我們繼續用反彙編的方法研究一下C語言的結構體:
例 19.3. 研究結構體
#include <stdio.h>
int main(int argc, char** argv)
{
struct {
char a;
short b;
int c;
char d;
} s;
s.a = 1;
s.b = 2;
s.c = 3;
s.d = 4;
printf("%u\n", sizeof(s));
return 0;
}main函數中幾條語句的反彙編結果如下:
s.a = 1;
80483d5: c6 45 f0 01 movb $0x1,-0x10(%ebp)
s.b = 2;
80483d9: 66 c7 45 f2 02 00 movw $0x2,-0xe(%ebp)
s.c = 3;
80483df: c7 45 f4 03 00 00 00 movl $0x3,-0xc(%ebp)
s.d = 4;
80483e6: c6 45 f8 04 movb $0x4,-0x8(%ebp)從訪問結構體成員的指令可以看出,結構體的四個成員在棧上是這樣排列的:
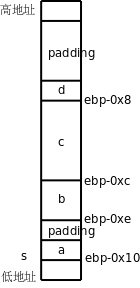
雖然棧是從高地址向低地址增長的,但結構體成員也是從低地址向高地址排列的,這一點和數組類似。但有一點和數組不同,結構體的各成員並不是一個緊挨一個排列的,中間有空隙,稱為填充(Padding),不僅如此,在這個結構體的末尾也有三個位元組的填充,所以sizeof(s)的值是12。注意,printf的%u轉換說明表示無符號數,sizeof的值是size_t類型的,是某種無符號整型。
為什麼編譯器要這樣處理呢?有一個知識點我此前一直迴避沒講,那就是大多數計算機體系統結構對於訪問內存的指令是有限制的,在32位平台上,訪問4位元組的指令(比如上面的movl)所訪問的內存地址應該是4的整數倍,訪問兩位元組的指令(比如上面的movw)所訪問的內存地址應該是兩位元組的整數倍,這稱為對齊(Alignment)。以前舉的所有例子中的內存訪問指令都滿足這個限制條件,讀者可以回頭檢驗一下。如果指令所訪問的內存地址沒有正確對齊會怎麼樣呢?在有些平台上將不能訪問內存,而是引發一個異常,在x86平台上倒是仍然能訪問內存,但是不對齊的指令執行效率比對齊的指令要低,所以編譯器在安排各種變數的地址時都會考慮到對齊的問題。對於本例中的結構體,編譯器會把它的基地址對齊到4位元組邊界,也就是說,ebp-0x10這個地址一定是4的整數倍。s.a占一個位元組,沒有對齊的問題。s.b占兩個位元組,如果s.b緊挨在s.a後面,它的地址就不能是兩位元組的整數倍了,所以編譯器會在結構體中插入一個填充位元組,使s.b的地址也是兩位元組的整數倍。s.c占4位元組,緊挨在s.b的後面就可以了,因為ebp-0xc這個地址也是4的整數倍。那麼為什麼s.d的後面也要有填充位填充到4位元組邊界呢?這是為了便于安排這個結構體後面的變數的地址,假如用這種結構體類型組成一個數組,那麼後一個結構體只需和前一個結構體緊挨着排列就可以保證它的基地址仍然對齊到4位元組邊界了,因為在前一個結構體的末尾已經有了填充位元組。事實上,C標準規定數組元素必須緊挨着排列,不能有空隙,這樣才能保證每個元素的地址可以按“基地址+n×元素大小”簡單計算出來。
合理設計結構體各成員的排列順序可以節省存儲空間,例如上例中的結構體改成這樣就可以避免產生填充位元組:
struct {
char a;
char d;
short b;
int c;
} s;此外,gcc提供了一種擴展語法可以消除結構體中的填充位元組:
struct {
char a;
short b;
int c;
char d;
} __attribute__((packed)) s;這樣就不能保證結構體成員的對齊了,在訪問b和c的時候可能會有效率問題,所以除非有特別的理由,一般不要使用這種語法。
以前我們使用的數據類型都是占幾個位元組,最小的類型也要占一個位元組,而在結構體中還可以使用Bit-field語法定義只占幾個bit的成員。下面這個例子出自王聰的網站(www.wangcong.org):
例 19.4. Bit-field
#include <stdio.h>
typedef struct {
unsigned int one:1;
unsigned int two:3;
unsigned int three:10;
unsigned int four:5;
unsigned int :2;
unsigned int five:8;
