深度神經網路(Deep Neural Network)
在開始寫程式前,先來看一下最基礎的神經網路DNN的架構圖
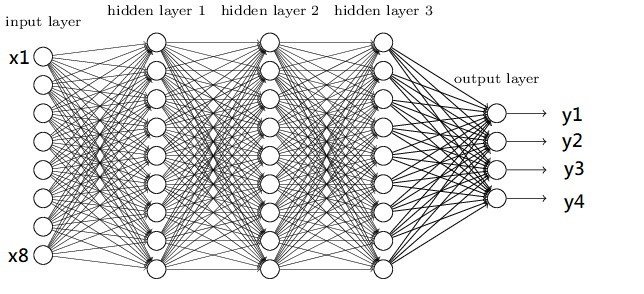
圖片來源:https://www.researchgate.net/figure/Deep-Neural-Network-DNN-example_fig2_341037496
圖片是不是看起來有點複雜,其實概念很的簡單,假設我們有個資料集要辨識4種類型得圖片y1~y4,每張圖片有8個特徵(Feature)x1~x8,那神經網路所扮演的角色就是訓練權重(weight)w1~w8,我們可以把權重當作是每一個特徵的分數,分數越高的結果,代表可能性越大,像是在架構圖中的圖片中我們可以用公式能表達為y = x1w1+x2w2+x3w3+x4w4+x5w5+x6w6+x7w7+x8w8,找到最高分數的y就是可能性最高的結果。
這樣是不是有一些概念了,接下來開始講解輸入層(input layer)、隱藏層(hidden layer)、輸出層(output layer)的概念。
輸入層(input layer)
神經網路的第一層被稱作輸入層,這層取得在外部的資源,像是圖片、文字、音訊、能被接受到的訊息,在這層中不會有任何的公式運算,只是傳送資料至下一層。
隱藏層(hidden layer)
隱藏層是在訓練中最重要的一個環節,神經網路就是在這層中學習特徵並產生權重的,一個神經網路至少要有一層隱藏層。
輸出層(output layer)
隱藏層會將資料丟給輸出層,這層的輸出大小會根據你所想要的任務而不同,像是辨識貓與狗的圖片(分類任務)輸出層就會是2(只有貓跟狗),若像是股票預測(回歸)輸出則為1。
看完以上的敘述後,有沒有發現一個問題,輸出是x1w1+...x8w8那不就會是線性了嗎?為瞭解決這個問題於是有了激勵函數(activation function),它能夠使神經網路變成非線性,比較常見的激勵函數有:relu、tanh、softmax、sigmoid等激勵函數,這些函數選用與解說我會在後續的實作課程中講解,這邊先有個概念就好。
建立環境
還記得第一天教的如何安裝函式庫嗎?
今天會用到的函式庫如下:
numpy:支援高階大量的維度陣列與矩陣運算,也針對陣列運算提供大量的數學函數函式庫
tensorflow:深度學習函式庫,在今天只會做為keras的後端並不會實際用到
keras:能夠串接tensorflow,使其能夠簡易的建立神經網路
jupyter:Web的互動式計算環境
那麼我們就開始使用pip安裝這些函式庫吧!!
pip install tensorflow==2.3.0
pip install keras==2.3.1
pip install jupyter
開啟jupyter notebook
安裝函式庫後,該怎麼開始深度學習的第一支程式呢?
在這邊我會建議先創立一個資料夾,避免資料會混亂,我們先將資料夾命名為"mnist手寫辨識"。

點進去資料夾裡面後按下ALT+D就會就會自動跳到網址列,我們只需要在網址列中輸入cmd。
接下來我們在cmd當中輸入jupyter notebook(注意開啟後cmd不能關掉)。
開啟jupyter後點擊右上角的new選擇python3創立檔案。
看到這個頁面就代表可以開始寫程式啦~

呼叫函式庫
首先我們要來學習如何呼叫函式庫
當我們想使用一個函式庫時只需用
import XXX(函示庫名稱)
像是要使用numpy,就能寫成
import numpy
之後就能使用功能了,例如將list轉換成array只需要在函式庫的名稱後面加入.就能使用function
list = [1,2,3]
list = numpy.array(list)
但如果今天覺得numpy這個名字太長了就能用以下的寫法
#import 函示庫 as 簡化的名稱
import numpy as np
list = [1,2,3]
list = np.array(list)
但這樣子import會把函式庫裡面的function通通放到程式裡出來,所以為了節省空間會將一些較常使用的function單獨呼叫
#from 函示庫 import 功能 as 簡化名稱
from numpy import array as ar
list = [1,2,3]
list = ar(list)
這就是在python呼叫函式庫的辦法,瞭解之後就開始進入今天的正題的MNIST手寫辨識吧!!
MNIST手寫辨識實作
在這邊我們先將程式分為幾個部分: 1.導入函式庫 2.資料前處理 3.模型的建構 4.模型的訓練
1.導入函式庫
import numpy as np
import tensorflow.keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.utils import to_categorical
函式庫說明:
1.keras.datasets:包含著一些著名的資料集例如:nmist、IMDB影評
2.keras.models:架構神經網路
3.keras.layers:創建神經網路Dense(DNN)、conv2d(CNN)
4.keras.utils:資料正規化
2.資料前處理(Data Preprocessing)
在資料前處理之前我們先讀取mnist的資料。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test : uint8 數組表示的灰度圖像,尺寸為(num_samples, 28, 28)。 y_train, y_test : uint8 數組表示的數字標籤(範圍在0-9 之間的整數),尺寸為(num_samples,)。
拿到資料後先來看一下資料的shape
print(x_train.shape)
------顯示------
(60000, 28, 28)
第一碼60000代表的是資料大小,總共有60000張圖片 第二碼則是長有28個pixel 第三碼則是寬有28個pixel
我們先回到一開始的架構圖,有沒有發現他的輸入是一整排的(一維),而我們的資料卻是二維,所以要將28x28(2維)的資料變成784(1維)的資料,在這裡我們是用reshape這個function重新list的大小。
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
------顯示------
(60000, 784)
現在來觀看一下第一筆訓練資料的內容
print(x_train[0])
------顯示------
[.... 18 18 18 126 136 175 26 166 255 ...0 0 0 0 0 0 0 0 0]
可以看到裡面有許多數值,這數值代表的是顏色越靠近0的是白色,越靠近255則是黑色,這也就是我們圖片的特徵值。
但是在神經網路中數值越大收斂越慢,且會受到極端值的影響,使訓練效果不佳,所以在這邊將數值除255讓數值能夠壓縮在0~1之間
x_train = x_train/255
x_test = x_test/255
這樣就處理完放入model的圖片資料了。
為了知道神經網路的準確率,我們需要給圖片一個標籤(Label),但是機器只會看懂0跟1,所以我們需要把數字正規化,在這邊使用one-hot-encoding作為正規化的方式。
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
假設的label裡面有1與2,那one-hot-encoding就會以位置表達數字的涵義
例如:label = [1,2] 那1就會被編譯成[1,0]、2就會被編譯成[0,1]
到這邊我們就完成圖片與標籤的資料前處理了
3.模型的建構
首先說明一下在本次訓練內用到的激勵函數relu與softmax。
relu:會將0以下的數值通通當作是0,這能夠加強資料的特徵,同時還能加速程式收斂的速度,通常會用於CNN、DNN等架構上。
softmax:會將數值歸一化,且輸出向量中擁有最大權重的項對應著輸入向量中的最大值,通常會定義在分類任務的輸出層。
# 建立模型
model = Sequential()
# 輸入層與隱藏層
model.add(Dense(units=256,input_dim=784, activation='relu'))
# 隱藏層
model.add(Dense(units=128, activation='relu'))
# 輸出層
model.add(Dense(units=10,activation='softmax'))
用keras建立模型相當的簡單,只需要將Sequential()宣告給一個變數後就能使用add就能加入層數,程式碼的範例是一個784大小的輸入層,並且有兩層隱藏層大小分別維256與128,最後輸出10個結果(辨識0~9)。
4.模型的訓練
建立模型之後當然是訓練它了,在訓練之前我們要先了解損失函數(Loss Function)與優化器(Optimizer)。
優化器(Optimizer):我們在國中應該都學過就是微積分找極值,而在深度學習中就是改良找極值的方式去做到最佳化的,我們叫這種方式為梯度下降(Gradient Descent)而這概念則與滑板場相同。想像今天有一個U型滑板場,只要沒有加速最終就會停留在U型的最底部,但若是W型的滑板場就不一定會找到低點了,我們可以想最深的坑會有最陡的坡,所以我們只要給予滑板一定的動力就能一路滑到最深的坑裡爬不出來,而這個名詞就叫做學習率(Learn Rate),若學習率太高(動力太大)就會找不到最低點,若是動力太小找到最低點則會非常的緩慢,所以就會使用一些偷吃步找到最低點,在深度學習中的偷吃步就是optimizer,可以利用不同optimizer來找的最合適的梯度下降法。
損失函數(Loss Function):一個模型學到特徵的好壞,最關鍵的點就是損失函數的設計,在keras中基本上只會使用到兩個:分類任務常用的categorical_crossentropy,以及回歸任務常用的MSE,當然這些都會是一定的,現階段只會會用就可以了。
# 宣告loss finction與optimizer
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 開始訓練model batch_size一次丟多少資料進去訓練 epochs總共要訓練幾次
history = model.fit(x_train, y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
#結果
Epoch 1/10
469/469 [==============================] - 1s 2ms/step - loss: 0.2677 - accuracy: 0.9238 - val_loss: 0.1259 - val_accuracy: 0.9622
Epoch 2/10
469/469 [==============================] - 1s 2ms/step - loss: 0.1011 - accuracy: 0.9696 - val_loss: 0.0968 - val_accuracy: 0.9697
Epoch 3/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0662 - accuracy: 0.9804 - val_loss: 0.0781 - val_accuracy: 0.9758
Epoch 4/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0457 - accuracy: 0.9858 - val_loss: 0.0725 - val_accuracy: 0.9762
Epoch 5/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0362 - accuracy: 0.9888 - val_loss: 0.0755 - val_accuracy: 0.9775
Epoch 6/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0266 - accuracy: 0.9913 - val_loss: 0.0672 - val_accuracy: 0.9784
Epoch 7/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0204 - accuracy: 0.9938 - val_loss: 0.0722 - val_accuracy: 0.9793
Epoch 8/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0167 - accuracy: 0.9946 - val_loss: 0.0744 - val_accuracy: 0.9796
Epoch 9/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0158 - accuracy: 0.9950 - val_loss: 0.0826 - val_accuracy: 0.9778
Epoch 10/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0130 - accuracy: 0.9955 - val_loss: 0.0845 - val_accuracy: 0.9784
我們可以看到用DNN訓練手寫辨識已經97.84%的辨識率了,是不是很簡單呢? 明天就來教一下CNN的架構與程式,那我們明天再見!
完整程式碼
import tensorflow.keras
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train/255
x_test = x_test/255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 建立模型
model = Sequential()
# 輸入層與隱藏層
model.add(Dense(units=256,input_dim=784, activation='relu'))
# 隱藏層
model.add(Dense(units=128, activation='relu'))
# 輸出層
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
課程中的程式碼都能從我的github專案中看到 https://github.com/AUSTIN2526/learn-AI-in-30-days
找到圖片的特徵-捲積神經網路(Convolutional neural network)
卷積神經網路(Convolutional neural network)
經過昨天使用DNN辨識手寫圖片,有沒有發現再怎麼調整參數,準確率都上不去了呢?
這是因為DNN的演算法就只能有這樣的效果,那我們要怎麼提高準確率呢?
也就是今天的主題卷積神經網路(Convolutional neural network)
跟昨天一樣先放一張架構圖
圖片來源:https://becominghuman.ai/building-a-convolutional-neural-network-cnn-model-for-image-classification-116f77a7a236
看到圖片後有沒有注意到攤平(Flatten)後的部分,是不是與昨天學習到到DNN相同,那兩者差別在哪呢?答案就是CNN會通過捲積(Convolution)、池化(Pooling)等運算方式提取出更重要的特徵,通過攤平(Flatten)將特徵放入到全連接層(DNN也是種全連接神經網路)的架構當中,得到更好的輸出結果。
知道上述的概念之後,接下來開始更深入的介紹捲積層(Convolution Layer)、池化層(Pooling Layer)、全連接層(Fully Connected Layer)究竟是什麼。
捲積層(Convolution Layer)
捲基層的原理是利用卷積核(Kernel)通過步長(Stride)的滑動對圖像提取訊息,若超過圖片大小則會對其填充(Padding)補值,我們用例子來說明:
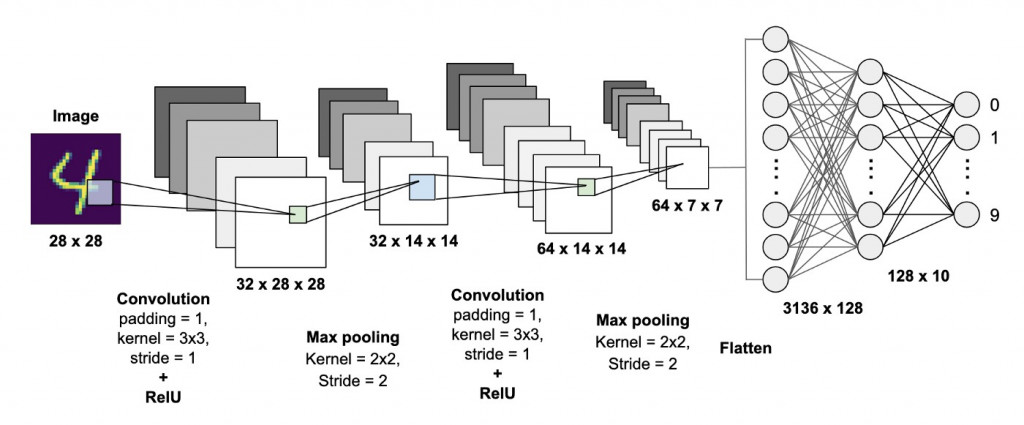
可以看到圖片中兩個英文單字X與A,那怎麼知道哪圖片是X又哪張圖片是A呢?
我們可以先畫個方框將圖片拆解
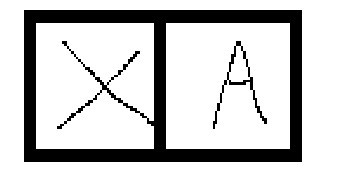
 這時候就能用些較簡單的邏輯分辨出特徵,例如:X左上角的區塊是由左上到右下畫出來的,而A左上角的區塊則是右上往左下畫出來的。在圖片中的紅框處,它會先加總方框內的圖像數值之後與卷積核相乘,並通過步長移動方框的位置,產生出新的陣列。
這時候就能用些較簡單的邏輯分辨出特徵,例如:X左上角的區塊是由左上到右下畫出來的,而A左上角的區塊則是右上往左下畫出來的。在圖片中的紅框處,它會先加總方框內的圖像數值之後與卷積核相乘,並通過步長移動方框的位置,產生出新的陣列。
我們架構圖的例子計算一次
 圖片的大小是28x28,而我們的捲積核大小為3x3,步長為1,那麼新的陣列大小就會是28(往右)/1(步長)x28(往下)/1(步長)=28x28。
圖片的大小是28x28,而我們的捲積核大小為3x3,步長為1,那麼新的陣列大小就會是28(往右)/1(步長)x28(往下)/1(步長)=28x28。
但在例子中3x3的捲積核移動26次(26+3)時就會發現超出圖片的範圍了,那該怎麼辦?這時候會使用填充的技巧,把超出外框的值做墊零(zero padding),這樣子就可以防止發生陣列大小不相等的問題了。
池化層(Pooling Layer)
當經過捲積層計算之後我們會取的一個含有圖片特徵陣列,而在那麼在這一層的工作就是利用pooling的方式處理這些特徵。
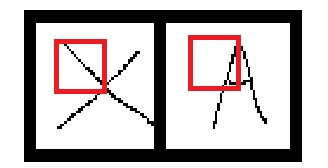
我們先來看到圖片中的MaxPooling是什麼?
 我們可以看到經過
我們可以看到經過MaxPooling後的陣列大小從28x28變成了14x14這是因為MaxPooling只會保留選取範圍的最大值,這樣子可以有效的取得特徵、並移除雜訊(noize),同時縮減陣列大小從而提高運算速度。
全連接層(Fully Connected Layer)
我們在前面的兩層看到的動作都是在做特徵擷取與強化,到了這層才是真正學習的過程,概念與我們昨天說到的DNN是相同的,這邊就不在講解了,如果沒有跟上的人可以到昨天的課程【day3】Deep Neural Network MNIST手寫辨識學習相關知識
CNN實作
今天的實作會分成以下的部分: 1.導入函式庫與介紹 2.資料前處理 3.建構網路&訓練模型 4.儲存模型 5.評估模型
1.導入函式庫與介紹
import numpy as np
import tensorflow.keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential,load_model,model_from_json
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.utils import to_categorical
from PIL import Image
import matplotlib.pyplot as plt
函式庫說明:
1.keras.datasets:包含著一些著名的資料集例如:nmist、IMDB影評
2.keras.models:架構神經網路、與神經網路相關操作
3.keras.layers:創建神經網路Dense(DNN)、conv2d(CNN)
4.keras.utils:資料正規化
5.PIL:圖像相關操作
6.matplotlib.pyplot:繪畫表格
2.資料前處理
我們今天使用的架構為CNN,當使用不同架構時都需要注意他的input_shape,在CNN中輸入則是(長,寬,色彩),經過昨天的實作我們知道我們的資料是(長,寬),所以在這邊我們只需要稍微修改昨天的作法將維度reshape成(長,寬,色彩)就可以了。
#讀取資料
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#CNN的輸入為(長,寬,色彩) 1代表黑白 3代表彩色
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#正規化圖像
x_train = x_train/255
x_test = x_test/255
#將label轉換為label
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
3.建構網路&訓練模型
這次選用的激勵函式都與昨天的實作相同,我們只需加入三層網路分別是捲積層Conv2D、池化層MaxPooling2D與攤平Flatten就能使網路從DNN架構轉變成CNN架構。
#建構網路
model = Sequential()
#CNN輸入為(長*寬*色彩)
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
#池化層(找最大值不用激勵函數)
model.add(MaxPooling2D(pool_size = 2))
#攤平(攤平不用激勵函數)
model.add(Flatten())
#全連接層
model.add(Dense(16, activation = 'relu'))
#輸出層
model.add(Dense(10, activation = 'softmax'))
# 宣告loss finction與optimizer
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 開始訓練model batch_size一次丟多少資料進去訓練 epochs總共要訓練幾次
history = model.fit(x_train, y_train,
batch_size=64,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
-----------------------------------顯示-----------------------------
Epoch 10/10
938/938 [==============================] - 9s 9ms/step - loss: 0.0424 - accuracy: 0.9973 - val_loss: 0.1313 - val_accuracy: 0.9836
val_accuracy: 0.9836是不是比之前DNN跑出來的準確率還要高呢!!
4.儲存模型
在keras中model有兩種儲存的方式:分別是model.save與model.save_weights,這兩者差別就在於是否有神經網路。
若我們使用model.save儲存模型,需要使用load_model讀取檔案
#儲存model(包含網路)
model.save('model.h5')
#讀取整個model
model = load_model('model.h5')
若是使用model.save_weights,需重新定義原本的神經網路以及使用load_weights讀取檔案
#只儲存權重
model.save_weights('model_weights.h5')
#需重新定義網路
model = Sequential()
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
model.add(MaxPooling2D(pool_size = 2))
model.add(Flatten())
model.add(Dense(16, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
#讀取權重
model.load_weights('model_weights.h5')
5.評估模型
當訓練好一個模型之後要怎麼知道這模型好不好呢?我們要先了解什麼是過擬合(Overfitting)與欠擬合(Underfitting)。
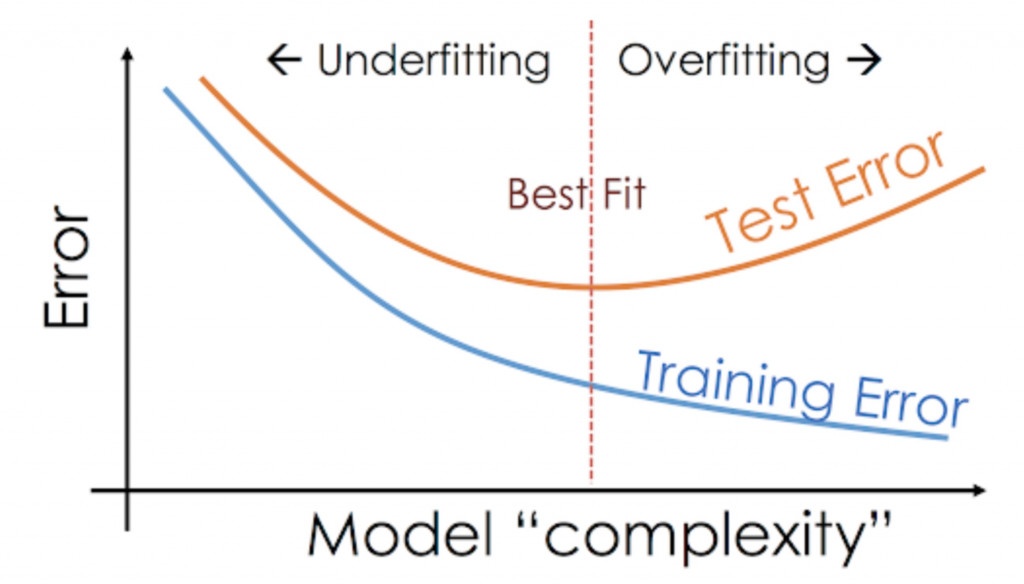
圖片來源:https://www.analyticsvidhya.com/blog/2020/02/underfitting-overfitting-best-fitting-machine-learning/
過擬合(Overfitting):是因為過度學習訓練資料,而變得無法順利去預測或分辨不是在訓練資料內的其他資料,也就是在圖片的右半邊train loss下降,但test loss卻不會再變動了甚至往上升的趨勢。
欠擬合(Underfitting):通常會發生在模型參數過少、模型結構過於簡單或資料過於雜亂時,導致無法捕捉到資料中的規律的現象,也就是我們圖片的左半邊,test loss始終追不上train loss。
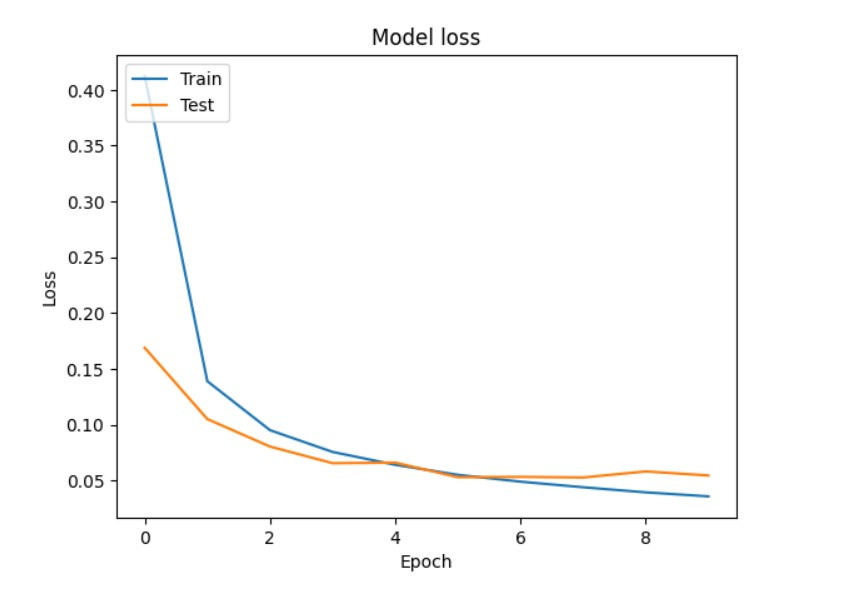
現在我們開始寫程式來繪出train loss與test loss的折線圖找到最好的訓練次數吧!!
我們先來查看訓練過程中的到的loss值
print('train loss:',history.history['loss'],'\n\ntest loss:',history.history['val_loss'])
------------------------------------顯示------------------------------------
train loss: [0.41220638155937195, 0.1390567123889923, 0.09521930664777756, 0.07572223246097565, 0.06420597434043884, 0.05522913485765457, 0.049094390124082565, 0.04410300403833389, 0.03952856734395027, 0.03593530133366585]
test loss: [0.16896437108516693, 0.10513907670974731, 0.08054570108652115, 0.06564835458993912, 0.06614525616168976, 0.05308758467435837, 0.053389910608530045, 0.052831731736660004, 0.05826638638973236, 0.05463290959596634]
我們可以看到keras會把每次epoch計算的loss值存成一個list,那我們就可以使用matplotlib.pyplot快速的畫出一張折線圖。
#train loss
plt.plot(history.history['loss'])
#test loss
plt.plot(history.history['val_loss'])
#標題
plt.title('Model loss')
#y軸標籤
plt.ylabel('Loss')
x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['Train', 'Test'], loc='upper left')
#顯示折線圖
plt.show()
這樣我們就能觀察到在第5或6次就會是模型最佳的結果
那們今天就到這邊,到現在程式都很簡單吧只需要瞭解一些理論就能簡單的實作出來,明天會來教近期最後一堂理論課程LSTM,之後就來玩點日常生活中AI的應用吧
完整程式碼
import numpy as np
import tensorflow.keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential,load_model,model_from_json
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.utils import to_categorical
from PIL import Image
import matplotlib.pyplot as plt
#讀取資料
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#CNN的輸入為(長,寬,色彩) 1代表黑白 3代表彩色
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#正規化圖像
x_train = x_train/255
x_test = x_test/255
#將label轉換為label
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#建構網路
model = Sequential()
#CNN輸入為28*28*1
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
#池化層
model.add(MaxPooling2D(pool_size = 2))
#攤平
model.add(Flatten())
#全連接層
model.add(Dense(16, activation = 'relu'))
#輸出層
model.add(Dense(10, activation = 'softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
#儲存model(包含網路)
model.save('model.h5')
#讀取整個model
model = load_model('model.h5')
#只儲存權重
model.save_weights('model_weights.h5')
#需重新定義網路
model = Sequential()
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
model.add(MaxPooling2D(pool_size = 2))
model.add(Flatten())
model.add(Dense(16, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
#讀取權重
model.load_weights('model_weights.h5')
爬蟲與股票預測-長短期記憶模型(Long short-term memory) (上)
遞迴神經網路(Recurrent Neural Networks)
在開始說明LSTM前,我們要先了解一下什麼是RNN架構。

