這一節介紹本章的範例代碼要用的幾個C標準庫函數。我們先體會一下這幾個函數的介面是怎麼設計的,Man Page是怎麼寫的。其它常用的C標準庫函數將在下一章介紹。
從現在開始我們要用到很多庫函數,在學習每個庫函數時一定要看Man Page。Man Page隨時都在我們手邊,想查什麼只要敲一個命令就行,然而很多初學者就是不喜歡看Man Page,寧可滿世界去查書、查資料,也不願意看Man Page。據我分析原因有三:
英文不好。那還是先學好了英文再學編程吧,否則即使你把這本書都學透了也一樣無法勝任開發工作,因為你沒有進一步學習的能力。
Man Page的語言不夠友好。Man Page不像本書這樣由淺入深地講解,而是平鋪直敘,不過看習慣了就好了,每個Man Page都不長,多看幾遍自然可以抓住重點,理清頭緒。本節分析一個例子,幫助讀者把握Man Page的語言特點。
Man Page通常沒有例子。描述一個函數怎麼用,一靠介面,二靠文檔,而不是靠例子。函數的用法無非是本章所總結的幾種模式,只要把本章學透了,你就不需要每個函數都得有個例子教你怎麼用了。
總之,Man Page是一定要看的,一開始看不懂硬着頭皮也要看,為了鼓勵讀者看Man Page,本書不會像[K&R]那樣把庫函數總結成一個附錄附在書後面。現在我們來分析strcpy(3)。
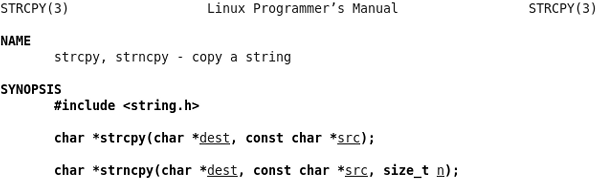
這個Man Page描述了兩個函數,strcpy和strncpy,敲命令man strcpy或者man strncpy都可以看到這個Man Page。這兩個函數的作用是把一個字元串拷貝給另一個字元串。SYNOPSIS部分給出了這兩個函數的原型,以及要用這些函數需要包含哪些標頭檔。參數dest、src和n都加了下劃線,有時候並不想從頭到尾閲讀整個Man Page,而是想查一下某個參數的含義,通過下劃線和參數名就能很快找到你關心的部分。
dest表示Destination,src表示Source,看名字就能猜到是把src所指向的字元串拷貝到dest所指向的內存空間。這一點從兩個參數的類型也能看出來,dest是char *型的,而src是const char *型的,說明src所指向的內存空間在函數中只能讀不能改寫,而dest所指向的內存空間在函數中是要改寫的,顯然改寫的目的是當函數返回後調用者可以讀取改寫的結果。因此可以猜到strcpy函數是這樣用的:
char buf[10]; strcpy(buf, "hello"); printf(buf);
至于strncpy的參數n是幹什麼用的,單從函數介面猜不出來,就需要看下面的文檔。

在文檔中強調了strcpy在拷貝字元串時會把結尾的'\0'也拷到dest中,因此保證了dest中是以'\0'結尾的字元串。但另外一個要注意的問題是,strcpy只知道src字元串的首地址,不知道長度,它會一直拷貝到'\0'為止,所以dest所指向的內存空間要足夠大,否則有可能寫越界,例如:
char buf[10]; strcpy(buf, "hello world");
如果沒有保證src所指向的內存空間以'\0'結尾,也有可能讀越界,例如:
char buf[10] = "abcdefghij", str[4] = "hell"; strcpy(buf, str);