unsigned int six:8;
} demo_type;
int main(void)
{
demo_type s = { 1, 5, 513, 17, 129, 0x81 };
printf("sizeof demo_type = %u\n", sizeof(demo_type));
printf("values: s=%u,%u,%u,%u,%u,%u\n",
s.one, s.two, s.three, s.four, s.five, s.six);
return 0;
}s這個結構體的佈局如下圖所示:
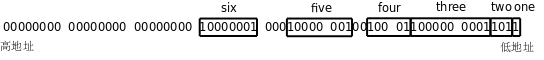
Bit-field成員的類型可以是int或unsigned int,表示有符號數或無符號數,但不表示它像普通的int型一樣占4個位元組,它後面的數字是幾就表示它占多少個bit,也可以像unsigned int :2;這樣定義一個未命名的Bit-field,即使不寫未命名的Bit-field,編譯器也有可能在兩個成員之間插入填充位,如上圖的five和six之間,這樣six這個成員就剛好單獨占一個位元組了,訪問效率會比較高,這個結構體的末尾還填充了3個位元組,以便對齊到4位元組邊界。以前我們說過x86的Byte Order是小端的,從上圖中one和two的排列順序可以看出,如果對一個位元組再細分,則位元組中的Bit Order也是小端的,因為排在結構體前面的成員(靠近低地址一邊的成員)取位元組中的低位。關於如何排列Bit-field在C標準中沒有詳細的規定,這跟Byte Order、Bit Order、對齊等問題都有關,不同的平台和編譯器可能會排列得很不一樣,要編寫可移植的代碼就不能假定Bit-field是按某一種固定方式排列的。Bit-field在驅動程式中是很有用的,因為經常需要單獨操作設備寄存器中的一個或幾個bit,但一定要小心使用,首先弄清楚每個Bit-field和實際bit的對應關係。
和前面幾個例子不一樣,在上例中我沒有給出反彙編結果,直接畫了個圖說這個結構體的佈局是這樣的,那我有什麼證據這麼說呢?上例的反彙編結果比較繁瑣,我們可以通過另一種手段得到這個結構體的內存佈局。C語言還有一種類型叫聯合體,用關鍵字union定義,其語法類似於結構體,例如:
例 19.5. 聯合體
#include <stdio.h>
typedef union {
struct {
unsigned int one:1;
unsigned int two:3;
unsigned int three:10;
unsigned int four:5;
unsigned int :2;
unsigned int five:8;
unsigned int six:8;
} bitfield;
unsigned char byte[8];
} demo_type;
int main(void)
{
demo_type u = {{ 1, 5, 513, 17, 129, 0x81 }};
printf("sizeof demo_type = %u\n", sizeof(demo_type));
printf("values: u=%u,%u,%u,%u,%u,%u\n",
u.bitfield.one, u.bitfield.two, u.bitfield.three,
u.bitfield.four, u.bitfield.five, u.bitfield.six);
printf("hex dump of u: %x %x %x %x %x %x %x %x \n",
u.byte[0], u.byte[1], u.byte[2], u.byte[3],
u.byte[4], u.byte[5], u.byte[6], u.byte[7]);
return 0;
}一個聯合體的各個成員占用相同的內存空間,聯合體的長度等於其中最長成員的長度。比如u這個聯合體占8個位元組,如果訪問成員u.bitfield,則把這8個位元組看成一個由Bit-field組成的結構體,如果訪問成員u.byte,則把這8個位元組看成一個數組。聯合體如果用Initializer初始化,則只初始化它的第一個成員,例如demo_type u = {{ 1, 5, 513, 17, 129, 0x81 }};初始化的是u.bitfield,但是通過u.bitfield的成員看不出這8個位元組的內存佈局,而通過u.byte數組就可以看出每個位元組分別是多少了。