圖片來源:李弘毅老師的youtube影片
先說明圖片中的一些重要參數,X1~Xn是我們帶有時間順序的輸入,像是股票的走勢、天氣的溫度、文本的文字,都是帶有時間的數據。H0~Hn是經過RNN計算過後保留下來的資料,初始狀態(H0)這一個狀態可以是0(未經過訓練),經過每一個輸入(X與上個節點的H)就會更改H的數值並與下一個節點進行運算,使程式有將資訊傳遞的效果。而Y1~Y8是將每一節點的輸出單獨取出的結果,並不會與下個節點計算。
舉一個例子來說:
假設一週的天氣數據是[X1,X2,X3,X4,X5,X6,X7],我們要讓RNN的神經網路預測第8天的數據,那在RNN的過程就會像是這個樣子第一節點輸入(H0,X1)->第一節點輸出(Y1,H1)->第二節點輸入(H1,X2)->第二節點輸出(Y2,H2)...第8節點輸出(Y8,H8)。
通過H傳遞每一節點的資料,使神經網路能夠瞭解前幾個節點的資料,從而資料帶有時間序而最終訓練的結果也就是我們的Hn狀態,此時狀態會與Yn相同,因為Y跟H是相同的,差別在於是否會進入到下個節點進行運算。
長短期記憶模型(Long Short-Term Memory)
LSTM是我們剛剛講解到的RNN模型的改良版,因為RNN模型有一個重大的缺點,就在於他是短期記憶(Short Term)我們可以看到,每節點的輸出是會被作為輸入不斷的被計算的,也就意味著會被不斷的稀釋,大概經過3~4節點最開始的輸入就被稀釋光了,LSTM則改良了這個問題。
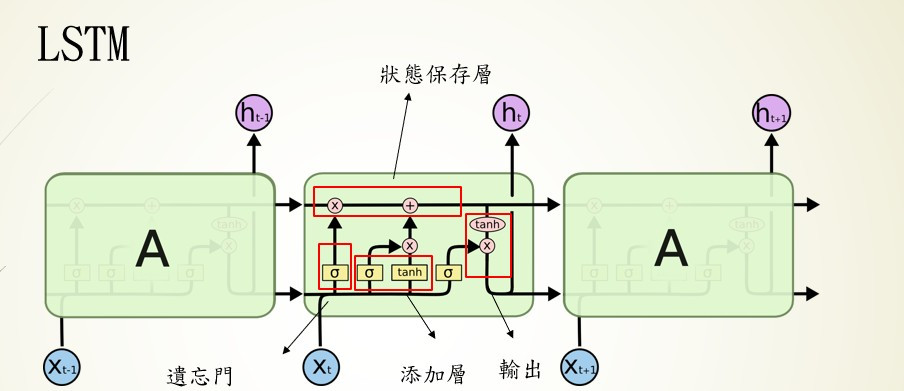 我們把LSTM拆解為4個區塊:
我們把LSTM拆解為4個區塊:狀態保存層(Cell State)、遺忘門層(Forget Gate Layer)、添加層、輸出層(Output Layer)。
狀態保存層(Cell State)
前面提到RNN的資料會隨著計算迅速消失,為瞭解決這個問題在LSTM中就將資料獨立儲存,並通過,遺忘門、添加層等運算,保留相關的資訊。
遺忘門層(Forget Gate Layer)
在這層中會對上一個節點的輸出與當前輸入的使用sigmoid計算,將上個節點的輸出資料傳送給狀態保存層,並丟棄無用的資料。簡單來說就是會忘記不重要的資料,保留重要的資料。
添加層
當然有丟棄資料的方式也要有新增資料的方法,所以我們這層的任務就是找到重要的資訊,將當前節點的輸入通過sigmoid計算,並通過tanh縮放資料權重,最後將資料傳送給狀態保存層。
輸出層(Output Layer)
這階段的作法與添加層的作法相似,也是通過sigmoid與tanh的計算取的所需要的資料,差別在於這次資料的來源是狀態保存層。
在這邊作一個簡易的統整:
狀態保存層:負責保留每個節點的資料
遺忘門層:輸入是上一個節點的輸出與當前輸入使用sigmoid計算,保留上個節點的輸出
添加層:輸入是上一個節點的輸出與當前輸入使用sigmoid與tanh計算,保留當前輸入
輸出層:輸入是狀態保存層與當前輸入使用sigmoid與tanh計算,重新計算下個節點的輸入
到這裡是不是瞭解LSTM中的構造了呢?但在開始LSTM之前我們來先來學一下爬蟲,準備我們LSTM所需要的資料
網路爬蟲
在python有兩個比較著名的爬蟲函式庫分別是requests與selenium,前者難度較高,所以今天會先採用selenium作為基礎教學,後續的課程中再教requests那們進入今天的正題我們先將程式分為幾個部分:
1.架構環境
2.導入函式庫與介紹
3.建立瀏覽器環境
4.迴圈取得網站資料
5.整理資料並存檔
1.架構環境
首先我們先到以下網址下載載驅動程式:
先找到自己瀏覽器的版本(這邊我就使用chrome作範例)到chrome://settings/help 查看瀏覽器版本
 到我們驅動程式的網站下載對應版本(我的版本是104版本)
到我們驅動程式的網站下載對應版本(我的版本是104版本)
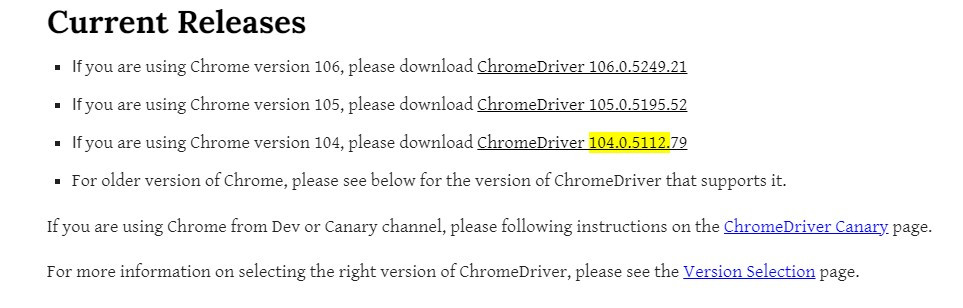 點進去後下載chromedriver_win32.zip(windows為例)
點進去後下載chromedriver_win32.zip(windows為例)
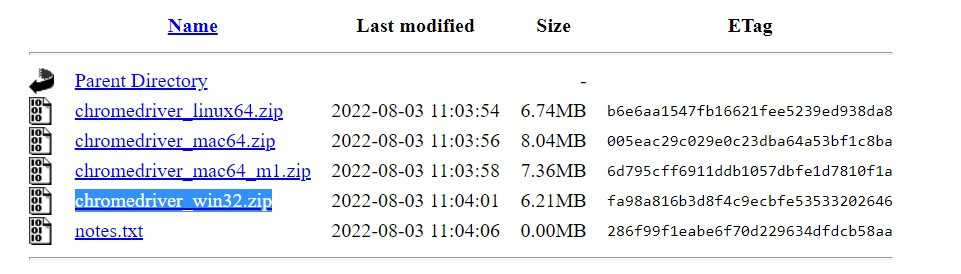 之後解壓縮到要寫程式的資料夾就可以了
之後解壓縮到要寫程式的資料夾就可以了
 再來我們安裝一下今天要使用到的函式庫不會的可以到我第一天的教學【day1】python&函式庫 安裝與介紹
再來我們安裝一下今天要使用到的函式庫不會的可以到我第一天的教學【day1】python&函式庫 安裝與介紹
pip install selenium
pip install bs4
pip install pandas
pip install sklearn
2.導入函式庫與介紹
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from time import sleep
import pandas as pd
1.selenium:動態爬蟲
2.bs4:分析html網址
3.time:時間相關操作
4.pandas:excel相關操作
3.建立瀏覽器環境
首先我們要知道網站會防止分散式阻斷服務(DDoS),所以會阻擋請求太頻繁或是爬蟲的請求標頭(request header)所以我們需要更改selenium的user agent。
#設定user agent防止網站鎖IP
chrome_options = Options()
chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
#指定驅動與導入設定
chrome = webdriver.Chrome('chromedriver',options=chrome_options)
設定好瀏覽器的環境後我們就可以開始解析網站了
4.迴圈取得網站資料
首先我們前往臺灣證券交易所的網站(臺積電股票為例),但這個網站卻只有2013/10月的股票數據,所以我們需要使用迴圈幫助我們。
https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date=20131001&stockNo=2330
先分析一下url,可以看到兩個參數data=20131001與stockNo=2330,這兩個參數很明顯的一個是日期,另一個是股票編號,所以我們可以統整出以下格式。
https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date={年/月/日}&stockNo={股票編號}
之後就可以使用迴圈去請求不同頁面的數據
#range的內部參數是range(開始, 結尾, 一次加多少)
#2010~2022年
for y in range(2010,2023):
#1~12月
for m in range(1,13):
#網址格式為yyyy/mm/dd 不能少一碼所以要補0
if m <10:
#m的格式是int所以要轉成str才能作文字的相加
m = '0'+str(m)
url = f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date={y}{m}01&stockNo=2330'
接下來我們來操作程式前往網站並獲取網站資料
#前往網站
chrome.get(url)
#獲取網站資料
soup = BeautifulSoup(chrome.page_source, 'html.parser')
接下來我們到網站按下F12可以看到一html的程式碼,可以觀察到我們需要的資料都在tbody>tr這個標籤裡面。
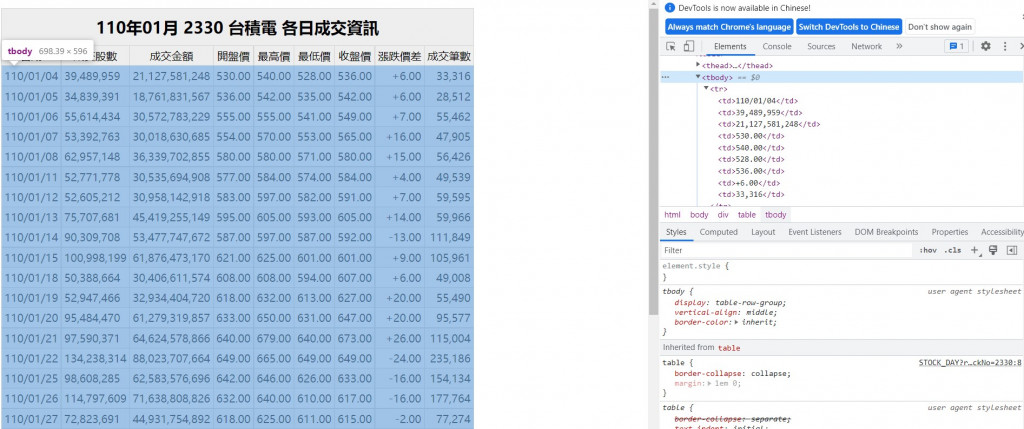
之後就可以利用bs4所提供的CSS選擇器來找到我們要的資料節點,就可以獲取我們想要的資料
soup.select('tbody > tr')
。
5.整理資料並存檔
我們可以看到soup.select('tbody > tr')獲取到的資料長這樣子
<tr>
<td>99/01/04</td>
<td>39,511,138</td>
<td>2,557,720,928</td>
<td>65.00</td>
<td>65.00</td>
<td>64.00</td>
<td>64.90</td>
<td>+0.40</td>
<td>8,255</td>
</tr>
我們所需要的資料只有裡面的數值,所以我們先把資料轉成str就能取得一個比較乾淨的結果
print(tr.text)
----------顯示----------
99/01/19
47,541,231
2,970,283,048
63.00
63.20
62.00
62.50
-0.40
14,132
但有沒有發現這些資料自動換行了,這代表這些字串有一個叫做\n的特殊符號,在程式中\n代表換行符號的意思,所以我們要先將這些資料移除掉,並返回list讓我們更好的處理資料,在這邊我們只要使用split()就可以了
#split('需要切割的字')返回是list
td = tr.text.split('\n')
----------------顯示----------------
['', ' 99/01/29', '98,124,608', '5,948,654,037', '60.10', '61.50', '59.40', '61.50', '+1.50', '18,337', '']
接下來為了存成csv檔,所以我們先創立一個dict當作存放資料的地方
#建立我們資料要的dict
data = {'日期':[],
'成交股數':[],
'成交金額':[],
'開盤價':[],
'最高價':[],
'最低價':[],
'收盤價':[],
'漲跌價差':[],
'成交筆數':[]}
並且通過append將所有的資料加入到個別的索引
#注意td[0] 是 ''
data['日期'].append(td[1])
data['成交股數'].append(td[2])
data['成交金額'].append(td[3])
data['開盤價'].append(td[4])
data['最高價'].append(td[5])
data['最低價'].append(td[6])
data['收盤價'].append(td[7])
data['漲跌價差'].append(td[8])
data['成交筆數'].append(td[9])
就能使用pandas裡面的功能將資料存成csv啦
#dict轉成dataframe
df = pd.DataFrame(data)
#存成csv檔案
df.to_csv("data.csv")
完整程式碼(爬蟲)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from time import sleep
import pandas as pd
#設定user agent防止網站鎖IP
chrome_options = Options()
chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
#指定驅動與導入參數
chrome = webdriver.Chrome('chromedriver',options=chrome_options)
#建立我們資料要的dict
data = {'日期':[],
'成交股數':[],
'成交金額':[],
'開盤價':[],
'最高價':[],
'最低價':[],
'收盤價':[],
'漲跌價差':[],
'成交筆數':[]}
#設定年月日(2010~2022)
for y in range(2010,2023):
for m in range(1,13):
#網址格式為yyyy/mm/dd 不能少一碼所以要補0
if m <10:
#m的格式是int所以要轉成str才能作文字的相加
m = '0'+str(m)
url = f'https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date={y}{m}01&stockNo=2330'
#前往網站
chrome.get(url)
#獲取網站資料
soup = BeautifulSoup(chrome.page_source, 'html.parser')
#透過CSS選擇器找到在tbody裡面所有的tr標籤
for tr in soup.select('tbody > tr'):
#將\n透過split()分割
td = tr.text.split('\n')
data['日期'].append(td[1])
data['成交股數'].append(td[2])
data['成交金額'].append(td[3])
data['開盤價'].append(td[4])
data['最高價'].append(td[5])
data['最低價'].append(td[6])
data['收盤價'].append(td[7])
data['漲跌價差'].append(td[8])
data['成交筆數'].append(td[9])
print(data)
#防止過度請求網站被鎖定IP
sleep(10)
#dict轉成dataframe
df = pd.DataFrame(data)
#存成csv檔案
df.to_csv("data.csv")
那今天就先到這邊好了,其實今天是想把東西全部教完的,但發現內容太多了,所以明天會接續今天的內容把LSTM實作做完,那我們明天再見。
爬蟲與股票預測-長短期記憶模型(Long short-term memory) (下)
LSTM股票預測
- 1.導入函式庫與介紹
- 2.資料前處理
- 3.架構模型與訓練
- 4.效能評估
1.導入函式庫與介紹
import numpy as np
import pandas as pd
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
1.numpy:陣列相關操作
2.keras.models:架構神經網路、與神經網路相關操作
3.keras.layers:創建神經網路
4.sklearn.preprocessing:數值正規化
5.matplotlib.pyplot:繪畫表格
2.資料前處理
首先我們先從pandas讀取昨天爬蟲拿到的csv檔,沒有的人可以觀看這篇【day5】爬蟲與股票預測-長短期記憶模型(Long short-term memory) (上)
df = pd.read_csv('data.csv')
我們在課堂的一開始有說到,大部分深度學習模型都要把數值壓縮到0~1之間,不只能加速收斂速度,所以今天我們股票預測要使用的方式是最大最小正規化(Min-Max Normalization)
def Min_Max_normalization(name):
#調整維度成[[資料1],[資料2]]
name = name.reshape(-1, 1)
#正規化數值
scaler = MinMaxScaler(feature_range=(0, 1)).fit(name)
sc = scaler.transform(name)
#[維度還原]
return sc.reshape(-1)
#df[row]:可以直接取一整排的數值回傳的type是dataframe
#values:轉成dataframe轉成array
open_p = Min_Max_normalization(df['開盤價'].values)
max_p = Min_Max_normalization(df['最高價'].values)
min_p = Min_Max_normalization(df['最低價'].values)
fin_p = Min_Max_normalization(df['收盤價'].values)
#replace(old,new)這裡是將文字中的,去除掉
len_p = np.array([int(i.replace(',','')) for i in df['成交筆數'].values])
len_p = Min_Max_normalization(len_p)
接下來我們來創建自己的資料集(Date set),首先我們取每10天的資料預測每第11天的資料,並個資料都要帶有5筆特徵(開盤價、最高價、最低價、收盤價、成交筆數)
data = []
tmp = []
label = []
#最後一筆label的範圍是最大數量-11天
for cnt in range(len(open_p)-11):
#獲取10天的資料
open_10 = open_p[cnt:cnt+10]
max_10 = max_p[cnt:cnt+10]
min_10 = min_p[cnt:cnt+10]
fin_10 = fin_p[cnt:cnt+10]
len_10 = len_p[cnt:cnt+10]
#zip可以將每筆資料都同時丟進for迴圈中
for i,j,k,m,n in zip(open_10,max_10,min_10,fin_10,len_10):
tmp.append([i, j, k, m, n])
data.append(tmp)
tmp = []
取得收盤價
label.append(fin_p[cnt+11:cnt+12][0])
這樣子我們就能得到一組擁有10天資料5個特徵的訓練資料了(資料數量,天數,特徵)
接下來我們把資料分8:2切割我們的訓練數據與測試數據
split_cnt = int(len(data)*0.8)
x_train,y_train = np.array(data[0:split_cnt]),np.array(label[0:split_cnt])
x_test,y_test = np.array(data[0:len(data)-split_cnt]),np.array(label[0:len(data)-split_cnt])
這樣資料前處理就完成了~~
3.架構模型
今天的模型架構也很簡單,但有一個比較需要注意的return_sequences = True,使我們能夠考慮到前後天的資料,而不是隻考慮到昨天的結果
model= Sequential()
model.add(LSTM(128,input_shape=(10, 5),return_sequences=True,activation='relu'))
model.add(LSTM(64,return_sequences=False,activation='relu'))
model.add(Dense(1))
#mse為跑回歸任務的其中一個loss function
#回歸任務沒有acc只有loss
model.compile(loss='mean_squared_error',optimizer='adam')
# 開始訓練model batch_size一次丟多少資料進去訓練 epochs總共要訓練幾次
history = model.fit(x_train, y_train,
batch_size=64,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
-------------------------------顯示-------------------------------
Epoch 10/10
39/39 [==============================] - 0s 8ms/step - loss: 7.0062e-05 - val_loss: 8.8297e-06
4.效能評估
我們直接拿實際值與預測出來的數值作比對
y_predicted = model.predict(x_test)
#預測
plt.plot(y_predicted)
#實際值
plt.plot(y_test)
#標題
plt.title('result')
#y軸標籤
plt.ylabel('days')
#x軸標籤
plt.xlabel('value')
#顯示折線的名稱
plt.legend(['predict', 'real'], loc='upper left')
#顯示折線圖
plt.show()
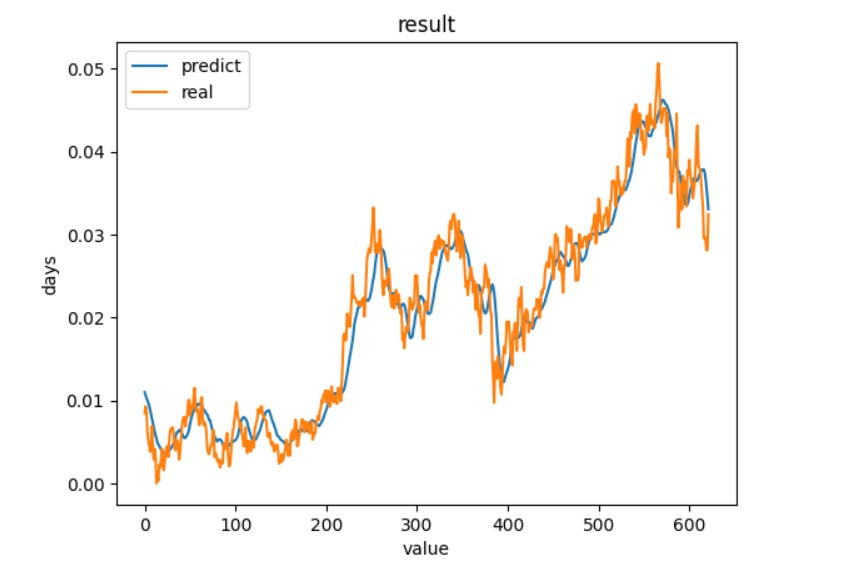
我們可以看到訓練出來的結果還是有貼近實際值,但實際值下降時,預測有時候是上升的,因為股票預測考慮的因素不只有這一些,考慮更多因素說不定能有更好的結果。
完整程式碼(LSTM)
import numpy as np
import pandas as pd
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
def Min_Max_normalization(name):
name = name.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1)).fit(name)
sc = scaler.transform(name)
return sc.reshape(-1)
df = pd.read_csv('data.csv')
open_p = Min_Max_normalization(df['開盤價'].values)
max_p = Min_Max_normalization(df['最高價'].values)
min_p = Min_Max_normalization(df['最低價'].values)
fin_p = Min_Max_normalization(df['收盤價'].values)
len_p = np.array([int(i.replace(',','')) for i in df['成交筆數'].values])
len_p = Min_Max_normalization(len_p)
data = []
tmp = []
label = []
for cnt in range(len(open_p)-11):
open_10 = open_p[cnt:cnt+10]
max_10 = max_p[cnt:cnt+10]
min_10 = min_p[cnt:cnt+10]
fin_10 = fin_p[cnt:cnt+10]
len_10 = len_p[cnt:cnt+10]
for i,j,k,m,n in zip(open_10,max_10,min_10,fin_10,len_10):
tmp.append([i, j, k, m, n])
data.append(tmp)
tmp = []
label.append(fin_p[cnt+11:cnt+12][0])
split_cnt = int(len(data)*0.8)
x_train,y_train = np.array(data[0:split_cnt]),np.array(label[0:split_cnt])
x_test,y_test = np.array(data[0:len(data)-split_cnt]),np.array(label[0:len(data)-split_cnt])
model= Sequential()
model.add(LSTM(128,input_shape=(10, 5),return_sequences=True,activation='relu'))
model.add(LSTM(64,return_sequences=False,activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_squared_error',optimizer='adam')
# 開始訓練model batch_size一次丟多少資料進去訓練 epochs總共要訓練幾次
history = model.fit(x_train, y_train,
batch_size=64,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
y_predicted = model.predict(x_test)
#預測
plt.plot(y_predicted)
#實際值
plt.plot(y_test)
#標題
plt.title('result')
#y軸標籤
plt.ylabel('days')
#x軸標籤
plt.xlabel('value')
#顯示折線的名稱
plt.legend(['predict', 'real'], loc='upper left')
#顯示折線圖
plt.show()
到這邊基礎技術基本上都教完了~明天來教一下如何使用pytorch吧
解析gz檔案 & 使用Pytorch做CIFAR10影像辨識 (上)
我們前幾天用的深度學習函式庫是Tensorflow作為後端,並用keras快速實現深度神經網路,這樣的做法雖然可以簡易的完成一些簡易的AI程式,但無法實現複雜的神經網路及預訓練模型(pre-trained model),所以通常會使用keras學習AI的基礎知識,再來使用Tensorflow或Pytorch作為最終的訓練工具,我這邊會推薦使用Pytorch,所以之後的課程都會以Pytorch為主
解析gz檔
在我們【day3】來辨識圖像-深度神經網路(Deep Neural Network)的課程中,可以看到透過keras下載的資料集是一個無法打開的文件,須通過程式內部的解析才能瞭解內容,但如果我今天想要裡面的圖片存在自己的電腦裡或做為資料集使用呢?所以今天要來教如何解開gz檔,在獲得資料的同時也能讓你更理解圖片維度的意義。
- 1.下載資料與安裝函式庫
- 2.讀取資料並整理資料
- 3.迴圈與儲存資料
下載資料與安裝函式庫
首先我們先到下載資料官方網站裡面下載CIFAR-10 python version

接下來我們把gz檔解壓縮,並且創一個叫做data的資料夾將data_batch_1~data_batch_5與test_batch存放起來,並且在外面創建一個python檔案,此時我們的畫面應該會長這個樣子

接下來是安裝函式庫
pip install opencv-python
這樣子就可以開始寫程式啦
讀取資料並整理資料
先來導入今天需要的函式庫
import pickle as pk
import numpy as np
import cv2
import os
接下來看到官方網站中有教我們該如何打開gz的方式,我們先觀察這樣會回傳什麼樣的資料。
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
print(unpickle('data/data_batch_1'))
----------------------------顯示----------------------------
{b'batch_label': b'training batch 1 of 5',
b'labels': [label資料]
b'data': array([[圖片資料]], dtype=uint8)
b'filenames': [檔案名稱]}
可以看到這個資料了型態會是一個dict,每一個資料裡面都是一個陣列,我們只需要將labels作為資料夾分類使用filenames作為data的圖片的檔名就可以存檔....個鬼,在官方網站中有這樣一段話
3072 bytes are the values of the pixels of the image. The first 1024 bytes are the red channel values, the next 1024 the green, and the final 1024 the blue. The values are stored in row-major order, so the first 32 bytes are the red channel values of the first row of the image.
(每張圖片共3072個資料,第一個1024個為紅色的通道的資料,接下來是1024個綠色通道,最後是1024個為藍色,每個資料都是按照優先順序排列的,因此前32個資料是第一行的紅色資料)。
在這裡就需要先說明一下電腦儲存影像的方式了首先我們可以知道三原色(紅R、綠G、藍B)可以組合出任一的顏色,所以我們只需要給予一個像素一組紅、綠、藍的資料再將這個資料組合在一起就可以變成一張圖片,在CIFAR10中圖片大小是32x32的,所以在文章中所提到的3072筆其實就是32x32x3。所以按照官方的意思我們在圖片1x1的位子就會是資料中的第0筆(R) 第1024筆(G) 第2048筆(B)並依照這個格式組成一張32x32的圖片。
我們先改寫一下官方的範例讓我們更好拿到資料
def unpickle(file):
#開啟檔案視為2進位
with open(file, 'rb') as fo:
#解析開啟後的gz檔
gz_dict = pk.load(fo, encoding='bytes')
return gz_dict[b'labels'],gz_dict[b'filenames'],gz_dict[b'data']
labels,names, datas = unpickle(f'data/data_batch_1')
接下來將每筆data放入迴圈中並將通道分成R,G,B
for data in datas:
R = data[:1024]
G = data[1024:2048]
B = data[2048:3072]
最後我們把數據組成圖片一張圖片
img,tmp = [],[]
#enumerate 計數程式用法與range(len(data))回傳值是(計數的值,資料)
for cnt,(r,g,b) in enumerate(zip(R,G,B),1):
#創立一個像素(在這邊使用b,g,r是因為opencv存檔的格式是bgr)
tmp.append([b, g, r])
#每32個像素換下一列
if cnt % 32 == 0:
#將整行的像素存入陣列中
img.append(tmp)
tmp = []
迴圈與儲存資料
剛剛只讀取了data_batch_1這個檔案,但我們今天需要重複6次相同的動作,這時我們可以透過os.listdir讀取資料夾內容的名稱,並透過迴圈讀取資料。
#os.listdir('路徑')回傳值為[檔名1~檔名n]
for path in os.listdir('data'):
labels,names, datas = unpickle(f'data/{path}')
為了儲存圖片可以使用makedirs創建資料夾,但makedirs在迴圈中就會因為創建過資料夾而導致程式錯誤,這邊就能使用try...except的語句做處理。
#嘗試做動作
try:
os.makedirs(f'pic/train/{label}')
os.makedirs(f'pic/test/{label}')
#若無法執行則會執行這裡
except:
#不做任何事情
pass
運用opencv儲存剛剛整理好的影像
cv2.imwrite(path, np.array(img))
可以知道資料集需要分成測試數據集與訓練數據集,在CIFAR10中test_batch就是我們的訓練數據集,所以我們就能用if判斷該資料是訓練還是測試資料。
#測試數據集
if path == 'test_batch':
#把資料存進剛剛建立好的資料夾中 過濾掉檔名裡面的'b'與'符號
cv2.imwrite(f'pic/test/{label}/{str(name)[2:-1]}', np.array(img))
else:
cv2.imwrite(f'pic/train/{label}/{str(name)[2:-1]}', np.array(img))
最後讓我們把程式組合起來
完整程式碼
import pickle as pk
import numpy as np
import cv2
import os
def unpickle(file):
with open(file, 'rb') as fo:
gz_dict = pk.load(fo, encoding='bytes')
return gz_dict[b'labels'],gz_dict[b'filenames'],gz_dict[b'data']
for path in os.listdir('data'):
labels,names, datas = unpickle(f'data/{path}')
for label, name, data in zip(labels,names,datas):
try:
os.makedirs(f'pic/train/{label}')
os.makedirs(f'pic/test/{label}')
except:
pass
R = data[:1024]
G = data[1024:2048]
B = data[2048:3072]
img,tmp = [],[]
for cnt,(r,g,b) in enumerate(zip(R,G,B),1):
tmp.append([b, g, r])
if cnt % 32 == 0:
img.append(tmp)
tmp = []
if path == 'test_batch':
cv2.imwrite(f'pic/test/{label}/{str(name)[2:-1]}', np.array(img))
else:
cv2.imwrite(f'pic/train/{label}/{str(name)[2:-1]}', np.array(img))
這樣子可以得到資料啦,明天先來說說GPU加速與再來開始pytorch的教學
解析gz檔案 & 使用Pytorch做CIFAR10影像辨識 (下)
為何要使用GPU加速
在實作CNN與LSTM時的因為資料量較小隻需用到CPU運算,但後續課程中的資料會越來越多,所以運算時間會越來越久,這時就會使用到GPU去加速程式。
我們先了解GPU為何能夠加速程式就要先知道GPU的構造,GPU是由許多的乘數累加器(Multiply Accumulate)組成,這種運算的動作是將資料相乘後加上累加器後再存入累加器(累加器1 <- 累加器1 + 資料1x資料2),而在神經網路中可以將矩陣放入累加器中運算,且在乘數累加器中只需使用一個指令就能完成上述的動作,從而提高運算的速度,簡單來說就是GPU能夠用簡短的方式傳輸大量資料。
CIFAR10影像辨識
今天的課程會有許多【day3】來辨識圖像-深度神經網路(Deep Neural Network)與【day4】找到圖片的特徵-捲積神經網路(Convolutional neural network)的知識與一些延伸,若是有不瞭解的地方可以回顧一下。
- 1.Pytorch版本安裝
- 2.函式庫介紹與安裝
- 3.創建資料集
- 4.架構神經網路
- 5.訓練神經網路
Pytorch版本安裝
我們前幾天再安裝函式庫都是使用pip install 函式庫名稱安裝程式,但使用這種方式安裝pytorch卻會發現是CPU版本,那麼該怎麼安裝GPU版本呢?
先到Pytorch的官方網站會看到INSTALL PYTORCH,之後選擇安裝的方式(pip)與cuda版本(基本上都是11.3),就會得到一串pip的指令
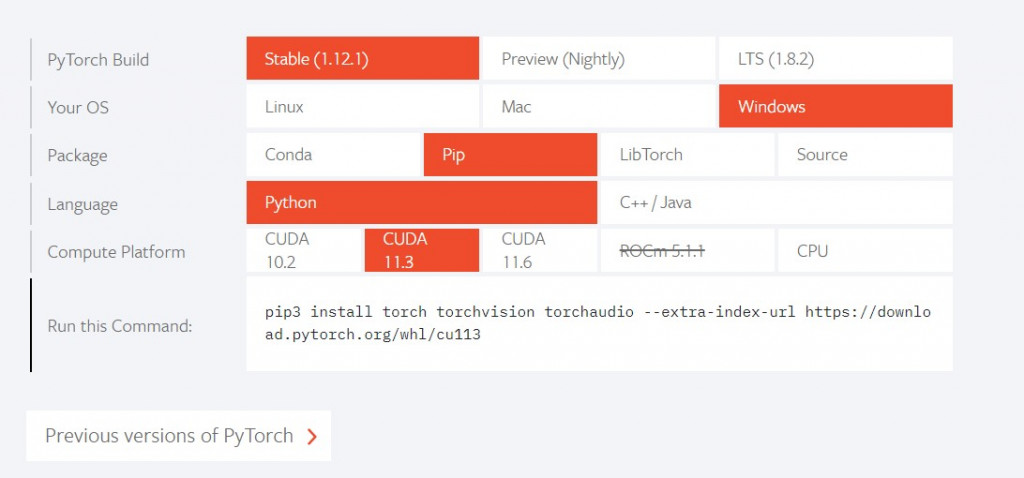
之後輸入就安裝完畢了
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
函式庫介紹與安裝
#如果到現在的課程都有跟上,那應該只會缺少tqdm函式庫
pip install tqdm
接下來介紹一下今天會使用的函式庫
#系統相關操作
import os
#深度學習函式庫
import torch
#神經元架構與損失函數
import torch.nn as nn
#激勵函數
import torch.nn.functional as F
#優化器
import torch.optim as optim
#圖像前處理
import torchvision.transforms as transforms
#矩陣操作
import numpy as np
#圖像操作
from cv2 import imread
#創建資料集
from torch.utils.data import Dataset, DataLoader
#顯示進度條
from tqdm import tqdm
創建資料集
我們前幾天的實作都是先將資料放入一個array中,再將array給予神經網路去運算,但是在pytorch中不會使用這種方式,因為pytorch沒辦法像keras那樣指定batch size與epoch,所以在pytorch中會先將變成dataset後再轉換成dataloader,才能夠指定batch size等參數,我們先看一下pytorch創建dataset的方式。
#繼承Dataset這一個class(需要繼承pytorch設定好的class並新增自己的資料)
class dataset(Dataset):
#初始化資料的地方
def __init__(self,data):
#創建資料的地方
#每次訓練時會通過__getitem__取得我們需要訓練的資料
def __getitem__(self,index):
#訓練當前的index與資料
#判斷資料的大小
def __len__(self):
#判斷index的上限
return len(self.data)
在這邊需要注意若我們需要的處理資料(讀檔、正規化),需要在init內完成,而不是在getitem裡面,因為pytorch在訓練的時候會從getitem這一個function裡取資料,如果寫在裡面會使每取一筆資料,就需要重新處理一次,這樣子會導致程式訓練的時間變得更久。
若使用GPU訓練的人要注意處理資料時千萬不要在建立資料時,將資料放入GPU中處理,例如:
def __init__(self,data):
#cuda()會將資料放入顯卡
self.data = data.cuda()
這樣子會將所有的資料放入顯卡當中,且不會釋放,若是要將資料放入GPU中,應先將資料變成dataloader的形式再使用cuda()放入到GPU當中。
接下來開始處理昨天解析出來的CRFAR10圖像,透過昨天學習到的listdir讀取圖片並放到list當中。
data = []
for label in os.listdir(path):
for pic in os.listdir(path + '/' + label):
#cv2.imread(path)可以將圖片轉換為array
cv_pic = imread(f'{path}/{label}/{pic}')
data.append([cv_pic, int(label)])
之後需要對圖片正規化,這裡可以利用transforms.Compose()定義我們想要做的操作。
#將資料轉化成Tensor後Normalize
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
這樣就可以把transform做為一個function使用了
transform(data)
我們將整個程式組合起來,這樣就可以創建資料集了
class CRFAR10(Dataset):
def __init__(self, path, transform):
self.data = []
for label in os.listdir(path):
for pic in os.listdir(path + '/' + label):
cv_pic = imread(f'{path}/{label}/{pic}')
self.data.append([cv_pic, int(label)])
def __getitem__(self,index):
datas = transform(self.data[index][0])
labels = torch.tensor(self.data[index][1])
return datas, labels
def __len__(self):
return len(self.data)
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
train_set = CRFAR10(r'pic/train/', transform)
test_set = CRFAR10(r'pic/test/', transform)
train_loader = DataLoader(train_set, batch_size = 128,shuffle = True, num_workers = 0)
test_loader = DataLoader(test_set, batch_size = 128, shuffle = True, num_workers = 0)
架構神經網路
先來看pytorch中該怎麼架構神經網路的格式。我們需要在init定義神經網路的種類與每層的輸入大小,並且使用forward來執行動作。
#繼承nn.Module
class CNN(nn.Module):
def __init__(self):
#呼叫nn.Module裡面init的資料
super().__init__()
#定義神經網路
def forward(self, x):
#定義操作
知道格式後,就可以來架構神經網路了,今天要的網路構造如下:
#![allow(unused)] fn main() { 捲積層1->池化層->捲積層2->池化層->全連接層 (CNN) }
這代表需要建立2個CNN、1個池化層與n個全連接層我們先看到官方說明:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
官方文件告訴我們在CNN中需要定義三個參數(in_channels, out_channels, kernel_size),在這之中輸入是唯一需要知道的參數,在CRFAR10資料集中圖片是彩色的,這代表我們的in_channels會是3(RGB),out_channels與kernel_size我們需要通過多次測試與經驗,才能知道最佳的結果,我們可以先隨便設定一個值(這邊先設定out_channels = 6與kernel_size = 5)。
self.conv1 = nn.Conv2d(3, 6, 5)
接下來設定第二層CNN神經網路(上層設定的out_channels是6,所以我們這層的in_channels一定要是6)
self.conv2 = nn.Conv2d(6, 16, 5)
然後我們來看一下池化層的說明:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
這層是做特徵強化只會縮小圖片大小,所以不會影響到in_channels,所以可以隨意的設定kernel_size
self.pool = nn.MaxPool2d(2, 2)
接下來就會比較困難了,因為要進入到全連接層之前需要將維度攤平,所以我們要先計算最後一層的大小,我們知道輸入的大小是3x32x32的圖像,在經過了第一層CNN之後in_channels = 3 會變成out_channels = 6,那32x32會變成什麼呢?這邊我們就需要套用到CNN參數計算的方式(長或寬 + 2*(padding) - 捲積核) / 步長 + 1,我們將第一層的數據套用到公式裡面(32 + 2*0 - 5) / 1 + 1 = 28(padding預設是0),所以經過第一層後我們的矩陣大小會變成6x28x28,在將矩陣放入池化層中(2x2)得到28/2=14,以此類推。最後會得到16x5x5的結果。
(3*32*32)捲積層1->(6*28*28)池化層->(6*14*14)捲積層2->(16*10*10)池化層->(16*5*5)全連接層(輸出10)
計算完之後就可以設定全連接層的參數
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
#最後輸出要為10(10分類)
self.fc3 = nn.Linear(84, 10)
這樣就建立好神經網路的架構了
def __init__(self):
super().__init__()
#捲積層1
self.conv1 = nn.Conv2d(3, 6, 5)
#捲積層2
self.conv2 = nn.Conv2d(6, 16, 5)
#池化層
self.pool = nn.MaxPool2d(2, 2)
#全連接層
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
接下來要定義這些神經網路的使用方式(攤平資料、激勵函數等計算)
def forward(self, x):
#第一層使用激勵函數relu計算CNN神經網路1後丟給池化層 input(3,32,32) output(6,14,14)
x = self.pool(F.relu(self.conv1(x)))
#第二層使用激勵函數relu計算CNN神經網路2後丟給池化層 input(6,14,14) output(16,5,5)
x = self.pool(F.relu(self.conv2(x)))
#將資料攤平
x = x.view(x.size(0),-1)
#放入全連接層
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
可以看到在pytorch建立神經網路的方式明顯比keras複雜很多,在keras中只需要定義輸入與激勵函數就能輕鬆建立神經網路,而pytorch卻需要計算每層的輸入與輸出,並且還要定義使用的方法,但也因為這樣子的操作更加的自由,使我們能夠做到keras無法做到的事情。
訓練神經網路
終於來到今天的最後一步了,架構好神經網路後當然是要訓練它囉,先來看一下最基本的範例。
for data,label in dataloader:
#將訓練資料放入model裡面做預測
outputs = model(data)
#通過預測結果與label運算損失值
loss = criterion(outputs, label)
#梯度歸0
optimizer.zero_grad()
#反向傳播每個梯度的損失值
loss.backward()
#更新損失值
optimizer.step()
#剛剛建立好的神經網路
model = CNN()
#定義 Loss function
criterion = nn.CrossEntropyLoss()
#定義優化器(模型參數,學習率)
optimizer = optim.adam(model.parameters(), lr=0.001)
這邊有幾個比較重要的資訊optimizer.zero_grad()、loss.backward()、optimizer.step(),
我們知道在深度學習中需要找對最低的梯度,而我們希望每一次訓練的結果是單獨計算的,所以在訓練時常常會看到optimizer.zero_grad()來將梯度初始化,你可能會問pytorch怎麼不直接初始化呢?在訓練神經網路時,有時候希望能持續累積梯度,並通過條件控制梯度的初始化時機,這時如果pytorch把這功能寫死,那可能會導致無法得到預期的效果或是無法訓練神經網路。
loss.backward()、optimizer.step()的概念就比較簡單了,通過設定的loss function做反向傳播(Backpropagation)計算梯度後,通過optimizer.step()將計算出來的loss值交給optimizer做運算,使loss能通過優化器更快速的下降。
接下來為了讓我們知道訓練還需要多久,就可以在剛剛的程式中加入tqdm將進度條顯示出來
#先宣告tqdm的資料
train = tqdm(train_loader)
#更改剛剛的for迴圈
for cnt,(data,label) in enumerate(train, 1):
#訓練
...
#顯示放在前面的文字(通常會放這是第幾次的epoch)
train.set_description(str)
#顯示放在後面的資料(通常會是loss與acc)
# train.set_postfix(dict)
我們也可以在訓練當中切換訓練模式與測試模式。
#訓練模式
model.train()
#測試模式
model.eval()
最後把acc與loss等的計算都加入到程式當中
epochs = 10
#訓練幾次
for epoch in range(epochs):
#訓練資料、loss、準確率
train_loss = 0
train_acc = 0
train = tqdm(train_loader)
#切換成訓練模式
model.train()
#開始訓練
for cnt,(data,label) in enumerate(train, 1):
#將資料放入GPU
data,label = data.cuda() ,label.cuda()
#模型預測
outputs = model(data)
#計算loss
loss = criterion(outputs, label)
#查看模型預測的結果
_,predict_label = torch.max(outputs, 1)
#梯度歸0
optimizer.zero_grad()
#反向傳播後傳給optimizer
loss.backward()
optimizer.step()
#計算當次epoch的loss值
train_loss += loss.item()
#計算當次epoch的acc
train_acc += (predict_label==label).sum()
#顯示
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss':float(train_loss)/cnt,'acc': float(train_acc)/cnt})
#切換測試模式
model.eval()
#測試資料、acc
test = tqdm(test_loader)
test_acc = 0
for cnt,(data,label) in enumerate(test, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
_,predict_label = torch.max(outputs, 1)
test_acc += (predict_label==label).sum()
test.set_description(f'test Epoch {epoch}')
test.set_postfix({'acc': float(test_acc)/cnt})
這樣就完成一支pytorch的訓練程式了~
完整程式碼
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
import numpy as np
from cv2 import imread
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
class CRFAR10(Dataset):
def __init__(self, path, transform):
self.data = []
for label in os.listdir(path):
for pic in os.listdir(path + '/' + label):
cv_pic = imread(f'{path}/{label}/{pic}')
self.data.append([cv_pic, int(label)])
def __getitem__(self,index):
datas = transform(self.data[index][0])
labels = torch.tensor(self.data[index][1])
return datas, labels
def __len__(self):
return len(self.data)
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
#(輸入 + 2*(padding) - 捲積核) / 移動 + 1
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(x.size(0),-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def train(train_loader,test_loader, model ,optimizer, criterion):
epochs = 10
for epoch in range(epochs):
train_loss = 0
train_acc = 0
train = tqdm(train_loader)
model.train()
for cnt,(data,label) in enumerate(train, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
loss = criterion(outputs, label)
_,predict_label = torch.max(outputs, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (predict_label==label).sum()
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss':float(train_loss)/cnt,'acc': float(train_acc)/cnt})
model.eval()
test = tqdm(test_loader)
test_acc = 0
for cnt,(data,label) in enumerate(test, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
_,predict_label = torch.max(outputs, 1)
test_acc += (predict_label==label).sum()
test.set_description(f'test Epoch {epoch}')
test.set_postfix({'acc': float(test_acc)/cnt})
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
train_set = CRFAR10(r'pic/train/', transform)
test_set = CRFAR10(r'pic/test/', transform)
train_loader = DataLoader(train_set, batch_size = 128,shuffle = True, num_workers = 0)
test_loader = DataLoader(test_set, batch_size = 128, shuffle = True, num_workers = 0)
model = CNN().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
train(train_loader, test_loader, model,optimizer,criterion)
今天是不是覺得難度突然上升了很多呢?當我們接觸到pytorch時就會發現,資料集需要學會如何使用class存放資料,建立神經網路需要了解網路構造與運算方式,訓練模型要學會如何使用優化器與損失函數找到最合適的梯度,這些都是keras中沒辦法接觸到的。
今天的課程因為有點複雜,有不懂的地方一定要回去看前面的資料,這樣子才能真正瞭解神經網路的構造與實作方式
讓電腦瞭解文字資料 & 使用Pytorch做IMDB影評分析
讓電腦瞭解文字資料
在前幾天的課程中,我們學會如何利用opencv讀取圖片與如何讀取股票資料,像這一些純數值的資料只需要處理矩陣維度後,就能放到神經網路中訓練。如果今天的輸入是文字呢?可能有些人想到了,就是使用在第3天使用到的正規化技術one-hot-encoding。可以將一段文字給予他實際的數字編號後透過one-hot-encoding將資料轉換成機器看得懂的方法。
例如:
#文字
text = I am a student
#給予編號
text_to_int = {I:0, am:1, a:2, student:3}
text = [text_to_int(i) for i in text]
#one-hot-encoding
to_categorical(text)
------------顯示------------
[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]
雖然這種方式電腦會看得懂,但會有兩個問題存在,分別是無法辨別一詞多意與資料量太龐大。
先來看以下的例子:
#![allow(unused)] fn main() { It's so cold, I've caught a cold }
我們可以知道第一個cold代表的是寒冷的意思,而第二個cold卻是感冒的意思。若使用one-hot-encoding會把這兩個轉換成相同的list,這代表兩者文字的意思是相同的,這樣訓練效果自然就會很差了。
再來是資料龐大的問題,一個資料集單中假設含有16000個英文單字,那在訓練時一個單字的矩陣大小就會是(1,16000),假設有100字就是(100,16000),光一個100字的文件就足以讓電腦負荷不了,我們昨天實作的圖片一張只有3x32x32,使用這樣的做法訓練一個檔案的時間,就會是昨天訓練大小的520倍!!
所以為了改善這兩個缺點從而衍生了另一種技術詞嵌入(World Embedding),這項技術是目前在自然語言處理(Natural Language Processing)當中最重要的技術,我們甚至可以說,NLP模型基本上就是建立出一個好的embedding結果,那到底什麼是embedding呢?
embedding其實只是一個降維的技術,我們可以將一個數值轉換成embedding的格式例如:
#文字
text = I am a student
#給予編號
text_to_int = {I:0, am:1, a:2, student:3}
text = [text_to_int(i) for i in text]
#假設embedding輸出是768維我們把I丟入
print(embedding(text[0]).shape)
#丟入 I am
print(embedding(text[0:1]).shape)
------------顯示------------
(1,768)
(2,768)
可以看到不管丟入多少個文字,最後輸出都會是(batch, embedding_size),通過embedding_size設定陣列大小,且矩陣內的每一個數值都是float,這代表將會有幾千萬種可能性能夠表達各種單字。再來就是可以通過神經網路訓練embedding層,這樣就能使相似的字或句排列在一起。
實際上是如何做到的呢?假設神經網路架構是使用LSTM,那就會變成使用左邊的文字去預測右邊的文字,或是右邊的文字預測左邊的文字(雙向),通過神經網路學習大量的資料就可以讓神經網路瞭解下一個機率最高的文字是什麼。
IMDB影評分析
接下來進入今天的重點IMDB影評分析。IMDB資料集是一個50000筆電影評論的文本資料集(25000筆訓練25000測試),我們可以通過神經網路的訓練embedding將偏向正面或負面的文字排列在一起,最後通過全連接層完成我們的分類任務
今天的目錄如下:
- 1.函式庫介紹
- 2.資料前處理與創建資料集
- 3.架構神經網路
- 4.訓練神經網路
函式庫介紹
#深度學習函式庫
import torch
#神經元架構與損失函數
import torch.nn as nn
#優化器
import torch.optim as opt
#激勵函數
import torch.nn.functional as F
#創建資料集
from torch.utils.data import Dataset,DataLoader
#系統相關操作
import os
#正規化表達操作
import re
#array操作
import numpy as np
#進度條
from tqdm import tqdm
#切割資料用
import torch.utils.data as data
#excel相關操作
import pandas as pd
資料前處理與創建資料集
在pytorch當創建資料集的方式都大同小異,只差在該如何對資料做前處理,而在NLP中需要經過相當多的資料轉換才能夠放入神經網路做訓練。
首先IMDB的資料集可以使用函式庫輕鬆的取得,但我非常不推薦這一種方式。
# import datasets
from torchtext.datasets import IMDB
train_iter = IMDB(split='train')
def tokenize(label, line):
return line.split()
tokens = []
for label, line in train_iter:
tokens += tokenize(label, line)
原因也很簡單,在訓練自己的資料集時不可能會用到這一個函式庫,若是在練習的時候都是使用這種方式呼叫檔案,那麼就算學會瞭如何架構神經網路與資料集,卻不瞭解這資料的型態與讀取方式就有點本末倒置了。所以在【day7】解析gz檔案 & 使用Pytorch做CIFAR10影像辨識 (上)時教了一些關於解析檔案的技術,藉由這種方式熟悉資料的組成,使程式能夠貼近實際的應用。
不過今天就不先從官方網站下載後解析gz檔開始了(有興趣的可以看我第7天的教學自行解析看看),而是使用CSV檔的方式(NLP的資料大多是CSV檔案),首先我們先到google dataset下載別人解析好的IMDB的影評資料點我下載這樣就可以來進入文字前處理的部分了。
為了不讓不相關的文字影響到我們訓練的效果,所以我們需要先將文字做前處理,我們在IMDB數據集當中有許多的html tag()、單一英文字母(a、b、c)、標點符號(@#$%),我們可以re正規表達式移除這些文字。
def preprocess_text(self,sentence):
#移除html tag
sentence = re.sub(r'<[^>]+>',' ',sentence)
#刪除標點符號與數字
sentence = re.sub('[^a-zA-Z]', ' ', sentence)
#刪除單個英文單字
sentence = re.sub(r"\s+[a-zA-Z]\s+", ' ', sentence)
#刪除多個空格
sentence = re.sub(r'\s+', ' ', sentence)
#轉小寫
return sentence.lower()
在這邊為了方便處理我們將文字多餘的空格刪除掉,只留下最後一個空格當作split()的參數來切割文字,最後再統一文字把文字都轉成小寫。
在NLP中可以把單字叫做令牌(Token)、解析token的東西叫做令牌解析器(Tokenize),我們需要將token通過tokenize轉換成數字才能放入embedding層作訓練,並且需要固定輸入的大小在NLP中最常做的事情就是截長補短,對短的資料作zero padding,所以我們要寫一個能夠找到所有的token後創立tokenize並找到我們文本的最大長度的function。
def get_token2num_maxlen(self, reviews):
token = []
for review in reviews:
#將每筆資料做資料前處理後通過split(' ')把文字存成list
review = self.preprocess_text(review)
token += review.split(' ')
#利用set()回傳一個聯集,並且通過迴圈創建一個文字對應的dict方便轉換
#list(set(token))是包含著我們文本裡面的所有文字資料的聯集
#這邊要注意開頭是1,0通常會作為padding token
token_to_num = {data:cnt for cnt,data in enumerate(list(set(token)),1)}
num = []
max_len = 0
for review in reviews:
review = self.preprocess_text(review)
tmp = []
for token in review.split(' '):
#將文字轉成數字
tmp.append(token_to_num[token])
#找最大值
if len(tmp) > max_len:
max_len = len(tmp)
num.append(tmp)
return num, max_len
接下來我們把程式組合起來後創建我們的資料集
class IMDB(Dataset):
def __init__(self, data):
self.data = []
#讀取文本資料
reviews = data['review'].tolist()
#讀取label
sentiments = data['sentiment'].tolist()
#將文字轉換成數字並且回傳最大文字上限作為padding的根據
reviews, max_len = self.get_token2num_maxlen(reviews)
#GPU不好的可以直接設定數值
#max_len = 500
for review, sentiment in zip(reviews,sentiments):
#防止文字維度大小不同需要做zero padding
if max_len > len(review):
padding_cnt = max_len - len(review)
review += padding_cnt * [0]
else:
review = review[:max_len]
#判斷label
if sentiment == 'positive':
label = 1
else:
label = 0
#創建訓練資料
self.data.append([review,label])
def __getitem__(self,index):
datas = torch.tensor(self.data[index][0])
labels = torch.tensor(self.data[index][1])
return datas, labels
def __len__(self):
return len(self.data)
def preprocess_text(self,sentence):
#移除html tag
sentence = re.sub(r'<[^>]+>',' ',sentence)
#刪除標點符號與數字
sentence = re.sub('[^a-zA-Z]', ' ', sentence)
#刪除單個英文單字
sentence = re.sub(r"\s+[a-zA-Z]\s+", ' ', sentence)
#刪除多個空格
sentence = re.sub(r'\s+', ' ', sentence)
return sentence.lower()
def get_token2num_maxlen(self, reviews):
token = []
for review in reviews:
#將每筆資料做資料前處理後通過split(' ')把文字存成list
review = self.preprocess_text(review)
token += review.split(' ')
#利用set()回傳一個聯集,並且通過迴圈創建一個文字對應的dict方便轉換
#這邊要注意開頭是1,0通常會作為padding token
token_to_num = {data:cnt for cnt,data in enumerate(list(set(token)),1)}
num = []
max_len = 0
for review in reviews:
review = self.preprocess_text(review)
tmp = []
for token in review.split(' '):
#將文字轉成數字
tmp.append(token_to_num[token])
#找最大值
if len(tmp) > max_len:
max_len = len(tmp)
num.append(tmp)
return num,max_len
架構神經網路
今天神經網路的架構如下
#![allow(unused)] fn main() { embedding->LSTM層->全連接層->全連接層1 }
我們先看到embedding的官方敘述
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, device=None, dtype=None)
在這邊只需要輸入兩個參數num_embeddings與embedding_dim,num_embeddings是前面所創立token的大小,embedding_dim則是我們要的輸出大小,這邊要注意embedding_dim太大會導致無法有效的訓練資料,太小則會導致訊息流失。
self.embedding = nn.Embedding(127561, self.embedding_dim)
接下來要了解LSTM層,如果有不太瞭解的地方建議先觀看【day5】爬蟲與股票預測-長短期記憶模型(Long short-term memory) (上)。
因為LSTM的官方文件有太多東西需要知道了官方文件,
這邊我先整理出來一些參數LSTM(input_size, Hidden_state, Num_layer, Bidirectional=True)接下來我來說明一下這些參數的作用。
Bidirectional:在這一層當中最好理解的參數就是他了,這個參數代表的是神經網路是否為雙向網路,當這個參數為True的時候就能從兩個方向(左到右、右到左)傳遞最後在拼接兩方向的資訊。
Num_layer:在我們第5天的課程內知道LSTM透過H傳遞每一節點的資料,而這個參數就是H的數量,數量的方向非常值觀一個方向為1,兩個方向為2。
Hidden_state:這個參數是指H的大小,若大小太大會影響訓練,太小則會丟失太多資訊
input_size:這個參數在LSTM中是最難理解且最複雜的參數了,我們在第5天提到LSTM每一層的輸入是X與H並通過狀態保存層(C)決定輸出,這在input_size中代表什麼意思呢?這代表我們需要定義X、H、C的維度,因為我們每一個LSTM節點都需要使用到這些,所以input_size在程式中到底長什麼樣子呢?答案就是
((seq_len, batch, input_size), #X
(num_layers * input_size, batch, hidden_size),#H
(num_layers * input_size, batch, hidden_size))#C
在這裡突然一次定義了一大堆的狀態是不是頭都花了呢?現在讓我來把整個架構重新整理一下。
X:首先seq_len就是定義的token大小、batch是資料量大小,input_size則是上層網路的輸出也就是embedding_dim。這跟CNN網路基本上是一樣的道理。 名稱|LSTM | CNN ------------- | ------------- in_channels|seq_len | RGB 資料大小|batch | batch 輸入|上層網路的輸出|上層網路的輸出
H & C:我們知道hidden_state(H)是上一節點的輸出,X是輸入,C是狀態保存層所保留的資訊,這邊快速的定義他們之間的關係。
| 名稱 | 輸入 |
|---|---|
| H | C與X |
| C | H與X |
| X | 上層網路的輸出 |
到這邊我們有沒有發現H與C都需要通過X來計算,所以我們可以知道H與C的輸入,就是X的大小,也就是embedding_dim,而我們的神經是雙向的所以num_layer = 2 ,所以我們會得到輸入大小是2 x embedding_dim。
到這邊是不是瞭解LSTM在幹嘛了,那我們開始架構神經網路吧
def __init__(self, embedding_dim, hidden_size, num_layer):
super().__init__()
#embedding輸出大小
self.embedding_dim = embedding_dim
#hidden_state大小
self.hidden_size = hidden_size
#雙向為2單向為1
self.num_layer = num_layer
#token大小,輸出
self.embedding = nn.Embedding(127561, self.embedding_dim)
#上層輸入大小,hidden state大小,單為1雙為2,單向還是雙向
self.lstm =nn.LSTM(self.embedding_dim, self.hidden_size, self.num_layer, bidirectional = True)
#最後輸出的結果為最後一個狀態的hidden_size * num_layer * 2為最後一個為度長度
self.fc = nn.Linear(hidden_size * self.num_layer * 2, 20)
self.fc1 = nn.Linear(20, 2)
def forward(self, x):
#將文字降維
x = self.embedding(x)
#此時狀態為(batch_size, token大小, embedding_dim)我們需要將他轉成LSTM格式
x = x.permute([1,0,2])
#(token大小,batch_size,embedding_dim)
states, hidden = self.lstm(x, None)#H跟C設定成0
#因為是雙向網路所以需要找到從左到右(最後一筆資料)的狀態與從右到左(第一筆資料)
x = torch.cat((states[0], states[-1]), 1)
#全連接層
x = F.relu(self.fc(x))
x = F.relu(self.fc1(x))
#二分法所以使用sigmoid
x = F.sigmoid(x)
return x
訓練神經網路
終於到這一步了,今天在這步驟完全跟昨天的方式一樣我們直接複製貼上就好
def train(train_loader,test_loader, model ,optimizer, criterion):
epochs = 10
for epoch in range(epochs):
train_loss = 0
train_acc = 0
train = tqdm(train_loader)
model.train()
for cnt,(data,label) in enumerate(train, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
loss = criterion(outputs, label)
_,predict_label = torch.max(outputs, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (predict_label==label).sum()
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss':float(train_loss)/cnt,'acc': float(train_acc)/cnt})
model.eval()
test = tqdm(test_loader)
test_acc = 0
for cnt,(data,label) in enumerate(test, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
_,predict_label = torch.max(outputs, 1)
test_acc += (predict_label==label).sum()
test.set_description(f'test Epoch {epoch}
-------------------------------------------顯示-------------------------------------------
train Epoch 4: 100%|████████████████████████████████████████████| 313/313 [00:18<00:00, 17.03it/s, loss=0.533, acc=95.1]
test Epoch 4: 100%|██████████████████████████████████████████████████████████| 79/79 [00:01<00:00, 73.57it/s, acc=93.2]
完整程式碼
import torch
import torch.nn as nn
import torch.optim as opt
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader
import os
import re
import numpy as np
from tqdm import tqdm
import torch.utils.data as data
import pandas as pd
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
class IMDB(Dataset):
def __init__(self, data, max_len =500):
self.data = []
reviews = data['review'].tolist()
sentiments = data['sentiment'].tolist()
reviews, max_len = self.get_token2num_maxlen(reviews)
max_len = 500
for review, sentiment in zip(reviews,sentiments):
if max_len > len(review):
padding_cnt = max_len - len(review)
review += padding_cnt * [0]
else:
review = review[:max_len]
if sentiment == 'positive':
label = 1
else:
label = 0
self.data.append([review,label])
def __getitem__(self,index):
datas = torch.tensor(self.data[index][0])
labels = torch.tensor(self.data[index][1])
return datas, labels
def __len__(self):
return len(self.data)
def preprocess_text(self,sentence):
#移除html tag
sentence = re.sub(r'<[^>]+>',' ',sentence)
#刪除標點符號與數字
sentence = re.sub('[^a-zA-Z]', ' ', sentence)
#刪除單個英文單字
sentence = re.sub(r"\s+[a-zA-Z]\s+", ' ', sentence)
#刪除多個空格
sentence = re.sub(r'\s+', ' ', sentence)
return sentence.lower()
def get_token2num_maxlen(self, reviews,enable=True):
token = []
for review in reviews:
review = self.preprocess_text(review)
token += review.split(' ')
token_to_num = {data:cnt for cnt,data in enumerate(list(set(token)),1)}
num = []
max_len = 0
for review in reviews:
review = self.preprocess_text(review)
tmp = []
for token in review.split(' '):
tmp.append(token_to_num[token])
if len(tmp) > max_len:
max_len = len(tmp)
num.append(tmp)
return num, max_len
class RNN(nn.Module):
def __init__(self, embedding_dim, hidden_size, num_layer):
super().__init__()
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.num_layer = num_layer
self.embedding = nn.Embedding(127561, self.embedding_dim)
self.lstm =nn.LSTM(self.embedding_dim, self.hidden_size, self.num_layer, bidirectional = True)
self.fc = nn.Linear(hidden_size * 4, 20)
self.fc1 = nn.Linear(20, 2)
def forward(self, x):
x = self.embedding(x)
states, hidden = self.lstm(x.permute([1,0,2]), None)
x = torch.cat((states[0], states[-1]), 1)
x = F.relu(self.fc(x))
x = F.relu(self.fc1(x))
x = F.sigmoid(x)
return x
def train(train_loader,test_loader, model ,optimizer, criterion):
epochs = 10
for epoch in range(epochs):
train_loss = 0
train_acc = 0
train = tqdm(train_loader)
model.train()
for cnt,(data,label) in enumerate(train, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
loss = criterion(outputs, label)
_,predict_label = torch.max(outputs, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (predict_label==label).sum()
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss':float(train_loss)/cnt,'acc': float(train_acc)/cnt})
model.eval()
test = tqdm(test_loader)
test_acc = 0
for cnt,(data,label) in enumerate(test, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
_,predict_label = torch.max(outputs, 1)
test_acc += (predict_label==label).sum()
test.set_description(f'test Epoch {epoch}')
test.set_postfix({'acc': float(test_acc)/cnt})
df = pd.read_csv('IMDB Dataset.csv')
dataset = IMDB(df)
train_set_size = int(len(dataset)*0.8)
test_set_size = len(dataset) - train_set_size
train_set, test_set = data.random_split(dataset, [train_set_size, test_set_size])
train_loader = DataLoader(train_set, batch_size = 128,shuffle = True, num_workers = 0)
test_loader = DataLoader(test_set, batch_size = 128, shuffle = True, num_workers = 0)
model = RNN(embedding_dim = 256, hidden_size = 64, num_layer = 2).cuda()
optimizer = opt.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
train(train_loader, test_loader, model,optimizer,criterion)
這幾天有沒有感覺到資訊量越來越多了,這幾天的pytorch內容盡量反覆閱讀與實作才能夠真正瞭解網路架構,所以我們明天就來學一些簡單東西來休息一下吧
人工智慧、機器學習、深度學習究竟差異在哪裡?
人工智慧、機器學習、深度學習