因為strcpy函數的實現者通過函數介面無法得知src字元串的長度和dest內存空間的大小,所以“確保不會寫越界”應該是調用者的責任,調用者提供的dest參數應該指向足夠大的內存空間,“確保不會讀越界”也是調用者的責任,調用者提供的src參數指向的內存應該確保以'\0'結尾。
此外,文檔中還強調了src和dest所指向的內存空間不能有重疊。凡是有指針參數的C標準庫函數基本上都有這條要求,每個指針參數所指向的內存空間互不重疊,例如這樣調用是不允許的:
char buf[10] = "hello"; strcpy(buf, buf+1);
strncpy的參數n指定最多從src中拷貝n個位元組到dest中,換句話說,如果拷貝到'\0'就結束,如果拷貝到n個位元組還沒有碰到'\0',那麼也結束,調用者負責提供適當的n值,以確保讀寫不會越界,比如讓n的值等於dest所指向的內存空間的大小:
char buf[10]; strncpy(buf, "hello world", sizeof(buf));
然而這意味着什麼呢?文檔中特別用了Warning指出,這意味着dest有可能不是以'\0'結尾的。例如上面的調用,雖然把"hello world"截斷到10個字元拷貝至buf中,但buf不是以'\0'結尾的,如果再printf(buf)就會讀越界。如果你需要確保dest以'\0'結束,可以這麼調用:
char buf[10]; strncpy(buf, "hello world", sizeof(buf)); buf[sizeof(buf)-1] = '\0';
strncpy還有一個特性,如果src字元串全部拷完了不足n個位元組,那麼還差多少個位元組就補多少個'\0',但是正如上面所述,這並不保證dest一定以'\0'結束,當src字元串的長度大於n時,不但不補多餘的'\0',連字元串的結尾'\0'也不拷貝。strcpy(3)的文檔已經相當友好了,為了幫助理解,還給出一個strncpy的簡單實現。

函數的Man Page都有一部分專門講返回值的。這兩個函數的返回值都是dest指針。可是為什麼要返回dest指針呢?dest指針本來就是調用者傳過去的,再返回一遍dest指針並沒有提供任何有用的信息。之所以這麼規定是為了把函數調用當作一個指針類型的表達式使用,比如printf("%s\n", strcpy(buf, "hello")),一舉兩得,如果strcpy的返回值是void就沒有這麼方便了。
CONFORMING TO部分描述了這個函數是遵照哪些標準實現的。strcpy和strncpy是C標準庫函數,當然遵照C99標準。以後我們還會看到libc中有些函數屬於POSIX標準但並不屬於C標準,例如write(2)。
NOTES部分給出一些提示信息。這裡指出如何確保strncpy的dest以'\0'結尾,和我們上面給出的代碼類似,但由於n是個變數,在執行buf[n - 1]= '\0';之前先檢查一下n是否大於0,如果n不大於0,buf[n - 1]就訪問越界了,所以要避免。
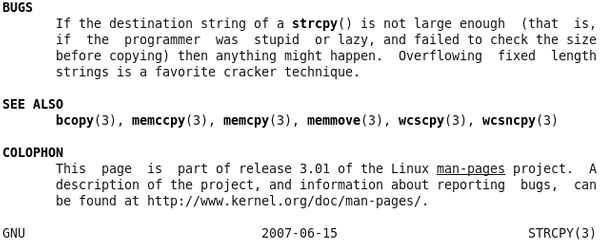
BUGS部分說明了使用這些函數可能引起的Bug,這部分一定要仔細看。用strcpy比用strncpy更加不安全,如果在調用strcpy之前不仔細檢查src字元串的長度就有可能寫越界,這是一個很常見的錯誤,例如:
void foo(char *str)
{
char buf[10];
strcpy(buf, str);
...
