立
上面是成立的,所以可以編譯通過。
推導總結
通過上面的學習相信大家可以很輕鬆完成Lifetime的推導,總之,記住兩點:
- 輸出值依賴哪些輸入值。
- 推導公式。
Lifetime in struct
上面我們更多討論了函數中Lifetime的應用,在struct中Lifetime同樣重要。
我們來定義一個Person結構體:
#![allow(unused)] fn main() { struct Person { age: &u8, } }
編譯時我們會得到一個error:
<anon>:2:8: 2:12 error: missing lifetime specifier [E0106]
<anon>:2 age: &str,
之所以會報錯,這是因為Rust要確保Person的Lifetime不會比它的age借用長,不然會出現Dangling Pointer的嚴重內存問題。所以我們需要為age借用聲明Lifetime:
#![allow(unused)] fn main() { struct Person<'a> { age: &'a u8, } }
不需要對Person後面的<'a>感到疑惑,這裡的'a並不是指Person這個struct的Lifetime,僅僅是一個泛型參數而已,struct可以有多個Lifetime參數用來約束不同的field,實際的Lifetime應該是所有fieldLifetime交集的子集。例如:
fn main() {
let x = 20_u8;
let stormgbs = Person {
age: &x,
};
}
這裡,生命週期/Scope的示意圖如下:
{ x stormgbs * }
所有者 x: |________________________|
所有者 stormgbs: |_______________| 'a
借用者 stormgbs.age: |_______________| stormgbs.age = &x
既然<'a>作為Person的泛型參數,所以在為Person實現方法時也需要加上<'a>,不然:
#![allow(unused)] fn main() { impl Person { fn print_age(&self) { println!("Person.age = {}", self.age); } } }
報錯:
<anon>:5:6: 5:12 error: wrong number of lifetime parameters: expected 1, found 0 [E0107]
<anon>:5 impl Person {
^~~~~~
正確的做法是:
#![allow(unused)] fn main() { impl<'a> Person<'a> { fn print_age(&self) { println!("Person.age = {}", self.age); } } }
這樣加上<'a>後就可以了。讀者可能會疑問,為什麼print_age中不需要加上'a?這是個好問題。因為print_age的輸出參數為(),也就是可以不依賴任何輸入參數, 所以編譯器此時可以不必關心和推導Lifetime。即使是fn print_age(&self, other_age: &i32) {...}也可以編譯通過。
如果Person的方法存在輸出值(借用)呢?
#![allow(unused)] fn main() { impl<'a> Person<'a> { fn get_age(&self) -> &u8 { self.age } } }
get_age方法的輸出值依賴一個輸入值&self,這種情況下,Rust編譯器可以自動推導為:
#![allow(unused)] fn main() { impl<'a> Person<'a> { fn get_age(&'a self) -> &'a u8 { self.age } } }
如果輸出值(借用)依賴了多個輸入值呢?
#![allow(unused)] fn main() { impl<'a, 'b> Person<'a> { fn get_max_age(&'a self, p: &'a Person) -> &'a u8 { if self.age > p.age { self.age } else { p.age } } } }
類似之前的Lifetime推導章節,當返回值(借用)依賴多個輸入值時,需顯示聲明Lifetime。和函數Lifetime同理。
其他
無論在函數還是在struct中,甚至在enum中,Lifetime理論知識都是一樣的。希望大家可以慢慢體會和吸收,做到舉一反三。
總結
Rust正是通過所有權、借用以及生命週期,以高效、安全的方式近乎完美地管理了內存。沒有手動管理內存的負載和安全性,也沒有GC造成的程序暫停問題。
閉包
閉包是什麼?先來看看維基百科上的描述:
在計算機科學中,閉包(英語:Closure),又稱詞法閉包(Lexical Closure)或函數閉包(function closures),是 引用了自由變量的函數。這個被引用的自由變量將和這個函數一同存在,即使已經離開了創造它的環境也不例外。所以,有另一種說法認為閉包是由函數和與其相關的引用環境組合而成的實體。閉包在運行時可以有多個實例,不同的引用環境和相同的函數組合可以產生不同的實例。
閉包的概念出現於60年代,最早實現閉包的程序語言是Scheme。之後,閉包被廣泛使用於函數式編程語言如ML語言和LISP。很多命令式程序語言也開始支持閉包。
可以看到,第一句就已經說明了什麼是閉包:閉包是引用了自由變量的函數。所以,閉包是一種特殊的函數。
在rust中,函數和閉包都是實現了Fn、FnMut或FnOnce特質(trait)的類型。任何實現了這三種特質其中一種的類型的對象,都是 可調用對象 ,都能像函數和閉包一樣通過這樣name()的形式調用,()在rust中是一個操作符,操作符在rust中是可以重載的。rust的操作符重載是通過實現相應的trait來實現,而()操作符的相應trait就是Fn、FnMut和FnOnce,所以,任何實現了這三個trait中的一種的類型,其實就是重載了()操作符。關於Fn、FnMut和FnOnce的說明請看第二節閉包的實現。
本章主要分四節講述:
閉包的語法
基本形式
閉包看起來像這樣:
#![allow(unused)] fn main() { let plus_one = |x: i32| x + 1; assert_eq!(2, plus_one(1)); }
我們創建了一個綁定,plus_one,並把它賦予一個閉包。閉包的參數位於管道(|)之中,而閉包體是一個表達式,在這個例子中,x + 1。記住{}是一個表達式,所以我們也可以擁有包含多行的閉包:
#![allow(unused)] fn main() { let plus_two = |x| { let mut result: i32 = x; result += 1; result += 1; result }; assert_eq!(4, plus_two(2)); }
你會注意到閉包的一些方面與用fn定義的常規函數有點不同。第一個是我們並不需要標明閉包接收和返回參數的類型。我們可以:
#![allow(unused)] fn main() { let plus_one = |x: i32| -> i32 { x + 1 }; assert_eq!(2, plus_one(1)); }
不過我們並不需要這麼寫。為什麼呢?基本上,這是出於“人體工程學”的原因。因為為命名函數指定全部類型有助於像文檔和類型推斷,而閉包的類型則很少有文檔因為它們是匿名的,並且並不會產生像推斷一個命名函數的類型這樣的“遠距離錯誤”。
第二個的語法大同小異。我會增加空格來使它們看起來更像一點:
#![allow(unused)] fn main() { fn plus_one_v1 (x: i32) -> i32 { x + 1 } let plus_one_v2 = |x: i32| -> i32 { x + 1 }; let plus_one_v3 = |x: i32| x + 1 ; }
捕獲變量
之所以把它稱為“閉包”是因為它們“包含在環境中”(close over their environment)。這看起來像:
#![allow(unused)] fn main() { let num = 5; let plus_num = |x: i32| x + num; assert_eq!(10, plus_num(5)); }
這個閉包,plus_num,引用了它作用域中的let綁定:num。更明確的說,它借用了綁定。如果我們做一些會與這個綁定衝突的事,我們會得到一個錯誤。比如這個:
#![allow(unused)] fn main() { let mut num = 5; let plus_num = |x: i32| x + num; let y = &mut num; }
錯誤是:
error: cannot borrow `num` as mutable because it is also borrowed as immutable
let y = &mut num;
^~~
note: previous borrow of `num` occurs here due to use in closure; the immutable
borrow prevents subsequent moves or mutable borrows of `num` until the borrow
ends
let plus_num = |x| x + num;
^~~~~~~~~~~
note: previous borrow ends here
fn main() {
let mut num = 5;
let plus_num = |x| x + num;
let y = &mut num;
}
^
一個囉嗦但有用的錯誤信息!如它所說,我們不能取得一個num的可變借用因為閉包已經借用了它。如果我們讓閉包離開作用域,我們可以:
#![allow(unused)] fn main() { let mut num = 5; { let plus_num = |x: i32| x + num; } // plus_num goes out of scope, borrow of num ends let y = &mut num; }
如果你的閉包需要它,Rust會取得所有權並移動環境:
#![allow(unused)] fn main() { let nums = vec![1, 2, 3]; let takes_nums = || nums; println!("{:?}", nums); }
這會給我們:
note: `nums` moved into closure environment here because it has type
`[closure(()) -> collections::vec::Vec<i32>]`, which is non-copyable
let takes_nums = || nums;
^~~~~~~
Vec<T>擁有它內容的所有權,而且由於這個原因,當我們在閉包中引用它時,我們必須取得nums的所有權。這與我們傳遞nums給一個取得它所有權的函數一樣。
move閉包
我們可以使用move關鍵字強制使我們的閉包取得它環境的所有權:
#![allow(unused)] fn main() { let num = 5; let owns_num = move |x: i32| x + num; }
現在,即便關鍵字是move,變量遵循正常的移動語義。在這個例子中,5實現了Copy,所以owns_num取得一個5的拷貝的所有權。那麼區別是什麼呢?
#![allow(unused)] fn main() { let mut num = 5; { let mut add_num = |x: i32| num += x; add_num(5); } assert_eq!(10, num); }
那麼在這個例子中,我們的閉包取得了一個num的可變引用,然後接著我們調用了add_num,它改變了其中的值,正如我們期望的。我們也需要將add_num聲明為mut,因為我們會改變它的環境。
如果我們加上move修飾閉包,會發生些不同:
#![allow(unused)] fn main() { let mut num = 5; { let mut add_num = move |x: i32| num += x; add_num(5); } assert_eq!(5, num); }
我們只會得到5。這次我們沒有獲取到外部的num的可變借用,我們實際上是把 num move 進了閉包。因為 num 具有 Copy 屬性,因此發生 move 之後,以前的變量生命週期並未結束,還可以繼續在 assert_eq! 中使用。我們打印的變量和閉包內的變量是獨立的兩個變量。如果我們捕獲的環境變量不是 Copy 的,那麼外部環境變量被 move 進閉包後,
它就不能繼續在原先的函數中使用了,只能在閉包內使用。
不過在我們討論獲取或返回閉包之前,我們應該更多的瞭解一下閉包實現的方法。作為一個系統語言,Rust給予你了大量的控制你代碼的能力,而閉包也是一樣。
這部分引用自The Rust Programming Language中文版
閉包的實現
Rust 的閉包實現與其它語言有些許不同。它們實際上是trait的語法糖。在這以前你會希望閱讀trait章節,和trait對象。
都理解嗎?很好。
理解閉包底層是如何工作的關鍵有點奇怪:使用()調用函數,像foo(),是一個可重載的運算符。到此,其它的一切都會明瞭。在Rust中,我們使用trait系統來重載運算符。調用函數也不例外。我們有三個trait來分別重載:
#![allow(unused)] fn main() { mod foo { pub trait Fn<Args> : FnMut<Args> { extern "rust-call" fn call(&self, args: Args) -> Self::Output; } pub trait FnMut<Args> : FnOnce<Args> { extern "rust-call" fn call_mut(&mut self, args: Args) -> Self::Output; } pub trait FnOnce<Args> { type Output; extern "rust-call" fn call_once(self, args: Args) -> Self::Output; } } }
你會注意到這些 trait 之間的些許區別,不過一個大的區別是self:Fn獲取&self,FnMut獲取&mut self,而FnOnce獲取self。這包含了所有3種通過通常函數調用語法的self。不過我們將它們分在 3 個 trait 裡,而不是單獨的 1 個。這給了我們大量的對於我們可以使用哪種閉包的控制。
閉包的|| {}語法是上面 3 個 trait 的語法糖。Rust 將會為了環境創建一個結構體,impl合適的 trait,並使用它。
這部分引用自The Rust Programming Language中文版
閉包作為參數和返回值
閉包作為參數(Taking closures as arguments)
現在我們知道了閉包是 trait,我們已經知道了如何接受和返回閉包;就像任何其它的 trait!
這也意味著我們也可以選擇靜態或動態分發。首先,讓我們寫一個獲取可調用結構的函數,調用它,然後返回結果:
#![allow(unused)] fn main() { fn call_with_one<F>(some_closure: F) -> i32 where F : Fn(i32) -> i32 { some_closure(1) } let answer = call_with_one(|x| x + 2); assert_eq!(3, answer); }
我們傳遞我們的閉包,|x| x + 2,給call_with_one。它正做了我們說的:它調用了閉包,1作為參數。
讓我們更深層的解析call_with_one的簽名:
#![allow(unused)] fn main() { fn call_with_one<F>(some_closure: F) -> i32 where F : Fn(i32) -> i32 { some_closure(1) } }
我們獲取一個參數,而它有類型F。我們也返回一個i32。這一部分並不有趣。下一部分是:
#![allow(unused)] fn main() { fn call_with_one<F>(some_closure: F) -> i32 where F : Fn(i32) -> i32 { some_closure(1) } }
因為Fn是一個trait,我們可以用它限制我們的泛型。在這個例子中,我們的閉包取得一個i32作為參數並返回i32,所以我們用泛型限制是Fn(i32) -> i32。
還有一個關鍵點在於:因為我們用一個trait限制泛型,它會是單態的,並且因此,我們在閉包中使用靜態分發。這是非常簡單的。在很多語言中,閉包固定在heap上分配,所以總是進行動態分發。在Rust中,我們可以在stack上分配我們閉包的環境,並靜態分發調用。這經常發生在迭代器和它們的適配器上,它們經常取得閉包作為參數。
當然,如果我們想要動態分發,我們也可以做到。trait對象處理這種情況,通常:
#![allow(unused)] fn main() { fn call_with_one(some_closure: &Fn(i32) -> i32) -> i32 { some_closure(1) } let answer = call_with_one(&|x| x + 2); assert_eq!(3, answer); }
現在我們取得一個trait對象,一個&Fn。並且當我們將我們的閉包傳遞給call_with_one時我們必須獲取一個引用,所以我們使用&||。
函數指針和閉包
一個函數指針有點像一個沒有環境的閉包。因此,你可以傳遞一個函數指針給任何函數除了作為閉包參數,下面的代碼可以工作:
#![allow(unused)] fn main() { fn call_with_one(some_closure: &Fn(i32) -> i32) -> i32 { some_closure(1) } fn add_one(i: i32) -> i32 { i + 1 } let f = add_one; let answer = call_with_one(&f); assert_eq!(2, answer); }
在這個例子中,我們並不是嚴格的需要這個中間變量f,函數的名字就可以了:
#![allow(unused)] fn main() { let answer = call_with_one(&add_one); }
返回閉包(Returning closures)
對於函數式風格代碼來說在各種情況返回閉包是非常常見的。如果你嘗試返回一個閉包,你可能會得到一個錯誤。在剛接觸的時候,這看起來有點奇怪,不過我們會搞清楚。當你嘗試從函數返回一個閉包的時候,你可能會寫出類似這樣的代碼:
#![allow(unused)] fn main() { fn factory() -> (Fn(i32) -> i32) { let num = 5; |x| x + num } let f = factory(); let answer = f(1); assert_eq!(6, answer); }
編譯的時候會給出這一長串相關錯誤:
error: the trait `core::marker::Sized` is not implemented for the type
`core::ops::Fn(i32) -> i32` [E0277]
fn factory() -> (Fn(i32) -> i32) {
^~~~~~~~~~~~~~~~
note: `core::ops::Fn(i32) -> i32` does not have a constant size known at compile-time
fn factory() -> (Fn(i32) -> i32) {
^~~~~~~~~~~~~~~~
error: the trait `core::marker::Sized` is not implemented for the type `core::ops::Fn(i32) -> i32` [E0277]
let f = factory();
^
note: `core::ops::Fn(i32) -> i32` does not have a constant size known at compile-time
let f = factory();
^
為了從函數返回一些東西,Rust 需要知道返回類型的大小。不過Fn是一個 trait,它可以是各種大小(size)的任何東西。比如說,返回值可以是實現了Fn的任意類型。一個簡單的解決方法是:返回一個引用。因為引用的大小(size)是固定的,因此返回值的大小就固定了。因此我們可以這樣寫:
#![allow(unused)] fn main() { fn factory() -> &(Fn(i32) -> i32) { let num = 5; |x| x + num } let f = factory(); let answer = f(1); assert_eq!(6, answer); }
不過這樣會出現另外一個錯誤:
error: missing lifetime specifier [E0106]
fn factory() -> &(Fn(i32) -> i32) {
^~~~~~~~~~~~~~~~~
對。因為我們有一個引用,我們需要給它一個生命週期。不過我們的factory()函數不接收參數,所以省略不能用在這。我們可以使用什麼生命週期呢?'static:
#![allow(unused)] fn main() { fn factory() -> &'static (Fn(i32) -> i32) { let num = 5; |x| x + num } let f = factory(); let answer = f(1); assert_eq!(6, answer); }
不過這樣又會出現另一個錯誤:
error: mismatched types:
expected `&'static core::ops::Fn(i32) -> i32`,
found `[closure@<anon>:7:9: 7:20]`
(expected &-ptr,
found closure) [E0308]
|x| x + num
^~~~~~~~~~~
這個錯誤讓我們知道我們並沒有返回一個&'static Fn(i32) -> i32,而是返回了一個[closure <anon>:7:9: 7:20]。等等,什麼?
因為每個閉包生成了它自己的環境struct並實現了Fn和其它一些東西,這些類型是匿名的。它們只在這個閉包中存在。所以Rust把它們顯示為closure <anon>,而不是一些自動生成的名字。
這個錯誤也指出了返回值類型期望是一個引用,不過我們嘗試返回的不是。更進一步,我們並不能直接給一個對象'static聲明週期。所以我們換一個方法並通過Box裝箱Fn來返回一個 trait 對象。這個幾乎可以成功運行:
fn factory() -> Box<Fn(i32) -> i32> { let num = 5; Box::new(|x| x + num) } fn main() { let f = factory(); let answer = f(1); assert_eq!(6, answer); }
這還有最後一個問題:
error: closure may outlive the current function, but it borrows `num`,
which is owned by the current function [E0373]
Box::new(|x| x + num)
^~~~~~~~~~~
好吧,正如我們上面討論的,閉包借用他們的環境。而且在這個例子中。我們的環境基於一個stack分配的5,num變量綁定。所以這個借用有這個stack幀的生命週期。所以如果我們返回了這個閉包,這個函數調用將會結束,stack幀也將消失,那麼我們的閉包指向了被釋放的內存環境!再有最後一個修改,我們就可以讓它運行了:
fn factory() -> Box<Fn(i32) -> i32> { let num = 5; Box::new(move |x| x + num) } fn main() { let f = factory(); let answer = f(1); assert_eq!(6, answer); }
通過把內部閉包添加move關鍵字,我們強制閉包使用 move 的方式捕獲環境變量。因為這裡的 num 類型是 i32,實際上這裡的 move 執行的是 copy, 這樣一來,閉包就不再擁有指向環境的指針,而是完整擁有了被捕獲的變量。並允許它離開我們的stack幀。
這部分引用自The Rust Programming Language中文版
集合類型
就像C++的stl一樣,Rust提供了一系列的基礎且通用的容器類型。善用這些集合類型,可以讓Rust編程更加方便輕鬆,但每種數據結構都會有其侷限性,合理的選型方能維持更好的效率。
本章目錄:
動態數組Vec
在第七章我們粗略介紹了一下Vec的用法。實際上,作為Rust中一個非常重要的數據類型,熟練掌握Vec的用法能大大提升我們在Rust世界中的編碼能力。
特性及聲明方式
和我們之前接觸到的Array不同,Vec具有動態的添加和刪除元素的能力,並且能夠以O(1)的效率進行隨機訪問。同時,對其尾部進行push或者pop操作的效率也是平攤O(1)的。
同時,有一個非常重要的特性(雖然我們編程的時候大部分都不會考量它)就是,Vec的所有內容項都是生成在heap空間上的,也就是說,你可以輕易的將Vec move出一個stack而不用擔心內存拷貝影響執行效率——畢竟只是拷貝的stack上的指針。
另外的就是,Vec<T>中的泛型T必須是Sized的,也就是說必須在編譯的時候就知道存一個內容項需要多少內存。對於那些在編譯時候未知大小的項(函數類型等),我們可以用Box將其包裹,當成一個指針。
new
我們可以用std::vec::Vec::new()的方式來聲明一個Vec。
#![allow(unused)] fn main() { let mut v1: Vec<i32> = Vec::new(); }
這裡需要注意的是,new函數並沒有提供一個能顯式規定其泛型類型的參數,也就是說,上面的代碼能根據v1的類型自動推導出Vec的泛型;但是,你不能寫成如下的形式:
#![allow(unused)] fn main() { let mut v1 = Vec::new::<i32>(); // 與之對比的,collect函數就能指定: // let mut v2 = (0i32..5).collect::<Vec<i32>>(); }
這是因為這兩個函數的聲明形式以及實現形式,在此,我們不做深究。
宏聲明
相比調用new函數,Rust提供了一種更加直觀便捷的方式聲明一個動態數組: vec! 宏。
#![allow(unused)] fn main() { let v: Vec<i32> = vec![]; // 以下語句相當於: // let mut temp = Vec::new(); // temp.push(1); // temp.push(2); // temp.push(3); // let v = temp; let v = vec![1, 2, 3]; let v = vec![0; 10]; //注意分號,這句話聲明瞭一個 內容為10個0的動態數組 }
從迭代器生成
因為Vec實現了FromIterator這個trait,因此,藉助collect,我們能將任意一個迭代器轉換為Vec。
#![allow(unused)] fn main() { let v: Vec<_> = (1..5).collect(); }
訪問及修改
隨機訪問
就像數組一樣,因為Vec藉助Index和IndexMut提供了隨機訪問的能力,我們通過[index]來對其進行訪問,當然,既然存在隨機訪問就會出現越界的問題。而在Rust中,一旦越界的後果是極其嚴重的,可以導致Rust當前線程panic。因此,除非你確定自己在幹什麼或者在for循環中,不然我們不推薦通過下標訪問。
以下是例子:
#![allow(unused)] fn main() { let a = vec![1, 2, 3]; assert_eq!(a[1usize], 2); }
那麼,Rust中有沒有安全的下標訪問機制呢?答案是當然有:—— .get(n: usize) (.get_mut(n: usize)) 函數。
對於一個數組,這個函數返回一個Option<&T> (Option<&mut T>),當Option==None的時候,即下標越界,其他情況下,我們能安全的獲得一個Vec裡面元素的引用。
#![allow(unused)] fn main() { let v =vec![1, 2, 3]; assert_eq!(v.get(1), Some(&2)); assert_eq!(v.get(3), None); }
迭代器
對於一個可變數組,Rust提供了一種簡單的遍歷形式—— for 循環。 我們可以獲得一個數組的引用、可變引用、所有權。
#![allow(unused)] fn main() { let v = vec![1, 2, 3]; for i in &v { .. } // 獲得引用 for i in &mut v { .. } // 獲得可變引用 for i in v { .. } // 獲得所有權,注意此時Vec的屬主將會被轉移!! }
但是,這麼寫很容易出現多層for循環嵌套,因此,Vec提供了一個into_iter()方法,能顯式地將自己轉換成一個迭代器。然而迭代器怎麼用呢?我們下一章將會詳細說明。
push的效率研究
前面說到,Vec有兩個O(1)的方法,分別是pop和push,它們分別代表著將數據從尾部彈出或者裝入。理論上來說,因為Vec是支持隨機訪問的,因此push效率應該是一致的。但是實際上,因為Vec的內部存在著內存拷貝和銷燬,因此,如果你想要將一個數組,從零個元素開始,一個一個的填充直到最後生成一個非常巨大的數組的話,預先為其分配內存是一個非常好的辦法。
這其中,有個關鍵的方法是reserve。
如下代碼(注意:由於SystemTime API在1.8以後才穩定, 請使用1.8.0 stable 以及以上版本的rustc編譯):
use std::time; fn push_1m(v: &mut Vec<usize>, total: usize) { let e = time::SystemTime::now(); for i in 1..total { v.push(i); } let ed = time::SystemTime::now(); println!("time spend: {:?}", ed.duration_since(e).unwrap()); } fn main() { let mut v: Vec<usize> = vec![]; push_1m(&mut v, 5_000_000); let mut v: Vec<usize> = vec![]; v.reserve(5_000_000); push_1m(&mut v, 5_000_000); }
在筆者自己的筆記本上,編譯好了debug的版本,上面的代碼跑出了:
➜ debug git:(master) ✗ time ./demo
time spend: Duration { secs: 0, nanos: 368875346 }
time spend: Duration { secs: 0, nanos: 259878787 }
./demo 0.62s user 0.01s system 99% cpu 0.632 total
好像並沒有太大差異?然而切換到release版本的時候:
➜ release git:(master) ✗ time ./demo
time spend: Duration { secs: 0, nanos: 53389934 }
time spend: Duration { secs: 0, nanos: 24979520 }
./demo 0.06s user 0.02s system 97% cpu 0.082 total
注意消耗的時間的位數。可見,在去除掉debug版本的調試信息之後,是否預分配內存消耗時間降低了一倍!
這樣的成績,可見,預先分配內存確實有助於提升效率。
有人可能會問了,你這樣糾結這點時間,最後不也是節省在納秒級別的麼,有意義麼?當然有意義。
第一,納秒也是時間,這還是因為這個測試的Vec只是最簡單的內存結構。一旦涉及到大對象的拷貝,所花費的時間可就不一定這麼少了。
第二,頻繁的申請和刪除heap空間,其內存一旦達到瓶頸的時候你的程序將會異常危險。
更多Vec的操作,請參照標準庫的api。
哈希表 HashMap
和動態數組Vec一樣,哈希表(HashMap)也是Rust內置的集合類型之一,同屬std::collections模塊下。
它提供了一個平均複雜度為O(1)的查詢方法,是實現快速搜索必備的類型之一。
這裡呢,主要給大家介紹一下HashMap的幾種典型用法。
HashMap的要求
顧名思義, HashMap 要求一個可哈希(實現 Hash trait)的Key類型,和一個編譯時知道大小的Value類型。 同時,Rust還要求你的Key類型必須是可比較的,在Rust中,你可以為你的類型輕易的加上編譯器屬性:
#![allow(unused)] fn main() { #[derive(PartialEq, Eq, Hash)] }
這樣,即可將你的類型轉換成一個可以作為Hash的Key的類型。
但是,如果你想要自己實現Hash這個trait的話,你需要謹記兩點:
-
- 如果 Key1==Key2 ,那麼一定有 Hash(Key1) == Hash(Key2)
-
- 你的Hash函數本身不能改變你的Key值,否則將會引發一個邏輯錯誤(很難排查,遇到就完的那種)
什麼?你看到 std::hash::Hash 這個 trait 中的函數沒有&mut self的啊!但是,你不要忘了Rust中還有Cell和RefCell這種存在,他們提供了不可變對象的內部可變性,具體怎麼變呢,請參照第20章。
另外,要保證你寫的Hash函數不會被很輕易的碰撞,即 Key1! = Key2,但 Hash(Key1)==Hash(Key2),碰撞的嚴重了,HashMap甚至有可能退化成鏈表!
這裡筆者提議,別費勁,就按最簡單的來就好。
增刪改查
對於這種實用的類型,我們推薦用一個例子來解釋:
#![allow(unused)] fn main() { use std::collections::HashMap; // 聲明 let mut come_from = HashMap::new(); // 插入 come_from.insert("WaySLOG", "HeBei"); come_from.insert("Marisa", "U.S."); come_from.insert("Mike", "HuoGuo"); // 查找key if !come_from.contains_key("elton") { println!("Oh, 我們查到了{}個人,但是可憐的Elton貓還是無家可歸", come_from.len()); } // 根據key刪除元素 come_from.remove("Mike"); println!("Mike貓的家鄉不是火鍋!不是火鍋!不是火鍋!雖然好吃!"); // 利用get的返回判斷元素是否存在 let who = ["MoGu", "Marisa"]; for person in &who { match come_from.get(person) { Some(location) => println!("{} 來自: {}", person, location), None => println!("{} 也無家可歸啊.", person), } } // 遍歷輸出 println!("那麼,所有人呢?"); for (name, location) in &come_from { println!("{}來自: {}", name, location); } }
這段代碼輸出:
Oh, 我們查到了3個人,但是可憐的Elton貓還是無家可歸
Mike貓的家鄉不是火鍋!不是火鍋!不是火鍋!雖然好吃!
MoGu 也無家可歸啊.
Marisa 來自: U.S.
那麼,所有人呢?
Marisa來自: U.S.
WaySLOG來自: HeBei
entry
我們在編程的過程中,經常遇到這樣的場景,統計一個字符串中所有的字符總共出現過幾次。藉助各種語言內置的Map類型我們總能完成這件事,但是完成的幾乎都並不令人滿意。很多人討厭的一點是:為什麼我要判斷這個字符在字典中有沒有出現,就要寫一個大大的if條件!煩不煩?煩!於是,現代化的編程語言開始集成了類似Python裡setdefault類似的特性(方法),下面是一段Python代碼:
val = {}
for c in "abcdefasdasdawe":
val[c] = 1 + val.setdefault(c, 0)
print val
唔,總感覺怪怪的。那麼Rust是怎麼解決這個問題的呢? 以下內容摘自標註庫api註釋:
#![allow(unused)] fn main() { use std::collections::HashMap; let mut letters = HashMap::new(); for ch in "a short treatise on fungi".chars() { let counter = letters.entry(ch).or_insert(0); *counter += 1; } assert_eq!(letters[&'s'], 2); assert_eq!(letters[&'t'], 3); assert_eq!(letters[&'u'], 1); assert_eq!(letters.get(&'y'), None); }
Rust為我們提供了一個名叫 entry 的api,它很有意思,和Python相比,我們不需要在一次迭代的時候二次訪問原map,只需要借用 entry 出來的Entry類型(這個類型持有原有HashMap的引用)即可對原數據進行修改。就語法來說,毫無疑問Rust在這個方面更加直觀和具體。
迭代器
在Rust中,迭代器共分為三個部分:迭代器、適配器、消費者。
其中,迭代器本身提供了一個惰性的序列,適配器對這個序列進行諸如篩選、拼接、轉換查找等操作,消費者則在前兩者的基礎上生成最後的數值集合。
但是,孤立的看這三者其實是沒有意義的,因此,本章將在一個大節裡聯繫寫出三者。
迭代器
從for循環講起
我們在控制語句裡學習了Rust的for循環表達式,我們知道,Rust的for循環實際上和C語言的循環語句是不同的。這是為什麼呢?因為,for循環不過是Rust編譯器提供的語法糖!
首先,我們知道Rust有一個for循環能夠依次對迭代器的任意元素進行訪問,即:
#![allow(unused)] fn main() { for i in 1..10 { println!("{}", i); } }
這裡我們知道, (1..10) 其本身是一個迭代器,我們能對這個迭代器調用 .next() 方法,因此,for循環就能完整的遍歷一個循環。
而對於Vec來說:
let values = vec![1,2,3];
for x in values {
println!("{}", x);
}
在上面的代碼中,我們並沒有顯式地將一個Vec轉換成一個迭代器,那麼它是如何工作的呢?現在就打開標準庫翻api的同學可能發現了,Vec本身並沒有實現 Iterator ,也就是說,你無法對Vec本身調用 .next() 方法。但是,我們在搜索的時候,發現了Vec實現了 IntoIterator 的 trait。
其實,for循環真正循環的,並不是一個迭代器(Iterator),真正在這個語法糖裡起作用的,是 IntoIterator 這個 trait。
因此,上面的代碼可以被展開成如下的等效代碼(只是示意,不保證編譯成功):
#![allow(unused)] fn main() { let values = vec![1, 2, 3]; { let result = match IntoIterator::into_iter(values) { mut iter => loop { match iter.next() { Some(x) => { println!("{}", x); }, None => break, } }, }; result } }
在這個代碼裡,我們首先對Vec調用 into_iter 來判斷其是否能被轉換成一個迭代器,如果能,則進行迭代。
那麼,迭代器自己怎麼辦?
為此,Rust在標準庫裡提供了一個實現:
#![allow(unused)] fn main() { impl<I: Iterator> IntoIterator for I { // ... } }
也就是說,Rust為所有的迭代器默認的實現了 IntoIterator,這個實現很簡單,就是每次返回自己就好了。
也就是說:
任意一個 Iterator 都可以被用在 for 循環上!
無限迭代器
Rust支持通過省略高位的形式生成一個無限長度的自增序列,即:
#![allow(unused)] fn main() { let inf_seq = (1..).into_iter(); }
不過不用擔心這個無限增長的序列撐爆你的內存,佔用你的CPU,因為適配器的惰性的特性,它本身是安全的,除非你對這個序列進行collect或者fold!
不過,我想聰明如你,不會犯這種錯誤吧!
因此,想要應用這個,你需要用take或者take_while來截斷他,必須? 除非你將它當作一個生成器。當然了,那就是另外一個故事了。
消費者與適配器
說完了for循環,我們大致弄清楚了 Iterator 和 IntoIterator 之間的關係。下面我們來說一說消費者和適配器。
消費者是迭代器上一種特殊的操作,其主要作用就是將迭代器轉換成其他類型的值,而非另一個迭代器。
而適配器,則是對迭代器進行遍歷,並且其生成的結果是另一個迭代器,可以被鏈式調用直接調用下去。
由上面的推論我們可以得出: 迭代器其實也是一種適配器!
消費者
就像所有人都熟知的生產者消費者模型,迭代器負責生產,而消費者則負責將生產出來的東西最終做一個轉化。一個典型的消費者就是collect。前面我們寫過collect的相關操作,它負責將迭代器裡面的所有數據取出,例如下面的操作:
#![allow(unused)] fn main() { let v = (1..20).collect(); //編譯通不過的! }
嘗試運行上面的代碼,卻發現編譯器並不讓你通過。因為你沒指定類型!指定什麼類型呢?原來collect只知道將迭代器收集到一個實現了 FromIterator 的類型中去,但是,事實上實現這個 trait 的類型有很多(Vec, HashMap等),因此,collect沒有一個上下文來判斷應該將v按照什麼樣的方式收集!!
要解決這個問題,我們有兩種解決辦法:
-
顯式地標明
v的類型:#![allow(unused)] fn main() { let v: Vec<_> = (1..20).collect(); } -
顯式地指定
collect調用時的類型:#![allow(unused)] fn main() { let v = (1..20).collect::<Vec<_>>(); }
當然,一個迭代器中還存在其他的消費者,比如取第幾個值所用的 .nth()函數,還有用來查找值的 .find() 函數,調用下一個值的next()函數等等,這裡限於篇幅我們不能一一介紹。所以,下面我們只介紹另一個比較常用的消費者—— fold 。
當然了,提起Rust裡的名字你可能沒啥感覺,其實,fold函數,正是大名鼎鼎的 MapReduce 中的 Reduce 函數(稍微有點區別就是這個Reduce是帶初始值的)。
fold函數的形式如下:
#![allow(unused)] fn main() { fold(base, |accumulator, element| .. ) }
我們可以寫成如下例子:
#![allow(unused)] fn main() { let m = (1..20).fold(1u64, |mul, x| mul*x); }
需要注意的是,fold的輸出結果的類型,最終是和base的類型是一致的(如果base的類型沒指定,那麼可以根據前面m的類型進行反推,除非m的類型也未指定),也就是說,一旦我們將上面代碼中的base從 1u64 改成 1,那麼這行代碼最終將會因為數據溢出而崩潰!
適配器
我們所熟知的生產消費的模型裡,生產者所生產的東西不一定都會被消費者買賬,因此,需要對原有的產品進行再組裝。這個再組裝的過程,就是適配器。因為適配器返回的是一個新的迭代器,所以可以直接用鏈式請求一直寫下去。
前面提到了 Reduce 函數,那麼自然不得不提一下另一個配套函數 —— map :
熟悉Python語言的同學肯定知道,Python裡內置了一個map函數,可以將一個迭代器的值進行變換,成為另一種。Rust中的map函數實際上也是起的同樣的作用,甚至連調用方法也驚人的相似!
#![allow(unused)] fn main() { (1..20).map(|x| x+1); }
上面的代碼展示了一個“迭代器所有元素的自加一”操作,但是,如果你嘗試編譯這段代碼,編譯器會給你提示:
warning: unused result which must be used: iterator adaptors are lazy and
do nothing unless consumed, #[warn(unused_must_use)] on by default
(1..20).map(|x| x + 1);
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
呀,這是啥?
因為,所有的適配器,都是惰性求值的!
也就是說,除非你調用一個消費者,不然,你的操作,永遠也不會被調用到!