來源:https://www.logicmonitor.com/blog/troubleshoot-faster-with-anomaly-visualization
在這張圖片我可以知道我們所說的AI其實包含者許許多多的技術,像是機器學習(Machine Learning)就是AI裡面的其中一個分支,在機械學習中深度學習((Deep Learning)又是另一個分支,那麼他們的差異在哪呢?
人工智慧(Artificial Intelligence)
在這邊AI的定義是人製造出來的機器所能表現出來的智慧都能夠稱之為AI,那該怎麼知道程式有沒有智慧呢?在1950年,圖靈提出了一個叫做圖靈測試(Turing test)實驗,這個實驗的內容非常的簡單,如果一個人(A)詢問這個機器人問題,但回答方一個是由真人(B),另一個則是電腦(C),並經過多輪的實驗,看A能不能每次都正確判斷B與C,只要A沒辦法分辨出來,那我們就可以說C是一種AI技術。
那撇除掉深度學習與機器學習這裡的AI還有什麼技術呢?在這邊比較有名的就是專家系統(Expert System),這項技術的核心其實就是資料庫加上推理機(Inference Engine),通過推理的資料庫中的路線找到最合適的解答。
ex:創建某個疾病的常見回答資料庫,並通過推理找到最合適的答案。
機器學習(Machine Learning)
機器學習是人工智慧的分支之一那麼差別在哪呢?剛剛提到的專家系統需要靠者許多專家建立資料,花費太多人力與時間,而在機器學習的領域中就能改善這項問題,因為機器學習最重要的技術就是讓機器可自主學習。
這裡讓機器學習的方式分成以下4種監督學習(Supervised Learning)、非監督學習(Unsupervised Learning)、半監督學習(Semi-supervised Learning)與強化學習(Reinforcement Learning)。
監督學習(Supervised Learning)
監督式學習的資料集是由輸入資料和人工標註物件出所組成的,通過資料集建立模式(learning model),在觀察完一些先前標記過的訓練範例(輸入資料和人工標註物件出)後,去預測這個模式可能出現的輸入與輸出,在機器學習中常見的有KNN演算法、SVM。
目前這種學習的方式基本用於深度學習的迴歸(Regression)任務與分類(classifier)任務中,像是之前實作的迴歸任務的股票預測,以及分類任務的IMDB影評情感分析、CRIFT10影像辨識、MNIST手寫辨識都是屬於監督學習。
非監督學習(Unsupervised Learning)
非監督學習與監督學習差別在於沒有預期輸出(也就是人工標註的物件),這種學習方式,會透過演算法將自行尋找出資料的規律,在機器學習中經常會用在把資料分群(clustering )上。
而非監督學習在深度學習中在我們的日常生活中就有很多案例了,例如:IG與抖音上的濾鏡、贏得美術比賽的AI繪圖軟體Midjourney、日本推特上引發熱門議題的仿畫繪圖工具Mimic都是屬於非監督是學習訓練出來的結果。
半監督學習(Semi-supervised Learning)
半監督學習的方式比較特殊,他與監督學習很相似,只差在我們資料的label並不是完整的,例如我們的資料集中只有100筆有標註,但卻有1000筆資料,這種訓練方式就會特過100筆的資訊推測並訓練其他900張圖片的結果最常見的技術就是生成任務。
強化學習(Reinforcement learning)
這種學習方式就與先前的三種不同了,這種學習方式會透過與電腦互動的方式不斷的計算,來達到最終設定的目標,簡單來說就是我每做出一個動作前,電腦就會計算出我的下一步分數是最高的,並且通過動態的方式不斷的改變這些分數,像是幾年前引發議題的AlphaGo就是以這種方式訓練出來的。
深度學習
我們剛剛可以看到在機械學習中講到了許多深度學習的內容,因為深度學習是機械學習的分支,所以機械學習中的概念大多能套用至深度學習,而兩者最大的差異就在於是不是能自動找到特徵與神經網路層。
在深度學習中我們只需要設定好各神經網路參數就能通過訓練自動截取特徵,並且通過不同神經網路的演算法找到一個最佳的結果,但機械學習中我們卻需要自行找到特徵,在把這個特徵放入的單一的演算法當中。
結論
今天看完了這些知識有沒有注意到,深度學習只是在AI這領域的一小部分,且我們在日常生活中也能看到這些模型的應用(車牌辨識、google翻譯、人臉辨識、物件檢測...等),而且在AI比賽當中有時取得最佳成績的是機器學習的方式,所以我們明天來看一些機器學習的技術吧。
集成式學習 & 使用xgboost過濾垃圾郵件
集成式學習(Ensemble learning)
集成式學習(Ensemble learning)是一種機器學習的學習方式,這種學習方式是將好幾個監督式學習的模型結合在一起,來獲得比使用單獨學習算法更好的效果。我們可以將它這學習方式分成三類,分別是引導聚集算法(Bagging),提升方法(Boosting),堆疊法(Stacking)。
引導聚集算法(Bagging)
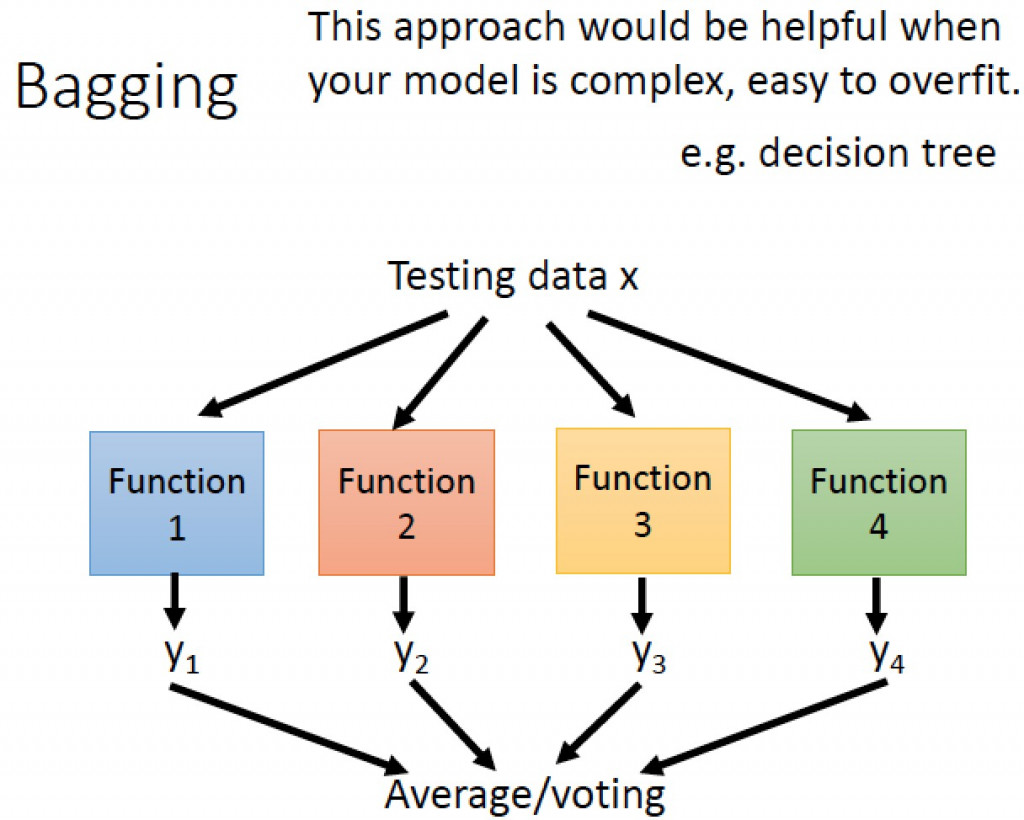
圖片來源:李弘毅老師youtube影片
引導聚集算法(Bagging)模型是基於統計學中的自助法(Bootstrapping)來實現的,這種算法是將資料集隨機抽樣建立類群後,在重新抽取下一個類群,不斷的重複這個過程後,訓練每個類群的結果拿來做整合,如果是迴歸任務,則會做平均。舉一個例子來說:我們從一個球池裡面隨機抽取幾個球並記錄裡面球的特徵,之後在放回球池當中,在繼續重複這樣的動作,最後統計每一個類群裡球的特徵找到最好的結果,常見的例子有隨機森林(Random Forest)與決策樹(Decision Tree)。
提升方法(Boosting)
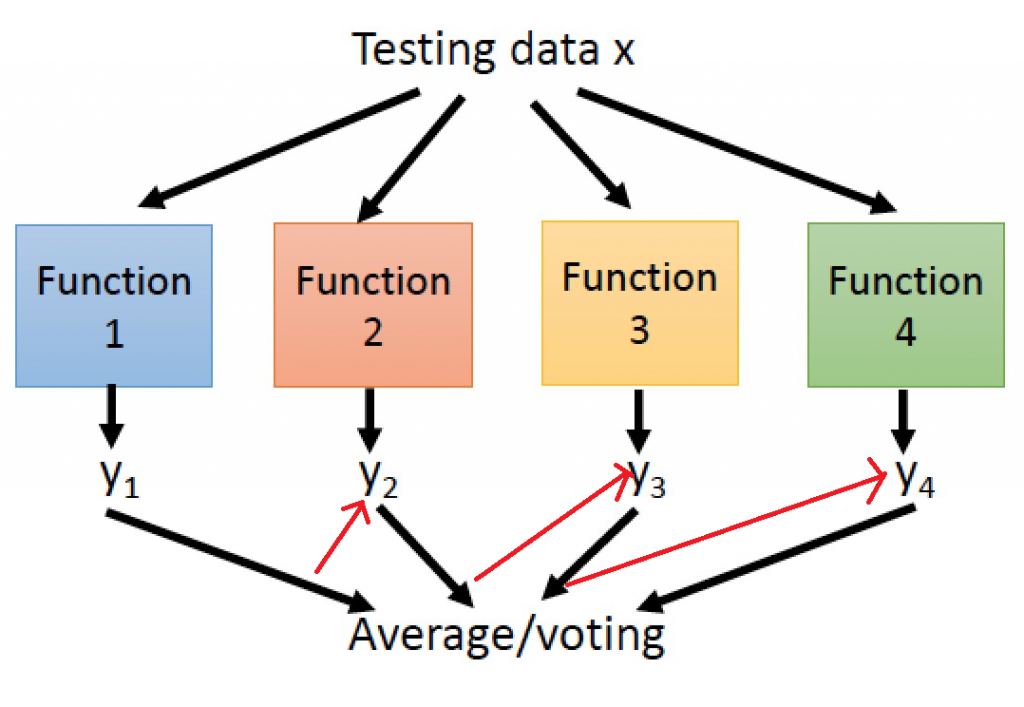 提升方法(Boosting)主要用來減小監督式學習中偏差與方差,一樣會先隨機抽取資料並分類,並通過迭代學習去計算這次模型的誤差(圖片中的紅色箭頭),之後更新每個樣本被抽到的機率,若前一次分類錯誤率愈高,則權重愈大,最終將每次迭代的結果一起計算,常見的例子
提升方法(Boosting)主要用來減小監督式學習中偏差與方差,一樣會先隨機抽取資料並分類,並通過迭代學習去計算這次模型的誤差(圖片中的紅色箭頭),之後更新每個樣本被抽到的機率,若前一次分類錯誤率愈高,則權重愈大,最終將每次迭代的結果一起計算,常見的例子極限梯度下降(Xgboost)、自適應增強(adaboost)。
堆疊法(Stacking)
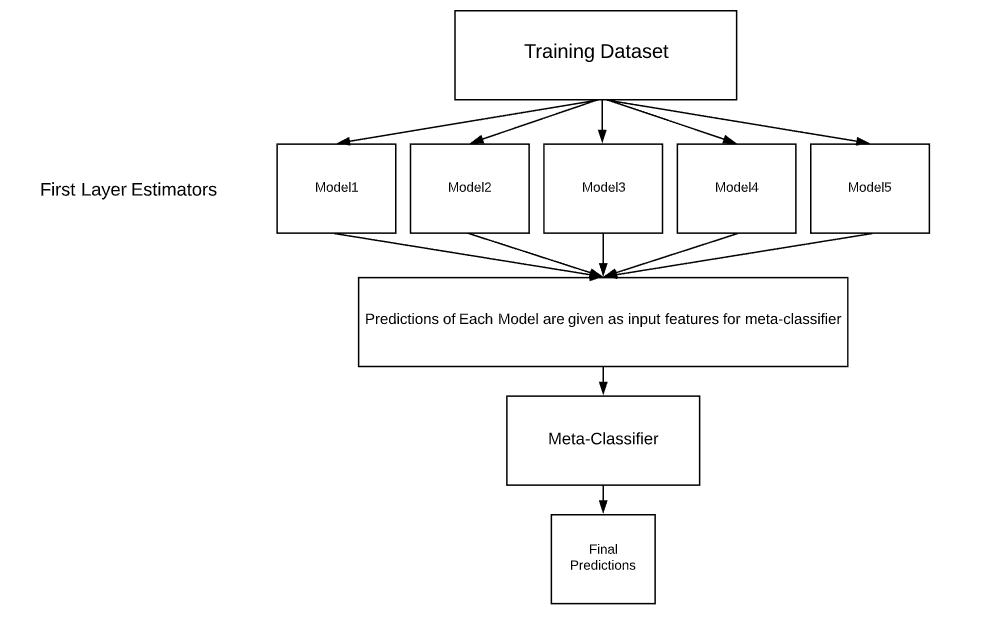
圖片來源:https://www.geeksforgeeks.org/stacking-in-machine-learning-2/
堆疊法(Stacking)與引導聚集算法非常的相似,只差在一個是訓練部分資料,一個是訓練全部的資料,意思就是堆疊法訓練出獨立模型,當作最終模型的輸入特徵,並且訓練這個最終模型,藉由這種方式補足某個模型中缺失的資訊,增強迷型的效果。
過濾垃圾郵件
今天的目錄如下: 1.安裝函式庫與建立基本環境 2.資料前處理 3.訓練模型 4.測試與比較
安裝函式庫與建立基本環境
安裝函式庫
pip install xgboost
引用函式庫
import pandas as pd
import numpy as np
import random
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.tree import DecisionTreeClassifier
導入資料集
今天的資料集是SMSSpamCollection點我下載,這個資料集包含者垃圾郵件與真實有用的文件,今天要做的事就是抽取個文件的特徵與分類。我們先利用pandas讀取資料後在開始做資料前處理吧
data = pd.read_csv('SMSSpamCollection.csv')
資料前處理
還記得我說過機器學習與深度學習差距究竟在哪嗎?沒錯就是特徵抽取(Feature extraction)的部分,所以我們在資料處理時就需要加入這一個步驟,而在文本中有一個非常好用的技術叫做TF-IDF(Term Frequency-Inverse Document Frequency),這個技術分成兩個部分詞頻(Term Frequecny)與逆向文件頻率(Inverse Document Frequency)。
我們來先看一下TF(詞頻)的公式計算
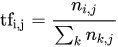
來源:https://zh.m.wikipedia.org/zh-tw/Tf-idf
在維基百科中是這樣解釋這個公式的
 這樣是不是有一點複雜?其實TF的概念就是出現在文本中的次數越多次,代表這個單字越沒有獨特性所以計算起來的分數越低。所以這公式的的意思其實就是
這樣是不是有一點複雜?其實TF的概念就是出現在文本中的次數越多次,代表這個單字越沒有獨特性所以計算起來的分數越低。所以這公式的的意思其實就是文字/文字在"單一文件"出現的次數。
那IDF(逆向文件頻率)是什麼呢?從名稱中可以瞭解他是一種反向的詞頻計算方式,他的概念與TF相反,在全部的文件中文字出現的越少,代表這文字該資料中是越有獨特性的。
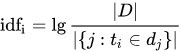
https://zh.m.wikipedia.org/zh-tw/Tf-idf
所以這公式又能解讀成
log10(文字/文字出現在"全部文件"次數)
為了使我們的資料能夠使用TF-IDF這項技術,所以我們需要先分類出垃圾郵件與真實使用到的郵件。
def classfier(data):
real, fake = [], []
for text, label in zip(data['sms'].values, data['class'].values):
if label == 'spam':
#記得將文字轉小寫
fake.append(text.lower())
else:
real.append(text.lower())
return fake,real
再來透過sklearn計算出這兩個文件TF-IDF分數,但在這邊要注意回傳的結果並不會是有順序的排列,所以我們還需要再另外寫一個function做氣泡序法(Bubble Sort),將數值從大到小排列出來方便我們取用。
def getTopScore(data,text):
n = len(data)
while n > 1:
n-=1
for i in range(n):
#若右側資料比左邊大就交換
if data[i] < data[i+1]:
#文字
text[i], text[i+1] = text[i+1], text[i]
#數值
data[i], data[i+1] = data[i+1], data[i]
return text
之後就能用計算TF-IDF分數,並使用剛剛建立的function創建前200分數最高的文字,作為資料的特徵。
def getTfIdfText(fake,real,max_val = 200):
#宣告變數
vectorizer = TfidfVectorizer()
#計算TF-IDF
X = vectorizer.fit_transform([' '.join(fake),' '.join(real)]).toarray()
#計算分數最高的文字
fake_text_top = getTopScore(X[0],vectorizer.get_feature_names())
real_text_top = getTopScore(X[1],vectorizer.get_feature_names())
#回傳指定的最大結果
return fake_text_top[:max_val],real_text_top[:max_val]
接下來我們通過這200個字將我們的原始資料轉換成數字的格式,若是數字有出現我們就設定2,若沒有出現那就設定成1,若超過範圍我們就做zero padding。
def text2num(data, top):
result = []
for i in data:
tmp = []
for j in i.split(' '):
if j in top:
tmp.append(2)
else:
tmp.append(1)
if len(tmp)<80:
tmp = tmp + (80-len(tmp))*[0]
else:
tmp = tmp[:80]
result.append(tmp)
tmp = []
return result
接下來需要將資料拆分成測試數據與訓練數據來驗證程式的準確率,為了讓資料平均分佈我們要先將真實郵件與垃圾郵件分別依照比例分割。
def splitData(data, split_rate=0.8):
cnt = int(len(data)*split_rate)
train_data=data[:cnt]
test_data =data[cnt:]
return train_data,test_data
f_train,f_test = splitData(fake_data)
r_train,r_test = splitData(real_data)
並將分割的數據組合起來並給予他們label,且需要打亂資料以免造成overfitting(前面學到的都是0後面學到都是1) def randomShuffle(x_batch,y_batch,seed=100): random.seed(seed) random.shuffle(x_batch) random.seed(seed) random.shuffle(y_batch)
return x_batch,y_batch
train_data,train_label = randomShuffle(f_train+r_train,[0 for i in range(len(f_train))]+[1 for i in range(len(r_train))]) test_data,test_label = randomShuffle(f_test + r_test,[0 for i in range(len(f_test))]+[1 for i in range(len(r_test))])
這樣就完成資料前處理了
測試與比較
首先我們先使用決策樹、亂數森林與極限梯度下降法這三個機器學習模型訓練。
我們先快速的建立一下訓練的function
def train(train_data,train_label):
#決策樹模型
model_tree = DecisionTreeClassifier(criterion = 'entropy', max_depth=6, random_state=42)
#訓練
model_tree.fit(train_data, train_label)
#預測結果
y_hat_tree = model_tree.predict(train_data)
#亂樹森林模型
model_RF = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
#訓練
model_RF.fit(train_data, train_label)
#預測結果
Y_hat_RF = model_RF.predict(train_data)
#極限梯度下降法模型
model_xgboost = XGBClassifier(n_estimators=100, learning_rate= 0.3)
#訓練
model_xgboost.fit(train_data, train_label)
#預測結果
Y_hat_xg = model_xgboost.predict(train_data)
#找到label大小作為準確率的分母
n=np.size(train_label)
#顯示機率
print('Accuarcy decisionTree: {:.2f}%'.format(sum(np.int_(y_hat_tree==train_label))*100./n))
print('Accuarcy RandomForest: {:.2f}%'.format(sum(np.int_(Y_hat_RF==train_label))*100./n))
print('Accuarcy XgBoost: {:.2f}%'.format(sum(np.int_(predicted==train_label))*100./n))
在這邊可以看到,在機器學習中建立模型的方式非常的簡單,只需要三步驟:宣告、訓練、看結果,就能完成訓練,且速度與深度學習相比快了好幾倍,因為我們只是通過公式的運算,而不是訓練神經網路,那我們來看一下最後訓練的結果。
訓練:
Accuarcy decisionTree: 88.31%
Accuarcy RandomForest: 99.42%
Accuarcy XgBoost: 98.95%
測試:
Accuarcy decisionTree: 88.98%
Accuarcy RandomForest: 99.46%
Accuarcy XgBoost: 99.46%
我們可以看到決策樹的效果相當的不好,最大的原因就是他每次規劃的路徑都是相同的這代表我們使用決策樹,最後的結果一定會overfitting。而亂樹森林則是以決策樹的方式加以改良,使用隨機抽取資料的方式,大幅增進最終的運算結果。今天的重頭戲xgoost可以看到在訓時準確率較低,但測試數據的準確率卻與亂樹森林相同,這是因我們們的資料比較單調以及數量較少的原因,若今天資料量較多xgboost能夠跌代計算出來的結果就會越準確,那差距就會與亂樹森林以及決策樹更大了。
預訓練模型訓練 & 應用- 使用OpenCV製作人臉辨識點名系統 (上)
到這邊我相信你已經有機器學習與深度學習的概念了,所以接下來的課程中我會開始來教一些預訓練模型的用法,而這次要做的就是使用OPENCV辨識人臉並成功點名,而我們今天要做的事情就是辨識臉部並創建自己的資料集。
辨識臉部
今天的目錄如下
- 1.開啟電腦鏡頭並顯示
- 2.下載xml與辨識臉部
- 3.減少電腦資源與可視化
開啟電腦鏡頭並顯示
在開始辨識人臉之前我們需要打開電腦鏡頭,這裡可以使用opencv當中VideoCaptured()開啟鏡頭,但在windows當中卻有一些BUG存在,就是無法每次都成功的開啟,所以我們可以寫一個while迴圈,判斷鏡頭是否開啟,來解決這個問題。
#開啟鏡頭
cap = cv2.VideoCapture(0)
#確保鏡頭完整的開啟
while(not cap.isOpened()):
cap = cv2.VideoCapture(0)
開啟鏡頭後,就能開始讀取資料了,透過cap.read()能讀取目前鏡頭的照片。
#是否有圖片type:bool,圖片本身
ret, frame = cap.read()
但在市面上的人臉辨識系統,都是以影片的樣式來表達,所以我們需要利用肉眼視覺暫留(Persistence of vision)的方式將圖片轉成影片,所以我們要將cap.read()這個function放入到while()當中進行迴圈,最後通過imshow將結果顯示出來,並且能夠使用imwrite來儲存圖片()
cnt = 0
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('live', frame)
cv2.imwrite(f'face/my_face_{cnt}.jpg',frame)
這樣我們就可以取得很多的人臉圖片