}str所指向的字元串有可能超過10個字元而導致寫越界,在第 4 節 “段錯誤”我們看到過,這種寫越界可能當時不出錯,而在函數返回時出現段錯誤,原因是寫越界覆蓋了保存在棧幀上的返回地址,函數返回時跳轉到非法地址,因而出錯。像buf這種由調用者分配並傳給函數讀或寫的一段內存通常稱為緩衝區(Buffer),緩衝區寫越界的錯誤稱為緩衝區溢出(Buffer Overflow)。如果只是出現段錯誤那還不算嚴重,更嚴重的是緩衝區溢出Bug經常被惡意用戶利用,使函數返回時跳轉到一個事先設好的地址,執行事先設好的指令,如果設計得巧妙甚至可以啟動一個Shell,然後隨心所欲執行任何命令,可想而知,如果一個用root權限執行的程序存在這樣的Bug,被攻陷了,後果將很嚴重。至于怎樣巧妙設計和攻陷一個有緩衝區溢出Bug的程序,有興趣的讀者可以參考[SmashStack]。
1、自己實現一個strcpy函數,儘可能簡潔,按照本書的編碼風格你能用三行代碼寫出函數體嗎?
2、編一個函數,輸入一個字元串,要求做一個新字元串,把其中所有的一個或多個連續的空白字元都壓縮為一個空格。這裡所說的空白包括空格、'\t'、'\n'、'\r'。例如原來的字元串是:
This Content hoho is ok
ok?
file system
uttered words ok ok ?
end.壓縮了空白之後就是:
This Content hoho is ok ok? file system uttered words ok ok ? end.
實現該功能的函數介面要求符合下述規範:
char *shrink_space(char *dest, const char *src, size_t n);
各項參數和返回值的含義和strncpy類似。完成之後,為自己實現的函數寫一個Man Page。
程序中需要動態分配一塊內存時怎麼辦呢?可以像上一節那樣定義一個緩衝區數組。這種方法不夠靈活,C89要求定義的數組是固定長度的,而程序往往在運行時才知道要動態分配多大的內存,例如:
void foo(char *str, int n)
{
char buf[?];
strncpy(buf, str, n);
...
}n是由參數傳進來的,事先不知道是多少,那麼buf該定義多大呢?在第 1 節 “數組的基本概念”講過C99引入VLA特性,可以定義char buf[n+1] = {};,這樣可確保buf是以'\0'結尾的。但即使用VLA仍然不夠靈活,VLA是在棧上動態分配的,函數返回時就要釋放,如果我們希望動態分配一塊全局的內存空間,在各函數中都可以訪問呢?由於全局數組無法定義成VLA,所以仍然不能滿足要求。
其實在第 5 節 “虛擬內存管理”提過,進程有一個堆空間,C標準庫函數malloc可以在堆空間動態分配內存,它的底層通過brk系統調用向操作系統申請內存。動態分配的內存用完之後可以用free釋放,更準確地說是歸還給malloc,這樣下次調用malloc時這塊內存可以再次被分配。本節學習這兩個函數的用法和工作原理。
#include <stdlib.h> void *malloc(size_t size); 返回值:成功返回所分配內存空間的首地址,出錯返回NULL void free(void *ptr);
