現在探討一下編譯器優化會對生成的指令產生什麼影響,在此基礎上介紹C語言的volatile限定符。看下面的例子。
例 19.7. volatile限定符
/* artificial device registers */
unsigned char recv;
unsigned char send;
/* memory buffer */
unsigned char buf[3];
int main(void)
{
buf[0] = recv;
buf[1] = recv;
buf[2] = recv;
send = ~buf[0];
send = ~buf[1];
send = ~buf[2];
return 0;
}我們用recv和send這兩個全局變數來模擬設備寄存器。假設某種平台採用內存映射I/O,串口發送寄存器和串口接收寄存器位於固定的內存地址,而recv和send這兩個全局變數也有固定的內存地址,所以在這個例子中把它們假想成串口接收寄存器和串口發送寄存器。在main函數中,首先從串口接收三個位元組存到buf中,然後把這三個位元組取反,依次從串口發送出去[31]。我們查看這段代碼的反彙編結果:
buf[0] = recv;
80483a2: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483a9: a2 1a a0 04 08 mov %al,0x804a01a
buf[1] = recv;
80483ae: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483b5: a2 1b a0 04 08 mov %al,0x804a01b
buf[2] = recv;
80483ba: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483c1: a2 1c a0 04 08 mov %al,0x804a01c
send = ~buf[0];
80483c6: 0f b6 05 1a a0 04 08 movzbl 0x804a01a,%eax
80483cd: f7 d0 not %eax
80483cf: a2 18 a0 04 08 mov %al,0x804a018
send = ~buf[1];
80483d4: 0f b6 05 1b a0 04 08 movzbl 0x804a01b,%eax
80483db: f7 d0 not %eax
80483dd: a2 18 a0 04 08 mov %al,0x804a018
send = ~buf[2];
80483e2: 0f b6 05 1c a0 04 08 movzbl 0x804a01c,%eax
80483e9: f7 d0 not %eax
80483eb: a2 18 a0 04 08 mov %al,0x804a018movz指令把字長較短的值存到字長較長的存儲單元中,存儲單元的高位用0填充。該指令可以有b(byte)、w(word)、l(long)三種尾碼,分別表示單位元組、兩位元組和四位元組。比如movzbl 0x804a019,%eax表示把地址0x804a019處的一個位元組存到eax寄存器中,而eax寄存器是四位元組的,高三位元組用0填充,而下一條指令mov %al,0x804a01a中的al寄存器正是eax寄存器的低位元組,把這個位元組存到地址0x804a01a處的一個位元組中。可以用不同的名字單獨訪問x86寄存器的低8位、次低8位、低16位或者完整的32位,以eax為例,al表示低8位,ah表示次低8位,ax表示低16位,如下圖所示。
但如果指定優化選項-O編譯,反彙編的結果就不一樣了:
$ gcc main.c -g -O
$ objdump -dS a.out|less
...
buf[0] = recv;
80483ae: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483b5: a2 1a a0 04 08 mov %al,0x804a01a
buf[1] = recv;
80483ba: a2 1b a0 04 08 mov %al,0x804a01b
buf[2] = recv;
80483bf: a2 1c a0 04 08 mov %al,0x804a01c
send = ~buf[0];
send = ~buf[1];
send = ~buf[2];
80483c4: f7 d0 not %eax
80483c6: a2 18 a0 04 08 mov %al,0x804a018
...前三條語句從串口接收三個位元組,而編譯生成的指令顯然不符合我們的意圖:只有第一條語句從內存地址0x804a019讀一個位元組到寄存器eax中,然後從寄存器al保存到buf[0],後兩條語句就不再從內存地址0x804a019讀取,而是直接把寄存器al的值保存到buf[1]和buf[2]。後三條語句把buf中的三個位元組取反再發送到串口,編譯生成的指令也不符合我們的意圖:只有最後一條語句把eax的值取反寫到內存地址0x804a018了,前兩條語句形同虛設,根本不生成指令。
為什麼編譯器優化的結果會錯呢?因為編譯器並不知道0x804a018和0x804a019是設備寄存器的地址,把它們當成普通的內存單元了。如果是普通的內存單元,只要程序不去改寫它,它就不會變,可以先把內存單元裡的值讀到寄存器緩存起來,以後每次用到這個值就直接從寄存器讀取,這樣效率更高,我們知道讀寄存器遠比讀內存要快。另一方面,如果對一個普通的內存單元連續做三次寫操作,只有最後一次的值會保存到內存單元中,所以前兩次寫操作是多餘的,可以優化掉。訪問設備寄存器的代碼這樣優化就錯了,因為設備寄存器往往具有以下特性:
設備寄存器中的數據不需要改寫就可以自己發生變化,每次讀上來的值都可能不一樣。