但我們觀察這張圖片就會發現,照片中含有太多的不是人臉的資料,這樣在訓練時可能就會使準確率下降,甚至是underfitting,所以這時就需要使用opencv的臉部辨識器,來找到我們的人臉。
下載xml與辨識臉部
首先我們前往opencv的github找到"haarcascade_frontalface_alt2.xml"點我前往
之後點擊紅框處複製文字
最後貼上記事本上並將檔案名稱命名為"haarcascade_frontalface_alt2.xml",這樣我們就有臉部辨識的設定檔了

我們剛剛下載的是程式設定檔,所以還需加入模型本身,在這邊只需要使用CascadeClassifier()就能建立一個臉部辨識器了。
classfier = cv2.CascadeClassifier(cv2.data.haarcascades +"haarcascade_frontalface_alt2.xml")
減少電腦資源與可視化
有了辨識器後我們需要去設定他的參數我們先看個範例
faceRects = classfier.detectMultiScale(gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
首先說明一下這些參數的意思
ScaleFactor:每次搜尋方塊減少的比例
minNeighbors:矩形個數
minSize:檢測對象最小值
這樣是不是還是看不懂?因為opencv中是使用一種叫做蒙地卡羅方法(Monte Carlo method)的方式,這種方法的中心技術就是猜與賭,這種做法就像是捕魚一樣,我們先灑網出去猜這個區域究竟有沒有魚,若是有魚我們就開始縮小魚網的範圍,最後把魚抓上來。
我們來看看在opencv中會使用哪些做法,首先使用較大範圍的方格去辨識臉部,在opencv中是使minNeighbors這個參數是來辨別相鄰方格的關聯性,關聯性大於等於這個值時電腦才認為區域內有臉部。若區域內有臉部會透過ScaleFactor數值減少範圍大小,直到指定的最小範圍時minSize時縮小才會停止,而使用這種技術可使減少消耗電腦的資源,畢竟圖像資源是非常吃效能的。
瞭解後我們會知道,圖片會有機會找不到人臉,這時程式正在擴大範圍在偵測,此時會消耗非常多的效能,若是在繼續執行動作可能會導致程式出現意外狀況,所以我們需要設定成當有人臉時才繼續接續的動作。
if faceRects:
當條件達成後代表faceRects裡面含有4個數值分別是x軸座標、y軸座標、寬、長,但可能不只讀到一張人臉,所以需要將程式寫在一個for迴圈中找到所有的人臉數值
for (x, y, w, h) in faceRects:
有了這些數值後我們能通過縮小圖片的範圍,並且畫出一個方形包住我們的人臉,代表程式有偵測到
face = frame[y - 10: y + h + 10, x - 10: x + w + 10]
#圖片,座標,長寬,線條顏色,粗度
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), (0,255,0), 2)
為了增加辨識臉部的準確率先將資料轉換成灰階,這可以使小區域的亮度降低防止單一像素過亮的問題,這種做法並不會改變圖片整體的亮度。
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
我們的程式是寫在一個while迴圈中,所以我們要設定一個跳脫條件,我們可以設定成按Q件離開,並且在離開後需要將視窗與鏡頭都一起關閉。
#按Q跳脫迴圈
if cv2.waitKey(1) == ord('q'):
break
#釋放鏡頭
cap.release()
#關閉視窗
cv2.destroyAllWindows()
最後將程式碼組合在一起就完成取得人臉的方式了
完整程式碼
import cv2
cap = cv2.VideoCapture(0)
while(not cap.isOpened()):
cap = cv2.VideoCapture(0)
cnt = 0
classfier = cv2.CascadeClassifier(cv2.data.haarcascades +"haarcascade_frontalface_alt2.xml")
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faceRects = classfier.detectMultiScale(gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0:
for (x, y, w, h) in faceRects:
face = frame[y - 10: y + h + 10, x - 10: x + w + 10]
c
cnt+=1
cv2.imwrite(f'face/my_face_{cnt}.jpg',face)
if cv2.waitKey(1) == ord('q'):
break
cv2.imshow('live', frame)
cap.release()
cv2.destroyAllWindows()
今天的難度是不是變成比較低了呢?因為今天只是在玩一些opencv的套件,明天的難度會開始提升,因為會來玩一下預訓練模型VGG-16
預訓練模型訓練 & 應用- 使用OpenCV製作人臉辨識點名系統 (下)
還記得我們在使用LSTM或是CNN時都需要創建Data與Label並花費一些時間訓練我們的神經網路嗎?我相信在訓練神經網路時是會花費相當多的時間的,我們在訓練的這些資料可能只有5萬筆訓練完的時間大約1分鐘左右就可以完成。但如果我們所訓練的資料是幾百萬或幾千萬呢?那就算是3090ti訓練一個月都還跑不完,若我們很需要這一些的訓練的結果呢?那就只能去找看看有沒有人有相似的模型來修改,所以這時就有遷移學習(Transfer Learning)這種方式來幫助我們。
遷移式學習(Transfer Learning)
首先我們知道,在訓練神經網路後,網路會學習到許多特徵資料與權重,以CNN神經網路為例,在捲積層與池化層會做特徵強化與擷取特徵的動作,最後通過全連接層計算結果。而在遷移式學習中就是將擷取特徵(進入全連接層前的資料)提取出來,並且通過我們任務的需求,去微調這些特徵的權重也就是用前一個模型的特徵,來找到我們想要的結果。
預訓練模型
知道的遷移式學習的概念,是不是知道預訓練模型的名稱由來了?因為我們這個模型就被訓練過了,我們只需將這模型的特徵運用在我們的某層神經網路之內,或是對原始模型進行微調就能的到一個很好的結果。目前的預訓練模型分為兩種方式,分別是基於特徵(feature-based)與微調(fine-tuen)的方法。
基於特徵(feature-based):這一種做法是使用一個經過大數據訓練過的模型結果(通常是特徵值),套入到模型的其中一層,並且通過自己的資料集,不斷的調整與學習資料。舉個例子在我們【day9】 讓電腦瞭解文字資料 & 使用Pytorch做IMDB影評分析中,使用到的神經網路embedding,在第9天我們是通過LSTM的文字前後關係,去更新embedding中的數值變化,若使用基於特徵的預訓練模型像是ELMO、Word2Vec,就能夠直接在embedding層當中導入這些已經被訓練好的特徵,這樣的效果就會比從0開始好非常的多。
微調(fine-tuen):這種方法會保留原始模型,讓我們新增資料去調整這個原始模型各階層之間的權重,之後通過一個額外的接口(fine-tunr中主要是訓練這個接口),來實現各種不同的下游任務,使一個模型來完成多種不同的結果,例如:BERT可以做問答機器人,也可以做分類器,也就是因為這種特性,下游任務的寫法也成為了另一個議題。
1.實作辨識人臉
今天的目錄如下:
- 1.VGG-16介紹
- 2.下載資料與資料前處理
- 3.創建資料集
- 4.使用VGG-16模型並訓練
- 5.VGG-16完整程式碼
VGG-16簡介
在開始寫程式之前我們需要了解一下VGG-16內部構造。VGG-16最重要的概念就是使用大量的3x3捲積核來實現大捲積核的資料,例如:假設輸入為8、步長為1的CNN神經網路,5x5的捲積核最終輸出會是4(輸入-捲積核大小 + 1),而3x3的捲積核,使用兩次輸出結果也會是4(第一次8-3+1=6 第二次6-3+1=4),這代表一個5x5的捲積核可以通過2個3x3的捲積核來表達,這種做法的好處,就是在3x3中的捲積核保留了更多圖像的特徵值。

來源:http://deanhan.com/2018/07/26/vgg16/
可以看到在VGG16的架構圖中其實就是一個CNN的神經網路,但通過大量的數據與拆解捲積核的方式卻能大幅提升準確率
下載資料與資料前處理
瞭解到VGG16的構造後,就可以開始使用Pytorch實作了,首先為了辨識這個人到底是誰,我們還需要一筆資料,也就是別人的人臉資料,來區分我們需要點名的對象,我們可以先到kaggle下載這些人臉的資料點我下載。
之後我們創建以下的資料夾與檔案,並且開啟jupyter notebook來開始今天的實作 code └─data(放資料的資料夾) | ├─myface(放自己臉部的資料夾) | └─other(放剛剛下載的圖片的資料夾) └─VGG-16.ipynb(jupyter notebook的檔案)
import今天會用到的函式庫
import torch
import torch.nn as nn
import torch.optim as opt
import torch.nn.functional as F
import torchvision as tv
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader,random_split
show = tv.transforms.ToPILImage()
接下來使用transforms.Compose()來創建要對圖片的操作,在這邊最重要的事情是我們需要將圖片縮放到224x224,因為這是VGG-16的輸入格式
transform = tv.transforms.Compose([
#轉成tensor格式
tv.transforms.ToTensor(),
#將短邊等比放大成224
tv.transforms.Resize(224),
#裁切多於的部分
tv.transforms.CenterCrop(224),
#正規化
tv.transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
這樣就能完成資料前處理了
創建資料集
還記得前幾天最麻煩的事情嗎?就是使用class的方式建立dataset,在pytorch當中建立"圖片"的dataset其實很容易搞定,只需要將圖片放入到不同資料夾當中,就可以用tv.datasets.ImageFolder()一次性的將資料變成dataset,還能指定參數,去完成前處理的工作,這樣子做是不是能夠省下許多時間呢。
data = tv.datasets.ImageFolder('../data/',transform = transform)
train_num = int(len(data)*0.7)
test_num =len(data)-train_num
train_set, test_set = torch.utils.data.random_split(data, [train_num,test_num])
batch_size = 4
train_loader = DataLoader(train_set, batch_size = batch_size,shuffle = True, num_workers = 0)
test_loader = DataLoader(test_set, batch_size = batch_size, shuffle = True, num_workers = 0)
我們的資料變成dataset後會依照資料夾名稱排列來當作label,像是我們我們的兩個資料夾myface與other可以知道按照英文排序m比o還要早出現,所以myface的label就會為0,other就會是1,我們可以觀察一下的資料是否如同我們所想並且顯示照片。
#label轉換成名稱
classes = {0:'myface', 1:'other'}
#返回處理過後的圖片與label
img, label = data[2000]
顯示名稱
print(classes[label])
#還原正規化結果並顯示
show(img*0.5+0.5)

使用VGG-16模型並訓練
pytorch中可以通過tv.models.vgg16函式,下載VGG-16的預訓練模型,之後只需要設定好優化器與損失函數就能開始訓練了。
model = tv.models.vgg16(pretrained=True).cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = opt.Adam(model.parameters(), lr=0.0001)
當我們不知道模型的架構時,可以使用print()來查看模型的疊法與詳細參數
print(model)
----------------顯示----------
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
最後訓練的部分基本上不會改變,所以我們直接把前幾天的程式抄過來,就能夠正常訓練了
epochs = 10
for epoch in range(epochs):
train_loss = 0
train_acc = 0
train = tqdm(train_loader)
model.train()
for cnt,(data,label) in enumerate(train, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
loss = criterion(outputs, label)
_,predict_label = torch.max(outputs, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (predict_label==label).sum()
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss':float(train_loss)/cnt,'acc': float(train_acc)/(cnt*batch_size)*100})
model.eval()
test = tqdm(test_loader)
test_acc = 0
for cnt,(data,label) in enumerate(test, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
_,predict_label = torch.max(outputs, 1)
test_acc += (predict_label==label).sum()
test.set_description(f'test Epoch {epoch}')
test.set_postfix({'acc': float(test_acc)/cnt})
可以看到結果第一次訓練準確率就高達了96.8%,這是一個非常好的效果。
train Epoch 0: 100%|███████████████████████████████████████████| 264/264 [01:54<00:00, 2.30it/s, loss=0.527, acc=92.8]
test Epoch 0: 100%|████████████████████████████████████████████████████████| 113/113 [00:16<00:00, 6.92it/s, acc=96.8]
訓練好了就能將我們數據集的權重保存下來之後連結上opencv了
torch.save(model.state_dict(), 'model_weights.pth')
訓練完整程式碼
import torch
import torch.nn as nn
import torch.optim as opt
import torch.nn.functional as F
import torchvision as tv
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader,random_split
from tqdm import tqdm
show = tv.transforms.ToPILImage()
transform = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Resize(224),
tv.transforms.CenterCrop(224),
tv.transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
data = tv.datasets.ImageFolder('data/',transform = transform)
train_num = int(len(data)*0.7)
test_num =len(data)-train_num
train_set, test_set = torch.utils.data.random_split(data, [train_num,test_num])
batch_size = 16
train_loader = DataLoader(train_set, batch_size = batch_size,shuffle = True, num_workers = 0)
test_loader = DataLoader(test_set, batch_size = batch_size, shuffle = True, num_workers = 0)
model = tv.models.vgg16(pretrained=True).cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = opt.Adam(model.parameters())
epochs = 1
for epoch in range(epochs):
train_loss = 0
train_acc = 0
train = tqdm(train_loader)
model.train()
for cnt,(data,label) in enumerate(train, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
loss = criterion(outputs, label)
_,predict_label = torch.max(outputs, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (predict_label==label).sum()
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss':float(train_loss)/cnt,'acc': float(train_acc)/(cnt*batch_size)*100})
model.eval()
test = tqdm(test_loader)
test_acc = 0
for cnt,(data,label) in enumerate(test, 1):
data,label = data.cuda() ,label.cuda()
outputs = model(data)
_,predict_label = torch.max(outputs, 1)
test_acc += (predict_label==label).sum()
test.set_description(f'test Epoch {epoch}')
test.set_postfix({'acc': float(test_acc)/(cnt*batch_size)*100})
torch.save(model.state_dict(), 'model_weights.pth')
是不是覺得少了很多pytorch的程式碼,因為我這次使用了快速創立資料的方式與預訓練模型,減少了建立dataset與創建model的步驟。接下來我們把model放入到opencv中吧。
2.人臉辨識點名系統
我們使用了opencv來找到我們影像中的臉部,也使用了VGG-16預訓練模型來增加預測人臉的效果,那是時候將這兩個技術結合在一起了。
- 1.建立初始環境
- 2.將模型加入鏡頭並顯示結果
- 3.VGG-16完整程式碼
建立初始環境
我們一樣先從導入函式庫開始
import torchvision as tv
import pandas as pd
import torch
import datetime
import cv2
接下來把把模型、權重、點名錶、臉部辨識器...等資料先載入進系統。
#需要辨識的人名(按照名稱排列)
name = ['myface','other']
#導入VGG-16模型
model = tv.models.vgg16(pretrained=True).eval()
#讀取訓練好的權重
model.load_state_dict(torch.load('model_weights.pth'))
#利用年月日創建資料
excel_path = 'attend/' + datetime.datetime.now().strftime('%Y-%m-%d') + '.csv'
try:
df = pd.read_csv(excel_path, index_col="ID")
except:
df = pd.DataFrame([[i,'未簽到'] for i in name],columns=['ID', '簽到日期'])
df.to_csv(excel_path, encoding='utf_8_sig', index=False)
df = pd.read_csv(excel_path, index_col="ID")
#圖像正規化操作
transform = tv.transforms.Compose([
tv.transforms.ToTensor(),
tv.transforms.Resize(224),
tv.transforms.CenterCrop(224),
tv.transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
臉部辨識器
classfier = cv2.CascadeClassifier(cv2.data.haarcascades +"haarcascade_frontalface_alt2.xml")
將模型加入鏡頭並顯示結果
在訓練時怎麼處理圖片,實際使用就需要用相同的方式,但因為圖片的維度是(3,224,224),訓練時卻是使用(圖片數量,3,224,224),所以需要再加入一個維度在第0維來解決這個問題。
face = transform(face)
#新增維度並預測
result = model(face.unsqueeze(0))
之後需要判斷這個人是否簽到完畢,如果有就不用再重新刷新時間了。最後我們在把使用者的ID放在畫面上
faceID = name[int(faceID[0])]
if df.loc[faceID]['簽到日期']=='未簽到':
df.loc[faceID]['簽到日期'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
df.to_csv(excel_path,encoding='utf_8_sig')
cv2.putText(frame,faceID ,(x - 30, y - 30),cv2.FONT_HERSHEY_SIMPLEX,0.5,(255,0,255),2)
一套人臉辨識點名系統,通常會將攝影機放置在一個固定的地方,並且需全天運轉,所以人臉辨識點名系統需要一個可以依照年月日不斷的創建excel的判斷式。
system_time = datetime.datetime.now().strftime('%H:%M:%S')
if system_time =='00:00:00':
excel_path = 'attend/' + datetime.datetime.now().strftime('%Y-%m-%d') + '.csv'
df = pd.DataFrame([[i,'未簽到'] for i in name],columns=['ID', '簽到日期'])
df.to_csv(excel_path, encoding='utf_8_sig', index=False)
df = pd.read_csv(excel_path)
最後我們把昨天的程式與今天的部分組合起來就能以下的效果

VGG-16版本完整程式碼
import torchvision as tv
import pandas as pd
import torch
import datetime
import cv2
name = ['myface','other']
model = tv.models.vgg16(pretrained=True).eval()
model.load_state_dict(torch.load('model_weights.pth'))
excel_path = 'attend/' + datetime.datetime.now().strftime('%Y-%m-%d') + '.csv'
transform = tv.transforms.Compose([
tv.transforms.ToTensor(),
tv.transforms.Resize(224),
tv.transforms.CenterCrop(224),
tv.transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
try:
df = pd.read_csv(excel_path, index_col="ID")
except:
df = pd.DataFrame([[i,'未簽到'] for i in name],columns=['ID', '簽到日期'])
df.to_csv(excel_path, encoding='utf_8_sig', index=False)
df = pd.read_csv(excel_path, index_col="ID")
classfier = cv2.CascadeClassifier(cv2.data.haarcascades +"haarcascade_frontalface_alt2.xml")
cap = cv2.VideoCapture(0)
while(not cap.isOpened()):
cap = cv2.VideoCapture(0)
cnt = 0
classfier = cv2.CascadeClassifier(cv2.data.haarcascades +"haarcascade_frontalface_alt2.xml")
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faceRects = classfier.detectMultiScale(gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0:
for (x, y, w, h) in faceRects:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), (0,255,0), 2)
face = frame[y - 10: y + h + 10, x - 10: x + w + 10]
face = transform(face)
result = model(face.unsqueeze(0))
_,faceID = torch.max(result,1)
faceID = name[int(faceID[0])]
cv2.putText(frame,faceID ,(x - 30, y - 30),cv2.FONT_HERSHEY_SIMPLEX,0.5,(255,0,255),2)
if df.loc[faceID]['簽到日期']=='未簽到':
df.loc[faceID]['簽到日期'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
df.to_csv(excel_path,encoding='utf_8_sig')
if cv2.waitKey(1) == ord('q'):
break
system_time = datetime.datetime.now().strftime('%H:%M:%S')
if system_time =='00:00:00':
excel_path = 'attend/' + datetime.datetime.now().strftime('%Y-%m-%d') + '.csv'
df = pd.DataFrame([[i,'未簽到'] for i in name],columns=['ID', '簽到日期'])
df.to_csv(excel_path, encoding='utf_8_sig', index=False)
df = pd.read_csv(excel_path, index_col="ID")
cv2.imshow('live', frame)
cap.release()
cv2.destroyAllWindows()
後話:更好的辨識方法Googl FaceNet
我們在使用VGG16的時候,新增或移除資料時都必須重新fine-tune模型,若有人離職或入職就須重新訓練程式,這樣子是很麻煩的事情,所以這時候就有方法叫做Triplet Loss,這一種loss function是將圖片的特徵映射到歐式距離中,選取特徵最不相像的圖片與最像的圖片同時進行特徵訓練來改進模型,這能夠使我們只需使用一張照片來創建臉部資料庫,不過我就不多講解這技術的應用了,有興趣的可以到我的git專案中看到Google的人臉辨識寫法點我
預測Hololive七期生的樣貌-生成式對抗網路(Generative Adversarial Network)(上)
生成式對抗網路(Generative Adversarial Network)
GAN是一種使用深度學習的模型,GAN在訓練中所做的事情非常簡單,就是利用判別器(Discriminator)來判別生成器(Generator)所創建的圖片,我們舉一個簡單的例子來說明。
假設今天有一個手藝不好卻想要製作假抄(圖片)的人A(生成器),與一個負責抓捕他的警察B(判別器),那最一開始的結果肯定是A一直被B抓到,可是每次A都在被抓的時候能學到一些經驗,並更換一些方法,於是B開始越來越分辨不出來A所製作出來的鈔票是真還是假的,甚至到最後完全分辨不出來,那麼A所製作的鈔票就是一個完美的結果(生成圖片)
簡單來說GAN的概念就是道高一尺,魔高一丈,利用這種方是我們可以產生一些非常厲害的圖像,換臉、自動修圖、畫風轉移,AI畫畫與許許多多的IG抖音濾鏡,都是一種GAN技術在生活中能看見的技術。
資料蒐集
還記得我們在【day5】爬蟲與股票預測-長短期記憶模型(Long short-term memory) (上)時介紹的爬蟲嗎?今天我們要使用的就是較困難的requests。
- 1.AJAX介紹
- 2.requests分析pixiv網站
- 3.建立瀏覽器環境
- 4.迴圈取得網站資料
- 5.整理資料並存檔
AJAX(Asynchronous JavaScript and XML)介紹
在傳統的網頁中,我們每次向伺服器請求資料時,伺服器會接收並處理傳來的請求,然後送回傳一個結果,但這個做法浪費了許多資源,因為請求與迴傳所看到的網站資訊大致上都相同,每次的請求都需要與伺服器之間做溝通,這會導致伺服器需要處理大量的資訊,導致使用者的網站常常卡住。而AJAX這個技術能夠只將必要的資訊送出,並回傳必要的資料,使我們只接收少量的資源達成相同的效果,那我們在網站中會看到那些AJAX的技術呢?我相信許多人每天都會用到只是不知道而已,這邊我舉幾個例子:youtube的影片清單網下滾動會更新,IG往下滾動會刷新資料,YT影片結束後會自動轉跳。這種在網站上發送請求後更改一小部分的技術基本上都是使用AJAX來達成的。
requests分析pixiv網站
首先我們為了要預測hololive的未來成員,可以使用到現有成員圖片來推測未來的風格,但官方的圖片又非常的少,於是我將目標放在二創的圖片上,也就是其他繪師的創作。
我們先前往pixiv搜尋hololive,這時候可以看到這個網址
https://www.pixiv.net/tags/hololive
但當我們對這個網站發送請求時,會發現找不到想要的資料,pixiv中圖片都是動態請求的資料,所以我們只能取得一些靜態的資料
r = requests.get(url)
那該怎麼取得動態的資料呢?我們需要去偽造一個AJAX的請求方式
首先我們先按下F12到NetWork的地方

接下來在pixiv中點擊插畫

這時候就會看到NetWork中多出了許多資料,這些資料就是瀏覽器對網站使用的AJAX請求的方式
所以我們只需要找到網站是使用了哪一個方式,來顯示我們看到的頁面,這樣就能找到我們要的資料。我們可以考慮網站動作的優先順序,想一下如果是要請求資料,那這個動作會放在哪裡?當然是請求的前幾筆!所以要找到的請求動作應該會靠在蠻前面的地方,我們可以點擊到paylod的地方觀察這些資料。
 這時候會看到我們關鍵字"hololive",並且在其他的請求中沒有這個字,那就大致上確定是這個網址了
這時候會看到我們關鍵字"hololive",並且在其他的請求中沒有這個字,那就大致上確定是這個網址了
之後將頁面切換到headers來取得AJAX的URL,與請求的cookies(若沒有隻能請求10頁)