現在,我們知道了map,那麼熟悉Python的人又說了,是不是還有filter!?答,有……用法類似,filter接受一個閉包函數,返回一個布爾值,返回true的時候表示保留,false丟棄。
#![allow(unused)] fn main() { let v: Vec<_> = (1..20).filter(|x| x%2 == 0).collect(); }
以上代碼表示篩選出所有的偶數。
其他
上文中我們瞭解了迭代器、適配器、消費者的基本概念。下面將以例子來介紹Rust中的其他的適配器和消費者。
skip和take
take(n)的作用是取前n個元素,而skip(n)正好相反,跳過前n個元素。
#![allow(unused)] fn main() { let v = vec![1, 2, 3, 4, 5, 6]; let v_take = v.iter() .cloned() .take(2) .collect::<Vec<_>>(); assert_eq!(v_take, vec![1, 2]); let v_skip: Vec<_> = v.iter() .cloned() .skip(2) .collect(); assert_eq!(v_skip, vec![3, 4, 5, 6]); }
zip 和 enumerate的恩怨情仇
zip是一個適配器,他的作用就是將兩個迭代器的內容壓縮到一起,形成 Iterator<Item=(ValueFromA, ValueFromB)> 這樣的新的迭代器;
#![allow(unused)] fn main() { let names = vec!["WaySLOG", "Mike", "Elton"]; let scores = vec![60, 80, 100]; let score_map: HashMap<_, _> = names.iter() .zip(scores.iter()) .collect(); println!("{:?}", score_map); }
而enumerate, 熟悉的Python的同學又叫了:Python裡也有!對的,作用也是一樣的,就是把迭代器的下標顯示出來,即:
#![allow(unused)] fn main() { let v = vec![1u64, 2, 3, 4, 5, 6]; let val = v.iter() .enumerate() // 迭代生成標,並且每兩個元素剔除一個 .filter(|&(idx, _)| idx % 2 == 0) // 將下標去除,如果調用unzip獲得最後結果的話,可以調用下面這句,終止鏈式調用 // .unzip::<_,_, vec<_>, vec<_>>().1 .map(|(idx, val)| val) // 累加 1+3+5 = 9 .fold(0u64, |sum, acm| sum + acm); println!("{}", val); }
一系列查找函數
Rust的迭代器有一系列的查找函數,比如:
find(): 傳入一個閉包函數,從開頭到結尾依次查找能令這個閉包返回true的第一個元素,返回Option<Item>position(): 類似find函數,不過這次輸出的是Option<usize>,第幾個元素。all(): 傳入一個函數,如果對於任意一個元素,調用這個函數返回false,則整個表達式返回false,否則返回trueany(): 類似all(),不過這次是任何一個返回true,則整個表達式返回true,否則falsemax()和min(): 查找整個迭代器裡所有元素,返回最大或最小值的元素。注意:因為第七章講過的PartialOrder的原因,max和min作用在浮點數上會有不符合預期的結果。
以上,為常用的一些迭代器和適配器及其用法,僅作科普,對於這一章。我希望大家能夠多練習去理解,而不是死記硬背。
好吧,留個習題:
習題
利用迭代器生成一個升序的長度為10的水仙花數序列,然後對這個序列進行逆序,並輸出
模塊和包系統、Prelude
前言
隨著工程的增大,把所有代碼寫在一個文件裡面,是一件極其初等及愚蠢的作法。大體來講,它有如下幾個缺點:
- 文件大了,編輯器打開慢;
- 所有代碼放在同一個文件中,無法很好地利用現代多窗口編輯器,同時查看編輯相關聯的兩個代碼片斷;
- 代碼數量過多,查找某一個關鍵詞過慢,定位到某一行代碼的效率會大大降低;
- 會大大增加上翻下翻的頻率,導致你的鼠標中間滾輪易壞;
- 不斷地上翻下翻,會導致你頭暈;
- 頭暈了,就容易寫出錯誤的代碼,甚至改錯文件中的某一行(相似的地方,改錯地方了);
- 出現bug,根據錯誤反饋,知道是哪一片邏輯的問題,但不容易快速定位;
因此,模塊是幾乎所有語言的基礎設施,儘管叫法各有不同。
包和模塊
包(crate)
Rust 中,crate 是一個獨立的可編譯單元。具體說來,就是一個或一批文件(如果是一批文件,那麼有一個文件是這個 crate 的入口)。它編譯後,會對應著生成一個可執行文件或一個庫。
執行 cargo new foo,會得到如下目錄層級:
foo
├── Cargo.toml
└── src
└── lib.rs
這裡,lib.rs 就是一個 crate(入口),它編譯後是一個庫。一個工程下可以包含不止一個 crate,本工程只有一個。
執行 cargo new --bin bar,會得到如下目錄層級:
bar
├── Cargo.toml
└── src
└── main.rs
這裡,main.rs 就是一個 crate(入口),它編譯後是一個可執行文件。
模塊(module)
Rust 提供了一個關鍵字 mod,它可以在一個文件中定義一個模塊,或者引用另外一個文件中的模塊。
關於模塊的一些要點:
- 每個 crate 中,默認實現了一個隱式的
根模塊(root module); - 模塊的命名風格也是
lower_snake_case,跟其它的 Rust 的標識符一樣; - 模塊可以嵌套;
- 模塊中可以寫任何合法的 Rust 代碼;
在文件中定義一個模塊
比如,在上述 lib.rs 中,我們寫上如下代碼:
#![allow(unused)] fn main() { mod aaa { const X: i32 = 10; fn print_aaa() { println!("{}", 42); } } }
我們可以繼續寫如下代碼:
#![allow(unused)] fn main() { mod aaa { const X: i32 = 10; fn print_aaa() { println!("{}", 42); } mod BBB { fn print_bbb() { println!("{}", 37); } } } }
還可以繼續寫:
#![allow(unused)] fn main() { mod aaa { const X: i32 = 10; fn print_aaa() { println!("{}", 42); } mod bbb { fn print_bbb() { println!("{}", 37); } } } mod ccc { fn print_ccc() { println!("{}", 25); } } }
模塊的可見性
我們前面寫了一些模塊,但實際上,我們寫那些模塊,目前是沒有什麼作用的。寫模塊的目的一是為了分隔邏輯塊,二是為了提供適當的函數,或對象,供外部訪問。而模塊中的內容,默認是私有的,只有模塊內部能訪問。
為了讓外部能使用模塊中 item,需要使用 pub 關鍵字。外部引用的時候,使用 use 關鍵字。例如:
mod ccc { pub fn print_ccc() { println!("{}", 25); } } fn main() { use ccc::print_ccc; print_ccc(); // 或者 ccc::print_ccc(); }
規則很簡單,一個 item(函數,綁定,Trait 等),前面加了 pub,那麼就它變成對外可見(訪問,調用)的了。
引用外部文件模塊
通常,我們會在單獨的文件中寫模塊內容,然後使用 mod 關鍵字來加載那個文件作為我們的模塊。
比如,我們在 src 下新建了文件 aaa.rs。現在目錄結構是下面這樣子:
foo
├── Cargo.toml
└── src
└── aaa.rs
└── main.rs
我們在 aaa.rs 中,寫上:
#![allow(unused)] fn main() { pub fn print_aaa() { println!("{}", 25); } }
在 main.rs 中,寫上:
mod aaa; use self::aaa::print_aaa; fn main () { print_aaa(); }
編譯後,生成一個可執行文件。
細心的朋友會發現,aaa.rs 中,沒有使用 mod xxx {} 這樣包裹起來,是因為 mod xxx; 相當於把 xxx.rs 文件用 mod xxx {} 包裹起來了。初學者往往會多加一層,請注意。
多文件模塊的層級關係
Rust 的模塊支持層級結構,但這種層級結構本身與文件系統目錄的層級結構是解耦的。
mod xxx; 這個 xxx 不能包含 :: 號。也即在這個表達形式中,是沒法引用多層結構下的模塊的。也即,你不可能直接使用 mod a::b::c::d; 的形式來引用 a/b/c/d.rs 這個模塊。
那麼,Rust 的多層模塊遵循如下兩條規則:
- 優先查找
xxx.rs文件main.rs、lib.rs、mod.rs中的mod xxx;默認優先查找同級目錄下的xxx.rs文件;- 其他文件
yyy.rs中的mod xxx;默認優先查找同級目錄的yyy目錄下的xxx.rs文件;
- 如果
xxx.rs不存在,則查找xxx/mod.rs文件,即xxx目錄下的mod.rs文件。
上述兩種情況,加載成模塊後,效果是相同的。Rust 就憑這兩條規則,通過迭代使用,結合 pub 關鍵字,實現了對深層目錄下模塊的加載;
下面舉個例子,現在我們建了一個測試工程,目錄結構如下:
src
├── a
│ ├── b
│ │ ├── c
│ │ │ ├── d.rs
│ │ │ └── mod.rs
│ │ └── mod.rs
│ └── mod.rs
└── main.rs
a/b/c/d.rs 文件內容:
#![allow(unused)] fn main() { pub fn print_ddd() { println!("i am ddd."); } }
a/b/c/mod.rs 文件內容:
#![allow(unused)] fn main() { pub mod d; }
a/b/mod.rs 文件內容:
#![allow(unused)] fn main() { pub mod c; }
a/mod.rs 文件內容:
#![allow(unused)] fn main() { pub mod b; }
main.rs 文件內容:
mod a; use self::a::b::c::d; fn main() { d::print_ddd(); }
輸出結果為:i am ddd.
仔細理解本例子,就明白 Rust 的層級結構模塊的用法了。
至於為何 Rust 要這樣設計,有幾下幾個原因:
- Rust 本身模塊的設計是與操作系統文件系統目錄解耦的,因為 Rust 本身可用於操作系統的開發;
- Rust 中的一個文件內,可包含多個模塊,直接將
a::b::c::d映射到a/b/c/d.rs會引起一些歧義; - Rust 一切從安全性、顯式化立場出發,要求引用路徑中的每一個節點,都是一個有效的模塊,比如上例,
d是一個有效的模塊的話,那麼,要求c, b, a分別都是有效的模塊,可單獨引用。
路徑
前面我們提到,一個 crate 是一個獨立的可編譯單元。它有一個入口文件,這個入口文件是這個 crate(裡面可能包含若干個 module)的模塊根路徑。整個模塊的引用,形成一個鏈,每個模塊,都可以用一個精確的路徑(比如:a::b::c::d)來表示;
與文件系統概念類似,模塊路徑也有相對路徑和絕對路徑的概念。為此,Rust 提供了 self 和 super 兩個關鍵字。
self 在路徑中,有兩種意思:
use self::xxx表示,加載當前模塊中的xxx。此時 self 可省略;use xxx::{self, yyy},表示,加載當前路徑下模塊xxx本身,以及模塊xxx下的yyy;
super 表示,當前模塊路徑的上一級路徑,可以理解成父模塊。
#![allow(unused)] fn main() { use super::xxx; }
表示引用父模塊中的 xxx。
另外,還有一種特殊的路徑形式:
#![allow(unused)] fn main() { ::xxx::yyy }
它表示,引用根路徑下的 xxx::yyy,這個根路徑,指的是當前 crate 的根路徑。
路徑中的 * 符號:
#![allow(unused)] fn main() { use xxx::*; }
表示導入 xxx 模塊下的所有可見 item(加了 pub 標識的 item)。
Re-exporting
我們可以結合使用 pub use 來實現 Re-exporting。Re-exporting 的字面意思就是 重新導出。它的意思是這樣的,把深層的 item 導出到上層目錄中,使調用的時候,更方便。接口設計中會大量用到這個技術。
還是舉上面那個 a::b::c::d 的例子。我們在 main.rs 中,要調用 d,得使用 use a::b::c::d; 來調用。而如果我們修改 a/mod.rs 文件為:
a/mod.rs 文件內容:
#![allow(unused)] fn main() { pub mod b; pub use b::c::d; }
那麼,我們在 main.rs 中,就可以使用 use a::d; 來調用了。從這個例子來看沒覺得方便多少。但是如果開發的一個庫中有大量的內容,而且是在不同層次的模塊中。那麼,通過統一導出到一個地方,就能大大方便接口使用者。
加載外部 crate
前面我們講的,都是在當前 crate 中的技術。真正我們在開發時,會大量用到外部庫。外部庫是通過
#![allow(unused)] fn main() { extern crate xxx; }
這樣來引入的。
注:要使上述引用生效,還必須在 Cargo.toml 的 dependecies 段,加上 xxx="version num" 這種依賴說明,詳情見 Cargo 項目管理 這一章。
引入後,就相當於引入了一個符號 xxx,後面可以直接以這個 xxx 為根引用這個 crate 中的 item:
#![allow(unused)] fn main() { extern crate xxx; use xxx::yyy::zzz; }
引入的時候,可以通過 as 關鍵字重命名。
#![allow(unused)] fn main() { extern crate xxx as foo; use foo::yyy::zzz; }
Prelude
Rust 的標準庫,有一個 prelude 子模塊,這裡麵包含了默認導入(std 庫是默認導入的,然後 std 庫中的 prelude 下面的東西也是默認導入的)的所有符號。
大體上有下面一些內容:
#![allow(unused)] fn main() { std::marker::{Copy, Send, Sized, Sync} std::ops::{Drop, Fn, FnMut, FnOnce} std::mem::drop std::boxed::Box std::borrow::ToOwned std::clone::Clone std::cmp::{PartialEq, PartialOrd, Eq, Ord} std::convert::{AsRef, AsMut, Into, From} std::default::Default std::iter::{Iterator, Extend, IntoIterator, DoubleEndedIterator, ExactSizeIterator} std::option::Option::{self, Some, None} std::result::Result::{self, Ok, Err} std::slice::SliceConcatExt std::string::{String, ToString} std::vec::Vec }
pub restricted
概覽
這是 rust1.18 新增的一個語法。在此之前的版本,item 只有 pub/non-pub 兩種分類,pub restricted 這個語法用來擴展 pub 的使用,使其能夠指定想要的作用域(可見範圍),詳情參見RFC 1422-pub-restricted.md。
在 Rust 中 crate 是一個模塊樹,可以通過表達式 pub(crate) item; 來限制 item 只在當前 crate 中可用,在當前 crate 的其他子樹中,可以通過 use + path 的語法來引用 item。
設計動因
Rust1.18 之前,如果我們想要設計一個 item x 可以在多處使用,那麼有兩種方法:
- 在根目錄中定義一個非
pubitem; - 在子模塊中定義一個
pubitem,同時通過use將這個項目引用到根目錄。
但是,有時候這兩種方法都並不是我們想要的。在一些情況下,我們希望對於某些特定的模塊,該item可見,而其他模塊不可見。
下面我們來看一個例子:
// Intent: `a` exports `I`, `bar`, and `foo`, but nothing else.
pub mod a {
pub const I: i32 = 3;
// `semisecret` will be used "many" places within `a`, but
// is not meant to be exposed outside of `a`.
fn semisecret(x: i32) -> i32 { use self::b::c::J; x + J }
pub fn bar(z: i32) -> i32 { semisecret(I) * z }
pub fn foo(y: i32) -> i32 { semisecret(I) + y }
mod b {
mod c {
const J: i32 = 4; // J is meant to be hidden from the outside world.
}
}
}
這段代碼編譯無法通過,因為 J 無法在 mod c 的外部訪問,而 fn semisecret 嘗試在 mod a 中訪問 J.
在 rust1.18 之前,保持J私有,並能夠讓 a 使用 fn semisecret 的正確寫法是,將 fn semisecret 移動到 mod c 中,並將其 pub,之後根據需要可以重新導出 semisecret。(如果不需要保持 J 的私有化,那麼可以對其進行 pub,之後可以在 b 中 pub use self::c::J 或者直接 pub c)
// Intent: `a` exports `I`, `bar`, and `foo`, but nothing else.
pub mod a {
pub const I: i32 = 3;
// `semisecret` will be used "many" places within `a`, but
// is not meant to be exposed outside of `a`.
// (If we put `pub use` here, then *anyone* could access it.)
use self::b::semisecret;
pub fn bar(z: i32) -> i32 { semisecret(I) * z }
pub fn foo(y: i32) -> i32 { semisecret(I) + y }
mod b {
pub use self::c::semisecret;
mod c {
const J: i32 = 4; // J is meant to be hidden from the outside world.
pub fn semisecret(x: i32) -> i32 { x + J }
}
}
}
這種情況可以正常工作,但是,這裡有個嚴重的問題:沒有人能夠十分清晰的說明 pub fn semisecret 使用到了哪些地方,需要通過上下文進行判斷:
- 所有可以訪問
semisecret的模塊; - 在所有可以訪問
semisecret的模塊中,是否存在semisecret的 re-export;
同時,如果在 a 中使用 pub use self::b::semisecret ,那麼所有人都可以通過 use 訪問 fn semisecret,但是實際上,這個函數只需要讓 mod a 訪問就可以了。
pub restricted 的使用
Syntax
old:
VISIBILITY ::= <empty> | `pub`
new:
VISIBILITY ::= <empty> | `pub` | `pub` `(` USE_PATH `)` | `pub` `(` `crate` `)`
pub(restriction) 意味著對 item,method,field等的定義加以可見範圍(作用域)的限制。
可見範圍(作用域)分為所有 crate (無限制),當前 crate,當前 crate 中的子模塊的絕對路徑。被限制的東西不能在其限制範圍之外直接使用。
pub無明確指定意味著無限制;pub(crate)當前 crate 有效;pub(in <path>)在<path>表示的模塊中有效。
修改示例
// Intent: `a` exports `I`, `bar`, and `foo`, but nothing else.
pub mod a {
pub const I: i32 = 3;
// `semisecret` will be used "many" places within `a`, but
// is not meant to be exposed outside of `a`.
// (`pub use` would be *rejected*; see Note 1 below)
use self::b::semisecret;
pub fn bar(z: i32) -> i32 { semisecret(I) * z }
pub fn foo(y: i32) -> i32 { semisecret(I) + y }
mod b {
pub(in a) use self::c::semisecret;
mod c {
const J: i32 = 4; // J is meant to be hidden from the outside world.
// `pub(in a)` means "usable within hierarchy of `mod a`, but not
// elsewhere."
pub(in a) fn semisecret(x: i32) -> i32 { x + J }
}
}
}
Note 1: 如果改成下面這種方式,編譯器會報錯:
pub mod a { [...] pub use self::b::semisecret; [...] }
因為 pub(in a) fn semisecret 說明這個函數只能在 a 中使用,不允許 pub 出 a 的範圍。
限制字段示例
mod a {
#[derive(Default)]
struct Priv(i32);
pub mod b {
use a::Priv as Priv_a;
#[derive(Default)]
pub struct F {
pub x: i32,
y: Priv_a,
pub(in a) z: Priv_a,
}
#[derive(Default)]
pub struct G(pub i32, Priv_a, pub(in a) Priv_a);
// ... accesses to F.{x,y,z} ...
// ... accesses to G.{0,1,2} ...
}
// ... accesses to F.{x,z} ...
// ... accesses to G.{0,2} ...
}
mod k {
use a::b::{F, G};
// ... accesses to F and F.x ...
// ... accesses to G and G.0 ...
}
Crate 限制示例
Crate c1:
pub mod a {
struct Priv(i32);
pub(crate) struct R { pub y: i32, z: Priv } // ok: field allowed to be more public
pub struct S { pub y: i32, z: Priv }
pub fn to_r_bad(s: S) -> R { ... } //~ ERROR: `R` restricted solely to this crate
pub(crate) fn to_r(s: S) -> R { R { y: s.y, z: s.z } } // ok: restricted to crate
}
use a::{R, S}; // ok: `a::R` and `a::S` are both visible
pub use a::R as ReexportAttempt; //~ ERROR: `a::R` restricted solely to this crate
Crate c2:
extern crate c1;
use c1::a::S; // ok: `S` is unrestricted
use c1::a::R; //~ ERROR: `c1::a::R` not visible outside of its crate
17.錯誤處理
錯誤處理是保證程序健壯性的前提,在編程語言中錯誤處理的方式大致分為兩種:拋出異常(exceptions)和作為值返回。
Rust 將錯誤作為值返回並且提供了原生的優雅的錯誤處理方案。
熟練掌握錯誤處理是軟件工程中非常重要的環節,讓我一起來看看Rust展現給我們的錯誤處理藝術。
17.1 Option和Result
謹慎使用panic:
fn guess(n: i32) -> bool { if n < 1 || n > 10 { panic!("Invalid number: {}", n); } n == 5 } fn main() { guess(11); }
panic會導致當前線程結束,甚至是整個程序的結束,這往往是不被期望看到的結果。(編寫示例或者簡短代碼的時候panic不失為一個好的建議)
Option
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
Option 是Rust的系統類型,用來表示值不存在的可能,這在編程中是一個好的實踐,它強制Rust檢測和處理值不存在的情況。例如:
#![allow(unused)] fn main() { fn find(haystack: &str, needle: char) -> Option<usize> { for (offset, c) in haystack.char_indices() { if c == needle { return Some(offset); } } None } }
find在字符串haystack中查找needle字符,事實上結果會出現兩種可能,有(Some(usize))或無(None)。
fn main() { let file_name = "foobar.rs"; match find(file_name, '.') { None => println!("No file extension found."), Some(i) => println!("File extension: {}", &file_name[i+1..]), } }
Rust 使用模式匹配來處理返回值,調用者必須處理結果為None的情況。這往往是一個好的編程習慣,可以減少潛在的bug。Option 包含一些方法來簡化模式匹配,畢竟過多的match會使代碼變得臃腫,這也是滋生bug的原因之一。
unwrap
#![allow(unused)] fn main() { impl<T> Option<T> { fn unwrap(self) -> T { match self { Option::Some(val) => val, Option::None => panic!("called `Option::unwrap()` on a `None` value"), } } } }
unwrap當遇到None值時會panic,如前面所說這不是一個好的工程實踐。不過有些時候卻非常有用:
- 在例子和簡單快速的編碼中 有的時候你只是需要一個小例子或者一個簡單的小程序,輸入輸出已經確定,你根本沒必要花太多時間考慮錯誤處理,使用
unwrap變得非常合適。 - 當程序遇到了致命的bug,panic是最優選擇
map
假如我們要在一個字符串中找到文件的擴展名,比如foo.rs中的rs, 我們可以這樣:
fn extension_explicit(file_name: &str) -> Option<&str> { match find(file_name, '.') { None => None, Some(i) => Some(&file_name[i+1..]), } } fn main() { match extension_explicit("foo.rs") { None => println!("no extension"), Some(ext) => assert_eq!(ext, "rs"), } }
我們可以使用map簡化:
#![allow(unused)] fn main() { // map是標準庫中的方法 fn map<F, T, A>(option: Option<T>, f: F) -> Option<A> where F: FnOnce(T) -> A { match option { None => None, Some(value) => Some(f(value)), } } // 使用map去掉match fn extension(file_name: &str) -> Option<&str> { find(file_name, '.').map(|i| &file_name[i+1..]) } }
map如果有值Some(T)會執行f,反之直接返回None。
unwrap_or
#![allow(unused)] fn main() { fn unwrap_or<T>(option: Option<T>, default: T) -> T { match option { None => default, Some(value) => value, } } }
unwrap_or提供了一個默認值default,當值為None時返回default:
fn main() { assert_eq!(extension("foo.rs").unwrap_or("rs"), "rs"); assert_eq!(extension("foo").unwrap_or("rs"), "rs"); }
and_then
#![allow(unused)] fn main() { fn and_then<F, T, A>(option: Option<T>, f: F) -> Option<A> where F: FnOnce(T) -> Option<A> { match option { None => None, Some(value) => f(value), } } }
看起來and_then和map差不多,不過map只是把值為Some(t)重新映射了一遍,and_then則會返回另一個Option。如果我們在一個文件路徑中找到它的擴展名,這時候就會變得尤為重要:
#![allow(unused)] fn main() { use std::path::Path; fn file_name(file_path: &str) -> Option<&str> { let path = Path::new(file_path); path.file_name().to_str() } fn file_path_ext(file_path: &str) -> Option<&str> { file_name(file_path).and_then(extension) } }
Result
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Result是Option的更通用的版本,比起Option結果為None它解釋了結果錯誤的原因,所以:
#![allow(unused)] fn main() { type Option<T> = Result<T, ()>; }
這樣的別名是一樣的(()標示空元組,它既是()類型也可以是()值)
unwrap
#![allow(unused)] fn main() { impl<T, E: ::std::fmt::Debug> Result<T, E> { fn unwrap(self) -> T { match self { Result::Ok(val) => val, Result::Err(err) => panic!("called `Result::unwrap()` on an `Err` value: {:?}", err), } } } }
沒錯和Option一樣,事實上它們擁有很多類似的方法,不同的是,Result包括了錯誤的詳細描述,這對於調試人員來說,這是友好的。
Result我們從例子開始
fn double_number(number_str: &str) -> i32 { 2 * number_str.parse::<i32>().unwrap() } fn main() { let n: i32 = double_number("10"); assert_eq!(n, 20); }
double_number從一個字符串中解析出一個i32的數字並*2,main中調用看起來沒什麼問題,但是如果把"10"換成其他解析不了的字符串程序便會panic
#![allow(unused)] fn main() { impl str { fn parse<F: FromStr>(&self) -> Result<F, F::Err>; } }
parse返回一個Result,但讓我們也可以返回一個Option,畢竟一個字符串要麼能解析成一個數字要麼不能,但是Result給我們提供了更多的信息(要麼是一個空字符串,一個無效的數位,太大或太小),這對於使用者是友好的。當你面對一個Option和Result之間的選擇時。如果你可以提供詳細的錯誤信息,那麼大概你也應該提供。
這裡需要理解一下FromStr這個trait:
#![allow(unused)] fn main() { pub trait FromStr { type Err; fn from_str(s: &str) -> Result<Self, Self::Err>; } impl FromStr for i32 { type Err = ParseIntError; fn from_str(src: &str) -> Result<i32, ParseIntError> { } } }
number_str.parse::<i32>()事實上調用的是i32的FromStr實現。
我們需要改寫這個例子:
use std::num::ParseIntError; fn double_number(number_str: &str) -> Result<i32, ParseIntError> { number_str.parse::<i32>().map(|n| 2 * n) } fn main() { match double_number("10") { Ok(n) => assert_eq!(n, 20), Err(err) => println!("Error: {:?}", err), } }
不僅僅是map,Result同樣包含了unwrap_or和and_then。也有一些特有的針對錯誤類型的方法map_err和or_else。
Result別名
在Rust的標準庫中會經常出現Result的別名,用來默認確認其中Ok(T)或者Err(E)的類型,這能減少重複編碼。比如io::Result
#![allow(unused)] fn main() { use std::num::ParseIntError; use std::result; type Result<T> = result::Result<T, ParseIntError>; fn double_number(number_str: &str) -> Result<i32> { unimplemented!(); } }
組合Option和Result
Option的方法ok_or:
#![allow(unused)] fn main() { fn ok_or<T, E>(option: Option<T>, err: E) -> Result<T, E> { match option { Some(val) => Ok(val), None => Err(err), } } }
可以在值為None的時候返回一個Result::Err(E),值為Some(T)的時候返回Ok(T),利用它我們可以組合Option和Result:
use std::env; fn double_arg(mut argv: env::Args) -> Result<i32, String> { argv.nth(1) .ok_or("Please give at least one argument".to_owned()) .and_then(|arg| arg.parse::<i32>().map_err(|err| err.to_string())) .map(|n| 2 * n) } fn main() { match double_arg(env::args()) { Ok(n) => println!("{}", n), Err(err) => println!("Error: {}", err), } }
double_arg將傳入的命令行參數轉化為數字並翻倍,ok_or將Option類型轉換成Result,map_err當值為Err(E)時調用作為參數的函數處理錯誤
複雜的例子
use std::fs::File; use std::io::Read; use std::path::Path; fn file_double<P: AsRef<Path>>(file_path: P) -> Result<i32, String> { File::open(file_path) .map_err(|err| err.to_string()) .and_then(|mut file| { let mut contents = String::new(); file.read_to_string(&mut contents) .map_err(|err| err.to_string()) .map(|_| contents) }) .and_then(|contents| { contents.trim().parse::<i32>() .map_err(|err| err.to_string()) }) .map(|n| 2 * n) } fn main() { match file_double("foobar") { Ok(n) => println!("{}", n), Err(err) => println!("Error: {}", err), } }
file_double從文件中讀取內容並將其轉化成i32類型再翻倍。
這個例子看起來已經很複雜了,它使用了多個組合方法,我們可以使用傳統的match和if let來改寫它:
use std::fs::File; use std::io::Read; use std::path::Path; fn file_double<P: AsRef<Path>>(file_path: P) -> Result<i32, String> { let mut file = match File::open(file_path) { Ok(file) => file, Err(err) => return Err(err.to_string()), }; let mut contents = String::new(); if let Err(err) = file.read_to_string(&mut contents) { return Err(err.to_string()); } let n: i32 = match contents.trim().parse() { Ok(n) => n, Err(err) => return Err(err.to_string()), }; Ok(2 * n) } fn main() { match file_double("foobar") { Ok(n) => println!("{}", n), Err(err) => println!("Error: {}", err), } }
這兩種方法個人認為都是可以的,依具體情況來取捨。
try!
#![allow(unused)] fn main() { macro_rules! try { ($e:expr) => (match $e { Ok(val) => val, Err(err) => return Err(::std::convert::From::from(err)), }); } }
try!事實上就是match Result的封裝,當遇到Err(E)時會提早返回,
::std::convert::From::from(err)可以將不同的錯誤類型返回成最終需要的錯誤類型,因為所有的錯誤都能通過From轉化成Box<Error>,所以下面的代碼是正確的:
#![allow(unused)] fn main() { use std::error::Error; use std::fs::File; use std::io::Read; use std::path::Path; fn file_double<P: AsRef<Path>>(file_path: P) -> Result<i32, Box<Error>> { let mut file = try!(File::open(file_path)); let mut contents = String::new(); try!(file.read_to_string(&mut contents)); let n = try!(contents.trim().parse::<i32>()); Ok(2 * n) } }
組合自定義錯誤類型
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; use std::num; use std::io; use std::path::Path; // We derive `Debug` because all types should probably derive `Debug`. // This gives us a reasonable human readable description of `CliError` values. #[derive(Debug)] enum CliError { Io(io::Error), Parse(num::ParseIntError), } impl From<io::Error> for CliError { fn from(err: io::Error) -> CliError { CliError::Io(err) } } impl From<num::ParseIntError> for CliError { fn from(err: num::ParseIntError) -> CliError { CliError::Parse(err) } } fn file_double_verbose<P: AsRef<Path>>(file_path: P) -> Result<i32, CliError> { let mut file = try!(File::open(file_path).map_err(CliError::Io)); let mut contents = String::new(); try!(file.read_to_string(&mut contents).map_err(CliError::Io)); let n: i32 = try!(contents.trim().parse().map_err(CliError::Parse)); Ok(2 * n) } }
CliError分別為io::Error和num::ParseIntError實現了From這個trait,所有調用try!的時候這兩種錯誤類型都能轉化成CliError。
總結
熟練使用Option和Result是編寫 Rust 代碼的關鍵,Rust 優雅的錯誤處理離不開值返回的錯誤形式,編寫代碼時提供給使用者詳細的錯誤信息是值得推崇的。
輸入與輸出
輸入與輸出可以說是一個實用程序的最基本要求,沒有輸入輸出的程序是沒有什麼卵用的。雖然輸入輸出被函數式編程語言鄙稱為副作用,但正是這個副作用才賦予了程序實用性,君不見某著名函數式語言之父稱他主導設計的函數式語言"is useless"。這章我們就來談談輸入輸出副作用。
讀寫 Trait
輸入最基本的功能是讀(Read),輸出最基本的功能是寫(Write)。標準庫裡面把怎麼讀和怎麼寫抽象出來歸到了 Read 和 Write 兩個接口裡面,實現了 Read 接口的叫 reader,而實現了 Write 的叫 writer。Rust裡面的 Trait 比其它語言裡面的接口更好的一個地方是 Trait 可以帶默認實現,比如用戶定義的 reader 只需要實現 read 一個方法就可以調用 Read trait 裡面的任意其它方法,而 writer 也只需要實現 write 和 flush 兩個方法。
Read 和 Write 這兩個 Trait 都有定義了好多方法,具體可以參考標準庫 API 文檔中的Read 和 Write
Read 由於每調用一次 read 方法都會調用一次系統API與內核交互,效率比較低,如果給 reader 增加一個 buffer,在調用時 read 方法時多讀一些數據放在 buffer 裡面,下次調用 read 方法時就有可能只需要從 buffer 裡面取數據而不用調用系統API了,從而減少了系統調用次數提高了讀取效率,這就是所謂的 BufRead Trait。一個普通的 reader 通過 io::BufReader::new(reader) 或者 io::BufReader::with_capacity(bufSize, reader) 就可以得到一個 BufReader 了,顯然這兩個創建 BufReader 的函數一個是使用默認大小的 buffer 一個可以指定 buffer 大小。BufReader 比較常用的兩個方法是按行讀: read_line(&mut self, buf: &mut String) -> Result<usize> 和 lines(&mut self) -> Lines<Self>,從函數簽名上就可以大概猜出函數的用法所以就不囉嗦了,需要注意的是後者返回的是一個迭代器。詳細說明直接看 API 文檔中的BufRead
同樣有 BufWriter 只不過由於其除了底層加了 buffer 之外並沒有增加新的寫方法,所以並沒有專門的 BufWrite Trait,可以通過 io::BufWriter::new(writer) 或 io::BufWriter::with_capacity(bufSize, writer) 創建 BufWriter。
輸入與輸出接口有了,我們接下來看看實際應用中最常用的兩類 reader 和 writer:標準輸入/輸出,文件輸入/輸出
Macro
簡介
學過 C 語言的人都知道 #define 用來定義宏(macro),而且大學很多老師都告訴你儘量少用宏,因為 C 裡面的宏是一個很危險的東西-宏僅僅是簡單的文本替換,完全不管語法,類型,非常容易出錯。聽說過或用過 Lisp 的人覺得宏極其強大,就連美國最大的創業孵化器公司創始人 Paul Gram 也極力鼓吹 Lisp 的宏是有多麼強大。那麼宏究竟是什麼樣的東西呢?這一章通過 Rust 的宏系統帶你揭開宏(Macro)的神秘面紗。
Rust 中的宏幾乎無處不在,其實你寫的第一個 Rust 程序裡面就已經用到了宏,對,就是那個有名的 hello-world。println!("Hello, world!") 這句看起來很像函數調用,但是在"函數名"後面加上了感嘆號,這個是專門用來區分普通函數調用和宏調用的。另外從形式上看,與函數調用的另一個區別是參數可以用圓括號(())、花括號({})、方括號([])中的任意一種括起來,比如這行也可以寫成 println!["Hello, world!"] 或 println!{"Hello, world!"},不過對於 Rust 內置的宏都有約定俗成的括號,比如 vec! 用方括號,assert_eq! 用圓括號。
既然宏看起來與普通函數非常像,那麼使用宏有什麼好處呢?是否可以用函數取代宏呢?答案顯然是否定的,首先 Rust 的函數不能接受任意多個參數,其次函數是不能操作語法單元的,即把語法元素作為參數進行操作,從而生成代碼,例如 mod, crate 這些是 Rust 內置的關鍵詞,是不可能直接用函數去操作這些的,而宏就有這個能力。
相比函數,宏是用來生成代碼的,在調用宏的地方,編譯器會先將宏進行展開,生成代碼,然後再編譯展開後的代碼。
宏定義格式是: macro_rules! macro_name { macro_body },其中 macro_body 與模式匹配很像, pattern => do_something ,所以 Rust 的宏又稱為 Macro by example (基於例子的宏)。其中 pattern 和 do_something 都是用配對的括號括起來的,括號可以是圓括號、方括號、花括號中的任意一種。匹配可以有多個分支,每個分支以分號結束。
還是先來個簡單的例子說明
macro_rules! create_function { ($func_name:ident) => ( fn $func_name() { println!("function {:?} is called", stringify!($func_name)) } ) } fn main() { create_function!(foo); foo(); }
上面這個簡單的例子是用來創建函數,生成的函數可以像普通函數一樣調用,這個函數可以打印自己的名字。編譯器在看到 create_function!(foo) 時會從前面去找一個叫 create_function 的宏定義,找到之後,就會嘗試將參數 foo 代入 macro_body,對每一條模式按順序進行匹配,只要有一個匹配上,就會將 => 左邊定義的參數代入右邊進行替換,如果替換不成功,編譯器就會報錯而不會往下繼續匹配,替換成功就會將右邊替換後的代碼放在宏調用的地方。這個例子中只有一個模式,即 $func_name:ident,表示匹配一個標識符,如果匹配上就把這個標識符賦值給 $func_name,宏定義裡面的變量都是以 $ 開頭的,相應的類型也是以冒號分隔說明,這裡 ident 是變量 $func_name 的類型,表示這個變量是一個 identifier,這是語法層面的類型(designator),而普通的類型如 char, &str, i32, f64 這些是語義層面的類型。在 main 函數中傳給宏調用 create_function 的參數 foo 正好是一個標識符(ident),所以能匹配上,$func_name 就等於 foo,然後把 $func_name 的值代入 => 右邊,成了下面這樣的
#![allow(unused)] fn main() { fn foo() { println!("function {:?} is called", stringify!(foo)) } }
所以最後編譯器編譯的實際代碼是
fn main() { fn foo() { println!("function {:?} is called", stringify!(foo)) } foo(); }
上面定義了 create_function 這個宏之後,就可以隨便用來生成函數了,比如調用 create_function!(bar) 就得到了一個名為 bar 的函數
通過上面這個例子,大家對宏應該有一個大致的瞭解了。下面就具體談談宏的各個組成部分。
宏的結構
宏名
宏名字的解析與函數略微有些不同,宏的定義必須出現在宏調用之前,即與 C 裡面的函數類似--函數定義或聲明必須在函數調用之前,只不過 Rust 宏沒有單純的聲明,所以宏在調用之前需要先定義,而 Rust 函數則可以定義在函數調用後面。宏調用與宏定義順序相關性包括從其它模塊中引入的宏,所以引入其它模塊中的宏時要特別小心,這個稍後會詳細討論。
下面這個例子宏定義在宏調用後面,編譯器會報錯說找不到宏定義,而函數則沒問題
fn main() { let a = 42; foo(a); bar!(a); } fn foo(x: i32) { println!("The argument you passed to function is {}", x); } macro_rules! bar { ($x:ident) => { println!("The argument you passed to macro is {}", $x); } }
上面例子中把宏定義挪到 main 函數之前或者 main 函數里面 bar!(a) 調用上面,就可以正常編譯運行。
宏調用雖然與函數調用很像,但是宏的名字與函數名字是處於不同命名空間的,之所以提出來是因為在有些編程語言裡面宏和函數是在同一個命名空間之下的。看過下面的例子就會明白
fn foo(x: i32) -> i32 { x * x } macro_rules! foo { ($x:ident) => { println!("{:?}", $x); } } fn main() { let a = 5; foo!(a); println!("{}", foo(a)); }
指示符(designator)
宏裡面的變量都是以 $ 開頭的,其餘的都是按字面去匹配,以 $ 開頭的變量都是用來表示語法(syntactic)元素,為了限定匹配什麼類型的語法元素,需要用指示符(designator)加以限定,就跟普通的變量綁定一樣用冒號將變量和類型分開,當前宏支持以下幾種指示符:
- ident: 標識符,用來表示函數或變量名
- expr: 表達式
- block: 代碼塊,用花括號包起來的多個語句
- pat: 模式,普通模式匹配(非宏本身的模式)中的模式,例如
Some(t),(3, 'a', _) - path: 路徑,注意這裡不是操作系統中的文件路徑,而是用雙冒號分隔的限定名(qualified name),如
std::cmp::PartialOrd - tt: 單個語法樹
- ty: 類型,語義層面的類型,如
i32,char - item: 條目,
- meta: 元條目
- stmt: 單條語句,如
let a = 42;
加上這些類型限定後,宏在進行匹配時才不會漫無目的的亂匹配,例如在要求標識符的地方是不允許出現表達式的,否則編譯器就會報錯。而 C/C++ 語言中的宏則僅僅是簡單的文本替換,沒有語法層面的考慮,所以非常容易出錯。
重複(repetition)
宏相比函數一個很大的不同是宏可以接受任意多個參數,例如 println! 和 vec!。這是怎麼做到的呢?