malloc的參數size表示要分配的位元組數,如果分配失敗(可能是由於系統內存耗盡)則返回NULL。由於malloc函數不知道用戶拿到這塊內存要存放什麼類型的數據,所以返回通用指針void *,用戶程序可以轉換成其它類型的指針再訪問這塊內存。malloc函數保證它返回的指針所指向的地址滿足系統的對齊要求,例如在32位平台上返回的指針一定對齊到4位元組邊界,以保證用戶程序把它轉換成任何類型的指針都能用。
動態分配的內存用完之後可以用free釋放掉,傳給free的參數正是先前malloc返回的內存塊首地址。舉例如下:
例 24.1. malloc和free
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
int number;
char *msg;
} unit_t;
int main(void)
{
unit_t *p = malloc(sizeof(unit_t));
if (p == NULL) {
printf("out of memory\n");
exit(1);
}
p->number = 3;
p->msg = malloc(20);
strcpy(p->msg, "Hello world!");
printf("number: %d\nmsg: %s\n", p->number, p->msg);
free(p->msg);
free(p);
p = NULL;
return 0;
}關於這個程序要注意以下幾點:
unit_t *p = malloc(sizeof(unit_t));這一句,等號右邊是void *類型,等號左邊是unit_t *類型,編譯器會做隱式類型轉換,我們講過void *類型和任何指針類型之間可以相互隱式轉換。雖然內存耗儘是很不常見的錯誤,但寫程序要規範,
malloc之後應該判斷是否成功。以後要學習的大部分系統函數都有成功的返回值和失敗的返回值,每次調用系統函數都應該判斷是否成功。free(p);之後,p所指的內存空間是歸還了,但是p的值並沒有變,因為從free的函數介面來看根本就沒法改變p的值,p現在指向的內存空間已經不屬於用戶,換句話說,p成了野指針,為避免出現野指針,我們應該在free(p);之後手動置p = NULL;。應該先
free(p->msg),再free(p)。如果先free(p),p成了野指針,就不能再通過p->msg訪問內存了。
上面的例子只有一個簡單的順序控制流程,分配內存,賦值,打印,釋放內存,退出程序。這種情況下即使不用free釋放內存也可以,因為程序退出時整個進程地址空間都會釋放,包括堆空間,該進程占用的所有內存都會歸還給操作系統。但如果一個程序長年累月運行(例如網絡伺服器程序),並且在循環或遞歸中調用malloc分配內存,則必須有free與之配對,分配一次就要釋放一次,否則每次循環都分配內存,分配完了又不釋放,就會慢慢耗盡系統內存,這種錯誤稱為內存泄漏(Memory Leak)。另外,malloc返回的指針一定要保存好,只有把它傳給free才能釋放這塊內存,如果這個指針丟失了,就沒有辦法free這塊內存了,也會造成內存泄漏。例如:
void foo(void)
{
char *p = malloc(10);
...
}foo函數返回時要釋放局部變數p的內存空間,它所指向的內存地址就丟失了,這10個位元組也就沒法釋放了。內存泄漏的Bug很難找到,因為它不會像訪問越界一樣導致程序運行錯誤,少量內存泄漏並不影響程序的正確運行,大量的內存泄漏會使系統內存緊缺,導致頻繁換頁,不僅影響噹前進程,而且把整個系統都拖得很慢。