在網址中可以看到幾個參數word、order、mode、s_mode、type、lang,在這邊我只看得懂word、type、lang這三個參數,所以我決定去找到其他標籤與分類的網址
https://www.pixiv.net/ajax/search/illustrations/hololive?word=hololive&order=date_d&mode=all&p=1&s_mode=s_tag_full&type=illust_and_ugoira&lang=zh_tw
https://www.pixiv.net/ajax/search/manga/ONEPIECE?word=ONEPIECE&order=date_d&mode=all&p=1&s_mode=s_tag_full&type=manga&lang=zh_tw
查看到變動的地方我們可以知道這個網址的參數涵義如下,接下來就能通過網址來操作了。
https://www.pixiv.net/ajax/search/{類型}/{搜尋名稱}?word={搜尋名稱}&order=date_d&mode=all&p={頁數}&s_mode=s_tag_full&type=illust_and_ugoira&lang={語系}
我們來看看我們用requests.get(AJAX_url)的結果,並通過JSON格式化工具來查看一下結構
可以看到作品的名稱、圖片網址、ID、上傳時間都在body -> illust的data裡面,所以我們只需要利用pythno保留這部分的資訊即可
datas = json.loads(r.text)["body"]["illust"]["data"]
最後把程式加入迴圈之中這樣就能換頁並獲取資訊了
headers = {'Referer':'https://www.pixiv.net/'}
#初始頁
i = 1
while(1):
#AJAX url
holo_url = f'https://www.pixiv.net/ajax/search/illustrations/hololive?word=hololive&order=date_d&mode=all&p={i}&s_mode=s_tag_full&type=illust_and_ugoira&lang=zh_tw'
r = requests.get(holo_url)
# 狀態錯誤跳脫迴圈
if r.status_code != 200:
break
#保留頁面資訊
datas = json.loads(r.text)["body"]["illust"]["data"]
for data in datas:
#找到作品名稱
name = data["alt"]
#找到作品ID
pic_id = data["id"]
保存圖片
我們剛剛取的到的資訊只有作品名稱與ID,那該如何找到圖片呢?首先先點進隨便一個圖片裡面,對圖片按右鍵->新分頁中開啟圖片應該會獲得
https://i.pximg.net/c/250x250_80_a2/img-master/img/2021/10/21/00/00/07/93576944_p0_square1200.jpg
不過怎麼點擊上面的網址都只會顯示403 error,因為我們在發送請求的資料沒有附帶網站的網域。我們知道pixiv的網址是https://www.pixiv.net/ ,但是我們找到的URL卻是https://i.pximg.net/ ,這代表網站需要標頭參數referer,所以我們需要加入pixiv的網址來解決這個問題
headers = {'Referer':'https://www.pixiv.net/'}
request.get(AJAXurl,headers=headers)
接下來為了能加入程式到迴圈之中,我們需要分析網址,我們可以得到以下的結果
https://i.pximg.net/img-master/img/{年}/{月}/{日}/{時}/{分}/{秒}(作品上傳日期)/{作品ID}_p{第幾張圖片}_master1200.jpg
所以我們只要將前面的作品ID與時間加入到我們的第二個網址中就能取得我們圖片的資訊,不過在日期中,包含了許多-、t、+、:等不需要的文字,所以先來處理一下格式問題,之後將網址組合起來就可以了。
def makeUrl(pic_id,creat_time,j):
creat_time=creat_time.replace("-",' ')
creat_time=creat_time.replace("T",' ')
creat_time=creat_time.replace(":",' ')
creat_time=creat_time.replace("+",' ')
creat_time =creat_time.split(' ')
url = f"https://i.pximg.net/img-master/img/{creat_time[0]}/{creat_time[1]}/{creat_time[2]}/{creat_time[3]}/{creat_time[4]}/{creat_time[5]}/{pic_id}_p{j}_master1200.jpg"
return url
接下來我們重新用requests.get得到圖片內容,之後用write的方式就能將圖片保存下來了
url = makeUrl(pic_id, creat_time, j)
r = requests.get(url, headers=headers)
if r.status_code != 200:
break
with open(f'./holo/{pic_id}_{j}.jpg','wb') as f:
f.write(r.content)
最後我們加入一些換頁的動作
完整程式碼
import json
import requests
def makeUrl(pic_id,creat_time,j):
creat_time=creat_time.replace("-",' ')
creat_time=creat_time.replace("T",' ')
creat_time=creat_time.replace(":",' ')
creat_time=creat_time.replace("+",' ')
creat_time =creat_time.split(' ')
url = f"https://i.pximg.net/img-master/img/{creat_time[0]}/{creat_time[1]}/{creat_time[2]}/{creat_time[3]}/{creat_time[4]}/{creat_time[5]}/{pic_id}_p{j}_master1200.jpg"
return url
headers = {'Referer':'https://www.pixiv.net/'}
i = 1
while(1):
holo_url = f'https://www.pixiv.net/ajax/search/illustrations/hololive?word=hololive&order=date_d&mode=all&p={i}&s_mode=s_tag_full&type=illust_and_ugoira&lang=zh_tw'
r = requests.get(holo_url)
if r.status_code != 200:
break
datas = json.loads(r.text)["body"]["illust"]["data"]
for data in datas:
name = data["alt"]
pic_id = data["id"]
creat_time = data["createDate"]
print(name)
j = 0
while(1):
url = makeUrl(pic_id, creat_time, j)
r = requests.get(url, headers=headers)
if r.status_code != 200:
break
with open(f'./holo/{pic_id}_{j}.jpg','wb') as f:
f.write(r.content)
j+=1
i+=1
明天來建構一個gan神經網路,來測試看看效果吧
預測Hololive七期生的樣貌-生成式對抗網路(Generative Adversarial Network)(下)
預測Hololive七期生的樣貌
昨天說到GAN是依靠生成器與辨識器不斷交互訓練的方式來產生圖片,所以我們可以建立一個CNN模型稍加修更一下,就能夠建構一個GAN的神經網路,這種網路的名稱叫做DCGAN(Deep Convolutional Generative Adversarial Networks)。
今天的目錄如下:
- 1.利用opencv辨識臉部
- 2.建立初始環境
- 3.建立判別器(Discriminator)
- 4.建立生成器(Generator)
- 5.訓練模型
利用opencv辨識臉部
由於pixiv中有許多不同的畫風,要讓機器學習沒有統一性的資料,訓練時間就會相當的久,甚至無法訓練成功,所以這次我使用了這篇文章的方式,利用opencv擷取角色的臉部,來減少一些無意義的圖像,這方式與我們在臉部辨識時的作法相同,只需要更換XML檔案。
首先我們先到這裡來下載XML檔案,之後利用OPENCV來建立角色頭像資料集,這邊在前面有說過怎麼做了就直接丟程式碼與註解快速帶過
import cv2
import os
#動漫人臉檢測
cascade = cv2.CascadeClassifier('lbpcascade_animeface.xml')
#找到檔案名稱
for i in os.listdir('data'):
#讀取
image = cv2.imread('data/'+i, cv2.IMREAD_COLOR)
#轉成灰階
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
#使用辨識器
faces = cascade.detectMultiScale(gray,scaleFactor = 1.1,minNeighbors = 5,minSize = (32, 32))
#有東西才執行
if len(faces) > 0:
#檢測不只會有一張人臉
for cnt,(x, y, w, h) in enumerate(faces):
face = image[y: y+h, x:x+w, :]
#我們要輸入的圖片大小(Lento採用的是96*96)
face = cv2.resize(face,(96,96))
#儲存
cv2.imwrite(f"faces/{i}_{cnt}.jpg",face)
建立初始環境
首先我們今天的資料夾結構是這個樣子 main.py ├─holo(資料夾) │ └─train(訓練圖片) ├─model(資料夾) └─pic(輸出影像資料夾)
之後我們開始導入函式庫與建立資料集 導入函式庫
import os
import torchvision as tv
import torch as t
import torch.nn as nn
from tqdm import tqdm
建立資料集
transforms = tv.transforms.Compose([
tv.transforms.Resize(96),
tv.transforms.CenterCrop(96),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = tv.datasets.ImageFolder('holo', transform = transforms)
dataloader = t.utils.data.DataLoader(dataset,batch_size = 128, shuffle=True,num_workers = 0,drop_last=True)
建立判別器(Discriminator)
接下來為了要判別圖片是生成器創作的還是pixiv爬蟲取得的,所以在DGCNN中是使用變種的CNN的方式來辨別圖像,首先先移除全連結層,再來maxpooling層都更換成BatchNorm2d(將圖片歸一化),因為我們不需要強化特徵,而是保有圖片本身,在這邊為了方便創建網路可以使用Sequential來快速創建
ndf = 64
self.main = nn.Sequential(
# 3 x 96 x 96
nn.Conv2d(3, ndf, 5, 3, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
建立生成器(Generator)
建立生成器前,我們要知道資料是有label還是沒有label的,例如我們想生成特定髮色與眼睛顏色,那就必須在建構資料集時定義每個圖像的髮色與眼睛顏色,但這個工程非常的浩大。所以今天只用一種比較簡單的方式,就是直接產生一個隨機的數值當作我們的輸入,這樣子就能夠產生圖片了。
train_noises = t.randn(128, 100, 1, 1).cuda()
在判別器我們是使用CNN將圖片從(batch_size,3,96,96)慢慢的變小變成(batch_size,1, 1, 1),所以我們要在生成器做一個逆向的動作,將一個(batch_size,輸入資料,1,1)放大到(3x96x96)。
剛剛的判別器輸入=3 輸出=64,之後以倍數增長,一直到輸出變成64x8時才會停止。所以生成器的輸入需要從64x8開始,以倍數遞減。
ngf = 64
self.main = nn.Sequential(
nn.ConvTranspose2d(100, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# (ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh()
# 3 x 96 x 96
)
訓練模型
GAN的訓練可以說是最重要的事情,在這裡我們要經過無數的測試,查看最適合這張圖片的loss值(或動態調整),每個人控制的方法可能會不太一樣可能是調整學習率,或是控制訓練次數。但在本質上只有一個,就是控制好生成器與辨識器的Loss值(通常其中一個上升另一個就會下降)。
不過在訓練前我們先定義一下、真圖片標籤、假圖標籤、與我們的輸入(noize)
#訓練生成器與辨識器的label 結果為128個1(希望生成器的結果是1)
fake_labels = t.ones(128).cuda()
#訓練辨識器的label 結果為0
true_labels = t.zeros(128).cuda()
#亂數產生訓練noize
train_noises = t.randn(128, 100, 1, 1).cuda()
接下來定義loss function與優化器、學習率。在這裡使用的loss function是BCELoss,因為BCELoss的輸出會包含所有輸入分類的loss值(保有更多的資料)。
model_G = Generator().cuda()
model_D = Discriminator().cuda()
criterion = t.nn.BCELoss().cuda()
optimizer_g = t.optim.Adam(model_G.parameters(),1e-4)
optimizer_d = t.optim.Adam(model_D.parameters(),1e-5)
之後就來看一下GAN該怎麼定義訓練方式吧,首先是判別器的訓練,需要判別一次真圖片與假圖片當作一個結果,這裡比較需要注意事情,是我們在訓練判別器時,需要使用生成器產生圖片,但在做這個動作時,生成器多做了一次計算,所以我們要避免這個問題,我們可以使用model.eval()或是detach()的方式來解決。
##真實圖片訓練方式
#判別器梯度歸0
optimizer_d.zero_grad()
#將真實圖片交給判別器判斷
output = model_D(real_img)
#利用計算真圖片loss
r_loss_d = criterion(output, true_labels)
#反向傳播
r_loss_d.backward()
#禁止生成器反向傳播(因為我們在訓練的是判別器而不是生成器)
fake_img = model_G(train_noises).detach()
#利用生成器產生的圖片判別結果
output = model_D(fake_img)
#計算假圖片loss
f_loss_d = criterion(output, fake_labels)
#反向傳播
f_loss_d.backward()
#這時才將兩個loss傳給優化器運算
optimizer_d.step()
all_loss_d+=f_loss_d.item()+r_loss_d.item()
生成器的訓練方式就與之前相同了,同樣的需要禁止判別器反向傳播
#生成器梯度歸0
optimizer_g.zero_grad()
#創造假圖片
fake_img = model_G(train_noises)
#交給判別器判別
output = model_D(fake_img)
#計算loss(這裡要判斷是true因為我們希望生成器是生成真的圖片)
loss_g = criterion(output, true_labels)
loss_g.backward()
#傳送給優化器
optimizer_g.step()
all_loss_g+=loss_g.item()
之後我們可以控通過控制 cnt的次數來調整兩者之間的loss值,就可以了
for epoch in range(20000):
all_loss_d = 0
all_loss_g = 0
tq = tqdm(dataloader)
for cnt, (img, _) in enumerate(tq,1):
real_img = img.cuda()
if cnt%1 ==0:
optimizer_d.zero_grad()
output = model_D(real_img)
r_loss_d = criterion(output, true_labels)
r_loss_d.backward()
fake_img = model_G(train_noises).detach()
output = model_D(fake_img)
f_loss_d = criterion(output, fake_labels)
f_loss_d.backward()
optimizer_d.step()
all_loss_d+=f_loss_d.item()+r_loss_d.item()
if cnt % 2 == 0:
optimizer_g.zero_grad()
fake_img = model_G(train_noises)
output = model_D(fake_img)
loss_g = criterion(output, true_labels)
loss_g.backward()
optimizer_g.step()
all_loss_g+=loss_g.item()
tq.set_description(f'Train Epoch {epoch}')
tq.set_postfix({'D_Loss':float(all_loss_d/cnt),'G_loss':float(all_loss_g/cnt*5)})
fix_fake_imgs = model_G(train_noises).detach()
tv.utils.save_image(fix_fake_imgs,f'pic/{epoch}.jpg')
t.save(model_D.state_dict(), f'model/model_D_{epoch}.pth')
t.save(model_G.state_dict(), f'model/model_G_{epoch}.pth')
接下來看看我使用2000多張的hololive二創圖片訓練1600多次出來的結果
 可以看到人物的輪廓與色彩都已經出來了,以一個2000多張的人臉照片來說,我認為效果還算不錯,而且我並沒有手動處理任何的圖像資料,導致訓練樣本裡面有根本不是人臉的圖片,這樣子也影響了些訓練效果,若要更好的效果可以增加圖片量與手動過濾一些圖片。
可以看到人物的輪廓與色彩都已經出來了,以一個2000多張的人臉照片來說,我認為效果還算不錯,而且我並沒有手動處理任何的圖像資料,導致訓練樣本裡面有根本不是人臉的圖片,這樣子也影響了些訓練效果,若要更好的效果可以增加圖片量與手動過濾一些圖片。
本來是想把結果跑完,但是電腦已經快要撐不住了...
完整程式碼
import os
import torchvision as tv
import torch as t
import torch.nn as nn
from tqdm import tqdm
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
ndf = 64
self.main = nn.Sequential(
# 3 x 96 x 96
nn.Conv2d(3, ndf, 5, 3, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
x = self.main(x)
x = x.view(-1)
return x
class Generator(nn.Module):
def __init__(self):
super().__init__()
ngf = 64
self.main = nn.Sequential(
nn.ConvTranspose2d(100, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh()
# 3 x 96 x 96
)
def forward(self, x):
x = self.main(x)
return x
transforms = tv.transforms.Compose([
tv.transforms.Resize(96),
tv.transforms.CenterCrop(96),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = tv.datasets.ImageFolder('holo', transform = transforms)
dataloader = t.utils.data.DataLoader(dataset,batch_size = 128, shuffle=True,num_workers = 0,drop_last=True)
model_G = Generator().cuda()
model_D = Discriminator().cuda()
optimizer_g = t.optim.Adam(model_G.parameters(), 1e-4)
optimizer_d = t.optim.Adam(model_D.parameters(), 1e-5)
criterion = t.nn.BCELoss().cuda()
fake_labels = t.ones(128).cuda()
true_labels = t.zeros(128).cuda()
test_noises = t.randn(128, 100, 1, 1).cuda()
train_noises = t.randn(128, 100, 1, 1).cuda()
for epoch in range(20000):
all_loss_d = 0
all_loss_g = 0
tq = tqdm(dataloader)
for cnt, (img, _) in enumerate(tq,1):
real_img = img.cuda()
if cnt % 1 ==0:
optimizer_d.zero_grad()
output = model_D(real_img)
r_loss_d = criterion(output, true_labels)
r_loss_d.backward()
fake_img = model_G(train_noises).detach()
output = model_D(fake_img)
f_loss_d = criterion(output, fake_labels)
f_loss_d.backward()
optimizer_d.step()
all_loss_d+=f_loss_d.item()+r_loss_d.item()
if cnt % 2 == 0:
optimizer_g.zero_grad()
fake_img = model_G(train_noises)
output = model_D(fake_img)
loss_g = criterion(output, true_labels)
loss_g.backward()
optimizer_g.step()
all_loss_g+=loss_g.item()
tq.set_description(f'Train Epoch {epoch}')
tq.set_postfix({'D_Loss':float(all_loss_d/cnt),'G_loss':float(all_loss_g/cnt*2)})
fix_fake_imgs = model_G(train_noises).detach()
tv.utils.save_image(fix_fake_imgs,f'pic/{epoch}.jpg')
if epoch %10==0:
t.save(model_D.state_dict(), f'model/model_D_{epoch}.pth')
t.save(model_G.state_dict(), f'model/model_G_{epoch}.pth'
NLP的首選模型Transformer介紹
我們已經在CV(影像辨識)的領域中學習瞭如何辨識圖像、使用pre-train model以及GAN生成圖像,而我們在NLP中只學會了情緒分析,所以我們這幾天要來學習,如何使用文本的pre-train model與生成文本,於是今天要先來瞭解電腦是怎麼樣生成文本資料的。
Seq2Seq(Sequence to sequence)
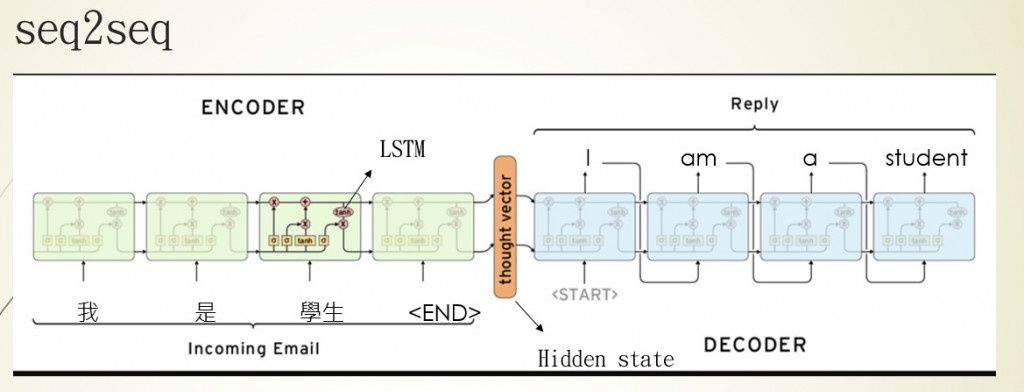
seq2seq是一種encoder-decoder的架構,架構中的encoder與我們在【day9】 讓電腦瞭解文字資料 & 使用Pytorch做IMDB影評分析的作法是相同的,利用RNN神經網路訓練文本資料,取得最後一個輸出狀態hidden state(Hn或是Yn),那這個hidden state就會是我們我們電腦瞭解的文本訊息。
我們在第9天的作法就是將hidden state通過激勵函數sigmoid把狀態縮放至0~1的範圍,之後使用二分法將結果分成正面與負面。但如果不使用激勵函數而是直接使用hidden state呢?這就是decoder的做法,decoder會利用每次RNN神經網路的輸出的hidden state當作模型的輸入,推敲文字之間的關係,找到下一個文字出現的機率,從而完成文本翻譯或是文本生成的任務。
簡單來說seq2seq的技術就是將資料通過encoder產生出hidden state,並且通過decoder解析hidden state所包含的內容,最後來達成文本生成或是翻譯的目的。
不過在seq2seq當中有一個重大的缺陷,還記得我們說過RNN會存在者資料經過計算消失的問題嗎?這一點雖然到LSTM有了些改善,但是還是沒辦法完整的保留資訊,這就會使的decoder所瞭解的資訊不足導致生成結果不佳。我們舉個例子來幫助理解。
假設有個老師(encoder)在讀書時只自己有用的資料保留下來,那他在教導學生(decoder)時就會把他認為的重點劃出來並且傳達給學生,但是學生連基礎的不好的情況下,卻吸收到了這些過於精簡的知識,導致無法理解老師想要表達什麼,這樣子的考試結果自然會不佳。
這時老師就想到了一個方式,把他在讀書時,學習知識的過程與與學習到知識都跟學生說,讓學生可以從老師讀書的方法中找到一個最佳的解法,而不是隻學習重點,這種方式在深度學習中就叫做注意力機制(attention)。
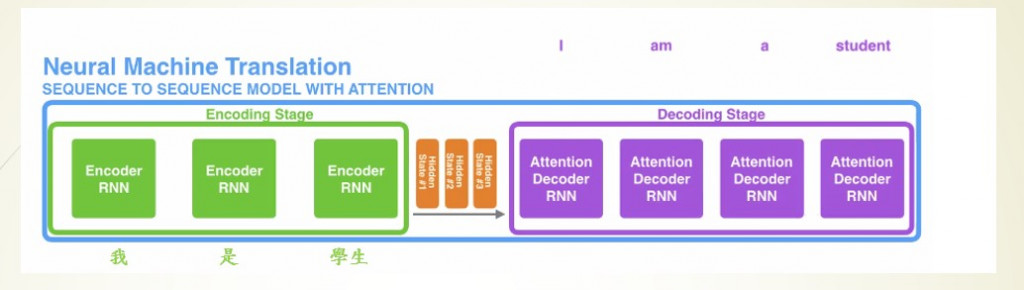 我們先來看加入attention後的seq2seq架構中,hidden state變成了不只一個,因為加入attention後,RNN神經網路會把他所訓練出來的所有結果(H0~Hn)通通交給encoder動態判斷哪一個hidden staete是我要的結果。
我們先來看加入attention後的seq2seq架構中,hidden state變成了不只一個,因為加入attention後,RNN神經網路會把他所訓練出來的所有結果(H0~Hn)通通交給encoder動態判斷哪一個hidden staete是我要的結果。
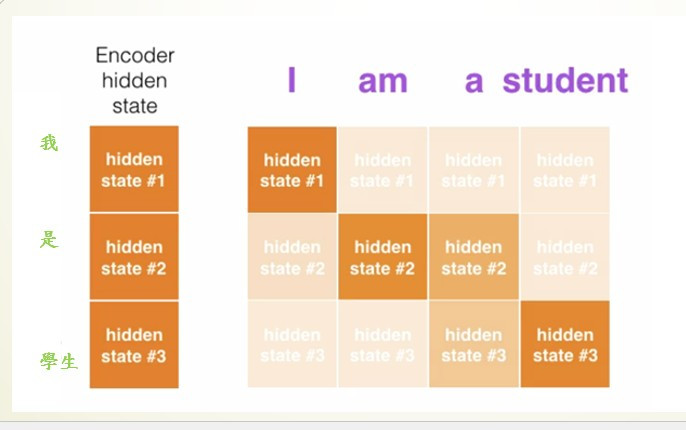 在encoder中不會只判斷一個hiddden state,而是一次判斷多個hidden state來找到最佳的結果,以圖片中的例子來說,我輸入我是學生,輸入"我"就會產生第一個hidden state,輸入"是"就會產生第二個,以此類推到最後時共有3個hidden state,那encoder就會認為"我"在第一個hidden state中是權重是最高的,而第二個hidden state當中也有包含"我"的資料,所以他考慮了這兩個hidden state的資料來產生"I"這個單字,當然實際訓練時所產生的例子絕對會更複雜。
在encoder中不會只判斷一個hiddden state,而是一次判斷多個hidden state來找到最佳的結果,以圖片中的例子來說,我輸入我是學生,輸入"我"就會產生第一個hidden state,輸入"是"就會產生第二個,以此類推到最後時共有3個hidden state,那encoder就會認為"我"在第一個hidden state中是權重是最高的,而第二個hidden state當中也有包含"我"的資料,所以他考慮了這兩個hidden state的資料來產生"I"這個單字,當然實際訓練時所產生的例子絕對會更複雜。
傳統RNN的問題
再來就是傳統RNN所產生的問題,不管是LSTM、GRU、simple RNN...等,都有一個相同的問題,就是RNN模型都需等待上一個節點計算完畢後,才能進行下一個節點的運算。若輸入資料維度太龐大,那這個訓練時長,將會比相同維度的CNN網路還要來的更久(LSTM無法平行運算),所以這時就有一個新的技術叫做transformer。
什麼是Transformer?
Transformer是於2017年由Google Brain團隊推出的一個模型,因計算的速度遠大於LSTM等RNN模型,所以成為了NLP的首選模型。那transformer是怎麼樣運作的呢?首先我們先看到這張圖片
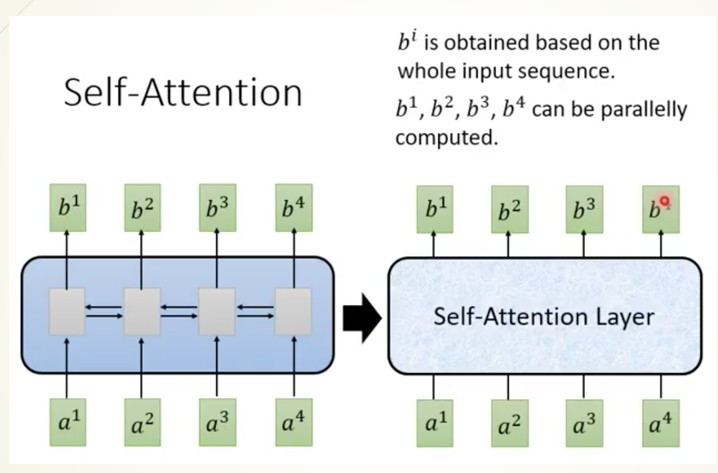
圖片來源:李弘毅老師youtube
在這張圖片中做了一件事情,將原始的RNN神經網路層改成一個自注意力機制(self-attention)層,而這個self-attention的做法就是利用矩陣計算來替代RNN網路,使原本要經過好幾個節的的計算過程,變得可平行運算,且所有輸出都能夠理解所有的輸入,所以接下來就來看看這個self-attention究竟是做了什麼樣的事吧。
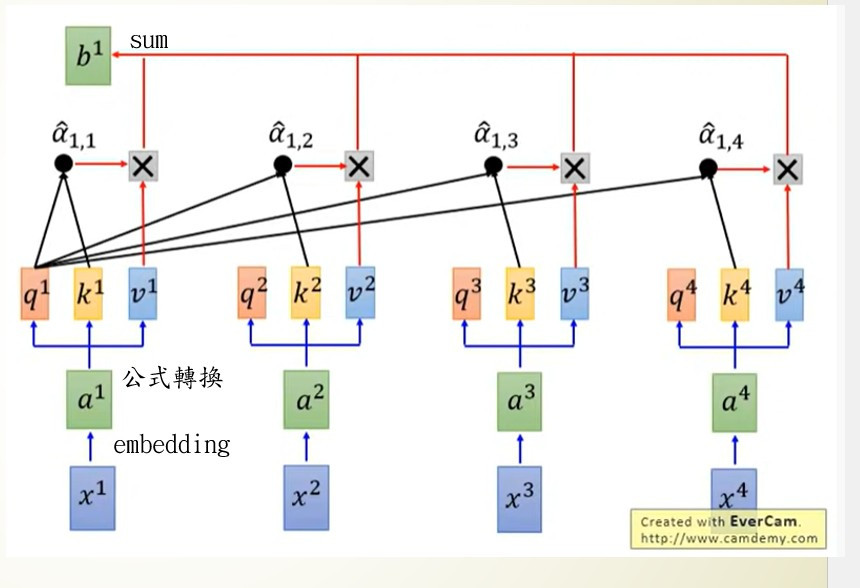 首先我們先看到
首先我們先看到x1~x4,這一個就是我們輸入的文字,在第9天時有說到高維度的文字需先降維(圖中採用embedding)才能夠交給電腦運算,這個結果就是a1~a4也是我們在self-attention裡實際計算的資料。
我們可以看到a1~a4還分出了3個參數q、k、v。這三個參數是在self-attention中相當重要的資料,我們先來看看這些參數所代表的含意
| 名稱 | 用處 |
|---|---|
| q | 找到輸入的所有k |
| k | 被所有q找到 |
| v | 代表文字本身a |
我們先來看一下圖片中b1的例子,首先會先計算q1·k1到q1·k4來得到結果a(1,1到1,4),之後用softmax來計算文字之間的分數,最後將a1,1到a4,4與我們的實際輸入v1到v4相乘後加總起來得到最後的輸出結果b1,公式表達是長這個樣子b1=sum(softmax(q1·k1/d^0.5)*v1+softmax(q1·k2/d^0.5)*v2+softmax(q1·k3d^0.5/)*v3+softmax(q1·k4/d^0.5)*v4),而前面提到v是我們的輸入、sofmax(q1·kn/d^0.5)是每個文字之間的分數,兩個數字相乘就代表這個文字1對文字n的分數,而最後加總的動作就是將文字1(因為是q1)對所有輸入文字的分數,這代表的意思就是的b1就是我們x1~x4之間的文字關係,並且在這個過程中皆採用矩陣平行運算,因此改善了原本RNN計算緩慢的問題,也改善了decoder看不見我們輸入的問題。
但我們原始的self-attention也會產生一種問題就是無法一次注意好幾個文字,我們在看文字時可能會一次關注好幾個相關的資訊,但是在self-attention當中只會找到最相關的,為了改善這個問題,於是衍生了另一種方式多頭注意力機制(Multi-Head Attention),這種方式非常的簡單就是將q、k、v三個參數分成多個,並且每個q、k、vˋ只會與自己相對編號的q、k、v進行運算。
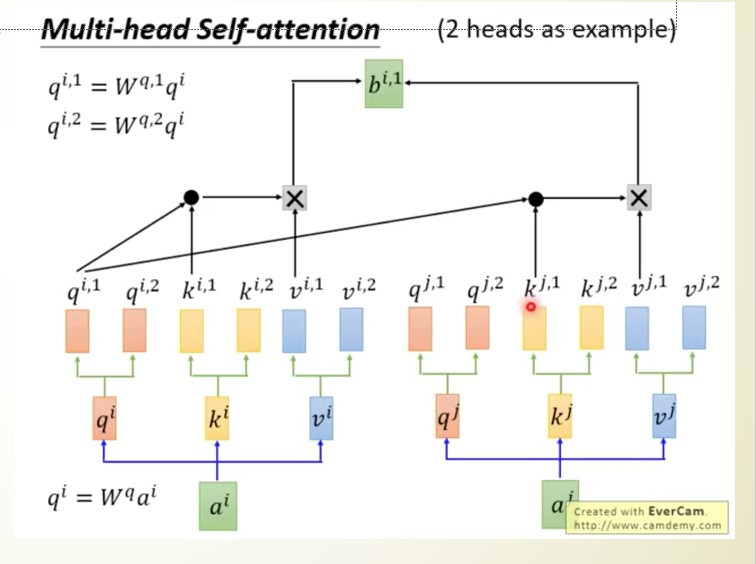 以圖片中為例qi只會找所有的ki,qj只會找所有的kj,利用這種方法使文字能夠關注到更多的資訊,從而運算出更好的結果。
以圖片中為例qi只會找所有的ki,qj只會找所有的kj,利用這種方法使文字能夠關注到更多的資訊,從而運算出更好的結果。
這樣是不是能瞭解transformer為何會在NLP中非常重要了呢?不過有沒有發現一件事情transformer中的encoder就是一種特徵擷取的方法,decoder則是一種生成方式,這是不是與我們昨天學習到的GAN非常相似。所以transformer其實不只能運用在NLP當中,也能用在圖像之中,只要是CNN可以做到的事情transformer也能夠做到,所以我認為transformer會是將來AI技術中最閃亮的一項技術。
假消息辨識-BERT(Bidirectional Encoder Representations from Transformers)(上)
BERT介紹
我們昨天說到了transformers,那今天就來談談transformers中最有名的NLP pre-train model,基於變換器的雙向編碼器表示技術(Bidirectional Encoder Representations from Transformers)簡稱BERT。BERT是一篇在2018年發表在IEEE的論文,並且在發布時屠殺了當時GLUE、SQuAD、SWAG數據集準確率的排行榜,穩穩地拿下第一的寶座,也影響了後續NLP任務的訓練方式,不過我們在開始介紹BERT之前,先來瞭解一下當時最強大的兩個語言模型
在BERT發表前的兩個重大model介紹
ELMO
在BERT的論文發布前,我們所使用的NLP模型,基本上都是使用transformers或LSTM的方法訓練而成的,例如BERT的前身語言模型嵌入(Embeddings from Language Models)簡稱ELMO,是一個featur-based的pre-train model。
來源:https://medium.com/programming-with-data/31-elmo-embeddings-from-language-models-%E5%B5%8C%E5%85%A5%E5%BC%8F%E8%AA%9E%E8%A8%80%E6%A8%A1%E5%9E%8B-c59937da83af
ELMO是利用BiLSTM所訓練出來的模型,這種LSTM的會創建雙層雙向的神經網路,最後將資訊拚接起來,而ELMO最大的特點就是使用了3層embedding,來訓練不同的結果。
第一層的embedding也叫做token embedding,與我們先前使用的embedding並沒有任何差異,這層embedding只代表文本之間最淺層的表示。
第二層的embedding也叫做segment embedding是來計算文字之間的上下文關係,在這層的embedding只有0與1,前句代表0,後句代表1,因為在文本中時常會有前文對應不上後文的情形,若將這種資料拿去訓練,神經網路訓練出來的結果就會非常不好,所以在這層embedding中就是為瞭解決這個問題。
經過了這兩層的輸出,ELMO得到了以下公式:y = W1xE1 + W2xE2(w:權重 e:embedding層), 通過兩層的embedding與兩層的LSTM來計算輸出,若是一句話當中前後句符合(W2E2)又是有邏輯的話(W1E1)那這個Y值就會是一個很高的分數。
最後是第三層的embedding也叫做positon embedding,在這層中紀錄著文本輸入的序列,因為我們都知道文字反過來念可能會有不同的涵義,例如"走開"跟"開走"就是一種完全不同的意思,所以我們需要記錄這些文字的位子,以免使神經網路搞錯實際的含意。
GPT2
GPT 是一種fine-tune的pre-train model,他是隻使用Transformers中的encocder來當作模型的基本,這代表他無法做NER、情緒辨識等需要encodoer的NLP任務,所以GPT只會用於文本生成,例如機器翻譯、文本摘要、文本生成等。如果有想了解GPT文本生成的方式可以觀看我昨天的文章【day16】NLP的首選模型Transformer介紹。
而這個模型的最大特點就是,模型參數量非常的巨大是當時參數量最龐大的語言模型(1542M),與ELMO(94M)相比足足大了16.4倍。GPT生產文字的方式就是利用transformers由左到右的讀取文字,並且通過巨量的文本資料(40GB的文本資料)來訓練,得到各文字之間的文字分佈。
在訓練資料時GPT使用了一種word piece的技巧,word piece的主要實現方式叫做雙字節編碼(Byte-Pair Encoding),BPE的過程可以理解為把一個單詞再拆分,減少資料大小,並且加強文字所代表的意思。例如:"loved"、"loving"、"loves"這三個單詞,本身的意思都是“愛”,但神經網路會認為這三個字是不相同的,只是他們的意思相近,當我們文本裡有太多這種資料,訓練結果肯定會有問題。
所以這時候BET演算法會找出頻率最高相鄰序列,並依次循環把序列合併,我們用以下這張圖片來看BET演算法的計算方式。
 看完了圖片後,是不是瞭解BET演算法的過程了呢?我們可以利用這種方式找到文字中的字根,拆解後墜與實際文字含意,來達成同字不同意的問題。
看完了圖片後,是不是瞭解BET演算法的過程了呢?我們可以利用這種方式找到文字中的字根,拆解後墜與實際文字含意,來達成同字不同意的問題。
總結一下GPT所做的事,第一個就是導入word piece的技巧,使後墜不相同的文字也能計算出相同的效果,第二個就是大力出奇蹟,使用了龐大的模型參數跟巨量的訓練集,訓練出一個很好的結果,GPT用了以上的方法在文本生成上取得了相當優良的成績。
BERT為何能屠榜
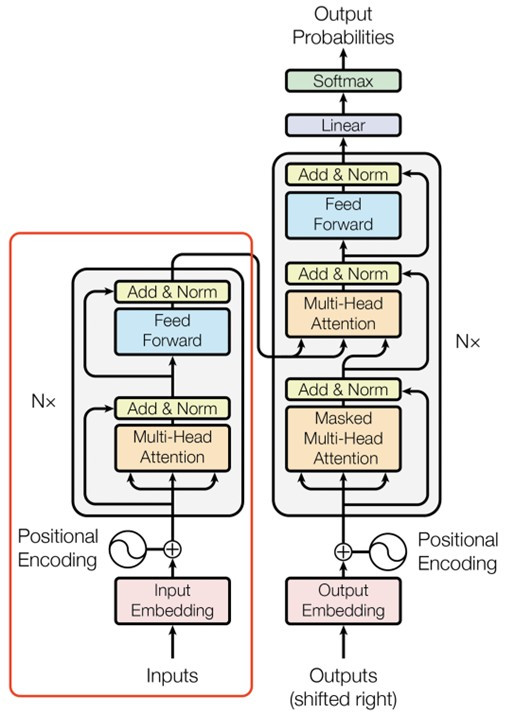
來源:李弘毅老師youtube 為何BERT能夠屠榜,原因就是作者改善了GPT、ELMO這兩個模型的共有缺點,並且結合兩者的優點,與改善缺點,最後通過MLM的方法,修正了文字只能從左到右理解的問題。
我們先來看BERT結合了哪些GPT與ELMO的優點好了,第一點就是使用GPT中word piece的方式來縮小token大小。再來就是使用ELMO的三層embedding來記錄輸入訊息與上下文關係。並且將ELMO的LSTM層換拋棄掉,改使用transformers中的encoder,因為是採用encoder的架構所以輸出都能看見所有的輸入,所以只需加入一個額外的輸出層,就能在NLP任務上得到不錯的結果。
再來是BERT有一些特殊標籤,來處理一些特殊問題,這點再GPT與ELMO當中雖然都擁有相似的標籤,但BERT的標籤功能是最多的,我們來看到以下表格。
| 名稱 | 說明 |
|---|---|
| [CLS] | 這個標籤會放在程式的開頭當中,輸出時這個CLS會作為整個序列的repr. |
| [SEP] | 有兩個句子的文本會被串接成一個輸入序列,並在兩句之間插入這個 token 以做區隔 |
| [UNK] | 沒出現在 BERT token裡頭的字會被這個 token 取代 |
| [PAD] | zero padding 遮罩,將長度不一的輸入序列補齊方便做 batch 運算 |
| [MASK] | 未知遮罩,僅在預訓練階段會用到 |
也許你看完後還不太懂,我們來看看BERT的輸入究竟是什麼樣子。假設今天的輸入是"我是學生,我在上學中",那經過特殊標籤的轉換就換變成[CLS]我是學生[SEP]我在上學中[SEP],這裡的CLS與SEP都是BERT在訓練下游任務中非常重要的標籤。CLS這個標籤的目的,就是希望我們文本訓練完的資料都能使用這個CLS來表達,因為BERT並沒有decoder,所以透過CLS這個標籤來當作最後的輸出最後與我們的下游任務憶起做計算。再來是SEP標籤,這個標籤的目是來分割上下文,使第二層的segment embedding能夠知道文字的前後關係
但這樣就能成為屠榜機器嗎?答案是否定的,BERT真正強大的地方就是使用了一個新的技巧叫做Masked Language Model(MLM),這種訓練方式可以讓輸入能夠考慮整個文本的資料,不像是ELMO與GPT只考慮一定方向,接下來我們來說說MLM的實際使用方法。
MLM會將先前創建的wordpiece以15%的機率替換為遮罩(Mask),之後有80%的機率轉換成特殊標籤[MASK],10%轉換成隨機字串,10%完全不替換,這邊只有80%的機率替換成[MASK]是因為[MASK]標籤只會出現在預訓練階段,實際使用時並沒有這個標籤,所以為了能夠更貼近下游任務,所以將剩下的20%來作為我們在實際訓練時會看到的數據
 我們來看一下BERT論文中的例子,來方便讓我們理解,為什麼這樣可以使BERT考量到整個文本。可以看到圖片中的文字my dog is hairy 替換成 my dog is [MASK],在這個階段當中,BERT會去想辦法還原被遮蔽掉的文字,並且經過了多次的運算,來找到MASK當中最適合填入哪些單字。
我們來看一下BERT論文中的例子,來方便讓我們理解,為什麼這樣可以使BERT考量到整個文本。可以看到圖片中的文字my dog is hairy 替換成 my dog is [MASK],在這個階段當中,BERT會去想辦法還原被遮蔽掉的文字,並且經過了多次的運算,來找到MASK當中最適合填入哪些單字。
也就是因為這個任務,更改了後續模型的訓練方式,由原本的單一方向,變成了多方考量,也衍生了許多MLM的變種,例如:採用GAN的方法生成文字來填充MASK這個單字、更換[MASK]特殊記號等方法。
看完了BERT的介紹後是不是想要來看看這麼model到底能做什麼樣的應用呢?所以我們明天要使用BERT辨識假消息,看看效果究竟會如何
假消息辨識-BERT(Bidirectional Encoder Representations from Transformers)(下)
該如何辨識假消息
首先我們要先知道假消息傳播的速度在網路中是相當快速的,所以我們只需要知道瀏覽器的一些演算法,就能透過快速的將自己想要的資訊傳播在網路上,所以我們要先聊聊這些演算法是如何運作的。
首先最直觀的想法就是越多人觀看,這篇文章的內容就會越有用,所以演算法應該要把觀看越多次數的文章推播到越上方,但這樣子只要有人特別去刷觀看次數,就算是廢文也能被他刷上到首頁,所以搜尋演算法並沒有這麼笨,演算法還會去考量網站裡實際的文字內容與不同網站之間轉跳的結果,來計算出最符合的答案。但有些人是直接使用相當有名的論壇,來大量傳播自己想要的資訊呢?這樣子就會有問題發生了,因為這些網站本來就是許多人會去點擊的,所以演算法很容易的就會將這些文章推送到搜尋第一頁,我們可能只創立了一些假帳號,或是買一些帳號來到處傳播這些消息,那麼,就會有許多人真的會相信這樣子的結果。
所以在這邊有幾種反制的方法,第一種就是找到一些專門製造假新聞的網站,通過AI分析這些URL的排序方式,來過濾掉這些網站或利用這些網站的內容,第二種方式就是找到散播假消息的ID,這些ID有可能只是用程式大量產生的假帳號,我們可以通過分析這些假ID的規律,來找到哪一些人可能是在發布假消息,並用AI來找到發布的內容之間的相似度,這樣子就可以順藤摸瓜找到一些被買來的帳號或惡意人士發布的訊息,甚至能夠找到消息的源頭。最後是關於通訊軟體的問題,我們可能常常會看到通訊軟體上有許多聳動標題的新聞或內容,這時就會點進去看看內容是什麼,這時候網站演算法就會發現,這個網站的客源來自於各大通訊軟體,這樣會使搜尋演算法認為文章的內容相當的重要,就會把這種造假的資訊放到搜尋第一頁當中,所以我們可以透過分析假消息的寫作風格,與真人的寫作風格來判別假消息。
說了這麼多我們先來看看BERT判別假消息的方式吧。
BERT假消息判別
我們昨天說到的BERT有許多的下游任務,這些下游任務所處理的功能都不相同,而我們為了要判別假消息,我們可以使用BertForSequenceClassification,來找到句子之間的關係,來訓練出一個能夠判別文章風格的假消息的AI模型。
今天的目錄如下:
- 1.導入BERT與函式庫
- 2.創建資料集
- 3.訓練模型
導入BERT與函式庫
首先我們在原始BERT的github上很難簡易的使用BERT model,所以有一個叫做hugging face的網站幫我們把一些非常複雜的pre-train model統整成了pytorch或是tensorflow的格式,並且將很多功能都直接包裝起來,不用一個一個自己寫,例如zero padding、text2num的方法,都能用一行程式執行完畢。
首先我們先來下載假新聞的資料集點我下載這一個資料集是國外新聞網被查證的假新聞與真實新聞資料集,我們今天要通過理解文意的方式來做一個分類器辨別出是真是假。
接下來導入今天用的函式庫,這邊的transformers是能夠幫助我們下載hugging face上所有的pre-train model的一個函式庫
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import Dataset,DataLoader
from tqdm.auto import tqdm
import torch.utils.data as data
import pandas as pd
import torch
import transformers
之後我們只需要呼叫就能製作出一個tokenizer與model。
tokenizer = BertTokenizer.from_pretrained("ydshieh/bert-base-uncased-yelp-polarity")
model = BertForSequenceClassification.from_pretrained("textattack/bert-base-uncased-yelp-polarity")
創建資料集
首先我們一樣先從讀取csv檔開始
df_fake = pd.read_csv('Fake.csv')
df_real = pd.read_csv('True.csv')
因為我們的資料是直接分成兩個檔案,所以可以直接利用文本的資料大小創建一個新的label
inputs = df_fake['text'].tolist() + df_real['text'].tolist()
targets = len(df_fake['text'].tolist())*[0]+len(df_real['text'].tolist())*[1]
接下來要使用pytorch的方式創建dataset,相信到現在已經對這種方式不陌生了,但在使用hugging face網站的model時我們還有一個方式,就是利用字典將我們想要的把索引,當輸入名稱來當作訓練資料,但我們要做這件事前,要先知道我們到底要輸入哪一些資料,首先我們可以先到hugging face中BERT的頁面點我前往
我們可以看到今天要使用的分類器BertForSequenceClassification的參數有非常多種