沒錯,就是重複(repetition)。模式的重複不是通過程序裡面的循環(for/while)去控制的,而是指定了兩個特殊符號 + 和 *,類似於正則表達式,因為正則表達式也是不關心具體匹配對象是一個人名還是一個國家名。與正則表達式一樣, + 表示一次或多次(至少一次),而 * 表示零次或多次。重複的模式需要用括號括起來,外面再加上 $,例如 $(...)*, $(...)+。需要說明的是這裡的括號和宏裡面其它地方一樣都可以是三種括號中的任意一種,因為括號在這裡僅僅是用來標記一個模式的開始和結束,大部分情況重複的模式是用逗號或分號分隔的,所以你會經常看到 $(...),*, $(...);*, $(...),+, $(...);+ 這樣的用來表示重複。
還是來看一個例子
macro_rules! vector { ($($x:expr),*) => { { let mut temp_vec = Vec::new(); $(temp_vec.push($x);)* temp_vec } }; } fn main() { let a = vector![1, 2, 4, 8]; println!("{:?}", a); }
這個例子初看起來比較複雜,我們來分析一下。
首先看 => 左邊,最外層是圓括號,前面說過這個括號可以是圓括號、方括號、花括號中的任意一種,只要是配對的就行。然後再看括號裡面 $(...),* 正是剛才提到的重複模式,重複的模式是用逗號分隔的,重複的內容是 $x:expr,即可以匹配零次或多次用逗號分隔的表達式,例如 vector![] 和 vector![3, x*x, s-t] 都可以匹配成功。
接著看 => 右邊,最外層也是一個括號,末尾是分號表示這個分支結束。裡面是花括號包起來的代碼塊,最後一行沒有分號,說明這個 macro 的值是一個表達式,temp_vec 作為表達式的值返回。第一條語句就是普通的用 Vec::new() 生成一個空 vector,然後綁定到可變的變量 temp_vec 上面,第二句比較特殊,跟 => 左邊差不多,也是用來表示重複的模式,而且是跟左邊是一一對應的,即左邊匹配到一個表達式(expr),這裡就會將匹配到的表達式用在 temp_vec.push($x); 裡面,所以 vector![3, x*x, s-t] 調用就會展開成
#![allow(unused)] fn main() { { let mut temp_vec = Vec::new(); temp_vec.push(3); temp_vec.push(x*x); temp_vec.push(s-t); temp_vec } }
看著很複雜的宏,細細分析下來是不是很簡單,不要被這些符號干擾了
遞歸(recursion)
除了重複之外,宏還支持遞歸,即在宏定義時調用其自身,類似於遞歸函數。因為rust的宏本身是一種模式匹配,而模式匹配裡面包含遞歸則是函數式語言裡面最常見的寫法了,有函數式編程經驗的對這個應該很熟悉。下面看一個簡單的例子:
macro_rules! find_min { ($x:expr) => ($x); ($x:expr, $($y:expr),+) => ( std::cmp::min($x, find_min!($($y),+)) ) } fn main() { println!("{}", find_min!(1u32)); println!("{}", find_min!(1u32 + 2 , 2u32)); println!("{}", find_min!(5u32, 2u32 * 3, 4u32)); }
因為模式匹配是按分支順序匹配的,一旦匹配成功就不會再往下進行匹配(即使後面也能匹配上),所以模式匹配中的遞歸都是在第一個分支裡寫最簡單情況,越往下包含的情況越多。這裡也是一樣,第一個分支 ($x:expr) 只匹配一個表達式,第二個分支匹配兩個或兩個以上表達式,注意加號表示匹配一個或多個,然後裡面是用標準庫中的 min 比較兩個數的大小,第一個表達式和剩餘表達式中最小的一個,其中剩餘表達式中最小的一個是遞歸調用 find_min! 宏,與遞歸函數一樣,每次遞歸都是從上往下匹配,只到匹配到基本情況。我們來寫寫 find_min!(5u32, 2u32 * 3, 4u32) 宏展開過程
std::cmp::min(5u32, find_min!(2u32 * 3, 4u32))std::cmp::min(5u32, std::cmp::min(2u32 * 3, find_min!(4u32)))std::cmp::min(5u32, std::cmp::min(2u32 * 3, 4u32))
分析起來與遞歸函數一樣,也比較簡單。
衛生(hygienic Macro)
有了重複和遞歸,組合起來就是一個很強大的武器,可以解決很多普通函數無法抽象的東西。但是這裡面會有一個安全問題,也是 C/C++ 裡面宏最容易出錯的地方,不過 Rust 像 Scheme 一樣引入了衛生(Hygiene)宏,有效地避免了這類問題的發生。
C/C++ 裡面的宏僅僅是簡單的文本替換,下面的 C 經過宏預處理後,宏外面定義的變量 a 就會與裡面定義的混在一起,從而按作用域 shadow 外層的定義,這會導致一些非常詭異的問題,不去看宏具體定義仔細分析的話,很難發現這類 bug。這樣的宏是不衛生的,不過也有些奇葩的 Hacker 覺得這是一個非常棒的特性,例如 CommanLisp 語言裡面的宏本身很強大,但不是衛生的,而某些 Hacker 還以這個為傲,搞一些奇技淫巧故意製造出這樣的 shadow 行為實現一些很 fancy 的效果。這裡不做過多評論,對 C 比較熟悉的同學可以分析一下下面這段代碼運行結果與第一印象是否一樣。
#define INCI(i) {int a=0; ++i;}
int main(void)
{
int a = 0, b = 0;
INCI(a);
INCI(b);
printf("a is now %d, b is now %d\n", a, b);
return 0;
}
衛生宏最開始是由 Scheme 語言引入的,後來好多語言基本都採用衛生宏,即編譯器或運行時會保證宏裡面定義的變量或函數不會與外面的衝突,在宏裡面以普通方式定義的變量作用域不會跑到宏外面。
macro_rules! foo { () => (let x = 3); } macro_rules! bar { ($v:ident) => (let $v = 3); } fn main() { foo!(); println!("{}", x); bar!(a); println!("{}", a); }
上面代碼中宏 foo! 裡面的變量 x 是按普通方式定義的,所以其作用域限定在宏裡面,宏調用結束後再引用 x 編譯器就會報錯。要想讓宏裡面定義的變量在宏調用結束後仍然有效,需要按 bar! 裡面那樣定義。不過對於 item 規則就有些不同,例如函數在宏裡面以普通方式定義後,宏調用之後,這個函數依然可用,下面代碼就可以正常編譯。
macro_rules! foo { () => (fn x() { }); } fn main() { foo!(); x(); }
導入導出(import/export)
前面提到宏名是按順序解析的,所以從其它模塊中導入宏時與導入函數、trait 的方式不太一樣,宏導入導出用 #[macro_use] 和 #[macro_export]。父模塊中定義的宏對其下的子模塊是可見的,要想子模塊中定義的宏在其後面的父模塊中可用,需要使用 #[macro_use]。
#![allow(unused)] fn main() { macro_rules! m1 { () => (()) } // 宏 m1 在這裡可用 mod foo { // 宏 m1 在這裡可用 #[macro_export] macro_rules! m2 { () => (()) } // 宏 m1 和 m2 在這裡可用 } // 宏 m1 在這裡可用 #[macro_export] macro_rules! m3 { () => (()) } // 宏 m1 和 m3 在這裡可用 #[macro_use] mod bar { // 宏 m1 和 m3 在這裡可用 macro_rules! m4 { () => (()) } // 宏 m1, m3, m4 在這裡均可用 } // 宏 m1, m3, m4 均可用 }
crate 之間只有被標為 #[macro_export] 的宏可以被其它 crate 導入。假設上面例子是 foo crate 中的部分代碼,則只有 m2 和 m3 可以被其它 crate 導入。導入方式是在 extern crate foo; 前面加上 #[macro_use]
#![allow(unused)] fn main() { #[macro_use] extern crate foo; // foo 中 m2, m3 都被導入 }
如果只想導入 foo crate 中某個宏,比如 m3,就給 #[macro_use] 加上參數
#![allow(unused)] fn main() { #[macro_use(m3)] extern crate foo; // foo 中只有 m3 被導入 }
調試
雖然宏功能很強大,但是調試起來要比普通代碼困難,因為編譯器默認情況下給出的提示都是對宏展開之後的,而不是你寫的原程序,要想在編譯器錯誤與原程序之間建立聯繫比較困難,因為這要求你大腦能夠人肉編譯展開宏代碼。不過還好編譯器為我們提供了 --pretty=expanded 選項,能讓我們看到展開後的代碼,通過這個展開後的代碼,往上靠就與你自己寫的原程序有個直接對應關係,往下靠與編譯器給出的錯誤也是直接對應關係。
目前將宏展開需要使用 unstable option,通過 rustc -Z unstable-options --pretty=expanded hello.rs 可以查看宏展開後的代碼,如果是使用的 cargo 則通過 cargo rustc -- -Z unstable-options --pretty=expanded 將項目裡面的宏都展開。不過目前是沒法只展開部分宏的,而且由於 hygiene 的原因,會對宏裡面的名字做些特殊的處理(mangle),所以程序裡面的宏全部展開後代碼的可讀性比較差,不過依然比依靠大腦展開靠譜。
下面可以看看最簡單的 hello-word 程序裡面的 println!("Hello, world!") 展開結果,為了 hygiene 這裡內部臨時變量用了 __STATIC_FMTSTR 這樣的名字以避免名字衝突,即使這簡單的一句展開後看起來也還是不那麼直觀的,具體這裡就不詳細分析了。
$ rustc -Z unstable-options --pretty expanded hello.rs
#![feature(prelude_import)]
#![no_std]
#[prelude_import]
use std::prelude::v1::*;
#[macro_use]
extern crate std as std;
fn main() {
::std::io::_print(::std::fmt::Arguments::new_v1({
static __STATIC_FMTSTR:
&'static [&'static str]
=
&["Hello, world!\n"];
__STATIC_FMTSTR
},
&match () { () => [], }));
}
Heap & Stack
簡介
heap和stack是計算機裡面最基本的概念,不過如果一直使用高級語言如 Python/Ruby/PHP/Java 等之類的語言的話,可能對heap和stack並不怎麼理解,當然這裡的stack(Stack)並不是數據結構裡面的概念,而是計算機對內存的一個抽象。相比而言,C/C++/Rust 這些語言就必須對heap和stack的概念非常瞭解才能寫出正確的程序,之所以有這樣的區別是因為它們的內存管理方式不同,Python 之類的語言程序運行時會同時會運行垃圾回收器,垃圾回收器與用戶程序或並行執行或交錯執行,垃圾回收器會自動釋放不再使用的內存空間,而 C/C++/Rust 則沒有垃圾回收器。
操作系統會將物理內存映射成虛擬地址空間,程序在啟動時看到的虛擬地址空間是一塊完整連續的內存。
stack內存從高位地址向下增長,且stack內存分配是連續的,一般操作系統對stack內存大小是有限制的,Linux/Unix 類系統上面可以通過 ulimit 設置最大stack空間大小,所以 C 語言中無法創建任意長度的數組。在Rust裡,函數調用時會創建一個臨時stack空間,調用結束後 Rust 會讓這個stack空間裡的對象自動進入 Drop 流程,最後stack頂指針自動移動到上一個調用stack頂,無需程序員手動干預,因而stack內存申請和釋放是非常高效的。
相對地,heap上內存則是從低位地址向上增長,heap內存通常只受物理內存限制,而且通常是不連續的,一般由程序員手動申請和釋放的,如果想申請一塊連續內存,則操作系統需要在heap中查找一塊未使用的滿足大小的連續內存空間,故其效率比stack要低很多,尤其是heap上如果有大量不連續內存時。另外內存使用完也必須由程序員手動釋放,不然就會出現內存洩漏,內存洩漏對需要長時間運行的程序(例如守護進程)影響非常大。
Rust 中的heap和stack
由於函數stack在函數執行完後會銷燬,所以stack上存儲的變量不能在函數之間傳遞,這也意味著函數沒法返回stack上變量的引用,而這通常是 C/C++ 新手常犯的錯誤。而 Rust 中編譯器則會檢查出這種錯誤,錯誤提示一般為 xxx does not live long enough,看下面一個例子
fn main() { let b = foo("world"); println!("{}", b); } fn foo(x: &str) -> &str { let a = "Hello, ".to_string() + x; &a }
之所以這樣寫,很多人覺得可以直接拷貝字符串 a 的引用從而避免拷貝整個字符串,然而得到的結果卻是 a does not live long enough 的編譯錯誤。因為引用了一個函數stack中臨時創建的變量,函數stack在函數調用結束後會銷燬,這樣返回的引用就變得毫無意義了,指向了一個並不存在的變量。相對於 C/C++ 而言,使用 Rust 就會幸運很多,因為 C/C++ 中寫出上面那樣的程序,編譯器會默默地讓你通過直到運行時才會給你報錯。
其實由於 a 本身是 String 類型,是使用heap來存儲的,所以可以直接返回,在函數返回時函數stack銷燬後依然存在。同時 Rust 中下面的代碼實際上也只是淺拷貝。
fn main() { let b = foo("world"); println!("{}", b); } fn foo(x: &str) -> String { let a = "Hello, ".to_string() + x; a }
Rust 默認使用stack來存儲變量,而stack上內存分配是連續的,所以必須在編譯之前瞭解變量佔用的內存空間大小,編譯器才能合理安排內存佈局。
Box
C 裡面是通過 malloc/free 手動管理heap上內存空間的,而 Rust 則有多種方式,其中最常用的一種就是 Box,通過 Box::new() 可以在heap上申請一塊內存空間,不像 C 裡面一樣heap上空間需要手動調用 free 釋放,Rust 中是在編譯期編譯器藉助 lifetime 對heap內存生命期進行分析,在生命期結束時自動插入 free。當前 Rust 底層即 Box 背後是調用 jemalloc 來做內存管理的,所以heap上空間是不需要程序員手動去管理釋放的。很多時候你被編譯器虐得死去活來時,那些 borrow, move, lifetime 錯誤其實就是編譯器在教你認識內存佈局,教你用 lifetime 規則去控制內存。這套規則說難不難,說簡單也不簡單,以前用別的語言寫程序時對內存不關心的,剛寫起來可能真的會被虐得死去活來,但是一旦熟悉這套規則,對內存佈局掌握清楚後,藉助編譯器的提示寫起程序來就會如魚得水,這套規則是理論界研究的成果在Rust編譯器上的實踐。
大多數帶 GC 的面嚮對象語言裡面的對象都是藉助 box 來實現的,比如常見的動態語言 Python/Ruby/JavaScript 等,其宣稱的"一切皆對象(Everything is an object)",裡面所謂的對象基本上都是 boxed value。
boxed 值相對於 unboxed,內存佔用空間會大些,同時訪問值的時候也需要先進行 unbox,即對指針進行解引用再獲取真正存儲的值,所以內存訪問開銷也會大些。既然 boxed 值既費空間又費時間,為什麼還要這麼做呢?因為通過 box,所有對象看起來就像是以相同大小存儲的,因為只需要存儲一個指針就夠了,應用程序可以同等看待各種值,而不用去管實際存儲是多大的值,如何申請和釋放相應資源。
Box 是heap上分配的內存,通過 Box::new() 會創建一個heap空間並返回一個指向heap空間的指針
nightly 版本中引入 box 關鍵詞,可以用來取代 Box::new() 申請一個heap空間,也可以用在模式匹配上面
#![feature(box_syntax, box_patterns)] fn main() { let boxed = Some(box 5); match boxed { Some(box unboxed) => println!("Some {}", unboxed), None => println!("None"), } }
下面看一個例子,對比一下 Vec<i32> 和 Vec<Box<i32>> 內存佈局,這兩個圖來自 Stack Overflow,從這兩張內存分佈圖可以清楚直觀地看出 Box 是如何存儲的
Vec<i32>
(stack) (heap)
┌──────┐ ┌───┐
│ vec1 │──→│ 1 │
└──────┘ ├───┤
│ 2 │
├───┤
│ 3 │
├───┤
│ 4 │
└───┘
Vec<Box<i32>>
(stack) (heap) ┌───┐
┌──────┐ ┌───┐ ┌─→│ 1 │
│ vec2 │──→│ │─┘ └───┘
└──────┘ ├───┤ ┌───┐
│ │───→│ 2 │
├───┤ └───┘
│ │─┐ ┌───┐
├───┤ └─→│ 3 │
│ │─┐ └───┘
└───┘ │ ┌───┐
└─→│ 4 │
└───┘
一些語言裡會有看起來既像數組又像列表的數據結構,例如 python 中的 List,其實就是與 Vec<Box<i32>> 類似,只是把 i32 換成任意類型,就操作效率而言比單純的 List 高效,同時又比數組使用更靈活。
一般而言,在編譯期間不能確定大小的數據類型都需要使用heap上內存,因為編譯器無法在stack上分配 編譯期未知大小 的內存,所以諸如 String, Vec 這些類型的內存其實是被分配在heap上的。換句話說,我們可以很輕鬆的將一個 Vec move 出作用域而不必擔心消耗,因為數據實際上不會被複制。
另外,需要從函數中返回一個淺拷貝的變量時也需要使用heap內存而不能直接返回一個指向函數內部定義變量的引用。
幾種智能指針
本章講解 Rc, Arc, Mutex, RwLock, Cell, RefCell 的知識和使用方法。
Rc 和 Arc
Rust 建立在所有權之上的這一套機制,它要求一個資源同一時刻有且只能有一個擁有所有權的綁定或 &mut 引用,這在大部分的情況下保證了內存的安全。但是這樣的設計是相當嚴格的,在另外一些情況下,它限制了程序的書寫,無法實現某些功能。因此,Rust 在 std 庫中提供了額外的措施來補充所有權機制,以應對更廣泛的場景。
默認 Rust 中,對一個資源,同一時刻,有且只有一個所有權擁有者。Rc 和 Arc 使用引用計數的方法,讓程序在同一時刻,實現同一資源的多個所有權擁有者,多個擁有者共享資源。
Rc
Rc 用於同一線程內部,通過 use std::rc::Rc 來引入。它有以下幾個特點:
- 用
Rc包裝起來的類型對象,是immutable的,即 不可變的。即你無法修改Rc<T>中的T對象,只能讀; - 一旦最後一個擁有者消失,則資源會被自動回收,這個生命週期是在編譯期就確定下來的;
Rc只能用於同一線程內部,不能用於線程之間的對象共享(不能跨線程傳遞);Rc實際上是一個指針,它不影響包裹對象的方法調用形式(即不存在先解開包裹再調用值這一說)。
例子:
#![allow(unused)] fn main() { use std::rc::Rc; let five = Rc::new(5); let five2 = five.clone(); let five3 = five.clone(); }
Rc Weak
Weak 通過 use std::rc::Weak 來引入。
Rc 是一個引用計數指針,而 Weak 是一個指針,但不增加引用計數,是 Rc 的 weak 版。它有以下幾個特點:
- 可訪問,但不擁有。不增加引用計數,因此,不會對資源回收管理造成影響;
- 可由
Rc<T>調用downgrade方法而轉換成Weak<T>; Weak<T>可以使用upgrade方法轉換成Option<Rc<T>>,如果資源已經被釋放,則 Option 值為None;- 常用於解決循環引用的問題。
例子:
#![allow(unused)] fn main() { use std::rc::Rc; let five = Rc::new(5); let weak_five = Rc::downgrade(&five); let strong_five: Option<Rc<_>> = weak_five.upgrade(); }
Arc
Arc 是原子引用計數,是 Rc 的多線程版本。Arc 通過 std::sync::Arc 引入。
它的特點:
Arc可跨線程傳遞,用於跨線程共享一個對象;- 用
Arc包裹起來的類型對象,對可變性沒有要求; - 一旦最後一個擁有者消失,則資源會被自動回收,這個生命週期是在編譯期就確定下來的;
Arc實際上是一個指針,它不影響包裹對象的方法調用形式(即不存在先解開包裹再調用值這一說);Arc對於多線程的共享狀態幾乎是必須的(減少複製,提高性能)。
示例:
use std::sync::Arc; use std::thread; fn main() { let numbers: Vec<_> = (0..100u32).collect(); let shared_numbers = Arc::new(numbers); for _ in 0..10 { let child_numbers = shared_numbers.clone(); thread::spawn(move || { let local_numbers = &child_numbers[..]; // Work with the local numbers }); } }
Arc Weak
與 Rc 類似,Arc 也有一個對應的 Weak 類型,從 std::sync::Weak 引入。
意義與用法與 Rc Weak 基本一致,不同的點是這是多線程的版本。故不再贅述。
一個例子
下面這個例子,表述的是如何實現多個對象同時引用另外一個對象。
use std::rc::Rc; struct Owner { name: String } struct Gadget { id: i32, owner: Rc<Owner> } fn main() { // Create a reference counted Owner. let gadget_owner : Rc<Owner> = Rc::new( Owner { name: String::from("Gadget Man") } ); // Create Gadgets belonging to gadget_owner. To increment the reference // count we clone the `Rc<T>` object. let gadget1 = Gadget { id: 1, owner: gadget_owner.clone() }; let gadget2 = Gadget { id: 2, owner: gadget_owner.clone() }; drop(gadget_owner); // Despite dropping gadget_owner, we're still able to print out the name // of the Owner of the Gadgets. This is because we've only dropped the // reference count object, not the Owner it wraps. As long as there are // other `Rc<T>` objects pointing at the same Owner, it will remain // allocated. Notice that the `Rc<T>` wrapper around Gadget.owner gets // automatically dereferenced for us. println!("Gadget {} owned by {}", gadget1.id, gadget1.owner.name); println!("Gadget {} owned by {}", gadget2.id, gadget2.owner.name); // At the end of the method, gadget1 and gadget2 get destroyed, and with // them the last counted references to our Owner. Gadget Man now gets // destroyed as well. }
Mutex 與 RwLock
Mutex
Mutex 意為互斥對象,用來保護共享數據。Mutex 有下面幾個特徵:
Mutex會等待獲取鎖令牌(token),在等待過程中,會阻塞線程。直到鎖令牌得到。同時只有一個線程的Mutex對象獲取到鎖;Mutex通過.lock()或.try_lock()來嘗試得到鎖令牌,被保護的對象,必須通過這兩個方法返回的RAII守衛來調用,不能直接操作;- 當
RAII守衛作用域結束後,鎖會自動解開; - 在多線程中,
Mutex一般和Arc配合使用。
示例:
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex}; use std::thread; use std::sync::mpsc::channel; const N: usize = 10; // Spawn a few threads to increment a shared variable (non-atomically), and // let the main thread know once all increments are done. // // Here we're using an Arc to share memory among threads, and the data inside // the Arc is protected with a mutex. let data = Arc::new(Mutex::new(0)); let (tx, rx) = channel(); for _ in 0..10 { let (data, tx) = (data.clone(), tx.clone()); thread::spawn(move || { // The shared state can only be accessed once the lock is held. // Our non-atomic increment is safe because we're the only thread // which can access the shared state when the lock is held. // // We unwrap() the return value to assert that we are not expecting // threads to ever fail while holding the lock. let mut data = data.lock().unwrap(); *data += 1; if *data == N { tx.send(()).unwrap(); } // the lock is unlocked here when `data` goes out of scope. }); } rx.recv().unwrap(); }
lock 與 try_lock 的區別
.lock() 方法,會等待鎖令牌,等待的時候,會阻塞當前線程。而 .try_lock() 方法,只是做一次嘗試操作,不會阻塞當前線程。
當 .try_lock() 沒有獲取到鎖令牌時,會返回 Err。因此,如果要使用 .try_lock(),需要對返回值做仔細處理(比如,在一個循環檢查中)。
點評:Rust 的 Mutex 設計成一個對象,不同於 C 語言中的自旋鎖用兩條分開的語句的實現,更安全,更美觀,也更好管理。
RwLock
RwLock 翻譯成 讀寫鎖。它的特點是:
- 同時允許多個讀,最多隻能有一個寫;
- 讀和寫不能同時存在;
比如:
#![allow(unused)] fn main() { use std::sync::RwLock; let lock = RwLock::new(5); // many reader locks can be held at once { let r1 = lock.read().unwrap(); let r2 = lock.read().unwrap(); assert_eq!(*r1, 5); assert_eq!(*r2, 5); } // read locks are dropped at this point // only one write lock may be held, however { let mut w = lock.write().unwrap(); *w += 1; assert_eq!(*w, 6); } // write lock is dropped here }
讀寫鎖的方法
.read().try_read().write().try_write()
注意需要對 .try_read() 和 .try_write() 的返回值進行判斷。
Cell, RefCell
前面我們提到,Rust 通過其所有權機制,嚴格控制擁有和借用關係,來保證程序的安全,並且這種安全是在編譯期可計算、可預測的。但是這種嚴格的控制,有時也會帶來靈活性的喪失,有的場景下甚至還滿足不了需求。
因此,Rust 標準庫中,設計了這樣一個系統的組件:Cell, RefCell,它們彌補了 Rust 所有權機制在靈活性上和某些場景下的不足。同時,又沒有打破 Rust 的核心設計。它們的出現,使得 Rust 革命性的語言理論設計更加完整,更加實用。
具體是因為,它們提供了 內部可變性(相對於標準的 繼承可變性 來講的)。
通常,我們要修改一個對象,必須
- 成為它的擁有者,並且聲明
mut; - 或 以
&mut的形式,借用;
而通過 Cell, RefCell,我們可以在需要的時候,就可以修改裡面的對象。而不受編譯期靜態借用規則束縛。
Cell
Cell 有如下特點:
Cell<T>只能用於T實現了Copy的情況;
.get()
.get() 方法,返回內部值的一個拷貝。比如:
#![allow(unused)] fn main() { use std::cell::Cell; let c = Cell::new(5); let five = c.get(); }
.set()
.set() 方法,更新值。
#![allow(unused)] fn main() { use std::cell::Cell; let c = Cell::new(5); c.set(10); }
RefCell
相對於 Cell 只能包裹實現了 Copy 的類型,RefCell 用於更普遍的情況(其它情況都用 RefCell)。
相對於標準情況的 靜態借用,RefCell 實現了 運行時借用,這個借用是臨時的。這意味著,編譯器對 RefCell 中的內容,不會做靜態借用檢查,也意味著,出了什麼問題,用戶自己負責。
RefCell 的特點:
- 在不確定一個對象是否實現了
Copy時,直接選RefCell; - 如果被包裹對象,同時被可變借用了兩次,則會導致線程崩潰。所以需要用戶自行判斷;
RefCell只能用於線程內部,不能跨線程;RefCell常常與Rc配合使用(都是單線程內部使用);
我們來看實例:
use std::collections::HashMap; use std::cell::RefCell; use std::rc::Rc; fn main() { let shared_map: Rc<RefCell<_>> = Rc::new(RefCell::new(HashMap::new())); shared_map.borrow_mut().insert("africa", 92388); shared_map.borrow_mut().insert("kyoto", 11837); shared_map.borrow_mut().insert("piccadilly", 11826); shared_map.borrow_mut().insert("marbles", 38); }
從上例可看出,用了 RefCell 後,外面是 不可變引用 的情況,一樣地可以修改被包裹的對象。
常用方法
.borrow()
不可變借用被包裹值。同時可存在多個不可變借用。
比如:
#![allow(unused)] fn main() { use std::cell::RefCell; let c = RefCell::new(5); let borrowed_five = c.borrow(); let borrowed_five2 = c.borrow(); }
下面的例子會崩潰:
#![allow(unused)] fn main() { use std::cell::RefCell; use std::thread; let result = thread::spawn(move || { let c = RefCell::new(5); let m = c.borrow_mut(); let b = c.borrow(); // this causes a panic }).join(); assert!(result.is_err()); }
.borrow_mut()
可變借用被包裹值。同時只能有一個可變借用。
比如:
#![allow(unused)] fn main() { use std::cell::RefCell; let c = RefCell::new(5); let borrowed_five = c.borrow_mut(); }
下面的例子會崩潰:
#![allow(unused)] fn main() { use std::cell::RefCell; use std::thread; let result = thread::spawn(move || { let c = RefCell::new(5); let m = c.borrow(); let b = c.borrow_mut(); // this causes a panic }).join(); assert!(result.is_err()); }
.into_inner()
取出包裹值。
#![allow(unused)] fn main() { use std::cell::RefCell; let c = RefCell::new(5); let five = c.into_inner(); }
一個綜合示例
下面這個示例,表述的是如何實現兩個對象的循環引用。綜合演示了 Rc, Weak, RefCell 的用法
use std::rc::Rc; use std::rc::Weak; use std::cell::RefCell; struct Owner { name: String, gadgets: RefCell<Vec<Weak<Gadget>>>, // 其他字段 } struct Gadget { id: i32, owner: Rc<Owner>, // 其他字段 } fn main() { // 創建一個可計數的Owner。 // 注意我們將gadgets賦給了Owner。 // 也就是在這個結構體裡, gadget_owner包含gadets let gadget_owner : Rc<Owner> = Rc::new( Owner { name: "Gadget Man".to_string(), gadgets: RefCell::new(Vec::new()), } ); // 首先,我們創建兩個gadget,他們分別持有 gadget_owner 的一個引用。 let gadget1 = Rc::new(Gadget{id: 1, owner: gadget_owner.clone()}); let gadget2 = Rc::new(Gadget{id: 2, owner: gadget_owner.clone()}); // 我們將從gadget_owner的gadgets字段中持有其可變引用 // 然後將兩個gadget的Weak引用傳給owner。 gadget_owner.gadgets.borrow_mut().push(Rc::downgrade(&gadget1)); gadget_owner.gadgets.borrow_mut().push(Rc::downgrade(&gadget2)); // 遍歷 gadget_owner的gadgets字段 for gadget_opt in gadget_owner.gadgets.borrow().iter() { // gadget_opt 是一個 Weak<Gadget> 。 因為 weak 指針不能保證他所引用的對象 // 仍然存在。所以我們需要顯式的調用 upgrade() 來通過其返回值(Option<_>)來判 // 斷其所指向的對象是否存在。 // 當然,這個Option為None的時候這個引用原對象就不存在了。 let gadget = gadget_opt.upgrade().unwrap(); println!("Gadget {} owned by {}", gadget.id, gadget.owner.name); } // 在main函數的最後, gadget_owner, gadget1和daget2都被銷燬。 // 具體是,因為這幾個結構體之間沒有了強引用(`Rc<T>`),所以,當他們銷燬的時候。 // 首先 gadget1和gadget2被銷燬。 // 然後因為gadget_owner的引用數量為0,所以這個對象可以被銷燬了。 // 循環引用問題也就避免了 }
類型系統中的幾個常見 trait
本章講解 Rust 類型系統中的幾個常見 trait。有 Into, From, AsRef, AsMut, Borrow, BorrowMut, ToOwned, Deref, Cow。
Into/From 及其在 String 和 &str 互轉上的應用
std::convert 下面,有兩個 Trait,Into/From,它們是一對孿生姐妹。它們的作用是配合泛型,進行一些設計上的歸一化處理。
它們的基本形式為: From<T> 和 Into<T>。
From
對於類型為 U 的對象 foo,如果它實現了 From<T>,那麼,可以通過 let foo = U::from(bar) 來生成自己。這裡,bar 是類型為 T 的對象。
下面舉一例,因為 String 實現了 From<&str>,所以 String 可以從 &str 生成。
#![allow(unused)] fn main() { let string = "hello".to_string(); let other_string = String::from("hello"); assert_eq!(string, other_string); }
Into
對於一個類型為 U: Into<T> 的對象 foo,Into 提供了一個函數:.into(self) -> T,調用 foo.into() 會消耗自己(轉移資源所有權),生成類型為 T 的另一個新對象 bar。
這句話,說起來有點抽象。下面拿一個具體的實例來輔助理解。
#![allow(unused)] fn main() { fn is_hello<T: Into<Vec<u8>>>(s: T) { let bytes = b"hello".to_vec(); assert_eq!(bytes, s.into()); } let s = "hello".to_string(); is_hello(s); }
因為 String 類型實現了 Into<Vec<u8>>。
下面拿一個實際生產中字符串作為函數參數的例子來說明。
在我們設計庫的 API 的時候,經常會遇到一個惱人的問題,函數參數如果定為 String,則外部傳入實參的時候,對字符串字面量,必須要做 .to_string() 或 .to_owned() 轉換,參數一多,就是一件又乏味又醜的事情。(而反過來設計的話,對初學者來說,又會遇到一些生命週期的問題,比較麻煩,這個後面論述)
那存不存在一種方法,能夠使傳參又能夠接受 String 類型,又能夠接受 &str 類型呢?答案就是泛型。而僅是泛型的話,太寬泛。因此,標準庫中,提供了 Into<T> 來為其做約束,以便方便而高效地達到我們的目的。
比如,我們有如下結構體:
#![allow(unused)] fn main() { struct Person { name: String, } impl Person { fn new (name: String) -> Person { Person { name: name } } } }
我們在調用的時候,是這樣的:
#![allow(unused)] fn main() { let name = "Herman".to_string(); let person = Person::new(name); }
如果直接寫成:
#![allow(unused)] fn main() { let person = Person::new("Herman"); }
就會報類型不匹配的錯誤。
好了,下面 Into 出場。我們可以定義結構體為
#![allow(unused)] fn main() { struct Person { name: String, } impl Person { fn new<S: Into<String>>(name: S) -> Person { Person { name: name.into() } } } }
然後,調用的時候,下面兩種寫法都是可以的:
fn main() { let person = Person::new("Herman"); let person = Person::new("Herman".to_string()); }
我們來仔細分析一下這一塊的寫法
#![allow(unused)] fn main() { impl Person { fn new<S: Into<String>>(name: S) -> Person { Person { name: name.into() } } } }
參數類型為 S, 是一個泛型參數,表示可以接受不同的類型。S: Into<String> 表示 S 類型必須實現了 Into<String>(約束)。而 &str 類型,符合這個要求。因此 &str 類型可以直接傳進來。
而 String 本身也是實現了 Into<String> 的。當然也可以直接傳進來。
然後,下面 name: name.into() 這裡也挺神秘的。它的作用是將 name 轉換成 String 類型的另一個對象。當 name 是 &str 時,它會轉換成 String 對象,會做一次字符串的拷貝(內存的申請、複製)。而當 name 本身是 String 類型時,name.into() 不會做任何轉換,代價為零(有沒有恍然大悟)。
根據參考資料,上述內容通過下面三式獲得:
#![allow(unused)] fn main() { impl<'a> From<&'a str> for String {} impl<T> From<T> for T {} impl<T, U> Into<U> for T where U: From<T> {} }
更多內容,請參考:
- http://doc.rust-lang.org/std/convert/trait.Into.html
- http://doc.rust-lang.org/std/convert/trait.From.html
- http://hermanradtke.com/2015/05/06/creating-a-rust-function-that-accepts-string-or-str.html
AsRef 和 AsMut
std::convert 下面,還有另外兩個 Trait,AsRef/AsMut,它們功能是配合泛型,在執行引用操作的時候,進行自動類型轉換。這能夠使一些場景的代碼實現得清晰漂亮,大家方便開發。
AsRef
AsRef 提供了一個方法 .as_ref()。