關於malloc和free還有一些特殊情況。malloc(0)這種調用也是合法的,也會返回一個非NULL的指針,這個指針也可以傳給free釋放,但是不能通過這個指針訪問內存。free(NULL)也是合法的,不做任何事情,但是free一個野指針是不合法的,例如先調用malloc返回一個指針p,然後連着調用兩次free(p);,則後一次調用會產生運行時錯誤。
[K&R]的8.7節給出了malloc和free的簡單實現,基于環形鏈表。目前讀者還沒有學習鏈表,看那段代碼會有點困難,我再做一些簡化,圖示如下,目的是讓讀者理解malloc和free的工作原理。libc的實現比這要複雜得多,但基本工作原理也是如此。讀者只要理解了基本工作原理,就很容易分析在使用malloc和free時遇到的各種Bug了。
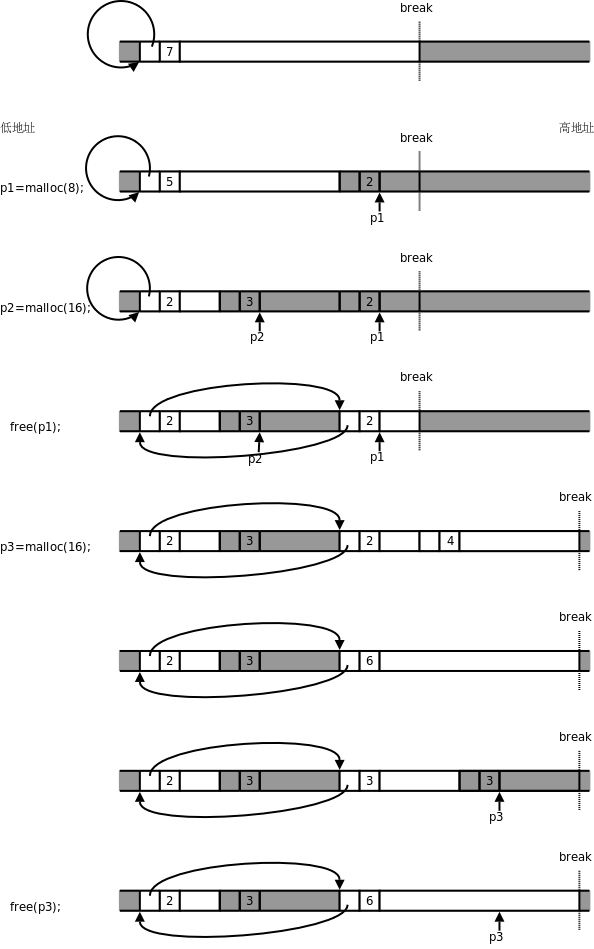
圖中白色背景的框表示malloc管理的空閒內存塊,深色背景的框不歸malloc管,可能是已經分配給用戶的內存塊,也可能不屬於當前進程,Break之上的地址不屬於當前進程,需要通過brk系統調用向內核申請。每個內存塊開頭都有一個頭節點,裡面有一個指針欄位和一個長度欄位,指針欄位把所有空閒塊的頭節點串在一起,組成一個環形鏈表,長度欄位記錄著頭節點和後面的內存塊加起來一共有多長,以8位元組為單位(也就是以頭節點的長度為單位)。
一開始堆空間由一個空閒塊組成,長度為7×8=56位元組,除頭節點之外的長度為48位元組。
調用
malloc分配8個位元組,要在這個空閒塊的末尾截出16個位元組,其中新的頭節點占了8個位元組,另外8個位元組返回給用戶使用,注意返回的指針p1指向頭節點後面的內存塊。又調用
malloc分配16個位元組,又在空閒塊的末尾截出24個位元組,步驟和上一步類似。調用
free釋放p1所指向的內存塊,內存塊(包括頭節點在內)歸還給了malloc,現在malloc管理着兩塊不連續的內存,用環形鏈表串起來。注意這時p1成了野指針,指向不屬於用戶的內存,p1所指向的內存地址在Break之下,是屬於當前進程的,所以訪問p1時不會出現段錯誤,但在訪問p1時這段內存可能已經被malloc再次分配出去了,可能會讀到意外改寫數據。另外注意,此時如果通過p2向右寫越界,有可能覆蓋右邊的頭節點,從而破壞malloc管理的環形鏈表,malloc就無法從一個空閒塊的指針欄位找到下一個空閒塊了,找到哪去都不一定,全亂套了。調用
malloc分配16個位元組,現在雖然有兩個空閒塊,各有8個位元組可分配,但是這兩塊不連續,malloc只好通過brk系統調用抬高Break,獲得新的內存空間。在[K&R]的實現中,每次調用sbrk函數時申請1024×8=8192個位元組,在Linux系統上sbrk函數也是通過brk實現的,這裡為了畫圖方便,我們假設每次調用sbrk申請32個位元組,建立一個新的空閒塊。新申請的空閒塊和前一個空閒塊連續,因此可以合併成一個。在能合併時要儘量合併,以免空閒塊越割越小,無法滿足大的分配請求。
在合併後的這個空閒塊末尾截出24個位元組,新的頭節點占8個位元組,另外16個位元組返回給用戶。
調用
free(p3)釋放這個內存塊,由於它和前一個空閒塊連續,又重新合併成一個空閒塊。注意,Break只能抬高而不能降低,從內核申請到的內存以後都歸malloc管了,即使調用free也不會還給內核。