但在這裡最重要的其實只有3個參數

在官方文件中寫了相當多的資訊,但其實概念很簡單,我們先看到以下表格
| 參數名稱 | 結果 |
|---|---|
| input_ids | 將文字轉換成數字 |
| token_type_ids | 判斷前後文的輸入 |
| attention_mask | zero padding的輸入 |
input_ids在理解上應該是沒有甚麼問題,就是我們之前所做的將文字轉換成數字,不過這個數字需要按照BERT當中的規則,token_type_ids這一個輸入就是segment embedding輸入的資料,在這個輸入當中只會有0與1的結果,attention_mask這個參數有一些人可能看完了BERT論文後把這一個mask當成了BERT在預訓練時的[mask],這一個mask其實只是在對文字做zero padding時,所標註的位子而已,當我們對文字進行補0時這一個矩陣相對位子也會為0。你可能會在想不是有三層embedding嗎?怎麼只有2個輸入,因為在positon embedding層的輸入就是我們文字輸入的序列,只需要將資料丟入到model當中就會自動記錄到文字的位子訊息。
接下來只需要將剛剛的文字使用tokenizer的方式轉換,就能當作輸入了
tokenizer('I am a student')
-------------------顯示-------------------
{'input_ids': [101, 1045, 2572, 1037, 3076, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1]}
不過在做假消息辨識時還需要加入label,因為我們做的事監督學習的方式,而不是非監督,所以要在原本產生的字典中加入labels的索引
t = tokenizer('I am a student')
t['labels'] = 1
-------------------顯示-------------------
{'input_ids': [101, 1045, 2572, 1037, 3076, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'lables':1}
知道了以上的作法後,我們就能使用pytorch來創建一個含有所有文本資料的字典了,我相信大家已經對創建資料集的方式很熟悉了,所以這邊就直接上程式碼。
class News(Dataset):
def __init__(self, inputs, targets, tokenizer, max_len=512):
t = tokenizer(inputs)
self.data = []
for ids,sep,mask,label in zip(t['input_ids'], t['token_type_ids'], t['attention_mask'], targets):
self.data.append({'input_ids':torch.tensor(ids[0:512])
,'token_type_ids':torch.tensor(sep[0:512])
,'attention_mask':torch.tensor(mask[0:512])
,'labels':torch.tensor(label)})
def __getitem__(self,index):
return self.data[index]
def __len__(self):
return len(self.data)
tokenizer = BertTokenizer.from_pretrained("ydshieh/bert-base-uncased-yelp-polarity")
model = BertForSequenceClassification.from_pretrained("textattack/bert-base-uncased-yelp-polarity")
df_fake = pd.read_csv('Fake.csv')
df_real = pd.read_csv('True.csv')
inputs = df_fake['text'].tolist() + df_real['text'].tolist()
targets = len(df_fake['text'].tolist())*[0]+len(df_real['text'].tolist())*[1]
dataset = News(inputs, targets, tokenizer)
train_set_size = int(len(dataset) * 0.8)
test_set_size = len(dataset) - train_set_size
train_set, test_set = data.random_split(dataset, [train_set_size, test_set_size])
訓練模型
隨然說是訓練模型,但在BERT中其實是在fine-tune模型,訓練分類器,在這訓練的過程中也沒有太多的差異,只是在取出資料時做法不相同而已,我們之前的loss值都是經過model與label經過loss function計算後的到的結果,所以我們必須定義一個loss function,但是在BERT中已經將loss function都整合好了,所以只需使用model(data),就能計算出我們的loss值,而這一個輸出也與我們的輸入一樣,只需使用一行程式,就能將值取出。
我們先來看看輸出結果。
SequenceClassifierOutput(loss=tensor(0.4921, device='cuda:0', grad_fn=<NllLossBackward0>), logits=tensor([[-0.0726, -0.5257]], device='cuda:0', grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
在這邊比較重要的就只有兩個數值,第一個就是loss,第二個則是logits,我們可以通過model.loss將loss取出,並且交給優化器來運算,而第二個數值所代表的意義就是我們的輸出結果,分數越高的結果就會是我們最後一個輸出的label,同樣的可以使用model.logits來取出數值。
瞭解到了這些之後我們將pytorch訓練方式與model組合在一起
model.cuda()
optimizer = torch.optim.AdamW(params = model.parameters(), lr = 1e-4)
for epoch in range(20):
model.train()
train = tqdm(train_loader)
for data in train:
for key in data.keys():
data[key] = data[key].cuda()
outputs = model(**data)
print(outputs)
loss = outputs.loss
train.set_description(f'Epoch {epoch}')
train.set_postfix({'Loss': loss.item()})
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
test = tqdm(test_loader)
correct = 0
for data in test:
for key in data.keys():
data[key] = data[key].cuda()
outputs = model(**data)
_,predict_label = torch.max(outputs.logits,1)
correct += (predict_label==data['labels']).sum()
test.set_description(f'Epoch {epoch}')
test.set_postfix({'acc':'{:.4f}'.format(correct / len(test_set) * 100)})
model.save_pretrained('model_{}'.format(epoch))
最後來看看我們測試數據集的結果
Epoch 0: 100%
160/160 [00:20<00:00, 8.71it/s, Loss=0.00601]
Epoch 0: 100%
40/40 [00:00<00:00, 41.81it/s, acc=97.5152]
可以看到這結果比我們之前用到的NLP模型準確率還要高出許多,僅使用一個epoch就能訓練一個很好的結果,這也能體現出BERT為何能夠在2018年時成為了最佳的模型。
完整程式碼
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import Dataset,DataLoader
from tqdm.auto import tqdm
import torch.utils.data as data
import pandas as pd
import torch
import transformers
class News(Dataset):
def __init__(self, inputs, targets, tokenizer, max_len=512):
t = tokenizer(inputs)
self.data = []
for ids,sep,mask,label in zip(t['input_ids'], t['token_type_ids'], t['attention_mask'], targets):
self.data.append({'input_ids':torch.tensor(ids[0:512])
,'token_type_ids':torch.tensor(sep[0:512])
,'attention_mask':torch.tensor(mask[0:512])
,'labels':torch.tensor(label)})
def __getitem__(self,index):
return self.data[index]
def __len__(self):
return len(self.data)
tokenizer = BertTokenizer.from_pretrained("ydshieh/bert-base-uncased-yelp-polarity")
model = BertForSequenceClassification.from_pretrained("textattack/bert-base-uncased-yelp-polarity")
df_fake = pd.read_csv('Fake.csv')[:100]
df_real = pd.read_csv('True.csv')[:100]
inputs = df_fake['text'].tolist() + df_real['text'].tolist()
targets = len(df_fake['text'].tolist())*[0]+len(df_real['text'].tolist())*[1]
dataset = News(inputs, targets, tokenizer)
train_set_size = int(len(dataset) * 0.8)
test_set_size = len(dataset) - train_set_size
train_set, test_set = data.random_split(dataset, [train_set_size, test_set_size])
train_loader = DataLoader(train_set,batch_size = 1,shuffle = True)
test_loader = DataLoader(test_set, batch_size = 1, shuffle = True)
model.cuda()
optimizer = torch.optim.AdamW(params = model.parameters(), lr = 1e-4)
for epoch in range(20):
model.train()
train = tqdm(train_loader)
for data in train:
for key in data.keys():
data[key] = data[key].cuda()
outputs = model(**data)
loss = outputs.loss
train.set_description(f'Epoch {epoch}')
train.set_postfix({'Loss': loss.item()})
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
test = tqdm(test_loader)
correct = 0
for data in test:
for key in data.keys():
data[key] = data[key].cuda()
outputs = model(**data)
_,predict_label = torch.max(outputs.logits,1)
correct += (predict_label==data['labels']).sum()
test.set_description(f'Epoch {epoch}')
test.set_postfix({'acc':'{:.4f}'.format(correct / len(test_set) * 100)})
model.save_pretrained('model_{}'.format(epoch))
不過我們做了這麼多,真的能判別假消息嗎?我認為只能做到輔助的功能,我們頂多能運用AI幫助我們初步篩選,然後透過人為的方式調查並且處理,這樣子才能真正到了解假消息的源頭以及真偽。
找到文章的重點-T5( Text-To-Text Transfer Transformer)(上)
NLP四大任務
我們在NLP任務當中,可以大致上分為四種:
第一種是分類任務,在分類中資料通常都是文本與相對的label,這類任務會找到文本之間的關係,並通過softmax(多分類)、sigmoid(二分法)來當作輸出的激勵函數,得到最後的結果。
第二種是自然語言生成(Natural Language Generation),我們在分類任務中資料都是文本與label,在生成任務中就是把label從數字更換成文本資料而已。使用前面的文本資料,來預測後面的文本資料出現的機率,這任務的輸出通常都只是一種文字的分佈機率,而不是一個確定的結果。
第三種則是文本相似度檢測(content similarity detection),文本相似度檢測其實與分類任務的做法相似,分類是使用embedding的結果並通過激勵函數計算出一個確定的結果,而文本相似度檢測是使用embedding的結果,並通過數學式計算,兩個文字或句子之間的高維空間距離,距離越相近的文字相似度就越高。
第四種是序列標註任務(Sequence Tagging),這個任務會先輸入的文本資料,將每一個文字都手動增加詞性在裡面,例如我喜歡蘋果就會被標註成 [名詞 我] [動詞 喜歡] [名詞 蘋果]。之後留下文字的詞性當作輸出,來完成標註任務。
為什麼要先介紹NLP四大任務呢?因為今天要介紹的T5模型,它將所有的NLP任務引入到一個統一的架構中,意思就是隻需一個模型就能夠完成所有NLP任務。
T5簡介
T5( Text-To-Text Transfer Transformer),是google在發布BERT一年後所開發出來的預訓練模型,這個模型與BERT相同,狠狠的刷新了GLUE、SuperGLUE等多個資料集的榜單,就算過了3年的時間也還在SuperGLUE的排行榜上位居第8,與第1名相差了1.9%的準確率。可見這模型的效能非常的強大。
這個模型強大的原因很簡單,就是與GPT相同,使用大力出奇蹟的方式,作者們從Common Crawl網站每個月爬取資料並且整理出了一份容量高達750GB的訓練數據,取名為C4(Colossal Clean Crawled Corpus),我們知道GPT2使用了40GB的訓練數據,而T5卻使用了將近19倍的訓練資料來完成這個模型。
圖片皆引用自T5論文:https://arxiv.org/pdf/1910.10683.pdf
當然只有數據是沒有用的,還要有一個良好的訓練方式,我們剛剛提到NLP的四大任務,都很難用一個模型來達成,最主要的問題是,encoder與decoder之間要將資訊拼接起來是有一定難度的。所以作者們在製作T5模型時,用了這750G的數據共做了70幾種的實驗方式(上圖結果),將每個語言問題轉換成文本到文本(text to text)的方式。
 T5在實際使用時text to text前都需要加入一個任務的名稱,來判別任務的需求,像是圖片中的範例英文轉換成德文,我們必須將原始的輸入文字前加入:translate English to German,假設我們想要的輸入英文是That is good,那對應的label就是Das ist gut。
T5在實際使用時text to text前都需要加入一個任務的名稱,來判別任務的需求,像是圖片中的範例英文轉換成德文,我們必須將原始的輸入文字前加入:translate English to German,假設我們想要的輸入英文是That is good,那對應的label就是Das ist gut。
不過你可能在想text to text 要怎麼做分類任務?其實很簡單,我們直接把整數的label當作文字就好,這樣也不需要再去做one-hot-encoding了。
T5的實驗方式
T5在技術上其實並沒有一太多創新的方式,而是通過分析當時比較有名的預訓練模型的訓練方式,並且經過實驗找到最適合的架構,在這邊分成了兩種區塊去做實驗,分別是:文本的遮蔽方式與transformer架購。
transformer架構
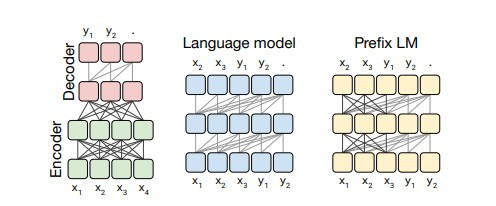 在原論文中大致把transformer模型分成了3種:
在原論文中大致把transformer模型分成了3種:
第一種是encoder-decoder架構,這種架構我們在【day16】NLP的首選模型Transformer介紹,時完整的介紹過了,這架構就是透過encoder學習我們輸入的資料,並且將學習過後的狀態給decoder做使用,這模型的缺點也蠻明顯的,就是decoder無法看見我們輸入的資料,完全依靠encoder學習到的資料來當作decoder的輸入。
第二種是隻使用了decoder的部分,我們在【day17】假消息辨識-BERT(Bidirectional Encoder Representations from Transformers)(上)就提到了這個架構的問題,就是隻能通過前一個文字的結果來推敲下個文字機率,所以效果自然很差。
第三種就比較特殊了,剛剛提到encoder-decoder的架構中,因為decoder無法看到我們的輸入,所以沒辦法考慮到更多的資訊。我們可以想像第三種transformer是BERT與GPT的混和版本,encoder可以看到一部份的完整輸入,decoder看見一部分先前的消息(而不是通過encoder),最後再將兩個模型組合起來。
作者們最後得到的結論是encoder-decoder的架構中最適合T5,當然其他兩種的架構不一定是一個錯誤的方法,這些架構直到了現在還是有很多不錯的成績,實驗結果僅能代表T5不適合這個架構而已。
文本的遮蔽方式
 一個好的模型,一定要有一個好的資料處理的方式,這一點在BERT當中已經幫我們證實過了,所以在T5中對文本的遮蔽方式用了非常多的技巧來找到最好的結果,在這裡又將實驗過程分成了
一個好的模型,一定要有一個好的資料處理的方式,這一點在BERT當中已經幫我們證實過了,所以在T5中對文本的遮蔽方式用了非常多的技巧來找到最好的結果,在這裡又將實驗過程分成了高級方法(High-level approaches)、破壞方式(Corruption strategies)、破壞率(Corruption rate)、破壞長度(Corruption span length)。
高級方法(High-level approaches)
語言模型法(Language modeling):這個方式與先前提到了很多次,這方式與GPT2方法相同,直接當作文本閱讀,從左側文字來預測右側文字
BERT-style法:這個方式就是跟BERT一樣,直接遮蔽或替換掉某些文字
順序還原法(Deshuffling):隨機將文本打亂最後想辦法還原出來。
在這邊是BERT的方式獲勝,不過我覺得順序還原法蠻有趣的,這很像我們在國中高中時,寫考卷會看到的文字重組,如果真的能完美的把文字重組回來,那我覺得效果會比BERT的方式還要來的佳,我認為在這裡會輸給BERT的原因主要是作者把文字打太亂了,我們來看一下作者的範例。

Thank you for inviting me to your fun party last week.
變成
party me for your to . last fun you inviting week Thank
這種打亂方式不用說是電腦,就算是人類也可能也會看不懂,雖然我們常常聽到順序不影響文字的閱讀,但僅限於一小部分的序列遭到變更,但官方的範例中,卻是將整個文本的順序打亂,導致毫無邏輯可言,這是我認為比較可惜的地方。
破壞方式(Corruption strategies)
剛剛提到上一輪獲勝的是BERT-style所以在這一輪之中,要來去對原始的BERT破壞方式做變更。
Mask法:這個方式與BERT相同,只不過是將[MASK]轉換成[M]這個特殊標籤而已。
替換法(Replace span):這種方法會將隨機替換掉單字並且以不同的特殊符號來表示,例如:替換掉第一個字用[X]表示,替換掉第二個用[Y]表示。
丟棄法(Drop):如同字面的意思,隨機丟棄文字。
在這一輪就變成了替換法的勝利而不是原始BERT的方法了,這也是許多人在討論的地方,因為BERT的MASK效果還不夠好,所以在後續衍生出了許多MASK方式。
破壞率(Corruption rate)
接下來就是決定要以多少的機率來替換掉這些文字,在這邊做了4個數值的實驗,分別是10%、15%、25%、50%,在這一輪勝出的機率與BERT相同都是15%。
破壞長度(Corruption span length)
最後是破壞長度,與破壞率相同也使用了4個數值的實驗,分別是2、3、5、10,實驗結果是一次破壞3個單字會是最好的效果。
看到了這邊,恭喜你~你已經讀完了一篇T5論文的精簡版,看完了之後是不是覺得T5使用的方法很多都是舊有的技術,只是通過大量的實驗來找到最佳的方式,但也是這種簡單暴力的方法,才能跳脫正常邏輯思維,使結果超乎我們的想像,所以我們明天來玩玩看T5這個模型吧。
找到文章的重點-T5( Text-To-Text Transfer Transformer)(下)
為何要找到文章的重點
現在社會的步調越來越快,資訊增長的速度卻越來越迅速,但我們所能利用的時間越來越稀少,那我們該如何從這些文章中,找到我們想看的呢?答案就是文本摘要的技術。
文本摘要與現在youtube的短影片概念相同,利用30秒的短影片試閱,若有興趣就可以點擊留言中的完整版網址,來找到想要觀看的影片。相同的方法也能套用在文本摘要中,我們可以利用這篇文章的重點來當作試閱文章,若讀者有興趣就能夠再去觀看完整版本。
T5文本摘要
在hugging face上面,也能下載到T5這一個預訓練模型,也因為被統整過的模型,所以訓練起來也與BERT相似。
今天的目錄如下:
- 1.導入T5與函式庫
- 2.創建資料集與訓練模型
- 3.資料評估
導入T5與函式庫
我們今天要使用的是點我下載資料集是Kondalarao Vonteru的數據集的擴展包,包含了大約9.8萬條新聞與專業作家的文本摘要,這個數據集還對這些新聞做了以下資料前處理。
1.刪除 URL、htmls 標籤、表情符號 2.將簡寫復原 2.將俚語復原 3.刪除標點符號(除了 . )非字符、換行符號、主題標籤 4.刪除標註其他的@與後面的ID 5.刪除停用詞(stop words) 所以我們在使用資料集時不需要再做資料前處理了
首先我們先安裝T5的必要涵式庫SentencePiece與評估的函式庫
pip install SentencePiece
pip install rouge
之後導入函式庫
from transformers import T5Tokenizer, T5ForConditionalGeneration
from torch.utils.data import Dataset,DataLoader
from tqdm.auto import tqdm
import torch.utils.data as data
import pandas as pd
import torch
import transformers
然後與前天一樣直接用transformers的方式下載預訓練模型
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
接下來開始來看看T5該如何創建我們的訓練資料吧。
創建資料集與訓練模型
昨天說到要對T5使用任務時,必須要加入一個任務名稱當作輸入,而我們今天的任務名稱是文本摘要,所以在讀取CSV之後我們還需要對輸入加入"summarize: "
data = pd.read_csv('cl_news_summary.csv')
input_text = data['text'].tolist()
input_text = ["summarize: " + i for i in input_text]
summary = data['summary'].tolist()
我們為了知道T5需要哪一些輸入,所以還是要到官方網站上查看詳細的說明點我前往。

在這邊我統整了三個需要的輸入資料,input_ids是代表文字的本身,attention_mask是對應填充的陣列,我相信前天寫過BERT之後對這兩個參數並不陌生。

昨天說明T5時提到了T5統一了所有NLP任務的架框(text to text),所以這裡的labels代表的,就是由專業人士撰寫文本摘要,這裡需要注意的一點是labels並沒有attention_mask的屬性,但我們一定會填充這些文字的訊息,所以在這裡官方給了我們一個辦法,就是將填充的文字轉通通轉換為-100,這樣就會被程式忽略掉。

這樣就可以來建立我們的訓練資料集了。
class NewsSummary(Dataset):
def __init__(self, text, summary, tokenizer,max_len = 512):
self.data = []
input_t = tokenizer(text,padding="longest")
label_t = tokenizer(summary,padding="longest")
for i,j,k in zip(input_t['input_ids'], input_t['attention_mask'], label_t['input_ids']):
#轉換-100
for cnt,tmp in enumerate(k):
if tmp == 0:
k[cnt] = -100
self.data.append({'input_ids':torch.tensor(i[:max_len]),
'attention_mask':torch.tensor(j[:max_len]),
'labels':torch.tensor(k[:max_len])})
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
data = pd.read_csv('cl_news_summary.csv')
input_text = data['text'].tolist()[:5000]
input_text = ["summarize: " + i for i in input_text]
summary = data['summary'].tolist()[:5000]
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
train_set = NewsSummary(input_text, summary, tokenizer,max_len = 512)
train_loader = DataLoader(train_set,batch_size = 1,shuffle = True)
接下來是訓練的部分,因為我們是做文本生成的任務,這類任務通常都會有自己的評估方式,所以我們在訓練時,只需將訓練數據放到pytorch當中訓練即可,不需要查看測試數據集的Loss值,這裡的方式也與BERT相同這裡就不多說了。
model.cuda()
optimizer = torch.optim.AdamW(params = model.parameters(), lr = 1e-4)
for epoch in range(20):
model.train()
train = tqdm(train_loader)
for data in train:
for key in data.keys():
data[key] = data[key].cuda()
outputs = model(**data)
loss = outputs.loss
train.set_description(f'Epoch {epoch}')
train.set_postfix({'Loss': loss.item()})
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.save_pretrained('model_{}'.format(epoch))
資料評估
Rouge(Recall-Oriented Understudy for Gisting Evaluation),是評估文本摘要與文本翻譯的一種方式。它通過機器生成的文字與實際文字進行比較計算,得出相應的分值,來衡量兩者之間的相似度。
在python中可以簡易的使用一行程式來完成Rouge的評估方法
rouge = Rouge()
rouge.get_scores("句子A","句子B")
接下來我們將剛剛訓練好的T5 model來測試看看,在python官方網站上出現的字會出現什麼樣子的文本摘要
text = 'The warning Weights from XXX not initialized from pretrained model means that the weights of XXX do not come pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning task.'
我們要通過model.generate的方式來產生文字
input_ids = tokenizer.encode(text, return_tensors = 'pt')
generated_ids = model.generate(input_ids, num_beams = 2, max_length = 400, repetition_penalty = 2.5, length_penalty = 1.0, early_stopping = True)
preds = [tokenizer.decode(i, skip_special_tokens = True, clean_up_tokenization_spaces = True) for i in generated_ids]
最後我們輸入與程式產生的摘要顯示出來,我們可以看到程式可以產生出一個語意通順且能表達重點的摘要了。
print(text)
print()
print(preds[0][2:])
--------------------------------------------顯示--------------------------------------------
The warning Weights from XXX not initialized from pretrained model means that the weights of XXX do not come pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning task.
This is a bug that has been fixed in the latest version of Python.
接下來我們來看看Rouge評估出來的結果
from rouge import Rouge
rouge = Rouge()
rouge.get_scores(text,preds[0][2:])
--------------------------------------------顯示--------------------------------------------
'rouge-1': {'r': 0.35714285714285715, 'p': 0.1724137931034483, 'f': 0.23255813514332083},
'rouge-2': {'r': 0.0, 'p': 0.0, 'f': 0.0},
'rouge-l': {'r': 0.35714285714285715, 'p': 0.1724137931034483, 'f': 0.23255813514332083}}
可以看到rouge-1與rouge-l都能達到35%的召回率(recall),這樣其實就是一個不錯的成績了,rouge-2都為0是因為我生成文本的方式不可能達成rouge-2的公式,所以才會都是0。
完整程式碼
from transformers import T5Tokenizer, T5ForConditionalGeneration
from torch.utils.data import Dataset,DataLoader
from tqdm.auto import tqdm
import torch.utils.data as data
import pandas as pd
import torch
import transformers
class NewsSummary(Dataset):
def __init__(self, text, summary, tokenizer,max_len = 512):
self.data = []
input_t = tokenizer(text,padding="longest")
label_t = tokenizer(summary,padding="longest")
for i,j,k in zip(input_t['input_ids'], input_t['attention_mask'], label_t['input_ids']):
for cnt,tmp in enumerate(k):
if tmp == 0:
k[cnt] = -100
self.data.append({'input_ids':torch.tensor(i[:max_len]),
'attention_mask':torch.tensor(j[:max_len]),
'labels':torch.tensor(k[:max_len])})
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
data = pd.read_csv('cl_news_summary.csv')
input_text = data['text'].tolist()[:200]
input_text = ["summarize: " + i for i in input_text]
summary = data['summary'].tolist()[:200]
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
train_set = NewsSummary(input_text, summary, tokenizer,max_len = 512)
train_loader = DataLoader(train_set,batch_size = 1,shuffle = True)
model.cuda()
optimizer = torch.optim.AdamW(params = model.parameters(), lr = 1e-4)
for epoch in range(20):
model.train()
train = tqdm(train_loader)
for data in train:
for key in data.keys():
data[key] = data[key].cuda()
outputs = model(**data)
loss = outputs.loss
train.set_description(f'Epoch {epoch}')
train.set_postfix({'Loss': loss.item()})
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.save_pretrained('model_{}'.format(epoch))
我們終於經過了2/3的課程了,如果到現在都有跟上,應該已經學會了架設基礎神經網路模型、靜態與動態爬蟲技巧、預訓練模型的使用、圖像與文字的判別與生成方式、AI之中的分支、機器學習的實作...等,我們不只學習瞭如何撰寫程式,還學會了這些模型的概念。但有沒有發現,我們每一個專案都是採用一種技術,所以接下來,我們要開始將深度學習、與機器學習這兩種方式開始混和在一起使用,並加強一些關於資料前處理的技巧,來完成更多更加有趣的功能。
分群?分類?傻傻分不清楚-分群演算法介紹
何謂分群(Clustering)?何謂分類(Classification)
我們在看一些AI文章時,可能會看到分群(Clustering)或分類(Classification)這兩個名詞,有些人會覺得這兩個名詞是相同的,但這樣子就大錯特錯了分群與分類是完全不一樣的技術,接下來我來說明一下兩者的差別。
分類(Classification)
假設我們有一筆數據投射在2維空間中長這一個樣子
如果叫你把這些數據分類,你會怎麼做呢?你可能會跟我一樣,直接在中間畫一條線,直接將數據分成兩類
那這樣做的根據是什麼呢?可能是中間很明顯有空白區域,也有可能是因為右上密度比左下還要高,不管是哪一種方式都是你使用你認為的規則來劃分這些數據。
 最後數據的分佈狀態,會因為我們所設立的規則,強制的將這些數據收斂到相對應的點當中。分類就像是一個硬幣分類機,將相同的面額放在一起(條件),最後得到一個明確的結果
最後數據的分佈狀態,會因為我們所設立的規則,強制的將這些數據收斂到相對應的點當中。分類就像是一個硬幣分類機,將相同的面額放在一起(條件),最後得到一個明確的結果
用一句話來說明分群就是,給予條件,去實現想要的結果。
分群(Clustering)
剛剛提到了分類,那分群是什麼呢?簡單來說就是使用演算法來計算數據框列出相似的的群體。在這些群體內因為是通過演算法分析,所以我們無法知道明確的結果,需要查看群體內的結果,才能去判別這個群體主題(Topic)。
 讓我們回到剛剛的圖片,若是採用分群的做法我們的數據分佈就可能會長這個樣子(不同顏色代表不同群),我們能看見,分群並不會像是分類一樣會改變原始數據的分佈狀態,而是通過演算法計算出這些數據該在哪群裡面。分群的結果也能代表著群內數據相似度較高,群外數據相似度較低
讓我們回到剛剛的圖片,若是採用分群的做法我們的數據分佈就可能會長這個樣子(不同顏色代表不同群),我們能看見,分群並不會像是分類一樣會改變原始數據的分佈狀態,而是通過演算法計算出這些數據該在哪群裡面。分群的結果也能代表著群內數據相似度較高,群外數據相似度較低
分群演算法
瞭解到分類與分群的差異後,來看看分群到底有哪一些常用的技術,這些技術又使用了那些方式來達成分群的效果。
K-means分群(K-means Clustering)
K-means是一種透過計算資料間的距離來作為分群的依據的演算法。K-means的演算法需要預設分群數量(k值),通過設定的分群數量產生相對應的隨機中心點,藉由這些中心點向外延伸,找到靠近各中心點的數據點,最後計算出各點到中心點的距離平均,重新建立一個新的中心點,一直不斷的重複以上的動作,直到中心點不再變更後才會停止。這樣說可能概念上有點模糊,我們用圖片的方式來看看K-means分群是如何達成的。
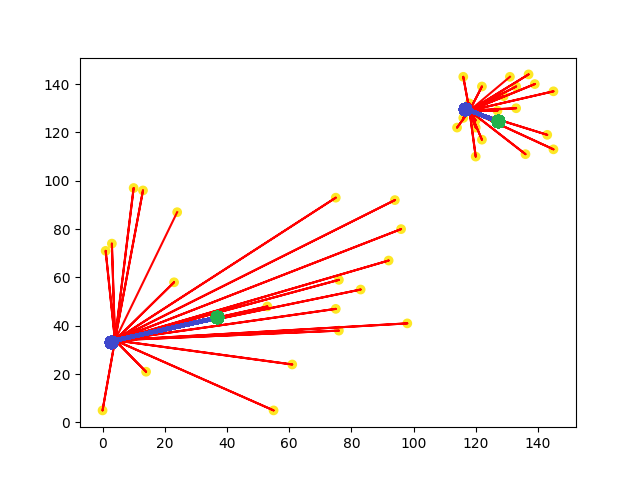 圖片中可以看到各中心點(藍點)會根據距離,來找到距離最近的所有數據點(黃點),並且計算數據點與各中心點之間的距離平均值,來重新移動中心點的位子,直到中心點不會在移動(綠點)。
圖片中可以看到各中心點(藍點)會根據距離,來找到距離最近的所有數據點(黃點),並且計算數據點與各中心點之間的距離平均值,來重新移動中心點的位子,直到中心點不會在移動(綠點)。
K-means的作法在數據分佈較乾淨時才能有較好的結果,若資料點較雜亂k-means就很難發揮其優點,我們看到以下例子。
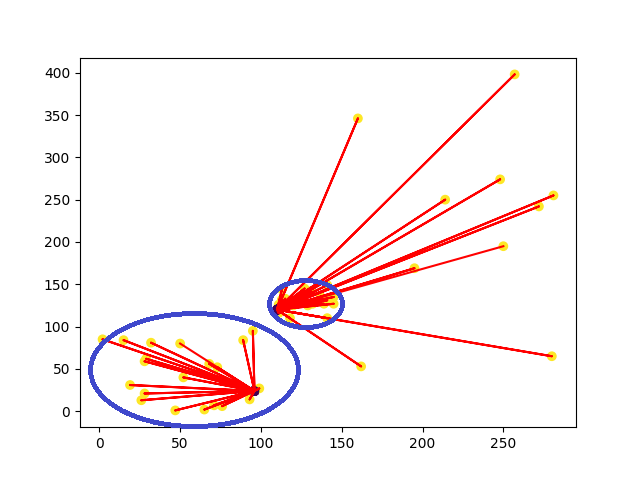 我們可以看到最理想的分類方式,就是移除掉無意義的雜訊,並將藍圈處的資料點分成一群,但是k-means卻會找到所有的數據點,這代表若資料集當中有許多的雜訊,就會因為這些雜訊導致中心點移動到很遠的地方,分群效果自然會不佳,所以k-means無法對資料分佈較大的數據分群,且容易受到雜訊影響。
我們可以看到最理想的分類方式,就是移除掉無意義的雜訊,並將藍圈處的資料點分成一群,但是k-means卻會找到所有的數據點,這代表若資料集當中有許多的雜訊,就會因為這些雜訊導致中心點移動到很遠的地方,分群效果自然會不佳,所以k-means無法對資料分佈較大的數據分群,且容易受到雜訊影響。
DBSCAN(Density-based spatial clustering of applications with noise)
DBSCAN(Density-based spatial clustering of applications with noise)顧名思義,就是基於密度的分群方式,與K-means相比DBSCAN不需要設定聚類數量,而是通過資料之間的密度來進行分群,這種分群的方式會將特徵相似且密度高的樣本劃分為一群,並且找出密度較低的異常點,我們先來看看DBSCAN的分群方式。
DBSCAN的分群方式是先隨便找到一點數據點,並通過設定的半徑畫圓來查看圓內的資料點有多少,若符合所設定的最低數據量,圓圈就會繼續往前移動,反之重新找到下一個未掃描的資料,一直到掃描完所有的資料點才會停止,我們可以看到下圖DBSCAN的分群結果(同顏色為一群,沒被匡列到的資料點為異常點)。
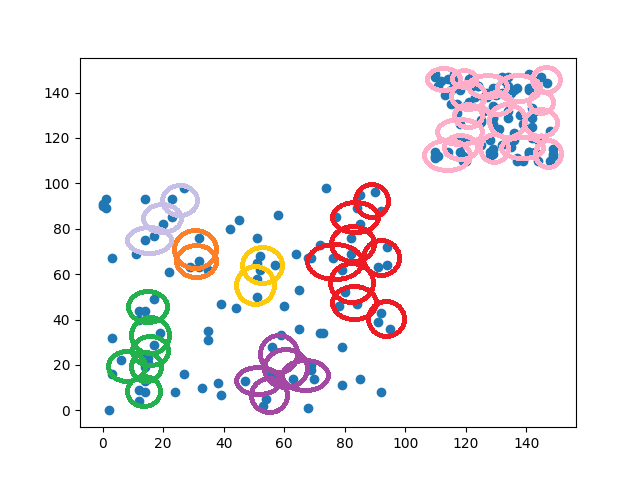
從結果來看DBSCAN能幫助我們更詳細的找出相似的資料,但再圖片中卻可以發現一個問題,就是在密度較高的區塊(右上方),有良好的分群效果,但在密度較低(左下方)的區塊,卻會被分類成較多群,這些密度較低群體之間可能也有一定的相似度,但DBSCAN卻會認為這幾組類別並不相同,這是因為DBSCAN若遇見密度差異大的資料集,就會導致效果會較差,這時只能去使用一些特徵分析的方式,將特徵較相似的群體合併在一起。
結論
從我們今天介紹了兩種分群演算法當中,可以發現到不同的分群演算法,能處理的資料集也都不相同,這就好比我們在深度學習中對圖片會使用CNN,對時間會使用LSTM,在分群演算法也是相同的道理,雖然不是不能做使用,但用錯方式得到的最終結果自然會不佳。
對Google評論自動分群-HDBSCAN與Sentence-BERT(上)
DBSCAN的問題
我們昨天提到了分群演算法DBSCAN的分群原理,也提到了密度不同會導致的問題,你可能會覺得這是一個小問題,但在實際使用上卻因這個密度,從而導致很多例外情況發生。我們先看以下例子
x = np.random.randint(0, 100, 100).tolist() + np.random.randint(150, 250, 100).tolist()
y = np.random.randint(0, 100, 100).tolist() + np.random.randint(150, 250, 100).tolist()
X = [[i,j] for i,j in zip(x,y)]
X = np.array(X)
首先我們先用程式創建一個密度相似的資料集,接下來透過DBSCAN分群來看看結果。
dbscan = DBSCAN(eps=30, min_samples=4)
dbscan.fit(X)
label_pred = dbscan.labels_
plt.scatter(X[:, 0], X[:, 1],c=label_pred)
plt.show()
可以看到圖片中分群效果是很好的,這是因為我們知道資料分佈的狀況,而且數據不混亂,所以可以很快地設定DBSCAN的參數。但在實際的數據中很難像圖片中一樣乾淨。所以我們現在加入一些雜訊,讓資料更能貼近實際狀況。
 在這裡我重新調整了DBSCAN的參數(eps=10,min_sample=3),調整完後可以看到DBSCAN還是能大致分類出兩大群,但效果已經沒有一開始的好,如果這時我們又加入了一筆資料呢?
在這裡我重新調整了DBSCAN的參數(eps=10,min_sample=3),調整完後可以看到DBSCAN還是能大致分類出兩大群,但效果已經沒有一開始的好,如果這時我們又加入了一筆資料呢?
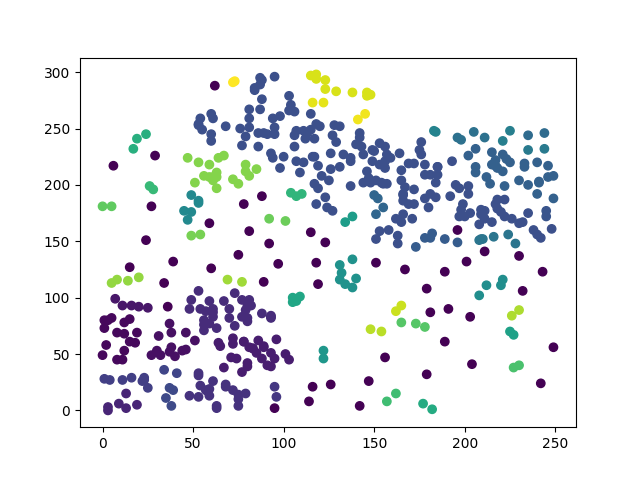 加入資料後分群的結果再度變成了另一種樣子,這就是DBSCAN特性造成的最大的缺點,只要去變動一點資料,或是稍微調整參數值,就會大幅度的改變原先的結果。而且調整DBSCAN的參數時,必須需要對原始資料非常熟悉,不然會非常的難調整參數,可能條整了半天都沒辦法達成想要的結果。
加入資料後分群的結果再度變成了另一種樣子,這就是DBSCAN特性造成的最大的缺點,只要去變動一點資料,或是稍微調整參數值,就會大幅度的改變原先的結果。而且調整DBSCAN的參數時,必須需要對原始資料非常熟悉,不然會非常的難調整參數,可能條整了半天都沒辦法達成想要的結果。
看到了DBSCAN的問題是不是覺得拿來做分群會非常的麻煩,所以我們需要了解一下HDBSCAN這個分群方式
HDBSCAN(Hierarchical DBSCAN)
HDBSCAN(Hierarchical DBSCAN)就是為瞭解決DBSCAN的這些問題從而誕生的技術,不過這一個技術說明起來會牽扯到非常多的相關知識,所以我在這邊挑幾個重點來講解HDBSCAN的分群方式。
空間變換
在我們分群時最頭痛的就是異常點,因為不管是K-means還是DBSCAN都會因為異常點從而影響到了分群的結果,為了改善異常點問題,HDBSCAN利用了密度的關係來作空間變換,因為異常點密度較低,所以只需密度較低的樹據,推移到更遙遠的地方,這樣子程式就更容易忽略這些異常點。
建立最小生成樹
通過了剛剛提到的空間變換,我們會取得一些密度較高,但各群組密度卻不相同的數據,因為這些群組的產生方式,是依照隨機半徑匡列出來的數據點,也因為密度不同的關係,若要有良好的分群效果必須要在這些群組內計算出最有可能的分群結果,所以我們需要在群內使用演算法產生出最小生成樹,來計算我們各點之間的權值。
構建與壓縮群組層次結構
我們給定群內的最小生成樹,下一步是將其轉換為連接組件的層次結構。根據樹之間的距離,對樹的邊緣進行按增加的順序排序,不斷的重複以上動作,直到每條邊都創建一個新的合併的群組(數據點較近的重新分成一群)。這樣子就能夠將龐大而復雜的群組拆分成更小的群組,如果群組內有少於最小的樣本的點,就會被當成異常點
統整了以上提到的三種技術,HDBSCAN實際上做了以下的事情來達成分群的效果。 1.隨機找到一個數據點當作圓心,並隨機產生半徑畫圓,匡列到的數據點都會被當成同一群類 2.通過各圓心得距離來初步排除異常點 3.在各群組內的建立最小生成樹 4.通過演算法將群內的數據點分成更小的群組,並根據設定的最小樣本數排除異常點 5.重複以上動作直到掃描完所有的數據點
與DBSCAN不同的地方是,因為半徑是由程式隨機產生,所以我們只需要控制圓圈內的最小數據點(最低密度),就能夠快速又穩定的完成分群。這樣子的作法雖然能夠達到較穩定的分群結果,但也因為在構建群組層次結構時會將這些結果再分的更小,所以我們基本上都需要手動合併一些主題。
說完了HDBSCAN,接下來我們來看看為何文字分群要使用S-BERT這一個model吧。
Sentence-BERT(S-BERT)
為了將文字轉換成能夠被分群的資料,我們需要透過一些方式轉換,像是可以通過先前接觸到的BERT,透過訓練文本之間的回歸任務,將文字拼接到網路之中,但如果是使用BERT方式,過程將會十分的緩慢,例如層次分群的方法,分群10,000個句子,BERT大約需要花費65個小時才能夠完成。但我們不可能只是為了分群就等了這麼久,所以我們要來看看S-BERT究竟是什麼?能不能替代BERT當作分群轉換方式。
S-BERT這是個model是對BERT分群的方式改進而產生的model,該model是使用孿生網路(Siamese network)和三重網絡(triplet networks)結構來產生一個有意義的embedding,embedding結果可以直接通過餘弦相似度或歐式距離等數學公式直接進行比對,這替代了原本BERT對句子之間做回歸的訓練時間。據S-BERT論文所說,可以將BERT原本65小時訓練時長縮短至僅僅5秒。
孿生網路(Siamese network)
在開始說明S-BERT之前我們要先知道什麼叫做孿生網路(Siamese network),所謂的孿生神經網路,就是由兩個權值共享(Shared Weights)的子網路所建構出的一個網路,你可能會想若是兩個相同的神經網路那並且權值共享,那不就等於是一個相同的網路嗎?幹嘛要多此一舉將一個網路能解決的是分成兩個。這個問題的答案非常簡單。
答案就是我們需要兩個embedding的結果來計算文本之間的相似度,所以我們需要有兩個輸入與兩個輸出,這時就使用一個網路就無法達成這個目的了。
三重網絡(triplet networks)
三重網絡是孿生網路的一種延伸,孿生不同的是,三重網路在訓練時,採用三個樣本為一組,分別是參考樣本、同類樣本、異類樣本,這三個樣本是使用相同的網路。
三重網路會有兩個輸出一個是參考樣本與同類樣本計算出來的相似距離,另一個是參考樣本與異類樣本計算出來的最不相似距離,通過這樣的訓練方式我們就可以找到最相似的樣本與最不相似的樣本。
三重網路的做法與我們在【day13】預訓練模型訓練 & 應用- 使用OpenCV製作人臉辨識點名系統 (下)稍微提及到的Google Face Net所要做的事情相同,只是對象從人臉變成了文字而已。
接下來我們來看看S-BERT的架構到底是什麼
S-BERT架構
 S-BERT做了些實驗比較孿生網路與三重網路哪種方式較佳,而這一方面由孿生網路勝出,所以我們可以看到圖片中S-BERT的基礎架構其實就是,將原始的BERT加上一層池化層並更改成孿生網路的模式而已。
S-BERT做了些實驗比較孿生網路與三重網路哪種方式較佳,而這一方面由孿生網路勝出,所以我們可以看到圖片中S-BERT的基礎架構其實就是,將原始的BERT加上一層池化層並更改成孿生網路的模式而已。
在S-BERT的網路中池化層的功用非常的重要,因為輸入的token都不同,所以輸出的維度也就會不平均,於是就需要在BERT的輸出後面,加入一層mean pooling來取token的平均值,這樣子就可以取得BERT該有的embedding大小。
通過這樣子的結果,我們就可以直接使用這個embedding來各句子之間的相似度,或是直接使用這個embedding來幫助我們對文字做分群。
結論
我們今天所講的兩個技術,都是在文字分群中相當重要的,因為我們在分群時最重要的就是準確率以及完成速度,若分群的速度過於緩慢,那不如自己手動分群。
所以我們需要拋棄掉BERT的方式,改用S-BERT幫助我們完成分群的動作,並且利用HDBSCAN這種不容易受到資料影響的分群方式,讓我們能夠找到更仔細的群組,接下來就是看我們該如何把這些群組合併或是移除了,我們明天就來看看如何使用這兩個技術,對google評論分群的效果。
對Google評論自動分群-HDBSCAN與Sentence-BERT(下)
對Google評論自動分群
今天的目錄如下:
- 1.取得Google地圖評論
- 2.S-BERT安裝與資料轉換
- 3.HDBSCAN安裝與資料合併
- 4.查看最終結果
取得Google地圖評論
今天我們要對"臺北101觀景臺"的google地圖評論自動分群,雖然這些評論都能用Google Map API取得,不過Google Map API使用太多次是要付費的,所以在這邊還是會使用爬蟲的方式取得我們需要的資料,這次的過程會和上次【day14】預測Hololive七期生的樣貌-生成式對抗網路(Generative Adversarial Network)(上)的方式差不多,但同樣的東西我當然不可能會讓你們看兩次,所以這次我會說明一些我常用的技巧,讓你能加快找到資料的速度。
之前在找資料時,都是透過網站載入的時間序來去尋找我們想要的AJAX網址,但這樣子的效率實在是太慢了,所以這次我們使用CTRL+F大法,直接搜尋我們要內容(這裡是文字),就可以通過這個內容快速找到對應的AJAX網址。
接下來點擊我們剛剛搜尋到的結果,就能夠快速的找到這個資料存放在哪一個AJAX網址裡面