對於一個類型為 T 的對象 foo,如果 T 實現了 AsRef<U>,那麼,foo 可執行 .as_ref() 操作,即 foo.as_ref()。操作的結果,我們得到了一個類型為 &U 的新引用。
注:
- 與
Into<T>不同的是,AsRef<T>只是類型轉換,foo對象本身沒有被消耗; T: AsRef<U>中的T,可以接受 資源擁有者(owned)類型,共享引用(shared referrence)類型 ,可變引用(mutable referrence)類型。
下面舉個簡單的例子:
#![allow(unused)] fn main() { fn is_hello<T: AsRef<str>>(s: T) { assert_eq!("hello", s.as_ref()); } let s = "hello"; is_hello(s); let s = "hello".to_string(); is_hello(s); }
因為 String 和 &str 都實現了 AsRef<str>。
AsMut
AsMut<T> 提供了一個方法 .as_mut()。它是 AsRef<T> 的可變(mutable)引用版本。
對於一個類型為 T 的對象 foo,如果 T 實現了 AsMut<U>,那麼,foo 可執行 .as_mut() 操作,即 foo.as_mut()。操作的結果,我們得到了一個類型為 &mut U 的可變(mutable)引用。
注:在轉換的過程中,foo 會被可變(mutable)借用。
Borrow, BorrowMut, ToOwned
Borrow
use std::borrow::Borrow;
Borrow 提供了一個方法 .borrow()。
對於一個類型為 T 的值 foo,如果 T 實現了 Borrow<U>,那麼,foo 可執行 .borrow() 操作,即 foo.borrow()。操作的結果,我們得到了一個類型為 &U 的新引用。
Borrow 可以認為是 AsRef 的嚴格版本,它對普適引用操作的前後類型之間附加了一些其它限制。
Borrow 的前後類型之間要求必須有內部等價性。不具有這個等價性的兩個類型之間,不能實現 Borrow。
AsRef 更通用,更普遍,覆蓋類型更多,是 Borrow 的超集。
舉例:
#![allow(unused)] fn main() { use std::borrow::Borrow; fn check<T: Borrow<str>>(s: T) { assert_eq!("Hello", s.borrow()); } let s = "Hello".to_string(); check(s); let s = "Hello"; check(s); }
BorrowMut
use std::borrow::BorrowMut;
BorrowMut<T> 提供了一個方法 .borrow_mut()。它是 Borrow<T> 的可變(mutable)引用版本。
對於一個類型為 T 的值 foo,如果 T 實現了 BorrowMut<U>,那麼,foo 可執行 .borrow_mut() 操作,即 foo.borrow_mut()。操作的結果我們得到類型為 &mut U 的一個可變(mutable)引用。
注:在轉換的過程中,foo 會被可變(mutable)借用。
ToOwned
use std::borrow::ToOwned;
ToOwned 為 Clone 的普適版本。它提供了 .to_owned() 方法,用於類型轉換。
有些實現了 Clone 的類型 T 可以從引用狀態實例 &T 通過 .clone() 方法,生成具有所有權的 T 的實例。但是它只能由 &T 生成 T。而對於其它形式的引用,Clone 就無能為力了。
而 ToOwned trait 能夠從任意引用類型實例,生成具有所有權的類型實例。
參考
Deref
Deref 是 deref 操作符 * 的 trait,比如 *v。
一般理解,*v 操作,是 &v 的反向操作,即試圖由資源的引用獲取到資源的拷貝(如果資源類型實現了 Copy),或所有權(資源類型沒有實現 Copy)。
Rust 中,本操作符行為可以重載。這也是 Rust 操作符的基本特點。本身沒有什麼特別的。
強制隱式轉換(coercion)
Deref 神奇的地方並不在本身 解引 這個意義上,Rust 的設計者在它之上附加了一個特性:強制隱式轉換,這才是它神奇之處。
這種隱式轉換的規則為:
一個類型為 T 的對象 foo,如果 T: Deref<Target=U>,那麼,相關 foo 的某個智能指針或引用(比如 &foo)在應用的時候會自動轉換成 &U。
粗看這條規則,貌似有點類似於 AsRef,而跟 解引 似乎風馬牛不相及。實際裡面有些玄妙之處。
Rust 編譯器會在做 *v 操作的時候,自動先把 v 做引用歸一化操作,即轉換成內部通用引用的形式 &v,整個表達式就變成 *&v。這裡面有兩種情況:
- 把其它類型的指針(比如在庫中定義的,
Box,Rc,Arc,Cow等),轉成內部標準形式&v; - 把多重
&(比如:&&&&&&&v),簡化成&v(通過插入足夠數量的*進行解引)。
所以,它實際上在解引用之前做了一個引用的歸一化操作。
為什麼要轉呢? 因為編譯器設計的能力是,只能夠對 &v 這種引用進行解引用。其它形式的它不認識,所以要做引用歸一化操作。
使用引用進行過渡也是為了能夠防止不必要的拷貝。
下面舉一些例子:
#![allow(unused)] fn main() { fn foo(s: &str) { // borrow a string for a second } // String implements Deref<Target=str> let owned = "Hello".to_string(); // therefore, this works: foo(&owned); }
因為 String 實現了 Deref<Target=str>。
#![allow(unused)] fn main() { use std::rc::Rc; fn foo(s: &str) { // borrow a string for a second } // String implements Deref<Target=str> let owned = "Hello".to_string(); let counted = Rc::new(owned); // therefore, this works: foo(&counted); }
因為 Rc<T> 實現了 Deref<Target=T>。
#![allow(unused)] fn main() { fn foo(s: &[i32]) { // borrow a slice for a second } // Vec<T> implements Deref<Target=[T]> let owned = vec![1, 2, 3]; foo(&owned); }
因為 Vec<T> 實現了 Deref<Target=[T]>。
#![allow(unused)] fn main() { struct Foo; impl Foo { fn foo(&self) { println!("Foo"); } } let f = &&Foo; f.foo(); (&f).foo(); (&&f).foo(); (&&&&&&&&f).foo(); }
上面那幾種函數的調用,效果是一樣的。
coercion 的設計,是 Rust 中僅有的類型隱式轉換,設計它的目的,是為了簡化程序的書寫,讓代碼不至於過於繁瑣。把人從無盡的類型細節中解脫出來,讓書寫 Rust 代碼變成一件快樂的事情。
Cow
直譯為奶牛!開玩笑。
Cow 是一個枚舉類型,通過 use std::borrow::Cow; 引入。它的定義是 Clone-on-write,即寫時克隆。本質上是一個智能指針。
它有兩個可選值:
Borrowed,用於包裹對象的引用(通用引用);Owned,用於包裹對象的所有者;
Cow 提供
- 對此對象的不可變訪問(比如可直接調用此對象原有的不可變方法);
- 如果遇到需要修改此對象,或者需要獲得此對象的所有權的情況,
Cow提供方法做克隆處理,並避免多次重複克隆。
Cow 的設計目的是提高性能(減少複製)同時增加靈活性,因為大部分情況下,業務場景都是讀多寫少。利用 Cow,可以用統一,規範的形式實現,需要寫的時候才做一次對象複製。這樣就可能會大大減少複製的次數。
它有以下幾個要點需要掌握:
Cow<T>能直接調用T的不可變方法,因為Cow這個枚舉,實現了Deref;- 在需要寫
T的時候,可以使用.to_mut()方法得到一個具有所有權的值的可變借用;- 注意,調用
.to_mut()不一定會產生克隆; - 在已經具有所有權的情況下,調用
.to_mut()有效,但是不會產生新的克隆; - 多次調用
.to_mut()只會產生一次克隆。
- 注意,調用
- 在需要寫
T的時候,可以使用.into_owned()創建新的擁有所有權的對象,這個過程往往意味著內存拷貝並創建新對象;- 如果之前
Cow中的值是借用狀態,調用此操作將執行克隆; - 本方法,參數是
self類型,它會“吃掉”原先的那個對象,調用之後原先的對象的生命週期就截止了,在Cow上不能調用多次;
- 如果之前
舉例
.to_mut() 舉例
#![allow(unused)] fn main() { use std::borrow::Cow; let mut cow: Cow<[_]> = Cow::Owned(vec![1, 2, 3]); let hello = cow.to_mut(); assert_eq!(hello, &[1, 2, 3]); }
.into_owned() 舉例
#![allow(unused)] fn main() { use std::borrow::Cow; let cow: Cow<[_]> = Cow::Owned(vec![1, 2, 3]); let hello = cow.into_owned(); assert_eq!(vec![1, 2, 3], hello); }
綜合舉例
#![allow(unused)] fn main() { use std::borrow::Cow; fn abs_all(input: &mut Cow<[i32]>) { for i in 0..input.len() { let v = input[i]; if v < 0 { // clones into a vector the first time (if not already owned) input.to_mut()[i] = -v; } } } }
Cow 在函數返回值上的應用實例
題目:寫一個函數,過濾掉輸入的字符串中的所有空格字符,並返回過濾後的字符串。
對這個簡單的問題,不用思考,我們都可以很快寫出代碼:
#![allow(unused)] fn main() { fn remove_spaces(input: &str) -> String { let mut buf = String::with_capacity(input.len()); for c in input.chars() { if c != ' ' { buf.push(c); } } buf } }
設計函數輸入參數的時候,我們會停頓一下,這裡,用 &str 好呢,還是 String 好呢?思考一番,從性能上考慮,有如下結論:
- 如果使用
String, 則外部在調用此函數的時候,- 如果外部的字符串是
&str,那麼,它需要做一次克隆,才能調用此函數; - 如果外部的字符串是
String,那麼,它不需要做克隆,就可以調用此函數。但是,一旦調用後,外部那個字符串的所有權就被move到此函數中了,外部的後續代碼將無法再使用原字符串。
- 如果外部的字符串是
- 如果使用
&str,則不存在上述兩個問題。但可能會遇到生命週期的問題,需要注意。
繼續分析上面的例子,我們發現,在函數體內,做了一次新字符串對象的生成和拷貝。
讓我們來仔細分析一下業務需求。最壞的情況下,如果字符串中沒有空白字符,那最好是直接原樣返回。這種情況做這樣一次對象的拷貝,完全就是浪費了。
於是我們心想改進這個算法。很快,又遇到了另一個問題,返回值是 String 的嘛,我不論怎樣,要把 &str 轉換成 String 返回,始終都要經歷一次複製。於是我們快要放棄了。
好吧,Cow君這時出馬了。奶牛君很快寫出瞭如下代碼:
#![allow(unused)] fn main() { use std::borrow::Cow; fn remove_spaces<'a>(input: &'a str) -> Cow<'a, str> { if input.contains(' ') { let mut buf = String::with_capacity(input.len()); for c in input.chars() { if c != ' ' { buf.push(c); } } return Cow::Owned(buf); } return Cow::Borrowed(input); } }
完美解決了業務邏輯與返回值類型衝突的問題。本例可細細品味。
外部程序,拿到這個 Cow 返回值後,按照我們上文描述的 Cow 的特性使用就好了。
Send 和 Sync
std::marker 模塊中,有兩個 trait:Send 和 Sync,它們與多線程安全相關。
標記為 marker trait 的 trait,它實際就是一種約定,沒有方法的定義,也沒有關聯元素(associated items)。僅僅是一種約定,實現了它的類型必須滿足這種約定。一種類型是否加上這種約定,要麼是編譯器的行為,要麼是人工手動的行為。
Send 和 Sync 在大部分情況下(針對 Rust 的基礎類型和 std 中的大部分類型),會由編譯器自動推導出來。對於不能由編譯器自動推導出來的類型,要使它們具有 Send 或 Sync 的約定,可以由人手動實現。實現的時候,必須使用 unsafe 前綴,因為 Rust 默認不信任程序員,由程序員自己控制的東西,統統標記為 unsafe,出了問題(比如,把不是線程安全的對象加上 Sync 約定)由程序員自行負責。
它們的定義如下:
如果 T: Send,那麼將 T 傳到另一個線程中時(按值傳送),不會導致數據競爭或其它不安全情況。
Send是對象可以安全發送到另一個執行體中;Send使被髮送對象可以和產生它的線程解耦,防止原線程將此資源釋放後,在目標線程中使用出錯(use after free)。
如果 T: Sync,那麼將 &T 傳到另一個線程中時,不會導致數據競爭或其它不安全情況。
Sync是可以被同時多個執行體訪問而不出錯;Sync防止的是競爭;
推論:
T: Sync意味著&T: Send;Sync + Copy = Send;- 當
T: Send時,可推導出&mut T: Send; - 當
T: Sync時,可推導出&mut T: Sync; - 當
&mut T: Send時,不能推導出T: Send;
(注:T, &T, &mut T,Box<T> 等都是不同的類型)
具體的類型:
- 原始類型(比如: u8, f64),都是
Sync,都是Copy,因此都是Send; - 只包含原始類型的複合類型,都是
Sync,都是Copy,因此都是Send; - 當
T: Sync,Box<T>,Vec<T>等集合類型是Sync; - 具有內部可變性的的指針,不是
Sync的,比如Cell,RefCell,UnsafeCell; Rc不是Sync。因為只要一做&Rc<T>操作,就會克隆一個新引用,它會以非原子性的方式修改引用計數,所以是不安全的;- 被
Mutex和RWLock鎖住的類型T: Send,是Sync的; - 原始指針(
*mut,*const)既不是Send也不是Sync;
Rust 正是通過這兩大武器:所有權和生命週期 + Send 和 Sync(本質上為類型系統)來為併發編程提供了安全可靠的基礎設施。使得程序員可以放心在其上構建穩健的併發模型。這也正是 Rust 的核心設計觀的體現:內核只提供最基礎的原語,真正的實現能分離出去就分離出去。併發也是如此。
併發,並行,多線程編程
本章講解 Rust 中,併發,並行,多線程編程的相關知識。
併發編程
併發是什麼?引用Rob Pike的經典描述:
併發是同一時間應對多件事情的能力
其實在我們身邊就有很多併發的事情,比如一邊上課,一邊發短信;一邊給小孩餵奶,一邊看電視,只要你細心留意,就會發現許多類似的事。相應地,在軟件的世界裡,我們也會發現這樣的事,比如一邊寫博客,一邊聽音樂;一邊看網頁,一邊下載軟件等等。顯而易見這樣會節約不少時間,幹更多的事。然而一開始計算機系統並不能同時處理兩件事,這明顯滿足不了我們的需要,後來慢慢提出了多進程,多線程的解決方案,再後來,硬件也發展到了多核多CPU的地步。在硬件和系統底層對併發的支持也來越多,相應地,各大編程語言也對併發處理提供了強力的支持,作為新興語言的Rust,自然也支持併發編程。那麼本章就將引領大家一覽Rust併發編程的相關知識,從線程開始,逐步嘗試進行數據交互,同步協作,最後進入到並行實現,一步一步揭開Rust併發編程的神秘面紗。由於本書主要介紹的是Rust語言的使用,所以本章不會對併發編程相關理論知識進行全面而深入地探討——要真那樣地話,一本書都不夠介紹的,而是更側重於介紹用Rust語言怎麼實現基本的併發。
首先我們會介紹線程的使用,線程是基本的執行單元,其重要性不言而喻,Rust程序就是由一堆線程組成的。在當今多核多CPU已經普及的情況下,各種大數據分析和並行計算又讓線程煥發出了更耀眼的光芒。如果對線程不甚瞭解,請先參閱操作系統相關的書籍,此處不過多介紹。然後介紹一些在解決併發問題時,需要處理的數據傳遞和協作的實現,比如消息傳遞,同步和共享內存。最後簡要介紹Rust中並行的實現。
24.1 線程創建與結束
相信線程對大家而言,一點也不陌生,在當今多CPU多核已經普及的情況下,大數據分析與並行計算都離不開它,幾乎所有的語言都支持它,所有的進程都是由一個或多個線程所組成的。既然如此重要,接下來我們就先來看一下在Rust中如何創建一個線程,然後線程又是如何結束的。
Rust對於線程的支持,和C++11一樣,都是放在標準庫中來實現的,詳情請參見std::thread,好在Rust從一開始就這樣做了,不用像C++那樣等呀等。在語言層面支持後,開發者就不用那麼苦兮兮地處理各平臺的移植問題。通過Rust的源碼可以看到,std::thread其實就是對不同平臺的線程操作的封裝,相關API的實現都是調用操作系統的API來實現的,從而提供了線程操作的統一接口。對於我而言,能夠這樣簡單快捷地操作原生線程,身上的壓力一下輕了不少。
創建線程
首先,我們看一下在Rust中如何創建一個原生線程(native thread)。std::thread提供了兩種創建方式,都非常簡單,第一種方式是通過spawn函數來創建,參見下面的示例代碼:
use std::thread; fn main() { // 創建一個線程 let new_thread = thread::spawn(move || { println!("I am a new thread."); }); // 等待新建線程執行完成 new_thread.join().unwrap(); }
執行上面這段代碼,將會看到下面的輸出結果:
I am a new thread.
就5行代碼,少得不能再少,最關鍵的當然就是調用spawn函數的那行代碼。使用這個函數,記得要先use std::thread。注意spawn函數需要一個函數作為參數,且是FnOnce類型,如果已經忘了這種類型的函數,請學習或回顧一下函數和閉包章節。main函數最後一行代碼即使不要,也能創建線程(關於join函數的作用和使用在後續小節詳解,此處你只要知道它可以用來等待線程執行完成即可),可以去掉或者註釋該行代碼試試。這樣的話,運行結果可能沒有任何輸出,具體原因後面詳解。
接下來我們使用第二種方式創建線程,它比第一種方式稍微複雜一點,因為功能強大一點,可以在創建之前設置線程的名稱和stack大小,參見下面的代碼:
use std::thread; fn main() { // 創建一個線程,線程名稱為 thread1, stack大小為4k let new_thread_result = thread::Builder::new() .name("thread1".to_string()) .stack_size(4*1024*1024).spawn(move || { println!("I am thread1."); }); // 等待新創建的線程執行完成 new_thread_result.unwrap().join().unwrap(); }
執行上面這段代碼,將會看到下面的輸出結果:
I am thread1.
通過和第一種方式的實現代碼比較可以發現,這種方式藉助了一個Builder類來設置線程名稱和stack大小,除此之外,Builder的spawn函數的返回值是一個Result,在正式的代碼編寫中,可不能像上面這樣直接unwrap.join,應該判定一下。後面也會有很多類似的演示代碼,為了簡單說明不會做的很嚴謹。
以上就是Rust創建原生線程的兩種不同方式,示例代碼有點然並卵的意味,但是你可以稍加修改,就可以變得更加有用,試試吧。
線程結束
此時,我們已經知道如何創建一個新線程了,創建後,不管你見或者不見,它就在那裡,那麼它什麼時候才會消亡呢?自生自滅,亦或者被幹掉?如果接觸過一些系統編程,應該知道有些操作系統提供了粗暴地幹掉線程的接口,看它不爽,直接幹掉,完全可以不理會新建線程的感受。是否感覺很爽,但是Rust不會再讓這樣爽了,因為std::thread並沒有提供這樣的接口,為什麼呢?如果深入接觸過併發編程或多線程編程,就會知道強制終止一個運行中的線程,會出現諸多問題。比如資源沒有釋放,引起狀態混亂,結果不可預期。強制幹掉那一刻,貌似很爽地解決問題了,然而可能後患無窮。Rust語言的一大特性就是安全,是絕對不允許這樣不負責任的做法的。即使在其他語言提供了類似的接口,也不應該濫用。
那麼在Rust中,新建的線程就只能讓它自身自滅了嗎?其實也有兩種方式,首先介紹大家都知道的自生自滅的方式,線程執行體執行完成,線程就結束了。比如上面創建線程的第一種方式,代碼執行完println!("I am a new thread.");就結束了。 如果像下面這樣:
use std::thread; fn main() { // 創建一個線程 let new_thread = thread::spawn(move || { loop { println!("I am a new thread."); } }); // 等待新創建的線程執行完成 new_thread.join().unwrap(); }
線程就永遠都不會結束,如果你用的還是古董電腦,運行上面的代碼之前,請做好心理準備。在實際代碼中,要時刻警惕該情況的出現(單核情況下,CPU佔用率會飆升到100%),除非你是故意為之。
線程結束的另一種方式就是,線程所在進程結束了。我們把上面這個例子稍作修改:
use std::thread; fn main() { // 創建一個線程 thread::spawn(move || { loop { println!("I am a new thread."); } }); // 不等待新創建的線程執行完成 // new_thread.join().unwrap(); }
同上面的代碼相比,唯一的差別在於main函數的最後一行代碼被註釋了,這樣主線程就不用等待新建線程了,在創建線程之後就執行完了,其所在進程也就結束了,從而新建的線程也就結束了。此處,你可能有疑問:為什麼一定是進程結束導致新建線程結束?也可能是創建新線程的主線程結束而導致的?事實到底如何,我們不妨驗證一下:
use std::thread; fn main() { // 創建一個線程 let new_thread = thread::spawn(move || { // 再創建一個線程 thread::spawn(move || { loop { println!("I am a new thread."); } }) }); // 等待新創建的線程執行完成 new_thread.join().unwrap(); println!("Child thread is finish!"); // 睡眠一段時間,看子線程創建的子線程是否還在運行 thread::sleep_ms(100); }
這次我們在新建線程中還創建了一個線程,從而第一個新建線程是父線程,主線程在等待該父線程結束後,主動睡眠一段時間。這樣做有兩個目的,一是確保整個程序不會馬上結束;二是如果子線程還存在,應該會獲得執行機會,以此來檢驗子線程是否還在運行,下面是輸出結果:
Child thread is finish!
I am a new thread.
I am a new thread.
......
結果表明,在父線程結束後,其創建的子線程還活著,這並不會因為父線程結束而結束。這個還是比較符合自然規律的,要不然真會斷子絕孫,人類滅絕。所以導致線程結束的第二種方式,是結束其所在進程。到此為止,我們已經把線程的創建和結束都介紹完了,那麼接下來我們會介紹一些更有趣的東西。但是在此之前,請先考慮一下下面的練習題。
練習題:
有一組學生的成績,我們需要對它們評分,90分及以上是A,80分及以上是B,70分及以上是C,60分及以上為D,60分以下為E。現在要求用Rust語言編寫一個程序來評分,且評分由新建的線程來做,最終輸出每個學生的學號,成績,評分。學生成績單隨機產生,學生人數100位,成績範圍為[0,100],學號依次從1開始,直到100。
消息傳遞
稍加考慮,上一節的練習題其實是不完整的,它只是評分系統中的一環,一個評分系統是需要先把信息從數據庫或文件中讀取出來,然後才是評分,最後還需要把評分結果再保存到數據庫或文件中去。如果一步一步串行地做這三個步驟,是完全沒有問題的。那麼我們是否可以用三個線程來分別做這三個步驟呢?上一節練習題我們已經用了一個線程來實現評分,那麼我們是否也可以再用一個線程來讀取成績,再用另個線程來實現保存呢? 如果能這樣的話,那麼我們就可以利用上多核多cpu的優勢,加快整個評分的效率。既然在此提出這個問題,答案就很明顯了。問題在於我們要怎麼在Rust中來實現,關鍵在於三個線程怎麼交換信息,以達到串行的邏輯處理順序?
為了解決這個問題,下面將介紹一種Rust在標準庫中支持的消息傳遞技術。消息傳遞是併發模型裡面大家比較推崇的模式,不僅僅是因為使用起來比較簡單,關鍵還在於它可以減少數據競爭,提高併發效率,為此值得深入學習。Rust是通過一個叫做通道(channel)的東西來實現這種模式的,下面直接進入主題。
初試通道(channel)
Rust的通道(channel)可以把一個線程的消息(數據)傳遞到另一個線程,從而讓信息在不同的線程中流動,從而實現協作。詳情請參見std::sync::mpsc。通道的兩端分別是發送者(Sender)和接收者(Receiver),發送者負責從一個線程發送消息,接收者則在另一個線程中接收該消息。下面我們來看一個簡單的例子:
use std::sync::mpsc; use std::thread; fn main() { // 創建一個通道 let (tx, rx): (mpsc::Sender<i32>, mpsc::Receiver<i32>) = mpsc::channel(); // 創建線程用於發送消息 thread::spawn(move || { // 發送一個消息,此處是數字id tx.send(1).unwrap(); }); // 在主線程中接收子線程發送的消息並輸出 println!("receive {}", rx.recv().unwrap()); }
程序說明參見代碼中的註釋,程序執行結果為:
receive 1
結果表明main所在的主線程接收到了新建線程發送的消息,用Rust在線程間傳遞消息就是這麼簡單!
雖然簡單,但使用過其他語言就會知道,通道有多種使用方式,且比較靈活,為此我們需要進一步考慮關於Rust的Channel的幾個問題:
- 通道能保證消息的順序嗎?是否先發送的消息,先接收?
- 通道能緩存消息嗎?如果能的話能緩存多少?
- 通道的發送者和接收者支持N:1,1:N,N:M模式嗎?
- 通道能發送任何數據嗎?
- 發送後的數據,在線程中繼續使用沒有問題嗎?
讓我們帶著這些問題和思考進入下一個小節,那裡有相關的答案。
消息類型
上面的例子中,我們傳遞的消息類型為i32,除了這種類型之外,是否還可以傳遞更多的原始類型,或者更復雜的類型,和自定義類型?下面我們嘗試發送一個更復雜的Rc類型的消息:
use std::fmt; use std::sync::mpsc; use std::thread; use std::rc::Rc; pub struct Student { id: u32 } impl fmt::Display for Student { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "student {}", self.id) } } fn main() { // 創建一個通道 let (tx, rx): (mpsc::Sender<Rc<Student>>, mpsc::Receiver<Rc<Student>>) = mpsc::channel(); // 創建線程用於發送消息 thread::spawn(move || { // 發送一個消息,此處是數字id tx.send(Rc::new(Student{ id: 1, })).unwrap(); }); // 在主線程中接收子線程發送的消息並輸出 println!("receive {}", rx.recv().unwrap()); }
編譯代碼,奇蹟沒有出現,編譯時錯誤,錯誤提示:
error: the trait `core::marker::Send` is not
implemented for the type `alloc::rc::Rc<Student>` [E0277]
note: `alloc::rc::Rc<Student>` cannot be sent between threads safely
看來並不是所有類型的消息都可以通過通道發送,消息類型必須實現marker trait Send。Rust之所以這樣強制要求,主要是為了解決併發安全的問題,再一次強調,安全是Rust考慮的重中之重。如果一個類型是Send,則表明它可以在線程間安全的轉移所有權(ownership),當所有權從一個線程轉移到另一個線程後,同一時間就只會存在一個線程能訪問它,這樣就避免了數據競爭,從而做到線程安全。ownership的強大又一次顯示出來了。通過這種做法,在編譯時即可要求所有的代碼必須滿足這一約定,這種方式方法值得借鑑,trait也是非常強大。
看起來問題得到了完美的解決,然而由於Send本身是一個不安全的marker trait,並沒有實際的API,所以實現它很簡單,但沒有強制保障,就只能靠開發者自己約束,否則還是可能引發併發安全問題。對於這一點,也不必太過擔心,因為Rust中已經存在的類,都已經實現了Send或!Send,我們只要使用就行。Send是一個默認應用到所有Rust已存在類的trait,所以我們用!Send顯式標明該類沒有實現Send。目前幾乎所有的原始類型都是Send,例如前面例子中發送的i32。對於開發者而言,我們可能會更關心哪些是非Send,也就是實現了!Send,因為這會導致線程不安全。更全面的信息參見Send官網API。
對於不是Send的情況(!Send),大致分為兩類:
- 原始指針,包括
*mut T和*const T,因為不同線程通過指針都可以訪問數據,從而可能引發線程安全問題。 Rc和Weak也不是,因為引用計數會被共享,但是並沒有做併發控制。
雖然有這些!Send的情況,但是逃不過編譯器的火眼金睛,只要你錯誤地使用了消息類型,編譯器都會給出類似於上面的錯誤提示。我們要擔心的不是這些,因為錯誤更容易出現在新創建的自定義類,有下面兩點需要注意:
-
如果自定義類的所有字段都是
Send,那麼這個自定義類也是Send。 反之,如果有一個字段是!Send,那麼這個自定義類也是!Send。 如果類的字段存在遞歸包含的情況,按照該原則以此類推來推論類是Send還是!Send。 -
在為一個自定義類實現
Send或者!Send時,必須確保符合它的約定。
到此,消息類型的相關知識已經介紹完了,說了這麼久,也該讓大家自己練習一下了:請實現一個自定義類,該類包含一個Rc字段,讓這個類變成可以在通道中發送的消息類型。
異步通道(Channel)
在粗略地嘗試通道之後,是時候更深入一下了。Rust的標準庫其實提供了兩種類型的通道:異步通道和同步通道。上面的例子都是使用的異步通道,為此這一小節我們優先進一步介紹異步通道,後續再介紹同步通道。異步通道指的是:不管接收者是否正在接收消息,消息發送者在發送消息時都不會阻塞。為了驗證這一點,我們嘗試多增加一個線程來發送消息:
use std::sync::mpsc; use std::thread; // 線程數量 const THREAD_COUNT :i32 = 2; fn main() { // 創建一個通道 let (tx, rx): (mpsc::Sender<i32>, mpsc::Receiver<i32>) = mpsc::channel(); // 創建線程用於發送消息 for id in 0..THREAD_COUNT { // 注意Sender是可以clone的,這樣就可以支持多個發送者 let thread_tx = tx.clone(); thread::spawn(move || { // 發送一個消息,此處是數字id thread_tx.send(id + 1).unwrap(); println!("send {}", id + 1); }); } thread::sleep_ms(2000); println!("wake up"); // 在主線程中接收子線程發送的消息並輸出 for _ in 0..THREAD_COUNT { println!("receive {}", rx.recv().unwrap()); } }
運行結果:
send 1
send 2
wake up
receive 1
receive 2
在代碼中,我們故意讓main所在的主線程睡眠2秒,從而讓發送者所在線程優先執行,通過結果可以發現,發送者發送消息時確實沒有阻塞。還記得在前面提到過很多關於通道的問題嗎?從這個例子裡面還發現什麼沒?除了不阻塞之外,我們還能發現另外的三個特徵:
1.通道是可以同時支持多個發送者的,通過clone的方式來實現。
這類似於Rc的共享機制。
其實從Channel所在的庫名std::sync::mpsc也可以知道這點。
因為mpsc就是多生產者單消費者(Multiple Producers Single Consumer)的簡寫。
可以有多個發送者,但只能有一個接收者,即支持的N:1模式。
2.異步通道具備消息緩存的功能,因為1和2是在沒有接收之前就發了的,在此之後還能接收到這兩個消息。
那麼通道到底能緩存多少消息?在理論上是無窮的,嘗試一下便知:
use std::sync::mpsc; use std::thread; fn main() { // 創建一個通道 let (tx, rx): (mpsc::Sender<i32>, mpsc::Receiver<i32>) = mpsc::channel(); // 創建線程用於發送消息 let new_thread = thread::spawn(move || { // 發送無窮多個消息 let mut i = 0; loop { i = i + 1; // add code here println!("send {}", i); match tx.send(i) { Ok(_) => (), Err(e) => { println!("send error: {}, count: {}", e, i); return; }, } } }); // 在主線程中接收子線程發送的消息並輸出 new_thread.join().unwrap(); println!("receive {}", rx.recv().unwrap()); }
最後的結果就是耗費內存為止。
3.消息發送和接收的順序是一致的,滿足先進先出原則。
上面介紹的內容大多是關於發送者和通道的,下面開始考察一下接收端。通過上面的幾個例子,細心一點的可能已經發現接收者的recv方法應該會阻塞當前線程,如果不阻塞,在多線程的情況下,發送的消息就不可能接收完全。所以沒有發送者發送消息,那麼接收者將會一直等待,這一點要謹記。在某些場景下,一直等待是符合實際需求的。但某些情況下並不需一直等待,那麼就可以考慮釋放通道,只要通道釋放了,recv方法就會立即返回。
異步通道的具有良好的靈活性和擴展性,針對業務需要,可以靈活地應用於實際項目中,實在是必備良藥!
同步通道
同步通道在使用上同異步通道一樣,接收端也是一樣的,唯一的區別在於發送端,我們先來看下面的例子:
use std::sync::mpsc; use std::thread; fn main() { // 創建一個同步通道 let (tx, rx): (mpsc::SyncSender<i32>, mpsc::Receiver<i32>) = mpsc::sync_channel(0); // 創建線程用於發送消息 let new_thread = thread::spawn(move || { // 發送一個消息,此處是數字id println!("before send"); tx.send(1).unwrap(); println!("after send"); }); println!("before sleep"); thread::sleep_ms(5000); println!("after sleep"); // 在主線程中接收子線程發送的消息並輸出 println!("receive {}", rx.recv().unwrap()); new_thread.join().unwrap(); }
運行結果:
before sleep
before send
after sleep
receive 1
after send
除了多了一些輸出代碼之外,上面這段代碼幾乎和前面的異步通道的沒有什麼區別,唯一不同的在於創建同步通道的那行代碼。同步通道是sync_channel,對應的發送者也變成了SyncSender。為了顯示出同步通道的區別,故意添加了一些打印。和異步通道相比,存在兩點不同:
- 同步通道是需要指定緩存的消息個數的,但需要注意的是,最小可以是0,表示沒有緩存。
- 發送者是會被阻塞的。當通道的緩存隊列不能再緩存消息時,發送者發送消息時,就會被阻塞。
對照上面兩點和運行結果來分析,由於主線程在接收消息前先睡眠了,從而子線程這個時候會被調度執行發送消息,由於通道能緩存的消息為0,而這個時候接收者還沒有接收,所以tx.send(1).unwrap()就會阻塞子線程,直到主線程接收消息,即執行println!("receive {}", rx.recv().unwrap());。運行結果印證了這點,要是沒阻塞,那麼在before send之後就應該是after send了。
相比較而言,異步通道更沒有責任感一些,因為消息發送者一股腦的只管發送,不管接收者是否能快速處理。這樣就可能出現通道里面緩存大量的消息得不到處理,從而佔用大量的內存,最終導致內存耗盡。而同步通道則能避免這種問題,把接受者的壓力能傳遞到發送者,從而一直傳遞下去。
共享內存
在消息傳遞之外,還存在一種廣為人知的併發模型,那就是共享內存。其實如果不能共享內存,消息傳遞也是不能在不同的線程間傳遞消息,也談不上在不同的線程間等待和通知了。共享內存是這一切得以發生的基礎。如果查看源碼,你會發現消息傳遞的內部實現就是借用了共享內存機制。相對於消息傳遞而言,共享內存會有更多的競爭,但是不用進行多次拷貝,在某些情況下,也需要考慮使用這種方式來處理。在Rust中,能共享內存的情況,主要體現在下面兩個方面:
static
Rust語言中也存在static變量,其生命週期是整個應用程序,並且在內存中某個固定地址處只存在一份實例。所有線程都能夠訪問到它。這種方式也是最簡單和直接的共享方式。幾乎大多數語言都存在這種機制。下面簡單看一下Rust中多個線程訪問static變量的用法:
use std::thread; static VAR: i32 = 5; fn main() { // 創建一個新線程 let new_thread = thread::spawn(move|| { println!("static value in new thread: {}", VAR); }); // 等待新線程先運行 new_thread.join().unwrap(); println!("static value in main thread: {}", VAR); }
運行結果:
static value in new thread: 5
static value in main thread: 5
VAR這個static變量在各線程中可以直接使用,非常方便。當然上面只是讀取,那麼要修改也是很簡單的:
use std::thread; static mut VAR: i32 = 5; fn main() { // 創建一個新線程 let new_thread = thread::spawn(move|| { unsafe { println!("static value in new thread: {}", VAR); VAR = VAR + 1; } }); // 等待新線程先運行 new_thread.join().unwrap(); unsafe { println!("static value in main thread: {}", VAR); } }
運行結果:
static value in new thread: 5
static value in main thread: 6
從結果來看VAR的值變了,從代碼上來看,除了在VAR變量前面加了mut關鍵字外,更加明顯的是在使用VAR的地方都添加了unsafe代碼塊。為什麼?所有的線程都能訪問VAR,且它是可以被修改的,自然就是不安全的。上面的代碼比較簡單,同一時間只會有一個線程讀寫VAR,不會有什麼問題,所以用unsafe來標記就可以。如果是更多的線程,還是請使用接下來要介紹的同步機制來處理。
static如此,那const呢? const會在編譯時內聯到代碼中,所以不會存在某個固定的內存地址上,也不存在可以修改的情況,並不是內存共享的。
heap
由於現代操作系統的設計,線程寄生於進程,可以共享進程的資源,如果要在各個線程中共享一個變量,那麼除了上面的static,還有就是把變量保存在heap上了。當然Rust也不例外,遵從這一設計。只是我們知道Rust在安全性上肯定又會做一些考量,從而在語言設計和使用上稍有不同。
為了在heap上分配空間,Rust提供了std::boxed::Box,由於heap的特點,存活時間比較長,所以除了我們這個地方介紹的線程間共享外,還有其他的用處,此處不詳細說明,若不甚瞭解,請學習或回顧heap、stack與Box章節的介紹。下面我們來看一下如何在多個線程間訪問Box創建的變量:
use std::thread; use std::sync::Arc; fn main() { let var : Arc<i32> = Arc::new(5); let share_var = var.clone(); // 創建一個新線程 let new_thread = thread::spawn(move|| { println!("share value in new thread: {}, address: {:p}", share_var, &*share_var); }); // 等待新建線程先執行 new_thread.join().unwrap(); println!("share value in main thread: {}, address: {:p}", var, &*var); }
運行結果:
share value in new thread: 5, address: 0x2825070
share value in main thread: 5, address: 0x2825070
你可能會覺得很奇怪,上面怎麼沒有看到Box創建的變量啊,這明明就是Arc的使用呀?Box創建的變量要想在多個線程中安全使用,我們還需要實現很多功能才行,需要是Sync,而Arc正是利用Box來實現的一個通過引用計數來共享狀態的包裹類。下面引用一段Arc::new的源碼即可看出它是通過Box來實現的:
#![allow(unused)] fn main() { pub fn new(data: T) -> Arc<T> { // Start the weak pointer count as 1 which is the weak pointer that's // held by all the strong pointers (kinda), see std/rc.rs for more info let x: Box<_> = box ArcInner { strong: atomic::AtomicUsize::new(1), weak: atomic::AtomicUsize::new(1), data: data, }; Arc { _ptr: unsafe { NonZero::new(Box::into_raw(x)) } } } }
通過上面的運行結果,我們也可以發現新建線程和主線程中打印的address是一樣的,說明狀態確實是在同一個內存地址處。
如果Box在heap上分配的資源僅在一個線程中使用,那麼釋放時,就非常簡單,使用完,及時釋放即可。如果是要在多個線程中使用,就需要面臨兩個關鍵問題:
- 資源何時釋放?