連續多次向設備寄存器中寫數據並不是在做無用功,而是有特殊意義的。
用優化選項編譯生成的指令明顯效率更高,但使用不當會出錯,為了避免編譯器自作聰明,把不該優化的也優化了,程序員應該明確告訴編譯器哪些內存單元的訪問是不能優化的,在C語言中可以用volatile限定符修飾變數,就是告訴編譯器,即使在編譯時指定了優化選項,每次讀這個變數仍然要老老實實從內存讀取,每次寫這個變數也仍然要老老實實寫回內存,不能省略任何步驟。我們把代碼的開頭幾行改成:
/* artificial device registers */ volatile unsigned char recv; volatile unsigned char send;
然後指定優化選項-O編譯,查看反彙編的結果:
buf[0] = recv;
80483a2: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483a9: a2 1a a0 04 08 mov %al,0x804a01a
buf[1] = recv;
80483ae: 0f b6 15 19 a0 04 08 movzbl 0x804a019,%edx
80483b5: 88 15 1b a0 04 08 mov %dl,0x804a01b
buf[2] = recv;
80483bb: 0f b6 0d 19 a0 04 08 movzbl 0x804a019,%ecx
80483c2: 88 0d 1c a0 04 08 mov %cl,0x804a01c
send = ~buf[0];
80483c8: f7 d0 not %eax
80483ca: a2 18 a0 04 08 mov %al,0x804a018
send = ~buf[1];
80483cf: f7 d2 not %edx
80483d1: 88 15 18 a0 04 08 mov %dl,0x804a018
send = ~buf[2];
80483d7: f7 d1 not %ecx
80483d9: 88 0d 18 a0 04 08 mov %cl,0x804a018確實每次讀recv都從內存地址0x804a019讀取,每次寫send也都寫到內存地址0x804a018了。值得注意的是,每次寫send並不需要取出buf中的值,而是取出先前緩存在寄存器eax、edx、ecx中的值,做取反運算然後寫下去,這是因為buf並沒有用volatile限定,讀者可以試着在buf的定義前面也加上volatile,再優化編譯,再查看反彙編的結果。
gcc的編譯優化選項有-O0、-O、-O1、-O2、-O3、-Os幾種。-O0表示不優化,這是預設的選項。-O1、-O2和-O3這幾個選項一個比一個優化得更多,編譯時間也更長。-O和-O1相同。-Os表示為縮小目標檔案的尺寸而優化。具體每種選項做了哪些優化請參考gcc(1)的Man Page。
從上面的例子還可以看到,如果在編譯時指定了優化選項,原始碼和生成指令的次序可能無法對應,甚至有些原始碼可能不對應任何指令,被徹底優化掉了。這一點在用gdb做源碼級調試時尤其需要注意(做指令級調試沒關係),在為調試而編譯時不要指定優化選項,否則可能無法一步步跟蹤原始碼的執行過程。
有了volatile限定符,是可以防止編譯器優化對設備寄存器的訪問,但是對於有Cache的平台,僅僅這樣還不夠,還是無法防止Cache優化對設備寄存器的訪問。在訪問普通的內存單元時,Cache對程序員是透明的,比如執行了movzbl 0x804a019,%eax這樣一條指令,我們並不知道eax的值是真的從內存地址0x804a019讀到的,還是從Cache中讀到的,如果Cache已經緩存了這個地址的數據就從Cache讀,如果Cache沒有緩存就從內存讀,這些步驟都是硬件自動做的,而不是用指令控制Cache去做的,程序員寫的指令中只有寄存器、內存地址,而沒有Cache,程序員甚至不需要知道Cache的存在。同樣道理,如果執行了mov %al,0x804a01a這樣一條指令,我們並不知道寄存器的值是真的寫回內存了,還是隻寫到了Cache中,以後再由Cache寫回內存,即使只寫到了Cache中而暫時沒有寫回內存,下次讀0x804a01a這個地址時仍然可以從Cache中讀到上次寫的數據。然而,在讀寫設備寄存器時Cache的存在就不容忽視了,如果串口發送和接收寄存器的內存地址被Cache緩存了會有什麼問題呢?如下圖所示。
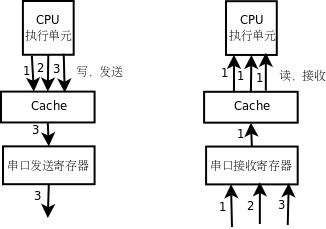
如果串口發送寄存器的地址被Cahce緩存,CPU執行單元對串口發送寄存器做寫操作都寫到Cache中去了,串口發送寄存器並沒有及時得到數據,也就不能及時發送,CPU執行單元先後發出的1、2、3三個位元組都會寫到Cache中的同一個單元,最後Cache中只保存了第3個位元組,如果這時Cache把數據寫回到串口發送寄存器,只能把第3個位元組發送出去,前兩個位元組就丟失了。與此類似,如果串口接收寄存器的地址被Cache緩存,CPU執行單元在讀第1個位元組時,Cache會從串口接收寄存器讀上來緩存,然而串口接收寄存器後面收到的2、3兩個位元組Cache並不知道,因為Cache把串口接收寄存器當作普通內存單元,並且相信內存單元中的數據是不會自己變的,以後每次讀串口接收寄存器時,Cache都會把緩存的第1個位元組提供給CPU執行單元。
通常,有Cache的平台都有辦法對某一段地址範圍禁用Cache,一般是在頁表中設置的,可以設定哪些頁面允許Cache緩存,哪些頁面不允許Cache緩存,MMU不僅要做地址轉換和訪問權限檢查,也要和Cache協同工作。
除了設備寄存器需要用volatile限定之外,當一個全局變數被同一進程中的多個控制流程訪問時也要用volatile限定,比如信號處理函數和多綫程。