找到了AJAX網址後我們來分析網址,之前我們都是通過手動找到網址的參數,不過當AJAX網址太長時,整理起來就會非常困難,所以在這邊可以直接點到Payload的頁面上,就能夠快速的看到這些網址究竟需要傳送哪一些參數。

接下來我們就能夠開始撰寫程式了,這邊也與先前用的方式不同,之前我們是直接複製AJAX網站,但這樣子會有些缺點,第一個就是管理起來太不方便了,若需要一次修改很多參數,我們就會一直修改某一段的網址然後再重組,而且這樣的方式也很難讓我們觀看這些參數,所以我們可以直接將剛剛的參數寫成一個字典,這樣子不只能方便觀看,還能夠快速地修改參數值。
import requests
params = {
'authuser': '0',
'hl': 'zh-TW',
'gl': 'tw',
'pb': '!1m2!1y3765761040530879049!2y15350791680915855665!2m1!2i10!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1sFsQyY9iuBv-Nr7wP3r6z2Ac!7e81'
}
r = requests.get('https://www.google.com/maps/preview/review/listentitiesreviews?' ,params = params)
用以上程式取得到JSON資料後,就可以來分析哪一個JSON的節點是我們想要的資料,在這邊需要通過一些JSON結構分析器(Preview也看的到)分析出JSON的結構,才能讓我們知道資料存放在哪些節點。不過我們需要注意一點,就是google map的JSON資料裡面前4碼是錯誤的,所以必須先將這4碼移除掉,分析器才能夠正常運作。
通過結構分析可以看到資料都存放在JSON的第三個節點中,但我們只需要評論資料,所以我們可以透過縮小節點條件的方式只保留文本資料。
r_json = json.loads(r[4:])
for i in r_json[2]:
print(i[3])
在爬蟲中必須要不斷的更換網址來達成翻頁的動作,所以我們需要去執行換頁的動作刷新URL來找到其中的規律。
!1m2!1y3765761040530879049!2y15350791680915855665!2m1!2i10!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1sr98yY9iDLrfP2roP7sWVsAc!7e81'
!1m2!1y3765761040530879049!2y15350791680915855665!2m1!2i20!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1sr98yY9iDLrfP2roP7sWVsAc!7e81'
可以看到第一頁的資料在2i10裡面,第二頁的資料在2i20裡面,所以只需要變換這個數字,就能夠達成翻頁的動作了。
最後我們設立停止條件來結束爬蟲(都是None時跳脫)
#![allow(unused)] fn main() { for i in r_json[2]: if i[3] == None: error_cnt+=1 else: comments.append(i[3]) if error_cnt ==10: flag = 1 if flag: break }
最後將這些評論存入CSV就完成我們今天要用的資料集了
google_comment_df = pd.DataFrame({"評價":comments})
google_comment_df.to_csv("臺北101觀景臺.csv")
爬蟲完整程式碼
import requests
import json
import pandas as pd
params = {
'authuser': '0',
'hl': 'zh-TW',
'gl': 'tw',
'pb': '!1m2!1y3765761040530879049!2y15350791680915855665!2m1!2i100!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1sr98yY9iDLrfP2roP7sWVsAc!7e81'
}
cnt = 0
comments = []
error_cnt =0
flag = 0
while(1):
params['pb'] = f'!1m2!1y3765761040530879049!2y15350791680915855665!2m1!2i{cnt*10}!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1sr98yY9iDLrfP2roP7sWVsAc!7e81'
r = requests.get('https://www.google.com/maps/preview/review/listentitiesreviews?' ,params=params).text
r_json = json.loads(r[4:])
print(cnt)
for i in r_json[2]:
if i[3] == None:
error_cnt+=1
else:
comments.append(i[3])
error_cnt = 0
if error_cnt ==10:
flag = 1
if flag:
break
cnt+=1
google_comment_df = pd.DataFrame({"評價":comments})
google_comment_df.to_csv("臺北101觀景臺.csv")
S-BERT安裝與使用
剛剛取得資料所以下一步就是將資料轉換成embedding的形式,才能夠被機器看懂,所以需先安裝S-BERT的函式庫
pip install sentence-transformers
這個函式庫的下載model的方式與hugging face相似,只是改成使用SentenceTransformer('model名稱')。不過S-BERT沒有專用的中文BERT model,所以我們直接用多國語言的版本來完成我們的轉換工作。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(sentence-transformers/distiluse-base-multilingual-cased-v2)
有了model後我們只需要剛讀取CSV檔案透過一行程式碼,就能把每一個句子都更換成embedding的格式啦
data = pd.read_csv("臺北101觀景臺.csv")['評價'].tolist()
embeddings = model.encode(data)
HDBSCAN安裝與資料合併
接下來我們需要安裝HDBSCAN,如果是跟我一樣是windows的用戶在安裝HDBSCAN之前必須下載 Visual Studio這樣才能夠使用pip安裝HDBSCAN。
pip install hdbscan
接下來隨便調整min_cluster_size就能夠分群了,因為HDBSCAN分群的效果較穩定,所以並不需要在HDBSCAN上做太多的調整,而是將重點放在合併主題的方式上。
cluster = hdbscan.HDBSCAN(min_cluster_size = 15).fit(embeddings)
分群完畢後你肯定會發現結果實在太多了,所以我們還需要把相似的主題合併為一個主題,在這裡可以使用TF-IDF或是相似度檢測的方式來合併。在這裡我會試範如何使用相似度檢測的方法合併主題,若對TF-IDF的方式有興趣的人可以在S-BERT的官方文件中找到程式範例點我前往。
這邊我採用一種比較暴力的方式,來交給S-BERT做相似度檢測 1.將所有主題內的句子合併成一個文件 2.使用餘弦相似度計算個主題之間的相似度 3.將大於0.5以上的文本合併 4.重複以上動作直到沒有結果符合步驟3
首先我們先將所有的文本合併在一起
topics = {}
for comment,label in zip(data, cluster.labels_):
topics[label]+=' ' + comment
corpus = [i for i in topics.values()]
接下來把文本轉換成embedding的形式,並且通過餘弦相似度來判別各主題之間的相似度
epochs = 100
for epoch in range(epochs):
#找到當前該被查詢的主題
i = epoch % len(corpus)
corpus_embeddings = model.encode(corpus)
query_embeddings = model.encode(corpus[i])
#計算該主題與其他主題的相似度
for query, query_embedding in zip(queries[i], query_embeddings):
#計算餘弦相似度
distances = scipy.spatial.distance.cdist([query_embedding], corpus_embeddings, "cosine")[0]
取得了個主題的相似度後,先將分數由高到低的排列來找到最相似的主題,在這邊我們只合併最相似的主題,這是為了防止這些主題過度合併。
#將分數由高排到低
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
#找到最佳的結果
for idx, distance in results[0]:
#只要分數>0.5就合併該主題
if 1-distance > 0.5:
corpus[i]+=corpus[idx]
corpus.remove(corpus[idx])
最後結果
合併完後我們需要將這些句子還原,因為合併時的方式是利用空白做分割,所以只需要用split()分割文字將結果還原就能存入CSV中觀看結果了。
results = {}
for cnt,i in enumerate(corpus):
results[cnt] = i.split(' ')
results_df = pd.DataFrame.from_dict(results, orient = 'index')
results_df = results_df.transpose()
results_df.to_csv('output_result.csv')