- 線程如何安全的併發修改和讀取?
由於上面兩個問題的存在,這就是為什麼我們不能直接用Box變量在線程中共享的原因,可以看出來,共享內存比消息傳遞機制似乎要複雜許多。Rust用了引用計數的方式來解決第一個問題,在標準庫中提供了兩個包裹類,除了上面一個用於多線程的std::sync::Arc之外,還有一個不能用於多線程的std::rc::Rc。在使用時,可以根據需要進行選擇。如果你一不小心把std::rc::Rc用於多線程中,編譯器會毫不客氣地糾正你的。
關於上面的第二個問題,Rust語言及標準庫提供了一系列的同步手段來解決。下面的章節我們將詳細講解這些方式和用法。
同步
同步指的是線程之間的協作配合,以共同完成某個任務。在整個過程中,需要注意兩個關鍵點:一是共享資源的訪問, 二是訪問資源的順序。通過前面的介紹,我們已經知道了如何讓多個線程訪問共享資源,但並沒介紹如何控制訪問順序,才不會出現錯誤。如果兩個線程同時訪問同一內存地址的數據,一個寫,一個讀,如果不加控制,寫線程只寫了一半,讀線程就開始讀,必然讀到的數據是錯誤的,不可用的,從而造成程序錯誤,這就造成了併發安全問題,為此我們必須要有一套控制機制來避免這樣的事情發生。就好比兩個人喝一瓶可樂,只有一根吸管,那肯定也得商量出一個規則,才能相安無事地都喝到可樂。本節就將具體介紹在Rust中,我們要怎麼做,才能解決這個問題。
繼續上面喝可樂的例子,一人一口的方式,就是一種解決方案,只要不是太笨,幾乎都能想到這個方案。具體實施時,A在喝的時候,B一直在旁邊盯著,要是A喝完一口,B馬上拿過來喝,此時A肯定也是在旁邊盯著。在現實生活中,這樣的示例比比皆是。細想一下,貌似同步中都可能涉及到等待。諸葛先生在萬事具備,只欠東風時,也只能等,因為條件不成熟啊。依照這個邏輯,在操作系統和各大編程語言中,幾乎都支持當前線程等待,當然Rust也不例外。
等待
Rust中線程等待和其他語言在機制上並無差異,大致有下面幾種:
- 等待一段時間後,再接著繼續執行。看起來就像一個人工作累了,休息一會再工作。通過調用相關的API可以讓當前線程暫停執行進入睡眠狀態,此時調度器不會調度它執行,等過一段時間後,線程自動進入就緒狀態,可以被調度執行,繼續從之前睡眠時的地方執行。對應的API有
std::thread::sleep,std::thread::sleep_ms,std::thread::park_timeout,std::thread::park_timeout_ms,還有一些類似的其他API,由於太多,詳細信息就請參見官網std::thread。 - 這一種方式有點特殊,時間非常短,就一個時間片,當前線程自己主動放棄當前時間片的調度,讓調度器重新選擇線程來執行,這樣就把運行機會給了別的線程,但是要注意的是,如果別的線程沒有更好的理由執行,當然最後執行機會還是它的。在實際的應用業務中,比如生產者製造出一個產品後,可以放棄一個時間片,讓消費者獲得執行機會,從而快速地消費才生產的產品。這樣的控制粒度非常小,需要合理使用,如果需要連續放棄多個時間片,可以借用循環實現。對應的API是
std::thread::yield_now,詳細信息參見官網std::thread。 - 1和2的等待都無須其他線程的協助,即可在一段時間後繼續執行。最後我們還遇到一種等待,是需要其他線程參與,才能把等待的線程叫醒,否則,線程會一直等待下去。好比一個女人,要是沒有遇到一個男人,就永遠不可能擺脫單身的狀態。相關的API包括
std::thread::JoinHandle::join,std::thread::park,std::sync::Mutex::lock等,還有一些同步相關的類的API也會導致線程等待。詳細信息參見官網std::thread和std::sync。
第一種和第三種等待方式,其實我們在上面的介紹中,都已經遇到過了,它們也是使用的最多的兩種方式。在此,也可以回過頭去看看前面的使用方式和使用效果,結合自己的理解,做一些簡單的練習。
毫無疑問,第三種方式稍顯複雜,要將等待的線程叫醒,必然基於一定的規則,比如早上7點必須起床,那麼就定一個早上7點的鬧鐘,到時間了就響,沒到時間別響。不管基於什麼規則,要觸發叫醒這個事件,就肯定是某個條件已經達成了。基於這樣的邏輯,在操作系統和編程語言中,引入了一種叫著條件變量的東西。可以模擬現實生活中的鬧鐘的行為,條件達成就通知等待條件的線程。Rust的條件變量就是std::sync::Condvar,詳情參見官網條件變量。但是通知也並不只是條件變量的專利,還有其他的方式也可以觸發通知,下面我們就來瞧一瞧。
通知
看是簡單的通知,在編程時也需要注意以下幾點:
- 通知必然是因為有等待,所以通知和等待幾乎都是成對出現的,比如
std::sync::Condvar::wait和std::sync::Condvar::notify_one,std::sync::Condvar::notify_all。 - 等待所使用的對象,與通知使用的對象是同一個對象,從而該對象需要在多個線程之間共享,參見下面的例子。
- 除了
Condvar之外,其實鎖也是具有自動通知功能的,當持有鎖的線程釋放鎖的時候,等待鎖的線程就會自動被喚醒,以搶佔鎖。關於鎖的介紹,在下面有詳解。 - 通過條件變量和鎖,還可以構建更加複雜的自動通知方式,比如
std::sync::Barrier。 - 通知也可以是1:1的,也可以是1:N的,
Condvar可以控制通知一個還是N個,而鎖則不能控制,只要釋放鎖,所有等待鎖的其他線程都會同時醒來,而不是隻有最先等待的線程。
下面我們分析一個簡單的例子:
use std::sync::{Arc, Mutex, Condvar}; use std::thread; fn main() { let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = pair.clone(); // 創建一個新線程 thread::spawn(move|| { let &(ref lock, ref cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; cvar.notify_one(); println!("notify main thread"); }); // 等待新線程先運行 let &(ref lock, ref cvar) = &*pair; let mut started = lock.lock().unwrap(); while !*started { println!("before wait"); started = cvar.wait(started).unwrap(); println!("after wait"); } }
運行結果:
before wait
notify main thread
after wait
這個例子展示瞭如何通過條件變量和鎖來控制新建線程和主線程的同步,讓主線程等待新建線程執行後,才能繼續執行。從結果來看,功能上是實現了。對於上面這個例子,還有下面幾點需要說明:
Mutex是Rust中的一種鎖。Condvar需要和Mutex一同使用,因為有Mutex保護,Condvar併發才是安全的。Mutex::lock方法返回的是一個MutexGuard,在離開作用域的時候,自動銷燬,從而自動釋放鎖,從而避免鎖沒有釋放的問題。Condvar在等待時,時會釋放鎖的,被通知喚醒時,會重新獲得鎖,從而保證併發安全。
到此,你應該對鎖比較感興趣了,為什麼需要鎖?鎖存在的目的就是為了保證資源在同一個時間,能有序地被訪問,而不會出現異常數據。但其實要做到這一點,也並不是只有鎖,包括鎖在內,主要涉及兩種基本方式:
原子類型
原子類型是最簡單的控制共享資源訪問的一種機制,相比較於後面將介紹的鎖而言,原子類型不需要開發者處理加鎖和釋放鎖的問題,同時支持修改,讀取等操作,還具備較高的併發性能,從硬件到操作系統,到各個語言,基本都支持。在標準庫std::sync::atomic中,你將在裡面看到Rust現有的原子類型,包括AtomicBool,AtomicIsize,AtomicPtr,AtomicUsize。這4個原子類型基本能滿足百分之九十的共享資源安全訪問的需要。下面我們就用原子類型,結合共享內存的知識,來展示一下一個線程修改,一個線程讀取的情況:
use std::thread; use std::sync::Arc; use std::sync::atomic::{AtomicUsize, Ordering}; fn main() { let var : Arc<AtomicUsize> = Arc::new(AtomicUsize::new(5)); let share_var = var.clone(); // 創建一個新線程 let new_thread = thread::spawn(move|| { println!("share value in new thread: {}", share_var.load(Ordering::SeqCst)); // 修改值 share_var.store(9, Ordering::SeqCst); }); // 等待新建線程先執行 new_thread.join().unwrap(); println!("share value in main thread: {}", var.load(Ordering::SeqCst)); }
運行結果:
share value in new thread: 5
share value in main thread: 9
結果表明新建線程成功的修改了值,並在主線程中獲取到了最新值,你也可以嘗試使用其他的原子類型。此處我們可以思考一下,如果我們用Arc::new(*mut Box<u32>)是否也可以做到? 為什麼? 思考後,大家將體會到Rust在多線程安全方面做的有多麼的好。除了原子類型,我們還可以使用鎖來實現同樣的功能。
鎖
在多線程中共享資源,除了原子類型之外,還可以考慮用鎖來實現。在操作之前必須先獲得鎖,一把鎖同時只能給一個線程,這樣能保證同一時間只有一個線程能操作共享資源,操作完成後,再釋放鎖給等待的其他線程。在Rust中std::sync::Mutex就是一種鎖。下面我們用Mutex來實現一下上面的原子類型的例子:
use std::thread; use std::sync::{Arc, Mutex}; fn main() { let var : Arc<Mutex<u32>> = Arc::new(Mutex::new(5)); let share_var = var.clone(); // 創建一個新線程 let new_thread = thread::spawn(move|| { let mut val = share_var.lock().unwrap(); println!("share value in new thread: {}", *val); // 修改值 *val = 9; }); // 等待新建線程先執行 new_thread.join().unwrap(); println!("share value in main thread: {}", *(var.lock().unwrap())); }
運行結果:
share value in new thread: 5
share value in main thread: 9
結果都一樣,看來用Mutex也能實現,但如果從效率上比較,原子類型會更勝一籌。暫且不論這點,我們從代碼裡面看到,雖然有lock,但是並麼有看到有類似於unlock的代碼出現,並不是不需要釋放鎖,而是Rust為了提高安全性,已然在val銷燬的時候,自動釋放鎖了。同時我們發現,為了修改共享的值,開發者必須要調用lock才行,這樣就又解決了一個安全問題。不得不再次讚歎一下Rust在多線程方面的安全性做得真是太好了。如果是其他語言,我們要做到安全,必然得自己來實現這些。
為了保障鎖使用的安全性問題,Rust做了很多工作,但從效率來看還不如原子類型,那麼鎖是否就沒有存在的價值了?顯然事實不可能是這樣的,既然存在,那必然有其價值。它能解決原子類型鎖不能解決的那百分之十的問題。我們再來看一下之前的一個例子:
use std::sync::{Arc, Mutex, Condvar}; use std::thread; fn main() { let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = pair.clone(); // 創建一個新線程 thread::spawn(move|| { let &(ref lock, ref cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; cvar.notify_one(); println!("notify main thread"); }); // 等待新線程先運行 let &(ref lock, ref cvar) = &*pair; let mut started = lock.lock().unwrap(); while !*started { println!("before wait"); started = cvar.wait(started).unwrap(); println!("after wait"); } }
代碼中的Condvar就是條件變量,它提供了wait方法可以主動讓當前線程等待,同時提供了notify_one方法,讓其他線程喚醒正在等待的線程。這樣就能完美實現順序控制了。看起來好像條件變量把事都做完了,要Mutex幹嘛呢?為了防止多個線程同時執行條件變量的wait操作,因為條件變量本身也是需要被保護的,這就是鎖能做,而原子類型做不到的地方。
在Rust中,Mutex是一種獨佔鎖,同一時間只有一個線程能持有這個鎖。這種鎖會導致所有線程串行起來,這樣雖然保證了安全,但效率並不高。對於寫少讀多的情況來說,如果在沒有寫的情況下,都是讀取,那麼應該是可以併發執行的,為了達到這個目的,幾乎所有的編程語言都提供了一種叫讀寫鎖的機制,Rust中也存在,叫std::sync::RwLock,在使用上同Mutex差不多,在此就留給大家自行練習了。
同步是多線程編程的永恆主題,Rust已經為我們提供了良好的編程範式,並強加檢查,即使你之前沒有怎麼接觸過,用Rust也能編寫出非常安全的多線程程序。
並行
理論上並行和語言並沒有什麼關係,所以在理論上的並行方式,都可以嘗試用Rust來實現。本小節不會詳細全面地介紹具體的並行理論知識,只介紹用Rust如何來實現相關的並行模式。
Rust的一大特點是,可以保證“線程安全”。而且,沒有性能損失。更有意思的是,Rust編譯器實際上只有Send Sync等基本抽象,而對“線程” “鎖” “同步” 等基本的並行相關的概念一無所知,這些概念都是由庫實現的。這意味著Rust實現並行編程可以有比較好的擴展性,可以很輕鬆地用庫來支持那些常見的並行編程模式。
下面,我們以一個例子來演示一下,Rust如何將線程安全/執行高效/使用簡單結合起來的。
在圖形編程中,我們經常要處理歸一化的問題: 即把一個範圍內的值,轉換到範圍1內的值。比如把一個顏色值255歸一後就是1。假設我們有一個表示顏色值的數組要進行歸一,用非並行化的方式來處理非常簡單,可以自行嘗試。下面我們將採用並行化的方式來處理,把數組中的值同時分開給多個線程一起並行歸一化處理。
extern crate rayon; use rayon::prelude::*; fn main() { let mut colors = [-20.0f32, 0.0, 20.0, 40.0, 80.0, 100.0, 150.0, 180.0, 200.0, 250.0, 300.0]; println!("original: {:?}", &colors); colors.par_iter_mut().for_each(|color| { let c : f32 = if *color < 0.0 { 0.0 } else if *color > 255.0 { 255.0 } else { *color }; *color = c / 255.0; }); println!("transformed: {:?}", &colors); }
運行結果:
original: [-20, 0, 20, 40, 80, 100, 150, 180, 200, 250, 300]
transformed: [0, 0, 0.078431375, 0.15686275, 0.3137255, 0.39215687, 0.5882353, 0.7058824, 0.78431374, 0.98039216, 1]
以上代碼是不是很簡單。調用par_iter_mut獲得一個並行執行的具有寫權限的迭代器,for_each對每個元素執行一個操作。僅此而已。
我們能這麼輕鬆地完成這個任務,原因是我們引入了 rayon 這個庫。它把所有的髒活累活都幹完了,把清晰安全易用的接口暴露出來給了我們。Rust還可以完全以庫的形式,實現異步IO、協程等更加高階的並行程序開發模式。
為了更深入的加深對Rust併發編程的理解和實踐,還安排了一個挑戰任務:實現一個Rust版本的MapReduce模式。值得你挑戰。
Unsafe、原始指針
本章開始講解 Rust 中的 Unsafe 部分。
unsafe
Rust的內存安全依賴於強大的類型系統和編譯時檢測,不過它並不能適應所有的場景。 首先,所有的編程語言都需要跟外部的“不安全”接口打交道,調用外部庫等,在“安全”的Rust下是無法實現的; 其次,“安全”的Rust無法高效表示複雜的數據結構,特別是數據結構內部有各種指針互相引用的時候;再次, 事實上還存在著一些操作,這些操作是安全的,但不能通過編譯器的驗證。
因此在安全的Rust背後,還需要unsafe的支持。
unsafe塊能允許程序員做的額外事情有:
- 解引用一個裸指針
*const T和*mut T
#![allow(unused)] fn main() { let x = 5; let raw = &x as *const i32; let points_at = unsafe { *raw }; println!("raw points at {}", points_at); }
- 讀寫一個可變的靜態變量
static mut
#![allow(unused)] fn main() { static mut N: i32 = 5; unsafe { N += 1; println!("N: {}", N); } }
- 調用一個不安全函數
unsafe fn foo() { //實現 } fn main() { unsafe { foo(); } }
使用unsafe
unsafe fn不安全函數標示如果調用它可能會違反Rust的內存安全語意:
#![allow(unused)] fn main() { unsafe fn danger_will_robinson() { // 實現 } }
unsafe block不安全塊可以在其中調用不安全的代碼:
#![allow(unused)] fn main() { unsafe { // 實現 } }
unsafe trait不安全trait及它們的實現,所有實現它們的具體類型有可能是不安全的:
#![allow(unused)] fn main() { unsafe trait Scary { } unsafe impl Scary for i32 {} }
safe != no bug
對於Rust來說禁止你做任何不安全的事是它的本職,不過有些是編寫代碼時的bug,它們並不屬於“內存安全”的範疇:
- 死鎖
- 內存或其他資源溢出
- 退出未調用析構函數
- 整型溢出
使用unsafe時需要注意一些特殊情形:
- 數據競爭
- 解引用空裸指針和懸垂裸指針
- 讀取未初始化的內存
- 使用裸指針打破指針重疊規則
&mut T和&T遵循LLVM範圍的noalias模型,除了如果&T包含一個UnsafeCell<U>的話。不安全代碼必須不能違反這些重疊(aliasing)保證- 不使用
UnsafeCell<U>改變一個不可變值/引用 - 通過編譯器固有功能調用未定義行為:
- 使用
std::ptr::offset(offset功能)來索引超過對象邊界的值,除了允許的末位超出一個字節 - 在重疊(overlapping)緩衝區上使用
std::ptr::copy_nonoverlapping_memory(memcpy32/memcpy64功能)
- 使用
- 原生類型的無效值,即使是在私有字段/本地變量中:
- 空/懸垂引用或裝箱
bool中一個不是false(0)或true(1)的值enum中一個並不包含在類型定義中判別式char中一個代理字(surrogate)或超過char::MAX的值str中非UTF-8字節序列
- 在外部代碼中使用Rust或在Rust中使用外部語言
裸指針
Rust通過限制智能指針的行為保障了編譯時安全,不過仍需要對指針做一些額外的操作。
*const T和*mut T在Rust中被稱為“裸指針”。它允許別名,允許用來寫共享所有權的類型,甚至是內存安全的共享內存類型如:Rc<T>和Arc<T>,但是賦予你更多權利的同時意味著你需要擔當更多的責任:
- 不能保證指向有效的內存,甚至不能保證是非空的
- 沒有任何自動清除,所以需要手動管理資源
- 是普通舊式類型,也就是說,它不移動所有權,因此Rust編譯器不能保證不出像釋放後使用這種bug
- 缺少任何形式的生命週期,不像
&,因此編譯器不能判斷出懸垂指針 - 除了不允許直接通過
*const T改變外,沒有別名或可變性的保障
使用
創建一個裸指針:
#![allow(unused)] fn main() { let a = 1; let b = &a as *const i32; let mut x = 2; let y = &mut x as *mut i32; }
解引用需要在unsafe中進行:
#![allow(unused)] fn main() { let a = 1; let b = &a as *const i32; let c = unsafe { *b }; println!("{}", c); }
Box<T>的into_raw:
#![allow(unused)] fn main() { let a: Box<i32> = Box::new(10); // 我們需要先解引用a,再隱式把 & 轉換成 * let b: *const i32 = &*a; // 使用 into_raw 方法 let c: *const i32 = Box::into_raw(a); }
如上說所,引用和裸指針之間可以隱式轉換,但隱式轉換後再解引用需要使用unsafe:
#![allow(unused)] fn main() { // 顯式 let a = 1; let b: *const i32 = &a as *const i32; //或者let b = &a as *const i32; // 隱式 let c: *const i32 = &a; unsafe { println!("{}", *c); } }
FFI
FFI(Foreign Function Interface)是用來與其它語言交互的接口,在有些語言裡面稱為語言綁定(language bindings),Java 裡面一般稱為 JNI(Java Native Interface) 或 JNA(Java Native Access)。由於現實中很多程序是由不同編程語言寫的,必然會涉及到跨語言調用,比如 A 語言寫的函數如果想在 B 語言裡面調用,這時一般有兩種解決方案:一種是將函數做成一個服務,通過進程間通信(IPC)或網絡協議通信(RPC, RESTful等);另一種就是直接通過 FFI 調用。前者需要至少兩個獨立的進程才能實現,而後者直接將其它語言的接口內嵌到本語言中,所以調用效率比前者高。
當前的系統編程領域大部分被 C/C++ 佔領,而 Rust 定位為系統編程語言,少不了與現有的 C/C++ 代碼交互,另外為了給那些"慢"腳本語言調用,Rust 必然得對 FFI 有完善的支持,本章我們就來談談 Rust 的 FFI 系統。
調用ffi函數
下文提到的ffi皆指cffi。
Rust作為一門系統級語言,自帶對ffi調用的支持。
Getting Start
引入libc庫
由於cffi的數據類型與rust不完全相同,我們需要引入libc庫來表達對應ffi函數中的類型。
在Cargo.toml中添加以下行:
[dependencies]
libc = "0.2.9"
在你的rs文件中引入庫:
#![allow(unused)] fn main() { extern crate libc }
在以前libc庫是和rust一起發佈的,後來libc被移入了crates.io通過cargo安裝。
聲明你的ffi函數
就像c語言需要#include聲明瞭對應函數的頭文件一樣,rust中調用ffi也需要對對應函數進行聲明。
#![allow(unused)] fn main() { use libc::c_int; use libc::c_void; use libc::size_t; #[link(name = "yourlib")] extern { fn your_func(arg1: c_int, arg2: *mut c_void) -> size_t; // 聲明ffi函數 fn your_func2(arg1: c_int, arg2: *mut c_void) -> size_t; static ffi_global: c_int; // 聲明ffi全局變量 } }
聲明一個ffi庫需要一個標記有#[link(name = "yourlib")]的extern塊。name為對應的庫(so/dll/dylib/a)的名字。
如:如果你需要snappy庫(libsnappy.so/libsnappy.dll/libsnappy.dylib/libsnappy.a), 則對應的name為snappy。
在一個extern塊中你可以聲明任意多的函數和變量。
調用ffi函數
聲明完成後就可以進行調用了。
由於此函數來自外部的c庫,所以rust並不能保證該函數的安全性。因此,調用任何一個ffi函數需要一個unsafe塊。
#![allow(unused)] fn main() { let result: size_t = unsafe { your_func(1 as c_int, Box::into_raw(Box::new(3)) as *mut c_void) }; }
封裝unsafe,暴露安全接口
作為一個庫作者,對外暴露不安全接口是一種非常不合格的做法。在做c庫的rust binding時,我們做的最多的將是將不安全的c接口封裝成一個安全接口。
通常做法是:在一個叫ffi.rs之類的文件中寫上所有的extern塊用以聲明ffi函數。在一個叫wrapper.rs之類的文件中進行包裝:
#![allow(unused)] fn main() { // ffi.rs #[link(name = "yourlib")] extern { fn your_func(arg1: c_int, arg2: *mut c_void) -> size_t; } }
#![allow(unused)] fn main() { // wrapper.rs fn your_func_wrapper(arg1: i32, arg2: &mut i32) -> isize { unsafe { your_func(1 as c_int, Box::into_raw(Box::new(3)) as *mut c_void) } as isize } }
對外暴露(pub use) your_func_wrapper函數即可。
數據結構對應
libc為我們提供了很多原始數據類型,比如c_int, c_float等,但是對於自定義類型,如結構體,則需要我們自行定義。
結構體
rust中結構體默認的內存表示和c並不兼容。如果要將結構體傳給ffi函數,請為rust的結構體打上標記:
#![allow(unused)] fn main() { #[repr(C)] struct RustObject { a: c_int, // other members } }
此外,如果使用#[repr(C, packed)]將不為此結構體填充空位用以對齊。
Union
比較遺憾的是,rust到目前為止(2016-03-31)還沒有一個很好的應對c的union的方法。只能通過一些hack來實現。(對應rfc)
Enum
和struct一樣,添加#[repr(C)]標記即可。
回調函數
和c庫打交道時,我們經常會遇到一個函數接受另一個回調函數的情況。將一個rust函數轉變成c可執行的回調函數非常簡單:在函數前面加上extern "C":
extern "C" fn callback(a: c_int) { // 這個函數是傳給c調用的 println!("hello {}!", a); } #[link(name = "yourlib")] extern { fn run_callback(data: i32, cb: extern fn(i32)); } fn main() { unsafe { run_callback(1 as i32, callback); // 打印 1 } }
對應c庫代碼:
typedef void (*rust_callback)(int32_t);
void run_callback(int32_t data, rust_callback callback) {
callback(data); // 調用傳過來的回調函數
}
字符串
rust為了應對不同的情況,有很多種字符串類型。其中CStr和CString是專用於ffi交互的。
CStr
對於產生於c的字符串(如在c程序中使用malloc產生),rust使用CStr來表示,和str類型對應,表明我們並不擁有這個字符串。
#![allow(unused)] fn main() { use std::ffi::CStr; use libc::c_char; #[link(name = "yourlib")] extern { fn char_func() -> *mut c_char; } fn get_string() -> String { unsafe { let raw_string: *mut c_char = char_func(); let cstr = CStr::from_ptr(my_string()); cstr.to_string_lossy().into_owned() } } }
在這裡get_string使用CStr::from_ptr從c的char*獲取一個字符串,並且轉化成了一個String.
- 注意to_string_lossy()的使用:因為在rust中一切字符都是採用utf8表示的而c不是,
因此如果要將c的字符串轉換到rust字符串的話,需要檢查是否都為有效
utf-8字節。to_string_lossy將返回一個Cow<str>類型, 即如果c字符串都為有效utf-8字節,則將其0開銷地轉換成一個&str類型,若不是,rust會將其拷貝一份並且將非法字節用U+FFFD填充。
CString
和CStr表示從c中來,rust不擁有歸屬權的字符串相反,CString表示由rust分配,用以傳給c程序的字符串。
#![allow(unused)] fn main() { use std::ffi::CString; use std::os::raw::c_char; extern { fn my_printer(s: *const c_char); } let c_to_print = CString::new("Hello, world!").unwrap(); unsafe { my_printer(c_to_print.as_ptr()); // 使用 as_ptr 將CString轉化成char指針傳給c函數 } }
注意c字符串中並不能包含\0字節(因為\0用來表示c字符串的結束符),因此CString::new將返回一個Result,
如果輸入有\0的話則為Error(NulError)。
不透明結構體
C庫存在一種常見的情況:庫作者並不想讓使用者知道一個數據類型的具體內容,因此常常提供了一套工具函數,並使用void*或不透明結構體傳入傳出進行操作。
比較典型的是ncurse庫中的WINDOW類型。
當參數是void*時,在rust中可以和c一樣,使用對應類型*mut libc::c_void進行操作。如果參數為不透明結構體,rust中可以使用空白enum進行代替:
#![allow(unused)] fn main() { enum OpaqueStruct {} extern "C" { pub fn foo(arg: *mut OpaqueStruct); } }
C代碼:
struct OpaqueStruct;
void foo(struct OpaqueStruct *arg);
空指針
另一種很常見的情況是需要一個空指針。請使用0 as *const _ 或者 std::ptr::null()來生產一個空指針。
內存安全
由於ffi跨越了rust邊界,rust編譯器此時無法保障代碼的安全性,所以在涉及ffi操作時要格外注意。
析構問題
在涉及ffi調用時最常見的就是析構問題:這個對象由誰來析構?是否會洩露或use after free?
有些情況下c庫會把一類類型malloc了以後傳出來,然後不再關係它的析構。因此在做ffi操作時請為這些類型實現析構(Drop Trait).
可空指針優化
當rust的一個enum為一種特殊結構:它有兩種實例,一種為空,另一種只有一個數據域的時候,rustc會開啟空指針優化將其優化成一個指針。
比如Option<extern "C" fn(c_int) -> c_int>會被優化成一個可空的函數指針。
ownership處理
在rust中,由於編譯器會自動插入析構代碼到塊的結束位置,在使用owned類型時要格外的注意。
extern { pub fn foo(arg: extern fn() -> *const c_char); } extern "C" fn danger() -> *const c_char { let cstring = CString::new("I'm a danger string").unwrap(); cstring.as_ptr() } // 由於CString是owned類型,在這裡cstring被rust free掉了。USE AFTER FREE! too young! fn main() { unsafe { foo(danger); // boom !! } }
由於as_ptr接受一個&self作為參數(fn as_ptr(&self) -> *const c_char),as_ptr以後ownership仍然歸rust所有。因此rust會在函數退出時進行析構。
正確的做法是使用into_raw()來代替as_ptr()。由於into_raw的簽名為fn into_raw(self) -> *mut c_char,接受的是self,產生了ownership轉移,
因此danger函數就不會將cstring析構了。
panic
由於在ffi中panic是未定義行為,切忌在cffi時panic包括直接調用panic!,unimplemented!,以及強行unwrap等情況。
當你寫cffi時,記住:你寫下的每個單詞都可能是發射核彈的密碼!
靜態庫/動態庫
前面提到了聲明一個外部庫的方式--#[link]標記,此標記默認為動態庫。但如果是靜態庫,可以使用#[link(name = "foo", kind = "static")]來標記。
此外,對於osx的一種特殊庫--framework, 還可以這樣標記#[link(name = "CoreFoundation", kind = "framework")].
調用約定
前面看到,聲明一個被c調用的函數時,採用extern "C" fn的語法。此處的"C"即為c調用約定的意思。此外,rust還支持:
- stdcall
- aapcs
- cdecl
- fastcall
- vectorcall //這種call約定暫時需要開啟abi_vectorcall feature gate.
- Rust
- rust-intrinsic
- system
- C
- win64
bindgen
是不是覺得把一個個函數和全局變量在extern塊中去聲明,對應的數據結構去手動創建特別麻煩?沒關係,rust-bindgen來幫你搞定。
rust-bindgen是一個能從對應c頭文件自動生成函數聲明和數據結構的工具。創建一個綁定只需要./bindgen [options] input.h即可。
項目地址
將Rust編譯成庫
上一章講述瞭如何從rust中調用c庫,這一章我們講如何把rust編譯成庫讓別的語言通過cffi調用。
調用約定和mangle
正如上一章講述的,為了能讓rust的函數通過ffi被調用,需要加上extern "C"對函數進行修飾。
但由於rust支持重載,所以函數名會被編譯器進行混淆,就像c++一樣。因此當你的函數被編譯完畢後,函數名會帶上一串表明函數簽名的字符串。
比如:fn test() {}會變成_ZN4test20hf06ae59e934e5641haaE.
這樣的函數名為ffi調用帶來了困難,因此,rust提供了#[no_mangle]屬性為函數修飾。
對於帶有#[no_mangle]屬性的函數,rust編譯器不會為它進行函數名混淆。如:
#![allow(unused)] fn main() { #[no_mangle] extern "C" fn test() {} }
在nm中觀察到為
...
00000000001a7820 T test
...
至此,test函數將能夠被正常的由cffi調用。
指定crate類型
rustc默認編譯產生rust自用的rlib格式庫,要讓rustc產生動態鏈接庫或者靜態鏈接庫,需要顯式指定。
- 方法1: 在文件中指定。
在文件頭加上
#![crate_type = "foo"], 其中foo的可選類型有bin,lib,rlib,dylib,staticlib.分別對應可執行文件, 默認(將由rustc自己決定),rlib格式,動態鏈接庫,靜態鏈接庫。 - 方法2: 編譯時給rustc 傳
--crate-type參數。參數內容同上。 - 方法3: 使用cargo,指定
crate-type = ["foo"],foo可選類型同1
小技巧: Any
由於在跨越ffi過程中,rust類型信息會丟失,比如當用rust提供一個OpaqueStruct給別的語言時:
#![allow(unused)] fn main() { use std::mem::transmute; #[derive(Debug)] struct Foo<T> { t: T } #[no_mangle] extern "C" fn new_foo_vec() -> *const c_void { Box::into_raw(Box::new(Foo {t: vec![1,2,3]})) as *const c_void } #[no_mangle] extern "C" fn new_foo_int() -> *const c_void { Box::into_raw(Box::new(Foo {t: 1})) as *const c_void } fn push_foo_element(t: &mut Foo<Vec<i32>>) { t.t.push(1); } #[no_mangle] extern "C" fn push_foo_element_c(foo: *mut c_void){ let foo2 = unsafe { &mut *(foo as *mut Foo<Vec<i32>>) // 這麼確定是Foo<Vec<i32>>? 萬一foo是Foo<i32>怎麼辦? }; push_foo_element(foo3); } }
以上代碼中完全不知道foo是一個什麼東西。安全也無從說起了,只能靠文檔。
因此在ffi調用時往往會喪失掉rust類型系統帶來的方便和安全。在這裡提供一個小技巧:使用Box<Box<Any>>來包裝你的類型。
rust的Any類型為rust帶來了運行時反射的能力,使用Any跨越ffi邊界將極大提高程序安全性。
#![allow(unused)] fn main() { use std::any::Any; #[derive(Debug)] struct Foo<T> { t: T } #[no_mangle] extern "C" fn new_foo_vec() -> *const c_void { Box::into_raw(Box::new(Box::new(Foo {t: vec![1,2,3]}) as Box<Any>)) as *const c_void } #[no_mangle] extern "C" fn new_foo_int() -> *const c_void { Box::into_raw(Box::new(Box::new(Foo {t: 1}) as Box<Any>)) as *const c_void } fn push_foo_element(t: &mut Foo<Vec<i32>>) { t.t.push(1); } #[no_mangle] extern "C" fn push_foo_element_c(foo: *mut c_void){ let foo2 = unsafe { &mut *(foo as *mut Box<Any>) }; let foo3: Option<&mut Foo<Vec<i32>>> = foo2.downcast_mut(); // 如果foo2不是*const Box<Foo<Vec<i32>>>, 則foo3將會是None if let Some(value) = foo3 { push_foo_element(value); } } }
這樣一來,就非常不容易出錯了。
運算符重載
Rust可以讓我們對某些運算符進行重載,這其中大部分的重載都是對std::ops下的trait進行重載而實現的。
重載加法
我們現在來實現一個只支持加法的閹割版複數:
use std::ops::Add; #[derive(Debug)] struct Complex { a: f64, b: f64, } impl Add for Complex { type Output = Complex; fn add(self, other: Complex) -> Complex { Complex {a: self.a+other.a, b: self.b+other.b} } } fn main() { let cp1 = Complex{a: 1f64, b: 2.0}; let cp2 = Complex{a: 5.0, b:8.1}; let cp3 = cp1 + cp2; print!("{:?}", cp3); }
輸出:
Complex { a: 6, b: 10.1}
這裡我們實現了std::ops::Add這個trait。這時候有同學一拍腦門,原來如此,沒錯……其實Rust的大部分運算符都是std::ops下的trait的語法糖!
我們來看看std::ops::Add的具體結構
#![allow(unused)] fn main() { impl Add<i32> for Point { type Output = f64; fn add(self, rhs: i32) -> f64 { // add an i32 to a Point and get an f64 } } }
神奇的Output以及動態分發
有的同學會問了,這個Output是腫麼回事?答,類型轉換喲親!
舉個不太恰當的栗子,我們在現實中會出現0.5+0.5=1這樣的算式,用Rust的語言來描述就是: 兩個f32相加得到了一個i8。顯而易見,Output就是為這種情況設計的。
還是看代碼:
use std::ops::Add; #[derive(Debug)] struct Complex { a: f64, b: f64, } impl Add for Complex { type Output = Complex; fn add(self, other: Complex) -> Complex { Complex {a: self.a+other.a, b: self.b+other.b} } } impl Add<i32> for Complex { type Output = f64; fn add(self, other: i32) -> f64 { self.a + self.b + (other as f64) } } fn main() { let cp1 = Complex{a: 1f64, b: 2.0}; let cp2 = Complex{a: 5.0, b:8.1}; let cp3 = Complex{a: 9.0, b:20.0}; let complex_add_result = cp1 + cp2; print!("{:?}\n", complex_add_result); print!("{:?}", cp3 + 10i32); }
輸出結果:
Complex { a: 6, b: 10.1 }
39
對範型的限制
Rust的運算符是基於trait系統的,同樣的,運算符可以被當成一種對範型的限制,我們可以這麼要求範型T必須實現了trait Mul<Output=T>。
於是,我們得到了如下的一份代碼:
use std::ops::Mul; trait HasArea<T> { fn area(&self) -> T; } struct Square<T> { x: T, y: T, side: T, } impl<T> HasArea<T> for Square<T> where T: Mul<Output=T> + Copy { fn area(&self) -> T { self.side * self.side } } fn main() { let s = Square { x: 0.0f64, y: 0.0f64, side: 12.0f64, }; println!("Area of s: {}", s.area()); }
對於trait HasArea<T>和 struct Square<T>,我們通過where T: Mul<Output=T> + Copy 限制了T必須實現乘法。同時Copy則限制了Rust不再將self.side給move到返回值裡去。
寫法簡單,輕鬆愉快。
屬性和編譯器參數
本章將介紹Rust語言中的屬性(Attribute)和編譯器參數(Compiler Options)。
屬性
屬性(Attribute)是一種通用的用於表達元數據的特性,借鑑ECMA-334(C#)的語法來實現ECMA-335中描述的Attributes。屬性只能應用於Item(元素、項),
例如 use 聲明、模塊、函數等。
元素
在Rust中,Item是Crate(庫)的一個組成部分。它包括
extern crate聲明use聲明- 模塊(模塊是一個Item的容器)
- 函數
type定義- 結構體定義
- 枚舉類型定義
- 常量定義
- 靜態變量定義
- Trait定義
- 實現(Impl)
這些Item是可以互相嵌套的,比如在一個函數中定義一個靜態變量、在一個模塊中使用use聲明或定義一個結構體。這些定義在某個作用域裡面的Item跟你把
它寫到最外層作用域所實現的功能是一樣的,只不過你要訪問這些嵌套的Item就必須使用路徑(Path),如a::b::c。但一些外層的Item不允許你使用路徑去
訪問它的子Item,比如函數,在函數中定義的靜態變量、結構體等,是不可以通過路徑來訪問的。
屬性的語法
屬性的語法借鑑於C#,看起來像是這樣子的
#![allow(unused)] fn main() { #[name(arg1, arg2 = "param")] }
它是由一個#開啟,後面緊接著一個[],裡面便是屬性的具體內容,它可以有如下幾種寫法:
- 單個標識符代表的屬性名,如
#[unix] - 單個標識符代表屬性名,後面緊跟著一個
=,然後再跟著一個字面量(Literal),組成一個鍵值對,如#[link(name = "openssl")] - 單個標識符代表屬性名,後面跟著一個逗號隔開的子屬性的列表,如
#[cfg(and(unix, not(windows)))]
在#後面還可以緊跟一個!,比如#![feature(box_syntax)],這表示這個屬性是應用於它所在的這個Item。而如果沒有!則表示這個屬性僅應用於緊接著的那個Item。
例如:
#![allow(unused)] fn main() { // 為這個crate開啟box_syntax這個新特性 #![feature(box_syntax)] // 這是一個單元測試函數 #[test] fn test_foo() { /* ... */ } // 條件編譯,只會在編譯目標為Linux時才會生效 #[cfg(target_os="linux")] mod bar { /* ... */ } // 為以下的這個type定義關掉non_camel_case_types的編譯警告 #[allow(non_camel_case_types)] type int8_t = i8; }
應用於Crate的屬性
-
crate_name- 指定Crate的名字。如#[crate_name = "my_crate"]則可以讓編譯出的庫名字為libmy_crate.rlib。 -
crate_type- 指定Crate的類型,有以下幾種選擇"bin"- 編譯為可執行文件;"lib"- 編譯為庫;"dylib"- 編譯為動態鏈接庫;"staticlib"- 編譯為靜態鏈接庫;"rlib"- 編譯為Rust特有的庫文件,它是一種特殊的靜態鏈接庫格式,它裡面會含有一些元數據供編譯器使用,最終會靜態鏈接到目標文件之中。
例
#![crate_type = "dylib"]。 -
feature- 可以開啟一些不穩定特性,只可在nightly版的編譯器中使用。 -
no_builtins- 去掉內建函數。 -
no_main- 不生成main這個符號,當你需要鏈接的庫中已經定義了main函數時會用到。 -
no_start- 不鏈接自帶的native庫。 -
no_std- 不鏈接自帶的std庫。 -
plugin- 加載編譯器插件,一般用於加載自定義的編譯器插件庫。用法是#![allow(unused)] fn main() { // 加載foo, bar兩個插件 #![plugin(foo, bar)] // 或者給插件傳入必要的初始化參數 #![plugin(foo(arg1, arg2))] } -
recursive_limit- 設置在編譯期最大的遞歸層級。比如自動解引用、遞歸定義的宏等。默認設置是#![recursive_limit = "64"]
應用於模塊的屬性
-
no_implicit_prelude- 取消自動插入use std::prelude::*。 -
path- 設置此mod的文件路徑。如聲明
mod a;,則尋找- 本文件夾下的
a.rs文件 - 本文件夾下的
a/mod.rs文件
#![allow(unused)] fn main() { #[cfg(unix)] #[path = "sys/unix.rs"] mod sys; #[cfg(windows)] #[path = "sys/windows.rs"] mod sys; } - 本文件夾下的
應用於函數的屬性
main- 把這個函數作為入口函數,替代fn main,會被入口函數(Entry Point)調用。plugin_registrar- 編寫編譯器插件時用,用於定義編譯器插件的入口函數。start- 把這個函數作為入口函數(Entry Point),改寫startlanguage item。test- 指明這個函數為單元測試函數,在非測試環境下不會被編譯。should_panic- 指明這個單元測試函數必然會panic。cold- 指明這個函數很可能是不會被執行的,因此優化的時候特別對待它。
#![allow(unused)] fn main() { // 把`my_main`作為主函數 #[main] fn my_main() { } // 把`plugin_registrar`作為此編譯器插件的入口函數 #[plugin_registrar] pub fn plugin_registrar(reg: &mut Registry) { reg.register_macro("rn", expand_rn); } // 把`entry_point`作為入口函數,不再執行標準庫中的初始化流程 #[start] fn entry_point(argc: isize, argv: *const *const u8) -> isize { } // 定義一個單元測試 // 這個單元測試一定會panic #[test] #[should_panic] fn my_test() { panic!("I expected to be panicked"); } // 這個函數很可能是不會執行的, // 所以優化的時候就換種方式 #[cold] fn unlikely_to_be_executed() { } }
應用於全局靜態變量的屬性
thread_local- 只可用於static mut,表示這個變量是thread local的。
應用於FFI的屬性
extern塊可以應用以下屬性
-
link_args- 指定鏈接時給鏈接器的參數,平臺和實現相關。 -
link- 說明這個塊需要鏈接一個native庫,它有以下參數:name- 庫的名字,比如libname.a的名字是name;kind- 庫的類型,它包括dylib- 動態鏈接庫static- 靜態庫framework- OS X裡的Framework
#![allow(unused)] fn main() { #[link(name = "readline")] extern { } #[link(name = "CoreFoundation", kind = "framework")] extern { } }
在extern塊裡面,可以使用
link_name- 指定這個鏈接的外部函數的名字或全局變量的名字;linkage- 對於全局變量,可以指定一些LLVM的鏈接類型( http://llvm.org/docs/LangRef.html#linkage-types )。
對於enum類型,可以使用
repr- 目前接受C,C表示兼容C ABI。
#![allow(unused)] fn main() { #[repr(C)] enum eType { Operator, Indicator, } }
對於struct類型,可以使用
repr- 目前只接受C和packed,C表示結構體兼容C ABI,packed表示移除字段間的padding。
用於宏的屬性
-
macro_use- 把模塊或庫中定義的宏導出來-
應用於
mod上,則把此模塊內定義的宏導出到它的父模塊中 -
應用於
extern crate上,則可以接受一個列表,如#![allow(unused)] fn main() { #[macro_use(debug, trace)] extern crate log; }則可以只導入列表中指定的宏,若不指定則導入所有的宏。
-
-
macro_reexport- 應用於extern crate上,可以再把這些導入的宏再輸出出去給別的庫使用。 -
macro_export- 應於在宏上,可以使這個宏可以被導出給別的庫使用。 -
no_link- 應用於extern crate上,表示即使我們把它裡面的庫導入進來了,但是不要把這個庫鏈接到目標文件中。
其它屬性
-
export_function- 用於靜態變量或函數,指定它們在目標文件中的符號名。 -
link_section- 用於靜態變量或函數,表示應該把它們放到哪個段中去。 -
no_mangle- 可以應用於任意的Item,表示取消對它們進行命名混淆,直接把它們的名字作為符號寫到目標文件中。 -
simd- 可以用於元組結構體上,並自動實現了數值運算符,這些操作會生成相應的SIMD指令。 -
doc- 為這個Item綁定文檔,跟///的功能一樣,用法是#![allow(unused)] fn main() { #[doc = "This is a doc"] struct Foo {} }
條件編譯
有時候,我們想針對不同的編譯目標來生成不同的代碼,比如在編寫跨平臺模塊時,針對Linux和Windows分別使用不同的代碼邏輯。
條件編譯基本上就是使用cfg這個屬性,直接看例子
#![allow(unused)] fn main() { #[cfg(target_os = "macos")] fn cross_platform() { // Will only be compiled on Mac OS, including Mac OS X } #[cfg(target_os = "windows")] fn cross_platform() { // Will only be compiled on Windows } // 若條件`foo`或`bar`任意一個成立,則編譯以下的Item #[cfg(any(foo, bar))] fn need_foo_or_bar() { } // 針對32位的Unix系統 #[cfg(all(unix, target_pointer_width = "32"))] fn on_32bit_unix() { } // 若`foo`不成立時編譯 #[cfg(not(foo))] fn needs_not_foo() { } }
其中,cfg可接受的條件有
-
debug_assertions- 若沒有開啟編譯優化時就會成立。 -
target_arch = "..."- 目標平臺的CPU架構,包括但不限於x86,x86_64,mips,powerpc,arm或aarch64。 -
target_endian = "..."- 目標平臺的大小端,包括big和little。 -
target_env = "..."- 表示使用的運行庫,比如musl表示使用的是MUSL的libc實現,msvc表示使用微軟的MSVC,gnu表示使用GNU的實現。 但在部分平臺這個數據是空的。 -
target_family = "..."- 表示目標操作系統的類別,比如windows和unix。這個屬性可以直接作為條件使用,如#[unix],#[cfg(unix)]。 -
target_os = "..."- 目標操作系統,包括但不限於windows,macos,ios,linux,android,freebsd,dragonfly,bitrig,openbsd,netbsd。 -
target_pointer_width = "..."- 目標平臺的指針寬度,一般就是32或64。 -
target_vendor = "..."- 生產商,例如apple,pc或大多數Linux系統的unknown。 -
test- 當啟動了單元測試時(即編譯時加了--test參數,或使用cargo test)。
還可以根據一個條件去設置另一個條件,使用cfg_attr,如
#![allow(unused)] fn main() { #[cfg_attr(a, b)] }
這表示若a成立,則這個就相當於#[cfg(b)]。
條件編譯屬性只可以應用於Item,如果想應用在非Item中怎麼辦呢?可以使用cfg!宏,如
#![allow(unused)] fn main() { if cfg!(target_arch = "x86") { } else if cfg!(target_arch = "x86_64") { } else if cfg!(target_arch = "mips") { } else { } }
這種方式不會產生任何運行時開銷,因為不成立的條件相當於裡面的代碼根本不可能被執行,編譯時會直接被優化掉。
Linter參數
目前的Rust編譯器已自帶的Linter,它可以在編譯時靜態幫你檢測不用的代碼、死循環、編碼風格等等。Rust提供了一系列的屬性用於控制Linter的行為
allow(C)- 編譯器將不會警告對於C條件的檢查錯誤。deny(C)- 編譯器遇到違反C條件的錯誤將直接當作編譯錯誤。forbit(C)- 行為與deny(C)一樣,但這個將不允許別人使用allow(C)去修改。warn(C)- 編譯器將對於C條件的檢查錯誤輸出警告。
編譯器支持的Lint檢查可以通過執行rustc -W help來查看。
內聯參數
內聯函數即建議編譯器可以考慮把整個函數拷貝到調用者的函數體中,而不是生成一個call指令調用過去。這種優化對於短函數非常有用,有利於提高性能。
編譯器自己會根據一些默認的條件來判斷一個函數是不是應該內聯,若一個不應該被內聯的函數被內聯了,實際上會導致整個程序更慢。
可選的屬性有:
#[inline]- 建議編譯器內聯這個函數#[inline(always)]- 要求編譯器必須內聯這個函數#[inline(never)]- 要求編譯器不要內聯這個函數
內聯會導致在一個庫裡面的代碼被插入到另一個庫中去。
自動實現Trait
編譯器提供一個編譯器插件叫作derive,它可以幫你去生成一些代碼去實現(impl)一些特定的Trait,如
#![allow(unused)] fn main() { #[derive(PartialEq, Clone)] struct Foo<T> { a: i32, b: T, } }
編譯器會自動為你生成以下的代碼
#![allow(unused)] fn main() { impl<T: PartialEq> PartialEq for Foo<T> { fn eq(&self, other: &Foo<T>) -> bool { self.a == other.a && self.b == other.b } fn ne(&self, other: &Foo<T>) -> bool { self.a != other.a || self.b != other.b } } impl<T: Clone> Clone for Foo<T> { fn clone(&self) -> Foo<T> { Foo { a: self.a.clone(), b: self.b.clone(), } } } }
目前derive僅支持標準庫中部分的Trait。
編譯器特性
在非穩定版的Rust編譯器中,可以使用一些不穩定的功能,比如一些還在討論中的新功能、正在實現中的功能等。Rust編譯器提供一個應用於Crate的屬性feature來啟用這些不穩定的功能,如
#![allow(unused)] #![feature(advanced_slice_patterns, box_syntax, asm)] fn main() { }
具體可使用的編譯器特性會因編譯器版本的發佈而不同,具體請閱讀官方文檔。
編譯器參數
本章將介紹Rust編譯器的參數。
Rust編譯器程序的名字是rustc,使用它的方法很簡單:
$ rustc [OPTIONS] INPUT
其中,[OPTIONS]表示編譯參數,而INPUT則表示輸入文件。而編譯參數有以下可選:
-
-h, --help- 輸出幫助信息到標準輸出; -
--cfg SPEC- 傳入自定義的條件編譯參數,使用方法如fn main() { if cfg!(hello) { println!("world!"); } }如上例所示,若
cfg!(hello)成立,則運行程序就會輸出"world"到標準輸出。我們把這個文件保存為hello.rs然後編譯它$ rustc --cfg hello hello.rs運行它就會看到屏幕中輸出了
world!。 -
-L [KIND=]PATH- 往鏈接路徑中加入一個文件夾,並且可以指定這個路徑的類型(Kind),這些類型包括dependency- 在這個路徑下找依賴的文件,比如說mod;crate- 只在這個路徑下找extern crate中定義的庫;native- 只在這個路徑下找Native庫;framework- 只在OS X下有用,只在這個路徑下找Framework;all- 默認選項。
-
-l [KIND=]NAME- 鏈接一個庫,這個庫可以指定類型(Kind)static- 靜態庫;dylib- 動態庫;framework- OS X的Framework。
如果不傳,默認為
dylib。此處舉一個例子如何手動鏈接一個庫,我們先創建一個文件叫
myhello.rs,在裡面寫一個函數#![allow(unused)] fn main() { // myhello.rs /// 這個函數僅僅向標籤輸出打印 Hello World! /// 不要忘記要把它標記為 pub 哦。 pub fn print_hello() { println!("Hello World!"); } }然後把這個文件編譯成一個靜態庫,
libmyhello.a$ rustc --crate-type staticlib myhello.rs然後再創建一個
main.rs,鏈接這個庫並打印出"Hello World!"// main.rs // 指定鏈接庫 myhello extern crate myhello; fn main() { // 調用庫函數 myhello::print_hello(); }編譯
main.rs$ rustc -L. -lmyhello main.rs運行
main,就會看到屏幕輸出"Hello World!"啦。 -
--crate-type- 指定編譯輸出類型,它的參數包括bin- 二進行可執行文件lib- 編譯為庫rlib- Rust庫dylib- 動態鏈接庫staticlib- 靜態鏈接庫
-
--crate-name- 指定這個Crate的名字,默認是文件名,如main.rs編譯成可執行文件時默認是main,但你可以指定它為foo$ rustc --crate-name foo main.rs則會輸出
foo可執行文件。 -
--emit- 指定編譯器的輸出。編譯器默認是輸出一個可執行文件或庫文件,但你可以選擇輸出一些其它的東西用於Debugasm- 輸出彙編llvm-bc- LLVM Bitcode;llvm-ir- LLVM IR,即LLVM中間碼(LLVM Intermediate Representation);obj- Object File(就是*.o文件);link- 這個是要結合其它--emit參數使用,會執行Linker再輸出結果;dep-info- 文件依賴關係(Debug用,類似於Makefile一樣的依賴)。
以上參數可以同時使用,使用逗號分割,如
$ rustc --emit asm,llvm-ir,obj main.rs同時,在最後可以加一個
=PATH來指定輸出到一個特定文件,如$ rustc --emit asm=output.S,llvm-ir=output.ir main.rs這樣會把彙編生成到
output.S文件中,把LLVM中間碼輸出到output.ir中。 -
--print- 打印一些信息,參數有crate-name- 編譯目標名;file-names- 編譯的文件名;sysroot- 打印Rust工具鏈的根目錄地址。
-
-g- 在目標文件中保存符號,這個參數等同於-C debuginfo=2。 -
-O- 開啟優化,這個參數等同於-C opt-level=2。 -
-o FILENAME- 指定輸出文件名,同樣適用於--emit的輸出。 -
--out-dir DIR- 指定輸出的文件夾,默認是當前文件夾,且會忽略-o配置。 -
--explain OPT- 解釋某一個編譯錯誤,比如若你寫了一個
main.rs,使用了一個未定義變量ffn main() { f }編譯它時編譯器會報錯:
main.rs:2:5: 2:6 error: unresolved name `f` [E0425] main.rs:2 f ^ main.rs:2:5: 2:6 help: run `rustc --explain E0425` to see a detailed explanation error: aborting due to previous error雖然錯誤已經很明顯,但是你也可以讓編譯器解釋一下,什麼是
E0425錯誤:$ rustc --explain E0425 // 編譯器打印的說明 -
--test- 編譯成一個單元測試可執行文件 -
--target TRIPLE- 指定目標平臺,基本格式是cpu-manufacturer-kernel[-os],例如## 64位OS X $ rustc --target x86_64-apple-darwin -
-W help- 打印Linter的所有可配置選項和默認值。 -
-W OPT, --warn OPT- 設置某一個Linter選項為Warning。 -
-A OPT, --allow OPT- 設置某一個Linter選項為Allow。 -
-D OPT, --deny OPT- 設置某一個Linter選項為Deny。 -
-F OPT, --forbit OPT- 設置某一個Linter選項為Forbit。 -
-C FLAG[=VAL], --codegen FLAG[=VAL]- 目標代碼生成的的相關參數,可以用-C help來查看配置,值得關注的幾個是linker=val- 指定鏈接器;linker-args=val- 指定鏈接器的參數;prefer-dynamic- 默認Rust編譯是靜態鏈接,選擇這個配置將改為動態鏈接;debug-info=level- Debug信息級數,0= 不生成,1= 只生成文件行號表,2= 全部生成;opt-level=val- 優化級數,可選0-3;debug_assertion- 顯式開啟cfg(debug_assertion)條件。
-
-V, --version- 打印編譯器版本號。 -
-v, --verbose- 開啟囉嗦模式(打印編譯器執行的日誌)。 -
--extern NAME=PATH- 用來指定外部的Rust庫(*.rlib)名字和路徑,名字應該與extern crate中指定的一樣。 -
--sysroot PATH- 指定工具鏈根目錄。 -
-Z flag- 編譯器Debug用的參數,可以用-Z help來查看可用參數。 -
--color auto|always|never- 輸出時對日誌加顏色auto- 自動選擇加還是不加,如果輸出目標是虛擬終端(TTY)的話就加,否則就不加;always- 給我加!never- 你敢加?
筒子們好,我們又見面了。之前第5章,我們一起探討了cargo的一些常用的基本技能。通過第5章的學習,大家基本能解決日常項目開發中遇到的大多數問題。但實際上,cargo提供給我們所使用的功能不僅限於此。我只想說一個字:cargo很好很強大,而且遠比你想象的強大。 本章將深入探討cargo的一些細節問題,這包括以下幾個方面:
- 基於語義化版本的項目版本聲明與管理
- cargo的toml描述文件配置字段詳細參考
基於語義化版本的項目版本聲明與管理
我們在使用toml描述文件對項目進行配置時,經常會遇到項目版本聲明及管理的問題,比如:
[package]
name = "libevent_sys"
version = "0.1.0"
[dependencies]
libc = "0.2"
這裡package段落中的version字段的值,以及dependencies段落中的libc字段的值,這些值的寫法,都涉及到語義化版本控制的問題。語義化版本控制是用一組簡單的規則及條件來約束版本號的配置和增長。這些規則是根據(但不侷限於)已經被各種封閉、開放源碼軟件所廣泛使用的慣例所設計。簡單來說,語義化版本控制遵循下面這些規則:
- 版本格式:主版本號.次版本號.修訂號,版本號遞增規則如下:
- 主版本號:當你做了不兼容的 API 修改,
- 次版本號:當你做了向下兼容的功能性新增,
- 修訂號:當你做了向下兼容的問題修正。
- 先行版本號及版本編譯信息可以加到“主版本號.次版本號.修訂號”的後面,作為延伸。
關於語義化版本控制的具體細節問題,大家可以參考這裡,我不再贅述。
cargo的toml描述文件配置字段詳細參考
[package]段落
啥也不多說了,直接上例子,大家注意我在例子中的中文解釋,個人覺得這樣比較一目瞭然:
[package]
# 軟件包名稱,如果需要在別的地方引用此軟件包,請用此名稱。
name = "hello_world"
# 當前版本號,這裡遵循semver標準,也就是語義化版本控制標準。
version = "0.1.0" # the current version, obeying semver
# 軟件所有作者列表
authors = ["you@example.com"]
# 非常有用的一個字段,如果要自定義自己的構建工作流,
# 尤其是要調用外部工具來構建其他本地語言(C、C++、D等)開發的軟件包時。
# 這時,自定義的構建流程可以使用rust語言,寫在"build.rs"文件中。
build = "build.rs"
# 顯式聲明軟件包文件夾內哪些文件被排除在項目的構建流程之外,
# 哪些文件包含在項目的構建流程中
exclude = ["build/**/*.o", "doc/**/*.html"]
include = ["src/**/*", "Cargo.toml"]
# 當軟件包在向公共倉庫發佈時出現錯誤時,使能此字段可以阻止此錯誤。
publish = false
# 關於軟件包的一個簡短介紹。
description = "..."
# 下面這些字段標明瞭軟件包倉庫的更多信息
documentation = "..."
homepage = "..."
repository = "..."
# 顧名思義,此字段指向的文件就是傳說中的ReadMe,
# 並且,此文件的內容最終會保存在註冊表數據庫中。
readme = "..."
# 用於分類和檢索的關鍵詞。
keywords = ["...", "..."]
# 軟件包的許可證,必須是cargo倉庫已列出的已知的標準許可證。
license = "..."
# 軟件包的非標許可證書對應的文件路徑。
license-file = "..."
依賴的詳細配置
最直接的方式在之前第五章探討過,這裡不在贅述,例如這樣:
[dependencies]
hammer = "0.5.0"
color = "> 0.6.0, < 0.8.0"
與平臺相關的依賴定義格式不變,不同的是需要定義在[target]字段下。例如:
# 注意,此處的cfg可以使用not、any、all等操作符任意組合鍵值對。
# 並且此用法僅支持cargo 0.9.0(rust 1.8.0)以上版本。
# 如果是windows平臺,則需要此依賴。
[target.'cfg(windows)'.dependencies]
winhttp = "0.4.0"
[target.'cfg(unix)'.dependencies]
openssl = "1.0.1"
#如果是32位平臺,則需要此依賴。
[target.'cfg(target_pointer_width = "32")'.dependencies]
native = { path = "native/i686" }
[target.'cfg(target_pointer_width = "64")'.dependencies]
native = { path = "native/i686" }
# 另一種寫法就是列出平臺的全稱描述
[target.x86_64-pc-windows-gnu.dependencies]
winhttp = "0.4.0"
[target.i686-unknown-linux-gnu.dependencies]
openssl = "1.0.1"
# 如果使用自定義平臺,請將自定義平臺文件的完整路徑用雙引號包含
[target."x86_64/windows.json".dependencies]
winhttp = "0.4.0"
[target."i686/linux.json".dependencies]
openssl = "1.0.1"
native = { path = "native/i686" }
openssl = "1.0.1"
native = { path = "native/x86_64" }
# [dev-dependencies]段落的格式等同於[dependencies]段落,
# 不同之處在於,[dependencies]段落聲明的依賴用於構建軟件包,
# 而[dev-dependencies]段落聲明的依賴僅用於構建測試和性能評估。
# 此外,[dev-dependencies]段落聲明的依賴不會傳遞給其他依賴本軟件包的項目
[dev-dependencies]
iron = "0.2"
自定義編譯器調用方式模板詳細參數
cargo內置五種編譯器調用模板,分別為dev、release、test、bench、doc,分別用於定義不同類型生成目標時的編譯器參數,如果我們自己想改變這些編譯模板,可以自己定義相應字段的值,例如(注意:下述例子中列出的值均為此模板字段對應的系統默認值):
# 開發模板, 對應`cargo build`命令
[profile.dev]
opt-level = 0 # 控制編譯器的 --opt-level 參數,也就是優化參數
debug = true # 控制編譯器是否開啟 `-g` 參數
rpath = false # 控制編譯器的 `-C rpath` 參數
lto = false # 控制`-C lto` 參數,此參數影響可執行文件和靜態庫的生成,
debug-assertions = true # 控制調試斷言是否開啟
codegen-units = 1 # 控制編譯器的 `-C codegen-units` 參數。注意,當`lto = true`時,此字段值被忽略
# 發佈模板, 對應`cargo build --release`命令
[profile.release]
opt-level = 3
debug = false
rpath = false
lto = false
debug-assertions = false
codegen-units = 1
# 測試模板,對應`cargo test`命令
[profile.test]
opt-level = 0
debug = true
rpath = false
lto = false
debug-assertions = true
codegen-units = 1
# 性能評估模板,對應`cargo bench`命令
[profile.bench]
opt-level = 3
debug = false
rpath = false
lto = false
debug-assertions = false
codegen-units = 1
# 文檔模板,對應`cargo doc`命令
[profile.doc]
opt-level = 0
debug = true
rpath = false
lto = false
debug-assertions = true
codegen-units = 1
需要注意的是,當調用編譯器時,只有位於調用最頂層的軟件包的模板文件有效,其他的子軟件包或者依賴軟件包的模板定義將被頂層軟件包的模板覆蓋。
[features]段落
[features]段落中的字段被用於條件編譯選項或者是可選依賴。例如:
[package]
name = "awesome"
[features]
# 此字段設置了可選依賴的默認選擇列表,
# 注意這裡的"session"並非一個軟件包名稱,
# 而是另一個featrue字段session
default = ["jquery", "uglifier", "session"]
# 類似這樣的值為空的feature一般用於條件編譯,
# 類似於`#[cfg(feature = "go-faster")]`。
go-faster = []
# 此feature依賴於bcrypt軟件包,
# 這樣封裝的好處是未來可以對secure-password此feature增加可選項目。
secure-password = ["bcrypt"]
# 此處的session字段導入了cookie軟件包中的feature段落中的session字段
session = ["cookie/session"]
[dependencies]
# 必要的依賴
cookie = "1.2.0"
oauth = "1.1.0"
route-recognizer = "=2.1.0"
# 可選依賴
jquery = { version = "1.0.2", optional = true }
uglifier = { version = "1.5.3", optional = true }
bcrypt = { version = "*", optional = true }
civet = { version = "*", optional = true }
如果其他軟件包要依賴使用上述awesome軟件包,可以在其描述文件中這樣寫:
[dependencies.awesome]
version = "1.3.5"
default-features = false # 禁用awesome 的默認features
features = ["secure-password", "civet"] # 使用此處列舉的各項features
使用features時需要遵循以下規則:
- feature名稱在本描述文件中不能與出現的軟件包名稱衝突
- 除了default feature,其他所有的features均是可選的
- features不能相互循環包含
- 開發依賴包不能包含在內
- features組只能依賴於可選軟件包
features的一個重要用途就是,當開發者需要對軟件包進行最終的發佈時,在進行構建時可以聲明暴露給終端用戶的features,這可以通過下述命令實現:
$ cargo build --release --features "shumway pdf"
關於測試
當運行cargo test命令時,cargo將會按做以下事情:
- 編譯並運行軟件包源代碼中被#[cfg(test)] 所標誌的單元測試
- 編譯並運行文檔測試
- 編譯並運行集成測試
- 編譯examples
配置構建目標
所有的諸如[[bin]], [lib], [[bench]], [[test]]以及 [[example]]等字段,均提供了類似的配置,以說明構建目標應該怎樣被構建。例如(下述例子中[lib]段落中各字段值均為默認值):
[lib]
# 庫名稱,默認與項目名稱相同
name = "foo"
# 此選項僅用於[lib]段落,其決定構建目標的構建方式,
# 可以取dylib, rlib, staticlib 三種值之一,表示生成動態庫、r庫或者靜態庫。
crate-type = ["dylib"]
# path字段聲明瞭此構建目標相對於cargo.toml文件的相對路徑
path = "src/lib.rs"
# 單元測試開關選項
test = true
# 文檔測試開關選項
doctest = true
# 性能評估開關選項
bench = true
# 文檔生成開關選項
doc = true
# 是否構建為編譯器插件的開關選項
plugin = false
# 如果設置為false,`cargo test`將會忽略傳遞給rustc的--test參數。
harness = true
測試與評測
本章講解 Rust 中內建的測試與評測相關知識。
測試
程序測試是一種找到缺陷的有效方式,但是它對證明沒有缺陷卻無能為力。
Edsger W. Dijkstra, "The Humble Programmer" (1972)
作為軟件工程質量保障體系的重要一環,測試是應該引起我們充分注意並重視的事情。前面說過,Rust 語言的設計集成了最近十多年中總結出來的大量最佳工程實踐,而對測試的原生集成也正體現了這一點。下面來看 Rust 是怎麼設計測試特性的。
Rust 的測試特性按精細度劃分,分為 3 個層次:
- 函數級;
- 模塊級;
- 工程級;
另外,Rust 還支持對文檔進行測試。
函數級測試
在本章中,我們用創建一個庫的實操來講解測試的內容。我們先用 cargo 建立一個庫工程:adder
$ cargo new adder
$ cd adder
#[test] 標識
打開 src/lib.rs 文件,可以看到如下代碼
#![allow(unused)] fn main() { #[test] fn it_works() { // do test work } }
Rust 中,只需要在一個函數的上面,加上 #[test] 就標明這是一個測試用的函數。
有了這個屬性之後,在使用 cargo build 編譯時,就會忽略這些函數。使用 cargo test 可以運行這些函數。類似於如下效果:
$ cargo test
Compiling adder v0.0.1 (file:///home/you/projects/adder)
Running target/adder-91b3e234d4ed382a
running 1 test
test it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
Rust 提供了兩個宏來執行測試斷言:
#![allow(unused)] fn main() { assert!(expr) 測試表達式是否為 true 或 false assert_eq!(expr, expr) 測試兩個表達式的結果是否相等 }
比如
#![allow(unused)] fn main() { #[test] fn it_works() { assert!(false); } }
運行 cargo test,你會得到類似下面這樣的提示
$ cargo test
Compiling adder v0.0.1 (file:///home/you/projects/adder)
Running target/adder-91b3e234d4ed382a
running 1 test
test it_works ... FAILED
failures:
---- it_works stdout ----
thread 'it_works' panicked at 'assertion failed: false', /home/steve/tmp/adder/src/lib.rs:3
failures:
it_works
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured
thread '<main>' panicked at 'Some tests failed', /home/steve/src/rust/src/libtest/lib.rs:247
#[should_panic] 標識
如果你的測試函數沒完成,或沒有更新,或是故意讓它崩潰,但為了讓測試能夠順利完成,我們主動可以給測試函數加上 #[should_panic] 標識,就不會讓 cargo test 報錯了。
如
#![allow(unused)] fn main() { #[test] #[should_panic] fn it_works() { assert!(false); } }
運行 cargo test,結果類似如下:
$ cargo test
Compiling adder v0.0.1 (file:///home/you/projects/adder)
Running target/adder-91b3e234d4ed382a
running 1 test
test it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
#[ignore] 標識
有時候,某個測試函數非常耗時,或暫時沒更新,我們想不讓它參與測試,但是又不想刪除它,這時, #[ignore] 就派上用場了。
#![allow(unused)] fn main() { #[test] #[ignore] fn expensive_test() { // code that takes an hour to run } }
寫上這個,運行 cargo test 的時候,就不會測試這個函數。
模塊級測試
有時,我們會組織一批測試用例,這時,模塊化的組織結構就有助於建立結構性的測試體系。Rust 中,可以類似如下寫法:
#![allow(unused)] fn main() { pub fn add_two(a: i32) -> i32 { a + 2 } #[cfg(test)] mod tests { use super::add_two; #[test] fn it_works() { assert_eq!(4, add_two(2)); } } }
也即在 mod 的上面寫上 #[cfg(test)] ,表明這個模塊是個測試模塊。一個測試模塊中,可以包含若干測試函數,測試模塊中還可以繼續包含測試模塊,即模塊的嵌套。
如此,就形式了結構化的測試體系,甚是方便。
工程級測試
函數級和模塊級的測試,代碼是與要測試的模塊(編譯單元)寫在相同的文件中,一般做的是白盒測試。工程級的測試,一般做的就是黑盒集成測試了。
我們看一個工程的目錄,在這個目錄下,有一個 tests 文件夾(沒有的話,就手動建立)
Cargo.toml
Cargo.lock
examples
src
tests
我們在 tests 目錄下,建立一個文件 testit.rs ,名字隨便取皆可。內容為:
#![allow(unused)] fn main() { extern crate adder; #[test] fn it_works() { assert_eq!(4, adder::add_two(2)); } }
這裡,比如,我們 src 中,寫了一個庫,提供了一個 add_two 函數,現在進行集成測試。
首先,用 extern crate 的方式,引入這個庫,由於是同一個項目,cargo 會自動找。引入後,就按模塊的使用方法調用就行了,其它的測試標識與前面相同。
寫完後,運行一下 cargo test,提示類似如下:
$ cargo test
Compiling adder v0.0.1 (file:///home/you/projects/adder)
Running target/adder-91b3e234d4ed382a
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Running target/lib-c18e7d3494509e74
running 1 test
test it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
文檔級測試
Rust 對文檔的哲學,是不要單獨寫文檔,一是代碼本身是文檔,二是代碼的註釋就是文檔。Rust 不但可以自動抽取代碼中的文檔,形成標準形式的文檔集合,還可以對文檔中的示例代碼進行測試。
比如,我們給上面庫加點文檔:
#![allow(unused)] fn main() { //! The `adder` crate provides functions that add numbers to other numbers. //! //! # Examples //! //! ``` //! assert_eq!(4, adder::add_two(2)); //! ``` /// This function adds two to its argument. /// /// # Examples /// /// ``` /// use adder::add_two; /// /// assert_eq!(4, add_two(2)); /// ``` pub fn add_two(a: i32) -> i32 { a + 2 } #[cfg(test)] mod tests { use super::*; #[test] fn it_works() { assert_eq!(4, add_two(2)); } } }
運行 cargo test,結果如下:
$ cargo test
Compiling adder v0.0.1 (file:///home/steve/tmp/adder)
Running target/adder-91b3e234d4ed382a
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Running target/lib-c18e7d3494509e74
running 1 test
test it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Doc-tests adder
running 2 tests
test add_two_0 ... ok
test _0 ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured
看到了吧,多了些測試結果。
結語
我們可以看到,Rust 對測試,對文檔,對文檔中的示例代碼測試,都有特性支持。從這些細節之處,可以看出 Rust 設計的周密性和嚴謹性。
但是,光有好工具是不夠的,工程的質量更重要的是寫代碼的人決定的。我們應該在 Rust 嚴謹之風的薰陶下,養成良好的編碼和編寫測試的習慣,掌握一定的分析方法,把質量要求貫徹到底。
性能測試
單元測試是用來校驗程序的正確性的,然而,程序能正常運行後,往往還需要測試程序(一部分)的執行速度,這時,f就需要用到性能測試。 通常來講,所謂性能測試,指的是測量程序運行的速度,即運行一次要多少時間(通常是執行多次求平均值)。Rust 竟然連這個特性都集成在語言基礎特性中,真的是一門很重視工程性的語言。
下面直接說明如何使用。
cargo new benchit
cd benchit
編輯 src/lib.rs 文件,在裡面添加如下代碼:
#![allow(unused)] #![feature(test)] fn main() { extern crate test; pub fn add_two(a: i32) -> i32 { a + 2 } #[cfg(test)] mod tests { use super::*; use test::Bencher; #[test] fn it_works() { assert_eq!(4, add_two(2)); } #[bench] fn bench_add_two(b: &mut Bencher) { b.iter(|| add_two(2)); } } }
注意:
- 這裡雖然使用了
extern crate test;,但是項目的Cargo.toml文件中依賴區並不需要添加對test的依賴; - 評測函數
fn bench_add_two(b: &mut Bencher) {}上面使用#[bench]做標註,同時函數接受一個參數,b就是 Rust 提供的評測器。這個寫法是固定的。
然後,在工程根目錄下,執行
cargo bench
輸出結果類似如下:
$ cargo bench
Compiling benchit v0.0.1 (file:///home/mike/tmp/benchit)
Running target/release/benchit-91b3e234d4ed382a
running 2 tests
test tests::it_works ... ignored