由左往右數,可以看到主題1是關於101的電梯設備,主題3是觀景臺的風景,主題4是門票的價格,在這個結果之中,除了主題2的分類較混亂,其餘的結果都是良好了,不過這個程式還有許多能改善的地方。
例如我們直接採用embedding的結果分群就會因為維度太大(768維),導致HDBSCAN分群效果沒有達到預期的成果,如果使用PCA、T-SNE等降維方式,不僅能改善這個問題,還能增加運算速度。
再來是相似度檢測的部分,在這裡我是直接將文字全部當作一個句子去計算相似度,但這樣子在一個句子就會包含太多訊息,這樣會導致S-BERT無法很好的辨識出結果,若比對個主題單一句子之間的相似度,效果肯定會比現在好很多。
最後就是文字前處理的部分,在這程式中我完全沒有做任何的資料前處理,若是能移除掉一些表情符號、URL、標點符號,結果應該會更好。
完整程式碼
from sentence_transformers import SentenceTransformer
import scipy.spatial
import hdbscan
model = SentenceTransformer(sentence-transformers/distiluse-base-multilingual-cased-v2)
data = pd.read_csv("臺北101觀景臺.csv")['評價'].tolist()
embeddings = model.encode(data)
cluster = hdbscan.HDBSCAN(min_cluster_size = 15).fit(embeddings)
topics = {}
for comment,label in zip(data, cluster.labels_):
topics[label]+=' ' + comment
corpus = [i for i in topics.values()]
corpus_embeddings = model.encode(corpus)
epochs = 100
for epoch in range(epochs):
#找到當前該被查詢的主題
i = epoch % len(corpus)
query_embeddings = model.encode(corpus[i])
#計算該主題與其他主題的相似度
for query, query_embedding in zip(queries[i], query_embeddings):
#計算餘弦相似度
distances = scipy.spatial.distance.cdist([query_embedding], corpus_embeddings, "cosine")[0]
#將分數由高排到低
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
#找到最佳的結果
for idx, distance in results[0]:
#只要分數>0.5就合併該主題
if 1-distance > 0.5:
corpus[i]+=corpus[idx]
corpus.remove(corpus[idx])
results = {}
for cnt,i in enumerate(corpus):
results[cnt] = i.split(' ')
results_df = pd.DataFrame.from_dict(results, orient = 'index')
results_df = results_df.transpose()
results_df.to_csv('output_result.csv')
加快程式的運算速度-學習常見的降維演算法
在過去23天內我們學習到了各神經網路模型的架構與原理,並且藉由小專案的方式來使用這些模型,但在AI的技術中除了要運用這些模型,還要學習如何輸入乾淨的的資料,所以在剩下的幾天之內,我會來補充一些實用的資料前處理技巧。
為何要降維(Dimension Reduction)
當我們在運算維度較高的資料時,運算就會需要花費較多的時間與資源,若今天有一個方式能夠將這些資料縮小,卻能保持原始的特性,那豈不是能夠完美的解決問題?所以今天要來說說降維究竟是什麼
降為可以幫我們縮小資料的維度,從而加快程式的運算速度,但降維不只能做到以上兩件事情,它還能夠幫助我們將資料視覺化(我們基本上只看得懂2維與3維),還能夠解決維數災難(curse of dimensionality)的問題。
維度災難的意思是,當一個資料維度太高空間的體積太大時,因而可用數據變得很稀疏(太多雜訊),導致資料沒有麼用處,但降維可以通過特徵抽取的方式來投影出更小的維度,所以能夠使用降維的方法來處理維度災難的發生。
也因為是一整特徵提取的方式,所以我們常常都會在機器學習的領域中看見這一技巧,瞭解降維能解決的問題後,我們開始進入今天的主題,我們來看看兩個最常見的降維方式PCA與t-SNE。
主成份分析(Principal component analysis)
主成份分析(Principal component analysis)簡稱PCA,也被稱為最簡單的降為方式,其主要方式就是提取高維度的資料特徵投影到一個低維度的空間,來達到化繁為簡效果,這種方式能夠讓我們的原始資料在沒有什麼損失的情況下,用更精簡的方式來表達原始資料。
為了知道PCA是如何達成資料降維的動作,我們來看看PCA的實際操作,不過這些操作牽扯到了太多線性代數公式,所以我在這邊舉一個簡單的例子來幫助你瞭解PCA的構造。
假設我們今天想要買一臺筆電但卻不知道該如何挑選,所以找了一些懂電腦的朋友幫助你挑選筆電,他們跟你說買筆電需要看,CPU、顯示卡、電池容量、記憶體大小、螢幕大小,但這兩個人判斷的結果不相同,效能派的朋友認為選擇筆電的優先順序是顯卡>CPU>記憶體>螢幕大小>電池容量,耐久派的朋友認為電池容量>CPU>記憶體>螢幕大小>顯卡,這時候如你是效能派就會在挑選筆電時,用效能派意見為主,耐久派的意見為輔,找到你最想要的筆電。
接下來我們把剛剛提到的例子轉換到PCA的概念上
最想要的筆電是最終目標
懂電腦的朋友是主成份分析
CPU、顯示卡、電池容量、記憶體大小、螢幕大小是擷取的特徵
效能派與耐久派分別代表為第一主成份與第二主成份
簡單來說PCA就是設立一個想要的目標,找出資料特徵,並且通過演算法計算第一主成份與第二主成份(這個主成份代表著資料維度),最後通過這些主成份來完成一個更低維度的資料。
t-隨機鄰近嵌入法(t-distributed Stochastic Neighbor Embedding)
t-隨機鄰近嵌入法(t-distributed stochastic neighbor embedding)簡稱t-SNE,這個演算法與PCA相同,都是為了將高維度的空間投影到低維度,不過t-SNE與PCA不相同地方的是,PCA在降維時空間結構會崩塌。
我們可以想像PCA處理降維的動作就是,對一個麵包大槌一揮把它打扁,硬生生的將高維空間扁成低維,這樣子會導致高維平面上的資料重疊。t-SNE則會將麵包分成好幾塊並且將小塊的麵包丟到更遠的地方,不過這解說起來比較複雜,所以我們先看看以下的例子。
假設我們在新生入學的演講現場,校長要求在附近的同學開始溝通,社交能力強的人附近就會有較多人,而沒有社交能力的人附近的人就會較稀少,這時校長根據人數給予各組彈力不同的彈簧,並要求每一組必須在固定的範圍內移動,若在範圍內遇見其他人就需要將他彈走,最後範圍內沒有人能夠彈的時,校長就在這些組別的蓋了一間教室當作它們的班級。
接下來我們把這了例子轉換到t-SNE上
附近的同學代表的是歐式距離(Euclidean distances)
社交能力強代表的是高斯分佈(Gaussian distribution)又稱常態分佈
社交能力弱代表的是 t分佈
範圍代表的是困惑度(Perplexity)
結合例子與實際的應用t-SNE實際在做的事情就是,計算各點之間的歐式距離,若密度較高的群組使用高斯分佈計算,密度較低則用t分佈計算,並且通過設定困惑度,將密度較低的點彈到更遠的地方或不見(因為不重要),密度適中得點會稍微移動,最後將這些群組或點保留在設定的平面上。通過這的方式排除無意義的資料,保留相似的資料並且還能保有一定的距離關係。但這樣的作法也有些缺點,就是t-SNE無法接受新的資料,需要重新訓練才行。
手刻最簡單的神經網路-單層感知器(Single Layer Perceptron)
課程剩下最後的6天,我們今天要來增加你對神經網路的印象,所以今天要來手刻最簡單的神經網路單層感知器(Single Layer Perceptron)
單層感知器(Single Layer Perceptron)
你有想過什麼是最基本的神經網路嗎?答案就是單層感知器(Single Layer Perceptron)。你可以把這個技術想像成我們在課堂最一開始學習到的DNN神經網路的前身,我們看到以下這張圖片你可能就瞭解為什麼我這麼說了。
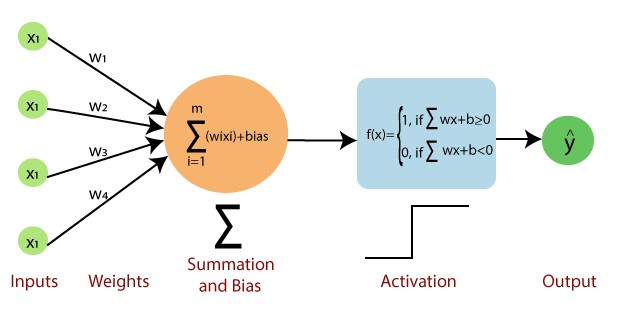
圖片來源:https://medium.com/nerd-for-tech/flux-prediction-using-single-layer-perceptron-and-multilayer-perceptron-cf82c1341c33
這張圖片已經包含了所有單層感知器該知道的知識,不過我們還是大致上說一下單層感知器做了哪些事情。單層感知器有三的必要的參數分別就是X、W、B,用數學式表達這三個之間的關係就是f(X) = WX+b,與我們DNN的意思相同X代表輸出,W代表權重(也是我們需要訓練的參數),B則是偏移量,單層感知器的作法就是利用WX+b的方式計算出f(x),並以0為分界線,來判斷出最後的結果,我們用程式表達的方式如下
if dot(W,X) - b >=0:
fx = 1
else:
fx = 0
我們可以看到單層感知器不像DNN一樣有很多個輸出,而是隻有一個輸出f(x),並且這一個輸出只會有0與1的結果,這代表單程感知器只能對資料做二分法,超過則沒辦法判斷。
訓練用的參數
先前我們在用pytorch訓練神經網路時,我們需要設定epoch、learn rate與還有損失函數(loss function)與反向傳播 (Backpropagation),但我們在單層感知器並沒有反向傳播的動作,所以單層感知器是隻使用前向傳播 (Forwardpropagation)的方式訓練出來的。
我們先來快速的講解一下反向傳播是什麼。反向傳播是一種用輸出與實際值比對(loss)後重新訓練神經網路的方式,我們目前的課程中,都有使用到反向傳播的方式來訓練程式的,反倒是沒有使用過"只有"前向傳播的網路,這是因為反向傳播能夠損失函數計算目前數值與實際數值之間的誤差,最後將這個誤差更新到每一個隱藏層,優化每個隱藏層神經網路。
那前向傳播是什麼呢?簡單來說就是判斷目標與實際值,如果數值太大就往下降,如果太小就往上增加,直接更新整個權重在重新做計算。
這樣你瞭解到為什麼只有前向傳播的網路到後期沒人在使用了吧,因為後期的神經網路越來越多層,越來越混亂,如果是更新全部的權重,可能會導致每次產生的結果完全不一樣,就算條件設立的在多都無法穩定的更新。
而我們今天要學習的單層感知器就是一種只有前向傳播的單的神經網路,所以我們只需要調整epoch與learn rate就可以了。
手刻單層感知器
今天的目錄如下:
- 1.設定數據集資料
- 2.架構神經網路模型與功能
- 3.使用模型與功能
設定數據集資料
我們今天要來用單層感知器來實現一些邏輯閘(AND、OR)的功能,所以第一步就是設立邏輯閘的資料。
AND_x_train = np.array([[0,0],[0,1],[1,0],[1,1]])
AND_y_train = np.array([0,0,0,1])
AND_x_test = np.array([[0,1],[1,1],[0,0],[1,0]])
OR_x_train = np.array([[0,0],[0,1],[1,0],[1,1]])
OR_y_train = np.array([0,1,1,1])
OR_x_test = np.array([[0,1],[1,1],[0,0],[1,0]])
架構神經網路模型與功能
接下來我們可以開始定義model內部的計算公式,剛剛提到公式是WX+b,在這裡的b指的就是向量的角度的數值,我們可以利用國中學習到的內積公式可以反推COSθ(a﹒b = |a|x|b|COSθ),最後ACOS算出b值,在這邊我將程式碼都寫成像是keras的方式方便讓你理解
class Perceptron:
def model(self,x):
self.b = np.dot(self.w, x) / (np.linalg.norm(self.w) * np.linalg.norm(x))
self.b = math.acos(self.b)
# W﹒X - b > 0
return np.dot(self.w, x) >= self.b
定義好model後我們就可以用開始定義訓練方式了,在最開始說到若數值大於0輸出為1,所以我們要透過公式來降低或提高權重,而這個公式就是W = W + lr*X這樣就可以使用學習率的方式來更新權重
#隨機初始化權重
self.w = np.random.uniform(-0.5, 0.5, X.shape[1])
#測試是否大於0
y_pred = self.model(x)
#若輸出要為1但是結果<0就要提高權重
if y == 1 and not y_pred:
self.w += lr * x
#若結果為0但結果>0就要降低權重
elif y == 0 and y_pred:
self.w -= lr * x
統計正確的結果,方便後續計算準確率
else:
acc+=1
將以上的程式加入epoch來重複訓練,並且紀錄每一個epoch的結果
def fit(self, X, Y, epochs = 100, lr = 0.05):
self.w = np.random.uniform(-0.5, 0.5, X.shape[1])
self.result = {'acc':[],
'w':[],
'b':[],
'epoch':[]
}
for i in range(epochs):
acc = 0
for x, y in zip(X, Y):
y_pred = self.model(x)
if y == 1 and not y_pred:
self.w += lr * x
elif y == 0 and y_pred:
self.w -= lr * x
else:
acc+=1
#紀錄資訊
self.result['epoch'].append(i)
self.result['acc'].append(acc/len(X))
self.result['w'].append(self.w)
self.result['b'].append(self.b)
#全部預測成功中斷程式
if acc / len(X) ==1:
break
為了觀看我們訓練的過程,我們一些資料化成圖表,一些資料用print的方式顯示出來
def show(self, title):
plt.plot(self.result['acc'])
plt.title(title)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.ylim([0, 1])
plt.show()
for i in range(len(self.result['acc'])): \
print(f"Epoch:{self.result['epoch'][i]}\
Wight:{self.result['w'][i]}\
θ:{self.result['b'][i]}\
Acc:{self.result['acc'][i]}\
")
最後定義一個使用模型的方式,這樣就架構好整個神經網路了。
def predict(self,X):
return [self.model(x) for x in X]
使用模型與功能
在這裡我們總共定義了三個方法、fit()、show、與predict(),我們先來使用fit()訓練神經網路
#定義model
AND_model = Perceptron()
OR_model = Perceptron()
#訓練
AND_model.fit(AND_x_train, AND_y_train)
OR_model.fit(OR_x_train, OR_y_train)
接下來為了知道模型訓練的效果我們將訓練的歷史紀錄都顯示出來
AND_model.show('AND')
OR_model.show('OR')
在圖片中可以看到我們的邏輯閘都被訓練完畢了,這時如果有要在使用自己的數據集就能夠用predict的方式呼叫,不需要再重新訓練了。
print(AND_model.predict(AND_x_test))
print(OR_model.predict(OR_x_test))
------------------顯示------------------
[False, True, False, False]
[True, True, False, True]
今天的課程中,有沒有更能幫助理解AI在python當中是如何被建造出來的,通過手刻神經網路來幫助你學習最扎實AI理論。
完整程式碼
import numpy as np
import matplotlib.pyplot as plt
import math
class Perceptron:
def model(self, x):
self.b = np.dot(self.w, x) / (np.linalg.norm(self.w) * np.linalg.norm(x))
self.b = math.acos(self.b)
return np.dot(self.w, x) >= self.b
def fit(self, X, Y, epochs = 100, lr = 0.05):
self.w = np.random.uniform(-0.5, 0.5, X.shape[1])
self.result = {'acc':[],
'w':[],
'b':[],
'epoch':[]
}
for i in range(epochs):
acc = 0
for x, y in zip(X, Y):
y_pred = self.model(x)
if y == 1 and not y_pred:
self.w += lr * x
elif y == 0 and y_pred:
self.w -= lr * x
else:
acc+=1
self.result['epoch'].append(i)
self.result['acc'].append(acc/len(X))
self.result['w'].append(self.w)
self.result['b'].append(self.b)
#全部預測成功中斷程式
if acc / len(X) ==1:
break
def show(self, title):
plt.plot(self.result['acc'])
plt.title(title)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.ylim([0, 1])
plt.show()
for i in range(len(self.result['acc'])): \
print(f"Epoch:{self.result['epoch'][i]}\
Wight:{self.result['w'][i]}\
θ:{self.result['b'][i]}\
Acc:{self.result['acc'][i]}\
")
def predict(self,X):
return [self.model(x) for x in X]
AND_model = Perceptron()
OR_model = Perceptron()
XOR_model = Perceptron()
AND_x_train = np.array([[0,0],[0,1],[1,0],[1,1]])
AND_y_train = np.array([0,0,0,1])
AND_x_test = np.array([[0,1],[1,1],[0,0],[1,0]])
OR_x_train = np.array([[0,0],[0,1],[1,0],[1,1]])
OR_y_train = np.array([0,1,1,1])
OR_x_test = np.array([[0,1],[1,1],[0,0],[1,0]])
print(AND_model.predict(AND_x_test))
print(OR_model.predict(OR_x_test))
手刻神經網路來解決XOR問題-多層感知器 (Multilayer perceptron) (上)
前向傳播、反向傳播
昨天大致上提到了前向傳播 (Forwardpropagation)與反向傳播 (Backpropagation),但因為是單層感知器所以我們沒有太深入瞭解,而且我去看昨天的文章發現有些部分會讓人誤會(截稿前才快寫完RRRR),所以今天要來重新講解,什麼是前向傳播什麼是反向傳播。
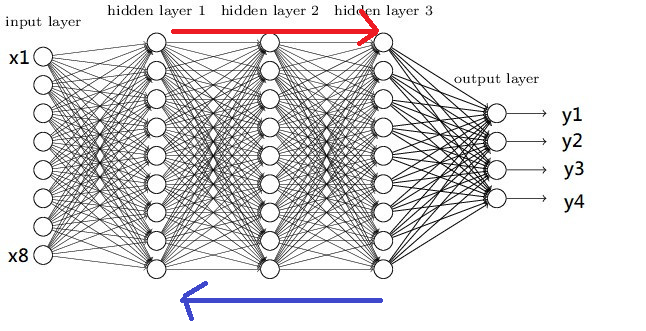 深度學習基本上就是在做前向傳播與反向傳播,而前向傳播的定義非常簡單,就是在圖片中紅色箭頭的部分,所謂的前向傳播算法就是,將上一層的輸出作為下一層的輸入,直到運算到輸出層為止,前向傳播的概念非常簡單,我們所有的神經網路模型都是要先進行前向傳播計算,從而計算loss值,任何在複雜的神經網路都能用以下公式來表達
深度學習基本上就是在做前向傳播與反向傳播,而前向傳播的定義非常簡單,就是在圖片中紅色箭頭的部分,所謂的前向傳播算法就是,將上一層的輸出作為下一層的輸入,直到運算到輸出層為止,前向傳播的概念非常簡單,我們所有的神經網路模型都是要先進行前向傳播計算,從而計算loss值,任何在複雜的神經網路都能用以下公式來表達Σσ(WnXn+b)(σ是激勵函數、b是偏移量),但昨天提到了前向傳播在單層感知器的更新方式是一次更新所有數值,所以只有前向傳播的網路效果自然會很差。
所以才會有了反向傳播的方式,反向傳播是一種與最佳化理論(Principle of optimality)結合使用的方法,這個方法會根據所有神經網路的權重來計算損失從而更新梯度,所以我們只需要計算每一層神經網路的梯度,就能夠完成反向傳播,接下來我們看到計算方式(左側為輸入,右側為梯度公式)。
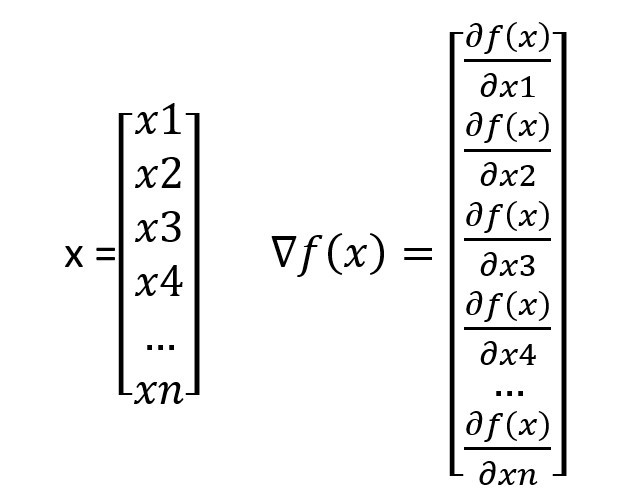
我們知道昨天計算的單層感知器,最後的輸出結果是W1X1+W2X2+b(矩陣表示為w.t+b),我們把他帶入到∇f公式裡面就會變成
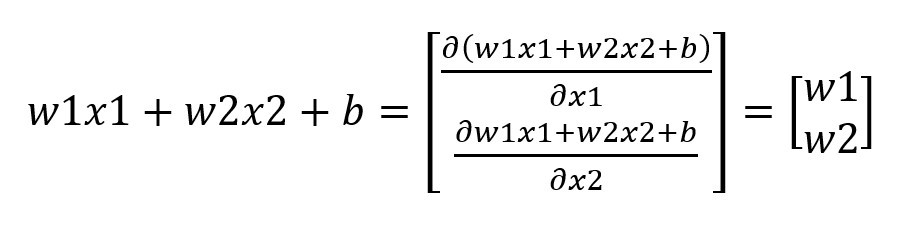 這時候我們就可以利用計算出來的梯度套用至梯度下降的公式裡面(
這時候我們就可以利用計算出來的梯度套用至梯度下降的公式裡面(更新後權重 = 前一次訓練的權重 - 學習率*前一次訓練的梯度)
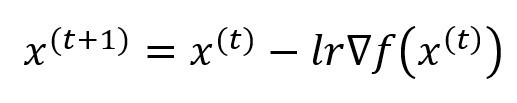
最後我們把整個神經網路的公式都統整起來
前向傳播:y = Σσ(WnXn+b)
反向傳播計算梯度:對所有輸入都做偏微分(含隱藏層輸入)
梯度下降:更新後權重 = 前一次訓練的權重 - 學習率x前一次訓練的梯度
這樣子就是所有神經網路所在做的計算了。
XOR問題
如果你昨天有嘗試過OR、AND以外的邏輯閘,你會發現NXOR與XOR不管怎麼調整學習率都無法完成訓練這是因為XOR在單層感知器上是不能被實現的。
我們把單層感知器視覺化,紅點代表XOR為0的數值,藍點代表為1的數值,紅線則是單層感知器,在這個例子中我們不管怎麼畫線都無法將紅點與藍點分開。
那我們該如何把紅藍點分開呢?答案很簡單就是畫兩條線就可以了
也就是我們要將只有單層的神經網路,多增加一層神經網路也就是下圖的形式,這種網路架構就稱之為多層感知機(Multilayer perceptron)簡稱MLP。
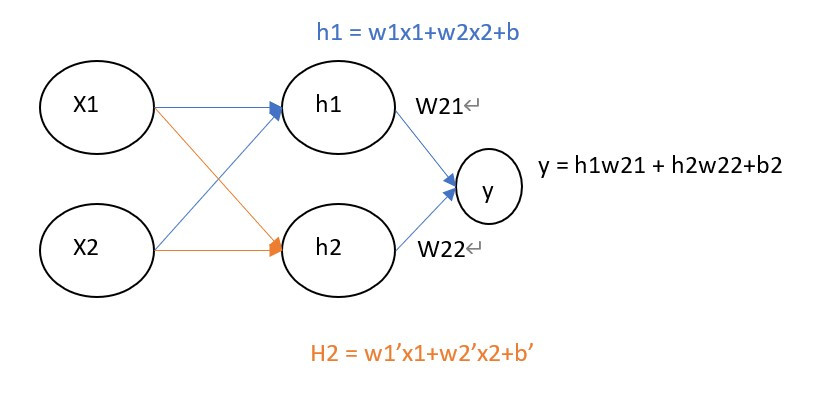
我們可以注意到一件事情,這與我們在【day3】來辨識圖像-深度神經網路(Deep Neural Network)學習到的DNN是不是很像呢?因為MLP其實與DNN是一樣的,差別在於中間的隱藏層數量不同,通常DNN是指隱藏層數量大於2層的神經網路(畢竟叫做Deep Neural Network),若只有一層我們通常就會叫他MLP,不過你把DNN與MLP混在一起大家還是會知道你在說什麼。
今天我們就先說到這裡好了,昨天接觸到了一些新程式所以今天只講解理論。明天我們要來講解如何手刻出MLP的神經網路,我們會一次比對兩種寫法分別是通過pytorch來快速的計算梯度與反向傳播,另一種則是手刻公式來計算梯度與反向傳播的方式。
手刻神經網路來解決XOR問題-多層感知器 (Multilayer perceptron) (下)
手刻多層感知器
今天的目錄如下:
1.建立與初始化資料 2.架構神經網路模型 3.更新參數 4.顯示結果
建立與初始化資料
與昨天相同我會把它寫成class的形式,因為是多層感知器,我們需要根據資料設定每一層的參數,在這裡我們先設定一下所有邏輯閘的資料集。
x = [[0.,0.], [0.,1.], [1.,0.], [1.,1.]]
x = torch.tensor(x)
XOR_y = torch.tensor([[0.], [1.], [1.], [0.]])
AND_y = torch.tensor([[0.], [0.], [0.], [1.]])
OR_y = torch.tensor([[0.], [1.], [1.], [1.]])
接下來要建立上圖的神經網路架構,所以需要來瞭解每一層的維度大小,首先輸入是(4,2),進入到隱藏層則要縮到(2,2),並且要完成y=wx+b這一個公式,根據上圖可以知道所有的隱藏層輸入都是h=w1x1+w2x2+b,只是每一個輸入的w1、w2、b都不相同而已。
所以我們將公式轉換為矩陣格式y = WX+b中的W、b必須符合輸入大小,所以輸入到隱藏層W是(2,2),隱藏層到輸出則是(2,1),最後寫在__init__裡就可以隨時調整各層的神經元數量了。
class model:
def __init__(self,inputs_shape , hidden_shape ,output_shape):
#requires_grad=True 表示之後能夠被反向傳播(pytorch用法)
#numpu改用np.random.uniform(size=(input_shape, hidden_shape))
self.w1 = torch.randn(inputs_shape, hidden_shape, requires_grad=True)
self.w2 = torch.randn(hidden_shape, output_shape, requires_grad=True)
self.b1 = torch.randn(1,hidden_shape, requires_grad=True)
self.b2 = torch.randn(1,output_shape, requires_grad=True)
self.loss = []
self.mse = MSELoss()
架構神經網路模型
昨天說到神經網路的三個步驟前向傳播、反向傳播計算梯度、梯度下降更新數值,不過在前向傳播前我們需要定義激勵函數,將我們每一層的結果都變成非線性的結果。
def sigmoid(self, x):
#numpy改用np.exp
return 1 / (1 + torch.exp(-x))
接下來開始定義前向傳播的公式wx+b,這邊用self的寫法是因為我們在反向傳播時還需要用到這些數值
def forward(self,x):
#pytorch中@代表矩陣相乘用*只會代表相同index的數字相乘
#numpy須將@改用dot EX:np.dot(x, self.w1)
#輸入到隱藏
h = x @ self.w1 + self.b1
h_out = self.sigmoid(h)
#隱藏到輸出
output = h_out @ self.w2 + self.b2
outpu_fin = self.sigmoid(output)
return outpu_fin
更新參數
pytorch
在pytorch當中計算梯度非常簡單,因為只需設定了requires_grad=True,就能夠直接使用.grad將梯度計算完畢。pytorch也能夠使用.backward()快速的做反向傳播更新梯度數值,這個我們先前用過了很多次只是我們不知道這個function的實際含意。
def updata(self, loss, lr):
loss.backward()
with torch.no_grad():
self.w1 -= self.w11.grad * lr
self.w2 -= self.w21.grad * lr
self.b2 -= self.b2.grad * lr
self.b1 -= self.b1.grad * lr
self.w11.grad.zero_()
self.w21.grad.zero_()
self.b1.grad.zero_()
self.b2.grad.zero_()
numpy
但numpy更新梯度的方式就很困難了,因為在這裡我們必須對所有要更新的數值做偏微分,而這個過程會非常的複雜。
經過昨天【day26】手刻神經網路來解決XOR問題-多層感知器 (Multilayer perceptron) (上)的課程中學習到的梯度計算方式,我們能夠知道若要計算出隱藏層的梯度,需要對計算出的loss值與輸入到隱藏層(w1)的資料做偏微分(O是預測輸出,W是輸入到隱藏層的資料、i是輸入、j連接到第幾個隱藏層神經元)
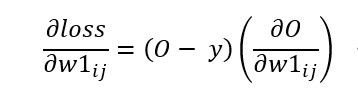
接下來分解∂O/∂w1
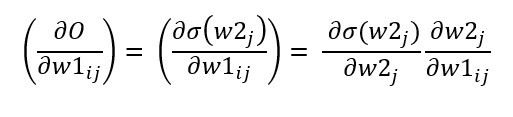
其中∂σ(w2)/∂w2)為sigmoid函數的導數f'(x) = f(x)(1 - f(x))。
輸入則是∂w2/∂w1 = xn(W = wx+b)
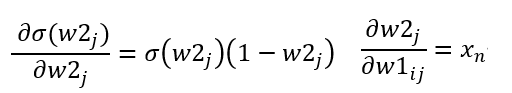
我們就會得到以下公式,這公式也代表(預測輸出-實際值)*delsigmoid(最後的輸出)*最後的權重*輸入
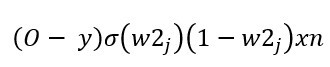
接下來計算好梯度後,就與pytorch更新梯度的方式相同了。
def updata(self, x, y, lr):
loss = 0.5 * (y - self.output_final) ** 2
self.loss.append(np.sum(loss))
error_term = (self.output_final - y)
#隱藏層梯度(注意這裡還多一層simgoid)
grad1 = x.T @ (((error_term * self.delsigmoid(self.output_final)) * self.w2.T) * self.delsigmoid(self.h1_out))
#輸出層梯度
grad2 = self.h1_out.T @ (error_term * self.delsigmoid(self.output_final))
self.w1 -= lr * grad1
self.w2 -= lr * grad2
self.b1 -= np.sum(lr * ((error_term * self.delsigmoid(self.output_final)) * self.w2.T) * self.delsigmoid(self.h1_out), axis=0)
self.b2 -= np.sum(lr * error_term * self.delsigmoid(self.output_final), axis=0)
def delsigmoid(self, x):
return x * (1 - x)
顯示結果
最後只要測試結果是否正確,以及繪製出loss折線圖就大功告成了
def predict(self, x):
#pytorch需要加入torch.no_grad
with torch.no_grad():
return self.forward(x) >= 0.5
def show(self, title):
plt.plot(self.loss)
plt.title(title)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
print(f'第一層W:{self.w11.tolist()} \n第二層W:{self.w21.tolist()} \n第一層?:{self.b1.tolist()} \n第二層?{self.b2.tolist()}')
model.show()
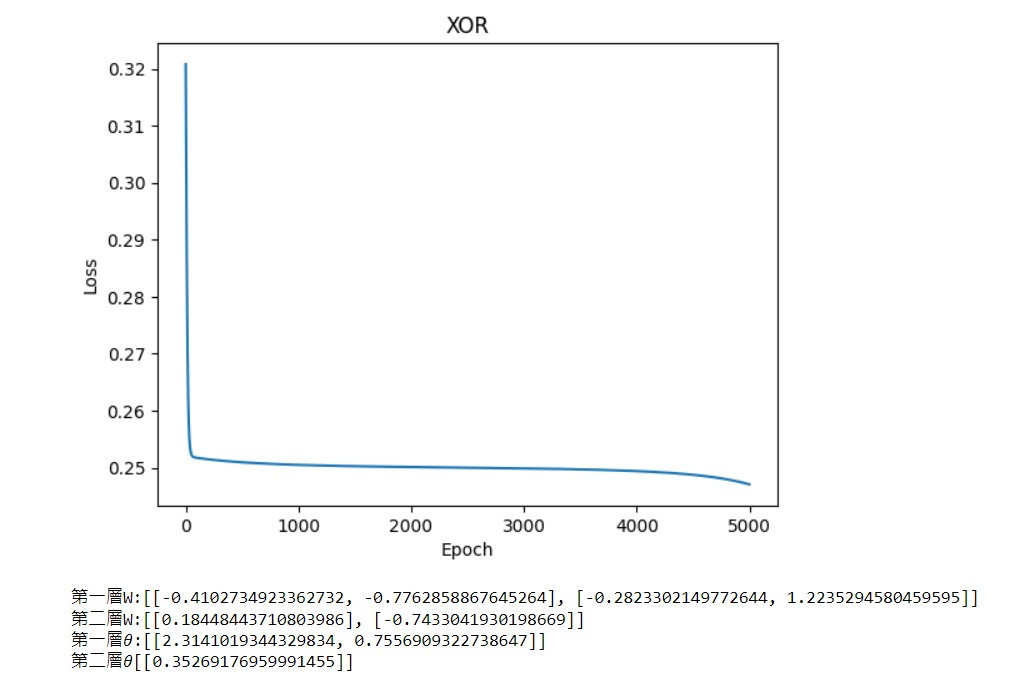
測試XOR結果
model.predict(x)
------------------------顯示------------------------
array([[ True],
[False],
[False],
[ True]])
今天的程式比單層神經網路還要複雜一點,最主要的原因還是反向傳播的計算,如果都瞭解了這些計算方式後,我相信手刻出其他神經網路就只是時間早晚的問題了。
完整程式碼(pytorch)
import torch
from torch.nn import MSELoss
import matplotlib.pyplot as plt
class model:
def __init__(self,inputs_shape , hidden_shape ,output_shape):
self.w1 = torch.randn(inputs_shape, hidden_shape, requires_grad=True)
self.w2 = torch.randn(hidden_shape, output_shape, requires_grad=True)
self.b1 = torch.randn(1,hidden_shape, requires_grad=True)
self.b2 = torch.randn(1,output_shape, requires_grad=True)
self.loss = []
self.mse = MSELoss()
def fit(self, x, y , lr=0.2, epoch=200):
for i in range(epoch):
output = self.forward(x)
loss = self.mse(output, y)
self.loss.append(float(loss))
self.updata(loss,lr)
def updata(self, loss, lr):
loss.backward()
with torch.no_grad():
self.w1 -= self.w1.grad * lr
self.w2 -= self.w2.grad * lr
self.b2 -= self.b2.grad * lr
self.b1 -= self.b1.grad * lr
self.w1.grad.zero_()
self.w2.grad.zero_()
self.b1.grad.zero_()
self.b2.grad.zero_()
def forward(self,x):
h = x @ self.w1 + self.b1
h_out = self.sigmoid(h)
output = h_out @ self.w2 + self.b2
outpu_fin = self.sigmoid(output)
return outpu_fin
def sigmoid(self, x):
return 1 / (1 + torch.exp(-x))
def predict(self, x):
with torch.no_grad():
return self.forward(x) >= 0.5
def show(self, title):
plt.plot(self.loss)
plt.title(title)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
print(f'第一層W:{self.w1.tolist()} \n第二層W:{self.w2.tolist()} \n第一層?:{self.b1.tolist()} \n第二層?{self.b2.tolist()}')
x = [[0.,0.], [0.,1.], [1.,0.], [1.,1.]]
x = torch.tensor(x)
XOR_y = torch.tensor([[0.], [1.], [1.], [0.]])
AND_y = torch.tensor([[0.], [0.], [0.], [1.]])
OR_y = torch.tensor([[0.], [1.], [1.], [1.]])
XOR_model = model(2, 2, 1)
AND_model = model(2, 2, 1)
OR_model = model(2, 2, 1)
XOR_model.fit(x, XOR_y, 0.2, 5000)
AND_model.fit(x, AND_y,0.2, 5000)
OR_model.fit(x, OR_y,0.2, 5000)
XOR_model.show('XOR')
AND_model.show('AND')
OR_model.show('OR')
print(XOR_model.predict(x),AND_model.predict(x),OR_model.predict(x),sep='\n\n')
完整程式碼(numpy)
import numpy as np
class model:
def __init__(self, input_shape, hidden_shape, output_shape):
self.w1 = np.random.uniform(size=(input_shape, hidden_shape))
self.w2 = np.random.uniform(size=(hidden_shape, output_shape))
self.b1 = np.random.uniform(size=(1, hidden_shape))
self.b2 = np.random.uniform(size=(1, output_shape))
self.loss = []
def updata(self, x, y, lr):
loss = 0.5 * (y - self.output_final) ** 2
self.loss.append(np.sum(loss))
error_term = (self.output_final - y)
#隱藏層梯度(注意這裡還多一層simgoid)
grad1 = x.T @ (((error_term * self.delsigmoid(self.output_final)) * self.w2.T) * self.delsigmoid(self.h1_out))
#輸出層梯度
grad2 = self.h1_out.T @ (error_term * self.delsigmoid(self.output_final))
self.w1 -= lr * grad1
self.w2 -= lr * grad2
self.b1 -= np.sum(lr * ((error_term * self.delsigmoid(self.output_final)) * self.w2.T) * self.delsigmoid(self.h1_out), axis=0)
self.b2 -= np.sum(lr * error_term * self.delsigmoid(self.output_final), axis=0)
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def delsigmoid(self, x):
return x * (1 - x)
def forward(self, x):
self.h1 = np.dot(x, self.w1) + self.b1
self.h1_out = self.sigmoid(self.h1)
self.output = np.dot(self.h1_out, self.w2) + self.b2
self.output_final = self.sigmoid(self.output)
return self.output_final
def predict(self, x):
return self.forward(x) >= 0.5
def fit(self,x,y,lr,epoch):
for _ in range(epoch):
self.forward(x)
self.updata(x,y,lr)
def show(self, title):
plt.plot(self.loss)
plt.title(title)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
print(f'第一層W:{self.w1.tolist()} \n第二層W:{self.w2.tolist()} \n第一層?:{self.b1.tolist()} \n第二層?{self.b2.tolist()}')
x = np.array([[0,0], [0,1], [1,0], [1,1]])
XOR_y = np.array([[0], [1], [1], [0]])
AND_y =np.array([[0], [0], [0], [1]])
OR_y = np.array([[0], [1], [1], [1]])
XOR_model = model(2, 2, 1)
AND_model = model(2, 2, 1)
OR_model = model(2, 2, 1)
XOR_model.fit(x, XOR_y, 0.2, 5000)
AND_model.fit(x, AND_y,0.2, 5000)
OR_model.fit(x, OR_y,0.2, 5000)
XOR_model.show('XOR')
AND_model.show('AND')
OR_model.show('OR')
print(XOR_model.predict(x),AND_model.predict(x),OR_model.predict(x),sep='\n\n')
要再用準確率(Accuracy)評估分類模型了!-混淆矩陣(Confusion Matrix)與評估指標
資料不平衡產生的問題
我們先前在判斷分類任務時,只使用了準確率(Accuracy)來判別,但只依靠Accuracy來判斷分類模型卻不是一種最佳的方法,我們先看到以下例子:
假如我正在做一個關於正面評論會造成什麼影響的研究,但資料集卻是不平衡的狀態,在資料集中負面評論比例高達了90%,正面評論卻只有僅僅10%,如果這時程式都猜測結果是負面的Accuracy就會高達90%,這樣子的評估方式肯定是有問題的。
混淆矩陣(Confusion Matrix)
 所以在分類任務中應該要根據需求去調整評估方式,我們今天的主題
所以在分類任務中應該要根據需求去調整評估方式,我們今天的主題混淆矩陣(Confusion Matrix),就一種是用於分類問題的評估技術,這種技術衍生出了許多不同的指標,接下來讓我先介紹圖片中的TP(Ture Positive)、FP(False Positive)、FN(False Negative)、TN(Ture Negative)所代表的含意。
| 名稱 | 說明 |
|---|---|
| TP(Ture Positive) | 預測為YES 實際也為YES |
| FP(False Positive) | 預測為YES 實際為NO |
| FN(False Negative) | 預測為NO 實際為YES |
| TN(Ture Negative) | 預測為NO 實際也為NO |
TP、TN代表程式預測正確,FP、FN代表預測失敗的結果,其中FP、FN則是在4個參數中最為重要的兩個指標,這就與我們在觀看餐廳評價時相同,我們不會觀看5星評價而是觀看1星評價(畢竟沒有人會想給自己店刷1星吧),所以在混淆矩陣中,我們會先考慮FP與FN的數值,因為通過這兩個指標我們能知道錯誤究竟在哪裡。
FP也會叫Type I Error,實驗中會非常在意Type I Error,因為這樣代表實驗中的理論是錯的,但實驗結果卻是對的。我們可能花費了一堆時間與金錢去做實驗,最後結果也是好的,但後來發現研究的理論跟方向是錯的,那就可就問題大了。所以Type I Error的數值通常都會設定很小,若實驗中超過這個數值就能拋棄掉這個做法了。
FN也叫做Type II Error,Type II Error與Type I Error相反,是代表理論正確,但實驗結果是錯誤的,這時只需要更換實驗方式來達成正確的結果。
混淆矩陣產生的評估指標
接下來我們來說到,從混淆矩陣中產生的4種最常見的評估指標準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1 Score。
| 名稱 | 公式 |
|---|---|
| 準確率(Accuracy) | (TP+TN)/total data |
| 精確率(Precision) | TP/(TP+FP) |
| 召回率(Recall) | TP/(TP+FN) |
| F1 Score | 2/(1/Precision)+(1/Recall)) |
我相信Accuracy大家都很熟悉了,所以我只說Precision、Recall與F1 Score。
精確率(Precision)與召回率(Recall)
Precision主要是計算警告誤報(False alarm)出現的的機率,這種評估方式是計算所有的正面結果中(實際值、預測值)實際為正面的機率,也就是說Precision是在判斷正面資料的準確率。
Recall則是再計算目標的判斷失誤率(Miss),這種評估方式與Precision相似,不過與精確率不同的是,Recall是在判斷成功的資料內,正面資料的準確率。
兩者都是判斷正面的準確率但好像又不太同,那麼這兩個評估方式該怎麼使用?該用在哪些狀況上面呢?我們舉兩個例子來幫助理解。
例子1: 今天有一個自動門的系統,當判斷這個人為大樓住戶時才會開啟,這時候我們只需要瞭解這一個系統判斷大樓住戶的成功率究竟是多少,這時我們就會利用Precision來評估這個系統。
例子2: 今天警政署做了一個系統,要來判斷哪些人是通緝犯,這時不能放過任何一個通緝犯,我們就需要使用Recall來評估這個系統
若我們想要做出一個叫重要的系統(例子2)我們就會參考Recall值來評估,這時程式的精確率可能很低(匡列到很多路人)但召回率卻很高(找出很多通緝犯)。
但若是比較簡易的系統(例子1)就會採用Precision,這時Precision就會比較高(判斷到的基本上是大樓的住戶),但recall卻會很低(大樓的住戶可能會被擋在外面)。
F1 Score
但今天覺得Recall與Precision都很重要呢?這時候就要用F1 Score這個評估方式,這個公式的計算方式其實就是計算Recall與Precision的調和平均數(harmonic mean),當這個分數越靠近1,我們系統的效能就會越好。
結論
在AI的模型中評估方式相當的重要,因為這直接代表了這個神經網路模型的好壞,而我們判斷一個神經網路模型,基本上不會只使用一個指標,因為如果只使用一種指標,只能代表這個評估方式與我們的神經網路模型相性很好,所以我們需要使用多樣評估方式,來評估神經網路的實際效能。
蒐集資料與訓練模型時會發生的常見問題 & 解決方式
今天是課程倒數第二天,我相信你在學習的過程中產生了很多的疑問,所以今天我要來統整在訓練時常見的問題與解決方式。但注意這些回答都是參考解答不一定是最佳解,因為在深度學習的技術中,我們沒有經過實驗是不會知道結果的。
loss值相關問題
Q1:train loss與test loss趨近不變 A1:這通常代表神經網路學習完畢,若準確率不足可以嘗試更換神經網路架構。
Q2:為什麼train loss與test loss不管怎麼樣訓練都會非常的高,但卻會穩定下降 A2:通常這種情況會發生在回歸任務,最主要是因為資料沒有縮放到0~1之間導致loss值很高。
Q3:train loss 下降,test卻不會變動了該怎麼辦? A3:神經網路已經overfitting了,若準確率足夠應該要做Early stopping的動作,若不足應該降低學習率或增加神經網路的深度來解決這個問題
Q4:train loss下降(不變),test卻上升了這是怎麼回事? A4:通常不會遇到這些種狀況,當你遇到這種情況最大的可能性就是資料集有問題(亂數資料),可以試試將資料前處理後再放入神經網路訓練,看問題能否被改善
Q5:train loss不斷上升,test loss不斷上升 A5:會產生這問題的主要原因是神經網路無法有效學習到資料的特徵,通常遇到此情況只要降低學習率就會有不錯的結果。
模型相關問題
Q1:神經網路的各層參數該選擇多少? A1:一般會以2的倍數去建立參數,若是圖片的部分(CNN)會有2n+1來設定,但還是要經過實驗才能知道最好的結果。
Q2:每層該選用那些激勵函數? A2:通常在RNN神經網路中會選用tanh當作激勵函數(在RNN中比較重要的是資料分佈狀態而不是特徵),在CNN中會選用relu(與RNN相反比較需要知道特徵而不是分佈),回歸任務會選擇liner(為了能夠貼近實際值),多分類任務會選擇softmax(softmax會回傳位子訊息及各機率很適合多分類),二分類任務會選用sigmoid(數值會在0~1之間可以使用0.5作為分界線)。
Q3:損失函數該怎麼選擇? A3:在回歸任務中若覺得異常資料不重要會選擇MAE,不重要則會選擇MSE,而在分類任務中多分類任務會選擇Categorical Crossentropy,二分法會選擇Binary Crossentropy
Q4:優化器該怎麼選擇? A4:最通用的優化器我認為是adam,但若有無法收斂的問題可以試試用SGD詳細內容可以看這裡
Q5:學習率多少才適合? A5:沒有特定的答案,通常我會使用1e-4來測試結果,若遇見問題再調整(可以觀看loss相關問題)
資料前處理相關問題
Q1:為何要將圖像灰階化 A1:因為灰階化能夠移除掉影像中的部分亮點,還能夠加速程式運算速度
Q2:圖片有雜訊、光影差距大該怎麼辦? A2:可以使用一些濾波器(中值濾波器、平均濾波器、高斯濾波器...等),來增強影像品質
Q3:有些圖片是斜的,但我需要這些數據可是會影響到準確率,該怎麼做? A3:可以使用透視變換(Perspective Transformation)的方式將圖片轉正
Q4:什麼時候該降維資料? A4:當資料維度太高、資料較混亂、需快速計算時都能夠使用
Q5:為何要資料標準化(縮放到0~1之間),可以不要嗎? A5:資料標準化是為了使梯度能夠快速且正常的下降,若沒有標準化loss值的差距就會過高,這樣不僅會影響準確率,還會增加訓練時間。
Q6:為何要做資料清洗(Data Cleansing) A6:在訓練神經網路時我們需要去計算出每個結果的權重,若放入的資料是較混亂的,那計算上肯定會發生問題。
Q7:做NLP任務時該把符號刪除嗎? A7:應該要刪除一些大量重複出現的符號(逗號、分號、引號),留下一些能表達語氣的符號(驚嘆號、問號)
Q8:該刪除停用語嗎? A8:這要看模型的架構才能夠決定,基本上無法解決多義詞的模型都應該刪除停用語
Q9:為何在做文字前處理時是將文字轉換成小寫而不是大寫 A9:這其實沒有什麼差,只是大寫符號通常在程式代表的是參數
Pytorch、爬蟲常見問題
Q1:為何我訓練的速度會越來越慢 A1:通常是因為CPU或GPU的散熱問題導致效能越來越差
Q2:在pytorch訓練中為什麼會跑到一半才會提示無法在將資料放入GPU中了 A2:這是因為放入GPU的時機不對,通常出現這個問題是因為在dataset建立時就放入GPU中了,這導致python認為你還需要這些變數因此無法正常釋放GPU空間(python會自動釋放無用變數)
Q3:為什麼我在網頁上能看到我想要爬的資料,但程式內看不到? A3:因為網站是採用AJAX的方式來取的資料的,所以我們該請求的網址應該是AJAX的網址。
Q4:selenium是一種動態爬蟲的方式可以簡易的寫出爬蟲程式為何大家都不用? A4:最主要的原因還是因為selenium太緩慢了,我們使用requests的爬蟲方式只須對單一AJAX網址發送請求,但selenium卻是模仿瀏覽器的動作一次性的請求過多無用資料。
Q5:request該如何操作網頁上的物件? A5:通常我們可以觀察網址中的參數來做一些基礎操作,但有些較複雜的動作(例如登入)就必須採用cookie的方式才能夠操作物件。
路途還很遙遠只有良好的基礎才能走向更遠的路-30天的技術總結與心得
前言
在過去的29天內我們共完成了13個專案,並用實作為主理論為輔的方式學習AI,過程中不單單只使用了別人的資料集,還使用到了在AI中相當重要的技術"網路爬蟲"來幫助我們獲取想要的資料,我們透過了以上的方法,讓你能一次瞭解"實際狀況"、"技術理論"與"程式撰寫"。
不過你可能會覺得程式都是複製貼上真的能學到東西嗎?我的答案是肯定的,因為我認為學習最快的方式就是模仿,不過模仿是要有技巧的,當你模仿完一個程式後,並不是隻需要讀懂它,而是要在不參考解答的情況下,將內容重新呈現出來,這樣才是學習程式的正確方法。
技術總結
今天是最後一天,所以我們不教任何新技術,而是開始加強我們先前學過技術,因為在AI的領域中要有一定的基礎與知識才能夠改善AI的結果,所以在這邊我幫大家統整出了在這29天內的文章,來幫助大家可以能夠快速的找到自己想要學習到的知識,並且能夠重頭看過一次,我相信在第二次閱讀時一定會更能理解到這些理論的意思,畢竟只有良好的基礎才能走向更遠的路。
Python基礎
基礎理論講解
1.DNN理論講解與keras實作 2.CNN理論講解與keras實作 3.LSTM理論講解與keras實作 4.單層感知器講解與實作 5.正向傳播與反向傳播 6.多層感知器講解與實作
網路爬蟲
1.selenium爬蟲 2.requests爬蟲
電腦視覺(CV)
1.CNN理論講解與keras實作 2.從解析gz檔來瞭解圖像在電腦中的組成 3.用Pytorch建立CNN網路 4.使用OpenCV辨識人臉 5.預訓練模型VGG-16圖像辨識 6.GAN生成圖片
自然語言處理(NLP)
1.用pytorch建立LSTM網路 2.Transformer介紹 3.預訓練模型BERT介紹 4.預訓練模型BERT辨識假新聞 5.預訓練模型T5介紹 6.預訓練模型T5文本摘要 7.HDBSCAN與S-BERT介紹
機器學習
1.機器學習分類講解與Xgboost實作 2.HDBSCAN與S-BERT介紹
知識補充
1.人工智慧、深度學習、機器學習的差異 2.分群與分類的不同 3.學習降維演算法 4.認識混淆矩陣與評估方式 5.訓練時常出現的問題解答
參賽心得
這次是我第一次參加鐵人賽,這次會參賽主要的目的就是想留下一個經驗,所以沒有做太多的準備,我在正式開始前只想好這30天的大綱就開始了。在開賽初期因為程式很簡單,理論也相當的基本,所以一天只需花費1~2兩小時就能夠完成文章,但到了課程中期程式碼越來越複雜,理論越來越多,到後面一篇文章都需花費5小時以上去才能夠結束,但我還是堅持過來了!!!
在參賽的過程中我最氣的就是發文系統,因為發文系統沒有自動存檔的緣故,我有時又手殘把網站關掉,於是我花費好幾小時的寫的文章就這樣不見了,當下是真的很無奈又很無助,只能跟朋友抱怨一下後繼續趕工...。不過參加鐵人賽我認為蠻有成就感的,當有人追蹤或訂閱系列文章時,我就會覺得我寫的文章能夠被人認可,這件事情讓我蠻開心的。
最後向大家致個歉,小弟我的文筆不太好表達可能不夠清楚,若有不明白的事情歡迎留言或站內信我,我看到後就會一一回答,那我們的課程就到這裡了,大家有緣再相見~