test tests::bench_add_two ... bench: 1 ns/iter (+/- 0)
test result: ok. 0 passed; 0 failed; 1 ignored; 1 measured
可以看到,Rust 的性能測試是以納秒 ns 為單位。
寫測評代碼的時候,需要注意以下一些點:
- 只把你需要做性能測試的代碼(函數)放在評測函數中;
- 對於參與做性能測試的代碼(函數),要求每次測試做同樣的事情,不要做累積和改變外部狀態的操作;
- 參數性能測試的代碼(函數),執行時間不要太長。太長的話,最好分成幾個部分測試。這也方便找出性能瓶頸所在地方。
代碼風格
空白
- 每行不能超出99個字符。
- 縮進只用空格,不用TAB。
- 行和文件末尾不要有空白。
空格
- 二元運算符左右加空格,包括屬性裡的等號:
#![allow(unused)] fn main() { #[deprecated = "Use `bar` instead."] fn foo(a: usize, b: usize) -> usize { a + b } }
- 在分號和逗號後面加空格:
#![allow(unused)] fn main() { fn foo(a: Bar); MyStruct { foo: 3, bar: 4 } foo(bar, baz); }
- 在單行語句塊或
struct表達式的開始大括號之後和結束大括號之前加空格:
#![allow(unused)] fn main() { spawn(proc() { do_something(); }) Point { x: 0.1, y: 0.3 } }
折行
- 對於多行的函數簽名,每個新行和第一個參數對齊。允許每行多個參數:
#![allow(unused)] fn main() { fn frobnicate(a: Bar, b: Bar, c: Bar, d: Bar) -> Bar { ... } fn foo<T: This, U: That>( a: Bar, b: Bar) -> Baz { ... } }
- 多行函數調用一般遵循和簽名統一的規則。然而,如果最後的參數開始了一個語句塊,塊的內容可以開始一個新行,縮進一層:
#![allow(unused)] fn main() { fn foo_bar(a: Bar, b: Bar, c: |Bar|) -> Bar { ... } // 可以在同一行: foo_bar(x, y, |z| { z.transpose(y) }); // 也可以在新一行縮進函數體: foo_bar(x, y, |z| { z.quux(); z.rotate(x) }) }
對齊
常見代碼不必在行中用多餘的空格來對齊。
#![allow(unused)] fn main() { // 好 struct Foo { short: f64, really_long: f64, } // 壞 struct Bar { short: f64, really_long: f64, } // 好 let a = 0; let radius = 7; // 壞 let b = 0; let diameter = 7; }
避免塊註釋
使用行註釋:
#![allow(unused)] fn main() { // 等待主線程返回,並設置過程錯誤碼 // 明顯地。 }
而不是:
#![allow(unused)] fn main() { /* * 等待主線程返回,並設置過程錯誤碼 * 明顯地。 */ }
文檔註釋
文檔註釋前面加三個斜線(///)而且提示你希望將註釋包含在 Rustdoc 的輸出裡。
它們支持 Markdown 語言
而且是註釋你的公開API的主要方式。
支持的 markdown 功能包括列在 GitHub Flavored Markdown 文檔中的所有擴展,加上上角標。
總結行
任何文檔註釋中的第一行應該是一行總結代碼的單行短句。該行用於在 Rustdoc 輸出中的一個簡短的總結性描述,所以,讓它短比較好。
句子結構
所有的文檔註釋,包括總結行,一個以大寫字母開始,以句號、問號,或者感嘆號結束。最好使用完整的句子而不是片段。
總結行應該以 第三人稱單數陳述句形式 來寫。 基本上,這意味著用 "Returns" 而不是 "Return"。
例如:
#![allow(unused)] fn main() { /// 根據編譯器提供的參數,設置一個缺省的運行時配置。 /// /// 這個函數將阻塞直到整個 M:N 調度器池退出了。 /// 這個函數也要求一個本地的線程可用。 /// /// # 參數 /// /// * `argc` 和 `argv` - 參數向量。在 Unix 系統上,該信息被`os::args`使用。 /// /// * `main` - 運行在 M:N 調度器池內的初始過程。 /// 一旦這個過程退出,調度池將開始關閉。 /// 整個池(和這個函數)將只有在所有子線程完成執行後。 /// /// # 返回值 /// /// 返回值被用作進程返回碼。成功是 0,101 是錯誤。 }
避免文檔內註釋
內嵌文檔註釋 只用於 註釋 crates 和文件級的模塊:
#![allow(unused)] fn main() { //! 核心庫。 //! //! 核心庫是... }
解釋上下文
Rust 沒有特定的構造器,只有返回新實例的函數。 這些在自動生成的類型文檔中是不可見的,因此你應該專門鏈接到它們:
#![allow(unused)] fn main() { /// An iterator that yields `None` forever after the underlying iterator /// yields `None` once. /// /// These can be created through /// [`iter.fuse()`](trait.Iterator.html#method.fuse). pub struct Fuse<I> { // ... } }
開始的大括號總是出現的同一行。
#![allow(unused)] fn main() { fn foo() { ... } fn frobnicate(a: Bar, b: Bar, c: Bar, d: Bar) -> Bar { ... } trait Bar { fn baz(&self); } impl Bar for Baz { fn baz(&self) { ... } } frob(|x| { x.transpose() }) }
match 分支有大括號,除非是單行表達式。
#![allow(unused)] fn main() { match foo { bar => baz, quux => { do_something(); do_something_else() } } }
return 語句有分號。
#![allow(unused)] fn main() { fn foo() { do_something(); if condition() { return; } do_something_else(); } }
行尾的逗號
#![allow(unused)] fn main() { Foo { bar: 0, baz: 1 } Foo { bar: 0, baz: 1, } match a_thing { None => 0, Some(x) => 1, } }
一般命名約定
通常,Rust 傾向於為“類型級”結構(類型和 traits)使用 CamelCase 而為“值級”結構使用 snake_case 。更確切的約定:
| 條目 | 約定 |
|---|---|
| Crates | snake_case (但傾向於單個詞) |
| Modules | snake_case |
| Types | CamelCase |
| Traits | CamelCase |
| Enum variants | CamelCase |
| Functions | snake_case |
| Methods | snake_case |
| General constructors | new 或 with_more_details |
| Conversion constructors | from_some_other_type |
| Local variables | snake_case |
| Static variables | SCREAMING_SNAKE_CASE |
| Constant variables | SCREAMING_SNAKE_CASE |
| Type parameters | 簡潔 CamelCase,通常單個大寫字母:T |
| Lifetimes | 短的小寫: 'a |
在 `CamelCase`中, 首字母縮略詞被當成一個單詞:用 `Uuid` 而不是 `UUID`。在 `snake_case` 中,首字母縮略詞全部是小寫: `is_xid_start`。
在 snake_case 或 SCREAMING_SNAKE_CASE 中,“單詞”永遠不應該只包含一個字母,
除非是最後一個“單詞”。所以,我們有btree_map 而不是 b_tree_map,PI_2 而不是 PI2。
引用函數/方法名中的類型
函數名經常涉及類型名,最常見的約定例子像 as_slice。如果類型有一個純粹的文本名字(忽略參數),
在類型約定和函數約定之間轉換是直截了當的:
| 類型名 | 方法中的文本 |
|---|---|
String | string |
Vec<T> | vec |
YourType | your_type |
涉及記號的類型遵循以下約定。這些規則有重疊;應用最適用的規則:
| 類型名 | 方法中的文本 |
|---|---|
&str | str |
&[T] | slice |
&mut [T] | mut_slice |
&[u8] | bytes |
&T | ref |
&mut T | mut |
*const T | ptr |
*mut T | mut_ptr |
避免冗餘的前綴
一個模塊中的條目的名字不應拿模塊的名字做前綴:
傾向於
#![allow(unused)] fn main() { mod foo { pub struct Error { ... } } }
而不是
#![allow(unused)] fn main() { mod foo { pub struct FooError { ... } } }
這個約定避免了口吃(像 io::IoError)。庫客戶端可以在導入時重命名以避免衝突。
Getter/setter 方法
一些數據類型不希望提供對它們的域的直接訪問,但是提供了 "getter" 和 "setter" 方法用於操縱域狀態 (經常提供檢查或其他功能)。
域 foo: T 的約定是:
- 方法
foo(&self) -> &T用於獲得該域的當前值。 - 方法
set_foo(&self, val: T)用於設置域。(這裡的val參數可能取&T或其他類型,取決於上下文。)
請注意,這個約定是關於通常數據類型的 getters/setters, 不是 關於構建者對象的。
斷言
- 簡單的布爾斷言應該加上
is_或者其他的簡短問題單詞作為前綴,e.g.,is_empty。 - 常見的例外:
lt,gt,和其他已經確認的斷言名。
導入
一個 crate/模塊的導入應該按順序包括下面各個部分,之間以空行分隔:
extern crate指令- 外部
use導入 - 本地
use導入 pub use導入
例如:
#![allow(unused)] fn main() { // Crates. extern crate getopts; extern crate mylib; // 標準庫導入。 use getopts::{optopt, getopts}; use std::os; // 從一個我們寫的庫導入。 use mylib::webserver; // 當我們導入這個模塊時會被重新導出。 pub use self::types::Webdata; }
避免 use *,除非在測試裡
Glob 導入有幾個缺點:
- 更難知道名字在哪裡綁定。
- 它們前向不兼容,因為新的上流導出可能與現存的名字衝突。
在寫 test 子模塊時,為方便導入 super::* 是合適的。
當模塊限定函數時,傾向於完全導入類型/traits。
例如:
#![allow(unused)] fn main() { use option::Option; use mem; let i: isize = mem::transmute(Option(0)); }
在 crate 級重新導出最重要的類型。
Crates pub use 最常見的類型為方便,因此,客戶端不必記住或寫 crate 的模塊結構以使用這些類型。
類型和操作在一起定義。
類型定義和使用它們的函數/模塊應該在同一模塊中定義,類型出現在函數/模塊前面。
Any和反射
熟悉Java的同學肯定對Java的反射能力記憶猶新,同樣的,Rust也提供了運行時反射的能力。但是,這裡有點小小的不同,因為 Rust 不帶 VM 不帶 Runtime ,因此,其提供的反射更像是一種編譯時反射。
因為,Rust只能對 'static 生命週期的變量(常量)進行反射!
舉個例子
我們會有這樣的需求,去某些路徑里加載配置文件。我們可能提供一個配置文件路徑,好吧,這是個字符串(String)。但是,當我想要傳入多個配置文件的路徑的時候怎們辦?理所應當的,我們傳入了一個數組。
這下可壞了……Rust不支持重載啊!於是有人就很單純的寫了兩個函數~~!
其實不用……我們只需要這麼寫……
use std::any::Any; use std::fmt::Debug ; fn load_config<T:Any+Debug>(value: &T) -> Vec<String>{ let mut cfgs: Vec<String>= vec![]; let value = value as &Any; match value.downcast_ref::<String>() { Some(cfp) => cfgs.push(cfp.clone()), None => (), }; match value.downcast_ref::<Vec<String>>() { Some(v) => cfgs.extend_from_slice(&v), None =>(), } if cfgs.len() == 0 { panic!("No Config File"); } cfgs } fn main() { let cfp = "/etc/wayslog.conf".to_string(); assert_eq!(load_config(&cfp), vec!["/etc/wayslog.conf".to_string()]); let cfps = vec!["/etc/wayslog.conf".to_string(), "/etc/wayslog_sec.conf".to_string()]; assert_eq!(load_config(&cfps), vec!["/etc/wayslog.conf".to_string(), "/etc/wayslog_sec.conf".to_string()]); }
我們來重點分析一下中間這個函數:
#![allow(unused)] fn main() { fn load_config<T:Any+Debug>(value: &T) -> Vec<String>{..} }
首先,這個函數接收一個泛型T類型,T必須實現了Any和Debug。
這裡可能有同學疑問了,你不是說只能反射 'static 生命週期的變量麼?我們來看一下Any限制:
#![allow(unused)] fn main() { pub trait Any: 'static + Reflect { fn get_type_id(&self) -> TypeId; } }
看,Any在定義的時候就規定了其生命週期,而Reflect是一個Marker,默認所有的Rust類型都會實現他!注意,這裡不是所有原生類型,而是所有類型。
好的,繼續,由於我們無法判斷出傳入的參數類型,因此,只能從運行時候反射類型。
#![allow(unused)] fn main() { let value = value as &Any; }
首先,我們需要將傳入的類型轉化成一個 trait Object, 當然了,你高興的話用 UFCS 也是可以做的,參照本章最後的附錄。
這樣,value 就可以被堪稱一個 Any 了。然後,我們通過 downcast_ref 來進行類型推斷。如果類型推斷成功,則 value 就會被轉換成原來的類型。
有的同學看到這裡有點懵,為什麼你都轉換成 Any 了還要轉回來?
其實,轉換成 Any 是為了有機會獲取到他的類型信息,轉換回來,則是為了去使用這個值本身。
最後,我們對不同的類型處以不同的處理邏輯。最終,一個反射函數就完成了。
說說注意的地方
需要注意的是,Rust本身提供的反射能力並不是很強大。相對而言只能作為一個輔助的手段。並且,其只能對'static週期進行反射的限制,的確限制了其發揮。還有一點需要注意的是,Rust的反射只能被用作類型推斷,絕對不能被用作接口斷言!
啥,你問原因?因為寫不出來啊……
安全(Safety)
本章不講解任何語言知識點,而是對 Rust 安全理念的一些總結性說明。
安全,本身是一個相當大的話題。安全性,本身也需要一個局部性的定義。
Rust 的定義中,凡是 可能 會導致程序內存使用出錯的特性,都被認為是 不安全的(unsafe)。反之,則是 安全的(safe)。
基於這種定義,C 語言,基本是不安全的語言(它是眾多不安全特性的集合。特別是指針相關特性,多線程相關特性)。
Rust 的這個定義,隱含了一個先決假設:人之初,性本惡。人是不可靠的,人是會犯錯誤的,即 Rust 不相信人的實施過程。在這一點上,C 語言的理念與之完全相反:C 語言完全相信人,人之初,性本善,由人進行完全地控制。
根據 Rust 的定義,C 語言幾乎是不安全的代名字。但是,從本質上來說,一段程序是否安全,並不由開發它的語言決定。用 C 語言開發出的程序,不一定就是不安全的代碼,只不過相對來說,需要花更多的精力進行良好的設計和長期的實際運行驗證。Rust 使開發出安全可靠的代碼相對容易了。
世界本身是骯髒的。正如,純函數式語言中還必須有用於處理副作用的 Monad 存在一樣,Rust 僅憑安全的特性集合,也是無法處理世界的所有結構和問題的。所以,Rust 中,還有 unsafe 部分的存在。實際上,Rust 的 std 本身也是建立在大量 unsafe 代碼的基礎之上的。所以,世界就是純粹建立在不純粹之上,“安全”建立在“不安全”之上。
因此,Rust 本身可以被認為是兩種編程語言的混合:Safe Rust 和 Unsafe Rust。
只使用 Safe Rust 的情況下,你不需要擔心任何類型安全性和內存安全性的問題。你永遠不用忍受空指針,懸掛指針或其它可能的未定義行為的干擾。
Unsafe Rust 在 Safe Rust 的所有特性上,只給程序員開放了以下四種能力:
- 對原始指針進行解引(Dereference raw pointers);
- 調用
unsafe函數(包括 C 函數,內部函數,和原始分配器); - 實現
unsafetraits; - 修改(全局)靜態變量。
上述這四種能力,如果誤用的話,會導致一些未定義行為,具有不確定後果,很容易引起程序崩潰。
Rust 中定義的不確定性行為有如下一些:
- 對空指針或懸掛指針進行解引用;
- 讀取未初始化的內存;
- 破壞指針重命名規則(比如同一資源的
&mut引用不能出現多次,&mut與&不能同時出現); - 產生無效的原生值:
- 空指針,懸掛指針;
- bool 值不是 0 或 1;
- 未定義的枚舉取值;
- char 值超出取值範圍 [0x0, 0xD7FF] 和 [0xE000, 0x10FFFF];
- 非 utf-8 字符串;
- Unwinding 到其它語言中;
- 產生一個數據競爭。
以下一些情況,Rust 認為不屬於安全性的處理範疇,即認為它們是“安全”的:
- 死鎖;
- 存在競爭條件;
- 內存洩漏;
- 調用析構函數失敗;
- 整數溢出;
- 程序被中斷;
- 刪除產品數據庫(:D);
參考
下面一些鏈接,給出了安全性更詳細的講解(部分未來會有對應的中文翻譯)。
常用數據結構實現
本章講解如何使用 Rust 進行一些常用數據結構的實現。實現的代碼僅作示例用,並不一定十分高效。真正使用的時候,請使用標準庫或第三方成熟庫中的數據結構。
stack
stack簡介
-
stack作為一種數據結構,是一種只能在一端進行插入和刪除操作的特殊線性表。
-
它按照先進後出的原則存儲數據,先進入的數據被壓入stack底,最後的數據在stack頂,需要讀數據的時候從stack頂開始彈出數據(最後一個數據被第一個讀出來)。
stack(stack)又名heapstack,它是一種運算受限的線性表。其限制是僅允許在表的一端進行插入和刪除運算。這一端被稱為stack頂,相對地,把另一端稱為stack底。向一個stack插入新元素又稱作進stack、入stack或壓stack,它是把新元素放到stack頂元素的上面,使之成為新的stack頂元素;從一個stack刪除元素又稱作出stack或退stack,它是把stack頂元素刪除掉,使其相鄰的元素成為新的stack頂元素。
stack的實現步驟:
- 定義一個stack結構
Stack - 定義組成stack結構的stack點
StackNode - 實現stack的初始化函數
new( ) - 實現進stack函數
push( ) - 實現退stack函數
pop( )
定義一個stack結構Stack
#![allow(unused)] fn main() { #[derive(Debug)] struct Stack<T> { top: Option<Box<StackNode<T>>>, } }
讓我們一步步來分析
- 第一行的
#[derive(Debug)]是為了讓Stack結構體可以打印調試。 - 第二行是定義了一個
Stack結構體,這個結構體包含一個泛型參數T。 - 第三行比較複雜,在定義
StackNode的時候介紹
定義組成stack結構的stack點StackNode
#![allow(unused)] fn main() { #[derive(Clone,Debug)] struct StackNode<T> { val: T, next: Option<Box<StackNode<T>>>, } }
在這段代碼的第三行, 我們定義了一個val保存StackNode的值。
現在我們重點來看看第四行: 我們從裡到外拆分來看看,首先是
Box<StackNode<T>,這裡的Box是 Rust 用來顯式分配heap內存的類型:
pub struct Box<T> where T: ?Sized(_);
詳細文檔請參考Rust的標準庫
在 Rust 裡面用強大的類型系統做了統一的抽象。在這裡相當於在heap空間裡申請了一塊內存保存
StackNode<T>。
為什麼要這麼做了?如果不用Box封裝會怎麼樣呢?
如果不用 Box 封裝,rustc 編譯器會報錯,在 Rust 裡面,rustc 默認使用stack空間,但是這裡的
StackNode定義的時候使用了遞歸的數據結構,next 屬性的類型是StackNode<T>,而這個類型是無法確定大小的,所有這種無法確定大小的類型,都不能保存在stack空間。所以需要使用Box來封裝。這樣的話next的類型就是一個指向某一塊heap空間的指針,而指針是可以確定大小的,因此能夠保存在stack空間。
那麼為什麼還需要使用
Option來封裝呢?
Option是 Rust 裡面的一個抽象類型,定義如下:
#![allow(unused)] fn main() { pub enum Option<T> { None, Some(T), } }
Option 裡面包括元素,None 和 Some(T) ,這樣就很輕鬆的描述了 next 指向stack尾的元素的時候,都是在 Option 類型下,方便了功能實現,也方便了錯誤處理。Option 還有很多強大的功能,讀者可以參考下面幾個連接:
rustbyexample 的 Error handling
實現 new( ) push( ) pop( )
接下來是實現 stack 的主要功能了。
#![allow(unused)] fn main() { impl<T> Stack<T> { fn new() -> Stack<T> { Stack{ top: None } } fn push(&mut self, val: T) { let mut node = StackNode::new(val); let next = self.top.take(); node.next = next; self.top = Some(Box::new(node)); } fn pop(&mut self) -> Option<T> { let val = self.top.take(); match val { None => None, Some(mut x) => { self.top = x.next.take(); Some(x.val) }, } } } }
-
new( )比較簡單,Stack 初始化的時候為空,stack頂元素top就沒有任何值,所以top為None。 -
push( )的主要功能是往stack裡面推入元素,把新的 StackNode 指向 Stack 裡面舊的值,同時更新 Stack stack頂指向新進來的值。
這裡有個需要注意的地方是第8行代碼裡面,
let next = self.top.take();,使用了 Option 類型的 take 方法:
fn take(&mut self) -> Option<T>它會把 Option 類型的值取走,並把它的元素改為 None
pop( )的功能是取出stack頂的元素,如果stack頂為 None 則返回 None。
完整代碼(包含簡單的測試)
#[derive(Debug)] struct Stack<T> { top: Option<Box<StackNode<T>>>, } #[derive(Clone,Debug)] struct StackNode<T> { val: T, next: Option<Box<StackNode<T>>>, } impl <T> StackNode<T> { fn new(val: T) -> StackNode<T> { StackNode { val: val, next: None } } } impl<T> Stack<T> { fn new() -> Stack<T> { Stack{ top: None } } fn push(&mut self, val: T) { let mut node = StackNode::new(val); let next = self.top.take(); node.next = next; self.top = Some(Box::new(node)); } fn pop(&mut self) -> Option<T> { let val = self.top.take(); match val { None => None, Some(mut x) => { self.top = x.next.take(); Some(x.val) }, } } } fn main() { #[derive(PartialEq,Eq,Debug)] struct TestStruct { a: i32, } let a = TestStruct{ a: 5 }; let b = TestStruct{ a: 9 }; let mut s = Stack::<&TestStruct>::new(); assert_eq!(s.pop(), None); s.push(&a); s.push(&b); println!("{:?}", s); assert_eq!(s.pop(), Some(&b)); assert_eq!(s.pop(), Some(&a)); assert_eq!(s.pop(), None); }
隊列
隊列簡介
隊列是一種特殊的線性表,特殊之處在於它只允許在表的前端(front)進行刪除操作,而在表的後端(rear)進行插入操作,和stack一樣,隊列是一種操作受限制的線性表。進行插入操作的端稱為隊尾,進行刪除操作的端稱為隊頭。隊列中沒有元素時,稱為空隊列。
在隊列的形成過程中,可以利用線性鏈表的原理,來生成一個隊列。基於鏈表的隊列,要動態創建和刪除節點,效率較低,但是可以動態增長。隊列採用的 FIFO(first in first out),新元素(等待進入隊列的元素)總是被插入到鏈表的尾部,而讀取的時候總是從鏈表的頭部開始讀取。每次讀取一個元素,釋放一個元素。所謂的動態創建,動態釋放。因而也不存在溢出等問題。由於鏈表由結構體間接而成,遍歷也方便。
隊列實現
下面看一下我們使用 Vec 來實現的簡單 Queue:
主要實現的new( ), push( ), pop( )三個方法
#[derive(Debug)] struct Queue<T> { qdata: Vec<T>, } impl <T> Queue<T> { fn new() -> Self { Queue{qdata: Vec::new()} } fn push(&mut self, item:T) { self.qdata.push(item); } fn pop(&mut self) -> T{ self.qdata.remove(0) } } fn main() { let mut q = Queue::new(); q.push(1); q.push(2); println!("{:?}", q); q.pop(); println!("{:?}", q); q.pop(); }
練習
看起來比我們在上一節實現的Stack簡單多了。不過這個Queue實現是有Bug的。
練習:在這個代碼的上找到 Bug,並修改。
提示:pop( )方法有 Bug,請參考 Stack 小節的實現,利用 Option 來處理。
二叉樹
二叉樹簡介
在計算機科學中,二叉樹是每個節點最多有兩個子樹的樹結構。通常子樹被稱作“左子樹”(left subtree)和“右子樹”(right subtree)。二叉樹常被用於實現二叉查找樹和二叉heap。
二叉查找樹的子節點與父節點的鍵一般滿足一定的順序關係,習慣上,左節點的鍵少於父親節點的鍵,右節點的鍵大於父親節點的鍵。
二叉heap是一種特殊的heap,二叉heap是完全二元樹(二叉樹)或者是近似完全二元樹(二叉樹)。二叉heap有兩種:最大heap和最小heap。最大heap:父結點的鍵總是大於或等於任何一個子節點的鍵;最小heap:父結點的鍵總是小於或等於任何一個子節點的鍵。
二叉樹的每個結點至多隻有二棵子樹(不存在度大於2的結點),二叉樹的子樹有左右之分,次序不能顛倒。二叉樹的第i層至多有2^{i-1}個結點;深度為k的二叉樹至多有2^k-1個結點;對任何一棵二叉樹T,如果其終端結點數為n_0,度為2的結點數為n_2,則n_0=n_2+1。
一棵深度為k,且有2^k-1個節點稱之為滿二叉樹;深度為k,有n個節點的二叉樹,當且僅當其每一個節點都與深度為k的滿二叉樹中,序號為1至n的節點對應時,稱之為完全二叉樹。
二叉樹與樹的區別
二叉樹不是樹的一種特殊情形,儘管其與樹有許多相似之處,但樹和二叉樹有兩個主要差別:
- 樹中結點的最大度數沒有限制,而二叉樹結點的最大度數為2。
- 樹的結點無左、右之分,而二叉樹的結點有左、右之分。
定義二叉樹的結構
二叉樹的每個節點由鍵key、值value與左右子樹left/right組成,這裡我們把節點聲明為一個泛型結構。
#![allow(unused)] fn main() { type TreeNode<K,V> = Option<Box<Node<K,V>>>; #[derive(Debug)] struct Node<K,V: std::fmt::Display> { left: TreeNode<K,V>, right: TreeNode<K,V>, key: K, value: V, } }
實現二叉樹的初始化與二叉查找樹的插入
由於二叉查找樹要求鍵可排序,我們要求K實現PartialOrd
#![allow(unused)] fn main() { trait BinaryTree<K,V> { fn pre_order(&self); fn in_order(&self); fn pos_order(&self); } trait BinarySearchTree<K:PartialOrd,V>:BinaryTree<K,V> { fn insert(&mut self, key:K,value: V); } impl<K,V:std::fmt::Display> Node<K,V> { fn new(key: K,value: V) -> Self { Node{ left: None, right: None, value: value, key: key, } } } impl<K:PartialOrd,V:std::fmt::Display> BinarySearchTree<K,V> for Node<K,V>{ fn insert(&mut self, key:K,value:V) { if self.key < key { if let Some(ref mut right) = self.right { right.insert(key,value); } else { self.right = Some(Box::new(Node::new(key,value))); } } else { if let Some(ref mut left) = self.left { left.insert(key,value); } else { self.left = Some(Box::new(Node::new(key,value))); } } } } }
二叉樹的遍歷
- 先序遍歷:首先訪問根,再先序遍歷左(右)子樹,最後先序遍歷右(左)子樹。
- 中序遍歷:首先中序遍歷左(右)子樹,再訪問根,最後中序遍歷右(左)子樹。
- 後序遍歷:首先後序遍歷左(右)子樹,再後序遍歷右(左)子樹,最後訪問根。
下面是代碼實現:
#![allow(unused)] fn main() { impl<K,V:std::fmt::Display> BinaryTree<K,V> for Node<K,V> { fn pre_order(&self) { println!("{}", self.value); if let Some(ref left) = self.left { left.pre_order(); } if let Some(ref right) = self.right { right.pre_order(); } } fn in_order(&self) { if let Some(ref left) = self.left { left.in_order(); } println!("{}", self.value); if let Some(ref right) = self.right { right.in_order(); } } fn pos_order(&self) { if let Some(ref left) = self.left { left.pos_order(); } if let Some(ref right) = self.right { right.pos_order(); } println!("{}", self.value); } } }
測試代碼
type BST<K,V> = Node<K,V>; fn test_insert() { let mut root = BST::<i32,i32>::new(3,4); root.insert(2,3); root.insert(4,6); root.insert(5,5); root.insert(6,6); root.insert(1,8); if let Some(ref left) = root.left { assert_eq!(left.value, 3); } if let Some(ref right) = root.right { assert_eq!(right.value, 6); if let Some(ref right) = right.right { assert_eq!(right.value, 5); } } println!("Pre Order traversal"); root.pre_order(); println!("In Order traversal"); root.in_order(); println!("Pos Order traversal"); root.pos_order(); } fn main() { test_insert(); }
練習
基於以上代碼,修改成二叉heap的形式。
優先隊列
簡介
普通的隊列是一種先進先出的數據結構,元素在隊列尾追加,而從隊列頭刪除。在優先隊列中,元素被賦予優先級。當訪問元素時,具有最高優先級的元素最先刪除。優先隊列具有最高級先出 (largest-in,first-out)的行為特徵。
優先隊列是0個或多個元素的集合,每個元素都有一個優先權或值,對優先隊列執行的操作有:
- 查找;
- 插入一個新元素;
- 刪除。
在最小優先隊列(min priority queue)中,查找操作用來搜索優先權最小的元素,刪除操作用來刪除該元素;對於最大優先隊列(max priority queue),查找操作用來搜索優先權最大的元素,刪除操作用來刪除該元素。優先權隊列中的元素可以有相同的優先權,查找與刪除操作可根據任意優先權進行。
優先隊列的實現:
首先定義 PriorityQueue 結構體
#![allow(unused)] fn main() { #[derive(Debug)] struct PriorityQueue<T> where T: PartialOrd + Clone { pq: Vec<T> } }
第二行的where T: PartialOrd + Clone指的是 PriorityQueue 存儲的泛型 T 是滿足 PartialOrd 和 Clone trait 約束的,意味著泛型 T 是可排序和克隆的。
後面是一些基本的方法實現,比較簡單,就直接看代碼吧。這個優先隊列是基於Vec實現的,有O(1)的插入和O(n)的最大/最小值出列。
#![allow(unused)] fn main() { impl<T> PriorityQueue<T> where T: PartialOrd + Clone { fn new() -> PriorityQueue<T> { PriorityQueue { pq: Vec::new() } } fn len(&self) -> usize { self.pq.len() } fn is_empty(&self) -> bool { self.pq.len() == 0 } fn insert(&mut self, value: T) { self.pq.push(value); } fn max(&self) -> Option<T> { if self.is_empty() { return None } let max = self.max_index(); Some(self.pq[max].clone()) } fn min(&self) -> Option<T> { if self.is_empty() { return None } let min = self.min_index(); Some(self.pq[min].clone()) } fn delete_max(&mut self) -> Option<T> { if self.is_empty() { return None; } let max = self.max_index(); Some(self.pq.remove(max).clone()) } fn delete_min(&mut self) -> Option<T> { if self.is_empty() { return None; } let min = self.min_index(); Some(self.pq.remove(min).clone()) } fn max_index(&self) -> usize { let mut max = 0; for i in 1..self.pq.len() - 1 { if self.pq[max] < self.pq[i] { max = i; } } max } fn min_index(&self) -> usize { let mut min = 0; for i in 0..self.pq.len() - 1 { if self.pq[i] < self.pq[i + 1] { min = i; } } min } } }
測試代碼:
fn test_keep_min() { let mut pq = PriorityQueue::new(); pq.insert(3); pq.insert(2); pq.insert(1); pq.insert(4); assert!(pq.min().unwrap() == 1); } fn test_keep_max() { let mut pq = PriorityQueue::new(); pq.insert(2); pq.insert(4); pq.insert(1); pq.insert(3); assert!(pq.max().unwrap() == 4); } fn test_is_empty() { let mut pq = PriorityQueue::new(); assert!(pq.is_empty()); pq.insert(1); assert!(!pq.is_empty()); } fn test_len() { let mut pq = PriorityQueue::new(); assert!(pq.len() == 0); pq.insert(2); pq.insert(4); pq.insert(1); assert!(pq.len() == 3); } fn test_delete_min() { let mut pq = PriorityQueue::new(); pq.insert(3); pq.insert(2); pq.insert(1); pq.insert(4); assert!(pq.len() == 4); assert!(pq.delete_min().unwrap() == 1); assert!(pq.len() == 3); } fn test_delete_max() { let mut pq = PriorityQueue::new(); pq.insert(2); pq.insert(10); pq.insert(1); pq.insert(6); pq.insert(3); assert!(pq.len() == 5); assert!(pq.delete_max().unwrap() == 10); assert!(pq.len() == 4); } fn main() { test_len(); test_delete_max(); test_delete_min(); test_is_empty(); test_keep_max(); test_keep_min(); }
練習
基於二叉heap實現一個優先隊列,以達到O(1)的出列和O(log n)的入列
鏈表
鏈表簡介
鏈表是一種物理存儲單元上非連續、非順序的存儲結構,數據元素的邏輯順序是通過鏈表中的指針鏈接次序實現的。鏈表由一系列結點(鏈表中每一個元素稱為結點)組成,結點可以在運行時動態生成。每個結點包括兩個部分:一個是存儲數據元素的數據域,另一個是存儲下一個結點地址的指針域。 由於不必須按順序存儲,鏈表在給定位置插入的時候可以達到O(1)的複雜度,比另一種線性表順序錶快得多,但是在有序數據中查找一個節點或者訪問特定下標的節點則需要O(n)的時間,而線性表相應的時間複雜度分別是O(logn)和O(1)。
使用鏈表結構可以克服數組需要預先知道數據大小的缺點,鏈表結構可以充分利用計算機內存空間,實現靈活的內存動態管理。但是鏈表失去了數組隨機讀取的優點,同時鏈表由於增加了結點的指針域,空間開銷比較大。鏈表最明顯的好處就是,常規數組排列關聯項目的方式可能不同於這些數據項目在內存或磁盤上的順序,數據的存取往往要在不同的排列順序中轉換。鏈表允許插入和移除表上任意位置上的節點,但是不允許隨機存取。鏈表有很多種不同的類型:單向鏈表,雙向鏈表以及循環鏈表。
下面看我們一步步實現鏈表:
定義鏈表結構
#![allow(unused)] fn main() { use List::*; enum List { // Cons: 包含一個元素和一個指向下一個節點的指針的元組結構 Cons(u32, Box<List>), // Nil: 表示一個鏈表節點的末端 Nil, } }
實現鏈表的方法
#![allow(unused)] fn main() { impl List { // 創建一個空鏈表 fn new() -> List { // `Nil` 是 `List`類型的。因為前面我們使用了 `use List::*;` // 所以不需要 List::Nil 這樣使用 Nil } // 在前面加一個元素節點,並且鏈接舊的鏈表和返回新的鏈表 fn prepend(self, elem: u32) -> List { // `Cons` 也是 List 類型的 Cons(elem, Box::new(self)) } // 返回鏈表的長度 fn len(&self) -> u32 { // `self` 的類型是 `&List`, `*self` 的類型是 `List`, // 匹配一個類型 `T` 好過匹配一個引用 `&T` match *self { // 因為`self`是借用的,所以不能轉移 tail 的所有權 // 因此使用 tail 的引用 Cons(_, ref tail) => 1 + tail.len(), // 基本規則:所以空的鏈表長度都是0 Nil => 0 } } // 返回連鏈表的字符串表達形式 fn stringify(&self) -> String { match *self { Cons(head, ref tail) => { // `format!` 和 `print!` 很像 // 但是返回一個heap上的字符串去替代打印到控制檯 format!("{}, {}", head, tail.stringify()) }, Nil => { format!("Nil") }, } } } }
代碼測試
fn main() { let mut list = List::new(); list = list.prepend(1); list = list.prepend(2); list = list.prepend(3); println!("linked list has length: {}", list.len()); println!("{}", list.stringify()); }
練習
基於以上代碼實現一個雙向循環鏈表。
雙向鏈表也叫雙鏈表,是鏈表的一種,它的每個數據結點中都有兩個指針,分別指向直接後繼和直接前驅。所以,從雙向鏈表中的任意一個結點開始,都可以很方便地訪問它的前驅結點和後繼結點。一般我們都構造雙向循環鏈表。 循環鏈表是另一種形式的鏈式存貯結構。它的特點是表中最後一個結點的指針域指向頭結點,整個鏈表形成一個環。
圖
圖的存儲結構
圖的存儲結構除了要存儲圖中各個頂點的本身信息外,同時還要存儲頂點與頂點之間的所有關係(邊的信息),因此,圖的結構比較複雜,很難以數據元素在存儲區中的物理位置來表示元素之間的關係,但也正是由於其任意的特性,故物理表示方法很多。常用的圖的存儲結構有鄰接矩陣、鄰接表等。
鄰接矩陣表示法
對於一個具有n個結點的圖,可以使用n*n的矩陣(二維數組)來表示它們間的鄰接關係。矩陣 A(i,j) = 1 表示圖中存在一條邊 (Vi,Vj),而A(i,j)=0表示圖中不存在邊 (Vi,Vj)。 實際編程時,當圖為不帶權圖時,可以在二維數組中存放 bool 值。
- A(i,j) = true 表示存在邊 (Vi,Vj),
- A(i,j) = false 表示不存在邊 (Vi,Vj);
當圖帶權值時,則可以直接在二維數值中存放權值,A(i,j) = null 表示不存在邊 (Vi,Vj)。
下面看看我們使用鄰接矩陣實現的圖結構:
#[derive(Debug)] struct Node { nodeid: usize, nodename: String, } #[derive(Debug,Clone)] struct Edge { edge: bool, } #[derive(Debug)] struct Graphadj { nodenums: usize, graphadj: Vec<Vec<Edge>>, } impl Node { fn new(nodeid: usize, nodename: String) -> Node { Node{ nodeid: nodeid, nodename: nodename, } } } impl Edge { fn new() -> Edge { Edge{ edge: false, } } fn have_edge() -> Edge { Edge{ edge: true, } } } impl Graphadj { fn new(nums:usize) -> Graphadj { Graphadj { nodenums: nums, graphadj: vec![vec![Edge::new();nums]; nums], } } fn insert_edge(&mut self, v1: Node, v2:Node) { match v1.nodeid < self.nodenums && v2.nodeid<self.nodenums { true => { self.graphadj[v1.nodeid][v2.nodeid] = Edge::have_edge(); //下面這句註釋去掉相當於把圖當成無向圖 //self.graphadj[v2.nodeid][v1.nodeid] = Edge::have_edge(); } false => { panic!("your nodeid is bigger than nodenums!"); } } } } fn main() { let mut g = Graphadj::new(2); let v1 = Node::new(0, "v1".to_string()); let v2 = Node::new(1, "v2".to_string()); g.insert_edge(v1,v2); println!("{:?}", g); }
鄰接表表示法
鄰接表是圖的一種最主要存儲結構,用來描述圖上的每一個點。
**實現方式:**對圖的每個頂點建立一個容器(n個頂點建立n個容器),第i個容器中的結點包含頂點Vi的所有鄰接頂點。實際上我們常用的鄰接矩陣就是一種未離散化每個點的邊集的鄰接表。
- 在有向圖中,描述每個點向別的節點連的邊(點 a->點 b 這種情況)。
- 在無向圖中,描述每個點所有的邊(點 a->點 b這種情況)
與鄰接表相對應的存圖方式叫做邊集表,這種方法用一個容器存儲所有的邊。
練習:
實現鏈接表表示法的圖結構。
標準庫示例
好了,本書到這裡也接近完結了。相信你一在學習了這麼多內容的之後,一定躍躍欲試了吧?
下面,我們將以代碼為主,講解幾個利用std庫,即標準庫來做的例子。希望大家能從中學到一點寫法,並開始自己的Rust之旅。
- 注: 由於筆者的電腦是openSUSE Linux的,所以本章所有代碼均只在
openSUSE Leap 42.1 && rustc 1.9.0-nightly (52e0bda64 2016-03-05)下編譯通過,對Linux適配可能會更好一點,其他系統的同學請自行參照。
另:本章原本設計的時候附加有時間api的處理,但是在本章寫作的時候Rust的大部分時間API還處於Unstable狀態,隨時可能遭到刪除或重寫。因此,我們暫時刪除了時間API的操作。等以後Rust的API穩定之後,再來補齊這一節。
系統命令:調用grep
我們知道,Linux系統中有一個命令叫grep,他能對目標文件進行分析並查找相應字符串,並該字符串所在行輸出。 今天,我們先來寫一個Rust程序,來調用一下這個 grep 命令
use std::process::*; use std::env::args; // 實現調用grep命令搜索文件 fn main() { let mut arg_iter = args(); // panic if there is no one arg_iter.next().unwrap(); let pattern = arg_iter.next().unwrap_or("main".to_string()); let pt = arg_iter.next().unwrap_or("./".to_string()); let output = Command::new("/usr/bin/grep") .arg("-n") .arg("-r") .arg(&pattern) .arg(&pt) .output() .unwrap_or_else(|e| panic!("wg panic because:{}", e)); println!("output:"); let st = String::from_utf8_lossy(&output.stdout); let lines = st.split("\n"); for line in lines { println!("{}", line); } }
看起來好像還不錯,但是,以上的程序有一個比較致命的缺點——因為Output是同步的,因此,一旦調用的目錄下有巨大的文件,grep的分析將佔用巨量的時間。這對於一個高可用的程序來說是不被允許的。
那麼如何改進呢?
其實在上面的代碼中,我們隱藏了一個 Child 的概念,即——子進程。
下面我來演示怎麼操作子進程:
use std::process::*; use std::env::args; // 實現調用grep命令搜索文件 fn main() { let mut arg_iter = args(); // panic if there is no one arg_iter.next(); let pattern = arg_iter.next().unwrap_or("main".to_string()); let pt = arg_iter.next().unwrap_or("./".to_string()); let child = Command::new("grep") .arg("-n") .arg("-r") .arg(&pattern) .arg(&pt) .spawn().unwrap(); // 做些其他的事情 std::thread::sleep_ms(1000); println!("{}", "計算很費時間……"); let out = child.wait_with_output().unwrap(); let out_str = String::from_utf8_lossy(&out.stdout); for line in out_str.split("\n") { println!("{}", line); } }
但是,這個例子和我們預期的並不太一樣!
./demo main /home/wayslog/rust/demo/src
/home/wayslog/rust/demo/src/main.rs:5:fn main() {
/home/wayslog/rust/demo/src/main.rs:9: let pattern = arg_iter.next().unwrap_or("main".to_string());
計算很費時間……
為什麼呢?
很簡單,我們知道,在Linux中,fork出來的函數會繼承父進程的所有句柄。因此,子進程也就會繼承父進程的標準輸出,也就是造成了這樣的問題。這也是最後我們用out無法接收到最後的輸出也就知道了,因為在前面已經被輸出出來了呀!
那麼怎麼做呢?給這個子進程一個pipeline就好了!
use std::process::*; use std::env::args; // 實現調用grep命令搜索文件 fn main() { let mut arg_iter = args(); // panic if there is no one arg_iter.next(); let pattern = arg_iter.next().unwrap_or("main".to_string()); let pt = arg_iter.next().unwrap_or("./".to_string()); let child = Command::new("grep") .arg("-n") .arg("-r") .arg(&pattern) .arg(&pt) // 設置pipeline .stdout(Stdio::piped()) .spawn().unwrap(); // 做些其他的事情 std::thread::sleep_ms(1000); println!("{}", "計算很費時間……"); let out = child.wait_with_output().unwrap(); let out_str = String::from_utf8_lossy(&out.stdout); for line in out_str.split("\n") { println!("{}", line); } }
這段代碼相當於給了stdout一個緩衝區,這個緩衝區直到我們計算完成之後才被讀取,因此就不會造成亂序輸出的問題了。
這邊需要注意的一點是,一旦你開啟了一個子進程,那麼,無論你程序是怎麼處理的,最後一定要記得對這個child調用wait或者wait_with_output,除非你顯式地調用kill。因為如果父進程不wait它的話,它將會變成一個殭屍進程!!!
注: 以上問題為Linux下Python多進程的日常問題,已經見怪不怪了。
目錄操作:簡單grep
上一節我們實現了通過Command調用subprocess。這一節,我們將通過自己的代碼去實現一個簡單的grep。當然了,這種基礎的工具你是能找到源碼的,而我們的實現也並不像真正的grep那樣注重效率,本節的主要作用就在於演示標準庫API的使用。
首先,我們需要對當前目錄進行遞歸,遍歷,每當查找到文件的時候,我們回調一個函數。
於是,我們就有了這麼個函數:
#![allow(unused)] fn main() { use std::env::args; use std::io; use std::fs::{self, File, DirEntry}; use std::path::Path; fn visit_dirs(dir: &Path, pattern: &String, cb: &Fn(&DirEntry, &String)) -> io::Result<()> { if try!(fs::metadata(dir)).is_dir() { for entry in try!(fs::read_dir(dir)) { let entry = try!(entry); if try!(fs::metadata(entry.path())).is_dir() { try!(visit_dirs(&entry.path(), pattern, cb)); } else { cb(&entry, pattern); } } }else{ let entry = try!(try!(fs::read_dir(dir)).next().unwrap()); cb(&entry, pattern); } Ok(()) } }
我們有了這樣的一個函數,有同學可能覺得這代碼眼熟。這不是標準庫裡的例子改了一下麼?
.
.
.
是啊!
好了,繼續,我們需要讀取每個查到的文件,同時判斷每一行裡有沒有所查找的內容。 我們用一個BufferIO去讀取各個文件,同時用String的自帶方法來判斷內容是否存在。
#![allow(unused)] fn main() { fn call_back(de: &DirEntry, pt: &String) { let mut f = File::open(de.path()).unwrap(); let mut buf = io::BufReader::new(f); for line in io::BufRead::lines(buf) { let line = line.unwrap_or("".to_string()); if line.contains(pt) { println!("{}", &line); } } } }
最後,我們將整個函數調用起來,如下:
use std::env::args; use std::io; use std::fs::{self, File, DirEntry}; use std::path::Path; fn visit_dirs(dir: &Path, pattern: &String, cb: &Fn(&DirEntry, &String)) -> io::Result<()> { if try!(fs::metadata(dir)).is_dir() { for entry in try!(fs::read_dir(dir)) { let entry = try!(entry); if try!(fs::metadata(entry.path())).is_dir() { try!(visit_dirs(&entry.path(), pattern, cb)); } else { cb(&entry, pattern); } } }else{ let entry = try!(try!(fs::read_dir(dir)).next().unwrap()); cb(&entry, pattern); } Ok(()) } fn call_back(de: &DirEntry, pt: &String) { let mut f = File::open(de.path()).unwrap(); let mut buf = io::BufReader::new(f); for line in io::BufRead::lines(buf) { let line = line.unwrap_or("".to_string()); if line.contains(pt) { println!("{}", &line); } } } // 實現調用grep命令搜索文件 fn main() { let mut arg_iter = args(); arg_iter.next(); // panic if there is no one let pattern = arg_iter.next().unwrap_or("main".to_string()); let pt = arg_iter.next().unwrap_or("./".to_string()); let pt = Path::new(&pt); visit_dirs(&pt, &pattern, &call_back).unwrap(); }
調用如下:
➜ demo git:(master) ✗ ./target/debug/demo "fn main()" ../
fn main() {
fn main() { }
fn main() {
pub fn main() {
pub fn main() {}
fn main() {
pub fn main() {
pub fn main() {}
網絡模塊:W貓的迴音
本例子中,W貓將帶大家寫一個大家都寫過但是沒什麼人用過的TCP ECHO軟件,作為本章的結尾。本程序僅作為實例程序,我個人估計也沒有人在實際的生活中去使用她。不過,作為標準庫的示例來說,已經足夠。
首先,我們需要一個一個服務器端。
#![allow(unused)] fn main() { fn server<A: ToSocketAddrs>(addr: A) -> io::Result<()> { // 建立一個監聽程序 let listener = try!(TcpListener::bind(&addr)) ; // 這個程序一次只需處理一個鏈接就好 for stream in listener.incoming() { // 通過match再次解包 stream到 match stream { // 這裡匹配的重點是如何將一個mut的匹配傳給一個Result Ok(mut st) => { // 我們總是要求client端先發送數據 // 準備一個超大的緩衝區 // 當然了,在實際的生活中我們一般會採用環形緩衝來重複利用內存。 // 這裡僅作演示,是一種很低效的做法 let mut buf: Vec<u8> = vec![0u8; 1024]; // 通過try!方法來解包 // try!方法的重點是需要有特定的Error類型與之配合 let rcount = try!(st.read(&mut buf)); // 只輸出緩衝區裡讀取到的內容 println!("{:?}", &buf[0..rcount]); // 回寫內容 let wcount = try!(st.write(&buf[0..rcount])); // 以下代碼實際上算是邏輯處理 // 並非標準庫的一部分了 if rcount != wcount { panic!("Not Fully Echo!, r={}, w={}", rcount, wcount); } // 清除掉已經讀到的內容 buf.clear(); } Err(e) => { panic!("{}", e); } } } // 關閉掉Serve端的鏈接 drop(listener); Ok(()) } }
然後,我們準備一個模擬TCP短鏈接的客戶端:
#![allow(unused)] fn main() { fn client<A: ToSocketAddrs>(addr: A) -> io::Result<()> { let mut buf = vec![0u8;1024]; loop { // 對比Listener,TcpStream就簡單很多了 // 本次模擬的是tcp短鏈接的過程,可以看作是一個典型的HTTP交互的基礎IO模擬 // 當然,這個通訊裡面並沒有HTTP協議 XD! let mut stream = TcpStream::connect(&addr).unwrap(); let msg = "WaySLOG comming!".as_bytes(); // 避免發送數據太快而刷屏 thread::sleep_ms(100); let rcount = try!(stream.write(&msg)); let _ = try!(stream.read(&mut buf)); println!("{:?}", &buf[0..rcount]); buf.clear(); } Ok(()) } }
將我們的程序拼接起來如下:
use std::net::*; use std::io; use std::io::{Read, Write}; use std::env; use std::thread; fn server<A: ToSocketAddrs>(addr: A) -> io::Result<()> { .. } fn client<A: ToSocketAddrs>(addr: A) -> io::Result<()> { .. } fn main() { let mut args = env::args(); args.next(); let action = args.next().unwrap(); if action == "s" { server(&args.next().unwrap()).unwrap(); } else { client(&args.next().unwrap()).unwrap(); } }
各位可以自己試一下結果
寫網絡程序,註定了要處理各種神奇的條件和錯誤,定義自己的數據結構,粘包問題等都是需要我們去處理和關注的。相較而言,Rust本身在網絡方面的基礎設施建設並不盡如人意,甚至連網絡I/O都只提供瞭如上的block I/O 。可能其團隊更關注於語言基礎語法特性和編譯的改進,但其實,有著官方出品的這種網絡庫是非常重要的。同時,我也希望Rust能夠湧現出更多的網絡庫方案,讓Rust的明天更好更光明。
實戰篇
本章舉 3 個實際中的例子,來小小展示一下 Rust 在實際中的應用。它們分別是:
- Json處理
- Web 應用開發入門
- 使用Postgresql數據庫
Rust json處理
JSON是一種比較重要的格式,尤其是現在的web開發領域,JSON相比於傳統的XML更加容易操作和減小傳輸。
Rust中的JSON處理依賴 cargo 中的rustc-serialize模塊
###先簡單的創建一個Rust項目工程
#![allow(unused)] fn main() { $ cargo new json_data --bin }
生成文件樹:
vagrant@ubuntu-14:~/tmp/test/rustprimer$ tree
.
`-- json_data
|-- Cargo.toml
`-- src
`-- main.rs
生成項目json_data,項目下文件介紹:
- Caogo.toml ,文件中填寫一些項目的相關信息,比如版本號,聯繫人,項目名,文件的內容如下:
[package]
name = "json_data"
version = "0.1.0"
authors = ["wangxxx <xxxxx@qq.com>"]
[dependencies]
- src 中放置項目的源代碼,main.rs 為項目的入口文件。
###一些必要的瞭解
rustc-serialize 這個是第三方的模塊,需要從cargo下載。 下載很簡單,只需修改一下cargo.toml文件就行了.
[package]
name = "json_data"
version = "0.1.0"
authors = ["wangxxx <xxxxx@qq.com>"]
[dependencies]
rustc-serialize = "0.3.18"
然後執行在當前目錄執行:
$ cargo build
注意一個問題由於國內網絡訪問github不穩定,這些第三方庫很多託管在github上,所以可能需要修改你的 網絡訪問
- 在安裝Rust之後,會在你的用戶目錄之下生成一個
.cargo文件夾,進入這個文件夾 - 在
.cargo文件夾下,創建一個config文件,在文件中填寫中科大軟件源,可能以後會出現其他的源,先用這個 config文件內容如下
[registry]
index = "git://crates.mirrors.ustc.edu.cn/index"
cargo build 執行之後的提示信息
Updating registry `git://crates.mirrors.ustc.edu.cn/index`
Downloading rustc-serialize v0.3.18 (registry git://crates.mirrors.ustc.edu.cn/index)
Compiling rustc-serialize v0.3.18 (registry git://crates.mirrors.ustc.edu.cn/index)
Compiling json_data v0.1.0 (file:///home/vagrant/tmp/test/rustprimer/json_data)
再次執行tree命令:
.
|-- Cargo.lock
|-- Cargo.toml
|-- src
| `-- main.rs
`-- target
`-- debug
|-- build
|-- deps
| `-- librustc_serialize-d27006e102b906b6.rlib
|-- examples
|-- json_data
`-- native
可以看到多了很多文件,重點關注cargo.lock,開打文件:
[root]
name = "json_data"
version = "0.1.0"
dependencies = [
"rustc-serialize 0.3.18 (registry+git://crates.mirrors.ustc.edu.cn/index)",
]
[[package]]
name = "rustc-serialize"
version = "0.3.18"
source = "registry+git://crates.mirrors.ustc.edu.cn/index"
是關於項目編譯的一些依賴信息
還有生成了target文件夾,生成了可執行文件json_data,因為main.rs中的執行結果就是打印hello world
$ cargo run
Hello, world!
###開始寫代碼 直接使用官方的 rustc_serialize 中的例子:
extern crate rustc_serialize; // 引入rustc_serialize模塊 use rustc_serialize::json; // Automatically generate `RustcDecodable` and `RustcEncodable` trait // implementations // 定義TestStruct #[derive(RustcDecodable, RustcEncodable)] pub struct TestStruct { data_int: u8, data_str: String, data_vector: Vec<u8>, } fn main() { // 初始化TestStruct let object = TestStruct { data_int: 1, data_str: "homura".to_string(), data_vector: vec![2,3,4,5], }; // Serialize using `json::encode` // 將TestStruct轉意為字符串 let encoded = json::encode(&object).unwrap(); println!("{}",encoded); // Deserialize using `json::decode` // 將json字符串中的數據轉化成TestStruct對應的數據,相當於初始化 let decoded: TestStruct = json::decode(&encoded).unwrap(); println!("{:?}",decoded.data_vector); }
當然我們也可以在文本中作為api的返回結果使用,下來的章節中,我們將討論這個問題
rust web 開發
rust既然是系統級的編程語言,所以當然也能用來開發 web,不過想我這樣凡夫俗子,肯定不能從頭自己寫一個 web 服務器,肯定要依賴已經存在的 rust web開發框架來完成 web 開發。
rust目前比較有名的框架是iron和nickel,我們兩個都寫一下簡單的使用教程。
##iron
接上一篇,使用cargo獲取第三方庫。cargo new mysite --bin
在cargo.toml中添加iron的依賴,
[dependencies]
iron = "*"
然後build將依賴下載到本地 cargo build
如果報ssl錯誤,那可能你需要安裝linux的ssl開發庫。
首先還是從 hello world 開始吧,繼續抄襲官方的例子:
extern crate iron; use iron::prelude::*; use iron::status; fn main() { Iron::new(|_: &mut Request| { Ok(Response::with((status::Ok, "Hello World!"))) }).http("localhost:3000").unwrap(); }
然後運行
cargo run
使用curl直接就可以訪問你的網站了。
curl localhost:3000
Hello World!
仔細一看,發現這個例子很無厘頭啊,對於習慣了寫python的我來說,確實不習慣。 簡單點看:
iron::new().http("localhost:3000").unwrap()
這句是服務器的基本的定義,new內部是一個rust lambda 表達式
#![allow(unused)] fn main() { let plus_one = |x: i32| x + 1; assert_eq!(2, plus_one(1)); }
具體的怎麼使用 ,可以暫時不用理會,因為你只要知道如何完成web,因為我也不會。。 結合之前一章節的json處理,我們來看看web接口怎麼返回json,當然也要 rustc_serialize 放到 cargo.toml 中
下面的代碼直接參考開源代碼地址
extern crate iron; extern crate rustc_serialize; use iron::prelude::*; use iron::status; use rustc_serialize::json; #[derive(RustcEncodable)] struct Greeting { msg: String } fn main() { fn hello_world(_: &mut Request) -> IronResult<Response> { let greeting = Greeting { msg: "Hello, World".to_string() }; let payload = json::encode(&greeting).unwrap(); Ok(Response::with((status::Ok, payload))) } Iron::new(hello_world).http("localhost:3000").unwrap(); println!("On 3000"); }
執行 cargo run 使用 curl 測試結果:
curl localhost:3000
{"msg":"Hello, World"}
當然可以可以實現更多的業務需求,通過控制自己的json。
既然有了json了,如果要多個路由什麼的,豈不是完蛋了,所以不可能這樣的,我們需要考慮一下怎麼實現路由的定製
不說話直接上代碼,同一樣要在你的cargo.toml文件中添加對router的依賴
extern crate iron; extern crate router; extern crate rustc_serialize; use iron::prelude::*; use iron::status; use router::Router; use rustc_serialize::json; #[derive(RustcEncodable, RustcDecodable)] struct Greeting { msg: String } fn main() { let mut router = Router::new(); router.get("/", hello_world); router.post("/set", set_greeting); fn hello_world(_: &mut Request) -> IronResult<Response> { let greeting = Greeting { msg: "Hello, World".to_string() }; let payload = json::encode(&greeting).unwrap(); Ok(Response::with((status::Ok, payload))) } // Receive a message by POST and play it back. fn set_greeting(request: &mut Request) -> IronResult<Response> { let payload = request.body.read_to_string(); let request: Greeting = json::decode(payload).unwrap(); let greeting = Greeting { msg: request.msg }; let payload = json::encode(&greeting).unwrap(); Ok(Response::with((status::Ok, payload))) } Iron::new(router).http("localhost:3000").unwrap(); }
這次添加了路由的實現和獲取客戶端發送過來的數據,有了get,post,所以現在一個基本的api網站已經完成了。不過 並不是所有的網站都是api來訪問,同樣需要html模版引擎和直接返回靜態頁面。等等
vagrant@ubuntu-14:~/tmp/test/rustprimer/mysite$ cargo build
Compiling mysite v0.1.0 (file:///home/vagrant/tmp/test/rustprimer/mysite)
src/main.rs:29:36: 29:52 error: no method named `read_to_string` found for type `iron::request::Body<'_, '_>` in the current scope
src/main.rs:29 let payload = request.body.read_to_string();
^~~~~~~~~~~~~~~~
src/main.rs:29:36: 29:52 help: items from traits can only be used if the trait is in scope; the following trait is implemented but not in scope, perhaps add a `use` for it:
src/main.rs:29:36: 29:52 help: candidate #1: use `std::io::Read`
error: aborting due to previous error
Could not compile `mysite`.
編譯出錯了,太糟糕了,提示說沒有read_to_string這個方法,然後我去文檔查了一下,發現有read_to_string方法 再看提示信息
src/main.rs:29:36: 29:52 help: items from traits can only be used if the trait is in scope; the following trait is implemented but not in scope, perhaps add a `use` for it:
src/main.rs:29:36: 29:52 help: candidate #1: use `std::io::Read`
讓我們添加一個std::io::Read,這個如果操作過文件,你一定知道怎麼寫,添加一下,應該能過去了,還是繼續出錯了,看看報錯
Compiling mysite v0.1.0 (file:///home/vagrant/tmp/test/rustprimer/mysite)
src/main.rs:30:36: 30:52 error: this function takes 1 parameter but 0 parameters were supplied [E0061]
src/main.rs:30 let payload = request.body.read_to_string();
^~~~~~~~~~~~~~~~
src/main.rs:30:36: 30:52 help: run `rustc --explain E0061` to see a detailed explanation
src/main.rs:31:46: 31:53 error: mismatched types:
expected `&str`,
found `core::result::Result<usize, std::io::error::Error>`
(expected &-ptr,
found enum `core::result::Result`) [E0308]
src/main.rs:31 let request: Greeting = json::decode(payload).unwrap();
^~~~~~~
src/main.rs:31:46: 31:53 help: run `rustc --explain E0308` to see a detailed explanation
src/main.rs:30:36: 30:52 error: cannot infer an appropriate lifetime for lifetime parameter `'b` due to conflicting requirements [E0495]
src/main.rs:30 let payload = request.body.read_to_string();
^~~~~~~~~~~~~~~~
src/main.rs:29:5: 35:6 help: consider using an explicit lifetime parameter as shown: fn set_greeting<'a>(request: &mut Request<'a, 'a>) -> IronResult<Response>
src/main.rs:29 fn set_greeting(request: &mut Request) -> IronResult<Response> {
src/main.rs:30 let payload = request.body.read_to_string();
src/main.rs:31 let request: Greeting = json::decode(payload).unwrap();
src/main.rs:32 let greeting = Greeting { msg: request.msg };
src/main.rs:33 let payload = json::encode(&greeting).unwrap();
src/main.rs:34 Ok(Response::with((status::Ok, payload)))
...
error: aborting due to 3 previous errors
Could not compile `mysite`.
第一句提示我們,這個read_to_string(),至少要有一個參數,但是我們一個都沒有提供。 我們看看read_to_string的用法
#![allow(unused)] fn main() { se std::io; use std::io::prelude::*; use std::fs::File; let mut f = try!(File::open("foo.txt")); let mut buffer = String::new(); try!(f.read_to_string(&mut buffer)); }
用法比較簡單,我們修改一下剛剛的函數:
fn set_greeting(request: &mut Request) -> IronResult<Response> {
let mut payload = String::new();
request.body.read_to_string(&mut payload);
let request: Greeting = json::decode(&payload).unwrap();
let greeting = Greeting { msg: request.msg };
let payload = json::encode(&greeting).unwrap();
Ok(Response::with((status::Ok, payload)))
}
從request中讀取字符串,讀取的結果存放到payload中,然後就可以進行操作了,編譯之後運行,使用curl提交一個post數據
$curl -X POST -d '{"msg":"Just trust the Rust"}' http://localhost:3000/set
{"msg":"Just trust the Rust"}
iron 基本告一段落 當然還有如何使用html模版引擎,那就是直接看文檔就行了。
##nickel
當然既然是web框架肯定是iron能幹的nicke也能幹,所以那我們就看看如何做一個hello 和返回一個html 的頁面
同樣我們創建cargo new site --bin,然後添加nickel到cargo.toml中,cargo build
#[macro_use] extern crate nickel; use nickel::Nickel; fn main() { let mut server = Nickel::new(); server.utilize(router! { get "**" => |_req, _res| { "Hello world!" } }); server.listen("127.0.0.1:6767"); }
簡單來看,也就是這樣回事。
- 引入了nickel的宏
- 初始化Nickel
- 調用utilize來定義路由模塊。
router!宏,傳入的參數是 get 方法和對應的路徑,"**"是全路徑匹配。- listen啟動服務器
#[macro_use] extern crate nickel; use std::collections::HashMap; use nickel::{Nickel, HttpRouter}; fn main() { let mut server = Nickel::new(); server.get("/", middleware! { |_, response| let mut data = HashMap::new(); data.insert("name", "user"); return response.render("site/assets/template.tpl", &data); }); server.listen("127.0.0.1:6767"); }
上面的信息你可以編譯,使用curl看看發現出現
$ curl http://127.0.0.1:6767
Internal Server Error
看看文檔,沒發現什麼問題,我緊緊更換了一個文件夾的名字,這個文件夾我也創建了。 然後我在想難道是服務器將目錄寫死了嗎?於是將上面的路徑改正這個,問題解決。
#![allow(unused)] fn main() { return response.render("examples/assets/template.tpl", &data); }
我們看一下目錄結構
.
|-- Cargo.lock
|-- Cargo.toml
|-- examples
| `-- assets
| `-- template.tpl
|-- src
| `-- main.rs
rust數據庫操作
編程時,我們依賴數據庫來存儲相應的數據,很多編程語言都支持對數據庫的操作,所以當然可以使用Rust操作數據庫。
不過在我自己操作時,發現很多問題,主要因為我不瞭解Rust在操作數據庫時,應該注意的事情,從而浪費了很多的時間,在進行數據查詢時。 具體遇到的坑,我會做一些演示,從而讓大家避免這些情況。
首先使用Rust操作PostgreSQL,因為PostgreSQL是我最喜歡的數據庫。
首先創建新項目 cargo new db --bin
在cargo.toml中添加 postgres 如下:
#![allow(unused)] fn main() { [package] name = "db" version = "0.1.0" authors = ["vagrant"] [dependencies] postgres="*" }
當然我們還是進行最簡單的操作,直接粘貼複製,代碼來源
extern crate postgres; use postgres::{Connection, SslMode}; struct Person { id: i32, name: String, data: Option<Vec<u8>> } fn main() { let conn = Connection::connect("postgres://postgres@localhost", SslMode::None) .unwrap(); conn.execute("CREATE TABLE person ( id SERIAL PRIMARY KEY, name VARCHAR NOT NULL, data BYTEA )", &[]).unwrap(); let me = Person { id: 0, name: "Steven".to_string(), data: None }; conn.execute("INSERT INTO person (name, data) VALUES ($1, $2)", &[&me.name, &me.data]).unwrap(); for row in &conn.query("SELECT id, name, data FROM person", &[]).unwrap() { let person = Person { id: row.get(0), name: row.get(1), data: row.get(2) }; println!("Found person {}", person.name); } }
這些簡單的,當然不是我們想要的東西,我們想要的是能夠進行一些分層,也就是 基本的一些函數邏輯劃分,而不是在一個main函數中,完成所有的一切。
##創建lib.rs文件
從上到下來看文件:
- 首先導入postgres的各種庫
- 創建一個Person 的struct,按照需求的字段和類型。
- 創建一個連接函數,返回連接對象。
- 創建一個插入函數,用來插入數據
- 創建一個查詢函數,用來查詢數據
- 創建一個查詢函數,用來查詢所有的數據。
當然這些函數都是有一定的功能侷限性。
#![allow(unused)] fn main() { extern crate postgres; use postgres::{Connection, SslMode}; use postgres::types::FromSql; use postgres::Result as PgResult; struct Person { id: i32, name: String, data: Option<Vec<u8>> } pub fn connect() -> Connection{ let dsn = "postgresql://postgres:2015@localhost/rust_example"; Connection::connect(dsn, SslMode::None).unwrap() } pub fn insert_info(conn : &Connection,title : &str, body: &str){ let stmt = match conn.prepare("insert into blog (title, body) values ($1, $2)") { Ok(stmt) => stmt, Err(e) => { println!("Preparing query failed: {:?}", e); return; } }; stmt.execute(&[&title, &body]).expect("Inserting blogposts failed"); } pub fn query<T>(conn: &Connection,query: &str) ->PgResult<T> where T: FromSql { println!("Executing query: {}", query); let stmt = try!(conn.prepare(query)); let rows = try!(stmt.query(&[])); &rows.iter().next().unwrap(); let row = &rows.iter().next().unwrap(); //rows.iter().next().unwrap() row.get_opt(2).unwrap() } pub fn query_all(conn: &Connection,query: &str){ println!("Executing query: {}", query); for row in &conn.query(query,&[]).unwrap(){ let person = Person{ id: row.get(0), name: row.get(1), data: row.get(2) }; println!("Found person {}", person.name); } } }
然後在main.rs 中調用相應的函數代碼如下
- extern db ,引入db,也就是將項目本身引入
- use db 使用db,中的可以被引入的函數
- 定義Blog,由於個人使用blog表,是自己創建,所以如果報錯說不存在表,需要你自己去創建
- 使用lib中定義的函數,進行最基本的一些操作
extern crate postgres; extern crate db; use postgres::{Connection, SslMode}; use db::*; struct Blog { title: String, body: String, } fn main() { let conn:Connection=connect(); let blog = Blog{ title: String::from("title"), body: String::from("body"), }; let title = blog.title.to_string(); let body = blog.body.to_string(); insert_info(&conn,&title,&body); for row in query::<String>(&conn,"select * from blog"){ println!("{:?}",row); } let sql = "select * from person"; query_all(&conn,&sql); }
自己遇到的坑
-
創建連接函數時,連接必須有一個返回值,所以必須指定返回值的類型, 對於一個寫Python的人而言,我覺得是痛苦的,我想按照官方的寫法match 一下,發現可能產生多個返回值。在編譯時直接無法通過編譯,所以最終 使用了unwrap,解決問題,不過我還是沒有學會,函數多值返回時我如何 定義返回值
-
在使用
&conn.query(query,&[]).unwrap()時,我按照文檔操作,文檔說 返回的是一個可迭代的數據,那也就是說,我可以使用for循環,將數據打印, 但是發現怎麼也不能實現:
#![allow(unused)] fn main() { pub fn query_all(conn: &Connection,query: &str){ println!("Executing query: {}", query); for row in &conn.query(query,&[]).unwrap(){ println!("Found person {:?}", row.get_opt(1)); } } }
報錯如下:
#![allow(unused)] fn main() { vagrant@ubuntu-14:~/tmp/test/rustprimer/db$ cargo run Compiling db v0.1.0 (file:///home/vagrant/tmp/test/rustprimer/db) src/lib.rs:53:37: 53:47 error: unable to infer enough type information about `_`; type annotations or generic parameter binding required [E0282] src/lib.rs:53 println!("Found person {:?}", row.get_opt(1)); ^~~~~~~~~~ <std macros>:2:25: 2:56 note: in this expansion of format_args! <std macros>:3:1: 3:54 note: in this expansion of print! (defined in <std macros>) src/lib.rs:53:3: 53:49 note: in this expansion of println! (defined in <std macros>) src/lib.rs:53:37: 53:47 help: run `rustc --explain E0282` to see a detailed explanation error: aborting due to previous error Could not compile `db`. }
然後去查看了關於postgres模塊的所有函數,嘗試了無數種辦法,依舊沒有解決。
可能自己眼高手低,如果從頭再把Rust的相關教程看一下,可能很早就發現這個問題, 也有可能是因為習慣了寫Python,導致自己使用固有的思維來看待問題和鑽牛角尖,才 導致出現這樣的問題,浪費很多的時間。
- 改變思維,把自己當作一個全新的新手,既要利用已有的思想來學習新的語言,同樣不要 被自己很精通的語言,固化自己的思維。
附錄I-術語表
- ADT(Algebraic Data Type:代數數據類型):
- ARC(Atomic Reference Counting:原子引用計數):
- associated function(關聯函數):
- associated type(關聯類型): Trait 裡面可以有關聯類型
- AST(Abstract Syntax Tree:抽象語法樹):
- benchmark(基準測試):
- bitwise copy:
- borrow(借用):
- bounds(約束):
- box:
- byte string():
- cargo:
- cast:
- channel:
- coercion:
- constructor(構造器):
- consumer:
- copy:
- crate:
- dangling pointer:
- deref(解引用):
- derive:
- designator(指示符):
- destructor():
- destructure(析構):
- diverging function(發散函數):
- drop:
- DST(Dynamically Sized Type):
- dynamic dispatch(動態分發):
- enum():
- feature gate(特性開關): nightly 版本中有特性開關可以啟用一些實驗性質的特性
- FFI(Foreign Function Interface:外部函數接口):
- guard:
- hygiene:
- inline function(內聯函數):
- item:
- iterator(迭代器):
- iterator adaptor(迭代器適配器):
- lifetime(生命週期):
- lifetime elision:
- literal string():
- macro by example:
- memberwise copy:
- module(模塊)
- move:
- option:
- ownership(所有權):
- panic(崩潰):
- phantom type:
- primitive type(基本類型): 整型、浮點、布爾等基本類型
- procedural macro:
- RAII():
- raw string:
- raw pointer:
- RC(Reference Counting:引用計數)
- result:
- shadowing:
- static dispatch(靜態分發):
- slice(切片): 某種數據類型的視圖,例如 string, vector
- statement(): 與 expression 相區別
- trait:
- trait object:
- tuple(元組):
- UFCS(Universal Function Call Syntax)
- unit():
- unwind:
- unwrap():
- wrap: